Devant notre écran de smartphone ou d’ordinateur, nous avons souvent l’impression de nous faire influencer, embarquer, accrocher, balader, manipuler, enfermer, empapaouter peut-être,… Où est passée notre liberté de choix ? Cet article de Mehdi Khamassi nous aide à nous y retrouver. Mais attention, il ne se contente pas d’aligner quelques formules simplistes. Il fait appel à notre liberté de réfléchir. Saisissons-là ! Serge Abiteboul & Thierry Viéville.
Toute une série de rapports et de propositions de régulations des interfaces numériques (notamment les réseaux sociaux) est parue ces derniers mois, aux niveaux français, européen et international. Un des objectifs importants est de limiter les mécanismes de captation de l’attention des utilisateurs, qui réduisent la liberté des individus en les maintenant engagés le plus longtemps possible, en les orientant subrepticement vers des publicités, ou en les incitant malgré eux à partager leurs données.
Le rapport de la Commission Bronner considère que « ce que nous pourrions penser relever de notre liberté de choix se révèle ainsi, parfois, le produit d’architectures numériques influençant nos conduites […] se jou[ant] des régularités de notre système cognitif, jusqu’à nous faire prendre des décisions malgré nous »[1]. Le rapport du Conseil National du Numérique stipule que « par certains aspects, l’économie de l’attention limite donc notre capacité à diriger notre propre attention, et in fine, notre liberté de décider et d’agir en pleine conscience »[2]. Pour le Conseil de l’Europe « les outils d’apprentissage automatique (machine learning) actuels sont de plus en plus capables non seulement de prédire les choix, mais aussi d’influencer les émotions et les pensées et de modifier le déroulement d’une action » ce qui peut avoir des effets significatifs sur « l’autonomie cognitive des citoyens et leur droit à se forger une opinion et à prendre des décisions indépendantes »[3]. Enfin, l’OCDE considère que ces influences relèvent parfois d’une véritable « manipulation », en particulier dans le cas de ce qu’on appelle les « dark patterns », qui désignent toute configuration manipulatrice des interfaces de façon à orienter nos choix malgré nous[4]. Certains auteurs parlent même de design de produits « addictifs »[5], qui de façon similaire aux machines à sous des casinos, « enferment les gens dans un flux d’incitation et de récompense »[6], « ne laissant plus aucune place au libre arbitre individuel »[7].
On voit donc que la préservation de l’autonomie et de la liberté de choix en conscience des utilisateurs est un des enjeux majeurs de la régulation des interfaces numériques.
Toutefois ces discussions sont minées par le très vieux débat sur le « libre arbitre » (entendu comme « libre décret », selon les termes de Descartes). Pour certains dont la position est dite « réductionniste », celui-ci n’existe pas, car tout se réduit aux interactions matérielles à l’échelle atomique. Il n’y a donc pas de problème de réduction de liberté par les interfaces numériques puisque nous ne sommes déjà pas libres au départ, du fait du déterminisme qui résulte du principe de causalité, épine dorsale de la science[8]. Ceci conduit à un fatalisme et à une déresponsabilisation. Circulez, il n’y a rien à voir !
A l’opposé, pour les tenants d’une position dite « libertarianiste », nous restons toujours libres puisqu’une entité immatérielle, notre âme, elle-même totalement « libre » en cela qu’elle ne subirait aucune influence externe, déterminerait causalement notre corps à agir selon notre propre volonté. Nous restons donc toujours entièrement libres et responsables de nos actes sur les interfaces numériques, et il n’y a pas lieu de les réguler. Continuez de circuler !
Une troisième voie est possible
Il existe pourtant une troisième voie, naturaliste[9] et ancrée dans la science, dans laquelle le déterminisme n’empêche pas une autre forme de liberté que le dit « libre arbitre ». Une forme qui préserve la responsabilité de l’humain pour ses actes et son aptitude au questionnement éthique. Il s’agit d’une liberté de penser et d’agir par nous-mêmes, selon nos déterminismes internes et moins selon les déterminismes externes. Pour simplifier, le ratio entre nos déterminismes internes et externes dans nos prises de décision pourrait ainsi définir une sorte de quantification de notre degré de liberté. Par exemple, si un stimulus externe comme la perception d’une publicité pour un produit sur Internet me pousse à cliquer dessus sans réfléchir (type de comportement qualifié de stimulus-réponse en psychologie, et que je mets dans la catégorie déterminisme externe pour simplifier), je suis moins libre que lorsque je décide sans voir de publicité qu’il est l’heure d’aller sur un site commercial car j’ai besoin d’acheter un produit en particulier (dit comportement orienté vers un but en psychologie). Je suis davantage libre dans le deuxième cas puisque ma décision est guidée par mon intention, même si des mécanismes déterministes internes à mon système nerveux m’ont conduit à formuler cette intention et à prévoir un plan d’actions en conséquence. Pourtant, il n’est pas si simple de définir ce qui est interne et qui reflèterait notre nature, et ce qui est externe. Toute chose qui nous affecte dépend à la fois de celle-ci et de ce que nous sommes (l’influence sur moi d’un stimulus tel que la photo d’un produit va dépendre de mon expérience antérieure d’interaction avec des stimuli de ce type, et de nombreux autres facteurs).
Les dialogues les plus récents entre philosophie et science cognitives[10] montrent comment il est possible de concilier déterminisme, liberté et responsabilité. Ceci est vrai notamment dans la philosophie de Spinoza, qui considère tout d’abord que le corps et l’esprit sont deux modes d’une même substance, deux manières de décrire la même chose dans deux espaces de description différents. Autrement dit, à tout état mental correspond un état cérébral, et il n’y a pas de causalité croisée entre les deux, mais seulement des causalités à l’intérieur de chaque espace : les états mentaux causent d’autres états mentaux, et les états physiques causent d’autres états physiques. Par exemple, la sensation d’avoir faim cause la décision d’aller manger ; ce qui correspond, en parallèle, à une causalité entre une activité neurophysiologique représentant un manque d’énergie pour le corps et une autre activité neurophysiologique qui déclenche une impulsion vers les muscles.
D’un point de vue scientifique, cela implique qu’il faut éviter de faire de la psychologie une province des neurosciences, en cherchant toutes les explications à l’échelle de l’activité des neurones. De même, toutes les propriétés du vivant ne peuvent pas être réduites aux propriétés des éléments physiques (ni même atomiques) qui le composent. D’une part, les recherches en neurosciences cognitives ont besoin de termes se référant au comportement et aux phénomènes psychologiques pour concevoir des expériences et faire sens des activités cérébrales mesurées[11]. D’autre part, si le naturalisme considère que le déterminisme causal est incontournable, cela n’implique pas nécessairement un réductionnisme. Les sciences actuelles s’inscrivent en effet dans la complexité. Les composantes d’un système complexe, les interactions entre celles-ci, ainsi que leur organisation, font émerger de nouvelles propriétés globales (causalité ascendantes) qui en retour exercent des contraintes sur l’ensemble des parties (causalités descendantes)[12]. Ainsi, il n’est pas possible de réduire les propriétés d’un système complexe aux propriétés des éléments qui le composent. C’est la notion d’émergence. Par exemple, dans un certain contexte et dans un certain état physiologique, je peux ressentir une émotion. Puis, par l’interaction avec la société, je peux mettre un mot sur cette émotion, donc mieux la catégoriser, mieux la comprendre. En retour, ma connaissance et ma compréhension du mot pourront elles-mêmes moduler l’émotion que je ressens.
Une liberté par degrés en philosophie comme en psychologie et en neurosciences
À partir de là, un des apports des dialogues entre philosophie et sciences cognitives consiste à souligner ce qui peut moduler ces différents degrés de liberté possibles à l’humain. Ceci nous donne des indications sur comment réguler les interfaces numériques pour favoriser la liberté plutôt que la réduire, comme c’est le cas actuellement.
Du côté de la philosophie, Spinoza considère que la connaissance adéquate des causes qui nous déterminent augmente notre liberté. Ce n’est qu’une fois que nous savons qu’un stimulus nous influence que nous pouvons y réfléchir et décider de lutter contre cette influence, ou au contraire de l’accepter lorsqu’elle nous convient. Cela veut dire qu’il faut imposer aux interfaces numériques une transparence sur les stimuli qu’elles utilisent, les algorithmes qui les déclenchent, et les données personnelles sur lesquelles ils s’appuient. Cette transparence permettrait de favoriser notre réflexivité sur nos interactions avec l’interface. Célia Zolynski, professeur de droit à La Sorbonne Paris 1, propose même de consacrer un droit au paramétrage, que la Commission Nationale Consultative des Droits de l’Homme a soutenu[13]. Ce droit permettrait à l’utilisateur de construire son propre espace informationnel afin d’y trier les influences qui lui semblent acceptables pour lui.
On pourrait y ajouter la possibilité de trier nos automatismes comportementaux sur les interfaces numériques. Du côté de la psychologie, on sait en effet depuis longtemps que toutes nos décisions ne sont pas toujours réfléchies ni guidées par une intention explicite, mais peuvent souvent être automatiques et du coup sujettes à davantage d’influence par les stimuli externes[14]. Par exemple, quand notre esprit critique se relâche, nous avons plus de risques de cliquer sur les publicités qui apparaissent à l’écran. Les connaissances les plus récentes en neurosciences[15] nous permettent de mieux comprendre les mécanismes neuraux par lesquels la perception de stimuli conditionnés (qui ont été associés de façon répétée avec une récompense, comme de la nourriture, du plaisir, ou une reconnaissance sociale) peuvent venir court-circuiter les réseaux cérébraux sous-tendant nos processus délibératifs, et ainsi favoriser la bascule vers des réseaux liés à un mode de contrôle plus implicite et automatique (donc souvent inconscient) de l’action.
Nous pouvons augmenter notre liberté par le tri de nos automatismes comportementaux, pour choisir ceux que nous gardons. Par exemple, je décide d’accepter l’automatisme de mon comportement quand je trie rapidement mes messages, car c’est ce qui me permet d’être efficace et d’économiser du temps. Mais je décide de combattre mon comportement consistant à automatiquement faire dérouler le fil sans fin d’actualités sur les réseaux sociaux. Car ceci m’amène à être encore connecté sur l’interface une demi-heure plus tard, alors que je voulais n’y passer que 5 minutes.
Enfin, il faut imposer aux interfaces de mettre en visibilité nos possibilités alternatives d’agir. En effet, la modélisation mathématique en sciences cognitives nous permet dorénavant de mieux comprendre les mécanismes cérébraux qui sous-tendent notre capacité à simuler mentalement les possibilités d’actions alternatives avant de décider. Malgré le déterminisme, grâce à la simulation mentale[16], il est possible de réduire l’influence relative des causes externes (stimuli) au profit de causes internes (notre mémoire, nos intentions ou buts, nos valeurs, notre connaissance d’actions alternatives), ces éléments internes ayant eux-mêmes des causes. C’est ce qui permet au mode intentionnel de prise de décision de s’exercer[17], par opposition aux automatismes comportementaux, et ainsi de nous rendre « libres de l’immédiateté » de l’influence des stimuli externes[18]. Une hypothèse consiste à considérer qu’en augmentant le temps de réflexion, nous augmentons la longueur et la complexité de la chaîne causale qui détermine notre choix d’action, nous pouvons par la réflexion moduler le poids relatif de chaque cause dans l’équation, et ainsi réduire l’influence relative des stimuli externes, donc être plus libres[19].
On comprend ainsi mieux pourquoi tout ce qui, sur les interfaces numériques, opacifie ou court-circuite notre réflexivité, nous empêche d’évaluer par la simulation mentale les conséquences à long-terme de nos actions. Comme il a été souligné récemment, « ce n’est pas tant que les gens accordent peu d’importance à leur vie privée, ou qu’ils sont stupides ou incapables de se protéger, mais le fait que les environnements [numériques], comme dans le cas des dark patterns, ne nous aident pas à faire des choix qui soient cohérents avec nos préoccupations et préférences vis-à-vis de la personnalisation [des services digitaux] et de la confidentialité des données. »[20]
Paradoxe d’une société de consommation qui exagère la promotion du libre-arbitre
Mais la liberté ne dépend pas que de l’individu et de ses efforts cognitifs. Il est important de prendre en compte les travaux en sciences humaines et sociales (SHS), notamment en sociologie, pour comprendre les autres dimensions qui influencent nos choix, comme les interactions avec les autres utilisateurs sur Internet et le rôle de la société. C’est pourquoi il faut ouvrir davantage les données des interfaces numériques aux recherches en SHS.
Ces réflexions à l’interface entre sciences et philosophie viennent en tout cas appuyer le constat qu’une société qui met en avant des influenceurs commerciaux et politiques, des discours simplistes, des publicités mettant en scène des stéréotypes, contribue à nous habituer à ne pas faire l’effort de sortir de nos automatismes de pensée. Cela contribue même à en créer de nouveaux, donc à nous rendre moins libres et à nous éloigner de l’idéal démocratique.
Nous sommes face à un paradoxe : celui d’une société de consommation qui acclame le libre arbitre, célèbre notre liberté de rouler plus vite à bord de notre véhicule privatif ou d’accéder à une quantité quasi-infinie de connaissances et d’information sur Internet, et pourtant gonfle notre illusion de liberté absolue tout en orientant nos choix et en nous proposant de choisir entre des produits plus ou moins équivalents. Le business model ancré sur la publicité et la surveillance des données[21] contribue à nous rendre moins libres par ses injonctions, par la manipulation de nos émotions, par le détournement de nos données et la captation de notre attention à nos dépens. Cette année le comité du prix Nobel de la paix a observé que « la vaste machinerie de surveillance des entreprises non seulement abuse de notre droit à la vie privée, mais permet également que nos données soient utilisées contre nous, sapant nos libertés et permettant la discrimination. »[22]
Conclusion
Vous l’aurez compris : le déterminisme n’empêche pas l’humain de disposer d’une certaine marge de liberté dans ses décisions. Il est la cause dernière de ses choix d’actions, garde la capacité de la réflexion éthique et ne peut donc être exempté d’une responsabilité sociétale et juridique[1]. Vous avez lu cet article jusqu’au bout. (Merci !) Il y avait des causes à cela. Et votre décision d’y re-réfléchir ou pas aura elle-même des causes internes et externes. Néanmoins, chercher à mieux comprendre ces causes contribue à nous rendre plus libres. Ceci peut nous aider à entrevoir les possibilités qui s’offrent à nous pour réguler les interfaces numériques de façon à ce qu’elles favorisent la liberté de penser par soi-même plutôt qu’elles ne la réduisent.
Mehdi Khamassi, directeur de recherche en sciences cognitives au CNRS
Remerciements
L’auteur souhaite remercier Stefana Broadbent, Florian Forestier, Camille Lakhlifi, Jean Lorenceau, Cyril Monier, Albert Moukheiber, Mathias Pessiglione et Célia Zolynski pour les nombreux échanges qui ont nourri ce texte
[1] Bigenwald, A., & Chambon, V. (2019). Criminal responsibility and neuroscience: no revolution yet. Frontiers in psychology, 10, 1406.
[1] Rapport de la Commision Bronner, janvier 2022.
[2] Rapport du Conseil National du Numérique, octobre 2022.
[3] Conseil de l’Europe (2019), Déclaration du Comité des ministres sur les capacités de manipulation des processus algorithmiques.
[4] OECD (2022), « Dark commercial patterns », OECD Digital Economy Papers, No. 336, OECD Publishing, Paris, https://doi.org/10.1787/44f5e846-en.
[5] Eyal, N. (2014). Hooked: How to build habit-forming products. Penguin.
[6] Natasha Schüll (2012) Addiction by design: Machine gambling in Las Vegas. Princeton Univ Press.
[7] Yuval Noah Harari, Homo Deus, Une brève histoire de l’avenir, Paris, Albin Michel, 2017.
[8] Dans le paradigme scientifique, tout ce qui constitue la nature obéit à des lois. Pour que la science existe nous devons considérer que les mêmes causes produiront les mêmes effets, si toutes choses sont équivalentes par ailleurs (ce qui est forcément une approximation et une simplification car il ne peut pas y avoir deux situations strictement identiques en tout point). Ce qui signifie que nous considérons qu’il existe un déterminisme causal et que ce positionnement métaphysique n’est en aucun cas démontrable, c’est une posture. Le fait que cette posture permette d’expliquer de plus en plus de phénomènes et de comportements plaide en sa faveur sans pour autant constituer une démonstration.
[9] C’est à dire que la nature est une, qu’elle est intelligible, et que nous pouvons l’étudier à l’aide d’une approche scientifique.
[10] Atlan, H. (2018). Cours de philosophie biologique et cognitiviste : Spinoza et la biologie actuelle. Éditions Odile Jacob. Voir aussi Monier, C. & Khamassi, M. (Eds.) (2021). Liberté et cognition. Intellectica, 2021/2(75), https://intellectica.org/fr/numeros/liberte-et-cognition.
[11] Krakauer, J. W., Ghazanfar, A. A., Gomez-Marin, A., MacIver, M. A., & Poeppel, D. (2017). Neuroscience needs behavior: correcting a reductionist bias. Neuron, 93(3), 480-490.
[12] Feltz, B. (2021). Liberté, déterminisme et neurosciences. Intellectica, 75.
[13] Avis de la CNCDH relatif à la lutte contre la haine en ligne du 8 juil. 2021, JORF 21 juil. 2021, proposition dont le CNNum s’est ensuite fait l’écho : CNNum, Votre attention s’il vous plaît, 2022.
[14] Houdé, O. (2020). L’inhibition au service de l’intelligence : penser contre soi-même. Paris, Presses universitaires de France-Humensis.
[15] Khamassi, M. (Ed.) (2021). Neurosciences cognitives. Grandes fonctions, psychologie expérimentale, neuro-imagerie, modélisation computationnelle. Éditions De Boeck Supérieur.
[16] Exemple de simulation mentale : si je me simule mentalement réalisant une action, je peux mieux estimer dans quelle situation je vais probablement me retrouver après avoir agi. Je peux alors estimer si c’est en adéquation avec mes buts et mes valeurs, et non plus être simplement en mode stimulus-réponse.
[17] Patrick Haggard (2008). Human volition: towards a neuroscience of will. Nature Neuroscience Reviews.
[18] Shadlen, M. N., & Gold, J. I. (2004). The neurophysiology of decision-making as a window on cognition. The cognitive neurosciences, 3, 1229-1441.
[19] Khamassi, M. & Lorenceau, J. (2021). Inscription corporelle des dynamiques cognitives et leur impact sur la liberté de l’humain en société. Intellectica, 2021/2(75), pages 33-72.
[20] Kozyreva, A., Lorenz-Spreen, P., Hertwig, R. et al. Public attitudes towards algorithmic personalization and use of personal data online: evidence from Germany, Great Britain, and the United States. Humanit Soc Sci Commun 8, 117 (2021). https://doi.org/10.1057/s41599-021-00787-w
[21] Shoshana Zuboff, L’âge du capitalisme de surveillance, Paris, Zulma, 2020.
[22] Cités par le rapport forum info démocratie, sept 2022.
[23] Bigenwald, A., & Chambon, V. (2019). Criminal responsibility and neuroscience: no revolution yet. Frontiers in psychology, 10, 1406.


 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », partageons une approche rendue encore plus indispensable avec le numérique : l’esprit critique. A l’heure des infox (fake news), du renforcement du complotisme, de la guerre qui est aussi devenue informationnelle, ou plus simplement de l’irruption de ChatGPT, l’apprentissage de l’esprit critique est/devrait être une priorité éducative. Mais … comment faire ? Et si nous commencions par regarder ce que les sciences de l’éducation nous proposent à travers ce petit texte issu des échanges tenus lors d’une table ronde. Thierry Vieville et Pascal Guitton.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », partageons une approche rendue encore plus indispensable avec le numérique : l’esprit critique. A l’heure des infox (fake news), du renforcement du complotisme, de la guerre qui est aussi devenue informationnelle, ou plus simplement de l’irruption de ChatGPT, l’apprentissage de l’esprit critique est/devrait être une priorité éducative. Mais … comment faire ? Et si nous commencions par regarder ce que les sciences de l’éducation nous proposent à travers ce petit texte issu des échanges tenus lors d’une table ronde. Thierry Vieville et Pascal Guitton.

 Disons, pour en discuter, que c’est à la fois un état d’esprit et un ensemble de compétences (résumées dans les carrés bleus) :
Disons, pour en discuter, que c’est à la fois un état d’esprit et un ensemble de compétences (résumées dans les carrés bleus) :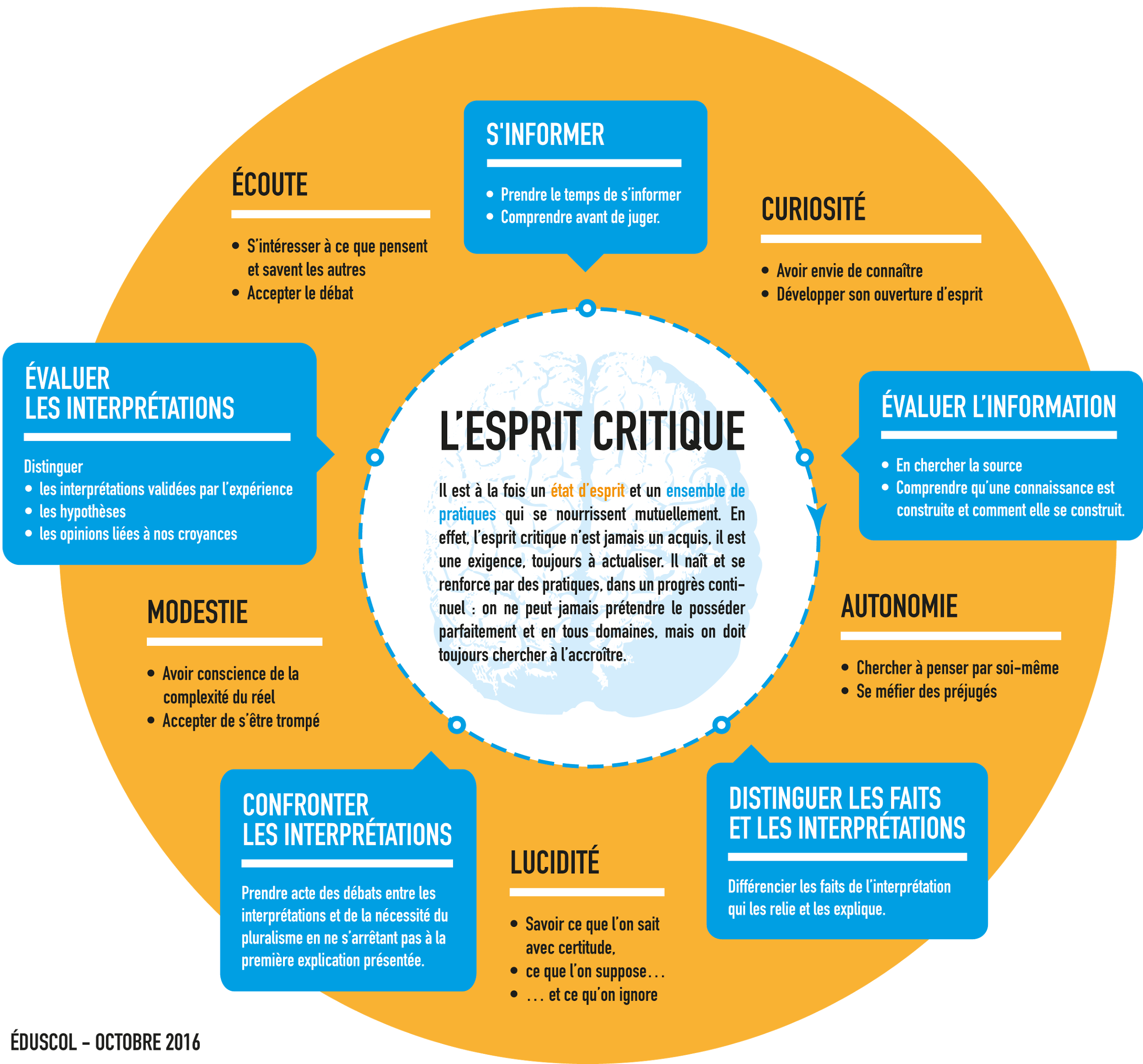









































 Guillaume Cabanac est un chercheur en informatique à l’Université Paul Sabatier et
Guillaume Cabanac est un chercheur en informatique à l’Université Paul Sabatier et