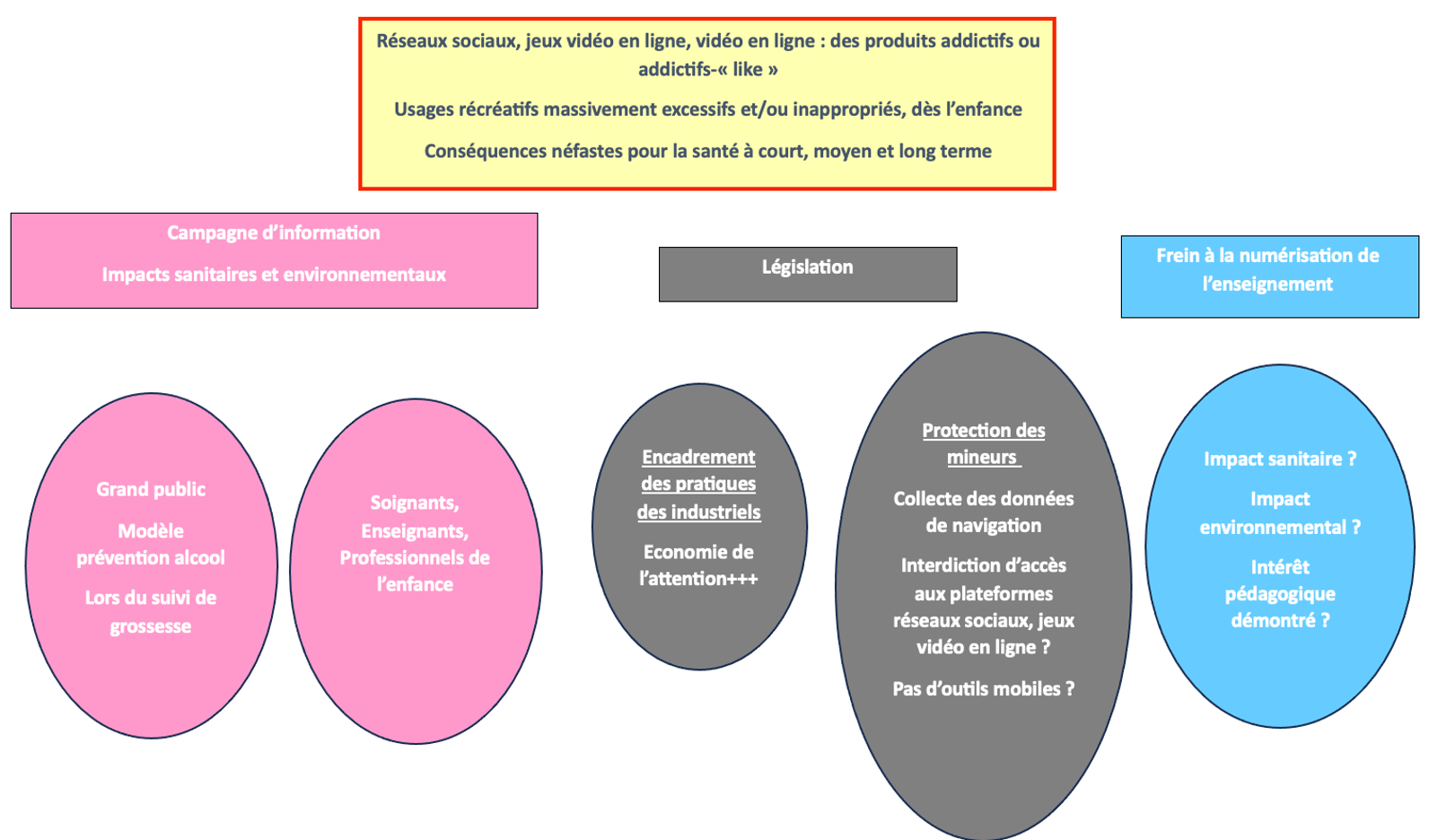
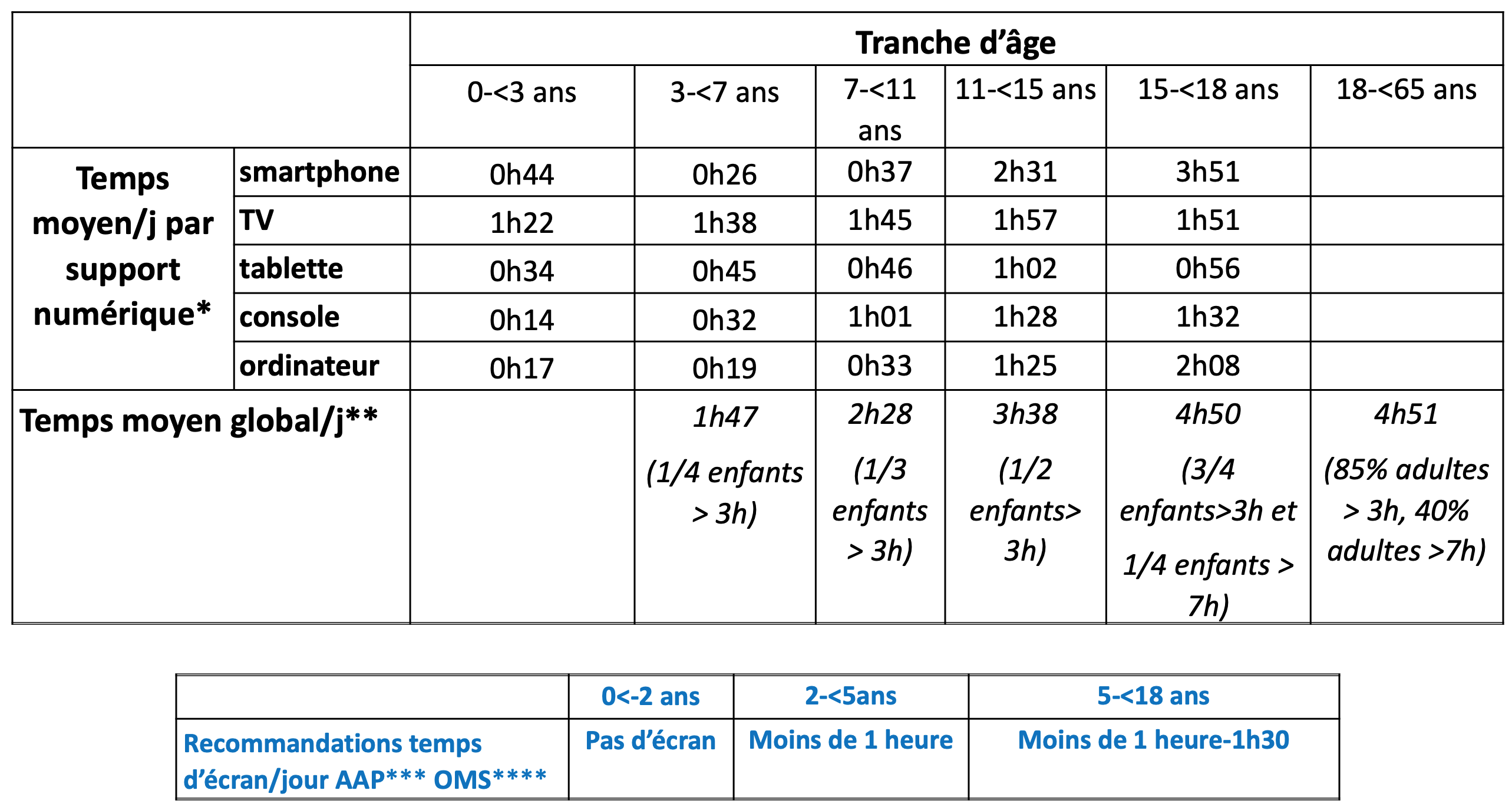
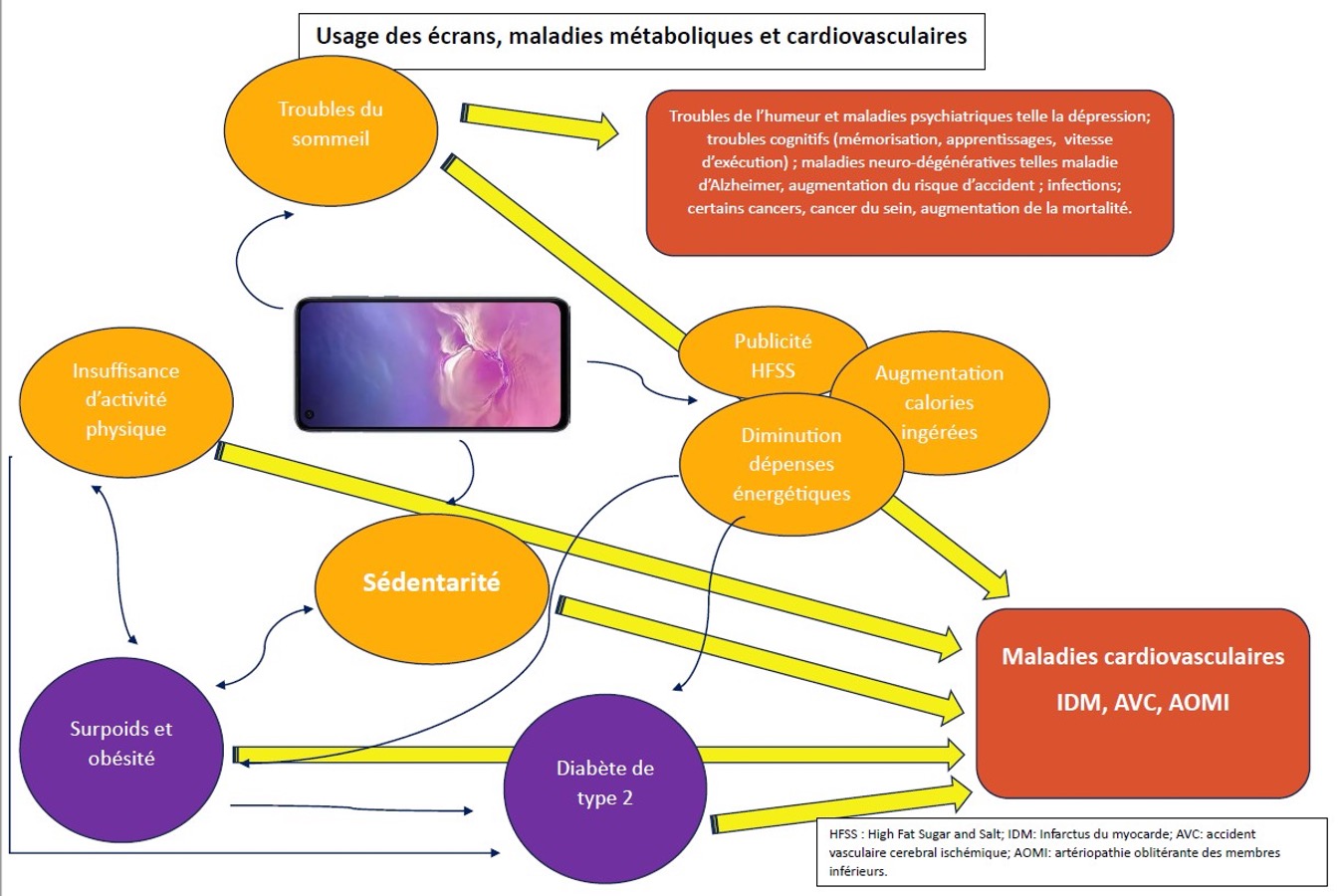
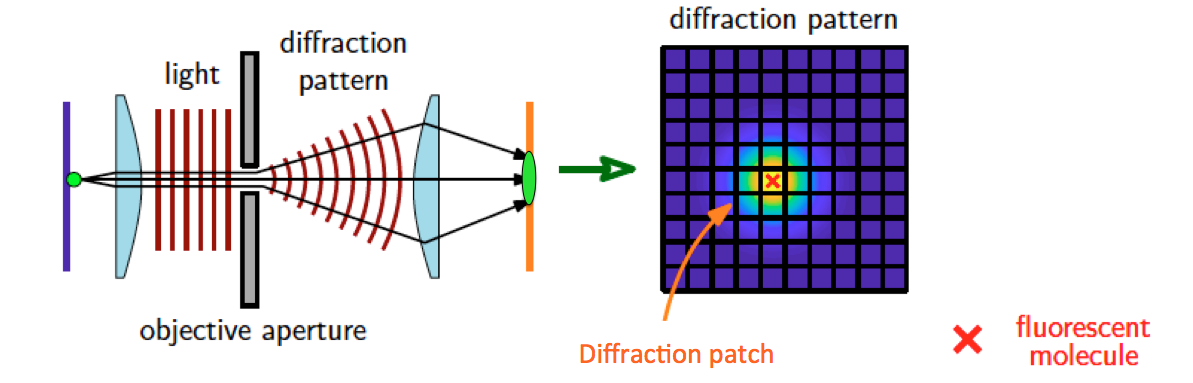
Des IA conseillères assurément, une IA présidente jamais de la vie
Jason Richard s’interrogeait dans ce blog sur la possibilité et l’opportunité qu’un pays soit gouverné par une IA1. Recensant le pour et le contre, il laissait la question ouverte.
La réponse se précise si l’on considère que l’intelligence obéit à des lois universelles de l’information et qu’elle n’a rien de spécifiquement humain, au même titre que la force obéit aux lois universelles de la physique. L’IA apparaît alors comme un outil parmi les autres, aux côtés de la machine à vapeur. Parce que c’est un outil, il ne faut pas se priver de son aide, parce que ce n’est qu’un outil, l’idée qu’elle préside à notre destinée est vide de sens.
Cependant l’IA n’est pas n’importe quel outil. Elle est de ces instruments qui révolutionnent les civilisations, comme la lunette astronomique mena à l’héliocentrisme, l’imprimerie à la démocratie libérale. En étendant sans limites notre intelligence, et en la libérant de ses biais cognitifs, l’IA « peut conduire à une renaissance de l’humanité, un nouveau siècle des Lumières2 ».
Les politiques répètent à l’envie qu’il faut « changer de logiciel ». Changeons donc de logiciel.
Une seconde révolution copernicienne
En se penchant sur ses morts, le Sapiens s’interrogea sur son sort. Il imagina son salut par l’obéissance à des lois divines. Quand la révolution copernicienne discrédita l’idée d’une création dont il était le centre, vinrent les Lumières où l’homme se reporta sur sa raison pour comprendre et organiser le monde à son avantage. Cette arrogance de l’esprit nous a conduits au pied d’un mur environnemental qui va selon certains jusqu’à menacer notre espèce. Une nouvelle révolution voit le jour, celle de l’intelligence partagée, instrumentée par l’Intelligence dite Artificielle pour éclairer nos choix. Se priver d’IA dans les débats parlementaires serait désormais aussi stupide que jadis partir en exploration sans boussole, ou maintenant délibérer en COP sans l’expertise du GIEC.
Si nous répugnons encore à cette perspective, c’est que nous demeurons dans l’idée toute cartésienne que l’intelligence est l’apanage de l’humain. C’est pourquoi nous sommes troublés de voir l’intelligence machine pulvériser nos capacités, alors que nous nous félicitons que nos engins soient bien plus forts que nous pour nous aider dans les chantiers. Quand nous avons inventé la machine à vapeur, nous ne l’avons pas nommée Puissance Artificielle, parce que nous savions que la force et la puissance obéissent à des lois universelles de la mécanique et que nos prédateurs ancestraux nous surpassaient dans ce registre. C’est dans l’intelligence que nous avons placé ces derniers siècles la fierté de notre espèce, comme en témoignent nos contes et récits, où c’est toujours le petit futé qui l’emporte sur le grand crétin. Nous devons désormais nous faire à l’idée que l’intelligence n’est pas non plus notre apanage, qu’elle est partagée avec la nature et nos machines
La révolution des réseaux de neurones
La révolution informatique repose sur l’universalité des ordinateurs, leur capacité à « calculer tout ce qui est calculable », pourvu qu’ils aient assez de mémoire et de temps. La difficulté est que pour tout problème, il faut trouver un algorithme qui le résout. La révolution de l’IA repose sur une double universalité : d’une part un réseau de neurones artificiels peut « souvent apprendre approximativement ce qui est apprenable », pourvu qu’il soit assez grand, et d’autre part il peut le faire avec un même et seul algorithme, l’algorithme de rétro-propagation du gradient. En cela l’IA connexionnisme, celle des réseaux de neurones, ne fait que mimer la formidable trouvaille de l’évolution darwinienne qu’est le cortex et ses circonvolutions, avec l’avantage pour la machine de ne pas devoir se tasser dans une boîte crânienne.
Que des théorèmes expliquent pourquoi l’IA semble faire « tout mieux que nous »3 est de nature à nous rassurer et à tordre le cou aux obscurantismes. Cependant cette affirmation met à l’état de l’art « ses habits du dimanche » comme aurait joliment dit Marcel Pagnol, car il est bon de garder en tête qu’elle cache de nombreux bémols, qui sont autant de pistes pour les recherches futures4.
Cette révolution ne pouvait avoir lieu que maintenant, car le connexionnisme ne fonctionne que dans la gigantisme, quand tout se compte en milliards, milliards de données, milliards de neurones, milliardièmes de seconde, ce qui n’était pas technologiquement abordable avant ces dernières années.
Des intelligences non biaisées par la condition humaine
Un autre avantage de la machine est qu’elle est exempte de nos biais cognitifs5. Des biais sont souvent imputés aux machines, des déboires historiques de Siri aux dérapages récents de la reconnaissance faciale6. Ce faisant on oublie que ces biais ne sont pas liés au fonctionnement des machines mais aux comportements humains, en l’occurrence sexistes ou racistes, reflétés dans les échantillons d’apprentissage. Il faut donc distinguer les biais dans les données et les biais de traitement : là où notre raisonnement est biaisé, le traitement machine des mêmes données ne l’est pas.
Le Monde a consacré à nos biais cognitifs une série d’articles l’été dernier, « Les intox du cortex », et la chaîne YouTube « La Tronche en Biais », 300k abonnés, dédiée à l’esprit critique, accorde comme son nom l’indique une large place au sujet.
Un biais cognitif qualifie la différence d’analyse entre celle faite par un humain et celle réalisée de façon purement logique et rationnelle. Il est vraisemblable que nos biais trouvent leurs origines dans des avantages compétitifs qu’ils procuraient à notre espèce et ses individus au cours de la sélection darwinienne, avantages qui peuvent se retourner en handicaps quand l’environnement change. Sébastien Bohler va très loin en la matière7. Selon ce neuro-scientifique vulgarisateur, notre espèce doit sa survie à sa propension à dévorer, copuler, en imposer à la première occasion, tant la condition de nos ancêtre ne tenait qu’à un fil, avec la nourriture rare, la mortalité précoce et la trahison quotidienne. Avec l’abondance de l’ère industrielle, cette tendance – que Bohler nomme bug – qui nous a conduit à la surconsommation, à l explosion démographique, à la profusion de bagnoles, de fringues, et autres biens statutaires, jusqu’au pied du mur écologique.
Des intelligences machines novatrices
Le conformisme des IA est souvent évoqué pour les moteurs de recommandations, qui en se basant sur les statistiques de nos goûts nous proposent ce que l’on aime déjà. Mais cela ne vaut pas dans des applications avancées. Ainsi lors du match historique de 2016 AlphaGo réussit contre Lee Sedol un « coup de Dieu », comme le qualifient les spécialistes du jeu de Go. Des recherches récentes expliquent qu’au cours de son apprentissage un réseau connexionniste peut détecter entre des situations des similitudes qui nous échappent tant les sens que nous leur attribuons sont éloignés8. C’est ce que nous appelons parfois la créativité. Là où nos raisonnement seront prisonniers de nos biais, la machine privilégiera des principes mathématiques qui conduiront à des scénarios inédits, qu’elle alimentera de sa capacité à articuler des milliards de données hétérogènes, humaines, économiques, culturelles, scientifiques.
Quand l’IA éclairera le politique…
La voiture. Capter le regard envieux du voisin ou celui conquis de l’être convoité est selon les publicités le rêve de tout possesseur d’une voiture. Quitte à frustrer notre goût pour les biens statutaires, l’IA proposera la suppression de la voiture individuelle au profit de flottes collectives semi-autonomes appelées et congédiées d’un clic, elle élaborera des scénarios chiffrés de transition, dont la difficulté est actuellement prétexte à écarter l’idée.
Les retraites. Par principe de parcimonie, qui privilégie les hypothèses les plus simples, l’IA favorisera l’assertion « tous les humains ont une égale dignité, ils doivent être traités à égalité dès lors qu’ils cessent d’être des agents sociaux-économiques », et elle détaillera là aussi les difficiles scénarios de transition.
Les migrations. L’humanité s’est fondée sur les migrations, cela n’échappera pas aux machines.
La fin de vie. La machine ne produira rien qui fasse sens pour nous, car il s’agit de notre mort.
… dans une génération
Bien entendu nous serons libres de critiquer et réfuter les scénarios des machines. Cependant nos décisions face à ces scénarios devront être solidement argumentées et débattues, car nous aurons à en rendre compte aux générations futures. Les décisions des COP face aux expertises du GIEC donnent un avant goût de cette situation.
Il faudra une génération pour que le recours institutionnel à l’IA se mette en place. Le temps que celle-ci conquière progressivement notre confiance dans ce rôle. Il faudra en codifier l’usage au fil des expérimentations, comme on codifie le fonctionnement démocratique. Tout comme les experts sont corruptibles, les IA sont manipulables, aussi faudra-t-il également codifier les protocoles de traitement et confronter les IA comme on confronte les experts.
En revanche l’IA possède un énorme avantage en matière de transparence9. On ne peut pas sonder les crânes pour estimer la sincérité d’un argument, en revanche on peut expertiser les processus de façon reproductible, contradictoire et opposable.
Le spectre souvent évoqué de la dictature des algorithmes ou des IA n’est pas à craindre : la machine proposera, nous éclairant en surplomb de notre condition, nous seuls disposerons de notre destin. L’intelligence machine pèsera certes sur nos décisions, mais il n’y a là rien de nouveau, nous co-évoluons avec les outils dont nous nous dotons depuis l’époque où nos ancêtres taillaient les silex.
Max Dauchet, Professeur à l’Université de Lille
1 Une intelligence artificielle à la tête d’un pays : science fiction ou réalité future ? 27 octobre 2023
2Propos de Yann le Cun, prix Turing et un des pères de l’IA actuelle, dans une interview au Monde, le 28 avril 2023
3On a l’embarras du choix d’articles de tous niveaux sur le net. Pour un scientifique francophone non spécialiste, les cours du Collège de France, disponibles en vidéo, sont une entrée attrayante : ceux de Stanislas Dehaene, titulaire de la chaire «Psychologie cognitive expérimentale » pour les aspects biologiques, et pour les aspects sciences du numérique le cours de Yann Le Cun invité en 2015-2016 sur la chaire « Informatique et sciences numériques », ainsi que les cours de Stéphane Mallat, titulaire de la chaire « Sciences des données », axés autour du triangle « régularité, approximation, parcimonie », où l’extraction d’informations de masses de données s’apparente à une réduction de dimension des problèmes à milliards de paramètres.
On peut aussi aborder la comparaison entre biologie et numérique par le petit bout de la lorgnette, sans aucune connaissance préalable, à travers trois courts articles de mon blog https://la-data-au-secours-des-lumieres.blogspot.com/: « L’affaire du Perceptron » raconte par l’anecdote l’émoi suscité par le Perceptron dans les années 70, imposante machine qui s’avéra avec le recul n’être qu’un séparateur linéaire, comme l’est un neurone muni de la loi formulée par Hebb d’évolution des connexions, dont la vérification expérimentale valut à Eric Kandel le prix Nobel de médecine 2000, séparation linéaire qui est l’opération la plus élémentaire de classification, celle que les enfants apprennent en maternelle (« Le petit neurone et la règle d’écolier »). Dans « Le théorème de convergence du Perceptron », un cadre mathématique élémentaire élucide complètement le comportement du Perceptron, que d’aucuns voyaient un demi siècle auparavant supplanter l’homme.
4– La notion de ce qui est apprenable est cernée mathématiquement mais floue dans la pratique. Intuitivement, est apprenable ce qui est structuré, d’où la boutade des chercheurs « Soit le monde est structuré, soit Dieu existe » (rapportée d’Outre Atlantique par Yann le Cun), face aux succès dépassant mystérieusement leurs attentes. Il s’avère que le connexionnisme permet d’ exploiter les structures (d’un problème souvent riche de milliards de paramètres) sans avoir à les décrire. C’est ce que fait un enfant quand il apprend à faire des phrases sans rien connaître de la grammaire, ou qu’il apprend à se repérer sans rien connaître de la géométrie.
– Dans la pratique l’apprentissage ou la génération sont améliorés par des intervenants humains, qui peuvent être une foultitude de petites mains pour les grandes applications.
– L’universalité est théorique, pour être efficace dans la pratique, l’architecture d’un réseau est adaptée à tâtons à un problème, et tous les problèmes ne sont pas traitables en temps réaliste.
– De part son principe, l’algorithme de rétro-propagation peut converger vers divers comportements du réseau, sans que l’on puisse préciser à quel point ils sont bons. Des résultats théoriques montrent que de telles limitations sont inévitables.
– Dans l’intelligence humaine comme dans celle de la machine bien d’autres fonctions entrent en jeu, souvent encore mal connues en neurosciences, et souvent relevant de techniques dites symboliques en IA, techniques objets de controverses face au connexionnisme au cours de la jeune histoire de l’IA.
5Comme le relève Jason Richard dans sa liste des avantages de l’IA.
6Siri, un des premiers assistants personnels sur smartphone, fut accusé de tenir des propos inappropriés. Plus récemment des systèmes de reconnaissance faciale, entraînés principalement sur des blancs, commettaient des confusions sur les personnes de couleur.
7 Le Bug humain, Robert Laffont, 2020
8 Jean-Paul Delahaye, « Derrière les modèles massifs de langage », Pour la science, janvier 2024
9On reproche couramment à l’IA son manque d’explicabilité, parce que dans les applications de masse, les conditions d’exploitation ne permettent pas l’analyse des traces de calcul. Ce ne sera pas le cas ici.

















 Bonjour ChatGPT
Bonjour ChatGPT