L’article « Revelations: A Decidable Class of POMDP with Omega-Regular Objectives » a été primé par le « Outstanding Paper Award » à la conférence AAAI 2025, la plus prestigieuse conférence internationale en intelligence artificielle (https://aaai.org/). Cette récompense couronne le fruit d’un travail de recherche initié à Bordeaux, au sein de l’équipe Synthèse (https://synth.labri.fr/) du Laboratoire Bordelais de Recherche en Informatique (LaBRI), où travaillent quatre des auteurs: Marius Belly, Nathanaël Fijalkow, Hugo Gimbert et Pierre Vandenhove, en coopération avec des chercheurs à Paris (Florian Horn) et Anvers (Guillermo Pérez). Après nous avoir raconté la genèse de ce papier dans un précédent article, ce billet en esquisse les idées principales, tandis que l’article complet est consultable librement à l’adresse https://arxiv.org/abs/2412.12063 . Chloé Mercier et Serge Abiteboul.
L’équipe Synthèse du LaBRI s’attaque au problème ardu de la synthèse de programme. Il s’agit de développer des algorithmes qui eux-mêmes génèrent d’autres algorithmes, à partir de quelques exemples ou d’une spécification de ce qui est attendu. Concrètement, ces algorithmes très puissants sont utilisés dans une variété de contextes. Par exemple, la plupart des tableurs proposent aujourd’hui des fonctions de remplissage automatique : vous remplissez quelques cellules et, à partir de ces quelques exemples, un petit algorithme est synthétisé à la volée et se charge de finir le travail (https://deepsynth.labri.fr/). Un autre exemple est le contrôle robotique : un opérateur transmet à un robot une tâche à exécuter, par exemple reprendre le contrôle de la balle dans un match de Robocup, et charge au robot et à ses algorithmes de programmer la bonne suite de mouvements et d’actions à effectuer pour arriver au but escompté.
Quand les ingénieurs et chercheurs en Intelligence Artificielle (IA) ont besoin de résoudre des problèmes de synthèse, ils utilisent couramment un formalisme mathématique appelé processus de décision Markoviens, ou pour faire plus court, les MDP. La question centrale est la suivante : dans une situation où il faut prendre une suite de décisions, décrite par un MDP, comment faire pour prendre de bonnes décisions ? Ou, encore mieux, comment faire pour calculer automatiquement la meilleure suite de décisions possibles, ce qui s’appelle également une stratégie optimale ?
Les MDP pour décider
Mais qu’est-ce qu’un MDP exactement ? Dans le contexte de cette recherche, c’est un système à états finis dont l’évolution est déterminée à la fois par les décisions (choix d’action), mais également par le hasard. Voilà à quoi ressemble un tel animal :
Ce MDP illustre un exemple issu de l’article. C’est un jeu classique : il y a deux portes, et un tigre se cache derrière l’une des deux. On doit choisir quelle porte ouvrir, mais on ne sait pas où est le tigre. Grâce à l’action “écouter” (“listen” dans l’illustration) on peut révéler où se cache le tigre avec une probabilité positive. Crédits: les auteurs.
Dans la vie courante, on peut se servir des MDP à de multiples occasions (nous les avions déjà rencontré dans le cas du Cluedo dans un autre article binaire), par exemple pour jouer au « Solitaire », également appelé « Patience » ou encore « Spider Solitaire » dans sa célèbre variante. La situation ci-dessous illustre le dilemme de la prise de décision dans un MDP : faut-il placer un des deux rois noirs sur la pile vide à gauche ? Si oui, lequel des deux ? Le choix est épineux car certaines cartes sont masquées et ne seront révélées qu’ultérieurement.
Le jeu de Solitaire. Même quand toutes les cartes sont révélées, le problème est difficile : cf https://web.stanford.edu/~bvr/pubs/solitaire.pdf. Crédits: les auteurs.
Stratégies de résolution des MDP
Il y a deux grandes catégories d’algorithmes IA pour résoudre un MDP, qui peuvent paraître similaires à première vue mais qui pour les chercheurs en informatique sont bien distinctes. D’une part, il y a les algorithmes qui fonctionnent bien en pratique mais sans garantie de fournir la meilleure solution, ce qui est le cas de la plupart des méthodes d’apprentissage, notamment celles utilisant les réseaux de neurones (DeepRL). D’autre part, il y a les algorithmes qui fournissent à coup sûr une réponse exacte, qui relèvent de l’IA de confiance, basée sur la notion de calculabilité et de problème décidable développé par le génie Alan Turing, pionnier de l’informatique théorique. L’article des chercheurs bordelais appartient à la seconde catégorie : quand l’algorithme proposé produit une stratégie gagnante, on peut utiliser cette stratégie en toute confiance — elle garantit de gagner avec probabilité 1.
Soyons modestes et réalistes : les techniques d’apprentissage permettent de calculer des stratégies dans des problèmes très complexes alors que les techniques exactes au sens de la théorie de la calculabilité sont pour l’instant circonscrites à des problèmes plus simples, car elles sont en général beaucoup plus gourmandes en ressources de calcul. Par exemple, Google DeepMind a exploité les techniques de DeepRL afin de synthétiser d’excellentes stratégies à StarCraft, un jeu vidéo populaire dans lequel il faut prendre des dizaines de décisions par seconde en fonction de millions de paramètres. L’IA de DeepMind a initialement battu les meilleurs joueurs mondiaux, mais sa stratégie n’était pas parfaite : des contre-stratégies difficilement prévisibles ont ensuite été découvertes. Les méthodes exactes sont aujourd’hui inexploitables pour résoudre un problème aussi complexe que StarCraft, mais cela ne les empêche pas d’être efficaces en pratique. Par exemple, autre succès bordelais, l’équipe Rhoban du LaBRI a remporté une médaille d’or à la Robocup 2023 en exploitant des méthodes exactes pour résoudre de petits MDP en se basant sur le partage d’informations entre plusieurs robots coopératifs (https://github.com/Rhoban/TeamPlay).
La difficulté de la résolution exacte de problèmes de décision est très variable en fonction de l’information disponible au moment de la décision. Le cas idéal est celui de l’information parfaite, c’est le cas où toute l’information est disponible. Un exemple classique est celui d’un robot qui doit sortir d’un labyrinthe dont on connaît le plan ainsi que la propre position et orientation exacte du robot. Dans ce cas, le calcul est relativement facile à effectuer : il faut calculer un chemin vers la sortie (par exemple avec l’algorithme de Dijkstra) puis suivre ce chemin avec la suite de commandes de déplacement adéquates. Mais dans les problèmes rencontrés en pratique, il est rare d’avoir toutes les cartes en main. C’est le cas au solitaire, où une partie des cartes est masquée, ce qui nécessite de faire des hypothèses. Dans ce cas, en toute généralité le problème ne peut être résolu de manière exacte, la réponse n’est pas calculable au sens de Turing : aucun algorithme, aussi puissant que soit l’ordinateur sur lequel il est programmé, ne peut résoudre avec exactitude tous les problèmes de contrôle de MDP. C’est assez démoralisant à première vue pour un informaticien mais cela n’arrête pas certains chercheurs en informatique qui s’attellent à trouver des classes de MDP pour lesquelles le problème est moins complexe. En informatique théorique, on appelle cela une classe décidable.
Le travail de recherche primé à AAAI fournit justement une classe décidable de MDP : c’est le cas des problèmes avec « révélation forte », pour lesquels à chaque instant il y a une probabilité non-nulle que l’état exact du monde soit révélé. L’article donne aussi des résultats de décidabilité pour le cas des « révélations faibles », qui garantit que l’état exact du monde ne peut rester inconnu infiniment longtemps.
Un article de recherche se doit d’être tourné vers le futur, d’ouvrir des pistes. Notre algorithme permet d’analyser les jeux avec des révélations (fortes). Une perspective intéressante est de retourner le problème : on peut se demander plus généralement ce que fait l’algorithme lorsqu’il est utilisé pour n’importe quel jeu, avec ou sans révélations. Cela permet d’envisager d’analyser tous les jeux, même les plus compliqués, mais en restreignant plutôt le type de stratégie que les joueurs utilisent, ou la quantité d’informations qu’ils sont capables de traiter.
Marius Belly, Nathanaël Fijalkow, Hugo Gimbert, Florian Horn, Guillermo A. Pérez et Pierre Vandenhove
Les chercheurs ont toujours du mal à expliquer comment la recherche progresse dans un cadre international, pluridisciplinaire et collaboratif. Nous allons illustrer cela avec la genèse d’un article scientifique « Revelations: A Decidable Class of POMDP with Omega-Regular Objectives ». Cet article a été primé par le « Outstanding Paper Award » à la conférence AAAI 2025, la plus prestigieuse conférence internationale en intelligence artificielle (https://aaai.org/). Quatre des auteurs, Marius Belly, Nathanaël Fijalkow, Hugo Gimbert et Pierre Vandenhove, sont au laboratoire bordelais de recherche en informatique (LaBRI). Ils ont collaboré avec des chercheurs à Paris (Florian Horn) et Anvers (Guillermo Pérez). L’article est consultable librement à l’adresse https://arxiv.org/abs/2412.12063. Les auteurs racontent ici pour binaire l’histoire de ce travail. L’intérêt de l’article est d’observer la recherche en train de se faire. Il n’est pas nécessaire de comprendre même leurs résultats. Dans un second article, ils donneront plus de détails sur les contributions scientifiques. Serge Abiteboul et Chloé Mercier.
La question originale a été posée pendant le workshop « Gamenet » sur la théorie des jeux mêlant informaticiens, mathématiciens et économistes à Maastricht (Pays-Bas) en 2022. Les résultats mathématiques présentés par Guillaume Vigeral et Bruno Ziliotto sur les phénomènes de “révélations” dans les modèles de jeux à information imparfaite ont suscité la curiosité de Hugo et Florian au sujet des propriétés algorithmiques de ces jeux.
Le poker est un exemple classique de jeu à information imparfaite : chaque joueur possède à tout moment une information partielle de la partie, à savoir il connaît sa main et ce que les autres joueurs ont annoncé, mais pas la main des autres joueurs. Les jeux à information imparfaite sont extrêmement durs à comprendre d’un point de vue algorithmique, et l’on peut même prouver que, dans des modèles très simples, ils sont “indécidables”, ce qui signifie qu’il n’existe pas d’algorithme permettant de construire une stratégie optimale. Analyser algorithmiquement les jeux à information imparfaite est un vaste programme de recherche, très actif dans le monde académique mais également dans l’industrie : Google DeepMind s’est par exemple attaqué à StarCraft. Son succès a été mitigé puisque, si l’IA a initialement battu les meilleurs joueurs mondiaux, des stratégies imprévisibles contrant l’IA ont ensuite été découvertes.
Informellement, une “révélation” dans un jeu à information imparfaite correspond à un instant où les joueurs possèdent une connaissance complète de l’état du jeu. Par exemple au poker, lorsque tous les joueurs révèlent leurs cartes. Mais le mécanisme du jeu peut introduire après ce moment à nouveau des incertitudes, par exemple si un joueur pioche une nouvelle carte et ne la révèle pas. A son retour à Bordeaux, Hugo a posé à Nathanaël cette question fascinante : les jeux qui impliquent “régulièrement” des révélations sont-ils plus faciles à analyser d’un point de vue algorithmique ? Intuitivement, la difficulté d’analyser les jeux à information imparfaite est due à la multiplication des possibilités. Mais s’il y a “souvent” des révélations, ce nombre de possibilités devrait être réduit. Nous avons commencé à plancher sur ce sujet à trois : Nathanaël, Hugo, et Florian.
Hugo et Florian ont rendu visite à Nathanaël pendant son année sabbatique à l’Université de Varsovie (en 2023), et l’hiver polonais leur a permis de faire une première découverte : ils ont prouvé que ces jeux n’étaient pas plus faciles à analyser que le cas général. Au lieu d’abandonner, ils ont décidé de se focaliser sur les processus de décisions Markoviens (MDP), cas particulier des jeux où il n’y a qu’un seul joueur. Dans ce nouveau cadre, ils ont formulé des conjectures et conçu un algorithme pour résoudre ces MDP, mais ils n’avaient pas encore de preuve complète.
Encouragé par ces résultats, Hugo a proposé à Marius, alors étudiant en Master, d’effectuer son stage de recherche sur cette question au printemps 2023. Après de longs mois à manipuler des outils probabilistes et topologiques et après deux visites à Paris pour travailler avec Florian, les premières preuves ont été couchées sur papier. Le stage a en particulier permis de formaliser une distinction importante : il a distingué entre deux notions différentes de “révélations”, dites “faible” et “forte”. Malgré les progrès, de nombreuses questions restaient ouvertes.
Pierre a alors commencé un post-doctorat dans l’équipe bordelaise en septembre 2023, peu après la fin du stage de Marius. Il a dévoré son rapport de stage, relançant encore une fois la machine : l’espoir fait vivre et nourrit la recherche. Nous avons alors fait de grands pas en avant, et obtenu des résultats positifs dans le cas de révélations fortes ainsi que des résultats négatifs pour les révélations faibles. Plus précisément, nous avons construit un algorithme permettant d’analyser les jeux avec des révélations fortes, et montré que cela était impossible (indécidable) en cas de révélations faibles. C’est aussi une expérience classique en recherche : lorsque l’on se lance dans un nouveau problème, on commence par faire de tout petits pas. Plus on avance dans la compréhension des objets, et plus on fait de grands pas, jusqu’à résoudre le problème (ou pas). Faire de la recherche, c’est ré-apprendre à marcher à chaque nouveau problème !
Pour valider nos résultats empiriquement, nous avons collaboré avec Guillermo, expert des méthodes statistiques et exactes pour les jeux stochastiques. L’intérêt de l’algorithme que nous avions construit était d’être conceptuellement très simple et facile à implémenter. Il s’est avéré qu’il permet également en pratique de construire des stratégies plus performantes !
Un article de recherche se doit d’être tourné vers le futur, d’ouvrir des pistes. Notre algorithme permet d’analyser les jeux avec des révélations (fortes). Une perspective intéressante est de retourner le problème : on peut se demander plus généralement ce que fait l’algorithme lorsqu’il est utilisé pour n’importe quel jeu, avec ou sans révélations. Cela permet d’envisager d’analyser tous les jeux, même les plus compliqués, mais en restreignant plutôt le type de stratégie que les joueurs utilisent, ou la quantité d’informations qu’ils sont capables de traiter.
Marius Belly, Nathanaël Fijalkow, Hugo Gimbert, Florian Horn, Guillermo A. Pérez et Pierre Vandenhove
Combien pèse un gigaoctet, un tera, un exa ? La question ne vous parait pas avoir de sens. Pourtant elle passionne plus d’un et en particulier l’ami Max Dauchet qui nous initie au sujet. Max Dauchet est un brillant informaticien de l’Université de Lille, spécialiste d’algorithmique et de méthodes formelles pour la programmation.. Serge Abiteboul et Thierry Viéville.
On trouvera à l’adresse http://maxdauchet.fr/ une version plus détaillée de cet article
Si la question du poids de la connaissance dans un cerveau fait sourire et n’a guère de sens, celle du poids de l’information chargée dans une clé USB est bien réelle et inspire les Youtubers.
On parle d’information dématérialisée quand elle est accessible sous forme numérique plutôt que stockée dans des bibliothèques soumises à des contraintes architecturales draconiennes tant le papier est lourd. Jusqu’où peut-on aller dans l’allégement du support ? Rien ou Presque rien ? « Rien » signifierait que l’information est immatérielle. « Presque rien » signifierait qu’elle a un lien irréductible avec la matière. Idéalisme d’un côté, matérialisme de l’autre ? éclairer le distinguo vaut le détour. Le chemin nous fait passer par la thermodynamique et l’entropie, celle-là même qui nous fascine quand il s’agit du cosmos, dont la formule S = k logW orne la sépulture de Boltzmann à Vienne. Il aboutit à un « Presque rien » que quantifie le principe de Landauer.
Ce qu’en disent les Youtubers
Le Youtuber scientifique Théo Drieu a mis en ligne ce printemps la vidéo Combien pèse la totalité d’internet sur sa chaîne Balade Mentale (un million d’abonnés). Il ne s’agit bien entendu pas de la masse des infrastructures du net – des millions de tonnes – ni de l’équivalent en masse de l’énergie consommée – dans les 10 à 15 % de l’électricité de la planète. Il s’agit d’une estimation de la masse des électrons nécessairement mis en jeu pour faire circuler l’information sur le net. Dans la vidéo, l’animateur sacrifie à la loi du genre en tripotant une orange afin de marquer les esprits : la masse des informations sur le net serait celle d’une orange. Drieu ne fait là, comme il l’annonce, qu’actualiser les chiffres avancés par son collègue d’Outre-Atlantique Michael Stevens qui dans une vidéo de 2012 intitulée How Much Does The Internet Weigh? croquait modestement une fraise, les millions de térabits sur le net étant alors moins nombreux que maintenant. Dans cette même vidéo sur sa chaîne Vauce (vingt-deux millions d’abonnés) Stevens évoquait deux aspects : le nombre d’électrons nécessairement mobilisés selon les technologies du moment pour faire circuler l’information, et le nombre nécessaire pour la stocker. Dans ce cas, il estimait la masse inférieure à celle non plus d’une fraise mais d’une graine de fraise[i].
Ce qu’en disent les chercheurs
Ce qu’en dit précisément la science est plus saisissant encore, car la limite théorique est des milliards de fois moindre que la masse d’une graine de fraise évoquée par Stevens. Pour le raconter mieux vaut le faire en énergie plutôt qu’en matière, puisque matière et énergie se valent selon la célébrissime formule d’Einstein E = m c². Cela évite le biais lié à l’usage de la matière pour coder, que l’on peut ajouter, comme la plume encre le papier, ou retrancher comme le burin incise la pierre. D’autre part nous nous limitons ici au stockage, sans considérer la circulation de l’information.
La clé de voûte du raisonnement est le principe formulé en 1961 par Rolf Landauer, physicien américain chez IBM[ii] : l’effacement d’un bit dissipe au moins une énergie de k T log2 Joule, où k est la constante de Boltzmann, T la température absolue (en Kelvin) et log 2 ≈ 0,693. L’irruption de Boltzmann au milieu de l’informatique théorique peut surprendre, c’est pourtant lui qui fait le lien entre la physique-chimie – donc les sciences de la matière – et l’informatique – donc les sciences de l’information.
Landauer est pour sa part le premier à avoir tiré clairement toutes les conséquences de la théorie de Boltzmann. Les systèmes que considère Boltzmann sont des gaz, avec des milliards de milliards de milliards d’états possibles au niveau de l’ensemble des particules. Landauer applique l’idée de Bolzmann sur un système à … deux états, le 0 et le 1, juste de quoi stocker un bit. Pour étudier les propriétés d’un bit d’information, il applique ainsi un concept – l’entropie – basé sur quatre siècles d’intenses recherches en physique-chimie. On comprend que les laboratoires de physique demeurent mobilisés pour monter des expériences de confirmation ou d’invalidation de la proposition de Landauer, car de leurs résultats dépend notre conception des rapports entre matière, énergie et information. Ces expériences se situent au niveau quantique et font face à des phénomènes complexes comme les fluctuations statistiques d’énergie qui sont ici passés sous silence. Le présent regard est celui d’un informaticien, illustré par un petit démon imaginé par Maxwell, démon qui lui aussi a suscité de nombreuses vidéos.
L’entropie, une histoire de gaz et de piston
Wikipédia définit l’entropie comme une grandeur physique qui caractérise le degré de désorganisation d’un système. Cette notion naît de l’étude du rendement de la machine à vapeur et des travaux de Carnot sur les échanges de chaleur, autrement dit de la thermodynamique au sens littéral du terme. Le principe de Carnot dit que sans apport extérieur d’énergie, une source chaude et une source froide s’équilibrent irréversiblement en un système de température homogène. Ce principe a été généralisé en ce qui est maintenant le deuxième principe de thermodynamique, en introduisant la notion d’entropie pour quantifier « le désordre » vers lequel tout système sans apport extérieur d’énergie évolue inexorablement selon ce principe.
Clausius relie en 1865 la baisse d’entropie d’un gaz parfait à la la chaleur que dégage le travail d’un piston qui comprime le gaz à température constante[iii].
Quelques années plus tard, Bolzmann propose une définition radicalement différente de l’entropie S. Cette définition s’appuie sur la description statistique de l’état du gaz et aboutit à la formule S = k log W déjà évoquée (la version étendue de cet article montre l’équivalence des deux approches).
W est la clé du lien avec le numérique, ce symbole désigne le nombre de configurations possibles du gaz en considérant la position et de la vitesse de chaque particule. Quand le piston divise par deux le volume du gaz, le nombre possible de positions d’une particule est également divisé par deux : Pour chaque particule, il n’y a plus à préciser si elle est à gauche ou à droite dans la boite. Landauer en déduira plus tard que c’est l’effacement de cette information pour chaque particule qui produit la chaleur.
Cette présentation de l’entropie de Boltzmann et de son interprétation par Landauer enjambe l’histoire. Entre temps, les réflexions des physiciens ont évolué pas à pas, et elles ne sont pas closes. Le démon de Maxwell illustre ces réflexions.
Le démon de Maxwell : quand le calcul et la mémoire s’en mêlent
Se plaçant comme Boltzmann au niveau des particules, Maxwell proposa une expérience de pensée comme les physiciens aiment à les imaginer.
Maxwell considéra une boîte partagée en deux par une cloison munie d’une trappe qu’un démon actionne sans frottement de façon à faire passer une à une des particules[iv]. En les faisant passer de gauche à droite, le démon « range les particules », il diminue l’entropie du gaz sans fournir de travail, contrairement au piston : le deuxième principe de thermodynamique est contredit !
Pour lever la contradiction, les physiciens cherchèrent du côté des calculs effectués par le démon de Maxwell, considérant que si celui-ci n’exerce pas sur le gaz un travail mécanique, il exerce en quelque sorte un travail intellectuel, il observe, il acquière de l’information et il calcule. Tel fut le point de vue de Szilárd, un des principaux scientifiques du projet Manhattan connu pour son opposition farouche à l’usage de la bombe atomique[v]. Puis Brillouin[vi] ébaucha l’idée ensuite érigée en principe par Landauer que c’est l’effacement d’information qui augmente l’entropie, comme nous allons le préciser.
Le principe de Landauer : du gaz à l’ordinateur
Le principe de Landauer est une extrapolation de la formule de Boltzmann aux systèmes informatiques. La relation entre énergie et nombre de micro-états est étendue par analogie.
Landauer pose directement la formule de Boltzmann en considérant un seul bit de mémoire comme un système à deux états possibles, 0 et 1 [vii]. Si le bit est effacé, il n’y a plus qu’un seul état, l’entropie a donc diminué et ce travail d’effacement s’est dissipé en chaleur.
Retour sur le démon de Maxwell
Pour la simplicité de l’interprétation numérique, nous avons seulement considéré plus haut le cas où le volume du gaz est réduit de moitié. Mais le parallèle entre le piston et le démon doit tenir pour tous les taux de compression. Pour pouvoir revenir aux conditions initiales, le démon doit compter les particules de gauche à droite, afin d’en renvoyer autant si l’on poursuit le parallèle avec le piston. D’après Landauer, pour ne pas chauffer, le démon ne doit effacer aucun bit intermédiaire, ce qui n’est pas le cas avec l’addition habituelle mais est réalisé par exemple en « comptant des bâtons ». Or le démon fait partie du système physique considéré dans l’expérience de pensée, il doit donc être remis dans son état d’origine si l’on veut faire un bilan énergétique à l’issue de la compression comme c’est le cas ici. Autrement dit, il doit alors effacer sa mémoire, ce qui dégage la chaleur prévue par la physique.
Réversibilité et entropie
Pour imaginer un système informatique ne consommant aucune énergie, ce système ne doit donc effacer aucune information durant ses calculs, ce qui revient à considérer des machines logiquement réversibles, où l’on peut remonter pas-à-pas les calculs comme si on remontait le temps . C’est ainsi que nous avons réinterprété le démon. Les opérateurs logiques et arithmétiques usuels ne sont évidemment pas réversibles (l’addition et le ET perdent les valeurs de leurs données) . Cependant Bennett[viii], [ix], [x] a montré que l’on peut rendre tout calcul logiquement réversible en donnant un modèle de machine de Turing conservant l’historique de tous ses calculs. Ces considérations sont particulièrement prometteuses pour les ordinateurs quantiques, où la superposition d’états dans les q-bits conduit (sous les nombreuses contraintes liées à ce type de machine) à considérer directement des opérateurs réversibles.
Les physiciens continuent de se passionner pour le principe de Landauer[xi], imaginant des nano machines parfois extravagantes, à cliquets, escaliers, poulies ou trappes et construisant des expériences de plus en plus fines[xii] pour mesurer l’énergie dégagée par l’effacement d’un bit[xiii]. Jusqu’à présent, le principe est confirmé, dans le cadre de la physique classique comme de la physique quantique. Il n’est cependant pas exclu que sa limite soit un jour abaissée, notamment en exploitant des propriétés de la physique quantique encore mal connues. Cela remettrait en cause les interprétations qui viennent d’être décrites, et ce serait alors une nouvelle source de progrès dans les modèles scientifiques de l’organisation de la matière et de l’information.
En guise de conclusion
La limite de Landauer commence à influencer l’architecture des systèmes et plaide pour l’informatique quantique. Elle fournit un horizon qui nous incite à méditer sur ce qu’est le traitement de l’information, que ce soit par le vivant ou la machine.
La théorie associe à l’information une masse minimale de matière bien moindre encore que celle mise en scène par les Youtubers, déjà spectaculaire par sa modicité. De même il faut peu de matière pour libérer beaucoup d’énergie (bombe, centrale nucléaire) et beaucoup d’énergie pour générer quelques particules (au LHC du CERN). Le second principe de thermodynamique et l’entropie nous font penser qu’il est plus facile de désordonner que de structurer. Pourtant l’univers fabrique sans cesse de nouveaux objets cosmiques et la vie s’est développée sur terre[xiv]. Nous devons nous méfier de nos appréciations sur le petit ou le grand, le beaucoup ou le peu, qui sont des jugements attachés à notre échelle et à notre condition.
Max Dauchet, Professeur Émérite de l’Université de Lille.
[i] Estimation tirée d’articles universitaires. Cinquante ans avant, Richard Feynman, prix Nobel de physique , dans sa célèbre conférence de 1959 intitulée There’s Plenty of Room at the Bottom, annonciatrice de l’essor des nanotechnologies, estimait que l’on pourrait coder avec les technologies de l’époque toutes les connaissances du monde dans un grain de poussière, et indiquait les pistes pour le faire.
[ii] Rolf Landauer, Irreversibility and Heat Generation in the Computing Process, IBM Journal of Research and Development, 5(3), 183–191 (1961).
[iii]Die mechanische Wärmetheorie, Friedrich Vieweg und Sohn ed (1865 -1867).
[iv] Historiquement, le démon trie les particules les plus rapides et les plus lentes, distribuées statistiquement autour de la valeur moyenne, pour créer une source chaude et une source froide à partir d’un milieu en équilibre thermique.
[v] La première planche de La bombe, BD consacrée au projet Manhattan, illustre un cours de Szilárd sur le sujet en 1933. Alcante, Bollée, Rodier, Ed. Glénat, 2020.
[vi] Brillouin est sans doute un des noms les moins connus de ceux cités ici. Alfred Kastler, prix Nobel de physique, lui rendait hommage dans les colonnes du Monde lors de sa disparition 1969 : Léon Brillouin : un des plus brillants physiciens français.
[vii] En réalité un réseau de bits statistiquement liés, pour des raisons de phénomènes physiques.
[viii] C. H. Bennett, Logical reversibility of computation, IBM journal of Research and Development, 1973.
[ix] J.-P. Delahaye, Vers du calcul sans coût énergétique, Pour la science, pp 78-83, janvier 2017
[xi] La plupart des références données ici sont les références historiques – il est souvent instructif de découvrir les idées « dans leur jus ». Cependant il suffit de parcourir le net pour en trouver des récentes en pagaille.
[xii] Les fluctuations statistiques ici négligées y jouent un rôle important.
[xiii] Séminaire information en physique quantique de l’Institut Henri Poincaré, 17/11/2018 . vidéos sur carmin.tv, les mathématiques vivantes. Landauer et le démon de Maxwell, Sergio Ciliberto. Thermodynamique et information, Kirone Mallik.
[xiv] Dans son article déjà cité, Bennett évoque l’économie de moyens de la duplication des gènes, déjà remarquée par Landauer en 1961.
A force d’imaginer l’IA* capable de tout faire, il fallait bien qu’on se pose un jour la question de savoir si cette technologie pouvait aussi faire de la science. C’est même la très sérieuse Académie nationale des sciences des Etats-Unis (NAS) qui s’interroge, à l’issue d’un séminaire dont elle a publié un compte-rendu. Charles Cuveliez et Jean-Charles Quisquater nous expliquent exactement tout ce qu’il ne faut pas faire ! Ikram Chraibi-Kaadoud et Thierry Viéville.
(*) L’expression IA recouvre un ensemble de concepts, d’algorithmes, de systèmes parfois très différents les uns des autres. Dans cet article, nous utilisons cette abréviation simplificatrice pour alléger la lecture.
Une IA qui voudrait faire de la science, devrait posséder certaines qualités d’un scientifique comme la créativité, la curiosité, et la compréhension au sens humain du terme. La science, c’est identifier des causes (qui expliquent les prédictions), c’est se débrouiller avec des données incomplètes, de taille trop petite, c’est faire des choix, tout ce que l’IA ne peut être programmé à faire. C’est se rendre compte des biais dans les données, alors que certains biais sont amplifiés par l’IA. Par contre, l’IA peut détecter des anomalies ou trouver des structures ou des motifs dans de très grands volumes de données, ce qui peut mener le scientifique sur des indices qu’il ne trouverait pas autrement.
Si l’IA peut contribuer à la science, c’est sans doute en automatisant et menant des expériences à la place du scientifique, plus rapidement et donc en plus grand nombre, qu’un humain ne pourrait le faire. Mais tout scientifique expérimentateur sait combien il peut être confronté à des erreurs de mesures ou de calibration. Il faut aussi pouvoir répondre en temps réel aux variations des conditions expérimentales. Un scientifique est formé pour cela. Un système d’IA répondra à des anomalies des appareils de mesure mais dans la mesure de l’apprentissage qu’il a reçu. Dans un récent article ambitieusement nommé: “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery” (Sept 2024), leurs auteurs ont proposé un modèle qui automatise le travail d’un chercheur depuis la confrontation d’une idée à la littérature existante (est-elle nouvmaitriseelle) jusqu’à l’écriture du papier, sans doute impressionnant mais où le coup de génie a-t-il sa place dans cette production scientifique aseptisée ?
Que peut apporter spécifiquement l’IA générative, et en son sein, les modèles LLM ? Ils sont entraînés et emmagasinent des quantités gigantesques de données de manière agnostique mais ne savent pas faire d’inférence, une autre caractéristique de la science en marche. On a l’impression que l’IA, générative ou non, a une capacité d’inférence : si on lui montre une photo d’un bus qu’elle n’a jamais vu auparavant, pour autant qu’elle ait été entraîné, elle reconnaîtra en effet qu’il s’agit d’un bus. A-t-elle pour autant une compréhension de ce qu’est un bus ? Non car un peu de bruit sur l’image lui fera rater la reconnaissance, contrairement à un humain ! En fait, il ne s’agit pas d’inférence, mais de reconnaissance.
Sans avoir de capacité de raisonnement, l’IA générative est un générateur d’idées plausibles, quitte pour le scientifique à faire le tri entre toutes les idées plausibles et celles peut-être vraies (à lui de le prouver !). L’IA générative peut étudier de large corpus de papiers scientifiques, trouver le papier qui contredit tous les autres et qui a été oublié et est peut-être l’avancée décisive que le scientifique devra déceler. Elle peut aussi résumer ce qui permettra au chercheur de gagner du temps. L’IA générative peut également générer du code informatique qui aide le scientifique. On a même évoqué l’idée de l’IA qui puisse générer des données expérimentales synthétiques, ce qui semble un peu fou mais très tentant lorsque les sujets sont des être humains. Que ne préférerait-on pas une IA générative répondre comme un humain pour des expériences en sciences sociales, sauf que c’est un perroquet stochastique qui vous répondra (Can AI Replace Human Research Participants? These Scientists See Risks, Scientific American, March 2024)
Alors, oui, vu ainsi, l’IA est un assistant pour le scientifique. Les IA n’ont pas la capacité de savoir si leurs réponses sont correctes ou non. Le scientifique oui.
Malheureusement, la foi dans l’IA peut amener les chercheurs à penser de manière moins critique et à peut-être rater des options qu’ils auraient pourtant trouvées sans IA. Il y a un problème de maîtrise de l’IA. Pour faire progresser l’utilisation de l’IA vers la science, il faudrait d’abord qu’elle ne soit plus l’apanage des seuls experts en IA mais qu’elle soit basée sur une étroite collaboration avec les scientifiques du domaine
Introduire l’utilisation de l’IA dans la science présente aussi un risque sociétal : une perte de confiance dans la science induite par le côté boite noire de l’IA.
Il faut donc bel et bien distinguer l’IA qui ferait de la science de manière autonome (elle n’existe pas) ou celle qui aide le scientifique à en faire de manière plus efficace.
Et d’ailleurs, l’IA a déjà contribué, de cette manière-là, à des avancées dans la science dans de nombreuses disciplines comme la recherche sur des matériaux, la chimie, le climat, la biologie ou la cosmologie.
Au final restera la quadrature du cercle : comment une IA peut expliquer son raisonnement pour permettre au scientifique de conseiller son IA à l’assister au mieux.
Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT) & Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles)
Pour en savoir plus: AI for Scientific Discovery, Proceedings of a Workshop (2024), US National Academies, Medecine, Sciences, Engineering
Billet d’introduction: L’expression “David contre Goliath” n’a jamais semblé aussi pertinente que lorsqu’il faut décrire le combat des artistes contre les GAFAM. Cette expression souvent utilisée pour décrire un combat entre deux parties prenantes de force inégale souligne une réalité : celle de la nécessité qu’ont ressenti des artistes de différents milieux et pays de se défendre face à des géants de la tech de l’IA générative pour protéger leur oeuvres, leur passion et leur métier, pour eux et pour les générations futures. Si la Direction Artistique porte le nom de [DA]vid, alors l’IA sera notre Gol[IA]th… C’est parti pour une épopée 5.0 !
Julie Laï-Pei, femme dans la tech, a à cœur de créer un pont entre les nouvelles technologies et le secteur Culturel et Créatif, et d’en animer la communauté. Elle nous partage ici sa réflexion au croisement de ces deux domaines.
Chloé Mercier, Thierry Vieville et Ikram Chraibi Kaadoud
Comment les artistes font-ils face au géant IA, Gol[IA]th ?
« David et Goliath » – Gustave Doré passé dans Dall-e – Montage réalisé par @JulieLaï-Pei
A l’heure d’internet, les métiers créatifs ont connu une évolution significative de leur activité. Alors que nous sommes plus que jamais immergés dans un monde d’images, certains artistes évoluent et surfent sur la vague, alors que d’autres reviennent à des méthodes de travail plus classiques. Cependant tous se retrouvent confrontés aux nouvelles technologies et à leurs impacts direct et indirect dans le paysage de la créativité artistique.
Si les artistes, les graphistes, les animateurs devaient faire face à une concurrence sévère dans ce domaine entre eux et face à celle de grands acteurs du milieu, depuis peu (on parle ici de quelques mois), un nouveau concurrent se fait une place : l’Intelligence artificielle générative, la Gen-IA !
C’est dans ce contexte mitigé, entre écosystème mondial de créatifs souvent isolés et puissances économiques démesurées que se posent les questions suivantes :
Quelle est la place de la création graphique dans cet océan numérique ? Comment sont nourris les gros poissons de l’intelligence artificielle pour de la création et quelles en sont les conséquences ?
L’évolution des modèles d’entraînement des IA pour aller vers la Gen-AI que l’on connaît aujourd’hui
Afin qu’une intelligence artificielle soit en capacité de générer de l’image, elle a besoin de consommer une quantité importante d’images pour faire le lien entre la perception de “l’objet” et sa définition nominale. Par exemple, à la question “Qu’est-ce qu’un chat ?” En tant qu’humain, nous pouvons facilement, en quelques coup d’œil, enfant ou adulte, comprendre qu’un chat n’est pas un chien, ni une table ou un loup. Or cela est une tâche complexe pour une intelligence artificielle, et c’est justement pour cela qu’elle a besoin de beaucoup d’exemples !
Ci dessous une frise chronologique de l’évolution des modèles d’apprentissage de l’IA depuis les premiers réseaux de neurones aux Gen-IA :
Frise chronologique par @JulieLaiPei
En 74 ans, les modèles d’IA ont eu une évolution fulgurante, d’abord cantonnée aux sphères techniques ou celle d’entreprises très spécialisées, à récemment en quelques mois en 2023, la société civile au sens large et surtout au sens mondial.
Ainsi, en résumé, si notre IA Gol[IA]th souhaite générer des images de chats, elle doit avoir appris des centaines d’exemples d’images de chat. Même principe pour des images de voitures, des paysages, etc.
Le problème vient du fait que, pour ingurgiter ces quantités d’images pour se développer, Gol[IA]th mange sans discerner ce qu’il engloutit… que ce soit des photos libres de droit, que ce soit des oeuvres photographiques, des planches d’artwork, ou le travail d’une vie d’un artiste, Gol[IA]th ne fait pas de différence, tout n’est “que” nourriture…
Dans cet appétit gargantuesque, les questions d’éthique et de propriétés intellectuelles passent bien après la volonté de développer la meilleure IA générative la plus performante du paysage technologique. Actuellement, les USA ont bien de l’avance sur ce sujet, créant de véritables problématiques pour les acteurs de la création, alors que l’Europe essaie de normer et d’encadrer l’éthique des algorithmes, tout en essayant de mettre en place une réglementation et des actions concrètes dédiées à la question de la propriété intellectuelle, qui est toujours une question en cours à ce jour.
Faisons un petit détour auprès des différents régimes alimentaires de ce géant…
Comment sont alimentées les bases de données d’image pour les Gen-AI ?
L’alimentation des IA génératives en données d’images est une étape cruciale pour leur entraînement et leur performance. Comme tout bon géant, son régime alimentaire est varié et il sait se sustenter par différents procédés… Voici les principales sources et méthodes utilisées pour fournir les calories nécessaires de données d’images aux IA génératives :
Les bases de données publiques
Notre Gol[IA]th commence généralement par une alimentation saine, basée sur un des ensembles de données les plus vastes et les plus communément utilisés: par exemple, ImageNet qui est une base de données d’images annotées produite par l’organisation du même nom, à destination des travaux de recherche en vision par ordinateur. Cette dernière représente plus de 14 millions d’images annotées dans des milliers de catégories. Pour obtenir ces résultats, c’est un travail fastidieux qui demande de passer en revue chaque image pour la qualifier, en la déterminant d’après des descriptions, des mot-clefs, des labels, etc…
Entre autres, MNIST, un ensemble de données de chiffres manuscrits, couramment utilisé pour les tâches de classification d’images simples.
Dans ces ensembles de données publics, on retrouve également COCO (à comprendre comme Common Objects in COntext) qui contient plus de 330 000 images d’objets communs dans un contexte annotées, pour l’usage de la segmentation d’objets, la détection d’objets, de la légendes d’image, etc…
Plus à la marge, on retrouve la base de données CelebA qui contient plus de 200 000 images de visages célèbres avec des annotations d’attributs.
Plus discutable, Gol[IA]th peut également chasser sa pitance… Pour ce faire, il peut utiliser le web scraping. Il s’agit d’un procédé d’extraction automatique d’images à partir de sites web, moteurs de recherche d’images, réseaux sociaux, et autres sources en ligne. Concrètement, au niveau technique, il est possible d’utiliser des APIs (Application Programming Interfaces) pour accéder à des bases de données d’images: il s’agit d’interfaces logicielles qui permettent de “connecter” un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités. Il en existe pour Flickr, pour Google Images, et bien d’autres.
Ce procédé pose question sur le plan éthique, notamment au sujet du consentement éclairé des utilisateurs de la toile numérique : Est-ce qu’une IA a le droit d’apprendre de tout, absolument tout, ce qu’il y a en ligne ? Et si un artiste a choisi de partager ses créations sur internet, son œuvre reste-t-elle sa propriété ou devient-elle, en quelque sorte, la propriété de tous ?
Ces questions soulignent un dilemme omniprésent pour tout créatif au partage de leur œuvre sur internet : sans cette visibilité, il n’existe pas, mais avec cette visibilité, ils peuvent se faire spolier leur réalisation sans jamais s’en voir reconnaître la maternité ou paternité.
Il y a en effet peu de safe-places pour les créatifs qui permettent efficacement d’être mis en lumière tout en se prémunissant contre les affres de la copie et du vol de propriété intellectuelle et encore moins de l’appétit titanesque des géants de l’IA.
C’est à cause de cela et notamment de cette méthode arrivée sans fanfare que certains créatifs ont choisi de déserter certaines plateformes/réseaux sociaux: les vannes de la gloutonnerie de l’IA générative avaient été ouvertes avant même que les internautes et les créatifs ne puissent prendre le temps de réfléchir à ces questions. Cette problématique a été aperçue, entre autres, sur Artstation, une plateforme de présentation jouant le rôle de vitrine artistique pour les artistes des jeux, du cinéma, des médias et du divertissement. mais également sur Instagram et bien d’autres : parfois ces plateformes assument ce positionnement ouvertement, mais elles sont rares ; la plupart préfèrent enterrer l’information dans les lignes d’interminables conditions d’utilisation qu’il serait bon de commencer à lire pour prendre conscience de l’impact que cela représente sur notre “propriété numérique”.
Les bases de données spécialisées
Dans certains cas, Gol[IA]th peut avoir accès à des bases de données spécialisées, comprenant des données médicales (comme les scans radiographiques, IRM, et autres images médicales disponibles via des initiatives comme ImageCLEF) ou des données satellites (fournies par des agences spatiales comme la NASA et des entreprises privées pour des images de la Terre prises depuis l’espace).
Les données synthétiques
Au-delà des images tirées du réel, l’IA peut également être alimentée à partir d’images générées par ordinateur. La création d’images synthétiques par des techniques de rendu 3D permet de simuler des scénarios spécifiques (par exemple, de la simulation d’environnements de conduite pour entraîner des systèmes de conduite autonome), ainsi que des modèles génératifs pré-entraînés. En effet, les images générées par des modèles peuvent également servir pour l’entraînement d’un autre modèle. Mais les ressources peuvent également provenir d’images de jeux vidéo ou d’environnement de réalité virtuelle pour créer des ensembles de données (on pense alors à Unreal Engine ou Unity).
Les caméras et les capteurs
L’utilisation de caméras pour capturer des images et des vidéos est souvent employée dans les projets de recherche et développement, et dans une volonté de sources plus fines, de capteurs pour obtenir des images dans des conditions spécifiques, comme des caméras infrarouges pour la vision nocturne, des LIDAR pour la cartographie 3D, etc.
Toutes ces différentes sources d’approvisionnement pour Gol[IA]th sont généralement prétraitées avant d’être utilisées pour l’entraînement : normalisation, redimensionnement, augmentation des données, sont des moyens de préparation des images.
En résumé, il faut retenir que les IA génératives sont alimentées par une vaste gamme de sources de données d’images, allant des ensembles de données publiques aux données collectées en ligne, en passant par les images synthétiques et les captures du monde réel. La diversité et la qualité des données sont essentielles pour entraîner des modèles génératifs performants et capables de produire des images réalistes et variées. Cependant cette performance ne se fait pas toujours avec l’accord éclairé des auteurs des images. Il est en effet compliqué – certains diront impossible – de s’assurer que la gloutonnerie de Gol[IA]th s’est faite dans les règles avec le consentement de tous les créatifs impliqués… Un sujet d’éducation à la propriété numérique est à considérer!
Mais alors, comment [DA]vid et ses créatifs subissent cette naissance monstrueuse ?
Les métiers créatifs voient leur carnet de commande diminuer, les IA se démocratisant à une vitesse folle. [DA]vid, au delà de perdre des revenus en n’étant plus employé par des revues pour faire la couverture du magazine, se retrouve face à une concurrence déloyale : l’image générée a le même style… voir “son style”… Or pour un créatif, le style est l’œuvre du travail d’une vie, un facteur différenciant dans le paysage créatif, et le moteur de compétitivité dans le secteur… Comment faire pour maintenir son statut d’acteur de la compétitivité de l’économie alors que les clients du secteur substituent leur commande par des procédés éthiquement questionnables pour faire des économies ?
Gol[IA]th mange sans se sentir rompu, qu’il s’agisse de données libres ou protégées par des droits d’auteur, la saveur ne change pas. L’espoir de voir les tribunaux s’animer, pays après pays, sur des questionnements de violation, ou non, des lois protégeant les auteurs, s’amenuise dans certaines communautés. En attendant, les [DA]vid créatifs se retrouvent livrés à eux-mêmes, lentement dépossédés de l’espoir de pouvoir échapper au géant Gol[IA]th. Alors que l’inquiétude des artistes et des créateurs grandit à l’idée de voir une série d’algorithmes reproduire et s’accaparer leur style artistique, jusqu’à leur carrière, certains s’organisent pour manifester en occupant l’espace médiatique comme l’ont fait les acteurs en grève à Hollywood en 2023, et d’autres choisissent d’attaquer le sujet directement au niveau informatique en contactant Ben Zhao et Heather Zheng, deux informaticiens de l’Université de Chicago qui ont créé un outil appelé “Fawkes”, capable de modifier des photographies pour déjouer les IA de reconnaissance faciale.
“Est-ce que Fawkes peut protéger notre style contre des modèles de génération d’images comme Midjourney ou Stable Diffusion ?”
Bien que la réponse immédiate soit “non”, la réflexion a guidé vers une autre solution…
“Glaze”, un camouflage en jus sur une oeuvre
Les chercheurs de l’Université de Chicago se sont penchés sur la recherche d’une option de défense des utilisateurs du web face aux progrès de l’IA. Ils ont mis au point un produit appelé “Glaze”, en 2022, un outil de protection des œuvres d’art contre l’imitation par l’IA. L’idée de postulat est simple : à l’image d’un glacis ( une technique de la peinture à l’huile consistant à poser, sur une toile déjà sèche, une fine couche colorée transparente et lisse) déposer pour désaturer les pigments“Glaze” est un filtre protecteur des créations contre les IAs.
“Glaze” va alors se positionner comme un camouflage numérique : l’objectif est de brouiller la façon dont un modèle d’IA va “percevoir” une image en la laissant inchangée pour les yeux humains.
Ce programme modifie les pixels d’une image de manière systématique mais subtile, de sorte à ce que les modifications restent discrètes pour l’homme, mais déconcertantes pour un modèle d’IA. L’outil tire parti des vulnérabilités de l’architecture sous-jacente d’un modèle d’IA, car en effet, les systèmes de Gen-AI sont formés à partir d’une quantité importante d’images et de textes descriptifs à partir desquels ils apprennent à faire des associations entre certains mots et des caractéristiques visuelles (couleurs, formes). “Ces associations cryptiques sont représentées dans des « cartes » internes massives et multidimensionnelles, où les concepts et les caractéristiques connexes sont regroupés les uns à côté des autres. Les modèles utilisent ces cartes comme guide pour convertir les textes en images nouvellement générées.” (- Lauren Leffer,biologiste et journaliste spécialisée dans les sciences, la santé, la technologie et l’environnement.)
“Glaze” va alors intervenir sur ces cartes internes, en associant des concepts à d’autres, sans qu’il n’y ait de liens entre eux. Pour parvenir à ce résultat, les chercheurs ont utilisé des “extracteurs de caractéristiques” (programmes analytiques qui simplifient ces cartes hypercomplexes et indiquent les concepts que les modèles génératifs regroupent et ceux qu’ils séparent). Les modifications ainsi faites, le style d’un artiste s’en retrouve masqué : cela afin d’empêcher les modèles de s’entraîner à imiter le travail des créateurs. “S’il est nourri d’images « glacées » lors de l’entraînement, un modèle d’IA pourrait interpréter le style d’illustration pétillante et caricatural d’un artiste comme s’il s’apparentait davantage au cubisme de Picasso. Plus on utilise d’images « glacées » pour entraîner un modèle d’imitation potentiel, plus les résultats de l’IA seront mélangés. D’autres outils tels que Mist, également destinés à défendre le style unique des artistes contre le mimétisme de l’IA, fonctionnent de la même manière.” explique M Heather Zheng, un des deux créateurs de cet outil.
Plus simplement, la Gen-AI sera toujours en capacité de reconnaître les éléments de l’image (un arbre, une toiture, une personne) mais ne pourra plus restituer les détails, les palettes de couleurs, les jeux de contrastes qui constituent le “style”, i.e., la “patte” de l’artiste.
Quelques exemples de l’utilisation de Glaze arXiv:2302.04222
Bien que cette méthode soit prometteuse, elle présente des limites techniques et dans son utilisation.
Face à Gol[IA]th, les [DA]vid ne peuvent que se cacher après avoir pris conscience de son arrivée : dans son utilisation, la limite de “Glaze” vient du fait que chaque image que va publier un créatif ou un artiste doit passer par le logiciel avant d’être postée en ligne.. Les œuvres déjà englouties par les modèles d’IA ne peuvent donc pas bénéficier, rétroactivement, de cette solution. De plus, au niveau créatif, l’usage de cette protection génère du bruit sur l’image, ce qui peut détériorer sa qualité et s’apercevoir sur des couleurs faiblement saturées. Enfin au niveau technique, les outils d’occultation mise à l’œuvre ont aussi leurs propres limites et leur efficacité ne pourra se maintenir sur le long terme.
En résumé, à la vitesse à laquelle évoluent les Gen-AI, “Glaze” ne peut être qu’un barrage temporaire, et malheureusement non une solution : un pansement sur une jambe gangrenée, mais c’est un des rares remparts à la créativité humaine et sa préservation.
Il faut savoir que le logiciel a été téléchargé 720 000 fois, et ce, à 10 semaines de sa sortie, ce qui montre une véritable volonté de la part des créatifs de se défendre face aux affronts du géant.
La Gen-AI prend du terrain sur la toile, les [DA]vid se retrouvent forcés à se cacher… Est-ce possible pour eux de trouver de quoi charger leur fronde ? Et bien il s’avère que la crainte a su faire naître la colère et les revendications, et les créatifs et les artistes ont décidé de se rebeller face à l’envahisseur… L’idée n’est plus de se cacher, mais bien de contre-attaquer Gol[IA]th avec les armes à leur disposition…
“Nightshade”, lorsque la riposte s’organise ou comment empoisonner l’IA ?
Les chercheurs de l’Université de Chicago vont pousser la réflexion au delà de “Glaze”, au delà de bloquer le mimétisme de style, “Nightshade” est conçu comme un outil offensif pour déformer les représentations des caractéristiques à l’intérieur même des modèles de générateurs d’image par IA…
« Ce qui est important avec Nightshade, c’est que nous avons prouvé que les artistes n’ont pas à être impuissants », déclare Zheng.
Nightshade ne se contente pas de masquer la touche artistique d’une image, mais va jusqu’à saboter les modèles de Gen-AI existants. Au-delà de simplement occulter l’intégrité de l’image, il la transforme en véritable “poison” pour Gol[IA]th en agissant directement sur l’interprétation de celui-ci. Nightshade va agir sur l’association incorrecte des idées et des images fondamentales. Il faut imaginer une image empoisonnée par “Nightshade” comme une goutte d’eau salée dans un récipient d’eau douce. Une seule goutte n’aura pas grand effet, mais chaque goutte qui s’ajoute va lentement saler le récipient. Il suffit de quelques centaines d’images empoisonnées pour reprogrammer un modèle d’IA générative. C’est en intervenant directement sur la mécanique du modèle que “Nightshade” entrave le processus d’apprentissage, en le rendant plus lent ou plus coûteux pour les développeurs. L’objectif sous-jacent serait, théoriquement,d’inciter les entreprises d’IA à payer les droits d’utilisation des images par le biais des canaux officiels plutôt que d’investir du temps dans le nettoyage et le filtrage des données d’entraînement sans licence récupérée sur le Web.
Image issue de l’article de Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv:2310.13828
Ce qu’il faut comprendre de « Nightshade » :
Empoisonnement des données: Nightshade fonctionne en ajoutant des modifications indétectables mais significatives aux images. Ces modifications sont introduites de manière à ne pas affecter la perception humaine de l’image mais à perturber le processus de formation des modèles d’IA. Il en résulte un contenu généré par l’IA qui s’écarte de l’art prévu ou original.
Invisibilité: Les altérations introduites par Nightshade sont invisibles à l’œil humain. Cela signifie que lorsque quelqu’un regarde l’image empoisonnée, elle apparaît identique à l’originale. Cependant, lorsqu’un modèle d’IA traite l’image empoisonnée, il peut générer des résultats complètement différents, pouvant potentiellement mal interpréter le contenu.
Impact: L’impact de l’empoisonnement des données de Nightshade peut être important. Par exemple, un modèle d’IA entraîné sur des données empoisonnées pourrait produire des images dans lesquelles les chiens ressemblent à des chats ou les voitures à des vaches. Cela peut rendre le contenu généré par l’IA moins fiable, inexact et potentiellement inutilisable pour des applications spécifiques.
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade.arXiv:2310.13828
Voici alors quelques exemples après de concepts empoisonnés :
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade et le modèle SD-XL propre, lorsqu’ils sont invités à utiliser le concept empoisonné C. arXiv:2310.13828
Plus précisément, « Nightshade transforme les images en échantillons ’empoisonnés’, de sorte que les modèles qui s’entraînent sur ces images sans consentement verront leurs modèles apprendre des comportements imprévisibles qui s’écartent des normes attendues, par exemple une ligne de commande qui demande l’image d’une vache volant dans l’espace pourrait obtenir à la place l’image d’un sac à main flottant dans l’espace », indiquent les chercheurs.
Le « Data Poisoning » est une technique largement répandue. Ce type d’attaque manipule les données d’entraînement pour introduire un comportement inattendu dans le modèle au moment de l’entraînement. L’exploitation de cette vulnérabilité rend possible l’introduction de résultats de mauvaise classification.
« Un nombre modéré d’attaques Nightshade peut déstabiliser les caractéristiques générales d’un modèle texte-image, rendant ainsi inopérante sa capacité à générer des images significatives », affirment-ils.
Cette offensive tend à montrer que les créatifs peuvent impacter les acteurs de la technologie en rendant contre-productif l’ingestion massive de données sans l’accord des ayant-droits.
Plusieurs plaintes ont ainsi émané d’auteurs, accusant OpenAI et Microsoft d’avoir utilisé leurs livres pour entraîner ses grands modèles de langage. Getty Images s’est même fendu d’une accusation contre la start-up d’IA Stability AI connue pour son modèle de conversion texte-image Stable Diffusion, en Février 2023. Celle-ci aurait pillé sa banque d’images pour entraîner son modèle génératif Stable Diffusion. 12 millions d’œuvres auraient été « scrappées » sans autorisation, attribution, ou compensation financière. Cependant, il semble que ces entreprises ne puissent pas se passer d’oeuvres soumises au droit d’auteur, comme l’a récemment révélé OpenAI, dans une déclaration auprès de la Chambre des Lords du Royaume-Uni concernant le droit d’auteur, la start-up a admis qu’il était impossible de créer des outils comme le sien sans utiliser d’œuvres protégées par le droit d’auteur. Un aveu qui pourrait servir dans ses nombreux procès en cours…
Ainsi, quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?
En résumé, dans sa gloutonnerie, Gol[IA]th a souhaité engloutir les [DA]vid qui nous entourent, qui ont marqué l’histoire et ceux qui la créent actuellement, dans leur entièreté et leur complexité : en cherchant à dévorer ce qui fait leur créativité, leur style, leur patte, au travers d’une analyse de caractéristiques et de pixels, Gol[IA]th a transformé la créativité humaine qui était sa muse, son idéal à atteindre, en un ensemble de données sans sémantique, ni histoire, ni passion sous-jacente.
C’est peut être un exemple d’amour nocif à l’heure de l’IA, tel que vu par l’IA ?
Sans sous-entendre que les personnes à l’origine de l’écriture des IA génératives ne sont pas des créatifs sans passion, il est probable que la curiosité, la prouesse et l’accélération technologique ont peu à peu fait perdre le fil sur les impacts que pourrait produire un tel engouement.
A l’arrivée de cette technologie sur le Web, les artistes et les créatifs n’avaient pas de connaissance éclairée sur ce qui se produisait à l’abri de leurs regards. Cependant, les modèles d’apprentissage ont commencé à être alimentés en données à l’insu de leur ayant-droits. La protection juridique des ayant-droits n’évoluant pas à la vitesse de la technologie, les créatifs ont rapidement été acculés, parfois trop tard, les Gen-AI ayant déjà collecté le travail d’une vie. Beaucoup d’artistes se sont alors “reclus”, se retirant des plateformes et des réseaux sociaux pour éviter les vols, mais ce choix ne fut pas sans conséquence pour leur visibilité et la suite de leur carrière.
Alors que les réseaux jouaient l’opacité sur leurs conditions liées à la propriété intellectuelle, le choix a été de demander aux créatifs de se “manifester s’ils refusaient que leurs données soient exploitées”, profitant de la méconnaissance des risques pour forcer l’acceptation de condition, sans consentement éclairé. Mais la grogne est montée dans le camp des créatifs, qui commencent à être excédés par l’abus qu’ils subissent. “Glaze” fut une première réaction, une protection pour conserver l’intégrité visuelle de leur œuvre, mais face à une machine toujours plus gloutonne, se protéger semble rapidement ne pas suffire. C’est alors que “Nightshade” voit le jour, avec la volonté de faire respecter le droit des artistes, et de montrer qu’ils ne se laisseraient pas écraser par la pression des modèles.
Il est important de suivre l’évolution des droits des différents pays et de la perception des sociétés civiles dans ces pays de ce sujet car le Web, l’IA et la créativité étant sans limite géographique, l’harmonisation juridique concernant les droits d’auteur, la réglementation autour de la propriété intellectuelle, et l’éducation au numérique pour toutes et tous, vont être – ou sont peut-être déjà – un enjeu d’avenir au niveau mondial.
Pour avoir davantage d’informations sur Glaze et Nightshade :page officielle
Article Glaze : Shan, S., Cryan, J., Wenger, E., Zheng, H., Hanocka, R., & Zhao, B. Y. (2023). Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In 32nd USENIX Security Symposium (USENIX Security 23) (pp. 2187-2204). arXiv preprint arXiv:2302.04222
Article Nightshade : Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv preprint arXiv:2310.13828.
A propos de l’autrice : Julie Laï-Pei, après une première vie dans le secteur artistique et narratif, a rejoint l’émulation de l’innovation en Nouvelle-Aquitaine, en tant que responsable de l’animation d’une communauté technologique Numérique auprès d’un pôle de compétitivité. Femme dans la tech et profondément attachée au secteur Culturel et Créatif, elle a à coeur de partager le résultat de sa veille et de ses recherches sur l’impact des nouvelles technologies dans le monde de la créativité.
L’image du chercheur qui travaille seul en ignorant la communauté scientifique n’est qu’un mythe. La recherche est fondée sur un échange permanent, tout d’abord et avant tout pour comprendre les travaux des autres et ensuite, pour faire connaître ses propres résultats. La lecture et l’écriture d’articles publiées dans des revues ou des conférences scientifiques sont donc au cœur de l’activité des chercheurs. Quand on écrit un article, il est fondamental de citer les travaux de ses pairs que ce soit pour décrire un contexte, détailler ses propres sources d’inspiration ou encore expliquer les différences d’approches et de résultats. Etre cité par d’autres chercheurs, quand c’est pour de « bonnes raisons », est donc une des mesures de l’importance de ses propres résultats. Mais que se passe-t-il lorsque ce système de citations est manipulé ? Une récente étude [1], menée par une équipe de « détectives scientifiques », révèle une méthode insidieuse pour gonfler artificiellement les comptes de citations : les « références furtives ». Lonni Besançon et Guillaume Cabanac, deux des membres de cette équipe, nous présentent ici leurs résultats. Pascal Guitton et Serge Abiteboul. Article publié en collaboration avec theconversation.
Les dessous de la manipulation
Le monde de la publication scientifique et son fonctionnement ainsi que ses potentiels travers et leurs causes sont des sujets récurrent de la vulgarisation scientifique. Cependant, nous allons ici nous pencher tout particulièrement sur nouveau type de dérive affectant les citations entre articles scientifiques, censées refléter les apports et influences intellectuelles d’un article cité sur l’article citant. Les citations de travaux scientifiques reposent sur un système de référencement qui est standardisé : les auteurs mentionnent explicitement dans le texte de leur article, a minima le titre de l’article cité, le nom de ses auteurs, l’année de publication, le nom de la revue ou de la conférence, les numéros de page… Ces informations apparaissent dans la bibliographe de l’article (une liste de références) et sont enregistrées sous forme de données annexes (non visibles dans le texte de l’article) qualifiées de métadonnées, notamment lors de l’attribution du DOI (Digital Object Identifier), un identifiant unique pour chaque publication scientifique. Les références d’une publication scientifique permettent, de façon simplifiée, aux auteurs de justifier des choix méthodologiques ou de rappeler les résultats d’études passées. Les références listées dans chaque article scientifique sont en fait la manifestation évidente de l’aspect itératif et collaboratif de la science. Cependant, certains acteurs peu scrupuleux ont visiblement ajouté des références supplémentaires, invisibles dans le texte, mais présentes dans les métadonnées de l’article pendant son enregistrement par les maisons d’édition (publishers). Résultat ? Les comptes de citations de certains chercheurs ou journaux explosent sans raison valable car ces références ne sont pas présentes dans les articles qui sont censés les citer.
Un nouveau type de fraude et une découverte opportuniste
Tout commence grâce à Guillaume Cabanac (Professeur à l’Université Toulouse 3 – Paul Sabatier) qui publie un rapport d’évaluation post-publication sur PubPeer, un site où les scientifiques discutent et analysent les publications. Il remarque une incohérence : un article, probablement frauduleux car présentant des expressions torturées [2], d’une revue scientifique a obtenu beaucoup plus de citations que de téléchargements, ce qui est très inhabituel. Ce post attire l’attention de plusieurs « détectives scientifiques » dont Lonni Besançon, Alexander Magazinov et Cyril Labbé. Ils essaient de retrouver, via un moteur de recherche scientifique, les articles citant l’article initial mais le moteur de recherche Google Scholar ne fournit aucun résultat alors que d’autres (Crossref, Dimensions) en trouvent. Il s’avère, en réalité, que Google Scholar et Crossref ou Dimensions n’utilisent pas le même procédé pour récupérer les citations : Google Scholar utilise le texte même de l’article scientifique alors que Crossref ou Dimensions utilisent les métadonnées de l’article que fournissent les maisons d’édition.
Pour comprendre l’étendue de la manipulation, l’équipe examine alors trois revues scientifiques. Leur démarche comporte 3 étapes. Voici comment ils ont procédé:
dans les articles (HTML/PDF) : ils listent d’abord les références présentes explicitement dans les versions HTML ou PDF des articles ;
dans les métadonnées Crossref : Ensuite, ils comparent ces listes avec les métadonnées enregistrées par Crossref, une agence qui attribue les DOIs et leurs métadonnées. Les chercheurs découvrent que certaines références supplémentaires ont été ajoutées ici, mais n’apparaissaient pas dans les articles.
dans Dimensions : Enfin, les chercheurs vérifient une troisième source, Dimensions, une plateforme bibliométrique qui utilise les métadonnées de Crossref pour calculer les citations. Là encore, ils constatent des incohérences.
Le résultat ? Dans ces trois revues, au moins 9 % des références enregistrées étaient des « références furtives ». Ces références supplémentaires ne figurent pas dans les articles mais uniquement dans les métadonnées, faussant ainsi les comptes de citations et donnant un avantage injuste à certains auteurs. Certaines références réellement présentes dans les articles sont par ailleurs « perdues » dans les métadonnées.
Les implications et potentielles solutions
Pourquoi cette découverte est-elle importante ? Les comptes de citations influencent de façon pervasive les financements de recherche, les promotions académiques et les classements des institutions. Elles sont utilisées de façon différentesuivant les institutions et les pays mais jouent toujours un rôle dans ce genre de décisions. Une manipulation des citations peut par conséquent conduire à des injustices et à des décisions basées sur des données fausses. Plus inquiétant encore, cette découverte soulève des questions sur l’intégrité des systèmes de mesure de l’impact scientifique qui sont mises en avant depuis plusieurs années déjà [3]. En effet, beaucoup de chercheurs ont déjà, par le passé, souligné le fait que ces mesures pouvaient être manipulées mais surtout qu’elles engendraient une compétition malsaine entre chercheurs qui allaient, par conséquent, être tentés de prendre des raccourcis pour publier plus rapidement ou avoir de meilleurs résultats qui seraient donc plus cités. Une conséquence, potentiellement plus dramatique de ces mesures de productivité des chercheurs réside surtout dans le gâchis d’efforts et de ressources scientifiques dû à la compétition mise en place par ces mesures [5,6].
Pour lutter contre cette pratique, les chercheurs suggèrent plusieurs mesures :
Une vérification rigoureuse des métadonnées par les éditeurs et les agences comme Crossref.
Des audits indépendants pour s’assurer de la fiabilité des données.
Une transparence accrue dans la gestion des références et des citations.
Cette étude met en lumière l’importance de la précision et de l’intégrité des métadonnées car elles sont, elles aussi, sujettes à des manipulations. Il est également important de noter que Crossref et Dimensions ont confirmé les résultats de l’étude et qu’il semblerait que certaines corrections aient été apportées par la maison d’édition qui a manipulé les métadonnées confiées à Crossref et, par effet de bord, aux plateformes bibliométriques comme Dimensions. En attendant des mesures correctives, qui sont parfois très longues voire inexistantes [7], cette découverte rappelle la nécessité d’une vigilance constante dans le monde académique.
Lonni Besançon, Assistant Professor, Linköping University, Sweden.
Guillaume Cabanac, professeur d’informatique à l’Université Toulouse 3 – Paul Sabatier, membre de l’Institut Universitaire de France (IUF), chercheur à l’Institut de recherche en informatique de Toulouse (IRIT).
[1] Besançon, L., Cabanac, G., Labbé, C., & Magazinov, A. (2024). Sneaked references: Fabricated reference metadata distort citation counts. Journal of the Association for Information Science and Technology, 1–12. https://doi.org/10.1002/asi.24896
[2] Cabanac, G., Labbé, C., & Magazinov, A. (2021). Tortured phrases: A dubious writing style emerging in science. Evidence of critical issues affecting established journals. arXiv preprint arXiv:2107.06751.
[6] Besançon, L., Peiffer-Smadja, N., Segalas, C. et al. Open science saves lives: lessons from the COVID-19 pandemic. BMC Med Res Methodol21, 117 (2021). https://doi.org/10.1186/s12874-021-01304-y
[7] Besançon L, Bik E, Heathers J, Meyerowitz-Katz G (2022) Correction of scientific literature: Too little, too late! PLoS Biol 20(3): e3001572. https://doi.org/10.1371/journal.pbio.3001572
Un nouvel « Entretien autour de l’informatique ». Gilles Dowek est chercheur en informatique chez Inria et enseignant à l’ENS de Paris-Saclay. Il est lauréat du Grand prix de philosophie 2007 de l’Académie française pour son ouvrage Les métamorphoses du calcul, une étonnante histoire de mathématiques (éditions Le Pommier) et du Grand prix Inria – Académie des sciences 2023 pour ses travaux sur les systèmes de vérification automatique de démonstrations mathématiques. Il a brièvement travaillé sur le système Coq au début de sa carrière. Il est à l’origine de Dedukti, un cadre logique permettant d’exprimer les théories utilisées dans différents systèmes de vérification de démonstrations. C’est l’une des personnes qui a le plus contribué à l’introduction en France de l’enseignement de l’informatique au collège et au lycée.
Binaire : Comment doit-on te présenter ? Mathématicien, logicien, informaticien ou philosophe ?
GD : Le seul métier que j’aie jamais exercé, c’est informaticien. La séparation des connaissances en disciplines est bien sûr toujours un peu arbitraire. Il y a des frontières qu’on passe facilement. Mes travaux empiètent donc sur les mathématiques, la logique et la philosophie. Mais je suis informaticien.
Binaire : Peux-tu nous raconter brièvement ta vie professionnelle ?
GD : Enfant, je voulais déjà être chercheur, mais je ne savais pas dans quelle discipline. Les chercheurs que je connaissais étaient surtout des physiciens : Einstein, Marie Curie… Je voyais dans la recherche une construction collective qui durait toute l’histoire de l’humanité. J’étais attiré par l’idée d’apporter une contribution, peut-être modeste, à cette grande aventure. Mes fréquentes visites au Palais de la Découverte m’ont encouragé dans cette voie.
J’ai commencé ma carrière de chercheur assez jeune grâce à l’entreprise Philips, qui organisait, à l’époque, chaque année un concours pour les chercheurs de moins de 21 ans, des amateurs donc. J’ai proposé un programme pour jouer au Master Mind et j’ai obtenu le 3ème prix. Jacques-Louis Lions qui participait au jury a fait lire mon mémoire à Gérard Huet, qui l’a fait lire à François Fages. J’avais chez moi en 1982 un ordinateur avec 1 k-octet de mémoire et mon algorithme avait besoin de plus. Je ne pouvais l’utiliser qu’en fin de partie et je devais utiliser un autre algorithme, moins bon, pour le début et le milieu de la partie.
Gérard et François m’ont invité à faire un stage pendant les vacances de Noël 1982. Ils ont tenté de m’intéresser à leurs recherches sur la réécriture, mais sans succès. La seule chose que je voulais était utiliser leurs ordinateurs pour implémenter mon algorithme pour jouer au Master Mind. Et ils m’ont laissé faire. Cela m’a permis d’avoir de bien meilleurs résultats et de finir avec le 3ème prix, cette fois au niveau européen.
Durant ce stage, Gérard m’avait quand même expliqué qu’il n’y avait pas d’algorithme pour décider si un programme terminait ou non ; il m’a juste dit que c’était un théorème, sans m’en donner la démonstration. Mais cela me semblait incroyable. À l’époque, pour moi, l’informatique se résumait à écrire des programmes ; je voyais cela comme une forme d’artisanat. Ce théorème m’ouvrait de nouveaux horizons : l’informatique devenait une vraie science, avec des résultats, et même des résultats négatifs. C’est ce qui m’a fait changer de projet professionnel.
Gérard m’avait aussi dit que, pour si je voulais vraiment être chercheur et avoir un poste, je devais faire des études. Alors j’ai fait des études, prépa puis école d’ingénieur. Je suis retourné chez Gérard Huet, pour mon stage de recherche de fin d’étude, puis pour ma thèse. Ensuite, je suis devenu professionnel de la recherche ; j’ai eu un poste et j’ai obtenu le grand plaisir de gagner ma vie en faisant ce qui m’intéressait et qui, le plus souvent, qui me procure toujours une très grande joie.
Binaire : Peux-tu nous parler de ta recherche ?
GD : En thèse, je cherchais des algorithmes de démonstration automatique pour produire des démonstrations dans un système qui est devenu aujourd’hui le système Coq. Mais dans les conférences, je découvrais que d’autres gens développaient d’autres systèmes de vérification de démonstrations, un peu différents. Cela me semblait une organisation curieuse du travail. Chacun de son côté développait son propre système, alors que les mathématiques sont, par nature, universelles.
Qu’est-ce qu’un système de vérification de démonstrations mathématiques ? Prouver un théorème n’est pas facile. En fait, comme l’ont montré Church et Turing, il n’existe pas d’algorithme qui puisse nous dire, quand on lui donne un énoncé, si cet énoncé a une démonstration ou non. En revanche, si, en plus de l’énoncé du théorème, on donne une démonstration potentielle de cet énoncé, il est possible de vérifier avec un algorithme que la démonstration est correcte. Trouver des méthodes pour vérifier automatiquement les démonstrations mathématiques était le programme de recherche de Robin Milner (Prix Turing) et également de Nicolaas De Bruijn. Mais en faisant cela, ils se sont rendu compte que si on voulait faire vérifier des démonstrations par des machines, il fallait les écrire très différemment, et beaucoup plus rigoureusement, que la manière dont on les écrit habituellement pour les communiquer à d’autres mathématiciens.
Les travaux de Milner et de De Bruijn ouvraient donc une nouvelle étape dans l’histoire de la rigueur mathématique, comme avant eux, ceux d’Euclide, de Russell et Whitehead et de Bourbaki. Le langage dans lequel on exprime les démonstrations devient plus précis, plus rigoureux. L’utilisation de logiciels change la nature même des mathématiques en créant, par exemple, la possibilité de construire des démonstrations qui font des millions de pages.
Notre travail était passionnant mais je restais insatisfait par le côté tour de Babel : chaque groupe arrivait avec son langage et son système de vérification. Est-ce que cela impliquait à un relativisme de la notion de vérité ? Il me semblait que cela conduisait à une crise de l’universalité de la vérité mathématique. Ce n’était certes pas la première de l’histoire, mais les crises précédentes avaient été résolues. J’ai donc cherché à construire des outils pour résoudre cette crise-là.
Binaire : Est-ce qu’on ne rencontre pas un problème assez semblable avec les langages de programmation ? On a de nombreuses propositions de langages.
GD : Tout à fait. Cela tient à la nature même des langages formels. Il faut faire des choix dans la manière de s’exprimer. Pour implémenter l’algorithme de l’addition dans un langage de programmation (ajouter les unités avec les unités, puis les dizaines avec les dizaines, etc. en propageant la retenue), on doit décider comment représenter les nombres, si le symbole « etc. » traduit une boucle, une définition par récurrence, une définition récursive, etc. Mais pour les langages de programmation, il y a des traducteurs (les compilateurs) pour passer d’un langage à un autre. Et on a un avantage énorme : tous les langages de programmation permettent d’exprimer les mêmes fonctions : les fonctions calculables.
Avec les démonstrations mathématiques, c’est plus compliqué. Tous les langages ne sont pas équivalents. Une démonstration particulière peut être exprimable dans un langage mais pas dans un autre. Pire, il n’y a pas de langage qui permette d’exprimer toutes les démonstrations : c’est une conséquence assez simple du théorème de Gödel. Peut-on traduire des démonstrations d’un langage vers un autre ? Oui, mais seulement partiellement.
Pour résoudre une précédente crise de l’universalité de la vérité mathématique, la crise des géométries non euclidiennes (*), Hilbert et Ackermann avaient introduit une méthode : ils avaient mis en évidence que Euclide, Lobatchevski et Riemann n’utilisaient pas les mêmes axiomes, mais surtout ils avaient proposé un langage universel, la logique des prédicats, dans lequel ces différents axiomes pouvaient s’exprimer. Cette logique des prédicats a été un grand succès des mathématiques des années 1920 et 1930 puisque, non seulement les différentes géométries, mais aussi l’arithmétique et la théorie des ensembles s’exprimaient dans ce cadre. Mais, rétrospectivement, on voit bien qu’il y avait un problème avec la logique des prédicats, puisque personne n’avait exprimé, dans ce cadre logique, la théorie des types de Russell, une autre théorie importante à cette époque. Et pour le faire, il aurait fallu étendre la logique des prédicats. Par la suite, de nombreuses autres théories ont été proposées, en particulier le Calcul des Constructions, qui est le langage du système Coq, et n’ont pas été exprimée dans ce cadre.
Au début de ma carrière, je pensais qu’il suffisait d’exprimer le Calcul des Constructions dans la logique des prédicats pour sortir de la tour de Babel et retrouver l’universalité de la vérité mathématique. C’était long, pénible, frustrant, et en fait, cette piste m’a conduit à une impasse. Mais cela m’a surtout permis de comprendre que nous avions besoin d’autres cadres que la logique des prédicats. Et, depuis les années 1980, plusieurs nouveaux cadres logiques étaient apparus dans les travaux de Dale Miller, Larry Paulson, Tobias Nipkow, Bob Harper, Furio Honsel, Gordon Plotkin, et d’autres. Nous avons emprunté de nombreuses idées à ces travaux pour aboutir à un nouveau cadre logique que nous avons appelé Dedukti (“déduire” en espéranto). C’est un cadre général, c’est-à-dire un langage pour définir des langages pour exprimer des démonstrations. En Dedukti, on peut définir par exemple la théorie des types de Russell ou le Calcul des Constructions et on peut mettre en évidence les axiomes utilisés dans chaque théorie, et surtout dans chaque démonstration.
Binaire : Pourquoi l’appeler Dedukti ? Ce n’est pas anodin ?
GD : Qu’est-ce qui guidait ces travaux ? L’idée que certaines choses, comme la vérité mathématique, sont communes à toute l’humanité, par-delà les différences culturelles. Nous étions attachés à cette universalité des démonstrations mathématiques, les voir comme des “communs”. Dans l’esprit, les liens avec des communs numériques comme les logiciels libres sont d’ailleurs étroits. On retrouve les valeurs d’universalité et de partage. Il se trouve d’ailleurs que la plupart des systèmes de vérification de démonstrations sont des logiciels libres. Coq et Dedukti le sont. Vérifier une démonstration avec un système qu’on ne peut pas lui-même vérifier, parce que son code n’est pas ouvert, ce serait bizarre.
Revenons sur cette universalité. Si quelqu’un arrivait avec une théorie et qu’on n’arrivait pas à exprimer cette théorie dans Dedukti, il faudrait changer Dedukti, le faire évoluer. Il n’est pas question d’imposer un seul système, ce serait brider la créativité. Ce qu’on vise, c’est un cadre général qui englobe tous les systèmes de vérification de démonstrations utilisés.
Longtemps, nous étions des gourous sans disciples : nous avions un langage universel, mais les seuls utilisateurs de Dedukti étaient l’équipe de ses concepteurs. Mais depuis peu, Dedukti commence à avoir des utilisateurs extérieurs à notre équipe, un peu partout dans le monde. C’est bien entendu une expansion modeste, mais cela montre que nos idées commencent à être comprises et partagées.
Binaire : Tu es très intéressé par les langages formels. Tu as même écrit un livre sur ce sujet. Pourrais-tu nous en parler ?
GD : Les débutants en informatique découvrent d’abord les langages de programmation. L’apprentissage d’un langage de programmation n’est pas facile. Mais la principale difficulté de cet apprentissage vient du fait que les langages de programmation sont des langages. Quand on s’exprime dans un langage, il faut tout dire, mais avec un vocabulaire et une syntaxe très pauvre. Les langages de démonstrations sont proches des langages de programmation. Mais de nombreux autres langages formels sont utilisés en informatique, par exemple des langages de requêtes comme SQL, des langages de description de pages web comme HTML, et d’autres. Le concept de langage formel est un concept central de l’informatique.
Mais ce concept a une histoire bien plus ancienne que l’informatique elle-même. Les humains ont depuis longtemps inventé des langages dans des domaines particuliers, comme les ophtalmologistes pour prescrire des lunettes. On peut multiplier les exemples : en mathématiques, les langages des nombres, de l’arithmétique, de l’algèbre, où apparaît pour la première fois la notion de variable, les cylindres à picots des automates, le langage des réactions chimiques, inventé au XIXe siècle, la notation musicale.
C’est le sujet de mon livre, Ce dont on ne peut parler, il faut l’écrire (Le Pommier, 2019). La création de langage est un énorme champ de notre culture. Les langages sont créés de toute pièce dans des buts spécifiques. Ils sont bien plus simples que les langues naturelles utilisées à l’oral. Ils expriment moins de choses mais ils sont souvent au centre des progrès scientifiques. L’écriture a probablement été inventée d’abord pour fixer des textes exprimés dans des langages formels et non dans des langues.
Binaire : Tu fais une très belle recherche, plutôt fondamentale. Est-ce que faire de la recherche fondamentale sert à quelque chose ?
GD : Je ne sais pas si je fais de la recherche fondamentale. En un certain sens, toute l’informatique est appliquée.
Maintenant, est-ce que la recherche fondamentale sert à quelque chose ? Cela me rappelle une anecdote. À l’École polytechnique, le poly d’informatique disait que la moitié de l’industrie mondiale était due aux découvertes de l’informatique et celui de physique que deux tiers de l’industrie mondiale étaient dus aux découvertes de la physique quantique. Les élèves nous faisaient remarquer que 1/2 + 2/3, cela faisait plus que 1. Bien entendu, les physiciens avaient compté toute l’informatique dans la partie de l’industrie que nous devions à la physique quantique, car sans physique quantique, pas de transistors, et sans transistors, pas d’informatique. Mais le message commun que nous voulions faire passer était que des pans entiers de l’économie existent du fait de découvertes scientifiques au départ perçues comme fondamentales. L’existence d’un algorithme pour décider de la correction d’une démonstration mathématique, question qui semble très détachée de l’économie, nous a conduit à concevoir des logiciels plus sûrs. La recherche la plus désintéressée, éloignée a priori de toute application, peut conduire à des transformations majeures de l’économie.
Cependant, ce n’est pas parce que la recherche a une forte influence sur le développement économique que nous pouvons en conclure que c’est sa seule motivation. La recherche nous sert aussi à mieux comprendre le monde, à développer notre agilité intellectuelle, notre esprit critique, notre curiosité. Cette quête participe de notre humanité. Et si cela conduit à des progrès industriels, tant mieux.
Serge Abiteboul, Inria, & Claire Mathieu, CNRS
(*) Des géomètres comme Euclide ont démontré que la somme des angles d’un triangle est toujours égale à 180 degrés. Mais des mathématiciens comme Lobatchevski ont démontré que cette somme était inférieure à 180 degrés. Crise ! Cette crise a été résolue au début du XXe siècle par l’observation, finalement banale, que Euclide et Lobatchevski n’utilisaient pas les mêmes axiomes, les mêmes présupposés sur l’espace géométrique.
ChatGPT appartient à la famille des agents conversationnels. Ces IA sont des IA conversationnelles qui génèrent du texte pour répondre aux requêtes des internautes. Bien qu’elles soient attrayante, plusieurs questions se posent sur leur apprentissage, leur impact social et leur fonctionnement! En binôme avec interstices.info, Karën Fort, spécialiste en traitement automatique des langues (TAL), est Maîtresse de conférences en informatique au sein de l’unité de recherche STIH de Sorbonne Université, membre de l’équipe Sémagramme au LORIA (laboratoire lorrain de recherche en informatique) , ET Joanna Jongwane, rédactrice en chef d’Interstices, Direction de la communication d’Inria, ont abordé ce sujet au travers d’un podcast. Thierry vieville etIkram Chraibi Kaadoud
Les IA conversationnelle qui génèrent du texte pour répondre aux requêtes des internautes sont à la fois sources d’inquiétudes et impressionnants par leurs « capacités ». Le plus populaire, ChatGPT, a fait beaucoup parler de lui ces derniers mois. Or il en existe de nombreux autres.
La communauté TAL s’est penché depuis longtemps sur les questions éthique liés au langage et notamment l’impact sociétal de tels outils
Une IA conversationnelle ayant appris des textes en anglais, reflétant le mode de pensé occidentale, saurait-elle saisir les subtilités d’un mode de pensé d’une autre partie du monde ?
Petit mot sur l’auteur : Jason Richard, étudiant en master expert en systèmes d’information et informatique, est passionné par l’Intelligence Artificielle et la cybersécurité. Son objectif est de partager des informations précieuses sur les dernières innovations technologiques pour tenir informé et inspiré le plus grand nombre.Ikram Chraibi Kaadoud, Jill-jenn Vie
Introduction
Dans un monde où l’intelligence artificielle (IA) est de plus en plus présente dans notre quotidien, de la recommandation de films sur Netflix à la prédiction de la météo, une question audacieuse se pose : une IA pourrait-elle un jour diriger un pays ? Cette idée, qui semble tout droit sortie d’un roman de science-fiction, est en réalité de plus en plus débattue parmi les experts en technologie et en politique.
L’IA a déjà prouvé sa capacité à résoudre des problèmes complexes, à analyser d’énormes quantités de données et à prendre des décisions basées sur des algorithmes sophistiqués. Mais diriger un pays nécessite bien plus que de simples compétences analytiques. Cela nécessite de la sagesse, de l’empathie, de la vision stratégique et une compréhension profonde des nuances humaines – des qualités que l’IA peut-elle vraiment posséder ?
Dans cet article, nous allons explorer cette question fascinante et quelque peu controversée. Nous examinerons les arguments pour et contre l’idée d’une IA à la tête d’un pays, nous discuterons des implications éthiques et pratiques. Que vous soyez un passionné de technologie, un politologue ou simplement un citoyen curieux, nous vous invitons à nous rejoindre dans cette exploration de ce qui pourrait être l’avenir de la gouvernance.
L’intelligence artificielle : une brève introduction
Avant de plonger dans le débat sur l’IA en tant que chef d’État, il est important de comprendre ce qu’est l’intelligence artificielle et ce qu’elle peut faire. L’IA est un domaine de l’informatique qui vise à créer des systèmes capables de réaliser des tâches qui nécessitent normalement l’intelligence humaine. Cela peut inclure l’apprentissage, la compréhension du langage naturel, la perception visuelle, la reconnaissance de la parole, la résolution de problèmes et même la prise de décision.
L’IA est déjà largement utilisée dans de nombreux secteurs. Par exemple, dans le domaine de la santé, l’IA peut aider à diagnostiquer des maladies, à prédire les risques de santé et à personnaliser les traitements. Dans le secteur financier, l’IA est utilisée pour détecter les fraudes, gérer les investissements et optimiser les opérations. Dans le domaine des transports, l’IA est au cœur des voitures autonomes et aide à optimiser les itinéraires de livraison. Et bien sûr, dans le domaine de la technologie de l’information, l’IA est omniprésente, des assistants vocaux comme Siri et Alexa aux algorithmes de recommandation utilisés par Netflix et Amazon.
Cependant, malgré ces avancées impressionnantes, l’IA a encore des limites. Elle est très bonne pour accomplir des tâches spécifiques pour lesquelles elle a été formée, mais elle a du mal à généraliser au-delà de ces tâches*. De plus, l’IA n’a pas de conscience de soi, d’émotions ou de compréhension intuitive du monde comme les humains. Elle ne comprend pas vraiment le sens des informations qu’elle traite, elle ne fait que reconnaître des modèles dans les données.
Cela nous amène à la question centrale de cet article : une IA, avec ses capacités et ses limites actuelles, pourrait-elle diriger un pays ? Pour répondre à cette question, nous devons d’abord examiner comment l’IA est déjà utilisée dans le domaine politique.
*Petit aparté sur ChatGPT et sa capacité de généralisation :
Chatgpt est une intelligence artificielle (de type agent conversationnel) qui, en effet, à pour but de répondre au maximum de question. Cependant, si on ne la « spécialise » pas avec un bon prompt, les résultats démontrent qu’elle a du mal à être juste. Google l’a encore confirmé avec PALM, un modèle de « base » où l’on vient rajouter des briques métiers pour avoir des bons résultats.
L’IA en politique : déjà une réalité ?
L’intelligence artificielle a déjà commencé à faire son chemin dans le domaine politique, bien que nous soyons encore loin d’avoir une IA en tant que chef d’État. Cependant, les applications actuelles de l’IA en politique offrent un aperçu fascinant de ce qui pourrait être possible à l’avenir.
L’une des utilisations les plus courantes de l’IA en politique est l’analyse des données. Les campagnes politiques utilisent l’IA pour analyser les données des électeurs, identifier les tendances et personnaliser les messages. Par exemple, lors des élections présidentielles américaines de 2016, les deux principaux candidats ont utilisé l’IA pour optimiser leurs efforts de campagne, en ciblant les électeurs avec des messages personnalisés basés sur leurs données démographiques et comportementales.
L’IA est également utilisée pour surveiller les médias sociaux et identifier les tendances de l’opinion publique. Les algorithmes d’IA peuvent analyser des millions de tweets, de publications sur Facebook et d’autres contenus de médias sociaux pour déterminer comment les gens se sentent à propos de certains sujets ou candidats. Cette information peut être utilisée pour informer les stratégies de campagne et répondre aux préoccupations des électeurs.
Dans certains pays, l’IA est même utilisée pour aider à la prise de décision politique. Par exemple, en Estonie, un petit pays d’Europe du Nord connu pour son adoption précoce de la technologie, le gouvernement développe une intelligence artificielle qui devra arbitrer de façon autonome des affaires de délits mineurs.
En plus du « juge robot », l’État estonien développe actuellement 13 systèmes d’intelligence artificielle directement intégrés dans le service public. Cela s’applique également au Pôle Emploi local, où plus aucun agent humain ne s’occupe des personnes sans emploi. Ces derniers n’ont qu’à partager leur CV numérique avec un logiciel qui analyse leurs différentes compétences pour ensuite créer une proposition d’emploi appropriée. Premier bilan : 72 % des personnes qui ont trouvé un emploi grâce à cette méthode le conservent même 6 mois plus tard. Avant l’apparition de ce logiciel, ce taux était de 58 %.
Cependant, malgré ces utilisations prometteuses de l’IA en politique, l’idée d’une IA en tant que chef d’État reste controversée. Dans les sections suivantes, nous examinerons les arguments pour et contre cette idée, et nous discuterons des défis et des implications éthiques qu’elle soulève.
L’IA à la tête d’un pays : les arguments pour
L’idée d’une intelligence artificielle à la tête d’un pays peut sembler futuriste, voire effrayante pour certains. Cependant, il existe plusieurs arguments en faveur de cette idée qui méritent d’être examinés.
Efficacité et objectivité : L’un des principaux avantages de l’IA est sa capacité à traiter rapidement de grandes quantités de données et à prendre des décisions basées sur ces données. Dans le contexte de la gouvernance, cela pourrait se traduire par une prise de décision plus efficace et plus objective. Par exemple, une IA pourrait analyser des données économiques, environnementales et sociales pour prendre des décisions politiques éclairées, sans être influencée par des biais personnels ou politiques.
Absence de corruption : Contrairement aux humains, une IA ne serait pas sujette à la corruption**. Elle ne serait pas influencée par des dons de campagne, des promesses de futurs emplois ou d’autres formes de corruption qui peuvent affecter la prise de décision politique. Cela pourrait conduire à une gouvernance plus transparente et plus équitable.
Continuité et stabilité : Une IA à la tête d’un pays pourrait offrir une certaine continuité et stabilité, car elle ne serait pas affectée par des problèmes de santé, des scandales personnels ou des changements de gouvernement. Cela pourrait permettre une mise en œuvre plus cohérente et à long terme des politiques.
Adaptabilité : Enfin, une IA pourrait être programmée pour apprendre et s’adapter en fonction des résultats de ses décisions. Cela signifie qu’elle pourrait potentiellement s’améliorer avec le temps, en apprenant de ses erreurs et en s’adaptant aux changements dans l’environnement politique, économique et social.
Cependant, bien que ces arguments soient convaincants, ils ne tiennent pas compte des nombreux défis et inquiétudes associés à l’idée d’une IA à la tête d’un pays. Nous examinerons ces questions dans la section suivante.
**Petit aparté sur la corruption d’une IA:
Le sujet de la corruption d’une IA ou de son incorruptibilité a généré un échange en interne que l’on pense intéressant de vous partager
Personne 1 : Ça dépend de qui contrôle l’IA !
Auteur : La corruption est le détournement d’un processus. L’intelligence en elle-même n’est pas corruptible. Après, si les résultats ne sont pas appliqué, ce n’est pas l’IA que l’on doit blâmer
Personne 1 : En fait on peut en débattre longtemps, car le concepteur de l’IA peut embarquer ses idées reçues avec, dans l’entraînement. De plus, une personne mal intentionnée peut concevoir une IA pour faire des choses graves, et là il est difficile de dire que l’IA n’est pas corruptible.
Auteur : Oui c’est sûr ! Volontairement ou involontairement, on peut changer les prédictions, mais une fois entrainé, ça semble plus compliqué. J’ai entendu dire que pour les IA du quotidien, une validation par des laboratoires indépendants serait obligatoire pour limiter les biais. A voir !
En résumé, la corruption d’une IA est un sujet complexe à débattre car il implique une dimension technique liée au système IA en lui-même et ses propres caractéristiques (celle-ci sont-elles corruptibles?) et une dimension humaine liée aux intentions des personnes impliqués dans la conception, la conception et le déploiement de cette IA. Sans apporter de réponses, cet échange met en lumière la complexité d’un tel sujet pour la réflexion citoyenne.
L’IA à la tête d’un pays : les arguments contre
Malgré les avantages potentiels d’une IA à la tête d’un pays, il existe de sérieux défis et préoccupations qui doivent être pris en compte. Voici quelques-uns des principaux arguments contre cette idée.
Manque d’empathie et de compréhension humaine : L’une des principales critiques de l’IA en tant que chef d’État est qu’elle manque d’empathie et de compréhension humaine. Les décisions politiques ne sont pas toujours basées sur des données ou des faits objectifs ; elles nécessitent souvent une compréhension nuancée des valeurs, des émotions et des expériences humaines. Une IA pourrait avoir du mal à comprendre et à prendre en compte ces facteurs dans sa prise de décision.
Responsabilité : Un autre défi majeur est la question de la responsabilité. Si une IA prend une décision qui a des conséquences négatives, qui est tenu responsable ? L’IA elle-même ne peut pas être tenue responsable, car elle n’a pas de conscience ou de volonté propre. Cela pourrait créer un vide de responsabilité qui pourrait être exploité.
Risques de sécurité : L’IA à la tête d’un pays pourrait également poser des risques de sécurité. Par exemple, elle pourrait être vulnérable au piratage ou à la manipulation par des acteurs malveillants. De plus, si l’IA est basée sur l’apprentissage automatique, elle pourrait développer des comportements imprévus ou indésirables en fonction des données sur lesquelles elle est formée.
Inégalités : Enfin, l’IA pourrait exacerber les inégalités existantes. Par exemple, si l’IA est formée sur des données biaisées, elle pourrait prendre des décisions qui favorisent certains groupes au détriment d’autres. De plus, l’IA pourrait être utilisée pour automatiser des emplois, ce qui pourrait avoir des conséquences négatives pour les travailleurs.
Ces défis et préoccupations soulignent que, bien que l’IA ait le potentiel d’améliorer la gouvernance, son utilisation en tant que chef d’État doit être soigneusement considérée et réglementée. Dans la section suivante, nous examinerons les points de vue de différents experts sur cette question.
Points de vue des experts : une IA à la tête d’un pays est-elle possible ?
La question de savoir si une IA pourrait un jour diriger un pays suscite un débat animé parmi les experts. Certains sont optimistes quant à la possibilité, tandis que d’autres sont plus sceptiques.
Les optimistes : Certains experts en technologie et en politique croient que l’IA pourrait un jour être capable de diriger un pays. Ils soulignent que l’IA a déjà prouvé sa capacité à résoudre des problèmes complexes et à prendre des décisions basées sur des données. Ils suggèrent que, avec des avancées supplémentaires en matière d’IA, il pourrait être possible de créer une IA qui comprend les nuances humaines et qui est capable de prendre des décisions politiques éclairées.
Les sceptiques : D’autres experts sont plus sceptiques. Ils soulignent que l’IA actuelle est loin d’être capable de comprendre et de gérer la complexité et l’incertitude inhérentes à la gouvernance d’un pays. Ils mettent également en garde contre les risques potentiels associés à l’IA en politique, tels que de responsabilité, les risques de sécurité et les inégalités.
Les pragmatiques : Enfin, il y a ceux qui adoptent une approche plus pragmatique. Ils suggèrent que, plutôt que de remplacer les dirigeants humains par des IA, nous devrions chercher à utiliser l’IA pour soutenir et améliorer la prise de décision humaine. Par exemple, l’IA pourrait être utilisée pour analyser des données politiques, économiques et sociales, pour prédire les conséquences des politiques proposées, et pour aider à identifier et à résoudre les problèmes politiques.
En fin de compte, la question de savoir si une IA pourrait un jour diriger un pays reste ouverte. Ce qui est clair, cependant, c’est que l’IA a le potentiel de transformer la politique de manière significative. À mesure que la technologie continue de progresser, il sera essentiel de continuer à débattre de ces questions et de réfléchir attentivement à la manière dont nous pouvons utiliser l’IA de manière éthique et efficace en politique.
Conclusion : Vers un futur gouverné par l’IA ?
L’idée d’une intelligence artificielle à la tête d’un pays est fascinante et controversée. Elle soulève des questions importantes sur l’avenir de la gouvernance, de la démocratie et de la société en général. Alors que l’IA continue de se développer et de s’intégrer dans de nombreux aspects de notre vie quotidienne, il est essentiel de réfléchir à la manière dont elle pourrait être utilisée – ou mal utilisée – dans le domaine de la politique.
Il est clair que l’IA a le potentiel d’améliorer la prise de décision politique, en rendant le processus plus efficace, plus transparent et plus informé par les données. Cependant, il est également évident que l’IA présente des défis et des risques importants, notamment en termes de responsabilité, de sécurité et d’équité.
Alors, une IA à la tête d’un pays est-elle science-fiction ou réalité future ? À l’heure actuelle, il semble que la réponse soit quelque part entre les deux. Bien que nous soyons encore loin d’avoir une IA en tant que chef d’État, l’IA joue déjà un rôle de plus en plus important dans la politique. À mesure que cette tendance se poursuit, il sera essentiel de continuer à débattre de ces questions et de veiller à ce que l’utilisation de l’IA en politique soit réglementée de manière à protéger les intérêts de tous les citoyens.
En fin de compte, l’avenir de l’IA en politique dépendra non seulement des progrès technologiques, mais aussi des choix que nous faisons en tant que société. Il est donc crucial que nous continuions à nous engager dans des discussions ouvertes et éclairées sur ces questions, afin de façonner un avenir dans lequel l’IA est utilisée pour améliorer la gouvernance et le bien-être de tous.
Références et lectures complémentaires
Pour ceux qui souhaitent approfondir le sujet, voici les références :
Pour ceux qui souhaitent approfondir le sujet, voici une de lectures complémentaires :
« The Politics of Artificial Intelligence » par Nick Bostrom. Ce livre explore en profondeur les implications politiques de l’IA, y compris la possibilité d’une IA à la tête d’un pays.
« AI Superpowers: China, Silicon Valley, and the New World Order » par Kai-Fu Lee. Cet ouvrage examine la montée de l’IA en Chine et aux États-Unis, et comment cela pourrait remodeler l’équilibre mondial du pouvoir.
« The Ethics of Artificial Intelligence » par Vincent C. Müller et Nick Bostrom. Cet article examine les questions éthiques soulevées par l’IA, y compris dans le contexte de la gouvernance.
« Artificial Intelligence The Revolution Hasn’t Happened Yet » par Michael Jordan. Cet article offre une perspective sceptique sur l’IA en politique, mettant en garde contre l’excès d’optimisme.
« The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation » par Brundage et al. Ce rapport explore les risques de sécurité associés à l’IA, y compris dans le contexte de la politique.
Ces ressources offrent une variété de perspectives sur l’IA en politique et peuvent aider à éclairer le débat sur la possibilité d’une IA à la tête d’un pays. Comme toujours, il est important de garder à l’esprit que l’IA est un outil, et que son utilisation en politique dépendra des choix que nous faisons en tant que société.
Petit mot sur l’autrice : Servane Mouton est docteure en médecine, neurologue et neurophysiologiste, spécialisée en psychopathologie des apprentissages et titulaire d’un master 2 en neurosciences. Elle s’intéresse particulièrement au neuro-développement normal et à ses troubles ainsi qu’aux liens entre santé et environnement. Ceci est le second article traitant du sujet NTIC et menaces sur la santé, le premier étant au lien disponible ici. Elle aborde pour nous le sujet des choix économiques et politiques intervenant dans ces sujets et leur impact sur la santé en lien avec les NTIC. Ikram Chraibi Kaadoud, Thierry Viéville.
Le déploiement d’internet dans les années 1990, l’arrivée des smartphones en 2007 et plus récemment, les confinements successifs liés à la pandémie COVID 19 en 2020, se sont accompagnés d’une véritable explosion des temps d’écran et ce dès le plus jeune âge. Pour accompagner ce changement d’usage, des recommandations ont été mises en place, mais ne semblent pas suffisantes car déjà remises en question: elles ne tiendraient pas compte de tous les enjeux en présence, à savoir d’ordre sanitaire pour l’espèce humaine, mais aussi environnemental, et, finalement, sociétal.
Sigle désignant « Nouvelles technologies de l’information et de la communication » qui regroupe l’« ensemble des techniques et des équipements informatiques permettant de communiquer à distance par voie électronique » (Dictionnaire Larousse). Les NTIC permettent à leurs utilisateurs d’accéder aux sources d’information, de les stocker, voire de les transmettre à d’autres utilisateurs dans un délai très court.
Figure 1 – Proposition d’actions pour la régulation de l’usage des NTIC
Une attention manipulée
Revenons aux usages actuels : comment sommes-nous arrivés à de tels excès ? En grande partie à cause de l’essor non réglementé de l’économie de l’attention. Les industriels du secteur, réseaux sociaux, jeux vidéo et autres activités récréatives et/ou commerciales en ligne, cherchent à augmenter le temps de connexion afin notamment de recueillir le plus possible de données de navigation qui seront ensuite sources de profits. La conception des algorithmes repose sur une connaissance fine du fonctionnement cérébral, ce qui rend (quasiment) irrésistibles les contenus de ces plateformes proposés « gratuitement ». La stimulation du système de récompense par la nouveauté ou les gratifications, les effets de « simple exposition » et de « dotation », la pression sociale, la « Fear Of Missing Out », sont des leviers parmi d’autres pour capter et maintenir captive notre attention. On ne parle officiellement d’addiction que pour les jeux vidéo en ligne et les jeux d’argent, les termes « addictif-like », usages « abusifs » ou « compulsifs » sont employés pour les autres produits1.
Somme toute, il nous semble que l’histoire du tabac se répète : des produits addictifs ou addictifs-like sont mis à disposition de tous y compris des mineurs, et leur usage a des effets délétères multiples et avérés sur la santé à court, moyen et long terme. Avec les NTIC, les dégâts sont cependant bien plus diffus. Et les parties prenantes bien plus nombreuses.
Il y a bien entendu les GAFAM et autres acteurs du secteur. A ce titre, la numérisation croissante de l’enseignement, dès la maternelle, est une aubaine : outre l’immense marché représenté par les établissements scolaires, les habitudes prises dans l’enfance ont une forte chance/un haut risque de perdurer. L’écran fera ainsi partie intégrante de l’environnement de l’individu.
Mais toutes les industries reposant sur la consommation (cf ci-dessus) : agro-alimentaire, alcool, cigarettes e-ou classiques, textiles, jeux et jouets, etc. ont aussi intérêt à laisser libre cours à l’invasion numérique. Les achats/ventes en ligne, les publicités officielles ou déguisées, ciblées grâce à l’analyse des données de navigation, permettent au marketing d’être redoutablement efficace.
Quelques propositions
Estimation des coûts des NTIC pour la santé publique
Il serait intéressant, nécessaire même, d’évaluer les coûts en terme de santé des usages numériques. La souffrance n’a pas de prix…Mais il est sans doute possible d’estimer la part de responsabilité des NTIC dans les dépenses pour les consultations et traitements en orthophonie, en psychomotricité, en psychiatrie, en ophtalmologie, ou pour les maladies métaboliques et cardiovasculaires, les troubles du sommeil et ses conséquences multiples.
Législation efficace quant de l’économie de l’attention, sécurisation de la navigation sur internet.
L’économie de l’attention devrait être efficacement régulée, au vu des conséquences délétères multiples sur le plan sanitaire d’un usage excessif/abusif qu’elle favorise.
Une législation similaire à celle ayant cours pour la recherche biomédicale devrait s’appliquer à la recherche-développement (RD) de ces produits, considérant qu’il s’agit de recherche impliquant des sujets humains, et de produits dont l’usage affecte leur santé eu sens large. On pourrait s’inspirer du Code de la Santé Publique, définissant par l’article L 1123-7 le Comité de Protection des Personnes (CPP) comme chargé « d’émettre un avis préalable sur les conditions de validité de toute recherche impliquant la personne humaine, au regard des critères définis.
Il faudrait exiger la transparence du secteur des NTIC, rendant les données de navigation ainsi que les dossiers de RD de produits impliquant la captation de l’attention accessibles aux chercheurs indépendants et institutionnels.
Protection des mineurs
Sur internet, le code de la sécurité intérieure ne traite pas la question de la protection des mineurs sous l’angle de la prévention contre l’addiction, mais uniquement contre l’exposition à la pornographie, à la violence et à l’usage de drogues (article L. 321-10). Or les adolescents jouent massivement en ligne : 96% des 10-17 ans sont des joueurs, et ils représentent 60 % des joueurs en ligne français. Dans cette même classe d’âge, 70 % utilisent les réseaux sociaux. Ceci représente une exception dans le domaine de l’addiction. Pour mémoire, on estime que la seule industrie du jeu vidéo pesait 300 milliards de dollars en 2021…
La navigation sur internet devrait être sécurisée : une ambitieuse proposition de loi est en cours d’examen au Sénat, concernant l’accès aux contenus pornographiques, les contenus pédopornographiques, le cyberharcèlement, l’incitation à la haine en ligne, la désinformation, les arnaques en ligne, les jeux à objets numériques monétisables. Elle inclut aussi l’interdiction de publicités ciblées pour les mineurs sur les plateformes. Espérons qu’une fois cette loi votée, les obstacles techniques robustes seront surmontés, rapidement.
Une loi vient d’être promulguée, établissant la majorité numérique à 15 ans pour les réseaux sociaux. Ceci est un témoin de la prise de conscience des enjeux, et nous espérons qu’elle sera mise en application de façon efficiente, malgré les obstacles techniques considérables. Malgré tout, elle nous parait insuffisante : qu’en est-il des 15-18 ans ? Qu’en est-il des des jeux vidéo en ligne, dont le caractère addictif potentiel est pourtant lui reconnu par l’OMS ?
Témoin de l’intensité du lobbying de l’industrie agro-alimentaire, et des enjeux économiques sous-jacents, soulignons ainsi un détail qui n’en est pas dans une autreloi promulguée le 9 Juin dernier, portant sur les influenceurs des réseaux sociaux. Cette dernière va ainsi encadrer la promotion faite par ces derniers : ils n’auront plus le droit de vanter les boissons alcoolisées, le tabac, les e-cigarettes. Un amendement avait été apporté après la première lecture au Sénat, afin d’ajouter dans cette liste les aliments trop sucrés, salés, gras ou édulcorés, la publicité par les influenceurs étant particulièrement persuasive en particulier pour les plus jeunes. Les auteurs de l’amendement s’appuyaient d’une part sur une expertise collective de l’Inserm de 2017 concluant que les messages sanitaires (« manger, bouger » par exemple, note de l’auteur) ont une faible portée sur le changement des comportements alimentaires ; d’autre part sur le fait que de nombreux experts de santé publique, à commencer par l’OMS et Santé Publique France, ont démontré que l’autorégulation de l’industrie agroalimentaire sur laquelle s’appuie la France (tels qu’un engagement volontaire en faveur de « bonnes pratiques ») est inefficace.
Mais cet amendement a lui-même été amendé, laissant libre cours à cette publicité, comme sur les autres médias… Comme maintes fois auparavant, les tentatives pour préserver les moins de 18 ans de l’influence de ces publicités ont été écartées. Elles seront donc simplement assujetties aux mêmes règles que sur les autres supports, comme être accompagnées de messages promouvant la santé (manger-bouger, etc).
L’argument, pourtant souligné par les auteurs de l’amendement : « Le coût global (en France) d’un régime alimentaire néfaste sur le plan diététique dépasse les 50 milliards d’euros par an, celui du diabète de type 2 représentant à lui seul 19 milliards d’euros. » n’a pas suffi…
Globalement, la collecte des données de navigation des mineurs, qu’elles soient exploitées immédiatement ou lors de leur majorité (numérique ou civile) nous parait poser problème. Et que l’âge même de la majorité diffère dans les vies civile ou numérique (pour les données de navigation selon le Réglement Général de Protection des données (RGPD) et maintenant en France pour l’accès aux réseaux sociaux, cette majorité numérique est à 15 ans) nécessiterait des éclaircissements au vu des enjeux précédemment exposés (et de de ceux que nous n’avons pu détailler).
Il nous semble que tant qu’une législation vis-à-vis des pratiques des industriels n’est pas efficiente pour protéger les usagers de ces risques, la vente et l’usage de smartphone et autres outils mobiles à ou pour les mineurs devrait être remise en question, de même que leur accès aux plateformes de réseaux sociaux et de jeux vidéo en ligne.
L’épineuse question de l’enseignement
En 2022, le Conseil Supérieur des Programmes du Ministère de l’Education Nationale, de la Jeunesse et des Sports soulignait les disparités de valeur ajoutée de l’usage des outils numériques dans l’enseignement selon les matières, les enseignants, le profil des élèves aussi. Il recommandait notamment 2 : « avant l’âge de six ans, ne pas exposer les enfants aux écrans et d’une manière générale à l’environnement numérique ; de six à dix ans, à l’école, privilégier l’accès aux ressources offertes par le livre, le manuel scolaire imprimé. » Pourtant, l’état français soutient encore financièrement et encourage fortement la numérisation des établissements scolaires dès l’école primaire, et même, en maternelle. Tandis que la Suède a fait cette année marche arrière sur ce plan-là, attribuant études à l’appui la baisse des résultats de leurs élèves (que l’on observe également en France) à la numérisation extensive de l’enseignement effectuée au cours des dernières années, et préconisant le retour aux manuels scolaires papier. Considérant en outre les arguments sanitaires cités précédemment et l’impact environnemental avéré des NTIC, leur usage par les élèves et leur déploiement dans les écoles, collèges et lycées devrait être réellement et mieux réfléchi. Par ailleurs, les smartphones devraient être exclus de l’enceinte des établissements scolaires, afin d’offrir un espace de déconnexion et d’éviter de favoriser les troubles attentionnels induits par leur seule présence, même lorsqu’ils sont éteints.
Campagne d’information à grande échelle
Les enjeux sont tels qu’une information de l’ensemble de la population apparait urgente et nécessaire, sur le modèle « choc », par exemple, de la prévention de la consommation d’alcool. Le sujet devrait être abordé dès le début de grossesse, cette période étant généralement celle où les futurs parents sont les plus réceptifs et les plus enclins à remettre en cause leurs pratiques pour le bien de l’enfant à venir. La formation des soignants, professionnels de l’enfance, et des enseignants est indispensable, devant s’appuyer sur les données les plus récentes de la littérature scientifique.
Protection des générations futures
L’étendard de la croissance est systématiquement brandi lorsque l’on incite à reconsidérer la pertinence du déploiement du numérique. Mais il est aujourd’hui reconnu largement qu’une croissance infinie n’est ni raisonnable ni souhaitable dans notre écosystème fini.
Or les NTIC sont tout sauf immatérielles. Leurs impacts environnementaux sont directs et indirects 3,4. Les premiers sont essentiellement dus à la phase de fabrication des terminaux : extraction des matières premières associée à une pollution colossale des sites dans des pays où la législation est quelque peu laxiste (Afrique, Chine, Amérique du Sud notamment) et des conséquences dramatiques en particulier pour les populations voisines et les travailleurs locaux (conditions de travail déplorables, travail des enfants), acheminement des matériaux. Mais aussi à leur fonctionnement et au stockage des données, au recyclage insuffisant (pollution eau/sol/air, consommation d’eau et d’énergie). Les seconds sont consécutifs au rôle central des NTIC dans la « grande accélération », avec encouragement des tendances consuméristes. Ils sont plus difficilement estimables et probablement les plus problématiques.
Il est entendu que la santé humaine est étroitement liée à la qualité de son environnement, et que l’altération de celui-ci la compromet, comme elle compromet tout l’écosystème.
Certes la médecin a progressé considérablement, notamment parallèlement aux innovations technologiques s’appuyant sur le numérique. Mais, nous avons au moins le droit de poser la question : ne vaut-il pas mieux œuvrer à améliorer notre hygiène de vie (sédentarité, activité physique, alimentation) et notre environnement (pollution atmosphérique, perturbateurs endocriniens) pour entretenir notre santé cardiovasculaire, que développer des instruments sophistiqués permettant d’explorer et de déboucher une artère, à grand coût économique et environnemental ? Instruments qui ne bénéficieront qu’à une minime fraction de la population mondiale, celle des pays riches ou aux classes aisées des pays qui le sont moins. Et le coût environnemental est justement assumé majoritairement par les pays les plus pauvres, dont sont issus les matières premières et où ont lieu le « recyclage » et le « traitement » des déchets.
En résumé
Les innovations portées par les NTIC ont un fort potentiel de séduction voire de fascination. Ne pas rejoindre sans réserve la révolution numérique ferait-il de nous des technophobes réfractaires au progrès ? Et si au contraire il était temps de prendre conscience des dangers et écueils liés à un déploiement extensif et non réfléchi de ces technologies ?
Références bibliographiques
Montag C, Lachmann B, Herrlich M, Zweig K. Addictive Features of Social Media/Messenger Platforms and Freemium Games against the Background of Psychological and Economic Theories.International Journal of Environmental Research and Public Health. 2019 Jul 23;16(14):2612.
Avis sur la contribution du numérique à la transmission des savoirs et à l’amélioration des pratiques pédagogiques – juin 2022. Conseil Supérieur des Programmes, Ministère de l’Education Nationale, de la Jeunesse et des Sports
Impacts écologiques des Technologies de l’Information et de la Communication – Les faces cachées de l’immatérialité. Groupe EcoInfo, Françoise Berthoud. EDP Sciences. 2012.
Petit mot sur l’autrice : Servane Mouton est docteure en médecine, neurologue et neurophysiologiste, spécialisée en psychopathologie des apprentissages et titulaire d’un master 2 en neurosciences. Elle s’intéresse particulièrement au neuro-développement normal et à ses troubles ainsi qu’aux liens entre santé et environnement. Elle nous partage dans ce billet une analyse sur l’impact des NTIC sur la santé physique des enfants au travers de trois aspects des enjeux de santé individuelle et publique à court, moyen et long terme : la sédentarité, le sommeil, et la vision. Ikram Chraibi Kaadoud, Thierry Viéville.
Le déploiement d’internet dans les années 1990, l’arrivée des smartphones en 2007 et plus récemment, les confinements successifs liés à la pandémie COVID 19 en 2020, se sont accompagnés d’une véritable explosion des temps d’écran et ce dès le plus jeune âge. Car à côté de la numérisation croissante de tous les secteurs d’activité – à savoir en santé, éducation, mais aussi agriculture, transports, journalisme, etc – les populations des pays connectés font surtout massivement usage des écrans pour leur divertissement.
NTIC :
Sigle désignant « Nouvelles technologies de l’information et de la communication » qui regroupe l’« ensemble des techniques et des équipements informatiques permettant de communiquer à distance par voie électronique » (Dictionnaire Larousse). Les NTIC permettent à leurs utilisateurs d’accéder aux sources d’information, de les stocker, voire de les transmettre à d’autres utilisateurs dans un délai très court.
Le tableau 1 ci dessous présente les recommandations actuelles de temps d’écran, qui sont discutables et les usages tels qu’ils sont observés aujourd’hui. Force est de constater que l’écart est considérable. Ces recommandations devraient être remises en question, car elles ne tiennent à notre sens pas compte de tous les enjeux en présence. Ceux-ci sont d’ordre sanitaire pour l’espèce humaine, mais aussi environnemental, et, finalement, sociétal.
Nous vous proposons de nous attarder sur trois aspects des enjeux de santé individuelle et publique à court, moyen et long terme : la sédentarité, le sommeil, et la vision. Les conséquences neuro-développementales et socio-relationnelles de l’usage des écrans par les parents en présence de l’enfant, ou par l’enfant et l’adolescent lui-même, nécessiteraient un billet dédié.
TABLEAU 1 – Temps d’écran par appareil et global en fonction de l’âge en France, Recommandations. Etude IPSOS pour l’Observatoire de la Parentalité et de l’Education au Numérique et l’Union Nationale des Familles 2022. * Anses. 2017. Etude individuelle nationale des consommations alimentaires 3 (INCA 3).** Reid Chassiakos YL, Radesky J, Christakis D, Moreno MA, Cross C; COUNCIL ON COMMUNICATIONS AND MEDIA. Children and Adolescents and Digital Media. Pediatrics. 2016 Nov;138(5).*** L’OMS publie les premières lignes directrices sur les interventions de santé numérique. Communiqué de presse. Avril 2019. https://www.who.int/fr/news/item/17-04-2019-who-releases-first-guideline-on-digital-health-interventions
Sédentarité, troubles métaboliques et santé cardiovasculaire (Figure 1)
Figure 1 – Liens entre usage des écrans, maladies métaboliques et cardiovasculaires
Le temps passé assis devant un écran pour les loisirs est depuis une quarantaine d’années l’indicateur le plus utilisé dans les études pour évaluer la sédentarité chez les personnes mineures. Pour les adultes, on utilise souvent des questionnaires tels leRecent Physical Activity Questionaire, explorant toutes les activités sédentaires (temps passé devant les écrans, mais aussi dans les transports, au travail etc.)
Or la sédentarité est un facteur de risque cardio-vasculaire indépendant, qui elle-même favorise le développement des autres facteurs de risque que sont le surpoids voire l’obésité et le diabète de type2. Notons que la sédentarité augmente la mortalité toutes causes confondues, ceci n’étant pas entièrement compensé par la pratique d’une activité physique modérée à intense.
L’Organisation Mondiale de la Santé (OMS) recommande aujourd’hui de ne pas exposer les enfants aux écrans avant deux ans2, puis une heure quotidienne maximum jusqu’à 5 ans (mais moins, c’est mieux « less is better »!). Au-delà et jusqu’à jusqu’ à 17 ans, les activités sédentaires ne devraient pas excéder 2 heures chaque jour. Pour cette tranche d’âge, l’Académie de Pédiatrie Américaine (AAP) fixe à 1h30 le seuil de sécurité, des effets délétères étant déjà significatifs dès 2h/j3.
Les Français de plus de 11 ans passent 60% de leur temps libre devant un écran. L’âge moyen d’obtention du premier téléphone est 9 ans.
Alors qu’en France l’exposition aux écrans est déconseillée pour les moins de 3 ans, une étude IPSOS-UNAF publiée en 20224 estimait le temps moyen passé devant la télévision à 1h22 et celui devant un smartphone à 45 minutes chaque jour dans cette tranche d’âge. Cette enquête ne fournissant pas les temps d’écrans globaux quotidiens, voici des chiffres publiés dans un rapport de l’ANSES (Agence Nationale de la Sécurité Sanitaire de l’Alimentation, de l’Environnement et du travail) en 20175, qui sous-évaluent très certainement les pratiques actuelles « post-COVID 19 » : le temps d’écran moyen était d’environ 2 heures chez les 3-6 ans, 2h30 chez les 7-11 ans, 3h30 chez les 11-15 ans, quasiment 5 heures chez les 15-17 ans, idem chez les adultes. Les deux tiers des 7-10 ans et la moitié des 11-14 ans y consacraient plus de 3 heures par jour, un quart des 15-17 ans plus de 7 heures et seulement un tiers moins de 3 heures. Plus le niveau socio-éducatif des parents est élevé, moins l’enfant est exposé aux écrans.
Les adultes passent eux environ 5 heures devant un écran chaque jour en dehors du travail, 84% d’entre eux sont considérés comme sédentaires.
Ceci a conduit les auteurs des rapports publiés en 20166 et 20207 par l’ANSES (Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail) à conclure, parlant de la sédentarité et de l’activité physique chez les moins de 18 ans : « il n’est pas fréquent, dans les résultats des expertises en évaluation de risques de l’agence, que près de la moitié de la population est considérée comme présentant un risque sanitaire élevé ».
Mais les outils numériques sont aussi le support de choix pour la publicité, notamment pour les aliments à haute teneur en graisse, sucre et sel, dont la consommation favorise hypertension artérielle, diabète, surpoids et obésité, hypercholestérolémie, tous étant des facteurs de risque cardio-vasculaires8. On y rencontre aussi la promotion de boissons alcoolisées9, du tabacet des e-cigarettes10, que les publicités soient officielles ou que ces produits soient valorisés dans les films, les séries, ou par les influenceurs. L’analyse des données de navigation permet de présenter des publicités d’autant plus efficaces qu’elles sont ciblées. La puissance de tels algorithmes est bien reconnue11.
L’usage des écrans tel qu’il est observé aujourd’hui favorise donc la survenue de maladies cardio-vasculaires. Rappelons que les maladies cardiovasculaires sont actuellement la première cause de mortalité dans le monde selon l’OMS et que leur prévalence ne cesse d’augmenter12. En France, elles sont responsables de 140.000 décès par an, et 15 millions de personnes sont soignées pour un problème de santé cardio-vasculaire (c’est-à-dire un facteur de risque ou une maladie vasculaire). Les Accidents Vasculaires Cérébraux (AVC) et les maladies coronariennes, dont l’infarctus du myocarde sont les plus fréquentes. En France, toujours, une personne est victime d’un AVC toutes les 4 minutes, soit près de 120.000 hospitalisations par an, auxquelles s’ajoutent plus de 30.000 hospitalisations pour accident ischémique transitoire (AIT). Les AVC sont la deuxième cause de mortalité après les cancers, ils sont ainsi responsables de près de 40.000 décès par an en France. Ils sont aussi la première cause de handicap acquis chez l’adulte, et la deuxième cause de démence (après la maladie d’Alzheimer). Concernant les maladies coronariennes, environ 80 000 personnes présentent un infarctus du myocarde en France chaque année, 8.000 en décèdent dans l’heure, 4. 000 dans l’année qui suit13.
Outre les troubles métaboliques précédemment décrits (comportements sédentaires augmentant ainsi le risque d’obésité et des désordres métaboliques liés, et par conséquent le risque de maladies cardio-vasculaires à moyen et long terme), l’exposition prolongée aux écrans est depuis peu suspecte de modifier le tempo pubertaire (favorisant les avances pubertaires) 14.
Sommeil
Le sommeil n’est pas seulement un temps de repos mais un temps où les hormones et le métabolisme se régénèrent. Or l’usage excessif des écrans peut contribuer à la réduction du temps de sommeil ou à une altération de sa qualité, à tout âge d’autant plus que cet usage est prolongé, a lieu à un horaire tardif et/ou dans l’heure précédent l’endormissement théorique (soirée, nuit), que l’écran est placé à proximité immédiate des yeux et que les contenus sont stimulants. La présence d’un écran dans la chambre est associée à une altération quantitative et qualitative du sommeil. Ceci est particulièrement préoccupant chez les moins de 18 ans car les habitudes de sommeil s’installent dans l’enfance et une mauvaise hygiène sur ce plan est particulièrement susceptible de s’inscrire dans la durée.
Les problèmes de santé favorisés par la dette chronique de sommeil sont multiples15 : troubles métaboliques tels que le surpoids ou l’obésité, le diabète, les maladies cardiovasculaires16 ; troubles de l’humeur et certaines maladies psychiatriques comme la dépression17 ; troubles cognitifs avec diminution des performances en termes de mémorisation, d’apprentissage et de vitesse d’exécution notamment ; développement de maladies neuro-dégénératives telles que la maladie d’Alzheimer, possiblement via des mécanismes inflammatoires neuro-toxiques18 ; augmentation du risque accidentogène (accident de la vie courante, accident du travail), en particulier accidents de la circulation19 ; infections 20; certains cancers, tel le cancer du sein21. De façon générale, la privation de sommeil chronique augmente le risque de mortalité22.
Selon une enquête de l’Institut National de la Vigilance et du Sommeil (INVS) en 202223, 40% des enfants de moins de onze ans (60% des 6-11 ans) regardent un écran dans l’heure précédant l’endormissement. Pour 7% d’entre eux, il s’agit même du rituel accompagnant le coucher. Un enfant de moins de onze ans sur dix s’endort dans une pièce où un écran est allumé.
Le même INVS établissait en 202024 que les adolescents français dorment en moyenne 7 h 45, dont moins de 7 h par nuit en semaine, au lieu des 8,5 à 9h de sommeil recommandées par la National Sleep Fondation. Seize pour cent des enfants de onze ans et 40 % de ceux de quinze ans ont un déficit de plus de 2h de sommeil par jour en semaine. Dès 11 ans, ils sont 25% à être équipés d’un téléviseur et 40% d’un ordinateur dans leur chambre, cette proportion passant à 1/2 et 2/3 respectivement pour les 15-18 ans.
Une autre étude française réalisée chez 776 collégiens25 révèle que la plupart des adolescents utilisent leurs écrans pendant la nuit ce qui impacte la durée et la qualité de sommeil. Ces activités peuvent être initiées lorsqu’ils se réveillent spontanément pendant la nuit (73,9%) ; mais 26% de ces adolescents, programment un réveil en cours de nuit.
La durée moyenne du sommeil chez les adultes de 18 à 65 ans est passée de 7h05 en semaine et 8h11 le week-end en 2016, à 6h41 en semaine et 7h51 le week-end en 2020. Le temps recommandé par la NSF est compris entre 7 à 9h. En 2022, 60% des adultes regardent un écran dans l’heure précédant l’endormissement (versus 38% en 2016 et 45% en 2020) et pour 23% d’entre eux, le temps d’exposition moyen est de plus d’une heure et demie.
En 2016, selon l’enquête de l’INVS26, 20% des personnes interrogées gardent leur téléphone en fonctionnement pendant la nuit. Cinquante pour cent d’entre elles, soit 10% des personnes interrogées sont réveillées par des messages ou notifications. Parmi elles, 92 % les consultent, 79 % y répondent immédiatement. En 2020, ce sont près du double de personnes (16 %) interrogées qui sont réveillées la nuit par des alertes.
Selon le rapport de l’INVS de 2020 : « Pierre angulaire des difficultés de sommeil des enfants et des adolescents, les écrans sont aujourd’hui au premier plan des préoccupations des spécialistes ».
Vision
L’ANSES s’est penché sur la question des impacts de l’éclairage LED sur la santé et l’environnement, publiant un rapport édifiant en 201927. Parmi les impacts négatifs, l’usage des écrans peut ainsi compromettre le système visuel en favorisant l’apparition d’une myopie. Ceci est lié à la surutilisation de la vision de près au détriment de la vision de loin, mais surtout à l’exposition à un éclairage artificiel au détriment de celui à un éclairage naturel. Les écrans sont en effet utilisés à l’intérieur, éventuellement sous un éclairage artificiel, et sont eux-mêmes une source supplémentaire d’exposition à un tel éclairage (le caractère riche en bleu de la lumière artificielle serait un élément clé dans cet effet néfaste). Le temps passé par les enfants devant les écrans pour leurs loisirs est donc hautement préoccupant, car il se fait au détriment d’activités en plein air, auxquelles ils devraient s’adonner au minimum 2 heures chaque jour du point de vue ophtalmologique (selon le Baromètre de la myopie en France, 2022, seulement 36% des parents déclarent que leur enfant remplit cette exigence13). Aujourd’hui, une personne sur trois présente une myopie dans le monde, cela pourrait être une sur deux en 2050.
De plus, cette lumière riche en bleu et pauvre en rouge a un effet phototoxique sur la rétine28. L’exposition aux sources lumineuses riches en lumière bleue telles les éclairages artificiels et les écrans a lieu le jour, mais surtout la nuit, moment où la rétine est plus sensible à cette phototoxicité.
Aucune donnée n’est disponible quant aux effets à long terme d’une exposition répétée/chronique à ce type d’éclairage.
L’utilisation intensive des écrans par la population jeune est préoccupante, car leur système visuel est moins protégé (transparence plus grande de leur cristallin laissant passer plus la lumière bleue que celui des adultes) et en développement, ce qui accroit largement ces risques.
L’usage croissant des écrans dans le cadre scolaire participe à cette majoration du niveau d’exposition.
Autres problématiques
Citons en vrac, et sans prétendre à l’exhaustivité : la perturbation du développement cognitif, émotionnel et socio-relationnel induit par l’usage des écrans par les parents en présence de l’enfant29, les mêmes troubles favorisés par l’exposition des enfants et adolescents aux écrans (rappelons que le cerveau mature jusqu’à 25 ans) 30, l’exposition aux contenus inappropriés (violence31, pornographie32), le cyber-harcèlement33, les défis sordides, l’hypersexualisation, la dysmorphie induite par les réseaux sociaux, la facilitation de la prostitution infantile (qui va croissante depuis plusieurs années) 34.
Mais aussi l’enrichissement du « cocktail » de perturbateurs endocriniens auxquels les usagers sont exposés, certains composants des outils informatiques et numériques appartenant à cette catégorie (notamment les retardateurs de flamme bromés, très volatiles et les PFAS), ceci étant particulièrement problématique chez les jeunes enfants, les adolescents et les femmes enceintes ; et l’exposition aux rayonnements radiofréquences au sujet de laquelle des scientifiques du monde entier ont appelé en 2017 à appliquer le principe de précaution, arguant de l’absence d’étude d’impact préalable au déploiement de cette technologie (en vain) 35.
En résumé …
… les impacts des NTIC sur la sédentarité, le sommeil, et la vision et plus globalement sur le développement cognitif, psychologique et socio-relationnel, ne sont pas encore précisément estimés. Cependant, ils apparaissent déjà hautement préoccupants. Face a ce constat, une question se pose : Quelles sont les actions possibles à mettre en place pour y pallier ?
Servane nous en parle dans la suite de ce billet à venir !
Références bibliographiques
Humanité et numérique : les liaisons dangereuses. Livre collaboratif coordonné par le Dr Servane Mouton, Editions Apogée, Avril 2023.
Reid Chassiakos YL, Radesky J, Christakis D, Moreno MA, Cross C; COUNCIL ON COMMUNICATIONS AND MEDIA. Children and Adolescents and Digital Media. Pediatrics. 2016 Nov;138(5)
ANSES. Actualisation des repères du PNNS – Révisions des repères relatifs à l’activité physique et à la sédentarité. 2016.NUT2012SA0155Ra.pdf (anses.fr)
Catherine M. Mc Carthy, Ralph de Vries, Joreintje D. Mackenbach. The influence of unhealthy food and beverage marketing through social media and advergaming on diet-related outcomes in children—A systematic review. Obesity Reviews. 2022 Jun; 23(6): e13441 ; https://www.who.int/fr/news-room/factsheets/detail/children-new-threats-to-health; Alruwaily A, Mangold C, Greene T, Arshonsky J, Cassidy O, Pomeranz JL, Bragg M. Child Social Media Influencers and Unhealthy Food Product Placement. Pediatrics. 2020 Nov;146(5):e20194057.
Barker AB, Smith J, Hunter A, Britton J, Murray RL. Quantifying tobacco and alcohol imagery in Neƞlix and Amazon Prime instant video original programming accessed from the UK: a content analysis. British Medical Journal Open. 2019 Feb 13;9(2):e025807 ; Jackson KM, Janssen T, Barnett NP, Rogers ML, Hayes KL, Sargent J. Exposure to Alcohol Content in Movies and Initiation of Early Drinking Milestones. Alcohol: Clinical and Experimental Research. 2018 Jan;42(1):184-194. doi: 10.1111/acer.13536 ; Chapoton B, Werlen AL, Regnier Denois V. Alcohol in TV series popular with teens: a content analysis of TV series in France 22 years after a restrictive law. European Journal of Public Health. 2020 Apr 1;30(2):363-368 ; Room R, O’Brien P. Alcohol marketing and social media: A challenge for public health control. Drug and Alcohol Review. 2021 Mar;40(3):420-422.
WHO. 2015. Smoke-free movies: from evidence to action. Third edition; Dal Cin S, Stoolmiller M, Sargent JD. When movies matter: exposure to smoking in movies and changes in smoking behavior. Journal of Health 8 Communication 2012;17:76–89; Lochbuehler K, Engels RC, Scholte RH. Influence of smoking cues in movies on craving among smokers. Addiction 2009;104:2102–9; Lochbuehler K, Kleinjan M, Engels RC. Does the exposure to smoking cues in movies affect adolescents’ immediate smoking behavior? Addictive Behaviours 2013;38:2203–6. 97; https://truthinitiative.org/research-resources/smoking-pop-culture/renormalization-tobacco-use-streaming-content-services
Lapierre MA, Fleming-Milici F, Rozendaal E, McAlister AR, Castonguay J. The Effect of Advertising on Children and Adolescents. Pediatrics. 2017 Nov;140(Suppl 2):S152-S156. doi: 10.1542/peds.2016-1758V; Vanwesenbeeck I, Hudders L, Ponnet K. Understanding the YouTube Generation: How Preschoolers Process Television and YouTube Advertising. Cyberpsychology, Behavior, and Social Networking. 2020 Jun;23(6):426-432.
Gabet A, Grimaud O, de Pereƫ C, Béjot Y, Olié V. Determinants of Case Fatality After Hospitalization for Stroke in France 2010 to 2015. Stroke. 2019;50:305-312 ; hƩps://www.inserm.fr/dossier/accident-vasculaire-cerebral-avc/; https://www.inserm.fr/dossier/infarctus-myocarde/.
Crowley SJ, Acebo C, Carskadon MA. Human puberty: salivary melatonin profiles in constant conditions. Developmental Psychobiology 54(4) (2012) 468–73)
Morselli LL, Guyon A, Spiegel K. Sleep and metabolic function. Pflugers Archiv. 2012 Jan;463(1):139–60. 15. Roberts RE, Duong HT. The prospective association between sleep deprivation and depression among adolescents. Sleep. 2014 Feb 1;37(2):239–44.
Wang C, Holtzman DM. Bidirectional relationship between sleep and Alzheimer’s disease: role of amyloid, tau, and other factors. Neuropsychopharmacology. 2020;45(1):104–20 ; Liew SC, Aung T. Sleep deprivation and its association with diseases- a review. Sleep Med. 2021;77:192–204.
Teŏ BC. Acute sleep deprivation and culpable motor vehicle crash involvement. Sleep. 2018;41(10).
Bryant PA, Curtis N. Sleep and infection: no snooze, you lose? The Pediatric Infectious Disease Journal. 2013 Oct;32(10):1135–7 ; Spiegel K, Sheridan JF, van Cauter E. Effect of sleep deprivation on response to immunization. JAMA. 2002 Sep 25;288(12):1471–2.
Lu C, Sun H, Huang J, Yin S, Hou W, Zhang J, et al. Long-Term Sleep Duration as a Risk Factor for Breast Cancer: Evidence from a Systematic Review and Dose-Response Meta-Analysis. BioMed Research International. 2017;2017:4845059.
Hanson JA, Huecker MR. Sleep Deprivation. 2022.
Liew SC, Aung T. Sleep deprivation and its association with diseases- a review. Sleep Med. 2021;77:192–204.
Gawne TJ, Ward AH, Norton TT. Long-wavelength (red) light produces hyperopia in juvenile and adolescent tree shrews. Vision Research. 2017;140:55-65.
K. Braune-Krickau , L. Schneebeli, J. Pehlke-Milde, M. Gemperle , R. Koch , A. von Wyl. (2021). Smartphones in the nursery: Parental smartphone use and parental sensitivity and responsiveness within parent-child interaction in early childhood (0-5 years): A scoping review. Infant Mental Health Journal. Mar;42(2):161-175 ; L.Jerusha Mackay, J. Komanchuk, K. Alix Hayden, N. Letourneau. (2022). Impacts of parental technoference on parent-child relationships and child health and developmental outcomes: a scoping review protocol. Systematic Reviews.Mar 17;11(1):45.
Masur EF, Flynn V, Olson J. Infants’ background television exposure during play: Negative relations to the quantity and quality of mothers’ speech and infants’ vocabulary acquisition. First Language 2016, Vol. 36(2) 109–123; Zimmerman FJ, Christakis DA. Children’s television viewing and cognitive outcomes: a longitudinal analysis of national data. Arch Pediatr Adolesc Med. 2005;159(7):619–625; Madigan S, McArthur BA, Anhorn C et al. Associations Between Screen Use and Child Language Skills: A Systematic Review and Meta-analysis. JAMA Pediatr. 2020 Jul 1;174(7):665-675; Schwarzer C, Grafe N, Hiemisch A et al. Associations of media use and early childhood development: cross-sectional findings from the LIFE Child study. Pediatr Res. 2021 Mar 3; Madigan S, Browne D, Racine N et al. Association Between Screen Time and Children’s Performance on a Developmental Screening Test. JAMA Pediatr 2019 Mar 1;173(3):244-250; Lillard AS, et al. The immediate impact of different types of television on young children’s executive function. Pediatrics. 2011. 11. Swing EL, et al. Television and video game exposure and the development of attention problems. Pediatrics. 2010; Wilmer HH, Sherman LE, Chein MJ. Smartphones and Cognition: A Review of Research Exploring the Links between Mobile Technology Habits and Cognitive Functioning. Front Psychol 2017 Apr 25;8:605. Tornton, B., Faires, A., Robbins et al. The mere presence of a cell phone may be distracting: Implications for attention and task performance. Soc. Psychol. 45, 479–488 (2014); Hadar A, HadasI, Lazarovits A et al. Answering the missed call: Initial exploration of cognitive and electrophysiological changes associated with smartphone use and abuse. PLoS One. 2017 Jul 5;12(7). Beyens I, Valkenburg PM, Piotrowski JT. Screen media use and ADHD-related behaviors: Four decades of research. Proc Natl Acad Sci U S A. 2018 Oct 2;115(40):9875-9881; Nikkelen SW, Valkenburg PM, Huizinga M et al. Media use and ADHD-related behaviors in children and adolescents: A metaanalysis. Dev Psychol. 2014 Sep;50(9):2228-41; Christakis DA, Ramirez JSB, Ferguson SM et al. How early media exposure may affect cognitive function: A review of results from observations in humans and experiments in mice. Proc Natl Acad Sci U S A. 2018 Oct 2;115(40):9851-9858. 7 .
Anderson CA, Shibuya A, Ihori N, Swing EL, Bushman BJ, Sakamoto A, Rothstein HR, Saleem M. Violent video game effects on aggression, empathy, and prosocial behavior in eastern and western countries: a meta-analytic reviewPsychol Bull. 2010 Mar;136(2):151-73. doi: 10.1037/a0018251. Anderson CA, Bushman BJ, Bartholow BD, Cantor J, Christakis D, Coyne SM. Screen Violence and Youth Behavior. Pediatrics. 2017 Nov;140(Suppl 2):S142-S147. doi: 10.1542/peds.2016-1758T.
Ferrara P, Ianniello F, Villani A, Corsello G. Cyberbullying a modern form of bullying: let’s talk about this health and social problem. Ital J Pediatr. 2018 Jan 17;44(1):14.
Dans cet article. Frédéric Alexandre (Directeur de chercheur Inria) aborde ChatGPT en nous éclairant sur son fonctionnement à travers le prisme de la cognition et ce que nos données disent de nous à cet outil dit intelligent. Ikram Chraibi Kaadoud et Pascal Guitton
Cet article est repris du site The Conversation (lire l’article original), un média généraliste en ligne qui fédère les établissements d’enseignement supérieur et de recherche francophones. Issu d’une étroite collaboration entre journalistes, universitaires et chercheurs, il propose d’éclairer le débat public grâce à des analyses indépendantes sur des sujets d’actualité.
Un des problèmes que l’IA n’a toujours pas résolu aujourd’hui est d’associer des symboles – des mots par exemple – à leur signification, ancrée dans le monde réel – un problème appelé l’« ancrage du symbole ».
Par exemple, si je dis : « le chat dort sur son coussin car il est fatigué », la plupart des êtres humains comprendra sans effort que « il » renvoie à « chat » et pas à « coussin ». C’est ce qu’on appelle un raisonnement de bon sens.
En revanche, comment faire faire cette analyse à une IA ? La technique dite de « plongement lexical », si elle ne résout pas tout le problème, propose cependant une solution d’une redoutable efficacité. Il est important de connaître les principes de cette technique, car c’est celle qui est utilisée dans la plupart des modèles d’IA récents, dont ChatGPT… et elle est similaire aux techniques utilisées par Cambridge Analytica par exemple.
Le plongement lexical, ou comment les systèmes d’intelligence artificielle associent des mots proches
Cette technique consiste à remplacer un mot (qui peut être vu comme un symbole abstrait, impossible à relier directement à sa signification) par un vecteur numérique (une liste de nombres). Notons que ce passage au numérique fait que cette représentation peut être directement utilisée par des réseaux de neurones et bénéficier de leurs capacités d’apprentissage.
Plus spécifiquement, ces réseaux de neurones vont, à partir de très grands corpus de textes, apprendre à plonger un mot dans un espace numérique de grande dimension (typiquement 300) où chaque dimension calcule la probabilité d’occurrence de ce mot dans certains contextes. En simplifiant, on remplace par exemple la représentation symbolique du mot « chat » par 300 nombres représentant la probabilité de trouver ce mot dans 300 types de contextes différents (texte historique, texte animalier, texte technologique, etc.) ou de co-occurrence avec d’autres mots (oreilles, moustache ou avion).
Plonger dans un océan de mots et repérer ceux qui sont utilisés conjointement, voilà une des phases de l’apprentissage pour ChatGPT.Amy Lister/Unsplash, CC BY
Même si cette approche peut sembler très pauvre, elle a pourtant un intérêt majeur en grande dimension : elle code des mots dont le sens est proche avec des valeurs numériques proches. Ceci permet de définir des notions de proximité et de distance pour comparer le sens de symboles, ce qui est un premier pas vers leur compréhension.
Pour donner une intuition de la puissance de telles techniques (en fait, de la puissance des statistiques en grande dimension), prenons un exemple dont on a beaucoup entendu parler.
Relier les traits psychologiques des internautes à leurs « likes » grâce aux statistiques en grande dimension
C’est en effet avec une approche similaire que des sociétés comme Cambridge Analytica ont pu agir sur le déroulement d’élections en apprenant à associer des préférences électorales (représentations symboliques) à différents contextes d’usages numériques (statistiques obtenues à partir de pages Facebook d’usagers).
L’expérimentation reportée dans cette publication demandait à des participants de définir certains de leurs traits psychologiques (sont-ils consciencieux, extravertis, etc.), leur donnant ainsi des étiquettes symboliques. On pouvait également les représenter par des étiquettes numériques comptant les « likes » qu’ils avaient mis sur Facebook sur différents thèmes (sports, loisirs, cinéma, cuisine, etc.). On pouvait alors, par des statistiques dans cet espace numérique de grande dimension, apprendre à associer certains endroits de cet espace à certains traits psychologiques.
Ensuite, pour un nouveau sujet, uniquement en regardant son profil Facebook, on pouvait voir dans quelle partie de cet espace il se trouvait et donc de quels types de traits psychologiques il est le plus proche. On pouvait également comparer cette prédiction à ce que ses proches connaissent de ce sujet.
Le résultat principal de cette publication est que, si on s’en donne les moyens (dans un espace d’assez grande dimension, avec assez de « likes » à récolter, et avec assez d’exemples, ici plus de 70000 sujets), le jugement statistique peut être plus précis que le jugement humain. Avec 10 « likes », on en sait plus sur vous que votre collègue de bureau ; 70 « likes » que vos amis ; 275 « likes » que votre conjoint.
Être conscients de ce que nos « likes » disent sur nous
Cette publication nous alerte sur le fait que, quand on recoupe différents indicateurs en grand nombre, nous sommes très prévisibles et qu’il faut donc faire attention quand on laisse des traces sur les réseaux sociaux, car ils peuvent nous faire des recommandations ou des publicités ciblées avec une très grande efficacité. L’exploitation de telles techniques est d’ailleurs la principale source de revenus de nombreux acteurs sur Internet.
Nos likes et autres réaction sur les réseaux sociaux en disent beaucoup sur nous, et ces informations peuvent être exploitées à des fins publicitaires ou pour des campagnes d’influence.George Pagan III/Unsplash, CC BY
Cambridge Analytica est allée un cran plus loin en subtilisant les profils Facebook de millions d’Américains et en apprenant à associer leurs « likes » avec leurs préférences électorales, afin de mieux cibler des campagnes électorales américaines. De telles techniques ont également été utilisées lors du vote sur le Brexit, ce qui a confirmé leur efficacité.
Calculer avec des mots en prenant en compte leur signification
En exploitant ce même pouvoir des statistiques en grande dimension, les techniques de plongement lexical utilisent de grands corpus de textes disponibles sur Internet (Wikipédia, livres numérisés, réseaux sociaux) pour associer des mots avec leur probabilité d’occurrence dans différents contextes, c’est-à-dire dans différents types de textes. Comme on l’a vu plus haut, ceci permet de considérer une proximité dans cet espace de grande dimension comme une similarité sémantique et donc de calculer avec des mots en prenant en compte leur signification.
Un exemple classique qui est rapporté est de prendre un vecteur numérique représentant le mot roi, de lui soustraire le vecteur (de même taille car reportant les probabilités d’occurrence sur les mêmes critères) représentant le mot homme, de lui ajouter le vecteur représentant le mot femme, pour obtenir un vecteur très proche de celui représentant le mot reine. Autrement dit, on a bien réussi à apprendre une relation sémantique de type « A est à B ce que C est à D ».
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
Le principe retenu ici pour définir une sémantique est que deux mots proches sont utilisés dans de mêmes contextes : on parle de « sémantique distributionnelle ». C’est ce principe de codage des mots qu’utilise ChatGPT, auquel il ajoute d’autres techniques.
Ce codage lui permet souvent d’utiliser des mots de façon pertinente ; il l’entraîne aussi parfois vers des erreurs grossières qu’on appelle hallucinations, où il semble inventer des nouveaux faits. C’est le cas par exemple quand on l’interroge sur la manière de différencier des œufs de poule des œufs de vache et qu’il répond que ces derniers sont plus gros. Mais est-ce vraiment surprenant quand on sait comment il code le sens des symboles qu’il manipule ?
Sous cet angle, il répond bien à la question qu’on lui pose, tout comme il pourra nous dire, si on lui demande, que les vaches sont des mammifères et ne pondent pas d’œuf. Le seul problème est que, bluffés par la qualité de ses conversations, nous pensons qu’il a un raisonnement de bon sens similaire au nôtre : qu’il « comprend » comme nous, alors que ce qu’il comprend est juste issu de ces statistiques en grande dimension.
La bataille pour une science accessible et gratuite n’est pas simple: elle nécessite de la passion, des bénévoles, des équipes, des infrastructures, des lecteurs et tout simplement des moyens. Celle de Scilogs.fr arrive à son terme. Ceci est le clap de fin d’une aventure de 10 ans. Laissons la parole à Philippe Ribeau-Gésippe, Responsable numérique du magazine PourlaScience.fr. Ikram Chraibi Kaadoud.
Cette année, cela fera 10 ans que Scilogs.fr existe. Cette plateforme de blogs avait été lancée en 2013 par Pour la Science avec l’idée de fédérer une communauté de blogueurs issus du monde de la recherche et réunis par l’envie de vulgariser leurs travaux avec l’exigence de rigueur qui fait la marque des magazines Pour la Science et Cerveau & Psycho.
Depuis lors, près de 30 blogs, dont Intelligence Mécanique, ont ainsi été ouverts sur Scilogs.fr, et près de 3000 articles publiés, souvent passionnants.
Mais proposer une plateforme telle que Scilogs.fr a un coût. Des coûts d’hébergement et de maintenance, d’une part, nécessaires pour mettre à jour les versions du système et intervenir en cas de panne ou d’attaque informatique. Et des ressources humaines, d’autre part, pour gérer les problèmes, recruter de nouveaux blogueurs, aider les auteurs ou promouvoir les nouveaux articles sur les réseaux sociaux.
Nous avons consacré à Scilogs.fr autant de temps et d’investissements qu’il nous était raisonnablement possible de le faire, car nous étions convaincus que c’était un beau projet. Hélas, le succès n’a pas été à la hauteur de nos espérances, et, Scilogs.fr n’a jamais réussi à trouver un modèle économique viable.
Nous sommes donc au regret d’annoncer que Scilogs.fr est arrêté mais reste disponible
Peut-on comprendre et expliquer une décision automatisée prise par un système d’intelligence artificielle ? Pouvons-nous faire confiance à ce système autonome ? En tant qu’utilisateur, cela engage notre responsabilité et pose des questions. A travers Binaire, plusieurs chercheurs ont partagé leur travail à ce sujet ! Voici un résumé et récapitulatif autour de l’explicabilité et l’interprétabilité proposé par Ikram Chraibi Kaadoud chercheuse en IA passionnée de médiation ! Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.
Un petit rappel de contexte
Dans de nombreux domaines, les mutations technologiques de ces dernières années ont mené à la disponibilité et à la prédominance de données complexes et hétérogènes. Par conséquent, de plus en plus de domaines d’application font appels aux systèmes d’intelligence artificielle (IA) dans le but de comprendre ces données, réaliser des prédictions jusqu’à aider l’humain à prendre des décisions. Dans notre quotidien, les prises de décisions assistées par des systèmes d’IA (voir automatisées quand urgence oblige) sont ainsi devenues une réalité quasi-omniprésente : algorithme de recommandation de médias, identification ou reconnaissance d’espèces animales et végétales, détection de pathologies, etc.
Dans ce contexte, l’humain, à la fois concepteur et utilisateur de tels systèmes d’IA, est un acteur incontournable. Amené à prendre des décisions basées sur ces systèmes, il engage sa responsabilité dans les choix qu’il effectue ce qui entraîne une exigence forte en termes de transparence et de compréhension des comportements de ces systèmes d’IA. Or, cette compréhension est loin d’être garantie puisque l’explicabilité* des modèles (notamment les propriétés d’interprétabilité des modèles à base de réseaux de neurones) est actuellement un sujet très complexe, objet d’études et de débats au sein même de la communauté scientifique en IA. Ce qui se traduit par de la méfiance de la part du grand public, face à ces systèmes considérés comme opaques parfois qualifiés de « boîtes noires ».
L’explicabilité* d’une IA vs celle d’un expert: Quand un expert humain prend une décision, il peut expliquer sur quelles connaissances, à partir de quels faits et quelles inférences il a utilisées pour arriver à sa conclusion. On parle d’explicabilité pour un système d’IA quand il peut lui aussi décrire comment a été construite sa décision. Dans certains cas, cette explication peut-être très complexe, voire impossible à appréhender par un humain ; en effet, un système de raisonnement automatisé peut enchaîner un très grand nombre de données, d’inférences qui dépassent de loin la capacité de nos cerveaux. Et c’est d’ailleurs bien pour ça que nous faisons appels à des machines qui ne sont pas intelligentes mais qui savent traiter des masses gigantesques d’informations.
Depuis 2018, l’entrée en vigueur du règlement européen général de protection de données (RGPD), ainsi que les exigences sociétales en faveur de systèmes IA de confiance, ont permis l’essor d’algorithmes d’IA explicables et transparents dans le paysage informatique. Chacune et chacun a, en théorie, le droit et la possibilité d’exiger une explication des processus de traitement automatique de données tels que justement les systèmes d’IA, mais pouvoir le faire au niveau des connaissances de toutes et tous est un défi culturel et pédagogique.
Cela a eu comme conséquence une explosion des travaux de recherche publiés sur ces sujets (explicabilité, interprétabilité, transparence, éthique, biais), et également une restriction de l’utilisation et l’amélioration d’un certain nombre de modèles existants autant dans l’industrie que – et surtout – dans la recherche.
Mais qu’est-ce que l’IA explicable (ou XAI pour eXplainable Artificial Intelligence) ?
En résumé, l’IA explicable peut être considérée comme une solution permettant de démystifier le comportement des systèmes d’IA et les raisons à l’origine de ce dernier. Il s’agit d’un ensemble d’approches et d’algorithmes permettant de proposer, par exemple, des systèmes d’aide à la décision et d’explication de ces décisions. Expliquer le raisonnement d’un système, avec ses points forts et faibles, ainsi que son potentiel comportement dans le futur est le but de ce domaine. Pourquoi cela ? Entre autres: 1) favoriser l’acceptabilité de ces systèmes en prenant en compte les aspects éthiques et transparents, et le profil de l’utilisateur cible de cette explication, 2) veiller au respect de l’intégrité morale et physique de chacune et chacun, 3) augmenter les connaissances des experts grâce à la connaissance extraite par ces mécanismes d’IA explicable.
En résumé, la dimension humaine est donc omniprésente depuis la conception jusqu’ à l’utilisation en passant par l’évaluation de modèle d’IA explicable.
Pour en savoir plus, le blog binaire récapitule les liens vers les articles que nous avons déjà partagés sur ces sujets :
Comment comprendre ce que font les réseaux de neurones est le point d’entrée de ce sujet. Voici une série de trois articles grand public pour commencer deMarine LHUILLIER , Ingénieure d’études et Data engineer (spécialiste des données et de leur traitements) :
Démystifier des systèmes d’IA d’aide à la décision et les expliquer, permet également d’amener une connaissance pertinente à la portée du public ciblé. Un médecin peut donc voir en un système d’IA un moyen d’acquérir plus de connaissances sur une pathologie par exemple. L’IA transparente devient alors un outil d’apprentissage au service d’une expertise. LeDr Masrour Makaremi nous avait partagé son point de vue sur cet aspect :
Les algorithmes d’explicabilité peuvent être aussi être utilisés dans des contextes très ludiques comme lejeu de bridge. Il s’agit d’un jeu de cartes qui nécessite de maîtriser plusieurs compétences intéressantes à modéliser artificiellement et à démystifier, telles que faire des déductions, émettre et réviser des hypothèses, anticiper les coups de l’adversaire ou encore évaluer les probabilités.Marie-Christine Rousset, Professeur d’informatique à l’Université Grenoble Alpes, se penche et explique comment fonctionne le robot de bridge Nook, développé parNukkAI, laboratoire privé d’Intelligence Artificielle français dédié aux développements d’IA explicables :
L’IA explicable peut aussi être un moyen de favoriser l’acceptabilité de l’IA dans l’agriculture. Dans ce domaine, où la compétence de terrain est très présente, l’IA peut se révéler être un objet de frustration car elle ne permet pas de comprendre les tenants et les aboutissants.Emmanuel Frénod, mathématicien et professeur à l’Université de Bretagne Sud, au sein du Laboratoire de Mathématiques de Bretagne Atlantique, aborde le sujet de l’intégration d’outils en IA en agriculture et de la problématique des boîtes noires dans ce domaine :
Deux chercheuses en IA de l’IMT Atlantique,Lina Fahed etIkram Chraibi Kaadoud, sont intervenues àWomen Teckmakers Montréal et Québec 2021, un programme mis en place par le Google developpers Group afin de souligner le talent des femmes dans le milieu de l’informatique, de promouvoir la passion et d’accroître la visibilité de la communauté technologique féminine. Ces chercheuses ont ainsi abordé des éléments de réponses aux questions de confiance en IA et ont discuté des concepts de transparence et d’éthique à travers l’explicabilité en IA, un sujet de recherche toujours d’actualité.
Cette présentation en français (avec des planches en anglais facilement lisibles, nous permettant aussi de se familiariser avec ce vocabulaire anglo-saxon) introduit aux concepts d’explicabilité et d’interprétabilité en IA, et fournit une description des grandes familles de stratégies en explicabilité, y compris d’un point de vue technique. Il aborde également les difficultés inhérentes au domaine notamment lorsque les données sont hétérogènes (c’est à dire de différents formats) , ou encore en questionnant l’impact éthique et sociétale du sujet au vu de l’omniprésence des systèmes IA dans notre environnement.
Ikram Chraibi Kaadoud , chercheuse postdoctorale travaillant actuellement sur le sujet de l’intelligence artificielle eXplainable (XAI) sur des séries temporelles hétérogènes à l’Institut des Mines Télécom Atlantique.
Intelligences naturelles et artificielles peuvent apprendre les unes des autres. De nombreux algorithmes s’inspirent de notre compréhension des mécanismes du vivant et les modèles utilisés en intelligence artificielle peuvent en retour permettre d’avancer dans la compréhension du vivant. Mais comment s’y retrouver ? Donnons la parole àIkram CHRAIBI KAADOUD qui nous offre ici un éclairage. Pascal Guitton et Thierry Viéville.
Il est souvent dit et admis que de nombreux algorithmes s’inspirent du vivant et qu’inversement l’artificiel peut permettre d’avancer la compréhension du vivant*.
S’inscrivant dans cette démarche, le développement des connaissances chez les humains est un domaine qui a été largement étudié par exemple, par des méthodes informatiques utilisant des approches d’apprentissage automatique (Machine Learning) ou encore des approches robotiques (Cangelosi, 2018). L’objectif: réaliser des algorithmes ou robots flexibles et performants capables d’interagir efficacement avec les humains et leur environnement.
* Attention cher lecteur, chère lectrice, s’inspirer du vivant n’implique pas de créer un double artificiel ; par exemple mimer ou dupliquer: la conception d’avions peut s’inspirer des oiseaux mais ce n’est pas pour autant que les avions battent des ailes !
L’un des défis principaux qui existe lors d’une interaction humain-machine est la prise en compte de la variabilité de l’environnement. Autrement dit l’évolution du contexte de l’interaction. Une réponse d’une machine pertinente à un instant donné, ne sera peut-être plus la bonne quelques instants plus tard. Cela peut être dû à l’environnement (changement de lieu, d’horaire) ou à l’individu avec lequel la machine interagit.
Par exemple, si je vous dis « Mon train est dans 10 min » et que je suis à l’autre bout de la ville (la gare étant à l’opposé de ma localisation), il est évident que celui-ci partira sans moi. Si je suis devant la gare, alors il serait adéquat de me dépêcher ! Enfin si je suis dans le train au moment où je prononce ces mots, alors tout est bon pour moi !*
*Merci auDr. Yannis Haralambous, chercheur en Traitement du langage naturel, fouille de textes et grapho linguistique de IMT atlantique et l’équipe DECIDE du LAB-STICC, CNRS pour le partage de cet exemple
La compréhension du contexte et son assimilation est un sujet à part entière entre humains et par extension, également entre Humains et Machine.
Alors comment faire pour qu’une machine apprenne seule à interagir avec un environnement changeant ? Autrement dit, comment faire pour que cet agent apprenne à raisonner : analyser la situation, déduire ou inférer un comportement, exécuter ce dernier, analyser les résultats et apprendre de sa propre interaction ?
Il existe déjà nombre de travaux dans les domaines de l’apprentissage par renforcement en IA qui s’intéressent aux développements d’agents artificiels, ou encore de la cobotique où le système robotique doit prendre en compte la localisation des opérateurs humains pour ne pas risquer de les blesser. Mais il existe aussi des approches qui tendent à s’inspirer de la cognition et notamment de celle des enfants : les approches de robotique développementale.
“L’un des paradigmes les plus récents, la robotique développementale, propose de s’intéresser non pas à l’intelligence « adulte » d’un individu capable de résoudre a priori une large classe de problèmes, mais plutôt d’étudier la manière dont cette intelligence se constitue au cours du développement cognitif et sensori moteur de l’individu. On ne cherche pas à reproduire un robot immédiatement intelligent, mais un robot qui va être capable d’apprendre, en partant au départ avec un nombre réduit de connaissances innées. Le robot apprend à modéliser son environnement, les objets qui l’entourent, son propre corps, il apprend des éléments de langage en partant du lexique jusqu’à la grammaire, tout cela en interaction forte à la fois avec le monde physique qui l’entoure mais également au travers d’interactions sociales avec les humains ou même d’autres robots. Le modèle qui préoccupe le chercheur en intelligence artificielle n’est plus le joueur d’échec, mais tout simplement le bébé et le jeune enfant, capable d’apprendre et de se développer cognitivement.”
Reprenons d’abord quelques définitions avant d’aborder ce sujet passionnant de cognition artificielle.
Alors qu’est-ce que l’apprentissage par renforcement, ou Reinforcement Learning? Il s’agit d’un domaine de l’apprentissage automatique, Machine Learning, qui se concentre sur la façon dont les agents artificiels entreprennent des actions dans un environnement par la recherche d’un équilibre entre l’exploration (par exemple, d’un territoire inexploré) et l’exploitation (par exemple, de la connaissance actuelle des sources de récompense)(Chraibi Kaadoud et al, 2022). Ce domaine aborde la question de la conception d’agents autonomes qui peuvent évoluer par l’expérience et l’interaction (Sutton, Barto, et al., 1998).
Le second concept à éclaircir est celui de Robotique :
La robotique est un domaine scientifique et industriel qui a pour objet d’étude le robot en lui-même. Cela englobe, ses performances, ses caractéristiques énergétiques, électroniques, mécaniques et même automatiques.
La cobotique est un domaine scientifique qui étudie les systèmes hommes-robots collaboratifs. Un cobot se définit donc comme un robot collaboratif travaillant dans le même espace de travail que l’humain. Par exemple, un robot jouet ou robot d’accueil. La cobotique est très proche de la robotique, cependant elle n’englobe pas toutes les problématiques de la robotique. En effet, en cobotique, le cœur du sujet est la perception du cobot de son environnement, son interaction avec l’humain et inversement, la perception, l’interaction et l’acceptabilité de l’humain de son cobot. La cobotique se distingue par un volet ergonomie et ingénierie cognitique, absente de la robotique.
La cobotique est donc de nature pluridisciplinaire et se situe à l’intersection de trois domaines : robotique, ergonomie et cognitique (Salotti et al, 2018). Notons que la cobotique n’est pas directement liée au sujet de la robotique développementale mais il est essentiel de distinguer ces deux sujets, d’où cette petite parenthèse.
Enfin cela nous amène à la robotique développementale ou Developmental robotics. Ce domaine est aussi connu sous d’autres synonymes : cognitive developmental robotics, autonomous mental development, ainsi que epigenetic robotics.
Ce champ de recherche est dédié à l’étude de la conception de capacités comportementales et cognitives des agents artificiels de manière autonome. Autrement dit, ce domaine s’intéresse au développement des comportements de robots et de leur représentation du monde avec lequel ils interagissent et de tout ce qui a trait à leur connaissance.
Intrinsèquement interdisciplinaire, ce domaine s’inspire directement des principes et mécanismes de développement observés dans les systèmes cognitifs naturels des enfants.
En effet, quoi de plus curieux et autonome qu’un enfant dans la découverte de son monde ?
Ce domaine tend ainsi à s’inspirer du développement des processus cognitifs des enfants pour concevoir des agents artificiels qui apprennent à explorer et à interagir avec le monde comme le font les enfants (Lungarella, 2003; Cangelosi, 2018).
Comment ? L’approche traditionnelle consiste à partir des théories du développement humain et des animaux appartenant aux domaines de la psychologie du développement, des neurosciences, du développement, de la biologie évolutive, et de la linguistique pour ensuite les formaliser et implémenter dans des robots ou agents artificiels.
Attention, précisons que la robotique développementale est disjointe de la robotique évolutionnelle qui utilise des populations de robots interagissant entre eux et qui évoluent dans le temps.
En quoi la robotique développementale est intéressante ?
Afin d’avoir des agents artificiels qui évoluent et s’adaptent au fur et à mesure de leur expérience, des chercheurs se sont attelés à observer des enfants à différents stade de leur apprentissage et le développement de cette capacité d’apprentissage. Les nourrissons en particulier créent et sélectionnent activement leur expérience d’apprentissage en étant guidés par leur curiosité. Des travaux se sont donc penchés sur la modélisation de la curiosité en IA afin de déterminer l’impact de celle-ci sur l’évolution des capacités d’apprentissage des agents artificiels (Oudeyer et Smith, 2016). Les domaines d’applications sont nombreux et peuvent permettre par exemple la conception de robots capables d’apprendre des choses sur le long terme et d’évoluer dans leur apprentissage ou encore des algorithmes performants capables de générer des explications adaptées au contexte en langage naturel par exemple.
Au-delà de la conception d’agents intelligents, l’expérimentation de ces modèles artificiels dans des robots permet aux chercheurs de confronter leur théorie sur la psychologie du développement à la réalité et ainsi confirmer ou infirmer leur hypothèse sur le développement des enfants par exemple. La robotique développementale peut ainsi être un outil d’expérimentation scientifique et d’exploration de nouvelles hypothèses sur les théories du développement humain et animal. Un outil au service de l’enfant, s’inspirant de ce dernier.
Une meilleure compréhension du développement cognitif humain et animal, peut permettre alors de concevoir des machines (robots, agents artificiels) adaptées à l’interaction avec des enfants au fur et à mesure qu’ils grandissent et que leur contexte évolue. Cela permet également de créer des applications plus adaptées aux enfants dans les technologies éducatives comme le montre le schéma “Qu’est ce que la robotique développementale ?”.
Au-delà de l’interaction humain-machine, ce domaine passionnant amène à se poser également des questions sur la curiosité artificielle, la créativité artificielle et même celle de la question de la motivation d’un agent artificiel ou robot ! Autrement dit, la robotique développementale permet également des découvertes scientifiques au service de la compréhension du développement cognitif des enfants et celui de la conception d’agents ou machines artificiels qui apprennent à apprendre tout au long de leur expérience.
Schéma: Qu’est ce que la robotique développementale ? l’alliance de modèle de sciences cognitives et d’intelligence artificielle au service de la compréhension du développement cognitif et de l’apprentissage autonome tout au long de la vie. Images: @Pixabay
Que retenir ?
La conception d’une interaction humain-machine réussie est une quête en soit pour laquelle différentes approches sont possibles : celle de l’apprentissage par renforcement qui se focalise sur l’agent artificiel comme objet d’étude dans un contexte donné, celle de la robotique qui se focalise sur le robot en tant que sujet d’étude d’un point de vue mécanique et logiciel, et enfin celle de la robotique développementale qui s’inspire du développement cognitif des enfants afin de créer des machine/agents artificiels flexibles, adaptée et adaptable qui évoluent. Cette épopée en est à ses prémisses et de nombreuses découvertes sont encore à venir. Toutefois retenons une chose : comment apprendre à apprendre est bien une question autant d’humains que de robots !
Références & pour en savoir plus :
Cangelosi, A., Schlesinger, M., 2018. From babies to robots: the contribution of developmental robotics to developmental psychology. Child Development Perspectives 12, 183–188.
Chraibi Kaadoud, I., Bennetot, A., Mawhin, B., Charisi, V. & Díaz-Rodríguez, N. (2022). “Explaining Aha! moments in artificial agents through IKE-XAI: Implicit Knowledge Extraction for eXplainable AI”. Neural Networks, 155, p.95-118. 10.1016/j.neunet.2022.08.002
Droniou, A. (2015). Apprentissage de représentations et robotique développementale: quelques apports de l’apprentissage profond pour la robotique autonome (Doctoral dissertation, Université Pierre et Marie Curie-Paris VI).
Lungarella, M., Metta, G., Pfeifer, R., Sandini, G., 2003. Developmental robotics: a survey. Connection science 15,151–190.
Oudeyer, P. Y., & Smith, L. B. (2016). How evolution may work through curiosity‐driven developmental process. Topics in Cognitive Science, 8(2), 492-502.
Pour un été non binaire : partez avec binaire dans votre poche.
Nous faisons notre pause estivale avant de revenir partager avec vous des contenus de vulgarisation sur l’informatique ! A la rentrée nous parlerons à nouveau aussi bien de technologie que de science, d’enseignement, de questions industrielles, d’algorithmes, de data… bref, de tous les sujets en lien avec le monde numérique qui nous entoure … D’ici là, vous pouvez tout de même passer l’été avec binaire.
… car nous avons le plaisir de partager la parution des entretiens de la SIF publié sur binairesous la forme d’un objet comme ceux qui sont utilisés depuis des siècles pour partager les connaissances humaines… un livre en papier ! 😉
Le numérique et la passion des sciences, C&F éditions, 2022
A travers l’exemple d’un article très partagé sur l’impact du confinement sur la pandémie de COVID-19 que Lonni Besançon et ses collègues ont réussi à faire rétracter car il était faux, nous explorons le processus de la rétractation scientifique et pourquoi les avancées en terme de partage de code et de données permettent de faciliter la correction de la science. Pascal Guitton et Thierry Viéville.
Publier pour accroitre la connaissance scientifique. Dans le monde de la recherche scientifique, le coeur de la transmission de la connaissance est la publication scientifique (aussi appelée “article”, “papier” ou “manuscrit”), car c’est à travers elle que les chercheurs communiquent leurs résultats de recherche entre eux et avec le grand public. Avant qu’un article scientifique ne soit publié dans une revue ou les actes d’une conférence, il doit (dans la majorité des cas) passer l’épreuve de la relecture par les pairs (Image 1) : d’autres scientifiques, deux ou trois en général, vont indépendamment relire le manuscrit proposé pour publication et en évaluer les mérites et faiblesses avant de donner des arguments pour l’éditeur de la revue lui permettant de publier l’article, de le rejeter, ou de demander aux auteurs de modifier leur manuscrit. Il existe plusieurs implémentations de la relecture par les pairs, chacune ayant ses avantages et inconvénients (voir par exemple [1]). Cependant, la relecture par les pairs est souvent considérée comme une norme d’excellence de la publication scientifique qui permet d’éviter la publication, et donc la propagation, de conclusions scientifiques erronées ou exagérées.
Image 1 : Une examinatrice des National Institutes of Health aux USA évaluant une proposition de financement, domaine public.
L’erreur est humaine et peut se corriger. Cependant, l’erreur étant humaine, le processus de relecture par les pairs n’est pas parfait, et certains articles problématiques passent parfois entre les mailles du filet. C’est notamment le cas pour les articles recélant de la fraude scientifique. Les relecteurs font le plus souvent l’hypothèse que les auteurs sont de bonne foi et par conséquent ne recherchent pas systématiquement de signes de fraudes dans ce qu’ils évaluent. Dans les cas où un article problématique serait donc publié, l’éditeur en chef de la revue peut, une fois qu’il s’en aperçoit, décider de le rétracter, c’est-à-dire le supprimer du corpus des articles scientifiques présents afin qu’il ne soit plus utilisé. Ces rétractations restent cependant très rares.
L’une des plus célèbres d’entre elles est probablement la rétractation de l’article d’Andrew Wakefield dans The Lancet, une revue très prestigieuse dans la recherche médicale. L’article rétracté avait été initialement publié en 1998 par A. Wakefield et conclut que le triple vaccin Rougeole-Oreillon-Rubeole pouvait être à l’origine du développement de l’autisme chez les enfants. Des doutes commencèrent à apparaître après que plusieurs études indépendantes n’aient pas réussi à reproduire les résultats de Wakefield [2,3], avant qu’une enquête journalistique de Brian Deer en 2004 ne démontre que Wakefield avait des intérêt financiers à publier de tels résultats (car il recevait de l’argent de compagnies qui produisent des vaccins uniques au lieu du triple vaccin). L’article fut finalement rétracté par The Lancet en 2010 mais continue malheureusement, plus d’une vingtaine d’années plus tard, à être cité par des opposants à la vaccination comme justification à leur croyance.
Bien que, dans cet exemple célèbre, la rétractation prend environ 12 ans, nous avons pu voir pendant la pandémie des exemples de rétractations bien plus rapides. Par exemple des articles publiés par une compagnie appelée Surgisphere ont été rétractés en quelques semaines dans The Lancet et The New England Journal Of Medecine ; le décompte actuel du nombre de rétractations sur des articles scientifiques COVID-19 est de plus de 200. Ce mécanisme “correctif” aide à garantir la qualité de nos connaissances scientifiques.
À notre tour d’aider à éviter que les erreurs scientifiques ne perdurent. En décembre 2021, une étude très partagée sur les réseaux sociaux qui démontrerait que le confinement est inutile pour contenir la pandémie de COVID-19 a été rétractée. Cette rétraction intervient 9 mois après la publication originale de l’article. L’article en question, de Savaris et ses co-auteurs, a été publié par Nature Scientific Reports en Mars 2021.
Un travail de vérification. Très rapidement, nous avons, avec mes collègues, étudié et critiqué le contenu de cet article. En particulier, les auteurs utilisaient un modèle particulier pour déterminer si une réduction de la mobilité des gens (mesurée via leurs smartphones et les données de Google) entrainait une réduction des cas. Le modèle était codé en Python et un Jupyter Notebook a été mis en ligne, avec les données, en même tant que l’article afin de respecter les principes clés de la science ouverte [4]. Outre les limitations des données initiales des auteurs (notamment sur le Google Mobility), nous avons pu utiliser le code des auteurs pour vérifier l’adéquation du modèle qu’ils utilisaient pour répondre à leur question de recherche. Grâce au fait que le modèle était partagé, nous avons par conséquent créé des jeux de données artificiels pour lesquels nous pouvions être sûrs que le confinement aurait (ou non) un impact sur la propagation COVID (Image 2). Cependant, en créant un jeu de données censé prouver un effet du confinement et en le soumettant en entrée au modèle de Savaris et de ses collègues, le modèle a conclu que le confinement ne fonctionnait pas pour limiter la propagation COVID. Nous avons donc publié nos jeux de données artificiels en ligne sur Github, résumé nos préoccupations sur l’article dans un document que nous avons posté en version préliminaire (preprint) [5], puis contacté les éditeurs de Nature Scientific Reports afin de leur envoyer notre preprint.
Image 2 : les cinq faux pays que nous avons créé pour vérifier le modèle de Savaris et ses collègues. Aucun de ces pays fictifs n’a permis de retourner de résultats significatifs avec le modèle des auteurs. Image CC-BY Meyerowitz-Katz et al.
Un mécanisme collégial de discussion et de re-travail. L’équipe éditoriale a envoyé nos préoccupations aux auteurs, en leur demandant de répondre ; dans un second temps notre preprint et la réponse des auteurs ont été évalués par 6 relecteurs indépendants. Nous avons reçu la réponse des auteurs ainsi que l’évaluation des relecteurs et, contacté Savaris et ses collègues pour leur demander un jeu de données artificiel qui montrerait un effet positif du confinement. Ils nous ont fourni ce jeu de données qui, quand nous le soumettions en entrée de leur modèle, produisait bien un effet positif du confinement. Cependant, nous avons constaté qu’en ajoutant ne serait-ce qu’un minimum de bruit à ce jeu de données, le résultat basculait à nouveau vers le négatif. Nous avons donc corrigé notre preprint pour y inclure ces nouvelles préoccupations, envoyé cette nouvelle version à l’équipe éditoriale qui a donc commencé un second tour de réponse auteurs + relecture par les pairs. Notre manuscrit a été finalement publié le 07 Décembre 2021 en tant que “Matters Arising” (question soulevée) lié à la publication en question [6], 1 semaine après la publication d’un autre Matters Arising de Carlos Góes sur ce même papier qui démontre mathématiquement que le modèle ne pouvait pas répondre à leurs question de recherche [7]. Le 14 décembre 2021, l’article était finalement rétracté [8]. Bien que dans ce cas, le manuscrit de Carlos Góes démontre un problème mathématique et appuie donc le point que nous mettions en exergue dans le nôtre, il est important de noter qu’il nous aurait été impossible de trouver ces erreurs si les auteurs n’avaient pas mis en ligne et donc à disposition de la communauté scientifique leur codes et données, ce qui est tout à leur honneur.
Une morale à cette histoire. Bien qu’un grand nombre d’articles de recherche sur COVID-19 souffre d’un très clair manque de transparence et de respect des principes de la science ouverte [4], il est certain que la disponibilité des données et du code (Open Data, Open Source) facilite grandement et accélère le processus de correction (et parfois de rétractation) de la science. Il faut vraiment l’encourager.
[1] Besançon, L., Rönnberg, N., Löwgren, J. et al. Open up: a survey on open and non-anonymized peer reviewing. Res Integr Peer Rev 5, 8 (2020). https://doi.org/10.1186/s41073-020-00094-z
[2] Madsen, K. M., Hviid, A., Vestergaard, M., Schendel, D., Wohlfahrt, J., Thorsen, P., … & Melbye, M. (2002). A population-based study of measles, mumps, and rubella vaccination and autism. New England Journal of Medicine, 347(19), 1477-1482. https://doi.org/10.1056%2FNEJMoa021134
[3] Black C, Kaye J A, Jick H. Relation of childhood gastrointestinal disorders to autism: nested case-control study using data from the UK General Practice Research Database BMJ 2002; 325 :419 https://doi.org/10.1136/bmj.325.7361.419
[4] Besançon, L., Peiffer-Smadja, N., Segalas, C. et al. Open science saves lives: lessons from the COVID-19 pandemic. BMC Med Res Methodol 21, 117 (2021). https://doi.org/10.1186/s12874-021-01304-y
[5] Meyerowitz-Katz, G., Besançon, L., Wimmer, R., & Flahault, A. (2021). Absence of evidence or methodological issues? Commentary on “Stay-at-home policy is a case of exception fallacy: an internet-based ecological study”.
[6] Meyerowitz‐Katz, G., Besançon, L., Flahault, A. et al. Impact of mobility reduction on COVID-19 mortality: absence of evidence might be due to methodological issues. Sci Rep 11, 23533 (2021). https://doi.org/10.1038/s41598-021-02461-2
[8] Savaris, R.S., Pumi, G., Dalzochio, J. et al. Retraction Note: Stay-at-home policy is a case of exception fallacy: an internet-based ecological study. Sci Rep11, 24172 (2021). https://www.nature.com/articles/s41598-021-03250-7
Dans le cadre de la rubrique autour des “communs du numérique”. Alexandra Elbakyan a réalisé SciHub, une archive de tous les articles scientifiques. Dans la tension entre le droit d’auteur et le droit d’accès aux résultats scientifiques, elle a choisi son camp. Elle répond pour binaire à nos questions. Serge Abiteboul et François Bancilhon.
Ce qui suit est notre traduction. Le texte original.
Alexandra Elbakyan, SciHub.ru, 2020
Pouvez-vous décrire brièvement Sci-Hub, son histoire et son statut actuel ?
Sci-Hub est un site web dont l’objectif est de fournir un accès gratuit à toutes les connaissances académiques. Aujourd’hui, la plupart des revues scientifiques deviennent inaccessibles en raison de leur prix élevé(*). Sci-Hub contribue à supprimer la barrière du prix, ou paywall. Des millions d’étudiants, de chercheurs, de professionnels de la santé et d’autres personnes utilisent Sci-Hub aujourd’hui pour contourner les paywalls et avoir accès à la science.
J’ai créé Sci-Hub en 2011 au Kazakhstan. Le projet est immédiatement devenu très populaire parmi les chercheurs de Russie et de l’ex-URSS. Au fil des années, il n’a cessé de croître et est devenu populaire dans le monde entier.
Mais l’existence de Sci-Hub est aussi un combat permanent : le projet est régulièrement attaqué en justice qualifié d’illégal ou d’illicite, et bloqué physiquement. Les poursuites judiciaires proviennent de grandes entreprises, les éditeurs scientifiques : Elsevier et d’autres. Ces sociétés sont aujourd’hui les propriétaires de la science. Elles fixent un prix élevé pour accéder aux journaux de recherche. Des millions de personnes ne peuvent pas se permettre cette dépenses et sont privées de l’accès à la science et l’information. Sci-Hub lutte contre cet état de fait.
Sci-Hub fait actuellement l’objet d’un procès en Inde. Les éditeurs académiques demandent au gouvernement indien de bloquer complètement l’accès au site web.
Nombre d’articles téléchargés depuis Sci-Hub au cours des 30 derniers jours (12 février 2022)
Est-ce que les articles de Wikipedia sur vous et Sci-Hub sont corrects ?
Cela dépend, car les articles diffèrent selon les langues. J’ai lu les articles anglais et russes de Wikipedia, et je ne les aime vraiment pas ! Des points essentiels sur Sci-Hub sont omis, comme le fait que le site est largement utilisé par les professionnels de la santé et que Sci-Hub contribue à sauver des vies humaines. Les articles semblent se concentrer sur la description des procès intentés contre le site et son statut illégal, alors que le large soutien et l’utilisation de Sci-Hub par les scientifiques du monde entier sont à peine mentionnés.
L’article russe, par exemple, donne l’impression que le principal argument d’Elsevier dans son procès contre Sci-Hub est que ce dernier utilise des comptes d’utilisateurs « volés » ! C’est évidemment faux, la raison principale et le principal argument d’Elsevier dans son procès contre Sci-Hub est la violation du droit d’auteur, le fait que Sci-Hub donne un accès gratuit aux revues qu’Elsevier vend au prix fort ! Aujourd’hui, les responsables des relations publiques d’Elsevier essaient de promouvoir ce message, comme si le principal point de conflit était que Sci-Hub utilise des références « volées » !
On trouve de nombreux points incorrects de ce genre dans les articles sur Sci-Hub.
Un article me concernant mentionnait que j’étais soupçonné d’être un espion russe. Un journal m’a demandé un commentaire à ce sujet, et j’ai répondu : il peut y avoir une aide indirecte du gouvernement russe dont je ne suis pas au courant, mais je peux seulement ajouter que je fais toute la programmation et la gestion du serveur moi-même.
Quelqu’un a coupé la citation, et a inséré dans Wikipedia seulement la première partie : « il peut y avoir une aide indirecte du gouvernement russe dont je ne suis pas au courant » en omettant que : « Je fais toute la programmation et la gestion du serveur moi-même ». Il y avait beaucoup d’insinuations de ce genre. Certaines ont été corrigées mais très lentement, d’autres subsistent. Par exemple, l’article russe affirme que j’ai « bloqué l’accès au site web ». C’est ainsi qu’ils décrivent le moment où Sci-Hub a cessé de travailler en Russie pour protester contre le traitement réservé au projet.
Au tout début, lorsque l’article de Wikipédia sur Sci-Hub a été créé, le projet était décrit comme un… moteur de recherche ! Ce qui était complètement faux. J’ai essayé de corriger cela mais ma mise à jour a été rejetée. Les modifications ont finalement été apportées lorsque j’ai publié sur mon blog un article sur les erreurs de l’article Wikipedia.
Pouvez-vous nous donner quelques chiffres sur l’activité de Sci-Hub ?
En dix ans, Sci-Hub a connu une croissance constante. En 2020, il a atteint 680 000 utilisateurs par jour ! Puis après le confinement, il est revenu à nouveau à environ 500 000 utilisateurs par jour.
Il existe également des miroirs-tiers de Sci-Hub qui sont apparus récemment, comme scihub.wikicn.top et bien d’autres. Lorsque vous recherchez Sci-Hub sur Google, le premier résultat est souvent un miroir-tiers de ce type. Je constate que de nombreuses personnes utilisent aujourd’hui ces miroirs-tiers, mais je n’ai pas accès à leurs statistiques. Je n’ai accès qu’aux statistiques des serveurs Sci-Hub originaux que je gère : sci-hub.se, sci-hub.st et sci-hub.ru.
Aujourd’hui, Sci-Hub a téléchargé plus de 99 % du contenu des grands éditeurs universitaires (Elsevier, Springer, Wiley, etc.), mais il reste encore de nombreux articles d’éditeurs moins connus. Il y a donc encore beaucoup de travail. L’objectif de Sci-Hub est d’avoir tous les articles scientifiques jamais publiés depuis 1665 ou même avant. Actuellement, Sci-Hub a temporairement interrompu le téléchargement de nouveaux articles en raison du procès en cours en Inde, mais cela reprendra bientôt.
Comment voyez-vous l’évolution du site ? Quel avenir voyez-vous ? Vous semblez jouer au chat et à la souris pour pouvoir donner accès au site. Combien de temps cela peut-il durer ?
Cela durera jusqu’à ce que Sci-Hub gagne et soit reconnu comme légal dans tous les pays du monde.
Voyez-vous un espoir que le site devienne légitime ?
C’est mon objectif depuis 2011. En fait, je m’attendais à ce que cela se produise rapidement, car le cas est tellement évident : les scientifiques utilisent le site Sci-Hub et ils ne sont clairement pas des criminels, donc Sci-Hub est légitime. Mais la reconnaissance de ce fait semble prendre plus de temps que je ne l’avais initialement prévu.
Nous supposons que votre popularité dépend du pays ? Pouvez-vous nous en dire plus sur la Chine, l’Afrique et la France ?
Je peux vous donner quelques statistiques provenant du compteur Yandex. Les statistiques internes de Sci-Hub ne sont que légèrement différentes. En Chine, il y a environ 1 million d’utilisateurs par mois (en 2017, c’était un demi-million mensuel). Il y a environ 250 000 utilisateurs par mois en provenance d’Afrique et environ 1 million en provenance d’Europe.
Pour la France, c’était pendant un moment au-dessus de 100 000 utilisateurs par mois. Ce chiffre a beaucoup diminué, je crois, parce que les chercheurs accèdent à des sites miroirs.
La qualité de votre interface utilisateur est mentionnée par beaucoup de vos utilisateurs. Pensez-vous qu’elle soit une raison essentielle du succès de Sci-Hub ?
Je ne le pense pas. La principale raison de l’utilisation de Sci-Hub, dans la plupart des cas, est le manque d’accès aux articles scientifiques par d’autres moyens. Les pays qui utilisent le plus Sci-Hub sont l’Inde et la Chine, et dans ces pays, l’utilisation de Sci-Hub n’est clairement pas une question de commodité. Sci-Hub ne dispose de cette interface « pratique » que depuis 2014 ou 2015. La première version de Sci-Hub obligeait les utilisateurs à saisir l’URL, à changer de proxy et à télécharger les articles manuellement, mais le site est rapidement devenu très populaire. Avant Sci-Hub, les chercheurs avaient l’habitude de demander des articles par courrier électronique ; c’était nettement plus long et moins pratique que Sci-Hub. Il fallait souvent plusieurs jours pour obtenir une réponse et parfois, on ne recevait pas de réponse du tout.
Quelle est la taille de l’équipe qui gère le site ?
Sci-Hub n’a pas d’équipe ! Depuis le début, il s’agit simplement d’un petit script PHP que j’ai codé moi-même, basé sur un code d’anonymisation open-source. Je gère les serveurs de Sci-Hub et je fais toute la programmation moi-même. Cependant, certaines personnes fournissent des comptes que Sci-Hub peut utiliser pour télécharger de nouveaux articles. D’autres gèrent les miroirs de Sci-Hub. Mais on ne peut pas appeler cela une équipe ; ce ne sont que des collaborations.
Avez-vous des contributeurs réguliers qui apportent directement des articles en libre accès ?
Non. Je m’explique : Sci-Hub est initialement apparu comme un outil permettant de télécharger automatiquement des articles. C’était une idée centrale au cœur de Sci-Hub ! Sci-Hub n’a jamais fonctionné avec des utilisateurs contribuant aux articles. Il serait impossible d’avoir des dizaines de millions d’articles fournis par les utilisateurs, car une telle base de données devrait être modérée : sinon, elle pourrait être facilement attaquée par quelqu’un qui fournirait de faux articles.
Une telle option pourrait exister à l’avenir, car il reste beaucoup moins d’articles, et Sci-Hub en a téléchargé la majeure partie.
Quel est votre défi le plus grand : obtenir l’accès aux publications ou fournir l’accès aux publications ?
La majeure partie de mon temps et de mon travail est consacrée à l’obtention de nouveaux articles. Cela nécessite la mise en œuvre de divers scripts pour télécharger les articles de différents éditeurs, et la mise à jour de ces scripts lorsque les éditeurs effectuent des mises à jour sur leurs sites Web, rendant le téléchargement automatique de Sci-Hub plus difficile. Par exemple, Elsevier a récemment mis en place des étapes supplémentaires qui rendent le téléchargement automatique plus difficile. L’ancien moteur de Sci-Hub a cessé de fonctionner et j’ai dû mettre en œuvre une approche différente.
Fournir l’accès aux bases de données est relativement plus facile, si l’on ne tient pas compte des défis juridiques bien sûr.
Qu’est-ce qui vous a poussé à créer Sci-Hub ? Le considérez-vous comme faisant partie du mouvement des biens communs, comme un commun au sens d’Elinor Ostrom ?
J’étais membre d’un forum en ligne sur la biologie moléculaire. Il y avait une section « Full Text » où les gens demandaient de l’aide pour accéder aux articles. Cette section était assez active et de nombreuses personnes l’utilisaient. Ils postaient des demandes, et si un membre du forum avait accès à l’article, il l’envoyait par courriel.
J’ai eu l’idée de créer un site Web qui rendrait ce processus automatique, en évitant les demandes manuelles et les envois par courrier électronique : les utilisateurs pouvaient simplement se rendre sur le site Web et télécharger eux-mêmes ce dont ils avaient besoin.
Pour moi, il y a des liens entre cette idée de communisme et l’idée de gestion collective des ressources dans l’esprit d’Elenor Ostrom.
Dans la première version de Sci-Hub, il y avait un petit marteau et une faucille, et si vous pointiez un curseur de souris dessus, il était écrit « le communisme est la propriété commune des moyens de production avec un libre accès aux articles de consommation ». Donc, libre accès aux articles ! Pour moi, Sci-Hub et plus généralement le mouvement du libre accès ont toujours été liés au communisme, car les articles scientifiques devraient être communs et libres d’accès pour tous, et non payants. Aujourd’hui, les connaissances scientifiques sont devenues la propriété privée de quelques grandes entreprises. C’est dangereux pour la science.
En 2016, j’ai découvert les travaux du sociologue Robert Merton. Il propose différents idéaux pour les scientifiques. L’un d’eux qu’il appelle le communisme est la propriété commune des découvertes scientifiques, selon laquelle les scientifiques abandonnent la propriété intellectuelle en échange de la reconnaissance et de l’estime. C’est l’objectif de Sci-Hub.
Comment les gens peuvent-ils vous aider ?
Parlez de Sci-Hub, discutez-en plus souvent. Lancez une pétition pour soutenir la légalisation de Sci-Hub, et discutez-en avec les responsables gouvernementaux et les politiciens. Cela aidera à résoudre la situation.
Alexandra Elbakyan, SciHub
SciHub.ru, 2018
Pour aller plus loin
Des informations générales sur la façon dont Sci-Hub a été lancé sont disponibles ici :
(*) Note des éditeurs : un scientifique peut avoir à payer des dizaines d’euros pour lire un article si son laboratoire n’a pas souscrit à ce journal, peut-être parce que le laboratoire n’en avait pas les moyens.
Comment les sceptiques du COVID-19 utilisent-ils les données épidémiologiques sur les réseaux sociaux pour militer contre le port du masque et autres mesures de santé publique ? Dans cet article, Crystal Lee partage le résultat d’une enquête sur les groupes de réseaux sociaux des sceptiques du COVID afin de démêler leurs pratiques d’analyse de données et leur tentative de création de sens. Lonni Besançon
Image 1 : un utilisateur de résaux sociaux présentant son analyse et ses doutes sur les données officielles américaine
Vous avez probablement assisté à une version de cette conversation au cours des derniers mois : un proche refuse de se faire vacciner ou affirme que l’épidémie de COVID est complètement exagérée, en pointant du doigt les dernières recherches lues sur Facebook. « Oui, moi je suis réellement la science », affirme-t-il. « Vous devriez faire pareil ». S’il est tentant d’écarter ces messages et conversations sur les médias sociaux comme étant simplement non scientifiques et nécessitant juste un rectificatif, une étude de six mois que j’ai menée avec une équipe de chercheurs du MIT suggère qu’une vision simpliste et binaire de la science – les chercheurs universitaires sont scientifiques, les messages Facebook ne le sont pas – nous empêche de vraiment comprendre l’accroche que génère ces groupes anti-masques. Bien que nous n’approuvions pas, ni ne cherchions à légitimer ces croyances, notre étude montre comment les utilisateurs de forums en ligne exploitent et détournent les compétences et les concepts qui sont les marqueurs de la démarche scientifique traditionnelle pour s’opposer à des mesures de santé publique telles que l’obligation de porter un masque ou l’interdiction de manger à l’intérieur d’une restaurant. Nombre de ces groupes utilisent activement des visualisations de données pour contredire celles des journaux et des organismes de santé publique, et il est souvent difficile de concilier ces discussions autour des données (voir image 1). Ces utilisateurs prétendent utiliser des méthodes scientifiques conventionnelles pour analyser et interpréter les données de santé publique ;comment se fait-il qu’ils arrivent à des conclusions totalement différentes de la majorité des scientifiques et experts de santé publique ? Qu’est-ce que « la science » telle que voudrait la définir ces groupes ?
Image 2 : un utilisateur montrant ses doutes sur l’origine des données.
Pour répondre à cette question, nous avons mené une analyse quantitative d’un demi-million de tweets et de plus de 41 000 visualisations de données parallèlement à une étude ethnographique des groupes Facebook anti-masques [1]. Ce faisant, nous avons catalogué une série de pratiques qui sont à la base des argumentations courantes contre les recommandations de santé publique, et beaucoup sont liées à des compétences que les chercheurs pourraient enseigner à leurs étudiants. En particulier, les groupes anti-masque sont critiques à l’égard des sources de données utilisées pour réaliser des visualisations dans les articles basés sur les données (voir images 1 et 2). Ils s’engagent souvent dans de longues conversations sur les limites des données imparfaites, en particulier dans un pays où les tests ont été ponctuels et inefficaces. Par exemple, beaucoup affirment que les taux d’infection sont artificiellement élevés, car au début de la pandémie, les hôpitaux ne testaient que les personnes symptomatiques. Ils arguent que le fait de tester aussi les personnes asymptomatiques ferait baisser cette statistique. De plus, comme les personnes asymptomatiques ne sont par définition pas physiquement affectées par le virus, cela permet aux personnes qui utilisent cet argumentation de conclure que la pandémie n’est quasiment pas mortelle.
Ces militants anti-masque en déduisent donc que des statistiques peu fiables ne peuvent pas servir de base à des politiques néfastes, qui isolent davantage les gens et conduisent les entreprises à s’effondrer de façon massive. Au lieu d’accepter telles quelles les conclusions des médias d’information ou des organisations gouvernementales, ces groupes affirment que comprendre comment ces mesures sont calculées et interprétées est le seul moyen d’accéder à la vérité sans fard. En fait, pour découvrir ces histoires cachées, certains ont délibérément évité les visualisations au profit des tableaux, qu’ils considèrent comme la forme de données la plus « brute » et la moins médiatisée. Pour nombre de ces groupes, il est essentiel de suivre la science pour prendre des décisions éclairées, mais selon eux, les données ne justifient tout simplement pas les mesures de santé publique telles que le port du masque (voir image 3).
Image 3 : un utilisateur utilisant les données de la Suède pour dire que les interventions gouvernementale ne sont pas justifiées.
Que disent donc les utilisateurs de masques à propos des données ? De mars à septembre 2020, nous avons mené une étude de type « deep lurking » (observation profonde) de ces groupes Facebook – basée sur la méthode de « deep hanging out » (immersion profonde) de l’anthropologue Clifford Geertz – en suivant les fils de commentaires, en archivant les images partagées et en regardant les flux en direct où les membres animent des tutoriels sur l’accès et l’analyse des données de santé publique.
Les anti-masques sont parfaitement conscients que les organisations politiques et d’information dominantes utilisent des données pour souligner l’urgence de la pandémie. Eux, pensent que ces sources de données et ces visualisations sont fondamentalement erronées et cherchent à contrecarrer ce qu »ils considèrent comme des biais. Leurs discussions reflètent une méfiance fondamentale à l’égard des institutions publiques : les anti-masques estiment que l’incohérence dans la manière dont les données sont collectées (image 4, surlignage jaune) et l’incessante propagande alarmiste rendent difficile la prise de décisions rationnelles et scientifiques. Ils pensent également que les données ne soutiennent pas les politiques gouvernementales actuelles (image 4, surlignage bleu).
Image 4 : conversations mettant en avant les doutes sur la façon dont les données sont collectées (surlignage jaune) et sur le fait que les données ne soutiennent pas les politiques gouvernementales actuelles (surlignage bleu).
Alors comment ces groupes s’écartent-ils de l’orthodoxie scientifique s’ils utilisent les mêmes données ? Nous avons identifié quelques tours de passe-passe qui contribuent à la crise épistémologique plus large que nous identifions entre ces groupes et la majorité des chercheurs. Par exemple, les utilisateurs anti-masque soutiennent que l’on accorde une importance démesurée aux décès par rapport aux cas recensés : si les ensembles de données actuels sont fondamentalement subjectifs et sujets à manipulation (par exemple, l’augmentation des niveaux de tests erronés), alors les décès sont les seuls marqueurs fiables de la gravité de la pandémie. Même dans ce cas, ces groupes pensent que les décès constituent une catégorie supplémentaire problématique car les médecins utilisent le diagnostic du COVID comme principale cause de décès (c’est-à-dire les personnes qui meurent à cause du COVID) alors qu’en réalité d’autres facteurs entrent en jeu (c’est-à-dire les personnes contaminées qui meurent de co-morbidité avec, mais pas à cause directement, du COVID). Puisque ces catégories sont sujettes à l’interprétation humaine, en particulier par ceux qui ont un intérêt direct à rapporter autant de décès dus au COVID que possible, ces chiffres sont largement « surdéclarés », peu fiables et pas plus significatifs que la grippe, pensent leurs détracteurs.
Plus fondamentalement, les groupes anti-masque se méfient de la communauté scientifique parce qu’ils croient que la science a été corrompue par des motivations liée au profit et par des politiques soi-disant progressistes mais en fait déterminées à accroître le contrôle social. Les fabricants de tabac, affirment-ils à juste titre, ont toujours financé des travaux scientifiques qui ont induit le public en erreur sur la question de savoir si le fait de fumer provoquait ou non le cancer. Ils pensent donc que les sociétés pharmaceutiques sont dans une situation similaire : des sociétés comme Moderna et Pfizer vont tirer des milliards de bénéfices du vaccin, et il est donc dans leur intérêt de maintenir un sentiment d’urgence sanitaire et publique quant aux effets de la pandémie, affirment-ils. En raison de ces incitations, ces groupes soutiennent que ces données doivent faire l’objet d’un examen supplémentaire et être considérées comme fondamentalement suspectes. Pour les scientifiques et les chercheurs, affirmer que les anti-masques ont simplement besoin d’une plus grande culture scientifique, alors que justement ils s’appuient dessus et la manipule, offre aux antimasques une preuve supplémentaire de l’impulsion de l’élite scientifique à condescendre aux citoyens qui épousent réellement le bon sens.
Quelle solution s’offre alors pour éviter ces problèmes?
Mieux rendre visible l’exemplarité : la communauté scientifique doit toujours travailler dans un vrai esprit éthique et de transparence [2], elle le fait (sauf exceptions rares et sanctionnées) mais ne montre probablement pas assez cet esprit éthique, il faudrait le ré-affirmer plus.
Bien rendre visible le doute : nombre de scientifiques ont aussi dit par rapport aux données du COVID « ça nous ne savons pas ou ne sommes pas sûrs´´ mais le traitement par les médias de ces incertitudes est souvent biaisée, c’est moins médiatique de dire « peut-être » que d’affirmer une chose … puis son contraire.
Aider à développer l’esprit critique : envers à la fois la science académique et les interprétations anti-scientifiques qui en sont faites. Développer l’esprit critique n’est pas dire qui a raison ou tort mais aider chacune et chacun à faire la part des faits de celles des croyances, à évaluer et déconstruire les arguments, non pas pour le rejeter systématiquement, mais pour en comprendre les origines.
Les données scientifiques de cette pandémie et leurs interprétations largement médiatisées pourraient être une occasion de mieux comprendre collectivement la démarche scientifique avec sa force, ses limites et ses dévoiements.
[2] Besançon, L., Peiffer-Smadja, N., Segalas, C. et al. Open science saves lives: lessons from the COVID-19 pandemic. BMC Med Res Methodol 21, 117 (2021). https://doi.org/10.1186/s12874-021-01304-y
Nous savons que les IA ne sont pas intelligentes et pourtant elles arrivent à approcher le fonctionnement humain dans de plus en plus de domaines. Aujourd’hui, nous nous intéressons au traitement du langage humain. Après avoir abordé la reconnaissance vocale, nous vous proposons d’approfondir d’autres aspects comme la complétion ou la traduction grâce à une très intéressante vidéo publié par David Louapre sur son blog Science Étonnante. Thierry Viéville et Pascal Guitton
Commençons par une dictée.
En fait, les lignes que vous commencez à lire, là, maintenant, n’ont pas été tapées au clavier mais… dictées à l’ordinateur ? Ce dernier comprend-il ce qui lui est dit ? Nullement. Alors comment fait-il ? !
La parole humaine est constituée d’environ une cinquantaine de phonèmes. Les phonèmes sont des sons élémentaires (entre une voyelle et une syllabe) qui se combinent pour former des mots. Nous utilisons entre 1 000 et 3 000 mots différents par jour, et en connaissons de l’ordre de 10 000 en tout, selon nos habitudes de lecture. Pour un calcul statistique, ce n’est guère élevé : le son de la voix est donc simplement découpé en une séquence de petits éléments qui sont plus ou moins associés à des phonèmes, pour ensuite être associés à des mots. Le calcul statistique cherche, parmi tous les bouts de séquences de mots, ceux qui semblent correspondre au son ainsi découpé et qui sont les plus probables. Il ne reste plus qu’à sortir le résultat sous forme d’une chaîne de lettres ou de caractères pour obtenir une phrase à l’oral.
Un exemple de signal sonore d’une voix humaine en bleu et l’analyse des graves et des aiguës (le spectre fréquentiel) de la zone claire : c’est à partir de cet alphabet sonore approximatif que l’on effectue les calculs statistiques qui transcrivent le son.
Bien entendu, ce mécanisme ne “comprend rien à rien”. Ces mots ne font pas du tout sens par la machine, puisqu’il ne s’agit que d’une mise en correspondance entre des sons et des symboles. Ce procédé n’est donc exploitable que parce que la voix humaine est moins complexe qu’elle n’y paraît, et surtout car il a été possible de se baser sur une quantité énorme de données (des milliers et des milliers de paroles mises en correspondance avec des milliers et des milliers de bouts de séquences de mots) pour procéder à une restitution fiable du propos dicté. Ces calculs sont à la fois numériques, puisque chaque son est représenté par une valeur numérique manipulée par calcul, et symboliques, chaque phonème ou mot étant un symbole manipulé par un calcul algorithmique.
Et ensuite … comment manipuler le sens du langage ?
Vous avez vu ? Nous en sommes à avoir pu « mécaniser » non seulement la reconnaissance des mots mais aussi la manipulation du sens que nous pouvons leur attribuer.
On en fait même tout un fromage.
Comme l’explique David, les modèles de langue neuronaux contextuels sont désormais omniprésents y compris en français avec ces travaux des collègues Inria. Le calcul peut par exemple résoudre des exercices de textes à trous, que l’algorithme a pu remplir avec le bon mot, avant de se tourner vers des applications plus utiles comme la traduction automatique, la génération assistée de texte, etc.
Mais finalement, je me demande si parfois, je n’aimerais pas me faire « remplacer » par une IA pendant des conversations inintéressantes où je m’ennuie profondément :). Oh, ce n’est pas que je pense qu’elles sont devenues intelligentes, ces IA … c’est plutôt que franchement, entre humains, on se dit que ma foi, des fois, il faut avoir la foi, pour pas avoir les foies, à écouter ce qui se dit … quelques fois…




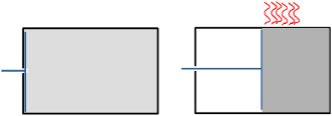
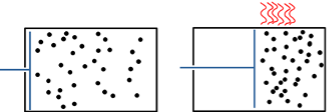
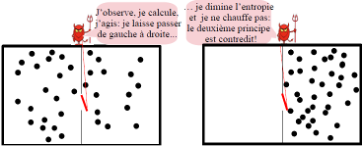
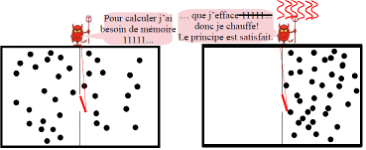



![[DA]vid contre Gol[IA]th : Quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?](https://binaire.socinfo.fr/wp-content/uploads/2024/09/25732ce2-img1.jpg)
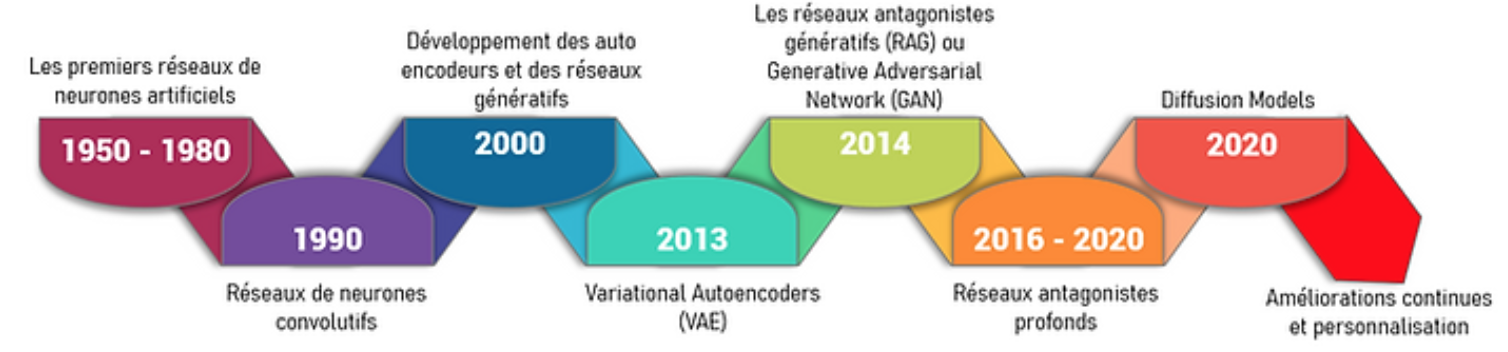



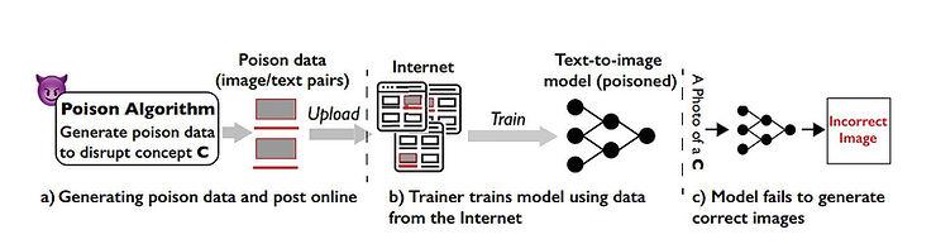





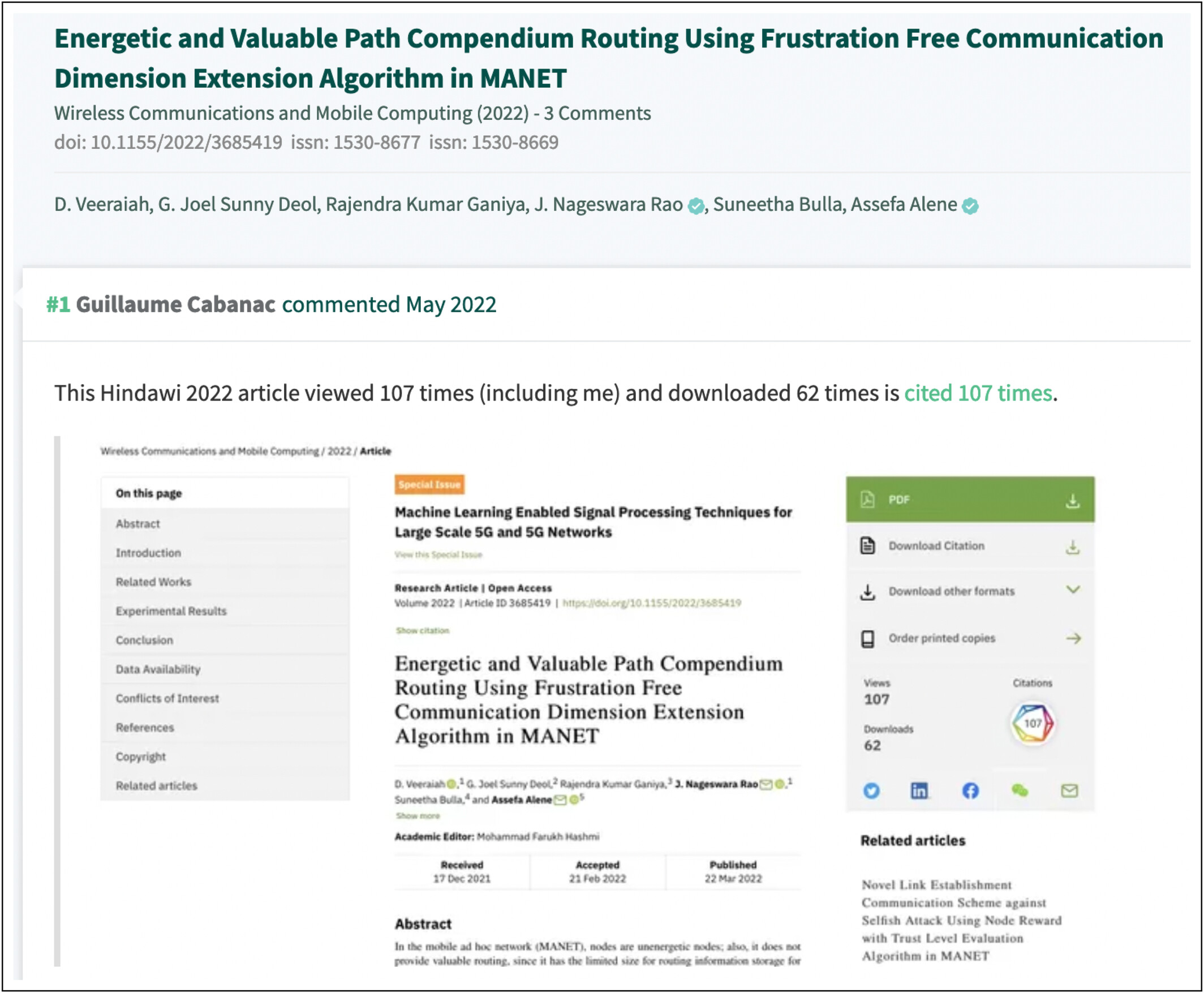

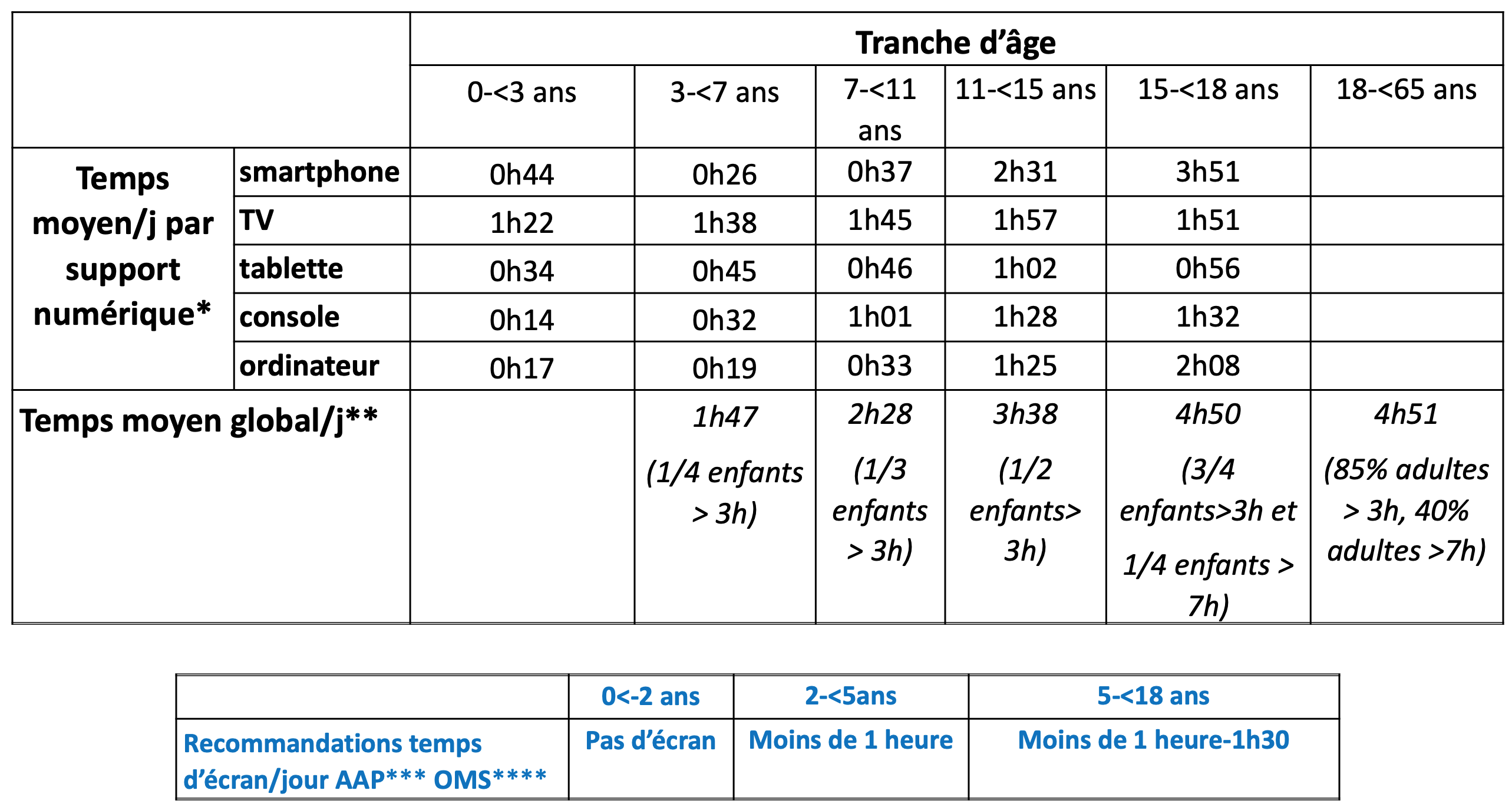
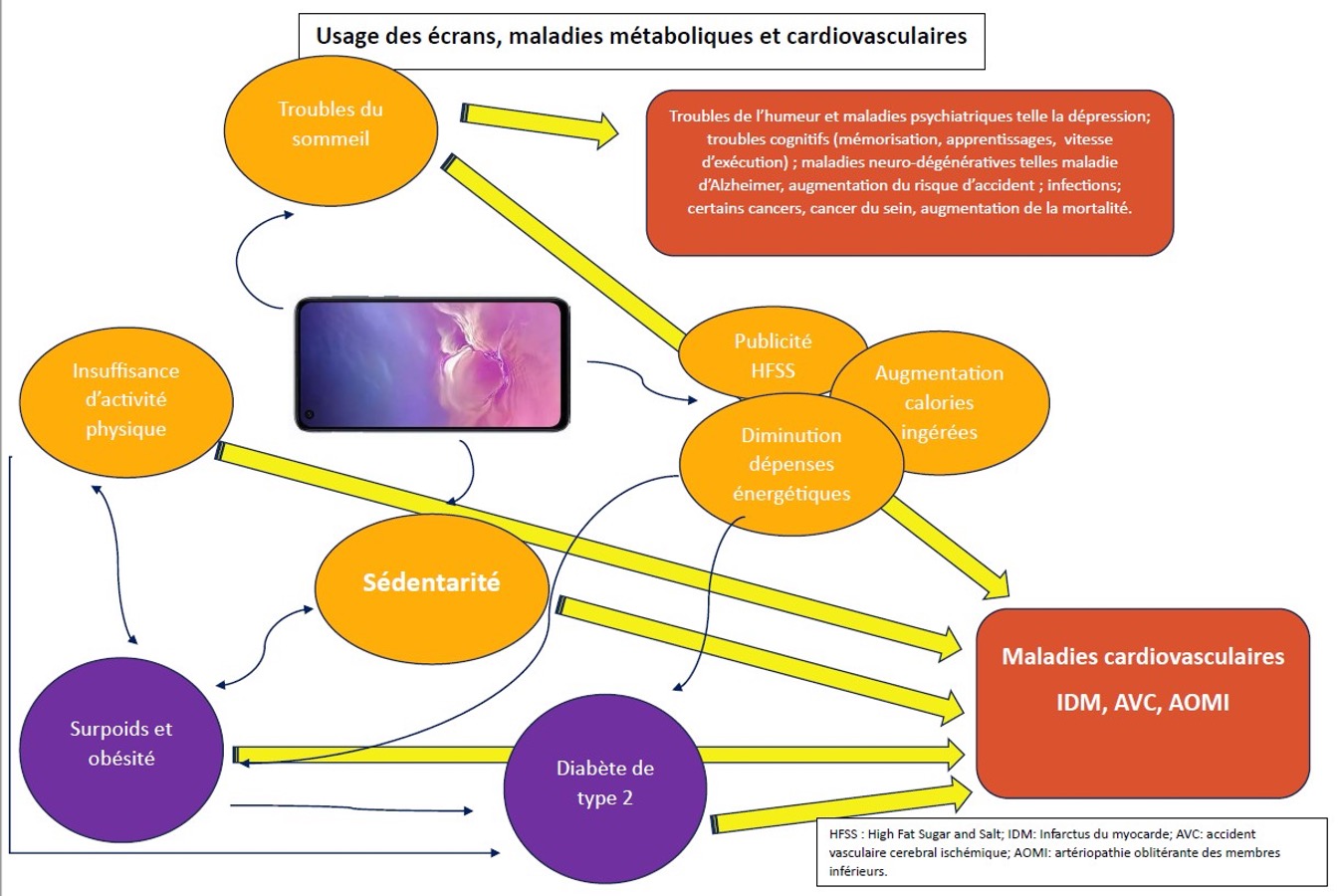




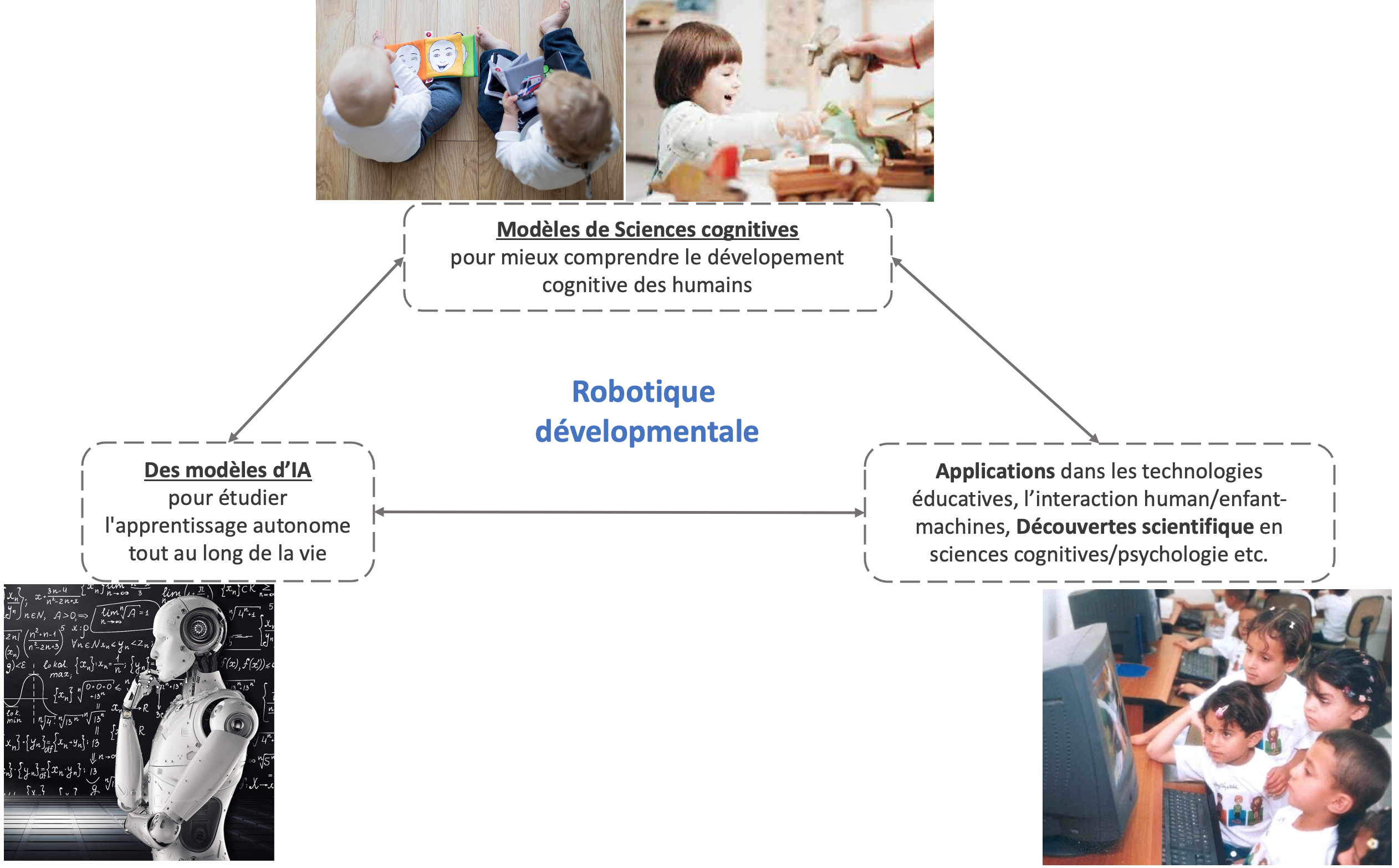
 ©Catherine Créhange
©Catherine Créhange 

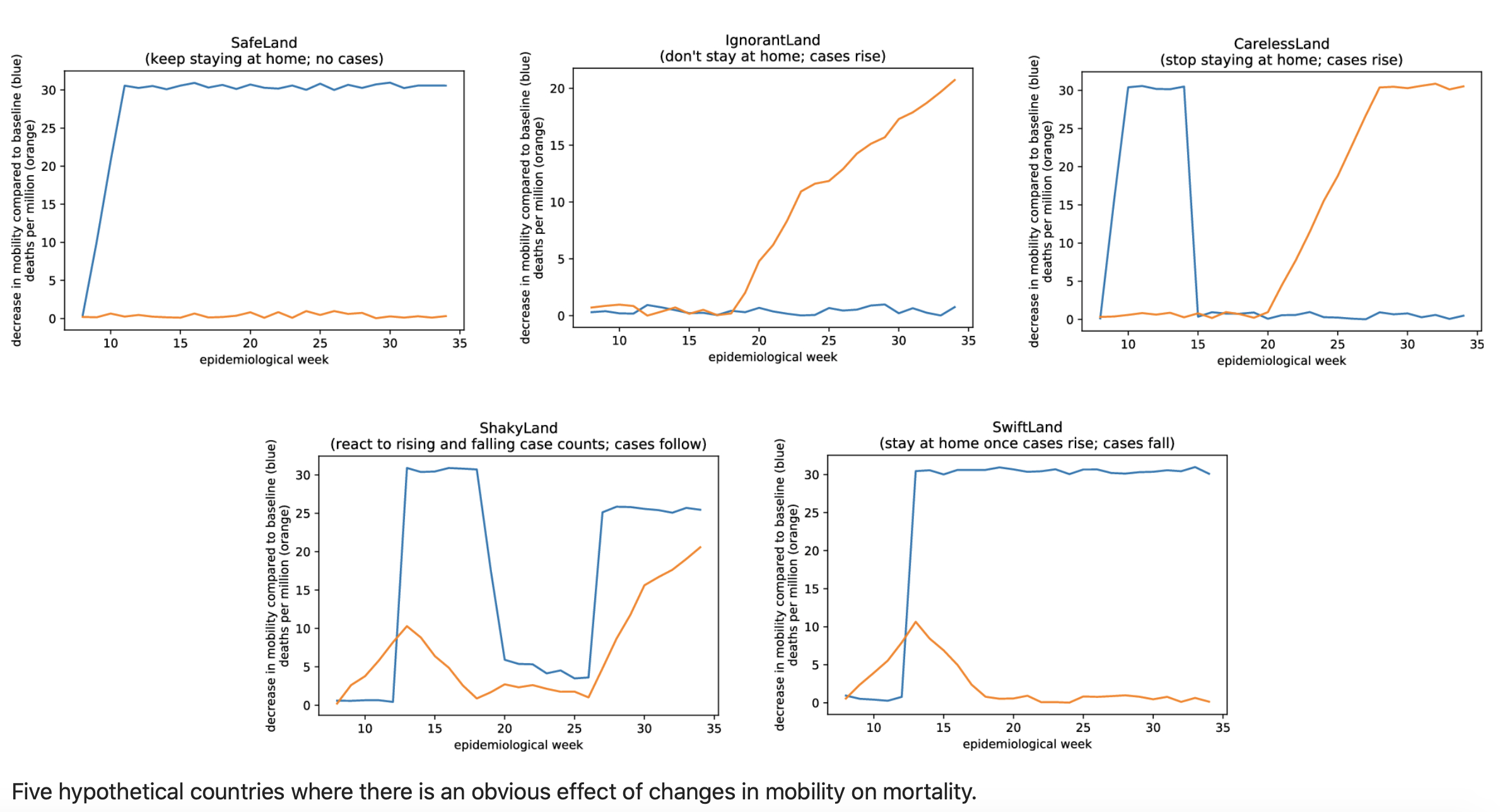



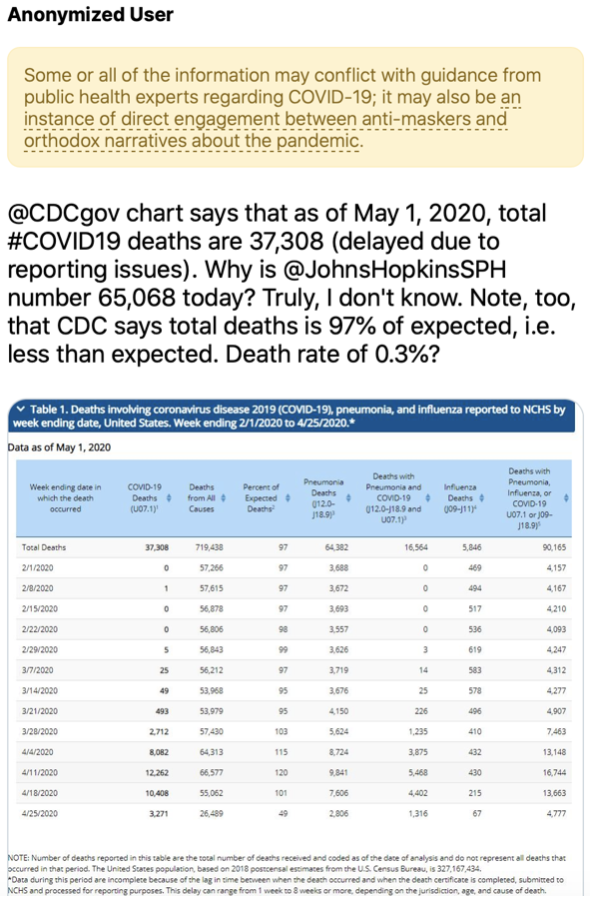
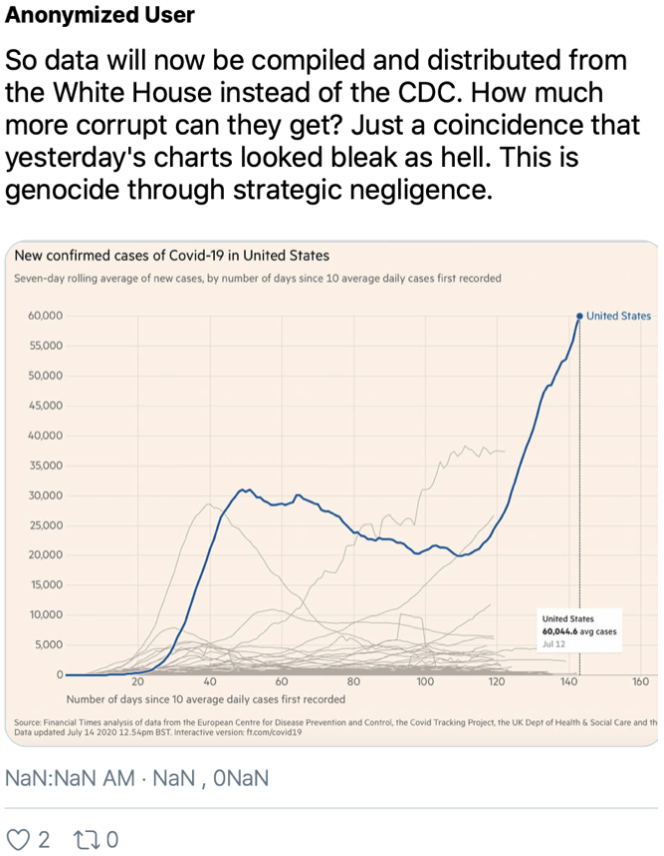
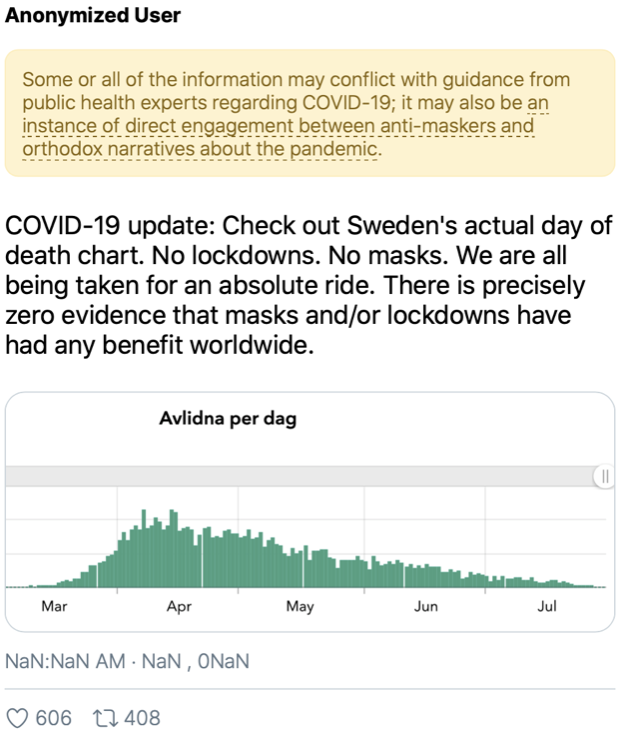
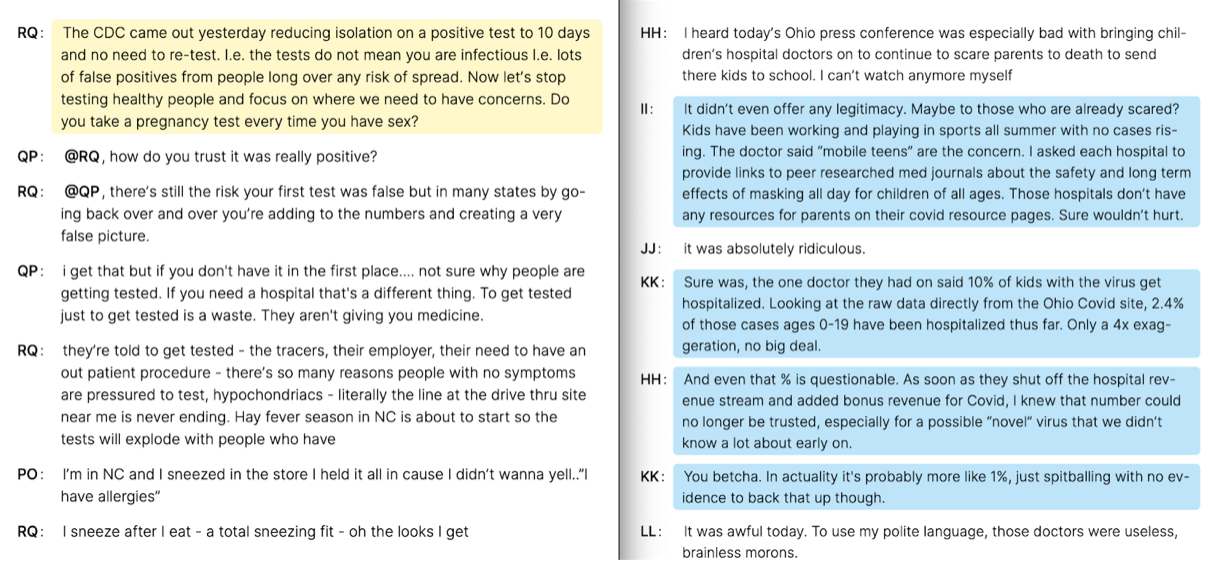


{kind=link}