Sur Interstices, la revue scientifique sur les sciences du numérique, Jean-Pierre Merlet, enrichit la rubrique sur la robotique d’une réflexion sur les problèmes soulevés par l’apparition de la robotique de service, et le fait que les robots évoluent de plus en plus au contact des humains. Un grand merci de nous permettre de reprendre ce billet ici. Thierry Viéville.

© Inria / Photo H. Raguet
Jusqu’à une période récente, l’utilisation des robots se cantonnait à des lieux où la présence humaine était totalement prohibée. Dans la plupart des cas, ces applications justifiaient l’étymologie du mot robot, qui vient de robota : corvée, travail pénible. Nous assistons actuellement à une évolution phénoménale de ce domaine avec, en particulier, l’apparition de la robotique de service. Les robots vont pénétrer dans tous les milieux, y compris dans la sphère privée. Ce changement s’accomplit suivant deux directions :
- Des dispositifs spécialisés dans l’exécution d’une tâche. On peut citer en exemple les aspirateurs ou les tondeuses robotisées. Ils dérivent d’objets déjà présents dans les milieux humains, c’est l’évolution technologique et scientifique qui les a rapprochés de la robotique. Les drones s’apparentent aussi à cette catégorie.
- Des dispositifs multi-fonctionnels, qui affichent en particulier des objectifs de symbiose avec l’humain. Pour simplifier, appelons-les « robots futuristes ». Les plus popularisés médiatiquement sont les robots humanoïdes. Lorsque est affichée l’ambition que le robot devienne un véritable partenaire pour l’homme, on parle de robot compagnon. On est ici très proche des mythes antiques comme les servantes artificielles du dieu boiteux Héphaïstos ou de la machine servante de Saint Albert le Grand qui, selon la légende, a été démolie à grands coups de canne par Saint Thomas d’Aquin qui y voyait un suppôt de Satan. Il existe également des animaux de compagnie robotisés comme le chien AIBO ou le phoque PARO. Les exo-squelettes comme l’ATLAS du CEA ont pour objectif de suppléer à des déficits de mobilité, voire d’augmenter la mobilité humaine. Les robots de collaboration (cobot) assistent au plus près le travailleur humain.
Un débat s’est engagé dans la communauté robotique pour déterminer si dans un futur relativement proche ces robots s’imposeraient. Examinons cette question non seulement d’un point de vue scientifique et technologique mais aussi d’un point de vue sociétal, sous l’angle de l’acceptation, des enjeux éthiques, etc.
Des progrès matériels
Les dispositifs spécifiques se développent grâce aux nouveaux matériels informatiques, des processeurs à très bas coût comme le Raspberry ou les Arduino qui ont été conçus pour permettre d’interfacer en quelques minutes les capteurs nécessaires aux robots, capteurs dont les coûts ont considérablement baissé. La recherche en robotique bénéficie de cette évolution : il est désormais possible de réaliser en quelques heures et pour quelques centaines d’euros seulement des robots qui auraient nécessité, ne serait-ce qu’il y a 10 ans, des centaines d’heures de travail et des dizaines de milliers d’euros.
Les robots futuristes bénéficient eux aussi des progrès en informatique, qui leur permettent de disposer d’une puissance de calcul importante, nécessaire même pour des fonctions basiques. Ainsi, le robot humanoïde NAO, un gros succès de la robotique française dont on a tout lieu de se réjouir, compte 25 servomoteurs qu’il faut simultanément contrôler pour que le robot puisse simplement marcher. Toutefois, cette puissance de calcul reste insuffisante. Ainsi, des robots encore plus sophistiqués, comme ceux utilisés pour les derniers challenges DARPA, souffrent d’une lenteur d’exécution visible sur les vidéos de présentation.
C’est une chose d’obtenir des flux de données massifs issus des capteurs sensoriels. Mais, même en disposant d’une multitude de moteurs, c’en est une autre d’exploiter ces flux, très bruités, pour réaliser une tâche simple comme ouvrir un placard quel qu’en soit le mode d’ouverture, ceci en dépit des progrès réalisés en apprentissage automatique (machine learning). Les robots humanoïdes peuvent réaliser avec élégance quelques tâches spécifiques, ce qui a toutefois nécessité un long travail de la part des mathématiciens et des automaticiens. Bien que la complexité de ces robots justifie pleinement un effort de recherche, il faut cependant reconnaître, au risque de heurter certains roboticiens, que l’expression « robots intelligents » prête à sourire, tant ils font preuve dans beaucoup de cas d’une stupidité déconcertante. Il convient d’ailleurs de ne pas se leurrer sur certaines vidéos spectaculaires comme celle du robot ASIMO serrant la main du premier ministre chinois… alors qu’il est discrètement téléopéré.
Des barrières techniques et économiques
Outre ces limitations « intellectuelles », les robots humanoïdes sont confrontés à des barrières physiques et économiques. La première de ces barrières est liée à la physique de la manipulation : un NAO, malgré son incroyable succès médiatique, aura du mal à soulever un boulon de voiture, tandis qu’un robot capable de soulever 30 kilos en pèsera 600 et requerra 7 kW de puissance électrique, soit un rendement de 5 à 10 %. Cette faible efficacité n’est pas due à un mauvais rendement des actionneurs, qui au contraire est excellent, mais à la structure même du robot : la recherche de l’universalité dans l’exécution des tâches a imposé des architectures mécaniques où une partie importante de l’énergie est consacrée à l’équilibre de la structure au détriment de l’énergie affectée à la tâche.
Et ce mauvais rendement conduit à se heurter à une autre barrière : l’autonomie énergétique. Certaines tâches courantes comme relever une personne ou monter une roue de voiture requièrent une énergie importante. De ce fait, elles sont hors de portée des robots humanoïdes, dont l’autonomie se limite à quelques dizaines de minutes sans réaliser ce genre de tâches.
Une autre barrière est le coût. Les robots humanoïdes font appel à un nombre important d’actionneurs et de capteurs. Ces derniers ont vu leur prix considérablement baisser, mais restent encore souvent relativement coûteux, entre 1000 et 5000 euros pour un scanner laser par exemple. Pour les actionneurs, on fait actuellement appel à des composants industriels très standards et massivement diffusés, dont il semble peu probable que le prix puisse fortement baisser. On entend souvent parler de nouveaux types d’actionneurs, moins coûteux, mais sans mentionner leur rendement. Par ailleurs, une intégration plus poussée faciliterait certainement leur mise en œuvre, mais ne devrait pas avoir un impact considérable sur le coût. Actuellement, il faut compter plusieurs milliers d’euros pour un simple robot de téléprésence, 15 000 euros pour un NAO et plusieurs centaines de milliers d’euros pour un humanoïde de taille plus conséquente. Il y a aussi eu quelques effets d’annonce pour les cobots avec des prix très attractifs comparés aux robots industriels classiques. Mais un examen des robots présentés montre qu’ils ont une puissance et une dextérité réduites, ce qui en limite forcément les usages.
Des mécanismes d’acceptation
 « Les robots sont vos amis » – Source : Flickr / Photo Thomas Hawk
« Les robots sont vos amis » – Source : Flickr / Photo Thomas Hawk
Une barrière commune à tous ces robots est le problème de l’acceptation par l’humain. Il est probablement moins critique pour certains robots spécifiques, simplement dérivés d’objets du quotidien. D’autres, dont le design s’éloigne de l’objet équivalent, peuvent susciter une appropriation forte. Par exemple, il existe des sites qui proposent des habits pour personnaliser des robots aspirateurs, comme s’il s’agissait d’un animal de compagnie.
Toutefois, d’autres robots spécifiques posent des problèmes d’acceptation : par exemple, l’utilisation des drones offrant la possibilité de pénétrer dans la sphère privée de tout individu a fait l’objet de réactions très violentes, allant jusqu’à la menace de les abattre.
Pour les robots humanoïdes, le mécanisme psychologique de l’acceptation, qui peut être extrême — du rejet brutal et définitif à une appropriation proche du fétichisme —, n’est pas bien compris.
Une théorie de l’acception est très en vogue en robotique humanoïde : la « vallée dérangeante » (Uncanny Valley). Elle explique que la non-acceptation est liée à des défauts d’apparence entre le robot et l’humain, qui sont jugés d’autant plus repoussants que sur d’autres aspects il peut faire illusion. En conséquence, un robot presque parfait peut être encore plus violemment rejeté que son prédecesseur. Mais la théorie stipule qu’une proximité encore plus proche permettra de passer ce creux, cette vallée du rejet, pour atteindre une acceptation complète. Cette théorie est toutefois très contestée car certaines études, comme celle menée par Christoph Bartneck, semblent montrer que même le plus parfait des humanoïdes n’atteindra jamais le seuil d’acceptation de robots plus simples dont l’apparence les fait classer clairement dans la catégorie des « machines » : la vallée serait plutôt une falaise inaccessible.
On sait en tout cas que les outils classiques d’évaluation comme les questionnaires sont souvent biaisés, car l’objet évalué est très proche de l’humain. Ainsi, les réponses traduisent plus l’image que l’utilisateur veut donner de lui vis-à-vis des nouvelles technologies que sa réelle appréciation du robot. Pourtant, l’étude de l’acceptation potentielle, en interaction avec des disciplines de sciences humaines et sociales, devrait intervenir très en amont de la conception, car elle peut imposer des contraintes scientifiques et technologiques très fortes. Par exemple, le président d’une association mondiale de handicapés, en fauteuil roulant, à qui l’on demandait quelles fonctionnalités il aimerait pouvoir ajouter à son fauteuil, a simplement répondu « qu’il soit beau, sinon c’est un frein à mes relations sociales, en particulier avec les enfants ».
Des questions éthiques
Les robots humanoïdes posent aussi de nombreux problèmes d’éthique. La liste en est trop longue pour tous les exposer, mais l’on peut en citer quelques-uns. La proximité avec des humains de machines qui peuvent être relativement puissantes ou qui sont censées les assister soulève des questions de risque et de responsabilité en cas d’accident. On évolue dans un domaine où la législation est encore extrêmement sommaire. Il est parfois invoqué l’implantation dans les robots des trois lois de la robotique d’Isaac Asimov pour assurer la protection des humains. Indépendamment du fait qu’on n’ait actuellement aucune idée du comment, c’est un peu vite oublier qu’Asimov s’est lui-même amusé à expliquer comment les détourner (dans son roman Face aux feux du Soleil par exemple).
Outre la gestion des risques, on peut se poser des questions sur le rôle des robots dans l’interaction sociale. En admettant que cela soit possible, est-il souhaitable qu’un robot devienne un substitut aux relations humaines ? On peut par exemple parfaitement envisager que la société, poussée par des contraintes économiques ou par sa propre évolution, réduise l’aide humaine aux personnes fragiles pour la remplacer par des machines. Dans Face aux feux du Soleil, Asimov décrit d’ailleurs une société qui a poussé la substitution jusqu’au bout, avec des humains devenus incapables d’assumer la présence physique de leurs semblables.
Dans un autre registre, la robotique, ou des technologies qui en sont dérivées, laissent entrevoir la possibilité de dispositifs d’assistance et de monitoring de la santé qui incontestablement pourraient avoir des impacts positifs. Elles permettraient par exemple de gérer voire de prévenir la chute des personnes âgées qui, chaque année, cause en France la mort de 10 000 personnes. Le premier problème éthique concerne la protection des données médicales recueillies, dont on ne peut pas exclure qu’elles soient utilisées à des fins malveillantes ou pour des escroqueries. Un second problème est soulevé par des psychologues qui craignent un risque de changement de comportement chez les utilisateurs. Les adeptes du Quantified self pourraient en effet devenir totalement fascinés par ces données, même s’ils s’en défendent vigoureusement. Ces psychologues soulignent que ces données peuvent modifier, parfois en mal, la perception d’événements de la vie courante.

Reconstitution d’un appartement complet expérimental. Cet appartement sera équipé d’une grue à cables, MARIONET-ASSIST, permettant d’aider au lever et à la marche et offrant des possibilités de manipulation d’objets. Il comportera aussi des objets communicants qui aideront à résoudre des problèmes de détresse, comme une chute.
© Inria / Photo Kaksonen.
Ces mêmes psychologues parlent aussi du risque de perte de l’imprévu, un élément pourtant essentiel dans la vie humaine, dans le cas où l’on suivrait trop strictement les recommandations de ces dispositifs, par exemple, ne pas goûter un aliment exotique parce que sa composition est inconnue ou qu’elle n’est pas à 100% compatible avec les recommandations de l’appareil. Des robots « prescripteurs » ne seraient pas simplement des machines destinées à supprimer ou alléger l’exécution de certains robota, car ils pourraient aller bien plus loin dans leur influence sur leur partenaire humain, de façon parfois fort subtile. La position des autorités de régulation sur ces problèmes est encore incertaine : par exemple, l’autorité américaine de la santé a récemment indiqué que les applications mobiles qui sont censées ne fournir que des informations sur l’état de santé de l’utilisateur, sans émettre de recommandations, ne seraient pas tenues d’être enregistrées auprès de cet organisme et ne font donc l’objet d’aucune vérification de fiabilité. Qu’en serait-il si l’application résidait dans un robot compagnon ?
Conclusion
L’évolution scientifique et technologique permet d’envisager l’utilisation de robots au plus proche de l’humain, certainement avec des effets bénéfiques et des perspectives scientifiques très riches et multidisciplinaires combinant théories et expérimentations. Toutefois, cette potentialité d’impact et la richesse scientifique des problématiques représentent paradoxalement un obstacle au développement du domaine. En effet, elles compliquent l’évaluation de cette recherche, qui nécessite un regard croisé d’experts de sphères différentes. De plus, les développements et les impacts potentiels sont forcément de long terme. Ils sont donc peu compatibles avec le fonctionnement par appel à projet, courant sur des délais relativement courts, alors que le montage d’une seule expérimentation avec des humains peut nécessiter plusieurs années.
Néanmoins, la perspective de robots « intelligents », capables d’accomplir de manière autonome un large éventail de tâches, incluant une interaction profonde avec un humain allant au-delà d’un rapport entre humain et animal, semble être une vision très lointaine dans le temps, même si la présentation médiatique de la robotique peut laisser croire le contraire. Les raisons de cet éloignement dans le temps, outre la difficulté d’élaborer des schémas intellectuels convaincants, repose sur des problématiques physiques et technologiques dont la résolution suppose un nombre important de ruptures technologiques majeures. Et, bien entendu, resteront posés des problèmes d’éthique, de droit et de choix de société qui sont pour le moment très peu traités.
Jean-Pierre Merlet. Version originale : https://interstices.info/robots-et-humains.


 En programmation orientée objet, le programmeur définit des types d’objets (des classes dans la terminologie orientée objet) et les comportements des objets dans ces classes. Concrètement, un objet est une structure de données dans un certain état (typiquement caché pour l’extérieur) qui répond à un ensemble de messages. L’ensemble des messages (des programmes) acceptés par l’objet détermine son comportement. Les objets interagissent entre eux par l’intermédiaire de ces messages. Il n’est pas nécessaire de connaître le programme correspondant à un objet pour pouvoir interagir avec cet objet. Il suffit de connaître son «interface», c’est-à-dire l’ensemble des messages qu’il comprend. (C’est sans doute ce principe d’indépendance qui est à la base du succès de la programmation orientée objet.)
En programmation orientée objet, le programmeur définit des types d’objets (des classes dans la terminologie orientée objet) et les comportements des objets dans ces classes. Concrètement, un objet est une structure de données dans un certain état (typiquement caché pour l’extérieur) qui répond à un ensemble de messages. L’ensemble des messages (des programmes) acceptés par l’objet détermine son comportement. Les objets interagissent entre eux par l’intermédiaire de ces messages. Il n’est pas nécessaire de connaître le programme correspondant à un objet pour pouvoir interagir avec cet objet. Il suffit de connaître son «interface», c’est-à-dire l’ensemble des messages qu’il comprend. (C’est sans doute ce principe d’indépendance qui est à la base du succès de la programmation orientée objet.)

 De la complexité du problème : Les contraintes entre les variables, © Openfisca
De la complexité du problème : Les contraintes entre les variables, © Openfisca
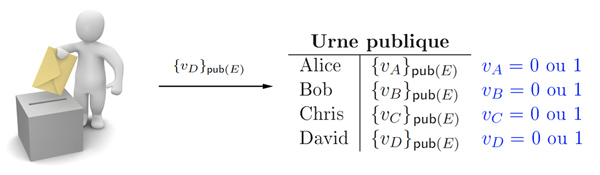
 Mettre au point un système de vote électronique sûr est un exercice délicat. En particulier, la vérifiabilité et la résistance à la coercition sont des propriétés antagonistes : il faut à la fois démontrer qu’un certain vote a été inclus dans le résultat et ne pas pouvoir montrer à un tiers comment on a voté.
Mettre au point un système de vote électronique sûr est un exercice délicat. En particulier, la vérifiabilité et la résistance à la coercition sont des propriétés antagonistes : il faut à la fois démontrer qu’un certain vote a été inclus dans le résultat et ne pas pouvoir montrer à un tiers comment on a voté.