Entretien autour de l’informatique : Olivier Marti, climatologue
Selon l’Agence américaine océanique et atmosphérique et la Nasa, l’année 2014 a été la plus chaude sur le globe depuis le début des relevés de températures en 1880. (Voir l’article de l’Obs). Depuis les débuts de l’informatique, la climatologie se nourrit des progrès de l’informatique et du calcul scientifique, et en même temps leur propose sans cesse de nouveaux défis. Dans un entretien réalisé par Christine Froidevaux et Claire Mathieu, Olivier Marti, climatologue au Laboratoire des Sciences du Climat et de l’Environnement, explique ses recherches en calcul scientifique et développement de modèles pour la climatologie, un domaine exigeant et passionnant.
Cet entretien parait simultanément en version longue sur le blog Binaire et en raccourcie sur 01Business.
 Olivier Marti
Olivier Marti
Le métier de climatologue
B : Qu’est-ce qui vous a amené à travailler en climatologie ?
OM : Dans ma jeunesse, j’ai fait de la voile. J’avais une curiosité pour la mer et un goût pour la géographie. J’ai choisi de faire l’ENSTA pour faire de l’architecture navale. Là, j’ai choisi l’environnement marin (aspect physique, pas biologie), et j’ai fait une thèse en modélisation, sur les premiers modèles dynamiques de l’océan ; au début, on ne parlait pas beaucoup de climatologie, ça s’est développé plus tard. Il y a un aspect pluridisciplinaire important, ma spécialité étant la physique de l’océan. J’ai ensuite été embauché au CEA et ai travaillé sur les climats anciens. Par exemple, l’étude du climat du quaternaire amène à étudier l’influence des paramètres orbitaux sur le climat.
B : En quoi consiste votre métier ?
OM : Je fais du développement de modèle. Il faut assembler des composants : un modèle d’océan, un modèle d’atmosphère etc. pour faire un modèle du climat. Mais quand on couple des modèles, c’est-à-dire, quand on les fait évoluer ensemble, on rajoute des degrés de liberté et il peut y avoir des surprises. Il faut qu’informatiquement ces objets puissent échanger des quantités physiques. C’est surtout un travail empirique. On réalise beaucoup d’expériences en faisant varier les paramètres des modèles. C’est vrai aussi que depuis 25 ans, on se dit qu’il faudrait pousser plus loin les mathématiques (convergence numérique, stabilité, etc.), marier calcul scientifique et schémas numériques. En climatologie, on n’a pas accès à l’expérience, c’est mauvais, du point de vue de la philosophie des sciences. On peut faire quelques expériences en laboratoire, mettre une plante sous cloche avec du CO2, mais on n’a pas d’expérience pour le système complet. La démarche du laboratoire est donc de documenter l’histoire du climat. Il y a d’abord un travail de récolte et d’analyse de données, puis une phase de modélisation : peut-on mettre le “système Terre” en équations ?
B : Allez-vous sur le terrain?
OM : J’y suis allé deux fois. En général, on fait en sorte que les gens qui manipulent les données sur l’ordinateur aient une idée de comment on récolte ces données, pour qu’ils se rendent compte, par exemple, qu’avoir 15 décimales de précision sur la température, c’est douteux. J’ai fait une campagne en mer, de prélèvement de mesure d’eau de mer et d’éléments de biologie marine. Lors des campagnes en mer, la plupart des analyses se font en surface sur le bateau : on a des laboratoires embarqués sur lesquels on calibre le salinomètre, etc. J’ai aussi fait une campagne dans le désert du Hoggar, pendant une semaine, pour récolter les sédiments lacustres (il y a 6000 ans, là-bas, il y avait des lacs). Récolter les pollens qui sont dans les sédiments, ça exige des procédés chimiques un peu lourds, donc on ne le fait pas sur place.
 Collecte de données dans le Hoggar
Collecte de données dans le Hoggar
B : Qu’est-ce qui motive les chercheurs en climatologie ?
OM : Il n’y a pas un seul profil, car c’est pluridisciplinaire. Chez nous, il y a des gens qui viennent de la dynamique des fluides et d’autres de l’agronomie. Ce n’est pas forcément facile de travailler ensemble ! Les gens qui font du calcul scientifique, quand ils arrivent, n’ont pas de compétences en climatologie, mais en travaillant sur les climats, ils ont l’impression d’être plus utiles à la société que s’ils développaient un logiciel pour faire du marketing par exemple. Ils participent à un projet d’ensemble qui a un rôle dans la société qui est positif, et c’est motivant.
B : Quels sont les liens de votre domaine avec l’informatique ?
OM : On évite d’utiliser le mot « informatique », car cela regroupe des métiers tellement différents. L’informatique en tant que discipline scientifique est bien sûr clairement définie, mais assez différemment de son acception par l’homme de la rue. Nous parlons de calcul scientifique. L’équipe que je dirigeais s’appelle d’ailleurs CalculS. Dans ma génération, si des personnes telles que moi disaient qu’elles faisaient de « l’informatique », elles voyaient débarquer dans leur bureau des collègues qui leur demandaient de “débugger » les appareils. Il y avait une confusion symptomatique et j’aurais préféré que le mot «informatique» n’existe pas. La Direction Informatique du CEA regroupait bureautique et calcul scientifique. Maintenant au contraire, le calcul scientifique ne dépend plus de la direction informatique. Les interlocuteurs comprennent mieux notre métier. Notre compétence n’est pas le microcode, et nous ne savons pas enlever les virus des ordinateurs.
Développer des modèles
B : Utilisez-vous des modèles continus ou discrets ?
OM : Les zones géographiques sont représentées par une grille de maille 200 km (l’océan a une grille plus fine). Le temps, qui est la plus grande dimension, est discret, et on fait évoluer le système pas à pas. Il faut entre 1 et 3 mois pour simuler entre 100 et 1000 ans de climat. On ne cherche pas à trouver un point de convergence mais à étudier l’évolution… On s’intéresse à des évolutions sur 100 000 ans ! Il y a des gens qui travaillent sur le passé d’il y a 500 millions d’années, et d’autres sur le passé plus récent. Nous, on essaie de travailler sur le même modèle pour le passé et pour le futur. Donc, par rapport aux autres équipes de recherche, cela implique qu’on n’ait pas un modèle à plus basse résolution pour le futur et un autre à plus haute résolution pour le passé. L’adéquation des modèles sur le passé est une validation du modèle pour le futur, mais on a une seule trajectoire du système – une seule planète dont l’existence se déroule une seule fois au cours du temps. Nos modèles peuvent éventuellement donner d’autres climats que celui observé, et cela ne veut pas forcément dire qu’ils sont faux, mais simplement qu’ils partent d’autres conditions initiales. On peut faire de la prévision climatique, mais on ne peut pas travailler sur des simulations individuelles, il faut étudier des ensembles. En particulier, les effets de seuil sont difficiles à prédire. On a besoin de puissance de calcul.
B : Dans votre domaine, y a-t-il des verrous qui ont été levés ?
OM : Cette évolution a eu lieu par raffinements successifs. Maintenant on sait que ce sont plutôt les paramètres orbitaux qui démarrent une glaciation, mais que le CO2 joue un rôle amplificateur, et on ne comprend pas complètement pourquoi. On se doute qu’aujourd’hui le climat glaciaire s’explique en partie parce que l’océan est capable de piéger plus de CO2 en profondeur, et je travaille en ce moment pour savoir si au bord du continent antarctique, où l’océan est très stratifié, on peut modéliser les rejets de saumure par la glace de mer ; on essaie de faire cette modélisation dans une hiérarchie de modèles pour voir s’il y a une convergence, ou pour quantifier tel phénomène qu’on n’avait pas identifié il y a 30 ans et qui joue un rôle majeur. L’effet de la saumure est variable selon qu’elle tombe sur le plateau continental ou non. Pour modéliser ces effets, il faut représenter la topographie du fond marin de façon fine, mais là on tombe sur un verrou, parce qu’on ne sait pas modéliser le fond de l’océan. On alterne les simulations longues à basse résolution simplifiée des rejets de sel, avec les modèles à plus haute résolution. Il y a des verrous qui sont levés parce qu’on sait faire des mesures plus fines au spectromètre et parce que la puissance de calcul augmente.
B : Dans dix ou vingt ans, qu’est-ce que vous aimeriez voir résolu?
OM : D’une part, en tant qu’océanographe, j’aimerais comprendre toute la circulation au fond de l’océan – c’est quelque chose de très inerte, de très lent, sauf quelques courants un peu plus rapides sur les bords. Il y a des endroits de l’océan qui sont très isolés à cause du relief. Je voudrais des simulations fines de l’océan pour comprendre son évolution très lente. On progresse, et un jour ce sera traité à des échelles pertinentes pour le climat.
D’autre part, dans l’atmosphère, on tombe sur d’autres problèmes – ainsi, les grands cumulo-nimbus tropicaux, ce sont des systèmes convectifs. Quand on a une maille à 100 km, on essaie d’en avoir une idée statistique. Quand on a une maille à 100 m, on résout ces systèmes explicitement. Mais entre les deux, il y a une espèce de zone grise, trop petite pour faire des statistiques mais trop grande pour faire de la résolution explicite. Dans 50 ans, on pourra résoudre des systèmes convectifs dans des modèles du climat. On commence à avoir la puissance de calcul pour s’en rapprocher.
Plus généralement c’est un exercice assez riche que de prendre des phénomènes à petite échelle et d’essayer de les intégrer aux phénomènes à grande échelle géographique, pour voir leur effet. L’écoulement atmosphérique est décrit par les équations de Navier-Stokes mais on ne peut pas résoudre toute la cascade d’effets vers les petites échelles, alors on fait de la modélisation. On se dit : il doit y avoir une certaine turbulence qui produit l’effet observé sur l’écoulement moyen. On observe les changements de phase, et il y a tout un travail pour essayer de modéliser cela correctement.
Mais c’est très difficile, dans les articles scientifiques, quand quelqu’un a fait un progrès en modélisation, de le reproduire à partir de l’article – d’une certaine façon, cette nouvelle connaissance est implicite. L’auteur vous donne ses hypothèses physiques, ses équations continues, mais ne va pas jusqu’à l’équation discrète et à la façon dont il a codé les choses, ce qui peut être une grosse partie du travail. On commence désormais à exiger que le code soit publié, et il y a des revues dont l’objectif est de documenter les codes, et dont la démarche est de rendre les données brutes et les codes disponibles. Sans le code de l’autre chercheur, vous ne pouvez pas reproduire son expérience. Mais ce sont là des difficultés qui sont en voie de résolution en ce moment.
 Un supercalculateur
Un supercalculateur
Les super-calculateurs sont de plus en plus complexes à utiliser.
Dans mon travail, je suis plutôt du côté des producteurs de données. Il y a des climatologues qui vont prendre les données de tout le monde et faire des analyses, donc vous avez un retour sur vos propres simulations, ce qui est extrêmement riche. C’est très intéressant pour nous de rendre les données disponibles, car on bénéficie alors de l’expertise des autres équipes. Cela nous donne un regard autre sur nos données. D’ailleurs, il y a une contrainte dans notre domaine : pour les articles référencés dans le rapport du GIEC, les données doivent obligatoirement être disponibles et mises sous format standard. C’est une contrainte de garantie de qualité scientifique.
B : Y a-t-il libre accès aux données à l’international ?
OM : Tous les 6 ou 7 ans, le rapport du GIEC structure les expériences et organise le travail à l’international. Il y a eu une phase, il y a 10 ans, où on voulait rassembler toutes les données dans un lieu commun, mais ce n’est pas fiable, il y a trop de données. Maintenant on a un portail web (ESGF) qui permet d’accéder aux données là où elles sont. Les gens peuvent rapatrier les données chez eux pour les analyser mais quand il y a un trop gros volume, pour certaines analyses, ils sont obligés de faire le travail à distance.
B : Parlons du « déluge de données, du big data. Vous accumulez depuis des années une masse considérable de données. Il y a aussi des problèmes pour les stocker, etc.
OM : Le big data, pour nous, c’est très relatif, car il y a plusieurs ordres de grandeur entre les données que nous avons et ce qu’ont Google ou Youtube par exemple. 80% du stockage des grands centres de la Recherche publique est le fait de la communauté climat-environnement. Notre communauté scientifique étudie la trajectoire du système, pas l’état à un seul instant. Il y a des phénomènes étudiés sur 1000 ans pour lesquels on met les données à jour toutes les 6 heures (les gens qui étudient les tempêtes par exemple). Mais c’est vrai que le stockage devient un problème majeur pour nous. GENCI finance les calculateurs, mais ce sont les hébergeurs de machines, le CNRS etc., qui financent les infrastructures des centres.
B : Qu’est-ce que les progrès de l’informatique ont changé dans votre domaine, et qu’est-ce que vous pouvez attendre des informaticiens ?
OM : Il y a une plus grande spécialisation. Lorsque j’étais en thèse, un jeune doctorant avait les bases en physique, mathématiques et informatique pour écrire un code qui tournait à 50% de la puissance de la machine. On n’avait pas besoin de spécialiste en informatique. Les physiciens apprenaient sur le tas. Maintenant l’évolution des machines fait qu’elles sont plus difficiles à programmer en programmation parallèle pour avoir un code pertinent et performant, et du coup les physiciens doivent collaborer avec des informaticiens. Les super-calculateurs sont de moins en moins faciles à utiliser. En ce qui concerne la formation, les jeunes qui veulent faire de la physique, et arrivent en thèse pour faire de la climatologie ne sont pas du tout préparés à utiliser un super-calculateur. Ils commencent à être formés à Matlab et à savoir passer des équations à des programmes, mais quand on met entre leurs mains un code massivement parallèle en leur disant de modifier un paramètre physique, on a vite fait de retrouver du code dont la performance est divisée par 10, voire par 100 ! On a besoin de gens qui comprennent bien l’aspect matériel des calculateurs, (comprendre où sont les goulots d’étranglement pour faire du code rapide), et qui sachent faire des outils pour analyser les endroits où ça ralentit. En informatique, les langages de programmation ont pris du retard sur le matériel. Il y a un travail qui est très en retard, à savoir, essayer de faire des langages et compilateurs qui transforment le langage du physicien en code performant. Il faut beaucoup d’intelligence pour masquer cette complexité à l’utilisateur. Aujourd’hui c’est plus difficile qu’il y a vingt ans.
B : Votre travail a-t-il des retombées sociétales ou économiques ?
OM : Nos docteurs sont embauchés chez les assureurs, cela doit vouloir dire que notre travail a des retombées pour eux ! Il y a aussi EDF qui s’intéresse à avoir une vision raisonnable de ce que sera le climat pour l’évolution des barrages, l’enfouissement des déchets nucléaires, etc. Mais, la « prévision du climat », on en a horreur : nous, on fait des scénarios, mais on ne peut pas maîtriser, en particulier, la quantité de gaz à effet de serre qui seront rejetés dans l’atmosphère par l’homme. On fait des scénarios et on essaie d’explorer les climats possibles, mais on évite de parler de prévisions. On participe vraiment à la collaboration internationale pour essayer de faire des scénarios climatiques. Il y a une partie validation – la partie historique, instrumentale, bien documentée, qui permet de voir quels sont les modèles qui marchent bien – et une partie où on essaie de comprendre ce qui ne marche pas. Il y a toute une problématique de mathématiques et statistiques pour l’évolution dans le futur.
B : Y a-t-il beaucoup de femmes chercheurs dans votre domaine?
OM : Cela dépend de ce qu’on appelle « mon domaine ». Dans le laboratoire, il y a un bon tiers de femmes. Mais c’est qu’on est dans les sciences de la Terre. En biologie, il y en a plus de la moitié. Dans les sciences dures, en physique, il y en a moins. Dans les réunions de climatologues, il y a environ un tiers de femmes. Mais dès qu’on est dans une réunion d’informaticiens la proportion chute à moins de 10%. C’est extrêmement frappant. Il y a plus de femmes, mais dans la partie informatique et calcul scientifique, cela ne s’améliore pas beaucoup.
B : Y a-t-il autre chose que vous aimeriez ajouter?
OM : Il faut faire attention de distinguer modélisation et simulation. Nous, on fait de la modélisation : on commence par faire un modèle physique, puis on discrétise pour faire un modèle numérique, puis on fait du code. La simulation c’est ce que vous faites une fois que vous avez le code, le modèle informatique.
Olivier Marti, CEA, Laboratoire des Sciences du Climat et de l’Environnement
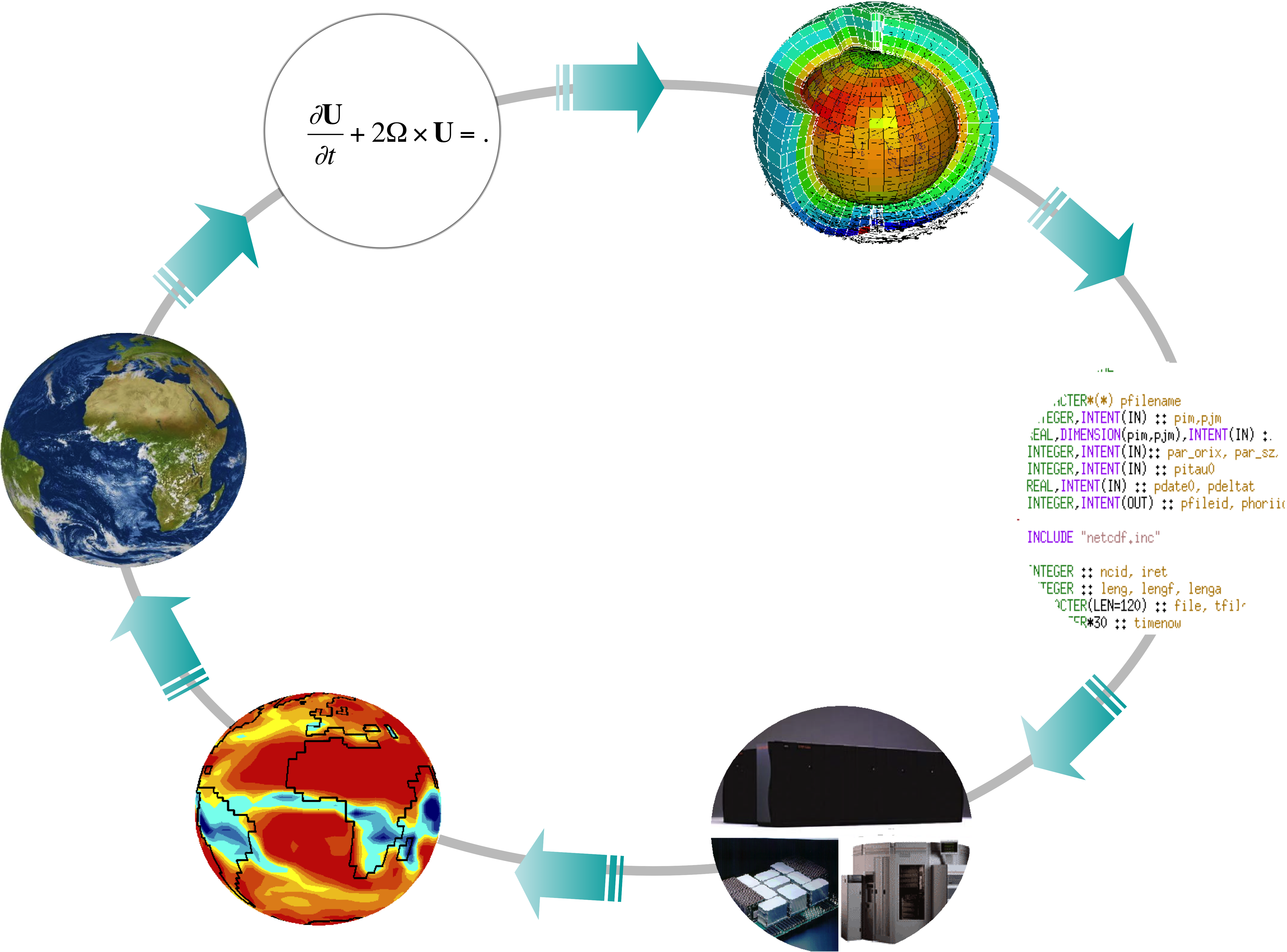
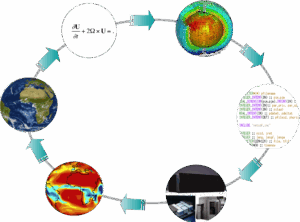 La démarche itérative de la simulation
La démarche itérative de la simulation



































 Afin de faire découvrir aux jeunes l’informatique et les sciences du numérique, et après le grand succès de la troisième édition 2013 (plus de 170 000 élèves dont 48% de filles et près de 1200 collèges ou lycées français ont participé), une nouvelle édition commence aujourd’hui : les épreuves 2014 se déroulent du 12 au 19 novembre 2014.
Afin de faire découvrir aux jeunes l’informatique et les sciences du numérique, et après le grand succès de la troisième édition 2013 (plus de 170 000 élèves dont 48% de filles et près de 1200 collèges ou lycées français ont participé), une nouvelle édition commence aujourd’hui : les épreuves 2014 se déroulent du 12 au 19 novembre 2014.{kind=link}