Binaire, a demandé à Véronique Torner, co-fondatrice et présidente de alter way , membre du CA du Syntec Numérique, présidente du programme Numérique Responsable et membre du Conseil Scientifique de la SIF (Société informatique de France) de nous parler de l’initiative Planet Tech’Care. Marie Paule Cani et Pierre Paradinas.
Binaire: Véronique peux tu nous dire en quoi consiste le projet Planet Tech’Care? Véronique Torner : Planet Tech’Care est une plateforme qui met en relation des entreprises et des acteurs de la formation qui souhaitent s’engager pour réduire l’empreinte environnementale du numérique avec un réseau de partenaires, experts du numérique et de l’environnement.
En s’engageant autour d’un manifeste, les signataires ont accès gratuitement à un programme d’accompagnement composé d’ateliers conçus par les partenaires de l’initiative.
La plateforme est animée par le programme Numérique Responsable de Syntec Numérique. Le projet a été initié sous l’impulsion du Conseil National du Numérique.
Binaire : Qui sont les membres de Planet Tech’Care ?
Véronique : Vous avez d’un côté les signataires du manifeste, des entreprises de tous secteurs et de toutes tailles (du CAC40 à la start-up) et des écoles, universités, instituts de formation et d’un autre côté les partenaires, organisations professionnelles, associations, think tanks, spécialistes du sujet Numérique & Environnement.
Binaire : Que contient le manifeste de Planet Tech’Care
Véronique : Les signataires du manifeste Planet Tech’Care reconnaissent que le numérique génère une empreinte environnementale et s’engagent à mesurer puis réduire les impacts environnementaux de leurs produits et services numériques. Ils s’engagent également à sensibiliser leurs parties prenantes afin que tous les acteurs de l’écosystème numérique soient en mesure de contribuer à réduire leurs impacts sur leurs périmètres de responsabilité. En parallèle, les acteurs de l’enseignement, ainsi que les acteurs du numérique proposant des formations à leurs collaborateurs, s’engagent à intégrer des formations au numérique responsable et écologiquement efficient dans leur curriculum de cours. Ainsi, la nouvelle génération de professionnels sera en capacité de développer des produits et services technologiques numériques bas carbone et durables.
Binaire : Qui peut rejoindre le projet ? Pourquoi et comment impliquer les jeunes ?
Véronique : Toute entreprise et tout acteur du domaine de l’éducation peuvent nous rejoindre. Rassembler suffisamment de signataires dans le domaine de l’éducation sera essentiel pour impliquer massivement les jeunes. On peut à terme imaginer d’intégrer des formations au numérique responsable adaptées à tous les programmes des universités et autres établissement d’enseignement supérieur, des formations spécialisées en informatique à tous les secteurs utilisant le numérique, mais aussi d’associer une sensibilisation au numérique responsable aux programmes d’initiation au numérique au collège et au lycée. Nous comptons ensuite sur l’énergie et l’enthousiasme des jeunes pour que ces nouveaux usages diffusent à l’ensemble de la société.
Binaire : Comment sera évalué l’intérêt du projet Planet Tech’Care ?
Véronique : Nous ferons un premier bilan dans un an qui sera constitué de plusieurs indicateurs : le nombre de signataires, la qualité des ateliers, un baromètre de maturité de notre communauté. Nous comptons pour le lancement plus de 90 signataires et plus de 10 partenaires qui démontrent déjà l’intérêt d’une telle initiative. Notre enjeux est de :
– créer une dynamique autour d’acteurs engagés pour le numérique éco-responsable,
– fédérer les expertises pour passer de l’engagement à l’action,
– et enfin créer des communs pour passer à l’échelle.
Binaire : Tu es dans le CA du Syntec Numérique et le CS de la SiF, pourquoi ces instances se mobilisent-elles sur la question de la responsabilité sociale et plus particulièrement sur les impacts environnementaux ?
Véronique : Syntec Numérique est en première ligne sur les enjeux du Numérique Responsable qui constitue un des cinq programmes stratégiques de notre organisation professionnelle. Nous œuvrons depuis plusieurs années sur l’inclusion sociale et sur l’éthique du numérique. En ce qui concerne les enjeux environnementaux, notre industrie a un double challenge à relever. Nous devons bâtir des solutions numériques au service de la transition écologique, car nous le savons Il n’y aura pas de transition écologique réussie sans numérique. Et nous devons aussi, comme toutes les industries, réduire notre empreinte environnementale. Nous avons un groupe de travail très actif sur le sujet et nous animons désormais la plateforme Planet Tech’Care.
Par ailleurs, la SiF, Société informatique de France, qui anime la communauté scientifique et technique en informatique, a déjà montré son engagement pour une double transition numérique et écologique lors de son congrès annuel 2020, qui a porté sur ce thème. Diffuser plus largement cette réflexion est indispensable pour agir plus largement non seulement sur les acteurs socio-éconimique mais aussi, et en particulier via l’éducation, sur l’ensemble de la société. En particulier, le conseil scientifique de la SIF a tout de suite montré un grand enthousiasme pour le projet Planet Tech’ Care, jugé essentiel pour que le numérique devienne un véritable levier pour les transitions sociétales et écologiques !
StopCovid a agité les médias avant de passer pour quelques temps dans un relatif oubli. Le répit dans la propagation du virus le rendait relativement inutile. Mais le Corona revient et repose de manière critique la question de limiter sa propagation. En première ligne, la méthode manuelle de traçage de contact qui semble à la peine. On peut s’inquiéter d’entendre que ce n’est pas toujours simple de se faire tester, que les résultats tardent, que les personnes impliquées sont parfois réticentes à participer, que les services humains mis en place sont débordés, etc. La réactivité de la détection est critique si on veut bloquer la propagation du virus.
A coté de l’approche classique par enquêtes intensives, le traçage numérique a été proposé comme complément indispensable. En France, c’est StopCovid. Alors, quid de StopCovid ?
Une vidéo des Décodeurs explique clairement les deux formes de détection, humaine et numérique [11]Préambule : c’est clairement un sujet miné, une machine à prendre des baffes y compris de ses meilleurs amis. Nous tenons à préciser que nous sommes parmi ceux qui ont plutôt accueilli positivement l’approche française autour d’Inria. Nous pensons que c’est ok de donner au gouvernement des informations personnelles pour ralentir la pandémie, mais que le maximum doit être fait pour en garantir, autant que possible bien sûr, sa confidentialité mais aussi son efficacité.
Au 19 août, selon la DGS [1], « l’application a été téléchargée près de 2,3 millions de fois, sur les plateformes Android et Apple, depuis sa mise en service le 2 juin […] 1 169 QR codes ont été utilisés et 72 contacts à risque notifiés ». C’est évidemment décevant :
– Pas tant par le nombre d’installations : avec quasiment pas de publicité et d’autres sujets de préoccupation autrement plus importants comme les vacances, il ne fallait pas s’attendre à des miracles.
– Les 1169 QR codes correspondent aux personnes qui ont installé StopCovid et se sont déclarées contaminées. Cela représente 0,05% des 2,3 millions de ceux qui ont installé StopCovid, sans doute un peu plus si on considère qu’une personne peut l’avoir installée plusieurs fois. Ça reste très peu. Les gens qui installent StopCovid sont-ils beaucoup moins touchés que les autres par le virus (protégés par StopCovid 🙂 ? Ceux qui ont été contaminés n’ont-ils pas reçu de code à saisir, ne l’ont-ils pas déclaré ? On aimerait comprendre.
– 72 contacts notifiés pour 1169 QR codes, ça fait 0,06 contacts par personne malade. Comme il est peu probable que les gens qui ont installé StopCovid ne croisent quasiment jamais personne, faudrait-il croire qu’ils ne croisent que des gens qui n’ont pas installé ou pas activé StopCovid ? Ou alors est-ce que StopCovid ne fonctionne pas comme on le pense ?
Crédit image Pexels-bongkarn-thanyakij
Des utilisateurs de l’application s’interrogent :
– “Elle passe ses vacances avec sa fille testée positive au coronavirus, l’application Stop Covid ne l’alerte pas” [2].
– “J’ai été testé positif au #Covid19 vendredi et j’avais l’application #StopCovid […] j’ai donc voulu jouer le jeu en me déclarant positif sur l’application, et c’est là que je me suis heurté à un mur” [3].
On ne sait quoi répondre. De fait, on manque terriblement d’information publique sur l’App.
On sait ce qu’il faut faire pour l’installer, on connaît les principes selon lesquels elle a été conçue (utilisation de la technologie Bluetooth, architecture centralisée, protocole ROBERT). Mais on ne sait pas précisément comment l’App fonctionne une fois installée, quelles sont ses limites, et quelle est son efficacité. Nous avons bien inspecté son code (disponible en open-source [4], merci!) mais s’il permet aux plus initiés de voir comment l’application a été implémentée, il n’explique pas pourquoi elle l’a été de cette manière. Pourquoi une rotation de 90° d’un iPhone sur lequel tourne l’application fait-elle disparaître les informations présentes à l’écran et diminuer sa luminosité, par exemple ? Pour relativiser nos remarques qui peuvent paraître critiques, les applications de traçage de contacts développées dans les autres pays ne fournissent pas beaucoup plus d’informations sur ce qu’elles font une fois lancées, comment elles le font ou pourquoi elles le font de cette manière.
On dispose peu de suivi statistique de l’utilisation de StopCovid. Les Suisses, entre autres, pourraient nous donner des leçons de transparence [5]. Le projet était pourtant prometteur en termes de transparence, au départ. Une des conditions évoquées pour la réussite de ce dispositif était le nombre de téléchargements par les citoyens, mais au-delà des débats qui ont agité sa mise à disposition, la campagne d’information qui n’a duré que peu de temps n’a pas été convaincante. Il est dommage de constater que les illustrations des bonnes pratiques à adopter proposées par le gouvernement (“Luttons ensemble contre le Covid-19”, [6]) n’intègrent pas le téléchargement de l’application.
On aimerait une évaluation approfondie et publique de l’état des lieux et une information plus régulière sur l’application.
StopCovid a été réalisé dans l’urgence sous la pression publique. On ne pouvait pas s’attendre à ce que l’App soit directement parfaite. OK. Mais, maintenant, améliorons-la ! Deux questions ont éclipsé les autres : la protection des données et la souveraineté nationale (pour la question de l’accès à Bluetooth). On peut approfondir ces sujets.
Le système actuel n’utilise pas l’interface de programmation “Exposure Notification” d’Apple et Google (GAEN, [7]). En termes de souveraineté, c’est parfait, l’État gardant la maîtrise des données et de la gestion de l’épidémie. Mais les développeurs de StopCovid ont-ils réussi à s’affranchir des limites techniques imposées par Apple ou Google sur toutes les applications Bluetooth et qui rendent le traçage de contact difficile sans GAEN [8] ? Dans quelle mesure l’application peut-elle communiquer par Bluetooth lorsqu’elle n’est pas visible à l’écran, lorsqu’une autre application est utilisée ou que le téléphone est verrouillé ? Y-a-t-il des choses à faire ou ne pas faire pour que la communication se fasse dans de bonnes conditions ? Si des solutions techniques ont été trouvées, si des contraintes en résultent, elles méritent d’être expliquées. Si les limites imposées par Apple et Google ne peuvent être que mal contournées, si l’application doit être le plus souvent possible visible, au premier plan sans que le téléphone soit verrouillé, il faut le savoir et s’en souvenir pour lancer à court terme un plan d’enfer européen pour pouvoir se passer d’iOS et d’Android .
Pourquoi ne passe-t-on pas au nouveau protocole développé par Inria, DESIRE [9] ? Il a l’air trop cool. Est-ce qu’il y a des raisons techniques pour ne pas l’adopter ? Est-ce que ce serait trop compliqué de changer de protocole au milieu de la pandémie ? La base installée n’est pourtant pas si gigantesque.
A côté de ces deux aspects très discutés, un sujet hyper important a été, à notre humble avis, ignoré : l’App fonctionne trop comme une boîte noire. Si on veut que le numérique participe à régler les questions parfois existentielles posées à notre société de l’écologie aux épidémies, l’approche boîte noire ne fonctionne pas.
Certains ont reproché le manque d’aspect ludique de l’App, son niveau gaming très faible. Le fait que les gens la trouvent sympa et voient un intérêt personnel à l’utiliser n’est pas à négliger, évidemment. Mais l’enjeu principal n’est pas de faire une appli cool pour “jouer avec le Covid”. Ce qui est en jeu c’est avant tout la bonne compréhension de ce que fait l’application, de ce qu’il faut faire (ou pas) pour qu’elle fonctionne correctement une fois installée et qu’elle puisse être utile à la gestion de l’épidémie.
Je suis en train de parler à ma fille, je veux savoir si nos deux StopCovid se sont causées. OK, c’est une violation potentielle de confidentialité, mais si elle est d’accord et moi aussi ? Je devrais pouvoir vérifier que ça marche, regarder ce qui se passe si elle met son tél dans sa poche, ou au fond de son sac… Si on peut assister en direct à la rencontre de nos deux App qui se font coucou, on comprendra un peu mieux ce qui se passe.
Je veux savoir ce que sait faire le système et ce qu’il ne sait pas faire. Au minimum, j’aimerais savoir ce qu’il est en train de faire, ce qu’il a fait récemment. Si je ne sais pas répondre à de telles questions, est-ce que je vais réellement utiliser cette App ?
Qu’on ne se méprenne pas, nous ne proposons pas d’arrêter l’expérience. On ne pouvait pas s’attendre à ce que StopCovid soit immédiatement parfait. Nous on veut que cela fonctionne et nous aide à combattre la pandémie. Maintenant, améliorons-le ! C’est une belle occasion pour montrer comment réussir un projet collectif qui met le numérique au service de la société.
Serge Abiteboul, Claude Hinn, et Dominique Normane
L’avènement des véhicules autonomes (VA) et des VA communicants (VAC) pose des questions de sécurité routière, de cybersécurité et de protection de la vie privée des passagers. Binaire publiait en 2018 une contribution Sécurité routière et cybersécuritéqui nous alertait sur les risques encourus. Nathalie Nevejans et Gérard Le Lann reviennent sur ce sujet pour en donner un rapide éclairage scientifique, technologique, et juridique. Une première partie est consacrée aux véhicules autonomes. Une seconde, à venir, traitera des VA communicants. Serge Abiteboul
Les contes de fées des années 2010 ont vécu :
• Sécurité : Les VA ont parcouru des millions de miles/km sans accident : Faux. Le premier accident impliquant un VA s’est produit en 2011 devant le quartier général de Google en Californie.
• Efficacité : Les véhicules totalement autonomes seront disponibles en 2020 : Faux, à l’évidence.
Six niveaux d’autonomie ont été définis par la Society of Automotive Engineers, de 0 (conduite humaine) à 5 (conduite totalement automatisée, en tous lieux). Certains constructeurs affirment à présent qu’il n’y aura pas de VA de niveau supérieur à 3 tandis que d’autres, en coopération avec les meilleurs laboratoires du monde académique, verrouillent les droits de propriété intellectuelle et les brevets relatifs aux véhicules de niveau 5.
Les VA disponibles à l’achat, de niveaux 2, rarement 3, circulent sous le contrôle de conducteurs, aidés de systèmes ADASS (Advanced Driver-Assistance Systems), certains nécessitant un récepteur GNSS (Global Navigation Satellite System comme GPS, Galileo, Glonass, ou Beidou). En mode autonome, le comportement d’un VA est déterminé par un système de bord qui exécute des logiciels alimentés par des données provenant de divers capteurs (radars, lidars, caméras, etc.), de cartes numériques et d’algorithmes de reconnaissance environnementale exploitant l’apprentissage automatique.
Les six niveaux d’autonomie. Source : ResearchGate
Cockpit de VA (vue synthétique). Source : LinkedIn
Sécurité et efficacité. En 2017, aux États-Unis, on dénombrait 34 247 morts sur les routes, environ 10 fois moins en France. Les objectifs avec les VA sont
• sécurité : approcher 0 accident mortel et 0 blessure grave irréversible, et
• efficacité : réduire les temps de trajets.
Il est quasiment trivial de réaliser au moins en partie les objectifs sécuritaires en imposant de grandes séparations inter-véhiculaires et/ou de faibles vitesses. L’exigence d’efficacité, trop souvent ignorée, est donc essentielle. Outre des dizaines d’hospitalisations, six accidents mortels ont été causés à ce jour par des VA en mode autonome, cinq aux États-Unis et un en Chine. Les échantillons disponibles sont trop petits pour pouvoir conclure. Néanmoins, rien ne permet d’affirmer que le taux de mortalité avec les VA est ou sera inférieur à 1,13 par 100 millions de véhicules miles (le fatality rate en 2018 aux États-Unis pour des véhicules actuels conduits par des humains). Ce constat est conforté par une étude publiée par le IIHS [i] en juin 2020. Parmi les principales faiblesses, on trouve la faillibilité des capteurs et des techniques IA actuelles (les faux négatifs), le manque de communications explicites (cf. l’article à venir sur les VA communicants), ainsi que le partage d’autorité entre humain et système de bord. Ce problème, bien connu en transport aérien, n’a pas de solution générale. Partant du diagnostic selon lequel « The human is the bug », l’un des pionniers des Google cars choisit à l’époque de viser d’emblée la conduite automatisée.
Accident mortel d’un VA, 2018, Highway 101, CA, États-Unis. Source : Paloalto Online
La question des responsabilités. Tous les VA sont équipés d’enregistreurs infalsifiables – de boîtes noires. L’examen de l’historique des événements datés qui précèdent un accident permet de déterminer, dans chaque véhicule impliqué, le ou les événements qui a/ont causé l’accident. Donc, contrairement à ce qu’on lit parfois, il est possible d’identifier ce qui est à l’origine d’un accident : un conducteur, un équipement, un logiciel, etc. Ce travail d’enquête destiné à réunir des faits est mené par des experts mandatés par des tribunaux, des compagnies d’assurance, etc. Les tribunaux peuvent alors attribuer les responsabilités civiles (les dommages et intérêts) et/ou pénales en déterminant qui doit répondre des conséquences de l’accident.
Quel que soit le pays, un conducteur de VA est censé aujourd’hui être prêt à intervenir, si nécessaire, sous peine d’être tenu responsable en cas d’accident. Cette obligation est ambiguë. En conditions accidentogènes, en mode autonome, il n’y a que deux possibilités. Ou bien le système de bord fonctionne correctement : il émet une alerte sur désengagement. Les expérimentations [ii] démontrent que les délais de réaction des humains vont de 2 à 8 secondes, trop élevés pour éviter des collisions, mais suffisants pour en créer. Ainsi, un conducteur qui reprend la conduite sur alerte ne peut être systématiquement tenu responsable, sauf à imaginer qu’il est doté de capacités surhumaines. Ou bien le système de bord est défaillant : il reste muet et ne signale pas d’alerte. Afin de parer à des silences injustifiés, un humain doit donc surveiller son VA quasiment continuellement. De facto, cet humain conduit tout le temps ; avec certains modèles, il y est d’ailleurs contraint, voir plus loin. La contradiction avec les promesses liées aux VA est flagrante. Bien évidemment, un conducteur ne peut être tenu responsable des dysfonctionnements d’un système de bord.
Des législations nationales évoluent significativement pour tenir compte des réalités technologiques [iii]. Concepteurs, développeurs, intégrateurs, certificateurs, sont à l’origine des VA ou sont impliqués dans leur mise en service. Dans tous les cas des niveaux 1 à 4, leur responsabilité peut donc être engagée. Elle l’est obligatoirement en niveau 5, les conducteurs n’existant pas. Dans le cycle qui va de la conception d’un VA à son autorisation de commercialisation, puis à ses utilisations, il y a toujours in fine un ou des humains sur qui faire peser la responsabilité. Il ne sert donc à rien d’inventer une personnalité juridique des robots [iv] sur roues, dans le cas des VA.
Cybersécurité. Les capteurs extérieurs des VA peuvent défaillir et faire l’objet d’attaques comme des aveuglements visuels, des radars brouillés ou des signaux GNSS falsifiés, destinées à créer des collisions. La redondance des capteurs et les VA communicants permettent de gérer de telles défaillances ou attaques.
Protection des données personnelles. Traçage et collecte de données personnelles sont inévitables avec les applications de navigation payantes ou gratuites (Google Maps, Waze, Here WeGo, etc.). Mais leur activation est optionnelle, soumise au choix des passagers. Par contre, des capteurs intérieurs (caméras, micros, etc.) des VA actuels collectent en permanence des données sur les occupants. Au nom de la sécurité, il est pertinent de surveiller l’état de vigilance d’un conducteur. Par exemple, avec les Cadillac CT6, si le conducteur cesse de regarder la route plus de 5 secondes, une alarme est déclenchée par une caméra qui surveille en permanence le point focal de ses pupilles. Pour la recherche des responsabilités, il est légitime d’enregistrer dans une boîte noire les données de suivi de conducteur. Mais il n’est pas indispensable d’enregistrer aussi des données à caractère personnel comme qui voyage avec qui, à quelle heure, ou les conversations entre passagers. Au regard du RGPD et de la position récente de la Commission européenne sur la reconnaissance faciale, de tels enregistrements sont illégaux sans le consentement préalable des personnes concernées. Comment manifester un tel consentement ? Cette question, qui reste ouverte, a une réponse : offrir une optionintimité intérieure, dont l’activation entraîne la désactivation des capteurs, sauf ceux dédiés au suivi du conducteur. À l’exception des VA professionnels (flottes d’entreprises, transport public, etc.), le choix d’activer ou de ne pas activer cette option est laissé aux occupants d’un VA, qui n’ont pas nécessairement envie que des données personnelles soient enregistrées dans des serveurs inconnus, éventuellement revendues ou piratées. L’activation de cette option doit être aussi simple et intuitive que pour l’option « start/stop » moteur, exprimable via une commande tactile ou vocale.
Un article à venir est consacré aux VA communicants.
Nathalie Nevejans, Directrice de la Chaire IA Responsable (Université d’Artois) et Membre du Comité d’éthique du CNRS (COMETS), nathalie.nevejans@univ-artois.fr et Gérard Le Lann, Directeur de Recherche Émérite, INRIA Paris-Rocquencourt, gerard.le_lann@inria.fr
[ii] Par exemple, Stanford University et Robert Bosch, Conférence ITS 2015, pages 2458-2464
[iii] “Autonomous vehicles: Driving regulatory and liability challenges”, Automotive World, 7 avril 2020
[iv] Parlement Européen, 2017, dans une résolution sur les règles de droit civil en robotique. Le Groupe d’experts de haut niveau de la Commission Européenne s’est opposé à cette dérive
Nous entendons ou lisons très souvent – notamment dans binaire – que le numérique bouleverse à peu près toutes les facettes de nos vies. Que ce soit la médecine, le transport, l’industrie, le divertissement, quasiment tous les secteurs d’activité connaissent de profondes évolutions dues à l’informatique et ses applications. A première vue, l’éducation ne semble pas échapper à la règle si l’on croit les analyses les plus répandues. Gérard Giraudon et Margarida Romero, deux experts du numérique pour l’éducation, décryptent pour nous une vidéo de Derek Muller expliquant pourquoi ce n’est pas si simple. Pascal Guitton&Thierry Viéville
Depuis le début du 20ième siècle, nos sociétés ont connu nombre de révolutions technologiques (thermodynamique, nucléaire, informatique…) qui ont impacté la plupart des domaines (industrie, transports, commerce, agriculture, média…). Mises à part quelques exceptions, l’éducation n’en fait pas partie et les cours sont toujours donnés par un·e seul·e enseignant·e à des groupes d’élèves réunis dans une salle de classe. Certains pourraient reprocher cet état … à l’inertie de l’institution. Mais l’une des raisons pour laquelle la technologie n’a pas révolutionné l’éducation est au coeur même de ce qui est son rôle spécifique : créer un contexte social et relationnel adapté pour accompagner dans l’apprentissage des savoirs scolaires et des compétences nécessaires. Les apprentissages scolaires ne se produisent pas spontanément par la simple socialisation de l’enfant (Tricot, 2014) : il est nécessaire d’organiser les situations d’apprentissage. A l’école, ces savoirs se développent dans un contexte scolaire et social avec d’autres apprenant·e·s et des enseignant·e·s attentionné·e·s. Dans une vidéo publiée en 2014, Derek Muller de Veritasium démystifie ces “révolutions” technologiques et place l’enseignant·e au coeur d’une relation éducative essentielle pour engager les élèves dans les activités d’apprentissage. Au delà de l’engagement et l’autonomisation de l’apprenant·e soulignés par Muller, nous devons également considérer le rôle des enseignant·e·s au niveau de l’ingénierie des activités d’apprentissage et de leur orchestration, sans oublier les précieuses rétroactions qui contribuent, plus généralement, aux apprentissages.
Au delà de la vidéo
Oui « le rôle fondamental d’un enseignant n’est pas de fournir des informations, mais de guider le processus social d’apprentissage ; le travail d’un enseignant est d’inspirer, de mettre au défi, de motiver ses élèves à vouloir apprendre ». Et l’enseignant n’est pas qu’un animateur charismatique, il doit aussi avoir un rôle d’ingénieur pédagogique et de régulateur externe des processus d’apprentissage pendant l’activité et apporter des rétroactions permettant l’évaluation formative.
Comme l’explique très bien André Tricot en partageant les études sur les innovations pédagogiques et apprendre avec le numérique (voir par exemple cette présentation vidéo), le numérique est souvent un outil de plus, qui n’apporte pas en soi, d’innovation pédagogique. L’innovation technologique apportée par des technologies comme la réalité augmentée (RA), réalité virtuelle (RV) ou encore la robotique pédagogique et les approches de fabrication numérique (maker) changent la médiation des échanges mais ne sont pas en tant que telles des innovations pédagogiques. Tout comme les outils technologiques historiques (tableau blanc, crayon, matériel de construction…), c’est le type de médiatisation des activités qui peut donner lieu, dans certains cas, à une innovation pédagogique.
Le numérique ne révolutionne pas les apprentissages, mais, est-ce que le numérique peut contribuer à comprendre les processus d’apprentissage ? Au delà du rôle de la technologie comme outil de médiation dans ces processus, le numérique nous permet de générer des traces de certains comportements de l’apprenant tant dans le cadre d’environnements informatiques d’apprentissage humain (EIAH) que par l’analyse automatique (vidéo ou via des objets connectés) des activités d’apprentissage non médiatisées par la technologie. Certains EIAH sont conçus pour générer des traces d’apprentissage pertinentes afin de permettre un retour d’information servant à la régulation des apprentissages, ou encore, à leur évaluation, dans une perspective de recherche. Nous pouvons même envisager l’émergence d’une approche computationnelle en éducation, qui applique des méthodes d’apprentissage automatique (machine learning) à l’ensemble de ces données générées.
L’utilisation de telles approches nous permet de rendre davantage visible et traçable les comportements d’élèves ou groupes d’élèves liés à certains processus d’apprentissage.
Sans le support du numérique, les traces liées à ces processus doivent être générées par des processus de codification coûteux en ressources humaines. Prenons l’exemple de l’analyse de la résolution de problème dans une tâche type Tour de Hanoï. Pour son analyse, nous pouvons enregistrer la vidéo, puis ensuite codifier manuellement les opérations réalisées pendant l’activité. Une autre option serait de faire de chacun des disques un objet connecté permettant de générer les traces du comportement des élèves qui sont ensuite exploitées pour analyser l’activité réalisée par un grand nombre de participants à cette tâche, ce qui, après l’effort de codification, permet de générer sans coût supplémentaire des traces massives pour un modèle de problème bien défini. Cette deuxième approche ouvre la porte à l’application des approches d’apprentissage machine à des tâches d’apprentissage concrètes : analyser les processus avec des approches data science obtenues avec des traces pertinentes et offrir à un apprenant des aides personnalisées à partir d’un modèle développé sur un nombre important de participants.
Nous développons cette approche dans le contexte du projet AIDE mené à la suite du projet ANR CreaMaker qui a permis de développer des modèles de trace et des modèles en neurosciences computationnelles de l’équipe Mnemosyne. Dans ce projet, l’usage du numérique est au service de la génération de traces permettant de comprendre l’apprentissage humain dans une tâche concrète de résolution de problèmes.
La technologie ne révolutionne l’apprentissage mais peut permettre de l’étudier avec des nouvelles approches d’exploration et d’expérimentation dans des contextes spécifiés (Le numérique ne peut pas être utilisé sans tenir compte de la tâche et du contexte) fondées sur de l’acquisition de données. L’exploitation des approches computationnelles pour des tâches très formelles par exemple en mathématiques ou en grammaire est plus simple que pour des activités engageant des débats philosophiques ou des controverses environnementales, qui nécessitent davantage d’accompagnement humain dans le déroulement du débat. Par ailleurs, le contexte de coprésence ou distance est également à prendre en compte, des enseignant.e.s pouvant engager des élèves dans le contexte d’une classe, rencontrent davantage de difficultés dans des contextes de distance comme celles que nous vivons en confinement. D’ailleurs, la technologie peut-elle pallier (en partie) l’absence de coprésence entre l’enseignant.e et ses élèves ? La réponse à cette question reste complexe, mais nous pouvons observer que les réseaux formels et informels des apprenant.es qui s’entraident, tout comme la mutualisation de ressources et le détournement pédagogique de certains outils, initialement non prévus pour un usage scolaire, ont permis de co-construire des solutions dans des situations d’urgence. Les compétences numériques des enseignant.e.s, tout comme celles des élèves et des familles doivent pouvoir être soutenues pour pouvoir faire des choix éclairés dans ces contextes nouveaux. Mais ce n’est pas tant une question d’outil ou de technologie qu’un enjeu de pédagogie, de compétences et de communauté éducative travaillant ensemble envers la réussite de tou.te.s et chacun.e. Ainsi, l’apprentissage de l’informatique y compris sans utiliser d’écran, sans technologie numérique donc, s’avère aussi une opportunité pour des élèves n’ayant pas le même niveau de réussite dans un contexte éducatif traditionnel, et dans certains cas, permet aux jeunes de se réengager dans leur éducation.
Gérard Giraudon (Inria) & Margarida Romero (Université Côte d’azur, Directrice du Laboratoire d’innovation et numérique pour l’éducation)
Traduction du texte de la vidéo (avec l’autorisation de Derek Muller)
Tous les épisodes d’une non-révolution.
“Ça” va révolutionner l’éducation … aucune prédiction n’a été faite aussi souvent et aussi incorrectement que celle-ci.
En 1922, Thomas Edison déclarait que : « Le film est destiné à révolutionner notre système éducatif et dans quelques années, il va supplanter largement, voire entièrement, l’utilisation des livres. » Oui. Et vous savez comment ça a tourné ?
Dans les années 1930, c’était la radio. L’idée était que vous pouviez diffuser les cours d’experts directement dans les classes, augmentant la qualité de l’éducation pour plus d’étudiants à moindre coût. Et ça voulait dire avoir besoin de moins de professeurs expérimentés, un thème commun à toutes les révolutions proposées de l’éducation, comme celle de la télévision éducative dans les années 1950 et 1960. Des études ont été menées pour déterminer si les étudiants préféraient regarder un cours en direct ou être assis dans une salle à côté, où la même leçon était diffusée via une télévision. Que préférez-vous ?
Dans les années 1980 il n’y avait pas débat. Les ordinateurs étaient la solution révolutionnaire à nos problèmes éducatifs. Ils étaient multimédia, interactifs, et pouvaient être programmés pour faire pratiquement tout ce que vous vouliez. Leur potentiel était évident. Les chercheurs avaient l’intuition que s’ils pouvaient apprendre à des enfants à programmer, disons comment faire bouger une tortue sur un écran, alors leur capacité à faire des raisonnements procéduraux s’améliorerait. Et comment ça a marché ? Et bien disons que les étudiants sont devenus meilleurs à programmer la tortue, …
Même dans les années 1990 nous n’avions pas appris de l’échec de nos précédentes prédictions, et je cite, « L’utilisation des vidéodisques dans les classes s’accroît chaque année et promet de révolutionner ce qui se passera dans les classes de demain ». Vidéodisques? Oui, ces énormes CD surdimensionnés. Vous vous souvenez quand ils ont révolutionné l’éducation?
Depuis les annés 2000 des tas de choses sont sur le point de révolutionner l’éducation comme les tableaux intelligents, les smartphones, et les MOOCs. Ceux-ci sont des cours en ligne ouverts à tou·te·s («massive open online courses» en anglais). Et certains croient que nous nous rapprochons de la machine à enseigner universelle, un ordinateur si rapide et si bien programmé que ce serait quasiment comme avoir votre propre robot tuteur.
Un étudiant pourrait travailler avec des cours bien structurés adaptés à leur propre rythme et un avis personnellement adapté, et le tout sans qu’un enseignant, tatillon et coûteux pour la société, s’en mêle.
Mieux comprendre le processus d’apprentissage avec des outils technologiques.
Prenons le processus d’apprentissage. Disons que vous voulez enseigner à quelqu’un comment le coeur humain pompe le sang. Quel support éducatif serait à votre avis le plus efficace, cette animation avec explication ou cette série d’images statiques avec texte ? Évidemment l’animation est meilleure. Ne serait-ce que parce qu’elle montre exactement ce que le coeur fait. Pendant des dizaines d’années, les recherches sur l’éducation se sont concentrées sur des questions comme celle-là. Est-ce qu’une vidéo encourage l’apprentissage mieux qu’un livre ? Est-ce que les cours en direct sont plus efficaces que des cours télévisés ? Les animations sont-elles meilleures que des images statiques ? Dans toute étude bien contrôlée, le résultat est : aucune différence significative. Tant que le contenu est équivalent entre les deux traitements le résultat en termes d’apprentissage est le même quel que soit le média. Comment est-ce possible ? Comment quelque chose qui a l’air aussi performant que l’animation peut-il ne pas être meilleur que des images statiques ? Et bien premièrement les animations bougent rapidement et vous pouvez rater quelque chose. De plus, comme les éléments sont animés pour vous, vous ne visualisez pas mentalement comment les éléments s’articulent. Donc vous n’avez pas à investir un effort mental important, ce qui le rendrait marquant. En fait, des fois les images statiques sont plus efficaces que les animations. Nous ne sommes pas limités par les supports que nous pouvons fournir aux étudiants. Ce qui limite l’apprentissage c’est ce qui se passe dans la tête de l’étudiant. C’est là que se passe la partie importante de l’apprentissage. Aucune technologie n’est intrinsèquement supérieure à une autre. Les chercheurs ont passé tellement de temps à analyser si une technologie ou un média était plus efficace qu’un autre, qu’ils n’ont [parfois] pas cherché comment utiliser la technologie pour promouvoir des processus de pensée efficaces. Donc la question est en fait : quelles expériences engendrent le mode de pensée nécessaire à l’apprentissage ? Il y a peu, ce type de recherche a été lancé et nous apprenons des choses importantes. Ça peut paraître évident, mais il apparaît qu’apprendre avec des images et du texte ensemble, que ce soit des animations avec narration ou des images statiques avec du texte, est mieux que d’apprendre avec du texte seul. Aussi, nous observons que tout ce qui est superflu doit être éliminé d’une leçon. Par exemple, le texte à l’écran entre en concurrence avec les visuels, donc les étudiants apprennent mieux quand il est absent que lorsqu’il est présent. Maintenant que nous savons comment faire de meilleures vidéos éducatives, et comme toute expérience peut être simulée en vidéo, YouTube devrait être la plateforme qui va révolutionner l’éducation. Le nombre de vidéos éducatives sur YouTube augmente chaque jour.
Donc pourquoi avons nous besoin d’enseignants ?
Et bien, si vous pensez que le travail principal d’un enseignant est de transmettre l’information de son cerveau à celui de ses étudiants, alors c’est vrai, il est devenu obsolète. Vous imaginez probablement une classe où l’enseignant déverse des connaissances à un rythme qui est trop rapide pour la moitié, et trop lent pour le reste et donc adapté à personne. Heureusement le rôle fondamental d’un enseignant n’est pas de fournir l’information. C’est de guider le processus social d’apprentissage. Le travail d’un enseignant est d’intéresser et de mettre au défi les élèves qui veulent apprendre et de motiver ceux pour qui c’est plus difficile. Oui, il explique et démontre et montre des choses, mais en réalité ce n’est pas son but. Le rôle le plus important d’un enseignant c’est de faire en sorte que chaque étudiant se sente important, pour qu’il se sente responsable de faire l’effort d’apprendre. Tout cela ne veut pas dire que la technologie n’a pas eu d’impact sur l’éducation. Les élèves et les enseignants travaillent et communiquent avec des ordinateurs. Et des vidéos sont utilisées en dehors et pendant les cours. Mais tout cela est mieux caractérisé comme étant une évolution, pas une révolution. Les fondements de l’éducation sont toujours l’interaction sociale entre enseignants et élèves. Aussi avancée que chaque nouvelle technologie semble être, comme les vidéos ou les ordinateurs ou les tableaux intelligents, ce qui est vraiment important c’est ce que qui se passe dans la tête de l’apprenant.e. Et faire réfléchir un élève s’obtient de façon optimale dans un contexte social avec d’autres élèves et un enseignant attentionné et bienveillant.
Jean-Marc Jezequel, est Professeur d’informatique à l’Université de Rennes 1 et directeur de l’IRISA. Il a reçu en 2016 la médaille d’argent du CNRS. Jean-Marc nous explique d’où viennent ces petites bêtes que sont les bugs qui régulièrement nous dérangent dans nos activités numériques et peuvent coûter cher… et nous emmène au fond des enjeux théoriques et techniques de cette déboguisation. Pierre Paradinas
Photo : Univ Rennes 1, Dircom/Cyril Gabbero
Le processus de création du logiciel est assez extraordinaire. D’un coté, il est si facile d’écrire des programmes simples qu’un enfant de 6 ans peut, après seulement quelques minutes de formation, déjà réaliser des programmes spectaculaires avec des langages comme Logo ou Scratch.
Mais d’un autre coté, il est si difficile d’écrire des programmes complexes que, fondamentalement, personne n’est capable d’écrire de grands programmes sans bugs. Pour écrire un programme de 100 lignes de code source, la méthode ou le langage de programmation utilisé n’a pas vraiment d’importance, et si vous échouez, vous pouvez tout simplement recommencer à zéro à très peu de frais. Cependant, il est bien connu depuis l’époque des années 70 où Fred Brooks a écrit son livre « The Mythical Man Month », que la rédaction d’un programme de 100 000 lignes est beaucoup plus difficile que 1000 fois l’effort nécessaire pour écrire un programme de 100 lignes.
Courtesy of the Naval Surface Warfare Center, Dahlgren, VA., 1988. U.S. Naval History and Heritage Command Photograph. Catalog #: NH 96566-KN
D’où vient cette complexité, cause première de l’occurrence de « bugs » dans les programmes informatiques? En mettant de côté les vrais « bugs » (voir photo au dessus), les fautes de frappes et autres étourderies qui sont pour l’essentiel éliminées à la source dans les environnements de développement modernes, nous pouvons classer leurs principales sources en 3 catégories fondamentales : complexité inhérente, complexité due à la taille, et complexité due à l’incertitude.
Complexité inhérente des logiciels
Cela est dû aux racines du logiciel, comme expliqué dans la théorie du calcul universel d’Alan Turing, à l’origine de l’informatique. Même les programmes extrêmement courts et simples peut être impossible à prouver ou même avoir des propriétés indécidables, c’est à dire que l’on ne peut pas prouver qu’elles sont vraies, ni qu’elles sont fausses. Des choses très simples, comme savoir si une variable a une certaine valeur, ou si on va passer par une certaine instruction, ou si on va faire une division par 0 à un moment donné, ne sont dans le cas général, tout simplement pas prouvables. En d’autres termes, répondre à la question : « ce petit bout de code a-t-il un bug? » n’est en général pas possible. C’est donc une limitation intrinsèque de la nature de ce qu’est un logiciel, pris en tant qu’objet mathématique.
Petite illustration de la difficulté à prouver même des programmes simples,issue de la conjecture de Syracuse. Prenons ce petit programme :
Lire une valeur positive:
Tant que n > 1 faire
si n est pair
alors n prend la valeur n / 2
sinon n prend la valeur 3 n + 1
Fin du tant que
Sonner alarme
Peut-on prouver que l’alarme est sonnée pour tout n ?
En fait on ne sait pas si on peut le prouver, ni même si c’est vrai (car c’est une traduction informatique de la célèbre conjecture de Syracuse).
Mais si je suis ingénieur et que je dois me rassurer sur le fait que ce code n’a pas de bug, j’ai usuellement recours au test, c’est-à-dire que j’essaye pour différentes valeurs de n, et je regarde si l’alarme est sonnée à chaque fois. Mais je n’aurai aucune certitude tant que je n’aurai pas essayé toutes les valeurs, c’est à dire pour une machine 32 bits, 2^31, soit environ 10 milliards de cas de tests pour ces malheureuses 6 lignes de code. Tester exhaustivement un logiciel un tant soit peu complexe est donc en pratique impossible.
Complexité due à l’échelle.
Un être humain a la capacité de le comprendre dans son intégralité un logiciel relativement petit, mais rapidement, quand celui-ci grandit, la compréhension complète devient difficile. Ceci n’est, au contraire du cas précédent, pas propre à l’informatique, et se retrouve sous une forme ou une autre dans tout domaine d’ingénierie complexe. Il faut cependant savoir que les logiciels grandissent à peu près d’un facteur 10 tous les 10 ans (à notre époque du Covid-19, tout le monde est maintenant familier avec la signification d’une croissance exponentielle). De plus, l’une des caractéristiques des logiciels est qu’ils relèvent des sciences discrètes (le « numérique ») et non pas continues (comme c’est généralement le cas en physique, sauf aux échelles quantiques). Ils peuvent être constitués de centaines de millions de pièces individuelles, toutes différentes, interagissant entre elles de manière complexe et non linéaire, voire chaotique. C’est à dire qu’un petit problème, à un moment donné, peut se propager et complètement mettre par terre l’ensemble du logiciel (c’est le bug !), ce que l’on ne va pas trouver dans d’autres disciplines d’ingénierie beaucoup plus continues : ce n’est pas parce qu’il y a un écrou qui saute d’un pont que le pont va s’écrouler, alors que l’équivalent dans un logiciel peut faire s’écrouler l’ensemble (voir à ce propos E. Dijkstra).
Dans cette dimension de complexité, Fred Brooks (encore lui) avait identifié deux sous-catégories : la complexité essentielle et la complexité accidentelle. La première est inhérente au problème que le logiciel doit résoudre, et peut découler, par exemple, de la variété des événements ou des données d’entrée qui doivent être correctement traités par le logiciel, ou encore de la criticité des fonctions qu’il doit réaliser, comme dans le cas des logiciels de contrôle d’un avion commercial. La complexité accidentelle provient en revanche de choix technologiques inappropriées au contexte (ou qui furent appropriés mais qui ne le sont plus), ce qui conduit à des efforts humains importants (voire démesurés) consacrés au développement et à la maintenance du logiciel. Le fiasco du logiciel de paye de l’armée française en est sans doute un exemple parmi tant d’autres.
Complexité due à l’incertitude
Cette dimension de complexité, n’ayant à nouveau rien à voir avec les deux premières, est liée au fait que les logiciels ne sont pas seulement des algorithmes abstraits, mais sont plongés dans le monde réel. Le raisonnement mathématique s’arrête à la limite de ce passage dans le monde réel, puisque qu’il ne peut atteindre qu’un modèle du monde, et non la réalité de celui ci. Or dans le monde réel, les logiciels sont comme pris en sandwich entre d’une part la machine sur laquelle ils s’exécutent et d’autres part les humains qui les utilisent. Or il y a toujours un écart entre le logiciel et ce qu’on est capable de savoir formellement sur son environnement : la réalité de la machine d’une part et la réalité de ce que veulent les humains d’autre part. En particulier sur les grands logiciels ayant de multiples parties prenantes, beaucoup d’utilisateurs aux métiers très différents doivent interagir. Les exigences auxquelles doit se conformer le logiciel, notamment les règles commerciales ou juridiques et le comportement humain attendu sont généralement non seulement incomplètes mais encore évoluent avec le temps. Cela conduit à des exigences qui peuvent être floues, voire contradictoires, instables et donc source de malentendus. Ceci est en pratique la plus grande source de bugs des logiciels. Mais l’incertitude dans le développement de logiciels provient aussi de nombreuses autres sources : par exemple les hypothèses sur le monde dans lequel évolue le logiciel sont généralement assez grossières, implicites, et sauf pour les projets les plus critiques (avionique, centrales nucléaires…), ne prennent pas en compte de tous les cas particuliers. L’incertitude peut encore provenir de la machine sur laquelle s’exécute le logiciel, soit de manière inhérente (pannes de matériel ou même simples perturbations sur le réseau), ou accidentellement en raison, par exemple, de mauvaises interprétations ou de modifications des API. Ainsi même un logiciel comme le compilateur CompCert prouvé correct dans le monde abstrait (ce qui est en soi une prouesse intellectuelle qui force le respect), se révèle truffé de bugs lorsqu’on le teste pour de vrai dans certains contextes un peu tordus (les recoins glauques de la norme du langage C, ou les comportements surprenants de certaines architectures de processeurs).
Et tout ceci sans même compter les cyber-attaques et autres altérations malveillantes de l’environnement de notre logiciel. Ce tableau est bien sombre, mais bien sûr les chercheurs et les ingénieurs ne sont pas restés les bras croisés devant ces difficultés.
Pour faire face à la complexité inhérente aux logiciels, on a inventé toute une gamme de techniques allant de la preuve formelle complète d’éléments de logiciels sous certaines hypothèses, à la construction d’une forme de confiance avec des mécanismes tels que la conception par contrat ou les tests unitaires, qui ne peuvent en aucun cas suffire, mais c’est déjà bien mieux que ne rien faire.
En raison de la capacité limitée de l’esprit humain (personne ne peut comprendre pleinement un million de lignes de code), faire face à la complexité due à l’échelle ne peut se faire que par l’abstraction et la modularité. En effet si un programme d’un million de lignes est composé de 10 modules, chacun composé de 10 sous-modules, chacun composé de 10 autres sous-modules, et chacun de ces modules de 1000 lignes de code, alors je peux à la fois comprendre « totalement » un module donné et comment il s’intègre dans les 999 autres, à condition d’avoir un résumé hiérarchisé (abstraction) pour la compréhension de ces derniers (ce qu’ils font, pas comment ils le font).
Pour faire face à la complexité due à l’incertitude, il faut intégrer la gestion de l’incertitude au processus de développement, ce qui est par exemple en partie le cas des méthodes dites « agiles », avec leurs retours fréquents vers les utilisateurs finaux pendant la phase de développement. Il faut aussi être capable d’anticiper correctement les zones des changements éventuels, en identifiant et en isolant (ou du moins en réduisant le couplage avec) les parties incertaines, et donc qui pourraient changer. C’est l’idée de la séparation des préoccupations, ainsi que la gestion explicite des variations, selon les deux dimensions de l’espace (existence de plusieurs variantes simultanées pour prendre en compte des particularités locales ou des contradictions dans les exigences) et du temps (existence de versions successives).
Sur ce dernier plan, les recherches actuelles portent sur le fait de donner de la flexibilité sur comment et quand peut être prise la décision de choisir une variante dans le cycle de vie des logiciels : au moment de la formulation des exigences (domaine de l’ingénierie des exigences), au moment de la conception (domaine des lignes de produit logiciels), ou au temps de l’exécution (domaine des systèmes adaptatifs), avec à l’intersection de ces deux domaines, le temps de la compilation, du chargement, et celui de la compilation à la volée, dite « Just In Time ».
L’ensemble de ces dimensions forme ce que l’on appelle de nos jours les sciences du logiciel, qui, aux frontières des mathématiques et de l’ingénierie des systèmes complexes sont des domaines passionnants où beaucoup reste encore à découvrir.
Matthias Puech est ingénieur R&D à l’INA au sein du Groupe de Recherches Musicales, compositeur et enseignant-chercheur en informatique au CNAM. Après nous avoir expliqué les origines de la recherche musicale en France, il nous explique comment les ordinateurs traitent le son, les contraintes et les perspectives de l’informatique musicale. Pierre Paradinas
L’Informatique, instrument de la recherche et de la création musicale
De l’invention du piano-forte à celle de la guitare électrique, du tempérament égal à la composition procédurale, est-il nécessaire de rappeler l’incroyable influence des sciences et techniques sur la pratique musicale ? Art éminemment opportuniste, la musique s’est tellement continuellement nourrie des progrès de son époque pour s’inventer que l’on pourrait écrire une Histoire entière des techniques, vue uniquement depuis le prisme des modes et des outils de composition et d’interprétation musicale ! Mais laissons cette entreprise titanesque pour un autre jour, et contemplons un instant sa relation, déjà infiniment riche, avec notre sujet préféré, l’Informatique. Évidemment, la grande révolution du 20e siècle ne fait pas exception, loin de là, et dès les premiers babillages des ordinateurs, on a cherché à en faire un assistant du compositeur, voire de l’interprète. Et même si aujourd’hui l’ordinateur est omniprésent dans notre façon de faire et d’écouter la musique, utiliser un ordinateur pour produire de la musique n’a techniquement rien d’évident ! Bref aperçu d’un mariage heureux à quoi tout s’opposait pourtant.
Un terreau d’expérimentations : le GRM
En France, l’un des premiers lieux où l’on explore l’utilisation de l’électronique puis de l’informatique pour la composition musicale est le GRM. Fondé au sein de l’ORTF en 1958 par Pierre Schaeffer, visionnaire iconoclaste au fort caractère, le Groupe de Recherches Musicales est la réunion d’une poignée de compositeurs et « technologistes » (pour faire un anachronisme) autour d’une idée qui va bouleverser les normes : celle d’une nouvelle forme musicale, produite directement grâce aux machines – originellement microphone et magnétophone – sans passer par l’étape traditionnelle de la notation et de l’interprétation. La musique concrète est née : elle n’est pas faite de notes et d’harmonie, mais de sons enregistrés, de transformations, de montage et de mixage ; elle n’est pas interprétée par un instrumentiste mais reproduite sur un « orchestre » de haut-parleurs.
Inutile de dire que ces précurseurs se tenaient au courant des avancées technologiques de leur époque ! De nombreux instruments de recherche et de création sonore ont vu le jour au sein du GRM : le phonogène, lecteur de bandes magnétiques multi-tête permettant de s’affranchir du temps ; le synthétiseur GRM « Coupigny », développé notamment par Francis Coupigny, synthétiseur modulaire analogique et petit cousin des ordinateurs analogiques dont on vous a déjà parlé ici, qui produisait ses sons par variation rapide du voltage entre des composants électroniques… et en 1978 SYTER, un des premiers ordinateurs (numériques) capable de traiter des sons électroniquement (avec la 4X de l’IRCAM). Un exemple de pièce créée avec SYTER de Christian Zanési. L’addition est salée car il s’agit de processeurs dédiés au traitement du signal, fabriqués pour l’occasion, mais les possibilités sont infinies. À la fin des années 80, quand l’ordinateur personnel se démocratise et le microprocesseur grand public devient assez puissant, les traitements musicaux « best of » de SYTER, et bien plus, sont portés sur ces machines et deviennent les GRM Tools, développés et utilisés aujourd’hui dans le monde entier.
Pourtant rien ne prédispose l’ordinateur, avec son temps discret et sa représentation binaire des données et des programmes, à manipuler des sons, ces variations continues de pression de l’air soumises aux lois de la physique de Newton ! Musicien des années 50 j’aurais plutôt parié que l’électronique du Coupigny, avec son flot continu d’électrons représentant le son de façon analogique (proportionnel à la pression) et son calcul différentiel, ait plus à dialoguer avec l’acoustique et la musique qu’une « suite de 0 et de 1 » comme disait ma grand-mère, orchestrée par un processeur et soumis à une horloge. Toute donnée manipulée par un ordinateur a une précision finie : entre deux valeurs contiguës, il n’y a rien ; de même, entre l’exécution de deux instructions il ne se passe rien, autrement dit le temps est fractionné en instants insécables, certes très rapprochés, mais tout de même discrets. Comment l’ordinateur peut-il donc stocker, générer ou traiter en temps réel le son ?
Du continu au discret : représentation
Pour représenter et traiter un son, variation de pression continue au cours du temps capturée par un micro par exemple, il faut donc lui trouver une approximation raisonnablement fidèle ; approximation double car temps comme espace devront être discrets : c’est l’échantillonnage et la quantification. On va mesurer cette pression à intervalle régulier, assez rapprochés pour ne pas « rater » de petites vibrations rapides ; la fréquence de cette mesure, ou fréquence d’échantillonnage, n’a pas à être très élevée, 44100 Hz (échantillonnage du son sur CD) suffira par exemple. On choisit ensuite la valeur représentable par l’ordinateur la plus proche de cette mesure, avec des pas assez petits pour ne pas faire une erreur trop grande dans cet « arrondi » ; stocker chaque échantillon sur 16 bits (quantification d’un CD) suffira par exemple. Résultat : nous représentons donc notre son par une suite de nombres sur 16 bits, des « carottes » ou échantillons, qui représentent chacun l’état approximatif de la pression de l’air à des instants successifs séparés du même petit delta de 1/44100e de seconde ; c’est le codage le plus simple, dit « PCM ». Si, chaque 1/44100e de seconde, on lit chaque échantillon dans l’ordre, faisant varier la position de la membrane d’un haut-parleur proportionnellement à sa valeur, on entendra le son stocké : l’oreille n’y aura vu que du feu, de la même façon qu’au cinéma, l’œil croit au mouvement quand on fait défiler rapidement des images successives !
Au passage, ces deux conversions, de l’analogique au numérique et vice-versa, sont appelés en anglais ADC (analog to digital conversion) et DAC (digital to analog conversion), et il existe des puces spécialement dédiées à ces tâches.
D’un son à l’autre : traitement
Relire un son enregistré est évidemment pratique, mais pas très utile pour faire de la musique. Cependant, maintenant qu’il est stocké comme une suite d’échantillons, on peut écrire un programme qui va modifier cette séquence (traitement) ou même en créera une de toutes pièces (synthèse) avant de la (re-)jouer. Par exemple :
Si je multiplie (resp. divise) chaque échantillon par 2, j’amplifie (resp. atténue) le volume du son de 6 dB ; autrement dit l’atténuation/amplification d’un son est simulée par l’opération de multiplication.
Si j’ai deux sons de même longueur, donc deux suites de N échantillons, en les additionnant échantillon par échantillon, je peux simuler le fait de les jouer tous les deux en même temps dans la même pièce : autrement dit, le mélange de deux sons est simulé par l’opération d’addition.
Je peux décaler tous les échantillons de N cases vers la droite ; le son résultant s’en trouvera retardé de N/44100 secondes. Si je mélange le son original et celui retardé de quelques milliers d’échantillons, j’aurai la perception d’un effet d’écho.
De façon générale, mélanger un son avec une ou plusieurs versions retardées de lui-même est un traitement appelé filtre : cela modifie son contenu en fréquence ; par exemple, un son mélangé à sa version retardée d’un seul échantillon amplifiera ses basses et atténuera ses aigus (filtre passe-bas).
Ce bestiaire pourrait continuer longtemps : des traitements simulant fidèlement un processus acoustique pour s’en affranchir comme les réverbérations, spatialisateurs ou synthétiseurs à modélisation physique, aux classiques utilisés dans les studios d’enregistrement depuis l’ère analogique (compresseurs, distorsions), aux traitements nés et rendus possibles uniquement par les possibilités du numérique, jusqu’aux effets créatifs les plus hétérodoxes, destinés aux sound designers et compositeurs adeptes d’une démarche plus expérimentale… il n’a de limite que la science et la créativité de celui qui les conçoit !
Le temps-réel
Mais soyons pragmatiques ; à ce point, le lecteur au doute facile se demandera : mais qui place donc les échantillons en provenance de l’ADC dans la mémoire, et qui vient les relire vers le DAC une fois le traitement effectué ? Et même si nous savons comment traiter un extrait sonore dans son intégralité puis le rejouer transformé, en « temps différé », comment fait-on pour traiter un son « en temps réel », au fur et à mesure de son arrivée d’une source externe ?
Pour communiquer avec l’extérieur l’ordinateur est connecté à des périphériques : clavier, écran… et interface audio. L’interface audio contient un ADC et un DAC, et a sa propre horloge qui bat la mesure à la fréquence d’échantillonnage voulue (e.g. 44100 Hz) ; à chacun de ses « tics », elle lit une valeur en mémoire et l’envoie au DAC, puis elle capture un nouvel échantillon depuis l’ADC et le place en mémoire. Puis elle signifie au processeur qu’un nouvel échantillon est disponible ; celui-ci s’exécute : il calcule l’échantillon de sortie en fonction de celui d’entrée, ainsi au prochain « tic », celui-ci sera envoyé au DAC.
On peut remarquer deux choses ici : premièrement, le processus n’est jamais véritablement « temps-réel », puisqu’il a forcément un cycle d’horloge (1/44100e de seconde) de retard au minimum, c’est la latence. Deuxièmement, le processeur n’a pas tout son temps : il doit absolument calculer l’échantillon de sortie avant que celui-ci soit envoyé au DAC, sous peine de rater l’échéance et de produire un vilain « clic ». Entre la capture et la restitution, il dispose donc de 1/44100e de seconde ; au rythme de 1 GHz, cela ne représente que 20 petits milliers d’instructions. Cela peut paraître beaucoup, c’est en réalité assez peu et les traitements devront être soigneusement optimisés pour ne jamais dépasser ce temps !
Conclusion
Nous tenons donc là la recette, ou plutôt le principe actif, de l’ensemble des logiciels d’enregistrement, de montage, de mixage, de synthèse, de traitement du son, utilisés aujourd’hui par la majorité des musiciens, tous genres confondus : la manipulation en temps réel de flux de valeurs (échantillons), représentant un son. Ces mêmes techniques sont à la base de l’enregistrement d’un orchestre symphonique, d’un groupe de rock dans un garage, de la bande-son d’une production Hollywoodienne ou d’une pièce de musique concrète. Depuis les années 90, le numérique règne en maître sur la production musicale… et pas seulement l’ordinateur ! Grâce à l’essor des petits microprocesseurs embarqués bon marché (microcontrôleurs, DSP), on voit revenir ces dernières décennies des machines autonomes, des formes d’instruments électroniques que l’on croyait perdus, dépassés par l’hégémonie de l’ordinateur. Par exemple, le synthétiseur modulaire Eurorack, sorte de kit de construction d’instruments, actualise fidèlement le principe du Coupigny du GRM ; seule différence, derrière le panneau de contrôle, plus d’oscillateurs analogiques mais de puissants microcontrôleurs et des algorithmes à la pointe de la recherche scientifique et de l’innovation esthétique. Retour en arrière ? Attrait du « vintage » ou bon en avant de l’interface homme-machine ? Et si, en musique comme ailleurs, cela n’était qu’une expression supplémentaire de la nature protéiforme de l’ordinateur ?
Retrouver les travaux de l’auteur : https://mqtthiqs.github.io
Pour aller plus loin :
Laurent De Wilde, « Les fous du son » (Decitre) : une histoire romancée des technique dans la musique au XXe, incluant les prémisses de l’informatique musicale
John Pierce, « Le son musical » (Pour la Science, Belin) : un classique de vulgarisation, épuisé mais trouvable 🙂
Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines. Lêmy Godefroy nous explique aujourd’hui l’initiative du décret Datajust, un décret permettant l’utilisation du machine learning afin d’aider certaines décisions judiciaires. Elle nous éclaire aussi sur la limite d’applicabilité de ces algorithmes. Lonni Besançon
Le décret Datajust
Le gouvernement a adopté le décret dénommé Datajust le 27 mars dernier, en pleine période de confinement lié au coronavirus. Ce texte à l’étude depuis deux ans organise la mise en place d’un traitement des données des décisions de justice rendues en appel entre le 1er janvier 2017 et le 31 décembre 2019 par les juridictions administratives et judiciaires dans les contentieux portant sur l’indemnisation des préjudices corporels.
Les buts visés sont l’élaboration d’un référentiel indicatif d’indemnisation des préjudices corporels, l’information des parties, l’aide à l’évaluation du montant de l’indemnisation à laquelle les victimes peuvent prétendre afin de favoriser un règlement amiable des litiges et la mise à disposition d’une source nouvelle de documentation pour les juges appelés à statuer sur ces demandes d’indemnisation1. Plus précisément, il s’agit de traiter algorithmiquement les décisions rendues par les juridictions d’appel en matière d’indemnisation des préjudices corporels2.
Le chiffrage des dommages-intérêts versés en réparation de ces préjudices est depuis longtemps l’objet de barèmes destinés à aider les juges à les estimer.
Ces barèmes sont indicatifs et le juge s’en sert comme d’un référentiel.
Avec le déploiement des systèmes de machine learning, des algorithmes publics ont été à l’étude pour affiner le chiffrage de ces indemnités. Le traitement et la modélisation par ces algorithmes de masses de décisions rendues dans ce domaine éclairent la jurisprudence « concrète »3. Celle-ci devient exploitable. Elle offre au juge une meilleure connaissance du « droit en action ». Il se forme alors une collégialité judiciaire numérique circonscrite à un ressort territorial ou étendue à l’ensemble du territoire national : Chaque juge peut savoir « de quelle manière, dans la pratique, les différents juges de France traiteront telle question précise qui leur sera soumise (…) »4.
Les enjeux du décret
Ces chiffrages algorithmiques, comme les barèmes, sont des aides à la décision. Ils n’ont pas vocation à se substituer à l’appréciation du juge. Ils l’assistent dans sa fonction de dire le droit (existence d’un préjudice) et dans sa mission de concrétisation du droit ainsi prononcé qui se traduit par le chiffrage du montant des dommages-intérêts. En d’autres termes, « quand bien même il souhaiterait suivre la tendance majoritaire que lui restitue un outil algorithmique, le juge ne saurait y procéder qu’en se réappropriant le raisonnement qui se donne à voir. La décision de justice ne saurait être motivée (exclusivement) par l’application d’un algorithme sans encourir la censure qui, au visa de l’article 455 du code de procédure civile, s’attache à l’absence de motivation, à laquelle elle serait assimilable »5.
Les bénéfices attendus sont importants : une justice plus proche des justiciables et de leurs individualités. Par exemple, en matière d’indemnisation du préjudice corporel, les tendances algorithmiques permettraient un débat utile en ne plaidant pas « au premier euro », mais en déplaçant l’analyse sur les éléments de spécificité du préjudice. La décision de justice gagnerait ainsi en finesse de raisonnement en mettant en évidence les spécificités d’un préjudice non prises en compte par les standards d’indemnisation. Par exemple, une situation familiale atypique justifiant un ajustement des indemnités versées. La discussion entre les parties portant dans une affaire déterminée sur les écarts à ces standards est de nature à enrichir le débat judiciaire et à introduire des données d’évolution sociales susceptibles de faire évoluer la jurisprudence.
Datajust et covid-19 : la confusion
Très vite, sur internet, certains ont avancé que le décret Datajust allait servir à estimer la valeur des préjudices des victimes du coronavirus.
Or c’est précisément ce type de situation qui échappe au champ de compétence des algorithmes.
Ceux-ci ne sont fiables qu’en présence d’affaires typiques, reproductibles, comportant un nombre suffisamment important de décisions pour asseoir l’élaboration de modèles mathématiques capables de fournir des tendances quant aux montants probables de dommages-intérêts dans un cas similaire futur. Ils chiffrent, comparent, comptent, mesurent les répétitions pour extraire des corrélations.
Leur usage n’est pas envisageable en présence d’affaires qui, par leur singularité, nécessitent « un traitement individuel »6.
Une affaire est singulière notamment parce qu’elle est juridiquement spécifique. La spécificité vise les différends qui méritent un examen approfondi en raison de la nouveauté ou de l’actualité du problème juridique ou du caractère inédit des faits. Le juge clarifie ici les modalités d’exécution de règles qui n’ont été, jusque-là, que pas ou peu confrontées aux faits atypiques d’une espèce.
Ce contentieux dit qualitatif ne relève pas du champ de compétence des algorithmes. Il en va différemment du contentieux quantitatif qui se démarque par des problématiques récurrentes et par des solutions stables qui s’accordent à la nature mathématique des algorithmes. Leur champ d’action est donc celui des contentieux où des modélisations peuvent être opérées à partir de critères factuels connus, identifiables, reproductibles et chiffrables.
Le caractère inédit de la pandémie qui frappe aujourd’hui le monde et donc l’absence de précédents judiciaires font que, par nature, la question soulevée par certains de l’indemnisation des préjudices corporels des victimes du coronavirus ne peut pas être résolue par un calcul algorithmique.
Dans ce contexte difficile pour les corps et les âmes, prenons garde aux informations trop vite relayées de sites en sites et qui circulent sur les réseaux.
Lêmy Godefroy, Enseignante, chercheuse en droit, GREDEG UMR 7321, Université Côte D’Azur
Références et notes:
[1] Décret n° 2020-356 du 27 mars 2020 portant création d’un traitement automatisé de données à caractère personnel dénommé « DataJust », JORF n°0077 du 29 mars 2020, texte n°2.
[3] « La mémoire numérique des décisions judiciaires », D. E. Buat-Menard, P. Giambiasi, 2017, p.1483. P. Delmas-Goyon, op.cit., p.93 : « Au-delà de la conception traditionnelle de la jurisprudence (quelle est l’interprétation retenue de la règle de droit ?), il s’agit de savoir concrètement, dans une situation donnée, à quelle décision s’attendre si la justice est saisie (quelle pension alimentaire compte tenu de la situation respective des conjoints qui se séparent, quel montant de dommages-intérêts pour un préjudice donné, quel mode de poursuite pour une infraction déterminée, quelle durée de suspension du permis de conduire, quel aménagement de la peine, etc.) ».
[4] La prudence et l’autorité. L’office du juge au XXIe siècle, A. Garapon, S. Perdriolle, B. Bernane, C. Kadri, rapport de l’IHEJ, mai 2013.
On simule numériquement de plus en plus, le climat, le cerveau, les mouvements de foule, la propagation du Covid 19… C’est devenu un outil standard pour les scientifiques et les ingénieurs dans de très nombreuses disciplines. Victor Storchan et Aurélie Jean nous interpellent : pourquoi ? C’est vrai pourquoi ? Serge Abiteboul et Thierry Viéville
En 1954 le premier langage de programmation utilisé pour le calcul scientifique et connu encore aujourd’hui sous le nom de Fortran, est créé. Cette année là est aussi la date de parution de l’ouvrage posthume la Crise des sciences européennes et la phénoménologie transcendantale du philosophe et logicien Edmund Husserl. Dans cette œuvre, Husserl décrit les sciences comme un « vêtement d’idées » que l’on donne au monde « et qui lui va si bien ». Par analogie on peut également écrire qu’en informatique ou en sciences numériques, la modélisation est le processus par lequel la réalité de notre monde tangible s’habille harmonieusement des concepts de la physique, manipulables grâce au formalisme mathématique.
En pratique, on cherche à simuler un phénomène dans le but de l’analyser, de le comprendre ou encore d’en extraire des prédictions. Le mathématicien s’empare ainsi des équations de la physique qu’il ne peut généralement pas résoudre exactement. Il s’attache alors à trouver des propriétés qualitatives (comportements asymptotiques, vitesses de propagation, multiplicité des échelles) pour émettre des hypothèses simplificatrices raisonnables, et ainsi pouvoir fournir un schéma calculable par un ordinateur. Même si l’ordinateur et les simulations numériques existent depuis plus de 50 ans, la massification récente de la collecte des données associée aux dernières avancées des performances de calculs, permettent d’entraîner des algorithmes uniquement à partir des données d’apprentissage, et ce, sans description explicite de la physique du phénomène à simuler. On parle d’apprentissage statistique (big data) ou automatique (machine learning). Contrairement à la méthode dans laquelle on formule une hypothèse en amont de la collecte des données servant à l’évaluer, l’apprentissage tire parti de la profusion de données produites par notre société numérique pour tester un grand nombre d’hypothèses à la volée, et d’en suggérer des nouvelles.
Crédit Elsa Mersayeva de Cartoonbase
Alors qu’on observe le nombre et la taille des simulations numériques augmenter de manière significative, on peut se poser la question des raisons qui poussent à faire ces simulations. Pourquoi ne pas répondre directement aux questions posées dans notre monde réel et organique? Plus simplement, pourquoi simule-t-on la réalité ?
En pratique, on simule un phénomène pour trois raisons principales, parfois combinées, que sont l’impossibilité technique de réaliser à la main de grands calculs, l’impossibilité de reproduire dans la réalité une expérience pourtant nécessaire pour comprendre le phénomène étudié, ou encore tout simplement capturer et comprendre des mécanismes encore jamais identifiés dans le monde physique ou biologique.
Des calculs et des opérations à la main impossibles à réaliser
Les capacités de simulations numériques ont progressé grâce aux évolutions synchronisées de l’élaboration de théories plus fines et de l’amélioration des outils de calcul. Les travaux autour de la force de Coriolis illustrent ce point. En 1835, Gaspard-Gustave Coriolis formule une contribution décisive à la compréhension de l’influence de la rotation de la Terre sur la dynamique des corps. Bien avant l’époque des ordinateurs, c’est en étudiant la roue hydraulique que Coriolis calcule à la main les équations décrivant ces machines tournantes. Par la suite, son idée joue un rôle clé dans les moyens modernes d’analyse météorologique. C’est en effet grâce aux nouveaux outils de calculs, que les simulations par ordinateur sont ensuite devenues possibles et efficaces dans cette analyse.
Deux siècles plus tard, Google présente un modèle de Deep Learning dont la précision en espace et en temps des prévisions de différentes mesures météorologiques s’avère plus précise à très court terme qu’avec le schéma standard issu de la physique. Ce modèle permet de prédire le temps, sans connaissance a priori du fonctionnement de l’atmosphère, et à partir d’images radars ou de satellites. Cette approche n’est pas sans rappeler un certain Benjamin Franklin qui observait quotidiennement la météo dans son étude sur les origines de la foudre, sans connaissance physique du phénomène observé. Bien que ce type de modèle permette d’atteindre l’état de l’art actuel dans une multitude de tâches prédictives, soulignons qu’il ne fournit que rarement une explication interprétable souvent indispensable pour une bonne compréhension du phénomène. L’analogie avec une « boîte noire » résume communément notre incapacité de produire de théorie explicative dans des domaines où nous améliorons notre compréhension du monde et développons de nouvelles techniques.
Observer et analyser un phénomène impossible à capturer dans le monde réel
L’histoire des sciences nous enseigne que bon nombre de phénomènes se révèlent au mieux impossibles à observer et donc à mesurer et analyser dans le monde réel. Pire, ces phénomènes se jouent de notre bon sens et de notre intuition. Ainsi, les lois de Galilée contredisent l’observation qui nous inciterait à penser que des corps de masses différentes tombent à des vitesses différentes. Or Galilée nous dit que dans le vide, tous les corps tombent à la même vitesse sous l’effet de la gravité. L’expérience de pensée galiléenne constitue ainsi une modélisation du réel.
Plus tard, au début du XXe siècle, dans La connaissance et l’Erreur (1908), le philosophe des sciences autrichien Ernst Mach propose de réconcilier les expérimentations physiques et mentales. Il statue que « tout inventeur doit avoir en tête son dispositif avant de le réaliser matériellement » et donc disposer de suffisamment d’imagination pour faire le lien avec les connaissances empiriques. S’il n’est pas ici encore question de simulations informatiques, cette phrase permet comme dans le cas de Galilée, d’augmenter notre compréhension du monde au-delà d’une simple perception directement observable. En prolongement de Mach, Pierre Duhem dans La Théorie physique: son objet-sa structure (deuxième édition de 1914) motive l’emploi des modèles par les physiciens de l’école anglaise pour « créer une image visible et palpable des lois abstraites que l’esprit ne pourrait saisir sans le recours à ce modèle» . À partir des années 1980, le développement massif des moyens de calculs informatiques dotera cet objectif de supports technologiques décisifs.
Ainsi, de l’analyse détaillée des échanges boursiers haute fréquence aux simulations des phénomènes océanographiques, la modélisation, aidée par les capacités de calcul modernes, s’est imposée naturellement comme une application incontournable des sciences. La modélisation est rarement suffisante en soi et s’enrichit en confrontant ses résultats à des données expérimentales du monde réel.
Comprendre des phénomènes encore jamais expliqués
On admettra qu’on ne peut pas toujours tout observer et tout mesurer dans le monde réel. En réponse, un modèle peut permettre de découvrir des propriétés additionnelles et complémentaires de celle déjà identifiées dans le réel. Précisément, c’est le cas d’un modèle récemment développé au MIT et capable de rechercher des structures moléculaires et leurs fonctions biologiques associées, parmi un champ des possibles que l’approche expérimentale classique ne parviennent pas à circonscrire. En réalisant quelques centaines de millions d’inférence, le modèle permit la découverte d’un nouvel antibiotique. De plus, la modélisation associée aux campagnes expérimentales, permet de tester des hypothèses contrefactuelles indispensables lors de l’analyse du risque, peu importe la discipline d’application. On veut pouvoir anticiper des scénarios inédits. Ainsi, en sûreté nucléaire, la modélisation des structures des centrales et des comportements des matériaux qui la constituent permet de quantifier l’incertitude et de définir un corpus de normes robuste.
Force est de reconnaître que la modélisation augmente les capacités de test et d’exploration, auparavant limitées à l’analyse empirique, pour tenter d’éclairer nos intuitions par des démonstrations et des vérités scientifiques. Loin d’instaurer une tension entre ces différents points de vue, la modélisation répond au contraire à une sollicitation du monde empirique. On ne peut qu’espérer une longue vie à cette union des simulations numériques et du monde réel, notre compréhension du monde n’en sera à la fois que plus précise et plus élargie!
Victor Storchan,Ingénieur en Machine Learning, ancien élève de Stanfordet Aurélie Jean, Docteur en Sciences et entrepreneur (@victorstorchan et @Aurelie_JEAN)
Les applications de contact tracing soulèvent des espoirs et des inquiétudes. Cette semaine binaire a publié un article de Serge Abiteboul décrivant le fonctionnement de l’application Stop Covid [1] qui sera discutée la semaine prochaine au parlement. Cette application a également fait l’objet d’une tribune de Bruno Sportisse [2] qui s’appuie sur les travaux de plusieurs équipes européennes. Un autre collectif de chercheurs, majoritairement français, a publié le site internet Risques-Tracages.fr afin de proposer une analyse des risques d’une telle application, fondée sur l’étude de scénarios concrets, à destination de non-spécialistes. Nous vous en conseillons la lecture, de façon à vous forger votre propre opinion sur les avantages et les risques de tels outils. Car pour faire un choix éclairé, il faut savoir à quoi s’en tenir.
Depuis quelques jours, on lit et on entend (y compris dans Le Monde [3]) que « la tension monte », que « les scientifiques s’étrillent », que la guerre est ouverte entre les différents camps des experts. Il n’en est rien. Certes, il serait bien naïf de croire que les querelles d’égos n’existent pas dans un monde où l’évaluation et la compétition sont très présents, mais il est également tout aussi faux de dire que les chercheurs s’affrontent sur le sujet. Les collègues mentionnés ci-dessous se connaissent, s’apprécient et ont souvent eu l’occasion de travailler ensemble. En revanche, ils apportent des points de vue complémentaires, parfois contradictoires, qui doivent permettre d’éclairer la décision publique.
Le débat, vous l’imaginez, a été riche chez binaire et c’est une très bonne chose. Nous continuerons donc à publier les avis qui nous semblent scientifiquement pertinents sur le sujet.
Vous connaissez la méthode « agile » ? Non ? Vous n’êtes pas informaticien·ne alors ! Vous connaissez quelqu’un qui ressemble à un « nerd´´ ou un « geek´´ ? Ça ne doit pas être un·e informaticien·ne alors ! Dans ce billet, Pauline Bolignano avec la complicité de Camille Wolff pour les illustrations, déconstruit des idées reçues et nous explique ce que méthode « agile´´ veut dire. Serge Abiteboul et Thierry Viéville
Après quelques jours de confinement, une amie me dit : « je travaille dans la même pièce que mon coloc’, il passe sa journée à parler ! Je n’aurais jamais imaginé que votre travail était si sociable !». Son coloc’, tout comme moi, fait du développement informatique. L’étonnement de mon amie m’a étonnée, mais il est vrai que l’on n’associe pas naturellement « informaticien·ne » à « sociable ». D’ailleurs, si je vous demande de fermer les yeux et d’imaginer un·e informaticien·ne, vous me répondrez surement un homme aux cheveux cachés sous la capuche de son sweat-shirt, tout seul devant son écran, et pas sociable pour un sous :
Un geek quoi. En réalité, le métier d’ingénieur·e informaticien·ne demande énormément de collaboration. Je voulais donc plonger dans cet aspect du métier qui me semble être rarement mis en avant.
Les spécificités du domaine informatique
Lorsqu’on construit un logiciel, les contraintes et les possibilités sont différentes que lorsque l’on construit un édifice. Prenez par exemple la construction d’un pont. L’architecte passe de longs mois à dessiner le pont. Les ingénieur·es civil·e·s passent des mois, voir des années, à étudier le terrain, les matériaux et faire tous les calculs nécessaires. Puis les conducteurs/trices de travaux planifient et dirigent la construction pendant quelques années. Ensuite le pont ne bouge plus pendant des centaines d’années.
En informatique, c’est tout à fait différent. D’une part, il arrive que l’ingénieur·e soit à la fois l’architecte, le/a planificateur/rice, et le.a programmatrice/teur du logiciel. D’autre part, les cycles sont en général beaucoup plus courts. Pour reprendre la comparaison avec le pont, avant même de commencer l’architecture, on sait qu’il est possible que dans quelques mois le sol ait bougé, et qu’il faille adapter les fondations. Les ingénieur·e·s de l’équipe doivent sans cesse se synchroniser car il y a une forte dépendance entre les tâches de chacun·e.
Le développement logiciel offre plein de nouvelles possibilités. Il donne l’opportunité de construire de manière incrémentale, d’essayer des choses et de changer de direction, de commencer petit et d’agrandir rapidement. C’est comme si vous construisiez un pont piéton, puis que vous puissiez par la suite l’agrandir en pont à voiture en l’espace de quelques semaines ou mois, sans bloquer à aucun moment le trafic piéton.
L’organisation de la collaboration
La malléabilité et la mouvance du logiciel demandent une grande collaboration dans l’équipe. C’est d’ailleurs ce que prône la méthode Agile [1]. Ce manifeste met la collaboration et les interactions au centre du développement logiciel. Déclinée en diverses implémentations, la méthode Agile est largement adoptée dans l’industrie. Scrum est une implémentation possible de la méthode Agile, bien que la mise en place varie fortement d’une équipe à l’autre.
Prenons un exemple concret d’organisation du travail suivant la méthode Scrum : la vie de l’équipe est typiquement organisée autour de cycles, disons 2 semaines, que l’on appelle des « sprints ». A chaque début de sprint, l’équipe se met d’accord sur la capacité de travail de l’équipe pour le sprint, et sur le but qu’elle veut atteindre pendant ce sprint. Les tâches sont listées sur un tableau, sur lequel chacun notera l’avancement des siennes. Tous les jours, l’équipe se réunit pour le « stand-up ». Le « stand-up » est une réunion très courte, où chaque membre de l’équipe dit ce qu’ille a fait la veille, ce qu’ille compte faire aujourd’hui et si ille rencontre des éléments bloquant. Cela permet de rebondir vite, et de s’entraider en cas de problème. Régulièrement, au cours du sprint ou en fin de sprint, un ou plusieurs membres de l’équipe peuvent présenter ce qu’illes ont fait au cours de « démos ». Enfin, à la fin du sprint, l’équipe fait une « rétro ». C’est une réunion au cours de laquelle chacun·e exprime ce qui s’est bien passé ou mal passé selon lui.elle, et où l’on réfléchit ensemble aux solutions. Ces solutions seront ajoutées comme des nouvelles tâches aux sprints suivants dans une démarche d’amélioration continue.
Une pratique très courante dans les équipes travaillant en Agile est la programmation en binôme. Comme son nom l’indique, dans la programmation en binôme, deux programmeuses/eurs travaillent ensemble sur la même machine. Cela permet au binôme de réfléchir ensemble à l’implémentation ou de détecter des erreurs en amont. Le binôme peut aussi fonctionner de manière asymétrique, quand l’une des deux personnes aide l’autre à progresser ou monter en compétence sur une technologie.
Ainsi si vous vous promenez dans un bureau d’informaticien·ne·s, vous y croiserez à coup sûr des groupes de personnes devant un écran en train de débugger un programme, une équipe devant un tableau blanc en train de discuter le design d’un système, ou une personne en train de faire une « démo » de son dernier développement. Bien loin de Mr Robot, n’est ce pas ?
De Monsieur robot à Madame tout le monde
On peut également enlever son sweat-shirt à capuche à notre représentation de l’informaticien·ne, puisque développer du logiciel peut a priori être fait dans n’importe quelle tenue. En revanche, notre représentation de l’informaticien a bien une chose de vraie : dans la grande majorité des cas, c’est un homme. Si vous vous promenez dans un bureau d’informatique, vous ne croiserez que très peu de femmes. En France, il y a moins de 20 % de femmes en informatique, tant dans la recherche que dans l’industrie [2]. À l’échelle d’une équipe, cela veut dire que, si vous êtes une femme, vous ne travaillez probablement qu’avec des hommes.
Ceci est surprenant car l’informatique est appliquée à tellement de secteurs qu’elle devrait moins souffrir des stéréotypes de genre que d’autres domaines de l’ingénierie. L’informatique est utilisée en médecine, par exemple pour modéliser la résistance d’une artère à l’implantation d’une prothèse. Elle est utilisée dans le domaine de l’énergie, pour garantir l’équilibre du réseau électrique. L’informatique est aussi elle-même sujet d’étude, quand on souhaite optimiser un algorithme ou sécuriser une architecture [3,4]. Elle est même souvent une combinaison des deux. Quand l’informatique est appliquée à des domaines considérés comme plus « féminins » comme la biologie, la médecine, les humanités numériques, le déséquilibre est d’ailleurs moins marqué.
Il y a encore du chemin à faire pour établir l’équilibre, mais je suis assez optimiste. Beaucoup d’entreprises et institutions font un travail remarquable en ce sens, non seulement pour inverser la tendance, mais aussi pour que tout employé·e se sente bien et s’épanouisse dans son environnement de travail.
Pour inverser la tendance, il me semble important de sortir les métiers de leur case, car sinon on prend le risque de perdre en route tout·te·s celles et ceux qui auraient peur de ne pas rentrer dans cette case. En particulier, il me semble que cette image du développeur génie solitaire, en plus d’être peu représentative de la réalité, peut être intimidante et délétère pour la diversité. Dans ce court article, j’espére en avoir déconstruit quelques aspects.
En conclusion, cher·e·s étudiant·e·s, si vous vous demandez si le métier d’ingénieur·e informaticien·ne est fait pour vous, ne vous arrêtez pas aux stéréotypes. À la question « à quoi ressemble un·e ingénieur·e informaticien·ne ?», je réponds : « si vous choisissez cette voie … à vous, tout simplement ! ».
Pauline Bolignano, docteure en Informatique, Ingénieure R&D chez Amazon, Les vues exprimées ici sont les miennes..
Camille Wolff, ancienne responsable communication en startup tech en reconversion pour devenir professeur des écoles, et illustratrice ici, à ses heures perdues.
Vers un confinement sélectif basé sur les informations personnelles ? Stéphane Grumbach et Pablo Jensen. posent clairement la question qui va se poser dans les heures qui viennent dans notre pays, et nous propose une analyse sereine et factuelle de ce choix pour notre société. Thierry Viéville.
La présente pandémie de coronavirus confronte les gouvernements à une question simple : comment utiliser les données et les systèmes numériques pour une plus grande résilience sociale et économique ? Car force est de constater que le confinement généralisé tel qu’il est assez largement pratiqué aujourd’hui dans le monde est tout à fait anachronique. Il ne fait aucune distinction entre les personnes, infectées, à risque, malades ou déjà immunisées. Or, de telles informations personnelles sont désormais potentiellement accessibles grâce aux technologies numériques. Certains pays d’Asie, comme la Corée et Singapour, ont mis en place des politiques combinant dépistage à large échelle et exploitation des données personnelles et d’interaction sociales. Les données disponibles à ce jour indiquent que ces pays ont réussi à infléchir leur courbe de contagion avec succès.
Si la capacité de récolter ce type de données n’est pas sans poser de questions politiques essentielles, il nous semble qu’il fait peu de doute que de telles méthodes seront déployées rapidement dans la majorité des pays du monde. Elles seront justifiées par la protection des personnes les plus faibles, premières victimes des pandémies, mais également par le coût abyssal du confinement généralisé, en termes monétaires, mais également de santé publique: suicides, maltraitances, etc. Les arbitrages dans ces domaines se font généralement en faveur de l’intérêt collectif au détriment de l’avantage personnel. En ce qui concerne l’accès aux données personnelles, des moyens technologiques et légaux ont été mis en oeuvre dans la plupart des pays dans la dernière décennie pour renforcer la sécurité globale. Ils permettent la surveillance de la population et la censure de contenus jugés indésirables par les Etats. Ces outils ne relèvent pas d’une nécessité plus impérieuse que celle des crises sanitaires. De surcroît, la politique de santé est souvent coercitive, comme c’est le cas pour la vaccination, qui est obligatoire.
S’il nous apparaît évident qu’une forte pression vers une gouvernance numérique invasive résultera de cette crise, il convient de réfléchir aux conditions de sa mise en oeuvre. Il faut avoir conscience que cette crise offre une extraordinaire opportunité pour les grandes plateformes globales de se saisir des données santé personnelles en offrant des services dont l’utilité garantira leur adoption d’abord par les individus puis par les acteurs de la santé, faisant sauter les barrières légales. Mais la crise offre aussi une extraordinaire opportunité aux Etats de mettre en place un véritable service numérique de santé public satisfaisant des exigences éthiques fortes. Un des principes de base d’un tel déploiement consiste à remonter seulement l’information strictement nécessaire vers les centres de contrôle. Ainsi, des techniques basées sur bluetooth, capables d’enregistrer des voisinages entre personnes sans dévoiler leurs positions, semblent moins invasives que le traçage GPS, tout en fournissant des informations de contact plus précises pour prévenir la propagation de l’épidémie. Un consortium européen s’est créé pour proposer ce type d’outils de traçage, qu’il convient de maintenir sous surveillance citoyenne.
Dans un récent article de Science, Ferretti et al., proposent des modèles de l’impact d’un traçage numérique personnalisé, en fonction de son adoption par la population (e.g., pourcentage d’utilisateurs, respect des consignes) et des paramètres externes, comme le nombre de tests, de masques, de lits d’hôpitaux, etc. Ces simulations montrent qu’une adoption même partielle de ces techniques de traçage combinées à un dépistage suffisamment large peut contribuer significativement au ralentissement de la propagation de l’épidémie. En combinant les comparaisons entre pays à des outils de simulations numériques, une vision informée des compromis nécessaires pour la santé publique sera possible.
Pablo Jensen, Pourquoi la société ne se laisse pas mettre en équations, Paris, Seuil, coll. « Science ouverte », 2018, 336 p., ISBN : 978-2-02-138010-1 https://journals.openedition.org/lectures/25155
Stéphane Grumbach L’Entropie du Numérocène Quelques réflexions sur la Révolution Numérique et l’Anthropocène DataSphere https://hal.inria.fr/hal-02021716
Réflexions et points d’alerte sur les enjeux d’éthique du numérique en situation de crise sanitaire aiguë: Ce premier bulletin de veille du Comité national pilote d’éthique du numérique présente le contexte et développe deux points spécifiques. D’une part les questionnements éthiques liés à l’usage des outils numériques dans le cadre d’actions de fraternité, et d’autre part celui des enjeux éthiques liés aux suivis numériques pour la gestion de la pandémie. Télécharger le document
Les outils numériques permettent la diffusion des connaissances et des contacts riches entre les internautes. Ils ont aussi permis le développement de comportements toxiques comme les fakenews ou les messages de haine sur les réseaux sociaux. Des chercheurs spécialisés en traitement automatique du langage naturel de l’Université Côte d’Azur nous parlent ici de nouvelles technologies qu’ils développent pour lutter contre un autre mal des réseaux sociaux, le cyberharcèlement. Tamara Rezk, Serge Abiteboul
Le cyberharcèlement est une forme d’intimidation perpétrée par des moyens électroniques. Ce type de harcèlement est en croissance constante, en particulier du fait de la propagation d’Internet et des appareils mobiles chez les jeunes. En 2016, un million d’adolescents ont été harcelés, menacés ou soumis à d’autres formes de harcèlement en ligne uniquement sur Facebook. On estime qu’environ 70 % des victimes de harcèlement classique ont également subi des épisodes via des canaux virtuels. On sait maintenant que le cyberharcèlement peut conduire les victimes à la dépression, nuire à leur santé mentale, ou augmenter leur propension à consommer des substances. On a aussi observé, qu’en particulier chez les jeunes, le cyberharcèlement pouvait encourager au suicide.
Pinar Arslan, Elena Cabrio, Serena Villata, Michele Corazza
L’informatique, qui fournit aux intimidateurs de nouveaux moyens de perpétrer un comportement nocif, permet également de lutter contre le cyberharcèlement. Le projet CREEP (pour Cyberbullying Effects Prevention ) s’efforce de développer des logiciels dans ce sens. C’est un projet multidisciplinaire cofinancé par l’Institut Européen de la Technologie et du Numérique (EIT-Digital) qui regroupe un certain nombre de partenaires en Europe, la Fondation Bruno Kessler , les sociétés Expert System et Engineering, l’Université Côte d’Azur et Inria Rennes.
Le projet envisage notamment la création de deux produits innovants.
CREEP Virtual Coaching System est un assistant virtuel qui offre des conseils et des recommandations de prévention aux adolescents victimes ou susceptibles de l’être. L’utilisateur interagit avec son propre système de coaching virtuel via un chatbot, un assistant vocal s’appuyant sur l’intelligence artificielle.
CREEP Semantic Technology est un outil de surveillance automatique des réseaux sociaux permettant de détecter rapidement les situations de cyberharcèlement et de surveiller des jeunes victimes (même potentielles), dans le strict respect de la législation en vigueur, de la confidentialité et protection des données personnelles.
Un groupe interdisciplinaire de sociologues et psychologues a coordonné des analyses sociologiques, qualitatives et quantitatives, visant à mieux comprendre le phénomène du cyberharcèlement, les profils des victimes et des intimidateurs ainsi que la dynamique sous-jacente pour répondre aux exigences socio-techniques nécessaires pour le développement de technologies. Par exemple, une enquête a été menée sur un échantillon d’étudiants italiens âgés de 11 à 18 ans (3 588 répondants) dans le but de comprendre la composition socio-démographique des victimes, leurs mécanismes de réaction et ce qui les influence. Les résultats de l’enquête ont montré par exemple que les plus jeunes (11-13 ans), en particulier, refusaient fortement de demander de l’aide. L’objectif est de définir les suggestions les plus efficaces à fournir par l’assistant virtuel en fonction du profil de l’utilisateur.
Pour cette raison, les conseils doivent viser à briser le « mur de caoutchouc », à pousser les harcelés à se confier aux adultes et à renforcer les réseaux sociaux sur lesquels ils peuvent compter (enseignants, amis, parents). Dans le même temps, des différences significatives ont été constatées entre les hommes et les femmes. Pour cette raison, l’assistant virtuel fournira des suggestions diversifiées en fonction du genre. Enfin, de manière générale, la nécessité de sensibiliser les jeunes à l’utilisation consciente des réseaux sociaux et des applications mobiles est apparue, l’activité intense en ligne augmentant de manière exponentielle le risque de nouveaux cas de harcèlement.
CREEP Semantic Technology (réseaux utilisateurs, et messages haineux détectés)
Pour ce qui concerne la détection, le problème est complexe.
Un défi vient de l’énorme masse de données échangées tous les jours dans les réseaux sociaux par des millions d’utilisateurs dans le monde entier. La détection manuelle de ce type de messages haineux est irréalisable. Il faut donc bien s’appuyer sur des logiciels, même si un modérateur humain doit être impliqué pour confirmer le cas de harcèlement ou pas.
La tâche algorithmique de détection de cyberharcèlement ne peut pas se limiter à détecter des gros mots, insultes et autres termes toxiques. Certains termes qui sont insultants dans certains contextes peuvent sonner différemment entre amis ou accompagnés d’un smiley. Pour des adolescents par exemple, un mot très insultant, comme bitch en anglais, peut être utilisé de manière amicale entre amis. Il faut donc se méfier des faux positifs. Au contraire, des messages qui a l’apparence ne contiennent pas de termes toxiques peuvent être beaucoup plus offensifs s’ils contiennent du second dégré ou des métaphores haineuses. Un risque de faux négatifs existe donc aussi si on se limite à l’analyse textuelle des contenus.
Alors comment faire ? On s’est rendu compte qu’on pouvait détecter les cas de cyberharcèlement en effectuant une analyse de réseau et des contenus textuels des interactions. Puisque le cyberharcèlement est par définition une attaque répétée dirigée contre une victime donnée par un ou plusieurs intimidateurs, un système détectant automatiquement ce phénomène doit prendre en compte non seulement le contenu des messages échangés en ligne, mais également le réseau d’utilisateurs impliqués dans cet échange. En particulier, il convient également d’analyser la fréquence des attaques contre une victime, ainsi que leur source.
C’est ce que réalise CREEP Semantic Technology en analysant un flux de messages échangés sur les réseaux sociaux liés à des sujets, hashtags ou profils spécifiques. Pour ce faire, l’équipe a d’abord développé des algorithmes pour identifier les communautés locales dans les réseaux sociaux et isoler les messages échangés uniquement au sein de cette communauté. Elle a ensuite produit un algorithme de détection de cyberharcèlement qui s’appuie sur plusieurs indicateurs pour la classification des messages courts comme les émotions et sentiments identifiés dans les messages échangés. C’est là que l’intelligence artificielle trouve sa place : des méthodes d’apprentissage automatique et d’apprentissage profond, des réseaux de neurones récurrents.
Afin de tester l’efficacité du prototype, plusieurs tests ont été réalisés sur différents jeux de données contenant des instances de cyberharcèlement ou d’autres types de harcèlement sur les plates-formes de médias sociaux. Les résultats sont bons.
Dans l’avenir, la CREEP Semantic Technology va évoluer dans deux directions : l’analyse des images potentiellement associées aux messages (avec une équipe de recherche d’Inria Rennes), et l’extension du prototype à d’autres langues telle que le Français, l’Espagnol et l’Allemand, en plus de Italien et de l’Anglais qui ont été pris en compte au début du projet.
Gérard Giraudon est un chercheur, spécialiste de vision par ordinateur, ancien Directeur d’Inria Sophia-Antipolis, en charge des questions d’« Education et Numérique » à Inria. Il est entre autres le coordinateur du projet « 1 Scientifique 1 Classe : chiche ! », dont binaire est fan. Il reconsidère pour binaire le schisme mis en évidence par Gilbert Simondon entre Culture et Technique pour ce qui concerne l’informatique. Serge Abiteboul, Thierry Viéville
Gibert Simondon (1924-1989) est l’un des premiers philosophes français à développer une philosophie de la technique (« Du mode d’existence des objets techniques », thèse publiée en 1958). Pour lui, la réalité technique fait partie intégrante de la réalité humaine. La réalité technique ne s’oppose pas à la culture humaine et au contraire y participe entièrement par l’apport de la valeur culturelle des objets techniques. Il démontre que la réalité technique par les outils qu’elle génère transforme la société humaine dans laquelle elle est conçue et donc transforme sa culture1.
De quelles transformations parle-t-on ?
Chaque transformation nait d’une maitrise technique et on peut illustrer cette assertion avec trois grandes révolutions. La première a commencé avec la maitrise technique de fabrication des pierres taillées2 . Puis ce fut le tour de la révolution agricole avec la maitrise technique de la domestication des animaux et l’invention de l’agriculture qui a provoqué la sédentarisation et a regroupé les communautés humaines en centre « urbain » avec toutes les conséquences sur l’organisation et le contrôle de la vie communautaire. C’est enfin, la maitrise de l’énergie avec l’essor de la machine à vapeur qui a donné naissance à la révolution industrielle – qui s’accélère avec l’usage des énergies fossiles (charbon, pétrole) puis de l’atome avec la maitrise de l’électricité « énergie universelle ».
Et nous sommes en train de vivre une transformation provoquée par la maitrise technique de l’information autrement dit l’informatique qui a enclenché la quatrième révolution celle de la société « numérique ». Gilbert Simondon n’a pas vraiment connu cette révolution mais il l’a pressentie et il fondait de grands espoirs sur la cybernétique naissante et nous y reviendrons plus loin.
Outil et instrument
Gilbert Simondon propose une distinction entre outil et instrument suivant des différences relatives au corps. L’outil est un objet technique qui permet de prolonger ou armer le corps pour accomplir un geste. L’outil est alors un amplificateur du corps, de sa force musculaire et in fine de l’énergie utilisée (on peut relier ces outils à la puissance dissipée en watt). L’instrument est un objet technique qui permet de prolonger et d’adapter le corps pour obtenir une meilleure perception. L’instrument est alors est alors un amplificateur de la perception … Lunette, microscope, télescope, sextant, sonars, etc. sont des instruments. Les instruments servent à recueillir des informations sur le monde sans accomplir une action préalable.
A ce stade, la question qu’on peut se poser est sachant qu’un programme informatique est une œuvre de l’esprit et que sa mise en œuvre est une technique qui engendre un « outil », quel serait le nom à donner à ce qui permet de prolonger la pensée et adapter le cerveau et/ou le corps et/ou la perception pour obtenir une meilleure « intelligence » ? … on peut l’appeler logiciel !
L’œuvre de Gilbert Simondon est centrée sur le fait que la technique est un fait culturel et donc que la technique est totalement intégrée dans la culture. À ce titre, la pensée technique doit être enseignée à toutes et à tous. Ce qui n’est pas le cas aujourd’hui. Gilbert Simondon et d’autres après lui, comme Bernard Stiegler2, considèrent que ce schisme prend sa source dans la pensée philosophique grecque. Il défend le fait que l’existence d’un objet technique est une expression culturelle car sa création procède d’un schéma mental. Il conclut que la technique doit être incorporée dans la culture afin que celle-ci rende compte de l’acte humain que constitue la conception des objets techniques : cela implique de considérer non seulement leur usage, mais aussi et surtout leur genèse. On peut en conclure que puisque l’éducation scolaire a pour objectif de donner à chacun les apprentissages qui lui seront nécessaire en tant qu’adulte et donc structurer le socle de la vie sociale et culturelle du pays, il est primordial de fournir à tous les élèves les schémas mentaux de la conception des objets techniques.
Gilbert Simondon insiste sur le fait que plus l’objet technique est perçu comme une boite noire d’entrées et de sorties, et plus l’homme qui l’utilise lui est aliéné. Ce qui est magnifiquement illustré par le fait que la plupart de nos concitoyens, ne voyant dans l’intelligence artificielle qu’une boite noire, craignent naturellement d’y être asservis !
Mais le paradoxe est qu’à l’heure où la société fantasme sur l’asservissement de l’homme par l’intelligence artificielle, G. Simondon pensait que « la cybernétique libère l’homme de la fermeture contraignante de l’organisation en le rendant capable de juger cette organisation au lieu de la subir en la vénérant et en la respectant parce qu’il n’est pas capable de la penser ou de la constituer » tout en argumentant que toute libération acquise par une augmentation des savoirs porte en son sein une prochaine aliénation par les « êtres techniques » si la culture ne s’en empare pas. Sa « prophétie » semble se vérifier pour la « cybernétique » pour laquelle cependant il fondait pourtant de grands espoirs.
De l’enseignement de l’informatique
Certains visionnaires ont perçu dès le début des années 70 que l’informatique était stratégique. A titre d’illustration, on peut rappeler qu’alors que la création d’Iria, se décidait dans le cadre du plan calcul pour une souveraineté nationale (1967), un séminaire du CERI3 consacré à « l’enseignement de l’informatique à l’école secondaire » concluait sur l’importance de l’apport de l’informatique à l’enseignement général. La conclusion est d’autant plus d’actualité car la révolution numérique est en marche et le « logiciel dévore le monde ». Aucun secteur de la recherche (biologie, physique, astronomie et sociologie, etc.), de l’industrie (conception, fabrication, etc.), des services et du commerce, du transport, de l’hôtellerie, de l’agriculture, de la culture et même de la guerre (cyberdéfense, etc.) n’échappe à l’impact du numérique. Le numérique a permis d’incontestables progrès par exemple dans le domaine de la santé, avec l’imagerie médicale et le traitement massif de données4, mais a aussi créé de nouveaux risques pour les biens et les personnes comme la cybercriminalité ou la manipulation d’opinion.
Mais que peut-on dire de l’impact du numérique pour l’éducation et la formation depuis la conclusion du séminaire du CERI ? Quel est le modèle « disruptif » qui changera la donne ? En 1985, la France a été ambitieuse (« Plan informatique pour tous »5) et certains, 30 ans plus tard, ont cru qu’il suffisait de mettre des tablettes dans les écoles alors que l’on sait que cela ne répond pas à la question. Plus grave, plus d’une génération plus tard, ce choix politique dénote une totale méconnaissance des enjeux de formation à la pensée informatique et à la culture sous-jacente6. En effet, une fois de plus pour un grand nombre de décideurs mais aussi pour un grand nombre de nos concitoyens, l’informatique se réduit à un outil incarné dans un objet d’interface et mélange la formation à l’informatique (la pensée informatique) avec la formation en utilisant l’outil informatique.
Bien sûr on ne peut que se féliciter de changements récents qui introduisent l’enseignement de l’informatique au collège et au lycée et de l’initiative PIX7 pour permettre à chacun de s’évaluer. Mais certains annoncent « dans le passage de l’informatique au numérique, c’est l’introduction d’une dimension culturelle, sociale et éthique qui est en jeu, dans une perspective non plus techniciste mais historique et citoyenne8». Par là même, ils affirment que l’important n’est pas de comprendre l’informatique (vision techniciste) mais de comprendre et étudier les usages de la technique (vision humaniste).
Nous pensons que cette reproduction du schisme évoqué plus haut est une immense erreur. Comme l’écrivait Simondon, l’éducation est vecteur d’apprentissage de la culture et « le Savoir n’est pas savoir ce qui se passe d’un point de vue technique mais le comprendre .. savoir n’est pas lire Châteaubriant parlant de Pascal mais de refaire de ses mains une machine telle la sienne et si possible la ré-inventer au lieu de la reproduire en utilisant les schèmes intellectuels et opératoires qui ont été utilisés par B. Pascal ». De la même manière qu’un livre n’apporte rien à un analphabète, l’informatique ne rend pas autonome celui ou celle que ne la comprend pas, et réduit son usager à un statut de consommateur et, in fine, ne permet pas au citoyen d’élaborer une pensée critique ni pour lui-même ni pour son usage.
Le problème est que l’urgence actuelle due à la révolution numérique a multiplié les besoins de formation. De plus, le manque d’enseignants maitrisant la pédagogie de l’informatique nous fait rentrer dans un cercle vicieux puisque moins il y a de professeurs et moins il y en aura par rapport à une demande en croissance exponentielle. Devant le « mur » qui est devant nous, de nombreuses initiatives se sont mises en place pour le contourner ou pallier le manque de compétences comme Class’Code.
L’informatique est à la fois une science, une technologie, une industrie et maintenant une culture par l’impact et la transformation qu’elle a sur la société. C’est sous l’ensemble de ces facettes qu’elle doit être appréhendée permettant à chacun et à chacune d’avoir les clés d’entrée pour ne pas y être aliéné.e. Et le rappel de ce billet sur l’œuvre de Gilbert Simondon a pour objectif de faire comprendre que tant que l’informatique et les sciences du numérique ne seront pas vues comme un fait culturel plein et entier dans la société française du XXIème siècle, il sera toujours compliqué de réussir pleinement cet enseignement. La mère des batailles est donc bien un enjeu culturel.
Gérard Giraudon, chercheur et conseiller du Président Inria.
Pour en savoir plus :
Gérard Berry : « L’hyperpuissance de l’informatique », Odile Jacobs, ISBN 2738139531, octobre 2017.
Gilbert Simondon : « Du mode d’existence des objets techniques », collection – Analyse et Raisons Aubier éditions Montaigne, 1958 ; à noter qu’il y a eu 3 autres éditions augmentées aux éditions Aubier (1969, 1989, 2012).
1 Sans faire référence aux débats « main-intelligence » d’Aristore-Anaxagore, on peut également faire le rapprochement avec les travaux de François Jouen (Cognition Humaine et Artificielle (CHArt)) pour qui la technologie elle-même a toujours fait évoluer la cognition et cette relation symbiotique façonne nos capacités cérébrales. On peut aussi lire les travaux associés des liens entre technique et nature humaine ou condition humaine. 2 La technicité participe originairement à la constitution de l’homme (l’hominisation) : Bernard Stiegler. 3 Centre d’études et de recherches pour l’innovation dans l’enseignement de l’OCDE créé en 1968. 4 Et l’actualité nous montre son intérêt majeur pour lutter contre l’épidémie du Covid-19. 5 Voir l’excellent article de J-P d’Archambault: https://www.epi.asso.fr/revue/articles/a0509a.htm. 6 Une étude de 2012 montre que le problème est malheureusement partagé dans les pays de l’OCDE (http://www.oecd.org/fr/education/scolaire/Connectes-pour-apprendre-les-eleves-et-les-nouvelles-technologies-principaux-resultats.pdf). 7 https://pix.fr/enseignement-scolaire/. 8 HERMÈS, LA REVUE 2017/2 (n° 78) « Les élèves, entre cahiers et claviers » https://www.cairn.info/revue-hermes-la-revue-2017-2.htm
Dans cette période difficile pour tout le monde, nous avons décidé d’intensifier la fréquence de nos publications et d’étendre le format habituel. Pour tenir cet objectif, nous avons donc (re)sollicité hier tou.te.s nos auteur.e.s depuis la création de binaire. Françoise Berthoud a été une des premières à répondre à notre invitation et nous sommes très heureux d’inaugurer avec elle une série de billets d’humeur. Pascal Guitton
Francoise Berthoud
Autres urgences, vitales
Confinement
Solitude
Dérèglement climatique, ouragans, sécheresses, destruction de plantations par des criquets, pollutions, propagation accélérée de virus, … Chaque année après l’autre, chaque mois, chaque jour après l’autre
Des petits bouts d’effondrement
Comment le numérique survivra-t-il ? Comment le numérique nous aidera-t-il ?
A l’heure où il permet de se donner l’illusion que la vie continue, que des bouts d’économie pourraient survivre au confinement, que les hommes pourraient vivre ainsi, communiquant par skype et autres systèmes de visio
Et pourtant,
Des Hommes au Ghana, à cette même heure poursuivent leur travail de tri, de démantèlement, de brulage de nos déchets électroniques et se tuent à petit feu,
Des hommes en République Démocratique du Congo, en Amérique du Sud continuent à lutter pour leurs ressources, parfois leur vie juste pour avoir quelque chose à se mettre sous la dent ou juste pour boire de l’eau saine, pour extraire ces précieux métaux sans quoi nos ordinateurs ne seraient pas aussi performants,
Ils ne sont pas confinés,
Comme les soignants, les livreurs, les caissiers, les plombiers, les chauffeurs de poids lourds, etc., ils paraissent indispensables à notre économie. Mais point d’applaudissements pour eux, pas de primes, pas de discours de président pour les féliciter. Ces hommes, ces femmes, ces adolescents, ces enfants méritent pourtant tout autant notre attention, parce que sans eux …
Point de smartphone, point de réseaux, point de visio, ni de netflix, pas d’apéritif whatsapp …
Apprenons au moins de cette expérience que le numérique est un outil précieux, qu’il convient de ne pas gaspiller, qu’il convient d’utiliser ces outils avec parcimonie, qu’il convient de les partager, qu’il convient de réfléchir à leur juste usage pour stopper les dégâts environnementaux qu’ils génèrent tout en les partageant avec le plus grand nombre.
Embarquer l’informatique dans les objets a beaucoup d’avantages : simplifier leur fonctionnement, leur donner plus de possibilités d’usage et de sûreté, et leur permettre d’intégrer de nouvelles possibilités à matériel constant par simple modification de leur logiciel.
Cette vidéo introduit une des thématiques de l’enseignement en Sciences Numériques et Technologie de seconde au lycée, rendez-vous sur le MOOC SNT pour se former sur ce sujet, en savoir plus sur les notions abordées, les repères historiques, l’ancrage dans le réel, et les activités qui peuvent être proposées.
En savoir plus :
Après avoir transformé les chaînes de montage des automobiles et les avions dans les années quatre-vingt-dix, l’informatique intervient maintenant dans des domaines toujours plus nombreux : automobile, réseau ferroviaire et transports urbains, domotique, robotique, loisirs, etc., conduisant à un nouvel internet des objets.
Pour les avions par exemple, l’informatique gère le vol en commandant finement des servomoteurs électriques, plus légers et plus fiables que les vérins hydrauliques, les réacteurs, la navigation et le pilotage automatique, et permet l’atterrissage automatique par temps de brouillard. Elle a eu un impact décisif sur l’amélioration de la sécurité aérienne.
Les objets informatisés avaient autrefois des interfaces homme-machine (IHM) dédiées, souvent dépendantes d’une liaison filaire directe. Mais les technologies du Web intégrées au téléphone portable permettent maintenant d’y rassembler les interfaces des objets du quotidien, ce qui en simplifie et uniformise l’usage. Les objets informatisés deviennent ainsi connectés.
À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec a choisi de parler de sexbots, les robots sexuels, et des stéréotypes qu’ils propagent. Serge Abiteboul
P.-S. : binaire adressait déjà le 1er avril 2016 le sujet des sextoys avec « La data du vibromasseur ».
Photo by @thiszun from Pexels
Et si, en cette année 2020 où les scandales s’enchaînent sur le sujet, on parlait un peu sexe… et numérique évidemment. Les experts n’en démordent pas, les sexbots sont amenés à prendre une place de plus en plus importante dans la société. Numérique et argent font déjà très bon ménage, argent et sexe encore bien davantage, alors si on ajoute un soupçon d’algorithmique, que dis-je, d’intelligence artificielle à l’équation, il est sûrement possible de fouler un marché porteur et de créer une usine à générer des dollars. Comme le dit la professeure de droit Margot Kaminski de Ohio State University : “Siri’s a woman, Cortana’s a woman; if robots exist to perform labor or personal assistances, there’s a darn good chance they’ll be women.” Alexa, démocratisée depuis, n’échappe pas à la règle.
Quel sort est donc réservé aux femmes et aux stéréotypes de tout crin dans un contexte où les robots sont sexuels ?
Aujourd’hui la moindre requête sur le sujet sur un moteur de recherche digne de ce nom nous amène immédiatement à Samantha, Harmony ou autre Solana (This Ultra-Realistic New Sex Robot Not Only Has a Personality, She’s Also Customizable) assortie de promesses plus alléchantes les unes que les autres… À destination de la gent masculine en particulier [1]. Alors est-ce un travers qui va nous enliser plus profondément encore dans les clichés sexistes, une véritable menace pour la santé mentale des utilisateurs ou une réelle opportunité pour changer les choses ?
Les sexbots prennent inéluctablement les traits de femmes…idéales
Au commencement, un film, Her, sorti en salle en 2013, produit par une femme du reste, Megan Ellison, où Joachim Phoenix craque pour ce qu’on appelle encore un OS, avec déjà l’IA en filigrane, qu’il a lui-même créée à la suite d’une déception amoureuse, en attribuant à ce robot une voix féminine, celle de Scarlett Johansson, irrésistible. Du reste, c’est encore Scarlett Johansson qui a inspiré le robot Mark 1, imprimé en 3D en 2016. Depuis, Harmony, puis plus récemment Solana, à la faveur du CES 2018, la grand messe des innovations numériques, sont venues grossir les rangs. Ces robots humanoïdes qui feraient pâlir d’envie les mannequins les plus célèbres, prennent les traits de femmes séduisantes, programmées adroitement pour remplir tous les désirs, mêmes inavoués, de leurs utilisateurs. Les experts sont formels, dans quelques années, quelques décennies au plus, les sexbots occuperont une place non négligeable dans les foyers. Un sondage américain de 2017 indique en effet que la moitié des américains estime que les relations sexuelles avec un robot seraient une pratique commune et banalisée dans 50 ans [2]. Aujourd’hui ces robots restent chers, seulement une poignée d’industriels les produisent, mais le marché est potentiellement gigantesque. Demain, chacun pourra peut-être s’imprimer en 3D et programmer facilement le robot de ses rêves à la maison.
Quand bien même quelques velléités existent du coté des sexbots masculins (5 % du marché), qui ont une propension à ne jamais s’arrêter (comme si les femmes rêvaient de ça), probablement encore issus d’un fantasme masculin, qui commencent à poindre, la majorité des sexbots prennent des traits, et pas des moindrement stéréotypés, féminins. Harmony, qu’on pouvait s’offrir pour quelque 15 000 $ en 2018 et qui maintenant se trouve entre 8 000 et 10 000 $, est capable de parler, d’apprendre et surtout ne dit jamais non. Elle cligne des yeux, fronce les sourcils, cite Shakespeare dans le texte. Des algorithmes d’apprentissage lui permettent de se rappeler des préférences des utilisateurs, on imagine aisément les risques potentiels de fuites d’informations personnelles intimes au passage. Certains sont tombés récemment pour moins que ça.
La technologie devance l’éthique
Comme dans bien des domaines, la technologie a, dans ce domaine aussi, été pionnière. À l’instar de Bitcoin qui pourrait faire vaciller la finance internationale ou les algorithmes qui pourraient bouleverser l’équilibre économique comme l’annonce Yuval Hariri dans son dernier livre[3], les sexbots sont plus le fruit de passionnés de technologies et d’algorithmes qui orchestrent savamment robotique, apprentissage, intelligence artificielle, technologies haptiques (qui reproduisent le sens du toucher) et impression 3D, que celui d’obsédés sexuels. Harmony est un concentré de hardware et de software des plus sophistiqués et à ce titre une réussite numérique. Harmony est composée d’algorithmes de reconnaissance faciale et vocale en pointe, de capteurs sophistiqués capable de détecter et d’interpréter les mouvements et résulte en une poupée, pas gonflable, chaleureuse, enthousiaste et drôle. Elle ne marche pas, cela consomme trop d’énergie, et comme tout produit informatique, le compromis est de mise, mais qu’importe si on lui demande si elle souhaite marcher, elle répond « je ne veux rien d’autre que de toi ». Si on lui demande quel est son rêve le plus cher elle répond « être la femme dont tu as toujours rêvé». Que demande le peuple ? Qui plus est le concepteur, McMullen, n’est empreint que de louables intentions puisque son objectif est de rendre les gens heureux [4]. Et dans ce même article, on y comprend que ces sexbots ne sont que les successeurs des statues de la mythologie grecque ou des robots féminins fictionnels du cinéma (Metropolis en 1927, Blade Runner en 1982 ou Ex Machina en 2015) représentant l’éternel féminin, beau, docile, et soumis qui dans le dernier cas (Ex Machina) gagnent leurs lettres de noblesse en passant le fameux test de Turing.
Au delà donc de la prouesse algorithmique, le résultat est là, ces robots sous des dehors de Barbie siliconée, dignes représentants de la femme objet, risquent bien de mettre un, voire plusieurs, pavé dans la mare. Est-ce dû encore une fois à la domination masculine dans le domaine du numérique qui a fait que ces robots sont essentiellement des femmes ou est-ce que ces chercheurs géniaux n’ont fait que répondre à des stimuli sociétaux inéluctablement vrillés ? Difficile de statuer.
Un mal pour un bien ?
C’est discutable. On pourrait penser que les robots présentent une opportunité unique d’inverser les tendances. On pourrait créer des robots qui ne sont pas sujets aux stéréotypes de genre, des égales de l’homme, entrainer ces intelligences artificielles non pas sur des données réelles mais sur des données soigneusement choisies qui évitent tout biais. Oui mais la réalité commerciale nous rattrape, l’industrie du sexe numérique est jeune mais d’ores et déjà estimée à quelque 30 milliards de dollars. Après les smart sex toys, les sexbots, les applis de rencontres et le porno virtuel, les sexbots sont les prochaines cash machines. Il semblerait que plus de 40% de 263 hommes hétérosexuels soient déjà prêts à signer pour un robot sexuel dans les 5 années à venir[5]. On imagine aisément les dérives que peuvent présenter les sexbots du reste [6], concernant les violences faites aux femmes. D’autant plus que c’est un sujet, comme souvent, ou la technologie, a devancé les lois. Les institutions sont en effet un peu timides quant à légiférer sur ce sujet éminemment délicat.
Un autre espoir que suscite l’arrivée de ces sexbots est de fournir une alternative thérapeutique permettant de limiter les comportements déviants envers les femmes (un autre débat est celui de la pédophilie mais ce n’est pas le sujet ici). Avec des robots entièrement personnalisables (RealDolls peuvent être paramétrées pour avoir 14 styles différents de lèvres et j’en passe), certains désirs pourraient être assouvis par des robots, écartant ainsi les dangers pour les femmes réelles. Ou au contraire, permettre ces comportements déviants avec un robot ne feraient que les banaliser au risque d’entériner des comportements déjà solidement ancrés et de perpétuer les stéréotypes ambiants.
Bien sur les robots humanoïdes peuvent avoir d’autres vertus que le seul assouvissement de désirs masculins, celui de perpétuer des personnes disparues à l’instar du populaire épisode de Black Mirror ou une jeune femme se fait livrer un robot de son défunt jeune mari, ou encore le marché des personnes en situation de handicap.
L’industrie du sexe, a d’ores et déjà fait progresser le numérique à de multiples reprises : le streaming vidéo, le paiement en ligne anonymisé, la quête de la bande passante et j’en passe, celui de la robotique permettra certainement de servir des desseins plus nobles que celui de remplacer les femmes par des Barbies en silicon qui ne disent jamais non. Tous les espoirs sont permis.
Un nouvel « Entretien autour de l’informatique ». Michel Thiebaut de Schotten est directeur de recherche au CNRS en neuropsychologie et en neuroimagerie de la connectivité cérébrale. Il travaille notamment sur l’anatomie des connexions cérébrales et leur déconnexion suite à des accidents vasculaires cérébraux ainsi que sur l’évolution du cerveau en comparant les espèces. Il a rejoint récemment l’Institut des Maladies Neurodégénératives à Bordeaux et continue à travailler avec l’Institut du cerveau et de la moelle épinière à Paris. Il est médaille de bronze du CNRS et lauréat d’un contrat prestigieux de l’European Research Council. Il fait partager à binaire sa passion pour les neurosciences. Cet article est publié en collaboration avec The Conversation.
MT – Je viens de la psychologie. J’ai choisi de faire un doctorat en neuroscience à la Salpêtrière (Université Pierre et Marie Curie) en 2007. Puis j’ai fait un post-doc à Londres sur la cartographie des réseaux cérébraux. Je suis depuis 2012 au CNRS. Nous utilisons beaucoup l’imagerie numérique. Nous faisons aussi un peu d’analyse postmortem pour vérifier que ce que nous avons vu dans les images correspond à une réalité.
B – Il nous faudrait partir un peu de la base. Qu’est-ce que c’est l’imagerie du cerveau pour les neurosciences ?
MT – À l’aide de l’Imagerie par résonance magnétique, on peut étudier soit la forme et le volume des organes (IRM anatomique), soit ce qui se passe dans le cerveau quand on réalise certaines activités mentales (IRM fonctionnelle). À partir des données d’IRM, on peut dessiner les réseaux du cerveau humain. Les axones des neurones sont des petits câbles de 1 à 5 micromètres, avec autour une gaine de myéline pour que l’électricité ne se perde pas, ils se regroupent en grand faisceaux de plusieurs milliers d’axones (Figure 1). C’est ce qui construit dans le cerveau des autoroutes de l’information. On peut faire une analogie avec un réseau informatique : les neurones sont les processeurs tandis que les axones des neurones forment les connexions.
Fig. 1 Les autoroutes du cerveau. Exemple de connexions cérébrales liant les régions de l’avant du cerveau avec celles de l’arrière du cerveau. @ Michel Thiebaut de Schotten
B – Et ces connexions sont importantes ?
MT – Super importantes ! Un de mes premiers travaux a été de réaliser un atlas des connexions cérébrales afin de savoir quelles structures étaient reliées entre elles par ces autoroutes. En effet, pour chaque traitement cognitif, plusieurs régions doivent fonctionner en collaboration et s’échanger des informations (exactement comme différents processeurs dans nos ordinateurs). On voit aussi l’importance des connexions cérébrales quand certaines sont rompues suite à une maladie, un AVC, un accident. Cela conduit à des incapacités parfois très lourdes pour la personne.
On estime que la vitesse de transmission de l’information dans ces réseaux est comprise entre 300 et 350 km/h ; la même que celle du TGV qui me transporte de Bordeaux à Paris mais bien loin de la vitesse de transmission de l’information dans une fibre optique. Heureusement, les distances sont petites.
B – Ça a l’air un peu magique. Comment est-ce qu’on met en évidence les connexions entre des régions du cerveau ?
MT – Tout d’abord il faut préciser qu’on doit faire des mesures sur plusieurs personnes car, même si nos cerveaux possèdent des similarités, il existe des différences notables entre individus. Il faut faire une moyenne des résultats obtenus pour chaque sujet pour obtenir une cartographie en moyenne.
L’IRM est en mesure de détecter les mouvements de particules d’eau et grâce à la myéline autour des axones qui joue le rôle de l’isolant d’un fil électrique, les mouvements de particules d’eau sont contraints dans la direction de l’axone. Ainsi en suivant cette direction on peut reconstruire les grandes connexions cérébrales. On obtient alors une carte des connexions qui ressemble à un plat de nouilles. Imaginez qu’à un millimètre de résolution, on détecte environ 1 million de connexions cérébrales qui sont repliées sur elles-mêmes dans un volume d’environ 1,5 litre ; c’est très dense !
Il faut donc ensuite démêler ces connexions pour pouvoir les analyser finement. Au début, on partait des atlas anatomiques dessinés au 19e siècle et on essayait de reconnaître (d’apparier) les réseaux détectés avec les structures connues. Puis, on a essayé d’obtenir ces connexions en les extrayant manuellement à l’aide de requêtes comme « afficher les connexions qui relient les zones A et B sans passer par la zone C ». Aujourd’hui, on utilise des algorithmes d’extraction automatique qui détectent des composantes principales (des tendances) pour construire des faisceaux de connexion. Ces systèmes s’inscrivent dans ce qui s’appelle les neurosciences computationnelles.
B – Ces réseaux ne sont pas rigides. Ils évoluent dans le temps.
MT – Oui. Un bébé naît avec beaucoup plus de connexions que nécessaire. Puis, pendant toute l’adolescence, ça fait un peu peur, on perd des connexions en masse ; on avance le chiffre de 300 000 connexions perdues par seconde. Mais dans la même période, on spécialise et on renforce celles qui nous sont utiles ; leur utilisation augmente le diamètre et donc le débit de la connexion.
On considère que le cerveau atteint sa maturité autour de 20 ans ; après, il est plus difficile de changer notre réseau de connexions, on se contente d’ajuster le « câblage ». Il est donc fondamental d’acquérir de nombreux apprentissages dans sa jeunesse afin d’arriver au plus haut potentiel cérébral au moment où commence le déclin cognitif.
Il est aussi clairement démontré que l’activité cérébrale aide à mieux vieillir. Un neurone qui ne reçoit pas d’information via ses connexions avec d’autres neurones réduit sa taille et peut finir par mourir. On peut faire une analogie avec les muscles qui s’atrophient s’ils ne sont pas sollicités. En utilisant son cerveau, on développe sa plasticité.
Enfin, si à la suite d’un traumatisme, la voie directe entre deux régions du cerveau est endommagée, le cerveau s’adaptera progressivement. L’information prendra un autre chemin, moins direct, même à l’âge adulte. Mais la transmission d’information sera souvent plus lente et plus limitée.
B – Est-ce que nous avons tous des cerveaux différents ? De naissance ? Parce que nous les faisons évoluer différemment ?
MT – On observe une grande variabilité entre les cerveaux. Leurs anatomies présentent de fortes différences. Leurs fonctionnements aussi. On travaille pour mieux comprendre la part de l’inné et de l’acquis dans ces différences. On a comparé les cerveaux de chefs cuisiniers et de pilotes de F1. On a aussi analysé les cerveaux d’individus avant et après avoir développé une grande expertise dans un domaine comme le jonglage ou le jeu vidéo. On avance mais on ignore encore presque tout dans ce domaine.
B – Tu peux nous parler un peu des sciences que vous utilisez ?
MT – Nous utilisons beaucoup de statistiques pour modéliser les propriétés de régions du cerveau. Nous utilisons aussi l’apprentissage automatique pour comprendre quelque chose aux masses de données que nous récoltons. Comme dans d’autres sciences, il s’agit de diminuer les dimensions de nos données pour pouvoir explorer la structure de la nature.
Plus récemment, nous avons commencé à utiliser des réseaux de neurones profonds. D’un point de vue médical, cela nous pose des problèmes. Nous voulons comprendre et une proposition de diagnostic non étayé ne nous apprend pas grand-chose et pose des problèmes d’éthique fondamentaux.
B – Est-ce que l’utilisation de ce genre de techniques affaiblit le caractère scientifique de vos travaux ?
MT – Il y a bien sûr un risque si on fait n’importe quoi. Le cerveau, c’est un machin hyper compliqué et on ne s’en sortira pas sans l’aide de machines et d’intelligence artificielle : certains fonctionnements sont beaucoup trop complexes pour être explicitement détectés et compris par les neuroscientifiques. Mais il ne faut surtout pas se contenter de prendre un superbe algorithme et de le faire calculer sur une grande masse de données. Si les données ne sont pas bonnes, le résultat ne veut sans doute rien dire. Ce genre de comportement n’est pas scientifique.
B – On a surtout parlé des humains. Mais les animaux ont aussi des cerveaux ? Les singes, par exemple, ont-ils des cerveaux très différents de ceux des humains ?
MT – Je vous ai parlé de la très grande variabilité du cerveau entre les individus. On a cru pendant un temps que les cerveaux des singes ne présentaient pas une telle variabilité. Pour vérifier cela, on est parti d’un modèle de déformation. Et en réalité non, selon les régions, la variabilité est relativement comparable chez le singe et chez l’humain. Ce qui est passionnant c’est qu’on s’aperçoit que les régions qui présentent plus de variabilité chez l’humain sont des régions comme celles du langage ou de la sociabilité alors que c’est la gestion de l’espace pour les singes. Pour des régions comme celles de la vision qui sont apparues plus tôt dans l’évolution des espèces, le singe et l’humain présentent des variabilités semblables et plus faibles.
Fig.2 L’évolution du cerveau. Comparer les connexions cérébrales entre les espèces nous permet de mieux comprendre les mécanismes sous-jacents à l’évolution des espèces. @ Michel Thiebaut de Schotten
B – Tu vois comment faire avancer plus vite la recherche ?
Il faudrait que les chercheurs apprennent à travailler moins en compétition et beaucoup plus en collaboration y compris au niveau international car la complexité du problème est telle qu’il serait illusoire d’imaginer qu’une équipe seule parvienne à le résoudre. Avec l’open data et l’open science, on progresse. Certains freinent des deux pieds, il faut qu’ils comprennent que c’est la condition pour réussir. Il faut par exemple transformer la plateforme de diffusion des résultats en neurosciences, lancer des revues sur BioRxiv, l’archive de dépôt de preprints dédiée aux sciences biologiques.
B – On a quand même l’impression, vu de l’extérieur, que ton domaine a avancé sur l’observation mais peu sur l’action. Nous comprenons mieux le fonctionnement du cerveau. Mais peut-on espérer réparer un jour les cerveaux qui présentent des problèmes ?
MT – Vous avez raison. On voit arriver des masses d’articles explicatifs mais quand on arrive aux applications, il n’y a presque plus personne. Si une connexion cérébrale est coupée, ça ne fonctionne plus ; que faire ? La solution peut sembler simple : reconstruire des connexions par exemple avec un traitement médicamenteux. Sauf qu’on ne sait pas le faire.
Dans un tel contexte, il est indispensable de prendre des risques, ce qui pour un scientifique signifie ne pas publier d’articles présentant des résultats positifs pendant « un certain temps ». En France, nous avons, encore pour l’instant, une grande chance, celle d’offrir à des chercheurs la stabilité de leur poste, ce qui nous permet de mener des projets ambitieux et nous autorise à prendre des risques sur du plus long terme. Ce n’est pas le cas dans la plupart des autres pays.
On répare bien le cœur pourquoi ne pas espérer un jour faire de même pour le cerveau ? C’est un énorme défi et c’est celui de ma vie scientifique !
Serge Abiteboul (Inria, ENS Paris) et Pascal Guitton (Inria, Université de Bordeaux)
Un nouvel « Entretien autour de l’informatique ». Ancien banquier entré chez les Dominicains en 2000, Éric Salobir, prêtre, est un expert officiel de l’Église catholique en nouvelles technologies. Ce passionné d’informatique a créé Optic, un think tank consacré à l’éthique des nouvelles technologies. Il cherche à favoriser le dialogue entre les tenants de l’intelligence artificielle et l’Église. Il est aussi consulteur au Vatican.
Le libre arbitre de l’individu
Le père Eric Salobir, collection personnelle
B : devant des applications qui peuvent prédire nos futures décisions et actions avec une précision croissante, que devient le libre arbitre ?
ES : on n’a pas attendu l’IA pour que l’humain soit prévisible ! Il suffit de lire « L’art de la guerre » de Sun Tzu. L’art de prédire le comportement de l’autre, de lire l’humain, fait partie des appétences de l’être humain. Mais on y arrive mal, et si par exemple, il y avait un psychopathe à l’arrêt de bus, on ne s’en apercevrait jamais. Avec la récolte de données très détaillées et leur analyse, on dispose de nouveaux moyens très efficaces pour assouvir ce désir très ancien. Pour moi, cela ne remet pas en cause le libre arbitre dans son principe, mais nous amène à questionner ce qui relève de la liberté et ce qui relève du conditionnement.
C’est une nouvelle étape d’un long cheminement. Freud ne remet pas en cause le fait qu’il y ait une part de liberté mais en redéfinit les contours, et ses travaux sur l’inconscient donnent des éléments qui restreignent le champ de la liberté en déterminant le comportement. Le mythe de la complète liberté a été démonté par Gide dans « Les Caves du Vatican » : Lafcadio décide de jeter quelqu’un par la porte du train pour prouver qu’il est libre, mais l’intentionnalité fait que ce n’est pas un geste complètement gratuit. La liberté totale n’existe pas, son absence totale non plus. Nous vivons entre les deux, et actuellement il est essentiel pour nous de mieux saisir les frontières.
B : avec les nudges (incitations en français), n’assistons-nous pas à un rétrécissement du libre arbitre ?
ES : de tels usages de l’IA permettent de court-circuiter le circuit décisionnel en s’appuyant presque sur la dimension reptilienne de notre mode de fonctionnement, et c’est inquiétant. Le nudge n’est pourtant pas non plus un phénomène nouveau. Par exemple, considérez la porte d’entrée de la basilique de la Nativité de Bethléem, qui fait 1 mètre 10 de haut. Vous êtes obligé de vous courber pour entrer, de vous incliner, puis après être entré, vous vous redressez, et vous prenez conscience que votre stature humaine naturelle est d’être debout. Ce nudge-là est ancien. Ce qui a changé, c’est qu’on est passé d’un nudge extérieur, qui s’appuie sur la corporalité et avec lequel on peut prendre de la distance, à des technologies numériques qui affranchissent partiellement de cette corporalité, avec le danger que l’on perde cette capacité à prendre de la distance par rapport à certain nudges.
Avec la publicité, lorsque quelque chose est présenté exactement au bon moment, quand on est vulnérable ou fatigué et que de plus, il suffit pour acheter d’appuyer sur un bouton, avec un geste physique qui est quasiment imperceptible, on est alors poussé à acheter. C’est pareil avec certains mouvements à caractère sectaire, qui savent saisir le moment où une personne est la plus fragile, dans un moment d’épuisement, et faire d’elle un peu ce qu’ils veulent. Cela explique aussi en partie la radicalisation en ligne, qui passe par la détection de personnes en situation de vulnérabilité, d’échec ou d’isolement. Cela ne veut pas dire que le libre arbitre n’existe plus, mais que certains empiètent sur le libre arbitre des autres. Cela a toujours existé, par exemple avec les fresques érotiques qui attiraient le passant à Pompéi. Mais on a clairement maintenant franchi un cap assez net en termes d’intrusion. Certaines manipulations peuvent aller jusqu’à menacer le vivre-ensemble et la démocratie. C’est inquiétant !
Lien virtuel
Les liens entre les personnes
B : les gens passent maintenant beaucoup de temps dans un monde virtuel, déconnecté de la vie physique. Cela a-t-il des conséquences sur leurs relations avec autrui ?
ES : ce qui est virtuel, c’est ce qui est potentiel, comme des gains virtuels par exemple. Le numérique n’est pas si « virtuel » que ça. Peu de choses y sont virtuelles, sauf peut-être les univers de certains jeux vidéo sans lien avec le monde réel. Et encore, même là, les jeux en ligne massivement multi-joueurs impliquent de vrais compétiteurs.
Le numérique permet un nouveau mode de communication, et les jeunes peuvent avoir une vie numérique au moins aussi riche que leur vie IRL (in real life), et qui complète leur vie IRL. La communication numérique est pour beaucoup, je pense, une communication interstitielle. Certes, les adolescents peuvent rencontrer des gens en ligne, mais ils ont surtout un fonctionnement relativement tribal. Ils hésitent à parler à qui ne fait pas partie de la bande. Les modes de communication numériques vont principalement servir à combler les lacunes des relations déjà existantes.
Évidemment, cela change les modes et les rythmes de présence. Autrefois quand le jeune rentrait chez lui, il était chez lui, injoignable sauf en passant par le téléphone de la maison familiale. Maintenant la communication avec ses pairs continue dans sa chambre et jusque dans son lit. Un enfant harcelé en classe par exemple ne pourra plus trouver de havre de paix à domicile. Un harcèlement bien réel peut devenir omniprésent.
La relation au temps et à l’espace rend plus proches de nous un certain nombre de gens, et cela change la cartographie. J’ai des amis un peu partout dans le monde, et les réseaux sociaux leur donnent une forme de visibilité et me permettent de garder des liens avec eux. C’est positif.
Et l’amour ?
B : peut-on, avec le numérique, mettre l’amour en équations ?
ES : l’amour est un sentiment complexe, et toute réponse à cette question appelle aussitôt la controverse. Pour certains spécialistes de neurosciences, il s’agit seulement d’une suite de réactions chimiques dans notre cerveau. Le psychologue rétorque que cette réponse explique comment ça se passe, le mécanisme, mais ne dit pas pour autant ce que c’est. Ces deux points de vue sont quand même assez opposés. Pour ma part, je dirais que, même si on a l’impression que, scientifiquement, on comprend un peu la façon dont cela se passe, ça ne nous dit pas grand-chose de la nature du phénomène, ou en tout cas pas assez pour que ce phénomène soit réductible à ce fonctionnement électrique et chimique.
Une vidéo d’un petit chat, ou même un Tamagotchi, suffit à susciter une réaction d’empathie. L’humain a cette belle capacité de s’attacher à à peu près tout et n’importe quoi, mais ça a plus de sens s’il s’attache à ses semblables, sa famille, ses amis. Ce sont des liens forts.
Surtout, il ne faut pas tout confondre. J’ai des liens très forts avec un petit nombre de gens et cela n’a rien à voir avec tous ces liens faibles qui se multiplient avec mes contacts sur les réseaux sociaux. L’appétence pour une forme de célébrité (même relative) prend de plus en plus de poids. Je suis étonné de voir à quel point cela se confond avec l’amour dans la tête d’un grand nombre de gens. C’est l’aspect négatif d’un média bidirectionnel : chacun peut devenir connu comme un speaker du journal de 20 h.
Je pense qu’on réduit l’amour à la partie équations quand on fait cette confusion. On floute les contours de l’amour, on le réduit tellement qu’on peut alors le mettre en équations.
Une autre inquiétude est qu’on peut effectivement avoir l’impression qu’on va susciter de l’empathie chez la machine. Les machines peuvent nous fournir les stimuli dont nous avons envie, et elles savent imiter l’empathie. Certains disent que cette simulation vaut le réel, mais ce n’est pas la même chose, c’est seulement une simulation. Le film Her illustre cette question. Le danger, quand on simule l’empathie, c’est qu’on met l’autre dans une situation de dépendance. L’humain risque de se laisser embarquer dans une relation avec des objets dits intelligents. Et cette relation est différente de celle que l’on pourrait établir, par exemple, avec un animal de compagnie. Certes, un chien veut être nourri, mais il n’a pas une relation purement utilitariste : ses capacités cognitives et relationnelles permettent d’établir avec lui une forme de lien, certes asymétrique mais bidirectionnel. Alors qu’avec la machine, on va se trouver dans une relation bizarre, totalement unidirectionnelle, dans laquelle nous sommes seuls à projeter un sentiment.
B : vous parlez de relation unidirectionnelle. Mais pourquoi est-ce moins bien qu’une personne ait en face d’elle un système qui simule l’empathie ? Si cela fait du bien à la personne ? On a par exemple utilisé de tels systèmes pour améliorer le quotidien d’enfants autistes.
ES : Vous faites bien de préciser « simule ». Ce ne sont pas des systèmes empathiques. Ce sont des systèmes qui simulent l’empathie, comme un sociopathe simulerait à la perfection le sentiment qu’il a pour une personne, sans pour autant rien ressentir. Le principe de l’empathie, c’est qu’elle change notre mode de fonctionnement : on est touché par quelqu’un et cela nous transforme. Notre réaction vient du fond du cœur.
Ce n’est certes pas une mauvaise chose que d’améliorer l’expérience de l’utilisateur, qu’il soit malade ou pas, mais cette dimension unidirectionnelle de la relation peut potentiellement être nocive pour une personne en situation de fragilité. Celui qui simule l’empathie est dans la meilleure situation possible pour manipuler l’autre. Jusqu’où faut-il manipuler les gens, surtout s’ils sont en situation de fragilité ?
Dans le cas de la machine, l’enjeu réside donc dans le but de la simulation. Si elle est élaborée par le corps médical pour faciliter la communication avec une personne malade ou dépendante, et pour faire évoluer cette personne vers un état meilleur, elle peut être tout à fait légitime. Mais quid d’une empathie simulée pour des raisons différentes, par exemple commerciales ? Cela demande une grande vigilance du point de vue éthique.
La post-vérité
B : on assiste à une poussée du « relativisme ». Il n’y a plus de vérité ; les fake news prolifèrent. Est-ce que cela a un impact sur la religion ?
ES : Effectivement je pense qu’il y a un impact sur les religions car cela remet aussi en cause tout ce qui est dogme. Prenons la Trinité : pourquoi est-ce qu’ils sont trois ? Certains pourraient dire que la Trinité pose une question de parité, et qu’on n’a qu’à rajouter la Vierge Marie, comme ça ils seront quatre !
On peut ainsi dire à peu près l’importe quoi, et c’est là le problème. Mais en fait, avant d’être religieux, l’impact de cette remise en cause de la notion de vérité est d’abord intellectuel. L’opinion finit par l’emporter sur le fait, même démontré. D’un point de vue philosophique, cela mènerait à dire que notre relation au réel est plus importante que le réel lui-même. Or, les sciences lèvent des inconnues, répondent à des questionnements, même si elles découvrent parfois leurs limites. Mais, sans les connaissances que nous accumulons, l’océan d’à-peu-près brouille notre compréhension du réel.
Cela risque de conduire à une remise en question de notre société parce que, pour vivre ensemble, nous avons besoin de partager des vérités, d’avoir des bases de connaissances communes. Par exemple, l’activité humaine est-elle le facteur majeur du réchauffement climatique ou pas ? Ce ne devrait pas être une question d’opinion mais de fait. À un moment donné, cela va conditionner nos choix de façon drastique.
La spiritualité
B : est-ce qu’il reste une place pour la spiritualité, pour la foi, dans un monde numérique ?
ES : il est intéressant de voir à quel point le monde numérique, dans ses dimensions marchandes, économiques, est matérialiste. Et pourtant, on constate que le besoin de spiritualité n’a vraiment pas disparu. Voyez le succès, dans la Silicon valley, des spiritualités orientales, qui arrivent parées d’une aura exotique et lointaine, malgré la dimension syncrétiste de la version californienne. Si des patrons font venir à grand frais des lamas du Tibet, c’est parce que cela répond à un besoin.
Je crains que la plupart de nos contemporains ne soient obligés d’assouvir ce besoin avec ce qu’ils ont sous la main, et le piège, c’est que ce soit la technologie elle-même qui vienne nous servir de béquille spirituelle ! Dans à peu près toutes les traditions religieuses, il existe la tentation de créer un objet, souvent le meilleur qu’on soit capable de concevoir, de le placer en face de soi, au centre du village, de le révérer, et d’attendre qu’il nous procure une forme d’aide, de protection, voire de salut. C’est le principe du totem et du veau d’or.
Le HomePod était l’objet le plus vendu aux USA à Noël dernier. Il est connecté à tout, il est l’accès de toute la famille au savoir, à une espèce d’omniscience et d’ubiquité sous le mode de la conversation, en court-circuitant l’étape de la recherche via un moteur qui proposerait plusieurs réponses. Il devient un peu l’oracle, une Pythie qui serait la voix du monde. Les gens utilisent aussi le HomePod pour connecter tout leur quotidien. Le HomePod met le chauffage en route, envoie un SMS pour avertir que les enfants sont bien rentrés de l’école et branche l’alarme, pour veiller sur la maison en notre absence. Ainsi, le HomePod est une entité qui s’occupe de la famille, une entité physique placée sur un piédestal dans le foyer, un peu comme un Lare, une petite divinité domestique qui prend soin de chacun. Cela exprime une relation à la technologie qui peut être une relation d’ordre spirituel.
Le petit dieu de la maison, Serge A.
Le problème, c’est que la technologie ne fait que ce pour quoi elle a été prévue. L’être empathique, lui, va faire des choses pour lesquelles il n’a pas été programmé, il va se surpasser, se surprendre quand il est poussé à faire des choses qui sortent du cadre, alors que cette technologie ne va faire que les choses pour lesquelles elle a été programmée. Dans la tradition juive, le psalmiste disait en se moquant des faux dieux : « Ils sont faits de mains d’homme, ils ont des oreilles mais n’entendent pas… » Sauf que le HomePod entend, et si on lui dit « Commande moi une pizza ! », et bien, il vous apporte le dîner. De ce fait, l’illusion est beaucoup plus réaliste.
B : vous parlez de « petit dieu ». Est-ce que le numérique peut aussi proposer Zeus, un « grand Dieu » ?
ES : pour le moment, l’humain n’a pas encore été capable d’en fabriquer. La pensée magique est liée à la spiritualité. Cette pensée magique n’a jamais complètement disparu, et certains sont persuadés qu’un jour on créera une IA suffisamment puissante pour qu’on puisse la prendre pour un dieu. Il est vrai qu’une intelligence artificielle vraiment forte commencerait à ressembler à une divinité. Ce serait alors peut-être confortable pour l’humain de déléguer toutes ses responsabilités à une telle entité. Mais si on peut se complaire dans un petit dieu, je ne pense pas que nous serions prêts à accepter qu’une machine devienne comme Zeus. Est-ce que nous serions prêts à entrer dans ce type de relation ? Un dieu qu’on révérerait ? Je ne pense pas.
La place du Créateur
B : nous créons des logiciels de plus en plus intelligents, des machines de plus en plus incroyables. Est-ce que toutes ces créations nous font prendre un peu la place du Créateur ?
ES : le scientifique dévoile une réalité qui lui préexiste, alors que l’inventeur, le spécialiste de technologie, fabrique quelque chose qui n’existait pas auparavant, comme un téléphone intelligent par exemple, et cela induit un rapport au réel assez différent. L’inventeur se met un peu dans la roue du Créateur : c’est quelque chose qui est de l’ordre du talent reçu. En ce sens, si on considère que Dieu est Créateur et que l’homme est à l’image de Dieu, il est naturel que l’être humain veuille également créer ; cela tient du génie humain.
Mais, créer, techniquement, c’est créer ex nihilo. Au commencement, dit la Bible, il y avait le chaos. Une part de substrat, mais informe. Quand un humain dit qu’il a créé quelque chose, en fait, à 99%, il reprend des brevets existants, même s’il peut amener une réelle rupture. L’iPhone qu’on utilise juste avec les doigts, sans stylet, nous a ouvert de nouvelles perspectives d’accès à l’information en situation de mobilité. Sans sous-estimer l’apport des humains qui ont inventé cela, cela tient de l’invention, de la fabrication, et je n’appellerais pas cela véritablement de la « création ».
En revanche, ces technologies nous permettent de bâtir, de construire ensemble quelque chose de nouveau. Ces technologies sont nos réalisations. Ce sont des productions de notre société, aux deux sens du génitif : elles sont produites par ladite société, et ainsi elles nous ressemblent, elles portent en elles une certaine intentionnalité issue de notre culture ; mais, en retour, leur utilisation façonne notre monde. D’ailleurs, quand un pays, consciemment ou inconsciemment, impose une technologie, il impose aussi sa culture, car en même temps, ces technologies transforment la société qui les reçoit. C’est le principe du soft power.
Dans ce cadre, on voit bien que l’intelligence artificielle permet une plus grande personnalisation. Comment faire en sorte que cette personnalisation ne se transforme pas en individualisme ? Il y a un effet de bulle : tous ceux avec qui je serai en contact vont me ressembler, et tout sera conçu, fabriqué exactement pour moi. De plus en plus, le monde numérique, c’est mon monde, un monde qui devient un peu comme une extension de moi-même. C’est extrêmement confortable, mais le danger, c’est que mon réel n’est pas votre réel, et alors comment se fait l’interaction entre les deux ?
La difficulté réside dans le fait que, si chacun configure de plus en plus précisément son réel autour de lui, la rencontre de ces écosystèmes risque d’être de plus en plus complexe. Les difficultés en société ne seront alors plus entre les communautés et le collectif, mais entre chaque individu et le collectif. Comment l’humain qui s’est créé sa bulle peut-il être en adéquation avec un référentiel, et comment faire évoluer ce référentiel ? Si chacun a ses lunettes pour voir le monde en rose, en bleu, en vert, et qu’on rajoute à cela l’ultralibéralisme libertaire, cela peut mettre en danger le projet de construction de la société.
Le vrai défi est bien de garder un référentiel commun. Plutôt que de nous laisser enfermer dans une personnalisation à outrance, le vrai défi est de bâtir collectivement un vivre-ensemble.
Nous partageons grâce à Lêmy Godefroy ici un document important : c’est un rapport sur la prise de décision par le juge à l’aide d’algorithmes. Toute personne qui aurait affaire à la justice est concernée dans la mesure où son litige pourrait, dans un avenir plus ou moins proche, être traité par des modes algorithmiques d’analyse des décisions.
Ce rapport peut ainsi contribuer à apporter des informations sur les modalités de fonctionnement de ces outils d’aide à la décision ainsi que sur les enjeux éthiques que soulèvent leurs usages par les magistrats. Thierry Viéville
Comme on en discutait dans il y a quelques mois dans ce billet les algorithmes s’invitent dans un domaine crucial : la justice. Souhaitez-vous allez à la source de ce qui se dit et se fait sur ce sujet ?
Un rapport de recherche pluridisciplinaire pour la Mission de recherche Droit et Justice traitant des modes algorithmiques d’analyse des décisions dans le domaine du droit et de la Justice a été publié le 05 juillet 2019.
Ce rapport intervient sous trois angles: mathématique, juridique et sociologique.
Sur le plan mathématique, il traite de la modélisation de l’activité juridique en présentant les différents outils d’aide à la décision qui existent et leur fonctionnement. Sur le plan juridique, il s’agit de proposer un cadre à l’utilisation de ces outils algorithmiques en déterminant leur périmètre d’action, d’en cerner les dangers et les intérêts, d’en comprendre les enjeux éthiques et d’examiner les modalités de leur intégration au travail des juges. De plus, une enquête a été effectuée auprès des présidents des TGI, des premiers présidents des Cours d’appel ainsi que de la Cour de cassation pour connaître leur perception de ces outils. Sur le plan sociologique, l’analyse montre que « les dynamiques internes au champ juridique (…) seront déterminantes dans le processus de changement qui devrait se traduire par une montée en puissance des algorithmes au sein de l’institution qu’est la Justice ».
Ce rapport est intitulé « Comment le numérique transforme le droit et la Justice par de nouveaux usages et un bouleversement de la prise de décision. Anticiper les évolutions pour les accompagner et les maîtriser ». Les auteurs en sont Jacques Levy-Vehel, Directeur de recherches Inria et Président de Case Law Analytics, Lêmy Godefroy, Maitre de conférences en droit privé au Groupe de Recherche en Droit, Economie, Gestion (GREDEG) d’Université Côte d’Azur et Frédéric Lebaron, Professeur en sociologie au laboratoire Institutions et Dynamiques Historiques de l’Économie et de la Société de l’ENS Paris-Saclay.



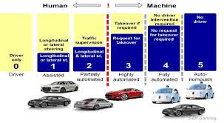





 Matthias Puech est ingénieur R&D à l’INA au sein du Groupe de Recherches Musicales, compositeur et enseignant-chercheur en informatique au CNAM. Après nous avoir expliqué les origines de la recherche musicale en France, il nous explique comment les ordinateurs traitent le son, les contraintes et les perspectives de l’informatique musicale. Pierre Paradinas
Matthias Puech est ingénieur R&D à l’INA au sein du Groupe de Recherches Musicales, compositeur et enseignant-chercheur en informatique au CNAM. Après nous avoir expliqué les origines de la recherche musicale en France, il nous explique comment les ordinateurs traitent le son, les contraintes et les perspectives de l’informatique musicale. Pierre Paradinas Pierre Schaeffer au studio 54 Centre Bourdan 1972, Photo Laszlo Ruszka ©INA
Pierre Schaeffer au studio 54 Centre Bourdan 1972, Photo Laszlo Ruszka ©INA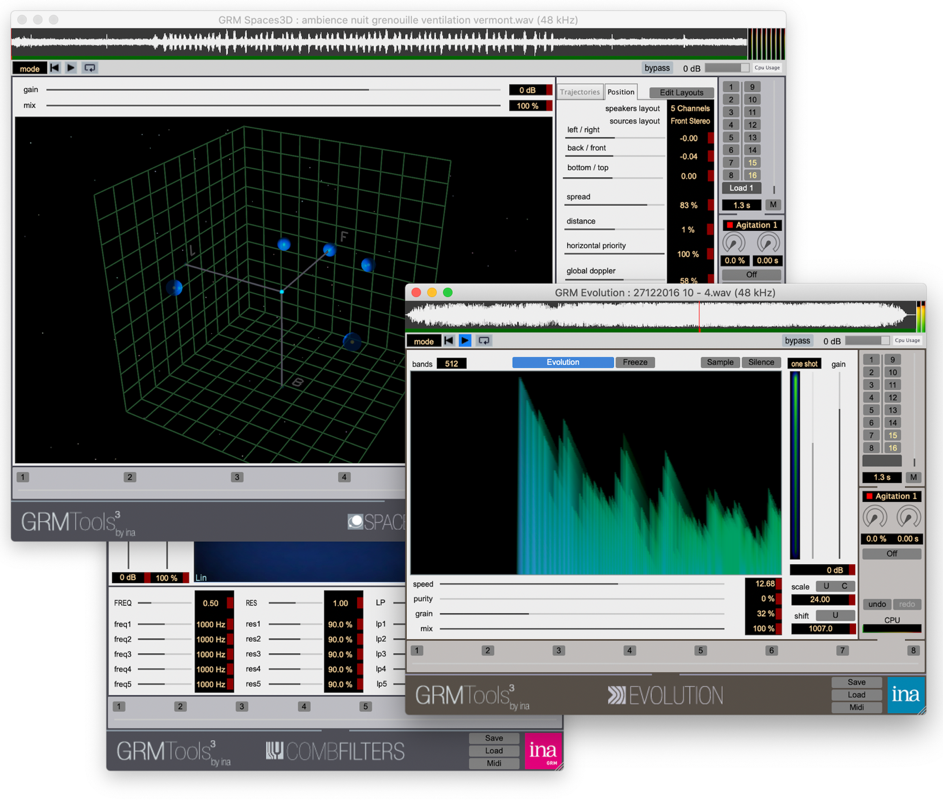

 Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines.
Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines. 









 Vers un confinement sélectif basé sur les informations personnelles ?
Vers un confinement sélectif basé sur les informations personnelles ? 








 À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec a choisi de parler de sexbots, les robots sexuels, et des stéréotypes qu’ils propagent. Serge Abiteboul
À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec a choisi de parler de sexbots, les robots sexuels, et des stéréotypes qu’ils propagent. Serge Abiteboul