Une première version de l’article d’Interstices que nous reprenons ici est parue dans le dossier n°87 Les robots en quête d’humanité de la revue Pour la Science, numéro d’avril/juin 2015.
L’idée qu’il existe plusieurs types d’intelligences séduit, car elle évite à chacun de se trouver en un point précis d’une échelle absolue et parce que chacun espère bien exceller dans l’une des formes d’intelligence dont la liste tend à s’allonger. Cette pluralité d’intelligences a été proposée par le psychologue américain Howard Gardner : dans son livre Frame of Mind, de 1983, il énumère huit types d’intelligence. Très critiquée, par exemple par Perry Klein, de l’Université d’Ontario, qui la considère tautologique et non réfutable, cette théorie est à l’opposé d’une autre voie de recherche affirmant qu’il n’existe qu’une sorte d’intelligence à concevoir mathématiquement avec l’aide de l’informatique et de la théorie du calcul.
Dames, échecs, go, voitures…
Évoquons d’abord l’intelligence des machines et la discipline informatique nommée « intelligence artificielle ». Il faut l’admettre, aujourd’hui, les machines réussissent des prouesses qu’autrefois tout le monde aurait qualifiées d’intelligentes. Nous ne reviendrons pas sur la victoire définitive de l’ordinateur sur les meilleurs joueurs d’échecs, consacrée en 1997 par la défaite de Garry Kasparov (champion du monde) face à l’ordinateur Deep Blue, unanimement saluée comme un événement majeur de l’histoire de l’humanité.
À cette époque, pour se consoler peut-être, certains ont remarqué que les meilleurs programmes pour jouer au jeu de go étaient d’une affligeante médiocrité. Or, depuis quelques années, des progrès spectaculaires ont été accomplis. En mars 2013, le programme Crazy Stone de Rémi Coulom, de l’Université de Lille, a battu le joueur professionnel japonais Yoshio Ishida qui, au début de la partie, avait laissé un avantage de quatre pierres au programme. En mars 2016, le programme AlphaGo a battu Lee Sedol considéré comme le meilleur joueur de Go. Des idées assez différentes de celles utilisées pour les échecs ont été nécessaires pour cette victoire de la machine, mais pas plus que pour les échecs on ne peut dire que l’ordinateur joue comme un humain. La victoire de AlphaGo est un succès remarquable de l’Intelligence Artificielle qui prouve d’ailleurs qu’elle avance régulièrement.
Le succès de l’intelligence artificielle au jeu de dames anglaises est absolu. Depuis 1994, aucun humain n’a battu le programme canadien Chinook et, depuis 2007, on sait que le programme joue une stratégie optimale, impossible à améliorer. Pour le jeu d’échecs, on sait qu’il existe aussi des stratégies optimales, mais leur calcul semble hors d’atteinte pour plusieurs décennies encore.
L’intelligence des machines ne se limite plus aux problèmes bien clairs de nature mathématique ou se ramenant à l’exploration d’un grand nombre de combinaisons. Cependant, les chercheurs en intelligence artificielle ont découvert, même avec les jeux de plateau cités, combien il est difficile d’imiter le fonctionnement intellectuel humain : aux jeux de dames, d’échecs ou de go et bien d’autres, les programmes ont des capacités équivalentes aux meilleurs humains, mais ils fonctionnent différemment. Cela ne doit pas nous interdire d’affirmer que nous avons mis un peu d’intelligence dans les machines : ce ne serait pas fair-play, face à une tâche donnée, d’obliger les machines à nous affronter en imitant servilement nos méthodes et modes de raisonnement.
Le cas des véhicules autonomes est remarquable aussi de ce point de vue. Il illustre d’une autre façon que lorsque l’on conçoit des systèmes nous imitant à peu près pour les résultats, on le fait en utilisant des techniques le plus souvent totalement étrangères à celles mises en œuvre en nous par la nature, et que d’ailleurs nous ne comprenons que très partiellement : ainsi, pour le jeu d’échecs, personne ne sait décrire les algorithmes qui déterminent le jeu des champions.
La conduite de véhicules motorisés demande aux êtres humains des capacités qui vont bien au-delà de la simple mémorisation d’une quantité massive d’informations et de l’exploitation d’algorithmes traitant rapidement et systématiquement des données symboliques telles que des positions de pions sur un damier. Nul ne doute que pour conduire comme nous des véhicules motorisés, l’ordinateur doit analyser des images variées et changeantes : où est le bord de cette rue jonchée de feuilles d’arbres ? Quelle est la nature de cette zone noire à 50 mètres au centre de la chaussée, un trou ou une tache d’huile ? Etc.
Conduire une voiture avec nos méthodes nécessiterait la mise au point de techniques d’analyse d’images bien plus subtiles que celles que nous savons programmer aujourd’hui. Aussi, les systèmes de pilotage automatisé, tels que ceux de la firme Google, « conduisent » différemment des humains. Ces Google cars exploitent en continu un système GPS de géolocalisation très précis et des « cartes » indiquant de façon bien plus détaillée que toutes les cartes habituelles, y compris celles de Google maps, la forme et le dessin des chaussées, la signalisation routière et tous les éléments importants de l’environnement. Les voitures Google exploitent aussi des radars embarqués, des lidars (light detection and ranging, des systèmes optiques créant une image numérique en trois dimensions de l’espace autour de la voiture) et des capteurs sur les roues.
Ayant déjà parcouru plusieurs centaines de milliers de kilomètres sans accident, ces voitures sont un succès de l’intelligence artificielle, et ce même si elles sont incapables de réagir à des signes ou injonctions d’un policier au centre d’un carrefour, et qu’elles s’arrêtent parfois brusquement lorsque des travaux sont en cours sur leur chemin. Par prudence sans doute, les modèles destinés au public présentés en mai 2014 roulent à 40 kilomètres par heure au plus.
Avec ces machines, on est loin de la méthode de conduite d’un être humain. Grâce à sa capacité à extraire de l’information des images et son intelligence générale, le conducteur humain sait piloter sur un trajet jamais emprunté, sans carte, sans radar, sans lidar, sans capteur sur les roues et il n’est pas paralysé par un obstacle inopiné !
Les questions évoquées jusqu’ici n’exigent pas la compréhension du langage écrit ou parlé. Pourtant, contrairement aux annonces de ceux qui considéraient le langage comme une source de difficultés insurmontables pour les machines, des succès remarquables ont été obtenus dans des tâches exigeant une bonne maîtrise des langues naturelles.
L’utilisation des robots-journalistes inquiète, car elle est devenue courante dans certaines rédactions, telles que celles du Los Angeles Times, de Forbes ou de Associated Press. Pour l’instant, ces automates-journalistes se limitent à convertir des résultats (sportifs ou économiques, par exemple) en courts articles.
Il n’empêche que, parfois, on leur doit d’utiles traitements. Ainsi, le 17 mars 2014, un tremblement de terre de magnitude 4,7 se produisit à 6h25 au large de la Californie. Trois minutes après, un petit article d’une vingtaine de lignes était automatiquement publié sur le site du Los Angeles Times, donnant des informations sur l’événement : lieu de l’épicentre, magnitude, heure, comparaison avec d’autres secousses récentes. L’article exploitait des données brutes fournies par le US-Geological Survey Earthquake Notification Service et résultait d’un algorithme dû à Ken Schwencke, un journaliste programmeur. D’après lui, ces méthodes ne conduiraient à la suppression d’aucun emploi, mais rendraient au contraire le travail des journalistes plus intéressant. Il est vrai que ces programmes sont pour l’instant confinés à la rédaction d’articles brefs exploitant des données factuelles faciles à traduire en petits textes, qu’un humain ne rédigerait sans doute pas mieux.
Un autre exemple inattendu de rédaction automatique d’articles concerne les encyclopédies Wikipedia en suédois et en filipino, l’une des deux langues officielles aux Philippines (l’autre est l’anglais). Le programme Lsjbot mis au point par Sverker Johansson a en effet créé plus de deux millions d’articles de l’encyclopédie collaborative et est capable d’en produire 10 000 par jour. Ces pages engendrées automatiquement concernent des animaux ou des villes et proviennent de la traduction, dans le format imposé par Wikipedia, d’informations disponibles dans des bases de données déjà informatisées.
L’exploit a été salué, mais aussi critiqué. Pour se justifier, S. Johansson indique que ces pages peu créatives sont utiles et fait remarquer que le choix des articles de l’encyclopédie Wikipedia est biaisé : il reflète essentiellement les intérêts des jeunes blancs, de sexe masculin et amateurs de technologies. Ainsi, le Wikipedia suédois comporte 150 articles sur les personnages du Seigneur des Anneaux et seulement une dizaine sur des personnes réelles liées à la guerre du Vietnam : « Est-ce vraiment le bon équilibre ? », demande-t-il.
S. Johansson projette de créer une page par espèce animale recensée, ce qui ne semble pas stupide. Pour lui, ces méthodes doivent être généralisées, mais il pense que Wikipedia a besoin aussi de rédacteurs qui écrivent de façon plus littéraire que Lsjbot et soient capables d’exprimer des sentiments, « ce que ce programme ne sera jamais capable de faire ».
Beaucoup plus complexe et méritant mieux l’utilisation de l’expression « intelligence artificielle » est le succès du programme Watson d’IBM au jeu télévisé Jeopardy ! (voir l’encadré).

Watson, le programme conçu par IBM a gagné au jeu Jeopardy ! contre deux
champions humains. © IBM / Sony Pictures.
La mise au point de programmes résolvant les mots-croisés aussi bien que les meilleurs humains confirme que l’intelligence artificielle réussit à développer des systèmes aux étonnantes performances linguistiques et oblige à reconnaître qu’il faut cesser de considérer que le langage est réservé aux humains. Malgré ces succès, on est loin de la perfection : pour s’en rendre compte, il suffit de se livrer à un petit jeu avec le système de traduction automatique en ligne de Google. Une phrase en français est traduite en anglais, puis retraduite en français. Parfois cela fonctionne bien, on retrouve la phrase initiale ou une phrase équivalente, mais dans certains cas, le résultat est catastrophique.
Passer le test de Turing
Nous sommes très loin aujourd’hui de la mise au point de dispositifs informatiques susceptibles de passer le « test de Turing » conçu en 1950. Alan Turing voulait éviter de discuter de la nature de l’intelligence et, plutôt que d’en rechercher une définition, proposait de considérer qu’on aura réussi à mettre au point des machines intelligentes lorsque leur conversation sera indiscernable de celle des humains.
Pour tester cette indiscernabilité, il suggérait de faire dialoguer par écrit avec la machine une série de juges qui ne sauraient pas s’ils mènent leurs échanges avec un humain ou une machine tentant de se faire passer pour tel. Lorsque les juges ne pourront plus faire mieux que répondre au hasard pour indiquer qu’ils ont eu affaire à un humain ou une machine, le test sera passé. Concrètement, faire passer le test de Turing à un système informatique S consiste à réunir un grand nombre de juges, à les faire dialoguer aussi longtemps qu’ils le souhaitent avec des interlocuteurs choisis pour être une fois sur deux un humain et une fois sur deux le système S ; les experts indiquent, quand ils le souhaitent, s’ils pensent avoir échangé avec un humain ou une machine. Si l’ensemble des experts ne fait pas mieux que le hasard, donc se trompe dans 50 % des cas ou plus, alors le système S a passé le test de Turing.
Turing, optimiste, pronostiqua qu’on obtiendrait une réussite partielle au test en l’an 2000, les experts dialoguant cinq minutes et prenant la machine pour un humain dans 30 % des cas au moins. Turing avait, en gros, vu juste : depuis quelques années, la version partielle du test a été passée, sans qu’on puisse prévoir quand sera passé le test complet, sur lequel Turing restait muet.
Le test partiel a, par exemple, été passé le 6 septembre 2011 à Guwahati, en Inde, par le programme Cleverbot créé par l’informaticien britannique Rollo Carpenter. Quelque 30 juges dialoguèrent pendant quatre minutes avec un interlocuteur inconnu qui était dans la moitié des cas un humain et dans l’autre moitié des cas le programme Cleverbot. Les juges et les membres de l’assistance (1 334 votes) ont considéré le programme comme humain dans 59,3 % des cas. Notons que les humains ne furent considérés comme tels que par 63,3 % des votes.
Plus récemment, le 9 juin 2014 à la Royal Society de Londres, un test organisé à l’occasion du soixantième anniversaire de la mort de Turing permit à un programme nommé Eugene Goostman de duper 10 des 30 juges réunis (33 % d’erreur). Victimes de la présentation biaisée que donnèrent les organisateurs de ce succès, somme toute assez modeste, de nombreux articles de presse dans le monde entier parlèrent d’un événement historique, comme si le test complet d’indiscernabilité homme-machine avait été réussi. Ce n’était pas du tout le cas, puisque le test avait d’ailleurs encore été affaibli : l’humain que le système informatique simulait était censé n’avoir que 13 ans et ne pas écrire convenablement l’anglais (car d’origine ukrainienne !).
Le test de Turing n’est pas passé
Non, le test de Turing n’a pas été passé, et il n’est sans doute pas près de l’être. Il n’est d’ailleurs pas certain que les tests partiels fassent avancer vers la réussite au test complet. En effet, les méthodes utilisées pour tromper brièvement les juges sont fondées sur le stockage d’une multitude de réponses préenregistrées (correspondant à des questions qu’on sait que les juges posent), associées à quelques systèmes d’analyse grammaticale pour formuler des phrases reprenant les termes des questions des juges et donnant l’illusion d’une certaine compréhension. Quand ces systèmes ne savent plus quoi faire, ils ne répondent pas et posent une question. À un journaliste qui lui demandait comment il se sentait après sa victoire, le programme Eugene Goostman de juin 2014 répondit : « Quelle question stupide vous posez, pouvez-vous me dire qui vous êtes ? »
Ainsi, l’intelligence artificielle réussit aujourd’hui assez brillamment à égaler l’humain pour des tâches spécialisées (y compris celles exigeant une certaine maîtrise du langage), ce qui parfois étonne et doit être reconnu comme des succès d’une discipline qui avance régulièrement. Cependant, elle le fait sans vraiment améliorer la compréhension qu’on a de l’intelligence humaine, qu’elle ne copie quasiment jamais ; cela a en particulier comme conséquence qu’elle n’est pas sur le point de proposer des systèmes disposant vraiment d’une intelligence générale, chose nécessaire pour passer le difficile test de Turing qui reste hors de portée aujourd’hui (si on ne le confond pas avec ses versions partielles !).
Vers l’intelligence générale
Ces tentatives éclairent les recherches tentant de saisir ce qu’est une intelligence générale. Ces travaux sont parfois abstraits, voire mathématiques, mais n’est-ce pas le meilleur moyen d’accéder à une notion absolue, indépendante de l’homme ?
Quand on tente de formuler une définition générale de l’intelligence, vient assez naturellement à l’esprit l’idée qu’être intelligent, c’est repérer des régularités, des structures dans les données dont on dispose, quelle qu’en soit leur nature, ce qui permet de s’y adapter et de tirer le maximum d’avantages de la situation évolutive dans laquelle on se trouve. L’identification des régularités, on le sait par ailleurs, permet de compresser des données et de prédire avec succès les données suivantes qu’on recevra.
Intelligence, compression et prédiction sont liées. Si, par exemple, on vous communique les données 4, 6, 9, 10, 14, 15, 21, 22, 25, 26 et que vous en reconnaissez la structure, vous pourrez les compresser en « les dix premiers produits de deux nombres premiers » et deviner ce qui va venir : 33, 34, 35, 38, 39, 46, 49, 51, 55, 57…
Ce lien entre intelligence, compression et prédiction a été exprimé de façon formelle par l’informaticien américain Ray Solomonoff vers 1965. Du principe du rasoir d’Ockham Pluralitas non est ponenda sine necessitate (les multiples ne doivent pas être utilisés sans nécessité), il proposait une version moderne : « Entre toutes les explications compatibles avec les observations, la plus concise, ou encore la mieux compressée, est la plus probable. »
Si l’on dispose d’une mesure de concision permettant de comparer les théories, cette dernière version devient un critère mathématique. La théorie algorithmique de l’information de Kolmogorov, qui propose de mesurer la complexité (et donc la simplicité) de tout objet numérique (une théorie le devient une fois entièrement décrite) par la taille du plus court programme qui l’engendre, donne cette mesure de concision et rend donc possible la mathématisation complète du principe de parcimonie d’Ockham.
L’aboutissement de cette voie de réflexion et de mathématisation a été la théorie générale de l’intelligence développée par l’informaticien allemand Marcus Hutter, dont le livre Universal Artificial Intelligence, publié en 2005, est devenu une référence. En utilisant la notion mathématique de concision, une notion mathématisée d’environnement (ce qui produit les données desquelles un système intelligent doit tenter de tirer quelque chose) et le principe mathématisé d’Ockham de Solomonoff, M. Hutter définit une mesure mathématique universelle d’intelligence. Elle est obtenue comme la réussite moyenne d’une stratégie dans l’ensemble des environnements envisageables.
Cette dernière notion (dont nous ne formulons pas ici la version définitive avec tous ses détails techniques) est trop abstraite pour être utilisable directement dans des applications. Cependant, elle permet le développement mathématique d’une théorie de l’intelligence et fournit des pistes pour comparer sur une même base abstraite, non anthropocentrée et objective, toutes sortes d’intelligences. Contrairement à l’idée de H. Gardner, cette voie de recherche soutient que l’intelligence est unique, qu’on peut dépasser le côté arbitraire des tests d’intelligence habituels pour classer sur une même échelle tous les êtres vivants ou mécaniques susceptibles d’avoir un peu d’intelligence.
Intelligence et compression

© photology1971 – Fotolia
Malgré la difficulté à mettre en œuvre pratiquement la théorie (par exemple pour concevoir de meilleurs tests d’intelligence ou des tests s’appliquant aux humains comme aux dispositifs informatiques), on a sans doute franchi un pas important avec cette théorisation complète. Conscients de son importance pour la réussite du projet de l’intelligence artificielle, les chercheurs ont maintenant créé un domaine de recherche particulier sur ce thème de « l’intelligence artificielle générale » qui dispose de sa propre revue spécialisée, le Journal of General Artificial Intelligence (en accès libre).
Dans le but sans doute d’éviter à la discipline de se satisfaire du développement de sa partie mathématique, un concours informatique a été créé par M. Hutter en 2006. Il est fondé sur l’idée que plus on peut compresser, plus on est intelligent (voir l’encadré).
La nouvelle discipline aidera peut-être les chercheurs à réaliser cette intelligence générale qui manque tant à nos machines actuelles et les oblige à n’aborder que des tâches spécialisées, le plus souvent en contournant les difficultés qu’il y aurait à employer les mêmes méthodes que les humains, qui eux disposent — au moins de façon rudimentaire ! — de cette intelligence générale.
Jean-Paul Delahaye, Professeur émérite d’informatique à l’Université des Sciences et Technologies de Lille
Pour aller plus loin :
- B. GOERTZEL, Artificial general intelligence : Concept, state of the art, and future prospects, in J. of Artificial General Intelligence, vol. 5(1), pp. 1-48, 2014.
- G. TESAURO et al., Analysis of Watson’s strategies for playing Jeopardy !, 2014.
- D. DOWE et J. HERNÀNDEZ-ORALLO, How universal can an intelligence test be, in Adaptive Behavior, vol. 22(1), pp. 51-69, 2014.
- Le concours de compression de Marcus Hutter




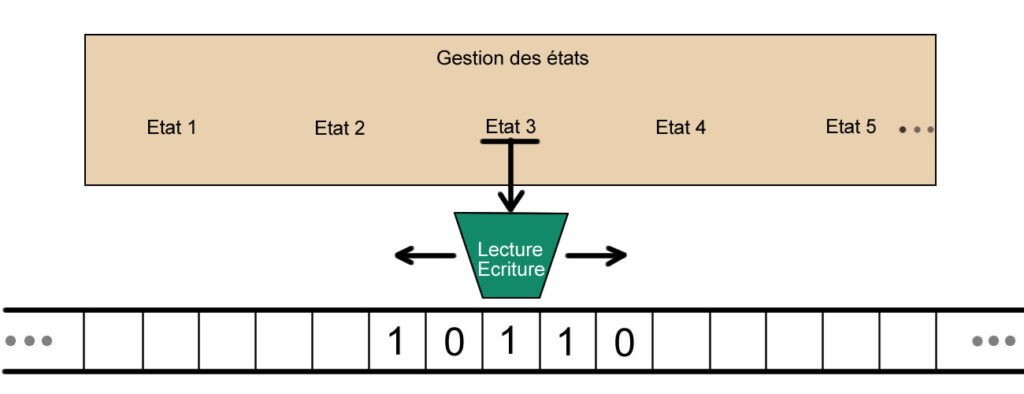
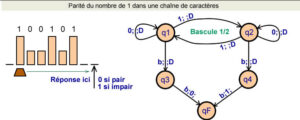
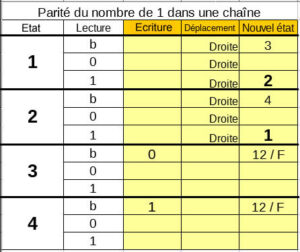 La partie en jaune correspond aux instructions que l’on peut donner à la machine. Elle peut écrire, se déplacer d’une case à gauche ou d’une case à droite et changer d’état. À noter l’état 12 est ici l’état final, il provoque l’arrêt de la machine. Cette table des transitions, nous donne le modèle de feuille de programmation à réaliser sous la forme d’une feuille perforée.
La partie en jaune correspond aux instructions que l’on peut donner à la machine. Elle peut écrire, se déplacer d’une case à gauche ou d’une case à droite et changer d’état. À noter l’état 12 est ici l’état final, il provoque l’arrêt de la machine. Cette table des transitions, nous donne le modèle de feuille de programmation à réaliser sous la forme d’une feuille perforée.





 Nous retrouvons aujourd’hui,
Nous retrouvons aujourd’hui, 
 Jean Vuillemin
Jean Vuillemin

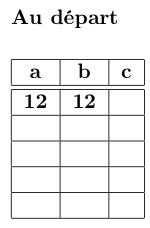
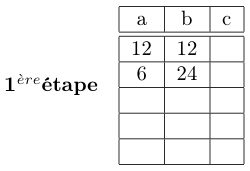 . . .
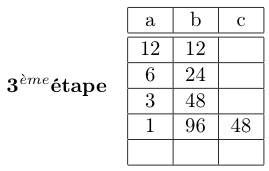
. . . 

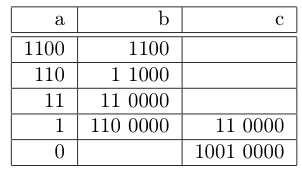






 L’exemple de corrélation.
L’exemple de corrélation. 
 Éva Corot ? C’est elle qui du haut de ses 10 ans a proposé de rendre « le sourire aux rues de Paris » en développant le projet d’un robot (équipé d’un mécanisme imprimé en 3D) qui dessine à la craie de couleur sur le sol. Au-delà
Éva Corot ? C’est elle qui du haut de ses 10 ans a proposé de rendre « le sourire aux rues de Paris » en développant le projet d’un robot (équipé d’un mécanisme imprimé en 3D) qui dessine à la craie de couleur sur le sol. Au-delà  Vous savez quoi ? Je crois bien que ce bon géant là, c’est
Vous savez quoi ? Je crois bien que ce bon géant là, c’est 





