Suivant la suggestion d’un ami, j’ai lu l’essai « L’homme nu. La dictature invisible du numérique » de Marc Dugain et Christophe Labbé (journaliste au point) qui vient de paraître chez Plon. La référence à Orwell est lourde. Le livre nous raconte (lourdement) comment l’humanité court à sa perte, rien de moins.
(Youtube)
Première surprise, Big data prend un nouveau sens. Les Big datas, ce sont maintenant les grandes entreprises du Web, Google et consorts. Ce mot, fort laid, qui a pourtant une définition précise, est aussi utilisé pour tout et n’importe quoi, alors pourquoi pas. Ça tombe bien d’ailleurs, le livre va les accuser de tout et n’importe quoi.
La thèse centrale du livre, c’est une conspiration secrète entre ces grandes entreprises (désolé je n’arrive pas à utiliser le terme Big datas) et les services secrets américains. En partant de faits exacts comme les « back doors » installées sur des serveurs de certaines de ces entreprises pour réaliser une surveillance de masse, le livre déduit le complot.
Oui, des lois, comme le Patriot Act aux Etats-Unis et la Loi de Renseignement en France, sont des menaces pour les démocraties. Nous faisons partie des gens qui se battent contre elles. Mais il ne faut pas dire n’importe quoi. Les grandes entreprises du Web ne les encouragent pas. Au contraire ! Leurs employés, leurs directions, sont probablement beaucoup plus contre ces lois que la citoyenne ou le citoyen moyen. Ne serait-ce que parce que c’est mauvais pour leur business. Et puis, parce qu’ils en comprennent le sens contrairement, par exemple, à cette énorme majorité de députés qui ont voté en France la Loi de Renseignement.
En plus de cette thèse discutable, le livre se livre à une mise en accusation systématique de toutes les transformations du numérique. C’est un plaidoyer sans nuance. J’avais déjà entendu à la radio Alain Finkelfraut s’essayer à démolir ces technologies. C’était de l’amateurisme car elles ne l’intéressent que peu finalement. Par contre, Marc Dugain et Christophe Labbé ont eux pris le temps d’étudier « La pieuvre », un mot qu’ils aiment utiliser.
Toutes les craintes, tous les fantasmes y passent. Ils ont fait une recherche exhaustive sur le Web et ils recensent tout. Le totalitarisme est dans les gênes de la moindre application de ces nouvelles technologies. Par exemple, elles facilitent l’accès à toutes les textes et toutes les connaissances. Dans cette « totalité », il y a du totalitarisme. Toujours plus de liberté avec le sens des mots ?
Prenons juste un exemple, un des plus triviaux. Ma montre qui compte mes pas. Je me suis habitué à elle. Quand même, grâce à elle, je marche beaucoup plus ; elle a peut-être plus fait pour ma santé que personne et je lui en suis reconnaissant. « L’homme nu » m’a appris qu’au contraire, elle ne faisait que servir les compagnies d’assurance. Suis-je con !
Sombrer dans cette espèce de délire anti-technologique, doublé d’une théorie du complot, n’offrirait d’autre solution que de se réfugier dans un lieu, loin d’Internet, et de l’électricité, s’il en existe encore. Bien sûr, une disruption pareille de notre monde ne se fait pas sans risques considérables, sans dégâts. Bien sûr, il ne s’agit pas d’adopter ces nouvelles technologies aveuglément, en technophiles béats. Mais, avec les algorithmes, avec l’informatique, avec le numérique, l’homme n’est pas nu. Il a des outils fantastiques à sa disposition. C’est à lui de décider de son avenir.
La SIF (Société Informatique de France) a organisé une journée scientifique le 23 mars sur l’IoT (Internet des Objets – Internet of Things, en anglais), accueillie par le Secrétariat d’état au numérique dans les locaux de l’Hôtel des ministres à Bercy. Cette journée a réuni 110 personnes.
Crédit photo : @PierreMetivier
Au delà du blabla habituel sur les sujets à la mode, la journée de la SIF a proposé des présentations scientifiques et techniques de très haut niveau, sur les défis informatiques de l’Internet des objets avec aussi des présentations sur les enjeux en terme de design des objets et de leurs applications ainsi que sur les problèmes posés pour le respect de la vie privée.
En effet, l’IoT introduit de nouveaux défis scientifiques. Dans beaucoup de cas, il ne s’agit pas de plaquer des techniques connues mais bien de repenser, de concevoir et d’inventer des éléments scientifiques et techniques qui vont résoudre des questions nouvelles apportées par cette prolifération de très nombreux petits objets connectés.
En savoir plus ? Binaire et le Labo des savoirs en ont profité pour réaliser une troisième émission qui a pour thème l’internet des objets.
Retrouvez l’émission sur celien, et écoutez les intervenants de cette journée comme si vous y étiez ! Vous pouvez aussi consulter les présentations des intervenants sur le site de la journée.
Nous avons rencontré Paul Vidonne, créateur de la société Lerti spécialisée dans l’Expertise et l’investigation numérique. Paul, ancien professeur d’université, directeur du Lerti, est expert judiciaire depuis 1992 auprès de la cour d’appel de Grenoble. Nous lui avons demandé de nous parler d’informatique légale.
Binaire : Comment définiriez vous l’informatique légale ? Est-ce la traduction littérale de Computer Forensic ?
Crédit photo : LERTI
Paul Vidonne : La traduction du terme « Computer Forensic » est effectivement « Informatique Légale », sa compréhension en est relativement facile pour tout le monde car elle fait le parallèle avec la médecine légale. Elle est ainsi définit dans Wikipedia : « On désigne par informatique légale ou investigation numérique légale, l’application de techniques et de protocoles d’investigation numériques respectant les procédures légales et destinée à apporter des preuves numériques à la demande d’une institution de type judiciaire par réquisition, ordonnance ou jugement. On peut encore la définir comme l’ensemble des connaissances et méthodes qui permettent de collecter, conserver et analyser des preuves issues de supports numériques en vue de les produire dans le cadre d’une action en justice. »
Binaire : Il y a une grande différence entre les fonctionnements de la justice entre les pays anglo-saxons et latins. Cela impacte-t-il votre pratique ?
PV : Dans beaucoup de pays, les analyses pratiquées par les experts sont les mêmes, il n’y a pas de différence dans les techniques d’investigation numérique. Néanmoins pour comprendre les différences, il est important de préciser comment sont régis les experts et l’expertise judiciaire.
Crédit photo : LERTI
En France les personnes reconnues pour leur expérience et leur expertise dans leur spécialité peuvent demander leur inscription sur des listes dressées par les Cours d’appel. Ils portent alors le titre d’« expert judiciaire ». Dans le domaine pénal, ils peuvent être désignés par les juges d’instruction et les parquets pour effectuer des expertises, rémunérées par l’État. En matière civile, ils sont désignés par ordonnance ou par jugement et seront payés par les parties, selon un montant et des modalités fixées par une décision de justice. En revanche, dans beaucoup de pays, de telles listes n’existent pas. Les experts des parties sont alors désignés et rémunérés par les parties elles-mêmes, les parties pouvant aussi échanger des preuves de manière privée avant le procès.
Binaire : Comment devient-on expert ?
PV : On devient expert après une longue expérience professionnelle de type cadre d’entreprise, direction ou professeur – il y très peu d’experts jeunes – et l’inscription sur une liste comme nous venons de le voir. Le titre d’expert judiciaire est un engagement de servir la Justice et non un gallon de plus ou une ligne à ajouter au CV. En échange de quoi, pour un prix raisonnable, la justice fait appel à vous pour réaliser des expertises dont elle a besoin pour mener à bien ses investigations et la recherche de la vérité. Un expert doit avoir un autre travail. Les experts sont inscrits sur des listes de Cour d’appel, mais leur compétence n’est pas limitée à leur Cour d’inscription.
Aperçu du PCB et de la puce Mémoire Samsung KLM8G1WEMB-B031 Crédit photo : LERTI
Binaire : Pourriez-vous nous parler des outils que vous utilisez ? C’est quoi votre boîte à outil ?
PV : Il existe tout un ensemble d’outils dédiés et spécifiques, la plupart étant des outils commerciaux. On trouve ainsi des outils pour expertiser et investiguer les disques durs, les téléphones mobiles et les GPS… Pour ces objets, on trouve des outils comme EnCase Forensic ou Forensic Toolkit qui permettent de retrouver des informations sur des disques durs et de passer à travers certaines protections des ordinateurs personnels et de bureau. Pour pratiquer des expertises plus exhaustives, il est parfois nécessaire de disposer de plusieurs logiciels car il y a des différences importantes dans les informations remontées par ces derniers.
Pour les téléphones mobiles, ce qui inclut aussi les tablettes et les GPS, nous utilisons les produits de la société suédoise MSAB ou israélienne Cellebrite. Ces produits permettent de connecter un grand nombre de téléphones et d’analyser leurs mémoires avec des logiciels pour en extraire des informations . On a aussi des produits de niche sous forme de « box » qui permettent de connecter des téléphones d’origine chinoise.
Ces éditeurs vendent les licences et des abonnements annuels ainsi que des formations pour être « expert agréé sur leurs logiciels ». Selon les pays, ces logiciels sont plus ou moins reconnus par les juridictions.
Il existe des solutions issues du monde du libre mais elles ont du mal à être à jour. Par ailleurs elles souffrent d’un manque de reconnaissance auprès des tribunaux.
Pour une société comme Lerti dont le chiffre d’affaire est de 500 K€, le coût des licences de ces outils n’est pas négligeable : il représente de l’ordre de 15% du chiffre d’affaire. On remarquera que pour un expert réalisant 1 ou 2 expertises par an, l’investissement dans ce type d’outil est quasiment impossible et il ne pourra mener à bien son expertise… qui pourra d’ailleurs être demandée à Lerti au final.
Mais on ne s’arrête pas là ! Par exemple, si un téléphone est cassé ou a été immergé, les puces mémoires peuvent ne pas être endommagées… Dans ce cas, après avoir enlevé les soudures, celles-ci sont mises sur un banc permet d’accéder aux données contenues dans la puce. Sous certaines conditions, un disque dur pourra être réparé en changeant les têtes de lectures si celles-ci sont défectueuses.
Extraction de la mémoire par points de contact sur le PCB. Crédit photo : LERTI
Binaire : Il fut un temps ou l’on recommandait d’effacer de très nombreuses fois un disque dur pour s’assurer que personne ne pourrait (re)lire les anciennes informations, qu’en est-il aujourd’hui ?
PV : Ces techniques nécessitaient la mise en œuvre de moyens considérables. Aujourd’hui, avec les disques durs modernes ce type de précaution n’est plus nécessaire.
Binaire : Quel est le protocole mis en place pour expertiser un objet ou un système informatique ?
PV : Il n’y a pas de protocole validé par des instances reconnues ou de norme, on est seulement dans les bonnes pratiques. Ainsi, on ne met jamais en marche un ordinateur – le faire serait une faute professionnelle -, on extrait le disque dur, on interpose un dispositif de blocage de toute écriture sur ce disque, on fait une copie de ce dernier avec des dispositifs techniques qui permettent de faire une copie de l’image physique, qui sera toujours signée avec une fonction de hachage pour avoir une copie « conforme » et non altérée.
La puce Skhynix après extraction (vues recto) Crédit photo : LERTI
Il est intéressant de remarquer que depuis le début des années 2000, la Gendarmerie avec l’IRCGN et la police disposent de cellules à même de mener des investigations numériques. La différence avec les experts judiciaires c’est que ces investigations sont rapidement et directement utilisés dans les enquêtes.
La puce Skhynix après extraction (vue verso). Crédit photo : LERTI
Binaire : Avez-vous un exemple d’affaires où l’informatique a joué le premier rôle ?
PV : Par exemple dans les affaires civiles, c’est l’expertise qui fait la décision dans des procès liés à des contrefaçons. De même, dans les procès aux assises, j’ai le souvenir d’une affaire ou un médecin gynécologue a été condamné pour agressions sexuelles ou viols de mineurs de moins de 15 ans ; les preuves, vidéos/photos des agissements du médecin, avaient été retrouvées sur des supports numériques. Sans ces éléments, le médecin aurait sans doute obtenu un non lieu ou un acquittement.
De même, l’expertise permet parfois de prouver la préméditation ou la bande organisée, ce qui change fortement le niveau de condamnation des coupables pour un délit ou un crime.
Binaire : Le crime numérique parfait existe-t-il ?
PV : Non… Pour un crime parfait, il vaut mieux ne pas toucher et/ou utiliser des outils numériques et détruire physiquement les objets…
Binaire : Un exemple de l’impuissance de l’informatique ?
PV : Oui, il y en a. Sous certaines conditions, la cryptographie permet de protéger des éléments d’information. L’autre nouveau défi pour les experts, c’est le volume colossal des informations à traiter : il n’est pas rare de devoir analyser des millions de fichiers sur un disque dur, 100 000 SMS/MMS dans un téléphone portable !
Binaire : Un dernier mot ?
PV : On rencontre lors de chaque affaire/expertise de nouvelles questions, c’est ce qui fait que c’est un métier passionnant.
Dans la nouvelle économie, l’informatique n’est plus une compétence optionnelle. C’est une compétence basique, comme la lecture, l’écriture, et l’arithmétique.
Non. Cette fois, ce n’est pas nous. C’est le Président Barack Obama, le 30 janvier 2016 en lançant l’initiative CS4ALL.
A la demande de Binaire, sa vidéo a été sous-titrée en anglais et en français par la communauté (un travail de crowd sourcing), un grand merci à toute l’équipe SLIDE du LIG à Grenoble et à Sihem Amer-Yahia en particulier !
Pour choisir les sous-titres, lancer la vidéo, puis choisir cc en bas et choisir la langue désirée.
Qui devrait voir cette vidéo ?
d’abord tous les responsables politiques à commencer par ceux du ministère de l’industrie et ceux de l’éducation nationale.
ensuite tous les élèves, les étudiants, leurs parents.
enfin tous les citoyens.
L’enseignement en France a bougé. Bravo ! Il faut maintenant réussir les réformes initiées, et il faut aller plus loin.
Le Big Data, l’analyse de données massives, peut être à l’origine d’avancées majeures en médecine notamment. Son utilisation sur des données personnelles pouvait déjà inquiéter. Avec les sex toys, le big data s’invite encore un peu plus loin dans l’intimité des utilisateurs des nouvelles technologies. Binaire a rencontré Andzelika Zabawki, la PDG de Galalit, une start-up qui vient de lancer Godissime, un vibromasseur connecté nourri au Big Data.
Depuis le OhMiBod, on ne compte plus les vibromasseurs connectés. Ils peuvent être contrôlés depuis un smartphone. Ils enrichissent les vies de couples, un partenaire pouvant guider à distance le plaisir de l’autre, peut-être même de la voix. Le vibromasseur Godissime de la société Galalit, en avant première au Salon de l’Érotisme, révolutionne la profession.
L’idée est simple, avec plusieurs capteurs, on récupère toutes les données de chaque utilisation du vibromasseur. On analyse ensuite ces données pour mieux accompagner les plaisirs. Les données d’une utilisation, ça ne va pas bien loin ? Vous n’y êtes pas. Les données de toutes les utilisations. Nous sommes dans le Big Data. L’analyse de toutes ces données va permettre de mettre en évidence des similarités entre les utilisateurs-trices, de comprendre ce qui fait vibrer. Ensuite, à l’écoute de tous ses capteurs, Godissime va accompagner l’utilisateur-trice, contrôler le plaisir avec ses différentes options de vibreurs, guider de la voix. On peut choisir la voix, peut-être Scarlett Johansson, ou Benedict Cumberbatch.
Les techniques rappellent celles expliquées pour la musique dans « J’ai deux passions, la musique et l’informatique » (Voir Binaire 13 avril 2015). Comme l’ordinateur est capable d’écouter un musicien humain, de communiquer, de jouer avec lui, le vibromasseur est à l’écoute, communique et se comporte comme un.e partenaire idéal.e.
Petit soucis quand même. Pour que cela marche, il faut que Godissime dispose des données de millions de séances de vibromassage. Une employée de Galalit (demandant l’anonymat) nous a confirmé que la société disposait déjà de telles données. Des vibromasseurs en béta-test transmettent déjà depuis plusieurs semaines de telles données aux serveurs de la société. Nous avons vérifiés les conditions générales d’utilisation. C’est écrit en tout petit, mais c’est écrit : c’est fait en toute légalité !
Vous qui utiliserez peut-être un jour Godissime, serez-vous conscients que des données aussi intimes circulent sur le réseau ? Est-ce que les plaisirs que vous pourriez trouver dans de tels sex toys seront suffisants pour vous faire accepter les risques ?
Nous voilà bien dans un dilemme classique du Big Data.
L’histoire drôle (si vous aimez ce genre d’humour) qui fait fureur chez Galalit : « Dieu aurait pu se contenter de créer la femme. Pourquoi a-t-il aussi créé l’homme ? Parce que Godissime n’existait pas. »
Le nom de code du prochain produit de Galalit est Tanguissime. Les amateurs de Carlos Gardel auront compris que l’on passait à une autre dimension.
Pour aller plus loin :
Very deep learning and applications to vibrating devices, Andżelika Zabawki, PhD thesis, 2015.
Big data analysis and the quest of orgasms, submitted to The Journal of Irreproducible Result, Andżelika Zabawki, 2016
Le mot « algorithme », qui désigne un objet bien précis en informatique, est utilisé dans la presse pour n’importe quelle utilisation de n’importe quelle technologie informatique dans n’importe quel cadre. Dans ce chaos médiatique, l’informaticien ne retrouve bien souvent pas ses petits. Pour binaire, David Monniaux, Directeur de Recherche au CNRS à Grenoble, résume le désarroi de la communauté informatique devant cette nouvelle habitude. Charlotte Truchet
« Les algorithmes. » Depuis la discussion de la loi sur le renseignement, cette expression revient sous la plume de journalistes et autres commentateurs, que ce soit pour désigner des méthodes mystérieuses censées retrouver les djihadistes sur le Net, ou celles employées par les grands services en ligne (Google, Amazon, Facebook, Twitter…) pour classer utilisateurs, produits et messages.
Le nom « algorithme » a subi un glissement de sens semblable à celui de « banlieue ». Le dictionnaire peut bien en donner comme définition « Territoire et ensemble des localités qui environnent une grande ville », on sait bien que « les banlieues », dans la langue de ceux qui ont accès aux médias, ne désigne pas Versailles ou le Vésinet, mais plutôt Le Blanc-Mesnil ou Vaulx-en-Velin… De même, un « algorithme », on ne sait pas vraiment ce que cela désigne précisément, mais c’est en tout cas effrayant.
Un algorithme, ce n’est jamais que la description non ambiguë d’un procédé de calcul, quel qu’il soit. Par exemple, une méthode pour trier des fiches par ordre alphabétique est un algorithme, et d’ailleurs l’étude des algorithmes de tri classiques est une étape obligée des cours d’algorithmique. Les professionnels de l’informatique trouvent donc assez curieux du point de vue du vocabulaire que l’on s’émeuve, par exemple, qu’un site comme Twitter envisage de trier des messages par un algorithme et non par ordre chronologique, alors qu’un simple tri par ordre chronologique découle déjà de l’application d’un ou plusieurs algorithmes…
L’algorithmique n’est pas une alchimie mystérieuse. Elle est enseignée à l’université, il y a de nombreux ouvrages traitant d’elle et de ses spécialités. Les grandes lignes des procédés mis en œuvre par les grandes entreprises du Net sont le plus souvent connus, même si leurs réglages fins et leurs combinaisons exactes relèvent du secret industriel.
Dans les médias, et pour ceux qui s’y réfèrent, le mot « algorithme » a pris un sens nouveau, qui n’est pas celui des professionnels de l’informatique. L’algorithme des médias est un procédé hautement mystérieux, complexe, aux paramètres obscurs, voire quasi-magique. Ceci ne peut que troubler ceux qui pensent, à mon avis à tort, que nous sommes dans une société « scientifique ».
L’écrivain de science-fiction Arthur C. Clarke, avec son sens de la formule, a énoncé que « toute technologie suffisamment avancée est indistinguable de la magie ». De fait, les débats sur les « algorithmes » montrent bien la pensée magique à l’œuvre, lorsqu’ils sont considérés par des décideurs publics et des commentateurs comme des solutions miracles, économiques et objectives, sans compréhension de leur fonctionnement et de leurs limitations et d’ailleurs sans esprit critique. L’opposition aux « algorithmes », quant à elle, relève souvent plus d’une vision romantique et quasi luddite (« l’homme remplacé par la machine ») plus que d’une analyse objective et informée.
Le 10 février dernier a eu lieu sur France Culture un débat « Faut-il avoir peur de l’intelligence artificielle ? ». Au delà du titre provocant et anxiogène, l’existence de pareils débats montre une demande d’information dans le grand public. Par exemple, l’annonce récente de succès informatiques au jeu de Go, naguère réputé résister à l’intelligence artificielle, suscite des interrogations. Pour démystifier ce résultat et bien poser ces interrogations, il se peut qu’il faille un enseignement informatique dispensé par des personnels formés. C’est là l’un des aspects du problème : ces question sont peu abordées dans l’enseignement général, ou alors en ordre dispersé dans des enseignements divers.
Une partie du travail du chercheur est d’informer la population, de contribuer à sa culture scientifique et technique, notamment en démystifiant des concepts présentés comme mystérieux et en déconstruisant des argumentations trompeuses. Que faire ?
Il n’est jamais trop tôt pour bien faire. Et l’informatique n’y fait pas exception. Elle est arrivée au lycée, mais cela aura pris le temps. Binaire s’intéresse à des expériences de la découverte de l’informatique à l’école primaire. Nathalie Revol et Cathy Louvier nous parlent d’une expérience en banlieue lyonnaise. Sylvie Boldo
Nathalie Revol, par elle-même
Prenez une classe de CM1 en banlieue lyonnaise. Une classe probablement dans la moyenne, avec des origines sociales et géographiques très mélangées : 26 enfants curieux, motivés, joueurs, remuants, faciles à déconcentrer.
Prenez une chercheuse en informatique qui se pose des questions sur ce qu’il est important de transmettre de sa discipline, dès le plus jeune âge.
Prenez une enseignante de CM1 désireuse de proposer un enseignement des sciences en général et de l’informatique en particulier, de façon attrayante et motivante, à ses élèves.
Faites en sorte que l’enseignante soit en charge de cette classe de CM1. Faites en sorte que la chercheuse ait des jumeaux dans cette classe de CM1, à défaut un seul enfant suffira, pas d’enfant du tout peut aussi faire l’affaire, il suffit que la rencontre ait lieu.
Laissez reposer quelques mois les questions et les idées qui tournent dans la tête de la chercheuse et vous aurez une ébauche de programme d’informatique pour des CM1.
Faites ensuite se rencontrer la chercheuse et l’enseignante au portail de l’école ou ailleurs, la première proposant d’expérimenter ce programme, la seconde acceptant bien volontiers de servir de cobaye. Quelques demandes d’autorisation plus tard, c’est ainsi que la chercheuse et l’enseignante ont démarré un programme de 8 séances de 45 minutes intitulé « informatique débranchée ».
Questions et réponses
La question qui tournait comme une rengaine dans la tête de la chercheuse était de savoir comment s’y prendre pour faire passer le message suivant :
L’informatique n’est pas plus la science des ordinateurs que l’astronomie n’est celle des téléscopes, aurait dit E. Dijkstra. En d’autres termes plus compréhensibles par les élèves du primaire, l’informatique n’est pas plus la science des ordinateurs que les mathématiques ne sont la maîtrise de la calculatrice.
Approche, accroche, algorithmes pour les gavroches, codage binaire sans anicroche
Ne le prenez pas, le parti était pris : ce serait un enseignement sans ordinateur. Cela tombait bien, le site « Computer Science Unplugged » regorge d’activités à pratiquer sans ordinateur, tout comme le site de Martin Quinson consacré à la médiation, ou le site pixees destiné à offrir des ressources pour les enseignant-e-s. D’ailleurs, le titre de ce projet d’informatique en CM1 est informatique débranchée, la traduction – sans les références musicales – de Computer Science unplugged.
L’approche étant choisie, il fallait encore définir le contenu. L’inspiration a été puisée dans le programme d’ISN : Informatique et Sciences du Numérique, élaboré pour les lycéen-ne-s de 1e et Terminale. Ce programme comporte quatre volets : 1 – langages et programmation, 2 – informations, 3 – machines, 4 – algorithmes. Les volets « algorithmes » et « informations » ont été retenus parce qu’ils se prêtent bien à des activités sans ordinateur. Pour la partie « informations », l’accent a été mis sur leur représentation utilisant le codage binaire.
Enfin, pour que les élèves adhèrent à ce projet d’informatique, une accroche basée sur les jeux a été choisie pour la partie algorithmique. Quant au codage binaire, c’est par des tours de magie qu’il a été présenté. On a privilégié les manipulations, qui permettent d’établir le lien entre les objets et la formalisation plus abstraite des algorithmes, ainsi que des activités engageant tout le corps, comme le réseau de tri pour les algorithmes et la transmission d’un message codé en binaire par la danse.
Cela permet d’accrocher l’attention des élèves et de les motiver pour qu’ils et elles se mettent en situation active de recherche, d’élaboration des algorithmes ou de compréhension du codage binaire.
Algorithmes
Chaque partie a demandé quatre séances. Côté algorithmes, on a commencé par le jeu de nim, popularisé par le film «L’année dernière à Marienbad » paraît-il (c’était la minute culturelle). Ce jeu se joue avec des jetons de belote et des règles simples… et il existe une stratégie pour gagner à tous les coups. Appelons cette stratégie un algorithme et laissons les enfants jouer par deux, en passant entre les tables pour les mettre sur la voie. En fin de séance, on a mis en commun les algorithmes trouvés et on a mis en évidence qu’il s’agissait de formulations différentes du même algorithme.
On a ensuite défini, avec l’aide du film «Les Sépas : les algorithmes », ce qu’était un algorithme, avec les mots des enfants.
Le jeu suivant est le crêpier psycho-rigide. Un crêpier veut, le soir avant de fermer boutique, ranger la pile de crêpes qui reste dans sa vitrine par taille décroissante, la plus grande en bas et la plus petite en haut. La seule opération qu’il peut effectuer consiste à glisser sa spatule entre deux crêpes, n’importe où dans la pile, et à retourner d’un seul coup toute la pile de crêpes posées sur sa spatule. Pourra-t-il ranger ses crêpes comme il le désire ? Il s’agit d’un jeu plus ambitieux : l’algorithme à découvrir est un algorithme récursif. Autrement dit, on effectue quelques manipulations pour se ramener au même problème, mais avec moins de crêpes à ranger. Pour faire «oublier » les crêpes déjà rangées, pour se concentrer sur les crêpes restantes, on a caché les crêpes déjà rangées par une feuille de papier… et cela a très bien marché ! On a aussi utilisé cet écran de papier pour cacher complètement la pile de crêpes, dès le début, et pour faire comprendre aux enfants qui dictaient l’algorithme – qui était donc exécuté derrière l’écran – qu’un algorithme s’applique à toutes les configurations, que ce n’est pas une construction ad hoc pour chaque pile de crêpes.
Le dernier algorithme a été abordé de manière fort différente. On a dessiné un réseau de tri au sol et cette fois-ci, les élèves étaient les porteurs des données (soit des petits nombres, soit des grands nombres, soit des mots) qui se déplacent dans le réseau, se comparent et finissent par se trier, comme ils l’ont rapidement compris, par ordre numérique ou par ordre alphabétique.
Codage binaire, représentation des données
Les quatre séances suivantes ont été consacrées au codage binaire des informations.
Pour la première séance, les enfants ont reçu un codage binaire (une suite de 0 et de 1) et une grille. Ils ont travaillé par 2 : l’un-e dictait les «0 » et les «1 » et l’autre laissait blanches ou noircissait les cases correspondantes de la grille. Ils ont fini par découvrir le dessin caché pixellisé et encodé en binaire. Ils ont alors créé leur propre dessin, l’ont encodé puis dicté à leur voisin pour vérifier que l’encodage puis le décodage préservait leur image.
Pour la deuxième séance, on a commencé par un tour de magie reposant sur le codage binaire des nombres. La magicienne devait deviner un nombre, entre 1 et 31, choisi par un enfant en lui montrant successivement 5 grilles de nombres et en lui demandant si son nombre se trouvait dans ces grilles. Avec leur attention ainsi acquise, on a écrit le codage binaire des nombres de 1 à 7 tous ensemble, puis de 1 à 31. Pour cela on est revenu à une représentation des nombres par des points, un nombre étant représenté par autant de points que d’unités, par exemple 5 est représenté par 5 points. On a utilisé de petites cartes porteuses de 1, 2, 4, 8 ou 16 points (oui, les puissances de 2, mais chut, vous allez trop vite). Chaque enfant s’est vu attribuer un nombre et devait choisir quelles cartes conserver pour obtenir le bon nombre de points ; c’était plus clair en classe avec les cartes… Bref, en notant «1 » quand la carte était retenue et «0 » quand elle ne l’était pas, nous avons le codage binaire des nombres et on a pu expliquer finalement comment marchait le tour de magie.
La troisième séance a de nouveau commencé par un tour de magie, reposant cette fois sur la notion de bit de parité. Après avoir dévoilé le truc et expliqué pourquoi il est utile de savoir détecter des erreurs (voire les corriger – mais on n’est pas allé jusque là), on a encodé les lettres de l’alphabet, en binaire, avec 6 bits dont 1 de parité. Chaque binôme a alors choisi un mot court, l’a écrit en binaire en utilisant le codage et l’a conservé pour la séance suivante.
La dernière séance a fait appel au corps : à tour de rôle, nous avons dansé nos mots, en levant le bras droit pour «1 » et en le baissant pour «0 » et nos spectateurs ont décodé sans se lasser.
Au final…
l’expérience s’est bien déroulée, les cobayes se sont prêtés au jeu avec beaucoup d’enthousiasme, le calibrage des activités en séances de 40-45mn était à peu près juste et pas exagérément optimiste, la gestion de la classe a été assurée par l’enseignante et c’est tant mieux, les moments de mise en commun également. L’enseignante est même partante pour renouveler seule ce projet… ce qui fait chaud au cœur de la chercheuse : un des objectifs était en effet de proposer un projet réalisable dans toutes les classes, sans nécessiter une aide extérieure qui peut être difficile à trouver.
On peut trouver le détail de ce projet, agrémenté de remarques après coup pour parfaire le déroulement de chaque séance, sur le site de pixees.
Cet article est publié en collaboration avec TheConversation.
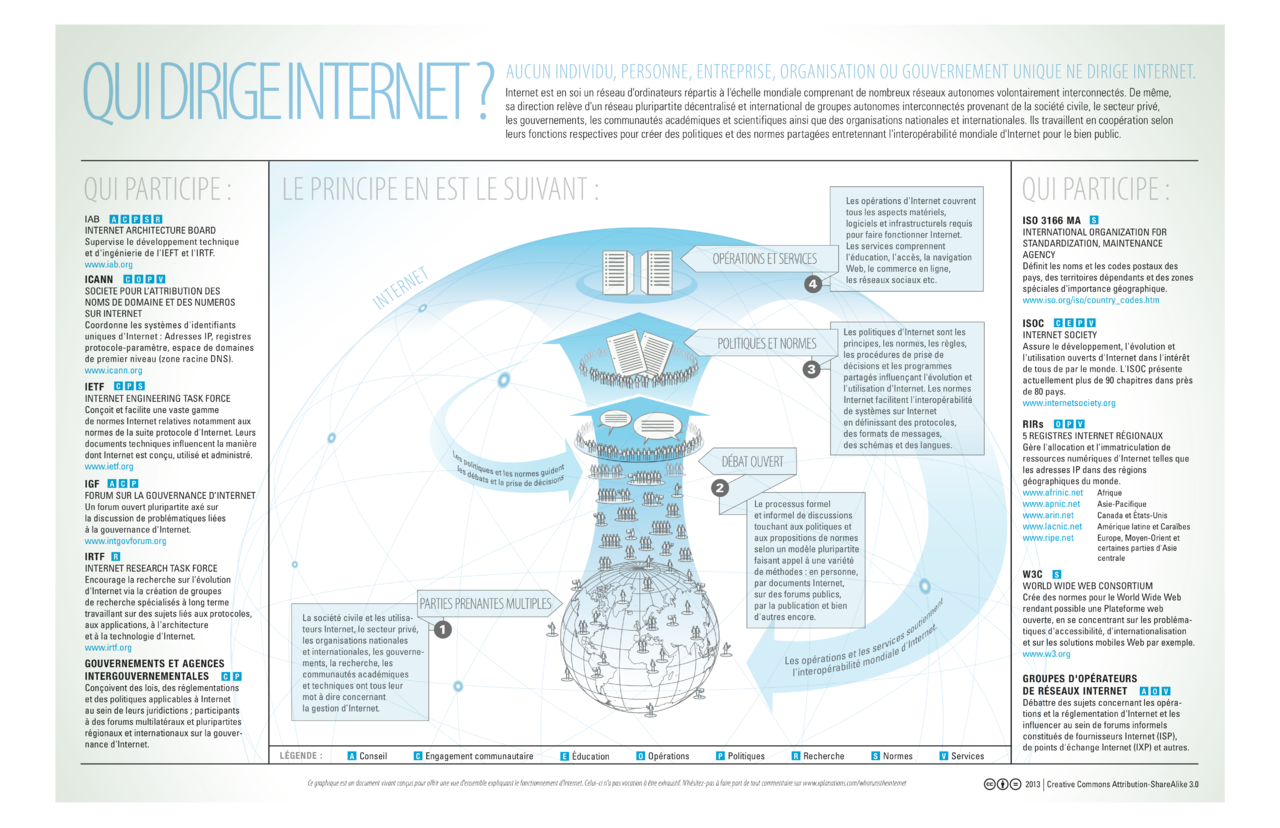
L’internet est désormais utilisé par plus de trois milliards de personnes, soit plus de 45% de la population de la planète. L’importance de l’Internet dans la vie des usagers est telle que l’on entend souvent la question : Qui gouverne l’internet ? Binaire a posé la question à un ami, Jean-François Abramatic, Directeur de recherche Inria. Si quelqu’un en France peut répondre à la question, c’est sans doute lui. Serge Abiteboul
Jean-François Abramatic, Wikipédia
Jean-François a partagé sa carrière entre la recherche (Inria, MIT) et l’industrie (Ilog, IBM). Il a présidé le World Wide Web Consortium (W3C) de 1996 à 2001. Il a été administrateur de l’ICANN (1999-2000). Il est, aujourd’hui, membre du Conseil Inaugural de la NETmundial initiative.
La gouvernance de l’internet est en pleine évolution alors que l’internet poursuit son déploiement au service de la société à travers le monde. La définition même de la gouvernance de l’internet fait l’objet de débats. Michel Serres, par exemple, explique qu’après l’écriture et l’imprimerie, l’internet est la troisième révolution de la communication. Alors que personne n’a jamais parlé de gouvernance de l’écriture ou de l’imprimerie, faut-il parler de gouvernance de l’internet ?
Pour aborder la question de manière plus détaillée, il est utile de comprendre comment a été créé l’internet afin d’identifier les acteurs dont les décisions ont conduit à l’évolution fulgurante que nous avons connue (plus de 800% de croissance pour la période 2000-2015).
L’internet est la plateforme de la convergence entre l’informatique, les télécommunications et l’audiovisuel. Dans un monde où les données sont numériques, l’internet permet d’envoyer ces données n’importe où sur la planète, les ordinateurs peuvent alors traiter ces données et extraire les informations utiles à l’usager. La convergence de l’informatique, des télécommunications et de l’audiovisuel a permis de créer un environnement universel de communication et d’interactions entre les personnes. L’internet est, ainsi, un enfant de l’informatique venu au monde dans un univers de communication dominé par les télécommunications et l’audiovisuel. Si les télécommunications et l’audiovisuel ont grandi dans des environnements gouvernementaux (avant d’évoluer à travers la mise en œuvre de politiques de dérégulation), l’internet a grandi dans un environnement global, ouvert et décentralisé dès le premier jour.
L’espace : Une gouvernance globale dès le premier jour
Lorsqu’un environnement de communication se développe, le besoin de gouvernance apparaît pour concevoir et déployer les standards (protocoles et conventions qui permettent aux composants, appareils et systèmes de communiquer) ainsi que pour répartir les ressources rares ou uniques (par exemple les bandes de fréquence ou les numéros de téléphone). Pour les télécommunications et l’audiovisuel, des organismes nationaux et internationaux ont été créés pour conduire les actions de standardisation et gérer l’attribution des ressources rares ou uniques.
Pour l’internet, l’approche a été globale dès le début et aucune organisation nationale ou régionale n’a été mise en place pour développer les standards de l’internet. L’attribution des ressources rares ou uniques (adressage et nommage) a été décentralisée régionalement après avoir été conçue globalement. De plus, la mise en place de l’infrastructure a été conduite par les concepteurs techniques. La fameuse citation de David Clark « We reject kings, presidents and voting, we believe in rough consensus and running code.» traduit l’état d’esprit qui régnait lors de la conception et le déploiement des standards qui sont au cœur de l’internet d’aujourd’hui.
Ainsi sont nées depuis les années 80 de nombreuses organisations (IETF, ISOC, W3C, ICANN) internationales, indépendantes des pouvoirs politiques et dédiées à des tâches précises nécessaires au bon fonctionnement de l’internet. Prises dans leur ensemble, ces organisations ont exercé le rôle de gouvernance de l’internet. Elles conçoivent les standards de l’internet et attribuent (ou délèguent l’attribution) des ressources rares ou uniques.
« Qui Dirige Internet » par Lynnalipinski of ICANN via Wikimedia Commons
Le temps : le développement et le déploiement simultanés des innovations
Les concepteurs de l’internet ont coutume de mettre en avant qu’ils ont fait le choix de « mettre l’intelligence aux extrémités du réseau». Ce choix d’architecture a permis à des centaines de milliers d’innovateurs de travailler en parallèle et de rendre disponibles les terminaux et les services que nous utilisons tous les jours.
Pour être plus concret, les développeurs de Wikipedia ou Le Bon Coin, de Google ou d’Amazon, de Le Monde ou Au féminin ont travaillé et travaillent encore en parallèle pendant que les ordinateurs personnels ou les tablettes, les téléphones portables intelligents ou les consoles de jeux s’équipent des logiciels qui permettent d’accéder à ces services. Les choix d’architecture technique ont donc permis le déploiement fulgurant, sans équivalent dans l’histoire, de ce que l’on appelle aujourd’hui, l’internet.
Les défis sociétaux de la gouvernance d’internet
Le déploiement de l’internet dans le grand public a été provoqué par l’arrivée du World Wide Web au début des années 90. Les pouvoirs publics se sont donc intéressés à son impact sur nos sociétés. Aux questions de gouvernance relatives au développement technique d’internet (standards et ressources rares ou uniques) se sont ajoutées les questions de gouvernance des activités menées sur l’internet.
En France, dès 1998, le rapport présenté au conseil d’état par Isabelle Falque-Pierrotin (aujourd’hui présidente de la CNIL) recommande d’adapter la réglementation de la communication à la convergence de l’informatique, de l’audiovisuel et des télécommunications. De manière à faire croître la confiance des utilisateurs, le rapport recommande de protéger les données personnelles et la vie privée, de sécuriser les échanges et les transactions, de reconnaître la signature électronique, d’adapter la fiscalité et le droit des marques, de valoriser les contenus par la protection de la propriété intellectuelle et la lutte contre la contrefaçon, de lutter contre les contenus illicites. Enfin, le rapport recommande d’adapter le droit existant et de ne pas créer un droit spécifique à internet.
Depuis le début des années 2000, ces sujets ont fait l’objet, à des degrés divers, de travaux aux niveaux local et international. Le Sommet Mondial sur la Société de l’Information (SMSI) organisé par les Nations Unies, puis l’Internet Governance Forum (IGF), et plus récemment la NETmundial initiative ont fourni ou fournissent un cadre pour ces travaux.
Construire une gouvernance multi-acteurs globale et décentralisée
Même si la gouvernance d’internet a profondément évolué, des règles générales se sont imposées au fil des quarante dernières années. Aucune personne, aucune organisation, aucune entreprise, aucun gouvernement ne gouverne l’internet. La gouvernance d’internet est exercée par un réseau de communautés d’acteurs comprenant les pouvoirs publics, les entreprises, le monde académique et la société civile. Certaines communautés associent des personnes physiques, d’autres des organisations publiques ou privées. Ces communautés choisissent leur mode de fonctionnement en respectant des principes partagés tels que l’ouverture, la transparence ou la recherche du consensus.
L’importance prise par l’internet a attiré l’attention sur son mode de fonctionnement. Il est apparu clairement que les questions posées en 1998 dans le rapport au conseil d’état étaient devenues, pour la plupart, des défis planétaires. En particulier, les révélations relatives à la surveillance de masse ont provoqué une prise de conscience à tous les niveaux de la société (gouvernements, entreprises, monde académique, société civile).
La complexité des problèmes à résoudre est, cependant, souvent sous-estimée. Pour de nombreuses communautés, il est tentant de projeter des mécanismes de gouvernance qui ont eu leur succès avant l’émergence d’internet. Il est rare qu’une telle approche soit efficace. Qu’il s’agisse de standards techniques ou de règlementations relatives à la protection de la vie privée, d’extension de la capacité d’adressage ou de contrôle de la diffusion de contenus illicites, de langages accessibles pour les personnes handicapées ou de surveillance de masse, la résolution des problèmes demande la contribution coopérative du monde académique, des entreprises, des gouvernements et de représentants de la société civile. De plus, ces contributions doivent tenir compte des différences d’environnements juridique, fiscal ou tout simplement culturel de milliards d’usagers.
La gouvernance d’internet devient donc un objet de recherche et d’innovation puisque aucune expérience passée ne permet de construire cette gouvernance par extension d’une approche existante.
C’est au grand défi de la mise en place d’une gouvernance multi-acteurs, globale et décentralisée que nous sommes donc tous confrontés pour les années qui viennent.
LeRaspberryPi (prononcé comme « Raze » « Berry » « Paille » en anglais) est un petit ordinateur de la taille d’une carte bancaire. Il a été conçu par une fondation éducative à but non-lucratif pour faire découvrir le monde de l’informatique sous un autre angle. C’est Alan, franco-irlandais qui nous raconte cette belle histoire. Charlotte Truchet et Pierre Paradinas.
Le récemment lancé « PiZero » : 60 x 35mm : commercialisé en France pour €8,90 Crédit Photo : Alex Eames – RasPi.TV
Une fracture entre informatique et société
Au milieu des années 2000, Eben Upton de la Faculté des Sciences Informatiques de l’Université de Cambridge (« Computer Science Lab ») en Angleterre s’est rendu compte d’un gros problème. Avec ses collègues, ils ont observé un déclin très marqué dans le nombre de candidats se présentant pour poursuivre des études en informatique. Entre l’année 1996 (année de sa propre entrée « undergraduate » à Cambridge) et 2006 (vers la fin de son doctorat), les dossiers de demande pour accéder à la Faculté se sont réduits de moitié. Le système de sélection britannique des futurs étudiants est basé sur des critères de compétition, compétence, expérience et des entretiens individuels. Eben, qui avait tenu le rôle de « Directeur des Études » également, était bien placé pour remarquer une deuxième difficulté. Au-delà du « quantitatif », les candidats qu’il rencontrait, malgré leur grand potentiel et capacités évidentes, avaient de moins en moins d’expérience en matière de programmation. Quelques années plus tôt, le rôle des professeurs était de convaincre les nouveaux arrivants en premier cycle universitaire qu’ils ne savaient pas tout sur le sujet. A l’époque de la première « bulle internet », beaucoup parmi eux avait commencé leur carrière d’informaticien dès leur plus jeune âge. Ils étaientfamilier avec plusieurs langages allant des « Code machine » et « Assembleur » (les niveaux les plus proches de la machine) jusqu’aux langages de plus haut niveaux. Au fil des années, cette expertise était en berne, à tel point qu’autour de 2005, le candidat typique maîtrisait à peine quelques éléments des technologies de l’internet, HTML et PHP par exemple.
En parallèle, les membres du monde académique anglais étaient bien conscients de la nécessité croissante pour l’industrie, et la société plus globalement, d’avoir une population formée à la compréhension du numérique. Le numérique était désormais omniprésent dans la vie quotidienne. Et ce sans parler des besoins spécifiques en ingénierie et sciences. De façon anecdotique, les cours de TICE à ce moment-là étaient souvent devenus des leçons de dactylographie et d’utilisation d’outils bureautiques. Bien que ce soit important, le numérique ne pouvait pas se résumer à ça. Face à ce dilemme, Dr Upton et ses autres co-fondateurs de la Raspberry Pi Foundation se posaient deux questions : pourquoi en est-on arrivé là et comment trouver une solution pour répondre à leur besoin immédiat, local (et peut-être au-delà) ?
Comprendre la cause avant de chercher le remède
L’explication qu’ils ont trouvée était la suivante. Dans les années 80, sur les machines de l’époque, on devait utiliser des commandes tapées dans une interface spartiate pour faire fonctionner, et même jouer sur les ordinateurs. Par exemple pour moi, c’était un « BBC Micro » d’Acorn en école primaire en Irlande comme pour Eben chez lui au Pays de Galles. C’était pareil en France, avec des noms comme Thomson, Amstrad, Sinclair, ou Commodore,… qui rappellent des souvenirs de ces années-là. Depuis cette date, nous étions passés à des ordinateurs personnels et consoles de jeu fermés et propriétaires qui donnaient moins facilement l’accès au « moteur » de l’environnement binaire caché sous le « capot » de sur-couches graphiques. Bien que ces interfaces soient pratiques, esthétiques et simples à l’utilisation, elles ont crée une barrière à la compréhension de ce qui se passe « dans la boîte noire ». Pour tous, sauf une minorité d’initiés, nous sommes passés d’une situation d’interaction avec une maîtrise réelle et créative, à un fonctionnement plutôt de consommation.
Quand une solution permet de changer le monde
Leur réponse à ce problème a été de concevoir une nouvelle plate-forme informatique accessible à tous autant par sa forme, que par son prix, et ses fonctionnalités. L’idée du Raspberry Pi est née et le produit fini a été lancé le 29 février 2012.
Le Raspberry Pi est un nano-ordinateur de la taille d’une carte bancaire (Modèle 2 : 85mm x 56.2mm). Le prix de base, dès le début, a été fixé à $25 USD (bien que d’autre modèles existent à ce jour de $5 à $35). Le système d’exploitation conseillé est l’environnement libre et gratuit GNU/Linux (et principalement une « distribution » (version) dite Raspbian). Le processeur est d’un type « ARM » comme trouvé dans la plupart des smartphones de nos jours. Tout le stockage de données se fait par défaut par le biais d’une carte Micro SD. L’ordinateur est alimenté par un chargeur micro-USB comme celui d’un téléphone portable. Le processeur est capable de traiter les images et vidéos en Haute Définition. Il suffit de le brancher sur un écran HDMI ou téléviseur, clavier, souris par port USB et éventuellement le réseau et nous avons un ordinateur complet et fonctionnel. Avec son processeur Quad Cœur 900 Mhz et 1 Go de mémoire vive, le Modèle 2 est commercialiséenFrance aux alentours d’une quarantaine d’Euros. A la différence de la plupart des ordinateurs en vente, la carte comporte 40 broches « GPIO » (Broches/picots d’Entrée-Sortie générale). C’est une invitation à l’électronique et l’interaction avec le monde extérieur. En quelques lignes de code, l’informatique dite « physique » devient un jeu d’enfant. Brancher résistance et une DEL et un bouton poussoir en suivant un tutoriel et les enfants découvrent immédiatement des concepts de l’automatisation et de robotique. C’est assez impressionnant que ce même petit circuit imprimé, que l’on peut facilement mettre entre les mains d’un enfant de 5 ans, est de plus en plus utilisé dans des solutions industrielles embarquées et intégrées.
Le nom « Raspberry Pi » vient du mot anglais pour la framboise (les marques de technologie prennent souvent les noms d’un fruit) et de « Python », un langage de programmation abordable, puissant et libre. Au début les inventeurs pensaient peut-être dans leur plus grands rêves vendre 10,000 unités. A ce jour, c’est bien plus de 6 millions de Raspberry Pi qui ont été vendus danslemondeentier. En se consacrant initialement 100% de leurs efforts en développement matériel aux cartes elles-mêmes, la Fondation a fait naître à leur insu tout un écosystème autour de la création d’accessoires et périphériques. Les « produits dérivés » vont de toute sorte de boîtier jusqu’à divers cartes d’extension pour tout usage imaginable.
Le Piano HAT : une carte d’extension pour apprendre à s’amuser en musique, avec un boitier Pibow coupé Crédit Photo : Pimoroni.com
De plus, ils ont su créer d’autres emplois « chez eux » grâce à l’ordinateur – aujourd’hui les cartes sont fabriqués « Made in Wales » (dans une usine de Sony au Pays de Galles). Il existe aussi un communauté global de passionnés de tout âge et tout horizon qui promeuvent la pédagogie numérique, réalisent des projets, organisent des événements et assurent de l’entre–aide autour de la « Framboise π« . La France n’est pas une exception avec pas mal d’activité dans l’Hexagone. La barrière initiale de la langue anglaise joue sans doute un rôle dans son manque de notoriété et utilisation par un plus grand publique chez nous – pour l’instant ce bijou technologique reste en grande partie le domaine des technophiles/ »geeks » et des lycées techniques.
Éducation
Le succès commercial fulgurant du Raspberry Pi fait oublier parfois que le but principal de la Fondation reste axé sur l’éducation. L’argent gagné à travers les ventes est réinvesti dans des actions et des fonds permettant de faire avancer leurs objectifs. Ce dernier temps, la Fondation a pu engager des équipes de personnes intervenant sur divers projets et initiatives un peu partout dans le monde. Ça concerne l’informatique, mais pas seulement. Dans le monde anglo-saxon, on parle souvent de « STEM », voire « STEAM » – acronyme pour la promotion des Sciences, Technologie, Ingénierie (Engineering), les Arts et Mathématiques. En France, le Raspberry Pi pourrait bien STIM-uler plus d’intérêt dans ces disciplines aussi !
Utilisation
Les applications potentielles de cet outil sont sans fin. Un petit tour d’internet laisse pas de doute sur les possibilités. Sortie de sa boîte, ça permet une utilisation en bureautique avec Libre Office, accès internet avec un navigateur web, l’apprentissage de la programmation avec Scratch, Python et Minecraft Pi ou Ruby et Sonic Pi. Plus loin il existe tout l’univers d’utilitaires libres et gratuits sous GNU/Linux.
Pour donner quelques exemples rapides intéressants :
Et enfin, on peut même envoyer ses expériences scientifiques dans l’Espace ! Dans l’esprit de la récente semaine d’une « HeuredeCode« , dans le projet AstroPi, deux Raspberry Pi viennent d’être envoyéssurlaStationSpatialeInternationale embarquant des capteurs et du code crée lors d’un concours par des enfants de primaire et secondaire en Grande Bretagne. Ça fait rêver !
Astro Pi : un concours pour des jeunes en Grande Bretagne pour envoyer leur Code sur l’ISS (Station Spatiale Internationale) Crédit Photo : Fondation Raspberry Pi {Artiste : Sam Adler}
Comme dit François Mocq, auteur et blogueur de « Framboise314.fr« , il y a bien une limitation à ce que nous pouvons faire avec un Raspberry Pi. C’est notre imagination !
Cet article a été écrit via un Raspberry Pi.
Pour plus d’information, rendez-vous sur « http://raspberrypi.org » (site officiel de la Fondation – anglophone) et/ou « http://framboise314.fr » (notre référence francophone).
« C’est notamment grâce aux technologies de l’analyse d’images et de la vision par ordinateur que Delair-Tech pourra devancer ses compétiteurs ». Olivier Faugeras, chercheur Inria Sophia, Membre de l’Académie des Sciences.
Contrairement aux drones grand public les plus répandus avec hélice, les drones professionnels de Delair-tech ressemblent à des avions miniatures. On retrouve dans le monde des drones la même distinction qu’entre hélicoptère et avion. L’avantage des drones à voilure fixe (et pas tournante), c’est leur autonomie qui leur permet de parcourir de grandes distances et de couvrir ainsi de larges zones.
Photo Delair-tech
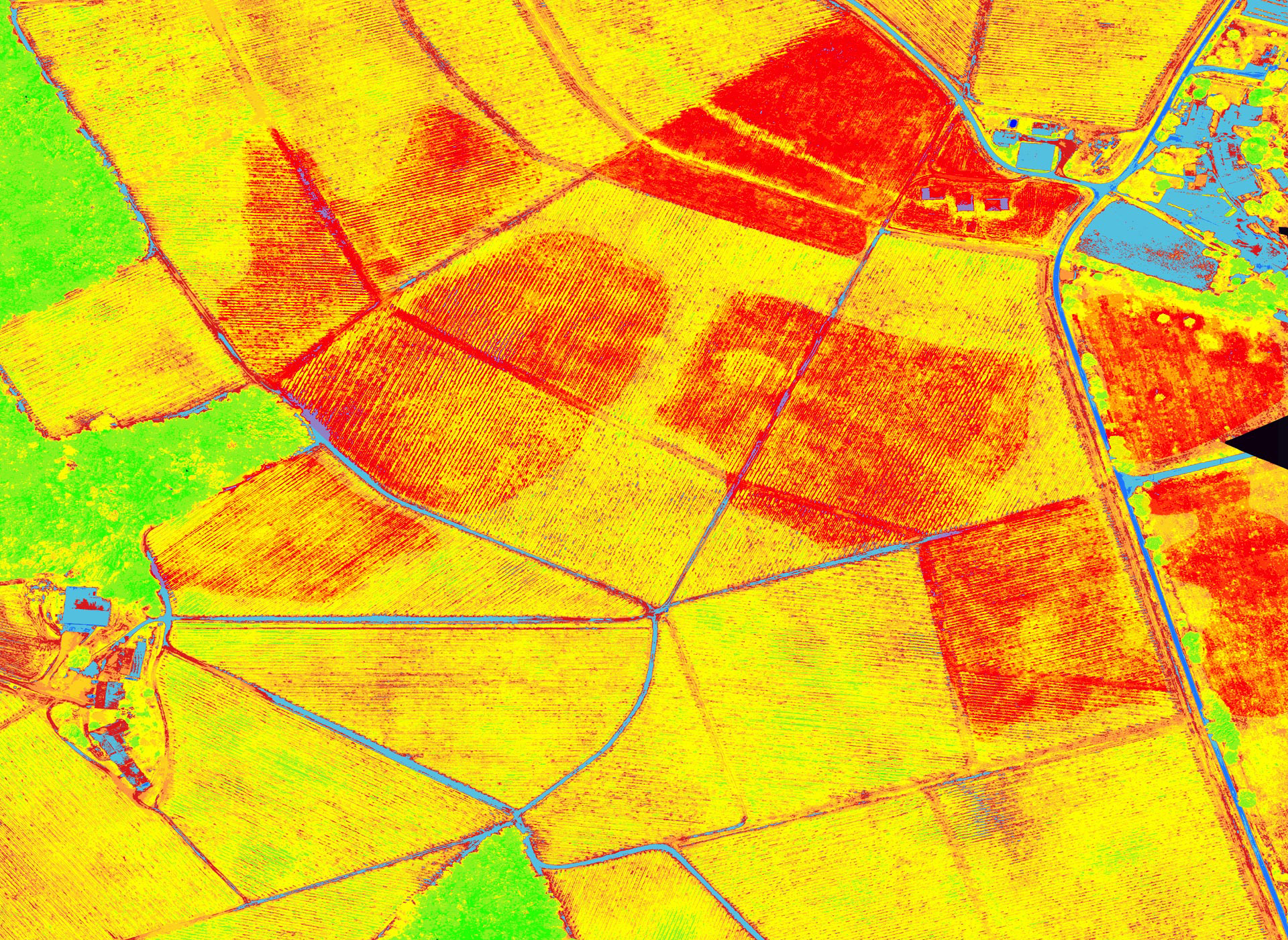
L’agriculture. A cause de la plus grande autonomie des drones à voilure fixe, l’un de leurs marchés les plus prometteurs n’est autre que l’agriculture. Un drone de Delair-tech permet par exemple de détecter depuis le ciel les parcelles d’un champ qui ont besoin d’azote. « La société était très orientée hardware au départ, mais nous travaillons de plus en plus sur des logiciels, notamment de traitement d’image » explique Benjamin Benharrosh, cofondateur de la startup. Pour analyser la quantité d’azote présente localement dans un champ, leurs logiciels permettent de réaliser une carte multispectrale et à partir de cela de calculer des indices biophysiques en différents points. Dans le cadre d’un projet de recherche sur quatre ans lancé en partenariat notamment avec l’INRA, Delair-tech cherche aussi à détecter des maladies des cultures, les besoins en désherbage, ou à permettre de mieux contrôler l’hydratation.
Photo Delair-tech
Les mines et le BTP. Si l’agriculture est un domaine porteur pour Delair-tech, le plus développé pour l’instant reste celui des mines et du bâtiment. « Les géomètres sont habitués à gérer des révolutions technologiques fréquentes. Beaucoup d’entre eux utilisent déjà des drones. » explique Benjamin Benharrosh. Delair-tech les aide par exemple à reconstituer un modèle 3D du terrain. Les drones peuvent aussi participer à la surveillance et l’inspection de réseaux comme des lignes électriques ou des voies ferrées. Des drones permettent de détecter par exemple de la végétation qui s’approche trop près de lignes électriques, ou des pelleteuses qui creusent un terrain alors qu’un oléoduc passe en-dessous. Si reconnaître de la végétation est une tâche relativement simple à l’aide de marqueurs de chlorophylle, pour reconnaître une pelleteuse, il faut avec des algorithmes de reconnaissance de formes ; c’est bien plus compliqué.
Photo Delair-tech
Dans le domaine de Delair-tech, les challenges sont très techniques. Pour obtenir l’autorisation de voler hors du champ visuel de l’opérateur, il a fallu construire un drone de moins de deux kilos. Cela écartait la solution simple qui consistait à combiner des composants du marché. Pour cela, la R&D de Delair-tech a dû monter en compétences dans des domaines aussi variés que les matériaux composites, les télécoms, les système embarqués, la mécanique. Une autre contrainte sérieuse est mentionnée par Benjamin Benharrosh : « La réglementation nous oblige à garder le contact avec le drone en permanence ». Une borne Wifi permet de garder ce contact jusqu’à une vingtaine de kilomètres. Et au delà, il faut installer des antennes relais.
La France est l’un des premiers pays au monde à avoir régulé les vols de drones hors vue. Le drone doit être léger, pour minimiser les risques en cas de chute. Il doit permettre un retour vidéo vers son opérateur, qui doit garder en permanence une communication avec lui. On ne peut pas par exemple passer par la 3G d’un opérateur, qui n’est pas considérée comme assez fiable. Le drone doit de plus inclure un système de défaillance permettant un retour forcé en cas de perte de contact, et d’un système de sécurité le conduisant à tomber avec peu d’énergie en cas de problème plus sérieux.
Pour être autorisé à réaliser des vols hors du champ visuel en France, un des premiers pays à avoir légiféré sur les drones hors vue, des drones de Delair-tech ont dû passer tous les tests exigés dans l’hexagone. Pourtant 75 % du chiffre d’affaire de la startup est réalisé à l’étranger dans les quelques pays ayant déjà mis en place une régulation… ainsi que dans ceux n’en ayant pas encore.
Le marché de Delair-tech est très compétitif. Les challenges sont techniques, principalement logiciels : étude topographique, génération et analyse de carte multispectrale, reconnaissance d’image… Ils sont loin d’être tous résolus avant que, par exemple, les drones de Delair-Tech puissent voler au dessus de 150m et se mêler au trafic aérien.
L’agriculture elle-aussi a été impactée par l’informatique. Dans le cadre des « Entretiens autour de l’informatique », Serge Abiteboul et Claire Mathieu ont rencontré François Houllier, Président directeur général de l’INRA, l’Institut National de Recherche en Agronomie. François Houllier raconte à Binaire les liens riches et complexes entre les deux disciplines, et ses inquiétudes autour du changement climatique.
François Houllier, PDG de l’INRA
La gestion des ressources forestières
Monsieur Houllier, qui êtes vous ?
François Houllier : Au départ, je suis un spécialiste de l’inventaire et de la modélisation des ressources forestières. J’ai été chercheur dans ce domaine. Aujourd’hui, je suis président directeur général de l’INRA. J’ai rencontré l’informatique dès le début de ma carrière, avec, pour ma thèse de doctorat l’utilisation de bases de données pour le dénombrement et la mesure d’arbres à partir de photos aériennes et d’observations de terrain. A l’Inventaire Forestier National, j’ai développé des modèles de production de forêt pour simuler les évolutions de massifs forestiers à l’échelle de cinq, dix, vingt ou trente ans, grâce aux bases de données et aux ordinateurs. Dans les années 80, nous avons réalisé un service « Minitel vert » pour donner accès librement aux informations statistiques sur les bois et les forêts dans un département ou une région. J’ai aussi dirigé des laboratoires de recherche où l’informatique était très présente, par exemple le laboratoire AMAP à Montpellier qui a essaimé en Chine, à l’École centrale de Paris et à l’Inria avec des chercheurs qui travaillaient sur la modélisation de l’architecture des plantes, de leur topologie, de leur géométrie et de leur morphogenèse. Cela demandait de faire dialoguer des botanistes, des agronomes, des écologues et des forestiers ayant le goût de la modélisation, avec des chercheurs qui maîtrisent les méthodes statistiques, les mathématiques appliquées, l’informatique.
La modélisation mathématique et informatique a pris une place considérable en agronomie ?
FH : Pour les forêts, ma spécialité initiale, la modélisation est particulièrement importante. On inventorie les forêts à l’échelle nationale et on se demande quelles seront les ressources en bois et la part qui pourra être exploitée dans dix, vingt ou cinquante ans. Nous sommes sur des échelles de temps longues, où l’expérience passée aide, mais où nous devons nous projeter dans le futur. Il faut tenir compte des problèmes de surexploitation ou de sous-exploitation, utiliser les techniques de sondage et la télédétection pour acquérir massivement des données. Nous partons de toutes les données dont nous disposons et, avec des modèles, nous essayons de prédire comment les forêts vont évoluer. C’est un peu comme les études en démographie humaine. Les particularités pour les forêts, c’est que les arbres ne se reproduisent pas comme des mouettes ou des humains, et qu’ils ne se déplacent pas. Mais, même si nos modèles sont parfois un peu frustes, les entreprises qui investissent dans les forêts, notamment pour alimenter les scieries ou les papeteries, attendent des prédictions raisonnables pour rentabiliser leurs investissements qui sont sur du long terme.
Les changements climatiques et la COP21
Quand vous vous projetez ainsi dans l’avenir, vous rencontrez la question du changement climatique. Ce changement a un impact sur les forêts ?
FH : Quand j’ai commencé à travailler sur les forêts, à la fin des années 1980, la question du changement climatique ne se posait pas. J’ai rencontré le sujet à l’occasion d’un séminaire réalisé par un chercheur travaillait sur le dépérissement des forêts. Il avait trouvé un résultat alors invraisemblable : le sapin grossissait dans les Vosges comme il n’avait jamais grossi depuis un siècle, plus de 50% plus vite que le même sapin un siècle plus tôt. C’était d’autant plus imprévisible qu’au départ ce chercheur s’intéressait au dépérissement des forêts du fait de ce qu’on appelait les « pluies acides ». Son résultat a ensuite été confirmé. L’explication ? Ce n’était pas le climat en tant que tel, la pluviométrie ou la température même si leurs variations interannuelles ont des effets sur la croissance des arbres. Cela venait de différents facteurs, dont l’accroissement de la teneur en CO2 de l’air et surtout les dépôts atmosphériques azotés qui ont un effet fertilisant. Ce n’est pas simple de séparer les différents facteurs qui ont des effets sur la croissance des autres effets potentiellement négatifs du changement climatique. Ce changement climatique, forcément, va avoir des effets majeurs sur les forêts, des effets immédiats et des effets décalés. Par exemple, comme un chêne pousse en bonne partie en fonction du climat de l’année antérieure, il y a un effet d’inertie. Quand j’ai commencé mes recherches, nous considérions le climat comme une constante, avec des variations interannuelles autour de moyennes stables. Maintenant, ce n’est plus possible.
Cela nous conduit à l’impact du changement climatique sur l’agriculture…
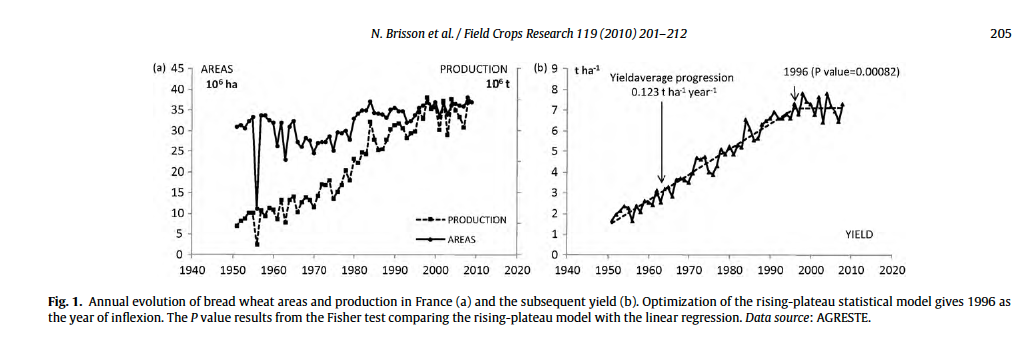
FH : Nous avons des échelles de temps très différentes entre les forêts et, par exemple, les céréales. Prenons le blé et son rendement depuis un siècle. On observe une faible augmentation de 1900 à 1950, puis une forte augmentation, d’un facteur quatre environ, de 1950 à 1995, et puis… la courbe devient irrégulière mais plutôt plate. (Voir la figure.) Comment expliquer cette courbe ? Après 1950, les progrès viennent des engrais, de nouvelles pratiques de culture, et beaucoup de la génétique.
En amélioration génétique des plantes, ça se passe un peu comme dans le logiciel libre avec un processus d’innovation ouverte où chacun peut réutiliser les variétés précédemment créées par d’autres améliorateurs. Chaque année, les sélectionneurs croisent des variétés ; ils filtrent ces croisements pour obtenir de nouvelles variétés plus performantes. Cela prend une dizaine d’années pour créer ainsi une nouvelle variété qui est ensuite commercialisée sans pour autant que son obtenteur paie de royalties à ceux qui avaient mis au point les variétés parentes dont elle est issue. Le progrès est cumulatif.
En 1995, les généticiens avaient-il atteint le rendement maximal ? Pas du tout. Le progrès génétique a continué, et aurait dû entraîner une hausse des rendements de l’ordre de 1% par an. Alors pourquoi la stagnation ? Des modèles ont montré qu’environ la moitié du progrès génétique a été effacée par le réchauffement climatique et par la multiplication des événements climatiques défavorables, et l’autre moitié a été perdue du fait des changements de pratiques agricoles, notamment de la simplification excessive de l’agriculture, un effet beaucoup plus subtil. Il y a plusieurs décennies, on avait des rotations, avec des successions d’espèces par exemple entre le blé et des légumineuses, telles que le pois. Quand on arrête ce type de rotations, le sol devient moins fertile.
Vous voyez, ce n’est pas simple de comprendre ce qui se passe quand on a plusieurs facteurs qui jouent et dont les effets se combinent. Nous travaillons beaucoup dans cette direction. Nous utilisons des modèles prédictifs pour déterminer selon différents scénarios climatiques et selon les endroits du globe, si les rendements agricoles vont augmenter ou pas. Les bases écophysiologiques de ces modèles sont bien connues mais il y a beaucoup de facteurs : la qualité des terres et des sols, le climat et les variations météorologiques, les espèces et les variétés, les pratiques agronomiques et les rotations. La complexité est liée au nombre de paramètres qui découlent de ces facteurs. En développant de nouveaux modèles, on comprend quelles informations manquent, on se trompe, on corrige, on affine les paramètres. C’est toute une communauté qui collectivement apprend et progresse par la comparaison des modèles entre eux et par la confrontation avec des données réelles.
Ce que nous avons appris. Pour les 10 ans à 20 ans qui viennent, pratiquement autant de prédictions indiquent des augmentations que des réductions des rendements agricoles, au niveau global. Mais si on se projette en 2100, 80% des prédictions annoncent des diminutions de rendement. Même s’il y aura des variations selon les endroits et les espèces, la majorité des cultures et des lieux seront impactés négativement !
Cela pose de vraies questions. Pour nourrir une population qui croît, on doit accroître la production. On peut le faire en augmentant le rendement ; c’est ce qui s’est passé quand l’Inde a multiplié en cinquante ans sa production de blé par six sans quasiment modifier la surface cultivée. Ou alors on peut utiliser des surfaces supplémentaires, par exemple en les prenant sur les forêts, mais cela pose d’autres problèmes. La vraie question, c’est évidemment d’arriver à produire plus de manière durable. Et avec le changement climatique, on peut craindre la baisse des rendements dans beaucoup d’endroits.
Image satellitaire infra-rouge. IGN. Via INRA.
Le monde agricole s’intéresse beaucoup au big data. Comme ailleurs, cela semble causer des inquiétudes, mais être aussi une belle source de progrès. Comment voyez-vous cela ?
FH : Nous voyons arriver le big data sous deux angles différents, sous celui de la recherche et sous celui de l’agriculture.
Premier angle : la recherche, pour laquelle le big data a une importance énorme. Considérons, par exemple, l’amélioration génétique classique : on cherche à utiliser de plus en plus précisément la connaissance du génome des animaux et des végétaux en repérant des « marqueurs » le long des chromosomes ; ces marqueurs permettent de baliser le génome et de le cartographier. Les caractères intéressants, comme le rendement ou la tolérance à la sécheresse, sont corrélés à de très nombreux marqueurs. On va donc faire des analyses sur les masses de données dont on dispose : beaucoup d’individus sur lesquels on identifie la présence ou l’absence de beaucoup de marqueurs qu’on corrèle avec un grand nombre de caractères. L’objectif c’est de trouver des combinaisons de marqueurs qui correspondent aux individus les plus performants. On sait faire cela de mieux en mieux, notamment à l’INRA. Les grands semenciers le font aussi : ils investissent entre 10 et 15% de leurs ressources dans la R&D. Aujourd’hui, la capacité bioinformatique à analyser de grandes quantités de données devient un facteur limitant.
On peut aussi considérer le cas des OGM, avec le maïs. La tolérance à un herbicide ou la résistance à un insecte ravageur peuvent être contrôlées par un seul gène ou par un petit nombre de gènes. Par contre, le rendement dépend de beaucoup de gènes différents : des dizaines, voire des centaines. D’où deux stratégies assez différentes. Pour les caractères dont le déterminisme génétique est simple, on peut utiliser une approche de modification génétique ciblée, les fameux OGM. Pour les caractères dont le déterminisme est multifactoriel, l’approche « classique » accélérée par l’usage des marqueurs associés aux gènes est celle qui marche actuellement le mieux. Donc, pour disposer d’un fond génétique qui améliore le rendement, le big data est la méthode indispensable aussi bien en France, sans OGM, qu’aux Etats-Unis, avec OGM.
Deuxième angle : l’utilisation du big data chez les agriculteurs. Un robot de traite est équipé de capteurs qui produisent des données. Un tracteur moderne peut aussi avoir des capteurs, par exemple pour mesurer la teneur en azote des feuilles. Avec les masses de données produites, nous avons vu se développer de nouveaux outils d’analyse et d’aide à la décision pour améliorer le pilotage des exploitations. Mais ce qui inquiète le monde agricole, c’est qui va être propriétaire de toutes ces données ? Qui va faire les analyses et proposer des conseils sur cette base ? Est-ce-que ces données vont être la propriété de grands groupes comme Monsanto, Google, ou Apple ou les fabricants de tracteurs ? En face de cela, même les grandes coopératives agricoles françaises peuvent se sentir petites. Le contrôle et le partage de toutes ces données constituent un enjeu stratégique.
L’agriculteur connecté
Il ressort de tout cela que l’agriculteur est souvent très connecté ?
FH : Il reste bien sûr des zones dans les campagnes qui sont mal couvertes par Internet, mais ce n’est pas la faute des agriculteurs. Les agriculteurs sont plutôt technophiles. Quand les tracteurs, les robots de traites ou les drones sont arrivés, ils se sont saisis de ces innovations. Il en va de même avec le numérique. Les agriculteurs qui font de l’agriculture biologique sont eux aussi favorables au numérique. Les nouvelles technologies permettent aux agriculteurs de gagner du temps, d’améliorer leur qualité de vie, de réduire la pénibilité de certaines activités. Ils sont conscients des améliorations que les applications informatiques peuvent leur apporter.
Automate de caractérisation des plantes. INRA.
La data et le territoire
Ils sont connectés et solidaires ?
FH : Les agriculteurs ont l’habitude de partager des pratiques et des savoir faire, ou des matériels agricoles, et d’exprimer des formes de solidarité. Par exemple, dans un même territoire, ils échangent « par dessus la haie », c’est-à-dire qu’ils regardent ce qui se fait à côté et imitent ce qui marche chez leurs voisins. Dans le domaine de la sélection animale la recherche publique, l’INRA, travaille depuis longtemps avec les différents organismes qui font de l’insémination artificielle et qui sélectionnent les meilleurs animaux pour la production de lait ou de viande, par exemple. Les races bovines sont certes différentes mais certaines méthodes sont identiques, comme le génotypage qui consiste à déterminer tout ou partie de l’information génétique d’un organisme. Jusqu’à récemment, il existait une forte solidarité entre les différentes filières animales : d’une certaine manière, les progrès méthodologiques réalisés sur les races bovines dédiées à la production laitière bénéficiaient aux autres races puis ensuite aux ovins ou aux caprins.
Ces dernières années, l’arrivée de nouvelles formes d’analyse à haut débit, très automatisées, spécialisées, a induit des changements. Cela a conduit au développement d’activités concurrentielles. Par exemple, il y a des sociétés qui proposent des services de génotypage pour analyser des milliers de bovins en identifiant leurs marqueurs génétiques. Ça peut se faire n’importe où dans le monde, à Jouy-en-Josas, comme au Canada : il suffit d’envoyer les échantillons. Les solidarités territoriales ou nationales qui existaient sont en train de se fracturer sous les effets combinés de la mondialisation et du libéralisme. Elles sont en train de se défaire du fait de la compétition au sein de métiers qui se segmentent, et de la création d’opérateurs internationaux sans ancrage territorial. Regardez le big data : les données ne sont pas localisées ; elles ne sont pas ancrées dans un territoire ; les calculs se réalisent quelque part « dans le cloud ». C’est une cause de l’inquiétude actuelle de nos collègues des filières animales ou végétales : l’angoisse du big data ne vient pas de la technologie en tant que telle, mais plutôt de la perte d’intermédiation, de la perte du lien avec le territoire.
L’agronome et l’agriculteur
Dans d’autres sciences, la distance entre les chercheurs et les utilisateurs de leurs recherches est souvent très grande. On a l’impression en vous entendant que c’est moins vrai des agronomes.
FH : Ça dépend. Prenez un chercheur qui travaille sur les mécanismes cellulaires fondamentaux de recombinaison génétique. Il révolutionnera peut-être la sélection végétale dans vingt ans, mais il peut faire des recherches sur ce sujet sans rencontrer d’agriculteurs. Nous avons des recherches de ce type à l’INRA, mais nous assurons aussi une continuité avec des travaux plus en aval au contact du monde agricole. Le plus souvent, nous ne réalisons pas nous mêmes les applications ; cela peut être fait par des entreprises, par des instituts techniques dédiés ou par des centres techniques industriels, financés pour partie par l’État et pour beaucoup par des fonds professionnels. De tels instituts existent pour les fruits et légumes, pour les céréales, pour les oléagineux, pour l’élevage en général ; il en existe un spécifique pour le porc, et un pour la volaille. Nous collaborons avec eux.
Informatique et agriculture
Comment se passe le dialogue entre vos spécialistes d’agronomie et les informaticiens ?
FH : Nous avons de plus en plus de besoin de compétences en modélisation, en bioinformatique, en mathématiques appliquées, en informatique, avec des capacités à conceptualiser, à traiter des grands ensembles de données, à simuler… Quelles sont les compétences d’un chercheur qu’on embauche à l’INRA aujourd’hui ? Cela évolue, les métiers changent et on en voit naître de nouveaux. Mais il est clair que même dans des disciplines « anciennes » comme l’agronomie ou la physiologie, les jeunes chercheurs que nous recrutons doivent et devront avoir des compétences ou pour le moins une sensibilité affirmée pour l’informatique et le big data. Nous avons fait un exercice de gestion prévisionnelle des emplois et des compétences : il en ressort que beaucoup des nouveaux besoins exprimés relèvent du numérique au sens large. Nous nous posons sans arrêt ces questions : quelle informatique voulons-nous faire ou avoir en interne ? Que voulons-nous faire en partenariat, notamment avec Inria avec qui nous collaborons beaucoup ? Parmi les organismes de recherche finalisés et non dédiés au numérique, nous sommes l’un des rares à être doté d’un département de mathématiques et informatique appliquées, héritier du département de biométrie. Même si c’est le plus petit des 13 départements de l’INRA et si ce n’est pas notre cœur de métier, de telles compétences sont vraiment essentielles pour nous aujourd’hui.
SAS, un grand éditeur de logiciel américain spécialiste de la statistique, doit beaucoup à l’agriculture. Quand ce n’était encore qu’une startup de l’Université de Caroline du Nord, SAS a eu besoin de puissances de calculs. C’est le monde agricole, le service de recherche agronomique du ministère de l’agriculture des États-Unis, qui a fourni l’accès à des moyens de calcul. Ce n’est pas vraiment surprenant quand on sait que l’agriculture a été très tôt un objet d’étude privilégié des statisticiens et a donné lieu à beaucoup de développements méthodologiques originaux. Voir https://en.wikipedia.org/wiki/Maurice_Kendall
Dans le même ordre d’idée, c’est intéressant de savoir que c’est l’INRA qui a commandé l’un des premiers ordinateurs personnels équipés d’un microprocesseur, le premier Micral vers 1970. Il était destiné à des études de bioclimatologie dirigées par Alain Perrier. Voir https://en.wikipedia.org/wiki/Micral
Dérèglement climatique ? Problèmes d’énergie et dégradations que nous faisons subir à notre planète ? La Conférence de Paris de 2015 sur le climat (qui inclut la COP21) est une excellente occasion de mettre la transition écologique au cœur du débat. De plus, nous baignons dans une autre transition, la transition numérique dont on mesure chaque jour un peu plus en quoi elle transforme notre monde de façon si fondamentale. Deux disruptions. Comment coexistent-elles ?
www.greenit.fr, un site de partage de ressources à propos d’informatique durable
Commençons par ce qui fâche le fana d’informatique que je suis : le coût écologique du numérique. Le premier ordinateur, Eniac, consommait autant d’électricité qu’une petite ville. Les temps ont changé ; votre téléphone intelligent a plus de puissance de calcul et ne consomme quasiment rien. Oui mais des milliards de telles machines, d’objets connectés, et les data centers ? La consommation énergétique de l’ensemble est devenue une part importante de la consommation globale ; plus inquiétante encore est la croissance de cette consommation. Et puis, pour fabriquer tous ces objets, il faut des masses toujours plus considérables de produits chimiques, et de ressources naturelles, parfois rares. Et je vous passe les déchets électroniques qui s’amoncellent. Il va falloir apprendre à être économes ! Vous avez déjà entendu cette phrase. Certes ! On ne fait pas faire tourner des milliards d’ordinateurs en cueillant silencieusement des fleurs d’Udumbara.
D’un autre coté, le monde numérique, c’est la promesse de nouveaux possibles, scientifiques, médicaux, économiques, sociétaux. C’est, entre tellement d’autres choses, la possibilité pour un adolescent de garder contact avec des amis partout dans le monde; pour un jeune parent, de travailler de chez lui en gardant un enfant malade ; pour une personne au fin fond de la campagne, au bout du monde, d’avoir accès à toute la culture, à tous les savoirs du monde ; pour une personne âgée de continuer à vivre chez elle sous une surveillance médicale permanente. C’est tout cela : de nouveaux usages, de nouveaux partages, de nouveaux modes de vie. Alors, il n’est pas question de « se déconnecter » !
Les transitions écologiques et numériques doivent apprendre à vivre ensemble.
Penser écologie quand on parle de numérique
Quand le numérique prend une telle place dans notre société, il faut que, comme le reste, il apprenne à être frugal. Cela conduit à la nécessité de construire des ordinateurs plus économes en électricité, d’arrêter de dépenser d’énormes volumes de temps de calcul pour mieux cibler quelques publicités. Cela conduit aussi à modifier nos habitudes en adoptant un faisceau de petits gestes : ne pas changer d’ordinateur, de téléphone intelligent, de tablette tous les ans juste pour pouvoir frimer avec le dernier gadget, ne pas inonder la terre entière de courriels, surtout avec des pièces jointes conséquentes, etc. Nous avons pris de mauvaises habitudes qu’il est urgent de changer. Les entreprises doivent aussi limiter leurs gaspillages d’énergie pour le numérique. On peut notamment réduire de manière significative l’impact écologique d’un data center, le rendre plus économe en matière d’énergie, voire réutiliser la chaleur qu’il émet. Bref, il faut apprendre à penser écologie quand on parle de numérique.
Oui, mais les liens entre les deux transitions vont bien plus loin. Le numérique et l’écologie se marient en promouvant des manières nouvelles, collectives de travailler, de vivre. Les réseaux sociaux du Web, des encyclopédies collaboratives comme Wikipedia, ne préfigurent-ils pas, même avec leurs défauts, le besoin de vivre ensemble, de travailler ensemble ? L’innovation débridée autour du numérique n’est-elle pas un début de réponse à l’indispensable nécessité d’innover pour répondre de manière urgente aux défis écologiques, dans toute leur diversité, avec toute leur complexité ?
adapté de pixabay.com
L’informatique et le numérique sont bien des outils indispensables pour résoudre les problèmes écologiques fondamentaux qui nous sont posés. Philippe Houllier, le PDG de l’INRA, peut, par exemple, bien mieux que moi expliquer comment ces technologies sont devenues incontournables dans l’agriculture. Il nous parle dans un article à venir sur binaire de l’importance des big data pour améliorer les rendements en agriculture, un sujet d’importance extrême quand les dérèglements climatiques et la pollution des sols tendent à faire diminuer ces rendements.
On pourrait multiplier les exemples mais il faut peut-être mieux se focaliser sur un fondement de la pensée écologique :
penser global, agir local.
On avait tendance à penser des équipements massifs, globaux, par exemple une centrale nucléaire, une production agricole intensive destinée à la planète, etc. Les temps changent. On parle maintenant d’énergie locale, diversifiée, d’agriculture de proximité. Mais si cette approche conduit à une économie plus durable, elle est plus complexe à mettre en place ; elle demande de faire collaborer de nombreuses initiatives très différentes, de s’adapter très vite et en permanence, de gérer des liens et des contraintes multiples. Elle ne peut se réaliser qu’en s’appuyant sur le numérique ! On peut peut-être faire fonctionner une centrale nucléaire sans ordinateur – même si je n’essaierais pas – mais on n’envisagerait pas de faire fonctionner un « smart-grid » (réseau de distribution d’électricité « intelligent ») sans. Un peu à la manière dont nos ordinateurs s’échangent des données sans cesse, on peut imaginer des échanges d’électricité entre un très grand nombre de consommateurs et plus nouveau de fournisseurs (panneaux solaires, éolienne, etc.), pour adapter en permanence production et consommation, pour en continu optimiser le système. Il s’agit bien d’une question d’algorithme. Et l’informatique est également omniprésente quand nous cherchons à modéliser le climat, les pollutions, à les prévoir.
Nous découvrons sans cesse de nouvelles facettes de la rencontre entre ces deux transitions. Nous découvrons sans cesse de nouveaux défis pour la recherche et le développement à leur frontière.
Le groupement de Service (G.D.S.) ÉcoInfo : des ingénieurs et des chercheurs (CNRS, INRIA, ParisTech, Institut Mines Télécom, RENATER, UJF…) à votre service pour réduire les impacts écologiques et sociétaux des TIC.
Ne pas connaître uniquement ses clients, mais aussi ses futurs clients, est le rêve de toute entreprise qu’elle soit petite ou grande. Pour y arriver, deux solutions s’offrent aux entrepreneurs : acheter une boule de cristal ou avoir recours aux services de Data Publica. Des tas de connaissances sur les entreprises sont à portée de clics, encore faut-il savoir les trouver, les comprendre et les consolider. C’est ce que propose Data Publica, fondée par François Bancilhon, entrepreneur récidiviste, et Christian Frisch. La startup récupère du web et de bases de données publiques un tas d’informations sur les entreprises. Avec comme impératif : que tout soit réalisé automatiquement.
Prenons la mesure du travail à réaliser. Parmi les 9 millions de numéros INSEE d’entreprises, seulement une partie représente des entreprises avec une vraie activité, et une partie encore plus restreinte a au moins un employé. Seules 590 000 d’entre elles ont un site Web. 590 000, ça fait quand même beaucoup d’entreprises à connaître. Ce sont les cibles de Data Publica qui annonce en couvrir déjà près de 95%. Data Publica a eu un Prix Mondial de l’Innovation, de la BPI, représentant un financement de 1 million d’euros.
Rentrons un peu dans la techno. Il faut trouver (automatiquement) les sites Web des entreprises en s’appuyant sur un crawler maison et des moteurs de recherche. Puis catégoriser les entreprises correspondantes en utilisant des techniques d’apprentissage (machine learning). On va regrouper les sites (automatiquement encore) en utilisant les similarités de vocabulaire. Un livreur de pizza et un fabricant de machines outils ne vont pas utiliser les mêmes termes. Donc ça marche plutôt bien.
Maintenant, essayons de comprendre un scénario pour une entreprise cliente – on est ici dans le B2B ou Business to Business, autrement dit les clients de Data Publica sont des entreprises qui vendent aux entreprises, et non à des particuliers. L’entreprise fourni sa base client (donc une liste d’entreprises), puis le logiciel de Data Publica analyse cette liste, la segmente à partir des données récupérées sur les sites Web des clients. Ensuite, pour chacun des segments détectés, le logiciel propose de potentiels futurs clients. Mieux connaître sa base client, trouver de nouveaux clients. C’est ce que François Bancilhon appelle « le marketing prédictif ». Un rêve pour le marketing et la vente ?
Mais les entreprises ne sont pas présentes sur la toile uniquement par leurs sites Web. Elles sont de plus en plus sur les réseaux sociaux, Facebook, Twitter, LinkedIn. En plus d’informations statiques, les messages postés sur ces systèmes donnent des informations « en temps réel ». Ces messages, là encore il faut les analyser. Cela concerne une offre d’emploi ? Une annonce financière ? Une promo ? Data Publica réalise donc pour ses clients le monitoring de ces messages et leur catégorisation. Ces informations aident les commerciaux en leur disant à quel moment appeler un prospect et à quel sujet l’appeler.
Pour permettre l’accès à de petites entreprises et pour faciliter l’accès de tous, Data Publica vient d’introduire une offre Freemium (*) sous le nom de C-radar. Le service de base coûte 99 euros par mois. Pour l’instant, seules les entreprises françaises et belges sont répertoriées, mais Data Publica est en train de traiter les entreprises du Royaume Uni et compte s’attaquer bientôt aux sociétés américaines, plus difficiles à gérer car elles ne sont pas référencées comme en France avec un numéro unique.
Quand on considère toutes les informations que l’on trouve sur le Web, on imagine bien que beaucoup de possibilités s’ouvrent à Data Publica. Améliorer encore sa technologie pour découvrir plus d’information, comprendre encore mieux les informations trouvées. Se développer dans de nouveaux secteurs demandeurs d’une telle technologie. Des domaines où on a besoin de mieux comprendre ce qui se passe sur le Web ? Ça ne doit pas être compliqué à trouver…
(*) Le freemium (mot-valise des mots anglais free : gratuit, et premium : prime) est une stratégie commerciale associant une offre gratuite, en libre accès, et une offre « Premium », plus haut de gamme, en accès payant. Ce modèle s’applique par sa nature aux produits et services à faibles coûts variables ou marginaux, permettant aux producteurs d’encourir un coût total limité et comparable à une offre publicitaire.
Dans une vie antérieure, François Bancilhon a été professeur d’informatique à l’Université d’Orsay (la future Université Paris Saclay). Puis, il a arrêté une recherche académique particulièrement brillante pour devenir entrepreneur au début des années 80. Dommage pour la recherche française, et tant mieux pour l’industrie. Sa plus belle réussite jusqu’à présent, O2 Technology, issue d’Inria, a été particulièrement novatrice dans le champ des bases de données objet.
Mise-à-jour : Paris, le 17 novembre 2015 – François Bancilhon, co-fondateur de Data Publica, s’est vu décerner le prix European Data Innovator 2015 lors de la conférence European Data Forum (EDF). Ce prix récompense son esprit d’entreprise, sa contribution à la gestion de données, et son outil de marketing prédictif B2B C-Radar.
La semaine prochaine, du 14 au 21 novembre, se déroule le concours Castor informatique ! L’édition 2014 avait touché plus de 220 000 élèves ! L’édition Française est organisée par l’association France-ioi, Inria et l’ENS Cachan, grâce à la contribution de nombreuses personnes. Ce concours international est organisé dans 36 pays. Plus de 920 000 élèves ont participé à l’épreuve 2014 dans le monde.
Les points à retenir, le concours est :
entièrement gratuit ;
organisé sur ordinateur ou sur tablette sous la supervision d’un enseignant ;
il dure 45 minutes ;
entre le 14 et 21 novembre 2015, à un horaire choisi par l’enseignant ;
avec une participation individuelle ou par binôme ;
aucune connaissance préalable en informatique n’est requise.
Nouveautés 2015 :
Ouverture aux écoles primaires : le concours est désormais ouvert à tous les élèves du CM1 à la terminale !
Niveau adaptable : chaque défi est interactif et se décline en plusieurs niveaux de difficultés pour accommoder les élèves de 9 à 18 ans.
Il est encore temps de s’inscrire pour les enseignants (vous pouvez le faire jusqu’au dernier jour, même si nous vous conseillons d’anticiper).
En attendant, ou si vous n’êtes plus à l’école, vous pouvez vous amuser à tester les défis des années précédentes depuis 2010, et en particulier les défis interactifs de 2014 !
Les objets connectés transforment chaque jour un peu plus notre monde. Ils nous offrent des possibilités qui n’existaient encore récemment que dans des livres de science fiction. Tout cela ne va pas sans risques que la technique doit nous aider à surmonter, que la société doit apprendre à réguler. Binaire a demandé à Philippe Pucheral, un des meilleurs spécialistes du domaine, de nous en parler. Serge Abiteboul.
Philippe Pucheral
Nous voici entrés de plain-pied dans l’ère de l’homme connecté, assisté, augmenté. Écartée la crainte du trou de mémoire face à un visage déjà rencontré, nos lunettes connectées nous délivrent instantanément l’identité et le CV de notre interlocuteur. Plus besoin de lire une carte ni même d’apprendre à conduire, notre véhicule connecté connait la route, évite les embouteillages et conduit avec une vigilance infaillible. Plus besoin d’éteindre la lumière ou de régler le chauffage, notre centrale domotique sait quand activer ou désactiver chacun des appareils électriques de la maison pour une gestion optimale de l’énergie, au niveau du foyer comme du quartier. Enfin, envolée la crainte de l’infarctus en grimpant un col de montagne, notre bracelet connecté veille sur notre rythme cardiaque.
Nous ne sommes pas dans une nouvelle d’Isaac Asimov ou d’Aldous Huxley mais bien en 2015. Certains considéreront que le monde perd en poésie ce qu’il gagne en efficacité et en prévisibilité. Mais laissons ce débat de côté. De toute évidence, un mouvement inexorable est enclenché. Le concept d’Internet des Objets est né en 1999 au centre Auto-ID du MIT avec l’idée d’associer à chaque objet du monde réel une puce RFID (*) permettant de l’identifier, de l’inventorier, de capturer ses déplacements. Et déjà, selon une étude de l’institut IDATE, 42 milliards d’objets sont connectés aujourd’hui et plus de 80 milliards le seront en 2020. Les objets connectés ont également gagné en puissance et en fonctionnalité. De puces RFID passives, ils sont devenus objets autonomes capables de mesurer leur environnement via des capteurs et d’interagir avec lui via des actuateurs (**). A chacun désormais de placer le curseur entre fonctionnalités utiles rendues par ces objets et l’asservissement qui en résulte. Pour éclairer ce choix, plusieurs dimensions devraient être considérées :
Source : IDATE DigiWorld in « Internet of things », Octobre 2015
Sûreté de fonctionnement : par sa capacité à prendre des décisions et à agir physiquement à notre place, l’objet connecté devient une prolongation de notre propre corps et un supplétif de notre conscience. Dès lors que l’objet intervient dans une tâche critique, par exemple freiner un véhicule, la confiance dans l’objet doit être absolue. Il est donc impératif de prouver formellement que le programme embarqué par l’objet est « zéro défaut ». La preuve de programme est une tâche complexe à laquelle de nombreuses équipes de recherche françaises et étrangères contribuent. Le lecteur pourra consulter avec intérêt le blog Binaire du 24 septembre 2015 traitant de ce sujet. Le matériel (hardware) qui compose l’objet doit également être zéro défaut et potentiellement redondant pour prévenir tout type de défaillance. A part pour des applications hautement sensibles telles que le contrôle de centrales nucléaires ou la commande d’avions de ligne, nous sommes loin aujourd’hui de ce niveau d’exigence.
Sécurité : le constat de dépendance vis-à-vis de l’objet est le même que pour la sûreté de fonctionnement mais la menace d’un dysfonctionnement vient ici d’une attaque malveillante. La psychose d’actions terroristes n’est jamais très éloignée. Deux pirates informatiques installés à Pittsburgh ont ainsi prouvé qu’ils pouvaient prendre le contrôle d’une voiture conduite par un journaliste volontaire circulant à Saint Louis. De même, en février 2015, BMW a dû diffuser un patch de protection comblant une faille de sécurité sur l’ordinateur de bord de plus de 2 millions de ses véhicules. L’omniprésence des objets connectés peut ainsi ouvrir la porte à des attaques de grande ampleur et ces anecdotes montrent que les industriels n’ont pas toujours pris la mesure du risque encouru. Alors que la voiture autonome (sans conducteur) fonctionne déjà en circuit fermé et est annoncée commercialement pour 2025, la sécurité reste un des grands défis à relever. Un problème similaire se pose avec les objets connectés à usage médical : à quand le crime parfait réalisé en piratant à distance une pompe à insuline ?
Confidentialité : les objets connectés captent une quantité considérable de données personnelles, données de santé, déplacements, consommation de ressources. A titre d’exemple, avec un compteur électrique intelligent captant la consommation avec une granularité de 1Hz, la plupart des équipements électriques domestiques ont une signature unique. Il devient alors possible de tracer l’intégralité de l’activité du foyer au cours d’une journée. Des chercheurs allemands ont montré qu’il était même possible d’identifier la chaîne de télévision regardée à un instant donné, en analysant, dans la trame sortante d’un compteur électrique intelligent, le spectre de consommation de l’écran de TV. Les exemples d’atteinte à la vie privée sont légion, du fait d’usages abusifs des données collectées ou d’attaques sur les serveurs. Face à cela, la communauté scientifique se mobilise pour concevoir des objets connectés moins intrusifs. Mais il est souvent difficile de concilier préservation du service et préservation de la vie privée. Comment par exemple récupérer l’adresse du restaurant Japonais le plus proche sans dévoiler notre localisation à un serveur ? En fonction des usages, différentes techniques existent pour limiter les risques de fuite d’information, comme par exemple exécuter les calculs utiles directement dans l’objet connecté plutôt que d’externaliser l’information vers un serveur, regrouper les données captées dans un serveur personnel sous le contrôle de chaque individu (Cloud Personnel), faire des calculs sécurisés distribués (ex: Secure Multi-party Computation), anonymiser ou ajouter du bruit dans les données émises (ex: differential privacy) ou encore passer par des relais de communication (ex: TOR). La capacité de croiser de multiples sources de données émanant de différents objets est un facteur complémentaire de complexité dans la recherche de solutions efficaces. Nous ne sommes donc qu’au début d’un chemin escarpé.
Source: National Institute of Standards and Technology
Durabilité environnementale : mais au fait, que deviennent les flux continus d’information captés par ces milliards d’objets intelligents ? A un mois de la conférence COP 21, la question mérite d’être posée. A l’instar d’Amazon qui a annoncé le lancement de son nouveau service d’hébergement de données issues de l’internet des objets, AWS IoT, Microsoft annonce la sortie d’Azure IoT Suite offrant un service similaire. Ainsi, la bataille pour l’analyse de ces données massives (big data) fait rage entre les géants de l’internet. Mais de quels volumes parle-t-on concrètement ? Selon une étude IDC parue en avril 2014, le volume de données numériques produit au niveau mondial devrait être multiplié par 10 entre 2013 (4,4 Zettaoctets) et 2020 (44 Zettaoctets). Soit 44 000 milliards de gigaoctets, ou, pour les amateurs d’analogies, une pile de DVD dépassant la moitié de la distance Terre-Mars. Les objets connectés sont à l’origine de plus de 20% de ce total. Faut-il réellement stocker toutes ces données sur des serveurs après les avoir acheminées via des réseaux ? Au même titre que dans le cerveau humain, mieux vaudrait être capable d’oublier le superflu pour rester efficace sur l’essentiel. Reste à être capable d’identifier le superflu.
Le Petit Prince d’Antoine de Saint-Exupéry, annotation Serge A.
A l’heure où le Conseil National de l’Ordre des Médecins préconise un remboursement des objets connectés de « mesure de soi » (quantified-self) par la sécurité sociale, où des compagnies d’assurances proposent des services de « Pay as you drive » en pistant votre conduite, où ERDF déploie des compteurs électriques intelligents Linky et où les constructeurs automobiles investissent massivement dans la voiture connectée et bientôt autonome, l’Internet des objets a de beaux jours devant lui. Mais cette révolution n’est pas que technologique. Elle bouscule aussi en profondeur nos modes de vie, nous fait nous interroger sur notre autonomie et notre libre arbitre. Faire remarcher une personne handicapée grâce à une puce retransmettant les commandes du cerveau touche au sublime. Mais a-t-on besoin d’un réfrigérateur connecté ? L’essentiel est que chacun puisse répondre. Pour cela, il serait inquiétant de laisser les industriels du secteur seuls modeler ce que doit devenir notre mode de vie connecté. Il y a donc urgence à développer des réflexions pluridisciplinaires sur ce sujet, avec notamment des informaticiens, des sociologues, des économistes et des juristes.
(*) La radio-identification, le plus souvent désignée par le sigle RFID (de l’anglais radio frequency identification), est une méthode pour mémoriser et récupérer des données à distance en utilisant des marqueurs appelés « radio-étiquettes » (« RFID tag » ou « RFID transponder » en anglais). (Wikipedia)
(**) Dans une machine, un actionneur est un organe qui transforme l’énergie qui lui est fournie en un phénomène physique utilisable. Le phénomène physique fournit un travail qui modifie le comportement ou l’état de la machine.
[3] L’Internet des Objets… Internet, mais en mieux, de Philippe Gautier et Laurent Gonzalez, préfacé par Gérald Santucci, postfacé par Daniel Kaplan (FING) et Michel Volle, Éditions AFNOR, 2011 (ISBN : 978-2-12-465316-4)
[4] Andy Greenberg (21 July 2015). « Hackers Remotely Kill a Jeep on the Highway—With Me in It ». Wired. Retrieved 21 July 2015.
Dans le cadre des « Entretiens autour de l’informatique », Serge Abiteboul et Claire Mathieu ont rencontré Stanislas de Maupeou, Directeur du secteur Conseil en sécurité chez Thalès. Stanislas de Maupeou parle à Binaire de failles de logiciels et de cybersécurité.
Stanislas de Maupeou
Failles, attaques et exploits… et certification
B : À quoi sont dûs les problèmes de sécurité informatique ?
SdM : Le code utilisé est globalement de mauvaise qualité et, de ce fait, il existe des failles qui ouvrent la porte à des attaques. Le plus souvent, ce sont des failles involontaires, qui existent parce que le code a été écrit de façon hâtive. Il peut y avoir aussi des failles intentionnelles, quelqu’un mettant volontairement un piège dans le code.
Il y a des sociétés, notamment aux USA, dont le travail est de trouver les failles dans le logiciel. C’est toute une économie souterraine : trouver une faille et la vendre. Quand on trouve une faille, on y associe un « exploit » (*), un code d’attaque qui va exploiter la faille. On peut vendre un exploit à un éditeur de logiciels (pour qu’il comble la faille) ou à des criminels. Si une telle vente est interdite par la loi en France, cela se fait dans le monde anglo-saxon. Pour ma part, si je trouve une faille dans un logiciel, je préviens l’éditeur en disant : « on vous donne trois mois pour le corriger, et si ce n’est pas fait, on prévient le public ».
C’est pour pallier au risque de faille qu’on met en place des processus de certification de code. Mais développer un code sans faille, ou avec moins de failles, cela peut avoir un coût faramineux. On ne peut pas repenser tout un système d’exploitation, et même dans des systèmes très stratégiques, il est impensable de réécrire tout le code. Ça coûterait trop cher.
B : Comment certifiez-vous le code ?
SdM : Il y a différentes méthodes. J’ai des laboratoires de certification. Nous n’écrivons pas le code. Nous l’évaluons selon un schéma de certification, suivant une échelle de sûreté qui va de 1 à 7. En France, la certification est gérée par l’ANSSI (Agence Nationale de la Sécurité des Systèmes d’Information). Le commanditaire dit : « Je voudrais que vous certifiez cette puce », et l’ANSSI répond « Adressez vous à l’un des laboratoires suivants qui ont été agréés». Sur l’échelle, le 1 signifie « J’ai une confiance minimum », et le 7 signifie « j’ai une confiance absolue ». Le niveau « évaluation assurance niveau 7 » ne peut être obtenu que par des méthodes formelles, de preuve de sécurité. Par exemple, nous avons certifié au niveau 7 un élément de code Java pour Gemalto. Il y a peu de spécialistes des méthodes formelles dans le monde, un seul dans mon équipe. Dans le monde bancaire, on se contente des niveaux 2 et 3. On fait des tests en laboratoire, on sollicite le code, on regarde la consommation électrique pour voir si c’est normal. On fait ça avec du laser, de l’optique, il y a tout un tas d’équipements qui permettent de s’assurer que le code « ne fuit pas ». Pour la certification de hardware, le contrôle se faire à un niveau très bas. On a le plan des puces, le composant, et on sait le découper en couches pour retrouver le silicium et faire des comparaisons.
B : Le code lui-même est-il à votre disposition?
SdM : Parfois oui, si on vise à développer la confiance dans les applications. C’est par exemple le cas pour l’estampille « visa » sur la carte bancaire qui donne confiance au commerçant. Dans d’autres contextes, on n’a pas accès au code. Par exemple, on nous demande de faire des tests d’intrusion. Il s’agit de passer les barrières de sécurité. Le but est de prendre le contrôle d’un système, d’une machine, par exemple avec une requête SQL bien ficelée.
B : Cela aide si le logiciel est libre ?
SdM : Le fait qu’un logiciel soit libre n’est pas un argument de sécurité. Par exemple, dans la librairie SSL de Debian, il y avait eu une modification de quelque chose de totalement anodin en apparence, mais du coup le générateur de nombres aléatoires pour la librairie SSL n’avait plus rien d’aléatoire ; on n’a découvert cette erreur que deux ans plus tard. Pendant deux ans tous les systèmes qui reposaient sur SSL avaient des clés faciles à prévoir. Ce n’est pas parce qu’un logiciel est libre qu’il est sûr ! Par contre, s’il est libre, qu’il est beaucoup utilisé, et qu’il a une faille, il y a de fortes chances que quelqu’un la trouve et que cela conduise à sa correction. Cela dit, pour la sécurité, un bon code, qu’il soit libre ou pas, c’est un code audité !
B : Est-ce que les méthodes formelles vont se développer ?
SdM : On a besoin aujourd’hui de méthodes formelles plus pour la fiabilité du composant que pour la sécurité. On fait de la gestion de risque, pas de la sécurité absolue qui n’existe pas. Vérifier les systèmes, c’est le Graal de la sécurité. On peut acheter un pare-feu au niveau 3, mais, transposer ça à tout un système, on n’y arrive pas. Notre palliatif, c’est une homologation de sécurité : on prend un système, on définit des objectifs de sécurité pour ce système (par exemple, que toute personne qui y accède doive être authentifiée), et on vérifie ces objectifs. On sait qu’il y aura toujours des trous, des risques résiduels, mais au moins, le système satisfait des règles conformes avec certains objectifs de sécurité. C’est une approche non déterministe, elle est floue, et on accepte qu’il y ait un risque résiduel.
Un problème c’est qu’on ne sait pas modéliser le risque. Je sais dire qu’un boulon casse avec probabilité 1%, cela a un sens, mais je ne sais pas dire quelle est la probabilité d’une attaque dans les 10 jours. Comme on ne peut pas modéliser la malveillance, on ne sait pas vraiment faire l’évaluation de la sécurité d’un système avec une approche rationnelle.
Les métiers de la cybersécurité
@Maev59
B : Quel est le profil des gens qui travaillent dans votre laboratoire ?
SdM : Ce sont des passionnés. Ils viennent plutôt d’écoles spécifiquement d’informatique que d’écoles d’ingénieur généralistes comme les Mines, ENSTA, ou Supélec, où les élèves sont moins passionnés par l’informatique.
B : Comment en êtes vous arrivé à vous intéresser à la cybersécurité ?
SdM : À l’origine j’étais militaire, et pas du tout en lien avec l’informatique. Étudiant, je n’avais pas accroché au Fortran ! Et puis, quand on fait une carrière militaire, après une quinzaine d’années, on suit une formation. Il était clair que le système militaire allait avoir de plus en plus d’informatique. J’ai suivi en 1996, un mastère de systèmes d’information à l’ENST avec stage chez Matra, et j’ai adoré. Même si à l’époque, on ne parlait absolument pas de sécurité, j’ai réorienté ma carrière vers le Service central de sécurité et services d’information, un petit service de 30 personnes, qui à l’origine ne servait guère qu’à garder le téléphone rouge du président. À l’époque, un industriel devait donner à l’état un double de sa clé de chiffrement. En 1999, il y a eu un discours de Lionel Jospin à Hourtin, dans lequel il a dit que ce n’était plus viable et qu’il fallait libéraliser la cryptographie, libérer ce marché. À l’époque il fallait déclarer toute clé de plus de 40 bits. Il a demandé qu’on élève le seuil à 128 bits, et c’est grâce à cela que les sites de la SNCF, la FNAC, etc., ont pu se développer. Ce service est devenu une agence nationale, passant de 30 à plus de 400 personnes, l’ANSSI.
Ensuite je suis passé chez Thalès où j’ai eu à manager des informaticiens. Ce n’est pas une population facile à manager. Et puis le domaine évolue très vite ; nous sommes en pleine période de créativité. On a encore plus besoin de management.
B : Qu’est ce qu’un informaticien devrait savoir pour être recruté dans votre domaine ?
SdM : J’aimerais qu’il connaisse les fondamentaux de la sécurité. J’aimerais qu’il y ait un cours « sécurité » qui fasse partie de la formation et qui ne soit pas optionnel. L’ennemi essaie de gagner des droits, des privilèges. Les fondamentaux de la sécurité, c’est, par exemple, la défense en profondeur, le principe du moindre privilège systématique sur des variables, la conception de codes segmentés, le principe du cloisonnement, les limites sur le temps d’exécution. Le moindre privilège est une notion essentielle. Le but est de tenir compte de la capacité du code à résister à une attaque. Déjà, avoir du code plus propre, de meilleure qualité au sens de la sécurité, avec plus de traçabilité, une meilleure documentation, cela aide aussi. Mais tout cela a un coût. Un code sécurisé, avec des spécifications, de l’évaluation, de la relecture de code, cela coûte 30 à 40% plus cher.
Etat et cybersécurité
@Maev59
B : Est-ce que l’ANSSI a un rôle important dans la sécurité informatique ?
SdM : L’ANSSI a un rôle extrêmement important, pour s’assurer que les produits qui seront utilisés par l’état ou par des opérateurs d’importance vitale (définis par décret, par exemple les télécommunications, les banques, EDF, la SNCF, Areva…) satisfont à des règles. L’ANSSI peut imposer des normes par la loi, garantissant un niveau minimum de qualité ou sécurité sur des éléments critiques, par le biais de décisions comme « Je m’autorise à aller chez vous faire un audit si je le décide. »
B : De quoi a-t-on peur ?
SdM : La première grande menace que l’État craint est liée à l’espionnage. En effet, l’immense majorité des codes et produits viennent de l’extérieur de la France. Un exemple de régulation : les routeurs Huawei sont interdits dans l’administration française. La deuxième menace, c’est le dysfonctionnement ou la destruction de système. L’État craint les attaques terroristes sur des systèmes industriels. Ces systèmes utilisent aujourd’hui des logiciels standard, et de ce fait, sont exposés à des attaques qui n’existaient pas auparavant. Une des grandes craintes de l’état, c’est la prise de contrôle d’un barrage, d’un avion, etc. C’est déjà arrivé, par exemple, il y a eu le cas du « ver informatique » Stuxnet en Iran, qui a été diffusé dans les centrales nucléaires iraniennes, qui est arrivé jusqu’aux centrifugeuses, qui y a provoqué des dysfonctionnements de la vitesse de la centrifugeuse, cependant que le contrôleur derrière son pupitre ne voyait rien. Avec Stuxnet, les US sont arrivés à casser plusieurs centrifugeuses, d’où des retards du programme nucléaire iranien. Un déni de service sur le système de déclaration de l’impôt fin mai, c’est très ennuyeux mais il n’y a pas de mort. Un déni de service sur le système de protection des trains, les conséquences peuvent être tout à fait dramatiques, d’un autre ordre de gravité.
Il y a aussi une troisième menace, sur la protection de la vie privée. Dans quelle mesure suis-je libre dans un monde qui sait tout de moi ? Dans les grands volumes de données, il y a des informations qui servent à influencer les gens et à leur faire prendre des décisions. C’est une préoccupation sociétale.
B : En quoi le fonctionnement de l’armée en temps de guerre a-t-il été modifié par l’informatique ?
SdM : L’armée aux États-Unis est beaucoup plus technophile que l’armée française, qui a mis un certain temps à entrer dans ce monde-là. Dans la fin des années 1990, les claviers sans fil étaient interdits, le wifi était interdit, le protocole Internet était interdit. Aujourd’hui, l’armée française en Afghanistan utilise énormément le wifi. Maintenant, il n’y a plus de système d’armes qui n’utilise pas d’informatique.
B : La sécurité est-elle une question franco-française ?
SdM : Il faut admettre que le monde de la sécurité est très connecté aux services de renseignement, ce qui rend les choses plus difficiles. Pour gérer les problèmes en avionique, on est dans un mode coopératif. Si un modèle pose un problème mécanique, on prévient tout le monde. En revanche, dans le monde de la sécurité informatique, si on trouve une faille, d’abord on commence par se protéger, puis on prévient l’état qui, peut-être, se servira de cette information. Ce sont deux logiques qui s’affrontent, entre la coopération et un monde plus régalien, contrôlé par l’État.
B : Avez vous un dernier mot à ajouter ?
SdM : Il faudrait développer en France une culture de la « sécurité ». Peu de systèmes échappent aujourd’hui à l’informatique. La sécurité devrait être quelque chose de complètement naturel, pas seulement pour les systèmes critiques. C’est comme si on disait, les bons freins, ce n’est que pour les voitures de sport. La sécurité doit être intégrée à tout.
(*) Exploit : prononcer exploït, anglicisme inspiré du verbe anglais “to exploit” qui signifie exploiter, lui-même inspiré du français du 15e siècle.
C’est une pièce de théâtre écrite et mise en scène par Orah de Mortcie, direction d’acteurs par Laetitia Grimaldi. Le Prochain Train parle très intelligemment des liens entre les personnes à l’ère du numérique. Où nous conduit cette nouvelle technologie ? Comment les réseaux sociaux, les blogs, les tweets, toutes ces applications vont-elles nous transformer ? Ce beau texte attaque bille en tête ces sujets complexes avec de l’humour, accompagné d’une jolie musique pas numérique du tout.
Vincent est un de ces « workaholics » que l’on croise de plus en plus, soumis à la dictature des mails. Karine est la spécialiste qu’il embauche pour gérer sa vie numérique. La pièce les plonge dans des rapports improbables. « J’ai grandi avec Internet et le numérique… j’ai du mal à utiliser Twitter, instatruc, et toutes ses applications qui arrivent chaque jour », avoue Elsa de Belilovsky qui joue le rôle de Karine. Pourtant, pendant une heure et demi nous avons cru qu’elle était la Reine du Numérique. Quel talent !
Le Prochain Train passe à la Manufacture des Abesses, à Paris, jusqu’à la fin de novembre. Il reste des places, courrez-y !
Il existe plusieurs musées consacrés à l’informatique ou au numérique à travers le monde. Pierre Paradinas, par ailleurs personnellement impliqué dans le projet #MINF de musée de l’informatique et du numérique en France, propose un petit aperçu de ce qui se fait dans certains pays, à la fois sur le plan muséal et au niveau du modèle d’affaires de ces lieux. Serge Abiteboul
En Allemagne à Padenborn, la fondation Nixdorf fait vivre un musée informatique important. Ce dernier expose sur 6 000 m2 l’informatique et contextualise son impact dans la vie des entreprises avec des reconstitutions du « bureau » à différentes époques. Un accent important est donné aux ordinateurs de la marque allemande Zuse. Ce musée est très impliqué dans la vie locale du land et l’université de Padenborn. Son modèle d’affaires repose sur un fort soutien de la fondation Nixdorf.
On remarque en particulier durant cette visite un métier à tisser de Jacquard qui en fonctionne ce qui permet de voir mais aussi d’entendre fonctionner cet appareil.
Métier à tisser Jacquard, Photo P. Paradinas
Une ligne du temps des interfaces du poste de travail est proposée. Le visiteur fait glisser un écran qui affiche l’interface offerte par les systèmes d’exploitation à l’utilisateur depuis les premiers ordinateurs personnels avec l’ancêtre MSDOS à ceux d’aujourd’hui, on voit ainsi les évolutions de l’expérience utilisateur en déplaçant un écran sur les différentes années.
Interface à regarder sur une ligne de temps, Photo P. Paradinas
En Allemagne, il y a aussi des présentations de l’informatique au Musée des Sciences de Munich et un projet pour un musée de l’internet doit ouvrir ces portes en 2016 à Berlin.
En Angleterre, on trouve aussi plusieurs initiatives. La plus récente « Information Age » est la rénovation de la section communication du Science Museum de Londres dont une grande partie du financement a été apporté par l’opérateur téléphonique historique (BT), un concepteur de microprocesseur très utilisé dans les plateformes mobiles (ARM) et un moteur de recherche très utilisé dans le monde (Google). La Reine s’était déplacée pour l’inauguration de ce nouvel espace en 2014.
Par ailleurs, d’autres initiatives intéressantes sont présentes sur le site de Bletchley Park rendu célèbre depuis les commémorations liées à la vie d’Alan Turing ainsi que le film Imitation Game. Dans ce National Museum of Computing , initialisé par Tony Sale, la reconstruction du Colossus a été entreprise, c’est le premier calculateur binaire électronique construit par Thomas Flowers pour « casser » le code des machines à chiffrer Lorenz utilisées pendant la seconde guerre mondiale.
Photo Colossus, Photo P. Paradinas
Porté à bout de bras par les bénévoles en terme de fonctionnement et de financement, le National Museum of Computing est confronté à des difficultés similaires à celles des initiatives françaises décrites dans un précédent article. Le musée britannique est très ouvert et offre de nombreuses activités aux acteurs de l’écosystème local. Il y a aussi des ateliers avec des plateformes rasberry PI qui permettent d’accueillir le public dans un esprit fablab.
Aux États-Unis, une des plus grandes et plus récentes initiatives est le Computer History Museum à Mountain View au milieu de la Silicon Valley à 2 pas de Google et Microsoft. Les chiffres sont vertigineux, dans les anciens locaux de la société Silicon Graphics, 12 000 m2, 75 000 visiteurs en 2012 et un budget de près de 6 M$. Une très grande surface d’exposition articulée autour d’un parcours au travers d’une vingtaine de « salles » sur les différentes périodes et domaines. Le CHM accueille des événements connexes dans ses locaux annexes.
Le parcours dans le HCM… Photo P. Paradinas
L’exposition ouverte en 2011, porte le nom de «Révolution». Elle présente l’informatique à travers une approche chronologique. Elle est centrée sur l’histoire de l’Informatique aux États-Unis. Cependant, les européens sont cités et en particulier la France avec le Minitel, et le réseau Cyclade…
Louis Pouzin et le projet Cyclade au HCM, Photo P. Paradinas
Le modèle d’affaire est simple, et typique des musées américains. Les revenus proviennent des revenus des placements du capital de la fondation support du musée, de versements annuels et récurrents d’entreprises partenaires, et enfin de ressources propres.
Il existe bien d’autres initiatives dans plusieurs autres pays, comme le musée Bolo appuyée sur une école d’ingénieurs suisse réputée à Lausanne, l’EPFL. Enfin, la Belgique vient de lancer une fondation en phase avec des initiatives locales dont le but est de construire un musée. Cette liste d’initiatives n’est pas exhaustive. L’engouement pour le numérique donne naissance à de nombreuses actions.
Et la France dans tout ça ?
Pour poser la question de ce que nous pourrions et devrions faire en France pour réaliser un « Musée de l’informatique et du numérique« , il est important de connaitre les possibles réalisés par d’autres pays. Nous reviendrons sur ce sujet dans un prochain article.
Pierre Paradinas, Prof. titulaire de la chaire Systèmes Embarqués au Cnam
Une partie des visites dans ces musées ont été réalisées dans le cadre d’une mission supportée par le Cnam et le Musée des arts et métiers dans le cadre de la réflexion menée pour la construction d’un musée de l’informatique et du numérique en France et présentée dans le cadre d’un colloque sur ce sujet.
Les équipes de recherche en informatique et leurs enseignants-chercheurs participent régulièrement à des séminaires. Ils sont sur le cœur du métier informatique et constituent un élément important de la démarche scientifique des chercheurs. Le but ici n’est pas de parler de ces séminaires mais de ceux organisés et animés aussi par des chercheurs, pas obligatoirement en informatique d’ailleurs, mais dans d’autres disciplines qui s’intéressent à l’informatique. Pierre Paradinas
Histoire de l’informatique
Le séminaire d’histoire de l’informatique a pour objectif de présenter et conserver la mémoire des travaux pionniers de l’informatique. Les intervenants sont soit les acteurs des débuts de cette discipline, soit des chercheurs s’intéressant aux développements de l’informatique dans l’industrie, l’économie, la recherche ou la société civile. Il est co-organisé par Francois Anceau, ancien professeur du Cnam, Pierre-Eric Mounier-Kuhn, historien, CNRS, Paris-Sorbonne et Isabelle Astic, responsable de collections au Musée des arts et métiers. Il a été initié dans le cadre du projet « Vers un musée de l’informatique et du numérique », vous pouvez accéder en ligne aux présentations sur le site du #MINF.
Le code objet de la pensée informatique
Histoire et philosophie de l’informatique
Le séminaire Histoire et philosophie de l’informatique, interroge sur « qu’est-ce que l’informatique ? » qui n’est pas seulement une question de philosophe ou d’historien cherchant à comprendre les concepts et les tensions que recouvre cette catégorie. La question se pose aussi, ce qui est plus rare, dans le champ scientifique, aux acteurs de ce domaine d’activité dont l’identité semble encore en devenir, cinquante-deux ans après l’invention du mot « informatique ». Ce séminaire réunit des informaticiens, des historiens, des spécialistes des sciences sociales et des philosophes, il est organisé par Maël Pégny (IHPST-CNRS), Baptiste Mélès et Pierre-Eric Mounier-Kuhn.
Interactions entre logique, langage et informatique. Histoire et Philosophie
Le but du séminaire Interactions entre logique, langage et informatique. Histoire et Philosophie est de penser les relations entre la logique, l’informatique et la linguistique. Pourquoi a-t-on besoin de la logique pour l’avancement de l’informatique et quel est le rôle de la linguistique ? Ce séminaire est organisé par Liesbeth De Mol (CNRS/STL, Université de Lille 3), Alberto Naibo (IHPST, Université Paris 1 Panthéon-Sorbonne, ENS), Shahid Rahman (STL, Université de Lille 3) et Mark van Atten (CNRS/SND, Université Paris-Sorbonne).
Cette liste n’est pas exhaustive, vous participez ou vous animez un séminaire qui est en lien avec l’informatique, n’hésitez pas à nous faire part des informations complémentaires.
Pierre Paradinas, Professeur titulaire de la chaire Systèmes Embarqués au Cnam
En préparant cet article, je n’ai pu m’empêcher de repenser à nos professeurs d’informatique de l’Université de Lille 1 – peu nombreux à l’époque – qui en 1983 nous avaient obligé à nous rendre dans une université voisine pour aller écouter un séminaire où intervenaient Jacques Arsac et Marcel-Paul Schützenberger. La présentation de ce dernier portait sur La métaphore informatique (disponible dans Informatique et connaissance, pages 45–63. UER de philosophie, Université Charles de Gaulle Lille III, 1988. Conférence en novembre 1983). Si vous vous demandez qu’est-ce qui peut inciter à devenir informaticien, la réponse est : en écoutant Arsac et Schütz !
Depuis 24 ans maintenant, durant toute une semaine, la science est à la fête partout en France. Avec plus d’un million de visiteurs, 7000 chercheurs impliqués et un foisonnement d’animations, d’expositions, de débats et d’initiatives originales, partout en France et pour tous les publics, la Fête de la science est une occasion de découvrir le monde des sciences et de rencontrer des scientifiques. Les sciences du numérique ne sont pas en reste, avec les multiples initiatives proposées par les établissements de recherche comme par exemple celles du CNRS et ou celles d’Inria que Marie-Agnès Enard a choisi de vous inviter à découvrir.
Dans le cadre du Circuit scientifique bordelais, les structures d’enseignement supérieur et de recherche et leurs laboratoires ouvrent leurs portes du 5 au 9 octobre, en proposant des ateliers ludiques aux élèves du primaire à l’université. C’est l’occasion de venir découvrir le monde passionnant de la recherche et les activités des scientifiques dans de nombreuses disciplines. Au centre Inria Bordeaux – Sud-Ouest, chercheurs et ingénieurs accueilleront les élèves de tous les niveaux et de toute l’académie pour leur transmettre leur passion pour les sciences du numérique. Pour vous inscrire, suivez le lien.
Inria Grenoble ouvre ses portes aux lycéens les 8 et 9 octobre pour une immersion dans le monde des sciences du numérique. Au programme : parcours de visite augmentée du centre de recherche, découverte de plateformes d’expérimentations, habitat intelligent, capture et modélisation de formes en mouvement, initiation aux notions de l’informatique par des activités ludiques sans ordinateurs, cryptologie et protection de messages, dialogue avec les scientifiques sur des problématiques de société.
Les scientifiques du centre de Lille interviendront dans les établissements scolaires (collèges et lycées) de la Métropole lilloise, du lundi 05 au vendredi 16 octobre 2015. Au programme : réalité virtuelle, programmation objet, imagerie de synthèse, intelligence artificielle… un partage de connaissances sur des sujets qui les passionnent et enrichissent d’ores et déjà notre quotidien.Une manière pour nos chercheurs de communiquer sur leur métier, leurs thématiques et d’échanger avec des élèves afin d’enrichir leur perception de la recherche. Un partage de connaissances sur des sujets passionnants qui enrichissent notre quotidien.
Scientifiques et médiateurs du centre vous donnent rendez-vous sur le site d’Artem les 9 et 10 octobre prochain, pour une approche plurielle de la science, où informatique rimera avec ludique ! Au programme : robots humanoïdes, informatique sans ordinateur, jeu de société, reconnaissance d’images, envolées de drones, numérique et santé,… Manifestation co-organisée par Mines Nancy, le LORIA, l’Institut Jean Lamour et GeoRessources, avec le soutien d’Inria Nancy – Grand Est.
Le centre Paris – Rocquencourt s’associe à la fête de la science Sorbonne Universités qui souhaite mettre en avant cette année le travail des scientifiques qui étudient le climat sous tous ses aspects. Du 9 au 11 octobre, l’équipe Ange du centre vous dira tout sur la dynamique des vagues, la houle, les énergies alternatives et vous propose une conférence sur le thème : Nouvelles vagues, de la simulation numérique à la conception.
Le centre Inria Rennes – Bretagne Atlantique sera présent au Village des sciences de Rennes du vendredi 9 au dimanche 11 octobre 2015, au Diapason sur le Campus Universitaire de Beaulieu. A cette occasion, nos scientifiques vous proposeront de créer un programme sur ordinateur puis de le tester sur un robot. Plusieurs épreuves ou défis seront proposés selon trois niveaux de difficulté permettant une acquisition progressive du langage de programmation.
Le centre de recherche Inria Saclay – Ile-de-France ouvre ses portes vendredi 9 et samedi 10 octobre et invite petits et grands à la découverte des sciences du numérique au travers d’animations ludiques reflétant l’interaction entre l’informatique, les mathématiques et les autres sciences. Au programme, plusieurs ateliers animés par les chercheurs du centre : découverte des secrets de la cryptographie, bio-informatique ludique, initiation aux bases de données, introduction à la programmation et aux robots, exploration du cerveau, et plongée au cœur d’un réseau.
Les scientifiques et médiateurs du centre invitent tous les publics, petits et grands à venir découvrir les sciences du numérique au travers d’approches concrètes et ludiques. Une programmation riche et variée vous attend à Antibes Juan-Les-Pins, Montpellier et La Seyne sur Mer les 10 et 11 octobre ainsi qu’ à Vinon-sur-Verdon le 17 octobre. Au programme : Maths de la planète Terre, traitement d’images, graphes et algorithmes, manipulations, coding goûters, initiation à la robotique, jeux de société, activités débranchées, tours de magie… Du 5 au 9 octobre, les scientifiques d’Inria interviendront également dans des lycées, un moment privilégié pour dialoguer avec les jeunes et débattre sur des thématiques ciblées, mais aussi pour parler de leur métier de scientifique tel qu’ils le vivent. Enfin nos chercheurs interviendront également dans les médiathèques de la communauté d’agglomération de Sophia Antipolis.
Nous vous souhaitons une belle semaine festive et scientifique ! Vous pouvez d’ailleurs partager vos découvertes sur Twitter en suivant le compte @FeteScience et son mot-dièse #FDS2015 ou sur Facebook.