La pandémie de COVID-19 en France et dans le monde a été l’occasion de débats scientifiques et médiatiques parfois violents. Ces débats ont montré les limites d’un système de recherche trop opaque et complexe qui a permis de répandre de fausses informations ou de partager des conclusions sans réels supports scientifiques. L’Open Science est une approche qui permet de limiter ces biais. Plusieurs chercheurs ont utilisé des technologies actuelles afin d’évaluer et d’analyser les articles de recherche sur la Covid-19 et ainsi quantifier la qualité et la véracité des informations relayées.
Photo de Prateek Katyal provenant de Pexels
Depuis plus de 10 ans, des centaines de scientifiques ont commencé à promouvoir l’Open Science ou science ouverte en Français. L’Open Science un mouvement qui cherche à rendre la recherche scientifique et les données qu’elle produit accessibles à tous et dans tous les niveaux de la société.
Pour rappel, le processus de publication scientifique est le même dans toutes les disciplines. Les scientifiques soumettent le résultat de leurs travaux à d’autres scientifiques du même domaine afin qu’ils évaluent la pertinence, la reproductibilité et qualité des résultats. Cette “revue” d’article fait l’objet d’un rapport (qui n’est pas systématiquement rendu publique). L’article est ensuite corrigé (ou pas) et mis à disposition sur des plateformes accessibles à tous s’il est accepté.
Avec l’Open Science, la démarche consiste à aller plus loin, en s’engageant à détailler toutes les étapes des travaux et leurs résultats, et en rendant accessibles, compréhensibles et réutilisables ces travaux à tous et toutes (amateurs comme experts). Face à l’urgence liée à la pandémie de COVID-19, les articles de recherche sur COVID-19 ont été vérifiés par d’autres scientifiques de façon bien plus rapide, de nombreux résultats scientifiques contradictoires et débats entre scientifiques ont été exposés au grand public et ont semé la confusion parmi chercheurs, journalistes ou citoyens.
Avec mes co-auteurs, de domaines de recherche différents, nous avons donc décidé d’analyser les articles de recherche sur COVID-19 afin d’évaluer le niveau de transparence, la qualité du travail scientifique et la rigueur des évaluations faites sur ces travaux. Cette étude fait l’objet d’un article qui, sur le principe de l’Open Science, est actuellement en attente de relecture par nos pairs : https://www.biorxiv.org/content/10.1101/2020.08.13.249847v1.full. Notre article fait l’état des lieux de la démarche de transparence et des erreurs commises dans les publications scientifiques sur la COVID-19 et propose des pistes d’améliorations (reposant sur les principes de l’Open Science) afin de les éviter à l’avenir.
Pour binaire, nous nous sommes principalement intéressés à deux questions :
1. Est-ce que la revue accélérée par les pairs a été faite de façon rigoureuse ?
2. Est-ce que les journalistes ont partagé des résultats non validés par la communauté scientifique ?
Revue accélérée par les pairs.
Nous avons analysé les articles scientifiques disponibles sur PubMed (la base de données de référence d’articles de médecine) pour retrouver les articles sur COVID-19 (12 682 articles quand nous avons débuté notre analyse) en utilisant un programme pour trouver tous les articles dont les métadonnées donnent le temps qu’ont passé les pairs pour la revue de ces articles. Sur l’ensemble des articles dont les temps de revue sont disponibles (8455 articles), 700 ont été validé par les pairs en moins de 24h. La durée classique d’une revue par les pairs, bien que dépendante du domaine de recherche, est en général bien plus longue (en général plusieurs semaines/mois). Nous nous sommes donc intéressés à ces 700 articles en particulier en les classant par catégorie :
– 123 lettres éditoriales
– 74 articles de recherche “courts”
– 503 articles de recherche ”classique”
Parmi ces deux dernières catégories, nous avons pu observer que les auteurs de certains articles étaient également membres du comité éditorial de la revue dans laquelle l’article est publié, constituant ainsi ce que l’on appelle un conflit éditorial. C’est le cas pour 41% des articles de recherche et 37% des articles courts. Bien que cela ne soit pas rare, la combinaison d’un conflit éditorial et d’un temps de revue très court est particulièrement suspecte, notamment lorsque les rapports de revue ne sont pas disponibles publiquement.
Partage de résultats non validés dans les médias
En étudiant les données, nous avons constaté que les articles non encore validés par les pairs avaient presque 10 fois plus de couverture médiatique si leur sujet était COVID-19. Bien qu’il soit normal de reporter des résultats de recherche récents, les articles non validés par les pairs peuvent contenir des approximations, des erreurs ou mêmes des conclusions non fondées par les données collectées. Un partage des contenus de ces articles participe donc directement à la potentielle désinformation du grand public.
Quelles solutions pour éviter ce genre de dérapages à l’avenir ?
Il s’agit en fait d’adopter directement les principes de transparence évoqués au début de cet article et de respecter leurs usages. Ils peuvent directement aider à rendre la recherche plus fiable, plus sérieuse et plus robuste. En voici l’illustration sur deux des points mentionnés :
1. Adopter les revues par les pairs ouvertes à tous. Cela permet de rendre disponible directement en ligne le rapport de revue avec l’article de recherche et de savoir si la revue a été faite de façon rigoureuse ou non.
2. Bien que le partage d’articles non validé par les pairs soit un des principes de la science ouverte et transparente, le public scientifique les consulte avec prudence quand à la validité des travaux. Cette approche de prudence et de réserve est le point central pour des publics non avertis. Si les médias s’en emparent pour une communication grand public, ils doivent eux aussi être transparents et mentionner que les conclusions de l’article pourraient changer une fois la revue par les pairs effectuée et que celui-ci est en attente de vérification par un public scientifique.
D’autres principes de l’Open Science qui auraient pu aider pendant cette pandémie sont mentionnés dans notre article. Nous évoquons par exemple l’article de The Lancet qui a du être rétracté de la revue scientifique pour soupçons de fabrication ou falsifications des données. Dans ce cas, le fait de devoir partager, en parallèle de la publication d’un manuscrit scientifique, le jeu de données sur lequel le manuscrit se base, est une solution évidente.
En attendant la relecture et publication officielle de notre manuscrit, nous avons entamé une démarche de co-signature de l’article par d’autres scientifiques qui a déjà collecté plus de 400 signatures à l’heure actuelle. L’appel à signature est disponible ici: http://tiny.cc/cosigningpandemicopen. Nous sommes convaincus qu’il y a un réel enjeu technologique, éthique et sociétal à participer à cette démarche Open Science. Nous espérons que le monde de la recherche puisse enfin devenir ce qu’il aurait dû toujours être: un bien commun, accessible avec une transparence complète et gage de qualité et de confiance.
Lonni Besançon, chercheur associé à l’université Monash (Australie)
Comment comprendre et expliquer une décision automatisée prise par un algorithme de ce qu’on appelle l’Intelligence Artificielle, ou IA, (par exemple un réseau de neurones) ? Il est plus qu’important de pouvoir expliquer et interpréter ces résultats, parfois bluffants, qui orientent souvent nos décisions humaines. Éclairage grâce à Marine LHUILLIER et Ikram CHRAIBI KAADOUD.Pascal Guitton et Thierry Viéville.
Interprétabilité vs explicabilité : comprendre vs expliquer son réseau de neurone (1/3) Premier d’une série de trois article ( ici et là ) qui questionnent sur les concepts d’interprétabilité et d’explicabilité des réseaux de neurones, on commence ici par une introduction aux problématiques liées à la compréhension de ces algorithmes de Machine Learning.
Cette problématique tire ses origines du concept même du Machine Learning également appelé Apprentissage Machine ou Apprentissage Automatique.
Le Machine Learning (ML) est un sous-domaine de recherche de l’intelligence artificielle qui consiste à donner une capacité d’apprentissage à une machine (un ordinateur) sans que celle-ci n’ait été explicitement programmée pour cela [WhatIs, 2016] et ce, en ajustant son calcul en fonction de données dites d’apprentissage. En d’autres termes, un algorithme de ML consiste à demander à notre machine d’effectuer une tâche sans que l’on ne code précisément les différentes étapes et actions qu’elle devra réaliser pour y arriver mais en ajustant les paramètres d’un calcul très général aux données fournies.
Justement, ces prises de décision automatisées, liées àl’utilisation d’algorithmes de Machine Learning, notamment les réseaux de neurones artificiels, dits profonds quand il y a de nombreuses couches de calcul (on parle alors de Deep Learning), soulèvent de nos jours de plus en plus de problématiques d’ordre éthique ou juridique [Hebling, 2019].
L’expression “prise de décision” d’un algorithme fait référence ici à la prise de décision réalisée par un humain suite à une proposition (i.e. prédiction) issue de cet algorithme. Il s’agit donc d’une proposition de décision.
Ces problématiques sont principalement dues à l’opacité de la plupart de ces algorithmes de Machine Learning. Elles amènent donc de plus en plus de chercheurs, de développeurs, d’entreprises et aussi d’utilisateurs de ces outils à se poser des questionsd’interprétabilité et d’explicabilité de ces algorithmes.
Figure 1 – Projet “Explainable AI” de la DARPA. Image extraite de Turek [2017] .
De la boîte noire à l’IA explicable
« La principale différence entre l’IA des années 1970 et celle d’aujourd’hui est qu’il ne s’agit plus d’une approche purement déterministe » [Vérine et Mir, 2019].
En effet, l’implémentation des algorithmes d’IA a fortement évolué ces dernières années. Précédemment fondés en majorité sur les choix des développeurs, l’agencement des formules et des équations mathématiques utilisées, ces algorithmes et leurs prises de décision étaient fortement influencés par les développeurs, leur culture, leur propre façon de penser. Désormais, ces règles sont bien plus issues des propriétés “cachées” dans les données à partir desquelles les algorithmes vont apprendre, c’est à dire ajuster leurs paramètres. Bien entendu, l’implémentation sera toujours influencée par le développeur mais la prise de décision de l’algorithme ne le sera plus tout autant. De ce fait, la prise de décision automatisée par ces algorithmes s’est opacifiée.
Ainsi, aujourd’hui si un réseau de neurones est assimilé à une « boîte noire » c’est parce que les données en entrée et en sortie sont connues mais son fonctionnement interne, spécifique après apprentissage, ne l’est pas précisément. Quand on étudie les couches cachées profondes d’un réseau (représentées sur notre figure 2 par le cadre le plus foncé) on observe que la représentation interne des données est très abstraite, donc complexe à déchiffrer, tout comme les règles implicites encodées lors de l’apprentissage.
Figure 2 – Représentation schématique d’un réseau de neurones selon le principe d’une « boîte noire », par les autrices.
Ce phénomène est notamment dû à l’approche que les nombreux chercheurs et développeurs en IA ont eu pendant des années : la performance de ces algorithmes a été mise au centre des préoccupations au détriment de leur compréhension.
Soulignons également un autre aspect impliqué dans ce phénomène de “boîte noire » : le volume croissant des données ! En effet, les corpus de données utilisés ont vu leur volume exploser ces dernières années, ce qui n’était pas le cas au début de l’IA. La taille désormais gigantesque des données prises en compte par les algorithmes gène, si ce n’est empêche, l’analyse et la compréhension de leurs comportements par un cerveau humain. Par exemple, si une personne peut analyser un ou dix tickets de caisse simultanément, il devient vite impossible pour elle de chercher des similitudes sur plus d’une centaine d’entre eux pour comprendre et prédire le comportement des consommateurs d’un supermarché. Cela est d’autant plus vrai lorsqu’il s’agit de milliers ou de millions de tickets de caisse en parallèle. Il devient par conséquent difficile de comprendre les décisions résultant de l’analyses et des prédictions de ces algorithmes.
Si la démystification des “boîtes noires” que représentent les réseaux de neurones devient un sujet majeur ces dernières années, c’est entre autre dû au fait que ces outils sont de plus en plus utilisés dans des secteurs critiques comme la médecine ou la finance. Il devient alors indispensable de comprendre les critères pris en compte derrière leurs propositions de décision afin de limiter au maximum par exemple, les biais moraux et éthiques présents dans ces dernières.
Justement, les propositions de décisions issues d’algorithme d’IA, posent des questions cruciales et générales notamment en termes d’acceptabilité de ces outils. Le besoin de confiance et de transparence est ainsi très présent et très prisé. Il y a donc aujourd’hui une vraie réorientation des problématiques liées au Machine Learning notamment le besoin de les expliquer [Crawford, 2019].
Effectivement, comment avoir confiance en la proposition de décision d’un algorithme d’IA si nous ne pouvons expliquer d’où elle provient ? L’entrée en vigueur du RGPD, particulièrement de l’article 22-1 stipulant qu’une décision ne peut être fondée exclusivement sur un traitement automatisé, ajoutée au fait qu’un humain a besoin d’éléments explicites et non opaques pour prendre une décision, ont fortement accéléré les recherches dans ce domaine.
Interprétabilité ou explicabilité ?
Les besoins de transparence et de confiance dans les algorithmes de Machine Learning (e.g. les réseaux de neurones ou les mécanismes d’apprentissage par renforcement) ont ainsi fait émerger deux concepts : l’interprétabilité et l’explicabilité. Souvent associés, il semble important d’expliciter que ce sont deux concepts différents : définissons-les !
L’interprétabilité consiste à fournir une information représentant à la fois le raisonnement de l’algorithme de Machine Learning et la représentation interne des données dans un format interprétable par un expert en ML ou des données. Le résultat fourni est fortement lié aux données utilisées et nécessite une connaissance de celles-ci mais aussi du modèle [Gilpin et al., 2018].
L’explicabilité quant à elle consiste à fournir une information dans un format sémantique complet se suffisant à lui-même et accessible à un utilisateur, qu’il soit néophyte ou technophile, et quelle que soit son expertise en matière de Machine Learning [Gilpin et al., 2018]. Par exemple, le métier de chercheuse ne sera pas expliqué de la même manière à des lycéennes, lycéens qu’à des étudiants en informatique. Le jargon utilisé est adapté à des concepts partagés par ceux qui émettent l’explication et ceux qui la reçoivent.
En d’autres termes, l’interprétabilité répond à la question « comment » un algorithme prend-il une décision (quels calculs ? quelles données internes ? …), tandis que l’explicabilité tend à répondre à la question « pourquoi » (quels liens avec le problème posé ? quelles relations avec les éléments applicatifs ? …). À noter que l’interprétabilité est la première étape à réaliser afin de faire de l’explicabilité. Un modèle explicable est donc interprétable mais l’inverse ne l’est pas automatiquement !
Cela explique aussi pourquoi nombreux sont ceux qui travaillent sur l’interprétabilité des réseaux de neurones artificiels. Champ de recherche vaste et passionnant, que chacun peut aborder à travers son propre prisme, il a connu une véritable explosion du nombre de travaux et de publications depuis la fin de l’année 2017 avec notamment le projet Explainable AI (XAI) de la DARPA, l’agence du département de la défense des Etats-Unis chargée de la recherche et du développement (Figure 1).
Domaines palpitants, l’interprétabilité et par extension l’explicabilité sont donc des sujets en plein essor dont de nombreuses questions d’actualités sont encore loin d’être résolues !
Que retenir ?
Sous domaines de recherche de l’IA, le Machine Learning, le Deep Learning et donc les réseaux de neurones, suscitent de nos jours un véritable intérêt tant leur impact devient important dans nos vies. En parallèle d’améliorer précision et performance, la communauté IA a de plus en plus besoin de comprendre la logique interne et donc, les causes des prises de décisions de ces algorithmes. Or comment s’assurer de la pertinence d’une prédiction d’un réseau de neurones si les raisons derrière celle-ci sont obscures ?
Par ailleurs, peut-on tout expliquer ou interpréter ? Qu’en est-il des décisions issues de contexte très complexes nécessitant de gros volumes de données où l’ensemble des éléments est bien trop vaste pour être assimilé par un cerveau humain ? Ces questions ouvertes sont justement l’objectif des travaux de recherche qui tendent vers une compréhension humaine des réseaux de neurones.
C’est donc dans le but de démystifier ces “boîtes noires” que les chercheurs, entreprises ou encore utilisateurs s’intéressent de plus en plus au domaine de l’interprétabilité, i.e. la compréhension de la logique interne des réseaux de neurones, et celui de l’explicabilité, i.e. la capacité d’expliquer les raisons à l’origine d’une prédiction de ces mêmes réseaux.
Nous verrons dans la suite de cette série de trois articles les questions auxquelles il est nécessaire de répondre afin de choisir entre deux approches d’interprétabilité à utiliser selon le cas d’usage mais aussi comment elles aident à rendre les IA plus transparentes et compréhensibles.
Ingénieure R&D en informatique en passe d’être diplômée de l’EPSI Bordeaux, Marine s’est spécialisée lors de sa dernière mission dans la recherche à la jonction de l’IA et des Sciences cognitives, notamment dans le domaine de l’interprétabilité.
Ikram quant à elle, chercheuse IA & Sciences cognitives, ainsi qu’ancienne Epsienne, se passionne pour la modélisation de la cognition ou autrement dit comment faire de l’IA inspirée de l’humain. Toutes deux ont collaboré dans le cadre d’un projet de recherche en Machine Learning sur l’interprétabilité des réseaux de neurones chez l’entreprise onepoint.
La génèse d’une idée scientifique n’est jamais facile à retracer. En partant d’un exemple concret, Jean Claude Derniame, nous fait parcourir un processus de découverte scientifique qui montre que ce n’est pas simple de dire qui est à l’origine de quoi. Pauline Bolignano et Thierry Viéville.
Bonjour Jean-Claude, qui es-tu ?
Bonjour, je suis un ancien… ancien professeur d’informatique à l’Université de Nancy 1, puis à l’INPL et chercheur au CRIN, puis au LORIA, professeur émérite de l’Université de Lorraine, spécialiste de génie logiciel, plateformes de développement, modèles de procédés de développement de logiciel ou software process.
Tu vas parler du cheminement d’une idée nouvelle, laquelle ?
C’est le cheminement d’une idée (plusieurs fois) nouvelle à propos … du cheminement dans un graphe. Un graphe est un objet mathématique composé d’un ensemble de points reliés entre eux. Il peut représenter des personnes qui se connaissent, un arbre généalogique, un réseau électrique ou encore un réseau routier, ou même la planification d’une tâche complexe, et bien d’autres. On s’en sert pour exprimer des problèmes, comme trouver ses ancêtres, ou trouver le meilleur (le plus court) chemin pour aller à une destination.
Les problèmes de cheminement consistent à associer à un ensemble de chemins joignant un couple de points d’un graphe, une information, comme par exemple une valeur logique (existence d’un chemin), un nombre (distance entre deux points), ou un chemin (ex: le plus court ou le plus long entre deux points). Voir cet article d’Interstices pour en savoir plus.
Bien entendu, ce serait du gaspillage que de construire d’abord l’ensemble des chemins, qui peut être très vaste et occuper beaucoup de place mémoire, pour en déduire ensuite l’information cherchée, d’où notre réflexion en 1967.
L’idée originale des chercheurs de Nancy consiste à travailler sur les algorithmes et transformer celui qui construit l’ensemble de chemins en celui qui donne l’information [7 , 9] grâce à des transformations algébriques : pour obtenir un algorithme donnant une des informations (valeur logique, nombre entier, distance, probabilité, chemin vérifiant une condition, etc…), il suffit d’interpréter autrement les opérations usuelles qui correspondent à la réunion ou au produit d’ensembles de chemins.
L’algèbre mise au service de l’algorithmique alors ?
Plus précisément il s’agit de créer une transformation réversible et continue de l’ensemble des ensembles de chemins vers celui des informations, tous deux étant structurés de la même manière (on parle de semi-anneauxunitaires).
On a pu proposer une vingtaine d’algorithmes de construction d’ensemble de chemins et de nombreuses variantes qui permettent aussi de retrouver les algorithmes bien connus de recherche du plus court chemin comme ceux de Dantzig, Warshall, Ford et autres. Y figurent également des algorithmes plus performants utilisant une structure informatique correspondant à une pile d’objets.
Tout ça date d’avant internet ! Comment travailliez vous alors ?
Les ordinateurs sont rares alors et les échanges entre chercheur.ses sont beaucoup moins abondants qu’aujourd’hui. La recherche bibliographique se fait sans moteur, en lisant les livres papiers et les rares revues. Les chercheur.ses se rencontrent q vraies uelquefois et s’envoient des lettres manuscrites, sur papier. Le bouche à oreille est efficace mais ne traverse guère l’Atlantique.
En France, les échanges sont possibles mais limités, le plus souvent en français, grâce aux séminaires, congrès, ainsi qu’à la revue d’une association qui s’est appelée AFCAL, AFIRO, AFCET et précédant la SIF d’aujourd’hui.
Au début de l’année 1966, Claude Pair, qui venait de soutenir sa thèse d’Etat [5], me propose de traiter le sujet du cheminement dans un graphe au cours d’une thèse de troisième cycle. Le travail commun donnera lieu à cinq publications dont une communication de Claude [6] pour un congrès à Rome, un article de Claude dans la revue RIRO [8] et un livre chez Dunod, à paraître en 1968, comme annoncé dans l’article ci-dessus, Le manuscrit transmis à Jacques Arsac, directeur de la Collection, a disparu de son bureau en mai 1968, ce que nous n’apprîmes que fin 1969. Nous n’étions pas encore à l’époque des photocopieuses à foison et nous n’en avions aucune sauvegarde. Il a fallu recommencer : la seconde version est parue en 1971 [9].
Cette idée va être la source d’un nombre important de publications, certaines allant plus loin que le travail nancéien, d’autres pas. La plupart ont été publiées en français, souvent dans la revue de l’AFCET, comme les travaux nancéiens (voir annexe).
Plus de trois ans de retard, à cause d’un manuscrit papier !
Oui et entre-temps, en 1970, la théorie des graphes est bien connue, particulièrement en France grâce entre autres à Claude Berge [3].
Comme expliqué précédemment, les échanges entre chercheur.ses étaient limités, ce qui peut expliquer, voire excuser, les redécouvertes et l’absence de citation, comme ce fut le cas à propos des travaux ci-dessus.
Que conclure de cette histoire, alors ?
Tout d’abord rappelons que ce cas est très loin d’être exceptionnel. L’informatique, tout comme les autres sciences n’a pas été créée dans les trois dernières années : cette histoire illustre aussi l’importance du travail bibliographique avant toute création scientifique, qui doit questionner les travaux … y compris du millénaire précédent.
Et ce qui est formidable après-tout c’est que peu importe ces aléas et peu importe finalement d’attribuer le mérite à telle ou telle personne : l’importance est que la science avance, et que ce soit au service de l’humanité et pour le meilleur.
Note : cet article a pour origine le colloque organisé à Nancy le 14 juin 2019 en l’honneur de Claude Pair, un des fondateurs de la science informatique. Pierre Lescanne a découvert cette situation lors des recherches bibliographiques qu’il a faites à cette occasion [1]. Une version plus détaillée de cet article est à paraître [17].
Annexe : chronologie des publications sur ce sujet
En 1968, P. Robert et J. Ferland proposent d’appliquer l’algorithme de Warshall au cas de la recherche de chemins optimaux en passant par des semi-anneaux de matrices et des applications pour passer de l’un à l’autre, sans traiter le cas général. Ils n’avaient pas vu notre article, ni nous le leur.
Dans leur livre sur les algorithmes [10], Aho, Hopcroft et Ullman affirment « l’absence d’une approche générique pour les algorithmes de plus court chemin » (1974) et ne mentionnent pas l’intervention de C. Pair [7] à la conférence de Rome, conférence qu’ils connaissent pourtant puisqu’ils en citent une autre.
En 1975, dans [10] M. Gondran précise : « On montre comment les problèmes de cheminement dans un graphe peuvent être résolus par des méthodes d’algèbre linéaire ». On y retrouve l’ensemble du travail nancéien, cité quatre fois pour les algorithmes et l’usage d’une pile, mais pas pour les transformations alors que c’est le sujet important de l’article de M. Gondran et du travail de Nancy.
En 1995, le livre bien connu de Gondran et Minoux [11 ] reprend les propositions de [10 ], mais sans référence aux travaux de Nancy.
En 1997, M.J. Macowicz soutient à l’INSA de Lyon une thèse intitulée ”Approche générique des traitements de graphes” [12] Il reprend l’idée originale pour l’approfondir et introduire une double généricité celle des algorithmes et celle des “matroïdes”, ce qui lui permet de construire une bibliothèque de solutions.
En 2002, l’article de Mehryar Mohri “Semiring Frameworks and Algorithms for Shortest-Distance Problems” [13] est nettement plus choquant. Il s’appuie, pour annoncer une “nouvelle approche”, sur la phrase du livre de Aho et Ulman, énoncée 28 ans auparavant, et citée ci-dessus. L’auteur redéfinit les semi-anneaux et fournit un nombre important de théorèmes connus. “Il faut séparer l’algèbre qui donne un cadre et les algorithmes qui s’en servent pour résoudre des problèmes dans les différents semi-anneaux, correspondant aux domaines d’application” : une paraphrase des propositions nancéiennes ! Tout cela n’est pas sans rappeler [7 , 8, 10 , 11]. On ne peut que recommander leur (re?)lecture à l’auteur !
En 2002 [14] puis en 2008 [15], Gondran et Minoux reprennent leurs propositions pour les étendre aux “problèmes réels”, c’est-à-dire concernant les chemins remplissant certaines conditions Ils introduisent une algèbre des endomorphismes et montrent que les algorithmes itératifs (Warshall, Bellmann, Dijkstra et autres) peuvent être étendus dans cette algèbre. Puis ils établissent une liste des applications aux différents problèmes de cheminement. Cette liste reprend celle de Nancy, dont les travaux ne sont pas cités alors qu’ils sont très similaires, y compris concernant les conditions.
De même, bien avant les travaux de Nancy, en 1959, B Roy publie un algorithme [5] pour la fermeture transitive d’un graphe ( tous les couples de points reliés par un chemin). Le même sera publié par Floyd, Bellman, Ford, Moore, Warshall et s’appelle aujourd’hui l’algorithme de Warshall. 🙂
[2] C. Berge , Théorie des graphes et ses applications , Dunod, Paris, 1958.
[3] S. Stigler,“Stigler’s Law of Eponymy”, dans Statistics on the Table : The History of Statistical Concepts and Methods, Cambridge, Massachusetts, Harvard University Press, p. 277-290, 1999.
[4] Roy B. Transitivité et connexité , CRAS 249, pp. 216-218, 1959.
[5] C. Pair Etude de la notion de pile, application à l’analyse syntaxique, Thèse de doctorat d’Etat, Nancy, Dec. 1965.
[6] C. Pair On algorithms for path problems in finite graphs », in Rosentiehl (ed.), Theory of Graphs (international symposium), Rome, Gordon and Breach (New York), pp. 271-300, Jul. 1966.
[7] C. Pair Mille et un algorithmes pour les problèmes de cheminement dans les graphes, (R.I.R.O.), B-3, pp 125_143, 1970.
C’est capable de faire des maths tout seul un ordinateur ? Pas tout à fait 😉 C’est bien notre cerveau humain qui conçoit la preuve mathématique, et la conduit à son terme … mais en utilisant un outil informatique, cela peut-être plus sûr et plus efficace. Marie Kerjean nous explique aussi simplement que si nous étions des enfants ! Charlotte Truchet et Thierry Viéville.
» Une pomme à 1 euros et six poulets à deux euros, ça fait 7 euros »
– Non tu triches ça fait 3 euros!
– Non !
– Si !
– ON REGARDE SUR LA MACHINE »
Et la caisse enregistreuse, cette calculatrice jouet, permit enfin de régler ce conflit : 13 euros donc.
Les nombres, et leurs opérations de bases, font partie des premiers objets abstraits que l’on manipule. On apprend le concept de nombre, on comprend pourquoi 1+6*2 = 13, mais on apprend aussi à se passer d’une calculatrice. A savoir faire tout ça de tête, vite et bien. Certaines trouvent ce jeu rigolo, d’autres détestent. Et pourtant, quand on doit faire des opérations très compliquées (par exemple, une pomme, six poulets et 1857 mg de safran), on est toutes et tous d’accord pour préférer vérifier le résultat sur une calculatrice.
Et quand on fait des mathématiques ardues avec autre chose que des nombres, comment fait-on ? Les calculatrices qui prouvent les mathématiques se nomment les assistants à la preuve. Les touches de la calculatrices sont les outils à disposition pour reconstruire brique par brique les mathématiques. Ces touches jouent un rôle très important : elles représentent le langage utilisé par l’assistant à la preuve.
Comment fait-on pour coder n’importe quel théorème – pas seulement des additions – et sa preuve dans un ordinateur ? C’est là qu’intervient le slogan de la correspondance de Curry-Howard : si vous écrivez votre théorème avec le bon langage, « une preuve est un programme ».
Une ado lève la tête de son écran.
« Quoi ? Mais qu’est-ce que je programme?
– Ben tu programmes un … théorème : une affirmation mathématique, que l’on peut prouver.
– Mais comment ?
– Par petits bouts, en partant d’hypothèses, puis on déroule des calculs, et -hop- on obtient la conclusion .
Par exemple, si tu veux prouver « 1*4 = 4 et 4*1=4 », tu peux dire à l’assistant à la preuve de s’attaquer d’abord à la preuve à gauche du « et » .
– Et ensuite ?
– Tu prouves facilement que « 1*4 = 4″et tu passes à la preuve de gauche
Un bon langage permettant d’écrire des théorèmes est celui de la théorie des types. En l’étudiant, les chercheurs et les chercheuses construisent en particulier l’assistant à la preuve Coq. Il sert ainsi à vérifier la preuve de gros théorèmes à l’aide d’un ordinateur (comme le théorème des quatre couleurs) , mais aussi à vérifier que certains programmes calculent bien ce qu’il sont censés calculer. Cela fonctionne même pour de gros programmes, comme le compilateur C du projet CompCert ! http://compcert.inria.fr
Deux enfants prennent leur goûter :
« Un bout de tarte aux pommes pour toi, un bout de tarte aux pommes pour moi, un bout de tarte aux pommes pour toi.
– Ah non tu dois couper un bout en deux.
– Mais alors je ne pourrai pas compter les bouts sur la machine !
– Tu préfère avoir moins de bouts de tarte mais pouvoir les vérifier sur la machine !?
– Et sur la machine on pouvait compter les moitiés de bouts de tarte ? »
En effet, et si la caisse enregistreuse possédait une nouvelle touche permettant de calculer avec les portions d’un objet (ces fameux calculs avec des fractions) ?
Faire de la sémantique c’est comme préparer un goûter, c’est utiliser de nouveaux objets pour interpréter le langage de la calculatrice. Ce sont des objets mathématiques, que l’on découvre sur papier, d’où le slogan* de la sémantique dénotationnelle : « un programme est une fonction (mathématique)».
En bref, ma recherche s’attache particulièrement à bien parler de fonctions avec la logique. À la fois en prouvant des bibliothèques d’analyse fonctionnelle à l’aide de l’assistant à la preuve Coq, mais aussi en rapprochant les objets modélisant la logique de ceux traditionnellement utilisés pour faire de l’analyse.
Marie Kerjean est post-doctorante Inria au LS2N après avoir fait sa thèse à l’IRIF et travaille à la frontière entre la logique formelle, la théorie des types et l’analyse fonctionnelle.
(*) Ce slogan permet parfois de rajouter dans les preuves de la logique de nouvelles règles : ce que l’on sait faire avec des fonctions, il y a un espoir de pouvoir le faire sur des preuves, ou des programmes. C’est ainsi que la logique linéaire introduit la notion de linéarité des preuves : une fonction linéaire c’est une fonction très très simple – une droite qui passe par zéro – et une preuve linéaire d’un théorème c’est aussi une sorte de preuve très très simple. On peut même parler de linéarisation d’une preuve, c’est à dire quelque chose qu’on nomme sa différentielle.
Au moment où beaucoup d’entre nous se demandent comment être utiles pour aider les scientifiques à comprendre la maladie, puis à mettre au point des traitements et in fine un vaccin, Lonni Besançon nous propose de participer à un projet collectif en mettant à leur disposition une partie des ressources matérielles de nos ordinateurs. Pascal Guitton
Si durant vos heures de confinement vous passez quelques minutes sur les réseaux sociaux ou devant les médias, vous avez sûrement entendu parler des raisons pour lesquelles le confinement a été mis en place. C’est l’une des solutions pour espérer réduire l’impact du virus. Parmi les espoirs des scientifiques et du reste de la population pour stopper la propagation du virus reste le développement d’un vaccin ou d’un traitement efficace. Que vous ayez une formation scientifique ou non, il s’avère que chacun peut apporter sa pierre à l’édifice dans la compréhension du virus via l’installation d’un simple programme sur son ordinateur. Ce programme, Folding@Home, repose sur la notion de calcul distribué validée initialement par le projet SETI@Home.
Folding@Home est donc un projet de calcul distribué qui permet de simuler la dynamique des protéines, y compris leur processus de repliement et leurs mouvements quand elles sont impliquées dans diverses maladies. Ces simulations demandent une énorme puissance de calcul que les scientifiques ne peuvent obtenir sur leurs seuls ordinateurs. L’idée de Folding@Home est donc d’utiliser les processeurs et cartes graphiques d’autres personnes, qu’elle soient chercheur.e.s ou non, afin de permettre de créer ces simulations plus rapidement. La liste des maladies étudiées par le projet Folding@home inclut Alzheimer, Parkinson ou Huttington et depuis peu COVID19. Le résultat de ses simulations permets aux scientifiques de mieux comprendre des mécanismes biologiques et donc de créer de nouvelles thérapies.
Image 1: l’écran d’accueil de Folding@Home
Comment participer à cette formidable initiative? C’est très simple. Il suffit d’abord de télécharger le programme via la page de téléchargement de Folding@Home puis de l’installer sur votre ordinateur. Il suffit ensuite de lancer FAHControl afin de commencer à partager son processeur et/ou sa carte graphique. Ce logiciel permet de contrôler les ressources que l’on donne au projet. Par exemple, le slider accessible sous “Folding Power” permet de déterminer la quantité de puissance de calcul que l’on souhaite donner au projet (voir l’Image1). Le logiciel permet aussi de s’identifier avec un nom d’utilisateur (via le bouton “Configure” et dans l’onglet “Identity”) afin de voir et comparer ses statistiques par rapport à d’autres utilisateurs.
Le programme Folding@Home est configuré pour automatiquement utiliser le processeur et la carte graphique (si elle est compatible, ce qui est rarement le cas sur les ordinateurs portable de chez Apple par exemple) de chaque ordinateur. Le client Folding@Home télécharge d’abord une unité de travail pour une protéine spécifique, commence un calcul sur cette unité de travail et, une fois le calcul achevé, envoie les résultats directement au projet avant de télécharger une nouvelle unité de travail. L’initiative Folding@Home est donc un moyen simple pour chaque citoyen possédant un ordinateur relativement récent et une puissance de calcul assez importante de contribuer à des projets scientifiques.
Le Travail d’Initiative Personnelle Encadré (TIPE) est une épreuve commune à la plupart des concours d’entrée aux grandes écoles scientifiques. Il permet d’évaluer les étudiant·e·s non pas sur une épreuve scolaire mais à travers un travail de recherche et de présentation d’un travail personnel original. C’est un excellent moyen d’évaluer les compétences. Cela peut être aussi une épreuve inéquitable dans la mesure où selon les milieux on accède plus ou moins facilement aux ressources et aux personnes qui peuvent aider. Pour aider à maintenir l’équité, les chercheuses et les chercheurs se sont mobilisés pour offrir des ressources et du conseil à toute personne pouvant les solliciter. Thierry Viéville.
Free-Photos Pixabay
TIPE ? Comme tous les ans, en lien avec sillages.info et l’UPS pour les CGPE, Interstices et Pixees vous proposent des ressources autour des sciences du numérique, informatique et mathématiques.
Le thème pour l’année 2020-2021 du TIPE commun aux filières BCPST, MP, PC, PSI, PT, TB, TPC et TSI est intitulé : enjeux sociétaux. Ce thème pourra être décliné sur les champs suivants : environnement, sécurité, énergie.
À l’heure où ces lignes sont écrites, une partie de l’humanité est confinée pour maîtriser la propagation de l’épidémie de coronavirus Covid-19. Cette crise sanitaire exceptionnelle en désagrégeant nos vies et nos organisations, a relativisé l’importance de nombreuses questions et a bousculé de nombreuses croyances. Bien malin qui peut décrire les conséquences à long terme de cette épidémie. Bien sûr, les rumeurs et les fausses informations sont toujours bien présentes mais une idée a retrouvé une place centrale dans le débat public : la science.
En cherchant à partir d’observations et de raisonnements rigoureux à construire des connaissances, la science permet de comprendre, d’expliquer mais aussi d’anticiper et parfois de prédire. Et aujourd’hui, les sciences du numérique (modélisation, simulation, communication, information…) ont un rôle capital.
Les thématiques abordées ci-dessous sont majeures : risques naturels, énergies, sécurité informatique, sobriété numérique, avec souvent des sujets reliant science et société. C’est l’occasion pour vous d’exercer vos connaissances, votre curiosité, votre capacité de synthèse. L’objectif n’est pas tant de résoudre l’une de ces questions que d’y donner un éclairage personnel et scientifique. Chacune des problématiques décrites ci-dessous ne constitue pas exactement un sujet de TIPE mais plutôt un thème duquel vous pourrez extraire votre sujet. Le TIPE s’articule souvent autour de la trilogie théorie/expérience/programme. Les recherches décrites ici portent sur les sciences du numérique, l’expérimentation numérique y a une grande place.
Même si, suite à l’épidémie de coronavirus Covid-19, les destructions ne sont pas matérielles, beaucoup est à refonder, à rebâtir. Et vous qui êtes étudiantes et étudiants de filières scientifiques, votre rôle sera prépondérant.
Pour conclure cette brève présentation et insister à nouveau sur l’importance de la science, je rappellerai l’article 9 de la charte de l’environnement (texte à valeur constitutionnelle) : « La recherche et l’innovation doivent apporter leur concours à la préservation et à la mise en valeur de l’environnement. »
La Commission européenne a publié le 11 mars 2020 un nouveau plan d’action contre le gaspillage dans l’UE de ressources naturelles. Il s’agit d’arriver à une limitation drastique des quantités de déchets (500 kilos par européen en 2017) et d’emballages (173 kilos). Sont visés en premier lieu, les appareils électroniques dont la fabrication est la cause d’un gaspillage d’énergie et de matières premières. Il est insensé d’avoir à changer si souvent son smartphone quand on pourrait utiliser des pièces remplaçables et réparables. Selon la Commission : « A l’heure actuelle, l’économie est encore essentiellement linéaire, puisque 12% seulement des matières et des ressources secondaires y sont réintroduites ». La Commission travaille sur des dispositions qui limiteront les usages uniques, permettront de lutter contre l’obsolescence prématurée et interdiront la destruction des marchandises durables invendues ». L’association « Les Amis de la Terre » salue cette avancée en regrettant l’absence d’objectifs chiffrés.
Fleur de tournesol éternelle, Everlasting
Parmi ces ressources gaspillées, il faut aussi s’intéresser aux fleurs dont la présence est essentielle à la survie des abeilles dont la disparition menacerait l’ensemble de la végétation. Le conseiller allemand, Dr. Seltsam, a donc annoncé qu’il était envisagé d’interdire la vente de fleurs à usage unique. Cela a fait flamber le cours d’une startup d’Indianola, Sunflower County, qui a mis au point une fleur de tournesol qui ne flétrit jamais. Everlasting propose déjà plusieurs variétés d’Ikébana à base de ces fleurs. Si le coût de la fleur peut donner à réfléchir (9.99 dollars), elles permettent de fleurir son appartement en permanence sans avoir à passer par le fleuriste. Contredisant le Grand Jacques, on pourra bientôt amener à son ou sa chérie des fleurs plutôt que des bonbons parce qu’elles seront moins périssables.
Je vous ai apporté des bonbons… Parce que les fleurs c’est périssable. Jacques Brel
La technique mise au point par Everlasting consiste à bloquer le processus de vieillissement de la fleur, ou plus précisément à introduire un gène correcteur de ce vieillissement. Un effet secondaire de la modification génétique est le blocage du mécanisme de pollinisation.
Le Dr. Seltsam a dit suivre les développements de cette technologie avec intérêt. Il envisagerait même de doter chaque citoyen d’un quota de fleurs que lui, ses parents ou ses descendants pourraient utiliser de la naissance à la mort, voire même se transmettre via les héritages.
Les fleurs en tissus (voir le tutorial), les couronnes de fleurs séchées, les fleurs en pots de terre cuite, la quête d’ornements floraux non périssables ne datent pas d’hier. On pourrait ajouter qu’une fleur est déjà éternelle, la « Petite fleur » de Sydney Bechet, à réécouter absolument.
Sidney Bechet : Petite Fleur CD (2006) – Intense, Oldies
On peut s’inquiéter de possibles effets délétères de fleurs génétiquement modifiées, et souligner que cela ne règlera pas l’extrême gravité de la dégradation de la biodiversité et de la disparition massive d’espèces de fleurs. Maintenir la biodiversité en la manipulant génétiquement ? Au secours ! L’application numérique Plant@net de sciences participatives aide à identifier des plantes à partir de photos. Pourrait-elle permettre de mettre en place un plan massif de sauvegarde des espèces de fleurs menacées ?
Poisson combattant, Aquaportail
La manipulation génétique pour vaincre la mort est un domaine de recherche actif, y compris pour les humains. Mais voulons-nous devenir immortels ? A plus court terme, Everlasting travaille sur des poissons d’aquarium qui vivraient éternellement. Ils expérimentent sur le Combattant à la « queue-de-voile » qui arrive déjà à vivre jusqu’à deux ou trois ans en aquarium. Madame Dagotte, la pédégère d’Everlasting, a déclaré : « Une difficulté pour notre recherche est que les tests prennent très longtemps ; nous expérimentons aussi des techniques d’accélération de la vie biologique pour vérifier la résistance de nos produits. » Allez comprendre les scientifiques !
Une biologiste d’Everlasting amène son poisson Combattant en balade. Serge A.
Qui n’a jamais entendu dire « c’est la faute de l’ordinateur » ou « l’informatique ce n’est pas pour les filles », ou encore que « les algorithmes décident à notre place » ? Ces préjugés ont la vie dure… Interstices nous propose une collection d’articles pour comprendre certaines de ces idées préconçues et se forger une vision qui permet de les dépasser.
La rencontre de chercheurs juristes et informaticiens dans le cadre du lancement du Centre Internet et Société et du montage du GdR Internet et Société, a été l’occasion de réflexions croisées et de soulever nombre de questions et premières pistes de recherche à explorer ensemble. Cet article résume le résultat d’une table ronde. Serge Abiteboul, Thierry Viéville
Photo by Fernando Arcos from Pexels
Les plateformes numériques et leur rôle dans la société occupent les médias et les instances gouvernantes. Nous, juristes et informaticien·e·s, les percevons comme des nouveaux marchés de la donnée. Plusieurs acteurs humains, artistes, auteurs, créateurs de contenu, développeurs de langages, développeurs de plateformes, développeurs d’applications, internautes consommateurs, acteurs publics et privés, gravitent autour de ces plateformes et sont exposés à deux types de risque :
– Le risque-données se réfère à la protection des données sur ces plateformes.
– Le risque-algorithmes se réfère aux dérives de discrimination algorithmique.
Ce document apporte une première réflexion sur comment appréhender les plateformes numériques et les risque-données et risque-algorithmes. Ces questions peuvent être abordées de deux points de vue complémentaires : le point de vue juridique dont le souci principal est de déterminer les cadres qui permettent d’identifier et de réguler ces risques, et le point de vue informatique dont le but est de développer les outils nécessaires pour quantifier et résoudre ces risques.
Les trois facettes du risque algorithmique.
Le risque-algorithmes peut être caractérisé de 3 façons.
Il s’agit d’abord de l’enfermement algorithmique qui peut aussi bien porter sur les opinions, la connaissance culturelle, ou encore les pratiques commerciales. En effet, les algorithmes confrontent l’internaute aux mêmes contenus, selon son profil et les paramètres intégrés, en dépit du respect du principe de la loyauté. C’est le cas sur les sites de recommandation de news comme Facebook ou les sites de recommandation de produits comme Amazon.
La deuxième facette du risque-algorithmique est liée à la maîtrise de tous les aspects de la vie d’un individu, de la régulation de l’information à destination des investisseurs jusqu’à ses habitudes alimentaires, ses hobbies, ou encore son état de santé. Ce traçage de l’individu laisse présager l’emprise d’une forme de surveillance qui contrevient à l’essence même de la liberté de l’individu.
La troisième est liée à la potentielle violation des droits fondamentaux. En particulier, à la discrimination algorithmique définie comme le traitement défavorable ou inégal, en comparaison à d’autres personnes ou d’autres situations égales ou similaires, fondé sur un motif expressément prohibé par la loi. Ceci englobe l’étude de l’équité (fairness) des algorithmes de classement (tri de personnes cherchant un travail en ligne), de recommandation, et d’apprentissage en vue de prédiction. Le problème des biais discriminatoires induits par des algorithmes concerne plusieurs domaines comme l’embauche en ligne sur MisterTemp’, Qapa et TaskRabbit, les décisions de justice, les décisions de patrouilles de police, ou encore les admissions scolaires.
Nous reprenons une classification des biais proposée par des collègues de Télécom ParisTech et discutée dans un rapport de l’Institut Montaigne à Paris. Nous adaptons cette classification aux risque-données et risque-algorithmes en mettant l’accent sur les biais.
Les données proviennent de sources différents et ont des formats multiples. Elles véhiculent différents types de biais.
Des risques aux biais sur les données et dans les algorithmes.
Le biais-données est principalement statistique
Le biais des données est typiquement présent dans les valeurs des données. Par exemple, c’est le cas pour un algorithme de recrutement entraîné sur une base de données dans laquelle les hommes sont sur-représentés exclura les femmes.
Le biais de stéréotype est une tendance qui consiste à agir en référence au groupe social auquel nous appartenons. Par exemple, une étude montre qu’une femme a tendance à cliquer sur des offres d’emplois qu’elle pense plus facile à obtenir en tant que femme.
Le biais de variable omise (de modélisation ou d’encodage) est un biais dû à la difficulté de représenter ou d’encoder un facteur dans les données. Par exemple, comme il est difficile de trouver des critères factuels pour mesurer l’intelligence émotionnelle, cette dimension est absente des algorithmes de recrutement.
Le biais de sélection est lui dû aux caractéristiques de l’échantillon sélectionné pour tirer des conclusions. Par exemple, une banque utilisera des données internes pour déterminer un score de crédit, en se focalisant sur les personnes ayant obtenu ou pas un prêt, mais ignorant celles qui n’ont jamais eu besoin d’emprunter, etc.
Le biais algorithmique tient principalement du raisonnement.
Un biais économique est introduit dans les algorithmes, volontairement ou involontairement, parce qu’il va être efficace économiquement. Par exemple, un algorithme de publicité oriente les annonces vers des profils particuliers pour lesquels les chances de succès sont plus importantes ; des rasoirs vont être plus présentés à des hommes, des fastfood à des populations socialement défavorisées, etc.
Il convient également de citer toute une palette de biais cognitifs
Les biais de conformité, dits du « mouton de Panurge », correspondent à notre tendance à reproduire les croyances de notre communauté. C’est le cas, par exemple, quand nous soutenons un candidat lors d’une élection parce que sa famille et ses amis le soutiennent.
Le biais de confirmation est une tendance à privilégier les informations qui renforcent notre point de vue. Par exemple, après qu’une personne de confiance nous a affirmé qu’untel est autoritaire, remarquer uniquement les exemples qui le démontrent.
Le biais de corrélation illusoire est une tendance à vouloir associer des phénomènes qui ne sont pas nécessairement liés. Par exemple, penser qu’il y a une relation entre soi-même et un événement extérieur comme le retard d’un train ou une tempête.
Le biais d’endogénéité est lié à une relative incapacité à anticiper le futur. Par exemple, dans le cas du credit scoring, il se peut qu’un prospect avec un mauvais historique de remboursement d’emprunt puisse changer de style de vie lorsqu’il décide de fonder une famille.
Les algorithmes sont une série d’instructions qui manipulent des données en entrée et retournent des données en sortie. Ces données en entrée véhiculent parfois des biais. Les biais peuvent aussi se trouver dans une ou plusieurs instructions des algorithmes.
Doit-on aborder les risque-données et risque-algorithmes sur les plateformes numériques ensemble ou séparément ?
Considérons deux exemples, le contexte de la technologie blockchain, et celui des systèmes d’Intelligence Artificielle.
Sur la blockchain, l’on retrouve tout d’abord les données, les risques et leur biais. Prenons l’exemple des données et des risques associés. La blockchain fonctionne par un chiffrement à double clés cryptographiques : des clés privées et des clés publiques. Beaucoup d’internautes confient aux plateformes leurs clés privées, leur délégant ainsi la gestion de leur adresse et les mouvements de fonds. Ces clés privées sont stockées soit dans un fichier accessible sur Internet (hot storage), soit sur un périphérique isolé (cold storage). Le premier est évidemment très vulnérable au piratage, tandis que 92 % des plateformes d’échange déclarent utiliser un système de cold storage. Depuis 2011, 19 incidents graves ont été recensés pour un montant estimé des pertes s’élevant à 1,2 milliards de dollars. Les causes de ces incidents sont multiples. La plus courante vient de la falsification des clés privées, suivie par l’introduction de logiciels malveillants. Le hack de la plateforme Coincheck au Japon, en janvier 2018, illustre la faiblesse de la protection du système de hot storage.
Autre exemple sur les algorithmes et les risques associés, l’échange de cryptomonnaies sur des plateformes voit se développer et se diversifier les infrastructures de marché. L’ambition est « de permettre la mise en place d’un environnement favorisant l’intégrité, la transparence et la sécurité des services concernés pour les investisseurs en actifs numériques, tout en assurant un cadre réglementaire sécurisant pour le développement d’un écosystème français robuste » . La France s’est dotée récemment d’un cadre juridique permettant de réguler ces activités de manière souple. Pour autant, au niveau mondial, les risques attachés à des cotations non transparentes ou à des transactions suspectes s’apparentant à des manipulations directes de cours ou de pratiques d’investisseurs informés, de type frontrunning. Le frontrunning est une technique boursière permettant à un courtier d’utiliser un ordre transmis par ses clients afin de s’enrichir. La technique consiste à profiter des décalages de cours engendrés par les ordres importants passés par les clients du courtier.
Venons en à la question « doit-on aborder les risque-données et risque-algorithmes sur les plateformes numériques ensemble ou séparément ? » Concernant la blockchain, la réponse du droit est séparée, car les risques saisis sont différents. D’un côté, certaines dispositions du droit pénal, de la responsabilité civile ou de la protection des données à caractère personnel seront mobilisées. Alors que de l’autre côté, en France, le récent cadre juridique visant à saisir les activités des prestataires de services sur actif numérique et à éviter le risque algorithmique est principalement régulatoire.
Sur les systèmes d’IA, nous prendrons pour répondre à notre question le prisme de la responsabilité (liability) et de la responsabilisation (accountability).
Cette question est diabolique car elle impose au juriste de faire une plongée dans le monde informatique pour comprendre ce en quoi consiste l’intelligence artificielle, ce mot-valise qui recouvre, en réalité, de nombreuses sciences et techniques informatiques. Et faut-il seulement utiliser ce terme, alors que le créateur du très usité assistant vocal Siri vient d’écrire un ouvrage dont le titre, un tantinet provocateur, énonce que l’intelligence artificielle n’existe pas… (Luc Julia, L’intelligence artificielle n’existe pas, First editions, 2019).
Un distinguo entre les systèmes d’IA est néanmoins souvent opéré : seuls certains systèmes sont véritablement « embarqués » dans un corps afin de lui offrir ses comportements algorithmiques : robot, véhicule « autonome »… Les autres systèmes d’IA prennent des décisions ou des recommandations algorithmiques qui peuvent avoir un effet immédiat sur le monde réel et l’esprit humain, sans avoir besoin de s’incarner dans un corps : recommandations commerciales à destination du consommateur, fil d’actualité des réseaux sociaux, justice prédictive et sont souvent considérés comme « dématérialisés ». Cependant, tous les systèmes d’IA finissent par être incorporés dans une machine : robot, véhicule, ordinateur, téléphone… et tous les systèmes d’IA peuvent potentiellement avoir un impact sur l’esprit ou le corps humains, voire sur les droits de la personnalité (M. Baccache, Intelligence artificielle et droits de la responsabilité, in Droit de l’intelligence artificielle, A. Bensamoun, G. Loiseau, (dir.), L.G.D.J., Les intégrales 2019, p. 71 s.), tant et si bien que nous choisirons ici de saisir la question de la responsabilité lors du recours aux systèmes d’IA d’une manière transversale.
La question transversale que précisément nous poserons consistera à nous demander si la spécificité des systèmes d’IA, tant au regard de leur nature évolutive et de leur gouvernance complexe, qu’au regard des risques découlant de leur mise en œuvre pour l’humain et la société n’appelle pas à préférer à la responsabilité, entendue comme la seule sanction a posteriori de la réalisation d’un risque, une complémentarité entre responsabilisation de la gouvernance de chaque système d’IA tout au long de son cycle de vie et responsabilité a posteriori. Si la responsabilisation est reconnue comme étape préalable à la responsabilité, elle impliquera d’envisager les risques-données et les risques-algorithmiques, de manière conjointe, préservant ainsi la spécificité de chacun de ces risques, mais en les reliant, parce c’est par la conjonction de ces deux types de risques, que des conséquences préjudiciables pour l’humain ou la société peuvent se réaliser.
En effet, dans ses « lignes directrices en matière d’éthique pour une IA digne de confiance » datant d’avril 2019, le Groupe d’experts de haut niveau sur l’intelligence artificielle, mandaté par la Commission européenne, rappelle dans l’une de ses propositions un point fondamental, à savoir les nécessaires reconnaissance et prise de conscience que « certaines applications d’IA sont certes susceptibles d’apporter des avantages considérables aux individus et à la société, mais qu’elles peuvent également avoir des incidences négatives, y compris des incidences pouvant s’avérer difficiles à anticiper, reconnaître ou mesurer (par exemple, en matière de démocratie, d’état de droit et de justice distributive, ou sur l’esprit humain lui-même) » (Groupe d’experts indépendants de haut niveau sur l’intelligence artificielle, Lignes directrices en matière d’éthique pour une IA digne de confiance, avril 2019, constitué par la Commission européenne en juin 2018,).
Ce faisant, le groupe d’experts de haut niveau en appelle à « adopter des mesures appropriées pour atténuer ces risques le cas échéant, de manière proportionnée à l’ampleur du risque » et, en se fondant sur les articles de la Charte des droits fondamentaux de l’Union européenne, à « accorder une attention particulière aux situations concernant des groupes plus vulnérables tels que les enfants, les personnes handicapées et d’autres groupes historiquement défavorisés, exposés au risque d’exclusion, et/ou aux situations caractérisées par des asymétries de pouvoir ou d’information, par exemple entre les employeurs et les travailleurs, ou entre les entreprises et les consommateurs ».
Alors même que certains risques et la protection de certains groupes vulnérables l’imposent, prendre les mesures appropriées n’est cependant pas aisé, et ce au-delà même de la tension récurrente entre principe d’innovation et principe de précaution. La raison en est que tant les briques techniques utilisées, que les personnes impliquées dans le fonctionnement d’un système d’IA sont nombreuses, variées et en interactions complexes, entraînant de nombreuses interactions qui ne sont pas aisées à maîtriser. Il convient de constater que le groupe d’experts de haut niveau formule un ensemble de propositions, à visées d’éthique et de robustesse technique des systèmes d’IA, qui véhiculent l’idée selon laquelle la confiance en un système d’IA, au regard des risques actuels du déploiement de ceux-ci, se doit de reposer sur une responsabilisation a priori de la gouvernance de celui-ci tout au long de son cycle de vie, qui passe, entre autres choses, par un objectif d’explicabilité de ces actions.
La notion d’accountability est à cet égard une notion centrale pour comprendre la complémentarité et le long continuum existant entre responsabilisation et responsabilité. Plus que par le terme de responsabilité, cette notion d’accountability peut justement être traduite par les notions de reddition de compte et/ou de responsabilisation. Cette responsabilisation permet d’envisager les risques-données et les risques-algorithmiques, de manière conjointe, préservant ainsi la spécificité de chacun de ces risques, mais en les reliant, parce c’est par la conjonction de ces deux types de risques, que des conséquences préjudiciables pour l’humain ou la société peuvent se réaliser.
En résumé. Le point de vue juridique différera selon les enjeux et les concepts applicables. Dans le cas de la blockchain, il est important de séparer le risque-données du risque-algorithmes puisqu’ils traitent de problématiques différentes et nécessitent des cadres de loi différents. Le premier traite de la question de la divulgation de l’identité des parties qui relève de la sécurité des données alors que le second traite de la question des actifs numériques frauduleux. Dans le cas des systèmes d’intelligence artificielle, tout déprendra du point de savoir s’il convient de prévenir le dommage ou de le sanctionner une fois qu’il s’est réalisé. Dans le cas d’une recherche de responsabilisation, il convient d’envisager les risques-données et les risques-algorithmes de manière conjointe.
Si la question est celle de la responsabilité (liability) et la responsabilisation (accountability), i.e., celle d’imputer la faute à une personne physique, il sera important de séparer les deux risques. Cette séparation est aussi celle qui est préconisée en informatique pour permettre d’identifier les “coupables”: données ou algorithmes. Les techniques de provenance des données et de trace algorithmique permettront d’isoler les raisons pour lesquelles il y a faute. Il s’agira d’abord d’identifier si la faute est due à un risque-données du type divulgation de la vie privée ou à un biais statistique dans les données, ou à un risque-algorithmes du type économique ou cognitif, ou si la faute est due aux deux. On ne pourra donc imputer la faute et déterminer les cadres de loi applicables que s’il y a séparation. De même si l’objectif est de “réparer” les données ou l’algorithme, l’étude des deux types de risque doit s’effectuer séparément. C’est ce qu’on appelle l’orthogonalité en informatique. Selon le dictionnaire, le jeu d’instructions d’un ordinateur est dit orthogonal lorsque (presque) toutes les instructions peuvent s’appliquer à tous les types de données. Un jeu d’instruction orthogonal simplifie la tâche du compilateur puisqu’il y a moins de cas particuliers à traiter : les opérations peuvent être appliquées telles quelles à n’importe quel type de donnée. Dans notre contexte, cela se traduirait par avoir un jeu de données parfait et voir comment l’algorithme se comporte pour déterminer s’il y a un risque-algorithmes et avoir un algorithme parfait et examiner les résultats appliqués à un jeu de données pour déterminer le risque-données. Ces stratégies ont de beaux jours devant elles.
L’Intelligence Artificielle (IA) s’est construite sur une opposition entre connaissances et données. Les neurosciences ont fourni des éléments confortant cette vision mais ont aussi révélé que des propriétés importantes de notre cognition reposent sur des interdépendances fortes entre ces deux concepts. Cependant l’IA reste bloquée sur ses conceptions initiales et ne pourra plus participer à cette dynamique vertueuse tant qu’elle n’aura pas intégré cette vision différenciée. Frédéric Alexandre nous l’explique. Thierry Viéville.
IA symbolique et numérique
La quête pour l’IA s’est toujours faite sur la base d’une polarité entre deux approches exclusives, symbolique ou numérique. Cette polarité fut déclarée dès ses origines, avec certains de ses pères fondateurs comme J. von Neumann ou N. Wiener proposant de modéliser le cerveau et le calcul des neurones pour émuler une intelligence, et d’autres comme H. Newell ou J. McCarthy soulignant que, tout comme notre esprit, les ordinateurs manipulent des symboles et peuvent donc construire des représentations du monde et les manipulations caractérisques de l’intelligence. Cette dualité est illustrée par l’expression des frères Dreyfus « Making a Mind versus Modelling the Brain », dans un article (Dreyfus & Dreyfus, 1991) où ils expliquent que, par leur construction même, ces deux paradigmes de l’intelligence sont faits pour s’opposer : Le paradigme symbolique met l’accent sur la résolution de problèmes et utilise la logique en suivant une approche réductionniste et le paradigme numérique se focalise sur l’apprentissage et utilise les statistiques selon une approche holistique.
On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.
Sommes-nous encore partis pour un cycle, à toujours nous demander laquelle de ces deux approches finira par démontrer qu’elle était la bonne solution, ou saurons-nous sortir du cadre et trancher le nœud gordien ? C’est dans cette dernière perspective que je propose de revenir aux fondamentaux. Puisque les deux approches s’accordent au moins sur le fait qu’elles cherchent à reproduire nos fonctions cognitives supérieures, ne devrait-on pas commencer par se demander si notre cognition est symbolique ou numérique ?
Mémoires implicite et explicite dans le cerveau
A cette question, les Sciences Cognitives répondent d’abord « les deux » et soulignent (Squire, 2004) que notre mémoire à long terme est soit explicite soit implicite. D’une part nous pouvons nous souvenir de notre repas d’hier soir (mémoire épisodique) ou avoir la connaissance que le ciel est bleu (mémoire sémantique) ; d’autre part nous avons appris notre langue maternelle et nous pouvons apprendre à faire du vélo (mémoire procédurale). Nous savons que (et nous en sommes conscients, nous savons l’expliquer) ou nous savons faire (et nous pouvons en faire la démonstration, sans être capable de ramener cette connaissance au niveau conscient). On retrouve ici les principes décrits respectivement en IA par la manipulation explicite de connaissances ou implicite de données.
Les neurosciences ont identifié des circuits cérébraux correspondants, avec en particulier les boucles entre les ganglions de la base et le cortex plutôt impliquées dans la mémoire implicite, et l’hippocampe et ses relations avec l’ensemble du lobe temporal médial, essentiel pour la mémoire explicite. Les deux modes d’apprentissage sont à l’œuvre dans deux phénomènes : La consolidation et la formation des habitudes.
Les mécanismes de la consolidation
Ces mémoires complémentaires sont construites avec un apprentissage lent et procédural dans le cortex et la formation rapide d’associations arbitraires dans l’hippocampe (McClelland et al., 1995). Prenons un exemple : allant toujours faire mes achats dans le même supermarché, je vais former, après de nombreuses visites, une représentation de son parking, mais à chaque visite, je dois aussi me souvenir de l’endroit précis où j’ai laissé ma voiture. Les modèles computationnels permettent de mieux comprendre ce qui est à l’œuvre ici. Les modèles d’apprentissage procédural implicite, généralement en couches, montrent que des régularités sont extraites statistiquement, à partir de nombreux exemples dont les représentations doivent se recouvrir pour pouvoir généraliser. Mais si l’on souhaite apprendre ensuite des données avec d’autres régularités, on va observer l’oubli catastrophique des premières relations apprises.
Inversement, dans un modèle d’apprentissage explicite de cas particuliers, généralement avec des réseaux récurrents, on va privilégier le codage de ce qui est spécifique plutôt que de ce qui est régulier dans l’information (pour retrouver ma voiture, je ne dois pas généraliser sur plusieurs exemples mais me souvenir du cas précis). Cet apprentissage sera plus rapide, puisqu’on ne cherchera pas à se confronter à d’autres exemples mais à apprendre par cœur un cas particulier. Mais l’expérimentation avec ce type de modèles montre des risques d’interférence si on apprend trop d’exemples proches, ainsi qu’un coût élevé pour le stockage des informations (ce qui n’est pas le cas pour l’apprentissage implicite). Il est donc impératif de limiter le nombre d’exemples stockés dans l’hippocampe.
Des transferts de l’hippocampe vers le cortex (que l’on appelle consolidation, se produisant principalement lors des phases de sommeil) traitent les deux problèmes évoqués plus haut. D’une part, lorsque des cas particuliers proches sont stockés dans l’hippocampe, leurs points communs sont extraits et transférés dans le cortex. D’autre part, l’hippocampe, en renvoyant vers le cortex des cas particuliers, lui permet de s’entrainer de façon progressive, en alternant cas anciens et nouveaux et lui évite l’oubli catastrophique.
La région colorée en violet foncé est le cortex cérébral. brainmaps.org, CC BY-SA
Les mécanismes de la formation des habitudes
La prise de décision peut se faire selon deux modes, réflexif et réflectif (Dolan & Dayan, 2013), tel que proposé historiquement par les behavioristes pour qui le comportement émergeait implicitement d’un ensemble d’associations Stimulus-Réponse et par les cognitivistes qui imaginaient plutôt la construction de cartes cognitives où des représentations intermédiaires explicites étaient exploitées. Là aussi, les apprentissages implicite et explicite sont à l’œuvre. Pour prendre une décision, une représentation explicite du monde permettra de façon prospective d’anticiper les conséquences que pourraient avoir nos actions et de choisir la plus intéressante. Avec sa capacité à former rapidement des associations arbitraires, l’hippocampe semble massivement impliqué dans la construction de ces cartes cognitives explicites.
Ensuite, après avoir longuement utilisé cette approche dirigée par les buts, on peut se rendre compte, par une analyse rétrospective portant sur de nombreux cas, que dans telle situation la même action est toujours sélectionnée, et se former une association situation-action dans le cortex par apprentissage lent, sans se représenter explicitement le but qui motive ce choix. On appelle cela la formation des habitudes.
Mais que fait l’IA ?
La dualité implicite/explicite a conforté l’IA dans ses aspects numériques/symboliques ou basés sur les données et sur les connaissances. L’IA n’a cependant pas intégré un ensemble de résultats qui montrent que, au delà d’une simple dualité, les mémoires implicites et explicites interagissent subtilement pour former notre cognition.
Concernant la consolidation, l’hippocampe est en fait alimenté presque exclusivement par des représentations provenant du cortex, donc correspondant à l’état courant de la mémoire implicite, ce qui indique que ces deux mémoires sont interdépendantes et co-construites. Comment ces échanges se réalisent entre le cortex et l’hippocampe et comment ils évoluent mutuellement restent des mécanismes très peu décrits et très peu connus en neurosciences.
Concernant la formation des habitudes, cette automatisation de notre comportement n’est pas à sens unique et nous savons figer un comportement puis le réviser par une remise en cause explicite quand il n’est plus efficace puis le reprendre si besoin. Là aussi, ces mécanismes sont très peu compris en neurosciences.
La modélisation a été une source d’inspiration pour aider les neurosciences à formaliser et à décrire les mécanismes de traitement de l’information à l’œuvre dans notre cerveau. Pourtant, concernant ces modalités d’associations flexibles entre nos mémoires implicites et explicites, l’IA ne joue pas son rôle d’aiguillon pour aider les neurosciences à avancer sur ces questions, car elle reste bloquée sur cette dualité rigide et stérile entre données et connaissances, alors que les relations entre connaissances et données devraient être au cœur des préoccupations d’une IA soucieuse de résoudre ses points de blocage. Il est donc temps d’exposer au grand jour ce hiatus et de demander à l’IA de jouer son rôle d’inspiration.
Frédéric Alexandre, Directeur de Recherche Inria en Neurosc iences Computationnelles, Équipe Mnemosyne.
Réferences:
Dreyfus H.L., Dreyfus S.E. (1991) Making a Mind Versus Modelling the Brain: Artificial Intelligence Back at the Branchpoint. In: Negrotti M. (eds) Understanding the Artificial: On the Future Shape of Artificial Intelligence. Artificial Intelligence and Society. Springer, London.
Lipton, Z. C. (2017). The Mythos of Model Interpretability. http://arxiv.org/abs/1606.03490
Squire, L. R. (2004). Memory systems of the brain : a brief history and current perspective. Neurobiology of Learning and Memory, 82, 171–177.
McClelland, J. L., McNaughton, B. L., & O’Reilly, R. C. (1995). Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological Review, 102(3), 419–457.
Dolan, R. J., & Dayan, P. (2013). Goals and Habits in the Brain. Neuron, 80(2), 312–325. https://doi.org/10.1016/j.neuron.2013.09.007
Nous partageons avec vous cette invitation à la prochaine journée Sciences & Médias, qui se tiendra à la Bibliothèque nationale de France le 16 janvier 2020 sur le thème « Femmes scientifiques à la Une ! »
En raison des mouvements sociaux, la journée Sciences et Médias, initialement prévue le 16 janvier, est reportée à une date ultérieure. Nous vous prions de nous excuser ce report de dernière minute et vous tiendrons informé de la nouvelle date pour cet événement.
Le thème abordé cette année concerne les femmes scientifiques, peu présentes dans les médias. Cette absence n’est pas seulement due à la
faible proportion de femmes dans certaines disciplines scientifiques,
mais à d’autres ressorts propres au fonctionnement des médias et de la
communauté scientifique. La journée s’articulera autour d’exposés et de
tables rondes, réunissant journalistes, scientifiques et médiateurs, qui
feront un état des lieux et proposeront des solutions :
Quelle est la représentation des femmes scientifiques dans les médias ?
Quel rôle joue le vocabulaire utilisé pour les noms de métier, et au-delà ?
Quelles bonnes pratiques peuvent être mises en œuvre par les institutions
scientifiques ? Et par les médias ?
Pour lutter contre la désaffection des jeunes pour les sciences, garçons et filles, les associations Parité Science et Femmes & Sciences et plusieurs partenaires ont pris le temps,le 9 novembre 2019, de faire le point sur l’égalité filles et garçons face à l’enseignement des sciences et à l’orientation scolaire dans notre pays, ainsi qu’aux sciences comme moteur d’intégration sociale, notamment grâce aux outils numériques. Pour partager quelques éléments clés, faisons l’interview imaginaire d’un petit garçon. Thierry Viéville.
Binaire : Bonjour Léandre, peux-tu citer le nom d’une femme scientifique ?
Léandre : Oui oui : « Isabelle Martin ».
Binaire : Ça alors ! Tu sais que la plupart des personnes auraient répondu « Marie Curie », c’est souvent la seule qu’on connaît parmi toutes les femmes scientifiques.
Léandre : Certes, mais ma sœur m’a expliqué que ça pose problème parce que si le seul modèle pour les filles qui veulent faire de la science est une personne complètement extraordinaire, alors elles vont se dire, que bon, je suis pas aussi excellente que Marie Curie, donc je n’ai aucune chance.
Binaire : Ah oui tu as raison, mais tu sais : je ne connais pas Isabelle Martin moi.
Léandre : Ben moi non plus, hihihi, mais ma sœur a fait un calcul de probabilité. Et comme Isabelle et Martin sont les prénoms et patronymes les plus courants, y’a quasiment aucune chance qu’il n’y ait pas une femme scientifique qui se nomme ainsi. C’est sûrement une personne ordinaire, qui a juste envie d’être chercheuse parce que cela lui plaît.
Binaire : Ah oui ! Mais dis moi pourquoi les filles s’autocensurent vis à vis des sciences ? Tu as vu par exemple avec la création du nouvel enseignement Numérique et science informatique qui permet enfin de s’initier à cette science récente et omniprésente avec tant de débouchés, il y a vraiment très peu de filles qui ne se sont pas autocensu…
Léandre : Hein ?!?!! A.u.t.o.-C.e.n.s.u.r.e. Faut arrêter là, non mais tu réalises pas … c’est de la censure sociale omniprésente dont on parle ici. Regarde, par exemple ça :
« On invite les filles à faire de la science au niveau européen ? C’est à travers un clip rempli d’un ramassis de clichés ! Barbie est (enfin !) informaticienne ? Elle s’occupe du graphique pendant que son mec fait la techno, comme vous l’aviez dénoncé sur binaire. Et mon horreur préférée est devant toi… regarde ces mappemondes. On en fait une rose pour les filles » . Seraient-elles trop c…s (avec 2 ‘n’) pour utiliser celles « réservées aux garçons » ? « Le fait de produire une mappemonde rose pour attirer les filles rend la bleue masculine, alors qu’elle était jusque là “normale”. De ce fait, les trucs normaux c’est pour les garçons, tandis que pour ces pauvres filles faut adapter… ».
Dès la naissance on commence à les traiter de manière biaisée. Donc NON : y a PAS d’autocensure des filles, y’a juste des filles qui finissent par baisser la tête devant la censure sociale, à force d’être exclues implicitement et très concrètement, comme le montre par exemple cette étude https://www.elephantinthevalley.com de 2015, actualisée en 2018.
Binaire : Tu exagères Léandre, les filles comme les garçons peuvent par exemple accéder aux revues scientifiques de vulgarisation.
Regarde bien, comme l’a étudié Clémence Perronnet, « sur 110 couvertures, les 4 femmes sont : (i) un robot, (ii) une statue, (iii) une surfeuse et (iv) une pauvre femme effrayée par les extra-terrestres », avec ça… vazy d’être incitée à faire de la science.
Et tu sais, il a fallu attendre 1975 (la loi Haby) pour que l’enseignement soit le même pour les filles et les garçons. Oui oui, avant , tout l’enseignement était différencié et parfois sexiste comme l’illustre cet exemple donné par la même autrice :
Binaire : Heureusement les choses progressent…
Léandre : Oui et non. Indéniablement oui à plusieurs niveaux, et c’est le résultat d’un véritable combat citoyen plus que centenaire. Mais dans plusieurs domaines et dans nos esprits, le chemin à parcourir reste long, comme on le voit ici pour les maths https://tinyurl.com/wjkgcro et comme c’est le cas en informatique où il y a même une régression. Il faudrait que les mecs se bougent un peu sur le fond.
Binaire : Attends, tu soulèves un point dont je voudrais parler en toute franchise. Beaucoup d’hommes se sentent concernés voire sont acteurs de la parité, comme dans le projet Class´Code. Mais sont parfois « piégés », juste sur un mot, une parole maladroite et paf ! le ou les voilà catalogués « vilain sexiste » alors que la personne agit pour l’égalité avec les meilleures intentions. Tu crois qu’il serait plus pédagogique de nous aider sans nous condamner d’emblée ?
Léandre : Oui, tu as raison, pas facile pour un homme de trouver sa place dans la lutte pour l’égalité… D’abord, il faut comprendre que les inégalités sont le produit du système de genre qui hiérarchise les hommes et les femmes et crée entre eux un rapport de domination.
Ce n’est pas la même chose d’agir pour l’égalité depuis la position dominante et depuis la position dominée : les hommes – qui sont du bon côté du rapport de force – ne sont jamais légitimes quand ils demandent aux femmes d’être « gentilles » dans leur lutte : la colère des opprimées est justifiée. Se battre contre des siècles d’histoire et toute la force des institutions, ça demande beaucoup d’efforts !
Là où tu as raison, c’est qu’à l’échelle individuelle et dans nos relations personnelles, la bienveillance, la pédagogie et l’humour sont nécessaires pour faire mieux et progresser, hommes et femmes ensemble.
Binaire : Ah oui je comprends mieux maintenant, et cela porte ses fruits ?
Léandre : Oui au-delà d’« activités pour les filles » qui permettent de corriger un peu les conséquences, au niveau individuel la priorité est d’éduquer les garçons, à l’égalité des sexes, Isabelle Collet parle encore d’équité*.
Et au niveau structurel, il y a des mesures vraiment efficaces qui agissent sur les causes. Elles sont validées parce que des chercheurs et chercheuses en psychologie, sociologie et science de l’éducation étudient scientifiquement le sujet. Par exemple s’imposer plus d’enseignantes dans les études supérieures scientifiques. Introduire une vraie information et formation sur le système de genre. Ou encore imposer temporairement une « discrimination positive » à l’embauche qui ne fait que compenser la vraie discrimination négative de la société, jusqu’au rétablissement d’une équité.
Binaire : C’est donc la science qui peut aider à permettre que les deux moitiés de l’humanité profitent de la science alors ?
Léandre : Et oui, la boucle est bouclée.
Contenus et relecture de Clémence Perronnet et Isabelle Collet, avec la complicité de « Léandre ».
(*) Égalité/Équité des sexes/genres , quelques précisions:
– « sexes » ou « genres » : puisque l’objectif est l’égalité entre les êtres humains quelles que soient leurs caractéristiques biologiques (organes génitaux) nous parlons bien de sexe, de l’abolition du processus social de hiérarchisation des données biologiques dans la production d’une bi-catégorisation sociale (qui correspond au genre = féminin/masculin). Pour atteindre l’égalité des hommes et des femmes, il faut déconstruire le genre, c’est-à-dire les concepts de féminin et masculin qui sont historiquement inégalitaires. Le genre étant défini comme la bi-catégorisation hiérarchisée des sexes, une « égalité des genres » est un oxymore.
– « égalité » ou « équité » : le débat est complexe car tout le monde n’attribue pas le même sens à ces mots. Dans le vocabulaire des SHS la notion d’équité implique une correction des inégalités, alors que la notion d’égalité suppose la non-production d’inégalités (à ne pas confondre avec « égalité des chances »), on va donc choisir égalité ou équité selon que l’on parle de l’abolition des inégalités ou de la compensation de leur permanence.
La conférence de clôture des Journées Nationales de l’APMEP (Association des Professeurs de Mathématiques de l’Enseignement Public) à Bordeaux (2018) a été l’occasion pour Gilles Dowek de livrer un plaidoyer pour l’enseignement des sciences de l’école au lycée. Cet article en reprend les idées principales. Gilles Dowek est chercheur et enseignant en informatique à l’INRIA et à l’ENS de Paris-Saclay. Il a milité activement pour l’introduction de l’algorithmique et plus généralement de l’informatique dans les programmes scolaires et pour la création du CAPES d’informatique.
Ce texte est paru dans la revue Au Fil des Maths de l’APMEP.
Une situation favorable
La révolution informatique que nous sommes en train de vivre est l’une des plus grandes révolutions scientifiques et techniques de l’histoire, qui transforme nos métiers, nos institutions, notre manière de communiquer avec nos proches… Elle s’appuie, bien entendu, sur les progrès de l’informatique, qui existe en tant que science structurée depuis les années 1930, mais aussi sur ceux des autres sciences, en particulier de la physique — par exemple de la physique des semi-conducteurs — et des mathématiques — par exemple de la théorie des nombres, sur laquelle repose une grande partie de la cryptologie. En retour, elle transforme toutes les sciences, métamorphosant l’instrumentation : le séquençage du génome humain, la découverte du boson de Higgs ou la démonstration du théorème de Hales étaient impossibles sans ordinateur. Elle transforme aussi les conditions de vérité d’un énoncé et les langages dans lesquels les sciences « dures » comme « humaines » s’écrivent : l’invention des langages de programmation, au XXe siècle, est une rupture aussi radicale que l’invention du langage de l’algèbre, au XVIe siècle.
La situation n’a donc jamais été aussi favorable pour enseigner les sciences et les techniques. Les élèves et les étudiants devraient se précipiter dans les cours de sciences, qui devraient être au centre du projet pédagogique de l’école, du collège et du lycée.
Il est donc paradoxal que l’enseignement des sciences soit aujourd’hui en crise. Pourtant cette crise est réelle et un certain nombre d’indices l’atteste.
Le constat d’une crise
Un premier indice est l’absence de culture scientifique de nos représentants, qui ont pourtant été à l’école avant d’avoir été élus ou fonctionnaires.
Alors que les sciences transforment le monde, ceux qui l’administrent ignorent parfois la différence entre un virus et une bactérie, un losange et un parallélogramme, un programme impératif et un programme fonctionnel.
Plutôt que leur jeter la pierre, nous devrions proposer que les écoles qui les forment — par exemple, à l’heure actuelle, l’École Nationale d’Administration — mettent la formation scientifique de leurs étudiants au centre de leur projet pédagogique.
Un autre indice de cette crise est la difficulté que nous avons à enseigner les sciences à l’école primaire. Ici aussi, une remédiation possible est de mettre la formation scientifique des étudiants au centre du projet pédagogique des écoles du professorat.
Mais le symptôme le plus inquiétant de cette crise est sans doute la place des sciences dans la réforme du lycée qui se met en place en cette rentrée 2019. Si l’idée de proposer aux élèves de choisir leurs cours dans un vaste catalogue et de construire eux-mêmes leur projet d’étude est bonne, ainsi que celle de garantir, par un tronc commun, l’acquisition par toutes et tous de savoirs fondamentaux, cette réforme nous renseigne sur la singulière vision que ses concepteurs ont des savoirs fondamentaux : sur les seize heures de tronc commun du programme de première générale, deux heures sont consacrées au sport, et les quatorze heures qui restent sont réparties en deux heures pour les sciences et douze heures pour les humanités. En fonction du choix des spécialités, la part des humanités varie donc entre 43 % et 86 %, quand la part des sciences varie entre 7 % et 50 %. Comme à l’époque des séries L, ES et S, les élèves ont donc le choix entre un enseignement entièrement consacré aux humanités et un enseignement équilibré entre les humanités et les sciences.
Le projet pédagogique du lycée reste donc fondamentalement le même : celui d’une domination des humanités. Ce projet est totalement anachronique, quand le reste du monde vit une révolution scientifique et technique sans précédent.
Des pistes pour une résolution de la crise
Plusieurs pistes permettent d’entrevoir une solution à cette crise. La première est bien entendu de revendiquer un équilibre des sciences et des humanités dans le tronc commun du lycée. Bien plus que la place des mathématiques, c’est la place des sciences dans leur ensemble qu’il convient de défendre, par exemple, en proposant un tronc commun constitué de sept heures consacrées aux humanités et de sept heures consacrées aux sciences. La part des humanités varierait alors de 25 % à 68 %, et la part des sciences également.
Mais, bien entendu, la solution ne peut venir de la revendication seule, et nous devons aussi nous demander ce que nous pouvons changer nous-mêmes pour résoudre cette crise. Deux pistes sont ici à explorer : la réconciliation des sciences et des techniques et le dialogue des sciences avec les humanités.
L’incroyable difficulté à faire de l’informatique une discipline à part entière avec ses programmes, ses horaires et ses enseignants — un CAPES d’informatique a été créé en 2019, alors que les premières revendications d’un tel CAPES datent des années 1970, soit il y a presque un demi-siècle — a des causes multiples.
L’une d’elles, qui n’est sans doute pas la principale, mais qui n’en reste pas moins paradoxale, a été l’inertie opposée par les enseignants des autres sciences, notamment de mathématiques, qui ont perçu en l’apparition d’une nouvelle discipline un risque de voir leur horaire amputé. Il est regrettable que ces enseignants n’aient pas perçu que l’extraordinaire opportunité que constitue un enseignement de l’informatique pour amener des élèves vers les sciences, et donc les mathématiques, compensait, de beaucoup, ce risque d’une diminution des horaires consacrés aux mathématiques. En particulier, un grand nombre de notions mathématiques sont utilisées en informatique : par exemple, la notion de coordonnée cartésienne en traitement d’image et, plus spécifiquement, la notion de projection pour la représentation en perspective des objets tridimensionnels. Se saisir de cette opportunité pour enseigner ces notions ne consiste pas à évoquer brièvement, dans des activités d’approche, l’utilité de la notion de coordonnée en traitement d’image, avant d’aborder le vif du sujet, mais à transformer entièrement l’enseignement de la notion de coordonnée, dans un projet multidisciplinaire, proposé conjointement par des enseignants de mathématiques et d’informatique. Par delà ces notions déjà enseignées, l’enseignement de l’informatique permet de renouveler l’enseignement des mathématiques en introduisant de nouvelles notions, en logique, en combinatoire, en théorie des nombres, en théorie des graphes…
La réconciliation des sciences et des techniques est également essentielle, car la première perception que les jeunes élèves ont des questions scientifiques est médiatisée par des objets techniques — ils conçoivent la notion de voiture avant celle de combustion des alcanes. Si les enseignants de mathématiques, et plus généralement les mathématiciens, ont heureusement, pour la plupart, abandonné l’idée selon laquelle la beauté des mathématiques réside dans leur inutilité, l’enseignement des sciences reste trop coupé de celui des techniques. Il est certes possible, sur le plan philosophique, de distinguer un résultat scientifique — l’établissement de la vérité d’un énoncé — d’un résultat technique — la production d’un objet, tels un avion ou un programme. Il est en revanche impossible, sur le plan historique, de séparer le développement des sciences de celui des techniques. L’enseignement de la physique, par exemple, peut nous laisser croire que le développement de la thermodynamique a été indépendant ou a précédé celui de la machine à vapeur, mais c’est oublier que le second principe de la thermodynamique a été énoncé par Sadi Carnot dans un texte intitulé Réflexions sur la puissance motrice du feu et sur les machines propres à développer cette puissance. En particulier, il est urgent d’abandonner l’idée que les sciences sont du domaine de l’abstrait / du cerveau, quand les techniques relèvent du concret / de la main. Il n’y a rien de plus abstrait qu’un programme, qui reste cependant un objet technique.
Renouer le dialogue avec les humanités est aussi essentiel, car la révolution scientifique et technique que nous vivons est aussi celle des sciences humaines. L’hostilité des enseignants de français, de philosophie, de langues et d’histoire-géographie serait moindre si nous dialoguions davantage avec eux et s’ils comprenaient, eux aussi, l’importance pour leurs élèves d’avoir une formation scientifique. Deux pistes méritent d’être explorées dans ce dialogue : la transformation de la méthode des sciences humaines qui disposent désormais de données massives et d’outils de modélisation. Par exemple, un professeur d’anglais, au lieu de donner à ses élèves les listes des adjectifs dont le comparatif se construit avec le suffixe « -er » et avec l’adverbe « more », peut leur donner un corpus formé d’un assez grand nombre de textes et les laisser construire ces listes eux-mêmes, dans un projet interdisciplinaire. Une autre piste à explorer est l’incorporation de l’histoire des sciences et des techniques dans les programmes d’histoire — la révolution galiléenne et la place que les mathématiques et l’expérimentation ont prise dans la science au XVIIe siècle pourraient constituer un chapitre entier d’un cours d’histoire moderne. La même chose pourrait être dite de l’éthique, dont les questions ont été complètement renouvelées par la révolution scientifique et technique que nous vivons. Peut-on / doit-on chiffrer ses courriers ? Voilà une question qui pourrait mobiliser non seulement les enseignants d’informatique et de mathématiques, mais aussi de philosophie.
Plus profondément, même en admettant que le but de l’École soit d’apprendre aux élèves « à lire et à écrire », nous pourrions nous entendre sur le fait que lire et écrire ne consiste pas uniquement à lire et écrire des textes exprimés dans des « langues », mais aussi des textes exprimés dans des « langages », tels les équations, les programmes, les formules développées des molécules, les figures géométriques, les partitions…
Dans cet article à plusieurs voix, nous avons quelques petites histoires à raconter avec plusieurs objectifs. D’une part montrer comment l’informatique et les mathématiques appliquées permettent de modéliser nos océans si précieux et parfois en danger ; d’autre part informer étudiantes et étudiants en classes préparatoires qui font justement cette année un travail personnel encadré sur ce sujet , un TIPE*, que les chercheuses et chercheurs sont à leur contact pour les aider à trouver des ressources et conseiller si besoin. Antoine Rousseau et Thierry Viéville.
Arctique, Atlantique, Austral, Indien, Pacifique : les océans couvrent à eux seuls plus des deux tiers de la surface du globe ! Ils jouent un rôle essentiel dans la vie sur Terre et partout dans le monde, les océans font l’objet de multiples études tant leur taille les rend à la fois mystérieux et essentiels à la compréhension du système Terre. Dans un contexte de dérèglement climatique, ils sont observés à la loupe : compte tenu de leur inertie, on sait que l’état des océans aujourd’hui nous dit beaucoup sur le futur de la planète. Avec quelques scientifiques d’Inria, voyons comment les océans peuvent être modélisés par des équations puis simulés grâce à des algorithmes et enfin instrumentés afin de fournir des diagnostics sur leur état (c’est grave, docteur ?). Comprendre les océans, c’est aussi comprendre comment l’énergie qu’ils renferment pourrait être utilisée par nos sociétés.
La dynamique des océans est fabuleusement riche. Les mouvements y ont lieu sur une gamme d’échelles extrêmement large, allant de quelques dizaines de centimètres (du clapot, de petits tourbillons…) à des milliers de kilomètres (les grands courants qui traversent des océans entiers). L’ensemble de cette dynamique est modélisée, c’est-à-dire représentée mathématiquement, par des équations complexes, qui tentent de prendre en compte l’ensemble des phénomènes : l’eau de mer est un fluide plus ou moins salé, sur une terre en rotation, qui interagit avec l’atmosphère, et qui est soumis à l’attraction de la lune (entre autres). Face à une telle complexité, plutôt que de chercher à tout comprendre d’un coup (ce qui est voué à l’échec), il est souvent très instructif d’isoler des phénomènes. C’est ce qu’ont fait de nombreux océanographes depuis plus d’un siècle, et il est frappant de voir comment des modèles très simples expliquent tel ou tel aspect de la dynamique océanique. Citons par exemple en vrac la circulation de grande échelle engendrée par le vent (circulation de Sverdrup), la circulation créée par les différences de densité de l’eau de mer (circulation « thermohaline » et le modèle de Stommel), les grands courants de bord ouest tels le Gulf Stream ou le Kuroshio (effet Beta et couche de Munk), le phénomène de dérive (spirale d’Ekman) ou encore les multiples ondes qui se propagent, en surface ou dans la profondeur de l’océan (houle, ondes de marée, ondes de Rossby et de Kelvin, ondes acoustiques…).
Depuis quelques années la production d’énergie renouvelable est un enjeu majeur de la société. Si la production électrique hydraulique à l’intérieur des continents, c’est-à-dire dans les barrages hydrauliques, est largement développée en France et dans le monde de nos jours, il n’en est pas de même pour le formidable potentiel des océans. Plusieurs types de procédés de récupération d’énergie marine peuvent être distingués en fonction de la forme de l’énergie qu’elle utilise : la marée, les vagues, les courants. Pour chacunes d’elles se posent des problèmes techniques, économique et environnementaux que les chercheuses et chercheurs, en industrie et à l’université, cherchent à résoudre:
• Comment optimiser le processus de récupération d’énergie ?
• Comment transporter l’énergie produite jusqu’au continent ?
• Comment estimer le potentiel d’un site de production et l’impact (sédimentaire ou sur l’éco-système) de l’implantation d’un dispositif de récupération d’énergie ?
Pour effectuer une prévision de la circulation océanique, on dispose de modèles numériques qui sont la transcription, sous forme de programme informatique, des équations de la mécanique des fluides et de la thermodynamique. Ces modèles permettent, à partir de l’état de l’océan actuel, de prévoir l’évolution dans le temps de ce système, et ainsi fournir une prévision de l’état de la mer qu’il fera dans les jours qui viennent. Cependant on ne connait pas avec précision la valeur actuelle, à chaque endroit, des quantités physiques qui sont nécessaires pour constituer la condition initiale (le point de départ) des modèles de prévision. On dispose heureusement de multiples sources d’observation de l’océan (bouées, radars, satellites, …), qui fournissent une information relativement précise, mais encore trop partielle de cette condition initiale. C’est en mélangeant ces sources d’information hétérogènes que sont les différentes observations et les résultats des modèles numériques au moyen de méthodes dites d’assimilation de données que l’on recompose l’état actuel de l’océan. La principale difficulté réside dans l’estimation et la description des statistiques d’erreurs associées à ces différentes sources d’information, afin de trouver le meilleur compromis possible. Ce dernier point, déterminant pour la qualité de la prévision est toujours un champ de recherche actif.
De nombreux processus physiques gouvernent les courants marins (gravité, vents, rotation de la terre, attraction de la lune, topographie des fonds marins, effets de bord, etc.). Il existe un processus physique simple qui permet d’expliquer les grandes lignes des courants planétaires, comme le Gulf Stream ou le Kuroshio. En quelques mots, il s’agit du processus élémentaire de la mise en mouvement de deux fluides de densités différentes, dans un même contenant, sous l’effet de la gravité : le fluide le plus dense (plus lourd) descend, celui qui est moins dense (plus léger) monte. Dans l’océan, en raison des différences de température et de salinité, la densité de l’eau de mer n’est pas toujours constante, et ce phénomène donne naissance à ce que l’on nomme la circulation thermohaline : imaginer de gigantesques tapis roulants des mers qui transportent des masses d’eau phénoménales sur toute l’étendue du globe.
Malgré la simplicité du processus, les équations sous-jacentes restent extrêmement complexes, car elles reposent sur celles de la mécanique des fluides (équations de Navier-Stokes). Les mathématicien·nes et physicien·nes ont donc recours à la simulation numérique pour étudier, modéliser, comprendre ce phénomène. Ce phénomène peut également faire l’objet d’une expérience simple accessible à tou·tes ! (réf 1)
Maëlle NODET (Université de Versailles-St Quentin)
Calculs et énergies marines renouvelables
Le développement des techniques liés aux énergies marines renouvelables (EMR) est souvent associé à des simulations numériques très poussées (énergie éolienne, hydrolienne ou encore houlomotrice), impliquant la conception et l’analyse de nouveaux algorithmes mathématiques. Ces derniers permettent en particulier de limiter la construction coûteuse de prototypes.
Pour obtenir un résultat sous forme numérique, le mathématicien décompose généralement son travail en une série d’étapes bien distinctes. La première consiste à fixer un modèle, c’est-à-dire un ensemble d’équations décrivant la physique du phénomène. Dans le cas des systèmes liés au EMR, le fluide est décrit des des équations aux dérivées partielles, par exemple l’équation de Navier-Stokes ou l’une de ses versions simplifiées (équation de Stokes, approximation par écoulement potentiel, équation de St-Venant…). Le dispositif extracteur (éolienne, bouée houlomotrice…) est quant à lui soit modélisé par l’intermédiaire de la mécanique des milieux continus, soit simplement par un solide fixe (hypothèse souvent considérée pour les pâles d’une éolienne par exemple). Le système global relève donc d’un champ de recherche appelé l’interaction fluide-structure, qui s’intéresse spécifiquement au couplage de modèles de mécanique des fluides et de mécanique du solide.
L’étape suivante est celle de la résolution numérique du modèle : il s’agit alors de construire des procédures de résolution numérique (des « schémas numériques », généralement approximatives) du système d’équations obtenu à l’étape précédente. Du point de vue mathématique, cette étape se traduit par une discrétisation en espace du domaine physique occupé par le dispositif et son environnement et d’une discrétisation en temps, si l’on considère les régimes transitoires. Les nombreux schémas qui peuvent être considérés (schémas Lax Friedrichs, Godunov, Roe, …) pour la simulation du fluide doivent alors prendre en compte l’interaction avec la machine sous forme de conditions de bord. Le travail mathématique consiste ici à évaluer, à l’aide de théorèmes, la qualité de l’approximation de la solution du modèle par la solution numérique (on parle d’analyse d’erreur).
Enfin, une fois la simulation validée, la procédure de calcul peut être utilisée en mode prédictif pour optimiser la technique : la géométrie de l’extracteur peut par exemple être modifiée de telle sorte que son rendement soit maximisé. Cette étape relève donc du champ de l’optimisation numérique où l’enjeu est de construire un algorithme itératif conduisant à l’optimisation d’une fonctionnelle (le rendement, par exemple). Les techniques utilisées sont d’ordre 0 (c’est-à-dire n’utilisant pas la dérivée de la fonctionnelle, comme l’algorithme du simplexe ou les algorithmes évolutionnaires), d’ordre 1 (mettant en jeu la dérivée de la fonctionnelle, i.e. son gradient, comme dans les algorithmes de gradient) voire d’ordre 2 (ayant recours à la dérivée seconde de la fonctionnelle, i.e. sa hessienne comme dans l’algorithme de Newton).
L’ensemble des techniques mathématiques mobilisées dans le cadre de la conception numérique de dispositifs extracteurs d’énergie marine est donc très vaste et va certainement se développer de manière importante dans les prochaines décennies, en particulier, par des collaborations plus poussées entre ingénieurs, mécaniciens et mathématiciens. Il donne bien sûr lieu à de nouvelles recherches spécifiques dans ces deux dernières communautés.
(*)Le Travail d’Initiative Personnelle Encadré est une épreuve commune à la plupart des concours d’entrée aux grandes écoles scientifiques. Il permet d’évaluer les étudiant·e·s non pas sur une épreuve scolaire mais à travers un travail de recherche et de présentation d’un travail personnel original. C’est un excellent moyen d’évaluer les compétences. Cela peut être aussi une épreuve inéquitable dans la mesure où selon les milieux on accède plus ou moins facilement aux ressources et aux personnes qui peuvent aider. Pour aider à maintenir les quitter les chercheuses et les chercheurs se sont mobilisés pour offrir des ressources et du conseil à toute personne pouvant les solliciter.
Autrefois, quand nous apprenions la chimie à l’école, faire une réaction consistait souvent à mélanger des réactifs dans un bécher, mélanger, chauffer, attendre, et trouver dans le bécher les produits de la réaction. C’est aussi comme cela que l’on réalise aujourd’hui quantité de réactions chimiques industrielles, pour faire, par exemple, des médicaments. Même si le bécher est remplacé par des cuves parfois gigantesques, le principe reste le même, d’où la difficulté de contrôler finement le processus. Comment s’assurer, par exemple, que la température dans la cuve est constante ? Pas simple !
Il y a quelques années, cette machinerie a été bouleversée par l’apparition d’une toute nouvelle façon de faire des réactions : la chimie en flux. Plus de bécher, plus de mélange aléatoire, plus d’attente : il suffit d’injecter en continu les réactifs dans un petit tube, dans lequel la réaction se produit en permanence. Comme la réaction est continue, à rendement égal, nous pouvons nous contenter d’un tube beaucoup plus petit qu’une cuve. Nous pouvons aussi mieux contrôler la réaction : pour chauffer le tube, il suffit par exemple de le faire passer dans un four.
En prime, avec cette méthode, il est nettement plus facile de collecter des échantillons et les analyser. Un système chimique en flux peut dès lors être vu comme une fonction, qui donne le rendement de la réaction en fonction de certains paramètres (température, pression, stœchiométrie, débit). Et que font des informaticiens avec une telle fonction ? Ils l’optimisent, bien sûr ! C’est l’objet d’un projet conduit à l’Université de Nantes, sur lequel nous travaillons.
Notre problématique est que l’on ne connaît pas la fonction à optimiser. Nous n’en avons pas de jolie expression, avec des x, des y et des z, facile à admirer, à calculer et à optimiser. Nous ne pouvons que mesurer, de façon expérimentale, des valeurs de la fonction en des points particuliers (les conditions courantes de la réaction) : pour cela, nous collectons les produits de la réaction, et nous les analysons.
Nous avons adapté pour ce type d’optimisation une méthode classique, la méthode de Nelder-Mead. Le principe est de sonder astucieusement l’espace de recherche en s’appuyant sur des déplacements d’un « polytope ». On commence au hasard : sur la base de deux paramètres à optimiser, on tire trois points dans l’espace de recherche et on mesure. L’espèce de triangle formé par les trois points s’appelle polytope de Nelder-Mead, et il se déplace ensuite dans l’espace de recherche en fonction des rendements que nous trouvons. Nous commençons par chercher le plus mauvais des trois points, puis nous retournons le triangle sur l’axe formé par les deux autres. Si nous trouvons un point bien meilleur, alors nous étirons le polytope dans cette direction. Si au contraire le point trouvé est moins bon, nous contractons le polytope. Bref, nous déformons ce polytope en étant guidé par les mesures. Et même si c’est un peu difficile à visualiser, la méthode marche aussi avec plus de deux paramètres, il suffit de remplacer le triangle par un polytope. Nous avons adapté cette méthode au cas particulier de la chimie en flux, en rajoutant des propriétés fortes pour respecter certaines règles de sécurité.
En haut, une paillasse classique, opérée par un humain. En bas, la même réaction, entièrement automatisée : l’ordinateur contrôle robot-à-pipeter, four, pompe, etc. Crédit : François-Xavier Felpin
Notre méthode a été intégrée à un système automatisé permettant de réaliser une réaction, de la contrôler et de l’optimiser de façon entièrement autonome : c’est un ordinateur qui s’occupe d’injecter les produits, de contrôler les conditions de la réaction, de prélever des échantillons et de les analyser, puis de collecter les résultats… Orchestrer tout cela a été un long travail d’orfèvrerie ! La mise au point a pris du temps mais maintenant, ce dispositif est entièrement autonome et permet l’optimisation de la synthèse de molécules complexes pouvant rentrer dans la conception de médicaments. Pour une des réactions, une étape de synthèse de la carpanone, notre méthode a même trouvé un meilleur rendement que ce qui était expérimentalement connu !
Charlotte Truchet (@chtruchet), François-Xavier Felpin, Université de Nantes
En 2013, le blog Intelligence mécanique voyait le jour sous l’impulsion de Thierry Viéville ! Grâce à lui, plusieurs d’entre vous, en savent plus sur le monde de l’informatique.
A l’époque l’objectif de ce blog était le suivant : parler de l’intelligence des machines, celle de l’informatique et surtout co-construire ensemble une culture scientifique liée à la science informatique pour maîtriser ce monde numérique qui nous entoure sans le subir ni se limiter à le consommer.
Ikram Chraibi Kaadoud
Ikram Chraibi Kaadoud a récemment repris le flambeau : même objectif qu’en 2013, avec toutefois une variante, plus de sciences cognitives !
Chaque article débute par une indication pour expliciter le niveau de complexité qui sera abordé dans l’article mais toujours dans un esprit de médiation :
Tout public, lycéen·ne·s : l’article contiendra peu ou pas de référence mathématique au delà du niveau de début de lycée, il servira de ressources aux lycéen·ne·s sur ces sujets
Public familial : l’article aura vocation à expliquer un concept, répondre à une question informatique d’un point de vue sociétal, sans pour autant imposer d’éléments techniques
Public averti : l’article contiendra des références en sciences informatiques et mathématiques et des notions plus techniques pourront être abordées, avec toujours les liens Wikipédia idoines
Jess Wade, chercheuse spécialisée dans les appareils électroniques en plastique, a décidé de s’attaquer au problème de la sous-représentation des femmes dans les branches scientifiques. Afin de mettre en avant les grandes femmes scientifiques, elle rédige des fiches Wikipédia sur certaines d’entre elles.
Des portraits qu’elle a partagés sur Twitter avec le hashtag #womeninSTEM (STEM désignant Science, Technology, Engineering, et Mathematics).
En six mois, Jess Wade a écrit 270 pages Wikipédia sur des femmes ayant eu une influence dans la recherche scientifique. De quoi susciter des vocations chez les jeunes filles.
L’automatique est une science qui traite de la commande de systèmes dynamiques tels qu’un barrage, une machine outil, un robot… Grâce à l’informatique, les commandes se sont énormément sophistiquées et permettent aujourd’hui de piloter des systèmes d’une très grande complexité. Pour en parler, nous reprenons cet article de Romain Postoyan qui dialogue avec Dragan Nesic. Thierry Viéville.
Dragan Nesic est professeur d’automatique à l’université de Melbourne en Australie. Ses recherches portent sur la commande des systèmes dynamiques et ses applications dans divers domaines de l’ingénierie et des sciences en général.
Romain Postoyan : Le grand public l’ignore souvent, mais l’automatique est au cœur de nombre d’avancées technologiques majeures au cours des derniers siècles.
Dragan Nesic : En effet, l’automatique a joué un rôle clef dans la plupart des grandes innovations technologiques et ce dès la révolution industrielle de la fin du XVIIIe siècle. Il est de notoriété publique que la machine à vapeur ouvrit la voie à la production de masse dans les usines tout en révolutionnant les transports terrestre et maritime.
Locomotive à vapeur. hpgruesen/pixnio.com, CC BY
On ignore souvent en revanche qu’un dispositif de commande, qui régulait la vitesse de rotation des machines (le régulateur à boules de Watt), fut essentiel pour leur mise en œuvre.
Le premier vol habité effectué par les frères Wright un siècle plus tard aurait été impossible sans un système de commande approprié. Des centaines de réussites similaires de l’automatique jalonnent l’histoire de nos avancées technologiques. De nos jours, nous vivons dans un monde où les organes de régulation sont omniprésents, ce qui est rendu possible par des millions de contrôleurs conçus à l’aide des techniques de l’automatique.
Le tout automatique. Rémy Malingrëy,
R.P. : Qu’est-ce que l’automatique ?
D.N. : L’automatique est une branche de l’ingénierie qui développe des techniques de commande pour des systèmes conçus par l’homme ou naturels, afin que ceux-ci se comportent de la manière souhaitée sans intervention humaine.
Prenons l’exemple d’un pilote automatique dans un Airbus A380. Celui-ci peut maintenir la vitesse, l’altitude et le cap désirés sans intervention du pilote. Un autre exemple est un drone qui peut identifier une fuite de gaz dans une usine et envoyer son emplacement exact à un centre d’expédition. Dans les deux cas, ce qui permet à l’avion et au drone de voler de la façon désirée est un algorithme appelé contrôleur ou régulateur, généralement implémenté sur un microprocesseur.
La couverture de Time réalisée avec des drones.
Cet algorithme connaît le comportement souhaité du système. Il collecte ensuite des mesures provenant des divers capteurs, puis traite ces données afin d’orchestrer les actionneurs qui agissent sur le système à piloter, à l’instar des moteurs électriques des drones et des moteurs à réaction de l’avion. Ainsi le système répond aux attentes, et ce malgré d’éventuelles perturbations imprévues.
R.P. : De nos jours, les données sont souvent transmises via des réseaux de communication numériques, comment cela impacte-t-il les contrôleurs ?
D.N. : Une grande partie de mon activité de recherche actuelle concerne les systèmes de commande dits en réseau dans lesquels le contrôleur communique avec les capteurs et les actionneurs via un réseau de télécommunication.
En raison du réseau, les signaux ne sont pas toujours transmis de manière fiable, ce qui peut fortement dégrader le fonctionnement du contrôleur.
Alors que nous nous dirigeons vers des systèmes hautement interconnectés et complexes, ce type d’architectures deviendra de plus en plus commun. Un exemple est celui des pelotons de véhicules sans conducteur, qui doivent se déplacer de manière autonome sur une route très fréquentée. Ceux-ci sont équipés de capteurs qui mesurent leur vitesse mais aussi leurs actions de contrôle. Ces signaux doivent être communiqués via un réseau de communication sans fil aux autres véhicules pour que le peloton conserve sa distance inter-véhicules dans des marges acceptables tout en roulant à la vitesse voulue.
Dans mes recherches, j’étudie l’interaction de l’algorithme de contrôle, des protocoles de communication et du calcul distribué au sein du système. C’est aussi le motif principal de ma collaboration avec le Centre de recherche en automatique de Nancy.
R.P. : Quels sont vos travaux actuels ?
D.N. : Nous travaillons sur de nouveaux modèles basés sur le réseau appelé FlexRay, qui est de plus en plus utilisé dans l’automobile. Il permet aux dizaines de contrôleurs présents dans une voiture de communiquer, à l’instar des systèmes de contrôle moteur et de direction ou d’arrêt. Cette avancée a ainsi permis de diminuer le poids des véhicules (réduisant ainsi la consommation de carburant) tout en offrant de meilleures performances.
En collaboration avec des chercheurs du CRAN, nous avons d’abord développé des modèles mathématiques fidèles aux systèmes pilotés via un réseau FlexRay.
Le modèle obtenu nous a permis d’analyser mathématiquement le comportement du système, ce qui a conduit au développement de techniques de conception de contrôleurs adaptés. Pour ce faire, nous utilisons des outils mathématiques de systèmes dits hybrides et de la théorie de la stabilité de Lyapunov afin de respecter les contraintes de communication imposées par le réseau tout en exploitant les flexibilités de conception offertes par le réseau FlexRay.
R.P. : Comment envisagez-vous le futur de l’automatique ?
D.N. : L’automatique permettra le développement d’avancées technologiques que l’on ne peut envisager que dans les films de science-fiction aujourd’hui. La recherche en automatique est tout à fait passionnante pour cela car de tels rêves nous forcent à aborder des questions de plus en plus complexes et, point important, multidisciplinaires.
Par exemple, la vie privée et la sécurité contre les attaques de logiciels malveillants et l’éthique commencent à influencer la recherche en automatique. Les voitures sans conducteur communiquant sans fil entre elles et avec leur environnement sont ainsi vulnérables aux attaques malveillantes qui peuvent corrompre les données échangées et provoquer des accidents.
La conception d’algorithmes de contrôle qui garantissent tous les objectifs fixés malgré de telles attaques attire actuellement l’attention de la communauté et requiert une collaboration étroite avec les informaticiens, les ingénieurs en télécommunication et les mathématiciens. Ceci n’est qu’un exemple de la nécessité d’une recherche multidisciplinaire. Les interactions avec la biologie et la médecine, avec la physique et la chimie, la finance et l’économie fourniront des idées nouvelles et de nouvelles problématiques permettant à terme le développement de sciences et de technologies fascinantes.
Romain Postoyan, Chargé de recherche CNRS, Université de Lorraine.
Oui ? Alors vous avez de la chance parce que c’est une revue de culture scientifique en sciences du numérique avec des articles écrits par les chercheuses et les chercheurs eux-mêmes, un vrai contact direct entre la recherche et le public.
Non ? Alors, allez vite le visiter et dégustez !
Aujourd’hui, nous avions envie de partager avec vous un article d’Interstices qui aborde la notion de choix en partant du très célèbre jeu du Loto. Savez-vous ce que peut penser un scientifique du fait de jouer au loto ? Que cela permet de payer les impôts supplémentaires ? Certes, mais c’est un tout petit peu plus drôle que ça … Laissons la parole à Gérard Berry et Jean-Paul Delahaye qui nous racontent une histoire presque vraie : jouer-ou-ne-pas-jouer-au-loto-telle-est-la-strategie
Musique, photographie, cinéma, danse, théâtre, autant de domaines artistiques dont les pratiques ont évolué sous l’impulsion du numérique, mais qu’en est-il de la question symétrique : les arts font-ils progresser les Sciences du numérique ? Pour nous éclairer sur ces questions et les illustrer avec quelques exemples, nous avons interrogé Martin Hachet (chercheur Inria à Bordeaux) qui s’y intéresse depuis longtemps. Pascal Guitton
Le numérique au service de l’Art
Les sciences du numérique ont d’abord permis un accès rapide et efficace à des œuvres artistiques. En particulier, les méthodes de compression audio et vidéo (par exemple JPEG, MPEG), issues de travaux de recherche en informatique et en traitement du signal, ont favorisé une diffusion large de créations artistiques, qui elles même ont inspiré de nouvelles créations. Au-delà du support de l’œuvre artistique, l’outil numérique a permis aux artistes d’explorer de nouvelles dimensions qui viennent compléter les supports d’expressions traditionnels. On peut notamment citer la musique électro (qui est aujourd’hui beaucoup plus informatique qu’électronique) ou l’animation 3D. Dans sa thèse, Florent Berthaut a par exemple exploré comment la réalité virtuelle pouvait offrir à des musicien·ne·s de nouveaux outils de création, et comment ces outils pouvaient offrir au public de nouvelles expériences audio-visuelles immersives.
Drile, instrument de musique virtuel développé dans le cadre de la thèse de Florent Berthaut.
[Photo Florent RV – Music]
Le numérique permet aussi de faciliter l’accès à un processus de création artistique à des non-experts. Aujourd’hui, avec des logiciels de musique, de dessin, ou de traitement vidéo, des utilisateurs novices arrivent à s’exprimer rapidement, alors que ces pratiques ont longtemps été réservées à des initiés. Bien-sûr, l’artiste en herbe ne rivalisera pas avec les artistes confirmés, ce n’est pas le but, mais en brisant la barrière du long apprentissage technique (par exemple solfège, puis doigté sur un manche de guitare) on lui offre un premier accès à la création artistique, plus rapide et plus large.
Art numérique vs. Art physique
Le numérique a fait évoluer les supports physiques dans de nombreux domaines artistiques. C’est notamment le cas de la photographie où les utilisatrices de l’argentique sont aujourd’hui de moins en moins nombreuses. Mais le numérique n’a bien sûr pas vocation à s’immiscer dans tous les domaines artistiques. Ressentir le son d’un souffle dans un basson, ou contempler un coup de pinceau sur une toile de maître, se fera toujours en laissant le numérique de côté. Si Art numérique et Art physique ont souvent évolué de façon séparée, ils ne doivent pas être opposés. Plusieurs expériences ont montré qu’il était intéressant de mélanger les approches numériques et les approches plus traditionnelles dans des même espaces hybrides. C’est notamment le cas des créations du Cirque Inachevé avec lequel nous avons collaboré[1], qui mélangent les Arts du cirque avec les Arts numériques (projection, contrôle de drones). Dans l’équipe Potioc, nous explorons également des approches basées sur la réalité augmentée spatiale et l’interaction tangible pour créer des environnements hybrides qui visent à favoriser la création artistique, ou à offrir de nouvelles expériences sensorielles et cognitives aux spectateur·trice·s. Par exemple, dans le cadre de notre travail1 avec la scénographe et plasticienne Cécile Léna, nous cherchons à enrichir ses maquettes physiques avec de la projection de contenus numériques interactifs. Les maquettes permettent de s’immerger dans l’univers de l’artiste au travers de spectacles miniatures. De son côté, la projection numérique vient augmenter, de façon subtile, des supports physiques (par exemple un billet de train dans La Table de Shanghaï illustrée ci-dessous) et va permettre aux spectateur·trice·s de tenir un rôle actif dans la découverte de cet univers. Cela ouvre la voie à de nouvelles formes de narrations. On peut trouver de tels exemples dans les actes de conférences scientifiques telles que NIME– New interfaces for Musical Expression.
Projection d’une vidéo sur un ticket de train dans la Table de Shanghaï.
Au travers de quelques exemples, nous avons pu voir comment le numérique pouvait servir aux pratiques artistiques. Les arts peuvent-ils rendre la politesse en servant le numérique ? Tout d’abord, de nombreux résultats de recherche en informatique ont été motivés par le domaine artistique. C’est notamment le cas de la compression audio/vidéo. A partir d’applications concrètes et directes, les chercheur·e·s sont invités à imaginer et à mettre au point des algorithmes de plus en plus performants. Ensuite, l’exploration de nouveaux espaces d’expression conduit les chercheurs à se confronter à des questions qui n’avaient jusque-là pas été posées. Pourtant, on entend parfois dire que les approches Art et sciences ne sont pas très rigoureuses, et les chercheu·r·e·s sont parfois invité·e·s à se concentrer sur des problèmes industriels « complexes et plus sérieux ». Je pense au contraire que la recherche numérique dans le domaine de l’Art est très exigeante, et non moins « utile ». Par exemple, dans le cas de la performance artistique live basée sur des technologies numériques, les scientifiques vont chercher à dépasser les limites des approches existantes malgré de fortes contraintes de temps réel. Ainsi, il n’est pas acceptable d’avoir le moindre délai entre le geste d’une musicienne et la génération du son associé, ce qui demande de concevoir des systèmes interactifs complexes (cf. l’interview d’Arshia Cont dans Binaire). A l’inverse, un léger délai dans de nombreux autres logiciels n’a en général que peu d’impact. La composante humaine est primordiale dans tout processus artistique, à la fois du point de vue de l’artiste et du point de vue du public. Or, qu’y a-t-il de plus complexe que la composante humaine dans tout processus interactif ? Les efforts de recherche dans les domaines artistiques, et les résultats obtenus sur ce sujet, peuvent servir dans d’autres contextes, et percoler largement dans la société.
La placedes émotions
A priori, l’Art va viser la création d’émotions, alors que la science va se concentrer sur la création de connaissances. Mais cette dualité n’est pas si binaire. L’émotion qui est recherchée en Art peut aussi être un ingrédient fondamental dans des problèmes de recherche. Par exemple, dans le domaine de l’éducation, de nombreuses recherches s’intéressent à améliorer les processus d’apprentissage des élèves grâce à l’introduction du numérique. Or, nous savons que l’engagement et les émotions positives jouent un rôle important dans les mécanismes d’apprentissage. Pour optimiser les questions d’apprentissage, le ou la scientifique a donc tout intérêt à s’intéresser de près à la question de l’esthétique qui servira de levier pour stimuler les émotions favorables aux objectifs visés. Cette dimension artistique pourra ainsi favoriser la construction de connaissances scientifiques fondamentales. Scientifiques et artistes ont donc beaucoup à gagner à travailler ensemble.
Martin Hachet (Directeur de recherche Inria, responsable de l’équipe-projet Potioc)
[1] Collaboration soutenue par le programme Art et Sciences de l’Idex – Université de Bordeaux


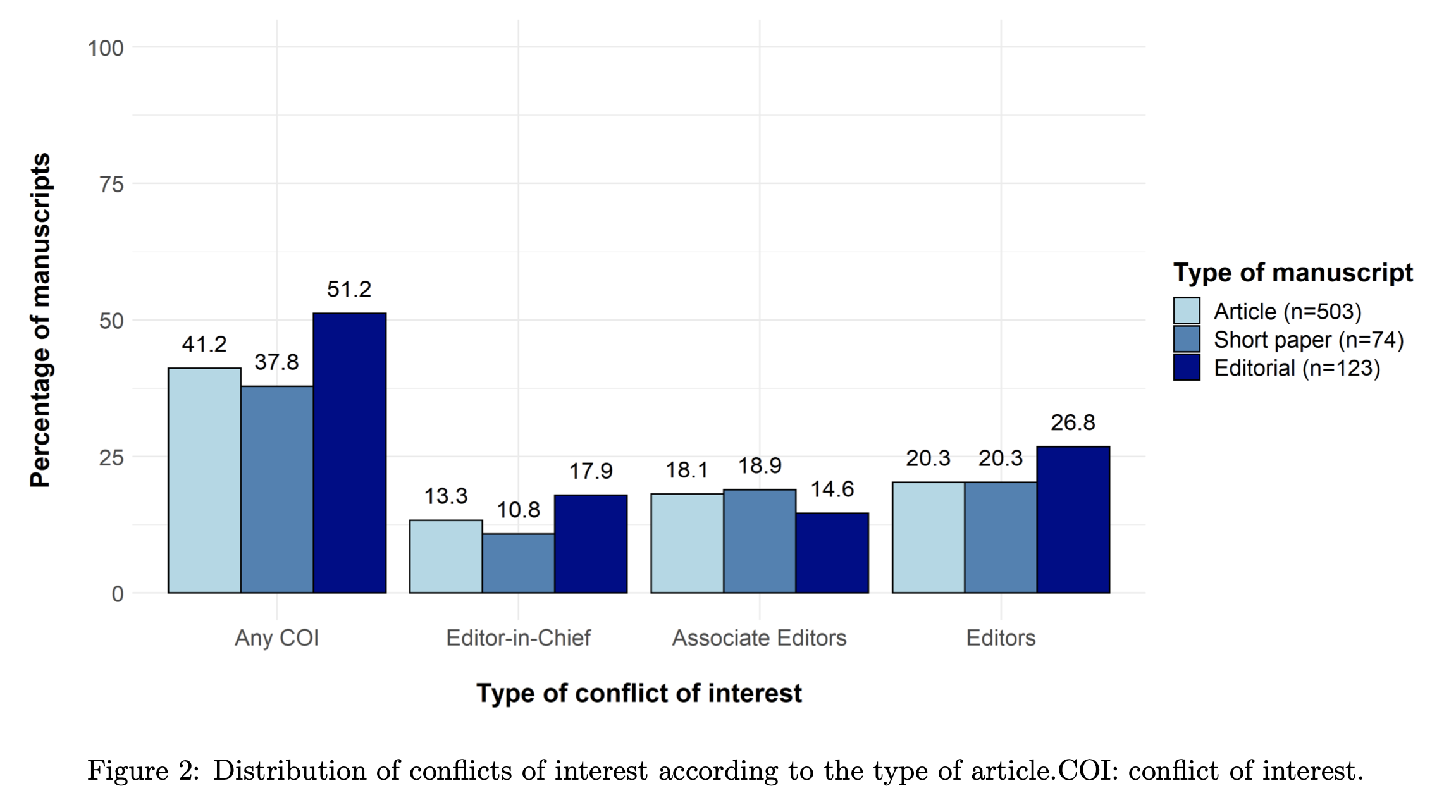
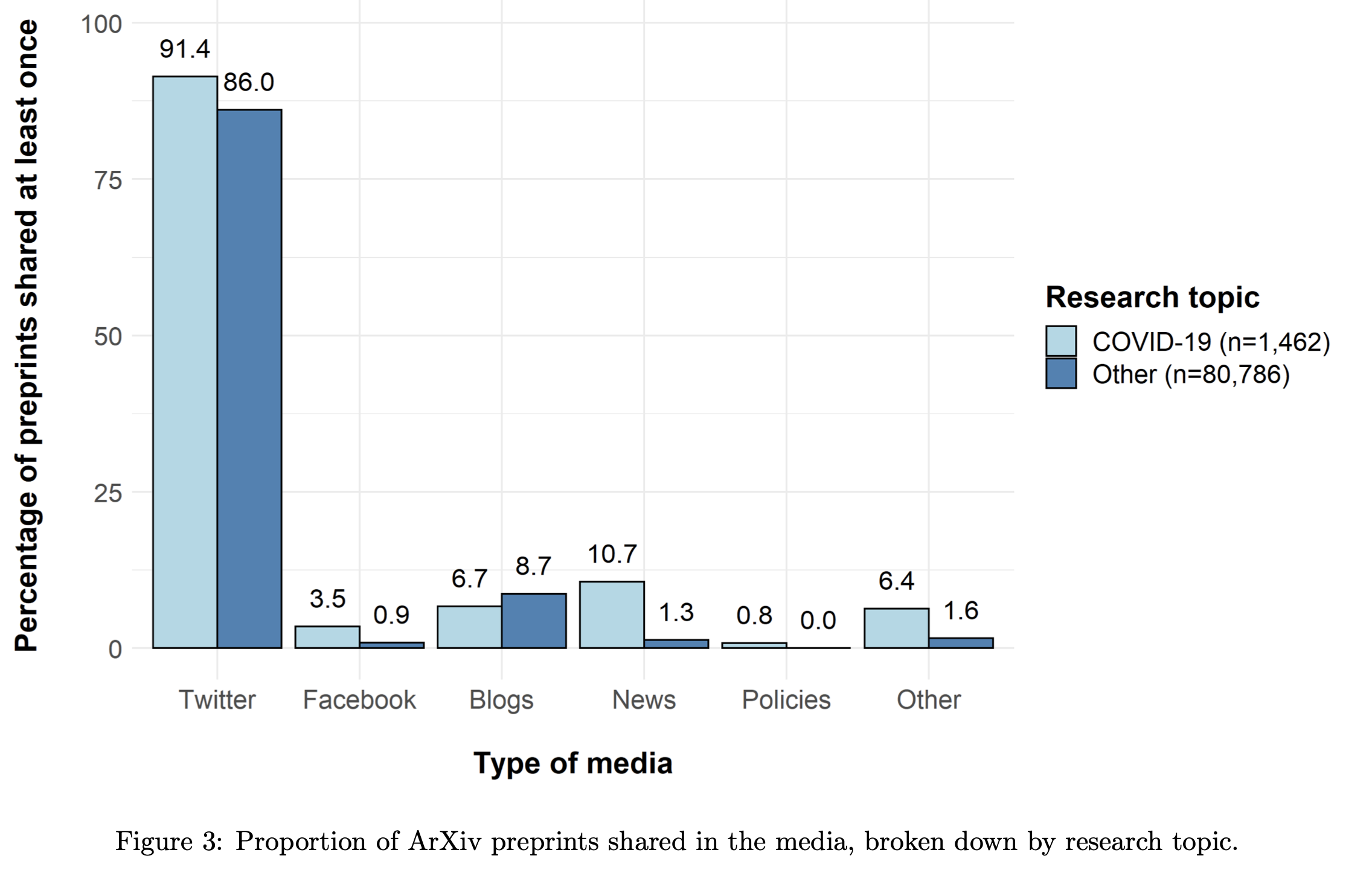
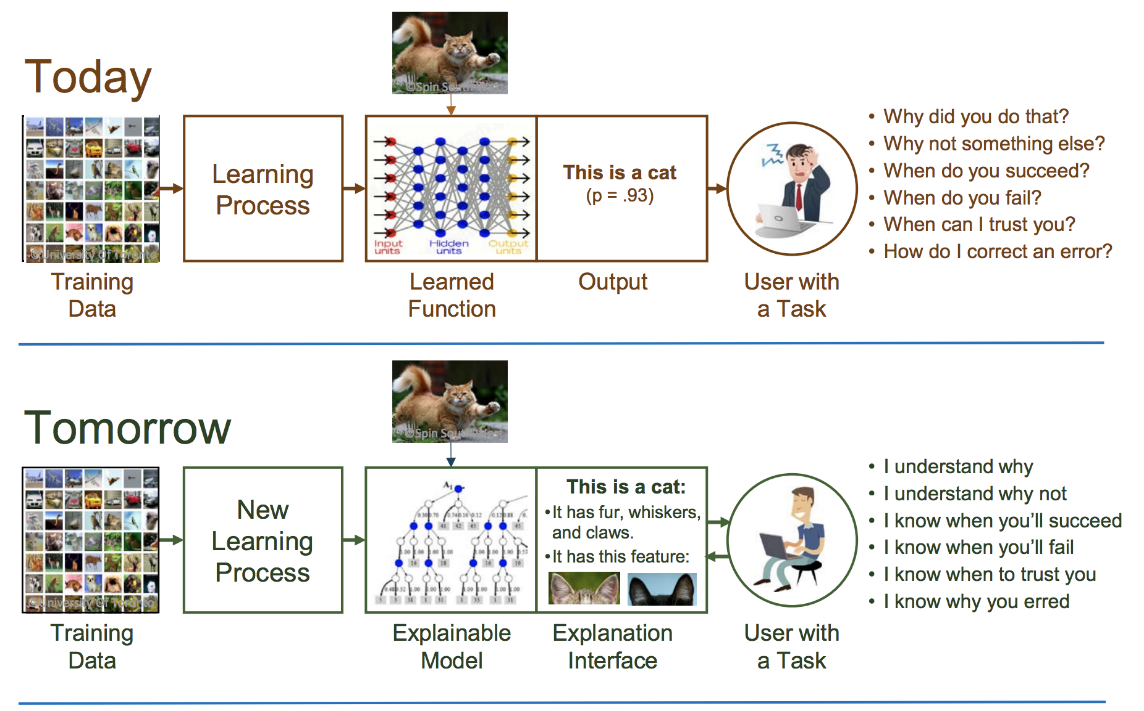
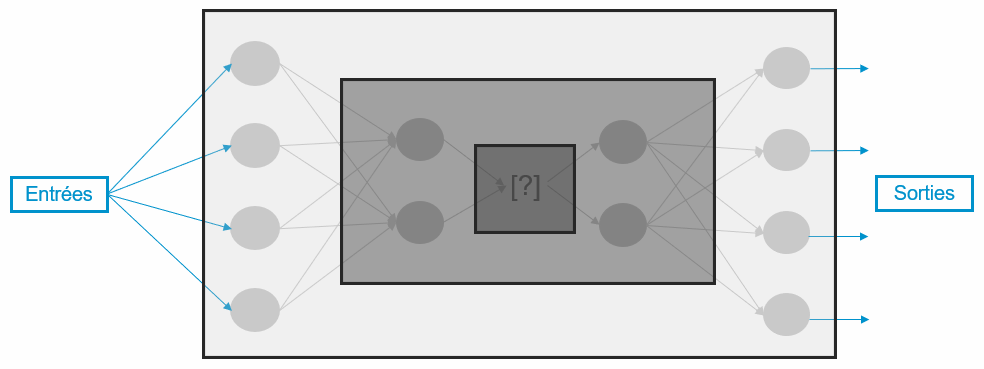
 La génèse d’une idée scientifique n’est jamais facile à retracer. En partant d’un exemple concret,
La génèse d’une idée scientifique n’est jamais facile à retracer. En partant d’un exemple concret, 

 Au début de l’année 1966, Claude Pair, qui venait de soutenir sa thèse d’Etat [5], me propose de traiter le sujet du cheminement dans un graphe au cours d’une thèse de troisième cycle. Le travail commun donnera lieu à cinq publications dont une communication de Claude [6] pour un congrès à Rome, un article de Claude dans la revue RIRO [8] et un livre chez Dunod, à paraître en 1968, comme annoncé dans l’article ci-dessus, Le manuscrit transmis à Jacques Arsac, directeur de la Collection, a disparu de son bureau en mai 1968, ce que nous n’apprîmes que fin 1969. Nous n’étions pas encore à l’époque des photocopieuses à foison et nous n’en avions aucune sauvegarde. Il a fallu recommencer : la seconde version est parue en 1971 [9].
Au début de l’année 1966, Claude Pair, qui venait de soutenir sa thèse d’Etat [5], me propose de traiter le sujet du cheminement dans un graphe au cours d’une thèse de troisième cycle. Le travail commun donnera lieu à cinq publications dont une communication de Claude [6] pour un congrès à Rome, un article de Claude dans la revue RIRO [8] et un livre chez Dunod, à paraître en 1968, comme annoncé dans l’article ci-dessus, Le manuscrit transmis à Jacques Arsac, directeur de la Collection, a disparu de son bureau en mai 1968, ce que nous n’apprîmes que fin 1969. Nous n’étions pas encore à l’époque des photocopieuses à foison et nous n’en avions aucune sauvegarde. Il a fallu recommencer : la seconde version est parue en 1971 [9]. Note : cet article a pour origine le colloque organisé à Nancy le 14 juin 2019 en l’honneur de Claude Pair, un des fondateurs de la science informatique. Pierre Lescanne a découvert cette situation lors des recherches bibliographiques qu’il a faites à cette occasion [1]. Une version plus détaillée de cet article est à paraître [17].
Note : cet article a pour origine le colloque organisé à Nancy le 14 juin 2019 en l’honneur de Claude Pair, un des fondateurs de la science informatique. Pierre Lescanne a découvert cette situation lors des recherches bibliographiques qu’il a faites à cette occasion [1]. Une version plus détaillée de cet article est à paraître [17]. C’est capable de faire des maths tout seul un ordinateur ? Pas tout à fait 😉 C’est bien notre cerveau humain qui conçoit la preuve mathématique, et la conduit à son terme … mais en utilisant un outil informatique, cela peut-être plus sûr et plus efficace.
C’est capable de faire des maths tout seul un ordinateur ? Pas tout à fait 😉 C’est bien notre cerveau humain qui conçoit la preuve mathématique, et la conduit à son terme … mais en utilisant un outil informatique, cela peut-être plus sûr et plus efficace. 

 Au moment où beaucoup d’entre nous se demandent comment être utiles pour aider les scientifiques à comprendre la maladie, puis à mettre au point des traitements et in fine un vaccin,
Au moment où beaucoup d’entre nous se demandent comment être utiles pour aider les scientifiques à comprendre la maladie, puis à mettre au point des traitements et in fine un vaccin, 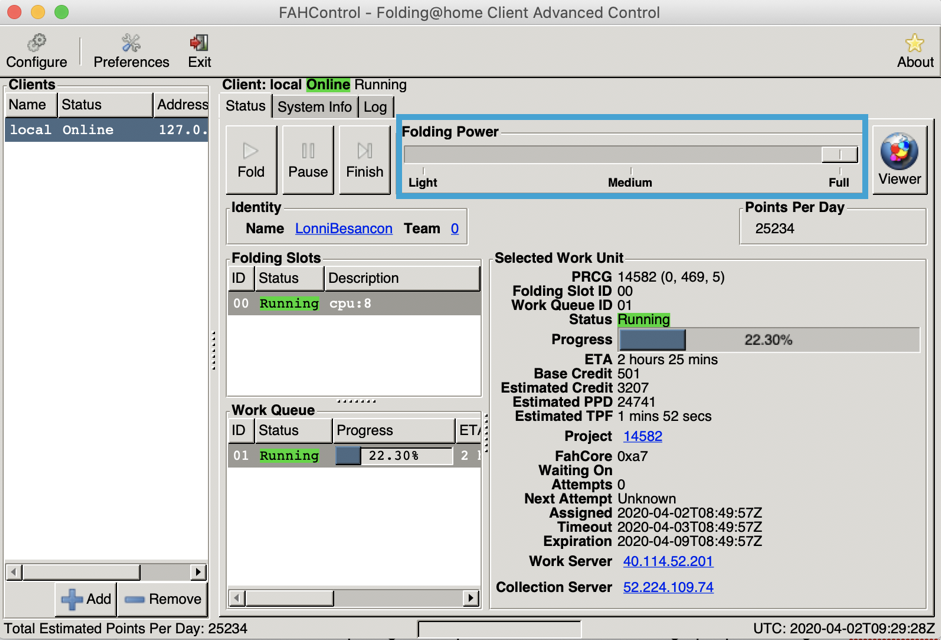









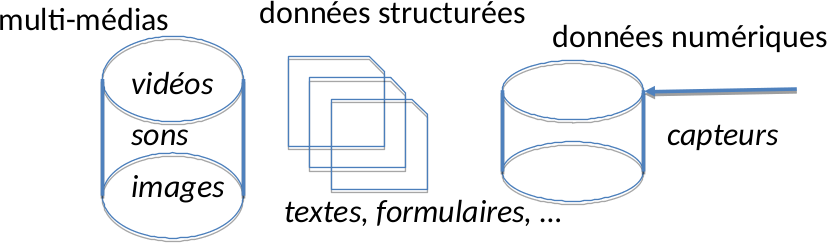
 On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.
On connaît la suite de l’histoire avec, tour à tour, chaque approche écrasant l’autre à l’occasion du succès éclatant d’une technique particulière, suivi de désillusions entraînant ce que l’on appelle un hiver de l’IA. Aujourd’hui, l’IA a fait des progrès indéniables, mais nous subissons toujours cette dualité, même si le vocabulaire a un peu évolué et que l’on parle maintenant d’IA basée sur les connaissances (pour le web sémantique) ou sur les données (et les data sciences). Nous sommes actuellement sans conteste dans une période numérique où tout le monde n’a que le Deep Learning à la bouche, même si des voix commencent à s’élever pour prédire une chute proche si l’on n’est pas capable d’associer ces techniques numériques à une interprétabilité (Lipton, 2017), permettant transparence et explications, deux notions du monde des connaissances.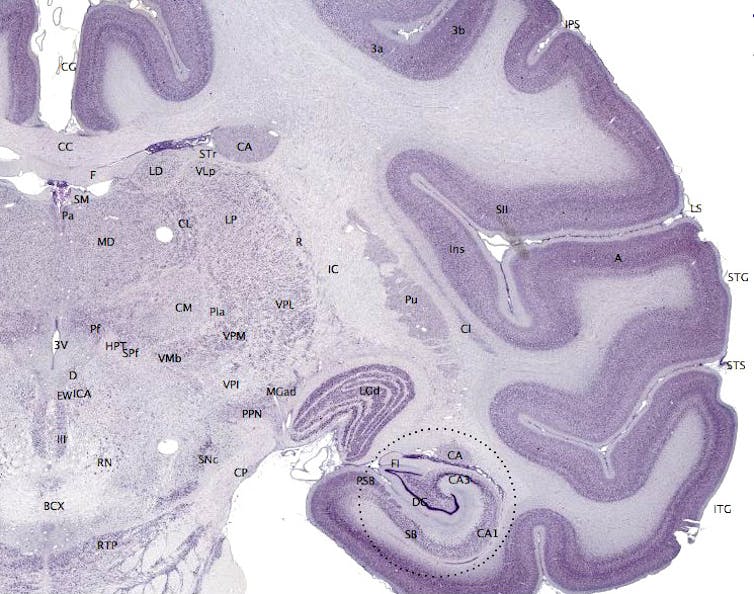












 Le livret d’activités «
Le livret d’activités « 




