
Interprétabilité vs explicabilité : comprendre vs expliquer son réseau de neurone (3/3)
Troisième et dernier article de notre série ( (vous pouvez trouver le premier article ici et le deuxième article là) qui questionne sur les concepts d’interprétabilité et d’explicabilité des réseaux de neurones, nous finissons ici par une ouverture sur les relations particulières entre l’interprétabilité, les biais, l’éthique et la transparence de ces réseaux.
Ces articles sont publiés conjointement avec le blog scilog, qui nous offre ce texte en partage.
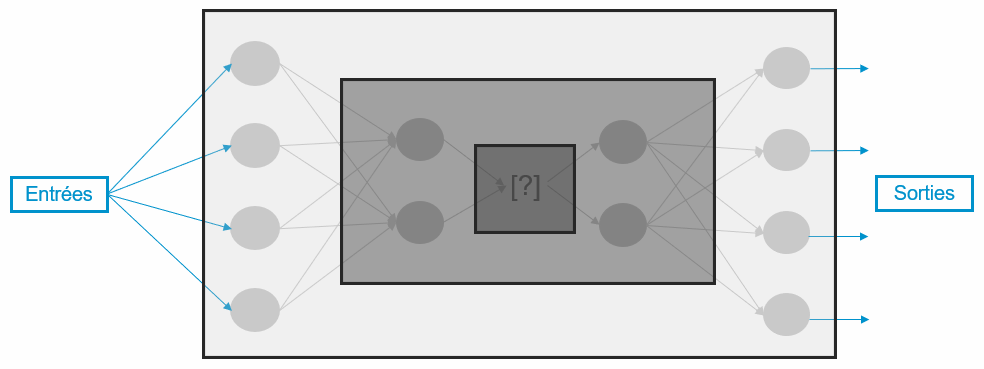
Le but d’une approche d’interprétabilité est de permettre d’accéder à la mémoire implicite d’un réseau de neurones afin d’en extraire les règles et représentations encodées (i.e. apprises ou extraites à partir des données) lors de son apprentissage ; l’extraction pouvant intervenir pendant ou après celui-ci. Autrement dit, on peut explorer et amener dans le domaine de l’explicite le« raisonnement » implicite qu’il s’est lui-même construit grâce aux nombreux exemples vus et à la pratique répétée (de façon assez similaire à celle d’un humain qui acquiert des connaissances par l’expérience et le vécu).
A l’image d’un humain qui possède une représentation du monde dans lequel il vit, construite en fonction de son vécu et de son expérience, un réseau de neurones, au fur et à mesure qu’il est alimenté de données, se construit sa propre représentation également. Celle-ci étant certes limitée par les données apprises, elle contient tout de même son savoir et par extension les raisons sur lesquelles se basent son comportement et ses prédictions.
Mais dans ce cas, que se passe-t-il lorsqu’un individu n’apprend qu’une seule vision du monde (exemple volontairement exagéré : le ciel est de couleur verte le jour et grise la nuit) ?
Alors peu importe le nombre d’images de levers et couchers de soleil, de nuits étoilées ou de ciels pluvieux, il considérera toujours que toutes ces images sont erronées et seul ce qu’il a appris est juste. En tant qu’humain, nous avons néanmoins une capacité de questionnement et de remise en cause qui peut, avec le temps, nous amener, à travers notre vécu, à relativiser notre apprentissage et à réaliser qu’il existe d’autres nuances de couleurs toutes aussi belles à observer dans le ciel.
Malheureusement les réseaux de neurones n’ont pas cette capacité car ils réalisent souvent une phase d’apprentissage unique (surtout dans le cas d’apprentissage supervisé), de plusieurs exemples certes, mais dans les cas les plus répandus en une seule fois. Autrement dit, une fois une règle apprise, elle devient immuable ! Dans le cas de la classification des couleurs du ciel, cela n’a pas grand impact mais imaginons que cet algorithme soit utilisé pour classer la valeur des individus en fonction de leurs résultats quels qu’ils soient. L’algorithme pourrait alors considérer selon le type de données qu’il a reçu et donc la ou les règles qu’il a implicitement encodée, que seuls les profils de femmes correspondent à un poste de secrétaire et au contraire que seuls les CV d’hommes doivent être retenus pour un poste technique dans l’automobile. Ces exemples stéréotypés, bien qu’assez simples et basiques, reflètent une bien triste réalité : les biais présents dans les IA peuvent s’avérer dangereux et discriminatoires.
En effet, les algorithmes d’IA et leurs prises de décisions sont influencés par les données qu’ils apprennent. Cela soulève donc une problématique autour des biais présents dans ces données mais aussi ceux issus directement des développeurs implémentant ces algorithmes. De mauvais jeux de données peuvent amener à des conséquences fâcheuses ainsi qu’à une implémentation biaisée. Si un algorithme d’IA apprend à partir des données, des règles erronées ou biaisées alors ses décisions le seront tout autant et reproduiront ce que l’on appelle des biais de sélection ou encore de jugement. Un exemple tristement célèbre est la description fournie par Google en 2015 sur une photo d’un couple de personnes afro-américaines classifiées comme étant des gorilles car le corpus de données n’était pas assez représentatif de la diversité de la population…
Nous le constatons, l’impact de ces biais peut s’avérer très grave surtout dans des domaines critiques tels que la santé, la défense ou encore la finance. De nos jours, de nombreux travaux existent sur ce sujet afin d’étudier ces biais. Néanmoins il est important de souligner qu’en prendre connaissance ne signifie pas obligatoirement que nous savons comment les éliminer [Crawford, 2019] ! De plus, la suppression de ces biais dans un algorithme peut s’avérer très coûteuse en termes de ressources car il faudrait relancer les apprentissages des réseaux de neurones après correction. Or selon leur profondeur, leur complexité et le volume de données à traiter, ce coût peut s’avérer très, voire trop, important. Ces biais sont ainsi parfois conservés par défaut car ils seraient trop coûteux et incertains à corriger. Par exemple, GPT-3, le modèle de langage développé par la société OpenAI en 2020 [Brown, 2020], nécessiterait une mémoire de plus de 350 Go, avec un coût lié à l’entraînement du modèle qui dépasserait les 12 millions de dollars.
Que retenir ?
Dans le cadre de la démystification des réseaux de neurones, algorithmes d’IA dit aussi “boîtes noires”, l’interprétabilité et l’explicabilité sont deux domaines de recherche distincts mais très liés. Si l’interprétabilité consiste à étudier et expliciter la logique interne des réseaux de neurones, autrement dit leur fonctionnement, l’explicabilité se focalise elle sur “comment” donner du sens à cette logique interne de manière la plus adaptée possible. Ainsi l’interprétabilité est souvent réalisée par des experts en Machine Learning pour d’autres experts alors que l’explicabilité peut être à destination de néophytes et d’experts.
L’intérêt que nous portons donc, tout comme de nombreux chercheurs, à ces deux domaines prend tout son sens dans les questions sociétales et éthiques abordées précédemment : l’impact des biais, la discrimination, le respect du RGPD, etc. En effet, réussir à mieux comprendre le fonctionnement de ces algorithmes nous permet d’aider à la démystification de l’IA et à rendre ces “boîtes noires” plus transparentes, intelligibles et compréhensibles. D’une manière plus générale, cela permet aussi d’améliorer la confiance de chacune et chacun d’entre nous en ces outils qui tendent à devenir omniprésents dans notre vie quotidienne ou, a contrario, de refuser ceux qui ne seraient pas suffisamment transparents.
Si nous avions accès au “comment” et au “pourquoi” les décisions des outils IA sont émises, peut-être pourrions-nous alors intervenir sur leur fonctionnement ainsi que sur les données leur servant de base d’apprentissage qui sont souvent nos propres données. Nous pourrions alors nous assurer que nous allons bien vers une société plus inclusive où chacune et chacun d’entre nous est respecté dans toute sa diversité…
Petit mot des autrices :
Cet article à vocation pédagogique présente une approche pour faire de l’interprétabilité. Il en existe d’autres et pour les plus curieux, la bibliographie de chaque billet est là pour vous ! Les billets n’ont pas non plus pour vocation de poser d’équivalence entre un humain et un réseau de neurones car un humain est beaucoup plus complexe ! Les exemples fournis sont justement présents à titre d’illustration pour permettre une meilleure assimilation des concepts. Nous serions toutefois heureuses d’en discuter plus amplement avec vous !
Marine LHUILLIER et Ikram CHRAIBI KAADOUD.
- Ingénieure R&D en informatique diplômée de l’EPSI Bordeaux, Marine s’est spécialisée lors de sa dernière mission dans la recherche à la jonction de l’IA et des Sciences cognitives, notamment dans le domaine de l’interprétabilité.
- Ikram quant à elle, chercheuse IA & Sciences cognitives, ainsi qu’ancienne Epsienne, se passionne pour la modélisation de la cognition ou autrement dit comment faire de l’IA inspirée de l’humain. Toutes deux ont collaboré dans le cadre d’un projet de recherche en Machine Learning sur l’interprétabilité des réseaux de neurones chez l’entreprise onepoint.
Références :
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv, arXiv:2005.14165.
Crawford Kate (2019) « Les biais sont devenus le matériel brut de l’IA ». URL : https://www.lemonde.fr/blog/internetactu/2019/10/03/kate-crawford-les-biais-sont-devenus-le-materiel-brut-de-lia/
 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. 
































{kind=link}
{kind=link}