
Combien de fois dans ma carrière, académique ou entrepreneuriale du reste, à la faveur de jurys, de comités de sélection, de comités de recrutement, voire même dans la sphère personnelle, n’ai je entendu cette litanie dès qu’on aborde la parité « Le pire c’est que les femmes sont encore plus dures avec les autres femmes que les hommes eux-mêmes ». Un peu comme on entend parfois que les femmes sont bien pires avec leurs belles-filles qu’avec leurs gendres, ou plus sévères que les hommes avec leurs brus, voire finissent toujours par bitcher un peu sur leurs copines. En fait les femmes sont-elles vraiment les pestes de service quand leurs alter-égos sont irréprochables sur le sujet ?

Dans le milieu professionnel, ce phénomène est encore plus marqué lorsque les femmes sont largement minoritaires, comme c’est le cas par exemple dans le numérique. Et chacun y va de son explication : qui d’expliquer que les femmes sont jalouses, qu’elles voient dans leurs congénères des rivales, qu’elles veulent conserver leur suprématie et j’en passe. Alors, mythe ou réalité ?
Mon objectif n’est évidemment pas de défendre les femmes mais d’essayer de faire l’inventaire de ce que l’on raconte à ce sujet, des explications plus ou moins rationnelles dont ces théories sont assorties pour essayer de comprendre où nous en sommes aujourd’hui. Il est intéressant de constater du reste que les anglo-saxons, ont même un nom pour ce phénomène : le syndrome Queen Bee, reine des abeilles en français, en référence au fait que cette reine n’accepte pas de partager son pouvoir dans la ruche. Intéressant du reste de voir que même le syndrome est genré, on avait pourtant le choix quand on sait que les mâles se dispute la place unique de chef de clan chez les loups ou les lions. Mais manifestement nul besoin de nommer explicitement un comportement hostile d’un homme envers un autre homme, c’est si naturel.
Si ce syndrome est donc bel et bien défini par nos amis d’outre-Atlantique comme celui qui pour une femme qui a percé dans son milieu professionnel, généralement numériquement dominé par les hommes, consiste à dénigrer voire brimer les autres femmes plutôt que de leur offrir son support inconditionnel, il s’applique du reste tout aussi bien à d’autres minorités, raciales, sexuelles ou sociales mais on en parle moins. Margareth Thatcher est souvent citée comme figure de proue de ce syndrome.
Donc nous en sommes là, alors même que des études soulignent que les hommes font preuve d’autant, voire plus, d’agressivité que les femmes, le stéréotype est ancré, colporté, discuté : nous avons quelque chose dans nos gènes qui nous rend hostiles aux autres femmes. Je vous livre donc un florilège d’explications potentielles que j’ai pu découvrir en discutant autour de moi et en observant les multiples réactions à des candidatures féminines.
Théorie numéro 1 : le complexe d’infériorité
Certains pensent que ce syndrome relève du simple complexe d’infériorité, c’est du reste cette explication qui s’adapte le mieux aussi aux autres minorités (raciales, sexuelles, etc.). L’explication viendrait du fait que les femmes sont dominées depuis la nuit des temps : certaines théories, en particulier défendues par Françoise Héritier [1] tendent à montrer que c’est en effet dès le néolithique que les hommes ont cherché à dominer les femmes en particulier en limitant leur accès à des nourritures très protéinés. La théorie est que les hommes, effrayés du pouvoir des femmes à enfanter, ont cherché à les diminuer de cette manière et qu’ainsi le dimorphisme physique ait été favorisé par des comportements sociaux de la préhistoire qui, s’ils étaient inconscients, étaient organisés. Notez que cette théorie est contestée [2] et je ne suis pas anthropologue mais je la trouve osée en tous cas.
Mais revenons à nos moutons, ainsi une femme, qui convaincue depuis son plus jeune âge, par la société qu’elle est « inférieure » en tous cas sur certains points à l’homme, applique ce complexe à toute représentante de son sexe et verra peut-être dans une candidature féminine, une infériorité dont elle souffre certes, mais dont elle a aussi largement accusé réception inconsciemment et qu’elle transmet inéluctablement.
Théorie numéro 2 : la peur d’être remplacée
Cette théorie est de loin la plus répandue et pourtant de mon point de vue la moins crédible. Elle consiste à expliquer que les femmes ont un comportement hostile vis à vis des autres femmes car elles ont une peur inconsciente d’être remplacées, en particulier dans certains milieux où en claire infériorité numérique, elles jouissent d’une situation particulière.
En prenant le risque de me faire traiter de féministe agressive, qui déteste les hommes (comme si ça allait avec), ce sont du reste surtout des hommes qui généralement soutiennent cette théorie.
C’est faire affront à notre bon sens que de penser ceci, il est bien évident pour toutes celles qui se trouvent dans des milieux très déséquilibrés en matière de parité, que nous aspirons à une plus grande diversité et que non seulement nous œuvrons pour la plupart à inciter plus de jeunes filles à embrasser des domaines éminemment masculins. Comme ce déséquilibre est un facteur aggravant pour l’engagement des jeunes filles dans ces disciplines, nous cherchons donc, pour la plupart, à défendre les femmes plus qu’à les dissuader.
Théorie numéro 3 : l’envie de voir les autres en baver autant
Cette théorie relève du fait que les femmes dans des milieux masculins en ont bavé pour arriver où elles en sont, en particulier en adoptant des modes de vie, de pensée, d’interaction, masculins, s’il en est. Ces femmes en particulier ont souvent mis leur bébé à la crèche à trois mois, n’ont pas nécessairement pris de congé parental, prennent des baby-sitters après l’école, adoptent un style d’interaction compatible avec leurs alter-égos etc. Quand bien même, elles affirment l’avoir fait délibérément et naturellement, elles ont parfois souffert de se voir malmener par la société ou leur entourage qui a pu tendre à les culpabiliser ou leur renvoyer une image de femme pour qui la carrière passe avant le reste, reproche assez peu formulé à l’égard des hommes.
Est-il possible que ces femmes attendent alors de leurs congénères d’en passer par là ? C’est une théorie qui a pu avoir un sens pour d’autres générations, à des époques où effectivement réussir pour une femme passait par un abandon quasi total de vie de famille, sociale, etc. En conséquence ces femmes en attendaient autant des autres femmes, voire leur rendaient la vie plus difficile pour les endurcir et mieux les préparer. Ce n’est plus le cas aujourd’hui à mon humble avis, surtout dans des domaines aussi jeune que celui du numérique et les femmes ne cherchent plus nécessairement à endurcir les plus jeunes mais plutôt à les guider.
Théorie numéro 4 : une simple réaction au machisme
Cette théorie est de loin la plus politiquement incorrecte. Elle consiste à expliquer un comportement hostile des femmes vis à vis des autres femmes en réaction au machisme ambiant. Prenons l’exemple, d’une femme qui bénéficie d’un jugement positif par des hommes dans un cadre scientifique en raison de critères qui sont tout sauf scientifiques. Clairement un jugement, favorable certes, mais sexiste de la part des hommes. En contrepoids, les femmes, potentiellement très agacées par la prise en compte de ces critères qui d’une part ne devraient pas intervenir, d’autre part sont clairement déplacés, peuvent réagir en recentrant le débat et en forçant le trait sur les critères éligibles. C’est souvent dans ce type de situation que les hommes en arrivent à la conclusion que les femmes sont décidément très jalouses entre elles et se retrouvent ainsi affublées de ce syndrome de Queen Bee.
Théorie numéro 5 : le double standard
Probablement la théorie la plus crédible. Est ce que tout ca ne vient pas tout simplement du fait que les réactions des femmes envers les femmes sont extrêmement stigmatisées ?
Comme je le voyais très récemment (juillet 2018) dans une vidéo de Girl gone international, quand un homme s’exprime de manière assurée, il est sûr de lui et c’est une qualité, une femme est plutôt perçue comme arrogante, quand un homme est incisif, une femme est plutôt agressive. L’équivalent d’un homme stratège est une femme manipulatrice, d’un bon manager est une femme qui cherche à contrôler. On est attendri par un homme féministe et agacé par ces femmes féministes, que l’on imagine constamment en colère contre le monde entier.
C’est ce qu’on appelle le double standard : si des hommes critiquent d’autres hommes, c’est du bon sens, s’ils se disputent, c’est normal voire sain. Du reste on attend des hommes qu’ils ne soient pas d’accord, qu’ils argumentent, qu’ils affirment leurs idées. Une femme qui se manifeste est en colère (ou pire, a ses règles), si elle critique une autre femme, elle devient rapidement une harpie, jalouse de la concurrence. Et cette perception est malheureusement perpétuée par les hommes et les femmes elles-mêmes parfois.
Pour conclure, nombreux (plus que nombreuses) s’accordent à dire que les femmes sont des chipies entre elles, et les théories fleurissent sur les explications au syndrome Queen Bee. Pourtant, il s’agit bien souvent de réactions normales simplement mal interprétées car les femmes ne encore pas soumises aux mêmes attentes et plutôt victimes de ce double standard. Et malheureusement ce double standard ne se cantonne pas aux comités de recrutement, mais touchent la sphère sociale, familiale, sexuelle etc. mais ça c’est une autre histoire !
Il semblerait que si le mythe persiste, ce syndrome soit bel et bien révolu comme le montre une étude brésilienne effectuée sur plus de huit millions de travailleurs de plus de 5000 organisations [5] et aujourd’hui les preuves [6] ne manquent pas pour montrer que les femmes luttent quotidiennement contre les stéréotypes de genre, que plus il y a de femmes dans un milieu professionnel, moins il y a de harcèlement et plus les écarts de salaires sont faibles. En outre, une femme recevra une meilleure écoute de son manager si c’est une femme que si c’est un homme concernant l’organisation familiale par exemple, une entrepreneuse aura plus de chances de lever des fonds si des femmes se trouvent parmi les investisseurs. S’il a jamais existé dans des générations précédentes, ce n’est plus une réalité aujourd’hui. Qu’on se le dise !
Anne-Marie Kermarrec, PDG de Mediego et Directrice de Recherche Inria
Références
[2] http://www.slate.fr/story/155300/patriarcat-steak-existe-pas
[3] https://www.huffingtonpost.com/2014/03/07/things-women-judged-for-double-standard_n_4911878.html
[4] https://uanews.arizona.edu/story/incivility-work-queen-bee-syndrome-getting-worse
[5] https://phys.org/news/2018-04-queen-bee-phenomenon-myth.html
[6] http://www.dailymail.co.uk/health/article-5612183/Queen-Bee-syndrome-isnt-real.html





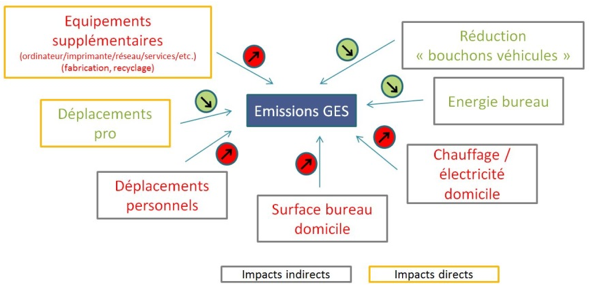

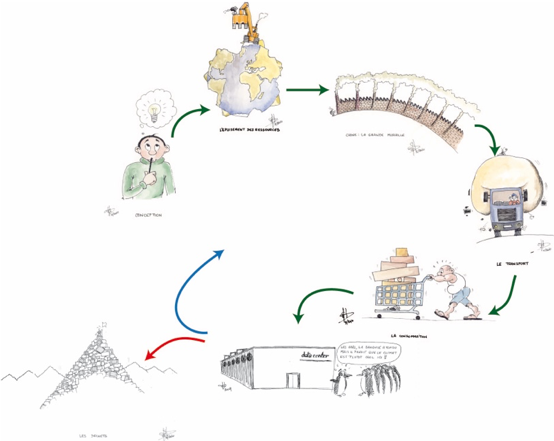










 On le sait, un des meilleurs moyens de se prémunir contre les cyberattaques est de mettre à jour sa machine, le plus vite possible, PC, laptop ou smartphone. Mais a-t-on déjà songé à la complexité du mécanisme de mise à jour pour le fabricant ou pour le concepteur du système d’exploitation ou du logiciel ? Il doit y veiller au niveau mondial et pour des centaines de millions d’utilisateurs. Dans le cas de systèmes d’exploitation très utilisés, la mise à jour, suite à un bug ou une vulnérabilité, doit parfois couvrir l’ensemble des versions, qui ont été produites avec cette vulnérabilité. Que faut-il faire ? Privilégier la version la plus récente et ainsi protéger la grande majorité des clients (mais en rendant vulnérables les utilisateurs de versions antérieures) ou attendre que la correction soit prête pour toutes les versions (un délai supplémentaire mis à profit par les hackers) ?
On le sait, un des meilleurs moyens de se prémunir contre les cyberattaques est de mettre à jour sa machine, le plus vite possible, PC, laptop ou smartphone. Mais a-t-on déjà songé à la complexité du mécanisme de mise à jour pour le fabricant ou pour le concepteur du système d’exploitation ou du logiciel ? Il doit y veiller au niveau mondial et pour des centaines de millions d’utilisateurs. Dans le cas de systèmes d’exploitation très utilisés, la mise à jour, suite à un bug ou une vulnérabilité, doit parfois couvrir l’ensemble des versions, qui ont été produites avec cette vulnérabilité. Que faut-il faire ? Privilégier la version la plus récente et ainsi protéger la grande majorité des clients (mais en rendant vulnérables les utilisateurs de versions antérieures) ou attendre que la correction soit prête pour toutes les versions (un délai supplémentaire mis à profit par les hackers) ?










 À notre connaissance, ce sont les
À notre connaissance, ce sont les  Tout au long du programme, l’étudiant est amené à réfléchir sur son propre projet à l’éclairage des différents enseignements qui lui sont proposés. Il est accompagné pendant son parcours de manière personnalisée grâce à l’expertise d’enseignants-chercheurs et de partenaires industriels. Le programme permet aussi de découvrir certains domaines dits “disruptifs” de la pédagogie : remise en cause des modèles pédagogiques et des savoirs dominants, recentrage de l’apprentissage sur la créativité et l’analyse critique,
Tout au long du programme, l’étudiant est amené à réfléchir sur son propre projet à l’éclairage des différents enseignements qui lui sont proposés. Il est accompagné pendant son parcours de manière personnalisée grâce à l’expertise d’enseignants-chercheurs et de partenaires industriels. Le programme permet aussi de découvrir certains domaines dits “disruptifs” de la pédagogie : remise en cause des modèles pédagogiques et des savoirs dominants, recentrage de l’apprentissage sur la créativité et l’analyse critique, Comprendre aussi comment se passe l’éducation ailleurs, ouvrir des possibilités de collaborations internationales sont deux des bénéfices de cette volonté d’ouverture.
Comprendre aussi comment se passe l’éducation ailleurs, ouvrir des possibilités de collaborations internationales sont deux des bénéfices de cette volonté d’ouverture.


 Mais les modèles économiques de ces deux formations sont très différents. La première aboutit à un diplôme national et est entièrement financée avec l’argent de l’État ; elle est donc accessible aux étudiant·e·s avec des frais d’inscription minimaux. L’autre est une
Mais les modèles économiques de ces deux formations sont très différents. La première aboutit à un diplôme national et est entièrement financée avec l’argent de l’État ; elle est donc accessible aux étudiant·e·s avec des frais d’inscription minimaux. L’autre est une 





 Depuis plus de 15 ans, j’ai communiqué sur à peu près tous les sujets sur lesquels les équipes de recherche d’Inria travaillent : réalité virtuelle, data, ingénierie logicielle, simulation, IHM, machine learning, robotique, internet des objets, réseaux, langages de programmation, … J’ai participé au déploiement du premier show-room d’Inria à Lille où j’ai scénarisé des démonstrateurs (salle d’opération, circuit de robot dans une ville, salle de classe) pour montrer la recherche différement. J’ai mis en place de nombreuses actions de médiation scientifique qui sont encore déployées aujourd’hui. Je viens en accompagnement à la stratégie de l’entreprise ou de l’établissement où je travaille pour piloter et déployer une communication sur-mesure. Dans mes différents postes, j’ai souvent réalisé des actions de com qui se voulaient décalées par rapport au contexte : des stands dans le domaine de la High-Tech avec une décoration en mur de pelouse ou avec un vrai jardin japonais, une campagne de changement de logo avec le visuel de Big Bang Theory, un jeu-concours sur Twitter pour faire voyager un badge #ILoveInriaLille, ou encore une vidéo parodique pour le départ en retraite d’un de mes directeurs. Je conjugue la communication au pluriel en gardant toujours à l’esprit les objectifs, les cibles et la pertinence des moyens.
Depuis plus de 15 ans, j’ai communiqué sur à peu près tous les sujets sur lesquels les équipes de recherche d’Inria travaillent : réalité virtuelle, data, ingénierie logicielle, simulation, IHM, machine learning, robotique, internet des objets, réseaux, langages de programmation, … J’ai participé au déploiement du premier show-room d’Inria à Lille où j’ai scénarisé des démonstrateurs (salle d’opération, circuit de robot dans une ville, salle de classe) pour montrer la recherche différement. J’ai mis en place de nombreuses actions de médiation scientifique qui sont encore déployées aujourd’hui. Je viens en accompagnement à la stratégie de l’entreprise ou de l’établissement où je travaille pour piloter et déployer une communication sur-mesure. Dans mes différents postes, j’ai souvent réalisé des actions de com qui se voulaient décalées par rapport au contexte : des stands dans le domaine de la High-Tech avec une décoration en mur de pelouse ou avec un vrai jardin japonais, une campagne de changement de logo avec le visuel de Big Bang Theory, un jeu-concours sur Twitter pour faire voyager un badge #ILoveInriaLille, ou encore une vidéo parodique pour le départ en retraite d’un de mes directeurs. Je conjugue la communication au pluriel en gardant toujours à l’esprit les objectifs, les cibles et la pertinence des moyens.














{kind=link}