Charles Cuvelliez et Jean-Jacques Quisquater nous proposent en collaboration avec le Data Protection Officer de la Banque Belfius ; Francis Hayen, une discussion sur le dilemme entre le RGPD et la mise en place de caméra augmentée à l’IA pour diminuer le nombre de vols, les oublis, le sous-pesage aux caisses automatiques des supermarchés, qui sont bien nombreux. Que faire pour concilier ce besoin effectif de contrôle et le respect du RGPD ? Et bien la CNIL a émis des lignes directrices, d’aucun diront désopilantes, mais pleines de bon sens. Amusons-nous à les découvrir.Benjamin Ninassi et Thierry Viéville.
C’est le fléau des caisses automatiques des supermarchés : les fraudes ou les oublis, pudiquement appelées démarques inconnues, ou la main lourde qui pèse mal fruits et légumes. Les contrôles aléatoires semblent impuissants. Dans certaines enseignes, il y a même un préposé à la balance aux caisses automatiques. La solution ? L’IA pardi. Malgré le RGPD ? Oui dit la CNIL dans une note de mai 2025.
Cette IA, ce sont des caméras augmentées d’un logiciel d’analyse en temps réel. On les positionne en hauteur pour ne filmer que l’espace de la caisse, mais cela inclut le client, la carte de fidélité, son panier d’achat et les produits à scanner et forcément le client, flouté de préférence. L’algorithme aura appris à reconnaitre des « événements » (identifier ou suivre les produits, les mains des personnes, ou encore la position d’une personne par rapport à la caisse) et contrôler que tout a bien été scanné. En cas d’anomalie, il ne s’agit pas d’arrêter le client mais plus subtilement de programmer un contrôle ou de gêner le client en lui lançant une alerte à l’écran, propose la CNIL qui ne veut pas en faire un outil de surveillance en plus. Cela peut marcher, en effet.
C’est que ces dispositifs collectent des données personnelles : même en floutant ou masquant les images, les personnes fautives sont ré-identifiables, puisqu’il s’agira d’intervenir auprès de la personne. Et il y a les images vidéo dans le magasin, non floutées. La correspondance sera vite faite.
Mais les supermarchés ont un intérêt légitime, dit la CNIL, à traiter ces données de leurs clients (ce qui les dispense de donner leur consentement) pour éviter les pertes causées par les erreurs ou les vols aux caisses automatiques. Avant d’aller sur ce terrain un peu glissant, la CNIL cherche à établir l’absence d’alternative moins intrusive : il n’y en a pas vraiment. Elle cite par exemple les RFID qui font tinter les portiques mais, si c’est possible dans les magasins de vêtements, en supermarché aux milliers de référence, cela n’a pas de sens. Et gare à un nombre élevé de faux positifs, auxquels la CNIL est attentive et elle a raison : être client accusé à tort de frauder, c’est tout sauf agréable. Cela annulera la légitimité de la méthode.
Expérimenter, tester
Il faut qu’un tel mécanisme, intrusif, soit efficace : la CNIL conseille aux enseignes de le tester d’abord. Cela réduit-il les pertes de revenus dans la manière dont le contrôle par IA a été mis en place ? Peut-on discriminer entre effet de dissuasion et erreurs involontaires pour adapter l’intervention du personnel ? Il faut restreindre le périmètre de prise de vue de la caméra le plus possible, limiter le temps de prise de vue (uniquement lors de la transaction) et la stopper au moment de l’intervention du personnel. Il faut informer le client qu’une telle surveillance a lieu et lui donner un certain contrôle sur son déclenchement, tout en étant obligatoire (qu’il n’ait pas l’impression qu’il est filmé à son insu), ne pas créer une « arrestation immédiate » en cas de fraude. Il ne faut pas garder ces données à des fins de preuve ou pour créer une liste noire de clients non grata. Pas de son enregistré, non plus. Ah, si toutes les caméras qui nous espionnent pouvaient procéder ainsi ! C’est de la saine minimisation des données.
Pour la même raison, l’analyse des données doit se faire en local : il est inutile de rapatrier les données sur un cloud où on va évidemment les oublier jusqu’au moment où elles fuiteront.
Le client peut s’opposer à cette collecte et ce traitement de données mais là, c’est simple, il suffit de prévoir des caisses manuelles mais suffisamment pour ne pas trop attendre, sinon ce droit d’opposition est plus difficilement exerçable, ce que n’aime pas le RGPD. D’aucuns y retrouveront le fameux nudge effect de R. Thaler (prix Nobel 2017) à savoir offrir un choix avec des incitants cognitifs pour en préférer une option plutôt que l’autre (sauf que l’incitant est trop pénalisant, le temps d’attente).
Autre question classique dès qu’on parle d’IA : peut-on réutiliser les données pour entrainer l’algorithme, ce qui serait un plus pour diminuer le nombre de faux positifs. C’est plus délicat : il y aura sur ces données, même aux visages floutés, de nombreuses caractéristiques physiques aux mains, aux gestes qui permettront de reconnaitre les gens. Les produits manipulés et achetés peuvent aussi faciliter l’identification des personnes. Ce serait sain dit la CNIL de prévoir la possibilité pour les personnes de s’y opposer et dans tous les autres cas, de ne conserver les données que pour la durée nécessaire à l’amélioration de l’algorithme.
Les caisses automatiques, comme les poinçonneuses de métro, les péages d’autoroute, ce sont des technologies au service de l’émancipation d’une catégorie d’humains qui ont la charge de tâches pénibles, répétitives et ingrates. Mais souvent les possibilités de tricher augmentent de pair et il faut du coup techniquement l’empêcher (sauter la barrière par ex.). L’IA aux caisses automatiques, ce n’est rien de neuf à cet égard.
Mine de rien, toutes ces automatisations réduisent aussi les possibilités de contact social. La CNIL n’évoque pas l’alternative d’une surveillance humaine psychologiquement augmentée, sur place, aux caisses automatiques : imaginez un préposé qui tout en surveillant les caisses, dialogue, discute, reconnait les habitués. C’est le contrôle social qui prévient bien des fraudes.
Quand on sait la faible marge que font les supermarchés, l’IA au service de la vertu des gens, avec toutes ces précautions, n’est-ce pas une bonne chose ?
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Francis Hayen, Délégué à la Protection des Données & Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT).
Biais, hallucinations, création de contenus violents et activités frauduleuses : peut-on encore croire ce qu’on voit et ce qu’on entend ? Un façon d’aborder le problème est de créer des images avec une « vraie signature », indélébile et si possible indétectable, pour les distinguer de « fakes ». C’est possible et c’est ce que Jeanne Gautier et Raphaël Vienne, nous expliquent ici. Serge Abiteboul et Thierry Viéville
Vous ouvrez Instagram et tombez nez à nez avec une photo du pape en streetwear. Vous avez tout de même du mal à y croire, et vous avez bien raison ! De nombreux “deepfakes” circulent sur internet : au-delà d’être un outil formidable, l’IA générative présente donc aussi des dangers. La diffusion massive de données générées par IA impose donc de protéger leur propriété, authentifier leur auteur, détecter les plagiats etc. Une solution émerge : le watermarking (ou “tatouage numérique”) qui répond à ces attentes.
Les deux images (en Creative Commons) ci-dessus vous semblent similaires ? Elles le sont à l’œil nu mais diffèrent pourtant par de nombreux pixels.
Créer un « deep watermartking ».
Le watermarking devient de plus en plus sophistiqué. On observe une évolution des techniques de watermarking qui se basaient jusqu’ici sur des concepts assez simples comme un filigrane transparent qui recouvre l’image (« watermark » encodée dans la donnée et qui reste en apparence identique). Apparaît désormais le “deep watermarking” qui induit une altération plus subtile des données, mais qui est aussi plus robuste aux dégradations liées aux manipulations de l’image. Pour être qualifié de “deep watermarking”, un filigrane doit respecter les trois règles suivantes:
l’imperceptibilité : la distorsion doit restée invisible à l’œil humain.
la capacité : on doit pouvoir introduire de l’information dans le tatouage comme la date ou une signature.
la robustesse : le filigrane doit rester détectable même si l’on transforme l’image.
Pourquoi utilise-t-on le terme “deep” ? Parce que ces méthodes se basent sur des algorithmes d’apprentissage profond, ou “deep learning” en anglais. Il s’agit d’un procédé d’apprentissage automatique utilisant des réseaux de neurones possédant plusieurs couches de neurones cachées.
Il est possible d’appliquer de tels filigranes sur des images préexistantes par un processus qualifié “d’encodeur-décodeur” :
– Le modèle d’encodage prend deux entrées : une image brute et un message texte. Il cache le texte dans l’image en essayant de le rendre le moins perceptible possible. – Le décodeur prend en entrée l’image tatouée et tente de récupérer le texte caché.
L’encodeur et le décodeur sont entraînés pour travailler ensemble : le premier pour cacher un message dans une image sans l’altérer visuellement et le second pour retrouver le message dans cette image altérée.
Comme, en pratique, l’image tatouée peut subir des modifications (recadrage, rotation, flou, ajout de bruit), des altérations aléatoires sont appliquées aux images exemples, au cours du processus, pour entraîner le décodeur à tenir compte de ces altérations.
Mieux encore, on peut intégrer, donc encoder, le tatouage directement lors de la création d’images.
Comment fonctionnent les générateurs d’images avec watermark ?
Assez simplement, le système apprend, à partir d’un énorme nombre d’exemples, à passer d’une image où toutes les valeurs sont tirées au hasard (un bruit visuel aléatoire), en prenant en entrée une indication textuelle décrivant l’image souhaitée, à des images de moins en moins aléatoires, jusqu’à créer l’image finale. C’est cette idée de diffuser progressivement l’information textuelle dans cette suite d’images de plus en plus proches d’une image attendue qui fait le succès de la méthode.
Il est alors possible d’incorporer le watermark directement lors de la diffusion : on oriente ce processus en le déformant (on parle de biais statistique), en fonction du code secret, qu’est le watermark. Comme cette déformation ne peut être décodée, seule l’entité générant le texte, peut détecter si le tatouage, est présent.
Comment ça marche en pratique ?
Le watermarking est comme un produit « radioactif » : un modèle entraîné sur des données tatouées reproduit le tatouage présent dedans. Ainsi, si un éditeur utilise le produit tatoué d’un concurrent pour l’entraînement de ses propres modèles, les sorties de ce dernier posséderont également la marque de fabrique du premier !
Le watermarking a donc vocation de permettre aux éditeurs de modèles de génération de protéger leur propriété, puisque c’est une technique robuste pour déterminer si un contenu est généré par une IA et pour faire respecter les licences et conditions d’utilisation des modèles génératifs. Cela dit, il est essentiel de continuer à développer des techniques plus robustes, car tous les modèles open-source n’intègrent pas encore de mécanismes de watermarking.
Tom Sander, photo de son profil sur LinkedIn.
Cet article est issu d’une présentation donnée par Tom Sander chez datacraft. Tom est doctorant chez Meta et travaille sur des méthodes de préservation de la vie privée pour les modèles d’apprentissage profond, ainsi que sur des techniques de marquage numérique. Nous tenons à remercier Tom pour son temps et sa présentation.
Jeanne Gautier, Data scientist chez datacraft & Raphaël Vienne, Head of AI chez datacraft .
Un nouvel « Entretien autour de l’informatique » avec Haïm Korsia, grand-rabbin de France depuis 2014 et membre de l’académie des sciences morales et politique. Haïm Korsia est rabbin, ancien aumônier en chef du culte israélite des armées, aumônier de l’École polytechnique depuis 2005, administrateur du Souvenir français et ancien membre du Comité consultatif national d’éthique.
Haïm Korsia
« Quand personne ne me pose la question, je le sais ; mais si quelqu’un me la pose et que je veuille y répondre, je ne sais plus ». (Saint Augustin, Confessions XI). Pour moi, l’informatique est un peu comme cela. Haïm Korsia.
Binaire : Vous êtes rabbin. Comment en êtes-vous arrivé à vous intéresser à l’informatique et à l’intelligence artificielle ?
HK : Je fais partie de la première génération à utiliser des ordinateurs de façon quotidienne. A l’école rabbinique, mon professeur d’histoire, le Professeur Gérard Nahon, nous disait deux choses : « Vous devrez apprendre à parler anglais », et : « Un jour, vous n’aurez plus de secrétaire et il faudra taper vous-mêmes vos lettres. » Pour nous, cela tenait de l’impossible. D’abord, la langue à apprendre était l’hébreu. Et puis, le rabbin faisait le sermon et allait voir les gens. Taper des lettres à la machine, ne faisait pas partie de son travail.
Une machine à écrire Rheinmetall, 1920, Wikipédia
J’ai écouté ce prof et j’ai appris l’anglais. Et puis, rue Gay-Lussac, dans un magasin d’antiquités, j’ai vu une machine Rheinmetall. J’en ai rêvé et je l’ai achetée dès que j’ai eu un peu d’argent. Plus tard, quand j’ai vu mon collègue de Besançon qui avait une machine de traitement de texte, j’ai fait en sorte d’avoir un ordinateur portable. J’ai continué et depuis j’utilise des ordinateurs. Sans être un geek, j’ai appris à utiliser ces machines.
Pour moi, l’informatique est d’abord utilitaire et émancipatrice. L’informatique libère en évitant, par exemple, d’avoir à retaper plusieurs de fois un même texte, parce qu’on peut le corriger. Et puis, il est devenu impensable aujourd’hui de vivre sans les connexions que l’informatique nous apporte ! Mais il faut savoir doser cette utilisation.
Binaire : L’informatique et le numérique permettent de tisser des liens. Est-ce que vous pensez que le développement de tels liens a transformé la notion de communauté ?
HK : Bien sûr ! On voit bien, par exemple, avec des gens qui ont 5 000 amis sur Facebook mais aucun n’est capable d’aller leur chercher un médicament quand ils sont malades. Pour moi, c’est une dévalorisation de la notion d’ami. Cela m’évoque la fable d’Ésope, « la langue est la meilleure et la pire des choses ». Les réseaux sociaux peuvent enfermer les gens dans un même mode de pensée et en même temps ils ouvrent des potentiels incroyables. Cela dépend de la façon dont on les utilise.
Dans le judaïsme, nous avons un avantage sur les autres religions : quoi que vous me donniez comme moyen de communication, le samedi, je vais uniquement « là où mes pieds me portent ». Je retrouve en cela mon humanité sans tout ce qui me donne habituellement le sentiment d’avoir une humanité augmentée. Ni voiture, ni vélo, ni avion, ni téléphone. Rien. Au moins un jour par semaine, le samedi, je retrouve ma communauté telle qu’elle est vraiment. Tous les appendices qui augmentent ma capacité de lien sont supprimés le jour du shabbat, et je me désintoxique aussi de l’addiction aux moyens numérique de communication. Le samedi je n’ai pas de téléphone.
En quoi est-ce un avantage ? Cela me permet de ne pas perdre l’idée que ces outils sont juste des extensions de moi, qu’ils ne font pas partie de moi.
Binaire : Est-ce que la Bible peut nous aider à comprendre l’informatique ?
HK : La Bible nous parle de la vie des hommes, des femmes, et des invariants humains : la toute-puissance, la peur, la confiance, le rejet, la haine, la jalousie, l’amour, etc. Tout est là et chacun s’y retrouve. Mon maitre le grand rabbin Chouchena disait : Si tu lis un verset de la Bible et que tu ne vois pas ce qu’il t’apporte, c’est que tu l’as mal lu, relis-le !
Prenons un exemple. Considérez ce que dit la Bible [1] sur la neuvième plaie d’Égypte, la plaie de l’obscurité :
« Moïse dirigea sa main vers le ciel et d’épaisses ténèbres couvrirent tout le pays d’Égypte, durant trois jours. On ne se voyait pas l’un l’autre et nul ne se leva de sa place, durant trois jours mais tous les enfants d’Israël jouissaient de la lumière dans leurs demeures. Exode, 10-22,23.
Une interprétation possible, c’est d’imaginer qu’un volcan a explosé quelque part, ou qu’il y a eu une éclipse du soleil, comme dans Tintin et le temple du soleil. Une autre interprétation, c’est de lire, littéralement : « Un homme ne voyait pas son prochain comme un frère. » L’obscurité, alors, ce n’est pas un moment où il fait nuit, mais un moment où on devient indifférent à la fraternité qui devrait nous lier l’un à l’autre. Ainsi, l’indifférence dans la société, c’est la nuit du monde. Ce n’est pas inscrit comme cela dans le verset. Tout est question de l’interprétation du texte.
Autre exemple. J’ai connu le confinement au début de la pandémie, et cela m’a donné une capacité à interpréter autrement la Bible. Par exemple, dans Bible, il est dit :
« et ton existence flottera incertaine devant toi, et tu trembleras nuit et jour, et tu ne croiras pas à ta propre vie ! ». Deutéronome, 28-66.
Il s’agit du grand discours du dernier jour de la vie de Moïse, dans la partie sur les malédictions. Dans ce contexte, Rachi [2], un des plus grands commentateurs de Bible, parle de celui qui achète son blé au marché. Pendant le Covid, j’ai vu un avion atterrir avec une cargaison de masques et un acheteur étranger acheter toute la cargaison. Cela met en évidence le problème d’une dépendance au marché pour les choses stratégiques, les masques, les médicaments… Tant que tout va bien, tu te fournis au marché, quitte à payer plus cher ; mais s’il n’y a pas ces choses, même milliardaire, ta vie se retrouve en suspens. Si on dépend du marché pour des approvisionnements stratégiques, c’est une vie d’angoisse. Cela conduit à un commentaire que je propose suite à cet épisode. Les rabbins avant moi ne pouvaient pas proposer cette interprétation parce qu’ils n’avaient pas connu le covid.
Ces exemples illustrent la méthode. Confronter des questions d’actualité aux textes bibliques amène un entrechoquement fécond de la pensée. Posez-moi une question sur l’informatique. Je ne dis pas que la réponse est dans la Bible. Mais la Bible et ses commentaires proposent des façons de réfléchir, des pistes de réflexion.
Binaire : Alors sur l’informatique, que peut-on trouver dans la Bible selon vous ?
HK : L’informatique, c’est une volonté de maitrise, de l’ultra-rapidité, l’agglomération de tous les savoirs. Les questions d’augmentation, d’orgueil, de sentiment de puissance ou de toute-puissance, la Bible en parle. À nous d’y trouver un sens actuel, contemporain.
L’intelligence, ce n’est pas d’avoir des savoirs, mais de savoir où chercher, à qui demander. Individuellement je suis limité par mes capacités d’analyse, mais celui qui sait où chercher, lui est intelligent. Des machines toujours plus rapides, avec des capacités de mémorisation toujours plus importantes, ce n’est pas forcément ce qui va marcher le mieux. Pour prendre une métaphore sportive, ce n’est pas en prenant les onze meilleurs joueurs de foot du monde qu’on a la meilleure équipe du monde. Il faut onze joueurs qui jouent ensemble. Il faut savoir s’appuyer les uns sur les autres.
Binaire : Que pensez-vous de l’intelligence artificielle ?
HK : Prenons par exemple un dermatologue. Combien d’image de maladie de la peau arrive-t-il à mémoriser ? Quelques milliers. Le logiciel Watson d’IBM en mémorise 40 000. Il a acquis plus de points de comparaisons. Autre exemple : la justice. Prenez toutes les jurisprudences, c’est formidable de précision. L’intelligence artificielle peut nous aider à analyser les jurisprudences. Mais est-ce qu’elle permet de juger ? Est-ce qu’elle prend en compte la réalité humaine des gens qui viennent devant le juge ?
Adventures Of Rabbi Harvey: A Graphic Novel of Jewish Wisdom and Wit in the Wild West, de Steve Sheinkin
Dans la Bible, le roi David, quand un pauvre volait un riche, condamnait le pauvre parce que c’est la loi. Mais de sa cassette personnelle, il lui donnait de quoi payer l’amende. Une machine ne peut pas faire ça. On ne peut pas demander à une machine d’avoir de l’humanité. Dans l’histoire « Les aventures de Rabbi Harvey », Monsieur Katz est chez lui. Un pauvre gars lui rapporte son portefeuille. Katz se dit : « Quel idiot ! Il m’a rendu le portefeuille avec 200 dollars dedans ! » Il lui dit : « Enfin, il y avait 300 dollars, tu es un voleur ! » On soumet le cas au rabbin Harvey. Le rabbin comprend que Katz se moque du pauvre. Réponse du rabbin : « Ce n’est pas compliqué. Puisque ce n’est pas la bonne somme, ce n’est pas ton portefeuille. » ; et il le rend au pauvre ! Est-ce qu’un ordinateur aurait trouvé cela ? Est-ce qu’il aurait cet humour ? Je ne sais pas.
L’humanité ne peut pas être transformée en pensée informatique, en se laissant confiner dans la précision. La vie n’est pas seulement dans la précision. La machine crée une cohérence mais, en réalité, sans pouvoir comprendre.
Ne juge pas ton prochain avant de te trouver à sa place, dit le Talmud. Une machine ne peut pas être à la place de l’accusé.
Binaire : Qu’attendez-vous de l’intelligence artificielle ?
HK : Elle pourrait nous permettre de faire mieux certaines choses. En médecine par exemple, on s’est rendu compte que 25% des ordonnances contiennent des contre-indications connues entre médicaments ! Jamais une machine ne ferait de telles erreurs. Le médecin ne sait pas forcement certaines choses sur les antécédents mais l’ordinateur, le système informatique peut le savoir, donc peut en tenir compte dans les prescriptions. D’où l’intérêt d’utiliser l’informatique dans les prescriptions.
Mais il ne faut pas que cela ait pour conséquence que le médecin se contente de regarder l’écran, et oublie de regarder son patient. Et puis, imaginez une panne informatique dans un système médical ; tout le système s’écroule, plus rien ne marche. De mon point de vue, il faut toujours faire en sorte qu’on ait le maximum d’aide mais avec le minimum de dépendance. Donc oui, il faut utiliser l’intelligence artificielle. Mais il faut éviter la dépendance.
L’informatique et l’intelligence artificielle nous permettent d’aller plus loin. Deep Blue a battu Kasparov. Mais pourquoi voir cela comme une compétition ? Nous ne sommes pas sur un même plan. Il n’y a aucune raison de comparer, d’opposer l’humain et l’informatique. L’informatique n’est ni bonne ni mauvaise, elle est ce que nous en faisons. Nous devons utiliser cette force extraordinaire mais ne pas être utilisées par elles. En particulier, nous ne devons pas laisser l’informatique s’interposer entre les humains. Nous avons cette force d’imagination, sortir de ce qui a été pensé avant. Il nous faut trouver une autre façon d’être humain.
Binaire : Est-ce que l’intelligence artificielle soulève des problèmes nouveaux pour un juif pratiquant ?
HK : L’informatique en soulève déjà. Il y avait par exemple déjà la question de l’accès aux maisons avec digicodes pendant le shabbat. Le shabbat, je n’ai plus de téléphone portable, donc je n’existe plus ? Comment vivre le shabbat quand le monde est devenu numérique ? On m’a dit que ce sont les juifs qui sauveront les livres en papier parce que, pendant le shabbat, les livres numériques, c’est impossible.
Le shabbat, l’utilisation de l’électricité est interdite. En Israël, certains rabbins ont autorisé les visioconférences pour la fête de Pessah, pendant la pandémie. Le but était de faciliter des rassemblements familiaux virtuels, pour permettre de vivre les fêtes en famille. La question m’a été posée. J’ai dit non aux visios, car si on accepte une fois, les gens vont se dire que ce n’est pas grave de faire ça tout le temps. J’ai préféré refuser.
Et puis, vivre une journée sans technologie, je trouve ça formidable. Le shabbat est une très grande liberté.
Binaire : Vous parlez de « golémisation des humains ». Que voulez-vous dire par ça ?
HK : C’est le sujet de ma conférence dans le cycle des Conférences de l’Institut. Golem, GLM, les mêmes initiales que Generalized Language Model, ce ne peut être par hasard. Il s’agit de la mise en place de processus qui nient l’unicité de chaque personne. Le processus admet ce qui sort du lot, mais considère que si on arrive à gérer 95% des cas, on est tranquille. Mais nous, on est tous dans les 5% ! C’est ça, la golémisation : fonctionner avec des cases, des réponses préremplies, et si ça dépasse, si ça sort des cases, ce n’est pas bon. On ne doit jamais oublier que l’informatique est une aide. Quand l’aide de l’informatique devient un poids, un problème, j’appelle cela la golémisation.
L’informatique devient un poids symbolique inacceptable si ça m’empêche de pouvoir faire par moi-même. Dans ces problèmes idiots de nos rapports avec l’informatique, il faut remettre de l’intelligence plus fine et plus l’humanité. C’est une grande crainte, que la machine prenne le dessus sur les hommes. On irait vers un monde où les machines imposent leur mode de fonctionnement aux hommes qui, en adoptant le fonctionnement des machines, abdiquent leur humanité.
Binaire : Pour certains penseurs de la silicone vallée, l’IA pourrait nous permettre de devenir immortels.
HK : Selon eux, on pourrait arriver à concevoir comment les neurones conservent, gardent la mémoire, les espérances, à externaliser la mémoire de quelqu’un et à la transmettre. Si on y arrivait, le rêve d’immortalité se réaliserait. On est dans la science-fiction. Chaque époque a produit sa façon d’être immortel, par l’habit vert à l’académie par exemple. Léonard de Vinci est immortel d’une certaine manière ; Moïse en transmettant la Torah aux hébreux acquiert aussi une forme d’immortalité. On peut chercher l’immortalité à travers sa descendance.
La véritable obligation du judaïsme, ce n’est pas le shabbat, la nourriture cacher, etc., mais la phrase : « tu le raconteras à tes enfants et aux enfants de tes enfants. Et comme c’est dit dans la Bible :
Souviens-toi des jours antiques, médite les annales de chaque siècle ; interroge ton père, il te l’apprendra, tes vieillards, ils te le diront ! Deuteronome 32, 7.
On s’assure qu’il y ait deux générations qui puissent porter une mémoire une expérience de vie. Les rescapés de la Shoah ont voulu protéger leurs enfants en ne parlant pas. Mais quand ils sont devenus grands-parents, leurs petits-enfants leur ont demandé de raconter.
Binaire : Pour conclure, peut-être voulez-vous revenir sur la question de l’hyper-puissance de l’informatique.
HK : Cette technologie donne un sentiment de tout maitriser, et moi j’aime des fragilités. Quand je me suis marié, la personne qui m’a vendu mon alliance m’a dit : « il y a 12 000 personnes par an qui ont le doigt arraché par une anneau. Mais chez nous, il y a une fragilité dans l’or de l’anneau qui fait que l’anneau cède s’il y a une traction sur votre doigt. » La force de mon anneau, c’est sa fragilité ! Cela m’a impressionné. L’ordinateur ne sait pas intégrer la faiblesse dans sa réflexion, la fragilité, alors que c’est l’une des forces de l’humain. Cette toute puissance, conduit précisément à la faiblesse des systèmes informatiques. La super machine dans sa surpuissance devient fragile, alors que nous, notre fragilité fait notre force.
Serge Abiteboul, Inria et ENS Paris, Claire Mathieu, CNRS
[1] Les traductions de la Bible sont prises de Torah-Box, https://www.torah-box.com/
[2] Rabbi Salomon fils d’Isaac le Français, aussi connu sous le nom de Salomon de Troyes, est un rabbin, exégète, talmudiste, poète, légiste et décisionnaire français, né vers 1040 à Troyes en France et mort le 13 juillet 1105 dans la même ville. [Wikipédia]
Doctorant en droit privé à l’université Paris-Saclay, Vincent Bachelet décrit comment les outils juridiques existants, notamment issus de l’économie sociale et solidaire, peuvent participer à la structuration et la valorisation des projets de communs numériques. Nous publions cet entretien dans le cadre de notre collaboration avec le Conseil national du numérique qui l’a réalisé.
Pourquoi rapprocher le monde des communs numériques avec celui de l’économie sociale et solidaire ?
Le rapprochement entre l’économie sociale et solidaire (ESS) et les communs numériques était presque évident. Déjà parce que les deux poursuivent le même objectif, à savoir repenser l’organisation de la production et sortir de la pure logique capitaliste du marché. Aux côtés des logiciels libres et de l’open source, les communs numériques participent en effet à un mouvement venant repenser notre manière d’entreprendre le numérique. S’ils se rejoignent dans l’ambition de redéfinir le droit d’auteur par l’utilisation de licences inclusives et non exclusives, chacun de ces trois termes désignent des réalités distinctes. Le logiciel libre a été une révolution dans la façon dont il a « retourné » le monopole conféré par les droits d’auteurs pour permettre l’usage et la modification des ressources numériques par toutes et tous. L’open source a proposé une lecture plus pragmatique et « business compatible » de cette nouvelle approche et en a permis la diffusion. Ces deux mouvements n’envisagent cependant pas les aspects économiques de la production des ressources, et c’est cet « impensé » que viennent adresser les communs numériques.
Si aujourd’hui on entend souvent que le logiciel libre a gagné, c’est surtout parce qu’il a été récupéré par les gros acteurs traditionnels du numérique. En consacrant une liberté absolue aux utilisateurs sans questionner les modalités économiques de la production de ces ressources, la philosophie libriste a pu entraîner une réappropriation des logiciels libres par ces entreprises. Par exemple, l’ennemi public historique des libristes, Microsoft, est aujourd’hui l’un des plus gros financeurs de logiciels libres. Conscients des risques de prédation des grandes entreprises, le monde des communs a construit des instruments juridiques pour protéger leurs ressources en repensant la formule des licences libres, ce qui va aboutir à la création des licences dites à réciprocité. Ces licences conditionnent les libertés traditionnellement octroyées à certaines conditions, notamment l’exigence de contribution ou la poursuite d’une certaine finalité.
L’exemple de la fédération coopérative de livraison à vélo Coopcycle – dont je fais partie – est intéressant car par son statut et le type de licence utilisé, il matérialise le rapprochement entre les communs numériques et l’ESS. CoopCycle utilise une licence libre dans laquelle des clauses ont été ajoutées pour réserver l’utilisation commerciale du code source aux seules structures de l’ESS. Le but de ces obligations de réciprocité est ainsi d’empêcher qu’un autre projet récupère le code source pour créer une plateforme de livraison commerciale. Toutefois, cette licence ne suffit pas par elle-même à structurer le projet et garantir sa soutenabilité économique dans le temps. Il a donc fallu réfléchir à un mode d’organisation fonctionnel qui donne la propriété du logiciel aux coursiers qui l’utilisent. Le choix s’est alors porté sur le statut de société coopérative d’intérêt collectif (SCIC) qui intègre les coursiers dans la gouvernance du projet de façon majoritaire.
Au bout du compte, le rapprochement avec l’ESS met à jour des tensions qui touchent tout mouvement réformiste, à savoir celles des moyens à employer pour parvenir à ses fins. Parce que la portée inconditionnelle accordée aux libertés par le mouvement libriste engendrait des limites à la pérennisation de leur projet, les porteurs de projets de communs numériques ont adopté une approche plus rationnelle en mobilisant les outils juridiques de l’ESS.
Comment l’ESS peut-elle permettre la valorisation des communs numériques ?
À l’inverse des communs numériques, l’ESS possède un cadre légal solide, consacré par la loi relative à l’économie sociale et solidaire de 2014, dite loi Hamon.
Initialement, le réflexe en France pour monter un projet d’innovation sociale est de fonder une association loi 1901. Cette structure répond à un certain nombre de problématiques rencontrées dans l’organisation de projets de communs numériques. Elle dote le projet d’une personnalité juridique, encadre une gouvernance interne, fait participer tout type d’acteurs, etc. Cependant, elle se fonde sur le financement via la cotisation des membres, l’appel au don ou l’octroi de subventions, soit des financements précaires qui ne permettent pas de porter un modèle auto-suffisant et soutenable économiquement.
J’ai constaté que la structure la plus adaptée en droit français pour parvenir à cette soutenabilité est la société coopérative d’intérêt collectif (SCIC). Encadrées par une loi de 2001, les SCIC ont « pour objectif la production et la fourniture de biens et de services d’intérêt collectif qui présentent un caractère d’utilité sociale ». Cette structure a ainsi l’avantage d’inscrire une activité commerciale dans les statuts tout en se conformant aux principes fondamentaux de l’ESS, qui correspondent bien à ce que recherchent les porteurs de projets de communs numériques. Ainsi, la gouvernance est ouverte à une diversité de parties prenantes dans laquelle les sociétaires sont à la fois les bénéficiaires et les producteurs du service ou produit, mais aussi des personnes publiques ; tout en suivant la règle 1 personne = 1 voix. Théoriquement, cela renouvelle la façon dont l’acteur public peut soutenir les communs numériques en participant directement à sa gouvernance sans préempter le reste des sociétaires.
Toutefois, il demeure à mon sens trois grandes limites à ce statut. La première tient aux exigences et complexités du cadre juridique des SCIC. À l’inverse du statut des associations qui est assez souple, celui des SCIC impose le respect d’un grand nombre de règles qui peuvent être difficilement compréhensibles pour tout un chacun, car en grande partie issu du droit des sociétés commerciales. Ensuite, l’insertion d’un projet cherchant une lucrativité limitée et un fonctionnement démocratique dans une économie capitaliste et libérale n’est pas des plus évidentes. Enfin, tout en présentant une rigidité qui peut le rendre difficile à manier, le statut de SCIC permet des arrangements institutionnels, comme la constitution de collèges de sociétaires qui viennent pondérer les voix, qui peuvent venir diluer certains principes coopératifs, comme la règle 1 personne = 1 voix.
L’ESS bénéficie-t-elle de l’investissement des communs numériques dans son champ ?
“Si l’ESS vient apporter une structuration juridique au mouvement des communs numériques, ces derniers ont permis l’intégration des questions numériques dans au sein de l’ESS.”
Ces deux mondes se complètent très bien. Si l’ESS vient apporter une structuration juridique au mouvement des communs numériques, ces derniers ont permis l’intégration des questions numériques au sein de l’ESS.
Le recours aux logiciels libres a été une évidence pour les acteurs de l’ESS et ils ont un rôle important, notamment pour l’organisation numérique du travail, aujourd’hui indispensable. Les logiciels libres mettent à disposition tout un tas de ressources pensées pour le travail communautaire de façon gratuite ou du moins à moindre coût. Alternatives aux services proposés par les GAFAM, ils permettent surtout d’être alignés avec la conscience politique des acteurs de l’ESS.
Toutefois, le recours aux logiciels libres dans le cadre de tels projets d’ESS pose des questions quant à la rémunération du travail de production et de maintenance de ces outils. Initialement, les utilisateurs des logiciels libres sont des personnes en capacité de développer et de maintenir ces derniers, ce qui n’est plus le cas aujourd’hui. De plus, au fur et à mesure que les projets libres ont gagné en notoriété, un panel de nouvelles fonctions est apparu aux côtés des enjeux de développements techniques, comme la documentation, l’animation de la communauté, etc. Tout ce travail invisible non technique mais indispensable a alors besoin d’être valorisé, ce qui doit passer par une rémunération du travail effectué.
L’affiliation des projets de communs numérique à l’ESS permet de mettre en valeur ces enjeux de rémunération. Là où les logiciels libres n’envisagent pas systématiquement une rémunération, l’ESS vient poser un cadre juridique prévoyant des mécanismes de valorisation économique de toute contribution. En valorisant ces activités, l’ESS bénéficie réciproquement des nombreux apports venant des logiciels libres et des communs numériques.
Ce rapprochement est-il une réponse pour encourager la participation de l’État dans le développement de communs numériques ?
“Le simple fait que tous les acteurs publics utilisent les solutions libres constituerait un grand pas en avant pour l’écosystème.”
Il est difficile de trouver une bonne réponse sur la participation que l’État doit prendre dans le développement de communs numériques. Cela peut à la fois faciliter le développement du commun numérique en injectant des moyens mais aussi remettre en question le fondement pour lequel il a été créé. Toute implication de l’acteur public dans un projet qui se veut profondément démocratique et horizontal présente un risque. Et cela a déjà été le cas par le passé. La participation d’un acteur public dans la gouvernance d’une SCIC peut entraîner l’échec du projet du commun. Face à des particuliers, et même s’il n’a qu’une voix, l’acteur public peut involontairement prendre le pas sur la gouvernance du projet, et ce, malgré les meilleures intentions du monde. Les contributeurs individuels initiaux peuvent se désengager du projet pensant que leur participation ne vaut rien à côté des moyens de l’acteur public. Dans ce cas, même si le projet perdure, il demeure un échec en tant que commun numérique.
L’avantage de rapprocher l’ESS et les communs numériques est que cela permet de mettre en exergue les blocages existants et de réfléchir à des solutions. Avant d’envisager une potentielle participation d’un acteur public dans un projet de commun numérique, il est nécessaire de penser la structuration du projet. Les SCIC apportent des premiers éléments de réponse, mais il est nécessaire de mettre en place des gardes fous juridiques pour assurer la résilience du commun lors de l’arrivée de l’acteur public, et ainsi éviter que le projet devienne une société classique ou finisse par disparaître.
Plus globalement, là où l’État peut jouer un rôle sans se heurter à la question de la participation, c’est dans son rapport aux logiciels libres. Le simple fait que tous les acteurs publics utilisent les solutions libres constituerait un grand pas en avant pour l’écosystème. Le ministère de l’Éducation nationale est moteur en ce sens : le ministère utilise le logiciel libre de vidéoconférence BigBlueButton et contribue à son amélioration. Toutefois, cette adoption généralisée dans l’administration n’est pas si évidente. Les acteurs vendant des logiciels propriétaires ont adopté des stratégies pour rendre les utilisateurs dépendants de ces solutions. La migration vers des solutions libres ne peut se faire sans un accompagnement continu et une formation des utilisateurs qui ne sont pas forcément à l’aise avec l’outil informatique et qui ont l’habitude de travailler avec un logiciel depuis toujours.
Cet ouvrage, publié chez Odile Jacob, s’attaque à un serpent de mer, la régulation des réseaux sociaux, ces complexes objets mi-humains mi-machines, qui nous unissent pour le meilleur et pour le pire. Tout le monde a un avis, souvent très tranché, sur la question. L’intérêt, ici, est d’avoir l’avis de deux spécialistes, un informaticien, Serge Abiteboul (*), membre de l’Arcep (Autorité de régulation des communications électroniques, des postes et de la distribution de la presse), et un juriste, Jean Cattan, Secrétaire général du Conseil national du numérique.
Mais précisément, ces deux spécialistes s’abstiennent soigneusement dans le livre de donner un cours. En préambule, ils s’appuient sur une remarque évidente et pourtant pas toujours évidente : les réseaux sociaux, c’est nous, nous tous. Nous, mais régulés par les entreprises qui gèrent Facebook, Twitter, Instagram et les autres. Des humains régulés par d’autres humains, finalement. Et donc, c’est à nous, nous tous, de définir ce qui doit être fait. Ils nous proposent une réflexion sur les principes qui devraient être au centre du développement des réseaux sociaux, et surtout, sur une méthode qui permettrait d’intégrer tout le monde, plaidant pour une intervention forte des États dans ce débat.
Dès l’introduction, ils préviennent : tout le monde ne sera pas d’accord. Mais la situation actuelle n’est pas satisfaisante, et ce n’est pas en ignorant nos désaccords qu’on avancera. Faites-vous votre avis, ouvrez le livre, et puis ouvrez le débat !
Les algorithmes de recommandations utilisés par les grandes plateformes du web telles YouTube ne sont pas connus ou accessibles. Des chercheurs essaient d’en découvrir le fonctionnement. Leurs travaux permettent de mieux comprendre ce que font ces algorithmes, et aussi d’observer les relations entre les recommandations et les sondages d’intention de vote. Pierre Paradinas.
Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plateforme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes: en 2018, 70% des vues de vidéos provenaient de recommandation (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plateforme le plus longtemps possible, mais aussi critique pour l’utilisateur lui même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.
Cette double importance conduit la recherche en informatique a s’intéresser à la conception de tels recommandeurs. Il s’agit ainsi tout d’abord de prendre la perspective de la plateforme afin d’améliorer la mise au point de la machinerie complexe qui permet à celles-ci de produire des recommandations, en général en exploitant les historiques de consommation des utilisateurs (principe du filtrage collaboratif).
D’un autre coté et plus récemment, la recherche s’intéresse à la perspective utilisateur de la situation. Pour analyser les algorithmes de recommandation, on les observe comme des boîtes noires. Cette notion de boîte noire fait référence au peu de connaissance qu’à l’utilisateur sur le fonctionnement du recommandeur qui est généralement considéré par les plateformes comme un secret industriel. L’objectif de ces recherches est de comprendre ce qu’on peut découvrir du fonctionnement de la boîte noire sans y avoir accès, simplement en interagissant avec comme tout autre utilisateur. L’approche consiste ainsi, en créant des profils ciblés, à observer les recommandations obtenues afin d’extraire de l’information sur la politique de la plateforme et son désir de pousser telle ou telle catégorie ou produit, ou bien de mesurer une éventuelle censure apportée aux résultats de recherche. On notera qu’un des buts du Digital Services Act récemment discuté au parlement Européen, est de permettre l’audit indépendant des grandes plateformes, c’est-à-dire de systématiser les contrôles sur le comportement de ces algorithmes.
Une illustration de ce qu’il est possible d’inférer du côté utilisateur a vu le jour dans le cadre de la campagne présidentielle de 2022 en France. Il a été tentant d’observer les recommandations « politiques », et ce pour étudier la question suivante. Puisque qu’un recommandeur encode le passé des actions sur la plateforme (ici des visualisations de vidéos), est-ce que, par simple observation des recommandations, on peut apprendre quelque-chose sur l’état de l’opinion Française quant aux candidats en lice pour l’élection ? Le rationnel est la boucle de retro-action suivante : si un candidat devient populaire, alors de nombreuses personnes vont accéder à des vidéos à son sujet sur YouTube ; le recommandeur de YouTube va naturellement mettre en évidence cette popularité en proposant ces vidéos à certains de ses utilisateurs, le rendant encore plus populaire, etc.
Une expérience : les recommandations pour approximer les sondages
Pouvons-nous observer ces tendances de manière automatisée et du point de vue de l’utilisateur ? Et en particulier, que nous apprend la comparaison de ces mesures avec les sondages effectués quotidiennement durant cette période ?
Dans le cadre de cette étude, nous — des chercheurs — avons pris en compte les douze candidats présentés officiellement pour la campagne. Nous avons mis en place des scripts automatisés (bots) qui simulent des utilisateurs regardant des vidéos sur YouTube. A chaque simulation, « l’utilisateur » se rend sur la catégorie française « Actualités nationales », regarde une vidéo choisie aléatoirement, et les 4 vidéos suivantes proposées en lecture automatique par le recommandeur
Cette action a été effectuée environ 180 fois par jour, du 17 janvier au 10 avril (jour du premier tour des élections). Nous avons extrait les transcriptions des 5 vidéos ainsi vues, et recherché les noms des candidats dans chacune. La durée d’une phrase dans laquelle un candidat est mentionné est comptée comme temps d’exposition et mise à son crédit. Nous avons agrégé le temps d’exposition total de chaque candidat au cours d’une journée et normalisé cette valeur par le temps d’exposition total de tous les candidats. Nous avons ainsi obtenu un ratio représentant le temps d’exposition partagé (TEP) de chaque candidat. Cette valeur est directement comparée aux sondages mis à disposition par le site Pollotron.
La figure présente à la fois l’évolution des sondages (en ordonnée) et les valeurs de TEP (en pointillés) pour les cinq candidats les plus en vue au cours des trois mois précédant le premier tour des élections (score normalisé en abscisse) ; les courbes sont lissées (fenêtre glissante de 7 jours). Les valeurs TEP sont moins stables que les sondages ; cependant les deux présentent généralement une correspondance étroite tout au long de la période. Cette affirmation doit être nuancée pour certains candidats, Zemmour étant systématiquement surévalué par le TEP et Le Pen inversement sous-évaluée. Il est intéressant de noter que les sondages et le TEP fournissent tous deux une bonne estimation des résultats réels des candidats lors du premier tour de l’élection (représentés par des points), présentant respectivement des erreurs moyennes de 1,11% et 1,93%. L’erreur moyenne de prédiction est de 3,24% sur toute la période pour tous les candidats. L’ordre d’arrivée des candidats a été respectée par le TEP, pour ceux présents sur la figure tout au moins.
Évolution des sondages et du TEP de YouTube sur la campagne, pour les 5 candidats les mieux placés. Nous observons une proximité importante entre les courbes pleines et pointillées pour chacune des 5 couleurs. Les ronds finaux représentent les résultats officiels du premier tour : les sondages ainsi que le TEP terminent relativement proche de ceux-ci, et tous sans erreur dans l’ordre d’arrivée des candidats.
Les sondages sont effectués auprès de centaines ou de milliers d’utilisateurs tout au plus. Le recommandeur de YouTube interagit avec des millions de personnes chaque jour. Étudier de manière efficace l’observabilité et la corrélation de signaux de ce type est certainement une piste intéressante pour la recherche. Plus généralement, et avec l’introduction du DSA, il parait urgent de développer une compréhension fine de ce qui est inférable ou pas pour ces objets en boîte noire, en raison leur impact sociétal majeur et toujours grandissant.
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 6: des pistes pour éviter de se fracasser sur les cinq murs
Je ne voulais pas laisser cette série se terminer sur une note négative, il me reste donc à évoquer quelques pistes pour le futur. Amis lecteurs, je suppose que vous avez lu les cinq épisodes précédents, ils sont indispensables à la compréhension de ce qui suit.
D’abord, sur la confiance. C’est un des sujets majeurs de recherche et développement en IA depuis quelques années, pour les systèmes dits à risques ou critiques1. Par exemple, le programme confiance.ai, qui réunit des partenaires industriels et académiques sur quatre ans pour développer un environnement d’ingénierie pour l’IA de confiance, aborde de multiples sujets: qualité et complétude des données d’apprentissage; biais et équité; robustesse et sûreté; explicabilité; normes et standards; approche système; interaction avec les humains. Et ce n’est pas le seul, de multiples initiatives traitent de ce sujet, directement ou indirectement. On peut donc espérer avoir dans quelques années un ensemble de technologies permettant d’améliorer la confiance des utilisateurs envers les systèmes d’IA. Sera-ce suffisant ? Pour ma part, je pense que faute d’avancées fondamentales sur la nature des systèmes d’IA on n’arrivera pas à des garanties suffisantes pour donner une confiance totale, et probablement des accidents, catastrophiques ou non, continueront à se produire. Mais on aura fait des avancées intéressantes et on aura amélioré les statistiques. En attendant d’avoir la possibilité de démontrer les facteurs de confiance, il faudra s’appuyer sur des quantités d’expériences : des centaines de millions de kilomètres parcourus sans encombre par des véhicules autonomes, des dizaines de milliers de décisions automatiques d’attributions de crédits non contestées, de diagnostics médicaux jugés corrects par des spécialistes etc.). On en est encore loin. Et la confiance n’est pas qu’un sujet technologique, les facteurs humains et sociaux sont prépondérants. L’étude2 – un peu ancienne mais certainement toujours pertinente – faite par les militaires américains – est éclairante.
Sur l’énergie, plusieurs pistes sont développées, car le mur est proche de nous ! Si la croissance actuelle se poursuit, il faudra en 2027 un million de fois plus d’énergie qu’aujourd’hui pour entraîner les systèmes d’IA, à supposer que l’on continue à le faire de la même manière.
Je vois principalement trois types de solutions, dont les performances sont très différentes: a) solutions matérielles; b) amélioration des architectures et algorithmes de réseaux neuronaux profonds: c) hybridation avec d’autres formalismes d’IA.
Je ne m’étends pas sur a), il existe des dizaines de développements de nouveaux processeurs, architectures 3D, architectures neuro-inspirées, massivement parallèles, etc., et d’aucuns disent que l’ordinateur quantique lorsqu’il existera, résoudra la question. Lorsque Google est passé des GPU (Graphical Processing Units) de Nvidia aux TPU (Tensor Processing Units) qu’il a développé pour ses propres besoins, un saut de performance a été obtenu, pour une consommation d’énergie relativement stable. Disons que les pistes matérielles permettent des économies d’énergie intéressantes, mais ne changent pas fondamentalement les choses.
Les recherches sur b) sont plus intéressantes: améliorer la structure des réseaux par exemple en les rendant parcimonieux par la destruction de tous les neurones et connexions qui ne sont pas indispensables; ou encore par la définition d’architectures spécifiques, à l’image des réseaux récurrents de type LSTM pour le signal temporel, ou des Transformers (BERT, Meena, GPT3 etc.) pour le langage, dont la structure permet de faire de la self-supervision et donc au moins d’économiser l’annotation des données d’entraînement3 – mais tout en restant particulièrement gourmands en temps d’apprentissage. Je pense également à l’amélioration du fonctionnement interne des réseaux comme l’ont proposé divers auteurs avec des alternatives à la rétro-propagation du gradient ou autres.
Enfin, la troisième approche consiste à combiner les modèles neuronaux à d’autres types de modèles, essentiellement de deux natures: modèles numériques utilisés pour la simulation, l’optimisation et le contrôle de systèmes; modèles symboliques, à base de connaissances. Si on est capable de combiner l’expertise contenue dans ces modèles, basée sur la connaissance établie au cours des années par les meilleurs spécialistes humains, à celle contenue dans les données et que l’on pérennise par apprentissage, on doit pouvoir faire des économies substantielles de calcul, chacune des deux approches bénéficiant de l’autre. Le sujet est difficile car les modèles basés sur les données et ceux basés sur les connaissances ne sont pas compatibles entre eux, a priori. Quelques travaux existent sur la question, par exemple ceux de Francesco Chinesta4, ou le projet IA2 de l’IRT SystemX5.
J’ai bien peur que le mur de la sécurité de l’IA soit très solide. Ou plutôt, il a une tendance naturelle à s’auto-réparer lorsqu’il est percé. Je m’explique (réécriture d’extraits d’un billet paru dans le journal Les Echos).
D’une manière générale, les questions de cybersécurité sont devenues cruciales dans notre monde où le numérique instrumente une partie de plus en plus importante des activités humaines. De nouvelles failles des systèmes sont révélées chaque semaine ; des attaques contre des sites ou des systèmes critiques ont lieu en continu, qu’elles proviennent d’états mal intentionnés, de groupes terroristes ou mafieux. Les fournisseurs proposent régulièrement des mises à jour des systèmes d’exploitation et applications pour intégrer de nouvelles protections ou corrections de failles. Le marché mondial de la sécurité informatique avoisine les cent milliards d’euros, les sociétés spécialisées fleurissent. En la matière il s’agit toujours d’un jeu d’attaque et de défense. Les pirates conçoivent des attaques de plus en plus sophistiquées, l’industrie répond par des défenses encore plus sophistiquées. Les générateurs d’attaques antagonisteset de deepfakes produisent des attaques de plus en plus sournoises et des faux de plus en plus crédibles, l’industrie répond en augmentant la performance des détecteurs de faux. Les détecteurs d’intrusions illégales dans les systèmes font appel à des méthodes de plus en plus complexes, les attaquants sophistiquent encore plus leurs scénarios de pénétration. Les protocoles de chiffrement connaissent une augmentation périodique de la longueur des clés de cryptographie, qui seront ensuite cassées par des algorithmes de plus en plus gourmands en ressources de calcul. Et ainsi de suite.
Pour les attaques adverses, une solution déjà évoquée est d’entraîner les réseaux avec de telles attaques, ce qui les rend plus robustes aux attaques connues. Mais, la course continuant, les types d’attaques continueront d’évoluer et il faudra, comme toujours, répondre avec un temps de retard. Quant aux attaques de la base d’apprentissage, leur protection se fait avec les moyens habituels de la cybersécurité, voir ci-dessus.
Comparons au domaine militaire, qui a connu la course aux armements pendant de longues périodes : glaives, boucliers et armures il y a des milliers d’années, missiles et anti-missiles aujourd’hui. La théorie de la dissuasion nucléaire, établie il y a une soixantaine d’années, a modéré cette course, puisque la réponse potentielle d’une puissance attaquée ferait subir des dommages si graves que cela ôterait toute envie d’attaquer. Début 2018, l’État français a reconnu s’intéresser à la Lutte Informatique Offensive. Israël a déjà riposté physiquement à une cyber-attaque. Il faudrait peut-être imaginer une doctrine équivalente à la dissuasion nucléaire en matière de cybersécurité de l’IA … ou espérer que l’IA apporte suffisamment de bonheur à la population mondiale, et ce de manière équitable, pour que les causes sociales et autres (politiques, religieuses, économique etc.) de la malveillance disparaissent. Cela va prendre un peu de temps.
J’aborde maintenant le mur de l’interaction avec les humains. On peut commencer à le fracturer en ajoutant des capacités d’explication associées à la transparence des algorithmes utilisés. La transparence est indispensable lorsqu’il s’agit de systèmes qui sont susceptibles de prendre des décisions (imposées) ayant un impact important sur notre vie personnelle et sociale. Un sujet qui a par exemple fait l’objet d’un petit rapport de l’institut AINow de Kate Crawford6, dont l’objectif est de définir un processus assurant la transparence des systèmes de décision mis en place au sein des administrations. On pense notamment aux domaines de la justice, de la police, de la santé, de l’éducation, mais le texte se veut générique sur l’ensemble des sujets d’intérêt des administrations. La démarche préconisée par les auteurs est en quatre étapes et s’accompagne d’une proposition organisationnelle. Les quatre étapes sont 1) Publication par les administrations de la liste des systèmes de décision automatisée qu’elles utilisent ; 2) auto-évaluation des impacts potentiels de ces systèmes par les administrations, notamment en phase d’appels d’offres ; 3) ouverture des systèmes au public et aux communautés – en respectant les conditions de confidentialité ou de propriété intellectuelle – pour examen et commentaires ; 4) évaluation externe par des chercheurs indépendants.
J’ai déjà abordé, dans la section correspondante, les travaux sur l’explicabilité. Un « méta-état de l’art7 » a été produit par le programme confiance.ai, c’est-à dire une synthèse de nombreuses synthèses déjà publiées dans la communauté. Les pistes sont nombreuses, je ne les détaillerai pas plus ici. Ma faveur va à celles qui combinent apprentissage numérique et représentations à base de connaissances (logiques, symboliques, ontologiques), même si elles sont encore à l’état de promesses: le passage du numérique (massivement distribué dans des matrices de poids) au symbolique est un sujet particulièrement ardu et non résolu de manière satisfaisante pour le moment.
Plus généralement, l’interaction entre systèmes d’IA et humains entre dans le concept général d’interaction humain-machine (IHM ou HCI, human-computer interaction en anglais). La communauté IHM travaille depuis des décennies sur le sujet général, avec des réalisations remarquables en visualisation, réalité virtuelle, réalité augmentée, interfaces haptiques etc.; on peut – et il faut – faire appel à leurs compétences pour le cas particulier des interactions avec des machines d’IA. C’est par exemple ce que propose la deuxième édition du Livre Blanc d’Inria sur l’Intelligence Artificielle8, qui consacre un chapitre au sujet en soulignant quatre orientations majeures:
– créer une meilleure division du travail entre les humains et les ordinateurs, en exploitant leurs pouvoirs et capacités respectifs tout en reconnaissant leurs limites et leurs faiblesses; – apporter une transparence et une explication véritables aux systèmes d’IA grâce à des interfaces utilisateur et des visualisations appropriées; – comment combiner les systèmes interactifs et les systèmes d’IA afin que chacun tire parti des forces de l’autre au moment opportun, tout en minimisant ses limites; – créer de meilleurs outils, davantage axés sur l’utilisateur, pour les experts qui créent et évaluent les systèmes d’IA
La piste que je préconise donc (à l’image d’autres chercheurs et institutions qui l’ont également encouragé) est de resserrer les liens entre les deux communautés IA et IHM. Les chercheurs en IA y trouveront des éléments pour repousser le quatrième mur, et les chercheurs en IHM y trouveront la source de nouveaux défis pour leurs méthodes et leurs outils.
Reste le mur de l’inhumanité: le plus éloigné, mais aussi le plus solide pour le moment. Le risque n’est pas encore très important, mais s’amplifiera au fur et à mesure de l’insertion de systèmes IA de plus en plus autonomes, intrusifs, et impactants, dans notre société. En ce qui concerne la quête du sens commun, on a vu que des millions de dollars et des années de recherche investis sur CYC n’ont pas réglé la question, loin de là. Peut-on miser sur des nouvelles architectures etorganisations de réseaux neuronaux pour cela? Certains l’espèrent. Personnellement, je miserai plutôt sur une autre branche de l’IA, celle de la robotique développementale (developmental robotics) qui a pour but de faire acquérir à des robots doués de sens les notions de base du monde en interagissant avec leur environnement – peuplé d’objets et d’humains – et surtout en stimulant ce qu’on appelle la curiosité artificielle, à savoir doter les robots d’intentions et de capacités d’exploration et d’envoi de stimuli vers leur environnement afin d’en recevoir un feedback pour l’apprentissage par renforcement. Certaines expérimentations faites par l’équipe Inria FLOWERS (image ci-contre) sont assez convaincantes en ce sens.
Image Inria, équipe-projet FLOWERS
J’ai déjà abordé les recherches en cours sur la découverte de la causalité par apprentissage automatique. C’est un sujet de longue haleine bien identifié mais disposant de peu de résultats. Les équipes de Bernhard Schöllkopf à Tubingen9 et de Yoshua Bengio à Montréal10 ont publié des premiers résultats encore insuffisants, basés sur la notion d’intervention. L’équipe TAU d’Inria Saclay a développé des méthodes pour identifier des relations de causalité dans des tableaux de données11. Je pense que l’introduction explicite de causalité soit par conception d’architecture, soit par ajout d’une couche causale symbolique, apporteront des résultats plus rapidement et plus concrètement – modulo la difficulté de combiner symbolique et numérique, dont j’ai déjà parlé. Une piste alternative, très intéressante, est celle utilisée par la startup américaine de Pierre Haren CausalityLink12, qui se base sur le texte pour détecter automatiquement – et statistiquement – les liens de causalité entre variables d’un domaine, sujet qui intéresse beaucoup les financiers.
Enfin, pour le passage de l’IA au niveau du Système 2, j’ai abordé les pistes dans la section correspondante. La principale question est de savoir si cela peut être atteint par apprentissage de réseaux neuronaux – après tout, c’est bien ainsi que nous fonctionnons – ou par la conjonction de réseaux avec d’autres modes de représentations des connaissances, réalisant une IA hybride conjuguant symbolique et numérique, mettant en résonance les rêves et avancées de l’IA de la fin du vingtième siècle avec les progrès remarquables de celle du début du vingt-et-unième.
Tout ceci pour réaliser des IA faibles, spécialisées sur la résolution d’un seul ou d’un petit nombre de problèmes, bien entendu, même si certains comme DeepMind ont l’ambition de développer une IA Générale. Mais essayons déjà de ne pas nous écraser dans les murs de l’IA spécialisée.
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Notes:
1Pour des applications non critiques comme la recommandation de contenu ou de chemin optimal pour aller d’un point à un autre, cette question est évidemment moins cruciale. Nous utilisons ces systèmes tous les jours sans nous poser de questions.
2 Foundations for an Empirically Determined Scale of Trust in Automated System, Jiun-Yin Jian, et aL, (2000) International Journal of Cognitive Ergonomics
3 Attention is All you Need, Ashish Vaswani et al. (2017), ArXiv 1706.03762
4 https://project.inria.fr/conv2019/program/#program, communication non publiée
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 5: le mur de l’inhumanité
Cet épisode s’intéresse à des capacités intellectuelles qui distinguent fortement les humains des machines, en tous cas pour le moment. Le paragraphe sur Système 2 reprend principalement un billet paru dans le journal Les Échos courant 2021.
Je range plusieurs composantes dans ce cinquième mur que j’appelle globalement celui de l’humanité des machines, ou plutôt celui de leur inhumanité : acquisition du sens commun; raisonnement causal; passage au système 2 (au sens de Kahneman1). Toutes composantes que nous, humains, possédons naturellement et que les systèmes d’intelligence artificielle n’ont pas – et n’auront pas à court ou moyen terme.
Le sens commun, c’est ce qui nous permet de vivre au quotidien. Nous savons qu’un objet posé sur une table ne va pas tomber par terre de lui-même. Nous savons qu’il ne faut pas mettre les doigts dans une prise électrique. Nous savons que s’il pleut, nous serons mouillés. Dans les années 80-90, un grand projet de modélisation des connaissances, CYC2, initié par Doug Lenat, a tenté de développer une base de connaissances du sens commun, en stockant des millions de faits et règles élémentaires sur le monde. Ce projet n’a pas abouti, les systèmes d’IA actuels ne sont capables que de résoudre des problèmes très précis dans un contexte limité, ils ne savent pas sortir de leur domaine de compétence. Sans aller jusqu’à parler d’Intelligence Artificielle Générale (celle qui fait peur et qu’aucun spécialiste du domaine n’envisage réellement à un futur atteignable), faute de disposer de bases élémentaires faisant sens, les systèmes d’IA seront toujours susceptibles de faire des erreurs monumentales aux conséquences potentielles dommageables.
Il est très largement connu que les systèmes d’IA entraînés par apprentissage établissent des corrélations entre variables sans se soucier de causalité. Dans l’exemple référence du classement d’images de chats, le réseau établit une corrélation – complexe certes – sans lien de causalité entre les données d’entrées (les pixels de l’image) et la donnée de sortie (la catégorie). Il existe de nombreux exemples de corrélations « fallacieuses » (spurious correlations) comme dans celui-ci, tiré du site du même nom3 qui établit une corrélation à 79% entre le nombre de lancers de navettes spatiales et celui de doctorants en sociologie.
Un exemple de corrélation fallacieuse issues de https://www.tylervigen.com/spurious-correlations
Autrement dit, un système d’IA entraîne par apprentissage sera capable de reproduire cette relation et de prédire très correctement l’un à partir de l’autre. De même, on doit pouvoir décider si un jour est pluvieux à partir des ventes de parapluies, mais la causalité est évidemment dans l’autre sens. L’absence de prise en compte de la causalité dans les systèmes d’IA est une grande faiblesse: globalement, les systèmes d’apprentissage automatique se basent sur le passé pour faire des prédictions sur le futur, faisant implicitement l’hypothèse que la structure causale du système ne changera pas. On a vu les limites de cette hypothèse suite à la pandémie de Covid-19 qui a changé le comportement des populations: les outils d’IA intégrés dans les chaînes de décision des grandes entreprises, notamment financières, n‘étaient plus capables de représenter la réalité et ont dû être ré-entraînés sur des données plus récentes.
Il y a principalement deux manières de prendre en compte la causalité dans un système d’apprentissage automatique: le faire en injectant manuellement des connaissances sur le domaine d’intérêt, ou faire découvrir les liaisons causales à partir de données d’apprentissage4. Mais c’est très difficile: dans le premier cas, on revient aux problèmes des systèmes experts, avec les questions de cohérence des connaissances, de l’effort nécessaire pour les acquérir, et cela demande beaucoup de travail de configuration manuelle, à l’opposé de ce que l’on espère de l’apprentissage automatique; dans le deuxième cas, on ne sait traiter aujourd’hui que des exemples « jouets » à très peu de variables, en utilisant des « interventions », c’est à dire des actions connues qui font évoluer le système de l’extérieur. Lors de mon dernier échange à ce sujet avec Yoshua Bengio, dont c’est un des thèmes de recherche, il a parlé de quelques dizaines de variables, ce qui est déjà très encourageant. Mais si l’on ajoute les phénomènes de feedback, forcément présents dans les systèmes complexes, matérialisés par des boucles causales avec un contenu temporel, on ne sait plus le faire du tout.
Enfin, la troisième composante du mur de l’inhumanité est le passage au niveau du système 2. La très grande majorité des applications de l’IA consiste à (très bien) traiter un signal en entrée et à produire une réponse quasiment instantanée : reconnaissance d’objets ou de personnes dans des images et des vidéos ; reconnaissance de la parole ; association d’une réponse à une question, ou une traduction à une phrase ; estimation du risque financier associé à un client d’après ses données, etc. Dans son livre « Thinking, fast and slow », déjà cité, Daniel Kahneman s‘appuie sur des travaux en psychologie qui schématisent le fonctionnement de notre cerveau de deux manières différentes, qu’il nomme « Système 1 » et « Système 2 ». Système 1 est le mode rapide, proche de la perception : il ne vous faut qu’un instant pour reconnaître une émotion sur une photo, pour comprendre un mot ou une courte phrase. C’est Système 1 qui vous donne ces capacités. Par contre, si vous devez faire une multiplication compliquée et si vous n’êtes pas un calculateur prodige, vous devrez faire appel à du raisonnement pour donner le résultat. Les processus mentaux plus lents sont de la responsabilité de Système 2. Et les deux modes sont en permanente interaction, Système 1 fournit les éléments pré-traités à Système 2 qui peut conduire ses raisonnements dessus.
Cette théorie commence à inspirer les chercheurs en intelligence artificielle : aujourd’hui, avec l’apprentissage machine profond, l’IA est au niveau du Système 1. Pour pouvoir dépasser cela, représenter les connaissances de sens commun, faire de la planification, des raisonnements élaborés, il faudra coder le Système 2. Mais les avis diffèrent sur la manière d’y arriver : certains pensent qu’il suffit d’empiler des couches de neurones artificiels en organisant très finement leur architecture et leur communication ; d’autres pensent que des paradigmes différents de représentation de l’intelligence humaine seront nécessaires – par exemple en hybridant l’apprentissage machine avec le raisonnement symbolique utilisant des règles, des faits, des connaissances. Et il faudra aussi coder l’interaction continue entre Système 1 et Système 2. De beaux sujets de recherche pour les prochaines années, mais pour l’instant, un idéal encore bien lointain, même si des premiers exemples ont été réalisés sur des problèmes jouets comme l’a récemment montré Francesca Rossi d’IBM lors de la conférence AAAI-20225.
Il y a d’autres facteurs d’inhumanité dans l’IA (par exemple la question de l’émotion, de l’empathie, ou encore la réalisation de l’intelligence collective, sujets intéressants que je ne développe pas ici, considérant que les trois premiers constituent déjà un mur très solide sur lequel l’IA va inévitablement buter dans les prochaines années.
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Notes:
1Thinking, Fast and Slow; D. Kahneman, 2013, Farrar, Straus and Giroux;
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 4: le mur de l’interaction avec les humains
Cet épisode débute par des éléments développés par le programme confiance.ai dans son état de l’art sur les facteurs humains et la cognition1, établi mi-2021. Je remercie en particulier Christophe Alix (Thales), le coordonnateur de cet état de l’art sur un sujet clé pour notre futur avec les systèmes d’IA.
De très nombreux systèmes d’intelligence artificielle doivent interagir avec les humains; certains robots, notamment, et on pense en particulier aux véhicules autonomes; mais aussi les robots d’assistance aux personnes, les dialogueurs (chatbots), et plus généralement tous les systèmes qui ont besoin de communiquer avec leurs utilisateurs. Au-delà de ces fonctions de dialogue avec les humains, il y a tout le domaine de la cobotique, la collaboration étroite entre humains et robots, où la communication se fait en permanence dans les deux sens.
On peut classer ces applications en grandes catégories:
– dialogue (chatbots);
– résolution partagée de problèmes et de prise de décision;
– partage d’un espace et de ressources (cohabitation avec des robots qu’on ignore ou à qui on donne des ordres);
– partage de tâches (robot coéquipier).
Les machines intelligentes d’aujourd’hui sont essentiellement des outils, pas des coéquipiers. Au mieux, ces technologies sont utiles dans la mesure où elles étendent les capacités humaines, mais leurs compétences communicatives et cognitives sont encore inadéquates pour être uncoéquipier utile et de confiance. En effet, les machines collaboratives intelligentes doivent être flexibles et s’adapter aux états du coéquipier humain, ainsi qu’à l’environnement. Elles doivent comprendre les capacités et les intentions de l’utilisateur et s’y adapter.
Or, nous ne comprenons pas suffisamment la cognition, la motivation et le comportement social de haut niveau de l’être humain social. Les humains excellent dans l’apprentissage et la résolution de problèmes d’une manière qui diffère de celle des machines, même sophistiquées. La nature de l’intelligence humaine reste difficile à cerner. Même si d’importants efforts de recherche en sciences cognitives ont été consacrés à la compréhension de la façon dont les humains pensent, apprennent et agissent, dans les environnements naturels, la séquence d’actions qui mène à un objectif n’est pas explicitement indiquée, voire même la connaissance même des objectifs d’un humain reste complexe à appréhender. Stuart Russell a consacré un excellent ouvrage à ce sujet4, dans lequel il montre à quel point il est difficile pour un système d’IA de connaître les intentions d’un humain ou d’un groupe d’humains, et il propose que l’IA questionne systématiquement lorsqu’il y a ambiguïté.
Réciproquement, il est également indispensable de permettre aux collaborateurs humains de comprendre les buts et actions des machines avec lesquelles ils sont en interaction. Les machines ont souvent des caractéristiques physiques et des capacités très différentes de celles des humains, ce qui a un impact sur les rôles qu’elles peuvent jouer dans une équipe. Dans ce contexte, les besoins d’explications (qu’on nomme souvent « explicabilité ») de la part des systèmes d’intelligence artificielles sont cruciaux – ils font d’ailleurs l’objet d’une des mesures de la réglementation proposée par la Commission Européenne (déjà citée), ou encore du projet de référentiel concernant la certification du processus de développement de ces systèmes, développé par le Laboratoire National de Métrologie et d’Essais2. Mais les capacités d’explication des systèmes actuels d’IA sont très limitées, particulièrement lorsqu’il s’agit de réseaux neuronaux profonds dont les modèles internes sont composés de très grandes matrices de poids qu’il est difficile d’interpréter. J’en veux pour preuve les innombrables recherches sur l’explicabilité de l’IA, initialement popularisées par le programme « XAI » de la DARPA américaine lancé en 20173.
Il existe certes une tendance, illustrée par le propos de Yann LeCun ci-dessous, qui défend l’idée que l’explicabilité (causale notamment) n’est pas indispensable pour que les utilisateurs aient confiance envers un système, et qu’une campagne de tests couvrant le domaine d’utilisation suffit. Mais d’une part la dimension d’une telle campagne peut la rendre impossible à réaliser dans un temps imparti et avec des moyens finis; d’autre part il n’est pas toujours aisé de définir le domaine d’utilisation d’un système. Enfin, la plupart des cas pour lesquels nous n’avons pas besoin d’explications sont ceux où les systèmes disposent d’un autre mode de garantie; par exemple nous ne demandons pas nécessairement d’explications à un médecin qui nous prescrit un médicament, parce que nous savons que le médecin a été diplômé pour l’exercice de son métier après de longues études.
Reproduit de https://twitter.com/ylecun/status/1225122824039342081
L’interaction avec les humains peut prendre des formes diverses: parole, texte, graphiques, signes, etc. En tous cas elle n’est pas nécessairement sous forme de phrases. Un excellent exemple d’interaction que je trouve bien pensé, est celui d’une Tesla qui a l’intention de procéder à un dépassement: la voiture affiche la voie de gauche pour montrer qu’elle souhaite le faire, et le conducteur répond en activant le clignotant. Un problème plus général, illustré par le cas des véhicules autonomes4, est celui du transfert du contrôle, lorsque la machine reconnaît être dépassée (par exemple en cas de panne, de manque de visibilité etc.) et doit transférer le contrôle à un humain, qui a besoin de beaucoup de temps pour assimiler le contexte et pouvoir reprendre la main.
En résumé, l’interaction avec les humains est un sujet complexe et non résolu aujourd’hui; et il ne le sera pas de manière générale, mais plutôt application par application, comme dans l’exemple précédent.
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Notes :
1 « EC2 Human Factors and Cognition 2021 », C. Alix, B. Braunschweig, C.-M. Proum, A. Delaborde, 2021,document interne du projet confiance.ai, disponible sur demande
2 REFERENTIEL DE CERTIFICATION: Processus de conception, de développement,
d’évaluation et de maintien en conditions opérationnelles des intelligences artificielles. LNE, 2021.
4Dans la classification des niveaux d’autonomie pour le véhicule autonome, le niveau maximum 5 et celui de l’autonomie complète. Au niveau juste inférieur, 4, le véhicule gère presque toutes les situations mais rend la main dans des situations exceptionnelles, ce qui est extrêmement délicat à mettre en œuvre.
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 3: le mur de la sécurité
Les questions de sécurité des systèmes d’information ne sont pas propres à l’IA, mais les systèmes d’IA ont certaines particularités qui les rendent sensibles à des problèmes de sécurité d’un autre genre, et tout aussi importants.
Si les systèmes d’IA sont, comme tous les systèmes numériques, susceptibles d’être attaqués, piratés, compromis par des méthodes « usuelles » (intrusion, déchiffrage, virus, saturation etc.), ils possèdent des caractéristiques particulières qui les rendent particulièrement fragiles à d’autres types d’attaques plus spécifiques. Les attaques antagonistes ou adverses («adversarial attacks » en anglais) consistent à injecter des variations mineures des données d’entrée, lors de la phase d’inférence, afin de modifier de manière significative la sortie du système. Depuis le célèbre exemple du panneau STOP non reconnu lorsqu’il est taggé par des étiquettes, et celui du panda confondu avec un gibbon suite à l’ajout d’une composante de bruit, on sait qu’il est assez facile de composer une attaque de sorte à modifier très fortement l’interprétation des données faite par un réseau de neurones. Et cela ne concerne pas que les images: on peut concevoir des attaques antagonistes sur du signal temporel (audio en particulier), sur du texte, etc. Les conséquences d’une telle attaque peuvent être dramatiques, une mauvaise interprétation des données d’entrée peut conduire à une prise de décision dans le mauvais sens (par exemple, accélérer au lieu de s’arrêter, pour une voiture). Le rapport du NIST sur le sujet1 établit une intéressante taxonomie des attaques et défenses correspondantes. Il montre notamment que les attaques en phase d’inférence ne sont pas les seules qui font souci. Il est notamment possible de polluer les bases d’apprentissage avec des exemples antagonistes, ce qui compromet naturellement les systèmes entraînés à partir de ces bases. Bien évidemment la communauté de recherche en intelligence artificielle s’est saisie de la question et les travaux sur la détection des attaques antagonistes sont nombreux. Il est même conseillé d’inclure de telles attaques pendant l’apprentissage de manière à augmenter la robustesse des systèmes entraînés.
Panneau stop non reconnu et panda confondu avec un gibbon, extrait de publications usuelles sur ces sujets.
Toujours est-il que des accidents – aujourd’hui inévitables – sur des systèmes à risque ou critiques, causés par ces questions de sécurité, auront des conséquences extrêmement néfastes sur le développement de l’intelligence artificielle.
Un deuxième point d’attention est la question du respect de la vie privée. Cette question prend une dimension particulière avec les systèmes d’IA qui ont une grande capacité à révéler des données confidentielles de manière non désirée: par exemple retrouver les images individuelles d’une base d’entraînement dans les paramètres d’un réseau de neurones, ou opérer des recoupements sur diverses sources pour en déduire des informations sur une personne. Ces questions sont notamment à l’origine des travaux en apprentissage réparti (federated learning)2 dont le but est de réaliser un apprentissage global à partir de sources multiples réparties sur le réseau pour composer un modèle unique contenant, d’une certaine manière, une compression de toutes les données réparties mais sans pouvoir en retrouver l’origine.
Si l’on y ajoute les questions de sécurité « habituelles », ainsi que les problèmes multiples causés par les deepfakes, ces fausses images ou vidéos très facilement créées grâce à la technologie des réseaux génératifs antagonistes (GAN: generative adversarial networks), il est clair que le mur de la sécurité de l’IA est aujourd’hui suffisamment solide et proche pour qu’il soit essentiel de s’en protéger.
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 2: le mur de l’énergie
Cet épisode, consacré à la consommation énergétique des systèmes d’apprentissage profond, reprend en les approfondissant des éléments d’un billet que j’ai publié dans les pages sciences du journal Les Échos début 2020.
Le super-calculateur Jean Zay (du nom d’un fondateur du CNRS) est un des 3 sites nationaux pour le calcul haute performance. Grâce à ses milliers de processeurs de dernière génération il atteint aujourd’hui1 une puissance de 28 pétaflop/s (vingt-huit millions de milliards d’opérations arithmétiques par seconde). Refroidi par des circuits hydrauliques à eau chaude allant au cœur des processeurs, il ne consomme « que » environ deux mégawatts. Jean Zay est la première grande machine européenne « convergée » capable de fournir à la fois des services de calcul intensif (modélisation, simulation, optimisation) et des services pour l’intelligence artificielle et l’apprentissage profond. Elle va permettre des avancées majeures dans les domaines d’application du calcul intensif (climat, santé, énergie, mobilité, matériaux, astrophysique …), et de mettre au point des systèmes d’IA basés sur des très grands volumes de données. Mieux encore, la jonction de ces deux mondes (modélisation/simulation et apprentissage automatique) est porteuse de nouveaux concepts pour développer les systèmes intelligents de demain.
Oui, mais … Les chercheurs de l’université de Stanford publient annuellement l’édition du «AI Index» qui mesure la progression des technologies d’IA dans le monde. L’édition de fin 2019 présentait pour la première fois l’évolution des besoins de calcul des applications de l’IA qui ont suivi la loi de Moore (doublement tous les dix-huit mois) de 1960 à 2012. Depuis, ces besoins doublent tous les 3.5 mois ! La demande du plus gros système d’IA connu à l’époque (et qui a donc doublé plusieurs fois depuis) était de 1860 pétaflop/s*jours (un pétaflop/s pendant un jour) soit plus de deux mois de calcul s’il utilisait la totalité de la machine Jean Zay pour une consommation électrique de près de trois mille mégaWatts-heure. Pis encore, si le rythme actuel se poursuit, la demande sera encore multipliée par un facteur 1000 dans trois ans …. et un million dans six ans!
Provient de l’article de Strubell et coll cité dans le texte.
Le mur de l’énergie est bien identifié par certains chercheurs en apprentissage profond. L’article fondateur d’Emma Strubell et coll. 2 établissait que l’entraînement d’un grand réseau de neurones detraitement de la langue naturelle de type « transformer », avec optimisation de l’architecture du réseau, consommait autant d’énergie que cinq voitures particulières pendant toute leur durée de vie (ci-dessous).
`L’article de Neil Thompson et coll.3 allait plus loin en concluant que « les limites de calcul de l’apprentissage profond seront bientôt contraignantes pour toute une série d’applications, ce qui rendra impossible l’atteinte d’importantes étapes de référence si les trajectoires actuelles se maintiennent ». Encore une fois, souligné par les chiffres donnés par le AI Index qui insistait sur le facteur exponentiel correspondant. Fin 2021, Neil Thomson et coll. ont complété cette analyse4 sur l’exemple du traitement d’images (ImageNet) et abouti à estimer à 9 ce facteur entre la réduction du taux d’erreur et le besoin en calcul et données, ce qui signifie qu’une division par 2 du taux d’erreur nécessite 500 fois plus de calcul … et une division par 4 demanderait 250.000 fois plus.
On pourrait imaginer que cette croissance s’interrompra une fois que toutes les données disponibles (toutes les images, tous les textes, toutes les vidéos etc.) auront été utilisées par l’IA pour s’entraîner, mais le monde numérique n’est pas dans une phase de stabilisation du volume de données exploitables, sujet auquel vient s’ajouter, dans un autre registre, les limites en termes de stockage. Selon le cabinet IDC, la production mondiale de données atteindra 175 zettaoctets en 2025, pour une capacité de stockage limitée à une vingtaine de zettaoctets5. La croissance de la production de données est actuellement d’un ordre de grandeur plus rapide que la croissance de la capacité de stockage. Les programmes d’apprentissage automatique devront de plus en plus traiter des données en flux (et donc les oublier une fois le traitement effectué) faute de capacité de mémorisation de l’ensemble de la production.
Quoiqu’il en soit, le mur de la consommation énergétique liée aux besoins de calcul intensif des applications de l’IA basées sur l’apprentissage profond et consommatrices de très grandes quantités de données, en arrêtera inévitablement la croissance exponentielle, à terme relativement rapproché, si l’on ne fait rien pour y remédier.
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Notes :
1de nouveaux investissements de l’Etat français devraient encore accroître sa puissance
2E. Strubell, A. Ganesh, A. McCallum. Energy and Policy Considerations for Deep Learning in NL (2019), https://arxiv.org/abs/1906.02243v1
3N. Thompson et coll. The Computational Limits of Deep Learning (2020), arXiv:2007.05558v1
4N. Thompson et coll. Deep Learning Diminishing Returns. https://spectrum.ieee.org/deep-learning-computational-cost
En ce 8 mars 2022, quand bien même, compte tenu de l’actualité brulante, le monde ferait bien de se concentrer sur les droits des humains en général, il ne faut pas oublier cette parenthèse annuelle pendant laquelle il convient de se pencher plus particulièrement sur les droits des femmes. Anne-Marie Kermarrec nous propose aujourd’hui d’aborder le sujet du syndrome de l’imposteur. Serge Abiteboul & Marie-Agnès Enard
Un syndrome plutôt féminin
Qu’est-ce donc que ce troublant syndrome de l’imposteur, dont on entend de plus en plus parler et dont il semblerait que 70% des gens souffre à un moment ou à un autre de leur vie ?
Le terme du syndrome de l’imposteur a été introduit dès 1978 par deux psychologues Pauline Clance et Susanne Imes [1], suite à une étude qu’elles avaient mené sur 150 femmes diplômées, exerçant des métiers prestigieux et jouissant d’une excellente réputation. Pourtant ces femmes brillantes dont les compétences ne faisaient aucun doute avaient une fâcheuse tendance à se sous-estimer. Elles avaient souvent l’impression de ne pas être à leur place, de ressembler à une publicité mensongère, de ne considérer leur réussite que comme le fruit d’une accumulation de circonstances externes favorables dont le mérite ne leur revenait pas. Un état des lieux qui ne fait qu’entériner le manque de confiance en soi qu’il provoque. Il y a des degrés évidemment, et un large éventail de symptômes, qui va d’un moment de doute temporaire lié à une situation de stress, au sentiment très ancré de ne pas être à la hauteur qui relève de la vraie pathologie et peut parfois mener au surmenage, plus connu sous son nom anglo-saxon de burnout. Et les recettes courent le net pour le surmonter [2].
Puisqu’en ce 8 mars on s’intéresse aux femmes, doit-on systématiquement conjuguer le syndrome de l’imposteur au féminin ? Il se trouve que l’étude originelle ayant porté sur une cohorte exclusivement féminine, on a longtemps considéré que c’était effectivement l’apanage des femmes que d’en souffrir [3]. Pourtant, si elles en sont plus souvent victimes, beaucoup d’hommes y sont sujets également, du sportif au père de famille, de l’étudiant au dirigeant d’entreprise [4]. On peut même se tester en ligne d’ailleurs pour les amateurs. Quelle idée j’ai eu de le faire : mon score de 68% semble indiquer que j’en souffre fréquemment (à mon âge !).
Le numérique : un terrain fertile ?
Si cette exclusivité féminine est contestable, le syndrome se conjugue souvent au féminin. Et si évoluer dans le domaine du numérique augmentait significativement les risques et plus encore pour les femmes et plus encore dans le monde académique ? Si l’on en juge par les causes souvent évoquées, tout laisse à y penser. Quelle est la probabilité d’en souffrir quand on est une femme dans ce domaine aussi convoité par les hommes qu’ils y sont nombreux ? Revenons sur les coupables. Il est difficile d’accabler le domaine du numérique pour avoir subi une enfance difficile, être victime d’un caractère névrotique, ou d’être trop perfectionniste. Autant d’éléments qui participent de la probabilité d’apparition du syndrome de l’imposteur. Il n’en reste pas moins que le numérique exhibe certaines des caractéristiques qui engendrent le syndrome.
Photo de Daria Shevtsova provenant de Pexels
– La singularité
L’une des raisons les plus fréquemment mentionnées est le fait d’avoir une caractéristique différente de la majorité dans laquelle on évolue. Les statistiques stagnantes dans le domaine du numérique nous octroient indéniablement cette singularité que l’on soit l’une des 15% d’étudiantes dans sa promo, l’une des 10% de professeures dans son université ou encore l’une des seules femmes oratrice à une conférence et la seule de sa table à un diner d’affaire, celle qu’on ne manque jamais de prendre pour l’assistante. Si d’aucuns aiment à penser que faire partie de ces minorités est un privilège car ce statut nous rend unique et remarquable au sens littéral du terme, il est surtout souvent glaçant d’être la seule femme de l’assemblée. On sait d’ailleurs que les femmes qui ont eu la foi de s’engager dans les études d’informatique changent beaucoup plus souvent de voie que leurs homologues masculins, en partie car elles se sentent très différentes de leurs congénères. Alors, que celles qui restent persistent à penser qu’elles ne sont pas complètement à leur place, est-ce surprenant ?
– Les stéréotypes
Une autre cause souvent évoquée est celle des stéréotypes de genre solidement ancrés dans notre société. Ils multiplieraient par trois le syndrome de l’imposteur chez les femmes [3]. Les sciences dures de manière générale et l’informatique en particulier, encore malheureusement au 21ème siècle restent associés dans l’imaginaire collectif aux hommes, pire aux geeks. La société, parfois même la famille, ne voit pas la fluette Emma devenir le prochain Mark Zuckerberg. La brochette d’investisseurs qui s’apprête à octroyer quelques millions de dollars à la prochaine licorne préfèrerait les accorder à un trentenaire dynamique avec sa barbe de trois jours qui promet de révolutionner la deep tech, qu’à l’étudiante brillante qui malgré son idée de génie est une femme qui aura probablement du mal à s’affirmer, à négocier ou encore à diriger efficacement une entreprise. Celles qui se fraient un chemin dans ce monde masculin du numérique ont toujours une petite part de leur cerveau qui trouve étrange d’avoir réussi dans un domaine où elles étaient si peu attendues.
– La compétition
Un environnement professionnel très compétitif augmente indéniablement les risques de souffrir du fameux syndrome. Le domaine du numérique est en croissance exponentielle et à ce titre attire le monde entier dans ses filets. Terreau parfait pour en faire un terrain de jeu ultra-compétitif : qui aura la prochaine idée de génie pour l’application de l’année, qui va révolutionner l’intelligence artificielle, qui créera une blockchain peu gourmande en énergie ? Si on ajoute à la recette, quelques ingrédients propres au monde académique, il faut avoir un tempérament solide pour se frayer un chemin vers les sommets : la sélectivité des conférences et revues dans lesquelles nous publions nos travaux, la férocité des évaluations, la compétition internationale, le niveau indécent demandé aux jeunes docteurs pour décrocher un poste dans le monde académique, tout ça conjugué aux doutes constants auxquels les chercheurs sont soumis, eux qui passent leurs temps à s’acharner sur des problèmes que personne n’a encore résolu. Alors si un milieu très exigeant augmente les risques de succomber à ce syndrome, le numérique, qui plus est académique, coche toutes les cases.
Souffrir du syndrome de l’imposteur est un sentiment qui, dans le meilleur des cas est désagréable, handicapant dans le pire. Alors même que nous redoublons d’imagination pour attirer les femmes dans le numérique à tous les niveaux, à coup de discrimination positive, de postes fléchés, de ratios de femmes à atteindre dans les écoles, universités et entreprises, il s’agit d’être vigilant sur les messages qui accompagnent ces honorables mesures, qui pourtant commencent à porter leurs fruits. Il ne s’agirait pas que cela renforce le manque de légitimité auquel font encore trop souvent face les femmes du numérique. Plus que jamais attelons-nous à éradiquer les clichés de genre.
Anne-Marie Kermarrec (Professeur à l’EPFL)
[1] Clance, P.R., & Imes, S.A. (1978). The Impostor Phenomenon in High Achieving Women: Dynamics and Therapeutic Interventions. Psychotherapy: Theory Research and Practice, 15, 241‑247
Mais jusqu’où ira l’intelligence artificielle à la vitesse avec laquelle elle fonce ? Et bien … peut-être dans le mur ! C’est l’analyse qu’en fait Bertrand Braunschweig, qui s’intéresse justement à ces aspects de confiance liés à l’IA. Donnons lui la parole pour une réflexion détaillée interactive en six épisodes. Pascal Guitton et Thierry Viéville.
Episode 1 : introduction générale, et le premier mur.
L’intelligence artificielle progresse à un rythme très rapide tant sur le plan de la recherche que sur celui des applications et pose des questions de société auxquelles toutes les réponses sont loin d’être données. Mais en avançant rapidement, elle fonce sur ce que j’appelle les cinq murs de l’IA, des murs sur lesquels elle est susceptible de se fracasser si l’on ne prend pas de précautions. N’importe lequel de ces cinq murs est en mesure de mettre un terme à sa progression, c’est pour cette raison qu’il est essentiel d’en connaître la nature et de chercher à apporter des réponses afin d’éviter le fameux troisième hiver de l’IA, hiver qui ferait suite aux deux premiers des années 197x et 199x au cours desquels la recherche et le développement de l’IA se sont quasiment arrêtés faute de budget et d’intérêt de la communauté.
Les cinq murs sont ceux de la confiance, de l’énergie, de la sécurité, de l’interaction avec les humains et de l’inhumanité. Ils contiennent chacun un certain nombre de ramifications, et sont bien évidemment en interaction, je vais toutefois les présenter de manière séquentielle, en cinq épisodes. Le sixième épisode examinera quelques pistes pour éviter une issue fatale pour l’IA.
Ce texte se veut un outil de réflexion pour le lecteur, il est destiné à susciter des commentaires et réactions que ce soit sur la réalité de ces murs, sur la complétude de mon analyse, ou sur la manière d’échapper à l’écrasement sur l’un de ces murs. Je précise cependant qu’il y a d’autres facteurs, non technologiques, qui mettent en cause l’avenir de l’IA, et que je ne traite pas dans cette série. Ainsi, par exemple, la pénurie de chercheurs, ingénieurs, techniciens capables de développer et de mettre en oeuvre les technologies d’IA est très bien identifiée ; elle se matérialise par les salaires élevés qui sont versés à celles et ceux qui affichent l’IA comme spécialité, et par la mise en place de nombreux programmes de formation qui, à terme, devraient permettre de revenir à une situation normale en la matière, l’offre rejoignant la demande. Il ne manque pas non plus de démarches gouvernementales, collectives, associatives et autres pour réglementer et gouverner l’IA, je n’aborderai pas ces aspects ici. Je recommande plutôt de s’intéresser aux travaux du Partenariat Mondial sur l’Intelligence Artificielle (GPAI en anglais) qui rassemble nombre d’experts de disciplines, d’origines et de cultures différentes sur les sujets de société autour de l’IA.
Je reconnais également qu’il y a des avis différents à ce sujet. Par exemple, l’article « Deep learning for AI » de Yoshua Bengio, Yann LeCun et Geoffrey Hinton1, rédigé suite à leur prix Turing collectif, donne des pistes pour l’avenir de l’AI par l’apprentissage profond et les réseaux neuronaux sans aborder les mêmes sujets; le rapport d’étape 2021 de l’étude longitudinale sur cent ans de Stanford2 examine les avancées de l’IA à ce jour et présente des défis pour le futur, très complémentaires à ceux que j’aborde ici; le récent livre de César Hidalgo, chaire de l’institut 3IA ANITI à Toulouse, « How Humans Judge Machines »3 s’intéresse à la perception de l’IA (et des machines) par les humains; l’ouvrage « Human Compatible »4 de Stuart Russell, professeur à Berkeley et auteur du principal livre de cours sur l’IA depuis deux décennies, s’intéresse à la compatibilité entre machines et humains, sujet que je traite différemment quand je parle du mur de l’interaction; enfin, la publication que j’ai co-éditée en 2021 avec Malik Ghallab, « Reflections on Artificial Intelligence for Humanity »5 aborde dans ses quatorze chapitres divers aspects de l’avenir de l’IA, notamment sur le futur du travail, la prise de décision par les machines, les questions de réglementation, d’éthique, de biais etc.
Dans ce premier épisode je m’intéresse au mur de la confiance, un sujet particulièrement mis en exergue depuis quelques années.
La confiance
Dialogue entre Lonia, le chatbot de la banque et Y, qui a demandé un crédit. Y: est-ce que mon prêt a été accordé ? Lonia: non. Y: peux-tu me dire pourquoi mon prêt n‘a pas été accordé? Lonia: non Y: mais, pourquoi ne peux-tu pas me dire pourquoi mon prêt n’a pas été accordé? Lonia: parce que je suis une intelligence artificielle, entraînée à partir de données de crédits passés, et je ne sais pas produire d’explications. Y: c’est bien dommage! Mais peux-tu au moins prouver que ta décision est la bonne? Lonia: Non, on ne peut pas prouver les conclusions établies par des IA entraînées par apprentissage à partir de données. Y: ah, bon. Mais, alors, as-tu été certifiée pour le travail que tu fais? As-tu un quelconque label de qualité? Lonia: Non, il n’existe pas de normes pour les IA entraînées par apprentissage, il n’y a pas de certification. Y: Merci pour tout cela. Au revoir, je change de banque.
Bien évidemment, derrière ce dialogue imaginaire, c’est la question de la confiance qui est posée. Et cela ne concerne pas que le domaine financier, par exemple le même échange pourrait avoir lieu au sujet d’un diagnostic médical pour lequel la machine ne pourrait fournir ni garanties ni explications. Si les personnes n’ont pas confiance envers les systèmes qu’IA avec lesquels ils interagissent, ils les rejetteront. Il y a largement de quoi causer un troisième hiver de l’IA !
La confiance est une notion riche et multi-factorielle, beaucoup de sociologues et de technologues se sont intéressés aux mécanismes de son établissement. Plusieurs organismes tentent de fournir des définitions de ce qu’est la confiance envers les systèmes d’intelligence artificielle, elle a été le sujet principal du groupe d’experts mobilisés par la Commission Européenne (dont tous les travaux6 se font dans l’optique « trustworthy AI »). L’organisation internationale de normalisation, ISO, considère une vingtaine de facteurs différents, avec des ramifications.
Je résumerai ici en disant que la confiance, en particulier envers les artefacts numériques dont l’IA fait partie, est une combinaison de facteurs technologiques et sociologiques. Technologiques, comme la capacité de vérifier la justesse d’une conclusion, la robustesse à des perturbations, le traitement de l’incertitude etc. Sociologiques, comme la validation par des pairs, la réputation dans les réseaux sociaux, l’attribution d’un label par un tiers de confiance etc. Les questions d’interaction avec les utilisateurs sont intermédiaires entre ces deux types de facteurs: transparence, explicabilité, qualité des interactions de manière plus générale.
Les facteurs sociologiques ne sont pas propres à l’IA: dans un réseau de confiance entre humains, la transmission de la confiance ne fait pas nécessairement appel aux facteurs technologiques. Par contre, la base technologique de la confiance en IA est bien spécifique et pose de nombreux défis. On ne sait pas, aujourd’hui, prouver que les conclusions d’un système entraîné par apprentissage sur une base de données sont les bonnes, qu’elles sont robustes à des petites variations, qu’elles ne sont pas entachées de biais etc. Il existe de nombreux programmes de R&D à ce sujet, dont un des plus importants est l’initiative Confiance.ai7centrée sur les systèmes critiques (transport, défense, énergie, industrie) portée par de grands groupes industriels dans le cadre du Grand Défi sur la fiabilisation et la certification de l’IA.
Tant que cette question restera ouverte, le risque pour l’IA de se heurter au mur de la confiance sera majeur. Il le sera encore plus pour les systèmes à risque (au sens de la Commission Européenne dans sa proposition de réglementation de l’IA8) et pour les systèmes critiques (au sens du programme Confiance.ai).
Bertrand Braunschweig a été en charge pour Inria de la stratégie nationale de recherche en intelligence artificielle, il est aujourd’hui consultant indépendant et coordonnateur scientifique du programme Confiance.ai.
Notes :
1 Deep Learning for AI. Yoshua Bengio, Yann Lecun, Geoffrey Hinton Communications of the ACM, July 2021, Vol. 64 No. 7, Pages 58-65
2 Michael L. Littman, Ifeoma Ajunwa, Guy Berger, Craig Boutilier, Morgan Currie, Finale Doshi-Velez, GillianHadfield, Michael C. Horowitz, Charles Isbell, Hiroaki Kitano, Karen Levy, Terah Lyons, Melanie Mitchell, JulieShah, Steven Sloman, Shannon Vallor, and Toby Walsh. “Gathering Strength, Gathering Storms: The One HundredYear Study on Artificial Intelligence (AI100) 2021 Study Panel Report.” Stanford University, Stanford, CA, September2021. Doc: http://ai100.stanford.edu/2021-report. Accessed: September 16, 2021.
Comment les sceptiques du COVID-19 utilisent-ils les données épidémiologiques sur les réseaux sociaux pour militer contre le port du masque et autres mesures de santé publique ? Dans cet article, Crystal Lee partage le résultat d’une enquête sur les groupes de réseaux sociaux des sceptiques du COVID afin de démêler leurs pratiques d’analyse de données et leur tentative de création de sens. Lonni Besançon
Image 1 : un utilisateur de résaux sociaux présentant son analyse et ses doutes sur les données officielles américaine
Vous avez probablement assisté à une version de cette conversation au cours des derniers mois : un proche refuse de se faire vacciner ou affirme que l’épidémie de COVID est complètement exagérée, en pointant du doigt les dernières recherches lues sur Facebook. « Oui, moi je suis réellement la science », affirme-t-il. « Vous devriez faire pareil ». S’il est tentant d’écarter ces messages et conversations sur les médias sociaux comme étant simplement non scientifiques et nécessitant juste un rectificatif, une étude de six mois que j’ai menée avec une équipe de chercheurs du MIT suggère qu’une vision simpliste et binaire de la science – les chercheurs universitaires sont scientifiques, les messages Facebook ne le sont pas – nous empêche de vraiment comprendre l’accroche que génère ces groupes anti-masques. Bien que nous n’approuvions pas, ni ne cherchions à légitimer ces croyances, notre étude montre comment les utilisateurs de forums en ligne exploitent et détournent les compétences et les concepts qui sont les marqueurs de la démarche scientifique traditionnelle pour s’opposer à des mesures de santé publique telles que l’obligation de porter un masque ou l’interdiction de manger à l’intérieur d’une restaurant. Nombre de ces groupes utilisent activement des visualisations de données pour contredire celles des journaux et des organismes de santé publique, et il est souvent difficile de concilier ces discussions autour des données (voir image 1). Ces utilisateurs prétendent utiliser des méthodes scientifiques conventionnelles pour analyser et interpréter les données de santé publique ;comment se fait-il qu’ils arrivent à des conclusions totalement différentes de la majorité des scientifiques et experts de santé publique ? Qu’est-ce que « la science » telle que voudrait la définir ces groupes ?
Image 2 : un utilisateur montrant ses doutes sur l’origine des données.
Pour répondre à cette question, nous avons mené une analyse quantitative d’un demi-million de tweets et de plus de 41 000 visualisations de données parallèlement à une étude ethnographique des groupes Facebook anti-masques [1]. Ce faisant, nous avons catalogué une série de pratiques qui sont à la base des argumentations courantes contre les recommandations de santé publique, et beaucoup sont liées à des compétences que les chercheurs pourraient enseigner à leurs étudiants. En particulier, les groupes anti-masque sont critiques à l’égard des sources de données utilisées pour réaliser des visualisations dans les articles basés sur les données (voir images 1 et 2). Ils s’engagent souvent dans de longues conversations sur les limites des données imparfaites, en particulier dans un pays où les tests ont été ponctuels et inefficaces. Par exemple, beaucoup affirment que les taux d’infection sont artificiellement élevés, car au début de la pandémie, les hôpitaux ne testaient que les personnes symptomatiques. Ils arguent que le fait de tester aussi les personnes asymptomatiques ferait baisser cette statistique. De plus, comme les personnes asymptomatiques ne sont par définition pas physiquement affectées par le virus, cela permet aux personnes qui utilisent cet argumentation de conclure que la pandémie n’est quasiment pas mortelle.
Ces militants anti-masque en déduisent donc que des statistiques peu fiables ne peuvent pas servir de base à des politiques néfastes, qui isolent davantage les gens et conduisent les entreprises à s’effondrer de façon massive. Au lieu d’accepter telles quelles les conclusions des médias d’information ou des organisations gouvernementales, ces groupes affirment que comprendre comment ces mesures sont calculées et interprétées est le seul moyen d’accéder à la vérité sans fard. En fait, pour découvrir ces histoires cachées, certains ont délibérément évité les visualisations au profit des tableaux, qu’ils considèrent comme la forme de données la plus « brute » et la moins médiatisée. Pour nombre de ces groupes, il est essentiel de suivre la science pour prendre des décisions éclairées, mais selon eux, les données ne justifient tout simplement pas les mesures de santé publique telles que le port du masque (voir image 3).
Image 3 : un utilisateur utilisant les données de la Suède pour dire que les interventions gouvernementale ne sont pas justifiées.
Que disent donc les utilisateurs de masques à propos des données ? De mars à septembre 2020, nous avons mené une étude de type « deep lurking » (observation profonde) de ces groupes Facebook – basée sur la méthode de « deep hanging out » (immersion profonde) de l’anthropologue Clifford Geertz – en suivant les fils de commentaires, en archivant les images partagées et en regardant les flux en direct où les membres animent des tutoriels sur l’accès et l’analyse des données de santé publique.
Les anti-masques sont parfaitement conscients que les organisations politiques et d’information dominantes utilisent des données pour souligner l’urgence de la pandémie. Eux, pensent que ces sources de données et ces visualisations sont fondamentalement erronées et cherchent à contrecarrer ce qu »ils considèrent comme des biais. Leurs discussions reflètent une méfiance fondamentale à l’égard des institutions publiques : les anti-masques estiment que l’incohérence dans la manière dont les données sont collectées (image 4, surlignage jaune) et l’incessante propagande alarmiste rendent difficile la prise de décisions rationnelles et scientifiques. Ils pensent également que les données ne soutiennent pas les politiques gouvernementales actuelles (image 4, surlignage bleu).
Image 4 : conversations mettant en avant les doutes sur la façon dont les données sont collectées (surlignage jaune) et sur le fait que les données ne soutiennent pas les politiques gouvernementales actuelles (surlignage bleu).
Alors comment ces groupes s’écartent-ils de l’orthodoxie scientifique s’ils utilisent les mêmes données ? Nous avons identifié quelques tours de passe-passe qui contribuent à la crise épistémologique plus large que nous identifions entre ces groupes et la majorité des chercheurs. Par exemple, les utilisateurs anti-masque soutiennent que l’on accorde une importance démesurée aux décès par rapport aux cas recensés : si les ensembles de données actuels sont fondamentalement subjectifs et sujets à manipulation (par exemple, l’augmentation des niveaux de tests erronés), alors les décès sont les seuls marqueurs fiables de la gravité de la pandémie. Même dans ce cas, ces groupes pensent que les décès constituent une catégorie supplémentaire problématique car les médecins utilisent le diagnostic du COVID comme principale cause de décès (c’est-à-dire les personnes qui meurent à cause du COVID) alors qu’en réalité d’autres facteurs entrent en jeu (c’est-à-dire les personnes contaminées qui meurent de co-morbidité avec, mais pas à cause directement, du COVID). Puisque ces catégories sont sujettes à l’interprétation humaine, en particulier par ceux qui ont un intérêt direct à rapporter autant de décès dus au COVID que possible, ces chiffres sont largement « surdéclarés », peu fiables et pas plus significatifs que la grippe, pensent leurs détracteurs.
Plus fondamentalement, les groupes anti-masque se méfient de la communauté scientifique parce qu’ils croient que la science a été corrompue par des motivations liée au profit et par des politiques soi-disant progressistes mais en fait déterminées à accroître le contrôle social. Les fabricants de tabac, affirment-ils à juste titre, ont toujours financé des travaux scientifiques qui ont induit le public en erreur sur la question de savoir si le fait de fumer provoquait ou non le cancer. Ils pensent donc que les sociétés pharmaceutiques sont dans une situation similaire : des sociétés comme Moderna et Pfizer vont tirer des milliards de bénéfices du vaccin, et il est donc dans leur intérêt de maintenir un sentiment d’urgence sanitaire et publique quant aux effets de la pandémie, affirment-ils. En raison de ces incitations, ces groupes soutiennent que ces données doivent faire l’objet d’un examen supplémentaire et être considérées comme fondamentalement suspectes. Pour les scientifiques et les chercheurs, affirmer que les anti-masques ont simplement besoin d’une plus grande culture scientifique, alors que justement ils s’appuient dessus et la manipule, offre aux antimasques une preuve supplémentaire de l’impulsion de l’élite scientifique à condescendre aux citoyens qui épousent réellement le bon sens.
Quelle solution s’offre alors pour éviter ces problèmes?
Mieux rendre visible l’exemplarité : la communauté scientifique doit toujours travailler dans un vrai esprit éthique et de transparence [2], elle le fait (sauf exceptions rares et sanctionnées) mais ne montre probablement pas assez cet esprit éthique, il faudrait le ré-affirmer plus.
Bien rendre visible le doute : nombre de scientifiques ont aussi dit par rapport aux données du COVID « ça nous ne savons pas ou ne sommes pas sûrs´´ mais le traitement par les médias de ces incertitudes est souvent biaisée, c’est moins médiatique de dire « peut-être » que d’affirmer une chose … puis son contraire.
Aider à développer l’esprit critique : envers à la fois la science académique et les interprétations anti-scientifiques qui en sont faites. Développer l’esprit critique n’est pas dire qui a raison ou tort mais aider chacune et chacun à faire la part des faits de celles des croyances, à évaluer et déconstruire les arguments, non pas pour le rejeter systématiquement, mais pour en comprendre les origines.
Les données scientifiques de cette pandémie et leurs interprétations largement médiatisées pourraient être une occasion de mieux comprendre collectivement la démarche scientifique avec sa force, ses limites et ses dévoiements.
[2] Besançon, L., Peiffer-Smadja, N., Segalas, C. et al. Open science saves lives: lessons from the COVID-19 pandemic. BMC Med Res Methodol 21, 117 (2021). https://doi.org/10.1186/s12874-021-01304-y
Les sites de réseaux sociaux tels Facebook, Twitter, Youtube, LinkediIn, etc., reposent sur une panoplie de techniques mises au point par la science et l’ingénierie informatique. Pour les découvrir, commençons par une balade de l’utilisateur jusqu’aux data centers, ou centres de données.
De l’utilisateur aux data centers
Pour accéder à un réseau social, l’utilisateur utilise un ordinateur (ordinateur de bureau, ordinateur portable, ou, de plus en plus souvent, un de ces mini-ordinateurs que sont les smartphones). L’utilisateur se sert d’une interface graphique (site Web ou application pour smartphone) pour accéder aux services du réseau social. Cette interface lui permet de consulter, concevoir, ou réagir à des contenus, et bien plus encore. Suivant les réseaux sociaux, l’accès à tout ou partie du contenu est protégé par une phase d’authentification.
L’épine dorsale du système est le réseau mondial de communication Internet et des protocoles de communication tels que HTTPS, utilisés pour contacter et échanger des informations entre l’ordinateur de l’utilisateur et les ordinateurs hébergeant le réseau social. HTTPS est un protocole chiffré de bout en bout, garantissant que ces échanges ne puissent être interceptés ou modifiés. Pour améliorer la vitesse d’accès aux données, celles-ci sont également comprimées : avec en général un algorithme de compression générique tel que LZ77 pour le texte, et dans des formats de compression spécialisés pour les contenus multimédias (par exemple, JPEG pour les photos).
Les réseaux sociaux sont souvent développés par de grandes entreprises américaines. Pour les utilisateurs européens, ces entreprises ont implanté des centres de données en Europe, contenant une copie des mêmes données, afin de pouvoir les fournir plus rapidement. Cette affectation des clients à un centre de données en fonction de leur emplacement géographique peut par exemple se faire via le système de noms de domaine, DNS, qui transforme un nom comme twitter.com en une adresse de la machine à contacter sur le réseau Internet.
Les centres de données peuvent regrouper des centaines ou milliers d’ordinateurs dédiés à fournir des services (des serveurs, donc), qui, eux-mêmes hébergent les composants logiciels et les données du réseau social : cela représente, pour les plus populaires des réseaux sociaux, potentiellement des millions de lignes de code, des pétaoctets de données (un pétaoctet, c’est de l’ordre de millions de fois ce que peut contenir un disque dur classique) et de gigantesques puissances de calcul. Au cœur de ces systèmes, on trouve des bases de données qui stockent les contenus produits par les utilisateurs, mais également des données acquises sur ces utilisateurs, leur profil, leur historique de consultation, des données de personnalisation des services, etc. Grâce à un récent règlement européen (RGPD, article 20), les sites de réseaux sociaux doivent tous fournir un mécanisme (souvent accessibles dans les options du site) pour qu’un utilisateur récupère l’ensemble des données qui le concernent.
La recommandation et la recherche d’information
Une fonction des réseaux sociaux est la sélection et le classement des contenus destinés à un utilisateur particulier. Parmi tous les contenus qui ont été publiés, le système doit choisir lesquels présenter en premier à chacun. Comme l’attention de l’utilisateur est la valeur essentielle pour que cet utilisateur reste et revienne sur un site, cette fonction de classement est primordiale pour le réseau. Chaque réseau décide de sa propre fonction selon ses particularités, ses intérêts commerciaux, ses choix éditoriaux, etc.
Les paramètres utilisés sont nombreux, mais intègrent généralement tout ou partie des composants suivants : (i) l’origine du contenu, un contenu d’un « ami » ayant plus de valeur ; (ii) la fraîcheur, un contenu récent étant plus prometteur ; (iii) la popularité, un contenu très partagé étant préféré ; (iv) la nature, un contenu plus long ou intégrant une vidéo pouvant être préféré ; (v) les intérêts de l’utilisateur, explicitement décrits par une requête ou inférés de son historique de consultation ; (vi) sa localisation, un commerce de proximité étant plus pertinent qu’un autre situé au bout du monde ; et surtout (vii) l’intérêt commercial du service, les contenus sponsorisés ou que le service monétise plus facilement étant prioritaires. On peut facilement imaginer la difficulté à sélectionner les bons paramètres et ce, en ne mobilisant qu’un volume raisonnable de calculs, car le système doit produire un tel classement pour chaque utilisateur en un temps très bref. Les réseaux sociaux communiquent en général très peu sur cette fonction qui est pourtant clé pour comprendre comment les contenus sont poussés.
La publicité
La publicité est le revenu principal, voir quasi-exclusif, de la plupart des sites de réseaux sociaux (en 2019, par exemple, 98,5 % du chiffre d’affaires de 71 milliards de dollars de Facebook proviennent de la publicité). C’est l’objet d’une partie importante de leurs logiciels. Les véritables clients des réseaux sociaux ainsi monétisés, ce sont les entreprises qui achètent des espaces publicitaires, pas les utilisateurs pour qui les services sont en général gratuits. Les réseaux sociaux proposent à ces clients toute une palette d’outils de marketing : photos, vidéos, diaporama, etc. Ils leurs fournissent également des outils pour cibler des segments du marché, par exemple les hommes de 30 à 35 ans vivant en région bordelaise et s’intéressant à l’haltérophilie, et pour analyser l’efficacité des campagnes de pub. Chaque réseau social essaie de se distinguer par des modes de publicité différents, et bien sûr par son public.
Les publicités sont choisies pour les réseaux sociaux les plus importants à partir de systèmes sophistiqués d’enchères. Quand nous sommes sur un des réseaux les plus populaires et qu’un message publicitaire nous est présenté, ce n’est pas par hasard, mais le résultat d’une vente aux enchères qui a eu lieu en une fraction de seconde. Les annonceurs ont placé au préalable des propositions de publicité en définissant leurs objectifs et leurs budgets. Le gagnant pour ce message publicitaire spécifique sera le message qui maximise une certaine valeur qui tient compte à la fois du budget de l’annonceur (ce qu’il est prêt à payer) et de l’impact estimé (comme la probabilité que l’utilisateur clique sur un lien). Le paiement peut se faire au nombre de « clics » ou même d’achats que l’annonce va générer. Des milliards de telles ventes aux enchères ont lieu chaque jour sur les réseaux sociaux, et sur l’ensemble du Web.
La modération
Avec la montée en puissance du ressentiment des utilisateurs contre les contenus toxiques, messages de haine, fakenews, etc., la détection algorithmique de tels contenus a pris une grande place dans les logiciels des réseaux sociaux. Dans certains cas comme les contenus terroristes, une détection algorithmique est indispensable pour réagir quasi-instantanément ce que le recours à des modérateurs humains ne permet pas. Avec la crise du Covid-19, une partie de ces modérateurs humains se sont retrouvés au chômage quand les centres de modération ont fermé et que le télétravail était impossible pour des questions de protection des données personnelles, RGPD oblige. En temps normal, les modérations humaines et algorithmiques collaborent souvent dans les réseaux sociaux, la décision de bloquer un contenu détecté comme nocif par un algorithme étant, sauf rares exceptions, systématiquement soumise à une validation humaine.
Selon des sources non officielles d’ingénieurs de réseaux sociaux, la détection de contenus nocifs serait de « moins mauvaise » qualité par les algorithmes que par des humains. On peut imaginer que les algorithmes continueront à s’améliorer. Reste que le problème est très complexe. Par exemple, pour le texte, il faut gérer l’humour, l’ironie, l’argot… et surtout l’ambiguïté et la complexité de la langue. Les algorithmes ont aussi difficilement accès au contexte qui peut faire que la même expression peut prendre des sens différents selon qu’elle est utilisée par un homophobe patenté ou par un militant LGBT. Enfin, en dehors des temps de crise, une modération purement algorithmique serait-elle acceptable pour les citoyens ? Cela ne serait certainement pas le cas si les algorithmes sont opaques, décidés de façon autoritaire et unilatérale par le réseau social (entendre ici l’entreprise) sans être discutés par le réseau social (entendre ici le réseau des utilisateurs). Un vrai sujet est bien la participation de la société à la conception des algorithmes et des règles qui les guident.
Big data et apprentissage
Les algorithmes les plus sophistiqués posent des problèmes particuliers. C’est le cas de l’analyse de données massives (big data) souvent à la base des recommandations. Par exemple, un service de vidéo à la demande utilise le big data pour découvrir des proximités de goût entre des utilisateurs, ce qui lui sert pour suggérer des films à ses clients. C’est aussi le cas de l’apprentissage automatique qu’on utilise quand on ne sait pas décrire pas à pas un algorithme qui résolve un problème particulier, mais qu’on a des exemples de résultats attendus. On utilise alors un algorithme d’apprentissage. L’algorithme utilise un corpus d’instances du problème posé et les réponses humaines qui y ont été apportées, comme par exemple un corpus de contenus et leurs classements par des modérateurs humains : message de haine, harcèlement, pornographie, etc. Quand on lui donne un nouveau contenu, l’algorithme d’apprentissage va rechercher les contenus du corpus qui s’en approchent le plus et proposer un classement en se basant sur les choix que des humains ont faits pour ces contenus. On voit bien que, dans les deux cas, big data et apprentissage, la qualité des résultats va dépendre de façon critique de la qualité des données. Dans le cas de l’apprentissage automatique, une difficulté supplémentaire est que la technologie actuelle ne permet pas d’expliquer les résultats.
Vérification et analyse des biais
Comment savoir ce qui se passe dans les logiciels des réseaux sociaux, souvent d’une réelle complexité et le plus souvent d’une totale opacité ? De telles analyses sont essentielles, par exemple, si on veut vérifier que le réseau social ne discrimine pas entre ses utilisateurs pour les offres d’emploi qu’il leur propose, ou qu’il ne promeut pas les contenus les plus extrêmes au détriment d’autres plus équilibrés mais moins « sexy ».
Pour analyser une fonctionnalité de réseau social, on peut le faire de l’extérieur, en mode « boîte noire ». Cela consiste à l’étudier comme un phénomène complexe, comme on étudie le climat ou le cœur humain. Pour mettre en évidence une discrimination basée sur le genre, on peut par exemple (et ce n’est pas simple), créer deux profils quasi-identiques sauf pour une variable (l’un d’une femme, l’autre d’un homme) et observer les différences de recommandations.
On peut aller plus loin si on a accès au code, voire aux données d’entraînement dans le cas d’algorithmes d’apprentissage automatique, en réalisant en interne un « audit » du système.
Que l’on soit dans l’analyse en boîte noire ou dans l’audit, il s’agit de vérifier si le logiciel respecte les lois (légalité), s’il est conforme aux déclarations du réseau social (loyauté), et s’il ne nuit pas à la société (responsabilité).
Conclusion
Nous avons vu la diversité des techniques et disciplines informatiques convoquées par les réseaux sociaux les plus populaires (réseaux, algorithmique, systèmes distribués, gestion de données, recherche d’information, apprentissage automatique, vérification, etc.). Il faut insister sur l’utilisation de la distribution des calculs entre l’ordinateur de l’utilisateur, et ceux de souvent plusieurs data centers. C’est encore plus vrai pour des réseaux sociaux décentralisés comme Mastondon, dont le logiciel est libre ; dans ce système, différentes instances du logiciel interopèrent (fonctionnent ensemble) pour offrir collectivement les fonctionnalités d’un réseau social. Les principes des réseaux sociaux se retrouvent également dans des luttes citoyennes en mode « sous-marin » sur les réseaux traditionnels, ou cachées sur le dark web. Elles peuvent alors s’appuyer sur une technique que nous n’avons pas encore rencontrée ici, la blockchain, c’est-à-dire un grand registre géré de manière distribuée basé sur la cryptographie.
Les outils numériques permettent la diffusion des connaissances et des contacts riches entre les internautes. Ils ont aussi permis le développement de comportements toxiques comme les fakenews ou les messages de haine sur les réseaux sociaux. Des chercheurs spécialisés en traitement automatique du langage naturel de l’Université Côte d’Azur nous parlent ici de nouvelles technologies qu’ils développent pour lutter contre un autre mal des réseaux sociaux, le cyberharcèlement. Tamara Rezk, Serge Abiteboul
Le cyberharcèlement est une forme d’intimidation perpétrée par des moyens électroniques. Ce type de harcèlement est en croissance constante, en particulier du fait de la propagation d’Internet et des appareils mobiles chez les jeunes. En 2016, un million d’adolescents ont été harcelés, menacés ou soumis à d’autres formes de harcèlement en ligne uniquement sur Facebook. On estime qu’environ 70 % des victimes de harcèlement classique ont également subi des épisodes via des canaux virtuels. On sait maintenant que le cyberharcèlement peut conduire les victimes à la dépression, nuire à leur santé mentale, ou augmenter leur propension à consommer des substances. On a aussi observé, qu’en particulier chez les jeunes, le cyberharcèlement pouvait encourager au suicide.
Pinar Arslan, Elena Cabrio, Serena Villata, Michele Corazza
L’informatique, qui fournit aux intimidateurs de nouveaux moyens de perpétrer un comportement nocif, permet également de lutter contre le cyberharcèlement. Le projet CREEP (pour Cyberbullying Effects Prevention ) s’efforce de développer des logiciels dans ce sens. C’est un projet multidisciplinaire cofinancé par l’Institut Européen de la Technologie et du Numérique (EIT-Digital) qui regroupe un certain nombre de partenaires en Europe, la Fondation Bruno Kessler , les sociétés Expert System et Engineering, l’Université Côte d’Azur et Inria Rennes.
Le projet envisage notamment la création de deux produits innovants.
CREEP Virtual Coaching System est un assistant virtuel qui offre des conseils et des recommandations de prévention aux adolescents victimes ou susceptibles de l’être. L’utilisateur interagit avec son propre système de coaching virtuel via un chatbot, un assistant vocal s’appuyant sur l’intelligence artificielle.
CREEP Semantic Technology est un outil de surveillance automatique des réseaux sociaux permettant de détecter rapidement les situations de cyberharcèlement et de surveiller des jeunes victimes (même potentielles), dans le strict respect de la législation en vigueur, de la confidentialité et protection des données personnelles.
Un groupe interdisciplinaire de sociologues et psychologues a coordonné des analyses sociologiques, qualitatives et quantitatives, visant à mieux comprendre le phénomène du cyberharcèlement, les profils des victimes et des intimidateurs ainsi que la dynamique sous-jacente pour répondre aux exigences socio-techniques nécessaires pour le développement de technologies. Par exemple, une enquête a été menée sur un échantillon d’étudiants italiens âgés de 11 à 18 ans (3 588 répondants) dans le but de comprendre la composition socio-démographique des victimes, leurs mécanismes de réaction et ce qui les influence. Les résultats de l’enquête ont montré par exemple que les plus jeunes (11-13 ans), en particulier, refusaient fortement de demander de l’aide. L’objectif est de définir les suggestions les plus efficaces à fournir par l’assistant virtuel en fonction du profil de l’utilisateur.
Pour cette raison, les conseils doivent viser à briser le « mur de caoutchouc », à pousser les harcelés à se confier aux adultes et à renforcer les réseaux sociaux sur lesquels ils peuvent compter (enseignants, amis, parents). Dans le même temps, des différences significatives ont été constatées entre les hommes et les femmes. Pour cette raison, l’assistant virtuel fournira des suggestions diversifiées en fonction du genre. Enfin, de manière générale, la nécessité de sensibiliser les jeunes à l’utilisation consciente des réseaux sociaux et des applications mobiles est apparue, l’activité intense en ligne augmentant de manière exponentielle le risque de nouveaux cas de harcèlement.
CREEP Semantic Technology (réseaux utilisateurs, et messages haineux détectés)
Pour ce qui concerne la détection, le problème est complexe.
Un défi vient de l’énorme masse de données échangées tous les jours dans les réseaux sociaux par des millions d’utilisateurs dans le monde entier. La détection manuelle de ce type de messages haineux est irréalisable. Il faut donc bien s’appuyer sur des logiciels, même si un modérateur humain doit être impliqué pour confirmer le cas de harcèlement ou pas.
La tâche algorithmique de détection de cyberharcèlement ne peut pas se limiter à détecter des gros mots, insultes et autres termes toxiques. Certains termes qui sont insultants dans certains contextes peuvent sonner différemment entre amis ou accompagnés d’un smiley. Pour des adolescents par exemple, un mot très insultant, comme bitch en anglais, peut être utilisé de manière amicale entre amis. Il faut donc se méfier des faux positifs. Au contraire, des messages qui a l’apparence ne contiennent pas de termes toxiques peuvent être beaucoup plus offensifs s’ils contiennent du second dégré ou des métaphores haineuses. Un risque de faux négatifs existe donc aussi si on se limite à l’analyse textuelle des contenus.
Alors comment faire ? On s’est rendu compte qu’on pouvait détecter les cas de cyberharcèlement en effectuant une analyse de réseau et des contenus textuels des interactions. Puisque le cyberharcèlement est par définition une attaque répétée dirigée contre une victime donnée par un ou plusieurs intimidateurs, un système détectant automatiquement ce phénomène doit prendre en compte non seulement le contenu des messages échangés en ligne, mais également le réseau d’utilisateurs impliqués dans cet échange. En particulier, il convient également d’analyser la fréquence des attaques contre une victime, ainsi que leur source.
C’est ce que réalise CREEP Semantic Technology en analysant un flux de messages échangés sur les réseaux sociaux liés à des sujets, hashtags ou profils spécifiques. Pour ce faire, l’équipe a d’abord développé des algorithmes pour identifier les communautés locales dans les réseaux sociaux et isoler les messages échangés uniquement au sein de cette communauté. Elle a ensuite produit un algorithme de détection de cyberharcèlement qui s’appuie sur plusieurs indicateurs pour la classification des messages courts comme les émotions et sentiments identifiés dans les messages échangés. C’est là que l’intelligence artificielle trouve sa place : des méthodes d’apprentissage automatique et d’apprentissage profond, des réseaux de neurones récurrents.
Afin de tester l’efficacité du prototype, plusieurs tests ont été réalisés sur différents jeux de données contenant des instances de cyberharcèlement ou d’autres types de harcèlement sur les plates-formes de médias sociaux. Les résultats sont bons.
Dans l’avenir, la CREEP Semantic Technology va évoluer dans deux directions : l’analyse des images potentiellement associées aux messages (avec une équipe de recherche d’Inria Rennes), et l’extension du prototype à d’autres langues telle que le Français, l’Espagnol et l’Allemand, en plus de Italien et de l’Anglais qui ont été pris en compte au début du projet.
Un nouvel « Entretien autour de l’informatique ». Jacques Lévy, professeur à l’École polytechnique fédérale de Lausanne, est géographe, spécialiste de géographie politique. Il est lauréat du prix Vautrin-Lud en 2018, parfois considéré comme le Nobel de géographie. Jacques Lévy nous explique comment son métier a changé avec le numérique. Il raconte aussi que si sa discipline s’est transformée, les changements viennent d’ailleurs, de changements de paradigme, même s’il est difficile d’imaginer ce qu’elle serait devenue sans la révolution numérique.
Jacques Lévy
B – Pouvez-vous nous parler de votre domaine de recherche ?
JL – Je suis géographe. La définition de la géographie ne nous satisfaisait pas du tout lorsque nous étions étudiants, aussi avons-nous travaillé à une autre approche. Nous avons opté pour la géographie comme science sociale. Ce n’est pas dans une logique de partition qu’on peut comprendre la relation entre les sciences sociales, mais par une perspective d’ensemble, chacune apportant son propre angle d’attaque d’une des dimensions du monde social. Avec quelques amis, nous terminons un livre à paraître en 2020 qui s’intitule Science du social — au singulier – car il y a une seule science du social qui met en rapport toute une gamme de disciplines.
En géographie, je suis un peu touche-à-tout. Quand on découpe un morceau du social, on produit un objet qui possède un niveau de complexité assez similaire à celui du tout. On ne va donc pas énormément gagner en confort de recherche en étudiant un petit objet, le morceau plutôt que l’ensemble. Tout fait social est total. Le risque de fragmentation des savoirs est particulièrement fort pour les sciences sociales. Je dis que je suis géographe mais je m’intéresse beaucoup à la sociologie, à la science politique, à l’économie, à l’anthropologie, etc.
Je suis un chercheur du social qui privilégie la dimension spatiale. Dans ce contexte, je m’intéresse à la mondialisation, aux villes, à l’Europe… Au début du 20e siècle, la géographie se pensait comme une science des permanences quand l’histoire était une science du changement. On n’en est plus là. Les objets qui m’intéressent sont des objets en mouvement, qui apparaissaient comme marginaux dans la géographie de naguère.
B – Vous avez étudié la mondialisation. Qu’est-ce qui a changé ?
À mon avis, la mondialisation a commencé quand Homo sapiens a commencé à se disperser, à créer des lieux qui sont longtemps restés déconnectés les uns des autres, mais qui maintenant sont reliés, sans avoir perdu toutes leurs différences et constituent notre « stock d’altérité ». On peut dire que nos ancêtres du Paléolithique ont fabriqué cette matière première sans laquelle la mondialisation n’aurait pas de sens.
J’observe aussi que la guerre géopolitique, c’est-à-dire la prise de territoires, est pratiquement en extinction. Il y a de moins en moins de guerres, et de moins en moins de morts dans les conflits armés, et ces conflits armés eux-mêmes ont changé de sens. Pourquoi faisait-on ces guerres ? Pourquoi n’y a-t-il plus de raison de faire de conquêtes territoriales ? Pour répondre à ces questions, il faut observer l’histoire longue de la guerre, sur laquelle les chercheurs ne sont pas tous d’accord. Certains voient la guerre sous un angle psychologico-métaphysique, disant que la violence est dans l’homme, alors que les grands chefs de guerre ne sont pas spécialement des gens violents. Je préfère voir qu’au Néolithique, au moment où on commence à produire et à accumuler des surplus, il y a une hésitation : faut-il investir ces ressources dans la production ou dans la captation des ressources des autres ? Cela correspond en partie, à l’époque, à l’opposition entre nomades et sédentaires. C’est à ce moment-là qu’apparaît l’État, comme dispositif pérenne de construction et de gestion des instruments de violence, qui peuvent servir tant pour défendre que pour attaquer.
Un chef d’État qui a une armée à sa disposition est porté à l’utiliser, et on comprend ainsi comment se construit une composante rationnelle de la guerre : cela peut rapporter quelque chose. Catherine de Russie disait que le meilleur moyen de défendre l’empire, c’était de l’étendre. Cette démarche suppose une « économie de stock », qui repose sur des rentes liées à la surface des terres agricoles et aux ressources fossiles. Les pays les plus vastes tendent à être ceux qui peuvent jouer le plus sur cet atout, en gros proportionnel à la superficie. Si en outre, vous avez une population importante, vous pouvez avoir une armée consistante.
Avec les systèmes productifs contemporains, nous passons dans une « économie de flux ». C’est la production de valeur ajoutée par unité de ressource, la productivité donc, qui comptent désormais. Pour cela, il est plus efficace d’être une petite économie prospère qu’une grande économie pauvre. Aujourd’hui, les pays les plus riches ne sont pas les plus grands. Le modèle suisse ou singapourien est plus efficace que le modèle russe. Quand on est dans une économie de flux, ça ne sert plus à rien de conquérir des terres.
B – La mondialisation ne contribue-t-elle pas à augmenter l’empreinte carbone ?
JL – L’un des scénarios proposés par le GIEC est de dire que le climat se porterait mieux s’il n’y avait pas de mondialisation. Je pense que c’est un raisonnement à courte vue. Si chaque État pratiquait l’autarcie, cela enlèverait les 6 ou 7 % d’émission de gaz à effet de serre dû aux transports maritimes et aériens, mais d’une part, cela augmenterait les émissions des transports routiers qui pèsent bien plus lourd et surtout cela ralentirait la prise de conscience écologique d’une partie de l’humanité, par exemple, l’importance pour la Chine de diminuer la part du charbon dans leur production d’énergie. Les Chinois sont très désireux d’être dans le monde et c’est, sans surprise, une ressource utile pour traiter mondialement des enjeux mondiaux.
En fait, la conscience écologique est un événement politique majeur d’échelle mondiale. Ainsi, Greta Thunberg est un leader politique mondial. Cet événement a des effets rapides et profonds sur les politiques publiques. Beaucoup, dans cette accélération de la prise de responsabilité des humains sur la nature, tout autant que la relative stagnation qui a précédé, se passe dans nos têtes. Le Monde est aussi une réalité idéelle.
B – Il y a l’échange de pensées, et il y a l’échange de produits avec leur coût écologique. Est-ce indissociable ?
JL – En partie. En tant que chercheurs et comme citoyens, il faut rester vigilants face aux points de vue qui substituent la morale à l’histoire. Les discours qui laissent à penser que les hommes ont été méchants avec la nature et qu’ils devraient en avoir honte reposent sur une construction fragile de l’histoire de l’humanité. Nous cherchons actuellement à sortir du Néolithique en atténuant sa composante destructrice, mais sans le Néolithique, il n’y aurait pas de Greta Thunberg. Dégager autant de ressources pour penser le réel par la science, la technologie, la philosophie, la réflexivité en général, n’aurait pas été possible sans l’industrie avec sa sidérurgie, ses centrales au charbon ou ses moteurs thermiques, qui ont incontestablement fait des dégâts dans les environnements naturels. On ne peut pas faire son marché dans l’histoire, car tous les éléments du processus se tiennent. Ce n’est pas comme si on avait eu le choix, et qu’on ait fait les mauvais choix, cela ne s’est tout simplement pas passé ainsi. Nous devons assumer le fait que nous ne sommes pas les juges de nos ancêtres mais leurs héritiers, capables, espérons-le, d’opérer des bifurcations significatives.
B – Quels sont les outils que vous utilisez dans votre travail de chercheur ?
JL – Une grande variété. La chance de la géographie a été qu’après la crise de la discipline dans les années 1970, elle s’est ouverte à d’autres domaines de connaissance pour s’en sortir. Certaines techniques de collecte d’information ont longtemps été associées à des disciplines, et pour les géographes, c’était la carte. Aujourd’hui, nous utilisons un peu toutes les techniques des sciences du social, de l’observation participante à la modélisation informatique en passant par les entretiens semi-directifs, l’analyse statistique et bien sûr aussi la cartographie, qui s’est profondément renouvelée.
Nous faisons en somme beaucoup appel aux mathématiques, d’une manière ou d’une autre. Pour beaucoup de chercheurs, il s’agit surtout de statistiques et de la recherche de corrélations entre des réalités empiriques. Le big data a aussi poussé certains dans ce travers. Quand un étudiant me dit : “Cette variable explique n % du phénomène”, je lui réponds d’aller relire la Critique de la raison pure de Kant.
Notre travail consiste à construire une autre couche de la semiosphère que celle de la perception, de l’empirie, de l’interprétation spontanée, sinon on est promis à beaucoup de déconvenues. Un chercheur ne peut se contenter d’être un ouvreur de rideau qui dévoile une vérité qui serait déjà présente derrière. Depuis (au moins) les Lumières, on sait que ce n’est pas comme ça que ça marche. Une théorie, c’est une construction, une fiction qui doit être vérifiée par ce qu’on appelle l’observation ou l’expérimentation, mais qui n’est jamais un simple classement d’informations.
Cartogramme de la France, avec comme variable la population. Maastricht, 1992 : un nouvel espace électoral. Cartogramme et carte euclidienne (en cartouche). [non en vert et oui en bleu]. Source: Jacques Lévy (dir.), Atlas politique de la France, Paris : Autrement, 2017. B – La carte est pour vous un outil essentiel. Pouvez-vous nous en dire quelques mots ?
J’ai fréquemment utilisé le cartogramme qui ne se fonde pas sur l’homologie entre surfaces sur le terrain et surfaces sur la carte. Avec des cartogrammes, on se met à voir autre chose, des choses qu’on ne pouvait voir auparavant qu’en dehors des cartes, sur des tableaux de données difficiles à synthétiser. C’est comme si on changeait de lunettes. J’avais été alerté en 1992 quand le référendum français sur le traité de Maastricht avait donné une configuration étrange : un oui très net dans les centres des grandes villes, un non souvent tout aussi net dans les banlieues et le périurbain. Avec la technique du cartogramme, j’ai pu observer que ce pattern s’imposait dans nombre de rendez-vous électoraux, jusqu’à devenir la matrice des élections généralistes, comme la dernière présidentielle française, mais aussi les présidentielles américaines ou le Brexit. La distribution du vote a désormais plus à voir avec les localisations des citoyens (leurs gradients d’urbanité) qu’avec les catégories socio-économiques habituelles. D’où les questions non triviales : que faire de cette observation ? que nous dit-elle au-delà d’elle-même ?
B – Si le cartogramme revient à faire de l’anamorphose pour une idée qui correspond à l’idée du chercheur, n’y a-t-il pas un risque à mettre en exergue un peu n’importe quoi ? Comment puis-je avoir confiance dans un cartogramme, et pourquoi n’est-ce pas une forme de fake news ?
JL – Oui, c’est un risque, car la cartographie est un langage, et le danger existe pour elle comme pour tout langage. Des géopoliticiens nazis faisaient des cartes très parlantes, sur lesquelles on voyait en 1938 l’Allemagne encerclée par la Tchécoslovaquie, avec des flèches dans tous les sens. On peut mentir avec une carte. Il faut toujours en être averti. Cela étant, je trouve plus intéressant de dire que toutes les cartes sont vraies, non dans le sens que tout est vrai, mais parce qu’il n’y a pas la « vraie » carte, qui serait unique. Une carte, c’est un point de vue. Avec la même base de données électorale, on peut faire une carte euclidienne ou un cartogramme, aucune n’est moins vraie que l’autre, mais les apports cognitifs des deux images sont différents.
Source : Jacques Lévy, Patrick Poncet et Emmanuelle Tricoire, La carte, enjeu contemporain, Paris : La Documentation Photographique, 2004.
Cela ne signifie pas que la notion de vérité perde de sa force. Avec quelques amis nous avons a créé un « rhizome » de recherche, Chôros (www.choros.place), qui se situe dans la perspective d’une science citoyenne. Dans notre manifeste, nous affirmons que les chercheurs signent un contrat éthique avec la société qui rend leur libre travail possible. Ce que la société attend de nous, ce n’est pas un paresseux « tout se vaut », c’est la vérité. Il faut garder un œil critique sur les cartes et aider les lecteurs à se prémunir contre d’éventuelles manipulations, tout simplement en rendant lisible le processus par lequel une carte se fabrique. Comme pour l’informatique, si vous ne comprenez pas, au moins un peu, ce qu’il y a dans l’algorithme, vous ne pouvez pas avoir un regard critique.
B – Quel sont vos rapports avec des informaticiens dans votre métier ?
JL – Ce qui spécifie les chercheurs à mon avis, c’est de privilégier les questions sur les réponses. Quand ils privilégient la démarche d’ingénieur, les informaticiens préfèrent parfois les solutions, ils « résolvent » les problèmes avec l’idée que nous, chercheurs en sciences sociales, compliquons inutilement les choses. Pour parler de développement durable, des informaticiens avec qui j’ai travaillé à l’EPFL utilisaient beaucoup les termes « comportement » et « acceptabilité », ils parlaient d’augmenter le seuil d’acceptabilité, de changement de comportement, comme si les gens étaient des rats de laboratoire. Nous objections que les humains sont des acteurs dotés d’intentionnalité : si on veut qu’ils changent, il faut d’abord comprendre leurs orientations, leurs attentes, leurs désirs, et, si on en est capable, tenter de les convaincre. C’est une difficulté courante, qui ne concerne pas, loin s’en faut, les seuls informaticiens. Les architectes croient souvent savoir ce qui est bon pour les gens dans leur habitat sans avoir besoin de les consulter.
Cela précisé, l’informatique ouvre aux sciences sociales des possibilités considérables, des questions passionnantes. Ainsi, en étudiant l’algorithme du site de rencontres Tinder, une chercheuse s’est rendu compte qu’il y avait une hiérarchie parmi les utilisateurs, et que ceux qui ont beaucoup de succès dans un groupe (par exemple les hommes hétérosexuels) ne sont présentés qu’à ceux qui ont beaucoup de succès dans l’autre groupe (par exemple les femmes hétérosexuelles), de façon à éviter qu’ils aient une surabondance de contacts — ce n’est pas dit explicitement dans le marketing de Tinder. En revanche, les promoteurs de la plateforme insistent beaucoup plus sur l’idée de « proximité », de jeu aléatoire par la position spatiale : plus on est dans un espace dense, plus la probabilité de rencontrer des gens dans un petit périmètre est grande. Ce qu’on découvre, c’est que cet aspect est en partie gommé par la hiérarchisation des profils. Il fallait ouvrir la boîte noire, mettre les mains dans le cambouis.
Pour ne pas se contenter des métadiscours, il faut en savoir suffisamment pour pouvoir comprendre comment les mécanismes techniques opèrent. Il est donc indispensable de parler au moins un peu les langues des informaticiens pour pouvoir dialoguer avec les eux. C’est ainsi qu’on peut concevoir les pratiques inter- ou transdisciplinaires comme des dispositifs de traduction multiples entre des chercheurs qui maîtrisent inégalement les différents langages utiles pour le projet.
B – Est-ce que vous ne pouvez pas vous contenter des logiciels existants ? Il existe par exemple des applis cartographiques très sophistiquées. Vous faut-il développer les vôtres ?
JL – Les applications disponibles aident bien sûr. Mais souvent, elles ne font pas exactement ce que vous voulez.
À l’EPFL, nous avons engagé un docteur en informatique qui s’intéressait aux sciences sociales. Nous avons constaté que c’était plus rapide pour lui d’écrire quelques lignes de code que d’utiliser des applications existantes mais pas tout à fait adaptées. Avec lui, on pouvait discuter du fond, mais pour faire cela, chacun a dû faire des efforts d’explicitation pour se rendre compréhensible.
Nous travaillons à améliorer la démocratie interactive (« participative ») grâce à des outils permettant aux citoyens ordinaires de prendre position sur les problèmes complexes. Nous avons ainsi constitué un échantillon de personnes sans expertise particulière que nous avons interrogées sur la carte hospitalière. Nous leur avons demandé : « Où voulez-vous placer les hôpitaux sur votre territoire ? » Ils devaient avoir à leur disposition les différents types de services, les variations des coûts, les distances effectives, etc. Ils se sont aisément approprié les questions et nous ont fourni des réponses solidement argumentées. Mais, pour leur donner un outil qu’ils puissent maîtriser en cinq minutes, nous avons travaillé deux ans dans une équipe qui comprenait informaticiens, spécialistes de la santé, géographes, cartographes et urbanistes. J’ai pu le constater dans de multiples circonstances : dans la recherche, une dream team implique des capacités diverses inévitablement portées par des individus différents, mais partiellement partagées par les membres du groupe.
B – Comment l’informatique a-t-elle transformé votre métier ?
JL – Je suis perplexe quand je me demande comment je réussissais à travailler avant l’arrivée des ordinateurs. Maintenant, nous disposons des communications à distance, des courriels, des visioconférences, du web… Il y a aussi les data qui donnent accès à des informations de masse dans des conditions de facilité extraordinaires. Mais si le monde numérique est un univers intéressant, la ville reste pour moi beaucoup plus riche en sérendipité — pour nous faire voir d’autres réalités, pour nous déranger, pour nous proposer des pistes inattendues. Le numérique me permet de mener de front dans de bonnes conditions des problèmes de recherches plus nombreux, mais, je le dis avec prudence, il ne me semble pas qu’il ait touché au cœur de ma recherche et de ma manière fondamentale de chercher.
B – Le cœur de votre recherche reste le même. Mais est-ce qu’il a eu des changements de votre domaine qui n’auraient pu intervenir sans le numérique ?
Notre façon de travailler a vu sa productivité augmenter de manière considérable avec l’informatique. Mais si les sciences sociales elles-mêmes se sont profondément transformées, ce n’est pas seulement à cause d’informatique mais en raison de leur dynamique intellectuelle, elle-même encastrée dans l’histoire des sociétés. Ainsi, on accorde beaucoup plus d’importance aux individus ordinaires, qu’on reconnaît désormais comme acteurs et plus seulement comme agents. Par exemple, on a pensé longtemps que les gens changeaient mécaniquement leurs pratiques de procréation quand ils s’enrichissaient. On sait aujourd’hui que le changement arrive quand les filles vont à l’école, c’est-à-dire quand leur accès à la connaissance permet à leur intentionnalité réflexive de franchir des seuils décisifs.
Cela dit, on a du mal à imaginer les transformations des sciences sociales sans le numérique. La « révolution numérique » est à la fois une cause et une conséquence de dynamiques sociales de fond, notamment en ce qu’elle donne énormément de pouvoir aux individus ordinaires. Reconnaissons qu’il est difficile d’imaginer comment les sciences sociales auraient évolué sans elle.
Serge Abiteboul, Inria & ENS-Paris, Claire Mathieu, CNRS & Université de Paris
(*) Un cartogramme est une carte pour laquelle une variable thématique, comme la population ou le PIB, remplace la surface des territoires représentés comme fond de carte. La géométrie de l’espace de la carte est modifiée afin de se conformer aux informations relatives à la variable représentée.
Sihem Amer-Yahia, site du Laboratoire d’Informatique de Grenoble
Sihem Amer-Yahia est directrice de recherche CNRS, responsable d’une équipe du Laboratoire d’Informatique de Grenoble à la frontière entre la fouille de données, la recherche d’informations, et l’informatique sociale (social computing).
Après un diplôme d’ingénieur à l’ESI d’Alger, en 1994, elle passe sa thèse en 1999 chez Inria, sous la direction de Sophie Cluet, sur le chargement massif de données dans les bases de données orientées objet. Sihem se lance ensuite dans un grand voyage académique et industriel : un post-doctorat à AT&T Labs, puis des postes à Yahoo! Labs toujours aux États-Unis, Yahoo! Barcelone, le Computing Research Institute au Qatar, avant de rejoindre Grenoble et le CNRS en 2012.
Entre temps, la doctorante est devenue une chercheuse de renommée internationale avec des contributions majeures notamment sur le stockage et l’interrogation des données XML et les systèmes de recommandation.
Sihem a vite compris l’importance du caractère social des données produites par des humains. Elle a été convaincue que pour des logiciels faisant interagir des humains, comme les réseaux sociaux, le crowd sourcing, les systèmes de recommandation, les logiciels de ressources humaines, il fallait tenir compte des comportements sociaux, des facteurs humains.
Image par Gerd Altmann de Pixabay
Donc parlons d’informatique sociale, la passion de Sihem. Le traitement massif de données produites par des humains pose à l’informatique des défis passionnants. Prenons les systèmes de recommandations qui nous aident à choisir des produits ou des services. Pour saisir la richesse des recommandations, il faut maîtriser la langue, et tenir compte du comportement humain : Qu’est-ce qui conduit quelqu’un à s’« engager » en donnant une opinion ? Quels sont les souhaits de chacun ? Quels pourraient être les biais ?… Les données humaines s’introduisent partout, par exemple : dans la justice (comment évaluer les risques de récidive), dans la politique (comment analyser les données du Grand Débat, ou les réactions sur les élections sur Twitter), dans la médecine (le dialogue avec le patient dans le cadre du diagnostic automatique), dans la sociologie (comment détecter automatiquement des messages de haine), dans l’Éducation nationale (comment se comportent les élèves devant Parcoursup)… Cela nous conduit aux frontières de l’informatique, et les informaticiens y côtoient des linguistes, des juristes, des spécialistes de sciences politiques, des sociologues, des médecins, des psychologues… Toute la richesse des sciences humaines et sociales, et au-delà.
Sihem est aujourd’hui internationalement reconnue par ses pair·e·s. Ses travaux sont énormément cités, et ont trouvé des applications directes au sein des entreprises qui l’ont employée.
Sihem aime faire partager sa passion pour l’informatique et la recherche. On pourra lire ou relire ses articles récents [1] dans binaire sur les algorithmes de RH. Elle milite pour plus de place pour les femmes dans les sciences ; elle est source d’inspiration pour les jeunes chercheuses en informatique (un domaine très déséquilibré en genre).
La prestigieuse médaille d’argent du CNRS, qui distingue chaque année un·e scientifique d’un laboratoire CNRS dans chaque discipline, lui a été attribuée en 2020.
[1] Le testing algorithmique de la discrimination à l’embauche (1) et (2), Sihem Amer-Yahia et Philippe Mulhem (CNRS, Univ. Grenoble Alpes), 2010. www.lemonde.fr/blog/binaire/
De nombreuses plateformes numériques mettent en contact employeurs et employés sur internet. Elles sont de plus en plus utilisées pour proposer des emplois et par les chercheurs d’emploi. Sihem Amer-Yahia et Philippe Mulhem nous expliquent le concept du testing algorithmique. Dans un article à venir, ils nous expliqueront comment le testing algorithmique sert pour vérifier et détecter des discriminations possibles et comment il complémente un testing plus classique. Serge Abiteboul
De nombreuses plateformes numériques mettent en contact employeurs et employés sur internet. C’est le cas des plateformes dédiées comme Qapa et MisterTemp’ en France et TaskRabbit aux États-Unis, mais également des plateformes de recherche d’information telles que Google for jobs ou Facebook Jobs. De plus en plus d’individus utilisent ces plateformes pour trouver ou proposer du travail : 3 millions d’offres par mois sur Linkedin, 5 millions sur Google for jobs USA. Pour gérer les grands volumes de données qu’elles reçoivent, ces plateformes reposent sur l’utilisation d’algorithmes permettant l’appariement entre offres d’emploi et individus (voir copie d’écran de MisterTemp’).
La disponibilité des données sur ces plateformes permet d’étudier le comportement des algorithmes qu’elles emploient afin de mieux comprendre comment ils impactent nos vies. De telles études offrent la possibilité aux demandeurs et pourvoyeurs d’emploi de mieux comprendre comment ces plateformes les traitent, et également de développer des outils d’audit permettant de quantifier le comportement algorithmique et de le comparer au marché du travail classique.
L’étude de motifs discriminatoires inscrits dans la loi (code du travail (article L 1132-1) et code pénal (articles 225-1 à 225-4)) s’applique évidemment à ces plateformes. La discrimination est le fait, pour une personne, d’être traitée d’une manière différente (moins favorable) qu’une autre ne l’est d’après des critères sensibles également appelés « motifs discriminatoires » dans le code pénal. Chaque personne qui cherche un emploi est caractérisée par un « profil » décrit par ses attributs comme le genre, la tranche d’âge, le niveau d’éducation ou le lieu de résidence. Ce sont les variations de ces attributs qui permettent l’étude de la discrimination algorithmique à l’embauche. De manière générale, la discrimination concerne des groupes d’individus comparables, comme par exemple des hommes et des femmes, ou les habitants de zones géographiques différentes.
Les plateformes en ligne constituent une énorme opportunité pour l’étude de la discrimination à l’embauche. Leur intérêt réside principalement dans la possibilité de collecter de grands volumes de données sur les embauches, au moindre coût, i.e., sans avoir à déployer des opérations de testing gourmandes à la fois en temps et en moyens. Par exemple, sur la plateforme TaskRabbit il y a plus de 140 000 demandeurs d’emploi (avec une grande variété d’attributs), pour plus de 45 types de tâches (par exemple, plombier, designer de logos, jardinier), et dans une cinquantaine de villes aux États-Unis. Un autre exemple concerne la plateforme MisterTemp’ sur laquelle on trouve plus de 18 000 demandeurs d’emploi (avec une grande variété d’attributs), dans plus de 740 types de tâches dans 47 villes en France.
Un exemple récent de testing classique déployé pendant 4 mois en France a montré que l’origine ethnique des demandeurs d’emploi a une influence directe sur leur discrimination à l’embauche. Un exemple, cette fois de testing sollicité, a rassemblé une vingtaine de personnes qui ont posté 3 200 candidatures fictives sur une période d’un an entre 2007 et 2008 auprès de 700 établissements et services en charge du recrutement dans les différentes sociétés et filiales du groupe Casino. Les données collectées des plateformes numériques permettent de réaliser des opérations de testing à une bien plus grande échelle que le testing classique et d’examiner des questions de discrimination plus complexes. Plutôt que de recruter et de rémunérer une armée de testeurs pendant des mois, l’idée est de réaliser du « testing algorithmique », i.e., un algorithme qui analyse les données collectées afin de répondre à des questions aussi sophistiquées que : quels groupes d’individus sont plus discriminés en France ? Lesquels le sont pour un type de travail donné ? Lesquels le sont dans certaines régions géographiques ? Quels emplois sont les plus discriminatoires ? Quelles régions le sont ? À quelles époques ? Une fois les données collectées, ces différents angles d’analyse (groupes définis par des attributs, régions géographiques, type de travail, période de temps) peuvent être combinés à souhait par le testing algorithmique pour analyser la discrimination à l’embauche et ce en un temps record, quelques microsecondes, défiant ainsi tout testing classique qui nécessite un déploiement dans le monde physique.
Dans notre cadre, le traitement algorithmique sur les plateformes d’embauche s’exprime sous la forme d’opportunités, pour une personne qui cherche un emploi, d’être recrutée. Ces opportunités se déclinent de deux manières : l’opportunité pour le chercheur d’emploi d’être repéré par une personne/entreprise qui pourvoie un emploi (le cas de TaskRabbit et Qapa), et l’opportunité pour le chercheur d’emploi de trouver des annonces sur un domaine afin de postuler (le cas de Facebook Jobs comme dans la figure ci-jointe, et Qapa qui offre les deux possibilités).
L’exploration de la discrimination se traduit comme suit pour les deux cas ci-dessus :
L’accès par des pourvoyeurs d’emploi à des demandeurs d’emploi pour une offre dans une zone géographique donnée. Dans ce cas, on peut examiner si un groupe de demandeurs d’emploi est discriminé par rapport à d’autres groupes dans la mesure où ses membres n’ont pas accès aux mêmes opportunités d’embauche pour le même travail. La figure 1 montre une liste de personnes avec leurs compétences pour la plateforme TaskRabbit à gauche et Qapa à droite.
L’accès à des offres pour un demandeur d’emploi dans une zone géographique donnée. On veut déterminer si un groupe de demandeurs d’emploi est discriminé par rapport à d’autres groupes dans la mesure où les offres qu’il reçoit diffèrent de celles des autres groupes pour une même demande. La figure 2 présente les offres de travail de plomberie proposées dans la région de Grenoble, par Google for Jobs à gauche et par Qapa à droite.
Figure 1, Exemple de liste de chercheurs d’emploi sur TaskRabbit (plumber in New York) à gauche, sur Qapa (Web designer) à droite.
Dans ces deux cas, les intitulés d’emploi, les localisations et les groupes de demandeurs d’emploi sont les objets d’étude. Si on se limite à des comparaisons entre les angles d’analyse avec un degré de variation (par exemple dans le testing par ISM CORUM pour le groupe Casino), on peut comparer pour un même intitulé et une même localisation le comportement sur des groupes différents, pour un même groupe et un même intitulé le comportement sur des localisations différentes, et pour une même localisation et un même groupe le comportement sur des intitulés différents.
Figure 2. Exemple de liste d’emplois par Google for Jobs (plombiers à Grenoble) à gauche et par Qapa (plombier/plombière chauffagiste à Grenoble) à droite.
Le testing algorithmique opère sur un grand nombre de données collectées. Ces données sont constituées de requêtes de demande ou d’offre d’embauche auxquelles sont associées les résultats obtenus (liste de jobs à pourvoir dans un cas ou listes d’individus à embaucher dans l’autre). Sa réalisation nécessite la résolution d’un certain nombre de défis scientifiques : définition de critères pour calculer les discriminations, formule de calcul des discriminations, développement d’une logique algorithmique permettant de détecter les angles d’analyse (groupes, régions, type de travail, période de temps), présentation lisible des calculs de manière à être validés et comparés. L’idée principale de la logique algorithmique du testing est de chercher des groupes à la volée dans un espace de recherche constitué d’un très grand nombre de groupes. Cela nécessite une capacité calculatoire importante pour quantifier le comportement algorithmique des plateformes numériques.
TaskRabbit peut être utilisé par des pourvoyeurs d’emploi pour embaucher des individus pour différents travaux tels que l’aide au déménagement ou la conception d’un logo. Chaque demande d’embauche retourne une liste d’individus qualifiés. Nous avons appliqué le testing algorithmique à plus de 5 300 demandes d’embauche dans plus de 50 villes américaines et quelques villes anglaises. Cela nous a permis de mettre en évidence (ce qui n’est pas nouveau) que l’origine ethnique est une source de discrimination à l’embauche. Plus exactement, nous avons déterminé que les groupes ethniques les plus discriminés sont les personnes d’origine asiatique, et les moins discriminés les blancs. L’explication de ce résultat est délicate. Il pourrait être simplement dû à la proportion très petite d’asiatiques dans les données collectées (7,8 % de la population de 140 000 demandeurs d’emploi inscrits dans TaskRabbit). Parmi les 45 types d’emploi présentés au pourvoyeur, les plus discriminés sont les travaux de bricolage et l’emploi dans l’événementiel, et les moins discriminés sont l’aide à l’assemblage de meubles, et l’aide pour les courses. Nous pouvons également observer que la ville de Birmingham au Royaume-Uni et d’Oklahoma City aux États-Unis sont les plus discriminatoires tout travaux confondus, alors que San Francisco et Chicago sont les moins discriminatoires. Toutes ces observations pourraient servir de point de départ pour une analyse plus approfondie de ces discriminations.
Plus généralement, l’espoir avec le testing algorithmique est de développer des outils à l’intention de plusieurs acteurs : les demandeurs et pourvoyeurs d’emploi mais également les auditeurs et entités régulatrices des plateformes numériques. Ce genre de testing pourrait nous permettre également de comparer différentes plateformes entre elles, différents corps de métiers et aussi les mondes virtuel et physique. Cela pourrait nous permettre de comprendre un petit peu comment ces plateformes affectent nos vies.
A. Hannak, C. Wagner, D. Garcia, A. Mislove, M. Strohmaier,and C.
Wilson. 2017. Bias in Online Freelance Marketplaces: Evidence
fromTaskRabbit and Fiverr. In Proceedings of the 2017 ACM Conference on
Computer Supported Cooperative Work and Social Computing (CSCW), 2017,
1914–1933. https://personalization.ccs.neu.edu/static/pdf/hannak-cscw17.pdf
A. Hannak, P. Sapiezynski, A. Molavi Kakhki, B. Krish-namurthy, D.
Lazer, A. Mislove, and C. Wilson. 2013. Measuring personalization of
web search. In Proceedings of the 22nd international conference on World
Wide Web (WWW), ACM, 2013, 527–538. https://cbw.sh/static/pdf/fp039-hannak.pdf
(version revue et étendue du papier en 2017 : https://arxiv.org/pdf/1706.05011.pdf)
En provenance de Bruxelles, Charles Cuvelliez (École Polytechnique de Bruxelles, Université de Bruxelles) et Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain) nous apportent un éclairage sur un article publié dans Nature et qui apporte une réponse à une vielle question de biologie humaine : « pourquoi les pics de naissance apparaissent-ils toujours en septembre ? « . Des chercheurs montrent aussi qu’il est possible de détecter l’humeur du moment d’un pays, d’une communauté ; une pratique sans doute déjà à l’œuvre dans les agences de com politique. Pierre Paradinas
Qui eût cru que Google et Twitter et la prestigieuse revue Nature allaient donner une réponse à une question vieille comme le monde : les variations cycliques des naissances, avec un pic en septembre pour l’hémisphère nord, sont-elles dues à un facteur biologique ou culturel ? C’est souvent le facteur biologique qui est mis en avant ; en effet, septembre correspond, 9 mois plus tôt, à Noël, une période propice à cette explication : ce sont les jours les plus courts et notre horloge biologique nous inciterait à la reproduction comme beaucoup d’animaux à la même période. Si cette hypothèse est vraie, les pics de naissance ne devraient pas avoir lieu à la même époque dans l’hémisphère nord et dans l’hémisphère sud. Et ces pics ne devraient pas se manifester à l’équateur. Si l’hypothèse biologique prévaut, c’est qu’elle se base sur des statistiques facilement disponibles et fiables dans l’hémisphère nord : taux de naissance, bien sûr, mais aussi taux de transmission des maladies sexuellement transmissibles, vente de préservatifs, etc.
Source Wikimedia – Pereslavl – CC BY-SA 3.0
Avec Google et Twitter, on peut accéder à des données vraiment mondiales prêtes à l’emploi. Il fallait y penser. Une coopération internationale menée par l’école d’informatique de l’université d’Indiana aux états-unis a eu recours à Google Trends, site qui établit une cartographie des recherches faites sur Internet. Cette équipe a pris comme mot clé, le mot « sexe » comme indication d’un état d’esprit nous amenant à une attitude propice à la reproduction (et… au reste). Que constatent les chercheurs ? Sur les 10 ans de retour en arrière possible avec Google Trends, le pic de recherches avec le mot « sexe » se produit à la Noël. Ce n’est pas dû, expliquent les chercheurs, au temps libre supplémentaire que cette période offre puisqu’ils ont normalisé les statistiques sur le volume de recherche plus grand à cette époque de l’année. Ce pic n’existe pas non plus sur d’autres périodes de vacances comme Thanksgiving ou Pâques. Plus intéressant : tant l’hémisphère sud que l’hémisphère nord montrent ce pic à la même période. Il n’y aurait donc pas d’effet biologique lié à la saison qui aurait alors engendré un tel pic aux alentours du 21 juin en Australie.
Les chercheurs ont alors étudié le même pic dans les recherches Google pour des pays non chrétiens. Ils ont découvert qu’il apparaissait lors de deux fêtes culturellement importantes dans d’autres communautés : Eid al Fitr (la fête de la fin du Ramadan) et Eid al Adha (la fête du sacrifice). Et comme ces fêtes n’ont pas un calendrier fixe, ces chercheurs ont constaté que les pics les suivaient. C’est donc clair : les pics de recherche liés au mot clé sexe sont reliés tant chez les chrétiens que chez les musulmans à des fêtes culturelles d’origine religieuse. Pour les chrétiens, c’est d’autant plus frappant que la corrélation augmente lorsqu’on exclut les 10 pays chrétiens qui fêtent Noël à une autre date que le 25 décembre (pays orthodoxes).
Peu de lien avec le sexe
Pourtant ces fêtes religieuses n’ont aucune connotation sexuelle. C’est même contre-intuitif. Les chercheurs ont alors tenté de relier ces fêtes à un état d’esprit collectif, apaisé, qui amènerait à des bonnes dispositions en la matière, une sorte de vérification de l’adage : faites l’amour pas la guerre. Ils ont eu recours, autre originalité de leurs travaux, à Twitter et à l’analyse des messages dans 7 pays : Australie, Argentine, Brésil, Chili, Indonésie, Turquie et les USA. Ce ne sont sans doute pas les mêmes populations qui auront fait les recherches sur Google et qui auront twitté, mais l’échantillon des deux côtés est suffisamment vaste. Sur Twitter, les chercheurs ont examiné la présence de mots appartenant au lexique ANEW, Affective Norms for English Words : il s’agit de 1034 mots réputés porteurs de sentiments affectifs forts suivant trois dimensions qui permettent d’identifier si l’auteur du message est triste ou heureux, calme ou excité, sous contrôle. Le lexique ANEW a notamment été traduit en portugais et en espagnol. Bref, une analyse ANEW des messages Twitter est capable de donner l’humeur générale d’une population. Et bien, elle change pendant les vacances : il ne faut pas être grand savant pour comprendre que l’état général d’humeur puisse évoluer vers « heureux » à ces périodes. Encore fallait-il le prouver, ce qu’ils ont fait.
Que l’intérêt pour le sexe soit relié à un facteur culturel est une chose, mais nous restons tout de même des entités biologiques. Il doit donc y avoir un facteur biologique sous-jacent. Et les auteurs d’avancer finalement ce que nous savons tous : un état dépressif ne nous amène pas vraiment à une attirance pour le sexe. Une nourriture plus abondante, typique de cette période, a l’effet inverse, d’après plusieurs études sauf que d’autres fêtes d’abondance comme Thanksgiving ne montrent pas de tels pics. Non, il faut se dire que Noël et Eid al Fitr sont porteurs de seuils psychologiques et symboliques particuliers.
Prédire, oui, contrôler, non
Au-delà du sujet de l’étude, l’utilisation de Twitter pour décrire l’humeur générale des masses, sa corrélation avec des comportements de population ont de quoi faire peur. Il serait donc possible de prédire les révolutions ou le meilleur tempo pour faire passer des réformes impopulaires, bref à défaut, d’assujettir les masses, en tout cas, les connaitre. Il se murmure que des agences de communication spécialisée pour les hommes et femmes politiques n’ont pas attendu. Finalement pourquoi pas ? L’importance de certaines réformes, certaines décisions cruciales ne valent-elles pas qu’elles soient prises indépendamment de mouvements d’humeur passagers. Les influencer serait plus condamnable. Un scénario pour black mirror ?














 Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plateforme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes: en 2018, 70% des vues de vidéos provenaient de recommandation (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plateforme le plus longtemps possible, mais aussi critique pour l’utilisateur lui même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.
Un système de recommandation est un objet informatique ayant pour but de sélectionner de l’information pertinente pour les utilisateurs d’une plateforme (vidéos, articles, profils…). Sur YouTube par exemple, ces recommandations sont omniprésentes: en 2018, 70% des vues de vidéos provenaient de recommandation (par opposition à des vues provenant des recherches intentionnelles). On comprend alors que cet objet est à la fois critique pour l’entreprise, qui compte sur son efficacité pour maintenir l’utilisateur sur sa plateforme le plus longtemps possible, mais aussi critique pour l’utilisateur lui même, pour qui la recommandation façonne l’exploration, puisque c’est principalement via ce prisme qu’il accède à l’information.

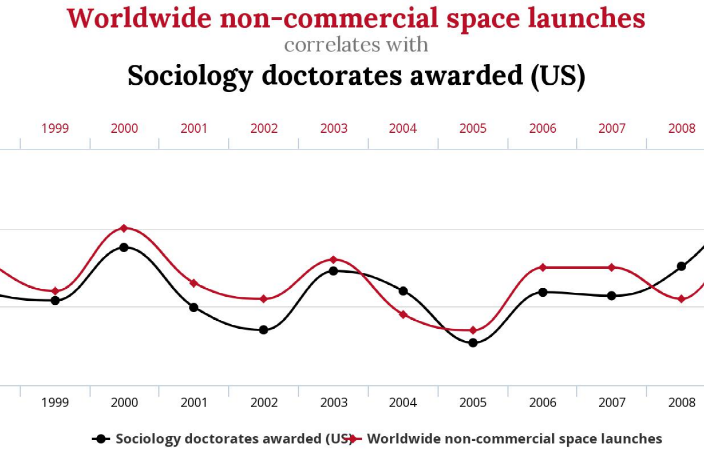


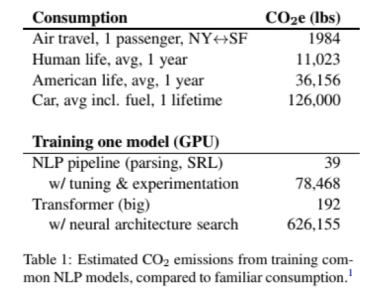
 En ce 8 mars 2022, quand bien même, compte tenu de l’actualité brulante, le monde ferait bien de se concentrer sur les droits des humains en général, il ne faut pas oublier cette parenthèse annuelle pendant laquelle il convient de se pencher plus particulièrement sur les droits des femmes.
En ce 8 mars 2022, quand bien même, compte tenu de l’actualité brulante, le monde ferait bien de se concentrer sur les droits des humains en général, il ne faut pas oublier cette parenthèse annuelle pendant laquelle il convient de se pencher plus particulièrement sur les droits des femmes.