Les progrès de la robotique et de l’intelligence artificielle sont sur le point de permettre la construction d’armes autonomes pour chercher et éliminer des cibles humaines. Ce serait une révolution dans l’industrie de l’armement : actuellement, même les drones sont commandés à distance. Jusqu’à présent, les robots sont des exécutants mais les décisions restent entre les mains d’un être humain qui prend, ou non, la décision de tuer. Cela pourrait changer, car la technologie va désormais donner la capacité de déployer des armes entièrement autonomes, et il ne faut pas beaucoup d’imagination pour s’inquiéter de la course aux armements qui s’en suivra et des risques afférents.
À l’occasion du grand congrès annuel de l’intelligence artificielle, IJCAI, les chercheurs en robotique et intelligence artificielle du monde entier se mobilisent contre ce développement et ont lancé une pétition réclamant l’interdiction d’armes autonomes.
À l’heure d’une pause estivale bien méritée et en attendant de vous retrouver le 19 août pour la rentrée de binaire, nous avons envie de partager avec vous un bilan de l’activité de notre blog :
170 articles publiés depuis sa création en janvier 2014,
un comité de rédaction qui a monté en puissance (6 femmes et 4 hommes),
660 abonnés au compte twitter @Blog_Binaire (rejoignez-les !),
des statistiques en croissance constante avec 10 à 15 000 visites par mois, pour 75% d’entre eux des visiteurs qui « reviennent » sur le blog, de France, du Canada, de Belgique, de Suisse, du Maroc, d’Algérie mais aussi des US, d’Angleterre, d’Allemagne…
Un grand merci à tous nos lecteurs, à ceux qui contribuent, à ceux qui commentent et à ceux qui nous encouragent chaque jour à proposer de nouveaux sujets. Et pourquoi pas vous ? Si un sujet sur l’informatique, le numérique, l’innovation technologique vous questionne, ou vous parait incompréhensible, demandez nous des explications ! Nous sommes là pour vous aider à découvrir ce qui se cache derrière les concepts et les lignes de code qui vous entourent.
En attendant, la rédaction de binaire vous souhaite de belles vacances.
C’est une expo, petite mais sympathique, qui raconte 40 ans de la carte à puce, de la carte de téléphone, à la carte SIM, à la carte de paiement, à la carte santé. Des milliards de telles cartes sont fabriquées chaque année.
Le commissaire scientifique de l’exposition est Pierre Paradinas, un des éditeurs de Binaire. Il est professeur titulaire de la chaire « Systèmes Embarqués » au Cnam. Il a notamment dirigé le laboratoire de recherche de Gemplus, un des industriels clés de l’histoire de la carte à puce.
Surtout ne pas rater le film de 5mn « Michel et la cryptographie » des Chevreaux Suprématistes. Un petit bonheur de drôlerie.
« Chercheurs et entrepreneurs : c’est possible ! Belles histoires du numérique à la française ». Dialogue à partir du livre de Antoine Petit (président d’Inria, l’institut national de recherche français dédié aux sciences du numérique) et Laurent Kott (président d’IT Translation, investisseur et cofondateur de startups techno-numériques issues de la recherche publique ou privée), chez Manitoba / Les Belles Lettres. 2015.
Serge Abiteboul : C’est clair, les auteurs savent de quoi ils parlent. Le livre raconte des startups technologiques, de très belles histoires comme celles d’Ilog, Vulog, ou O2-technology. Il fourmille d’informations sur la création de ces entreprises, sur leur croissance. Mais…
Thierry Viéville : Mais tu n’as pas l’air très enthousiaste ?
Serge : C’est un sujet passionnant. Alors, pourquoi je boude mon plaisir ? Pour moi, une telle entreprise est la rencontre entre un rêve de chercheur, et un projet d’entreprise. Le livre dit beaucoup sur le projet et pas grand chose sur le rêve. On en apprend finalement assez peu sur les développements techniques et scientifiques qui ont conduit à des produits qu’on a vendu.
Thierry : Tu en demandes peut-être trop. C’est juste un livre qui donne plein d’informations sur la création de startups Inria. Je suis plutôt fier quand les travaux de recherche fondamentale des collègues participent au développement de l’économie, à la création d’emplois.
Voici un exemple que j’aime bien ; c’est en France, à Lyon, c’est au milieu du 18ème siècle, et c’est déjà de l’informatique. Des inventeurs ont apporté la prospérité à tout un éco-système [ref1] avec l’idée de la « technologie ouverte » comme levier. Pour son invention d’une machine à tisser les fils de soie, Michel Berthet a reçu une récompense qui impliquait de transférer cette technologie aux autres fabricants. La « gestion publique de l’innovation, fondée sur la négociation partagée de l’utilité technique et la diffusion rapide des techniques nouvelles » va permettre de devancer les concurrents européens en proposant plus de 200 propositions d’améliorations [ref2].
Cette avancée collective va conduire à implémenter une notion rudimentaire de programme avec un système de cartes perforées portées par un prisme dû à Jean-Baptiste Falcon , et à une première tentative de machine pour robotiser les métiers à tisser, grâce à Jacques Vaucanson. Les concepts fondateurs de la science informatique sont déjà là. On retrouve l’idée fondamentale du codage de l’information. Ici l’information, ce sont les motifs à tisser devenus trop complexes pour être créés manuellement. On trouve même le traitement automatisé ; on parlera plus tard d’algorithme.
Serge : C’est un bel exemple. Les histoires d’entreprises de chercheur-e-s/entrepreneur-e-s peuvent être très belles.
Thierry : Et ta conclusion sur le livre d’Antoine Petit et Laurent Kott ?
Serge : De belles histoires de startups Inria restent à mon avis encore à écrire. Faire partager l’aventure de ces créations et mettre en lumière ces hommes et femmes qui innovent, c’est aussi ce que nous avons envie de partager, à Binaire, avec le récit de startups d’aujourd’hui. Et pour finir, juste un détail : pourquoi un tel livre n’existe-t-il pas en version numérique ?
En informatique, des mots de la vie courante prennent un sens particulier, précis, peut-être inattendu. Nous allons expliquer ici l’expression « clé de données ».
Les clés en informatique
Vous savez sûrement ce qu’est une clé. Rappelez-vous ces petits objets métalliques dans votre poche ou votre sac. Bon c’est vrai que dans certains hôtels, ils sont devenus cartes plastiques. Mais quand même vous voyez bien ce que c’est. Une clé ? Pour ouvrir la porte ? L’informatique va évidemment essayer de vous embrouiller. En informatique, une clé peut être suivant les besoins :
Une clé de chiffrement : un paramètre utilisé pour des opérations cryptographiques comme le chiffrement/déchiffrement de message, ou une signature numérique. La clé vous permet d’ « entrer » dans un espace virtuel privé.
Une clé USB : Une clé USB est un support de stockage informatique amovible à base mémoire flash. Là, le nom provient de la ressemblance avec une clé classique.
Une clé de données. Nous allons parler ici de ce type de clé.
Photos d’objets du Musée du Quai de Branly. Wikipédia
La clé de données
Une structure de données essentielle en informatique est la relation, un tableau avec des lignes et des colonnes. Dans la figure précédente, la première colonne, qui se nomme IDB pour identifiant de Branly, est une « clé ». C’est à dire que deux enregistrements distincts doivent avoir des valeurs distinctes dans cette colonne. C’est extrêmement utile. Si je veux vous parler d’un objet de la collection, il me suffit d’utiliser sa clé et il n’y aura pas de confusion possible. Dans la base de données du musée, je peux aussi utiliser ces clés, par exemple pour lister les objets dans une salle particulière.
On retrouve des clés partout. On peut utiliser, comme dans la bible, le prénom de la personne et celui de son père comme clé :
Seth
Adam
131 AM
Enosch
Seth
236 AM
Kénan
Enosch
326 AM
Mahalaleel
Kénan
395 AM
Seulement quand la population devient trop importante, cela crée des ambiguïtés. Alors on cherche d’autres clés, (nom, prénom, date de naissance). On finit par inventer des identifiants pour garantir l’unicité. Un numéro de sécurité sociale identifie une personne, un URL (pour Universal Ressource Locator) une page du Web, et un ISBN (pour International Standard Book Number) une édition d’un livre publié.
Il n’est pas toujours simple d’identifier un objet. Vous pouvez installer un livre sur plusieurs supports, liseuse, ordinateur, téléphone, tablette. Pour identifier l’objet livre dans votre bibliothèque numérique personnelle, l’ISBN ne suffit plus. Vous pouvez par exemple utiliser comme clé (ISBN, modèle, numéro de série). Un bref détour dans le fabuleux musée du Quai de Branly va nous permettre d’illustrer un autre aspect du lien complexe qui peut exister entre un objet et la clé qui l’identifie.
Identifiants orphelins et objets sous X
Le musée regroupe des objets venus d’horizons divers, de différentes collections. À sa création, peut-être même avant, des liens qui reliaient des objets à leurs identifiants se sont brisés :
Identifiant orphelin : Un identifiant s’est retrouvé « orphelin » de l’objet qui avait conduit à sa création. On aimerait imaginer cet objet poursuivant sa vie dans le bureau d’un ethnologue professionnel ou amateur qui le chérit, qui lui peaufine une histoire, plutôt que sur une étagère de magasin.
Objet sous X : À l’inverse, un objet a pu perdre (par exemple dans le déménagement vers le Quai de Branly) l’étiquette qui le reliait à son identifiant et ainsi à sa description dans la base de données. Le pauvre objet a perdu son histoire. Il s’est vu attribuer un numéro débutant par un « X ». Il renaissait « sous X ».
Des milliers d’identifiants orphelins.
Et pour conclure, une pensée émue pour ces milliers d’objets sous X entre les mains d’X-ologues chargés de leur construire une nouvelle histoire.
Pour en savoir plus sur les objets sous X : Tiziana Nicoletta Beltrame, Classer les inclassables, dans Penser, Classer, Administrer, Pour une Histoire Croisée des Collections Scientifiques, Musée d’Histoire Naturelle, 2014
Une excellente émission à podcaster sur l’enseignement de l’informatique. La question est souvent posée sur les antennes mais les vrais sujets sont rarement abordés comme ils le sont ici. Enfin, une vision réaliste, optimiste sans cacher les problèmes lourds ! Un discours positif qui reconnait les vraies avancées, un discours positif sur les profs des écoles, collèges et lycée, en accord avec ce que je connais, et qui fait plaisir à entendre. Serge Abiteboul.
Du 6 au 11 juillet, Lille accueille ICML (International Conference on Machine Learning), le rendez-vous annuel des chercheurs en apprentissage automatique (machine learning). Léon Bottou, chercheur connu pour ses nombreux résultats en apprentissage automatique, et récemment recruté par le laboratoire Facebook, propose de nous expliquer comment fonctionnent deux algorithmes d’apprentissage automatique.
Dans le blog binaire du 23 juin 2015, Colin de la Higuera écrit que l’apprentissage automatique représente une rupture entre programmer – c’est à dire détailler la séquence d’opérations à effectuer pour accomplir une tâche donnée – et entrainer – c’est à dire doter la machine de la capacité d’apprendre et obtenir le comportement désiré par l’exemple.
Les moteurs de cette rupture sont les augmentations permanentes du volume de données disponibles et de la rapidité des ordinateurs. Lorsque le volume des données augmente, il devient plus difficile au programmeur d’envisager tous les cas de figure et de concevoir un programme correct. Mais cela signifie aussi que l’on a beaucoup d’exemples à montrer à une machine capable d’apprendre. Cela signifie que l’apprentissage automatique devient plus intéressant chaque jour. En pratique cette rupture s’étale sur plusieurs décades et prend la forme d’une série de succès applicatifs qui deviennent de plus en plus fréquents et remarqués.
Les deux exemples qui suivent illustrent cette rupture et montrent comment fonctionne l’apprentissage automatique pour des applications bien réelles.
1. La catégorisation de textes
L’une des tâches fondamentales de la gestion des informations consiste à classer des documents rédigés en langage naturel en examinant leur contenu. Par exemple, un lecteur éduqué peut facilement séparer les nouvelles politiques des autres nouvelles. En revanche, ce même lecteur aura bien des difficultés si on lui demande de formuler un critère général permettant de reconnaître les documents dont le sujet est politique. Il est donc difficile de programmer un ordinateur pour accomplir cette séparation de façon automatique.
On espérait dans les années 1970 résoudre ce genre de problèmes en accumulant la connaissance d’experts humains. Un lecteur peut souvent expliquer pourquoi il pense que le sujet d’un document particulier est politique, par exemple en faisant remarquer que le document contient des noms de politiciens connus. Chacune de ces explications suggère une règle qui peut être programmée par un informaticien et exécutée par l’ordinateur. Malheureusement, on trouve toujours des documents qui échappent aux règles que l’on connaît déjà. En outre les experts humains ne cessent de proposer de nouvelles règles qui parfois contredisent celles qu’ils ont énoncées quelques heures auparavant. Pour gérer ces contradictions, on eut l’idée d’associer des poids aux règles. Par exemple, on compte un poids positif si le document contient les mots « conjoncture économique » et un poids négatif si le document contient les mots « enquête policière ». Si la somme de tous ces poids dépasse un certain seuil, on classe le document parmi ceux qui traitent de politique. Le problème consiste alors à définir manuellement les poids associés à chaque règle. Cela devient rapidement délicat parce que le nombre de règles augmente inévitablement.
L’apprentissage automatique remplace les explications des experts humains par le volume des données. La première étape consiste donc par la collecte des données, par exemple quelques centaines de milliers de documents que l’on aura étiquetés comme politique ou non-politique. Ensuite on donne un poids à chaque mot du dictionnaire. Au départ tous ces poids sont initialisés à zéro. L’apprentissage consiste à lancer un programme qui ajuste tous les poids en répétant par exemple les opérations suivantes jusqu’à ce que tous les documents d’apprentissage soient catégorisés sans erreurs :
Choisir un document au hasard dans l’ensemble d’apprentissage.
Calculer la somme des poids correspondant aux mots qu’il contient.
Si la somme est positive alors que le document n’est pas politique,
soustraire une petite quantité aux poids associés à tous les mots présent dans le document (laissant les autres poids inchangés.)
Si la somme est négative alors que le document est politique,
ajouter une petite quantité aux poids associés à tous les mots présent dans le document (laissant les autres poids inchangés.)
Cet algorithme simple s’appelle l’algorithme du Perceptron et fut inventé par Frank Rosenblatt en 1957 : chaque fois qu’un document est mal catégorisé, on ajuste tous les poids concernés de façon à déplacer leur somme dans la direction désirée. S’il existe un ensemble de poids qui permet de séparer correctement tous les documents d’apprentissage, on peut prouver que cet algorithme va le trouver.
Figure 1 – Etant donné une machine qui calcule un score et dont le fonctionnement dépend d’un grand nombre de poids, un algorithme d’apprentissage ajuste les poids de façon à obtenir le comportement désiré sur les exemples d’apprentissage.
La figure 1 ci-dessus résume le système : nous avons défini une machine qui prend un article de journal et produit un score qui en mesure le caractère politique. Ce que fait cette machine dépend d’un grand nombre de paramètres – les poids – qu’un algorithme d’apprentissage ajuste de façon à obtenir le comportement désiré sur un grand nombre d’exemples.
On peut évidemment ajouter de nombreux raffinements. Outre les poids associés à chaque mot du dictionnaire, on peut associer des poids à toutes les séquences de deux ou trois mots qui apparaissent suffisamment souvent dans les documents d’apprentissage. Si malgré cela il n’existe pas d’ensemble de poids qui catégorisent correctement tous les documents d’apprentissage, il suffit de réduire progressivement la quantité que l’on ajoute ou soustrait aux poids, ce qui leur permet de se stabiliser près des valeurs qui minimisent le nombre d’erreurs.
Il y a aussi des subtilités importantes. Par exemple, il est vraisemblable qu’une séquence de trente mots apparaissant dans un document d’apprentissage n’apparaît dans aucun autre. Si on associe des poids à de telles séquences, il est facile de catégoriser correctement tous les documents d’apprentissage, mais cela revient à reconnaître la question après avoir appris toutes les réponses par cœur. Un tel système n’est pas désirable car il a peu de chances de catégoriser correctement un document nouveau. C’est pourquoi on travaille souvent avec plusieurs ensembles de documents distincts : un ensemble d’apprentissage pour déterminer les poids, un ensemble de validation pour évaluer comment le système fonctionne sur des documents nouveaux et comparer plusieurs variantes, et un ensemble de test pour mesurer la performance finale du système sur des documents qu’il n’a jamais vus.
Ces techniques d’apprentissage sont simples mais très utilisées et très bien comprises. C’est avec ce genre de techniques que les moteurs de recherche scorent leurs réponses. C’est aussi avec ce genre de techniques que les réseaux sociaux sélectionnent les annonces publiées par nos proches. C’est souvent avec ce genre de techniques que les sites marchands recommandent des produits.
2. La reconnaissance visuelle d’objets
La reconnaissance automatique d’objets dans des photographies numériques est évidemment une tâche importante.
Imaginons par exemple un programme qui signale la présence d’une fleur dans une photographie et fonctionne pour toutes les espèces de fleurs, dans toutes les conditions d’éclairage, que la fleur soit entière ou partiellement cachée par un autre objet, etc.
La figure 2 ci-après montre pourtant ce que peut faire système moderne de reconnaissance d’objets qui fonctionne par apprentissage. Fondamentalement, il s’agit aussi d’une machine dont le fonctionnement dépend d’un grand nombre de poids calculés par un algorithme d’apprentissage. Mais au lieu d’avoir quelques dizaines de milliers de poids comme un système de catégorisation de textes, cette machine utilise quelques dizaines de millions de poids organisés d’une façon astucieuse qui respecte la nature des images et que l’on appelle un réseau convolutionnel.
Figure 2 – Localisation et identification d’objets (Oquab et al., CVPR 2015). Ce système particulier est entrainé en deux étapes. Pendant la première étape, les images d’apprentissage contiennent un seul objet situé au centre de l’image et dont la catégorie est connue. Pendant la seconde étape, les images d’apprentissages peuvent contenir plusieurs objets avec des positions variées. Chaque image est étiquetée avec la liste des objets présents mais sans en spécifier la position.
Dans la mémoire d’un ordinateur, une image photographique numérisée est une grille dont les cases sont appelées pixels. Chaque pixel représente un point de l’image avec trois nombres représentant les intensités des trois canaux associés aux couleurs élémentaires rouge, vert, et bleu. On peut aussi imaginer des « images » contenant un nombre de canaux arbitraire. Par exemple, les objets reconnus peuvent être représenté par une « image » dont le nombre de canaux est égal au nombre de catégories d’objets : l’intensité pour le canal C d’un pixel P indique alors si un objet du type correspondant au canal C a été reconnu à la position correspondant au pixel P. La figure 3 ci-après montre six des canaux calculés par un réseau convolutionnel pour l’image affichée sur la gauche.
Figure 3 – Couches de sortie d’un réseau convolutionnel (Oquab et al., CVPR 2014)
Le calcul effectué par un réseau convolutionnel est en fait une succession d’opérations qui chacune transforment une image d’entrée en une image résultat. Chacune de ces opérations dépend de poids qui seront déterminés pendant d’apprentissage du réseau, de façon à ce qu’appliquer cette séquence d’opérations à une image photographique (trois canaux) produise une « image » représentant les objets reconnus.
Chacune de ces opérations possède une propriété importante. Imaginez une petite machine qui prend comme entrées une petite grille de 3×3 pixels voisins dans une image donnée et calcule un pixel d’une image résultat. Comme le montre la figure 4 ci-après, appliquer cette machine à toutes les positions de l’image initiale produit une image résultat ayant a peu près le même nombre de pixels. Mais comme on utilise les mêmes poids pour toutes les positions, chaque pixel de l’image résultat est calculé en effectuant en prenant les pixels correspondants dans l’image d’entrée et en effectuant le même calcul pour toutes les positions de l’image. C’est très astucieux parce que l’apparence d’un objet dans une image ne dépend pas de sa position. C’est cette propriété qui fait le réseau convolutionnel et qui a révolutionné la vision par ordinateur ces trois dernières années.
Figure 4 – Une convolution
L’étape suivante consiste à déterminer les poids qui définissent les convolutions successives à l’aide de quelques millions d’images représentant des objets connus. L’algorithme de base est très similaire à celui décrit dans la section précédente car il consiste à répéter les opérations suivantes :
Choisir quelques images au hasard parmi les images d’apprentissage.
Calculer les images de sortie du réseau convolutionnel.
Si ces images de sortie ne décrivent pas assez bien les objets présents dans les images d’apprentissage, ajuster légèrement les poids des convolutions de façon à rendre les images de sorties plus conforme à nos souhaits.
Faire cela à cette échelle est évidemment bien plus délicat que faire fonctionner un algorithme d’apprentissage pour la catégorisation de texte parce que le volume des calculs est considérable. Certains utilisent des grappes composés des centaines d’ordinateurs. D’autres utilisent moins de machines mais les équipent de processeurs graphiques puissants que l’on peut utiliser pour ces calculs. Malgré ces difficultés, la reconnaissance d’objets (et de personnes) dans les photographies numérisées est aujourd’hui une réalité et fait l’objet d’investissements importants par les grande compagnies technologiques…
Certains trouvent troublant que rien dans la structure d’un réseau convolutionnel ne dit comment il reconnaît un chat d’un chien, quelles que soient leurs positions et quelles que soient les conditions d’éclairage. Tout cela est entièrement déterminé par la procédure d’apprentissage sur la base des exemples qu’on lui a donné. C’est bien là une rupture entre programmer un ordinateur digital et entrainer une machine capable d’apprendre.
Toujours dans le cadre de ICML (International Conference on Machine Learning) qui se passe à Lille du 6 au 11 juillet, Binaire a réuni à Nantes trois chercheurs pour qu’ils nous parlent d’apprentissage automatique :
Colin de la Higuera, professeur en informatique, directeur adjoint du Lina, Laboratoire d’Informatique Nantes Atlantique. éditeur du blog binaire,
Yannick Aoustin, chercheur en robotique à l’IRCCyN, l’Institut de Recherche en Communication et Cybernétique de Nantes, et
Jeff Abrahamson, ancien de Google Londres, co-fondateur de Jellybooks.
Podcast : Quand les machines apprennent
Une émission organisée par binaire en partenariat avec le Labo des savoirs, et animée par Guillaume Mézières, avec à la technique, Claire Sizorn.
Quand Cécile Morel, co-fondatrice de la startup Mobi rider, nous propose de « mettre notre téléphone dans sa boite ! », nous imaginons le pire. Notre téléphone va-t-il disparaître ? Etre transformé en lapin ? Après quelques secondes d’attente, nous voilà rassuré : le téléphone est toujours là. La boite, appelée Mobi one (les fans de Star Wars apprécieront), est en fait une « cage de Faraday* ». Elle bloque toutes les communications, 3G, E, tout. Tout ? Presque, il reste les communications qui viennent de l’intérieur de la Mobi one elle-même. C’est comme quand vous passez une frontière. Votre téléphone perd le réseau, puis s’ouvre très largement aux communications pour retrouver une nouvelle compagnie de téléphone disponible. Avec cette boîte, vous passez de France au monde de Mobi one.
Nous sentons alors une nouvelle panique nous assaillir : vont-ils nous dérober toutes nos données ? Nous installer des logiciels espions ? On se calme. Mobi one se contente de profiter de l’ouverture des communications du téléphone pour lui envoyer des messages. Dans la plupart des cas, il s’agit d’un SMS du genre « Bienvenue dans votre magasin préféré ». Tout ça pour ça ?
L’expérience de la cage de Faraday au Palais de la découverte à Paris. Wikipédia.
Pour ne pas mourir dans l’ignorance, nous nous faisons expliquer à quoi cela peut bien servir. En mettant votre téléphone dans la boite, vous avez établi un lien entre votre monde numérique (dont le téléphone est l’ambassadeur) et un monde physique, une agence, un magasin, un musée… (représenté par la boite). Le message vous proposera le plus souvent de télécharger une application mobile sur un App Store. Tout ça pour ça ?
Pourquoi pas ne pas utiliser bêtement un QR-code** ? Parce que peu de gens utilisent vraiment le QR-code. Trop compliqué. Alors que tout ce que vous demande Mobi one c’est de mettre un téléphone dans une boite. Tout le monde sait faire.
QR-code de Binaire
Si tout ceci parait bien simple, encore fallait-il avoir l’idée d’un nouveau pont entre le monde numérique et le monde physique. Il fallait aussi penser à couper les communications pour mieux les ouvrir. Bref, il fallait penser au principe essentiel du Kiss (Keep it simple stupid) (***).
Peut-être utiliserez-vous un jour une Mobi one, mais en attendant… Si vous avez une boite à chaussure inutile chez vous, garnissez-en le fond avec un joli coussin bien confortable ; proposez à vos invités d’y déposer leurs téléphones intelligents (ou pas). Ça s’appelle un Binaire one et c’est garanti digital-free.
Serge Abiteboul, Marie Jung
(*) Cage de Faraday : Une cage de Faraday est une enceinte utilisée pour protéger des nuisances électriques et subsidiairement électromagnétiques extérieures ou inversement empêcher un appareillage de polluer son environnement. Wikipédia.
(**) Le code QR (pour quick response) est un type de code-barres en deux dimensions constitué de modules noirs disposés dans un carré à fond blanc. L’agencement de ces points définit l’information que contient le code. Wikipédia
(***) Kiss : Keep it simple stupid ! Principe fondamental de l’informatique. Son non-respect est à l’origine de nombreux plantages.
Du 6 au 11 juillet, Lille accueille ICML (International Conference on Machine Learning), le rendez-vous annuel des chercheurs en apprentissage automatique (machine learning). Mais comment expliquer à ma garagiste ou à mon fleuriste ? Et à quoi bon ! Donnons la parole à des chercheurs qui prennent le risque de soulever pour nous le capot du moteur et de nous l’expliquer.
L’apprentissage automatique est là. Pour le meilleur comme pour le pire.
Comme nous le développions il y a quelques jours, l’apprentissage automatique est désormais partout dans notre quotidien. Votre téléphone portable complète vos phrases en fonction de vos habitudes. Lorsque vous cherchez un terme avec votre moteur de recherche favori, vous recevez une liste de pages pertinentes très différente de celle que recevra une personne d’un autre âge ou d’un autre pays. C’est aussi un algorithme qui propose la publicité que vous subissez.
Dans les différents cas ci-dessus, il s’agit bien de calculer automatiquement des préférences, de faire évoluer un logiciel en fonction des données.
L’apprentissage automatique est associé au phénomène Big Data, et quand certains journaux s’inquiètent du pouvoir des algorithmes, il y a fort à parier que les algorithmes en question sont justement ceux qui s’intéressent aux données –aux vôtres en particulier- et essayent d’en extraire une connaissance nouvelle ; par exemple pour offrir un diagnostic médical plus précis. Ou, dans le contexte de la loi sur le renseignement votée récemment, pour récolter et traiter nos données privées.
https://canvas.northwestern.edu/
Alors il y a quelque chose d’inévitable si nous voulons ne pas subir tout cela : il faut comprendre comment ça marche.
Bien alors en deux mots : comment ça marche ?
En deux mots ? apprendre (construire un modèle) et prédire (utiliser le modèle appris). Et pour ce qui est de prédire l’avenir … on en a brulé pour moins que ça !
Apprendre : où l’on récolte des données pour mieux les mettre en boîte.
La première problématique consiste à construire, automatiquement, un modèle : il s’agit donc de comprendre quelque chose dans les données. Par exemple dans tous ces résultats médicaux quelle est la loi statistique ? Ou bien dans ces nombreuses données financières, quelle est la fonction cachée ? Ou encore dans ces énormes corpus de textes, quels sont les motifs, les règles ? Et ailleurs, dans le parcours du robot, les résultats transmis par ses capteurs font-ils émerger un plan de la pièce ?
Cette modélisation peut être vue comme une simple tâche de compression : remplacer des très grands volumes de données par une description pertinente de celles-ci. Mais il s’agit aussi d’abstraire, de généraliser, c’est à dire de rechercher des règles ou des motifs expliquant les données. Autrement dit, on essaye d’oublier intelligemment les données brutes en les remplaçant par une information structurée plus compacte.
Cette construction est de nature algorithmique et la diversité des algorithmes est gigantesque. Mais essayons de nous y retrouver.
Apprentissage supervisé ou non.
Si les données sont étiquetées, donc qu’on connait la valeur que l’on voudrait prédire, alors il s’agit d’un apprentissage supervisé : les données peuvent être utilisées pour prédire ce qui est correct et ce qui ne l’est pas.
La valeur peut être un nombre (par exemple le cours d’une action dans trois mois) ou une classe (par exemple, dans le cas d’une image médicale, la présence ou l’absence d’un motif qui serait associé à une maladie). Dans le premier cas, on parle de régression, dans le second, de classification.
Si les données ne sont pas étiquetées, le but sera de trouver une organisation dans ces données (par exemple comment répartir en groupes homogènes les votants d’un parti politique, ou organiser les données en fonction de la proximité de leurs valeurs). Cette fois, l’apprentissage est non supervisé, puisque personne ne nous a dit à l’avance quelle est la bonne façon de mesurer, de ranger, de calculer.
Apprentissage passif ou actif
Les données, elles, ont été le plus souvent collectées à l’avance, mais il peut également s’agir de données que le même programme va chercher à obtenir par interaction avec l’environnement : on parle alors d’apprentissage actif.
On peut formaliser le fait qu’il reçoit à chaque étape une récompense (ou une punition) et ajuste son comportement au mieux en fonction de ce retour. Ce type d’apprentissage a aussi été formalisé, on parle d’apprentissage par renforcement.
Les trois grands types de modèles.
Le modèle peut être de nature géométrique : typiquement, les données sont des points dans un espace de très grande dimension, et le modèle donne l’équation pour séparer le mieux possible les différentes étiquettes. Le modèle peut-être logique : il sera alors un ensemble de règles qui permettront dans le futur de dire si un nouvel objet est d’une catégorie ou d’une autre. Le modèle peut être probabiliste : il nous permettra de définir, pour un nouvel objet, la probabilité d’être dans telle ou telle catégorie.
Inférer : où l’informatique fait concurrence aux devins.
Reste à savoir utiliser le modèle appris, ou choisir parmi un ensemble de modèles possibles. L’inférence est souvent un problème d’optimisation : trouver la meilleure prédiction étant donné le(s) modèle(s) et les données. Les arbres de décision (étudiés aujourd’hui au lycée) permettent, pour les valeurs d’un modèle et des données, de calculer la probabilité de rencontrer ces données si on considère le modèle et ses valeurs. La question de l’inférence est en quelque sorte l’inverse, celle de choisir le modèle étant donné un certain ensemble de données.
Ici on raisonne souvent en terme de probabilité, il faut donc évaluer le risque, au delà du coût lié à chaque choix.
Ouaouh ! Alors il y a des maths en dessous ?
Oui oui ! Et de très jolies mathématiques, par exemple on peut se poser la question suivante :
De quel nombre m de données ai-je besoin
pour faire une prédiction avec une erreur ε en prenant un risque δ ?
Croyez-nous ou non, pour certains modèles la formule existe, et elle peut prendre cette forme :
et nous la trouvons même assez jolie. C’est Leslie Valiant qui l’a proposée dans un cadre un peu idéal. Son formalisme permet de convertir ce qui était fondamentalement un problème mal posé, en un problème tout à fait mathématique. Leslie Valiant a d’ailleurs reçu le Turing Award (l’équivalent du prix Nobel pour l’informatique) en 2011 pour cela. D’autres chercheurs, comme Vladimir Vapnik, ont proposé d’autres formules pour quantifier dans quelle mesure ces algorithmes sont capable de généraliser ce qui a été appris à n’importe quel autre donnée qui peut arriver.
Il ne s’agit pas d’un pur problème de statistique, c’est aussi un enjeu en terme de complexité. Si le nombre m de données explose (augmente exponentiellement) en fonction des autres paramètres, aucun algorithme ne fonctionnera en pratique.
Mais ce petit détour vers les maths nous montre que l’on peut donc utiliser le résultat de l’apprentissage pour prendre des décisions garanties. À condition que la modélisation soit correcte et appropriée au problème donné. Si on utilise tout ça sans chercher à bien comprendre, ou pour leur faire dire et faire des choses hors de leur champ d’application, alors ce sera un échec.
Ce n’est donc peut-être pas des algorithmes dont il faut avoir peur aujourd’hui, mais de ceux qui essayent de s’en servir sans les avoir compris.
Philippe Preux, Marc Tommasi, Thierry Viéville et Colin de la Higuera
Rares sont ceux qui se disent adversaires de l’égalité entre les sexes. Mais la réalité est différente. C’est bien pour cela que la première formation en ligne, dédiée à l’égalité femmes-hommes, lancée ce mois-ci, est importante. Nous l’avons testée et comme nous l’avons trouvée intéressante, nous avons demandé à Nathalie Van de Wiele, qui est à son origine, de nous en parler. Serge Abiteboul et Thierry Viéville.
Les FLOT (Formations en Ligne Ouvertes à Tous), acronyme français de MOOC (Massive Open Online Courses), sont appelés à jouer un rôle important dans notre système de formation universitaire et professionnelle et leur développement mérite d’être suivi avec attention depuis leur apparition il y a environ deux ans.
Il se trouve que c’est la première fois dans l’histoire des FLOT/MOOC, en France et dans le monde, qu’une formation en ligne libre et gratuite, ouverte à toutes et tous, est dédiée à l’égalité femmes-hommes.
Intitulé « Être en responsabilité demain : se former à l’égalité femmes-hommes », ce FLOT traite de l’égalité réelle entre les femmes et les hommes, en abordant l’éducation, les stéréotypes, l’orientation, la parité et la mixité des filières et des métiers, le sexisme ordinaire, le harcèlement et les violences faites aux femmes, pour conclure en terme de responsabilité et vie citoyenne.
La formation est structurée en 7 séquences représentant chacune 2 heures de travail, soit environ 14 heures de travail à planifier selon les besoins de l’apprenant-e. Une quarantaine de courtes vidéos (archives d’actualités, animations, explication de concepts, etc.) accompagnent la formation. De nombreux tests permettent une auto-évaluation tout au long du parcours.
On peut commencer cette formation, et la suivre en autonomie, à tout moment de l’année, mais il est conseillé de s’inscrire pour bénéficier d’un forum où partager ses questions et son expérience avec les autres apprenant-e-s et avec l’équipe d’accompagnement. La première session est ouverte jusqu’au 31 juillet 2015.
Du 6 au 11 juillet, Lille accueille ICML (International Conference on Machine Learning), le rendez-vous annuel des chercheurs en machine learning, ce qu’on traduit souvent en français par apprentissage automatique ou apprentissage artificiel. Donnons la parole à Colin de la Higuera pour nous faire découvrir ce domaine. Thierry Viéville et Sylvie Boldo.
Il est très probable qu’à l’heure où vous lisez ces lignes, vous aurez utilisé le résultat d’algorithmes d’apprentissage automatique plusieurs fois aujourd’hui : votre réseau social favori vous peut-être a proposé de nouveaux amis et le moteur de recherche a jugé certaines pages pertinentes pour vous mais pas pour votre voisin. Vous avez dicté un message sur votre téléphone portable, utilisé un logiciel de reconnaissance optique de caractères, lu un article qui vous a été proposé spécifiquement en fonction de vos préférences et qui a peut-être été traduit automatiquement.
Et même sans avoir utilisé un ordinateur, vous avez été peut être écouté les informations : or la météo entendue ce matin, la plupart des transactions et des décisions boursières qui font et défont une économie, et de plus en plus de diagnostics médicaux reposent bien plus sur les qualités de l’algorithme que sur celles d’un expert humain incapable de traiter la montagne d’informations nécessaire à une prise de décision pertinente.
De tels algorithmes ont appris à partir de données, ils font de l’apprentissage automatique. Ces algorithmes construisent un modèle à partir de données dans le but d’émettre des prédictions ou des décisions basées sur les données [1].
Mais depuis quand confie t’on cela à des algorithmes ?
L’idée de faire apprendre la machine pour lui donner des moyens supplémentaires est presque aussi ancienne que l’informatique. C’est Alan Turing lui-même qui après avoir, en 1936, jeté les bases conceptuelles du calcul sur machine, donc de l’ordinateur, allait s’intéresser à cette possibilité. Il envisage en 1948 des « learning machines » susceptibles de construire elles-mêmes leurs propres codes.
Tout compte fait, c’est une suite logique de cette notion de machine de calcul dite universelle (c’est à dire qui peut exécuter tous les algorithmes, comme le sont nos ordinateurs ou nos smartphone). Puisque le code d’une machine, le programme, n’est qu’une donnée comme les autres, il est raisonnable d’envisager qu’un autre programme puisse le transformer. Donc pourquoi ne pas apprendre de nouveaux programmes à partir de données?
Vue la quantité astronomique de donnée, on peut apprendre simplement en les analysant. Mais les chercheurs se sont rendus compte que dans ce contexte, un programme qui se comporte de manière déterministe n’est pas si intéressant. C’est le moment où on découvre les limites de ce qui est décidable ou indécidable avec des algorithmes. Il faut alors introduire une autre idée : celle d’exploration, de recours au hasard, pour que de telles machines soient capables de comportements non prévus par leur concepteur.
Il y a donc une rupture entre programmer, c’est à dire imaginer et implémenter un calcul sur la machine pour résoudre un problème, et doter la machine de la capacité d’apprendre et de s’adapter aux données. De ce fait, on ne peut plus systématiquement prévoir un comportement donné, mais uniquement spécifier une classe de comportements possibles.
Alors … ça y est ? Nous avons créé de l’intelligence artificielle (IA) ?
C’est une situation paradoxale, car le terme d’IA veut dire plusieurs choses. Quand on évoque l’intelligence artificielle, on pense à apprendre, évoluer, s’adapter. Ce sont des termes qui font référence à des activités cognitives qui nous paraissent un ordre de grandeur plus intelligentes que ce que peut produire un calcul programmé.
Et c’est vrai qu’historiquement, les premiers systèmes qui apprennent sont à mettre au crédit des chercheurs en IA. Il s’agissait de repousser les frontières de la machine, de tenter de reproduire le cerveau humain. Les systèmes proposés devaient permettre à un robot d’être autonome, à un agent de répondre à toute question, à un joueur de s’améliorer défaite après défaite.
Mais, on s’accorde à dire que l’intelligence artificielle n’a pas tenu ses promesses [2]. Pourtant ces algorithmes d’apprentissage automatique, une de ses principales composantes, sont bel et bien présents un peu partout aujourd’hui. Et ceci, au delà, du fait que ces idées sont à la source de nombreuses pages de science-fiction.
C’est peut-être notre vision de l’intelligence qui évolue avec la progression des sciences informatiques. Par exemple, pour gagner aux échecs il faut être bougrement intelligent. Mais quand un algorithme qui se contente de faire des statistiques sur un nombre colossal de parties défait le champion du monde, on se dit que finalement l’ordinateur a gagné « bêtement ». Ou encore: une machine qui rassemble toutes les connaissances humaines de manière structurée pour que chacun y accède à loisir sur simple demande, est forcément prodigieusement intelligente. Mais devant wikipédia, qui incarne ce rêve, il est clair que non seulement une vision encyclopédique de l’intelligence est incomplète, mais que notre propre façon de profiter de notre intelligence humaine est amenée à évoluer, comme nous le rappelle Michel Serres [3].
Passionnant ! Mais à Lille … que va t’il se passer ?
L’apprentissage automatique est maintenant devenu une matière enseignée dans de nombreux cursus universitaires. Son champ d’application augmente de jour en jour : dès qu’un domaine dispose de données, la question de l’utilisation de celles-ci pour améliorer les algorithmes du domaine se pose systématiquement.
Mais c’est également un sujet de recherche très actif. Les chercheurs du monde entier qui se retrouveront à Lille dans quelques jours discuteront sans doute, parmi d’autres, des questions suivantes :
Une famille d’algorithmes particulièrement efficace aujourd’hui permet d’effectuer un apprentissage profond (le « deep learning »). De tels algorithmes simulent une architecture complexe, formées de couches de neurones artificiels, qui permettent d’implémenter des calculs distribués impossibles à programmer explicitement.
L’explosion du phénomène du big data est un levier. Là où dans d’autres cas, la taille massive des données est un obstacle, ici, justement, c’est ce qui donne de la puissance au phénomène. Les algorithmes, comme ceux d’apprentissage profond, deviennent d’autant plus performants quand la quantité de données augmente.
Nul doute que des modèles probabilistes de plus en plus sophistiqués seront discutés. L’enjeu aujourd’hui est d’apprendre en mettant à profit le hasard pour explorer des solutions impossibles à énumérer explicitement.
La notion de prédiction sera une problématique majeure pour ces chercheurs qui se demanderont comment utiliser l’apprentissage sur une tâche pour prévoir comment en résoudre une autre.
Les applications continueront à être des moteurs de l’innovation dans le domaine et reposent sur des questions nouvelles venant de secteurs les plus variés : le traitement de la langue, le médical, les réseaux sociaux, les villes intelligentes, l’énergie, la robotique…
Il est possible –et souhaitable- que les chercheurs trouvent également un moment pour discuter des questions de fond, de société, soulevées par les résultats de leurs travaux. Les algorithmes apprennent aujourd’hui des modèles qui reconnaissent mieux un objet que l’œil humain, qui discernent mieux les motifs dans des images médicales que les spécialistes les mieux entrainés. La taille et la complexité des modèles en font cependant parfois des boîtes noires : la machine peut indiquer la présence d’une tumeur sans nécessairement pouvoir expliquer ce qui justifie son diagnostic : sa « décision » reposera peut-être sur une combinaison de milliers de paramètres, combinaison que l’humain ne connaît pas.
Or, quand votre médecin vous explique qu’il serait utile de traiter une pathologie, il vous explique pourquoi. Mais quand la machine nous proposera de subir une intervention chirurgicale, avec une erreur moindre que le meilleur médecin, sans nous fournir une explication compréhensible, que ferons-nous ?
Pour l’apprentissage automatique, nous allons vous lancer un défi. Revenez sur binaire dans quelques jours et nous allons oser vous expliquer ce qui se trouve sous le capot : comment la machine construit des modèles et les exploite ensuite. Et vous verrez que si un sorcier ou une sorcière avait osé proposé une telle machine il y a quelques siècles, c’est sur un bûcher qu’elle ou il aurait fini.
En informatique, un problème est décidable s’il est possible d’écrire un algorithme qui résolve ce problème. Certains problèmes sont indécidables. Considérons par exemple le « problème de l’arrêt ». Le problème de l’arrêt consiste à déterminer, étant donné un programme informatique et des données en entrée pour ce programme, si le programme va finir pas s’arrêter ou s’il va continuer pour toujours. Alan Turing a prouvé en 1936 qu’il n’existait pas d’algorithme qui permette de résoudre le problème de l’arrêt, que ce problème était indécidable. L’informatique ne peut donc pas résoudre tous les problèmes. À binaire, on s’en doutait. Encore fallait-il le prouver. Turing l’a fait.
Cette notion de décidabilité se retrouve en logique. Une affirmation logique est dite décidable si on peut la démontrer ou démontrer sa négation dans le cadre d’une théorie donnée. Gödel a démontré (avant Turing, en 1933) un résultat d’incomplétude sur la décidabilité en logique. Certains résultats ne sont donc ni vrais ni faux, mais indécidables : cela signifie que l’on a démontré, à tout jamais, que nous pourrons pas savoir s’ils sont vrais ou faux. Alors si vous avez été frustré parce que vous n’avez pas compris certains cours de maths, consolez vous. Les mathématiques aussi ont des limites. Et oui …
Cette notion d’indécidabilité a une conséquence plus subjective, dans nos rapports avec la science. Nous ne sommes pas confrontés à un dogme surpuissant et sans limite, mais bien à une démarche qui cherche à comprendre ce qu’il est possible de comprendre, qui explore sans cesse ses propres limites.
Il est important que, des actrices et acteurs … aux utilisateurs et utilisatrices du numérique, nous partagions une culture en sciences du numérique, pour comprendre et maîtriser les technologies qui en sont issues.
Pour concrétiser ce partage avec le monde de la recherche, la Société Informatique de France, Inria et le CNRS proposent deux revues et un blog : profitons-en !
1024 ? Une revue pour les professionnelles et les professionnels du monde de l’enseignement, de la recherche et de l’industrie de l’informatique qui permet de découvrir les différentes facettes de cette science.
)I(nterstices ? La revue de culture scientifique en ligne qui invite à explorer les sciences du numérique, à comprendre ses notions fondamentales, à mesurer ses enjeux pour la société, à rencontrer ses acteurs et actrices.
Binaire ? Le blog du monde.fr qui parle de l’informatique, de ses réussites, de son enseignement, de ses métiers, de ses risques, des cultures et des mondes numériques.
A binaire, nous pensons que l’informatique concerne tout le monde. C’est pourquoi ces journées de la SIF autour de l’enseignement de l’informatique pour les humanités et les sciences sociales nous paraissent particulièrement importantes. Serge Abiteboul, Thierry Vieville.
Inscriptions ouvertes !
23 & 24 juin 2015 à Paris, CNAM
Enseignement de l’informatique
pour les humanités et les sciences sociales
la SIF organise deux journées pédagogiques sur le thème de « L’enseignement de l’informatique pour les humanités et les sciences sociales ».
Quelques points abordés :
État des lieux, en France et à l’étranger
Quelle informatique nécessaire aux humanités, sciences sociales ?
Approches pédagogiques et didactiques pour enseigner l’informatique aux humanités et sciences sociales
Humanités numériques
Formation des professeurs des écoles à l’informatique
En juin 2014, le gouvernement a lancé une démarche originale et inédite nommée «La France s’engage» . Elle a vocation à mettre en valeur et faciliter l’extension d’initiatives socialement innovantes, d’intérêt général, portées bénévolement par des individus, des associations, des fondations, des entreprises. Cette initiative est portée par le ministre de la Ville, de la Jeunesse et des Sports. Parmi tous les projets sélectionnés, celui de Wi-FIlles a retenu tout particulièrement l’attention de Binaire car il s’adresse aux jeunes filles pour les initier aux métiers techniques de l’informatique et du numérique. Engagez-vous qu’ils disaient ! C’est ce que nous comptons faire en vous expliquant ce projet. Wi-FIlles est à ce jour un des seuls programmes en France qui s’adresse aux jeunes filles pour leur faire découvrir, dès la 4ème, les métiers de l’informatique et du numérique de demain. Il est porté par le Club d’entreprises FACE Seine-Saint-Denis (membre de la Fondation Agir Contre l’Exclusion). Claire Etien, sa directrice nous résume son ambition : faire en sorte que les filles ne soient pas mises à l’écart des futurs enjeux économiques de demain.
« Il est de notre responsabilité à tous de ne pas laisser 50% de l’humanité, les femmes, passer à côté de cet enjeu fondamental : le numérique. »
La deuxième promotion a vu le jour en février de cette année avec comme objectif revendiqué : atteindre l’égalité Femme – Homme dans le secteur technique de l’informatique. Avec le soutien des institutions publiques et de partenaires privés, WI-FIlles travaille à éduquer, inspirer et équiper les jeunes filles, avec les compétences et les ressources nécessaires, dans un seul but : saisir les opportunités professionnelles dans le domaine technique de l’informatique. « Le constat est éloquent : nous ne formons pas assez d’ingénieurs et les femmes représentent environ 10% des diplômés dans le secteur informatique » nous explique Claire Etien [1].
Le Club FACE Seine-Saint-Denis a donc décidé de créer ce projet, en co-construction avec des partenaires industriels comme DELL, ERDF et Orange ou académique comme la Région Île-de-France. Concrètement la fondation propose aux filles, via des sensibilisations dans leur établissement scolaire, d’intégrer un parcours de découvertes, de rencontres, d’acquisition de compétences techniques IT. « En bref on leur apprend à coder et à maitriser l’environnement informatique et numérique ! » dixit Claire Etien.
Ces sensibilisations sont accessibles à toutes les filles de 4ème et de 3ème sans aucun pré-requis scolaires. Elles sont informées du programme non pas par leur environnement familial, comme le sont en règle générale les élèves les plus favorisées, mais par des sensibilisations au sein des établissements scolaires, en présence de leurs parents. À l’issu des sensibilisations, les collégiennes motivées et disponibles, hors temps scolaires, sont invitées à intégrer la promotion WI-FIlles. Un parcours WI-FIlles c’est 20 futures Ambassadrices du Numérique, plus de 180h de formations et de rencontres et de mises en situation.
À l’issue du parcours, les ambassadrices sont coachées pour organiser un WI-Fille Girls Camp, événement partenaire du Festival Futur en Seine. Ce sont elles qui présentent auprès des partenaires, de leur communauté éducative le fruit de leur travail. Elles sont récompensées par un diplôme remis par les partenaires. L’objectif a long terme est que ces jeunes femmes puissent être les futures ambassadrices pour accompagner de nouvelles recrues et que cette initiative s’étende bien au-delà de la Seine-Saint Denis.
En participant au challenge « La France s’engage », et après avoir été sélectionné parmi 600 projets, nul doute que le projet Wi-FIlles va faire parler de lui mais surtout d’elles ! Le 22 juin, 15 projets seront lauréats. Ils seront aidés financièrement et accompagnés pour rayonner nationalement. Nous sommes convaincus qu’elles seront récompensées pour leur initiative mais pour leur donner encore plus de chance, nous vous invitons à les encouragez. Rendez-vous sur le site www.lafrancesengage.fr/je-vote , et votez pour Wi-FIlles ! N’hésitez surtout pas à partager autour de vous, elles comptent sur vous !
La Fondation internet nouvelle génération a été créée il y a 15 ans par Daniel Kaplan, Jacques-François Marchandise et Jean-Michel Cornu. Binaire fait partie des admirateurs et amis de cette fondation. À l’occasion de cet anniversaire, Serge Abiteboul a rencontré Daniel Kaplan délégué général de la Fing.
Daniel Kaplan , 2009, Wikipédia
Est-ce que tu peux définir la Fing en une phrase ?
Nous avons changé plusieurs fois de manière de définir la Fing, mais celle que je préfère (et vers laquelle nous sommes en train de revenir) est la suivante : « la Fing explore le potentiel transformateur des technologies, quand il est placé entre des millions de mains. »
La Fing a 15 ans, quels ont été selon toi ses plus beaux succès ? Ses échecs ?
Nous avons su produire des idées neuves qui font aujourd’hui leur chemin comme la « ville 2.0 » en 2007 ou le self data (le retour des données personnelles aux gens) à partir de 2012. Nous avons (avec d’autres, bien sûr) joué un rôle déterminant dans le développement des open data et des Fab Labs en France. Nous avons contribué à la naissance de beaux bébés qui ont pris leur indépendance, comme la Cantine (devenue Numa à Paris, mais qui a aussi essaimée ailleurs en France), la 27e Région, InnovAfrica. Internet Actu est devenu un média de référence pour des dizaines de milliers de lecteurs.
Il y a des réussites qui se transforment en déceptions. Le concept d’ « espaces numériques de travail » (ENT) dans l’éducation est largement issu de la Fing, mais 13 ans plus tard, il est difficile de s’en vanter quand on voit (à des exceptions près) la pauvreté de ce qu’ils proposent en pratique aux enseignants comme aux élèves. En 2009, avec la « Montre Verte », nous étions les pionniers de la mesure environnementale distribuée, mais nous avons eu tort de poursuivre nous-mêmes le développement de ce concept, parce que nous étions incapables d’en assurer le développement industriel.
Même si nous avons beaucoup de relations à l’international, trop peu de nos projets sont nativement internationaux. La rigidité des financements européens y est pour beaucoup, et il nous faut trouver d’autres moyens de financer de tels projets.
Mais au fond, notre vrai succès, c’est que dans toute une série de domaines, on ne pense plus au lien entre innovation, technologie, mutations économiques et transformations sociales, sans un peu de « Fing inside ». C’est sans doute pourquoi l’Agence nationale de la recherche nous a confiés (en 2010) le pilotage de son Atelier de réflexion prospective sur les « innovations et ruptures dans la société et l’économie numériques », qui a mobilisé le meilleur de la recherche française en sciences humaines et sociales.
Est-ce que vous avez l’intention de changer ?
La Fing a muté à peu près tous les 5 ans et en effet, elle va encore le faire. Parce que le paysage numérique a bougé. Le numérique n’est plus « nouveau » en revanche, le sens de la révolution numérique pose question. Dans le numérique et autour de lui, des communautés nouvelles émergent sans cesse et ne savent pas nécessairement qui nous sommes. D’autres sujets technosociaux montent en importance, par exemple autour du vivant, de la cognition ou bien sûr, de l’environnement. Enfin, les demandes qui s’adressent à nous évoluent. On veut des idées, mais aussi les manières de les mettre en œuvre ou encore, des preuves de concept plus avancées, de la prospective, mais utile à l’action immédiate. Déjà très collaboratif, notre travail doit s’ouvrir encore plus largement et la dimension européenne devient essentielle.
Comment vois-tu le futur d’Internet ?
Comme un grand point d’interrogation ! S’agissant du réseau soi-même, nous avons tenu 20 ans (depuis l’ouverture commerciale de l’internet) en ne changeant rien de fondamental à l’architecture de l’internet, du moins officiellement. D’un côté, c’est un exploit presque incroyable : le réseau a tenu, il s’est adapté à une multiplication par 10 000 du nombre d’utilisateurs et à des usages sans cesse plus divers et plus exigeants. Mais cela a un prix : les évolutions majeures se sont en fait produites « au bord » de l’internet, par exemple dans les réseaux de distribution de contenus (CDN), dans les sous-réseaux des opérateurs (mobiles, distribution vidéo, objets connectés) et bien sur, dans tous les services dits over the top. Les solutions ad hoc se multiplient, les standards de fait sont plus qu’auparavant le produit de purs rapports de force, l’interopérabilité devient problématique (et ce n’est pas toujours fortuit)…
Nous n’échapperons pas à la nécessité de repenser les fondements de l’internet – en fait, ne pas le faire, c’est déjà un choix, celui de favoriser les plus forts. Ce ne sera pas facile, parce que certaines valeurs essentielles que l’internet d’aujourd’hui incorpore comme l’intelligence aux extrémités se sont imposées d’une manière un peu fortuite. Si l’on remet l’ouvrage sur le métier, il ne sera pas si facile de les défendre. Ce sera une discussion mondiale et fondamentalement politique. Lawrence Lessig écrivait Code is Law (le code fait Loi), j’ajouterais : « et l’architecture fait Constitution ». Mais il est vraisemblable qu’elle ne se présentera pas d’emblée sous cette forme, plutôt sous celle de programmes de recherche et d’expérimentations sur les réseaux du futur. La technicité des efforts masquera les choix économiques et politiques, il faudra être vigilant ou, mieux, proactif.
Quelles sont les plus grandes menaces pour Internet, pour le Web ?
D’un côté, l’internet et le web ont « gagné ». L’idée folle selon laquelle un même inter-réseau aurait vocation à connecter tous les humains et tous les objets, se réalise ; du côté des données, des documents et des applications, le cloud et le mobile consacrent la victoire du Web. Mais cette victoire est technique ou logistique, les idéaux fondateurs, eux, s’éloignent.
Il serait naïf de croire que des dispositifs techniques puissent à eux tout seuls amener un monde plus égalitaire, démocratique, collaboratif. Notre raison ne l’a jamais vraiment crû, je suppose. Mais notre cœur, si, et puis tout ce qui allait en ce sens était bon à prendre. Aujourd’hui, les puissances politiques et économiques reprennent la main et le contrôle, parfois pour les meilleures raisons du monde – la sécurité, par exemple.
Le risque majeur, au fond, ce n’est pas Big Brother, ni Little Sister (la surveillance de tous par tous). Il ne faut pas négliger ces risques, mais je crois qu’ils peuvent rester contrôlés. Le vrai risque, c’est la banalisation : que l’internet et le web cessent d’être la nouvelle frontière de notre époque, qu’ils deviennent de pures infrastructures matérielles et logicielles pour distribuer des services et des contenus. Cela arrivera quand la priorité ne sera plus de rendre possible l’émergence de la prochaine application dont on ne sait encore rien, mais d’assurer la meilleure qualité de service possible pour celles que l’on connaît. Nous n’en sommes pas loin.
Est-ce que le Web va continuer à nous surprendre ? Qu’est-ce qui va changer ?
On peut être inquiet et confiant à la fois ! Au quotidien, le web reste l’espace des possibles, celui dont se saisissent de très nombreux innovateurs pour tenter de changer l’ordre des choses – certains avec des finalités totalement commerciales, d’autres à des fins sociales, et beaucoup avec en tête l’un et l’autre. On peut sourire à l’ambition de tous ces jeunes entrepreneurs, sociaux ou non, qui affirment vouloir changer le monde, et en même temps se dire que ça vaut mieux que le contraire.
Ce qui se passe sur le Web, autour de lui, continue en effet de nous surprendre, et ce n’est pas fini. L’essor récent de la consommation collaborative, celui de nouvelles formes de monnaie, la montée en puissance des données (big, open, linked, self, smart, etc.), les disruptions numériques engagées dans la santé ou l’éducation, etc. Il se passe chaque jour quelque chose ! Il y a une sorte de force vitale qui fait aujourd’hui du numérique le pôle d’attraction de millions d’innovateurs et d’entrepreneurs et la source de la transformation d’à peu près tous les secteurs, tous les domaines d’activité humaine, toutes les organisations, tous les territoires.
En revanche, le numérique en général et par conséquent, le web et l’internet, sont de plus en plus questionnés sur ce qu’ils produisent, sur les valeurs qu’incorporent leurs architectures, les intentions derrière leurs applications, les rapports de force qu’encodent leurs plateformes. Dans la dernière édition de notre cycle annuel de prospective, Questions Numériques, nous écrivions : « Le numérique change tout. C’est sa force. Mais il ignore en quoi. C’est sa faiblesse. » La faiblesse de l’apprenti sorcier, qui devient difficilement tolérable quand celui-ci n’a plus de maître.
Je pense que notre prochaine frontière se situe au croisement des deux grandes transitions contemporaines, la transition numérique et la transition écologique. La transition écologique sait formuler son objectif, mais trois décennies après le sommet de Rio, force est de constater qu’elle ne sait pas décrire le chemin pour y arriver. La transition numérique, c’est le contraire : elle sait créer le changement, mais elle en ignore la direction. Chacune a besoin de l’autre. Nous allons chercher à les rapprocher.
Le débat sur le collège ne peut pas se résumer à ce qu’on enlève. Il convient également de voir ce qui va arriver. Colin de la Higuera nous en parle ici en prenant un peu de hauteur et en regardant au delà de nos frontières. Thierry Viéville.
La très sérieuse Chaîne Parlementaire nous résume les clés du débat sur la réforme du collège et distingue en première position la question du latin. Les autres sujets essentiels sont ensuite discutés, et, surprise, la question de la place de l’informatique, et de façon plus générale la formation aux nouvelles technologies ne semble intéresser personne, ni du côté des politiques, ni de celui des journalistes. Ces gens n’ont-ils pas le problème de tous les parents, c’est-à-dire celui de se demander si l’école ne pourrait pas contribuer à ce que nos enfants trouvent un emploi plus tard et apprennent à bien vivre dans la future société ?
En effet, tout laisse penser que notre société est en pleine mutation, que les digital natives (qu’il convient d’appeler aujourd’hui les enfants du numérique) ne sont en aucun cas des surdoués qui savent tout de façon innée. La numérisation de tous les métiers et de tous les aspects de notre vie n’est pas sur le point de s’arrêter. Il ne s’agit pas simplement de savoir utiliser ses deux pouces pour taper un message : il s’agit d’avoir eu la formation adéquate permettant de comprendre les concepts et de pouvoir ainsi, sur la base d’acquis solides, s’adapter aux technologies sans cesse mouvantes et devenir un acteur de la société de demain.
C’est d’ailleurs pour cette raison qu’autour de nous tous les pays prennent la question à bras le corps et introduisent l’informatique en tant que discipline, qu’elle s’appelle Computer Science, Informatik ou Informática [1].
Femme tenant des tablettes et un stylet (Pompéi, Ier siècle)
http://commons.wikimedia.org/wiki/File:Pompeii-couple.jpg#/media/File:Pompeii-couple.jpg
En France, le Conseil Supérieur des Programmes a également choisi d’introduire, à différents endroits, l’enseignement de l’informatique : celle-ci serait bientôt enseignée dès le collège, avec une initiation à certains aspects dès le primaire et l’opportunité de découvrir le codage dans le cadre périscolaire. Un enseignement d’une vraie discipline. Mais d’une discipline qui est elle-même pluridisciplinaire.
Si tout n’est pas parfait [2], il parait important de ne pas résumer la réforme du collège à la baisse du niveau en latin ou à un débat concernant la préservation du programme de telle ou telle discipline. Cette réforme pourrait être celle par laquelle nos enfants se prépareront au monde numérique, à en devenir acteurs plutôt qu’à le subir et pourront aspirer aux emplois de demain et à devenir des citoyennes et citoyens éclairés sur ces sujets.
[2] Pourquoi regretter l’absence d’une discipline informatique ? Uniquement parce que les enseignants ne seront pas complètement formés à ce nouveau domaine, comme on forme aujourd’hui les enseignants des autres matières.
À l’occasion de la sortie du dernier film animé des studios Disney « les nouveaux héros », nous avons demandé à Christian Duriez, responsable d’une équipe de recherche d’Inria Lille – Nord Europe, de nous parler des technologies innovantes qui sont en train d’émerger en matière de robotique et plus particulièrement de nous expliquer si le robot mou de Baymax est une fiction ou si la recherche en la matière est une réalité. Partons à la découverte de ces robots mous (ou « soft-robot » en anglais). Cet article est une co-publication avec )i(nterstices, la revue de culture scientifique en ligne, créée par des chercheurs pour vous inviter à explorer les sciences du numérique. Marie-Agnès Enard.
Dans son dernier long métrage, Disney nous invite à nous plonger dans San Fransokyo, ville futuriste inspirée des deux rivages du pacifique, et capitale de la robotique. Dans cette ville, les habitants ont une passion frénétique pour les robots, et plus particulièrement pour les combats de robots. Les acteurs économiques sont prêts à lancer des intrigues pour récupérer les dernières inventions. Hiro, un petit génie exclu des parcours scolaires, s’amuse à construire des robots de combats avec son frère tout en réalisant des recherches dans un laboratoire sur Baymax, un robot infirmier qui sera le héros de ce film. Or la particularité de Baymax… c’est qu’il est mou ! Une sorte de bonhomme Michelin gonflable, programmé pour prévenir les problèmes de santé des humains qui l’entourent. Disney rejoint là des technologies très innovantes en train d’émerger en robotique, ces fameux robots mous (ou « soft-robot » en anglais).
Je fais partie de cette nouvelle communauté de chercheurs qui s’intéresse à ces robots qui ne sont plus conçus à partir de squelettes rigides articulés et actionnés par des actionneurs placés au niveau des articulations comme nous les connaissons traditionnellement. Au contraire, ces robots sont constitués de matière « molle » : silicone, caoutchouc ou autre matériau souple, et ont donc, naturellement, la possibilité d’adapter leur forme et leur flexibilité à la tâche, à des environnements fragiles et tortueux, et d’interagir en toute sécurité avec l’homme. Ces robots ont typiquement une souplesse semblable aux matières organiques et leur design est souvent inspiré de la nature (trompe d’éléphant, poulpe, vers de terre, limace, etc.). Pour fabriquer ces robots, nous avons naturellement recours à l’impression 3D qui permet déjà d’imprimer des matières déformables ou de fabriquer ces robots par moulage.
La robotique est une science du mouvement. La robotique classique crée ce mouvement par articulation. Pour les soft-robot, le mouvement est créé par déformation, exactement comme des muscles. On peut le faire en insérant de l’air comprimé dans des cavités placées dans la structure déformable du robot, en injectant des liquides sous pression ou en utilisant des polymères électro actifs qui se déforment sous un champ électrique. Dans mon équipe de recherche, nous utilisons, plus simplement, des câbles reliés à des moteurs pour appliquer des forces sur la structure du robot et venir la déformer, un peu comme les tendons ou les ligaments que l’on trouve dans les organismes vivants.
Les domaines d’applications que nous pouvons envisager sont nombreux pour ces soft-robots : En robotique chirurgicale, pour naviguer dans des zones anatomiques fragiles sans appliquer d’efforts importants ; en robotique médicale, pour proposer des exosquelettes ou orthèses actives qui seraient bien plus confortables que les solutions actuelles ; en robotique sous-marine pour développer des flottes importantes de robots ressemblant à des méduses, peu chères à fabriquer, et capable d’aller explorer les fonds sous-marins ; pour l’industrie, pour fabriquer des robots bon marché et robustes ou des robots capables d’interagir avec les hommes sans aucun danger ; pour l’art et le jeu, avec des robots plus organiques, capables de mouvements plus naturels …
Mais ce qui nous intéresse aussi dans ces travaux est qu’ils sont porteurs de nouveaux défis pour la recherche. En particulier, le fait de revisiter les méthodes de design, de modélisation et de contrôle de ces robots. Nous passons d’un monde où le mouvement se décrit par une dizaine voire une vingtaine d’articulations, au maximum, à une robotique déformable qui a, en théorie, une infinité de degré de liberté. Autrement dit, pour développer l’usage et le potentiel de ces soft-robots, il va falloir totalement revoir nos logiciels . C’est cette mission que s’est confiée notre équipe (équipe Defrost, DEFormable RObotic SofTware, commune avec Inria et l’Université Lille 1) et qui rend ces travaux passionnants et ambitieux.
Nous souhaitons relever le défi de la modélisation et le contrôle des robots déformables : il existe de modèles des théories de la mécaniques des objets déformables (appelée mécanique des milieux continues). Ces modèles n’ont pas de solution analytique dans le cas général et il faut passer par des méthodes numériques souvent complexes et couteuses en temps de calcul, comme la méthode des éléments finis, pour obtenir des solutions approchées. Or, pour le pilotage d’un robot, la solution du modèle doit pouvoir être trouvée à tout instant en temps-réel (autrement dit en quelques millisecondes). Si cela est obtenu depuis longtemps pour les modèles rigides articulés, c’est une autre paire de manche pour les modèles par éléments finis. C’est le premier défi que nous devons affronter dans notre travail de recherche, mais d’autres défis, encore plus complexes, nous attendent. En voici quelques exemples :
Une fois le modèle temps réel obtenu, il faudra l’inverser : en effet le modèle nous donne la déformation de la structure du robot quand on connait les efforts qui s’appliquent sur lui. Mais pour piloter un robot, il faut, au contraire, trouver quels efforts nous devons appliquer par les actionneurs (les moteurs, les pistons, etc.) du robot, pour pouvoir le déformer de la manière que l’on souhaite. Or s’il est déjà complexe d’obtenir un modèle éléments finis en temps-réel, obtenir son inverse en temps-réel est un bien plus complexe encore !
Autre challenge : l’environnement du robot. Contrairement à une approche classique en robotique rigide où l’on cherche l’anticollision (le fait de déployer le robot sans toucher les parois de l’environnement), les robots déformables peuvent venir au contact de leur environnement sans l’abimer. Dans certaines applications, il est même plutôt souhaitable que le robot puisse venir entrer en contact. Cependant il faut maitriser les intensités des efforts appliqués par ces contacts et particulièrement dans des applications en milieu fragile (comme en chirurgie par exemple). Un paramètre important dans ce contexte est que l’environnement va lui aussi déformer le robot. Il faut donc impérativement en tenir compte dans la réalisation du modèle. Quand l’environnement correspond à des tissus biologiques, il faut alors prévoir d’ajouter un modèle biomécanique de l’environnement…
Un dernier exemple de défi, plus fondamental, est lié à l’utilisation de capteurs. Si l’on imite la nature, notre système nerveux nous donne un retour d’information (vision, toucher, son, etc.) qui nous aide à contrôler nos mouvements et à appréhender notre environnement. Les ingénieurs ont donc très vite pensé à équiper les robots de capteurs qui permettent de compenser et d’adapter les modèles utilisés pour les piloter. La théorie du contrôle permet de donner un cadre mathématique à ces méthodes d’ingénierie des systèmes. Or la complexité de cette théorie dépend essentiellement du nombre de variables nécessaires à décrire l’état du système et du couplage entre ces variables… Avec une infinité (théorique) de degrés de liberté, couplés par la mécanique des milieux continus, il faudra forcément revisiter cette théorie pour l’adapter.
Bien d’autres défis sont encore à considérer comme la création de nouveaux outils de CAO (Conception Assistée par Ordinateur) pour concevoir ces robots, ou la programmation de leur fabrication en lien avec l’impression 3D. Enfin, si l’on veut un jour avoir notre Baymax, en chair et sans os, capable d’être notre infirmier personnel à domicile, il faudra aussi lui apporter une certaine forme d’autonomie voire d’intelligence… mais ceci est une autre histoire !
Elodie Darquié & Maryse Urruty préparent un spectacle dont un premier extrait sera présenté à Pas Sage en Seine en juin 2015. Elles veulent expliquer Internet aux enfants. Intrigué, Binaire a demandé à Valérie Schafer d’aller se renseigner. Elle nous invite à suivre le travail d’Elodie et Maryse.François Hollande détaillait il y a quelques jours le plan pour le numérique à l’école, qui passe notamment par des équipements mobiles à destination des collégiens, des outils et ressources pédagogiques, la formation des personnels et une réflexion sur l’enseignement de l’informatique au lycée ou celui de la programmation à l’école. Relevant d’ambitions qui, si elles peuvent être complémentaires, n’en poursuivent pas moins des objectifs et approches très différentes entre familiarisation aux environnements numériques et découverte de la science informatique, cette réflexion politique prend acte et stimule par le haut des initiatives qui prennent corps depuis plusieurs années sur le terrain. Elles sont ainsi pensées au sein des milieux scientifiques (voir les échanges au sein de ce blog ou de la Société informatique de France sur l’enseignement de l’informatique), du corps enseignant, ou encore dans le cadre d’associations et de projets qui œuvrent à développer l’appétence des jeunes pour l’informatique ou les littératies numériques (coding goûters, ateliers comme ceux de Magic Makers, association L’enfant @ l’hôpital, etc.)
Au sein de ces initiatives variées et stimulantes, celle de Maryse Urruty et Elodie Darquié a un positionnement original, à rebours de certains discours qui voient dans l’équipement, la pratique et la manipulation, la meilleure (voire la seule) façon d’éveiller la curiosité des plus jeunes au numérique. « Nous avons aussi choisi le spectacle vivant pour privilégier l’interaction avec le public. Nous voulons parler de technologies que nous percevons à travers des écrans dans un rapport direct avec les spectateurs. Passer par des personnages nous aide à créer une nouvelle relation entre le public et la technologie », explique Maryse. « En général, on traite du numérique avec des formats et une esthétique assez technologiques. Nous, nous avons choisi de parler de technologie avec un format très ancien : un récit conté », complète Elodie.
Accueillies en résidence à l’Agora de Nanterre, dans le cadre du festival Nanterre Digital, leurs premières représentations de Il était une fois l’Internet sont prévues pour octobre 2015. Au cœur du spectacle destiné aux 8-12 ans, il y a le voyage de leur héroïne Data au sein du réseau des réseaux. Ces jeunes diplômées de Science Po Toulouse ont trouvé leur inspiration dans Il était une fois la vie mais aussi dans une culture éclectique, ancrée dans son temps. Elles mentionnent en vrac : Alain Damasio, the Lego movie, Terry Pratchett, C’est pas Sorcier, Mario Kart, XKCD, Benjamin Bayart, la légende de Korra, Claude Ponti, Child of Light, la Trilogie des Fourmis. Elles ont su combiner leurs expériences et passions : celle de Maryse pour le théâtre, celle d’Élodie pour le numérique, mais aussi la médiation scientifique qu’elle a pu découvrir chez Inria. C’est d’ailleurs de cette dernière expérience et en particulier de celle du jeu Datagramme que leur est venue l’envie de développer en complément un jeu sur plateau qui œuvre comme le spectacle à matérialiser Internet. Car ce sont bien les aspects matériels et les réalités technologiques des couches basses du réseau qui sont au centre de cette découverte et des ateliers associés : il s’agit de suivre la charmante et amoureuse Data dans la boite noire, dans les coulisses de l’Internet, un parcours « dans les tuyaux » que ne renierait pas Andrew Blum.
Les moyens pour faire pénétrer les enfants dans cet univers technologique complexe de manière ludique et pédagogique sont pensés jusque dans les moindres détails. « Les images sont animées, mais subtilement, pour ne pas monopoliser l’attention des spectateurs. Nos principales sources d’inspiration sont les gif et le gif-art » explique Elodie, tandis que Maryse ajoute: « Le visuel est lent et répétitif comme un motif qui laisse la narration libre et la complète selon les besoins de chaque spectateur. Nous cherchons également à créer une ambiance sonore, entre un cocon musical et les bruits des machines ».
En attendant de découvrir un extrait du spectacle à Pas Sage en Seine en juin 2015, on a envie de souhaiter tous nos vœux de succès à ce projet pour plein de raisons.
D’abord, il pose la question difficile des matérialités, des matériels, des infrastructures et considère les environnements numériques dans leur globalité et non uniquement par leur face visible et la manipulation. Il communique aux enfants le goût pour les infrastructures. (Et pour les parents, nous conseillons un autre artiste, le génial John Oliver, hilarant et passionnant quand il vous parle de Neutralité de l’Internet ou encore d’infrastructures).
Et puis, le projet est ambitieux. Il combine le spectacle vivant, des ateliers et du jeu. Un « Guide du Routeur” est distribué aux spectateurs. Ce livret explicite les références du conte et les recontextualise par exemple en parlant des datacenters ou du routage, via une Pirate box (un dispositif créant un petit réseau wifi autour de lui pour partager librement des fichiers).
Enfin Maryse et Elodie nous offrent une merveilleuse réponse en récit et images aux questions que se pose la recherche sur les Temps et temporalités du Web, que résume en quelques mots Maryse : « Le conte c’est un genre qui va chercher du côté de l’enfance, du merveilleux et du fantastique. Il nous a permis de façonner un univers complet dans lequel nous pouvions recréer des interactions entre les personnages, et un nouveau rapport au temps. L’histoire du spectacle ne dure en réalité qu’une milliseconde, mais dans notre monde imaginaire, nous prenons le temps de vivre chacune des péripéties de Data, notre héroïne, à une vitesse compréhensible par nos spectateurs ».
Une parenthèse de poésie, un peu de « slow science », une cyberflânerie ; que tout cela est bienvenu !
Valérie Schafer, ISCC, CNRS/Paris-Sorbonne/UPMC
Note : L’activité pédagogique qui recrée le voyage de Data s’appuiera sur des ordinateurs offerts par le collectif Emmabuntüs et l’association « Les Amis d’Emmabuntüs ». Elodie et Maryse collaborent également avec l’Electrolab, le plus grand hackerspace d’Europe basé à Nanterre, où elles fabriquent une partie de leur scénographie et de leur matériel pédagogique.





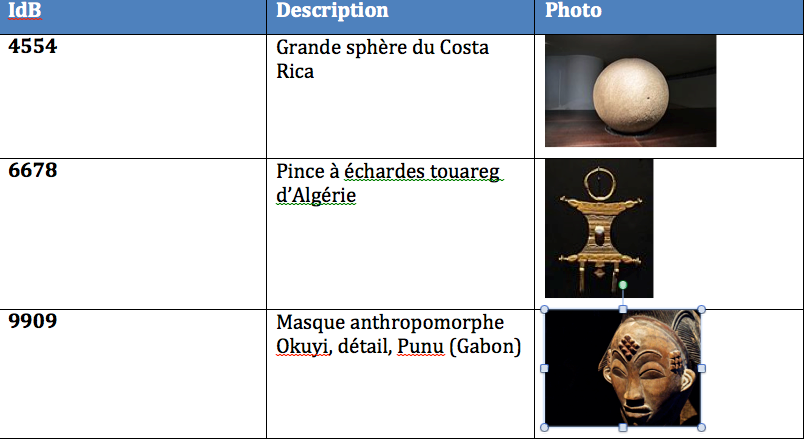


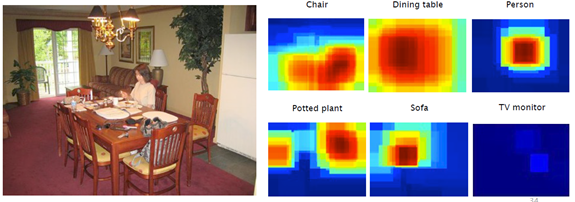






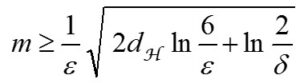







 Femme tenant des tablettes et un stylet (Pompéi, Ier siècle)
http://commons.wikimedia.org/wiki/File:Pompeii-couple.jpg#/media/File:Pompeii-couple.jpg
Femme tenant des tablettes et un stylet (Pompéi, Ier siècle)
http://commons.wikimedia.org/wiki/File:Pompeii-couple.jpg#/media/File:Pompeii-couple.jpg



{kind=link}