Votre ordinateur est souffreteux ? Il rame, est à bout de souffle, charger la moindre page web vous prend plus de temps que la lire ? Une seule solution : changer votre ordinateur ! Oui, mais l’écran est encore bon, le clavier est comme neuf et la souris toujours aussi véloce. Cette vidéo vous montre comment faire un ordinateur pour seulement 50 €. Une manière simple et peu onéreuse de maintenir à jour un parc d’ordinateurs dans une salle d’informatique. Car le Raspberry Pi est sûrement plus efficace que votre PC qui date de 5 ans…
Yves Papegay est chargé de recherche dans l’équipe HEPHAISTOS d’Inria Sophia-Antipolis. Il s’intéresse aux robots à câbles et à la robotique d’assistance. Il est spécialiste des outils de modélisation et de simulation, de calcul symbolique et d’analyse par intervalles.
Pour aller plus loin
Autour du Raspberry Pi
Manuel d’utilisation du Raspberry Pi (format pdf, in English « Adventures in Rasperry Pi & Rasperry Pi User Guide) à destination des adolescents pour découvrir toutes les possibilités du Raspberry Pi
Dans le monde du numérique, un monde dominé par les sciences et les techniques, l’art reste souvent aux marges. Pourtant, les algorithmes étant amené à remplacer les humains dans leurs activités de simple subsistance, le monde en devenir est appelé à étendre le territoire des arts. Dans un temps où toutes les sciences deviennent numériques, où le monde lui-même devient numérique, nous pouvons nous interroger sur le sens d’un art ailleurs que numérique ? Nous avons demandé à Norbert Hillaire, théoricien de l’art et des technologies, artiste, professeur à l’université de Nice et directeur de recherche à Paris 1 Panthéon-Sorbonne, président de l’association « Les murs ont des idées », de nous parler de ce sujet. Son texte se savoure, tout comme d’ailleurs ce texte aussi beau que surprenant de Paul Valery dont il fait son point de départ. Serge Abiteboul et Claire Mathieu.
Norbert Hillaire
Paul Valéry, dans un texte prophétique de 1928 intitulé « la conquête de l’ubiquité[1] », nous explique que ce n’est rien moins que la notion même de l’art qui est en jeu dans le changement des techniques et des sciences porté par cette conquête de l’ubiquité, à travers « la distribution de la réalité sensible à domicile » qui l’accompagne. Aujourd’hui, nous y sommes, et la prophétie de Valéry est en train de se réaliser sous nos yeux avec Internet.
Je tire de Wikipédia cette définition de l’art numérique : « L’art numérique désigne un ensemble varié de catégories de création utilisant les spécificités du langage numérique. Il s’est développé comme genre artistique depuis le début des années 1980. Portée par la puissance de calcul de l’ordinateur et le développement d’interfaces électroniques autorisant une interaction entre le sujet humain, le programme et le résultat de cette rencontre, la création numérique s’est considérablement développée en déclinant des catégories artistiques déjà bien identifiées. »
Il est certes exact de considérer que les formes de l’art doivent épouser ou coïncider avec l’évolution des techniques, et qu’au fond, il est normal qu’à l’âge numérique, les artistes utilisent des techniques numériques
Lignes de fuite 10 – Le vecteur des archives – Norbert Hillaire
Pourtant, entre l’art et la technique, entre le message et le médium, c’est, à rebours d’une telle vision idyllique, toujours d’une relation flottante, ambigüe, instable qu’il s’agit. Cette instabilité ne fait qu’augmenter avec le temps, comme en témoignent les rapports de fascination/répulsion que les artistes entretiennent avec la technique, au fur et à mesure que celle-ci impose son hégémonie dans le monde moderne avec la première révolution industrielle.
Une histoire mouvementée, donc, qui témoigne plutôt d’une dynamique de ruptures en cascades, de transferts complexes entre les arts et les techniques (voyez par exemple les « portraits de machines » de Picabia, les compressions de César), de survivances et d’anachronismes, plutôt que d’un enchaînement de figures et de styles dont le mouvement s’ajusterait sans heurt au progrès des sciences et des techniques.
La conquête de l’ubiquité est contemporaine de la conquête de l’autonomie de l’art. Et en un sens, comme le prétend Valéry, cette « conquête de l’ubiquité » ne peut laisser indemne jusqu’à « la notion même de l’art » Mais en un autre sens, l’art n’a de cesse de promouvoir et d’afficher sa liberté nouvelle, son autonomie par rapport aux divers pouvoirs qui n’ont cessé de chercher à encadrer son devenir : religion, magie, technique, et désormais science et industrie. Envers et contre tout, l’art cherche sa liberté, soit dans l’approfondissement du langage même du médium qu’il se donne, soit dans l’affranchissement de toute tutelle technique, dans la libération de toute forme de dépendance par rapport à un matériau, une technique, ou un médium. Ainsi l’artiste sera de moins en moins l’homme d’une technique une, et de plus en plus l’homme d’une panoplie infiniment diverse de matériaux et de techniques : ainsi, l’artiste contemporain est de plus en plus un polytechnicien.
Ce qui s’affiche dès lors, c’est l’accession définitive de l’artiste plasticien au monde des arts libéraux, et son affranchissement de ce statut encore trop artisanal dans lequel sa virtuosité technique le cantonnait. Si bien qu’est venu un temps, le nôtre, dans lequel cela n’a plus guère de sens d’évoquer un artiste en relation avec une technique, aussi nouvelle soit-elle. Si l’on parle encore d’un vidéaste, d’un photographe, d’un peintre, d’un sculpteur, on n’en préfère pas moins aujourd’hui évoquer la figure d’un artiste plasticien, tant il est vrai que la vogue des installations, le mélange des médias, la prolifération des supports d’inscription rendent de plus en plus difficile l’indexation de l’œuvre et plus encore de l’artiste sur un médium unique et, en somme, l’annexion de l’œuvre par un support.
Série les Oiseaux 2 – fusain, calque, graphite sur papier – Norbert Hillaire, 2007
C’est là sans doute la raison de cette résistance ancienne et tenace que l’art contemporain oppose à l’art numérique, et par conséquent, la relégation de celui-ci dans un ghetto qui l’éloigne du marché, auquel il aspire pourtant. Et c’est sans doute aussi la raison qui explique la volonté de rehausser l’appellation ringardisée « art numérique », par un label plus novateur : l’art post-digital, qui entend souligner moins la disparition du numérique, que sa banalisation, ou mieux, sa naturalisation (en particulier aux yeux des digital natives), et ainsi de faciliter, par cette transition conceptuelle, l’assimilation de l’art numérique au champ de l’art contemporain.
Pourtant, cette option n’est pas non plus satisfaisante, si l’on continue d’admettre avec Paul Valéry, que la conquête de l’ubiquité est aussi appelée à changer jusqu’à la notion même de l’art. Et il est vrai que le numérique est bien plus qu’une technologie, bien plus qu’un médium : c’est l’horizon d’attente dans lequel l’ensemble des choses, des êtres et des lieux semble prêt à basculer, comme emporté dans le vortex d’un processus de numérisation qui ne laisse rien lui échapper et jusqu’au monde lui-même[2]. Comme le souligne Patrice Maniglier, « La question n’est pas de savoir si un art, ou une époque de l’art, est aussi bon qu’un autre, mais s’il s’agit bien d’art dans le même sens. Et d’ailleurs, pour défaire cette équivoque, il faut peut-être en défaire une autre, plus profonde. L’erreur porte en effet ici non pas sur l’art numérique, mais sur le statut du numérique comme tel. Tant que l’on conçoit celui-ci comme une technologie particulière, une branche de l’industrie, un secteur particulier du monde, on ne comprend pas ce dont il est question dans l’adjonction de ce petit adjectif, « numérique », à quoi que ce soit. Le numérique n’est pas une région particulière de la réalité : c’est l’horizon dans laquelle toute la réalité peut être réinterprétée[3].
Dans cette mesure, le numérique, ajoute le philosophe, c’est le lieu d’une transition ontologique, d’un changement d’être : « Convenons d’appeler art numérique non pas un art qui fait appel à telle ou telle technologie, mais un art qui explore cette transition ontologique – ce que nous pourrions appeler, en suivant certaines propositions récentes de Bruno Latour – cette passe ontologique[4]. »
Dans les relations entre l’art et la technique, le numérique vient ainsi brouiller les frontières qui séparaient le « message » et « le médium », les « intentions » de l’artiste et les « moyens techniques » qu’il se donne : et c’est pourquoi, sans doute, certaines œuvres participent d’une forme de réversibilité de la technique dans l’art et de l’art dans la technique, au croisement de la Duchamp-land, et de la Turing-land, pour reprendre la jolie formule de Lev Manovitch.
L’art numérique est éternellement de l’art même, et éternellement de l’art autre (et c’est pour cela qu’il recouvre un champ de plus en plus vaste d’œuvres, de langages, de supports, d’objets, de dispositifs très différents), ouvert à l’altérité d’un devenir imprévisible quant aux frontières qu’il ne cesse de déplacer et de replacer entre les corps et les lieux, entre les formes et le sens, entre l’œuvre et l’objet, entre le matériau et l’immatériau, entre la carte et le territoire (comme la multiplication de ces œuvres ayant par exemple pour thème Google Earth), entre l’espace et le temps, et plus fondamentalement encore, entre l’art et l’artifice. Si bien qu’il serait presque aussi légitime de conjecturer l’assimilation progressive du numérique au champ de l’art contemporain (à travers la transmutation de l’art numérique en art post-digital), que de risquer l’hypothèse selon laquelle l’art contemporain serait appelé à devenir un jour peut-être une province du numérique comme horizon d’attente de l’homme neuronal.
Norbert Hillaire, Professeur à l’Université de Nice-Sophia Antipolis
[1] http://livre-rose.hyper-media.eu/wp-content/uploads/2014/03/valery_conquete_ubiquite.pdf
[2] Je reprends ici certaines hypothèses développées dans La fin de la modernité sans fin, L’Harmattan, coll. Ouverture Philosophique, 2013
[3] Cette idée est très proche de celle développée par Warren Sack dans ses recherches en cours sur ce qu’il appelle la « réécriture du monde » à travers la culture numérique : The Software Arts, à paraître chez MIT Press dans la collection « Software Studies ».
[4] Voir Bruno Latour, Enquête sur les modes d’existence, Paris, La Découverte, 2012.
Des publications de Norbert Hillaire
L’art Numérique, avec Edmond Couchot, Champs Arts (2009)
L’art dans le Tout Numérique, Manucius (2015)
La fin de la Modernité sans fin, l’Harmattan (2013)
L’Origine du Monde, 2001, tirage lambda sur diasec avec chassis aluminium, 56 x 46 cm. Reynald Drouhin @Reynald Drouhin, photo utilisée en couverture de L’art Numérique, de Edmond Couchot et Norbert Hillaire, Champs Arts (2009)
Tout le monde a un ordinateur, un smartphone ou peut-être une télé connectée. Tous ces objets ont été créés sur le même modèle, la même architecture. Sans chercher pour le moment à entrer dans le détail du fonctionnement d’un ordinateur, cette vidéo propose d’en démonter un afin d’en montrer les différents éléments, véritables organes d’un ordinateur…
Erwan Kerrien est chercheur en imagerie médicale dans l’équipe Inria MAGRIT. Ses recherches visent à enrichir l’environnement visuel du chirurgien pendant l’opération, par des techniques de vision par ordinateur, réalité augmentée et simulation guidée par l’image. Il est chargé de mission pour la médiation scientifique du centre Inria Nancy-Grand Est et anime de nombreuses initiatives en médiation scientifique. Il est un des concepteurs et auteurs du MOOC ICN.
Les machines d’aujourd’hui et de demain, Albert Cohen, CanalU, collection Inria Science Info Lycée Profs ; 86 mn. montrant les liens entre la science informatique et l’architecture des ordinateurs
Microcontrôleur : Comment ça marche ? – SILIS Electronique, 25 févr. 2016 : 5 mn 34
Tout objet numérique n’a pas un processeur, une carte graphique, un disque dur…, alors pourquoi dit-on que tous ces objets fonctionnent sur le même schéma ? Parce qu’ils intègrent un microcontrôleur, et un microcontrôleur suit la même architecture matérielle. Cette video vous en donne une introduction courte et claire.
Le numérique transforme en profondeur notre monde. Repérer ces transformations, comprendre les principes profonds du monde numérique et les changements de valeurs induits, pour mieux s’interroger sur notre devenir. Une invitation à revisiter les questions traditionnelles de la philosophie sous ce nouvel éclairage …
Alexandre Monnin est docteur en philosophie de l’Université Paris 1 Panthéon-Sorbonne où il a fait sa thèse sur l’architecture et la philosophie du Web*. Il est chercheur dans l’équipe Inria Wimmics et expert Open Data auprès de la mission Etalab sous la responsabilité du Premier Ministre. Il a initié plusieurs projets mobilisant les technologies du Web de données, à l’instar du DBpedia francophone et de Re-Source, le système d’information de la Fondation des Galeries Lafayette pour l’art contemporain.
* Vers une philosophie du Web : le Web comme devenir-artefact de la philosophie (entre URIs, tags, ontologie (s) et ressources). Thèse. Philosophie. Université Panthéon-Sorbonne – Paris I, 2013. Français. <tel-00879147v3>
L’apprentissage de l’algorithmique et de la programmation a été inscrit dans les nouveaux programmes. Même si l’accessibilité numérique est une priorité, pour les jeunes qui n’ont pas la vision de la majorité, il n’existait pas encore de solution similaire à celle proposée aux élèves voyants. Sandrine Boissel, maître formatrice et enseignante spécialisée dans la déficience visuelle, a relevé ce défi avec AccessiDVScratch devenu Mall&t’Algo en Main. Donnons-lui la parole. Serge Abiteboul et Thierry Viéville.
Les élèves qui me sont confiés sont mal-voyants et aveugles, scolarisés en inclusion de la 6° à la 3° en ULIS TFV (Unité Localisée pour l’Inclusion Scolaire pour élèves ayant des Troubles de la Fonction Visuelle) au collège et au lycée. J’ai mis au point le dispositif AccessiDVScratch [devenu désormais https://manipulatelearnlooktouch.wordpress.com]qui permet une inclusion active de ces jeunes. C’est un outil qui permet aux élèves déficients visuels de travailler sur Scratch mais qui leur offre aussi la possibilité de devenir les aidants des élèves voyants.
Les origines :Qu’est-ce que la déficience visuelle ? Quel est son impact sur l’apprentissage de l’algorithmique et de la programmation ?
Ce handicap se manifeste de façon très variée, selon les paramètres de la vision atteints (acuité visuelle, champ visuel, perception des couleurs, perception et distinction fond/forme, relations complexes à la lumière…) Entre un élève présentant une acuité visuelle inférieure à 4/10 après correction (seuil légal de la déficience visuelle) et un jeune souffrant de cécité complète la palette est très étendue.
Depuis septembre, les nouveaux programmes de collège mettent l’accent sur l’algorithmique et la programmation. Le logiciel proposé dans les documents d’accompagnement Eduscol est Scratch. Celui-ci n’est pas du tout accessible pour une personne mal-voyante ou non-voyante. En effet, certaines tâches comme déplacer des images, ou emboîter des objets avec la souris (sans les voir, ou en ne voyant qu’une très petite partie de l’espace) n’est pas adaptable.
J’ai également essayé d’en faire une exploration avec un terminal braille Esys et la synthèse vocale NVDA. J’ai seulement réussi à naviguer dans les différents menus. Pour un certain nombre de cases, il est impossible de saisir des valeurs numériques ou encore de faire défiler certains petits menus déroulants. Quant aux images…
Ces quelques photos ci-dessous, simulant quelques pathologies visuelles, vous permettront de vous faire une idée des difficultés rencontrées par ces jeunes sur un écran.
La proposition: Quelles solutions pour accéder à la programmation ? Comment la mettre en œuvre au sein de l’Éducation Nationale ?
J’ai donc mis au point un outil qui se devait d’être inclusif et donc fidèle au logiciel Scratch. C’est ainsi qu’est née la mallette AccessiDVScratch. J’ai adapté toutes les instructions du logiciel en pièces de Lego, sur lesquels j’ai ajouté des gros caractères, du braille mathématique français et des formes géométriques saillantes. J’ai réalisé les nappes à l’aide de scotch d’électricien.
Photo 1
Photo 2
On ne code donc pas dans le logiciel, mais sous forme d’activité débranchée. J’ai également mis au point trois substituts d’écran en relief qui permettent aux élèves de conceptualiser en amont, de relire leur script, et de toucher le résultat obtenu à l’écran. On va donc manipuler manuellement pas à pas les éléments en suivant les instructions de la construction en légo.
La mallette a été validée par le Ministère le 14 décembre. Nous travaillons depuis à sa fabrication et sa diffusion. Nous envisageons également une application smartphone pour une interaction directe du script AccessiDVScratch et du logiciel Scratch.
Depuis septembre, j’ai cherché ce qui était expérimenté ailleurs (voir comparatif en annexe). J’ai consulté mes autres collègues ULIS TFV en créant une liste de diffusion après des jours de compilation sur les sites des différentes académies. J’ai pu échanger avec certains professeurs de l’INJA. Je fais également partie de l’équipe IREM de Grenoble et j’ai beaucoup discuté avec mes collègues sur l’algorithmique débranchée.
La proposition principale de l’INJA était l’utilisation d’Execalgo. Ce logiciel de programmation linéaire n’est pas compatible avec l’inclusion (tous les autres élèves travaillant sur Scratch). De plus, pour un brailliste débutant, le repérage est très difficile en ayant qu’une ligne sous les doigts. Et pour un élève novice en programmation le suivi de boucle est extrêmement difficile. Pour un élève travaillant en Arial 40 à l’écran les difficultés sont les mêmes…
Mes collègues de l’IREM, les professeurs du collège voudraient une mallette par élève et pas seulement pour l’élève déficient visuel. C’est d’ailleurs ce qu’avait pressenti M. Robert Cabane Inspecteur Général de l’Éducation Nationale lors de la présentation du 14 décembre.
Mes élèves utilisent la mallette AccessiDVScratch depuis 7 mois. Elle leur a permis de faire toutes les acquisitions de cycle 4 et au lycée de programmer des suites numériques et des fonctions. Elle a été acceptée pour le passage des épreuves du brevet de ces élèves cette année.
C’est surtout un outil adapté à tous : aveugles, mal-voyants, troubles dys, troubles mnésiques, élèves « dits ordinaires » permettant de :
concevoir des scripts concis et efficaces,
raisonner au lieu de procéder uniquement par essai/erreur,
conceptualiser et segmenter aisément la problématique d’un exercice grâce au substitut d’écran.
Avec AccessiDVScratch, les aveugles et malvoyants pourront eux aussi acquérir les bases de la programmation informatique, de manière gagnante-gagnante avec les voyants.
Références: AccessiDVScratch a déjà fait l’objet de plusieurs publications (INS HEA, ORNA, CARDIE…) et présentations (EdsupotFrance, APMEP, IREM, INS HEA, Edencast…). On peut avoir accès à toutes ces informations sur le dossier AccessiDVScratch .
https://player.vimeo.com/video/209544379
Annexe: AccessiDVScratch et les autres solutions.
Les solutions débranchées avec les étiquettes en papier ou les aimants, après les avoir tester, montrent un certain nombre de faiblesses et de lacunes que j’ai comblées avec AccessiDVScratch :
Les étiquettes papiers ne sont pas stables à la lecture, le traitement des boucles n’est pas pris en charge.
Les aimants sont plus stables mais ne permettent pas d’insérer facilement une instruction (il faut tout décaler). Retirer un ensemble d’instructions pour créer un bloc est très complexe pour la même raison. Le fait de travailler à plat (en 2D) ne permet pas d’avoir une lecture diagonale/séquentielle, ne facilite pas le suivi de boucle, ni leur extension. Cela exclut la possibilité de conserver et de déplacer un morceau de script.
Enfin les scripts ne sont pas suffisamment compacts pour être manipulés facilement ou déplacés près des yeux. Pour terminer, dans ces deux cas, les blocs sont difficilement gérés, et l’élève ne peut pas isoler ou donner un morceau de son script à son camarade pour lui expliquer sa procédure…. En comparaison les grandes forces d’AccessiDVScratch, sont :
un inventaire complet des pièces nécessaires pour répondre aux programmes officiels,
sa stabilité à la lecture tactile,
la possibilité d’une lecture linéaire sur la face principale et une lecture diagonale/séquentielle sur la tranche droite du script comme on peut le voir sur la photo,
la possibilité de rapprocher ou déplacer le programme et de l’avoir en main,
la possibilité de conserver des morceaux physiques de scripts,
son adaptabilité à tous les niveaux,
la prise en charge des facteurs variables, capteurs, de plusieurs blocs différents… La photo 1 montre l’usage des blocs. La photo 2 met en évidence l’usage des variables, l’ajout d’un opérateur, et l’utilisation d’un capteur.
sa fidélité à Scratch permettant une inclusion très aisée. En particulier, les couleurs sont conservées pour les voyants ; mais une forme géométrique saillante sur la tranche droite permet au non-voyants de les distinguer très rapidement.
l’insertion, modification, comparaison terme à terme simple et rapide. Il suffit en effet de fixer sous le début du script les deux issues possibles côte à côte.
des boucles extensibles très faciles à suivre par deux voies possibles (par la nappe côté gauche ou en lecture séquentielle sur la tranche droite) – photo 1
un substitut d’écran très performant pour réfléchir aux différents stades. On peut observer son usage dans les différentes vidéos en ligne sur le site indiqué plus bas.
et bientôt une application smartphone pour communiquer avec l’ordi.
Nous venons d’apprendre le décès d’Alain Colmerauer et il nous semble important de dire quelle était sa place dans le paysage de l’informatique mondiale. Alain est l’inventeur du langage Prolog, qui a joué un rôle clé dans le développement de l’IA, il se trouve que plusieurs binairiens ont programmé avec ce langage, pour leur recherche ou pour payer leurs études ainsi que de proposer des extensions. Un collègue ami d’Alain, Philippe Jorrand, Directeur de recherche émérite au CNRS, nous parle de son parcours. Pierre Paradinas.
Photo : Alain Colemrauer
Alain Colmerauer était un ancien de l’IMAG (Institut d’Informatique et de Mathématiques Appliquées de Grenoble), devenu une personnalité scientifique de premier plan par le rayonnement international de l’œuvre majeure de sa recherche, le langage PROLOG.
Alain Colmerauer était un élève de la première promotion de l’ENSIMAG, diplômée en 1963. Il a débuté sa recherche au Laboratoire de Calcul de l’Université de Grenoble, l’ancêtre du LIG. Dans sa thèse, soutenue en 1967, il développait les bases théoriques d’une méthode d’analyse syntaxique. Puis, pendant son séjour de deux ans à l’Université de Montréal, c’est en imaginant une utilisation originale des grammaires à deux niveaux (les « W-grammaires »), qu’il a établi les bases embryonnaires de ce qui allait devenir PROLOG.
De retour en France en 1970, il accomplit ensuite toute sa carrière à l’Université de Marseille, où il devient professeur. C’est là, au Groupe d’Intelligence Artificielle du campus de Luminy, qu’il forme avec détermination une petite équipe de jeunes doctorants, puis d’enseignants-chercheurs, pour développer la PROgrammation en LOGique. Sous sa direction, c’est ce petit groupe qui a élaboré les fondements théoriques de cette approche originale de la programmation, puis conçu et mis en œuvre les versions successives du langage qui allait connaître un succès international et être la source d’un courant de recherche fertile : PROLOG I, PROLOG II, PROLOG III où les contraintes linéaires venaient rejoindre la logique puis Prolog IV avec une théorie d’approximation plus aboutie, des contraintes sur les intervalles, et un solveur.
Prolog III, manuel de référence, Prologia, Marseille, 1996
Par ailleurs, le langage Prolog sera adopté par le projet d’ordinateur de 5ème génération développé par le MITI au Japon dont l’objectif était de créer une industrie et les technologies de l’intelligence artificielle à la fin des années 80. Une entreprise PrologIA, distribuera le langage dans ses différentes version.
Alain Colmerauer a toujours été un esprit original. Il se défiait de tout ce qui peut ressembler à une pensée unique, et n’hésitait pas à exprimer des idées parfois iconoclastes, mais souvent fécondes. Il croyait à ce qu’il faisait, et sa ténacité lui a souvent été utile face à quelques difficultés institutionnelles et à l’incrédulité de collègues plus installés que lui dans les modes scientifiques. Pour ceux qui l’ont bien connu pendant de longues années, Alain était un ami solide.
Alain Colmerauer est décédé à Marseille, le vendredi 12 mai 2017.
L’exposition «Terra Data, nos vies à l’ère du numérique» a ouvert ses portes à la Cité des sciences et de l’industrie. Que dire pour vous donner envie de visiter cette exposition ? Une amie de binaire, Christine Leininger, nous la fait visiter. Thierry Vieville. Ce billet est repris du site pixees.fr
Lors de l’inauguration, Bruno Maquart, président d’Universcience, a souligné dans son discours combien rendre le numérique tangible dans une exposition était un défi. Venez voir par vous-mêmes comment les commissaires d’exposition, Pierre Duconseille et Françoise Vallas, ont relevé ce défi !
Dans un espace délimité par de grands miroirs, vous serez accueilli par le commissaire scientifique de l’exposition, Serge Abiteboul, ou plutôt sa vidéo quasiment grandeur nature.
Vous créerez votre parcours autour d’une trentaine de grandes tables carrées regroupées selon quatre thèmes : Les données, qu’est-ce que c’est ? Comment les traite-t-on ? Qu’est-ce que ça change ? Où ça nous mène ?
Vous pourrez ainsi expérimenter plusieurs algorithmes pour faire un nœud de cravate, plonger dans l’Histoire de Venise, découvrir où les données provenant de chaque pays sont stockées…
Vous pourrez aussi vous initier au datajournalisme et à la datavisualisation…
Vous pourrez encore revoir votre parcours dans l’exposition à partir du traçage de votre smartphone, vérifier que votre visage photographié à l’entrée est reconnu…
Vous êtes enseignant ? Une page web spécifique vous est dédiée.
Le monde numérique rend possible des accès à l’information, aux connaissances, inimaginables encore récemment. Mais il permet aussi la diffusion de toutes les erreurs, tous les mensonges, toutes les désinformations. Que puis-je croire dans le flot d’information qui me submerge ? Comment séparer le bon grain de l’ivraie ? Fake news, fact checking, post-news. Le vocabulaire est anglais, mais les sujets nous concernent au plus haut point. Binaire a demandé à une directrice de recherche d’Inria qui travaille sur le fact checking de nous faire partager son expérience. Serge Abiteboul.
Ioana Manolescu
Avez-vous fait des courses récemment ? Si oui, vous reste-t-il un ticket de caisse ? Retournez-le, et vous avez des fortes chances d’y lire « Imprimé sur du papier ne contenant pas de BPA ». Le BPA, quésaco ? Appelé plus cérémonieusement bisphénol A, c’est une substance chimique longtemps utilisée, entre autres, dans le procédé dit « thermique » d’impression des tickets de caisse, mais aussi pour tapisser l’intérieur des cannettes et boîtes de conserve, pour les empêcher de réagir chimiquement avec les boissons et autres aliments contenus. De la sorte, le BPA nous évite de boire ou manger la rouille et autres produits peu ragoûtants de ces réactions chimiques…
Malheureusement, ses bons services s’accompagnent de sacrés risques sanitaires, car le BPA est un perturbateur endocrinien ; chez les souris, même une faible exposition in utero conduit à des changements hormonaux observés sur 4 générations… Fâcheux, quand on pense que trois millions de tonnes en sont produites encore chaque année dans le monde. (Voir wikiwix.)
Mère de deux enfants, j’ai ma petite histoire avec le BPA. Lorsque mon premier utilisait des biberons, le BPA était déjà interdit dans la composition des biberons, et sa réputation noircie sur la place publique, au Canada… mais pas encore en Europe. En France, des amies mamans me conseillaient gentiment d’arrêter la paranoïa et d’utiliser sans râler les mêmes biberons que tout le monde… Lorsqu’il a fallu biberonner mon deuxième, l’on enseignait « déjà » ici à toute jeune maman les dégâts potentiels du BPA et on leur apprenait à l’éviter.
Nous avons constamment à faire des choix. Dans le pays qui a donné au monde Descartes, nous nous targuons de faire ces choix sur la base de faits, en pesant tant que faire se peut le pour et le contre, en nous appuyant sur les informations dont nous disposons. La loi proscrit aujourd’hui le BPA même des tickets de caisse, non seulement des biberons ; il n’en était rien, il y a de cela quelques années.
Le processus est classique. La science émet des doutes. De longues études sont menées. Après examen par les élus, les doutes se transforment en certitudes, conduisent à des réglementations, des lois. Mais, ce processus est lent et peut prendre des années.
On le voit, la construction de la vérité est longue et ardue : il est bien plus facile de croire, que de savoir. Mais cette construction est à la base de tout processus de connaissance et de pensée, depuis que nos ancêtres ont dû être bien certains des baies et racines que l’on peut manger, si on ne veut pas finir ses jours empoisonné… De nos jours, scientifiques, journalistes, et experts de tout poil s’y attèlent. Il nous apportent tantôt l’interdiction du BPA, tantôt des gros mensonges à résultats tragiques comme l’étude truquée faisant croire à un lien entre les vaccins et l’autisme, retirée depuis par la revue l’ayant publiée, mais étude gardant des croyants bien tenaces, au grand dam des autorités sanitaires.
Quoi de neuf, alors, dans cet effort vieux comme le monde pour démêler le vrai du faux ?
Le Web, évidemment ! Il n’a jamais été si simple de publier une idée, information, rumeur ou bobard, et tout cela se propage plus vite et plus rapidement que jamais. Le travail de vérification de ces informations est-il devenu impossible ? Non, parce que l’informatique peut donner un coup de main, nous aider à détecter les mensonges.
Un politicien s’attribue le mérite d’une réduction spectaculaire du chômage pendant son mandat ? Des algorithmes proposés à l’Université de Duke, aux Etats-Unis permettent de voir que cette réduction était en fait bien amorcée avant le début de son mandat, et ne peuvent donc pas être mise à son crédit. Cette connaissance n’est accessible qu’en s’appuyant sur une base de données de référence, dans ce cas des statistiques du chômage dans lesquelles on a confiance. De telles bases de données sont, par exemple, celles construites à grands frais par des instituts financés par les États, tels que l’INSEE ou des instituts de veille sanitaire en France.
Cet exemple illustre le fact checking (vérification de faits), c’est-dire la comparaison d’une affirmation (« M. X a fait baisser le chômage ») avec une base de référence (évolution du chômage dans le temps), ce qui permet soit de prouver que M. X aurait avancé un chiffre faux, soit (dans notre cas) que l’interprétation qu’il en faisait n’était pas correcte.
Les limites de ces approches sont atteintes lorsque les données de référence sont muettes ou incomplètes sur un sujet, soit parce qu’un problème n’a pas été quantifié ou documenté, soit parce qu’il ne l’a été que par des acteurs s’accusant mutuellement de partialité ou directement de mensonge. Un exemple en est fourni par les débats très vif autour de l’introduction des OGM dans l’alimentation, notamment concernant les expériences de M. Seralini.
L’informatique permet ainsi de vérifier un fait, en s’appuyant sur d’autres ; elle ne permettrait donc d’établir que ce que l’on savait déjà ! Mais son aide est essentielle lorsque les volumes de données et informations à traiter dépassent (de loin) la capacité humaine.
Un autre scénario de fact checking exploite de façon ingénieuse l’intelligence humaine, recueillie, coordonnée et analysée par l’informatique. Il s’agit du crowd-sourcing, où l’on demande à des multiples utilisateurs de résoudre des « tâches » (déterminer si un paragraphe parle d’un certain sujet, étiqueter une photo…) puis on croise et intègre leurs réponses par des moyens informatiques et statistiques. Dans le domaine journalistique, une première approche collaborative de ce genre a été constituée par l’International Consortium of Investigative Journalism, à l’origine des publications du grand scandale d’évasion fiscale « Panama Papers » : des rédactions de journaux du monde entier ont mis en commun leurs données et leurs traitements, afin de « connecter les points » et de faire émerger l’histoire.
Dans l’histoire récente, une grosse partie des mensonges, manipulations et bobards sont publiés et propagés par les réseaux sociaux. Ceux-ci sont, d’un côté une arme puissante dans les mains des manipulateurs, mais ils fournissent en même temps une clé pour les débusquer : examiner les connexions sociales d’un utilisateur permet de se faire une idée de son profil et de la bonne foi et la véracité des informations qu’il ou elle propage. Les journalistes ne s’y trompent pas, qui utilisent des plateformes d’analyse et classification de contenus publiés sur les réseaux sociaux ainsi que de leurs auteurs.
Enfin, au delà de la vérification par des données et de la vérification par le réseau social, le style et les mots utilisés dans un document peuvent être exploités par les algorithmes d’analyse du langage naturel. Une telle classification permet par exemple de savoir si un texte est plutôt d’accord, plutôt pas d’accord, plutôt neutre ou complètement étranger à un certain propos, tel que « Donald Trump est soutenu par le Pape ». Une fois que l’énorme masse de textes à analyser a été ainsi classifiée par la machine, l’attention précieuse des humains peut se concentrer juste sur les textes qui soutiennent tel propos, ou encore, cibler l’analyse sociale (cf. ci-dessus) juste sur les auteurs de ceux-ci. Il s’agit ici d’utiliser le pouvoir informatique pour épargner l’effort humain, le plus cher et le plus précieux, puisqu’il peut effectuer des tâches « fines » d’analyse qu’on ne sait pas encore complètement automatiser. C’est dans cette optique que le problème de classification de texte ci-dessus a été proposé pour la première édition du Fake News Challenge, une compétition organisée conjointement par des journalistes et des informaticiens.
Ceci nous amène à une autre remarque fondamentale : le journaliste est seul capable de choisir les faits à partir desquels tirer un article, à choisir la nuance des mots pour en parler, et ceci demande de connaître ses lecteurs, la tradition du journal, l’angle de présentation etc. Les outils informatiques de fact checking sont des aides, des « bêtes à besogne », même s’ils sont loin d’être bêtes. Leur but est d’aider… des humains à communiquer avec des humains, pas de remplacer les journalistes.
Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?
Dans un magnifique article intitulé « Défense contre les forces des ténèbres : propagande et contre-propagande en réseau », Jonathan Stray cite une étude qui estime que le gouvernement chinois publie, par le biais de ses employés dédiés à cette tâche, 448 millions messages sur les réseaux sociaux, avec notamment une production de « nouvelles » accrues les jours où des informations défavorables au gouvernement circulent sur les mêmes réseaux. La stratégie est très simple » noyer le message indésirable dans la masse des contenus favorables, pour le rendre invisible. J. Stray note aussi, amèrement, que le fact checking vient nécessairement après un coup de désinformation, et que si celui-ci a été bien calculé et amplement diffusé, la fausse image créée dans les esprits va s’imposer. Mais cet article donne aussi une piste vers la solution : contre l’armée des forces des ténèbres, constituer l’armée des bons sorciers, qui, en mode crowd-sourcing (évidemment !), établiront l’atlas des sources de désinformation, afin que la connaissance gagnée par les uns profite à tous.
Le projet CrossCheck, un partenariat d’une vingtaine de grands médias dont Le Monde, est un pas dans cette direction.
Les scientifiques travaillent aussi sur le fact checking. Dans le projet ContentCheck, financé par l’Agence Nationale de la Recherche (ANR), nous élaborons par exemple des modèles de données et des outils pour le fact checking s’appuyant sur les contenus tels que les données ou les textes. La lutte contre la désinformation et les fake news (fausses nouvelles) est un sujet très actif dans la fouille des données ou l’analyse des réseaux… La consolidation des données contradictoires et partielles en des bases de confiance, avec ou sans appel au crowd-sourcing, apporte aussi un soutien évident au fact checking.
Mais, finalement, on pourrait se demander si le sujet est vraiment si important ? Nous vivons dans un monde qui doit gérer des guerres, des famines, du terrorisme international et les changements climatiques. Est-ce bien raisonnable d’investir des efforts pour savoir si ce que l’on vous dit est vrai ? La réponse à cette question, je ne la trouve pas uniquement dans mes expériences d’enfance dans une dictature, la Roumanie communiste, où la vérité était encore plus rare à trouver que les denrées de première nécessité. Je la trouve dans cette simple phrase : La liberté, c’est la liberté de dire que deux et deux font quatre. Si on vous accorde cela, tout le reste va suivre, Orwell, 1984.
Nous prenons de plus en plus conscience de l’importance que les algorithmes ont pris dans nos vies, et du fait qu’il ne faut pas accepter qu’ils soient utilisés pour faire n’importe quoi. Nous entendons de plus en plus parler de régulation, de responsabilité, d’éthique des algorithmes. François Pellegrini, professeur au LaBRI à Bordeaux, nous a fait part de critique d’éléments de langage, de son point de vue. Nous avons pensé que cela devrait intéresser nos lecteurs.Serge Abiteboul, Pierre Paradinas.
Crédit : Marion Bachelet – Inria
De plus en plus, dans le débat public, apparaissent les termes de « loyauté des algorithmes » ou d’« éthique des algorithmes ». Ces éléments de langage sont à la fois faux et dangereux.
Ils sont faux parce que les algorithmes n’ont ni éthique ni loyauté : ce sont des constructions mathématiques purement abstraites, conçues pour répondre à un problème scientifique ou technique. Ils appartiennent au fonds commun des idées, et sont de libre parcours une fois divulgués.
Ils sont dangereux, parce qu’ils amènent à confondre les notions d’algorithme (l’abstrait), de programme (ce que l’on veut faire faire à un ordinateur) et de traitement (ce qui s’exécute effectivement et peut être soumis à des aléas et erreurs transitoires issues de l’environnement).
Toute activité de recherche s’inscrivant dans un contexte socio-culturel, les questions éthiques ne sont bien évidemment pas absentes des étapes de conception. Les scientifiques qui, en 1942, travaillaient à l’optimisation de la fission nucléaire incontrôlée, savaient bien qu’ils participaient à la création d’une arme. Pour autant, si la décision de participer à un projet scientifique relève de choix moraux individuels, la question de l’usage effectif des technologies doit être traitée au niveau collectif, à la suite d’un débat public, par la mise en place de législations adaptées.
Ces éléments de langage focalisent donc improprement le débat sur la phase de conception algorithmique, alors que l’enjeu principal concerne les conditions de mise en œuvre effective des traitements de données, majoritairement de données personnelles. Ce sont les responsables de ces traitements qui, en fonction de leur mise en œuvre logicielle et de leurs relations économiques avec des tiers, choisissent de rendre un service déloyal ou inéquitable à leurs usagers (comme par exemple de calculer un itinéraire passant devant le plus de panneaux publicitaires possible).
Cela est encore plus évident dans le cas des algorithmes auto-apprenants. La connaissance de l’algorithme importe moins que la nature du jeu de données qui a servi à l’entraîner dans le contexte d’un traitement spécifique. C’est du choix de ce jeu de données que découlera l’existence potentielle de biais qui, en pénalisant silencieusement certaines catégories de personnes, détruiront l’équité supposée du traitement.
L’enjeu réel de ces débats est donc la régulation des rapports entre les usagers et les responsables de traitements. Un traitement ne peut être loyal que si son responsable informe explicitement les usagers, dans les Conditions générales d’utilisation de ses services, de la finalité du traitement, de sa nature et des tiers concernés par les données collectées et/ou injectées. Cette « transparence des traitements » (et non « des algorithmes ») a déjà été instaurée par la loi « République numérique » pour les traitements mis en œuvre par la puissance publique ; il est naturel qu’elle soit étendue au secteur privé. La description fonctionnelle abstraite des traitements n’est pas de nature à porter atteinte au secret industriel et rassurera les usagers sur la loyauté des traitements et l’éthique de leurs responsables.
« Mal nommer les choses, c’est ajouter au malheur de ce monde », disait Camus. N’y participons pas. Laissons les algorithmes à leur univers abstrait, et attachons-nous plutôt aux humains et à leurs passions.
On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
Parmi les domaines notoirement touchés par la féminisation, on compte l’enseignement, la médecine et la magistrature qui, au fil des ans, ont perdu de leur panache. Pour plusieurs raisons : ces métiers se sont largement démocratisés à mesure que les jeunes filles poursuivaient elles aussi des études, que ces métiers embrassaient des scénarios moins prestigieux, par exemple un avocat traite aujourd’hui davantage de cas de divorce ou de petite délinquance que de subtiles affaires propices à faire briller la défense ; l’enseignement primaire et secondaire ont pâti du fait que, compte tenu de l’allongement des études, il devenait moins exceptionnel de mener des élèves au bac qu’auparavant, ou encore la salarisation de la profession, puisque nombre de femmes médecins aujourd’hui s’accordent le mercredi pour s’occuper des enfants. Ceci représente un mode d’exercice propre aux femmes – puisqu’on en est encore là – qui contribue à banaliser la profession [2]. Ceci étant, même dans ces domaines, les stéréotypes sont bien gardés, puisque les femmes sont plutôt des juges pour enfants que des présidentes d’assises et les avocates plutôt surreprésentées en droit de la famille quand les avocats d’affaires sont plutôt des hommes de pouvoir. À ceci s’ajoute un facteur purement objectif, les jeunes filles sont meilleures dans les études et de fait plus propices à obtenir des concours compétitifs comme ceux de médecine ou de la magistrature.
Benjamin Carro, Mediego, Creative Commons
Irons-nous jusqu’à conclure que lorsqu’une profession perd en prestige, elle se féminise comme le prétendait Bourdieu en 1978, où est ce le fait que les femmes l’embrassent pour d’autres raisons qui la rend moins virile et de fait la dévalorise [2] ? Il s’avère que les femmes s’approprient souvent un secteur plutôt parce qu’il est délaissé par les hommes que parce qu’elles en rêvent. Ainsi les domaines de prédilection des hommes après avoir été l’enseignement, le droit ou la médecine sont désormais l’ingénierie, la finance ou l’entrepreneuriat. Les femmes viennent rarement marcher sur ces plates-bandes masculines, elles se faufilent dans les places laissées vacantes. L’armée néanmoins reste une exception en la matière, son prestige ne cesse de décliner sans qu’elle ne se féminise pour autant [1] !
L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion.
Les algorithmes, s’ils existent depuis très longtemps, sont clairement associés aux informaticiens qui les créent, les implémentent et les optimisent depuis l’apparition de la discipline. Leur importance n’a cessé de s’affirmer au point qu’aujourd’hui on pense à les taxer et leur inventer une justice. Ils sont ubiquitaires, dans nos ordinateurs, nos téléphones, ils décident du film que nous allons voir, de l’ordre dans lequel nos recherches dans les moteurs sont ordonnées, de celui des posts de nos amis sur les réseaux sociaux, du cours de la bourse, du montant de nos primes d’assurances, du prix de nos billets d’avion. Ils permettent d’éclairer les villes ou de réguler le trafic routier. Ils sont aux commandes des médias, rendent virales certaines informations, voire nous font avaler des couleuvres avec de fausses informations, ils assistent nos chirurgiens, ils nous battent au jeu de go, sont capables de bluffer au poker, sont en passe de conduire nos voitures, servent de moyen de contraception [3] et nous font aujourd’hui miroiter des espérances de vie allant jusqu’à 150 ans. On leur attribue à l’envi intelligence, bienveillance ou encore machiavélisme. Ils nous effraient parce qu’ils nous manipuleraient, ou encore parce qu’ils menacent de nombreux métiers. Ils sont transversaux à tous les domaines de notre société des médias à la santé, des transports aux cours de la bourse.
Si l’avenir appartenait certes à ceux qui se lèvent tôt, il appartient bien davantage à ceux d’entre nous qui sauront concevoir et mettre en œuvre des algorithmes.
Un algorithme n’a pas de sexe mais il semble aujourd’hui clair que leurs concepteurs en ont un, souvent le même. À l’instar d’une étude récente qui montre que des enfants attribuent naturellement l’intelligence aux hommes et la bienveillance aux femmes, notre monde conjugue les algorithmes au masculin.
Notre société évolue à deux à l’heure sur le sujet malgré un cadre législatif pourtant bien en place. Le plafond de verre existe toujours bel et bien, les femmes sont jugées à une autre aune que leurs homologues masculins, on encense bien moins, et on punit moins aussi d’ailleurs, les petites filles que les petits garçons, les femmes gagnent en moyenne 15% de moins à qualifications égales, en France les levées de fond des startups dirigées par les femmes représentent 13% de la totalité pour un montant qui ne représente que 7%. Hors la loi, le sexisme, cette croyance qu’il existe une hiérarchie entre les hommes et les femmes, est tenace qui diffuse son venin au quotidien dans les médias, les publicités, les pauses café, etc. Profitons du cadre législatif égalitaire, des nombreux élans de parité et faisons de nos jeunes filles des déesses du numérique, des entrepreneuses du Web. Convainquons nos jeunes filles que les carrières du futur sont celles qui riment avec numérique, algorithme et informatique et aidons les à y accéder sans qu’elles aient besoin d’attendre leur déclin (qui pour l’heure semble infiniment lointain).
Ce serait d’autant plus juste que l’informatique menace surtout les femmes. Des études montrent que les nanotechnologies, la robotique et l’intelligence artificielle remplaceront environ 5 millions d’emplois en 2020 [4]. Il s’avère que l’automatisation affecte majoritairement des secteurs féminins (administration, marketing, opérations financières). À l’inverse les hommes s’accaparent les secteurs générateurs d’emplois comme ingénierie, informatique, mathématiques. À ce rythme, les femmes seront les plus grandes victimes des algorithmes et tout cela ne fera qu’accroitre les inégalités existantes.
Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion
Il faut aussi exploiter les « role models », favoriser le mentorat qui permet aux femmes de s’entretenir avec un supérieur, ou une personne plus senior dans la profession, sur leurs carrières de manière explicite, de lever l’autocensure et de pallier le manque de confiance qui est parfois un frein à l’ambition et l’avancement des carrières féminines.
[1] Cacouault-Bitaud Marlaine, « La féminisation d’une profession est-elle le signe d’une baisse de prestige ? », Travail, genre et sociétés, 1/2001 (N° 5), p. 91-115.
[2] Malochet Guillaume, « La féminisation des métiers et des professions. Quand la sociologie du travail croise le genre », Sociologies pratiques, 1/2007 (n° 14), p. 91-99.
[3] Natural Cycle, Elina Berglund
[4] Future of Jobs, The World Economic Forum’s (Future of Jobs).
Les lycéennes et lycéens de toutes sections commencent à apprendre de l’informatique pour ne plus être de simples consommateurs mais devenir créateur du numérique : c’est l’enseignement de l’option « Informatique et Création Numérique, I.C.N. », de la seconde à la terminale pour toutes les sections.
Comment aider les enseignants d’I.C.N ? Quels savoirs partager avec eux ? Quelles ressources sélectionner ? Quelles compétences leur transmettre pour qu’ils puissent assurer ce nouvel enseignement ?
C’est sous la forme d’un MOOC social et coopératif, que quelques collègues Inria en binôme avec des professeur-e-s de lycée proposent un espace de formation, et un endroit de partage et d’entraide, où chacune et chacun construira son parcours selon ses besoins et ce qu’il sait déjà, un espace qui va évoluer avec le temps ; on le commence quand on veut et on y revient aussi longtemps qu’on en a besoin. Il est réalisé en partenariat avec Class’Code, qui y apporte tous les éléments de formation initiaux dont on peut avoir besoin.
Des grains de culture scientifique pour découvrir le numérique et ses sciences dans le réel, lié au quotidien de ces jeunes. Commencer à apprendre l’informatique et ses fondements. S’outiller pour accompagner les initiatives de création et les projets scientifiques des élèves. L’ICN est une vraie formation par le faire à travers des projets.
Si ce MOOC est principalement destiné aux enseignants de lycée qui enseignent l’ICN, il n’y a besoin d’aucun prérequis en informatique et on y parle aussi des enjeux sociétaux liés au numérique, il intéresse aussi les citoyennes et citoyens qui veulent être éclairé-e-s sur ces sujets.
Bon, c’est un projet fou ce MOOC : tant mieux, nos enfants le méritent bien.
On retrouve une nouvelle fois Alan Mc Cullagh notre ami irlandais du Vaucluse (Orange) qui nous avait conté l’histoire de la carte RaspberryPi. Cette fois, il nous parle d’un projet de la « BeeB » qui a marqué des générations, propulsant à nouveau de petits matériels simples et pas chers pour accéder aux joies de la programmation et du faire soit même (« DiY »). Et chers/chères lecteurs/lectrice : vous y apprendrez aussi d’où vient le processeur de votre smartphone… Pierre Paradinas.
Un peu d’histoire
Au début des années 80, le groupe de chaînes publiques au Royaume-Uni, la « British Broadcasting Corporation », dite BBC, lança un appel à projet pour créer un ordinateur éducatif à destination des écoliers et des écoles. Une jeune entreprise de Cambridge « Acorn » (« gland » en anglais) fut retenue pour créer cette plateforme. Le « BBC Micro » était né. Beaucoup de personnes qui ont grandi à cette époque dans les « îles britanniques » (y compris moi-même en Irlande) peuvent remercier ces pionniers d’avoir favorisé nos premiers pas dans l’informatique au sein des établissements de l’enseignement publique. On peut lire l’engouement que j’avais déjà à l’âge de 5 ans dans mon bulletin scolaire ! Dans la même période, ici en France, nous avons connu une initiative comparable avec le Plan Informatique pour Tous basé sur des micro-ordinateurs Thomson MO5 (et TO7/70).
Photo @tyrower. Le BBC micro:bit
Plus récemment, quand les membres fondateurs du Raspberry Pi commencèrent à concrétiser leurs rêves d’un nano-ordinateur éducatif, ils voulurent y inscrire en guise de clin d’œil le label « BBC ». Ce droit ne leur fut pas octroyé ; néanmoins un journaliste high-tech de la célèbre « Corporation » sur son blog et sur la chaîne YouTube leur donna un coup de projecteur qui lancera le mouvement autour du Raspberry Pi.
L’histoire se répète
En 2012, trente ans plus tard, la BBC s’est « remis dans le bain » en lançant un objectif très ambitieux : envisager un « ordinateur de poche programmable permettant aux enfants d’explorer la créativité technologique ». Elle voulait formuler une réponse à la fracture numérique et aux lacunes perçues des compétences informatiques des citoyens. Dans l’environnement fertile des startups technologiques du Royaume Uni et inspiré par l’énergie des « makers » et « programmeurs » autour des cartes « hackables » comme l’Arduino, le Raspberry Pi, Beaglebone et bien d’autres, la BBC a de nouveau monté une initiative d’éducation numérique dans la continuité du projet « Make It Digital » (créer le numérique). Ils ont su rapidement rassembler une trentaine de partenaires et des industriels. Aujourd’hui, ces partenaires sont réunis dans la Fondation Micro:bit.
Photo @tyrower.
Un million de cartes micro:bit ont déjà été fabriquées pour équiper gratuitement les élèves de « Year 7 » (âgé de 11-12 ans – équivalent de la 6e en France) au Royaume Uni (ainsi que leur enseignants). La plateforme est désormais disponible en ligne et de nombreux fournisseurs britanniques la distribuent depuis l’été 2016. La distribution en France devrait s’officialiser normalement courant 2017 (gardons un œil sur kubii.fr). Le prix de vente de la carte seule est actuellement de £13 (ce qui revient à un peu moins de 16€). Il existe aussi différents kits comme l’ensemble pour « invention électronique » à £37,50 (≈45€).
Photo @tyrower. La carte ne pèse que 8g et contient : un processeur : CPU 32-bit ARM® Cortex™ Mo; avec la connectivité Bluetooth (BLE) ou Filaire (USB) ; un accéléromètre et une boussole ; un afficheur et des Led …
La prise en main
Pour l’utiliser, on peut créer son script via plusieurs interfaces de programmation. Une fois compilé et le « code machine » généré en format «*.hex » (du binaire compréhensible par la machine), il suffit de « glisser-déposer » depuis un ordinateur vers le micro:bit connectée (ce dernier est reconnu comme un « disque externe ») ou de transférer par Bluetooth à partir d’un smartphone ou d’une tablette. Après un redémarrage du micro:bit, le script est lancé et le code s’exécute!
Photo @tyrower. Et pour programmer, on peut utiliser : MicroPython (Python) ; Code Kingdoms (JavaScript) ; Block Editor Microsoft (logique similaire à Scratch/Snap/Blockly) ; Touch Develop (interface pour écran tactile) ; PXT Microsoft (blocks/JavaScript) Yotta (C/C++) ; … et connecter un mobile : Android (micro:bit Samsung app, micro:bit Blue app) ou iOS.
A travers le site officiel, des tutoriels en ligne, des présentations YouTube et d’autres ressources, les jeunes peuvent facilement trouver de quoi s’inspirer pour apprendre à exploiter toutes les fonctionnalités du micro:bit. La réussite de cette action dépendra de l’engagement non seulement des jeunes mais surtout de l’énergie et de la passion du corps enseignant. Heureusement, avec la mise à disposition de ressources pédagogiques adaptées qui facilitent la prise en main ce type de réalisation est accessible à un grand nombre de personnes. La force de ce projet est qu’avec une trentaine de partenaires engagés et compétents dans divers secteurs un très grand nombre de supports, guides, projets, idées et ressources sont d’ores et déjà à disposition gratuitement et librement à tous. Evidemment, il va falloir plusieurs années pour voir si les objectifs ont été vraiment atteints mais les retours des premiers trimestres sont positifs.
“From little acorns great oaks grow” (depetits glandsde grands chênespoussent)
Pour boucler la boucle, j’aimerais revenir sur les racines des projets éducatifs informatiques de la BBC et leurs premiers partenaires. La petite entreprise « Acorn », dont on a fait référence tout au début de cet article, a aujourd’hui grandi pour devenir un grand « chêne » ! Elle s’est transformée et est devenue un des acteurs les plus importants dans le monde des smartphones et des objets connectés/embarqués (« embedded ») qui nous entourent. La technologie Acorn est devenue Acorn/Advanced Risc Machines, mieux connue sous le trigramme « ARM ». La vente de puces et de processeurs basés sur leurs architectures de silicium ne cesse pas de croître ; atteignant 15 milliards d’unités rien qu’en 2015 ! Le processeur au cœur du micro:bit est de la même famille, il s’agit d’un 32-bit ARM® Cortex™ M0 qui intègre les fonctionnalités dernier cri de connectivité Bluetooth Low Energy. ARM est présent en France, surtout à Sophia Antipolis en région PACA, où une douzaine de salariés sont actifs dans le Code Club France afin d’animer des activités d’initiation à la programmation via Scratch dans le périscolaire. Code Club est également un partenaire du micro:bit.
Photo @tyrower. Des salariés volontaires d’ARM à Sophia Antipolis aident dans l’animation de Code Club en France – activités péri- et parascolaire d’initiation à la programmation.
Peut-être qu’un ordinateur éducatif développé par France Télévisions n’est pas pour demain, mais on peut rêver qu’un jour le grand public, à commencer par les plus jeunes, s’intéressera aux enjeux de l’informatique et des technologies du numérique grâce à un projet dans l’esprit du micro:bit.
Éducation Informatique et Matériel
À la rentrée 2014, le ministère de l’éducation en Grande-Bretagne (« Department of Education ») a mis à jour les programmes scolaires anglais pour y inclure formellement l’informatique (« Computer Science/ Coding ») en tant que matière. Ce changement se faisait en réponse aux débats et rapports tels que celui de la « Royal Society » (2012). En France, nous connaissons des appels similaires comme celui de l’Académie des Sciences (2013). Aujourd’hui, nous continuons à chercher les réponses de demain. Avec l’introduction du code à l’école chez nous depuis la rentrée 2016 et grâce à des initiatives comme « Class’Code » et « 1, 2, 3… Codez ! », nous allons dans la bonne direction. En Angleterre, l’accent a été mis plus sur la formation et la pédagogie que sur des achats massifs. Si les constats au bout de 2 ans sont parfois mitigés chez nos voisins, ces changements commencent à néanmoins porter ses fruits. Les anciens cours « ICT » de dactylographie et d’utilisation de suites bureautiques ont en général évolué vers des choses plus fondamentales, pour donner une compréhension profonde de l’objet informatique et numérique. Outre-manche, s’il a bien eu des investissements récents dans l’infrastructure et le matériel pour l’éducation numérique dans les établissements britanniques, la priorité a été clairement mise ailleurs que sur le « hardware ». Dans cet esprit, le plus grand avantage du projet Micro:bit est que le support peut être facilement interfacé avec les équipements existants. Il n’y a pas besoin d’acheter de « systèmes compatibles » ou de logiciels propriétaires car la plupart des plateformes, même vétustes, peuvent servir d’office dans l’apprentissage, voire dans l’innovation et la création avec la carte. On peut même voir là-dedans un petit geste pour la planète – un peu de retro-compatibilité et de minimalisme dans notre monde d’obsolescence programmée et de la Loi de Moore. Le Micro:bit est 18 fois plus rapide que le BBC Micro des années 80, 617 fois plus léger, 440 fois plus petit et consomme 1000 fois moins (environ 30mW même avec les DELs allumées).
Elles ont nos données ; « elles », ce sont les grandes entreprises du Web : Google, Facebook, Yahoo!, Amazon… et les moins grandes, toutes aussi agressives dans l’entreprise de captation de données. Nous échangeons des messages avec un ami sur des vacances hypothétiques en Crète, et nous voilà inondés de pubs pour des hôtels, des transports… pour la Crète. Certaines viennent manifestement d’une analyse des emails échangés, mais les autres ? Comment sont-ils au courant ?
Regardons d’abord comment fonctionne le Web. Que se passe-t-il quand je visite la page http://www.unsite.com/unepage.html ? Petit dialogue explicatif :
Mon navigateur :
Hum, qui est www.n-importe-quel-site.com ?
Un service (DNS) de mon fournisseur d’accès à Internet :
C’est le serveur Web 203.0.113.42
(par exemple 🙂 )
Mon navigateur :
Bonjour 203.0.113.42.
Le Serveur Web :
Bonjour Vous !
Mon navigateur :
Pouvez-vous me donner la page /unepage.html ?
Oh, et puis, voici un tas d’autres choses sur ce que je suis, sur mes préférences…
Oh, et puis, voilà ces données incompréhensibles que vous m’avez demandé de retenir la dernière fois que je vous ai rendu visite (un cookie (+)).
Le serveur Web :
Voici votre page. Mais, il vous faut d’autres trucs pour la visualiser en entier.
Chargez tous ces scripts et images. Et tant que vous y êtes…
Chargez aussi ces scripts depuis Twitter, Facebook, Google, Oracle…
Mon navigateur :
Hum ok, bien sûr.
Mon navigateur :
Hey Twitter, UnSite m’a dit de vous demander des petits trucs.
Pouvez-vous me donner…
Oh, et puis, voici un tas d’autres choses sur ce que je suis, sur mes préférences…Oh, et puis, voilà ces données incompréhensibles que vous m’avez demandé de retenir la dernière fois que je vous ai rendu visite (un cookie tiers).
(Idem pour les autres Facebook…)
Mon navigateur :
Voilà. J’ai tout. Je n’ai plus qu’à exécuter tous ces scripts qui vont sans doute me faire rencontrer d’autres « amis » du net à qui j’aurai des tas de choses à raconter… Et, bien sûr, si ces scripts me demandent d’aller chercher du nouveau contenu, je le ferai. Je suis serviable…
Est-ce que cela se passe toujours comme ça ? Non, mais très souvent, et de plus en plus. Prenons l’exemple du blog que vous êtes en train de lire hébergé par lemonde.fr. À chaque fois que vous accédez à ce blog, vous effectuez également des demandes de ressources complémentaires (images, scripts, données) à d’autres serveurs qui n’ont rien à voir avec le journal Le Monde.
Au jour de la rédaction de ce billet, il s’agit (par ordre décroissant du nombre de ressources) de : Google, Facebook, Cedexis (fournisseur de services d’optimisation de trafic Web), Twitter, LinkedIn, Outbrain (publicité ciblée), Kameleoon (marketing), Inria (Institut de recherche prestigieux), Chartbeat (mesure d’audience), Automattic (créateur du système de gestion de contenu WordPress), comScore (marketing), AT Internet (mesure d’audience), et Wizbii (une plate-forme de recherche d’emplois).
Certains de ces accès aux ressources externes sont parfaitement légitimes : ainsi, une image issue du site d’Inria a été utilisée comme illustration. Les autres sont là parce qu’ils fournissent des services supplémentaires, pour le lecteur, le gestionnaire du blog ou la plate-forme d’hébergement : partage sur les réseaux sociaux, publicité, mesure d’audience, mise en commun de certaines ressources sur des sites tiers pour plus d’efficacité, etc.
Mais quelle qu’en soit la raison, l’ensemble de ces sites tiers peut ainsi savoir, s’ils y font attention, que vous avez consulté cette page, et même faire le lien avec votre identité et les autres sites que vous consultez.
Quand vous naviguez sur le Web, vous procurez des données volontairement, par exemple en remplissant des formulaires. Mais le plus gros des données qui partent de chez vous vient de votre navigateur qui donne aux sites que vous visitez, et à l’ensemble des sites hébergeant des ressources annexes, des informations sur vos préférences, votre identité, votre historique de navigation. Et ce que vous devez savoir : ces données, beaucoup d’entreprises les récupèrent, les stockent, les analysent, les échangent, les vendent.
Bien sûr, une partie de cette information est échangée « pour mieux vous servir ». Par exemple, votre adresse IP est indispensable pour router vos données ; des informations techniques sur votre connexion internet vous permettent de visualiser des vidéos dans de meilleures conditions, etc. Mais cette adresse IP permet également de vous localiser. Et c’est inévitable, sans cela Internet ne marcherait pas : comment fournir de l’information sans voir sous une forme où une autre une adresse ? Mais cela permet de vous identifier partiellement aussi, du coup. Au final, toute cette information est utilisée pour déterminer votre profil. Et ce profil va être utilisé pour mieux capturer votre attention, par exemple en vous proposant des contenus dans la langue que vous maîtrisez. Il va surtout permettre de vendre cette attention plus cher en ciblant de la publicité.
Les schémas d’échange d’informations entre entreprises du Web peuvent être complexes et aller au-delà des sites contenant des ressources référencées sur un site que vous visitez. Supposons par exemple que vous demandez un contenu et vous vous retrouvez avec un « cookie » d’une société, appelons-la SSP (*), qui va gérer les pubs du site que vous visitez. Vous cliquez sur une des pubs proposées et vous êtes en contact avec une nouvelle entreprise. Rien de surprenant, vous l’avez choisie ! Mais pour savoir quelle pub vous présenter, SSP a mis, sur une place de marché, les informations vous concernant, permettant à un client de cette place de marché, appelons-le DSP, de vous identifier et de vous proposer de la publicité correspondant à votre historique de navigation. Vous n’aviez pourtant aucun contact direct avec DSP. Que s’est-il passé ? Les cookies de SSP et de DSP se sont parlés. Vous êtes identifié…
Nous ne voulons pas encourager votre paranoïa. Après tout, il s’agit surtout de publicité plus ou moins anxiogène. Et il est des personnes qui trouvent intéressant de recevoir des publicités ciblées qui correspondent à leurs besoins, ce qui peut faire gagner du temps, ou affirment qu’elles ou ils n’ont rien à cacher. Mais, est-ce que ce sera toujours le cas quand notre santé pourrait avoir décliné sans qu’on veuille le faire savoir, ou que le régime politique se durcirait ? Si vous voulez vraiment vous protéger, quelques précautions :
Commencez par mieux comprendre comment l’informatique fonctionne, suivez des MOOCs, apprenez à programmer.
Utilisez un navigateur Web open source et hautement configurable comme Firefox, Chromium, ou Pale Moon.
Activez l’option « Do Not Track » (même si sa définition est tout sauf claire)
Utilisez des plugins comme AdBlock Plus ou uBlock Origin pour bloquer des publicités tierces sur les site que vous consultez.
Utilisez des Plugins tels que Ghostery ou DoNotTrackMe pour bloquer les cookies qui vous tracent.
Utilisez des Plugins tels que NoScript pour bloquer sélectivement les scripts…
Mettez vos données plutôt sur un Pims (système d’information personnelle) que sur des plateformes comme Apple ou Google.
Utilisez si vous le pouvez plutôt GnuSocial que Facebook (pas de chance, tous vos amis sont sur Facebook)…
Et pour allez plus loin, vous trouverez plus d’information dans l’excellent livre de Tristan Nitot, C&F Editions.
Attention ! Certains sites Web ne fonctionneront plus pour vous. Après tout, nous nous sommes habitués à un Web gratuit et il faut bien que quelqu’un paye pour tout ça : la pub. Mais si seulement les systèmes étaient un peu moins opaques que ceux qui se sont mis en place… La loi et la réglementation devraient mettre un peu d’ordre dans tout cela. Mais quand ?
Un point quand même est réconfortant. Tous ces services Web qui pillent vos données ne reviennent pas si cher : quelques euros par mois par utilisateur pour les plus coûteux d’entre eux. Il faudrait juste passer à d’autres modèles commerciaux que celui des services web actuels basés sur la publicité ciblée.
Et si vous devenez vraiment parano, disparaissez ! Masquez votre IP, par exemple, avec le navigateur Tor. Partez, peut-être, pour un village perdu où Internet n’arrive pas encore. Mais ce serait dommage car vous vous priveriez alors de tous les services super cools de l’informatique.
(*) SSP = supply-side platform comme Google DFP ou Rubicon
DSP = demand-side platform comme Criteo ou AppNexus
(+) Un cookie est défini par le protocole de communication HTTP comme étant une suite d’informations envoyée par un serveur HTTP à un client HTTP, que ce dernier retourne lors de chaque interrogation du même serveur HTTP sous certaines conditions. Le cookie est l’équivalent d’un fichier texte de petite taille, stocké sur le terminal de l’internaute. Wikipédia 2016.
Nous vous invitons à découvrir le principe de fonctionnement des algorithmes de recommandation, ceux utilisés pas les grandes plateformes de vente du Web qui vous disent ce qu’ont acheté les autres acteurs ou qui vous enferment dans une bulle informationnelle. Nous nous concentrons ici sur les aspects techniques et auront sans doute d’autres occasions de considérer des aspects sociétaux, comme l’importance de la recommandation sur les résultats d’élections. Nous avons demandé à Raphaël Fournier-S’niehotta, spécialiste de ces algorithmes, de nous en dire plus. Pierre Paradinas
Dans les jours qui ont suivi l’annonce des résultats de l’élection présidentielle, le 8 novembre dernier, la polémique a enflé : comment la plupart des sondeurs et des journalistes avaient-ils pu autant sous-estimer le nombre d’électeurs de Donald Trump ? Ceux-ci représentent au final quasiment la même proportion d’Américains que ceux d’Hillary Clinton. Les réseaux sociaux, Facebook en tête, ont été pointés du doigt, accusés d’avoir enfermé de nombreux utilisateurs dans une « bulle personnelle d’information ». Chacun d’entre eux ne verrait avant tout que des contenus proches de ses idées, le conduisant à ignorer l’existence d’autres personnes aux avis opposés. Ces ”bulles” sont créées par les algorithmes de filtrage et de recommandation mis en place pour sélectionner les contenus affichés sur le réseau social.
Figure 1 – REUTERS/Mike Segar
Un peu d’histoire
L’apparition des ordinateurs, à la moitié du XXe siècle, a permis de numériser l’information, en commençant par les ouvrages stockés dans les bibliothèques. Une suite naturelle a consisté à développer les moyens d’automatiser la recherche dans ces ouvrages : c’est ainsi que sont nés les premiers moteurs de recherche. Avec la création du Web en 1989, la taille des collections documentaires est progressivement devenue colossale. À tel point que les requêtes effectuées renvoyaient trop de résultats, et les utilisateurs ne pouvaient envisager de les consulter tous. Plutôt que de s’en remettre exclusivement au seul classement effectué par les machines, l’idée est venue de réintégrer des humains dans le processus, par l’intermédiaire de leurs avis.
En 1992, Paul Resnick et John Riedl, deux chercheurs en informatique, ont proposé le premier système de recommandation, pour les articles d’Usenet*. Ce système collecte des notes données par les utilisateurs lorsqu’ils lisent des articles. Ces notes sont ensuite utilisées pour prédire à quel point les personnes n’ayant pas lu un article sont susceptibles de l’apprécier. Cette recommandation automatisée repose, comme hors ligne, sur l’évaluation par les pairs : si les amis d’Alice lui suggèrent de lire un livre qu’ils ont aimé, il est probable qu’elle le lise et l’apprécie aussi, davantage qu’un livre que ses proches n’auraient pas lu ou pas aimé.
Un peu de technique
Ce principe, à l’origine des premiers systèmes de recommandation, s’appelle le ”filtrage collaboratif”. L’idée qui sous-tend cet algorithme est la suivante : si Alice a des idées similaires à Bob sur un sujet, alors il y a des chances qu’Alice partage son avis sur un autre sujet, plutôt que celui de quelqu’un pris au hasard.
Lorsqu’un système veut proposer des objets intéressants à Alice, il doit tâcher de prédire ses opinions sur ces objets. Il collecte les avis des utilisateurs sur les objets qui constituent sa collection. Les ”objets” sur Facebook, ce sont les statuts et articles partagés ; sur Amazon, ce sont les produits ; ce sont des morceaux de musique ou des films sur Spotify ou Netflix. Les avis collectés peuvent être explicitement donnés par les utilisateurs du système, comme le sont les ”likes” Facebook, les notes sur Netflix, les favoris sur Twitter, etc. Ils peuvent aussi être extrapolés à partir de l’observation du comportement de l’utilisateur : temps passé sur une page, achat d’un livre, visionnage d’un film. Cet ensemble de ”notes” constituent une représentation (plus ou moins fidèle) des centres d’intérêts de l’utilisateur. Elle permet d’enrichir le profil (déjà constitué des noms, professions, âge, genre, etc.).
L’étape suivante consiste à rechercher les utilisateurs qui ont les avis les plus similaires à ceux d’Alice, en se servant des notes de chacun. Le système détermine ensuite facilement les objets que ces utilisateurs ont vus mais qu’Alice n’a pas encore consultés. Avec leurs avis, il est ensuite possible d’estimer la note qu’elle pourrait donner à chacun de ces objets. L’algorithme n’a alors plus qu’à rassembler ces notes, les trier de la meilleure à la moins bonne, et afficher les 5 ou 10 objets les mieux classés.
Mathématiquement, il existe de nombreuses variations sur la façon d’effectuer la détermination des utilisateurs les plus proches (combien en retient-on, comment estime-t-on la proximité d’opinions, etc.) ainsi que la prédiction des notes (moyenne simple, moyenne pondérée, etc.). La représentation commune repose sur une matrice, dont chaque ligne correspond à un utilisateur, et chaque colonne correspond à un produit. Chaque case de la matrice de coordonnées (i,j) contient la note que l’utilisateur i a attribué à l’objet j.
Figure 2 – L’utilisateur u1 a donné la note de 5 à l’objet i3, la note de 2 à l’objet i4. Le système de recommandation doit tenter de prédire les notes là où les cases sont vides.
Une manière de prédire la note d’un utilisateur i pour un objet j est d’agréger les notes de tous les autres utilisateurs sous la forme d’une moyenne, celle-ci étant pondérée par un score de similarité. Ainsi, plus les avis passés sont similaires, plus l’avis de cette personne compte dans le calcul, et inversement. Pour vous impressionner, voici une formule qui peut être utilisée pour estimer la note :
(où dans la formule, r^ij désigne la note de l’utilisateur i sur l’objet j que l’on cherche à estimer, r ̄i est la moyenne des notes de l’utilisateur i, U est l’ensemble des utilisateurs, les ωu′,i sont les scores de similarité entre les utilisateurs.) Même si vous ne comprenez pas, reconnaissez-lui une certaine esthétique !
Bien entendu, ces techniques ont été raffinées et améliorées durant les vingt dernières années. Il s’avère en pratique que calculer des similarités entre utilisateurs est souvent très complexe. Il est plus efficace de renverser le problème en cherchant d’abord des similarités entre produits. C’est ce que fait Amazon en indiquant les articles que ”les clients ayant achetés cet article ont aussi acheté”. L’expérience prouve que les résultats sont beaucoup moins probants.
Figure 4 – Des recommandations de produits sur Amazon.
Quelques difficultés à surmonter
Les systèmes de recommandation automatisés posent divers problèmes techniques à leurs concepteurs. Il est en effet régulièrement nécessaire d’évaluer les opinions de millions d’utilisateurs sur des dizaines de milliers de produits. Effectuer les comparaisons de chaque ligne de la matrice avec toutes les autres nécessite beaucoup d’opérations, coûteuses en terme de performance. Si certains éléments du calcul peuvent être conservés et réutilisés, d’autres doivent tenir compte des mises à jour de la matrice (quand les utilisateurs notent un objet, par exemple). La taille des systèmes a aussi un autre effet qui diminue la possibilité de proposer des recommandations pertinentes : chaque objet n’a généralement été noté que par un ensemble très réduit de personnes, rendant délicate la recherche d’utilisateurs similaires. (En d’autres termes, la matrice est pleine de zéros ; on parle de matrice très « creuse »).
Outre ces problèmes de dimension, pour lesquelles diverses techniques ont été développées, les systèmes de recommandation doivent confronter d’autres difficultés. comme, par exemple, le ”démarrage à froid ». C’est ce qui désigne le problème particulier que posent les nouveaux utilisateurs du système. Comme on ne sait rien d’eux, comment leur faire des recommandations pertinentes ? Il faut se limiter à leur recommander des objets populaires (les meilleures ventes, par exemple) au risque de leur recommander des produits qu’ils ont déjà ou qui ne les intéressent en rien.
Nous mentionnerons un dernier problème majeur, la diversité, ou plutôt l’absence de diversité. Cela se manifeste à deux niveaux, global (pour tout le système) et local (pour chaque utilisateur).
L’absence de diversité globale consiste à ne recommander aux utilisateurs que les objets populaires. Un objet très peu vu ne reçoit que peu de notes et ne se retrouve quasiment jamais recommandé. Inversement, recommander systématiquement des objets populaires conduit à accroitre encore leur popularité.
L’absence de diversité locale consiste à ne recommander à un utilisateur que des objets en rapport avec les centres d’intérêts que le système lui connaît. Cet effet se renforce de lui-même avec le temps. Ainsi, un amateur de films d’horreur aura peu de chances de se voir proposer des comédies romantiques ou, dans un autre contexte, un partisan d’Hillary Clinton à se voir exposé à des articles en faveur de Donald Trump.
Pour compenser l’absence de diversité, il est bien entendu possible de modifier l’algorithme au cœur du système, par exemple, pour introduire plus de sérendipité pour l’utilisateur ou pour mieux équilibrer les profits commerciaux entre tous les vendeurs qui proposent des produits.
Les algorithmes ne sont que des transpositions informatiques de règles adoptées par des humains. Lorsque celles-ci ne nous satisfont pas, nous pouvons les faire évoluer… et du coup transformer les algorithmes qui leurs sont associés.
Raphaël Fournier-S’niehotta, maître de conférences en informatique au Conservatoire national des Arts et Métiers.
(*) Usenet est un système de discussion en ligne, que l’on peut voir comme l’ancêtre des forums actuels (voire de la fonctionnalité ”Groupes” sur Facebook)
À propos de l’analyse du rôle de Facebook dans l’élection américaine:
L’auteur de ces lignes est membre du projet ANR Algodiv, qui étudie la diversité au sein des algorithmes de recommandation ;
Un atelier interdisciplinaire sur les systèmes de recommandation aura lieu les 22 et 23 mai prochains à Paris ;
Sur l’impact social et politique des algorithmes de filtrage, outre les travaux de Dominique Cardon (Science-Po/Medialab), également membre d’Algodiv, les lecteurs intéressés pourront lire le blog du chercheur Olivier Ertzscheid ;
Pour approfondir les connaissances sur les divers algorithmes mis en œuvre, les annales de la conférence ACM RecSys constituent une référence.
La cryptographie fait partie intégrante de notre quotidien et elle suscite l’intérêt dès le lycée. Cette science à la conjonction des mathématiques et de l’informatique repose sur des algorithmes qui s’expliquent en termes simples : des boîtes, des cadenas et des clés… Le concours Alkindi sur le thème de la cryptanalyse a regroupé 17 000 élèves lors de sa première édition. En attendant la 2ème édition, Binaire vous propose de découvrir un peu la cryptographie et ce concours. Allez l’essayer, vous verrez on se prend vite au jeu. Pierre Paradinas.
En cliquant sur ce lien vous pouvez vous-même commencer le concours ou simplement vous entrainer.
Les exercices d’Alkindi sont constitués de trois versions qui correspondent à trois niveaux de difficultés – selon le modèle du Castor informatique. La première version attend une solution naïve, la version 3 étoiles attend une méthode plus construite alors que la version 4 étoiles demande une méthode quasi-optimale.
Regardons la solution de la question dans sa version 3 étoiles de l’exercise disponible sur le schéma. Alice utilise sa boite de chiffrage pour chiffrer son message et l’envoie à Bob. Il ne peut pas encore lire le message puisqu’il n’a pas la bonne clé. Il le chiffre à son tour pour le renvoyer à Alice. Alice enlève son chiffrement pour retourner le message à Bob. Finalement, Bob n’a plus qu’à le déchiffrer avec sa boîte et peut lire “COUCOU”.
Cette succession d’étapes peut se réaliser en pratique sans aucun logiciel de chiffrage. Alice met son message dans un coffre qu’elle ferme avec un cadenas. Elle envoie ce coffre à Bob par la poste. Bob rajoute un cadenas au coffre avant de renvoyer ce fameux coffre à Alice. Si vous suivez toujours, le coffre est maintenant fermé avec deux cadenas ! Alice retire son cadenas avant de renvoyer le coffre à Bob. Bob retire son propre cadenas et peut lire le message d’Alice. Le postier n’a jamais pu avoir accès au message car le coffre était toujours fermé avec au moins un cadenas.
Si dans l’exercice on utilise des boîtes de chiffrement, dans l’exemple on utilise des cadenas. Mais alors, est-ce que cette méthode permet de transmettre un message secret par e-mail ? Alice écrit son message dans un fichier et mélange les lettres situées sur des positions paires en suivant une permutation secrète, Bob reçoit le message incompréhensible et mélange les lettres situées sur des positions impaires en suivant une nouvelle permutation secrète. Ensuite Alice remet les lettres des positions paires à leur place initiale et envoie à Bob, qui remet les lettres des positions impaires à la place et peut lire le message.
Algorithme cryptographique
Diffie et Hellman ont anticipé l’importance qu’allait jouer la cryptographie pour l’internet où on ne se connecte pas seulement pour lire des informations mais aussi pour accéder à des espaces privés ou pour collaborer. La concrétisation de leurs idées, le protocole de Diffie et Hellman, est similaire à la méthode précédente (voir le billet sur le prix Turing 2016) et permet à deux personnes Alice et Bob de choisir une clé secrète commune.
Le lecteur peu familier avec ces notions de mathématique peu sauter le paragraphe suivant et passer à la description du concours, ou aller s’amuser avec les exercices…
On utilise des concepts mathématiques : un groupe G à n éléments dans lequel un élément g est générateur : la liste g, g2, … , gn contient tous les éléments du groupe. Dans un premier temps, Alice génère un nombre aléatoire a entre 1 et n, évalue ga et l’envoie à Bob. De son côté Bob suit les mêmes étapes : génère un nombre aléatoire b entre 1 et n, évalue gb et l’envoie à Alice.
Dans un deuxième temps Alice élève le nombre reçu de Bob à la puissance a, et Bob élève le nombre reçu de Alice à la puissance b. Les propriétés mathématiques de l’exponentiation garantissent que Alice et Bob ont obtenu le même résultat, gab, qui est leur secret commun.
Quant à un tiers qui a intercepté les messages, celui-ci ne connaît ni a ni b donc ne peut pas faire la dernière partie du calcul. D’ailleurs on peut traduire parfaitement l’exercice à l’aide du groupe G. À place de chiffrer par la machine d’Alice (resp.Bob) on éleve à la puissance a (resp. b). Le déchiffrage par la machine d’Alice (resp. Bob) traduit le fait d’élever à la puissance a’ (resp. b’), l’unique entier inférieur à p tel que a·a’- 1 est multiple de p-1 (resp. b·b’-1 est multiple de p-1).
Contexte et déploiement
Sur internet, la confidentialité des mots de passe est assurée grâce au protocole https (pour http sécurisé), indiqué dans l’adresse des pages internet et accompagné éventuellement par un cadenas vert. L’ordinateur de la personne qui écrit le mot de passe, l’ordinateur client, joue le rôle d’Alice alors que le serveur qui vérifie le mot de passe joue le rôle de Bob. Grâce au protocole de Diffie et Hellman, le client et le serveur choisissent une clé secrète, une séquence de 128 bits. Tout se passe dans quelques millisecondes et conduit à choisir un secret commun. Ensuite, tout le reste de la session, on utilise un chiffrement plus rapide basé sur le secret commun. L’exemple le plus connu, AES, a hérité des principes de la cryptographie militaire des siècles précédents.
Le concours
Le concours ne se limite pas à quelques défis. Ensuite, les élèves forment des équipes de maximum quatre personnes et ont deux semaines pour casser un code secret, tout comme Alan Turing et son équipe l’ont fait jadis. Si la cryptologie était difficile et laborieuse pour les militaires du XIXe siècle, elle devient simple et amusante pour les élèves d’aujourd’hui. Munie d’un ordinateur et de quelques algorithmes simples comme la substitution automatique d’un caractère par un autre, ils sont capables de casser les codes ADFGX, utilisés par les Allemands entre 1914 et 1918.
C’est pour familiariser les plus jeunes à cette culture de la sécurité informatique, que les associations France-ioi et Animath ont créé le concours Alkindi. La cryptologie se trouvant à la jonction des domaines de l’informatique et des mathématiques, les deux associations apportent leur expertise.
Mathias Hiron (France-IOI), Matthieu Lequesne (Animath) et Razvan Barbulescu (CNRS)
Animath est une association dont le but est de promouvoir l’activité des mathématiques chez les jeunes tout en développant le plaisir de faire des mathématiques.
France-ioi est une association dont l’objectif est de faire découvrir la programmation et l’algorithmique au plus grand nombre de personnes possible.
Le 15 novembre 2016, la SIF (Société Informatique de France) a organisé une deuxième journée sur la Blockchain : émergence d’une nouvelle forme de confiance numérique. Récit et séance de rattrapage pour ceux qui n’ont pas eu la chance d’y être.
Cette journée s’est déroulée dans les locaux de Telecom Paris Tech à Paris. Elle a réuni 150 personnes et plusieurs n’ont pu s’inscrire faute de place.
Crédit photo : @PierreMetivier
Réunissant plusieurs scientifiques et des start up travaillant dans ce domaine, la journée a commencé par une introduction de la technologie de la Blockchain. Il est bon parfois de revenir sur les fondements de ces technologies et de comprendre comment elles fonctionnent. L’autre grande question qui se pose avec ces systèmes, est de savoir s’ils sont sûrs. Si j’ai des bitcoins ou si je mets un contrat dans une Blockchain, le premier pirate venu va-t-il me les prendre ? De même quand un commerçant accepte un bitcoin ce dernier ne va-t-il pas être dépensé en même temps ailleurs sur la planète au risque qu’un des deux soit invalidé ! L’après midi la start up Ledger expliquera pourquoi et comment mes bitcoins doivent être protégés et conservés dans mon environnement numérique – et vous, vous laissez votre portefeuille ouvert ? La généralisation du bitcoin via Ethereum conduit à des « organisations autonomes décentralisées » (DAO) ou encore des «ordinateurs-mondes», ou comment peut-on se passer d’autorité et/ou de service centralisé dont le contrôle est problématique.
L’après midi fut axé sur les diverses applications de la technologie blockchain. Le premier exposé, présenté par un avocat spécialiste, releva l’absence de régime juridique pour la block Chain. Le droit applicable dépend donc actuellement des cas d’usage et beaucoup de questions juridiques restent en suspens. Le développement de cette technologie ne pourra s’accentuer qu’en définissant un cadre large sécurisant les acteurs. La deuxième présentation, donnée par un spécialiste en finance, a esquissé les multiples applications de cette technologie tel que la traçabilité des processus post-marché, l’inclusion financière des individus sans compte en banque et l’implémentation des minibons. Dans le domaine des assurances, les smart contracts rendus possibles par la blockchain pourraient se substituer aux assureurs actuels tout en apportant une réduction des coûts et un raccourcissement des délais de paiement. Deux start-ups ont ensuite présenté leurs solutions. La première, KeeeX, propose un système permettant de notariser toute donnée en se servant d’une blockchain. L’utilisateur certifie ses données et les conserve ainsi que tous les éléments des dossiers de preuve. Les tiers peuvent ensuite demander des preuves de date et d’existence à cette blockchain. L’une des applications, nommée PhotoProof permet de notariser sur une blockchain des photos prise par son mobile. La deuxième start-up, Ledger, propose une solution matérielle sous forme de carte à puce pour sécuriser les porte-crypto-monnaies des utilisateurs. En effet, les possesseurs de crypto monnaies doivent protéger avec le plus grand soin les clés privées liées à leurs comptes sans quoi ils risquent de perdre leurs avoirs.
L’après midi s’est terminé par une table ronde où le public a pu interroger les orateurs sur des points laissés en suspens ou litigieux. Il est apparu que le chemin est encore long dans certains domaines pour observer un déploiement massif de cette technologie. La blockchain se révèle toutefois très prometteuse et probablement destinée à devenir ubiquitaire à plus ou moins long terme.
Crédit photo : @PierreMetivier
Lire, écouter et voir la journée en replay.
Vous n’y étiez pas ? Voici comment profiter des contenus de la journée.
Lire les slides de présentations sur le site de la SIF.
Écouter les interviews de présentateurs réalisés en partenariat avec Binaire et le Labo des savoirs qui en ont profité pour réaliser une quatrième émission sur le thème de la Blockchain. Retrouvez l’émission sur ici.
Voir les vidéos des interventions de cette journée réalisées avec un partenariat entre la SIF et le Campus Fonderie de l’Image.
Sans oublier les articles de Binaire publiés sur le sujet dont vous trouverez la liste ci-dessous
Retrouver aussi les autres Podcasts Binaire/Labo des savoirs :
Nous sommes le 24 Octobre 2014, Sa majesté la Reine Elizabeth II envoie son 1er tweet : « It is a pleasure to open the Information Age exhibition today at the @ScienceMuseum and I hope people will enjoy visiting ». Pierre est allé visiter cette galerie permanente dans le Musée de la Science de Londres et il en est ressorti tout à fait heureux. Récit. Thierry Viéville.
« C’est un plaisir d’ouvrir l’exposition sur l’ère de l’information aujourd’hui à @ScienceMuseum. J’espère que cette visite sera appréciée. » Par ces mots la Reine d’Angleterre elle même, inaugure le dernier grand musée/exposition dédié à l’informatique en date. Cette exposition permanente a pris comme thème –comme son intitulé l’indique- de se concentrer sur l’information.
On y retrace les 200 dernières années de la place de l’information dans notre société. Le parti pris est de regarder cette transformation et ces évolutions à travers 6 périodes de la transmission de l’information.
Les 6 périodes correspondent à six zones consacrées aux différentes époques et « réseaux » de communication. On y retrouve donc le Câble, le Téléphone, la Télévision (Broadcast), les Satellites (The Constellation), les réseaux cellulaires (The Cell) et le Web.
L’exposition est très « moderne » avec de très nombreux écrans interactifs ou pas, et à plusieurs endroits des montages et des objets avec lesquels on peut interagir. De même, des parcours avec des objets connectés en liens avec des applications mobiles sont disponibles. Cette dernière ayant donné lieu à un travail artistique.
Photo : P. ParadinasPhoto : P. Paradinas
Rompant avec l’approche muséale classique qui conduit à imposer un parcours –comme dans certains magasins d’ameublement d’origine scandinave- l’exposition se tient dans une très grande pièce rectangulaire avec un « parcours » lisible ovale autour de la pièce qui passe à travers les 6 périodes ou types de réseau. La vision et le parcours, sont complétés par un autre parcours en mezzanine qui au travers de ce chemin aérien suspendu permet de voir l’exposition sous un autre angle et/ou de découvrir d’autres objets.
Plan de l’exposition
Le cheminement global est historique. Pour chaque période, la technologie est présentée et explicitée. Au delà de la technique, les usages sont détaillés et illustrés. Par exemple, le sauvetage de rescapés du Titanic suite à un câble ou les numéros de téléphone du type SOS-Amitié. Plus récemment, l’impact de la téléphonie mobile (The Cell) et aussi démontré au travers d’une boutique de distribution vente et d’un centre de réparation/hacking de téléphone au Cameroun.
L’informatique utilisée comme moyen est aussi présente et occupe une belle place. L’informatique anglaise y trouve bien sûr une juste place, avec les premières machines issues des travaux du Bletchley Park, du National Physical Laboratory (NPL) pour les réseaux, mais aussi les projets BBC-Community ou la création de la société Advanced RISC Machine, plus connue sous le nom de ARM dont les processeurs sont au cœur de la majorité de tout les téléphones mobiles du monde.
Une belle vidéo de l’inventeur du Web Tim Berners Lee pour expliquer cette dernière période de l’exposition : The Web.
Photo : P. Paradinas
On ne peut pas ne pas être impressionné par l’immense émetteur de la station radio de Rugby en bois.
Apple Newton Ph : P. Paraddinas
Et puis, pour les nostalgiques, les amateurs du touché des choses, un grand stand au milieu de l’exposition permet d’utiliser de vieux téléphones fixes, les premiers portables (enfin transportables car de la taille d’une boite de chaussures) et un Newton-Message Pad d’Apple en état de marche.
D’un point de vue plus technique, l’exposition permanente « Information Age » occupe de 2.500 m². Elle contient plus de 800 objets et a été réalisée avec un budget de 15,6 M £ (plus de 17 M€). Les principaux sponsors par ordre d’importance sont la Fondation de la Loterie, British Telecom, ARM, Bloomberg Philanthropies, Google et de nombreuses autres fondations (Motorola, Qualcomm,…) ou entreprises (Accenture,..).
Et puis, juste avant de partir une autre exposition dans le musée sur les données qui sont nos vies (« Our Lives in Data »)… avec de très nombreuses explications sur les données des différentes applications et ce que celles-ci révèlent.
Pierre Paradinas, Envoyé spécial de Binaire (Cnam)
Pour aller plus loin ou avant d’y aller : visitez le site web de l’expo
Aujourd’hui, nous sommes tous des usagers du numérique ; du plus grand au plus petit (la formule de 7 à 77 ans est devenue obsolète), nous cherchons de l’information, nous utilisons des applications les plus diverses et variées, nous publions des photos ou bien encore nous fournissons nos données à une large gamme de sites sur internet, pour les plus aguerris. Par contre, nous ne sommes pas forcément tous égaux devant cet environnement numérique, certains sont même totalement démunis devant l’usage d’internet. Parmi les 2,5 millions de résultats proposés par votre moteur de recherche sur le terme de « ressource numérique », nous vous proposons de vous arrêter sur un site : NetPublic. Pourquoi ? Tout simplement parce qu’il propose « d’accompagner et de favoriser l’accès de tous à la maîtrise des usages du numérique ».
NetPublic est un site édité par l’Agence du Numérique directement rattachée au Ministère de l’Économie et des Finances. Le site est organisé par grandes sections reflétant les grands axes de cet ambitieux programme : les espaces publics numériques (EPN), les emplois d’avenir numériques (Eavnum), le passeport internet et multimédia (PIM), les initiatives liées au numérique, les ressources classées par publics ou besoins et une rubrique spécifique pour les animateurs en chargent de la transmission et de l’accompagnement pédagogique auprès de tout type de population.
Les objectifs affichés sont de :
faire connaître à tous les lieux d’accès public et d’accompagnement à l’Internet et les services qu’ils proposent, faciliter la recherche de ces services,
offrir aux professionnels et aux bénévoles qui animent ces lieux et ces services un espace gratuit d’information, de ressources, de partage et de valorisation de leurs initiatives,
favoriser la mutualisation de ressources, les échanges entre les acteurs et contribuer au développement d’une communauté de professionnels de l’accompagnement à l’Internet et au numérique.
NetPublic est donc moins destiné aux usagers qui ont besoin d’être encadrés dans leur pratique ou découverte du numérique qu’aux acteurs et professionnels de l’accompagnement aux Technologies de l’Information et de la Communication, aux responsables et animateurs d’espace public numérique (EPN), aux médiateurs numériques. Par effet de bord, le site connait une popularité grandissante auprès de tous ceux dont l’activité est liée au numérique, autant dire énormément de monde.
NetPublic regorge de contenus et de liens permettant d’enrichir sa culture numérique. On imagine sans mal la petite équipe derrière ce portail ; un ou deux rédacteurs appuyés par un social média manager ? Il m’a fallu moins de 10 minutes pour recevoir une réponse à ma demande de contact en ligne et comprendre que toutes ces compétences sont le fait d’une seule personne mais pas des moindres. Jean-Luc Raymond est consultant senior en stratégie et projets numériques et l’un des premiers français à s’être engagé sur les réseaux sociaux et à s’y investir. Il a d’ailleurs récemment été classé premier dans le top 10 des « influenceurs » français.
Jean-Luc Raymond – Copyright Nikos Aliagas
Jean-Luc Raymond anime NetPublic depuis sa création, le site a d’ailleurs fêté en toute discrétion ses 6 ans d’existence en juin dernier.
Cet expert des médias sociaux a donc mis ses compétences et ses valeurs au service de la réussite de ce portail. 40% de son activité est dédiée à NetPublic, le reste de son temps est consacré à ses autres projets professionnels et une production éditoriale très abondante sur les réseaux sociaux.
Il parle de NetPublic avec passion et fierté ; « C’est un site de ressources dont 95% est en Creative Commons. En terme d’audience, nous avons entre 100 000 et 150 000 visiteurs par mois, c’est le site qui fait le plus d’audience à l’Agence du Numérique. Nous sommes d’ailleurs très honorés d’être le seul site externe à figurer sur la page de Pole Emploi (pointant sur les lieux d’accès public à internet que référence NetPublic)».
L’anecdote rapportée par Jean-Luc Raymond sur le fait que NetPublic a d’abord débuté sur Twitter avant même que le site soit ouvert (pour des raisons de calendrier), met l’accent sur l’importance donnée à la promotion des articles via les réseaux sociaux. 25% du trafic sur le site passe par ce biais, les quelques 36 300 abonnés sur Twitter et plus de 5000 fans sur Facebook en sont la preuve.
Le rythme de 3 à 4 publications par jour soit environ 40 à 50 articles par mois se maintient grâce à un travail de veille important via les réseaux labellisés ou par les acteurs publics du numérique. La mise en lumière des initiatives locales ou internationales, dès lors que le contenu est francophone (principalement du Canada, de Suisse, de Belgique ou du Luxembourg), a fait notamment exploser l’audience. Les idées d’articles sont donc principalement liées à cette veille qui permet de cerner l’évolution des pratiques, d’être en alerte sur les sujets d’actualités ou sur les besoins exprimés par les animateurs confrontés aux usagers en quête de sens qui déplorent de ne pas trouver des ressources adaptées sur certains sujets. On déplore juste que le site soit esthétiquement désuet et qu’il ne soit pas adaptatif mais comme l’explique Jean-Luc Raymond, la priorité est donnée à la production de contenus pour répondre à la demande de celles et ceux qui accompagnent tous les publics au monde du numérique.
Ce qui participe sans aucun doute à la qualité de ce portail de ressources, ce sont les règles éditoriales qui sont fixées. La neutralité des contenus est privilégiée ainsi que la pertinence des initiatives et la qualité pédagogique des ressources. NetPublic est conscient de sa responsabilité sociale par rapport à l’éducation au numérique à destination du grand public ou des publics en difficulté : informer, éduquer, faire comprendre pour mieux appréhender le potentiel et les risques. A titre d’exemple, les derniers articles publiés reflètent bien la diversité des ressources et des publics. Vous y trouverez par exemple un lexique du numérique pour les seniors, des guides pratiques pour l’accompagnement au numérique à destination des commerçants et artisans, une liste d’applications gratuites pour flouter un visage dans une photo ou une vidéo. La grande fierté qu’évoque son animateur est que le site sert de vitrine à des initiatives locales ce qui a permis à certaines personnes de trouver des emplois grâce à la visibilité qu’avait apporté le site à leur projet.
Et, non, cet article n’est pas de la publicité. C’est juste que Binaire aime beaucoup ce que fait NetPublic. Quelque soit votre niveau de compétences en terme d’usages du numérique, il y aura toujours un article qui pourra vous intéresser sur NetPublic, il vous permettra d’explorer des ressources et des projets modestes ou ambitieux dans le seul but de parfaire votre éducation au numérique.
L’association Fréquence écoles s’engage depuis bientôt 20 ans à favoriser « une attitude critique des jeunes face aux médias ». Composée de professionnels de la communication, de chefs de projets pédagogiques ou d’experts médias, l’association organise des événements, propose des interventions ou des formations ainsi qu’une multitude de ressources à destination des enfants et des adolescents mais aussi pour des enseignants ou des éducateurs. Parmi toutes les actions proposées par l’association pour mieux comprendre notre environnement face aux informations transmises par les médias, binaire a souhaité mettre en avant l’exposition dédiée à la culture numérique.
Cette exposition est organisée autour de 5 thèmes :
Jeu-vidéo
Média
Data
Makers
Enfance
Fréquence écoles
Au total 39 panneaux permettent d’explorer ces thèmes par le biais d’infographies, de chiffres, de définitions, ou encore de pistes de réflexion.
Parce que la culture numérique se partage, comme nous le rappellent nos amis de Pixees qui proposent eux aussi, des ressources autour des sciences du numérique, Fréquence écoles a mis à disposition en téléchargement l’ensemble des contenus de l’exposition (sous licence Creative Commons).
Et pour terminer sur une petite anecdote, jetez un œil à la composition de l’équipe permanente de l’association, vous aurez un bel exemple que le numérique se conjugue aussi aux féminins.
Le milieu des startups et des grandes entreprises d’informatique s’excite régulièrement sur un nouveau sujet. On voit défiler les modes à grande vitesse : big data, internet des objets, machine learning… et le petit dernier, la « blockchain ». Nous allons parler ici de startups françaises dans ce domaine. Nous allons supposer que le lecteur est vaguement familier avec la technologie blockchain, comme expliqué, par exemple, dans l’article récent de Jean-Paul Delahaye pour Binaire.
Laure Cornu
Un rappel rapide :
Une blockchain est un registre numérique public (sur le web). Les données sont écrites dans un « grand livre » dont chaque ordinateur participant a une copie identique. On peut ajouter aux registres des transactions (au sens informatique comme au sens bancaire du terme) et ce de manière totalement distribuée, et sécurisée, assurant l’intégrité de ces transactions. Les transactions sont réalisées l’une après l’autre. La blockchain permet donc de concevoir des architectures véritablement décentralisées ; ce n’est pas simple parce que plusieurs transactions peuvent vouloir s’ajouter en même temps au registre et une seule doit y arriver. À chaque instant, la blockchain contient tout l’historique des transactions. La technologie blockchain est à l’origine d’une cryto-monnaie, le Bitcoin, qui agite beaucoup les milieux financiers. Les Bitcoins servent d’ailleurs eux-mêmes de « ressources » pour le fonctionnement des blockchains. Les blockchains semblent conduire à des échanges sécurisés distribués qui se libèrent du tiers de confiance (une banque centrale) ou d’une plateforme centralisatrice.
Cette techno n’est pas si vieille. L’an 0 du Bitcoin, c’est 2008. Mais pourquoi tant d’intérêt soudain : sans doute en partie à cause du succès de chain.com qui, autour du Bitcoin, propose une plateforme pour des échanges financiers entre entreprises. La technologie a muri, ce que l’on observe également avec une plateforme opensource de blockchain très populaire, Ethereum.
On notera d’abord des startups autour des technologies financières comme Paymium et Ledger Wallet. La première permet d’acheter et vendre des Bitcoins, la seconde propose un portefeuille sécurisé sur smartcard ou clé USB. Mais la techno blockchain ouvre de nombreuses autres possibilités techniques, même si ses usages se cherchent encore.
Pour entrer dans ce nouveau domaine, il faut faire une distinction essentielle entre la blockchain public ou privé. Dans le public, utilisé pour les Bitcoins, chacun peut participer, par exemple en achetant ou en vendant des Bitcoins. Dans le privé, pour participer, il faut être « approuvé » par une autorité. Les vraies nouveautés semblent venir plutôt du coté des blockchains privées.
Une belle startup pour commencer : Stratumn. La techno blockchain est compliquée. Stratumn va la proposer « as a service ». On touche là à un des freins des blockchains : c’est une techno encore jeune et les outils sont encore compliqués à utiliser. Stratumn essaie de les simplifier pour vous. Un beau programme. Vous venez avec votre idée d’application à coup de blockchain. Vous pouvez vous consacrer à cette application, Stratumn gère la techno.
Mais pour développer quelle application ? Là vous avez le choix. Vous avez Ledgys qui développe un place de marché sécurisée au dessus de la technologie blockchain, ou pourquoi pas Belem qui vise la gestion de données distribuées et la transmission d’informations sécurisée. Vous avez aussi Keeex qui attaque le travail collaboratif avec encore de la gestion sécurisée de données décentralisées, ou Woleet qui s’intéresse à la propriété intellectuelle, et la certification entre autres choses.
Il y a du monde sur le créneau
Elles sont trop nombreuses ces startups. Il faudrait parler de Aedeus, « la Première solution blockchain 100% française » (sic), ou de Kaiko « We organize Bitcoin’s information by making the tools businesses need to succeed in the uncharted world of Bitcoin, and blockchain technology » (dans la version française de leur site).
Nous ne sommes pas certains d’avoir toujours compris ce que ces startups faisaient. Certaines nous ont paru encore très préliminaires. D’autres startups que nous avons regardées nous ont semblé bien trop fumeuses pour être mentionnées. Nous avons probablement raté de jolies perles. En tous cas, nous ressortons de cette balade dans les startups françaises du blockchain avec la sensation confuse qu’il est en train de se passer quelque chose, que si mille fleurs ne sont pas prêtes à surgir, quelques beaux bourgeons pourraient bien éclore.







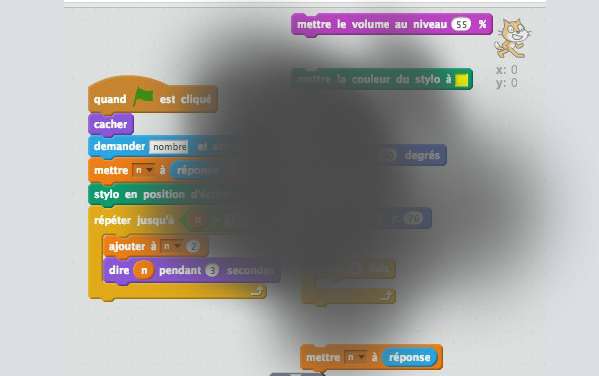

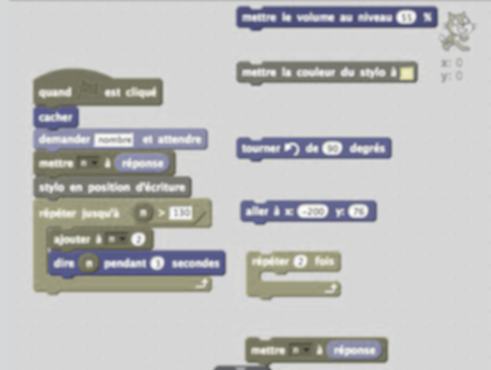








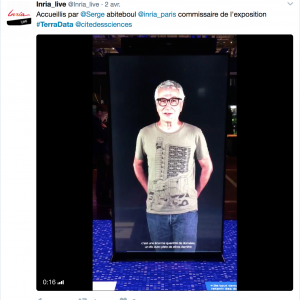 délimité par de grands miroirs, vous serez accueilli par le commissaire scientifique de l’exposition,
délimité par de grands miroirs, vous serez accueilli par le commissaire scientifique de l’exposition, 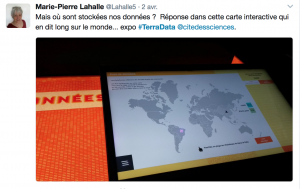
 Vous pourrez aussi vous initier au datajournalisme et à la datavisualisation…
Vous pourrez aussi vous initier au datajournalisme et à la datavisualisation…
 Vous êtes enseignant ? Une
Vous êtes enseignant ? Une 



 Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?
Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?
 On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
 L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion.
L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion. Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion
Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion


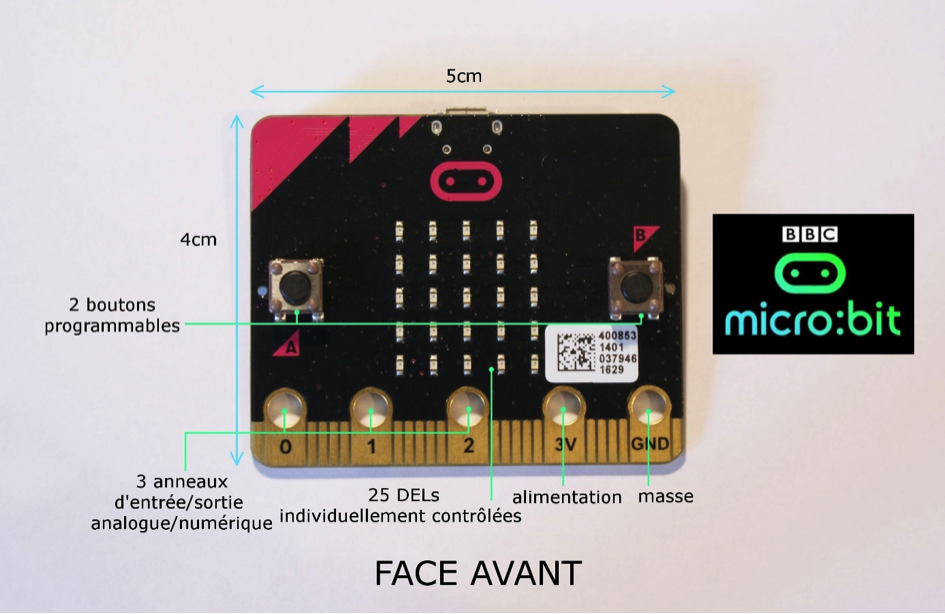





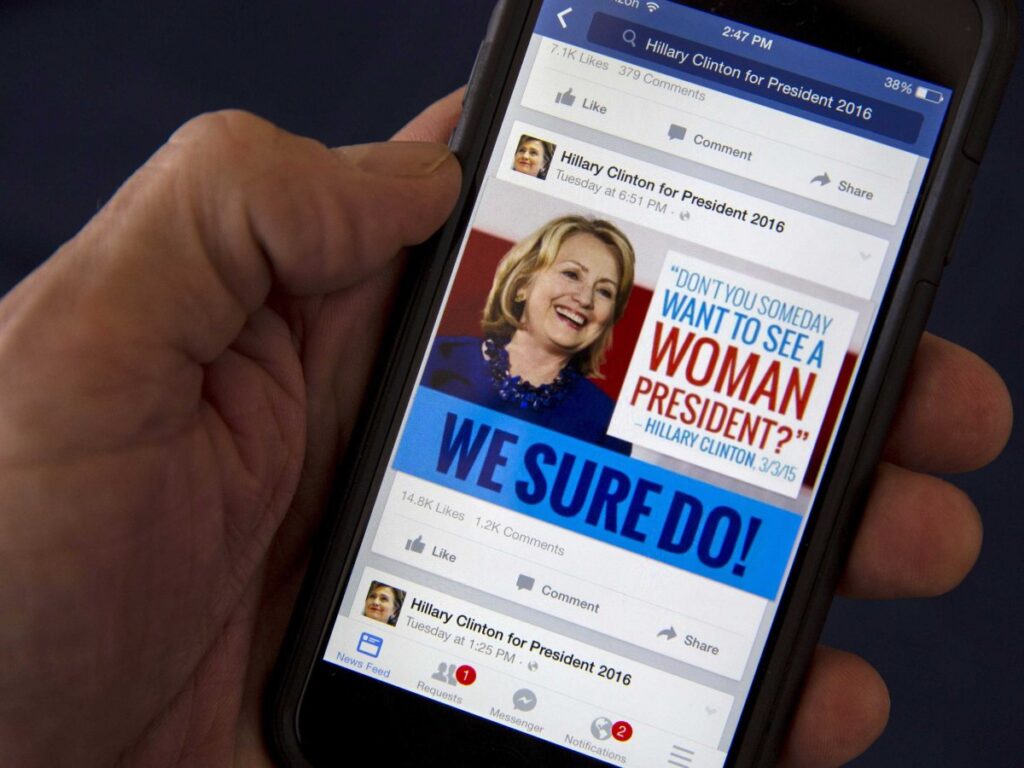
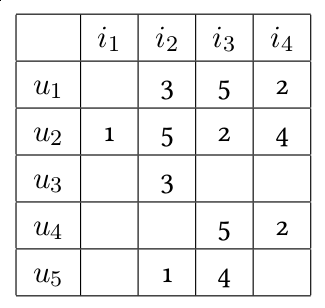
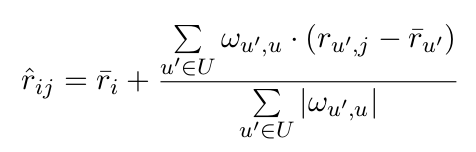

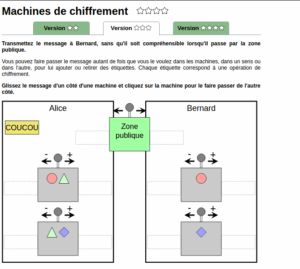










 NetPublic est un site édité par l’
NetPublic est un site édité par l’


