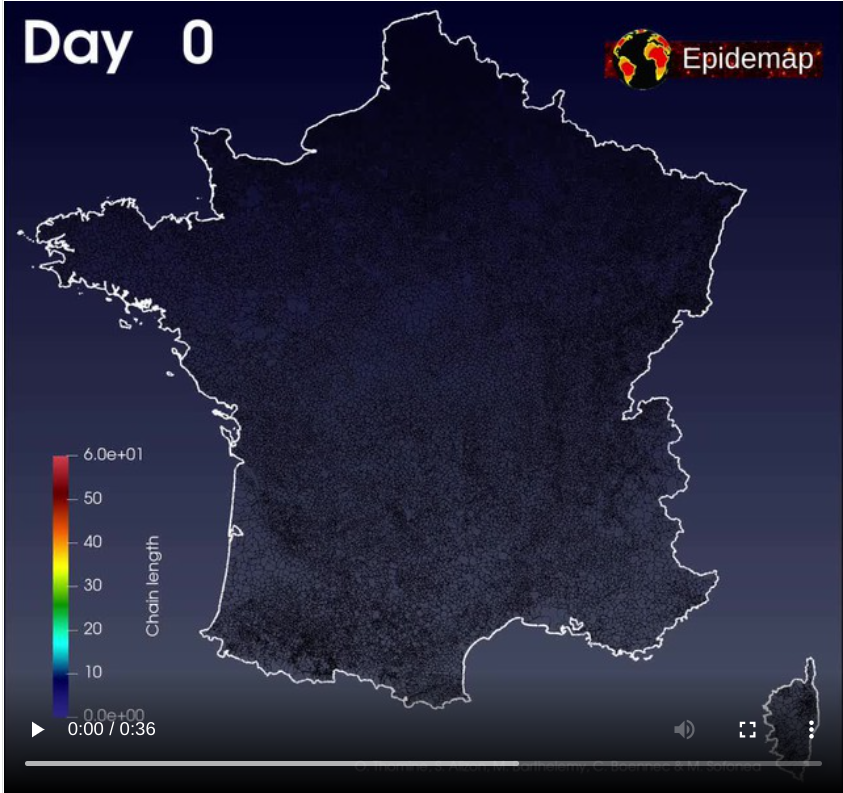
Binaire : Qu’est-ce que le mot commun évoque pour toi ?
Mehdi Benchoufi : Une des grandes passions de ma vie est les mathématiques. La première chose que m’évoque les communs c’est le commun des mathématiques. Les mathématiques appartiennent à tous et sont développées par tous. Que serait le monde aujourd’hui si le théorème de Pythagore était propriétaire ? Ce commun a un impact invraisemblable sur le monde. C’est mon goût personnel pour les mathématiques qui m’a donné le goût de la culture du partage telle qu’on la voit dans l’ouverture des données ou du logiciel. On s’inscrit dans une tradition historique de mise en commun, on croise les apports des uns et des autres, et on consolide une connaissance commune.
Peux-tu nous parler du commun sur lequel tu travailles aujourd’hui ?
Je travaille depuis longtemps sur un outil pour mettre l’échographie à la portée de tout le monde. Quand j’étais interne, j’ai réalisé l’intérêt de pouvoir faire des échographies sur le lieu de prise en charge des malades. Notamment, j’ai été marqué par le cas de patients victimes de ruptures d’anévrismes de l’aorte et dont on aurait augmenté les chances de survie si les équipes mobiles de prise en charge avaient disposé d’un matériel échographique de tri, pas cher, miniaturisé et connecté.
C’est ce qui m’a donné l’idée du projet ouvert et collaboratif echOpen au côté de mes collègues Olivier de Fresnoye, Pierre Bourrier et Luc Jonveaux, le premier avec une longue expérience humanitaire, le second radiologue expert de l’échographie, le troisième ingénieur et maker versé dans les technologies acoustiques. L’objectif est de produire une sonde ultrason ouverte, connectée à un smartphone afin de transformer de manière radicale le processus de diagnostic dans les hôpitaux, les cabinets de médecine générale et les déserts médicaux. On tient à ce qu’elle soit abordable, bien moins chère que les produits actuellement sur le marché.
Nous avons créé une association en 2015 pour organiser les développements de la communauté. Dans une première phase qui a duré 3-4 ans, nous avons mis en place tous les outils utilisés dans la fabrication d’un échographe ; c’est en accès libre sur github et des équipes l’utilisent dans le monde entier. Dans un second temps, pour passer du démonstrateur au produit, nous nous sommes structurés en entreprise, tout en tâchant de continuer à associer la communauté.
Commençons par la première phase, peux-tu nous parler de votre communauté ?
Il y avait un noyau d’une trentaine de contributeurs. Et puis d’autres personnes ont soutenu le projet de diverses manières, par exemple, en participant à son financement ou en nous encourageant. Je dirais peut-être un millier de personnes réparties sur 5 continents, des informaticiens, des physiciens, des médecins, des spécialistes en acoustique en électronique, etc.
Pour prendre un exemple, parmi tous ces soutiens, nous avions ce Canadien, un super développeur qui avait fait la une de Hacker News. Il est passé à Paris et a demandé à nous rencontrer. Il est resté 10 jours chez nous et nous a fait gagner un facteur 10 dans les performances de l’application. C’est le genre d’agilité et de créativité que nous apportait la communauté au sens large.
Un autre exemple. Les membres de notre communauté du Pérou nous ont fait connaître une pathologie atypique, un cancer du foie que même nos collègues médecins français ignoraient. Ce sont des formes très rares dans le monde mais fréquentes dans ce pays qui touchent des gens entre 15 et 25 ans en milieu rural. Le malade arrive pour le diagnostic avec une espèce de pastèque dans le ventre et c’est déjà trop tard. Il faudrait dépister cette maladie à temps. Nous nous disions que notre petit échographe serait capable de faire cette détection à distance.
Pour revenir à la contribution d’echOpen aux communs de façon plus générale, dans le logiciel Open Source, la difficulté majeure à laquelle nous avons été confrontées est le caractère inapplicable, dans le domaine de la santé, du principe « give to get » qui peu ou prou régit le développement libre ou open source, c’est-à-dire je donne quand je sais que je vais recevoir. Si je contribue au logiciel libre d’édition de texte emacs, j’apporte une brique qui complète un ensemble dont je vais être l’utilisateur. Mais cette règle-là n’est pas évidente dans notre cas. Dans le domaine de la santé, les membres de la communauté ne sont pas nécessairement les consommateurs de la technologie.
Est-ce que la communauté a défini ses propres règles de fonctionnement ?
Il y a des règles, mais honnêtement ces règles n’ont jamais été vraiment formalisées. On travaille sur Github. Mais c’est aussi important pour la communauté de se retrouver physiquement pour travailler ensemble dans les mêmes locaux. C’est ce que nous avons pu faire dans les locaux de l’hôpital Hôtel Dieu à Paris.
Donc en 2018, vous basculez vers une organisation différente : une entreprise privée. Qu’est-ce qui motive ce choix ?
Au bout de trois ans de développement, s’est reposée notre motivation initiale : avoir de l’impact sur le travail des praticiens et servir les patients. Nous avons compris que notre prototype n’était pas industrialisable. Il fallait un travail d’une tout autre nature, d’une tout autre ampleur, pour satisfaire notamment les exigences en termes de certification et de sécurité. Nous avions réalisé notre mission en tant que Fablab et nous nous sommes lancés dans l’aventure entrepreneuriale, et sommes repartis “from scratch » pour viser la qualité d’un dispositif médical. Pour cela, il fallait des financements et des efforts conséquents. Il s’agissait de financements importants,et les fonds comme ceux que nous avions obtenus auprès des fondations qui nous avaient soutenus depuis le début, la fondation Pierre Fabre, la fondation Sanofi Espoir et la Fondation Altran pour l’Innovation, ne pouvaient suffire. Nous nous sommes transformés en startup.
Le monde est ce qu’il est ; nous sommes dans une économie capitalistique dont le modèle est assis sur la propriété. Personne n’investit un euro dans une société qui n’est pas propriétaire de sa technologie. Je trouve cette logique contestable mais c’est la réalité.
La mise en place de notre première recherche de fonds a été difficile. Les capitaux-risqueurs que nous avons rencontrés ne trouvaient pas leur intérêt dans une solution bas coût, lorsque les compétiteurs vendent substantiellement plus chers. Mais nous avons tenu bon et avons pu trouver les moyens de nous financer jusqu’à aujourd’hui !
Comment s’est passée le passage du commun à l’entreprise ?
Très bien. Toute la communauté contributrice a participé aux discussions quant à l’évolution de notre organisation, à la répartition des titres de l’entreprise à due concurrence des contributions effectuées. L ‘association est toujours en place et elle a une part substantielle de l’entreprise privée, elle a ainsi co-fondé le véhicule industriel echOpen factory. Elle a concentré et intensifié ses activités pour adresser un enjeu de santé publique majeure au niveau mondiale, la santé maternelle dans les pays à faible revenu. Aujourd’hui l’aventure continue. Nous continuons à travailler main dans la main avec nos communautés technique et médicale en les impliquant dans l’expérimentation de nouveaux usages du dispositif. Avec toujours le même objectif en ligne de mire : rendre l’imagerie médicale accessible partout dans le monde.
Les membres de votre communauté, les 30 et les 1000, ont tous accepté ?
Nous avons mobilisé l’ensemble des contributeurs actifs d’echOpen, soit une trentaine de personnes. Tous ceux auxquels nous avons proposé des parts ont accepté, sauf le développeur Canadien dont je vous ai parlé.
On a bien eu deux départs mais c’était avant la transformation en entreprise. Deux personnes ont quitté le projet pour des différences de points de vue techniques et opérationnels. L’une d’entre elles, Luc Jonveaux, a proposé un fork sur Github et a continué à développer son projet de matériel de recherche, ce qui montre là une façon intéressante de gérer le dissensus au sein d’une communauté. Nous sommes toujours en très bons termes avec ces deux personnes.
Vous construisez un appareil. Qu’est ce qui est ouvert ? Le design général ? Le matériel ? Le logiciel ?
Dans la première phase Fablab, tout ce qui était réalisé l’était en open source ! Si on est parvenu à diminuer le coût du dispositif, c’est parce qu’on a pris cette approche. On n’est pas parti de l’existant comme l’aurait fait un industriel, ni d’un processus de transfert technologique comme dans un laboratoire. On est parti de la page blanche en nous appuyant sur des briques logicielles en open source. C’était un chemin possible pour arriver à un design raisonnable en termes de qualité, et industrialisable dans des conditions de coût qui étaient les nôtres.
Notre modèle était assez original avec notamment à la fin une phase FabLab qui était constitutive de la communauté et relativement productive puisqu’on a aujourd’hui des universités qui utilisent les cartes électroniques ou des petits logiciels qu’on a développés. En revanche, à l’issue de cette phase, on ne pouvait pas viser une sonde de qualité médicale. Nous sommes repartis de zéro.
Je pense que toute start-up qui reprendrait le travail de la communauté serait capable de refaire ce que nous avons réalisé. En tout cas, nous lui avons donné les bases pour le faire.
Plusieurs brevets d’invention ont été déposés. Notre volonté est d’ouvrir la technologie dès lors qu’une nouvelle version s’y substitue. Donc, à chaque fois que nous remplaçons une version, nous ouvrons le code de la précédente. Nous nous protégeons. Nous voulons éviter qu’un concurrent modifie le produit à la marge, brevette, et ensuite nous empêche d’exploiter le fruit de nos travaux. Enfin, c’est ce qui est prévu parce que, pour l’instant, nous n’avons pas encore sorti la deuxième version qui nous permettra d’ouvrir la première.
Deuxième élément en gestation et en discussion : la possibilité de permettre à des tiers de développer les algorithmes, par exemple des algorithmes d’intelligence artificielle sur la base de notre sonde. Nous sommes contactés par différentes entreprises et d’autres structures qui veulent s’appuyer sur un appareil qui n’est pas cher.
Et ce à quoi nous réfléchissons, c’est à open-sourcer des outils d’interfaçage à notre solution pour des tiers développant des services complémentaires aux nôtres. C’est en discussion et je ne sais pas quand ça va atterrir, mais ça fait partie de nos réflexions.
Où en êtes-vous aujourd’hui ?
Notre startup fonctionne bien. Nous sommes même la première startup à avoir l’AP-HP dans notre capital. Nous avons aujourd’hui un produit opérationnel qui a déjà passé l’essai clinique. Il est en cours de finalisation.
Serge Abiteboul, Inria et ENS, François Bancilhon, serial entrepreneur


 On y offre un tiers lieu d’activités scientifiques pour populariser ces sciences. Mais c’est surtout la concrétisation du rêve d’un petit groupe de chercheurs autour de
On y offre un tiers lieu d’activités scientifiques pour populariser ces sciences. Mais c’est surtout la concrétisation du rêve d’un petit groupe de chercheurs autour de 
 Et cela jusque dans les fondatrices de l’entreprise elles-mêmes: l’une est entre autre maçonne, l’autre est aussi
Et cela jusque dans les fondatrices de l’entreprise elles-mêmes: l’une est entre autre maçonne, l’autre est aussi  La
La  En alliant science et créativité, esprit critique et développement durable, l’atelier montre aux enfants concrètement que tout ne s’achète pas, mais peut se construire, et démontre que ce qu’ils apprennent à l’école peut permettre de faire plein de choses passionantes et super au quotidien.
En alliant science et créativité, esprit critique et développement durable, l’atelier montre aux enfants concrètement que tout ne s’achète pas, mais peut se construire, et démontre que ce qu’ils apprennent à l’école peut permettre de faire plein de choses passionantes et super au quotidien.  En construisant son propre robot à partir de la vision imagée que l’on peut en avoir, l’atelier démystifie robotique et intelligence artificielle pour les enfants : rien de magique, juste des algorithmes devenus suffisamment complexes pour effectuer des tâches intellectuelles (“cognitives´´ pour employer le terme exact) qui auraient été intelligentes si elles avaient été faites par un humain.
En construisant son propre robot à partir de la vision imagée que l’on peut en avoir, l’atelier démystifie robotique et intelligence artificielle pour les enfants : rien de magique, juste des algorithmes devenus suffisamment complexes pour effectuer des tâches intellectuelles (“cognitives´´ pour employer le terme exact) qui auraient été intelligentes si elles avaient été faites par un humain. Oui, ce travail se fait aussi avec le conseil de chercheur·e·s du laboratoire
Oui, ce travail se fait aussi avec le conseil de chercheur·e·s du laboratoire 

 structures de recherche (CNRS, Inria et Université Côte d’Azur), des composantes de l’Éducation Nationale, des partenaires associatifs ou socio-économiques, aux profils complémentaires afin de bénéficier des compétences scientifiques, pédagogiques, techniques et technologiques nécessaires au développement du projet.
structures de recherche (CNRS, Inria et Université Côte d’Azur), des composantes de l’Éducation Nationale, des partenaires associatifs ou socio-économiques, aux profils complémentaires afin de bénéficier des compétences scientifiques, pédagogiques, techniques et technologiques nécessaires au développement du projet. Trains et jeux en ligne pour comprendre les algorithmes de recommandation
Trains et jeux en ligne pour comprendre les algorithmes de recommandation Géométrie et polyèdres avec écran sphérique
Géométrie et polyèdres avec écran sphérique  Smart City
Smart City