Le prix Jeune Chercheu-r-se Inria – Académie des Sciences, a été décerné cette année à Véronique Cortier, Directrice de Recherche du CNRS à Nancy. Véronique est une amie de Binaire qui a déjà écrit plusieurs articles pour nous. Ses recherches portent sur la vérification automatique de programmes, notamment l’analyse des protocoles de sécurité. Nous avons demandé à une autre spécialiste de ce domaine, Stéphanie Delaune, de nous parler du parcours de cette chercheuse brillante qui, partie des mathématiques, et, malgré quelques réticences, a fini par être séduite par l’informatique. Serge Abiteboul.
Véronique Cortier
Les protocoles cryptographiques sont des petits programmes destinés à sécuriser nos communications. Sans même nous en apercevoir, nous les utilisons tous les jours pour effectuer des tâches plus ou moins critiques. Ils sont utilisés par exemple pour garantir la confidentialité de nos données bancaires lors d’un achat en ligne, ou encore le respect de notre anonymat lors d’une procédure de vote électronique. J’en profite d’ailleurs pour vous inviter à consulter sur ce blog la série d’articles rédigés par Véronique autour du vote électronique (voir en fin d’article).
L’utilisation de ces protocoles est en général indolore, mais un protocole mal conçu peut avoir des conséquences désastreuses. Une faille dans un protocole peut permettre à un agent malveillant d’effectuer des opérations frauduleuses sur votre compte bancaire ou de truquer les résultats d’une élection. Indolore… pas tant que ça !
Afin de pouvoir garantir en amont qu’un protocole particulier satisfait les propriétés de sécurité souhaitées, il est important de les vérifier. Le but des recherches menées par Véronique, et par les chercheurs de son équipe, consiste à développer des techniques d’analyse rigoureuses, et si possible automatiques, pour assurer le bon fonctionnement de ces protocoles de sécurité. Pour cela, il faut traduire protocoles et propriétés de sécurité en formules mathématiques, et développer des méthodes permettant de les analyser.
Véronique Cortier s’est intéressée, dès son plus jeune âge, aux mathématiques. Elle rejoint l’École Normale Supérieure de Cachan en 1997. Elle avait alors une piètre opinion de l’informatique, qui consistait pour elle principalement à modifier les fichiers de configuration de Windows. Grâce à des professeurs comme Antoine Petit et Hubert Comon-Lundh, elle découvre une discipline fascinante, pleine de problèmes d’actualité, et où les mathématiques jouent un rôle beaucoup plus grand qu’elle ne l’imaginait, un terrain de jeu idéal pour cette passionnée de sciences !
L’informatique se conjugue aussi brillamment au féminin !
Michel Raynal, Professeur à l’Université de Rennes 1 et membre senior de l’Institut Universitaire de France est un passionné. Il aime les voyages, adore la littérature, ne se lasse pas des côtes bretonnes (malgré ses origines du Sud-Ouest), encore moins du rugby (probablement en raison de ces mêmes origines). Michel aurait pu devenir un grand scientifique dans bien des domaines. C’est dans l’informatique qu’il est tombé, et plus particulièrement dans cette même région de l’Ouest où d’autres se sont retrouvés dans une marmite de potion magique. Michel Raynal est le lauréat du SIROCCO Innovation Award 2015 pour ses travaux en informatique distribuée. C’est l’occasion de découvrir ce domaine passionnant.
Un système distribué est un système composé de plusieurs entités (téléphone, capteur, ordinateur par exemple), connectées par un réseau de communication, c’est-à-dire qui peuvent communiquer (en filaire, par wifi, etc.) et qui, ensemble, s’attaquent à un problème comme de réaliser un calcul ou chercher de l’information. Nous vivons aujourd’hui dans un monde où la majorité des systèmes est distribuée. Par exemple, les données relatives aux comptes Facebook d’un ensemble d’amis sont dispersées aux quatre coins du monde ; pourtant lorsqu’un utilisateur met à jour son statut, tous ses amis doivent être notifiés, qu’ils soient connectés depuis le Maroc ou la Chine et que leurs données soient hébergées en Inde ou dans la Silicon Valley. Nos données, comme celles des entreprises, sont distribuées sur des serveurs ; on parle du cloud. La même donnée peut être répliquée sur plusieurs serveurs pour des raisons de fiabilité notamment.
Turing s’est un jour posé la question de ce que sa machine universelle était capable de calculer. Malheureusement, son formalisme ne s’applique pas aux systèmes distribués. Évidemment, les experts se sont posés la question de savoir ce qu’il est possible de calculer dans un système distribué, notamment le problème du consensus qui a été particulièrement étudié. Le problème est le suivant : chaque entité propose une valeur et à la fin du calcul toutes doivent s’être mises d’accord sur l’une de ces valeurs. C’est le type de fonctionnalité dont on a besoin, par exemple, pour assurer la cohérence de données répliquées dans le Cloud. Pour illustrer le besoin de consensus, prenons l’exemple de données bancaires répliquées sur les machines A en France et B aux États-Unis. Ces données sont répliquées pour des raisons de tolérance aux pannes, de sorte que si une machine contenant ces données tombe en panne, l’autre continue de fonctionner. Ceci permet en outre aussi aux utilisateurs des États-Unis d’avoir un accès rapide depuis la machine B et aux utilisateurs européens d’avoir un accès rapide depuis la machine A. Considérons maintenant la situation suivante : Alice effectue un débit de 100$ depuis la France (sur la machine A) de son compte, dont le solde est de 1000$. L’ordre de débit est envoyé à la machine A mais aussi à la machine B pour assurer que les comptes soient cohérents. Le banquier, depuis la machine B, lui décide de verser des intérêts de 10% sur ce compte. Cet ordre de calcul d’intérêt est aussi envoyé aux deux machines. La communication prend du temps pour traverser l’Atlantique, si bien que la machine A reçoit d’abord l’ordre de débit puis celui des intérêts, appliquant donc 10% à un solde de 900$, le solde résultant est alors 990$, alors que la machine B, applique les intérêts, puis le débit, le solde étant alors de 1000$. Pour assurer un bon fonctionnement il est essentiel que les deux machines exécutent les instructions dans le même ordre et pour ce faire doivent atteindre un consensus.
Fisher, Lynch et Patterson [FLP85] ont montré en 1985 que le consensus était impossible dans un système réparti asynchrone* dans lequel les machines peuvent tomber en panne. La preuve est longue et intriquée et il faudrait demander à Michel Raynal de nous l’expliquer. Pour faire court, dans un système asynchrone, si une entité ne répond pas, on ne sait pas différencier si c’est une question de lenteur, ou si c’est une défaillance de l’entité. Et on peut soit attendre éternellement le message alors que l’entité est défaillante ou alors prendre une décision et voir le message arriver trop tard et contredire notre décision. Michel Raynal a reçu le Sirocco Innovation Award en particulier pour ses travaux relatifs à ce problème de consensus, développant de nouveaux résultats à partir du théorème d’impossibilité de Fisher, Lynch et Patterson.
Que peut faire un chercheur en algorithmique distribuée quand un problème est impossible à résoudre ? Il étudie les hypothèses à relâcher pour que le problème devienne résoluble. Par exemple, pour le problème du consensus, on peut décider de prendre l’hypothèse que les messages entre les entités prennent un temps borné. Le consensus devient alors possible. Que peut-il faire quand on sait résoudre le problème ? Il peut chercher un algorithme plus efficace, par exemple plus rapide, demandant moins de messages, moins de calcul. Afin de contourner l’impossibilité du consensus en asynchrone, Michel Raynal avec ses collègues Achour Mostéfaoui et Sergio Rajsbaum ont par exemple proposé une nouvelle méthode à base de conditions [2]. L’idée est de dénombrer les « conditions », c’est à dire les configurations pour lesquelles on sait comment obtenir un consensus. Michel a alors conçu des algorithmes qui permettaient de s’adapter à ces conditions, rendant ainsi l’obtention d’un consensus possible [3].
Le prix de Michel Raynal reconnait ses contributions scientifiques. Pour conclure, on pourrait souligner que Michel assure la relève formant des jeunes chercheurs, et en leur transmettant son enthousiasme et sa passion.
Anne-Marie Kermarrec, Inria Rennes
(*) Dans un système synchrone, les opérations sont coordonnées sous un contrôle centralisé basé sur les signaux d’une horloge. Par opposition, un système asynchrone, en revanche, n’a pas d’horloge globale. Les différentes entités doivent utiliser des communications pour coordonner leurs tâches.
Références
[1] Michael J. Fisher, Nancy A. Lynch, and Michael S. Paterson. Impossibility of distributed consensus with one faulty process. Journal of the Association for Computing Machinery, 32(2) :374–382, april 1985.
[2] Achour Mostéfaoui, Sergio Rajsbaum, Michel Raynal: Conditions on input vectors for consensus solvability in asynchronous distributed systems. J. ACM 50(6): 922-954 (2003)
Parmi ces faiblesses, une attaque amusante mais peu connue est « l’attaque à l’italienne ». Cette attaque est possible dès que l’espace des votes est important. Qu’est-ce que l’espace des votes ? En France, les élections sont en général « simples »: il s’agit de choisir un candidat (ou une liste) parmi une dizaine tout au plus. La situation est très différente dans d’autres pays. Prenons le cas de l’Allemagne. Lors de l’élection de la chambre d’un Lander (par exemple celui de la Hesse), les électeurs ont la liberté de composer la chambre de leur choix. Chaque parti politique propose une liste composée des candidats, dont le nombre est variable selon les partis. Un électeur peut choisir une liste et sélectionner ainsi tous les candidats de cette liste. Mais il peut également ajouter des voix à certains candidats, rayer certains candidats et ajouter des candidats d’autres listes. Un règlement complexe a été mis en place pour lever les éventuelles ambiguïtés et éviter un trop grand nombre de bulletins invalides. J’invite le lecteur curieux à lire l’article wikipedia (en allemand) pour une explication détaillée et illustrée des différentes règles, ou bien à utiliser l’interface mise en place pour explorer les différentes manières de remplir correctement un bulletin.
En quoi ce type d’élections peut-il être exploité pour mener une attaque ? La clef de l’attaque est la taille de l’espace des votes. Considérons ainsi le cas extrême du bulletin de vote utilisé lors d’une élection au sein de la commune de Francfort en 2011, où plus de 861 candidats étaient proposés pour un total de 93 sièges. Sans même calculer toutes les possibilités, un rapide calcul indique qu’il y a plus 93 choix parmi 861 soit plus de 10^126 façons différentes de remplir un bulletin. Si, de plus, on tient compte de la position des croix (1ère, 2ème ou 3ème colonne), on arrive alors à plus de 10^172 possibilités.
Un attaquant peut utiliser ce large choix pour « signer » un bulletin. Considérons le cas simplifié où les électeurs disposent de seulement 15 voix chacun et supposons que Charlie souhaite forcer Alice à voter pour le parti politique C sur le bulletin affiché ci-dessous. Il exige alors qu’elle remplisse le bulletin de la manière suivante:
2 croix devant chaque candidat de la liste C (soit 8 voix au total)
7 croix placées selon une combinaison particulière choisie par Charlie.
Bulletin rempli d’après une image de Sven Teschke (Licence : CC-BY-SA-2.0-DE)
Lors du dépouillement, Charlie s’assurera qu’un tel bulletin est bien présent dans l’urne. Comme il est très improbable qu’un autre électeur ait choisi exactement la même combinaison des votes (notamment pour la partie affichée en rouge sur la figure), Alice est obligée d’obéir à Charlie sous peine de représailles après le dépouillement.
En France, ce type de scénarios est improbable car le nombre de choix est très limité. Cependant, c’est exactement pour cette raison qu’il est interdit d’apposer un signe distinctif sur un bulletin, que ce soit un symbole ou un mot particulier, ou bien un pliage original (un bulletin en forme de girafe par exemple). Notons tout de même que malgré cette interdiction, Charlie a encore la possibilité de forcer Alice à s’abstenir, ou plus précisément, de la forcer à voter nul. Il suffit en effet que Charlie demande à Alice de plier son bulletin en forme de girafe (ou tout autre signe distinctif convenu à l’avance). Un tel bulletin sera comptabilisé comme un vote nul et Charlie pourra s’assurer qu’Alice a bien suivi sa consigne en assistant au dépouillement.
À la suite de la publication de ce billet, Roberto Di Cosmo m’a signalé que les attaques à l’italienne sont encore très vivaces dans la mémoire des Italiens. Ainsi, un film, « Le porteur de Serviette » avec Nanni Moretti, de 1991, fait de ce type d’attaque un élément de son histoire (voir l’extrait en italien). Une pétition (en italien) rappelle l’usage massif fait dans le passé de l’attaque à l’italienne sur les élections à choix multiples, qui ont été remplacées par d’autres schéma de votes. Cette pétition dévoile de nouvelles méthodes utiliséespar la Mafia, signale qu’un vote peut se vendre 50 Euros au marché noir, et demande de nouveaux changements des règles électorales.
Du 6 au 11 juillet, Lille accueille ICML (International Conference on Machine Learning), le rendez-vous annuel des chercheurs en apprentissage automatique (machine learning). Mais comment expliquer à ma garagiste ou à mon fleuriste ? Et à quoi bon ! Donnons la parole à des chercheurs qui prennent le risque de soulever pour nous le capot du moteur et de nous l’expliquer.
L’apprentissage automatique est là. Pour le meilleur comme pour le pire.
Comme nous le développions il y a quelques jours, l’apprentissage automatique est désormais partout dans notre quotidien. Votre téléphone portable complète vos phrases en fonction de vos habitudes. Lorsque vous cherchez un terme avec votre moteur de recherche favori, vous recevez une liste de pages pertinentes très différente de celle que recevra une personne d’un autre âge ou d’un autre pays. C’est aussi un algorithme qui propose la publicité que vous subissez.
Dans les différents cas ci-dessus, il s’agit bien de calculer automatiquement des préférences, de faire évoluer un logiciel en fonction des données.
L’apprentissage automatique est associé au phénomène Big Data, et quand certains journaux s’inquiètent du pouvoir des algorithmes, il y a fort à parier que les algorithmes en question sont justement ceux qui s’intéressent aux données –aux vôtres en particulier- et essayent d’en extraire une connaissance nouvelle ; par exemple pour offrir un diagnostic médical plus précis. Ou, dans le contexte de la loi sur le renseignement votée récemment, pour récolter et traiter nos données privées.
https://canvas.northwestern.edu/
Alors il y a quelque chose d’inévitable si nous voulons ne pas subir tout cela : il faut comprendre comment ça marche.
Bien alors en deux mots : comment ça marche ?
En deux mots ? apprendre (construire un modèle) et prédire (utiliser le modèle appris). Et pour ce qui est de prédire l’avenir … on en a brulé pour moins que ça !
Apprendre : où l’on récolte des données pour mieux les mettre en boîte.
La première problématique consiste à construire, automatiquement, un modèle : il s’agit donc de comprendre quelque chose dans les données. Par exemple dans tous ces résultats médicaux quelle est la loi statistique ? Ou bien dans ces nombreuses données financières, quelle est la fonction cachée ? Ou encore dans ces énormes corpus de textes, quels sont les motifs, les règles ? Et ailleurs, dans le parcours du robot, les résultats transmis par ses capteurs font-ils émerger un plan de la pièce ?
Cette modélisation peut être vue comme une simple tâche de compression : remplacer des très grands volumes de données par une description pertinente de celles-ci. Mais il s’agit aussi d’abstraire, de généraliser, c’est à dire de rechercher des règles ou des motifs expliquant les données. Autrement dit, on essaye d’oublier intelligemment les données brutes en les remplaçant par une information structurée plus compacte.
Cette construction est de nature algorithmique et la diversité des algorithmes est gigantesque. Mais essayons de nous y retrouver.
Apprentissage supervisé ou non.
Si les données sont étiquetées, donc qu’on connait la valeur que l’on voudrait prédire, alors il s’agit d’un apprentissage supervisé : les données peuvent être utilisées pour prédire ce qui est correct et ce qui ne l’est pas.
La valeur peut être un nombre (par exemple le cours d’une action dans trois mois) ou une classe (par exemple, dans le cas d’une image médicale, la présence ou l’absence d’un motif qui serait associé à une maladie). Dans le premier cas, on parle de régression, dans le second, de classification.
Si les données ne sont pas étiquetées, le but sera de trouver une organisation dans ces données (par exemple comment répartir en groupes homogènes les votants d’un parti politique, ou organiser les données en fonction de la proximité de leurs valeurs). Cette fois, l’apprentissage est non supervisé, puisque personne ne nous a dit à l’avance quelle est la bonne façon de mesurer, de ranger, de calculer.
Apprentissage passif ou actif
Les données, elles, ont été le plus souvent collectées à l’avance, mais il peut également s’agir de données que le même programme va chercher à obtenir par interaction avec l’environnement : on parle alors d’apprentissage actif.
On peut formaliser le fait qu’il reçoit à chaque étape une récompense (ou une punition) et ajuste son comportement au mieux en fonction de ce retour. Ce type d’apprentissage a aussi été formalisé, on parle d’apprentissage par renforcement.
Les trois grands types de modèles.
Le modèle peut être de nature géométrique : typiquement, les données sont des points dans un espace de très grande dimension, et le modèle donne l’équation pour séparer le mieux possible les différentes étiquettes. Le modèle peut-être logique : il sera alors un ensemble de règles qui permettront dans le futur de dire si un nouvel objet est d’une catégorie ou d’une autre. Le modèle peut être probabiliste : il nous permettra de définir, pour un nouvel objet, la probabilité d’être dans telle ou telle catégorie.
Inférer : où l’informatique fait concurrence aux devins.
Reste à savoir utiliser le modèle appris, ou choisir parmi un ensemble de modèles possibles. L’inférence est souvent un problème d’optimisation : trouver la meilleure prédiction étant donné le(s) modèle(s) et les données. Les arbres de décision (étudiés aujourd’hui au lycée) permettent, pour les valeurs d’un modèle et des données, de calculer la probabilité de rencontrer ces données si on considère le modèle et ses valeurs. La question de l’inférence est en quelque sorte l’inverse, celle de choisir le modèle étant donné un certain ensemble de données.
Ici on raisonne souvent en terme de probabilité, il faut donc évaluer le risque, au delà du coût lié à chaque choix.
Ouaouh ! Alors il y a des maths en dessous ?
Oui oui ! Et de très jolies mathématiques, par exemple on peut se poser la question suivante :
De quel nombre m de données ai-je besoin
pour faire une prédiction avec une erreur ε en prenant un risque δ ?
Croyez-nous ou non, pour certains modèles la formule existe, et elle peut prendre cette forme :
et nous la trouvons même assez jolie. C’est Leslie Valiant qui l’a proposée dans un cadre un peu idéal. Son formalisme permet de convertir ce qui était fondamentalement un problème mal posé, en un problème tout à fait mathématique. Leslie Valiant a d’ailleurs reçu le Turing Award (l’équivalent du prix Nobel pour l’informatique) en 2011 pour cela. D’autres chercheurs, comme Vladimir Vapnik, ont proposé d’autres formules pour quantifier dans quelle mesure ces algorithmes sont capable de généraliser ce qui a été appris à n’importe quel autre donnée qui peut arriver.
Il ne s’agit pas d’un pur problème de statistique, c’est aussi un enjeu en terme de complexité. Si le nombre m de données explose (augmente exponentiellement) en fonction des autres paramètres, aucun algorithme ne fonctionnera en pratique.
Mais ce petit détour vers les maths nous montre que l’on peut donc utiliser le résultat de l’apprentissage pour prendre des décisions garanties. À condition que la modélisation soit correcte et appropriée au problème donné. Si on utilise tout ça sans chercher à bien comprendre, ou pour leur faire dire et faire des choses hors de leur champ d’application, alors ce sera un échec.
Ce n’est donc peut-être pas des algorithmes dont il faut avoir peur aujourd’hui, mais de ceux qui essayent de s’en servir sans les avoir compris.
Philippe Preux, Marc Tommasi, Thierry Viéville et Colin de la Higuera
Du 6 au 11 juillet, Lille accueille ICML (International Conference on Machine Learning), le rendez-vous annuel des chercheurs en machine learning, ce qu’on traduit souvent en français par apprentissage automatique ou apprentissage artificiel. Donnons la parole à Colin de la Higuera pour nous faire découvrir ce domaine. Thierry Viéville et Sylvie Boldo.
Il est très probable qu’à l’heure où vous lisez ces lignes, vous aurez utilisé le résultat d’algorithmes d’apprentissage automatique plusieurs fois aujourd’hui : votre réseau social favori vous peut-être a proposé de nouveaux amis et le moteur de recherche a jugé certaines pages pertinentes pour vous mais pas pour votre voisin. Vous avez dicté un message sur votre téléphone portable, utilisé un logiciel de reconnaissance optique de caractères, lu un article qui vous a été proposé spécifiquement en fonction de vos préférences et qui a peut-être été traduit automatiquement.
Et même sans avoir utilisé un ordinateur, vous avez été peut être écouté les informations : or la météo entendue ce matin, la plupart des transactions et des décisions boursières qui font et défont une économie, et de plus en plus de diagnostics médicaux reposent bien plus sur les qualités de l’algorithme que sur celles d’un expert humain incapable de traiter la montagne d’informations nécessaire à une prise de décision pertinente.
De tels algorithmes ont appris à partir de données, ils font de l’apprentissage automatique. Ces algorithmes construisent un modèle à partir de données dans le but d’émettre des prédictions ou des décisions basées sur les données [1].
Mais depuis quand confie t’on cela à des algorithmes ?
L’idée de faire apprendre la machine pour lui donner des moyens supplémentaires est presque aussi ancienne que l’informatique. C’est Alan Turing lui-même qui après avoir, en 1936, jeté les bases conceptuelles du calcul sur machine, donc de l’ordinateur, allait s’intéresser à cette possibilité. Il envisage en 1948 des « learning machines » susceptibles de construire elles-mêmes leurs propres codes.
Tout compte fait, c’est une suite logique de cette notion de machine de calcul dite universelle (c’est à dire qui peut exécuter tous les algorithmes, comme le sont nos ordinateurs ou nos smartphone). Puisque le code d’une machine, le programme, n’est qu’une donnée comme les autres, il est raisonnable d’envisager qu’un autre programme puisse le transformer. Donc pourquoi ne pas apprendre de nouveaux programmes à partir de données?
Vue la quantité astronomique de donnée, on peut apprendre simplement en les analysant. Mais les chercheurs se sont rendus compte que dans ce contexte, un programme qui se comporte de manière déterministe n’est pas si intéressant. C’est le moment où on découvre les limites de ce qui est décidable ou indécidable avec des algorithmes. Il faut alors introduire une autre idée : celle d’exploration, de recours au hasard, pour que de telles machines soient capables de comportements non prévus par leur concepteur.
Il y a donc une rupture entre programmer, c’est à dire imaginer et implémenter un calcul sur la machine pour résoudre un problème, et doter la machine de la capacité d’apprendre et de s’adapter aux données. De ce fait, on ne peut plus systématiquement prévoir un comportement donné, mais uniquement spécifier une classe de comportements possibles.
Alors … ça y est ? Nous avons créé de l’intelligence artificielle (IA) ?
C’est une situation paradoxale, car le terme d’IA veut dire plusieurs choses. Quand on évoque l’intelligence artificielle, on pense à apprendre, évoluer, s’adapter. Ce sont des termes qui font référence à des activités cognitives qui nous paraissent un ordre de grandeur plus intelligentes que ce que peut produire un calcul programmé.
Et c’est vrai qu’historiquement, les premiers systèmes qui apprennent sont à mettre au crédit des chercheurs en IA. Il s’agissait de repousser les frontières de la machine, de tenter de reproduire le cerveau humain. Les systèmes proposés devaient permettre à un robot d’être autonome, à un agent de répondre à toute question, à un joueur de s’améliorer défaite après défaite.
Mais, on s’accorde à dire que l’intelligence artificielle n’a pas tenu ses promesses [2]. Pourtant ces algorithmes d’apprentissage automatique, une de ses principales composantes, sont bel et bien présents un peu partout aujourd’hui. Et ceci, au delà, du fait que ces idées sont à la source de nombreuses pages de science-fiction.
C’est peut-être notre vision de l’intelligence qui évolue avec la progression des sciences informatiques. Par exemple, pour gagner aux échecs il faut être bougrement intelligent. Mais quand un algorithme qui se contente de faire des statistiques sur un nombre colossal de parties défait le champion du monde, on se dit que finalement l’ordinateur a gagné « bêtement ». Ou encore: une machine qui rassemble toutes les connaissances humaines de manière structurée pour que chacun y accède à loisir sur simple demande, est forcément prodigieusement intelligente. Mais devant wikipédia, qui incarne ce rêve, il est clair que non seulement une vision encyclopédique de l’intelligence est incomplète, mais que notre propre façon de profiter de notre intelligence humaine est amenée à évoluer, comme nous le rappelle Michel Serres [3].
Passionnant ! Mais à Lille … que va t’il se passer ?
L’apprentissage automatique est maintenant devenu une matière enseignée dans de nombreux cursus universitaires. Son champ d’application augmente de jour en jour : dès qu’un domaine dispose de données, la question de l’utilisation de celles-ci pour améliorer les algorithmes du domaine se pose systématiquement.
Mais c’est également un sujet de recherche très actif. Les chercheurs du monde entier qui se retrouveront à Lille dans quelques jours discuteront sans doute, parmi d’autres, des questions suivantes :
Une famille d’algorithmes particulièrement efficace aujourd’hui permet d’effectuer un apprentissage profond (le « deep learning »). De tels algorithmes simulent une architecture complexe, formées de couches de neurones artificiels, qui permettent d’implémenter des calculs distribués impossibles à programmer explicitement.
L’explosion du phénomène du big data est un levier. Là où dans d’autres cas, la taille massive des données est un obstacle, ici, justement, c’est ce qui donne de la puissance au phénomène. Les algorithmes, comme ceux d’apprentissage profond, deviennent d’autant plus performants quand la quantité de données augmente.
Nul doute que des modèles probabilistes de plus en plus sophistiqués seront discutés. L’enjeu aujourd’hui est d’apprendre en mettant à profit le hasard pour explorer des solutions impossibles à énumérer explicitement.
La notion de prédiction sera une problématique majeure pour ces chercheurs qui se demanderont comment utiliser l’apprentissage sur une tâche pour prévoir comment en résoudre une autre.
Les applications continueront à être des moteurs de l’innovation dans le domaine et reposent sur des questions nouvelles venant de secteurs les plus variés : le traitement de la langue, le médical, les réseaux sociaux, les villes intelligentes, l’énergie, la robotique…
Il est possible –et souhaitable- que les chercheurs trouvent également un moment pour discuter des questions de fond, de société, soulevées par les résultats de leurs travaux. Les algorithmes apprennent aujourd’hui des modèles qui reconnaissent mieux un objet que l’œil humain, qui discernent mieux les motifs dans des images médicales que les spécialistes les mieux entrainés. La taille et la complexité des modèles en font cependant parfois des boîtes noires : la machine peut indiquer la présence d’une tumeur sans nécessairement pouvoir expliquer ce qui justifie son diagnostic : sa « décision » reposera peut-être sur une combinaison de milliers de paramètres, combinaison que l’humain ne connaît pas.
Or, quand votre médecin vous explique qu’il serait utile de traiter une pathologie, il vous explique pourquoi. Mais quand la machine nous proposera de subir une intervention chirurgicale, avec une erreur moindre que le meilleur médecin, sans nous fournir une explication compréhensible, que ferons-nous ?
Pour l’apprentissage automatique, nous allons vous lancer un défi. Revenez sur binaire dans quelques jours et nous allons oser vous expliquer ce qui se trouve sous le capot : comment la machine construit des modèles et les exploite ensuite. Et vous verrez que si un sorcier ou une sorcière avait osé proposé une telle machine il y a quelques siècles, c’est sur un bûcher qu’elle ou il aurait fini.
En informatique, un problème est décidable s’il est possible d’écrire un algorithme qui résolve ce problème. Certains problèmes sont indécidables. Considérons par exemple le « problème de l’arrêt ». Le problème de l’arrêt consiste à déterminer, étant donné un programme informatique et des données en entrée pour ce programme, si le programme va finir pas s’arrêter ou s’il va continuer pour toujours. Alan Turing a prouvé en 1936 qu’il n’existait pas d’algorithme qui permette de résoudre le problème de l’arrêt, que ce problème était indécidable. L’informatique ne peut donc pas résoudre tous les problèmes. À binaire, on s’en doutait. Encore fallait-il le prouver. Turing l’a fait.
Cette notion de décidabilité se retrouve en logique. Une affirmation logique est dite décidable si on peut la démontrer ou démontrer sa négation dans le cadre d’une théorie donnée. Gödel a démontré (avant Turing, en 1933) un résultat d’incomplétude sur la décidabilité en logique. Certains résultats ne sont donc ni vrais ni faux, mais indécidables : cela signifie que l’on a démontré, à tout jamais, que nous pourrons pas savoir s’ils sont vrais ou faux. Alors si vous avez été frustré parce que vous n’avez pas compris certains cours de maths, consolez vous. Les mathématiques aussi ont des limites. Et oui …
Cette notion d’indécidabilité a une conséquence plus subjective, dans nos rapports avec la science. Nous ne sommes pas confrontés à un dogme surpuissant et sans limite, mais bien à une démarche qui cherche à comprendre ce qu’il est possible de comprendre, qui explore sans cesse ses propres limites.
À l’occasion de la sortie du dernier film animé des studios Disney « les nouveaux héros », nous avons demandé à Christian Duriez, responsable d’une équipe de recherche d’Inria Lille – Nord Europe, de nous parler des technologies innovantes qui sont en train d’émerger en matière de robotique et plus particulièrement de nous expliquer si le robot mou de Baymax est une fiction ou si la recherche en la matière est une réalité. Partons à la découverte de ces robots mous (ou « soft-robot » en anglais). Cet article est une co-publication avec )i(nterstices, la revue de culture scientifique en ligne, créée par des chercheurs pour vous inviter à explorer les sciences du numérique. Marie-Agnès Enard.
Dans son dernier long métrage, Disney nous invite à nous plonger dans San Fransokyo, ville futuriste inspirée des deux rivages du pacifique, et capitale de la robotique. Dans cette ville, les habitants ont une passion frénétique pour les robots, et plus particulièrement pour les combats de robots. Les acteurs économiques sont prêts à lancer des intrigues pour récupérer les dernières inventions. Hiro, un petit génie exclu des parcours scolaires, s’amuse à construire des robots de combats avec son frère tout en réalisant des recherches dans un laboratoire sur Baymax, un robot infirmier qui sera le héros de ce film. Or la particularité de Baymax… c’est qu’il est mou ! Une sorte de bonhomme Michelin gonflable, programmé pour prévenir les problèmes de santé des humains qui l’entourent. Disney rejoint là des technologies très innovantes en train d’émerger en robotique, ces fameux robots mous (ou « soft-robot » en anglais).
Je fais partie de cette nouvelle communauté de chercheurs qui s’intéresse à ces robots qui ne sont plus conçus à partir de squelettes rigides articulés et actionnés par des actionneurs placés au niveau des articulations comme nous les connaissons traditionnellement. Au contraire, ces robots sont constitués de matière « molle » : silicone, caoutchouc ou autre matériau souple, et ont donc, naturellement, la possibilité d’adapter leur forme et leur flexibilité à la tâche, à des environnements fragiles et tortueux, et d’interagir en toute sécurité avec l’homme. Ces robots ont typiquement une souplesse semblable aux matières organiques et leur design est souvent inspiré de la nature (trompe d’éléphant, poulpe, vers de terre, limace, etc.). Pour fabriquer ces robots, nous avons naturellement recours à l’impression 3D qui permet déjà d’imprimer des matières déformables ou de fabriquer ces robots par moulage.
La robotique est une science du mouvement. La robotique classique crée ce mouvement par articulation. Pour les soft-robot, le mouvement est créé par déformation, exactement comme des muscles. On peut le faire en insérant de l’air comprimé dans des cavités placées dans la structure déformable du robot, en injectant des liquides sous pression ou en utilisant des polymères électro actifs qui se déforment sous un champ électrique. Dans mon équipe de recherche, nous utilisons, plus simplement, des câbles reliés à des moteurs pour appliquer des forces sur la structure du robot et venir la déformer, un peu comme les tendons ou les ligaments que l’on trouve dans les organismes vivants.
Les domaines d’applications que nous pouvons envisager sont nombreux pour ces soft-robots : En robotique chirurgicale, pour naviguer dans des zones anatomiques fragiles sans appliquer d’efforts importants ; en robotique médicale, pour proposer des exosquelettes ou orthèses actives qui seraient bien plus confortables que les solutions actuelles ; en robotique sous-marine pour développer des flottes importantes de robots ressemblant à des méduses, peu chères à fabriquer, et capable d’aller explorer les fonds sous-marins ; pour l’industrie, pour fabriquer des robots bon marché et robustes ou des robots capables d’interagir avec les hommes sans aucun danger ; pour l’art et le jeu, avec des robots plus organiques, capables de mouvements plus naturels …
Mais ce qui nous intéresse aussi dans ces travaux est qu’ils sont porteurs de nouveaux défis pour la recherche. En particulier, le fait de revisiter les méthodes de design, de modélisation et de contrôle de ces robots. Nous passons d’un monde où le mouvement se décrit par une dizaine voire une vingtaine d’articulations, au maximum, à une robotique déformable qui a, en théorie, une infinité de degré de liberté. Autrement dit, pour développer l’usage et le potentiel de ces soft-robots, il va falloir totalement revoir nos logiciels . C’est cette mission que s’est confiée notre équipe (équipe Defrost, DEFormable RObotic SofTware, commune avec Inria et l’Université Lille 1) et qui rend ces travaux passionnants et ambitieux.
Nous souhaitons relever le défi de la modélisation et le contrôle des robots déformables : il existe de modèles des théories de la mécaniques des objets déformables (appelée mécanique des milieux continues). Ces modèles n’ont pas de solution analytique dans le cas général et il faut passer par des méthodes numériques souvent complexes et couteuses en temps de calcul, comme la méthode des éléments finis, pour obtenir des solutions approchées. Or, pour le pilotage d’un robot, la solution du modèle doit pouvoir être trouvée à tout instant en temps-réel (autrement dit en quelques millisecondes). Si cela est obtenu depuis longtemps pour les modèles rigides articulés, c’est une autre paire de manche pour les modèles par éléments finis. C’est le premier défi que nous devons affronter dans notre travail de recherche, mais d’autres défis, encore plus complexes, nous attendent. En voici quelques exemples :
Une fois le modèle temps réel obtenu, il faudra l’inverser : en effet le modèle nous donne la déformation de la structure du robot quand on connait les efforts qui s’appliquent sur lui. Mais pour piloter un robot, il faut, au contraire, trouver quels efforts nous devons appliquer par les actionneurs (les moteurs, les pistons, etc.) du robot, pour pouvoir le déformer de la manière que l’on souhaite. Or s’il est déjà complexe d’obtenir un modèle éléments finis en temps-réel, obtenir son inverse en temps-réel est un bien plus complexe encore !
Autre challenge : l’environnement du robot. Contrairement à une approche classique en robotique rigide où l’on cherche l’anticollision (le fait de déployer le robot sans toucher les parois de l’environnement), les robots déformables peuvent venir au contact de leur environnement sans l’abimer. Dans certaines applications, il est même plutôt souhaitable que le robot puisse venir entrer en contact. Cependant il faut maitriser les intensités des efforts appliqués par ces contacts et particulièrement dans des applications en milieu fragile (comme en chirurgie par exemple). Un paramètre important dans ce contexte est que l’environnement va lui aussi déformer le robot. Il faut donc impérativement en tenir compte dans la réalisation du modèle. Quand l’environnement correspond à des tissus biologiques, il faut alors prévoir d’ajouter un modèle biomécanique de l’environnement…
Un dernier exemple de défi, plus fondamental, est lié à l’utilisation de capteurs. Si l’on imite la nature, notre système nerveux nous donne un retour d’information (vision, toucher, son, etc.) qui nous aide à contrôler nos mouvements et à appréhender notre environnement. Les ingénieurs ont donc très vite pensé à équiper les robots de capteurs qui permettent de compenser et d’adapter les modèles utilisés pour les piloter. La théorie du contrôle permet de donner un cadre mathématique à ces méthodes d’ingénierie des systèmes. Or la complexité de cette théorie dépend essentiellement du nombre de variables nécessaires à décrire l’état du système et du couplage entre ces variables… Avec une infinité (théorique) de degrés de liberté, couplés par la mécanique des milieux continus, il faudra forcément revisiter cette théorie pour l’adapter.
Bien d’autres défis sont encore à considérer comme la création de nouveaux outils de CAO (Conception Assistée par Ordinateur) pour concevoir ces robots, ou la programmation de leur fabrication en lien avec l’impression 3D. Enfin, si l’on veut un jour avoir notre Baymax, en chair et sans os, capable d’être notre infirmier personnel à domicile, il faudra aussi lui apporter une certaine forme d’autonomie voire d’intelligence… mais ceci est une autre histoire !
Le numérique a contribué à améliorer le travail des chercheurs en enrichissant le contenu des publications numériques, en favorisant la recherche d’un article dans la masse gigantesque de documents disponibles, et en optimisant les modalités et le temps d’accès à l’information. Malheureusement, dans le même temps, ces évolutions se sont accompagnées de dérives qui pourrissent la vie des scientifiques.
Certains ont cru détecter la poule aux œufs d’or dans l’évolution numérique de l’édition scientifique. Sont apparues de nulle part des sociétés « expertes» de la création de revues (et de conférences) traitant de tous les sujets et ouvertes à tous. Concrètement, un chercheur reçoit très souvent (plusieurs fois par mois) des messages d’invitation à soumettre ses travaux dans des revues ou des conférences « SPAM (*) » ou alors à participer à leurs comités de lecture qui n’en possèdent que le nom. Certains se laissent abuser, le plus souvent par négligence en n’étant pas assez critique sur la qualité de la revue, parfois par malhonnêteté en espérant augmenter leur visibilité.
L’évaluation par les pairs, comme tout processus humain, peut faillir et conduire à des publications erronées, voire totalement loufoques. Il ne s’agit pourtant là que de dysfonctionnements non représentatifs de la qualité générale du travail de publication. Une évaluation un tant soit peu sérieuse détectera ce type de publication. Il convient toutefois pour les scientifiques de rester vigilants devant l’augmentation récente de ce nombre de situations qui est directement reliée à l’augmentation du nombre de revues et de conférences « parasites ».
Au delà de ces dérives mercantiles, le principal problème résulte de la culture de l’évaluation à outrance qui a progressivement envahi le monde de l’enseignement et la recherche que ce soit au niveau des individus (recrutement, promotions), des laboratoires (reconnaissance, financements) ou des universités/écoles/organismes (visibilité, attractivité).
Entendons-nous bien, ce n’est pas la nécessité d’une évaluation qui est ici remise en cause mais les façons dont elle est trop souvent mise en œuvre. Illustration : dans un premier temps, le nombre de publications d’un chercheur est devenue la référence principale de jugement ; bien que simple et naturel, un comptage brutal ne tient pas compte de leur qualité et de leur ampleur, produisant des « spécialistes » de la production à la chaîne d’articles sans réel impact. (Il est quasiment impossible de s’accorder sur le nombre des articles jamais cités par d’autres scientifiques mais il est élevé). On observe aussi des équipes qui alignent leurs thématiques de recherche sur les sujets « chauds » des revues et/ou synchronisent leurs activités sur le calendrier des conférences importantes, délaissant leur libre arbitre et le propre pilotage de leur recherche.
Dans un deuxième temps, sont apparus des indicateurs numériques sensés remédier à ce problème, en calculant des scores basés sur le nombre de citations que recueille un article. L’idée a d’autant plus de sens que les explosions conjointes au niveau mondial des nombres de chercheurs et de revues ont conduit à une inflation jamais connue jusque là de la production d’articles scientifiques ; s’interroger sur l’impact réel d’une publication est légitime et a suscité de nombreuses méthodes dont les plus connues sont la famille des h-index apparue en 2005 pour les articles et les facteurs d’impact en 2006 pour les revues.
Malheureusement, cette bonne idée souffre de nombreux défauts : tout d’abord, le mélange incroyable entre citations positives (pour mettre en exergue un résultat) et négatives (pour critiquer tout ou partie du travail) ! Ensuite, la taille des communautés qui est le plus souvent oubliée dans l’exploitation de ces indicateurs ; comment raisonnablement comparer des index si le nombre de chercheurs d’un domaine est très différent d’un autre ; pensons par exemple à une thématique émergente qui ne concerne initialement qu’un petit cercle : faut-il l’ignorer parce qu’elle arrive loin dans les classements ? Ce n’est surement pas de cette façon que nous produirons les innovations tant attendues. Par ailleurs, les bases de données utilisées pour calculer ces taux de citation ne couvrent qu’une partie de la littérature scientifique ; en informatique par exemple, moins de la moitié de la production est référencée dans les plus célèbres d’entre elles. Et puis, des esprits malintentionnés ont dévoyé cette bonne idée en mettant en œuvre des pratiques frauduleuses : autocitations abusives, « découpage » artificiel d’un résultat en plusieurs articles pour augmenter le nombre de publications et de citations, cercles de citations réciproques entre auteurs complices, « recommandation appuyée » de certains éditeurs de citer des articles de leur propre revue, etc.
En résumé, ces indicateurs ne devraient fournir qu’un complément d’information à une évaluation plus qualitative et donc plus fine. Malheureusement, une telle analyse nécessite plus de temps et aussi de mobiliser de vrais experts. Il est infiniment plus « facile » de la remplacer par l’examen de quelques chiffres dans un tableur sensés représenter une activité scientifique dont il est bien entendu impossible de réduire ainsi la richesse et la diversité. On peut faire l’analogie avec la qualité d’un livre qui ne serait jugée qu’à travers son nombre de lecteurs ou celle d’une chaîne de télévision qu’à travers son Audimat.
Terminons en rappelant encore une fois qu’il ne s’agit pas d’ignorer ces indicateurs mais bien de les exploiter pour ce qu’ils sont et de les associer systématiquement à des analyses qualitatives réalisées par des experts.
Initialement gérée par les sociétés savantes, l’édition scientifique a progressivement été envahie par une grande diversité d’éditeurs privés. Comme beaucoup d’autres secteurs économiques, elle a connu une forte concentration autour de quelques grands acteurs : Elsevier, Springer, Wiley etc. Depuis sa création, ses ressources provenaient des abonnements que lui payaient les structures académiques pour recevoir les exemplaires des revues souhaitées. Ce système a fonctionné pendant longtemps mais connaît de très grandes difficultés depuis quelques années à cause des augmentations de prix constantes imposées sans réelle justification par ces acteurs dominants. La combinaison de ces hausses avec les baisses que connaissent les budgets de la recherche un peu partout dans le monde a produit un mélange détonnant qui est en train d’exploser. L’attitude intransigeante de ces grands acteurs qui refusent de prendre en compte ces réductions budgétaires et, au contraire, augmentent leurs tarifs et leurs profits est assez surprenante et le changement de modèle économique induit par la transition achat d’exemplaires papier-droit d’accès à des ressources en ligne ne suffit pas à l’expliquer.
Face à cet abus de position dominante, les chercheurs s’organisent pour tenter de résister. En France par exemple, le monde académique s’est mis d’accord pour, d’une part, échanger des informations sur les pratiques respectives vis à vis des éditeurs, et d’autre part, présenter un front uni lors de négociations collectives face à ces sociétés. Certaines communautés, notamment mathématiciennes, françaises et étrangères, se sont mobilisées pour lutter contre ces monopoles en appelant au boycott, non seulement des abonnements, mais également de l’ensemble des processus éditoriaux. En effet, il faut rappeler que sans l’implication primordiale des chercheurs – qui font la recherche, rédigent des articles et les expertisent – offerte gratuitement à ces sociétés privées, elles n’existeraient plus.
Début de solution : l’accès ouvert
Le logo Open Access
C’est notamment pour lutter contre ces dérives en offrant un modèle alternatif que des solutions de type libre accès (Open Access) aux ressources documentaires ont été développées. Initialement, il s’agissait d’offrir un accès gratuit aux publications stockées sur des sites de dépôts gérés par des organisations scientifiques. En France, c’est l’archive ouverte HAL qui joue depuis 2001 un rôle central dans cette démarche en liaison étroite avec les autres grandes archives internationales comme ArXiv créée en 1991. Outre la maîtrise des coûts, l’accès ouvert renforce la visibilité des articles déposés sur une archive ouverte comme le montre plusieurs études.
Ce mouvement en faveur des archives ouvertes est soutenu par de nombreux pays (Canada, Chine, Etats-unis, Grande Bretagne…). Récemment, l’Union européenne et en particulier la France ont pris des positions encore plus nettes en faveur du libre accès. Par exemple, depuis 2013, la direction d’Inria a rendu obligatoire le dépôt des publications sur HAL et seules ces publications sont communiquées aux experts lors des évaluations ou affichées sur le site web de l’Institut.
Les grands éditeurs ont très vite compris le danger pour leurs profits que représentaient ces initiatives ; ils ont donc commencé par adopter des politiques de dénigrement systématique en les moquant, puis, devant l’échec relatif de cette posture, ils ont transformé ce risque en opportunité en se présentant comme les chantres, voire même les inventeurs, de l’accès ouvert et l’expression Open Access fleurit aujourd’hui sur la plupart des sites de ces éditeurs.
Il convient de préciser qu’il existe deux approches principales d’accès ouvert :
la voie verte (green access) où le dépôt par l’auteur et l’accès par le lecteur sont gratuits ;
la voie dorée (gold access), dite aussi auteur-payeur, où l’auteur finance la publication (de quelques centaines à quelques milliers d’euros) qui est ensuite accessible en ligne gratuitement.
Le green est aujourd’hui la solution la plus vertueuse mais n’oublions pas que la gratuité n’est qu’apparente car ces infrastructures et ces services représentent un coût non négligeable supporté pour HAL principalement par le CNRS à travers le CCSD. Par ailleurs, certains éditeurs imposent un délai avant le dépôt d’une publication sur une archive ouverte publique (par exemple, 6 mois après sa parution). Outre la légalité parfois discutable de cet embargo, il faut rappeler qu’il est possible de déposer des versions dites preprint, sur des archives ouvertes comme HAL, pour remédier temporairement à ce problème.
Le gold quant à lui présente l’avantage de déplacer en amont et de rendre explicite le coût d’une publication. Cependant, il comporte des inconvénients majeurs, principalement le coût souvent élevé et donc le risque d’accroitre le fossé entre les établissements, voire pays, « riches » et « pauvres ».
Malheureusement, la qualité et la puissance économique du lobbying des grands éditeurs ont réussi à pénétrer beaucoup de cercles de décision nationaux comme européens et à faire confondre l’open access et le gold. Nous entendons et lisons donc des charges contre le libre accès qui n’évoquent que le modèle auteur-payeur et contre lesquelles il est indispensable de faire preuve de pédagogie pour démonter l’artifice.
Encore mieux : les epi-journaux
Le logo http://episciences.org
Au delà du dépôt des articles, il convient de s’interroger sur leur éditorialisation si l’on souhaite proposer une alternative de qualité, et par conséquent crédible, aux revues commerciales. La notion d’epi-journal a donc vu le jour ; il s’agit de construire « au dessus » d’une archive ouverte des structures éditoriales de type revues ou actes. La démarche est tout à fait similaire à celle de l’édition classique : diffusion des règles éditoriales, dépôt des propositions sur un site dédié, expertise par un comité de lecture dont la composition est publique, annonce des résultats aux auteurs, mise en ligne des articles retenus après réalisation des corrections demandées et en respectant une charte graphique, référencement par les moteurs de recherche après saisie des méta-données associées.
Basée sur le projet Episciences, développé et hébergé par le CCSD, il existe dans le domaine Informatique et Mathématiques appliquées une structure qui propose des services pour gérer des épi-journaux :
les articles sont déposés dans une archive ouverte (HAL, ArXiv, CWI, etc.),
après lecture et analyse par les éditeurs, les articles soumis reçoivent la validation du comité de lecture,
ils sont alors publiés en ligne et identifiés exactement comme dans une revue classique (ISSN, DOI, etc.),
ils sont référencés par les principales plateformes (DOAJ, DBLP, Google scholar…),
l’epi-journal respecte des règles éthiques,
il assure un travail de visibilité à travers les conférences et les réseaux sociaux.
Vous pouvez par exemple consulter la revue JDMDH qui vient de démarrer sur ce principe.
Et en conclusion
Ces epi-journaux sont la dernière évolution importante dans le domaine de la publication scientifique. S’ils offrent une réponse potentielle particulièrement adaptée aux problèmes causés par l’augmentation déraisonnable du coût des abonnements aux grands éditeurs, ils sont aujourd’hui encore balbutiants. La principale interrogation provient de leur jeunesse et de leur manque de reconnaissance par les communautés scientifiques. Concrètement, si un jury doit expertiser un dossier individuel ou collectif (équipe, laboratoire), il attachera plus de poids à des publications parues dans des revues installées depuis longtemps et donc plus reconnues.
La seule motivation « militante » pour publier de cette façon ne suffit pas, notamment si l’on pense aux jeunes chercheurs qui sont à la recherche d’un emploi : il est aujourd’hui très difficile de leur faire prendre ce risque sans concertation et réflexion préalables de la part de leurs encadrants qui sont souvent des scientifiques établis qui n’ont plus de souci majeur de carrière. C’est pourquoi il est absolument indispensable que les chercheurs les plus seniors s’impliquent clairement en faveur de ces initiatives : en participant aux comités de lecture de ces épi-journaux afin de les faire bénéficier de leur visibilité individuelle, en contribuant à en créer de nouveaux et surtout en expliquant dans toutes les instances d’évaluation et de recrutement (jurys, comités de sélection, CNU…), la qualité de ces premiers epi-journaux et du crédit que l’on peut leur accorder.
Là encore, ne tombons pas dans l’angélisme, un épi-journal n’est pas un gage de qualité en lui même, mais au moins laissons lui la chance de prouver sa valeur de la même façon qu’une revue papier et évaluons le avec les mêmes critères.
Il s’agit vraiment de bâtir une nouveau paradigme de publication et nous, scientifiques, en sommes tous les premiers responsables avant d’en devenir les bénéficiaires dans un futur proche.
Pascal Guitton,Professeur Université de Bordeaux et Inria
(*) Le spam, courriel indésirable ou pourriel (terme recommandé au Québec) est une communication électronique non sollicitée, en premier lieu via le courrier électronique. Il s’agit en général d’envois en grande quantité effectués à des fins publicitaires. [Wikipedia]. À l’origine le mot SPAM désignait de la « fake meat« .
B : Arshia, en quoi consiste ta recherche ?
AC : Nous travaillons dans le domaine de l’informatique musicale. Les gens ont commencé à faire de la musique avec des ordinateurs depuis les débuts de l’informatique. Déjà Ada Lovelace parlait explicitement de la musique dans ses textes. Nous nous intéressons à ce qu’on ne sait pas encore bien faire. Quand plusieurs musiciens jouent ensemble, chaque musicien a des tâches précises à réaliser en temps réel, mais doit coordonner ses actions avec les autres musiciens. Ils arrivent à s’écouter et à se synchroniser, pour jouer un quatuor de Mozart par exemple. L’œuvre est écrite sur une partition, et c’est toujours la même œuvre qu’on écoute, mais à chaque exécution, c’est toujours différent et pourtant c’est sans faute. Et même s’il y a des fautes, le concert ne va pas s’arrêter pour autant. Cette capacité à s’écouter les uns les autres, se coordonner et se synchroniser, avec une tolérance incroyable aux variantes, aux erreurs mêmes, c’est une capacité humaine extraordinaire qu’on aimerait donner à la machine.
Prenons trois musiciens qui ont l’habitude de jouer ensemble. On leur ajoute un quatrième musicien, à savoir, un ordinateur qui va jouer avec eux, et qui, pour cela, doit écouter les autres et s’adapter à eux. L’ordinateur doit être capable d’interagir, de communiquer avec les humains. Cette association de musiciens humains et de musiciens ordinateurs est une pratique musicale qu’on appelle la musique mixte, et qui est répandue aujourd’hui dans le monde entier.
Le dialogue se passe pendant l’exécution, mais il faut aussi un langage pour décrire la richesse de tels scénarios qui sont à la fois attendus (puisqu’on connaît la partition) et en même temps à chaque fois différents.
B : Vous travaillez sur des langages pour la musique mixte ?
AC : Oui. Prenez des œuvres écrites pour de grands orchestres, avec vingt ou trente voix différentes en parallèle. Le compositeur qui a écrit cela n’avait pas accès à un orchestre dans sa salle à manger pendant qu’il l’écrivait. Pendant des siècles, les musiciens ont été obligés d’inventer un langage, un mode de communication, qui soit compréhensible par les musiciens, qui puisse être partagé, et qui soit suffisamment riche pour ne pas rendre le résultat rigide. Mozart, Beethoven ou Mahler ont été obligés d’écrire sur de grandes feuilles de papier, des partitions d’orchestre, en un langage compris par les musiciens qui allaient jouer ces morceaux. Ce langage, avec des éléments fixes et des éléments libres, permet un passage direct de l’écriture à la production de l’œuvre. On rejoint ici un but essentiel en informatique de langages de programmation qui permettent de réaliser des opérations complexes, avec des actions à exécuter, parfois plusieurs en même temps, avec des contraintes temporelles imposées par l’environnement.
Prenez l’exemple d’un avion. On voudrait que l’avion suive son itinéraire à peu près sans faute mais là encore ça ne se passe pas toujours pareil. Il faut un langage qui permette d’exprimer ce qu’on voudrait qu’il se passe quelle que soit la situation.
Pour la musique, le langage doit permettre un passage immédiat à l’imaginaire. Pour cela, nous travaillons avec des musiciens, et ce qui est particulièrement intéressant, c’est quand ils ont en tête des idées très claires mais qu’ils ont du mal à les exprimer. Nous développons pour eux des langages qui leur permettent d’exprimer la musique qu’ils rêvent et des environnements pour la composer.
B : Ça semble avoir beaucoup de liens avec les langages de programmation en informatique. Tu peux nous expliquer ça ?
AC : La musique, c’est une organisation de sons dans le temps. Une partition avec trente voix, c’est un agencement d’actions humaines qui ont des natures temporelles très variées mais qui co-existent. Ce souci de faire “dialoguer” différentes natures temporelles, on le retrouve beaucoup dans des systèmes informatiques, notamment dans des systèmes temps réel. Il y a donc beaucoup de liens entre ce que nous faisons et les langages utilisés pour les systèmes temps-réel critiques, les langages utilisés par exemple dans les avions d’Airbus ou dans des centrales nucléaires. C’est d’ailleurs un domaine où la France est plutôt leader.
Démonstration d’Antescofo, @Youtube
B : Tu parles de temps-réel. Dans une partition il y a un temps quasi-absolu, celui de la partition, mais quand l’orchestre joue, il y a le temps de chaque musicien, plus complexe et variable ?
AC : Plutôt que d’un temps absolu, je préfère parler d’une horloge. Par exemple le métronome utilisé en musique occidentale peut battre au rythme d’un battement par second, et c’est le tempo “noire = 60” qui est écrit sur la partition, mais il s’agit juste d’une indication. En fait, dans l’exécution aucune musique ne respecte cette horloge, même pas à 90%. Le temps est toujours une notion relative (contrairement à la hauteur des notes, qui dans certaines traditions musicales est absolue). Dans un quatuor a cordes, il n’y a pas un temps unique idéal, pas une manière unique idéale de se synchroniser. En musique, il y a la notion de phrase musicale, et quand vous avez des actions qui ont une étendue temporelle, on peut avoir des relations temporelles variées. Par exemple on veut généralement finir les phrases ensemble. Dans certaines pratiques de musique indienne, il y a des grilles rythmiques que les musiciens utilisent quand ils jouent ensemble : ils les ont en tête, et un musicien sait quand démarrer pour que dix minutes plus tard il finisse ensemble avec les autres ! Ce type de condition doit être dans le langage. C’est cela qui est très difficile. Les musiciens qui arrivent à finir ensemble ont une capacité d’anticipation presque magique. Ils savent comment jouer au temps t pour pouvoir finir ensemble au temps t+n. C’est le « Ante » de Antescofo, notre logiciel. Comme les musiciens qui savent anticiper d’une façon incroyable, Antescofo essaie d’anticiper.
B : Et le chef d’orchestre, là-dedans. Son rôle est de synchroniser tout le monde ?
AC : Les musiciens travaillent avec l’hypothèse que la vitesse du son est infinie, qu’ils entendent un son d’un autre musicien à l’instant où ce son est émis. Mais dans un grand orchestre cette hypothèse ne marche pas. Le son de l’autre bout de l’orchestre arrive après un délai et, si on s’y fie, on ralentit les autres. Pour remédier à ça, on met un chef d’orchestre que chacun peut voir et la synchronisation se fait à la vue, avec l’hypothèse que la vitesse de la lumière est infinie. Nous avons d’ailleurs un projet en cours sur le suivi de geste, afin que le musicien-ordinateur puisse aussi suivre le geste du chef d’orchestre. Mais c’est compliqué. Il faut s’adapter aux chefs d’orchestre qui utilisent des gestuelles complexes.
La machine doit apprendre à écouter
B : Tu utilises beaucoup de techniques d’apprentissage automatique . Tu peux nous en parler ?
AC : Nous utilisons des méthodes d’apprentissage statistique. Nous apprenons à la machine à écouter la musique. La musique est définie par des hauteurs, des rythmes, plusieurs dimensions que nous pouvons capter et fournir à nos programmes informatiques. Mais même la définition de ces dimensions n’est pas simple, par exemple, la définition d’une « hauteur » de son qui marche quel que soit l’instrument. Surtout, nous sommes en temps-réel, dans une situation d’incertitude totale. Les sons sont complexes et « bruités ». Nous humains, quand nous écoutons, nous n’avons pas une seule machine d’écoute mais plusieurs que nous utilisons. Nous sommes comme une machine multi-agents, une par exemple focalisée sur la hauteur des sons, une autre sur les intervalles, une autre sur les rythmes pulsés. Toutes ces machines ont des pondérations différentes selon les gens et selon la musique. Si nous humains pouvons avoir une écoute quasi-parfaite, ce n’est pas le résultat d’une machine parfaite mais parce que notre cerveau sait analyser les résultat de plusieurs machines faillibles. C’est techniquement passionnant. Vous avez plusieurs machines probabilistes en compétition permanente, en train d’essayer d’anticiper l’avenir, participant à un système hautement dynamique d’apprentissage en ligne adaptatif. C’est grâce à cela qu’Antescofo marche si bien. Antescofo sait écouter et grâce à cela, réagir correctement. Réagir, c’est presque le coté facile.
Des sentiments des machines
B : Il y a des musiques tristes ou sentimentales. Un musicien sait exprimer des sentiments. Peut-on espérer faire rentrer des sentiments dans la façon de jouer de l’ordinateur ?
AC : C’est un vieux rêve. Mais comment quantifier, qualifier, et contrôler cet effet magique qu’on appelle sentiment ? Il y a un concours international, une sorte de test de Turing des sentiments musicaux, pour qu’à terme les machines gagnent le concours Chopin. Beaucoup de gens travaillent sur l’émotion en musique. Là encore, on peut essayer de s’appuyer sur l’apprentissage automatique. Un peu comme un humain apprend pendant des répétitions, on essaie de faire que l’ordinateur puisse apprendre en écoutant jouer. En termes techniques, c’est de l’apprentissage supervisé et offline. Antescofo apprend sur scène, et à chaque instant il est en train de s’ajuster et de réapprendre.
B : Y a-t-il d’autres questions que tu aurais aimé que nous te posions ?
AC : Il y a une dimension collective chez l’homme qui me passionne. Cent cinquante musiciens qui jouent ensemble et produisent un résultat harmonieux, c’est magique ! C’est une jouissance incroyable. Peut-on arriver à de telles orchestrations, de tels niveaux de collaboration, avec l’informatique ? C’est un vrai challenge.
Autre question, la musique est porteuse de beaucoup d’éléments humains et touche aussi à notre vie privée. Aujourd’hui tout le monde consomme de la musique – comment peut-on rendre cela plus disponible à tous via l’informatique ? Récemment on a commencé à travailler sur des mini ordinateurs à 50 euros. Comment rendre le karaoké disponible pour tout le monde ? Comment faire pour que tous puissent faire de la musique même sans formation musicale ? Peut-être que cela donnerait aux gens un désir de développement personnel – quand un gamin peut jouer avec l’orchestre de Paris, c’est une perspective grisante, et l’informatique peut rendre ces trésors accessibles.
La passion de la musique et de l’informatique
B : Pour conclure, tu peux nous dire pourquoi tu as choisi ce métier ?
AC : Je suis passionné de création musicale depuis l’adolescence, mais j’étais aussi bon en science, alors je me posais la question : musique ou science ? Avec ce métier, je n’ai pas eu à choisir : je fais les deux. Je ne pourrais pas être plus heureux. C’est un premier message aux jeunes : si vous avez une passion, ne la laissez pas tomber. Pour ce qui est de l’informatique, je l’ai découverte par hasard. Pendant mes études j’ai fait des mathématiques, du traitement du signal. Après ma thèse, en explorant la notion de langage, je me suis rendu compte qu’il me manquait des connaissances fondamentales en informatique. L’informatique, c’est tout un monde, c’est une science fantastique. C’est aujourd’hui au cœur de ma recherche. Mon second message serait, quelle que soit votre passion, à tout hasard, étudiez aussi l’informatique…
Arshia Cont, Ircam
Directeur de recherche dans une équipe Inria/CNRS/Ircam
Directeur du département Recherche/Créativité des Interfaces
En découvrir plus avec deux articles d’Interstices sur ce sujet :
Un nouvel « entretien autour de l’informatique ». Serge Abiteboul et Claire Mathieu interviewent Gérard Huet , Directeur de recherche émérite à Inria. Gérard Huet a apporté des contributions fondamentales à de nombreux sujets de l’informatique, démonstration automatique, unification, édition structurée, réécriture algébrique, calcul fonctionnel, langages de programmation applicatifs, théorie des types, assistants de preuve, programmation relationnelle, linguistique computationnelle, traitement informatique du sanskrit, lexicologie, humanités numériques, etc. Ses travaux sur CAML et Coq (voir encadrés en fin d’article) ont notamment transformé de manière essentielle l’informatique.
B : Tu as eu un parcours de chercheur singulier, avec des contributions fondamentales dans un nombre incroyable de sujets de l’informatique. Est-ce qu’il y a des liens entre tous tes travaux ?
G : Il existe des liens profonds entre la plupart de ces sujets, notamment une vision du cœur de la discipline fondée sur l’algèbre, la logique et les mathématiques constructives. Le calcul fonctionnel (le lambda-calcul dans le jargon des théoriciens) sous-tend nombre d’entre eux. Le calcul fonctionnel, pour simplifier, c’est une théorie mathématique avec des fonctions qui ne s’appliquent pas juste à des réels comme celles que vous avez rencontrées en cours de maths. Ces fonctions, ou plus précisément ces algorithmes, peuvent s’appliquer à d’autres objets et notamment à des objets fonctionnels. Vous pouvez avoir une fonction qui trie des objets. Vous allez passer comme argument à cette fonction une autre fonction qui permet de comparer l’âge de deux personnes et vous obtenez une fonction qui permet de trier un ensemble de personnes par ordre d’âge.
Ce qui montre que ce calcul fonctionnel est une notion fondamentale, c’est à la fois l’ossature des programmes informatiques, et dans sa version typée la structure des démonstrations mathématiques (la déduction naturelle dans le jargon des logiciens). Vous n’avez pas besoin de comprendre tous les détails. La magie, c’est que le même objet mathématique explique à la fois les programmes informatiques et les preuves mathématiques. Il permet également les représentations linguistiques à la fois de la syntaxe, du discours, et du sens des phrases de la langue naturelle (les grammaires de Lambek et les grammaires de Montague dans le jargon des linguistes). Reconnaître cette unité est un puissant levier pour appliquer des méthodes générales à plusieurs champs applicatifs.
Je suis tombé sur d’autres sujets au fil de hasards et de rencontres parfois miraculeuses.
Les programmes sont des preuves constructives
B : Les programmes sont des preuves. Ça te paraît évident mais ça ne l’est pas pour tout le monde. Pourrais-tu nous expliquer comment on est arrivé à ces liens entre programmes et preuves ?
G : Tout commence avec la logique mathématique. En logique, il y a deux grandes familles de systèmes de preuves. La première, la déduction naturelle, avec des arbres de preuves, c’est comme le lambda-calcul typé, et les propositions de la logique sont les types des formules de lambda-calcul. Ce n’est pas quelque chose qui a été compris au début. Le livre standard sur la déduction naturelle, paru en 1965, ne mentionne même pas le λ calcul, car l’auteur n’avait pas vu le rapport. C’est dans les années 70, qu’on a découvert qu’on avait développé deux théories mathématiques équivalentes, chacun des deux domaines ayant développé des théorèmes qui en fait étaient les mêmes. Quand on fait le pont entre les deux, on comprend que, les programmes, ce sont des preuves.
Un arbre de preuve
En mathématiques, on raisonne avec des axiomes et des inférences pour justifier la démonstration des théorèmes, mais souvent on évacue un peu la preuve elle-même en tant qu’objet mathématique en soi. La preuve, pour un mathématicien, c’est comme un kleenex : on la fait, et puis ça se jette. La preuve passe, le théorème reste. D’ailleurs, on donne aux théorèmes des noms de mathématiciens, mais, les preuves, on s’en moque. Ça, c’est en train de changer grâce à l’informatique. Pour nous, les preuves sont des objets primordiaux. Plus précisément, ce qui est important pour nous, ce sont les algorithmes. En effet, un théorème peut avoir plusieurs preuves non équivalentes. L’une d’entre elles peut ne pas être constructive, c’est à dire par exemple montrer qu’un objet existe sans dire comment le construire. Ça intéresse moins l’informaticien. Les autres preuves donnent des constructions. Ce sont des algorithmes. Un théorème dit par exemple que si on a un ensemble d’objets que l’on peut trier, alors on peut construire une séquence triée de ces objets. C’est un théorème – il est complètement trivial pour un mathématicien. Mais pour nous pas du tout. Si vous voulez trier un million d’enregistrements, vous aimeriez que votre algorithme soit rapide. Alors les informaticiens ont développé de nombreux algorithmes pour trier des objets qu’ils utilisent suivant les contextes, des preuves différentes de ce théorème trivial qui sont plus utiles qu’une preuve non constructive. Et ce sont de beaux objets !
Voilà, quand on a compris qu’un algorithme c’est une preuve, on voit bien que plusieurs algorithmes peuvent avoir la même spécification et donc que la preuve importe.
B : La mode aujourd’hui est d’utiliser le mot « code » pour parler de programmes informatiques. Tu ne parles pas de code ?
G : Au secours ! Le mot « code » est une insulte à la beauté intrinsèque de ces objets. La représentation d’un entier sous forme de produit de nombres premiers, on ne doit pas appeler cela un « codage » ! Non, cette représentation des entiers est canonique, et découle du Théorème Fondamental de l’Arithmétique. C’est extrêmement noble. Dans le terme « codage », il y a l’idée de cacher quelque chose, alors qu’au contraire, il s’agit de révéler la beauté de l’objet en exhibant l’algorithme.
L’esthétique des programmes
B : Les gens voient souvent les programmes informatiques comme des suites de symboles barbares, des trucs incompréhensibles. C’est beaucoup pour cela que le blog binaire milite pour l’enseignement de l’informatique, pour que ces objets puissent être compris par tous. Mais tu as dépassé l’état de le compréhension. Tu nous parles d’esthétique : un programme informatique peut-il être beau ?
GH : Bien sûr. Son rôle est d’abord d’exposer la beauté de l’algorithme sous-jacent. L’esthétique, c’est plus important qu’il n’y paraît. Elle a des motivations pratiques, concrètes. D’abord, les programmes les plus beaux sont souvent les plus efficaces. Ils vont à l’essentiel sans perdre du temps dans des détails, des circonvolutions inutiles. Et puis un système informatique est un objet parfois très gros qui finit par avoir sa propre vie. Les programmeurs vont et viennent. Le système continue d’être utilisé. La beauté, la lisibilité des programmes est essentielle pour transmettre les connaissances qui s’accumulent dans ces programmes d’une génération de programmeurs à l’autre qui ont comme mission de pérenniser le fonctionnement du système.
Pour les programmes, de même que pour les preuves, il ne faut jamais se satisfaire du premier jet. On est content quand ça marche, bien sûr, mais c’est à ce moment là que le travail intéressant commence, qu’on regarde comment nettoyer, réorganiser le programme, et c’est souvent dans ce travail qu’on découvre les bonnes notions. On peut avoir à le réécrire tout ou en partie, l’améliorer, le rendre plus beau.
Vaughan Pratt, Wikipedia
Prenez le cas d’Unix (*). Unix, c’est beau, c’est très beau ! Il faut savoir voir Unix comme une très grande œuvre d’art. Unix a été réalisé dans le laboratoire de recherche de Bell, par une équipe de chercheurs. Vaughan Pratt (+) disait dans les années 80 :« Unix, c’est le troisième Testament ». Vaughan Pratt, c’est quelqu’un d’incroyable ! Il ne dit pas n’importe quoi (rire de Gérard). Eh bien, Unix a été fait dans une équipe de spécialistes de théorie des langages et des automates. C’est une merveille de systèmes communiquant par des flots d’octets, tout simplement. C’est minimaliste. Ils ont pris le temps qu’il fallait, ils ont recherché l’élégance, la simplicité, l’efficacité. Ils les ont trouvées !
B : Parmi tes nombreux travaux, y en a-t-il un qui te tient particulièrement à cœur ?
GH : Je dirais volontiers que mon œuvre préférée, c’est le « zipper ». C’est une technique de programmation fonctionnelle. Elle permet de traverser des structures de données les plus utilisées en informatique comme des listes et des arbres pour mettre à jour leur contenu.
Le zipper (voir aussi la page), je suis tombé dessus pour expliquer comment faire des calculs applicatifs sur des structures de données, sans avoir cette espèce de vision étroite de programmation applicative où, pour faire des remplacements dans une structure de données, tu gardes toujours le doigt sur le haut de ta structure, ton arbre, et puis tu te balades dedans, mais tu continues à regarder ta structure d’en haut. Le zipper, au lieu de cela, tu rentres dans la structure, tu vis à l’intérieur, et alors, ce qui compte, c’est d’une part l’endroit où tu es, et d’autre part le contexte qui permet de te souvenir de comment tu es arrivé là. C’est une structure fondamentale qui avait totalement échappé aux informaticiens. Des programmeurs faisaient peut-être bien déjà du zipper sans le savoir comme M. Jourdain faisait de la prose. J’ai su formaliser le concept en tant que structure de donnée et algorithmes pour la manipuler. Maintenant, on peut enseigner le zipper, expliquer son essence mathématique.
La mystique de la recherche
B : Qu’est-ce qui est important pour réussir une carrière en recherche ?
GH : Le plus important finalement, dans le choix du sujet de recherche, ce sont trois choses : le hasard, la chance, et les miracles. Je m’explique. Premièrement, le hasard. Il ne se contrôle pas. Deuxièmement, la chance. C’est d’être au bon moment au bon endroit, mais surtout de savoir s’en apercevoir et la saisir.
Par exemple, dans le Bâtiment 8 (++) où je travaillais à l’INRIA Rocquencourt, il passait beaucoup de visiteurs. Le hasard c’est un jour la visite de Corrado Böhm , un des maîtres du lambda-calcul, une vraie encyclopédie du domaine. Je lui explique ce que je fais, et il me conseille de lire un article qui était alors, en 1975, inconnu de presque tous les informaticiens : c’était l’algorithme de Knuth-Bendix. C’est un résultat majeur d’algèbre constructive permettant de reformuler des résultats d’algèbre de manière combinatoire. La chance, j’ai su la saisir. J’ai vu tout de suite que c’était important. Cela m’a permis d’être un précurseur des systèmes de réécriture un peu par ce hasard. Voilà, j’ai su saisir ma chance. On se rend compte qu’il y a quelque chose à comprendre, et on creuse. Donc il faut être en éveil, avoir l’esprit assez ouvert pour regarder le truc et y consacrer des efforts.
À une certaine époque, j’étais un fréquent visiteur des laboratoires japonais. Une fois, je suis resté une quinzaine de jours dans un laboratoire de recherche. Je conseillais aux étudiants japonais d’être en éveil, d’avoir l’esprit ouvert. Je leurs répétais : « Be open-minded! ». Ils étaient étonnés, et mal à l’aise de questionner les problèmes qui leur avaient été assignés par leur supérieur hiérarchique. Un an plus tard, je suis repassé dans le même labo. Ils avaient gardé ma chaise à une place d’honneur, et ils l’appelaient (rire de Gérard) « the open-mindedness chair » !
B : Esthétique, miracle, troisième testament… Il y aurait une dimension mystique à ton approche de la recherche ?
GH : En fait, souvent, derrière les mystères, il y a des explications. Un exemple : je suis parti aux USA sur le mirage de l’intelligence artificielle. Une fois là-bas, quelle déception. J’ai trouvé qu’en intelligence artificielle, la seule chose qui à l’époque avait un peu de substance, c’était la démonstration automatique. J’ai essayé. Et puis, j’ai fait une croix dessus car cela n’aboutissait pas. Cela semblait inutile, et je voulais faire des choses utiles. Alors j’ai regardé ailleurs, des trucs plus appliqués comme les blocages quand on avait des accès concurrents à des ressources. Par hasard, je suis tombé sur deux travaux. Le premier, un article de Karp et Miller, m’a appris ce que c’était que le Problème de Correspondance de Post (PCP), un problème qui est indécidable – il n’existe aucun algorithme pour le résoudre. Le second était une thèse récemment soutenue à Princeton qui proposait un algorithme pour l’unification d’ordre supérieur. Je ne vais pas vous expliquer ces deux problèmes, peut-être dans un autre article de Binaire. L’algorithme de la thèse, je ne le comprenais pas bien. Surtout, ça ne m’intéressait pas trop, car c’était de la démonstration automatique et je pensais en avoir fini avec ce domaine. Eh bien, un ou deux mois plus tard, je rentre chez moi après une soirée, je mets la clé dans la serrure de la porte d’entrée, et, paf ! J’avais la preuve de l’indécidabilité de l’unification d’ordre supérieur en utilisant le PCP. J’avais établi un pont entre les deux problèmes. Bon ça montrait aussi que le résultat de la thèse était faux. Mais ça arrive, les théorèmes faux. Pour moi, quel flash ! J’avais résolu un problème ouvert important. Quand je parle de miracle, c’est quelque chose que je ne sais pas expliquer. J’étais à mille lieues de me préoccuper de science, et je ne travaillais plus là dessus. C’est mon inconscient qui avait ruminé sur ce problème du PCP, et c’est un cheminement entièrement inconscient qui a fait que la preuve s’est mise en place. Mais il faut avoir beaucoup travaillé pour arriver à ça, avoir passé du temps à lire, à comprendre, à essayer des pistes infructueuses, à s’imprégner de concepts que l’on pense important, à comprendre des preuves. C’est beaucoup de travail. La recherche, c’est une sorte de sacerdoce.
Bon, il faut aussi savoir s’arrêter, ne pas travailler trop longtemps sur un même problème. Faire autre chose. Sinon, eh bien on devient fou.
Caml (prononcé camel, signifie Categorical Abstract Machine Language) est un langage de programmation généraliste conçu pour la sécurité et la fiabilité des programmes. Descendant de ML, c’est un langage de programmation directement inspiré du calcul fonctionnel, issu des travaux de Peter Landin et Robin Milner. À l’origine simple langage de commandes d’un assistant à la preuve (LCF), il fut développé à l’INRIA dans l’équipe Formel sous ses avatars de Caml puis d’OCaml. Les auteurs principaux sont Gérard Huet, Guy Cousineau, Ascánder Suárez, Pierre Weis, Michel Mauny pour Caml ; Xavier Leroy, Damien Doligez et Didier Rémy et Jérôme Vouillon pour OCaml.
Coq est un assistant de preuve fondé au départ sur le Calcul des Constructions (une variété de calcul fonctionnel typé) introduit par Thierry Coquand et Gérard Huet. Il permet l’expression d’assertions mathématiques, vérifie automatiquement les preuves de ces affirmations, et aide à trouver des preuves formelles. Thierry Coquand, Gérard Huet, Christine Paulin-Mohring, Bruno Barras, Jean-Christophe Filliâtre, Hugo Herbelin, Chet Murthy, Yves Bertot, Pierre Castéran ont obtenu le prestigieux 2013 ACM Software System Award pour la réalisation de Coq.
(*) Unix : Unix est un système d’exploitation multitâche et multi-utilisateur créé en 1969. On peut le voir comme l’ancêtre de systèmes aussi populaires aujourd’hui que Linux, Android, OS X et iOS.
(+) Vaughan Pratt est avec Gérard Huet un des grands pionniers de l’informatique. Il a notamment dirigé le projet Sun Workstation, à l’origine de la création de Sun Microsystems.
(++) Bâtiment 8 ; Bâtiment quasi mythique d’Inria (de l’IRIA ou de l’INRIA) Rocquencourt pour les informaticiens français, qui a vu passer des chercheurs disparus comme Philippe Flajolet et Gilles Kahn, et de nombreuses autres stars de l’informatique française toujours actifs, souvent à l’instigation de Maurice Nivat. Gilles Kahn sur la photo était une sorte de chef d’orchestre, parmi un groupe de chercheurs plutôt anarchistes dans leur approche de la recherche.
L’intelligence artificielle est un vrai sujet, mais c’est aussi une source de fantasmes dont la forme contemporaine est issue de textes d’Alan Turing. Isabelle Collet, Maître d’enseignement et de recherche à la Faculté des sciences de l’éducation de l’université de Genève, nous offre ici un éclairage inattendu et nous aide à dépasser les idées reçues. Elle attire notre attention sur le fait que c’est avant tout une histoire de « mecs ». À déguster donc… Thierry Viéville.
Quand je faisais mes études d’informatique, j’avais entendu parler du « test de Turing ». Pour moi, il s’agissait simplement de faire passer un test à un ordinateur pour savoir s’il était intelligent (ou s’il était programmé d’une façon suffisamment maline pour donner cette impression).
Face à un ordinateur, l’humain est-il une femme ou un homme ?
En faisant des recherches dans le cadre de ma thèse, j’ai lu un peu plus sur le « test de Turing »… et j’ai découvert avec fascination que quand les informaticiens prétendaient le mettre en place, ils en oubliaient la moitié : le jeu ne se met pas en place avec un humain et un ordinateur, mais avec un homme et une femme. Un observateur devra déterminer lequel de ses interlocuteurs est un homme et lequel est une femme. Il devra les interroger sans avoir aucun autre indice que le contenu des réponses que l’homme et la femme formulent. Puis, au bout d’un « certain temps », on remplace l’homme par l’ordinateur. Si l’observateur pense qu’il joue encore à détecter la différence des sexes et ne remarque rien, c’est que l’ordinateur a l’air au moins aussi intelligent que l’homme. À l’époque, je ne voyais pas bien l’intérêt de ce passage par la différence des sexes… Jusqu’à ce que je lise un texte de Jean Lassègue, auteur d’un autre texte sur Turing sur ce blog, et que je l’associe aux recherches de l’anthropologue Françoise Héritier. Je vais parler ici de cette connexion, avec tous mes remerciements à Jean Lassègue pour son excellente analyse du jeu de l’imitation .
On pourrait considérer que la première partie du jeu (entre un homme et une femme) n’est qu’un prétexte pour permettre ensuite la substitution en aveugle avec l’ordinateur et que Turing aurait pu choisir un autre critère que la différence des sexes pour amorcer le jeu. Pour Jean Lassègue1, le critère de la différence des sexes est tout à fait capital : « il s’agit de passer d’un écart physique maximal entre êtres humains à un écart maximal entre espèces différentes (si on considère l’ordinateur comme une nouvelle espèce) ». Sur cette base, l’observateur est supposé en déduire que : « puisque la différence physique la plus profonde entre les êtres humains (être homme et être femme) n’est pas apparente dans le jeu n°1, la différence physique encore plus profonde entre les êtres humains d’une part et l’ordinateur d’autre part ne sera pas apparente dans le jeu n°2 non plus. ». Évidemment, si le jeu n°1 échoue, il n’est plus question de passer au jeu n°2 qui perd sa capacité démonstrative.
Lors de la première phase de l’expérience, Turing signale que : « La meilleure stratégie pour [la femme] est sans doute de donner des réponses vraies. Elle peut ajouter à ses réponses des choses comme : ‘‘C’est moi la femme, ne l’écoutez pas’’ mais cela ne mène à rien puisque l’homme peut faire des remarques semblables ».
Photo @Maev59
Pourquoi Turing assigne-t-il ainsi les stratégies de jeu entre l’homme et la femme ? Toujours selon Lassègue, la stratégie de la femme est en fait une absence de stratégie. Dans le jeu de l’imitation, la femme est la seule qui s’imite elle-même, alors que l’homme imite la femme et que l’ordinateur imite l’homme imitant la femme.
Dans une interview, un de ses anciens collègues, Donald Michie, rapporte ces propos de Turing : « Le problème avec les femmes, c’est qu’il faut leur parler. Quand tu sors avec une fille, tu dois discuter avec elle et trop souvent, quand une femme parle, j’ai l’impression qu’une grenouille jaillit de sa bouche. »1
Revenons au jeu de l’imitation : les femmes, qui sont supposée être de manière générale à ce point dépourvues d’à-propos dans une conversation, doivent se contenter d’être elles-mêmes dans ce jeu, c’est-à-dire, indiscutablement une femme, un être incapable de faire abstraction de son sexe. L’homme, par contre, va tenter de tromper l’interrogateur, et pour cela, il devrait être capable de se détacher de son sexe, c’est à dire de son corps sexué, pour réussir à imiter la femme. Et en fin de compte, ce que l’ordinateur va devoir réussir, c’est d’imiter l’homme qui imite la femme, ou, plus simplement, d’imiter la femme.
Finalement, l’homme et l’ordinateur ont des stratégies tout à fait similaires. L’intelligence ainsi imitée par la machine est celle de l’homme et le jeu de l’imitation a pour conséquences, d’une part, d’écarter les femmes dès qu’on parle d’intelligence, et, d’autre part, de placer l’intelligence de l’homme (et non pas de l’humain) à un niveau universel.
Il est en effet remarquable au début du jeu n°1 que Turing semble signifier que la différence des sexes se traduit clairement par les attributs physiques. Plus particulièrement, il pense qu’il y a une essence féminine (différente de l’essence masculine) et qu’une de ses manifestations fiables est l’apparence de la femme. Dans le premier et seul exemple de l’article proposé pour le jeu n°1, l’observateur pose une question relative à la longueur des cheveux de son interlocuteur-trice. Turing reprend ici, volontairement ou non, le présupposé sexiste largement répandu qui prétend, d’une part, que les femmes sont davantage asservies à leur corps que les hommes et, d’autre part, que leur apparence se superpose à leur personnalité. Rousseau disait déjà que la femme est femme à chaque instant, alors que l’homme n’est homme (c’est-à-dire un être mâle) qu’à des instants précis… le reste du temps, il est universel (c’est à dire un universel masculin, puisque de toute manière, la femme n’y est pas conviée).
Notons que pour que le jeu puisse fonctionner, il faut bien que la femme soit elle-même, et ne puisse être qu’elle-même. La différence est alors produite par la capacité de l’homme à se détacher de son corps, car son esprit lui permet d’imiter un être pris dans un autre corps, et ainsi de jouer, sur ce plan, jeu égal avec la machine. On en vient à penser que l’intelligence universelle est plutôt du côté de la machine.
Dans son jeu, Turing se débarrasse de la différence des sexes simplement en se débarrassant des femmes. Si l’intelligence que recherche Turing est universelle, ce n’est pas parce qu’elle a fusionné les sexes, mais parce qu’il n’en reste plus qu’un, auquel peut se comparer l’intelligence artificielle.
On retrouve ce même fantasme quand il décrit les machines autorisées à participer au jeu : « Nous souhaitons enfin exclure de la catégorie des machines les hommes nés de la manière habituelle. […] On pourrait par exemple requérir que les ingénieurs soient tous du même sexe, mais cela ne serait pas vraiment satisfaisant »2. Cette phrase, qui peut être considérée comme un trait d’humour, possède en fait deux éléments essentiels pour comprendre la vision que Turing a de la machine. Tout d’abord, la machine est considérée comme étant littéralement l’enfant des ingénieurs, puisque s’il était produit par une équipe d’hommes et de femmes ingénieurs, cela jetterait le doute sur un possible engendrement biologique. D’autre part, pour que la machine puisse être éligible au jeu de l’imitation, une condition nécessaire est qu’elle ne soit pas issue de la différence des sexes.
De plus, l’équipe d’ingénieurs de même sexe qui engendrerait une machine, serait selon toutes probabilités dans l’esprit de Turing, une équipe d’hommes. Sa vision de la création d’une machine de type ordinateur est non seulement un auto-engendrement, mais surtout un auto-engendrement masculin se débarrassant des femmes au moment de la conception sous prétexte, en quelque sorte, de ne pas tricher.
Un paradis sans altérité !
Photo @Maev59
La cybernétique nous explique que, puisque le niveau supérieur de compréhension de l’univers implique l’étude des relations entre ses objets et non la connaissance de la structure des objets, les matières et les corps ne sont pas vraiment ce qui importe. Piégées dans leur corps, les femmes n’ont pas accès à ce niveau supérieur de compréhension de l’univers que propose le paradigme informationnel. Elles en seront même éventuellement écartées pour permettre à l’intelligence d’atteindre un idéal androgyne débarrassé du féminin. A cet instant, la perspective d’un monde idéal dans lequel l’homme pourrait se reproduire à l’identique devient possible.
Les fantasmes d’auto-engendrement apportent une solution à ce que Françoise Héritier3 appelle le privilège exorbitant des femmes à pouvoir se reproduire à l’identique mais aussi au différent. Les femmes sont les seules capables de mettre au monde non seulement leurs filles mais aussi les fils des hommes. Selon Françoise Héritier, on retrouve dans de nombreux mythes des groupes non mixtes vivant séparément et pacifiquement, chacun étant capable de se reproduire à l’identique. L’harmonie primitive résidait dans l’absence d’altérité, jusqu’à ce qu’elle soit gâchée par un événement violent (en général : une copulation que (les) dieu(x) ne désirai(en)t pas).
Philippe Breton estimait dans son livre de 1990 « La tribu informatique » que : « La reproduction au sein de la tribu se fait fantasmatiquement grâce […] à l’union de l’homme et de la machine ». Sur ce point, je ne suis pas d’accord. À mon sens, il n’y a pas d’union avec la machine, mais un auto-engendrement dont la machine est soit le produit (du temps où on fantasmait sur les robots) soit le support (depuis qu’on imagine des IA uniquement logicielle). Or, un auto-engendrement et une reproduction via une « matrice biologique » sont des procédés qui se présentent comme mutuellement exclusifs. C’est pourquoi je suis d’accord quand il ajoute : « Dans ce sens, l’existence même de la tribu informatique est en partie conditionnée par l’exclusion des femmes qui constituent une concurrence non désirée.»
Le monde scientifique des années 1950 peut être un exemple du paradis sans altérité de Françoise Héritier. Le monde de l’informatique d’aujourd’hui n’en est pas très loin. L’auto-engendrement cybernétique au cours duquel l’homme seul duplique son intelligence dans une machine permettrait de faire fonctionner pleinement ce « paradis », il possède le double avantage de supprimer la différence des sexes en écartant les femmes du processus de reproduction et de permettre aux êtres mâles de se reproduire à l’identique.
1Lee, J. A. N. and Holtzman, G. « 50 Years After Breaking the Codes: Interviews with Two of the Bletchley Park Scientists. » The Annals of the History of Computing vol. 17 n°1 (1995) p. 32-43
2Alan Turing, Jean-Yves Girard, La machine de Turing, 1995
3Françoise Héritier, Masculin / Féminin, Dissoudre la hiérarchie. (2002).
Après Ada Lovelace hier et à l’occasion de la Journée internationale de la femme, Anne-Marie Kermarrec nous parle d’une autre grande pionnière de l’informatique, Grace Hopper. Inventeure d’un des langages de programmation qui a été le plus utilisé, Cobol, Grace Hopper est une grande dame dans un style très différent d’Ada Lovelace. Serge Abiteboul.
Grace Hopper, Wikipedia
Grace Hopper (1906-1992) est américaine, elle obtient un doctorat en mathématiques à Yale et commence à enseigner la discipline à Vassar College en 1931. En 1943, elle s’engage dans l’armée américaine comme beaucoup d’autres femmes, dans l’unité exclusivement féminine WAVES. Ces femmes étaient appelés les « ordinateurs humains » et étaient en charge, pendant que les hommes étaient au front, d’étudier en particulier des trajectoires balistiques. Grace Hopper est affectée à Harvard comme lieutenant pour y programmer l’ordinateur Mark 1. Son supérieur H. Aiken, un peu réticent à l’idée d’avoir comme second une femme, accuse cependant très vite réception des qualités de Grace Hopper pour la discipline. Le Mark 1 est un calculateur générique, programmable par cartes perforées. Grace Hopper s’attèle à la programmation de cette machine dont les résultats seront très importants dans ce contexte de guerre. Grace Hopper décide alors de nommer le processus d’écrire des instructions, le codage (coding). Il est amusant de noter que ce terme, remplacé par celui de programmation, vient d’être récemment remis au goût du jour. À l’issue de la guerre, Grace Hopper ne peut réintégrer la Navy en raison de son âge trop avancé, et doit quitter Harvard qui n’attribue pas de postes de professeurs aux femmes.
Elle rejoint alors Eckert-Machly Computer Corporation, une « startup » qui souhaite commercialiser l’ordinateur, et l’équipe qui développe l’Univac. Grace Hopper est parmi les premières à défendre l’idée d’un langage de programmation qui serait d’une part indépendant des machines (de multiples ordinateurs fleurissent à l’époque) et d’autre part possible d’être exprimé non pas avec des symboles mais à l’aide d’un langage proche de l’anglais, permettant ainsi à des gens qui n’auraient pas de doctorat en mathématiques ou informatique de pouvoir programmer des ordinateurs. Elle introduit alors avec cinquante ans d’avance le concept de réutilisation. Les langages de programmation de haut niveau étaient nés. Elle écrit en 1952 le premier compilateur. Elle introduit en particulier la notion de subroutines, réalise qu’elles peuvent être stockées et assemblées par l’ordinateur lui-même. Elle écrit alors un morceau de code, un compilateur, pour effectuer ces tâches automatiquement. C’est en 1959, qu’avec une poignée d’autres scientifiques, elle pose les bases du langage Cobol, très largement inspiré du FLOW-MATIC qu’elle avait inventé quelques années auparavant. Cobol sera une vraie révolution industrielle.
Enfin, Grace Hopper est connue pour avoir rendu populaire la notion de « bug », même si le terme était déjà utilisé pour désigner des phénomènes inexplicables. Le terme de « bug » est associé à la découverte d’un insecte, en l’occurrence une mite, qui avait provoqué un faux contact et une erreur dans l’exécution d’un programme.
Une féministe à sa manière, Grace Hopper croyait fermement que les femmes disposaient des mêmes capacités (ça c’est faire preuve de féminisme) et des mêmes opportunités (ça moins, un manque de discernement étonnant pour une femme de ce calibre) que les hommes. Ceux qui connaissent Grace Hopper ont en tête l’image de la vieille dame, amiral de l’armée américaine, austère, en uniforme. Grace Hopper s’est pourtant imposée dans ce monde informatique en construction, largement dominé par les hommes, à renforts de sarcasmes, d’humour mais aussi de charme, selon ses propres mots [1]. En revanche, elle n’a jamais admis que les droits des femmes avaient besoin d’être défendus d’une quelconque manière. Trop optimiste sur la condition humaine il semblerait. Qu’importe, son nom aujourd’hui est clairement associée à une réussite féminine en informatique. Toute féministe qu’elle était, il est amusant de noter que le nom Hopper est en fait celui de l’homme avec qui elle s’est mariée en 1930 et dont elle a divorcé en 1945.
Contrairement à Ada Lovelace, Grace Hopper a été très primée tout au long de sa vie. Elle reçoit en particulier en 1969, le prix de l’homme de l’année en informatique (Computer Sciences Man of the Year award). En 1973, elle devient la première personne américaine et la première femme, toutes nationalités confondues, à recevoir la distinction « Distinguished Fellow of the British Computer Society ». En 1971, l’ACM crée le prix Grace Murray Hopper, qui récompense le(la) jeune informaticien(e) de l’année.
Voilà quarante ans que nous célébrons les femmes le 8 mars, depuis 1975, année internationale de la femme, pour accuser réception de la lutte historique concernant l’amélioration des conditions de vie des femmes. Vaste programme, comme dirait l’autre. Toujours cet arrière goût d’inachevé… Pour l’occasion, Anne-Marie Kermarrec nous parle de grandes pionnières de l’informatique, aujourd’hui Ada Lovelace. Le premier programmeur de l’histoire était une programmeure ! Serge Abiteboul.
1967 : autant de bachelières que de bacheliers, pour la première fois. 2015 : à peine 10% de femmes dans les cursus d’ingénieurs. L’informatique continue de se sinistrer doucement mais surement. Au cours du congrès annuel de la SIF (Société informatique de France), consacré cette année à « Femmes et Informatique », nous n’avons pu que constater les statistiques en berne, qu’il s’agisse d’étudiantes, de chercheuses et enseignantes-chercheuses. Plus encore, à mesure que les grades augmentent, les femmes se raréfient. Same old story. D’aucun pourrait se réjouir du reste et conclure que l’informatique prend du galon, arguant du fait qu’une discipline qui se féminise est clairement en perte de prestige et de vitesse… Nous avons débattu deux jours sur les raisons de cet état de fait. Qui de l’image, des clichés, etc. …. et cette impuissance, prégnante, à inverser la tendance. Oui quelques idées flottent bien, comme de convaincre les filles qu’elles aiment aussi la technique, de revamper les cours d’informatique ou encore d’enseigner l’informatique dès le primaire. On attend toujours le déclic sociétal…
2014, si elle était le quarantième anniversaire de la légalisation de l’IVG, était aussi celle du centenaire d’Alan Turing, le père de l’informatique. Turing, malheureusement encore trop peu connu du grand public quand il devrait mériter au moins autant d’égards qu’Einstein. Tout le monde connaît l’espiègle moustachu qui tire la langue, quand bien même la théorie de la relativité échappe à la majorité des gens, ou encore Freud, dont on sait qu’il interprète les rêves. Turing, lui les aura réalisés. Pourtant, personne ne le connaît, quand la moitié de la planète tweete à longueur de journée, sur ses traces…
2015 commence bien. Hollywood s’en mêle. Deux films consacrés à des scientifiques de renom : Alan Turing (Imitation game) justement et Stephen Hawkings (The theory of everything). Imitation Game retrace les activités de Turing pendant la seconde guerre mondiale pour craquer Enigma, au creux de Bletchey Park, où mille délicates oreilles féminines interceptent les messages pendant que quelques cerveaux masculins s’évertuent à les décoder. Pourtant, déchainement de critiques : impossible de comprendre précisément comment Enigma a été craquée, le concept de la machine de Turing est à peine évoqué, pas plus que le test éponyme permettant de différencier intelligence artificielle et intelligence humaine, qui pourtant donne son titre au film, Turing a l’air d’un autiste, l’homosexualité est trop timidement affichée, etc. Soyons sérieux, quel scénariste, aussi talentueux soit-il, serait capable d’expliquer clairement la crypto au grand public dans un film hollywoodien ? Réjouissons nous plutôt que ce film ait du succès et permettent de mettre en lumière le père de l’informatique. Quand à The theory of everything, peut-être que le fait que Hawkings, lui même, ait rendu un verdict positif, suffira à faire taire les puristes des trous noirs.
Mais revenons à nos moutons, en cette veille de journée de la femme 2015, c’est une pionnière de l’informatique, que j’aimerais mettre sous le feu des projecteurs.
Ada Lovelace, Wikipedia
La visionnaire Ada Lovelace (1815-1852)
Ada Lovelace est le fruit des amours tumultueuses de Lord Byron, poète romantique dont le talent n’a d’égal que le goût pour les frasques amoureuses, père qu’elle ne connaitra jamais d’ailleurs, et de Anabella Milanke, mathématicienne, que Byron aimait à appeler sa « Princess of parallelograms »… De l’importance du niveau d’instruction des mères pour celle des jeunes filles. Poussée par sa mère, elle étudie les mathématiques. Elle rencontre à 17 ans, Charles Babbage, mathématicien, professeur à l’Université de Cambridge. Fascinée par les machines qu’il conçoit, Ada y consacrera une grande partie de sa courte vie.
Babbage, dont les travaux couvrent un spectre aussi large qu’hétéroclite, du pare-buffle pour locomotive à l’analyse des troncs pour y déceler l’âge des arbres, de l’invention du timbre poste unique aux premiers ordinateurs, conçoit sa machine à différence, sur les traces de la Pascaline de Pascal, initialement pour pallier les erreurs humaines et fournir ainsi des tables nautiques, astronomiques et mathématiques exactes, y incorporant des cartes perforées du métier Jacquard. Ce métier, inventé par Jacquard afin d’éviter aux enfants les travaux pénibles, permettait de reproduire un motif grâce à des cartes perforées qui n’actionnaient que les crochets nécessaires à effectuer le motif choisi sur un métier à tisser. La légende dit que Jacquard s’en est toujours voulu de l’invention de cette machine qui, outre d’être à l’origine de la révolte des canuts, a certes détourné les enfants des métiers à tisser, mais ne leur a pas épargné des travaux pénibles dans d’autres secteurs et parfois dans des conditions encore plus difficiles.
Le premier programmeur de l’histoire est une femme
Babbage se concentre bientôt sur la conception d’une machine plus puissante, la machine analytique dont le design a déjà tout d’un ordinateur moderne. Si Babbage avait en tête de pouvoir effectuer grâce à sa machine de nombreux calculs algébriques, celle qui l’a réellement programmée pour la première fois est Ada Lovelace. En 1842, à la faveur d’un séminaire de Babbage à l’Université de Turin, Louis Menebrea, publie en français un mémoire décrivant la machine analytique de Babbage. Babbage, impressionné par les qualités intellectuelles et mathématiques d’Ada, et dont la compréhension fine de sa machine ne lui aura pas échappé, décide de lui confier la traduction de cet article. Elle s’attellera à cette tâche avec une grande application et à la faveur de cet exercice, augmentera l’article de nombreuses notes, qui triplent sa taille. Ces notes, dont la publication l’a rendue « célèbre », démontrent que si elle appréhende le fonctionnement de la machine aussi bien que Babbage, elle en voit beaucoup plus clairement l’énorme potentiel.
Ceci valut à Ada d’être considérée comme le premier programmeur de l’histoire. Elle a, la première, clairement identifié des notions essentielles en informatique que sont les entrées (les cartes perforées contenant données et instructions), les sorties (cartes perforées contenant les résultats), l’unité centrale (le moulin) et la mémoire (le magasin permettant de stocker les résultats intermédiaires). À la faveur de la conception de l’algorithme permettant le calcul des nombres de Bernoulli, elle a introduit la notion de branchements, mais également expose comment une répétition d’instructions peut être utilisée pour un traitement, introduisant ainsi le concept de la boucle que l’on connaît bien en programmation.
Cent ans d’avance. Dans ses notes, Ada décrit en particulier comment la machine peut être utilisée pour manipuler pas uniquement des nombres mais aussi des lettres et des symboles. Ada est une visionnaire, elle est celle qui, la première, entrevoit l’universalité potentielle d’une telle machine, bien au delà de ce que ses contemporains pouvaient appréhender. Ada avait eut cette vision du calculateur universel bien avant l’heure, vision qu’Alan Turing formalisera quelque cent ans plus tard. En particulier elle fut, tellement en avance, en mesure d’imaginer la composition musicale effectuée par un ordinateur. Dans sa fameuse note G, la note finale, elle décrit un programme, comme nous l’appellerions aujourd’hui, qui permettrait à la machine analytique de faire des calculs sans avoir les réponses que les humains auraient pu calculer d’abord. Virage radical par rapport à ce que l’on attendait initialement de la machine analytique.
Ada Lovelace était une femme, non conventionnelle, athée quand sa mère et son mari étaient de fervents catholiques. Sur la fin de sa vie, Ada avait pour seul objectif de financer la machine de Babbage, elle croit avoir découvert une méthode mathématique lui permettant de gagner aux courses, qui la laissera dans une situation financière délicate. Elle meurt à 36 ans d’un cancer de l’utérus.
Une femme trop peu célébrée. Même si un langage de programmation porte son nom, Ada est restée assez discrète dans la discipline. Étudiante en informatique, j’ai entendu parler de Turing, de von Neuman ou de Babbage. Jamais d’Ada Lovelace. C’est Babbage qui fut récompensé par la médaille d’or de la Royal Astronomical Society en 1824. La vision d’Ada prendra son sens quelque cent ans plus tard dans les travaux de Turing. Alors même qu’il apparaît clairement que les notes d’Ada jetaient les premières bases de la machine de Turing, aucune des nombreuses biographies consacrées à Turing ne la mentionne. Il semblerait pourtant qu’il ait lu la traduction de Lovelace et ses notes quand il travaillait à Bletchey Park. Pire encore, certains historiens lui en retirent même la maternité comme l’historien Bruce Collier [1]. Si cette interprétation est largement contestée, cela en dit long sur la crédibilité qu’on accorde parfois aux esprits féminins.
Bruce Collier. The Little Engine That Could’ve. 1990
Suw Charman-Anderson. Ada Lovelace: Victorian computing visionary, chapitre de Women in STEM anthology, A passion for Science : Tales of Discovery and Invention.
La publication scientifique est un modèle économique improbable ! Le produit de base est créé par des chercheurs qui réalisent un travail de recherche et écrivent un article pour transmettre ce qu’ils ont appris à d’autres chercheurs. La valeur ajoutée provient également des chercheurs qui évaluent l’article et suggèrent des améliorations. Les clients sont principalement des chercheurs qui à travers leurs laboratoires paient de plus en plus cher pour pouvoir lire leurs articles. Quelque chose vous choque ? ils paient pour accéder à leur propre travail ? Nous avons demandé à Pascal Guitton de nous expliquer pourquoi et comment nous en sommes arrivé à une telle arnaque. Dans un premier article, il nous explique ce qu’est une publication scientifique et son passage au numérique. Serge Abiteboul et Thierry Viéville.
La notion de publication scientifique n’est pas vraiment comprise du grand public qui la rencontre principalement dans les médias quand ces derniers citent, souvent de façon maladroite et partielle, des résultats qu’ils jugent « spectaculaires » ou bien lors de controverses portées sur la place publique comme pour la mémoire de l’eau ou les méfaits d’un maïs transgénique sur des rats. Outil de base du quotidien de tous les scientifiques, nous allons essayer d’expliquer ce qu’est une publication scientifique pour que chacun puisse mieux discerner son impact pour la société. Nous évoquerons dans un second article les dérives induites par des changements récents et leurs conséquences sur le travail des chercheurs.
C’est quoi une publi ?
Pour commencer, il faut préciser qu’il n’existe pas une définition unique mais que cohabitent plusieurs formes de publications scientifiques avec de grandes différences entre les domaines de recherche. Synthétique (moins d’une dizaine de pages), de grande ampleur (plusieurs centaines), fréquente (plusieurs par an), espacée (de plusieurs années), principalement basée sur des résultats chiffrés ou bien rédaction plus littéraires, publiée dans des revues ou dans des actes de conférence, la forme de la publication n’est pas unique mais bien diverse à l’image des communautés de chercheurs.
Il est cependant possible de distinguer des caractéristiques communes à toutes les cultures scientifiques qui relèvent de la nature du travail de recherche «générique».
Avant toute autre chose et quelques soient les sciences, un chercheur doit en permanence connaître les résultats obtenus par ses collègues, d’abord pour ne pas réinventer la roue et ensuite pour essayer de les améliorer en s’en inspirant ou mieux encore en créant une approche originale. Ce travail d’écoute et de compréhension se réalise en lisant les publications rédigées par d’autres chercheurs. Le chercheur doit ensuite faire appel à son imagination et faire preuve de créativité pour développer de nouvelles idées qui sont le plus souvent présentées puis discutées et débattues avec ses collègues les plus proches dans un premier temps.
Photo @Maev59
L’étape suivante consiste à prouver l’intérêt de son idée à l’ensemble de la communauté. Selon les domaines, il s’appuie sur une démonstration mathématique, une argumentation littéraire, des mesures réalisées pendant une expérience physique ou chimique, les résultats d’une étude sociologique, des mesures biologiques… Toutes ces formes n’ont qu’un objectif : étayer l’idée originale avancée par l’auteur afin d’emporter la conviction de ses interlocuteurs. Le chercheur place donc cette preuve au cœur d’un texte qui décrit ses travaux depuis l’hypothèse initiale jusqu’à la conclusion en passant par les résultats préexistants (qu’il est indispensable de citer pour situer les progrès) et les éventuelles expérimentations réalisées. Ce texte scientifique est donc publié et diffusé le plus largement possible afin de permettre aux autres chercheurs de prendre connaissance de ses travaux, bouclant ainsi le cycle.
Le but : la diffusion des résultats de recherche
La raison d’être d’une publication est de diffuser les résultats des recherches au sein de la communauté scientifique. Mais l’on peut se demander en quoi est-ce différent d’une publication en général ? Contrairement à un article publié dans un journal « standard » qui est relu par un rédacteur en chef ou bien à un billet ou un commentaire sur un blog, elle s’appuie sur un principe dit d’évaluation par les pairs qui consiste à faire vérifier par d’autres scientifiques experts du domaine les qualités d’un article avant de le publier. Cette étape est fondamentale. De la qualité de ce processus, déroule directement la confiance que l’on accorde à une publication scientifique.
La démarche : une évaluation par les pairs
Dans l’immense majorité des cas, une publication est rédigée par des chercheurs pour ses pairs. La rédaction d’un tel document obéit donc à des règles et à des styles bien particuliers que les jeunes chercheurs apprennent principalement lors de la préparation de leur thèse. En d’autres termes et contrairement à ce que peuvent laisser penser certains, les articles sont des textes spécialisés le plus souvent incompréhensibles pour qui n’est pas du domaine.
Les modèles de diffusion
Les revues ou journaux représentent la voie la plus classique de publication : l’auteur ou un groupe d’auteurs (le travail scientifique étant souvent collectif) soumet une première version de son document à l’éditeur en chef qui sollicite des membres du comité de lecture pour examiner la soumission. À l’issue de cette analyse, les relecteurs émettent un avis négatif (la soumission est rejetée) ou positif (elle est acceptée), le plus souvent avec des demandes de révision tant sur la forme que sur le fond. Une fois le texte amendé par l’auteur en fonction de ces remarques (parfois en plusieurs aller-retour), la version définitive est alors publiée dans un numéro de la revue.
Dans certaines sciences comme l’informatique, il existe une autre voie de publication toute aussi importante : les conférences qui regroupent pendant plusieurs jours des chercheurs qui exposent leurs travaux. Pour certaines conférences, les auteurs rédigent en amont de la manifestation un texte qui suit une procédure de validation semblable à celle des revues. Pour d’autres, le texte est produit après la conférence. D’autres enfin se contentent d’un résumé succinct. Évidemment, suivant la procédure suivie, l’ouvrage (appelé « actes de conférence ») qui peut accompagner la conférence est reconnu comme de qualité équivalente à celle des revue, ou pas.
Pour juger de la qualité d’une expertise et, plus globalement, d’une revue ou d’une conférence, les scientifiques utilisent plusieurs critères :
L’expertise des relecteurs : la première chose que fait un chercheur qui découvre une nouvelle revue/conférence est de parcourir la liste des membres de son comité de lecture/programme afin d’en estimer la qualité.
L’anonymat : un auteur ne sait pas qui expertise son article et ce pour garantir l’indépendance de l’analyse ; parfois le relecteur ne sait pas qui sont les auteurs (on parle alors de « double-aveugle »). Les relecteurs sont aussi tenus de respecter des règles éthiques les excluant en cas de conflit d’intérêt qu’il soit positif ou négatif. Le but est évidemment de garantir autant que possible «l’honnêteté» du processus de sélection.
Le nombre de relecteurs : en cas d’expertises non unanimes, un éditeur en chef doit pouvoir s’appuyer sur un nombre « suffisant » d’avis. Trois semblent un minimum ; dans certaines conférences a été mise en place une organisation arborescente avec des relecteurs, des méta-relecteurs et l’éditeur au sommet de façon à structurer un éventuel débat contradictoire.
Le déroulement de la procédure : les délais de réponse sont-ils raisonnables ? Le contenu des expertises communiqué aux auteurs est-il suffisant pour réellement améliorer la qualité du document…
Il existe aussi des critères numériques pour estimer la qualité d’une revue/conférence :
compter le nombre de soumissions pour juger de l’intérêt porté par les chercheurs,
calculer le ratio obtenu en divisant le nombre de publications acceptées par le nombre de soumissions pour juger de sa sélectivité (des ratios de 1/7 sont standards pour certaines conférences en informatique),
comptabiliser le nombre de fois où un des articles qu’elle a publié est cité comme référence dans d’autres articles.
Des évolutions
Originellement basé sur la transmission orale, le travail d’écoute et de compréhension des travaux des autres chercheurs s’est enrichi de façon très importante avec les arrivées successives de l’écriture et de l’imprimerie qui ont autorisé une diffusion beaucoup plus importante des idées et des résultats. Ces formes nouvelles ont entraîné des bouleversements dans les pratiques scientifiques elles-mêmes.
Une autre modification profonde a porté sur la langue de communication : d’abord maternelle, donc tour de Babel, puis internationale : chinois, arabe, latin, grec, français, allemand, russe, anglais. Depuis la 2ème guerre mondiale, l’anglais s’est imposé dans de nombreux domaines comme langue d’échange, permettant d’élargir le cercle des lecteurs et par conséquent la portée d’une publication.
Plus récemment, la révolution numérique a provoqué des mutations profondes : encore tapée à la machine à écrire au début des années 80, la publication scientifique est progressivement devenue numérique grâce à l’apparition des systèmes de traitement de texte et d’édition comme Word ou LaTeX par exemple. Cette technologie a également facilité l’inclusion d’éléments comme des images, des figures et aujourd’hui des sons ou des vidéos. Sont alors apparus des documents réellement multimédias enrichissant la description des travaux des chercheurs. Un point important de ces évolutions, le scientifique est devenu également l’éditeur de l’article, au sens de la réalisation du document numérique qui constitue l’article.
Le deuxième impact de la révolution numérique s’est fait sentir avec l’invention des hypertextes incluant des liens vers des documents extérieurs, base du développement d’Internet et de ses contenus (pages, puis services). Il devient possible par exemple de donner accès à la description détaillée d’expériences (jusqu’à permettre de les reproduire) et aux données brutes qu’elles ont générées.
La troisième mutation numérique résulte de la mise en ligne des publications scientifiques qui remplace progressivement l’accès uniquement sous forme papier qu’ont connu les générations précédentes de chercheurs. Les bibliothèques étaient auparavant le principal moyen d’accéder à la connaissance alors qu’aujourd’hui, les chercheurs utilisent principalement des moteurs de recherche et autres portails spécialisés pour chercher, accéder et lire les articles qui leurs sont nécessaires. Par exemple, quand j’ai préparé ma thèse à l’Université de Bordeaux, le seul moyen de découvrir la littérature scientifique dans mon domaine était de se rendre dans une bibliothèque : soit elle détenait les exemplaires des revues concernées, soit dans le cas contraire (le plus fréquent), je remplissais un formulaire papier avec les références qui m’intéressaient. Ce document était expédié au centre de documentation Inria de Rocquencourt qui renvoyait une photocopie de l’article à la bibliothèque. L’accumulation des délais postaux et des temps de traitement conduisait à une durée d’attente pouvant atteindre plusieurs semaines. Bien entendu ce service possédait un coût et je n’avais le droit qu’à un nombre limité de demandes. Aujourd’hui je peux accéder à l’ensemble des articles en quelques clics au bureau comme à la maison ou en déplacement. Une fois de temps en temps, très rarement, le plus souvent parce qu’il s’agit d’un vieil article, je n’y ai pas accès ; je demande alors à des copains s’ils peuvent m’aider.
Précisons que cette démarche a nécessité de s’appuyer sur des informations essentielles de la publication scientifique : les métadonnées. Elles sont stockées dans les champs d’une base de données (le nom et l’affiliation des auteurs, des mots-clés, les dates de parution, etc.) afin que les moteurs de recherche puissent retrouver la bonne publication.
L’innovation dans la publication
Parchemin, livre, disque dur, le support a beaucoup évolué ; mais au delà des textes hypermédia qui sont devenus la norme, apparaissent des formes encore plus innovantes. Elsevier a proposé d’ajouter à un article un bref texte lu par l’auteur pour commenter sa publication. Le même éditeur permet d’inclure des logiciels exécutables directement dans le corps de la publication. Il est alors possible de modifier dynamiquement des paramètres du logiciel ou même les instructions du code. Encore plus avancée, la revue IPOL spécialisée dans l’analyse d’images diffuse des articles composés de textes, de sources logicielles et des données.
Le principe d’évaluation anonyme par les pairs au sein des comités de lecture et de programme est lui aussi soumis à évolution. L’arrivée des réseaux sociaux a entraîné de nouvelles expérimentations basées sur la mise en ligne d’une version préliminaire d’un article, les commentaires des membres du réseau, la prise en compte par l’auteur des précisions/modifications qu’il juge pertinentes et au delà la validation par les membres du réseau de la qualité de la publication. Précisons qu’il ne s’agit pas d’un réseau social ouvert mais bien d’un réseau professionnel dont l’accès est restreint à des scientifiques experts identifiés. Ce principe n’est encore pas complètement abouti mais il est intéressant d’y réfléchir.
Peut-être que dans quelque temps, les billets sur le blog binaire seront eux aussi validés de façon collective et répartie ! Oui mais évidemment nous sortons là de la publication scientifique…
Pascal Guitton, Professeur Université de Bordeaux et Inria.






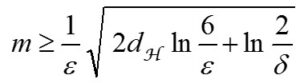

























{kind=link}
{kind=link}