
Pascal Guitton nous a expliqué les principes de la publication scientifique et son passage au numérique dans un premier article. Il aborde maintenant pour nous des dérives récentes du système. Il nous parle d’un futur souhaitable fait de publications ouvertes et d’épi-journaux. Serge Abiteboul et Thierry Viéville.
Le numérique a contribué à améliorer le travail des chercheurs en enrichissant le contenu des publications numériques, en favorisant la recherche d’un article dans la masse gigantesque de documents disponibles, et en optimisant les modalités et le temps d’accès à l’information. Malheureusement, dans le même temps, ces évolutions se sont accompagnées de dérives qui pourrissent la vie des scientifiques.
Dérive 1 : Le spam dans l’édition scientifique

Certains ont cru détecter la poule aux œufs d’or dans l’évolution numérique de l’édition scientifique. Sont apparues de nulle part des sociétés « expertes» de la création de revues (et de conférences) traitant de tous les sujets et ouvertes à tous. Concrètement, un chercheur reçoit très souvent (plusieurs fois par mois) des messages d’invitation à soumettre ses travaux dans des revues ou des conférences « SPAM (*) » ou alors à participer à leurs comités de lecture qui n’en possèdent que le nom. Certains se laissent abuser, le plus souvent par négligence en n’étant pas assez critique sur la qualité de la revue, parfois par malhonnêteté en espérant augmenter leur visibilité.
L’évaluation par les pairs, comme tout processus humain, peut faillir et conduire à des publications erronées, voire totalement loufoques. Il ne s’agit pourtant là que de dysfonctionnements non représentatifs de la qualité générale du travail de publication. Une évaluation un tant soit peu sérieuse détectera ce type de publication. Il convient toutefois pour les scientifiques de rester vigilants devant l’augmentation récente de ce nombre de situations qui est directement reliée à l’augmentation du nombre de revues et de conférences « parasites ».
Dérive 2 : L’évaluation mal réalisée

Au delà de ces dérives mercantiles, le principal problème résulte de la culture de l’évaluation à outrance qui a progressivement envahi le monde de l’enseignement et la recherche que ce soit au niveau des individus (recrutement, promotions), des laboratoires (reconnaissance, financements) ou des universités/écoles/organismes (visibilité, attractivité).
Entendons-nous bien, ce n’est pas la nécessité d’une évaluation qui est ici remise en cause mais les façons dont elle est trop souvent mise en œuvre. Illustration : dans un premier temps, le nombre de publications d’un chercheur est devenue la référence principale de jugement ; bien que simple et naturel, un comptage brutal ne tient pas compte de leur qualité et de leur ampleur, produisant des « spécialistes » de la production à la chaîne d’articles sans réel impact. (Il est quasiment impossible de s’accorder sur le nombre des articles jamais cités par d’autres scientifiques mais il est élevé). On observe aussi des équipes qui alignent leurs thématiques de recherche sur les sujets « chauds » des revues et/ou synchronisent leurs activités sur le calendrier des conférences importantes, délaissant leur libre arbitre et le propre pilotage de leur recherche.
Dans un deuxième temps, sont apparus des indicateurs numériques sensés remédier à ce problème, en calculant des scores basés sur le nombre de citations que recueille un article. L’idée a d’autant plus de sens que les explosions conjointes au niveau mondial des nombres de chercheurs et de revues ont conduit à une inflation jamais connue jusque là de la production d’articles scientifiques ; s’interroger sur l’impact réel d’une publication est légitime et a suscité de nombreuses méthodes dont les plus connues sont la famille des h-index apparue en 2005 pour les articles et les facteurs d’impact en 2006 pour les revues.
Malheureusement, cette bonne idée souffre de nombreux défauts : tout d’abord, le mélange incroyable entre citations positives (pour mettre en exergue un résultat) et négatives (pour critiquer tout ou partie du travail) ! Ensuite, la taille des communautés qui est le plus souvent oubliée dans l’exploitation de ces indicateurs ; comment raisonnablement comparer des index si le nombre de chercheurs d’un domaine est très différent d’un autre ; pensons par exemple à une thématique émergente qui ne concerne initialement qu’un petit cercle : faut-il l’ignorer parce qu’elle arrive loin dans les classements ? Ce n’est surement pas de cette façon que nous produirons les innovations tant attendues. Par ailleurs, les bases de données utilisées pour calculer ces taux de citation ne couvrent qu’une partie de la littérature scientifique ; en informatique par exemple, moins de la moitié de la production est référencée dans les plus célèbres d’entre elles. Et puis, des esprits malintentionnés ont dévoyé cette bonne idée en mettant en œuvre des pratiques frauduleuses : autocitations abusives, « découpage » artificiel d’un résultat en plusieurs articles pour augmenter le nombre de publications et de citations, cercles de citations réciproques entre auteurs complices, « recommandation appuyée » de certains éditeurs de citer des articles de leur propre revue, etc.
En résumé, ces indicateurs ne devraient fournir qu’un complément d’information à une évaluation plus qualitative et donc plus fine. Malheureusement, une telle analyse nécessite plus de temps et aussi de mobiliser de vrais experts. Il est infiniment plus « facile » de la remplacer par l’examen de quelques chiffres dans un tableur sensés représenter une activité scientifique dont il est bien entendu impossible de réduire ainsi la richesse et la diversité. On peut faire l’analogie avec la qualité d’un livre qui ne serait jugée qu’à travers son nombre de lecteurs ou celle d’une chaîne de télévision qu’à travers son Audimat.
Terminons en rappelant encore une fois qu’il ne s’agit pas d’ignorer ces indicateurs mais bien de les exploiter pour ce qu’ils sont et de les associer systématiquement à des analyses qualitatives réalisées par des experts.
Dérive 3 : le modèle économique

Initialement gérée par les sociétés savantes, l’édition scientifique a progressivement été envahie par une grande diversité d’éditeurs privés. Comme beaucoup d’autres secteurs économiques, elle a connu une forte concentration autour de quelques grands acteurs : Elsevier, Springer, Wiley etc. Depuis sa création, ses ressources provenaient des abonnements que lui payaient les structures académiques pour recevoir les exemplaires des revues souhaitées. Ce système a fonctionné pendant longtemps mais connaît de très grandes difficultés depuis quelques années à cause des augmentations de prix constantes imposées sans réelle justification par ces acteurs dominants. La combinaison de ces hausses avec les baisses que connaissent les budgets de la recherche un peu partout dans le monde a produit un mélange détonnant qui est en train d’exploser. L’attitude intransigeante de ces grands acteurs qui refusent de prendre en compte ces réductions budgétaires et, au contraire, augmentent leurs tarifs et leurs profits est assez surprenante et le changement de modèle économique induit par la transition achat d’exemplaires papier-droit d’accès à des ressources en ligne ne suffit pas à l’expliquer.
Face à cet abus de position dominante, les chercheurs s’organisent pour tenter de résister. En France par exemple, le monde académique s’est mis d’accord pour, d’une part, échanger des informations sur les pratiques respectives vis à vis des éditeurs, et d’autre part, présenter un front uni lors de négociations collectives face à ces sociétés. Certaines communautés, notamment mathématiciennes, françaises et étrangères, se sont mobilisées pour lutter contre ces monopoles en appelant au boycott, non seulement des abonnements, mais également de l’ensemble des processus éditoriaux. En effet, il faut rappeler que sans l’implication primordiale des chercheurs – qui font la recherche, rédigent des articles et les expertisent – offerte gratuitement à ces sociétés privées, elles n’existeraient plus.
Début de solution : l’accès ouvert
C’est notamment pour lutter contre ces dérives en offrant un modèle alternatif que des solutions de type libre accès (Open Access) aux ressources documentaires ont été développées. Initialement, il s’agissait d’offrir un accès gratuit aux publications stockées sur des sites de dépôts gérés par des organisations scientifiques. En France, c’est l’archive ouverte HAL qui joue depuis 2001 un rôle central dans cette démarche en liaison étroite avec les autres grandes archives internationales comme ArXiv créée en 1991. Outre la maîtrise des coûts, l’accès ouvert renforce la visibilité des articles déposés sur une archive ouverte comme le montre plusieurs études.
Ce mouvement en faveur des archives ouvertes est soutenu par de nombreux pays (Canada, Chine, Etats-unis, Grande Bretagne…). Récemment, l’Union européenne et en particulier la France ont pris des positions encore plus nettes en faveur du libre accès. Par exemple, depuis 2013, la direction d’Inria a rendu obligatoire le dépôt des publications sur HAL et seules ces publications sont communiquées aux experts lors des évaluations ou affichées sur le site web de l’Institut.
Les grands éditeurs ont très vite compris le danger pour leurs profits que représentaient ces initiatives ; ils ont donc commencé par adopter des politiques de dénigrement systématique en les moquant, puis, devant l’échec relatif de cette posture, ils ont transformé ce risque en opportunité en se présentant comme les chantres, voire même les inventeurs, de l’accès ouvert et l’expression Open Access fleurit aujourd’hui sur la plupart des sites de ces éditeurs.
Il convient de préciser qu’il existe deux approches principales d’accès ouvert :
- la voie verte (green access) où le dépôt par l’auteur et l’accès par le lecteur sont gratuits ;
- la voie dorée (gold access), dite aussi auteur-payeur, où l’auteur finance la publication (de quelques centaines à quelques milliers d’euros) qui est ensuite accessible en ligne gratuitement.
Le green est aujourd’hui la solution la plus vertueuse mais n’oublions pas que la gratuité n’est qu’apparente car ces infrastructures et ces services représentent un coût non négligeable supporté pour HAL principalement par le CNRS à travers le CCSD. Par ailleurs, certains éditeurs imposent un délai avant le dépôt d’une publication sur une archive ouverte publique (par exemple, 6 mois après sa parution). Outre la légalité parfois discutable de cet embargo, il faut rappeler qu’il est possible de déposer des versions dites preprint, sur des archives ouvertes comme HAL, pour remédier temporairement à ce problème.
Le gold quant à lui présente l’avantage de déplacer en amont et de rendre explicite le coût d’une publication. Cependant, il comporte des inconvénients majeurs, principalement le coût souvent élevé et donc le risque d’accroitre le fossé entre les établissements, voire pays, « riches » et « pauvres ».
Malheureusement, la qualité et la puissance économique du lobbying des grands éditeurs ont réussi à pénétrer beaucoup de cercles de décision nationaux comme européens et à faire confondre l’open access et le gold. Nous entendons et lisons donc des charges contre le libre accès qui n’évoquent que le modèle auteur-payeur et contre lesquelles il est indispensable de faire preuve de pédagogie pour démonter l’artifice.
Encore mieux : les epi-journaux

Au delà du dépôt des articles, il convient de s’interroger sur leur éditorialisation si l’on souhaite proposer une alternative de qualité, et par conséquent crédible, aux revues commerciales. La notion d’epi-journal a donc vu le jour ; il s’agit de construire « au dessus » d’une archive ouverte des structures éditoriales de type revues ou actes. La démarche est tout à fait similaire à celle de l’édition classique : diffusion des règles éditoriales, dépôt des propositions sur un site dédié, expertise par un comité de lecture dont la composition est publique, annonce des résultats aux auteurs, mise en ligne des articles retenus après réalisation des corrections demandées et en respectant une charte graphique, référencement par les moteurs de recherche après saisie des méta-données associées.
Basée sur le projet Episciences, développé et hébergé par le CCSD, il existe dans le domaine Informatique et Mathématiques appliquées une structure qui propose des services pour gérer des épi-journaux :
- les articles sont déposés dans une archive ouverte (HAL, ArXiv, CWI, etc.),
- après lecture et analyse par les éditeurs, les articles soumis reçoivent la validation du comité de lecture,
- ils sont alors publiés en ligne et identifiés exactement comme dans une revue classique (ISSN, DOI, etc.),
- ils sont référencés par les principales plateformes (DOAJ, DBLP, Google scholar…),
- l’epi-journal respecte des règles éthiques,
- il assure un travail de visibilité à travers les conférences et les réseaux sociaux.
Vous pouvez par exemple consulter la revue JDMDH qui vient de démarrer sur ce principe.
Et en conclusion
Ces epi-journaux sont la dernière évolution importante dans le domaine de la publication scientifique. S’ils offrent une réponse potentielle particulièrement adaptée aux problèmes causés par l’augmentation déraisonnable du coût des abonnements aux grands éditeurs, ils sont aujourd’hui encore balbutiants. La principale interrogation provient de leur jeunesse et de leur manque de reconnaissance par les communautés scientifiques. Concrètement, si un jury doit expertiser un dossier individuel ou collectif (équipe, laboratoire), il attachera plus de poids à des publications parues dans des revues installées depuis longtemps et donc plus reconnues.
La seule motivation « militante » pour publier de cette façon ne suffit pas, notamment si l’on pense aux jeunes chercheurs qui sont à la recherche d’un emploi : il est aujourd’hui très difficile de leur faire prendre ce risque sans concertation et réflexion préalables de la part de leurs encadrants qui sont souvent des scientifiques établis qui n’ont plus de souci majeur de carrière. C’est pourquoi il est absolument indispensable que les chercheurs les plus seniors s’impliquent clairement en faveur de ces initiatives : en participant aux comités de lecture de ces épi-journaux afin de les faire bénéficier de leur visibilité individuelle, en contribuant à en créer de nouveaux et surtout en expliquant dans toutes les instances d’évaluation et de recrutement (jurys, comités de sélection, CNU…), la qualité de ces premiers epi-journaux et du crédit que l’on peut leur accorder.
Là encore, ne tombons pas dans l’angélisme, un épi-journal n’est pas un gage de qualité en lui même, mais au moins laissons lui la chance de prouver sa valeur de la même façon qu’une revue papier et évaluons le avec les mêmes critères.
Il s’agit vraiment de bâtir une nouveau paradigme de publication et nous, scientifiques, en sommes tous les premiers responsables avant d’en devenir les bénéficiaires dans un futur proche.
Pascal Guitton, Professeur Université de Bordeaux et Inria
(*) Le spam, courriel indésirable ou pourriel (terme recommandé au Québec) est une communication électronique non sollicitée, en premier lieu via le courrier électronique. Il s’agit en général d’envois en grande quantité effectués à des fins publicitaires. [Wikipedia]. À l’origine le mot SPAM désignait de la « fake meat« .





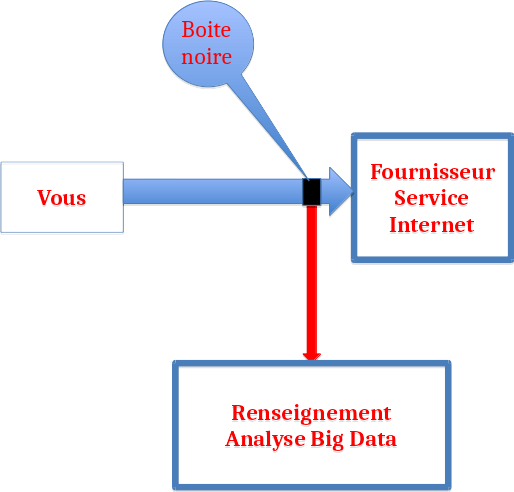






 De la complexité du problème : Les contraintes entre les variables, © Openfisca
De la complexité du problème : Les contraintes entre les variables, © Openfisca
 Mettre au point un système de vote électronique sûr est un exercice délicat. En particulier, la vérifiabilité et la résistance à la coercition sont des propriétés antagonistes : il faut à la fois démontrer qu’un certain vote a été inclus dans le résultat et ne pas pouvoir montrer à un tiers comment on a voté.
Mettre au point un système de vote électronique sûr est un exercice délicat. En particulier, la vérifiabilité et la résistance à la coercition sont des propriétés antagonistes : il faut à la fois démontrer qu’un certain vote a été inclus dans le résultat et ne pas pouvoir montrer à un tiers comment on a voté.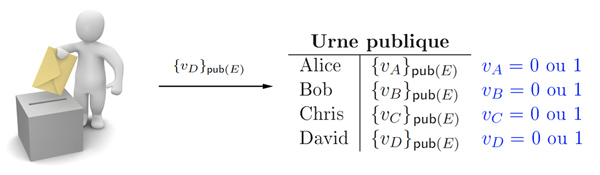

















{kind=link}