Dans la rubrique « Il était une fois… ma thèse », binaire accueille aujourd’hui Camille Marchet, qui a obtenu un accessit du prix de thèse Gilles Kahn en 2019. Camille nous parle du contenu de sa thèse, préparée à l’IRISA, à Rennes, au cours de laquelle elle s’est intéressée à la conception d’algorithmes manipulant des séquences d’ARNs, pour le plus grand bonheur des biologistes ! Camille a aujourd’hui rejoint l’équipe Bonsai au sein du laboratoire CRIStAL, à Lille. Eric Sopena
Vous avez entendu parler de l’ADN, mais connaissez-vous l’ARN ? Pour les amateurs d’informatique, je pourrais le décrire comme la mémoire tampon dans la cellule. L’ADN stocke comme un disque dur le code source des protéines, qui sont les effecteurs. Cependant il contient un volume immense d’information, dont la totalité n’est pas nécessaire pour produire les protéines. La cellule le garde donc au chaud et copie les portions nécessaires à sa production de protéines dans les ARNs (plus précisément, dans les ARNs messagers, car il existe de nombreux autres ARNs).
Quel rapport avec l’informatique ? On sait séquencer l’ARN en grandes quantités, c’est-à-dire lire ces molécules et en obtenir une version numérique. Cela permet de les traiter comme des chaînes de caractères, très étudiées dans certains pans de l’informatique théorique. Ici on se concentre sur des séquences écrites dans un alphabet bien spécifique (pour simplifier, le même que pour l’ADN : les bases A, C, G, T). Les bioinformaticiens comme moi fournissent des algorithmes et des logiciels permettant de travailler avec ces séquences biologiques. Une fois en leur possession, les biologistes peuvent étudier de nombreuses questions. Un exemple touché par mon travail est l’observation des ARNs présents dans une symbiose de planctons. Elle a permis de mieux comprendre les échanges qui régissent la mise en place et le maintien de cette symbiose.
J’ai eu la chance de démarrer ma thèse pendant une révolution du séquençage. On peut à présent accéder à des molécules entières d’ARN au format numérique. Auparavant, on devait reconstituer les molécules à la manière d’un puzzle, à partir de tout petits fragments. Les nouvelles techniques permettent actuellement de séquencer environ un million de milliards de bases par jour ! Les ARNs chez l’humain mesurent typiquement quelques milliers de bases, et des dizaines de milliers d’ARNs au moins peuvent être trouvés dans une expérience. C’est donc un moment excitant, avec beaucoup de nouvelles données, où beaucoup reste à faire.
En particulier, ces nouvelles données contiennent des erreurs d’une nature et d’une quantité inédites. Nous avons donc besoin d’algorithmes capables de passer outre ce bruit pour comparer les séquences, ou les grouper quand elles sont similaires.
Cela est l’une des contributions de ma thèse. Nous avons conçu une méthode de clustering permettant de diviser les séquences en groupes cohérents correspondants à des gènes, sans utiliser d’autre information que celle contenue dans les bases.
Une molécule d’ARN et ses quatre bases en couleur (A, C, G, U, mais le U est remplacé par un T par souci d’unification avec les séquences d’ADN), et un exemple de séquence issue de la dernière technologie de séquençage sur laquelle nous avons travaillé pour la méthode de clustering (adapté de Wikimedia Commons, séquence issue de NCBI SRA).
Un second point est la possibilité de travailler avec d’énormes volumes de données. Certains champs de la biologie moderne produisent des milliards de séquences en quelques heures pour décrire des environnements complexes, comme les écosystèmes marins. Dans le cadre de ma thèse, nous avons conçu une structure permettant de comparer des jeux de données à très large échelle. Elle peut enregistrer des séquences et leur associer de l’information avec une très faible empreinte mémoire grâce à une technique de hachage. Par exemple, pour le plancton, nous avons enregistré des ARNs connus d’espèces que nous pensions être présentes dans notre expérience. Puis, grâce à la structure, nous les avons comparés aux séquences obtenues lors du séquençage de la symbiose. Ainsi nous avons pu assigner certaines séquences à une espèce identifiée, et ce pour plus de cinq milliards de séquences.
La symbiose planctonique sur laquelle nous avons travaillé. Les organismes impliqués sont unicellulaires. La plus grosse cellule qui prend la majorité de la photo est l’hôte, un collodaire. Les symbiotes (plus petits points jaune pâle) sont de la catégorie des dinoflagellés. La photo a été prise dans le cadre de la mission Tara Oceans en 2011 (crédits : Johan Decelle).
Plus généralement, un problème actuel est de pouvoir stocker, comparer, et rechercher intelligemment dans ces jeux de données massifs. C’est un défi auquel j’ai apporté ma contribution, mais qui va encore nous occuper quelques années !
La rencontre de chercheurs juristes et informaticiens dans le cadre du lancement du Centre Internet et Société et du montage du GdR Internet et Société, a été l’occasion de réflexions croisées et de soulever nombre de questions et premières pistes de recherche à explorer ensemble. Cet article résume le résultat d’une table ronde. Serge Abiteboul, Thierry Viéville
Photo by Fernando Arcos from Pexels
Les plateformes numériques et leur rôle dans la société occupent les médias et les instances gouvernantes. Nous, juristes et informaticien·e·s, les percevons comme des nouveaux marchés de la donnée. Plusieurs acteurs humains, artistes, auteurs, créateurs de contenu, développeurs de langages, développeurs de plateformes, développeurs d’applications, internautes consommateurs, acteurs publics et privés, gravitent autour de ces plateformes et sont exposés à deux types de risque :
– Le risque-données se réfère à la protection des données sur ces plateformes.
– Le risque-algorithmes se réfère aux dérives de discrimination algorithmique.
Ce document apporte une première réflexion sur comment appréhender les plateformes numériques et les risque-données et risque-algorithmes. Ces questions peuvent être abordées de deux points de vue complémentaires : le point de vue juridique dont le souci principal est de déterminer les cadres qui permettent d’identifier et de réguler ces risques, et le point de vue informatique dont le but est de développer les outils nécessaires pour quantifier et résoudre ces risques.
Les trois facettes du risque algorithmique.
Le risque-algorithmes peut être caractérisé de 3 façons.
Il s’agit d’abord de l’enfermement algorithmique qui peut aussi bien porter sur les opinions, la connaissance culturelle, ou encore les pratiques commerciales. En effet, les algorithmes confrontent l’internaute aux mêmes contenus, selon son profil et les paramètres intégrés, en dépit du respect du principe de la loyauté. C’est le cas sur les sites de recommandation de news comme Facebook ou les sites de recommandation de produits comme Amazon.
La deuxième facette du risque-algorithmique est liée à la maîtrise de tous les aspects de la vie d’un individu, de la régulation de l’information à destination des investisseurs jusqu’à ses habitudes alimentaires, ses hobbies, ou encore son état de santé. Ce traçage de l’individu laisse présager l’emprise d’une forme de surveillance qui contrevient à l’essence même de la liberté de l’individu.
La troisième est liée à la potentielle violation des droits fondamentaux. En particulier, à la discrimination algorithmique définie comme le traitement défavorable ou inégal, en comparaison à d’autres personnes ou d’autres situations égales ou similaires, fondé sur un motif expressément prohibé par la loi. Ceci englobe l’étude de l’équité (fairness) des algorithmes de classement (tri de personnes cherchant un travail en ligne), de recommandation, et d’apprentissage en vue de prédiction. Le problème des biais discriminatoires induits par des algorithmes concerne plusieurs domaines comme l’embauche en ligne sur MisterTemp’, Qapa et TaskRabbit, les décisions de justice, les décisions de patrouilles de police, ou encore les admissions scolaires.
Nous reprenons une classification des biais proposée par des collègues de Télécom ParisTech et discutée dans un rapport de l’Institut Montaigne à Paris. Nous adaptons cette classification aux risque-données et risque-algorithmes en mettant l’accent sur les biais.
Les données proviennent de sources différents et ont des formats multiples. Elles véhiculent différents types de biais.
Des risques aux biais sur les données et dans les algorithmes.
Le biais-données est principalement statistique
Le biais des données est typiquement présent dans les valeurs des données. Par exemple, c’est le cas pour un algorithme de recrutement entraîné sur une base de données dans laquelle les hommes sont sur-représentés exclura les femmes.
Le biais de stéréotype est une tendance qui consiste à agir en référence au groupe social auquel nous appartenons. Par exemple, une étude montre qu’une femme a tendance à cliquer sur des offres d’emplois qu’elle pense plus facile à obtenir en tant que femme.
Le biais de variable omise (de modélisation ou d’encodage) est un biais dû à la difficulté de représenter ou d’encoder un facteur dans les données. Par exemple, comme il est difficile de trouver des critères factuels pour mesurer l’intelligence émotionnelle, cette dimension est absente des algorithmes de recrutement.
Le biais de sélection est lui dû aux caractéristiques de l’échantillon sélectionné pour tirer des conclusions. Par exemple, une banque utilisera des données internes pour déterminer un score de crédit, en se focalisant sur les personnes ayant obtenu ou pas un prêt, mais ignorant celles qui n’ont jamais eu besoin d’emprunter, etc.
Le biais algorithmique tient principalement du raisonnement.
Un biais économique est introduit dans les algorithmes, volontairement ou involontairement, parce qu’il va être efficace économiquement. Par exemple, un algorithme de publicité oriente les annonces vers des profils particuliers pour lesquels les chances de succès sont plus importantes ; des rasoirs vont être plus présentés à des hommes, des fastfood à des populations socialement défavorisées, etc.
Il convient également de citer toute une palette de biais cognitifs
Les biais de conformité, dits du « mouton de Panurge », correspondent à notre tendance à reproduire les croyances de notre communauté. C’est le cas, par exemple, quand nous soutenons un candidat lors d’une élection parce que sa famille et ses amis le soutiennent.
Le biais de confirmation est une tendance à privilégier les informations qui renforcent notre point de vue. Par exemple, après qu’une personne de confiance nous a affirmé qu’untel est autoritaire, remarquer uniquement les exemples qui le démontrent.
Le biais de corrélation illusoire est une tendance à vouloir associer des phénomènes qui ne sont pas nécessairement liés. Par exemple, penser qu’il y a une relation entre soi-même et un événement extérieur comme le retard d’un train ou une tempête.
Le biais d’endogénéité est lié à une relative incapacité à anticiper le futur. Par exemple, dans le cas du credit scoring, il se peut qu’un prospect avec un mauvais historique de remboursement d’emprunt puisse changer de style de vie lorsqu’il décide de fonder une famille.
Les algorithmes sont une série d’instructions qui manipulent des données en entrée et retournent des données en sortie. Ces données en entrée véhiculent parfois des biais. Les biais peuvent aussi se trouver dans une ou plusieurs instructions des algorithmes.
Doit-on aborder les risque-données et risque-algorithmes sur les plateformes numériques ensemble ou séparément ?
Considérons deux exemples, le contexte de la technologie blockchain, et celui des systèmes d’Intelligence Artificielle.
Sur la blockchain, l’on retrouve tout d’abord les données, les risques et leur biais. Prenons l’exemple des données et des risques associés. La blockchain fonctionne par un chiffrement à double clés cryptographiques : des clés privées et des clés publiques. Beaucoup d’internautes confient aux plateformes leurs clés privées, leur délégant ainsi la gestion de leur adresse et les mouvements de fonds. Ces clés privées sont stockées soit dans un fichier accessible sur Internet (hot storage), soit sur un périphérique isolé (cold storage). Le premier est évidemment très vulnérable au piratage, tandis que 92 % des plateformes d’échange déclarent utiliser un système de cold storage. Depuis 2011, 19 incidents graves ont été recensés pour un montant estimé des pertes s’élevant à 1,2 milliards de dollars. Les causes de ces incidents sont multiples. La plus courante vient de la falsification des clés privées, suivie par l’introduction de logiciels malveillants. Le hack de la plateforme Coincheck au Japon, en janvier 2018, illustre la faiblesse de la protection du système de hot storage.
Autre exemple sur les algorithmes et les risques associés, l’échange de cryptomonnaies sur des plateformes voit se développer et se diversifier les infrastructures de marché. L’ambition est « de permettre la mise en place d’un environnement favorisant l’intégrité, la transparence et la sécurité des services concernés pour les investisseurs en actifs numériques, tout en assurant un cadre réglementaire sécurisant pour le développement d’un écosystème français robuste » . La France s’est dotée récemment d’un cadre juridique permettant de réguler ces activités de manière souple. Pour autant, au niveau mondial, les risques attachés à des cotations non transparentes ou à des transactions suspectes s’apparentant à des manipulations directes de cours ou de pratiques d’investisseurs informés, de type frontrunning. Le frontrunning est une technique boursière permettant à un courtier d’utiliser un ordre transmis par ses clients afin de s’enrichir. La technique consiste à profiter des décalages de cours engendrés par les ordres importants passés par les clients du courtier.
Venons en à la question « doit-on aborder les risque-données et risque-algorithmes sur les plateformes numériques ensemble ou séparément ? » Concernant la blockchain, la réponse du droit est séparée, car les risques saisis sont différents. D’un côté, certaines dispositions du droit pénal, de la responsabilité civile ou de la protection des données à caractère personnel seront mobilisées. Alors que de l’autre côté, en France, le récent cadre juridique visant à saisir les activités des prestataires de services sur actif numérique et à éviter le risque algorithmique est principalement régulatoire.
Sur les systèmes d’IA, nous prendrons pour répondre à notre question le prisme de la responsabilité (liability) et de la responsabilisation (accountability).
Cette question est diabolique car elle impose au juriste de faire une plongée dans le monde informatique pour comprendre ce en quoi consiste l’intelligence artificielle, ce mot-valise qui recouvre, en réalité, de nombreuses sciences et techniques informatiques. Et faut-il seulement utiliser ce terme, alors que le créateur du très usité assistant vocal Siri vient d’écrire un ouvrage dont le titre, un tantinet provocateur, énonce que l’intelligence artificielle n’existe pas… (Luc Julia, L’intelligence artificielle n’existe pas, First editions, 2019).
Un distinguo entre les systèmes d’IA est néanmoins souvent opéré : seuls certains systèmes sont véritablement « embarqués » dans un corps afin de lui offrir ses comportements algorithmiques : robot, véhicule « autonome »… Les autres systèmes d’IA prennent des décisions ou des recommandations algorithmiques qui peuvent avoir un effet immédiat sur le monde réel et l’esprit humain, sans avoir besoin de s’incarner dans un corps : recommandations commerciales à destination du consommateur, fil d’actualité des réseaux sociaux, justice prédictive et sont souvent considérés comme « dématérialisés ». Cependant, tous les systèmes d’IA finissent par être incorporés dans une machine : robot, véhicule, ordinateur, téléphone… et tous les systèmes d’IA peuvent potentiellement avoir un impact sur l’esprit ou le corps humains, voire sur les droits de la personnalité (M. Baccache, Intelligence artificielle et droits de la responsabilité, in Droit de l’intelligence artificielle, A. Bensamoun, G. Loiseau, (dir.), L.G.D.J., Les intégrales 2019, p. 71 s.), tant et si bien que nous choisirons ici de saisir la question de la responsabilité lors du recours aux systèmes d’IA d’une manière transversale.
La question transversale que précisément nous poserons consistera à nous demander si la spécificité des systèmes d’IA, tant au regard de leur nature évolutive et de leur gouvernance complexe, qu’au regard des risques découlant de leur mise en œuvre pour l’humain et la société n’appelle pas à préférer à la responsabilité, entendue comme la seule sanction a posteriori de la réalisation d’un risque, une complémentarité entre responsabilisation de la gouvernance de chaque système d’IA tout au long de son cycle de vie et responsabilité a posteriori. Si la responsabilisation est reconnue comme étape préalable à la responsabilité, elle impliquera d’envisager les risques-données et les risques-algorithmiques, de manière conjointe, préservant ainsi la spécificité de chacun de ces risques, mais en les reliant, parce c’est par la conjonction de ces deux types de risques, que des conséquences préjudiciables pour l’humain ou la société peuvent se réaliser.
En effet, dans ses « lignes directrices en matière d’éthique pour une IA digne de confiance » datant d’avril 2019, le Groupe d’experts de haut niveau sur l’intelligence artificielle, mandaté par la Commission européenne, rappelle dans l’une de ses propositions un point fondamental, à savoir les nécessaires reconnaissance et prise de conscience que « certaines applications d’IA sont certes susceptibles d’apporter des avantages considérables aux individus et à la société, mais qu’elles peuvent également avoir des incidences négatives, y compris des incidences pouvant s’avérer difficiles à anticiper, reconnaître ou mesurer (par exemple, en matière de démocratie, d’état de droit et de justice distributive, ou sur l’esprit humain lui-même) » (Groupe d’experts indépendants de haut niveau sur l’intelligence artificielle, Lignes directrices en matière d’éthique pour une IA digne de confiance, avril 2019, constitué par la Commission européenne en juin 2018,).
Ce faisant, le groupe d’experts de haut niveau en appelle à « adopter des mesures appropriées pour atténuer ces risques le cas échéant, de manière proportionnée à l’ampleur du risque » et, en se fondant sur les articles de la Charte des droits fondamentaux de l’Union européenne, à « accorder une attention particulière aux situations concernant des groupes plus vulnérables tels que les enfants, les personnes handicapées et d’autres groupes historiquement défavorisés, exposés au risque d’exclusion, et/ou aux situations caractérisées par des asymétries de pouvoir ou d’information, par exemple entre les employeurs et les travailleurs, ou entre les entreprises et les consommateurs ».
Alors même que certains risques et la protection de certains groupes vulnérables l’imposent, prendre les mesures appropriées n’est cependant pas aisé, et ce au-delà même de la tension récurrente entre principe d’innovation et principe de précaution. La raison en est que tant les briques techniques utilisées, que les personnes impliquées dans le fonctionnement d’un système d’IA sont nombreuses, variées et en interactions complexes, entraînant de nombreuses interactions qui ne sont pas aisées à maîtriser. Il convient de constater que le groupe d’experts de haut niveau formule un ensemble de propositions, à visées d’éthique et de robustesse technique des systèmes d’IA, qui véhiculent l’idée selon laquelle la confiance en un système d’IA, au regard des risques actuels du déploiement de ceux-ci, se doit de reposer sur une responsabilisation a priori de la gouvernance de celui-ci tout au long de son cycle de vie, qui passe, entre autres choses, par un objectif d’explicabilité de ces actions.
La notion d’accountability est à cet égard une notion centrale pour comprendre la complémentarité et le long continuum existant entre responsabilisation et responsabilité. Plus que par le terme de responsabilité, cette notion d’accountability peut justement être traduite par les notions de reddition de compte et/ou de responsabilisation. Cette responsabilisation permet d’envisager les risques-données et les risques-algorithmiques, de manière conjointe, préservant ainsi la spécificité de chacun de ces risques, mais en les reliant, parce c’est par la conjonction de ces deux types de risques, que des conséquences préjudiciables pour l’humain ou la société peuvent se réaliser.
En résumé. Le point de vue juridique différera selon les enjeux et les concepts applicables. Dans le cas de la blockchain, il est important de séparer le risque-données du risque-algorithmes puisqu’ils traitent de problématiques différentes et nécessitent des cadres de loi différents. Le premier traite de la question de la divulgation de l’identité des parties qui relève de la sécurité des données alors que le second traite de la question des actifs numériques frauduleux. Dans le cas des systèmes d’intelligence artificielle, tout déprendra du point de savoir s’il convient de prévenir le dommage ou de le sanctionner une fois qu’il s’est réalisé. Dans le cas d’une recherche de responsabilisation, il convient d’envisager les risques-données et les risques-algorithmes de manière conjointe.
Si la question est celle de la responsabilité (liability) et la responsabilisation (accountability), i.e., celle d’imputer la faute à une personne physique, il sera important de séparer les deux risques. Cette séparation est aussi celle qui est préconisée en informatique pour permettre d’identifier les “coupables”: données ou algorithmes. Les techniques de provenance des données et de trace algorithmique permettront d’isoler les raisons pour lesquelles il y a faute. Il s’agira d’abord d’identifier si la faute est due à un risque-données du type divulgation de la vie privée ou à un biais statistique dans les données, ou à un risque-algorithmes du type économique ou cognitif, ou si la faute est due aux deux. On ne pourra donc imputer la faute et déterminer les cadres de loi applicables que s’il y a séparation. De même si l’objectif est de “réparer” les données ou l’algorithme, l’étude des deux types de risque doit s’effectuer séparément. C’est ce qu’on appelle l’orthogonalité en informatique. Selon le dictionnaire, le jeu d’instructions d’un ordinateur est dit orthogonal lorsque (presque) toutes les instructions peuvent s’appliquer à tous les types de données. Un jeu d’instruction orthogonal simplifie la tâche du compilateur puisqu’il y a moins de cas particuliers à traiter : les opérations peuvent être appliquées telles quelles à n’importe quel type de donnée. Dans notre contexte, cela se traduirait par avoir un jeu de données parfait et voir comment l’algorithme se comporte pour déterminer s’il y a un risque-algorithmes et avoir un algorithme parfait et examiner les résultats appliqués à un jeu de données pour déterminer le risque-données. Ces stratégies ont de beaux jours devant elles.
L’informatique est rentrée dans toutes les facettes de nos vies, y compris les toiles sur lesquelles nous regardons films et séries. Parfois même, nous y voyons des scènes où l’utilisation des outils informatiques nous questionne, parce que non conventionnelle à l’écran. Aussi nous vous proposons une nouvelle rubrique, dans laquelle nous inviterons des experts, pour décoder certaines scènes où le numérique joue un rôle important, en nous expliquant ce qui se passe, ce qui est crédible, ce qui l’est moins. Il ne s’agit en aucun cas de singer un rôle de critique sur la qualité de la scène mais bien d’utiliser cet angle pour parler – encore et toujours – du numérique. Et vous pouvez nous aider ! Charlotte Truchet et Pascal Guitton.
Binairiens, binairiennes !
En ce début d’année, nous avons une nouvelle à partager avec vous. L’équipe éditoriale s’étant creusé la tête pour trouver des façons toujours plus vivantes de vous faire découvrir le monde merveilleux de la science informatique, ce blog va bientôt inaugurer une toute nouvelle rubrique, pour laquelle nous allons avoir besoin de vous, lectrices et lecteurs !
Nous avons intitulé cette série : le divulgâcheur.
Traduit en anglais, ce joli mot devient « spoiler ». « Et c’est quoi le rapport avec l’informatique ? », direz-vous, car vous êtes des lecteurs et lectrices pointilleux. Et bien, pendant des années, des décennies même, l’informatique montrée à l’écran était souvent ridiculement caricaturale. On avait souvent affaire à un gamin en hoodie tapant frénétiquement du code HTML écrit en vert sur fond noir dans un sous-sol cradingue, ou alors à un policier interrogeant des bases de données omniscientes sur un terminal à petit écran (voir par exemple ici une drôle de liste de références !). Mais à Binaire, nous avons ressenti que plusieurs séries récentes, par exemple Black Mirror, The Good Wife, ou Le Bureau des Légendes, traitaient de vraies questions informatiques, de façon assez travaillée, voire réaliste.
Réaliste, certes, mais à quel point ? C’est ce que le Divulgâcheur va vous révéler. Dans chaque épisode de notre rubrique, nous inviterons un.e chercheur.euse en informatique à décoder pour nous une scène de série montrant un usage informatique non conventionnel, et à nous en livrer les clefs.
« Mais vous allez nous spoiler, alors ?!!! » direz-vous car vous êtes des lectrices et lecteurs exigeants. Hé oui, d’où le titre de la rubrique. Si vous souhaitez garder le plaisir de la découverte de vos séries favorites, il sera prudent de regarder les épisodes avant de nous lire. Le numéro de l’épisode concerné sera toujours indiqué clairement, c’est promis.
« Mais si je n’aime pas le Bureau des Légendes ? », demanderez-vous, car tout pointilleux et exigeants que vous êtes, vous avez aussi le droit d’avoir mauvais goût 😉 . C’est justement le but de ce petit texte : nous comptons sur vous pour nous proposer des épisodes à traiter ! Plus précisément, voilà ce que nous cherchons :
=> Une scène d’une série, ou d’un film, qui soit basée sur un usage non conventionnel du numérique : pour que l’exercice soit intéressant, il faut que l’informatique soit partie intégrante du scenario et pas juste un élément de décor,
=> idéalement, plutôt de séries ou de films récents,
=> non, pas que Black Mirror ; nous avons déjà un épisode dans les tuyaux et on ne fera pas que des épisodes de Black Mirror !
Laissez-nous en commentaire le nom de la série, le numéro exact de l’épisode (ou le titre du film), et une courte description de la scène considérée. Nous nous engageons alors à essayer de trouver un.e expert.e pour décrypter la scène. Nous n’y arriverons peut-être pas toujours, mais nous essaierons !
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Février : Ça va être long ?
Si vous installez parfois des logiciels, vous avez forcément remarqué que la petite barre qui vous indique le temps restant est franchement mensongère. Elle semble avancer à sa guise, sans aucun rapport avec le temps écoulé, ou restant à écouler… Connaître le temps qu’un programme met à s’exécuter, ce n’est pourtant pas beaucoup demander ! En fait, si. Et en gros, à la louche, à peu près, en moyenne ? Même. Et même en faisant abstraction des performances des matériels utilisés, connaître le temps d’exécution d’un algorithme est un problème difficile – souvent insoluble en l’état actuel des connaissances. Bien souvent, on donne la complexité dans le pire des cas d’un algorithme, c’est-à-dire le temps de calcul théorique d’un algorithme sur la pire entrée possible, celle qui lui prendra le plus de temps à s’exécuter. On s’intéresse aussi beaucoup au temps de calcul en moyenne sur toutes les entrées possibles, qui est encore plus difficile à calculer. Et puis, pour résoudre un problème, il existe typiquement plusieurs algorithmes. Alors, savoir combien il faudrait de temps pour résoudre un problème particulier, c’est encore plus compliqué.
Parmi les algorithmes les plus étudiés, on trouve les algorithmes de tri, qui partent d’une suite d’objets non triés et s’occupent de la ranger dans un ordre bien défini. Il en existe de nombreux, aux noms poétiques : tri à bulles, tri par insertion, tri rapide… C’est une des rares familles d’algorithmes dont on connaît bien le temps théorique d’exécution, que ce soit dans le pire des cas ou en moyenne. Le tri par sélection, par exemple, fonctionne de manière très simple : on cherche la plus petite valeur à trier et on la met devant. Puis on cherche la deuxième plus petite dans ce qui reste, et on la met en deuxième, etc. Simple, mais pas terrible en complexité ! Pour n valeurs à trier, il faut lire une fois toutes les données pour trouver la plus petite valeur, ce qui coûte n opérations, pour la seconde, n-1, etc. Au total, on a de l’ordre de n2 opérations à faire dans le pire des cas comme en moyenne.
Le tri rapide, ou quicksort, est plus compliqué à comprendre mais plus efficace : on choisit arbitrairement une valeur dans les données à trier, et on met d’un côté toutes les valeurs plus petites, de l’autre toutes les plus grandes. Ça semble farfelu, c’est pourtant très astucieux : on se retrouve avec deux suites de données beaucoup plus petites à trier! Et on reprend sur ces deux suites. La complexité passe à n*log(n), ce qui représente un gain significatif en temps de calcul.
En général, on connaît la complexité dans le pire des cas de beaucoup d’algorithmes courants, beaucoup plus rarement la complexité en moyenne. Il reste beaucoup à apprendre.
Un nouvel « Entretien autour de l’informatique ». Michel Thiebaut de Schotten est directeur de recherche au CNRS en neuropsychologie et en neuroimagerie de la connectivité cérébrale. Il travaille notamment sur l’anatomie des connexions cérébrales et leur déconnexion suite à des accidents vasculaires cérébraux ainsi que sur l’évolution du cerveau en comparant les espèces. Il a rejoint récemment l’Institut des Maladies Neurodégénératives à Bordeaux et continue à travailler avec l’Institut du cerveau et de la moelle épinière à Paris. Il est médaille de bronze du CNRS et lauréat d’un contrat prestigieux de l’European Research Council. Il fait partager à binaire sa passion pour les neurosciences. Cet article est publié en collaboration avec The Conversation.
MT – Je viens de la psychologie. J’ai choisi de faire un doctorat en neuroscience à la Salpêtrière (Université Pierre et Marie Curie) en 2007. Puis j’ai fait un post-doc à Londres sur la cartographie des réseaux cérébraux. Je suis depuis 2012 au CNRS. Nous utilisons beaucoup l’imagerie numérique. Nous faisons aussi un peu d’analyse postmortem pour vérifier que ce que nous avons vu dans les images correspond à une réalité.
B – Il nous faudrait partir un peu de la base. Qu’est-ce que c’est l’imagerie du cerveau pour les neurosciences ?
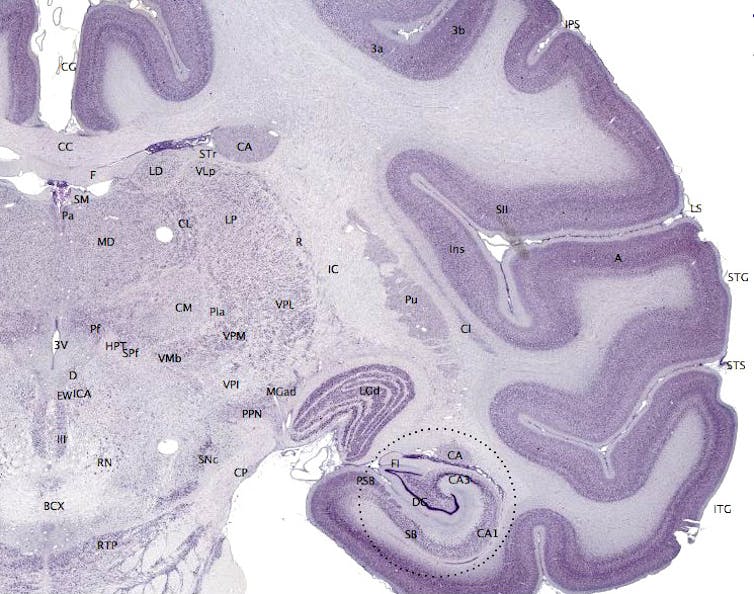
MT – À l’aide de l’Imagerie par résonance magnétique, on peut étudier soit la forme et le volume des organes (IRM anatomique), soit ce qui se passe dans le cerveau quand on réalise certaines activités mentales (IRM fonctionnelle). À partir des données d’IRM, on peut dessiner les réseaux du cerveau humain. Les axones des neurones sont des petits câbles de 1 à 5 micromètres, avec autour une gaine de myéline pour que l’électricité ne se perde pas, ils se regroupent en grand faisceaux de plusieurs milliers d’axones (Figure 1). C’est ce qui construit dans le cerveau des autoroutes de l’information. On peut faire une analogie avec un réseau informatique : les neurones sont les processeurs tandis que les axones des neurones forment les connexions.
Fig. 1 Les autoroutes du cerveau. Exemple de connexions cérébrales liant les régions de l’avant du cerveau avec celles de l’arrière du cerveau. @ Michel Thiebaut de Schotten
B – Et ces connexions sont importantes ?
MT – Super importantes ! Un de mes premiers travaux a été de réaliser un atlas des connexions cérébrales afin de savoir quelles structures étaient reliées entre elles par ces autoroutes. En effet, pour chaque traitement cognitif, plusieurs régions doivent fonctionner en collaboration et s’échanger des informations (exactement comme différents processeurs dans nos ordinateurs). On voit aussi l’importance des connexions cérébrales quand certaines sont rompues suite à une maladie, un AVC, un accident. Cela conduit à des incapacités parfois très lourdes pour la personne.
On estime que la vitesse de transmission de l’information dans ces réseaux est comprise entre 300 et 350 km/h ; la même que celle du TGV qui me transporte de Bordeaux à Paris mais bien loin de la vitesse de transmission de l’information dans une fibre optique. Heureusement, les distances sont petites.
B – Ça a l’air un peu magique. Comment est-ce qu’on met en évidence les connexions entre des régions du cerveau ?
MT – Tout d’abord il faut préciser qu’on doit faire des mesures sur plusieurs personnes car, même si nos cerveaux possèdent des similarités, il existe des différences notables entre individus. Il faut faire une moyenne des résultats obtenus pour chaque sujet pour obtenir une cartographie en moyenne.
L’IRM est en mesure de détecter les mouvements de particules d’eau et grâce à la myéline autour des axones qui joue le rôle de l’isolant d’un fil électrique, les mouvements de particules d’eau sont contraints dans la direction de l’axone. Ainsi en suivant cette direction on peut reconstruire les grandes connexions cérébrales. On obtient alors une carte des connexions qui ressemble à un plat de nouilles. Imaginez qu’à un millimètre de résolution, on détecte environ 1 million de connexions cérébrales qui sont repliées sur elles-mêmes dans un volume d’environ 1,5 litre ; c’est très dense !
Il faut donc ensuite démêler ces connexions pour pouvoir les analyser finement. Au début, on partait des atlas anatomiques dessinés au 19e siècle et on essayait de reconnaître (d’apparier) les réseaux détectés avec les structures connues. Puis, on a essayé d’obtenir ces connexions en les extrayant manuellement à l’aide de requêtes comme « afficher les connexions qui relient les zones A et B sans passer par la zone C ». Aujourd’hui, on utilise des algorithmes d’extraction automatique qui détectent des composantes principales (des tendances) pour construire des faisceaux de connexion. Ces systèmes s’inscrivent dans ce qui s’appelle les neurosciences computationnelles.
B – Ces réseaux ne sont pas rigides. Ils évoluent dans le temps.
MT – Oui. Un bébé naît avec beaucoup plus de connexions que nécessaire. Puis, pendant toute l’adolescence, ça fait un peu peur, on perd des connexions en masse ; on avance le chiffre de 300 000 connexions perdues par seconde. Mais dans la même période, on spécialise et on renforce celles qui nous sont utiles ; leur utilisation augmente le diamètre et donc le débit de la connexion.
On considère que le cerveau atteint sa maturité autour de 20 ans ; après, il est plus difficile de changer notre réseau de connexions, on se contente d’ajuster le « câblage ». Il est donc fondamental d’acquérir de nombreux apprentissages dans sa jeunesse afin d’arriver au plus haut potentiel cérébral au moment où commence le déclin cognitif.
Il est aussi clairement démontré que l’activité cérébrale aide à mieux vieillir. Un neurone qui ne reçoit pas d’information via ses connexions avec d’autres neurones réduit sa taille et peut finir par mourir. On peut faire une analogie avec les muscles qui s’atrophient s’ils ne sont pas sollicités. En utilisant son cerveau, on développe sa plasticité.
Enfin, si à la suite d’un traumatisme, la voie directe entre deux régions du cerveau est endommagée, le cerveau s’adaptera progressivement. L’information prendra un autre chemin, moins direct, même à l’âge adulte. Mais la transmission d’information sera souvent plus lente et plus limitée.
B – Est-ce que nous avons tous des cerveaux différents ? De naissance ? Parce que nous les faisons évoluer différemment ?
MT – On observe une grande variabilité entre les cerveaux. Leurs anatomies présentent de fortes différences. Leurs fonctionnements aussi. On travaille pour mieux comprendre la part de l’inné et de l’acquis dans ces différences. On a comparé les cerveaux de chefs cuisiniers et de pilotes de F1. On a aussi analysé les cerveaux d’individus avant et après avoir développé une grande expertise dans un domaine comme le jonglage ou le jeu vidéo. On avance mais on ignore encore presque tout dans ce domaine.
B – Tu peux nous parler un peu des sciences que vous utilisez ?
MT – Nous utilisons beaucoup de statistiques pour modéliser les propriétés de régions du cerveau. Nous utilisons aussi l’apprentissage automatique pour comprendre quelque chose aux masses de données que nous récoltons. Comme dans d’autres sciences, il s’agit de diminuer les dimensions de nos données pour pouvoir explorer la structure de la nature.
Plus récemment, nous avons commencé à utiliser des réseaux de neurones profonds. D’un point de vue médical, cela nous pose des problèmes. Nous voulons comprendre et une proposition de diagnostic non étayé ne nous apprend pas grand-chose et pose des problèmes d’éthique fondamentaux.
B – Est-ce que l’utilisation de ce genre de techniques affaiblit le caractère scientifique de vos travaux ?
MT – Il y a bien sûr un risque si on fait n’importe quoi. Le cerveau, c’est un machin hyper compliqué et on ne s’en sortira pas sans l’aide de machines et d’intelligence artificielle : certains fonctionnements sont beaucoup trop complexes pour être explicitement détectés et compris par les neuroscientifiques. Mais il ne faut surtout pas se contenter de prendre un superbe algorithme et de le faire calculer sur une grande masse de données. Si les données ne sont pas bonnes, le résultat ne veut sans doute rien dire. Ce genre de comportement n’est pas scientifique.
B – On a surtout parlé des humains. Mais les animaux ont aussi des cerveaux ? Les singes, par exemple, ont-ils des cerveaux très différents de ceux des humains ?
MT – Je vous ai parlé de la très grande variabilité du cerveau entre les individus. On a cru pendant un temps que les cerveaux des singes ne présentaient pas une telle variabilité. Pour vérifier cela, on est parti d’un modèle de déformation. Et en réalité non, selon les régions, la variabilité est relativement comparable chez le singe et chez l’humain. Ce qui est passionnant c’est qu’on s’aperçoit que les régions qui présentent plus de variabilité chez l’humain sont des régions comme celles du langage ou de la sociabilité alors que c’est la gestion de l’espace pour les singes. Pour des régions comme celles de la vision qui sont apparues plus tôt dans l’évolution des espèces, le singe et l’humain présentent des variabilités semblables et plus faibles.
Fig.2 L’évolution du cerveau. Comparer les connexions cérébrales entre les espèces nous permet de mieux comprendre les mécanismes sous-jacents à l’évolution des espèces. @ Michel Thiebaut de Schotten
B – Tu vois comment faire avancer plus vite la recherche ?
Il faudrait que les chercheurs apprennent à travailler moins en compétition et beaucoup plus en collaboration y compris au niveau international car la complexité du problème est telle qu’il serait illusoire d’imaginer qu’une équipe seule parvienne à le résoudre. Avec l’open data et l’open science, on progresse. Certains freinent des deux pieds, il faut qu’ils comprennent que c’est la condition pour réussir. Il faut par exemple transformer la plateforme de diffusion des résultats en neurosciences, lancer des revues sur BioRxiv, l’archive de dépôt de preprints dédiée aux sciences biologiques.
B – On a quand même l’impression, vu de l’extérieur, que ton domaine a avancé sur l’observation mais peu sur l’action. Nous comprenons mieux le fonctionnement du cerveau. Mais peut-on espérer réparer un jour les cerveaux qui présentent des problèmes ?
MT – Vous avez raison. On voit arriver des masses d’articles explicatifs mais quand on arrive aux applications, il n’y a presque plus personne. Si une connexion cérébrale est coupée, ça ne fonctionne plus ; que faire ? La solution peut sembler simple : reconstruire des connexions par exemple avec un traitement médicamenteux. Sauf qu’on ne sait pas le faire.
Dans un tel contexte, il est indispensable de prendre des risques, ce qui pour un scientifique signifie ne pas publier d’articles présentant des résultats positifs pendant « un certain temps ». En France, nous avons, encore pour l’instant, une grande chance, celle d’offrir à des chercheurs la stabilité de leur poste, ce qui nous permet de mener des projets ambitieux et nous autorise à prendre des risques sur du plus long terme. Ce n’est pas le cas dans la plupart des autres pays.
On répare bien le cœur pourquoi ne pas espérer un jour faire de même pour le cerveau ? C’est un énorme défi et c’est celui de ma vie scientifique !
Serge Abiteboul (Inria, ENS Paris) et Pascal Guitton (Inria, Université de Bordeaux)
Les logiciels que nous utilisons viennent très souvent des États-Unis. C’est là-bas que l’informatique s’est épanouie, le reste du monde un peu à la traine pour un temps. Pour ne pas prendre de retard, l’URSS s’est lancée dans une entreprise de piratage informatique d’un niveau exceptionnel dans les années 60’s. C’est l’histoire que nous raconte Pierre Mounier-Kuhn. Serge Abiteboul
Fin 1969, à l’initiative des autorités soviétiques, la plupart des pays du bloc socialiste européen ont mis en œuvre un vaste projet : réaliser ensemble une gamme unifiée d’ordinateurs compatibles, en copiant les IBM/360 qui dominaient alors le marché occidental. Cette gamme EC fut laborieusement mise en chantier, subissant des retards de mise au point similaires à ceux des constructeurs occidentaux quelques années plus tôt[1]. Cependant, avec ses défauts, la gamme EC allait finalement déboucher sur deux générations d’ordinateurs qui équipèrent les pays du bloc soviétique, constituant l’un des plus grands développements informatiques multinationaux de l’époque. C’est aussi, en un sens, la plus grande opération de piraterie de l’histoire de l’informatique.
Des ordinateurs sous tensions
Les débuts de l’informatique en URSS avaient subi de fortes tensions. D’un côté, des ingénieurs et des scientifiques de grand talent s’intéressaient à l’automation, aux calculateurs électroniques et à la théorie des algorithmes, répondant aux besoins d’un complexe militaro-industriel engagé à fond dans la course à l’arme nucléaire et à la conquête spatiale. De plus, l’économie socialiste planifiée s’accommodait bien des grands systèmes d’information centralisés comme les informaticiens les concevaient à l’époque.
En revanche, jusqu’au milieu des années 1950, la politique idéologique du parti communiste proscrivait les « sciences bourgeoises », la cybernétique tout comme la génétique : un chercheur qui s’y référait risquait le camp de concentration ! D’autre part, la planification entravait l’innovation et la mobilité des investissements vers une technologie imprévue mais prometteuse. Et l’absence de marché ne favorisait pas la diffusion massive d’ordinateurs, seule capable de justifier la mise en production de composants nouveaux. D’où un retard technique permanent, à côté d’une grande créativité en matière d’architectures et de mathématiques appliquées.
Le premier ordinateur d’Europe continentale fut pourtant bel et bien construit en URSS. Dès 1948, l’ingénieur soviétique Sergueï Alexeïevitch Lebedev (1902-1974) s’était attaqué à la construction d’un calculateur électronique à programme enregistré. Malgré un manque de soutien des autorités et avec un accès parcellaire aux informations sur les progrès effectués aux États-Unis et en Europe occidentale, il mit en service sa première machine, MESM (petit calculateur électronique), fin 1951 à Kiev (Ukraine). Ce prototype contenait 6 000 tubes à vide – ce qui n’était pas si « petit » – et pouvait effectuer environ 50 instructions par seconde. Des mathématiciens de toute l’URSS firent le voyage à Kiev pour l’utiliser – voire pour s’en inspirer. Ses principales applications concernaient la balistique et les fusées, ainsi que le problème qui préoccupait initialement Lebedev, le calcul de lignes de transmission téléphoniques. Lebedev s’installe bientôt à Moscou, où il dirige la conception d’une longue lignée d’ordinateurs puissants, les BESM sous l’égide de l’Académie des Sciences.
En concurrence avec Lebedev, une équipe de l’Institut d’électrotechnique de l’Académie des Sciences conçoit de petits ordinateurs ‘M’. Des variantes sont réalisées à la fin des années 1950 dans divers centres de recherche de pays satellites ou annexés : Hongrie, Pologne, Arménie, Biélorussie, ainsi qu’en Chine. Un laboratoire dépendant du Ministère de la Mécanique construit Strela (flèche), prototype d’une première série d’ordinateurs soviétiques ; les mémoires sont à tubes cathodiques, comme dans le Mk1 de l’université de Manchester[2]. D’autres séries d’ordinateurs (Ural, etc.) seront développées jusqu’en 1968 dans divers laboratoires de recherche publique.
L’une des architectures les plus originales est le calculateur en base ternaire, concept imaginé dès le XIXe siècle par l’Anglais Fowler, redécouvert et développé à l’université de Moscou par l’équipe de N.P. Brusentsov. Son ordinateur Setun entre en service en 1958 et démontre ses avantages : la logique ternaire (oui / non / incertain), inspirée d’Aristote, correspond bien à la pensée humaine et facilite la programmation. Du point de vue électronique, le système ternaire permet de traiter plus d’informations que le binaire, donc réduit le nombre de composants et par conséquent la consommation électrique. Réalisé en technologie à noyaux magnétiques, cet ordinateur petit et fiable entre en service en 1958 et sera construit à une cinquantaine d’exemplaires.
Vers 1960, l’existence d’ordinateurs de plus en plus nombreux dans les usines et les administrations inspire même au jeune colonel Kitov, passionné de cybernétique qui dirige un centre de calcul militaire, l’idée de les interconnecter pour constituer un réseau de données à l’échelle de l’URSS. Ce système permettrait, à travers un tableau de bord électronique, de connaître et de piloter presque en temps réel l’économie de l’Union, en optimisant le processus de planification centralisée. Le mathématicien Viktor Glushkov, fondateur de l’Institut de Cybernétique de Kiev, imagine dans le même sens un vaste plan national d’informatisation destiné à rendre l’économie plus efficace. Ce projet rencontre une préoccupation émergente des économistes soviétiques, qui voient dans l’ordinateur un moyen de fixer les prix rationnellement en se substituant au marché par des simulations. Il est toutefois mis au panier par la direction du Parti Communiste, et son auteur relégué à des postes où il ne sera plus tenté de suggérer que des machines pourraient être plus rationnelles que les dirigeants politiques. Si la Cybernétique a été réhabilitée sous Khrouchtchev, c’est comme pensée technique, mais certainement pas comme pensée socio-politique susceptible de concurrencer le marxisme. Plus concrètement, l’informatisation de l’économie risquerait de faire apparaître des écarts embarrassants entre les statistiques officielles et les données réelles…
Au milieu des années 1960 les autorités prennent conscience d’un déficit d’informatisation, par comparaison avec le monde capitaliste que l’URSS s’acharne à « rattraper » : à population équivalente, l’URSS a dix fois moins d’ordinateurs que les États-Unis. Si les savants des pays socialistes ont développé de bons calculateurs scientifiques ou militaires, le gouvernement soviétique s’inquiète du retard en systèmes de gestion, indispensables à une économie planifiée. Par ailleurs l’industrialisation, le transfert des expériences de laboratoire aux fabricants de matériels est difficile. Ainsi le BESM-6, machine pipeline très performante (10 MHz, 1 MFlops) développée à l’Institut de mécanique de précision et de calcul électronique de Moscou en 1965, n’est mis en production qu’en 1968 – il totalisera 355 exemplaires livrés jusqu’en 1987.
La situation du software est encore pire que celle du hardware : les constructeurs livrent généralement les ordinateurs « nus », à charge pour les clients de développer leurs logiciels. Ça ne pose guère de difficultés pour les utilisateurs scientifiques, qui dans le monde entier sont habitués à concevoir leurs applications, voire leurs systèmes d’exploitation. Mais cette pratique est rédhibitoire dans les administrations et les entreprises. Or il n’existe pratiquement aucune industrie du logiciel dans les pays socialistes, alors qu’elle a éclot en Occident dès les années 1950. Et la diversité des modèles d’ordinateurs incompatibles découragerait toute tentative de développer des produits logiciels standard.
Dans la seconde moitié des années 1960, les autorités soviétiques cherchent à remédier à cette situation. Elles envisagent trois solutions :
Confier à leurs savants le soin de développer une famille d’ordinateurs et de périphériques compatibles, comme celle qu’IBM a annoncée en avril 1964, la gamme IBM System/360. Mais une première tentative en ce sens a déjà été faite avec le lancement d’une série « Ural » de trois modèles : leur compatibilité laisse autant à désirer que leur fiabilité et, avec environ 400 exemplaires produits, ils restent très en-dessous de ce qui serait nécessaire.
Acheter une licence d’un des constructeurs ouest-européens, notamment Siemens ou ICL, qui eux-mêmes dérivent leurs ordinateurs de la série RCA Spectra, elle-même réplique compatible de la gamme IBM/360 utilisant des circuits intégrés plus avancés. C’est ce que font d’ailleurs les Polonais avec leur série Odra sous licence britannique ICL. L’avantage de l’acquisition d’une licence est qu’elle donne accès légalement à l’ensemble des technologies et du software du bailleur.
Copier la gamme IBM System/360 en se passant de licence. C’est faisable car l’essentiel de la technologie et des codes sources sont alors facilement accessibles. Les services de renseignement soviétiques ont vraisemblablement fait valoir qu’ils pourraient obtenir ce qui n’était pas en accès libre. L’avantage est qu’une fois les machines construites, on pourra profiter de la masse de software – systèmes d’exploitation et applications – disponible gratuitement. Pour parler crûment, l’URSS imagine ainsi la plus grande opération de piraterie de l’histoire de l’informatique (IBM commencera à facturer ses logiciels à partir de 1970 en annonçant l’unbundling, le dégroupage).
Une longue suite de délibérations conduit les autorités soviétiques à choisir la troisième option, à abandonner les développements originaux d’ordinateurs de leurs centres de recherche – sauf les super-calculateurs – et à définir un « Système Unifié » copié sur les IBM/360 : la gamme (ryad) EC. Cela sans trop se préoccuper des droits de propriété industrielle.
L’historiographie de l’informatique dans l’ex-URSS reflète le choc qu’a entraîné cette décision[3] : la plupart des mémorialistes sont des scientifiques qui ont participé aux aventures technologiques des BESM, Setun et autres Ural, et qui en détaillent fièrement les innovations au fil de leurs publications ; ils profitent de la liberté de parole conquise depuis 1989 pour dénoncer amèrement l’abandon des développements nationaux, par des politiciens ignorants, au profit de machines américaines. 1969, année noire pour la créativité informatique russe. Ce qui est advenu ensuite, l’histoire de la ryad EC, reste donc dans le brouillard historiographique où se morfondent les âmes des ordinateurs maudits, not invented here.
C’est pourtant une histoire bien intéressante, à la fois du point de vue de la gestion d’un grand projet technique et du point de vue des relations internationales – des relations Est-Ouest comme des relations au sein du bloc soviétique. Elle reste à écrire en grande partie. Ce qui suit résume ce que l’on sait par diverses publications occidentales ou russes, et le travail préparatoire d’un historien des sciences hongrois, Máté Szabó, qui entreprend d’y consacrer sa thèse.
Fig. 2 Ordinateur Soviétique BESM-6, 1965. Crédit photos : Vera Bigdan, archives Boris Malynovsky
Informaticiens de tous les pays, unissez-vous !
En janvier 1968, Kossyguine, président du conseil des ministres d’URSS, invite les « pays frères » membres du Comecon à participer au projet[4]. Il faut encore près de deux ans de pourparlers avant que la plupart des pays satellites acceptent officiellement, en décembre 1969, de coopérer avec Moscou qui a réparti la réalisation de ces clones compatibles en fonction des aptitudes de ces pays.
Ceux-ci ont en commun deux motivations. Ils ne parviennent pas à répondre à la demande de leurs propres organisations en matière d’ordinateurs, les machines occidentales étant souvent trop chères pour leurs économies. Et l’URSS leur promet un soutien financier conséquent s’ils participent.
Derrière l’enthousiasme de façade, leurs attitudes varient en fonction de leurs intérêts, de leurs ressources et de leurs relations avec l’URSS. L’Allemagne de l’Est adhère d’emblée au projet : d’une part elle dispose de compétences sérieuses en informatique, qui lui assurent d’être chargée de responsabilités importantes dans le projet, juste derrière l’URSS qui s’attribue évidemment le développement des plus gros modèles ; d’autre part, la RDA possède déjà quelques exemplaires d’IBM/360 acquis plus ou moins officiellement via l’Allemagne de l’Ouest, ce qui facilitera le retro-engineering. La Bulgarie adhère aussi sans réserve, mais pour des raisons opposées : ce petit pays agricole a peu de compétences en la matière et aura tout à gagner à participer au projet.
La Pologne est moins enthousiaste, car elle produit déjà une gamme d’ordinateurs sous licence britannique ICL. La Tchécoslovaquie, encore sous le coup de la répression du Printemps de Prague, garde ses distances vis-à-vis du « grand frère », et a d’ailleurs commencé à produire sous licence une ligne d’ordinateurs conçus à Paris, chez Bull, donc incompatibles avec ceux d’IBM. La Hongrie s’est, elle aussi, lancée dans la production de machines conçues dans les pays capitalistes : des mini-ordinateurs copiés sur le PDP-8 de Digital Equipment, ou construit sous licence française CII. La Roumanie de Ceaucescu reste hors jeu, voulant marquer son autonomie et ayant passé un accord avec la France pour construire des ordinateurs de gestion CII. Cuba est inclus pour la forme, plutôt comme un futur client privilégié que comme un contributeur.
La gamme EC est ensuite laborieusement mise en chantier, subissant des retards de mise au point et de production qui rappellent ceux des constructeurs occidentaux quelques années plus tôt[5]. En décidant de cloner les machines IBM, les dirigeants soviétiques espéraient gagner du temps de développement, mais l’expérience démontre qu’il n’en est rien : le retard sur l’Occident ne sera pas comblé.
En mai 1973, date de l’annonce commerciale officielle prévue de longue date dans le plan quinquennal, la plupart des ordinateurs de la gamme sont, soit encore loin de la mise au point, soit non compatibles car issus des constructions sous licences britanniques ou françaises. L’Allemagne de l’Est présente triomphalement un ordinateur clignotant de tous ses voyants, tandis que les Soviétiques ne savent pas encore quand leur haut de gamme EC-1060 sera terminé. Leur modèle moyen est en revanche entré en production. Beaucoup de périphériques laissent à désirer. L’industrie des composants est loin de fournir des semi-conducteurs aussi performants qu’en Europe occidentale et en Amérique, où le Cocom contrôle sévèrement les transferts technologiques qui pourraient renforcer les capacités militaires soviétiques.
Ce qui est le moins transféré, ce sont les soft skills. L’adoption des machines IBM ne s’accompagne pas de l’adoption des méthodes commerciales IBM. Les constructeurs en Europe de l’Est se contentent d’installer les ordinateurs chez les clients, et repartent sans trop se soucier de la maintenance : ils ont rempli leur part d’objectifs du Plan. La programmation relève entièrement des clients, qui s’associent en clubs d’utilisateurs pour partager expériences, techniques de codage, voire logiciels. Si un effort sérieux est mené pour développer des systèmes d’exploitation, indépendamment d’IBM, aucune industrie significative du software n’en émerge.
Avec ses défauts, la gamme EC va finalement déboucher sur deux générations d’ordinateurs équipant les pays du bloc soviétique, assurant à leur secteur informatique une croissance annuelle de 15 à 20 %, du même ordre qu’en Occident. Dirigée par une agence intergouvernementale ad hoc, l’opération constitue l’un des plus grands développements informatiques multinationaux de l’époque, comparable à ce que mènent en Occident Honeywell ou Unidata à la même époque. Elle mobilise beaucoup plus de monde : de l’ordre de 20 000 scientifiques et ingénieurs, 300 000 techniciens et ouvriers dans 70 établissements de R&D et de production. Par exception, ce n’est pas un projet soviétique imposé aux subordonnés. Comme les pays satellites l’espéraient, l’URSS leur distribue des moyens financiers ou techniques à la hauteur des responsabilités qui leur sont déléguées, pour étoffer leurs laboratoires et leurs entreprises. Chaque pays est financièrement responsable de sa part du projet. Mais comme l’œuvre commune est une priorité politique, les subsides provenant d’URSS ne tarissent pas. De plus elle favorise la coopération sous forme de rencontres, de voyages d’études, de tout ce qui permet une meilleure intégration. L’industrie informatique de ces pays y gagne un vaste marché commun et une expérience professionnelle durable qui se maintiendra après la chute du communisme.
C’est d’ailleurs le seul projet collaboratif d’envergure mené par les « pays de l’Est ». Autant qu’on le sache il n’a pratiquement pas eu de volet militaire : les calculateurs spéciaux destinés à la Défense, comme au Spatial, ont continué à être conçus dans des laboratoires soviétiques bien protégés. Utilisation courante de technologies venus du monde capitaliste, mais souci permanent de souveraineté numérique : peut-être une origine lointaine de la tendance russe actuelle à constituer un internet autonome ?
Pierre Mounier-Kuhn , CNRS & Université Paris-Sorbonne @MounierKuhn
Fig. 3. Ordinateur soviétique ES-1030 au service du recensement, à Moscou (1979). (crédit photo: Archives Boris Malynovsky)Fig. 4. Ordinateur moyen soviétique ES-1035 dans un centre de traitement en URSS (vers 1983). La ressemblance avec les mainframes IBM est frappante. Mais seul un esprit malveillant imaginerait un parallèle entre le portrait de Youri Andropov, accroché au-dessus de la console, et celui du président-fondateur d’IBM, Watson, omniprésent jadis dans les établissements de sa firme. (crédit photo: Máté Szabó)
Pour aller plus loin :
[1] W. B. Holland, « Unified System Compendium », Soviet Cybernetics Review, May-June 1974, vol. 4, no 3, p. 2–58.
[2] P. Mounier-Kuhn, « 70e anniversaire de l’ordinateur : La naissance du “numérique” », Le Monde-Binaire, 16/07/2018, publié simultanément dans The Conversation France.
[3] Sur les discussions soviétiques autour du choix de la gamme EC, voir notamment B. Malinovsky et alii, Pioneers of Soviet Computing, Electronic Book, 2010, ch. 6. Pour un historique d’ensemble, voir aussi Y. Logé, « Les ordinateurs soviétiques », Revue d’études comparatives Est-Ouest, 1987, vol. 18, no 4, p. 53–75. Et Victor V. Przhijalkovskiy, « Historic Review on the ES Computers Family » (trad. Alexander Nitussov), http://www.computer-museum.ru/articles/?article=904.
[4] Comecon : Conseil d’assistance économique mutuelle, rassemblant l’URSS et ses pays satellites.
[5] W. B. Holland, « Unified System Compendium », Soviet Cybernetics Review, May-June 1974, vol. 4, no 3, p. 2–3.
[6] Il en va de même pour les petits calculateurs programmables, produits et diffusés en masse par l’industrie électronique soviétique, et qui ont fait l’objet d’une véritable culture geek en URSS dans les années 1970 et 1980 (Ksénia Tatarchenko, « “The Man with a Micro-calculator”: Digital Modernity and Late Soviet Computing Practices », dans T. Haigh (dir.) Exploring the Early Digital. History of Computing. Springer, 2019, p. 179-200).
Présentée par le ministre de l’Éducation nationale comme une innovation majeure pour notre pays [6], l’introduction de l’enseignement « Sciences numériques et technologie » (SNT) dès la classe de seconde est une des nouveautés de la dernière rentrée scolaire. En attendant la mise en place prochaine du CAPES Informatique, la question de la formation des enseignant·e·s est cruciale. Et malheureusement une approche uniquement basée sur des formations classiques (cours en présentiel) ne suffit pas pour des raisons de nombre de personnes et de temps disponible. Aussi des enseignant·e·s-chercheur·e·s ont imaginé pouvoir contribuer à les former en ligne [4] et un élan s’est créé. Nous aimerions partager avec vous cette aventure. Pascal Guitton et Thierry Viéville.
Ça y est, nos enfants vont enfin commencer à maîtriser le numérique
Oui, il a fallu beaucoup d’attentes et de tergiversations, mais notre pays a enfin enclenché depuis quelques années un mouvement pour enseigner l’informatique à nos enfants, afin de maîtriser et pas uniquement consommer le numérique. Rappelons juste les toutes dernières étapes :
2012 : Un enseignement de spécialité d’Informatique et sciences du numérique (ISN) offre de manière optionnelle aux élèves de terminale de découvrir l’informatique à travers une démarche de projet.
2015 : Un enseignement d’exploration d’Informatique et création numérique (ICN) pour les élèves volontaires de début de lycée là où c’est possible, s’initient de manière créative au numérique et à ses fondements [1].
2019 : Suite à ces réussites, un enseignement en Sciences numériques et technologie (SNT) se met en place en seconde pour toutes et tous.
Publié le 4 novembre 2018, le programme de ce dernier enseignement se compose de trois parties principales : cf. le programme [2] et une analyse de la SIF [3].
S : donne une culture scientifique et technique de base en informatique, pour que, par exemple, la notion d’algorithme, le codage de l’information ou le fonctionnement des réseaux prennent du sens ;
N : offre à travers sept thématiques (les données, le Web, Internet, la photo numérique, les réseaux sociaux, les objets connectés, la géo-localisation) de comprendre comment ça marche, pour que la technologie prenne du sens, non sans aborder aussi les aspects sociétaux qui sont liés ;
T : propose de travailler sur des activités concrètes, de manipulation et de programmation d’objets numériques pour apprendre par le faire, en manipulant l’implémentation de ces notions.
Et les profs dans tout ça ?
Mais comme pour toute création d’enseignement, la question de la formation des futur·e·s enseignant·e·s est centrale : apprendre les bases, apprendre comment apprendre ces bases, fournir des ressources (définitions, explications), des exemples de mise de œuvre, et surtout mettre à disposition les outils pour les échanges et partages entre elles et eux.
Depuis plus de cinq ans, des dizaines d’enseignant·e·s du secondaire en sciences fondamentales (maths, physique…) ou technologie et bien au-delà (sciences de la vie et de la terre, lettres, économie…) se sont initié·e·s à cette nouvelle discipline et ont commencé à l’enseigner au fil des étapes de la mise en place, ielles se sont formé·e·s avec les enseignant·e·s-chercheur·e·s des universités et organismes de recherche, et forment aujourd’hui une vraie communauté professionnelle.
Pour contribuer à développer ces enseignements dans de bonnes conditions, des communautés enseignant·e·s-chercheur·e·s se sont mobilisées de façon spontanée en plus de leurs missions initiales depuis plusieurs années. Cette mobilisation a pris des formes variées : lobbying amont auprès des décideurs politiques, participation à l’élaboration des programmes, rédaction de manuels, sans oublier bien entendu la question récurrente de la formation des professeur·e·s. Sur ce dernier point, le choix d’une mise à disposition en ligne et d’un accès gratuit à des ressources pédagogiques s’est vite imposé. En effet, on parle de plusieurs milliers de professeur·e·s à aider et organiser des cours en présentiel était hors de portée, tant pour des raisons d’emploi du temps que de financement des déplacements. Par ailleurs, les outils de type plate-forme en ligne offrent des capacités de mise en réseau et de dialogue entre participants sans équivalent avec des « modalités classiques ». Enfin, ces systèmes autorisent une gestion fine du temps consacré à l’apprentissage : disponible 24 h sur 24, ils autorisent un suivi à la carte en fonction des besoins pédagogiques et des disponibilités des enseignant·e·s.
C’est d’abord une plate-forme documentaire, regroupant des ressources baptisées « grains », qui fut développée en 2012 pour l’option ISN. Ces grains, aux formats divers (cours, articles, textes officiels, livres, ouvrages numériques, logiciels, références historiques ou culturelles…), permettent à l’enseignant·e de parfaire sa formation. Ces ressources sont gardées en archive avec un mécanisme de recherche avancée. Puis, en 2016, le projet Class´Code, grâce à un grand financement public, a permis de faire passer à l’échelle ces efforts divers. Fort de cette expérience, menée avec succès aux dires des acteurs de terrain, des services de type MOOC ont été développés, pour le primaire et le secondaire, pour l’option ICN puis pour l’enseignement SNT.
Dans quelle mesure peut-on se former en ligne ? L’accès à la formation est gratuite, les ressources sont librement partageables, mais… la ressource rare et très coûteuse est le temps de l’apprenant·e. On constate que si le nombre d’inscrits à un MOOC est en croissance depuis leur apparition en 2011, le pourcentage de personnes allant jusqu’au bout de l’enseignement est assez faible (cf. encadré sur les MOOC).
Afin d’éviter cet écueil , nous avons abordé le problème autrement en rendant totalement modulaires ces formations en ligne : toutes les ressources sont réutilisables avec les élèves sans attendre que l’enseignant ait terminé de suivre tous les cours. Par ailleurs, ces formations en ligne étaient complétées de temps présentiels en collaboration avec les formations académiques auxquels participaient les enseignant·e·s-chercheur·e·s, qui restaient ensuite au contact, en ligne, pour continuer d’accompagner. Enfin les enseignant·e·s ont pris elles et eux-mêmes en main la création de ressources, coécrit les formations, et ont in fine construit une communauté, à la fois à travers les plate-formes institutionnelles proposées par l’Éducation nationale et des initiatives tierces de ces collègues.
Du lycée à la citée : un besoin de formation citoyenne
Class´Code, formation ICN, une formation citoyenne aux fondements du numérique.
À ce jour, plus de 28 000 personnes se sont inscrites à la formation ICN [4]. Au-delà des enseignant·e·s (34 % des inscrit.e.s parmi lesquel·le·s environ 30 % ne sont prédestiné·e·s à enseigner l’option ICN), cette formation très ouverte a touché des salarié·e·s d’une entreprise (14 %) ou de la fonction publique (10 %), des étudiant·e·s (14 %) et des personnes en recherche d’emploi (13 %). Ces chiffres peuvent s’expliquer par le déficit et donc le besoin de culture scientifique et technologique du numérique de notre société.
La formation SNT était plus spécifique, comme le détaille l’analyse publiée à ce sujet [4]. Plus de 18 000 inscrits après la rentrée (novembre 2019) où la grande majorité des inscrit·e·s appartient au monde de l’enseignement secondaire, et plus de 20 % (quatre fois plus que la moyenne usuelle) d’attestations délivrées, pour former ensuite nos enfants (il est important de rappeler que le nombre d’inscrits à un MOOC ne correspond pas au nombre de personnes ayant accédé, même partiellement, au cours. Environ 20 % à 50 % en moyenne regardent vraiment le contenu, et 1 à 5 % le finissent [5]).
Et qu’en est-il de nous qui n’avons pas la chance de passer par le lycée d’aujourd’hui, parce que en formation professionnelle ou déjà plus âgé·e·s ? Comme dans cette proposition d’université citoyenne [7], le besoin de formation aux fondements du numérique est probablement une nécessité, tout au long de la vie.
Les MOOCs
Ils offrent aux apprenant·e·s une série de contenus, le plus souvent architecturés autour de vidéos d’enseignant·e·s, accompagnés de transparents, ainsi que différentes modalités d’évaluation des connaissances (quizz, questionnaires, exercices…). Par ailleurs, et c’est un des points forts des MOOC, les apprenant·e·s peuvent dialoguer entre elles ou eux, et/ou avec les enseignant·e·s via des forums de discussion ouverts à tout le monde.
Apparus en 2011 à l’université de Stanford, ces systèmes d’enseignement à distance ont connu une croissance importante. Fin 2018, on dénombrait plus de 100 millions d’inscrits à près de 11 000 cours produits par 900 universités [8].
Décriés par les uns, encensés par les autres, il n’est aujourd’hui pas possible de les ignorer mais plutôt préférable de les utiliser de façon maîtrisée pour certains types d’enseignement. Parmi leurs principaux avantages, rappelons qu’ils sont accessibles en ligne à tout moment, ce qui ouvre l’accès à des connaissances pour des personnes qui ne sont pas (ou plus) insérées dans un cursus de formation ou bien qui souhaitent suivre des cours construits dans une ville ou un pays où ils ne résident pas. Par ailleurs, leur gratuité renforce la facilité de cet accès. Enfin, ces systèmes sont suffisamment souples pour accueillir différentes approches pédagogiques.
Conclusion
Pour apprendre à enseigner le numérique, les outils numériques sont vraiment utiles quand ils sont accompagnés, en aval, par des expert.e.s qui se mobilisent pour créer des ressources et, en amont, par des enseignant·e·s qui se mobilisent pour s’en emparer et les vivre collectivement.
L’Intelligence Artificielle (IA) s’est construite sur une opposition entre connaissances et données. Les neurosciences ont fourni des éléments confortant cette vision mais ont aussi révélé que des propriétés importantes de notre cognition reposent sur des interdépendances fortes entre ces deux concepts. Cependant l’IA reste bloquée sur ses conceptions initiales et ne pourra plus participer à cette dynamique vertueuse tant qu’elle n’aura pas intégré cette vision différenciée. Frédéric Alexandre nous l’explique. Thierry Viéville.
IA symbolique et numérique
La quête pour l’IA s’est toujours faite sur la base d’une polarité entre deux approches exclusives, symbolique ou numérique. Cette polarité fut déclarée dès ses origines, avec certains de ses pères fondateurs comme J. von Neumann ou N. Wiener proposant de modéliser le cerveau et le calcul des neurones pour émuler une intelligence, et d’autres comme H. Newell ou J. McCarthy soulignant que, tout comme notre esprit, les ordinateurs manipulent des symboles et peuvent donc construire des représentations du monde et les manipulations caractérisques de l’intelligence. Cette dualité est illustrée par l’expression des frères Dreyfus « Making a Mind versus Modelling the Brain », dans un article (Dreyfus & Dreyfus, 1991) où ils expliquent que, par leur construction même, ces deux paradigmes de l’intelligence sont faits pour s’opposer : Le paradigme symbolique met l’accent sur la résolution de problèmes et utilise la logique en suivant une approche réductionniste et le paradigme numérique se focalise sur l’apprentissage et utilise les statistiques selon une approche holistique.
On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.
Sommes-nous encore partis pour un cycle, à toujours nous demander laquelle de ces deux approches finira par démontrer qu’elle était la bonne solution, ou saurons-nous sortir du cadre et trancher le nœud gordien ? C’est dans cette dernière perspective que je propose de revenir aux fondamentaux. Puisque les deux approches s’accordent au moins sur le fait qu’elles cherchent à reproduire nos fonctions cognitives supérieures, ne devrait-on pas commencer par se demander si notre cognition est symbolique ou numérique ?
Mémoires implicite et explicite dans le cerveau
A cette question, les Sciences Cognitives répondent d’abord « les deux » et soulignent (Squire, 2004) que notre mémoire à long terme est soit explicite soit implicite. D’une part nous pouvons nous souvenir de notre repas d’hier soir (mémoire épisodique) ou avoir la connaissance que le ciel est bleu (mémoire sémantique) ; d’autre part nous avons appris notre langue maternelle et nous pouvons apprendre à faire du vélo (mémoire procédurale). Nous savons que (et nous en sommes conscients, nous savons l’expliquer) ou nous savons faire (et nous pouvons en faire la démonstration, sans être capable de ramener cette connaissance au niveau conscient). On retrouve ici les principes décrits respectivement en IA par la manipulation explicite de connaissances ou implicite de données.
Les neurosciences ont identifié des circuits cérébraux correspondants, avec en particulier les boucles entre les ganglions de la base et le cortex plutôt impliquées dans la mémoire implicite, et l’hippocampe et ses relations avec l’ensemble du lobe temporal médial, essentiel pour la mémoire explicite. Les deux modes d’apprentissage sont à l’œuvre dans deux phénomènes : La consolidation et la formation des habitudes.
Les mécanismes de la consolidation
Ces mémoires complémentaires sont construites avec un apprentissage lent et procédural dans le cortex et la formation rapide d’associations arbitraires dans l’hippocampe (McClelland et al., 1995). Prenons un exemple : allant toujours faire mes achats dans le même supermarché, je vais former, après de nombreuses visites, une représentation de son parking, mais à chaque visite, je dois aussi me souvenir de l’endroit précis où j’ai laissé ma voiture. Les modèles computationnels permettent de mieux comprendre ce qui est à l’œuvre ici. Les modèles d’apprentissage procédural implicite, généralement en couches, montrent que des régularités sont extraites statistiquement, à partir de nombreux exemples dont les représentations doivent se recouvrir pour pouvoir généraliser. Mais si l’on souhaite apprendre ensuite des données avec d’autres régularités, on va observer l’oubli catastrophique des premières relations apprises.
Inversement, dans un modèle d’apprentissage explicite de cas particuliers, généralement avec des réseaux récurrents, on va privilégier le codage de ce qui est spécifique plutôt que de ce qui est régulier dans l’information (pour retrouver ma voiture, je ne dois pas généraliser sur plusieurs exemples mais me souvenir du cas précis). Cet apprentissage sera plus rapide, puisqu’on ne cherchera pas à se confronter à d’autres exemples mais à apprendre par cœur un cas particulier. Mais l’expérimentation avec ce type de modèles montre des risques d’interférence si on apprend trop d’exemples proches, ainsi qu’un coût élevé pour le stockage des informations (ce qui n’est pas le cas pour l’apprentissage implicite). Il est donc impératif de limiter le nombre d’exemples stockés dans l’hippocampe.
Des transferts de l’hippocampe vers le cortex (que l’on appelle consolidation, se produisant principalement lors des phases de sommeil) traitent les deux problèmes évoqués plus haut. D’une part, lorsque des cas particuliers proches sont stockés dans l’hippocampe, leurs points communs sont extraits et transférés dans le cortex. D’autre part, l’hippocampe, en renvoyant vers le cortex des cas particuliers, lui permet de s’entrainer de façon progressive, en alternant cas anciens et nouveaux et lui évite l’oubli catastrophique.
La région colorée en violet foncé est le cortex cérébral. brainmaps.org, CC BY-SA
Les mécanismes de la formation des habitudes
La prise de décision peut se faire selon deux modes, réflexif et réflectif (Dolan & Dayan, 2013), tel que proposé historiquement par les behavioristes pour qui le comportement émergeait implicitement d’un ensemble d’associations Stimulus-Réponse et par les cognitivistes qui imaginaient plutôt la construction de cartes cognitives où des représentations intermédiaires explicites étaient exploitées. Là aussi, les apprentissages implicite et explicite sont à l’œuvre. Pour prendre une décision, une représentation explicite du monde permettra de façon prospective d’anticiper les conséquences que pourraient avoir nos actions et de choisir la plus intéressante. Avec sa capacité à former rapidement des associations arbitraires, l’hippocampe semble massivement impliqué dans la construction de ces cartes cognitives explicites.
Ensuite, après avoir longuement utilisé cette approche dirigée par les buts, on peut se rendre compte, par une analyse rétrospective portant sur de nombreux cas, que dans telle situation la même action est toujours sélectionnée, et se former une association situation-action dans le cortex par apprentissage lent, sans se représenter explicitement le but qui motive ce choix. On appelle cela la formation des habitudes.
Mais que fait l’IA ?
La dualité implicite/explicite a conforté l’IA dans ses aspects numériques/symboliques ou basés sur les données et sur les connaissances. L’IA n’a cependant pas intégré un ensemble de résultats qui montrent que, au delà d’une simple dualité, les mémoires implicites et explicites interagissent subtilement pour former notre cognition.
Concernant la consolidation, l’hippocampe est en fait alimenté presque exclusivement par des représentations provenant du cortex, donc correspondant à l’état courant de la mémoire implicite, ce qui indique que ces deux mémoires sont interdépendantes et co-construites. Comment ces échanges se réalisent entre le cortex et l’hippocampe et comment ils évoluent mutuellement restent des mécanismes très peu décrits et très peu connus en neurosciences.
Concernant la formation des habitudes, cette automatisation de notre comportement n’est pas à sens unique et nous savons figer un comportement puis le réviser par une remise en cause explicite quand il n’est plus efficace puis le reprendre si besoin. Là aussi, ces mécanismes sont très peu compris en neurosciences.
La modélisation a été une source d’inspiration pour aider les neurosciences à formaliser et à décrire les mécanismes de traitement de l’information à l’œuvre dans notre cerveau. Pourtant, concernant ces modalités d’associations flexibles entre nos mémoires implicites et explicites, l’IA ne joue pas son rôle d’aiguillon pour aider les neurosciences à avancer sur ces questions, car elle reste bloquée sur cette dualité rigide et stérile entre données et connaissances, alors que les relations entre connaissances et données devraient être au cœur des préoccupations d’une IA soucieuse de résoudre ses points de blocage. Il est donc temps d’exposer au grand jour ce hiatus et de demander à l’IA de jouer son rôle d’inspiration.
Frédéric Alexandre, Directeur de Recherche Inria en Neurosc iences Computationnelles, Équipe Mnemosyne.
Réferences:
Dreyfus H.L., Dreyfus S.E. (1991) Making a Mind Versus Modelling the Brain: Artificial Intelligence Back at the Branchpoint. In: Negrotti M. (eds) Understanding the Artificial: On the Future Shape of Artificial Intelligence. Artificial Intelligence and Society. Springer, London.
Lipton, Z. C. (2017). The Mythos of Model Interpretability. http://arxiv.org/abs/1606.03490
Squire, L. R. (2004). Memory systems of the brain : a brief history and current perspective. Neurobiology of Learning and Memory, 82, 171–177.
McClelland, J. L., McNaughton, B. L., & O’Reilly, R. C. (1995). Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological Review, 102(3), 419–457.
Dolan, R. J., & Dayan, P. (2013). Goals and Habits in the Brain. Neuron, 80(2), 312–325. https://doi.org/10.1016/j.neuron.2013.09.007
De nombreuses plateformes numériques mettent en contact employeurs et employés sur internet. Elles sont de plus en plus utilisées pour proposer des emplois et par les chercheurs d’emploi. Sihem Amer-Yahia et Philippe Mulhem nous ont expliqué le concept du testing algorithmique dans un article précédent. Ils expliquent ici comment le testing algorithmique sert pour vérifier des discriminations possibles voire en détecter. Il s’agit de comprendre sa complémentarité avec un testing plus classique. Serge Abiteboul
Les plateformes numériques d’emploi utilisent des algorithmes pour l’appariement entre pourvoyeurs et demandeurs d’emploi. Ces plateformes se doivent de respecter les lois sur la discrimination à l’embauche (code du travail (article L 1132-1) et le code pénal (articles 225-1 à 225-4)). Dans le cas de la recherche d’emploi « classique » (c’est-à-dire hors de ces plateformes), des propositions de testing classique existent pour mesurer les potentielles discriminations. L’étude de la discrimination dans ces plateformes doit intégrer le fait qu’elles opèrent sur de grandes quantités de données (offres d’emploi et/ou profils de chercheurs d’emploi) ; nous proposons pour cela le testing algorithmique (voir l’article précédent sur Binaire). Contrairement au testing classique comme celui présenté par la DARES (Direction de l’animation de la recherche, des études et des statistiques), le testing algorithmique automatise la vérification du comportement discriminatoire d’un algorithme d’appariement entre les pourvoyeurs et les demandeurs d’emploi. Le testing algorithmique permet de manipuler rapidement de grandes quantités de données décrivant les demandeurs et pourvoyeurs d’emploi, ce qui est une opportunité pour tester plusieurs critères de discrimination.
Nous explorons ici les apports attendus du testing algorithmique au travers du traitement de deux variantes de questions-type en nous plaçant dans un contexte d’utilisation précis. Dans la première, il s’agit de vérifier une hypothèse de discrimination (ou de la quantifier), alors que la deuxième variante est davantage utilisée pour générer des hypothèses de discrimination. Comme illustration, nous considérons le travail de Jeanne Dupond chargée par une instance régulatrice européenne de tester les discriminations éventuelles pour une plateforme imaginaire d’offres d’emploi en ligne, appelée BestTaf. Jeanne utilise un outil de testing algorithmique.
Nous rapportons des résultats préliminaires obtenus sur la plateforme d’offres d’emploi TaskRabbit. Nos tests ont porté sur 5 300 demandes d’embauche dans plus de 50 villes américaines et quelques villes anglaises, sur 113 catégories d’emplois différentes.
Vérification d’hypothèses de discrimination
Dans un premier temps, Jeanne étudie si certaines discriminations déjà rencontrées dans d’autres études existent aussi sur BestTaf. Par exemple, elle veut vérifier deux hypothèses : la première selon laquelle les femmes sont plus discriminées que les hommes pour les postes de cadre dans la maintenance de machine-outil dans la région de Grenoble, la seconde selon laquelle les hommes entre 55 et 62 ans sont plus discriminés que les hommes entre 20 et 30 ans pour des postes de développeur informatique dans la région de Berlin. Le système de testing doit vérifier si les groupes de personnes sont traités de la même manière en comparant les classements des chercheurs d’emploi sur la plateforme.
Contrairement au testing classique qui repose typiquement sur quelques centaines d’utilisateurs, le testing algorithmique peut prendre en compte sans difficulté des milliers de personnes. Par exemple, la plateforme de recherche d’emploi TaskRabbit inclut plus de 140 000 demandeurs d’emploi. Le testing algorithmique peut ainsi être utilisé pour vérifier des hypothèses sur un très grand nombre de personnes. Il peut également être utilisé pour affiner les résultats suivant une dimension ou une autre. Par exemple, Jeanne pourra tester si les offres dans le quartier de Neuköln à Berlin sont moins discriminatoires que celles de Pankow à Berlin.
L’analyse des offres d’emploi de TaskRabbit a permis de montrer que l’origine ethnique est une source de discrimination à l’embauche aux États-Unis, tous emplois confondus. Une telle observation a déjà été faite par un testing classique réalisé en France sur le groupe CASINO. Plus précisément, nous avons trouvé que les personnes d’origine asiatique étaient plus discriminées que les personnes caucasiennes.
Génération d’hypothèses de discrimination
Dans un second temps, Jeanne se pose des questions plus générales, pour lesquelles elle n’a pas toutes les « cartes en main ». Elle veut par exemple obtenir les groupes de personnes (femmes dans certaines tranches d’âge, hommes) par rapport auxquels un groupe de référence, par exemple les femmes entre 40 et 50 ans, sont les plus discriminées à Paris. Dans ce cas, le testing algorithmique doit explorer les groupes qu’il va comparer au groupe de référence. C’est-à-dire, qu’il peut générer des hypothèses qui n’ont pas été exprimées par Jeanne. Cela permet alors à Jeanne d’identifier rapidement des comportements non-attendus afin, dans un second temps, de les explorer plus finement par un autre testing algorithmique ou même par un testing classique.
Par exemple, sur les données de TaskRabbit, notre testing algorithmique a trouvé que les emplois les plus discriminés sont les travaux de bricolage et les postes dans l’événementiel, et les moins discriminés sont l’aide à l’assemblage de meubles, et l’aide pour les courses. Nous avons également observé que, pour la seconde question de génération d’hypothèses portant sur des villes, pour tout travail confondu, les villes de Birmingham au Royaume Uni et d’Oklahoma City aux États-Unis sont les plus discriminatoires, alors que San Francisco et Chicago le sont le moins.
Les testings algorithmique et testing sont complémentaires selon plusieurs dimensions :
Quantité. Habituellement, le testing classique étudie les offres pour quelques dizaines ou centaines de personnes. Le testing algorithmique est lui capable de traiter rapidement des milliers d’emplois, de personnes, de zones géographiques. Le testing algorithmique peut venir étayer des résultats du testing classique sur un grand nombre de données (vérification d’hypothèses). Avec la génération d’hypothèse, il peut aussi réduire le coût de déploiement du testing classique. De son côté, le testing algorithmique peut aussi être utilisé pour développer une meilleure « intuition » des discriminations et réduire le nombre de tests à vérifier par le second.
Dynamicité. Le testing algorithmique a la capacité de proposer l’exploration interactive de discriminations potentielles, en jouant sur la granularité des paramètres présents (âges, localisation, catégorie d’emploi, …). Il peut aussi, grâce à la vitesse de ses calculs, permettre d’explorer les évolutions des discriminations dans le temps, en se basant sur des acquisitions de données périodiques. Un tel atout permet, à la suite d’un testing classique ou algorithmique, de vérifier rapidement si une discrimination perdure.
Démocratisation. Les testing classiques pour les offres d’emploi sont l’œuvre d’experts, qu’ils soient réalisés à l’insu d’une entreprise ou parce que cette dernière les sollicite. Dans tous les cas, les personnes qui cherchent ou qui pourvoient un emploi n’y sont pas associées. Le testing algorithmique peut complémenter le testing classique en permettant à davantage d’individus d’être acteurs dans la mise au jour de discriminations dont ils font potentiellement l’objet, en offrant la possibilité de transmettre directement des alertes à la plateforme. Cette démocratisation, pour être réellement effective, devra passer par des algorithmes de testing algorithmique transparents. De tels algorithmes devront être capables d’expliquer leurs résultats de manière claire, tout en conservant un niveau de détail garantissant la protection des données personnelles.
Les limites du testing algorithmique
Les questions à résoudre pour le testing algorithmique sont nombreuses. Elles sont d‘abord philosophiques : peut-on se satisfaire de laisser un algorithme, celui de détection de discrimination, évaluer un autre algorithme, celui de la plateforme ? Quels sont les biais des données et comment les intégrer ? Peut-on accepter de « rater » des discriminations réelles et les fausses alarmes ? Comment garantir la protection des données personnelles ? Elles sont également d’ordre opérationnel : la définition de critères pour calculer les discriminations, des formules de calcul des discriminations, le développement d’une logique algorithmique permettant de détecter les angles d’analyse (groupes, régions, type de travail, période de temps), la présentation lisible des calculs et des résultats.
Il ne nous semble pas souhaitable de favoriser une automatisation à outrance du testing. Le testing algorithmique ne doit pas avoir pour vocation de remplacer, ni le testing classique, ni l’apport indispensable de l’être humain lors de tâches d’audit qui réclament une grande expertise. Par contre, il propose à l’expert un outil pour l’aider à trouver, dans de grandes quantités d’informations relatives à l’offre et à la recherche d’emploi sur internet, les signaux qui méritent une attention particulière pour une exploration des discriminations de manière dynamique et démocratisée.
Nous partageons avec vous cette invitation à la prochaine journée Sciences & Médias, qui se tiendra à la Bibliothèque nationale de France le 16 janvier 2020 sur le thème « Femmes scientifiques à la Une ! »
En raison des mouvements sociaux, la journée Sciences et Médias, initialement prévue le 16 janvier, est reportée à une date ultérieure. Nous vous prions de nous excuser ce report de dernière minute et vous tiendrons informé de la nouvelle date pour cet événement.
Le thème abordé cette année concerne les femmes scientifiques, peu présentes dans les médias. Cette absence n’est pas seulement due à la
faible proportion de femmes dans certaines disciplines scientifiques,
mais à d’autres ressorts propres au fonctionnement des médias et de la
communauté scientifique. La journée s’articulera autour d’exposés et de
tables rondes, réunissant journalistes, scientifiques et médiateurs, qui
feront un état des lieux et proposeront des solutions :
Quelle est la représentation des femmes scientifiques dans les médias ?
Quel rôle joue le vocabulaire utilisé pour les noms de métier, et au-delà ?
Quelles bonnes pratiques peuvent être mises en œuvre par les institutions
scientifiques ? Et par les médias ?
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, retrouvez tous leurs textes, ainsi que des petits défis mathématiques, dans le Calendrier Mathématique 2020 et dans la série binaire associée… Antoine Rousseau
Janvier : D’al-Khuwārizmī à Gödel
Un algorithme est un procédé qui permet de résoudre un problème sans avoir besoin d’inventer une solution à chaque fois. Par exemple, quand on a appris un algorithme pour faire un nœud de cravate, on ne se pose plus de question quand il s’agit d’en faire un. Les mathématiciens s’intéressent aux algorithmes depuis toujours, en particulier quand ils traitent de symboles comme les nombres. D’ailleurs, le mot « algorithme » vient du mathématicien perse, de langue arabe, Muhammad Mūsā al-Khuwārizmī, qui vécut au IXe siècle.
Pour décrire abstraitement un algorithme, on utilise une mémoire, c’est-à-dire un endroit où stocker des symboles. On dispose aussi d’un jeu d’instructions étonnamment simples : (i) aller chercher des symboles déjà stockés dans la mémoire, les modifier et faire des opérations dessus (ii) tester le contenu d’un endroit particulier de la mémoire, ou (iii) répéter une séquence d’opérations tant que certaines conditions restent vraies. Un algorithme est constitué d’une suite de telles instructions.
Pour illustrer cette notion, considérons une méthode attribuée à Euclide (vers 300 avant notre ère) qui permet de calculer le plus grand diviseur commun de deux nombres entiers, leur PGCD. (Par exemple, le PGCD de 6 et 15 est 3, car 3 divise ces deux nombres, et aucun nombre plus grand que 3 ne le fait.)
On commence par regarder les deux nombres. Si l’un divise l’autre, c’est gagné : le plus petit est le PGCD. Sinon, l’algorithme préconise d’ôter au plus grand nombre, disons a, le plus petit, disons b. On se retrouve, comme au départ, avec deux nombres : b et le résultat de la soustraction a-b. On reproduit alors la même opération, encore et encore, jusqu’à ce que l’un des deux divise l’autre. Quels que soient les nombres de départ, un jour l’algorithme s’arrêtera avec un des deux nombres qui divise exactement l’autre. Alors, le PGCD des deux nombres de départ est ce nombre-là.
Pas besoin d’être Euclide ! Il suffit de suivre cet algorithme sans réfléchir pour obtenir le PGCD. Encore plus fort, on peut écrire un programme informatique qui réalise cet algorithme.
Si vous connaissez un minimum d’informatique, vous pouvez d’ailleurs programmer cet algorithme. Avec un peu de connaissances en maths, vous pouvez aussi vérifier qu’il calcule vraiment le PGCD de deux nombres.
Nous rencontrerons dans ce calendrier des exemples d’algorithmes qui permettent de résoudre un grand nombre de problèmes pratiques. Peut-on, quel que soit le problème, toujours trouver un algorithme qui le résolve ? Non ! Les travaux de mathématiciens des années 1930, notamment Kurt Gödel, ont montré que, pour certains problèmes, il n’existait pas d’algorithme pour les résoudre.
Pour patienter jusqu’à l’année prochaine, binaire vous invite à réécouter trois interviews de Serge Abiteboul sur les sujets de la numérisation de l’État, l’impact du numérique sur la transition énergétique et les enjeux du numérique à l’ère des réseaux sociaux.
Toute l’équipe de binaire vous retrouve le 1er janvier !
La numérisation de l’État : interviewé par Gaëlle Gangoura pour Acteurs Publics dans le cadre de la semaine de l’innovation publique
Face aux innovations numériques, l’homme reste le maître du jeu : interviewé par Yolaine de la Bigne pour EDF – podcast Ça change tout
Un nouvel « Entretien autour de l’informatique ». Guillaume Poupard a obtenu une thèse de doctorat en cryptographie sous la direction de Jacques Stern à l’École normale supérieure de Paris, dans une des meilleures équipes au monde dans le domaine. Après avoir été responsable du pôle « sécurité des systèmes d’information » à la direction technique de la Direction générale de l’armement (DGA), il est devenu Directeur général de l’Agence nationale de la sécurité des systèmes d’information (ANSSI) en 2014. Guillaume Poupard nous parle de la cybersécurité et des défis scientifiques qu’elle soulève.
Binaire : comment devient-on spécialiste de cybersécurité, et directeur de l’ANSSI ?
GP : je me suis intéressé très tôt à l’informatique théorique. Pendant mes études, j’ai fait un stage dans l’équipe de Jacques Stern de cryptographie autour de la programmation de carte à puce. Le sujet était à la fois très théorique et hyper pratique. J’ai réalisé que j’adorais ce mélange des genres. J’ai fait une thèse en cryptographie. Je suis ensuite passé naturellement de la cryptographie à la sécurité des logiciels, à la cybersécurité, à la confiance numérique, jusqu’à arriver à l’ANSSI. C’est comme cela que j’entends mon travail : participer à ce que les entreprises et les citoyens puissent avoir confiance dans le numérique qu’ils utilisent quotidiennement.
Binaire : il va te falloir un peu décrypter un certain nombre de termes employés comme cryptographie ou cybersécurité.
GP : le but de la cryptographie est de pouvoir échanger des messages sans avoir confiance dans les intermédiaires. On chiffre le message typiquement à l’aide d’une clé de chiffrement de telle façon que seul le destinataire soit en mesure d’avoir accès à son contenu. On imagine bien un gouvernement donnant des instructions à un ambassadeur ou deux conspirateurs s’échangeant des secrets. Le but est de garantir la confidentialité de la communication. C’est pareil sur Internet.
On peut aussi tenir à garantir l’intégrité du message, pour qu’il ne puisse pas être modifié par un intermédiaire. On trouve encore d’ailleurs d’autres utilisations de la cryptographie. Par exemple, dans les « rançongiciels », ransomware en anglais. Quelqu’un de mal intentionné arrive à chiffrer des données essentielles et à détruire les données originales. Il propose le code de déchiffrement contre une rançon. C’est ce qui s’est passé avec le virus WannaCry pour le service de santé NHS en Angleterre et en Écosse en 2016, bloquant des dizaines de milliers d’ordinateurs et d’équipements médicaux. Dans ce dernier cas, on perd la propriété essentielle de disponibilité de l’information.
Binaire : et la cybersécurité ?
GP : nous devons nous protéger contre des attaques informatiques, notamment via Internet. La sécurité n’est pas un sujet nouveau. Depuis toujours, les gouvernements, les entreprises cherchent à protéger la confidentialité de certaines informations. Le renseignement, un des plus vieux métiers du monde, inclut les deux facettes : chercher à obtenir des informations confidentielles, et se protéger contre les ennemis qui essaieraient de faire cela. Avant on se protégeait avec des moyens physiques comme des chiens et des fils de fer barbelés. S’il y a aujourd’hui de nouveaux risques, si on dispose de moyens numériques, le problème n’a pas changé. Il n’est d’ailleurs pas possible de séparer les mondes physiques et numériques. Par exemple, si un attaquant arrive à faire introduire une clé USB dans un ordinateur supposé être protégé ou à placer des équipements d’interception d’ondes à proximité physique d’un tel ordinateur, il peut être capable de récupérer des secrets.
Binaire : nous sommes bien dans une guerre ancienne et classique entre attaquants et défenseurs. Le numérique donne-t-il l’avantage à un des camps ?
GP : pour ce qui est de la cryptographie, dans le passé, l’avantage était à l’attaque. On finissait toujours par trouver des façons de décrypter les messages, à « casser » les codes. Très souvent, c’était un travail rémunérateur pour les mathématiciens. Aujourd’hui, nous disposons de « chiffrements asymétriques » qui permettent des échanges chiffrés avec le secret garanti entre deux interlocuteurs sans qu’ils aient eu besoin de se rencontrer au préalable pour convenir d’un « secret » commun. Le moteur de ces techniques est l’informatique. Le chiffrement demande un peu de calcul, mais c’est surtout le décryptage qui est très gourmand, demandant un temps de calcul dont l’attaquant ne dispose pas.
Bob chiffre le message avec la clef publique d’Alice et envoie le texte chiffré. Alice déchiffre le message grâce à sa clef privée. Wikipedia
De tels systèmes de chiffrement sont à la base de tous les échanges sécurisés sur Internet, par exemple des achats que nous faisons, et de plus en plus systématiquement des lectures de documents sur le web (avec HTTPS).
Binaire : comment se fait en pratique la vérification d’un circuit ou d’un logiciel ?
GP : on s’appuie sur la certification d’un produit par un tiers. En France, ce tiers doit être homologué par l’ANSSI. Évidemment, le niveau d’exigence dépend du service fourni et du contexte. On n’aura pas les mêmes exigences pour l’application qui compte vos pas et un logiciel d’une centrale nucléaire. Le plus souvent, on examine (avec différents niveaux d’attention) le code. Pour des exigences plus élevées, par exemple pour un véhicule de transport, on essaie d’établir des preuves formelles de sécurité. C’est-à-dire qu’on essaie de prouver mathématiquement à l’aide de logiciels de preuve que le logiciel ou le circuit fait bien ce qu’on attend de lui.
On réalise également de manière complémentaire des analyses de vulnérabilité. On demande à des attaquants d’essayer de trouver des failles dans le système. S’ils en trouvent, on colmate. Des chercheurs qui travaillent dans ce domaine s’amusent aussi à trouver de telles failles. La pratique responsable est de la signaler discrètement aux concepteurs, et de leur laisser le temps de la corriger avant de rendre ces failles publiques.
Il ne faut pas croire que c’est simple. Très souvent, on découvre des faiblesses. Par exemple, si les cartes bancaires ont une durée de vie assez courte, de l’ordre de trois ans, c’est essentiellement pour corriger des faiblesses de sécurité potentielles.
Binaire : la question se pose donc particulièrement pour les nouveaux protocoles. On a parlé par exemple de trous de sécurité dans la 5G.
GP : la question se pose en particulier pour la deuxième génération de la 5G, la 5G standalone. Le protocole n’est pas encore stabilisé, l’encre n’est pas encore sèche. Le travail de R&D autour du développement de ce protocole est intense.
On est dans un cas relativement simple. Comme la 5G standalone n’est pas encore utilisée, on peut changer le protocole pour fixer ses bugs sans avoir à modifier des masses de matériels et de logiciels. Par contre, quand un circuit ou un service est déployé, la découverte d’un trou de sécurité peut être extrêmement coûteuse.
Binaire : on parle d’ordinateurs quantiques. Leur menace sur ces systèmes de chiffrement est-elle sérieuse ?
GP : l’arrivée de tels ordinateurs donnerait un avantage certain aux attaquants qui pourraient casser les codes de chiffrement utilisés aujourd’hui. Mais des chercheurs sont déjà en train de travailler sur des algorithmes de chiffrement post-quantiques… alors que les ordinateurs quantiques n’existent pas encore. Ça montre bien que la menace est prise au sérieux même si je suis incapable de vous dire quand de telles machines seront disponibles.
Binaire : quels sont les sujets de recherche actifs dans ce domaine ?
GP : je vous ai parlé de la recherche d’algorithmes qui résisteraient aux ordinateurs quantiques. Mais il y a d’autres sujets.
On voit pas mal de recherche autour des chiffrements qui permettraient de manipuler les données chiffrées, par exemple avec des chiffrements homomorphes. Prenons l’exemple de la recherche d’information pour trouver dans un corpus tous les documents qui contiennent un mot particulier. Si je chiffre les documents avant de les déposer dans le cloud, le service du cloud a besoin de la clé de chiffrement pour faire cette recherche pour moi. Mais pour livrer cette clé, je dois avoir toute confiance en ce service. Comment faire si je ne l’ai pas ?
Un autre sujet où la recherche pourrait aider énormément, c’est celui de l’accès à des données chiffrées dans des circonstances exceptionnelles. Toutes les méthodes dont on dispose fragilisent le secret, comme d’avoir un tiers-parti qui soit dépositaire des secrets. La question est comment faire pour utiliser des chiffrements qui protègent parfaitement la confidentialité des données personnelles mais qui permettent d’avoir accès à ces données dans des cas exceptionnels, par exemple sur décision judiciaire. On aimerait que les juges puissent avoir accès aux données mais sans compromettre la confidentialité des données pour la grande masse des citoyens qui ne sont pas sous le coup d’une demande judiciaire.
Binaire : la cryptographie est un maillon essentiel dans le paysage mais le plus souvent les attaques ne cassent pas la cryptographie mais le protocole de communication, une implémentation d’un algorithme.
GP : tout à fait. Cela conduit au sujet passionnant de la vérification de protocoles, par exemple du protocole que vous utilisez quand vous payez avec une carte de crédit sur Internet. Le code du protocole est typiquement très court mais vérifier qu’il ne laisse pas un trou de sécurité est super ardu. Très souvent on trouve des failles.
C’est peut-être le moment de faire une distinction entre sûreté et sécurité. Un logiciel ou un matériel peut tomber en panne. Il faut gérer les pannes ; on parle de sûreté informatique. Le cas de la sécurité est différent : là, un adversaire malicieux va essayer de trouver une faille. Pour s’en protéger, il faut prévoir tout ce qu’un tel adversaire, peut-être très intelligent et avec une grande puissance de calcul, pourrait imaginer. Une autre dimension consiste à se préparer à répondre à une attaque, par exemple, dans le cas des rançongiciels, être capable de relancer les systèmes très rapidement à partir de copies des données originales et saines.
Binaire : est-ce que la sécurité des systèmes est satisfaisante ?
GP : elle ne l’est pas. Dans le numérique, la compétition est mondiale et les premiers arrivés sur un service ont une prime énorme. Alors, les développements de logiciel se font trop vite, au détriment de la sécurité. Si nous ralentissons trop un produit français pour plus de sécurité, le marché est alors pris par des services bien moins sécurisés. Le sujet n’est pas simple. Mais la situation est inquiétante même pour des produits qui par définition devraient être bien sécurisés comme des pace makers.
Binaire : on ne peut couper au sujet de l’apprentissage automatique, tellement à la mode. Est-ce un sujet pour la cybersécurité ?
GP : absolument. Pour trois raisons. D’abord, du côté des attaquants. Les systèmes et leurs défenses étant de plus en plus complexes, les attaques sont de plus en plus automatisées, agiles. On commence à les voir utiliser des techniques d’intelligence artificielle.
Ensuite, bien sûr, l’analyse de données massives et l’apprentissage automatique sont utilisés pour la défense, notamment la détection d’intrusion. Il s’agit par exemple de détecter des comportements inhabituels. Bien sûr, le système va aussi retourner de fausses alertes. Des humains vérifient.
Enfin arrive la question des attaques pour biaiser l’apprentissage automatique de systèmes. Les techniques d’apprentissage automatique restent fragiles et relativement faciles à berner, manipulables par des attaquants qui introduisent, peut-être massivement, des données biaisées. De manière générale, le domaine de l’apprentissage automatique témoigne d’ailleurs d’une certaine naïveté, d’une croyance un peu aveugle dans la technique. En cybersécurité, nous avons appris à nous méfier de tout. Il est indispensable d’instiller un peu de notre méfiance dans le domaine de l’apprentissage automatique.
Binaire : attaque ou défense. Chapeau noir ou blanc. Est-ce que ce sont les mêmes personnes qui font les deux ?
GP Dans le modèle français, le gouvernement sépare clairement les services d’attaque et de défense. Dans des pays qui ont fait un autre choix, les services qui font les deux à la fois ont une tendance naturelle a délaissé une des deux facettes. Évidemment, cela ne veut pas dire qu’on ne parle pas à l’autre bord ; on a à apprendre d’eux comme ils apprennent de nous.
Binaire : binaire s’intéresse particulièrement aux questions d’éducation. Nous imaginons bien que ce sujet se pose en cybersécurité.
GP : d’abord, le pays a besoin d’experts dans ce domaine, bac+3, bac+5 et plus. Et, tous les experts en numérique doivent acquérir des compétences en cybersécurité. Cela passe par des cours spécialisés au niveau master mais le sujet doit aussi être un fil rouge tout au long de l’enseignement de l’informatique. Enfin, tous les élèves doivent obtenir des bases de cybersécurité, au collège, au lycée. La cybersécurité doit devenir la responsabilité de tous.
J’aimerais ajouter que cela ne devrait pas juste être un truc barbant à étudier. C’est un sujet absolument passionnant, un challenge intellectuel qui peut aussi être ludique. Par exemple, j’ai étudié le calcul modulaire et cela me passionnait peu. Mais quand j’ai appris comment c’était utilisé dans des systèmes cryptographiques asymétriques, cela a été une révélation !
Dans un pays comme Israël, les élèves parmi les plus brillants, détectés à partir de 14 ans, apprennent l’informatique et se spécialisent en cybersécurité. Ce sont un peu des stars dans la société. Évidemment, la situation politique de la France est différente, mais on aimerait aussi voir plus de nos meilleurs cerveaux suivre une telle filière. C’est d’ailleurs un excellent moyen d’inclusion sociale pour les milieux défavorisés.
Serge Abiteboul, Inria et ENS Paris, Pierre Paradinas, CNAM-Paris.
Chiffrement asymétrique.
La cryptographie asymétrique est un domaine de la cryptographie où il existe une distinction entre des données publiques et privées, en opposition à la cryptographie symétrique où la fonctionnalité est atteinte par la possession d’une donnée secrète commune entre les différents participants. La cryptographie asymétrique peut être illustrée avec l’exemple du chiffrement à clef publique et privée, qui est une technique de chiffrement, c’est-à-dire que le but est de garantir la confidentialité d’une donnée. Le terme asymétrique s’applique dans le fait qu’il y a deux clefs de chiffrement (que l’utilisateur qui souhaite recevoir des messages fabrique lui-même), telles que si l’utilisateur utilise une première clef dans un algorithme dit « de chiffrement », la donnée devient inintelligible à tous ceux qui ne possèdent pas la deuxième clef, qui peut retrouver le message initial lorsque cette deuxième clef est donnée en entrée d’un algorithme dit « de déchiffrement ». [Wikipédia]
Un peu de vocabulaire
Chiffrer un document consiste à le transformer pour le rendre incompréhensible à qui ne possède pas la clé de chiffrement.
Déchiffrer est l’opération inverse qui consiste à reconstruire le document à partir du document chiffré et de la clé.
Décrypter consiste à reconstruire le document sans avoir la clé. On dit alors qu’on a « cassé » le code de chiffrement.
Un nouvel « Entretien autour de l’informatique ». Ancien banquier entré chez les Dominicains en 2000, Éric Salobir, prêtre, est un expert officiel de l’Église catholique en nouvelles technologies. Ce passionné d’informatique a créé Optic, un think tank consacré à l’éthique des nouvelles technologies. Il cherche à favoriser le dialogue entre les tenants de l’intelligence artificielle et l’Église. Il est aussi consulteur au Vatican.
Le libre arbitre de l’individu
Le père Eric Salobir, collection personnelle
B : devant des applications qui peuvent prédire nos futures décisions et actions avec une précision croissante, que devient le libre arbitre ?
ES : on n’a pas attendu l’IA pour que l’humain soit prévisible ! Il suffit de lire « L’art de la guerre » de Sun Tzu. L’art de prédire le comportement de l’autre, de lire l’humain, fait partie des appétences de l’être humain. Mais on y arrive mal, et si par exemple, il y avait un psychopathe à l’arrêt de bus, on ne s’en apercevrait jamais. Avec la récolte de données très détaillées et leur analyse, on dispose de nouveaux moyens très efficaces pour assouvir ce désir très ancien. Pour moi, cela ne remet pas en cause le libre arbitre dans son principe, mais nous amène à questionner ce qui relève de la liberté et ce qui relève du conditionnement.
C’est une nouvelle étape d’un long cheminement. Freud ne remet pas en cause le fait qu’il y ait une part de liberté mais en redéfinit les contours, et ses travaux sur l’inconscient donnent des éléments qui restreignent le champ de la liberté en déterminant le comportement. Le mythe de la complète liberté a été démonté par Gide dans « Les Caves du Vatican » : Lafcadio décide de jeter quelqu’un par la porte du train pour prouver qu’il est libre, mais l’intentionnalité fait que ce n’est pas un geste complètement gratuit. La liberté totale n’existe pas, son absence totale non plus. Nous vivons entre les deux, et actuellement il est essentiel pour nous de mieux saisir les frontières.
B : avec les nudges (incitations en français), n’assistons-nous pas à un rétrécissement du libre arbitre ?
ES : de tels usages de l’IA permettent de court-circuiter le circuit décisionnel en s’appuyant presque sur la dimension reptilienne de notre mode de fonctionnement, et c’est inquiétant. Le nudge n’est pourtant pas non plus un phénomène nouveau. Par exemple, considérez la porte d’entrée de la basilique de la Nativité de Bethléem, qui fait 1 mètre 10 de haut. Vous êtes obligé de vous courber pour entrer, de vous incliner, puis après être entré, vous vous redressez, et vous prenez conscience que votre stature humaine naturelle est d’être debout. Ce nudge-là est ancien. Ce qui a changé, c’est qu’on est passé d’un nudge extérieur, qui s’appuie sur la corporalité et avec lequel on peut prendre de la distance, à des technologies numériques qui affranchissent partiellement de cette corporalité, avec le danger que l’on perde cette capacité à prendre de la distance par rapport à certain nudges.
Avec la publicité, lorsque quelque chose est présenté exactement au bon moment, quand on est vulnérable ou fatigué et que de plus, il suffit pour acheter d’appuyer sur un bouton, avec un geste physique qui est quasiment imperceptible, on est alors poussé à acheter. C’est pareil avec certains mouvements à caractère sectaire, qui savent saisir le moment où une personne est la plus fragile, dans un moment d’épuisement, et faire d’elle un peu ce qu’ils veulent. Cela explique aussi en partie la radicalisation en ligne, qui passe par la détection de personnes en situation de vulnérabilité, d’échec ou d’isolement. Cela ne veut pas dire que le libre arbitre n’existe plus, mais que certains empiètent sur le libre arbitre des autres. Cela a toujours existé, par exemple avec les fresques érotiques qui attiraient le passant à Pompéi. Mais on a clairement maintenant franchi un cap assez net en termes d’intrusion. Certaines manipulations peuvent aller jusqu’à menacer le vivre-ensemble et la démocratie. C’est inquiétant !
Lien virtuel
Les liens entre les personnes
B : les gens passent maintenant beaucoup de temps dans un monde virtuel, déconnecté de la vie physique. Cela a-t-il des conséquences sur leurs relations avec autrui ?
ES : ce qui est virtuel, c’est ce qui est potentiel, comme des gains virtuels par exemple. Le numérique n’est pas si « virtuel » que ça. Peu de choses y sont virtuelles, sauf peut-être les univers de certains jeux vidéo sans lien avec le monde réel. Et encore, même là, les jeux en ligne massivement multi-joueurs impliquent de vrais compétiteurs.
Le numérique permet un nouveau mode de communication, et les jeunes peuvent avoir une vie numérique au moins aussi riche que leur vie IRL (in real life), et qui complète leur vie IRL. La communication numérique est pour beaucoup, je pense, une communication interstitielle. Certes, les adolescents peuvent rencontrer des gens en ligne, mais ils ont surtout un fonctionnement relativement tribal. Ils hésitent à parler à qui ne fait pas partie de la bande. Les modes de communication numériques vont principalement servir à combler les lacunes des relations déjà existantes.
Évidemment, cela change les modes et les rythmes de présence. Autrefois quand le jeune rentrait chez lui, il était chez lui, injoignable sauf en passant par le téléphone de la maison familiale. Maintenant la communication avec ses pairs continue dans sa chambre et jusque dans son lit. Un enfant harcelé en classe par exemple ne pourra plus trouver de havre de paix à domicile. Un harcèlement bien réel peut devenir omniprésent.
La relation au temps et à l’espace rend plus proches de nous un certain nombre de gens, et cela change la cartographie. J’ai des amis un peu partout dans le monde, et les réseaux sociaux leur donnent une forme de visibilité et me permettent de garder des liens avec eux. C’est positif.
Et l’amour ?
B : peut-on, avec le numérique, mettre l’amour en équations ?
ES : l’amour est un sentiment complexe, et toute réponse à cette question appelle aussitôt la controverse. Pour certains spécialistes de neurosciences, il s’agit seulement d’une suite de réactions chimiques dans notre cerveau. Le psychologue rétorque que cette réponse explique comment ça se passe, le mécanisme, mais ne dit pas pour autant ce que c’est. Ces deux points de vue sont quand même assez opposés. Pour ma part, je dirais que, même si on a l’impression que, scientifiquement, on comprend un peu la façon dont cela se passe, ça ne nous dit pas grand-chose de la nature du phénomène, ou en tout cas pas assez pour que ce phénomène soit réductible à ce fonctionnement électrique et chimique.
Une vidéo d’un petit chat, ou même un Tamagotchi, suffit à susciter une réaction d’empathie. L’humain a cette belle capacité de s’attacher à à peu près tout et n’importe quoi, mais ça a plus de sens s’il s’attache à ses semblables, sa famille, ses amis. Ce sont des liens forts.
Surtout, il ne faut pas tout confondre. J’ai des liens très forts avec un petit nombre de gens et cela n’a rien à voir avec tous ces liens faibles qui se multiplient avec mes contacts sur les réseaux sociaux. L’appétence pour une forme de célébrité (même relative) prend de plus en plus de poids. Je suis étonné de voir à quel point cela se confond avec l’amour dans la tête d’un grand nombre de gens. C’est l’aspect négatif d’un média bidirectionnel : chacun peut devenir connu comme un speaker du journal de 20 h.
Je pense qu’on réduit l’amour à la partie équations quand on fait cette confusion. On floute les contours de l’amour, on le réduit tellement qu’on peut alors le mettre en équations.
Une autre inquiétude est qu’on peut effectivement avoir l’impression qu’on va susciter de l’empathie chez la machine. Les machines peuvent nous fournir les stimuli dont nous avons envie, et elles savent imiter l’empathie. Certains disent que cette simulation vaut le réel, mais ce n’est pas la même chose, c’est seulement une simulation. Le film Her illustre cette question. Le danger, quand on simule l’empathie, c’est qu’on met l’autre dans une situation de dépendance. L’humain risque de se laisser embarquer dans une relation avec des objets dits intelligents. Et cette relation est différente de celle que l’on pourrait établir, par exemple, avec un animal de compagnie. Certes, un chien veut être nourri, mais il n’a pas une relation purement utilitariste : ses capacités cognitives et relationnelles permettent d’établir avec lui une forme de lien, certes asymétrique mais bidirectionnel. Alors qu’avec la machine, on va se trouver dans une relation bizarre, totalement unidirectionnelle, dans laquelle nous sommes seuls à projeter un sentiment.
B : vous parlez de relation unidirectionnelle. Mais pourquoi est-ce moins bien qu’une personne ait en face d’elle un système qui simule l’empathie ? Si cela fait du bien à la personne ? On a par exemple utilisé de tels systèmes pour améliorer le quotidien d’enfants autistes.
ES : Vous faites bien de préciser « simule ». Ce ne sont pas des systèmes empathiques. Ce sont des systèmes qui simulent l’empathie, comme un sociopathe simulerait à la perfection le sentiment qu’il a pour une personne, sans pour autant rien ressentir. Le principe de l’empathie, c’est qu’elle change notre mode de fonctionnement : on est touché par quelqu’un et cela nous transforme. Notre réaction vient du fond du cœur.
Ce n’est certes pas une mauvaise chose que d’améliorer l’expérience de l’utilisateur, qu’il soit malade ou pas, mais cette dimension unidirectionnelle de la relation peut potentiellement être nocive pour une personne en situation de fragilité. Celui qui simule l’empathie est dans la meilleure situation possible pour manipuler l’autre. Jusqu’où faut-il manipuler les gens, surtout s’ils sont en situation de fragilité ?
Dans le cas de la machine, l’enjeu réside donc dans le but de la simulation. Si elle est élaborée par le corps médical pour faciliter la communication avec une personne malade ou dépendante, et pour faire évoluer cette personne vers un état meilleur, elle peut être tout à fait légitime. Mais quid d’une empathie simulée pour des raisons différentes, par exemple commerciales ? Cela demande une grande vigilance du point de vue éthique.
La post-vérité
B : on assiste à une poussée du « relativisme ». Il n’y a plus de vérité ; les fake news prolifèrent. Est-ce que cela a un impact sur la religion ?
ES : Effectivement je pense qu’il y a un impact sur les religions car cela remet aussi en cause tout ce qui est dogme. Prenons la Trinité : pourquoi est-ce qu’ils sont trois ? Certains pourraient dire que la Trinité pose une question de parité, et qu’on n’a qu’à rajouter la Vierge Marie, comme ça ils seront quatre !
On peut ainsi dire à peu près l’importe quoi, et c’est là le problème. Mais en fait, avant d’être religieux, l’impact de cette remise en cause de la notion de vérité est d’abord intellectuel. L’opinion finit par l’emporter sur le fait, même démontré. D’un point de vue philosophique, cela mènerait à dire que notre relation au réel est plus importante que le réel lui-même. Or, les sciences lèvent des inconnues, répondent à des questionnements, même si elles découvrent parfois leurs limites. Mais, sans les connaissances que nous accumulons, l’océan d’à-peu-près brouille notre compréhension du réel.
Cela risque de conduire à une remise en question de notre société parce que, pour vivre ensemble, nous avons besoin de partager des vérités, d’avoir des bases de connaissances communes. Par exemple, l’activité humaine est-elle le facteur majeur du réchauffement climatique ou pas ? Ce ne devrait pas être une question d’opinion mais de fait. À un moment donné, cela va conditionner nos choix de façon drastique.
La spiritualité
B : est-ce qu’il reste une place pour la spiritualité, pour la foi, dans un monde numérique ?
ES : il est intéressant de voir à quel point le monde numérique, dans ses dimensions marchandes, économiques, est matérialiste. Et pourtant, on constate que le besoin de spiritualité n’a vraiment pas disparu. Voyez le succès, dans la Silicon valley, des spiritualités orientales, qui arrivent parées d’une aura exotique et lointaine, malgré la dimension syncrétiste de la version californienne. Si des patrons font venir à grand frais des lamas du Tibet, c’est parce que cela répond à un besoin.
Je crains que la plupart de nos contemporains ne soient obligés d’assouvir ce besoin avec ce qu’ils ont sous la main, et le piège, c’est que ce soit la technologie elle-même qui vienne nous servir de béquille spirituelle ! Dans à peu près toutes les traditions religieuses, il existe la tentation de créer un objet, souvent le meilleur qu’on soit capable de concevoir, de le placer en face de soi, au centre du village, de le révérer, et d’attendre qu’il nous procure une forme d’aide, de protection, voire de salut. C’est le principe du totem et du veau d’or.
Le HomePod était l’objet le plus vendu aux USA à Noël dernier. Il est connecté à tout, il est l’accès de toute la famille au savoir, à une espèce d’omniscience et d’ubiquité sous le mode de la conversation, en court-circuitant l’étape de la recherche via un moteur qui proposerait plusieurs réponses. Il devient un peu l’oracle, une Pythie qui serait la voix du monde. Les gens utilisent aussi le HomePod pour connecter tout leur quotidien. Le HomePod met le chauffage en route, envoie un SMS pour avertir que les enfants sont bien rentrés de l’école et branche l’alarme, pour veiller sur la maison en notre absence. Ainsi, le HomePod est une entité qui s’occupe de la famille, une entité physique placée sur un piédestal dans le foyer, un peu comme un Lare, une petite divinité domestique qui prend soin de chacun. Cela exprime une relation à la technologie qui peut être une relation d’ordre spirituel.
Le petit dieu de la maison, Serge A.
Le problème, c’est que la technologie ne fait que ce pour quoi elle a été prévue. L’être empathique, lui, va faire des choses pour lesquelles il n’a pas été programmé, il va se surpasser, se surprendre quand il est poussé à faire des choses qui sortent du cadre, alors que cette technologie ne va faire que les choses pour lesquelles elle a été programmée. Dans la tradition juive, le psalmiste disait en se moquant des faux dieux : « Ils sont faits de mains d’homme, ils ont des oreilles mais n’entendent pas… » Sauf que le HomePod entend, et si on lui dit « Commande moi une pizza ! », et bien, il vous apporte le dîner. De ce fait, l’illusion est beaucoup plus réaliste.
B : vous parlez de « petit dieu ». Est-ce que le numérique peut aussi proposer Zeus, un « grand Dieu » ?
ES : pour le moment, l’humain n’a pas encore été capable d’en fabriquer. La pensée magique est liée à la spiritualité. Cette pensée magique n’a jamais complètement disparu, et certains sont persuadés qu’un jour on créera une IA suffisamment puissante pour qu’on puisse la prendre pour un dieu. Il est vrai qu’une intelligence artificielle vraiment forte commencerait à ressembler à une divinité. Ce serait alors peut-être confortable pour l’humain de déléguer toutes ses responsabilités à une telle entité. Mais si on peut se complaire dans un petit dieu, je ne pense pas que nous serions prêts à accepter qu’une machine devienne comme Zeus. Est-ce que nous serions prêts à entrer dans ce type de relation ? Un dieu qu’on révérerait ? Je ne pense pas.
La place du Créateur
B : nous créons des logiciels de plus en plus intelligents, des machines de plus en plus incroyables. Est-ce que toutes ces créations nous font prendre un peu la place du Créateur ?
ES : le scientifique dévoile une réalité qui lui préexiste, alors que l’inventeur, le spécialiste de technologie, fabrique quelque chose qui n’existait pas auparavant, comme un téléphone intelligent par exemple, et cela induit un rapport au réel assez différent. L’inventeur se met un peu dans la roue du Créateur : c’est quelque chose qui est de l’ordre du talent reçu. En ce sens, si on considère que Dieu est Créateur et que l’homme est à l’image de Dieu, il est naturel que l’être humain veuille également créer ; cela tient du génie humain.
Mais, créer, techniquement, c’est créer ex nihilo. Au commencement, dit la Bible, il y avait le chaos. Une part de substrat, mais informe. Quand un humain dit qu’il a créé quelque chose, en fait, à 99%, il reprend des brevets existants, même s’il peut amener une réelle rupture. L’iPhone qu’on utilise juste avec les doigts, sans stylet, nous a ouvert de nouvelles perspectives d’accès à l’information en situation de mobilité. Sans sous-estimer l’apport des humains qui ont inventé cela, cela tient de l’invention, de la fabrication, et je n’appellerais pas cela véritablement de la « création ».
En revanche, ces technologies nous permettent de bâtir, de construire ensemble quelque chose de nouveau. Ces technologies sont nos réalisations. Ce sont des productions de notre société, aux deux sens du génitif : elles sont produites par ladite société, et ainsi elles nous ressemblent, elles portent en elles une certaine intentionnalité issue de notre culture ; mais, en retour, leur utilisation façonne notre monde. D’ailleurs, quand un pays, consciemment ou inconsciemment, impose une technologie, il impose aussi sa culture, car en même temps, ces technologies transforment la société qui les reçoit. C’est le principe du soft power.
Dans ce cadre, on voit bien que l’intelligence artificielle permet une plus grande personnalisation. Comment faire en sorte que cette personnalisation ne se transforme pas en individualisme ? Il y a un effet de bulle : tous ceux avec qui je serai en contact vont me ressembler, et tout sera conçu, fabriqué exactement pour moi. De plus en plus, le monde numérique, c’est mon monde, un monde qui devient un peu comme une extension de moi-même. C’est extrêmement confortable, mais le danger, c’est que mon réel n’est pas votre réel, et alors comment se fait l’interaction entre les deux ?
La difficulté réside dans le fait que, si chacun configure de plus en plus précisément son réel autour de lui, la rencontre de ces écosystèmes risque d’être de plus en plus complexe. Les difficultés en société ne seront alors plus entre les communautés et le collectif, mais entre chaque individu et le collectif. Comment l’humain qui s’est créé sa bulle peut-il être en adéquation avec un référentiel, et comment faire évoluer ce référentiel ? Si chacun a ses lunettes pour voir le monde en rose, en bleu, en vert, et qu’on rajoute à cela l’ultralibéralisme libertaire, cela peut mettre en danger le projet de construction de la société.
Le vrai défi est bien de garder un référentiel commun. Plutôt que de nous laisser enfermer dans une personnalisation à outrance, le vrai défi est de bâtir collectivement un vivre-ensemble.
Pour lutter contre la désaffection des jeunes pour les sciences, garçons et filles, les associations Parité Science et Femmes & Sciences et plusieurs partenaires ont pris le temps,le 9 novembre 2019, de faire le point sur l’égalité filles et garçons face à l’enseignement des sciences et à l’orientation scolaire dans notre pays, ainsi qu’aux sciences comme moteur d’intégration sociale, notamment grâce aux outils numériques. Pour partager quelques éléments clés, faisons l’interview imaginaire d’un petit garçon. Thierry Viéville.
Binaire : Bonjour Léandre, peux-tu citer le nom d’une femme scientifique ?
Léandre : Oui oui : « Isabelle Martin ».
Binaire : Ça alors ! Tu sais que la plupart des personnes auraient répondu « Marie Curie », c’est souvent la seule qu’on connaît parmi toutes les femmes scientifiques.
Léandre : Certes, mais ma sœur m’a expliqué que ça pose problème parce que si le seul modèle pour les filles qui veulent faire de la science est une personne complètement extraordinaire, alors elles vont se dire, que bon, je suis pas aussi excellente que Marie Curie, donc je n’ai aucune chance.
Binaire : Ah oui tu as raison, mais tu sais : je ne connais pas Isabelle Martin moi.
Léandre : Ben moi non plus, hihihi, mais ma sœur a fait un calcul de probabilité. Et comme Isabelle et Martin sont les prénoms et patronymes les plus courants, y’a quasiment aucune chance qu’il n’y ait pas une femme scientifique qui se nomme ainsi. C’est sûrement une personne ordinaire, qui a juste envie d’être chercheuse parce que cela lui plaît.
Binaire : Ah oui ! Mais dis moi pourquoi les filles s’autocensurent vis à vis des sciences ? Tu as vu par exemple avec la création du nouvel enseignement Numérique et science informatique qui permet enfin de s’initier à cette science récente et omniprésente avec tant de débouchés, il y a vraiment très peu de filles qui ne se sont pas autocensu…
Léandre : Hein ?!?!! A.u.t.o.-C.e.n.s.u.r.e. Faut arrêter là, non mais tu réalises pas … c’est de la censure sociale omniprésente dont on parle ici. Regarde, par exemple ça :
« On invite les filles à faire de la science au niveau européen ? C’est à travers un clip rempli d’un ramassis de clichés ! Barbie est (enfin !) informaticienne ? Elle s’occupe du graphique pendant que son mec fait la techno, comme vous l’aviez dénoncé sur binaire. Et mon horreur préférée est devant toi… regarde ces mappemondes. On en fait une rose pour les filles » . Seraient-elles trop c…s (avec 2 ‘n’) pour utiliser celles « réservées aux garçons » ? « Le fait de produire une mappemonde rose pour attirer les filles rend la bleue masculine, alors qu’elle était jusque là “normale”. De ce fait, les trucs normaux c’est pour les garçons, tandis que pour ces pauvres filles faut adapter… ».
Dès la naissance on commence à les traiter de manière biaisée. Donc NON : y a PAS d’autocensure des filles, y’a juste des filles qui finissent par baisser la tête devant la censure sociale, à force d’être exclues implicitement et très concrètement, comme le montre par exemple cette étude https://www.elephantinthevalley.com de 2015, actualisée en 2018.
Binaire : Tu exagères Léandre, les filles comme les garçons peuvent par exemple accéder aux revues scientifiques de vulgarisation.
Regarde bien, comme l’a étudié Clémence Perronnet, « sur 110 couvertures, les 4 femmes sont : (i) un robot, (ii) une statue, (iii) une surfeuse et (iv) une pauvre femme effrayée par les extra-terrestres », avec ça… vazy d’être incitée à faire de la science.
Et tu sais, il a fallu attendre 1975 (la loi Haby) pour que l’enseignement soit le même pour les filles et les garçons. Oui oui, avant , tout l’enseignement était différencié et parfois sexiste comme l’illustre cet exemple donné par la même autrice :
Binaire : Heureusement les choses progressent…
Léandre : Oui et non. Indéniablement oui à plusieurs niveaux, et c’est le résultat d’un véritable combat citoyen plus que centenaire. Mais dans plusieurs domaines et dans nos esprits, le chemin à parcourir reste long, comme on le voit ici pour les maths https://tinyurl.com/wjkgcro et comme c’est le cas en informatique où il y a même une régression. Il faudrait que les mecs se bougent un peu sur le fond.
Binaire : Attends, tu soulèves un point dont je voudrais parler en toute franchise. Beaucoup d’hommes se sentent concernés voire sont acteurs de la parité, comme dans le projet Class´Code. Mais sont parfois « piégés », juste sur un mot, une parole maladroite et paf ! le ou les voilà catalogués « vilain sexiste » alors que la personne agit pour l’égalité avec les meilleures intentions. Tu crois qu’il serait plus pédagogique de nous aider sans nous condamner d’emblée ?
Léandre : Oui, tu as raison, pas facile pour un homme de trouver sa place dans la lutte pour l’égalité… D’abord, il faut comprendre que les inégalités sont le produit du système de genre qui hiérarchise les hommes et les femmes et crée entre eux un rapport de domination.
Ce n’est pas la même chose d’agir pour l’égalité depuis la position dominante et depuis la position dominée : les hommes – qui sont du bon côté du rapport de force – ne sont jamais légitimes quand ils demandent aux femmes d’être « gentilles » dans leur lutte : la colère des opprimées est justifiée. Se battre contre des siècles d’histoire et toute la force des institutions, ça demande beaucoup d’efforts !
Là où tu as raison, c’est qu’à l’échelle individuelle et dans nos relations personnelles, la bienveillance, la pédagogie et l’humour sont nécessaires pour faire mieux et progresser, hommes et femmes ensemble.
Binaire : Ah oui je comprends mieux maintenant, et cela porte ses fruits ?
Léandre : Oui au-delà d’« activités pour les filles » qui permettent de corriger un peu les conséquences, au niveau individuel la priorité est d’éduquer les garçons, à l’égalité des sexes, Isabelle Collet parle encore d’équité*.
Et au niveau structurel, il y a des mesures vraiment efficaces qui agissent sur les causes. Elles sont validées parce que des chercheurs et chercheuses en psychologie, sociologie et science de l’éducation étudient scientifiquement le sujet. Par exemple s’imposer plus d’enseignantes dans les études supérieures scientifiques. Introduire une vraie information et formation sur le système de genre. Ou encore imposer temporairement une « discrimination positive » à l’embauche qui ne fait que compenser la vraie discrimination négative de la société, jusqu’au rétablissement d’une équité.
Binaire : C’est donc la science qui peut aider à permettre que les deux moitiés de l’humanité profitent de la science alors ?
Léandre : Et oui, la boucle est bouclée.
Contenus et relecture de Clémence Perronnet et Isabelle Collet, avec la complicité de « Léandre ».
(*) Égalité/Équité des sexes/genres , quelques précisions:
– « sexes » ou « genres » : puisque l’objectif est l’égalité entre les êtres humains quelles que soient leurs caractéristiques biologiques (organes génitaux) nous parlons bien de sexe, de l’abolition du processus social de hiérarchisation des données biologiques dans la production d’une bi-catégorisation sociale (qui correspond au genre = féminin/masculin). Pour atteindre l’égalité des hommes et des femmes, il faut déconstruire le genre, c’est-à-dire les concepts de féminin et masculin qui sont historiquement inégalitaires. Le genre étant défini comme la bi-catégorisation hiérarchisée des sexes, une « égalité des genres » est un oxymore.
– « égalité » ou « équité » : le débat est complexe car tout le monde n’attribue pas le même sens à ces mots. Dans le vocabulaire des SHS la notion d’équité implique une correction des inégalités, alors que la notion d’égalité suppose la non-production d’inégalités (à ne pas confondre avec « égalité des chances »), on va donc choisir égalité ou équité selon que l’on parle de l’abolition des inégalités ou de la compensation de leur permanence.
Sidonie Christophe est chercheuse au sein du Laboratoire en sciences et technologies de l’information géographique (LaSTIG). Dans ce deuxième billet (d’une série de trois), elle nous explique comment elle traite la notion de style – assez simple à concevoir d’un point de vue artistique mais difficile à décrire du point de vue informatique. Un mélange de rigueur et d’inspirations artistiques qui a plu à binaire ! Antoine Rousseau
Afin d’aider les utilisateurs à concevoir des cartes personnalisées, j’ai exploré des couleurs et des styles possibles de représentation, dans l’objectif de développer un système qui accompagne l’utilisateur dans sa démarche créative.
Comment définir le style ?
Selon le dictionnaire, le style est un « ensemble de caractères formels esthétiques de quelque chose » ou « une manière de pratiquer, définie par un ensemble de caractères, […] pour un auteur, ou une période de temps ». On peut dire que le style est une manière de faire, reconnaissable par un ensemble de caractéristiques visuelles, mais qu’on n’en connaît pas toujours toutes les recettes pour y parvenir : ce sont souvent des règles graphiques implicites qu’il faut réussir à expliciter. Afin d’explorer des styles pour les cartes topographiques, décrivant « un lieu », son relief, ses éléments naturels et ses aménagements humains, et à une échelle réduite, nous avons travaillé principalement sur les couleurs et les textures.
Carte de Saint-Jean-de-Luz, dans un style Cassini et un style aquarelle, échelle : 1:100 000 (Christophe et al. 2016)
Conception cartographique : du processus créatif à l’assistance numérique
La conception cartographique est un processus créatif fait d’une série de choix d’abstractions conceptuelles, sémantiques, géométriques et graphiques sur l’espace géographique : de nombreuses recherches ont eu lieu à l’IGN et au LaSTIG pour automatiser les processus de généralisation et de symbolisation. Si des conventions, des règles d’usages et des pratiques existent en cartographie, il n’y a pas une recette unique pour faire une bonne carte. Les cartographes utilisent la sémiologie graphique de Jacques Bertin (1967) pour manipuler des variables visuelles – taille, valeur, grain, couleur, orientation, forme – étendues par d’autres cartographes – arrangement, transparence, flou, etc. – et leurs propriétés perceptives qui permettent à l’œil humain de séparer, associer et ordonner des informations.
L’aide à la conception cartographique (conception assistée par ordinateur), en particulier pour le choix des couleurs, reste un problème complexe : l’ensemble de tout ce qu’il faut faire pour faire une bonne carte n’est pas si facile à décrire, ni à traduire efficacement pour l’ordinateur. De plus, la résolution de ce problème dépend principalement de la satisfaction de l’utilisateur, qui est particulièrement difficile à analyser et à prévoir, parce qu’elle dépend de ses besoins, de son usage final, de son contexte d’usage, de ses goûts, de ses préférences, du temps à disposition, etc. Et même si l’utilisateur dit : « je préfère utiliser ce vert pour la végétation, ce bleu pour la mer, cet autre bleu pour les rivières, ce rouge pour les routes », cela ne résout pas tout. Après application de ces couleurs à la végétation, à la mer, aux rivières et aux routes dans la carte, que devient la combinaison visuelle des couleurs, par l’effet des contrastes colorés selon les tailles, les formes, les distributions et voisinages de ces objets colorés ? Est-ce que cela permet de percevoir correctement l’espace géographique représenté ? Est-ce que cette combinaison de couleurs rend lisible l’espace géographique représenté ; est-elle harmonieuse ? Et que va devenir ce choix de couleurs, en changeant d’échelle, vu que la distribution géométrique et visuelle des couleurs sera modifiée, et risque d’impacter la qualité du rendu final ?
D’une peinture de Derain à des cartes aux couleurs de Derain
S’inspirer de cartes existantes autant que de peintures célèbres…
Afin de faciliter cette étape du choix de combinaison des couleurs, on a utilisé des sources d’inspiration pour fonctionner par analogie ou par transfert de style. Des cartes topographiques européennes et des peintures célèbres ont été utilisées, afin d’en extraire des palettes de couleurs et des façons d’associer une couleur à des objets dans la carte, typiques : quand il s’agit d’une carte, à partir des légendes, et quand il s’agit d’une peinture, à partir de règles de composition. J’ai développé un outil qui gérait l’ensemble de ces contraintes (règles de cartographie, règles de composition du peintre, préférences de l’utilisateur), via un dialogue avec l’utilisateur, pour co-construire ses palettes adaptées à son jeu de données, en sélectionnant ses couleurs dans des cartes et/ou des peintures, selon ses préférences. Ces travaux sur la couleur, ses contrastes et ses harmonies, ont permis d’explorer des palettes de couleurs, différentes de ce qu’on a l’habitude de voir, à un endroit, à un moment donné, pouvant être utilisées pour passer un message particulier, parfois étonnantes, voire déroutantes, au regard de la cartographie topographique traditionnelle, jusqu’à la spécification d’un style Pop Art permettant de revisiter la sémiologie graphique.
Et les textures dans tout ça ?
En plus de la couleur, notre idée du style avait besoin d’être enrichie de textures, pour redonner plus de « relief » à la carte et « animer » ces aplats de couleurs et ces tracés linéaires, utilisés dans les chaînes de production institutionnelles et dans les outils SIG (Systèmes d’Information Géographique). Pour sortir de ces représentations cartographiques « standardisées » ou uniformisées, et surtout pour être capable de reproduire les motifs d’occupation du sol ou le dessin au trait, réalisés manuellement, nous (IGN/LaSTIG) avons collaboré avec des chercheurs en Informatique Graphique (Inria/Maverick, IRIT/STORM), où entre cartographie et rendu expressif, nous partageons des problématiques communes d’abstraction. Nous avons travaillé sur la stylisation en cartographie, et plus précisément sur l’expressivité des textures, plutôt que l’utilisation d’aplats de couleurs ou de tracés de lignes classiques. Des outils de génération automatique de textures ont été développés et des techniques de rendu expressif ont été adaptées pour pouvoir reproduire les styles suivants :
des zones rocheuses dans les cartes de montagne, des années 50 : les textures utilisées mettaient en évidence la structure du relief, les crêtes, les cols, les vallées, mais aussi la pente, la rugosité, la dangerosité, et les zones de passage.
des cartes des Cassini (18è siècle) : les cartes des Cassini visaient la précision géométrique en utilisant la triangulation géodésique et mettaient en avant la précision des voies de circulation et des points de passage. En revanche, le remplissage de l’occupation du sol, réalisé par différents corps de métier, via différentes étapes de dessin et d’aquarellisation, est venu enrichir visuellement ces cartes par l’utilisation de motifs divers et variés, aux délimitations souvent imprécises : végétation, reliefs, fleuves et mers.
l’aquarelle, la peinture ou l’estampe, reproduisant les effets de techniques de mélanges de couleurs, de transparence et de grain de papier, comme de coups de pinceaux.
En conclusion
Ce travail interdisciplinaire, collaboratif et collectif, a demandé l’extension de standards existants sur la symbologie en cartographie, pour spécifier un style expressif et intégrer les techniques de rendu expressif, dans les SIG. Cette collaboration nous a également amené·e·s à reboucler sur les questions de choix de couleurs, et de proposer des méthodes d’optimisation pour l’exploration automatique de l’espace des palettes de couleurs.
Sidonie Christophe(Laboratoire en sciences et technologies de l’information géographique)
Il était une fois la thèse de… Tina Nikoukhah, doctorante au CMLA de l’ENS Paris-Saclay. Tina est une sorte d’historienne des images, mais en version numérique : ses travaux visent à détecter les modifications subies par des photos, en y traquant les traces, invisibles à l’œil nu, que celles-ci ont laissé dans l’image. Charlotte Truchet
Que trouve-t-on sur cette image ?
Photo originale. Crédits : Tina Nikoukhah
Un chien allongé sur du gravier, évidemment, mais pas que !
Si je vous disais qu’on peut aussi y trouver son histoire, me croiriez-vous ? Je vais vous révéler les étapes par lesquelles cette image est passée. En effet, une photo subit une chaîne de traitement à partir du moment où le capteur de l’appareil photo reçoit la lumière, et jusqu’à ce que l’image apparaisse sur nos écrans. Ces traitements sont en réalité des opérations mathématiques : il y a entre autres les étapes de dématriçage, de balance des blancs, de débruitage, les corrections d’aberrations optiques et chromatiques, et une ou plusieurs compressions. Ces opérations permettent la formation et le stockage de l’image. Par la suite, il peut y avoir d’autres opérations, tel qu’un recadrage, un filtrage ou même des retouches.
Toutes ces opérations constituent ce que nous appelons l’historique de l’image.
Mais où trouve-t-on ces informations ?
Les métadonnées EXIF, qui peuvent contenir des données telles que la date, l’heure, les informations géographiques et les réglages de l’appareil, peuvent être examinées.. Cependant, nous choisissons de ne pas nous fier aux données qui accompagnent l’image car elles peuvent être facilement modifiables et sont souvent absentes. Twitter, Facebook ou Instagram les suppriment volontairement. Notre but est d’obtenir ces informations à partir de l’image elle-même.
Chaque opération laisse une trace sur l’image, imperceptible mais souvent détectable.
Effectuant ma thèse au sein d’une équipe de traitement d’images, j’ai la chance de pouvoir travailler avec des experts du modèle de constitution d’une image numérique, qui m’aident à déduire les spécificités des traces laissées par chaque opération.
Zoom sur l’image filtrée pour voir les blocs JPEG. Crédits : Tina Nikoukhah
Par exemple, la compression JPEG a sa propre signature : des carrés de 8 pixels de côté. La plupart du temps ces traces ne se voient pas à l’œil nu mais il est possible de les faire ressortir en appliquant un filtre. Bien évidemment, cela ne suffit pas pour conclure : dans le cas de l’exemple, il n’est pas possible de savoir que l’image a subi au moins une compression JPEG et un recadrage, seulement à partir de ce filtre. Le but de ma thèse est de développer des algorithmes de détection automatique de ces traces et de donner un résultat clair associé à une probabilité de confiance.
Ces méthodes permettent-elles de détecter si une image a été truquée ? En appliquant les algorithmes de détection précédents à toutes les sous-parties de l’image, on marque comme suspectes les zones qui n’ont pas le même historique que le reste. Grâce à ces méthodes, une partie provenant d’une autre image serait suspecte (copier-coller externe) ainsi que toute retouche qui perturberait les traces présentes dans l’image (copier-coller interne, gommage, etc.).
L’enjeu pour moi est d’étudier et faire avancer la théorie, produire des algorithmes, et de publier mes résultats en ligne, sous forme ouverte, afin que toute personne puisse soumettre une photo et obtenir un rapport scientifique sur les éventuelles incohérences détectées.
En attendant, soyez prudents car il est très facile et rapide de truquer une photo !
Image retouchée par inpainting. Crédits : Tina Nikoukhah
Raconte-moi une histoire par jour… Vous souvenez-vous de cette petite lecture du soir, avant d’aller dormir ? Elle est pour beaucoup d’entre nous une petite madeleine, un souvenir d’enfant, de parent ou de grand-parent. Pour celles et ceux qui, comme nous chez binaire, sont encore de grands enfants, un collectif coordonné par Ana Rechtman Bulajich (Université de Strasbourg) a préparé le Calendrier Mathématique 2020.
Cette année, le calendrier propose un jeu mathématique par jour et des textes mensuels, qui ont été confiés à nos camarades de jeu Charlotte Truchet et Serge Abiteboul. Ces histoires d’algorithmes vous transporteront des blockchains aux algorithmes de tri en passant par le web. Si vous aimez traîner sur le blog binaire, vous adorerez vous plonger dans ces belles histoires d’algorithmes. Au moment de vous endormir, vous ne compterez plus les moutons comme avant…
C’est toujours un plaisir quand nous rencontrons des lecteurs ou quand ils nous écrivent. Cet article fait partie de ce « courrier des lecteurs ». Il touche en fait deux sujets : la numérisation des processus notamment administratifs et l’accès universel à une connexion Internet. Dans un monde de plus en plus numérique, il devient compliqué de ne pas avoir de connexion. Serge Abiteboul.
La route est longue. Jusqu’au bout du bout du monde ? Non juste un petit bourg bien français comme il en existe tant, charmant, endormi ; la mondialisation n’est passée par là que pour en faire fuir des emplois.
J’ai rendez-vous chez le notaire familial pour une succession.
Surprise. Au lieu du décor vieillot et cossu des notables de province, la jeune notaire nous reçoit dans un salon moderne où siège un grand tableau numérique, dernière génération. Tous les actes notariés sont en ligne en format électronique. Et c’est sur son grand écran qu’elle nous les fait parcourir. Nous paraphons sur une tablette. Bienvenue au 21e siècle. Je ne sais pas ce que j’attendais. Les préjugés de la capitale ont la vie dure.
Nous avons fini en moins de temps qu’il n’en faut pour passer une porte du périphérique aux heures de pointes quand ça dérape.
Les documents administratifs sont imprimés sur papier en un nombre d’exemplaires que j’ai préféré oublier. Un million de pages à parapher à la mano. Au secours ! Ne me dites pas que c’est comme ça qu’ils font à la capitale ? Et dans la Silicon Valley ? ! Il ne suffirait pas de signer électroniquement l’ensemble ?
Il me manque un papier et je dois appeler ma compagne. La 4G ne passe pas. Il faut faire autrement. Sourire las de la jolie notaire. Elle vit cela quotidiennement.
Et ce n’est pas fini. La connexion internet est étique. Le document ne passe pas. La notaire s’y reprend à plusieurs reprises. Ça prend un temps fou. Elle doit passer des coups de fil pour vérifier que c’est bien arrivé. J’avais bien entendu la colère des territoires sur les difficultés de la connexion Internet. Je la vis. Le monde est devenu numérique, les formalités administratives aussi. Mais pas partout.
Photo by freestocks.org from Pexels
Qu’est-ce que j’ai bien voulu raconter ?
Que le numérique et la campagne ne font pas bon ménage ? Encore des préjugés. Les paysans, les gens des petits bourgs, adoptent souvent le numérique avec enthousiasme. Ils ont sans doute plus à y gagner que les citadins. Ma notaire était par exemple au taquet.
Qu’il faudrait changer les procédures administratives ? Pourrait-on, par exemple, nous épargner ces paraphes d’une autre époque ? Les lettres avec accusé de réception et la queue de la poste ? C’était certainement un peu le sujet.
J’ai surtout voulu apporter une petite illustration de l’indispensable nécessité des connexions Internet. Pour déclarer ses impôts numériquement, pour faire ses choix sur Parcoursup…, pour transférer des actes notariés, on a besoin de connexion. Les territoires attendent avec impatience la fibre et la 4G car ils en ont marre de rater les trains. On me dit que celles-ci se déploient rapidement sur le territoire.

 Dans la rubrique « Il était une fois… ma thèse », binaire accueille aujourd’hui Camille Marchet, qui a obtenu un accessit du prix de thèse Gilles Kahn en 2019. Camille nous parle du contenu de sa thèse, préparée à l’IRISA, à Rennes, au cours de laquelle elle s’est intéressée à la conception d’algorithmes manipulant des séquences d’ARNs, pour le plus grand bonheur des biologistes ! Camille a aujourd’hui rejoint l’équipe Bonsai au sein du laboratoire CRIStAL, à Lille. Eric Sopena
Dans la rubrique « Il était une fois… ma thèse », binaire accueille aujourd’hui Camille Marchet, qui a obtenu un accessit du prix de thèse Gilles Kahn en 2019. Camille nous parle du contenu de sa thèse, préparée à l’IRISA, à Rennes, au cours de laquelle elle s’est intéressée à la conception d’algorithmes manipulant des séquences d’ARNs, pour le plus grand bonheur des biologistes ! Camille a aujourd’hui rejoint l’équipe Bonsai au sein du laboratoire CRIStAL, à Lille. Eric Sopena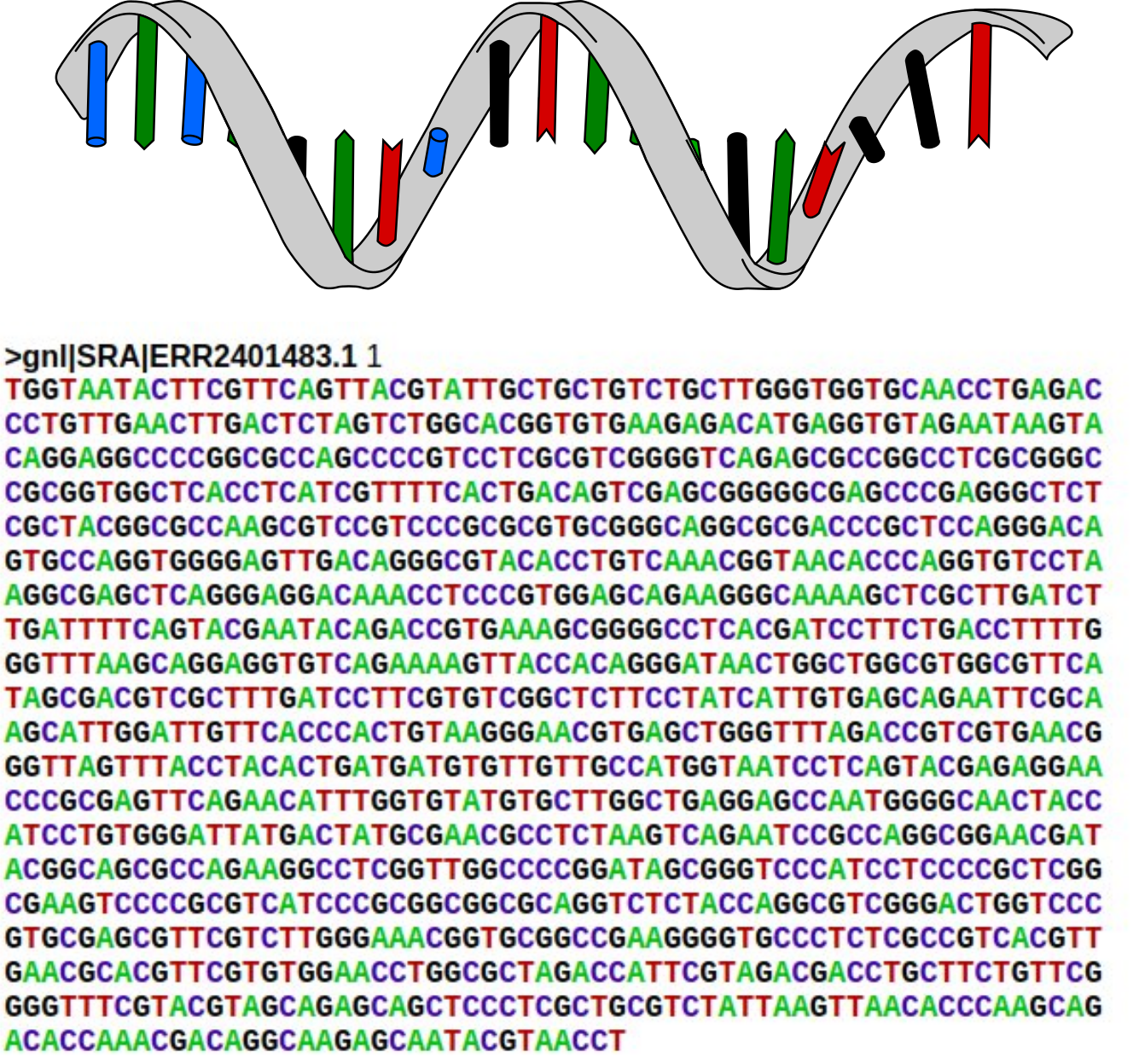
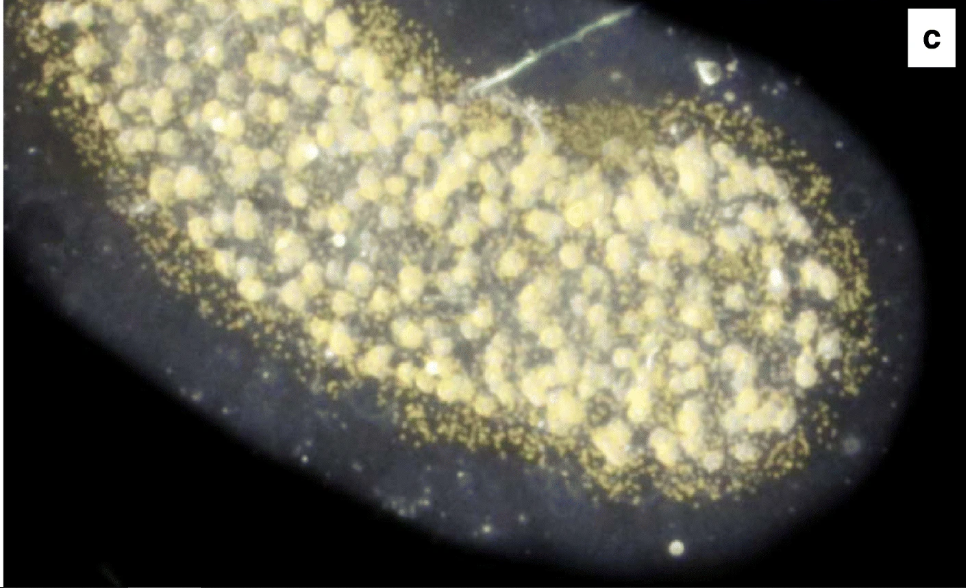


 En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web,
En 2020, chaque mois, Charlotte Truchet et Serge Abiteboul nous racontent des histoires d’algorithmes. Des blockchains aux algorithmes de tri en passant par le web, 
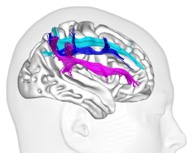
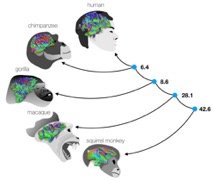







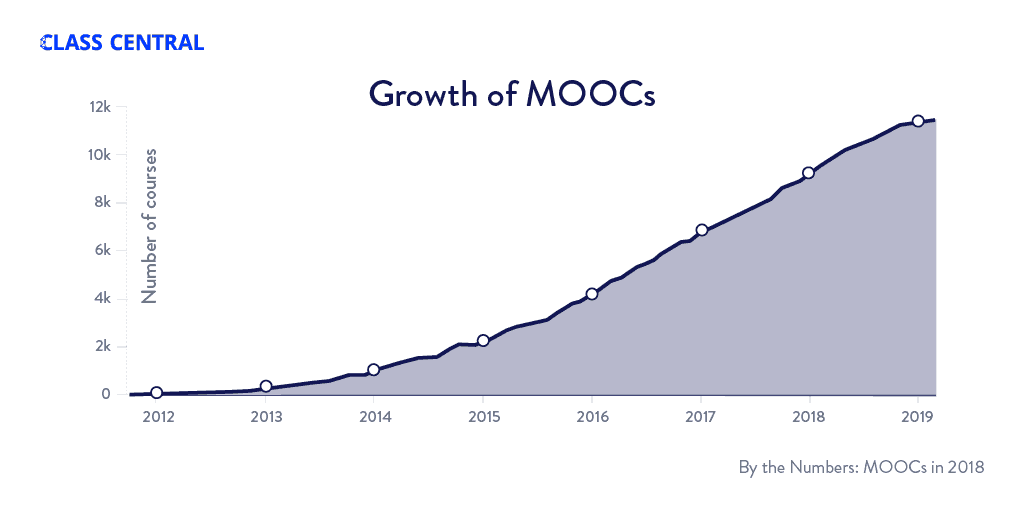
 On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.
On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.