La vente d’espace publicitaire sur le web a priori ce n’est pas particulièrement notre tasse de thé. Ce genre de pub nous paraît tenir souvent de la pollution. Pourtant, il nous paraissait intéressant de comprendre comment une startup française pouvait devenir une licorne. Le livre de Jean-Baptiste Rudelle, « On m’avait dit que c’était impossible » aux éditions Stock, a été une agréable surprise : Enfin un patron de startup français optimiste, et content de ce qu’offre la France.
Rudelle raconte son expérience de créateur de 3 startups : un échec, un résultat mitigé, et le grand succès Criteo. Criteo, valorisée à plus de 2 milliards de dollars, est aujourd’hui présente dans 85 pays. Avec ses algorithmes de prédiction, elle achète et revend en quelques millisecondes des emplacements publicitaires sur internet. Elle affiche une belle croissance à deux chiffres.
Le fait que Rudelle vive et travaille à moitié en France et à moitié aux US lui permet de faire des comparaisons intéressantes, bien loin du French Bashing des américains, des français, des « Pigeons » en particulier. Les impôts sont plutôt plus bas en France, les employés plus productifs, l’administration pas pire qu’ailleurs.
Autre thèse originale de Rudelle : l’importance du jeu collectif. Pour lui, une startup ne se crée pas seul mais avec des associés complémentaires, des employés de top qualité, des vicis intelligents ; les stocks options doivent être partagées entre tous les employés.
Au delà du récit d’une expérience intéressante entre la France et les Etats-Unis, Rudelle touche de nombreux sujets : le partage des ressources avec des références appuyées à Piketty, les impôts, l’héritage, le capital risque, l’art du pivot pour les startups, la pub bien sûr… Est-ce à cause de son éducation (mère historienne, père artiste peintre) que Jean-Baptiste Rudelle sait si bien raconter, et qu’il est capable d’une telle distance ?
Le sujet de la formation à l’informatique a été beaucoup débattu en France récemment. Mais en dehors de l’hexagone ? On se pose les mêmes questions ? D’autres pays auraient-ils eu l’audace de prendre de l’avance sur nous ? Binaire a proposé à Françoise Tort, chercheuse à l’ENS Cachan et co-responsable en France du concours CASTOR informatique, d’interroger des collègues à l’étranger. Leurs réponses apportent beaucoup à nos débats parfois trop franchouillards.
Dans le cadre de la rubrique « Il était une fois… ma thèse », Binaire a demandé à Matthieu Dorier, qui a effectué sa thèse à l’ENS Rennes et au laboratoire IRISA et qui est maintenant en postdoc à Argonne National Laboratory (Illinois) de nous présenter ses travaux. Derrière de nombreuses découvertes scientifiques se cachent de plus en plus souvent des millions d’heures de calculs effectués par de gigantesques machines. Vous ne savez pas comme c’est compliqué de commander des centaines de milliers, des millions de travailleurs-processeurs, peut-être obéissants mais bien loin d’avoir l’intelligence et la créativité de travailleurs humains. Et si vous pensez que c’est trop facile, ou si vous pensez que c’est trop compliqué, juste impossible, demandez à Matthieu et il vous envoie une copie de sa thèse. Si vous demandez poliment, il vous laissera peut-être voir ses milliers de lignes de code… Torride ! Serge Abiteboul.
Matthieu Dorier (source: Matthieu Dorier)
En 2010, je m’envolai pour l’université d’Illinois à Urbana-Champaign, aux Etats-Unis, un coin paumé au milieu des champs de maïs, parfois frôlé par des tornades. Les tornades, c’était justement le domaine de recherche de mes collègues, qui voulaient en simuler le comportement sur un ordinateur. Ils me tendirent une feuille pleine de nombres. Le premier qui me frappa fut celui-ci : 300 000, le nombre de processeurs (ou « cœurs ») nécessaires pour exécuter ce genre de simulation. Trop dingue ? « A-t-on une telle puissance de calcul sous la main, demandai-je ? Non, répondirent-ils, mais nous l’aurons plus tôt que tu ne l’imagines. » Il n’en fallait pas plus pour m’accrocher. J’allais m’éclater à Urbana-Champaign. Difficile à croire, mais vrai !
Une tornade (source: Wikipedia)
Dans la science fiction, on parle souvent d’ordinateurs super puissants. Maintenant, on les fabrique. Comment ? On sait fabriquer un cœur. Et bien on va combiner un max de cœurs pour obtenir des supercalculateurs avec de super puissances de calcul. Et effectivement, le plus puissant au monde aujourd’hui possède plus de 3 millions de cœurs. Ces supercalculateurs sont utilisés par des chercheurs dans de nombreux domaines : météo, biologie, astrophysique, etc. J’ai eu la chance, l’honneur, le plaisir, la redoutable tâche de travailler sur un de ces supercalculateurs.
Le supercalculateur « Intrepid » d’Argonne National Laboratory (source: Wikipedia)
Les problèmes arrivent lorsque les programmes que l’on exécute sur un tel nombre de cœurs produisent des données. Si chaque cœur produit ne serait-ce qu’un fichier de 60 Méga octets (plus que l’espace disque par une chanson dans votre téléphone) toutes les 30 minutes, et que le programme est exécuté pendant une semaine (c’est le cas de notre simulation de tornades, par exemple) avec 300 000 cœurs, on se retrouve avec 5.6 Peta-octets de données réparties dans 100 millions de fichiers. Pour vous donner une idée, cela représente 5 600 disques durs de 1 To ! Les supercalculateurs ont bien sûr des « super systèmes de stockage », mais écrire de grandes quantités de données prend du temps, et les programmes sont donc ralentis. De plus, comment retrouver des informations scientifiques intéressantes dans une telle masse de données ?
Visualisation d’une simulation atmosphérique via le logiciel Damaris (source: Matthieu Dorier)
L’ensemble de ma thèse a donc consisté à résoudre ces problèmes : d’une part faire en sorte que la production de données ne ralentisse pas les simulations, d’autre part faire en sorte de pouvoir trouver facilement une information scientifique pertinente sans avoir à lire des centaines de milliers voir des millions de fichiers. Pour cela, j’ai développé un logiciel nommé Damaris. Celui-ci se « branche » sur une simulation et lui « emprunte » un certain nombre de ses cœurs, qu’il va utiliser pour traiter les données produites avant qu’elles ne soient écrites dans des fichiers. Ce logiciel sert aussi d’interface entre une simulation et son utilisateur, qui peut s’y connecter en temps réel et demander à ce qu’il produise des images de la simulation. Tout cela sans avoir besoin d’écrire les données dans des fichiers ! Grâce à cette méthode, les scientifiques peuvent obtenir les résultats qu’ils cherchent avant même que la simulation ne soit terminée.
Après avoir soutenu ma thèse fin 2014, je me suis de nouveau envolé pour l’Illinois, cette fois-ci à Argonne National Laboratory, près de Chicago. J’y travaille toujours sur la gestion de données dans les supercalculateurs.
Le mot « algorithme », qui désigne un objet bien précis en informatique, est utilisé dans la presse pour n’importe quelle utilisation de n’importe quelle technologie informatique dans n’importe quel cadre. Dans ce chaos médiatique, l’informaticien ne retrouve bien souvent pas ses petits. Pour binaire, David Monniaux, Directeur de Recherche au CNRS à Grenoble, résume le désarroi de la communauté informatique devant cette nouvelle habitude. Charlotte Truchet
« Les algorithmes. » Depuis la discussion de la loi sur le renseignement, cette expression revient sous la plume de journalistes et autres commentateurs, que ce soit pour désigner des méthodes mystérieuses censées retrouver les djihadistes sur le Net, ou celles employées par les grands services en ligne (Google, Amazon, Facebook, Twitter…) pour classer utilisateurs, produits et messages.
Le nom « algorithme » a subi un glissement de sens semblable à celui de « banlieue ». Le dictionnaire peut bien en donner comme définition « Territoire et ensemble des localités qui environnent une grande ville », on sait bien que « les banlieues », dans la langue de ceux qui ont accès aux médias, ne désigne pas Versailles ou le Vésinet, mais plutôt Le Blanc-Mesnil ou Vaulx-en-Velin… De même, un « algorithme », on ne sait pas vraiment ce que cela désigne précisément, mais c’est en tout cas effrayant.
Un algorithme, ce n’est jamais que la description non ambiguë d’un procédé de calcul, quel qu’il soit. Par exemple, une méthode pour trier des fiches par ordre alphabétique est un algorithme, et d’ailleurs l’étude des algorithmes de tri classiques est une étape obligée des cours d’algorithmique. Les professionnels de l’informatique trouvent donc assez curieux du point de vue du vocabulaire que l’on s’émeuve, par exemple, qu’un site comme Twitter envisage de trier des messages par un algorithme et non par ordre chronologique, alors qu’un simple tri par ordre chronologique découle déjà de l’application d’un ou plusieurs algorithmes…
L’algorithmique n’est pas une alchimie mystérieuse. Elle est enseignée à l’université, il y a de nombreux ouvrages traitant d’elle et de ses spécialités. Les grandes lignes des procédés mis en œuvre par les grandes entreprises du Net sont le plus souvent connus, même si leurs réglages fins et leurs combinaisons exactes relèvent du secret industriel.
Dans les médias, et pour ceux qui s’y réfèrent, le mot « algorithme » a pris un sens nouveau, qui n’est pas celui des professionnels de l’informatique. L’algorithme des médias est un procédé hautement mystérieux, complexe, aux paramètres obscurs, voire quasi-magique. Ceci ne peut que troubler ceux qui pensent, à mon avis à tort, que nous sommes dans une société « scientifique ».
L’écrivain de science-fiction Arthur C. Clarke, avec son sens de la formule, a énoncé que « toute technologie suffisamment avancée est indistinguable de la magie ». De fait, les débats sur les « algorithmes » montrent bien la pensée magique à l’œuvre, lorsqu’ils sont considérés par des décideurs publics et des commentateurs comme des solutions miracles, économiques et objectives, sans compréhension de leur fonctionnement et de leurs limitations et d’ailleurs sans esprit critique. L’opposition aux « algorithmes », quant à elle, relève souvent plus d’une vision romantique et quasi luddite (« l’homme remplacé par la machine ») plus que d’une analyse objective et informée.
Le 10 février dernier a eu lieu sur France Culture un débat « Faut-il avoir peur de l’intelligence artificielle ? ». Au delà du titre provocant et anxiogène, l’existence de pareils débats montre une demande d’information dans le grand public. Par exemple, l’annonce récente de succès informatiques au jeu de Go, naguère réputé résister à l’intelligence artificielle, suscite des interrogations. Pour démystifier ce résultat et bien poser ces interrogations, il se peut qu’il faille un enseignement informatique dispensé par des personnels formés. C’est là l’un des aspects du problème : ces question sont peu abordées dans l’enseignement général, ou alors en ordre dispersé dans des enseignements divers.
Une partie du travail du chercheur est d’informer la population, de contribuer à sa culture scientifique et technique, notamment en démystifiant des concepts présentés comme mystérieux et en déconstruisant des argumentations trompeuses. Que faire ?
Il n’est jamais trop tôt pour bien faire. Et l’informatique n’y fait pas exception. Elle est arrivée au lycée, mais cela aura pris le temps. Binaire s’intéresse à des expériences de la découverte de l’informatique à l’école primaire. Nathalie Revol et Cathy Louvier nous parlent d’une expérience en banlieue lyonnaise. Sylvie Boldo
Nathalie Revol, par elle-même
Prenez une classe de CM1 en banlieue lyonnaise. Une classe probablement dans la moyenne, avec des origines sociales et géographiques très mélangées : 26 enfants curieux, motivés, joueurs, remuants, faciles à déconcentrer.
Prenez une chercheuse en informatique qui se pose des questions sur ce qu’il est important de transmettre de sa discipline, dès le plus jeune âge.
Prenez une enseignante de CM1 désireuse de proposer un enseignement des sciences en général et de l’informatique en particulier, de façon attrayante et motivante, à ses élèves.
Faites en sorte que l’enseignante soit en charge de cette classe de CM1. Faites en sorte que la chercheuse ait des jumeaux dans cette classe de CM1, à défaut un seul enfant suffira, pas d’enfant du tout peut aussi faire l’affaire, il suffit que la rencontre ait lieu.
Laissez reposer quelques mois les questions et les idées qui tournent dans la tête de la chercheuse et vous aurez une ébauche de programme d’informatique pour des CM1.
Faites ensuite se rencontrer la chercheuse et l’enseignante au portail de l’école ou ailleurs, la première proposant d’expérimenter ce programme, la seconde acceptant bien volontiers de servir de cobaye. Quelques demandes d’autorisation plus tard, c’est ainsi que la chercheuse et l’enseignante ont démarré un programme de 8 séances de 45 minutes intitulé « informatique débranchée ».
Questions et réponses
La question qui tournait comme une rengaine dans la tête de la chercheuse était de savoir comment s’y prendre pour faire passer le message suivant :
L’informatique n’est pas plus la science des ordinateurs que l’astronomie n’est celle des téléscopes, aurait dit E. Dijkstra. En d’autres termes plus compréhensibles par les élèves du primaire, l’informatique n’est pas plus la science des ordinateurs que les mathématiques ne sont la maîtrise de la calculatrice.
Approche, accroche, algorithmes pour les gavroches, codage binaire sans anicroche
Ne le prenez pas, le parti était pris : ce serait un enseignement sans ordinateur. Cela tombait bien, le site « Computer Science Unplugged » regorge d’activités à pratiquer sans ordinateur, tout comme le site de Martin Quinson consacré à la médiation, ou le site pixees destiné à offrir des ressources pour les enseignant-e-s. D’ailleurs, le titre de ce projet d’informatique en CM1 est informatique débranchée, la traduction – sans les références musicales – de Computer Science unplugged.
L’approche étant choisie, il fallait encore définir le contenu. L’inspiration a été puisée dans le programme d’ISN : Informatique et Sciences du Numérique, élaboré pour les lycéen-ne-s de 1e et Terminale. Ce programme comporte quatre volets : 1 – langages et programmation, 2 – informations, 3 – machines, 4 – algorithmes. Les volets « algorithmes » et « informations » ont été retenus parce qu’ils se prêtent bien à des activités sans ordinateur. Pour la partie « informations », l’accent a été mis sur leur représentation utilisant le codage binaire.
Enfin, pour que les élèves adhèrent à ce projet d’informatique, une accroche basée sur les jeux a été choisie pour la partie algorithmique. Quant au codage binaire, c’est par des tours de magie qu’il a été présenté. On a privilégié les manipulations, qui permettent d’établir le lien entre les objets et la formalisation plus abstraite des algorithmes, ainsi que des activités engageant tout le corps, comme le réseau de tri pour les algorithmes et la transmission d’un message codé en binaire par la danse.
Cela permet d’accrocher l’attention des élèves et de les motiver pour qu’ils et elles se mettent en situation active de recherche, d’élaboration des algorithmes ou de compréhension du codage binaire.
Algorithmes
Chaque partie a demandé quatre séances. Côté algorithmes, on a commencé par le jeu de nim, popularisé par le film «L’année dernière à Marienbad » paraît-il (c’était la minute culturelle). Ce jeu se joue avec des jetons de belote et des règles simples… et il existe une stratégie pour gagner à tous les coups. Appelons cette stratégie un algorithme et laissons les enfants jouer par deux, en passant entre les tables pour les mettre sur la voie. En fin de séance, on a mis en commun les algorithmes trouvés et on a mis en évidence qu’il s’agissait de formulations différentes du même algorithme.
On a ensuite défini, avec l’aide du film «Les Sépas : les algorithmes », ce qu’était un algorithme, avec les mots des enfants.
Le jeu suivant est le crêpier psycho-rigide. Un crêpier veut, le soir avant de fermer boutique, ranger la pile de crêpes qui reste dans sa vitrine par taille décroissante, la plus grande en bas et la plus petite en haut. La seule opération qu’il peut effectuer consiste à glisser sa spatule entre deux crêpes, n’importe où dans la pile, et à retourner d’un seul coup toute la pile de crêpes posées sur sa spatule. Pourra-t-il ranger ses crêpes comme il le désire ? Il s’agit d’un jeu plus ambitieux : l’algorithme à découvrir est un algorithme récursif. Autrement dit, on effectue quelques manipulations pour se ramener au même problème, mais avec moins de crêpes à ranger. Pour faire «oublier » les crêpes déjà rangées, pour se concentrer sur les crêpes restantes, on a caché les crêpes déjà rangées par une feuille de papier… et cela a très bien marché ! On a aussi utilisé cet écran de papier pour cacher complètement la pile de crêpes, dès le début, et pour faire comprendre aux enfants qui dictaient l’algorithme – qui était donc exécuté derrière l’écran – qu’un algorithme s’applique à toutes les configurations, que ce n’est pas une construction ad hoc pour chaque pile de crêpes.
Le dernier algorithme a été abordé de manière fort différente. On a dessiné un réseau de tri au sol et cette fois-ci, les élèves étaient les porteurs des données (soit des petits nombres, soit des grands nombres, soit des mots) qui se déplacent dans le réseau, se comparent et finissent par se trier, comme ils l’ont rapidement compris, par ordre numérique ou par ordre alphabétique.
Codage binaire, représentation des données
Les quatre séances suivantes ont été consacrées au codage binaire des informations.
Pour la première séance, les enfants ont reçu un codage binaire (une suite de 0 et de 1) et une grille. Ils ont travaillé par 2 : l’un-e dictait les «0 » et les «1 » et l’autre laissait blanches ou noircissait les cases correspondantes de la grille. Ils ont fini par découvrir le dessin caché pixellisé et encodé en binaire. Ils ont alors créé leur propre dessin, l’ont encodé puis dicté à leur voisin pour vérifier que l’encodage puis le décodage préservait leur image.
Pour la deuxième séance, on a commencé par un tour de magie reposant sur le codage binaire des nombres. La magicienne devait deviner un nombre, entre 1 et 31, choisi par un enfant en lui montrant successivement 5 grilles de nombres et en lui demandant si son nombre se trouvait dans ces grilles. Avec leur attention ainsi acquise, on a écrit le codage binaire des nombres de 1 à 7 tous ensemble, puis de 1 à 31. Pour cela on est revenu à une représentation des nombres par des points, un nombre étant représenté par autant de points que d’unités, par exemple 5 est représenté par 5 points. On a utilisé de petites cartes porteuses de 1, 2, 4, 8 ou 16 points (oui, les puissances de 2, mais chut, vous allez trop vite). Chaque enfant s’est vu attribuer un nombre et devait choisir quelles cartes conserver pour obtenir le bon nombre de points ; c’était plus clair en classe avec les cartes… Bref, en notant «1 » quand la carte était retenue et «0 » quand elle ne l’était pas, nous avons le codage binaire des nombres et on a pu expliquer finalement comment marchait le tour de magie.
La troisième séance a de nouveau commencé par un tour de magie, reposant cette fois sur la notion de bit de parité. Après avoir dévoilé le truc et expliqué pourquoi il est utile de savoir détecter des erreurs (voire les corriger – mais on n’est pas allé jusque là), on a encodé les lettres de l’alphabet, en binaire, avec 6 bits dont 1 de parité. Chaque binôme a alors choisi un mot court, l’a écrit en binaire en utilisant le codage et l’a conservé pour la séance suivante.
La dernière séance a fait appel au corps : à tour de rôle, nous avons dansé nos mots, en levant le bras droit pour «1 » et en le baissant pour «0 » et nos spectateurs ont décodé sans se lasser.
Au final…
l’expérience s’est bien déroulée, les cobayes se sont prêtés au jeu avec beaucoup d’enthousiasme, le calibrage des activités en séances de 40-45mn était à peu près juste et pas exagérément optimiste, la gestion de la classe a été assurée par l’enseignante et c’est tant mieux, les moments de mise en commun également. L’enseignante est même partante pour renouveler seule ce projet… ce qui fait chaud au cœur de la chercheuse : un des objectifs était en effet de proposer un projet réalisable dans toutes les classes, sans nécessiter une aide extérieure qui peut être difficile à trouver.
On peut trouver le détail de ce projet, agrémenté de remarques après coup pour parfaire le déroulement de chaque séance, sur le site de pixees.
Des contributeurs/contributrices de Wikipédia ont conçu un MOOC (cours en ligne, gratuit et ouvert à tous) pour découvrir Wikipédia et apprendre à y contribuer. Les inscriptions au WikiMOOC sont ouvertes sur la plateforme FUN (France Université Numérique) jusqu’au 29 février.
Wikipédia est aujourd’hui le septième site le plus visité au monde. C’est aussi l’un des rares sites connus à être hébergé par une fondation à but non-lucratif. Étudiants, professeurs, professionnels, particuliers : nombreux sont les internautes à utiliser cette encyclopédie en ligne, qui compte plus de 36 000 000 d’articles en 280 langues, dont 1,7 million en français.
Si vous souhaitez découvrir le fonctionnement de l’un des sites les plus visités au monde, source majeure d’information, et/ou apprendre à y contribuer vous-même pour aider à partager la connaissance au plus grand nombre, ce cours est fait pour vous. Et cela que vous soyez étudiant(e), chercheuse ou chercheur, professionnel(le) de n’importe quel secteur d’activité, inactif ou inactive, ou bien encore retraité(e).
On rappelle que Binaire est à l’initiative d’une série d’actions regroupées sous le nom de code « Cabale Informatique de France ». Il s’agit de contribuer aux pages de Wikipédia sur l’informatique, en français. C’est co-organisé avec la Société Informatique de France et Wikimédia France, donc Binaire ne peut que soutenir ce MOOC.
En voyage au pays du soleil levant, le correspondant de binaire Colin de la Higuera partage avec nous, ses étonnements avec ses yeux d’informaticien remplis de codes et d’algorithmes…
Quand un informaticien voyage, sa curiosité fait qu’il a envie de comprendre les algorithmes utilisés au quotidien par les habitants. Plutôt que de s’extasier devant une coutume ou même d’en discuter son importance, l’informaticien aura envie de décoder celle-ci comme on décode un programme qui s’exécute.
Au risque de prêter le flanc aux stéréotypes, il y a des cas où c’est plus facile que d’autres. Dans certains pays (au hasard latins) il est difficile de comprendre les algorithmes suivis parce qu’une large part est laissée à l’imagination, à l’esprit du moment : quand dans une situation similaire deux personnes vont avoir deux attitudes différentes, on admettra volontiers qu’il ne s’agit pas d’une situation codifiée ou que le code n’est pas très rigide.
Kodai-ji, Kyoto
Dans d’autres pays, c’est tout aussi difficile, mais pour des raisons bien différentes : ainsi, au Japon, de nombreux gestes sont codifiés, de nombreuses situations sont parfaitement et logiquement prévues. C’est cependant difficile de décoder. Sans doute parce que les codes sont très anciens et ont été lissés par des siècles d’histoire différente de la nôtre. Ainsi, le prince Shotoku a-t-il rédigé les premiers articles de sa constitution dès l’an 604.
L’informaticien se trouve alors au Japon en terrain ami et face à une tâche qu’il connait : la reverse engineering… regarder les résultats du code et essayer d’imaginer, de reconstruire celui-ci. Certains informaticiens s’en sont fait une spécialité : des entreprises, en particulier en Inde, sont capables même de reconstruire un compilateur à partir de programmes écrits dans un langage informatique éteint, le genre de défis que le linguiste et l’historien aimeraient relever par le Linéaire A…
Au Japon donc, les codes sont rois. Il suffit de se retrouver deux fois de suite dans des situations similaires mais des lieux différents pour se rendre compte que ce n’est pas l’improvisation qui prime.
Payer au supermarché, prendre le train ou l’autobus, lever son verre en disant Kampai, sans parler des règles très différentes à suivre au sanctuaire plutôt qu’au temple, tout est précis, logique et… différent.
Ainsi on entre dans le bus par l’arrière et on prend tout de suite un billet. Au moment de descendre, ce billet montrera où on est monté et permettra de calculer le tarif. Logique.
On paye toujours en posant l’argent sur le plateau… Si vous tentez autre chose, l’argent reviendra inévitablement sur le plateau, ce qui déclenche un bien étrange discours, un calcul de la monnaie à rendre et un rendu de celle-ci. Dans un supermarché, si la loi de Poisson (la même que la nôtre, ouf) fait qu’une nouvelle caisse s’ouvre, la caissière s’empressera d’aller chercher le premier de la file d’attente pour qu’il inaugure la caisse ouverte et ne soit pas frustré…
On peut fumer dans un restaurant mais pas dans un jardin public ; on peut circuler à vélo sur un trottoir mais pas transporter celui-ci par train jusqu’à la prochaine gare…
Le train est d’ailleurs un endroit où l’on voit l’importance des codes : malgré la complexité due à la compétition entre plusieurs lignes différentes, la coordination est à la minute près : deux trains arriveront en même temps sur un quai permettant l’échange de leurs passagers. Dans ce train, les uns dorment, les autres regardent un écran. Certains sièges peuvent être utilisés par tous, d’autres pas, d’autre seulement à certaines heures ; certains wagons ne sont accessibles qu’aux femmes…
Personnage à Asuka
Bien entendu, on peut se poser des questions sur les effets de tous ces codes sur la santé mentale des individus. Sur celle du narrateur mais aussi sur celle des habitants d’un pays dans lequel les codes pèsent si lourd.
Différents moyens existent heureusement pour y échapper : une liberté vestimentaire étonnante, des vendredi soirs aux abus notoires (essayez une sortie entre collègues ou un banquet d’entreprise…). Et si cela ne suffit pas, promenez-vous le long de la rivière Kamo. Sous les ponts saxophonistes et clarinettistes soufflent, soufflent…
Serge Abiteboul nous parle d’une startup, Cozy Cloud, qui développe un système de gestion d’informations personnelles. Il nous explique ce que sont ses systèmes, quels sont leurs buts. Avec les enjeux autour du contrôle des données personnelles, cette nouvelle approche prend tout son sens. Une startup qui mérite vraiment qu’on la suive de près.
2 février 2016 : La startup Cozy Cloud et le bureau d’enregistrement Gandi sont lauréats de la 2ème édition du Concours d’Innovation Numérique pour leur projet de cloud personnel grand public.
@Maev59
Nos données sont un peu partout, dans des services, dans de plus en plus de services différents. Nous finissons par ne plus très bien savoir, où elles sont, ni même ce qu’elles sont, ou ce qu’on fait avec. Donc, nous ne nous y retrouvons plus. Par exemple, nous nous rappelons que nous avons l’adresse de ce copain, mais nous ne savons pas la trouver : dans nos contacts, dans nos mails, sur Linkedin, sur Facebook, dans un SMS peut-être, ou qui sait sur WhatsApp… Chacun de ces systèmes nous rend un service particulier, mais leur multiplication devient chaque jour un peu plus notre problème. Des systèmes se proposent de corriger cela, les systèmes de gestion de données personnelles, les Pims (pour Personal Information Management Systems).
Si vos données sont partout, c’est qu’elles ne sont nulle part, Benjamin André, PDG de Cozy Cloud
L’idée est simple : plutôt que de regrouper les données par services (les données sur les courriels de millions d’utilisateurs avec Gmail, sur les films avec Netflix, sur les déplacements avec Waze, etc.), on va regrouper les données par utilisateur. Donc nous aurons notre système à nous, pour nous, avec toutes les données des applications que nous utilisons. Ces données, nous voudrions qu’elles soient disponibles en permanence, de partout, on va dire que c’est « notre cloud personnel ».
Pourquoi promouvoir les Pims ? Parce que la situation actuelle avec quelques sociétés, en caricaturant les Géants du Web, s’appropriant toutes les données du monde est fondamentalement malsaine. D’abord, à terme, nous y perdons notre liberté : nous sommes profilés par ceux qui savent tout de nous, qui choisissent pour nous ; et les services qu’ils nous offrent deviennent incontournables parce que eux seuls ont certaines informations et peuvent les fournir. Ensuite, ces grandes sociétés finissent par être à même d’étouffer la compétition. Internet et le web qui ont servi véritablement de catalyse pour l’innovation, sont en train de devenir le royaume des oligopoles, les fossoyeurs des belles idées de liberté et de diffusion libre des connaissances des débuts. Bon, c’est résumé un peu rapide, un peu brutal. Mais le lecteur intéressé pourra trouver un développement de ces idées [1] dans CACM, la principale revue de l’ACM, une organisation internationale dédiée à l’informatique.
Donc, partons de l’hypothèse qu’il faille que chacun regroupe toutes ses données dans un système unique. Un geek saura installer un serveur, et en voiture Linux ! Mais la plupart des gens n’ont pas cette compétence, et même s’ils l’ont ou pourraient l’acquérir, ils ont probablement d’autres façons de dépenser leurs temps libre (le sport, les expos, le farniente,…).
Il y aurait bien une solution, ce serait de choisir les grands de l’internet. Pourquoi pas tout mettre chez eux ? Parce que nous aimerions avoir confiance dans le gardien de nos données. La confiance, le gros mot… Nous avons fait confiance aux fondateurs de Google, Brin et Page, quand ils disaient « Don’t be evil ! ». Mais qui dirige Google aujourd’hui ? Des actionnaires qui veulent maximiser leurs revenus ? Pour protéger nos données personnelles, nous aimerions plus que de vagues promesses. Nous voulons des garanties ! Nous allons donc plutôt choisir un tiers de confiance.
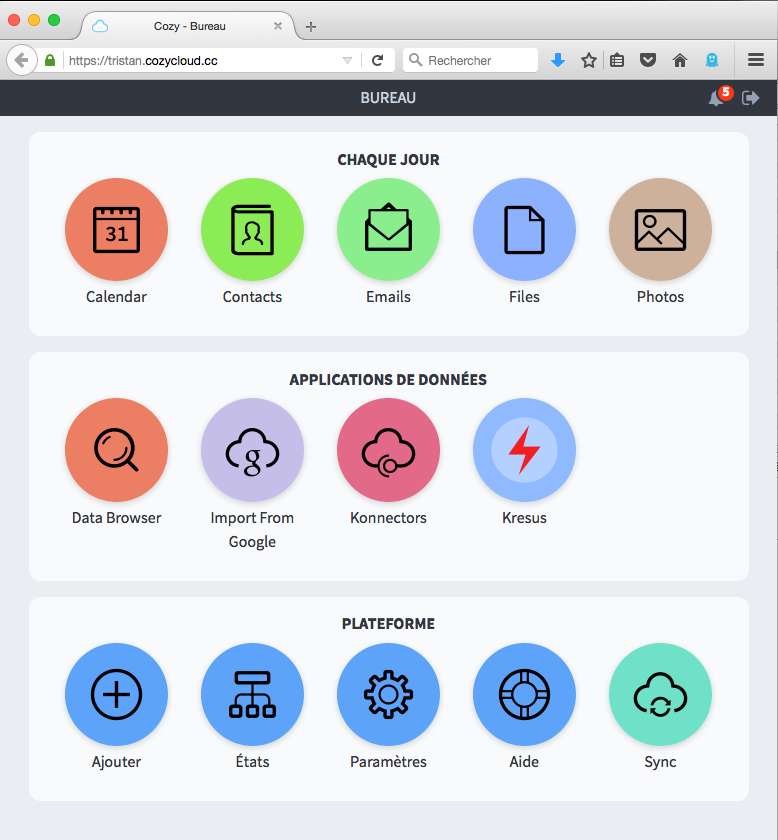
Copie d’écran : le bureau de Cozy Cloud
Un de ces tiers de confiance possibles, c’est la startup Cozy Cloud. Pour écrire cet article, j’ai rencontré son PDG Benjamin André. J’ai aussi côtoyé au Conseil national du numérique, son CPO, Tristan Nitot. Je suis fan des deux. Il faut rajouter que je suis un fervent supporteur des Pims, et que ma recherche porte sur les Pims. Donc je ne suis pas toujours objectif quand j’en parle. Je pourrais parler objectivement de la recherche sur des Pims. Mais ce n’est pas le sujet de cet article. Ce qui m’intéresse ici c’est la gestion de données avec des Pims comme levier pour aller vers une société meilleure. Donc j’ai plus une casquette de militant que de scientifique. Cet article ne revendique donc aucune objectivité. Pourtant, je tiens quand même à souligner pour éviter les malentendus que je n’ai aucune participation financière dans Cozy Cloud ou d’ailleurs dans quelque société de Pims que ce soit.
Un vrai argument des Pims (en tous cas, dans ma vision des Pims), c’est que leur logiciel est open-source. Bien sûr, nous n’avons pas le temps d’aller auditer leur code, mais d’autres peuvent le faire pour nous. Cette transparence sur la gestion des données est essentielle pour garantir que la plate-forme ne va pas faire n’importe quoi avec nos données. Excusez du peu. Sans vouloir nous angoisser, toutes les données que nous avons à droite ou à gauche, des informations peut-être stratégiques pour nos entreprises, des informations intimes surement, les nôtres et celles de nos amis. Nous ne savons pas ce qu’on fait d’elles. Nous ne savons pas où elles atterrissent. Bon le mieux, c’est de ne pas trop y penser, ça va pourrir l’ambiance.
Le fait que le logiciel de la plate-forme soit open-source et la transparence donc qui en résulte, est une qualité essentielle de ces systèmes. Cela facilite la vérification. Il faut aussi mentionner un autre aspect : la « portabilité ». N’ayez pas peur, c’est technique mais ça s’explique très bien.
La portabilité des données, c’est la possibilité pour un internaute de récupérer ses données depuis les grands services centralisés pour les mettre où il le veut. Pour lui, c’est une liberté fondamentale, celle de pouvoir « déplacer sa vie numérique » où bon lui semble, y compris chez lui. Tristan Nitot, CPO de Cozy Cloud
Pour comprendre la portabilité, prenons un exemple de portabilité dans un autre domaine, l’automobile. Nous avons une Peugeot. Et puis, un jour, nous voulons changer de voiture. Nous sommes libres, d’acheter une Renault, même une Volkswagen, ce que nous voulons. Notre expérience de conducteur, nous la « portons » sous d’autres cieux. Nous n’avons pas à réapprendre. Dans les applications numériques, ça peut être un peu différent. Nous avons choisi le Kindle d’Amazon. Et bien, c’est un super système, mais nous nous sommes fait avoir. Nous ne pouvons pas passer à un autre système sans perdre toute la librairie que nous avons achetée. Nous accumulons des années d’information, de données, dans un système et on nous dit « Restes avec nous ou perds tout ! » C’est l’emprisonnement par le vendeur (vendor lock-in en anglais). Nous aimerions pouvoir partir en « emportant » nos données dans le nouveau système – sans avoir à payer en argent, en temps, en quoi que ce soit. Le système doit nous garantir la portabilité, c’est à dire votre liberté de dire quand nous le souhaitons : « Ciao ! Sans rancune. »
Des systèmes comme Cozy Cloud nous permettent de partir quand nous le voulons, avec nos données. Nous restons si nous le voulons. C’est drôle de réaliser que le droit de partir peut devenir un argument pour choisir de rester. Google disait « Don’t be evil » et il fallait croire sur parole qu’ils ne seront pas diaboliques. Dans un système qui garantit structurellement la portabilité, nous n’avons pas à les croire, ils n’ont d’autre choix que d’être angéliques s’ils veulent que nous restions. Cela pourrait être indiqué dans la loi. Des gens y travaillent.
Les députés ont validé le principe de récupération des données personnelles par les internautes. Il sera ainsi possible de transférer sa playlist iTunes vers Spotify, ou ses photos Instagram vers une autre application. En revanche, cette obligation ne s’appliquerait qu’aux services grand public, excluant, devant la levée de boucliers des éditeurs de logiciels, les services inter-entreprises. Le Monde Economie, 19.01.2016 Sarah Belouezzane et Sandrine Cassini
Essayons de comprendre un peu mieux la techno. Cozy Cloud développe une plateforme pour gérer nos données personnelles. Nous pourrons un jour tout y mettre, nos contacts, nos courriels, nos déplacements GPS, nos documents, nos comptes bancaires, notre compta… Ils nous proposent des applications qui réalisent certaines fonctionnalités (comme l’agenda) ou qui nous permettent juste de récupérer nos données d’autres services, par exemple nos mails de Gmail. Cette plateforme, nous pouvons l’installer sur une machine personnelle, ou nous pouvons demander à une société de l’héberger pour nous, par exemple OVH. Et à quoi sert Cozy Cloud à part développer la plate-forme ? Ils peuvent gérer le système pour nous.
Nous n’avons pas dit grand-chose du business model de Cozy Cloud. Bien sûr, c’est une startup, alors ils ont un business model qui montre qu’ils veulent se développer, ils cherchent des investisseurs, ils vont gagner plein d’argent. Mais nous pensons (nous espérons sans nous tromper) que Benjamin André, Tristan Nitot et les autres de Cozy Cloud veulent d’abord changer le monde, en faire un endroit où il fait meilleur de vivre. Nous avons l’impression d’avoir entendu ça des tas de fois ; ça peut prêter un peu à sourire ; mais avec Cozy Cloud, c’est tellement rafraichissant.
Allez un peu de fiction pour conclure, tout en restant conscient de la difficulté de prédire l’avenir. Nous aurons, vous et nous, (bientôt) toutes nos données chez l’hébergeur de notre choix, elles seront gérées par un cloud personnel fonctionnant avec Cozy Cloud (un Pimseur français), et nous procureront un point d’entrée unique de toutes nos données. Le système les rendra accessibles de partout, les synchronisera, les archivera, gèrera nos Internet des objets, nous servira d’assistant personnel, suivra notre santé, notre vie sociale. Nous pourrons réaliser des analyses qui utilisent nos données mais qui, contrairement aux analyses Big data des autres, le fera pour notre bien et pas pour maximiser le profit des autres. Et puis notre Pims pourra causer avec les Pims de nos amis… C’est dingue, nous étions totalement périphériques dans le monde des Gafas, nous voilà transportés au centre du monde grâce aux Pims…
[1] Managing your digital life : Serge Abiteboul, Benjamin André, Daniel Kaplan, Communications of the ACM, 58:5, 2015.
Tristan Nitot sur Twitter : @nitot
Cet article est publié en collaboration avec TheConversation.
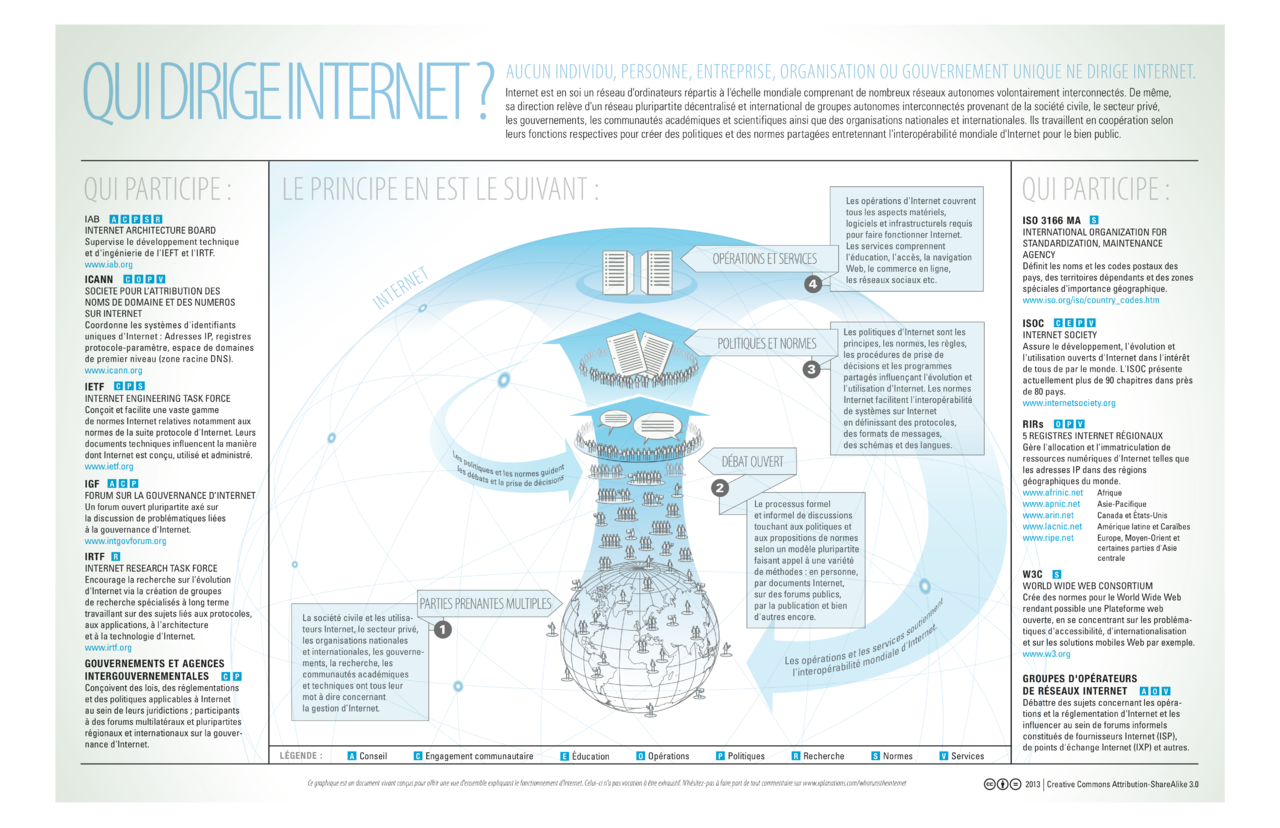
L’internet est désormais utilisé par plus de trois milliards de personnes, soit plus de 45% de la population de la planète. L’importance de l’Internet dans la vie des usagers est telle que l’on entend souvent la question : Qui gouverne l’internet ? Binaire a posé la question à un ami, Jean-François Abramatic, Directeur de recherche Inria. Si quelqu’un en France peut répondre à la question, c’est sans doute lui. Serge Abiteboul
Jean-François Abramatic, Wikipédia
Jean-François a partagé sa carrière entre la recherche (Inria, MIT) et l’industrie (Ilog, IBM). Il a présidé le World Wide Web Consortium (W3C) de 1996 à 2001. Il a été administrateur de l’ICANN (1999-2000). Il est, aujourd’hui, membre du Conseil Inaugural de la NETmundial initiative.
La gouvernance de l’internet est en pleine évolution alors que l’internet poursuit son déploiement au service de la société à travers le monde. La définition même de la gouvernance de l’internet fait l’objet de débats. Michel Serres, par exemple, explique qu’après l’écriture et l’imprimerie, l’internet est la troisième révolution de la communication. Alors que personne n’a jamais parlé de gouvernance de l’écriture ou de l’imprimerie, faut-il parler de gouvernance de l’internet ?
Pour aborder la question de manière plus détaillée, il est utile de comprendre comment a été créé l’internet afin d’identifier les acteurs dont les décisions ont conduit à l’évolution fulgurante que nous avons connue (plus de 800% de croissance pour la période 2000-2015).
L’internet est la plateforme de la convergence entre l’informatique, les télécommunications et l’audiovisuel. Dans un monde où les données sont numériques, l’internet permet d’envoyer ces données n’importe où sur la planète, les ordinateurs peuvent alors traiter ces données et extraire les informations utiles à l’usager. La convergence de l’informatique, des télécommunications et de l’audiovisuel a permis de créer un environnement universel de communication et d’interactions entre les personnes. L’internet est, ainsi, un enfant de l’informatique venu au monde dans un univers de communication dominé par les télécommunications et l’audiovisuel. Si les télécommunications et l’audiovisuel ont grandi dans des environnements gouvernementaux (avant d’évoluer à travers la mise en œuvre de politiques de dérégulation), l’internet a grandi dans un environnement global, ouvert et décentralisé dès le premier jour.
L’espace : Une gouvernance globale dès le premier jour
Lorsqu’un environnement de communication se développe, le besoin de gouvernance apparaît pour concevoir et déployer les standards (protocoles et conventions qui permettent aux composants, appareils et systèmes de communiquer) ainsi que pour répartir les ressources rares ou uniques (par exemple les bandes de fréquence ou les numéros de téléphone). Pour les télécommunications et l’audiovisuel, des organismes nationaux et internationaux ont été créés pour conduire les actions de standardisation et gérer l’attribution des ressources rares ou uniques.
Pour l’internet, l’approche a été globale dès le début et aucune organisation nationale ou régionale n’a été mise en place pour développer les standards de l’internet. L’attribution des ressources rares ou uniques (adressage et nommage) a été décentralisée régionalement après avoir été conçue globalement. De plus, la mise en place de l’infrastructure a été conduite par les concepteurs techniques. La fameuse citation de David Clark « We reject kings, presidents and voting, we believe in rough consensus and running code.» traduit l’état d’esprit qui régnait lors de la conception et le déploiement des standards qui sont au cœur de l’internet d’aujourd’hui.
Ainsi sont nées depuis les années 80 de nombreuses organisations (IETF, ISOC, W3C, ICANN) internationales, indépendantes des pouvoirs politiques et dédiées à des tâches précises nécessaires au bon fonctionnement de l’internet. Prises dans leur ensemble, ces organisations ont exercé le rôle de gouvernance de l’internet. Elles conçoivent les standards de l’internet et attribuent (ou délèguent l’attribution) des ressources rares ou uniques.
« Qui Dirige Internet » par Lynnalipinski of ICANN via Wikimedia Commons
Le temps : le développement et le déploiement simultanés des innovations
Les concepteurs de l’internet ont coutume de mettre en avant qu’ils ont fait le choix de « mettre l’intelligence aux extrémités du réseau». Ce choix d’architecture a permis à des centaines de milliers d’innovateurs de travailler en parallèle et de rendre disponibles les terminaux et les services que nous utilisons tous les jours.
Pour être plus concret, les développeurs de Wikipedia ou Le Bon Coin, de Google ou d’Amazon, de Le Monde ou Au féminin ont travaillé et travaillent encore en parallèle pendant que les ordinateurs personnels ou les tablettes, les téléphones portables intelligents ou les consoles de jeux s’équipent des logiciels qui permettent d’accéder à ces services. Les choix d’architecture technique ont donc permis le déploiement fulgurant, sans équivalent dans l’histoire, de ce que l’on appelle aujourd’hui, l’internet.
Les défis sociétaux de la gouvernance d’internet
Le déploiement de l’internet dans le grand public a été provoqué par l’arrivée du World Wide Web au début des années 90. Les pouvoirs publics se sont donc intéressés à son impact sur nos sociétés. Aux questions de gouvernance relatives au développement technique d’internet (standards et ressources rares ou uniques) se sont ajoutées les questions de gouvernance des activités menées sur l’internet.
En France, dès 1998, le rapport présenté au conseil d’état par Isabelle Falque-Pierrotin (aujourd’hui présidente de la CNIL) recommande d’adapter la réglementation de la communication à la convergence de l’informatique, de l’audiovisuel et des télécommunications. De manière à faire croître la confiance des utilisateurs, le rapport recommande de protéger les données personnelles et la vie privée, de sécuriser les échanges et les transactions, de reconnaître la signature électronique, d’adapter la fiscalité et le droit des marques, de valoriser les contenus par la protection de la propriété intellectuelle et la lutte contre la contrefaçon, de lutter contre les contenus illicites. Enfin, le rapport recommande d’adapter le droit existant et de ne pas créer un droit spécifique à internet.
Depuis le début des années 2000, ces sujets ont fait l’objet, à des degrés divers, de travaux aux niveaux local et international. Le Sommet Mondial sur la Société de l’Information (SMSI) organisé par les Nations Unies, puis l’Internet Governance Forum (IGF), et plus récemment la NETmundial initiative ont fourni ou fournissent un cadre pour ces travaux.
Construire une gouvernance multi-acteurs globale et décentralisée
Même si la gouvernance d’internet a profondément évolué, des règles générales se sont imposées au fil des quarante dernières années. Aucune personne, aucune organisation, aucune entreprise, aucun gouvernement ne gouverne l’internet. La gouvernance d’internet est exercée par un réseau de communautés d’acteurs comprenant les pouvoirs publics, les entreprises, le monde académique et la société civile. Certaines communautés associent des personnes physiques, d’autres des organisations publiques ou privées. Ces communautés choisissent leur mode de fonctionnement en respectant des principes partagés tels que l’ouverture, la transparence ou la recherche du consensus.
L’importance prise par l’internet a attiré l’attention sur son mode de fonctionnement. Il est apparu clairement que les questions posées en 1998 dans le rapport au conseil d’état étaient devenues, pour la plupart, des défis planétaires. En particulier, les révélations relatives à la surveillance de masse ont provoqué une prise de conscience à tous les niveaux de la société (gouvernements, entreprises, monde académique, société civile).
La complexité des problèmes à résoudre est, cependant, souvent sous-estimée. Pour de nombreuses communautés, il est tentant de projeter des mécanismes de gouvernance qui ont eu leur succès avant l’émergence d’internet. Il est rare qu’une telle approche soit efficace. Qu’il s’agisse de standards techniques ou de règlementations relatives à la protection de la vie privée, d’extension de la capacité d’adressage ou de contrôle de la diffusion de contenus illicites, de langages accessibles pour les personnes handicapées ou de surveillance de masse, la résolution des problèmes demande la contribution coopérative du monde académique, des entreprises, des gouvernements et de représentants de la société civile. De plus, ces contributions doivent tenir compte des différences d’environnements juridique, fiscal ou tout simplement culturel de milliards d’usagers.
La gouvernance d’internet devient donc un objet de recherche et d’innovation puisque aucune expérience passée ne permet de construire cette gouvernance par extension d’une approche existante.
C’est au grand défi de la mise en place d’une gouvernance multi-acteurs, globale et décentralisée que nous sommes donc tous confrontés pour les années qui viennent.
Si le nom de Marvin Minsky, qui vient de décéder à Boston à l’âge de 88 ans, est indissociable du domaine de l’Intelligence Artificielle, dont il est un fondateur et reste un des chercheurs les plus influents, son impact a été encore plus large, aussi bien dans le domaine de l’informatique (prix Turing en 1969) que dans celui de la philosophie de l’esprit ou des sciences cognitives. Il a en effet aussi bien travaillé à décrire les processus de pensée des humains en termes mécaniques qu’à développer des modèles d’intelligence artificielle pour des machines.
Connu pour son charisme et la qualité de ses cours, il était professeur d’informatique au MIT à Boston, où il a créé dès 1959 le laboratoire d’IA avec John Mac Carthy (autre prix Turing, inventeur du terme “Intelligence Artificielle”). Ce laboratoire et le plus récent Media Lab auquel il a également appartenu, ont eu des impacts très importants dans de nombreux domaines de l’informatique.
Ce que l’on retient en général de Marvin Minsky, c’est sa participation, avec Mac Carthy, mais aussi Newell et Simon, à la conférence de Dartmouth en 1956, généralement considérée comme fondatrice du domaine de l’intelligence artificielle. Il avait péché alors par excès d’optimisme en prédisant que le problème de la création d’une intelligence artificielle serait résolu d’ici une génération. La tradition veut qu’on retienne également sa participation, avec Seymour Papert, à un livre qui allait montrer les limitations des réseaux de neurones de type Perceptron et participer à ce que certains ont appelé l’hiver de l’intelligence artificielle, quand dans les années 70 les financeurs se sont détournés de ce domaine jugé trop irréaliste.
Ce que Minsky a cherché à montrer tout au long de ses travaux c’est que l’intelligence est un phénomène trop complexe pour être capturé par un seul modèle ou un seul mécanisme. Selon lui, l’intelligence n’est pas comme l’électromagnétisme : au lieu de chercher un principe unificateur, il vaut mieux la décrire comme la somme de composants divers, chacun avec sa justification. Il parlait ainsi d’intelligence artificielle débraillée (‘scruffy’ en anglais). Il insistait cependant sur le fait que chacun de ces composants pouvait être lui-même dépourvu d’intelligence.
Ce positionnement est très bien rendu dans son livre le plus connu, publié en 1985, “The society of mind”, où il décompose l’intelligence en un grand nombre de modules, ou d’agents, hétérogènes et parfois extrêmement simples, ce qui alimentait sa vision de l’esprit réductible à une machine. Il a poursuivi cette description dans un livre plus récent (“The emotion machine”, en 2006), avec d’autres processus plus abstraits, comme les sentiments. Avant ces écrits pour le grand public, il avait déjà proposé des contributions similaires pour le domaine de l’informatique, avec ses travaux sur le raisonnement de sens commun et la représentation de connaissances à l’aide de ‘frames’ qui, dans les années 70, peuvent être vues comme précurseur de la programmation orientée-objet et qui lui ont en tout cas permis d’explorer de nombreux domaines de l’informatique relatifs à la perception visuelle et au langage naturel, ce qui l’a amené à être consulté par Stanley Kubrick pour son film “2001, Odyssée de l’espace”, pour savoir comment les ordinateurs pourraient parler en 2001…
Parmi les multiples domaines d’intérêt de ce touche-à-tout génial (dont la musique et les extra-terrestres), notons que ses premières recherches sur l’intelligence l’ont aussi amené à réaliser des travaux pionniers en robotique, incluant des dispositifs tactiles, mécaniques et optiques. Il a par exemple inventé et construit le premier microscope confocal. Autres réalisations à mettre à son actif : des machines inutiles, dont une inventée lorsqu’il était sous la direction de Claude Shannon aux Bells Labs et qui a inspiré un personnage de la Famille Adams.
Enfin, ce que je veux retenir également de Marvin Minsky, c’est que des générations d’enseignants en intelligence artificielle lui sont redevables d’une des définitions les plus robustes de ce domaine et qui, passé le moment d’amusement, reste au demeurant un des meilleurs moyens de lancer un débat fructueux avec les étudiants : l’intelligence artificielle est la science de faire faire à des machines des choses qui demanderaient de l’intelligence si elles étaient faites par des humains (artificial intelligence is the science of making machines do things that would require intelligence if done by men).
Dans le cadre d’une nouvelle rubrique « Il était une fois… ma thèse », Binaire a demandé à Pauline Bolignano, qui effectue sa thèse à Inria Rennes Bretagne Atlantique et dans la société Prove & Run de nous présenter ses travaux. Par ailleurs, Binaire tient à remercier Pauline et Charlotte qui en discutant ont initié l’idée de cette rubrique. Nous attendons impatiemment la suite des autres histoires de thèses… Binaire.
« – Tu penses que c’est possible que quelqu’un pirate ton portable et écoute tes conversations, ou accède à tes données bancaires ?
– Non ça n’arrive que dans les séries ça ! Et puis moi de toute façon je ne télécharge que des applis de confiance…»
En fait, avec en moyenne 25 applications installées sur un téléphone, nous ne sommes pas à l’abri d’un bug dans l’une d’entre elles.
Il y a même fort à parier que nos applications contiennent toutes plusieurs bugs. Or, certains bugs permettent à une personne mal intentionnée, sachant l’exploiter, d’accéder à des ressources privées. Ce problème est d’autant plus préoccupant que de plus en plus de données sensibles transitent sur nos téléphones et peuvent interférer entre elles. C’est encore pire quand les téléphones servent à la fois pour un usage personnel et professionnel !
Actuellement, l’accès aux ressources (appareil photo, micro, répertoire et agendas,…) dans un smartphone se fait un peu comme dans un bac à sable : toutes les applications peuvent prendre le seau et la pelle des autres, et rien n’empêche une application de détruire le château d’une autre… L’angoisse !
Pour mettre de l ‘ordre dans tout ça, une solution est d’ajouter une couche de logiciel qui contrôle de manière précise l’accès aux ressources, une sorte de super superviseur ; d’ailleurs, on appelle ça un hyperviseur. L’hyperviseur permet par exemple d’avoir deux « bacs à sable » sur son téléphone, de telle manière qu’aucune information sensible ne fuite entre les deux. Cela n’empêche pas les occupants d’un même bac à sable de se taper dessus avec des pelles mais on a la garantie que cela n’a pas d’impact sur le bac d’à coté. L’hyperviseur peut également interdire aux applications l’accès direct aux ressources. Il autorise les occupants du bac à sable de faire un pâté mais c’est lui qui tient le seau. Il peut de cette manière imposer qu’un voyant lumineux s’allume lorsque le micro est en marche. On a ainsi la certitude que lorsque le voyant est éteint, le micro est éteint et que personne ne peut nous écouter.
Vous l’avez peut être remarqué, il nous reste un problème majeur : comment s’assurer que l’hyperviseur n’a pas de bug ? L’hyperviseur ayant accès à toutes les ressources, un bug chez lui peut avoir des conséquences très graves. Il devient donc une cible de choix pour des pirates. Si on se contente de le tester, on passe potentiellement à coté de nombreux bugs. En effet la complexité d’un hyperviseur est telle que les tests ne peuvent pas prévoir tous les cas d’usage. La seule solution qui permette de s’approcher de l’absence de bug est la preuve formelle de programme. L’idée est d’exprimer des propriétés sur le programme, par exemple « les occupants d’un bac à sable n’interfèrent pas avec les occupants d’un autre bac à sable », puis de les prouver mathématiquement. Les propriétés sont exprimées dans un langage informatique et on les prouve grâce un outil qui vérifie que nos preuves sont correctes (et qui parfois même fait les preuves à notre place !).
Actuellement la preuve de programme n’est pas très répandue car elle est très couteuse et longue à mener. Elle est réservée aux systèmes critiques. Par exemple, des propriétés formelles ont été prouvées sur les lignes automatiques (1 et 14) du métro parisien. Je prouve en ce moment des propriétés d’isolation sur la ressource « mémoire » d’un hyperviseur, c’est à dire qu’il n’y a pas de mélange de sable entre deux bacs à sable. Le but de ma thèse est de fournir des méthodes afin d’alléger l’effort de preuve sur ce type de systèmes.
Binaire : Antoinette Rouvroy, qui êtes-vous ?
Antoinette Rouvroy : J’ai fait des études de droit, que j’ai poursuivies par une thèse de doctorat en philosophie du droit à l’Institut universitaire européen de Florence (*). Je m’intéresse depuis lors aux enjeux philosophiques, politiques et juridiques de la « numérisation » du monde et de ses habitants et de l’autonomisation croissante des systèmes informatiques .
Le problème de la protection des données personnelles se pose aujourd’hui de façon aigüe ?
Il est vrai que le phénomène des « données massives » (Big data) met les régimes juridiques de protection des données personnelles « en crise ». Ce qui pose problème, avec la prolifération exponentielle, extrêmement rapide, de données numériques diverses, c’est tout d’abord que les régimes de protection des données semblent peu aptes à faire face aux défis inédits posés par les phénomènes de profilage et de personnalisation propres à la société numérisée.
Aujourd’hui, toute donnée numérique est potentiellement susceptible de contribuer à nous identifier ou à caractériser très précisément nos comportements singuliers si elle est croisée avec d’autres données même peu « personnelles ». Ce qui paraît nous menacer, dès-lors, ce n’est plus prioritairement le traitement inapproprié de données personnelles, mais surtout la prolifération et la disponibilité même de données numériques, fussent-elles impersonnelles, en quantités massives. Les informaticiens le savent : l’anonymat, par exemple est une notion obsolète à l’heure des Big data. Les possibilités illimitées de croisements de données anonymes et de métadonnées (données à propos des données) permettent très facilement de ré-identifier les personnes quand bien même toutes les données auraient été anonymisées.
C’est la quantité plus que la qualité des données traitées qui rend le traitement éventuellement problématique.
Ces quantités massives de données et les Big data entrent en opposition frontale avec les grands principes de la protection des données : la minimisation (on ne collecte que les données nécessaires au but poursuivi), la finalité (on ne collecte les données qu’en vue d’un but identifié, déclaré, légitime), la limitation dans le temps (les données doivent être effacées une fois le but atteint, et ne peuvent être utilisées, sauf exceptions, à d’autres fins que les fins initialement déclarées). Les Big data, c’est au contraire une collecte maximale, automatique, par défaut, et la conservation illimitée de tout ce qui existe sous une forme numérique, sans qu’il y ait, nécessairement, de finalité établie a priori. L’utilité des données ne se manifeste qu’en cours de route, à la faveur des pratiques statistiques de datamining, de machine-learning, etc.
Darpa Big data. Wikimedia Commons
Pourtant, on ne peut pas étendre le champ des données protégées ? Cela reviendrait à soumettre aux régimes juridiques de protection des données quasiment toutes les données numériques, cela signerait la mise à mort de l’économie numérique européenne. Il y a autre chose à faire ?
L’urgence, aujourd’hui, c’est de se confronter à ce qui fait réellement problème plutôt que de continuer à fétichiser la donnée personnelle tout en flattant l’individualisme possessif de nos contemporains à travers des promesses de contrôle individuel accru, voire de propriété et de libre disposition commerciale de chacun sur « ses » données. Si l’on se place du point-de-vue de l’individu, d’ailleurs, le problème n’est pas celui d’une plus grande visibilité sociale ni d’une disparition de la sphère privée. On assiste au contraire à une hypertrophie de la sphère privée au détriment de l’espace public.
Les technologies contemporaines de l’information et de la communication ne nous rendent pas vraiment plus « visibles ». Les « demoiselles du téléphone » de jadis, entremetteuses incontournables et pas toujours discrètes des rendez-vous galants dans des microcosmes sociaux avides de rumeurs, représentaient une menace au moins aussi importante pour la protection des données personnelles et de la vie privée des personnes que les algorithmes aveugles et sourds des moteurs de recherche d’aujourd’hui. Peut-être n’avons-nous jamais été moins « visibles », moins « signifiants » dans l’espace public en tant que sujets, en tant que personnes, qu’aujourd’hui. La prolifération des selfies et autres performances identitaires numériques est symptomatique à cet égard. L’incertitude d’exister induit une pulsion d’édition de soi sans précédent : se faire voir pour croire en sa propre existence.
Le vrai enjeu : la disparition de la « personne »
Ce qui intéresse les bureaucraties privées et publiques qui nous « gouvernent », c’est de détecter automatiquement nos « potentialités », nos propensions, ce que nous pourrions désirer, ce que nous serions capables de commettre, sans que nous en soyons nous-mêmes parfois même conscients. Une propension, un risque, une potentialité, ce n’est pas encore une personne. L’enjeu, ce n’est pas la donnée personnelle, mais bien plutôt la disparition de la « personne » dans les deux sens du terme. Il nous devient impossible de n’être « personne », d’être « absents » (nous ne pouvons pas ne pas laisser de traces) et il nous est impossible de compter en tant que « personne ». Ce que nous pourrions dire de nous mêmes ne devient-il pas redondant, sinon suspect, face à l’efficacité et à l’objectivité machinique des profilages automatiques dont nous faisons l’objet ?
Les traces parlent de/pour nous mais ne disent pas qui nous sommes : elles disent ce dont nous sommes capables. Aux injonctions explicites de performance-production et de jouissance-consommation qui caractérisaient le néolibéralisme s’ajoute la neutralisation de « ce dont nous serions capables », de « ce que nous pourrions vouloir ». Dans le domaine militaire et sécuritaire, c’est l’exécution par drones armés ou les arrestations préventive de potentiels combattants ou terroristes. Dans le domaine commercial, il ne s’agit plus tant de satisfaire la demande, mais de l’anticiper.
N’y-a-t-il pas contradiction entre la disparition de la « personne » et l’hyperpersonnalisation ?
Oui, il peut paraître paradoxal que, dans le même temps, l’on fasse l’expérience à la fois de la personnalisation des environnements numériques, des interactions administratives, commerciales, sécuritaires,… grâce à un profilage de plus en plus intensif et de la disparition de la personne ! L’hyperpersonnalisation des environnements numériques, des offres commerciales, voire des interactions administratives, porte moins la menace d’une disparition de la vie privée que celle d’une hypertrophie de la sphère privée au détriment de l’espace public. D’une part, il devient de plus en plus rare, pour l’individu, d’être exposé à des choses qui n’ont pas été prévues pour lui, de faire, donc, l’expérience d’un espace public, commun ; d’autre part, les critères de profilage des individus échappent à la critique et à la délibération collective,… alors même qu’ils ne sont, pas plus que la réalité sociale dont ils se prétendent le reflet passif, justes et équitables. Par ailleurs, les individus sont profilés non plus en fonction de catégories socialement éprouvées (origine ethnique, genre, expérience professionnelle, etc.) dans lesquelles ils pouvaient se reconnaître, à travers lesquels ils pouvaient faire valoir des intérêts collectifs, mais en fonction de « profils » produits automatiquement en fonction de leurs trajectoires et interactions numériques qui ne correspondent plus à aucune catégorie socialement éprouvée. Ce qui me semble donc surtout menacé, aujourd’hui, ce n’est pas la sphère privée (elle est, au contraire, hypertrophiée), mais l’espace public, l’ « en commun ».
Nous intéressons les plateformes, comme Google, Amazon, ou Facebook, en tant qu’émetteurs et agrégats temporaires de données numériques, c’est-à-dire de signaux calculables. Ces signaux n’ont individuellement peu de sens, ne résultent pas la plupart du temps d’intentions particulières d’individu, mais s’apparentent plutôt aux « traces » que laissent les animaux, traces qu’ils ne peuvent ni s’empêcher d’émettre, ni effacer, des phéromones numériques, en quelque sorte. Ces phéromones numériques nourrissent des algorithmes qui repèrent, au sein de ces masses gigantesques de données des corrélations statistiquement significatives, qui servent à produire des modèles de comportements. Les causes, les raisons, les motivations, les justifications des individus, les conditions socio-économiques ou environnementales ayant présidé à tel ou tel état du « réel » transcrit numériquement n’importent plus du tout dans cette nouvelle forme de rationalité algorithmique. Non seulement on peut s’en passer, mais en plus la recherche des causes, des motivations psychologiques, l’explicitation des trajectoires biographiques devient moralement condamnable : « Expliquer, c’est déjà un peu vouloir excuser », disait Manuel Vals le 10 janvier à l’occasion d’une cérémonie organisée sur la Place de la République à Paris en mémoire des victimes d’une attaque terroriste. On est dans une logique purement statistique, purement inductive. Il ne reste aux « sujets » plus rien à dire : tout est toujours déjà « pré-dit ». Les données parlent d’elles-mêmes ; elles ne sont plus même censées rien « représenter » car tout est toujours déjà présent, même l’avenir, à l’état latent, dans les données. Dans cette sorte d’idéologie technique, les Big data, avec une prétention à l’exhaustivité, seraient capables d’épuiser la totalité du réel, et donc aussi la totalité du possible.
Le processus de formalisation et d’expression du désir est court-circuité.
Ce qui intéresse les plateformes de commerce en ligne, par exemple, c’est de court-circuiter les processus à travers lesquels nous construisons et révisons nos choix de consommation, pour se brancher directement sur nos pulsions pré-conscientes, et produire ainsi du passage à l’acte d’achat si possible en minimisant la réflexion préalable de notre part. L’abandon des catégories générales au profit du profilage individuel conduit à l’hyper-individualisation, à une disparition du sujet, dans la mesure où, quelles que soient ses capacités d’entendement, de volonté, de réflexivité, d’énonciation, celles-ci ne sont plus ni présupposées, ni requises. L’automatisation fait passer directement des pulsions de l’individu à l’action ; ses désirs le précèdent. Ce que cela met à mal – et on pourrait se rapporter pour cela à Deleuze et Spinoza – c’est la puissance des sujets, c’est-à-dire, leur capacité à ne pas faire tout ce dont ils sont capables. Du fait de la détection automatique de l’intention, le processus de formalisation et d’expression du désir est court-circuité.
Je ne condamne pas ici dans l’absolu l’ « intelligence des données », ni la totalité des usages et applications qui peuvent être faits des nouveaux traitements de données de type Big data. Il y a des applications formidables, dans de nombreux domaines scientifiques notamment. La « curiosité automatique » des algorithmes capables de naviguer dans les données sans être soumis au joug de la représentation et sans être limités par l’idée du point-de-vue toujours situé de l’observateur humain, tout cela ouvre des perspectives inédites et promet des découvertes inattendues. Ce dont je m’inquiète ici, c’est des usages contemporains de cette rationalité algorithmique pour la modélisation et le gouvernement des comportements humains.
Mais, est-ce que c’est nouveau ? L’individu fait ses choix et décide en fonction de ce qu’il sait. Quand un algorithme fait une recommandation, n’est-ce pas une chance, pour l’individu d’être mieux informé, et donc de faire des choix plus éclairés, moins arbitraires ?
Bien sûr, nous n’avons jamais été les êtres parfaitement rationnels et autonomes, unités fondamentales du libéralisme fantasmés notamment par les économistes néoclassiques. La seule liberté que nous ayons, écrivait Robert Musil, c’est celle de faire volontairement ce que nous voulons involontairement. Mais, si nous ne maîtrisons pas ce qui détermine effectivement nos choix, il doit nous être néanmoins possible, après coup, de nous y reconnaître, de nous y retrouver, d’adhérer au fait d’avoir été motivés dans nos choix, dans nos décisions, par tel ou tel élément que nous puissions, après-coup, identifier, auquel nous puissions, après coup toujours, souscrire. La liberté consiste donc, pour moi, en la capacité que nous avons de rendre compte de nos choix alors même que nous ne maîtrisons pas les circonstances qui ont présidé à la formation de nos préférences.
Par contre, il n’est pas vrai, à mon sens, que l’individu fasse toujours des choix et prenne des décisions seulement ni prioritairement en fonction de ce qu’il connaît. La détection des profils psychologiques de consommateurs et la personnalisation des offres en fonction de ces profils permet d’augmenter les ventes, mais pas nécessairement d’émanciper les individus, qui pourraient très bien, alors qu’ils sont de fait extrêmement sensibles à l’argument de la popularité, préférer parfois cultiver l’objet rare ou, alors qu’ils sont victimes de leurs pulsions tabagiques ou alcooliques, préférer n’être pas incités à consommer ces substances addictives. Le profilage algorithmique, dans le domaine du marketing, permet l’exploitation des pulsions conformistes ou addictives dont les individus peuvent préférer n’être pas affectés. C’est bien d’un court-circuitage des processus réflexifs qu’il s’agit en ce cas.
Les algorithmes de recommandation automatique pourraient aussi intervenir dans la prise de décision administrative ou judiciaire à l’égard de personnes. Imaginez par exemple un système d’aide à la décision fondé sur la modélisation algorithmique du comportement des personnes récidivistes. Alors qu’il ne s’agit en principe que de « recommandations » automatisées laissant aux fonctionnaires toute latitude pour suivre la recommandation ou s’en écarter, il y a fort à parier que très peu s’écarteront de la recommandation négative (suggérant le maintien en détention plutôt qu’une libération conditionnelle ou anticipée) quelle que soit la connaissance personnelle qu’ils ont de la personne concernée et quelle que soit leur intime conviction quant aux risques de récidive, car cela impliquerait de prendre personnellement la responsabilité d’un éventuel échec. De fait, la recommandation se substitue en ce cas à la décision humaine, et les notions de choix, mais aussi de décision, et de responsabilité, sont éclipsées par l’opérationnalité des machines.
Dans le cas de la libération conditionnelle, entre un algorithme qui se trompe dans 5% des cas et un décideur qui se trompe dans 8% des cas, il faut se méfier de l’algorithme et ne croire qu’en la dimension humaine ?
En premier lieu, il est difficile de dire quand exactement un algorithme « se trompe ». Si l’on peut effectivement évaluer le nombre de « faux négatifs » (le nombre de récidivistes non détectés et donc libérés), il est en revanche impossible d’évaluer le nombre de « faux positifs » (les personnes maintenues en détention en raison d’un « profil » de récidivistes potentiels, mais qui n’auraient jamais récidivé si elles avaient été libérées). Faut-il tolérer un grand nombre de faux positifs si cela permet d’éviter quelques cas de récidive ? C’est une question éthique et politique qui mérite d’être débattue collectivement. La problématique est assez similaire à celle d’une éventuelle arrestation préventive de personnes désignées, sur la seule base d’un profilage algorithmique, comme terroristes potentiels. En principe, la présomption d’innocence fait encore partie du fond commun de la culture juridique dans nos pays. Il ne faudrait pas que cela change sans qu’il en soit débattu politiquement. La modélisation algorithmique du comportement récidiviste peut être utile et légitime, mais seulement à titre purement indicatif. La difficulté est de maintenir ce caractère « purement indicatif », de ne pas lui accorder d’avantage d’autorité. La décision de libération peut être justifiée au niveau de la situation singulière d’un individu dont pourtant le comportement correspond au modèle d’un comportement de futur récidiviste. Beaucoup des éléments qui font la complexité d’une personne échappent à la numérisation. De plus, une décision à l’égard d’une personne a toujours besoin d’être justifiée par celui qui la prend en tenant compte de la situation singulière de l’individu concerné. Or les recommandations automatiques fonctionnent bien souvent sur des logiques relativement opaques, difficilement traduisibles sous une forme narrative et intelligible. Les algorithmes peuvent aider les juges, mais ne peuvent les dispenser de prendre en compte l’incalculable, le non numérisable, ni de justifier leurs décisions au regard de cette part d’indécidable.
Les algorithmes sont toxiques si nous nous en servons pour optimiser l’intolérable en abdiquant de nos responsabilités – celle de nous tenir dans une position juste par rapport à notre propre ignorance et celle de faire usage des capacités collectives que nous avons de faire changer le monde. Les algorithmes sont utiles, par contre, lorsqu’ils nous permettent de devenir plus intelligents, plus sensibles au monde et à ses habitants, plus responsables, plus inventifs. Le choix de les utiliser d’une manière paresseuse et toxique ou courageuse et émancipatrice nous appartient.
(*) Antoinette Rouvroy, Human Genes and Neoliberal Governance. A foucauldian Critique, Routledge-Cavendish, 2007.
Pour aller plus loin :
Mireille Hildebrandt & Antoinette Rouvroy (eds.), Law, Human Agency and Autonomic Computing. The Philosophy of Law Meets the Philosophy of Technology, Routledge, 2011.
La préparation de cette émission avec le Labo des Savoirs a commencé avant les attentats de novembre. Il s’agissait pour nous d’ouvrir la boite noire des dispositifs de renseignement. Nous allons donc parler de surveillance numérique avec, comme binaire aime le faire, un regard technique.
La didactique de l’informatique ? Des chercheurs étudient cette question et font régulièrement le point sur comment il faut enseigner l’informatique. En janvier, c’est à Namur qu’aura lieu la conférence Didapro6-Didastic. J’ai rencontré Étienne Vandeput, responsable de cet événement, pour lui poser quelques questions pour Binaire.
Étienne Vandeput
Étienne Vandeput est un mathématicien de formation qui a d’abord enseigné au lycée en Communauté française de Belgique (notamment l’informatique dès la fin des années 70), puis la didactique de l’informatique en Belgique et en Suisse. Colin de la Higuera
Le thème du congrès Didapro6-Didastic, c’est la didactique de l’informatique et des STIC. Mais en quoi est-ce une question ? Qui est concerné ?
Étienne Vandeput : L’informatique est une discipline enseignée à l’Université, dans les écoles supérieures et, même si c’est plus confidentiel, à l’école obligatoire. Or l’acte d’enseigner ne peut cacher l’intention de transmettre la connaissance, le savoir-faire, avec le souci d’y parvenir dans un laps de temps restreint et avec une certaine efficience. Il vise aussi à toucher le plus grand nombre. Enseigner nécessite donc que l’on réfléchisse tant aux aspects épistémologiques (la question du quoi enseigner) qu’aux aspects didactiques (la question du comment le faire avec un minimum d’efficacité). Attention, ce n’est pas uniquement de méthodologie dont il est question, mais de démarches conduisant à une compréhension fine des concepts souvent complexes de l’informatique et donc, de tout ce qu’il est possible de mettre en place pour la faciliter. Tous ceux qui enseignent l’informatique, à quelque niveau que ce soit, sont donc concernés par cette réflexion. D’autre part, si le citoyen lambda n’est pas nécessairement directement concerné par l’apprentissage de l’informatique, il évolue dans un monde numérique. L’information et de la communication sont donc aussi l’objet d’une investigation scientifique de même type. L’usage des réseaux sociaux, par exemple, est régi par quelques principes simples. Il est question de profil, de compte, de permissions, autant de concepts dont une connaissance élémentaire permet de réguler, voire de catalyser nos comportements parfois impulsifs et spontanés. Mieux, ces concepts se retrouvent dans de multiples autres applications. Cette transversalité est donc intéressante à exploiter.
Quelles sont les spécificités de l’informatique, quand on considère la question du point de vue de la didactique ? Autrement dit, est-ce différent d’enseigner l’informatique plutôt qu’une autre matière ?
EV : Toutes les didactiques ont leur spécificité. Peut-être certaines sont-elles plus proches que d’autres ? La didactique des langues et celle des mathématiques se distinguent en ce sens qu’elles font appel à des paradigmes d’enseignement très différents. Si d’un côté, on peut privilégier les processus conversationnels en acceptant erreurs grammaticales, de prononciation, voire de vocabulaire, de l’autre, c’est la rigueur et la compréhension sans équivoque qui serviront souvent de toiles de fond à la réflexion didactique. En ce qui concerne l’informatique, ce qui est d’abord fondamental, c’est de mettre le doigt sur les fondements théoriques les plus à même de rendre des services aux apprenants, autrement dit, de les rendre autonomes. C’est vrai dans une démarche de conception de programme comme à l’occasion de l’usage d’un des très nombreux et très variés produits de l’informatique. Les quelques décennies d’enseignement de la programmation ont permis de réaliser un travail intéressant. C’est ainsi que la programmation structurée, dans les années 70, a avantageusement pris le relais d’une programmation jusque-là très intuitive et dès lors réservée à une catégorie d’individus particulièrement doués. Ce qui faisait dire à un enseignant côtoyé lors d’un séminaire et peu enclin à la réflexion didactique : « il y a ceux qui savent quoi faire et à qui nous ne sommes pas utiles et puis les autres qui ne comprendront jamais rien. ». Les réflexions menées ont permis de structurer la démarche de programmation et d’organiser son enseignement ce qui a permis de la rendre accessible à un plus grand nombre. Donc oui, la didactique de l’informatique est très spécifique et justifie son développement si on veut la rendre accessible et, oserai-je dire sympathique à un plus grand nombre.
L’informatique que nous utilisons tous les jours a beaucoup changé en 10 ans et changera encore dans les prochaines années. Est-ce que la vitesse de ce changement est un enjeu ? Change-t-on les concepts, les méthodes ou finalement rien du tout ?
EV : Cette question est très importante car elle conditionne l’attitude que l’on peut avoir vis-à-vis de l’apprentissage de l’informatique et des questions numériques. En considérant que tout change très vite et en permanence, on apporte de l’eau au moulin de ceux qui prétendent que l’informatique ne s’enseigne pas, mais se pratique et qu’elle n’a pas d’essence propre. On maintient l’apprenant dans une sorte de stress permanent qui nie toute stabilité possible et l’oblige à entrer dans un processus de veille permanente. En même temps, on entretient le flou en ce qui concerne les fondements d’une discipline, voire on nie qu’elle en est une. L’autre attitude consiste à rechercher ces fondements, à regarder l’informatique dans ce qu’elle a de permanent, d’incontournable, d’essentiel. L’avantage de cette démarche est justement la recherche de la stabilité et conduit à percevoir les révolutions comme des évolutions.
Didapro6-Didastic se veut un point de rencontre entre didacticiens et enseignants. En quoi les uns et les autres peuvent bénéficier de ce type de contacts ?
EV : C’est un lieu commun de dire que notre enseignement s’est complexifié, que l’enseignant d’aujourd’hui doit être un chercheur, un professionnel soucieux d’adapter son enseignement à toutes les circonstances dont le monde d’aujourd’hui ne nous prive pas. Un enseignant doit être à la fois et à son niveau, un pédagogue et un didacticien. Il ne peut cependant se consacrer totalement à des recherches dans ces domaines. Rencontrer des didacticiens est donc une opportunité de faire avancer sa propre réflexion en la confrontant à celles de personnes qui s’y consacrent totalement. Par ailleurs, le didacticien doit pouvoir valider le fruit de sa réflexion et qui d’autre, sinon l’enseignant de terrain, peut l’aider à le faire avec autant de pertinence ? La richesse d’un tel colloque se mesure à la présence des uns et des autres afin d’éviter tant la dérive théorique que celle du simple partage d’expériences.
Un autre aspect spécifique est celui de la production de ressources éducatives libres (REL). Est-ce que les enseignants en informatique sont « en avance » sur cette question ?
EV : Il est difficile d’établir des statistiques sur ce point. Ce que l’on peut dire, sans risque de se tromper, c’est que les informaticiens possèdent, sans doute plus que d’autres, cette culture du partage, de la transparence et de la collaboration. C’est ce qui a fait et fait encore le succès du logiciel libre et de l’accès à des données ouvertes, par exemple. Le développement des ressources éducatives libres en informatique a certainement pu profiter de ces habitudes culturelles. À l’occasion de chaque innovation technologique, on peut dire que les informaticiens sont généralement ceux qui montrent la voie.
Les Actes du Colloque seront en ligne dans quelques jours sur le site du colloque.
Les liens vers des publications plus anciennes se trouvent sur la page « Historique » du site de la conférence.
didapro5 s’est tenue à Clermont-Ferrand. Un résumé des actes est disponible ici.
Pour ce qui concerne l’enseignement de l’informatique, on peut recommander le site de l’EPI et pour toutes les questions traitant des technologies de l’information et de la communication en éducation, le portique Adjectif.
Le langage Algol 60 a été un des premiers langages de programmation, et a eu une importance considérable. Peter Naur a été un de ces concepteurs. À l’occasion de son décès, Binaire a demandé à deux amis de revenir sur la contribution de Peter Naur à l’informatique. Une note biographique a été préparée par Pierre Mounier Kuhn historien des sciences. Sacha Krakowiak qui vient d’être nommé membre d’honneur de la Société Informatique de France nous parle de l’influence de Peter Naur et d’Algol sur la pensée informatique à travers des souvenirs et anecdotes. Pierre Paradinas
Le Danois Peter Naur laisse son nom à la Backus-Naur Form, l’une de ses principales contributions à l’élaboration du langage Algol 60 et à l’étude des langages de programmation. Il reçut le prix Turing en 2005 : « for fundamental contributions to programming language design and the definition of Algol 60, to compiler design, and to the art and practice of computer programming ».
Peu convaincu de l’existence d’une computer science, il a enseigné une discipline qu’il nommait datalogie.
Né en 1928, Peter Naur étudia l’astronomie à l’université de Copenhague et devint assistant à l’observatoire. Un séjour à Cambridge en 1950-1951 lui permit de mener des recherches dans deux domaines qui émergeaient dans les années 1950 : la radioastronomie et la programmation d’ordinateurs (rappelons que l’équipe de Maurice Wilkes à Cambridge a publié le premier traité de programmation en 1951). Naur fait partie de cette première génération d’informaticiens qui provenaient de disciplines préexistantes, et où certains astronomes jouèrent un rôle moteur. L’astronomie le conduisit aux États-Unis, où il rencontra notamment Howard Aiken à Harvard et John von Neumann à Princeton – respectivement le dernier représentant de la filière des calculateurs programmables inspirée par Babbage et l’inventeur du concept d’ordinateur à programme enregistré.
Rentré au Danemark, Peter Naur rejoignit à Copenhague le centre de calcul Regnecentralen, participant à la conception et à la programmation du premier ordinateur danois, Dask. Il s’intégra alors au comité international de chercheurs qui développaient un nouveau langage de programmation, bientôt baptisé Algol 60. Se passionnant pour ce projet, il devint le principal auteur du rapport décrivant ce langage – rapport présenté en 1959 au premier congrès mondial de traitement de l’information, tenu à Paris sous les auspices de l’Unesco. C’est lui qui prit la décision, vivement discutée alors, d’y inclure les procédures récursives. Collaborant avec John Backus, l’inventeur de Fortran chez IBM, il y introduisit également un procédé de notation formelle, connu depuis sous le nom de Backus-Naur Form (BNF). La BNF permettait de définir rigoureusement la syntaxe des langage de programmation et, au-delà, de les étudier et de les enseigner d’une manière formalisée.
Dans la décennie suivante, tout en dirigeant l’Algol Bulletin et le journal scandinave BIT, Peter Naur contribua à établir l’informatique comme discipline académique au Danemark. En 1966, il inventa un mot pour la nommer : datalogie. Cette « science des données » est d’abord une réaction contre le terme computer science ; elle est plus proche de l’informatique, définie en France par un autre astronome, Jacques Arsac, comme la science des structures d’information. Naur, tout en enseignant les fondements de l’informatique, incitait vivement ses étudiants à travailler sur ses applications dans d’autres domaines. En 1969 il fut nommé professeur à l’Institut de Datalogie à l’université de Copenhague, où il passa toute la suite de sa carrière jusqu’à sa retraite en 1999, à 70 ans.
Son insistance à distinguer sa datalogie de la computer science l’amena en 1970 à s’opposer vigoureusement à la doctrine de Programmation Structurée promue par Edsger Dijkstra et Niklaus Wirth. Tandis que ceux-ci prêchaient comment l’on devrait idéalement programmer, Naur mena des enquêtes empiriques pour observer comment l’on pratiquait la programmation[1].
Après sa retraite, ses préoccupations se déplacèrent vers des problèmes de philosophie et de psychologie. Il exposa ses réflexions dans un article, « A Synapse-State Theory of Mental Life » (2004). Puis dans une conférence à l’ACM Turing Lecture, « Computing vs. Human Thinking »[2], concluant que « le système nerveux n’a aucune similitude avec un ordinateur ». Et que le test de Turing est à rejeter.
Naur était profondément convaincu que le travail descriptif est au cœur de la science, beaucoup plus que la recherche des « causes ».
[1] P. Naur, Concise Survey of Computer Methods, 1974.
[2] http://amturing.acm.org/vp/naur_1024454.cfm ou https://www.youtube.com/watch?v=mYivRwrATTA
Sacha Krakowiak nous parle de Peter NaurBinaire : Sacha, peux-tu nous dire comment tu as rencontré Peter Naur ? Sacha : En juillet 1962, je prenais mes fonctions au Bassin d’Essai des Carènes de la Marine Nationale, où j’étais chargé d’études sur des problèmes d’hydrodynamique. Quelques mois plus tard, arrivait un ordinateur Gier (construit par la société danoise Regnecentralen). Pourquoi cette machine ? Simplement parce que le directeur du Bassin, à l’époque l’ingénieur général Roger Brard, était ami de son homologue danois, qui avait lui même acquis cette machine; ils comptaient ainsi échanger des programmes d’application (ce qui fut fait). Je n’avais aucune notion d’informatique, mais je suis allé voir la machine par curiosité, et j’ai demandé comment s’en servir. On m’a alors donné un petit fascicule gris, d’allure rébarbative, intitulé « Revised Report on the Algorithmic Language Algol 60 », réalisé par Peter Naur. Je l’ai emporté chez moi et je me suis plongé dedans. Cela a été un des plus grands chocs intellectuels de ma carrière. La description du langage en BNF, et la récursivité des définitions ont été pour moi un éblouissement. Peu de temps après, j’écrivais mon premier programme. Quelques mois plus tard, j’étais responsable du service informatique du Bassin des Carènes…
Binaire : Mais qu’est-ce qu’il y avait de si génial dans ce livre ? SK : Le point de départ est donc le langage de programmation, Algol 60, pour ALGOrithmic Language 1960. Peter Naur et Jørn Jensen avaient réalisé le premier compilateur du langage complet – donc un programme qui traduisait des programmes écrits en Algol 60 en code exécutable par une machine. Le Gier était équipé de ce compilateur d’Algol 60. Cette réalisation était en soi un exploit, non seulement conceptuel, mais aussi technique, car la mémoire centrale de la machine était minuscule (1000 mots de 40 bits). Il fallait 6 passes au compilateur pour transformer le programme en code exécutable. Un autre trait remarquable du Gier était son lecteur de ruban perforé, qui lisait 2000 caractères par seconde : le ruban s’échappait du lecteur à grande vitesse et était recueilli dans une corbeille placée 2 mètres plus loin ! La première passe du compilateur traitait le programme lu à la volée à cette même vitesse.
Couverture du petit livre gris.Crédit Photo S. Krakowiak
En fait, Peter Naur était venu au Bassin préparer l’arrivée de la machine, mais c’était avant ma propre arrivée, et je ne l’ai pas rencontré alors. Apparemment, il n’avait pas été impressionné par les pratiques courantes : on m’a rapporté qu’il avait parlé de «programmation de l’âge de pierre»… Il est vrai que la programmation se faisait alors principalement en assembleur.
J’ai soigneusement gardé le petit livre gris et j’avoue qu’il m’arrive encore de m’y plonger de temps en temps. La citation de Wittgenstein qui figure en épigraphe m’avait à l’époque intrigué. En rassemblant mes bribes d’allemand scolaire, j’étais arrivé à la traduire : « Ce qui peut se dire, peut se dire clairement ; et sur ce dont on ne peut parler, il faut garder le silence ». Cette phrase s’applique parfaitement au Rapport Algol 60.
Une page du manuel Algol 60 à propos du « si alors sinon, et du goto ». Crédit Photo S. Krakowiak
Marie-Paule Cani rêve de logiciels qui permettraient à chacun de créer en 3D. En savoir plus ? Voici un podcast sympatique comme Marie Paule sur France Inter, avec Fabienne Chauvière pour Les Savanturiers.
LeRaspberryPi (prononcé comme « Raze » « Berry » « Paille » en anglais) est un petit ordinateur de la taille d’une carte bancaire. Il a été conçu par une fondation éducative à but non-lucratif pour faire découvrir le monde de l’informatique sous un autre angle. C’est Alan, franco-irlandais qui nous raconte cette belle histoire. Charlotte Truchet et Pierre Paradinas.
Le récemment lancé « PiZero » : 60 x 35mm : commercialisé en France pour €8,90 Crédit Photo : Alex Eames – RasPi.TV
Une fracture entre informatique et société
Au milieu des années 2000, Eben Upton de la Faculté des Sciences Informatiques de l’Université de Cambridge (« Computer Science Lab ») en Angleterre s’est rendu compte d’un gros problème. Avec ses collègues, ils ont observé un déclin très marqué dans le nombre de candidats se présentant pour poursuivre des études en informatique. Entre l’année 1996 (année de sa propre entrée « undergraduate » à Cambridge) et 2006 (vers la fin de son doctorat), les dossiers de demande pour accéder à la Faculté se sont réduits de moitié. Le système de sélection britannique des futurs étudiants est basé sur des critères de compétition, compétence, expérience et des entretiens individuels. Eben, qui avait tenu le rôle de « Directeur des Études » également, était bien placé pour remarquer une deuxième difficulté. Au-delà du « quantitatif », les candidats qu’il rencontrait, malgré leur grand potentiel et capacités évidentes, avaient de moins en moins d’expérience en matière de programmation. Quelques années plus tôt, le rôle des professeurs était de convaincre les nouveaux arrivants en premier cycle universitaire qu’ils ne savaient pas tout sur le sujet. A l’époque de la première « bulle internet », beaucoup parmi eux avait commencé leur carrière d’informaticien dès leur plus jeune âge. Ils étaientfamilier avec plusieurs langages allant des « Code machine » et « Assembleur » (les niveaux les plus proches de la machine) jusqu’aux langages de plus haut niveaux. Au fil des années, cette expertise était en berne, à tel point qu’autour de 2005, le candidat typique maîtrisait à peine quelques éléments des technologies de l’internet, HTML et PHP par exemple.
En parallèle, les membres du monde académique anglais étaient bien conscients de la nécessité croissante pour l’industrie, et la société plus globalement, d’avoir une population formée à la compréhension du numérique. Le numérique était désormais omniprésent dans la vie quotidienne. Et ce sans parler des besoins spécifiques en ingénierie et sciences. De façon anecdotique, les cours de TICE à ce moment-là étaient souvent devenus des leçons de dactylographie et d’utilisation d’outils bureautiques. Bien que ce soit important, le numérique ne pouvait pas se résumer à ça. Face à ce dilemme, Dr Upton et ses autres co-fondateurs de la Raspberry Pi Foundation se posaient deux questions : pourquoi en est-on arrivé là et comment trouver une solution pour répondre à leur besoin immédiat, local (et peut-être au-delà) ?
Comprendre la cause avant de chercher le remède
L’explication qu’ils ont trouvée était la suivante. Dans les années 80, sur les machines de l’époque, on devait utiliser des commandes tapées dans une interface spartiate pour faire fonctionner, et même jouer sur les ordinateurs. Par exemple pour moi, c’était un « BBC Micro » d’Acorn en école primaire en Irlande comme pour Eben chez lui au Pays de Galles. C’était pareil en France, avec des noms comme Thomson, Amstrad, Sinclair, ou Commodore,… qui rappellent des souvenirs de ces années-là. Depuis cette date, nous étions passés à des ordinateurs personnels et consoles de jeu fermés et propriétaires qui donnaient moins facilement l’accès au « moteur » de l’environnement binaire caché sous le « capot » de sur-couches graphiques. Bien que ces interfaces soient pratiques, esthétiques et simples à l’utilisation, elles ont crée une barrière à la compréhension de ce qui se passe « dans la boîte noire ». Pour tous, sauf une minorité d’initiés, nous sommes passés d’une situation d’interaction avec une maîtrise réelle et créative, à un fonctionnement plutôt de consommation.
Quand une solution permet de changer le monde
Leur réponse à ce problème a été de concevoir une nouvelle plate-forme informatique accessible à tous autant par sa forme, que par son prix, et ses fonctionnalités. L’idée du Raspberry Pi est née et le produit fini a été lancé le 29 février 2012.
Le Raspberry Pi est un nano-ordinateur de la taille d’une carte bancaire (Modèle 2 : 85mm x 56.2mm). Le prix de base, dès le début, a été fixé à $25 USD (bien que d’autre modèles existent à ce jour de $5 à $35). Le système d’exploitation conseillé est l’environnement libre et gratuit GNU/Linux (et principalement une « distribution » (version) dite Raspbian). Le processeur est d’un type « ARM » comme trouvé dans la plupart des smartphones de nos jours. Tout le stockage de données se fait par défaut par le biais d’une carte Micro SD. L’ordinateur est alimenté par un chargeur micro-USB comme celui d’un téléphone portable. Le processeur est capable de traiter les images et vidéos en Haute Définition. Il suffit de le brancher sur un écran HDMI ou téléviseur, clavier, souris par port USB et éventuellement le réseau et nous avons un ordinateur complet et fonctionnel. Avec son processeur Quad Cœur 900 Mhz et 1 Go de mémoire vive, le Modèle 2 est commercialiséenFrance aux alentours d’une quarantaine d’Euros. A la différence de la plupart des ordinateurs en vente, la carte comporte 40 broches « GPIO » (Broches/picots d’Entrée-Sortie générale). C’est une invitation à l’électronique et l’interaction avec le monde extérieur. En quelques lignes de code, l’informatique dite « physique » devient un jeu d’enfant. Brancher résistance et une DEL et un bouton poussoir en suivant un tutoriel et les enfants découvrent immédiatement des concepts de l’automatisation et de robotique. C’est assez impressionnant que ce même petit circuit imprimé, que l’on peut facilement mettre entre les mains d’un enfant de 5 ans, est de plus en plus utilisé dans des solutions industrielles embarquées et intégrées.
Le nom « Raspberry Pi » vient du mot anglais pour la framboise (les marques de technologie prennent souvent les noms d’un fruit) et de « Python », un langage de programmation abordable, puissant et libre. Au début les inventeurs pensaient peut-être dans leur plus grands rêves vendre 10,000 unités. A ce jour, c’est bien plus de 6 millions de Raspberry Pi qui ont été vendus danslemondeentier. En se consacrant initialement 100% de leurs efforts en développement matériel aux cartes elles-mêmes, la Fondation a fait naître à leur insu tout un écosystème autour de la création d’accessoires et périphériques. Les « produits dérivés » vont de toute sorte de boîtier jusqu’à divers cartes d’extension pour tout usage imaginable.
Le Piano HAT : une carte d’extension pour apprendre à s’amuser en musique, avec un boitier Pibow coupé Crédit Photo : Pimoroni.com
De plus, ils ont su créer d’autres emplois « chez eux » grâce à l’ordinateur – aujourd’hui les cartes sont fabriqués « Made in Wales » (dans une usine de Sony au Pays de Galles). Il existe aussi un communauté global de passionnés de tout âge et tout horizon qui promeuvent la pédagogie numérique, réalisent des projets, organisent des événements et assurent de l’entre–aide autour de la « Framboise π« . La France n’est pas une exception avec pas mal d’activité dans l’Hexagone. La barrière initiale de la langue anglaise joue sans doute un rôle dans son manque de notoriété et utilisation par un plus grand publique chez nous – pour l’instant ce bijou technologique reste en grande partie le domaine des technophiles/ »geeks » et des lycées techniques.
Éducation
Le succès commercial fulgurant du Raspberry Pi fait oublier parfois que le but principal de la Fondation reste axé sur l’éducation. L’argent gagné à travers les ventes est réinvesti dans des actions et des fonds permettant de faire avancer leurs objectifs. Ce dernier temps, la Fondation a pu engager des équipes de personnes intervenant sur divers projets et initiatives un peu partout dans le monde. Ça concerne l’informatique, mais pas seulement. Dans le monde anglo-saxon, on parle souvent de « STEM », voire « STEAM » – acronyme pour la promotion des Sciences, Technologie, Ingénierie (Engineering), les Arts et Mathématiques. En France, le Raspberry Pi pourrait bien STIM-uler plus d’intérêt dans ces disciplines aussi !
Utilisation
Les applications potentielles de cet outil sont sans fin. Un petit tour d’internet laisse pas de doute sur les possibilités. Sortie de sa boîte, ça permet une utilisation en bureautique avec Libre Office, accès internet avec un navigateur web, l’apprentissage de la programmation avec Scratch, Python et Minecraft Pi ou Ruby et Sonic Pi. Plus loin il existe tout l’univers d’utilitaires libres et gratuits sous GNU/Linux.
Pour donner quelques exemples rapides intéressants :
Et enfin, on peut même envoyer ses expériences scientifiques dans l’Espace ! Dans l’esprit de la récente semaine d’une « HeuredeCode« , dans le projet AstroPi, deux Raspberry Pi viennent d’être envoyéssurlaStationSpatialeInternationale embarquant des capteurs et du code crée lors d’un concours par des enfants de primaire et secondaire en Grande Bretagne. Ça fait rêver !
Astro Pi : un concours pour des jeunes en Grande Bretagne pour envoyer leur Code sur l’ISS (Station Spatiale Internationale) Crédit Photo : Fondation Raspberry Pi {Artiste : Sam Adler}
Comme dit François Mocq, auteur et blogueur de « Framboise314.fr« , il y a bien une limitation à ce que nous pouvons faire avec un Raspberry Pi. C’est notre imagination !
Cet article a été écrit via un Raspberry Pi.
Pour plus d’information, rendez-vous sur « http://raspberrypi.org » (site officiel de la Fondation – anglophone) et/ou « http://framboise314.fr » (notre référence francophone).
Véronique Cortier est une spécialiste de la vérification qui a déjà écrit plusieurs articles passionnants pour Binaire, notamment sur le vote électronique. Elle intervient cette fois au Café techno d’Inria Alumni.
Café techno : Inria Alumni, en partenariat avec NUMA et le blog binaire, vous invite à débattre avec Véronique Cortier, Cnrs, Loria, le Lundi 18 janvier 2016, de 18:30 à 20:30.
NUMA Sentier, 39 rue du Caire, 75002 Paris
Peut-on avoir confiance dans le vote électronique ?
L’irruption des scrutins par voie numérique (on parle de « vote électronique ») soulève de nombreux enjeux en termes de garanties de bon fonctionnement et de sécurité informatique : comment m’assurer que mon vote sera bien pris en compte ? Est-ce qu’un tiers peut savoir comment j’ai voté ? Puis-je faire confiance au résultat annoncé ? Ces questions sont parfaitement légitimes et les systèmes de vote électronique n’y apportent pas encore de réponse claire. Mais les mêmes questions se posent pour les scrutins plus classiques qui ont recours au « papier ».
Cet article est publié en collaboration avec TheConversation.
Dans le cadre des « Entretiens autour de l’Informatique« , Binaire a rencontré l’artiste et chercheur Jon McCormack, grande figure du creative coding, un courant peu représenté en France qui fait de l’informatique un moyen d’expression. Non content d’avoir ses œuvres exposées dans salles les plus prestigieuses, comme le Musée d’Art Moderne de New York, Jon McCormack est professeur d’informatique à Monash University à Melbourne, et Directeur du Sensilab. Jon McCormack parle de créativité et d’ordinateurs à Charlotte Truchet, de Binaire.
Dans votre travail, vous vous êtes souvent intéressé à des processus génératifs. Pourriez-vous nous en décrire un exemple ?
Oui, j’ai par exemple une exposition en ce moment à Barcelone intitulée « Fifty sisters », une oeuvre créée pour le Musée Ars Electronica. Il s’agit une série de cinquante images évolutives, créées à partir d’un modèle de la croissance des plantes. A la base, j’ai choisi d’utiliser des logos de compagnies pétrolières. J’ai repris des éléments géométriques de ces logos, qui viennent nourrir le modèle de développement. Ensuite, j’utilise une grammaire, un ensemble de règles qui modélisent l’évolution d’une plante – à l’origine, cette grammaire permet de représenter la structure de plantes du Jurassique. J’utilise cette grammaire dans un processus itératif qui alterne des étapes de calcul par l’ordinateur, et des choix de ma part. D’abord, à partir des logos pétroliers, l’ordinateur calcule une premier génération de plantes en appliquant la grammaire. Cela produit plusieurs plantes, parmi lesquelles je choisis celles qui me semblent les plus étranges, ou intéressantes. Et l’on recommence. C’est donc bien l’humain qui conduit l’algorithme.
De cette façon, les plantes sont réellement constituées d’éléments graphiques des logos. Les images finales ont des structures très complexes, et elles sont calculées à très haute définition de façon à ce que l’on puisse zoomer dans les plantes et découvrir de nouveaux détails.
C’est un sacré travail !
Plante ayant évolué à partir du logo Shell, de la série des Fifty Sisters (crédit Jon McCormack)
Oui, en fait la partie la plus dure a été de calculer le rendu. J’avais loué une ferme d’ordinateurs, mais au bout de 24h nous nous sommes fait jeter dehors parce que nous consommions trop de temps de calcul ! Alors, nous avons installé le programme qui calcule le rendu, petit morceau d’image par petit morceau d’image, sur tous les ordinateurs inutilisés du labo, ceux de tout le monde… C’est impressionnant car la grammaire qui sert à faire les générations est très courte, elle fait 10 lignes, et elle génère pourtant des objets extrêmement complexes.
Comment avez-vous découvert l’informatique ?
J’ai toujours aimé les ordinateurs, depuis l’enfance. Dans mon école, il y avait un ordinateur, un seul, c’était un TRS80 de Radioshack. Personne ne voulait l’utiliser. Je l’ai trouvé fascinant, parce qu’il faisait des calculs, et qu’il permettait de générer des choses. Le TRS80 avait des graphismes très crus, mais on pouvait faire des images avec, allumer des pixels, les éteindre… D’abord, je l’ai utilisé pour dessiner des fonctions, et puis j’ai commencé à écrire mes propres programmes : je voulais voir les fonctions en 3D. Aujourd’hui, la 3D est une technique couramment utilisée, mais ce n’était pas le cas alors ! Donc j’ai programmé une visualisation 3D. Elle n’était pas parfaite, mais elle me suffisait. C’est là que j’ai compris que l’ordinateur permettait de faire des films, de l’animation, de l’interaction. Il faut dire que c’est fascinant de construire un espace et un temps qui reflètent la réalité, même si cette réflexion n’est pas parfaite.
Est-ce qu’il y a aujourd’hui des nouveaux langages artistiques basés sur les données numériques ou l’algorithmique ?
C’est une question difficile. Je ne crois pas que l’ordinateur soit accepté, en soi, dans le courant dominant de l’art contemporain (« mainstream art »). Il y a des résistances. Par moment, le monde de l’art accepte l’ordinateur, puis il le rejette. Je ne pense pas que l’on puisse dire que les ordinateurs soient devenus centraux dans la pratique artistique. Mais je crois que l’informatique a ouvert des possibilités artistiques, qu’elle apporte quelque chose de réellement nouveau. C’est un peu comme le bleu. Autrefois, on ne savait pas fabriquer la couleur bleue. Dans l’histoire de l’art, la découverte du bleu a été un évènement important. C’était une question scientifique, un vrai problème technologique. Lorsque l’on a commencé à le fabriquer, le bleu était cher. Dans les peintures du début de la Renaissance, on ne l’utilisait que pour les personnes très importantes.
Pour moi, l’ordinateur suit un chemin similaire à celui du bleu. C’est vrai dans l’art pictural mais aussi dans la musique, le cinéma, l’architecture…
Jon McCormack devant l’exposition Fifty Sisters au musée Ars Electronica, avril 2013 (crédit Jon McCormack)
Pensez-vous que les artistes doivent apprendre l’informatique ?
Je ne le formulerais pas de façon aussi stricte. Je ne dirais pas qu’ils en ont besoin, qui est un terme trop fort, mais qu’ils devraient. Au delà des artistes d’ailleurs, tout le monde devrait apprendre au moins un peu d’informatique. C’est indispensable pour comprendre le monde, au même titre que les mathématiques ou les autres sciences.C’est important d’ajouter aux cursus la pensée algorithmique et la programmation. Et cela ouvre de nouvelles possibilités pour tout le monde, comme aucun autre medium ne le fait.
Est-ce que le code créatif est une activité similaire à la programmation classique, ou différente ?
Je crois que c’est juste un outil pour la créativité, car toutes les activités créatives ont été numérisées. C’est lié à ce que nous disions tout à l’heure : les gens qui travaillent dans le design, la musique ou l’architecture, utilisent l’ordinateur tout le temps, même si ce n’est que pour éditer des fichiers.
Prenons l’exemple de Photoshop. C’est un outil fabriqué par d’excellents développeurs, qui y ont ajouté d’excellentes fonctionnalités. Mais ce sont leurs fonctionnalités. Quand on l’utilise, on n’exprime pas ses idées, mais les leurs. Et tout le monde fait la même chose ! Dès lors, la question devient : voulez-vous exprimer votre créativité, ou celle de quelqu’un d’autre ?
Ici nous avons un projet en cours d’examen avec l’Université de Sydney pour enseigner le code créatif aux biologistes. Ils ont de gros besoins en visualisation de données statistiques, et ils utilisent en général des outils dédiés très classiques comme Excel ou le langage R. Mais l’outil a une énorme influence sur ce que l’on fait et la façon dont on perçoit les choses. Nous voulons leur apprendre à fabriquer leurs propres outils.
Tout le monde devrait apprendre le code créatif : les ingénieurs, les biologistes, les chimistes, etc. !
Dans le futur, quelle technologie vous ferait vraiment rêver ?
Pour certains projets, nous avons eu ici des interfaces avec le cerveau. Pendant longtemps, la conception des ordinateurs s’est faite sans considérer le corps humain. On accordait peu d’importance au fait que nous sommes incarnés dans un corps. Regardez le clavier ! Maintenant, on a les écrans tactiles.
La question est maintenant de concevoir des machines qui fonctionnent avec nos corps. Regardez les travaux de Stelarc sur l’obsolescence du corps humain. Il s’agit de se réapproprier la technologie. Alors que l’on voyait l’ordinateur comme un outil externe, le corps devient un outil d’interaction. C’est le même principe que la cane pour les aveugles : au début, quand on a une cane, on la voit comme un objet externe. Mais on peut l’utiliser pour tester une surface par exemple, ou pour sentir un mur. Elle devient une extension du corps. Je pense que l’on peut voir la technologie comme extension du corps humain.

 Rudelle raconte son expérience de créateur de 3 startups : un échec, un résultat mitigé, et le grand succès Criteo. Criteo, valorisée à plus de 2 milliards de dollars, est aujourd’hui présente dans 85 pays. Avec ses algorithmes de prédiction, elle achète et revend en quelques millisecondes des emplacements publicitaires sur internet. Elle affiche une belle croissance à deux chiffres.
Rudelle raconte son expérience de créateur de 3 startups : un échec, un résultat mitigé, et le grand succès Criteo. Criteo, valorisée à plus de 2 milliards de dollars, est aujourd’hui présente dans 85 pays. Avec ses algorithmes de prédiction, elle achète et revend en quelques millisecondes des emplacements publicitaires sur internet. Elle affiche une belle croissance à deux chiffres.