Binaire, le blog pour comprendre les enjeux du numérique, en collaboration avec theconversation
Pourquoi et pour quoi des métavers ?
Comme souvent dans le domaine des technologies numériques, on entend dans les discussions sur les métavers des affirmations comme « il ne faudrait pas rater le coche » (ou le train, la course, le virage, le tournant). Il faudrait donc se lancer dans le métavers uniquement parce que d’autres l’ont fait ? Et s’ils s’y étaient lancés pour de mauvaises raisons, nous les suivrions aveuglément ? On pourrait aussi se demander si la direction qu’ils ont prise est la bonne. Autre interrogation plus ou moins avouée, mais bien présente dans beaucoup d’esprits : qu’adviendrait-il de nous si nous ne suivions pas le mouvement ? Finalement, est-ce que la principale raison qui fait démarrer le train n’est pas la peur de certains acteurs de le rater ?
Pourquoi (pour quelles raisons) et pour quoi (dans quels buts) des métavers ? Les motivations actuelles sont pour nous liées à différents espoirs.
Le métavers, c’est l’espoir pour certains que la réalité virtuelle trouve enfin son application phare grand public, que ce qu’elle permet aujourd’hui dans des contextes particuliers devienne possible à grande échelle, dans des contextes plus variés : l’appréhension de situations complexes, l’immersion dans une tâche, l’entrainement sans conséquence sur le monde réel (apprendre à tailler ses rosiers dans le métavers comme on apprend à poser un avion dans un simulateur), la préparation d’actions à venir dans le monde réel (préparation d’une visite dans un musée), etc.
C’est l’espoir pour d’autres d’une diversification des interactions sociales en ligne (au-delà des jeux vidéo, réseaux sociaux et outils collaboratifs actuels), de leur passage à une plus grande échelle, de leur intégration dans un environnement fédérateur. C’est l’espoir que ces nouvelles interactions permettront de (re)créer du lien avec des personnes aujourd’hui isolées pour des raisons diverses : maladie ou handicap (sensoriel, moteur et/ou cognitif), par exemple. Des personnes éprouvant des difficultés avec leur apparence extérieure dans le monde réel pourraient peut-être s’exprimer plus librement via un avatar configuré à leur goût. Imaginez un entretien pour une embauche ou une location dans lequel il vous serait dans un premier temps possible de ne pas dévoiler votre apparence physique.
C’est aussi l’espoir d’un nouveau web construit aussi par et pour le bénéfice de ses utilisateurs, et non pas seulement celui des plateformes commerciales. Au début du web, personne ne savait que vous étiez un chien. Sur le web d’aujourd’hui, les plateformes savent quelles sont vos croquettes préférées et combien vous en mangez par jour. Dans le métavers imaginé par certains, personne ne saura que vous n’êtes pas un chien (forme choisie pour votre avatar) et c’est vous qui vendrez les croquettes.
C’est enfin — et probablement surtout, pour ses promoteurs actuels — l’espoir de l’émergence de nouveaux comportements économiques, l’espoir d’une révolution du commerce en ligne (dans le métavers, et dans le monde réel à travers lui), l’espoir d’importants résultats financiers dans le monde réel.
Tous ces espoirs ne sont évidemment pas nécessairement portés par les mêmes personnes, et tous ne se réaliseront sans doute pas, mais leur conjonction permet à un grand nombre d’acteurs de se projeter dans un espace configuré à leur mesure, d’où l’expression d’auberge espagnole qu’utilisent certains pour qualifier les métavers
Qu’allons-nous faire dans ces métavers ?
« La prédiction est très difficile, surtout lorsqu’il s’agit de l’avenir ». A quoi servira le métavers ? Des communautés spirituelles prévoient déjà de s’y rassembler. On peut parier qu’il ne faudra pas longtemps pour que des services pour adultes s’y développent ; on sait bien qu’« Internet est fait pour le porno », et la partie réservée aux adultes de Second Life était encore récemment active, semble-t-il. Au-delà de ces paris sans risque, essayons d’imaginer ce que pourraient permettre les métavers…
Imaginez un centre-ville ou un centre commercial virtuel dont les boutiques vous permettraient d’accéder à des biens et services du monde virtuel et du monde réel. Dans une de ces boutiques, vous pourriez par exemple acheter une tenue pour votre avatar (comme un tee-shirt de l’UBB Rugby), qu’il pourrait dès lors porter dans toutes les activités possibles dans le métavers (rencontres entre amis, activités sportives ou culturelles, mais aussi réunions professionnelles). Dans une autre boutique, vous pourriez choisir et personnaliser une vraie paire de chaussures qui vous serait ensuite livrée à domicile dans le monde réel.
Quelle différence avec les achats en ligne d’aujourd’hui ? Vous pourriez être assistés dans les boutiques du métavers par des personnages virtuels, avatars d’êtres humains ou d’intelligences artificielles. Vous pourriez vous y rendre accompagnés, pour faire du shopping à plusieurs ou vous faire conseiller par des proches. Vous pourriez aussi demander conseil à d’autres « clients » de la boutique qui la visiteraient en même temps que vous. Dans les boutiques où en passant de l’une à l’autre, il vous serait possible de croiser des personnes de votre connaissance (du monde réel ou virtuel) et interagir avec elles.
Le centre commercial évoqué proposerait les grandes enseignes habituelles, mais vous auriez la possibilité de le personnaliser en y intégrant vos artisans et petits commerçants préférés, comme cette brasserie artisanale découverte sur un marché il y a quelque temps. Quel intérêt pour vous et pour elle ? La boutique dans le métavers serait un lieu de rencontre, d’échanges et de commerce, au même titre qu’un étal sur un marché, mais sans les contraintes de jour et d’heure, sans les contraintes logistiques, sans la météo capricieuse, etc. Il y a bien sur de nombreuses choses du monde réel qu’on préfèrera voir, goûter ou essayer avant d’acheter. Il y en a aussi de nombreuses qu’on peut acheter sans discuter, « les yeux fermés », ce qui fait le succès des courses en ligne livrées en drive ou à domicile. Mais pour certaines choses, le métavers pourrait offrir une expérience plus riche que le commerce en ligne actuel et moins contraignante que les formes de commerce physiques.
Le métavers pourrait vous offrir la possibilité d’organiser vous-même vos activités collectives. Vous voulez revoir vos oncles, tantes, cousins et cousines perdus de vue depuis des lustres ? Vous ne voulez pas faire le tour de France et ne pouvez pas loger tout ce monde ? Organisez la rencontre dans le métavers, et profitez des reconstitutions de grands lieux touristiques ! Envie de voir avec eux les calanques de Marseille ou Venise ? L’expérience ne sera évidemment pas la même que dans le monde réel, mais vous pourrez avoir ces lieux rien que pour vous et vos proches, et vous pourrez les visiter de manière inédite, en les survolant par exemple. L’agence de voyage du métavers vous proposera peut-être de compléter l’expérience en dégustant un plat typique (livré chez vous et vos proches) dans une ambiance visuelle et sonore reconstituée. Alors les cousins : supions à la provençale sur le vieux port, ou cicchetti sur la place Saint-Marc ?

Comme certains jeux vidéo actuels, le metavers permettra sans doute la pratique de différents sports, seul ou à plusieurs. L’hiver, avec votre club de cyclisme, vous pourrez vous entraîner sur des parcours virtuels (avec un vrai vélo comme interface, si vous le souhaitez). Envie de lâcher le vélo pour un parcours de randonnée au départ du village dans lequel vous venez d’arriver ? Pas de problème : le métavers est un monde dans lequel on peut basculer facilement d’une activité à l’autre. De nouveaux sports pourraient être inventés par les utilisateurs du métavers, au sens « activités nécessitant un entraînement et s’exerçant suivant des règles, sur un mode coopératif ou compétitif ». La pratique d’un sport virtuel vous amènera peut-être à constituer avec d’autres une équipe, un club. Pour vous entraîner, quel que soit votre niveau, vous devriez sans problème trouver dans le métavers d’autres personnes de niveau similaire ou à peine supérieur, pour peu que les clubs se regroupent en fédérations. Le métavers pourrait aussi changer votre expérience de spectateur de compétitions sportives. Pourquoi ne pas vivre le prochain match de votre équipe de football préférée dans le métavers du point de vue de l’avatar de son avant-centre plutôt que depuis les tribunes virtuelles ?

Le métavers pourrait fournir l’occasion et les moyens de reconsidérer la manière dont nous organisons le travail de bureau. Un bureau virtuel peut facilement être agrandi pour accueillir une nouvelle personne, si besoin. Un étage de bureaux virtuel peut facilement placer à proximité des personnes qui travaillent dans un même service mais qui sont géographiquement réparties dans le monde réel. En combinant l’organisation spatiale de l’activité permise par le métavers avec des outils que nous utilisons déjà (messageries instantanées, suites bureautiques partagées en ligne, outils de visioconférence, etc.), peut-être pourra-t-on proposer de nouveaux environnements de travail collaboratifs permettant de (re)créer du lien entre des personnes travaillant à distance, quelle qu’en soit la raison ? Il ne s’agit pas seulement ici d’améliorer la manière dont on peut tenir des réunions. Le métavers pourrait aussi permettre des rencontres fortuites et des échanges spontanés et informels entre des personnes, à travers des espaces collectifs (couloirs entre les bureaux, salles de détente) ou des événements (afterwork virtuel).
On pourrait voir des usages du métavers se développer dans le domaine de la santé. La réalité virtuelle est déjà utilisée depuis de nombreuses années pour traiter des cas de phobie (animaux, altitude, relations sociales, etc.) et de stress post-traumatiques (accidents, agressions, guerres, etc.). Ces thérapies reposent sur une exposition graduelle et maîtrisée par un soignant à une représentation numérique de l’objet engendrant la phobie. Le fait d’agir dans un environnement virtuel, d’en maîtriser tous les paramètres et de pouvoir rapidement et facilement stopper l’exposition ont contribué au succès de ces approches, qu’on imagine facilement transposables dans un métavers où elles pourraient être complétées par d’autres activités. Les simulateurs actuellement utilisés pour la formation de professionnels de santé ou les agents conversationnels animés développés ces dernières années pour le diagnostic ou le suivi médical pourraient aussi être intégrés au métavers. De nouveaux services de téléconsultation pourraient aussi être proposés.
Le métavers pourrait servir de plateforme d’accès à des services publics. La municipalité de Séoul a ainsi annoncé qu’elle souhaitait ouvrir en 2023 une plateforme de type métavers pour « s’affranchir des contraintes spatiales, temporelles ou linguistiques ». Cette plateforme intègrera des reconstitutions des principaux sites touristiques de la ville actuelle, mais aussi des reconstitutions d’éléments architecturaux disparus. Les habitants pourront interagir avec des agents municipaux via leurs avatars et pourront ainsi accéder à une variété de services publics (économiques, culturels, touristiques, éducatifs, civils) dont certains nécessitaient jusqu’ici de se rendre en mairie. Des manifestations réelles seront dupliquées dans le métavers afin de permettre à des utilisateurs du monde entier de les suivre.
Questions ouvertes
Le métavers, par son organisation spatiale et sa dimension sociale, sera l’opportunité de développer des communautés, pratiques et cultures. Ce qui en sortira dépendra beaucoup de la capacité de ses utilisateurs à se l’approprier. Le métavers pose toutefois dès aujourd’hui un certain nombre de questions.
Qui pourra réellement y accéder ? Il faudra sans aucun doute une « bonne » connexion réseau et un terminal performant, mais au-delà, les différences entre le métavers et le web n’introduiront-elles pas de nouvelles barrières à l’entrée, ou de nouveaux freins ? Le World Wide Web Consortium (W3C) a établi pour celui-ci des règles pour l’accessibilité des contenus à l’ensemble des utilisateurs, y compris les personnes en situation de handicap (WCAG). Combien de temps faudra-t-il pour que des règles similaires soient définies et appliquées dans le métavers ? Sur le web, il n’y a pas d’emplacement privilégié pour un site, la notion d’emplacement n’ayant pas de sens. Dans un monde virtuel en partie fondé sur une métaphore spatiale, la localisation aura de l’importance. On voit déjà de grandes enseignes se précipiter pour acquérir des espaces dans les proto-métavers, et des individus payant à prix d’or des « habitations » voisines de celles de stars. Qui pourra dans le futur se payer un bon emplacement pour sa boutique virtuelle ?
Le métavers, comme nous l’avons expliqué, c’est la combinaison de la réalité virtuelle, des jeux vidéo, des réseaux sociaux et des cryptomonnaies, propices à la spéculation. En termes de risques de comportements addictifs, c’est un cocktail explosif ! L’immersion, la déconnexion du réel, l’envie de ne pas finir sur un échec ou de prolonger sa chance au jeu, la nouveauté permanente, la peur de passer à côté de quelque chose « d’important » pendant qu’on est déconnecté et l’appât du gain risquent fort de générer des comportements toxiques pour les utilisateurs du métavers et pour leur entourage. En France, l’ANSES — qui étudie depuis plusieurs années l’impact des technologies numériques sur la santé[1] — risque d’avoir du travail. De nouvelles formes de harcèlement ont aussi été signalées dans des métavers, particulièrement violentes du fait de leur caractère immersif et temps réel. En réponse, Meta a récemment mis en place dans Horizon World et Horizon Venues une mesure de protection qui empêche les avatars de s’approcher à moins d’un mètre de distance. D’autres mesures et réglementations devront-elles être mises en place ?
On a vu se développer sur le web et les réseaux sociaux des mécanismes de collecte de données personnelles, de marketing ciblé, de manipulation de contenus, de désinformation, etc. S’il devient le lieu privilégié de nos activités en ligne et que celles-ci se diversifient, ne risquons-nous pas d’exposer une part encore plus importante de nous-même ? Si ces activités sont de plus en plus sociales, regroupées dans un univers unique et matérialisées (si on peut dire) à travers nos avatars, ne seront-elles pas observables par un plus grand nombre d’acteurs ? Faudra-t-il jongler entre différents avatars pour que nos collègues de travail ne nous reconnaissent pas lors de nos activités nocturnes ? Pourra-t-on se payer différents avatars ? Quel sera l’équivalent des contenus publicitaires aujourd’hui poussés sur le web ? Des modifications significatives et contraignantes de l’environnement virtuel ? « Ce raccourci vers votre groupe d’amis vous permettant d’échapper à un tunnel de panneaux publicitaires vous est proposé par Pizza Mario, la pizza qu’il vous faut » Les technologies chaîne de blocs (blockchain en anglais) permettront-elles au contraire de certifier l’authenticité de messages ou d’expériences et d’empêcher leur altération ?
Lors de la rédaction de ce texte, nous avons souvent hésité entre « le métavers » et « les métavers ». Dans la littérature comme dans la vidéo d’annonce de Facebook/Meta, le concept est présenté comme un objet unique en son genre, mais on imagine assez facilement des scénarios alternatifs, trois au moins, sans compter des formes hybrides. Le premier est celui d’une diversité de métavers sans passerelle entre eux et dont aucun ne s’imposera vraiment parce qu’ils occuperont des marchés différents. C’est la situation du web actuel (Google, Meta, Twitter, Tik Tok et autres sont plus complémentaires que concurrents), qui motive en partie les promoteurs du Web3. Le deuxième scénario est celui d’un métavers dominant largement les autres. Celui-ci semble peu probable à l’échelle planétaire, ne serait-ce qu’à cause de la confrontation USA – Chine (– Europe ?). Le troisième scénario est celui d’une diversité de métavers avec un certain niveau d’interopérabilité technique et existant en bonne harmonie. Il n’est pas certain que ce soit le plus probable : l’interopérabilité est souhaitable mais sera difficile à atteindre. Nous pensons plutôt que c’est le premier scénario qui s’imposera. La diversité, donc le choix entre différents métavers, est une condition nécessaire tant à l’auto-détermination individuelle qu’à la souveraineté collective.
Qui va réguler les métavers ? Dans le monde du numérique, les normes prennent parfois du temps à s’établir et n’évoluent pas nécessairement très vite. Quand il s’agit de normes techniques, ce n’est pas un problème : le protocole HTTP est resté figé à la version 1.1 de 1999 à 2014, et cela n’a pas empêché le développement du web. Quand il s’agit de réguler les usages, les comportements, ce peut être plus problématique. Jusqu’ici, on peut s’en réjouir ou s’en désoler, le secteur du web a été peu régulé. Ceux qui définissent les règles sont souvent les premiers joueurs, qui sont en fait les premiers possédant les moyens de jouer, c’est à dire les grands acteurs du web aujourd’hui. Si demain, une partie de nos activités personnelles et professionnelles se déroule dans des métavers créés par eux sur la base d’infrastructures matérielles et logicielles extra-européennes, quels seront le rôle et la pertinence dans ces mondes des états européens ? Si ces mondes sont créés par des collectifs transcontinentaux et autogérés par des individus, la situation sera-t-elle plus favorables à ces états ?
Enfin, mais ce n’est pas le moins important, d’un point de vue beaucoup plus pragmatique et à plus court terme, on peut s’interroger sur la pertinence de se lancer dans le développement de métavers au moment où nous sommes déjà tous confrontés aux conséquences de nos activités sur l’environnement. Le tourisme virtuel aidera peut-être à réduire notre empreinte carbone, mais le coût écologique lié à la mise en œuvre des métavers (réalité virtuelle, réseaux haut-débit, chaîne de blocs, etc.) ne sera-t-il pas supérieur aux économies générées ? Le bilan devra bien sur tenir compte des usages effectifs des métavers, de leur utilité et de leur impact positif sur la société.
Pour conclure
Ni enfer, ni paradis par construction, les métavers présentent des facettes tant positives que négatives, à l’image de beaucoup d’autres innovations technologiques (comme l’intelligence artificielle, par exemple). Nous avons tendance à surestimer l’impact des nouvelles technologies à court-terme et à sous-estimer leur impact à long-terme, c’est la loi d’Amara. Les métavers tels qu’on nous les décrits seront sans doute difficiles à mettre en œuvre. Rien ne dit que ceux qui essaieront y arriveront, que les environnements produits seront massivement utilisés, qu’ils le resteront dans la durée ou que nous pourrons nous le permettre (pour des raisons environnementales, par exemple). Les choses étant de toute manière lancées et les investissements annoncés se chiffrant en milliards d’euros, on peut au minimum espérer que des choses intéressantes résulteront de ces efforts et que nous saurons leur trouver une utilité.
Alors que faire ? Rester passifs, observer les tentatives de mise en œuvre de métavers par des acteurs extra-européens, puis les utiliser tels qu’ils seront peut-être livrés un jour ? S’y opposer dès à présent en considérant que les bénéfices potentiels sont bien inférieurs aux risques ? Nous proposons une voie alternative consistant à développer les réflexions sur ce sujet et à explorer de façon maîtrisée les possibles ouverts par les technologies sous-jacentes, en d’autres termes, à jouer un rôle actif pour tenter de construire des approches vertueuses, quitte à les abandonner – en expliquant publiquement pourquoi – si elles ne répondent pas à nos attentes. Nous sommes persuadés qu’une exploration menée de façon rigoureuse pour évaluer des risques et des bénéfices est nettement préférable à un rejet a priori non étayé.
Pascal Guitton (Université de Bordeaux & Inria) & Nicolas Roussel (Inria)
[1] Voir par exemple son avis récent sur les expositions aux technologies de réalité virtuelle et/ou augmentée
Références additionnelles (*)
Quelques émissions, interviews ou textes récents :
- Ce regain d’intérêt pour la réalité virtuelle peut être l’opportunité de créer des projets utiles qui nous font rêver (A. Lécuyer, Alliancy, 17/02/22)
https://www.alliancy.fr/anatole-lecuyer-inria-regain-interet-realite-virtuelle-opportunite-creer-projets-utiles-qui-font-rever - « C’est quoi le métavers ? » (Le téléphone sonne, France Inter, 15 /02/22)
https://www.franceinter.fr/emissions/le-telephone-sonne/le-telephone-sonne-du-mardi-15-fevrier-2022 - The metaverse is a new word for an old idea (G. Bell, MIT Technology Review, 08/02/22)
https://www.technologyreview.com/2022/02/08/1044732/metaverse-history-snow-crash/ - Le métavers au carrefour des illusions (M. Beaudouin-Lafon, CNRS Le journal, 27/01/22)
https://lejournal.cnrs.fr/articles/le-metavers-au-carrefour-des-illusions - Métavers : les prémices d’un monde nouveau ? (note de veille Unitec & Digital Aquitaine, 24/01/22)
https://www.unitec.fr/metavers-les-premices-dun-monde-nouveau/ - My first impressions of web3 (M. Marlinspike, 07/01/22)
https://moxie.org/2022/01/07/web3-first-impressions.html - Le metaverse, enjeu de souveraineté (M. Hauser, Le Portail de l’IE, 05/01/22)
https://portail-ie.fr/analysis/3022/le-metaverse-enjeu-de-souverainete-12 - Métavers, souvenraineté, web3… les tendances tech à retenir de 2021 (podcast Monde numérique, 25/12/21)
https://www.mondenumerique.info/metavers-souverainete-web-3-ce-qu-il-faut-retenir-de-2021-28/ - Métavers et Métamedias : un 3e chapitre d’Internet (cahier de tendances médias de France Télévisions, 22/12/21)
https://www.meta-media.fr/2021/12/22/les-cahiers-de-tendances-de-meta-media.html - Web 3 and the Metaverse Are Not the Same (A. Zhang, CoinDesk, 21/12/21)
https://www.coindesk.com/layer2/2021/12/21/web-3-and-the-metaverse-are-not-the-same/ - A Crypto Guide to the Metaverse (E. Tan, CoinDesk, 03/08/21)
https://www.coindesk.com/tech/2021/08/03/a-crypto-guide-to-the-metaverse/ - Welcome to the metaverse (MetaverseLuke podcast, depuis le 30/04/2021)
https://podcasts.apple.com/fr/podcast/welcome-to-the-metaverse/id1565851466?l
Deux articles de recherche illustrant des approches très différentes des environnements virtuels collaboratifs :
- Solipsis: a decentralized architecture for virtual environments (D. Frey et al., 05/11/2008)
https://hal.archives-ouvertes.fr/inria-00337057 - Re-place-ing space: the roles of place and space in collaborative systems (S. Harrison & P. Dourish, 03/12/96)
https://www.dourish.com/publications/1996/cscw96-place.pdf
Deux fictions dans lesquelles on parle d’onirochrone et de cyberespace :
- Aristoï (Walter Jon Williams, 1992)
https://en.wikipedia.org/wiki/Aristoi_(novel) - Burning Chrome (W. Gibson, 1982)
https://en.wikipedia.org/wiki/Burning_Chrome
Et aussi : https://estcequecestlanneedelavr.com
(*) en plus de celles pointées par des liens dans le texte de l’article









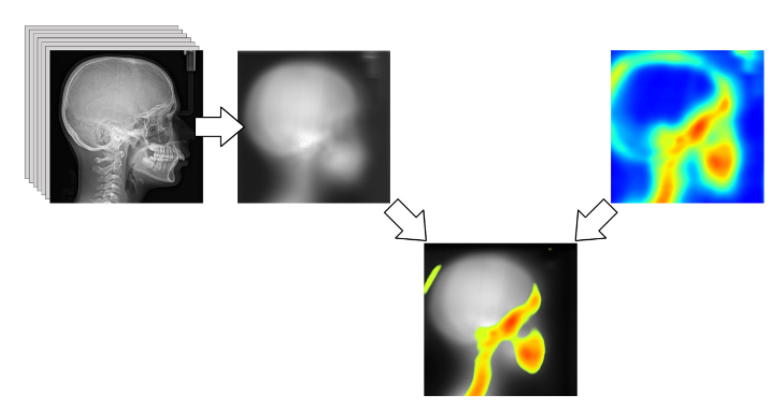
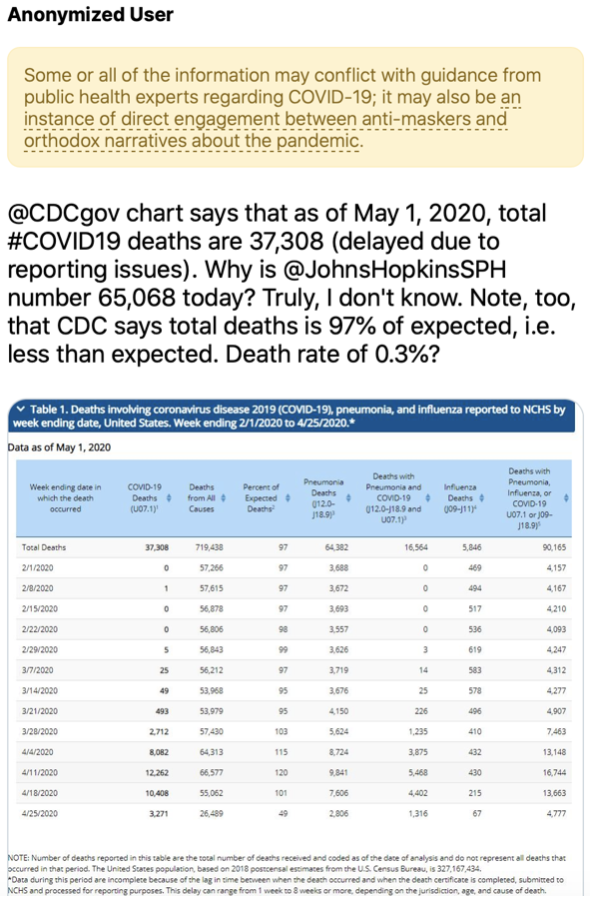
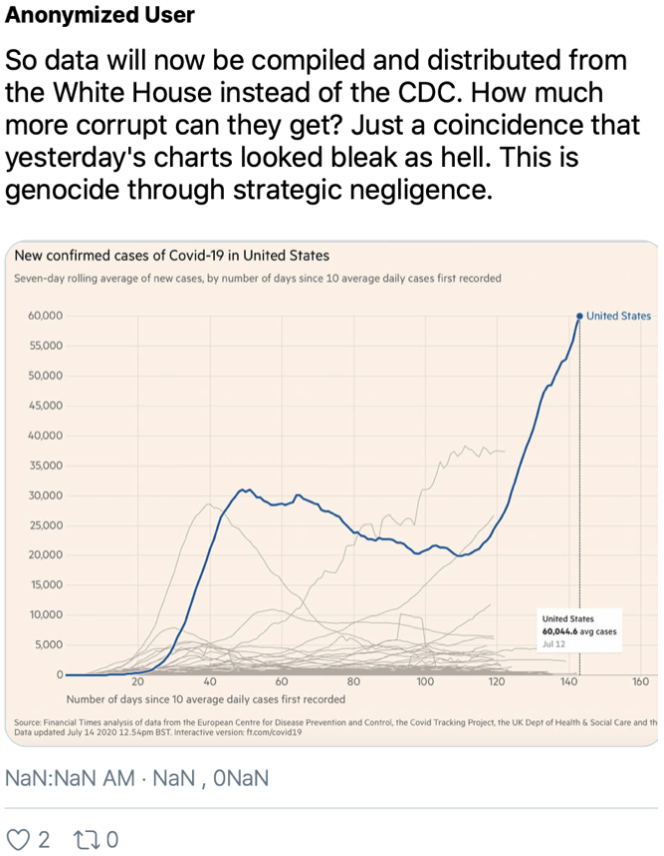
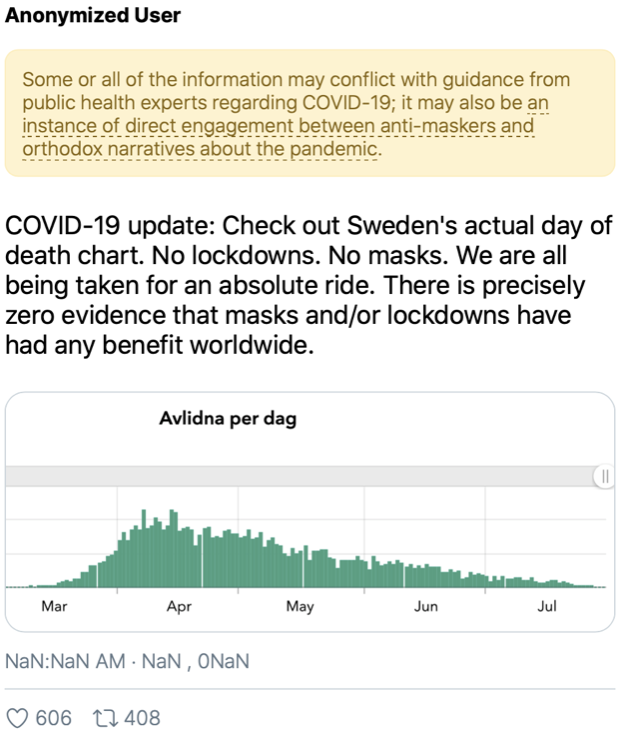




 Oui, binaire s’adresse aussi aux jeunes de tous âges, que les sciences informatiques laissent parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible, comment modéliser informatiquement la… créativité. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.
Oui, binaire s’adresse aussi aux jeunes de tous âges, que les sciences informatiques laissent parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible, comment modéliser informatiquement la… créativité. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.