Nous vous invitons à partager les réflexions déambulatoires de Sylvain Petitjean et Samuel Nowakowski à l’occasion de la parution du livre « Demain est-il ailleurs ? Odyssée urbaine autour de la transition numérique ». La qualité de leurs échanges et de leurs questionnements sur l’impact du numérique dans notre société nous ont donné envie de les partager sur binaire. Avec l’aimable autorisation des auteurs et du site Pixees, nous republions l’intégralité de l’article. Marie-Agnès Enard et Thierry Vieville.
Ce texte est un échange épistolaire qui s’est installé suite à la parution du livre «Demain est-il ailleurs ? Odyssée urbaine autour de la transition numérique» co-écrit par Bruno Cohen, scénographe, réalisateur et metteur en scène, et Samuel Nowakowski, maître de conférences à l’université de Lorraine et chercheur au LORIA.
Paru en octobre 2020 chez FYP Editions, ce livre rassemble les rencontres avec celles et ceux qui vivent aujourd’hui cette transformation radicale. Au cours d’une déambulation de 24 heures dans la ville, les personnes rencontrées abordent les notions de temps, parlent du déséquilibre, de leurs incertitudes et du mal-être, mais aussi de leurs émerveillements et de leurs rêves. Elles questionnent des thèmes centraux de notre société que sont la surveillance, le contrôle, le développement d’un capitalisme numérique prédateur. Elles parlent aussi de cet ailleurs des pionniers qui s’est matérialisé dans nos sociétés en réseau, traversées par les nécessaires réflexions à mener sur l’éthique, l’écologie, l’apprentissage, la transmission et le rapport au savoir. Arpentant l’univers de la ville à la recherche de la transition, nous découvrons petit à petit qu’elle s’incarne sous différentes formes chez les uns ou les autres, dans l’espace public et privé, et dans tous les milieux au sein desquels nous évoluons — naturels, sociaux, politiques, éducatifs, technologiques…
Sylvain Petitjean est l’une de ces personnes rencontrées. Sylvain est chercheur au centre Inria à Nancy. Il est également président du Comité opérationnel d’évaluation des risques légaux et éthiques (Coerle) chez Inria.
Sylvain et Samuel ont souhaité poursuivre la conversation entamée dans le livre, ouvrant ainsi d’autres champs de réflexion. Cet échange s’est étalé sur plusieurs semaines, sous forme épistolaire, dans des conditions temporelles à rebours de l’urgence et de l’immédiateté ambiante. En voici le contenu.
Samuel : L’éthique kantienne sur laquelle notre société moderne s’est construite, s’énonce ainsi : « Agis de telle sorte que tu puisses également vouloir que ta maxime devienne loi universelle ». Or aujourd’hui, au vu des enjeux, des transitions multiples auxquelles nous faisons face, ne sommes-nous pas devant un besoin de disposer d’une éthique basée sur le principe de responsabilité à l’égard des générations futures et de notre environnement. Hans Jonas énonce le Principe responsabilité : « Agis de telle façon que les effets de ton action soient compatibles avec la permanence d’une vie authentiquement humaine sur Terre ». Ce qui implique que le nouveau type de l’agir humain consiste à prendre en considération davantage que le seul intérêt « de l’homme » et que notre devoir s’étend plus loin et que la limitation anthropocentrique de toute éthique du passé ne vaut plus ?
Dans le cadre du numérique, et de tout ce qui se présente à nous aujourd’hui en termes d’avancées scientifiques, dans le domaine qui est le nôtre, ne devons-nous pas repenser ce rapport au vivant et nos pratiques ?
Sylvain : Il est vrai qu’il n’est plus possible de considérer que les interventions techniques de l’humain sur son environnement sont superficielles et sans danger, et que la nature trouvera toujours comment rétablir elle-même ses équilibres fondamentaux. La crise écologique et les menaces pesant sur l’humanité et la planète impliquent quasi naturellement, pour Jonas et d’autres, d’orienter l’agir vers le bien commun en accord avec notre sentiment de responsabilité. D’où la proposition de refonder l’éthique comme une éthique de la responsabilité et du commun capable d’affronter l’ampleur des problèmes auxquels fait face la civilisation technologique, pour le bien-être et la survie des générations futures.
Les technologies du numérique présentent par ailleurs un autre défi de taille, probablement inédit, du point de vue de l’éthique. Cela a notamment trait à la logique grégaire associée à l’usage des services Internet : plus un service est utilisé par d’autres usagers, plus chacun trouve intéressant de l’utiliser parce qu’il peut en obtenir davantage d’informations et de contacts, créant un effet boule de neige. Cet «effet de multitude», comme l’ont baptisé les économistes, transforme en effet l’étendue et la nature des enjeux éthiques. Alors que l’éthique est usuellement un sujet qui arrive a posteriori du progrès, dès lors que des dérives sont constatées, il sera de plus en plus difficile, avec la démultiplication des possibilités et le changement d’échelle, d’être avec le numérique dans la réaction face à un problème éthique. En d’autres termes, les problématiques éthiques et juridiques vont devenir insolubles si on ne les traite pas en amont de la conception des technologies numériques (ethics by design). Cela dessine les contours d’une éthique plus proactive, en mesure d’accompagner de façon positive le développement et l’innovation.
Malheureusement, nous n’en sommes vraisemblablement qu’aux balbutiements de l’étude et de la maîtrise de ces questions dans le domaine du numérique. Il suffit de faire un pas de côté en direction de la biomédecine et des biotechnologies et de mesurer le chemin parcouru autour des lois de bioéthique pour s’en convaincre. Or le temps presse…
Samuel : Imprégnés de l’actualité qui est la nôtre, et en paraphrasant Tocqueville, « on ne saurait douter [qu’aujourd’hui] l’instruction du peuple serve puissamment [à la compréhension des enjeux de notre temps qu’ils soient politiques, technologiques, écologiques]. [N’en sera-t-il pas] ainsi partout où l’on ne séparera point l’instruction qui éclaire l’esprit de l’éducation qui règle les mœurs ? » La maîtrise de toutes ces questions ne doit-elle pas passer par cette nécessaire instruction du plus grand nombre ? Comment nous préserver du fossé qui risque de se creuser entre ceux qui sont instruits de ces enjeux et ceux qui n’y ont pas accès parce qu’ils font face à un horizon scolaire et social bouché ? Or, la méthode la plus efficace que les humains ont trouvée pour comprendre le monde (la science) et la meilleure façon qu’ils ont trouvée afin d’organiser le processus de décision collective (les modes démocratiques) ont de nombreux points communs : la tolérance, le débat, la rationalité, la recherche d’idées communes, l’apprentissage, l’écoute du point de vue opposé, la conscience de la relativité de sa place dans le monde. La règle centrale est d’avoir conscience que nous pouvons nous tromper, de conserver la possibilité de changer d’avis lorsque nous sommes convaincus par un argument, et de reconnaître que des vues opposées aux nôtres pourraient l’emporter.
Malheureusement, à l’école, les sciences sont souvent enseignées comme une liste de « faits établis » et de « lois », ou comme un entraînement à la résolution de problèmes. Cette façon d’enseigner s’oppose à la nature même de la pensée scientifique. Alors qu’enseigner, c’est enseigner l’esprit critique, et non le respect des manuels ; c’est inviter les étudiants à mettre en doute les idées reçues et les professeurs, et non à les croire aveuglément.
Aujourd’hui, et encore plus en ces temps troublés, le niveau des inégalités et des injustices s’est intensifié comme jamais. Les certitudes religieuses, les théories du complot, la remise en cause de la science et de la démocratie s’amplifient et séparent encore plus les humains. Or, l’instruction, la science et la pensée doivent nous pousser à reconnaître notre ignorance, que chez « l’autre » il y a plus à apprendre qu’à redouter et que la vérité est à rechercher dans un processus d’échange, et non dans les certitudes ou dans la conviction si commune que « nous sommes les meilleurs ».
L’enseignement pour permettre [la compréhension des enjeux de notre temps qu’ils soient politiques, technologiques, écologiques] doit donc être l’enseignement du doute et de l’émerveillement, de la subversion, du questionnement, de l’ouverture à la différence, du rejet des certitudes, de l’ouverture à l’autre, de la complexité, et par là de l’élaboration de la pensée qui invente et qui s’invente perpétuellement. L’école se caractérise ainsi à la fois par la permanence et l’impermanence. La permanence dans le renouvellement des générations, le « devenir humain », l’approche du monde et de sa complexité par l’étudiant sur son parcours personnel et professionnel. L’impermanence, dans les multiples manières de « faire humain »… et donc dans les multiples manières d’enseigner et d’apprendre. Entre permanence et impermanence, la transition ?
Sylvain : En matière d’acculturation au numérique et plus globalement d’autonomisation (empowerment) face à une société qui se technologise à grande vitesse, il faut jouer à la fois sur le temps court et le temps long. Le temps court pour agir, pour prendre en main, pour ne pas rester à l’écart ; le temps long pour réfléchir et comprendre, pour prendre du recul, pour faire des choix plus éclairés.
Daniel Blake, ce menuisier du film éponyme de Ken Loach victime d’un accident cardiaque, se retrouve désemparé, humilié face à un simple ordinateur, point de passage obligé pour faire valoir ses droits à une allocation de chômage. Où cliquer ? Comment déplacer la souris ? Comment apprivoiser le clavier ? Ces questions qui semblent évidentes à beaucoup le sont beaucoup moins pour d’autres. La dématérialisation de la société est loin d’être une aubaine pour tous. Prenons garde à ce qu’elle ne se transforme pas en machine à exclure. L’administration — dans le film — fait peu de cas de ceux qui sont démunis face à la machine ; on peut même se demander si ça ne l’arrange pas, s’il n’y a pas une volonté plus ou moins consciente d’enfoncer ceux qui ont déjà un genou à terre tout en se parant d’équité via l’outil numérique. Daniel Blake, lui, veut juste pouvoir exercer ses droits de citoyen et entend ne pas se voir nier sa dignité d’être humain. De la fable contemporaine à la réalité de nos sociétés il n’y a qu’un pas. Réduire la fameuse fracture numérique, qui porte aujourd’hui encore beaucoup sur les usages, doit continuer d’être une priorité qui nécessite de faire feu de tout bois et à tous les niveaux. Et il faut absolument s’attacher à y remettre de l’humain.
Mais ce n’est pas suffisant. Les politiques d’e-inclusion doivent aussi travailler en profondeur et dans le temps long. De même que l’on associe au vivant une science qui s’appelle la biologie (qui donne un fil conducteur permettant d’en comprendre les enjeux et les questions de société liées, et de structurer un enseignement), on associe au numérique une science qui est l’informatique. Pour être un citoyen éclairé à l’ère du numérique et être maître de son destin numérique, il faut pouvoir s’approprier les fondements de l’informatique, pas uniquement ses usages. « Il faut piger pourquoi on clique » disait Gérard Berry. Car si les technologies du numérique évoluent très vite, ces fondements et les concepts sur lesquels ils s’appuient ont eux une durée de vie beaucoup plus grande. Les maîtriser aujourd’hui, c’est s’assurer d’appréhender non seulement le monde numérique actuel mais aussi celui de demain. Y parvenir massivement et collectivement prendra du temps. Le décalage entre la culture informatique commune de nos contemporains et ce que nécessiteraient les enjeux actuels est profond et, franchement, assez inquiétant, mais sans surprise : la révolution numérique a été abrupte, l’informatique est une science jeune, il faut former les formateurs, etc.
Conquérir le cyberespace passe aussi par le fait de remettre à l’honneur l’enseignement des sciences et des techniques, à l’image du renouveau dans les années cinquante impulsé par les pays occidentaux confrontés à la « crise du Spoutnik » et à la peur d’être distancés par les Soviétiques dans la conquête spatiale, comme le rappelle Gilles Dowek. Or la révolution scientifique et technologique que nous vivons est bien plus profonde que celle d’alors. Et il importe de commencer à se construire une culture scientifique dès le plus jeune âge, à apprendre à séparer le fait de l’opinion, à se former au doute et à la remise en cause permanente. « C’est dès la plus tendre enfance que se préparent les chercheurs de demain. Au lieu de boucher l’horizon des enfants par un enseignement dogmatique où la curiosité naturelle ne trouve plus sa nourriture, il nous faut familiariser nos élèves avec la recherche et l’expérimentation. Il nous faut leur donner le besoin et le sens scientifiques. […] La formation scientifique est — comme toute formation d’ailleurs, mais plus exclusivement peut-être — à base d’expériences personnelles effectives avec leur part d’inconnues et donc leurs risques d’échecs et d’erreurs ; elle est une attitude de l’esprit fondée sur ce sentiment devenu règle de vie de la perméabilité à l’expérience, élément déterminant de l’intelligence, et moteur de la recherche indéfinie au service du progrès. » Ces mots datent de 1957, au moment de la crise du Spoutnik ; ils sont du pédagogue Célestin Freinet qui concevait l’éducation comme un moyen d’autonomisation et d’émancipation politique et civique. Ils n’ont pas pris une ride. Continuité des idées, des besoins, des enjeux ; renouvellement des moyens, des approches, des savoirs à acquérir. Permanence et impermanence…
Samuel : Tant d’années ! Tant de nouveaux territoires du savoir dévoilés ! Et toujours les mêmes questions, toujours le même rocher à hisser au sommet de la même montagne !
Qu’avons-nous foiré ou que n’avons-nous pas su faire ? Ou plutôt, quelles questions n’avons-nous pas ou mal posées ?
« S’il y a une chose qui rend les jeunes êtres humains allergiques à l’imagination, c’est manifestement l’école » ont écrit Eric Liu et Scott Noppe-Brando dans Imagination first. Alors que se passerait-il si l’école devenait pour les jeunes êtres humains une expérience vivante et valorisante ? Et si nous étions là pour les accompagner vers l’idée qu’il n’existe pas qu’une seule réponse, une seule manière d’être dans le monde, une seule voie à suivre ? Que faut-il faire pour que les jeunes êtres humains aient la conviction que tout est possible et qu’ils peuvent réaliser tout ce dont ils se sentent capables ?
A quoi ressemblerait la société ?
Alors, à rebours de l’imaginaire populaire dans lequel on imagine l’immuabilité des lieux et des choix effectués, comment agir pour favoriser l’émergence d’« agencements » comme chez Deleuze, ou encore d’« assemblages » suivant la notion empruntée à Bruno Latour ? Non pas une matrice dans laquelle nous viendrions tous nous insérer, mais en tant qu’acteurs ne cessant de se réinventer dans une création continue d’associations et de liens dans un « lieu où tout deviendrait rythme, paysage mélodique, motifs et contrepoints, matière à expression ». Chaque fois que nous re-dessinons le monde, nous changeons la grammaire même de nos pensées, le cadre de notre représentation de la réalité. En fait, avec Rutger Bregmann, « l’incapacité d’imaginer un monde où les choses seraient différentes n’indique qu’un défaut d’imagination, pas l’impossibilité du changement ». Nos avenirs nous appartiennent, il nous faut juste les imaginer et les rendre contagieux. Nos transitions ne seraient-elles pas prendre déjà conscience que « si nous attendons le bon vouloir des gouvernements, il sera trop tard. Si nous agissons en qualité d’individu, ça sera trop peu. Mais si nous agissons en tant que communautés, il se pourrait que ce soit juste assez, juste à temps ».
Pour cela, il nous faudra explorer la manière dont les acteurs créent ces liens, et définissent ce que doit être la société. Et la société est d’autant plus inventive que les agencements qu’elle fait émerger sont inventifs dans l’invention d’eux-mêmes.
Des avenirs s’ouvrent peut-être, par une voie difficile et complexe nécessitant de traverser la zone, les ruines, les turbulences et les rêves. Nous pourrions imaginer essaimer l’essence vitale de cette planète, en proie à des destructions physiques et métaphysiques, pour faire renaître l’humanité, la vie, la flore et la faune dans les étoiles. Nous pourrions, avec d’autres, former le projet de partir à bord d’un vaisseau emportant dans ses flancs, outre des embryons humains et animaux, un chargement de graines, spécimens, outils, matériel scientifique, et de fichiers informatiques contenant toute la mémoire du monde et, plus lourd encore, le « poids considérable des rêves et des espoirs ».
Ou alors nous pourrions tout simplement former un projet non pas de « revenir à l’âge de pierre [un projet] pas réactionnaire ni même conservateur, mais simplement subversif parce qu’il semble que l’imagination utopique soit piégée […] dans un futur unique où il n’est question que de croissance ». Ce projet que nous pourrions essayer de mener à bien « c’est d’essayer de faire dérailler la machine ». Ces quelques mots d’Ursula Le Guin nous rappellent que nos avenirs nous appartiennent et que nous avons le pouvoir d’imaginer, d’expérimenter de construire à notre guise et de jouer avec nos avenirs communs et individuels afin de commencer à désincarcérer le futur.
Sylvain : Comment panser l’avant et penser l’après, alors que toutes les menaces semblent s’accélérer, alors que tous les risques semblent se confirmer ? Comment essayer de réinventer un futur véritablement soutenable ?
Certains ingrédients sont connus : décroitre, renforcer la justice sociale, déglobaliser, réduire la pression sur les ressources naturelles, développer l’économie circulaire, etc. Je voudrais ici en évoquer deux autres, sous la forme d’un devoir et d’un écueil.
Le devoir consiste à se dépouiller de cet « humanisme dévergondé » (C. Lévi-Strauss) issu de la tradition judéo-chrétienne et, plus près de nous, de la Renaissance et du cartésianisme, « qui fait de l’homme un maître, un seigneur absolu de la création », agissant envers plantes ou animaux « avec une irresponsabilité, une désinvolture totales » qui ont conduit à mettre la nature en coupe réglée et, en particulier, à la barbarie de l’élevage industriel. Quelque chose d’absolument irremplaçable a disparu nous dit Lévi-Strauss, ce profond respect pour la vie animale et végétale qu’ont les peuples dits « primitifs » qui permet de maintenir un équilibre naturel entre l’homme et le milieu qu’il exploite. Or « se préoccuper de l’homme sans se préoccuper en même temps, de façon solidaire, de toutes les autres manifestations de la vie, c’est, qu’on le veuille ou non, conduire l’humanité à s’opprimer elle-même, lui ouvrir le chemin de l’auto-oppression et de l’auto-exploitation. » L’ethnologue pose le principe d’une éthique qui ne prend pas sa source dans la nature humaine ethnocentrée mais dans ce qu’il appelle « l’humilité principielle » : « l’homme, commençant par respecter toutes les formes de vie en dehors de la sienne, se mettrait à l’abri du risque de ne pas respecter toutes les formes de vie au sein de l’humanité même ». Cette vision des droits dus à la personne humaine comme cas particulier des droits qu’il nous faut reconnaître aux entités vivantes, cet humanisme moral inclusif nous ramène immanquablement à notre point de départ, et à Jonas.
L’écueil consiste à systématiquement réduire chaque problème humain (politique, social, environnemental) à une question technique à laquelle la technologie numérique apporte une solution, en traitant les effets des problèmes sans jamais s’intéresser à leurs causes et en négligeant les possibles déterminismes et biais qui la composent. « Si nous nous y prenons bien, je pense que nous pouvons réparer tous les problèmes du monde » fanfaronnait Eric Schmidt, président exécutif de Google, en 2012. Diminuer le CO2 ? Il y a une application pour ça ! E. Morozov montre bien les limites et effets pervers de cette idéologie qu’il appelle le « solutionnisme technologique », qui s’accompagne d’un affaiblissement du jeu démocratique et aboutit au triomphe de l’individualisme et de la marchandisation. « Révolutionnaires en théorie, [les technologies intelligentes] sont souvent réactionnaires en pratique. » Et elles s’attaquent bien souvent à des problèmes artificiels à force de simplification. « Ce qui est irréaliste, dit Naomi Klein, est de penser que nous allons pouvoir faire face à ces crises mondiales avec quelques minuscules ajustements de la loi du marché. C’est ça qui est utopique. Croire qu’il va y avoir une baguette magique technologique est ridicule. Cela relève de la pensée magique, portée par ceux qui ont un intérêt économique à maintenir le statu quo. » Il ne s’agit bien sûr pas d’éliminer la technologie de la boîte à outils de la résolution de problème. Il importe en revanche de dépasser l’optimisme béat et la quasi-piété en ses pouvoirs et de comprendre qu’elle n’est qu’un levier qui n’a du sens qu’en conjonction d’autres (Ethan Zuckerman). Il est urgent, au fond, de réhabiliter la nuance, la pluralité et la complexité dans le débat et de trouver une voie pour traiter les problèmes difficiles avec des solutions nouvelles selon une approche systémique.
Demain est peut-être ailleurs, mais si l’humanité veut tenter un nouveau départ, les premiers pas vers le renouveau doivent être effectués ici et maintenant.




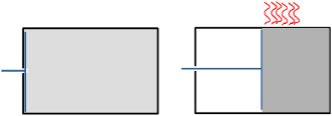
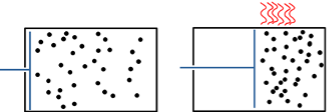
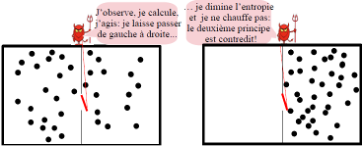
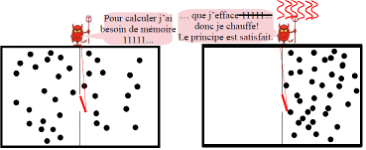












 Guillaume Cabanac est un chercheur en informatique à l’Université Paul Sabatier et
Guillaume Cabanac est un chercheur en informatique à l’Université Paul Sabatier et 


 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible l’optimisation multi-objectif. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible l’optimisation multi-objectif. Marie-Agnès Enard, Pascal Guitton et Thierry Viéville.




 Tu as faim ? J’ai une pomme. Partageons là. Du coup, je n’ai mangé qu’une demi-pomme. Mais j’ai gagné ton amitié.
Tu as faim ? J’ai une pomme. Partageons là. Du coup, je n’ai mangé qu’une demi-pomme. Mais j’ai gagné ton amitié.  Du coup, nous voilà toi et moi avec une idée. Mieux encore : ton idée vient de m’en susciter une autre que je te repartage, en retour. Pour te permettre d’en trouver une troisième peut-être.
Du coup, nous voilà toi et moi avec une idée. Mieux encore : ton idée vient de m’en susciter une autre que je te repartage, en retour. Pour te permettre d’en trouver une troisième peut-être. Pour
Pour





{kind=link}