Entretien avec Serge Abiteboul, directeur de recherche à Inria et à l’ENS Paris. Propos recueillis par Olivier Voizeux.
Peut-on dire que, plus que le jeu d’échecs, les réseaux de neurones ont dopé la recherche sur l’intelligence artificielle ?
Ce serait un peu du bourrage de crâne. Un système comme Deep Blue, d’IBM, qui a battu le champion du monde d’échecs Gary Gasparov en 1997, embarquait des années de recherches, le plus souvent développées pour autre chose. Toutes les techniques informatiques ont des applications considérables qui sont à l’œuvre tous les jours, qui marchent très bien et ont pour nom « gestion de données », « système d’exploitation », « compilateur », « communication numérique », « interface humain-machine », « calcul parallèle », « raisonnement logique », etc. Ce qu’on observe depuis une dizaine d’années, c’est l’arrivée d’algorithmes d’apprentissage automatique, qui ont obtenu des résultats superbes dans des domaines qui nous bloquaient jusque-là. Mais internet et votre téléphone portable fonctionnent en grande partie sans eux, même si on utilise de plus en plus l’apprentissage automatique, par exemple dans les assistants vocaux.
Pouvez-vous préciser l’apport de l’apprentissage automatique ?
Sur certains problèmes, les approches dites « symboliques », fondées sur le calcul et le raisonnement, ne progressaient presque plus. Je pense notamment à des problèmes tout bêtes comme de distinguer l’image d’un chat de celle d’un chien, ou, plus intéressant, de reconnaître une tumeur cancéreuse. Et, assez soudainement, des techniques connues depuis longtemps et qui avaient souvent des résultats médiocres, les réseaux de neurones, se sont mises à fonctionner. La traduction automatique des langues, par exemple, s’est améliorée considérablement (lire l’entretien avec Thierry Poibeau). Avec l’apprentissage automatique et les méthodes statistiques, ainsi nommées parce qu’elles s’appuient sur de gros volumes d’informations, un logiciel apprend de données fournies par des humains, en observant son environnement, en simulant des situations, etc. Pour faire une analogie, vous pouvez apprendre à jouer au tarot parce que des amis vous en expliquent les règles, mais vous pouvez aussi vous former en regardant des joueurs. Souvent, les deux modes coexistent. On connaissait depuis des années des algorithmes pour faire apprendre aux machines, notamment les réseaux de neurones. Pourquoi tout à coup sont-ils devenus plus performants ?
Il y a eu une sorte de conjonction de planètes avec l’arrivée, presque au même moment, de beaucoup plus de puissance de calcul, de plus en plus de corpus de données pour nourrir l’apprentissage, et du développement de nouveaux algorithmes dits « d’apprentissage profond »
(deep learning, en anglais). D’un coup, des problèmes qui nous résistaient depuis des années se sont mis à tomber. Cela avait un côté génial. Mais, encore une fois, cette approche n’a pas remplacé ce qui existait avant. Même quand AlphaGo, de DeepMind, a battu le joueur de go Lee Sedol, il n’utilisait pas uniquement des algorithmes d’apprentissage profond.
Le revers de ces méthodes n’est-il pas leur opacité ?
En effet, quand on fait tourner un algorithme d’apprentissage profond, on ne sait pas expliquer pourquoi on arrive à un résultat particulier. Les longs calculs réalisés ne font pas à proprement parler un raisonnement, en tout cas un raisonnement qu’un humain serait capable de comprendre. On peut penser que, tant pis, seule l’efficacité prime, mais ce n’est pas si simple. Prenons deux exemples en médecine : un algorithme d’apprentissage qui aide à retrouver des tumeurs cancéreuses (voir La fée IA au chevet des malades, par N. Ayache) examine des milliers d’images annotées par des médecins, et à partir de toute cette connaissance se prononce sur les images qu’on lui soumettra. Impossible pour un humain de se former en étudiant toutes ces images : il y en a trop. Et de toute façon, il y aura un médecin, voire une équipe, pour discuter l’avis de la machine qui sera un avis comme un autre, pris comme tel. En revanche, en matière de diagnostic médical, si vous rentrez dans un programme un grand nombre d’informations sur un patient, et qu’à la fin ce logiciel décide « c’est une hépatite », ça ne peut pas suffire au médecin qui a besoin d’explications. Il ou elle a besoin d’entendre que, en fonction des observations du malade, statistiquement ce peut être telle maladie avec 95 % de chances, mais aussi telle autre avec 5% de chances, et qu’il faudrait poser telle question au malade pour écarter telle possibilité, ou demander tel examen complémentaire, etc. Dans les deux cas, il y a un travail collaboratif entre machine et humains. Dans le premier, nul besoin d’explications (les techniques d’apprentissage automatique un peu brutales sont efficaces). Dans le second, des explications sont indispensables.
Où finit l’informatique « ordinaire », où commence l’intelligence artificielle ?
Cette distinction n’a pas vraiment de sens. On a, à l’intérieur de l’informatique, un vrai continuum.
Quelle est alors votre définition de l’intelligence artificielle ?
Pour Alan Turing, une activité d’une machine sera qualifiée d’« intelligence artificielle » si elle est considérée comme intelligente quand un humain s’y livre. À ses yeux, ce ne peut être qu’une imitation de l’intelligence humaine, une simulation. J’utilise la définition de Turing mais, honnêtement, ça ne me dit pas grand-chose puisque, tout comme lui, je ne sais pas définir l’intelligence humaine. En fait, j’ai un problème : je vous en parle, mais je ne sais pas trop ce qu’est l’intelligence artificielle ! L’expression fait fantasmer. Mais qu’est-ce qu’elle signifie ? Depuis ma thèse, je travaille sur des systèmes de gestion de base de données, qui répondent aux questions des humains. C’est quand même intelligent de répondre à des questions ! J’ai travaillé sur des bases de connaissances qui font de la déduction. Là encore, c’est intelligent de raisonner. Plus récemment, l’apprentissage automatique m’a permis d’introduire de nouvelles fonctionnalités dans des systèmes sur lesquels nous travaillons avec des étudiants. Distinguer ce qui en informatique tient de l’intelligence artificielle ou pas, ça n’aide en rien. Pour moi, c’est avant tout un buzzword, surtout utile pour récupérer des financements ou impressionner des amis. Le truc cool, aujourd’hui, n’est pas l’intelligence artificielle, mais l’apprentissage automatique qui vient compléter d’autres techniques essentielles de l’informatique.
Donc vous ne cherchez jamais à développer des programmes « plus intelligents » ?
Je cherche à faire des programmes qui résolvent des problèmes, qui répondent aux besoins de leurs utilisateurs. Cela dit, je ne connais pas beaucoup d’informaticiens qui essaient d’écrire des programmes idiots… même si on ne sait pas définir l’intelligence.
Quel est l’objectif de la recherche en intelligence artificielle ? Dépasser l’humain ?
Vous l’avez compris, je ne sais pas distinguer recherche en intelligence artificielle et en informatique. Les chercheurs en informatique veulent repousser les limites de la science. Certains se posent des questions théoriques, par exemple sur la calculabilité ou la puissance du raisonnement, presque du ressort des mathématiques pures. À l’autre bout du spectre, d’autres développent des produits informatiques prêts à être utilisés le mois d’après comme les logiciels scikit-learn (une bibliothèque Python pour l’apprentissage automatique) et Caml (un langage de programmation et un environnement populaire). Parfois, une recherche très théorique comme celle des universitaires Ronald Rivest, Adi Shamir et Leonard Adleman débouche sur un algorithme de chiffrement très pratique, le RSA, qui est à la base de tous les échanges chiffrés sur internet. Pour moi, cette diversité est la grande richesse de la recherche dans ma discipline. Les humains sont de magnifiques machines à résoudre des problèmes. Pourquoi ne pas essayer de les imiter avec des ordinateurs ? C’est le genre de défi qui fait avancer les sciences. Quant à les dépasser… pourquoi pas ? À vrai dire, l’informatique accomplit déjà des tas de choses dont nous sommes incapables. Reproduire à la main des calculs que votre smartphone traite à toute vitesse prendrait un temps dingue à des centaines de milliers de personnes qui commettraient des millions d’erreurs. Les ordinateurs calculent bien mieux que nous. Faire mieux que l’humain n’est pas si difficile.
Mais, d’une calculette, on ne dit pas qu’elle est intelligente…
Un des trucs qu’on apprend à l’école primaire, c’est calculer, non ? Moi, je trouve ça intelligent. Le chien du voisin, sait-il calculer ?
Peut-être ce déni s’explique-t-il parce que la calculette est devenue ordinaire ?
En effet, comme c’est un objet de notre quotidien, on lui interdit d’être vraiment intelligent. Peut-être que ce qu’on sait expliquer par une suite d’opérations est dénué de vraie intelligence. La preuve automatique d’un théorème mathématique, on peut la décortiquer pas à pas. Et une machine reproduira « bêtement » le calcul, donc ça ne doit pas être bien sorcier. Mais comme on ne comprend pas comment fonctionne l’apprentissage automatique, alors c’est forcément intelligent.
Est-ce qu’il y a, sur l’intelligence artificielle, une approche particulière à la France ?
Non. La recherche en informatique est devenue extrêmement mondiale, il ne peut pas y avoir d’approche hexagonale. Il y a une grande fluidité entre les pays. J’ai fait ma thèse aux États-Unis comme beaucoup de collègues, on interagit sans cesse avec des collègues américains, européens, africains, asiatiques, nos labos sont peuplés de doctorants, postdoctorants, visiteurs, etc., de multiples nationalités. Si on voulait vraiment chercher une coloration française, ce serait plutôt du côté de la formation scolaire et universitaire. Nos étudiants avaient jusqu’à récemment, en moyenne, une formation plus mathématique que ceux venus d’ailleurs. Cela leur donnait des bases théoriques vraiment solides. J’espère que cela ne va pas changer.
Ils ne sont pas capables de créativité tout court : ni en maths, ni en biologie, ni en littérature. On y travaille, on fait des progrès, mais les poèmes que nos algorithmes créent sont encore médiocres. Ce qu’on sait faire, c’est donner plein d’exemples de beaux tableaux d’un peintre à une machine, et lui demander de produire une œuvre dans le même genre. Elle ne crée pas vraiment, elle singe. D’ailleurs, on retrouve la même difficulté de définition qu’avec l’intelligence, je ne sais pas définir formellement la beauté ou la créativité. À ce sujet, les travaux du jeune chercheur en IA Antoine Cully dans sa thèse m’ont passionné. Il montre, par exemple, comment un robot à six pattes a pu inventer une nouvelle façon de marcher avec une patte abîmée ou manquante. Mais ce robot a-t-il vraiment découvert une nouvelle façon de marcher ? Ou cette nouvelle démarche était-elle plus ou moins déjà inscrite dans tous les calculs qu’on lui avait demandés avant ?
Sauriez-vous développer un algorithme de bêtise artificielle ?
Vous ne trouvez pas qu’il y a assez de bêtise naturelle ?
Imaginez qu’il n’y en ait pas autour de nous et qu’on ait besoin d’une machine bête pour nous divertir.
S’il s’agit de programmer un générateur de formules fausses, je peux facilement le faire. Mais si vous voulez en plus qu’elles soient drôles, c’est de l’humour. Là, c’est encore plus dur que la créativité.
L’intelligence artificielle est sortie des laboratoires, elle est entrée dans la cité, et elle y produit des effets. Lesquels vous paraissent les plus importants ?
Il y a deux questions qui me semblent particulièrement critiques en ce moment, et elles sont liées : c’est la sobriété énergétique et le travail. Selon les sources, le numérique représenterait aujourd’hui de 3 à 4% des émissions de gaz à effet de serre dans le monde, et cela croît. Je ne sais pas chiffrer la proportion de l’intelligence artificielle dedans. Ce n’est pas énorme, mais cela augmente aussi. Pour limiter notre impact sur l’environnement, il va nous falloir changer nos modes de vie par exemple arrêter de changer de téléphone tous les deux ans ou de passer du temps à visionner des films en haute résolution sur un téléphone cellulaire. Il y a beaucoup de gaspillage, comme avec les « chaînes de blocs » (blockchains), ces procédés de stockage sécurisés et décentralisés, qui pourraient fonctionner en consommant plusieurs ordres de grandeur d’énergie en moins pour le même résultat. Dans le numérique comme pour le reste, il va nous falloir apprendre à être frugaux.
Et concernant le monde du travail ?
L’ensemble de la technologie numérique a une incidence sur l’emploi, pas seulement l’intelligence artificielle. Aujourd’hui, on peut faire fonctionner une usine avec très peu d’individus grâce à l’informatique en général. Il est vrai qu’avec l’intelligence artificielle on va aller encore plus loin dans le remplacement de l’humain. Après sa force physique, son travail intellectuel devient de plus en plus remplaçable. Le hiatus est qu’on veut une société plus sobre énergétiquement, qui produise et pollue moins, et qu’on veut aussi moins travailler, donc utiliser plus de machines. Or il faut de l’énergie pour fabriquer les machines et elles ont des rendements souvent moins bons que les nôtres. Pour y arriver, de sérieuses avancées scientifiques et d’importantes mesures d’économie seront nécessaires. Et puis, si les machines remplacent les humains, qui va être rétribué ? Uniquement ceux qui les possèdent ? Dans ce cas, la grande masse de la population sera non seulement privée d’activité, mais aussi de quoi se nourrir. Ce ne sera pas socialement tenable. Dans les vingt à cinquante ans à venir, une transformation complète de la société s’imposera, exigeant que l’économie soit beaucoup plus redistributive. Voilà pour le volet sociétal, qui se double d’un volet humain. Dans notre culture, on nous apprend dès l’enfance que le travail est la grande valeur. Comment fera-t-on dans un monde où une grande partie d’entre nous sera sans emploi, ou avec de l’emploi partiel, ou des travaux associatifs ou d’aide à la personne, non « productifs » dans le sens économique actuel ? Il nous faut inventer une nouvelle philosophie du travail, de son utilité sociale, une nouvelle philosophie des loisirs. Le côté génial, c’est que, si on ne se plante pas écologiquement ou socialement, l’informatique nous permet d’avoir l’ambition la plus dingue, celle d’une société égalitaire où tout le monde vivrait bien, en s’éduquant, avec autant de loisir que souhaité. Ce n’est pas de la science- fiction… Enfin, je l’espère.
https://www.pourlascience.fr/sd/informatique/j-ai-un-probleme-je-ne-sais-pas-trop-ce-qu-est-l-intelligence-artificielle-23682.php

 ©Catherine Créhange
©Catherine Créhange 




 Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plateforme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes: en 2018, 70% des vues de vidéos provenaient de recommandation (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plateforme le plus longtemps possible, mais aussi critique pour l’utilisateur lui même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.
Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plateforme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes: en 2018, 70% des vues de vidéos provenaient de recommandation (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plateforme le plus longtemps possible, mais aussi critique pour l’utilisateur lui même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.



 Les algorithmes de génération ou d’analyse d’image ont connu un boom au cours des dix dernières années – et ils continuent toujours de s’améliorer, sans qu’aucune limite de saturation ne se dessine quant à leurs performances ni leurs champs d’application. Ainsi, un ordinateur peut facilement indiquer si une image contient un chien ou un chat, et identifier les pixels concernés. Plus spectaculairement, en combinaison avec de l’analyse de texte, des approches comme DALL-E 2 permettent aujourd’hui
Les algorithmes de génération ou d’analyse d’image ont connu un boom au cours des dix dernières années – et ils continuent toujours de s’améliorer, sans qu’aucune limite de saturation ne se dessine quant à leurs performances ni leurs champs d’application. Ainsi, un ordinateur peut facilement indiquer si une image contient un chien ou un chat, et identifier les pixels concernés. Plus spectaculairement, en combinaison avec de l’analyse de texte, des approches comme DALL-E 2 permettent aujourd’hui 
 La cryptographie est une branche de l’informatique qui s’intéresse de manière générale à la protection de données et communications numériques. Elle est primordiale dans notre société où la majeure partie de nos données personnelles sont en effet numériques (par exemple, nos transactions bancaires).
La cryptographie est une branche de l’informatique qui s’intéresse de manière générale à la protection de données et communications numériques. Elle est primordiale dans notre société où la majeure partie de nos données personnelles sont en effet numériques (par exemple, nos transactions bancaires).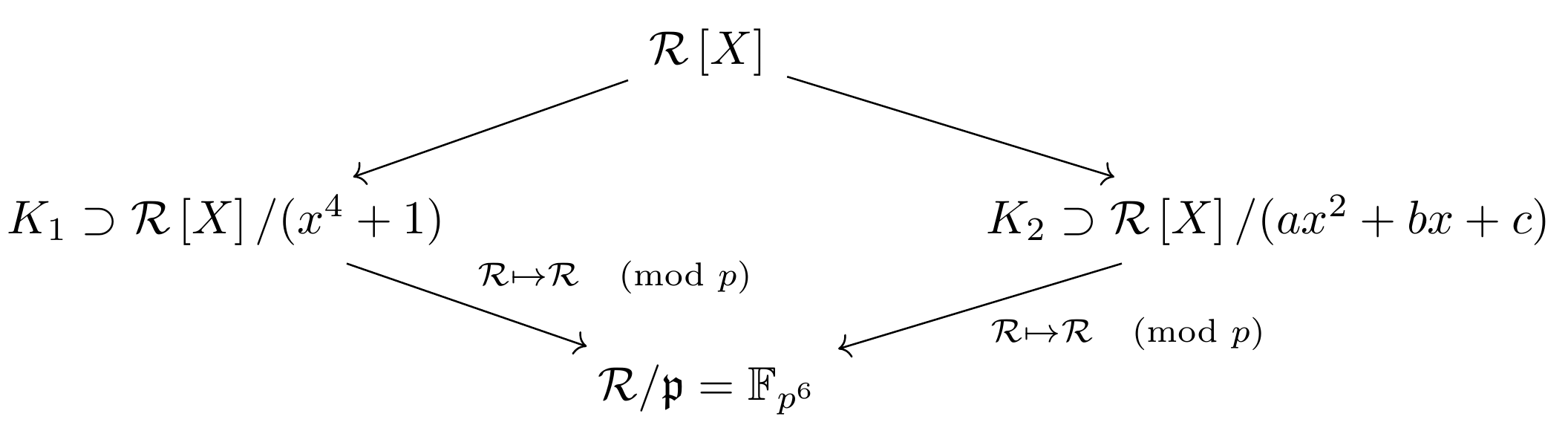




 Du cahier manuscrit relevant les températures dans les vignes aux capteurs installés sur des tracteurs de plus en plus robotisés, l’agriculture a toujours produit des données. Grâce à Serge Zaka (
Du cahier manuscrit relevant les températures dans les vignes aux capteurs installés sur des tracteurs de plus en plus robotisés, l’agriculture a toujours produit des données. Grâce à Serge Zaka ( Figure 1 – Le modèle Vintel de ITK est un outil qui permet de piloter les décisions pour les vignobles.
Figure 1 – Le modèle Vintel de ITK est un outil qui permet de piloter les décisions pour les vignobles.
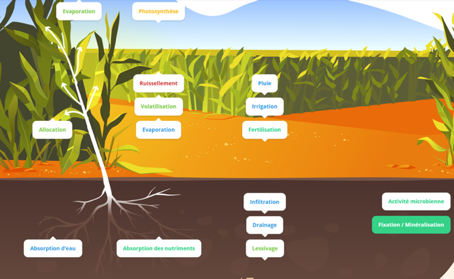 Figure 2 – Exemple des facteurs à prendre en compte dans la modélisation agricole. Il concerne le compartiment « sol », « plante » et « air ». Ces compartiments et sous-compartiments sont en interaction : ils échangent matières et énergies. Il est difficile d’appréhender l’évolution du système sans la modélisation (image du site internet du projet
Figure 2 – Exemple des facteurs à prendre en compte dans la modélisation agricole. Il concerne le compartiment « sol », « plante » et « air ». Ces compartiments et sous-compartiments sont en interaction : ils échangent matières et énergies. Il est difficile d’appréhender l’évolution du système sans la modélisation (image du site internet du projet 
 Figure 3 – Exemple d’expérimentation en chambre de culture (conditions thermiques contrôlées) pour produire des données expérimentales afin de renseigner de nouvelles fonctions aux modèles de cultures. Chaque jours feuilles, tiges et photosynthèse sont mesurées pour chaque pots.
Figure 3 – Exemple d’expérimentation en chambre de culture (conditions thermiques contrôlées) pour produire des données expérimentales afin de renseigner de nouvelles fonctions aux modèles de cultures. Chaque jours feuilles, tiges et photosynthèse sont mesurées pour chaque pots.


 Figure 4 – L’observation de terrain est essentiel pour ajuster les modèles en cours de saison : phénologie, nombres de feuilles, compositions des feuilles etc.
Figure 4 – L’observation de terrain est essentiel pour ajuster les modèles en cours de saison : phénologie, nombres de feuilles, compositions des feuilles etc.


