

B : Pourrais-tu nous parler de ton parcours ?
SA : J’ai toujours refusé de me spécialiser. Lors de mes études, j’ai travaillé en parallèle la biologie, que j’aimais bien, mais aussi les mathématiques et la physique, et je me suis retrouvé au CNRS. En France, les mathématiques sont une discipline très cloisonnée, et la biologie aussi. Mais, en fait, les maths sont utilisées en biologie depuis plus d’un siècle, avec par exemple la dynamique des populations. Mon activité de recherche se situe à cette interface entre biologie et mathématiques, sur les maladies infectieuses et la biologie de l’évolution.
B : Tu n’as pas encore mentionné l’informatique ?
SA : Par ma formation, je viens de la biologie mathématique avec papier et crayon. Ma thèse portait sur la caractérisation de ce qui se passe entre système immunitaire et parasites. Il n’y avait pas de données : c’était de la belle modélisation. Au début, j’utilisais surtout l’informatique pour des résolutions numériques, avec Mathematica par exemple.
Puis j’ai été confronté à des données en écologie de l’évolution. Les implémentations informatiques sont essentielles dans ce domaine, qui s’intéresse aux populations et aux interactions entre individus plus qu’aux individus isolément. Pendant un deuxième postdoc, j’ai découvert les inférences d’arbres phylogénétiques à partir de séquences. Il s’agit de retracer l’histoire des populations à partir de données génomiques. C’est la révolution de l’ADN qui a permis cela. L’idée est que plus deux individus ou deux espèces ont divergé depuis longtemps, moins leur ADN se ressemble. Au final, on a aboutit à des objets qui ressemblent à des arbres généalogiques. Au début des années 80, ça se faisait à la main, mais aujourd’hui on fait des généalogies avec des dizaines de milliers de séquences ou plus.
C’est un exemple parmi d’autres car aujourd’hui, l’informatique est devenue essentielle en biologie, en particulier, pour des simulations.
B : Comment s’est passée ta vie de chercheur de biologiste au temps du Covid ?
Quand l’épidémie est arrivée, on était en pleine recherche sur les papillomavirus. On s’est vite rendu compte des besoins en épidémiologie humaine en France. Début mars on reprenait les outils britanniques pour calculer, par exemple, le nombre de reproductions de base en France. Puis, comme les outils que nous utilisions au quotidien étaient assez bien adaptés pour décrire l’épidémie, nous avons conçu des modèles assez classiques à compartiments. Nous avons alors eu la surprise de voir qu’ils étaient repris, entre autres, par des groupes privés, qui conseillaient le gouvernement et les autorités régionales de santé. Du coup nous avons développé des approches plus ambitieuses, surtout au niveau statistique, pour analyser l’épidémie en France avec un certain impact .
L’équipe a aussi passé un temps très conséquent à répondre aux journalistes, aux associations, ou au grand public, avant tout pour des raisons de santé publique. En effet, la diffusion des savoir est une des interventions dites “non pharmaceutiques” les plus efficaces pour limiter la croissance de l’épidémie. Donc, quand des collègues me demandaient ce qu’ils pouvaient faire, je leur répondais : expliquez ce qu’est une croissance exponentielle, un virus, une épidémie, et d’autres choses essentielles pour que chacun puisse comprendre ce qui nous arrive.
Ce manque de culture scientifique et mathématique s’est malheureusement reflété à tous les niveaux en France. A priori, le pays avait toutes les cartes en main au moins dès le 3 mars 2020, quand le professeur Arnaud Fontanet explique la croissance exponentielle devant le président de la républiques, des ministres et des sommités médicales. La réaction attendra deux semaines plus tard et le rapport de l’équipe de Neil Ferguson à Imperial College. Au final, les approches aboutissaient à des résultats similaires mais celles des britanniques s’appuyaient aussi sur des simulations à base d’ agents individuels, ce qui leur a probablement conféré plus d’impact. De plus, les britanniques avaient aussi mis en place depuis plusieurs années un processus de dialogue entre les épidémiologistes et le gouvernement.
B : Pouvez-vous nous donner un exemple plus spécifique de tes travaux ?
AS : Dans cette lignée des modèles agents, le plus impressionnant est sans doute EPIDEMAP. Cet outil qui repose massivement sur du calcul haute performance a été mis en place par Olivier Thomine, qui à l’époque était au CEA. Il utilise les données du projet OpenStreetMap.org qui propose des données géographiques en accès libre de manière très structurés. Pour la France, la base est très complète puisqu’elle contient le cadastre. Dans ce modèle, on répartit 66 millions d’agents dans des bâtiments. Chaque individu va chaque jour visiter deux bâtiments en plus du sien. On fait tourner cette simulation sur toute la durée d’une d’épidémie, soit environ un an. Grâce au talent d’Olivier, cela ne prend que 2 heures sur un bon ordinateur de bureau classique ! Pour donner une idée, les simulateurs existants ont une résolution moindre et ne peuvent gérer que quelques centaines de milliers d’agents. Ceci est entre autres permis par l’extrême parcimonie du modèle, qui parvient à décrire tout cela avec seulement 3 paramètres. Nous avons aidé Olivier à rajouter un modèle de transmission dans EPIDEMAP. Ceci a permis d’explorer des phénomènes épidémiques nationaux avec une résolution inégalée. Les extensions possibles sont très nombreuses comme par exemple identifier les villes les plus à risque ou élaborer des politiques de santé adaptées aux différences entre les territoires.
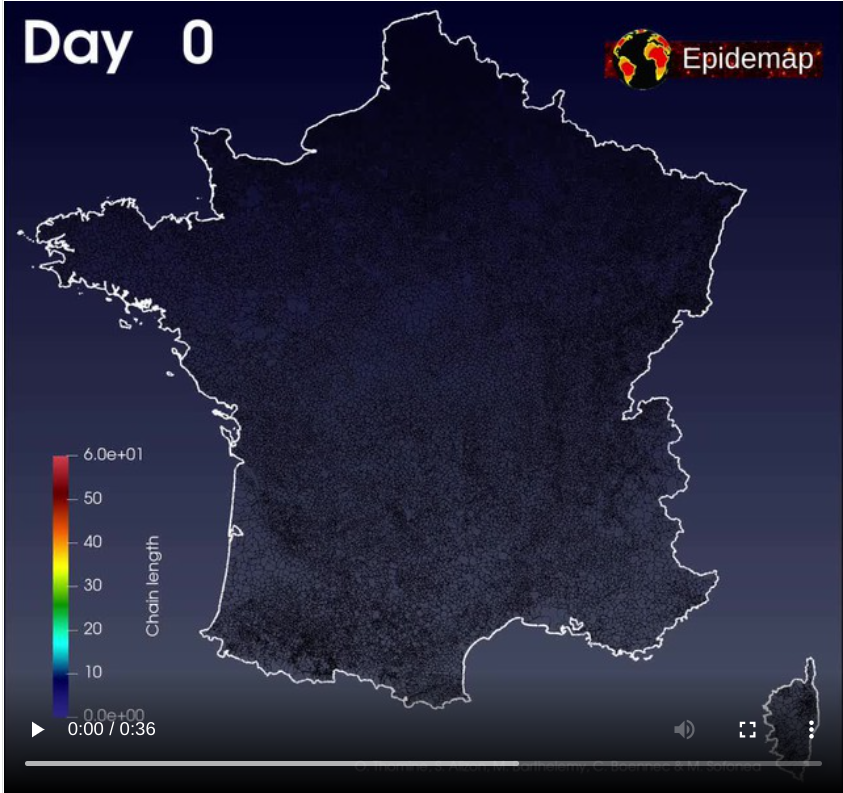
B : Ces modèles sont-ils proches de ce qui se passe dans la réalité ?
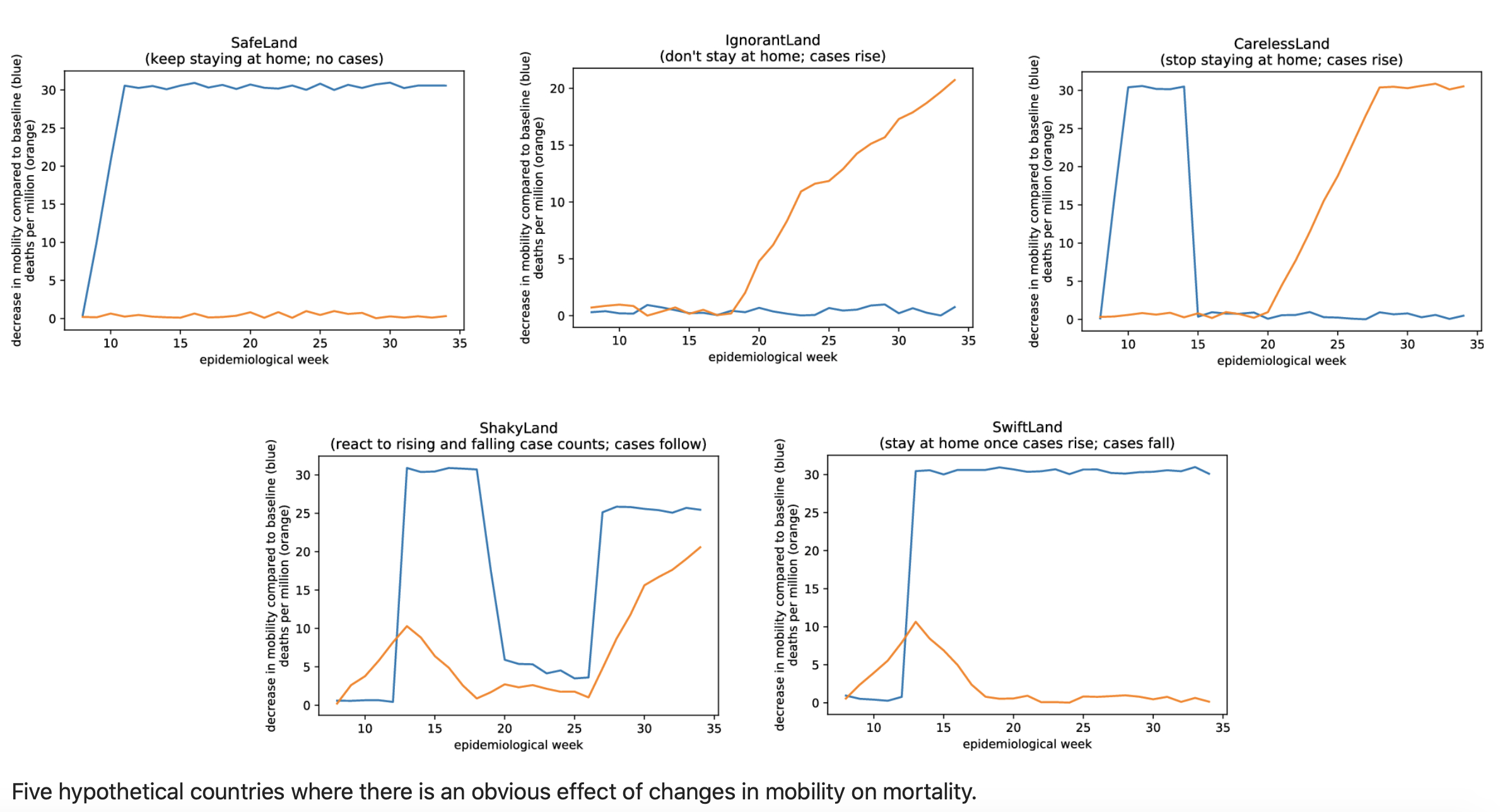
SA : Un modèle n’est jamais la réalité. Mais il est vrai que certains processus sont plus facilesfacile à capturer que d’autres. Par exemple, les modèles qui anticipent la dynamique hospitalière à court terme marchent assez bien : nos scénarios sont robustes pour des prédictions de l’ordre de cinq semaines sachant que dès que vous dépassez les deux semaines, la suite du scénario dépend de la politique du gouvernement. C’est pour cela que l’on préfère parler de “scénarios”. Évidemment, le domaine des possibles est immense et c’est pour cela qu’il y a une valeur ajoutée à avoir plusieurs équipes travaillant de concert et confrontant leurs modèles. En France, ce nombre est très réduit, ce qui renforce cette fausse idée que les modèles sont des prévisions. Au Royaume-Uni ou aux USA, bien plus d’équipes sont soutenues et les analyses rétrospectives sont aussi plus détaillées.. Par exemple, le Centers for Diseases Control aux USA permet de visualiser les vraies données avec les modèles passés pour les évaluer.
B : Est-ce que tu te vois comme un modélisateur, un concepteur de modèles mathématiques ?
SA : C’est une question. Je suis plutôt dans l’utilisation d’outils informatiques ou mathématiques existants que dans leur conception. Je fais des modèles, c’est vrai, mais l’originalité et la finalité est plus du côté de la biologie que des outils que je vais utiliser. Je me présente davantage comme biologiste.
B : Qu’est-ce qu’un “bon” modèle d’un point de vue biologique ?
SA : Ça dépend de l’objectif recherché. Certains modèles sont faits pour décrire. Car les données “brutes” ça n’existe pas : il y a toujours un modèle. D’autres modèles aident à comprendre les processus et notamment leurs interactions. Enfin, les plus médiatiques sont les modèles prévisionnels, qui tentent d’anticiper ce qui peut se passer. Les modèles de compréhension et de prévision ont longtemps été associés mais de plus en plus avec le deep learning on peut prévoir sans comprendre.
Notre équipe se concentre sur la partie compréhension en développant des modèles analytiques et souvent à compartiments. Pour cela, on peut s’appuyer sur des phénomènes reproductibles. Par exemple, on peut anticiper la croissance d’une colonie bactérienne dans une boîte de Pétri. Grâce aux lois de la physique, on sait aussi assez bien anticiper une propagation sur un réseau de contacts. Ce qui est plus délicat, c’est comment on articule tout cela avec la biologie. Le nombre d’hypothèses possibles est quasi infini. Ce qui guide l’approche explicative, c’est la parcimonie. Autrement dit, déterminer quels paramètres sont absolument nécessaires dans le modèle pour expliquer le phénomène en fonction des données qu’on possède ? Le but de la modélisation n’est pas de mimer la réalité mais de simplifier la réalité pour arriver à la comprendre.
L’autre école en modélisation – pas la nôtre – consiste à mettre dans le modèle tous les détails connus, et avoir confiance en notre connaissance du système, pour ensuite utiliser la simulation pour extrapoler. Mais en biologie, il y a un tel niveau de bruit, de stochasticité, sur chacune des composantes que cela rend les approches super-détaillées délicates à utiliser. Les hypothèses possibles sont innombrables, et il n’y a pas vraiment de recette pour faire un “bon” modèle.
Si on met quatre équipes de modélisation sur un même problème et avec les mêmes données, elles vont créer quatre modèles différents. Si les résultats sont cohérents, c’est positif, mais s’ils sont en désaccord, c’est encore plus intéressant. On ne peut pas tricher en modélisation. Il y a des hypothèses claires, et quand les résultats sont différents, ça nous apprend quelque-chose, quelles hypothèses étaient douteuses par exemple. Un modèle est faux parce qu’il simplifie la réalité et c’est ce qui nous fait progresser.
B : Qu’est-ce que les modèles nous ont appris depuis le début de l’épidémie ?
SA : En février 2020, l’équipe d’Imperial College, avec des modèles très descriptifs, faisait l’hypothèse d’une proportion de décès supérieure à 1% et ces décès survenaient en moyenne 18 jours après l’infection. Ça, c’est exact. Déjà à ce moment-là, on en savait énormément sur ce qui se passait avec des modèles très simples.
L’équipe de Ferguson a aussi fait dans son rapport quelque chose qu’on fait rarement : en mars 2020 ils ont prolongé leur courbe jusqu’à fin 2021 pour illustrer la notion de “stop-and-go”. Dans leur simulation, entre mars 2020 et fin 2021, il y avait 6 à 7 pic épidémiques, et dans la réalité on n’en est pas très loin. On avait encore des modèles très frustes. Il est vrai qu’ils n’incluaient pas les variants. Pourtant, qualitativement leur scénario s’est révélé très juste. Autrement dit, si on avait un peu plus regardé ces modèles on aurait pu mieux se préparer au lieu de réagir au coup par coup.
B : Cela pose la question de l’appropriation des résultats des scientifiques par les politiques.
SA : Les rapports sont difficiles. Fin octobre 2020, à la veille du deuxième confinement, le président Macron a dit : “Quoi que nous fassions, il y aura 9 000 personnes en réanimation.” Quand on a entendu ça, on a été surpris. D’autant qu’il se basait a priori sur des scénarios de l’institut Pasteur. En réalité, comme toujours, il y avait plusieurs scénarios explorant des tendances si on ne faisait rien, si on diminuait les contacts de 10 %, de 20 %, etc. Mais c’était trop compliqué pour les politiques qui ont (seuls) choisi un des scénarios, celui où “on ne changeait rien”. Heureusement, dès qu’on prend des mesures, cela change les choses, et au final on a “seulement” atteint la limite des capacités nationales en réanimation (soit 5000 lits).
Là où cette bévue est rageante, c’est qu’elle était évitable. En 2017 déjà, lors d’un séminaire à Santé Publique France, nous discutions de l’expérience des britanniques qui avaient conclu que la ou le porte-parole des scientifiques du projet devait absolument pouvoir parler directement à la personne qui décide ou, en tout cas, avec un minimum d’intermédiaires. Faute de quoi, à chaque étape les personnes qui ne connaissent rien au sujet omettent des informations critiques ou simplifient le tout à leur façon.
Ce couac national met aussi en évidence un paradoxe. Lorsque dans le scénario le plus probable les choses se passent mal, une action est prise pour que ces anticipations ne se réalisent pas. Contrairement à la météo, on peut agir pour influencer le résultat. C’est d’ailleurs un dilemme bien connu, en Santé Publique : si les mesures prises sont insuffisantes, de nombreuses morts risquent de se produire et on critiquera alors, à raison, le manque d’anticipation. Mais, à l’inverse, si on met en place tellement de mesures que toute catastrophe sanitaire est évitée, c’est l’excès de zèle et l’alarmisme qui seront pointées du doigt.
Le début 2021 est un exemple tragique de ces liens difficiles entre modélisation et pouvoirs publics. Notre équipe, comme deux autres en France, détecte la croissance du variant alpha, dont on savait qu’il avait explosé en Angleterre. Le Conseil Scientifique alerte là-dessus début janvier. Le gouvernement refuse de confiner et reste sur les mesures de couvre-feu à 18h, plus télétravail, ce qui au passage concentre quasiment tous les défauts du confinement sans en avoir le bénéfice en termes de santé publique. Début janvier, cette position se défendait car impossible de savoir l’effet qu’aura une nouvelle mesure Mais fin janvier on avait du recul sur ce confinement à 18h et on voyait que ce ne serait pas suffisant pour empêcher l’explosion d’alpha. Le conseil a de nouveau alerté là-dessus fin janvier mais l’exécutif a persisté. Et en avril, à peu près à la date anticipée par les modèles, on a heurté le mur avec des services de réanimation au bord de la rupture.
Impossible de savoir avec certitude ce qui se serait passé si le Conseil Scientifique avait été écouté. Les modèles mathématiques sont les plus adaptés pour répondre à cette question. Les nôtres suggèrent qu’avec un confinement de la même durée que celui d’avril mais mis en place dès février on aurait au minimum pu éviter de l’ordre de 14.000 décès. Après, il ne faudrait pas croire que la situation est plus rose ailleurs. Le Royaume-Uni a à la fois les meilleurs modélisateurs et le meilleur système de surveillance de l’épidémie au monde, et pourtant leur gouvernement a parfois pris des décisions aberrantes. À la décharge des gouvernants, comme nos scénarios explorent à la fois des hypothèses optimistes et pessimistes, il y a de quoi être perdu. Un des points à améliorer pour les modélisateurs est la pondération des scénarios. L’idéal serait même de mettre à jour leurs probabilités respectives au fur et à mesure que les informations se précisent.
B : De quoi avez-vous besoin pour votre recherche ?
SA : Les besoins en calcul sont de plus en plus importants. Mais on les trouve. Le temps disponible est une denrée bien plus rare. Enfin, il y a le souci de l’accès aux données. Avant la pandémie, notre équipe travaillait plutôt sur des virus animaux ou végétaux car les données sont plus facilement partagées. Dès qu’on touche à la santé humaine, les enjeux augmentent.
B : Mais est-ce cela ne devrait pas encourager le partage des données ?
SA : Aujourd’hui ce que les institutions de recherche mettent en avant c’est la concurrence qui encourage fortement le non-partage des données Nous avons initié des démarches auprès d’autorités publiques dès mars 2020 mais la plupart n’ont pas abouti. Évidemment il ne s’agit pas là de sous-estimer l’énorme travail de terrain qui a été fait et qui est fait pour générer et compiler ces données. Mais il est frustrant de voir que la majorité de ce travail n’est justement pas exploité au dixième de ce qu’il pourrait l’être. En tout cas, heureusement que des laboratoires privés et des Centre Hospitaliers Universitaires nous ont fait confiance. Coté recherche, cela a conduit à un certain nombre de publications scientifiques et coté santé publique nous avons fourni aux autorités les premières estimations de croissance des variants Delta ou Omicron en France. Mais on aurait pu faire tellement plus qu’on reste insatisfaits.
Samuel Alizon, directeur de recherche CNRS
https://binaire.socinfo.fr/les-entretiens-de-la-sif/








 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible l’optimisation multi-objectif. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible l’optimisation multi-objectif. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.


















 En ce 8 mars 2022, quand bien même, compte tenu de l’actualité brulante, le monde ferait bien de se concentrer sur les droits des humains en général, il ne faut pas oublier cette parenthèse annuelle pendant laquelle il convient de se pencher plus particulièrement sur les droits des femmes.
En ce 8 mars 2022, quand bien même, compte tenu de l’actualité brulante, le monde ferait bien de se concentrer sur les droits des humains en général, il ne faut pas oublier cette parenthèse annuelle pendant laquelle il convient de se pencher plus particulièrement sur les droits des femmes. 
{kind=link}