Angie Gaudion, chargée de relations publiques au sein de Framasoft, revient sur l’histoire de l’association, son financement, son évolution, leur positionnement dans l’écosystème numérique et, plus largement, le soutien apporté aux communs numériques. Cet article a été publié le 21 octobre 2022 sur le site de cnnumerique.fr et est remis en partage ici, les en remerciant. Serge Abiteboul et Thierry Viéville.
Framasoft, qu’est-ce que c’est ?
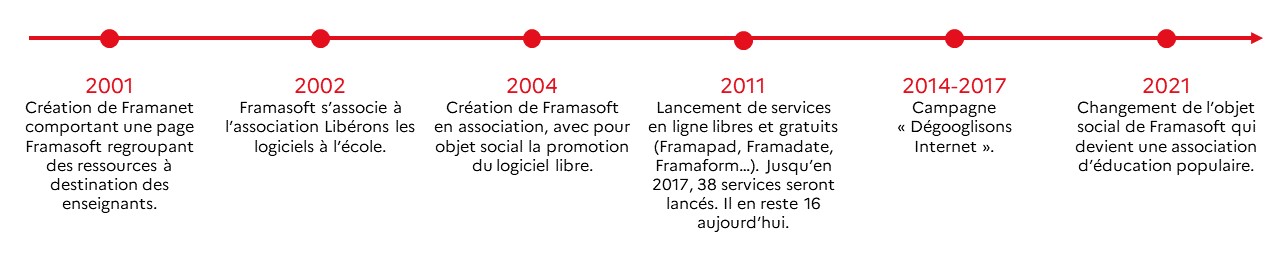
Pour comprendre Framasoft, il faut s’intéresser à son histoire. Née en 2001, Framasoft était d’abord une sous-catégorie du site participatif Framanet, lequel regroupait des ressources à destination des enseignants et mettait en avant des logiciels éducatifs gratuits (libres et non-libres). Framasoft est devenu « indépendant » et 100% libre plusieurs années plus tard. Mais il y a déjà une volonté de valoriser le logiciel libre dans le milieu de l’enseignement. D’ailleurs, en juin 2002, Framasoft est, avec l’AFUL, à l’origine de l’action Libérons les logiciels libres à l’école.
Entre 2001 et 2004, un collectif se structure autour de la promotion des logiciels libres et propose des interventions sur ces questions (conférences, ateliers, stands, etc.). C’est en 2004 que Framasoft se structure en association avec pour objet la promotion du logiciel libre et de la culture libre. Pour atteindre cet objectif, apparaissent entre 2004 et 2014 plusieurs projets comme les Framakey (clé USB contenant des logiciels libres permettant de les utiliser sans avoir à les installer sur son ordinateur), Framabook (maison d’édition d’ouvrages sous licence libre), Framablog (chroniques autour du Libre, traductions originales et annonces des nouveautés de l’ensemble du réseau Framasoft), etc…
À partir de 2011 (10 ans), Framasoft se diversifie et décide de proposer des services libres en ligne : Framapad (mars 2011), Framadate (juin 2011), Framacalc (février 2012), Framindmap et Framavectoriel (février 2012), Framazic (novembre 2013) et Framasphère (2014).
En octobre 2014, nous lançons la campagne “Dégooglisons Internet” dont l’objectif est de proposer des services libres alternatifs à ceux proposés par les géants du web à des fins de monopole et d’usage dévoyé des données personnelles. Cette campagne nous fait connaître du grand public et, entre 2014 et 2017, on déploie jusqu’à 38 services en ligne. L’égalité de l’accès à ces applications est un engagement fort : en les proposant gratuitement, Framasoft souhaite promouvoir leur usage envers le plus grand nombre et illustrer par l’exemple qu’un Internet décentralisé et égalitaire est possible. En parallèle, nous lançons en 2016 le Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS). Framasoft cherche a faire connaître et essaimer des hébergeurs alternatifs aux GAFAM proposant des services libres et respectueux de la vie privée. En effet, nous ne souhaitons pas concentrer toutes les démarches alternatives, mais plutôt partager le gâteau avec d’autres structures (nous ne voulons pas devenir “le Google du libre”).
2017 marque la fin de la campagne “Dégooglisons Internet” : les services existants sont conservés mais nous n’en déployons plus de nouveaux. Depuis 2019, nous avons fermé progressivement une partie de ces services. Nous avons fait le choix de ne conserver que ceux qui n’étaient pas proposés ailleurs et ceux qui sont les plus utilisés. Par exemple, le service Framalistes (un outil de listes de discussion) est utilisé par 960 000 personnes et envoie chaque jour près d’un million d’emails. On sait donc que si l’on supprime ce service, cela manquera aux personnes qui l’utilisent. La décision d’arrêter certains services a aussi été prise en fonction de la difficulté technique à les maintenir. Par exemple Framasite était utilisé par de nombreuses personnes mais présentait une dette technique énorme. Néanmoins, depuis son arrêt, nous nous rendons bien compte que le service manque parce qu’il n’y a pas vraiment d’alternatives.
2017, c’est aussi le lancement de la campagne Contributopia. On est parti du constat que pour changer le positionnement des gens, il fallait non plus faire pour elleux, mais avec elleux (faire ensemble). L’objectif est de décloisonner le libre de son ornière technique pour développer ses valeurs éthiques et sociales (donc politiques). On a donc décidé de proposer différents dispositifs pour valoriser la contribution (méconnue, mal valorisée et trop complexe) et outiller celles et ceux qui veulent « faire » des communs. Contributopia prend de nombreuses formes : on continue à développer des alternatives lorsqu’elles n’existent pas (PeerTube, Mobilizon), on essaie de faire émerger d’autres acteurices à l’international, on développe les partenariats avec des structures dont les valeurs sont proches des nôtres pour les outiller (archipélisation). Et on essaie d’être le plus résilient en faisant tout cela, tout en valorisant la culture du partage.
En 2021, nous actons, par la modification des statuts, que Framasoft est devenue une association d’éducation populaire aux enjeux du numérique et des communs culturels. Notre objet social n’est plus de faire la promotion du logiciel libre, mais de transmettre des connaissances, des savoirs et de la réflexion autour de pratiques numériques émancipatrices. Pourtant, nous continuons à offrir des services en ligne afin de démontrer que ces outils existent et sont des alternatives probantes aux services des géants du web. Nous transmettons davantage désormais connaissances et savoirs-faire sur ces outils et accompagnons les internautes dans leur autonomisation vis-à-vis des géants du web.
Aujourd’hui, 37 personnes sont membres de l’association, dont 10 salariées. Mais cela ne veut pas dire que nous ne sommes que 37 à contribuer. On estime qu’entre 500 et 800 personnes nous aident régulièrement, que ce soit pour de la traduction d’articles, des propositions de lignes de codes pour les logiciels que nous développons, du repérage de bugs, des illustrations, des contributions au forum d’entraide de la communauté… Pour finir, en terme de nombre de bénéficiaires, on ne peut donner qu’une estimation parce que nous ne collectons quasiment aucune donnée, mais on estime à 1,2 millions le nombre de personnes qui utilisent nos services chaque mois. Cependant, on ne s’attarde pas vraiment sur les chiffres, on ne veut pas d’un monde où on compte, d’un monde où on analyse systématiquement l’impact.
Quel est votre modèle de financement ?
Framasoft est actuellement une association dont le modèle économique repose sur le don, donc exclusivement sur des financements privés. Notre budget s’élève à 630 000 € en 2021. 98,42 % de ce montant est financé par les dons, qui se répartissent entre :
- 12,56 % provenant de fondations
- 85,86 % provenant de dons de particuliers.
Les 1,58 % qui ne proviennent pas des dons viennent de la vente de prestations. Par exemple, Framasoft a développé pour le site apps.education.fr un plugin d’authentification unique sur PeerTube, permettant de connecter au service la base de tous les login et mots de passe d’enseignants à l’échelle nationale et d’éviter ainsi qu’ils aient à se créer un nouveau compte.
Ce budget sert principalement à financer les salaires des 10 salariées. À cela s’ajoutent quelques prestations techniques (développement et design), du soutien à d’autres acteurs du logiciel libre et des frais de fonctionnement divers.
Cette question du mode de financement est particulièrement importante pour nous. Le modèle du don convient parfaitement à Framasoft même si nous sommes conscients qu’il est difficilement reproductible pour des projets de grande envergure. Cela reste un choix politique. Nous savons que de nombreuses structures du libre sont aujourd’hui financées par les géants du net. C’est un paradoxe assez fort, d’autant plus qu’il est évident que toutes ces structures préféreraient que ce ne soit pas le cas. Mais en l’absence d’autres sources de financement, elles n’ont pas toujours le choix. Et il serait vraiment dommage que les services qu’elles proposent n’existent pas faute de financement. Il y a donc un réel enjeu de soutien de ces structures, notamment pour assurer leur pérennité.
Que pensez-vous de l’idée ou des réactions de celles et ceux qui se disent que les initiatives du libre ont du mal à « passer à l’échelle » ?
Pour mettre fin à la dépendance envers les géants du numériques, un moyen d’y parvenir, sans avoir besoin d’acquérir une taille critique et une position dominante est de s’associer à d’autres projets et de collaborer ensemble à une autre vision du web.
On peut s’interroger sur cette recherche permanente de croissance : s’il est indispensable que des services alternatifs aux modèles dominants du net existent, est-ce nécessaire qu’une seule et même entité concentre l’ensemble des services ? La centralisation peut conférer une certaine force, mais chez Framasoft nous avons fait le choix de nous passer de cette force : l’essaimage nous semble le meilleur moyen de passer à l’échelle. Si la priorité est de mettre fin à la dépendance envers les géants du numériques, un moyen d’y parvenir, sans avoir besoin d’acquérir une taille critique et une position dominante est de s’associer à d’autres projets et de collaborer ensemble à une autre vision du web.
Chez Framasoft, nous ne souhaitons pas le passage à l’échelle. D’ailleurs, nous ne savons même pas de quelle échelle on parle ! Dans les faits, l’association a grossi au fil du temps, mais notre volonté est d’avoir une croissance limitée et raisonnée parce que nous sommes convaincus qu’il vaut mieux être plusieurs acteurs qu’un seul. Nous ne voulons donc pas centraliser les usages et les profits. Si le but premier est d’avoir de plus en plus d’utilisateurs de logiciels libres – ce qui était l’objectif avec « Dégooglisons Internet » – peu importe que ce soit chez Framasoft ou chez d’autres. Tant que les internautes ont fait leur migration vers des logiciels libres, pour nous le « passage à l’échelle » est réussi. C’est une vision différente des structures productivistes : nous visons un « passage à l’échelle » côté utilisateurs et non côté entreprise. La priorité, pour nous, c’est le changement de société.
Le passage à l’échelle pose aussi, selon nous, la question de la façon dont on traite les humains. Si l’on veut prendre soin des humains il faut des relations de confiance et d’empathie entre individus. Tisser de tels liens nous semble difficile si l’on est sans cesse en train de doubler nos effectifs. Cela explique aussi le fait que nous soyons une association de cooptation où tout le monde se connaît.
Du fait de notre ADN issu du logiciel libre, nous ne voulons pas entrer dans le modèle du capitalisme néolibéral et du productivisme. Nous tenons à défendre le modèle associatif. Nous sommes dans un contexte où les associations et leurs financements sont très mis à mal par les politiques publiques de ces dernières années. C’est donc un véritable choix que de garder ce modèle pour le soutenir et montrer que le modèle économique du don est viable.
Nous visons un « passage à l’échelle » côté utilisateurs et non côté entreprise. La priorité, pour nous, c’est le changement de société.
Si on rentre plus précisément dans la perspective de « Dégooglisation », comment vous positionnez-vous par rapport aux géants du web ?
Notre objectif est de permettre à toute personne qui le souhaite de remplacer les services des géants du web qu’elle utilise par des alternatives. Nous ne nous positionnons donc pas vraiment en concurrence car, en tant qu’hébergeurs de services alternatifs, nous ne cherchons pas systématiquement à reproduire à l’identique les services de ces géants. Par exemple, le service Framadate propose exactement les mêmes fonctionnalités que Doodle (et même davantage puisqu’il permet de réaliser des sondages classiques). En revanche, le service Framapad (basé sur le logiciel Etherpad) ne fait pas exactement la même chose que Google Docs et pourtant nous considérons que c’est son alternative. Il ne permet pas la gestion d’un espace de stockage, mais simplement l’édition collaborative en simultané d’un texte. Le service est chrono-compostable : le pad disparaît après un certain délai. Nous avons proposé une alternative à Google Drive avec le service Framadrive que nous avons limité à 5 000 comptes, lesquels ont été pris d’assaut. Nous allons prochainement proposer un nouveau service alternatif de cloud et d’édition collaborative basé sur le logiciel Nextcloud. Ce service ne sera pas commercialisé et sera proposé aux organisations actrices du progrès et de la justice sociale avec des limitations (taille du stockage, nombre d’utilisateurs) pour leur montrer qu’il existe une alternative viable et les inciter à transiter dans un second temps vers des services libres plus complets proposés par certaines structures membres du collectif CHATONS. Notre objectif est de permettre d’expérimenter et ensuite de rediriger vers d’autres partenaires proposant, eux, des solutions pérennes.
J’aimerais que l’on (les hébergeurs de services alternatifs) devienne une alternative viable à grande échelle. Ce serait possible, mais cela voudrait dire que nous aurions changé très fortement le système. On peut se dire qu’avec le mouvement fort des communs, et pas uniquement des communs numériques, une partie de la population a pris conscience qu’il est temps de mettre en cohérence ses usages numériques avec ses valeurs. Il demeure cependant ardu de mesurer si ces initiatives augmentent. La question est : que mesure-t-on ? Est-ce que l’on mesure le nombre de projets ? Ou le nombre de personnes dans ces communautés qui gèrent des communs ? À cet égard, il y a un enjeu de sous-estimation parce que beaucoup de « commoners » s’ignorent comme tels. Les bénévoles qui gèrent des associations sportives sont un bon exemple. Ensuite, plus que de dénombrer ces projets, il serait plus intéressant d’en analyser l’impact sur la société. Cela implique de financer la recherche pour qu’elle travaille sur ces questions, ce qui n’est pas suffisamment le cas aujourd’hui. Même si quelques projets existent néanmoins, tels que le projet de recherche TAPAS (There Are Platforms As Alternatives).
L’État contribue-t-il aujourd’hui aux communs ? Cette contribution est-elle souhaitable ?
L’État contribue aux communs. Par exemple, l’Éducation nationale propose la page apps.education.fr qui référence un ensemble de services pédagogiques en ligne basés sur du logiciel libre. Mais l’État est paradoxal : il contribue aux communs et signe des accords avec Microsoft pour implémenter Windows sur les postes informatiques des écoles. De plus, cette initiative de l’Éducation nationale est très bonne, mais elle reste très méconnue du corps enseignant. Au-delà de la contribution, il y a donc aussi un enjeu important de promotion.
Cette contribution étatique ne nous pose aucun problème, tant que cela ne crée pas de situations de dépendance et qu’il n’y a pas d’exigences de ces institutions publiques en termes d’impact ou de performance. Il faudrait, notamment, que les financements soient engagés sur plusieurs années. Il faudrait aussi arrêter le financement de projets et privilégier des financements du fonctionnement. Ensuite, nous pensons que certains dispositifs mis en place ces dernières années par les pouvoirs publics ne devraient pas exister. Par exemple, le contrat d’engagement républicain, qui doit obligatoirement être signé par une association pour qu’elle puisse bénéficier de financements publics, met ces dernières dans des positions difficiles. L’association doit satisfaire aux principes qui y sont présentés et, si tel n’est pas le cas, le financement peut être suspendu, voire il peut être demandé de rembourser les montants précédemment engagés. Mais la forme sous laquelle ce contrat est rédigé est si floue que les termes utilisés peuvent être interprétés de multiples manières. Il devient alors assez facile de tordre le texte pour mettre la pression, voire faire cesser l’activité d’une association. Ce n’est donc pas le principe de ce contrat qui me gêne, mais ce flou sur la formulation des termes qui fait qu’on ne sait pas où est la limite de son application. C’est d’ailleurs ce qui s’est passé le 13 septembre dernier quand le Préfet de la Vienne a sommé par courrier la ville et la métropole de Poitiers de retirer leurs subventions destinées à soutenir un village des alternatives organisé par l’association Alternatiba Poitiers. Pour quel motif ? Au sein de cet événement, une formation à la désobéissance civile non-violente a été jugée « incompatible avec ce contrat d’engagement républicain ». Signée par 65 organisations (dont Framasoft), une tribune rappelle que la désobéissance civile relève de la liberté d’expression, du répertoire d’actions légitimes des associations et qu’elle s’inscrit dans le cadre de la démocratie et de la république.
Framasoft est aussi signataire de la tribune Pour que les communs numériques deviennent un pilier de la souveraineté numérique européenne parue en juin dernier. En effet, dans le cadre des travaux engagés au sein de l’Union européenne, il semblait important de rappeler quel’espace numérique ne doit pas être laissé à la domination des plateformes monopolistiques. Et que pour pallier à cela, l’Union européenne doit, plus que jamais, initier des politiques d’envergure afin que les communs numériques puissent mieux se développer et permettre de maintenir une diversité d’acteurs sur le Web.
Plus largement, on peut se demander pourquoi il devrait y avoir une contrepartie au développement d’un commun. Pourquoi le simple fait de créer, développer et maintenir un commun ne suffirait-il pas ?
Communs numériques et ergonomie font-ils bon ménage ?
C’est le marronnier quand on vient à parler de communs numériques ! Pour ce qui concerne les services en ligne alternatifs, il est évident que le design et l’expérience utilisateur devraient être davantage pris en compte et mériteraient des financements plus importants au sein des structures qui les développent. Chez Framasoft, nous faisons appel depuis plusieurs années à des designers pour réfléchir aux interfaces des logiciels que nous développons (PeerTube et Mobilizon). Cette prise de conscience est récente. Dans le monde du libre, il me semble que, pendant assez longtemps, il n’y a pas vraiment eu de réflexion quant à l’adoption des outils par le plus grand nombre.
Les services numériques tels qu’ils existent aujourd’hui nous ont fait prendre des habitudes et ont créé un réflexe de comparaison. Mais passer d’iPhone à Android ou l’inverse génère aussi des crispations. Le passage aux communs en générera naturellement aussi et peut-être plus. C’est d’ailleurs un discours que l’on porte beaucoup chez Framasoft : c’est plus simple d’aller au supermarché que d’avoir une pratique éthique d’alimentation. Il en va de même en ligne. Modifier ses pratiques numériques demande un effort. Mais cela ne veut évidemment pas dire que l’on ne peut pas améliorer les interfaces de nos services. Cependant, cela nécessite des financements qui ne sont pas toujours faciles à avoir. Les utilisateurs de services libres devraient en prendre conscience pour davantage contribuer à l’amélioration de ces communs. On peut lier ce mécanisme à la problématique du passager clandestin : tout le monde souhaite des services libres avec une meilleure expérience utilisateur mais peu sont prêts à les financer. Aujourd’hui, les projets de communs ont des difficultés à trouver des financements pour cet aspect de leurs services.
Angie Gaudion, chargée de relations publiques au sein de Framasoft,





 Ancien enseignant et professeur agrégé de mathématiques, il a créé puis coordonné pendant de nombreuses années le pôle de compétences « logiciels libres » du SCÉRÉN, jouant un rôle de premier plan dans la légitimation et le développement du libre dans le système éducatif.
Ancien enseignant et professeur agrégé de mathématiques, il a créé puis coordonné pendant de nombreuses années le pôle de compétences « logiciels libres » du SCÉRÉN, jouant un rôle de premier plan dans la légitimation et le développement du libre dans le système éducatif.