Sur le blog binaire, nous aimons aussi la fiction, et Henri d’Agrain, nous partage ici une petite nouvelle bien … édifiante. Plaise à la vie que cela reste bien de la fiction. Yves Bertrand & Serge Abiteboul
Dessiné aux bons soins de l’auteur par ChatGPT, qui ne s’est pas fait prier…
Bruxelles, le 4 juillet 2025, par notre envoyé spécial, Jean Pacet-Démayeur
Une décision historique et lourde de conséquences vient bouleverser les relations entre les États-Unis et l’Union européenne. Dans un contexte de tension croissante depuis six mois, le Président Trump a annoncé hier soir, à la veille des célébrations de l’Independence Day, qu’il avait signé un Executive Order avec effet immédiat, interdisant aux entreprises technologiques américaines de délivrer des produits et des services numériques au Danemark, membre de l’Union européenne. Cette mesure de rétorsion, sans précédent entre alliés historiques, est la conséquence du conflit diplomatique majeur que Donald Trump a provoqué en annonçant au début de l’année, et avant d’entrer à la Maison blanche le 20 janvier 2025, son projet d’annexion par les États-Unis du Groenland, y compris par la force armée.
Une annexion qui embrase les relations internationales
Tout a commencé il y a six mois en effet, lorsque Donald Trump a annoncé sa volonté d’annexer le Groenland, éventuellement par la force armée. L’île principale de l’Atlantique Nord représente en effet un atout géostratégique majeur en raison de sa proximité avec les routes maritimes critiques reliant l’Europe, l’Asie et l’Amérique du Nord, ainsi que pour ses riches réserves en matières premières stratégiques. Déjà en 2019, une rumeur prêtait à Donald Trump, au cours de son premier mandat, l’intention d’acheter le Groenland au Danemark.
Malgré des protestations fermes de l’Union européenne et des appels au dialogue international, le Président Donald Trump a justifié sa décision par des impératifs stratégiques et de sécurité nationale. En réponse, le Danemark a saisi le Conseil de sécurité des Nations Unis, appelant à une mobilisation diplomatique mondiale.
Un embargo numérique aux conséquences vertigineuses
Hier soir, dans une escalade sans précédent, la Maison-Blanche a annoncé qu’elle interdisait à toutes les entreprises américaines de la tech de continuer à fournir leurs services au Danemark et à son économie. Cette décision inclut des géants tels que Microsoft, Google, Amazon, Meta et Apple, dont les infrastructures, les logiciels et les plateformes sont omniprésents dans l’économie danoise. Il a par ailleurs annoncé que les États-Unis lèveront cet embargo numérique lorsque le Danemark aura accepté de leur vendre le Groenland à un prix raisonnable et conforme à l’offre d’achat formulée en avril 2025.
Le ministre danois de l’Économie a qualifié cette décision de « déclaration de guerre économique », prévenant que son pays faisait face à une « paralysie imminente ». En effet, le fonctionnement de l’économie danoise repose largement sur les services cloud de fournisseurs américains, tandis que son administration publique et son système éducatif dépendent étroitement d’outils tels que Microsoft 365. Plusieurs organisations professionnelles danoises ont par ailleurs appelé le Gouvernement a engager des négociations avec les États-Unis pour éviter l’effondrement de l’économie du pays.
Les conséquences sociales se font déjà sentir : la plupart des administrations publiques sont à l’arrêt, des milliers d’entreprises se retrouvent coupées de leurs outils de gestion, les services bancaires numériques sont indisponibles, et les citoyens constatent qu’ils ne peuvent plus accéder à leurs services du quotidien comme les applications de messagerie, les réseaux sociaux ou les plateformes de streaming. Les hôpitaux, quant à eux, s’inquiètent de l’accès à leurs systèmes de données patient, majoritairement hébergés sur des serveurs américains.
Une vulnérabilité européenne mise à nu
Cette crise expose cruellement le caractère systémique des dépendances numériques des États européens et de leur économie à l’égard des technologies américaines. Si le Danemark est le seul à être touché, d’autres États européens redoutent des mesures de rétorsions similaires. La Commission européenne, par la voix de sa Présidente, a déclaré que « l’Union européenne déplore de telles attaques contre l’intégrité économique et numérique de l’un de ses membres. » Elle a appelé au dialogue entre les États-Unis et le Danemark et à l’apaisement des tensions. Elle a par ailleurs proposé aux États membres d’apporter un soutien technique au Danemark. Elle suggère enfin de lancer les travaux nécessaires pour accélérer les stratégies d’investissements de l’Union dans des alternatives européennes, notamment en mettant en œuvre les préconisations inscrites dans le rapport que Mario Draghi, l’ancien président de la Banque centrale européenne, lui avait remis en septembre 2024.
Les réponses possibles du Danemark
Face à cette situation inédite, le gouvernement danois tente de réagir. Des négociations d’urgence ont été ouvertes avec des acteurs non américains pour assurer une transition vers des systèmes alternatifs, mais de telles démarches de migration prendront des mois, voire des années. Parallèlement, le pays envisage des mesures de rétorsion, comme le blocage des actifs américains sur son territoire, mais son poids économique relativement faible limite ses marges de manœuvre.
En attendant, les citoyens danois se préparent à vivre une crise sans précédent. Certains experts avertissent que cette situation pourrait entraîner une radicalisation de l’opinion publique contre les États-Unis, renforçant les partis politiques favorables à un rapprochement avec d’autres puissances mondiales.
Une fracture durable ?
Alors que la situation semble s’envenimer, de nombreux observateurs redoutent que cette crise ne marque un tournant dans les relations transatlantiques. L’embargo numérique américain pourrait non seulement remodeler les alliances stratégiques comme l’OTAN, mais aussi accélérer le développement de systèmes technologiques régionaux indépendants, que ce soit en Europe ou ailleurs. Une chose est certaine : le Danemark est devenu, bien malgré lui, le théâtre d’une confrontation qui pourrait redéfinir l’ordre international.
Un nouvel entretien autour de l’informatique. Anne Canteaut est une chercheuse française en cryptographie de l’Inria (Institut national de recherche en sciences et technologues du numérique). Ses recherches portent principalement sur la conception et l’analyse d’algorithmes cryptographiques symétriques. Elle a reçu en 2023 le Prix Irène-Joliot-Curie de la Femme scientifique de l’année. Elle a été élue en 2025 à l’Académie des sciences.
Anne Canteaut, Wikipedia
Binaire : Pourrais-tu nous raconter comment tu es devenue une chercheuse de renommée internationale de ton domaine ?
AC : Par hasard et par essais et erreurs. Longtemps, je n’ai pas su ce que je voulais faire. En terminale, j’ai candidaté dans des prépas à la fois scientifiques et littéraires. J’ai basculé côté scientifique par paresse, parce que cela demandait moins de travail. Après la prépa scientifique, la seule chose que je savais, c’était que je ne voulais pas faire d’informatique. Je voyais l’informatique comme un hobby pour des gars dans un garage qui bidouillent des trucs en buvant du coca et en mangeant des pizzas ; très peu pour moi. J’ai découvert l’informatique à l’ENSTA : une science comme les maths ou la physique, et pas du bricolage.
J’aimais beaucoup les maths. Alors, j’ai réalisé un stage de maths « pures » et je me suis rendu compte que le côté trop abstrait n’était pas pour moi. Faire des raisonnements sur des objets que l’on pouvait manipuler plus concrètement, comme on le fait en informatique, me convenait bien mieux. J’ai fait ma thèse à l’Inria-Rocquencourt, un postdoc à l’ETH à Zurich, puis j’ai été recrutée à l’Inria où j’ai fait toute ma carrière, sauf une année sabbatique au Danemark. A l’Inria, j’ai été responsable d’une équipe nommée Secret, déléguée scientifique[1] du Centre de Paris et présidente de la commission d’évaluation[2] d’Inria pendant 4 ans.
Binaire : Peux-tu nous parler de ton sujet de recherche ?
AC : Je suis cryptographe. La cryptographie a de nombreuses facettes. Dans une messagerie chiffrée ou un protocole de vote électronique comme Belenios, on trouve différents éléments cryptographiques élémentaires, et puis on les combine. J’aime bien la comparaison que fait Véronique Cortier[3]. Dans une bibliothèque IKEA, on part de planches, et d’une notice de montage. Celui qui fait la notice suppose que les planches sont bien faites et explique comment construire la bibliothèque en assemblant les planches. Dans le cadre de la cryptographie, mon travail consiste à réaliser des planches aussi parfaites que possible pour qu’elles puissent être utilisées par des collègues comme Véronique Cortier dans leurs notices. Les planches, ce sont les blocs cryptographiques de base. Les notices, ce sont, par exemple, les protocoles cryptographiques.
Le chiffrement est un de ces blocs de base. J’ai surtout étudié le « chiffrement symétrique ». Il suppose que deux interlocuteurs partagent un même secret (une clé) qu’ils utilisent pour s’envoyer un message très long. Du temps du téléphone rouge entre la Maison Blanche et le Kremlin, la clé était communiquée par la valise diplomatique, un canal de communication fiable qui ne peut pas être intercepté. Cela permettait de s’échanger des clés très longues. Aujourd’hui, on veut pouvoir communiquer une clé (une chaine de bits) de manière confidentielle sans disposer de valise diplomatique. Plutôt que de se passer « physiquement » une clé, on utilise un chiffrement asymétrique, ce qui nous oblige à utiliser des clés relativement courtes. Dans ces protocoles asymétriques, on dispose d’une clé publique et d’une clé privée. Tout le monde peut m’envoyer un message en le chiffrant avec la clé publique ; il faut détenir la clé privée pour pouvoir le déchiffrer. Le problème est que ce chiffrement asymétrique est très coûteux, alors on envoie la clé d’un chiffrement symétrique, et on passe ensuite à un chiffrement symétrique qui est bien moins coûteux.
Dans tous les cas, le problème central est « combien ça coûte de casser un chiffrement, c’est-à-dire de décrypter un message chiffré, ou encore mieux de retrouver la clé secrète ? ». Quel est le coût en temps, en mémoire ? Comment peut-on utiliser des informations annexes ? Par exemple, que peut-on faire si on dispose de messages chiffrés et de leurs déchiffrements (le contexte de la pierre de Rosette[4]) ?
Binaire : Tu te vois plutôt comme conceptrice de chiffrement ou comme casseuse de code ?
AC : On est toujours des deux côtés, du côté de celui qui conçoit un système de chiffrement assez sûr, et du côté de celui qui essaie de le casser. Quand on propose une méthode de chiffrement, on cherche soi-même à l’analyser pour vérifier sa solidité, et en même temps à la casser pour vérifier qu’elle ne comporte pas de faiblesse. Et, quand on a découvert une faiblesse dans une méthode de chiffrement, on cherche à la réparer, à concevoir une nouvelle méthode de chiffrement.
Comme l’art minimaliste, la crypto minimaliste
Il faut bien sûr contenir compte du contexte. J’ai par exemple travaillé sur des méthodes de chiffrements quand on dispose de très peu de ressources énergétiques. Dick Cheney, ancien vice-président états-uniens, avait un implant cardiaque, un défibrillateur. Il craignait une cyberattaque sur son implant et avait obtenu de ses médecins de désactiver son défibrillateur pendant ses meetings publics. Pour éviter cela, on est conduit à sécuriser les interactions avec le défibrillateur, mais cela demande d’utiliser sa pile, donc de limiter sa durée de vie. Cependant, changer une telle pile exige une opération chirurgicale. Sujet sérieux pour tous les porteurs de tels implants ! La communauté scientifique a travaillé pendant des années pour concevoir un système de chiffrement protégé contre les attaques et extrêmement sobre énergétiquement. Un standard a finalement été publié l’an dernier. J’appelle cela de la crypto minimaliste. Pour faire cela, il a fallu interroger chaque aspect du chiffrement, questionner la nécessité de chaque élément pour la sécurité.
Binaire : Tu as travaillé sur le chiffrement homomorphe. Pourrais-tu nous en parler ?
AC : Chiffrer des données, c’est un peu comme les mettre dans un coffre-fort. Le chiffrement homomorphe permet de manipuler les données qui sont dans le coffre-fort, sans les voir. On peut par exemple effectuer des recherches, des calculs sur des données chiffrées sans avoir au préalable à les déchiffrer, par exemple pour faire des statistiques sur certaines d’entre elles.
On a besoin de combiner ces techniques homomorphes, avec du chiffrement symétrique. Problème : les gens qui font du chiffrement homomorphe ne travaillent pas avec des nombres binaires. Par exemple, ils peuvent travailler dans le corps des entiers modulo p, où p est un nombre premier. Dans le monde de la cryptographie symétrique, nous travaillons habituellement en binaire. On n’a pas envie quand on combine les deux techniques de passer son temps à traduire du codage de l’un à celui de l’autre, et vice versa. Donc nous devons adapter nos techniques à leur codage.
On rencontre un peu le même problème avec les preuves à minimum de connaissance (zero-knowledge proofs). Nous devons adapter les structures mathématiques des deux domaines.
Binaire : Tu es informaticienne, mais en fait, tu parles souvent de structures mathématiques sous-jacentes. Les maths sont présentes dans ton travail ?
AC : Oui ! Maths et informatique sont très imbriquées dans mon travail. Une attaque d’un système cryptographique, est par nature algorithmique. On essaie de trouver des critères pour détecter des failles de sécurité. Résister à une attaque de manière « optimale », ça s’exprime généralement en se basant sur des propriétés mathématiques qu’il faut donc étudier. On est donc conduit à rechercher des objets très structurés mathématiquement.
Le revers de la médaille c’est que quand on a mis dans le système un objet très structuré mathématiquement, cette structure peut elle-même suggérer de nouvelles attaques. Vous vous retrouvez avec un dialogue entre les maths (l’algèbre) et l’informatique.
Binaire : Peux-tu nous donner un exemple de problème mathématique que vous avez rencontré ?
AC : Une technique de cryptanalyse bien connue est la cryptanalyse différentielle. Pour lui résister, une fonction de chiffrement doit être telle que la différence f(x+d)-f(x), pour tout d fixé, soit une fonction (dans le cadre discret) dont la distribution soit proche de l’uniforme. Cela soulève le problème mathématique : existe-t-il une fonction f bijective telle que chaque valeur possible des différences soit atteinte pour au plus deux antécédents x (ce qui est le plus proche de l’uniforme que l’on puisse atteindre en binaire) ?
Même sans avoir besoin de comprendre les détails, vous voyez bien que c’est un problème de math. Que sait-on de sa solution ? Pour 6 bits, on connait une solution. Pour 8 bits, ce qui nous intéresse en pratique, on ne sait pas. Une réponse positive permettrait d’avoir des méthodes de chiffrement moins coûteuses, donc des impacts pratiques importants. Des chercheurs en math peuvent bosser sur ce problème, chercher à découvrir une telle fonction, sans même avoir besoin de comprendre comment des cryptographes l’utiliseraient.
Binaire : Les bons citoyens n’ont rien à cacher. Depuis longtemps, des voix s’élèvent pour demander l’interdiction de la cryptographie. Qu’en penses-tu ?
AC : Le 11 septembre a montré que les terroristes pouvaient utiliser les avions à mauvais escient, et on n’a pas pour autant interdit les avions. D’abord, il faut avoir en tête que la crypto sert aussi à protéger les données personnelles, et les données des acteurs économiques. Ensuite, comment fait-on pour interdire l’usage de la cryptographie ? Comme fait-on pour interdire un algorithme ?
Il faut comparer, en informatique aussi, les avantages et les inconvénients d’une utilisation particulière. On le fait bien pour les médicaments en comparant bénéfices et effets secondaires. Pour prendre un exemple, dans un lycée que je connais, il a été question de remplacer le badge de cantine par une identification biométrique (lecture de la paume de la main). J’ai préféré payer quelques euros de plus pour garder le badge et ne pas partager des informations biométriques stockées on ne sait où par on ne sait qui. Dans ce cas, les avantages me semblaient clairement inférieurs aux risques.
Binaire : As-tu quelque chose à dire sur l’attractivité de l’informatique pour les femmes ? Comment expliques-tu le manque d’attractivité, et vois-tu des solutions ?
AC : Côté explication, mon point de vue découle de mon expérience personnelle. Il y a des problèmes à tous les niveaux des études, mais un aspect crucial est que, encore maintenant en 2025, on enseigne très peu l’informatique au collège et au lycée. Du coup, comme les jeunes savent mal ce que c’est, ils se basent sur l’image renvoyée par la société : l’informatique est pour les hommes, pas pour les femmes. Même les déjà rares jeunes femmes qui commencent une spécialité NSI [5] abandonnent la voie informatique dans des proportions considérables. Elles imaginent que l’informatique tient d’une culture « geek » très masculine, et que cela donne donc une supériorité aux hommes.
Le problème est assez semblable en math. Il est superbement traité dans le livre « Matheuses », aux Éditions du CNRS.
Je ne vois pas de solution unique. Mais, par exemple, peut-être faudrait-il revoir la part trop importante accordée au volontariat. Les filles candidatent moins ; à compétence égale, elles sont moins inclines à se mettre en avant. Ça peut aller de se présenter aux Olympiades de maths au lycée, jusqu’à faire une demande de prime au mérite dans un institut de recherche. C’est pourquoi les candidatures au concours de cryptanalyse Alkindi, destiné aux élèves de collège et de lycée, ne se basent pas entièrement sur le volontariat. Ce n’est pas un élève d’une classe qui participe, mais toute la classe. Résultat : parmi les gagnants, il y a autant de filles que de garçons.
Binaire : tu viens d’être élue à l’Académie des sciences, tu as eu le prix Irène-Joliot-Curie. Comment vis-tu ces reconnaissances des qualités de tes recherches ?
AC : Je suis évidemment très flattée. Mais je crains que cela donne une image faussée de la recherche, beaucoup trop individuelle. La recherche dans mon domaine est une affaire éminemment collective. J’ai écrit très peu d’articles seule. Pour obtenir des résultats brillants dans le domaine du chiffrement qui est le mien, on a vraiment besoin d’une grande diversité de profils, certains plus informaticiens et d’autres plus mathématiciens. D’ailleurs, c’est vrai pour la recherche en informatique en général. C’est plus une affaire d’équipes, que d’individus.
Serge Abiteboul, Inria ENS, Paris, Claire Mathieu, CNRS et Université Paris Cité
[1] Assure la coordination scientifique du centre.
[2] Plus importante instance scientifique d’Inria au niveau national.
[4] La pierre de Rosette est un fragment de stèle gravée de l’Égypte antique portant trois versions d’un même texte qui a permis le déchiffrement des hiéroglyphes au XIXe siècle. [Wikipédia]
La confiance et le numérique responsable reposent tout deux, entre autres, sur la nécessité de développer des systèmes fiables et sûrs. Cette exigence concerne à la fois la conception hardware (ex : IOT, robotique, cobotique) et celle du software (ex: IA, jumeaux numériques, modélisation numérique). A l’heure où les objets connectés font partie inhérente de nos quotidiens en tant que consommateurs lambda, industriels ou chercheurs, il semble important de questionner les concepts de fiabilité et sécurité dans la conception électronique des objets qui nous entourent. Sébastien SALAS,Chef de projet d’un pôle d’innovation digitale (DIH, Digital Innovation Hub) et directeur de formation au sein du programme CAP’TRONIC dédié à l’expertise des systèmes électroniques pour l’innovation et l’industrie manufacturière, de JESSICA France, nous partage son éclairage sur ce sujet.Ikram Chraibi-Kaadoud et Chloé Mercier.
La conception électronique hardware
Dans l’industrie, un système embarqué est constitué a minima d’une carte avec un microcontrôleur, qui est programmée spécifiquement pour gérer les tâches de l’appareil dans lequel elle s’insère.
Nous interagissons avec des systèmes embarqués tous les jours, souvent sans même nous en rendre compte. Par exemple, la machine à laver qui règle ses cycles de nettoyage selon la charge et le type de linge, le micro-ondes qui chauffe le repas à la perfection avec juste quelques pressions sur des boutons, ou encore le système de freinage dans la voiture qui assure la sécurité en calculant continuellement la pression nécessaire pour arrêter le véhicule efficacement, etc …
Ces systèmes sont « embarqués » car ils font partie intégrante des appareils qu’ils contrôlent. Ils sont souvent compacts, rapides, et conçus pour exécuter leur tâche de manière autonome avec une efficacité maximale et une consommation d’énergie minimale.
C’est le rôle du technicien et ingénieur conception du bureau d’étude de concevoir ce système dit embarqué avec une partie hardware et une partie software.
La conception électronique hardware moderne est un métier très exigeant techniquement qui nécessite une solide compréhension des évolutions technologiques des composants, des besoins des utilisateurs mais aussi de son écosystème technologique. De la conception, au déploiement, au dépannage, à la maintenance, ce métier nécessite de suivre les progrès réalisés dans le domaine de la technologie numérique qui englobe électronique et informatique.
En conception de systèmes embarqués industriels, la prise en compte des notions de Fiabilité – Maintenabilité – Disponibilité – Sécurité, noté aussi sous le sigle FMDS incluant la Sûreté de Fonctionnement (SdF) et la sécurité fonctionnelle est de plus en plus partie intégrante des exigences clients. Intégrer de tels concepts dans les produits peut se passer en douceur si l’entreprise y est bien préparée.
Ces notions représentent les fondamentaux qui assurent la pérennité et l’efficacité des produits une fois en cours d’utilisation. La mise en œuvre de ces notions permet de garantir le meilleur niveau de performance et de satisfaction utilisateur. Comprendre leur implication tout en reconnaissant leur interdépendance est crucial pour les ingénieurs et concepteurs qui visent l’excellence dans la création de produits électroniques pour l’industrie.
La sécurité fonctionnelle est une facette critique de la sûreté de fonctionnement centrée sur l’élimination ou la gestion des risques liés aux défaillances potentielles des systèmes électroniques. Elle concerne la capacité d’un système à rester ou à revenir dans un état sûr en cas de défaillance. La sécurité fonctionnelle est donc intrinsèquement liée à la conception et à l’architecture du produit, nécessitant une approche méthodique pour identifier, évaluer et atténuer les risques de défaillance. Cela inclut des mesures telles que les systèmes de détection d’erreurs, les mécanismes de redondance, et les procédures d’arrêt d’urgence.
L’importance de la sécurité fonctionnelle
À l’ère des objets connectés (aussi connus sous le sigle de IoT pour Internet Of Things) et des systèmes embarqués, la sécurité fonctionnelle est devenue un enjeu majeur, en particulier dans des secteurs critiques tels que l’automobile, l’aéronautique, et la santé, où une défaillance peut avoir des conséquences graves. Chaque secteur propose sa propre norme qui a le même objectif, assurer non seulement la protection des utilisateurs mais contribuer également à la confiance et à la crédibilité du produit sur le marché.La sécurité fonctionnelle est garante d’un fonctionnement sûr même en présence de défaillances. Cette dernière requiert une attention particulière dès les premières étapes de conception pour intégrer des stratégies et des mécanismes qui préviennent les incidents.
Que surveiller pour une sécurité fonctionnelle optimale ?
Il existe de nombreux paramètres à surveiller et de nombreuses méthodes à mettre en place pour une sécurité fonctionnelle optimale. Ici deux seront soulignés : La fiabilité et la cybersécurité.
> La fiabilité : La fiabilité mesure la probabilité qu’un produit performe ses fonctions requises, sans faille, sous des conditions définies, pour une période spécifique. C’est la quantification de la durabilité et de la constance d’un produit. Dans la conception hardware, cela se traduit par des choix de composants de haute qualité, des architectures robustes et surtout des tests rigoureux. On aborde ici des notions comme le taux de défaillance, ou encore le calcul de temps moyen entre pannes ou durée moyenne entre pannes, souvent désigné par son sigle anglais MTBF(Mean Time Between Failures) et qui correspond à la moyenne arithmétique du temps de fonctionnement entre les pannes d’un système réparable.
La fiabilité des composants électroniques contribue aux démarches de sûreté de fonctionnement et de sécurité fonctionnelle essentielle dans des domaines où le temps de fonctionnement est critique. Ce sont les disciplines complémentaires à connaître pour anticiper et éviter les défaillances des systèmes. Pour les produits électroniques, il est important de comprendre les calculs de fiabilité et de savoir les analyser.
> La (cyber)sécurité : C’est la protection contre les menaces malveillantes ou les accès non autorisés qui pourraient compromettre les fonctionnalités du produit. Dans le domaine de l’électronique, cela implique la mise en place de barrières physiques (ex: un serveur dans une salle fermée à clé) et logicielles (ex: des mots de passe ou l’obligation d’un VPN) pour protéger les données et les fonctionnalités des appareils. La sécurité est particulièrement pertinente dans le contexte actuel de connectivité accrue, où les risques de cyberattaques et de violations de données sont omniprésents. Ce sujet a été abordé avec Jean Christophe Marpeau, référent cybersécurité chez #CAPTRONIC.
La conception électronique hardware moderne est un équilibre délicat entre sûreté de fonctionnement, fiabilité et sécurité. Ces concepts, bien que distincts, travaillent de concert pour créer des produits non seulement performants mais aussi dignes de confiance et sûrs. Les professionnels de l’électronique ont pour devoir d’harmoniser ces aspects pour répondre aux attentes croissantes en matière de qualité et de sécurité dans notre société connectée.
Sébastien SALASest chef de projet d’un pôle d’innovation digitale (DIH, Digital Innovation Hub) et directeur de formation au sein du programme CAP’TRONIC de JESSICA France. Il s’attelle à proposer des formations pour les entreprises au croisement des dernières innovations technologiques et des besoins des métiers du numérique et de l’électronique en particulier, pour les aider à développer leurs compétences et leur maturité technologique.
Qui mieux que Rachid Guerraoui, un ami de binaire, pour nous parler de la grande panne informatique. Rachid est professeur d’informatique à l’École Polytechnique Fédérale de Lausanne (EPFL) et membre du comité de pilotage du Collège of Computing à l’UM6P. Il a été chercheur aux laboratoires Hewlett Packard de la Silicon Valley et professeur invité au MIT et au Collège de France. Serge Abiteboul et Pierre Paradinas.
Dans le film La Grande Vadrouille, Bourvil vole un uniforme de colonel allemand dans le hammam de la mosquée de Paris pour sauver un pilote britannique caché à l’opéra. Lors d’une représentation de Berlioz dirigée par De Funès devant les hauts gradés allemands, Bourvil, vêtu de son uniforme, accède aux coulisses sans être inquiété. La réalité dépasse parfois la fiction. En avril 2024, des malfrats ont dévalisé les habitants d’une petite commune française grâce à un stratagème ingénieux : l’un d’eux se faisait passer pour un plombier venu vérifier des fuites d’eau, puis ses complices, déguisés en policiers, prétendaient enquêter sur ce faux plombier pour accéder aux coffres des victimes.
Le monde numérique, lui, nous réserve des scénarios encore plus incroyables. Le vendredi 19 juillet 2024, des « policiers » virtuels ont pris la relève de leurs prédécesseurs pour mieux protéger les systèmes informatiques : aéroports, banques, hôpitaux, médias, administrations et entreprises. Leur mission : détecter d’éventuels intrus et les bloquer. Mais ces nouveaux « policiers », une fois introduits dans le cœur des systèmes, les ont bloqués au lieu de les protéger. Près de dix millions d’ordinateurs se sont arrêtés, entraînant un chaos mondial. Avant de tirer les leçons de cette panne informatique sans précédent, posons-nous quelques questions : Qui sont ces « policiers » ? Qui les a envoyés ? Pourquoi ont-ils remplacé les anciens systèmes qui semblaient fonctionner correctement ? Comment ont-ils pu pénétrer le cœur des systèmes et les bloquer à une telle échelle ?
Ces « policiers » sont des segments de programmes envoyés par des messages Internet aux systèmes Windows de Microsoft. Grâce à sa solution Office 365 (Word, Excel, PowerPoint, Outlook, Skype, Teams, etc.), Microsoft est le leader mondial de la bureautique, équipant plus d’un milliard d’utilisateurs. Windows, son système d’exploitation, fait tourner la majorité des ordinateurs de la planète. Les segments de programmes visent à renforcer la sécurité de Windows en s’intégrant au système existant pour contrôler son exécution.
Les messages contenant ces programmes sont envoyés automatiquement par le logiciel Falcon Sensor, hébergé sur le cloud pour le compte de Crowdstrike, un leader mondial de la cybersécurité. Crowdstrike s’est forgé une réputation grâce à ses enquêtes sur des cyberattaques majeures. Son logiciel Falcon Sensor analyse et bloque les attaques informatiques en s’adaptant de manière autonome aux nouvelles menaces, sans intervention humaine, ce qui a séduit Microsoft.
Ces mécanismes de défense jouissent de droits élevés (sous forme de « signatures »), et aucun autre logiciel ne peut les stopper. Ils s’introduisent au cœur du système Windows et s’exécutent avant les autres applications. Toutefois, le mécanisme envoyé le 19 juillet était défaillant. Une « erreur logique » dans un fichier de configuration critique a provoqué une « erreur physique » : des adresses mémoire ont été calculées incorrectement et affectées sans vérification, conduisant Windows à lancer sa procédure de blocage (« Blue Screen Of Death ») sur plus de 8 millions d’ordinateurs.
La panne a coûté plus d’un milliard de dollars. Elle aurait pu être pire, seulement 1 % des machines Windows ont été touchées, et l’envoi du mécanisme a été stoppé après 88 minutes. De nombreux vols ont été annulés, et des interventions médicales reportées, mais heureusement, aucune perte humaine n’est à déplorer.
Deux fausses bonnes idées ont été proposées par certains médias au lendemain de la panne :
Revenir au crayon et au papier pour se passer du numérique. C’est juste est irréaliste parce que le numérique fait désormais partie intégrante de notre quotidien.
La souveraineté numérique n’aurait pas prévenu la panne. Les États-Unis, très autonomes dans ce domaine, ont été touchés. Le fait que certains pays, comme la Chine et la Russie, s’en soient mieux sortis tient simplement à ce qu’ils n’utilisent pas Windows et Crowdstrike.
Par contre, je retiendrais au moins trois leçons de la panne :
Le numérique est un ensemble : les données, l’IA, les réseaux, les systèmes d’exploitation, la sécurité, etc., sont interconnectés et doivent être traités de manière globale. La conception d’un logiciel doit être vérifiée de bout en bout avec des méthodes de génie logiciel. Ajouter des segments de programmes à un logiciel certifié, sans revalider l’ensemble, est une faute grave.
La probabilité d’erreur n’est jamais nulle, même avec des tests et vérifications. Il ne faut donc pas dépendre d’une seule infrastructure. Ici, des millions de machines cruciales étaient toutes sous le même système d’exploitation et logiciel de sécurité. Espérons que les infrastructures informatiques ne dépendront plus uniquement de Microsoft et Crowdstrike à l’avenir.
Les architectures ouvertes et décentralisées sont essentielles. La plateforme blockchain de Bitcoin, attaquée régulièrement, fonctionne sans accroc majeur depuis 2009. Bien que le code soit accessible et modifiable par tous, il ne peut être déployé que s’il est accepté par la communauté, contrairement au code fermé de Falcon Sensor, déployé de manière non transparente.
En résumé, un logiciel devrait être considéré dans son intégralité et il faudrait vérifier ses algorithmes et tester sa mise en œuvre de bout en bout ; on ne doit pas dépendre d’un seul type de logiciel pour une infrastructure. critique ; et il faudrait privilégier les architectures ouvertes et décentralisées. Le législateur pourrait imposer aux sociétés informatiques d’ouvrir leurs logiciels et d’offrir des interfaces standards pour diversifier les fournisseurs. La résilience de l’infrastructure DNS, grâce à la diversité de ses implémentations, prouve que cet objectif est réalisable.
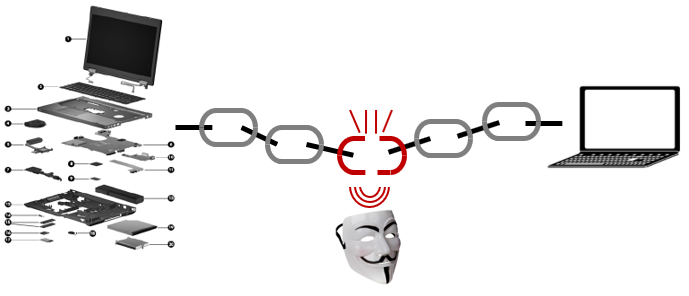
Les cyberattaques nous sont – malheureusement – devenues familières ; pas un jour où une nouvelle annonce d’une fuite de données ou du blocage d’un service numérique ne fasse la une de l’actualité. Si des spécialistes cherchent en permanence à concevoir des solutions visant à diminuer leur nombre et leur portée, il convient ensuite de les mettre en œuvre dans les systèmes numériques pour les contrer. L’histoire que nous racontent Charles Cuveliez et Jean-Charles Quisquater est édifiante : elle nous explique exactement tout ce qu’il ne faut pas faire ! Pascal Guitton
C’est une plainte en bonne et due forme qu’a déposée la Commission américaine de réglementation et de contrôle des marchés financiers (SEC) contre la société SolarWinds et son Chief Information Security Officer dans le cadre de l’attaque qu’elle a subie. Elle avait fait du bruit car elle a permis à des hackers de diffuser, depuis l’intérieur des systèmes de la société, une version modifiée du logiciel de gestion des réseaux que la compagnie propose à ses clients (Orion). Il faut dire que les dégâts furent considérables puisque les entreprises qui avaient installé la version modifiée permettaient aux hackers d’entrer librement dans leur réseau.
L’enquête de la SEC relatée dans le dépôt de plainte montre l’inimaginable en termes de manque de culture de sûreté, de déficience et de négligence, le tout mâtiné de mauvaise foi.
Absence de cadre de référence de sûreté
SolarWinds a d’abord prétendu et publié qu’il avait implémenté la méthodologie de l’agence chargée du développement de l’économie notamment en développant des normes (NIST, National Institute of Standards and Technology) pour évaluer les pratiques de cybersécurité et pour atténuer les risques organisationnels mais ce n’était pas vrai. Des audits internes ont montré qu’une petite fraction seulement des contrôles de ce cadre de référence était en place (40 %). Les 60% restants n’étaient tout simplement pas implémentés. SolarWinds, dans le cadre de ses évaluations internes, avait identifié trois domaines à la sécurité déficiente : la manière de gérer cette sécurité dans les logiciels tout au long de leur vie commerciale, les mots de passe et les contrôles d’accès aux ressources informatiques.
Un développement sans sécurité
Le logiciel de base qui sert à son produit Orion, faisait partie des développements qui ne suivaient absolument aucun cadre de sécurité. L’enquête a montré en 2018 qu’il y avait eu un début d‘intention pour introduire du développement sûr de logiciel mais qu’il fallait commencer par le début… une formation destinée aux développeurs pour savoir ce qu’est un développement sûr, suivi par des expériences pilotes pour déployer graduellement cette méthodologie, par équipe, sans se presser, sur une base trimestrielle. Entretemps, SolarWinds continuait à prétendre qu’elle pratiquait ses développements en suivant les méthodes de sécurité adéquates.
Mot de passe
La qualité de la politique des mots de passe était elle aussi défaillante : à nouveau, entre ce que SolarWinds prétendait et ce qui était en place, il y avait un fossé. La politique des mots de passe de SolarWinds obligeait à les changer tous les 90 jours, avec une longueur minimum et, comme toujours, imposait des caractères spéciaux, lettres et chiffres. Malheureusement, cette politique n’était pas déployée sur tous les systèmes d’information, applications ou bases de données. La compagnie en était consciente mais les déficiences ont persisté des années durant. Un employé de SolarWinds écrivit même un courriel au nouveau patron de l’informatique que des mots de passe par défaut subsistaient toujours pour certaines applications. Le mot de passe ‘password’ fut même découvert ! Un audit a mis en évidence plusieurs systèmes critiques sur lesquels la politique des mots de passe n’était pas appliquée. Des mots de passe partagés ont été découverts pour accéder à des serveurs SQL. Encore pire : on a trouvé des mots de passe non chiffrés sur un serveur public web, des identifiants sauvés dans des fichiers en clair. C’est via la société Akamai qui possède des serveurs un peu partout dans le monde et qui duplique le contenu d’internet notamment (les CDN, Content Distribution Networks) que SolarWinds distribuait ses mises à jour. Un chercheur fit remarquer à SolarWinds que le mot de passe pour accéder au compte de l’entreprise sur Akamai se trouvait sur Internet. Ce n’est pourtant pas via Akamai que la modification et la diffusion du logiciel eut lieu. Les hackers l’ont fait depuis l’intérieur même des systèmes de SolarWinds.
Gestion des accès
La gestion des accès c’est-à-dire la gestion des identités des utilisateurs, les autorisations d’accès aux systèmes informatique et la définition des rôles et fonctions pour savoir qui peut avoir accès à quoi dans l’entreprise étaient eux aussi déficients. La direction de SolarWinds savait entre 2017 et 2020 qu’on donnait de manière routinière et à grande échelle aux employés des autorisations qui leur permettaient d’avoir accès à plus de systèmes informatiques que nécessaires pour leur travail. Dès 2017, cette pratique était bien connue du directeur IT et du CIO. Pourquoi diable a-t-on donné des accès administrateurs à des employés qui n’avaient que des tâches routinières à faire ? Cela a aussi compté dans l’attaque.
Les VPN furent un autre souci bien connu et non pris en compte. A travers le VPN pour accéder au réseau de SolarWinds, une machine qui n’appartient pas à SolarWinds pouvait contourner le système qui détecte les fuites de données (data loss prevention). L’accès VPN contournait donc cette protection. Comme d’habitude, serait-on tenté de dire à ce stade, c’était su et connu de la direction. Toute personne avec n’importe quelle machine, grâce au VPN de SolarWinds et un simple identifiant (volé), pouvait donc capter des données, de manière massive sans se faire remarquer. En 2018, un ingénieur leva l’alerte en expliquant que le VPN tel qu’il avait été configuré et installé pouvait permettre à un attaquant d’accéder au réseau, d’y charger du code informatique corrompu et de le stocker dans le réseau de SolarWinds. Rien n’y fit, aucune action correctrice ne fut menée. En octobre 2018, SolarWinds, une vraie passoire de sécurité, faisait son entrée en bourse sans rien dévoiler de tous ces manquements. C’est d’ailleurs la base de la plainte de la SEC, le régulateur américain des marchés. Toutes ces informations non divulguées n’ont pas permis aux investisseurs de se faire une bonne idée de la valeur de la société. Solarwinds ne se contenta pas de mentir sur son site web : dans des communiqués de presse, dans des podcasts and des blogs, SolarWinds faisait, la main sur le cœur, des déclarations relatives à ses bonnes pratiques cyber.
Avec toutes ces déficiences dont la direction était au courant, il est clair pour la SEC que la direction de SolarWinds aurait dû anticiper qu’il allait faire l’objet d’une cyberattaque.
Alerté mais silencieux
Encore plus grave : SolarWinds avait été averti de l’attaque par des clients et n’a rien fait pour la gérer. C’est bien via le VPN que les attaquants ont pénétré le réseau de SolarWinds via des mots de passe volés et via des machines qui n’appartenaient pas à SolarWinds (cette simple précaution de n’autoriser que des machines répertoriées par la société aurait évité l’attaque). Les accès via le VPN ont eu lieu entre janvier 2019 et novembre 2020. Les criminels eurent tout le temps de circuler dans le réseau à la recherche de mots de passe, d’accès à d’autres machines pour bien planifier l’attaque. Celle-ci a donc finalement consisté à ajouter des lignes de code malicieuses dans Orion, le programme phare de SolarWinds, utilisé pour gérer les réseaux d’entreprise. Ils n’ont eu aucun problème pour aller et venir entre les espaces de l’entreprise et les espaces de développement du logiciel, autre erreur de base (ségrégation et segmentation). A cause des problèmes relevés ci-dessus avec les accès administrateurs, donnés à tout bout de champ, notamment, les antivirus ont pu être éteints. Les criminels ont ainsi pu obtenir des privilèges supplémentaires, accéder et exfiltrer des lignes de codes sans générer d’alerte. Ils ont aussi pu récupérer 7 millions de courriels du personnel clé de Solarwind.
Jusqu’en février 2020, ils ont testé l’inclusion de lignes de code inoffensives dans le logiciel sans être repérés. Ils ont donc ensuite inséré des lignes de code malicieuses dans trois produits phares de la suite Orion. La suite, on connait : ce sont près de 18 000 clients qui ont reçu ces versions contaminées. Il y avait dans ces clients des agences gouvernementales américaines.
On s’est bien retranché, chez SolarWinds, derrière une soi-disant attaque d’un État pour justifier la gravité de ce qui s’est passé et sous-entendre qu’il n’y avait rien à faire pour la contrer mais le niveau de négligence, analyse la SEC, est si immense qu’il ne fallait pas être un État pour mettre en œuvre Sunburst, le surnom donné à l’attaque. Il y a aussi eu des fournisseurs de service (MSP) attaqués : ceux-ci utilisent les produits de SolarWinds pour proposer des services de gestion de leur réseau aux clients, ce qui donc démultipliait les effets.
Alors que des clients ont averti que non seulement le produit Orion était attaqué mais que les systèmes même de SolarWinds étaient affectés, la société a tu ces alertes. Elle fut aussi incapable de trouver la cause de ces attaques et d’y remédier. SolarWinds a même osé prétendre que les hackers se trouvaient déjà dans le réseau des clients (rien à avoir avec SolarWinds) ou que l’attaque était contre le produit Orion seul (sur laquelle une vulnérabilité aurait été découverte par exemple) alors que cette attaque avait eu lieu parce que les hackers avaient réussi à infester le réseau de SolarWinds
Pour la SEC, le manque de sécurité mise en place justifie déjà à lui seul la plainte et l’attaque elle-même donne des circonstances aggravantes.
L’audit interne a montré que de nombreuses vulnérabilités étaient restées non traitées depuis des années. De toute façon le personnel était largement insuffisant, a pu constater la SEC dans les documents internes, pour pouvoir traiter toutes ces vulnérabilités en un temps raisonnable. On parlait d’années. Lors de l’attaque, SolarWinds a menti sur ce qui se passait. Au lieu de dire qu’une attaque avait lieu, SolarWinds avait écrit que du code dans le produit Orion avait été modifié et pourrait éventuellement permettre à un attaquant de compromettre les serveurs sur lesquels le produit Orion avait été installé et tournait !
Que retenir de tout ceci ? Il ne faut pas se contenter des déclarations des fournisseurs sur leurs pratiques de sécurité. En voilà un qui a menti tout en sachant que son produit était une passoire. Ce qui frappe est la quantité d’ingénieurs et d’employés qui ont voulu être lanceurs d’alerte au sein de SolarWinds. Ils ne furent pas écoutés. Faut-il légiférer et prévoir une procédure de lanceur d’alerte sur ces matières-là aussi vers des autorités ? On se demande aussi si dans tous les clients d’Orion, il n’y en a eu aucun pour faire une due diligence avec des interviews sur site. Il est quasiment certain que des langues se seraient déliées.
Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT) & Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles)
Pour en savoir plus : Christopher BRUCKMANN, (SDNY Bar No. CB-7317), SECURITIES AND EXCHANGE COMMISSION, Plaintiff, Civil Action No. 23-cv-9518, against SOLARWINDS CORP. and TIMOTHY G. BROWN
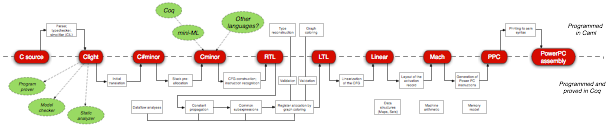
Sandrine Blazy, Professeure à l’université de Rennes et directrice adjointe de l’IRISA, est une spécialiste des compilateurs et des logiciels sûrs. Elle a développé avec Xavier Leroy, CompCert, le premier compilateur pour le langage C vérifié à l’aide de Coq. Pour ce véritable tour de force scientifique et technique, elle a obtenu la médaille d’argent du CNRS (une des plus belles récompenses scientifiques en France). Si vous ne comprenez pas en quoi cela consiste, Sandrine va l’expliquer à binaire et ce sera l’occasion d’un peu mieux comprendre ce qui se passe dans un ordinateur.Serge Abiteboul et Pierre Paradinas
La sémantique de ces langages et la vérification déductive
Dès l’invention des premiers langages de programmation, s’est posée la question de savoir comment définir précisément un langage, c’est-à-dire comment décrire le comportement de tout programme. Une première réponse pragmatique a été de considérer qu’un langage est défini par son compilateur (compiler le programme pour l’exécuter ensuite et observer certains de ses comportements). Une seconde réponse est venue à nouveau des mathématiques, cette fois-ci de la logique mathématique. En effet, indépendamment du développement des premiers ordinateurs, des logiciens ont proposé des théories des langages de programmation, focalisées sur des langages de programmation théoriques, comme le lambda calcul de Church (1930), dont les principes seront par la suite mis en œuvre dans les langages de programmation fonctionnelle. Ainsi sont apparus les formalismes fondamentaux caractérisant un langage de programmation, notamment la syntaxe, la sémantique formelle (caractériser sans ambiguïté le comportement attendu de tout programme, quelles que soient ses valeurs fournies en entrée) et ses différents styles, et les principes de raisonnement déductif associés. Ces formalismes sont toujours l’objet de recherches actives.
Un de ces styles sémantiques est à l’origine de la vérification déductive, qui permet d’avoir des garanties très fortes sur l’absence d’erreurs dans les logiciels. Cela été l’occasion de revisiter et pousser plus loin les premières intuitions de Turing lorsqu’il avait démontré la correction de son organigramme. La vérification déductive permet de démontrer mathématiquement la correction d’un logiciel, c’est-à-dire qu’il satisfait sa spécification, écrite dans un langage logique pour éviter toute ambiguïté du langage humain. Aujourd’hui, grâce à la vérification déductive, on dispose de logiciels vérifiés, constitués d’un logiciel et d’une preuve de sa correction, qu’on peut rejouer ou fournir à un tiers de confiance. Cette preuve nécessite de raisonner sur des propriétés du langage dans lequel est écrit le logiciel, en particulier sur la sémantique formelle de ce langage.
Avec des langages réalistes, le raisonnement ne peut plus se faire à la main, mais il nécessite d’être automatisé par des outils logiciels d’aide à la preuve. Les premiers de ces outils sont apparus au début des années 70. De même que les premières machines ont été conçues pour mécaniser la résolution d’équations, les sémantiques formelles et la logique ont permis de mécaniser le raisonnement déductif sur les programmes, et donc de développer les outils logiciels automatisant les idées issues des intuitions de la fin des années 60. Ces outils ont beaucoup progressé ces dernières années. Ils se regroupent en deux familles :
les logiciels de preuve automatique, qui prennent en charge la totalité d’une preuve, en déchargeant les formules logiques à prouver vers des solveurs de logique capables de déterminer si ces formules sont vraies ou fausses; et
les assistants à la preuve, des logiciels qui permettent de mener une preuve mathématique vérifiée par ordinateur, c’est-à-dire une démonstration en interaction avec l’assistant de preuve, au moyen de commandes indiquant comment progresser. L’assistant de preuve automatise une partie du raisonnement, s’assure que la démonstration est complète et respecte les lois de la logique mathématique, alors que l’utilisateur décide comment raisonner et progresser dans le raisonnement.
Mener une preuve de correction est une activité à part entière, qui nécessite d’inventer puis établir les invariants (sémantiques) du logiciel, qui sont des assertions devant être garanties à tout moment de l’exécution du programme. Cela peut nécessiter de définir les principes de raisonnement associés. Le programme “majorité” (Boyer, Moore, 1980) déterminant de façon efficace le candidat majoritaire (i.e., qui remporte une élection à scrutin majoritaire) d’un ensemble de bulletins de vote en est une illustration. Le programme est surprenant de par sa simplicité, mais sa compréhension demande à réfléchir à son invariant qui est difficile à trouver, car cela nécessite d’imaginer un arrangement des bulletins de vote, qui n’est pas calculé par le programme. On se retrouve ainsi dans le cas plus général où il est nécessaire d’inventer pour les besoins de la preuve une structure de données qui n’est pas utile au programme.
Retournons au début des années 70. Le premier programme dont la preuve a été mécanisée est un compilateur rudimentaire d’un langage d’expressions arithmétiques (Milner, 1972, LCF). Un compilateur était un exemple représentatif d’un programme particulièrement complexe. Le théorème de correction d’un compilateur exprime que le code produit doit s’exécuter comme prescrit par la sémantique du programme source dont il est issu. C’est une propriété de préservation sémantique, qui devient mathématiquement précise dès lors qu’on dispose de sémantiques formelles (pour les langages source et cible du compilateur). Ici, il devient : pour toute expression, sa valeur calculée par la sémantique du langage source est exactement la valeur renvoyée par l’exécution du code de l’expression compilée. Ce théorème est établi une seule fois, pour toute expression donnée en entrée au compilateur. Désormais, la vérification de ce petit compilateur jouet de 1972 est enseignée à titre d’exercice dans des cours de master.
Aujourd’hui, le compilateur demeure un logiciel particulièrement complexe (de par les nombreuses optimisations qu’il effectue afin de produire du code efficace), mais également le point de passage obligé dans la chaîne de production du logiciel. Aussi, le vérifier permet de s’assurer qu’aucune erreur n’est introduite lors de la compilation, et de préserver les garanties obtenues au niveau source sur le logiciel. L’idée d’avoir un théorème unique démontré une fois pour toutes, ainsi qu’une preuve lisible était déjà présente en 1972, mais il a fallu attendre plusieurs dizaines d’années pour que la compilation vérifiée se développe et passe à l’échelle.
CompCert est le premier compilateur optimisant ciblant plusieurs architectures et utilisé dans l’industrie, qui soit doté d’une preuve mathématique de correction vérifiée par ordinateur. Cette preuve a été menée avec l’assistant à la preuve Coq. C’est un compilateur modérément optimisant du langage C, le langage le plus utilisé dans l’industrie pour programmer des logiciels embarqués critiques, dont le mauvais comportement peut avoir des conséquences catastrophiques. C’est aussi un projet de recherche qui a démarré il y a vingt ans, et également un logiciel commercialisé par la société AbsInt, qui a été employé dans l’industrie pour compiler des logiciels embarqués critiques utilisés dans l’avionique et le nucléaire. Dans ces domaines, l’intérêt pour CompCert a résulté d’un besoin d’améliorer les performances du code produit, tout en garantissant des exigences de traçabilité requises par les processus de développement en vigueur dans ces domaines critiques, ce qu’a effectivement permis CompCert.
Le langage C a été conçu au début des années 70, afin de laisser davantage de liberté aux écrivains de compilateurs pour programmer au plus près de la machine. Ce langage n’a pas été conçu avec l’optique d’être mathématiquement défini. Établir la correction de CompCert a nécessité de définir une sémantique formelle du langage C qui décrit non seulement des programmes fournissant un résultat final (comme le compilateur jouet de 1972), mais aussi des programmes dont l’exécution ne termine jamais, comme ceux utilisés par les commandes de vol d’un avion. Le théorème de correction établit que ces comportements sont préservés lors de la compilation.
Pour mener cette preuve, il a fallu résoudre plusieurs défis :
se fonder sur des formalismes adaptés,
avoir des principes de raisonnement associés (notamment proposer un style sémantique adapté au raisonnement inductif), et plus généralement une méthodologie de preuve passant à l’échelle, et enfin,
disposer d’outils logiciels facilitant la mise en oeuvre de ces formalismes et automatisant le raisonnement.
CompCert a reçu plusieurs récompenses, dont l’ACM software system award en 2022, le prix le plus prestigieux décerné à un logiciel issu de la recherche, qui a par la passé été décerné aux compilateurs C les plus utilisés, GCC (2015) et LLVM (2012).
CompCert est un jalon. Il a montré qu’il est désormais possible de mener des preuves sur des objets aussi complexes que des compilateurs réalistes. Les formalismes et la méthodologie de preuve qu’il propose ont été réutilisés dans plusieurs projets de recherche en France et à l’étranger. Par exemple, à Rennes, nous poursuivons nos travaux dans le but de doter CompCert de davantage de possibilités de compilation, et d’offrir des garanties supplémentaires en matière de sécurité logicielle.
Sandrine Blazy, Professeure à l’université de Rennes et directrice adjointe de l’IRISA, est une spécialiste des compilateurs et des logiciels sûrs. Elle a développé avec Xavier Leroy, CompCert, le premier compilateur pour le langage C vérifié à l’aide de Coq. Pour ce véritable tour de force scientifique et technique, elle a obtenu la médaille d’argent du CNRS (une des plus belles récompenses scientifiques en France). Si vous ne comprenez pas en quoi cela consiste, Sandrine va l’expliquer à binaire et ce sera l’occasion d’un peu mieux comprendre ce qui se passe dans un ordinateur.Serge Abiteboul et Pierre Paradinas
Les liens entre mathématiques et informatique sont féconds. Dans les années quarante, la nécessité de mécaniser des calculs numériques permettant de résoudre des équations mathématiques a permis le développement des premières machines de calcul à grande échelle, qui ont préfiguré les premiers ordinateurs. Ces calculateurs universels enchaînaient en séquence des opérations mathématiques élémentaires, décomposant des calculs modélisant des phénomènes physiques. Aujourd’hui, ces calculs sont réalisés par une simple calculette de bureau.
Chaque opération était fidèlement décrite par un code constitué de commandes compréhensibles par la machine, c’est-à-dire des suites de chiffres zéros et un (signifiant l’absence et la présence de courant dans les composants d’un circuit électronique). Aussi, faire exécuter une opération par un calculateur était une véritable gageure. Les experts dont c’était le travail devaient encoder l’opération (c’est-à-dire trouver les nombres adéquats pour représenter l’opération, ainsi que les valeurs auxquelles elle s’appliquait qui étaient encodées sur des cartes perforées), en plus d’effectuer des manipulations physiques sur la machine. Ces experts écrivaient ces codes sur papier, avant de les fournir à la machine, dont ils devaient de plus comprendre le fonctionnement électromécanique. Ces premières machines étaient gigantesques et complexes à manipuler. En guise d’écran, des marteaux (tels que ceux utilisés par les machines à écrire) imprimaient sur papier des caractères. Par contre, elles avaient l’avantage de fonctionner sans cesse et d’accélérer grandement les temps de calcul de chaque opération, en enchaînant en des temps records des successions de calculs variés, ce qui a fait leur succès.
Le succès aidant et les calculs devenant de plus en plus complexes, il a été nécessaire de rendre l’écriture des codes moins absconse et d’automatiser davantage l’enchaînement des calculs. Une première réponse a été l’utilisation répandue d’une notation plus expressive et graphique (à l’aide de boîtes reliées par des flèches) pour représenter l’enchaînement des calculs. Les diagrammes résultants, appelés organigrammes permettaient de représenter simplement non seulement des séquences de calculs, mais aussi des décisions à prendre en fonction de résultats intermédiaires, et donc des enchaînements plus sophistiqués de calculs (comme la répétition d’étapes de calculs jusqu’à atteindre un certain seuil). Ces diagrammes permettaient de s’abstraire du matériel, et de décomposer un problème avant d’écrire du code. Plus faciles à comprendre par des humains, ils permettaient de réutiliser une opération lorsque la machine évoluait en fonction des progrès technologiques fréquents.
L’expressivité des organigrammes a favorisé l’émergence d’”algorithmes”, c’est-à-dire d’enchaînements plus efficaces des calculs (c’est-à-dire réduisant le temps de calcul), du fait de la représentation particulière des nombres en machine. Par exemple, en 1949, Alan Turing a proposé une nouvelle façon de calculer la fonction mathématique factorielle, sans utiliser les opérations coûteuses de multiplication mais seulement des additions. Il se demande alors comment être sûr que ce que calcule son organigramme est effectivement le même résultat que celui de la fonction factorielle du mathématicien, en d’autres termes que son organigramme est correct. Pour y répondre, il a effectué ce qu’on appellerait aujourd’hui la première preuve de programme, en annotant son organigramme avec des assertions, dont il a ensuite vérifié la cohérence.
L’effort pour démocratiser la mécanisation des calculs s’est poursuivi avec l’invention des premiers langages de programmation. Les organigrammes ont fait place au pseudo-code, puis aux algorithmes et programmes écrits dans un langage dont la syntaxe est plus intuitive. Un langage de programmation définit un ensemble de commandes abstraites mais précises pour effectuer toutes les opérations exprimables dans un organigramme, avec des mots-clés en anglais (plus faciles à appréhender que les seuls nombres d’un code). Le premier livre sur la programmation paraît en 1951, alors que très peu de machines sont en service; il est utilisé pour des recherches en physique, astronomie, météorologie et biochimie.
Les langages de programmations et les compilateurs
Le langage de programmation devient un intermédiaire nécessaire entre l’humain et la machine, et il devient indispensable d’automatiser la traduction des programmes en code machine. Le premier compilateur A-0 mis au point par Grace Hopper est disponible en 1952. Ce terme résulte de son premier usage, mettre bout à bout des portions de code, à la manière d’une bibliothécaire qui rassemble des documents sur un sujet précis. Pour expliquer de plus les possibilités prometteuses offertes par un tel programme de traduction (d’un langage source en un code machine), Grace Hopper utilise la métaphore d’une ligne de production dans une usine, qui produirait des nombres (plutôt que des automobiles) et plus généralement des données au moyen d’outils (tables de calcul, formules, calculs numériques).
Le compilateur devient un point de passage obligé pour traduire tout programme écrit par un humain en un code compréhensible par la machine, et la traduction de l’un vers l’autre est un défi scientifique. En effet, un problème se pose du fait de la faible vitesse des calculs, des capacités très limitées de stockage, mais aussi de l’abstraction et la généralité des programmes écrits : plus le programme source est facile à comprendre pour un humain, moins l’exécution du code machine engendré est efficace.
En 1953, le langage Fortran est le premier à être dédié au calcul numérique, et donc à s’abstraire du matériel spécifique à une machine. C’est aussi le premier qui devient un standard: pour la première fois, les programmeurs parlent un même langage, quelle que soit la machine qu’ils utilisent. IBM consacre un effort notable à développer son compilateur, afin qu’il produise un code efficace. C’est le début de l’invention de nouvelles techniques de compilation, les premières optimisations (ex. compiler séparément des portions de code, ou encore détecter des calculs communs pour les factoriser). Le manuel de Fortran est disponible en 1956, et son compilateur en 1957.
Cet effort pour démocratiser la programmation se poursuit avec le langage Cobol dédié au traitement des données. Désormais, l’ordinateur ne calcule pas que des nombres; il permet plus généralement de structurer des données et de les traiter efficacement. COBOL ouvre la voie à de nouvelles applications. Le premier programme COBOL est compilé en 1960; en 1999 la grande majorité des logiciels seront écrits en COBOL, suite à son utilisation massive dans les domaines de la banque et de l’assurance. Ainsi, dans les années 60, la pratique de la programmation se répand et devient une science; les langages de programmation foisonnent. Aujourd’hui encore, les langages de programmation évoluent sans cesse, pour s’adapter aux nouveaux besoins.
Nos collègues chercheurs Charles CUVELLIEZ et Jean-Jacques QUISQUATER nous proposent un angle original pour traiter les risques de cyberattaques : celui des assureurs. A partir d’un rapport publié par la société d’assurance Allianz Global Corporate Services (AGCS), ils nous expliquent les évolutions, à la fois dans les attaques mais surtout dans leur prise en charge qui ne se réduit plus qu’à une question informatique mais qui rejoint la responsabilité sociétale des entreprises (RSE) . Pascal Guitton et Thierry Viéville
ll y a de la sophistication et de l’imagination dans l’air, si l’on en croit le rapport d’Allianz Global Corporate Services (AGCS) sur la menace cyber. Dans son rôle de vigie, un assureur a évidemment des choses à nous dire qu’il vaut mieux savoir….
On connaissait déjà les doubles extorsions dans le cas des rançongiciels. Les criminels demandent non seulement une rançon pour débloquer les données chiffrées par le rançongiciels mais aussi pour ne pas dévoiler les données qu’ils auront pris soin d’exfiltrer avant le chiffrement. Place à la triple extorsion ! Désormais, les criminels qui se trouvent en possession de données des clients ou de fournisseurs de la victime leur demandent aussi une rançon ! Les rançons sont maintenant calculées avec précision par les groupes de criminels, par rapport aux capacités de la victime à payer. En réalité, le volume de cibles faciles diminue car tout le monde fait désormais des efforts en cybersécurité. Les criminels essaient dès lors d’exploiter au maximum les attaques qui réussissent et font tout pour arriver à extorquer de l’argent en harcelant au maximum leurs victimes. Et cela marche : en 2021, les demandes de rançon ont augmenté de 144 % et le paiement moyen des rançons de 78 % d’après des chiffres récoltés auprès de Palo Alto Networks. Près de la moitié des victimes, 46 % pour être précis, ont payé la rançon. Ce sont les secteurs manufacturiers et les services publics qui sont les plus vulnérables : ils sont moins bien protégés et une interruption de service trop longue leur met la pression. C’est dans ces secteurs qu’on trouve les rançons moyennes les plus élevées, de l’ordre de 2 millions d’USD.
Législation rançongiciel
Plusieurs états sont occupés à construire des législations pour cadrer le paiement des rançons, à défaut de les interdire. Ces paiements doivent parfois être justifiés, rapportés ou connus. En 2021, seulement 1 % des états avait une législation en ce sens ; AGCS prévoit qu’en 2025, ce pourcentage atteindra 30 %. Renforcer le cadre légal autour des rançons rendra les paiements moins faciles et plus transparents. Il forcera les entreprises à en faire plus pour se protéger mais en contrepartie, nul doute que les cybercriminels trouveront d’autres manières de monétiser les cyberattaques. Les petites et moyennes sociétés sont toujours les cibles de choix pour les rançongiciels, parce que la plupart d’entre elles ne gèrent pas (encore) les risques et ne mettent pas en place des contrôles cyber performants. Quand une grande entreprise (avec un chiffre d’affaires de plus de 100 millions de USD) est quand même frappée par un rançongiciel, la cause est très souvent un trou de sécurité laissé béant et passé inaperçu. C’est le cas de 80 % des sinistres déclarés à AGCS.
Business Email Compromise
Autre évolution, l’attrait croissant pour les Business Email Compromise : des boites email sont piratées et leur contenu, qui a fuité, sert à d’autres criminels pour récupérer les adresses des futures victimes, pour initier des paiements indus ou pour collecter de l’information sensible. Les données volées sont offertes, avec indexation, dans le dark web à d’autres criminels : il est alors facile de copier le format d’une facture ou de faire le suivi d’un courrier trouvé dans la messagerie (en le détournant à son avantage). Attention aussi à l’utilisation des plateformes de communication ou de réunion qui associent de plus en plus fournisseurs, clients et l’entreprise elle-même : elles sont d’autres vecteurs de collecte d’information ou de fraude à la présidence (qui consiste pour un criminel à se faire passer pour un dirigeant de la société pour solliciter en urgence un paiement à un tiers). Est-on toujours bien sûr que toutes les personnes qui sont connectées sur une plate-forme dans le cadre d’une réunion ont bien à s’y trouver ? Qui ne s’est jamais demandé quel était ce profil qui ne dit rien (au sens propre et figuré) présent lors d‘une téléconférence ?
Clause de guerre dans les cyberasssurances
La guerre en Ukraine va amener une clarification des clauses des contrats qui excluent de la couverture des faits de guerre. Il est temps car les attaques cyber sont une composante clé des guerres hybrides. Tout devient alors fait de guerre. Il faudra faire bien attention aux renouvellements des contrats qui seront de plus en plus précis sur ce point.
Quant à l’impact des cyberattaques, on (ne) sera (pas trop) étonné d’apprendre qu’il se situe principalement au niveau de l’interruption du travail occasionné dans l’entreprise victime : 57 % des déclarations de sinistres et des dégâts associés ont trait à ce type de perte. Et ce ne sont pas que les attaques cyber qui en sont à l’origine : des simples problèmes informatiques (matériel ou logiciel), des erreurs humaines ou des soucis du même type chez les fournisseurs en sont à l’origine.
Il devient aussi de plus en plus difficile de souscrire une assurance pour couvrir les dommages liés aux cyberattaques: on observe un mouvement des entreprises vers des captives d’assurance (c’est-à-dire créer au sein de l’entreprise sa propre compagnie d’assurance pour s’auto-assurer) en y associant parfois d’autres entreprises. Elles auto-financent leurs propres assurances et peuvent alors faire appel à de la réassurance. Airbus, Michelin et BASF ont ainsi créé leur propre captive – Miris Insurance – dédiée au risque cyber qu’ils ont établie en Belgique (avec Veolia, Adeo, Sonepar et Solvay) . Publicis les a suivis.
Ce qui est certain, c’est que la cybersécurité est en train de migrer dans le domaine (vaste) des RSE : l’impact d’une cyberattaque devient tellement important sur le fonctionnement d’un pays et sa population, sur la vie d’un secteur d’activité, qu’il en va de la responsabilité sociétale de l’entreprise de l’éviter. Pensons aussi aux données de clients qui s’évanouissent dans la nature, aux hôpitaux ou aux transports publics paralysés.
Placer la cybersécurité dans les risques de gouvernance, de société et d’environnement va lui donner une autre dimension qui ne la réduira plus à un problème informatique auquel on s’habitue.
Les cyberattaques sont de plus en plus nombreuses, de plus en plus inquiétantes et touchent tant les entreprises, les états que les individus (1). Malgré ce constat, la cybersécurité est-elle suffisamment prise au sérieux par tous les acteurs ? Et dans ce domaine comme dans d‘autres, ne dépendons-nous pas trop de technologies venues d’ailleurs ouvrant ainsi la voie à des vulnérabilités supplémentaires ? Nous avons demandé à deux collègues, Hubert Duault et Ludovic Mé, spécialistes de cybersécurité de nous éclairer. Il semble que la France, qui avait déjà des atouts dans ce domaine, ait choisi de forcer l’allure. Cocorico ! Serge Abiteboul et Pascal Guitton.
L’actualité nous rappelle quasi-quotidiennement combien la transformation numérique des entreprises, des administrations et de l’ensemble de la société a fait de la cyber sécurité un enjeu majeur. Il est même parfois souhaitable de choisir des fournisseurs de produits ou de services de sécurité en fonction du contexte géopolitique. La guerre en Ukraine a ainsi conduit récemment nombre d’acteurs à un changement de solution antivirale. La maîtrise d’une offre nationale et européenne de technologies et services de cyber sécurité apparait donc indispensable à l’exercice de notre souveraineté numérique.
Dans ce contexte, le constat dressé en 2015 dans le cadre du plan cyber sécurité pour la nouvelle France industrielle[1] reste d’actualité : la filière industrielle française en cyber sécurité se caractérise par l’existence de quelques grands groupes, très orientés vers le marché de la défense, et de nombreuses petites ou très petites entreprises, à l’expertise parfois très grande, mais qui ne peuvent pas viser un marché très large. On peut ajouter que les solutions nationales peuvent en outre, même sur leur marché local, être ignorées au profit de celles de grands acteurs internationaux. Face à ce constat, la revue préconise en particulier d’inciter les grands industriels à davantage investir les marchés civils, de favoriser la création d’ETI à partir des PME les plus prometteuses, de multiplier le nombre de startup innovantes. Cette dernière préconisation s’appuie bien entendu sur la stimulation de l’innovation publique et privée.
Si recherche et innovation technologique sont des concepts distincts, ils sont évidemment très liés. La recherche consiste à produire des connaissances nouvelles ; le transfert de ces connaissances vers le monde économique participe à l’innovation. Dans certains domaines, les connaissances produites sont plus directement exploitables. C’est le cas de la cyber sécurité, domaine pour lequel la composante technologique est essentielle puisqu’il faut tenir compte pour la sécuriser efficacement de la réalité des machines existantes : leurs bases matérielles (hardware), leurs systèmes d’exploitation, leurs logiciels, les technologies réseau qui permettent de les faire communiquer.
On sait cependant que le transfert technologique, qui implique de passer d’un prototype de recherche prouvant la validité d’un concept à un produit minimal, demande un travail important. Pour soutenir ce transfert, les interactions entre les entreprises et les équipes de recherche doivent être facilitées et renforcées, afin de rendre plus aisée l’identification de problèmes industriels intéressant les chercheurs, dont les travaux seront alors susceptibles d’apporter des réponses à des besoins concrets dans le cadre de cas d’usage réels.
Le Campus Cyber
Dans le cadre de France 2030[2], une « stratégie d’accélération[3] Cybersécurité[4] » a été définie, dont une des priorités est précisément de renforcer les liens entre les acteurs de la filière, comprise ici au sens large d’un écosystème d’innovation intégrant chercheurs, start-up, PME, grands industriels, utilisateurs, services de l’État, acteurs de la formation, capital-risqueurs. Cette stratégie d’accélération repose sur la conviction que la réponse aux enjeux de la cyber sécurité passe par une implication équilibrée et sans exclusive de l’ensemble des acteurs cet écosystème. Une opération majeure concrétisant cette vision a été la création, début 2022, du « Campus Cyber » localisé à la Défense près de Paris. Ce campus regroupe d’ores et déjà près d’un millier de personnes dans un espace commun d’environ vingt mille mètres-carrés. Cette logique est en outre déclinée dans certaines régions, où des « campus cyber territoriaux » sont en cours de création.
Campus Cyber
Le Campus Cyber ambitionne de fédérer les acteurs industriels et de la recherche en multipliant les échanges et en développant une dynamique collective dépassant les clivages habituels. Il vise à apporter à chacun de ses membres des avantages en termes de performances et de compétitivité. A cette fin, il propose un accès à des moyens communs, comme le partage d’information sur les menaces cyber. Il permet de colocaliser des équipes et de jouer sur l’effet de proximité pour développer des partenariats entre elles. Il offre à ses membres une visibilité et une capacité de communication visant à les rendre plus visibles sur la carte de la cyber sécurité européenne et mondiale. Enfin, il entend aussi favoriser la formation initiale et continue en cyber sécurité, action essentielle quand le recrutement de talents est une difficulté majeure pour tous les acteurs de la filière, quel que soit leur type. Le Campus Cyber se positionne ainsi très clairement sur le triptyque Formation-Recherche-Innovation et Entrepreneuriat.
Programme de Transfert du Campus Cyber
La communauté académique française en cyber sécurité est constituée de chercheurs d’organismes de recherche (principalement le CEA, le CNRS et Inria) et d’enseignants-chercheurs d’universités et d’écoles d’ingénieurs. La majorité de ces personnels sont en fait souvent regroupées dans des équipes communes à plusieurs institutions, par exemple dans le cadre d’Unités Mixte de Recherche (UMR) du CNRS ou d’équipe-projet Inria. En outre, cette communauté est animée globalement sur le plan scientifique dans le cadre du groupement de recherche (GDR) en sécurité informatique, auquel participent tous les acteurs. L’implication de ces mêmes acteurs dans le Campus Cyber passe par un programme spécifique piloté par Inria, baptisé Programme de Transfert du Campus Cyber (PTCC). Doté de quarante millions d’euros, ce programme permet en particulier, en cohérence avec les objectifs du Campus Cyber, de susciter et d’assurer la mise en œuvre de projets de recherche cherchant à lever des verrous technologiques actuels et considérés comme importants par des industriels et des organismes étatiques telle que l’Agence Nationale pour la Sécurité des Système d’Information (ANSSI). Plusieurs projets de ce type sont d’ores et déjà en cours de montage pour un lancement avant la fin 2022. Ces projets disposeront d’espaces et de facilités (plateformes numériques, Fab Lab) installées sur le Campus Cyber. Le PTCC va aussi permettre de soutenir la création et le développement d’entreprises innovantes, tout particulièrement en continuité des projets qui auront été réalisés. Enfin, le PTCC va également inclure un volet formation, répondant au besoin des entreprises en exploitant l’expertise de la communauté académique.
Programmes et Équipements Prioritaires de Recherche
La stratégie nationale d’accélération en cyber sécurité intègre aussi un programme spécifique destinée au monde académique, via une action baptisée « Programmes et Équipements Prioritaires de Recherche » (PEPR). Il s’agit de susciter et mettre en œuvre des projets de recherche sur des sujets estimés prioritaires, projets qui devront chercher à produire de nouvelles connaissances (on pourrait parler de recherche amont), même si l’objectif de transfert à terme est souhaité.
La communauté académique française est internationalement reconnue pour son excellence dans certains sous-domaines de la cyber sécurité, tels que la cryptographie et les méthodes formelles. En revanche, d’autres sous-domaines sont moins clairement perçus au niveau international et demandent à être renforcés. Doté de soixante-cinq million d’euros et piloté conjointement par le CEA, le CNRS et Inria, le PEPR Cybersécurité vise donc à maintenir et développer l’excellence de la recherche française en cyber sécurité dans ses sous-domaines forts, tout en en renforçant son impact là où elle est actuellement moins présente. Au final, le souhait est clairement de créer les conditions permettant à terme de produire des produits et services de sécurité souverains dans les différents sous-domaines.
Réunion de lancement du PEPR Cybersécurité – Crédit photo : Inria – E. Marcadé
Pour identifier les thématiques des projets des PEPR, l’état a mis en œuvre une démarche à mi-chemin entre financement pérenne et appels à projets ouverts. Ainsi, en consultant des instances jugées représentatives de la communauté de recherche en cyber sécurité, ont été identifiés des sujets d’importance, pour lesquels il pouvait exister une recherche nationale forte ou bien pour lesquels cette recherche demandait à être renforcée. Chacun de ces sujets a ensuite été confié à un ou une scientifique reconnue pour ses travaux antérieurs sur ce sujet et, sur la base de sa connaissance du milieu scientifique national, cette personne a rassemblé un groupe de chercheurs qui a proposé des travaux précis à réaliser dans les 6 ans à venir.
Cette démarche, jugée insuffisamment ouverte par une partie de la communauté, a bousculé les habitudes du monde académique. Son objectif était de répondre à certaines imperfections des modes de financement usuels. Les financements pérennes ne facilitent pas toujours l’émergence spontanée et rapide de compétences dans des thématiques jusque-là peu explorées. Les financements par appels à projets, qui impliquent la constitution de consortium soumettant une réponse qui sera jugée à priori par un comité de sélection constitué de pairs, et qui entrainent le rejet de nombreuses propositions et par là-même le gâchis d’une part importante du travail réalisé par les soumissionnaires.
Au final, sept projets ont ainsi été construits ces derniers mois. Ils impliquent environ 200 chercheurs et enseignants-chercheurs permanents spécialistes de plusieurs disciplines (mathématiques, informatique, électronique, traitement du signal). Ils permettront en outre à près de cent cinquante doctorants de réaliser une thèse dans le domaine de la cyber sécurité. Enfin, des postdoctorants et des ingénieurs de recherche seront aussi financés. Le rôle de ces derniers est particulièrement important dans l’optique du transfert technologique à moyen terme qui est recherché.
Ces sept projets du PEPR visent à étudier la sécurisation du matériel, du logiciel et des données. Lancés en juin 2022, ils portent sur la protection des données personnelles (solutions théoriques et techniques compatibles avec la réglementation française et européenne et tenant compte des contraintes d’acceptabilité), la sécurité des calculs (mécanismes cryptographiques permettant d’assurer la sécurité des données y compris lors du traitement de ces données en environnement non maîtrisé comme dans le Cloud), la vérification des protocoles de sécurité permettant de prouver une identité ou de voter à distance, par exemple (vérification tant au niveau des spécifications de ces protocoles que de leurs implémentations), la défense contre les programmes malveillants (virus comme les rançongiciels, botnet, etc.), la supervision de la sécurité (détection et réponse aux attaques informatiques), la sécurisation des processeurs (RISC-V 32 bits utilisés pour le objets de « l’internet des objets » et à sécuriser contre des attaques physiques ; RISC-V 64 bits utilisés pour des applications plus riches et à sécuriser contre les attaques logicielles exploitant des failles matérielles), la recherche de vulnérabilités (ou la preuve d’absence de telles vulnérabilités). En outre, trois autres projets seront financés prochainement, mais cette fois sur la base d’un appel à projets ouvert opéré par l’Agence Nationale de la Recherche (ANR). Les thématiques retenues pour cet appel à projets sont la protection des données multimédias (marquage vidéo, biométrie, sécurité des systèmes à base d’intelligence artificielle), les techniques d’exploitation des vulnérabilités, la cryptanalyse (recherche de problème dans les primitives cryptographiques et donc l’évaluation de leur sécurité).
On le voit, l’ensemble des projets couvrent largement le domaine de la cyber sécurité, sans toutefois prétendre à l’exhaustivité. Il faut noter également que tout ce qui touche au « risque quantique » est traité dans un autre PEPR, précisément dédié aux techniques quantiques.
Nous avons présenté dans cet article deux actions lancées récemment qui visent à renforcer la production de connaissances et de mécanismes technologiques innovants dans divers sous-domaines relevant de la cyber sécurité : le Programme de Transfert du Campus Cyber et le PEPR Cyber Sécurité. Ces actions cherchent à favoriser le transfert des connaissances et innovations issue du monde académique vers le milieu industriel, contribuant ainsi à créer ou enrichir des produits et services de sécurité souverains, sans lesquels notre souveraineté numérique resterait illusoire. La recherche académique en cyber sécurité souhaite ainsi se montrer en mesure d’apporter sa contribution à la construction de la souveraineté numérique française.
Hubert Duault et Ludovic Mé (Inria)
(1) pour vous en convaincre ;), vous pouvez par exemple saisir le mot Cybersécurité dans notre moteur de recherche (à droite de l’écran) et constater le nombre d’articles de binaire consacré à ce sujet.
[2] Nom donné au quatrième Plan d’Investissement d’Avenir (PIA 4), qui vise à rattraper le retard de la France dans certains secteurs et la création de nouvelles filières industrielles et technologiques.
[3] D’autre stratégies d’accélérations ont aussi été définies : cloud, 5G, quantique, IA, mais aussi santé numérique, systèmes agricoles durables, ou développement de l’hydrogène décarboné. Pour plus de détail, voir https://www.gouvernement.fr/strategies-d-acceleration-pour-l-innovation
Dans le domaine de la cybersécurité, il existe de nombreuses phases du développement et du déploiement des systèmes logiciels qui sont sensibles. A l’occasion de la publication d’un rapport du NIST, c’est aux failles logicielles et à leurs correctifs que nous nous intéressons. Trois experts, Charles Cuvelliez, Jean-Jacques Quisquater & Bram Somers nous expliquent les principaux problèmes évoqués dans ce rapport. Pascal Guitton.
Tous les jours, des failles sur les logiciels sont annoncées par leurs éditeurs, dès lors qu’un correctif est disponible. Plus rarement, la faille n’est pas découverte en interne chez l’éditeur ou ni même de façon externe, par un chercheur ; elle l’est alors d’une part par des hackers malveillants qui se gardent bien d’en faire la publicité mais les dégâts causés par leur exploitation la font vite connaître. D’autre part, par les services secrets de certains pays qui les apprécient beaucoup pour réaliser des attaques plus furtives.
Le volume des failles à traiter quotidiennement devient de plus en plus souvent ingérable pour les entreprises. Parfois l’éditeur du logiciel ne supporte même plus la version pour laquelle une vulnérabilité a été découverte : il n’y aura pas de correctif. Appliquer un correctif peut demander du temps, nécessiter la mise à l’arrêt des équipements, leur redémarrage, le temps de l’installer. Cette indisponibilité est parfois incompatible avec l’utilisation d’un logiciel qui doit fonctionner en permanence : un correctif ne s’applique pas n’importe quand. Dans des cas plus rares, le correctif ne peut être appliqué que par le fabricant, pour des raisons de conformité ou de certification.
Si on ne peut ou ne veut pas appliquer de correctif, on peut désactiver le logiciel ou le module dans laquelle la faille a été identifiée. On peut installer une version plus récente du logiciel mais avec un autre risque : que ce dernier fonctionne différemment et perturbe toute la chaîne opérationnelle au sein de laquelle il est un maillon. On peut isoler le logiciel pour qu’aucune personne extérieure ne puisse l’atteindre en vue d’exploiter la faille (en segmentant le réseau et en le plaçant dans un segment sûr). On peut même décider que l’impact – si la faille est exploitée – est minime : on accepte alors le risque (ce n’est tout de même pas conseillé). On peut aussi confier le logiciel à un fournisseur à qui incombera la responsabilité de gérer les correctifs.
Un véritable cycle
Si on décide d’installer le correctif, c’est tout un cycle qui démarre et qui ne se réduit pas à le télécharger et à l’installer d’un clic comme on le pense souvent. Il faut chercher où, dans l’organisation, le logiciel est installé. Cela commence par détenir l’inventaire des logiciels dans son entreprise, qui n’est correct que si on connait parfaitement toutes les machines installées. D’ailleurs ce ne sont pas toujours les logiciels d’une machine qu’on doit mettre à jour, c’est parfois la machine elle-même et son système d’exploitation. Dans le cas de l’Internet des objets, la situation se complique : on peut quasiment toujours mettre à jour le firmware de ces derniers mais la tâche est immense : où sont-ils sur le terrain ? Comment les mettre à jour tous sans en oublier un ? Faut-il envoyer des techniciens sur place ? Combien de temps faudra-t-il pour tous les mettre à jour ? Il peut même arriver qu’on doive passer à une nouvelle mise à jour alors l’ancienne n’est pas terminée pour tous les objets, au risque donc de désynchronisation de l’ensemble.
Si on a pu installer le correctif, après avoir planifié son déploiement, l’avoir testé pour voir si le programme qu’on utilisait fonctionne toujours correctement comme avant, il faut observer le programme mis à jour : le correctif peut lui-même receler une faille (car il est souvent développé dans l’urgence) ou avoir été compromis par un hacker (ce sont les fameuses attaques dites supply chain). Par erreur, un utilisateur peut désinstaller la mise à jour, réinstaller la version précédente, lors par exemple d’une restauration d’une sauvegarde. Si on a opté pour éteindre la machine ou le logiciel car on ne peut appliquer de correctif, il faut aussi surveiller que personne ne la/le redémarre. Un correctif peut par erreur remettre à zéro la configuration du programme qui l’intègrera, y compris les réglages de sécurité.
Toutes ces opérations ne s’organisent pas à la dernière minute, lorsqu’une faille critique est annoncée.
Sécuriser les environnements
On peut mettre en place un environnement plus sûr de sorte qu’une faille y ait moins d’impact ou n’y trouve pas de terrain favorable. Cela commence par ne mettre à disposition les logiciels qu’aux personnes qui en ont vraiment besoin. De deux logiciels équivalents, on peut privilégier celui qui a un historique plus favorable en nombre (réduit) de failles. On peut vérifier la rigueur du développement, la fréquence des correctifs, leur nombre, les problèmes relayés par les communautés d’utilisateurs à propos des failles. On peut aussi installer ses logiciels dans des environnements plus favorables et plus faciles à l’application de correctifs comme les containers cloud.
Dans son rapport, le NIST distingue quatre réponses aux failles : l’application de correctifs au fil de l’eau, en respectant un planning et des contraintes comme le week-end pour les logiciels dont on ne peut tolérer l’interruption. Il y a les correctifs à appliquer d’urgence. Si un correctif n’existe pas (encore), ce sont des mesures d’atténuation qu’on appliquera en fonction des instructions du fournisseur. Si le fournisseur n’apporte plus de support, il faudra isoler la machine qui héberge le logiciel pour le rendre inatteignable sauf par ses utilisateurs, si on ne peut s’en passer.
Que faire face à cette complexité ? Le NIST propose de classer les actifs informatiques dans des groupes de maintenance. Appliquer un correctif ou gérer une faille, c’est de la maintenance de sécurité. Chaque groupe de maintenance aura sa politique de gestion des failles.
Et de citer comme groupe de maintenance les ordinateurs portables des employés où les failles et les correctifs ont trait au système d’exploitation même de la machine, les firmwares et autres programmes installés. Les portables des utilisateurs ont une plus grande tolérance à une interruption et l’impact est limité si un ordinateur subit une faille puisqu’il y a des logiciels de contrôle et d’alerte à la moindre infection qui tourne sur ces machines puissantes. Ces éléments permettent une politique de mise à jour des failles adaptée.
A l’autre extrême, on trouve le groupe de maintenance « serveur de données (data center) » qui ne peut tolérer quasiment aucune interruption, qui ne peut être mis à l’arrêt qu’à des moments planifiés longuement à l’avance. Les mesures d’atténuation du risque sont tout autre, la défense en profondeur, les protections mises en place dans le réseau, la segmentation.
Autre exemple : le groupe de maintenance liés aux tablettes et autres smartphones utilisés par les employés, avec, aussi, sa tolérance aux interruptions, ses mesures propres de protection… Avoir une politique de mise à jour et de correction des failles par groupe de maintenance évite le goulot d’étranglement de tout vouloir faire en même temps et au final de laisser des failles béantes, peut-être critiques.
Le déploiement des correctifs.
Le NIST propose de déployer le correctif par groupes d’utilisateurs pour voir si tout se déroule correctement, puis de l’étendre graduellement pour limiter l’impact d’un correctif qui ne serait pas au point. Le déploiement progressif peut se faire en fonction de la qualification des utilisateurs, de leur compétence. Même pour les correctifs à appliquer d’urgence, le NIST propose ce déploiement graduel (mais plus rapide, en heures, sinon en minutes plutôt qu’en jours).
S’il n’y pas de correctifs disponibles, on est dans les mesures d’atténuation, comme isoler le logiciel quand on ne peut pas s’en passer, migrer dans un segment la machine qui le contient, adapter les droits d’accès des utilisateurs : on parle de micro-segmentation ou de « software-defined perimeters ». Tout ceci ne se fait pas le jour où l’entreprise fait face pour la première fois à un logiciel qui n’aura (plus) jamais de correctif. Les architectes doivent avoir réfléchi et proposé à l’avance les bonnes politiques et manière de faire. Il faut d’ailleurs les réévaluer en permanence car le réseau évolue : le risque est-il bien limité et le reste-t-il avec cette architecture ?
Oublier qu’il y a là une partie du réseau qui héberge les cas à problèmes serait la pire chose à faire. Il faut aussi interpeller les utilisateurs à intervalles réguliers pour voir s’ils utilisent vraiment ce logiciel vulnérable ? Peut-on se permettre de garder un trou de sécurité ? N’y a-t-il pas une alternative sur le marché ?
Métrique
L’organisation et sa direction doivent pouvoir vérifier que la politique d’application des correctifs est efficace. Mesurer et affirmer que 10 % des machines ou des logiciels n’ont pas pu recevoir des correctifs n’apporte aucune information si ce n’est faire peur car on imagine ces 10 % des machines ouvertes à tout vent.
Le NIST propose de donner trois indicateurs : la proportion de correctifs appliqués à temps par rapport à un objectif fixé, le temps moyen et le temps médian d’application du correctif (qui doivent bien sûr être inférieur à l‘objectif). Cet objectif peut être fixé par groupe de maintenance ou selon la criticité de la vulnérabilité et l’importance du logiciel dans le fonctionnement de l’entreprise.
En fin de compte, le mieux est d’acquérir un logiciel qui connaitra le moins de failles possibles : il faut mener, dit le NIST, une véritable due diligence avec le fournisseur : combien de failles, combien par année ? Combien de temps pour produire un correctif quand une faille est trouvée ? Les correctifs sont-ils groupés ? Publiez-vous les correctifs sur la base de données des vulnérabilités CVE ? Publiez-vous les correctifs ad hoc ou à intervalles réguliers ? Cela vous arrive-t-il de ne pas publier des correctifs mais d’alors proposer des mesures d’évitement ? Vos correctifs ont-ils déjà créé des problèmes ? Testez-vous les correctifs avant de les publier ? Quel est le retour de vos clients ?
Les réponses à ces questions en diront long sur le sérieux du fournisseur.
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain) & Bram Somers (Group Chief Technology Officer, Belfius Banque)
Sur binaire, nous avons souvent traité du sujet des cyberattaques qui se développent de plus en plus. La sinistre actualité nous a conduit à « attendre » que de telles agressions se déroulent tant en Ukraine que dans les autres pays. Pour l’instant, il semblerait que rien de tel ne se soit encore produit.
Pour mieux comprendre cette situation, nous avons interrogé plusieurs experts dont les noms ne peuvent pas apparaitre pour des obligations de réserve et qui ont choisi Jean-Jacques Quisquater comme porte-parole. Pascal Guitton & Pierre Paradinas
Photo de Tima Miroshnichenko provenant de Pexels
Alors que tout le monde s’y attendait, il semblerait qu’à l’heure où nous publions ce texte aucune cyberattaque d’ampleur n’a eu lieu de la part de la Russie contre l’Occident, en réponse aux sanctions économiques, ni même contre l’Ukraine : à peine a-t-on relevé deux effaceurs de données (wipers en anglais) dont on n’est même plus très sûr de l’origine offensive. Il s’agit de HermeticWiper et WhisperGate (déjà actif au moins de janvier) et IsaacWiper sans compter quelques variantes. Ils devaient s’infiltrer dans des réseaux informatiques des autorités ukrainennes, effacer le contenu des disques durs jusque dans la partie qui empêche ensuite la machine de redémarrer. HermeticWiper, lancé quelques heures avant l’attaque, se cachait derrière un rançongiciel (HermeticRansom) qui avait pour but de leurrer les victimes et de détourner leur attention. HermeticRansom s’avère de piètre qualité car des chercheurs des sociétés Crowdstrike et Avast ont pu proposer un script et un outil de déchiffrement, comme si le code avait été écrit à la va-vite sans être testé. Il n’utilisait même pas les techniques classiques de brouillages des rançongiciels. Son préfixe, Hermetic, vient du certificat numérique usurpé à une société : Hermetica Digital Ltd. Les auteurs ont pu se faire passer pour cette société et acquérir le certificat en tout régularité.
Aujourd’hui, l’Ukraine est toujours une cible : les sociétés qui offrent un service de blocage d’accès à des serveurs web compromis, ont vu une augmentation (d’un facteur 10) des requêtes bloquées provenant d’Ukraine : c’est la preuve qu’on clique de plus en plus souvent sur des liens d’hameçonnage ou que des malwares essaient d’établir une connexion avec un site à partir duquel ils peuvent être dirigés.
Entretemps, les certificats numériques utilisant les protocoles SSL/TLS venant de Russie ne pourront plus être renouvelés à la date d’échéance à titre d’embargo. « Les Russes émettent maintenant leurs propres certificats que les navigateurs les plus répandus n’accepteront pas », ont déjà annoncé les Google et autres Microsoft qui les conçoivent. Ces certificats « made in Russia » posent d’ailleurs plus un problème pour les russes que pour les étrangers : c’est une porte ouverte pour mieux espionner les citoyens qui, dans leurs communications sur le web, utiliseront des certificats dont les clés de chiffrement sont connues des autorités russes….
Plus problématique est l’apparition des protestwares : il s’agit de modifications apportées dans les logiciels open source qui s’activeront si la bibliothèque est utilisée sur une machine avec des réglages russes : un message inoffensif de protestation contre la guerre s’affiche. Cette initiative n’est cependant pas innocente car elle met à mal le paradigme même de la communauté open source, à savoir la bonne volonté et la transparence, pas l’hacktivisme. A ce stade, les protestware sont anecdotiques et minimalistes mais c’est une nouvelle menace à suivre, surtout pour les développeurs
Pourquoi lancer une cyberattaque contre l’Occident ?
Si le gouvernement russe n’a pas lancé de cyberattaque contre l’Occident, c’est peut-être par manque de prévoyance car il ne s’attendait sans doute pas à une réaction si vive des démocraties occidentales. Il a sous-estimé la cohésion de nos pays à s’opposer, sanctions à la clé en un rien de temps, à son coup de force. Peut-être pensait-il pouvoir faire un remake du printemps de Prague avec un Occident qui n’avait pas prise sur l’Union Soviétique à moins d’entrer en guerre avec elle. Mais contrairement à l’Union Soviétique, la Russie fait partie du système économique mondial. Le président russe doit casser cette cohésion occidentale, poussée et soutenue par les opinions publiques dans tous les pays. Des attaques cyber ont ce potentiel, en perturbant le fonctionnement de l’économie via la mise à l’arrêt d’infrastructures critiques, de transports, de banques, de services de l’administration. Le but est de saper la confiance du citoyen face à ses gouvernants qui n’auraient alors plus l’assise – ni le temps du fait des « perturbations cyber » sur leurs propres économies – pour consacrer tous leurs efforts à lutter contre l’agresseur. Celui-ci peut encore lancer des attaques de déni de service (DDoS en anglais) qui inondent les réseaux de requêtes artificielles pour les saturer et rendre inaccessibles les sites web des banques ou leurs applications mobiles, et qui peuvent aussi mettre à plat les systèmes de paiement ou les réseaux de carte de crédit. Les institutions financières remarquent une augmentation des attaques de déni de service, qu’on peut sans doute attribuer à un « échauffement » des forces cyber-russes qui testent leur force de frappe au cas où.
Les institutions financières sont une cible de choix : elles sont directement reliées à Internet pour permettre à leurs clients de s’y connecter et d’y mener leurs opérations. Les attaques de déni de service sont très bien contrées mais il faut rester humbles : on ne sait pas ce que les attaquants pourraient avoir préparé. Toujours avec l’objectif de saper la confiance, le président russe pourrait ordonner de défigurer les sites des banques pour faire peur aux clients qui n’auraient alors plus confiance dans leurs banques incapables d’éviter des graffitis sur leurs sites. Avec la mise au ban des banques russes via Swift, le gouvernement russe pourrait chercher à faire œil pour œil, dent pour dent et aller un cran plus loin : pénétrer les réseaux des infrastructures de marchés financiers (Financial Market Infrastructure ou FMI en anglais). Ce sont les organisations-rouages des marchés financiers, peu connues du grand public, qui sont essentielles à leur fonctionnement. Il en va de même pour MasterCard et Visa qui, eux aussi, sont allés un cran plus loin en suspendant leurs services en Russie.
Ce sont des scénarios mais c’est ainsi qu’il faut procéder. Ils prennent en compte le mobile du crime pour ne pas disperser ses efforts et cerner la menace. Imaginer ce que visent les autorités russes dans une éventuelle cyberattaque, c’est cibler le renforcement des défenses là où c’est nécessaire et détecter au plus vite les signes annonciateurs.
Que faire ?
Sans savoir quand viendra le coup, et même si on sait d’où il viendra et ce qu’il visera, il faut appliquer la tolérance-zéro en cyber-risque.
Toutes les entreprises, surtout celles qui administrent des infrastructures critiques ou qui opèrent des services essentiels, comme les banques, doivent doper leur threat intelligence, c’est-à-dire activer tous les canaux qui peuvent les renseigner sur les malwares qui circulent, d’où ils viennent, comment les repérer, inclure leur empreinte numérique dans les systèmes de détection interne dans le réseau IT. Il existe, heureusement, une communauté cyber efficace qui publie et relaie tout ce qu’un de ses membres trouve : ce sont les sociétés de sécurité promptes à découvrir ces malwares pour mettre à jour leurs propres produits en publiant sur leur blog leur trouvaille comme preuve de leur savoir-faire. Mentionnons également les agences de cybersécurité nationale (comme l’ANSSI en France), les CERT et les agences gouvernementales qui relaient ces informations.
Les entreprises doivent corriger (patcher) les vulnérabilités qui apparaissent dans les logiciels et composants informatiques qu’elles utilisent, dès que les constructeurs les annoncent avec un correctif à la clé. Il faudra aussi penser à prioriser ces mises à jour correctives car c’est tous les jours que des vulnérabilités sont annoncées grâce au dynamisme des scientifiques qui, jusqu’à présent, sont plus rapides que les attaquants. Cependant, soyons honnêtes, cela ne suffit pas car ces derniers ont toujours tout le loisir d’exploiter des vulnérabilités anciennes que trop d’entreprises tardent à corriger. On voit régulièrement apparaître des mises en garde sur des vulnérabilités qui, tout à coup, sont exploitées par des hackers pour compromettre les systèmes des entreprises qui ne les ont pas mis à jour. Il est alors minuit moins une pour ces dernières.
Il faut par ailleurs continuer à surveiller les groupes d’activistes ou les espions étatiques, ce qui permet de savoir quel type de cible est visé au niveau des états. Aujourd’hui, c’est l’Ukraine, demain, ce sera peut-être un autre pays. On surveillera les groupes de hackers notoirement connus pour avoir des accointances en Russie. Ils vont sûrement s’exercer dans le sens d’une mission « freelance » que pourrait leur demander leur pays de tutelle.
Enfin, les entreprises doivent refaire le tour des mesures techniques qui rendent leurs réseaux étanches aux attaques, mesures qu’elles appliquent déjà certainement mais il faut contrôler qu’aucune exception qui aurait été accordée n’est restée active par mégarde. Les plus avancées parmi les entreprises auront déjà implémenté le concept de réseau zéro confiance (zero-trust network), une nouvelle manière de penser les réseaux d’entreprise. Son principe est que toute machine dans le réseau de son entreprise pourrait, à l’insu de tous, avoir été compromise. Aucune machine ne peut faire confiance à aucune machine, comme sur Internet. C’est considérer son propre réseau comme un Far-West équivalent à Internet. L’autre concept est la défense en profondeur : une défense informatique doit toujours être en tandem avec une autre défense informatique. Si l’une est compromise, l’autre fonctionnera encore et l’attaque sera un échec.
L’authentification à deux facteurs que certains activent déjà pour leurs compte Gmail est un exemple. Ne connaitre que le mot de passe et le login ne vous permet plus d’accéder à votre boite email. Il faut encore un code qui parviendra à votre smartphone par exemple. Pour vaincre ces deux couches, un voleur doit non seulement connaitre le mot de passe et login mais aussi posséder le smartphone du titulaire du login.
Plus prosaïquement, les sociétés seraient bien inspirées de jeter un coup d’œil à leurs sous-traitants et contractants qui pourraient connaitre des manquements bien pires que les leurs.
Enfin, tout cette communauté peut avoir du personnel lié aux zones de conflit, donc très affecté par la situation, qui pourrait partir protéger leur famille, aller combattre ou qui serait tenté par des actions patriotiques sur leur lieu de travail avec les ressources IT de leur employeur. Deutsche Bank en fait pour l’instant l’amère expérience : cette banque dispose d’un centre à Moscou où travaillent 1500 experts dont la banque a besoin tous les jours en support de son trading. Elle est forcée d’élaborer à toute vitesse des plans d’urgence pour « accompagner » la perte future de ce centre, soit parce que le gouvernement russe le ferme en représailles, soit parce que l’embargo occidental intense rend impossible la collaboration, soit parce Deutsche Bank n’arrive tout simplement plus à verser les salaires du fait de l’isolement financier de la Russie. Elle a par exemple mené récemment un stress test en fonctionnant trois jours sans faire appel à son centre de Moscou.
Ce qui ne manque pas de frapper, c’est le niveau inédit de coopération public-privé : on voit un Microsoft coopérer directement avec le gouvernement ukraininen. Les partenariats privé-public sont depuis des années appelés de leur vœux en cybersécurité. Les voilà mis en œuvre, enfin.
Quand la Russie attaquera-t-elle au niveau cyber ?
On se perd en conjectures sur l’absence d’attaques cyber d’ampleur pour l’instant à l’extérieur de l’Ukraine : certains analystes pensent que le président russe n’a pas averti/impliqué ses agences de renseignement à temps pour les prévenir de l’imminence de l’attaque, de sorte que ces dernières n’ont rien préparé et ont continué leurs opérations d’infiltrations/espionnages habituelles. Lancer une attaque cyber sur plusieurs pays à la fois, simultanément, cela se prépare. Ce n’est pas comme s’introduire dans une entreprise donnée à la recherche de secrets ou pour lancer un petit rançongiciel, histoire de garder la main.
Jean-Jacques Quisquater (Université de Louvain Ecole Polytechnique de Louvain).
Depuis plusieurs jours le réseau SWIFT est à la une de tous les médias qui décrivent les sanctions envisagées contre le gouvernement russe. Il s’agit d’un réseau auquel sont connectées les banques et qui est utilisé pour les échanges financiers internationaux. Pour aller plus loin et comprendre précisément à quoi sert SWIFT, nous avons interrogé trois experts : Jean-Jacques Quisquater, Charles Cuvelliez et Gael Hachez. Pascal Guitton & Pierre Paradinas
Photo de Life Of Pix provenant de Pexels
Depuis plusieurs jours, la coupure de l’accès de 7 grandes banques russes au système SWIFT occupe le devant de la scène comme si elle était de nature à changer le cours de la guerre. Pourquoi et surtout à quoi sert SWIFT au point d’avoir cet espoir ?
Tout d’abord, SWIFT n’a pas vraiment de concurrent et toutes les banques sont connectées à ce service qui fonctionne très bien. En effet, bien que SWIFT ne soit pas une institution financière, c’est un pilier de la finance mondiale car il permet à une banque de transférer de l’argent à toute autre banque dans le monde (11 000 banques dans 200 pays y sont connectées). Pour le commun des mortels, transférer de l’argent entre comptes semble aller tellement de soi qu’on peut se demander pourquoi il faut un système comme SWIFT. Le plus simple est d’imaginer SWIFT comme un service de messagerie très sécurisé entre banques utilisant des messages standardisés. Contrairement à un système classique d’échange d’e-mail, SWIFT garantit l’identité des banques connectées et la sécurité des messages.
Pour pouvoir transférer de l’argent entre une banque A et une banque B dans un autre pays, il faut qu’elles entretiennent une relation commerciale. Si tel est le cas et qu’elles sont toutes les deux connectées à SWIFT, le transfert va passer par des messages respectant un format spécifique (MT103) en utilisant comme identifiant le code BIC de la banque. Si A n’a pas de relation commerciale avec B, la situation se complique car il faut passer par des banques intermédiaires dites correspondantes car elles ont une relation commerciale avec A et B. Les messages SWIFT, qui donnent les ordres de transfert de proche en proche, constituent donc le fil d’Ariane du transfert d’argent entre A et B.
SWIFT transporte 40 millions de message par jour : à peine 1% implique les banques russes. C’est une coopérative dont les actionnaires sont les banques elles-mêmes. Les messages SWIFT ont aussi des fonctionnalités avancées de groupe comme l’implémentation de plafond ou l’imposition de contingences imposées par une banque centrale ….
Si SWIFT n’existait pas, le transfert de A vers B pourrait fonctionner quand même mais au prix d’une coordination sans faille, avec une synchronisation avec la/les banques intermédiaires via plusieurs systèmes de messagerie et de formats différents.
Comme nous l’avons écrit précédemment, pour que A puisse transférer de l’argent vers B, il faut qu’il existe une relation commerciale entre elles qui se traduit dans SWIFT par un système d’autorisation (B accepte de recevoir des messages de A). En d’autres termes, on aurait pu isoler les banques russes en demandant tout simplement à toutes les banques non russes de ne plus avoir de relation commerciale avec elles. C’est l’objectif de ces sanctions mais elles ne sont pas appliquées par exemple par des banques chinoises. Pour des banques, établir une relation commerciale l’une avec l’autre n’est pas innocent. La société J.P. Morgan qui est une des principales banques correspondantes dans le monde, au point d’être une plaque tournante des transferts internationaux, n’acceptera pas n’importe qui comme nouvelle banque. Dans la banque de détail, il existe un examen approfondi (screening) pour chaque nouveau client (via la procédure dite KYC pour Know Your Customer en anglais) pour éviter d’héberger les comptes d’un criminel ou d’un terroriste. Sachez que ce contrôle existe aussi entre banques qui acceptent de correspondre entre elles.
Les risques
Que tous les échanges entre établissements financiers reposent sur un unique système de messagerie constitue un risque systémique majeur. Si pour une raison ou une autre, SWIFT tombait en panne, c’est la finance mondiale qui s’arrêterait. Une attaque par déni de service qui arriverait à bloquer SWIFT (qui n’est pas connecté à Internet) ferait autant de dégâts.
L’autre risque majeur avec SWIFT, c’est le vol d’argent. Le Bangladesh a connu cette mésaventure : la Réserve Fédérale américaine reçut un jour plusieurs ordres de versement d’argent d’un compte détenu par la banque centrale du Bangladesh vers différents comptes dont celui d’un particulier. Cette demande particulièrement étrange (une banque centrale ne transfère pas d’argent sur le compte d’un particulier) a permis de détecter la fraude mais une partie de l’argent avait déjà été versée. Cette malversation venait à coup sûr d’un expert du système financier car il fallait détenir beaucoup de connaissances : savoir utiliser le terminal SWIFT, savoir que la banque centrale du Bangladesh possédait de l’argent dans la Réserve Fédérale, sur quel compte…. Le personnel qui manipule les terminaux SWIFT doit évidemment faire l’objet d’un examen approfondi que certaines banques vont certainement réitérer au vu des tensions entre deux pays dont les ressortissants pourraient très bien se trouver au contact de terminaux SWIFT.
Comment cela va se passer.
Concrètement, quand SWIFT, une société de droit belge, recevra l’obligation légale (sous quelle forme ?) d’exclure les 7 banques russes, elle bloquera sans doute les transactions depuis et à destination de ces établissements sur la base de leur code BIC. Elle appliquera l’article 16c de ses statuts qui mentionne que le conseil d’administration peut suspendre ou révoquer un actionnaire s’il n’a pas respecté ses engagements ou si une régulation amène à une contradiction à le garder connecté à SWIFT. Mais ce n’est pas sans risque car certaines opérations faites via SWIFT s’étalent dans le temps. Le blocage pourrait par exemple arrêter une opération commencée plus tôt. L’interrompre en plein milieu risque de provoquer des déséquilibres dans des flux de paiement et des transferts qui peuvent déboucher sur une situation chaotique.
Photo de Mohamed Almari provenant de Pexels
Pour l’éviter, il est question de créer des sauf-conduits pour garantir à une opération en cours de s’achever même sous un régime de sanctions. L’autre défi est l’immédiateté de la sanction. Lorsqu’une régulation impose un changement dans les règles, du temps est laissé à SWIFT pour s’adapter. Ici, du jour au lendemain, il faut adapter les règles de surveillance des transactions. Des opérations légitimes qui utilisent les banques russes comme intermédiaires risquent d’être stoppées sans raison et interprétées comme illégales. La décision de couper les 7 banques russes a été prise le 2 mars mais ne sera d’application que le 12 mars : 10 jours pour s’adapter, c’est peu !
Alternatives
La Russie n’a pas réussi à développer un système alternatif à SWIFT : elle a tenté de mettre sur pied le SPFS sur lequel 23 banques sont connectées en provenance de pays comme l’Arménie, le Belarus, le Kazakhstan, plus quelques pays européens et la Suisse, mais sa taille réduite le handicape. Il y a bien des plans pour interconnecter SPFS avec les systèmes de paiement en Chine, Inde et Iran. La Russie peut aussi se connecter sur le système CIPS chinois mais la Chine ne serait sans doute pas prête à subir des sanctions secondaires qui le priverait d’un accès au dollar. La Russie peut aussi se passer de SWIFT et tenter d’effectuer des paiements en direct, de gré à gré, à des banques étrangères mais celles-ci refuseront certainement.
Ce qui est sûr, c’est que la légalité de la coupure sera attaquée si la Russie prend cette peine.
Ce dont on parle moins
Comme on l’a dit plus haut, la déconnexion de SWIFT a un impact mais il est limité car le régime de sanctions impose déjà à la plupart des banques dans le monde de ne plus travailler avec ces banques russes. Via le(s) système(s) SPFS et/ou CIPS, elles pourraient toujours travailler avec des banques qui n’appliquent pas ces sanctions. SWIFT à défaut d’être l’arme économique ultime aura été une arme médiatique pour exprimer la volonté et l’unité de l’Europe. Si SWIFT n’était pas installé en Belgique, soumise à la législation européenne mais en Asie qui marque très peu d’empressement à appliquer des sanctions économiques, il n’est pas sûr que les banques russes eussent été bannies.
Jean-Jacques Quisquater (Université de Louvain Ecole Polytechnique de Louvain), Charles Cuvelliez (Université de Bruxelles, Ecole Polytechnique de Bruxelles) et Gael Hachez (expert en gestion du risque technologique dans le secteur financier)
Un bug ne se manifeste pas nécessairement dès l’instant où il est dans un système. Les bugs les plus discrets sont d’ailleurs souvent les plus dangereux. Quand ils surgissent, la catastrophe peut être terrible comme celle d’Ariane 5 en 1996, qu’on a qualifiée de bug le plus cher de l’histoire. Plus rares, il y a des bugs dont l’effet nuisible n’apparaît que lentement et progressivement, sans qu’on ose ou puisse les corriger et dont les conséquences désastreuses s’empirent jusqu’à devenir gravissimes. Celui dont nous parle ici Jean-Paul Delahaye est de ce type. Serge Abiteboul, Thierry Viéville.
Il s’agit du bug dans le protocole de distribution de l’incitation du réseau Bitcoin, la fameuse cryptomonnaie. On va voir qu’il est bien pire que celui d’Ariane 5.
Pour que le réseau Bitcoin fonctionne et fasse circuler en toute sécurité l’argent auquel il donne vie, il faut que des volontaires acceptent de participer à sa surveillance et à la gestion des informations importantes qu’il gère et qui s’inscrivent sur une « chaîne de pages », ou « blo
ckchain ». Une rémunération a donc été prévue pour récompenser ces volontaires, appelés validateurs. Elle provient de nouveaux Bitcoins créés ex-nihilo et est distribuée toutes les 10 minutes environ à un et un seul des validateurs. Qu’il n’y en ait qu’un à chaque fois n’est pas grave car dix minutes est un intervalle court et donc la récompense est distribuée un grand nombre de fois — plus de 50000 fois par an. Reste que distribuer cette incitation pose un problème quand les ordinateurs ne sont pas obligés d’indiquer qui les contrôle, ce qui est le cas du réseau Bitcoin où tout le monde peut agir anonymement en utilisant des pseudonymes ou ce qui revient au même un simple numéro de compte.
Distribuer l’incitation par un choix au hasard qui donne la même chance à chaque validateur d’être retenu serait une solution parfaite si tout le monde était honnête. Ce n’est pas le cas bien sûr, et un validateur pourrait apparaître sous plusieurs pseudonymes différents pour augmenter la part de l’incitation qu’il recevrait avec un tel système. Avec k pseudonymes un validateur tricheur toucherait l’incitation k fois plus souvent que les validateurs honnêtes. S’il apparaît sous mille pseudonymes différents, il toucherait donc mille fois plus qu’un validateur honnête… qui ne le resterait peut-être pas. Le réseau serait en danger. En langage informatique, on appelle cela une « attaque Sybil » du nom d’une patiente en psychiatrie qui était atteinte du trouble des personnalités multiples ou trouble dissociatif de l’identité. Plusieurs solutions sont possibles pour empêcher ces attaques, et le créateur du protocole Bitcoin dont on ne connait d’ailleurs que le pseudonyme, Satoshi Nakamoto, en a introduite une dans son système qu’au départ on a jugée merveilleuse, mais dont on a compris trop tard les conséquences désastreuses. Ces conséquences sont si graves qu’on peut affirmer que le choix de la méthode retenue et programmée par Nakamoto pour contrer les attaques Sybil est un bug.
Sa solution est « la preuve de travail » (« Proof of work » en anglais). L’idée est simple : on demande aux validateurs du réseau de résoudre un problème arithmétique nouveau toutes les dix minutes. La résolution du problème exige un certain temps de calcul avec une machine de puissance moyenne, et elle ne s’obtient qu’en cherchant au hasard comme quand on tente d’obtenir un double 6 en jetant de manière répétée deux dés. Le premier des validateurs qui résout le problème gagne l’incitation pour la période concernée. Toutes les dix minutes un nouveau problème est posé permettant à un validateur de gagner l’incitation.
Si tous les validateurs ont une machine de même puissance les gains sont répartis équitablement entre eux, du moins sur le long terme. Si un validateur utilise deux machines au lieu d’une seule pour résoudre les problèmes posés, il gagnera deux fois plus souvent car avec ses deux machines c’est comme s’il lançait deux fois plus souvent les dés que les autres. Cependant c’est acceptable car il aura dû investir deux fois plus que les autres pour participer ; son gain sera proportionné à son investissement. Il pourrait gagner plus souvent encore en achetant plus de machines, mais ce coût pour multiplier ses chances de gagner l’incitation impose une limite. On considère que ce contrôle des attaques Sybil est satisfaisant du fait que les gains d’un validateur sont fixés par son investissement. Il faut noter que celui qui apparaît avec k pseudonymes différents ne gagne rien de plus que s’il apparait sous un seul, car les chances de gagner sont proportionnelles à la puissance cumulée des machines qu’il engage. Qu’il engage sa puissance de calcul sous un seul nom ou sous plusieurs ne change rien pour lui. Avec la preuve de travail, il semble que la répartition des gains ne peut pas être trop injuste car si on peut améliorer ses chances de gagner à chaque période de dix minutes, cela à un coût et se fait proportionnellement à l’investissement consenti.
Le réseau bitcoin fonctionne selon le principe de la preuve de travail. Au départ tout allait bien, les validateurs se partageaient les bitcoins créés et mis en circulation à l’occasion de chaque période, sans que cela pose le moindre problème puisque leurs machines avaient des puissances comparables et que personne n’en utilisait plusieurs pour augmenter ses chance de gagner. La raison principale à cette situation est qu’en 2009 quand le réseau a été mis en marche, un bitcoin ne valait rien, pas même un centime de dollar. Investir pour gagner un peu plus de bitcoins n’avait pas d’intérêt. Cependant, petit à petit, les choses ont mal tourné car le bitcoin a pris de la valeur. Il est alors devenu intéressant pour un validateur de se procurer du matériel pour gagner plus souvent les concours de calcul que les autres. Plus la valeur du bitcoin montait plus il était intéressant de mettre en marche de nombreuses machines pour augmenter ses gains en gagnant une plus grande proportion des concours de calcul. Une augmentation de la capacité globale de calcul du réseau s’est alors produite. Elle n’a pas fait diminuer le temps nécessaire pour résoudre le problème posé chaque dix minutes, car Nakamoto, très malin, avait prévu un mécanisme qui fait que la difficulté des problèmes soumis s’ajuste automatiquement à la puissance totale du réseau. Depuis 2009, il faut dix minutes environ pour qu’un des ordinateurs du réseau résolve le problème posé et gagne l’incitation, et cette durée n’a jamais changée car le réseau est conçu pour cela.
Du bitcoin à la blockchain : dans ce double podcast Jean-Paul prend le temps d’expliquer comment ça marche aux élève de l’enseignement SNT en seconde et au delà.
Les validateurs associés parfois avec d’autres acteurs spécialisés dans la résolution des problèmes posés par le réseau — et pas du tout dans la validation — ont accru leurs capacités de calcul. La puissance cumulée de calcul du réseau a en gros été multipliée par dix tous les ans entre 2010 et maintenant. C’est énorme !
Les spécialistes de la résolution des problèmes posés par le réseau sont ce qu’on nomme aujourd’hui les « mineurs » : ils travaillent pour gagner des bitcoins comme des mineurs avec leurs pioches tirent du minerai du sous sol. Il faut soigneusement distinguer leur travail de celui des validateurs : les validateurs gèrent vraiment le réseau et lui permettent de fonctionner, les mineurs calculent pour aider les validateurs à gagner l’incitation. Si parfois des validateurs sont aussi mineurs, il faut bien comprendre que deux type différents de calculs sont faits : il y a le travail de validation et le travail de minage.
Entre 2010 et maintenant, la puissance du réseau des mineurs a été multipliée par 1011, soit 100 milliards. L’unité de calcul pour mesurer ce que font les mineurs est le « hash ». En janvier 2022, on est arrivé à 200×1018 hashs pas seconde, soit 200 milliards de milliards de hashs par seconde, un nombre colossal.
Bien sûr les machines utilisées ont été améliorées et on a même fabriqué des circuits électroniques pour calculer rapidement des hashs, et on les perfectionne d’année en année. Cependant, et c’est là que le bug est devenu grave, même en dépensant de moins en moins d’électricité pour chaque hash calculé, on en a dépensée de plus en plus, vraiment de plus en plus ! La logique économique est simple : plus le cours du bitcoin est élevé —il s’échange aujourd’hui à plus de 30 000 euros— plus il vaut la peine d’investir dans des machines et d’acheter de l’électricité dans le but de miner car cela permet de gagner plus fréquemment le concours renouvelé toutes les dix minutes, et cela rentabilise les investissements et dépenses courantes du minage.
Une concurrence féroce entre les mineurs s’est créée, pour arriver en 2022 à une consommation électrique des mineurs qu’on évalue à plus de 100 TWh/an. La valeur 50 TWh est un minimum absolument certain, mais 100 TWh/an ou plus est très probable. Sachant qu’un réacteur nucléaire de puissance moyenne produit 8 TWh/an, il y a donc l’équivalent de plus de 12 réacteurs nucléaires dans le monde qui travaillent pour produire de l’électricité servant à organiser un concours de calcul qui fixe toutes les dix minutes quel est le validateur qui gagne l’incitation. Je me permets d’insister : l’électricité n’est pas dépensée pour le fonctionnement en propre du réseau, mais uniquement pour désigner le validateur gagnant. Quand on étudie le fonctionnement du réseau bitcoin, on découvre qu’il y a au moins mille fois plus d’électricité dépensée par le réseau pour choisir le gagnant toutes les dix minutes, que pour son fonctionnement propre. S’il dépense beaucoup, c’est donc à cause de la preuve de travail, pas à cause de sa conception comme réseau distribué et bien sécurisé permettant la circulation des bitcoins.
Est-ce que cette situation justifie vraiment de parler de bug ? Oui, car il existe d’autres solutions que la preuve de travail et ces autres solutions n’engendrent pas cette dépense folle d’électricité. La solution alternative la plus populaire dont de multiples variantes ont été proposées et mises en fonctionnement sur des réseaux concurrents du bitcoin se nomme « la preuve d’enjeu ». Son principe ressemble un peu à celui de la preuve de travail. Les validateurs qui veulent avoir une chance de se voir attribuer l’incitation distribuée périodiquement, engage une somme d’argent en la mettant sous séquestre sur le réseau où elle se trouve donc bloquée temporairement. Plus la somme mise sous séquestre est grande plus la probabilité de gagner à chaque période est grande. Comme pour la preuve de travail, avec la preuve d’enjeu il ne sert à rien de multiplier les pseudonymes car votre probabilité de gagner l’incitation sera proportionnelle à la somme que vous engagerez. Que vous le fassiez en vous cachant derrière un seul pseudonyme, ou derrière plusieurs ne change pas cette probabilité. Quand un validateur souhaite se retirer, il récupère les sommes qu’il a engagées ; ce qu’il a gagné n’est donc pas amputé par des achats de machines et d’électricité.
Cette méthode ne provoque pas de dépenses folles en électricité et achats de matériels, car il n’y en a pas ! Avec des configurations équivalentes de décentralisation et de sécurisation un réseau de cryptomonnaie utilisant la preuve d’enjeu dépensera mille fois moins d’électricité qu’un réseau utilisant la preuve de travail. Il y a une façon simple d’interpréter les choses. La preuve d’enjeu et la preuve de travail limitent toutes les deux les effets des attaques Sybil en distribuant l’incitation proportionnellement aux engagements de chaque validateur —soit du matériel de calcul et de l’électricité, soit un dépôt d’argent —. Cependant la preuve d’enjeu rend son engagement au validateur quand il cesse de participer, et donc rien n’est dépensé pour participer, alors que la preuve de travail consomme définitivement l’électricité utilisée et une partie de la valeur des matériels impliqués. En un mot, la preuve de travail est une preuve d’enjeu qui confisque une partie des sommes engagées et les brûle.
Avoir utilisé la preuve de travail, avec les conséquences qu’on observe aujourd’hui est de toute évidence une erreur de programmation dans le protocole du réseau du bitcoin. Le bug n’est apparu que progressivement mais il est maintenant là, gravissime. Le plus terrible, c’est qu’une fois engagé avec la preuve de travail le réseau bitcoin est devenu incapable de revenir en arrière. Corriger le bug alors que le réseau est en fonctionnement est quasiment impossible.
En effet, le pouvoir pour faire évoluer la façon dont fonctionne du réseau, ce qu’on appelle sa gouvernance, est aux mains de ceux qui disposent de la puissance de calcul pour le minage. Ils ont acheté du matériel, installé leurs usines, appris à se procurer de l’électricité bon marché, ils ne souhaitent pas du tout que la valeur de leurs investissements tombe à zéro. Ils ne souhaitent donc pas passer à la preuve d’enjeu. La correction du bug est donc devenue très improbable. Aujourd’hui le réseau Ethereum qui est le second en importance dans cette catégorie essaie malgré tout de passer de la preuve de travail à la preuve d’enjeu. Il a beaucoup de mal à le faire et il n’est pas certain qu’il y arrive. Du côté du bitcoin rien n’est tenté. Sans interventions extérieures, le bug du bitcoin va donc continuer à provoquer ses effets absurdes.
Est-ce le plus gros bug de l’histoire ? Celui d’Ariane 5 a été évalué à environ 5 millions de dollars. Si on considère, ce qui semble logique, que tout l’argent dépensé en minage représente le coût du bug du bitcoin alors c’est beaucoup plus, puisqu’en ordre de grandeur le minage depuis 2009 a coûté entre 5 et 10 milliards de dollars et peut-être plus. Le piège économique qui est résulté du bug est d’une perversité peut-être jamais rencontrée.
Une tribune intitulée «Il est urgent d’agir face au développement du marché des cryptoactifs et de séparer le bon grain de l’ivraie » portant sur le problème de la régulation des cryptoactifs a été publiée par Le Monde le jeudi 10 février 2022. Vous pouvez en voir le texte avec la liste des signataires et éventuellement ajouter votre signature en allant en : https://institut-rousseau.fr/liste-des-signataires-tribune-regulation-cryptoactifs/
Attaquant autant les individus que les organisations (entreprises, hôpitaux…), les rançongiciels (ou ransomware en anglais) sont devenus un des fléaux les plus répandus dans le monde numérique. Nos amis Lorenzo Bernardi, Charles Cuveliez et Jean-Jacques Quisquater nous expliquent le fonctionnement de ces logiciels et s’interrogent sur les conséquences des législations qui sont discutées actuellement aux Etats-unis : déplaceront-elles les cibles de ces attaques vers d’autres zones géographiques ?Pascal Guitton et Thierry Viéville.
Le 13 octobre dernier, la députée LREM Valéria Faure-Muntian a publié un rapport pour l’Assemblée nationale relatif à la cyber-assurance qui préconise d’interdire aux assureurs de payer les rançons. C’est un choix sociétal qui a pris de l’avance outre-Atlantique avec une effervescence législative dans le même sens : interdire le paiement des rançons pour stopper cette criminalité très rentable. De fait, si la France et l’Europe ne font rien, les hackers risquent de déferler chez nous si, aux USA, il n’est plus possible de payer (discrètement) les rançons. La sénatrice démocrate E. Warren a ainsi proposé une loi qui imposerait de déclarer les paiements de rançon dans les 48 heures pour toutes les sociétés. Un site web serait mis en place pour permettre aussi à tout un chacun de déclarer sur base volontaire les paiements de rançon. Le Department of Homeland Security ou DHS (le ministère américain de l’intérieur) aurait alors la tâche d’exploiter ces données (le montant, les devises utilisées – crypto ou pas – et tout ce que la victime a pu comprendre/apprendre du gang avec qui il a négocié).
Image de Maulucioni extraite du site WikiMedia.
L’objectif ? Comprendre l’écosystème criminel, dans une optique ‘follow the money’ qui manque, c’est vrai, à la plupart des lois qui imposent de notifier des incidents de sécurité. Cela dit, une telle obligation et la publicité négative qui en résulterait pourraient aussi dissuader les entreprises de payer la rançon et les conduire à se mettre ainsi dans une situation parfois irrécupérable.
Déclarer un incident dans un laps de temps aussi court, en pleine crise, n’est pas un cadeau : il y a d’autres priorités à gérer. Ce n’est pas comme rapporter une brèche de sécurité dans les 72 heures de sa découverte comme l’impose le RGPD : une fois découverte, elle a déjà eu lieu et il n’y a plus rien à gérer d’autre que les dégâts, déjà actés.
Dans une autre proposition de loi, elle aussi déposée en septembre, c’est dans les 24 heures cette fois que les organisations de plus de 50 personnes seraient obligée de déclarer le paiement de rançon et les opérateurs d’infrastructure critiques devraient rapporter leurs incidents de sécurité dans les 72 heures. Les autorités devraient poursuivre activement toutes les sociétés qui ne respecteraient pas cette obligation et leur interdire de devenir sous-traitant des administrations fédérales. L’autorité compétente, le CISA (agence américaine de cybersécurité et de sécurité des infrastructures), aurait ainsi, d’après les auteurs de la loi, une vue globale des cyberattaques sur le territoire américain.
Cryptomonnaie aussi
Les cryptomonnaies ne sont pas oubliées : une proposition de loi du Sénat américain chargerait le département du Trésor de suivre activement le minage des cryptomonnaies dans le monde. Le résultat de leur analyse serait communiqué au Congrès : il s’agirait de voir quel pays régule ou, au contraire, encourage les cryptomonnaies. Il faut dire qu’en plus d’être un moyen de paiement des rançons, elles sont accusées de bien d’autres maux : redémarrage des centrales à charbon pour faire face à la demande d’électricité pour le minage, pénurie de microprocesseurs et hausse des prix, dues, dit-on, à la demande de puces pour le minage aussi. On imagine facilement l’étape suivante : les USA qui appliqueraient des sanctions aux pays trop complaisants. La Chine n’en ferait pas partie car elle vient d’interdire toutes les transactions en cryptomonnaie.
La soudaine inflation de lois, très opérationnelles, du côté US est impressionnante. Elle traduit et s’attaque au manque de compréhension des rançongiciels, à leur étendue et aux dégâts qu’elle engendre. Le FBI, dans une audition au Sénat en marge du dépôt de ces lois, a annoncé qu’en 2020, 350 millions de dollars avaient été payés en rançon rien qu’aux USA, une augmentation de 311 % par rapport à 2019. La moyenne des rançons payées est de 300 000 USD.
La victime idéale
Aucun pays européen ne va aussi loin et encore moins la Commission européenne au nom de tous. Mais on peut se demander si les USA ne sont pas déjà en retard d’une guerre : la société KE-LA connue pour ses capacités d’infiltration du dark web a mis en évidence le profil idéal de victime d’un rançongiciel en analysant les forums d’acheteurs d’accès aux entreprises. Car les hackers ne veulent plus perdre de temps à d’abord pénétrer dans le réseau des victimes. Leur temps précieux se concentre sur l’attaque et le blocage de l’entreprise, la partie utile, en fait.
Par profil idéal, il faut comprendre le portrait de la société qui paiera facilement une rançon. Elle est américaine, avec un chiffre d’affaires de 100 millions de dollars. Pour la moitié des acheteurs d’accès, qui, au fond, sur ces forums, ne font rien d’autre que de publier un cahier de charge, la victime ne doit pas être active dans le secteur médical ni dans l’éducation, un peu pour des raisons éthiques disent-ils, un peu parce qu’elles n’auront pas les moyens de payer la rançon.
L’accès est payé jusqu’à 100 000 USD, en moyenne 56 000 USD. Il peut aussi y avoir une partie de la rançon partagée. L’accès n’est pas forcément un accès au réseau de la victime lui-même mais toute forme de point d’entrée : dans une base de données, un serveur courriel (comme ce fut le cas pour la vulnérabilité sir Microsoft Exchange), un site web. Si cet accès ne peut être utilisé pour répandre un rançongiciel, il servira à bien d’autres « plaisirs » : minage, installation d’un malware qui sera ensuite redistribué aux gens qui vont sur le site désormais contaminé, collecte de données dans la base de données infiltrée, utilisation des ressources infiltrées pour du spam ou phishing. Les Etats-unis sont de loin le pays le plus recherché dans les « cahiers des charges » avec 47 % des demandes. Le Canada vient ensuite pour 37 %, l’Australie pour 37 % et enfin, l’Europe, tous pays confondus pour 31 %. Que se passera-t-il quand les 47 % d‘attaques vers les USA devront trouver d’autres preneurs ? Et évidemment, les pays de l’ex-Union Soviétique restent toujours en dehors des accès recherchés, comme quoi règne toujours la règle selon laquelle on ne mord pas la main de celui qui vous nourrit.
Comment se fait-on piéger par un rançongiciel ?
Qu’on se le dise, puisque la vague américaine de rançongiciels va refluer vers nos côtes : les emails restent un point d’entrée préféré, car simple, des rançongiciels, via une pièce attachée ou un lien à cliquer vers un exécutable qui relâche un ransomware. Il y a aussi les sites web infectés, sous le contrôle des pirates, à partir desquels rien qu’en y navigant ou en cliquant sur un lien, un malware ou un rançongiciel peut être téléchargé sur votre machine. Ce malware pénètre via des plugins vulnérables du navigateur web et arrive en arrière-plan sans qu’on s’en rende compte. Ces points d’entrée un peu trop évidents pour lesquels l’utilisateur final porte hélas souvent une lourde responsabilité de leur donner une suite justifient, ô combien, les ennuyantes restrictions que les salariés rencontrent dans leur entreprise : ne pas pouvoir accéder à un site web sans qu’il ne passe par un filtre de classification de son contenu et de reconnaissance de son innocuité (au point de devoir attendre 24 heures si ce site n’a jamais été identifié auparavant). Les liens dans les emails ne sont plus cliquables tels quels : ils vous redirigent vers un site relais qui sert de bouclier testeur du site réellement accédé auquel vous n’accéderez d’ailleurs qu’à travers ce bouclier.
Image extraite du site wezengroup
Il y a des rançongiciels plus sophistiqués qui tirent profit de vulnérabilités non corrigées dans le système IT de l’organisation qui auront été identifiées auparavant par d’autres. Pour échapper à la détection, le rançongiciel peut s’installer morceau par morceau mais en tout cas, une fois qu’il s’active, après avoir bien reconnu le réseau de la victime, on estime qu’il peut chiffrer 1000 fichiers sur un laps de temps entre 16 s et 18 min (pour échapper à la détection de par sa lenteur). Soit le rançongiciel chiffre à l’aide des primitives de chiffrement contenus dans le système d’exploitation de la machine même (Linux, iOS, Windows), soit ce sont des primitives de chiffrement faites maison pour leurrer les outils de détection qu’un processus de chiffrage est en cours d’exécution. Souvent, des copies des fichiers de la victime sont exfiltrées avant leurs chiffrements avec une menace de les dévoiler publiquement si l’entreprise ne paie pas la rançon. Mais la tentation de payer (et de ne rien dire) l’emporte car si bâtir une réputation exige beaucoup de temps, il peut suffire d’un cyber incident pour la détruire. Et pourtant, ce souci de discrétion est souvent vain car sur les forums spécialisés dans le dark web, les gangs de rançongiciels auront tôt fait d’annoncer qu’ils ont frappé une nouvelle victime, non pour se vanter mais pour avertir d’autres acteurs de la chaîne de valeur qu’ils peuvent prendre le relais (récolter le paiement,…). C’est la raison pour laquelle il vaut mieux, en tant que victime être le premier à annoncer avoir été impacté par un rançongiciel : la transparence paie et montrera que vous gérez la situation. Autre erreur fatale : rapidement réinstaller les machines, ne garder aucune trace de ce qui s’est passé. C’est permettre au hacker de revenir par la même porte par laquelle il est entré la première fois car on n’aura pas pris le temps de comprendre comment il a pu venir. Effacer les fichiers chiffrés ou redémarrer les machines pour stopper le rançongiciel sont des réflexes naturels mais, dans un cas, on perd aussi la clé de déchiffrement qui se trouve parfois cachée dans le fichier chiffré. Dans le deuxième cas, le hacker peut le repérer et bloquer la machine elle-même en représailles.
Tout sauf paniquer
Quand un rançongiciel est détecté, il faut déconnecter les machines infectées, déconnecter le réseau et les espaces de stockage partagés (et ce n’est pas le moment de chercher la carte du réseau). Les réseaux en un seul tenant seront désavantagés car on ne pourra pas en isoler certaines parties. Il faut sécuriser ses sauvegardes, les déconnecter si possible, stopper toutes les synchronisations entre serveurs qui propageraient les fichiers chiffrés à la place du rançongiciel. Toutes les techniques qui permettent de se mouvoir latéralement dans le réseau doivent être désactivées (veillez à les documenter et à les connaitre pour votre propre réseau) comme par exemple les serveurs virtuels reliant des serveurs physiques et les machines virtuelles (stoppez-les quand c’est possible, ne les éteignez pas car ils peuvent contenir des infos précieuses sur le rançongiciel, les clés utilisées pour chiffrer,…).. Et ce n’est pas parce qu’un rançongiciel a été détecté et isolé que vous en êtes quitte. Certains sont disséminés en plusieurs exemplaires sur le réseau pour prendre le relais en cas d’isolement et de neutralisation du premier.
Il est intéressant de déterminer le type de ransomware qui vous a frappé, par exemple via le message que vous aurez reçu : vous pourrez alors à l’aide d’experts déterminer son modus operandi et mieux réagir qu’en mode « on déconnecte tout, on réfléchit après ». Vous saurez ainsi, par l’expérience d’autrui, si ce rançongiciel peut redémarrer plus tard quand vous pensez qu’il a fini son œuvre ou s’il est susceptible de revenir après un redémarrage, ce qui pose la question de sa persistance dans le réseau. Il faut aussi déterminer par où il a pénétré dans votre système car en fonction de ce point d’entrée, vous saurez quelle partie du réseau sera atteinte et quelles parties ne le seront pas, si vous avez appliqué une politique de segmentation forte du réseau. Cela ne sert à rien de stopper toute l’entreprise si on peut l’éviter mais qui arrive à garder la tête froide dans de telles circonstances ?
Quant à la question des outils de déchiffrement offerts par les autorités, ils fonctionneront d‘autant mieux que vous aurez été frappé par un rançongiciel ancien. Mais il en existe peu pour les rançongiciels récents. Quant aux sauvegardes, préparez-vous à être déçus : peu de sociétés en possèdent qui soient intégraux, les seuls capables de restaurer votre environnement dans l’état où il était avant l’attaque. La plupart des organisations ont des sauvegardes fragmentées mises en place pour tenir compte d’une corruption isolée d’une base de données, d’un crash disque et non pas d’un chiffrement 360° de toute votre informatique.
L’initiative des Etats-Unis montrera qu’agir seul en cybersécurité ne supprime pas la menace, elle la déplace : c’est l’Europe et l’Asie qui vont hériter du dynamisme du marché des rançongiciels. L’OCDE vient de se mettre d’accord sur une taxe minimum pour les GAFAs. Et si les initiatives législatives pour tarir les flux financiers des rançongiciels (et au passage pour cadrer les cryptomonnaies) se prenaient à ce niveau aussi.
Lorenzo Bernardi (Offensive Security Lead, Ernst & Young), Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles) et Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain).
Les logiciels libres ont pris aujourd’hui une place importante dans le développement de pratiquement tous les systèmes numériques. Malheureusement, dans certains cas, l’utilisation de composants parfois obsolètes posent des questions de sécurité. Après nous avoir expliqué les attaques supply chain dans un article précédent, Charles Cuveliez, Jean-Jacques Quisquater et Tim Vaes commentent une étude portant sur 1500 logiciels qui révèle un grand nombre de failles dues à ces dépendances mal maîtrisées. Pascal Guitton
Aujourd’hui, la plupart des programmes informatiques utilisent du code open source, c’est-à-dire des composants et des librairies informatiques prêts à l’emploi, proposés librement sur le Net par une communauté qui les maintient, ainsi que par des sociétés commerciales. Cela permet aux développeurs informatique de ne pas devoir chaque fois réinventer la roue quand ils mettent au point leurs propres applications. Ils peuvent se concentrer sur ce qui est nouveau, fera la différence et ne pas perdre de temps à reprogrammer ce que d’autres ont fait avant eux. En fait, pratiquement tous les programmes commerciaux, y compris des systèmes d’exploitation comme Windows ou MacOSX, font largement appel à l’open source.
L’open source se retrouve donc dans un large spectre de contextes depuis des librairies écrites par des développeurs isolés sans connaissance particulière en sécurité jusque des librairies entretenues par des organisations professionnelles avec des standards de sécurité élevés. Dans le premier cas, il est facile pour un hacker malveillant de compromettre le code open source sous couvert de participer au développement. Dans le deuxième cas, on retrouve l ‘Apache Software Foundation ou la Linux Foundation qui maintiennent des suites entières de logiciels open source au sein desquels chaque changement fait l’objet d’une revue par les pairs et est discuté par plusieurs échelons de développeurs (par exemple, dans des forums). Ce type d’approche peut permettre à des codes open source d’atteindre une meilleure qualité que des logiciels proposés par des sociétés commerciales.
La garantie de sécurité de ces codes open source reste pourtant vague. Elle se base sur l’idée – pas totalement fausse, mais pas garantie – que la communauté qui participe à un projet open source demeurera active dans la durée. Quand cette communauté fonctionne bien, les logiciels open source sont revus en permanence par la communauté qui y ajoute souvent en continu de nouvelles fonctionnalités. Des sociétés commerciales proposent, en sus de la communauté, du support et de la maintenance à leurs clients qui voudraient utiliser cet open source sans s’y investir eux-mêmes. Un bel exemple de ce modèle vertueux est Kubernetes (un logiciel pour le déploiement d’applications) qui est énormément utilisé et qu’on retrouve dans de nombreux systèmes informatiques et qui se décline en plusieurs variantes professionnelles avec support et maintenance (Red Hat Openshift, Azure Kubernetes, Google Kubernetes Engine, etc.).
Malheureusement cette belle réussite ne s’applique pas à la majorité des codes open source disponibles en ligne. Les chiffres révélés par Synopsys, une société spécialisée dans la promotion de logiciels de qualité, le mettent en évidence. En 2020, elle a audité 1500 programmes pour le compte de clients. Parmi eux, 84 % contenaient au moins une vulnérabilité provenant de l’open source. C’est 9 % de plus qu’en 2019. De plus, 60 % contenait une vulnérabilité à haut risque, c’est-à-dire dire qui pouvait être exploitée par des moyens déjà connus. Plus ennuyant : le top 10 des vulnérabilités qui apparaissaient le plus en 2019 se retrouvent dans le palmarès 2020. Le problème ne se résout pas.
Dépendance des composants. Extrait de https://xkcd.com/2347/ Licence Creative Commons
S’il y a un domaine où l’open source règne en maitre, c’est bien celui des applications pour smartphones sous Android : 98 % d’entre elles contiennent de l’open source et selon le constat de Synopsys, 63 % révélaient une vulnérabilité critique. Comme pendant la pandémie, les utilisateurs ont téléchargé encore plus d’applications que précédemment, le risque de malveillances a donc augmenté mécaniquement.
Parmi les 1500 programmes analysées, 91 % contenaient des dépendances à des codes open sources qui ne connaissaient plus de développement actif, d’amélioration du code, de résolution des soucis rencontrés sur les deux dernières années. Le fait que la communauté ne soit plus active augmente considérablement les risques. Et puis, 85 % des programmes contenaient des dépendances à du code open source périmé depuis 4 ans. De nouvelles versions existaient qui résolvaient peut-être les vulnérabilités mais les programmes n’en tenaient pas compte.
Pourquoi?
Comment expliquer des chiffres aussi alarmants ? Les équipes de développement se battent avec le côté ultra dynamique des codes open sources qui évoluent en permanence et dont l’usage s’est installé partout. Une bibliothèque open source qui à un moment donné est, sans vulnérabilité, peut ne pas le rester pas longtemps car son environnement évolue vite . Le bât blesse au niveau organisationnel car il faudrait mettre en place un moyen simple d’avertir les développeurs, lorsqu’ils utilisent une bibliothèque open source, qu’une vulnérabilité y a été détectée. Mais comment ? Cela demande beaucoup de discipline au sein même de l’entreprise et de ses développeurs. Cela se complique encore plus si l’entreprise fait appel à des tiers pour ses développements.
Des plateformes comme GitHub dont l’activité consiste à mettre à disposition des codes open source jouent un rôle important pour combler ce trou sécuritaire : elles intègrent des contrôles de sécurité, scannent les codes qui s’y trouvent, même gratuitement quand il s’agit de code open source. Elles s’attaquent au problème à la source (en équipant les développeurs eux-mêmes avec les outils adéquats) plutôt que de laisser cette tâche du côté des utilisateurs d’open source qui n’auraient pas tous la même discipline.
Il se peut aussi que la mémoire collective « oublie » la vulnérabilité d’une librairie de logicielle. La vulnérabilité a bien été détectée mais elle a été mal ou pas documentée et de nouveaux développeurs l’ignorent. Ou bien encore, on continue à utiliser de vieilles bibliothèques qui ne sont plus maintenues alors que leur ancienneté procure un faux sentiment de confiance : s’il existait une vulnérabilité, cela se saurait, pense-t-on. Or le bug Heartbleed a prouvé le contraire : cette bibliothèque était animée et entretenue par des doctorants pendant leur thèse mais un jour ce travail cessa faute de combattants sans que tous ne soient prévenus de l’arrêt de la maintenance.
Symbole utilisé pour communiquer sur HeartBleed. Par Leena Snidate – WikiMedia
Le problème des licences
Il n’y a pas que les vulnérabilités qui posent problème, il faut aussi évoquer les licences. Ces licences sont plus ou moins libres d’utilisation et un logiciel peut proposer (involontairement) des usages qui ne respectent pas les licences de logiciel open source qu’il utilise. Par exemple, 65 % des programmes analysés par Synopsys recelaient un conflit de licence. Et les 3/4 d’entre elles étaient en conflit spécifiquement avec une version ou un autre de la célèbre « GNU General Public Licence » qui est très limitante.
26% des programmes utilisaient de l’open source sans licence ou alors avec une licence modifiée par l’auteur, ce qui place souvent l’utilisateur en conflit car la licence risque d’être mal (ré)écrite ou pas adaptée à l’usage qui est fait du code. Les conflits sur les licences open sources sont d’ailleurs en croissance (copyright, contrat, antitrust, brevet et fair usage). Et il y a parfois des situations ubuesques : la licence GNU General Public Licence v2 crée un conflit si le code est inclus dans un programme commercial compilé et distribué mais ce ne sera pas le cas si c’est un service de type SaaS car on ne distribue pas de code SaaS, on y accède….
Dans un article précédent, nous avons décrit les attaques supply chain qui utilisaient des codes sur lesquels s’appuyaient un logiciel. Mais au moins, le ou les fournisseurs de tels codes dans une supply chain sont connus. Avec l’open source, la situation est encore plus complexe : qui est le fournisseur des codes qu’on utilise ?
Ceci dit, Synopsys a pu faire ce rapport et établir ces statistiques grâce à une transparence qui est dans l’ADN de l’open source. Avec un code commercial, le secret qui l’entoure ne permettrait même pas d’établir un tel état des lieux.
Que faire à court terme du côté utilisateur ?
Pour affronter ces nouveaux défis, on peut réaliser soi-même une vérification approfondie des logiciels open source qu’on utilise : comment le code est-il maintenu ? Combien de développeurs travaillent sur le projet ? Informent-ils sur les vulnérabilités ? Combien de temps entre deux versions successives du logiciel ? Le code est-il revu par les pairs ? La licence est-elle compatible avec l’usage qu’on veut en faire ? C’est tout un faisceau de questions qu’on pourrait tout aussi bien poser pour les logiciels commerciaux.
Une telle vérification n’est pas la fin de l’histoire. Il faut aussi vérifier dans le temps que le logiciel et les bibliothèques restent à jour et sûres. Des outils qui partent du principe que les vulnérabilités sont de toute façon présentes dans le code voient aussi le jour. Ils protègent le code considéré comme « vulnérable par défaut » contre des modèles d’attaques à la manière d’un mini-firewall dans le logiciel même en fonctionnement.
Enfin, même si toutes ces barrières se sont révélées inefficaces, il faut aussi mettre en place des outils pour détecter les attaques. On a compris l’ampleur de l’attaque SolarWinds suite à une détection lancée par Fireeye qui en a été victime.
Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain) & Tim Vaes (Ernst & Young, Cyber Security Lead, EY Financial Services)
La créativité des malfaiteurs numériques ne connait pas de limite. Nos amis Charles Cuveliez, Jean-Michel Dricot et Jean-Jacques Quisquater nous parlent d’un type d’attaque, dite « supply chain » qui exploitent les vulnérabilités des logiciels complexes entraînées par la cascade de composants nécessaires à leur conception. Laissons-leur la parole ! Pascal Guitton
L’attaque SolarWinds, du nom d’un logiciel de gestion de réseaux professionnels, dont une mise à jour contaminée a impacté des dizaines de milliers de clients dans le monde, semble faire partie des menaces imparables
On nous répète sans arrêt qu’il faut installer les mises à jour des programmes dès qu’elles arrivent parce qu’elles fixent peut-être des trous de sécurité. Si de surcroit, elles nous parviennent automatiquement par le biais du vendeur lui-même, de manière sécurisée, pourquoi s’en inquiéter ? Et voilà qu’en installant l’une d’elles, on contamine son réseau ; c’est ce qu’on appelle les attaques supply chain. Un pirate s’infiltre dans votre réseau via un partenaire, un fournisseur, dans ce cas via une mise à jour d’un de ses programmes.
C’est que pour concevoir des produits numériques, la chaîne de valeur est devenue d’une complexité inouïe avec chaque maillon fournissant le composant souvent essentiel dans le produit final. Mais parfois, la hiérarchie des responsabilités entre développeurs majeurs et sous-traitants « en cascade » est tellement diluée, qu’on ne peut plus la tracer avec certitude et ainsi assurer la sureté d’un composant. »
Graphe de dépendance visualisant la complexité du logiciel Parrot (environ 250.000 lignes de code C). Image produite par Bram Adams et extraite du Dossier: Les systèmes complexes. Le Magazine de l’Université de Mons. T. Mens & M. Goeminne
En plus, ces attaques supply chain sont attirantes : compromettre un logiciel, c’est avoir une porte d’entrée chez les milliers de clients qui l’ont acquis sans s’échiner à forcer la porte. C’est le client lui-même qui le fait pour vous en installant la mise à jour vérolée.
Ces logiciels peuvent avoir un rôle central comme, pour SolarWinds, contrôler le réseau de l’entreprise. Ces logiciels demandent aussi souvent des privilèges élevés pour s’installer de façon à être plus efficaces, ce que nous leur accordons facilement : pensons aux antivirus, aux logiciels d’accès à distance au réseau de l’entreprise… Ces logiciels communiquent beaucoup avec l’extérieur pour les mises à jour et l’envoi de données de télémétrie. C’est autant de trafic dans lequel peut se cacher celui des pirates qui vont même parfois interdire aux mises à jour « légitimes » de parvenir au bon endroit. Une fois dans le réseau, le logiciel compromis, et par conséquent l’attaquant, a accès à tout : il est vu comme légitime par le système infecté.
Comment le malfaiteur s’y prend-t-il ?
Le malfaiteur cherche à s’infiltrer dans le réseau de la société qui a conçu le logiciel : il peut alors compromettre les mises à jour qu’elle s’apprêtait à distribuer en y insérant son propre code. Le pirate peut également contourner la signature du code (code signing en anglais), c’est-à-dire la preuve que le logiciel reçu dans la mise à jour est bien celui qui, au caractère près, a été mis au point par l’équipe de développement officielle.
Plus subtil : il peut compromettre ou utiliser des vulnérabilités des codes open source qui sont réemployés dans des logiciels existants, y compris ceux des sociétés privées qui y piochent (et elles ont bien raison !). Le dernier rapport de Synopsys paru en avril 2021 est à cet égard édifiant : il a audité plus de 1500 codes et a ainsi découvert que 84 % d’entre eux contenaient au moins une vulnérabilité dans l’open source qu’ils utilisaient. Pire : 60 % des codes contenait une vulnérabilité à haut risque. Selon le domaine d’activités, de 70 % à 89 % des logiciels qui sont développés contiennent de l’open source sauf dans les télécoms et le e-commerce.
Les pirates proposent parfois leurs propres bibliothèques en ne changeant qu’une lettre par rapport à la version correcte. Les développeurs distraits ne s’en rendent pas compte et les intègrent alors dans leur logiciel !
Enfin, le malfaiteur peut également s’infiltrer chez un fournisseur ou un sous-fournisseur de la société qui a conçu le programme.
Les pirates qui recourent à ces attaques sont hautement spécialisés et très compétents. Ils élaborent une liste de cibles les intéressant et sur lesquelles ils se concentreront une fois l’attaque lancée pendant qu’ils laisseront toutes les autres entreprises infectées avec un réseau compromis. Les attaquants vont ensuite introduire du logiciel supplémentaire sur les systèmes des « heureux élus » pour exfiltrer les données qu’ils convoitent. Ils ne vont pas dépenser beaucoup d’argent à mettre au point cette attaque juste pour tout détruire.
Rupture de la chaîne de confiance. Conçue par les auteurs.
Comment en est-on arrivé là ?
Le monde du logiciel est rempli de paradoxes : son écosystème est massivement basé sur la confiance (par exemple via les communautés open source) et massivement interdépendant puisque fait de briques diverses et de réutilisations de logiciels à large échelle, ce qui expose cette industrie à des vulnérabilités systémiques. Les interdépendances maillées sont, en général une source de résilience pour éviter des défaillances en cascade car un système dépendant linéairement d’un autre peut le faire s’effondrer. Mais dans le monde cyber, cette connectivité peut, au contraire, faciliter les effondrements en cascades dans les industries basées sur un fonctionnement en réseaux comme les télécoms, l’énergie ou les services financiers. Pour se prémunir, il faut notamment introduire de la diversité dans les architectures et les produits utilisés, de la même façon, au fond, que la monoculture ou le monoélevage intensif créent un terrain propice aux infections véritables cette fois. Franchement, est-il raisonnable de n’utiliser qu’un seul logiciel pour gérer tout un réseau ? Est-il normal que le même fournisseur puisse équiper toutes les sociétés du top 500 US ? C’était le cas d’Orion : son logiciel, SolarWinds, était au centre de tout : gestion du réseau, de l’infrastructure, gestion de performances, etc. C’est un risque de concentration inacceptable.
Trust me. Extrait du site teepublic.co
Les clients doivent prendre l’hypothèse qu’ils sont perméables.
Ce n’est pas parce qu’un logiciel reçoit un label de confiance parce qu’il a été testé, qu’il restera digne de confiance sur un temps long. Le résultat d’un test n’est valable que le jour où il a été réalisé et par ailleurs, on sait qu’il n’est que partiel parce qu’il est totalement impossible de tester l’exhaustivité des configurations et des conditions d’usage (même si des techniques existent pour contourner cette impossibilité). La valeur de la certification et du test ne repose que sur l’équipe qui les ont réalisés. Ils ne doivent pas créer un faux sentiment d’invincibilité d’autant plus qu’un label « tested and approved » fièrement mis en avant va décourager des organismes indépendants de retester et les clients de les payer : à quoi bon ?
Quelle serait la solution ultime ?
Mais alors, comment garantir que tous les composants d’un logiciel ou d’un produit sont sûrs ? Il y a des solutions techniques comme les certificats, à clé publique/clé privée, les mêmes qui garantissent en cascade que site web que vous contactez est bien celui qu’il prétend être. Ces certificats de garantie d’origine contrôlée se valident en cascade, dans une chaine de confiance qu’on pourrait appliquer à tous les sous-traitants dans l’écriture d’un programme par exemple. Mais ces infrastructures à clé publique prendront des années à se mettre en place. Peut-être la solution viendra-t-elle d’une utilisation originale (et rapide) d’un blockchain ?
On peut faire des dues diligences, inspirées de celles qui se font quand une société A veut acheter une société B qui doit alors se mettre à nu. La due diligence, appliqué aux logiciels critiques, impliquerait d’avoir accès à toutes les facettes du développement du code, comment il a eu lieu, avec toute l’assurance-qualité requise. Il faudrait énumérer et connaitre les sous-traitants, les freelances impliqués, leur nationalité…
On doit aussi s’assurer que la société qui a développé le logiciel publie bien les vulnérabilités de ses produits
On doit contrôler qu’elle intègre les pratiques de sécurité aussi dans le développement du code et qu’elle connait bien tous ses sous-traitants et les sous-traitants de ses sous-traitants (et en rester là en termes de couches successives de sous-traitants).
La liste des contrôles n’est pas finie : applique-t-elle l’analyse de code statique et dynamique, fait-elle une revue manuelle du code, fait-elle des tests de pénétrations de son logiciel. Son code est-il vérifié par un tiers ? Comment gère-t-elle la distribution des correctifs ? Se soumet-elle à des audits ?
Une fois en fonctionnement, on peut imposer aux logiciels lorsqu’ils discutent avec Internet de n’y accéder que de manière restreinte vers une seule adresse IP et le site avec les mises à jour. Au moins si le logiciel essaie de s’en écarter, c’est une alerte de son détournement mais ce n’est pas la panacée. Les adresses IP peuvent changer et le vendeur peut lui aussi utiliser un cloud pour fournir le service.
Enfin on peut exiger plus de tests de l’intégrité du logiciel de la part du client ou les imposer via les régulateurs, ce qui mécaniquement en fera baisser le coût. C’est vrai qu’on peut espérer qu’une obligation créera un appel d’air pour plus d’acteurs sur ce marché, donc plus de concurrence….
Il y a du pain sur la planche en termes de prévention. Il ne reste à court terme que de privilégier la résilience.
Charles Cuvelliez et Jean-Michel Dricot (Ecole Polytechnique de Bruxelles, Université de Bruxelles), Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain
Acheter en ligne, réaliser des transactions bancaires, communiquer de façon sécurisée, autant d’opérations qui nécessitent d’être protégées par des fonctions (ou primitives) cryptographiques. Notre confiance envers ces briques de base repose sur la cryptanalyse, c’est à dire l’analyse de la sécurité par des experts, qui essayent de “casser” les primitives cryptographiques proposées, et ainsi déterminer celles qui semblent robustes et qu’on pourra recommander, ou celles qui semblent dangereuses et qu’il ne faut pas utiliser. C’est ce que nous explique Maria Naya-Plasencia dans deux articles qui terminent la série entamée à l’occasion de la publication par Inria du livre blanc sur la cybersécurité. Dans ce second article, Maria nous décrit la situation actuelle et les évolutions envisagées dans ce domaine. Pascal Guitton .
D’où peuvent venir les faiblesses ?
L’expérience nous montre que des attaques sur les primitives cryptographiques sont basées sur différents types de faiblesse. Dans le cas de la cryptographie asymétrique, la faille vient parfois d’un assouplissement dans la preuve pour lier le problème cryptographique au problème mathématique associé. Dans d’autres cas, le problème mathématique considéré s’avère plus facile à résoudre que prévu. Des faiblesses peuvent aussi venir d’une configuration ou de paramètres spécifiques d’une certaine instance, parfois non apparents, qui rendent le problème moins difficile que l’original.
Dans le cas des primitives symétriques, les preuves formelles de sécurité reposent sur des suppositions irréalistes, mais cela ne les rend pas faciles à attaquer pour autant. Si jamais une attaque est trouvée (rappelons qu’elle doit être plus efficace que l’attaque générique), la primitive correspondante est considérée comme cassée. Ce fut le cas par exemple du chiffrement Gost.
Le besoin de la transparence
Nous avons vu que même les primitives cryptographiques les plus robustes ne possèdent pas de véritable preuve de sécurité – tout au plus des indices qui semblent garantir leur sûreté, mais sans qu’on en soit absolument certain.
La mesure de sécurité la plus tangible et la plus acceptée par la communauté cryptographique est en fin de compte la résistance avérée à la cryptanalyse : si une fonction cryptographique a résisté aux attaques de dizaines d’experts pendant des décennies, on est en droit de se sentir en bonne sécurité (malgré le manque de preuve formelle).
C’est en fait le rôle principal de la cryptanalyse : la mesure empirique de la sécurité. Elle est donc la base de la confiance que nous portons aux algorithmes cryptographiques. C’est une tâche essentielle qui n’a pas de fin.
Il est important de réaliser que cette sécurité ne peut s’obtenir que grâce à une transparence totale : si on conçoit un algorithme cryptographique, il faut le rendre complètement public dans ses moindres détails pour le soumettre à l’analyse des cryptographes, car seuls leurs efforts continus pour casser cet algorithme pourront être un gage tangible de sa sécurité (s’ils échouent, bien sûr). Ce principe est paradoxalement dû à un militaire et connu depuis plus de 100 ans sous le nom de principe de Kerkhoffs.
Le symétrique est également vrai : les cryptanalystes doivent publier leur travaux et leurs avancées pour permettre à la communauté scientifique de réutiliser leurs idées, et ainsi disposer des meilleures techniques pour analyser les crypto-systèmes existants.
Cette première transparence – celle des algorithmes cryptographiques – est assez communément appliquée, même si certains acteurs s’entêtent à concevoir des crypto-systèmes “cachés” en espérant que cela augmentera leur sécurité. Par contre, il reste assez commun, pour des hackers isolés comme pour de grosses organisations, privées ou publiques (comme la NSA américaine), de conserver leurs progrès pour eux, en espérant peut-être obtenir un avantage stratégique s’ils parvenaient à cryptanalyser avec succès un algorithme que le reste du monde considère sûr. Nous avons donc un réel besoin de cryptanalystes bienveillants, travaillant dans la transparence et ayant pour but de faire progresser la cryptographie en général.
Forces et faiblesses
Un aspect préoccupant vient du fait que la sécurité n’est jamais prouvée. Quelle que soit la fonction cryptographique, on ne pourra jamais écarter complètement la possibilité d’une cryptanalyse, même très tardive.
Un aspect rassurant est que le modus operandi est très bien établi, depuis des décennies. La communauté des cryptographes adopte par défaut une attitude qu’on pourrait qualifier de paranoïaque quand il s’agit d’évaluer si tel ou tel algorithme pourrait se faire attaquer. En effet, la cryptanalyse moderne parvient très rarement à véritablement “casser” un crypto-système, et la plupart des résultats sont en fait des attaques partielles, c’est-à-dire sur une version réduite du système. Par exemple, en cryptographie symétrique, de nombreuses primitives sont formées en appliquant R fois une même fonction interne : on parle de R tours. Très souvent, les cryptanalystes s’attaquent à une version réduite, avec un nombre de tours r inférieur à R. On peut alors jauger la “marge” de sécurité grâce à la différence entre le plus grand r d’une attaque et le nombre de tours R (si r = R, la fonction est véritablement cassée). Pour éviter tout risque, de nombreuses primitives sont abandonnées tout en restant loin d’avoir été cassées : on a besoin de peu de primitives cryptographiques, au final, et les plus sûres ont une marge de sécurité très importante. Pour que ce système reste valide, il est important que la cryptanalyse bienveillante reste très active et dynamique.
L’exemple d’AES
AES est le standard actuel de chiffrement à clé secrète. Nous allons analyser l’effet de la cryptanalyse sur la version de l’AES qui utilise une clé de 128 bits. Cette version utilise 10 tours, c’est à dire qu’on applique 10 fois la même fonction interne.
En 1998, lors de sa conception, la meilleure attaque connue, trouvée par les auteurs, s’appliquait sur 6 tours du chiffrement : il existait donc une attaque, meilleure que l’attaque générique, mais seulement sur une version affaiblie qui n’applique que 6 fois la fonction interne. La marge de sécurité était donc de 4 tours sur 10. En 2001, une attaque sur 7 tours fut découverte. Bien que la marge fut donc réduite de 4 à 3 tours, AES était loin d’être cassé.
Depuis 2001, plus de 20 nouvelles attaques sur des versions réduites de l’AES ont été publiées, améliorant la complexité, c’est-à dire diminuant la quantité de calcul nécessaire. Aujourd’hui, la meilleure attaque connue est toujours sur 7 tours : pendant 18 ans, la marge de sécurité en nombre de tours n’a pas bougé. Plusieurs compromis sur le temps de calcul, la quantité de données et de mémoire nécessaire à l’attaque sont possibles, mais celle qui optimise le temps de calcul a tout de même besoin de 299 opérations, et d’une quantité de données et de mémoire équivalente. Ce nombre énorme (à 30 chiffres) est bien au delà de la capacité de calcul de l’ensemble des ordinateurs de la planète, même pendant des centaines d’années. Et la comparaison avec l’attaque générique, qui a besoin de 2128 opérations mais d’une quantité de données et de mémoire négligeable, n’est pas si évidente en termes d’implémentation.
De toute évidence, en prenant en compte tous les efforts fournis par la communauté cryptographique pendant tant d’années, il semble très peu probable que des attaques sur la version complète apparaissent en l’état actuel. On laisse peu de place aux surprises ! AES reste encore un des chiffrements les plus analysés au monde, et de nouveaux résultats pour mieux comprendre sa sécurité et son fonctionnement apparaissent tous les ans.
Etdansunmondepost-quantique?
Imaginons des attaquants ayant accès à un ordinateur quantique, qui utilise les propriétés quantiques des particules élémentaires pour effectuer certains types de calculs de manière beaucoup plus performante que les ordinateurs classiques (cf ces articles [1], [2] récent de binaire). De tels attaquants pourraient casser la plupart des crypto-systèmes asymétriques utilisés actuellement. C’est d’ailleurs une des applications les plus prégnantes de l’ordinateur quantique tel qu’on l’imagine.
Les crypto-systèmes dit “post-quantiques” sont en plein essor pour répondre à ce besoin. En ce moment même, le NIST américain organise une compétition pour trouver des nouveaux standards de chiffrement post-quantique. Ces crypto-systèmes se basent sur des problèmes difficiles qui – contrairement à la factorisation des entiers, base de RSA – résisteraient, dans l’état actuel des connaissances, à l’arrivée de l’ordinateur quantique. Ces primitives post-quantiques, asymétriques et symétriques, ont besoin, de la même façon que dans le cas classique, d’avoir leur sécurité analysée face à un attaquant quantique, et la cryptanalyse quantique est donc d’une importance primordiale.
Mentionnons que la cryptographie doit parfois pouvoir résister dans le temps : on voudrait pouvoir garder certains documents confidentiels à long terme, malgré les progrès scientifiques en matière de cryptanalyse (incluant donc l’arrivée possible de l’ordinateur quantique). Il serait donc opportun de commencer dès aujourd’hui à utiliser des crypto-systèmes qu’on pense résistants même dans un contexte post-quantique.
L’importance des recommandations.
Il ne faut pas sous-estimer l’importance de suivre les recommandations de la communauté scientifique cryptographique. Notamment, seule la poignée de primitives recommandées par cette communauté doit être utilisée, car ce sont celles qui focalisent la cryptanalyse et dont la marge de sécurité est de loin la meilleure. Heureusement, ce principe est de mieux en mieux respecté par la communauté informatique dans son ensemble, comme vous pourrez le constater avec légèreté en effectuant une recherche sur le Web d’images contenant les termes “roll your own crypto”. Une notion également importante et parfois plus négligée est de rester à jour, et de réagir rapidement quand la communauté cryptographique recommande d’abandonner un crypto-système précédemment recommandé, mais jugé insuffisamment sûr à l’aune de progrès récents.
Les grandes failles de sécurité informatique sont souvent le cas de mauvaises implémentations, mais la faute incombe parfois à l’usage de crypto-systèmes non recommandés. Citons par exemple une attaque parue en 2013 sur le protocole TLS (qui protège les connexions https sur nos navigateurs), utilisant des failles du stream cipher RC4 dont on connaissait l’existence depuis 2001 ! Pire : en 2015, l’attaque FREAK exploitait la petite taille des clés RSA-512, qu’on savait trop faible depuis les années 90.
Ces brèches de sécurité et beaucoup d’autres auraient pu et dû être évitées !
Conclusion
Ces illustrations montrent que la cryptanalyse demande des efforts soutenus et continus, par des chercheurs bienveillants travaillant dans un contexte transparent, et publiant leurs résultats.
Que ce soit dans un contexte classique ou post-quantique, la cryptanalyse doit rester une thématique en constante évolution, afin d’assurer la maintenance des algorithmes utilisés, ainsi que pour évaluer les nouveaux types d’algorithmes cryptographiques. Mieux vaut prévenir que guérir et garder une longueur d’avance sur les adversaires malveillants !
Acheter en ligne, réaliser des transactions bancaires, communiquer de façon sécurisée, autant d’opérations qui nécessitent d’être protégées par des fonctions (ou primitives) cryptographiques. Notre confiance envers ces briques de base repose sur la cryptanalyse, c’est à dire l’analyse de la sécurité par des experts, qui essayent de “casser” les primitives cryptographiques proposées, et ainsi déterminer celles qui semblent robustes et qu’on pourra recommander, ou celles qui semblent dangereuses et qu’il ne faut pas utiliser. C’est ce que nous explique Maria Naya-Plasencia dans deux articles qui terminent la série entamée à l’occasion de la publication par Inria du livre blanc sur la cybersécurité. Dans ce premier article, Maria pose les bases des mécanismes de la cryptanalyse. Pascal Guitton .
Nos communications doivent être protégées pour assurer leur confidentialité et intégrité, et pour les authentifier. Des protocoles de sécurité bien réfléchis sont utilisés dans ce but, et les briques de base de tous ces protocoles sont les primitives cryptographiques. Ces primitives cryptographiques peuvent être divisées en deux grandes familles.
La cryptographie symétrique (parfois dite “à clé secrète”) est la plus ancienne. Si Alice et Bob veulent communiquer à distance de façon confidentielle, malgré les risques d’interception de leurs messages, ils vont d’abord se réunir et se mettre d’accord sur une clé secrète, que tous les deux (et personne d’autre) connaissent. Quand Alice veut envoyer un message à Bob, il lui suffit alors de cacher l’information à l’aide de la clé secrète, avant de l’envoyer. Quand Bob recevra le message chiffré, il peut le déchiffrer à l’aide de la même clé secrète pour récupérer le message original : la clé secrète sert à chiffrer et à déchiffrer. Bob peut lui aussi envoyer un message à Alice avec la même clé, qui est utilisable dans les deux sens.
Cette méthode présente l’inconvénient de devoir se réunir (en secret, sans risque d’interception ou espionnage) avant de pouvoir établir des communications éloignées et sécurisées. Comment pourraient faire Alice et Bob pour communiquer confidentiellement sans se réunir avant ?
Ils peuvent utiliser la cryptographie asymétrique (dite ”à clé publique”), introduite dans les années 70. Les détails sur ce types de primitives sont présentés dans l’article “De la nécessité des problèmes que l’on ne sait pas résoudre”.
La cryptographie asymétrique permet d’éviter que les parties qui veulent communiquer se réunissent avant établir la communication sécurisée, mais elle est aussi lente et coûteuse, pouvant devenir impraticable pour des longs messages. De son côté, la cryptographie symétrique nécessite un échange de clés avant de pouvoir commencer la communication, mais une fois la clé secrète répartie, elle est considérablement plus efficace. Pour exemple, le standard symétrique actuel, AES, recommandé depuis 2002 et utilisé dans la plupart des navigateurs web, peut chiffrer plusieurs gigaoctets par seconde, là où les standards asymétriques actuels peinent à atteindre un mégaoctet par seconde (plus de 1000 fois plus lents). On utilise donc le plus souvent des systèmes mixtes : la cryptographie asymétrique pour échanger une clé secrète, normalement de petite taille (par exemple 128 bits), et ensuite la cryptographie symétrique (en utilisant la clé secrète échangée) pour chiffrer les messages.
Pour que les communications soient sûres, les primitives cryptographiques utilisées doivent répondre à un cahier des charges précis en matière de sécurité. La cryptanalyse constitue le moyen essentiel de s’assurer du respect prolongé de ce cahier des charges.
Quelles primitives utiliser ?
La sécurité des primitives asymétriques (à clé publique) repose en général sur la difficulté d’un problème mathématique bien établi et jugé difficile, c’est-à-dire à priori insoluble dans un laps de temps raisonnable. Par exemple, le chiffrement RSA repose sur le problème de la factorisation (étant donné un entier naturel non nul, trouver sa décomposition en produit de nombres). Déchiffrer RSA reviendrait donc à résoudre le problème de la factorisation de très grandes nombres entiers, ce qui constituerait une véritable bombe dans le milieu scientifique, car de très nombreux chercheurs étudient ce problème en vain depuis des décennies.
Du côté de la cryptographie symétrique, on peut prouver formellement de nombreuses propriétés de sécurité d’un chiffrement symétrique idéal si on suppose qu’il génère pour chaque message un chiffre aléatoire, ce qui ne nous permettrait pas de retrouver de l’information sur le message original. Mais il est par essence impossible de construire efficacement une telle fonction, et les primitives symétriques essaient d’imiter ce comportement avec des fonctions déterministes. Pour jauger la sécurité, on s’en remet donc à la résistance aux attaques des cryptanalystes.
Une attaque est jugée efficace (et la primitive attaquée est alors dite « cassée ») si elle peut se faire plus facilement (plus rapidement, ou en utilisant moins de ressources de calcul) que les meilleures attaques génériques, c’est à dire une attaque qu’on peut toujours appliquer, même sur les primitives idéales. Par exemple, une attaque générique sur un chiffrement symétrique est la recherche exhaustive de la clé secrète : en essayant toutes les clés possibles, on parviendra toujours à trouver la bonne. Comme on ne veut pas qu’une telle attaque soit réalisable, les clés secrètes ont des tailles variant entre 128 à 256 bits, selon la sécurité voulue : cela implique qu’il faudrait essayer respectivement 2128 ( environ à 340 milliards de milliards de milliards de milliards, soit un 3 suivi de 38 zéros) et 2256 clés différentes. Tester 2128 clés est à l’heure actuelle hors de portée mais il est difficile de prédire pendant combien de temps ce sera le cas ; pour des clés de 256 bits une recherche exhaustive est cependant totalement au-delà des capacités de l’ensemble des ressources de calcul de la planète.
L’existence de toute attaque plus performante que ces attaques génériques est considérée comme une faiblesse grave de la primitive.
Nous poursuivons notre balade avec David Pointcheval, Directeur du Laboratoire d’informatique de l’École Normale Supérieure, Paris, dans « l’agrégation confidentielle ». Il nous conduit aux frontières de ce domaine de recherche. Serge Abiteboul
Pexels
Nous avons vu dans un premier article que le FHE (chiffrement complètement homomorphe) permettait d’effectuer des calculs sur les chiffrés. Mais il ne permet pas le partage des résultats : toute personne capable de déchiffrer le résultat final est en mesure de déchiffrer les entrées du calcul, puisque le tout est chiffré sous la même clef. Le chiffrement fonctionnel [1] fournit un outil complémentaire : il permet la diffusion de résultats, restreints par les capacités de la clef que possède l’utilisateur et les contraintes choisies par l’émetteur des chiffrés. Par exemple, la clef peut ne permettre le déchiffrement que sous certaines conditions d’accès (chiffrement basé sur l’identité, ou sur des attributs), mais peut aussi restreindre le déchiffrement à certaines agrégations sur les clairs, et à rien d’autre. Usuellement, à partir d’un chiffré E(x) de x, la clef de déchiffrement permet de retrouver le clair x. Avec le chiffrement fonctionnel, plusieurs clefs de déchiffrement peuvent être générées, selon différentes fonctions f. A partir d’un chiffré E(x) de x, la clé de déchiffrement kf associée à la fonction f permet d’obtenir f(x) et aucune autre information sur x. Ainsi, la fonction f peut tester l’identité du destinataire (intégrée dans le clair x au moment du chiffrement), avant de retourner ou non le clair, ce qui conduit à un simple contrôle d’accès. Mais la fonction f peut également faire des calculs plus complexes, et notamment ne donner accès qu’à certains types d’agrégations.
Agrégations de données
Le grand intérêt du chiffrement fonctionnel est en effet la contrainte by design des informations partielles obtenues sur la donnée en clair, par exemple une moyenne, des agrégations et toutes sortes de statistiques, sans jamais révéler d’information supplémentaire. On peut notamment effectuer des chiffrements de vecteurs et n’autoriser que certains calculs statistiques. Mais contrairement au FHE qui retourne le calcul sous forme chiffrée et nécessite donc de posséder la clef de déchiffrement qui permet non seulement de retrouver le résultat en clair mais également les données initiales en clair, la clef de déchiffrement fonctionnel effectue le calcul et fournit le résultat en clair. Cette dernière ne permet en revanche pas de déchiffrer les données initiales. Il a été montré possible de générer des clefs pour évaluer n’importe quel circuit sur des données chiffrées [2]. Néanmoins, ce résultat générique est très théorique, sous des hypothèses très fortes, et notamment la possibilité d’obfusquer (*) du code, ce pour quoi nous n’avons pas encore de solution. Ainsi, la première construction effective a été donnée pour la famille des produits scalaires, ou moyennes pondérées [3] : les messages clairs sont des vecteurs et les clefs de déchiffrement fonctionnel sont associées à des vecteurs. L’opération de déchiffrement retourne le produit scalaire entre le vecteur chiffré et le vecteur associé à la clef.
Moyennes sur des données temporelles
Il s’agit certainement du cas d’usage le plus classique. Bien que très simple, il semble adapté à de nombreuses situations concrètes : des séries de données temporelles sont générées, et le propriétaire de ces données souhaite ne diffuser que des agrégations sous formes de moyennes pondérées, à chaque période de temps. Ces pondérations peuvent dépendre des destinataires, voire s’affiner au cours du temps. Pour cela, pour chaque vecteur de pondérations, une clef de déchiffrement fonctionnel est générée par le propriétaire des données, une bonne fois pour toutes, et transmise au destinataire autorisé. A chaque période de temps, la série de données est publiée chiffrée, et chaque propriétaire de clef peut obtenir le calcul agrégé autorisé, et rien de plus. Tous les destinataires ont accès aux mêmes données chiffrées, mais selon la clef en leur possession, des agrégations différentes seront accessibles.
Plus récemment, des versions multi-clients [4] ont été définies, permettant à des fournisseurs de données distincts de contribuer à la série temporelle, et de garder le contrôle des clefs fonctionnelles générées. Les exemples d’applications sont multiples, dans la finance, en sécurité, ou dans le domaine médical. Considérons les compagnies d’assurance, qui sont en forte concurrence, et qui n’imaginent pas un instant partager les volumes dans chaque catégorie de sinistres rencontrés par leurs clients. Par contre, ces clients seraient intéressés par le volume global, au niveau national, toutes compagnies d’assurance confondues. Cela rentre exactement dans le contexte d’une somme pondérée générée régulièrement sur des données chiffrées. Et bien sûr, les compagnies d’assurance doivent contribuer à la génération des clefs fonctionnelles, afin de s’assurer qu’elles permettront un calcul qu’elles autorisent. Un autre cas d’usage similaire en sécurité est la remontée des attaques subies par les entreprises. Ces données sont sensibles au niveau de chaque entreprise, mais sont très utiles à un niveau global pour connaître les menaces, et réagir de façon adaptée. Le chiffrement fonctionnel, y compris multi-client, est quant à lui parfaitement opérationnel sur des données réelles, pour obtenir de telles moyennes pondérées. En effet, les calculs à effectuer demeurent relativement simples et peu coûteux.
Chiffrement fonctionnel et apprentissage
Est-ce la fin de l’histoire ? Non, car de fortes limitations subsistent. La technique permet de réaliser un grand nombre de statistiques basées sur des additions avec des coefficients. Elle permet notamment des techniques de classification de données, mais de médiocre qualité. On aimerait aller au-delà de tels calculs linaires. C’est indispensable pour réaliser des calculs statistiques plus riches, par exemple des calculs de variance. Ça l’est aussi pour pouvoir utiliser des méthodes d’apprentissage automatique plus sophistiquées [6]. Il n’y a pas d’impossibilité, juste de belles opportunités pour les scientifiques.
Conclusion
Avec le RGPD (ou Règlement Général sur la Protection des Données), la protection de la vie privée et des données personnelles est désormais une exigence pour toute entité qui stocke et traite des informations à caractère personnel. La cryptographie propose des outils opérationnels pour des traitements simples, tels que la recherche par mots-clefs parmi des données chiffrées, la classification de données chiffrées, et les calculs statistiques sur des données chiffrées. Même l’apprentissage fédéré peut être efficacement traité. Mais selon les contextes d’applications, des choix doivent être faits qui auront un impact important sur l’efficacité, voire la faisabilité.
David Pointcheval, CNRS, ENS/PSL et Inria
(*) obfusquer(du vieux français offusquer) : Obscurcir, assombrir. En Informatique, rendre un programme ou des données illisibles pour éviter qu’ils soient exploités de façon non autorisée.
[1] Dan Boneh, Amit Sahai et Brent Waters. Functional encryption: Definitions and challenges. TCC 2011
[2] Sanjam Garg, Craig Gentry, Shai Halevi, Mariana Raykova, Amit Sahai et Brent Waters. Candidate indistinguishability obfuscation and functional encryption for all circuits. FOCS 2013
[3] Michel Abdalla, Florian Bourse, Angelo De Caro et David Pointcheval. Simple functional encryption schemes for inner products. PKC 2015
[4] Jérémy Chotard, Edouard Dufour-Sans, Romain Gay, Duong Hieu Phan, et David Pointcheval. Decentralized multi-client functional encryption for inner product. ASIACRYPT 2018
[5] Théo Ryffel, Edouard Dufour-Sans, Romain Gay, Francis Bach et David Pointcheval. Partially encrypted machine learning using functional encryption. NeurIPS 2019
[6] Théo Ryffel, Edouard Dufour-Sans, Romain Gay, Francis Bach et David Pointcheval. Partially encrypted machine learning using functional encryption. NeurIPS 2019
Dans de nombreuses situations, on a envie de garder chaque information confidentielle, mais réaliser, sur leur ensemble, une agrégation, leur somme, leur moyenne, leur évolution dans le temps, etc. Par exemple, en tant que cycliste, vous n’avez pas peut-être pas envie que le reste du monde sache où vous êtes, mais vous aimeriez bien savoir qu’il faut éviter le Boulevard Sébastopol à Paris à cause de sa surcharge. Ça semble impossible ? Et pourtant des avancées scientifiques basées sur la cryptographie permettent de le faire. Ce n’est pas de la magie mais de l’algorithmique super astucieuse avec plein de maths derrière. Alors, en voiture avec David Pointcheval, Directeur du Laboratoire d’informatique de l’École Normale Supérieure, Paris, pour une balade incroyable dans « l’agrégation confidentielle ». Serge Abiteboul
David Pointcheval, Cryptographe
L’externalisation des données est devenue pratique courante et la volonté de mettre des informations en commun, pour détecter des anomalies, prédire des événements ou juste effectuer des calculs s’intensifie. Nombre de ces données restent néanmoins sensibles, et leur confidentialité doit être garantie.
Un exemple d’actualité est l’analyse massive de données médicales pour suivre une épidémie, son mode d’expansion et son évolution chez les malades. Les hôpitaux ont de telles informations en grande quantité, mais elles sont d’une extrême sensibilité.
La cryptographie a développé plusieurs outils pour concilier ces besoins contradictoires que sont le partage des données et leur confidentialité, à savoir le « calcul multi-parties sécurisé », MPC pour Multi-Party Computation, le chiffrement complètement homomorphe, FHE, pour Fully Homomorphic Encryption, et le chiffrement fonctionnel, FE, pour Functional Encryption. Nous allons rapidement rappeler les deux premières solutions. Dans un prochain article, nous nous attarderons plus longuement sur la dernière approche, développée plus récemment, qui répond efficacement à des besoins concrets de calculs sur des données mutualisées sensibles.
Photo de Cottonbro – Pexels
Le calcul multi-parties sécurisé (MPC)
Le MPC a été proposé il y a plus de 30 ans [1], pour permettre à des utilisateurs, possédant chacun des données secrètes, d’effectuer un calcul commun et d’obtenir le résultat tout en gardant les entrées confidentielles. Intuitivement, le MPC permet de remplacer la situation idéale, où chacun transmettrait sa donnée à un tiers de confiance et ce dernier effectuerait le calcul pour ne retourner que le résultat, par un protocole interactif entre les seuls participants. Contrairement à l’utilisation d’un tiers de confiance, dont la capacité à protéger les données et les échanges est essentiel, le MPC ne requiert aucune confiance en qui que ce soit.
Un exemple pour illustrer cela est le vote électronique, où tous les participants ont leur choix de candidat à l’esprit, et le résultat commun annoncé est le nombre total de voix pour chaque candidat. Néanmoins, même les opérations simples, telles que ces sommes dans le cas du vote, nécessitent un très grand nombre d’interactions entre tous les participants. Avec seulement deux utilisateurs, on dispose de solutions particulièrement efficaces, avec notamment les versions optimisées de Garbled Circuits [2]. Un exemple célèbre du calcul sécurisé entre deux individus est le « problème du millionnaire », où deux personnes fortunées veulent savoir laquelle est la plus riche, mais sans pour autant révéler les montants en question. Il s’agit donc d’effectuer une comparaison sur deux données secrètes.
De telles comparaisons sont également la base de techniques d’apprentissage automatique, au niveau de la fonction d’activation de neurones. Il est donc possible de tester un réseau de neurones, entre le propriétaire de la donnée à classifier et le possesseur du réseau, sans qu’aucune information autre que le résultat de classe ne soit disponible au deux.
Le chiffrement complètement homomorphe (FHE)
Pour éviter les interactions, les données doivent être stockées en un même lieu, de façon chiffrée pour garantir la confidentialité. Le chiffrement permet de stocker des données tout en les maintenant à l’abri des regards. Il permet aussi d’exclure toute forme de manipulation, pour en garantir l’intégrité. Cependant, certaines propriétés algébriques ont été utilisées, et notamment la multiplicativité, avec des schémas de chiffrement qui permettent de générer, à partir de deux chiffrés, le chiffré du produit des clairs. En d’autres termes, à partir des valeurs chiffrées E(a) et E(b), de deux données a et b, il est possible de calculer la valeur chiffrée E(a*b) de a*b sans avoir à connaitre a et b. D’autres schémas proposent l’additivité, ce qui permet d’obtenir le chiffré de la somme des clairs par une simple opération sur les chiffrés.
Mais à quoi cela peut-il servir ? La propriété d’additivité est par exemple largement exploitée au sein de systèmes de vote électronique. Les votants chiffrent leur choix (1 ou 0, selon que la case est cochée ou non), et une opération publique permet d’obtenir le chiffré de la somme de leurs votes. Le déchiffrement final, mené par le bureau de vote, permet de prendre connaissance du résultat, sans avoir besoin de déchiffrer chaque vote individuellement.
On connaissait des méthodes qui permettent l’additivité et d’autres la multiplicativité. Les deux ont semblé longtemps incompatibles jusqu’aux travaux de Craig Gentry [3]. En 2009, il a présenté la première construction permettant ces deux opérations en nombre illimité sur les clairs, par des opérations publiques sur les chiffrés. Il devient alors possible d’évaluer n’importe quel circuit booléen sur des entrées chiffrées, avec le résultat chiffré sous la même clef. Comment passe-t-on de ces deux propriétés aux circuits booléens ? Un circuit est composé de portes logiques qui peuvent se traduire en termes d’additions, de négations et de multiplications. Ce FHE permet alors à une personne d’externaliser des calculs sur ses données confidentielles, sans aucune interaction. Il lui suffit de les chiffrer sous sa propre clef ; le prestataire peut faire tous les calculs souhaités sur ces données, sans en prendre connaissance ; l’utilisateur peut enfin récupérer le résultat chiffré toujours sous sa propre clef. Un exemple peut être le stockage de photos, permettant de faire tourner des algorithmes d’atténuation des yeux rouges ou de regroupement selon la reconnaissance faciale, tout en garantissant la confidentialité. On peut même imaginer poser des requêtes chiffrées à un moteur de recherche et obtenir des réponses pertinentes, sans révéler ni les questions, ni les réponses.
Les applications de ces techniques sont extrêmement nombreuses. Mais elles ont une énorme limitation : la confidentialité est garantie au prix d’énormes quantités de calculs, de temps parfois prohibitifs même pour un supercalculateur.
David Pointcheval, CNRS, ENS/PSL et Inria
[1] Oded Goldreich, Silvio Micali et Avi Wigderson. How to play any mental game or A completeness theorem for protocols with honest majority. STOC 1987
[2] Andrew Chi-Chih Yao. How to generate and exchange secrets. FOCS 1986