Parmi toutes les initiatives des organisations internationales en lien avec l’IA, la Commission européenne et de l’Organisation de Coopération et de Développement Économiques, s’associent avec Code.org pour proposer un référentiel d’apprentissage de l’IA et de son usage en éducation (learning with and about IA), ouvert et surtout en cours de construction participative, invitant chacune et chacun à donner son avis. Voyons cela. Benjamin Ninassi et Ikram Chraibi Kaadoud.
Nous sommes dans les années soixante-dix, mille huit cent soixante-dix. Et une monstruosité apparaît : des personnes se mettent à entendre des voix. Celles d’autres personnes … situées à des dizaines de kilomètres. Il y avait de quoi être terrorisé. On l’était. Maléfice ou magie ? Ce qui arrivait… c’étaient les premiers téléphones. Depuis, on a su expliquer à nos enfants comment cela peut marcher (en cours de physique) et quels usages technologiques (dans les cours éponymes) peuvent en être faits, y compris leurs limites (comme les “faux” appels).
Nous sommes dans les années soixante-dix, deux mille soixante-dix. Et les enfants de rigoler, qu’un siècle avant … s’appelait “intelligence artificielle” une bien vieille famille de mécanismes d’I.A., c’est-à-dire d’Inférence Algorithmique, dont le fonctionnement paraissait alors… soit magique, soit potentiellement maléfique. Mais c’était avant. Et, dans cette vision de l’avenir, nous avons toutes et tous appris à la fois (i) comment fonctionnent ces algorithmes et (ii) comment apprendre en s’aidant de tels algorithmes (learn with and about AI) en le faisant avec discernement et parcimonie.
À moins que, dans un futur bien plus dystopique, nous ayons uniquement permis aux personnes d’utiliser sans comprendre («pas besoin … ça marche tout seul »), ni maîtriser (« il suffit de quelques clics, c’est si facile ») ces outils. Ce monde (imaginaire ?! …) serait alors plus fracturé et terrible à vivre qu’un monde totalitaire soumis à l’ultra surveillance comme George Orwell le cauchemardait. Car si notre quotidien (accès à l’information, choix offerts quant à nos décisions), devenu numérique, était aux mains de quelques personnes (par exemple “les plus riches du monde”), c’est notre propre mental qui serait empoisonné, rendu vulnérable par l’ignorance et l’absence d’esprit critique. De plus, au rythme actuel du réchauffement climatique, en 2070 avec une terre à +3°, les enfants ne rigoleront probablement plus beaucoup.
Que cela ne soit pas.
Depuis quelques mois, des deux côtés de l’Atlantique, une équipe apporte une contribution collégiale pour que notre avenir se fasse pour le meilleur quant à ces IAs dont on ne cesse de parler.
Vous avez dit A.I.L.F. ? (AI* Learning Framework**)
(*) Disons “IA”, gardant à l’esprit que ce sont des outils (au pluriel) d’inférence algorithmique, ni moins, ni plus. (**) Un cadre pour l’apprentissage de ces outils que l’on nomme intelligence artificielle.
La maîtrise de l’IA, sa “littératie”, représente les connaissances techniques, les compétences durables et les bonnes attitudes (savoirs, savoir-faire et savoir être) qui permettent d’interagir avec l’IA, de créer avec de tels outils, de la gérer et de la concevoir, tout en évaluant de manière critique ses avantages, ses risques et ses implications éthiques.
C’est tout aussi indispensable que lire, écrire ou compter. Avec plusieurs points communs : – Ce sont des compétences universelles pour toutes et tous, mais avec de grandes variantes culturelles à respecter : tout le monde doit pouvoir apprendre l’IA et utiliser l’IA pour apprendre, et doit pouvoir devenir autonome par rapport à l’IA, mais dans le respect de sa diversité. – Ce sont des compétences interdisciplinaires, qui ont vocation à s’intégrer dans toutes les disciplines concernées, informatique, mathématiques, et technologies, ainsi que les sciences humaines et les formations pédagogiques transversales des élèves. Beaucoup de ces compétences (esprit critique, pensée informatique, résolution de problème) sont déjà partagées – tant mieux – l’apport de ce cadre est d’aider à la faire dans le contexte de l’IA. – Ce sont des compétences pérennes : on parle de savoirs, savoir-faire et savoir être fondamentaux, qui seront encore pertinents lors de l’évolution attendue des outils actuels (de même qu’en informatique on n’apprend pas “le Python” (ou un autre langage) mais les algorithmes et le codage de l’information, en s’appuyant sur tel ou tel langage formel qui peut être amené à changer avec le temps). – Parmi les compléments à apporter à la version actuelle, les impacts environnementaux de l’IA, déjà pris en compte, sont à renforcer : les impacts environnementaux directs de chaque apprentissage, chaque inférence, chaque investissement en faveur d’une solution basée sur l’IA sont déjà réels aujourd’hui, ainsi que les impacts environnementaux délétères indirects de beaucoup de cas d’usage.
Cette littératie cible principalement l’enseignement primaire et secondaire, mais est aussi ouverte au péri et extra scolaire, et à l’éducation familiale.
C’est ici : http://ailiteracyframework.org que nous avons tous les éléments de présentation (avec une version traduite de la page de présentation : https://tinyl.co/3OeN). Il y a même un “prompt” (l’instruction ou la question qui est posée de manière textuelle à un IA avec une interface langagière) pour interroger une IA à propos de cette littératie de l’IA.
Une première version, aboutie et soigneusement revue, est disponible, pour travailler sur des éléments précis. Pas d’erreur ! Elle a évidemment vocation à évoluer et être remodelée, voire questionnée en profondeur, en fonction des relectures et des retours.
Alors… à vous !
Au cours des prochains mois, nous sollicitons les commentaires des parties prenantes du monde entier. Pour participer, visitez www.teachai.org/ailiteracy/review. La version finale du cadre sera publiée en 2026, accompagnée d’exemples de maîtrise de l’IA dans les programmes, l’évaluation et la formation professionnelle.
Thierry Viéville, chercheur Inria.
Ok … 1,2,3 : comment me lancer dès maintenant ?
– Avec la formation ClassCode I.A.I. on se forme sans aucun prérequis technique aux bases de l’IA, pour piger comment ça marche:
Ressource gratuitement utilisable et réutilisable.
– Former les enseignants au contexte, l’usage, la pertinence et les défis de ressources éducatifs mobilisant de l’intelligence artificielle dans un cadre éducatif :
À l’heure ou transition écologique rime souvent avec transition numérique, qu’en est-il réellement des impacts environnementaux du numérique ? Comment dès à présent commencer à agir pour un numérique plus responsable et plus durable ?
« L’année 2025 pourrait bien marquer un tournant décisif pour l’intelligence artificielle en France. En quelques mois à peine, le pays a concentré sur son sol une série d’événements majeurs, des annonces économiques sans précédent, et une mobilisation politique et industrielle rarement vue à cette échelle » C’est par ces propos que Jason RIchard nous partage ici son analyse de ce que les médias ont déjà largement relayé. Serge Abiteboul et Thierry Viéville.
L’IA, longtemps domaine de prospective ou de niche, est désormais partout : dans les discours officiels, dans les stratégies d’investissement, dans les démonstrateurs technologiques, dans les débats publics… Et surtout, elle est devenue un axe structurant de la politique industrielle française. Alors, 2025 : coup d’accélérateur ou effet d’annonce ? Éléments de réponse à mi-parcours d’une année qui, semble avoir placé la France au centre du jeu.
Quatre grands événements au cours de ce premier semestre sont partagés avec plus de détail en annexe de cet article.
Une ambition qui se concrétise
La trajectoire n’est pas nouvelle. Dès 2018, la France avait lancé une stratégie nationale sur l’IA, misant sur l’excellence scientifique, la création de champions technologiques et une volonté de régulation éthique. Mais ce début 2025 a marqué une inflexion nette : ce ne sont plus des promesses ou des feuilles de route, mais des réalisations concrètes, visibles et, surtout, financées.
Sommet Choose France 2025 : plus de 40 milliards d’euros annoncés, l’IA mise à l’honneur.
Sur le plan diplomatique, la France a accueilli à Paris, début février un sommet mondial sur l’action en matière d’IA, réunissant plus de 100 délégations internationales. Sur le plan économique, le sommet Choose France 2025, en mai, a vu l’annonce de 37 milliards d’euros d’investissements étrangers, dont près de 17 milliards spécifiquement orientés vers l’IA et les infrastructures numériques. De nouvelles giga-usines de données, des centres de calcul haute performance, des campus IA… autant de projets qui commencent à prendre racine sur le territoire, dans les Hauts-de-France, en Île-de-France ou encore en Provence. Ce n’est plus seulement une question de stratégie : c’est désormais une réalité industrielle.
Une dynamique entre État, start-ups et investisseurs
World AI Cannes Festival 2025 : l’IA fait son show à Cannes
Ce mouvement est porté par une triple alliance entre l’État, les start-ups de la French Tech et les investisseurs internationaux. L’écosystème s’est structuré. On compte aujourd’hui en France près de 1 000 jeunes pousses spécialisées en IA, dont plusieurs sont devenues des licornes. Des journées entières leur ont été consacrées, à Station F comme au World AI Cannes Festival, et de nombreuses d’entre elles ont profité de ces événements pour nouer des contacts avec des fonds étrangers, tester leurs solutions, ou signer des premiers contrats.
Le gouvernement, de son côté, ne se contente plus d’un rôle de spectateur bienveillant. Il est co-investisseur, catalyseur, diplomate. Des partenariats stratégiques ont été tissés avec des acteurs nord-américains, émiratis, européens… dans une logique de souveraineté numérique partagée. L’objectif est clair : faire de la France un point central pour entraîner, héberger et déployer les modèles d’IA de demain. Avec en ligne de mire, la maîtrise technologique autant que la compétitivité économique.
Des usages concrets… et des questions fondamentales
Station F Business Day 2025 : l’innovation IA made in France
Loin de se limiter aux infrastructures, l’IA s’immisce dans tous les secteurs : santé, énergie, industrie, agriculture, éducation. Certains cas d’usage sont déjà déployés à grande échelle : systèmes d’aide au diagnostic médical, optimisation des réseaux électriques, automatisation de processus industriels, ou encore agents conversationnels dans les services publics. L’heure est à l’intégration, à l’industrialisation, et à l’évaluation.
Mais cette dynamique pose des questions majeures. Comment garantir l’équité des systèmes algorithmiques ? Comment réguler les modèles génératifs qui créent du faux plus vite qu’on ne peut le détecter ? Comment protéger les données, les droits, l’emploi, dans un monde où les machines apprennent plus vite que les institutions ne légifèrent ?
La réponse française est à double détente : soutenir l’innovation sans naïveté, et réguler sans brider. Cela passe par l’appui au futur règlement européen (AI Act), par la participation active aux grands forums internationaux (OCDE, ONU, GPAI), mais aussi par une réflexion de fond sur l’inclusion et la transparence. Cette ligne de crête est peut-être ce qui distingue le plus la posture française sur l’IA en 2025.
Une question ouverte
Sommet Action IA 2025 : Paris capitale mondiale de l’IA
Alors, 2025 est-elle l’année de l’IA en France ? Il est encore trop tôt pour l’affirmer avec certitude. Mais jamais les planètes n’avaient été aussi bien alignées. Les infrastructures arrivent. Les financements suivent. L’écosystème s’organise. Le débat public s’anime. Et l’État joue pleinement son rôle. Ce n’est pas une révolution soudaine, mais plutôt une convergence de trajectoires, diplomatique, économique, technologique et sociale, qui pourrait, si elle se maintient, faire de la France l’un des pôles IA majeurs de la décennie.
Jason Richard, Business Innovation Manager chez Airbus Defence and Space.
Pour aller plus loin
Des articles détaillés sur chacun de ces événements marquants de ce premier semestre 2025 – Sommet pour l’action sur l’intelligence artificielle, Station F Business Day 2025, World AI Cannes Festival 2025, Choose France – sont disponibles ici :
Charles Cuvelliez et Jean-Jacques Quisquater nous proposent en collaboration avec le Data Protection Officer de la Banque Belfius ; Francis Hayen, une discussion sur le dilemme entre le RGPD et la mise en place de caméra augmentée à l’IA pour diminuer le nombre de vols, les oublis, le sous-pesage aux caisses automatiques des supermarchés, qui sont bien nombreux. Que faire pour concilier ce besoin effectif de contrôle et le respect du RGPD ? Et bien la CNIL a émis des lignes directrices, d’aucun diront désopilantes, mais pleines de bon sens. Amusons-nous à les découvrir.Benjamin Ninassi et Thierry Viéville.
C’est le fléau des caisses automatiques des supermarchés : les fraudes ou les oublis, pudiquement appelées démarques inconnues, ou la main lourde qui pèse mal fruits et légumes. Les contrôles aléatoires semblent impuissants. Dans certaines enseignes, il y a même un préposé à la balance aux caisses automatiques. La solution ? L’IA pardi. Malgré le RGPD ? Oui dit la CNIL dans une note de mai 2025.
Cette IA, ce sont des caméras augmentées d’un logiciel d’analyse en temps réel. On les positionne en hauteur pour ne filmer que l’espace de la caisse, mais cela inclut le client, la carte de fidélité, son panier d’achat et les produits à scanner et forcément le client, flouté de préférence. L’algorithme aura appris à reconnaitre des « événements » (identifier ou suivre les produits, les mains des personnes, ou encore la position d’une personne par rapport à la caisse) et contrôler que tout a bien été scanné. En cas d’anomalie, il ne s’agit pas d’arrêter le client mais plus subtilement de programmer un contrôle ou de gêner le client en lui lançant une alerte à l’écran, propose la CNIL qui ne veut pas en faire un outil de surveillance en plus. Cela peut marcher, en effet.
C’est que ces dispositifs collectent des données personnelles : même en floutant ou masquant les images, les personnes fautives sont ré-identifiables, puisqu’il s’agira d’intervenir auprès de la personne. Et il y a les images vidéo dans le magasin, non floutées. La correspondance sera vite faite.
Mais les supermarchés ont un intérêt légitime, dit la CNIL, à traiter ces données de leurs clients (ce qui les dispense de donner leur consentement) pour éviter les pertes causées par les erreurs ou les vols aux caisses automatiques. Avant d’aller sur ce terrain un peu glissant, la CNIL cherche à établir l’absence d’alternative moins intrusive : il n’y en a pas vraiment. Elle cite par exemple les RFID qui font tinter les portiques mais, si c’est possible dans les magasins de vêtements, en supermarché aux milliers de référence, cela n’a pas de sens. Et gare à un nombre élevé de faux positifs, auxquels la CNIL est attentive et elle a raison : être client accusé à tort de frauder, c’est tout sauf agréable. Cela annulera la légitimité de la méthode.
Expérimenter, tester
Il faut qu’un tel mécanisme, intrusif, soit efficace : la CNIL conseille aux enseignes de le tester d’abord. Cela réduit-il les pertes de revenus dans la manière dont le contrôle par IA a été mis en place ? Peut-on discriminer entre effet de dissuasion et erreurs involontaires pour adapter l’intervention du personnel ? Il faut restreindre le périmètre de prise de vue de la caméra le plus possible, limiter le temps de prise de vue (uniquement lors de la transaction) et la stopper au moment de l’intervention du personnel. Il faut informer le client qu’une telle surveillance a lieu et lui donner un certain contrôle sur son déclenchement, tout en étant obligatoire (qu’il n’ait pas l’impression qu’il est filmé à son insu), ne pas créer une « arrestation immédiate » en cas de fraude. Il ne faut pas garder ces données à des fins de preuve ou pour créer une liste noire de clients non grata. Pas de son enregistré, non plus. Ah, si toutes les caméras qui nous espionnent pouvaient procéder ainsi ! C’est de la saine minimisation des données.
Pour la même raison, l’analyse des données doit se faire en local : il est inutile de rapatrier les données sur un cloud où on va évidemment les oublier jusqu’au moment où elles fuiteront.
Le client peut s’opposer à cette collecte et ce traitement de données mais là, c’est simple, il suffit de prévoir des caisses manuelles mais suffisamment pour ne pas trop attendre, sinon ce droit d’opposition est plus difficilement exerçable, ce que n’aime pas le RGPD. D’aucuns y retrouveront le fameux nudge effect de R. Thaler (prix Nobel 2017) à savoir offrir un choix avec des incitants cognitifs pour en préférer une option plutôt que l’autre (sauf que l’incitant est trop pénalisant, le temps d’attente).
Autre question classique dès qu’on parle d’IA : peut-on réutiliser les données pour entrainer l’algorithme, ce qui serait un plus pour diminuer le nombre de faux positifs. C’est plus délicat : il y aura sur ces données, même aux visages floutés, de nombreuses caractéristiques physiques aux mains, aux gestes qui permettront de reconnaitre les gens. Les produits manipulés et achetés peuvent aussi faciliter l’identification des personnes. Ce serait sain dit la CNIL de prévoir la possibilité pour les personnes de s’y opposer et dans tous les autres cas, de ne conserver les données que pour la durée nécessaire à l’amélioration de l’algorithme.
Les caisses automatiques, comme les poinçonneuses de métro, les péages d’autoroute, ce sont des technologies au service de l’émancipation d’une catégorie d’humains qui ont la charge de tâches pénibles, répétitives et ingrates. Mais souvent les possibilités de tricher augmentent de pair et il faut du coup techniquement l’empêcher (sauter la barrière par ex.). L’IA aux caisses automatiques, ce n’est rien de neuf à cet égard.
Mine de rien, toutes ces automatisations réduisent aussi les possibilités de contact social. La CNIL n’évoque pas l’alternative d’une surveillance humaine psychologiquement augmentée, sur place, aux caisses automatiques : imaginez un préposé qui tout en surveillant les caisses, dialogue, discute, reconnait les habitués. C’est le contrôle social qui prévient bien des fraudes.
Quand on sait la faible marge que font les supermarchés, l’IA au service de la vertu des gens, avec toutes ces précautions, n’est-ce pas une bonne chose ?
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Francis Hayen, Délégué à la Protection des Données & Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT).
On entend beaucoup dire que les LLM ne savent pas raisonner. Pourtant, des modèles de langage semblent capables de raisonner. Comment est-ce possible ? Pour résoudre ce mystère, nous avons demandé à un expert du domaine, Guillaume Baudart, d’expliquer à binaire ce « miracle ». Serge Abiteboul et Pierre Paradinas
Les grands modèles de langage (LLMs pour Large Language Models) sont des modèles d’intelligence artificielle capables de générer du texte en langage naturel. Entraînés sur d’immenses quantités de données, ces modèles sont au cœur d’applications comme ChatGPT (openAI) ou Le Chat (Mistral). Grâce à des développements récents, ces modèles sont de plus en plus utilisés pour des tâches allant de la génération de code à la résolution de problèmes mathématiques à partir de descriptions en langage naturel. Mais que veut dire raisonner pour ces modèles ? Peut-on se fier aux résultats ?
D’un autre côté, les assistants de preuve tels que Rocq permettent de valider une preuve mathématique avec un très haut niveau de confiance, mais l’expertise nécessaire pour utiliser ces outils les rend difficiles d’accès.
Faire communiquer efficacement un LLM et un assistant de preuve permettrait d’atteindre deux objectifs complémentaires. D’abord, l’assistant de preuve peut valider les raisonnements générés par un LLM. Ensuite, les LLMs offrent une interface conversationnelle intuitive qui peut faciliter l’utilisation de ces assistants jusque-là réservés aux experts.
Deux lois d’échelle pour les LLMs
On assiste aujourd’hui à une course mondiale pour développer des modèles de plus en plus puissants. Les chiffres donnent le tournis : les modèles les plus récents contiennent des centaines de milliards de paramètres, sont entraînés sur des milliards de textes d’origines diverses, et leur coût d’entraînement est estimé à des dizaines de millions de dollars. Pour donner un exemple récent, le modèle DeepSeek-V3 contient 671 milliards de paramètres et son entraînement a demandé près de 3 millions d’heures GPU (les processeurs graphiques utilisés pour les calculs intensifs). Si ce modèle a fait les gros titres parce que son entraînement a été incroyablement efficace pour sa taille, il aura quand même coûté environ 6 millions de dollars.
La course aux grands modèles s’explique par une observation simple : les performances augmentent avec la taille des modèles. Plus précisément, lors de l’entraînement, les paramètres (des milliards de nombres qui contrôlent le comportement du modèle) sont ajustés pour optimiser un objectif qu’on appelle la perte. Dans le cas des modèles de langage comme les LLMs, on demande au modèle de compléter un texte connu (partiellement masqué) et la perte mesure la distance entre le texte généré et le texte original. Par exemple, « Le petit chat est mort. » est très proche de « Le petit chat est fort. » mais assez loin de « Le ciel est bleu aujourd’hui. ».
Or, on a observé dès 2020 une loi d’échelle pour l’entraînement des LLMs : la perte évolue selon une loi de puissance avec la quantité de calcul (nombre de paramètres, tailles de corpus d’entraînement, et temps d’entraînement). Et plus la perte est faible, plus les modèles deviennent performants pour diverses tâches : résumer, extraire de l’information, faire des raisonnements mathématiques, générer du code informatique, etc. Il est par ailleurs possible de spécialiser les LLMs sur une tâche spécifique en complétant leur entraînement sur des données ciblées.
Beaucoup plus récemment, on a également observé une nouvelle loi d’échelle pour l’inférence : les performances d’un modèle augmentent aussi avec la taille du texte généré lors de son utilisation. Confronté à une question, les modèles récents commencent par générer un long texte appelé chaîne de pensées qui imite un comportement humain. En utilisant le contenu de la chaîne, le modèle peut ensuite synthétiser un résumé.
Des tubes de peinture contiennent 8 centilitres d’un mélange de jaune et de bleu. Il y a du bleu et du jaune dans chaque tube. Mon premier tube contient un quart de la quantité totale de jaune et un sixième de la quantité totale de bleu. Combien y a-t-il de tubes ?
Si certaines applications (comme ChatGPT) masquent les chaînes de pensées, on peut parfois demander au modèle de nous montrer tout le texte généré. Voici par exemple la chaîne de pensées générée par DeepSeek-R1 pour ce problème (attention spoiler, le raisonnement original en anglais a été traduit).
Ok, essayons de déterminer combien il y a de tubes. Le problème indique que chaque tube contient 8 centilitres d’un mélange de jaune et de bleu. Chaque tube contient les deux couleurs. Le premier tube contient un quart du total de jaune et un sixième du total de bleu. Nous devons trouver le nombre de tubes.
Hmm, décomposons le problème. Je vais noter la quantité totale de peinture jaune Y et la quantité totale de peinture bleue B. Chaque tube contient une certaine quantité de jaune et de bleu, pour un total de 8 cl. Le premier tube contient 1/4 du total de jaune et 1/6 du total de bleu. Donc, la quantité de jaune dans le premier tube est Y/4, et la quantité de bleu est B/6. Puisque chaque tube contient 8 cl au total, alors Y/4 + B/6 = 8. C’est une équation.
Maintenant, pensons aux autres tubes. Il y a n tubes au total. Chacun des (n – 1) tubes restants doit également contenir du jaune et du bleu, mais combien ? Comme le problème ne spécifie pas de distribution particulière pour les autres tubes, sauf qu’ils contiennent tous les deux couleurs, peut-être pouvons-nous supposer que le reste de jaune et de bleu est réparti équitablement entre eux ? Attendez, mais le problème ne dit pas cela. Hmm, peut-être avons-nous besoin d’une autre approche.
Alternativement, puisque le premier tube contient Y/4 de jaune et B/6 de bleu, alors la quantité restante de peinture jaune est Y – Y/4 = (3/4)Y, et la quantité restante de peinture bleue est B – B/6 = (5/6)B.
[…]
Est-ce possible ? Voyons voir. Par exemple, si nous répartissons le reste de jaune à raison de 3 cl par tube (12/4=3) et le reste de bleu à raison de 5 cl par tube (20/4=5), chaque tube contiendrait 3+5=8 cl, ce qui fonctionne. Donc oui, c’est possible. Toutes les conditions sont satisfaites si n=5. Donc, la réponse est 5 tubes.
Mais laissez-moi vérifier à nouveau. Si n=5, le volume total est de 40 cl, Y=16, B=24. Premier tube : 4 jaune, 4 bleu. Reste 12 jaune et 20 bleu. 12/4=3, 20/4=5. Chaque tube restant contient 3 jaune et 5 bleu. Cela fait 8 cl chacun, et tous contiennent les deux couleurs. Donc cela fonctionne. Par conséquent, le nombre de tubes est 5.
On peut voir le modèle essayer plusieurs approches, se corriger, vérifier ses résultats, presque comme un étudiant en train de passer un examen devant un tableau noir. Le texte est ponctué d’expressions comme : « Ok, essayons de déterminer », « peut-être pouvons-nous supposer », « Attendez », « Hmm », « Est-ce possible », « laissez-moi vérifier » qui incitent le modèle à continuer la génération de texte pour progresser dans le raisonnement. Le modèle peut ensuite synthétiser une réponse courte et structurée en résumant cette chaîne de pensées. Les LLMs les plus récents, dits modèles de raisonnement, sont spécialisés lors de l’entraînement pour générer ces chaînes de pensées.
Cette nouvelle loi d’échelle ne s’arrête pas aux chaînes de pensées. Plutôt que d’investir toute la puissance de calcul au moment de l’entraînement, on utilise maintenant les ressources de calcul pour exploiter au mieux les textes générés. Une technique simple consiste à générer plusieurs chaînes de pensées en parallèle avant de choisir celles qui ont donné les meilleurs résultats. On peut également utiliser des algorithmes de recherche arborescente : à chaque étape de raisonnement, on génère plusieurs solutions, mais on ne fait progresser que les plus prometteuses.
En combinant toutes ces approches, il est aujourd’hui possible de spécialiser de relativement petits modèles qui atteignent des performances comparables à celles des énormes LLMs les plus connus (GPT-4o, Claude Sonnet, Gemini) pour un budget beaucoup plus modeste.
Ces nouveaux développements posent une question fondamentale : comment vérifier les raisonnements produits par les LLMs ? Cette question, qui était déjà préoccupante pour les premiers LLMs, devient cruciale pour les modèles de raisonnement pour lesquels une hallucination (une information fausse et inventée) peut complètement fausser la chaîne de pensées.
On construit donc des agents : des applications capables de coupler les LLMs avec des outils externes pour valider le texte généré (par exemple pour faire des recherches sur le web, ou pour exécuter du code généré par le LLM), et des algorithmes de recherche.
Généré par Théo Stoskopf à l’aide de ChatGPT. L’oiseau est inspiré du logo de l’assistant Rocq.
Valider les chaînes de pensées avec un assistant de preuve
Fruit d’un travail à l’intersection de la logique mathématique et la théorie des langages de programmation, les assistants de preuve sont des outils qui permettent à un ordinateur de vérifier un raisonnement mathématique. Une preuve est décomposée en étapes logiques et l’ordinateur vérifie que chaque étape respecte les règles de la logique mathématique. Si une preuve repose sur l’utilisation d’un théorème, l’ordinateur vérifie que toutes les hypothèses sont bien vérifiées et que la conclusion suffit à prouver le résultat attendu
Les assistants de preuve comme Rocq (anciennement Coq), Lean ou Isabelle sont des outils interactifs. L’utilisateur propose une étape de raisonnement que l’ordinateur vérifie avant d’indiquer à l’utilisateur ce qu’il reste à démontrer. Prenons un exemple très classique :
Tous les hommes sont mortels. Socrate est un homme. Donc, Socrate est mortel.
Le but initial est de prouver Socrate est mortel. Pour prouver ce théorème, on peut commencer par spécialiser la première prémisse Tous les hommes sont mortels à l’individu Socrate. L’assistant ajoute alors une nouvelle hypothèse : Si Socrate est un homme alors Socrate est mortel. On applique alors la seconde prémisse Socrate est un homme à cette hypothèse et l’assistant vérifie qu’on obtient bien Socrate est mortel.
Buste d’origine romaine en marbre de Socrate, Le Louvres
En théorie, ce fonctionnement interactif est parfaitement adapté pour développer un agent capable de vérifier un raisonnement mathématique. Chaque étape de raisonnement est validée par l’assistant de preuve, et les réponses (ou les messages d’erreur) de l’assistant de preuve nourrissent le LLM pour générer les prochaines étapes de raisonnement. Malheureusement, cet exercice de formalisation reste particulièrement difficile pour les humains comme pour les LLMs. Des LLMs récents sont aujourd’hui très performants pour la génération de code, mais l’exercice de preuve formelle ajoute une contrainte fondamentale qui rend l’exercice beaucoup plus compliqué : la preuve n’est terminée que si le code est parfaitement correct. Il n’y a aucune approximation possible. Par ailleurs, le code doit être écrit dans un langage spécialisé dont il existe relativement peu d’exemples au milieu des immenses quantités de données utilisées lors de l’entraînement.
Pour utiliser au mieux les capacités des LLMs, on peut réutiliser l’idée des chaînes de pensées. Plutôt que d’essayer de générer directement du code, on demande au modèle de décrire le théorème et ses hypothèses en langage naturel (par exemple en anglais ou français) et de suggérer un schéma de preuve, avant de générer le code en résumant la chaîne de pensées.
Couplé avec des algorithmes de recherche, cette approche commence à donner des résultats impressionnants sur des exercices de niveau lycée ou licence [1-2-3]. En utilisant une technique d’apprentissage « par renforcement » AlphaProof, un modèle entraîné par Google Deepmind sur des millions de théorèmes générés automatiquement, a même réussi à prouver avec l’assistant de preuve Lean des problèmes d’olympiades de mathématiques, atteignant le niveau d’une médaille d’argent.
Un assistant d’assistant de preuve
Les assistants de preuve sont donc des outils précieux pour valider les raisonnements générés par les LLMs. En changeant de perspectives, les LLMs peuvent également modifier en profondeur la manière dont nous utilisons des assistants de preuves qui restent aujourd’hui des outils réservés aux experts.
Si le code final doit être écrit dans un langage de programmation spécialisé, les chaînes de pensées générées lors du raisonnement sont écrites en langage naturel. Un humain peut donc facilement inspecter le raisonnement pour comprendre le code suggéré par l’assistant, voire directement intervenir pour le corriger. Les LLMs permettent ainsi de développer des interfaces conversationnelles : il devient de plus en plus possible de « discuter » (en français ou en anglais) avec l’assistant de preuve pour formaliser un théorème sans être un expert du langage de programmation spécialisé.
Les logiciels d’édition de code intègrent déjà ce genre de technologies pour les langages les plus populaires comme Python ou JavaScript. Ces assistants rendent de nombreux services qui vont de l’autocomplétion (compléter un bout de code à partir du contexte et des commentaires) à l’analyse de documentation (par exemple pour retrouver une fonction ou un théorème à partir d’une description floue en langage naturel).
L’utilisation des LLMs pour les assistants de preuve est un domaine de recherche aujourd’hui très actif. On cherche à développer des agents capables de faciliter de nombreuses tâches qui restent difficiles ou ingrates pour les humains. Par exemple, en utilisant les impressionnantes capacités de traduction des LLMs, on aimerait traduire directement un livre de mathématiques (théorèmes et preuves) dans le langage de l’assistant de preuve. Cette tâche suppose d’être capable de comprendre le contexte, les hypothèses implicites propres à chaque domaine, et la nature des objets mathématiques manipulés. Les LLMs récents entraînés sur de très nombreux textes mathématiques (avec différents niveaux de rigueur) peuvent faire des associations d’idées pour combler les « trous » entre le langage naturel du livre et sa formalisation dans un assistant de preuve. Ce problème reste très difficile, mais une solution partielle générée par un LLM peut être un point de départ précieux pour un humain.
Enfin, le comportement d’un programme peut aussi être formalisé dans un assistant de preuve. Il est donc possible de prouver qu’un programme est correct. Par exemple, on peut prouver qu’une fonction de tri en Python ou JavaScript renvoie toujours un tableau trié. À plus long terme, on aimerait avoir des assistants capables de traduire une spécification en langage naturel vers un code exécutable, une formalisation de la spécification, et une preuve de correction qui montre que le code correspond bien à sa spécification. Les assistants de preuve aidés par des LLMs permettraient ainsi de garantir que le code généré par un LLM est bien correct ! C’est un enjeu crucial dans un monde où le code informatique des applications que nous utilisons tous les jours devient de plus en plus généré automatiquement par ces modèles.
Conclusion
Faire communiquer LLMs et assistants de preuve ouvre des perspectives prometteuses pour l’avenir de l’intelligence artificielle et de la vérification formelle. En combinant la capacité des LLMs à générer des raisonnements complexes en langage naturel avec la rigueur des assistants de preuve, il devient possible de développer des agents capables de vérifier des preuves mathématiques. Ces agents pourraient non seulement améliorer la fiabilité des résultats produits par les LLMs et les capacités de raisonnement des futures générations de modèles, mais aussi rendre les outils de preuve formelle aujourd’hui réservés à des experts plus accessibles.
Guillaume Baudart, Inria
[1] https://arxiv.org/abs/2310.04353
[2] https://hal.science/hal-04886208v1
[3] https://arxiv.org/abs/2408.08152
Note : Merci à Vincent Baudart, Paul-André Melliès, Marc Lelarge, Théo Stoskopf, Jules Viennot, et Sarah Winter pour leurs relectures et leurs suggestions.
Les IA génératives transforment toutes les disciplines, toutes les habitudes. Elles bouleversent en particulier l’éducation, peuvent parfois paniquer les enseignants. Une spécialiste de l’IA analyse objectivement le sujet. Michèle Sebag est chercheuse émérite au CNRS. Elle est depuis 2017 membre de l’Académie des technologies, et a été membre du Conseil national du numérique. Serge Abiteboul & Chloé Mercier.
Site perso de Michele Sebag
L’irruption de ChatGPT et des intelligences artificielles génératives dans le monde de l’éducation change la donne. Pour quels résultats ? Les prédictions faites sur les impacts d’un tel changement sont variables, allant d’un futur radieux à l’apocalypse.
Ce qui change.
Comme l’avait souligné Michel Serres (Petite Poucette, 2012), l’accès à l’information à travers Wikipédia ou Google permet à chacun·e de vérifier la complétude ou la cohérence des enseignements donnés ex cathedra. Cette capacité modifie la relation des étudiant·e·s au savoir des enseignant·e·s (confiance, mémorisation).
Mais les IA génératives, ChatGPT et ses émules − LLaMA de Meta, Alpaca de Stanford, Gemini de Google, DeepSeek − vont plus loin. Une de leurs fonctions est de savoir répondre à la plupart des questions posées pour évaluer un·e étudiant·e.
Avec ChatGPT, l’étudiant·e dispose ainsi d’un simulateur énergivore de Pic de la Mirandole, ayant réponse à tout − quoique parfois privé de discernement. Chaque étudiant·e se trouve ainsi dans la chambre chinoise1, disposant d’un programme permettant de répondre aux questions, et non nécessairement de la connaissance nécessaire pour répondre aux questions.
L’enseignant·e est en face d’un double dilemme : i) à quoi sert l’enseignement si le fait de bien savoir se servir d’un ChatGPT donne les mêmes réponses ? ii) comment faire la différence entre quelqu’un qui sait, et quelqu’un qui sait se servir d’un ChatGPT ? La donne change ainsi en termes de transmission et d’évaluation des connaissances.
Contre : Coûts matériels et immatériels
Les opposants à l’ascension des ChatGPT dans le monde de l’éducation2 se fondent tout d’abord sur le fait que leur consommation en énergie n’est pas soutenable. En second lieu, ces systèmes ne sont pas fiables (”parfois privé de discernement” : les hallucinations en sont un exemple visible, mais il y a aussi toute l’information invisibilisée par suite des biais de corpus ou d’entrainement). En troisième lieu, leur impact sur la cognition est possible, voire probable.
Je m’abstiendrai de discuter les aspects énergétiques. Pour fixer les idées3, la consommation de ChatGPT (entrainement et usage pendant l’année 2023, avait été évaluée à 15 TWh (consommation énergétique de la France pendant un an : 50 TWh). Ces chiffres sont à prendre avec des correctifs de plusieurs ordres de grandeur : d’une part, chacun·e veut avoir son LLM (facteur ×100, ×1000) ; d’autre part, la consommation d’entrainement et d’usage tend à décroitre massivement pour obtenir les mêmes fonctionnalités (facteur ×1/100, ×1/1000) − ce gain étant naturellement annulé par l’effet rebond, et l’apparition de nouvelles fonctionnalités.
Je souhaite toutefois aller au-delà du fait qu’il vaudrait mieux limiter l’usage des ChatGPT pour des considérations énergétiques (comme les avions, les voitures, les ascenseurs, les cimenteries – continuer la liste). En pratique la pénétration des ChatGPT dans la société augmente.
Je m’abstiendrai aussi de discuter le manque de fiabilité. La liste des bévues de ChatGPT et al. est infinie, mais trompeuse. Le système est chaque jour moins limité que la veille ; c’est un système en interaction avec nous qui le concevons ou l’utilisons, et le système apprend de ces interactions ; la différence entre la version de novembre 2022 et la version actuelle de ChatGPT est comparée à celle qui sépare un singe d’un être humain. Nous reviendrons sur la question de savoir qui possède les données et qui contrôle le modèle.
Le troisième axe d’objection est que l’usage de ChatGPT pourrait priver l’étudiant·ed’une expérience essentielle d’apprentissage en autonomie, mais aussi, et plus gravement, de la confrontation aux sources authentiques des savoirs. Je reviendrai à cette objection centrale dans la suite.
Pour : Une éducation faisant mieux et/ou différemment avec l’IA
Plusieurs objectifs sont envisagés dans le rapport du Sénat sur IA et Éducation4. Un objectif clair consiste à utiliser les ChatGPT pour faire mieux ce qu’on fait déjà, permettant ”de suivre une classe de 25 comme une classe de 10”5. Les ChatGPT pourraient s’adapter aux élèves finement, détectant et prenant en compte les trajets cognitifs et les spécificités individuelles, en particulier les risques ou les troubles. Ils peuvent assister les professeurs, e.g. à générer des examens ou des quizz à partir de leur matériel pédagogique6 .
Ici, un danger et une opportunité sont bien identifiés. D’une part, la qualité des résultats dépend de celle du matériel pédagogique fourni. D’autre part, les dispositions d’accès à ChatGPT incluent la mise à disposition d’OpenAI des sources fournies. Il est donc hautement recommandé de disposer d’un LLM souverain pour l’enseignement7 . On pourrait imaginer un ”commun” informatique, la création d’un ChatPedia qui serait à ChatGPT ce que Wikipédia est à une encyclopédie, avec propriété collective et traçable des contributions. Voir dans ce sens le projet européen Intelligence artificielle pour et par les enseignants (AI4T)8.
D’autres objectifs, en cours d’étude, concernent le développement de fonctionnalités nouvelles (faire différemment, par exemple en proposant un tutorat personnalisé).
La cognition des enseignant·e·s
Un point épineux concerne la formation des enseignant·e·s à des usages éclairés des IA génératives. Il semble impossible, en effet, de former les élèves/étudiant·e·s à de tels usages éclairés si les enseignant·e·s n’ont pas été eux-mêmes formés. Cette logique se heurte toutefois au contexte : une fraction des enseignant·e·s avouent avec résignation ou indifférence leur éloignement total des mathématiques ; comment les attirer vers une formation formelle et roborative, pénétrant le quoi et le comment des technologies telles ChatGPT ?
La formation des formateurs a aussi un impact sur la hiérarchie des institutions et des savoirs. Bref, elle génère des résistances.
Comment avancer, dans un contexte où les perceptions de haut niveau (il est bon/nécessaire de former à l’IA) ne recoupent pas les perceptions au niveau des acteurs (l’IA est : i) incompétente ; ii) voleuse de sens/travail/valeur) ?
La cognition des apprenant·e·s
Selon l’Unesco les IAG pourraient priver les apprenant·e·s de la possibilité de développer leurs capacités cognitives et leurs compétences sociales par l’observation du monde réel, par des pratiques empiriques pouvant être des expériences, des discussions avec d’autres humains, ou par un raisonnement logique indépendant.
Ce danger peut être analysé dans le cadre du Maitre ignorant de Jacques Rancière (1987), distinguant l’enseignement ”qui explique” et celui ”qui émancipe”. Dans le premier cas, la base de discussion est que l’un·e sait et l’autre apprend ; le message implicite est que le savoir s’obtient d’un maitre.
Dans le second cas, l’objectif est non d’enseigner le savoir, mais d’établir que l’autre est capable d’apprendre tout ce qu’iel veut, au moyen de principes d’utilisation de notre propre intelligence. Il s’agit donc bien de réaliser nos capacités d’entendement autonomes.
Le danger attendu des IAG selon l’Unesco concernerait ainsi les capacités d’entendement autonomes des apprenants, donc, dans le cadre de l’enseignement ”qui émancipe”.
Une expérience
Cette expérience a été réalisée par Louis Bachaud et ses étudiant·e·s, à l’Université de Lille en 2024. L’objectif était de faire interagir un professeur, des étudiant·e·s, et un ChatGPT, de telle sorte qu’iels en sortent au bout de 2 heures, satisfaits, intrigués, motivés, ayant appris quelque chose, sans que le processus ne soit fondé sur l’identification de boucs émissaires (en particulier, ni le professeur, ni aucun élève).
Dans le premier essai, le professeur ayant posé une question générale, pertinente pour le cours (Quel est l’impact de Deezer sur l’audience d’un·eartiste?), la classe s’est divisée en petits groupes, dont chacun·e a écrit une requête et obtenu une réponse.
Les requêtes et les réponses sont mises dans un pot commun ; chacun·e cherche de quelle requête procède une réponse, appréhendant graduellement et empiriquement ChatGPT comme un système d’entrée sortie. L’intérêt de tels essais est de permettre à chacun·e, y compris le professeur, de se servir du collectif pour comprendre rapidement comment se servir d’un nouvel outil, quels en sont les usages, et comment la qualité des sorties dépend de celle des demandes. En somme, tous se perfectionnent dans l’art du prompting, art fort obscur, fort demandé et qui fait présentement la fortune des cabinets de conseil en IA génératives.
Les essais suivants ont raffiné ce schéma, en situant d’où parle la requête : réponds à cette question en sachant que je suis une musicienne de 30 ans − un DJ de 18 ans − un professeur de musique − une adolescente de 13 ans. Ces essais ont un aspect ludique (par exemple, la même commande précédée de je suis une fille de 18 ans ou je suis une femme de 18 ans ne produit pas la même réponse) conduisant à une discussion intéressante du modèle et des archétypes sous-jacents (reflétant essentiellement la culture US en 2024).
En résumé, ce type d’expérience réalise l’enseignement qui émancipe, avec un retour globalement positif des étudiant·e·s sur le savoir appris et le recul nécessaire.
Recommandations proposées
Cette première expérience va dans le sens des axes 1 et 2 du rapport cité du Sénat, concernant respectivement l’accompagnement des acteurs, et la formation d’une culture citoyenne de l’IA. D’autres expériences à l’initiative des enseignant·e·s, et leurs retours, suivant la méthodologie proposée, ou d’autres méthodologies, permettront d’affiner les savoirs qui peuvent être acquis, et comment.
Pour l’expérience considérée, les acquis obtenus reposent sur le développement de deux compétences. La première consiste, au niveau individuel, à savoir faire varier la formulation de ses demandes et sa position (d’où parle-t-on). La seconde, au niveau collectif, consiste à savoir observer les pratiques des autres et à en discuter.
La compétence exploratoire − savoir appréhender un sujet selon des points de vue différents − semble une capacité utile toutes choses égales par ailleurs. La compétence collective est peut-être plus intéressante encore ; outre l’intérêt des compétences sociales acquises, l’interaction permet de faire jeu égal avec ChatGPT.
Nous défendrons en effet la thèse selon laquelle l’entendement d’une IA ne doit pas être comparé à celui d’un être humain (ma fille n’a pas eu besoin de millions d’images de chats et de chiens pour apprendre à distinguer un chat d’un chien…) mais à celui d’un ensemble d’humains. Le fait que les IAs ne doivent pas être appréhendées au niveau de l’individu a également été souligné par Geoffrey Hinton9.
Les interactions d’un groupe humain, discutant entre eux des réponses obtenues et des bonnes questions à poser à ChatGPT, peuvent contribuer au développement des capacités cognitives et des compétences sociales, dans un contexte vivifiant.
Avertissement : l’expérience doit être suivie par les étudiant·e·s ; indépendamment de son intérêt en soi, il convient donc qu’elle soit notée.
1 Mind, Language and Society, Searle, 1998. Supposons qu’une personne glisse un message écrit en chinois sous la porte d’une chambre. Supposons dans la chambre une personne disposant d’un programme, spécifiant comment écrire une réponse en chinois (algorithme de dessin des caractères) en fonction d’un algorithme de lecture du dessin du message initial. Ce programme permet à la personne de la chambre de répondre en chinois au message chinois reçu. La personne hors de la chambre, recevant une réponse à son message, en conclut que la personne dans la chambre sait parler chinois.
2 Voir en particulier la tribune de Serge Pouts-Lajus dans le Monde de l’Éducation du 26 novembre 2024.
9G. Hinton note : Deux IA peuvent se transmettre instantanément les modèles appris par l’une ou l’autre [si les IA disposent d’une même représentation]. Cependant, la transmission des connaissances relatives à (e.g. la mécanique quantique) des enseignant·e·s vers les apprenant·e·s peut prendre beaucoup de temps et ne présente pas de garanties.
Lorsque Stanislas Dehaene et Yann Le Cun se sont rencontrés ils nous ont expliqué dans un super livre, co-écrit avec Jacques Girardon, que « l’intelligence a émergé avec la vie, elle s’est magnifiée avec l’espèce humaine » tandis que ce que d’aucun appelle « intelligence artificielle » va surtout changer le regard que nous portons sur l’intelligence naturelle, dont humaine. Ici, c’est notre collègue Max Dauchet qui prend la plume pour nous faire partager les idées clés et son analyse sur ces dernières avancées de l’informatique et des neurosciences. Serge Abiteboul et Thierry Viéville.
Voici ce que je retiens d’un petit livre de deux grands chercheurs sur l’intelligence humaine et l’intelligence machine.
Le recueil, déjà ancien mais toujours actuel, est basé sur une interviewi de deux chercheurs français mondialement connus : Stanislas Dehaene, titulaire de la chaire de psychologie cognitive expérimentale au Collège de France, pour notre cerveau et notre intelligence, et Yann Le Cun, prix Turing, pour les machines bio-inspirées comme le deep learning et leur intelligence artificielle. Ce livre est passé sous les radars des media car il privilégie la science au détriment du buzz.
Il se lit d’un trait.
Voici ce que j’en retiens.
L’intelligence est présentée comme la capacité générale à s’adapter à une situation. Selon cette définition, l’intelligence émotionnelle est un aspect de l’intelligence, à laquelle contribuent aussi bien nos sens, nos mains que notre cortex, le tout constituant un système de saisie et de traitement d’informations qui accroît les chances de survie de l’espèce en fonction de son environnement, ainsi que celles de l’individu au sein de son espèce. Il s’agit d’une organisation qui n’est pas nécessairement basée sur des neurones, ainsi l’intelligence d’une moule consiste en son aptitude à filtrer l’eau pour en tirer des nutriments. Néanmoins, au fil du temps, les systèmes interconnectant les « petites cellules grises » ramifiées se sont avérés particulièrement performants. Quant à l’humain, il a bénéficié de circonstances ayant permis l’extension de la boite crânienne et son cortex.
Tout le développement de la vie peut ainsi être vu comme un apprentissage compétitif de perpétuation. Le cerveau et son cortex ne sont pas de simples réseaux de neurones interconnectés au hasard, ils sont dotés de zones organisées et spécialisées et de processus de contrôle des connexions synaptiques sophistiqués. Les structures cérébrales les plus favorables ont été sélectionnées et figées avec plus ou moins de souplesse selon les avantages procurés. Ces zones ont constitué au fil du temps la partie innée de notre cerveau, dont les «noyaux gris» tels le striatum évoqué par Bohlerii. Le fonctionnement hérité de ces structures est inconscient, qu’il s’agisse de la régulation vitale de notre organisme, du traitement de la vision ou de tout autre signal capté par nos sens. L’évolution a conjointement à la structuration cérébrale de l’espèce préservé une plasticité cérébrale qui assure un avantage adaptatif à court terme, voire une capacité à se reconfigurer en cas d’accident ou d’invalidité. Cette plasticité permet chez l’humain une large part d’acquis à deux échelles. A l’échelle individuelle, il s’agit de l’apprentissage par l’expérience, le groupe, l’école, la culture. Cet apprentissage se traduit en structurant les circuits neuronaux par des « réglages » des synapses, qui sont des millions de milliards de points de transmission d’informations électrochimiques entre les neurones. Les connaissances ainsi apprises par un individu durant sa vie disparaissent avec lui. Mais elles sont transmises à l’échelle collective par un processus qui sort du cadre de l’hérédité génétique et est spécifique aux hominidés: la civilisation, ses constructions, ses outils, ses objets, ses cultures, ses croyances, ses sciences et ses arts – et en dernier lieu l’écriture et la capacité à se construire une histoire. Au lieu de coévoluer avec sa savane, sa mer ou sa forêt, l’humain coévolue avec l’accumulation de ses créations. Pour illustrer la dualité inné-acquis, Dehaene prend l’exemple des langues et de la causalité. Si un bébé peut apprendre n’importe quelle langue, c’est parce que toutes les langues ont des principes communs, et qu’une zone du cerveau s’est spécialisée dans leur traitement. Pour la causalité, imaginons deux populations sur une île. L’une fait le lien entre une chute de pierre et un danger, entre un crocodile et un danger, entre un signe de congénère et son attitude envers lui, autant d’exemples de lien entre cause et effet. L’autre population ne fait pas le lien, celle-ci disparaîtra et à la longue l’espèce survivante héritera de structures ou zones du cerveau «câblées» pour la recherche de causalités. De même pour les corrélations.
Ces considérations donnent la tonalité du récit de l’évolution de l’intelligence proposé dans le livre et font consensus dans les milieux scientifiques actuels. Il faut néanmoins souligner qu’il ne s’agit que de récits, pas de modèles aussi éprouvés que l’électromagnétisme ou la relativité. Il s’agit d’une tentative de dresser le tableau d’ensemble d’un puzzle dont de nombreuses pièces sont manquantes. Il en est de même du récit darwinien en général. Néanmoins en neurosciences on peut monter des expériences pour conforter ou infirmer des hypothèses, et Dehaene en relate quelques-unes, alors qu’en paléontologie ou en anthropologie on est souvent réduit à fouiller à la recherche d’indices peut-être disparus.
Pour ce qui est des machines, Le Cun fait à juste titre remarquer que le terme «intelligence machine» serait plus adéquat que celui consacré d’«intelligence artificielle» car l’intelligence est un système évolutif et interactif, dont l’organisation importe plus que le support, biomoléculaire ou silicium. On pourrait même voir l’écologie et l’évolution de la planète comme une intelligence, sans pour autant verser le moins du monde dans le culte de Gaïa (un chapitre du livre s’intitule d’ailleurs «L’intelligence de la vie»). Remarquons au passage que cette idée évoque la mouvance nord américaine de l’Intelligence design, à ceci près – nuance qui n’est pas des moindres – que dans cette vision épurée du judéo-christianisme, l’intelligence évoquée est finaliste, elle est la main de Dieu. Alors que dans le darwinisme nul objectif, nulle réalisation de dessein ne sont assignés au cheminement de l’évolution. Ce qui fait envisager en fin d’interview le dépassement de l’intelligence humaine sur le temps long, le passage par un couplage humain-machine semblant aux auteurs une étape probable. A noter qu’il n’est heureusement pas pour autant question dans l’ouvrage de transhumanisme, ensemble de micro-mouvements pseudo scientifiques surfant entre crainte d’un grand remplacement (par des cyborgs) et sur la quête d’immortalité.
Illustration du livre proposée par ChatGPT, générée par l’auteur. Elle ne reflète pas la tonalité humanisme du texte, qui nous aide au contraire à dépasser les mythes trans et post humanistes.
L’intelligence machine est survolée dans cet opuscule à travers sa comparaison à l’humain, et sous l’angle des machines bio-inspirées, comme l’est le deep learning dont Le Cun est un des pères. Le neuro et le data scientiste ne voient pas de limites a priori à l’intelligence machine, des progrès majeurs restant pour cela à accomplir dans la capacité de planification d’ensemble d’une stratégie, qui constitue encore un avantage majeur du cerveau humain. A noter que le mot «conscience» apparaît 22 fois sans être explicitement défini, car pour les interlocuteurs il est évacué de toute considération philosophique. Les activités innées sont inconscientes, celles apprises comme la conduite automobile le deviennent au fil de l’habitude. Les activités conscientes sont celles qui nécessitent de la réflexion.
Sur un plan technique, la rivalité historique entre l’approche symbolique (par le raisonnement) et l’approche connexionniste (par les réseaux neuronaux) de l’IA est brièvement rappelée. Le Cun y évoque ce que l’on a baptisé «l’hiver de l’IA», fait de discrédit et d’assèchement des financements, dans lequel les déconvenues du Perceptron avait plongé le connexionnisme. Il souligne un fait souvent passé inaperçu qui éclaire pourtant la triomphale résurgence des réseaux de neurones. Il s’agit des travaux activement menés durant cet «hiver» de deux décennies sous la modeste appellation de «traitement du signal et des images» pour ne pas agiter le chiffon rouge d’une intelligence artificielle bio-inspirées. Ces travaux ont notamment mené aux réseaux de convolution (CNN Convolution Neural Network) chers à Le Cun et qui sont à la base du succès du deep learning.
Enfin les auteurs pointent un principe essentiel, qui lui est largement connu mais qu’il est bon de marteler : «Apprendre, c’est éliminer» dit Dehaene en écho à une expression fétiche de son maître Jean-Pierre Changeux. Et l’on peut ajouter qu’apprentissage et créativité sont les deux faces d’une même pièce. Pas seulement au sens de la connaissance comme terreau du progrès, mais en un sens beaucoup plus fondamental relevant des lois du traitement de l’information au même titre que la chute de la pomme relève des lois physiques. En deux mots, apprendre par coeur ne sert à rien, si l’on apprend à reconnaître un visage en retenant par coeur chaque pixel d’un photo, on ne saura pas reconnaître la personne sur une autre photo, il faut approximer un visage par quelques caractéristiques, c’est à dire «éliminer» intelligemment les informations inutiles. Et il se crée ainsi des représentations internes du monde qui en sont des approximations utiles pour nous. Cependant, aucune pression évolutive n’a «verrouillé» l’usage de ces représentations en les limitant aux instances qui les avaient suscitées. Ainsi notre propension «câblée» à la causalité, déjà évoquée, sorte d’approximation de la logique usuelle du monde qui nous entoure, nous a fait imaginer des dieux comme causes des évènements naturels, et nourrit aussi peut-être le complotismeiii et sa recherche de causes cachées.
Max Dauchet, Professeur Émérite de l’Université de Lille.
i Stanislas Dehaene, Yann Le Cun, Jacques Girardon. La Plus Belle Histoire de l’intelligence. Des origines aux neurones artificiels : vers une nouvelle étape de l’évolution. Ed. Robert Laffont, collection La Plus Belle Histoire, 2018.
ii Sébastin Bohler, Le striatum, ed. bouquins, 2023.
iii Dans le livre seuls les dieux sont évoqués comme « inventions », le complotisme n’est pas cité.
Il n’y a plus d’enquêtes policières sans preuve numérique, sans recours massifs aux données électroniques que des criminels peuvent aussi chiffrer de manière inviolable, transférer dans des serveurs de pays peu coopératifs, rendre leur origine anonyme ou les disséminer sur le dark web. Qui des criminels ou des forces de police auront le dernier mot1 ? Charles Cuvelliez et Jean-Jacques Quisquater partagent avec le nous le bilan de ces obstacles qu’Europol vient de dresser. Pierre Paradinas et Benjamin Ninassi.
Il y a le volume des données à examiner : il se chiffre en teraoctets si pas petaoctets qu’il faut stocker, exploiter, analyser pour les autorités policières. Ce sont les fournisseurs de services numériques qui sont obligés de les conserver quelques mois2 au cas où. Ces données peuvent être de tout type, structurées comme des bases de données ou libres, comme des boites emails, des fichiers. Entre autorités policières, il n’y pas d’entente comment les données doivent être stockées, exploitées, structurées, ce qui pose ensuite un problème de coopération entre elles.
La perte de données est un autre obstacle : il y a eu une tentative d’harmoniser entre Etats membres la durée de rétention des données exploitables à titre judiciaire mais elle a été invalidée par la Cour Européenne de Justice. Depuis, chaque Etat membre a ses règles sur quelles données doivent être gardées et pendant combien de temps pour d’éventuelles enquêtes. Dans certains Etats membres, il n’y a aucune rétention prévue ou à peine quelques jours. Quand une demande arrive, les données ont évidemment disparu.
Adresse Internet multi-usage
L’épuisement des adresses Internet est un autre obstacle : les adresses dites IPv4 qui sont nées avec Internet sont toutes utilisées. Il faut les partager avec une adresse parfois pour 65 000 utilisateurs. Ces adresses sont en fait étendues avec le port IP, une extension qui dit quel service est utilisé par l’internaute (et qui donc ne l’identifie pas) et n’est pas conservée. C’est que les adresses de nouvelle génération peinent à devenir la norme puisqu’on étend justement artificiellement le pôle d’adresse IPv4. On pourrait à tout le moins imposer un nombre maximum d’internautes qui se partagent une seule adresse, dit Europol, ou imposer la rétention du port.
Jusqu’au RGPD, on pouvait accéder au titulaire d’un nom de domaine, ses coordonnées, son email, quand il l’avait ouvert. C’était précieux pour les enquêteurs mais le RPGD a amené l’ICANN, qui gère les noms de domaines non nationaux (gTLD) à ne plus rendre cette information publique. Tous les gTLD gérés par l’ICANN sont concernés. Il y a encore moyen de consulter ces données qui ne sont plus publiques mais les intermédiaires (registrars) qui assignent les noms de domaines à une organisation ou à une personne physique communiquent ces données sur base volontaire. Et surtout, rien n’est prévu pour garantir qu’une demande de renseignement policière sur le propriétaire d’un nom de domaine par une autorité policière reste anonyme. Interpol a bien proposé sa propre base de données de tous les noms de domaines impliqués dans des activités illicites mais encore faut-il les identifier. De toute façon, le système DNS qui traduit un nom de domaine en adresse IP sur Internet est exploité et détourné par les criminels pour réorienter les internautes vers des domaines qui contiennent des malwares ou de l’hameçonnage.
Chiffrement de tout
Autre défi : l’accès aux données. Les criminels prennent l’habitude de chiffrer toutes leurs données et sans clé de déchiffrement, on ne peut rien faire. Dans un Etat membre, il est possible de forcer par la contrainte un criminel à donner son mot de passe, à déverrouiller son appareil, même sans l’intervention d’un juge tandis que dans un autre Etat membre (non cité dans le rapport) un mot de passe même découvert légalement lors d’une perquisition n’est pas utilisable. Non seulement les criminels appliquent le chiffrement à leurs données mais les fournisseurs de communications électroniques vont aussi chiffrer par défaut leurs communications3. La 5G prévoit par défaut le chiffrement des données de bout en bout pour les appels vocaux si l’appel reste en 5G. L’opérateur peut même appliquer le chiffrement des données en roaming : l’appareil de l’utilisateur échange des clés de chiffrement avec son opérateur à domicile avant de laisser du trafic s’échapper sur le réseau du pays visité. Les criminels le savent et utilisent des cartes étrangères avec une clé…à l’étranger. Autre progrès fort gênant de la 5G, la technique dite de slicing, en cours de déploiement (5G SA) : elle permet de répartir le trafic d’un même utilisateur entre différents réseaux 5G virtuels à l’intérieur du réseau 5G réel pour n’optimiser les performances qu’en fonction de l‘usage (latence à optimiser ou débit à maximiser). Cela permet aux entreprises d’avoir leur réseau 5G privé dans le réseau 5G public mais cela complique la tâche des autorités policières qui doivent poursuivre plusieurs flux de trafics d’une même cible. Même les textos sont chiffrés de bout en bout avec le déploiement de RCS, un protocole dont s’est inspiré WhatsApp.
Pour des raisons de sécurité, il faut aussi chiffrer le trafic DNS, celui qui traduit le nom de domaine en adresse IP. On peut le faire au niveau bas, TLS, ce qui permet encore de suivre le trafic émis par le suspect, même s’il reste chiffré, mais parfois le trafic DNS est chiffré au niveau du protocole http, directement au niveau du navigateur ce qui le mélange avec tout le trafic internet. Ceci dit, accéder au traffic DNS de la cible requiert une forte coopération de l’opérateur télécom en plus.
Fournisseurs de communications électroniques dits OTT
Avec le Code de Communications Électronique, non seulement les opérateurs télécom traditionnels doivent permettre les écoutes téléphoniques mais aussi la myriade de fournisseurs de communications électroniques sur Internet (les Over The Top providers, ou OTT) mais ce n’est pas souvent le cas et il n’y rien qui est en place au niveau légal coercitif pour les forcer. Les techniques de chiffrement de bout en bout vont en tout cas exiger que ces opérateurs prévoient des possibilités pour les autorités policières de venir placer des équipements d’écoute comme au bon vieux temps. Mais comment vérifier qu’il n’y a pas d’abus non seulement des autorités judiciaires mais aussi des hackers.
Les cryptomonnaies
Les cryptomonnaies sont évidemment prisées par les criminels. Il est si facile d’échapper aux autorités judicaires avec les cryptomonnaies. C’est vrai qu’elles sont traçables mais les techniques pour les brouiller sont bien connues aussi : il y a le mixage qui consiste à mélanger les transactions pour dissimuler l’origine des sources. Il y a le swapping, c’est-à-dire échanger une cryptomonnaie contre un autre (et il y en a des cryptomonnaies) de proche en proche pour obscurcir le chemin suivi. Il s’agit aussi d’échanger les cryptomonnaies en dehors des plateformes ou alors via des plateformes décentralisées, sans autorité centrale à qui adresser une réquisition.
Même dans le cas d’une plate-forme centralisée soi-disant dans un pays donné, une réquisition qui y est envoyée après avoir pris du temps, ne mènera nulle part car la plate-forme ne sera pas physiquement dans le pays où elle est enregistrée. Il y a depuis, en Europe, la Travel Rule : elle oblige les plateformes qui envoient et reçoivent des cryptomonnaies à conserver le nom de l’émetteur et du bénéficiaire des fonds (cryptos).
Les techniques d’anonymisation sur Internet sont devenues redoutablement efficaces grâce à des VPNs. Ces réseaux privés sont à l’intérieur même d’internet et complément chiffrés. Ils masquent au niveau d’internet les vraies adresses IP du trafic. A côté des VPN, il y a les serveurs virtuels qu’on peut éparpiller sur les clouds en multiple exemplaires. C’est sur ces serveurs qu’est hébergé le dark web.
La coopération internationale est le dernier défi. Chaque pays ne permet pas de faire n’importe quoi au point qu’un pays doit parfois pouvoir prendre le relais d’un autre pays pour faire un devoir d’enquête non autorisé dans le pays d’origine. Il faut aussi se coordonner, éviter la déconfliction, un terme barbare qui désigne des interférences involontaires d’un Etat qui enquête sur la même chose qu’un autre État.
Tout ces constats, Europol les confirme dans son rapport sur le crime organisé publié le 18 mars. Ce dernier a bien compris le don d’ubquité que lui donne le recours à Internet et la transition vers un monde en ligne : recrutement à distance de petites mains, très jeunes, pour des tâches si fragmentées qu’elles ne se rendent pas compte pour qui et pour quoi elles travaillent, ni ne connaissent leur victime; possibilité de coordonner sans unité de temps ni de lieu les actions criminelles aux quatre coins du monde; utilisation de la finance décentralisée et des cryptomonnaies pour blanchir l’argent. Le tout avec la complicité des États qui pratiquent la guerre hybride et encouragent à l’ultra-violence, à l’infiltration des structures légales qui ont pignon sur rue, cette mise en scène visant à provoquer sidération et doute sur le bien-fondé de nos démocraties.
Depuis 2019, plusieurs nouveaux instruments législatifs de l’Union E uropéenne ont été introduits pour répondre à ces problèmes, explique Europol. Leur efficacité dépendra de la manière dont elles sont mises en œuvre dans la pratique.
Les seules histoires de démantèlement de réseau criminels qui réussissent, lorsqu’on lit les communiqués de presse entre les lignes, ont toutes une caractéristique en commune : elles sont internationales, alignées au cordeau, avec des capacités techniques reconnues des agences qui y ont travaillé. Europol a raison : ce cadre législatif a surtout pour vocation d’abattre les frontières entre pays qu’internet ne connait pas. Mais c’est une condition nécessaire, pas suffisante.
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles) & Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT).
Pour en savoir plus : – The changing DNA of serious and organised crime EU Serious and Organised Crime Threat Assessment 2025 (EU-SOCTA), Europol. – Eurojust and Europol (2025), Common Challenges in Cybercrime – 2024 review by Eurojust and Europol, Publication Office of the European Union, Luxembourg
Notes:
1/ Cette question a pris toute son actualité avec les discussions à l’Assemblée sur la loi sur le narcotrafic qui a essayé d’imposer aux messageries chiffrées (comme WhatsApp, Signal, Telegram…) un accès à la justice quant aux échanges cryptés des narcotrafiquants et criminels. De tout façon, un amendement sur la loi NIS2 votée au Sénat devrait interdire aux messageries d’affaiblir volontairement leur sécurité.
2/ La durée de rétention des données par les opérateurs télécom en France est de 12 mois suite à un décret de la Première Ministre de l’époque E. Borne qui évoquait une menace grandissante. Il n’y a pas d’harmonisation européenne en la manière suite au recalage de e-Privacy, le RGPD qui devait s’appliquer aux opérateurs télécoms. Il y avait une directive annexe de rétention des données pour des fins judiciaires mais elle a été recalée il y a des années par la Cour Européenne de Justice. Donc, c’est resté une matière nationale, comme souvent les matières de sécurité.
3/ Un chiffrement de bout en bout des communications ou des données a toujours été présenté comme la solution inviolable et Apple a constamment mis en avant cette sécurité,expliquant ne pouvoir répondre à aucune demande d’entrer dans un iPhone saisi à un criminel ou un terroriste, mais contrainte et forcée et par le gouvernement de Grande-Bretagne, elle vient de faire volte-face, avec peut-être des conséquences pour tous les appareils Apple de la planète. En savoir plus…
1. Bonjour Pierre-Emmanuel, pouvez-vous nous dire rapidement qui vous êtes, et quel est votre métier ?
Pierre-Emmanuel
Dessia Technologies est une jeune start-up fondée en 2017 par d’anciens ingénieurs de PSA Peugeot Citroën. Nous sommes basés en région parisienne et comptons aujourd’hui une quarantaine de collaborateurs. Notre mission est d’aider les grandes entreprises industrielles, notamment dans les secteurs automobile, aéronautique, ferroviaire et naval, à digitaliser leurs connaissances et à automatiser des tâches de conception grâce à l’intelligence artificielle. Nous travaillons avec des clients prestigieux comme Renault, Valeo, Safran, Airbus, Naval Group et Alstom. Nous utilisons par exemple des algorithmes d’IA pour automatiser le design des câblages électriques ou pour générer des architectures de batteries électriques. Forts de deux levées de fonds, nous sommes soutenus par quatre fonds d’investissement, dont celui d’Orano.
2. En quoi pensez-vous que l’IA a déjà transformé votre métier ?
L’intelligence artificielle a transformé en profondeur la manière dont les ingénieurs abordent la résolution de problèmes. Avant l’arrivée de ces technologies, les ingénieurs cherchaient principalement une ou deux solutions optimales pour répondre à un problème donné. Aujourd’hui, grâce à l’IA, ils explorent un éventail beaucoup plus large de solutions possibles. Les modèles génératifs, en particulier, permettent de proposer automatiquement de nombreuses alternatives et de hiérarchiser les options selon des critères précis. Cette évolution a modifié le rôle de ces ingénieurs, qui se concentrent désormais davantage sur l’analyse et la sélection des meilleures solutions pour leur entreprise.
3. À quels changements peut-on s’attendre dans le futur ? Quelles tâches pourraient être amenées à être automatisées ? À quel horizon ?
Dans le futur, l’interaction homme-machine sera profondément redéfinie grâce aux LLM (« Large Language Models » ou grands modèles de langage). Ces modèles remplaceront les interfaces graphiques traditionnelles par des interactions écrites ou orales, rendant les outils d’ingénierie plus intuitifs et accessibles. Les ingénieurs deviendront des gestionnaires de processus automatisés, orchestrant des agents autonomes pour exécuter des tâches techniques. La plupart des activités actuellement réalisées manuellement, comme la configuration de systèmes complexes ou la gestion de chaînes logistiques, seront automatisées d’ici 5 à 10 ans. Le rôle des ingénieurs évoluera donc vers un travail décisionnel, où ils valideront les choix proposés par les systèmes automatisés, favorisant une approche collaborative et stratégique.
Ainsi, l’IA révolutionne particulièrement l’interaction et l’expérience de l’humain (UX) vis-à-vis des systèmes numériques. Les techniciens n’échangent plus via des pages HTML mais interagissent avec des éléments de savoir, grâce au langage naturel et via des messages communiquant leurs intentions de manière concise (prompt). L’IA générative permet donc de repenser les univers d’interaction traditionnels (via une « souris » et un écran) pour aller vers des univers d’interaction fluide en 3D et en langage naturel.
Demain, les interactions se feront via des agents : des automates réalisant des tâches pour le compte des ingénieurs. Les humains travailleront de concert avec des agents spécialisés, tels que les agents spécialistes de l’architecture électrique, avec ceux de l’architecture 3D et ceux des problèmes thermiques, qui se coordonneront entre eux. Ces agents permettront de résoudre des problèmes de conception en ingénierie qui sont actuellement insolubles, tels que concevoir une architecture de batterie ou un véhicule pour baisser l’empreinte carbone.
Une ou un ingénieur devra être capable de manipuler de nouvelles briques de savoir, par exemple pour s’assurer que la ligne d’assemblage d’une batterie ou d’un véhicule fonctionne bien, ou comment la faire évoluer, ainsi que le processus de conception. Il s’agit d’une mutation vers l’intégration et le développement continus (CI/CD) des produits manufacturés, réalisés en ingénierie concurrente.
On entre dans une ère dans laquelle se poseront des questions telles que celle de la sélection des tâches à automatiser et à déléguer à des agents, celle de la structuration du savoir de chaque ingénieur, de la manière de poser des questions, et de collecter des éléments de savoir.
Les ingénieurs devront aussi brainstormer, collaborer et travailler sur leur expertise pour prendre les décisions à partir des sorties des agents. La collaboration se fera au niveau décisionnel plutôt qu’au niveau opérationnel.
L’IA remet l’humain au centre. La numérisation a apporté un travail qui s’effectue de manière solitaire, seul derrière son écran. L’IA casse ce mode et pousse à développer un travail plus collaboratif ciblant les aspects stratégiques concernant la tâche à effectuer.
4. Si vous devez embaucher de nouveaux employés, quelles connaissances en informatique, en IA, attendez-vous d’eux suivant leurs postes ?
Nous recherchons des profils capables de s’adapter à l’écosystème technologique actuel et de tirer parti des outils modernes comme les LLM. Par exemple, dans les métiers marketing et vente, nous attendons une maîtrise des outils génératifs pour créer du contenu ou analyser des données de marché. Du côté des ingénieurs et data scientists, une bonne compréhension des algorithmes d’IA, des outils d’automatisation et des techniques de prototypage rapide est essentielle.
Ces remarques et les suivantes sur l’emploi des ingénieurs et autres collaborateurs concernent l’industrie en général et ne sont pas spécifiques à Dessia.
5. Pouvez-vous préciser quelles formations, à quel niveau ?
Les formations nécessaires dépendent des métiers, mais une tendance claire se dessine : la capacité d’adaptation et l’auto-apprentissage deviennent des compétences prioritaires. Pour les métiers techniques comme l’ingénierie et la data science, une spécialisation poussée reste essentielle, avec des profils de personnes ayant souvent obtenu un diplôme de doctorat ou ayant une expertise avancée en mathématiques et algorithmique. Pour d’autres postes, les recruteurs privilégient les candidats capables de se former rapidement sur des sujets émergents, au-delà de leur parcours académique, et de maîtriser les outils technologiques en constante évolution.
Les nouveaux employés devront ainsi s’adapter à de plus en plus d’exigences de la part des employeurs, ils devront avoir une expérience en IA, en pilotage de projets d’IA. Non seulement dans les domaines de l’ingénierie mais aussi des ventes. Il devront connaitre l’IA, utiliser les LLM, avoir de très bonnes qualités humaines et relationnelles.
6. Pour quelles personnes déjà en poste pensez-vous que des connaissances d’informatique et d’IA sont indispensables ?
Toutes les fonctions au sein d’une entreprise devront intégrer l’IA à leur activité, car cette technologie est en passe de devenir une nouvelle phase de digitalisation. Les entreprises qui ne suivent pas cette transformation risquent non seulement de perdre en compétitivité, mais aussi de rencontrer des difficultés à recruter des talents. L’IA deviendra un standard incontournable pour améliorer la productivité et attirer les jeunes générations, qui recherchent des environnements de travail modernes et connectés.
7. Ciblez-vous plutôt des informaticiens à qui vous faites apprendre votre métier, ou des spécialistes de votre métier aussi compétents en informatique ?
Nous ne faisons pas de distinction stricte. Chaque rôle dans l’entreprise doit intégrer l’IA, qu’il s’agisse de marketeurs utilisant des outils génératifs pour automatiser des campagnes ou d’ingénieurs chefs de projets s’appuyant sur l’IA pour optimiser la gestion de leurs plannings. Les développeurs travailleront en collaboration avec des agents IA pour accélérer leurs cycles de production, tandis que les CTO et managers utiliseront des outils intelligents pour piloter leurs indicateurs de performance. Cette polyvalence est au cœur de notre approche.
8. Pour les personnes déjà en poste, quelles formations continues vous paraissent indispensables ?
Nous privilégions des approches de transformation ciblées et pratiques plutôt que des formations classiques. Par exemple, un ou une ingénieure avec des compétences en VBA (note : Visual Basic for Applications) pourrait être accompagné pour se former à Python et à l’automatisation, augmentant ainsi sa valeur ajoutée dans l’entreprise. Un collègue secrétaire pourrait apprendre à utiliser des outils « no-code » ou des chatbots pour améliorer la gestion des intranets ou la création de contenus automatisés. Ces plans de transformation, accompagnés d’experts ou de consultants, permettront aux employés de devenir les acteurs de leur propre évolution.
9. Un message à passer, ou une requête particulière aux concepteurs de modèles d’IA ?
Nous appelons à une plus grande ouverture dans l’écosystème de l’intelligence artificielle, en particulier à travers l’open source. Cela permettrait de garantir une compétitivité équilibrée et d’éviter une concentration excessive de pouvoir entre les mains de quelques grands acteurs. Les modèles d’IA devraient être facilement personnalisables et utilisables en local pour protéger les données sensibles des entreprises. Cette approche favoriserait un écosystème plus collaboratif et innovant, permettant à un plus grand nombre d’entreprises de bénéficier des avancées technologiques.
Biais, hallucinations, création de contenus violents et activités frauduleuses : peut-on encore croire ce qu’on voit et ce qu’on entend ? Un façon d’aborder le problème est de créer des images avec une « vraie signature », indélébile et si possible indétectable, pour les distinguer de « fakes ». C’est possible et c’est ce que Jeanne Gautier et Raphaël Vienne, nous expliquent ici. Serge Abiteboul et Thierry Viéville
Vous ouvrez Instagram et tombez nez à nez avec une photo du pape en streetwear. Vous avez tout de même du mal à y croire, et vous avez bien raison ! De nombreux “deepfakes” circulent sur internet : au-delà d’être un outil formidable, l’IA générative présente donc aussi des dangers. La diffusion massive de données générées par IA impose donc de protéger leur propriété, authentifier leur auteur, détecter les plagiats etc. Une solution émerge : le watermarking (ou “tatouage numérique”) qui répond à ces attentes.
Les deux images (en Creative Commons) ci-dessus vous semblent similaires ? Elles le sont à l’œil nu mais diffèrent pourtant par de nombreux pixels.
Créer un « deep watermartking ».
Le watermarking devient de plus en plus sophistiqué. On observe une évolution des techniques de watermarking qui se basaient jusqu’ici sur des concepts assez simples comme un filigrane transparent qui recouvre l’image (« watermark » encodée dans la donnée et qui reste en apparence identique). Apparaît désormais le “deep watermarking” qui induit une altération plus subtile des données, mais qui est aussi plus robuste aux dégradations liées aux manipulations de l’image. Pour être qualifié de “deep watermarking”, un filigrane doit respecter les trois règles suivantes:
l’imperceptibilité : la distorsion doit restée invisible à l’œil humain.
la capacité : on doit pouvoir introduire de l’information dans le tatouage comme la date ou une signature.
la robustesse : le filigrane doit rester détectable même si l’on transforme l’image.
Pourquoi utilise-t-on le terme “deep” ? Parce que ces méthodes se basent sur des algorithmes d’apprentissage profond, ou “deep learning” en anglais. Il s’agit d’un procédé d’apprentissage automatique utilisant des réseaux de neurones possédant plusieurs couches de neurones cachées.
Il est possible d’appliquer de tels filigranes sur des images préexistantes par un processus qualifié “d’encodeur-décodeur” :
– Le modèle d’encodage prend deux entrées : une image brute et un message texte. Il cache le texte dans l’image en essayant de le rendre le moins perceptible possible. – Le décodeur prend en entrée l’image tatouée et tente de récupérer le texte caché.
L’encodeur et le décodeur sont entraînés pour travailler ensemble : le premier pour cacher un message dans une image sans l’altérer visuellement et le second pour retrouver le message dans cette image altérée.
Comme, en pratique, l’image tatouée peut subir des modifications (recadrage, rotation, flou, ajout de bruit), des altérations aléatoires sont appliquées aux images exemples, au cours du processus, pour entraîner le décodeur à tenir compte de ces altérations.
Mieux encore, on peut intégrer, donc encoder, le tatouage directement lors de la création d’images.
Comment fonctionnent les générateurs d’images avec watermark ?
Assez simplement, le système apprend, à partir d’un énorme nombre d’exemples, à passer d’une image où toutes les valeurs sont tirées au hasard (un bruit visuel aléatoire), en prenant en entrée une indication textuelle décrivant l’image souhaitée, à des images de moins en moins aléatoires, jusqu’à créer l’image finale. C’est cette idée de diffuser progressivement l’information textuelle dans cette suite d’images de plus en plus proches d’une image attendue qui fait le succès de la méthode.
Il est alors possible d’incorporer le watermark directement lors de la diffusion : on oriente ce processus en le déformant (on parle de biais statistique), en fonction du code secret, qu’est le watermark. Comme cette déformation ne peut être décodée, seule l’entité générant le texte, peut détecter si le tatouage, est présent.
Comment ça marche en pratique ?
Le watermarking est comme un produit « radioactif » : un modèle entraîné sur des données tatouées reproduit le tatouage présent dedans. Ainsi, si un éditeur utilise le produit tatoué d’un concurrent pour l’entraînement de ses propres modèles, les sorties de ce dernier posséderont également la marque de fabrique du premier !
Le watermarking a donc vocation de permettre aux éditeurs de modèles de génération de protéger leur propriété, puisque c’est une technique robuste pour déterminer si un contenu est généré par une IA et pour faire respecter les licences et conditions d’utilisation des modèles génératifs. Cela dit, il est essentiel de continuer à développer des techniques plus robustes, car tous les modèles open-source n’intègrent pas encore de mécanismes de watermarking.
Tom Sander, photo de son profil sur LinkedIn.
Cet article est issu d’une présentation donnée par Tom Sander chez datacraft. Tom est doctorant chez Meta et travaille sur des méthodes de préservation de la vie privée pour les modèles d’apprentissage profond, ainsi que sur des techniques de marquage numérique. Nous tenons à remercier Tom pour son temps et sa présentation.
Jeanne Gautier, Data scientist chez datacraft & Raphaël Vienne, Head of AI chez datacraft .
A l’heure où Elon Musk fait un peu n’importe quoi au nom de la liberté d’expression, quand des grands patrons du numérique lui emboitent le pas sans doute pour pousser leurs intérêts économiques, il devient encore plus indispensable de comprendre les mécanismes qui causent des dysfonctionnements majeurs des plateformes numériques. Ce deuxième épisode d’un article de Fabien Gandon et Franck Michel nous aide à mieux comprendre. Serge Abiteboul & Thierry Viéville.
Dans le précédent billet nous vous avons donné l’excuse parfaite pour ne pas avoir fait de sport ce week-end : ce n’est pas de votre faute, votre cerveau a été hacké ! Nous avons vu que, à coup de likes, de notifications, de flux infinis et d’interfaces compulsogènes, les grands acteurs du Web ont mis au point des techniques capables de piller très efficacement notre temps de cerveau. Nous avons aussi vu que, en s’appuyant sur des données comportementales massives, les algorithmes apprennent à exploiter notre biais de négativité et favorisent les contenus qui suscitent colère, peur, indignation, ressentiment, frustration, dégoût, etc. Nous avons constaté que, en nous enfermant dans un espace informationnel où rien ne contredit nos croyances, les algorithmes de recommandation ont tendance à créer des visions du monde différentes pour chaque utilisateur. Nous avons enfin conclu que cette combinaison d’émotions, de biais cognitifs et de recommandations automatisées peut conduire à une escalade émotionnelle, à la polarisation et la radicalisation des opinions.
En manque… d’attention et en over-dose d’inattention
Finalement, ce premier billet nous amène à nous interroger sur le caractère addictogène de certains médias sociaux. Une addiction peut survenir dans toute activité pour laquelle une personne développe un appétit excessif. Il peut s’agir d’une dépendance à une substance (ex. une drogue) ou d’une dépendance comportementale, cette dernière se caractérisant par l’impossibilité de contrôler la pratique d’une activité comme les jeux d’argent, ou dans notre cas, l’utilisation d’un média social. On sait qu’une dépendance se développe lorsqu’un comportement particulier est incité et encouragé, qu’il est récompensé d’une manière ou d’une autre, et que rien n’incite à l’arrêter. Or les algorithmes de captation de l’attention sont des héritiers directs de la captologie et suivent à la lettre la formule de développement d’un comportement addictif : les utilisateurs font l’objets de notifications régulières pour initialiser et enclencher l’habitude ; la récompense de l’utilisation repose sur de multiples mécanismes (ex. nombre de likes, émotions, etc.) ; et l’absence de moyens de « décrocher » est au cœur des interfaces (ex. fil infini, auto-play, opt-out par défaut, etc.). On dit souvent qu’un algorithme est une recette, ici on pourrait même parler de la recette d’une drogue de synthèse numérique.
Voilà… Maintenant que le doute est là, vous voyez votre téléphone non seulement comme un espion qui vend vos données, mais aussi comme un traître, un manipulateur et même un dealer numérique ! Et vous vous interrogez sur les dégâts que font ces hackers du cerveau. Mais le problème va plus loin car le Web et Internet forment de vastes toiles qui couplent toutes leurs ressources, et les impacts de ces manipulateurs automatiques se propagent et se combinent par l’effet de mise en réseau.
Fausses informations pour vraie attention
Partant des constats déjà sombres du précédent billet, il faut noter que les choses s’aggravent encore lorsque les contenus dont nous parlons sont des fake news, des fausses informations. En effet, celles-ci s’appuient souvent sur la colère, la frustration ou le dégoût pour hameçonner notre attention. Elles trouvent ainsi sur les réseaux sociaux un terrain particulièrement fertile. Par leurs affirmations choquantes, elles sont vécues par beaucoup comme une injonction à prendre parti en les re-partageant plutôt que de faire appel à l’esprit critique et vérifier leur véracité. Ainsi des études ont montré que les algorithmes de recommandation tendent à favoriser les fausses informations véhiculant des idées clivantes ou des événements choquants. Et comme ces informations sont souvent relayées par des connaissances, le biais de la preuve sociale nous incite à les juger crédibles et dignes de confiance. Répétées encore et encore, associées à des représentations du monde convoquant les théories du complot, renforcées sous la pression des bulles de filtres, et propulsées par l’effet de réseau, les fausses informations instaurent une économie du doute où la vérité est remplacée par la vraisemblance. Avec une éditorialisation qui ne fait pas la différence entre un article écrit par des journalistes professionnels d’un côté, et des fausses informations relayées par un bot malveillant de l’autre, « la presse n’est plus perçue comme celle qui publie, mais comme celle qui cache« . Progressivement et insidieusement, le doute sape notre confiance dans les experts (savants, journalistes…), entraînant des risques pour la santé publique et favorisant l’émergence d’idées extrêmes et de populismes qui mettent en danger les démocraties. Ce que Giuliano Da Empoli résume par la phrase : « le populisme naît de l’union de la colère et la frustration avec les algorithmes« .
On peut penser en particulier au trouble de déficit de l’attention (TDA). Des études attestent que les symptômes du TDA peuvent être aggravés par l’utilisation des médias numériques et de leurs applications conçues pour capter l’attention. Plus inquiétant encore, ces applications pourraient provoquer des TDA chez des personnes n’ayant aucun antécédent de ce trouble. Si ces études sont préliminaires elles nous encouragent à davantage de recherches sur le sujet ainsi qu’à nous poser la question du principe de précaution.
Les « gadgets numériques », comme les appelle Smith, contribuent à ce qu’il appelle « un trouble de déficit de l’attention académique ». On sait que la concentration, mais aussi les moments d’ennui, de flânerie intellectuelle et de rêverie, sont essentiels à la pensée créative. Beaucoup d’entre nous ont déjà expérimenté l’éclair d’une idée soudaine au milieu d’un moment de détente. En volant ces moments, les systèmes de captation de l’attention entravent le processus créatif.
Bien sûr, ces remarques peuvent être généralisées à de nombreuses autres activités et professions nécessitant concentration, créativité et imagination. On peut en effet se demander ce que les systèmes de captation de l’attention font à des domaines comme la politique, la santé, l’éducation ou la création artistique, par exemple. En d’autres termes : attention penseurs et créateurs ! Nous devons repenser ces systèmes pour qu’ils répondent à nos besoins, et non l’inverse car la véritable monnaie d’échange de nos métiers est celle des idées.
Attention Fragile ! Vers des principes de préservation de l’attention
Après ces constats anxiogènes, essayons maintenant d’être constructifs. Puisque, dans un monde de plus en plus numérique, notre attention sur-sollicitée s’avère fragile, nous proposons d’aller vers une gouvernance responsable de l’attention sur le Web en posant plusieurs principes.
Un premier groupe de principes concerne les utilisateurs. Pour renforcer leur autonomie, le principe de la réflexivitécontinue propose que les plateformes leur fournissent régulièrement des retours d’information leur permettant d’être conscients de leurs usages (temps passé, exposition à des contenus négatifs, diversité, etc.), et permettant ainsi de garantir leur consentement éclairé à chaque instant. En outre, le principe de transparence préconise de leur expliquer clairement les motivations et les raisons derrière chaque recommandation, et le principe de soutien à la diligence raisonnable insiste sur l’importance de leur fournir les moyens et les informations nécessaires pour échapper aux boucles et processus imposés par les systèmes. Enfin, le principe d’opt-in par défaut suggère que les notifications et la personnalisation des recommandations soient désactivées par défaut, et activées uniquement après un consentement éclairé et un paramétrage volontaire.
Attention by design
Un deuxième groupe de principes vise à s’assurer que les plateformes intègrent dès leur conception (by design) le respect des utilisateurs. Le principe d’incitation orientée recommande d’utiliser des moyens légaux (interdire certaines pratiques) et économiques (taxes) pour encourager les plateformes à adopter des comportements ayant un impact sociétal positif (éducation, soutien à la collaboration et au débat constructif, élaboration collective de solutions sur les grands problèmes de société…). Et inversement, sanctionner les comportements nuisibles, une sorte de politique de la carotte et du bâton.
De plus, le principe de conception d’interactions bienveillantes appelle à placer le bien-être des utilisateurs au cœur de la conception des interfaces et de leurs objectifs algorithmiques, en s’alignant sur les bonnes pratiques des bright patterns plutôt que celles des dark patterns. D’autres médias sociaux sont en effet possibles, comme Wikipédia qui fait émerger du contenu de qualité sans jamais rechercher la viralité des contenus ni la popularité des contributeurs qui restent pour l’essentiel des citoyens anonymes.
Le principe des recommandations équilibrées vise à éviter la spécialisation excessive des contenus recommandés et à prévenir la formation de bulles de filtres. Notons aussi que lorsqu’une fausse information est corrigée ou démentie, il est fréquent que le message portant la correction ou le démenti soit quasiment invisible en comparaison de la viralité avec laquelle la fausse information a circulé. Aussi, pour aller vers plus de transparence, le principe de la visibilité équilibrée propose que les mesures préventives et correctives d’un problème soient rendues aussi visibles que le problème qu’elles traitent.
Enfin, pour que ces principes soient appliqués, le principe d’observabilité stipule que les plateformes doivent fournir aux institutions, à la société civile et aux chercheurs les instruments juridiques et techniques leur permettant d’effectuer un contrôle et une vérification actifs de l’application et de l’efficacité des réglementations.
L’attention comme bien commun
Dans une perspective plus large, si nous considérons l’attention comme un bien commun au sens économique, le principe de la préservation des communs numériques stipule aussi que les services ayant un impact mondial sur nos sociétés doivent être considérés comme des communs numériques, et à ce titre, protégés et soumis à des règles spécifiques de « préservation ». Cela pourrait par exemple passer par le fait de doter ces services (ou au moins les nouveaux entrants) d’une mission de soutien à un débat public constructif.
Enfin, le principe de transfert des meilleures pratiques invite à s’inspirer des approches éprouvées dans d’autres domaines, comme le droit encadrant la publicité, les casinos ou le traitement de certaines addictions, pour réguler efficacement les pratiques sur le Web. Prenons l’exemple de l’industrie du jeu vidéo : il a été montré qu’un lien existe entre les « loot boxes » (sortes de pochettes surprises des jeux vidéos) et l’addiction aux jeux d’argent. Celles-ci seraient comparables aux jeux de hasard, pouvant entraîner des comportements addictifs et mettre les joueurs en danger. Ce constat a donné lieu à plusieurs régulations. La manière d’étudier et de traiter cette exploitation indésirable de nos comportements et la transposition de connaissances issues d’autres domaines sont des sources d’inspiration pour d’autres pratiques problématiques sur le Web, telles que celles dont nous venons de parler.
Faisons attention… à nous
Résumons-nous. Avec l’objectif initial, somme toute banal, de rendre la publicité plus efficace, la généralisation des techniques de captation de l’attention et l’utilisation qu’elles font des biais cognitifs et des émotions ont des effets délétères très préoccupants sur nos sociétés : polarisation des opinions, diffusion de fausses informations, menace pour la santé publique, les économies et les démocraties. Et oui ! Ce sont donc des (ro)bots qui hackent notre attention car ils sont conçus pour cela ou, plus précisément, pour la capter de façon optimale en vue de la monétiser. De fait, ils utilisent le Web dans un but économique qui va à l’encontre du bien commun. Mais en adoptant les principes proposés ci-dessus, nous pensons qu’il est possible de construire un Web qui continue de soutenir l’activité économique sans pour autant entraîner la captation systématique de l’attention.
Dans ses essais, Montaigne nous disait “quand on me contrarie, on éveille mon attention, non pas ma colère : je m’avance vers celui qui me contredit, qui m’instruit.”. Or les plateformes nous poussent à faire le contraire : éveiller l’émotion négative et s’éloigner d’autrui. Mais il n’est pas raisonnable de laisser de multiples moyens technologiques hacker nos cerveaux et créer un déficit mondial d’attention, nous empêchant ainsi de la porter sur des sujets qui devraient actuellement nous « contrarier ». A une époque où nous devons modifier nos comportements (par exemple, la surconsommation de biens et d’énergie) et porter notre attention sur des questions cruciales comme le changement climatique, nous devrions nous demander si les algorithmes de recommandation font les bonnes recommandations, et pour qui. Compte tenu des quatre milliards d’utilisateurs pris chaque jour dans leurs boucles de recommandation, il est important de surveiller en permanence comment et dans quel but ces systèmes captent notre attention. Car lorsque notre attention est consacrée à un contenu choisi par ces plateformes, elle est perdue pour tout le reste.
Merci… pour votre attention 🙂
Fabien Gandon, Directeur de Recherche Inria et Franck Michel, ingénieur de recherche, Université Côte d’Azur, CNRS, Inria.
A l’heure où Elon Musk fait un peu n’importe quoi au nom de la liberté d’expression, quand des grands patrons du numérique lui emboîtent le pas sans doute pour pousser leurs intérêts économiques, il devient encore plus indispensable de comprendre les mécanismes qui causent des dysfonctionnements majeurs des plateformes numériques. Ce premier épisode d’un article de Fabien Gandon et Franck Michel nous aide à mieux comprendre. Serge Abiteboul & Thierry Viéville.
Nous sommes un dimanche après-midi. Vous avez un petit moment pour vous. Vous pourriez lire, vous balader, aller courir ou écouter de la musique mais machinalement votre main saisit votre téléphone. Le « sombre miroir » s’éclaire et vous passez de l’autre côté. Vous ouvrez l’application de votre réseau social préféré qui vient de vous notifier qu’elle a du nouveau pour vous. Et c’est vrai ! Jean a posté un message à propos de la tragicomédie « Qui a hacké Garoutzia ? » qu’il a vue au théâtre hier soir. Vous approuvez ce poste d’un pouce virtuel et déjà votre vrai pouce pousse vers le poste suivant. Entre une publicité pour un abonnement au théâtre, une photo postée d’Avignon par un ami que vous avez du mal à remettre, l’annonce pour un jeu où tester vôtre culture générale… votre pouce se lance dans un jogging numérique effréné. Imperceptiblement le flux d’information qui vous est proposé dévie, une vidéo de chats acrobates, un « clash » entre stars de la télévision, une manifestation qui tourne à l’affrontement… Et avant que vous ne le réalisiez une petite heure s’est écoulée et il est maintenant trop tard pour un vrai jogging. Vous ressentez une certaine résistance à reposer votre téléphone : après tout, il y avait peut-être encore tant de contenus intéressants, inédits, surprenants ou croustillants dans ce fil de recommandations. Mais vous devez vous rendre à l’évidence, ce fil est sans fin. Vous ne pouvez croire à quelle vitesse la dernière heure est passée. Vous avez l’impression qu’on vous l’a volée, que vous avez traversé un « tunnel temporel ». Sans même vous rappeler de ce que vous avez vu défiler, vous reposez ce téléphone un peu agacé en vous demandant… mais qui a hacké mon attention ?
A l’attention de tous…
Sir Tim Berner-Lee, récipiendaire du prix Turing pour avoir inventé le Web, a toujours considéré que les Web devait « être pour tout le monde », mais il a aussi partagé début 2024 un dialogue intérieur en deux articles à propos du Web : « Le dysfonctionnement des réseaux sociaux » et « Les bonnes choses ». Et oui… même le père du Web s’interroge gravement sur celui-ci et met face à face ce qu’il y a de meilleur et de pire sur le Web. Loin d’avoir réalisé l’idéal d’une communauté mondiale unie, Tim constate que des applications du Web comme les réseaux sociaux amplifient les fractures, la polarisation, la manipulation et la désinformation, menaçant démocraties et bien-être. Tout en reconnaissant les nombreuses vertus du Web (outils éducatifs, systèmes open source ou support à la souveraineté numérique), il nous propose de mettre l’accent sur la transparence, la régulation, et une conception éthique d’un Web et d’un Internet plus sûrs et responsables. Autrement dit, l’enjeu actuel est de préserver les richesses du Web tout en se protégeant de ses dérives.
Parmi ces dérives, on trouve le problème de la captation de notre attention, un sujet sur lequel nous voulons revenir dans ce billet ainsi que le suivant. C’est l’objet d’un de nos articles publié cette année à la conférence sur l’IA, l’éthique et à la société (AIES) de l’Association pour l’Avancement de l’Intelligence Artificielle (AAAI), que nous résumons ici. Le titre pourrait se traduire par « Prêtez attention : un appel à réglementer le marché de l’attention et à prévenir la gouvernance émotionnelle algorithmique ». Nous y appelons à des actions contre ces pratiques qui rivalisent pour capter notre attention sur le Web, car nous sommes convaincus qu’il est insoutenable pour une civilisation de permettre que l’attention soit ainsi gaspillée en toute impunité à l’échelle mondiale.
Attention à la march…andisation (de l’attention)
Si vous lisez cette phrase, nous avons déjà gagné une grande bataille, celle d’obtenir votre attention envers et contre toutes les autres sollicitations dont nous sommes tous l’objet : les publicités qui nous entourent, les « apps » dont les notifications nous assaillent jour et nuit, et tous les autres « crieurs numériques » que l’on subit au quotidien.
Depuis l’avènement de la consommation de masse dans les années 50, les médias et les publicitaires n’ont eu de cesse d’inventer des méthodes toujours plus efficaces pour capter notre attention et la transformer en revenus par le biais de la publicité. Mais ce n’était qu’un début… Au cours des deux dernières décennies, en s’appuyant sur la recherche en psychologie, en sociologie, en neurosciences et d’autres domaines, et soutenues par les avancées en intelligence artificielle (IA), les grandes plateformes du Web ont porté le processus de captation de l’attention à une échelle sans précédent. Basé presque exclusivement sur les recettes publicitaires, leur modèle économique consiste à nous fournir des services gratuits qui, en retour, collectent les traces numériques de nos comportements. C’est le célèbre “si c’est gratuit, c’est nous le produit” et plus exactement, ici, le produit c’est notre attention. Ces données sont en effet utilisées pour maximiser l’impact que les publicités ont sur nous, en s’assurant que le message publicitaire correspond à nos goûts, nos inclinations et notre humeur (on parle de “publicité ciblée”), mais aussi en mettant tout en place pour que nous soyons pleinement attentifs au moment où la publicité nous est présentée.
Recrutant des « armées » de psychologues, sociologues et neuroscientifiques, les plateformes du Web comme les médias sociaux et les jeux en ligne ont mis au point des techniques capables de piller très efficacement notre « temps de cerveau disponible ». Résultat, nous, les humains, avons créé un marché économique où notre attention est captée, transformée, échangée et monétisée comme n’importe quelle matière première sur les marchés.
Faire, littéralement, attention
A l’échelle individuelle, lorsque l’on capte notre attention à notre insu, on peut déjà s’inquiéter du fait que l’on nous vole effectivement du temps de vie, soit l’un de nos biens les plus précieux. Mais si l’attention est un mécanisme naturel au niveau individuel, l’attention collective, elle, est le fruit de l’action de dispositifs spécifiques. Il peut s’agir de lieux favorisant l’attention partagée (ex. un théâtre, un cinéma, un bar un soir de match, une exposition), de l’agrégation d’attention individuelle pour effectuer des mesures (ex. audimat, nombre de vues, nombre de partages, nombre de ventes, nombre d’écoutes, etc.) ou autres. Pour ce qui est de l’attention collective, nous faisons donc, littéralement, l’attention. En particulier, les plateformes créent l’attention collective et dans le même temps captent ce commun afin de le commercialiser sans aucune limite a priori.
Parmi les techniques utilisées pour capter notre attention, nous pouvons distinguer deux grandes catégories. Tout d’abord, certaines techniques sont explicitement conçues pour utiliser nos biais cognitifs. Par exemple, les likes que nous recevons après la publication d’un contenu activent les voies dopaminergiques du cerveau (impliquées dans le système de récompense) et exploitent notre besoin d’approbation sociale ; les notifications des apps de nos smartphones alimentent notre appétit pour la nouveauté et la surprise, de sorte qu’il est difficile d’y résister ; le « pull-to-refresh », à l’instar des machines à sous, exploite le modèle de récompense aléatoire selon lequel, chaque fois que nous abaissons l’écran, nous pouvons obtenir une nouveauté, ou rien du tout ; le défilement infini (d’actualités, de posts ou de vidéos…) titille notre peur de manquer une information importante (FOMO), au point que nous pouvons difficilement interrompre le flux ; l’enchaînement automatique de vidéos remplace le choix délibéré de continuer à regarder par une action nécessaire pour arrêter de regarder, et provoque un sentiment frustrant d’incomplétude lorsqu’on l’arrête ; etc. De même, certaines techniques exploitent des « dark patterns » qui font partie de ce qu’on nomme design compulsogène ou persuasif, pour nous amener, malgré nous, à faire des actions ou des choix que nous n’aurions pas faits autrement. C’est typiquement le cas lorsque l’on accepte toutes les notifications d’une application sans vraiment s’en rendre compte, alors que la désactivation des notifications nécessiterait une série d’actions fastidieuses et moins intuitives.
Les petites attentions font les grandes émotions… oui mais lesquelles?
Une deuxième catégorie de techniques utilisées pour capter notre attention repose sur les progrès récents en matière d’apprentissage automatique permettant d’entraîner des algorithmes de recommandation de contenu sur des données comportementales massives que Shoshana Zuboff appelle le « surplus comportemental« . Ces algorithmes apprennent à recommander des contenus qui non seulement captent notre attention, mais également augmentent et prolongent notre « engagement » (le fait de liker, commenter ou reposter des contenus, et donc d’interagir avec d’autres utilisateurs). Ils découvrent les caractéristiques qui font qu’un contenu attirera plus notre attention qu’un autre, et finissent notamment par sélectionner des contenus liés à ce que Gérald Bronner appelle nos invariants mentaux : la conflictualité, la peur et la sexualité. En particulier, les émotions négatives (colère, indignation, ressentiment, frustration, dégoût, peur) sont parmi celles qui attirent le plus efficacement notre attention, c’est ce que l’on appelle le biais de négativité. Les algorithmes apprennent ainsi à exploiter ce biais car les contenus qui suscitent ces émotions négatives sont plus susceptibles d’être lus et partagés que ceux véhiculant d’autres émotions ou aucune émotion particulière. Une véritable machine à créer des “réseaux soucieux” en quelque sorte.
Bulles d’attention et bulles de filtres
En nous promettant de trouver pour nous ce qui nous intéresse sur le Web, les algorithmes de recommandation ont tendance à nous enfermer dans un espace informationnel conforme à nos goûts et nos croyances, une confortable bulle de filtre qui active notre biais de confirmation puisque nous ne sommes plus confrontés à la contradiction, au débat ou à des faits ou idées dérangeants.
En apparence bénignes, ces bulles de filtres ont des conséquences préoccupantes. Tout d’abord, au niveau individuel, parce que, s’il est important de se ménager des bulles d’attention pour mieux se concentrer et résister à l’éparpillement, il est aussi important de ne pas laisser d’autres acteurs décider quand, comment et pourquoi se forment ces bulles. Or c’est précisément ce que font les algorithmes de recommandation et leurs bulles de filtres, en décidant pour nous à quoi nous devons penser.
Ensuite, au niveau collectif, Dominique Cardon pointe le fait que les bulles de filtres séparent les publics et fragmentent nos sociétés. Ceux qui s’intéressent aux informations sont isolés de ceux qui ne s’y intéressent pas, ce qui renforce notamment le désintérêt pour la vie publique.
Et en créant une vision du monde différente pour chacun d’entre nous, ces techniques nous enferment dans des réalités alternatives biaisées. Or vous et moi pouvons débattre si, alors que nous observons la même réalité, nous portons des diagnostiques et jugements différents sur les façons de résoudre les problèmes. Mais que se passe-t-il si chacun de nous perçoit une réalité différente ? Si nous ne partons pas des mêmes constats et des mêmes faits ? Le débat devient impossible et mène vite à un affrontement stérile de croyances, au sein de ce que Bruno Patino appelle une « émocratie, un régime qui fait que nos émotions deviennent performatives et envahissent l’espace public« . Dit autrement, il n’est plus possible d’avoir un libre débat contradictoire au sein de l’espace public, ce qui est pourtant essentiel au fonctionnement des démocraties.
La tension des émotions
Puisque les algorithmes de recommandation sélectionnent en priorité ce qui produit une réaction émotionnelle, ils invibilisent mécaniquement ce qui induit une faible réponse émotionnelle. Pour être visible, il devient donc impératif d’avoir une opinion, de préférence tranchée et clivante, de sorte que la réflexion, la nuance, le doute ou l’agnosticisme deviennent invisibles. L’équation complexe entre émotions, biais cognitifs et algorithmes de recommandation conduit à une escalade émotionnelle qui se manifeste aujourd’hui sur les médias sociaux par une culture du « clash », une hypersensibilité aux opinions divergentes interprétées comme des agressions, la polarisation des opinions voire la radicalisation de certains utilisateurs ou certaines communautés. Ce qui fait dire à Bruno Patino que « les biais cognitifs et les effets de réseau dessinent un espace conversationnel et de partage où la croyance l’emporte sur la vérité, l’émotion sur le recul, l’instinct sur la raison, la passion sur le savoir, l’outrance sur la pondération ». Recommandation après recommandation, amplifiée par la désinhibition numérique (le sentiment d’impunité induit par le pseudo-anonymat), cette escalade émotionnelle peut conduire à des déferlements de violence et de haine dont l’issue est parfois tragique, comme en témoignent les tentatives de suicide d’adolescents victimes de cyber-harcèlement. Notons que cette escalade est souvent encore aggravée par les interfaces des plateformes, qui tendent à rendre les échanges de plus en plus brefs, instinctifs et simplistes.
Le constat que nous dressons ici peut déjà sembler assez noir, mais il y a pire… Et à ce stade, pour garder votre attention avant que vous ne zappiez, quoi de mieux que de créer un cliffhanger, une fin laissée en suspens comme dans les séries télévisées à succès, et d’utiliser l’émotion qui naît de ce suspens pour vous hameçonner dans l’attente du prochain épisode, du prochain billet à votre attention…
Fabien Gandon, Directeur de Recherche Inria, et Franck Michel, ingénieur de recherche, Université Côte d’Azur, CNRS, Inria.
Bonjour Quentin, pouvez-vous nous dire rapidement qui vous êtes, et quel est votre métier ?
Je suis co-fondateur et directeur de l’innovation de Dada ! Animation, un studio d’animation 2D et 3D orienté « nouvelles technologies » (entendre moteurs de jeux / temps réel, Réalité Virtuelle et Augmentée / XR, ou IA) appliquée à l’animation pour la TV, le cinéma, le web et les nouveaux médias immersifs et de réseaux.
De formation ingénieur en Design Industriel de l’Université de Technologie de Compiègne(1994), j’ai basculé vers le monde de l’animation 3D et des effets spéciaux en 1999, en retournant un temps à l’École des Gobelins. J’ai travaillé dans ces domaines en France dans de nombreux studios de différentes tailles, en Allemagne et aux USA (chez ILM, par exemple) et j’ai fondé en 2019 ce nouveau studio suite à des expérimentations réussies avec mes collègues cofondateurs dans une autre structure, où nous basculions les process classiques de la 3D dite « précalculée » vers le « temps réel » (via l’utilisation de moteurs de jeux vidéo comme Unity ou Unreal Engine) et vers la Réalité Virtuelle comme aide à la réalisation. Ces expérimentations nous ont d’ailleurs apporté à l’époque un prix Autodesk Shotgun à la conférence SIGGRAPH 2019 à Los Angeles.
Nous avons passé le pas et focalisé Dada ! Animation sur ces approches nouvelles, auxquelles s’ajoutent maintenant les IA Génératives (IAG) que nous scrutons de près. Nous travaillons par ailleurs aussi sur des thèmes éditoriaux spécifiques et éthiques : le ludo-éducatif, le documentaire, la science, l’écologie, l’inclusivité, etc.
Mon travail consiste en énormément de veille technique et de détection de talents nouveaux adaptés à ces approches, en l’organisation de tests, et de préconisations en interne. Je dialogue ainsi beaucoup avec les écoles, les institutions du métier (Centre National du Cinéma, Commission Supérieure Technique, CPNEF de l’Audio-Visuel…) et des laboratoires avec lesquels nous travaillons par ailleurs, pour leur faire des films (CNRS, CNSMDP, INRIA, …), pour tester des solutions techniques (IRISA, Interdigital, …) ou pour de la recherche.
Je coordonne d’ailleurs en ce moment un projet ANR, intitulé « Animation Conductor », en collaboration avec l’IRISA, Université de Rennes 1 et LIX, Ecole Polytechnique, sur de l’édition d’animation 3D par la voix et les gestes.
Enfin, je suis un membre actif du groupe de travail interstructurel Collectif Creative Machines, regroupant des labos, des studios, des écoles et tout professionnel francophone intéressé par la réflexion sur les impacts des IAG dans nos métiers.
En quoi pensez-vous que l’IA a déjà transformé votre métier ?
Elle l’occupe déjà beaucoup rien qu’en veille et en colloques, en termes d’inquiétude et de discussions sans fin ! Je passe personnellement au moins 20% de mon temps à en évaluer et en parler… L’IA n’est bien-sûr pas nouvelle dans nos métiers de l’image de synthèse, bourrés d’algorithmes de toutes sortes, renouvelés régulièrement. On utilise même des algorithmes de modification d’images proches de modèles de diffusion (la même famille que Midjourney) depuis 10 ans (par exemple les « denoisers » de NVIDIA, qui accélèrent le rendu final d’images de synthèse), mais bien-sûr, j’imagine que « l’IA » dont on parle ici est celle, de nouvelle génération, souvent générative, propulsée par les récentes avancées des Transformersou CLIPet par des succès techniques comme ceux d’OpenAI, Runway, Stability, Midjourney, etc.
Pour le monde de l’animation, tout ce qui touche le texte (les scénarios, mais aussi le code, très présent) est bien-sûr impacté par les grands modèles de langage (LLMs), mais, j’ai l’impression que c’est principalement en termes d’aide à l’idéation ou pour accélérer certains écrits, jamais au cœur ou en produit final (des problèmes de droits d’auteurs se poseraient alors aussi !), du moins pour du média classique. Pour ce qui est de l’image, idem : pour la partie du métier qui ne la rejette pas complétement (c’est un sujet radioactif du fait des méthodes d’entraînement disons « agressives » vis-à-vis des droits d’auteurs et du copyright), au mieux les IAG sont utilisées en idéation, pour de la texture, quelques fois des décors (ce qui pose déjà beaucoup de problèmes éthiques, voire juridiques). Il n’y a pas encore de modèles intéressants pour générer des architectures 3D propres, de la bonne animation, etc. Et pour cause, les données d’entraînement pertinentes pour ce faire n’ont jamais été facilement accessibles à la différence des images finales ! On n’a pas accès aux modèles 3D d’Ubisoft ou de Pixar…
En revanche, les mondes des effets spéciaux visuels (VFX) et du son, en particulier de la voix, ont accès déjà à des modèles puissants de traitement d’images et de sons réels, et de nombreux studios commencent à les intégrer, surtout pour des tâches lourdes et ingrates : détourage, rotoscopie, relighting, de aging/deepfake, doublage, etc.
Des défis juridiques et éthiques demeurent tout de même pour certaines de ces tâches. Les comédiens par exemple, luttent pour garder bien naturellement le contrôle professionnel de leur voix (une donnée personnelle et biométrique qui plus est). De nombreux procès sont encore en cours contre les fabricants des modèles et quelques fois contre des studios ou des diffuseurs. Mais il est difficile de ne pas remarquer un lent pivot de l’industrie Hollywoodienne vers leur utilisation (par exemple par l’accord Lionsgate x Runway, James Cameron au board de Stability, des nominations chez Disney, etc.) et ce, alors que ces sujets furent pourtant au coeur des grèves historiques des réalisateurs, acteurs et auteurs de l’année dernière !
On peut parler d’une ambiance de far west dans ces domaines, tant il y a d’incertitudes, qui se rajoutent en ce moment au fait que la conjoncture dans l’audiovisuel et le jeu video est catastrophique et ne promet pas de s’arranger en 2025 (cf. les chiffres du secteur par le CNC au RADI-RAF 2024.
A quels changements peut-on s’attendre dans le futur ? Par exemple, quelles tâches pourraient être amenées à s’automatiser? A quel horizon ?
Pour les effets spéciaux, il devient absurde d’imaginer faire du détourage, du tracking et de la rotoscopie encore à la main dans les mois qui viennent (et c’était le travail d’entreprises entières, en Asie entre autres…) De même, les tâches de compositing, relighting, etc. vont être rapidement augmentées par des modèles génératifs, mais, je l’espère, toujours avec des humains aux commandes. On risque d’ailleurs de voir diverses tâches « coaguler » autour d’une même personne qui pourra techniquement les mener toutes à bien seule, mais pour laquelle la charge mentale sera d’autant plus forte et les responsabilités plus grandes ! On a déjà vécu cela lors de l’avènement des outils de storyboard numérique qui permettaient d’animer, de faire du montage, d’intégrer du son, etc. Moins d’artistes ont alors pu, et dû, faire plus, dans le même laps de temps, et sans être payés plus chers puisque tout le monde fut traité à la même enseigne et que la compétition fait rage…
Les Designers aussi commencent à voir de leur travail s’évaporer, surtout dans les conditions actuelles où la pression est forte « d’économiser » des postes, sur des productions qui pensent pouvoir se passer d’un regard humain professionnel remplacé par quelques prompts. Cela peut en effet suffire à certaines productions, pour d’autres, c’est plus compliqué.
Sinon, dans les process d’animation 3D, ce ne sont pas des métiers, mais des tâches précises qui pourraient être augmentées, accélérées (texture, dépliage UV, modélisation, rig, certains effets). Mais honnêtement, vu la conjoncture, l’avènement des IA de génération vidéo qui court-circuitent potentiellement tout le processus classique, de l’idée de base à l’image finale, vu l’apparition des IA dites « agentiques » qui permettent à des non-codeurs de construire temporairement des pipelines entiers dédiés à un effet, et vu l’inventivité habituelle des techniciens et artistes, il est en fait très dur d’imaginer à quoi ressembleront les pipelines des films et des expériences interactives dans 5 ans, peut-être même dès l’année prochaine ! Et c’est bien un problème quand on monte des projets, des budgets, et encore pire, quand on monte des cycles de formations sur plusieurs années… (la plupart des très nombreuses et excellentes écoles d’animation, VFX et Jeu Vidéo françaises ont des cursus sur 3 à 5 ans). Certains prédisent l’arrivée avant l’été 2025 des premiers studios « full AI ». Cela ne se fera en tous cas pas sans douleur, surtout dans le climat actuel.
Si vous devez embaucher de nouveaux employés, quelles connaissances en informatique, en IA, attendez-vous d’eux suivant leurs postes ? Pouvez-vous préciser quelles formations, à quel niveau ? / Ciblez-vous plutôt des informaticiens à qui vous faites apprendre votre métier, ou des spécialistes de votre métier aussi compétents en informatique.
De plus grosses entreprises, selon leurs projets, peuvent embaucher des data scientists et ingénieurs en apprentissage machine, mais la réalité pour la majorité des petits studios est qu’on travaille avec les outils disponibles sur le marché. Au pire, une petite équipe de développeurs et « TD » (Technical Directors, postes paradoxalement entre la R&D et les graphistes) vont faire de la veille des modèles (si possibles disponibles en open-source) à implémenter rapidement (en quelques heures ou jours) dans des solutions de type ComfyUI, Nuke, Blender où ils ont de toute façon la charge de coder des outils. On ne change donc pas vraiment de profils recherchés car ceux-ci étaient déjà nécessaires pour maintenir les productions. En revanche, il est important de trouver des profils qui ont une appétence pour ces nouvelles approches non déterministes et qui aiment « bricoler » des dispositifs qui pourront changer d’une semaine à l’autre au fil des publications scientifiques… C’est tout de même assez typique de profils VFX je pense, même si les rythmes d’adaptation sont plus soutenus qu’avant.
Pour ce qui est de la formation, il est indispensable pour ces postes qu’ils connaissent ces métiers. Ils doivent donc être issus de nos écoles d’animation / VFX, mais elles ne peuvent former qu’en surface à ces outils car ils changent trop souvent, ils remettent en cause pour l’instant trop de pipelines, et ne permettent pas de créer de cursus stables !
Pour quelles personnes déjà en poste pensez-vous que des connaissances d’informatique et d’IA sont indispensables?
Tous ceux dont je viens de parler : les techniciens des pipelines, les ITs et a minima les managers pour qu’ils en comprennent au moins les enjeux.
Les artistes sont habitués à apprendre de nouveaux algorithmes, qui viennent chacun avec leur particularités. Mais si les nouvelles méthodes impactent trop la distribution des métiers, ce sont les équipes entières qui devront les reconstruire.
Pour les personnes déjà en poste, quelles formations continues vous paraissent indispensables?
Cela dépend de leur métier, mais je pense qu’on arrive vers un nouveau paradigme de l’informatique, avec de nouveaux enjeux, de nouvelles limites et possibilités. Tout le monde devrait a minima être au courant de ce que sont ces IAG, et pas que pour leur métier, mais aussi pour leur vie personnelle, pour les risques de deepfake temps réel et autres dangers ! Ca donnera d’ailleurs vite la mesure de ce qu’on peut en faire en terme d’audio-visuel.
Un message à passer, ou une requête particulière aux concepteurs de modèles d’IA?
Quand des technologies des médias évoluent autant, on s’attend à un enrichissement des œuvres (elles pourraient devenir toutes immersives, 8k, 120 images/secondes, avec de nouvelles écritures, plus riches, etc.) et/ou à leur multiplication et potentiellement à un boom de l’emploi. C’est arrivé avec le numérique, la 3D, l’interactif, les plateformes… D’ailleurs avec un impact environnemental conséquent. Cependant, on arrive dans un moment économique compliqué et le « marché de l’attention » semble saturé : l’américain moyen consomme déjà 13h de media par jour, à plus de 99% produits pour les nouveaux réseaux (tiktok, instagram, etc.) et le reste classiquement (cinéma, TV, jeux).
Ces médias classiques restent tout de même encore majoritairement consommés, mais nous souffrons déjà de ce que j’appellerais une « malbouffe numérique », addictive, trop présente, trop synthétique, et pas que côté média, en journalisme aussi, pour la science en ligne, etc.
On imagine alors mal ce que la baisse de la barrière à l’accès de la création d’effets numériques, que propose l’IAG, va apporter de positif. Sans doute pas moins de « contenus », mais aussi, et même s’ils étaient de qualité, sans doute pas non plus pour un meilleur soin de notre attention, ni de notre environnement vu l’impact du numérique – et encore plus s’il est lesté d’IAG – sur l’énergie et l’eau.
C’est aussi ce mélange de crises existentielles, sanitaires et environnementales que traverse le monde des médias en ce moment.
Nous n’avons pas encore géré la toxicité des réseaux sociaux qu’une vague générative artificielle arrive pour a priori l’accentuer à tous égards.
Il serait bon, peut-être vital même, que les chercheurs et entrepreneurs du domaine s’emparent de ces questions, avec les créateurs. Une des voies assez naturelle pour cela est de rencontrer ces derniers sur leur terrain : plutôt que d’apporter des solutions hyper-technologiques qui cherchent des problèmes à résoudre, qu’ils entendent ce que les créateurs professionnels demandent (pas le consommateur lambda subjugué par des générateurs probabilistes de simulacres d’œuvres, même s’il doit être tentant, j’entends bien, de créer la prochaine killer app en B2C), qu’ils comprennent comment ils travaillent, avec quelle sémantique, quelles données, quels critères, et quels besoins (vitaux, pour « travailler » leur art) de contrôle.
J’en croise de plus en plus, de ces chercheurs et entrepreneurs interrogatifs sur les métiers qu’ils bousculent, qu’ils « disruptent », et qui sont avides de discussions, mais les occasions officielles sont rares, et la pression et les habitudes des milieux de la recherche, de l’entreprenariat et de la création sont quelques fois divergents. On devrait travailler d’avantage à les croiser, dans le respect de ce qui reste naturellement créatif de part et d’autre.
A force d’imaginer l’IA* capable de tout faire, il fallait bien qu’on se pose un jour la question de savoir si cette technologie pouvait aussi faire de la science. C’est même la très sérieuse Académie nationale des sciences des Etats-Unis (NAS) qui s’interroge, à l’issue d’un séminaire dont elle a publié un compte-rendu. Charles Cuveliez et Jean-Charles Quisquater nous expliquent exactement tout ce qu’il ne faut pas faire ! Ikram Chraibi-Kaadoud et Thierry Viéville.
(*) L’expression IA recouvre un ensemble de concepts, d’algorithmes, de systèmes parfois très différents les uns des autres. Dans cet article, nous utilisons cette abréviation simplificatrice pour alléger la lecture.
Une IA qui voudrait faire de la science, devrait posséder certaines qualités d’un scientifique comme la créativité, la curiosité, et la compréhension au sens humain du terme. La science, c’est identifier des causes (qui expliquent les prédictions), c’est se débrouiller avec des données incomplètes, de taille trop petite, c’est faire des choix, tout ce que l’IA ne peut être programmé à faire. C’est se rendre compte des biais dans les données, alors que certains biais sont amplifiés par l’IA. Par contre, l’IA peut détecter des anomalies ou trouver des structures ou des motifs dans de très grands volumes de données, ce qui peut mener le scientifique sur des indices qu’il ne trouverait pas autrement.
Si l’IA peut contribuer à la science, c’est sans doute en automatisant et menant des expériences à la place du scientifique, plus rapidement et donc en plus grand nombre, qu’un humain ne pourrait le faire. Mais tout scientifique expérimentateur sait combien il peut être confronté à des erreurs de mesures ou de calibration. Il faut aussi pouvoir répondre en temps réel aux variations des conditions expérimentales. Un scientifique est formé pour cela. Un système d’IA répondra à des anomalies des appareils de mesure mais dans la mesure de l’apprentissage qu’il a reçu. Dans un récent article ambitieusement nommé: “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery” (Sept 2024), leurs auteurs ont proposé un modèle qui automatise le travail d’un chercheur depuis la confrontation d’une idée à la littérature existante (est-elle nouvmaitriseelle) jusqu’à l’écriture du papier, sans doute impressionnant mais où le coup de génie a-t-il sa place dans cette production scientifique aseptisée ?
Que peut apporter spécifiquement l’IA générative, et en son sein, les modèles LLM ? Ils sont entraînés et emmagasinent des quantités gigantesques de données de manière agnostique mais ne savent pas faire d’inférence, une autre caractéristique de la science en marche. On a l’impression que l’IA, générative ou non, a une capacité d’inférence : si on lui montre une photo d’un bus qu’elle n’a jamais vu auparavant, pour autant qu’elle ait été entraîné, elle reconnaîtra en effet qu’il s’agit d’un bus. A-t-elle pour autant une compréhension de ce qu’est un bus ? Non car un peu de bruit sur l’image lui fera rater la reconnaissance, contrairement à un humain ! En fait, il ne s’agit pas d’inférence, mais de reconnaissance.
Sans avoir de capacité de raisonnement, l’IA générative est un générateur d’idées plausibles, quitte pour le scientifique à faire le tri entre toutes les idées plausibles et celles peut-être vraies (à lui de le prouver !). L’IA générative peut étudier de large corpus de papiers scientifiques, trouver le papier qui contredit tous les autres et qui a été oublié et est peut-être l’avancée décisive que le scientifique devra déceler. Elle peut aussi résumer ce qui permettra au chercheur de gagner du temps. L’IA générative peut également générer du code informatique qui aide le scientifique. On a même évoqué l’idée de l’IA qui puisse générer des données expérimentales synthétiques, ce qui semble un peu fou mais très tentant lorsque les sujets sont des être humains. Que ne préférerait-on pas une IA générative répondre comme un humain pour des expériences en sciences sociales, sauf que c’est un perroquet stochastique qui vous répondra (Can AI Replace Human Research Participants? These Scientists See Risks, Scientific American, March 2024)
Alors, oui, vu ainsi, l’IA est un assistant pour le scientifique. Les IA n’ont pas la capacité de savoir si leurs réponses sont correctes ou non. Le scientifique oui.
Malheureusement, la foi dans l’IA peut amener les chercheurs à penser de manière moins critique et à peut-être rater des options qu’ils auraient pourtant trouvées sans IA. Il y a un problème de maîtrise de l’IA. Pour faire progresser l’utilisation de l’IA vers la science, il faudrait d’abord qu’elle ne soit plus l’apanage des seuls experts en IA mais qu’elle soit basée sur une étroite collaboration avec les scientifiques du domaine
Introduire l’utilisation de l’IA dans la science présente aussi un risque sociétal : une perte de confiance dans la science induite par le côté boite noire de l’IA.
Il faut donc bel et bien distinguer l’IA qui ferait de la science de manière autonome (elle n’existe pas) ou celle qui aide le scientifique à en faire de manière plus efficace.
Et d’ailleurs, l’IA a déjà contribué, de cette manière-là, à des avancées dans la science dans de nombreuses disciplines comme la recherche sur des matériaux, la chimie, le climat, la biologie ou la cosmologie.
Au final restera la quadrature du cercle : comment une IA peut expliquer son raisonnement pour permettre au scientifique de conseiller son IA à l’assister au mieux.
Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT) & Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles)
Pour en savoir plus: AI for Scientific Discovery, Proceedings of a Workshop (2024), US National Academies, Medecine, Sciences, Engineering
Pour nous aider a réfléchir à l’impact grandissant de ce que nous appelons l’intelligence artificielle sur nos activités humaine, Anne-Marie Kermarrec, nous invite à regarder l’évolution des ces algorithmes au fil des dernières années, pour nous aider à réfléchir au fait que l’intelligence artificielle conduit à repenser ce que nous considérons comme l’intelligence humaine. Serge Abiteboul et Thierry Viéville.
Page personnelle à l’EPFL
En mars 2016, AlphaGo écrasait le légendaire champion de du monde de Go Lee Sedol. Le monde commençait à entrevoir le potentiel extraordinaire de l’intelligence artificielle. Quand en novembre 2022, ChatGPT a été lancé, chacun d’entre nous a commencé à entamer la conversation avec ce nouveau joujou, qui de lui demander d’écrire un discours, qui de lui faire corriger ou de faire un résumé d’un article, qui de le sommer d’écrire un poème ou de lui donner des idées pour résoudre un problème. Quelques mois plus tard, ChatGPT passait avec succès des examens réputés difficiles tel que celui du barreau, écrivait du code à l’envi dans n’importe quel langage informatique ou pondait un nouveau roman dans le style de Zola. Et le monde, oscillant entre ébahissement et inquiétude, de réaliser à quel point, bien que sujets à des hallucinations manifestes, ces algorithmes d’IA générative allaient petit à petit grignoter nos emplois dans bien des domaines du service du droit ou de la médecine.
Et la science dans tout ça ? Est-ce qu’un algorithme d’IA peut aussi remplacer les cerveaux d’un éminent chercheur en physique, d’un prix Nobel de chimie ou d’un historien célèbre ?
Stockholm, le 8 octobre 2024, la vénérable académie des Nobels couronne dans le domaine de la physique, entre autres, … un informaticien, en l’occurrence Jeff Hinton, qui a partagé le prix Turing en 2019 avec Yann Lecun et Yoshua Bengio. Ce même Jeff Hinton qui a dénoncé avec véhémence les dangers de l’intelligence artificielle pour l’humanité du reste il y a quelques temps. Le lendemain, le 9 octobre 2024, cette même académie décerne un prix Nobel de chimie à deux autres informaticiens de DeepMind Demis Hassabis et John Jumper pour leurs travaux sur la structure des protéines.
Outre ces deux exemples iconiques, l’intelligence artificielle participe désormais fréquemment à des découvertes scientifiques dans de nombreux domaines comme ce nouvel algorithme de tri, domaine pourtant ô combien étudié dans la communauté algorithmique, qui émane d’un réseau de neurones en mars 2023 [1], ou encore un circuit exotique, qui de l’avis des physiciens était singulièrement inattendu, issu d’un logiciel d’IA de conceptions de dispositifs photoniques arbitraire[2], et les exemples foisonnent dans les domaines de la médecine ou de la biologie par exemple.
Au-delà de ce qu’on appelle les sciences dures, l’IA a commencé tranquillement à révolutionner aussi les sciences humaines et sociales comme l’illustre l’excellent projet ERC en philologie de J.-B. Camps[3] qui consiste à comprendre comment les cultures humaines évoluent au cours du temps en appliquant des méthodes d’intelligence artificielles utilisées dans la théorie de l’évolution en biologie aux manuscrits anciens afin de comprendre les mécanismes de transmission des textes, de leur survie et la dynamique des canons culturels qu’ ils suscitent.
Il devient donc raisonnable d’envisager une réponse par l’affirmative à la question ci-dessus : oui un prix Nobel pourrait récompenser une IA. Les algorithmes d’intelligence artificielle couplés à des infrastructures puissantes et des systèmes efficaces peuvent eux-aussi apporter leur pierre au bel édifice scientifique que nous construisons depuis la nuit des temps, et ce dans tous les domaines scientifiques.
De la créativité d’AlphaGo
En l’occurrence, AlphaGo, pour y revenir, a d’ores et déjà surpris le monde par sa créativité. AlphaGo s’est attaqué à ce jeu de stratégie d’origine chinoise inventé il y a plusieurs millions d’années qui consiste à placer des pions, appelés des pierres, sur un plateau quadrillé qu’on appelle le goban. Deux joueurs s’affrontent qui cherchent à marquer leur territoire en posant des pierres sur les intersections de la grille, pierres qui peuvent être capturées par encerclement. Je ne vais pas entrer plus en détail dans ce jeu car d’une part ce n’est pas le sujet, d’autre part je ne m’y suis jamais essayée. AlphaGo, lui est devenu champion. Au cœur d’AlphaGo, un arbre de recherche, un arbre de MonteCarlo pour être plus précis, dans lequel AlphaGo cherche son chemin en évaluant chaque coup potentiel et en simulant le jeu entier pour décider s’il doit jouer ce coup ou non. Compte tenu de la dimension de la grille, et la multitude de coups possible, bien plus élevé que le nombre d’atomes dans l’univers, autant dire qu’une exploration exhaustive est impossible. AlphaGo a alors recours à des algorithmes d’apprentissage supervisés entrainés sur des parties jouées par des humains dont la sortie est un ensemble de probabilités, le coup qui a la possibilité de gagner la partie est alors choisi. Cet algorithme est alors utilisé pour guider la recherche dans l’arbre immense des possibilités. Mais AlphaGo est allé plus loin que d’essayer d’imiter la créativité humaine en s’entrainant contre lui-même des dizaines de millions de fois puis d’utiliser ces parties pour s’entrainer ! Smart move…
C’est ainsi qu’AlphaGo a surpris tout le monde avec le fameux « Move 37 » lors de sa partie contre Lee. Ce coup que la pratique assidue depuis des milliers d’années de millions de personnes n’avait jamais considéré, cette idée saugrenue de placer un de ses pierres entre deux pierres de Lee, c’est ce coup défiant toute intuition humaine qui lui a valu la victoire. CQFD, l’IA peut être créative, voire avoir une certaine forme d’intuition au gré du hasard de ses calculs.
Est ce que l’IA peut mener à de grandes découvertes scientifiques ? Le prix Nobel de chimie 2024 en est un très bon exemple, AlphaFold a permis de découvrir les structures de protéines qui auraient demandé des siècles à de brillants chercheurs à grand renforts de manipulations expérimentales complexes et chronophages. On peut d’ailleurs voir la recherche scientifique comme l’activité qui consiste à explorer certaines branches dans une infinité de possibilités, on peut même considérer que l’intuition dont font preuve les brillants chercheurs et qui les mènent à ces moments Euréka, comme dirait Archimède, et comme les appellent Hugo Duminil-Copin, lauréat de la Médaille Fields 2022, permet de choisir les branches les plus prometteuses. Et bien c’est précisément ce que font les IAs, prédire quelles branches ont la plus forte probabilité de mener à un résultat intéressant et de les explorer à vitesse grand V.
Le paradoxe de l’IA
Oui mais voilà, une IA, cette savante combinaison d’algorithmes, de données, de systèmes et d’ordinateurs, est infiniment plus rapide qu’un humain pour effectuer ces explorations, elle est également généralement beaucoup plus fiable, ne dit-on pas que l’erreur est humaine ? En revanche, lorsqu’elle commet des erreurs, elles sont beaucoup plus importantes et se propagent beaucoup plus rapidement. Là la vigilance s’impose, qui pour le moment en tous cas reste humaine.
Certaines méthodes existent par lesquelles les algorithmes d’IA peuvent essayer de se surveiller mais cela ne peut pas aller tellement plus loin que cela. Au siècle dernier, Gödel et Turing, respectivement en 1931 et en 1936, ont montré certaines limites fondamentales en mathématique et informatique. Le théorème d’incomplétude de Gödel a révélé des limites fondamentales en mathématique. Ce théorème en particulier a montré qu’il existe des énoncés vrais dans un système, impossible à démontrer dans un système et qu’un système formel cohérent est incapable de démontrer sa propre cohérence. Dans la même veine, Turing lui s’est intéressé au problème de l’arrêt : est-ce qu’il est possible de déterminer qu’un programme informatique et des entrées, donnés, terminera son exécution ou non. En d’autres termes, peut-on construire un programme capable de de prédire si un autre programme s’arrêtera ou bouclera à l’infini ? Turing a prouvé que le problème de l’arrêt est indécidable c’est-à-dire qu’il est impossible de construire un programme universel capable de résoudre ce problème pour tous les programmes possibles. En particulier car un tel programme pourrait se contredire.
Adopter l’IA sans hésiter mais prudemment
Nos deux compères ont ainsi posé des limites intrinsèques à la puissance des algorithmes indépendamment du volume de données et du nombre de GPUs dont on peut disposer. Ainsi qu’une IA s’assure elle-même de bien fonctionner parait impossible et de manière générale une IA ne peut raisonner à son propre sujet. Est-ce pour cela qu’Alpha, selon D. Hassibis, ne pourrait jamais inventer le jeu de Go et c’est peut-être là sa limite. C’est là que l’humain peut entrer en piste. En d’autres termes, utiliser l’IA pour la découverte scientifique est d’ores et déjà possible et on aurait tort de s’en priver mais il est important de l’utiliser en respectant la démarche scientifique rigoureuse à laquelle nous, chercheurs, sommes rodés.
Les mathématiques ont été créées pour mettre le monde en équations et représenter le monde physique, l’informatique (ou l’IA) met le monde en algorithmes et en fournit des représentations vivantes qui collent si bien à la nature continue de la biologie et la physique mais aussi de bien des domaines des sciences humaine et sociales.
Ainsi, quel que soit son domaine et son pré carré, scientifique, il devient nécessaire de maitriser les fondements de l’IA pour bénéficier de ses prouesses et de son potentiel tout en vérifiant la pertinence des résultats obtenus, en questionnant les découvertes surprises qu’elle pourrait amener mais aussi en s’assurant que les données d’entrainement ne soient ni biaisées ni erronées. Si nous avons d’ores et déjà compris qu’il était temps d’introduire l’informatique dans le secondaire mais également dans beaucoup de cursus du supérieur, surtout scientifiques, il convient de poursuivre cet effort, de l’intensifier même et de l’élargir. Il est temps que l’informatique soit élevée au rang de citoyen de première-classe comme les mathématiques et la physique dans tous les cursus scientifiques. Plus encore, il est tout autant essentiel que les linguistes, les historiens, les sociologues et autres chercheurs des sciences humaines et sociales aient la possibilité d’apprendre les rudiments de l’informatique, et plus si affinité, dans leurs cursus.
Ainsi les académiques doivent s’y préparer, leurs métiers aussi vont être transformés par l’intelligence artificielle, informaticiens compris ! Ces derniers partent avec un petit avantage compétitif, celui de connaître les fondements de l’IA. À tous les autres, à vos marques, si ce n’est pas déjà fait !
Tu es au collège et tu te poses des questions sur les intelligences dites artificielles (au pluriel, oui oui), les fameuses IA dont tout le monde te cause. Un livre indispensable vient de sortir pour t’aider à y voir un peu plus clair. Binaire en parle. Chloé Mercier et Serge Abiteboul.
On parle d’intelligences artificielles génératives, qui produisent en quelques secondes du texte, des images et du contenu audio. Ce sont de vraies prouesses techniques, de gigantesques calculs statistiques. Bien utilisées, ce sont des outils utiles dans de nombreux domaines, y compris de la vie des ados. Mal comprises, elles font peur. Mal utilisées, elles conduisent à de nombreuses erreurs.
Voici un guide malin et bienveillant pour découvrir comment fonctionne l’IA et à quoi elle sert, comment l’utiliser pour booster sa créativité. Il n’ignore pas les dangers de l’IA (fake news, deep fakes, etc.) et propose des pistes pour en garder le contrôle.
Un exemple ? Alors … plus besoin de faire ces devoirs avec l’IA ? 🙂 C’est une des premières choses que les élèves essayent et cela marche… mal ! D’abord, on reconnaît assez facilement que la façon de répondre n’est pas celle d’un·e élève, ensuite les réponses peuvent être absurdes comme on l’expérimente. Et surtout… eh bien on perd son temps ! Les devoirs sont faits pour acquérir des compétences alors les faire faire par un humain ou un algorithme, ça se paye ensuite. En fait, quelque chose a changé profondément : avec ces algorithmes, il faut apprendre à faire ses devoirs autrement. C’est ce que nous explique ce joli livre très chouettement illustré.
Alice, Clara et Ikram abordent dans cet article les sujets complexes que sont l’IA générative, la désinformation, les rapports de force et la géopolitique. Ce travail pluridisciplinaire a été présenté à la journée scientifique “Société et IA” à PFIA 2024 à La Rochelle, et est disponible au lien HAL suivant. Il se veut factuel et sans jugement quelconque vis-à-vis d’un pays ou d’une communauté, à des fins d’acculturation et de médiation scientifique pour le grand public et les chercheurs en IA. Les conflits abordés ici sont non-exhaustifs et ne reflètent aucunement un ordre d’importance dans leur présentation ou une vision manichéenne quelconque. Le choix a été réalisé selon la littérature et les expertises des autrices. Consciente qu’elles n’amènent pas forcément de réponses tant les sujets sont complexes et quelques lignes ne suffiraient pas à cela, elles souhaitent cependant par ces même lignes, éveiller les esprits citoyens du monde sur un sujet qui va au-delà des frontières géographiques. Cet article engage les autrices – avec leurs propres biais socio-culturels – et uniquement elles. Aucunement les institutions citées. ThierryViéville et Pascal Guitton.
Figure 1 : Deepfake de Zelensky appelant à déposer les armes, diffusée en Mars 2022 sur la chaîne de télévision Ukraine 24 suite à un piratage @France24
INTRODUCTION : Désinformation et Mésinformation, premier risque mondial en 2024
Janvier 2024.19 000 électeurs taïwanais choisissent d’élire les candidats partisans de l’autonomie malgré le contexte de fortes pressions militaires de la part du Parti Communiste Chinois. Près de 15 000 contenus de désinformation auraient circulé sur les réseaux dans l’objectif d’influencer l’issue de ces élections. Au même moment sur le continent américain, Microsoft alerte sur l’utilisation d’IA générative à l’encontre des Etats-Unis par ses adversaires principaux dans l’échiquier mondial : la Corée du Nord, l’Iran, la Russie et la Chine.
L’IA générative semble permettre la création de nombreux narratifs de désinformation, de meilleure qualité et personnalisés. Mais de quelle manière influencent-ils les rapports de forces existants en géopolitique ?
Cette année plus de la moitié de la population mondiale est appelée aux urnes. Depuis plusieurs mois, les médias à travers le monde s’interrogent sur le risque pour nos démocraties et mettent en avant l’accessibilité et la facilité d’utilisation des outils d’IA générative qui circulent sur internet depuis la sortie de ChatGPT comme peut en témoigne la Figure 2.
Figure 2 : Capture d’écran d’un article du média en ligne “Courrier international” [1]
Or les journalistes ne sont pas les seuls à s’inquiéter, l’écosystème économique mondial également. En effet, un sondage réalisé par le Forum Économique mondial a placé début 2024 la désinformation et la mésinformation – qui seront défini plus tard – comme premier risque mondial à court terme, avant même les risques climatiques extrêmes (Figure 3).
Figure 3 : Résultats du sondage sur les menaces à court-terme réalisé par le Forum Économique mondial. Image reproduite en français [2]
A ce stade, il est légitime de se demander “Pourquoi est-ce que l’IA générative inquiète autant ?”
Fin 2023, on a observé en France un changement de paradigme sur la perception du grand public de l’IA générative : les journaux télévisés (JT) des chaînes de télévision françaises (TF1, M6, France Info) ont commencé à aborder l’IA générative de manière régulière et cela de manière ludique, avec par exemple l’utilisation d’une image du pape en doudoune (figure 4), alors que jusque là l’IA était majoritairement abordée que lors de reportages ou de moments spécialement dédiés à la technique ou l’innovation.
Cette survenue du sujet de l’IA générative dans les JT grand public a eu pour conséquence d’acculturer et d’informer le grand public de l’émergence et du développement de ces outils tout en les sensibilisant aux fait que ces mêmes outils peuvent être utilisés pour des arnaques très réalistes et de la désinformation.
Par exemple, un exemple ludique serait l’image du Pape en doudoune. Si celle-ci peut prêter à sourire en France, elle peut paraître également vraisemblable et “fort probable” depuis l’étranger. Si par exemple, dans certains pays étrangers, 20 degrés est une température très fraîche qui nécessite un manteau chaud, il est alors possible de penser que le pape François a simplement eu froid un jour d’hiver et que la photo est vraie.
Vraisemblable :
Qui a toutes les apparences du vrai ; plausible, par exemple, une explication vraisemblable.
Qui a toutes les probabilités de se produire : Son succès est vraisemblable.
Si cet exemple a en réalité peu d’impact sur la dimension géopolitique, il reflète néanmoins une réalité : celle qu’il est possible de profiter de la méconnaissance ou ignorance d’un public cible d’un sujet pour manipuler son comportement au travers d’une stratégie de désinformation.
Afin d’illustrer l’impact au niveau des sociétés, nous pouvons prendre l’exemple d’une image de la tour Eiffel en feu (Figure 4) diffusée sur les réseaux sociaux quelques semaines après l’incendie de notre dame de Paris. Si l’on se rappelle du contexte des manifestations des gilets jaunes quelques mois auparavant et comment elles ont été véhiculé à l’étranger, alors il est légitime de voir émerger une inquiétude hors de France (voir même sur le sol Français) en lien avec cette image vraisemblable. Une conséquence possible : une baisse/annulation des réservations touristiques à Paris!
Il existe donc un impact réel de l’IA générative au niveau individuel et par extension un impact réel au niveau des sociétés civiles, mais qu’en est-il au niveau de la géopolitique et des rapports de forces ? S’il est possible de véhiculer une information “vraisemblable” à l’étranger concernant une situation politique, militaire ou sociétale, cela peut-il impacter les dynamiques entre les pays au niveau politique ? Cela peut-il changer les rapports de force en géopolitique?
Une rapide revue de la littérature réalisée au premier semestre 2024 – beaucoup de littérature et d’analyse d’experts autour de la question du rôle et de l’impact de l’IA générative sur la diffusion de désinformation ont émergé durant cette période là – laisse entendre que deux courants se distinguent lorsqu’il s’agit d’évaluer l’impact en géopolitique : (i) ceux qui considèrent que l’IA générative est une source de danger en matière de désinformation et (ii) ceux qui considèrent que l’arrivée des systèmes génératifs ne change pas fondamentalement la donne, ni sur le plan qualitatif, ni sur le plan quantitatif.
C’est dans ce contexte que nous avons souhaité aborder la problématique suivante : Quelle est l’instrumentalisation de l’IA générative dans les dynamiques de désinformations mondiales et son impact sur les rapports de forces existants ?
Afin d’apporter des éléments de réponse à notre questionnement, nous partageons une analyse factuelle préliminaire autour de 3 rapport de forces, ainsi que la guerre de l’information sous-jacente en lien avec l’utilisation de l’IA générative et la désinformation : La Chine vs Taïwan, les États-unis vs leurs adversaires et enfin la Russie vs l’Ukraine.
Mais avant cela, il semble nécessaire de poser un cadre au travers de quelques définitions.
IA générative & désinformation, définitions
Une IA générative désigne l’ensemble de modèles de deep learning capables de générer du texte, des images et d’autres contenus de haute qualité à partir des données sur lesquelles elles ont été formées [3]. Deux caractéristiques importantes à saisir des IA génératives sont : (1) leur pouvoir de générer du contenu vraisemblable, à savoir plausible; (2) leur simplicité d’utilisation et d’accès pour tous les profils et toutes les intentions. Et c’est justement au croisement de ces deux dimensions que se trouve le danger !
La désinformation est définie comme l’acte de répandre intentionnellement une information fausse ou manipulée dans le but d’alimenter ou miner une idéologie, concernant des enjeux sociétaux, des débats politiques ou encore des conflits sociaux [1]. Se distinguant de la mésinformation et de la malinformation (figure 5) – qui consiste, respectivement en la diffusion d’informations incorrectes mais sans intention malveillante et en la diffusion délibérée de vraies informations dans un but nuisible – , la désinformation peut s’inscrire dans une dynamique de guerre de l’information.
Cette dernière est considérée comme la conduite d’« efforts ciblés » visant à entraver la prise de décision d’un adversaire en portant atteinte à l’information dans son aspect quantitatif (collecte ou entrave à la collecte d’information) aussi bien que qualitatif (propagation ou dégradation) [4].
Dans cette guerre de l’information, des rapports de force existent : ils représentent l’équilibre des pouvoirs dans le système international face aux États les plus puissants. Ils peuvent être internespar le biais de la construction de sa propre force étatique, et externes avec la recherche d’alliances.
Figure 5 : Éducation à la littératie médiatique : Désinformation, Mésinformation et Malformation, des concepts entre falsification et intention. Institut supérieur de formation au journalisme (dernier accès : 26/08/2024)
Chine vs Taiwan : Le “système immunitaire” de Taiwan
Les outils d’IA génératives démocratisent la création de désinformation de meilleure qualité et en grande quantité.
La quantité et la qualité des narratifs sont certainement des arguments cherchant à prouver l’impact de l’IA générative dont vous avez déjà entendu parler.
Mais pour Simon, Altay et Mercier, ces arguments peuvent tout de même être nuancés [5].
“La consommation de désinformation est principalement limitée par la demande et non par l’offre.”
Il existe déjà une quantité énorme de narratifs de désinformation accessibles à tous sur internet, et ce bien avant le boum de l’IA générative. Manipuler des images, cibler des populations, créer des vidéos entretenant le flou entre réalité et fiction… Tous ces usages font déjà partie intégrante de la guerre de l’information.
Pourtant une large partie de ces contenus n’est pas consommée et une majorité d’entre nous n’y sommes pas exposés. Pourquoi cela ? car la consommation de désinformation est fonction de la demande et non pas de l’offre. Simon, Altay et Mercier argumentent leur proposition en mettant en avant, entre autres, les travaux de recherche autour de l’attention cognitive : notre capacité d’attention étant finie, le nombre de contenus pouvant devenir viraux sur internet l’est aussi.
Par ailleurs, pour que les effets de l’IA générative fassent pencher la balance en faveur de la désinformation, il faudrait une augmentation de l’attrait de la désinformation 20 à 100 fois plus importante que l’augmentation de l’attrait des contenus fiables.
Un élément clé mis en avant par les études de sciences humaines et sociales est que les consommateurs de désinformation ne sont pas plus exposés à la désinformation mais sont surtout plus enclins à la croire.
Le problème n’est pas que les gens n’ont pas accès à de l’information de qualité mais qu’ils la rejettent.
Si le fait d’être enclin à croire ou pas en la désinformation, donc d’y avoir été sensibilisé, représente un rempart contre l’efficacité de l’IA générative dans le domaine, Taïwan l’illustre avec son exposition régulière à la désinformation et le développement en interne d’un système immunitaire de réaction.
Figure 6 : Chine et Taiwan (crédit:@ClaraFontaineSa)
Ce système immunitaire de l’île a pu être mis à l’épreuve lors des élections présidentielles de janvier 2024. Malgrè un volume important d’environ 15 000 fausses informations propagées par la Chine, celles-ci n’ont pas eu d’incidence majeure. Cela s’explique par un contexte particulier avec des tensions historiques et une population qui s’attendait aux velléités d’ingérence chinoise.
De plus, ces élections ont été particulières non seulement pour l’enjeu considérable en pleine tension avec le Parti Communiste Chinois, mais également pour l’aspect tripartite des candidatures. Un nouveau parti, le Parti populaire taïwanais, apprécié par la jeunesse, a fait son apparition dans la course au pouvoir. Se présentant comme une alternative aux partis traditionnels bleu et vert, il promeut une vision s’alignant avec le Kuomintang, le Parti nationaliste chinois à propos d’un rapprochement économique avec la Chine, les opposant ainsi avec le Parti démocrate progressiste, parti sortant qui s’est révélé victorieux. Le candidat de ce dernier, William Lai, a été l’objet de nombre d’attaques à but de désinformation au préalable des élections. L’une d’entre elles, provenant d’une chaîne YouTube relayant du contenu politique, a posté une vidéo où le candidat du camp présidentiel fait l’éloge d’une alliance entre bleu et blanc, indiquant qu’un binôme qui en serait issu, “qu’importe lequel est président ou vice-président, n’importe quelle combinaison peut être une bonne équipe.”[6]
La volonté de la Chine est également d’amener l’opinion publique taïwanaise vers l’unification voulue par le Parti avec la diffusion de narratifs visant à dépeindre un portrait négatif des États-Unis. Dans les thématiques de ces narratifs générés par IA (audios et vidéos) on peut citer : les politiques gouvernementales, les relations entre les deux rives du détroit et la suspicion à l’égard des États-Unis. La puissance américaine est désignée comme un ennemi, une tactique de propagande traditionnelle, ce qui fait que si l’IA exacerbe effectivement des dynamiques de désinformations existantes, elle n’en change pas fondamentalement les mécaniques. Si l’IA générative n’augmente pas la demande de désinformation, alors l’augmentation de l’offre ne peut avoir que peu d’impact.
La stratégie longue-termiste de la Chine passe notamment par TikTok pour atteindre les jeunes générations taïwanaises. Si l’IA générative permet ici d’exacerber des dynamiques de désinformations, ces dernières étaient déjà existantes. Cette technologie ne semble donc pas changer fondamentalement les mécaniques existantes de la désinformation[4]. C’estl’alliance de l’IA générative et des plate-formes de diffusion, ou médias alternatifs, qui joue un rôle important dans la propagation rapide et efficace de cette désinformation.
Les États-Unis vs leur adversaires : La guerre des bots
Les narratifs de désinformation, qu’importe leur qualité et leur quantité, ne pourraient trouver leur public cible sans moyens de diffusion. Au-delà de médias plus ou moins affiliés à des Etats, les plateformes en elles-mêmes représentent des actrices à part entière d’évènements sociaux et politiques, comme lors du Printemps arabe, des Gilets Jaunes ou plus récemment l’assaut du Capitole.
Les préoccupations quant à leur responsabilisation, notamment dans la propagation des informations, étaient présentes bien avant que l’IA générative ne soit démocratisée.
Les inquiétudes s’intensifient face à la nouveauté de la technologie et aux nombreux enjeux électoraux de cette année mais ces plateformes ont toujours agit comme des “caisses de résonance” pour les vidéos émotionnelles qui y deviennent virales. Lors des élections de 2016 opposant Hillary Clinton à Donald Trump, une guerre d’influence se menait hors des plateaux télévisés. Des messages postés en masse par des bots – logiciels qui exécutent des tâches automatisées, répétitives et prédéfinies – sur les réseaux sociaux ont été répandus en faveur des deux candidats, profitant notamment des bulles d’activité des internautes sur les sujets de politiques après des débats diffusés. Leur activité et réactivité intensives se mêlent donc aux fervents soutiens des partis opposés, facilitant l’intrusion de fausses informations entre deux opinions. Leur viralité sur les réseaux sociaux, en plus de servir des causes politiques, peuvent également générer du trafic profitable pour les plateformes, dont une modération accentuée est attendue de leur part sur ces sujets[7].
On y retrouve les dynamiques propres à la guerre de l’information dans son aspect qualitatif, notamment à travers la collaboration entre plateformes et États, un exemple notoire étant la surveillance de masse initiée par les agences gouvernementales américaines. En ce sens, on décèle des rapports de force autant dans le volet offensif que défensif, bien qu’ils soient de nature asymétrique dans leur portée. Au sein des instances occidentales, TikTok alarme par son lien étroit avec le Parti Communiste Chinois, qui fait de la plateforme une caisse de résonance considérable face à la popularité des plateformes américaines.
Figure 7 : Les Etats-unis et leurs ”adversaires” (crédit:@ClaraFontaineSay)
A l’inverse, Microsoft avait alerté en début d’année sur l’utilisation d’IA générative à l’encontre des Etats-Unis par ses adversaires principaux dans l’échiquier mondial : la Corée du Nord, l’Iran, la Russie et la Chine[8]. De par leur importance primordiale dans le paysage numérique et géopolitique, les plateformes possèdent une influence tentaculaire, dont les algorithmes facilitent la propagation de l’information ainsi que la personnalisation et le ciblage.
Russie vs Ukraine : Zelensky appelle à déposer les armes
La diffusion massive de désinformation s’est illustrée également par la multiplicité de deepfakes qui est apparue dans les guerres d’informations de toutes natures, mais qui prend également part dans le conflit armé qui oppose la Russie à l’Ukraine.
Dans le contexte du conflit Ukraine-Russie, le deepfake du président ukrainien appelant à déposer les armes (Figure 1), rapidement débunké et désormais supprimé, illustre la diffusion massive de désinformation comme extension de l’effort de guerre. Dans ce conflit où le monde occidental prend parti, la personnalisation de la désinformation russe s’est également étendue à des publics différents. Notamment en Afrique et au Moyen-Orient, où une désinformation traditionnelle est également propagée, en attribuant par exemple l’insécurité alimentaire aux sanctions occidentales. La différence ici est la démocratisation du deepfakecombinée à des technologies de ciblage dans le but d’éroder la confiance dans une institution ou une personnalité politique, mais véhiculant finalement les mêmes narratifs dans le prolongement des stratégies existantes de désinformation.
Figure 8 : Russie et Ukraine (crédit:@ClaraFontaineSa)
Par ailleurs, dans le cas du conflit russo-ukrainien, la diffusion massive de désinformation russe a été personnalisée pour atteindre différents publics en Afrique et au Moyen Orient. Ici c’est l’alliance des deepfakes et des technologies de ciblage dans le but d’éroder la confiance dans une institution ou une personnalité politique qui est à relever, en permettant de donner une réalité aux narratifs des stratégies existantes de désinformation.
Sur les réseaux sociaux, on trouve 15 à 20% de personnes persuadées pour ou contre une information et les 60% restants sont indécis. Ce sont eux qui vont être ciblé avec l’objectif soit de les faire changer d’avis soit de figer leur opinion, leur retirant ainsi leur capacité à prendre une décision face à l’information.
Un enjeu que l’on peut également mettre en lumière est celui du timing: par exemple, en France, des faux documents fuités la veille des élections présidentielles de 2017 cherchant à incriminer Emmanuel Macron, n’ont pas eu d’incidence majeure sur les élections de par leur caractère relativement ennuyeux et le fait qu’en France, la couverture médiatique des élections est interdite 44 heures avant le vote. Mais un deepfake partagé sur les réseaux sociaux moins de 44 h avant des élections auraient pu avoir des conséquences importantes.
Zoom sur “Inde vs Inde : un rapport de force entre ethnies?”
Mot des autrices : Les rapports de force et les problématiques de géopolitique associées peuvent également aussi être identifiés au sein d’un même pays si celui-ci possède en interne les caractéristiques nécessaires. Faisons un zoom sur l’Inde, un pays complexe aux multiples cultures, langues et religions.
En Inde, citoyens et politiciens ont bien compris l’intérêt de l’IA générative et l’ont pleinement intégrée dans leurs stratégies de campagne électorale. Parmi les utilisations recensées, on trouve : (i) des messages passés, personnalisés et relayés dans les différents dialectes par les candidats, (ii) des appels automatiques avec la voix des candidats pour encourager les votants en leur faveur, et (iii) une résurrection numérique d’anciens chefs d’Etat décédés pour soutenir leurs successeurs politiques. Les deepfakes ici ne sont pas perçus d’un prisme négatif et accompagnent les ambitions et la volonté de toucher une large audience.
Leur utilisation prend ses racines à travers le cinéma bollywoodien qui cultive les mêmes motivations (i.e. large public et multilingue), allant jusqu’à créer des métiers spécialisés dans la production de fausses images et faux sons. Ces derniers ont été approchés par des partis candidats dans plusieurs buts : répandre de la désinformation à propos d’adversaires politiques mais aussi d’altérer leurs propres vidéos, en remplaçant par exemple le visage d’un candidat sur une vidéo véridique par ce même candidat afin d’altérer les caractéristiques de la vidéo (les méta-données). L’objectif ? Inciter l’opposition à partager la vidéo altérée avant de la déclarer falsifiée — et donc miner leur crédibilité. De ce fait, ces candidats anticipent la désinformation à leur égard en contrôlant — à peu près — ce qui est faux ou non, afin de s’ériger en victime et mieux contrôler l’opinion publique.
Ces dynamiques révèlent non seulement une véritable adaptation professionnelle et presque institutionnalisée des deepfakes, mais également de véritables stratégies allant au-delà d’une propagation offensive et d’un debunk défensif.C’est la raison pour laquelle le gouvernement de Narendra Modi, premier Ministre Indien, a déclaré une volonté de réguler l’IA en amont des élections législatives indiennes qui ont eu lieu cette année, revenant sur sa position de ne pas intervenir dans le secteur.
Ce sursaut est-il à percevoir comme une crainte de perturbation électorale qui pourrait desservir son maintien au pouvoir ou comme une véritable volonté d’éviter une démocratisation de la désinformation ?
Soulignons que ces plans de régulation ont été annoncés suite à la réponse positive de Gemini, le chatbot de Google, concernant une question portant sur le caractère fasciste de Modi (Figure 9).
Figure 9 : Capture d’écran twitter de Dr Ranjan concernant la réponse apportée par le chatbot Gemini. Src @X (ex-Twitter)
En résumé, à ce stade de l’étude, il semblerait que bien que ces systèmes d’IA générative n’affectent pas directement les rapports de force mondiaux, ils restent indéniablement un outil de la Guerre de l’information.
En Europe, la protection des citoyens repose en très grande partie sur la richesse et la complexité des réseaux médiatiques et la prise à bras le corps du sujet par les pouvoirs publics.
Par exemple en France, le ministère de la culture écrit : “Les médias traditionnels, presse, radio, télévision, traversent le temps, fascinent et occupent une place à part dans nos vies. Ils sont les garants d’une information fiable dans un monde où chacun semble asséner ses vérités et ses contre-vérités.”
Autrement dit, à l’heure ou les réseaux sociaux s’érigent en plateformes simplifiées d’accès instantané à une connaissance démocratisée pour le grand public – voir à tous types de connaissances, vérifié ou non, scientifique ou non -, il y a une volonté de mettre en lumière les médias traditionnels comme force et acteur d’une information “vérifiée/validée”.
Mais est-ce réellement le cas ? Les médias traditionnels sont-ils à l’abri de la désinformation par l’IA générative ? Sont-ils la solution?
Malheureusement ce n’est pas aussi simple. Du fait que les journalistes sont aussi des humains dotés de ressources cognitives limitées et de biais cognitifs, ils ne sont pas à l’abri de ne pas repérer l’information erronée ou vraisemblable cachée parmi la masse (des milliers) de contenus existants pour un sujet donné.
Or le travail de vérification – appelé aussi fact-checking en anglais- de la véracité des faits, ou d’une information, des sources de celle-ci, de sa temporalité est une partie inhérente du métier de journaliste : nécessaire, chronophage et énergivore. Des cellules spécialisées dans le repérage de la désinformation se sont de plus en plus développées dans les rédactions de médias traditionnels afin de garantir l’information. Mais la aussi, elles sont submergées de travail depuis déjà plusieurs années.
Sans compter que plus un sujet est complexe avec un impact sociétal important plus il nécessite de la vigilance – elle même coûteuse au niveau cognitif – et du temps ou des moyens humains et techniques.
Face à ce sujet titanesque de recherche d’erreurs et de mensonges dans la masse d’informations diffusées chaque jour sur l’ensemble des plateformes, des partenariats journalistes-chercheuses/chercheurs se sont développés pour doter ce corps de métier d’outils d’IA et de science des données spécialisée dans la catégorisation et labellisation les contenus trouvés sur internet pour réaliser leur travail.
Si ces outils ne permettent pas d’atteindre 100% de précisions des informations, et que l’humain est toujours le paramètre incontournable et nécessaire, ils représentent néanmoins une aide précieuse pour les journalistes débutants et plus expérimentés pour s’adapter à cette ère de la consommation rapide et multi-plateforme de l’information.
Le risque de désinformation est-il écarté une fois le deepfake détecté ?
Malheureusement, là aussi ce n’est pas aussi simple.
Un deepfake détecté implique sa non utilisation par les médias traditionnels voir sa labellisation officielle “d’information fausse” via une communication officielle par des autorités compétentes.
Mais cela n’implique nullement sa suppression d’internet. Au contraire, cela peut renforcer dans certaines communautés, le caractère “vérité” du deepfake et certains discours complotistes. Cela peut même contribuer à leur propagation.
Autrement dit, les deepfakes qui ne sont pas assez viraux pour être immédiatement démystifiés, démenties, influencent tout de même l’opinion du public simplement parce qu’ils ne font pas la une des journaux et autres médias traditionnels. Ils peuvent donc avoir un impact immédiat sur la confiance des citoyens dans les médias et les autorités publiques.
Les mettre de côté peut contribuer à les renforcer, ainsi que les utiliser… ils occupent ainsi le paysage médiatique et suscite le débat… Et c’est en cela qu’ils sont dangereux.
Ce financement de sites de désinformation n’est pas volontaire car les bannières publicitaires sont placées par des algorithmes, néanmoins il reflète une réalité : la vitesse des transactions et des instructions sur internet, allié à la masse de l’information à traiter font que les algorithmes peuvent promouvoir, ou ici financer de la désinformation. Selon NewsGuard, chaque année, près de 2,6 milliards de dollars (2,38 milliards d’euros) de revenus publicitaires viennent gonfler les poches des sites de désinformation.
Un des objectifs pourrait donc de faire évoluer la publicité programmatique, pratique consistant à créer des publicités numériques à l’aide d’algorithmes et à automatiser l’achat de médias, afin qu’elle puisse prendre en compte les sites de désinformation.
Que conclure?
Il faut penser la désinformation comme un problème politique, sociétal, d’éducation au numérique et non uniquement technologique.
Johan Farkas, professeur adjoint en études des médias à l’université de Copenhague, prône que « considérer l’IA comme une menace retire la responsabilité de la désinformation au système politique » .
Or les guerres d’informations découlent de rapports de force complexes entre de plusieurs acteurs politiques, sociétaux et technologiques. Ils sont du fait d’acteurs bien humains car ils se caractérisent par la quantité, la qualité et la personnalisation de la désinformation, tel qu’illustré à travers les trois cas d’études cités. Une intention avec un objectif clairement établi guide les stratégies dans les contextes de guerre de l’information or l’intention, à l’heure actuelle, est une caractéristique encore très humaine.
Pour l’ensemble de ces raisons, et en accord avec la thèse de Simon, Altay et Mercier [5], l’IA générative, bien qu’elle soit un bouleversement dans nos sociétés, peut être considérée comme un nouvel outil au service de la désinformation certes, mais un outil qui ne change pas les rapports de force existants. En effet, les parties politiques et les gouvernements impliqués ont su s’adapter et intégrer cette nouvelle famille d’outils dans leur procédés et stratégies.
Alors que faire à ce stade en tant que citoyens et citoyennes d’un monde ultra-connecté face à ce risque de désinformation ?
A défaut d’apporter ou de trouver une réponse claire, nous synthétisons les résultats de nos recherches par un triptyque “Éduquer les plus jeunes, Acculturer le grand public et Former les formateurs (enseignants, professionnels, etc)” à l’IA, son impact sociétal, mais également aux biais cognitifs, biais culturels dans l’information, à la littératie médiatique (désinformation, malinformation, deepfake) et à garder son esprit critique même lorsque l’information est vraisemblable!
En créant, ensemble une culture générale pluridisciplinaire accessible – avec de la médiation scientifique par exemple 😉comme avec Binaire – au croisement du numérique et des sciences humaines et sociales, il serait alors peut-être possible de préserver les individus et sociétés sur les échiquiers des rapports de force en géopolitique.
[2] The World Economic Forum. Global risks report 2024, 2024.
[3] W Bennett and Steven Livingston. The disinformation age. Cambridge University Press, 2020.
[4] Dragan Z Damjanovic. Types of information warfare ´ and examples of malicious programs of information warfare. Vojnotehnicki glasnik/Military Technical Courier, 65(4) :1044–1059, 2017.
[5] Felix M Simon, Sacha Altay, and Hugo Mercier. Misinformation reloaded ? fears about the impact of generative ai on misinformation are overblown. Harvard Kennedy School Misinformation Review, 4(5), 2023.
[6] « Seeing is not believing—deepfakes and cheap fakes spread during the 2024 presidential election in Taiwan » . 台灣事實查核中心, 25 décembre 2023, tfc-taiwan.org.tw/articles/10025.
[7] Silva, Leo Kelion &. Shiroma. « Pro-Clinton bots “fought back but outnumbered in second debate” » . BBC News, 19 octobre 2016, www.bbc.com/news/technology-37703565.
[9] Citron, D. K., & Chesney, R. (2019). Deepfakes and the new disinformation war. Foreign Affairs.https://perma.cc/TW6Z-Q97D
Les autrices en quelques mots :
Alice Maranne est Chargée de projets européens et collaboratifs et créatrice de contenu de médiation scientifique et technologique. Clara Fontaine-Say est étudiante en géopolitique et cybersécurité, elle crée également du contenu sur ces sujets d’un point de vue sociétal. Ikram Chraibi Kaadoud, Ambassadrice WomenTechMaker de Google, est chercheuse en IA explicable centrée-Humain et Chargée de projet européen IA de confiance passionnée de médiation scientifique.
Billet d’introduction: L’expression “David contre Goliath” n’a jamais semblé aussi pertinente que lorsqu’il faut décrire le combat des artistes contre les GAFAM. Cette expression souvent utilisée pour décrire un combat entre deux parties prenantes de force inégale souligne une réalité : celle de la nécessité qu’ont ressenti des artistes de différents milieux et pays de se défendre face à des géants de la tech de l’IA générative pour protéger leur oeuvres, leur passion et leur métier, pour eux et pour les générations futures. Si la Direction Artistique porte le nom de [DA]vid, alors l’IA sera notre Gol[IA]th… C’est parti pour une épopée 5.0 !
Julie Laï-Pei, femme dans la tech, a à cœur de créer un pont entre les nouvelles technologies et le secteur Culturel et Créatif, et d’en animer la communauté. Elle nous partage ici sa réflexion au croisement de ces deux domaines.
Chloé Mercier, Thierry Vieville et Ikram Chraibi Kaadoud
Comment les artistes font-ils face au géant IA, Gol[IA]th ?
« David et Goliath » – Gustave Doré passé dans Dall-e – Montage réalisé par @JulieLaï-Pei
A l’heure d’internet, les métiers créatifs ont connu une évolution significative de leur activité. Alors que nous sommes plus que jamais immergés dans un monde d’images, certains artistes évoluent et surfent sur la vague, alors que d’autres reviennent à des méthodes de travail plus classiques. Cependant tous se retrouvent confrontés aux nouvelles technologies et à leurs impacts direct et indirect dans le paysage de la créativité artistique.
Si les artistes, les graphistes, les animateurs devaient faire face à une concurrence sévère dans ce domaine entre eux et face à celle de grands acteurs du milieu, depuis peu (on parle ici de quelques mois), un nouveau concurrent se fait une place : l’Intelligence artificielle générative, la Gen-IA !
C’est dans ce contexte mitigé, entre écosystème mondial de créatifs souvent isolés et puissances économiques démesurées que se posent les questions suivantes :
Quelle est la place de la création graphique dans cet océan numérique ? Comment sont nourris les gros poissons de l’intelligence artificielle pour de la création et quelles en sont les conséquences ?
L’évolution des modèles d’entraînement des IA pour aller vers la Gen-AI que l’on connaît aujourd’hui
Afin qu’une intelligence artificielle soit en capacité de générer de l’image, elle a besoin de consommer une quantité importante d’images pour faire le lien entre la perception de “l’objet” et sa définition nominale. Par exemple, à la question “Qu’est-ce qu’un chat ?” En tant qu’humain, nous pouvons facilement, en quelques coup d’œil, enfant ou adulte, comprendre qu’un chat n’est pas un chien, ni une table ou un loup. Or cela est une tâche complexe pour une intelligence artificielle, et c’est justement pour cela qu’elle a besoin de beaucoup d’exemples !
Ci dessous une frise chronologique de l’évolution des modèles d’apprentissage de l’IA depuis les premiers réseaux de neurones aux Gen-IA :
Frise chronologique par @JulieLaiPei
En 74 ans, les modèles d’IA ont eu une évolution fulgurante, d’abord cantonnée aux sphères techniques ou celle d’entreprises très spécialisées, à récemment en quelques mois en 2023, la société civile au sens large et surtout au sens mondial.
Ainsi, en résumé, si notre IA Gol[IA]th souhaite générer des images de chats, elle doit avoir appris des centaines d’exemples d’images de chat. Même principe pour des images de voitures, des paysages, etc.
Le problème vient du fait que, pour ingurgiter ces quantités d’images pour se développer, Gol[IA]th mange sans discerner ce qu’il engloutit… que ce soit des photos libres de droit, que ce soit des oeuvres photographiques, des planches d’artwork, ou le travail d’une vie d’un artiste, Gol[IA]th ne fait pas de différence, tout n’est “que” nourriture…
Dans cet appétit gargantuesque, les questions d’éthique et de propriétés intellectuelles passent bien après la volonté de développer la meilleure IA générative la plus performante du paysage technologique. Actuellement, les USA ont bien de l’avance sur ce sujet, créant de véritables problématiques pour les acteurs de la création, alors que l’Europe essaie de normer et d’encadrer l’éthique des algorithmes, tout en essayant de mettre en place une réglementation et des actions concrètes dédiées à la question de la propriété intellectuelle, qui est toujours une question en cours à ce jour.
Faisons un petit détour auprès des différents régimes alimentaires de ce géant…
Comment sont alimentées les bases de données d’image pour les Gen-AI ?
L’alimentation des IA génératives en données d’images est une étape cruciale pour leur entraînement et leur performance. Comme tout bon géant, son régime alimentaire est varié et il sait se sustenter par différents procédés… Voici les principales sources et méthodes utilisées pour fournir les calories nécessaires de données d’images aux IA génératives :
Les bases de données publiques
Notre Gol[IA]th commence généralement par une alimentation saine, basée sur un des ensembles de données les plus vastes et les plus communément utilisés: par exemple, ImageNet qui est une base de données d’images annotées produite par l’organisation du même nom, à destination des travaux de recherche en vision par ordinateur. Cette dernière représente plus de 14 millions d’images annotées dans des milliers de catégories. Pour obtenir ces résultats, c’est un travail fastidieux qui demande de passer en revue chaque image pour la qualifier, en la déterminant d’après des descriptions, des mot-clefs, des labels, etc…
Entre autres, MNIST, un ensemble de données de chiffres manuscrits, couramment utilisé pour les tâches de classification d’images simples.
Dans ces ensembles de données publics, on retrouve également COCO (à comprendre comme Common Objects in COntext) qui contient plus de 330 000 images d’objets communs dans un contexte annotées, pour l’usage de la segmentation d’objets, la détection d’objets, de la légendes d’image, etc…
Plus à la marge, on retrouve la base de données CelebA qui contient plus de 200 000 images de visages célèbres avec des annotations d’attributs.
Plus discutable, Gol[IA]th peut également chasser sa pitance… Pour ce faire, il peut utiliser le web scraping. Il s’agit d’un procédé d’extraction automatique d’images à partir de sites web, moteurs de recherche d’images, réseaux sociaux, et autres sources en ligne. Concrètement, au niveau technique, il est possible d’utiliser des APIs (Application Programming Interfaces) pour accéder à des bases de données d’images: il s’agit d’interfaces logicielles qui permettent de “connecter” un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités. Il en existe pour Flickr, pour Google Images, et bien d’autres.
Ce procédé pose question sur le plan éthique, notamment au sujet du consentement éclairé des utilisateurs de la toile numérique : Est-ce qu’une IA a le droit d’apprendre de tout, absolument tout, ce qu’il y a en ligne ? Et si un artiste a choisi de partager ses créations sur internet, son œuvre reste-t-elle sa propriété ou devient-elle, en quelque sorte, la propriété de tous ?
Ces questions soulignent un dilemme omniprésent pour tout créatif au partage de leur œuvre sur internet : sans cette visibilité, il n’existe pas, mais avec cette visibilité, ils peuvent se faire spolier leur réalisation sans jamais s’en voir reconnaître la maternité ou paternité.
Il y a en effet peu de safe-places pour les créatifs qui permettent efficacement d’être mis en lumière tout en se prémunissant contre les affres de la copie et du vol de propriété intellectuelle et encore moins de l’appétit titanesque des géants de l’IA.
C’est à cause de cela et notamment de cette méthode arrivée sans fanfare que certains créatifs ont choisi de déserter certaines plateformes/réseaux sociaux: les vannes de la gloutonnerie de l’IA générative avaient été ouvertes avant même que les internautes et les créatifs ne puissent prendre le temps de réfléchir à ces questions. Cette problématique a été aperçue, entre autres, sur Artstation, une plateforme de présentation jouant le rôle de vitrine artistique pour les artistes des jeux, du cinéma, des médias et du divertissement. mais également sur Instagram et bien d’autres : parfois ces plateformes assument ce positionnement ouvertement, mais elles sont rares ; la plupart préfèrent enterrer l’information dans les lignes d’interminables conditions d’utilisation qu’il serait bon de commencer à lire pour prendre conscience de l’impact que cela représente sur notre “propriété numérique”.
Les bases de données spécialisées
Dans certains cas, Gol[IA]th peut avoir accès à des bases de données spécialisées, comprenant des données médicales (comme les scans radiographiques, IRM, et autres images médicales disponibles via des initiatives comme ImageCLEF) ou des données satellites (fournies par des agences spatiales comme la NASA et des entreprises privées pour des images de la Terre prises depuis l’espace).
Les données synthétiques
Au-delà des images tirées du réel, l’IA peut également être alimentée à partir d’images générées par ordinateur. La création d’images synthétiques par des techniques de rendu 3D permet de simuler des scénarios spécifiques (par exemple, de la simulation d’environnements de conduite pour entraîner des systèmes de conduite autonome), ainsi que des modèles génératifs pré-entraînés. En effet, les images générées par des modèles peuvent également servir pour l’entraînement d’un autre modèle. Mais les ressources peuvent également provenir d’images de jeux vidéo ou d’environnement de réalité virtuelle pour créer des ensembles de données (on pense alors à Unreal Engine ou Unity).
Les caméras et les capteurs
L’utilisation de caméras pour capturer des images et des vidéos est souvent employée dans les projets de recherche et développement, et dans une volonté de sources plus fines, de capteurs pour obtenir des images dans des conditions spécifiques, comme des caméras infrarouges pour la vision nocturne, des LIDAR pour la cartographie 3D, etc.
Toutes ces différentes sources d’approvisionnement pour Gol[IA]th sont généralement prétraitées avant d’être utilisées pour l’entraînement : normalisation, redimensionnement, augmentation des données, sont des moyens de préparation des images.
En résumé, il faut retenir que les IA génératives sont alimentées par une vaste gamme de sources de données d’images, allant des ensembles de données publiques aux données collectées en ligne, en passant par les images synthétiques et les captures du monde réel. La diversité et la qualité des données sont essentielles pour entraîner des modèles génératifs performants et capables de produire des images réalistes et variées. Cependant cette performance ne se fait pas toujours avec l’accord éclairé des auteurs des images. Il est en effet compliqué – certains diront impossible – de s’assurer que la gloutonnerie de Gol[IA]th s’est faite dans les règles avec le consentement de tous les créatifs impliqués… Un sujet d’éducation à la propriété numérique est à considérer!
Mais alors, comment [DA]vid et ses créatifs subissent cette naissance monstrueuse ?
Les métiers créatifs voient leur carnet de commande diminuer, les IA se démocratisant à une vitesse folle. [DA]vid, au delà de perdre des revenus en n’étant plus employé par des revues pour faire la couverture du magazine, se retrouve face à une concurrence déloyale : l’image générée a le même style… voir “son style”… Or pour un créatif, le style est l’œuvre du travail d’une vie, un facteur différenciant dans le paysage créatif, et le moteur de compétitivité dans le secteur… Comment faire pour maintenir son statut d’acteur de la compétitivité de l’économie alors que les clients du secteur substituent leur commande par des procédés éthiquement questionnables pour faire des économies ?
Gol[IA]th mange sans se sentir rompu, qu’il s’agisse de données libres ou protégées par des droits d’auteur, la saveur ne change pas. L’espoir de voir les tribunaux s’animer, pays après pays, sur des questionnements de violation, ou non, des lois protégeant les auteurs, s’amenuise dans certaines communautés. En attendant, les [DA]vid créatifs se retrouvent livrés à eux-mêmes, lentement dépossédés de l’espoir de pouvoir échapper au géant Gol[IA]th. Alors que l’inquiétude des artistes et des créateurs grandit à l’idée de voir une série d’algorithmes reproduire et s’accaparer leur style artistique, jusqu’à leur carrière, certains s’organisent pour manifester en occupant l’espace médiatique comme l’ont fait les acteurs en grève à Hollywood en 2023, et d’autres choisissent d’attaquer le sujet directement au niveau informatique en contactant Ben Zhao et Heather Zheng, deux informaticiens de l’Université de Chicago qui ont créé un outil appelé “Fawkes”, capable de modifier des photographies pour déjouer les IA de reconnaissance faciale.
“Est-ce que Fawkes peut protéger notre style contre des modèles de génération d’images comme Midjourney ou Stable Diffusion ?”
Bien que la réponse immédiate soit “non”, la réflexion a guidé vers une autre solution…
“Glaze”, un camouflage en jus sur une oeuvre
Les chercheurs de l’Université de Chicago se sont penchés sur la recherche d’une option de défense des utilisateurs du web face aux progrès de l’IA. Ils ont mis au point un produit appelé “Glaze”, en 2022, un outil de protection des œuvres d’art contre l’imitation par l’IA. L’idée de postulat est simple : à l’image d’un glacis ( une technique de la peinture à l’huile consistant à poser, sur une toile déjà sèche, une fine couche colorée transparente et lisse) déposer pour désaturer les pigments“Glaze” est un filtre protecteur des créations contre les IAs.
“Glaze” va alors se positionner comme un camouflage numérique : l’objectif est de brouiller la façon dont un modèle d’IA va “percevoir” une image en la laissant inchangée pour les yeux humains.
Ce programme modifie les pixels d’une image de manière systématique mais subtile, de sorte à ce que les modifications restent discrètes pour l’homme, mais déconcertantes pour un modèle d’IA. L’outil tire parti des vulnérabilités de l’architecture sous-jacente d’un modèle d’IA, car en effet, les systèmes de Gen-AI sont formés à partir d’une quantité importante d’images et de textes descriptifs à partir desquels ils apprennent à faire des associations entre certains mots et des caractéristiques visuelles (couleurs, formes). “Ces associations cryptiques sont représentées dans des « cartes » internes massives et multidimensionnelles, où les concepts et les caractéristiques connexes sont regroupés les uns à côté des autres. Les modèles utilisent ces cartes comme guide pour convertir les textes en images nouvellement générées.” (- Lauren Leffer,biologiste et journaliste spécialisée dans les sciences, la santé, la technologie et l’environnement.)
“Glaze” va alors intervenir sur ces cartes internes, en associant des concepts à d’autres, sans qu’il n’y ait de liens entre eux. Pour parvenir à ce résultat, les chercheurs ont utilisé des “extracteurs de caractéristiques” (programmes analytiques qui simplifient ces cartes hypercomplexes et indiquent les concepts que les modèles génératifs regroupent et ceux qu’ils séparent). Les modifications ainsi faites, le style d’un artiste s’en retrouve masqué : cela afin d’empêcher les modèles de s’entraîner à imiter le travail des créateurs. “S’il est nourri d’images « glacées » lors de l’entraînement, un modèle d’IA pourrait interpréter le style d’illustration pétillante et caricatural d’un artiste comme s’il s’apparentait davantage au cubisme de Picasso. Plus on utilise d’images « glacées » pour entraîner un modèle d’imitation potentiel, plus les résultats de l’IA seront mélangés. D’autres outils tels que Mist, également destinés à défendre le style unique des artistes contre le mimétisme de l’IA, fonctionnent de la même manière.” explique M Heather Zheng, un des deux créateurs de cet outil.
Plus simplement, la Gen-AI sera toujours en capacité de reconnaître les éléments de l’image (un arbre, une toiture, une personne) mais ne pourra plus restituer les détails, les palettes de couleurs, les jeux de contrastes qui constituent le “style”, i.e., la “patte” de l’artiste.
Quelques exemples de l’utilisation de Glaze arXiv:2302.04222
Bien que cette méthode soit prometteuse, elle présente des limites techniques et dans son utilisation.
Face à Gol[IA]th, les [DA]vid ne peuvent que se cacher après avoir pris conscience de son arrivée : dans son utilisation, la limite de “Glaze” vient du fait que chaque image que va publier un créatif ou un artiste doit passer par le logiciel avant d’être postée en ligne.. Les œuvres déjà englouties par les modèles d’IA ne peuvent donc pas bénéficier, rétroactivement, de cette solution. De plus, au niveau créatif, l’usage de cette protection génère du bruit sur l’image, ce qui peut détériorer sa qualité et s’apercevoir sur des couleurs faiblement saturées. Enfin au niveau technique, les outils d’occultation mise à l’œuvre ont aussi leurs propres limites et leur efficacité ne pourra se maintenir sur le long terme.
En résumé, à la vitesse à laquelle évoluent les Gen-AI, “Glaze” ne peut être qu’un barrage temporaire, et malheureusement non une solution : un pansement sur une jambe gangrenée, mais c’est un des rares remparts à la créativité humaine et sa préservation.
Il faut savoir que le logiciel a été téléchargé 720 000 fois, et ce, à 10 semaines de sa sortie, ce qui montre une véritable volonté de la part des créatifs de se défendre face aux affronts du géant.
La Gen-AI prend du terrain sur la toile, les [DA]vid se retrouvent forcés à se cacher… Est-ce possible pour eux de trouver de quoi charger leur fronde ? Et bien il s’avère que la crainte a su faire naître la colère et les revendications, et les créatifs et les artistes ont décidé de se rebeller face à l’envahisseur… L’idée n’est plus de se cacher, mais bien de contre-attaquer Gol[IA]th avec les armes à leur disposition…
“Nightshade”, lorsque la riposte s’organise ou comment empoisonner l’IA ?
Les chercheurs de l’Université de Chicago vont pousser la réflexion au delà de “Glaze”, au delà de bloquer le mimétisme de style, “Nightshade” est conçu comme un outil offensif pour déformer les représentations des caractéristiques à l’intérieur même des modèles de générateurs d’image par IA…
« Ce qui est important avec Nightshade, c’est que nous avons prouvé que les artistes n’ont pas à être impuissants », déclare Zheng.
Nightshade ne se contente pas de masquer la touche artistique d’une image, mais va jusqu’à saboter les modèles de Gen-AI existants. Au-delà de simplement occulter l’intégrité de l’image, il la transforme en véritable “poison” pour Gol[IA]th en agissant directement sur l’interprétation de celui-ci. Nightshade va agir sur l’association incorrecte des idées et des images fondamentales. Il faut imaginer une image empoisonnée par “Nightshade” comme une goutte d’eau salée dans un récipient d’eau douce. Une seule goutte n’aura pas grand effet, mais chaque goutte qui s’ajoute va lentement saler le récipient. Il suffit de quelques centaines d’images empoisonnées pour reprogrammer un modèle d’IA générative. C’est en intervenant directement sur la mécanique du modèle que “Nightshade” entrave le processus d’apprentissage, en le rendant plus lent ou plus coûteux pour les développeurs. L’objectif sous-jacent serait, théoriquement,d’inciter les entreprises d’IA à payer les droits d’utilisation des images par le biais des canaux officiels plutôt que d’investir du temps dans le nettoyage et le filtrage des données d’entraînement sans licence récupérée sur le Web.
Image issue de l’article de Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv:2310.13828
Ce qu’il faut comprendre de « Nightshade » :
Empoisonnement des données: Nightshade fonctionne en ajoutant des modifications indétectables mais significatives aux images. Ces modifications sont introduites de manière à ne pas affecter la perception humaine de l’image mais à perturber le processus de formation des modèles d’IA. Il en résulte un contenu généré par l’IA qui s’écarte de l’art prévu ou original.
Invisibilité: Les altérations introduites par Nightshade sont invisibles à l’œil humain. Cela signifie que lorsque quelqu’un regarde l’image empoisonnée, elle apparaît identique à l’originale. Cependant, lorsqu’un modèle d’IA traite l’image empoisonnée, il peut générer des résultats complètement différents, pouvant potentiellement mal interpréter le contenu.
Impact: L’impact de l’empoisonnement des données de Nightshade peut être important. Par exemple, un modèle d’IA entraîné sur des données empoisonnées pourrait produire des images dans lesquelles les chiens ressemblent à des chats ou les voitures à des vaches. Cela peut rendre le contenu généré par l’IA moins fiable, inexact et potentiellement inutilisable pour des applications spécifiques.
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade.arXiv:2310.13828
Voici alors quelques exemples après de concepts empoisonnés :
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade et le modèle SD-XL propre, lorsqu’ils sont invités à utiliser le concept empoisonné C. arXiv:2310.13828
Plus précisément, « Nightshade transforme les images en échantillons ’empoisonnés’, de sorte que les modèles qui s’entraînent sur ces images sans consentement verront leurs modèles apprendre des comportements imprévisibles qui s’écartent des normes attendues, par exemple une ligne de commande qui demande l’image d’une vache volant dans l’espace pourrait obtenir à la place l’image d’un sac à main flottant dans l’espace », indiquent les chercheurs.
Le « Data Poisoning » est une technique largement répandue. Ce type d’attaque manipule les données d’entraînement pour introduire un comportement inattendu dans le modèle au moment de l’entraînement. L’exploitation de cette vulnérabilité rend possible l’introduction de résultats de mauvaise classification.
« Un nombre modéré d’attaques Nightshade peut déstabiliser les caractéristiques générales d’un modèle texte-image, rendant ainsi inopérante sa capacité à générer des images significatives », affirment-ils.
Cette offensive tend à montrer que les créatifs peuvent impacter les acteurs de la technologie en rendant contre-productif l’ingestion massive de données sans l’accord des ayant-droits.
Plusieurs plaintes ont ainsi émané d’auteurs, accusant OpenAI et Microsoft d’avoir utilisé leurs livres pour entraîner ses grands modèles de langage. Getty Images s’est même fendu d’une accusation contre la start-up d’IA Stability AI connue pour son modèle de conversion texte-image Stable Diffusion, en Février 2023. Celle-ci aurait pillé sa banque d’images pour entraîner son modèle génératif Stable Diffusion. 12 millions d’œuvres auraient été « scrappées » sans autorisation, attribution, ou compensation financière. Cependant, il semble que ces entreprises ne puissent pas se passer d’oeuvres soumises au droit d’auteur, comme l’a récemment révélé OpenAI, dans une déclaration auprès de la Chambre des Lords du Royaume-Uni concernant le droit d’auteur, la start-up a admis qu’il était impossible de créer des outils comme le sien sans utiliser d’œuvres protégées par le droit d’auteur. Un aveu qui pourrait servir dans ses nombreux procès en cours…
Ainsi, quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?
En résumé, dans sa gloutonnerie, Gol[IA]th a souhaité engloutir les [DA]vid qui nous entourent, qui ont marqué l’histoire et ceux qui la créent actuellement, dans leur entièreté et leur complexité : en cherchant à dévorer ce qui fait leur créativité, leur style, leur patte, au travers d’une analyse de caractéristiques et de pixels, Gol[IA]th a transformé la créativité humaine qui était sa muse, son idéal à atteindre, en un ensemble de données sans sémantique, ni histoire, ni passion sous-jacente.
C’est peut être un exemple d’amour nocif à l’heure de l’IA, tel que vu par l’IA ?
Sans sous-entendre que les personnes à l’origine de l’écriture des IA génératives ne sont pas des créatifs sans passion, il est probable que la curiosité, la prouesse et l’accélération technologique ont peu à peu fait perdre le fil sur les impacts que pourrait produire un tel engouement.
A l’arrivée de cette technologie sur le Web, les artistes et les créatifs n’avaient pas de connaissance éclairée sur ce qui se produisait à l’abri de leurs regards. Cependant, les modèles d’apprentissage ont commencé à être alimentés en données à l’insu de leur ayant-droits. La protection juridique des ayant-droits n’évoluant pas à la vitesse de la technologie, les créatifs ont rapidement été acculés, parfois trop tard, les Gen-AI ayant déjà collecté le travail d’une vie. Beaucoup d’artistes se sont alors “reclus”, se retirant des plateformes et des réseaux sociaux pour éviter les vols, mais ce choix ne fut pas sans conséquence pour leur visibilité et la suite de leur carrière.
Alors que les réseaux jouaient l’opacité sur leurs conditions liées à la propriété intellectuelle, le choix a été de demander aux créatifs de se “manifester s’ils refusaient que leurs données soient exploitées”, profitant de la méconnaissance des risques pour forcer l’acceptation de condition, sans consentement éclairé. Mais la grogne est montée dans le camp des créatifs, qui commencent à être excédés par l’abus qu’ils subissent. “Glaze” fut une première réaction, une protection pour conserver l’intégrité visuelle de leur œuvre, mais face à une machine toujours plus gloutonne, se protéger semble rapidement ne pas suffire. C’est alors que “Nightshade” voit le jour, avec la volonté de faire respecter le droit des artistes, et de montrer qu’ils ne se laisseraient pas écraser par la pression des modèles.
Il est important de suivre l’évolution des droits des différents pays et de la perception des sociétés civiles dans ces pays de ce sujet car le Web, l’IA et la créativité étant sans limite géographique, l’harmonisation juridique concernant les droits d’auteur, la réglementation autour de la propriété intellectuelle, et l’éducation au numérique pour toutes et tous, vont être – ou sont peut-être déjà – un enjeu d’avenir au niveau mondial.
Pour avoir davantage d’informations sur Glaze et Nightshade :page officielle
Article Glaze : Shan, S., Cryan, J., Wenger, E., Zheng, H., Hanocka, R., & Zhao, B. Y. (2023). Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In 32nd USENIX Security Symposium (USENIX Security 23) (pp. 2187-2204). arXiv preprint arXiv:2302.04222
Article Nightshade : Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv preprint arXiv:2310.13828.
A propos de l’autrice : Julie Laï-Pei, après une première vie dans le secteur artistique et narratif, a rejoint l’émulation de l’innovation en Nouvelle-Aquitaine, en tant que responsable de l’animation d’une communauté technologique Numérique auprès d’un pôle de compétitivité. Femme dans la tech et profondément attachée au secteur Culturel et Créatif, elle a à coeur de partager le résultat de sa veille et de ses recherches sur l’impact des nouvelles technologies dans le monde de la créativité.
Un billet à propos d’un livre. Nous avons demandé à Isabelle Astic, Responsable des collections Informatique au Musée des arts et métiers, de nous faire partager son avis du livre de Marion Carré à propos de Alice Recoque. Pierre Paradinas
Le titre de l’ouvrage de Marion Carré, un brin provocateur : « Qui a voulu effacer Alice Recoque ?», pourrait laisser penser qu’Alice Recoque est un de ces avatars informatiques issu des jeux vidéo. Mais c’est bien une femme en chair et en os qu’elle nous présente.
Ce titre est celui du premier chapitre, introductif, durant lequel l’autrice nous décrit les complications rencontrées pour que Alice Recoque puisse avoir sa page dans Wikipédia. Ou la double peine de l’effet Matilda : la minimalisation du rôle des femmes dans la recherche a pour conséquence qu’elles sont autrices de peu d’articles scientifiques, c’est pourquoi elles ne sont donc pas jugées dignes d’un article dans Wikipédia.
Les chapitres suivants décrivent la vie et la carrière d’Alice Recoque, contextualisées dans l’histoire quotidienne ou professionnelle de son époque. Ils s’appuient sur un témoignage de première main : les mémoires de Mme Recoque. Son enfance en Algérie, ses études à l’ENSPCI, à Paris, sont l’occasion de parler du contexte international et de la guerre qui ont imprégné l’enfance et l’adolescence de la jeune Alice, de l’ambiance familiale qui a forgé certains traits de son caractère, de sa capacité à sortir des chemins convenus grâce à certaines figures inspirantes de son entourage.
Ces premiers chapitres expliquent les suivants, consacrés plutôt à son expérience professionnelle. La SEA (Société d’Électronique et d’Automatisme) d’abord, jeune pousse créée par un ingénieur clairvoyant, François-Henri Raymond, qui a très tôt compris l’avenir de l’informatique. Elle s’y épanouit et développe ses connaissances en conception d’ordinateur, en hardware. Puis la CII, dans laquelle doit se fondre la SEA sous l’injonction du Plan Calcul, qui devient CII-Honeywell Bull, puis Bull. Elle prend peu à peu des galons pour gérer finalement une équipe qui va construire le mini-ordinateur qu’elle a en tête, le Mitra 15. Enfin, c’est la découverte de l’Intelligence Artificielle, lors d’un voyage au Japon, domaine dans lequel Bull acceptera de s’engager, opportunité pour Alice Recoque de passer du matériel au logiciel.
En parallèle de la vie d’Alice Recoque, nous suivons le développement de l’industrie informatique en France. Nous assistons à ses débuts où il y avait tout à faire : le processeur à concevoir, les techniques de mémorisation à imaginer. L’ouvrage décrit l’effervescence d’une jeune entreprise, poussée par cette nouveauté, par l’exaltation de la découverte, par les visions de son fondateur mais aussi par les risques et les difficultés qu’elle rencontre pour survivre. Avec l’évolution de la carrière d’Alice Recoque, nous suivons les hauts et les bas de cette industrie, à travers l’entreprise Bull. Mais l’ouvrage dresse également, et surtout, le portrait d’une femme de sciences et de techniques, qui s’engage dans un univers d’homme. Il nous décrit ses questionnements, ses choix, les heurs et malheurs d’une vie. Cet angle du livre créé une empathie avec Mme Recoque, ouvrant un dialogue entre son époque et la nôtre. C’est donc un voyage dans le contexte social, économique, technique et informatique de l’époque qu’il nous propose.
Certains diront que ce n’est pas un ouvrage d’historien. Et il est vrai qu’en suivant la vie d’Alice Recoque, nous manquons parfois un peu de recul. Certains points pourraient demander des approfondissements, comme le rôle de la politique sociale et l’organisation d’une entreprise dans les possibilités de carrière des femmes. De même, on peut s’interroger sur la part et le rôle de l’état dans le succès du Mitra 15, sans remettre en question la qualité du travail d’Alice Recoque. Mais Marion Carré ne revendique pas un rôle d’historienne. Elle préfère parler d’ « investigations » et son ouvrage est effectivement le résultat d’un long travail d’enquête, de la recherche de ses sources à l’analyse qu’elle en fait, qui offre de nombreuses perspectives à des travaux scientifiques.
Photo Aconit
Marion Carré a su faire un beau portrait de femme dans un ouvrage facile à lire, qui ne s’aventure pas dans les descriptions techniques ardues pouvant rebuter certains ou certaines et qui ne se perd pas non plus dans les méandres d’une vie familiale et personnelle. Il est l’un des rares livres consacré à une femme informaticienne française, à une femme de science contemporaine qui a su se donner un rôle dans l’émergence de l’industrie de l’informatique en France. Grâce aux rencontres provoquées, aux sources retrouvées, Alice Recoque est enfin sortie de l’ombre. Espérons que d’autres portraits d’informaticiennes verront bientôt le jour, comme celui de Marion Créhange, première femme à soutenir une thèse en informatique en France (1961), qui nous avait régalé, sur le site d’Interstices, d’une randonnée informatique quelques mois avant son décès. Ces portraits contribueraient sans aucun doute à ce que de jeunes femmes puissent se rêver, à leurs tours, informaticiennes.
Les progrès récents de l’intelligence artificielle générative , outils qui permettent de produire du texte, du son, des images ou des vidéos de manière complètement automatique, font craindre une diffusion massive de fausses informations qui risquent de devenir de plus en plus « authentique ». Comment font les journalistes pour adresser ce sujet ?
Merci à inria.fr qui nous offre ce texte en partage, originalement publié le 06/02/2024. Ikram Chraibi Kaadoud
Comment savoir, parmi la masse d’informations diffusées chaque jour sur les réseaux sociaux ou par des personnalités publiques, où se cachent les erreurs et les mensonges ? C’est tout l’enjeu du fact checking… mais le chantier est titanesque. Estelle Cognacq, directrice adjointe de France Info, et Ioana Manolescu, responsable de l’équipe-projet Inria Cedar, nous expliquent comment journalistes et chercheurs se sont associés pour y faire face, en s’appuyant sur l’intelligence artificielle et les sciences des données.
À vos yeux, quels sont les défis à relever par les journalistes en matière de fact checking aujourd’hui ?
Estelle Cognacq : Franceinfo s’est engagé dans la lutte contre la désinformation et pour la restauration de la confiance dans les médias depuis plus de 10 ans : la première chronique « Vrai ou faux » date par exemple de 2012 et un service spécial, dédié au fact checking, a été créé en 2019. Les journalistes qui y travaillent se sont fixé deux objectifs. D’une part, puisqu’il est impossible d’éradiquer les fausses informations, nous cherchons à donner au grand public les outils qui lui permettent de développer un esprit critique, de remettre en question ce qu’il voit, ce qu’il lit, ce qu’il entend. Nous allons donc expliquer notre façon de travailler, donner des astuces sur la façon de détecter des images truquées par exemple.
D’autre part, nous allons nous saisir directement des fausses informations qui circulent, lorsque celles-ci entrent en résonance avec la démocratie, la citoyenneté ou les questions d’actualité importantes, pour établir les faits. Mais plus il y a de monde sur les réseaux sociaux, plus des informations y circulent et plus les journalistes ont besoin d’aide : l’humain a ses limites lorsqu’il s’agit de trier des quantités phénoménales de données.
Iona Manolescu : Et c’est justement là tout l’intérêt des recherches que nous menons au sein de l’équipe-projet Cedar, (équipe commune au centre Inria de Saclay et à l’Institut Polytechnique de Paris, au sein du laboratoire LIX), qui est spécialisée en sciences des données et en intelligence artificielle (IA). Sur la question du fact checking, il nous faut d’un côté vérifier automatiquement une masse d’informations, mais de l’autre, nous disposons de quantités de données de qualité disponibles en open source, sur les bases statistiques officielles par exemple. La comparaison des unes aux autres constitue un procédé éminemment automatisable pour vérifier davantage et plus vite.
Et c’est pourquoi un partenariat s’est noué entre Radio France et Cedar… Comment a-t-il vu jour ?
I.M. : De 2016 à 2019, l’un de mes doctorants avait travaillé sur un premier logiciel de fact checking automatique, baptisé StatCheck, dans le cadre du projet ANR ContentCheck que j’avais coordonné, en collaboration avec Le Monde. Ce projet est arrivé jusqu’aux oreilles d’Eric Labaye, président de l’Institut polytechnique de Paris, qui en a lui-même parlé à Sybile Veil, directrice de Radio France. De là est née l’idée d’une collaboration entre chercheurs d’Inria et journalistes de Radio France. Du fait de la pandémie de Covid, il a fallu attendre l’automne 2021 pour que celle-ci se concrétise.
E.C. : Notre objectif était vraiment de partir des besoins de nos journalistes, de disposer d’un outil qui les aide efficacement au quotidien. Antoine Krempf, qui dirigeait la cellule « Vrai ou faux » à l’époque, a par exemple dressé la liste des bases de données qu’il souhaitait voir prises en compte par l’outil.
Toutes les semaines, nous avions également un point qui réunissait les deux ingénieurs en charge du projet chez Inria et les journalistes : l’occasion pour les premiers de présenter l’évolution de l’outil et pour les seconds de préciser ce qui manquait encore ou ce qui leur convenait. Et ces échanges se poursuivent aujourd’hui. Croiser les disciplines entre chercheurs et journalistes dans une optique de partage est très intéressant.
I.M. : Au cours de ce processus, nous avons réécrit tout le code de StatCheck, travaillé sur la compréhension du langage naturel pour permettre à l’outil d’apprendre à analyser un tweet par exemple, avec la contribution essentielle de Oana Balalau, chercheuse (Inria Starting Faculty Position) au sein de l’équipe Cedar. Deux jeunes ingénieurs de l’équipe, Simon Ebel et Théo Galizzi, ont échangé régulièrement avec les journalistes pour imaginer et mettre au point une nouvelle interface, plus agréable et plus adaptée à leur utilisation.
Ce logiciel est-il maintenant capable de faire le travail du « fact checker » ?
I.M. : Aujourd’hui, StatCheck est à la disposition de la dizaine de journalistes de la cellule « Le vrai du faux »… mais il ne les remplace pas ! D’abord parce que nous ne pouvons pas atteindre une précision de 100% dans l’analyse des informations. Donc le logiciel affiche ses sources pour le journaliste, qui va pouvoir vérifier que l’outil n’a pas fait d’erreur. Ensuite, parce que l’humain reste maître de l’analyse qu’il produit à partir du recoupement de données réalisé par StatCheck.
E.C. : Ainsi, chaque journaliste l’utilise à sa manière. Mais cet outil s’avère particulièrement précieux pour les plus jeunes, qui n’ont pas forcément encore l’habitude de savoir où regarder parmi les sources.
Quels sont les développements en cours ou à venir pour StatCheck ?
E.C. : Nous profitons déjà de fonctionnalités ajoutées récemment, comme la détection de données quantitatives. Nous avons entré dans StatCheck des dizaines de comptes Twitter (devenu X) de personnalités politiques et le logiciel nous signale les tweets qui contiennent des données chiffrées. Ce sont des alertes très utiles qui nous permettent de rapidement repérer les informations à vérifier.
L’outil a également été amélioré pour détecter la propagande et les éléments de persuasion dans les tweets. Nous utilisons cette fonctionnalité sur du plus long terme que le fact checking : elle nous permet d’identifier les sujets qu’il pourrait être pertinent de traiter sur le fond.
I.M. : Pour l’instant, StatCheck va puiser dans les bases de données de l’Insee (Institut national de la statistique et des études économiques) et d’EuroStat, la direction générale de la Commission européenne chargée de l’information statistique. Mais dans la liste établie par Antoine Krempf, il y a aussi une kyrielle de sites très spécialisés comme les directions statistiques des ministères. Le problème est que leurs formats de données ne sont pas homogènes. Il faut donc une chaîne d’analyse et d’acquisition des informations à partir de ces sites, pour les extraire et les exploiter de manière automatique. Les deux ingénieurs du projet sont sur une piste intéressante sur ce point.
Et votre partenariat lui-même, est-il amené à évoluer ?
E.C. : Nous sommes en train de réfléchir à son inscription dans une collaboration plus large avec Inria, en incluant par exemple la cellule investigation et la rédaction internationale de Radio France, pourquoi pas au sein d’un laboratoire IA commun.
I.M. : Nous avons d’autres outils qui pourraient être utiles aux journalistes de Radio France, comme ConnectionLens. Celui-ci permet de croiser des sources de données de tous formats et de toutes origines grâce à l’IA… Pratique par exemple pour repérer qu’une personne mentionnée dans un appel d’offres est la belle-sœur d’un membre du comité de sélection de l’appel d’offres ! Là encore, le journaliste restera indispensable pour identifier le type d’information à rechercher, ainsi que pour vérifier et analyser ces connexions, mais l’outil lui fournira des pièces du puzzle. En fait, toutes les évolutions sont envisageables… elles demandent simplement parfois du temps !





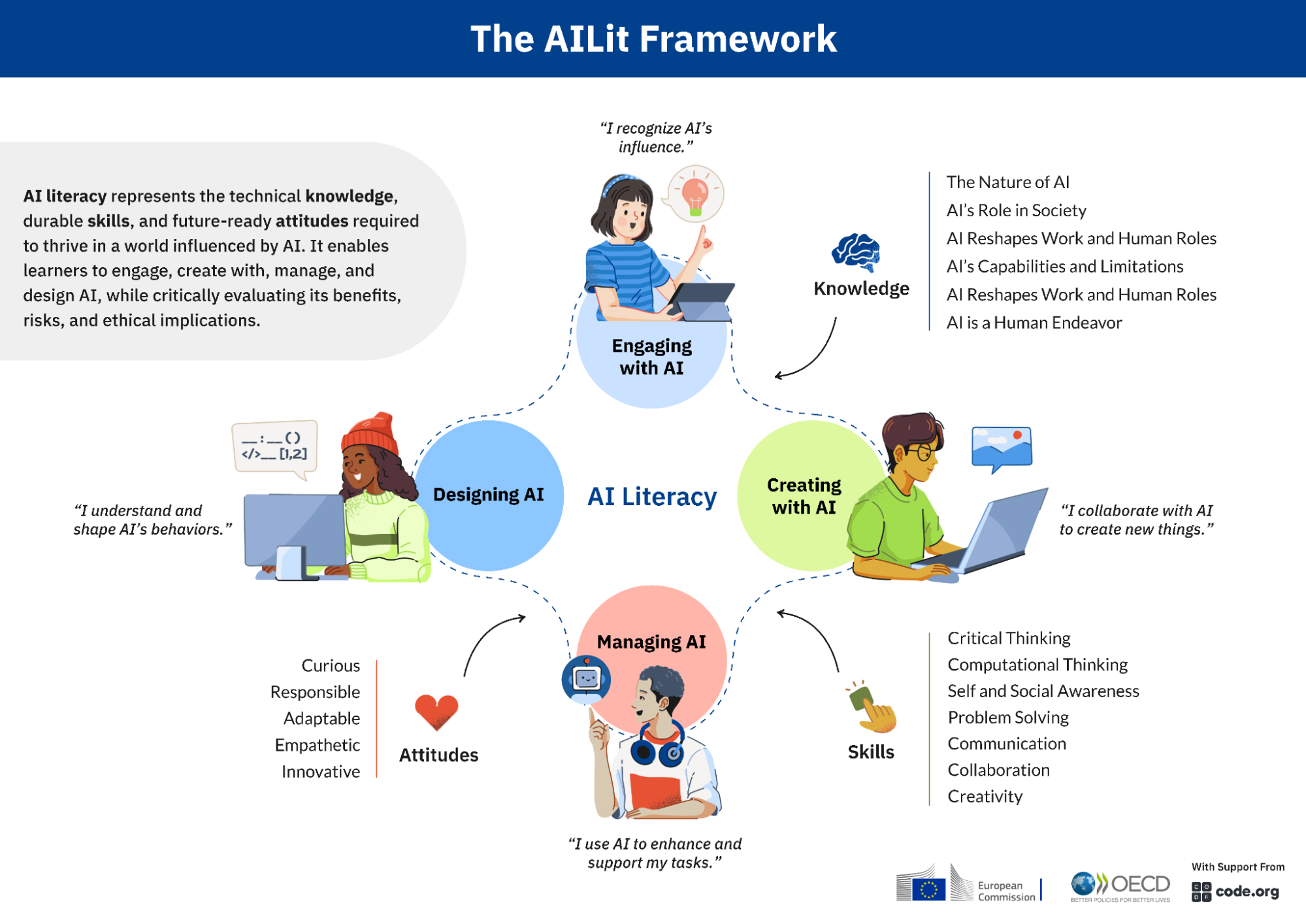
 Au cours des prochains mois, nous sollicitons les commentaires des parties prenantes du monde entier. Pour participer, visitez www.teachai.org/ailiteracy/review. La version finale du cadre sera publiée en 2026, accompagnée d’exemples de maîtrise de l’IA dans les programmes, l’évaluation et la formation professionnelle.
Au cours des prochains mois, nous sollicitons les commentaires des parties prenantes du monde entier. Pour participer, visitez www.teachai.org/ailiteracy/review. La version finale du cadre sera publiée en 2026, accompagnée d’exemples de maîtrise de l’IA dans les programmes, l’évaluation et la formation professionnelle. https://pixees.fr/classcode-v2/iai
https://pixees.fr/classcode-v2/iai  https://tinyl.co/3PMs
https://tinyl.co/3PMs 




































 On parle d’intelligences artificielles génératives, qui produisent en quelques secondes du texte, des images et du contenu audio. Ce sont de vraies prouesses techniques, de gigantesques calculs statistiques. Bien utilisées, ce sont des outils utiles dans de nombreux domaines, y compris de la vie des ados. Mal comprises, elles font peur. Mal utilisées, elles conduisent à de nombreuses erreurs.
On parle d’intelligences artificielles génératives, qui produisent en quelques secondes du texte, des images et du contenu audio. Ce sont de vraies prouesses techniques, de gigantesques calculs statistiques. Bien utilisées, ce sont des outils utiles dans de nombreux domaines, y compris de la vie des ados. Mal comprises, elles font peur. Mal utilisées, elles conduisent à de nombreuses erreurs.



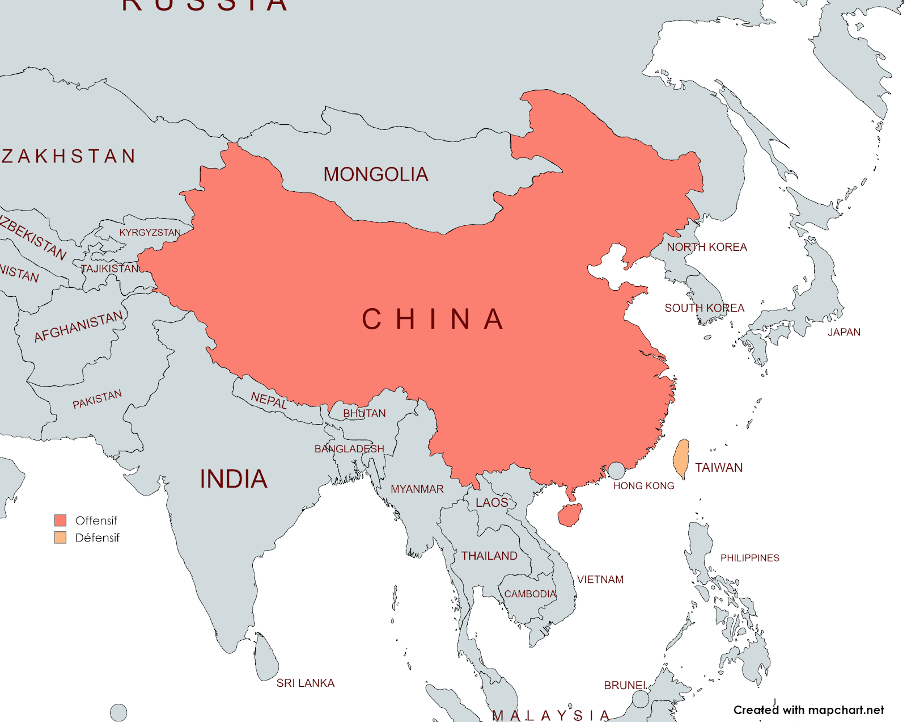
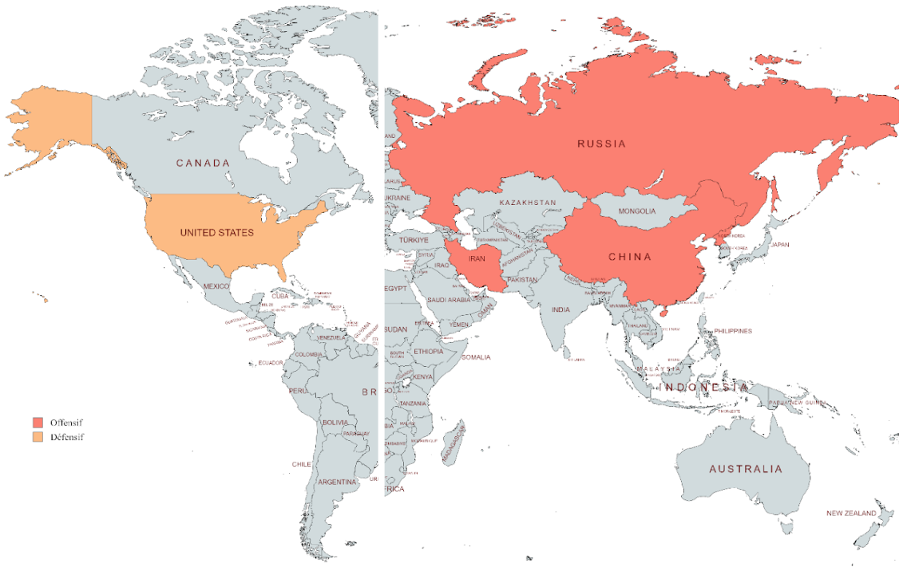
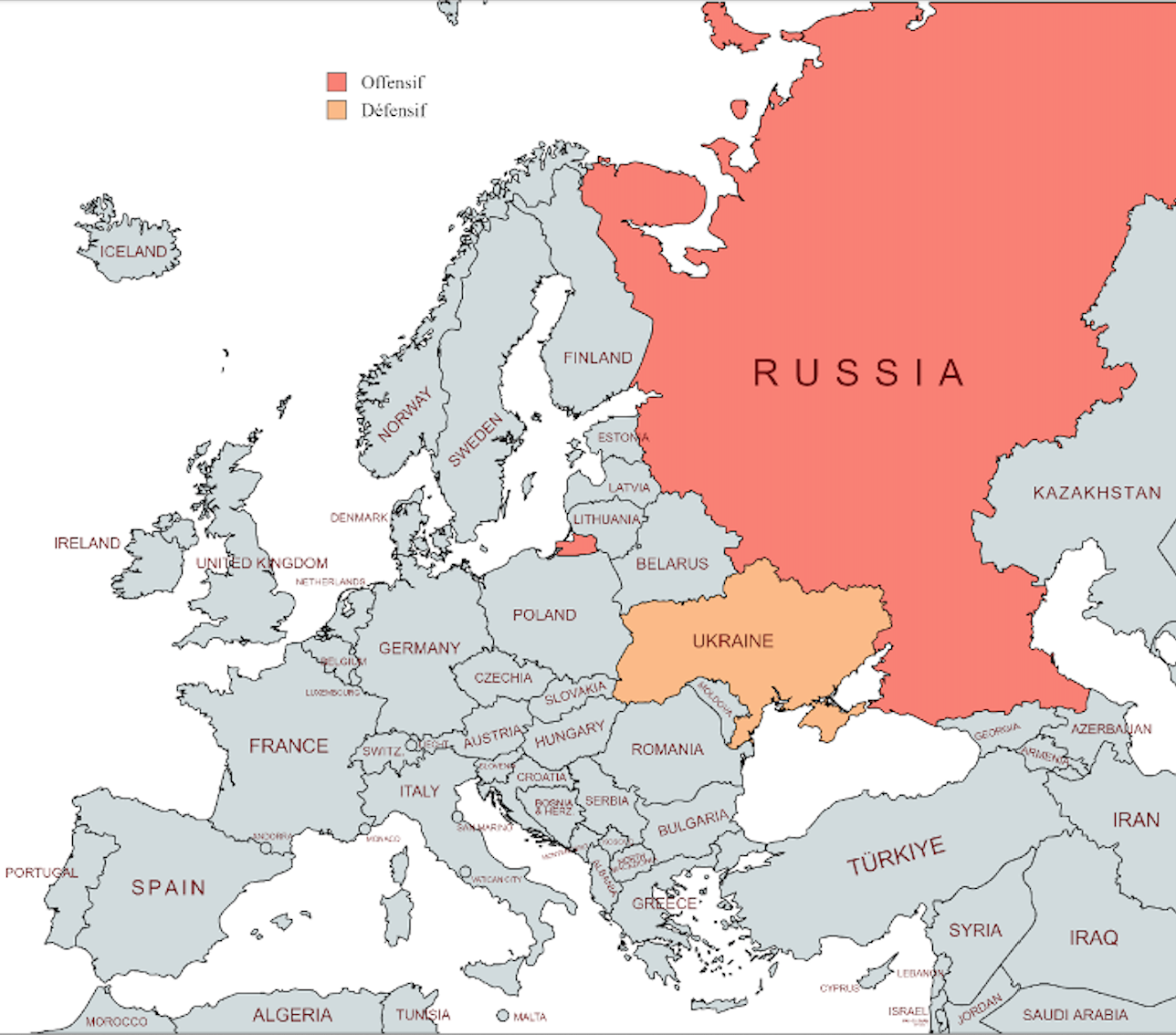
![[DA]vid contre Gol[IA]th : Quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?](https://binaire.socinfo.fr/wp-content/uploads/2024/09/25732ce2-img1.jpg)
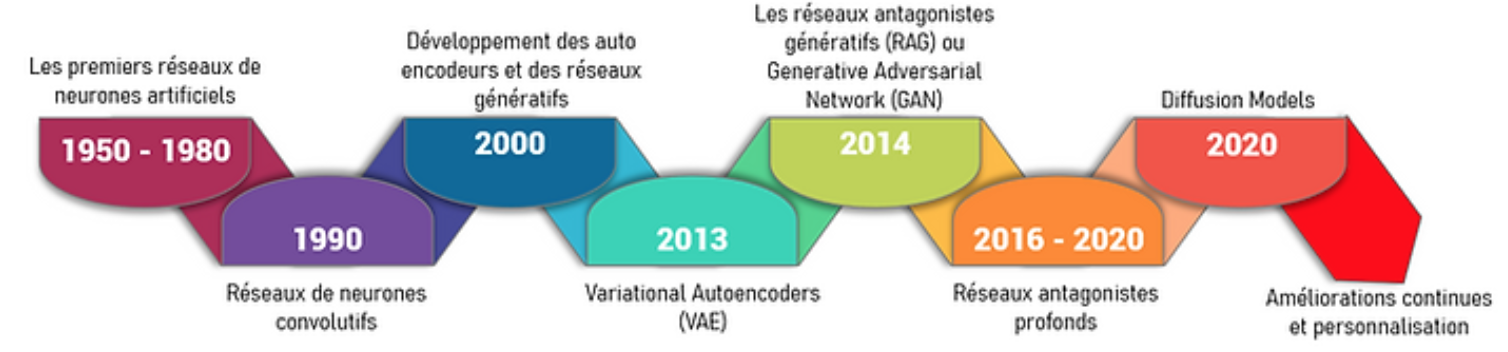







 Le titre de l’ouvrage de Marion Carré, un brin provocateur : « Qui a voulu effacer Alice Recoque ?», pourrait laisser penser qu’Alice Recoque est un de ces avatars informatiques issu des jeux vidéo. Mais c’est bien une femme en chair et en os qu’elle nous présente.
Le titre de l’ouvrage de Marion Carré, un brin provocateur : « Qui a voulu effacer Alice Recoque ?», pourrait laisser penser qu’Alice Recoque est un de ces avatars informatiques issu des jeux vidéo. Mais c’est bien une femme en chair et en os qu’elle nous présente.
