La Différentiation Algorithmique est une technique informatique destinée au monde du calcul scientifique.La … quoi ? Et bien restez avec nous quelques lignes, Laurent Hascoet, va soulever le capot d’un outil méconnu des sciences et techniques informatiques, qui change pourtant complètement l’ingénierie.
Sylvie Boldo.
Oh oh j’ai de belles équations. Prenons une personne spécialiste du calcul scientifique, qui vient de choisir avec soin les équations mathématiques qui modélisent précisément le système qu’elle étudie, puis d’écrire un programme (l’algorithme) qui résout ces équations. Elle est fière d’elle-même, et elle a bien raison, car à l’issue de cet énorme travail, elle a une description quantitative de ce qu’elle doit étudier, développer ou améliorer.
Elle dispose en fait d’un simulateur, c’est à dire d’une boîte munie d’un grand nombre de petits leviers (des paramètres) qui, pour chaque réglage des leviers, calcule l’état résultant du système étudié.
Euh : Par exemple ? Eh bien, par exemple, pour étudier les performances d’un bateau, d’un avion ou d’un moteur à partir de leur géométrie, ce simulateur est bien plus rapide et plus économique que de construire réellement l’objet puis de le tester. Autre exemple : la simulation de l’évolution de l’atmosphère et de l’océan à partir de leur état actuel, pour dans cinq jours ou pour dans cent ans.
Toujours plus ! Ce simulateur est tellement commode que le spécialiste veut maintenant aller plus loin, et chercher le réglage des leviers qui produit le meilleur état possible, ou en tout cas le plus proche d’un état cible prédéfini.La meilleure forme d’avion, par exemple, ou ce qu’il faudrait faire au niveau planétaire pour infléchir le réchauffement climatique.
Problème difficile car les leviers sont nombreux, ils ont des tas de positions possibles, et les essayer toutes prendrait un temps colossal.
Le retour des maths. Heureusement en calcul scientifique la plupart des problèmes sont « différentiables ». Cela veut dire qu’il existe une opération mathématique (la différentiation) qui donne, à partir des équations, de nouvelles équations pour les « tendances » du système (on dit aussi son gradient).
Pas à pas, en suivant ce gradient et en le recalculant à chaque pas, on avance sur la ligne de plus grande pente jusqu’à atteindre un optimum (local).
Grâce à ce gradient tout est plus rapide, puisqu’il dit dans quel sens bouger chaque levier pour se rapprocher de l’état cible. On peut atteindre la position optimale des leviers en quelques pas seulement. Les domaines d’application sont immenses : ingénierie, aéronautique, climatologie, biologie ou même économie.
Tout ça c’est bien joli, mais … ! Notre spécialiste vient de travailler des mois à choisir ses équations puis à écrire le programme qui les résout, pour découvrir maintenant qu’il faut écrire les équations différentiées pour le gradient puis écrire le nouveau programme qui les résout. Écrire les équations du gradient, passe encore, mais le programme pour les résoudre sera drôlement dur à écrire. Ce gradient est une chose plutôt abstraite et on pourra moins s’aider de son intuition. Et si on se trompe (et on se trompe toujours au moins une fois), comment aller chercher le bug dans tout ce fatras de calculs ?
Avouez qu’il y a de quoi hésiter un peu!
Pourrait-on être plus astucieux ? C’est là qu’intervient la Différentiation Algorithmique. Après tout, l’algorithme du simulateur lui-même est « presque » équivalent aux équations mathématiques qu’il résout (pour ceux qui veulent le détail: la grosse différence est qu’il « discrétise » en échantillonant l’espace et le temps; tout ça cause de légères approximations, et on peut vivre avec). Bref, les équations mathématiques et l’algorithme informatique sont presques interchangeables.
Certes l’algorithme est bien moins élégant, moins concis, mais il aboutit au même résultat à l’issue d’une longue chaîne de milliards d’opérations élémentaires (additions, multiplications, divisions…). Et comme on sait écrire le gradient d’une telle chaîne de fonctions élémentaires, il suffit d’appliquer mécaniquement la recette. Souvenez-vous. C’était au lycée, on parlait de la dérivée de «f rond g». On peut donc transformer directement l’algorithme du simulateur en un nouvel algorithme qui calcule son gradient. C’est la Différentiation Algorithmique (DA).
Et c’est là que l’informatique vient à la rescousse. On y est presque. Si l’algorithme du simulateur est court, on peut écrire à la main l’algorithme de son gradient. Il faut cependant être rigoureux et systématique car c’est une transformation lourde, en particulier parce que le gradient se calcule « en marche arrière » de l’algorithme du simulateur.
Mais le code du simulateur se mesure plutôt en milliers de lignes et il est quasiment impossible de le transformer sans se tromper. Voie sans issue ? Non, parce qu’une grande force de l’informatique est qu’on peut écrire des programmes qui travaillent sur presque tout, y compris d’autres programmes. Un peu comme les compilateurs qui transforment un code informatique en langage machine.
Puisque la DA est complètement mécanique, laissons le travail à l’ordinateur. L’outil de DA va analyser l’algorithme source et produire l’algorithme gradient, en quelques secondes pour un code de plusieurs milliers de lignes. Cerise sur le gâteau l’outil de DA, tout comme un compilateur, emploie des analyses sophistiquées pour optimiser le gradient, pour le rendre plus rapide et moins gourmand en mémoire.
Du laboratoire de recherche au monde industriel. Depuis plusieurs années, une équipe d’Inria étudie la DA et développe Tapenade, un outil de DA. Même si cet outil sert surtout à tester les nouvelles méthodes pour rester en pointe dans la recherche, il a aussi un joli succès auprès d’utilisateurs industriels qui ont acquis une licence pour l’utiliser dans leur chaîne de développement. On y retrouve l’aéronautique avec Dassault Aviation, Rolls-Royce ou Boeing, la chimie avec BASF ou Cargill, le pétrole avec Total ou Exxon-Mobil, mais aussi quelques banques et institutions financières. Parallèlement, de nombreux centres académiques l’utilisent gratuitement pour leurs recherches, et un serveur web permet de l’utiliser directement sans installation.
La SIF (Société Informatique de France) a organisé une journée scientifique le 23 mars sur l’IoT (Internet des Objets – Internet of Things, en anglais), accueillie par le Secrétariat d’état au numérique dans les locaux de l’Hôtel des ministres à Bercy. Cette journée a réuni 110 personnes.
Crédit photo : @PierreMetivier
Au delà du blabla habituel sur les sujets à la mode, la journée de la SIF a proposé des présentations scientifiques et techniques de très haut niveau, sur les défis informatiques de l’Internet des objets avec aussi des présentations sur les enjeux en terme de design des objets et de leurs applications ainsi que sur les problèmes posés pour le respect de la vie privée.
En effet, l’IoT introduit de nouveaux défis scientifiques. Dans beaucoup de cas, il ne s’agit pas de plaquer des techniques connues mais bien de repenser, de concevoir et d’inventer des éléments scientifiques et techniques qui vont résoudre des questions nouvelles apportées par cette prolifération de très nombreux petits objets connectés.
En savoir plus ? Binaire et le Labo des savoirs en ont profité pour réaliser une troisième émission qui a pour thème l’internet des objets.
Retrouvez l’émission sur celien, et écoutez les intervenants de cette journée comme si vous y étiez ! Vous pouvez aussi consulter les présentations des intervenants sur le site de la journée.
Tous les ans les étudiantes et étudiants des classes préparatoires aux écoles d’ingénieur-e-s font un travail d’initiative personnelle encadré (TIPE) qui permet de les évaluer, au delà de compétences plus scolaires, sur leur capacités à proposer un projet de recherche en équipe et le mener à bien. Ce travail pourrait défavoriser les candidat-e-s éloignés des ressources humaines et documentaires utiles, mais la mission de médiation scientifique Inria se met au service de toutes et tous à ce propos, avec Interstices (sélection des ressources) et Pixees (accompagnement et ressources), en lien avec ePrep. Cette année le thème est Optimalité : choix, contraintes, hasard, c’est un sujet scientifique passionnant ; laissons à la parole* Guy Cohen, Pierre Bernhard et ses collègues pour nous l’expliquer. Thierry Viéville.
Optimiser pour résoudre un problème ? Une idée d’ingénieur-e !
Faire « le mieux possible » est somme toute une attitude naturelle dans la vie courante. Pour un ingénieur également, c’est un objectif permanent lorsqu’il a par exemple en charge la conception d’un équipement ou le dimensionnement d’une installation.
Mais, l’expression doit être relativisée. Tout dépend des contraintes, par exemple de budget ou de sécurité, tandis que le choix du critère à optimiser a fait l’objet de décisions préalables et souvent extérieures au travail à réaliser.
L’arbitraire du choix du critère et des contraintes ne fait donc pas partie du formalisme. Cet arbitraire est la marge de manœuvre qui permet à l’utilisateur ou au client d’exprimer ses désirs plus ou moins précis, voir même contradictoires.
Une fois ces spécifications arrêtées, il faut expliciter une solution (ou une décision) qui soit « meilleure » que toutes les autres. Il s’agit alors de modéliser le problème : caractériser cette solution pour la reconnaître (conditions d’optimalité) car la définition informelle de l’optimalité n’est pas utilisable de façon opérationnelle. On peut ensuite voir comment la faire calculer.
Soit. Mais une compréhension de la méthode mathématique et informatique qui vient ensuite permettre de guider ces choix est très utile, y compris aux « utilisateurs finaux », évitant par exemple des formulations difficiles à résoudre, fournissant des retours sur la nature du problème posé, quantifier dans une certaine mesure les choix a priori les uns par rapport aux autres.
Regardons alors cet aspect.
Optimiser pour résoudre un problème ? Une idée d’informathématicien-ne !
Cette façon de poser le problème place la théorie de l’optimisation dans une famille plus large dite des « problèmes variationnels » qui contient notamment tous les problèmes d’équilibre rencontrés dans de nombreuses branches de la physique, des problèmes de transport, de théorie des jeux, les algorithmes d’apprentissage automatique, etc. Inversement, certains états d’équilibre de la Nature peuvent se réinterpréter comme les solutions de problèmes d’optimisation, ce qui donne souvent des moyens efficaces pour étudier leurs propriétés. Ainsi considère-t-on, en général que les espèces au cours de leurs évolutions se sont adaptées au mieux à l’environnement. Et si ingénieurs et mathématinformaticiens ont l’habitude de poser les problèmes d’optimisation en termes de minimisation (d’un coût), les économistes aussi utilisent ce paradigme mais eux maximisent (un profit).
On se convaincra que c’est (au signe près : maximiser une fonction est bien équivalent à minimiser son opposé) la même théorie qui s’applique.
Quel est le levier pour résoudre un tel problème ? Une « cuisine » algorithmique. Une fois que le mathématicien a su caractériser une solution, et se prononcer sur son existence, voire son unicité, l’ingénieur voudrait bien pouvoir calculer cette solution. Il est hors de question de passer en revue tout ce qui est imaginable ou autorisé; il s’agit d’aller au plus vite vers la solution en améliorant par touches successives une ébauche de celle-ci.
Il y a une première idée très simple : partir d’une proposition initiale raisonnable voir même choisie au hasard. Ensuite, regarder dans son voisinage si une autre proposition ne serait pas encore meilleure. Oui ? Prenons là alors ! C’est déjà ça de gagné. Et recommençons avec cette nouvelle proposition, regardant de proche en proche comment améliorer. Rien de meilleur dans le voisinage ? Dans ce cas, cela signifie que la proposition est localement optimale. Facile, non ?
Racontons l’histoire avec un langage mathématique.
Brrr il fait froid ici ! Trouvons un endroit, une position p, idéale où il fasse bien chaud. Comme c’est des maths, j’écris T(p) = 30 pour dire : « je veux une position p où la température T est de 30 degrés ». C’est la solution à mon problème. Mais … comment deviner quelle est la bonne position : le bon p ? Essayons avec ma position actuelle, je la nomme p0. Je calcule T(p0) = 10. Dix degrés : Ouf ! Ça caille. Allez, bougeons un peu, vers la droite j’arrive à une position p1, avec T(p1) = 5. Mauvaise pioche. Et vers la gauche ? Là j’arrive à une position p2, avec T(p2) = 15. C’est déjà mieux. Je vais alors tester le voisinage et aller vers un endroit encore plus chaud. Exactement comme lorsque nous étions enfants et nous jouions à deviner une cachette en guidant le joueur à force de « tu te réchauffes » ou « tu refroidis » jusqu’au « tu brûles » qui … bon. Tout le monde a compris.
Au lieu de trouver la bonne solution à un problème, on utilise un algorithme qui va améliorer d’itération en itération la solution initiale pour trouver la meilleure solution. Ici, le mieux est l’ami du bien.
De belles mathématiques pour que l’idée fonctionne.
Que faut-il pour que cette idée fonctionne bien ? Les mathématiques nous fournissent deux grandes idées : la première est la continuité. Dans cet exemple, il faut que la température varie continument pour que ma recherche ait un sens. Si, à contrario, tout change dans tous les sens dans le voisinage je vais vite errer de manière chaotique à la merci de valeurs difficiles à relier entre elles.
Une deuxième grande idée est la convexité. Finalement, avec mon mécanisme, je ne fait que trouver un optimum local. Qui me dit que si je n’explore pas plus loin, quitte à passer par une zone fort froide, je ne vais pas trouver finalement un bon coin de feu, tout à fait réchauffant ? Garantir qu’il n’y a qu’un seul optimum global, sans concavité (autrement dit sans minimum local qui empêcherait de rechercher plus loin une meilleure solution) a été étudié en détail, c’est cette notion de convexité.
Et quand l’informatique vient au secours des mathématiques.
Dans beaucoup de problèmes d’ingénierie (ou d’économie), on sait calculer la fonction objectif, mais au prix d’un programme complexe. Dans certains cas on sait aussi calculer les variations de cette fonction pour aller vers l’optimum, mais encore au prix d’un programme compliqué (parfois déduit automatiquement du précédent). Dans des cas plus graves, on ne sait même pas calculer les variations exactes. Et puis il y a beaucoup de situations où il n’existe pas « un » optimum global mais plusieurs optima locaux qui ne s’obtiennent pas avec une formule mathématique, il faut alors ajouter des mécanismes d’exploration.
Il existe ainsi un grand nombre d’algorithmes d’optimisation. Par exemple des algorithmes génétiques, qui s’inspirent de ce que l’on comprend de l’évolution génétique des systèmes biologiques pour coupler optimisation locale d’une solution, avec un mécanisme de mutation vers de nouvelles solutions inédites. En pratique, c’est le dernier recours quand rien de plus efficace n’est possible !
L’étude des algorithmes d’optimisation, plus ou moins sophistiqués, est donc un sujet de la plus haute importance. Certains auteurs ont voulu opposer une mathématique “traditionnelle”, préoccupée de théorèmes, à une informatique “contemporaine”, préoccupée d’algorithmes. Mais que serait un algorithme sans un théorème disant qu’il calcule effectivement ce qu’on veut ? La création et l’étude des algorithmes est un objet essentiel, aussi ancien que les mathématiques elles-mêmes, et qui requiert des théorèmes de convergence, de cohérence (“consistency”, c’est à dire que si l’algorithme converge, c’est bien vers le résultat recherché) et qui mobilise tout l’arsenal des mathématiques « traditionnelles ».
Des humains aux cellules … Dame Nature ferait-elle de l’optimisation ?
Regardons deux exemples d’applications un peu inattendues.
Embouteillages. Dans une ville encombrée, les automobilistes ont le choix entre plusieurs routes possibles pour se rendre d’un point à un autre. Tous souhaitent éviter les encombrements, et, disons, effectuer leur déplacement dans le temps le plus court possible. Pour fluidifier la circulation, les pouvoirs publics peuvent (en dépensant beaucoup d’argent !) ouvrir de nouvelles voies ou améliorer considérablement la vitesse de parcours de certaines. Mais il est arrivé (Stuttgart 1969) que cela fasse tellement empirer la situation de tout le monde qu’il faille fermer une voie récemment ouverte. (Paradoxe de Braess). On a pu observer ce paradoxe à New York lors de la fermeture de la 42ème rue.
Bref il faut parfois « bloquer des voies » pour … limiter les embouteillages.
L’étude de cette question, notamment par John Glenn Wardrop (1952), et Dietrich Braess (1968) rejoint des questions de théorie des jeux, et pose de nombreuses questions annexes : l’occurence d’un paradoxe de Braess est-elle fréquente ou exceptionnelle ? Pourrait-on améliorer le trafic en étant plus directif, et de combien ?, etc.
Une chercheuse Inria, Paola Goattin, étudie ce type de problème et … sauve des vies humaines en montrant que lors de l’évacuation d’une foule (par exemple dans un cinéma en feu) il faut mettre des poteaux qui freinent les gens (en fait évitent les phénomènes de bousculade) pour optimiser les chances que tout le monde sorte vivant. Ce qui est remarquable c’est que le modèle est celui d’un fluide dont les humains seraient les particules et dont on éviterait les turbulences.
Évolution des espèces. On admet que l’évolution des espèces biologiques a sélectionné les comportements les plus efficaces. Pourquoi, donc, observe-t-on des comportements différents au sein d’une même espèce ?
Un peu de dynamique des populations (comment évoluent les effectifs des populations) permet de répondre. L’exemple type est celui dit « des faucons et des colombes » par référence non pas à deux espèces animales (on parle bien de variablité intra-spécifique : au sein d’une même espèce) mais à la terminologie désignant au congrès des USA les députés belliqueux ou pacifistes. «Être agressif ou ne pas l’être» ? that is the question, here 🙂 La coexistence de plusieurs comportements au sein d’une même espèce vivante est prédite C’est un phénomène de théorie des jeux. L’équilibre de l’évolution est atteint quand plusieurs comportements donnent le même résultat, et, c’est ce qui est original par rapport à une simple non-unicité de l’optimum, quand la proportion des individus qui adoptent chaque comportement est exactement celle qui permet l’équilibre. C’est exactement la même chose que la multiplicité des trajets utilisés par les automobilistes qui tous prennent le chemin le plus rapide. (́Équilibre de Wardop) C’est très voisin du phénomène des stratégies aléatoires (on dit « mixtes », mauvaise traduction de “mixed”, mélangées) en théorie des jeux.
Plus généralement, la théorie de l’évolution introduit aussi une source d’optimalité par le hasard. La reproduction de notre ADN via les ribosomes et l’ARN messager produit des erreurs de recopie. Ces erreurs donnent naissance à des individus « mutés ». La plupart d’entre eux sont non ou peu viables. Mais si une mutation aléatoire donne naissance à un animal mieux adapté (disons avec une meilleure efficacité reproductive) il peut être à l’origine d’un nouveau groupe d’animaux (une nouvelle espèce) qui va petit à petit envahir toute la « niche écologique ». La reproduction et ses mutations aléatoires se comporte donc comme un algorithme de recherche aléatoire de la meilleure efficacité reproductive.
Récemment, un chercheur en neuroscience (Karl Friston 2006) a pris le risque de proposer une explication « unifiée » du comportement d’un système biologique : assurer sa survie, en s’assurant que ses variables vitales restent dans des intervalles de valeurs « acceptable ». Mais comme un tel système ignore le fonctionnement de son environnement et ce qu’il peut y arriver, le système va alors se doter d’un modèle interne de son environnement et de lui-même. Il va activement inférer les paramètres de ce modèle, de façon à pouvoir optimiser ses perceptions et ses actions. Cette théorie prédit que minimiser la surprise par rapport à ce qui pourrait lui arriver (y compris en explorant pour mieux connaître cet environnement donc éviter les surprises futures) est le comportement optimal, compte-tenu de ce qui est observable. Depuis près de dix ans, cette théorie explique pas à pas les fonctionnalités de notre cerveau et notre survie. Comme souvent en science, si la personne citée est anglo-saxonne, l’antériorité est plus internationale. Dès 1980, Jean-Pierre Aubin, Patrick Saint-Pierre et leurs collaborateurs développent cette idée et les outils mathématiques qui vont avec sous le nom de théorie de la viabilité. Le théorème de départ est dû à Georges Haddad, dans sa thèse préparée sous la direction de J-P. Aubin, 1981.
Si Dieu, qu’Elle ou Il soit, nous prête vie :).
(*) Ce texte est repris et adapté de l’introduction du cours de Guy «convexité et optimisation», donné à l’École des Ponts et Chaussées entre 2000 et 2010 et de deux cours de Pierre sur l’optimisation.
Pierre Bernhard et Guy Cohen, avec l’aide de Charlotte Truchet, Colin de la Higuera, Corinne Touati, sur une suggestion et avec un travail d’édition de Valérie François et Martine Courbin-Coulaud.
La société se trouve à la croisée des chemins. Aller vers des données ouvertes ou contractualiser ad nauseam. Le sujet a une importance considérable pour les chercheurs, mais aussi pour l’industrie. Binaire a demandé à un ami d’Inria, Florent Masseglia, de nous éclairer sur les enjeux. Serge Abiteboul.
Pour les chercheurs, accéder aux publications de leurs pairs est une nécessité quotidienne. Mais avec l’accélération constante de la production d’écrits scientifiques arrivent deux constats :
Il peut devenir humainement difficile de faire le tri, manuellement, dans l’ensemble de la production scientifique.
Les machines pourraient faire sur ces écrits ce qu’elles font déjà très bien sur le big data : transformer les données en valeur.
Pour un acteur industriel, la valeur extraite à partir des données peut-être commerciale. C’est ce que le business a très bien compris, avec des géants du Web qui font fortune en valorisant des données (par exemple, en créant des profils utilisateurs pour vendre de la publicité ou des services). Mais valoriser des données ce n’est pas obligatoirement en tirer un profit commercial. Cette valorisation peut se traduire dans l’éducation, dans les sciences, dans la société, etc. C’est exactement ce que le TDM (Text and Data Mining, la fouille de textes et de données) peut faire quand il est appliqué aux données de la recherche : créer de la valeur scientifique.
Pour expliquer cela, j’aimerais introduire rapidement les notions de données et d’information. J’emprunte ici l’introduction de l’excellent article sur « les données en question », de Patrick Valduriez et Stéphane Grumbach : « Une donnée est la description élémentaire d’une réalité ou d’un fait, comme par exemple un relevé de température, la note d’un élève à un examen, l’état d’un compte, un message, une photo, une transaction, etc. Une donnée peut donc être très simple et, prise isolément, peu utile. Mais le recoupement avec d’autres données devient très intéressant. Par exemple, une liste de températures pour une région donnée sur une longue période peut nous renseigner sur le réchauffement climatique. »
La température à un instant précis est donc une donnée. L’évolution de cette température dans le temps peut apporter une information.
Le data mining, ou la fouille de données, c’est l’ensemble des méthodes et des algorithmes qui vont permettre à ces données de nous parler. La fouille de données peut nous révéler des informations que l’on n’aurait peut-être jamais soupçonnées et que l’on ne pourrait pas obtenir en explorant ces données « à la main ». Des informations utiles et qui auront un impact sur nos décisions. Et plus la quantité d’information est grande, plus la crédibilité des informations découvertes est renforcée.
Pour découvrir ces informations nouvelles, chaque algorithme fonctionne comme un engrenage. Et dans l’engrenage d’un algorithme de fouille de données, les pièces (les roues dentées) vont s’imbriquer et se mettre en mouvement. Elles vont dialoguer entre elles. Chaque pièce, chaque roue dentée, va jouer un rôle précis en travaillant sur une source de données particulière. On peut ainsi fabriquer un engrenage à chaque fois qu’on veut découvrir des informations dans les données.
Si vous voulez découvrir une éventuelle relation entre la météo et la fréquentation des médiathèques, vous pouvez fabriquer un engrenage qui utilisera deux roues. Une roue pour travailler sur les données de la météo des dernières années. Et une autre qui travaillera sur les données de fréquentation des médiathèques. Si ces données sont accessibles, que vous connaissez leur format et leur emplacement, alors il ne reste plus qu’à fabriquer les roues de l’engrenage et les assembler !
Mais vous pouvez aller encore plus loin. Par exemple, si vous ne savez pas encore quelle information sera révélée mais vous pensez qu’elle se trouve quelque part entre la météo, la fréquentation des médiathèques, et le budget que ces dernières allouent aux activités pour la jeunesse. Est-ce la météo qui influence la fréquentation ? Ou plutôt le budget ? Ou bien les deux ? Et c’est là tout l’intérêt de la fouille de données. On ne sait pas, à l’avance, ce que les algorithmes vont nous permettre de découvrir. On ne sait pas quelles sources de données seront les plus impliquées dans l’information à découvrir. Alors on croise des données, et on met les engrenages en place. Plus on utilise de sources de données différentes et plus on peut découvrir des informations qui étaient peut-être au départ insoupçonnables !
L’open-access, ça change quoi pour le TDM ?
Les données de la recherche (publications, projets, données d’expérimentations, etc.) sont un véritablement gisement pour les algorithmes de fouille de données. Pour expliquer cela, fabriquons ensemble un engrenage qui fonctionne sur ces données pour découvrir de nouvelles informations dans un domaine scientifique comme, par exemple, l’agronomie. Nous voulons savoir s’il y a des facteurs qui favorisent l’apparition d’un bio-agresseur. Nous aimerions utiliser des données concernant les champs (pour chaque champ : le type de culture, la hauteur de haie, type de faunes, bosquets, etc.) mais nous voudrions aussi utiliser des données concernant l’environnement (la météo, les zones humides, etc.) et enfin nous allons utiliser des études scientifiques existantes sur les bio-agresseurs (comme leur localisation, périodes d’apparitions, etc.). En utilisant l’ensemble de ces données, à très grande échelle, nous espérons découvrir un ensemble de facteurs souvent associés à la présence de ces bio-agresseurs, ce qui permettra de mieux lutter contre ces derniers.
La bonne nouvelle, c’est que toutes ces données existent ! Et les algorithmes, eux aussi, existent… Cependant, le monde de la recherche française se trouve face à deux voies.
Dans la première voie, toutes ces données sont accessibles facilement. Les données concernant les champs et leur environnement sont publiques. Les données concernant les articles scientifiques le sont, au moins, pour la communauté académique. C’est la voie de l’open-access.
Dans la deuxième voie, toutes les données ne sont pas accessibles librement. On peut avoir accès aux données concernant les champs car elles sont toujours publiques, mais pour les autres c’est plus difficile. Par exemple, les articles scientifiques sont la propriété des éditeurs. Ou encore, les données d’expérimentations sont sur des ordinateurs de différents chercheurs et ne sont pas rendues publiques. Pour y accéder, il faut passer par des filtres, mis en place par les ayants-droit selon leurs conditions. C’est la voie de la contractualisation du TDM.
En avril 2016, la France doit faire un choix entre ces deux voies. Le sénat étudie le projet de loi pour « une république numérique ». C’est la souveraineté scientifique de la France qui est en balance dans ce débat.
Avec l’open-access pour le TDM, vous pouvez regarder librement le format de toutes les données. Vous pouvez les lire, les copier, les transformer, etc. Vous pouvez fabriquer vos propres roues dentées pour qu’elles travaillent sur ces données. Et vous pouvez donc fabriquer vos propres engrenages. Sans limite. Sans condition, autre que l’éthique scientifique.
Avec la contractualisation, ce sont les ayants-droit qui vont fabriquer les roues pour vous. Si la roue n’est pas au bon format pour votre engrenage, si elle n’est pas compatible avec ses pièces voisines, ou alors si elle vient tout simplement à manquer… Alors votre engrenage ne tournera pas. Et il n’est pas question de remplacer la roue mise en cause par une autre car les données, hébergées chez l’ayant-droit, ne sont accessibles que par cette roue et aucune autre. Cependant, si on ne peut pas fabriquer l’engrenage qui utilise toutes les données, alors on pourrait se contenter d’un engrenage plus petit, qui n’utilise que les roues fabriquées par un seul et même ayant-droit, donc compatibles entre elles. Oui, mais cet engrenage ne fonctionnerait que sur les données de ce dernier. Les nouvelles informations découvertes le seraient donc sur un sous-ensemble très restreint des données. On ne verrait alors qu’une toute petite partie de l’image globale. Cela n’aurait aucun sens. De plus, il se trouve que certains organismes de recherche traitent avec 80 éditeurs différents ! Il faudrait alors fabriquer 80 engrenages différents au lieu d’un seul ? Le pire c’est que, utilisés tous ensemble, ces 80 engrenages n’arriveraient pas à la cheville de l’engrenage global fabriqué pour l’ensemble des données. Tout simplement parce que l’engrenage global peut croiser toutes les données alors que ces 80 engrenages différents, avec chacun des roues différentes, ne peuvent pas le faire. Ils n’ont accès qu’à un sous-ensemble des données et dans leur cas l’union ne fait pas la force… Ils ne peuvent pas s’échanger les données entre eux pour les croiser. Ainsi, pour lutter contre nos bio-agresseurs, mais aussi de manière générale pour extraire de nouvelles informations et découvrir des connaissances dans tous les domaines scientifiques, la recherche française doit pouvoir utiliser le tandem TDM & open access !
Effectivement, dans le cas de l’open-access, ce serait radicalement différent. Puisque les données seraient accessibles facilement, il deviendrait tout à fait possible pour notre engrenage de trouver, par exemple, des liens entre quelques variables qui concernent les champs, d’autres variables sur l’environnement, et encore avec d’autres variables issues d’articles scientifiques sur les bio-agresseurs. Et les informations découvertes auraient alors une sorte de force statistique bien plus grande. Elles seraient validées par le fait que l’on travaille sur l’ensemble des données. Sans restriction.
Grâce au droit d’exploiter les données de la recherche en open-access avec des outils de TDM complets, la recherche française disposera, comme ses concurrentes anglaises, japonaises, américaines ou allemandes, d’une vue d’ensemble sur les données, dont elle manque aujourd’hui. Et ce n’est pas un problème de technologie. La technologie est disponible. Elle fonctionne très bien dans d’autres domaines et elle est largement prometteuse pour les données scientifiques ! Si on leur donnait accès aux données de la recherche, les engrenages de la fouille de données fonctionneraient certainement à plein régime pour révéler des informations qui seraient peut-être surprenantes, ou qui pourraient confirmer des théories. Mais cela ne pourrait aller que dans une seule direction : encore plus de découvertes scientifiques.
Cet article est publié en collaboration avec TheConversation.
L’an dernier, Binaire se demandait où sont les femmes : on le sait, bien trop peu de jeunes filles choisissent les sciences [1], en particulier l’informatique et les mathématiques. On le constate, on le déplore, on travaille à les encourager, les motiver, les convaincre. Certaines finissent par s’y lancer. Quelles carrières se présentent alors à cette minorité aventurière ? Est ce qu’on la chouchoute ou continuons-nous tranquillement à nous engluer dans les stéréotypes tenaces concernant les femmes et les sciences ? Où en est-on 40 ans après l’officialisation des Nations Unies de célébrer les droits des femmes chaque année le 8 mars ? Serge Abiteboul
2013, Bruxelles, dans le temple de l’excellence scientifique européen, le président de l’ERC (European Research Council) rappelle aux évaluateurs, qui s’apprêtent à passer la semaine à plancher sur les meilleurs dossiers tous domaines confondus, qu’aucun critère lié aux pays d’origine, à la parité ou au domaine de recherche ne doit être retenu dans l’évaluation.
2015, même endroit, même président, sensiblement mêmes évaluateurs : le discours a singulièrement évolué. Certes l’excellence scientifique reste le critère le plus important mais la vigilance au sujet de la parité est de mise, suite aux résultats issus du groupe de travail en charge de l’équilibre des genres[2]. Ces études montrent en effet que le pourcentage de dossiers féminins acceptés au premier tour d’évaluation est significativement plus faible que celui des candidatures masculines. L’échantillon étant indéniablement statistiquement significatif, de deux choses l’une : soit les femmes sont en moyenne moins brillantes que leurs homologues masculins, soit des biais s’immiscent dans le processus.
Il semblerait bien, qu’insidieusement, les préjugés se perpétuent, rampants, pour continuer d’écarter les femmes des postes prestigieux et limiter leur ascension dans nos institutions académiques. Elles s’en écartent parfois elles-mêmes du reste, par manque de confiance, ou parce que cela implique de faire quelques aménagements familiaux qu’elles redoutent ou encore qui les forceraient à s’éloigner des lieux communs.
Ce plafond de verre existe toujours bel et bien dans les carrières scientifiques et est du en grande partie à une concomitance de facteurs aggravants.
Facteur numéro 1 : le vocabulaire.
La plupart des fiches de postes à responsabilité regorgent d’un vocabulaire saillant, de métaphores sportives (plutôt football américain que danse classique) voire d’épithètes guerrières dans lesquelles les femmes se reconnaissent parfois difficilement. Il faut être solide pour accepter de se présenter comme un leader charismatique quand il va de soi qu’une femme doit être douce et compréhensive et surtout ne jamais se montrer autoritaire au risque d’émasculer son fragile entourage. Attirer l’attention de nos dirigeants sur l’importance d’une formulation neutre (e.g. capacité à rassembler plutôt que leadership) permettrait aux femmes de se projeter davantage dans ces postes, sans pour autant pénaliser les hommes.
Facteur numéro 2 : les ruptures de carrières.
Certes les choses évoluent, les congés de paternité s’allongent, les hommes mettent un tablier, mais les ruptures de carrières liées à la grossesse restent l’apanage des femmes. En outre ces ruptures surviennent à une période clé de la carrière, celle où on est le plus productif, où on doit faire ses preuves, travailler d’arrache pied pour asseoir ses résultats, allonger sa liste de publications et voyager pour faire connaître son travail. Malgré la joie dont elles sont généralement assorties, elles ne représentent jamais un avantage pour l’avancement. Ces ruptures sont du reste de plus en plus prises en compte explicitement dans les textes qui régissent recrutements et promotions. L’ERC, par exemple, accorde 18 mois par enfant aux femmes (si il y a une limite dans le dépôt d’une candidature, par exemple s’il est possible de candidater à un projet jusqu’à 12 ans après une thèse, pour une femme avec deux enfants cette limite ira jusqu’à 15 ans après la thèse). Et pourtant. J’ai parfois entendu que la croissance du h-index ne s’arrêtait pas pendant un congé de maternité…
Facteur numéro 3 : les préjugés involontaires
Il est aujourd’hui avéré que le style varie selon que l’auteur d’un dossier est un candidat ou une candidate mais aussi qu’il ou elle soit le sujet des discussions. Certes c’est un peu caricatural mais on pourrait presque aller jusqu’à dire que les femmes subissent la double peine. Non seulement elles ont moins tendance à utiliser un style incisif, à présenter des dossiers ambitieux ou à faire preuve d’autosatisfaction et d’assurance, qui sont autant d’attributs associés à l’excellence chez un homme, mais en plus, si une femme s’y engouffre, on risque de la trouver arrogante et prétentieuse. Et ceux ou celles qui trouvent que mes propos sont exagérés n’ont pas fréquenté assez de jurys.
Les évaluateurs ou les rédacteurs de lettres de références (dans le milieu académique, les lettres de recommandations émanant de personnalités du domaine sont décisives dans le processus de recrutement et promotion) tombent eux aussi dans ce piège. Là encore les clichés sont activés, souvent inconsciemment évidemment. Au point que cela fait par exemple l’objet de recommandations particulières de la part du programme des chaires de recherche au Canada (http://www.chairs-chaires.gc.ca/program-programme/referees-repondants-fra.aspx#prejuges) qui consacre plusieurs paragraphes sur la manière de limiter ces préjugés involontaires. En un mot, les lettres de recommandation pour les femmes sont plus brèves, moins complètes, comptent moins de termes dithyrambiques et beaucoup plus d’éléments semant le doute (certes elle est excellente mais elle a travaillé sous la direction de X, éminent chercheur du domaine).
L’article intitulé Exploring the color of glass: letters of recommendation for female and male medical faculty [3] présente une analyse empirique de près de 300 lettres de recommandation dans le domaine médical. Les études montrent des biais très clairs des « recommandeurs », essentiellement des hommes d’âge respectable, représentatifs des personnalités scientifiques que l’on contacte dans ce genre de cas. L’étude présentée montre que les lettres écrites pour les femmes sont plus courtes, alors même que la même étude conclue que plus la lettre est longue, mieux elle est perçue. On trouve aussi beaucoup plus de termes relatifs au genre dans les lettres pour femmes et une habitude qui tend insidieusement à conjuguer l’effort au féminin et le talent au masculin, l’enseignement au féminin et la recherche au masculin. Ces différences de traitement, souvent involontaires, reflètent des stéréotypes profondément enracinés, qui peuvent s’avérer réellement discriminatoires dans le recrutement et la promotion des femmes
Une ébauche de solution ? Ne jamais négliger ces facteurs
Il est donc crucial de se forcer à la vigilance, tous, candidates et jurys de recrutement, de promotions, ou de sélections, instituts de recherche et universités, pour surveiller les carrières de nos jeunes recrues comme du lait sur le feu et tenter à la fois de rééquilibrer nos laboratoires et de faire évoluer les choses. Veillons à chaque étape du recrutement à éviter la perte en ligne injustifiée. Il ne s’agit pas de décider que toutes les femmes ont des dossiers exceptionnels mais à l’issue d’un concours ayant 15% de candidatures féminines, en moyenne le taux de femmes admises doit rester sensiblement le même. Il n’y a pas de raisons objectives que cela ne le soit pas.
L’ERC a mis un peu de temps mais redouble maintenant de vigilance, c’est aussi le cas du CNRS, avec la mission pour la place des femmes, ou des universités qui ont adopté une charte pour l’égalité. Un comité nouvellement créé à Inria, coordonné par Serge Abiteboul et Liliana Cucu-Grosjean, s’est également penché sur le sujet, et a proposé des recommandations concrètes et une charte , sorte de guide aux jurys de recrutement et promotions.
Pour conclure, il ne suffit pas d’inciter les jeunes filles à faire des sciences, il faut également rester infiniment attentif quant au développement de leur carrière. On peut rêver d’inverser la tendance, de voir disparaître petit à petit les stéréotypes solidement ancrés dans la société et les institutions, y compris celles qui se targuent de la plus grande prudence à cet égard, et imaginer qu’un jour évoquer la parité soit ringard. C’est un processus long, très long. En attendant, il faut accuser réception de ces biais, qui suintent des comités de sélections, à leur insu, et les combattre pour rétablir un équilibre que l’on mérite amplement. Enfin, laissons aussi aux femmes le loisir d’être leurs propres ambassadrices : je me suis vue, alors que, en comité de sélection, j’attirais l’attention du jury sur l’un de ces biais inconscients, me faire gentiment rétorquer, de la part de personnes, certes paternalistes mais dont je sais qu’elles sont de bonne foi et sensibles au sujet : « Pour ce qui concerne la défense des candidatures féminines : laisse ça aux hommes, ma chère, cela aura plus de poids. »
Remerciements : à tous mes collègues du groupe recrutement des chercheurs de la commission parité/égalité Inria, avec qui nous avons longuement discuté sur le sujet et concocté la charte.
Références :
[1] Why so Few ? Women in Science, Technology, engineering and mathematics. Catherine Hill, Christianne Corbett, Andresses St Rose. AAUW
[2] ERC funding activities 2007-2013 Key facts, patterns and trends
[3] Exploring the color of glass: letters of recommendation for female and male medical faculty. France Strix and Carolyn Psenka, Sage publications 2003, diversity.berkeley.edu/sites/default/files/exploring-the-color-of-glass.pdf
Dans le cadre de la rubrique « Il était une fois… ma thèse », Binaire a demandé à Matthieu Dorier, qui a effectué sa thèse à l’ENS Rennes et au laboratoire IRISA et qui est maintenant en postdoc à Argonne National Laboratory (Illinois) de nous présenter ses travaux. Derrière de nombreuses découvertes scientifiques se cachent de plus en plus souvent des millions d’heures de calculs effectués par de gigantesques machines. Vous ne savez pas comme c’est compliqué de commander des centaines de milliers, des millions de travailleurs-processeurs, peut-être obéissants mais bien loin d’avoir l’intelligence et la créativité de travailleurs humains. Et si vous pensez que c’est trop facile, ou si vous pensez que c’est trop compliqué, juste impossible, demandez à Matthieu et il vous envoie une copie de sa thèse. Si vous demandez poliment, il vous laissera peut-être voir ses milliers de lignes de code… Torride ! Serge Abiteboul.
Matthieu Dorier (source: Matthieu Dorier)
En 2010, je m’envolai pour l’université d’Illinois à Urbana-Champaign, aux Etats-Unis, un coin paumé au milieu des champs de maïs, parfois frôlé par des tornades. Les tornades, c’était justement le domaine de recherche de mes collègues, qui voulaient en simuler le comportement sur un ordinateur. Ils me tendirent une feuille pleine de nombres. Le premier qui me frappa fut celui-ci : 300 000, le nombre de processeurs (ou « cœurs ») nécessaires pour exécuter ce genre de simulation. Trop dingue ? « A-t-on une telle puissance de calcul sous la main, demandai-je ? Non, répondirent-ils, mais nous l’aurons plus tôt que tu ne l’imagines. » Il n’en fallait pas plus pour m’accrocher. J’allais m’éclater à Urbana-Champaign. Difficile à croire, mais vrai !
Une tornade (source: Wikipedia)
Dans la science fiction, on parle souvent d’ordinateurs super puissants. Maintenant, on les fabrique. Comment ? On sait fabriquer un cœur. Et bien on va combiner un max de cœurs pour obtenir des supercalculateurs avec de super puissances de calcul. Et effectivement, le plus puissant au monde aujourd’hui possède plus de 3 millions de cœurs. Ces supercalculateurs sont utilisés par des chercheurs dans de nombreux domaines : météo, biologie, astrophysique, etc. J’ai eu la chance, l’honneur, le plaisir, la redoutable tâche de travailler sur un de ces supercalculateurs.
Le supercalculateur « Intrepid » d’Argonne National Laboratory (source: Wikipedia)
Les problèmes arrivent lorsque les programmes que l’on exécute sur un tel nombre de cœurs produisent des données. Si chaque cœur produit ne serait-ce qu’un fichier de 60 Méga octets (plus que l’espace disque par une chanson dans votre téléphone) toutes les 30 minutes, et que le programme est exécuté pendant une semaine (c’est le cas de notre simulation de tornades, par exemple) avec 300 000 cœurs, on se retrouve avec 5.6 Peta-octets de données réparties dans 100 millions de fichiers. Pour vous donner une idée, cela représente 5 600 disques durs de 1 To ! Les supercalculateurs ont bien sûr des « super systèmes de stockage », mais écrire de grandes quantités de données prend du temps, et les programmes sont donc ralentis. De plus, comment retrouver des informations scientifiques intéressantes dans une telle masse de données ?
Visualisation d’une simulation atmosphérique via le logiciel Damaris (source: Matthieu Dorier)
L’ensemble de ma thèse a donc consisté à résoudre ces problèmes : d’une part faire en sorte que la production de données ne ralentisse pas les simulations, d’autre part faire en sorte de pouvoir trouver facilement une information scientifique pertinente sans avoir à lire des centaines de milliers voir des millions de fichiers. Pour cela, j’ai développé un logiciel nommé Damaris. Celui-ci se « branche » sur une simulation et lui « emprunte » un certain nombre de ses cœurs, qu’il va utiliser pour traiter les données produites avant qu’elles ne soient écrites dans des fichiers. Ce logiciel sert aussi d’interface entre une simulation et son utilisateur, qui peut s’y connecter en temps réel et demander à ce qu’il produise des images de la simulation. Tout cela sans avoir besoin d’écrire les données dans des fichiers ! Grâce à cette méthode, les scientifiques peuvent obtenir les résultats qu’ils cherchent avant même que la simulation ne soit terminée.
Après avoir soutenu ma thèse fin 2014, je me suis de nouveau envolé pour l’Illinois, cette fois-ci à Argonne National Laboratory, près de Chicago. J’y travaille toujours sur la gestion de données dans les supercalculateurs.
Il n’est jamais trop tôt pour bien faire. Et l’informatique n’y fait pas exception. Elle est arrivée au lycée, mais cela aura pris le temps. Binaire s’intéresse à des expériences de la découverte de l’informatique à l’école primaire. Nathalie Revol et Cathy Louvier nous parlent d’une expérience en banlieue lyonnaise. Sylvie Boldo
Nathalie Revol, par elle-même
Prenez une classe de CM1 en banlieue lyonnaise. Une classe probablement dans la moyenne, avec des origines sociales et géographiques très mélangées : 26 enfants curieux, motivés, joueurs, remuants, faciles à déconcentrer.
Prenez une chercheuse en informatique qui se pose des questions sur ce qu’il est important de transmettre de sa discipline, dès le plus jeune âge.
Prenez une enseignante de CM1 désireuse de proposer un enseignement des sciences en général et de l’informatique en particulier, de façon attrayante et motivante, à ses élèves.
Faites en sorte que l’enseignante soit en charge de cette classe de CM1. Faites en sorte que la chercheuse ait des jumeaux dans cette classe de CM1, à défaut un seul enfant suffira, pas d’enfant du tout peut aussi faire l’affaire, il suffit que la rencontre ait lieu.
Laissez reposer quelques mois les questions et les idées qui tournent dans la tête de la chercheuse et vous aurez une ébauche de programme d’informatique pour des CM1.
Faites ensuite se rencontrer la chercheuse et l’enseignante au portail de l’école ou ailleurs, la première proposant d’expérimenter ce programme, la seconde acceptant bien volontiers de servir de cobaye. Quelques demandes d’autorisation plus tard, c’est ainsi que la chercheuse et l’enseignante ont démarré un programme de 8 séances de 45 minutes intitulé « informatique débranchée ».
Questions et réponses
La question qui tournait comme une rengaine dans la tête de la chercheuse était de savoir comment s’y prendre pour faire passer le message suivant :
L’informatique n’est pas plus la science des ordinateurs que l’astronomie n’est celle des téléscopes, aurait dit E. Dijkstra. En d’autres termes plus compréhensibles par les élèves du primaire, l’informatique n’est pas plus la science des ordinateurs que les mathématiques ne sont la maîtrise de la calculatrice.
Approche, accroche, algorithmes pour les gavroches, codage binaire sans anicroche
Ne le prenez pas, le parti était pris : ce serait un enseignement sans ordinateur. Cela tombait bien, le site « Computer Science Unplugged » regorge d’activités à pratiquer sans ordinateur, tout comme le site de Martin Quinson consacré à la médiation, ou le site pixees destiné à offrir des ressources pour les enseignant-e-s. D’ailleurs, le titre de ce projet d’informatique en CM1 est informatique débranchée, la traduction – sans les références musicales – de Computer Science unplugged.
L’approche étant choisie, il fallait encore définir le contenu. L’inspiration a été puisée dans le programme d’ISN : Informatique et Sciences du Numérique, élaboré pour les lycéen-ne-s de 1e et Terminale. Ce programme comporte quatre volets : 1 – langages et programmation, 2 – informations, 3 – machines, 4 – algorithmes. Les volets « algorithmes » et « informations » ont été retenus parce qu’ils se prêtent bien à des activités sans ordinateur. Pour la partie « informations », l’accent a été mis sur leur représentation utilisant le codage binaire.
Enfin, pour que les élèves adhèrent à ce projet d’informatique, une accroche basée sur les jeux a été choisie pour la partie algorithmique. Quant au codage binaire, c’est par des tours de magie qu’il a été présenté. On a privilégié les manipulations, qui permettent d’établir le lien entre les objets et la formalisation plus abstraite des algorithmes, ainsi que des activités engageant tout le corps, comme le réseau de tri pour les algorithmes et la transmission d’un message codé en binaire par la danse.
Cela permet d’accrocher l’attention des élèves et de les motiver pour qu’ils et elles se mettent en situation active de recherche, d’élaboration des algorithmes ou de compréhension du codage binaire.
Algorithmes
Chaque partie a demandé quatre séances. Côté algorithmes, on a commencé par le jeu de nim, popularisé par le film «L’année dernière à Marienbad » paraît-il (c’était la minute culturelle). Ce jeu se joue avec des jetons de belote et des règles simples… et il existe une stratégie pour gagner à tous les coups. Appelons cette stratégie un algorithme et laissons les enfants jouer par deux, en passant entre les tables pour les mettre sur la voie. En fin de séance, on a mis en commun les algorithmes trouvés et on a mis en évidence qu’il s’agissait de formulations différentes du même algorithme.
On a ensuite défini, avec l’aide du film «Les Sépas : les algorithmes », ce qu’était un algorithme, avec les mots des enfants.
Le jeu suivant est le crêpier psycho-rigide. Un crêpier veut, le soir avant de fermer boutique, ranger la pile de crêpes qui reste dans sa vitrine par taille décroissante, la plus grande en bas et la plus petite en haut. La seule opération qu’il peut effectuer consiste à glisser sa spatule entre deux crêpes, n’importe où dans la pile, et à retourner d’un seul coup toute la pile de crêpes posées sur sa spatule. Pourra-t-il ranger ses crêpes comme il le désire ? Il s’agit d’un jeu plus ambitieux : l’algorithme à découvrir est un algorithme récursif. Autrement dit, on effectue quelques manipulations pour se ramener au même problème, mais avec moins de crêpes à ranger. Pour faire «oublier » les crêpes déjà rangées, pour se concentrer sur les crêpes restantes, on a caché les crêpes déjà rangées par une feuille de papier… et cela a très bien marché ! On a aussi utilisé cet écran de papier pour cacher complètement la pile de crêpes, dès le début, et pour faire comprendre aux enfants qui dictaient l’algorithme – qui était donc exécuté derrière l’écran – qu’un algorithme s’applique à toutes les configurations, que ce n’est pas une construction ad hoc pour chaque pile de crêpes.
Le dernier algorithme a été abordé de manière fort différente. On a dessiné un réseau de tri au sol et cette fois-ci, les élèves étaient les porteurs des données (soit des petits nombres, soit des grands nombres, soit des mots) qui se déplacent dans le réseau, se comparent et finissent par se trier, comme ils l’ont rapidement compris, par ordre numérique ou par ordre alphabétique.
Codage binaire, représentation des données
Les quatre séances suivantes ont été consacrées au codage binaire des informations.
Pour la première séance, les enfants ont reçu un codage binaire (une suite de 0 et de 1) et une grille. Ils ont travaillé par 2 : l’un-e dictait les «0 » et les «1 » et l’autre laissait blanches ou noircissait les cases correspondantes de la grille. Ils ont fini par découvrir le dessin caché pixellisé et encodé en binaire. Ils ont alors créé leur propre dessin, l’ont encodé puis dicté à leur voisin pour vérifier que l’encodage puis le décodage préservait leur image.
Pour la deuxième séance, on a commencé par un tour de magie reposant sur le codage binaire des nombres. La magicienne devait deviner un nombre, entre 1 et 31, choisi par un enfant en lui montrant successivement 5 grilles de nombres et en lui demandant si son nombre se trouvait dans ces grilles. Avec leur attention ainsi acquise, on a écrit le codage binaire des nombres de 1 à 7 tous ensemble, puis de 1 à 31. Pour cela on est revenu à une représentation des nombres par des points, un nombre étant représenté par autant de points que d’unités, par exemple 5 est représenté par 5 points. On a utilisé de petites cartes porteuses de 1, 2, 4, 8 ou 16 points (oui, les puissances de 2, mais chut, vous allez trop vite). Chaque enfant s’est vu attribuer un nombre et devait choisir quelles cartes conserver pour obtenir le bon nombre de points ; c’était plus clair en classe avec les cartes… Bref, en notant «1 » quand la carte était retenue et «0 » quand elle ne l’était pas, nous avons le codage binaire des nombres et on a pu expliquer finalement comment marchait le tour de magie.
La troisième séance a de nouveau commencé par un tour de magie, reposant cette fois sur la notion de bit de parité. Après avoir dévoilé le truc et expliqué pourquoi il est utile de savoir détecter des erreurs (voire les corriger – mais on n’est pas allé jusque là), on a encodé les lettres de l’alphabet, en binaire, avec 6 bits dont 1 de parité. Chaque binôme a alors choisi un mot court, l’a écrit en binaire en utilisant le codage et l’a conservé pour la séance suivante.
La dernière séance a fait appel au corps : à tour de rôle, nous avons dansé nos mots, en levant le bras droit pour «1 » et en le baissant pour «0 » et nos spectateurs ont décodé sans se lasser.
Au final…
l’expérience s’est bien déroulée, les cobayes se sont prêtés au jeu avec beaucoup d’enthousiasme, le calibrage des activités en séances de 40-45mn était à peu près juste et pas exagérément optimiste, la gestion de la classe a été assurée par l’enseignante et c’est tant mieux, les moments de mise en commun également. L’enseignante est même partante pour renouveler seule ce projet… ce qui fait chaud au cœur de la chercheuse : un des objectifs était en effet de proposer un projet réalisable dans toutes les classes, sans nécessiter une aide extérieure qui peut être difficile à trouver.
On peut trouver le détail de ce projet, agrémenté de remarques après coup pour parfaire le déroulement de chaque séance, sur le site de pixees.
Dans le cadre d’une nouvelle rubrique « Il était une fois… ma thèse », Binaire a demandé à Pauline Bolignano, qui effectue sa thèse à Inria Rennes Bretagne Atlantique et dans la société Prove & Run de nous présenter ses travaux. Par ailleurs, Binaire tient à remercier Pauline et Charlotte qui en discutant ont initié l’idée de cette rubrique. Nous attendons impatiemment la suite des autres histoires de thèses… Binaire.
« – Tu penses que c’est possible que quelqu’un pirate ton portable et écoute tes conversations, ou accède à tes données bancaires ?
– Non ça n’arrive que dans les séries ça ! Et puis moi de toute façon je ne télécharge que des applis de confiance…»
En fait, avec en moyenne 25 applications installées sur un téléphone, nous ne sommes pas à l’abri d’un bug dans l’une d’entre elles.
Il y a même fort à parier que nos applications contiennent toutes plusieurs bugs. Or, certains bugs permettent à une personne mal intentionnée, sachant l’exploiter, d’accéder à des ressources privées. Ce problème est d’autant plus préoccupant que de plus en plus de données sensibles transitent sur nos téléphones et peuvent interférer entre elles. C’est encore pire quand les téléphones servent à la fois pour un usage personnel et professionnel !
Actuellement, l’accès aux ressources (appareil photo, micro, répertoire et agendas,…) dans un smartphone se fait un peu comme dans un bac à sable : toutes les applications peuvent prendre le seau et la pelle des autres, et rien n’empêche une application de détruire le château d’une autre… L’angoisse !
Pour mettre de l ‘ordre dans tout ça, une solution est d’ajouter une couche de logiciel qui contrôle de manière précise l’accès aux ressources, une sorte de super superviseur ; d’ailleurs, on appelle ça un hyperviseur. L’hyperviseur permet par exemple d’avoir deux « bacs à sable » sur son téléphone, de telle manière qu’aucune information sensible ne fuite entre les deux. Cela n’empêche pas les occupants d’un même bac à sable de se taper dessus avec des pelles mais on a la garantie que cela n’a pas d’impact sur le bac d’à coté. L’hyperviseur peut également interdire aux applications l’accès direct aux ressources. Il autorise les occupants du bac à sable de faire un pâté mais c’est lui qui tient le seau. Il peut de cette manière imposer qu’un voyant lumineux s’allume lorsque le micro est en marche. On a ainsi la certitude que lorsque le voyant est éteint, le micro est éteint et que personne ne peut nous écouter.
Vous l’avez peut être remarqué, il nous reste un problème majeur : comment s’assurer que l’hyperviseur n’a pas de bug ? L’hyperviseur ayant accès à toutes les ressources, un bug chez lui peut avoir des conséquences très graves. Il devient donc une cible de choix pour des pirates. Si on se contente de le tester, on passe potentiellement à coté de nombreux bugs. En effet la complexité d’un hyperviseur est telle que les tests ne peuvent pas prévoir tous les cas d’usage. La seule solution qui permette de s’approcher de l’absence de bug est la preuve formelle de programme. L’idée est d’exprimer des propriétés sur le programme, par exemple « les occupants d’un bac à sable n’interfèrent pas avec les occupants d’un autre bac à sable », puis de les prouver mathématiquement. Les propriétés sont exprimées dans un langage informatique et on les prouve grâce un outil qui vérifie que nos preuves sont correctes (et qui parfois même fait les preuves à notre place !).
Actuellement la preuve de programme n’est pas très répandue car elle est très couteuse et longue à mener. Elle est réservée aux systèmes critiques. Par exemple, des propriétés formelles ont été prouvées sur les lignes automatiques (1 et 14) du métro parisien. Je prouve en ce moment des propriétés d’isolation sur la ressource « mémoire » d’un hyperviseur, c’est à dire qu’il n’y a pas de mélange de sable entre deux bacs à sable. Le but de ma thèse est de fournir des méthodes afin d’alléger l’effort de preuve sur ce type de systèmes.
Marie-Paule Cani rêve de logiciels qui permettraient à chacun de créer en 3D. En savoir plus ? Voici un podcast sympatique comme Marie Paule sur France Inter, avec Fabienne Chauvière pour Les Savanturiers.
LeRaspberryPi (prononcé comme « Raze » « Berry » « Paille » en anglais) est un petit ordinateur de la taille d’une carte bancaire. Il a été conçu par une fondation éducative à but non-lucratif pour faire découvrir le monde de l’informatique sous un autre angle. C’est Alan, franco-irlandais qui nous raconte cette belle histoire. Charlotte Truchet et Pierre Paradinas.
Le récemment lancé « PiZero » : 60 x 35mm : commercialisé en France pour €8,90 Crédit Photo : Alex Eames – RasPi.TV
Une fracture entre informatique et société
Au milieu des années 2000, Eben Upton de la Faculté des Sciences Informatiques de l’Université de Cambridge (« Computer Science Lab ») en Angleterre s’est rendu compte d’un gros problème. Avec ses collègues, ils ont observé un déclin très marqué dans le nombre de candidats se présentant pour poursuivre des études en informatique. Entre l’année 1996 (année de sa propre entrée « undergraduate » à Cambridge) et 2006 (vers la fin de son doctorat), les dossiers de demande pour accéder à la Faculté se sont réduits de moitié. Le système de sélection britannique des futurs étudiants est basé sur des critères de compétition, compétence, expérience et des entretiens individuels. Eben, qui avait tenu le rôle de « Directeur des Études » également, était bien placé pour remarquer une deuxième difficulté. Au-delà du « quantitatif », les candidats qu’il rencontrait, malgré leur grand potentiel et capacités évidentes, avaient de moins en moins d’expérience en matière de programmation. Quelques années plus tôt, le rôle des professeurs était de convaincre les nouveaux arrivants en premier cycle universitaire qu’ils ne savaient pas tout sur le sujet. A l’époque de la première « bulle internet », beaucoup parmi eux avait commencé leur carrière d’informaticien dès leur plus jeune âge. Ils étaientfamilier avec plusieurs langages allant des « Code machine » et « Assembleur » (les niveaux les plus proches de la machine) jusqu’aux langages de plus haut niveaux. Au fil des années, cette expertise était en berne, à tel point qu’autour de 2005, le candidat typique maîtrisait à peine quelques éléments des technologies de l’internet, HTML et PHP par exemple.
En parallèle, les membres du monde académique anglais étaient bien conscients de la nécessité croissante pour l’industrie, et la société plus globalement, d’avoir une population formée à la compréhension du numérique. Le numérique était désormais omniprésent dans la vie quotidienne. Et ce sans parler des besoins spécifiques en ingénierie et sciences. De façon anecdotique, les cours de TICE à ce moment-là étaient souvent devenus des leçons de dactylographie et d’utilisation d’outils bureautiques. Bien que ce soit important, le numérique ne pouvait pas se résumer à ça. Face à ce dilemme, Dr Upton et ses autres co-fondateurs de la Raspberry Pi Foundation se posaient deux questions : pourquoi en est-on arrivé là et comment trouver une solution pour répondre à leur besoin immédiat, local (et peut-être au-delà) ?
Comprendre la cause avant de chercher le remède
L’explication qu’ils ont trouvée était la suivante. Dans les années 80, sur les machines de l’époque, on devait utiliser des commandes tapées dans une interface spartiate pour faire fonctionner, et même jouer sur les ordinateurs. Par exemple pour moi, c’était un « BBC Micro » d’Acorn en école primaire en Irlande comme pour Eben chez lui au Pays de Galles. C’était pareil en France, avec des noms comme Thomson, Amstrad, Sinclair, ou Commodore,… qui rappellent des souvenirs de ces années-là. Depuis cette date, nous étions passés à des ordinateurs personnels et consoles de jeu fermés et propriétaires qui donnaient moins facilement l’accès au « moteur » de l’environnement binaire caché sous le « capot » de sur-couches graphiques. Bien que ces interfaces soient pratiques, esthétiques et simples à l’utilisation, elles ont crée une barrière à la compréhension de ce qui se passe « dans la boîte noire ». Pour tous, sauf une minorité d’initiés, nous sommes passés d’une situation d’interaction avec une maîtrise réelle et créative, à un fonctionnement plutôt de consommation.
Quand une solution permet de changer le monde
Leur réponse à ce problème a été de concevoir une nouvelle plate-forme informatique accessible à tous autant par sa forme, que par son prix, et ses fonctionnalités. L’idée du Raspberry Pi est née et le produit fini a été lancé le 29 février 2012.
Le Raspberry Pi est un nano-ordinateur de la taille d’une carte bancaire (Modèle 2 : 85mm x 56.2mm). Le prix de base, dès le début, a été fixé à $25 USD (bien que d’autre modèles existent à ce jour de $5 à $35). Le système d’exploitation conseillé est l’environnement libre et gratuit GNU/Linux (et principalement une « distribution » (version) dite Raspbian). Le processeur est d’un type « ARM » comme trouvé dans la plupart des smartphones de nos jours. Tout le stockage de données se fait par défaut par le biais d’une carte Micro SD. L’ordinateur est alimenté par un chargeur micro-USB comme celui d’un téléphone portable. Le processeur est capable de traiter les images et vidéos en Haute Définition. Il suffit de le brancher sur un écran HDMI ou téléviseur, clavier, souris par port USB et éventuellement le réseau et nous avons un ordinateur complet et fonctionnel. Avec son processeur Quad Cœur 900 Mhz et 1 Go de mémoire vive, le Modèle 2 est commercialiséenFrance aux alentours d’une quarantaine d’Euros. A la différence de la plupart des ordinateurs en vente, la carte comporte 40 broches « GPIO » (Broches/picots d’Entrée-Sortie générale). C’est une invitation à l’électronique et l’interaction avec le monde extérieur. En quelques lignes de code, l’informatique dite « physique » devient un jeu d’enfant. Brancher résistance et une DEL et un bouton poussoir en suivant un tutoriel et les enfants découvrent immédiatement des concepts de l’automatisation et de robotique. C’est assez impressionnant que ce même petit circuit imprimé, que l’on peut facilement mettre entre les mains d’un enfant de 5 ans, est de plus en plus utilisé dans des solutions industrielles embarquées et intégrées.
Le nom « Raspberry Pi » vient du mot anglais pour la framboise (les marques de technologie prennent souvent les noms d’un fruit) et de « Python », un langage de programmation abordable, puissant et libre. Au début les inventeurs pensaient peut-être dans leur plus grands rêves vendre 10,000 unités. A ce jour, c’est bien plus de 6 millions de Raspberry Pi qui ont été vendus danslemondeentier. En se consacrant initialement 100% de leurs efforts en développement matériel aux cartes elles-mêmes, la Fondation a fait naître à leur insu tout un écosystème autour de la création d’accessoires et périphériques. Les « produits dérivés » vont de toute sorte de boîtier jusqu’à divers cartes d’extension pour tout usage imaginable.
Le Piano HAT : une carte d’extension pour apprendre à s’amuser en musique, avec un boitier Pibow coupé Crédit Photo : Pimoroni.com
De plus, ils ont su créer d’autres emplois « chez eux » grâce à l’ordinateur – aujourd’hui les cartes sont fabriqués « Made in Wales » (dans une usine de Sony au Pays de Galles). Il existe aussi un communauté global de passionnés de tout âge et tout horizon qui promeuvent la pédagogie numérique, réalisent des projets, organisent des événements et assurent de l’entre–aide autour de la « Framboise π« . La France n’est pas une exception avec pas mal d’activité dans l’Hexagone. La barrière initiale de la langue anglaise joue sans doute un rôle dans son manque de notoriété et utilisation par un plus grand publique chez nous – pour l’instant ce bijou technologique reste en grande partie le domaine des technophiles/ »geeks » et des lycées techniques.
Éducation
Le succès commercial fulgurant du Raspberry Pi fait oublier parfois que le but principal de la Fondation reste axé sur l’éducation. L’argent gagné à travers les ventes est réinvesti dans des actions et des fonds permettant de faire avancer leurs objectifs. Ce dernier temps, la Fondation a pu engager des équipes de personnes intervenant sur divers projets et initiatives un peu partout dans le monde. Ça concerne l’informatique, mais pas seulement. Dans le monde anglo-saxon, on parle souvent de « STEM », voire « STEAM » – acronyme pour la promotion des Sciences, Technologie, Ingénierie (Engineering), les Arts et Mathématiques. En France, le Raspberry Pi pourrait bien STIM-uler plus d’intérêt dans ces disciplines aussi !
Utilisation
Les applications potentielles de cet outil sont sans fin. Un petit tour d’internet laisse pas de doute sur les possibilités. Sortie de sa boîte, ça permet une utilisation en bureautique avec Libre Office, accès internet avec un navigateur web, l’apprentissage de la programmation avec Scratch, Python et Minecraft Pi ou Ruby et Sonic Pi. Plus loin il existe tout l’univers d’utilitaires libres et gratuits sous GNU/Linux.
Pour donner quelques exemples rapides intéressants :
Et enfin, on peut même envoyer ses expériences scientifiques dans l’Espace ! Dans l’esprit de la récente semaine d’une « HeuredeCode« , dans le projet AstroPi, deux Raspberry Pi viennent d’être envoyéssurlaStationSpatialeInternationale embarquant des capteurs et du code crée lors d’un concours par des enfants de primaire et secondaire en Grande Bretagne. Ça fait rêver !
Astro Pi : un concours pour des jeunes en Grande Bretagne pour envoyer leur Code sur l’ISS (Station Spatiale Internationale) Crédit Photo : Fondation Raspberry Pi {Artiste : Sam Adler}
Comme dit François Mocq, auteur et blogueur de « Framboise314.fr« , il y a bien une limitation à ce que nous pouvons faire avec un Raspberry Pi. C’est notre imagination !
Cet article a été écrit via un Raspberry Pi.
Pour plus d’information, rendez-vous sur « http://raspberrypi.org » (site officiel de la Fondation – anglophone) et/ou « http://framboise314.fr » (notre référence francophone).
Cet article est publié en collaboration avec TheConversation.
Dans le cadre des « Entretiens autour de l’Informatique« , Binaire a rencontré l’artiste et chercheur Jon McCormack, grande figure du creative coding, un courant peu représenté en France qui fait de l’informatique un moyen d’expression. Non content d’avoir ses œuvres exposées dans salles les plus prestigieuses, comme le Musée d’Art Moderne de New York, Jon McCormack est professeur d’informatique à Monash University à Melbourne, et Directeur du Sensilab. Jon McCormack parle de créativité et d’ordinateurs à Charlotte Truchet, de Binaire.
Dans votre travail, vous vous êtes souvent intéressé à des processus génératifs. Pourriez-vous nous en décrire un exemple ?
Oui, j’ai par exemple une exposition en ce moment à Barcelone intitulée « Fifty sisters », une oeuvre créée pour le Musée Ars Electronica. Il s’agit une série de cinquante images évolutives, créées à partir d’un modèle de la croissance des plantes. A la base, j’ai choisi d’utiliser des logos de compagnies pétrolières. J’ai repris des éléments géométriques de ces logos, qui viennent nourrir le modèle de développement. Ensuite, j’utilise une grammaire, un ensemble de règles qui modélisent l’évolution d’une plante – à l’origine, cette grammaire permet de représenter la structure de plantes du Jurassique. J’utilise cette grammaire dans un processus itératif qui alterne des étapes de calcul par l’ordinateur, et des choix de ma part. D’abord, à partir des logos pétroliers, l’ordinateur calcule une premier génération de plantes en appliquant la grammaire. Cela produit plusieurs plantes, parmi lesquelles je choisis celles qui me semblent les plus étranges, ou intéressantes. Et l’on recommence. C’est donc bien l’humain qui conduit l’algorithme.
De cette façon, les plantes sont réellement constituées d’éléments graphiques des logos. Les images finales ont des structures très complexes, et elles sont calculées à très haute définition de façon à ce que l’on puisse zoomer dans les plantes et découvrir de nouveaux détails.
C’est un sacré travail !
Plante ayant évolué à partir du logo Shell, de la série des Fifty Sisters (crédit Jon McCormack)
Oui, en fait la partie la plus dure a été de calculer le rendu. J’avais loué une ferme d’ordinateurs, mais au bout de 24h nous nous sommes fait jeter dehors parce que nous consommions trop de temps de calcul ! Alors, nous avons installé le programme qui calcule le rendu, petit morceau d’image par petit morceau d’image, sur tous les ordinateurs inutilisés du labo, ceux de tout le monde… C’est impressionnant car la grammaire qui sert à faire les générations est très courte, elle fait 10 lignes, et elle génère pourtant des objets extrêmement complexes.
Comment avez-vous découvert l’informatique ?
J’ai toujours aimé les ordinateurs, depuis l’enfance. Dans mon école, il y avait un ordinateur, un seul, c’était un TRS80 de Radioshack. Personne ne voulait l’utiliser. Je l’ai trouvé fascinant, parce qu’il faisait des calculs, et qu’il permettait de générer des choses. Le TRS80 avait des graphismes très crus, mais on pouvait faire des images avec, allumer des pixels, les éteindre… D’abord, je l’ai utilisé pour dessiner des fonctions, et puis j’ai commencé à écrire mes propres programmes : je voulais voir les fonctions en 3D. Aujourd’hui, la 3D est une technique couramment utilisée, mais ce n’était pas le cas alors ! Donc j’ai programmé une visualisation 3D. Elle n’était pas parfaite, mais elle me suffisait. C’est là que j’ai compris que l’ordinateur permettait de faire des films, de l’animation, de l’interaction. Il faut dire que c’est fascinant de construire un espace et un temps qui reflètent la réalité, même si cette réflexion n’est pas parfaite.
Est-ce qu’il y a aujourd’hui des nouveaux langages artistiques basés sur les données numériques ou l’algorithmique ?
C’est une question difficile. Je ne crois pas que l’ordinateur soit accepté, en soi, dans le courant dominant de l’art contemporain (« mainstream art »). Il y a des résistances. Par moment, le monde de l’art accepte l’ordinateur, puis il le rejette. Je ne pense pas que l’on puisse dire que les ordinateurs soient devenus centraux dans la pratique artistique. Mais je crois que l’informatique a ouvert des possibilités artistiques, qu’elle apporte quelque chose de réellement nouveau. C’est un peu comme le bleu. Autrefois, on ne savait pas fabriquer la couleur bleue. Dans l’histoire de l’art, la découverte du bleu a été un évènement important. C’était une question scientifique, un vrai problème technologique. Lorsque l’on a commencé à le fabriquer, le bleu était cher. Dans les peintures du début de la Renaissance, on ne l’utilisait que pour les personnes très importantes.
Pour moi, l’ordinateur suit un chemin similaire à celui du bleu. C’est vrai dans l’art pictural mais aussi dans la musique, le cinéma, l’architecture…
Jon McCormack devant l’exposition Fifty Sisters au musée Ars Electronica, avril 2013 (crédit Jon McCormack)
Pensez-vous que les artistes doivent apprendre l’informatique ?
Je ne le formulerais pas de façon aussi stricte. Je ne dirais pas qu’ils en ont besoin, qui est un terme trop fort, mais qu’ils devraient. Au delà des artistes d’ailleurs, tout le monde devrait apprendre au moins un peu d’informatique. C’est indispensable pour comprendre le monde, au même titre que les mathématiques ou les autres sciences.C’est important d’ajouter aux cursus la pensée algorithmique et la programmation. Et cela ouvre de nouvelles possibilités pour tout le monde, comme aucun autre medium ne le fait.
Est-ce que le code créatif est une activité similaire à la programmation classique, ou différente ?
Je crois que c’est juste un outil pour la créativité, car toutes les activités créatives ont été numérisées. C’est lié à ce que nous disions tout à l’heure : les gens qui travaillent dans le design, la musique ou l’architecture, utilisent l’ordinateur tout le temps, même si ce n’est que pour éditer des fichiers.
Prenons l’exemple de Photoshop. C’est un outil fabriqué par d’excellents développeurs, qui y ont ajouté d’excellentes fonctionnalités. Mais ce sont leurs fonctionnalités. Quand on l’utilise, on n’exprime pas ses idées, mais les leurs. Et tout le monde fait la même chose ! Dès lors, la question devient : voulez-vous exprimer votre créativité, ou celle de quelqu’un d’autre ?
Ici nous avons un projet en cours d’examen avec l’Université de Sydney pour enseigner le code créatif aux biologistes. Ils ont de gros besoins en visualisation de données statistiques, et ils utilisent en général des outils dédiés très classiques comme Excel ou le langage R. Mais l’outil a une énorme influence sur ce que l’on fait et la façon dont on perçoit les choses. Nous voulons leur apprendre à fabriquer leurs propres outils.
Tout le monde devrait apprendre le code créatif : les ingénieurs, les biologistes, les chimistes, etc. !
Dans le futur, quelle technologie vous ferait vraiment rêver ?
Pour certains projets, nous avons eu ici des interfaces avec le cerveau. Pendant longtemps, la conception des ordinateurs s’est faite sans considérer le corps humain. On accordait peu d’importance au fait que nous sommes incarnés dans un corps. Regardez le clavier ! Maintenant, on a les écrans tactiles.
La question est maintenant de concevoir des machines qui fonctionnent avec nos corps. Regardez les travaux de Stelarc sur l’obsolescence du corps humain. Il s’agit de se réapproprier la technologie. Alors que l’on voyait l’ordinateur comme un outil externe, le corps devient un outil d’interaction. C’est le même principe que la cane pour les aveugles : au début, quand on a une cane, on la voit comme un objet externe. Mais on peut l’utiliser pour tester une surface par exemple, ou pour sentir un mur. Elle devient une extension du corps. Je pense que l’on peut voir la technologie comme extension du corps humain.
La recherche aime bien avoir ses challenges qui galvanisent les énergies. L’intérêt d’un tel challenge peut avoir de nombreuses raisons, la curiosité (le plus ancien os humain), l’importance économique (une énergie que l’on puisse stoker), la difficulté technique (le théorème de Fermat). En informatique, un problème tient de ces deux dernières classes : c’est l’«isomorphisme de graphe» (nous allons vous dire ce que c’est !) . On comprendra l’excitation des informaticiens quand un chercheur de la stature de Laszlo Babai de l’Université de Chicago a annoncé une avancée fantastique dans notre compréhension du problème. Binaire a demandé à une amie, Christine Solnon, Professeure à l’INSA de Lyon, de nous parler de ce problème. Serge Abiteboul, Colin de la Higuera.
À la rencontre de Laszlo et de son problème
Laszlo Babai, professeur aux départements d’informatique et de mathématiques de l’université de Chicago, a présenté un exposé le 10 novembre 2015 intitulé Graph Isomorphism in Quasipolynomial Time. Si le nom « isomorphisme de graphes » ne vous dit rien, vous avez probablement déjà rencontré ce problème, et vous l’avez peut être même déjà résolu « à la main » en comparant, par exemple, des schémas ou des réseaux, afin de déterminer s’ils ont la même structure.
Le problème est déroutant et échappe à toute tentative de classification : d’une part, il est plutôt bien résolu en pratique par un algorithme qui date du début des années 80 ; d’autre part, personne n’a jamais réussi à trouver un algorithme dont l’efficacité soit garantie dans tous les cas. Mais surtout, il est un atout sérieux pour tenter de prouver ou infirmer la plus célèbre conjecture de l’informatique : P≠NP.
Nous allons donc présenter ici un peu plus en détails ce problème, en quoi il occupe une place atypique dans le monde de la complexité des problèmes, et pourquoi l’annonce de Babai a fait l’effet d’une petite bombe dans la communauté des chercheurs en informatique.
Qu’est-ce qu’un graphe ?
Pour résoudre de nombreux problèmes, nous sommes amenés à dessiner des graphes, c’est-à-dire des points (appelés sommets) reliés deux à deux par des lignes (appelées arêtes). Ces graphes font abstraction des détails non pertinents pour la résolution du problème et permettent de se focaliser sur les aspects importants. De nombreuses applications utilisent les graphes pour modéliser des objets. Par exemple:
By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Un réseau de transport (routier, ferroviaire, métro, etc) peut être représenté par un graphe dont les sommets sont des lieux (intersections de rues, gares, stations de métro, etc) et les arêtes indiquent la possibilité d’aller d’un lieu à un autre (par un tronçon de route, une ligne de train ou de métro, etc.)
By This SVG image was created by Medium69. Cette image SVG a été créée par Medium
Une molécule peut être représentée par un graphe dont les sommets sont les atomes, et les arêtes les liaisons entre atomes.
Un réseau social peut être représenté par un graphe dont les sommets sont les membres, et les arêtes les relations entre membres
Le problème d’isomorphisme de graphes
Étant donnés deux graphes, le problème d’isomorphisme de graphes (Graph Isomorphism Problem) consiste à déterminer s’ils ont la même structure, c’est-à-dire, si chaque sommet d’un graphe peut être mis en correspondance avec exactement un sommet de l’autre graphe, de telle sorte que les arêtes soient préservées (deux sommets sont reliés par une arête dans le premier graphe si et seulement si les sommets correspondants sont reliés par une arête dans le deuxième graphe). Considérons par exemple ces trois graphes :
G1
Les graphes G1 et G2 sont isomorphes car la correspondance
{ a ↔ 1; b ↔ 2; c ↔ 3; d ↔ 4; e ↔ 5; f ↔ 6; g ↔ 7}
préserve toutes les arêtes.
Par exemple :
– a et b sont reliés par une arête dans G1, et 1 et 2 aussi dans G2
– a et c ne sont pas reliés par une arête dans G1, et 1 et 3 non plus dans G2 ;
etc.
En revanche, G1 n’est pas isomorphe à G3
(ce qui n’est pas évident à vérifier).
G2
G3
Notons qu’il est plus difficile de convaincre quelqu’un que les graphes G1 et G3 ne sont pas isomorphes car nous ne pouvons pas fournir de « certificat » permettant de vérifier cela rapidement, comme nous venons de le faire pour montrer que G1 et G2 sont isomorphes. Pour se convaincre que deux graphes ne sont pas isomorphes, il faut se convaincre qu’il n’existe pas de correspondance préservant les arêtes, et la question de savoir si on peut faire cela efficacement (autrement qu’en énumérant toutes les correspondances possibles) est véritablement au cœur du débat.
Ce problème se retrouve dans un grand nombre d’applications : dès lors que des objets sont modélisés par des graphes, le problème de la recherche d’un objet identique à un objet donné, par exemple, s’y ramène. Il est donc de première importance de disposer d’algorithmes efficaces.
Mais, au delà de cet aspect pratique, le problème occupe aussi une place très particulière dans un monde théorique au sein de la science informatique : celui de la complexité .
Petite digression sur la complexité des problèmes
La théorie de la complexité s’intéresse à la classification des problèmes en fonction de la complexité de leur résolution.
La classe des problèmes faciles (P). La classe P regroupe tous les problèmes « faciles ». Nous dirons qu’un problème est facile s’il existe un algorithme « efficace » pour le résoudre, et nous considèrerons qu’un algorithme est efficace si son temps d’exécution croît de façon polynomiale lorsqu’on augmente la taille du problème à résoudre. Par exemple, le problème consistant à trouver un chemin reliant deux sommets d’un graphe appartient à la classe P car il existe des algorithmes dont le temps d’exécution croît de façon linéaire par rapport à la taille du graphe (son nombre de sommets et d’arêtes).
La classe des problèmes dont les solutions sont faciles à vérifier (NP). La classe NP regroupe l’ensemble des problèmes pour lesquels il est facile de vérifier qu’une combinaison donnée (aussi appelée certificat) est une solution correcte au problème. Par exemple, le problème de recherche d’un chemin entre deux sommets appartient également à NP car étant donnée une succession de sommets, il est facile de vérifier qu’elle correspond bien à un chemin entre les deux sommets. De fait, tous les problèmes de P appartiennent à NP.
La question inverse est plus délicate, et fait l’objet de la célèbre conjecture P≠NP.
La classe des problèmes difficiles (NP-complets). Certains problèmes de la classe NP apparaissent plus difficiles à résoudre dans le sens où personne ne trouve d’algorithme efficace pour les résoudre. Les problèmes les plus difficiles de NP définissent la classe des problèmes NP-complets.
Considérons par exemple le problème consistant à rechercher dans un réseau social un groupe de personnes qui sont toutes amies deux à deux. Le problème est facile si on ne pose pas de contrainte sur la taille du groupe. Il devient plus difficile si on impose en plus que le groupe comporte un nombre fixé à l’avance de personnes. Si on modélise le réseau social par un graphe dont les sommets représentent les personnes et les arêtes les relations entre les personnes, alors ce problème revient à chercher un sous-ensemble de k sommets tous connectés deux à deux par une arête. Un tel sous-ensemble est appelé une clique.
Si nous avons un sous-ensemble de sommets candidats, alors nous pouvons facilement vérifier s’il forme une clique ou non. En revanche, trouver une clique de taille donnée dans un graphe semble plus difficile. Nous pouvons résoudre ce problème en énumérant tous les sous-ensembles possibles de sommets, et en testant pour chacun s’il forme une clique. Cependant, le nombre de sous-ensembles candidats explose (c’est-à-dire, croît exponentiellement) en fonction du nombre de sommets des graphes, ce qui limite forcément ce genre d’approche à des graphes relativement petits.
Actuellement, personne n’a trouvé d’algorithme fondamentalement plus efficace que ce principe fonctionnant par énumération et test. Évidemment, il existe des algorithmes qui ont de bien meilleures performances en pratique (qui utilisent des heuristiques et des raisonnements qui permettent de traiter des graphes plus gros) mais ces algorithmes ont toujours des temps d’exécution qui croissent de façon exponentielle par rapport au nombre de sommets.
La question pratique qui se cache derrière la question « P≠NP ? » est : Existe-t-il un algorithme efficace pour rechercher une clique de k sommets dans un graphe ?
Autrement dit : est-ce parce que nous ne sommes pas malins que nous n’arrivons pas à résoudre efficacement ce problème, ou bien est-ce parce que cela n’est pas possible ?
Il existe un très grand nombre de problèmesNP-complets, pour lesquels personne n’a réussi à trouver d’algorithme efficace. Ces problèmes interviennent dans de nombreuses applications de la vie quotidienne : faire un emploi du temps, ranger des boites rectangulaires dans un carton sans qu’il n’y ait de vide, chercher un circuit passant exactement une fois par chacun des sommets d’un graphe, etc. Pour ces différents problèmes, on connait des algorithmes qui fonctionnent bien sur des problèmes de petite taille. En revanche, quand la taille des problèmes augmente, ces algorithmes sont nécessairement confrontés à un phénomène d’explosion combinatoire.
Un point fascinant de la théorie de la complexité réside dans le fait que tous ces problèmes sont équivalents dans le sens où si quelqu’un trouvait un jour un algorithme efficace pour un problème NP-complet (n’importe lequel), on saurait en déduire des algorithmes polynomiaux pour tous les autres problèmes, et on pourrait alors conclure que P = NP. La question de savoir si un tel algorithme existe a été posée en 1971 par Stephen Cook et n’a toujours pas reçu de réponse. La réponse à cette question fait l’objet d’un prix d’un million de dollars par l’institut de mathématiques Clay.
La classe des problèmes ni faciles ni difficiles (NP-intermédiaires). Le monde des problèmes NP serait bien manichéen s’il se résumait à cette dichotomie entre les problèmes faciles (la classe P) et les problèmes dont on conjecture qu’ils sont difficiles (les problèmes NP-complets). Un théorème de Ladner nous dit qu’il n’en est rien : si la conjecture P≠NP est vérifiée, alors cela implique nécessairement qu’il existe des problèmes de NP qui ne sont ni faciles (dans P) ni difficiles (NP-complets). Ces problèmes sont appelés NP-intermédiaires. Notons que le théorème ne nous dit pas si P est différent de NP ou pas : il nous dit juste que si P≠NP, alors il existe au moins un problème qui est NP-intermédiaire… sans nous donner pour autant d’exemple de problème NP-intermédiaire. Il faudrait donc réussir à trouver un problème appartenant à cette classe pour démontrer que P≠NP. On dispose d’une liste (assez courte) de problèmes candidats (voir par exemple https ://en.wikipedia.org/wiki/NP-intermediate)… et c’est là que l’isomorphisme de graphes entre en jeu.
Que savait-on sur la complexité de l’isomorphisme de graphes jusqu’ici ?
Nous pouvons facilement vérifier que deux graphes sont isomorphes dès lors qu’on nous fournit une correspondance préservant les arêtes (comme nous l’avons fait précédemment pour les graphes G1 et G2). On peut donc facilement vérifier les solutions, nous sommes dans la classe NP. Mais sa complexité exacte n’est pas (encore) connue. Des algorithmes efficaces (polynomiaux) ont été trouvés pour des cas particuliers, les plus utilisés étant probablement pour les arbres (des graphes sans cycle) et les graphes planaires (des graphes qui peuvent être dessinés sur un plan sans que leurs arêtes ne se croisent). Dans le cas de graphes quelconques, les meilleurs algorithmes connus jusqu’ici ont une complexité exponentielle. Pour autant, personne n’a réussi à démontrer que le problème est NP-complet.
Il est donc conjecturé que ce problème est NP-intermédiaire. C’est même sans aucun doute le candidat le plus célèbre pour cette classe, d’une part parce qu’il est très simple à formuler, et d’autre part parce qu’on le retrouve dans de nombreux contextes applicatifs différents.
Que change l’annonce de Babai ?
L’annonce de Babai n’infirme pas la conjecture selon laquelle le problème est NP-intermédiaire, car son nouvel algorithme est quasi-polynomial, et non polynomial.
Plus exactement, pour les matheuses et les matheux, si les graphes comportent n sommets, alors le temps d’exécution de l’algorithme croît de la même façon que la fonction 2log(n)c où c est une valeur constante. Si c est égal à 1, alors l’algorithme est polynomial. Ici, c est supérieur à 1, de sorte que l’algorithme n’est pas polynomial, mais son temps d’exécution se rapproche plus de ceux d’algorithmes polynomiaux que de ceux d’algorithmes exponentiels.
Ce résultat est une avancée majeure parce qu’il rapproche le problème de la classe P, mais aussi parce que l’existence de cet algorithme quasi-polynomial ouvrira peut être une piste pour trouver un algorithme polynomial, ce qui permettrait d’éliminer le problème de la courte liste des problèmes dont on conjecture qu’ils sont NP-intermédiaires. Notons que le dernier problème qui a été enlevé de cette liste est le problème consistant à déterminer si un nombre entier donné est premier, pour lequel un algorithme polynomial a été trouvé en 2002.
D’un point de vue purement pratique, en revanche, cette annonce risque fort de ne pas changer grand chose quant à la résolution du problème, car on dispose déjà d’algorithmes performants : ces algorithmes sont capables de le résoudre pour la très grande majorité des graphes, et n’ont un temps d’exécution exponentiel que pour très peu de graphes.
De l’annonce au résultat établi. Le résultat de Babai en est encore au stade de l’annonce. Il faut maintenant qu’il soit détaillé dans un ou plusieurs articles, vérifiés par ses pairs, puis publiés dans des journaux. Ce résultat viendra alors grandir le corpus des vérités scientifiques établies. Il peut arriver que lors de ce cheminement, on trouve des « trous » dans la démonstration ; c’est arrivé pour le théorème de Fermat et ils ont été comblés. Il se peut aussi qu’on trouve une erreur dans la démonstration (y compris après la publication de l’article) ce qui renvoie les scientifiques à leurs tableaux noirs .
Pour un exemple d’algorithme pratique, l’algorithme Nauty 4 introduit en 1981 par Brendan McKay.
László Babai, né le 20 juillet 1950 à Budapest, est un professeur de mathématiques et d’informatique hongrois, enseignant actuellement à l’université de Chicago. Il est connu pour les systèmes de preuve interactive, l’introduction du terme « algorithme de Las Vegas » et l’utilisation de méthodes de la théorie des groupes pour le problème de l’isomorphisme de graphes. Il est lauréat du prix Gödel 1993. Wikipedia (2016).
Montée du niveau des mers, érosion côtière, perte de biodiversité… Les impacts sociétaux de ces bouleversements dus au réchauffement climatique ne seront pas dramatiques dans un futur proche si et seulement si nous changeons radicalement nos comportements collectifs et individuels et mettont en place de vraies solutions.
Joanna Jongwane
L’informatique et les mathématiques appliquées contribuent à relever le défi de la transition énergétique, pour changer par exemple l’usage des voitures en ville ou encore pour contrôler la consommation d’énergie dans les bâtiments. A contrario, quand la nature et la biodiversité inspirent les informaticiens, cela aboutit à des projets d’écosystèmes logiciels qui résistent mieux à divers environnements.
Accéder au dossier
C’est sur Interstices, la revue de culture scientifique en ligne qui invite à explorer les sciences du numérique, à comprendre ses notions fondamentales, à mesurer ses enjeux pour la société, à rencontrer ses acteurs que chercheuses et chercheurs nous proposent de découvrir quelques grains de science sur ces sujets. Morceaux choisis :
Accéder au document
«Le niveau des mers monte, pour différentes raisons liées au réchauffement climatique. Les glaciers de l’Antarctique et du Groenland, qu’on appelle calottes polaires ou inlandsis, jouent un rôle majeur dans l’évolution du niveau des mers. Peut-on prévoir l’évolution future de ces calottes polaires et en particulier le vêlage d’icebergs dans l’océan ?»
Accéder au document
«À l’heure de la COP21, toutes les sonnettes d’alarme sont tirées pour alerter sur l’urgence climatique. Si les simulations aident à prédire les évolutions du climat, elles peuvent aussi être vues comme un outil de dialogue science-société, selon Denis Dupré. On en parle avec lui dans cet épisode du podcast audio.»
Accéder au document
«Si au lieu de distribuer des millions de copies identiques, les fabricants de logiciels avaient la possibilité de distribuer des variantes, et que ces variantes avaient la possibilité de s’adapter à leur environnement, ces « écosystèmes logiciels » ne pourraient-ils pas renforcer la résistance de tous les services qui nous accompagnent au quotidien ?»
Extraits d’Interstices, Joanna Jongwane, Rédactrice en chef d’Interstices et Jocelyne Erhel, Directrice de Recherche et Responsable scientifique du comité éditorial, avec Christine Leininger et Florent Masseglia membres du comité exécutif.
Parmi les grandes familles d’approches et de langages informatiques, on entend parfois parler de « programmation par contraintes ». Un chercheur du domaine vous expliquerait peut-être que « c’est un paradigme de programmation déclarative permettant de traiter des problèmes fortement combinatoires ». Euh… Heureusement, Binaire a son joker : une enseignante-chercheure Charlotte Truchet, spécialiste du domaine, qui sait expliquer ses recherches. Thierry Viéville.
Photo de www.picturalium.com CC-BY
Venez, je vous emmène visiter la boutique de Denis, fleuriste dans un petit village, un beau matin de printemps. Denis vend des fleurs à l’unité, et des bouquets. Comme c’est le printemps, il a ce matin un beau stock de fleurs fraîches, disons : bégonias, marguerites, roses, hortensias et pissenlits. Chaque fleur a des caractéristiques différentes (certaines fleurs sont par exemple associées à des occasions particulières), un standing différent (qui influence le prix), une couleur, etc.
Le matin, à l’ouverture, Denis prépare des bouquets tout prêts pour les clients pressés. Attention, l’exercice est délicat, il ne peut pas faire n’importe quoi. D’abord, il ne peut pas utiliser plus de fleurs qu’il n’en a en stock. Ensuite, il a des goûts : Denis aime bien l’association bégonia-rose, mais il n’aime pas les bouquets mélangeant des pissenlits et des marguerites, il préfèrerait fermer boutique plutôt que vendre de telles horreurs. Et puis, il doit faire tourner son commerce, et pour cela, il doit vendre ses bouquets à un bon prix, qui dépend des marges qu’il réalise sur chaque fleur du bouquet. Bref, Denis se trouve devant un problème compliqué : comment composer ses bouquets, en tenant compte de ses goûts, ses stocks et ses coûts ?
Il pourrait faire ses bouquets au petit bonheur, un peu au hasard, mais il rencontre un problème. Un phénomène tragique l’attend au tournant : l’explosion combinatoire. Un bien grand mot pour dire que le nombre de bouquets possibles est gigantesque, le nombre de possibilités à considérer dépasse l’entendement du pauvre Denis. Imaginons que Denis ait en stock 10 bégonias, 20 marguerites, 15 roses, 5 hortensias et 30 pissenlits. Il peut mettre dans son bouquet : 1 bégonias et rien d’autre, 2 bégonias et rien d’autre, … et ainsi de suite jusqu’à 10 bégonias et rien d’autre. Puis il attaque la série de bouquets avec seulement des marguerites (20 possibilités), seulement des roses (15 possibilités), etc. Ensuite, il commence à associer des fleurs : 1 bégonia, 1 rose et rien d’autre, 1 bégonia et 2 roses, etc : encore un sacré paquet de possibilités, 62496 exactement. Et on est encore loin du compte ! Bref, le nombre de possibilités est vraiment très grand, même pour un seul bouquet (11*21*16*6*31-1 soit environ 680 000). Mais surtout, ce nombre augmente de façon catastrophique dès que l’on augmente le nombre de bouquets : pour deux bouquets, on a 680 000 au carré possibilités, soit environ 470 milliards, pour trois bouquets, 680 000 au cube que je n’ai même pas envie de calculer, etc. C’est la catastrophe (et le « fortement combinatoire » de la phrase du chercheur). Pauvre fleuriste en ce triste matin de printemps !
Vous me direz, taratata, mon fleuriste fait des bouquets tous les jours, et il n’en fait pas un plat. C’est vrai : en fait, Denis n’a pas besoin d’essayer toutes les possibilités, et c’est ce qui le sauve. Il sait que certaines possibilités sont impossibles pour des raisons diverses. Ce que faisant, il raisonne sur les contraintes de son problème : stocks, goûts et coûts. Par exemple, Denis veut gagner de l’argent, et on peut supposer que les bouquets plus variés se vendent plus chers : Denis évite donc les bouquets monofleurs, ce qui élimine déjà 10 + 20 + 15 + 5 + 30 possibilités. C’est une petite simplification, mais elle est gratuite à opérer, donc elle fait gagner du temps. De même, il n’aime pas la combinaison pissenlits-marguerites. Si on interdit la présence de ces deux fleurs simultanément, on économise 630 000 possibilités ! Avant de crier victoire, remarquons qu’il en reste encore plus de 50 000. Mais tout de même, c’est un pas de géant. Denis n’a donc pas besoin d’essayer toutes les possibilités : il fait des bouquets guidé par son intuition. Ce type de raisonnement, qui permet d’éliminer des possibilités parce qu’elles sont à l’évidence inutiles dans le problème, est au cœur de la programmation par contraintes.
La programmation par contraintes consiste à faire des beaux bouquets dans un monde assez similaire à la boutique de Denis, mais un peu plus formel. On travaille sur des problèmes avec des inconnues, les variables : ici, le nombre de chaque fleur par bouquet. On ne sait pas combien valent ces variables, justement, c’est ce que l’on cherche. Cela dit, ces variables doivent rester dans un ensemble donné : de même qu’on sait qu’il y a 15 roses en stock (donc le nombre de roses dans chaque bouquet est entre 0 et 15), chaque variable vient avec un domaine de valeurs possibles. Si on note R1 le nombre de roses dans le premier bouquet, on appelle domaine de R1 l’ensemble des entiers entre 0 et 15.
Enfin, on écrit des contraintes sur les variables. Supposons pour simplifier que Denis se contente de deux bouquets, car son échoppe est modeste. D’abord, il faut s’assurer qu’il ne dépense pas plus que ses 15 roses en stock : cela se formalise avec une contrainte R1+R2<= 15, et de même pour les bégonias, pissenlits, marguerites et hortensias. Ensuite, Denis peut ajouter des contraintes en fonction de ses envies. Comme il déteste l’association marguerites-pissenlits, il peut écrire : M1*P1=0, ce qui force au moins l’une des deux valeurs à être nulle. S’il aime bien les roses et les bégonias, il peut imposer d’en avoir un minimum dans son gros bouquet : par exemple, R1>5 et B1>5. Et ainsi de suite. Les coûts aussi peuvent être écrits avec une formule similaire, en soustrayant au prix du bouquet la somme des prix de chaque fleur.
Ce que l’on appelle contrainte, c’est une formule construire comme cela, à partir des variables du problème et avec des formules mathématiques. Il y a mille et une façons d’écrire ces formules, c’est une étape importante et difficile que l’on appelle « modélisation du problème ». On obtient un problème de satisfaction de contraintes (souvent abrégé en CSP, pour Constraint Satisfaction Problem en anglais) : le problème formalisé avec des variables, des domaines et des contraintes. Résoudre le problème, c’est faire un bouquet, ou encore trouver pour chaque variable une valeur de son domaine telle que les contraintes soient vraies.
Au lieu de réfléchir, Denis pourrait utiliser un solveur de contraintes, c’est-à-dire un programme qui résout pour lui le CSP des bouquets, un programme qui sait résoudre de tels problèmes en général. Un solveur de contraintes commence par procéder à un raisonnement sur les contraintes pour éliminer des valeurs inutiles dans les domaines : par exemple, la contrainte R1>5 permet d’éliminer 0,1, 2, 3 et 4 du domaine de R1. En général, cela ne suffit pas à résoudre le problème, il reste encore de nombreuses possibilités. Alors, le solveur devient « bourrin » : il fait des essais. Il donne une valeur à une variable (il commence un bouquet avec 1 rose), il re-raisonne un petit coup et si ça ne suffit pas, il continue (il ajoute des bégonias), etc. Un solveur alterne ainsi des étape de raisonnement et des étapes de commencements de bouquets, ce que l’on appelle instanciation. S’il s’avère que le bouquet commencé est mauvais, et qu’on n’arrive pas à le compléter correctement (par exemple, si on a commencé avec 1 marguerite et 1 pissenlit), le solveur trouve un échec : il revient en arrière, enlève le nombre de fleurs qu’il faut (il enlève le pissenlit) et ré-essaie autrement (avec 0 pissenlits).
Bref, un solveur de contraintes commence des tonnes de bouquets et finit bien par un trouver un qui convienne. Si le problème a une solution, il la trouve. S’il n’en a pas, il le prouve, ce qui est toujours bon à savoir : Denis est trop exigeant, voilà tout. Il faut qu’il reconsidère ses contraintes.
Il reste encore des choses à noter dans l’échoppe de Denis.
D’abord, à aucun moment, Denis n’a réfléchi à une méthode de résolution pour son problème. Il s’est contenté de décrire ce qu’il voulait, et se moque bien de savoir comment le solveur travaille. C’est ce que l’on appelle de la programmation déclarative dans le jargon informatique. C’est assez rare en informatique (pas le jargon, la programmation déclarative). En programmation, en général, il faut construire un algorithme qui arrive à obtenir le résultat voulu. Ici, ce n’est pas la peine, et c’est très pratique pour Denis, qui n’y connaît rien en algorithmique.
Ensuite, quand j’ai dit que le fleuriste pouvait écrire des formules pour décrire les bouquets, je vous ai arnaqués ! En informatique, pour pouvoir écrire une formule, il faut savoir dans quel langage, sinon on écrit n’importe quoi. Ainsi Denis a le droit d’écrire R1>5 mais il n’aurait pas le droit d’écrire R1/(bleu vif)+(il existe une herbe verte)=beaucoup de tune. En fait, il existe des langages de contraintes que l’on sait traiter et Denis doit s’y tenir. La plupart des solveurs de contraintes autorisent des langages assez proches les uns des autres. On a le droit aux formules mathématiques basiques, construites avec des nombres, des opérations comme +, -, *, etc, et des prédicats comme =, <, /=. Et, on a aussi le droit d’utiliser des contraintes « prêtes à l’emploi », faites sur mesure par les chercheurs pour faciliter la vie de Denis. On les appelle contraintes globales. Elles sont recensées dans un grand catalogue qui en compte plus de 350 (http://sofdem.github.io/gccat/gccat/sec5.html). N’hésitez pas à aller les visiter, c’est un peu austère mais vous aurez sous vos yeux l’état de l’art de la recherche sur les contraintes globales !
choco-solver.org est un solveur de contrainte libre et dont le code est ouvert
La plus célèbre et la plus couramment utilisée des contraintes globales est certainement celle que l’on appelle alldifferent. Pour la comprendre, il faut imaginer qu’un jour, Denis se réveille d’humeur fantasque. En ce beau matin de printemps, il se dit : j’en ai assez de faire des bouquets ennuyeux avec 6 bégonias et 6 roses. Ça tombe mal dans le vase. Aujourd’hui, j’ai envie de bouquets bizarres, étonnants, asymétriques. Aujourd’hui, je veux des compositions avec un nombre différent de chaque fleur ! Le malheureux perd un peu la boule, si vous voulez mon avis, mais on n’y peut rien.
Il se met donc à composer des bouquets où il est interdit d’avoir autant de roses que de bégonias, autant de bégonias que de marguerites, etc. Essayons d’y réfléchir. Ce matin là, il lui reste 3 camélias, 2 bégonias, 25 tulipes, 7 poinsettias et 2 hortensias. Il veut faire un gros bouquet avec un peu de chaque fleur (C>0, B>0, etc). Comme il n’a que 2 bégonias et 2 hortensias, il peut déduire qu’il doit forcément mettre dans son bouquet exactement 3 camélias, et au moins 3 tulipes et poinsettias. En effet, s’il met 1 bégonia, il est obligé de mettre 2 hortensias (donc plus de trois des autres fleurs). De même, s’il met 1 hortensia, il doit mettre 2 bégonias et rebelote (plus de trois des autres fleurs). Dans tous les cas, il doit mettre au moins 3 camélias et au plus 3 camélias (car il n’en a pas plus en stock), donc exactement 3 camélias, et plus de 4 tulipes et poinsettias.
Voilà qui aide grandement ! On élimine d’un seul coup beaucoup de possibilités, on trouve même directement le bon nombre de camélias ! Même si l’exemple choisi ici est simple, il faut imaginer qu’on pourrait appliquer le même raisonnement pour des nombres beaucoup plus grands. Il faut bien voir que pour trouver cette simplification, Denis a dû cette fois raisonner sur toutes les fleurs en même temps. C’est le principe d’une contrainte globale : elle exprime une propriété globale sur plusieurs variables en même temps, soit pour raisonner plus efficacement, soit pour exprimer des propriétés plus complexes que le langage basique sus-cité. Une contrainte globale embarque sa propre méthode de déduction, qui est utilisée directement par le solveur.
Les questions explorées par les chercheurs en contraintes sont évidemment nombreuses et dépassent parfois un peu le cadre de la boutique du fleuriste, mais elles tournent tout de même beaucoup autour de l’organisation du procédé décrit plus haut : comment bien modéliser un problème ? Comment rendre la résolution efficace ? Comment bien programmer le solveur ? Peut-on le rendre interactif ? Peut-on écrire des contraintes un peu subtiles, pour exprimer par exemple des préférences ? Et cætera.
Quant aux applications, elles sont assez variées. Une contrainte comme alldifferent écrit par Denis porte sur des fleurs, mais elle aurait aussi bien pu porter sur des avions (à ranger dans un aéroport), des fréquences (à placer dans une bande radio), des régions limitrophes (à colorier sur une carte), des notes de musique (à organiser harmonieusement sur une partition), des cartons de formes diverses (à ranger dans un container), des enseignements (à placer dans des emplois du temps), etc. On trouve donc la programmation par contraintes, avec ses cousins comme la programmation linéaire en nombres entiers, les métaheuristiques, l’optimisation linéaire ou non-linéaire, etc, dans beaucoup d’applications où le nombre de variables est très grand comme la logistique ou l’ordonnancement de tâches. Mais sa nature déclarative (qui permet de fabriquer des langages à destination de non-informaticiens) la tourne aussi vers des applications moins informatico-centrées, comme en médecine, musique, visualisation, graphisme, biologie, urbanisme, etc.
Charlotte Truchet, Université de Nantes
@chtruchet
La semaine prochaine, du 14 au 21 novembre, se déroule le concours Castor informatique ! L’édition 2014 avait touché plus de 220 000 élèves ! L’édition Française est organisée par l’association France-ioi, Inria et l’ENS Cachan, grâce à la contribution de nombreuses personnes. Ce concours international est organisé dans 36 pays. Plus de 920 000 élèves ont participé à l’épreuve 2014 dans le monde.
Les points à retenir, le concours est :
entièrement gratuit ;
organisé sur ordinateur ou sur tablette sous la supervision d’un enseignant ;
il dure 45 minutes ;
entre le 14 et 21 novembre 2015, à un horaire choisi par l’enseignant ;
avec une participation individuelle ou par binôme ;
aucune connaissance préalable en informatique n’est requise.
Nouveautés 2015 :
Ouverture aux écoles primaires : le concours est désormais ouvert à tous les élèves du CM1 à la terminale !
Niveau adaptable : chaque défi est interactif et se décline en plusieurs niveaux de difficultés pour accommoder les élèves de 9 à 18 ans.
Il est encore temps de s’inscrire pour les enseignants (vous pouvez le faire jusqu’au dernier jour, même si nous vous conseillons d’anticiper).
En attendant, ou si vous n’êtes plus à l’école, vous pouvez vous amuser à tester les défis des années précédentes depuis 2010, et en particulier les défis interactifs de 2014 !
Une blague d’informaticiens que vous ne comprenez pas ?
Un T-shirt de geek incompréhensible ?
Binaire vous explique (enfin) l’humour des informaticien(ne)s !
Quelle est la différence entre Halloween et Noël ? Il n’y en a pas, car Oct 31 = Dec 25.
Les nombres entiers peuvent s’écrire en base 10 (c’est la façon usuelle pour les humains), en base 2 (c’est la façon usuelle pour les ordinateurs), ou en une autre base. C’était d’ailleurs un exercice classique en primaire il y a quelques décennies. Nous avons encore l’habitude de la base 60 en considérant les heures/minutes/secondes: 90 minutes correspondent à 1 heure et 30 minutes.
Citrouille d’Halloween, par 663highland (CC-BY-SA-3.0)
Revenons à la blague qui repose sur un changement de base.
« Dec 25 » signifie le nombre 25 interprété en décimal (base 10) donc 2×10+5. Il s’agit donc du 25 usuel.
« Oct 31 » signifie le nombre 31 interprété en octal (base 8). Il vaut donc 3×8+1=24+1=25. Il correspond donc au 25 usuel en décimal.
Les deux valeurs, interprétées comme des nombres avec l’indication de la base pour les représenter, sont donc égales. Vous pourrez dorénavant déposer une citrouille au pied du sapin !
Les équipes de recherche en informatique et leurs enseignants-chercheurs participent régulièrement à des séminaires. Ils sont sur le cœur du métier informatique et constituent un élément important de la démarche scientifique des chercheurs. Le but ici n’est pas de parler de ces séminaires mais de ceux organisés et animés aussi par des chercheurs, pas obligatoirement en informatique d’ailleurs, mais dans d’autres disciplines qui s’intéressent à l’informatique. Pierre Paradinas
Histoire de l’informatique
Le séminaire d’histoire de l’informatique a pour objectif de présenter et conserver la mémoire des travaux pionniers de l’informatique. Les intervenants sont soit les acteurs des débuts de cette discipline, soit des chercheurs s’intéressant aux développements de l’informatique dans l’industrie, l’économie, la recherche ou la société civile. Il est co-organisé par Francois Anceau, ancien professeur du Cnam, Pierre-Eric Mounier-Kuhn, historien, CNRS, Paris-Sorbonne et Isabelle Astic, responsable de collections au Musée des arts et métiers. Il a été initié dans le cadre du projet « Vers un musée de l’informatique et du numérique », vous pouvez accéder en ligne aux présentations sur le site du #MINF.
Le code objet de la pensée informatique
Histoire et philosophie de l’informatique
Le séminaire Histoire et philosophie de l’informatique, interroge sur « qu’est-ce que l’informatique ? » qui n’est pas seulement une question de philosophe ou d’historien cherchant à comprendre les concepts et les tensions que recouvre cette catégorie. La question se pose aussi, ce qui est plus rare, dans le champ scientifique, aux acteurs de ce domaine d’activité dont l’identité semble encore en devenir, cinquante-deux ans après l’invention du mot « informatique ». Ce séminaire réunit des informaticiens, des historiens, des spécialistes des sciences sociales et des philosophes, il est organisé par Maël Pégny (IHPST-CNRS), Baptiste Mélès et Pierre-Eric Mounier-Kuhn.
Interactions entre logique, langage et informatique. Histoire et Philosophie
Le but du séminaire Interactions entre logique, langage et informatique. Histoire et Philosophie est de penser les relations entre la logique, l’informatique et la linguistique. Pourquoi a-t-on besoin de la logique pour l’avancement de l’informatique et quel est le rôle de la linguistique ? Ce séminaire est organisé par Liesbeth De Mol (CNRS/STL, Université de Lille 3), Alberto Naibo (IHPST, Université Paris 1 Panthéon-Sorbonne, ENS), Shahid Rahman (STL, Université de Lille 3) et Mark van Atten (CNRS/SND, Université Paris-Sorbonne).
Cette liste n’est pas exhaustive, vous participez ou vous animez un séminaire qui est en lien avec l’informatique, n’hésitez pas à nous faire part des informations complémentaires.
Pierre Paradinas, Professeur titulaire de la chaire Systèmes Embarqués au Cnam
En préparant cet article, je n’ai pu m’empêcher de repenser à nos professeurs d’informatique de l’Université de Lille 1 – peu nombreux à l’époque – qui en 1983 nous avaient obligé à nous rendre dans une université voisine pour aller écouter un séminaire où intervenaient Jacques Arsac et Marcel-Paul Schützenberger. La présentation de ce dernier portait sur La métaphore informatique (disponible dans Informatique et connaissance, pages 45–63. UER de philosophie, Université Charles de Gaulle Lille III, 1988. Conférence en novembre 1983). Si vous vous demandez qu’est-ce qui peut inciter à devenir informaticien, la réponse est : en écoutant Arsac et Schütz !
Le progrès scientifique, la diffusion des sciences, reposent sur le langage. C’est pourquoi les mots ont tellement d’importance en sciences. C’est le cas aussi en informatique, une science naissante qui repose sur un vocabulaire forgé récemment et en évolution permanente. Un historien des sciences, Pierre Mounier-Kuhn revient pour Binaire sur la genèse de mots essentiels comme code ou langage. Serge Abiteboul et Gilles Dowek.
L’historien Mathias Dörries a noté que les scientifiques, quand une métaphore leur vient à l’esprit, ne se contentent pas de l’employer comme outil expressif : ils la poussent au bout de ses implications pour explorer toute sa valeur heuristique. C’est précisément ce que l’on observe en étudiant l’émergence de la notion de langage en programmation. Je la résumerai d’abord en évoquant les étapes de cette évolution dans le petit milieu des proto-informaticiens français aux temps héroïques des ordinosaures, puis en nous portant sur la scène internationale.
En novembre 1949, le fondateur d’une start-up abritée dans une ancienne usine automobile bombardée à Courbevoie, la Société d’électronique et d’automatisme (SEA), rédige un rapport interne qui constitue le premier projet d’ordinateur en France. En résulte aussitôt un contrat de recherche avec le bureau des missiles de l’Armée de l’Air. Cette synthèse des réflexions de François-Henri Raymond et de son équipe décrit brièvement l’architecture d’un ordinateur, donne le tableau des « codes d’ordre » de von Neumann prévus pour l’EDVAC de Princeton, et fournit un exemple d’application mathématique. Du point de vue de la programmation, il ne parle que de coding et de code, défini comme « la suite des ordres précis telle qu’elle se trouve enregistrée en mémoire. »
L’EDVAC installé au bâtiment 328 du Ballistics Research Laboratory. Wikipedia
Quelques années plus tard, en 1955, la SEA installe ses premiers ordinateurs chez des clients. Dans une série d’articles destinés aux ingénieurs, le chef d’entreprise explique leurs principes et leur fonctionnement, insistant sur leur nouveauté : on doit les considérer non seulement comme des calculatrices, mais comme des systèmes conçus pour traiter des programmes ; non plus comme des machines, mais comme des automates. Raymond explique que le principe même de machine universelle fonctionnant en binaire implique « une traduction entre notre langage et le sien. » Et, filant la métaphore linguistique, il décrit le symbolisme permettant d’exprimer un processus de calcul comme « une convention d’écriture, qui constitue une règle de la grammaire du langage fonctionnel de la machine ». L’année suivante, dans un congrès à Milan, il parle à nouveau de ces « conventions de langage » qui permettent la « programmation automatique », laquelle revient à « un problème de traduction automatique ».
Tandis qu’IBM apporte Fortran à Paris en 1957, la SEA élabore son propre langage de programmation, PAF (Programmation Automatique des Formules), présenté en 1960. C’est d’emblée un langage conversationnel. La métaphore du langage et de la communication homme/ machine est poussée assez loin dans sa mise en œuvre technique, puisqu’il suffit de taper au clavier le début d’une formule pour que la machine la complète automatiquement : la « CAB 500 » donne à son utilisateur le sentiment qu’elle comprend même ses intentions !
CAB 2022 de la SEA, installée en 1955 chez Matra (photo SEA).
Simultanément, le CNRS et l’Armement créent un Centre d’études de la traduction automatique, où se croisent la programmation, la logique et le traitement automatique des langues. Tandis qu’un aventurier français de la recherche mathématique, Marcel-Paul Schützenberger, écrit avec le linguiste américain Noam Chomsky un article qui apporte un éclairage théorique à la programmation et jette les bases de la linguistique computationnelle. Ce rapprochement est manifeste avec la création, dès 1963-1964, des premiers Instituts universitaires de programmation, à Paris et à Grenoble, où les théories du langage ont d’emblée leur place dans l’enseignement.
Comment l’informatique est-elle ainsi passée du codage au langage ? Au-delà du cas français que je viens d’évoquer, un groupe d’historiens fédérés dans un projet européen s’est plongé dans les archives et dans les mémoires des pionniers pour comprendre ce processus. Processus décisif pour la construction de l’informatique elle-même, comme discipline et comme activité professionnelle. Et qui s’observe d’abord dans les pays pionniers : l’Angleterre et les États-Unis, puis l’Allemagne.
L’idée de machines avec lesquelles on puisse communiquer s’est répandue après la guerre. Notamment avec l’ouvrage de Norbert Wiener, Cybernetics, or Control and Communication in the Animal and the Machine (1948) et l’article d’Alan Turing, paru dans Mind en 1950, dont le fameux test décrivait un dialogue en langage naturel avec un être humain et un ordinateur. Si l’on pouvait construire des « cerveaux électroniques », le langage ne devait-il pas être un de leurs attributs ? Ces réflexions cybernétiques ouvraient des perspectives inédites, mais leur anthropomorphisme allait rapidement les éloigner des préoccupations des praticiens.
J. et J. Poyen, Le Langage électronique (1963)
Si dès 1947 apparaît aux États-Unis le terme « langage machine » pour désigner le code binaire traité par les circuits électriques des grands calculateurs, c’est le mot code ou codage qui domine. Et, pendant des années, chaque ordinateur aura son système de codage particulier, développé localement par son équipe de programmeurs. Ce qui ne présente guère d’inconvénients tant que ces machines sont peu nombreuses – il en existe au plus 200 dans le monde en 1955. Les améliorations consistent à développer des autocodes, déchargeant le programmeur de tâches routinières comme la traduction de formules algébriques en langage machine. Le résultat le plus abouti est la première version de ForTran, présentée en 1954 sur l’IBM 704.
Les changements vont être impulsés par une convergence d’intérêts et de projets très divers. Le premier est d’ordre économique, lié à la croissance rapide du parc d’ordinateurs. Dès le milieu des années cinquante, les plus gros centres de calcul, dans l’armement ou l’aéronautique, possèdent plusieurs ordinateurs de modèles différents ou commencent à remplacer leurs premiers « cerveaux électroniques » par des machines de série. Ils découvrent le coût grandissant de la re-programmation : on doit non seulement réécrire chaque programme, mais aussi former de nouveaux programmeurs aux particularités de chaque architecture, dans une tension forte entre la rareté des compétences et la pression exercée sur la R & D par les besoins de la guerre froide.
Ces grands utilisateurs commencent donc à imaginer des techniques de programmation communes. IBM soutient cette tendance, comprenant que l’inflation incontrôlée des charges du software dissuaderait les clients d’acheter des matériels ; la mise au point de Fortran est un élément de solution. En mai 1954, lors d’un symposium sur les techniques de programmation automatique organisé par l’Office of Naval Research, plusieurs mathématiciens (Saul Gorn, John Carr, etc.) exposent leurs expériences : élaborer un « code universel » ou un « universal computer language », appuyé sur des méthodes de conception utilisant des schémas normalisés (ordinogrammes ou flowcharts), indépendants des modèles particuliers de machines, permettrait à la fois de maîtriser les coûts, d’améliorer la lisibilité et la qualité des programmes. Et de proposer aux étudiants des cours de programmation qui ne se limiteraient pas à des « recettes de cuisine ».
S’y ajoute une motivation politique. Ces universitaires voient dans un futur langage universel (« commun », précise-t-on souvent) un moyen d’échapper à l’emprise grandissante des constructeurs d’ordinateurs. Et de conserver la libre circulation des idées au sein des communautés de chercheurs, dans l’Université comme dans l’Armement.
En 1955 un autre mouvement s’amorce dans le même sens : les clubs d’utilisateurs. Les utilisateurs commencent à s’organiser en groupes spécialisés par type d’ordinateurs. Leur principale activité consiste à échanger, à mettre en commun des programmes et des techniques de programmation, à établir des standards qui transcendent les particularismes locaux. La tâche se complique d’autant que commencent à se multiplier les langages adaptés à chaque famille d’application.
C’est dans ce contexte que sont initiés quatre projets. Inspirée par les travaux d’Alan Perlis sur la compilation, IBM s’appuie sur son groupe d’utilisateurs SHARE pour rendre Fortran utilisable sur ses différents calculateurs scientifiques. Le groupe d’utilisateurs d’Univac, USE, imagine un supra-langage qui faciliterait l’échange de bibliothèques de programmes, et qui inspire un projet similaire de l’US Army. Le Department of Defense réunit un comité pour définir un Common business-oriented language (Cobol). Enfin plusieurs organisations s’associent pour élaborer un « langage intermédiaire », entre les langages d’application et les codes machines ; ce Universal computer-oriented language (Uncol) serait plus économique, espère-t-on, que le développement d’un compilateur pour chaque langage d’application. Cette usine à gaz linguistique sera enterrée en 1961, tandis que Cobol et Fortran décolleront sur des trajectoires durables. Mais tous ces efforts installent progressivement l’idée que la programmation peut être pensée en elle-même, sans lien avec un matériel spécifique.
Instruction Fortran ORTRAN sur une carte perforée. Wikipedia
Entre temps, des sociétés savantes se sont attaquées au problème. L’Association for computing machinery (ACM) crée en 1957 un comité des langages. Elle est contactée par la société allemande de Mécanique et Mathématiques appliquées (GAMM), en vue de définir un langage scientifique commun. Démarche bien naturelle : les mathématiciens sont habitués à une représentation traditionnelle des mathématiques en termes linguistiques, comme « langage de la Nature », comme « grammaire de la Science », puis au XXe siècle comme un système symbolique formel. Rapidement le projet emprunte donc les chemins bien balisés de l’internationale des mathématiciens.
Ce projet Algol (Algorithmic Language) reflète aussi leurs valeurs : universalité, rigueur dans l’expression, définition in abstracto indépendamment des contingences matérielles. Il vise deux objectifs : être à la fois un langage utilisable sur tout ordinateur et un moyen rigoureux d’expression et de communication des algorithmes. Présenté en 1959 à Paris au premier congrès international de traitement de l’information, il est spécifié l’année suivante sous le nom Algol 60, et devient un véritable programme de recherches en même temps qu’un outil de programmation. Pour la première fois, un langage informatique est défini formellement : l’auteur du Fortran, John Backus, et le Norvégien Peter Naur inventent une notation qui porte leurs noms (Backus-Naur Form, BNF), permettant de décrire les règles syntaxiques des langages. La programmation devient une discipline scientifique. Cinq ans plus tard, deux des acteurs centraux de cette histoire, John Carr et Saul Gorn, décideront de créer un prix pour couronner d’éminents travaux dans cette spécialité en rendant hommage à la mémoire d’un pionnier tombé dans l’oubli : Alan Turing.
Pierre Mounier-Kuhn, Historien, CNRS et Université Paris-Sorbonne.
Pour aller plus loin,
[1] Pierre Mounier-Kuhn, « L’Informatique en France de la seconde guerre mondiale au Plan Calcul. L’Émergence d’une science », Presses de l’Université Paris-Sorbonne, 2010.
[2] Le projet européen « Soft-EU » a rassemblé pendant quatre ans une douzaine d’historiens venus des deux côtés de l’Atlantique. Je résume ici l’article de D. Nofre, M. Priestley et G. Alberts, « When Technology Became Language: the Origins of the Linguistic Conception of Computer Programming », Technology and Culture, 55, 1 (2014):40-75.
[3] P. Mounier-Kuhn, « Les clubs d’utilisateurs : entre syndicats de clients, instruments marketing et logiciel libre avant la lettre”, Entreprises et Histoire, décembre 2010, vol. 60, n° 3, p. 158-169. http://www.cairn.info/resume.php?ID_ARTICLE=EH_060_0158.
Depuis 24 ans maintenant, durant toute une semaine, la science est à la fête partout en France. Avec plus d’un million de visiteurs, 7000 chercheurs impliqués et un foisonnement d’animations, d’expositions, de débats et d’initiatives originales, partout en France et pour tous les publics, la Fête de la science est une occasion de découvrir le monde des sciences et de rencontrer des scientifiques. Les sciences du numérique ne sont pas en reste, avec les multiples initiatives proposées par les établissements de recherche comme par exemple celles du CNRS et ou celles d’Inria que Marie-Agnès Enard a choisi de vous inviter à découvrir.
Dans le cadre du Circuit scientifique bordelais, les structures d’enseignement supérieur et de recherche et leurs laboratoires ouvrent leurs portes du 5 au 9 octobre, en proposant des ateliers ludiques aux élèves du primaire à l’université. C’est l’occasion de venir découvrir le monde passionnant de la recherche et les activités des scientifiques dans de nombreuses disciplines. Au centre Inria Bordeaux – Sud-Ouest, chercheurs et ingénieurs accueilleront les élèves de tous les niveaux et de toute l’académie pour leur transmettre leur passion pour les sciences du numérique. Pour vous inscrire, suivez le lien.
Inria Grenoble ouvre ses portes aux lycéens les 8 et 9 octobre pour une immersion dans le monde des sciences du numérique. Au programme : parcours de visite augmentée du centre de recherche, découverte de plateformes d’expérimentations, habitat intelligent, capture et modélisation de formes en mouvement, initiation aux notions de l’informatique par des activités ludiques sans ordinateurs, cryptologie et protection de messages, dialogue avec les scientifiques sur des problématiques de société.
Les scientifiques du centre de Lille interviendront dans les établissements scolaires (collèges et lycées) de la Métropole lilloise, du lundi 05 au vendredi 16 octobre 2015. Au programme : réalité virtuelle, programmation objet, imagerie de synthèse, intelligence artificielle… un partage de connaissances sur des sujets qui les passionnent et enrichissent d’ores et déjà notre quotidien.Une manière pour nos chercheurs de communiquer sur leur métier, leurs thématiques et d’échanger avec des élèves afin d’enrichir leur perception de la recherche. Un partage de connaissances sur des sujets passionnants qui enrichissent notre quotidien.
Scientifiques et médiateurs du centre vous donnent rendez-vous sur le site d’Artem les 9 et 10 octobre prochain, pour une approche plurielle de la science, où informatique rimera avec ludique ! Au programme : robots humanoïdes, informatique sans ordinateur, jeu de société, reconnaissance d’images, envolées de drones, numérique et santé,… Manifestation co-organisée par Mines Nancy, le LORIA, l’Institut Jean Lamour et GeoRessources, avec le soutien d’Inria Nancy – Grand Est.
Le centre Paris – Rocquencourt s’associe à la fête de la science Sorbonne Universités qui souhaite mettre en avant cette année le travail des scientifiques qui étudient le climat sous tous ses aspects. Du 9 au 11 octobre, l’équipe Ange du centre vous dira tout sur la dynamique des vagues, la houle, les énergies alternatives et vous propose une conférence sur le thème : Nouvelles vagues, de la simulation numérique à la conception.
Le centre Inria Rennes – Bretagne Atlantique sera présent au Village des sciences de Rennes du vendredi 9 au dimanche 11 octobre 2015, au Diapason sur le Campus Universitaire de Beaulieu. A cette occasion, nos scientifiques vous proposeront de créer un programme sur ordinateur puis de le tester sur un robot. Plusieurs épreuves ou défis seront proposés selon trois niveaux de difficulté permettant une acquisition progressive du langage de programmation.
Le centre de recherche Inria Saclay – Ile-de-France ouvre ses portes vendredi 9 et samedi 10 octobre et invite petits et grands à la découverte des sciences du numérique au travers d’animations ludiques reflétant l’interaction entre l’informatique, les mathématiques et les autres sciences. Au programme, plusieurs ateliers animés par les chercheurs du centre : découverte des secrets de la cryptographie, bio-informatique ludique, initiation aux bases de données, introduction à la programmation et aux robots, exploration du cerveau, et plongée au cœur d’un réseau.
Les scientifiques et médiateurs du centre invitent tous les publics, petits et grands à venir découvrir les sciences du numérique au travers d’approches concrètes et ludiques. Une programmation riche et variée vous attend à Antibes Juan-Les-Pins, Montpellier et La Seyne sur Mer les 10 et 11 octobre ainsi qu’ à Vinon-sur-Verdon le 17 octobre. Au programme : Maths de la planète Terre, traitement d’images, graphes et algorithmes, manipulations, coding goûters, initiation à la robotique, jeux de société, activités débranchées, tours de magie… Du 5 au 9 octobre, les scientifiques d’Inria interviendront également dans des lycées, un moment privilégié pour dialoguer avec les jeunes et débattre sur des thématiques ciblées, mais aussi pour parler de leur métier de scientifique tel qu’ils le vivent. Enfin nos chercheurs interviendront également dans les médiathèques de la communauté d’agglomération de Sophia Antipolis.
Nous vous souhaitons une belle semaine festive et scientifique ! Vous pouvez d’ailleurs partager vos découvertes sur Twitter en suivant le compte @FeteScience et son mot-dièse #FDS2015 ou sur Facebook.
Ce n’est pas la première et probablement pas la dernière fois que les chercheurs se font insulter ou humilier dans les médias. Mais cet exemple a quelque chose de particulier : il concentre le pire en moins de 30 secondes essayons de décrypter.
Cliquer sur l’image pour avoir la citation vidéo de C dans l’air 25 septembre 2015
Voici le propos: « La recherche, juste la recherche, quand … moi qui suis [de Grenoble], il y a des centres de recherche énormes et avec des gens qui étaient nommés à vie, comment voulez vous qu’on cherche et surtout qu’on trouve pendant toute une vie, quand ils arrivent à 25 ans, 28 ans. ils sont plein d’ardeur et puis après ils vont sur les pistes de ski et dans les clubs de tennis, à Grenoble c’était comme ça, c’était tous les chercheurs qui étaient là, bien évidemment, ils sont nommés à vie, c’est terrible ça n’a pas de sens, donc y’a vraiment des domaines où on peut engager des réformes. » C dans l’air, H. Pilichowski, 25 septembre 2015.
Du journalisme du lieu commun et de la stigmatisation.
On ne prendra même pas la peine de se demander ce que la personne qui parle faisait dans les « clubs de ski » pour pouvoir constater que «tous les chercheurs» étaient là, ni quelles sont ses sources, ou les données qui étayent ses affirmations. Nous sommes dans le journalisme du lieu commun. Et ce qui est dans l’air en l’occurrence a l’odeur d’une flatulence.
Le chroniqueur a ceci de bien qu’il remplace le journalisme du radio-trottoir : plus besoin de prendre une caméra pour aller manipuler la parole du peuple de la rue en lui faisant dire en quelques secondes le lieu commun qui va faire de l’audience, le chroniqueur -dans cet exemple- le remplace haut la main.
On est forcément le métèque de quelqu’un. Et on peut saluer le fait cette attaque est tellement loin de la réalité qu’elle peine à être crédible.
Mais il y a pire.
Voleurs ! De notre liberté d’expression.
Nous sommes dans un pays libre, y compris de dire le faux. Et c’est bien. Puissions-nous ne jamais perdre ce droit fondamental.
Mais disposons-nous pleinement de notre liberté d’expression ? Nous avons la liberté de dire, certes, mais moins celle d’être entendu. Cela est vrai pour les scientifiques, mais aussi pour chacune et chacun.
Les journalistes ne se sont-ils pas accaparés notre liberté d’expression, parlant à notre place ? Le temps de parole des personnes de la société dans les médias diminuent, et des porte-parole se sont installés qui disposent de notre droit à être écouté.
Ainsi [un certain] journalisme scientifique se sent souvent obligé de faire de l’exceptionnel, de surfer d’effet d’annonce en effet d’annonce (on a eu le dépassement de la vitesse de la lumière, les robots qui vont dominer le monde, récemment les spermatozoïdes artificiels), pour mieux démentir ensuite (ah ben oui, il ne faisait que son métier de journaliste, il a juste dit «peut-être»). Nous aimerions entendre un peu plus les scientifiques eux-mêmes parler de leur métier, de leur recherches, de leurs passions [en collaboration avec les vrais journalistes scientifiques PROPOS CORRECTIF RAJOUTÉ le 02/10/2015].
Rendre la parole scientifique aux chercheurs.
Ils sont un peu moins médiatiques à écouter, mais ils partagent des grains de science qui augmentera le niveau de culture scientifique de toutes et tous dans notre société.
Au delà de http://www.scilogs.fr , il y a des sites où s’expriment des chercheuses et des chercheurs. Voici quelques suggestions pour les sciences du numérique.
Interstices ? La revue de culture scientifique en ligne qui invite à explorer les sciences du numérique, à comprendre ses notions fondamentales, à mesurer ses enjeux pour la société, à rencontrer ses acteurs.
Binaire ? Le blog du monde.fr qui parle de l’informatique, de ses réussites, de son enseignement, de ses métiers, de ses risques, des cultures et des mondes numériques.
1024 ? Une revue pour les professionnels du monde de l’enseignement, de la recherche et de l’industrie de l’informatique qui permet de découvrir les différentes facettes de cette science.
Et laissons ce genre de chroniqueurs aller voir sur les « pistes de tennis » qui est vraiment en train de glander.
Et on aime aussi beaucoup rire de nous même.
Mais c’est un vrai métier, alors laissons le mot de la fin à un véritable artiste .
Les Chercheurs, Patrick Timsit, citation vidéo (photo wikipédia) : cliquer sur l’image pour voir la vidéo.
Thierry Viéville, et un précieux travail de relecture de @chtruchet.


 Écoulement perturbé par son passage dans un tuyau coudé. On calcule automatiquement le gradient (voir texte) de la perte de pression sur la paroi du tuyau, avec le logiciel Tapenade. ©Queen Mary University of London
Écoulement perturbé par son passage dans un tuyau coudé. On calcule automatiquement le gradient (voir texte) de la perte de pression sur la paroi du tuyau, avec le logiciel Tapenade. ©Queen Mary University of London























![By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://binaire.socinfo.fr/wp-content/uploads/2015/11/Plan_metro_tram_chemin.svg_.png)
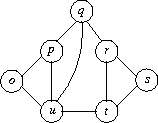
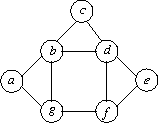




















{kind=link}