Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection A la plage, Dunod, juin 2020)
Le titre de ce livre pourrait laisser croire à une nouvelle biographie d’Alan Turing dans la lignée du film « Imitation game » ou de la pièce « La machine de Turing » or il n’en est rien. Le sous-titre, « L’Intelligence Artificielle dans un transat », a toute son importance : il s’agit d’une introduction, très accessible, à l’intelligence artificielle. Le lien avec Turing ? Des références permanentes à ses écrits, des citations qui mettent en avant l’aspect précurseur de Turing, des extraits de ses articles qui parlent de l’informatique telle que nous la connaissons, ses questionnements qui sont toujours d’actualité.
Le livre commence avec les notions d’algorithmes et de machines, des dispositifs tout d’abord mécaniques puis électroniques qui réalisent ces algorithmes. Très vite, la formalisation de la notion d’algorithme et ses limites — qui ont constitué le cœur des travaux d’Alan Turing avant guerre, avec en particulier la fameuse machine de Turing, modèle théorique d’algorithme — sont abordées. Les progrès pratiques, en termes de puissance de calcul, y sont présentés.
Or les algorithmes sont le composant fondamental des intelligences artificielles. De plus en plus souvent, les performances des intelligences artificielles nous surprennent, comme nous le montre le livre, que ce soit en battant des champions aux jeux d’échecs ou de go, ou en reconnaissant des chats dans des images. Le livre présente aussi, rapidement, les notions de complexité des problèmes et les questions encore ouvertes en ce domaine, comme « P versus NP » ou « P versus NC » (voir l’article la théorie de la complexité algorithmique).
Turing avait anticipé le fait que, quand la difficulté des tâches à résoudre augmente, la difficulté à écrire les algorithmes correspondants deviendrait intraitable par un humain et il avait déjà proposé, en 1950, le principe des learning machines, principe sous-jacent aux algorithmes auto-apprenants, très présents dans l’intelligence artificielle que nous connaissons aujourd’hui.
Se pose alors la question de savoir distinguer une intelligence humaine d’une intelligence artificielle : du célèbre « test de Turing » publié en 1950 à d’autres expériences (de pensée ou non), de l’art avec ce que cela suppose de créativité, aux algorithmes inspirés par la nature comme les automates cellulaires ou les algorithmes génétiques, différentes approches sont exposées.
Avant de conclure sur la « théorie hérétique » de Turing que nous vous laissons le plaisir de (re-)découvrir, les auteurs présentent aussi les facettes inquiétantes de l’utilisation des intelligences artificielles, qu’il s’agisse d’usages malveillants ou d’effets secondaires non anticipés et non désirés.
Ce livre peut tout à fait se lire à la plage, dans un transat, dans un hamac ou sous un plaid au coin du feu : il aborde très clairement les notions fondamentales de l’intelligence artificielle, avec une grande variété et une grande pertinence dans les exemples choisis. S’il faut toutefois mettre un léger bémol à cet enthousiasme, on pourra parfois regretter une transposition de certains résultats de l’informatique à la vie de tous les jours, comme par exemple avec le choix de cette citation de Scott Aronson au sujet de la question « P versus NP » : « Si P = NP, alors le monde est un endroit profondément différent de ce qu’on imagine habituellement. Il n’y aurait aucune valeur spécifique au « saut créatif », aucun fossé séparant le fait de résoudre un problème et celui de reconnaître la validité d’une solution trouvée. Tous ceux capables d’apprécier une symphonie seraient Mozart ; tous ceux capables de suivre un raisonnement étape par étape seraient Gauss. » Certes les auteurs ne sont pas responsables de cette citation, mais ils ont choisi de relayer une telle extrapolation, peut-être quelque peu excessive.
Avec peu d’évolution dans les traitements médicaux et un manque criant de moyens humains, financiers, et thérapeutiques, les maladies mentales demeurent le parent pauvre de la médecine contemporaine. L’intelligence artificielle pourrait apporter des solutions dans l’aide au diagnostic et au suivi de certaines maladies comme la schizophrénie. Nous faisons le point sur la question avec Maxime Amblard dans cet épisode du podcast audio.
Tandis que la crise sanitaire ne fait qu’accentuer les difficultés dans la prise en charge des troubles psychiatriques, les sciences du numérique ouvrent de nouvelles voies dans le traitement et le suivi de ces pathologies.
Comme nous l’explique Maxime Amblard, l’intelligence artificielle (IA) peut être utile dans le suivi de certaines maladies mentales comme la schizophrénie, à la fois dans le cadre d’un diagnostic précoce, pour une meilleure détection et prise en charge du patient en amont, mais aussi en aval pour gérer les crises liées à la pathologie. Le chercheur, spécialisé dans le traitement automatique des langues (TAL) — un domaine pluridisciplinaire impliquant la linguistique, l’informatique et l’intelligence artificielle — nous présente, à travers deux projets de recherche dans lesquels il est impliqué, MePheSTO et ODIM, les moyens par lesquels l’IA peut contribuer au suivi des maladies mentales.
« Numérique et pandémie – Les enjeux d’éthique un an après »
organisé conjointement par le
Comité national pilote d’éthique du numérique et
l’Institut Covid-19 Ad Memoriam
le vendredi 11 juin 2021 de 9h à 16h15.
Systèmes d’information pour les professionnels de santé
Souveraineté numérique
Télé-enseignement
La pandémie Covid-19 est la première de l’ère numérique. Par cette dimension, elle ne ressemble pas aux crises sanitaires des époques précédentes : dès mars 2020, les activités économiques et sociales ont été partiellement maintenues grâce aux smartphones, ordinateurs et autres outils numériques. Mais les usages de ces outils ont eux aussi changé depuis le printemps 2020. La rapidité de ces évolutions n’a pas encore permis de dégager le sens qu’elles auront pour notre société, ni de saisir leurs effets à long terme. Ce colloque fera un premier pas dans cette direction. Qu’avons-nous appris ? Quelles sont les avancées que nous voudrions préserver après la fin de la crise ? À quelles limites se heurte la numérisation accélérée de notre quotidien ?
Laëtitia Atlani-Duault
Présidente de l’Institut Covid-19 Ad Memoriam, Université de Paris
Jean-Francois Delfraissy
Président du CCNE pour les sciences de la vie et de la santé
Président d’honneur de l’Institut Covid-19 Ad Memoriam
Claude Kirchner
Directeur du Comité National Pilote d’Éthique du Numérique
Nous avons rencontré pour Binaire, Lou Welgryn, la présidente de l’association Data for Good. Elle est aussi Carbon Data Analyst chez Carbone4 Finance, un cabinet de conseil qui aide les entreprises à réduire leurs émissions de gaz à effet de serre.
Data for Good est une association fondée en 2015, une communauté de data scientists principalement. Chaque membre a une autre activité qui lui apporte un salaire mais, pour Data for Good, il passe bénévolement quelques heures chaque semaine sur des projets sociaux ou environnementaux. On entend dire : « The best mind of our times are thinking about how to make people click on ads » (Les meilleurs esprits de notre temps réfléchissent à la manière de faire cliquer les internautes sur des pubs) et ce n’est pas faux. Lou Welgryn nous explique que l’esprit de l’asso, c’est au contraire de : « Mettre notre temps de cerveau disponible au service de causes utiles. » L’entraide est au cœur du dispositif. Par exemple, tout le code développé doit être en open source pour pouvoir aussi servir à d’autres.
Le martin-pêcheur de Data For Good
L’association Data for Good apporte principalement des ressources humaines à des structures qu’elle choisit d’aider. À qui apporte-t-elle son soutien ? À des associations, des startups, des organisations plutôt artisanales qui n’ont pas les moyens d’embaucher les data scientists dont elles auraient besoin mais aussi des entreprises plus établies voulant mettre en place un projet à impact positif. L’association fonctionne avec chaque année deux « saisons d’accélération » de 3 mois. Pour une saison, une dizaine de projets est sélectionnée. Les membres de l’association choisissent alors le projet qui les intéresse. Ensuite, chaque semaine pendant 3 mois, ils travaillent sur le projet. Ils s’engagent à donner entre 4 à 12 h de leur temps par semaine. Le Covid a fait basculer le travail en distanciel mais ne l’a pas interrompu. Avec Data for Good, on ne produit pas des idées ou du papier. La règle est celle du minimum viable product, pas forcément un truc grandiose mais du code, une solution testable.
Chacun des 10 projets sélectionnés doit progresser. Il a un responsable qui l’accompagne pendant les trois mois pour s’assurer qu’il fonctionne bien, recadrer et réorganiser l’équipe si besoin. Suivant l’importance du projet, l’équipe est plus ou moins importante, une dizaine de membres de l’association en moyenne.
Le financement de l’asso ? Pas grand-chose. L’immobilier ? Des copains, Le Wagon et Liberté Living-Lab, prêtent des espaces. Alors, Data for Good, un petit truc dans un coin ? Non ! L’asso apporte la vraie richesse de ses 2 000 membres. Et ça dépote. La preuve : nous avons eu du mal à ne choisir que 2 projets parmi les 51 listés sur leur site en avril 2021. Nous aurions aimé parler de beaucoup d’autres.
1) OpenFoodFacts C’est le Wikipédia de la nourriture. Pour lutter contre la malbouffe, pour aider les citoyens à mieux manger, l’association OpenFoodFacts propose une base de données de produits alimentaires avec leur composition. Data for Good les a aidés à développer un éco-score, un indicateur de l’impact environnemental des produits. Pour reprendre une phrase sur le site d’OpenFoodFacts « On est ce que l’on mange. », ce travail est donc vraiment important.
Yuka
Yuka, la célèbre application pour iOS et Android, permet de scanner les produits alimentaires et cosmétiques en vue d’obtenir des informations détaillées sur l’impact d’un produit sur la santé. Yuka a longtemps utilisé la base de données d’OpenFoodFacts et elle y contribue maintenant.
2) Pyroneer est un projet qui n’a pas encore atteint cette ampleur. Il développe un logiciel gratuit et open source de détection précoce des feux de forêt. Le logiciel de détection fonctionne avec des caméras économiques. Un algorithme de traitement d’images basé sur l’apprentissage profond détecte les indices visuels de départ de feu. Plus besoin d’avoir des pompiers en permanence dans une tour de guet, des caméras prennent leur place. Pyroneer est en phase de test dans l’Ardèche.
Feu de forêt dans le Montana, Wikipédia
Il y a sûrement beaucoup d’organisations qui font des trucs bien et qui ont des besoins en tech et pas mal de data scientists qui aimeraient donner du sens à leur travail. Data for good a de l’espace pour grandir.
Serge Abiteboul, Inria & ENS Paris, et Jill-Jênn Vie, Inria
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de 5G. Marie-Agnès Enard etPascal Guitton.
– C’est vrai Mamie que de ton temps, avant Internet, les téléphones avaient des fils qui les reliaient au mur ?
– Oui mon grand. Et tout le monde n’avait pas le téléphone.
– Pourquoi ce fil ? Pour pas qu’on les vole ?
– Ne te moque pas ! La communication passait alors par les fils. Un jour, on est passé au téléphone cellulaire, au téléphone sans fil. La communication passe alors par les airs, en empruntant des ondes électromagnétiques.
– Comme un rayon lumineux ?
– Oui, sauf que les ondes du téléphone ne se voient pas.
La téléphonie sans fil
Un téléphone cellulaire transforme la voix, un message audio, en une onde électromagnétique qui va jusqu’à une station radio. Pour la 1G, la station radio transforme ce message en un signal électrique analogique qui passe par un câble électrique pour aller rejoindre le correspondant. La représentation est analogique, c’est-à-dire qu’elle est proportionnelle à l’information du message initial, de la voix. Dans la 2G, la représentation consiste en une séquence de 0 et de 1, des nombres ; c’est pour ça qu’on dit que c’est numérique. C’est un message numérique qui est transporté dans le réseau de télécommunications. Avec la 2G, le réseau est devenu numérique.
2G, 3G, 4G, 5G, Arcep
– Alors, Mamie, avec la 2G, on passe au numérique. Et après, on a la 3G, la 4G, la 5G. On n’est pas arrivé !
– La patience n’est pas ton point fort, mon petit Jules. C’est bon, j’accélère. La 2G, c’est vers 1990. En gros, tous les dix ans, les gens qui développent les technos de téléphones cellulaires se mettent d’accord pour faire un gros paquet cadeau avec tous les progrès techniques des dix dernières années. Avec le nouveau millénaire et la 3G, le téléphone nous a fait passer dans le monde d’Internet. Et avec la 4G, on a pu voir des vidéos en bonne définition.
– Et ce coup là, qu’apporte la 5G ?
– Plus de débit, une meilleure latence, plus de densité.
Le débit, c’est la quantité de données qui peut passer dans une communication. Plus de débit, ça veut dire, par exemple, des films en plus haute définition.
La latence, c’est le temps que met un message pour aller de mon téléphone au serveur, et revenir. Une meilleure latence va faciliter les jeux en réseaux, ou des conversations avec des hologrammes.
La densité, c’est le nombre de connexions simultanées avec la station radio. On parle de millions d’objets au kilomètre carré.
– Je veux bien, mais concrètement, la 5G va changer quoi pour toi ? demande Jules.
– Euh… Pas grand chose. C’est l’arrivée de la 4G et de la fibre dans ma maison de la Creuse qui va me changer vraiment la vie. Bientôt !
– Et pour moi à Marseille ?
– Pas grand-chose non plus. Ça évitera que les réseaux soient saturés dans le centre ville.
– Alors pourquoi on cause tant de ce truc si ça change que dalle ?
– Parce que ça va transformer l’industrie, la gestion des villes et des régions, et peut-être la médecine, les transports collectifs. On ne sait pas encore à quel point, mais on s’attend à ce que ça change plein de trucs.
– Juste à cause du débit, de la latence, de la densité.
– Oui, parce que cela va permettre de développer de nouveaux services. Dans une usine par exemple, on n’aura plus besoin de tous ces câbles pour connecter les machines, les robots. Cela se fera en 5G. Et puis, il y a aussi d’autres innovations techniques dont je ne t’ai pas causé. Il y en a une que tu devrais aimer : le réseau en tranches de saucisson.
– Késaco ?
– On va pouvoir découper le réseau en tranches comme du saucisson. Ensuite, c’est comme si on avait plusieurs réseaux qu’on peut utiliser différemment. Une tranche pour des opérations médicales et une autre pour des jeux en réseau. Si tu t’éclates sur ton jeu, tu ne gênes pas le chirurgien du coin.
– Les jeux vidéo. Continue, Mamie, là tu m’intéresses.
– On se calme. Pour tes jeux, la 4G suffit bien.
– Alors, je n’ai pas vraiment besoin de te demander un téléphone 5G pour mon anniversaire ?
– Non, mon grand. La fabrication de téléphones, ce n’est pas bon pour la planète. Donc on essaie de ne pas en changer trop souvent. On reste sur le vélo pour ton anniversaire !
Trafic de données consommées sur les réseaux mobiles, Arcep
– OK, mais Mamie, le voisin dit qu’il faut pas la 5G, que c’est dangereux pour la santé, que ça pourrit la planète, la vie, et tout. C’est vrai ?
– Mon grand. Ce n’est pas parce que quelque-chose est nouveau qu’il faut en avoir peur. Ce n’est pas non plus parce qu’une nouvelle techno arrive qu’il faut se précipiter.
– Oui mais je lui dis quoi au voisin ? Que c’est un gros nul ?
– On ne parle pas comme ça. Il a le droit de poser des questions. Ses questions ne sont pas sottes. Qu’est-ce que je te répète toujours ?
– Je sais Mamie. Il n’y a pas de questions idiotes, ce sont les réponses qui le sont souvent.
– C’est ça mon grand. Allez, on va causer avec Monsieur Michu !
Après les salamalecs du bonjour, bonsoir, comment va Madame Michu, un café, non merci, pourquoi nous sommes venus vous voir, et tout…
– J’ai entendu dire que la 5G, c’était dangereux pour la santé ? démarre M. Michu.
– Aucune étude n’a permis d’établir un tel danger, ou alors à super haute dose, explique Mamie. Et pourtant, c’est un sujet qui a été hyper étudié par les scientifiques. On impose d’ailleurs des contraintes sévères sur les quantités d’ondes électromagnétiques autorisées, bien plus que ce que l’on sait dangereux pour la santé. Pour ce qui est des ondes électromagnétiques, on dit qu’il ne faut pas laisser les bébés jouer avec un téléphone cellulaire. Pour le reste, pas d’inquiétude.
– Il faut penser aux gens électro-sensibles. Non ?
– Ces personnes ont de vrais symptômes mais à chaque fois qu’on a essayé de lier cela aux ondes électromagnétiques, on n’y est pas arrivé. Comme elles souffrent bien, il faut plus de recherche pour comprendre ce qui cause leurs problèmes. Mais, cela semble bien ne rien à voir avec les ondes électromagnétiques.
– Bon, je veux bien, admet Monsieur Michu. Mais il y a aussi des impacts énormes sur l’environnement. La 4G suffisait.
– La 4G consomme beaucoup plus d’électricité pour la même quantité de données ? Et elle est moins efficace. Les réseaux 4G saturaient en centre-ville et cela conduisait à multiplier les stations 4G. En restant avec la 4G on allait dans le mur.
– Alors pourquoi, ils disent que la 5G va conduire à une explosion de la consommation d’électricité ?
– C’est à cause de l’effet de rebond, explique Mamie. J’en ai parlé avec Jules. Il va nous l’expliquer.
– La 5G, raconte Jules, fier de ramener sa récente science, permet beaucoup plus de débit. Alors les gens vont se mettre à faire n’importe quoi, regarder des vidéos en super résolution dans les couloirs du métro ou jouer à des jeux vidéos au marché, et la consommation de données sur les téléphones portables va exploser. Et…
– On ne veut pas de ça ! Coupe Monsieur Michu. Non ?
– Oui, la vraie question, ce n’est pas s’il faut la 5G ou pas, propose Mamie. A mon avis, il faut la 5G pour les usines, pour les réseaux de transports, pour les villes intelligentes, etc. La vraie question, c’est qu’il ne faut pas faire n’importe quoi avec.
– Bon alors je peux m’acheter un téléphone 5G ? interroge Monsieur Michu.
– Votre téléphone est cassé ? C’est un vieux truc ? questionne Mamie.
– Pas du tout. Madame Michu m’en a acheté un tout neuf pour mon anniversaire, l’an dernier. Je ne sais pas encore trop bien m’en servir…
Ce texte est publié dans le cadre de la chronique « Société numérique », proposée par les chercheuses et chercheurs du département Sciences économiques et sociales de Télécom ParisTech, membres de l’Institut interdisciplinaire de l’innovation (CNRS).
On a, au début des années 2000, beaucoup parlé de « fracture numérique » en s’intéressant à la fois aux inégalités d’accès et d’usages. Les rapports annuels du CREDOC montrent que les catégories populaires ont commencé à rattraper leur retard de connexion depuis une dizaine d’années : entre 2006 et 2017, en France, la proportion d’employés ayant une connexion Internet à domicile est passée de 51 % à 93 %, celle des ouvriers de 38 à 83 % (CREDOC 2017 : 48).
C’est désormais l’âge et non le revenu ou le niveau de diplôme qui est le facteur le plus clivant (parmi ceux qui ne se connectent jamais à Internet, huit personnes sur dix ont 60 ans ou plus). Si la question de l’accès est en passe d’être résolue, les usages des classes populaires restent moins variés et moins fréquents que ceux des classes moyennes et supérieures, nous apprennent ces mêmes rapports. Les individus non diplômés ont plus de mal à s’adapter à la dématérialisation des services administratifs, font moins de recherches, pratiquent moins les achats, se lancent très rarement dans la production de contenus. Bref, il y aurait en quelque sorte un « Internet du pauvre », moins créatif, moins audacieux, moins utile en quelque sorte…
Changer de focale
Peut-être faut-il adopter un autre regard ? Ces enquêtes statistiques reposent sur un comptage déploratif des manques par rapport aux pratiques les plus innovantes, celles des individus jeunes, diplômés, urbains. On peut partir d’un point de vue différent en posant a priori que les pratiques d’Internet privilégiées par les classes populaires font sens par rapport à leur besoins quotidiens et qu’elles sont des indicateurs pertinents de leur rapport au monde et des transformations possibles de ce rapport au monde.
Comme Jacques Rancière l’a analysé à propos des productions écrites d’ouvriers au XIXe siècle, il s’agit de poser l’égalité des intelligences comme point de départ de la réflexion pour comprendre comment « une langue commune appropriée par les autres » peut être réappropriée par ceux à qui elle n’était pas destinée. (Rancière 2009 : 152).
Un tel changement de focale permet d’entrevoir des usages qui n’ont rien de spectaculaire si ce n’est qu’ils ont profondément transformé le rapport au savoir et aux connaissances de ceux qui ne sont pas allés longtemps à l’école. Ce sont par exemple des recherches sur le sens des mots employés par les médecins ou celui des intitulés des devoirs scolaires des enfants. Pour des internautes avertis, elles pourraient paraître peu sophistiquées, mais, en attendant, elles opèrent une transformation majeure en réduisant l’asymétrie du rapport aux experts et en atténuant ces phénomènes de « déférence subie » des classes populaires face au monde des sachants – qu’Annette Lareau a analysée dans un beau livre, Unequal Childhoods (2011).
Recherche en ligne : s’informer et acheter
Des salariés qui exercent des emplois subalternes et n’ont aucun usage du numérique dans leur vie professionnelle passent aussi beaucoup de temps en ligne pour s’informer sur leur métier ou leurs droits : le succès des sites d’employés des services à la personne est là pour en témoigner. Des assistantes maternelles y parlent de leur conception de l’éducation des enfants, des aides-soignantes ou des agents de service hospitaliers de leur rapport aux patients. On pourrait aussi souligner tout ce que les tutoriels renouvellent au sein de savoir-faire traditionnellement investis par les classes populaires : ce sont des ingrédients jamais utilisés pour la cuisine, des manières de jardiner ou bricoler nouvelles, des modèles de tricot inconnus qui sont arrivés dans les foyers.
Apprendre donc, mais aussi acheter. Pour ceux qui vivent dans des zones rurales ou semi rurales, l’accès en quelques clics à des biens jusqu’alors introuvables dans leur environnement immédiat paraît a priori comme une immense opportunité. Mais en fait, les choses sont plus compliquées. La grande vitrine marchande en ligne est moins appréciée pour le choix qu’elle offre que pour les économies qu’elle permet de réaliser en surfant sur les promotions. C’est la recherche de la bonne affaire qui motive en priorité : c’est aussi qu’elle permet de pratiquer une gestion par les stocks en achetant par lots. En même temps, ces gains sont coupables puisqu’ils contribuent à fragiliser le commerce local, ou du moins ce qu’il en reste.
Dans une société d’interconnaissance forte où les commerçants sont aussi des voisins, et parfois des amis, la trahison laisse un goût amer des deux côtés. À l’inverse, les marchés de biens d’occasion entre particuliers, à commencer par Le Bon Coin qui recrute une importante clientèle rurale et populaire, sont décrits comme des marchés vertueux : ils offrent le plaisir d’une flânerie géolocalisée – c’est devenu une nouvelle source de commérage !-, évitent de jeter, et permettent de gagner quelques euros en sauvegardant la fierté de l’acheteur qui peut se meubler et se vêtir à moindre coût sans passer par des systèmes de dons. L’achat en ligne a donc opéré une transformation paradoxale du rapport au local, en détruisant certains liens et en en créant d’autres.
Lire et communiquer sur Internet
Enfin, Internet c’est une relation à l’écrit, marque de ceux qui en ont été les créateurs. Elle ne va pas de soi pour des individus qui ont un faible niveau de diplôme et très peu de pratiques scripturales sur leur lieu de travail. Le mail, qui demande une écriture normée, est largement délaissé dans ces familles populaires : il ne sert qu’aux échanges avec les sites d’achat et les administrations -le terme de démêlés serait en l’occurrence plus exact dans ce dernier cas.
C’est aussi qu’il s’inscrit dans une logique de communication interpersonnelle et asynchrone qui contrevient aux normes de relations en face à face et des échanges collectifs qui prévalent dans les milieux populaires. Facebook a bien mieux tiré son épingle du jeu : il permet l’échange de contenus sous forme de liens partagés, s’inscrit dans une dynamique d’échange de groupe et ne demande aucune écriture soignée. Ce réseau social apparaît être un moyen privilégié pour garder le contact avec les membres de sa famille large et les très proches, à la recherche d’un consensus sur les valeurs partagées. C’est un réseau de l’entre-soi, sans ouverture particulière sur d’autres mondes sociaux.
Car si l’Internet a finalement tenu de nombreuses promesses du côté du rapport au savoir, il n’a visiblement pas réussi à estomper les frontières entre les univers sociaux.
Suite à l’article dans Binaire, « L’informatique, quelques questions pour se fâcher entre amis », nous avons reçu une proposition d’article à propos de l’absence ou du manque de considération porté aux systèmes d’exploitation de Éric Sanchis. La pluralité des points de vue nous parait essentielle, c’est pourquoi vous retrouverez ici son point de vue, à vous de vous faire une idée, puis sans se fâcher, d’engager la discussion… Pierre Paradinas
Algorithme par-ci, algorithme par-là : des titres comme « Ma vie sous algorithmes », « A quoi rêvent les algorithmes », « Algorithmes : la bombe à retardement » ou bien « Le temps des algorithmes » font florès dans les librairies ! Dans le prolongement du billet « L’informatique, quelques questions pour se fâcher entre amis », on pourrait se demander si la place accordée au concept d’algorithme et aux notions connexes (langage, formalisation) n’est pas exagérée au sein même de la discipline informatique. En d’autres termes, est ce que la «pensée algorithmique » serait l’alpha et l’oméga de la « pensée informatique » ? Au risque de provoquer quelque agacement, je répondrais par la négative. Bien sûr, cette position doit être précisée.
Tout d’abord, insistons sur le fait que la notion d’algorithme était à la fois connue et utilisée bien avant la naissance de l’informatique. Il en est de même pour les aspect langages formels et calcul. Alors qu’est ce qui apporte ce supplément d’originalité à notre discipline ? Nul doute que chacun, suivant sa spécialité, pourrait apporter sa propre réponse. Quant à moi, pour expliciter mon point de vue, je mettrai de côté la définition de l’informatique définie par la SIF :
L’informatique est la science et la technique de la représentation de l’information d’origine artificielle ou naturelle, ainsi que des processus algorithmiques de collecte, stockage, analyse, transformation, communication et exploitation de cette information, exprimés dans des langages formels ou des langues naturelles et effectués par des machines ou des êtres humains, seuls ou collectivement.
au profit de celle-ci :
L’informatique est la discipline réunissant la science, la technique et la technologie relatives au traitement et à la gestion automatisés de l’information discrétisée.
Même s’il n’est pas possible de commenter dans ce billet les différents aspects contenus dans cette caractérisation, j’en relèverai deux utiles à mon propos. Tout d’abord, l’informatique est une discipline multiniveau. Ces niveaux étant fortement hétérogènes, il semble difficile qu’une « pensée unique » puisse les animer. Ensuite, selon mon point de vue, ce qui est porteur d’originalité dans la discipline informatique n’est pas la partie traitement automatisé (déjà effectué de manière sommaire par des dispositifs préexistants à l’informatique) mais plutôt la partie gestion automatisée. Celle-ci est mise en œuvre par le système d’exploitation de la machine. Mais que peut bien avoir d’original cette couche logicielle ? Ce sont ses fonctions d’exécution et de de partage optimal des ressources physiques et logiques.
On pourrait objecter qu’un système d’exploitation n’est qu’un (gros) programme écrit dans un langage de programmation classique. En fait, pas tout à fait : c’est plutôt un ensemble de programmes en interaction, interaction portée par le matériel. Il en résulte que bien des concepts et problèmes liés à cette couche ont peu à voir avec ceux traités par la « pensée algorithmique ». Abordons quelques-uns de ces concepts et problèmes. Tout d’abord, un système d’exploitation est un logiciel confronté à un matériel perpétuellement changeant (périphériques). Concevoir une interface qui sépare efficacement ce qui change de ce qui reste stable est bien plus complexe que la conception d’une interface uniquement confrontée à un environnement logiciel. Même si la décomposition en couches est la solution privilégiée, elle reste néanmoins limitée. Cette limitation est essentiellement due aux impératifs d’efficience. C’est la raison pour laquelle le nombre de couches présentes dans un système d’exploitation est relativement faible vis-à-vis du nombre de services qu’il réalise. Ce sont ces mêmes impératifs d’efficience qui ont conduit les concepteurs de systèmes d’exploitation à s’autoriser le court-circuitage de couches, écornant le principe théorique de décomposition en couches strictement ordonnées.
Illustrons cette « pensée système » à l’aide d’un deuxième et dernier exemple : l’allocation de ressources et le problème de l’interblocage. La littérature spécialisée regorge de propositions de solutions. Or il s’avère qu’une bonne partie d’entre elles sont inutilisables en pratique. Les concepteurs du système UNIX ont simplement décidé d’ignorer le problème. Pourquoi ? Parce que la fréquence d’apparition d’un interblocage dans un système est largement inférieure à la fréquence d’arrêt de ce système dû à d’autres causes (défaillances matérielles, bogues au sein du système d’exploitation ou autres). Pour des raisons de performances, il est alors plus judicieux d’ignorer la théorie et d’adopter une solution pragmatique.
Diagramme montrant les principaux systèmes d’exploitation Unix et ses dérivés.
En conclusion, réduire la « pensée informatique » à l’unique « pensée algorithmique » appauvrirait sérieusement notre discipline, la privant d’un savoir et savoir-faire qui ont largement contribué à son épanouissement. À l’heure où l’enseignement de l’informatique entre pleinement dans les lycées, il est primordial de redonner à la « pensée système » la place qui lui revient [1].
Eric Sanchis
Université Toulouse Capitole
[1] Le domaine des systèmes d’exploitation qui véhicule cette « pensée système » est quasiment absent des ouvrages destinés à l’enseignement de l’option ISN :
dans l’ouvrage « Introduction à la science informatique » (Repères pour agir), 2011 : environ 3 pages dans une section « Compléments » (sic)
dans l’ouvrage « Informatique et sciences du numérique » (Gilles Dowek), Eyrolles, 2012 : 2 pages
TIPE ? C’est cette épreuve des concours des écoles d’ingénieur·e·s où les élèves ne sont pas uniquement jugé de manière « scolaire´´ mais sur leur capacité à choisir un sujet, mener un projet, s’organiser … du vrai travail d’ingénieur·e quoi ! Oui … mais comment les aider pour que ce soit équitable ? C’est là que Pixees et Interstices, s’associent pour proposer des ressources et des pistes. En miroir de leur contenu, reprenons cela ici. Thierry Viéville et Pascal Guitton
TIPE ? Comme tous les ans, en lien avec sillages.info et l’UPS pour les CGPE, Interstices et Pixees vous proposent des ressources autour des sciences du numérique, de l’information et des mathématiques.
les textes ci-dessous pour aider à débroussailler le sujet (coordination Hugues Berry, Adjoint au directeur scientifique d’Inria pour la biologie et la santé numérique),
Comme probablement tous les secteurs de l’activité humaine, le numérique est en train de s’ancrer profondément en santé. Cette tendance a débuté il y a longtemps avec les premiers logiciels liés à l’imagerie médicale et la généralisation des outils numériques de gestion médico-administrative, comme les dossiers patients informatisés ou l’informatisation des données de remboursement de soins. Avec cette évolution, les données de santé sont devenues de plus en plus accessibles aux chercheurs et aux chercheuses dans des volumes importants, ce qui permet principalement d’envisager aujourd’hui la mise en place de systèmes capables d’assister les médecins lors des étapes de la décision médicale personnalisée: diagnostic, prédiction de l’évolution de la maladie ou choix de la meilleure thérapie.
Le domaine de la prévention des maladies est lui aussi impacté par cette évolution. Au niveau médical par exemple, l’émergence de données « de vie réelle » capturées hors des salles de soin proprement dites (caméras, smartphones, capteurs) promet un suivi automatisé et personnalisé de l’évolution de la pathologie des patients. Au niveau de la population, de nouveaux outils numériques permettent d’analyser les données des bases médico-administratives pour des objectifs issus de l’épidémiologie, c’est-à-dire l’étude de la fréquence, la distribution et les facteurs associés aux problèmes de santé de la population et la surveillance de leur évolution. Bien entendu, les crises actuelles liées aux maladies infectieuses fournissent elles aussi le cadre d’une implication accrue du numérique, par exemple pour optimiser les politiques d’intervention, concernant les stratégies de confinement, de test, de vaccination, ou de gestion des populations de vecteur animaux. Les exemples ci-dessous illustrent quelques-unes des nombreuses applications du numérique dans le domaine de la santé et de la prévention.
Hugues Berry, Adjoint au directeur scientifique d’Inria pour la biologie et la santé numérique
La reconnaissance vidéo d’activités pour le suivi personnalisé de patients atteints de troubles cognitifs
Les progrès récents de la vision artificielle permettent aujourd’hui d’observer et d’analyser nos comportements. On pense immédiatement à Big Brother, mais bien d’autres applications, tout à fait louables, sont envisagées. En particulier dans un domaine qui manque cruellement de réponses : le diagnostic, le suivi de patients présentant des déficits cognitifs liés au vieillissement et à l’apparition de maladies neurodégénératives comme la maladie d’Alzheimer, et le maintien à domicile de ces personnes âgées.
Les recherches de l’équipe Stars visent notamment à quantifier le déclin cognitif des patients Alzheimer. Il est important de détecter le plus tôt possible les premiers signes annonciateurs de difficultés à venir. Nous testons par exemple au CHU de Nice un dispositif visant à évaluer la situation d’un patient en lui proposant de passer cinq minutes dans une pièce équipée de capteurs vidéo, où il doit effectuer une liste de tâches comme préparer une boisson, téléphoner, lire, arroser des plantes… Nos logiciels permettent ainsi d’obtenir automatiquement une évaluation normalisée des éventuels déficits cognitifs de chaque patient et ainsi de leur proposer un traitement adapté.
A. König, C. Crispim, A. Covella, F. Bremond, A. Derreumaux, G. Bensadoum, R. David, F. Verhey, P. Aalten and P.H. Robert. Ecological Assessment of Autonomy in Instrumental Activities of Daily Living in Dementia Patients by the means of an Automatic Video Monitoring System, Frontiers in Aging Neuroscience – open access publication and the eBook – http://dx.doi.org/10.3389/fnagi.2015.00098, 02 June 2015
S. Das, S. Sharma, R. Dai, F. Bremond et M. Thonnat. VPN: Learning Video-Pose Embedding for Activities of Daily Living. ECCV 2020. ⟨hal-02973787⟩ https://hal.archives-ouvertes.fr/hal-02973787
D. Yang, R. Dai, Y. Wang, R. Mallick, L. Minciullo, G. Francesca et F. Bremond. Selective Spatio-Temporal Aggregation Based Pose Refinement System: Towards Understanding Human Activities in Real-World Videos. WACV 2021. ⟨hal-03121883⟩https://hal.archives-ouvertes.fr/hal-03121883
Nouvelles approches d’optimisation pour définir les tests groupés – ou « group testing »
Afin de dépister une population, on peut soit tester l’ensemble des individus un par un, ce qui implique un nombre important de tests, ou bien tester des groupes d’individus. Dans ce cas, toutes les personnes subissent un prélèvement, et l’on réalise un seul test dans le groupe : s’il s’avère négatif, cela signifie que tout le groupe est négatif ; s’il est positif, on procède alors à des tests individuels complémentaires. Cette approche permet ainsi de réduire nettement le nombre d’analyses à réaliser, tout en restant fiable.
D’autres approches basées sur le même principe mais plus complexes peuvent être considérées.
Les chercheurs de l’équipe projet Inocs (Integrated Optimization with Complex Structure) du centre Inria Lille-Nord Europe ont apporté une réponse à la question suivante dans le cadre de la Covid 19: Comment former ces groupes – et selon quels critères – afin de garantir l’efficacité de la procédure ?
Plus précisément des modèles d’optimisation basés sur la théorie des graphes ont été définis. Des méthodes de résolutions exactes ont été développées afin de déterminer la taille optimale des groupes ainsi que leurs constitution de façon à atteindre différents objectifs en tenant compte de contraintes spécifiques des tests. Les objectifs peuvent être la minimisation du nombre de tests, la minimisation du nombre de faux négatifs, la minimisation du nombre de faux positifs ou une combinaison de ces critères.
L’efficacité des méthodes de résolutions est prouvéepar des tests sur des données publiques ou des données issues du CHU de Lille.
Pour aller plus loin :
Références scientifiques :
T. Almeftah 1 L. Brotcorne 1 D. Cattaruzza B. Fortz 1 K. Keita 1 M. Labbé 1 M. Ogier 1 F. Semet, « Group design in group testing for COVID-19 : A French case-study », https://hal.archives-ouvertes.fr/hal-03000715/
H. Aprahamian, D. R. Bish, E. K. Bish, Optimal risk-based group testing, Management Science 65 (9) (2018) 4365–4384, https://doi.org/10.1287/mnsc.2018.3138
Épidémiologie numérique : améliorer l’efficacité des soins et prévenir les risques grâce aux données
L’épidémiomogie est révolutionnée par l’utilisation des outils numériques [1,2]. L’épidémiologie s’intéresse à faire des corrélations entre des facteurs (génétiques, démographiques, traitements) et la survenue d’événements médicaux. Des questions usuelles sont par exemple: un traitement est-il réellement efficace ou non ? dans quelles circonstances un traitement à des effets indésirables ?
L’utilisation de méthodes d’analyse statistique, d’analyse de données ou d’intelligence artificielle appliquées à de grandes bases de données médicales offre de nouvelles perspectives à l’épidémiologie : elles permettent de répondre rapidement aux questions de santé publique, et elles permettent d’identifier des corrélations à propos des situations rares grâce à leur capacité à traiter de très grands volumes de données.
Mais quelles bases de données peuvent être utilisées ? Ce peut être des bases constituées spécifiquement pour répondre à une question mais les épidémiologistes disposent également de base de données collectées auprès des patients dans les hôpitaux [3] ou par l’asurrance maladie [4]. Ces dernières permettent de reconstruire nos parcours de soins.
Dans un cadre réglementaire strict, ces données peuvent servir à répondre à certaines questions épidémiologiques. L’épidéliologiste devient alors un analyste : face à ces bases de données, il doit les faire « parler » et mobiliser pour cela toute une
panoplie d’outils numériques qui vont l’aider à sélectionner des cohortes de patients, détecter des facteurs/événements médicaux
d’intérêt, identifier les corrélations et les relier à des connaissances médicales. Et pour faire face à la complexité et à la volumétrie des données, il utilise les techniques numériques les plus avancées en analyse de données et intelligence artificielle.
De la dengue à la lutte antivectorielle biologique
Le virus de la dengue, mais aussi ceux du chikungunya, de la fièvre zika, de la fièvre jaune, sont transmis aux humains par plusieurs espèces de moustiques du genre Aedes. La fièvre jaune est la plus grave de ces maladies. Elle touche 200.000 personnes par an dans le monde entier, dont 30.000 décèdent. Aucun remède n’est connu, mais un vaccin préventif existe, sûr et efficace (obligatoire par exemple pour voyager en Guyane…).
Pour les autres maladies, il n’existe actuellement aucun vaccin satisfaisant, et aucun remède. La plus répandue est la dengue, avec près de 400 millions de cas annuels, dont 500.000 prennent une forme hémorragique grave, mortelle dans 2,5% des cas. Ainsi, la mortalité de la dengue est bien inférieure à celle de la fièvre jaune, mais l’ordre de grandeur des décès qu’elles provoquent est le même.
Près de 4 milliards de personnes vivent dans des zones où elles risquent d’attraper la dengue. Initialement présente dans les régions tropicales et subtropicales du monde, cette maladie s’étend aux zones tempérées des deux hémisphères, en suivant la lente invasion de ces régions (probablement favorisée par le réchauffement climatique) par l’espèce Aedes albopictus — le fameux moustique tigre, plus résistant au froid que le vecteur « historique » qui peuple les régions tropicales, Aedes ægypti. Non détecté en France métropolitaine avant 2004, le moustique tigre est maintenant considéré comme installé dans 64 de ses départements.
La dengue a touché l’Europe dans le prolongement de cet essor, apportée de zones endémiques par des voyageurs infectés, puis transmise lors d’une piqûre à des moustiques locaux. En 2020, 834 cas de dengue importés ont été confirmés en France métropolitaine, mais aussi 13 cas autochtones.
En l’absence de vaccin, la prévention individuelle contre ces maladies consiste essentiellement en des mesures de protection contre les piqûres. La prévention collective repose sur divers moyens de lutte antivectorielle. Il s’agit en premier lieu de mesures d’éducation sanitaire et de mobilisation sociale destinées à réduire les gîtes de ponte. Par ailleurs, l’usage d’insecticides tend actuellement à diminuer: non seulement l’absence de spécificité de ces produits les rend dangereux à d’autres espèces, mais ils induisent un phénomène de résistance qui réduit leur efficacité.
Des méthodes de lutte biologique, plus spécifiques, sont maintenant étudiées. La plus ancienne est la technique de l’insecte stérile, consistant à lâcher dans la nature de grandes quantités de moustiques mâles élevés en laboratoire, et stérilisés par irradiation dans des installations spécialisées: leur accouplement avec les femelles en liberté a pour effet de réduire la taille de la population sauvage, et de diminuer ainsi la propagation des virus. Une autre méthode, plus récemment conçue, consiste à inoculer ces moustiques avec une bactérie appelée Wolbachia, naturellement présente chez la plupart des arthropodes. Cette bactérie a la propriété remarquable de réduire leur capacité de transmettre la dengue, le zika et le chikungunya à ceux qu’ils piquent. Elle passe de la mère à la progéniture, et c’est en lâchant des moustiques intentionnellement infectés en laboratoire par Wolbachia que l’on compte réaliser sa mise en œuvre. Des essais correspondants commencent à avoir lieu en plusieurs points du globe, y compris en Nouvelle-Calédonie. Les mathématiques appliquées participent à l’analyse qualitative et quantitative de la faisabilité de ces méthodes de lutte contre des infections graves émergeant en Europe.
Avez-vous déjà jeté un ordinateur car la carte mère était cassée ou jeté un téléphone car l’écran était brisé ? Si oui, vous vous êtes peut-être demandé si on ne pouvait pas réutiliser des composants plutôt que de tout jeter. La réponse est que c’est possible, mais difficile. Mickaël Bettinelli effectue sa thèse au laboratoire LCIS de l’Université Grenoble Alpes, il vient nous expliquer dans binaire pourquoi la réutilisation des composants électroniques est un processus compliqué, et comment l’intelligence artificielle peut faciliter ce processus. Pauline Bolignano
Mickael Bettinelli
Les produits jetés au quotidien sont des produits qui ne remplissent plus leur rôle, souvent parce qu’une pièce cassée mais aussi parce que nous décidons de renouveler notre matériel électronique au profit de nouveaux produits plus performants. Certains composants de ces produits sont pourtant toujours fonctionnels. Par exemple, la batterie d’un téléphone âgé peut être la seule cause de la panne mais nous jetons l’ensemble du téléphone.
Le recyclage répond partiellement au problème puisqu’il permet de récupérer les matériaux des produits que l’on jette. Malheureusement, tous les matériaux et tous les produits ne sont pas recyclés. Pire, en plus d’être un procédé coûteux, le recyclage ne permet pas toujours de récupérer tous les matériaux des produits que nous recyclons. Prenons l’exemple des batteries de véhicules électriques, on estime pouvoir n’en recycler qu’environ 65% à 93% [1] et cette récupération est complexe à mettre en œuvre. De plus, une batterie de véhicule électrique ne peut plus être utilisée dans l’automobile après 20% de perte de ses capacités. Nous nous retrouvons donc avec un grand nombre de batteries en bon état qui ne peuvent plus être utilisées dans leur application initiale et dont le recyclage est coûteux.
C’est pourquoi de nombreuses études proposent de réutiliser ces batteries pour stocker les énergies renouvelables irrégulières comme l’énergie éolienne ou solaire [2]. Leur réutilisation nous permet à la fois de remplir un besoin et de maximiser l’utilisation des batteries. De manière plus générale, ce procédé est appelé le remanufacturing. C’est une pratique récente et encore peu développée qui consiste à démonter des produits jetés pour remettre à neuf et réintégrer leurs composants fonctionnels dans de nouvelles applications. Il s’agit par exemple de téléphones neufs qui ont été produits à l’aide de composants récupérés sur d’autres modèles défectueux. Puisque les produits remanufacturés n’utilisent pas que des composants neufs, ils ont l’avantage de coûter moins cher à la fabrication et à la vente, mais surtout, ils permettent d’économiser de l’énergie et des matériaux.
Déchets éléctroniques – Image par andreahuyoff de Pixabay
Face à la grande quantité et la diversité de composants dont nous disposons, il n’est pas évident pour un humain de les réutiliser au mieux durant le processus de remanufacturing. Aujourd’hui, les entreprises qui pratiquent le remanufacturing utilisent souvent un nombre de composants limité. Les employés peuvent donc les mémoriser et les réutiliser au besoin. Mais avec le développement du remanufacturing, le nombre de composants pourrait vite exploser, rendant l’expertise humaine inefficace à gérer autant de stock.
Pour répondre à ce besoin, ma thèse se concentre sur la conception d’un système d’aide à la décision permettant d’élaborer de nouveaux produits à partir d’un inventaire de composants réutilisables. Un opérateur humain peut interagir avec le système pour lui demander de concevoir des produits possédant certaines caractéristiques physiques spécifiques. Une fois l’objectif entré dans le système, celui-ci cherche parmi les composants disponibles ceux qui sont utilisables pour répondre au besoin de l’utilisateur. Mais attention, les composants nécessaires à l’utilisateur ne sont pas forcément tous disponibles dans l’inventaire ! Il doit donc être capable de faire un compromis entre ce que veut l’utilisateur et ce qu’il peut réaliser.
Pour réaliser ce système d’aide à la décision, nous nous aidons des systèmes multi-agents, un sous domaine de l’intelligence artificielle. Un système multi-agent est composé d’une multitude de programmes autonomes, appelés agents, capables de réfléchir par eux même et de communiquer ensemble. Comme chez les humains, leur capacité de communication leur permet de s’entraider et de résoudre des problèmes complexes. Dans le cadre de notre système d’aide à la décision, chaque composant de l’inventaire est représenté comme un agent. Leur problème va être de former des groupes dont l’ensemble des membres doit représenter un produit le plus proche possible de la demande utilisateur. Par exemple, si un utilisateur demande au système de lui concevoir un tout nouveau téléphone portable avec 64Go de mémoire, les agents qui représentent des composants mémoire vont former un groupe ensemble jusqu’à être le plus proche possible des 64Go. Ils peuvent ensuite s’assembler avec un écran, une batterie, un boîtier, etc. Une fois tous les composants du téléphone présents dans le groupe, le système d’aide à la décision peut proposer à l’utilisateur ceux qui ressemblent le plus à sa demande. Si l’utilisateur est satisfait, il peut alors acheter les composants proposés. Ces derniers iront ensuite à l’assemblage pour construire le produit physique.
Avec le développement du remanufacturing, nous pouvons espérer que les produits soient conçus de manière à être réparés et leurs composants réutilisés. Dans ce cas, l’avantage de ce système d’aide à la décision sera sa capacité à gérer une grande quantité de composants issus d’une grande diversité de produits. On pourrait alors imaginer concevoir des produits en mêlant des composants issus d’objets très différents comme dans le cas de la réutilisation des batteries de véhicules électriques pour le stockage des énergies renouvelables, et ainsi réduire de plus en plus notre impact environnemental.
Mickaël Bettinelli, doctorant au laboratoire LCIS de l’Université Grenoble Alpes, Grenoble INP.
[2] DeRousseau, M., Gully, B., Taylor, C., Apelian, D., & Wang, Y. (2017). Repurposing used electric car batteries: a review of options. Jom, 69(9), 1575-1582.
Cet entretien avec deux lycéennes de Haute-Savoie réalisé par David Roche, nous donne une vision sur ce nouvel enseignement de spécialité des fondements du numérique et des sciences informatiques au lycée en première et en terminale : il est tellement important que notre jeunesse, les deux moitiés de notre jeunesse, maîtrisent le numérique au delà de l’utiliser. Laissons leur la parole, grâce à la revue 1024 de la Société Informatique de France, d’où ce contenu est repris. Thierry Viéville.
Alors que les statistiques nationales indiquent que les filles sont peu nombreuses à choisir la spécialité « Numérique et sciences informatiques », elles représentent 40 % de l’effectif de la classe de terminale de David Roche au lycée Guillaume Fichet à Bonneville en Haute-Savoie. 1024 a donc demandé à David de recueillir les témoignages de quelques unes de ses élèves pour tenter une explication. Mélisse Clivez et Émeline Cholletont accepté de jouer le jeu.
Si vous suivez ce qu’il s’est passé depuis 2012 au lycée, mise en place de la spécialité « informatique et sciences du numérique » puis récemment de « numérique et sciences informatiques » (NSI), vous avez sûrement déjà croisé la route de David Roche. Initialement professeur de physique, reconverti en professeur d’informatique, il a produit pour ses enseignements d’informatique de nombreux supports de qualité qu’il met à la disposition de la communauté sous forme de ressources éducatives libres sur https://pixees.fr/informatiquelycee.
Ces ressources accompagnent toujours bon nombre d’enseignants et leur ont parfois évité quelques nuits blanches. N’oubliez pas de le citer si vous utilisez sa production (sous licence Creative Commons).
– David Roche, D. R. : « Pourquoi avez-vous choisi NSI en première ? »
– Mélisse Clivaz, M. C. : À ce stade de ma scolarité et de mon parcours avenir, je n’étais pas encore décidée entre mes deux choix d’orientation qui étaient le social et l’informatique. Mes trois choix de spécialité se sont donc porté sur SES (pour le social), NSI (pour l’informatique) et AMC puisque l’anglais est, pour moi, toujours utile.
– Émeline Chollet, É. C. : J’ai choisi NSI en première car j’avais pris informatique aussi en seconde. Pour le choix de mes spécialités, j’ai pris maths, physique-chimie, et après j’avais le choix entre SVT et informatique. Puis, au fur et à mesure de l’année j’ai préféré l’informatique aux sciences de la vie et de la terre.
–D. R. : « Pourquoi avez-vous choisi de continuer NSI en terminale ? »
– M. C. : Mon choix de spécialité fait en classe de première fut, en réalité, un choix stratégique. Il avait pour objectif de me laisser le plus de liberté possible pour mon orientation future. Le choix de terminale fut en totale cohérence avec mon parcours avenir qui s’est affiné au fil du temps. La spécialité NSI est un moyen de garder un lien avec les mathématiques même si vous ne vous considérez pas comme quelqu’un de « matheux ». De plus, les cours de NSI sont totalement différents des cours magistraux dans la plupart des autres matières ; ce sont des cours qui mélangent théorie et pratique. Ceci permet de se rendre compte en temps réel de l’utilité de ce qu’on apprend.
– É. C. : En terminale, nous devons enlever une de nos trois spécialités. Je devais garder obligatoirement maths, mais ensuite, j’avais le choix entre physique et informatique. D’un côté, je voulais garder une plus grande diversité en termes de connaissances, pour éviter de me fermer des portes dès la classe de terminale et avoir moins de difficultés ensuite dans le supérieur si je choisis une classe préparatoire. D’un autre coté, j’avais de très bonnes notes en informatique ce qui n’était pas le cas en physique et j’aimais cette matière. Alors, je me suis décidée à garder NSI aussi en terminale et j’ai bien fait. En NSI, les cours sont totalement différents d’un autre cours, ce ne sont pas des cours magistraux, et notre professeur a fait un site dans lequel il y a tout le cours bien organisé et bien expliqué ; ce qui nous permet d’avan- cer à notre rythme. Quand tout le monde a fini un point du cours, il nous fait un résumé au tableau. Une fois par mois environ, nous faisons des projets où l’on doit programmer quelque chose ; ces projets sont très enrichissants et nous entraînent à programmer. J’apprécie cette manière de travailler car on a pas mal d’autonomie et on est assez libre, tout en avançant sur le programme rapidement.
– D. R. : « Est-ce que NSI a un rapport avec votre orientation ? »
– M. C. : Comme dit précédemment, mon parcours avenir s’est créé au fil du temps ; notamment grâce au cours d’informatique mais également grâce à des stages en en- treprise. Je souhaite travailler dans le domaine du Web Design, et mes deux années d’informatique constitueront un point positif sur mon CV lorsque je candidaterai à des écoles formant à ces métiers (ces écoles accordant une valeur importante à la connaissance technique lorsqu’elle vient en plus des aspects créatifs).Il est certain que le domaine de l’informatique est très peu fréquenté par les filles car le stéréotype des filles littéraires et des garçons scientifiques persiste. De plus, l’image que l’on a d’un cours d’informatique et des personnes qui le suivent est celle de garçons scotchés devant leur ordinateur depuis la naissance alors, qu’en réalité, n’importe qui ayant un minimum de curiosité pour la technologie et l’informatique peut suivre ce cours, le comprendre et y prendre goût.
– É. C. : L’année prochaine, je veux suivre un cursus master en ingénierie en informa- tique à Chambéry. Je pense que mes trois années d’informatique au lycée m’aideront bien. Par ailleurs, cette année, j’ai aussi pris maths expertes dans le but d’avoir un bon niveau en maths.
– D. R. : « Une fille pour une classe de garçons ? »
– É. C. : Je n’ai pas peur d’être dans une classe de garçons. D’un côté, je préfère être dans une classe formée que de garçons plutôt que dans une classe composée uniquement de filles. Et puis, leur compagnie ne me dérange pas. Souvent, ils savent plus de choses que moi alors ils m’apprennent des choses et inversement.
1024, c’est aussi le bulletin de la Société informatique de France (SIF). Il est imprimé et distribué gratuitement deux fois par an à tous ses adhérents et partenaires et consultable en accès libre sur le site de la SIF. Pour Binaire, 1024, ce sont des copains avec qui nous échangeons sur les sujets que nous voulons traiter, avec qui nous partageons parfois des articles. Serge Abiteboul & Thierry Viéville
À qui s’adresse-il et que partage-t-il ?
Il s’adresse à toute personne pour qui l’informatique est un métier, une passion, toute personne désireuse de se tenir au courant de nouvelles expériences pédagogiques ou d’approfondir les thématiques scientifiques du domaine. 1024 propose aussi des articles à connotation scientifique ou historique, des dossiers thématiques; il met en lumière les actualités des associations partenaires et propose aux jeunes docteurs de résumer leurs travaux de recherche en 1024 caractères exactement. À chaque numéro, une partie récréative présente une énigme algorithmique résolue dans le numéro suivant. Les femmes y sont également à l’honneur avec une rubrique qui leur est dédiée.
L’informatique s’enseigne aussi au lycée désormais ?
Le dernier numéro d’avril 2021 publie un dossier spécial dédié au tsunami numérique nommé « Numérique et sciences informatiques », et enseignement de spécialité d’informatique au lycée qui permet enfin de former vraiment nos jeunes à l’informatique pour qu’elles et ils deviennent créateurs ou développeuses de la société numérique d’aujourd’hui et demain.
On y donne la parole à plusieurs personnes impliquées dans ce changement : Jean-Marie Chesneaux, inspecteur général de mathématiques en charge de NSI nous éclaire sur ce que signifie concrètement l’introduction d’une nouvelle discipline au lycée ; Isabelle Guérin Lassous, présidente du jury du nouveau CAPES NSI, accompagnée de Fabien Tarissan et Marie Duflot-Kremer, nous présente le concours et nous propose un retour sur la première édition ; Charles Poulmaire, professeur de mathématiques et informatique, formateur dans l’académie des Yvelines, partage avec nous son regard sur l’introduction de l’informatique au lycée; Marc de Falco et Yann Salmon, professeurs d’informatique en classes préparatoires nous expliquent comment ces dernières s’adaptent à l’arrivée des nouveaux bacheliers, en modifiant leurs programme mais aussi en créant une nouvelle filière spécifique MPI (mathématiques, physique, informatique) pour l’accueil des bacheliers NSI. Enfin, grâce à David Roche, professeur de physique et d’informatique, nous recueillons le témoignage de deux lycéennes de Haute-Savoie qui ont choisi de suivre la spécialité NSI en première et terminale. Nous le savions déjà, l’informatique est aussi une affaire de femmes ! Pour ce numéro, nous aurions également souhaité avoir le point de vue des IUT (instituts universitaires de technologie) qui sont actuellement obligés de réviser leur programme pédagogique national suite à la mise en place du BUT (bachelors universitaires de technologie) et des universités qui accueillent des bacheliers avec des profils différents .
Nous vous invitons à suivre la sortie du prochain bulletin en novembre 2021 pour en savoir davantage, et n’hésitez pas à nous faire parvenir vos témoignages ou expériences sur l’accueil de ces nouveaux bacheliers ou sur tout autre sujet à cette adresse 1024@societe-informatique-de-france.fr.
où on retrouve chaque chiffre entre 0 et 9 une fois et une seule …
Plus sérieusement, comme 1024 = 210, c’est aussi une mesure de stockage, le kilobyte, la taille mémoire adressable avec une adresse de 10 octets. Mais, comme c’est presque 1000 = 10^3, on passe vite à un système décimal. Il fallait être un peu geek pour choisir cela comme titre d’un magazine.
Et même certain de ressentir la poésie de 2^10, la beauté de 2x2x2x2x2x2x2x2x2x2.
D’ailleurs … et à votre avis ? N’hésitez pas à proposer vos réponses dans les commentaires.
Denis Pallez, Chercheur en Informatique à l’Université Côte d’Azur.
Les systèmes d’Intelligence Artificielle sont souvent vus comme des systèmes d’aide à la décision. Est-ce que cela veut dire que l’on sait modéliser la décision ? Que l’on sait faire ou veut faire des machines qui décident comme des humains ? C’est en tout cas un sujet qui intéresse l’équipe Inria Mnemosyne de Fréderic Alexandre, spécialisée dans l’étude des fonctions cognitives supérieures par l’étude du cerveau, qui modélise les circuits cérébraux de la décision. Marie-Agnès Enard et Thierry Viéville.
Expliquons tout d’abord comment cette fonction cognitive qu’est la décision, est décrite en langage mathématique et comment nous la transcrivons et l’adaptons en circuits neuronaux. Nous tâcherons d’indiquer comment, pour un sujet de décision éco-responsable, ce point de vue est associé à celui d’autres disciplines pour innover dans l’aide à la décision. Nous évoquerons aussi la prise en compte de nos biais cognitifs, et comment les expliquer.
Mieux comprendre comment s’opèrent les choix dans notre cerveau et son fonctionnement, c’est ce que propose d’expliquer le neurobiologiste bordelais Thomas Boraud dans son dernier ouvrage.
Définir la décision sous l’angle des mathématiques
Décider de la validité d’une proposition, c’est recueillir des indices en faveur ou contre cette proposition, observer que l’accumulation de ces indices fait pencher la balance d’un coté ou de l’autre et, à un certain moment, trancher, c’est à dire penser qu’on a une vue assez représentative de la situation pour transformer cette oscillation entre deux pôles en une décision catégorique : oui ou non ou bien encore cette proposition est vraie ou fausse. Cet énoncé suggère plusieurs types de difficultés liées à la décision. Commençons par les plus évidentes. Premièrement, il faut avoir entendu, de façon équitable, les deux parties (le pour et le contre) et savoir évaluer chacun des arguments présentés pour les mettre sur une échelle commune et savoir les comparer. Deuxièmement, il faut avoir entendu assez longtemps les deux parties pour se faire un avis non biaisé, mais aussi, à la fin, il faut décider ; on ne peut pas rester tout le temps dans l’indécision. Il y a à trouver ici un compromis entre la vitesse et la justesse de la décision.
Pour ces deux types de difficultés, les mathématiques développent des outils intéressants. Certains sont proposés pour coder et comparer l’information de la façon la plus objective (la moins biaisée) possible. D’autres permettent de définir, pour un niveau de précision souhaité, le seuil optimal de différence entre les avis « Pour » et « Contre » qu’il faut atteindre avant de décider. Ces modèles mathématiques ont été mis en œuvre pour des tâches de décision perceptive élémentaires : vous voyez un nuage de points en mouvement et vous devez décider si, globalement, ces points vont plutôt à droite ou à gauche. Il est possible de rendre cette tâche très difficile en programmant le mouvement de chacun des points avec des fonctions en grande partie aléatoires, ce qui rend une décision locale impossible. Or on peut montrer que ces modèles mathématiques parviennent à reproduire très fidèlement la décision humaine, aussi bien dans ses performances que dans ses caractéristiques temporelles.
Ces modèles mathématiques sont également intéressants car, en les analysant, on peut observer les grandeurs et les phénomènes critiques au cours de la décision. Bien sûr, on trouve dans cette liste la détection de chaque indice, mais aussi leur accumulation, la différence entre les solutions alternatives, leur comparaison au seuil de décision, etc. Des études d’imagerie cérébrale permettent d’identifier les différentes régions du cerveau impliquées dans l’évaluation de chacun de ces critères et, au cours de la décision, l’ordre dans lequel ces régions sont activées. Notre équipe de recherche travaille dans la réalisation de réseaux de neurones artificiels qui, d’une part, calculent de façon similaire à ces modèles mathématiques et d’autre part, sont organisés selon une architecture globale reproduisant la circuiterie observée par imagerie et reproduisant également la dynamique d’évaluation. C’est à ce stade que nous pouvons constater que les modèles mathématiques évoqués plus haut ont un certain nombre de limitations et que nous pouvons modifier et adapter nos réseaux de neurones pour considérer des cas plus réalistes.
Quand les mathématiques ne suffisent plus
Au-delà, il nous faut considérer plus que des sciences formelles : des sciences humaines. Nous nous intéressons en particulier à trois types de limitation des modèles mathématiques.
– Premièrement, nous pouvons aller au-delà de ces modèles qui considèrent uniquement des décisions binaires (droite/gauche) en introduisant, dans les calculs neuronaux, des étapes de codage supplémentaires et des non-linéarités permettant de pouvoir considérer plusieurs catégories.
– Deuxièmement, les modèles mathématiques sont le plus souvent appliqués à des indices perceptifs alors que des arguments de nature différente peuvent être présentés pour emporter une décision (l’évocation de souvenirs ou de valeurs émotionnelles par exemple). Nous cherchons à bénéficier du fait que nos réseaux de neurones sont inscrits dans la circuiterie de l’architecture cérébrale et à étudier comment ajouter d’autres indices (mnésiques ou émotionnels) provenant d’autres aires cérébrales.
– Troisièmement, alors que nous avons parlé jusqu’à présent de décisions mathématiquement fondées (certains disent logiques ou rationnelles), il est connu que les humains sont soumis à différents types de biais quand ils font des jugements, ce qui laisse souvent penser que nous ne sommes pas rationnels.
En collaboration avec les sciences humaines et sociales qui étudient et décrivent ces biais, nous cherchons à montrer que nous pouvons les expliquer et les reproduire en manipulant certains paramètres de nos modèles. Nous prétendons aussi que ces biais ne montrent pas une faiblesse de notre jugement mais plutôt une orientation de ce jugement tout à fait pertinente pour un être vivant évoluant dans des conditions écologiques. Donnons quelques exemples. Au lieu d’intégrer tous les arguments de la même manière dans notre jugement, nous pouvons être soumis à un biais de récence ou de primauté, selon que les indices les plus récents ou les plus anciens vont jouer un rôle plus important dans la décision. Ce type de jugement, qu’on peut reproduire en modifiant certains paramètres internes du calcul neuronal, peut paraître plus adapté pour certaines situations avec des conditions changeantes (récence) ou stables (primauté). On sait par ailleurs que détecter ce type de conditions nous fait émettre des neurohormones qui modifient la nature du calcul neuronal en modifiant certains de leurs paramètres. Nous essayons de reproduire ces mécanismes dans nos modèles.
Un autre biais, appelé aversion au risque, fait que nous surestimons les indices défavorables par rapport aux indices favorables. Il a été montré expérimentalement en économie que les neurones qui codent les pertes et les gains ne sont pas soumis aux mêmes non-linéarités dans leurs calculs, ce que l’on sait simplement reproduire dans nos modèles. Ici aussi, on peut comprendre que, pour un être vivant qui ne fait pas que calculer des bilans financiers, il est judicieux d’accorder plus d’importance à ce qui peut nous nuire (et potentiellement nous blesser) qu’à ce qui est positif (et qu’on aura d’autres occasions de retrouver). De façon similaire, d’autres types de biais, appelés de référence ou de préférence, font que nous allons accorder plus d’importance à des indices faisant référence à un événement récent ou à une préférence personnelle. Ici aussi, introduire des mécanismes cérébraux connus de types mnésiques permet de reproduire ces phénomènes, dont l’intérêt adaptatif semble aussi clair. Enfin un dernier type de biais concerne la différence entre les valeurs que nous donnons à des situations et les valeurs que nous donnons aux actions pour les atteindre ou les éviter et que l’on connaît bien en addictologie : alors que l’on sait très bien que alcool, tabac et autres drogues sont mauvais pour nous, diminuer nos actions de consommation n’est pas forcément simple. On sait que dans le cerveau ces valeurs sont dissociées, autrement dit que nos actions ne reflètent pas toujours nos pensées.
L’équipe-projet Mnemosyne d’Inria commune avec le Labri et l’IMN à Bordeaux travaille sur la modélisation des fonctions cognitives du cerveau, de manière pluri-disciplinaire. (Crédit : Inria / Photo H.Raguet).
Une application concrète : aider à avoir un comportement plus éco-responsable
Avec l’aide de la Région Nouvelle Aquitaine, d’Inria et des universités de Bordeaux et de La Rochelle, nous sommes actuellement impliqués dans un projet visant à mieux comprendre les décisions humaines relatives au changement climatique et à la transition écologique. Il s’agit d’un sujet de décision visant à changer nos comportements. On peut constater que la plupart des biais mentionnés plus haut s’appliquent : est-on prêts à changer d’habitude maintenant (prendre le bus plutôt que la voiture) pour des résultats à long terme (modifier la température moyenne dans 30 ans) ? Quitter des comportements faciles et observés autour de soi (prendre sa voiture comme tout le monde) et mettre en œuvre nos convictions citoyennes (différence entre ce qu’on pense et ce qu’on fait) ? Etc.
Ce projet va nous permettre à la fois de recueillir des informations pour affiner nos modèles et de tester leurs prédictions en interagissant avec les utilisateurs. Pour cela, nous utilisons une application que des personnes volontaires auront installée sur leurs smartphones. Cette application les aide à choisir leur mode de transport pour aller travailler et les informe sur les caractéristiques éco-responsables de leurs choix. Nous aurons ainsi accès aux décisions qui auront été prises, en fonction des situations mais aussi des informations données. Nous avons l’espoir que cette approche nous permettra d’évaluer la pertinence et le poids de différents types d’arguments que nous aurons préparés en amont avec nos collègues des sciences humaines et sociales, reposant en particulier sur des hypothèses issues de nos modèles et sur des mécanismes supposés de la prise de décision.
Dans ce projet, nous avons orienté notre approche selon les convictions suivantes :
– D’une part, si nous savons bien décrire les caractéristiques de cette prise de décision et en particulier pourquoi et quand elle est difficile, nous pouvons proposer des mises en situations qui seront plus favorables à des prises de décision responsables.
– D’autre part, nous faisons également le pari du citoyen informé et proactif. Si nous décrivons ces mécanismes de décision, leurs biais et leur inscription cérébrale, cela peut permettre de déculpabiliser (ce sont des mécanismes biologiques à la base de ces biais) et de donner des leviers pour travailler sur nos processus mentaux et réviser nos modes de pensée.
Quand on conçoit un algorithme, une question est : « est-ce qu’il fait bien le boulot ? » Une autre est : « combien de temps il va prendre ?» Si ça met deux plombes pour me dire où trouver une pizza, ça m’intéresse moins. Le domaine qui traite du temps que va prendre un algorithme (ou de la quantité de mémoire dont il va avoir besoin) s’appelle « la complexité algorithmique ». Une série d’articles va aborder ce sujet, avec pour commencer une introduction à ce domaine de l’informatique. Allez ! Enfourchez votre balai pour rejoindre avec nous le fameux sorcier Henri Potier et ses amis. Serge Abiteboul
L’école Poudlard a été envahie par le-méchant-dont-on-ne-doit-pas-prononcer-le-nom. Henri a été capturé, et ses amis Hermine et Renaud vont devoir mettre en œuvre tout leur savoir magique pour le délivrer, car le château est protégé par des sorts puissants pour empêcher nos héros d’accéder au donjon où vous-savez-qui séquestre Henri. Vont-ils parvenir à sauver leur ami des griffes du seigneur des ténèbres ?
Première difficulté, il leur faut d’abord parvenir à franchir le pont-levis ultra-sécurisé.
– Dépêchons-nous Renaud, derrière cette porte il va falloir trouver les horcruxes ! Mais il y a d’abord ce maudit Pavétactile dont le code change toutes les cinq minutes…
Illustration Pierre Perifel
À ce moment précis, le pigeon d’Hermine lui apporte un indice crucial arraché de mains malfaisantes : les 5 chiffres du code secret à entrer sont aux positions 2, 4, 8, 16 et 32 dans le produit des deux nombres
45332114286503538748298493013368940560645810452563 et 18501921802355806067839342577359599275135595217788.
– Facile, il suffit de calculer le produit et on a le code, propose Renaud. Passe-moi un stylo Hermine. Je me souviens de mes cours de primaire, je vais te le calculer ce produit.
– Cette méthode est bien trop lente, Renaud. Tu n’y arriveras jamais, on n’a que 5 minutes ! Laisse-moi faire.
Hermine écrit à toute vitesse des symboles incompréhensibles sur son carnet. Ses efforts finissent par payer : le pont-levis s’abaisse enfin. Il était temps, le code allait de nouveau changer. Renaud en reste bouche bée.
– Ta méthode naïve nécessitait trop d’opérations pour le temps qu’on avait, lui explique Hermine. J’ai appliqué une autre méthode bien plus rapide. Elle est plus compliquée, c’est pour ça que tu ne la connais pas. La tienne aurait nécessité environ 2500 opérations simples, alors que j’en ai eu besoin de moins de 200, sans compter que je calcule plus vite que toi.
– Mais comment est-ce que tu sais tout ça, encore ?
– En informatique, une méthode pour résoudre un problème, ça s’appelle un algorithme. C’est une succession d’opérations qu’on peut programmer sur un ordinateur. Pour un même problème, il existe en général plein d’algorithmes pour le résoudre, des simples et des compliqués, des beaux et des laids, continue Hermine. Tu voulais utiliser la méthode de l’école primaire pour multiplier deux nombres : c’est un algorithme. Moi, j’ai utilisé un autre algorithme, plus astucieux, pour résoudre le même problème. La différence, c’est que le tien nécessite plus de n2 opérations pour multiplier deux nombres de n chiffres (Hermine écrit sur son ardoise magique ci-dessous), alors que le mien n’en utilise que n*ln(n) environ (voir l’encadré du prof de magie mathématique). Mon algo était juste plus rapide que ton truc d’escargot.
– Frimeuse !
Hermine : On veut multiplier deux entiers x et y de n chiffres chacun. La méthode de l’école primaire multiplie x par chaque chiffre de y et additionne les résultats obtenus (après décalage). La multiplication de x par un chiffre de y nécessite de parcourir tous les chiffres de x, soit n opérations. On répète n fois ce processus, ce qui fait n2 opérations, plus les additions pour obtenir le résultat final.
Al-Khwârizmî (professeur de magie mathématique) : ln(n) désigne la fonction logarithme. Tout ce que vous avez besoin de savoir est que ln(n) est beaucoup plus petit que n, donc n*ln(n) bien plus petit que n*n.
Exercice à réaliser sans utilisation de magie : montrer comment multiplier deux nombres avec n*ln(n) opérations élémentaires. Indication : voir Harvey et van der Hoeven, https://hal.archives-ouvertes.fr/hal-02070778v2
Ignorant l’interruption de Renaud, Hermine poursuit :
– La complexité algorithmique est un domaine de l’informatique qui essaie de classer les problèmes en fonction de leur difficulté. Par exemple, résoudre le problème de la multiplication revient à donner un algorithme pour calculer le produit de deux entiers quelconques x et y. Deux entiers particuliers (par exemple, x = 43 et y = 47) forment ce qu’on appelle une instance du problème, que l’on donne ensuite à l’algorithme pour obtenir la solution correspondante (ici, 2021 = 43*47). Et comme on l’a fait pour la multiplication, on mesure le nombre d’opérations d’un algorithme pour un problème en fonction de la taille de l’instance, que l’on note n. En effet, plus la taille n de l’instance est grande (comme les deux entiers de 50 chiffres pour le Pavétactile) et plus le nombre f(n) d’opérations à effectuer (plus de 2500 avec ta méthode, Renaud) sera important.
– Donc plus les nombres à multiplier sont grands, plus il faudra d’opérations.
– C’est comme ça avec presque tous les algorithmes, explique Hermine. Par exemple, tu comprends bien qu’il faudra plus de temps pour trier une liste de n = 100.000 nombres par exemple, que pour trier une liste de n = 5 nombres. Le nombre d’opérations dépend de la taille du problème.
– Mais on peut tout faire avec n*ln(n) opérations avec ton astuce, non ?
– Rêve Renaud ! « Mon » astuce n’est valable que pour la multiplication. On sait depuis 1965 grâce au théorème de hiérarchie de Hartmanis et Stearns que lorsqu’on se permet plus d’opérations, on peut résoudre plus de problèmes.
Hermine griffonne quelque chose sur son ardoise magique.
Théorème – Pour « tout » nombre d’opérations f(n), il existe des problèmes résolubles par un algorithme effectuant f(n)2 opérations, mais par aucun algorithme effectuant moins de f(n) opérations.
Par exemple, on connaît des problèmes résolubles en n6 opérations, mais qu’on ne peut pas résoudre en n3 opérations ou moins.
Idée de la démonstration : à Pré-au-Lard (comme à Séville) il y a un barbier. Ce barbier a un but dans la vie : raser exactement ceux qui ne se rasent pas eux-mêmes et qui ont moins de 40 ans. Peut-il avoir moins de 40 ans ? Si c’était le cas, alors on obtiendrait une contradiction. En effet, s’il ne se rase pas lui-même alors il devrait se raser d’après sa raison d’être. Mais à l’inverse, s’il se rase lui-même, il ne devrait pas se raser. On en conclut que le barbier a plus de 40 ans.
On démontre le théorème de manière similaire où le rôle du barbier est joué par un algorithme, et où son âge est remplacé par f(n)2 et celui des clients par f(n).
Illustration Pierre Perifel
Renaud reste perplexe face à tant de science.
– Mais on ne va quand même pas s’amuser à connaître la fonction f(n) exacte pour chaque problème ?
– Héhé bien vu. On regroupe les problèmes en « classes de complexité ». Par exemple, la classe P est celle des problèmes résolubles en un nombre polynomial d’opérations, n, ou n2, ou n3, etc. Ils sont généralement considérés comme « faciles » par opposition à des problèmes nécessitant un nombre exponentiel d’opérations comme 2n car ces nombres sont vraiment gigantesques même quand la taille de l’instance est petite, regarde !
Hermione griffonne à nouveau sur son ardoise magique.
– Ah oui, c’est clair, quand on est pressé il vaut mieux un algorithme qui fait n2 opérations plutôt que 2n , ou encore pire ! s’exclame Renaud. Mais à quoi ça sert de savoir qu’un problème nécessite beaucoup d’opérations ? Moi ce que je veux c’est juste le résoudre.
– Déjà ça permet de comprendre un peu mieux le problème, poursuit Hermine. Ça pousse à trouver des algorithmes plus efficaces pour résoudre un problème particulier. Et puis si on a prouvé qu’un problème est hyper complexe, ça t’évite de chercher inutilement un algorithme efficace qui n’existe pas. En plus, cette théorie est aussi utilisée en cryptographie. On chiffre un message de telle façon qu’il est facile de le déchiffrer quand on connaît la clé secrète, mais hyper complexe de le faire si on ne l’a pas.
– Genre sans la clé, je pourrais peut-être déchiffrer ton message secret avec l’ordinateur le plus rapide au monde, mais il me faudrait cent ans.
– Exactement ! Mais assez parlé Renaud, Henri a besoin de nous et il nous faut trouver la carte des horcruxes…
Sylvain Perifel, maître de conférences, Université de Paris » et Guillaume Lagarde, postdoctorant, Université de Bordeaux »
Acheter en ligne, réaliser des transactions bancaires, communiquer de façon sécurisée, autant d’opérations qui nécessitent d’être protégées par des fonctions (ou primitives) cryptographiques. Notre confiance envers ces briques de base repose sur la cryptanalyse, c’est à dire l’analyse de la sécurité par des experts, qui essayent de “casser” les primitives cryptographiques proposées, et ainsi déterminer celles qui semblent robustes et qu’on pourra recommander, ou celles qui semblent dangereuses et qu’il ne faut pas utiliser. C’est ce que nous explique Maria Naya-Plasencia dans deux articles qui terminent la série entamée à l’occasion de la publication par Inria du livre blanc sur la cybersécurité. Dans ce second article, Maria nous décrit la situation actuelle et les évolutions envisagées dans ce domaine. Pascal Guitton .
D’où peuvent venir les faiblesses ?
L’expérience nous montre que des attaques sur les primitives cryptographiques sont basées sur différents types de faiblesse. Dans le cas de la cryptographie asymétrique, la faille vient parfois d’un assouplissement dans la preuve pour lier le problème cryptographique au problème mathématique associé. Dans d’autres cas, le problème mathématique considéré s’avère plus facile à résoudre que prévu. Des faiblesses peuvent aussi venir d’une configuration ou de paramètres spécifiques d’une certaine instance, parfois non apparents, qui rendent le problème moins difficile que l’original.
Dans le cas des primitives symétriques, les preuves formelles de sécurité reposent sur des suppositions irréalistes, mais cela ne les rend pas faciles à attaquer pour autant. Si jamais une attaque est trouvée (rappelons qu’elle doit être plus efficace que l’attaque générique), la primitive correspondante est considérée comme cassée. Ce fut le cas par exemple du chiffrement Gost.
Le besoin de la transparence
Nous avons vu que même les primitives cryptographiques les plus robustes ne possèdent pas de véritable preuve de sécurité – tout au plus des indices qui semblent garantir leur sûreté, mais sans qu’on en soit absolument certain.
La mesure de sécurité la plus tangible et la plus acceptée par la communauté cryptographique est en fin de compte la résistance avérée à la cryptanalyse : si une fonction cryptographique a résisté aux attaques de dizaines d’experts pendant des décennies, on est en droit de se sentir en bonne sécurité (malgré le manque de preuve formelle).
C’est en fait le rôle principal de la cryptanalyse : la mesure empirique de la sécurité. Elle est donc la base de la confiance que nous portons aux algorithmes cryptographiques. C’est une tâche essentielle qui n’a pas de fin.
Il est important de réaliser que cette sécurité ne peut s’obtenir que grâce à une transparence totale : si on conçoit un algorithme cryptographique, il faut le rendre complètement public dans ses moindres détails pour le soumettre à l’analyse des cryptographes, car seuls leurs efforts continus pour casser cet algorithme pourront être un gage tangible de sa sécurité (s’ils échouent, bien sûr). Ce principe est paradoxalement dû à un militaire et connu depuis plus de 100 ans sous le nom de principe de Kerkhoffs.
Le symétrique est également vrai : les cryptanalystes doivent publier leur travaux et leurs avancées pour permettre à la communauté scientifique de réutiliser leurs idées, et ainsi disposer des meilleures techniques pour analyser les crypto-systèmes existants.
Cette première transparence – celle des algorithmes cryptographiques – est assez communément appliquée, même si certains acteurs s’entêtent à concevoir des crypto-systèmes “cachés” en espérant que cela augmentera leur sécurité. Par contre, il reste assez commun, pour des hackers isolés comme pour de grosses organisations, privées ou publiques (comme la NSA américaine), de conserver leurs progrès pour eux, en espérant peut-être obtenir un avantage stratégique s’ils parvenaient à cryptanalyser avec succès un algorithme que le reste du monde considère sûr. Nous avons donc un réel besoin de cryptanalystes bienveillants, travaillant dans la transparence et ayant pour but de faire progresser la cryptographie en général.
Forces et faiblesses
Un aspect préoccupant vient du fait que la sécurité n’est jamais prouvée. Quelle que soit la fonction cryptographique, on ne pourra jamais écarter complètement la possibilité d’une cryptanalyse, même très tardive.
Un aspect rassurant est que le modus operandi est très bien établi, depuis des décennies. La communauté des cryptographes adopte par défaut une attitude qu’on pourrait qualifier de paranoïaque quand il s’agit d’évaluer si tel ou tel algorithme pourrait se faire attaquer. En effet, la cryptanalyse moderne parvient très rarement à véritablement “casser” un crypto-système, et la plupart des résultats sont en fait des attaques partielles, c’est-à-dire sur une version réduite du système. Par exemple, en cryptographie symétrique, de nombreuses primitives sont formées en appliquant R fois une même fonction interne : on parle de R tours. Très souvent, les cryptanalystes s’attaquent à une version réduite, avec un nombre de tours r inférieur à R. On peut alors jauger la “marge” de sécurité grâce à la différence entre le plus grand r d’une attaque et le nombre de tours R (si r = R, la fonction est véritablement cassée). Pour éviter tout risque, de nombreuses primitives sont abandonnées tout en restant loin d’avoir été cassées : on a besoin de peu de primitives cryptographiques, au final, et les plus sûres ont une marge de sécurité très importante. Pour que ce système reste valide, il est important que la cryptanalyse bienveillante reste très active et dynamique.
L’exemple d’AES
AES est le standard actuel de chiffrement à clé secrète. Nous allons analyser l’effet de la cryptanalyse sur la version de l’AES qui utilise une clé de 128 bits. Cette version utilise 10 tours, c’est à dire qu’on applique 10 fois la même fonction interne.
En 1998, lors de sa conception, la meilleure attaque connue, trouvée par les auteurs, s’appliquait sur 6 tours du chiffrement : il existait donc une attaque, meilleure que l’attaque générique, mais seulement sur une version affaiblie qui n’applique que 6 fois la fonction interne. La marge de sécurité était donc de 4 tours sur 10. En 2001, une attaque sur 7 tours fut découverte. Bien que la marge fut donc réduite de 4 à 3 tours, AES était loin d’être cassé.
Depuis 2001, plus de 20 nouvelles attaques sur des versions réduites de l’AES ont été publiées, améliorant la complexité, c’est-à dire diminuant la quantité de calcul nécessaire. Aujourd’hui, la meilleure attaque connue est toujours sur 7 tours : pendant 18 ans, la marge de sécurité en nombre de tours n’a pas bougé. Plusieurs compromis sur le temps de calcul, la quantité de données et de mémoire nécessaire à l’attaque sont possibles, mais celle qui optimise le temps de calcul a tout de même besoin de 299 opérations, et d’une quantité de données et de mémoire équivalente. Ce nombre énorme (à 30 chiffres) est bien au delà de la capacité de calcul de l’ensemble des ordinateurs de la planète, même pendant des centaines d’années. Et la comparaison avec l’attaque générique, qui a besoin de 2128 opérations mais d’une quantité de données et de mémoire négligeable, n’est pas si évidente en termes d’implémentation.
De toute évidence, en prenant en compte tous les efforts fournis par la communauté cryptographique pendant tant d’années, il semble très peu probable que des attaques sur la version complète apparaissent en l’état actuel. On laisse peu de place aux surprises ! AES reste encore un des chiffrements les plus analysés au monde, et de nouveaux résultats pour mieux comprendre sa sécurité et son fonctionnement apparaissent tous les ans.
Etdansunmondepost-quantique?
Imaginons des attaquants ayant accès à un ordinateur quantique, qui utilise les propriétés quantiques des particules élémentaires pour effectuer certains types de calculs de manière beaucoup plus performante que les ordinateurs classiques (cf ces articles [1], [2] récent de binaire). De tels attaquants pourraient casser la plupart des crypto-systèmes asymétriques utilisés actuellement. C’est d’ailleurs une des applications les plus prégnantes de l’ordinateur quantique tel qu’on l’imagine.
Les crypto-systèmes dit “post-quantiques” sont en plein essor pour répondre à ce besoin. En ce moment même, le NIST américain organise une compétition pour trouver des nouveaux standards de chiffrement post-quantique. Ces crypto-systèmes se basent sur des problèmes difficiles qui – contrairement à la factorisation des entiers, base de RSA – résisteraient, dans l’état actuel des connaissances, à l’arrivée de l’ordinateur quantique. Ces primitives post-quantiques, asymétriques et symétriques, ont besoin, de la même façon que dans le cas classique, d’avoir leur sécurité analysée face à un attaquant quantique, et la cryptanalyse quantique est donc d’une importance primordiale.
Mentionnons que la cryptographie doit parfois pouvoir résister dans le temps : on voudrait pouvoir garder certains documents confidentiels à long terme, malgré les progrès scientifiques en matière de cryptanalyse (incluant donc l’arrivée possible de l’ordinateur quantique). Il serait donc opportun de commencer dès aujourd’hui à utiliser des crypto-systèmes qu’on pense résistants même dans un contexte post-quantique.
L’importance des recommandations.
Il ne faut pas sous-estimer l’importance de suivre les recommandations de la communauté scientifique cryptographique. Notamment, seule la poignée de primitives recommandées par cette communauté doit être utilisée, car ce sont celles qui focalisent la cryptanalyse et dont la marge de sécurité est de loin la meilleure. Heureusement, ce principe est de mieux en mieux respecté par la communauté informatique dans son ensemble, comme vous pourrez le constater avec légèreté en effectuant une recherche sur le Web d’images contenant les termes “roll your own crypto”. Une notion également importante et parfois plus négligée est de rester à jour, et de réagir rapidement quand la communauté cryptographique recommande d’abandonner un crypto-système précédemment recommandé, mais jugé insuffisamment sûr à l’aune de progrès récents.
Les grandes failles de sécurité informatique sont souvent le cas de mauvaises implémentations, mais la faute incombe parfois à l’usage de crypto-systèmes non recommandés. Citons par exemple une attaque parue en 2013 sur le protocole TLS (qui protège les connexions https sur nos navigateurs), utilisant des failles du stream cipher RC4 dont on connaissait l’existence depuis 2001 ! Pire : en 2015, l’attaque FREAK exploitait la petite taille des clés RSA-512, qu’on savait trop faible depuis les années 90.
Ces brèches de sécurité et beaucoup d’autres auraient pu et dû être évitées !
Conclusion
Ces illustrations montrent que la cryptanalyse demande des efforts soutenus et continus, par des chercheurs bienveillants travaillant dans un contexte transparent, et publiant leurs résultats.
Que ce soit dans un contexte classique ou post-quantique, la cryptanalyse doit rester une thématique en constante évolution, afin d’assurer la maintenance des algorithmes utilisés, ainsi que pour évaluer les nouveaux types d’algorithmes cryptographiques. Mieux vaut prévenir que guérir et garder une longueur d’avance sur les adversaires malveillants !
Acheter en ligne, réaliser des transactions bancaires, communiquer de façon sécurisée, autant d’opérations qui nécessitent d’être protégées par des fonctions (ou primitives) cryptographiques. Notre confiance envers ces briques de base repose sur la cryptanalyse, c’est à dire l’analyse de la sécurité par des experts, qui essayent de “casser” les primitives cryptographiques proposées, et ainsi déterminer celles qui semblent robustes et qu’on pourra recommander, ou celles qui semblent dangereuses et qu’il ne faut pas utiliser. C’est ce que nous explique Maria Naya-Plasencia dans deux articles qui terminent la série entamée à l’occasion de la publication par Inria du livre blanc sur la cybersécurité. Dans ce premier article, Maria pose les bases des mécanismes de la cryptanalyse. Pascal Guitton .
Nos communications doivent être protégées pour assurer leur confidentialité et intégrité, et pour les authentifier. Des protocoles de sécurité bien réfléchis sont utilisés dans ce but, et les briques de base de tous ces protocoles sont les primitives cryptographiques. Ces primitives cryptographiques peuvent être divisées en deux grandes familles.
La cryptographie symétrique (parfois dite “à clé secrète”) est la plus ancienne. Si Alice et Bob veulent communiquer à distance de façon confidentielle, malgré les risques d’interception de leurs messages, ils vont d’abord se réunir et se mettre d’accord sur une clé secrète, que tous les deux (et personne d’autre) connaissent. Quand Alice veut envoyer un message à Bob, il lui suffit alors de cacher l’information à l’aide de la clé secrète, avant de l’envoyer. Quand Bob recevra le message chiffré, il peut le déchiffrer à l’aide de la même clé secrète pour récupérer le message original : la clé secrète sert à chiffrer et à déchiffrer. Bob peut lui aussi envoyer un message à Alice avec la même clé, qui est utilisable dans les deux sens.
Cette méthode présente l’inconvénient de devoir se réunir (en secret, sans risque d’interception ou espionnage) avant de pouvoir établir des communications éloignées et sécurisées. Comment pourraient faire Alice et Bob pour communiquer confidentiellement sans se réunir avant ?
Ils peuvent utiliser la cryptographie asymétrique (dite ”à clé publique”), introduite dans les années 70. Les détails sur ce types de primitives sont présentés dans l’article “De la nécessité des problèmes que l’on ne sait pas résoudre”.
La cryptographie asymétrique permet d’éviter que les parties qui veulent communiquer se réunissent avant établir la communication sécurisée, mais elle est aussi lente et coûteuse, pouvant devenir impraticable pour des longs messages. De son côté, la cryptographie symétrique nécessite un échange de clés avant de pouvoir commencer la communication, mais une fois la clé secrète répartie, elle est considérablement plus efficace. Pour exemple, le standard symétrique actuel, AES, recommandé depuis 2002 et utilisé dans la plupart des navigateurs web, peut chiffrer plusieurs gigaoctets par seconde, là où les standards asymétriques actuels peinent à atteindre un mégaoctet par seconde (plus de 1000 fois plus lents). On utilise donc le plus souvent des systèmes mixtes : la cryptographie asymétrique pour échanger une clé secrète, normalement de petite taille (par exemple 128 bits), et ensuite la cryptographie symétrique (en utilisant la clé secrète échangée) pour chiffrer les messages.
Pour que les communications soient sûres, les primitives cryptographiques utilisées doivent répondre à un cahier des charges précis en matière de sécurité. La cryptanalyse constitue le moyen essentiel de s’assurer du respect prolongé de ce cahier des charges.
Quelles primitives utiliser ?
La sécurité des primitives asymétriques (à clé publique) repose en général sur la difficulté d’un problème mathématique bien établi et jugé difficile, c’est-à-dire à priori insoluble dans un laps de temps raisonnable. Par exemple, le chiffrement RSA repose sur le problème de la factorisation (étant donné un entier naturel non nul, trouver sa décomposition en produit de nombres). Déchiffrer RSA reviendrait donc à résoudre le problème de la factorisation de très grandes nombres entiers, ce qui constituerait une véritable bombe dans le milieu scientifique, car de très nombreux chercheurs étudient ce problème en vain depuis des décennies.
Du côté de la cryptographie symétrique, on peut prouver formellement de nombreuses propriétés de sécurité d’un chiffrement symétrique idéal si on suppose qu’il génère pour chaque message un chiffre aléatoire, ce qui ne nous permettrait pas de retrouver de l’information sur le message original. Mais il est par essence impossible de construire efficacement une telle fonction, et les primitives symétriques essaient d’imiter ce comportement avec des fonctions déterministes. Pour jauger la sécurité, on s’en remet donc à la résistance aux attaques des cryptanalystes.
Une attaque est jugée efficace (et la primitive attaquée est alors dite « cassée ») si elle peut se faire plus facilement (plus rapidement, ou en utilisant moins de ressources de calcul) que les meilleures attaques génériques, c’est à dire une attaque qu’on peut toujours appliquer, même sur les primitives idéales. Par exemple, une attaque générique sur un chiffrement symétrique est la recherche exhaustive de la clé secrète : en essayant toutes les clés possibles, on parviendra toujours à trouver la bonne. Comme on ne veut pas qu’une telle attaque soit réalisable, les clés secrètes ont des tailles variant entre 128 à 256 bits, selon la sécurité voulue : cela implique qu’il faudrait essayer respectivement 2128 ( environ à 340 milliards de milliards de milliards de milliards, soit un 3 suivi de 38 zéros) et 2256 clés différentes. Tester 2128 clés est à l’heure actuelle hors de portée mais il est difficile de prédire pendant combien de temps ce sera le cas ; pour des clés de 256 bits une recherche exhaustive est cependant totalement au-delà des capacités de l’ensemble des ressources de calcul de la planète.
L’existence de toute attaque plus performante que ces attaques génériques est considérée comme une faiblesse grave de la primitive.
Thibaut Sohier est doctorant au sein du Laboratoire des Technologies d’Intégration 3D du CEA, rattaché à l’école doctorale des Mines de Saint-Etienne. Il est finaliste de la région Lyonnaise au concours « Ma thèse en 180 secondes« . Thibaut vient nous expliquer dans binaire ce qu’est le piratage par voie physique, et la solution qu’il développe dans le cadre de sa thèse pour s’en prémunir. Pauline Bolignano.
Thibaut Sohier
La mention d’une cyberattaque renvoie directement dans l’imaginaire collectif à un film de science-fiction mettant en scène des hackeurs de génie capables d’étudier du code défilant à toute vitesse sur des écrans. Quand d’un coup, le message « accès autorisé » leur ouvre les portes de systèmes ultra-sécurisés. Toutefois, dans le monde réel ce n’est pas aussi simple… Et heureusement ! Les protections algorithmiques évoluent sans cesse, compliquant grandement le piratage. Aujourd’hui, l’algorithme de chiffrement appelé AES (pour « Advanced Encryption Standard ») offre une protection efficace contre les cyberattaques ciblant les données (voir cet article). S’il fallait tester toutes les combinaisons permettant de trouver la clef secrète qui a permis ce chiffrement, il faudrait plus de 100 milliards d’années et la contribution de 7 milliards d’ordinateurs. Ce n’est évidemment pas réalisable… Les hackers se sont donc adaptés : ils peuvent s’en prendre directement à des systèmes physiques, y compris à des objets connectés dont ils exploitent des failles pour infiltrer le réseau auquel ils sont reliés. La méthode consiste à perturber physiquement (optiquement ou électromagnétiquement) les composants électroniques afin de générer une sorte de « bug » qui laissera échapper des informations permettant de déduire la clé de chiffrement et ainsi d’accéder aux informations convoitées. Dans notre monde hyper-connecté, cette technique est amenée à se développer, que ce soit dans le domaine militaire (acquisition des données archivées dans le drone) ou dans le domaine économique (piratage d’une entreprise via des objets connectés tels que des caméras de surveillance, voire la machine à café !).
Une cyber-attaque par voie physique ? et puis quoi encore ?!?
Pour bien comprendre ce nouveau mode de piratage, il faut se représenter ce qu’est réellement un dispositif électronique. Ce qui s’en rapproche le plus : c’est vous ! Ou plus précisément votre cerveau. Alors comment un hacker pourrait-il découvrir vos secrets les plus intimes?
La première solution, la plus évidente, consisterait à vous faire parler de tout et de rien, tout en étudiant l’activité de votre cerveau via la pose de sondes (comme pour un encéphalogramme). On découvrira ainsi où se situe votre zone mémoire, l’analyse et l’étude des signaux enregistrés permettra de savoir ce qui vous rend heureux, ce qui vous fait réfléchir, et même quand vous mentez… Et de fil en aiguille, en déduire vos petits secrets… Dans le jargon, on parle d’attaque par « canaux auxiliaires » ou « side channel » ; on recherche des pics de température, de courant, de champ électromagnétique… émanant du dispositif électronique en fonctionnement. Après de nombreuses analyses, toutes les informations récoltées permettent de reconstituer la clé de chiffrement en un temps record.
Equipement de test
Si cette première méthode échoue car vous êtes entrainé à ne pas parler sous la pression et à n’exprimer aucune émotion, il y a toujours un moyen plus direct d’obtenir ces informations… La torture ! Dans ce cas, l’attaquant va ouvrir votre boite crânienne afin d’accéder à votre cerveau. Il va ensuite soumettre vos neurones à des stimuli extrêmes tels que des radiations, des hausses de température ou encore de fortes impulsions lumineuses afin de générer des lapsus révélateurs.
Pour un composant électronique, c’est exactement la même chose, excepté que les neurones sont ce que l’on appelle des transistors et que la torture se nomme joliment « injection de fautes ». Mais comment s’en prémunir ?
Par analogie, on va chercher à reproduire les mécanismes de protection du cerveau ! Pour cela on réalise un boitier physique (boite crânienne) et on introduit des capteurs (récepteurs sensoriels/nerfs) qui transmettent un message d’alerte au cerveau en cas d’intrusion (douleur).
Toutefois, de même que les récepteurs sensoriels sont rendus insensibles lors d’une anesthésie, les capteurs peuvent être inhibés par une action physique ciblée.
Alors que faire ? C’est là que j’interviens !
Ma thèse
Mon travail de thèse consiste à étudier les mécanismes utilisés pour réaliser ces attaques afin de proposer une protection adéquate.
L’objectif de mon travail est de développer un boitier sécuritaire pour les composants électroniques, en intégrant des détecteurs « nouvelle génération » difficiles à « anesthésier » ! Pour ce faire, un phénomène magnétique extrêmement sensible appelé Magnéto Impédance Géante (GMI en Anglais) a été utilisé. Un maillage imitant un réseau nerveux a été généré. Il assure à la fois le rôle de barrière physique et de détecteur. Pourquoi ces détecteurs sont-ils si spéciaux ? Tout simplement car ils sont aussi émetteurs d’informations. Autrement dit, ils sont très bavards ! Chacun de ces détecteurs a l’étonnante capacité de « discuter » avec ses proches voisins via un couplage magnétique. Chaque détecteur envoie constamment à ses voisins un unique message d’origine magnétique dont le contenu dépend des messages qu’il reçoit de ses propres voisins. C’est une sorte d’équilibre. Tant que la structure du boitier est intègre, l’ensemble des messages reste constant. En cas de tentative de pénétration dans le boitier sécuritaire, un des capteurs sera nécessairement altéré, engendrant de ce fait un changement de l’information du message magnétique. L’équilibre est alors rompu, générant un effet boule de neige qui permet de repérer une modification même infime de la protection, et ainsi de prendre les mesures nécessaires pour empêcher l’accès aux données sensibles, quitte à les détruire….
Pour un humain, ce n’est pas l’idéal, mais pour de la protection de nos données, c’est rudement efficace !
Vue du dessus de la contremesure à base de matériaux magnétiques réalisée au cours de la thèse (Jaune)
Conclusion
Ma thèse peut donc se résumer au développement et à la mise en place d’un réseau de capteurs communiquant par effet magnétique. Il constitue un coffre-fort appelé « packaging sécurisé » pour les composants électroniques, afin que vos petits secrets restent bien à l’abri…
Monique Grandbastien a consacré une grande part de son temps à enseigner l’informatique pour former des informaticiens, mais aussi à favoriser le développement de l’informatique dans le second degré en formant des professeurs, en animant diverses structures nationales et académiques et en développant des recherches sur la conception d’environnements numériques destinés aux professeurs et aux élèves. Elle évoque donc quelques souvenirs qui jalonnent cette longue aventure souvent commune avec l’EPI. Pascal Guitton et Thierry Viéville.
Dans ce bel article de la revue de la revue de l’Association Enseignement Public & Informatique qui fête ces 50 ans cette année, elle y évoque quelques souvenirs qui jalonnent cette longue aventure émaillée de nombreux « stop and go », pour reprendre une expression actuelle, pour nous aider à se demander quelles leçons on peut retenir de ces 50 années pour accompagner élèves et professeurs dans le monde de demain.
On vous en recommande la lecture parce qu’il propose une vision dans la durée des nombreuses expériences vécues par Monique, et que loin d’être auto-centrée, elle nous fait découvrir le travail et l’engagement de tou·te·s ces collègues pour que nos enfants maîtrisent le numérique au lieu de simplement le subir ou le consommer.
On en parlait depuis longtemps dans les labos de recherche, une startup française l’a fait : le premier FFP2 intelligent. Il s’appelle le Smart-Shield.
Photo Engin Akyurt – Pexels
La jeune startup périgourdine « Plus qu’un masque » propose une nouvelle génération de masques avec des technologies alliant nouveaux matériaux, IA, reconnaissance faciale, capteurs sensoriels, réalité virtuelle, et blockchain. Le Smart-Shield est certifié FFP2. Son matériau révolutionnaire ne limite quasiment pas la respiration mais quand le masque détecte une personne à proximité, ses micros éléments se restructurent pour faire un barrage aussi sérieux au Covid que celui des meilleurs FFP2 classiques. Compatible IPV6 et 5G, le Smart-Shield est un véritable couteau-Suisse qui, en plus de protéger du Covid, répond à toute une gamme de besoins :
Le masque “Meet me” : vous n’avez pas encore rencontré l’âme sœur. Ce masque vibre dès que vous croisez une personne qui matche à plus de 80% avec vous.
Le masque “Faut que j’arrête » : vous êtes accroc au tabac, alcool, sucre. Ce masque analyse en permanence votre haleine et vous alerte discrètement sur vos consommations excessives.
Le masque “Masque” : vous choisissez parmi une centaine de personnages célèbres, et votre masque se reconfigure en masque de Dracula ou de Macron. Encore plus drôle, vous pouvez lui demander d’être le masque de votre conjoint.e ou celui de la personne que vous rencontrez.
Le masque “True me” : si vous le souhaitez, le masque change d’apparence suivant les situations. Il analyse vos sentiments et sourit si vous appréciez une plaisanterie, rougit si vous êtes embarrassé, se colore en bleu si vous avez le blues…
La librairie de modules du Smart-Shield est riche et vous pouvez encore l’enrichir en programmant en scratch de nouveaux modules.
Photo cottonbro -Pexels
Le Smart-Shield coûte quand même la bagatelle de 990 euros, et certains modules sont en supplément. Il est conseillé de le laver après quatre heures d’utilisation et il est garanti pour 50 lavages. On pourrait objecter que cela fait quand même cher mais Ada Maschera, la pédégère de “Plus qu’un masque”, nous a déclaré : si ça vous sauve de la Covid, du tabac, vous fait rencontrer votre âme sœur et tout le reste, moi je trouve ça tout à fait justifié, voire même bon marché…
A la question “Est-ce que la 5G était indispensable pour le Smart-Shield ?”, Ada Maschera a répondu que cela n’était pas forcément utile, voire carrément inutile, mais que son équipe marketing le lui avait fortement conseillé pour faire tendance et que personnellement elle trouvait cela très chic. Pour ce qui est de l’IPV6, elle a fini par admettre qu’elle ne savait pas bien ce que c’était mais que son CTO avait menacé de démissionner si le produit n’était pas compatible IPV6. Il se murmure que la prochaine version intégrera un calculateur quantique. La pédégère n’a pas confirmé mais a juste commenté : on saura vous impressionner…
Elle a par ailleurs annoncé que leur prochain masque, aujourd’hui en bêta-test, sortira bientôt. Il est équipé d’une voix que vous sélectionnez ; Marion Cotillard ou Omar Sy. Vous murmurez ou entrez du texte sur votre téléphone, et le masque parle avec la voix choisie.
Ses inventeurs ont équipé cette future version d’un module ’’humour”. Mais pas sûr que vous appréciez, par exemple, le bruit de prout qui se déclenche automatiquement quand une réunion devient lassante. Un prout ? Au secours ! Nous sommes sans doute très nombreuses et nombreux à détester ce genre d’humour potache. Mais rassurez-vous, on peut débrancher ce module, comme d’ailleurs tous les autres modules du Smart-Shield pour le transformer en un FFP2 classique.
Le développement de la démocratie participative a fait émerger de nouvelles formes de consultations avec un grand nombre de données à analyser. Les réponses sont complexes puisque chacun s’exprime sans contrainte de style ou de format. Des méthodes d’intelligence artificielle ont donc été utilisées pour analyser ces réponses mais le résultat est-il vraiment fiable ? Une équipe de scientifiques lillois s’est penchée sur l’analyse des réponses au grand débat national et nous explique le résultat de leur recherche . Pierre Paradinas, Pascal Guitton et Marie-Agnès Enard.
Dans le cadre d’un développement de la démocratie participative, différentes initiatives ont vu le jour en France en 2019 et 2020 comme le grand débat national et la convention citoyenne sur le climat. Toute consultation peut comporter des biais : ceux concernant l’énoncé des questions ou la représentativité de la population répondante sont bien connus. Mais il peut également exister des biais dans l’analyse des réponses, notamment quand celle-ci est effectuée de manière automatique.
Nous prenons ici comme cas d’étude la consultation participative par Internet du grand débat national, qui a engendré un grand nombre de réponses textuelles en langage naturel dont l’analyse officielle commandée par le gouvernement a été réalisée par des méthodes d’intelligence artificielle. Par une rétro-analyse de cette synthèse, nous montrons que l’intelligence artificielle est une source supplémentaire de biais dans l’analyse d’une enquête. Nous mettons en évidence l’absence totale de transparence sur la méthode utilisée pour produire l’analyse officielle et soulevons plusieurs questionnements sur la synthèse, notamment quant au grand nombre de réponses exclues de celle-ci ainsi qu’au choix des catégories utilisées pour regrouper les réponses. Enfin, nous suggérons des améliorations pour que l’intelligence artificielle puisse être utilisée avec confiance dans le contexte sensible de la démocratie participative.
Le matériau à analyser
Nous considérons le traitement des 78 questions ouvertes du grand débat national dont voici deux exemples :
« Que faudrait-il faire pour mieux représenter les différentes sensibilités politiques ?” du thème “La démocratie et la citoyenneté”
“Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” dans le cadre des propositions de solutions de mobilité alternative du thème “La transition écologique”
Les réponses aux questions sont des textes rédigés par les participants qui vont de quelques mots à plusieurs centaines de mots avec une longueur moyenne de 17 mots. Pour chaque question, on dispose de quelques dizaines de milliers de réponses textuelles à analyser. Le traitement d’une telle quantité de données est difficile pour des humains, d’où la nécessité de l’automatiser au moins partiellement. Lorsque les questions sont fermées (avec un nombre prédéfini de réponses), il suffit de faire des analyses quantitatives sous forme de comptes, moyennes, histogrammes et graphiques. Pour des questions ouvertes, il faut se tourner vers des méthodes d’intelligence artificielle.
Que veut-dire analyser des réponses textuelles ?
Il n’est pas facile de répondre à cette interrogation car, les questions étant ouvertes, les répondants peuvent laisser libre cours à leurs émotions, idées et propositions. On peut ainsi imaginer détecter les émotions dans les réponses (par exemple la colère dans une réponse comme “C’est de la foutaise, toutes les questions sont orientées ! ! ! On est pas là pour répondre à un QCM !”), ou encore chercher des idées émergentes (comme l’utilisation de l’hydrogène comme énergie alternative). L’axe d’analyse retenu dans la synthèse officielle, plus proche de l’analyse des questions fermées, consiste à grouper les réponses dans des catégories et à compter les effectifs. Il peut être formulé comme suit : pour chaque question ouverte et les réponses textuelles associées :
1. Déterminer des catégories et sous-catégories sémantiquement pertinentes ;
2. Affecter les réponses à ces catégories et sous-catégories ;
3. Calculer les pourcentages de répartition.
L’étude officielle, réalisée par Opinion Way (l’analyse des questions ouvertes étant déléguée à l’entreprise QWAM) est disponible sur le site du grand débat. Pour chacune des questions ouvertes, elle fournit des catégories et sous-catégories définies par un intitulé textuel et des taux de répartition des réponses dans ces catégories.
Par exemple, pour la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?”, l’analyse a catégorisé les réponses de la façon suivante :
Les acteurs publics
43,4%
Les solutions envisagées
8,8%
Les acteurs privés
6,6%
Autres contributions trop peu citées ou inclassables
22,5%
Non réponses, (les réponses vides)
30,2%
On constate que les catégories se chevauchent, que la catégorie “Les solutions envisagées” ne correspond pas à une réponse à la question et que le nombre d’inclassables est élevé (22.5% soit environ 35 000 réponses non prises en compte).
L’analyse officielle : la méthode
Regrouper des données dans des catégories correspond à une tâche appelée classification non supervisée ou clustering. C’est une tâche difficile car on ne connaît pas les catégories a priori, ni leur nombre, les catégories peuvent se chevaucher. De surcroît, les textes en langage naturel sont des données complexes. De nombreuses méthodes d’intelligence artificielle peuvent être utilisées comme, par exemple, la LDA pour “Latent Dirichlet Analysis” et ses nombreux dérivés.
Quelle est la méthode utilisée par l’entreprise QWAM ? À notre connaissance, les seules informations disponibles se trouvent dans la présentation de la méthodologie. On y décrit l’utilisation de méthodes internes qui sont “des algorithmes puissants d’analyse automatique des données textuelles en masse (big data), faisant appel aux technologies du traitement automatique du langage naturel couplées à des techniques d’intelligence artificielle (apprentissage profond/deep learning)” et le post-traitement par des humains : “une intervention humaine systématique de la part des équipes qualifiées de QWAM et d’Opinion Way pour contrôler la cohérence des résultats et s’assurer de la pertinence des données produites”.
Regard critique sur l’analyse officielle
Il semble que l’utilisation d’expressions magiques telles que “intelligence artificielle” ou “big data”, ou bien encore “deep learning” vise ici à donner une crédibilité à la méthode aux résultats en laissant penser que l’intelligence artificielle est infaillible. Nous faisons cependant les constats suivants :
– Les codes des algorithmes ne sont pas fournis et ne sont pas ouverts ;
– La méthode de choix des catégories, des sous-catégories, de leur nombre et des intitulés textuels associés n’est pas spécifiée ;
– Les affectations des réponses aux catégories ne sont pas fournies ;
– Malgré l’intervention humaine avérée, aucune mesure d’évaluation des catégories par des humains n’est fournie.
Nous n’avons pas pu retrouver les résultats de l’analyse officielle malgré l’usage de plusieurs méthodes. Dans la suite, nous allons voir s’il est possible de les valider autrement.
Une rétro-analyse de la synthèse officielle
Notre rétro-analyse consiste à tenter de ré-affecter les contributions aux catégories et sous-catégories de l’analyse officielle à partir de leur contenu textuel. Notre approche consiste à affecter une contribution à une (sous-)catégorie si le texte de la réponse et l’intitulé de la catégorie sont suffisamment proches sémantiquement. Cette proximité sémantique est mesurée à partir de représentations du texte sous forme de vecteurs de nombre, qui constituent l’état de l’art en traitement du langage (voir encadré).
Nous avons testé plusieurs méthodes de représentation des textes et plusieurs manières de calculer la proximité sémantique entre les réponses et les catégories. Nous avons obtenu des taux de répartitions différents selon ces choix, sans jamais retrouver (même approximativement) les taux donnés dans l’analyse officielle. Par exemple, la figure ci-dessous donne les taux de répartitions des réponses dans les catégories obtenus avec différentes approches pour la question « Quelles sont toutes les choses qui pourraient être faites pour améliorer l’information des citoyens sur l’utilisation des impôts ? ».
Pour compléter notre rétro-analyse automatique, nous avons mis en œuvre une annotation manuelle sur la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” du thème Transition Ecologique et la catégorie Les acteurs publics et avons trouvé un taux de 54.5% à comparer avec un taux de 43.4% pour l’analyse officielle, soit une différence de 15 000 réponses ! Les réponses à cette question sont globalement difficiles à analyser, car souvent longues et argumentées (25000 réponses contenant plus de 20 mots). Notre étude manuelle des réponses nous a fait remarquer certaines réponses comme “moi-même”, “les citoyens”, “c’est mon problème”, “les français sont assez intelligents pour les trouver seuls” ou encore “les citoyens sont les premiers maîtres de leur choix”. Pour ces réponses, nous avons considéré une catégorie Prise en charge par l’individu qui n’est pas présente dans la synthèse officielle bien qu’ayant une sémantique forte pour la question. Un classement manuel des réponses donne un taux de 4.5% des réponses pour cette catégorie, soit environ 7000 réponses, taux supérieur à certaines catégories existantes. Ceci met en évidence un certain arbitraire et des biais dans le choix des catégories de la synthèse officielle.
En résumé, notre rétro-analyse de la synthèse officielle montre :
L’impossibilité de retrouver les résultats de la synthèse officielle ;
La différence de résultats selon les approches ;
Des biais dans le choix des catégories et sous-catégories.
La synthèse officielle n’est donc qu’une interprétation possible des contributions.
Recommandations pour utiliser l’IA dans la démocratie participative
L’avenir des consultations participatives ouvertes dépend en premier lieu de leur prise en compte politique, mais il repose également sur des analyses transparentes, dignes de confiance et compréhensibles par le citoyen. Nous proposons plusieurs pistes en ce sens :
Transparence des analyses : les méthodes utilisées doivent être clairement décrites, avec, si possible, une ouverture du code. La chaîne de traitement dans son ensemble (comprenant le traitement humain) doit également être précisément définie. Enfin, il est nécessaire de publier les résultats obtenus à une granularité suffisamment fine pour permettre une validation indépendante (par des citoyens, des associations ou encore des chercheurs).
Considérer différents axes d’analyse et confronter différentes méthodes : la recherche de catégories aurait pu être complétée par la recherche de propositions émergentes ou l’analyse de sentiments et d’émotions. Par ailleurs, pour un axe d’analyse donné, il existe différentes méthodes reposant sur des hypothèses et biais spécifiques et la confrontation de plusieurs analyses est utile pour nuancer certaines conclusions et ainsi mener à une synthèse finale plus fiable.
Concevoir des consultations plus collaboratives et interactives : publier les affectations des réponses aux catégories permettrait à tout participant de voir comment ses contributions ont été classées. Il serait alors possible de lui demander de valider ou non ce classement et d’ainsi obtenir une supervision humaine partielle utilisable pour améliorer l’analyse. D’autres manières de solliciter cette supervision humaine peuvent être considérées, par exemple faire annoter des textes par des volontaires (voir l’initiative de la Grande Annotation) ou encore permettre aux participants de commenter ou de voter sur les contributions des autres.
Si l’intelligence artificielle permet désormais de considérer des enquêtes à grande échelle avec des questions ouvertes, elle est susceptible de biais comme toute méthode automatique. Il est donc nécessaire d’être transparent et de confronter les méthodes. Dans un contexte de démocratie participative, il est également indispensable de donner une véritable place aux citoyens dans le processus d’analyse pour engendrer la confiance et favoriser la participation.
Pour aller plus loin : les résultats détaillés de l’étude, ainsi que le code source utilisé pour réaliser cette rétro-analyse, sont consultables dans l’article.
Représenter des textes comme des vecteurs de nombre
Qui aurait prédit au début des années 2000 au vu de la complexité du langage naturel, que les meilleurs logiciels de traduction automatique représentent les mots, les suites de mots, les phrases et les textes par des vecteurs de nombres ? C’est pourtant le cas et voyons comment !Les représentations vectorielles des mots et des textes possèdent une longue histoire en traitement du langage et en recherche d’information. Les premières représentations d’un texte ont consisté à compter le nombre d’apparitions des mots dans les textes. Un exemple classique est la représentation tf-idf (pour « term frequency-inverse document frequency’’) où on pondère le nombre d’apparitions d’un mot par un facteur mesurant l’importance du mot dans l’ensemble des documents. Ceci permet de diminuer l’importance des mots fréquents dans tous les textes (comme le, et, donc, …) et d’augmenter l’importance de mots plus rares, ceci pour mieux discriminer les textes pertinents pour une requête dans un moteur de recherche. Les vecteurs sont très longs (plusieurs centaines de milliers de mots pour une langue) et très creux (la plupart des composantes sont nulles car un texte contient peu de mots). On ne capture pas de proximité sémantique (comme emploi et travail, taxe et impôt) puisque chaque mot correspond à une composante différente du vecteur.Ces limitations ont conduit les chercheurs à construire des représentations plus denses (quelques centaines de composantes) à même de mieux modéliser ces proximités. Après avoir utilisé des méthodes de réduction de dimension comme la factorisation de matrices, on utilise désormais des méthodes neuronales. Un réseau de neurones est une composition de fonctions qui se calcule avec des multiplications de matrices et l’application de fonctions simples, et qui peut être entraîné à prédire un résultat attendu. On va, par exemple, entraîner le réseau à prédire le mot central d’une fenêtre de 5 mots dans toutes les phrases extraites d’un corpus gigantesque comme Wikipedia. Après cet entraînement (coûteux en ressources), le réseau fournit une représentation de chaque mot (groupe de mots, phrase et texte) par un vecteur. Les représentations les plus récentes comme ELMo et BERT produisent des représentations de phrases et des représentations contextuelles de mots (la représentation d’un mot varie selon la phrase). Ces représentations vectorielles ont apporté des gains considérables en traitement du langage naturel, par exemple en traduction automatique.
En cette période de pandémie de Covid-19, l’association Enseignement Public et Informatique fête son 50e anniversaire.
Il y a dix ans, nous intitulions l’éditorial de notre numéro spécial « 40 ans : un bel âge pour une association ». Une décennie plus tard, nous n’avons pas pu résister à l’idée de reprendre ce titre, en l’actualisant bien sûr ! L’EPI a été fondée en 1971 (JO du 1er février) par les premiers stagiaires « lourds » chez les constructeurs de l’époque (IBM, CII, Honeywell-Bull). Depuis cette date, l’EPI a été partie prenante de tous les épisodes du déploiement, parfois hésitant voire chaotique, parfois accéléré – on pense au Plan Informatique pour Tous de 1985 –, de l’informatique pédagogique au sein du système éducatif.
Des fils d’Ariane se sont imposés dès le départ. Ils demeurent : la pluralité des approches ; leur complémentarité, ainsi l’informatique est-elle à la fois instrument pédagogique et objet d’enseignement pour tous car élément de la culture générale à notre époque ; l’impérieuse nécessité d’une solide formation diversifiée de tous les enseignants ; une didactique appropriée ; une recherche pédagogique active. Et l’EPI, force de proposition inscrit son action dans le Service public à la promotion duquel elle est attachée.
Nous parlons de déploiement parfois chaotique de l’informatique pédagogique et il nous est arrivé d’avoir raison trop tôt, mais les faits sont têtus. Il faut se souvenir qu’à la fin du siècle dernier, il était encore de bon ton dans certains milieux de proclamer que l’informatique était une mode et que comme toute mode elle passerait. Le développement d’Internet a définitivement tordu le cou à ce genre de propos. Ces résistances à l’émergence du « nouveau informatique » ne sont pas une exception. Au contraire c’est la loi du genre qui ne date pas d’hier. Si le « nouveau » finit par s’imposer, c’est toujours dans une certaine douleur. Déjà, Confucius mettait en garde : « Lorsque tu fais quelque chose, sache que tu auras contre toi ceux qui voulaient faire la même chose, ceux qui voulaient faire le contraire et l’immense majorité de ceux qui ne voulaient rien faire. »
Pour se faire sa place, le « nouveau informatique » a dû aider à une clarification des problématiques car les résistances s’accompagnent d’une certaine confusion. Il a fallu dire que les enjeux et les statuts de l’informatique dans le système éducatif sont divers et qu’il faut les distinguer. L’informatique est un outil pédagogique, transversal et spécifique, qui a fait ses preuves et qu’il faut utiliser à bon escient d’une manière raisonnée. L’informatique contribue à l’évolution de l’« essence » des disciplines (leurs objets, leurs outils et leurs méthodes). Il suffit de penser aux sciences expérimentales avec l’EXAO et la simulation, à la géographie avec les SIG, aux disciplines des enseignements techniques et professionnels. L’informatique est outil de travail personnel et collectif des enseignants, des élèves, de l’ensemble de la communauté éducative. Et l’informatique est discipline scientifique et technique, composante de la culture générale scolaire au XXIe siècle. Tous ces statuts sont complémentaires et se renforcent mutuellement. Ils doivent être tous présents. Et l’un ne saurait se substituer à l’autre.
Cette dernière décennie, l’EPI s’est inscrite dans la continuité des périodes précédentes. Des actions ont été menées en étroite relation avec des personnalités, des associations de spécialistes informatiques, en premier lieu la SIF, l’APRIL, association du logiciel libre, les parents d’élèves de la PEEP… Ce furent des rencontres au ministère de l’Éducation nationale, notamment auprès de l’Inspection générale, des conférences avec nos partenaires, des articles dans la presse nationale, la publication de notre revue mensuelle gratuite EpiNet.
En 2013, l’EPI a participé au groupe de travail qui a préparé le rapport de l’Académie des sciences L’enseignement de l’informatique en France – Il est urgent de ne plus attendre[1].
Parmi les nombreuses rencontres de la décennie passée, mentionnons qu’avec la Ligue des Droits de l’Homme, la Ligue de l’Enseignement, la PEEP, la SIF et Creis-Terminal, la FCPE étant excusée, l’EPI a rencontré le 27 novembre 2017 la Mission sur « Les données numériques à caractère personnel au sein de l’Éducation nationale ». La rencontre s’inscrivait dans la continuité de la demande d’audience que nous avions faite au ministre de l’Éducation nationale suite au courrier du directeur du numérique du 12 mai 2017, courrier qui avait suscité une grande et légitime émotion de la part des parents d’élèves, de syndicats d’enseignants, d’associations. Nous avons réaffirmé que l’on ne doit pas donner les clés de la maison Éducation nationale aux GAFAM et rappelé que si les GAFAM sont là, c’est aussi parce que l’institution éducative les invite depuis de longues années.
Tout en gardant le cap de « la complémentarité des approches », l’EPI a amplifié ses efforts, avec d’autres, pour obtenir des pouvoirs publics une intégration de l’informatique dans l’enseignement de culture générale pour tous les élèves. L’omniprésence de cette science qui sous-tend le numérique, les besoins d’informaticiens nécessitent des efforts considérables du système éducatif. On se souvient que, dans les années 90, il y avait eu les suppressions de l’option informatique puis la création du B2i : un désert explicatif. En 2007, notre rencontre à l’Élysée avait relancé et élargi l’action pour l’informatique. le groupe ITIC avait été créé, au sein de l’ASTI, à l’initiative de l’EPI. La décennie qui vient de s’écouler a vu la création d’ISN, SNT, NSI et la création d’un Capes NSI. Des avancées significatives mais il reste encore beaucoup à faire : nombre de postes mis au concours correspondant aux besoins, et on attend toujours la création d’une agrégation d’informatique. L’EPI n’est plus seule, les choses évoluent même si elles évoluent trop lentement. Ainsi la pratique du numérique dans les différentes disciplines et activités ne se développe-t-elle pas à la mesure de son intérêt didactique et pédagogique. Toujours et encore l’insuffisante formation des enseignant·e·s.
Pour terminer ce numéro spécial d’EpiNet, nous disons merci à tous les amis, compagnons de route dont vous pourrez lire les témoignages. Merci à toutes celles et ceux qui ont participé à la réalisation de ce numéro spécial. Merci à tous ceux qui se sont investis au fil des années pour que l’informatique et le numérique aient leur place pleine et entière dans le système éducatif. Merci à tous les fidèles lecteurs d’EpiNet. Et nous aurons une pensée pour notre ami Maurice Nivat qui nous a quittés le 21 septembre 2017. Maurice était membre d’honneur de l’EPI.

 Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection A la plage, Dunod, juin 2020)
Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection A la plage, Dunod, juin 2020)
 « Numérique et pandémie – Les enjeux d’éthique un an après »
« Numérique et pandémie – Les enjeux d’éthique un an après »


 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de 5G. Marie-Agnès Enard et Pascal Guitton.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de 5G. Marie-Agnès Enard et Pascal Guitton. 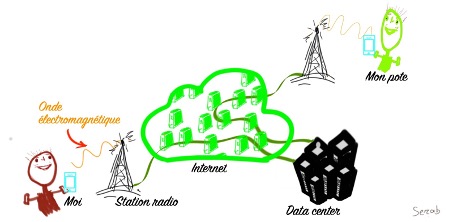
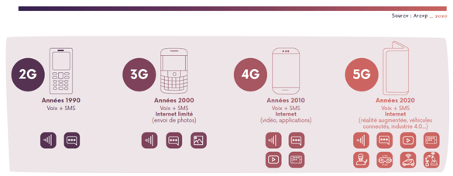








 Mieux comprendre comment s’opèrent les choix dans notre cerveau et son fonctionnement, c’est ce que propose d’expliquer le neurobiologiste bordelais
Mieux comprendre comment s’opèrent les choix dans notre cerveau et son fonctionnement, c’est ce que propose d’expliquer le neurobiologiste bordelais  Décider est souvent peser le pour et le contre, de manière non biaisée, c’est ce que l’on représente au niveau de l’allégorie de la justice avec le bandeau et la balance à fléau. ©
Décider est souvent peser le pour et le contre, de manière non biaisée, c’est ce que l’on représente au niveau de l’allégorie de la justice avec le bandeau et la balance à fléau. © L’équipe-projet Mnemosyne d’Inria commune avec le Labri et l’IMN à Bordeaux travaille sur la modélisation des fonctions cognitives du cerveau, de manière pluri-disciplinaire. (Crédit : Inria / Photo H.Raguet).
L’équipe-projet Mnemosyne d’Inria commune avec le Labri et l’IMN à Bordeaux travaille sur la modélisation des fonctions cognitives du cerveau, de manière pluri-disciplinaire. (Crédit : Inria / Photo H.Raguet).
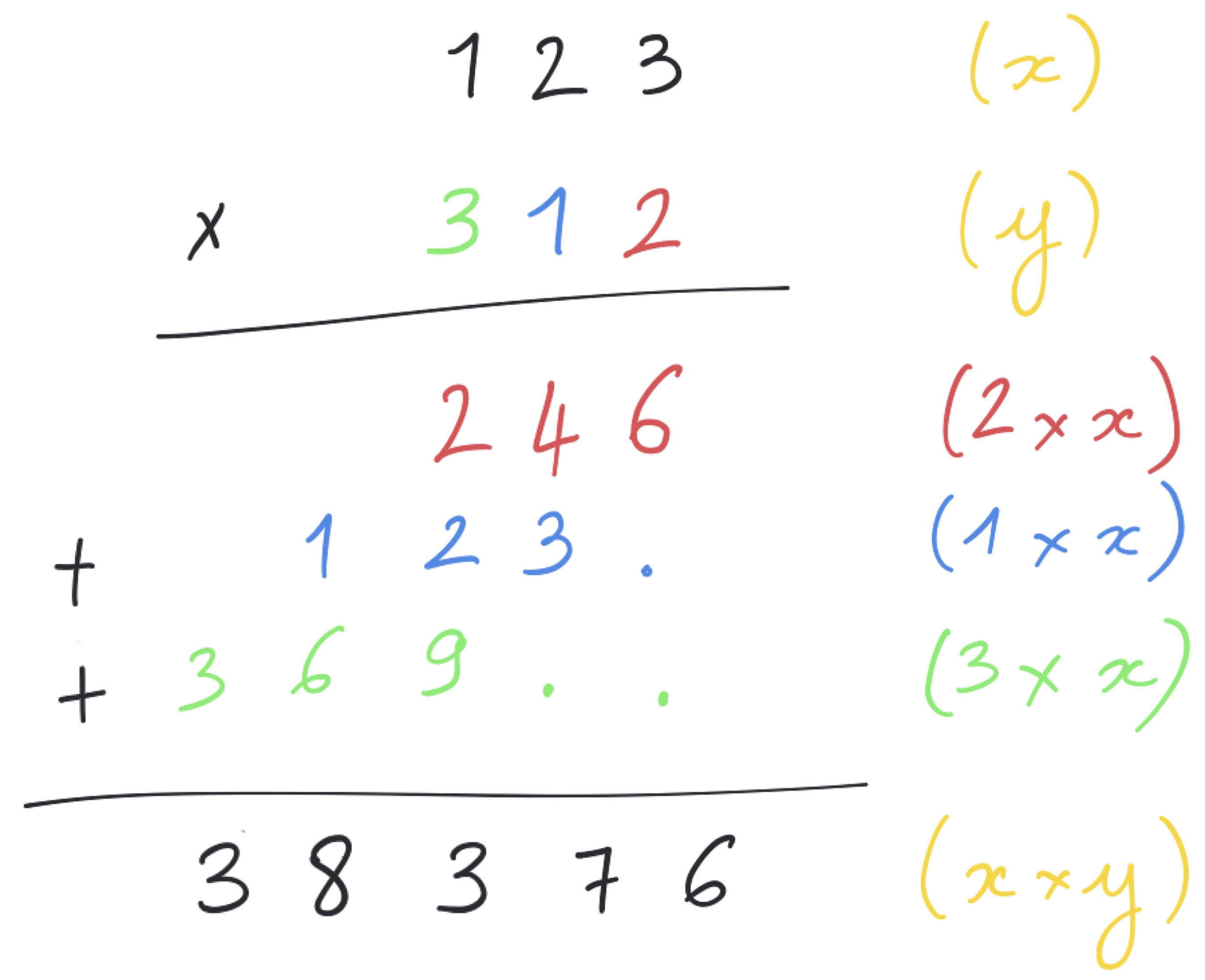

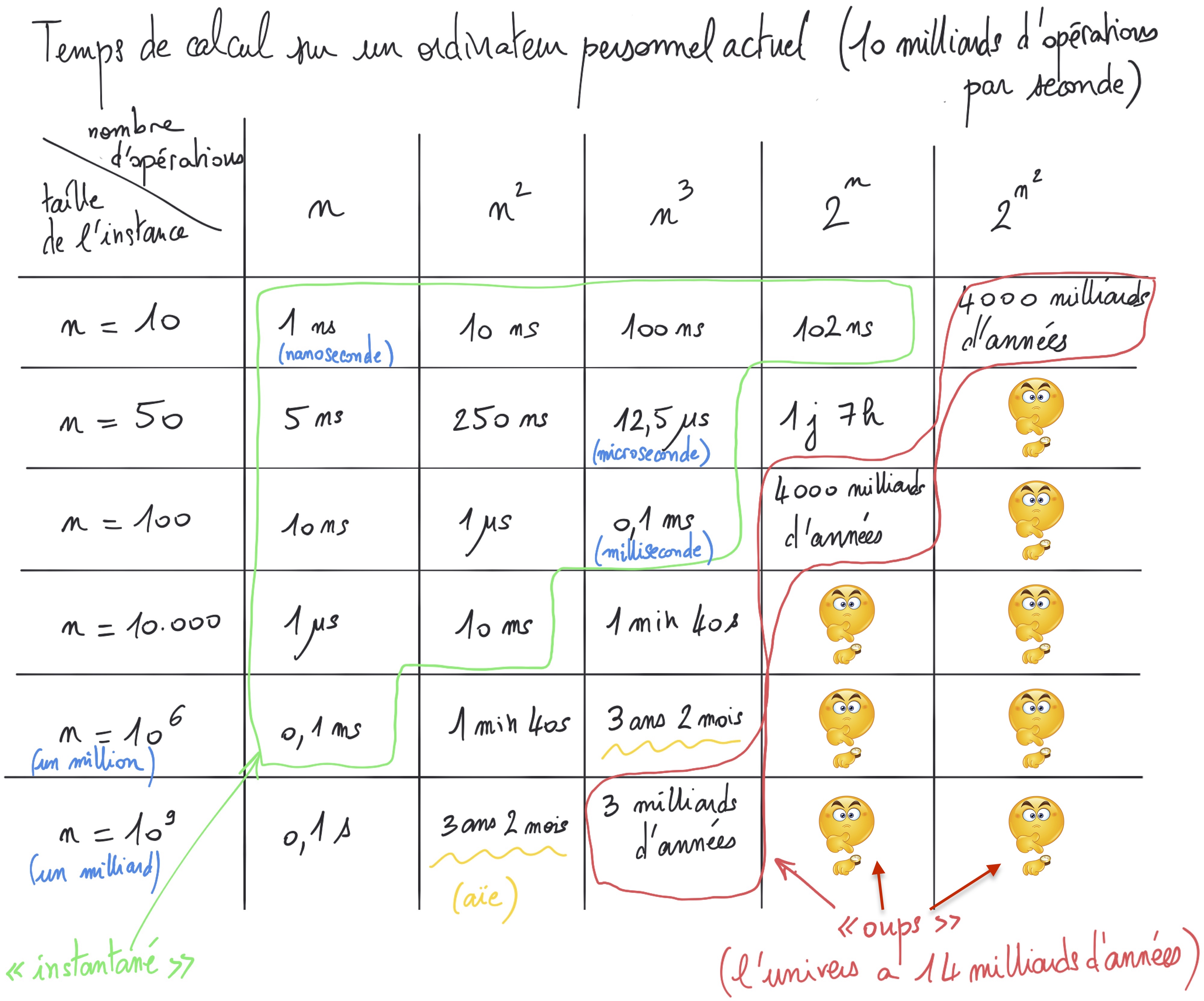








#/media/Fichier:Estatueta_Justi%C3%A7a.JPG){kind=link}