Le 25 octobre 2017, une session passionnante d’Inria Alumni était consacrée au phénomène des Fake News au Conservatoire National des Arts et Métiers en partenariat avec la Société Informatique de France, avec Francesca Musiani (CNRS), Ioana Manolescu (Inria) et Benjamin Thierry (Université Paris-Sorbonne). Ce dernier est maître de conférences en histoire contemporaine et Vice-président chargé des Humanités numériques et des Systèmes d’information à l’Université Paris-Sorbonne. Binaire lui a demandé de nous apporter son point de vue d’historien sur le sujet. Serge Abiteboul.

Fake News et post-vérité ont été mis sous le feu des projecteurs en 2016 à l’occasion de la dernière présidentielle états-unienne. À la suite de cette couverture médiatique mondiale, le dictionnaire Oxford choisit « post-truth » comme mot de l’année. Le terme est pourtant déjà ancien puisqu’on le voit émerger dès 2004 dans les travaux de Ralph Keyes[1]. Ce dernier étudie alors la viralité qui semble désormais primer sur la véracité dans la circulation de plus en plus massifiée, décentralisée et accélérée de l’information.
C’est alors que Donald Trump est porté à la magistrature suprême que le grand public découvre par la presse que des entreprises de manipulation de grande envergure ont accompagné et probablement favorisé la défaite d’Hillary Clinton et la victoire du candidat républicain. Au-delà de l’espace nord-américain, ces fausses nouvelles seraient désormais la norme et de nombreuses analyses convergent pour expliquer les conditions supposées du débat public à l’heure des réseaux.
Anatomie d’une fausse nouvelle
En premier lieu, c’est la composante technique du débat public qui est le plus régulièrement pointée du doigt. Fabrice Arfi considère le numérique responsable d’ « une forme d’horizontalité et de viralité très particulière » qui favorise le recours au mensonge comme arme politique[2] ; Frank Rebillard dans son article sur le PizzaGate considère que « les schèmes conspirationnistes, dont la rumeur en ligne constitue l’un des véhicules privilégiés, trouvent avec le numérique et l’Internet des éléments documentaires de nature à renforcer l’illusion d’une démonstration de leurs constructions intellectuelles[3]. » Bruno Patino voit également dans nos nouveaux outils d’information et l’habitude prise du partage immédiat le ferment de la post-vérité : « Ce qu’on appelle « post-vérité » et fake news, c’est le symptôme d’une transition qui a commencé avec le smartphone. On a oublié ce qu’est un fait : le fait commence à exister avec le télégraphe. Les endroits où il y a un pouvoir ou bien où il se passe quelque chose, télégraphient le fait brut : « Le ministre a déclaré que… », « Il y a douze morts à tel endroit ». La séparation fait /analyse, fondatrice du journalisme, vient de là. On transmettait l’info, sans transformation, puis on hiérarchisait et on commentait ces informations. Aujourd’hui, le fait ne se transmet plus, il se partage. Or le partage transforme le fait à tout moment, à tel point que la traçabilité du fait est désormais une question essentielle[4]. »
Autre facteur souvent cité pour expliquer l’irruption des fausses rumeurs et fortement lié à la supposée dictature technique des réseaux, notre tendance à rechercher l’immédiateté dans la consommation, mais surtout dans les relais que nous donnons à l’information. « Tout a lieu en temps réel et instantanément. Il n’y a pas de temps pour la réflexion ni de pause pour la pensée ou le souvenir […] nous n’avons plus besoin de nous souvenir puisque la technique le fait pour nous[5] » nous explique Manya Steinkoler avant de souligner que nous sommes également poussés à chercher les informations qui nous confortent dans nos opinions et croyances plutôt que des éléments déstabilisants parce que divergents d’avec nos idéologies personnelles ; tendance encore renforcée par les phénomènes de bulles filtrantes. Ajoutons les réseaux sociaux qui, dans leur fonctionnement même, n’ont pas fondamentalement intérêt – hors des déclarations d’intention de leurs fondateurs pour rassurer utilisateurs et autorités – à limiter le recours au mensonge : une information est une information qu’elle soit vraie ou fausse : « Facebook a intérêt à ce que l’info se partage beaucoup et vite et une info scandaleuse et fausse se partage mieux et plus vite qu’une info ennuyeuse, mais vraie[6]. »
Enfin, il existe un marché de la rumeur, instrumentalisée à des fins partisanes, comme l’a montré le New York Times avec l’exemple de Cameron Harris et d’autres.
Modernité technologique chaotique, horizontalité, recherche d’immédiateté effrénée et acteurs intéressés à la monétisation du mensonge, voici les principaux éléments qui sont évoqués pour expliquer la prolifération des fake news et l’entrée dans l’ère de la post-vérité dont notre époque serait frappée.
La longue histoire du faux
Tous ces facteurs semblent s’entretenir mutuellement, mais contribuent-ils réellement à créer une rupture dans l’histoire de l’information et de ses rapports à nos démocraties occidentales ? Ne cédons-nous pas à une idéalisation du passé comme à chaque fois que le présent nous déçoit ?
Force est d’abord de constater que l’instrumentalisation du mensonge et de la rumeur ne date pas d’hier. Les formes mêmes de cette instrumentalisation n’ont finalement pas beaucoup changé. Dans un article important de 2017, Catherine Bertho rappelle que les mazarinades au XVIIe siècle ou les campagnes de dénigrement de Marie-Antoinette au siècle suivant reposent elles aussi sur le mensonge structuré autour d’« un labyrinthe de textes éphémères, elliptiques, bourrés d’allusions aux événements du jour, rompu à toutes les ruses de la controverse[7]. » Les calomnies circulent « par rebonds. Les textes, loin de développer des argumentaires cohérents, se répondent de façons confuses et embrouillées ». Ces opérations de guérilla médiatique visent à la désacralisation et à la déligitimisation du pouvoir en place et de l’adversaire. Dans le cas des libelles contre Marie-Antoinette, « ils sont fabriqués par des officines et diffusés par des médias marginaux avant d’alimenter la rumeur avec une impitoyable efficacité. L’accusation d’inceste, par exemple, poursuivra la reine jusque devant le tribunal révolutionnaire[8]. »
Confortablement installés dans notre modernité technologique contemporaine, nous n’échappons pas non plus à ce brouillage du réel dont les effets ne sont certes et heureusement pas comparables. Dans son numéro 115, Le Monde Diplomatique publie une enquête saisissante sur l’économie des « pièges à clics » qui incarnent la forme numérisée de la presse à scandale au travers de plusieurs témoignages de salariés de Melty, Konbini ou BuzzFeed. Gouvernées par la recherche du lectorat à tout prix au moyen d’outils de surveillance des tendances supposées de l’actualité, ces rédactions font elles aussi peu cas de la « vérité » tel qu’on peut s’y attendre chez des journalistes : « Dès que l’algorithme voyait un sujet remonter dans les statistiques, il fallait faire un article dessus, même s’il n’y avait pas d’info. Une fois, je suis allée voir la rédactrice en chef, et je lui ai dit que je n’avais pas d’info sur le thème demandé (la chanteuse Britney Spears). Elle m’a répondu : ‘Ce n’est pas grave, tu spécules’[12]. »
Les fake news sont-elles faites pour être crues ?
Lecteurs abusés, citoyens déboussolés et trompés, ce panorama peut faire craindre un affaiblissement possiblement fatal de notre capacité à fonder notre jugement. L’information conçue depuis la loi de 1881 comme l’élément déterminant de l’exercice raisonné de la citoyenneté est de moins en moins fiable. À l’heure du fake globalisé, c’est désormais sur le fonctionnement même de nos démocraties que pèse la menace du grand brouillage rendant notre action citoyenne dépourvue de sens.
Un premier élément de réflexion à la lumière des exemples évoqués ci-dessus pourrait être qu’il ne faut pas idéaliser un passé que l’on érigerait en âge d’or de la vérité. Le lecteur de ou du Figaro était-il mieux informé et moins soumis à l’orientation de ses lectures que l’internaute d’aujourd’hui ? Le contexte est différent et la surcharge informationnelle a succédé à la rareté, mais considérer nos aïeux comme de parfaits acteurs rationnels en matière politique est une erreur que la littérature historienne sur le vote, l’histoire de la république et le politique en général a démystifiés depuis belle lurette.
Un second point qui mérite notre attention est soulevé par Jean-Claude Monod relisant Arendt à l’heure des Fake News : la vérité n’est pas la seule valeur dans la sphère politique d’une démocratie. L’utilisation massive du mensonge et de la rumeur dans le cadre de la présidentielle de 2016 ainsi que son traitement sous cet angle, conduit à nous faire oublier le poids des opinions. Comme le rappelle Arendt dans Vérité de fait et opinion politique qui est initialement publié dans le New Yorker le 25 février 1967, « on peut dire que l’opinion, plus que la vérité, constitue le véritable fondement de la démocratie[13] ». L’opinion c’est « savoir un peu et croire beaucoup » pourrait-on dire en forme de boutade.
Deux questions valent la peine d’être posées une fois ce constat dressé : à quoi peuvent bien servir les fake news si elles ne sont pas toutes entières contenues dans le projet de tromper leurs destinataires et que nous disent-elles de notre modernité sur le plan informationnel ?
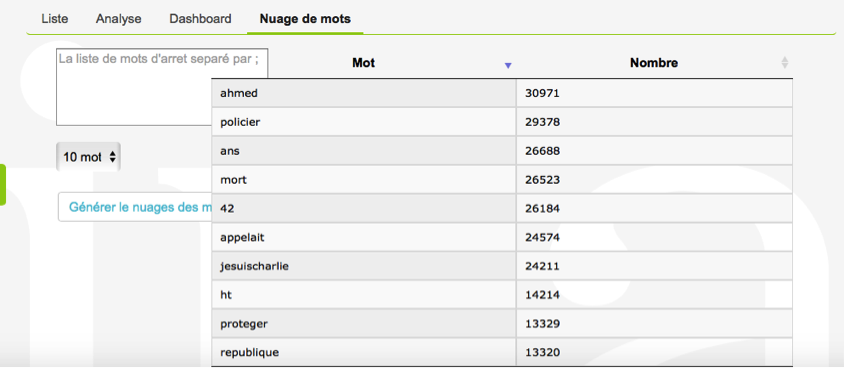
La fausse nouvelle en ce qu’elle est virale comme l’ont souligné nombre d’analystes, ne circule que grâce aux truchements de la multitude, c’est-à-dire nous. Mais nous ne la relayons pas uniquement parce qu’elle est prise pour vraie, mais pour beaucoup d’autres raisons. Pour faire communauté avec celles et ceux qui partagent une indignation ou un engagement commun par exemple. Quand un site parodique déclare que des prostituées russes ont témoigné avoir eu des relations sexuelles avec le futur président américain et qu’il est affublé d’un micropénis[14], peut-être certains seront portés à le croire, mais à en croire les commentaires sur les réseaux sociaux ou les forums, cela sert avant tout au dénigrement caricatural de Donald Trump dans une version actualisée des poires de Daumier[15].
Quand en 2015, la photographie de Justin Trudeau en visite dans une mosquée canadienne[16] est reprise sur plusieurs sites proches de l’extrême droite et qu’on y ajoute des interrogations sur sa « possible » conversion à l’islam, est-ce toujours une fake news puisqu’elle n’affirme rien ou plutôt une instrumentalisation politique par insinuation pour dénoncer la proximité de Trudeau avec les musulmans canadiens ?
Quelques études commencent à montrer que la seule alternative entre le vrai et le faux n’est pas la bonne focale pour comprendre le phénomène des fake news. Quand ils essayent d’apprécier l’impact de ces dernières sur l’élection de Trump[17], Hunt Allcott et Matthew Gentzkow revoient considérablement à la baisse l’hypothèse d’une tromperie généralisée des électeurs au moyen des fausses nouvelles. John Bullock et ses coauteurs ont également montré qu’un panel représentatif d’électeurs choisissait délibérément d’ignorer les fausses nouvelles et de ne pas les faire circuler si l’on intéressait cet acte de sélection par une légère rémunération[18]…
Pour massif que le phénomène soit, son impact est donc à relativiser. Il ne s’agit pas non plus d’en faire un détail sans importance. Qu’on souhaite la combattre ou la comprendre, la fausse nouvelle comme la rumeur ouvrent des perspectives sur nos mentalités collectives en ce qu’elles « font appel aux émotions élémentaires et aux souhaits réprimés[19]. » En 1921, Marc Bloch qui avait servi sous les drapeaux et dans la boue des tranchées, ne disait pas autre chose en invitant l’historien à se pencher avec lui sur les rumeurs du front, « ces singulières efflorescences de l’imagination collective » qui en disent parfois plus sur les acteurs qu’ils n’en déclarent eux-mêmes, car « l’erreur ne se propage, ne s’amplifie, ne vit enfin qu’à une condition : trouver dans la société où elle se répand un bouillon de culture favorable. En elle, inconsciemment, les hommes expriment leurs préjugés, leurs haines, leurs craintes, toutes leurs émotions fortes[20]. »
Pour finir, je pense que ces trop courts développements à propos d’un phénomène complexe invitent à deux attitudes complémentaires.
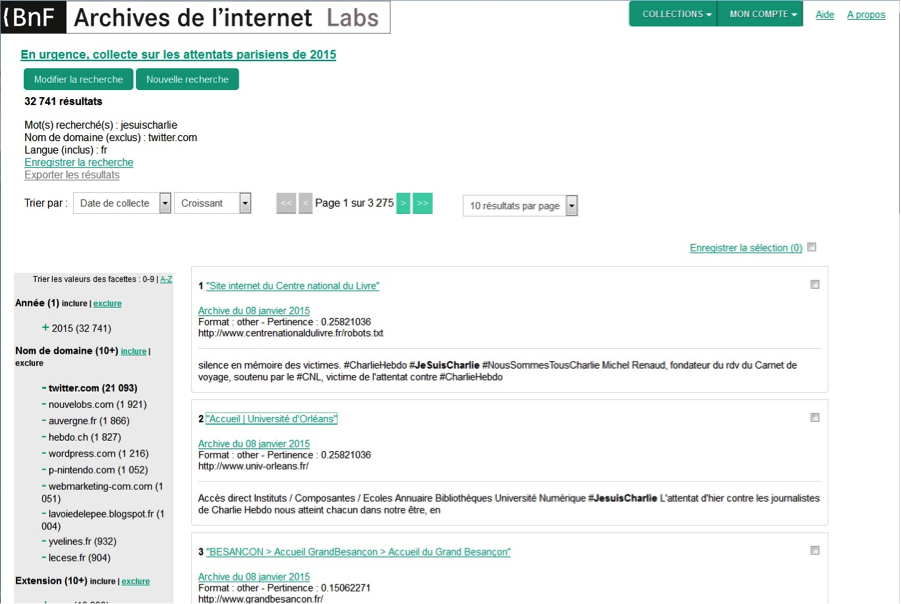
En tant qu’historien, les fake news constituent un « terrain de jeu » sans pareil pour, dans les pas de Bloch, ouvrir la boîte noire des idéologies contemporaines en abandonnant la vision surplombante et stérile de la disqualification a priori du « faux ». Les collègues intéressés à la pratique d’une histoire immédiate appuyée sur les archives nouvelles que sont les archives du Web ont un champ nouveau et passionnant à investir.
En tant que citoyen enfin et dans le sillage d’Arendt cette fois, il s’agit de garder à l’esprit que si la démocratie ne peut se passer de « vérité factuelle », la tentation d’opposer une vérité parfaite au mensonge est tout bonnement illusoire et contre-productif. La démocratie n’est pas affaire de spécialistes du vrai transformés en censeurs des opinions dissidentes et la mobilisation politique passe par bien d’autres voies que l’adhésion au vrai et le simple rejet du faux.
Benjamin Thierry, Université Paris-Sorbonne, @BGThierry
[1]. KEYES Ralph, The Post-Truth Era. Dishonesty and Deception in Contemporary Life, St. Martin’s Press, New York, 2004, 312 p.
[2]. « Rendre public ». Entretien avec Fabrice Arfi, in Médium, n°52-53, 2017, p. 59-84.
[3]. REBILLARD Franck, La rumeur du durant la présidentielle de 2016 aux États-Unis. Les appuis documentaires du numérique et de l’Internet à l’agitation politique, in Réseaux, n°202-203, 2017, p. 273-310.
[4]. Pouvoirs de l’algorithmie. Entretien avec Bruno Patino, in Médium, n°52-53, 2017, p. 174.
[5]. STEINKOLER Manya, Mar a logos. L’élection de Trump et les fake news, in Savoirs et clinique, n°23, 2017, p. 30.
[6]. Pouvoirs de l’algorithmie. Entretien avec Bruno Patino, in Médium, n°52-53, 2017, p. 178.
[7]. Ibid.
[8]. Ibid.
[9]. Brian Denis, Pulitzer: A Life, Wiley, New York, 2001, 464 p.
[10]. Taguieff Pierre-André, Les Protocoles des Sages de Sion. Faux et usages d’un faux, Fayard, Paris, 2004, 489 p.
[11]. ZAKHAROVA Larissa, Accéder aux outils de communication en Union soviétique sous Staline, in Annales. Histoire, sciences sociales, 2, 2013, p. 463-497.
[12]. EUSTACHE Sophie & TROCHET Jessica, De l’information au piège à clics. Ce qui se cache derrière Melty, Konbini, Buzzfeed…, in Le Monde diplomatique, n°115, 2017, p. 21.
[13]. MONOD Jean-Claude, Vérité de fait et opinion politique, in Esprit, octobre 2017, p. 143-153.
[14]. Voire par exemple https://www.snopes.com/trump-russian-poorly-endowed/, consulté le 20/11/2017.
[15]. Qui entretient une relation certaine avec le travail d’Illma Gore, voire ici : http://www.huffingtonpost.fr/2016/04/18/donald-trump-nu-micropenis-artiste-risque-proces_n_9719306.html.
[16]. https://www.islametinfo.fr/2015/10/22/photos-canada-le-nouveau-premier-ministre-serait-il-converti-a-lislam/, consulté le 06/11/2017.
[17]. ALLCOTT Hunt & GENTZKOW Matthew, Social Media and Fake News in the 2016 Election, in Journal of economic perspectives, voL. 31, n°2, 2017, p. 211-236.
[18]. BULLOCK John G., GERBER, ALAN S., HILL Seth J. & HUBER Gregory A. et al., Partisan bias in factual beliefs about politics, in Quarterly Journal of Political Science, vol. 10, 2015, p. 519-578.
[19]. STEINKOLER Manya, Mar a logos. L’élection de Trump et les fake news, in Savoirs et clinique, n°23, 2017, p. 28.
[20]. Bloch Marc, Réflexions d’un historien sur les fausses nouvelles de la guerre, Allia, Paris, 1999, p. p. 23.
Pour aller plus loin
« Rendre public ». Entretien avec Fabrice Arfi, in Médium, n°52-53, 2017, p. 59-84.
ALLCOTT Hunt & GENTZKOW Matthew, Social Media and Fake News in the 2016 Election, in Journal of economic perspectives, voL. 31, n°2, 2017, p. 211-236.
BELIN Célia, Comment anticiper la politique étrangère de Donald Trump ?, in Esprit, n°1, 2017, p. 131-139.
BERTHO-LAVENIR Catherine, Déjà-vu, in Médium, n°52-53, 2017, p. 85-100.
BLOCH Marc, Réflexions d’un historien sur les fausses nouvelles de la guerre, Allia, Paris, 1999, 64 p.
BRIAN Denis, Pulitzer: A Life, Wiley, New York, 2001, 464 p.
BULLOCK John G., GERBER, ALAN S., HILL Seth J. & HUBER Gregory A. et al., Partisan bias in factual beliefs about politics, in Quarterly Journal of Political Science, vol. 10, 2015, p. 519-578.
COLIN Nicolas & VERDIER Henri, L’âge de la multitude. Entreprendre et gouverner après la révolution numérique, Armand Colin, Paris, 2015, 304 p.
EUSTACHE Sophie & TROCHET Jessica, De l’information au piège à clics. Ce qui se cache derrière Melty, Konbini, Buzzfeed…, in Le Monde diplomatique, n°115, 2017, p. 21.
MONOD Jean-Claude, Vérité de fait et opinion politique, in Esprit, octobre 2017, p. 143-153.
Pouvoirs de l’algorithmie. Entretien avec Bruno Patino, in Médium, n°52-53, 2017, p. 173-185.
REBILLARD Franck, La rumeur du durant la présidentielle de 2016 aux États-Unis. Les appuis documentaires du numérique et de l’Internet à l’agitation politique, in Réseaux, n°202-203, 2017, p. 273-310.
STEINKOLER Manya, Mar a logos. L’élection de Trump et les fake news, in Savoirs et clinique, n°23, 2017, p. 23-33.
TAGUIEFF Pierre-André, Les Protocoles des Sages de Sion. Faux et usages d’un faux, Fayard, Paris, 2004, 489 p.
ZAKHAROVA Larissa, Accéder aux outils de communication en Union soviétique sous Staline, in Annales. Histoire, sciences sociales, 2, 2013, p. 463-497.












 Tout le monde sait faire du
Tout le monde sait faire du  Garantir la sécurité d’un programme est un problème difficile. Cela n’est sûrement pas une nouvelle pour vous étant données toutes les cyberattaques dont on entend parler dans les journaux aujourd’hui (
Garantir la sécurité d’un programme est un problème difficile. Cela n’est sûrement pas une nouvelle pour vous étant données toutes les cyberattaques dont on entend parler dans les journaux aujourd’hui (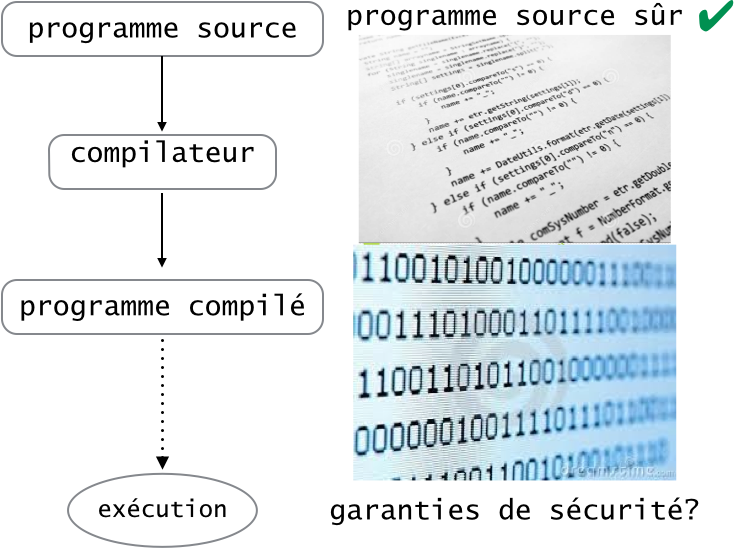
 Tahina Ralitera, jeune informaticienne malgache, actuellement en troisième année de doctorat au Laboratoire d’Informatique et de Mathématiques de l’Université de La Réunion, figure parmi les lauréates.
Tahina Ralitera, jeune informaticienne malgache, actuellement en troisième année de doctorat au Laboratoire d’Informatique et de Mathématiques de l’Université de La Réunion, figure parmi les lauréates.








 décembre. Plus de 500 000 élèves du CM1 à la terminale y participent.
décembre. Plus de 500 000 élèves du CM1 à la terminale y participent. «Merci pour ce concours, 3 ans que je le fais passer aux élèves. La plupart prennent beaucoup de plaisir et certains se découvrent même des capacités et prennent de la confiance en eux pour le reste de l’année. — Antoine, enseignant au collège dans l’académie de Nantes.
«Merci pour ce concours, 3 ans que je le fais passer aux élèves. La plupart prennent beaucoup de plaisir et certains se découvrent même des capacités et prennent de la confiance en eux pour le reste de l’année. — Antoine, enseignant au collège dans l’académie de Nantes.






{kind=link}
{kind=link}