« C’est notamment grâce aux technologies de l’analyse d’images et de la vision par ordinateur que Delair-Tech pourra devancer ses compétiteurs ». Olivier Faugeras, chercheur Inria Sophia, Membre de l’Académie des Sciences.
Contrairement aux drones grand public les plus répandus avec hélice, les drones professionnels de Delair-tech ressemblent à des avions miniatures. On retrouve dans le monde des drones la même distinction qu’entre hélicoptère et avion. L’avantage des drones à voilure fixe (et pas tournante), c’est leur autonomie qui leur permet de parcourir de grandes distances et de couvrir ainsi de larges zones.
Photo Delair-tech
L’agriculture. A cause de la plus grande autonomie des drones à voilure fixe, l’un de leurs marchés les plus prometteurs n’est autre que l’agriculture. Un drone de Delair-tech permet par exemple de détecter depuis le ciel les parcelles d’un champ qui ont besoin d’azote. « La société était très orientée hardware au départ, mais nous travaillons de plus en plus sur des logiciels, notamment de traitement d’image » explique Benjamin Benharrosh, cofondateur de la startup. Pour analyser la quantité d’azote présente localement dans un champ, leurs logiciels permettent de réaliser une carte multispectrale et à partir de cela de calculer des indices biophysiques en différents points. Dans le cadre d’un projet de recherche sur quatre ans lancé en partenariat notamment avec l’INRA, Delair-tech cherche aussi à détecter des maladies des cultures, les besoins en désherbage, ou à permettre de mieux contrôler l’hydratation.
Photo Delair-tech
Les mines et le BTP. Si l’agriculture est un domaine porteur pour Delair-tech, le plus développé pour l’instant reste celui des mines et du bâtiment. « Les géomètres sont habitués à gérer des révolutions technologiques fréquentes. Beaucoup d’entre eux utilisent déjà des drones. » explique Benjamin Benharrosh. Delair-tech les aide par exemple à reconstituer un modèle 3D du terrain. Les drones peuvent aussi participer à la surveillance et l’inspection de réseaux comme des lignes électriques ou des voies ferrées. Des drones permettent de détecter par exemple de la végétation qui s’approche trop près de lignes électriques, ou des pelleteuses qui creusent un terrain alors qu’un oléoduc passe en-dessous. Si reconnaître de la végétation est une tâche relativement simple à l’aide de marqueurs de chlorophylle, pour reconnaître une pelleteuse, il faut avec des algorithmes de reconnaissance de formes ; c’est bien plus compliqué.
Photo Delair-tech
Dans le domaine de Delair-tech, les challenges sont très techniques. Pour obtenir l’autorisation de voler hors du champ visuel de l’opérateur, il a fallu construire un drone de moins de deux kilos. Cela écartait la solution simple qui consistait à combiner des composants du marché. Pour cela, la R&D de Delair-tech a dû monter en compétences dans des domaines aussi variés que les matériaux composites, les télécoms, les système embarqués, la mécanique. Une autre contrainte sérieuse est mentionnée par Benjamin Benharrosh : « La réglementation nous oblige à garder le contact avec le drone en permanence ». Une borne Wifi permet de garder ce contact jusqu’à une vingtaine de kilomètres. Et au delà, il faut installer des antennes relais.
La France est l’un des premiers pays au monde à avoir régulé les vols de drones hors vue. Le drone doit être léger, pour minimiser les risques en cas de chute. Il doit permettre un retour vidéo vers son opérateur, qui doit garder en permanence une communication avec lui. On ne peut pas par exemple passer par la 3G d’un opérateur, qui n’est pas considérée comme assez fiable. Le drone doit de plus inclure un système de défaillance permettant un retour forcé en cas de perte de contact, et d’un système de sécurité le conduisant à tomber avec peu d’énergie en cas de problème plus sérieux.
Pour être autorisé à réaliser des vols hors du champ visuel en France, un des premiers pays à avoir légiféré sur les drones hors vue, des drones de Delair-tech ont dû passer tous les tests exigés dans l’hexagone. Pourtant 75 % du chiffre d’affaire de la startup est réalisé à l’étranger dans les quelques pays ayant déjà mis en place une régulation… ainsi que dans ceux n’en ayant pas encore.
Le marché de Delair-tech est très compétitif. Les challenges sont techniques, principalement logiciels : étude topographique, génération et analyse de carte multispectrale, reconnaissance d’image… Ils sont loin d’être tous résolus avant que, par exemple, les drones de Delair-Tech puissent voler au dessus de 150m et se mêler au trafic aérien.
À quoi servent les mathématiques ? Il faut évidemment rappeler que « […] le but unique de la science, c’est l’honneur de l’esprit humain et […] sous ce titre, une question de nombres vaut autant qu’une question de système du monde »
Mais cela ne les empêche pas de nous aider aussi au quotidien et il y a bien peu de secteurs de l’activité humaine dont elles soient absentes. C’est particulièrement vrai pour la compréhension de notre environnement : climat, économie, géologie, écologie, science spatiale, régulation démographique, politique mondiale, etc.
Aller sur le site
Le livre collectif Brèves de maths (Éditions Nouveau Monde) illustre, de façon accessible, la variété des problèmes scientifiques dans lesquels la recherche mathématique actuelle joue un rôle important. Cet ouvrage propose une sélection des meilleures contributions du projet Un jour, une brève de l’initiative internationale Mathématiques de la planète Terre.
L’agriculture elle-aussi a été impactée par l’informatique. Dans le cadre des « Entretiens autour de l’informatique », Serge Abiteboul et Claire Mathieu ont rencontré François Houllier, Président directeur général de l’INRA, l’Institut National de Recherche en Agronomie. François Houllier raconte à Binaire les liens riches et complexes entre les deux disciplines, et ses inquiétudes autour du changement climatique.
François Houllier, PDG de l’INRA
La gestion des ressources forestières
Monsieur Houllier, qui êtes vous ?
François Houllier : Au départ, je suis un spécialiste de l’inventaire et de la modélisation des ressources forestières. J’ai été chercheur dans ce domaine. Aujourd’hui, je suis président directeur général de l’INRA. J’ai rencontré l’informatique dès le début de ma carrière, avec, pour ma thèse de doctorat l’utilisation de bases de données pour le dénombrement et la mesure d’arbres à partir de photos aériennes et d’observations de terrain. A l’Inventaire Forestier National, j’ai développé des modèles de production de forêt pour simuler les évolutions de massifs forestiers à l’échelle de cinq, dix, vingt ou trente ans, grâce aux bases de données et aux ordinateurs. Dans les années 80, nous avons réalisé un service « Minitel vert » pour donner accès librement aux informations statistiques sur les bois et les forêts dans un département ou une région. J’ai aussi dirigé des laboratoires de recherche où l’informatique était très présente, par exemple le laboratoire AMAP à Montpellier qui a essaimé en Chine, à l’École centrale de Paris et à l’Inria avec des chercheurs qui travaillaient sur la modélisation de l’architecture des plantes, de leur topologie, de leur géométrie et de leur morphogenèse. Cela demandait de faire dialoguer des botanistes, des agronomes, des écologues et des forestiers ayant le goût de la modélisation, avec des chercheurs qui maîtrisent les méthodes statistiques, les mathématiques appliquées, l’informatique.
La modélisation mathématique et informatique a pris une place considérable en agronomie ?
FH : Pour les forêts, ma spécialité initiale, la modélisation est particulièrement importante. On inventorie les forêts à l’échelle nationale et on se demande quelles seront les ressources en bois et la part qui pourra être exploitée dans dix, vingt ou cinquante ans. Nous sommes sur des échelles de temps longues, où l’expérience passée aide, mais où nous devons nous projeter dans le futur. Il faut tenir compte des problèmes de surexploitation ou de sous-exploitation, utiliser les techniques de sondage et la télédétection pour acquérir massivement des données. Nous partons de toutes les données dont nous disposons et, avec des modèles, nous essayons de prédire comment les forêts vont évoluer. C’est un peu comme les études en démographie humaine. Les particularités pour les forêts, c’est que les arbres ne se reproduisent pas comme des mouettes ou des humains, et qu’ils ne se déplacent pas. Mais, même si nos modèles sont parfois un peu frustes, les entreprises qui investissent dans les forêts, notamment pour alimenter les scieries ou les papeteries, attendent des prédictions raisonnables pour rentabiliser leurs investissements qui sont sur du long terme.
Les changements climatiques et la COP21
Quand vous vous projetez ainsi dans l’avenir, vous rencontrez la question du changement climatique. Ce changement a un impact sur les forêts ?
FH : Quand j’ai commencé à travailler sur les forêts, à la fin des années 1980, la question du changement climatique ne se posait pas. J’ai rencontré le sujet à l’occasion d’un séminaire réalisé par un chercheur travaillait sur le dépérissement des forêts. Il avait trouvé un résultat alors invraisemblable : le sapin grossissait dans les Vosges comme il n’avait jamais grossi depuis un siècle, plus de 50% plus vite que le même sapin un siècle plus tôt. C’était d’autant plus imprévisible qu’au départ ce chercheur s’intéressait au dépérissement des forêts du fait de ce qu’on appelait les « pluies acides ». Son résultat a ensuite été confirmé. L’explication ? Ce n’était pas le climat en tant que tel, la pluviométrie ou la température même si leurs variations interannuelles ont des effets sur la croissance des arbres. Cela venait de différents facteurs, dont l’accroissement de la teneur en CO2 de l’air et surtout les dépôts atmosphériques azotés qui ont un effet fertilisant. Ce n’est pas simple de séparer les différents facteurs qui ont des effets sur la croissance des autres effets potentiellement négatifs du changement climatique. Ce changement climatique, forcément, va avoir des effets majeurs sur les forêts, des effets immédiats et des effets décalés. Par exemple, comme un chêne pousse en bonne partie en fonction du climat de l’année antérieure, il y a un effet d’inertie. Quand j’ai commencé mes recherches, nous considérions le climat comme une constante, avec des variations interannuelles autour de moyennes stables. Maintenant, ce n’est plus possible.
Cela nous conduit à l’impact du changement climatique sur l’agriculture…
FH : Nous avons des échelles de temps très différentes entre les forêts et, par exemple, les céréales. Prenons le blé et son rendement depuis un siècle. On observe une faible augmentation de 1900 à 1950, puis une forte augmentation, d’un facteur quatre environ, de 1950 à 1995, et puis… la courbe devient irrégulière mais plutôt plate. (Voir la figure.) Comment expliquer cette courbe ? Après 1950, les progrès viennent des engrais, de nouvelles pratiques de culture, et beaucoup de la génétique.
En amélioration génétique des plantes, ça se passe un peu comme dans le logiciel libre avec un processus d’innovation ouverte où chacun peut réutiliser les variétés précédemment créées par d’autres améliorateurs. Chaque année, les sélectionneurs croisent des variétés ; ils filtrent ces croisements pour obtenir de nouvelles variétés plus performantes. Cela prend une dizaine d’années pour créer ainsi une nouvelle variété qui est ensuite commercialisée sans pour autant que son obtenteur paie de royalties à ceux qui avaient mis au point les variétés parentes dont elle est issue. Le progrès est cumulatif.
En 1995, les généticiens avaient-il atteint le rendement maximal ? Pas du tout. Le progrès génétique a continué, et aurait dû entraîner une hausse des rendements de l’ordre de 1% par an. Alors pourquoi la stagnation ? Des modèles ont montré qu’environ la moitié du progrès génétique a été effacée par le réchauffement climatique et par la multiplication des événements climatiques défavorables, et l’autre moitié a été perdue du fait des changements de pratiques agricoles, notamment de la simplification excessive de l’agriculture, un effet beaucoup plus subtil. Il y a plusieurs décennies, on avait des rotations, avec des successions d’espèces par exemple entre le blé et des légumineuses, telles que le pois. Quand on arrête ce type de rotations, le sol devient moins fertile.
Vous voyez, ce n’est pas simple de comprendre ce qui se passe quand on a plusieurs facteurs qui jouent et dont les effets se combinent. Nous travaillons beaucoup dans cette direction. Nous utilisons des modèles prédictifs pour déterminer selon différents scénarios climatiques et selon les endroits du globe, si les rendements agricoles vont augmenter ou pas. Les bases écophysiologiques de ces modèles sont bien connues mais il y a beaucoup de facteurs : la qualité des terres et des sols, le climat et les variations météorologiques, les espèces et les variétés, les pratiques agronomiques et les rotations. La complexité est liée au nombre de paramètres qui découlent de ces facteurs. En développant de nouveaux modèles, on comprend quelles informations manquent, on se trompe, on corrige, on affine les paramètres. C’est toute une communauté qui collectivement apprend et progresse par la comparaison des modèles entre eux et par la confrontation avec des données réelles.
Ce que nous avons appris. Pour les 10 ans à 20 ans qui viennent, pratiquement autant de prédictions indiquent des augmentations que des réductions des rendements agricoles, au niveau global. Mais si on se projette en 2100, 80% des prédictions annoncent des diminutions de rendement. Même s’il y aura des variations selon les endroits et les espèces, la majorité des cultures et des lieux seront impactés négativement !
Cela pose de vraies questions. Pour nourrir une population qui croît, on doit accroître la production. On peut le faire en augmentant le rendement ; c’est ce qui s’est passé quand l’Inde a multiplié en cinquante ans sa production de blé par six sans quasiment modifier la surface cultivée. Ou alors on peut utiliser des surfaces supplémentaires, par exemple en les prenant sur les forêts, mais cela pose d’autres problèmes. La vraie question, c’est évidemment d’arriver à produire plus de manière durable. Et avec le changement climatique, on peut craindre la baisse des rendements dans beaucoup d’endroits.
Image satellitaire infra-rouge. IGN. Via INRA.
Le monde agricole s’intéresse beaucoup au big data. Comme ailleurs, cela semble causer des inquiétudes, mais être aussi une belle source de progrès. Comment voyez-vous cela ?
FH : Nous voyons arriver le big data sous deux angles différents, sous celui de la recherche et sous celui de l’agriculture.
Premier angle : la recherche, pour laquelle le big data a une importance énorme. Considérons, par exemple, l’amélioration génétique classique : on cherche à utiliser de plus en plus précisément la connaissance du génome des animaux et des végétaux en repérant des « marqueurs » le long des chromosomes ; ces marqueurs permettent de baliser le génome et de le cartographier. Les caractères intéressants, comme le rendement ou la tolérance à la sécheresse, sont corrélés à de très nombreux marqueurs. On va donc faire des analyses sur les masses de données dont on dispose : beaucoup d’individus sur lesquels on identifie la présence ou l’absence de beaucoup de marqueurs qu’on corrèle avec un grand nombre de caractères. L’objectif c’est de trouver des combinaisons de marqueurs qui correspondent aux individus les plus performants. On sait faire cela de mieux en mieux, notamment à l’INRA. Les grands semenciers le font aussi : ils investissent entre 10 et 15% de leurs ressources dans la R&D. Aujourd’hui, la capacité bioinformatique à analyser de grandes quantités de données devient un facteur limitant.
On peut aussi considérer le cas des OGM, avec le maïs. La tolérance à un herbicide ou la résistance à un insecte ravageur peuvent être contrôlées par un seul gène ou par un petit nombre de gènes. Par contre, le rendement dépend de beaucoup de gènes différents : des dizaines, voire des centaines. D’où deux stratégies assez différentes. Pour les caractères dont le déterminisme génétique est simple, on peut utiliser une approche de modification génétique ciblée, les fameux OGM. Pour les caractères dont le déterminisme est multifactoriel, l’approche « classique » accélérée par l’usage des marqueurs associés aux gènes est celle qui marche actuellement le mieux. Donc, pour disposer d’un fond génétique qui améliore le rendement, le big data est la méthode indispensable aussi bien en France, sans OGM, qu’aux Etats-Unis, avec OGM.
Deuxième angle : l’utilisation du big data chez les agriculteurs. Un robot de traite est équipé de capteurs qui produisent des données. Un tracteur moderne peut aussi avoir des capteurs, par exemple pour mesurer la teneur en azote des feuilles. Avec les masses de données produites, nous avons vu se développer de nouveaux outils d’analyse et d’aide à la décision pour améliorer le pilotage des exploitations. Mais ce qui inquiète le monde agricole, c’est qui va être propriétaire de toutes ces données ? Qui va faire les analyses et proposer des conseils sur cette base ? Est-ce-que ces données vont être la propriété de grands groupes comme Monsanto, Google, ou Apple ou les fabricants de tracteurs ? En face de cela, même les grandes coopératives agricoles françaises peuvent se sentir petites. Le contrôle et le partage de toutes ces données constituent un enjeu stratégique.
L’agriculteur connecté
Il ressort de tout cela que l’agriculteur est souvent très connecté ?
FH : Il reste bien sûr des zones dans les campagnes qui sont mal couvertes par Internet, mais ce n’est pas la faute des agriculteurs. Les agriculteurs sont plutôt technophiles. Quand les tracteurs, les robots de traites ou les drones sont arrivés, ils se sont saisis de ces innovations. Il en va de même avec le numérique. Les agriculteurs qui font de l’agriculture biologique sont eux aussi favorables au numérique. Les nouvelles technologies permettent aux agriculteurs de gagner du temps, d’améliorer leur qualité de vie, de réduire la pénibilité de certaines activités. Ils sont conscients des améliorations que les applications informatiques peuvent leur apporter.
Automate de caractérisation des plantes. INRA.
La data et le territoire
Ils sont connectés et solidaires ?
FH : Les agriculteurs ont l’habitude de partager des pratiques et des savoir faire, ou des matériels agricoles, et d’exprimer des formes de solidarité. Par exemple, dans un même territoire, ils échangent « par dessus la haie », c’est-à-dire qu’ils regardent ce qui se fait à côté et imitent ce qui marche chez leurs voisins. Dans le domaine de la sélection animale la recherche publique, l’INRA, travaille depuis longtemps avec les différents organismes qui font de l’insémination artificielle et qui sélectionnent les meilleurs animaux pour la production de lait ou de viande, par exemple. Les races bovines sont certes différentes mais certaines méthodes sont identiques, comme le génotypage qui consiste à déterminer tout ou partie de l’information génétique d’un organisme. Jusqu’à récemment, il existait une forte solidarité entre les différentes filières animales : d’une certaine manière, les progrès méthodologiques réalisés sur les races bovines dédiées à la production laitière bénéficiaient aux autres races puis ensuite aux ovins ou aux caprins.
Ces dernières années, l’arrivée de nouvelles formes d’analyse à haut débit, très automatisées, spécialisées, a induit des changements. Cela a conduit au développement d’activités concurrentielles. Par exemple, il y a des sociétés qui proposent des services de génotypage pour analyser des milliers de bovins en identifiant leurs marqueurs génétiques. Ça peut se faire n’importe où dans le monde, à Jouy-en-Josas, comme au Canada : il suffit d’envoyer les échantillons. Les solidarités territoriales ou nationales qui existaient sont en train de se fracturer sous les effets combinés de la mondialisation et du libéralisme. Elles sont en train de se défaire du fait de la compétition au sein de métiers qui se segmentent, et de la création d’opérateurs internationaux sans ancrage territorial. Regardez le big data : les données ne sont pas localisées ; elles ne sont pas ancrées dans un territoire ; les calculs se réalisent quelque part « dans le cloud ». C’est une cause de l’inquiétude actuelle de nos collègues des filières animales ou végétales : l’angoisse du big data ne vient pas de la technologie en tant que telle, mais plutôt de la perte d’intermédiation, de la perte du lien avec le territoire.
L’agronome et l’agriculteur
Dans d’autres sciences, la distance entre les chercheurs et les utilisateurs de leurs recherches est souvent très grande. On a l’impression en vous entendant que c’est moins vrai des agronomes.
FH : Ça dépend. Prenez un chercheur qui travaille sur les mécanismes cellulaires fondamentaux de recombinaison génétique. Il révolutionnera peut-être la sélection végétale dans vingt ans, mais il peut faire des recherches sur ce sujet sans rencontrer d’agriculteurs. Nous avons des recherches de ce type à l’INRA, mais nous assurons aussi une continuité avec des travaux plus en aval au contact du monde agricole. Le plus souvent, nous ne réalisons pas nous mêmes les applications ; cela peut être fait par des entreprises, par des instituts techniques dédiés ou par des centres techniques industriels, financés pour partie par l’État et pour beaucoup par des fonds professionnels. De tels instituts existent pour les fruits et légumes, pour les céréales, pour les oléagineux, pour l’élevage en général ; il en existe un spécifique pour le porc, et un pour la volaille. Nous collaborons avec eux.
Informatique et agriculture
Comment se passe le dialogue entre vos spécialistes d’agronomie et les informaticiens ?
FH : Nous avons de plus en plus de besoin de compétences en modélisation, en bioinformatique, en mathématiques appliquées, en informatique, avec des capacités à conceptualiser, à traiter des grands ensembles de données, à simuler… Quelles sont les compétences d’un chercheur qu’on embauche à l’INRA aujourd’hui ? Cela évolue, les métiers changent et on en voit naître de nouveaux. Mais il est clair que même dans des disciplines « anciennes » comme l’agronomie ou la physiologie, les jeunes chercheurs que nous recrutons doivent et devront avoir des compétences ou pour le moins une sensibilité affirmée pour l’informatique et le big data. Nous avons fait un exercice de gestion prévisionnelle des emplois et des compétences : il en ressort que beaucoup des nouveaux besoins exprimés relèvent du numérique au sens large. Nous nous posons sans arrêt ces questions : quelle informatique voulons-nous faire ou avoir en interne ? Que voulons-nous faire en partenariat, notamment avec Inria avec qui nous collaborons beaucoup ? Parmi les organismes de recherche finalisés et non dédiés au numérique, nous sommes l’un des rares à être doté d’un département de mathématiques et informatique appliquées, héritier du département de biométrie. Même si c’est le plus petit des 13 départements de l’INRA et si ce n’est pas notre cœur de métier, de telles compétences sont vraiment essentielles pour nous aujourd’hui.
SAS, un grand éditeur de logiciel américain spécialiste de la statistique, doit beaucoup à l’agriculture. Quand ce n’était encore qu’une startup de l’Université de Caroline du Nord, SAS a eu besoin de puissances de calculs. C’est le monde agricole, le service de recherche agronomique du ministère de l’agriculture des États-Unis, qui a fourni l’accès à des moyens de calcul. Ce n’est pas vraiment surprenant quand on sait que l’agriculture a été très tôt un objet d’étude privilégié des statisticiens et a donné lieu à beaucoup de développements méthodologiques originaux. Voir https://en.wikipedia.org/wiki/Maurice_Kendall
Dans le même ordre d’idée, c’est intéressant de savoir que c’est l’INRA qui a commandé l’un des premiers ordinateurs personnels équipés d’un microprocesseur, le premier Micral vers 1970. Il était destiné à des études de bioclimatologie dirigées par Alain Perrier. Voir https://en.wikipedia.org/wiki/Micral
Ce conte pour enfant, un spectacle « coup de cœur » de binaire, passe à la Cité des Sciences. Voir l’article de Valérie Schafer. Entrée libre dans la limite des places disponibles.
La recherche aime bien avoir ses challenges qui galvanisent les énergies. L’intérêt d’un tel challenge peut avoir de nombreuses raisons, la curiosité (le plus ancien os humain), l’importance économique (une énergie que l’on puisse stoker), la difficulté technique (le théorème de Fermat). En informatique, un problème tient de ces deux dernières classes : c’est l’«isomorphisme de graphe» (nous allons vous dire ce que c’est !) . On comprendra l’excitation des informaticiens quand un chercheur de la stature de Laszlo Babai de l’Université de Chicago a annoncé une avancée fantastique dans notre compréhension du problème. Binaire a demandé à une amie, Christine Solnon, Professeure à l’INSA de Lyon, de nous parler de ce problème. Serge Abiteboul, Colin de la Higuera.
À la rencontre de Laszlo et de son problème
Laszlo Babai, professeur aux départements d’informatique et de mathématiques de l’université de Chicago, a présenté un exposé le 10 novembre 2015 intitulé Graph Isomorphism in Quasipolynomial Time. Si le nom « isomorphisme de graphes » ne vous dit rien, vous avez probablement déjà rencontré ce problème, et vous l’avez peut être même déjà résolu « à la main » en comparant, par exemple, des schémas ou des réseaux, afin de déterminer s’ils ont la même structure.
Le problème est déroutant et échappe à toute tentative de classification : d’une part, il est plutôt bien résolu en pratique par un algorithme qui date du début des années 80 ; d’autre part, personne n’a jamais réussi à trouver un algorithme dont l’efficacité soit garantie dans tous les cas. Mais surtout, il est un atout sérieux pour tenter de prouver ou infirmer la plus célèbre conjecture de l’informatique : P≠NP.
Nous allons donc présenter ici un peu plus en détails ce problème, en quoi il occupe une place atypique dans le monde de la complexité des problèmes, et pourquoi l’annonce de Babai a fait l’effet d’une petite bombe dans la communauté des chercheurs en informatique.
Qu’est-ce qu’un graphe ?
Pour résoudre de nombreux problèmes, nous sommes amenés à dessiner des graphes, c’est-à-dire des points (appelés sommets) reliés deux à deux par des lignes (appelées arêtes). Ces graphes font abstraction des détails non pertinents pour la résolution du problème et permettent de se focaliser sur les aspects importants. De nombreuses applications utilisent les graphes pour modéliser des objets. Par exemple:
By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Un réseau de transport (routier, ferroviaire, métro, etc) peut être représenté par un graphe dont les sommets sont des lieux (intersections de rues, gares, stations de métro, etc) et les arêtes indiquent la possibilité d’aller d’un lieu à un autre (par un tronçon de route, une ligne de train ou de métro, etc.)
By This SVG image was created by Medium69. Cette image SVG a été créée par Medium
Une molécule peut être représentée par un graphe dont les sommets sont les atomes, et les arêtes les liaisons entre atomes.
Un réseau social peut être représenté par un graphe dont les sommets sont les membres, et les arêtes les relations entre membres
Le problème d’isomorphisme de graphes
Étant donnés deux graphes, le problème d’isomorphisme de graphes (Graph Isomorphism Problem) consiste à déterminer s’ils ont la même structure, c’est-à-dire, si chaque sommet d’un graphe peut être mis en correspondance avec exactement un sommet de l’autre graphe, de telle sorte que les arêtes soient préservées (deux sommets sont reliés par une arête dans le premier graphe si et seulement si les sommets correspondants sont reliés par une arête dans le deuxième graphe). Considérons par exemple ces trois graphes :
G1
Les graphes G1 et G2 sont isomorphes car la correspondance
{ a ↔ 1; b ↔ 2; c ↔ 3; d ↔ 4; e ↔ 5; f ↔ 6; g ↔ 7}
préserve toutes les arêtes.
Par exemple :
– a et b sont reliés par une arête dans G1, et 1 et 2 aussi dans G2
– a et c ne sont pas reliés par une arête dans G1, et 1 et 3 non plus dans G2 ;
etc.
En revanche, G1 n’est pas isomorphe à G3
(ce qui n’est pas évident à vérifier).
G2
G3
Notons qu’il est plus difficile de convaincre quelqu’un que les graphes G1 et G3 ne sont pas isomorphes car nous ne pouvons pas fournir de « certificat » permettant de vérifier cela rapidement, comme nous venons de le faire pour montrer que G1 et G2 sont isomorphes. Pour se convaincre que deux graphes ne sont pas isomorphes, il faut se convaincre qu’il n’existe pas de correspondance préservant les arêtes, et la question de savoir si on peut faire cela efficacement (autrement qu’en énumérant toutes les correspondances possibles) est véritablement au cœur du débat.
Ce problème se retrouve dans un grand nombre d’applications : dès lors que des objets sont modélisés par des graphes, le problème de la recherche d’un objet identique à un objet donné, par exemple, s’y ramène. Il est donc de première importance de disposer d’algorithmes efficaces.
Mais, au delà de cet aspect pratique, le problème occupe aussi une place très particulière dans un monde théorique au sein de la science informatique : celui de la complexité .
Petite digression sur la complexité des problèmes
La théorie de la complexité s’intéresse à la classification des problèmes en fonction de la complexité de leur résolution.
La classe des problèmes faciles (P). La classe P regroupe tous les problèmes « faciles ». Nous dirons qu’un problème est facile s’il existe un algorithme « efficace » pour le résoudre, et nous considèrerons qu’un algorithme est efficace si son temps d’exécution croît de façon polynomiale lorsqu’on augmente la taille du problème à résoudre. Par exemple, le problème consistant à trouver un chemin reliant deux sommets d’un graphe appartient à la classe P car il existe des algorithmes dont le temps d’exécution croît de façon linéaire par rapport à la taille du graphe (son nombre de sommets et d’arêtes).
La classe des problèmes dont les solutions sont faciles à vérifier (NP). La classe NP regroupe l’ensemble des problèmes pour lesquels il est facile de vérifier qu’une combinaison donnée (aussi appelée certificat) est une solution correcte au problème. Par exemple, le problème de recherche d’un chemin entre deux sommets appartient également à NP car étant donnée une succession de sommets, il est facile de vérifier qu’elle correspond bien à un chemin entre les deux sommets. De fait, tous les problèmes de P appartiennent à NP.
La question inverse est plus délicate, et fait l’objet de la célèbre conjecture P≠NP.
La classe des problèmes difficiles (NP-complets). Certains problèmes de la classe NP apparaissent plus difficiles à résoudre dans le sens où personne ne trouve d’algorithme efficace pour les résoudre. Les problèmes les plus difficiles de NP définissent la classe des problèmes NP-complets.
Considérons par exemple le problème consistant à rechercher dans un réseau social un groupe de personnes qui sont toutes amies deux à deux. Le problème est facile si on ne pose pas de contrainte sur la taille du groupe. Il devient plus difficile si on impose en plus que le groupe comporte un nombre fixé à l’avance de personnes. Si on modélise le réseau social par un graphe dont les sommets représentent les personnes et les arêtes les relations entre les personnes, alors ce problème revient à chercher un sous-ensemble de k sommets tous connectés deux à deux par une arête. Un tel sous-ensemble est appelé une clique.
Si nous avons un sous-ensemble de sommets candidats, alors nous pouvons facilement vérifier s’il forme une clique ou non. En revanche, trouver une clique de taille donnée dans un graphe semble plus difficile. Nous pouvons résoudre ce problème en énumérant tous les sous-ensembles possibles de sommets, et en testant pour chacun s’il forme une clique. Cependant, le nombre de sous-ensembles candidats explose (c’est-à-dire, croît exponentiellement) en fonction du nombre de sommets des graphes, ce qui limite forcément ce genre d’approche à des graphes relativement petits.
Actuellement, personne n’a trouvé d’algorithme fondamentalement plus efficace que ce principe fonctionnant par énumération et test. Évidemment, il existe des algorithmes qui ont de bien meilleures performances en pratique (qui utilisent des heuristiques et des raisonnements qui permettent de traiter des graphes plus gros) mais ces algorithmes ont toujours des temps d’exécution qui croissent de façon exponentielle par rapport au nombre de sommets.
La question pratique qui se cache derrière la question « P≠NP ? » est : Existe-t-il un algorithme efficace pour rechercher une clique de k sommets dans un graphe ?
Autrement dit : est-ce parce que nous ne sommes pas malins que nous n’arrivons pas à résoudre efficacement ce problème, ou bien est-ce parce que cela n’est pas possible ?
Il existe un très grand nombre de problèmesNP-complets, pour lesquels personne n’a réussi à trouver d’algorithme efficace. Ces problèmes interviennent dans de nombreuses applications de la vie quotidienne : faire un emploi du temps, ranger des boites rectangulaires dans un carton sans qu’il n’y ait de vide, chercher un circuit passant exactement une fois par chacun des sommets d’un graphe, etc. Pour ces différents problèmes, on connait des algorithmes qui fonctionnent bien sur des problèmes de petite taille. En revanche, quand la taille des problèmes augmente, ces algorithmes sont nécessairement confrontés à un phénomène d’explosion combinatoire.
Un point fascinant de la théorie de la complexité réside dans le fait que tous ces problèmes sont équivalents dans le sens où si quelqu’un trouvait un jour un algorithme efficace pour un problème NP-complet (n’importe lequel), on saurait en déduire des algorithmes polynomiaux pour tous les autres problèmes, et on pourrait alors conclure que P = NP. La question de savoir si un tel algorithme existe a été posée en 1971 par Stephen Cook et n’a toujours pas reçu de réponse. La réponse à cette question fait l’objet d’un prix d’un million de dollars par l’institut de mathématiques Clay.
La classe des problèmes ni faciles ni difficiles (NP-intermédiaires). Le monde des problèmes NP serait bien manichéen s’il se résumait à cette dichotomie entre les problèmes faciles (la classe P) et les problèmes dont on conjecture qu’ils sont difficiles (les problèmes NP-complets). Un théorème de Ladner nous dit qu’il n’en est rien : si la conjecture P≠NP est vérifiée, alors cela implique nécessairement qu’il existe des problèmes de NP qui ne sont ni faciles (dans P) ni difficiles (NP-complets). Ces problèmes sont appelés NP-intermédiaires. Notons que le théorème ne nous dit pas si P est différent de NP ou pas : il nous dit juste que si P≠NP, alors il existe au moins un problème qui est NP-intermédiaire… sans nous donner pour autant d’exemple de problème NP-intermédiaire. Il faudrait donc réussir à trouver un problème appartenant à cette classe pour démontrer que P≠NP. On dispose d’une liste (assez courte) de problèmes candidats (voir par exemple https ://en.wikipedia.org/wiki/NP-intermediate)… et c’est là que l’isomorphisme de graphes entre en jeu.
Que savait-on sur la complexité de l’isomorphisme de graphes jusqu’ici ?
Nous pouvons facilement vérifier que deux graphes sont isomorphes dès lors qu’on nous fournit une correspondance préservant les arêtes (comme nous l’avons fait précédemment pour les graphes G1 et G2). On peut donc facilement vérifier les solutions, nous sommes dans la classe NP. Mais sa complexité exacte n’est pas (encore) connue. Des algorithmes efficaces (polynomiaux) ont été trouvés pour des cas particuliers, les plus utilisés étant probablement pour les arbres (des graphes sans cycle) et les graphes planaires (des graphes qui peuvent être dessinés sur un plan sans que leurs arêtes ne se croisent). Dans le cas de graphes quelconques, les meilleurs algorithmes connus jusqu’ici ont une complexité exponentielle. Pour autant, personne n’a réussi à démontrer que le problème est NP-complet.
Il est donc conjecturé que ce problème est NP-intermédiaire. C’est même sans aucun doute le candidat le plus célèbre pour cette classe, d’une part parce qu’il est très simple à formuler, et d’autre part parce qu’on le retrouve dans de nombreux contextes applicatifs différents.
Que change l’annonce de Babai ?
L’annonce de Babai n’infirme pas la conjecture selon laquelle le problème est NP-intermédiaire, car son nouvel algorithme est quasi-polynomial, et non polynomial.
Plus exactement, pour les matheuses et les matheux, si les graphes comportent n sommets, alors le temps d’exécution de l’algorithme croît de la même façon que la fonction 2log(n)c où c est une valeur constante. Si c est égal à 1, alors l’algorithme est polynomial. Ici, c est supérieur à 1, de sorte que l’algorithme n’est pas polynomial, mais son temps d’exécution se rapproche plus de ceux d’algorithmes polynomiaux que de ceux d’algorithmes exponentiels.
Ce résultat est une avancée majeure parce qu’il rapproche le problème de la classe P, mais aussi parce que l’existence de cet algorithme quasi-polynomial ouvrira peut être une piste pour trouver un algorithme polynomial, ce qui permettrait d’éliminer le problème de la courte liste des problèmes dont on conjecture qu’ils sont NP-intermédiaires. Notons que le dernier problème qui a été enlevé de cette liste est le problème consistant à déterminer si un nombre entier donné est premier, pour lequel un algorithme polynomial a été trouvé en 2002.
D’un point de vue purement pratique, en revanche, cette annonce risque fort de ne pas changer grand chose quant à la résolution du problème, car on dispose déjà d’algorithmes performants : ces algorithmes sont capables de le résoudre pour la très grande majorité des graphes, et n’ont un temps d’exécution exponentiel que pour très peu de graphes.
De l’annonce au résultat établi. Le résultat de Babai en est encore au stade de l’annonce. Il faut maintenant qu’il soit détaillé dans un ou plusieurs articles, vérifiés par ses pairs, puis publiés dans des journaux. Ce résultat viendra alors grandir le corpus des vérités scientifiques établies. Il peut arriver que lors de ce cheminement, on trouve des « trous » dans la démonstration ; c’est arrivé pour le théorème de Fermat et ils ont été comblés. Il se peut aussi qu’on trouve une erreur dans la démonstration (y compris après la publication de l’article) ce qui renvoie les scientifiques à leurs tableaux noirs .
Pour un exemple d’algorithme pratique, l’algorithme Nauty 4 introduit en 1981 par Brendan McKay.
László Babai, né le 20 juillet 1950 à Budapest, est un professeur de mathématiques et d’informatique hongrois, enseignant actuellement à l’université de Chicago. Il est connu pour les systèmes de preuve interactive, l’introduction du terme « algorithme de Las Vegas » et l’utilisation de méthodes de la théorie des groupes pour le problème de l’isomorphisme de graphes. Il est lauréat du prix Gödel 1993. Wikipedia (2016).
Montée du niveau des mers, érosion côtière, perte de biodiversité… Les impacts sociétaux de ces bouleversements dus au réchauffement climatique ne seront pas dramatiques dans un futur proche si et seulement si nous changeons radicalement nos comportements collectifs et individuels et mettont en place de vraies solutions.
Joanna Jongwane
L’informatique et les mathématiques appliquées contribuent à relever le défi de la transition énergétique, pour changer par exemple l’usage des voitures en ville ou encore pour contrôler la consommation d’énergie dans les bâtiments. A contrario, quand la nature et la biodiversité inspirent les informaticiens, cela aboutit à des projets d’écosystèmes logiciels qui résistent mieux à divers environnements.
Accéder au dossier
C’est sur Interstices, la revue de culture scientifique en ligne qui invite à explorer les sciences du numérique, à comprendre ses notions fondamentales, à mesurer ses enjeux pour la société, à rencontrer ses acteurs que chercheuses et chercheurs nous proposent de découvrir quelques grains de science sur ces sujets. Morceaux choisis :
Accéder au document
«Le niveau des mers monte, pour différentes raisons liées au réchauffement climatique. Les glaciers de l’Antarctique et du Groenland, qu’on appelle calottes polaires ou inlandsis, jouent un rôle majeur dans l’évolution du niveau des mers. Peut-on prévoir l’évolution future de ces calottes polaires et en particulier le vêlage d’icebergs dans l’océan ?»
Accéder au document
«À l’heure de la COP21, toutes les sonnettes d’alarme sont tirées pour alerter sur l’urgence climatique. Si les simulations aident à prédire les évolutions du climat, elles peuvent aussi être vues comme un outil de dialogue science-société, selon Denis Dupré. On en parle avec lui dans cet épisode du podcast audio.»
Accéder au document
«Si au lieu de distribuer des millions de copies identiques, les fabricants de logiciels avaient la possibilité de distribuer des variantes, et que ces variantes avaient la possibilité de s’adapter à leur environnement, ces « écosystèmes logiciels » ne pourraient-ils pas renforcer la résistance de tous les services qui nous accompagnent au quotidien ?»
Extraits d’Interstices, Joanna Jongwane, Rédactrice en chef d’Interstices et Jocelyne Erhel, Directrice de Recherche et Responsable scientifique du comité éditorial, avec Christine Leininger et Florent Masseglia membres du comité exécutif.
Dérèglement climatique ? Problèmes d’énergie et dégradations que nous faisons subir à notre planète ? La Conférence de Paris de 2015 sur le climat (qui inclut la COP21) est une excellente occasion de mettre la transition écologique au cœur du débat. De plus, nous baignons dans une autre transition, la transition numérique dont on mesure chaque jour un peu plus en quoi elle transforme notre monde de façon si fondamentale. Deux disruptions. Comment coexistent-elles ?
www.greenit.fr, un site de partage de ressources à propos d’informatique durable
Commençons par ce qui fâche le fana d’informatique que je suis : le coût écologique du numérique. Le premier ordinateur, Eniac, consommait autant d’électricité qu’une petite ville. Les temps ont changé ; votre téléphone intelligent a plus de puissance de calcul et ne consomme quasiment rien. Oui mais des milliards de telles machines, d’objets connectés, et les data centers ? La consommation énergétique de l’ensemble est devenue une part importante de la consommation globale ; plus inquiétante encore est la croissance de cette consommation. Et puis, pour fabriquer tous ces objets, il faut des masses toujours plus considérables de produits chimiques, et de ressources naturelles, parfois rares. Et je vous passe les déchets électroniques qui s’amoncellent. Il va falloir apprendre à être économes ! Vous avez déjà entendu cette phrase. Certes ! On ne fait pas faire tourner des milliards d’ordinateurs en cueillant silencieusement des fleurs d’Udumbara.
D’un autre coté, le monde numérique, c’est la promesse de nouveaux possibles, scientifiques, médicaux, économiques, sociétaux. C’est, entre tellement d’autres choses, la possibilité pour un adolescent de garder contact avec des amis partout dans le monde; pour un jeune parent, de travailler de chez lui en gardant un enfant malade ; pour une personne au fin fond de la campagne, au bout du monde, d’avoir accès à toute la culture, à tous les savoirs du monde ; pour une personne âgée de continuer à vivre chez elle sous une surveillance médicale permanente. C’est tout cela : de nouveaux usages, de nouveaux partages, de nouveaux modes de vie. Alors, il n’est pas question de « se déconnecter » !
Les transitions écologiques et numériques doivent apprendre à vivre ensemble.
Penser écologie quand on parle de numérique
Quand le numérique prend une telle place dans notre société, il faut que, comme le reste, il apprenne à être frugal. Cela conduit à la nécessité de construire des ordinateurs plus économes en électricité, d’arrêter de dépenser d’énormes volumes de temps de calcul pour mieux cibler quelques publicités. Cela conduit aussi à modifier nos habitudes en adoptant un faisceau de petits gestes : ne pas changer d’ordinateur, de téléphone intelligent, de tablette tous les ans juste pour pouvoir frimer avec le dernier gadget, ne pas inonder la terre entière de courriels, surtout avec des pièces jointes conséquentes, etc. Nous avons pris de mauvaises habitudes qu’il est urgent de changer. Les entreprises doivent aussi limiter leurs gaspillages d’énergie pour le numérique. On peut notamment réduire de manière significative l’impact écologique d’un data center, le rendre plus économe en matière d’énergie, voire réutiliser la chaleur qu’il émet. Bref, il faut apprendre à penser écologie quand on parle de numérique.
Oui, mais les liens entre les deux transitions vont bien plus loin. Le numérique et l’écologie se marient en promouvant des manières nouvelles, collectives de travailler, de vivre. Les réseaux sociaux du Web, des encyclopédies collaboratives comme Wikipedia, ne préfigurent-ils pas, même avec leurs défauts, le besoin de vivre ensemble, de travailler ensemble ? L’innovation débridée autour du numérique n’est-elle pas un début de réponse à l’indispensable nécessité d’innover pour répondre de manière urgente aux défis écologiques, dans toute leur diversité, avec toute leur complexité ?
adapté de pixabay.com
L’informatique et le numérique sont bien des outils indispensables pour résoudre les problèmes écologiques fondamentaux qui nous sont posés. Philippe Houllier, le PDG de l’INRA, peut, par exemple, bien mieux que moi expliquer comment ces technologies sont devenues incontournables dans l’agriculture. Il nous parle dans un article à venir sur binaire de l’importance des big data pour améliorer les rendements en agriculture, un sujet d’importance extrême quand les dérèglements climatiques et la pollution des sols tendent à faire diminuer ces rendements.
On pourrait multiplier les exemples mais il faut peut-être mieux se focaliser sur un fondement de la pensée écologique :
penser global, agir local.
On avait tendance à penser des équipements massifs, globaux, par exemple une centrale nucléaire, une production agricole intensive destinée à la planète, etc. Les temps changent. On parle maintenant d’énergie locale, diversifiée, d’agriculture de proximité. Mais si cette approche conduit à une économie plus durable, elle est plus complexe à mettre en place ; elle demande de faire collaborer de nombreuses initiatives très différentes, de s’adapter très vite et en permanence, de gérer des liens et des contraintes multiples. Elle ne peut se réaliser qu’en s’appuyant sur le numérique ! On peut peut-être faire fonctionner une centrale nucléaire sans ordinateur – même si je n’essaierais pas – mais on n’envisagerait pas de faire fonctionner un « smart-grid » (réseau de distribution d’électricité « intelligent ») sans. Un peu à la manière dont nos ordinateurs s’échangent des données sans cesse, on peut imaginer des échanges d’électricité entre un très grand nombre de consommateurs et plus nouveau de fournisseurs (panneaux solaires, éolienne, etc.), pour adapter en permanence production et consommation, pour en continu optimiser le système. Il s’agit bien d’une question d’algorithme. Et l’informatique est également omniprésente quand nous cherchons à modéliser le climat, les pollutions, à les prévoir.
Nous découvrons sans cesse de nouvelles facettes de la rencontre entre ces deux transitions. Nous découvrons sans cesse de nouveaux défis pour la recherche et le développement à leur frontière.
Le groupement de Service (G.D.S.) ÉcoInfo : des ingénieurs et des chercheurs (CNRS, INRIA, ParisTech, Institut Mines Télécom, RENATER, UJF…) à votre service pour réduire les impacts écologiques et sociétaux des TIC.
Langages de programmation et langues naturelles. Le néophyte est un peu perdu. Il n’est pas certain que l’informaticien ait vraiment réfléchi aux liens, aux différences. Maurice Nivat, un des grands pionniers de l’informatique, nous livre quelques réflexions sur le sujet. Il en dégage des pistes intéressantes pour l’enseignement de l’informatique aux enfants. Serge Abiteboul.
Il est bien connu que l’informatique a donné naissance à une étonnante quantité de langages de programmation, il y en a des milliers et je pense qu’il en apparaît toujours de nouveaux.
Après bien des hésitations, des décisions ministérielles récentes vont faire que ces langages, du moins certains d’entre eux, fassent l’objet d’un enseignement pour les élèves du second degré et, avec eux bien sûr, la programmation ou l’art d’écrire dans ces langages des textes baptisés programmes qui permettent de faire réaliser des actions par des machines électroniques. Les programmes décrivent des façons de faire que l’on appelle des algorithmes d’un mot un peu barbare mais ancien puisqu’il apparaît dès le treizième siècle.
Clair de Lune, Verlaine.
Votre âme est un paysage choisi
Que vont charmant masques et bergamasques
Jouant du luth et dansant et quasi
Tristes sous leurs déguisements fantasques.
Tout en chantant sur le mode mineur
L’amour vainqueur et la vie opportune
Ils n’ont pas l’air de croire à leur bonheur
Et leur chanson se mêle au clair de lune,
Au calme clair de lune triste et beau,
Qui fait rêver les oiseaux dans les arbres
Et sangloter d’extase les jets d’eau,
Les grands jets d’eau sveltes parmi les marbres.
On peut difficilement programmer si l’on n’a pas une idée précise de l’algorithme qu’il s’agit de décrire, comme il est difficile de parler si l’on ne sait pas quoi dire. Et pour avoir une idée de l’algorithme que l’on va programmer il est nécessaire d’avoir un but clairement défini et de savoir de quels moyens on dispose. La prolifération des langages de programmation vient de ce qu’il y a beaucoup de façons de décrire un algorithme comme il y a beaucoup de façons d’exprimer quelque chose que l’on veut dire, beaucoup de langages, c’est dire de systèmes de notation possibles, dans lesquels on peut écrire et aussi de nombreuses écritures possibles dans un même langage.
Je bondis toujours quand je lis, dans des manuels d’informatique, que le corrigé de l’exercice n°17 page 234 est « le » programme suivant, l’exercice consistant à écrire un programme pour décrire un petit algorithme décrit tant bien que mal en français augmenté de quelques formules plus ou moins mathématiques en Python ou ce que vous voudrez. C’est aussi absurde que le serait de dire qu’il y a un seul texte en français décrivant une situation donnée ou rendant compte de faits observés. Il ne faut pas enseigner longtemps la programmation pour se rendre compte qu’à un tel exercice, les élèves peuvent apporter les réponses les plus diverses et parfois toutes exactes. La correction des copies rendues s’apparente plus à celle des compositions françaises par le professeur de français qu’à celle d’un devoir de math et peut se révéler cauchemardesque pour le prof, tout en apparaissant assez arbitraire à l’élève.
Dans la plupart des manuels c’est avec les premières lignes écrites dans un langage de programmation que commence l’apprentissage de l’informatique et de la programmation et je pense que c’est grand dommage car les élèves, quels qu’ils soient, ont commencé à utiliser des programmes bien avant, quand ils ont appris à compter, à faire des additions et multiplications et aussi les règles de phonétique et de grammaire permettant de lire à haute voix un texte écrit en français ou d’écrire sous la dictée. Ces programmes que les enfants apprennent (non sans mal souvent) dès le CP à l’âge de six ans sont écrits en français, seul langue ou langage qu’ils connaissent, et décrivent soit des algorithmes simples comme celui de l’addition soit des algorithmes très complexes comme celui de l’orthographe.
En fait les enfants ont dans la tête quantité d’algorithmes, plus ou moins précis, plus ou moins bien décrits, appris, connus, en français ou dans quelque chose de très près du français, un français élémentaire avec des ajouts de vocabulaire tenant au domaine dans lequel se situe l’algorithme, qui peut être celui du comportement en général, de la vie sociale, du jeu, du sport, de matières scolaires.
En commençant l’enseignement de l’informatique par la présentation d’un langage de programmation artificiel, on donne l’impression que l’informatique est un domaine nouveau, quelque peu ésotérique, concernant les ordinateurs et eux seulement, ce qui est méconnaître que la recherche d’algorithmes pour faire ceci ou cela, avec les moyens qu’on a, est une activité que tout le monde pratique et ce depuis sa plus tendre enfance.
Dire qu’apprendre la programmation c’est apprendre à « coder » est une absurdité, le premier codage que l’on apprend c’est la langue maternelle qui n’est qu’un code, au sens strict, faisant correspondre, de façon très arbitraire (il y en a quand même plusieurs milliers dans le monde), des mots à des objets, des actions, des gestes, des sensations, des sentiments, des idées.
L’enfant est déjà habitué à toutes espèces de restrictions, distorsions, extensions de sa langue maternelle pour répondre aux divers besoins de communication rapide ou secrète ou de dénominations d’objets et d’actions liés à des activités ou des situations particulières qui ne sont pas dans le dictionnaire. Il a déjà senti qu’il y a des façons de dire l’histoire, ou la géographie, ou la science, ou la littérature qui ne sont pas les mêmes, même s’il est incapable de préciser en quoi ces façons diffèrent. On lui a même appris à se servir d’un dictionnaire plus ou moins encyclopédique et de divers livres de classe pour y rechercher et éventuellement trouver des informations en réponse à des questions qu’on lui pose ou qu’il se pose.
Je pense qu’il serait de bonne pédagogie de construire les connaissances de l’informatique qu’on cherche à donner aux enfants sur ce savoir. Il s’agit aussi bien de la connaissance explicite de quelques algorithmes, que de celle, diffuse, de beaucoup d’autres, en s’appuyant sur leur expérience déjà vécue des niveaux de langue, des changements de sens des mots et de phrases quand on change de contexte ou de type de discours.
Le problème de savoir dire en français, dans la langue de tout le monde ce que fait l’informatique, ce qu’est un algorithme, ou comment marche un programme déborde largement le cadre de l’enseignement dans les écoles, lycées et collèges.
La diffusion souhaitable d’une culture informatique à tous les jeunes scolarisés mais aussi tous les citoyens a pour but de permettre à tous de se diriger et se comporter dans un monde où le travail humain est inextricablement mêlé à celui de très nombreuses machines au sein de systèmes complexes dont le bon fonctionnement repose sur des algorithmes de plus en plus nombreux et sophistiqués. Le but de l’enseignement de l’informatique au plus grand nombre qui n’écrira jamais de programme autre que jouet est de faire comprendre ce mouvement d’informatisation galopante, de démythifier la machine et de rendre familiers les algorithmes, ces curieux objets qu’on ne voit jamais (comme les nombres), que nous utilisons tout le temps sans souvent nous en rendre compte et qui cependant de plus en plus nous gouvernent.
Il s’agit surtout de pouvoir parler, dans notre langue, en français, de l’informatique comme on peut parler de cuisine, de jardinage, de bagnoles, de football sans être cuisinier, jardinier, constructeur de voiture ou joueur professionnel.
Vous avez peut-être déjà bloqué devant des parfois « infâmes » EULA, en anglais pour « End User License Agreement », ou CGU en français pour Conditions générale d’utilisation (voir Dangerous Terms: A User’s Guide to EULAs). Ces conditions sous lesquelles vous avez accès à un produit ou à un service sur le Web sont souvent longues, rébarbatives, incompréhensives pour un profane. D’ailleurs, on ne les lit pas, on clique, et on se livre à la merci de leur contenu. C’est le syndrome du « TL;DR », pour « Too long; didn’t read » : trop long, pas lu. Binaire a demandé à Nicolas Rougier de nous parler du sujet. Serge Abiteboul.
En 2005, PC Pitstop offrait 1000 dollars à qui lirait ses conditions générales d’utilisation. Et bien entendu, l’offre était écrite dans les dites conditions générales d’utilisation. Ils durent attendre 4 mois avant que quelqu’un ne réclame les 1000$ (voir It Pays To Read License Agreements).
Pour le 1er avril 2010, la chaîne de magasin gamestation qui était spécialisée dans les jeux vidéos d’occasion, ajouta le petit paragraphe suivant à ses conditions d’utilisation:
« By placing an order via this Web site on the first day of the fourth month of the year 2010 Anno Domini, you agree to grant Us a non transferable option to claim, for now and for ever more, your immortal soul. Should We wish to exercise this option, you agree to surrender your immortal soul, and any claim you may have on it, within 5 (five) working days of receiving written notification from gamesation.co.uk or one of its duly authorised minions… We reserve the right to serve such notice in 6 (six) foot high letters of fire, however we can accept no liability for any loss or damage caused by such an act. If you a) do not believe you have an immortal soul, b) have already given it to another party, or c) do not wish to grant Us such a license, please click the link below to nullify this sub-clause and proceed with your transaction. »
En résumé, gamestation demandait à chaque utilisateur de leur céder leur âme immortelle. Ce qu’ont fait joyeusement 88% de ses utilisateurs.
Dans un autre registre, vous seriez surpris d’apprendre que les conditions d’utilisation du service iTunes vous empêchent explicitement d’utiliser iTunes pour fabriquer des armes nucléaires :
« Vous acceptez également de ne pas utiliser ces produits à des fins prohibées par le droit des États-Unis, ceci y compris et sans toutefois s’y limiter, le développement, la conception, la fabrication ou la production d’armes nucléaires, de missiles ou d’armes chimiques ou biologiques. » (iTunes Store – Conditions générales du service).
On n’est jamais trop prudent ! Parce qu’il s’agit bien ici d’essayer de se protéger par tous les moyens. Les avocats ont la gâchette facile aux États-Unis (où la plupart de ces services voient le jour).
Et la réalité qu’elles cachent
Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple Terms of Services, Didn’t read) et même des bandes dessinées. Ainsi, vous seriez surpris d’apprendre les droits que s’arrogent Google, Facebook ou Twitter sur tous les contenus que vous postez. Pour en savoir plus, je ne saurais trop vous conseiller « Les Nouveaux Loups du Web » qui sortira le 6 janvier 2016 et qui nous apprend, entre autre chose, que toutes ces licences sont généralement irrévocables, mondiales, perpétuelles, illimitées, transférables, modifiables, etc.
Oh, une dernière chose, une espèce de petite cerise sur la gâteau si vous comptiez effacer tout vos contenus suite à la lecture de ce court billet : sachez que ces service n’oublient rien. Mais vraiment rien. En 2010, Max Schrems, un étudiant en droit autrichien, demanda à Facebook l’ensemble des données relatives à son compte en vertu des lois européennes (Facebook Europe étant basée à Dublin). Quelle ne fût pas sa surprise de recevoir un document PDF de 1200 pages relatant toute son histoire ainsi que tous les contenus postés, y compris… ceux qu’il avait effacés (voir Max Schrems, le « gardien » des données personnelles qui fait trembler les géants du Web).
Parmi les grandes familles d’approches et de langages informatiques, on entend parfois parler de « programmation par contraintes ». Un chercheur du domaine vous expliquerait peut-être que « c’est un paradigme de programmation déclarative permettant de traiter des problèmes fortement combinatoires ». Euh… Heureusement, Binaire a son joker : une enseignante-chercheure Charlotte Truchet, spécialiste du domaine, qui sait expliquer ses recherches. Thierry Viéville.
Photo de www.picturalium.com CC-BY
Venez, je vous emmène visiter la boutique de Denis, fleuriste dans un petit village, un beau matin de printemps. Denis vend des fleurs à l’unité, et des bouquets. Comme c’est le printemps, il a ce matin un beau stock de fleurs fraîches, disons : bégonias, marguerites, roses, hortensias et pissenlits. Chaque fleur a des caractéristiques différentes (certaines fleurs sont par exemple associées à des occasions particulières), un standing différent (qui influence le prix), une couleur, etc.
Le matin, à l’ouverture, Denis prépare des bouquets tout prêts pour les clients pressés. Attention, l’exercice est délicat, il ne peut pas faire n’importe quoi. D’abord, il ne peut pas utiliser plus de fleurs qu’il n’en a en stock. Ensuite, il a des goûts : Denis aime bien l’association bégonia-rose, mais il n’aime pas les bouquets mélangeant des pissenlits et des marguerites, il préfèrerait fermer boutique plutôt que vendre de telles horreurs. Et puis, il doit faire tourner son commerce, et pour cela, il doit vendre ses bouquets à un bon prix, qui dépend des marges qu’il réalise sur chaque fleur du bouquet. Bref, Denis se trouve devant un problème compliqué : comment composer ses bouquets, en tenant compte de ses goûts, ses stocks et ses coûts ?
Il pourrait faire ses bouquets au petit bonheur, un peu au hasard, mais il rencontre un problème. Un phénomène tragique l’attend au tournant : l’explosion combinatoire. Un bien grand mot pour dire que le nombre de bouquets possibles est gigantesque, le nombre de possibilités à considérer dépasse l’entendement du pauvre Denis. Imaginons que Denis ait en stock 10 bégonias, 20 marguerites, 15 roses, 5 hortensias et 30 pissenlits. Il peut mettre dans son bouquet : 1 bégonias et rien d’autre, 2 bégonias et rien d’autre, … et ainsi de suite jusqu’à 10 bégonias et rien d’autre. Puis il attaque la série de bouquets avec seulement des marguerites (20 possibilités), seulement des roses (15 possibilités), etc. Ensuite, il commence à associer des fleurs : 1 bégonia, 1 rose et rien d’autre, 1 bégonia et 2 roses, etc : encore un sacré paquet de possibilités, 62496 exactement. Et on est encore loin du compte ! Bref, le nombre de possibilités est vraiment très grand, même pour un seul bouquet (11*21*16*6*31-1 soit environ 680 000). Mais surtout, ce nombre augmente de façon catastrophique dès que l’on augmente le nombre de bouquets : pour deux bouquets, on a 680 000 au carré possibilités, soit environ 470 milliards, pour trois bouquets, 680 000 au cube que je n’ai même pas envie de calculer, etc. C’est la catastrophe (et le « fortement combinatoire » de la phrase du chercheur). Pauvre fleuriste en ce triste matin de printemps !
Vous me direz, taratata, mon fleuriste fait des bouquets tous les jours, et il n’en fait pas un plat. C’est vrai : en fait, Denis n’a pas besoin d’essayer toutes les possibilités, et c’est ce qui le sauve. Il sait que certaines possibilités sont impossibles pour des raisons diverses. Ce que faisant, il raisonne sur les contraintes de son problème : stocks, goûts et coûts. Par exemple, Denis veut gagner de l’argent, et on peut supposer que les bouquets plus variés se vendent plus chers : Denis évite donc les bouquets monofleurs, ce qui élimine déjà 10 + 20 + 15 + 5 + 30 possibilités. C’est une petite simplification, mais elle est gratuite à opérer, donc elle fait gagner du temps. De même, il n’aime pas la combinaison pissenlits-marguerites. Si on interdit la présence de ces deux fleurs simultanément, on économise 630 000 possibilités ! Avant de crier victoire, remarquons qu’il en reste encore plus de 50 000. Mais tout de même, c’est un pas de géant. Denis n’a donc pas besoin d’essayer toutes les possibilités : il fait des bouquets guidé par son intuition. Ce type de raisonnement, qui permet d’éliminer des possibilités parce qu’elles sont à l’évidence inutiles dans le problème, est au cœur de la programmation par contraintes.
La programmation par contraintes consiste à faire des beaux bouquets dans un monde assez similaire à la boutique de Denis, mais un peu plus formel. On travaille sur des problèmes avec des inconnues, les variables : ici, le nombre de chaque fleur par bouquet. On ne sait pas combien valent ces variables, justement, c’est ce que l’on cherche. Cela dit, ces variables doivent rester dans un ensemble donné : de même qu’on sait qu’il y a 15 roses en stock (donc le nombre de roses dans chaque bouquet est entre 0 et 15), chaque variable vient avec un domaine de valeurs possibles. Si on note R1 le nombre de roses dans le premier bouquet, on appelle domaine de R1 l’ensemble des entiers entre 0 et 15.
Enfin, on écrit des contraintes sur les variables. Supposons pour simplifier que Denis se contente de deux bouquets, car son échoppe est modeste. D’abord, il faut s’assurer qu’il ne dépense pas plus que ses 15 roses en stock : cela se formalise avec une contrainte R1+R2<= 15, et de même pour les bégonias, pissenlits, marguerites et hortensias. Ensuite, Denis peut ajouter des contraintes en fonction de ses envies. Comme il déteste l’association marguerites-pissenlits, il peut écrire : M1*P1=0, ce qui force au moins l’une des deux valeurs à être nulle. S’il aime bien les roses et les bégonias, il peut imposer d’en avoir un minimum dans son gros bouquet : par exemple, R1>5 et B1>5. Et ainsi de suite. Les coûts aussi peuvent être écrits avec une formule similaire, en soustrayant au prix du bouquet la somme des prix de chaque fleur.
Ce que l’on appelle contrainte, c’est une formule construire comme cela, à partir des variables du problème et avec des formules mathématiques. Il y a mille et une façons d’écrire ces formules, c’est une étape importante et difficile que l’on appelle « modélisation du problème ». On obtient un problème de satisfaction de contraintes (souvent abrégé en CSP, pour Constraint Satisfaction Problem en anglais) : le problème formalisé avec des variables, des domaines et des contraintes. Résoudre le problème, c’est faire un bouquet, ou encore trouver pour chaque variable une valeur de son domaine telle que les contraintes soient vraies.
Au lieu de réfléchir, Denis pourrait utiliser un solveur de contraintes, c’est-à-dire un programme qui résout pour lui le CSP des bouquets, un programme qui sait résoudre de tels problèmes en général. Un solveur de contraintes commence par procéder à un raisonnement sur les contraintes pour éliminer des valeurs inutiles dans les domaines : par exemple, la contrainte R1>5 permet d’éliminer 0,1, 2, 3 et 4 du domaine de R1. En général, cela ne suffit pas à résoudre le problème, il reste encore de nombreuses possibilités. Alors, le solveur devient « bourrin » : il fait des essais. Il donne une valeur à une variable (il commence un bouquet avec 1 rose), il re-raisonne un petit coup et si ça ne suffit pas, il continue (il ajoute des bégonias), etc. Un solveur alterne ainsi des étape de raisonnement et des étapes de commencements de bouquets, ce que l’on appelle instanciation. S’il s’avère que le bouquet commencé est mauvais, et qu’on n’arrive pas à le compléter correctement (par exemple, si on a commencé avec 1 marguerite et 1 pissenlit), le solveur trouve un échec : il revient en arrière, enlève le nombre de fleurs qu’il faut (il enlève le pissenlit) et ré-essaie autrement (avec 0 pissenlits).
Bref, un solveur de contraintes commence des tonnes de bouquets et finit bien par un trouver un qui convienne. Si le problème a une solution, il la trouve. S’il n’en a pas, il le prouve, ce qui est toujours bon à savoir : Denis est trop exigeant, voilà tout. Il faut qu’il reconsidère ses contraintes.
Il reste encore des choses à noter dans l’échoppe de Denis.
D’abord, à aucun moment, Denis n’a réfléchi à une méthode de résolution pour son problème. Il s’est contenté de décrire ce qu’il voulait, et se moque bien de savoir comment le solveur travaille. C’est ce que l’on appelle de la programmation déclarative dans le jargon informatique. C’est assez rare en informatique (pas le jargon, la programmation déclarative). En programmation, en général, il faut construire un algorithme qui arrive à obtenir le résultat voulu. Ici, ce n’est pas la peine, et c’est très pratique pour Denis, qui n’y connaît rien en algorithmique.
Ensuite, quand j’ai dit que le fleuriste pouvait écrire des formules pour décrire les bouquets, je vous ai arnaqués ! En informatique, pour pouvoir écrire une formule, il faut savoir dans quel langage, sinon on écrit n’importe quoi. Ainsi Denis a le droit d’écrire R1>5 mais il n’aurait pas le droit d’écrire R1/(bleu vif)+(il existe une herbe verte)=beaucoup de tune. En fait, il existe des langages de contraintes que l’on sait traiter et Denis doit s’y tenir. La plupart des solveurs de contraintes autorisent des langages assez proches les uns des autres. On a le droit aux formules mathématiques basiques, construites avec des nombres, des opérations comme +, -, *, etc, et des prédicats comme =, <, /=. Et, on a aussi le droit d’utiliser des contraintes « prêtes à l’emploi », faites sur mesure par les chercheurs pour faciliter la vie de Denis. On les appelle contraintes globales. Elles sont recensées dans un grand catalogue qui en compte plus de 350 (http://sofdem.github.io/gccat/gccat/sec5.html). N’hésitez pas à aller les visiter, c’est un peu austère mais vous aurez sous vos yeux l’état de l’art de la recherche sur les contraintes globales !
choco-solver.org est un solveur de contrainte libre et dont le code est ouvert
La plus célèbre et la plus couramment utilisée des contraintes globales est certainement celle que l’on appelle alldifferent. Pour la comprendre, il faut imaginer qu’un jour, Denis se réveille d’humeur fantasque. En ce beau matin de printemps, il se dit : j’en ai assez de faire des bouquets ennuyeux avec 6 bégonias et 6 roses. Ça tombe mal dans le vase. Aujourd’hui, j’ai envie de bouquets bizarres, étonnants, asymétriques. Aujourd’hui, je veux des compositions avec un nombre différent de chaque fleur ! Le malheureux perd un peu la boule, si vous voulez mon avis, mais on n’y peut rien.
Il se met donc à composer des bouquets où il est interdit d’avoir autant de roses que de bégonias, autant de bégonias que de marguerites, etc. Essayons d’y réfléchir. Ce matin là, il lui reste 3 camélias, 2 bégonias, 25 tulipes, 7 poinsettias et 2 hortensias. Il veut faire un gros bouquet avec un peu de chaque fleur (C>0, B>0, etc). Comme il n’a que 2 bégonias et 2 hortensias, il peut déduire qu’il doit forcément mettre dans son bouquet exactement 3 camélias, et au moins 3 tulipes et poinsettias. En effet, s’il met 1 bégonia, il est obligé de mettre 2 hortensias (donc plus de trois des autres fleurs). De même, s’il met 1 hortensia, il doit mettre 2 bégonias et rebelote (plus de trois des autres fleurs). Dans tous les cas, il doit mettre au moins 3 camélias et au plus 3 camélias (car il n’en a pas plus en stock), donc exactement 3 camélias, et plus de 4 tulipes et poinsettias.
Voilà qui aide grandement ! On élimine d’un seul coup beaucoup de possibilités, on trouve même directement le bon nombre de camélias ! Même si l’exemple choisi ici est simple, il faut imaginer qu’on pourrait appliquer le même raisonnement pour des nombres beaucoup plus grands. Il faut bien voir que pour trouver cette simplification, Denis a dû cette fois raisonner sur toutes les fleurs en même temps. C’est le principe d’une contrainte globale : elle exprime une propriété globale sur plusieurs variables en même temps, soit pour raisonner plus efficacement, soit pour exprimer des propriétés plus complexes que le langage basique sus-cité. Une contrainte globale embarque sa propre méthode de déduction, qui est utilisée directement par le solveur.
Les questions explorées par les chercheurs en contraintes sont évidemment nombreuses et dépassent parfois un peu le cadre de la boutique du fleuriste, mais elles tournent tout de même beaucoup autour de l’organisation du procédé décrit plus haut : comment bien modéliser un problème ? Comment rendre la résolution efficace ? Comment bien programmer le solveur ? Peut-on le rendre interactif ? Peut-on écrire des contraintes un peu subtiles, pour exprimer par exemple des préférences ? Et cætera.
Quant aux applications, elles sont assez variées. Une contrainte comme alldifferent écrit par Denis porte sur des fleurs, mais elle aurait aussi bien pu porter sur des avions (à ranger dans un aéroport), des fréquences (à placer dans une bande radio), des régions limitrophes (à colorier sur une carte), des notes de musique (à organiser harmonieusement sur une partition), des cartons de formes diverses (à ranger dans un container), des enseignements (à placer dans des emplois du temps), etc. On trouve donc la programmation par contraintes, avec ses cousins comme la programmation linéaire en nombres entiers, les métaheuristiques, l’optimisation linéaire ou non-linéaire, etc, dans beaucoup d’applications où le nombre de variables est très grand comme la logistique ou l’ordonnancement de tâches. Mais sa nature déclarative (qui permet de fabriquer des langages à destination de non-informaticiens) la tourne aussi vers des applications moins informatico-centrées, comme en médecine, musique, visualisation, graphisme, biologie, urbanisme, etc.
Charlotte Truchet, Université de Nantes
@chtruchet
Ne pas connaître uniquement ses clients, mais aussi ses futurs clients, est le rêve de toute entreprise qu’elle soit petite ou grande. Pour y arriver, deux solutions s’offrent aux entrepreneurs : acheter une boule de cristal ou avoir recours aux services de Data Publica. Des tas de connaissances sur les entreprises sont à portée de clics, encore faut-il savoir les trouver, les comprendre et les consolider. C’est ce que propose Data Publica, fondée par François Bancilhon, entrepreneur récidiviste, et Christian Frisch. La startup récupère du web et de bases de données publiques un tas d’informations sur les entreprises. Avec comme impératif : que tout soit réalisé automatiquement.
Prenons la mesure du travail à réaliser. Parmi les 9 millions de numéros INSEE d’entreprises, seulement une partie représente des entreprises avec une vraie activité, et une partie encore plus restreinte a au moins un employé. Seules 590 000 d’entre elles ont un site Web. 590 000, ça fait quand même beaucoup d’entreprises à connaître. Ce sont les cibles de Data Publica qui annonce en couvrir déjà près de 95%. Data Publica a eu un Prix Mondial de l’Innovation, de la BPI, représentant un financement de 1 million d’euros.
Rentrons un peu dans la techno. Il faut trouver (automatiquement) les sites Web des entreprises en s’appuyant sur un crawler maison et des moteurs de recherche. Puis catégoriser les entreprises correspondantes en utilisant des techniques d’apprentissage (machine learning). On va regrouper les sites (automatiquement encore) en utilisant les similarités de vocabulaire. Un livreur de pizza et un fabricant de machines outils ne vont pas utiliser les mêmes termes. Donc ça marche plutôt bien.
Maintenant, essayons de comprendre un scénario pour une entreprise cliente – on est ici dans le B2B ou Business to Business, autrement dit les clients de Data Publica sont des entreprises qui vendent aux entreprises, et non à des particuliers. L’entreprise fourni sa base client (donc une liste d’entreprises), puis le logiciel de Data Publica analyse cette liste, la segmente à partir des données récupérées sur les sites Web des clients. Ensuite, pour chacun des segments détectés, le logiciel propose de potentiels futurs clients. Mieux connaître sa base client, trouver de nouveaux clients. C’est ce que François Bancilhon appelle « le marketing prédictif ». Un rêve pour le marketing et la vente ?
Mais les entreprises ne sont pas présentes sur la toile uniquement par leurs sites Web. Elles sont de plus en plus sur les réseaux sociaux, Facebook, Twitter, LinkedIn. En plus d’informations statiques, les messages postés sur ces systèmes donnent des informations « en temps réel ». Ces messages, là encore il faut les analyser. Cela concerne une offre d’emploi ? Une annonce financière ? Une promo ? Data Publica réalise donc pour ses clients le monitoring de ces messages et leur catégorisation. Ces informations aident les commerciaux en leur disant à quel moment appeler un prospect et à quel sujet l’appeler.
Pour permettre l’accès à de petites entreprises et pour faciliter l’accès de tous, Data Publica vient d’introduire une offre Freemium (*) sous le nom de C-radar. Le service de base coûte 99 euros par mois. Pour l’instant, seules les entreprises françaises et belges sont répertoriées, mais Data Publica est en train de traiter les entreprises du Royaume Uni et compte s’attaquer bientôt aux sociétés américaines, plus difficiles à gérer car elles ne sont pas référencées comme en France avec un numéro unique.
Quand on considère toutes les informations que l’on trouve sur le Web, on imagine bien que beaucoup de possibilités s’ouvrent à Data Publica. Améliorer encore sa technologie pour découvrir plus d’information, comprendre encore mieux les informations trouvées. Se développer dans de nouveaux secteurs demandeurs d’une telle technologie. Des domaines où on a besoin de mieux comprendre ce qui se passe sur le Web ? Ça ne doit pas être compliqué à trouver…
(*) Le freemium (mot-valise des mots anglais free : gratuit, et premium : prime) est une stratégie commerciale associant une offre gratuite, en libre accès, et une offre « Premium », plus haut de gamme, en accès payant. Ce modèle s’applique par sa nature aux produits et services à faibles coûts variables ou marginaux, permettant aux producteurs d’encourir un coût total limité et comparable à une offre publicitaire.
Dans une vie antérieure, François Bancilhon a été professeur d’informatique à l’Université d’Orsay (la future Université Paris Saclay). Puis, il a arrêté une recherche académique particulièrement brillante pour devenir entrepreneur au début des années 80. Dommage pour la recherche française, et tant mieux pour l’industrie. Sa plus belle réussite jusqu’à présent, O2 Technology, issue d’Inria, a été particulièrement novatrice dans le champ des bases de données objet.
Mise-à-jour : Paris, le 17 novembre 2015 – François Bancilhon, co-fondateur de Data Publica, s’est vu décerner le prix European Data Innovator 2015 lors de la conférence European Data Forum (EDF). Ce prix récompense son esprit d’entreprise, sa contribution à la gestion de données, et son outil de marketing prédictif B2B C-Radar.
La semaine prochaine, du 14 au 21 novembre, se déroule le concours Castor informatique ! L’édition 2014 avait touché plus de 220 000 élèves ! L’édition Française est organisée par l’association France-ioi, Inria et l’ENS Cachan, grâce à la contribution de nombreuses personnes. Ce concours international est organisé dans 36 pays. Plus de 920 000 élèves ont participé à l’épreuve 2014 dans le monde.
Les points à retenir, le concours est :
entièrement gratuit ;
organisé sur ordinateur ou sur tablette sous la supervision d’un enseignant ;
il dure 45 minutes ;
entre le 14 et 21 novembre 2015, à un horaire choisi par l’enseignant ;
avec une participation individuelle ou par binôme ;
aucune connaissance préalable en informatique n’est requise.
Nouveautés 2015 :
Ouverture aux écoles primaires : le concours est désormais ouvert à tous les élèves du CM1 à la terminale !
Niveau adaptable : chaque défi est interactif et se décline en plusieurs niveaux de difficultés pour accommoder les élèves de 9 à 18 ans.
Il est encore temps de s’inscrire pour les enseignants (vous pouvez le faire jusqu’au dernier jour, même si nous vous conseillons d’anticiper).
En attendant, ou si vous n’êtes plus à l’école, vous pouvez vous amuser à tester les défis des années précédentes depuis 2010, et en particulier les défis interactifs de 2014 !
Les objets connectés transforment chaque jour un peu plus notre monde. Ils nous offrent des possibilités qui n’existaient encore récemment que dans des livres de science fiction. Tout cela ne va pas sans risques que la technique doit nous aider à surmonter, que la société doit apprendre à réguler. Binaire a demandé à Philippe Pucheral, un des meilleurs spécialistes du domaine, de nous en parler. Serge Abiteboul.
Philippe Pucheral
Nous voici entrés de plain-pied dans l’ère de l’homme connecté, assisté, augmenté. Écartée la crainte du trou de mémoire face à un visage déjà rencontré, nos lunettes connectées nous délivrent instantanément l’identité et le CV de notre interlocuteur. Plus besoin de lire une carte ni même d’apprendre à conduire, notre véhicule connecté connait la route, évite les embouteillages et conduit avec une vigilance infaillible. Plus besoin d’éteindre la lumière ou de régler le chauffage, notre centrale domotique sait quand activer ou désactiver chacun des appareils électriques de la maison pour une gestion optimale de l’énergie, au niveau du foyer comme du quartier. Enfin, envolée la crainte de l’infarctus en grimpant un col de montagne, notre bracelet connecté veille sur notre rythme cardiaque.
Nous ne sommes pas dans une nouvelle d’Isaac Asimov ou d’Aldous Huxley mais bien en 2015. Certains considéreront que le monde perd en poésie ce qu’il gagne en efficacité et en prévisibilité. Mais laissons ce débat de côté. De toute évidence, un mouvement inexorable est enclenché. Le concept d’Internet des Objets est né en 1999 au centre Auto-ID du MIT avec l’idée d’associer à chaque objet du monde réel une puce RFID (*) permettant de l’identifier, de l’inventorier, de capturer ses déplacements. Et déjà, selon une étude de l’institut IDATE, 42 milliards d’objets sont connectés aujourd’hui et plus de 80 milliards le seront en 2020. Les objets connectés ont également gagné en puissance et en fonctionnalité. De puces RFID passives, ils sont devenus objets autonomes capables de mesurer leur environnement via des capteurs et d’interagir avec lui via des actuateurs (**). A chacun désormais de placer le curseur entre fonctionnalités utiles rendues par ces objets et l’asservissement qui en résulte. Pour éclairer ce choix, plusieurs dimensions devraient être considérées :
Source : IDATE DigiWorld in « Internet of things », Octobre 2015
Sûreté de fonctionnement : par sa capacité à prendre des décisions et à agir physiquement à notre place, l’objet connecté devient une prolongation de notre propre corps et un supplétif de notre conscience. Dès lors que l’objet intervient dans une tâche critique, par exemple freiner un véhicule, la confiance dans l’objet doit être absolue. Il est donc impératif de prouver formellement que le programme embarqué par l’objet est « zéro défaut ». La preuve de programme est une tâche complexe à laquelle de nombreuses équipes de recherche françaises et étrangères contribuent. Le lecteur pourra consulter avec intérêt le blog Binaire du 24 septembre 2015 traitant de ce sujet. Le matériel (hardware) qui compose l’objet doit également être zéro défaut et potentiellement redondant pour prévenir tout type de défaillance. A part pour des applications hautement sensibles telles que le contrôle de centrales nucléaires ou la commande d’avions de ligne, nous sommes loin aujourd’hui de ce niveau d’exigence.
Sécurité : le constat de dépendance vis-à-vis de l’objet est le même que pour la sûreté de fonctionnement mais la menace d’un dysfonctionnement vient ici d’une attaque malveillante. La psychose d’actions terroristes n’est jamais très éloignée. Deux pirates informatiques installés à Pittsburgh ont ainsi prouvé qu’ils pouvaient prendre le contrôle d’une voiture conduite par un journaliste volontaire circulant à Saint Louis. De même, en février 2015, BMW a dû diffuser un patch de protection comblant une faille de sécurité sur l’ordinateur de bord de plus de 2 millions de ses véhicules. L’omniprésence des objets connectés peut ainsi ouvrir la porte à des attaques de grande ampleur et ces anecdotes montrent que les industriels n’ont pas toujours pris la mesure du risque encouru. Alors que la voiture autonome (sans conducteur) fonctionne déjà en circuit fermé et est annoncée commercialement pour 2025, la sécurité reste un des grands défis à relever. Un problème similaire se pose avec les objets connectés à usage médical : à quand le crime parfait réalisé en piratant à distance une pompe à insuline ?
Confidentialité : les objets connectés captent une quantité considérable de données personnelles, données de santé, déplacements, consommation de ressources. A titre d’exemple, avec un compteur électrique intelligent captant la consommation avec une granularité de 1Hz, la plupart des équipements électriques domestiques ont une signature unique. Il devient alors possible de tracer l’intégralité de l’activité du foyer au cours d’une journée. Des chercheurs allemands ont montré qu’il était même possible d’identifier la chaîne de télévision regardée à un instant donné, en analysant, dans la trame sortante d’un compteur électrique intelligent, le spectre de consommation de l’écran de TV. Les exemples d’atteinte à la vie privée sont légion, du fait d’usages abusifs des données collectées ou d’attaques sur les serveurs. Face à cela, la communauté scientifique se mobilise pour concevoir des objets connectés moins intrusifs. Mais il est souvent difficile de concilier préservation du service et préservation de la vie privée. Comment par exemple récupérer l’adresse du restaurant Japonais le plus proche sans dévoiler notre localisation à un serveur ? En fonction des usages, différentes techniques existent pour limiter les risques de fuite d’information, comme par exemple exécuter les calculs utiles directement dans l’objet connecté plutôt que d’externaliser l’information vers un serveur, regrouper les données captées dans un serveur personnel sous le contrôle de chaque individu (Cloud Personnel), faire des calculs sécurisés distribués (ex: Secure Multi-party Computation), anonymiser ou ajouter du bruit dans les données émises (ex: differential privacy) ou encore passer par des relais de communication (ex: TOR). La capacité de croiser de multiples sources de données émanant de différents objets est un facteur complémentaire de complexité dans la recherche de solutions efficaces. Nous ne sommes donc qu’au début d’un chemin escarpé.
Source: National Institute of Standards and Technology
Durabilité environnementale : mais au fait, que deviennent les flux continus d’information captés par ces milliards d’objets intelligents ? A un mois de la conférence COP 21, la question mérite d’être posée. A l’instar d’Amazon qui a annoncé le lancement de son nouveau service d’hébergement de données issues de l’internet des objets, AWS IoT, Microsoft annonce la sortie d’Azure IoT Suite offrant un service similaire. Ainsi, la bataille pour l’analyse de ces données massives (big data) fait rage entre les géants de l’internet. Mais de quels volumes parle-t-on concrètement ? Selon une étude IDC parue en avril 2014, le volume de données numériques produit au niveau mondial devrait être multiplié par 10 entre 2013 (4,4 Zettaoctets) et 2020 (44 Zettaoctets). Soit 44 000 milliards de gigaoctets, ou, pour les amateurs d’analogies, une pile de DVD dépassant la moitié de la distance Terre-Mars. Les objets connectés sont à l’origine de plus de 20% de ce total. Faut-il réellement stocker toutes ces données sur des serveurs après les avoir acheminées via des réseaux ? Au même titre que dans le cerveau humain, mieux vaudrait être capable d’oublier le superflu pour rester efficace sur l’essentiel. Reste à être capable d’identifier le superflu.
Le Petit Prince d’Antoine de Saint-Exupéry, annotation Serge A.
A l’heure où le Conseil National de l’Ordre des Médecins préconise un remboursement des objets connectés de « mesure de soi » (quantified-self) par la sécurité sociale, où des compagnies d’assurances proposent des services de « Pay as you drive » en pistant votre conduite, où ERDF déploie des compteurs électriques intelligents Linky et où les constructeurs automobiles investissent massivement dans la voiture connectée et bientôt autonome, l’Internet des objets a de beaux jours devant lui. Mais cette révolution n’est pas que technologique. Elle bouscule aussi en profondeur nos modes de vie, nous fait nous interroger sur notre autonomie et notre libre arbitre. Faire remarcher une personne handicapée grâce à une puce retransmettant les commandes du cerveau touche au sublime. Mais a-t-on besoin d’un réfrigérateur connecté ? L’essentiel est que chacun puisse répondre. Pour cela, il serait inquiétant de laisser les industriels du secteur seuls modeler ce que doit devenir notre mode de vie connecté. Il y a donc urgence à développer des réflexions pluridisciplinaires sur ce sujet, avec notamment des informaticiens, des sociologues, des économistes et des juristes.
(*) La radio-identification, le plus souvent désignée par le sigle RFID (de l’anglais radio frequency identification), est une méthode pour mémoriser et récupérer des données à distance en utilisant des marqueurs appelés « radio-étiquettes » (« RFID tag » ou « RFID transponder » en anglais). (Wikipedia)
(**) Dans une machine, un actionneur est un organe qui transforme l’énergie qui lui est fournie en un phénomène physique utilisable. Le phénomène physique fournit un travail qui modifie le comportement ou l’état de la machine.
[3] L’Internet des Objets… Internet, mais en mieux, de Philippe Gautier et Laurent Gonzalez, préfacé par Gérald Santucci, postfacé par Daniel Kaplan (FING) et Michel Volle, Éditions AFNOR, 2011 (ISBN : 978-2-12-465316-4)
[4] Andy Greenberg (21 July 2015). « Hackers Remotely Kill a Jeep on the Highway—With Me in It ». Wired. Retrieved 21 July 2015.
Dans le cadre des « Entretiens autour de l’informatique », Serge Abiteboul et Claire Mathieu ont rencontré Stanislas de Maupeou, Directeur du secteur Conseil en sécurité chez Thalès. Stanislas de Maupeou parle à Binaire de failles de logiciels et de cybersécurité.
Stanislas de Maupeou
Failles, attaques et exploits… et certification
B : À quoi sont dûs les problèmes de sécurité informatique ?
SdM : Le code utilisé est globalement de mauvaise qualité et, de ce fait, il existe des failles qui ouvrent la porte à des attaques. Le plus souvent, ce sont des failles involontaires, qui existent parce que le code a été écrit de façon hâtive. Il peut y avoir aussi des failles intentionnelles, quelqu’un mettant volontairement un piège dans le code.
Il y a des sociétés, notamment aux USA, dont le travail est de trouver les failles dans le logiciel. C’est toute une économie souterraine : trouver une faille et la vendre. Quand on trouve une faille, on y associe un « exploit » (*), un code d’attaque qui va exploiter la faille. On peut vendre un exploit à un éditeur de logiciels (pour qu’il comble la faille) ou à des criminels. Si une telle vente est interdite par la loi en France, cela se fait dans le monde anglo-saxon. Pour ma part, si je trouve une faille dans un logiciel, je préviens l’éditeur en disant : « on vous donne trois mois pour le corriger, et si ce n’est pas fait, on prévient le public ».
C’est pour pallier au risque de faille qu’on met en place des processus de certification de code. Mais développer un code sans faille, ou avec moins de failles, cela peut avoir un coût faramineux. On ne peut pas repenser tout un système d’exploitation, et même dans des systèmes très stratégiques, il est impensable de réécrire tout le code. Ça coûterait trop cher.
B : Comment certifiez-vous le code ?
SdM : Il y a différentes méthodes. J’ai des laboratoires de certification. Nous n’écrivons pas le code. Nous l’évaluons selon un schéma de certification, suivant une échelle de sûreté qui va de 1 à 7. En France, la certification est gérée par l’ANSSI (Agence Nationale de la Sécurité des Systèmes d’Information). Le commanditaire dit : « Je voudrais que vous certifiez cette puce », et l’ANSSI répond « Adressez vous à l’un des laboratoires suivants qui ont été agréés». Sur l’échelle, le 1 signifie « J’ai une confiance minimum », et le 7 signifie « j’ai une confiance absolue ». Le niveau « évaluation assurance niveau 7 » ne peut être obtenu que par des méthodes formelles, de preuve de sécurité. Par exemple, nous avons certifié au niveau 7 un élément de code Java pour Gemalto. Il y a peu de spécialistes des méthodes formelles dans le monde, un seul dans mon équipe. Dans le monde bancaire, on se contente des niveaux 2 et 3. On fait des tests en laboratoire, on sollicite le code, on regarde la consommation électrique pour voir si c’est normal. On fait ça avec du laser, de l’optique, il y a tout un tas d’équipements qui permettent de s’assurer que le code « ne fuit pas ». Pour la certification de hardware, le contrôle se faire à un niveau très bas. On a le plan des puces, le composant, et on sait le découper en couches pour retrouver le silicium et faire des comparaisons.
B : Le code lui-même est-il à votre disposition?
SdM : Parfois oui, si on vise à développer la confiance dans les applications. C’est par exemple le cas pour l’estampille « visa » sur la carte bancaire qui donne confiance au commerçant. Dans d’autres contextes, on n’a pas accès au code. Par exemple, on nous demande de faire des tests d’intrusion. Il s’agit de passer les barrières de sécurité. Le but est de prendre le contrôle d’un système, d’une machine, par exemple avec une requête SQL bien ficelée.
B : Cela aide si le logiciel est libre ?
SdM : Le fait qu’un logiciel soit libre n’est pas un argument de sécurité. Par exemple, dans la librairie SSL de Debian, il y avait eu une modification de quelque chose de totalement anodin en apparence, mais du coup le générateur de nombres aléatoires pour la librairie SSL n’avait plus rien d’aléatoire ; on n’a découvert cette erreur que deux ans plus tard. Pendant deux ans tous les systèmes qui reposaient sur SSL avaient des clés faciles à prévoir. Ce n’est pas parce qu’un logiciel est libre qu’il est sûr ! Par contre, s’il est libre, qu’il est beaucoup utilisé, et qu’il a une faille, il y a de fortes chances que quelqu’un la trouve et que cela conduise à sa correction. Cela dit, pour la sécurité, un bon code, qu’il soit libre ou pas, c’est un code audité !
B : Est-ce que les méthodes formelles vont se développer ?
SdM : On a besoin aujourd’hui de méthodes formelles plus pour la fiabilité du composant que pour la sécurité. On fait de la gestion de risque, pas de la sécurité absolue qui n’existe pas. Vérifier les systèmes, c’est le Graal de la sécurité. On peut acheter un pare-feu au niveau 3, mais, transposer ça à tout un système, on n’y arrive pas. Notre palliatif, c’est une homologation de sécurité : on prend un système, on définit des objectifs de sécurité pour ce système (par exemple, que toute personne qui y accède doive être authentifiée), et on vérifie ces objectifs. On sait qu’il y aura toujours des trous, des risques résiduels, mais au moins, le système satisfait des règles conformes avec certains objectifs de sécurité. C’est une approche non déterministe, elle est floue, et on accepte qu’il y ait un risque résiduel.
Un problème c’est qu’on ne sait pas modéliser le risque. Je sais dire qu’un boulon casse avec probabilité 1%, cela a un sens, mais je ne sais pas dire quelle est la probabilité d’une attaque dans les 10 jours. Comme on ne peut pas modéliser la malveillance, on ne sait pas vraiment faire l’évaluation de la sécurité d’un système avec une approche rationnelle.
Les métiers de la cybersécurité
@Maev59
B : Quel est le profil des gens qui travaillent dans votre laboratoire ?
SdM : Ce sont des passionnés. Ils viennent plutôt d’écoles spécifiquement d’informatique que d’écoles d’ingénieur généralistes comme les Mines, ENSTA, ou Supélec, où les élèves sont moins passionnés par l’informatique.
B : Comment en êtes vous arrivé à vous intéresser à la cybersécurité ?
SdM : À l’origine j’étais militaire, et pas du tout en lien avec l’informatique. Étudiant, je n’avais pas accroché au Fortran ! Et puis, quand on fait une carrière militaire, après une quinzaine d’années, on suit une formation. Il était clair que le système militaire allait avoir de plus en plus d’informatique. J’ai suivi en 1996, un mastère de systèmes d’information à l’ENST avec stage chez Matra, et j’ai adoré. Même si à l’époque, on ne parlait absolument pas de sécurité, j’ai réorienté ma carrière vers le Service central de sécurité et services d’information, un petit service de 30 personnes, qui à l’origine ne servait guère qu’à garder le téléphone rouge du président. À l’époque, un industriel devait donner à l’état un double de sa clé de chiffrement. En 1999, il y a eu un discours de Lionel Jospin à Hourtin, dans lequel il a dit que ce n’était plus viable et qu’il fallait libéraliser la cryptographie, libérer ce marché. À l’époque il fallait déclarer toute clé de plus de 40 bits. Il a demandé qu’on élève le seuil à 128 bits, et c’est grâce à cela que les sites de la SNCF, la FNAC, etc., ont pu se développer. Ce service est devenu une agence nationale, passant de 30 à plus de 400 personnes, l’ANSSI.
Ensuite je suis passé chez Thalès où j’ai eu à manager des informaticiens. Ce n’est pas une population facile à manager. Et puis le domaine évolue très vite ; nous sommes en pleine période de créativité. On a encore plus besoin de management.
B : Qu’est ce qu’un informaticien devrait savoir pour être recruté dans votre domaine ?
SdM : J’aimerais qu’il connaisse les fondamentaux de la sécurité. J’aimerais qu’il y ait un cours « sécurité » qui fasse partie de la formation et qui ne soit pas optionnel. L’ennemi essaie de gagner des droits, des privilèges. Les fondamentaux de la sécurité, c’est, par exemple, la défense en profondeur, le principe du moindre privilège systématique sur des variables, la conception de codes segmentés, le principe du cloisonnement, les limites sur le temps d’exécution. Le moindre privilège est une notion essentielle. Le but est de tenir compte de la capacité du code à résister à une attaque. Déjà, avoir du code plus propre, de meilleure qualité au sens de la sécurité, avec plus de traçabilité, une meilleure documentation, cela aide aussi. Mais tout cela a un coût. Un code sécurisé, avec des spécifications, de l’évaluation, de la relecture de code, cela coûte 30 à 40% plus cher.
Etat et cybersécurité
@Maev59
B : Est-ce que l’ANSSI a un rôle important dans la sécurité informatique ?
SdM : L’ANSSI a un rôle extrêmement important, pour s’assurer que les produits qui seront utilisés par l’état ou par des opérateurs d’importance vitale (définis par décret, par exemple les télécommunications, les banques, EDF, la SNCF, Areva…) satisfont à des règles. L’ANSSI peut imposer des normes par la loi, garantissant un niveau minimum de qualité ou sécurité sur des éléments critiques, par le biais de décisions comme « Je m’autorise à aller chez vous faire un audit si je le décide. »
B : De quoi a-t-on peur ?
SdM : La première grande menace que l’État craint est liée à l’espionnage. En effet, l’immense majorité des codes et produits viennent de l’extérieur de la France. Un exemple de régulation : les routeurs Huawei sont interdits dans l’administration française. La deuxième menace, c’est le dysfonctionnement ou la destruction de système. L’État craint les attaques terroristes sur des systèmes industriels. Ces systèmes utilisent aujourd’hui des logiciels standard, et de ce fait, sont exposés à des attaques qui n’existaient pas auparavant. Une des grandes craintes de l’état, c’est la prise de contrôle d’un barrage, d’un avion, etc. C’est déjà arrivé, par exemple, il y a eu le cas du « ver informatique » Stuxnet en Iran, qui a été diffusé dans les centrales nucléaires iraniennes, qui est arrivé jusqu’aux centrifugeuses, qui y a provoqué des dysfonctionnements de la vitesse de la centrifugeuse, cependant que le contrôleur derrière son pupitre ne voyait rien. Avec Stuxnet, les US sont arrivés à casser plusieurs centrifugeuses, d’où des retards du programme nucléaire iranien. Un déni de service sur le système de déclaration de l’impôt fin mai, c’est très ennuyeux mais il n’y a pas de mort. Un déni de service sur le système de protection des trains, les conséquences peuvent être tout à fait dramatiques, d’un autre ordre de gravité.
Il y a aussi une troisième menace, sur la protection de la vie privée. Dans quelle mesure suis-je libre dans un monde qui sait tout de moi ? Dans les grands volumes de données, il y a des informations qui servent à influencer les gens et à leur faire prendre des décisions. C’est une préoccupation sociétale.
B : En quoi le fonctionnement de l’armée en temps de guerre a-t-il été modifié par l’informatique ?
SdM : L’armée aux États-Unis est beaucoup plus technophile que l’armée française, qui a mis un certain temps à entrer dans ce monde-là. Dans la fin des années 1990, les claviers sans fil étaient interdits, le wifi était interdit, le protocole Internet était interdit. Aujourd’hui, l’armée française en Afghanistan utilise énormément le wifi. Maintenant, il n’y a plus de système d’armes qui n’utilise pas d’informatique.
B : La sécurité est-elle une question franco-française ?
SdM : Il faut admettre que le monde de la sécurité est très connecté aux services de renseignement, ce qui rend les choses plus difficiles. Pour gérer les problèmes en avionique, on est dans un mode coopératif. Si un modèle pose un problème mécanique, on prévient tout le monde. En revanche, dans le monde de la sécurité informatique, si on trouve une faille, d’abord on commence par se protéger, puis on prévient l’état qui, peut-être, se servira de cette information. Ce sont deux logiques qui s’affrontent, entre la coopération et un monde plus régalien, contrôlé par l’État.
B : Avez vous un dernier mot à ajouter ?
SdM : Il faudrait développer en France une culture de la « sécurité ». Peu de systèmes échappent aujourd’hui à l’informatique. La sécurité devrait être quelque chose de complètement naturel, pas seulement pour les systèmes critiques. C’est comme si on disait, les bons freins, ce n’est que pour les voitures de sport. La sécurité doit être intégrée à tout.
(*) Exploit : prononcer exploït, anglicisme inspiré du verbe anglais “to exploit” qui signifie exploiter, lui-même inspiré du français du 15e siècle.
C’est une pièce de théâtre écrite et mise en scène par Orah de Mortcie, direction d’acteurs par Laetitia Grimaldi. Le Prochain Train parle très intelligemment des liens entre les personnes à l’ère du numérique. Où nous conduit cette nouvelle technologie ? Comment les réseaux sociaux, les blogs, les tweets, toutes ces applications vont-elles nous transformer ? Ce beau texte attaque bille en tête ces sujets complexes avec de l’humour, accompagné d’une jolie musique pas numérique du tout.
Vincent est un de ces « workaholics » que l’on croise de plus en plus, soumis à la dictature des mails. Karine est la spécialiste qu’il embauche pour gérer sa vie numérique. La pièce les plonge dans des rapports improbables. « J’ai grandi avec Internet et le numérique… j’ai du mal à utiliser Twitter, instatruc, et toutes ses applications qui arrivent chaque jour », avoue Elsa de Belilovsky qui joue le rôle de Karine. Pourtant, pendant une heure et demi nous avons cru qu’elle était la Reine du Numérique. Quel talent !
Le Prochain Train passe à la Manufacture des Abesses, à Paris, jusqu’à la fin de novembre. Il reste des places, courrez-y !
Il existe plusieurs musées consacrés à l’informatique ou au numérique à travers le monde. Pierre Paradinas, par ailleurs personnellement impliqué dans le projet #MINF de musée de l’informatique et du numérique en France, propose un petit aperçu de ce qui se fait dans certains pays, à la fois sur le plan muséal et au niveau du modèle d’affaires de ces lieux. Serge Abiteboul
En Allemagne à Padenborn, la fondation Nixdorf fait vivre un musée informatique important. Ce dernier expose sur 6 000 m2 l’informatique et contextualise son impact dans la vie des entreprises avec des reconstitutions du « bureau » à différentes époques. Un accent important est donné aux ordinateurs de la marque allemande Zuse. Ce musée est très impliqué dans la vie locale du land et l’université de Padenborn. Son modèle d’affaires repose sur un fort soutien de la fondation Nixdorf.
On remarque en particulier durant cette visite un métier à tisser de Jacquard qui en fonctionne ce qui permet de voir mais aussi d’entendre fonctionner cet appareil.
Métier à tisser Jacquard, Photo P. Paradinas
Une ligne du temps des interfaces du poste de travail est proposée. Le visiteur fait glisser un écran qui affiche l’interface offerte par les systèmes d’exploitation à l’utilisateur depuis les premiers ordinateurs personnels avec l’ancêtre MSDOS à ceux d’aujourd’hui, on voit ainsi les évolutions de l’expérience utilisateur en déplaçant un écran sur les différentes années.
Interface à regarder sur une ligne de temps, Photo P. Paradinas
En Allemagne, il y a aussi des présentations de l’informatique au Musée des Sciences de Munich et un projet pour un musée de l’internet doit ouvrir ces portes en 2016 à Berlin.
En Angleterre, on trouve aussi plusieurs initiatives. La plus récente « Information Age » est la rénovation de la section communication du Science Museum de Londres dont une grande partie du financement a été apporté par l’opérateur téléphonique historique (BT), un concepteur de microprocesseur très utilisé dans les plateformes mobiles (ARM) et un moteur de recherche très utilisé dans le monde (Google). La Reine s’était déplacée pour l’inauguration de ce nouvel espace en 2014.
Par ailleurs, d’autres initiatives intéressantes sont présentes sur le site de Bletchley Park rendu célèbre depuis les commémorations liées à la vie d’Alan Turing ainsi que le film Imitation Game. Dans ce National Museum of Computing , initialisé par Tony Sale, la reconstruction du Colossus a été entreprise, c’est le premier calculateur binaire électronique construit par Thomas Flowers pour « casser » le code des machines à chiffrer Lorenz utilisées pendant la seconde guerre mondiale.
Photo Colossus, Photo P. Paradinas
Porté à bout de bras par les bénévoles en terme de fonctionnement et de financement, le National Museum of Computing est confronté à des difficultés similaires à celles des initiatives françaises décrites dans un précédent article. Le musée britannique est très ouvert et offre de nombreuses activités aux acteurs de l’écosystème local. Il y a aussi des ateliers avec des plateformes rasberry PI qui permettent d’accueillir le public dans un esprit fablab.
Aux États-Unis, une des plus grandes et plus récentes initiatives est le Computer History Museum à Mountain View au milieu de la Silicon Valley à 2 pas de Google et Microsoft. Les chiffres sont vertigineux, dans les anciens locaux de la société Silicon Graphics, 12 000 m2, 75 000 visiteurs en 2012 et un budget de près de 6 M$. Une très grande surface d’exposition articulée autour d’un parcours au travers d’une vingtaine de « salles » sur les différentes périodes et domaines. Le CHM accueille des événements connexes dans ses locaux annexes.
Le parcours dans le HCM… Photo P. Paradinas
L’exposition ouverte en 2011, porte le nom de «Révolution». Elle présente l’informatique à travers une approche chronologique. Elle est centrée sur l’histoire de l’Informatique aux États-Unis. Cependant, les européens sont cités et en particulier la France avec le Minitel, et le réseau Cyclade…
Louis Pouzin et le projet Cyclade au HCM, Photo P. Paradinas
Le modèle d’affaire est simple, et typique des musées américains. Les revenus proviennent des revenus des placements du capital de la fondation support du musée, de versements annuels et récurrents d’entreprises partenaires, et enfin de ressources propres.
Il existe bien d’autres initiatives dans plusieurs autres pays, comme le musée Bolo appuyée sur une école d’ingénieurs suisse réputée à Lausanne, l’EPFL. Enfin, la Belgique vient de lancer une fondation en phase avec des initiatives locales dont le but est de construire un musée. Cette liste d’initiatives n’est pas exhaustive. L’engouement pour le numérique donne naissance à de nombreuses actions.
Et la France dans tout ça ?
Pour poser la question de ce que nous pourrions et devrions faire en France pour réaliser un « Musée de l’informatique et du numérique« , il est important de connaitre les possibles réalisés par d’autres pays. Nous reviendrons sur ce sujet dans un prochain article.
Pierre Paradinas, Prof. titulaire de la chaire Systèmes Embarqués au Cnam
Une partie des visites dans ces musées ont été réalisées dans le cadre d’une mission supportée par le Cnam et le Musée des arts et métiers dans le cadre de la réflexion menée pour la construction d’un musée de l’informatique et du numérique en France et présentée dans le cadre d’un colloque sur ce sujet.
Binaire a failli être pris au dépourvu ! Mais le 2 novembre 2015 ne s’achèvera pas sans que nous célébrions l’anniversaire d’un scientifique sans lesquels l’informatique n’aurait pas pu exister. Ca, pour l’Histoire. Et pour l’histoire, quelqu’un dont le nom est devenu un adjectif connu de millions d’étudiants et d’étudiantes.
Toute étudiante d’informatique doit un jour travailler son algèbre de Boole. Celle-ci est utilisée quand elle écrit un algorithme et qu’elle doit combiner des conditions pour sortir d’une boucle ou gérer une conditionnelle. La même algèbre permet d’organiser des requêtes complexes en bases de données. Et surtout, elle permet de comprendre l’architecture des ordinateurs : si les 0 et les 1 pour tout décrire on le doit plutôt à Leibnitz, le fait que ces mêmes 0 et les 1 peuvent servir à tout calculer, ça c’est à George Boole qu’on le doit.
George Boole, ca. 1860, wikimedia commons
Informatiquement, le calcul Booléen se substitue à tous les autres calculs : il suffit (!) alors d’imaginer une façon de réaliser physiquement les portes de base qui combinent un bit (valant 1 ou 0, vrai ou faux) et un second bit pour redonner un 1 ou un 0…
Quelques portes logiques. wikipedia commons
George Boole est né le 2 novembre 1815. 200 ans plus tard ses idées sont présentes dans tous les objets numériques que nous manipulons.
Il a son cratère sur la lune et est un possible modèle pour le Professeur Moriarty. Et il est devenu un adjectif qualificatif, ce qui est tout de même rare !
Une blague d’informaticiens que vous ne comprenez pas ?
Un T-shirt de geek incompréhensible ?
Binaire vous explique (enfin) l’humour des informaticien(ne)s !
Quelle est la différence entre Halloween et Noël ? Il n’y en a pas, car Oct 31 = Dec 25.
Les nombres entiers peuvent s’écrire en base 10 (c’est la façon usuelle pour les humains), en base 2 (c’est la façon usuelle pour les ordinateurs), ou en une autre base. C’était d’ailleurs un exercice classique en primaire il y a quelques décennies. Nous avons encore l’habitude de la base 60 en considérant les heures/minutes/secondes: 90 minutes correspondent à 1 heure et 30 minutes.
Citrouille d’Halloween, par 663highland (CC-BY-SA-3.0)
Revenons à la blague qui repose sur un changement de base.
« Dec 25 » signifie le nombre 25 interprété en décimal (base 10) donc 2×10+5. Il s’agit donc du 25 usuel.
« Oct 31 » signifie le nombre 31 interprété en octal (base 8). Il vaut donc 3×8+1=24+1=25. Il correspond donc au 25 usuel en décimal.
Les deux valeurs, interprétées comme des nombres avec l’indication de la base pour les représenter, sont donc égales. Vous pourrez dorénavant déposer une citrouille au pied du sapin !
Dans le cadre des Entretiens autour de l’informatique, Binaire interviewe Zvi Galil, doyen en informatique au « Georgia Institute of Technology » aux USA après une carrière de professeur et chercheur en algorithmique, complexité, cryptographie et conception expérimentale d’algorithmes. Il nous parle de la haute administration dans le monde universitaire et du développement des MOOCs. Claire Mathieu et Maurice Nivat.
Zvi Galil
B : Vous avez été doyen de l’école d’ingénierie à l’université de Columbia, président de l’université de Tel-Aviv, et, maintenant, doyen de l’informatique à Georgia Tech. Comment êtes-vous passé du statut de professeur et chercheur renommé à la haute administration ?
ZG : Quand j’étais directeur de département à l’Université de Columbia, je pouvais faire cela et continuer à faire de la recherche dans le même temps. Mais il y a eu un moment charnière en 1995, quand on m’a demandé d’être le doyen de l’ingénierie à Columbia. J’ai hésité. Je savais que si je disais oui, ce serait un changement de carrière. Je me rendais compte que cela signifierait pour ma recherche. Ce fut une décision importante pour moi : dans les années 1990, j’étais classé numéro un pour les publications aux conférences FOCS et STOC (*). Même en n’y ayant plus rien publié depuis 1995, je suis toujours le numéro huit. De plus, j’adore faire de la recherche avec les étudiants en doctorat, ils sont comme des membres de ma famille. Je me lie d’amitié avec eux. Il y en a certains qui sont devenus des amis très proches. Ainsi, c’était un choix difficile. Je me posais également la question : ai-je atteint le sommet de ma carrière de chercheur ? En 1995, j’étais âgé de quarante-huit ans. Je me disais que j’avais atteint le sommet, et je savais que la qualité de mon travail de recherche allait diminuer. L’informatique théorique est un domaine extrêmement concurrentiel, et vous devez rester au courant des dernières évolutions. Mes principaux domaines de recherche sont les algorithmes de graphes et la ”Stringologie” (terme que j’ai inventé). Ces travaux ont eu un certain impact, et certains des résultats sont encore actuellement les meilleurs. Mais d’un autre côté, il y avait cette occasion qui se présentait d’être un leader du monde universitaire, d’être un doyen. Cette perspective m’intéressait aussi. Une chose qui est bien quand on est directeur ou doyen, c’est l’interaction avec de nombreuses personnes dans de nombreux contextes différents, et, pour ma part, de par mon caractère j’aime interagir avec les gens. Lorsque vous êtes doyen, vous essayez d’améliorer votre école. Finalement, je décidai de répondre oui. Et, pendant que j’y ai été doyen, l’école d’ingénierie de l’université de Columbia est passée du rang 31 au rang 19.
B : Quelles nouvelles idées avez-vous eu en tant que leader universitaire ?
ZG : Tout d’abord, l’enseignement est très important pour moi. Dans une université, un doyen n’a pas besoin de dire à la faculté que la recherche est importants, car c’est évident pour tout le monde, mais cela n’est pas vrai en ce qui concerne l’enseignement. J’insistais donc beaucoup sur l’enseignement. À Georgia Tech, j’ai fait augmenter le taux de participation des étudiants aux enquêtes, jusqu’à environ 75% de participation, et l’enseignement s’est amélioré. Les trois quarts des cours sont maintenant évalués au dessus de 4.17, dans un intervalle de 1 à 5 ! J’ai eu une influence sur l’enseignement en invitant les mauvais enseignants dans mon bureau pour une conversation …
Et puis, lorsqu’on est doyen, quelquefois on veut emmener son unité dans de nouvelles directions. À l’Université de Columbia, j’ai joué un rôle dans la création d’un nouveau département d’ingénierie biomédicale. À Georgia Tech, nous développons l’apprentissage machine. Je me rends compte que c’est une sous-discipline très important de la science informatique. Mais tout cela est initié par les professeurs. Moi, je parle aux gens et j’écoute leurs idées. Il faut une certaine humilité pour cela.
B : Et lorsque vous, personnellement, avez une opinion sur une certaine direction de recherche qui vous semble importante, comment faites-vous pour convaincre les universitaires d’aller dans cette direction ?
ZG : En tant que doyen, ma tâche principale est de recruter des gens. Les professeurs sont ceux qui décident qui embaucher. Pour collaborer avec les directeurs de département, je gagne leur confiance, et ensuite je peux à mon tour leur faire confiance. Par exemple, en ce moment aux États-Unis l’informatique est dans une situation de boom incroyable, tout le monde embauche partout, alors il est très difficile de recruter d’excellents candidats, car ils obtiennent plusieurs offres, et ils vont parfois à de meilleurs endroits. À Georgia Tech, les directeurs de département choisissent de n’embaucher personne plutôt que quelqu’un qu’ils n’ont pas vraiment aimé, ils préfèrent attendre et me font confiance pour leur redonner le poste l’année suivante.
Par l’enseignement de cours en ligne (MOOCs), nous apprenons de nouveaux aspects de ce que la technologie peut faire pour aider à l’éducation.
Cours en ligne sur l’apprentissage automatique de Georgia Tech. Capture d’écran.
Un Mastère en ligne
B : Comment le Mastère en ligne a-t-il commencé à Georgia Tech?
ZG : À Georgia Tech, nous avons la tradition de faire des choses que personne n’a jamais faites auparavant. La dernière en date est le programme de Mastère en ligne. En Septembre 2012, cela faisait peu de temps que les MOOCs existaient, Sebastian Trun est venu me voir et m’a fait une suggestion : faisons un diplôme de Mastère pour un coût de mille dollars. J’ai répondu, mille dollars, ça ne marchera pas, mais peut-être que quatre mille dollars pourraient suffire. En fin de compte, le diplôme coûte six mille six cents dollars. Même en France, un tel diplôme pourrait être intéressant parce que, même si les frais de scolarité sont très faibles en France, cela permettrait d’économiser de l’argent public. J’ai adoré cette idée. Il y avait là une occasion d’innover. Je savais aussi que ce serait une direction d’avenir pour l’enseignement supérieur. Donc, je me suis jeté à l’eau, et maintenant j’apprends à nager !
Quelqu’un a dit deux choses au sujet des MOOCs : qu’ils sont comme une œuvre philanthropique venant d’universités d’élite, et que, tant qu’il n’y a pas de référence pour les MOOCs, ils sont comme une sorte d’éducation de deuxième classe pour la plèbe. Personnellement, je considère les MOOCs comme des sortes de manuels sophistiqués. Mais les gens veulent des diplômes, des références, et c’est pourquoi nous avons créé un Mastère. Je prévoyais que les médias allaient réagir, mais nous avons été totalement dépassés par l’ampleur de la réaction. Le premier groupe d’étudiants terminera en décembre. Parmi eux, beaucoup ont déjà des emplois, et après avoir obtenu ce diplôme certains d’entre eux vont déjà obtenir une promotion. Vingt-quatre des étudiants sont déjà titulaires d’un doctorat et veulent peut-être une réorientation de carrière. Jusqu’à présent, tout se passe très bien.
B : Quel a été votre plus grande surprise à propos de ce Master en ligne à ce jour?
ZG : Tout d’abord, le degré d’investissement des étudiants. Ils utilisent des réseaux sociaux tels que Google+ ou Facebook, beaucoup plus que les étudiants sur le campus, pour étudier, interagir et s’aider les uns les autres. Nous avons maintenant près de 2300 étudiants inscrits. Un défi majeur est d’obtenir des correcteurs et des assistants d’enseignement. Je croyais que nos étudiants en ligne ne seraient pas intéressés par ces emplois parce les assistants d’enseignement sont peu payés par rapport à leur emploi principal, et parce qu’ils sont déjà très occupés. Mais si, ils le font, parce qu’ils aiment l’interaction, et ils aiment bien rendre service ; ils ne font pas ça pour l’argent ; ils le font pour donner en retour de ce qu’ils ont reçu. Ce programme permet d’attirer des gens différents des étudiants classiques, y compris beaucoup qui ne s’inscriraient pas à un Mastère traditionnel parce que ça coûte trop cher, mais de leur point de vue ce n’est pas un diplôme de Mastère mais plutôt une formation continue. Ils ont onze ans de plus que les étudiants classiques, et nous avons donc atteint une population différente, qui n’empiète par sur le programme de Mastère classique sur le campus. Pour le moment, la plupart sont des étudiants des USA, mais à mesure que le temps passe, le Mastère va devenir plus international.
Ainsi, nous nous sommes jetés à l’eau, c’est une nouvelle expérience, et nous sommes nous-mêmes en phase d’apprentissage. Nous sommes surpris par ce qu’on peut accomplir avec la technologie. Par exemple, quelqu’un a dit qu’il pensait que les discussions qui ont normalement lieu en classe ne se produiraient pas en ligne. Mais en fait, il se trouve que le contexte en ligne fonctionne bien pour les discussions. Notre devise est : l’accessibilité grâce au faible coût et à la technologie. Nous ne savons pas encore où la technologie nous emmènera.
B : À quoi les MOOCs ne peuvent-ils pas servir ?
ZG : Initialement il y a un très grand nombre d’étudiants, mais la plupart d’entre eux abandonnent et ne reçoivent pas de diplôme. Cela ne fonctionne que pour ceux qui sont extrêmement motivés.
Nous sommes l’université
B : Y a-t-il autre chose que vous souhaitiez ajouter ?
ZG : Je crois en la communauté universitaire. Une université, c’est une communauté de professeurs, d’étudiants, de parents, de personnels. Tout le monde doit avoir droit à la parole. Dans la haute administration, nous ne sommes pas obligés de faire ce qu’ils nous disent, mais nous avons l’obligation de les écouter. En 1948, quand Eisenhower est devenu le président de Columbia, il a dit aux professeurs : « Vous autres, membres du corps professoral, êtes les employés de l’université ». I.I. Rabi (prix Nobel) a levé la main et a dit: « M. le Président, nous autres professeurs ne sommes pas les employés de l’université ; nous sommes l’université. » Et c’est un point de vue auquel j’adhère.
Claire Mathieu et Maurice Nivat
(*) Deux conférences sélectives et prestigieuses en informatique théorique.
Les équipes de recherche en informatique et leurs enseignants-chercheurs participent régulièrement à des séminaires. Ils sont sur le cœur du métier informatique et constituent un élément important de la démarche scientifique des chercheurs. Le but ici n’est pas de parler de ces séminaires mais de ceux organisés et animés aussi par des chercheurs, pas obligatoirement en informatique d’ailleurs, mais dans d’autres disciplines qui s’intéressent à l’informatique. Pierre Paradinas
Histoire de l’informatique
Le séminaire d’histoire de l’informatique a pour objectif de présenter et conserver la mémoire des travaux pionniers de l’informatique. Les intervenants sont soit les acteurs des débuts de cette discipline, soit des chercheurs s’intéressant aux développements de l’informatique dans l’industrie, l’économie, la recherche ou la société civile. Il est co-organisé par Francois Anceau, ancien professeur du Cnam, Pierre-Eric Mounier-Kuhn, historien, CNRS, Paris-Sorbonne et Isabelle Astic, responsable de collections au Musée des arts et métiers. Il a été initié dans le cadre du projet « Vers un musée de l’informatique et du numérique », vous pouvez accéder en ligne aux présentations sur le site du #MINF.
Le code objet de la pensée informatique
Histoire et philosophie de l’informatique
Le séminaire Histoire et philosophie de l’informatique, interroge sur « qu’est-ce que l’informatique ? » qui n’est pas seulement une question de philosophe ou d’historien cherchant à comprendre les concepts et les tensions que recouvre cette catégorie. La question se pose aussi, ce qui est plus rare, dans le champ scientifique, aux acteurs de ce domaine d’activité dont l’identité semble encore en devenir, cinquante-deux ans après l’invention du mot « informatique ». Ce séminaire réunit des informaticiens, des historiens, des spécialistes des sciences sociales et des philosophes, il est organisé par Maël Pégny (IHPST-CNRS), Baptiste Mélès et Pierre-Eric Mounier-Kuhn.
Interactions entre logique, langage et informatique. Histoire et Philosophie
Le but du séminaire Interactions entre logique, langage et informatique. Histoire et Philosophie est de penser les relations entre la logique, l’informatique et la linguistique. Pourquoi a-t-on besoin de la logique pour l’avancement de l’informatique et quel est le rôle de la linguistique ? Ce séminaire est organisé par Liesbeth De Mol (CNRS/STL, Université de Lille 3), Alberto Naibo (IHPST, Université Paris 1 Panthéon-Sorbonne, ENS), Shahid Rahman (STL, Université de Lille 3) et Mark van Atten (CNRS/SND, Université Paris-Sorbonne).
Cette liste n’est pas exhaustive, vous participez ou vous animez un séminaire qui est en lien avec l’informatique, n’hésitez pas à nous faire part des informations complémentaires.
Pierre Paradinas, Professeur titulaire de la chaire Systèmes Embarqués au Cnam
En préparant cet article, je n’ai pu m’empêcher de repenser à nos professeurs d’informatique de l’Université de Lille 1 – peu nombreux à l’époque – qui en 1983 nous avaient obligé à nous rendre dans une université voisine pour aller écouter un séminaire où intervenaient Jacques Arsac et Marcel-Paul Schützenberger. La présentation de ce dernier portait sur La métaphore informatique (disponible dans Informatique et connaissance, pages 45–63. UER de philosophie, Université Charles de Gaulle Lille III, 1988. Conférence en novembre 1983). Si vous vous demandez qu’est-ce qui peut inciter à devenir informaticien, la réponse est : en écoutant Arsac et Schütz !


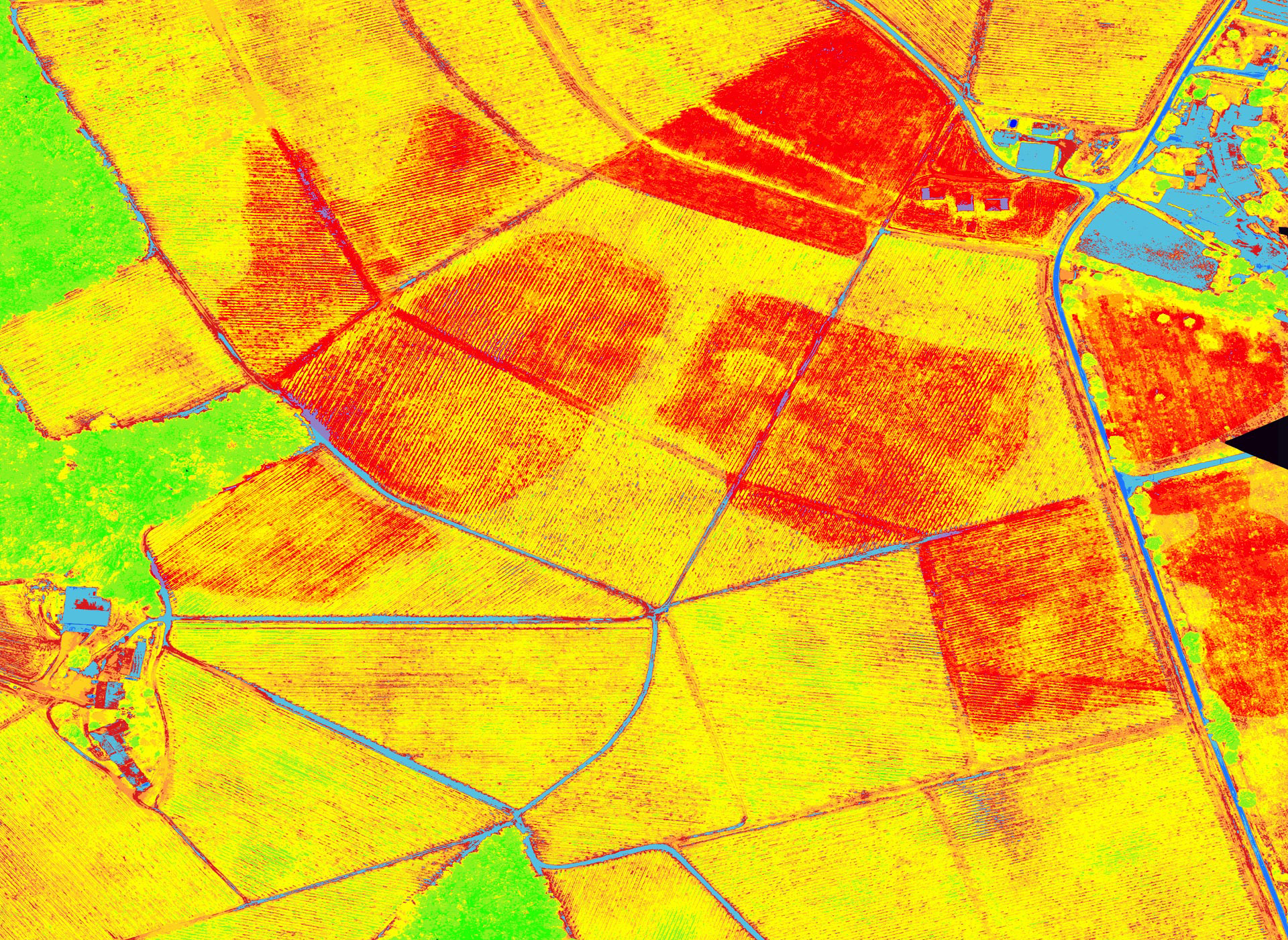




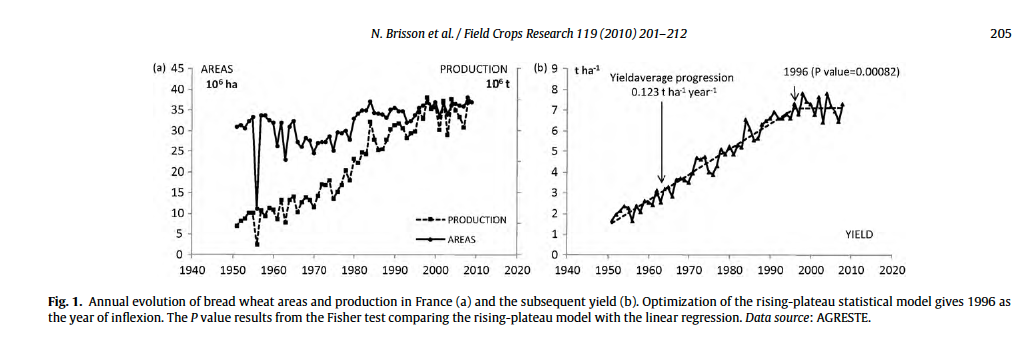



![By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://binaire.socinfo.fr/wp-content/uploads/2015/11/Plan_metro_tram_chemin.svg_.png)
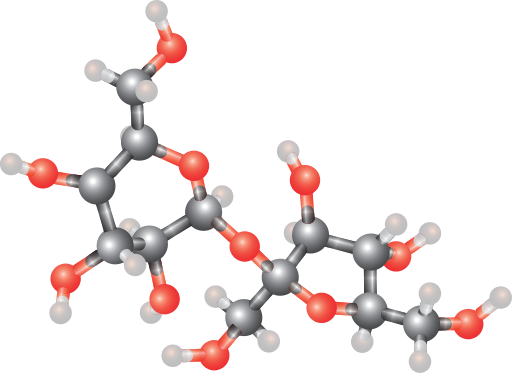
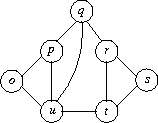
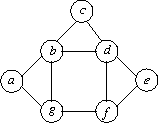









 Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple
Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple 




















{kind=link}