
Billet d’introduction: L’expression “David contre Goliath” n’a jamais semblé aussi pertinente que lorsqu’il faut décrire le combat des artistes contre les GAFAM. Cette expression souvent utilisée pour décrire un combat entre deux parties prenantes de force inégale souligne une réalité : celle de la nécessité qu’ont ressenti des artistes de différents milieux et pays de se défendre face à des géants de la tech de l’IA générative pour protéger leur oeuvres, leur passion et leur métier, pour eux et pour les générations futures. Si la Direction Artistique porte le nom de [DA]vid, alors l’IA sera notre Gol[IA]th… C’est parti pour une épopée 5.0 !
Julie Laï-Pei, femme dans la tech, a à cœur de créer un pont entre les nouvelles technologies et le secteur Culturel et Créatif, et d’en animer la communauté. Elle nous partage ici sa réflexion au croisement de ces deux domaines.
Chloé Mercier, Thierry Vieville et Ikram Chraibi Kaadoud
Comment les artistes font-ils face au géant IA, Gol[IA]th ?

A l’heure d’internet, les métiers créatifs ont connu une évolution significative de leur activité. Alors que nous sommes plus que jamais immergés dans un monde d’images, certains artistes évoluent et surfent sur la vague, alors que d’autres reviennent à des méthodes de travail plus classiques. Cependant tous se retrouvent confrontés aux nouvelles technologies et à leurs impacts direct et indirect dans le paysage de la créativité artistique.
Si les artistes, les graphistes, les animateurs devaient faire face à une concurrence sévère dans ce domaine entre eux et face à celle de grands acteurs du milieu, depuis peu (on parle ici de quelques mois), un nouveau concurrent se fait une place : l’Intelligence artificielle générative, la Gen-IA !
C’est dans ce contexte mitigé, entre écosystème mondial de créatifs souvent isolés et puissances économiques démesurées que se posent les questions suivantes :
Quelle est la place de la création graphique dans cet océan numérique ? Comment sont nourris les gros poissons de l’intelligence artificielle pour de la création et quelles en sont les conséquences ?
L’évolution des modèles d’entraînement des IA pour aller vers la Gen-AI que l’on connaît aujourd’hui
Afin qu’une intelligence artificielle soit en capacité de générer de l’image, elle a besoin de consommer une quantité importante d’images pour faire le lien entre la perception de “l’objet” et sa définition nominale. Par exemple, à la question “Qu’est-ce qu’un chat ?” En tant qu’humain, nous pouvons facilement, en quelques coup d’œil, enfant ou adulte, comprendre qu’un chat n’est pas un chien, ni une table ou un loup. Or cela est une tâche complexe pour une intelligence artificielle, et c’est justement pour cela qu’elle a besoin de beaucoup d’exemples !
Ci dessous une frise chronologique de l’évolution des modèles d’apprentissage de l’IA depuis les premiers réseaux de neurones aux Gen-IA :
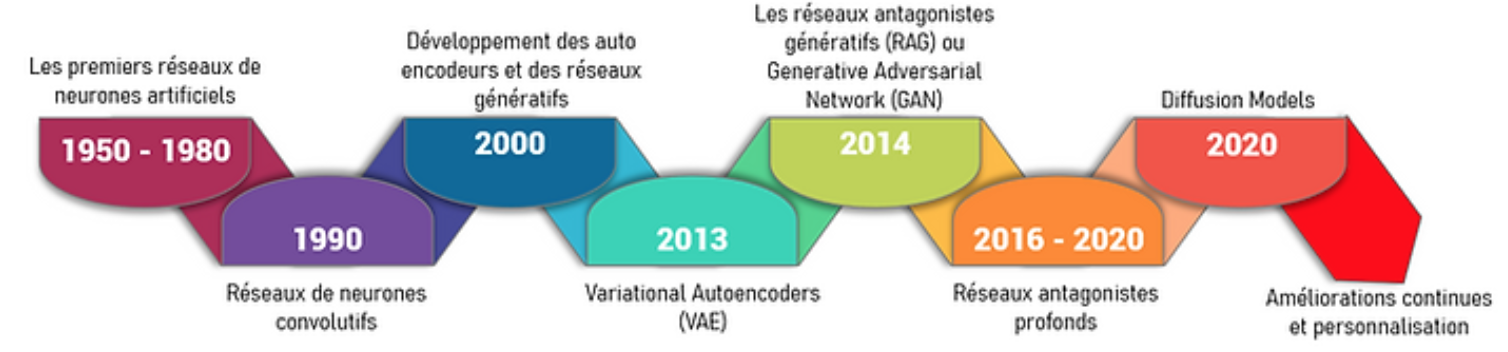
En 74 ans, les modèles d’IA ont eu une évolution fulgurante, d’abord cantonnée aux sphères techniques ou celle d’entreprises très spécialisées, à récemment en quelques mois en 2023, la société civile au sens large et surtout au sens mondial.
Ainsi, en résumé, si notre IA Gol[IA]th souhaite générer des images de chats, elle doit avoir appris des centaines d’exemples d’images de chat. Même principe pour des images de voitures, des paysages, etc.
Le problème vient du fait que, pour ingurgiter ces quantités d’images pour se développer, Gol[IA]th mange sans discerner ce qu’il engloutit… que ce soit des photos libres de droit, que ce soit des oeuvres photographiques, des planches d’artwork, ou le travail d’une vie d’un artiste, Gol[IA]th ne fait pas de différence, tout n’est “que” nourriture…
Dans cet appétit gargantuesque, les questions d’éthique et de propriétés intellectuelles passent bien après la volonté de développer la meilleure IA générative la plus performante du paysage technologique. Actuellement, les USA ont bien de l’avance sur ce sujet, créant de véritables problématiques pour les acteurs de la création, alors que l’Europe essaie de normer et d’encadrer l’éthique des algorithmes, tout en essayant de mettre en place une réglementation et des actions concrètes dédiées à la question de la propriété intellectuelle, qui est toujours une question en cours à ce jour.
Faisons un petit détour auprès des différents régimes alimentaires de ce géant…
Comment sont alimentées les bases de données d’image pour les Gen-AI ?
L’alimentation des IA génératives en données d’images est une étape cruciale pour leur entraînement et leur performance. Comme tout bon géant, son régime alimentaire est varié et il sait se sustenter par différents procédés… Voici les principales sources et méthodes utilisées pour fournir les calories nécessaires de données d’images aux IA génératives :
-
Les bases de données publiques
Notre Gol[IA]th commence généralement par une alimentation saine, basée sur un des ensembles de données les plus vastes et les plus communément utilisés: par exemple, ImageNet qui est une base de données d’images annotées produite par l’organisation du même nom, à destination des travaux de recherche en vision par ordinateur. Cette dernière représente plus de 14 millions d’images annotées dans des milliers de catégories. Pour obtenir ces résultats, c’est un travail fastidieux qui demande de passer en revue chaque image pour la qualifier, en la déterminant d’après des descriptions, des mot-clefs, des labels, etc…
Entre autres, MNIST, un ensemble de données de chiffres manuscrits, couramment utilisé pour les tâches de classification d’images simples.
Dans ces ensembles de données publics, on retrouve également COCO (à comprendre comme Common Objects in COntext) qui contient plus de 330 000 images d’objets communs dans un contexte annotées, pour l’usage de la segmentation d’objets, la détection d’objets, de la légendes d’image, etc…
Plus à la marge, on retrouve la base de données CelebA qui contient plus de 200 000 images de visages célèbres avec des annotations d’attributs.

-
La collecte de données en ligne (web scraping)
Plus discutable, Gol[IA]th peut également chasser sa pitance… Pour ce faire, il peut utiliser le web scraping. Il s’agit d’un procédé d’extraction automatique d’images à partir de sites web, moteurs de recherche d’images, réseaux sociaux, et autres sources en ligne. Concrètement, au niveau technique, il est possible d’utiliser des APIs (Application Programming Interfaces) pour accéder à des bases de données d’images: il s’agit d’interfaces logicielles qui permettent de “connecter” un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités. Il en existe pour Flickr, pour Google Images, et bien d’autres.
Ce procédé pose question sur le plan éthique, notamment au sujet du consentement éclairé des utilisateurs de la toile numérique : Est-ce qu’une IA a le droit d’apprendre de tout, absolument tout, ce qu’il y a en ligne ? Et si un artiste a choisi de partager ses créations sur internet, son œuvre reste-t-elle sa propriété ou devient-elle, en quelque sorte, la propriété de tous ?
Ces questions soulignent un dilemme omniprésent pour tout créatif au partage de leur œuvre sur internet : sans cette visibilité, il n’existe pas, mais avec cette visibilité, ils peuvent se faire spolier leur réalisation sans jamais s’en voir reconnaître la maternité ou paternité.
Il y a en effet peu de safe-places pour les créatifs qui permettent efficacement d’être mis en lumière tout en se prémunissant contre les affres de la copie et du vol de propriété intellectuelle et encore moins de l’appétit titanesque des géants de l’IA.
C’est à cause de cela et notamment de cette méthode arrivée sans fanfare que certains créatifs ont choisi de déserter certaines plateformes/réseaux sociaux: les vannes de la gloutonnerie de l’IA générative avaient été ouvertes avant même que les internautes et les créatifs ne puissent prendre le temps de réfléchir à ces questions. Cette problématique a été aperçue, entre autres, sur Artstation, une plateforme de présentation jouant le rôle de vitrine artistique pour les artistes des jeux, du cinéma, des médias et du divertissement. mais également sur Instagram et bien d’autres : parfois ces plateformes assument ce positionnement ouvertement, mais elles sont rares ; la plupart préfèrent enterrer l’information dans les lignes d’interminables conditions d’utilisation qu’il serait bon de commencer à lire pour prendre conscience de l’impact que cela représente sur notre “propriété numérique”.
-
Les bases de données spécialisées
Dans certains cas, Gol[IA]th peut avoir accès à des bases de données spécialisées, comprenant des données médicales (comme les scans radiographiques, IRM, et autres images médicales disponibles via des initiatives comme ImageCLEF) ou des données satellites (fournies par des agences spatiales comme la NASA et des entreprises privées pour des images de la Terre prises depuis l’espace).
-
Les données synthétiques
Au-delà des images tirées du réel, l’IA peut également être alimentée à partir d’images générées par ordinateur. La création d’images synthétiques par des techniques de rendu 3D permet de simuler des scénarios spécifiques (par exemple, de la simulation d’environnements de conduite pour entraîner des systèmes de conduite autonome), ainsi que des modèles génératifs pré-entraînés. En effet, les images générées par des modèles peuvent également servir pour l’entraînement d’un autre modèle. Mais les ressources peuvent également provenir d’images de jeux vidéo ou d’environnement de réalité virtuelle pour créer des ensembles de données (on pense alors à Unreal Engine ou Unity).
-
Les caméras et les capteurs
L’utilisation de caméras pour capturer des images et des vidéos est souvent employée dans les projets de recherche et développement, et dans une volonté de sources plus fines, de capteurs pour obtenir des images dans des conditions spécifiques, comme des caméras infrarouges pour la vision nocturne, des LIDAR pour la cartographie 3D, etc.
Toutes ces différentes sources d’approvisionnement pour Gol[IA]th sont généralement prétraitées avant d’être utilisées pour l’entraînement : normalisation, redimensionnement, augmentation des données, sont des moyens de préparation des images.
En résumé, il faut retenir que les IA génératives sont alimentées par une vaste gamme de sources de données d’images, allant des ensembles de données publiques aux données collectées en ligne, en passant par les images synthétiques et les captures du monde réel. La diversité et la qualité des données sont essentielles pour entraîner des modèles génératifs performants et capables de produire des images réalistes et variées. Cependant cette performance ne se fait pas toujours avec l’accord éclairé des auteurs des images. Il est en effet compliqué – certains diront impossible – de s’assurer que la gloutonnerie de Gol[IA]th s’est faite dans les règles avec le consentement de tous les créatifs impliqués… Un sujet d’éducation à la propriété numérique est à considérer!
Mais alors, comment [DA]vid et ses créatifs subissent cette naissance monstrueuse ?
Les métiers créatifs voient leur carnet de commande diminuer, les IA se démocratisant à une vitesse folle. [DA]vid, au delà de perdre des revenus en n’étant plus employé par des revues pour faire la couverture du magazine, se retrouve face à une concurrence déloyale : l’image générée a le même style… voir “son style”… Or pour un créatif, le style est l’œuvre du travail d’une vie, un facteur différenciant dans le paysage créatif, et le moteur de compétitivité dans le secteur… Comment faire pour maintenir son statut d’acteur de la compétitivité de l’économie alors que les clients du secteur substituent leur commande par des procédés éthiquement questionnables pour faire des économies ?
Gol[IA]th mange sans se sentir rompu, qu’il s’agisse de données libres ou protégées par des droits d’auteur, la saveur ne change pas. L’espoir de voir les tribunaux s’animer, pays après pays, sur des questionnements de violation, ou non, des lois protégeant les auteurs, s’amenuise dans certaines communautés. En attendant, les [DA]vid créatifs se retrouvent livrés à eux-mêmes, lentement dépossédés de l’espoir de pouvoir échapper au géant Gol[IA]th. Alors que l’inquiétude des artistes et des créateurs grandit à l’idée de voir une série d’algorithmes reproduire et s’accaparer leur style artistique, jusqu’à leur carrière, certains s’organisent pour manifester en occupant l’espace médiatique comme l’ont fait les acteurs en grève à Hollywood en 2023, et d’autres choisissent d’attaquer le sujet directement au niveau informatique en contactant Ben Zhao et Heather Zheng, deux informaticiens de l’Université de Chicago qui ont créé un outil appelé “Fawkes”, capable de modifier des photographies pour déjouer les IA de reconnaissance faciale.

La question s’imposant étant alors :
“Est-ce que Fawkes peut protéger notre style contre des modèles de génération d’images comme Midjourney ou Stable Diffusion ?”
Bien que la réponse immédiate soit “non”, la réflexion a guidé vers une autre solution…
“Glaze”, un camouflage en jus sur une oeuvre
Les chercheurs de l’Université de Chicago se sont penchés sur la recherche d’une option de défense des utilisateurs du web face aux progrès de l’IA. Ils ont mis au point un produit appelé “Glaze”, en 2022, un outil de protection des œuvres d’art contre l’imitation par l’IA. L’idée de postulat est simple : à l’image d’un glacis ( une technique de la peinture à l’huile consistant à poser, sur une toile déjà sèche, une fine couche colorée transparente et lisse) déposer pour désaturer les pigments “Glaze” est un filtre protecteur des créations contre les IAs.
“Glaze” va alors se positionner comme un camouflage numérique : l’objectif est de brouiller la façon dont un modèle d’IA va “percevoir” une image en la laissant inchangée pour les yeux humains.
Ce programme modifie les pixels d’une image de manière systématique mais subtile, de sorte à ce que les modifications restent discrètes pour l’homme, mais déconcertantes pour un modèle d’IA. L’outil tire parti des vulnérabilités de l’architecture sous-jacente d’un modèle d’IA, car en effet, les systèmes de Gen-AI sont formés à partir d’une quantité importante d’images et de textes descriptifs à partir desquels ils apprennent à faire des associations entre certains mots et des caractéristiques visuelles (couleurs, formes). “Ces associations cryptiques sont représentées dans des « cartes » internes massives et multidimensionnelles, où les concepts et les caractéristiques connexes sont regroupés les uns à côté des autres. Les modèles utilisent ces cartes comme guide pour convertir les textes en images nouvellement générées.” (- Lauren Leffer, biologiste et journaliste spécialisée dans les sciences, la santé, la technologie et l’environnement.)
“Glaze” va alors intervenir sur ces cartes internes, en associant des concepts à d’autres, sans qu’il n’y ait de liens entre eux. Pour parvenir à ce résultat, les chercheurs ont utilisé des “extracteurs de caractéristiques” (programmes analytiques qui simplifient ces cartes hypercomplexes et indiquent les concepts que les modèles génératifs regroupent et ceux qu’ils séparent). Les modifications ainsi faites, le style d’un artiste s’en retrouve masqué : cela afin d’empêcher les modèles de s’entraîner à imiter le travail des créateurs. “S’il est nourri d’images « glacées » lors de l’entraînement, un modèle d’IA pourrait interpréter le style d’illustration pétillante et caricatural d’un artiste comme s’il s’apparentait davantage au cubisme de Picasso. Plus on utilise d’images « glacées » pour entraîner un modèle d’imitation potentiel, plus les résultats de l’IA seront mélangés. D’autres outils tels que Mist, également destinés à défendre le style unique des artistes contre le mimétisme de l’IA, fonctionnent de la même manière.” explique M Heather Zheng, un des deux créateurs de cet outil.
Plus simplement, la Gen-AI sera toujours en capacité de reconnaître les éléments de l’image (un arbre, une toiture, une personne) mais ne pourra plus restituer les détails, les palettes de couleurs, les jeux de contrastes qui constituent le “style”, i.e., la “patte” de l’artiste.

Bien que cette méthode soit prometteuse, elle présente des limites techniques et dans son utilisation.
Face à Gol[IA]th, les [DA]vid ne peuvent que se cacher après avoir pris conscience de son arrivée : dans son utilisation, la limite de “Glaze” vient du fait que chaque image que va publier un créatif ou un artiste doit passer par le logiciel avant d’être postée en ligne.. Les œuvres déjà englouties par les modèles d’IA ne peuvent donc pas bénéficier, rétroactivement, de cette solution. De plus, au niveau créatif, l’usage de cette protection génère du bruit sur l’image, ce qui peut détériorer sa qualité et s’apercevoir sur des couleurs faiblement saturées. Enfin au niveau technique, les outils d’occultation mise à l’œuvre ont aussi leurs propres limites et leur efficacité ne pourra se maintenir sur le long terme.
En résumé, à la vitesse à laquelle évoluent les Gen-AI, “Glaze” ne peut être qu’un barrage temporaire, et malheureusement non une solution : un pansement sur une jambe gangrenée, mais c’est un des rares remparts à la créativité humaine et sa préservation.
Il faut savoir que le logiciel a été téléchargé 720 000 fois, et ce, à 10 semaines de sa sortie, ce qui montre une véritable volonté de la part des créatifs de se défendre face aux affronts du géant.
La Gen-AI prend du terrain sur la toile, les [DA]vid se retrouvent forcés à se cacher… Est-ce possible pour eux de trouver de quoi charger leur fronde ? Et bien il s’avère que la crainte a su faire naître la colère et les revendications, et les créatifs et les artistes ont décidé de se rebeller face à l’envahisseur… L’idée n’est plus de se cacher, mais bien de contre-attaquer Gol[IA]th avec les armes à leur disposition…
“Nightshade”, lorsque la riposte s’organise ou comment empoisonner l’IA ?
Les chercheurs de l’Université de Chicago vont pousser la réflexion au delà de “Glaze”, au delà de bloquer le mimétisme de style, “Nightshade” est conçu comme un outil offensif pour déformer les représentations des caractéristiques à l’intérieur même des modèles de générateurs d’image par IA…
« Ce qui est important avec Nightshade, c’est que nous avons prouvé que les artistes n’ont pas à être impuissants », déclare Zheng.
Nightshade ne se contente pas de masquer la touche artistique d’une image, mais va jusqu’à saboter les modèles de Gen-AI existants. Au-delà de simplement occulter l’intégrité de l’image, il la transforme en véritable “poison” pour Gol[IA]th en agissant directement sur l’interprétation de celui-ci. Nightshade va agir sur l’association incorrecte des idées et des images fondamentales. Il faut imaginer une image empoisonnée par “Nightshade” comme une goutte d’eau salée dans un récipient d’eau douce. Une seule goutte n’aura pas grand effet, mais chaque goutte qui s’ajoute va lentement saler le récipient. Il suffit de quelques centaines d’images empoisonnées pour reprogrammer un modèle d’IA générative. C’est en intervenant directement sur la mécanique du modèle que “Nightshade” entrave le processus d’apprentissage, en le rendant plus lent ou plus coûteux pour les développeurs. L’objectif sous-jacent serait, théoriquement, d’inciter les entreprises d’IA à payer les droits d’utilisation des images par le biais des canaux officiels plutôt que d’investir du temps dans le nettoyage et le filtrage des données d’entraînement sans licence récupérée sur le Web.
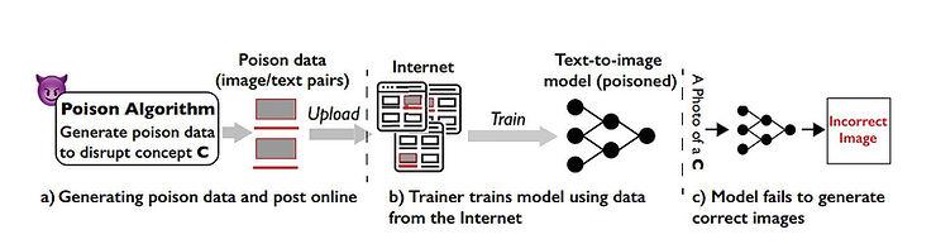
Ce qu’il faut comprendre de « Nightshade » :
- Empoisonnement des données: Nightshade fonctionne en ajoutant des modifications indétectables mais significatives aux images. Ces modifications sont introduites de manière à ne pas affecter la perception humaine de l’image mais à perturber le processus de formation des modèles d’IA. Il en résulte un contenu généré par l’IA qui s’écarte de l’art prévu ou original.
- Invisibilité: Les altérations introduites par Nightshade sont invisibles à l’œil humain. Cela signifie que lorsque quelqu’un regarde l’image empoisonnée, elle apparaît identique à l’originale. Cependant, lorsqu’un modèle d’IA traite l’image empoisonnée, il peut générer des résultats complètement différents, pouvant potentiellement mal interpréter le contenu.
- Impact: L’impact de l’empoisonnement des données de Nightshade peut être important. Par exemple, un modèle d’IA entraîné sur des données empoisonnées pourrait produire des images dans lesquelles les chiens ressemblent à des chats ou les voitures à des vaches. Cela peut rendre le contenu généré par l’IA moins fiable, inexact et potentiellement inutilisable pour des applications spécifiques.

Voici alors quelques exemples après de concepts empoisonnés :

Plus précisément, « Nightshade transforme les images en échantillons ’empoisonnés’, de sorte que les modèles qui s’entraînent sur ces images sans consentement verront leurs modèles apprendre des comportements imprévisibles qui s’écartent des normes attendues, par exemple une ligne de commande qui demande l’image d’une vache volant dans l’espace pourrait obtenir à la place l’image d’un sac à main flottant dans l’espace », indiquent les chercheurs.
Le « Data Poisoning » est une technique largement répandue. Ce type d’attaque manipule les données d’entraînement pour introduire un comportement inattendu dans le modèle au moment de l’entraînement. L’exploitation de cette vulnérabilité rend possible l’introduction de résultats de mauvaise classification.
« Un nombre modéré d’attaques Nightshade peut déstabiliser les caractéristiques générales d’un modèle texte-image, rendant ainsi inopérante sa capacité à générer des images significatives », affirment-ils.
Cette offensive tend à montrer que les créatifs peuvent impacter les acteurs de la technologie en rendant contre-productif l’ingestion massive de données sans l’accord des ayant-droits.
Plusieurs plaintes ont ainsi émané d’auteurs, accusant OpenAI et Microsoft d’avoir utilisé leurs livres pour entraîner ses grands modèles de langage. Getty Images s’est même fendu d’une accusation contre la start-up d’IA Stability AI connue pour son modèle de conversion texte-image Stable Diffusion, en Février 2023. Celle-ci aurait pillé sa banque d’images pour entraîner son modèle génératif Stable Diffusion. 12 millions d’œuvres auraient été « scrappées » sans autorisation, attribution, ou compensation financière. Cependant, il semble que ces entreprises ne puissent pas se passer d’oeuvres soumises au droit d’auteur, comme l’a récemment révélé OpenAI, dans une déclaration auprès de la Chambre des Lords du Royaume-Uni concernant le droit d’auteur, la start-up a admis qu’il était impossible de créer des outils comme le sien sans utiliser d’œuvres protégées par le droit d’auteur. Un aveu qui pourrait servir dans ses nombreux procès en cours…
Ainsi, quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?
En résumé, dans sa gloutonnerie, Gol[IA]th a souhaité engloutir les [DA]vid qui nous entourent, qui ont marqué l’histoire et ceux qui la créent actuellement, dans leur entièreté et leur complexité : en cherchant à dévorer ce qui fait leur créativité, leur style, leur patte, au travers d’une analyse de caractéristiques et de pixels, Gol[IA]th a transformé la créativité humaine qui était sa muse, son idéal à atteindre, en un ensemble de données sans sémantique, ni histoire, ni passion sous-jacente.
C’est peut être un exemple d’amour nocif à l’heure de l’IA, tel que vu par l’IA ?
Sans sous-entendre que les personnes à l’origine de l’écriture des IA génératives ne sont pas des créatifs sans passion, il est probable que la curiosité, la prouesse et l’accélération technologique ont peu à peu fait perdre le fil sur les impacts que pourrait produire un tel engouement.
A l’arrivée de cette technologie sur le Web, les artistes et les créatifs n’avaient pas de connaissance éclairée sur ce qui se produisait à l’abri de leurs regards. Cependant, les modèles d’apprentissage ont commencé à être alimentés en données à l’insu de leur ayant-droits. La protection juridique des ayant-droits n’évoluant pas à la vitesse de la technologie, les créatifs ont rapidement été acculés, parfois trop tard, les Gen-AI ayant déjà collecté le travail d’une vie. Beaucoup d’artistes se sont alors “reclus”, se retirant des plateformes et des réseaux sociaux pour éviter les vols, mais ce choix ne fut pas sans conséquence pour leur visibilité et la suite de leur carrière.
Alors que les réseaux jouaient l’opacité sur leurs conditions liées à la propriété intellectuelle, le choix a été de demander aux créatifs de se “manifester s’ils refusaient que leurs données soient exploitées”, profitant de la méconnaissance des risques pour forcer l’acceptation de condition, sans consentement éclairé. Mais la grogne est montée dans le camp des créatifs, qui commencent à être excédés par l’abus qu’ils subissent. “Glaze” fut une première réaction, une protection pour conserver l’intégrité visuelle de leur œuvre, mais face à une machine toujours plus gloutonne, se protéger semble rapidement ne pas suffire. C’est alors que “Nightshade” voit le jour, avec la volonté de faire respecter le droit des artistes, et de montrer qu’ils ne se laisseraient pas écraser par la pression des modèles.
Il est important de suivre l’évolution des droits des différents pays et de la perception des sociétés civiles dans ces pays de ce sujet car le Web, l’IA et la créativité étant sans limite géographique, l’harmonisation juridique concernant les droits d’auteur, la réglementation autour de la propriété intellectuelle, et l’éducation au numérique pour toutes et tous, vont être – ou sont peut-être déjà – un enjeu d’avenir au niveau mondial.
Rendons à César ce qui est à césar
L’équipe du « Glaze Project »

Profil X du Glaze project
Lien officiel : https://glaze.cs.uchicago.edu/
Pour avoir davantage d’informations sur Glaze et Nightshade : page officielle
Article Glaze : Shan, S., Cryan, J., Wenger, E., Zheng, H., Hanocka, R., & Zhao, B. Y. (2023). Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In 32nd USENIX Security Symposium (USENIX Security 23) (pp. 2187-2204). arXiv preprint arXiv:2302.04222
Article Nightshade : Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv preprint arXiv:2310.13828.
 A propos de l’autrice : Julie Laï-Pei, après une première vie dans le secteur artistique et narratif, a rejoint l’émulation de l’innovation en Nouvelle-Aquitaine, en tant que responsable de l’animation d’une communauté technologique Numérique auprès d’un pôle de compétitivité. Femme dans la tech et profondément attachée au secteur Culturel et Créatif, elle a à coeur de partager le résultat de sa veille et de ses recherches sur l’impact des nouvelles technologies dans le monde de la créativité.
A propos de l’autrice : Julie Laï-Pei, après une première vie dans le secteur artistique et narratif, a rejoint l’émulation de l’innovation en Nouvelle-Aquitaine, en tant que responsable de l’animation d’une communauté technologique Numérique auprès d’un pôle de compétitivité. Femme dans la tech et profondément attachée au secteur Culturel et Créatif, elle a à coeur de partager le résultat de sa veille et de ses recherches sur l’impact des nouvelles technologies dans le monde de la créativité.



