En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Décembre : On peut se passer des patrons
Un algorithme superbe scientifiquement peut avoir un intérêt social contrasté. C’est le cas de l’algorithme blockchain (chaîne de blocs) inventé vers 2008 par un informaticien connu sous le nom de Satoshi Nakamoto.
Cet algorithme permet de maintenir un registre numérique unique de transactions sans aucune autorité centrale. N’importe qui peut lire le registre, écrire dedans, ou même maintenir localement une copie du registre. La garantie que la réalisation des transactions est correcte est obtenue collectivement. Le problème est d’arriver à assurer que les copies restent identiques. Plus précisément, on veut éviter que Bob puisse acheter sur une des copies du registre une pomme à Alice avec tout l’argent qu’il possède, et, en même temps, échanger cet argent contre une orange avec Suzanne. La solution de Nakamoto est de décider à un instant particulier quelle
est la copie de référence unique ; elle seule a le droit de rajouter un bloc de transactions. L’algorithme résout ainsi un des problèmes les plus complexes d’algorithmique distribuée : le problème du consensus, qui consiste à élire un membre parmi une communauté de pairs.
Pour devenir patron pour un instant, un pair doit résoudre un problème supercomplexe, comme un sudoku gigantesque. Le premier pair ayant trouvé la solution gagne le droit d’enregistrer la transaction, ce qui est rémunéré. Le problème étant complexe, il est quasi impossible que deux pairs le résolvent en même temps. La victoire doit être reconnue par le plus grand nombre de pairs et ceci force Bob à attendre un certain temps avant de manger la pomme.
Cette technologie s’est d’abord fait connaître avec une cryptomonnaie, le bitcoin, un mécanisme monétaire tout à fait fonctionnel, sans autorités centrales. Comme tout
se fait anonymement, des bitcoins sont utilisés, entre autres, sur le dark web.
La résolution de ce problème nécessite une puissance de calcul informatique énorme. L’avantage social de pou- voir se passer d’une autorité de gestion du registre se paie avec un coût écologique discutable.
Scientifiquement, l’algorithme blockchain pose des défis fantastiques à l’algorithmique : on continue à chercher des algorithmes de blockchain peu coûteux en énergie, ajouter des preuves que ces algorithmes ne sont pas buggés, réfléchir à d’autres utilisations comme les smart contracts qui simplifient les échanges commerciaux entre des entreprises sans avoir à choisir de leader ni à fixer à l’avance de liste de participants, etc.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Novembre : « On n’apprend bien qu’en se trompant »*
*Proverbe turc
Un enfant apprend sa langue maternelle en écoutant les personnes qui parlent autour de lui, en les imitant sans rien comprendre, dans un premier temps, à la grammaire, aux conjugaisons et aux déclinaisons. Il est incapable d’expliquer pourquoi il ne faut pas dire « j’ai allé à l’école », mais « je suis allé à l’école » ; il finit par savoir que cela ne se dit pas. De la même façon qu’on est souvent incapable de caractériser une phrase correcte, il existe de nombreux problèmes que les humains savent résoudre sans vraiment pouvoir en décrire précisément une solution algorithmique. Les algorithmes d’apprentissage servent dans ces cas là. Intuitivement, on entraîne d’abord l’algorithme d’apprentissage sur des cas particuliers du problème en lui donnant les solutions. L’algorithme dégage ensuite un modèle mathématique à partir de ces exemples. Confronté à un nouveau problème de la même famille, il essaie de faire au mieux en appliquant le modèle qu’il a élaboré. C’est peut être surprenant, mais cette façon de procéder par imitation fonctionne plutôt bien dans de nombreuses situations.
Par exemple, pour la traduction automatique entre l’anglais et le français, on part de tas d’exemples de couples <<texte – traduction>>. On utilise des méthodes basées sur les statistiques de traduction de groupes de mots par d’autres groupes de mots. On arrive à améliorer la qualité de la traduction en utilisant des “réseaux de neurones artificiels”, dont le fonctionnement est inspiré (d’assez loin) par des processus biologiques. Ils consistent en un empilage de couches de neurones artificiels. Chaque neurone traite un petit bout d’information. Tant que le résultat n’est pas satisfaisant on applique entre chaque couche, localement, des traitements correctifs. Le système finit par s’adapter à la masse d’exemples qu’on lui fait avaler. Ainsi, ses traductions s’améliorent au cours de l’apprentissage, au fil du temps.
Les techniques d’apprentissage, qui combinent toute une gamme d’algorithmes, ont de nombreuses applications. Ils ont, par exemple, permis aux programmes qui jouent au go de beaucoup progresser, jusqu’à battre les meilleurs joueurs. Dans le cas du jeu de go, l’espace de recherche a une taille gigantesque et les algorithmes d’exploration de cet espace s’y perdent. Des techniques d’ <<apprentissage par renforcement>> leur permettent de favoriser les bons choix, c’est-à-dire ceux qui ont conduit à des victoires dans des parties déjà jouées.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Octobre : Pour quelques octets de moins
Un fichier contenant du texte, du son ou une image, fait facilement plusieurs méga (106) octets. Pourtant, on arrive à le compresser en un fichier de quelques kilos (103), gagnant ainsi espace mémoire, temps, énergie, quand on transfère le fichier par exemple. Après décompression, on peut lire, écouter, voir le fichier de départ. Les fichiers contiendraient-ils du vide ?
En fait, la longueur du fichier ne mesure pas forcément la quantité d’information contenue dedans. Comparons un fichier qui contient 50 000 000 fois <<ga bu zo meu>>, et un autre qui contient toutes les pièces de Molière. Le deuxième fait moins de signes que le premier, et pourtant, il contient plus d’information ! Pour compresser le premier, il suffit de stocker quelque part le motif <<ga bu zo meu>> et de prévenir qu’il faut le répéter 50 000 000 fois. Pour le deuxième, c’est une autre paire de manches… On peut remplacer chaque occurrence d’un mot fréquent, comme <<femme>>, par un code plus court, comme #34#, et se souvenir que #34#=femme. On gagne un peu… Peut-on faire mieux ?
Un des algorithmes les plus classiques de compression est celui de Lempel-Ziv-Welch, qui date de 1984. Comprimons l’extrait : <<Un sot savant est sot plus qu’un sot ignorant>>. D’abord, on stocke une table, appelée dictionnaire, contenant tout l’alphabet. Ensuite, il faut imaginer lire le texte, lettre par lettre. La première lettre, <<U>>, est déjà dans la table : on écrit dans le nouveau fichier sa place dans le dictionnaire. On procède ainsi tant qu’on lit de nouvelles lettres. Un jour ou l’autre, on lit une lettre qu’on avait déjà vue : cela arrive au <<s>> de savant. Alors, on regarde la lettre suivante, <<a>>, et on rajoute au dictionnaire la combinaison « sa ». On écrit dans le nouveau fichier la place de cette nouvelle combinaison. On continue ! A chaque fois qu’on découvre une nouvelle suite de caractères, on étend le dictionnaire. Si on applique cet algorithme à phrase considérée, on arrive ainsi à factoriser parfaitement le mot <<sot>>. Et plus le texte est long, plus on en factorise de gros morceaux.
Il est relativement simple, à partir du fichier compressé, de retrouver le fichier de départ. Les deux fichiers contiennent exactement la même information. Et pourtant, ils n’ont pas le même nombre de caractères !
L’algorithme de LZW que nous venons de décrire est encore de nos jours au coeur d’algorithmes de compression de textes (gzip) ou d’images (gif). Vous avez sans doute rencontré ces termes comme suffixe de fichiers. Et oui, ils viennent des algorithmes de compression utilisés.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Septembre : Yicha nineez agaanstsiin aak’ee*
Depuis sans doute aussi longtemps qu’on sait écrire, on chiffre des messages pour éviter que n’importe qui puisse les lire. On a retrouvé en Irak un document avec une recette chiffrée de poterie qui date du XVIe siècle avant JC. Aujourd’hui, les communications électroniques peuvent être chiffrées pour protéger leur confidentialité comme, par exemple, dans les services Signal ou WhatsApp. Avec le protocole https les pages Web sont également chiffrées pour éviter qu’elles puissent être lues depuis les serveurs par lesquels elles transitent, ainsi que pour garantir leur provenance.
Le principe du “chiffrement asymétrique” permet d’éviter d’avoir à partager une clé secrète commune avant de communiquer. Pour un tel chiffrement, je dispose de deux clés, une publique que je publie sur Internet et une privée que je ne donne à personne. Si vous voulez m’écrire, vous chiffrez votre message avec la clé publique. Je pourrais le lire, mais quelqu’un ne disposant pas de la clé privée sera incapable de le décrypter.
Le principe de chiffrement asymétrique a été proposé en 1976. Deux ans plus tard, Ronald Rivest, Adi Shamir et Leonard Adleman, inventaient le chiffrement RSA (pour les premières lettres des trois noms).
Reprenons l’exemple de Wikipédia. Nous vous cacherons par manque de place comment Alice a obtenu ses deux clés : sa clé publique (33, 3) et sa clé privée (33, 7). Bob veut transmettre le message “4” à Alice. Il le chiffre avec la clé publique : 43 mod 33, soit 31. Alice calcule 317 mod 33, c’est à dire “4”. Elle a bien récupéré le message.
Il est important de savoir que n (ici 33) est le produit de deux nombres premiers. Pour qu’un ennemi puisse décrypter ce message, il lui “suffirait” de décomposer 33 en un produit de deux nombres premiers. Facile ! Mais en pratique, la clé de chiffrement n est le produits de deux nombres premiers très grands et pour trouver sa décomposition, c’est une toute autre histoire. Cela nécessite une énorme quantité de calculs. Nos communications et notre commerce électronique sont en réalité protégées par l’immensité du temps de calcul nécessaire à les décrypter.
A l’avenir, peut-être sera-t-il possible de réaliser rapidement une telle factorisation avec des ordinateurs quantiques. Heureusement, personne ne sait réaliser de telles machines. En attendant, les cryptologues travaillent sur des algorithmes qui résisteraient même aux machines quantiques.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Août : Alea jacta la machine
Les algorithmes sont mécaniques. Tels Dieu, ils ne jouent pas aux dés. Ils ne sont, par nature, pas aléatoires. Mais aussi surprenant que cela puisse être, l’aléatoire est souvent un ingrédient algorithmique très utile.
Certains algorithmes doivent explorer un espace très grand, trop grand, tellement grand parfois que l’âge de l’Univers ne suffirait pas à le visiter de manière systématique. L’algorithme doit alors faire des choix, dont certains sont bons, d’autres mauvais. Quand on sait toujours faire les bons choix, on peut terminer raisonnablement vite. Mais quand on ne sait pas, l’algorithme peut perdre énormément de temps sur des paris malheureux. Pour éviter cela, on utilise judicieusement des ingrédients aléatoires. Par exemple, si l’on soupçonne l’algorithme d’être coincé dans une série de mauvais choix, couic, on l’arrête et on le relance en choisissant un <<ailleurs>> aléatoire. Ce procédé, qu’on appelle random restart, permet à un algorithme de visiter un grand espace en évitant de se laisser piéger dans des régions sans espoir.
Dans d’autres cas, l’aléatoire permet de résoudre des problèmes que l’on ne saurait pas résoudre autrement. C’est le cas lorsque l’on veut calculer la surface de l’intérieur de certaines courbes spécifiées par des équations. Un tel calcul peut exiger la résolution d’intégrales trop compliquées pour les meilleurs mathématiciens. On peut alors utiliser une méthode très simple à base d’échantillonnage. On utilise un carré qui contient la courbe ; comme c’est un carré, il est simple de calculer sa surface. Ensuite, on tire au hasard un grand nombre de points dans ce carré. C’est facile de savoir si un point est à l’intérieur ou à l’extérieur de la courbe, grâce à son équation. On compte le pourcentage de points dans la courbe par rapport au nombre de points dehors. Le produit de ce pourcentage par la surface du carré donne une estimation de la surface cherchée. C’est super simple à réaliser. Et en choisissant beaucoup de points au hasard, on peut être très précis.
De façon un peu paradoxale, l’aléatoire se révèle souvent utile dans le monde des algorithmes. Mais, fabriquer aléatoirement une donnée sur un ordinateur n’est pas chose aisée ! On y parvient en effectuant des calculs suffisamment tarabiscotés sur des données pas du tout aléatoires, ou en utilisant du hardware spécialisé. Les résultats, s’ils ne sont pas vraiment aléatoires, sont suffisamment imprévisibles pour le paraître.
Nous utilisons donc, à l’intérieur d’algorithmes, des donnés aléatoires produites par une machine, alors que les machines sont en théorie complètement déterministes.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Juillet : Une maille à l’endroit, une maille à l’envers
Assez souvent, les mondes virtuels ressemblent au monde réel. Parfois même, ils le copient, aussi fidèlement que possible ; on trouve ainsi toute une catégorie d’algorithmes qui ne servent qu’à reproduire des phénomènes physiques existant déjà dans la nature. Cela peut sembler une drôle d’idée ! Mais c’est loin d’être idiot : une fois qu’on a reproduit un phénomène physique in silico, on peut alors l’étudier, jouer avec, par exemple, en le faisant évoluer très vite, plus vite que dans la réalité, ou en changeant certains de ses paramètres.
Le coeur de beaucoup de ces algorithmes est la simulation par maillage. Imaginons que l’on veuille reproduire ce qui se passe à l’intérieur d’un matériau. Cela suppose des calculs compliqués dans un espace continu, et en pratique, c’est infaisable. Le maillage est une façon de contourner cet obstacle : au lieu de calculer ce qui se passe en tout point du matériau, on se contente d’identifier des points d’intérêt, suffisamment denses pour être représentatifs mais pas trop nombreux non plus. Si, par exemple, on s’intéresse à la déformation du matériau sous l’effet d’une compression, les petites déformations locales sont calculées de proche en proche sur les points du maillage. De même, pour calculer la propagation d’une vibration dans le matériau, on transmet les forces uniquement sur le maillage. On obtient ainsi une simulation, imparfaite mais calculable, du phénomène physique considéré. En prime, comme ces algorithmes reposent sur des calculs en partie indépendants, ils peuvent être parallélisés. Et ce principe fonctionne pour un matériau soumis à des contraintes physiques, pour des masses d’air parcourues de vents, pour des fluides en mouvement, etc.
Les simulations par maillage sont omniprésentes dans de nombreuses sciences expérimentales, allant parfois jusqu’à remplacer les expériences. Par exemple, en météorologie, on utilise des maillages et des simulations à partir de données récoltées pour faire des prévisions. On peut aussi les utiliser pour reproduire un phénomène physique dans des systèmes impossibles. Vous êtes-vous déjà demandé quel son produirait un gong de 2 km de large frappé en son centre par un maillet de trois tonnes ? Jamais personne n’entendra ce son, et pourtant, on peut le simuler : il suffit de mailler le gong imaginaire, en lui donnant ces dimensions délirantes, et d’y propager l’onde créée par le maillet tout aussi imaginaire. Le calcul de l’onde donne le son résultant !
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Juin : Éternelle cadette
Si vous avez, disons, une grande sœur de deux ans votre aînée, lorsque vous étiez enfant vous avez probablement eu des pensées du genre : certes, je n’ai que 4 ans alors que ma sœur en a 6, mais un jour j’aurai 7 ans et je la dépasserai ! Et pourquoi pas, après tout ? C’est logique : chaque année, vous gagnez un an, vous aurez donc forcément 7 ans un jour ou l’autre. Certes, votre sœur aussi gagne parfois un an, mais c’est compliqué, négligeons ce détail… Bien sûr, une fois adulte, vous vous rendez compte que cette ambition est vouée à l’échec : une grande soeur sera toujours plus grande.
En informatique, les propriétés (comme « être plus vieille »), qui sont toujours vraies pendant l’exécution d’un programme, s’appellent des invariants. Peut-on démontrer qu’il y a un invariant comme “être la plus vieille” pour un programme qui prendrait en entrée un entier n (l’année pour laquelle on fait le calcul) et calculerait vos deux âges cette année-là le jour de votre anniversaire ? La difficulté c’est que, dans ce programme, les deux âges ne seraient sans doute pas directement reliés par un calcul. Il n’est donc pas immédiatement évident que votre âge reste inférieur à celui de votre sœur. On pourrait laisser tourner le programme, année après année, et vérifier à chaque fois. Si on ne met pas de borne, la vérification ne s’arrêtera jamais. Alors ajoutons une borne, mais… laquelle ? 120 ans ? On a envie de prendre large, mais il ne faut pas oublier que plus la borne est grande, plus on a de calculs à faire. De plus, dans de nombreux programmes, il est impossible d’établir de telles bornes.
On peut aussi faire un raisonnement inductif : la propriété est vraie l’année de votre naissance, puisque votre grande soeur a deux ans et vous en avez 0. Si elle est vraie une année quelconque, l’année suivante les deux âges auront augmenté de 1 et donc la propriété est toujours vraie. Elle est donc éternellement vraie. On dit alors qu’on fait un raisonnement par récurrence. Ce genre de raisonnement est un des piliers de la vérification de programme, et on sait dans certains cas les algorithmiser. En vérifiant que certaines propriétés bien choisies sont toujours vraies quand on fait tourner un programme, on peut être sûr de ne pas rencontrer certains effets indésirables, par exemple que la valeur d’une variable devienne trop grande et dépasse les valeurs acceptées par la machine.
La démonstration automatique d’invariants est à la base de logiciels de vérification de codes informatiques. Ces logiciels servent en particulier à démontrer l’absence de bug dans des logiciels critiques, dans le transport aérien, les stimulateurs cardiaques, les centrales nucléaires… des situations où le coût d’un bug est jugé inacceptable. On sait aujourd’hui vérifier que le code machine d’un gros logiciel (le compilateur CompCert) est conforme à sa spécification dans un langage formel.
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Mai : Les chemins d’Internet
Internet, avec tous ses serveurs et ses fibres optiques dont certaines traversent les océans, n’a rien de virtuel. C’est un réseau gigantesque qui connecte des ordinateurs du monde entier. En fait, c’est même un réseau de réseaux, avec des connections qui permettent de passer d’un ordinateur à l’autre dans chaque réseau, et des connections entre les réseaux.
Les relations internationales obéissent à des <<protocoles>>, c’est-à-dire des règles à observer pour le bien de ces relations. Quand des millions d’ordinateurs s’échangent des données sur Internet, pour que cela fonctionne, c’est pareil : il faut qu’ils obéissent à un ensemble de règles et de conventions : le protocole Internet.
Le point de départ est un service d’adressage qui permet d’identifier les ordinateurs connectés au réseau. Une adresse est par exemple 128.93.162.84.
Ensuite, cela fonctionne de façon bizarre. On découpe les données à envoyer (votre dernière photo de vacances) en petits paquets. On met un petit paquet dans une enveloppe, on écrit les adresses du destinataire et de l’expéditeur sur l’enveloppe, et on balance à un <<voisin>> sur le réseau. On fait ça pour chaque paquet. Le système fonctionne parce que les logiciels qui composent le réseau savent <<router>> les messages : à partir de l’adresse de l’ordinateur destination, ils savent décider à quel ordinateur voisin ils doivent envoyer le paquet pour qu’il arrive un jour à destination.
L’algorithme ne garantit pas que les messages prendront le même chemin, qu’ils arriveront dans l’ordre, ni même qu’ils arriveront tous à bon port. On s’en moque ! On les remet dans l’ordre à l’arrivée. Et si besoin, on demande à la source de renvoyer le paquet 432 qui s’est perdu en route : cela aussi est prévu dans le protocole.
Il n’y a quasiment pas de gouvernance dans Internet. Cela fonctionne sur le principe du volontariat et tout ce qu’on demande à un serveur pour participer, c’est de suivre le protocole commun. On n’a pas à obéir à un chef ou à se disputer avec. Et personne n’y est indispensable ! Le protocole fonctionne malgré les arrêts, les pannes de l’un ou de l’autre. On peut d’ailleurs voir dans le succès d’Internet et son adoption universelle une démonstration de l’efficacité de l’absence de gouvernement… une fois que des règles de bases fondées sur une certaine forme d’équité, une absence de discrimination, ont été établies.
De loin en loin, quand, sur Internet, vous écoutez de la musique, vous visionnez un film, vous conversez avec un ami, ou vous surfez juste sur le web… ayez une petite pensée pour les cheminements de ces mini paquets de données qui voyagent sur le réseau pour vous. Vous savez maintenant qu’il n’y a aucune magie là-dedans, juste un protocole, un algorithme.
Jean Vuillemin Professeur à l’École Normale Supérieure, nous parle ici de multiplication égyptienne. Pourquoi ? Car cet algorithme, très ancien, est redevenu un outil majeur, sous le nom de produit binaire. Le lecteur intéressé par les détails historiques se reportera à la version disponible ici.
En 1703, Leibnitz publie son Explication de l’arithmétique binaire. Il n’utilise qu’une seule page pour donner la table des nombres binaires et décrire les 4 opérations +, −, ×, ÷ (addition, soustraction, multiplication et division). Les trois autres pages font une large place aux considérations historiques : « cette Arithmétique par 0 & 1 se trouve contenir le mystère des lignes d’un ancien Roi & Philosophe nommé Fohy, qu’on croit avoir vécu il y a plus de 4000 ans, et que les Chinois regardent comme le Fondateur de leur Empire et de leur Science ». Pouvait-il deviner que, un peu moins de trois siècles plus tard, des milliards de pucerons utiliseraient ce calcul ?
Et on retrouve cet algorithme de la multiplication sur l’antique Papyrus de Rhind !
L’égyptologue écossais Rhind achète à Louxor un Papyrus qui porte maintenant son nom et qui est conservé au British Museum. Ce Papyrus date des Hyksos (vers – 1800). Son auteur, le scribe Ahmès, indique reprendre des documents du Moyen Empire (vers – 2000).
Détail de la première moitié du papyrus Rhind, original 199,5 × 32 cm, British Museum (EA 10058).
Ce document contient une initiation à l’Art du Calcul, avec près d’une centaine d’exemples pratiques, explicites et instructifs. Faisons abstraction des premières lectures – allez voir l’article de Jean Vuillemin qui étudie le sujet en détail – et ignorons tout ce qui concerne les fractions et le texte illustratif. Le fragment de fond ainsi extrait contient une dizaine d’exemples de produits entiers avec un algorithme commun qui est la Multiplication égyptienne. Cet algorithme jusqu’à aujourd’hui tient une place unique dans l’Histoire du Calcul.
L’approche décrite réduit la multiplication à une suite d’opérations primitives, exclusivement déterminée par les valeurs des opérandes entiers. Elle est donc indépendante du choix de la numération (base de représentation des nombres), modulo les trois opérations primitives que nous allons voir.
Le carré de 12, en hiéroglyphe et en hiératique extrait de K. Sethe.
Regardons comment ça marche !
Un peu de patience et d’attention, vous verrez ce n’est pas dur… Calculons le carré de 12, donc 12 * 12 en base 10. Le point clé est que nous ne « savons pas » faire de multiplication. Ici, on a juste le droit de diviser et multiplier par deux, et faire des additions.
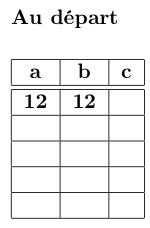
On cherche avec cet algorithme à obtenir a*b (la multiplication de a par b). Pour cela, on effectue le calcul en 3 colonnes comme sur la figure ci-dessous, avec une ligne pour chaque étape (itération). On démarre la 1ère ligne avec la valeur de a et b de départ (ici 12 * 12).
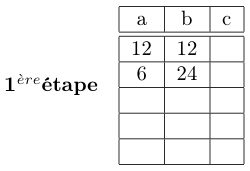
On calcule une nouvelle ligne ainsi, dans la colonne de a en calculant la division entière par 2 de la dernière valeur (ici 12 divisé par 2 = 6). On passe à la ligne suivante dans la colonne b en dupliquant b, ce qui revient à le multiplier par 2 (ici 12*2 = 24). Pour la colonne c, si le résultat précédent de la colonne a est pair, on recopie la valeur précédente de la colonne c sinon (résultat impair) on fait la somme des colonnes précédentes b et c.
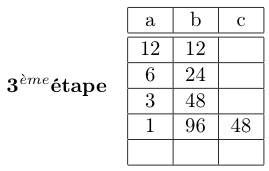
. . .
Et on obtient à la fin
Autrement dit, on «bascule » de division par deux en multiplication par deux, la valeur du nombre a sur celui du nombre b.
Mais à quoi bon faire ainsi ?
Oui ! Pour quoi, me direz vous on ressort ce vieil algorithme…Eh bien parce que le Produit Binaire[1] de Leibnitz n’est rien d’autre que la Multiplication Égyptienne, en base 2. Ce petit algorithme, du rang de CuriositéMathématique, va passer à celui d’Algorithme Fondamental avec les premiers ordinateurs, sous l’influence de Von Neumann et de bien d’autres.
En effet, la particularité de cet algorithme, c’est qu’il est très rapide: chaque division divise a par 2 (élimine un bit de a, diront les informaticiens), jusqu’à ce que a = 0.
Plus précisément: le nombre de lignes du tableau est donc égal à la longueur de l’écriture binaire de l’opérande a, soit l = l2(a) = ⌈log2(a + 1)⌉. Le calcul de a*b nécessite l= l2(a) division et l−1 duplications; ce dernier nombre correspond au nombre de bits non nuls dans l’écriture binaire de a.
Attendez ! En langage plus simple: vous prenez un nombre, disons 1024, divisons le par 2, jusqu’à trouver 0 (ici, 1024 → 512 → 256 → 128 → 64 → 32 → 16→ 8 → 4 → 2 → 1→ 0) on a fait 11 divisions alors que le nombre est un peu plus grand que 1000, bref on réduit très rapidement même un très grand nombre en le divisant successivement par deux (pour un milliard on ne fait qu’une trentaine de divisions : essayez :)). C’est pour cela que l’algorithme est très rapide (et oui c’est bien cela ce fameux logarithme que l’on apprend en maths).
La bonne nouvelle est que pour les processeurs qui travaillent en base 2, l’addition est une opération simple et la duplication (la division par 2 d’un côté et multiplication par 2 de l’autre) n’est qu’un décalage des deux nombres.
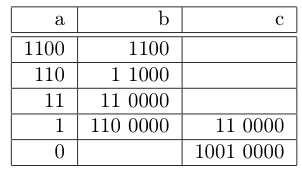
Plus précisément c’est un décalage vers les poids forts (à gauche) d’un bit, avec l’insertion d’un 0 en poids faible. La division est un décalage dans l’autre sens, et la parité c’est le bit de poids faible ainsi expulsé ! Le calcul des 3 opérations primitives devient alors simple et rapide. Pour vous en convaincre le même exemple en base 2 :
La multiplication de 12 * 12 en binaire.
c’est finalement encore plus simple en binaire, non ?
Tout microprocesseur moderne calcule chacune de ces opérations en quelques nanosecondes. Par souci d’économie, la grande majorité des processeurs ne dispose pas de multiplicateur câblé. On les dote alors d’un multiplieur logiciel en compilant le code de ce petit algorithme. Ce que le matériel ne peut pas faire directement, le logiciel le compense. C’est ainsi, que chaque microseconde, des milliards de circuits de notre monde numérique calculent à l’aide de la Multiplication égyptienne en base 2.
Nous continuons la rubrique « Si j’étais un algorithme » avec Anne-Marie Kermarrec qui est Directrice de Recherche Inria à Rennes, et récemment CEO and co-fondatrice de la startup « Mediego ». C’est une spécialiste, entre autres, des systèmes distribués en pair-à-pair, et des algorithmes épidémiques. Anne-Marie, une longue contributrice et amie de Binaire, a choisi de nous parler justement d’algorithmes épidémiques. Serge Abiteboul. Cet article est publié en collaboration avec The Conversation.
Aujourd’hui, difficile de faire un faux pas quand on est une célébrité sans que le monde entier ne soit au courant… Échapper au buzz quand il se manifeste à l’échelle planétaire relève de l’impossible : qu’on le veuille ou non, chacun d’entre nous a fini par vaguement se dandiner sur le rythme de Gangnam Style, cet improbable coréen, devenu brutalement une star du Web. Et les exemples foisonnent. On parle d’ailleurs de diffusion virale, on met en garde nos adolescents « soyez vigilants au sujet des contenus que vous postez sur Facebook, ils se diffusent comme une trainée de poudre ». Comment cette information se propage exactement ? Pourquoi est-ce un modèle de communication si efficace ? Et bien, tout cela est orchestré par des algorithmes de diffusion épidémique.
Épidémique ?
Une épidémie est une maladie, comme la grippe, la peste, le choléra, qui se propage très rapidement au sein d’une population et le plus souvent par contagion de personne à personne. Tiens, c’est aussi comme ça qu’une rumeur se propage, très vite, entre des personnes qui se croisent et qui, de manière extrêmement efficace et décentralisée, diffusent cette rumeur. Épidémies et rumeurs se caractérisent par une contamination très rapide et très efficace et il s’avère que les mathématiques sous-jacentes, les mathématiques épidémiques, ont été très étudiées dans de nombreux domaines.
Le rapport avec l’informatique ?
Si nous remplaçons les gens par des ordinateurs et les commérages par des messages électroniques, nous obtenons un nouveau modèle de communication fiable, rapide, capable de passer à l’échelle. C’est le Graal pour diffuser une information rapidement sur Internet !
Justement, les algorithmes épidémiques ont été utilisés dans de nombreux contextes sur Internet : pour diffuser des messages à un très grand nombre de gens, pour améliorer la qualité et la latence du streaming vidéo, pour surveiller de grands systèmes informatiques comme par exemple s’assurer qu’aucun ordinateur n’est défaillant dans un centre de données ou encore tout simplement pour diffuser des données sur les réseaux sociaux.
Pourquoi ces algorithmes épidémiques sont-ils si séduisants pour la diffusion. Dans tous ces contextes, l’objectif est d’envoyer une information (la vidéo, un tweet, une alerte, etc.) à un grand nombre de destinataires. Quels sont les critères qui importent ? Que l’information arrive (1) vite et (2) à tout le monde. Les algorithmes candidats pour ce faire sont nombreux.
@Maev59
Les algorithmes centralisés
C’est la solution qui vient en premier à l’esprit : on confie la responsabilité de l’envoi de l’information à l’ensemble des destinataires à un serveur central. En théorie, le message arrive vite et bien (c’est à dire à tout le monde). Oui, mais deux problèmes se posent quand on l’applique à un système informatique de très grande taille.
Le serveur central doit faire tout le travail et le « tuyau de communication » qui sort de cette entité pour aller sur Internet a bel et bien un diamètre limité (on parle de bande passante). Donc le serveur ne peut pas envoyer simultanément les messages à des millions de destinataires, il faut qu’il les envoie l’un après l’autre… Et ça prend du temps.
Le deuxième problème, c’est que ce serveur central doit rester au top pendant tout le processus. Si pour une raison ou une autre il est défaillant (panne de courant, bug, attaque), les destinataires qui n’avaient pas encore reçu le message ne le recevront pas toute de suite, peut-être jamais. Et il n’est pas nécessaire de vous dire que les ordinateurs ne fonctionnent pas toujours comme ils le devraient. Vous avez sûrement déjà remarqué.
Les algorithmes hiérarchiques
Une alternative est d’organiser tous les destinataires en une hiérarchie, un arbre par exemple, pour se partager le boulot. L’envoyeur original envoie le message à n destinataires, qui chacun le renverront à n autres, etc. Cette solution nous force tout d’abord à organiser tous les destinataires en arbre mais elle présente l’avantage d’éviter qu’un seul serveur fasse tout le travail. Tous les nœuds intermédiaires de l’arbre participent. Le message arrive assez rapidement à chacun. En revanche, si un des ces intermédiaires tombe en panne, tous les destinataires qui en dépendent ne le recevront peut-être jamais. Avec cette technique, on a résolu le passage à l’échelle mais les défaillances posent toujours problème.
@Maev59
Les algorithmes épidémiques, c’est mieux !
Remarquez que les épidémies continuent à se propager si quelques personnes sont clouées au lit avant d’avoir pu transmettre le virus à quiconque et les rumeurs ne sont clairement pas étouffées parce que quelques personnes bien intentionnées résistent à la tentation de les colporter.
Diffuser de l’information avec un algorithme épidémique dans un très grand système consiste donc d’abord à demander à tous les destinataires de participer pour être certain que cela fonctionnera même avec un grand nombre de destinataires. Il faut ensuite accepter qu’un nœud reçoive plusieurs fois le même message : c’est le prix pour résister aux pannes. Enfin, il faut utiliser l’aléatoire pour éviter que le nombre de messages ne devienne abusif et avoir de bonnes propriétés de propagation.
Considérons donc une entité qui doit envoyer une information à un très grand nombre N de destinataires.
L’entité choisit au hasard n destinataires et leur envoie l’information.
À la réception de ce message, chaque destinataire
S’il a déjà reçu l’information, ne fait rien (il est déjà infecté).
Sinon, il devient infecté et il contribue alors à la dissémination : il choisit à son tour n destinataires au hasard et leur envoie l’information.
Et ainsi de suite, jusqu’à ce que l’information cesse d’être diffusée car l’ensemble des N destinataires a été déjà infecté.
Cet algorithme est rapide, capable de passer à l’échelle et supporte admirablement bien les défaillances des uns et des autres. Il est rapide car le nombre de personnes recevant le message se multiplie à chaque étape lors de la première phase (ensuite bien entendu, il est de moins en moins probable de toucher quelqu’un« non-infecté´´). Mais il est fiable car la probabilité que tous les destinataires reçoivent l’information est très très élevée, y compris si certains destinataires ne transmettent pas l’information, parce qu’ils sont en panne par exemple. Il passe à l’échelle car si chaque participant doit envoyer son information à un nombre n de destinataires environ égal au logarithme de N, alors toutes ses propriétés sont garanties. Logarithme ? Par exemple si chaque entité transmet son information à 6 destinataires dans un système de 1 million de participants, cela convient. De plus sa charge de travail passe à 9, donc augmente très peu quand on passe à un système de 1 milliard de participants. C’est dans tous les cas beaucoup plus faible que le nombre d’amis que chacun d’entre nous a sur Facebook !
Vous avez dit « logarithme´´ ? La définition informatique est très facile !
C’est tout simplement «combien de fois je peux diviser un grand nombre par un autre nombre, disons dix». On essaye ? Prenons N = 1000 destinataires, divisé par dix, cela fait 100, divisé encore par dix, cela fait 10, et encore divisé par dix, voilà 1, divisé par dix, ah … non, ce n’est pas possible, on a fini. Je peux donc diviser N = 1000, n = 3 fois de suite par dix avant de trouver 1. Le logarithme décimal de 1000 est donc 3. Celui de un million ? Ce sera 6, essayez.
En tout, c’est plus facile à expliquer que la définition mathématique 🙂
En fait il existe beaucoup d’autres algorithmes épidémiques qui se distinguent par exemple, par le choix des destinataires, comme les « influenceurs » qui ont de nombreux followers sur Twitter. Pour certains autres de ces algorithmes, c’est le destinataire qui demande, quand il le souhaite, le message, etc.
Des algorithmes, qui fonctionnent un peu comme les épidémies ou les rumeurs, permettent des mécanismes de diffusion puissants, efficaces et robustes aux défaillances, bien adaptés aux très grands systèmes informatiques dont la taille ne cesse d’augmenter. Et puis ces algorithmes peuvent très facilement être mis en œuvre sans aucune autorité centrale, ce qui est pratique dans le cas de nombreux systèmes, par exemple, les systèmes de l’internet des objets, très tendances !
Nous continuons cette rubrique avec Gilles Dowek qui est Directeur de Recherche Inria et Enseignant à l’École Normale Supérieure de Cachan. Gilles est un informaticien, qui a déjà contribué à Binaire. Il est, entre autres, spécialiste mondial de démonstration automatique. Gilles a choisi de nous parler de l’algorithme d’unification de Robinson au travers d’un problème que cet algorithme permet de résoudre. Pour une présentation plus formelle, vous pourrez trouver des détails dans un article (qui se mérite) de Wikipédia. Serge Abiteboul, Charlotte Truchet.
Gilles Dowek [Wikipédia]En français, l’algorithme pour calculer le pluriel d’un nom commun consiste à lui ajouter la lettre « s » à la fin, sauf pour
les mots qui se terminent par les lettres « s », « x » et « z », dont le pluriel est identique au singulier,
les mots qui se terminent par les lettres « au », « eau », « eu », dont le pluriel est obtenu en ajoutant la lettre « x » à la fin, et
les mots qui se terminent par les lettres « al », dont le pluriel est obtenu en supprimant ces deux lettres, puis en ajoutant les lettres « aux » à la fin du mot ainsi obtenu.
Il y a, en outre, quelques dizaines d’exceptions à cette règle, parmi lesquelles : pneus, hiboux, festivals, coraux, yeux…
Quand on cherche à exprimer cet algorithme dans un langage de programmation, on commence par tester si le mot dont on cherche à « calculer » le pluriel est dans la liste des exceptions. Si ce n’est pas le cas, on teste si ce mot se termine par « s », « x » ou « z », puis si ce mot se termine par « au » …
Qu’est-ce qu’un mot qui se termine par « s » ?
Quand on applique cet algorithme, par exemple, au mot « souris », on doit donc, à un certain moment, tester si ce mot se termine par la lettre « s ». Pour cela on calcule en général la dernière lettre de ce mot, puis on la compare avec la lettre « s ». Toutefois cette manière de faire est fastidieuse et on obtient une expression plus élégante de l’algorithme si on définit les mots qui se terminent par la lettre « s » comme les mots de la forme y + « s », où y est n’importe quelle suite de lettres. Ainsi, le mot « souris » se termine par la lettre « s » car il peut se décomposer en « souri » + « s ». L’algorithme se reformule alors facilement de la manière suivante
(1) y + « s » → y + « s » (2) y + « x » → y + « x » (3) y + « z » → y + « z » (4) y + « au » → y + « aux » (5) y + « eau » → y + « eaux » (6) y + « eu » → y + « eux » (7) y + « al » → y + « aux » (8) y → y + « s »
La septième règle (y + « al » → y + « aux ») est particulièrement élégante : « cheval » se décompose en « chev » + « al », dont le pluriel est donc « chev » + « aux ». Pas besoin de supprimer les deux dernières lettres « al ». Le fait d’avoir défini les mots qui se terminent en « al » comme ceux qui se décomposent en y + « al », nous donne directement accès à la suite de lettres y : « chev ».
La huitième règle (y → y + « s ») est celle qui exprime que le pluriel d’un mot se calcule, en général, en ajoutant un « s » à la fin du mot. Elle peut en théorie toujours s’appliquer. C’est pourquoi, il faut, dans la formulation de cet algorithme, définir une priorité entre les règles. Quand deux règles peuvent s’appliquer : par exemple la septième (« chev » + « al » → « chev » + « aux ») et la huitième (« cheval » → « cheval » + « s »), c’est la première, dans l’énumération ci-dessus, qui prime.
Cette notion de priorité permet aussi d’incorporer les quelques dizaines d’exceptions, comme des règles qui s’appliquent à un mot unique, par exemple « festival » → « festivals », qui doit bien entendu primer sur y + « al » → y + « aux ».
Cette notion de priorité entre règles est la signification du mot « exception », si fréquent en grammaire : dire que la règle « festival » → « festivals » est une exception à la règle y + « al » → y + « aux » est dire que quand les deux s’appliquent, c’est première qui prime.
De la reconnaissance de forme à la résolution d’équations
Une fois l’algorithme de la mise d’un mot au pluriel ainsi exprimé sous la forme d’une liste de règles, il faut, pour l’exécuter, être capable de reconnaître que le mot « souris », par exemple, est de la forme y + « s », mais non de la forme y + « al » – autrement dit, qu’il se termine par « s », mais non par « al ». Cette notion de « reconnaissance de forme » est en fait identique à une autre notion plus familière : celle de résolution d’équation.
Reconnaître que le mot « souris » est de la forme y + « s » c’est reconnaître que l’équation
y + « s » = « souris »
a une solution : y = « souri », alors que l’équation
y + « al » = « souris »
n’en a pas. Et il faut, pour résoudre ces équations portant sur des expressions linguistiques – mots, arbres, etc. – d’autres algorithmes, que l’on appelle « algorithmes d’unification ».
Une question pour les plus joueurs parmi les lecteurs de Binaire : chercher toutes les solutions de l’équation y1+ « a » + y2 + « a » + y3 = « abracadabra »
On a longtemps cru que le premier algorithme d’unification avait été proposé par J. Alan Robinson en 1965. Le problème que cherchait à résoudre Robinson n’était pas celui d’exprimer des règles de grammaire, mais celui de concevoir des algorithmes pour démontrer des théorèmes. La question que se posait Robinson était celle de comprendre comment, sachant que pour tout a et b,
(a + b)² = a² + 2 × a × b + b²
nous pouvions déduire que :
(5 + 3)² = 5² + 2 × 5 × 3 + 3²
La solution proposée par Robinson pour reconnaître que
« (5 + 3)² = 5² + 2 × 5 × 3 + 3² »
est un cas particulier de l’identité remarquable « pour tout a et b,
(a + b)² = a² + 2 × a × b + b² »
était de résoudre l’équation, qui porte sur des expressions – et non sur des nombres –
Et pour cela, il a conçu un algorithme : l’algorithme d’unification de Robinson. Ce n’est que quelques années plus tard que l’on s’est rendu compte de toute la puissance de cet algorithme, notamment pour programmer avec des règles, notamment en grammaire.
L’algorithme de Robinson, consiste à simplifier, étape par étape, les équations, jusqu’à obtenir des équations dont le membre gauche n’est qu’une variable. Il s’illustre simplement sur l’exemple
cette équation porte sur deux expressions « (a + b)² = a² + 2 × a × b + b² » et « (5 + 3)² = 5² + 2 × 5 × 3 + 3² », qui expriment elles-mêmes l’égalité de deux termes. Pour rendre ces deux expressions identiques, il faut rendre identiques les membres gauches de ces deux égalités et leurs membres droits, ce qui mène au système de deux équations, plus simple :
« (a + b)² » = « (5 + 3)² »
« a² + 2 × a × b + b² » = « 5² + 2 × 5 × 3 + 3² »
Ce système se simplifie, de même, à son tour en :
« a + b » = « 5 + 3 »
« a² + 2 × a × b + b² » = « 5² + 2 × 5 × 3 + 3² »
puis en :
« a » = « 5 »
« b » = « 3 »
« a² + 2 × a × b + b² » = « 5² + 2 × 5 × 3 + 3² »
puis en
« a » = « 5 »
« b » = « 3 »
« a² » = « 5² »
« 2 × a × b » = « 2 × 5 × 3 »
« b² » = « 3² »
etc. jusqu’à donner à la fin
« a » = « 5 »
« b » = « 3 »
« a » = « 5 »
« a » = « 5 »
« b » = « 3 »
« b » = « 3 »
dont la solution est évidemment a = « 5 » et b = « 3 ».
Cela dit, les grands algorithmes ont souvent un précurseur et les historiens ont découvert plus tard que, dès les années trente du XXe siècle, le logicien Jacques Herbrand avait conçu l’un des premiers algorithmes d’unification. Par cette contribution involontaire à la démonstration automatique, Herbrand a donné son nom à un prix, remis chaque année à un chercheur pour « sa contribution remarquable à la démonstration automatique », prix que Robinson a reçu en 1996.
Nous démarrons cette rubrique avec Laurent Fribourg qui est Directeur de Recherche CNRS au Laboratoire Spécification et Vérification de l’ENS Cachan. Laurent est informaticien, spécialiste de vérification automatique de modèles de systèmes concurrents. Serge Abiteboul.
Laurent Fribourg [Site Web personnel]Ulam, mathématicien et calculateur prodige, travaillait à Los Alamos en 1946 sur le développement de la bombe H (l’arme qui allait redonner la prépondérance aux États-Unis qui venaient bêtement de s’être fait piquer les plans de la bombe A). Entre autres choses, Ulam était passionné par les problèmes de combinatoire. La combinatoire (ou science du dénombrement) vise à compter le nombre de solutions d’un problème donné : par exemple, on apprend à l’école que, pour un ensemble à n éléments, le nombre de sous-ensembles à p éléments est égal à (n*(n-1)…*(n-p+1))/(p*(p-1)*…1). Justement, Ulam se cassait la tête sur un problème compliqué de combinatoire lié à la diffusion des neutrons. Et voilà qu’il tombe malade. Cloué au lit, il se met à faire des réussites pour passer le temps, et se pose machinalement un petit problème amusant de combinatoire : quelle est la proportion de parties gagnantes sur le nombre total de parties ? En d’autres termes, en supposant que le tirage des cartes est équiprobable, quelle est la probabilité de gagner en jouant au hasard ? Malheureusement, sans doute affaibli, il échoue à trouver la solution. Dépité, il « triche » en comptant sur une centaine de parties jouées le nombre de parties gagnées. Il sélectionne ainsi un échantillon statistique pour obtenir une solution approchée à son problème combinatoire. La loi des grand nombres lui assure que plus grande est la taille de l’échantillon, plus grande est sa chance d’avoir une bonne approximation.
Tel Archimède sortant tout nu de sa baignoire, il se précipite en pyjama chez son collègue et chef, John von Neumann, pour lui raconter sa découverte. Von Neumann était un mathématicien et physicien américano-hongrois, et ce qui nous intéresse particulièrement ici, un informaticien de génie.
Von Neumann était lui-même en train de se détendre en écrivant de petits programmes pour le super-ordinateur ENIAC qu’il avait conçu et fait construire pour résoudre des équations de physique nucléaire. L’idée d’Ulam est simple : simulons de très nombreuses réactions de diffusion de neutrons en utilisant, à chaque fois qu’il y a un choix entre plusieurs évènements, un tirage aléatoire de la même façon qu’on tire des cartes pour faire une réussite. Von Neumann, emballé, pose et résout en quelques jours les éléments algorithmiques qui permettent de répondre aux questions d’implémentation de la méthode comme :
comment faire générer à un ordinateur des nombres aléatoires ?
Comment simuler de manière aléatoire des réactions de diffusion de neutrons ?
Comment générer des distributions de probabilité non uniformes (tous les évènements n’ont pas la même probabilité de se produire) ?
Comment converger plus rapidement vers le résultat ?
Von Neumann va programmer tout ça assez rapidement, ce qui va relancer le programme de la bombe H pour aboutir en 1952 à une explosion thermonucléaire (Toujours facétieux, les Russes vont en faire sauter une plus chouette quelques semaines plus tard. « Rien ne va plus !» dira Ulam.) Un jeune physicien de l’équipe de Los Alamos, Nick Metropolis, enthousiaste lui aussi, propose le nom de « Monte Carlo » pour la méthode en raison du penchant supposé d’Ulam pour les jeux de chance et d’argent.
Bien entendu, c’est un Français qui avait inventé le procédé des siècles auparavant : en l’occurrence, le grand naturaliste Buffon qui s’amusait, lui, à lancer une aiguille sur des lattes en bois de même largeur pour calculer le nombre pi. (Comme le casino de Monte Carlo n’existait pas à l’époque, son nom n’est pas lié à un algorithme, mais fait plutôt penser au zoo du Jardin des Plantes.)
L’équipe de Los Alamos était si enthousiaste qu’elle a organisé peu après (1949) un workshop sur la méthode, sponsorisé par RAND et Oak Ridge Laboratory. C’était le début d’un grand succès de l’algorithmique, qui va conduire à des réalisations moins inquiétantes que la bombe H, comme par exemple la victoire de l’ordinateur sur l’homme au jeu de Go [2].
Et si je devais être un algorithme, quel algorithme serais-je ?
Tant qu’à faire, j’aurais bien aimé être la version améliorée de Monte Carlo, appelée « Monte Carlo Markov Chain », mais l’éditeur de Binaire a trouvé que c’était trop compliqué. Si la suite des aventures du jeune Nick vous intéresse, vous pouvez consulter la page « MCMC ».
Laurent Fribourg, CNRS & ENS Cachan
Références
[1] C. Robert & G. Casella. “A short history of Markov Chain Monte Carlo: Subjective recollections from incomplete data”. Handbook of Markov Chain Monte Carlo, chapter 2, 2011.
[2] O. Teytaud et al. “The Computational Intelligence of MoGo Revealed in Taiwan’s Computer Go Tournaments”. IEEE Transactions on Computational Intelligence and AI in games, 2009.

 En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau Jean Vuillemin
Jean Vuillemin

 . . .
. . . 




![[Wikipeédia]](/wp-content/uploads/2016/06/Gilles_Dowek-200x300.jpg)
![Laurent Fribour [Site Web personnel]](/wp-content/uploads/2016/06/laurent-300x225.jpeg)