
Il n’est jamais trop tôt pour bien faire. Et l’informatique n’y fait pas exception. Elle est arrivée au lycée, mais cela aura pris le temps. Binaire s’intéresse à des expériences de la découverte de l’informatique à l’école primaire. Isabelle Glas nous parle d’une initiation en Île-de-France sur le temps périscolaire. Sylvie Boldo
Je ne suis pas informaticienne. Mon créneau, c’est la communication, l’événementiel et la gestion administrative. Recrutée en 2013 par le Labex DigiCosme* pour animer le réseau et mettre en œuvre ses activités, je me suis retrouvée parachutée dans l’univers parallèle et insoupçonné des chercheurs en informatique.
Lorsque j’ai abordé ce nouveau secteur (pensez abordage, le sabre au clair et l’âme prête au au combat), il me paraissait évident que tout le monde se préoccupait d’enseigner l’informatique aux générations futures. L’omniprésence des technologies numériques, la virtualisation des échanges, l’introduction de programmes dans tous les produits issus de l’industrie (voitures, montres, télévisions…) semblaient amplement justifier qu’on se préoccupât de munir les jeunes français(e)s d’un bagage minimum en informatique. De fait, je fus stupéfaite de découvrir l’ampleur et la durée du combat mené par les chercheurs de la discipline pour imposer cette conviction et inscrire l’informatique dans les programmes depuis les classes de primaire jusqu’aux cursus des écoles d’ingénieurs (voir http://www.epi.asso.fr).
Par « informatique » , entendez la science et, dans un premier temps, la programmation. Il ne s’agit pas de développer à tout prix le parc numérique des écoles et de remplacer les encyclopédies papier par Wikipédia, mais d’inculquer aux enfants les bases de l’algorithmique. L’objectif est de leur laisser entrevoir la complexité des programmes derrière le lissé des interfaces, mais de façon telle qu’il ne se sentent pas intimidés par cette complexité. Pour ceux qui n’ont jamais programmé, la tâche semble insurmontable, magique, comme si l’apprentissage du code nécessitait un rite initiatique assorti d’un sacrifice à quelque déité païenne. En réalité, la programmation obéit à des bases très simples que tout le monde peut s’approprier, à condition de les apprendre et de les pratiquer. Plus que toute autre discipline, l’art de la programmation est question de rigueur, d’habitude, de réflexe. C’est l’une des raisons pour lesquelles il faut s’y prendre tôt.
Une bonne occasion a été donnée au Labex DigiCosme d’œuvrer pour l’initiation à l’informatique des plus jeunes avec la réforme des rythmes scolaires de 2013 et l’instauration des fameux Temps d’Activités Périscolaires (TAP). Un peu de pragmatisme ne faisant pas toujours de mal, pourquoi ne pas investir ces plages horaires et profiter du « temps de cerveau disponible » pour instiller un peu d’informatique dans les chères têtes blondes et brunes ?
Le plan a très vite fonctionné. Plusieurs chercheurs et ingénieurs volontaires (souvent parents eux-même) se sont manifestés pour participer au projet, proposer des activités et se rendre dans les écoles pour encadrer des séances. Une ébauche de programme a rapidement vu le jour, faisant appel aux outils pédagogiques crées par les chercheurs de France et du monde entier (laby, ressources pixees, concours Castor, scratch). Côté institutionnel, il n’a pas été très difficile de susciter l’intérêt de Mairies et d’établissements, séduits par le concept éducatif (et peut-être le caractère bénévole de l’animation).
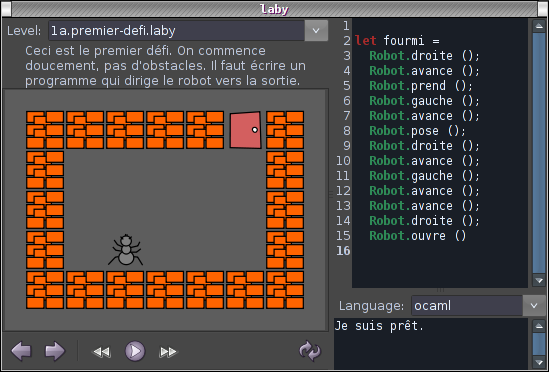
Copie d’écran du logiciel Laby
Cela nous mène au centre de loisirs du parc de la grande maison à Bures-sur-Yvette, l’après-midi du mercredi 27 mai 2015. Nous nous étions mis d’accord avec la Mairie pour venir tester certaines activités avec des groupes d’enfants du CE2 au CM2. Nous étions trois, Mathias Hiron (président de France-IOI), Christine Paulin (professeur à l’université Paris-Sud) et moi-même, entourés par l’équipe d’animation du centre. Le programme était divisé en deux ateliers : une partie « Castor » encadrée par Mathias Hiron et une partie « découverte de la programmation » menée par Christine Paulin et moi, centrée sur l’utilisation de Scratch Junior. Nous avions dans notre besace des tablettes flambant neuves, des castors savants et autres animaux virtuels, ainsi qu’une unité centrale et un téléphone hors d’usage prêts à exhiber leurs entrailles électroniques pour satisfaire la curiosité des enfants.
La participation des enfants à l’activité était volontaire, dans la limite du nombre de participants que nous pensions pouvoir gérer sans nous laisser déborder. 18 enfants se présentèrent, ce qui était légèrement plus que prévu mais constituait une belle victoire sur le soleil qui brillait ce jour là avec insolence. Informatique 1 – balle aux prisonnier 0 ! Si l’un des enfant pensait qu’il allait être question de fusées, je suis raisonnablement sûre que la plupart d’entre eux avaient au moins une vague idée de ce dont il allait être question.
Neuf enfants suivirent Mathias Hiron jusqu’aux sièges colorés au fond de la salle pendant que Christine Paulin et moi prenions en main le reste de l’effectif. L’idée était de s’échanger les groupes en cours de route. Je ne ferai pas le compte-rendu de l’atelier Castor – disons simplement que les enfants en sont sortis ravis.
De notre côté, nous commençâmes, comme il se doit, par le début, c’est-à-dire une discussion pour tester les connaissances de notre public et établir une définition de l’ « ordinateur ». Qu’est-ce qu’un ordinateur, après tout ? Qu’est-ce qui le différencie le smartphone et le PC de la machine à laver ? Les enfants se montrèrent très réactifs sur ce thème déjà familier et la conversation permit assez facilement d’identifier les caractéristiques de l’ordinateur (pluralité des tâches, etc.). En récompense, les participants eurent le plaisir de découvrir l’intérieur d’une unité centrale et d’un téléphone portable, démontés à leur intention par l’équipe du LRI. L’étape suivante eut moins de succès et le questionnaire prévu sur les entrées (saisie clavier, clics de souris…) /sorties (affichage, son…) ne suscita qu’un intérêt modéré.
Apparemment, il est déconseillé d’aborder trop de concepts dans une même séance. Les enfants purent se reposer devant un petit film sur les algorithmes présenté par les Sépas, des extraterrestres pas très futés qui ont grand besoin de s’instruire.
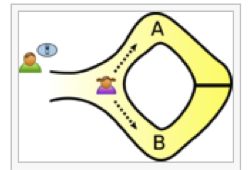
Pour la suite, nous avions prévu de jouer au « Robot idiot », grand classique des activités débranchées. Le jeu consiste à demander à un enfant de guider un camarade hors d’un labyrinthe en lui fournissant des instructions précises et exhaustives. Tel un robot exécutant un programme, l’enfant guidé doit suivre exactement les instructions, sans en corriger les insuffisances – la finalité étant de montrer que l’origine des « bugs » se trouve dans les programmes. L’activité était conçue pour que les participants construisent d’abord l’algorithme à l’aide de flèches directionnelles dessinées sur des cartons avant de passer à la mise en situation. Il fut toutefois difficile d’obtenir la dichotomie théorie / test, les enfants apparaissant nettement plus attirés par l’aspect jeu de rôle que par la réflexion sur le processus. Nous assistâmes cependant à de mémorables interprétations de R2D2.
Pour finir en beauté et emporter définitivement l’adhésion de notre public, nous pouvions compter sur « l’effet tablette ». La technologie a cet étrange pouvoir de transformer les enfants fatigués et agités en chérubins sages et motivés (si-si). Nous vîmes même des enfants sacrifier leur pause pour profiter plus longtemps de Scratch junior. Malgré leur empressement, les enfants se montrèrent très civils dans le partage du medium afin que chaque membre du groupe puisse en profiter.
Scratch (et son dérivé utilisable sur tablette, Scratch junior) est l’un des outils les plus connus en matière d’initiation ludique à l’informatique. Conçu par le MIT, il permet d’élaborer des animations en programmant les actions de personnages et objets placés dans un décor au choix de l’utilisateur (plusieurs paysages sont proposés, en ville, à la campagne, sur la lune ou sous l’océan…). Les commandes de programmation sont matérialisées par des briques (avancer, tourner, agrandir …) à associer pour faire bouger chaque élément.
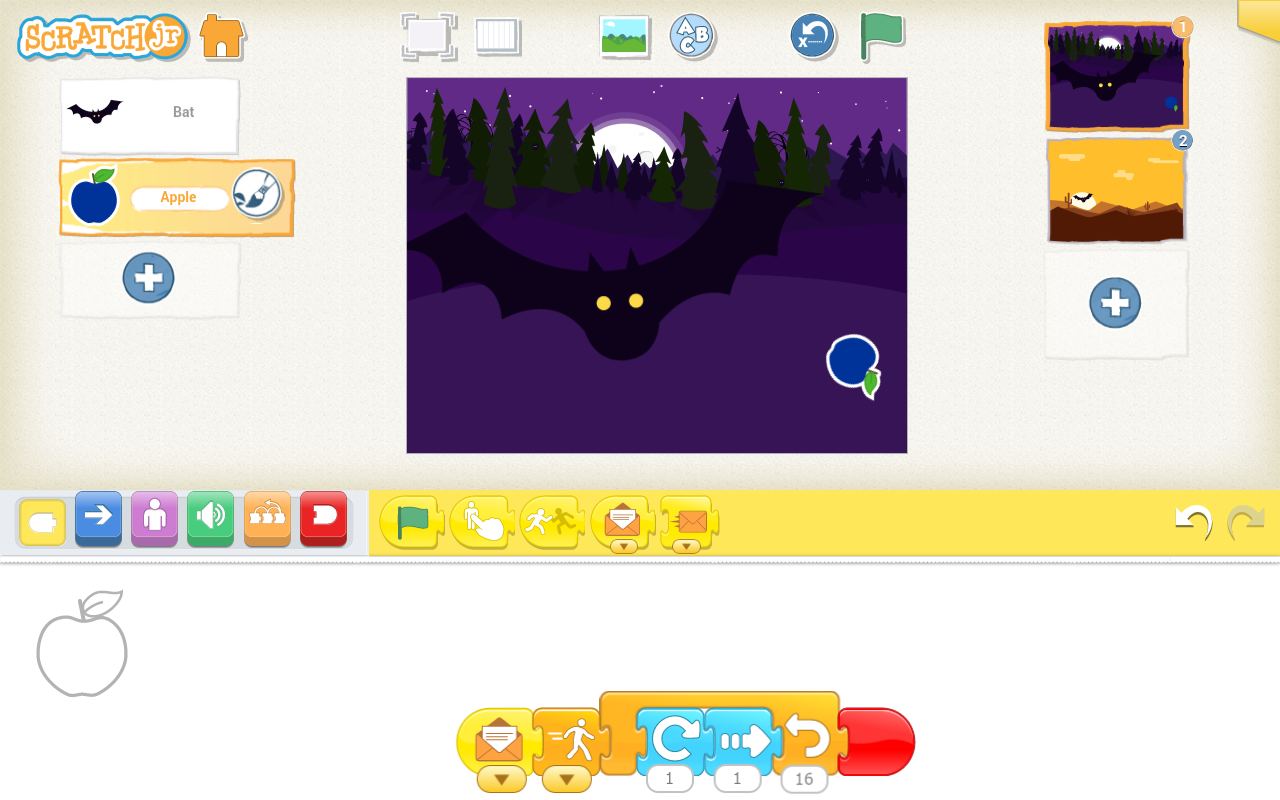
Exemple de création, © MIT et les enfants de Bures-sur-Yvette
L’application connut un grand succès auprès des enfants qui demandèrent même le lien pour la retrouver en ligne. La prise en main étant très intuitive, notre groupe n’eut pas de mal à s’approprier les fonctions de base suite à une simple (et courte) démonstration des principaux outils. Ravis par les horizons ouverts à leur créativité (notamment les outils interactif permettant d’enregistrer sa voix, de colorier les personnages), les enfants s’emparèrent immédiatement du jeu pour proposer les scénarios les plus variés et réaliser des créations, parfois très esthétiques.
L’expérience fut moins concluante sur l’aspect algorithmique. Peu d’élèves s’intéressèrent aux fonctions plus avancées, la majorité préférant se servir des éléments immédiatement utilisables. C’est toutefois ce qui fait l’ingéniosité de Scratch : les outils plus complexes apparaissant lorsque l’utilisateur souhaite créer des animations plus riches, c’est l’imagination qui sert de guide à l’apprentissage. Jamais bloqués dans leur élan, les enfants viennent eux-même s’informer sur les concepts lorsqu’ils deviennent nécessaires à leur création.
Dans notre cas, la grande faiblesse du dispositif résidait dans l’impossibilité de télécharger les projets pour les stocker hors des tablettes (option possible avec Scratch sur PC). Très fiers de leur(s) projet(s), nos informaticiens en herbe auraient aimé pouvoir les retrouver pour les montrer à leurs parents. A défaut, nous eûmes le privilège d’assister à des démonstrations itératives de chauves souris en vol et d’atterrissage de fusées au fond de la mer.
À la fin de l’après-midi, fourbus mais heureux, nous fûmes récompensés par une petite voix qui nous demanda avec espoir « mais alors, vous revenez quand ? ».
Isabelle GLAS, chargée de projets communication et formation, Labex DigiCosme
(*) Le Laboratoire d’Excellence Digicosme est un projet financé par les Investissements d’Avenir qui fédère les laboratoires en informatique de 11 établissements et instituts de recherche de l’Université Paris-Saclay.











































{kind=link}
{kind=link}