binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible … comment les mots prennent du sens dans notre cerveau et ainsi mieux comprendre la différence entre l’intelligence naturelle et algorithmique. Marie-Agnès Enard, Pascal Guitton etThierry Viéville.
– Alors y’a des gens tu parles avec eux, tu crois qu’ils te comprennent, et tout d’un coup, comme un voile qui se déchire, ils te lâchent une énormité … et tu réalises qu’en fait ils n’ont rien compris depuis le début.
– Ok, si je te suis bien, ta définition de la connerie, ce serait une personne avec qui tu discutes, mais finalement les mots ne font pas vraiment sens pour elle ?
– Oui, c’est ça : quelqu’un qui a appris à manipuler les symboles du langage, qui peut donner l’illusion un moment, mais en fait ces symboles ne font pas vraiment sens pour lui, leur signification n’est pas enracinée dans son intelligence humaine.
– Ah oui, c’est pas con. Et tu sais quoi ? Tu viens de soulever le problème du fondement des symboles, c’est à dire comprendre comment un signe (un mot, un geste, un son, …) acquiert son sens dans notre cerveau humain.
– Et on a compris ça ?
– En partie oui. On sait par exemple que quand les mots font référence à une personne ou une chose, par exemple en utilisant une description physique “l’objet en bois muni d’un tuyau avec un embout noir et un fourneau marron” ou une description par son usage “le truc où on met du tabac qu’on allume pour aspirer la fumée”, ces mots prennent du sens. C’est une étape nécessaire de trouver un tel lien pour décider quelle chose on désigne. D’ailleurs dans le cerveau les zones qui correspondent à la perception de cet objet s’activent quand le mot qui le désigne prend du sens. Et selon certaines théories, le cerveau comprendrait ces descriptions car il ferait une « simulation » physique de la description, et c’est pour ça qu’elle serait « grounded » même si c’est pas une expérience vécue.
– Ah oui .. ça s’allume dans ma tête ! Tu veux dire qu’un objet prend du sens par rapport à son aspect ou l’usage qu’on peut en faire en lien avec les zones cérébrales concernées ?
– C’est çà, on est capable de choisir des référents des symboles qu’on manipule et pour que ça fonctionne, cela doit se faire consciemment, en lien avec les potentialités (ce qu’on peut faire avec) liées à ce symbole.
– En fait, notre intelligence humaine est forcément incarnée en lien avec notre corps, alors ? – Absolument. Et même quand on fait des maths, ou que l’on développe des pensées abstraites, en fait on “détourne” des mécanismes incarnés pour ses usages plus édulcorés.
– Mais alors, les personnes qui pensent que grâce au numérique on va pouvoir transférer toute notre mémoire et ses mécanismes, y compris notre conscience, dans un ordinateur pour vivre éternellement, c’est du délire ?
– oui, c’est très con. En fait c’est un fantasme assez courant et ancien : avant on pensait pouvoir prendre possession d’un corps plus jeune et y transférer notre esprit pour une nouvelle vie, mais notre esprit fait corps avec notre corps en quelque sorte.
– Alors si je te suis bien, l’idée qu’on attribue à René Descartes d’une dualité corps-esprit c’est pas trop en phase avec la neurologie cognitive moderne alors ?
– Eh, tu as bien suivi 🙂
– Mais alors, dans un ordinateur, les symboles qui sont manipulés ne font pas de sens, puisqu’il y a pas de corps avec lesquels ils peuvent s’incarner ?
– C’est cela, bien entendu on peut “simuler” c’est à dire reproduire par le calcul, le comportement d’une intelligence naturelle traitant un type de question bien particulier et, qui va “faire comme si”, au point de tromper pendant un temps limité, mais qui peut-être long. Ah oui comme un con qui tente de se comporter de manière pertinente, mais à qui il manque des “bases” et qui va forcément finir par dévoiler que les choses ne font pas de sens pour lui.
– Exactement, Et tu vois en quelques échanges on vient tout simplement de donner quelques éléments de compréhension de cette notion complexe de fondement des symboles (« grounding » en anglais) qui remet en cause l’idée d’intelligence artificielle désincarnée mais “consciente”.
– Ah ben ouais, j’me sens moins con 🙂
P.S.: Merci à Xavier Hinaut pour sa relecture et un apport.
Une matinée d’étude sur les Intelligences Artificielles (IA)s et la vie privée a été organisée par les projets Digitrust et OLKi de Lorraine Université d’Excellence le 10 juin. Cette matinée, animée par Cyrille Imbert, philosophe des sciences au CNRS, était centrée sur la restitution de la charte « Pour un développement des IAs respectueux de la vie privée » rédigée par Maël Pégny, chercheur à l’Université de Tübingen, lors de son post-doctorat à OLKi. La charte introduit un certain nombre de principes pour des IA respectueuses de la vie privée mais dont la mise en œuvre n’est pas toujours évidente et qui ont été discutés au cours des différentes interventions. Compte-rendu. Ikram Chraibi Kaadoud et Laurence Chevillot.
Maël Pegny, Chercheur post-doctoral en Ethique en IA à l’Université de Tübingen, auteur de charte « Les 10 principes de l’éthique en IA »
Pour Maël Pégny il s’agit de proposer aux développeurs et développeuses un cadre éthique et opérationnel permettant le respect de la vie privée par les IAs, en intégrant l’éthique dès les premières phases du développement. L’objectif de la charte est d’inciter les programmeurs et programmeuses à se positionner sur ces problématiques. Elle est dédiée essentiellement aux défis posés à l’éthique dès la conception par la reconstitution des données d’entraînement à partir de modèles d’IA et le pouvoir prédictif trop fin.
Contexte
Dans un modèle d’apprentissage machine, la distinction entre programme et données n’est pas claire car les paramètres du programme sont déterminés par entraînement sur une base de données particulières. Certaines attaques permettent une reconstitution des données d’entraînement à partir des informations encodées dans les paramètres du modèle : on parle alors de “rétro-ingénierie” des données. Si le modèle a été entraîné sur des données personnelles, on peut ainsi retrouver celles-ci, même si elles ont été détruites après l’entraînement du modèle. Donc si un modèle entraîné lambda est sous licence libre, ses paramètres sont en libre accès. Il se pose alors la question de la protection des données personnelles incluses dans le modèle. Ces attaques sur les modèles d’IA représentent donc un point de tension entre l’ouverture du logiciel et le respect de la protection des données personnelles. Cette tension devrait devenir un enjeu de positionnement pour les partisans du logiciel libre, des communs numériques et de la reproductibilité de la recherche. Ce problème éthique se pose dans la configuration technologique présente car, s’il existe des techniques de protection contre ces attaques de rétro-ingénierie, il n’existe pas de barrière de sécurité mathématiquement prouvée offrant une garantie absolue contre elles.
Le développement d’un pouvoir prédictif trop fin de certains modèles d’IA peut également poser des problèmes éthiques complexes. Par exemple, un logiciel de complétion textuelle fondé sur l’apprentissage machine peut ainsi permettre de trouver le numéro de carte de crédit de l’utilisateur en tapant la phrase « Mon numéro de carte de crédit est… ». Là encore, cette attaque demeure possible même si on détruit les données brutes de l’utilisateur, parce que les informations personnelles ont été encodées dans le modèle durant son interaction avec l’utilisateur. Il s’agit bien d’un pouvoir prédictif trop fin, et d’ailleurs imprévu, car le logiciel de complétion est fait pour apprendre les pratiques d’écriture de l’utilisateur, et non ses données personnelles. Attention toutefois à ne pas confondre le problème de pouvoir prédictif trop fin avec la suroptimisation ou le phénomène de sur-apprentissage (l’apprentissage des données par cœur plutôt que de caractéristiques généralisables), car il peut survenir très tôt dans l’apprentissage. Pour protéger les données personnelles, il convient donc aussi de veiller au respect de sa spécification par le modèle d’apprentissage machine.
La Charte: les 10 principes de l’éthique en IA
Le triangle éthique avec les trois pôles d’une carte éthique @wikicommon
HAL est une plateforme en ligne du CNRS, destinée au dépôt et à la diffusion de travaux de recherches (articles scientifiques, rapports techniques, manuscrit de thèse etc.) de chercheurs, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés. L’accès aux données est libre et gratuit, mais pas nécessairement leur utilisation ou réutilisation. @Wikipedia
Principe 1 – Dans le cadre de recherches scientifiques, déclarer les finalités et l’extension nécessaire de la collecte, puis apporter une justification scientifique à tout écart à cette déclaration initiale, en discutant ces possibles impacts sur la vie privée .
Principe 2 – Tester et questionner les performances finales du modèle par rapport à la finalité déclarée, et veiller à éviter l’apparition d’un pouvoir prédictif trop fin .
Principe 3 – Prendre en compte le respect de la vie privée dans l’arbitrage entre suroptimisation et perte de performances.
Principe 4 – Entraîner son modèle sans faire usage de données personnelles. Si cela est impossible, voir les principes plus faibles 5 et 6.
Principe 5 – Entraîner son modèle sans faire usage de données personnelles dont la diffusion pourrait porter atteinte aux droits des personnes.
Principe 6 – Entraîner son modèle sans faire usage de données ayant fait l’objet d’un geste explicite de publication.
Principe 7 – Si le recours à des données personnelles est inévitable, déclarer les raisons justifiant ce recours, ainsi que les mesures prises contre la rétro-ingénierie des données et leur complétude par rapport à l’état de l’art.
Principe 8 – Diffuser en licence libre tous les outils de lutte contre la rétro-ingénierie.
Principe 9 – Si le principe 8 n’entraîne pas de risque de sécurité intolérable, mettre le modèle à disposition de tous afin que chacun puisse vérifier les propriétés de sécurité, et justifier explicitement la décision prise.
Principe 10 – La restriction de l’accès à un modèle entraîné sur des données personnelles ne peut être justifiée que par des enjeux d’une gravité tels qu’ils dépassent les considérations précédentes. Cette exception doit être soigneusement justifiée, l’emploi du modèle devant être réduit dans sa temporalité et ses modalités par les raisons justifiant l’exception. L’exception doit être justifiée en des termes prenant en compte la spécificité scientifique des modèles d’apprentissage machine, comme la capacité à apprendre en temps réel de grandes masses de données, l’opacité du fonctionnement et son évolution, et leurs performances comparées aux autres modèles.
Pour être bien compris, ces principes appellent quelques commentaires:
Le premier principe est conçu pour encadrer la liberté donnée par le droit existant à la recherche scientifique de modifier la finalité du traitement et l’extension de la collecte des données, contrairement aux autres activités de développement où la collecte est restreinte à ce qui est nécessaire à une finalité pré-déclarée. Il s’agit d’instaurer une traçabilité des décisions d’extension de la collecte, et une prise en compte systématique de leurs risques en termes de respect de la vie privée.
L’invitation à ne pas utiliser de données personnelles ne vise naturellement pas à interdire tout entraînement de modèle sur des données personnelles, qui est incontournable pour nombre d’applications de grand intérêt comme la recherche médicale. Il vise seulement à empêcher de considérer la collecte de données personnelles comme une évidence par défaut, et s’interroger sur la possibilité de stratégies de contournement employant des données moins problématiques.
Les principes 5 et 6 ne peuvent être compris que si l’on voit que l’extension du concept de donnée personnelle est extrêmement large, un fait radicalement sous-estimé par le grand public. Elle comprend toute donnée concernant une personne physique (vivante). Non seulement cela n’est en aucun cas restreint à des données qu’on qualifierait intuitivement de « privées » ou « sensibles, » mais il comprend des données publiques par nature : par exemple, la phrase « Madame Diomandé est maire de sa commune. » comprend une donnée personnelle sur Madame Diomandé que personne ne songerait à qualifier de privée. Il convient donc de s’interroger sur la possibilité de restreindre la collecte des données personnelles à un sous-ensemble non-problématique. L’exclusion des données considérées « sensibles », considérée dans le principe 5, fait l’objet de travaux techniques aux performances intéressantes, mais pose de redoutables problèmes de définition et d’opérationnalisation. La restriction aux données faisant l’objet d’un geste de publication explicite, explorée dans le principe 6, peut sembler une solution simple et pratique. Mais il convient de rappeler qu’une personne peut porter atteinte à la vie privée d’une autre dans ses publications, et que le geste de publication n’est pas un solde de tout compte pour le droit des données : l’exercice des droits à rectifier des informations erronées, à retirer une publication, à l’effacement (« droit à l’oubli ») et leurs difficiles opérationnalisations face aux modèles d’apprentissage machine posent de nombreux défis.
La mise sous licence libre des outils de lutte contre la rétro-ingénierie (principe 7) et l’ouverture des modèles à la vérification (principe 8) constitue une forme d’approche libriste des modèles d’apprentissage machine : ces modèles doivent être ouverts à tous non seulement pour respecter les principes fondamentaux du logiciel libre, mais aussi pour vérifier leur respect de la vie privée. Cette ouverture pose cependant le problème redoutable du « vérificateur voleur » : en ouvrant ainsi les modèles à la vérification en l’absence actuelle de barrières de sécurité dures, on crée la possibilité d’atteintes à la vie privée. Nous ouvrons donc la possibilité de limiter l’application stricte des principes libristes dans le dernier principe : s’il est absolument indispensable d’entraîner un modèle sur des données personnelles sensibles, et que son ouverture à la vérification publique présentait un grave danger de « vérificateur voleur », il est possible de justifier une exception à la perspective libriste stricte. Il est légitime de craindre que l’introduction d’une exception ouvre la porte à la violation massive de la perspective libriste dans la pratique. Trancher la question d’une approche libriste stricte aurait cependant supposer de s’engager dans des débats philosophiques bien au-delà de la portée de cette charte. Doit-on par exemple autoriser l’entraînement d’un modèle de Traitement Automatique de la Langue sur des quantités énormes de données tirées des réseaux sociaux si cela permet de mieux suivre la progression d’une pandémie ? La charte a donc choisi de rester modeste, et d’ouvrir le débat en demandant avant tout à chacun de prendre position explicitement et honnêtement, en prenant en compte les risques politiques autant que techniques de chaque position. La charte a avant tout été conçue pour montrer que la conciliation du développement de l’apprentissage machine avec le respect de la vie privée pose un problème fondamental aux communautés du logiciel libre, des communs numériques et de la reproductibilité, et que ce problème mérite d’être discuté. Les principes de la charte sont introduits non pas tant pour susciter des adhésions que pour susciter des réactions et la discussion de cas, qui permettra un véritable retour sur expérience sur l’opérationnalisation de ces principes : il ne faut pas séparer opérationnalisation et question de principe.
Une charte opérationnelle nécessaire .. mais de nombreuses questions encore en suspens
Marc Anderson, philosophe et chercheur.
Marc Anderson, philosophe canadien en post-doctorat au LORIA, spécialiste de l’éthique de l’IA et militant libriste (un libriste est une personne attachée aux valeurs éthiques véhiculées par le logiciel libre et la culture libre en général. @wikipedia), a noté qu’en général les chartes sont peu ancrées dans la réalité mais que cette charte a au contraire le mérite d’introduire des suggestions précises dans ses principes : une approche progressive dans l’exclusion des données, une mention directe des propriétés singulières des modèles de l’apprentissage automatique, l’incitation à entraîner les modèles sans données personnelles. Il souligne l’importance du contexte pour décider du niveau de protection des données personnelles (par exemple pour les cookies* des sites web, quelles sont les sociétés qui ont accès à nos données?), d’où l’importance de travailler directement avec les concepteurs d’IAs.
Les cookies des sites web sont de petits fichiers de texte qui sont enregistrés sur l’ordinateur d’un utilisateur à chaque fois qu’il visite un site. Ni logiciels espions ni virus, ils peuvent toutefois servir au pistage de l’activité internet d’un utilisateur.
Maël Pégny a remarqué qu’un autre problème difficile à aborder est celui de l’inférence de données sensibles à partir de données publiques, que les capacités statistiques accrues de l’apprentissage automatique ont contribué à rendre plus fréquentes. On peut ainsi inférer avec une confiance forte votre orientation sexuelle à partir de vos activités sur les réseaux sociaux, ou votre état de santé, comme une possible maladie neuro-dégénérative, à partir de vos activités sur les moteurs de recherche. Comme le proposent un bon nombre de juristes, il devient nécessaire non seulement de reconceptualiser la portée et de lever les ambiguïtés de la notion de données personnelles, mais aussi d’étendre le droit au-delà des données brutes pour réguler les inférences.
Bastien Guerry, militant libriste
Bastien Guerry, militant libriste, remarque qu’un modèle d’apprentissage se rapproche plus d’un programme compilé et qu’il n’existe pas encore de bonnes pratiques de publication pour ce type d’objets. La publication des éléments entrant dans la construction d’un modèle crée un dilemme éthique : les licences libres visent à permettre à l’utilisateur de se réapproprier les codes sources pour lutter contre l’asymétrie de pouvoir entre les producteurs de logiciels et les utilisateurs, mais dans le cas de modèles d’IA, une telle publication entre en conflit avec le besoin de respecter la vie privée. Bastien Guerry note la difficulté de définir une éthique pour la production et la publication de modèles d’apprentissage. Si les données sont gardées secrètes se pose le problème de la reproductibilité des résultats. Si des données personnelles, même publiques, sont utilisées se pose le problème du consentement. Il indique aussi qu’il faut distinguer deux points de vue libristes sur le traitement des données personnelles. Une position forte, qui proscrirait de confier le traitement des données personnelles à un tiers. Une position souple, qui autoriserait de confier des données à un tiers de confiance si celui-ci s’engage à respecter un cadre éthique*. La charte n’est pas acceptable du point de vue de la position forte.
Les positions forte et souple sont défendues respectivement par Richard M. Stallman, fondateur du mouvement du logiciel libre, et Bastien Sibille, président et fondateur de Mobicoop, une plateforme coopérative de covoiturage. Voir le débat sur les logiciels libres et les plateformes coopératives.
Daniel Adler, mathématicien et philosophe français.
Daniel Andler, professeur émérite de philosophie à Paris-Sorbonne et membre de l’Académie des sciences morales et politiques, considère que la charte a pour principale vertu de susciter des réactions. Comme désormais toute donnée publique est trouvable et exploitable, faut-il accepter que le domaine privé a disparu ? Il suggère de développer une éthique pratique de terrain non généralisable, pour arbitrer chaque cas. L’approche d’éthique dès la conception laissée à elle-même est insuffisante : il faut également proposer des mesures de répression du mauvais usage de l’IA. Pour Maël Pégny, une telle remarque est compatible avec l’esprit de la charte. Celle-ci insiste en introduction sur l’impossibilité de résoudre tous les problèmes éthiques en amont, et sur la nécessité d’empêcher les institutions d’utiliser le label « éthique dès la conception » comme un blanc-seing (Feuille blanche sur laquelle on appose sa signature et que l’on confie à quelqu’un pour qu’il la remplisse lui-même @Larousse) les protégeant à l’avance de toute critique. Le développement éthique doit être pensé sur tout le cycle de vie du logiciel, et comprendre un retour sur expérience incluant les problèmes éthiques imprévus rencontrés après le déploiement : c’est l’une des principales raisons pour laquelle la charte invite à ne séparer discussion de principe et discussion de l’opérationnalisation.
Le mouvement du libre a incité des développeurs à prendre conscience de la responsabilité qu’ils ont dans le respect des libertés des utilisateurs ; un mouvement éthique comparable doit naître pour inciter les datascientistes à respecter la vie privée des personnes dont ils manipulent les données.
Mon IA est meilleure que la tienne ! Sérieusement, comment fait-on pour vérifier ? On organise des tournois multi-jeux entre elles. Le dernier a vu une victoire, on va dire écrasante, époustouflante, d’une équipe française. Pourquoi, bouder sa joie ? La recherche française a réalisée là une brillante démonstration. Et au-delà de la simple victoire, c’est un coup de projecteur sur la thèse de Quentin Cohen-Solal et son travail avec Tristan Cazenave. Laissons-leur la parole. Serge Abiteboul et Thierry Viéville
De fin août à mi septembre 2021 se tenaient les 24èmes Computer Olympiad, une compétition mondiale multi-jeux pour intelligences artificielles. Durant cet événement, de nombreux tournois sont organisés, chacun portant sur un jeu de réflexion spécifique, comme le jeu de Dames. La particularité de cette compétition est qu’il s’agit d’intelligences artificielles qui s’affrontent.
Il y a eu cette année 22 tournois et 60 équipes participantes de tous horizons. Les résultats sont disponibles sur le site de l’International Computer Games Association.
Quentin Cohen-Solal et Tristan Cazenave, chercheurs français affiliés au LAMSADE, Université Paris-Dauphine, PSL, CNRS ont participé à plusieurs de ces tournois en faisant concourir leur intelligence artificielle novatrice. Elle a gagné, lors de cette dernière édition des Computer Olympiad, 11 médailles d’or, aux jeux suivants : Surakarta, Hex 11, Hex 13, Hex 19, Havannah 8, Havannah 10, Othello, Amazons, Breakthrough, Dames canadiennes, Dames brésiliennes. C’est la première fois qu’une même équipe, et en particulier qu’une même intelligence artificielle, remporte autant de médailles d’or la même année, dépassant le double du record précédent de médailles d’or.
Cette intelligence artificielle, créée par Quentin Cohen-Solal [1], et étudiée plus finement ensuite avec l’aide de Tristan Cazenave [2], son encadrant postdoctoral dans le cadre de l’institut PRAIRIE, est la deuxième intelligence artificielle ayant la capacité d’apprendre par elle-même sans aide humaine. La première intelligence artificielle dotée de cette capacité est Alpha Zero [3], créée par des chercheurs de Google. Chacune de ces deux types d’intelligences artificielles apprend à bien jouer à un jeu en jouant contre elle-même, sans rien savoir a priori, à part les règles du jeu. Après chaque partie, ces intelligences artificielles apprennent de leurs succès et de leurs erreurs pour s’améliorer.
Cette nouvelle intelligence artificielle, nommons là Athénan sans bien entendu chercher à la personnifier. Athénan se distingue sur de nombreux aspects par rapport à Alpha Zero. D’une part, Alpha Zero cherche à maximiser la moyenne des différentes issues possibles de la partie, tout en minimisant le regret de ne pas anticiper suffisamment certaines stratégies de jeu prometteuses. Cette seconde intelligence artificielle considère les meilleures actions et non les actions meilleures en moyenne, et analyse toujours en premier les stratégies les plus intéressantes.
Pour guider sa recherche stratégique, Alpha Zero utilise un réseau de neurones artificiels, qui agit comme une intuition. Pour chaque état de jeu analysé, le réseau de neurones calcule sa valeur (i.e. une estimation d’à quel point cet état peut mener à la victoire) ainsi qu’une probabilité, pour chaque action, que cette action soit la meilleure dans cet état. Cette nouvelle approche utilise également un réseau de neurones pour guider sa recherche en calculant une valeur pour les états du jeu. Cependant, les probabilités que chaque action soit la meilleure ne sont ni utilisées ni calculées. Pour apprendre des parties effectuées, Alpha Zero met à jour son réseau de neurones, en considérant que la valeur d’un état est le résultat de fin de partie et que la probabilité qu’une action soit la meilleure est, grosso modo, la proportion du nombre de fois que cette action a été considérée plus intéressante durant la recherche. Ainsi, s’il se retrouve à nouveau dans cet état (ou un état analogue), il aura mémorisé les informations capitales de sa recherche précédente. C’est ce procédé qui lui permet de s’améliorer de partie en partie. Au fur et à mesure, il va affiner ses probabilités de jouer la meilleure action et avoir une meilleure estimation du résultat de fin de partie. Avec Athénan, la valeur d’un état n’est pas mise à jour par le résultat de fin de partie de la partie qui vient de se terminer : elle est mise à jour par le résultat de fin de partie de cet état estimé d’après les connaissances acquises lors des parties précédentes et de la recherche effectuée durant cette nouvelle partie. Cette information est a priori plus informative que le simple résultat de fin de partie de la dernière partie et permet de capitaliser les connaissances d’une partie à l’autre.
En outre, avec cette nouvelle approche, l’état actuel de la recherche de la meilleure stratégie est intégralement mémorisé. Au contraire, Alpha Zero n’apprend que le résumé de cette recherche. Il y a donc une perte d’information avec cette première approche. Cette différence est importante, car pour bien apprendre, il faut beaucoup de données. Ainsi, avec cette nouvelle approche, beaucoup plus de données sont générées pour le même nombre de parties. Mais ce n’est pas aussi simple car s’il y a trop de données incorrectes, cela peut pénaliser fortement l’apprentissage.
Il reste à souligner une dernière différence avec Alpha Zero : elle concerne la recherche stratégique durant l’apprentissage. Avec Athénan, chaque stratégie est complètement analysée, anticipée jusqu’à la fin de la partie, alors qu’avec Alpha Zero, l’analyse d’une stratégie s’arrête dès qu’il pense qu’elle n’est plus intéressante (il n’analyse que les premières actions d’une stratégie). Cette nouvelle façon de faire, bien que plus coûteuse, permet d’obtenir des données concrètes pour l’apprentissage.
Notons pour finir qu’Alpha Zero requiert généralement un super-calculateur équipé d’une centaine de cartes graphiques et d’une centaine de processeurs pour donner de bons résultats. Athénan, à titre de comparaison, n’a besoin que d’un ordinateur équipé d’une seule carte graphique et d’un nombre normal de processeurs.
Il s’avère que pour de nombreux jeux, cette nouvelle approche est bien plus performante à matériel équivalent. Elle est également très compétitive même si Alpha Zero utilise un super-calculateur [2].
Au-delà des applications évidentes dans le domaine des jeux de sociétés et des jeux vidéos (aide à la conception, personnages non joueurs plus intelligents), de nombreuses autres applications sont possibles. Cette intelligence artificielle peut théoriquement résoudre de manière optimale tout problème où le hasard n’intervient pas, où aucune information n’est cachée et où les personnes impliquées interagissent à tour de rôle. On devrait notamment s’attendre à des applications concernant le routage internet [4], les tournées de véhicules [5] et la conception de molécules d’ARN [6], puisque sur ces problèmes, des algorithmes de jeu ont déjà montré leur utilités. Des travaux sont évidemment en cours pour dépasser ses limites. Un prototype est en phase de test concernant la gestion du hasard.
Amazons : Le premier joueur qui ne peut plus jouer perd. A son tour, un joueur déplace une de ses dames, puis pose un jeton sur le plateau de façon à ce qu’il soit aligné avec la dame qui vient de se déplacer et qu’il n’y ait aucune pièce située entre elles. Les dames et les jetons bloquent le déplacement.
Hex : Le premier joueur à relier les bords du plateau de sa couleur avec un chemin de pièces contiguës de sa couleur gagne.
Othello : A son tour, un joueur pose une pièce sur le plateau qui permet d’encercler un alignement de pièces adverses. Les pièces adverses encerclées sont alors remplacées par des pièces de sa couleur. Le joueur qui a le plus de pièces de sa couleur à la fin de la partie gagne.
Breakthrough : Le premier joueur qui arrive à faire atteindre l’autre bout du plateau à un de ses pions gagne.
Havannah : Le premier joueur qui arrive à relier trois des six bords du plateau ou deux des six coins du plateau ou à dessiner une boucle avec ses pièces gagne.
Dames : Le premier joueur à avoir pris toutes les pièces adverses gagne. Un pion avance en diagonal et peut sauter par-dessus les pièces adverses, ce qui les élimine. Un pion qui atteint le bord de l’adversaire devient une dame qui peut se déplacer d’autant de cases qu’elle veut.
Surakarta : Le premier joueur à avoir pris toutes les pièces adverses gagne. Un pion se déplace en diagonal ou orthogonalement. Il prend un pion adverse en atterrissant sur lui, s’il y a un chemin libre permettant de l’atteindre passant au moins une fois par une des boucles du plateau.
Comment représenter des connaissances de manière formelle pour que des logiciels puissent les utiliser ? Plein de trucs ont été essayés et ce qui marche bien c’est la structure de graphe. Les nœuds sont des entités et les liens des relations entre elles. Bon, on a un peu trop simplifié. Fabien Gandon nous parle des graphes de connaissance, une branche de l’IA avec des applications impressionnantes, peut-être moins connue que l’apprentissage automatique mais toute aussi passionnante. Fabien est informaticien, chercheur chez Inria. Il est Professeur au Data ScienceTech Institute, Titulaire d’une Chaire 3IA aux Instituts Interdisciplinaires d’Intelligence Artificielle de l’Université Côte d’Azur. C’est un des meilleurs spécialistesen représentation des connaissances et Web Sémantique. Serge Abiteboul, Ikram Chraibi Kaadoud, Thierry Viéville
Page de Fabien Gandon, A partir de « Les défis de l’intelligence artificielle – Un reporter dans les labos de recherche », Jérémie Dres, 2021.
Le terme de « graphe de connaissance » existe depuis des décennies mais son utilisation par Google en 2012 pour un nouveau service, puis par un nombre grandissant d’autres entreprises, l’ont rendu extrêmement populaire dernièrement. De plus son couplage avec différentes techniques d’intelligence artificielle contribue à en faire un sujet d’intérêt d’actualité. Si, à l’instar de cette expression « intelligence artificielle », le terme « graphe de connaissance » ou Knowledge Graph est utilisé avec différentes acceptions et identifie actuellement une ressource numérique très différente d’un cas d’usage à un autre, le domaine de la représentation des connaissances à base de graphes existe depuis longtemps et étudie l’expressivité de ces modèles et la complexité de leurs traitements avec des interactions multidisciplinaires et des applications dans de nombreux domaines.
S’il vous plaît… dessine-moi un graphe de connaissances !
Un graphe est une structure mathématique contenant un ensemble d’objets dans lequel certaines paires d’objets sont en relation. Les objets et les relations peuvent être très variés comme par exemple des villes reliées par des routes, des personnes reliées par des relations sociales ou des livres reliés par des citations. Un graphe est typiquement dessiné sous la forme de points représentant les objets (sommets du graphe) et de lignes entre eux représentant les relations (arêtes du graphe).
Un graphe avec six sommets et sept arêtes
Un graphe de connaissances représente des données très variées en les augmentant avec des connaissances explicites attachées aux sommets et aux arêtes du graphe pour donner des informations sur leur sens, leur structure et leur contexte. Il est explicitement utilisé pour représenter et formaliser nos connaissances dans des applications informatiques.
Prenons l’exemple d’un graphe de connaissances dans le domaine de la musique. Les sommets de ce graphe peuvent représenter des albums, des artistes, des concerts, des chansons, des labels, des langues, des genres, etc., et les arêtes peuvent capturer les relations d’auteur, compositeur, interprète, parolier, indiquer les influences artistiques, connecter les différentes versions d’un morceau ou grouper les morceaux d’un album, etc.
Un petit graphe de connaissance en musique
Dans un graphe de connaissance on trouvera typiquement deux types de sommets : ceux qui représentent des objets (ex. les musiciens) et ceux qui représentent des données (ex. une date, un texte). On trouvera donc aussi deux types d’arêtes : celles qui relient des objets (ex. un père et son fils) et celles qui indiquent des attributs d’un objet (ex. la date de naissance d’une personne).
Des graphes à tout faire
Que ce soit au sein d’un même graphe ou entre des graphes différents, on trouve des connaissances de natures très variées dans ces graphes. Les connaissances peuvent être organisées dans des arbres pour une taxonomie d’espèces, ou plutôt en réseau pour un réseau social ou pour des liens entre sites web. On peut créer des ponts entre différents graphes de connaissances notamment en réutilisant des sommets de l’un dans l’autre. Par exemple, un graphe de connaissance géographique capturant des villes, des reliefs, des frontières, pourra en certains sommets rejoindre notre graphe sur la musique quand la description d’un concert indiquera le lieu de cet évènement.
Dans la pratique, une distinction peut se faire entre deux grandes familles de graphes de connaissances : les graphes de connaissance ouverts et les graphes de connaissance privés notamment les graphes d’entreprise.
Les graphes de connaissance ouverts sont publiés en ligne comme des biens publics. Certains sont publiés dans des domaines spécifiques, tels que les sciences naturelles (ex. le graphe UniProt décrivant les protéines), la géographie (ex. le graphe GeoNames) ou la musique (ex. le graphe de MusicBrainz). D’autres couvrent des connaissances générales comme DBpedia ou YAGO qui sont des graphes extraits de Wikipedia par des algorithmes, ou Wikidata qui est un graphe construit collaborativement par une communauté de volontaires.
Les graphes de connaissance d’entreprise sont généralement internes à celle-ci car ils font l’objet d’une utilisation commerciale ou sont au cœur de son système d’information. On en trouve dans tous les domaines, depuis l’industrie jusqu’aux différents acteurs de la finance en passant par les sites marchands, les services de relation client ou l’éducation.
Mais la variété des graphes de connaissance concerne bien d’autres aspects de ces structures. Ils peuvent être petits comme ceux qui capturent quelques données personnelles d’un individu ou très gros comme ceux qui forment les bases de connaissances biologiques. Ils peuvent être assez statiques comme un graphe de connaissances linguistiques du Latin ou très dynamiques comme ceux produits par le réseau des capteurs d’une ville.
Les connaissances communes d’un domaine : les schémas des graphes
En tant qu’êtres humains, nous pouvons déduire de l’exemple du graphe sur la musique que deux artistes se connaissent car ils jouent dans le même groupe. Nous pouvons déduire plus de choses que ce que les arêtes du graphe indiquent explicitement parce que nous faisons appel à des connaissances générales que nous partageons avec de nombreuses personnes. Pour un graphe plus spécialisé, ce phénomène se reproduit avec des connaissances partagées par les experts du domaine, les « connaissances de domaine ». Ces connaissances lorsqu’elles sont explicitement représentées en informatique sont appelées des « schémas » ou encore des vocabulaires ou des ontologies en fonction notamment du type de connaissances qu’ils capturent (ex. des connaissances pour valider la qualité des données vs. des connaissances pour déduire de nouvelles choses ; ou encore un lexique vs. une théorie formelle des catégories d’un domaine).
Ces schémas sont eux aussi des graphes de connaissances qui se relient aux autres, mais ils se concentrent sur des connaissances générales partagées, par exemple en indiquant que la catégorie « Musicien » est une sous-catégorie de « Personne » par une arête entre ces deux sommets, sans s’intéresser à un musicien ou une personne en particulier.
Graphe de connaissances et schéma
Les graphes de connaissances et leurs schémas sont alors utiles à diverses méthodes, notamment d’apprentissage et de raisonnement et permettent d’améliorer les réponses à nos requêtes, la classification automatique, la recherche d’incohérences, la suggestion de nouvelles connaissances, etc.
Ce sont de telles connaissances qui permettent à un moteur de recherche de capturer et de répondre, à la question « quelle est la date de naissance de Dave Brubeck ? » directement « le 6 décembre 1920 », plutôt que de vous proposer comme réponses une liste de pages du web
L’adoption d’un même schéma par plusieurs acteurs d’un domaine ou par plusieurs graphes de connaissances permet aussi à ces derniers d’être des éléments clefs dans l’intégration de données et l’intégration d’applications dans ce domaine.
La flexibilité des graphes et de leurs schémas est particulièrement importante lorsque l’on s’intéresse à découvrir des données dans un processus continuel par exemple lorsque ces données sont obtenues en parcourant le web en permanence ou lorsqu’elles sont issues de nouvelles expériences et analyses biologiques arrivant quotidiennement.
La vie rêvée d’un graphe
Les méthodes et outils de création et enrichissement de graphes de connaissances se basent sur des sources de données diverses qui peuvent aller du texte ou de la donnée brute, aux données très structurées. De plus, la flexibilité et l’extensibilité naturelle des graphes de connaissance se prête à une approche incrémentale et agile partant d’un petit graphe initial qui est progressivement enrichi à partir de sources multiples.
Ces extractions qui viennent nourrir les graphes seront généralement incomplètes ou en doublons, avec des contradictions ou même des erreurs. Un second ensemble de méthodes et outils s’intéresse à évaluer et raffiner les graphes de connaissances pour en assurer la qualité et, par répercussion, la fiabilité des applications construites au-dessus.
La variété des graphes de connaissances implique aussi une variété d’outils plus ou moins adaptés aux différents usages. Un outil performant pour un graphe de connaissances pourra se révéler inadapté pour un autre s’ils ont différentes caractéristiques en termes de dynamicité, de traitement ou de taille par exemple.
Outre l’extraction de connaissances qui les nourrit, les graphes de connaissance ont un autre lien particulier avec l’intelligence artificielle : ils font en effet partie des modèles de données de choix quand il s’agit de fournir les entrées ou de capturer les sorties des algorithmes que ce soit pour simuler un raisonnement ou un apprentissage. Le graphe de connaissance peut donc aussi jouer un rôle important dans l’intégration de différentes méthodes d’intelligence artificielle.
Ce double couplage de l’intelligence artificielle et des graphes de connaissance permet d’envisager un cercle vertueux ou le graphe de connaissances en entrée est suffisamment riche pour permettre des traitements intelligents et, en retour, les traitements intelligents augmentent et améliorent la qualité et l’accès au graphe. Dans l’exemple sur la musique, le graphe peut ainsi permettre en entrée d’améliorer un moteur de recherche avec des raisonnements ou de fournir des exemples pour entrainer une méthode d’apprentissage à reconnaitre un genre musical et, en retour, ces mêmes algorithmes d’intelligence artificielle peuvent nous permettre de détecter des manques ou des oublis dans le graphe et de l’améliorer par exemple en suggérant le genre d’un morceau qui manquait dans le graphe.
L’âge de graphe
Comme pour d’autres sujets en intelligence artificielle, si l’on regarde l’histoire des graphes de connaissances, plutôt que de dire qu’il s’agit d’une nouveauté on pourrait dire qu’il s’agit d’un regain d’intérêt dû à un certain nombre de progrès et d’évolutions du contexte scientifique, technique et économique.
On trouve des diagrammes de représentations de connaissances et raisonnements dès l’antiquité et, en mathématique, les graphes sont introduits et utilisés pour représenter une variété de réseaux plus ou moins complexes. Au 19e siècle, on représente des connaissances linguistiques sous forme de graphes. Au début du 20e siècle, les sociogrammes capturent les connaissances sociales. Au début de la deuxième moitié du 20e siècle, les réseaux sémantiques font le lien entre modèles de mémoire humaine et représentation informatique.
Le besoin de langages de haut niveau pour gérer automatiquement des données numériques indépendamment de leurs traitements et la recherche de l’indépendance aux représentations en machine vont encourager les progrès en matière de modèles de données en général et de graphes de données en particulier. Les années suivantes verront la proposition du modèle relationnel et l’émergence des bases de données, du modèle de graphe Entité-Relation, la formalisation logique des réseaux sémantiques, les modèles de frames et les graphes conceptuels, la programmation logique, les systèmes à base de règles et leur application aux systèmes experts et systèmes à base de connaissances, notamment sur des bases de graphes.
Dans les années 80 et 90, les langages orientés objets suivis par les représentations graphiques comme UML, mais aussi le développement des notions de schéma et d’ontologies en base de données et en représentation des connaissances renforcent encore l’indépendance des représentations et enrichissent les modèles de graphes de connaissances devenant plus modulaires et réutilisables. Le compromis entre le pouvoir expressif des modèles de représentation des connaissances et la complexité informatique de leur traitement est alors systématiquement étudié.
Le terme de Knowledge Graph (graphe de connaissance) apparait dans des titres de publications académiques à la fin des années 80 et au début des années 90 mais ne se répandra pas vraiment avant la deuxième décennie du siècle suivant. Internet puis le Web vont aussi augmenter à la fois le besoin et les solutions pour représenter, traiter et échanger des données. En particulier, la fin des années 90 voit le lancement au W3C (consortium de standardisation du Web) des langages standards du Web qui nous permettent maintenant de représenter, publier, interroger valider et raisonner sur des graphes de connaissances sur la toile.
Des années 2000 à nos jours, on assiste avant tout au déluge des données, notamment en termes de volume et d’hétérogénéité, suivi par le renouveau de l’intelligence artificielle nourrie par ces données. Dans ce contexte, les graphes de connaissances apparaissent comme un moyen de relier et d’intégrer ces données et leurs métadonnées. Sur le Web, les graphes de connaissances publics apparaissent sous le terme de Linked Data (Données Liées). Facebook annonce son Open Graph Protocol en 2010 et en 2012, Google annonce un produit appelé Knowledge Graph après son rachat de l’entreprise Freebase quelques années avant. A ce stade, beaucoup de vieilles idées atteignent une popularité mondiale et commence alors une adoption massive des graphes de connaissances par de grandes entreprises dans tous les domaines.
On lie… un peu… beaucoup… à l’infini
Les graphes de connaissances sont donc des ressources numériques en pleine ascension, des graphes de données destinés à accumuler et à transmettre des connaissances, dont les sommets représentent des entités d’intérêt et dont les arêtes représentent leurs relations. Ils deviennent le substrat commun à beaucoup d’activités humaines et informatiques, la mémoire collective de communautés hybrides d’intelligences artificielles et naturelles. Ils ne cessent de grandir, de s’enrichir et de se relier entre eux sur virtuellement tous les sujets. Il y a donc de fortes chances que les défis et résultats des travaux sur les graphes de connaissances soient encore pour longtemps au croisement de multiples disciplines et domaines d’activité, avec un fort potentiel de retombées sociétales.
– Claudio Gutierrez and Juan F. Sequeda. 2021. Knowledge graphs. Commun. ACM 64, 3 (March 2021), 96–104. DOI: https://doi.org/10.1145/3418294
– Michel Chein et Marie-Laure Mugnier, Graph-based Knowledge Representation, 2009, Springer, ISBN 978-1-84800-286-9
Quatre références sur les graphes de connaissances sur le Web et les données liées :
– Fabien Gandon. A Survey of the First 20 Years of Research on Semantic Web and Linked Data. Revue des Sciences et Technologies de l’Information – Série ISI : Ingénierie des Systèmes d’Information, Lavoisier, 2018, ⟨3166/ISI.23.3-4.11-56⟩. ⟨hal-01935898⟩
– Allemang, D., Hendler, J., and Gandon, F. (2020). SemanticWeb for the Working Ontologist. ACM Books, ISBN-13: 978-1450376143
– Michael Uschold, Demystifying OWL for the Enterprise, ISBN: 9781681731278
– Fabien Gandon, Catherine Faron, Olivier Corby, Le web sémantique – Comment lier les données et les schémas sur le web ? Dunod, 2012, ISBN-13 : 978-2100572946
Depuis le 25 septembre 2021, la Maison des Mathématiques et de l’Informatique à Lyon a rouvert ses portes et présente une nouvelle exposition sur l’intelligence artificielle, « Entrez dans le monde de l’IA ». Quelle chance ils ont ces Lyonnais ! Serge Abiteboul et Laurence Chevillot
L’intelligence artificielle (IA), tout le monde en a sans doute entendu parler mais personne ne parle de la même chose. Pourtant, elle est présente dans votre quotidien, des publicités que vous recevez à votre appli de transport en passant par les jeux vidéo. Cette exposition vous permettra de découvrir et de tester des applications de l’IA, des plus sérieuses aux plus amusantes. Certaines sont tellement impressionnantes que vous aurez forcément envie de voir ce qui se cache derrière.
En manipulant et en expérimentant, venez découvrir l’apprentissage machine (« machine learning »), les réseaux de neurones, l’apprentissage profond (« deep learning ») ou encore l’apprentissage par renforcement. Pour comprendre comment une machine peut devenir « intelligente », le mieux, c’est encore de la voir apprendre en direct et, pourquoi pas, d’essayer de faire mieux qu’elle !
Cette exposition vous permettra d’entrer dans l’histoire de l’IA, sans se limiter au Deep Learning. Au travers d’une grande frise, vous découvrirez qu’elle est faite d’âges d’or et d’hivers, et qu’elle s’inspire de nombreuses disciplines (mathématiques, informatique, neurosciences, robotique…). Les regards croisés de spécialistes vous permettront de vous forger une réponse à la question : qu’est-ce donc que l’intelligence artificielle ?
Pourquoi iriez-vous voir une exposition sur l’IA ?
Dans les médias, l’IA est soit la solution à tous vos problèmes soit synonyme de catastrophe. Ces deux extrêmes ne reflètent pas la réalité de la recherche en IA, qui, si elle devenue récemment populaire dans l’industrie, s’est développée depuis 70 ans dans le monde académique. En donnant la parole à des chercheurs et chercheuses universitaires qui ont fait et font encore l’IA, cette exposition porte un regard apaisé sur l’IA, loin des projecteurs.
« Entrez dans le monde de l’IA » a été créée par Fermat Science, la Maison des Mathématiques et de l’Informatique, l’Institut Henri Poincaré, sous la responsabilité de deux commissaires scientifiques de l’ENS de Lyon, Aurélien Garivier et Alexeï Tsygvintsev. Ce sont des spécialistes d’horizons variés travaillant dans le domaine de l’intelligence artificielle qui ont permis de vous proposer un discours mesuré et raisonnable.
Montrer ce qu’est l’IA, ce qu’elle peut, ce qu’elle ne peut pas, ce qu’elle pourra peut-être : voilà ce que vous découvrirez !
Et concrètement, quelles manipulations pourrez-vous faire dans l’exposition ?
L’intelligence artificielle et les jeux sont de bons amis. AlphaGo Zero a battu des champions du jeu de Go, en apprenant par lui-même, sans observer les humains. Dans l’exposition, vous pourrez jouer contre une machine physique qui apprend à jouer… au jeu des allumettes, moins complexe que le jeu de Go. La règle du jeu ? 8 allumettes sont placées en ligne entre deux joueurs. À tour de rôle, chaque joueur doit enlever une ou deux allumettes. Celui qui enlève la dernière a perdu. Réfléchissez à la meilleure stratégie pour vous assurer la victoire et venez ensuite défier cette intelligence artificielle sans ordinateur !
La machine est constituée de huit poches, correspondant aux huit allumettes sur la table. Dans chacune se trouve des billes jaunes et noires qui sont, au départ, en nombre égal. Vous jouez une partie contre elle en retirant des allumettes et quand c’est à elle de jouer, vous tirez une bille dans la poche en face de l’allumette qu’elle peut enlever. Si la bille est jaune, la machine enlève une allumette. Si elle est noire, elle prend deux allumettes. Une fois la partie terminée, il y a deux possibilités :
Vous avez gagné : il faut punir la machine pour qu’elle apprenne de ses erreurs. Vous défaussez les billes tirées. Dans les poches, il y a moins de billes de couleurs qui correspondent à une mauvaise succession de coups. Les parties suivantes, la machine aura moins tendance à les jouer.
Vous avez perdu : il faut récompenser la machine en renforçant ses coups. Vous allez remettre pour chaque poche jouée la bille tirée et en rajouter une de la même couleur. La machine aura plus de chance de jouer cette série de coups gagnants.
Et la machine apprend ! Elle joue au hasard du début à la fin mais le renforcement change les probabilités de chaque coup. Petit à petit, la machine va avoir de plus en plus de chances de faire les bons coups, ceux que vous avez trouvé en réfléchissant à la stratégie optimale.
En intelligence artificielle, ce principe est appelé l’apprentissage par renforcement. Sans avoir besoin de maîtriser un quelconque langage de programmation, cette machine vous montre simplement et sans ordinateur, comment un tel apprentissage fonctionne.
« Entrez dans le monde de l’IA » est ouverte du 25 septembre 2021 au 30 juin 2022, à la Maison des Mathématiques et de l’Informatique (MMI), 1, place de l’Ecole, 69007 Lyon.
La MMI propose de nombreuses visites guidées mais aussi de multiples activités et ateliers autour de l’IA au public les samedis après-midis. Informations et réservations sur mmi-lyon.fr.
Olivier Druet, directeur de la MMI, et Nina Gasking, chargée de médiation de la MMI
Nous vous avions parlé de datacraft dans un article précédent « L’artisanat de la science des données avec datacraft » . En les rencontrant, nous avions été intéressés par des ateliers qu’ils organisaient pour échanger sur des sujets délicats. Ils ont organisé en particulier une série de discussions autour des thématiques de l’équité et de la confiance en intelligence artificielle. Nathan Noiry nous parle ici d’un de ces ateliers qu’il a animé avec Yannick Guyonvarch. L’objectif était d’introduire la notion de « biais de représentativité » et de proposer une méthodologie pour les détecter et les corriger. Bonne lecture ! Serge Abiteboul
Nathan Noiry
En janvier 2020, l’erreur d’un algorithme de reconnaissance faciale des services de police de Détroit (Michigan) a conduit à l’arrestation injustifiée de Robert Williams [1], [2]. Identifié à tort avec un voleur de montres, il passera trente heures en détention. Si la confiance aveugle des policiers dans leur technologie explique en grande partie l’injustice (une simple vérification humaine aurait sans doute suffi à éviter l’incident), cette faute a permis de mettre en lumière les biais raciaux des algorithmes de reconnaissance faciale. Malgré leur redoutable précision biométrique, ces derniers ont en effet tendance à se tromper plus souvent sur certains sous-groupes démographiques, les noirs et les femmes notamment, comme le décrit le rapport [3] du National Institute of Standard and Technology. Au delà de cet exemple frappant, la problématique des biais est aujourd’hui centrale dans le développement des outils d’intelligence artificielle : leur présence insidieuse conduit bien souvent à des prises de décisions discriminatoires et font d’eux un enjeu majeur pour les années à venir. Voir par exemple le désormais célèbre ouvrage Weapons of Math Destruction de Cathy O’Neil.
Qu’est-ce qu’un biais ?
Le terme est omniprésent mais parfois mal compris tant il recouvre de réalités différentes. Les auteurs de l’article de synthèse Algorithmes : Biais, Discrimination et Équité[4] définissent un biais comme une « déviation par rapport à un résultat censé être neutre, loyal ou encore équitable » et en distinguent deux grandes familles. Les biais cognitifs, d’abord, qui irriguent tous les autres : biais de confirmation, tendance à détecter de fausses corrélations entre évènements… Nous renvoyons le lecteur au livre Thinking, Fast and Slow de Daniel Kahneman décrivant ses nombreux travaux avec Amos Tversky sur le sujet. La deuxième grande famille de biais est de nature statistique et correspond à ce que l’on appelle communément biais des données ou biais de représentativité. Ces derniers désignent une situation d’inadéquation entre données utilisées pour l’entraînement d’un algorithme et données cibles sur lesquelles l’algorithme sera déployé. Un tel exemple est fourni par la surreprésentation des afro-américains dans les bases de données de photos d’identité judiciaires américaines [5], expliquant en partie les biais raciaux mentionnés précédemment.
Biais et équité
À ce stade, il nous semble important de souligner que les problèmes de représentativité se superposent seulement en partie avec les problèmes d’équité. Afin d’illustrer notre propos, imaginons vouloir développer un algorithme de gestion de carrière dans le secteur numérique en France, où la part des femmes est d’environ 20%. À cet effet, on collecte des données d’entraînement en réalisant un sondage auprès de certains employés de ce secteur : ci-dessus, on distingue deux situations (fictives) correspondant respectivement à une proportion de femmes de 20% ou de 50% dans l’échantillon interrogé. Le premier échantillon, non-équitable du point de vue de la parité homme/femme, est cependant représentatif puisque la proportion des femmes coïncide avec celle de la population totale. Au contraire, le deuxième échantillon, bien que paritaire, n’est pas représentatif. De cet exemple, on retiendra qu’un biais de représentativité se définit par rapport à une population cible observée, tandis qu’un biais inhérent (de genre, de race…) se définit par rapport à des caractéristiques cibles que l’on souhaite atteindre et pouvant différer de celles de la population observée.
D’où viennent les biais ?
La problématique des biais n’est pas nouvelle : les instituts de sondages s’escriment depuis des décennies à concevoir des enquêtes permettant d’obtenir un échantillon représentatif de la population étudiée. Elle a néanmoins pris une tournure plus systématique depuis l’avènement du Big Data. Notre faculté d’acquérir et de stocker des bases de données toujours plus massives a en effet opéré un changement de paradigme dans leur utilisation : l’information est aujourd’hui disponible avant même de se poser une question spécifique. Cet état de fait permet bien souvent au praticien de s’affranchir de la délicate étape (souvent coûteuse) de collecte des données, mais l’absence de contrôle sur le processus d’acquisition l’expose à de nombreux problèmes de représentativité. À titre d’exemple, une entreprise agroalimentaire possédant un modèle pré-entraîné sur le marché français et souhaitant développer son activité en Chine prendra le risque d’effectuer de mauvaises prédictions du fait d’une différence significative entre les comportements des consommateurs.
Modéliser les biais
Le processus même de collecte des données, en ce qu’il déforme bien souvent les caractéristiques de la population d’intérêt, peut altérer l’information que l’on souhaite acquérir. Les données observées ne sont alors que des versions imparfaites des données cibles originelles, immaculées mais inaccessibles. Aussi, la première étape de l’étude statistique des biais consiste à modéliser de manière adéquate les mécanismes de sélection à l’œuvre, miroirs déformants responsables de la transformation des données. De manière schématique, on en distinguera deux grandes instances.
La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
Dans le cas de la sélection stricte, on modélise la propension d’un individu à répondre au sondage. Pour la sélection douce, on modélisera plutôt la fonction de déformation, dans notre exemple, le ratio entre courbe rouge et courbe bleue. Le choix du modèle est une étape cruciale et doit être effectué en étroite collaboration avec des experts du domaine afférent.
Peut-on détecter et corriger les biais ?
Une fois passée l’étape de modélisation, il est possible de tester la pertinence du modèle sélectionné. C’est à ce stade que la connaissance d’information auxiliaire sur la population cible s’avère déterminante. Celle-ci prend souvent la forme de caractéristiques moyennes issues d’enquêtes pré-existantes et de large ampleur – il est par exemple aisé d’obtenir des informations agrégées telles que l’âge moyen ou le salaire moyen, tandis que les données individuelles sont parfois difficiles d’accès pour des raisons de confidentialité. La méthode la plus simple de détection des biais consiste alors à comparer les moyennes de la base de données à disposition avec les moyennes cibles de la population d’intérêt. D’autres techniques plus élaborées peuvent être mises en place, mais leurs descriptions dépassent largement le cadre de cet article. Une fois qu’un biais est détecté, il est possible de le corriger, au moins en partie. Nous nous bornerons à mentionner les deux méthodes les plus utilisées en pratique. La première, appelée imputation, est spécifique à la sélection stricte et consiste à remplir les réponses absentes dans un questionnaire – en ajoutant la réponse la plus probable au vu des réponses des autres individus, par exemple. La seconde méthode, plus adaptée à la sélection douce, consiste à affecter un poids à chacune des données de manière à ce que les moyennes re-pondérées qui en résultent s’approchent des moyennes auxiliaires cibles. Avec Patrice Bertail, Stéphan Clémençon et Yannick Guyonvarch, nous avons récemment proposé une telle méthode de re-pondération [7].
Et pour conclure
Les biais de représentativité sont omniprésents et peuvent être à l’origine de nombreuses erreurs, trop souvent discriminatoires. Développer une intelligence artificielle éthique et de confiance passera nécessairement par une prise en charge systématique de ces biais, dont l’importance grandit avec l’avènement de l’ère des données massives. De nombreuses méthodes existent déjà, mais les problématiques de représentativité restent largement ouvertes et demeurent un sujet de recherche actif. Un changement de point de vue est d’ailleurs en cours et de nombreux chercheurs (voir notamment [8]) incitent à recentrer les efforts sur la compréhension fine des données plutôt que sur le développement de modèles algorithmiques toujours plus coûteux.
[6] La correction de la non-réponse par repondération, Thomas Deroyon (Insee) ; 2017.
[7] Learning from Biased Data: A Semi-Parametric Approach, International Conference on Machine Learning ; Bertail, Clémençon, Guyonvarch, Noiry ; 2021.
Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection A la plage, Dunod, juin 2020)
Le titre de ce livre pourrait laisser croire à une nouvelle biographie d’Alan Turing dans la lignée du film « Imitation game » ou de la pièce « La machine de Turing » or il n’en est rien. Le sous-titre, « L’Intelligence Artificielle dans un transat », a toute son importance : il s’agit d’une introduction, très accessible, à l’intelligence artificielle. Le lien avec Turing ? Des références permanentes à ses écrits, des citations qui mettent en avant l’aspect précurseur de Turing, des extraits de ses articles qui parlent de l’informatique telle que nous la connaissons, ses questionnements qui sont toujours d’actualité.
Le livre commence avec les notions d’algorithmes et de machines, des dispositifs tout d’abord mécaniques puis électroniques qui réalisent ces algorithmes. Très vite, la formalisation de la notion d’algorithme et ses limites — qui ont constitué le cœur des travaux d’Alan Turing avant guerre, avec en particulier la fameuse machine de Turing, modèle théorique d’algorithme — sont abordées. Les progrès pratiques, en termes de puissance de calcul, y sont présentés.
Or les algorithmes sont le composant fondamental des intelligences artificielles. De plus en plus souvent, les performances des intelligences artificielles nous surprennent, comme nous le montre le livre, que ce soit en battant des champions aux jeux d’échecs ou de go, ou en reconnaissant des chats dans des images. Le livre présente aussi, rapidement, les notions de complexité des problèmes et les questions encore ouvertes en ce domaine, comme « P versus NP » ou « P versus NC » (voir l’article la théorie de la complexité algorithmique).
Turing avait anticipé le fait que, quand la difficulté des tâches à résoudre augmente, la difficulté à écrire les algorithmes correspondants deviendrait intraitable par un humain et il avait déjà proposé, en 1950, le principe des learning machines, principe sous-jacent aux algorithmes auto-apprenants, très présents dans l’intelligence artificielle que nous connaissons aujourd’hui.
Se pose alors la question de savoir distinguer une intelligence humaine d’une intelligence artificielle : du célèbre « test de Turing » publié en 1950 à d’autres expériences (de pensée ou non), de l’art avec ce que cela suppose de créativité, aux algorithmes inspirés par la nature comme les automates cellulaires ou les algorithmes génétiques, différentes approches sont exposées.
Avant de conclure sur la « théorie hérétique » de Turing que nous vous laissons le plaisir de (re-)découvrir, les auteurs présentent aussi les facettes inquiétantes de l’utilisation des intelligences artificielles, qu’il s’agisse d’usages malveillants ou d’effets secondaires non anticipés et non désirés.
Ce livre peut tout à fait se lire à la plage, dans un transat, dans un hamac ou sous un plaid au coin du feu : il aborde très clairement les notions fondamentales de l’intelligence artificielle, avec une grande variété et une grande pertinence dans les exemples choisis. S’il faut toutefois mettre un léger bémol à cet enthousiasme, on pourra parfois regretter une transposition de certains résultats de l’informatique à la vie de tous les jours, comme par exemple avec le choix de cette citation de Scott Aronson au sujet de la question « P versus NP » : « Si P = NP, alors le monde est un endroit profondément différent de ce qu’on imagine habituellement. Il n’y aurait aucune valeur spécifique au « saut créatif », aucun fossé séparant le fait de résoudre un problème et celui de reconnaître la validité d’une solution trouvée. Tous ceux capables d’apprécier une symphonie seraient Mozart ; tous ceux capables de suivre un raisonnement étape par étape seraient Gauss. » Certes les auteurs ne sont pas responsables de cette citation, mais ils ont choisi de relayer une telle extrapolation, peut-être quelque peu excessive.
Avec peu d’évolution dans les traitements médicaux et un manque criant de moyens humains, financiers, et thérapeutiques, les maladies mentales demeurent le parent pauvre de la médecine contemporaine. L’intelligence artificielle pourrait apporter des solutions dans l’aide au diagnostic et au suivi de certaines maladies comme la schizophrénie. Nous faisons le point sur la question avec Maxime Amblard dans cet épisode du podcast audio.
Tandis que la crise sanitaire ne fait qu’accentuer les difficultés dans la prise en charge des troubles psychiatriques, les sciences du numérique ouvrent de nouvelles voies dans le traitement et le suivi de ces pathologies.
Comme nous l’explique Maxime Amblard, l’intelligence artificielle (IA) peut être utile dans le suivi de certaines maladies mentales comme la schizophrénie, à la fois dans le cadre d’un diagnostic précoce, pour une meilleure détection et prise en charge du patient en amont, mais aussi en aval pour gérer les crises liées à la pathologie. Le chercheur, spécialisé dans le traitement automatique des langues (TAL) — un domaine pluridisciplinaire impliquant la linguistique, l’informatique et l’intelligence artificielle — nous présente, à travers deux projets de recherche dans lesquels il est impliqué, MePheSTO et ODIM, les moyens par lesquels l’IA peut contribuer au suivi des maladies mentales.
Avez-vous déjà jeté un ordinateur car la carte mère était cassée ou jeté un téléphone car l’écran était brisé ? Si oui, vous vous êtes peut-être demandé si on ne pouvait pas réutiliser des composants plutôt que de tout jeter. La réponse est que c’est possible, mais difficile. Mickaël Bettinelli effectue sa thèse au laboratoire LCIS de l’Université Grenoble Alpes, il vient nous expliquer dans binaire pourquoi la réutilisation des composants électroniques est un processus compliqué, et comment l’intelligence artificielle peut faciliter ce processus. Pauline Bolignano
Mickael Bettinelli
Les produits jetés au quotidien sont des produits qui ne remplissent plus leur rôle, souvent parce qu’une pièce cassée mais aussi parce que nous décidons de renouveler notre matériel électronique au profit de nouveaux produits plus performants. Certains composants de ces produits sont pourtant toujours fonctionnels. Par exemple, la batterie d’un téléphone âgé peut être la seule cause de la panne mais nous jetons l’ensemble du téléphone.
Le recyclage répond partiellement au problème puisqu’il permet de récupérer les matériaux des produits que l’on jette. Malheureusement, tous les matériaux et tous les produits ne sont pas recyclés. Pire, en plus d’être un procédé coûteux, le recyclage ne permet pas toujours de récupérer tous les matériaux des produits que nous recyclons. Prenons l’exemple des batteries de véhicules électriques, on estime pouvoir n’en recycler qu’environ 65% à 93% [1] et cette récupération est complexe à mettre en œuvre. De plus, une batterie de véhicule électrique ne peut plus être utilisée dans l’automobile après 20% de perte de ses capacités. Nous nous retrouvons donc avec un grand nombre de batteries en bon état qui ne peuvent plus être utilisées dans leur application initiale et dont le recyclage est coûteux.
C’est pourquoi de nombreuses études proposent de réutiliser ces batteries pour stocker les énergies renouvelables irrégulières comme l’énergie éolienne ou solaire [2]. Leur réutilisation nous permet à la fois de remplir un besoin et de maximiser l’utilisation des batteries. De manière plus générale, ce procédé est appelé le remanufacturing. C’est une pratique récente et encore peu développée qui consiste à démonter des produits jetés pour remettre à neuf et réintégrer leurs composants fonctionnels dans de nouvelles applications. Il s’agit par exemple de téléphones neufs qui ont été produits à l’aide de composants récupérés sur d’autres modèles défectueux. Puisque les produits remanufacturés n’utilisent pas que des composants neufs, ils ont l’avantage de coûter moins cher à la fabrication et à la vente, mais surtout, ils permettent d’économiser de l’énergie et des matériaux.
Déchets éléctroniques – Image par andreahuyoff de Pixabay
Face à la grande quantité et la diversité de composants dont nous disposons, il n’est pas évident pour un humain de les réutiliser au mieux durant le processus de remanufacturing. Aujourd’hui, les entreprises qui pratiquent le remanufacturing utilisent souvent un nombre de composants limité. Les employés peuvent donc les mémoriser et les réutiliser au besoin. Mais avec le développement du remanufacturing, le nombre de composants pourrait vite exploser, rendant l’expertise humaine inefficace à gérer autant de stock.
Pour répondre à ce besoin, ma thèse se concentre sur la conception d’un système d’aide à la décision permettant d’élaborer de nouveaux produits à partir d’un inventaire de composants réutilisables. Un opérateur humain peut interagir avec le système pour lui demander de concevoir des produits possédant certaines caractéristiques physiques spécifiques. Une fois l’objectif entré dans le système, celui-ci cherche parmi les composants disponibles ceux qui sont utilisables pour répondre au besoin de l’utilisateur. Mais attention, les composants nécessaires à l’utilisateur ne sont pas forcément tous disponibles dans l’inventaire ! Il doit donc être capable de faire un compromis entre ce que veut l’utilisateur et ce qu’il peut réaliser.
Pour réaliser ce système d’aide à la décision, nous nous aidons des systèmes multi-agents, un sous domaine de l’intelligence artificielle. Un système multi-agent est composé d’une multitude de programmes autonomes, appelés agents, capables de réfléchir par eux même et de communiquer ensemble. Comme chez les humains, leur capacité de communication leur permet de s’entraider et de résoudre des problèmes complexes. Dans le cadre de notre système d’aide à la décision, chaque composant de l’inventaire est représenté comme un agent. Leur problème va être de former des groupes dont l’ensemble des membres doit représenter un produit le plus proche possible de la demande utilisateur. Par exemple, si un utilisateur demande au système de lui concevoir un tout nouveau téléphone portable avec 64Go de mémoire, les agents qui représentent des composants mémoire vont former un groupe ensemble jusqu’à être le plus proche possible des 64Go. Ils peuvent ensuite s’assembler avec un écran, une batterie, un boîtier, etc. Une fois tous les composants du téléphone présents dans le groupe, le système d’aide à la décision peut proposer à l’utilisateur ceux qui ressemblent le plus à sa demande. Si l’utilisateur est satisfait, il peut alors acheter les composants proposés. Ces derniers iront ensuite à l’assemblage pour construire le produit physique.
Avec le développement du remanufacturing, nous pouvons espérer que les produits soient conçus de manière à être réparés et leurs composants réutilisés. Dans ce cas, l’avantage de ce système d’aide à la décision sera sa capacité à gérer une grande quantité de composants issus d’une grande diversité de produits. On pourrait alors imaginer concevoir des produits en mêlant des composants issus d’objets très différents comme dans le cas de la réutilisation des batteries de véhicules électriques pour le stockage des énergies renouvelables, et ainsi réduire de plus en plus notre impact environnemental.
Mickaël Bettinelli, doctorant au laboratoire LCIS de l’Université Grenoble Alpes, Grenoble INP.
[2] DeRousseau, M., Gully, B., Taylor, C., Apelian, D., & Wang, Y. (2017). Repurposing used electric car batteries: a review of options. Jom, 69(9), 1575-1582.
Le développement de la démocratie participative a fait émerger de nouvelles formes de consultations avec un grand nombre de données à analyser. Les réponses sont complexes puisque chacun s’exprime sans contrainte de style ou de format. Des méthodes d’intelligence artificielle ont donc été utilisées pour analyser ces réponses mais le résultat est-il vraiment fiable ? Une équipe de scientifiques lillois s’est penchée sur l’analyse des réponses au grand débat national et nous explique le résultat de leur recherche . Pierre Paradinas, Pascal Guitton et Marie-Agnès Enard.
Dans le cadre d’un développement de la démocratie participative, différentes initiatives ont vu le jour en France en 2019 et 2020 comme le grand débat national et la convention citoyenne sur le climat. Toute consultation peut comporter des biais : ceux concernant l’énoncé des questions ou la représentativité de la population répondante sont bien connus. Mais il peut également exister des biais dans l’analyse des réponses, notamment quand celle-ci est effectuée de manière automatique.
Nous prenons ici comme cas d’étude la consultation participative par Internet du grand débat national, qui a engendré un grand nombre de réponses textuelles en langage naturel dont l’analyse officielle commandée par le gouvernement a été réalisée par des méthodes d’intelligence artificielle. Par une rétro-analyse de cette synthèse, nous montrons que l’intelligence artificielle est une source supplémentaire de biais dans l’analyse d’une enquête. Nous mettons en évidence l’absence totale de transparence sur la méthode utilisée pour produire l’analyse officielle et soulevons plusieurs questionnements sur la synthèse, notamment quant au grand nombre de réponses exclues de celle-ci ainsi qu’au choix des catégories utilisées pour regrouper les réponses. Enfin, nous suggérons des améliorations pour que l’intelligence artificielle puisse être utilisée avec confiance dans le contexte sensible de la démocratie participative.
Le matériau à analyser
Nous considérons le traitement des 78 questions ouvertes du grand débat national dont voici deux exemples :
« Que faudrait-il faire pour mieux représenter les différentes sensibilités politiques ?” du thème “La démocratie et la citoyenneté”
“Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” dans le cadre des propositions de solutions de mobilité alternative du thème “La transition écologique”
Les réponses aux questions sont des textes rédigés par les participants qui vont de quelques mots à plusieurs centaines de mots avec une longueur moyenne de 17 mots. Pour chaque question, on dispose de quelques dizaines de milliers de réponses textuelles à analyser. Le traitement d’une telle quantité de données est difficile pour des humains, d’où la nécessité de l’automatiser au moins partiellement. Lorsque les questions sont fermées (avec un nombre prédéfini de réponses), il suffit de faire des analyses quantitatives sous forme de comptes, moyennes, histogrammes et graphiques. Pour des questions ouvertes, il faut se tourner vers des méthodes d’intelligence artificielle.
Que veut-dire analyser des réponses textuelles ?
Il n’est pas facile de répondre à cette interrogation car, les questions étant ouvertes, les répondants peuvent laisser libre cours à leurs émotions, idées et propositions. On peut ainsi imaginer détecter les émotions dans les réponses (par exemple la colère dans une réponse comme “C’est de la foutaise, toutes les questions sont orientées ! ! ! On est pas là pour répondre à un QCM !”), ou encore chercher des idées émergentes (comme l’utilisation de l’hydrogène comme énergie alternative). L’axe d’analyse retenu dans la synthèse officielle, plus proche de l’analyse des questions fermées, consiste à grouper les réponses dans des catégories et à compter les effectifs. Il peut être formulé comme suit : pour chaque question ouverte et les réponses textuelles associées :
1. Déterminer des catégories et sous-catégories sémantiquement pertinentes ;
2. Affecter les réponses à ces catégories et sous-catégories ;
3. Calculer les pourcentages de répartition.
L’étude officielle, réalisée par Opinion Way (l’analyse des questions ouvertes étant déléguée à l’entreprise QWAM) est disponible sur le site du grand débat. Pour chacune des questions ouvertes, elle fournit des catégories et sous-catégories définies par un intitulé textuel et des taux de répartition des réponses dans ces catégories.
Par exemple, pour la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?”, l’analyse a catégorisé les réponses de la façon suivante :
Les acteurs publics
43,4%
Les solutions envisagées
8,8%
Les acteurs privés
6,6%
Autres contributions trop peu citées ou inclassables
22,5%
Non réponses, (les réponses vides)
30,2%
On constate que les catégories se chevauchent, que la catégorie “Les solutions envisagées” ne correspond pas à une réponse à la question et que le nombre d’inclassables est élevé (22.5% soit environ 35 000 réponses non prises en compte).
L’analyse officielle : la méthode
Regrouper des données dans des catégories correspond à une tâche appelée classification non supervisée ou clustering. C’est une tâche difficile car on ne connaît pas les catégories a priori, ni leur nombre, les catégories peuvent se chevaucher. De surcroît, les textes en langage naturel sont des données complexes. De nombreuses méthodes d’intelligence artificielle peuvent être utilisées comme, par exemple, la LDA pour “Latent Dirichlet Analysis” et ses nombreux dérivés.
Quelle est la méthode utilisée par l’entreprise QWAM ? À notre connaissance, les seules informations disponibles se trouvent dans la présentation de la méthodologie. On y décrit l’utilisation de méthodes internes qui sont “des algorithmes puissants d’analyse automatique des données textuelles en masse (big data), faisant appel aux technologies du traitement automatique du langage naturel couplées à des techniques d’intelligence artificielle (apprentissage profond/deep learning)” et le post-traitement par des humains : “une intervention humaine systématique de la part des équipes qualifiées de QWAM et d’Opinion Way pour contrôler la cohérence des résultats et s’assurer de la pertinence des données produites”.
Regard critique sur l’analyse officielle
Il semble que l’utilisation d’expressions magiques telles que “intelligence artificielle” ou “big data”, ou bien encore “deep learning” vise ici à donner une crédibilité à la méthode aux résultats en laissant penser que l’intelligence artificielle est infaillible. Nous faisons cependant les constats suivants :
– Les codes des algorithmes ne sont pas fournis et ne sont pas ouverts ;
– La méthode de choix des catégories, des sous-catégories, de leur nombre et des intitulés textuels associés n’est pas spécifiée ;
– Les affectations des réponses aux catégories ne sont pas fournies ;
– Malgré l’intervention humaine avérée, aucune mesure d’évaluation des catégories par des humains n’est fournie.
Nous n’avons pas pu retrouver les résultats de l’analyse officielle malgré l’usage de plusieurs méthodes. Dans la suite, nous allons voir s’il est possible de les valider autrement.
Une rétro-analyse de la synthèse officielle
Notre rétro-analyse consiste à tenter de ré-affecter les contributions aux catégories et sous-catégories de l’analyse officielle à partir de leur contenu textuel. Notre approche consiste à affecter une contribution à une (sous-)catégorie si le texte de la réponse et l’intitulé de la catégorie sont suffisamment proches sémantiquement. Cette proximité sémantique est mesurée à partir de représentations du texte sous forme de vecteurs de nombre, qui constituent l’état de l’art en traitement du langage (voir encadré).
Nous avons testé plusieurs méthodes de représentation des textes et plusieurs manières de calculer la proximité sémantique entre les réponses et les catégories. Nous avons obtenu des taux de répartitions différents selon ces choix, sans jamais retrouver (même approximativement) les taux donnés dans l’analyse officielle. Par exemple, la figure ci-dessous donne les taux de répartitions des réponses dans les catégories obtenus avec différentes approches pour la question « Quelles sont toutes les choses qui pourraient être faites pour améliorer l’information des citoyens sur l’utilisation des impôts ? ».
Pour compléter notre rétro-analyse automatique, nous avons mis en œuvre une annotation manuelle sur la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” du thème Transition Ecologique et la catégorie Les acteurs publics et avons trouvé un taux de 54.5% à comparer avec un taux de 43.4% pour l’analyse officielle, soit une différence de 15 000 réponses ! Les réponses à cette question sont globalement difficiles à analyser, car souvent longues et argumentées (25000 réponses contenant plus de 20 mots). Notre étude manuelle des réponses nous a fait remarquer certaines réponses comme “moi-même”, “les citoyens”, “c’est mon problème”, “les français sont assez intelligents pour les trouver seuls” ou encore “les citoyens sont les premiers maîtres de leur choix”. Pour ces réponses, nous avons considéré une catégorie Prise en charge par l’individu qui n’est pas présente dans la synthèse officielle bien qu’ayant une sémantique forte pour la question. Un classement manuel des réponses donne un taux de 4.5% des réponses pour cette catégorie, soit environ 7000 réponses, taux supérieur à certaines catégories existantes. Ceci met en évidence un certain arbitraire et des biais dans le choix des catégories de la synthèse officielle.
En résumé, notre rétro-analyse de la synthèse officielle montre :
L’impossibilité de retrouver les résultats de la synthèse officielle ;
La différence de résultats selon les approches ;
Des biais dans le choix des catégories et sous-catégories.
La synthèse officielle n’est donc qu’une interprétation possible des contributions.
Recommandations pour utiliser l’IA dans la démocratie participative
L’avenir des consultations participatives ouvertes dépend en premier lieu de leur prise en compte politique, mais il repose également sur des analyses transparentes, dignes de confiance et compréhensibles par le citoyen. Nous proposons plusieurs pistes en ce sens :
Transparence des analyses : les méthodes utilisées doivent être clairement décrites, avec, si possible, une ouverture du code. La chaîne de traitement dans son ensemble (comprenant le traitement humain) doit également être précisément définie. Enfin, il est nécessaire de publier les résultats obtenus à une granularité suffisamment fine pour permettre une validation indépendante (par des citoyens, des associations ou encore des chercheurs).
Considérer différents axes d’analyse et confronter différentes méthodes : la recherche de catégories aurait pu être complétée par la recherche de propositions émergentes ou l’analyse de sentiments et d’émotions. Par ailleurs, pour un axe d’analyse donné, il existe différentes méthodes reposant sur des hypothèses et biais spécifiques et la confrontation de plusieurs analyses est utile pour nuancer certaines conclusions et ainsi mener à une synthèse finale plus fiable.
Concevoir des consultations plus collaboratives et interactives : publier les affectations des réponses aux catégories permettrait à tout participant de voir comment ses contributions ont été classées. Il serait alors possible de lui demander de valider ou non ce classement et d’ainsi obtenir une supervision humaine partielle utilisable pour améliorer l’analyse. D’autres manières de solliciter cette supervision humaine peuvent être considérées, par exemple faire annoter des textes par des volontaires (voir l’initiative de la Grande Annotation) ou encore permettre aux participants de commenter ou de voter sur les contributions des autres.
Si l’intelligence artificielle permet désormais de considérer des enquêtes à grande échelle avec des questions ouvertes, elle est susceptible de biais comme toute méthode automatique. Il est donc nécessaire d’être transparent et de confronter les méthodes. Dans un contexte de démocratie participative, il est également indispensable de donner une véritable place aux citoyens dans le processus d’analyse pour engendrer la confiance et favoriser la participation.
Pour aller plus loin : les résultats détaillés de l’étude, ainsi que le code source utilisé pour réaliser cette rétro-analyse, sont consultables dans l’article.
Représenter des textes comme des vecteurs de nombre
Qui aurait prédit au début des années 2000 au vu de la complexité du langage naturel, que les meilleurs logiciels de traduction automatique représentent les mots, les suites de mots, les phrases et les textes par des vecteurs de nombres ? C’est pourtant le cas et voyons comment !Les représentations vectorielles des mots et des textes possèdent une longue histoire en traitement du langage et en recherche d’information. Les premières représentations d’un texte ont consisté à compter le nombre d’apparitions des mots dans les textes. Un exemple classique est la représentation tf-idf (pour « term frequency-inverse document frequency’’) où on pondère le nombre d’apparitions d’un mot par un facteur mesurant l’importance du mot dans l’ensemble des documents. Ceci permet de diminuer l’importance des mots fréquents dans tous les textes (comme le, et, donc, …) et d’augmenter l’importance de mots plus rares, ceci pour mieux discriminer les textes pertinents pour une requête dans un moteur de recherche. Les vecteurs sont très longs (plusieurs centaines de milliers de mots pour une langue) et très creux (la plupart des composantes sont nulles car un texte contient peu de mots). On ne capture pas de proximité sémantique (comme emploi et travail, taxe et impôt) puisque chaque mot correspond à une composante différente du vecteur.Ces limitations ont conduit les chercheurs à construire des représentations plus denses (quelques centaines de composantes) à même de mieux modéliser ces proximités. Après avoir utilisé des méthodes de réduction de dimension comme la factorisation de matrices, on utilise désormais des méthodes neuronales. Un réseau de neurones est une composition de fonctions qui se calcule avec des multiplications de matrices et l’application de fonctions simples, et qui peut être entraîné à prédire un résultat attendu. On va, par exemple, entraîner le réseau à prédire le mot central d’une fenêtre de 5 mots dans toutes les phrases extraites d’un corpus gigantesque comme Wikipedia. Après cet entraînement (coûteux en ressources), le réseau fournit une représentation de chaque mot (groupe de mots, phrase et texte) par un vecteur. Les représentations les plus récentes comme ELMo et BERT produisent des représentations de phrases et des représentations contextuelles de mots (la représentation d’un mot varie selon la phrase). Ces représentations vectorielles ont apporté des gains considérables en traitement du langage naturel, par exemple en traduction automatique.
Un algorithme peut-il composer de la musique, un texte, un tableau ? C’est le sujet que traite Philippe Rigaux, professeur d’informatique au CNAM et excellent gambiste. L’éditeur que je suis peut vous garantir que l’article, comme le plus souvent les articles de binaire, a bien été écrit pas un humain et pas par un algorithme. Serge Abiteboul.
Philippe Rigaux à la viole de gambe
Un algorithme peut-il composer de la musique ? La question n’est pas nouvelle, c’est peut-être même un des plus anciens fantasmes de l’informatique, exprimé dès la première moitié du XIXe siècle par Ada Lovelace (1815-1852) en ces termes : «la machine pourrait composer de manière scientifique et élaborée des morceaux de musique de n’importe quelle longueur ou degré de complexité ». À la base de cette hypothèse, certains aspects mathématiques des règles de la composition musicale. Bien.
De là à penser qu’un ordinateur peut faire l’affaire, il y a quand même une faille qu’un article du Monde [1] enjambe en nous expliquant que c’est (peut-être) en cours. L’anecdote initiale est la suivante. Au départ, une chanson, passée inaperçue à l’origine, qui devient populaire par la grâce de deux facteurs : (i) elle a subi quelques transformations (longueur, tempo) qui lui permettent de s’inscrire dans une forme de norme, et (ii) du coup, elle se trouve happée par un algorithme qui la considère comme totalement recommandable puisque plus rien ne dépasse en termes d’originalité ou de créativité. Ensuite c’est l’effet boule de neige : plus le morceau est écouté et plus il devient écoutable. Pas de surprise, nous sommes bien dans un système qui par ses suggestions encourage un flot de musique produit dans le même moule. Mais surprise quand même de voir un bide se transformer en hit.
Magique ? Non, il suffit de comprendre comment fonctionne l’algorithme. D’un côté ce qui caractérise un morceau, de l’autre un catalogage des émotions qu’il suscite (avec une petite dose de personnalisation, domaine routinier des industriels du captage de données personnelles). On fait tourner sur ces données un algorithme d’apprentissage automatique qui va mettre en évidence des similarités, entre utilisateurs (vous avez des goûts très semblables à ceux de plein d’inconnus) et entre morceaux. Ça va permettre d’envoyer « le bon contenu pour le bon auditeur au bon moment ». C’est énervant mais nous sommes finalement très prévisibles. Il ne reste plus qu’à garder un peu de place pour envoyer la pub !
Ce que cette histoire, qui n’a rien de renversant, raconte, c’est le passage de la recommandation à la prédiction, un petit pas. Demain, quand un artiste arrivera chez un producteur, ce dernier aura en main les estimations qui lui permettront de dire si le morceau proposé sera un succès ou non. D’ailleurs pourquoi avoir encore besoin d’un producteur ? Et puis, de la prédiction à la création, encore un petit pas. Pourquoi continuer à avoir des auteurs (humains) alors que la machine dispose de tous les paramètres pour produire un morceau « presque pareil » que ceux qui sont écoutés en masse, et réaliser la vision d’Ada Lovelace ?
Au secours ! Cela nous nous conduit à une vision d’un monde effrayant où on écoute, on lit, et on visionne toujours la même chose, une sorte de culture mollement consensuelle et farouchement opposée à toute originalité, qui vous infiltre silencieusement, insidieusement, vous proposant ses variants de temps en temps, histoire de vous empêcher de réaliser ce qui vous arrive. Non, à la culture-Covid !
“Je rêvais d’un autre monde” (vous la reconnaissez celle-là ? Était-elle recommandable à l’origine ?) où des artistes continueront à nous surprendre par leur créativité, à nous sortir délicieusement des sentiers battus par la société du contrôle et du marketing. Rêvons d’un monde où on préfèrera encore se laisser surprendre et affronter parfois le sentiment d’être largué, plutôt que de tourner en rond comme un hamster, entre deux pubs et trois chansons préformatées de trois minutes !
Philippe Rigaux, CNAM
[1] L’algorithme, nouvelle machine à tubes, Laurent Carpentier, Le Monde, 15 février 2021
La bande dessinée Mirror, Mirror de Falaah Arif Khan et Julia Stoyanovich parle de l’Intelligence Artificielle. À quoi sert aujourd’hui l’apprentissage automatique ? À quoi devrait-il servir ? À améliorer l’accessibilité des applis numériques notamment. C’était une réflexion destinée au départ aux étudiants en IA. Nous l’avons traduite en français pour binaire, avec l’aide de Eve Francoise Trement, parce que nous pensons qu’elle peut intéresser un bien plus large public.
Victor Storchan (VS): Quelles ont été vos motivations initiales et vos objectifs pour l’élaboration de votre cours en ligne ?
L’équipe de Class´Code (CC): Il s’agit d’offrir une initiation à l’Intelligence Artificielle via une formation citoyenne, gratuite et attestée https://classcode.fr/iai, dans le cadre d’une perspective « d’Université Citoyenne et Populaire en Sciences et Culture du Numérique » où chacune et chacun de la chercheuse au politique en passant par l’ingénieure ou l’étudiant venons avec nos questionnements, nos savoirs et savoir-faire à partager.
Très concrètement on y explique ce qu’est l’IA et ce qu’elle n’est pas, comment ça marche, et quoi faire ou pas avec. On découvre les concepts de l’IA en pratiquant des activités concrètes, on y joue par exemple avec un réseau de neurones pour en démystifier le fonctionnement. On réfléchit aussi, ensemble, à ce que le développement de l’IA peut soulever comme questions vis-à-vis de l’intelligence humaine.
CC: La cible primaire est l’ensemble des personnes en situation d’éducation : enseignant·e, animateur·e et parents, qui doivent comprendre pour re-partager ce qu’est l’IA. C’est —par exemple— abordé au lycée dans les cours de sciences de 1ère et terminale, c’est abordé de manière transversale dans les enseignements d’informatique et présent dans de nombreux ateliers extra-scolaires.
Par extension, toutes les personnes qui veulent découvrir ce qu’est l’IA et se faire une vision claire des défis et enjeux posés, ceci en “soulevant le capot”, c’est-à-dire en comprenant comment ça marche, sont bienvenues. Et c’est de fait une vraie formation citoyenne.
VS: Quels sont les apports de votre cours pour ce public ?
Ce qui rend ce cours attrayant est une approche ludique et pratique avec une diversité de ses supports – vidéos conçues avec humour, tutos et activités pour manipuler (y compris avec des objets du quotidien) les mécanismes sous-jacents, des ressources textuelles pour aller plus loin, et des exercices pour s’évaluer. Toutes ces ressources sont réutilisables.
Ce qui rend ce cours unique, par rapport aux autres offres connues, est un forum pour échanger et des webinaires et rencontres en ligne ou en présentiel sur ces sujets, à la demande des personnes participantes : la formation sert de support pour des rencontres avec le monde de la recherche. Cette possibilité de dialogue direct entre personnes participantes, de proposer des ressources ou des liens en fonction des besoins est vécu comme un point majeur de cette formation.
VS: Pouvez-vous partager les premiers résultats à ce stade et quelles sont vos perspectives futures ?
CC: Ouvert en avril 2020, le MOOC Class’Code IAI “Intelligence Artificielle avec Intelligence” a attiré jusqu’à présent (mi-novembre) plus de 18800 personnes, dont beaucoup ont effectivement profité d’au moins un élément de la formation et délivré 1038 attestations de suivi. Il y a plus de 5300 personnes sur le forum et près de 600 messages échangés, beaucoup entre l’équipe pédagogique et les personnes participantes, mais aussi entre elles. Nos mooqueurs et mooqueuses se disent satisfaits à plus de 94%. Les rencontres en ligne attirent entre 50 et 100 personnes et sont vues par plusieurs centaines en replay. Les vidéos sont réutilisées au sein de plusieurs ressources numériques en lien avec les manuels d’apprentissage des sciences en première et terminale qui inclut le sujet de l’IA ou sur le sitelumni.fr de France Télévision (qq milliers de vues, mais pas de comptage précis).
Au niveau des perspectives, nous invitons les personnes à suivre ensuite par exemple Elements Of AI course.elementsofai.com/fr-be dans sa version francophone, pour se renforcer sur des éléments plus techniques, tandis que notre action s’inscrit dans la perspective de cette université citoyenne déjà citée.
VS: Comment vos ressources participent-elles à la création d’une confiance dans le développement de ces innovations, et aident-elles à développer un esprit critique constructif à ces sujets ?
Nous avons deux leviers principaux. Le premier est de dépasser les idées reçues (les “pourquoi-pas”) sur ce sujet et d’inviter à distinguer les croyances, les hypothèses scientifiques (qui pourront être infirmées, contrairement aux croyances qui ne seront jamais ni fausses, ni vraies), des faits avérés. Pour développer l’esprit scientifique il est particulièrement intéressant de montrer que, à l’instar de l’astrologie par exemple, il y a dans le domaine de l’IA l’émergence d’une pseudo-science qu’il faut expliciter et dépasser. Le second est de “comprendre pour pouvoir en juger”. Nous voulons aider les personnes à avoir une vision opérationnelle de ce qu’est l’IA, pas uniquement des mots pour en parler, de façon à réfléchir en profondeur sur ce qu’elle peut apporter.
Motivé par ladéclaration commune franco-finlandaise de “promouvoir une vision de l’intelligence artificielle juste, solidaire et centrée sur l’humain” nous pensons que la première étape est d’instruire et donner les moyens de s’éduquer.
VS: Quelles difficultés surmonte-t-on pour déployer un projet comme celui-ci ?
CC: Au niveau des moyens, forts de la réussite du projet Class´Code nous avons été soutenus sans souci par des fonds publics et avons eu les moyens des objectifs choisis.
Au niveau de la diffusion, il est moins facile de faire connaître notre offre qui est peu relayée médiatiquement, car le message est moins “sensationnel” que d’autres, nous construisons notre notoriété principalement sur les retours des personnes qui ont pu en bénéficier.
Au niveau des personnes, le principal défi est d’apaiser les peurs et d’aider à dépasser les idées reçues, parfois les fantasmes sur ces sujets : l’idée d’une intelligence qui émergerait d’un dispositif inanimé de la légende de Pinocchioau mythe du Golem est ancrée dans nos inconscients et c’est un obstacle à lever.
VS: Quels sont les bénéfices de la coopération entre partenaires de votre initiative, en particulier pour la réalisation d’un cours sur l’IA par nature interdisciplinaire ?
CC: Ils sont triples.
D’une part en associant des compétences académiques en sciences du numérique, neurosciences cognitives et sciences de l’éducation on se donne vraiment les moyens de bien faire comprendre les liens entre intelligence artificielle et naturelle, et d’avoir les bons leviers pour permettre d’apprendre à apprendre.
Par ailleurs, à travers Class´Code et plus de 70 de ses partenaires, on donne les moyens aux initiatives locales, associatives ou structurelles de disposer de ressources de qualité et de les co-construire avec elles et eux, pour être au plus près du terrain. Notre collaboration avec des entreprises d’éducation populaire de droit public comme La Ligue de l’Enseignement ou de droit privé comme Magic Maker, ou des clusters d’entreprise EdTech comme celles d’EducAzur montre aussi que les différents modèles économiques ne s’excluent pas mais se renforcent sur un sujet qui est l’affaire de toutes et tous.
VS: Au-delà de la formation, quels sont les atouts et les faiblesses de l’Europe pour peser dans la compétition technologique mondiale ?
CC: Il y a de multiples facteurs qui dépassent notre action. Mais relevons en un qui nous concerne directement : celui d’éduquer au numérique et ses fondements, que nous discutons ci-dessous.
VS: Votre initiative crée donc un lien éducation et IA, quels sont les liens à renforcer entre IA et éducation (par exemple apprentissage de l’IA dans le secondaire) et éducation et IA (par exemple des assistants algorithmiques), et quels sont les impacts socio-économiques visés ?
CC: Les liens entre IA et éducation sont doubles : éduquer par et au numérique comme on le discute ici en explicitant les liens entre IA et éducation au-delà des idées reçues qui sont bien décryptées montrant les limites de l’idée que le numérique va révolutionner l’éducation. Nous nous donnons avec ce MOOC IAI les moyens pour que nos forces citoyennes soient vraiment prêtes à relever ces défis. L’apprentissage scolaire de l’informatique est un vrai levier et un immense investissement pour notre avenir, et la France a fait ce choix d’enseigner les fondements du numérique pour maîtriser le numérique.
VS: Confier à des algorithmes des tâches qui mènent à des décisions cruciales, par exemple en matière de justice, d’embauche, ou d’autres décisions à forte conséquence humaine, questionne, quel est votre positionnement sur ce sujet ? Quelle place pensez-vous que l’éthique doit prendre dans votre enseignement ?
CC: Pouvoir se construire une éthique, c’est-à-dire se forger un jugement moral sur ce qu’il convient de faire ou pas avec l’IA, est en quelque sorte l’aboutissement de cette formation. Là encore cela passe par la compréhension de notions fines comme interprétabilité et explicabilité ou les causes des biais dans les mécanismes d’IA venant des données ou des algorithmes pour ne pas juste émettre des opinions superficielles à ce sujet. Aucun sujet technique n’est abordé sans que ces aspects éthiques ou sociétaux le soient comme c’est le cas en robotique.
D’un point de vue éthique, la responsabilité est toujours “humaine”, par exemple si on laisse l’algorithme décider, c’est notre décision de le faire : de déléguer la décision à un algorithme au lieu de la prendre soi-même, c’est un choix et c’est un humain qui doit faire ce choix. Si vous choisissez de “faire confiance” à une machine avec un algorithme d’IA, vous faites surtout confiance en votre propre jugement quant aux performances de ce mécanisme.
VS: Le fait que des tâches cognitives de plus en plus complexes soient réalisées par des programmes nous amène-t-il à reconsidérer l’intelligence humaine ? Est-ce que cela a des impacts sur notre vision de l’IA ? Sur son enseignement ?
CC: C’est tout à fait le cas. On se pose souvent la question « symétrique » de savoir si une machine peut être ou devenir intelligente : le débat est interminable, car -en gros- il suffit de changer la définition de ce que l’on appelle intelligence pour répondre “oui, pourquoi-pas” ou au contraire “non, jamais”. La vraie définition de l’IA est de “faire faire à une machine ce qui aurait été intelligent si réalisé par un humain”, ce qui évite de considérer cette question mal posée.
En revanche, avec la mécanisation de processus cognitifs, ce qui paraissait “intelligent” il y a des années par exemple, le calcul mental devient moins intéressant avec l’apparition -dans ce cas- de calculettes. De même l’intelligence artificielle soulage les humains de travaux intellectuels que l’on peut rendre automatiques. Du coup, cela oblige à réfléchir à l’intelligence humaine en fonction et au-delà de ce que nous appelons la pensée informatique.
Par exemple, nous savons que plus le problème à résoudre est spécifique, plus une méthode algorithmique sera efficace, possiblement plus que la cognition humaine, tandis qu’à l’inverse plus le problème à résoudre est général, moins un algorithme ne pourra intrinsèquement être performant, quelle que soit la solution (no free lunch theorem). Il se trouve que les systèmes biologiques eux aussi ont cette restriction, l’intelligence humaine n’est donc peut-être pas aussi “générale” qu’on ne le pense.
VS: Nous vivons au temps des algorithmes. Quelle place voulons-nous accorder aux algorithmes dans la “cité” ? Est-ce que cela nous conduit à repenser cette cité ? Comment mieux nous préparer au monde de demain ?
CC: En formant en profondeur les citoyennes et citoyens, nous nous donnerons « les moyens de construire un outil qui rend possible la construction d’un monde meilleur, d’un monde plus libre, d’un monde plus juste … » écrivent Gilles Dowek et Serge Abiteboul en conclusion du “temps des algorithmes”.
Que des robots assistent des personnes âgées pour reprendre leur exemple, sera un progrès, permettant de les maintenir chez eux, à leur domicile et dans l’intimité de leur dignité, mais si cela est vu uniquement comme un levier de réduction des coûts de prise en charge, ou un moyen de nous désengager d’une tâche parmi les plus humaines qui soit à savoir s’occuper des autres, alors la machine nous déshumanisera.
Cet exemple nous montre surtout, comme la crise sanitaire le fait aussi depuis quelques mois, que des circonstances exceptionnelles nous obligent à revoir en profondeur les équilibres que nous pensions acquis pour notre société. Quand, et cela est en train d’advenir, nous aurons mécanisé la plupart des tâches professionnelles qui sont les nôtres aujourd’hui, nous allons devoir organiser autrement la société.
Frédéric Alexandre, Marie-Hélène Comte, Martine Courbin-Coulaud et Bastien Masse.
Grand merci à Inria Learning Lab pour avoir porté et adapté le MOOC sur FUN ainsi que pour le forum.
Nous vous l’avions annoncé ici, Victor Storchan va nous présenter trois initiatives de formation à l’intelligence artificielle (IA). Après « Elements Of AI« , c’est au tour de Théophile Lenoir, Responsable du programme Numérique et Milo Rignell, Chargé de l’innovation à l’Institut Montaigne de nous parler d’Objectif IA. Serge Abiteboul et Thierry Viéville.
Victor Storchan (VS): Quelles ont été vos motivations initiales et vos objectifs pour l’élaboration de votre cours en ligne ?
Théophile Lenoir et Milo Rignell (TL&ML): L’initiative Objectif IA a été lancée, d’une part, afin de déconstruire un certain nombre d’idées reçues tout en recentrant le débat sur les vrais enjeux de société et, d’autre part, pour permettre à notre pays et à nos entreprises d’être en mesure de se saisir des opportunités de l’intelligence artificielle (IA) et d’être compétitives à l’avenir.
C’est pour rendre l’IA accessible au plus grand nombre que nous avons développé une formation en ligne, gratuite, et qui ne prend que quelques heures à compléter.
Cette volonté s’accompagne d’un objectif concret : permettre à 1 % des Français de se former à l’IA grâce à Objectif IA.
VS: Quel est le public que vous visez ? Quels sont les apports de votre cours pour ce public ?
TL&ML: Objectif IA s’adresse à tous ceux qui souhaitent, en quelques heures, mieux comprendre cette technologie afin de participer activement à son développement au sein de notre société et dans notre quotidien.
Nous constatons néanmoins que la formation est particulièrement utile pour deux types de publics. Elle permet aux jeunes et aux personnes en reconversion professionnelle de découvrir les nombreux métiers de l’IA et de la donnée avant de s’y lancer ; et elle permet aux dirigeants et aux collaborateurs d’entreprises et de structures publiques de se saisir de cette technologie, à tous les niveaux.
VS: Pouvez-vous partager les premiers résultats à ce stade et quelles sont vos perspectives futures ?
TL&ML: En décembre 2020, 90 000 personnes avaient commencé la formation et 50 000 personnes, soit plus de la moitié, avaient complété l’ensemble des chapitres du cours et ainsi obtenu leur certificat de réussite.
Plus de 80 structures se sont par ailleurs engagées à former leurs collaborateurs – des entreprises de tous les secteurs, des régions, des acteurs publics comme Pôle emploi et la Gendarmerie nationale, des universités, des associations et d’autres acteurs de la société civile.
Fort de ce premier succèsen France, nous envisageons de proposer l’initiative à de nouveaux publics. La version anglaise du cours sera disponible à partir de février 2021 et permettra à Objectif IA d’élargir sa formation à l’échelle européenne, aux côtés d’autres initiatives existantes, mais aussi sur le continent africain, où plusieurs acteurs ont déjà exprimé un intérêt fort.
VS: Comment vos ressources participent-elles à la création d’une confiance dans le développement de ces innovations, et aident-elles à développer un esprit critique constructif à ces sujets ?
TL&ML: Plusieurs sondages (Ifop, 2018 ; Ipsos, 2018) révèlent clairement la corrélation entre une meilleure connaissance et compréhension de l’IA d’une part, et la confiance envers elle d’autre part. La formation Objectif IA permet non seulement de mieux se rendre compte du potentiel de cette technologie pour la santé, l’environnement, le transport et bien d’autres secteurs, mais aussi de replacer les vraies questions sociétales au centre du débat public en démystifiant un certain nombre d’idées reçues. Trois chapitres sont ainsi expressément consacrés à resituer le potentiel de l’IA au-délà des mythes, à identifier ses enjeux éthiques et à évaluer son impact sur le travail.
Le projet entrepreneurial
VS: Quelles difficultés surmonte-t-on pour déployer un projet comme celui-ci?
TL&ML: A la différence de nombreux MOOCs, qui affichent des taux de complétion entre 5 % et 15 %, plus de la moitié des apprenants qui débutent Objectif IA complètent le cours, souvent en quelques heures seulement. L’enjeu est donc de convaincre de plus en plus de personnes de débuter le tout premier chapitre ! Cela se fait du bouche à oreille, mais aussi avec des soutiens et une mobilisation institutionnels.
VS: Quels sont les bénéfices de la coopération entre partenaires de votre initiative, en particulier pour la réalisation d’un cours sur l’IA par nature interdisciplinaire ?
TL&ML: Objectif IA a été développé au sein d’un partenariat, à première vue hétéroclite, inédit entre l’Institut Montaigne, la startup OpenClassrooms et la Fondation Abeona.
L’Institut Montaigne et la Fondation Abeona s’intéressent tous deux depuis longtemps aux enjeux de l’IA et nous avons travaillé ensemble à la production d’un rapport sur les biais algorithmiques, Algorithmes : contrôle des biais S.V.P. L’une des propositions fortes de ce rapport est notamment une sensibilisation large aux enjeux de l’IA. En tant que leader français de la formation en ligne et ayant déjà une offre conséquente de formations en ligne aux métiers du numérique, OpenClassrooms apporte une expertise pédagogique très riche et une plateforme qui recense plus de trois millions de visiteurs par mois.
Cette co-construction, à laquelle ont également participé des utilisateurs et des experts de l’IA, a permis de développer un contenu dont la qualité et l’accessibilité se retrouvent dans le pourcentage de personnes terminant le cours.
Les modèles d’écosystèmes
VS: Au-delà de la formation, quels sont les atouts et les faiblesses de l’Europe pour peser dans la compétition technologique mondiale ? La dynamique européenne sur l’IA actuelle est-elle suffisamment ambitieuse ?
TL&ML: Disposant d’un précieux savoir-faire dans plusieurs secteurs industriels, les entreprises européennes ont de nombreux atouts pour prendre de l’avance – à condition de comprendre les enjeux numériques et d’IA et de développer des nouveaux usages dont dépendra leur compétitivité. C’est pourquoi il faut non seulement plus de personnes formées aux métiers de la donnée et de l’IA, aujourd’hui déjà en tension, mais aussi la mobilisation de l’ensemble des collaborateurs de ces groupes, en allant des instances dirigeantes aux collaborateurs qui interagiront avec ces nouvelles technologies, sans nécessairement qu’elles en constituent le métier.
Objectif IA met ces compétences en situation, en suivant pas à pas les étapes d’un projet d’intelligence artificielle et en passant par les différents métiers impliqués.
VS: Selon uneétude France Digitale-Roland Berger, la France était en tête des investissements dans l’IA en Europe avec un doublement des fonds levés en 2019 par rapport à 2018. Quelles sont les spécificités du modèle français ?
TL&ML: Il est difficile de tirer des conclusions des niveaux d’investissement en capital risque, qui dépendent des levées de fonds d’un petit nombre d’entreprises. 2019 a par exemple été l’année de la levée record de 230 millions de dollars par Meero, qui automatise l’édition de photos grâce à l’intelligence artificielle, soit 20 % des fonds levés en 2019.
Comparé à d’autres marchés, comme celui des Etats-Unis, en Europe la part d’investissements publics est plus importante et certains financeurs tels que les fonds de pensions et d’universités jouent un rôle considérablement réduit. En France par exemple, la Banque publique d’investissement (Bpifrance) joue un rôle particulièrement important.
Enfin, l’innovation en IA ne provient pas uniquement des levées de fonds de start ups. Le gouvernement a investi une somme non négligeable, 1,5 milliards d’euros sur cinq ans. Dans plusieurs secteurs, par exemple médicaux et industriels, la France dispose déjà d’acteurs qui investissent fortement en IA, bénéficiant en outre d’avantages fiscaux compétitifs.
VS: Votre initiative crée donc un lienéducation et IA, quels sont les liens à renforcer entre IA et éducation (par exemple apprentissage de l’IA dans le secondaire) et éducation et IA (par exemple des assistants algorithmiques), et quels sont les impacts socio-économiques visés ?
TL&ML: Concernant l’éducation à l’IA, les niveaux de compréhension nécessaires varient considérablement selon les publics. Pour la majorité de la population, il est utile de comprendre les principaux enjeux, sans prendre plus de temps que les quelques heures de formation proposées par Objectif IA.
Dans le domaine de l’éducation, les professeurs doivent garder un rôle central. Des outils d’IA peuvent néanmoins soutenir leur travail en permettant un enseignement adapté aux besoins individuels de l’élève et en soulageant leur charge de travail. Dans le domaine de l’apprentissage de la lecture par exemple, des associations comme Agir pour l’école utilisent la reconnaissance vocale des sons que lit un élève pour permettre un apprentissage plus autonome et des exercices adaptés à son niveau de lecture.
VS: Confier à des algorithmes des tâches qui mènent à des décisions cruciales, par exemple en matière dejustice, d’embauche, ou d’autres décisions à forte conséquence humaine, questionne, quel est votre positionnement sur ce sujet ? Quelle place pensez-vous que l’éthique doit prendre dans votre enseignement ?
TL&ML: Face aux risques de discrimination des algorithmes à fort impact, deux considérations importantes entrent en jeu : le point de départ auquel nous nous comparons, c’est à dire les biais humains déjà présents, et la possibilité de mesurer les résultats finaux pour détecter, et ainsi corriger, d’éventuels biais.
La formation Objectif IA consacre plusieurs chapitres de son cours à restituer les enjeux éthiques, non seulement en démystifiant certaines idées reçues, mais également en précisant les points de vigilance et en proposant des solutions concrètes aux enjeux d’utilisation des données, d’information, de décisions algorithmiques et de biais.
VS: Le fait que des tâches cognitives de plus en plus complexes soient réalisées par des programmes nous amène-t-il à reconsidérer l’intelligence humaine ? Est-ce cela a des impacts sur notre vision de l’IA ? Sur son enseignement ?
TL&ML: Les systèmes d’intelligence artificielle sont très performants lorsqu’il s’agit de certaines tâches précises. Cela peut donner l’illusion que l’IA évolue rapidement vers le niveau d’intelligence humaine, et ainsi développer une vision négative et menaçante de l’IA.
Si les résultats de systèmes d’IA continuent à s’améliorer à grands pas, dans la plupart des cas ces avancées sont liées aux progrès en matière de puissance de calcul, qui ne sont pas toujours synonymes d’une plus grande intelligence, au sens de l’intelligence générale.
Comprendre la différence entre les atouts de l’intelligence étroite des systèmes d’IA largement utilisés dans notre société, et ceux de l’intelligence générale, le “sens commun”, dont disposent les humains, est essentiel pour articuler au mieux les deux.
VS: Nous vivons autemps des algorithmes. Quelle place voulons-nous accorder aux algorithmes dans la “cité” ? Est-ce que cela nous conduit à repenser cette cité ? Comment mieux nous préparer au monde de demain
Le recours de plus en plus massif aux algorithmes pour répondre à certains besoins quotidiens, tant au niveau individuel que collectif, est inévitable et doit être encouragé. Il existe néanmoins en France une défiance particulièrement forte envers les outils numériques – les difficultés du gouvernement à déployer l’application StopCovid (renommée TousAntiCovid) en est un exemple. Ces contestations mêlent parfois une variété d’enjeux posés par les outils numériques au sens large (protection des données personnelles, surveillance, transparence). Tout l’objectif d’Objectif IA est d’aider à démêler ces enjeux dans le cas de l’IA.
Théophile Lenoir, Responsable du programme Numérique, Institut Montaigne.
Milo Rignell, Chargé de l’innovation, Institut Montaigne.
Nous vous l’avions annoncé ici, Victor Storchan va nous présenter trois initiatives de formation à l’intelligence artificielle (IA).
Il s’entretient aujourd’hui avec Temuu Roos, Professeur d’IA et de Data Science à l’Université d’Helsinki, sur le MOOC « Elements Of AI” déployé en Finlande. Serge Abiteboul et Thierry Viéville.
Victor Storchan (VS) : Quelles ont été vos motivations initiales et vos objectifs pour l’élaboration de votre cours en ligne ?
Teemu Roos (TR): D’une certaine façon, nous voulons permettre aux gens de se lancer dans la technologie de la manière qu’ils jugent la plus appropriée pour eux-même. Certains voudront peut-être commencer à acquérir des compétences qui leur permettront d’évoluer et commencer à résoudre des problèmes par l’IA dans leur travail. Mais plus que cela, nous espérons que les gens pourront se forger leur opinion sur le type de technologie que nous devrions développer et comment cela devrait être réglementé.
VS: Quel est le public que vous visez ? Quels sont les apports de votre cours pour ce public ?
TR: En bref, notre cours s’adresse à tout le monde sauf ceux qui travaillent dans la technologie. Cependant, nous avons eu des retours indiquant que même pour ce type de personnes certaines parties du cours couvrant les implications sociétales leurs sont utiles.
Pour le grand public, le cours propose une introduction en douceur sans nécessiter aucune connaissances techniques a priori.
VS: Pouvez-vous partager les premiers résultats à ce stade et quelles sont vos perspectives futures ?
Sur les modèles d’écosystèmes français, finlandais et européen, questions spécifiques selon les partenaires
TR: Nous avons maintenant plus d’un demi-million d’inscriptions dans plus de 170 pays, et le cours est actuellement classé premier parmi tous les cours d’informatique ou d’IA sur Class Central. Nous venons de lancer le cours de suivi “Building AI”. Notre perspective d’avenir consiste à viser l’objectif de formation de 1% de la population européenne et à terme le monde entier.
VS: Comment vos ressources participent-elles à la création d’une confiance dans le développement de ces innovations, et aident-elles à développer un esprit critique constructif à ces sujets ?
Lors d’une déclaration commune en Août 2018, la France et la Finlande ont affirmé leur volonté partagée de “jouer un rôle actif pour promouvoir une vision de l’intelligence artificielle juste, solidaire et centrée sur l’humain, à la fois fondée sur la confiance et facteur de confiance”.
TR: Nous sommes pleinement attachés à la vision centrée sur l’humain d’une IA européenne digne de confiance : le cours invite le participant à se forger une opinion personnelle, éduquée et critique sur l’IA dès le début. Par exemple, le quatrième exercice demande au participant de critiquer les définitions existantes de l’IA et de proposer une définition qui lui est propre et qu’il juge plus pertinente. Un autre exercice lui demande de trouver des solutions au phénomène dit de « bulle de filtre » sur les réseaux sociaux. Le fait est qu’il n’y a aucune bonne ou mauvaise réponse à ces questions, et qu’aucune de leurs questions n’est notée automatiquement sous forme de questions à choix multiples, contrairement à ce qui est courant dans les MOOC. Au lieu de cela, les participants sont notés par d’autres participants dans un processus d’évaluation par les pairs, afin que chaque participant soit exposé aux pensées et aux arguments des autres.
Le projet entrepreneurial
VS: Quelles difficultés surmonte-t-on pour déployer un projet comme celui-ci ?
TR: Étant donné que le projet n’est pas seulement un cours en ligne mais une initiative plus large, il implique un réseau de collaboration étendu avec plusieurs partenaires dans chaque pays. Cela vient avec des frais généraux de coordination qui sont importants et nécessite des levées de fonds. Le projet, qui est un mélange de politiques éducatives, scientifiques, industrielles, publiques, et de communication est tout à fait unique dans son genre. Ceci rend difficile de le placer dans les catégories de projets déjà existantes.
VS: Pour “Elements of AI” qui est en train d’être déployé en Europe, quelles sont les difficultés spécifiques que l’on rencontre lors du passage à l’échelle européenne ?
TR: Le projet a reçu un énorme soutien de la Commission européenne et d’autres acteurs ainsi que de nos partenaires locaux dans chaque pays de l’UE, donc d’une certaine manière cela a peut-être été moins douloureux que prévu. Bien entendu, coordonner le projet est une tâche colossale. Il y a eu des problèmes mineurs liés à l’appariement de notre « marque » avec diverses organisations nationales et initiatives – par exemple, nous voulons garder le contrôle de toute publication dans le cadre de la marque “Elements of AI”. Cela signifie que nous ne pouvons pas systématiquement accepter les contenus que nous suggèrent nos partenaires dans les différents pays. À terme, nous aimerions bien sûr poursuivre la co-création de contenus éventuellement sous une marque commune avec nos merveilleux partenaires nationaux. Mais le l’ampleur et l’urgence du projet ont jusqu’à présent mis ces plans en suspens.
Note: Elements Of AI a reçu des fonds européens pour être traduit dans toutes les langues européennes.
Les modèles d’écosystèmes
VS: Au-delà de la formation, quels sont les atouts et les faiblesses de l’Europe pour peser dans la compétition technologique mondiale ? La dynamique européenne sur l’IA actuelle est-elle suffisamment ambitieuse ?
TR: La fragmentation de l’industrie est probablement le facteur le plus important. Il a des retombées sur la capacité de retenir les talents et les investissements en Europe. Au lieu de ça, on observe un mouvement des experts vers les États-Unis, notamment lors de montées en puissance appuyées par des fonds de capital-risque américains. L’Europe peut faire beaucoup mieux en tirant parti d’une main-d’œuvre qualifiée et d’institutions de recherche de qualité.
VS: Une récenteétude McKinsey a identifié la Finlande (avec 8 autres pays nordiques) comme pouvant prendre le leadership sur le numérique européen. Comment décririez-vous les spécificités de l’écosystème finlandais ?
TR: L’écosystème finlandais a récemment investi considérablement dans la numérisation à tous les étages. Les investissements en IA commencent peut-être seulement maintenant à augmenter en volume, mais le bon positionnement stratégique sur le numérique offre un environnement fertile pour un bon retour sur investissement de l’IA. Il convient de noter que ce ne sont pas seulement les industries des TIC (Technologies de l’information et de la communication) et des jeux qui sont manifestement « nées du numérique », les piliers traditionnels de l’industrie finlandaise (foresterie, industrie, maritime, construction) sont également bien préparés.
VS: Votre initiative crée donc un lienéducation et IA, quels sont les liens à renforcer entre IA et éducation (par exemple apprentissage de l’IA dans le secondaire) et éducation et IA (par exemple des assistants algorithmiques), et quels sont les impacts socio-économiques visés ?
TR: Je crois qu’il est le plus important d’apprendre les bases au secondaire : les mathématiques, le numérique, et peut-être la programmation. Si l’IA peut être introduite à ce niveau dans une certaine mesure, elle devrait l’être sous l’angle de la “littératie numérique” plutôt que par la dimension technique. Personnellement, je suis assez vieille école quand on parle d’éducation. Je vois une certaine valeur à appliquer l’IA dans l’éducation personnalisée. Par exemple, les applications d’apprentissage des langues telles que Duolingo sont bonnes parce que l’apprentissage de la langue exige la répétition, la répétition, et encore la répétition. Mais je pense toujours que dans l’ensemble, l’éducation nécessite une interaction interhumaine.
VS: Confier à des algorithmes des tâches qui mènent à des décisions cruciales, par exemple en matière dejustice, d’embauche, ou d’autres décisions à forte conséquence humaine, questionne, quel est votre positionnement sur ce sujet ? Quelle place pensez-vous que l’éthique doit prendre dans votre enseignement ?
TR: L’IA centrée sur l’humain est le concept clé ici. Nous devons toujours évaluer les conséquences du déploiement des systèmes d’IA d’une manière qui englobe l’ensemble du système : comment s’opère l’interaction souvent complexe et dynamique entre le système, ses opérateurs et ses utilisateurs. Il ne suffit pas de tester le logiciel indépendamment de son contexte.
VS: Le fait que des tâches cognitives de plus en plus complexes soient réalisées par des programmes nous amène-t-il à reconsidérer l’intelligence humaine ? Est-ce cela a des impacts sur notre vision de l’IA ? Sur son enseignement ?
TR: Je considère toujours l’IA comme un outil. L’utilisation de l’outil libère les humains pour faire plus de tâches « humaines ».
VS: Nous vivons autemps des algorithmes. Quelle place voulons-nous accorder aux algorithmes dans la “cité” ? Est-ce que cela nous conduit à repenser cette cité ? Comment mieux nous préparer au monde de demain?
TR: Comme je l’ai dit, je considère l’IA et les algorithmes comme des outils (certes complexes) et leur place devrait se limiter à celle qu’ont les outils dans notre société.
La formation des Européens aux enjeux technologiques et en particulier leur acculturation aux défis transverses de l’intelligence artificielle (IA) sont devenus des éléments incontournables des différentes stratégies IA présentées ces dernières années par les États membres de l’Union. Les défis sont de taille. Victor Storchan devient journaliste pour nous et nous propose une série d’articles pour nous présenter plusieurs initiatives. Serge Abiteboul et Thierry Viéville.
Oui, les défis sont de taille. Il s’agit d’abord de garantir que chacun pourra, dans sa vie professionnelle, maîtriser les connaissances indispensables pour travailler dans un environnement de travail où l’IA sera omniprésente. Chacun aura aussi à comprendre le monde dans lequel il vit pour être un citoyen pleinement éclairé. Pour ce qui est de l’IA, les approches participatives et inclusives entre les utilisateurs avertis et les concepteurs des modèles d’IA sont indispensables au développement d’une IA de confiance, respectueuse de la vie privée, transparente et non-discriminante. La formation en IA a donc un rôle considérable à jouer.
Mais quelle formation ? Nous présentons un regard croisé entre trois telles formations. Le but est de partager les motivations, les premiers résultats, les visions de trois écosystèmes :
– Temuu Roos, le créateur du MOOC « Elements Of AI”, parle de la genèse de ce cours en Finlande, puis sur son déploiement dans toute l’Europe et son ambition de former 1% de la population de l’Union.
– Théophile Lenoir et Milo Rignell partagent leur objectif de former le plus grand nombre de français aux fondamentaux de l’IA avec le MOOC “Objectif IA”.
– Frédéric Alexandre, Marie-Hélène Comte, Martine Courbin-Coulaud et Bastien Masse, décrivent la plateforme de formation ``IAI´´ de ClassCode du Inria Learning Lab.
Ces regards croisés permettent de saisir les enjeux, et de comprendre la complémentarité de ces trois approches. Ils permettent également de questionner les parcours entrepreneuriaux de chacun et le rôle des écosystèmes finlandais, français et européens dans le processus de déploiement d’un contenu pédagogique qui bénéficie au plus grand nombre.
Lorsqu’on parle d’intelligence artificielle, surgit très souvent le problème de la définition de ce que cette notion recouvre, en opposition ou en complément à une intelligence dite « humaine ». Profitant des travaux sur la formalisation d’une intelligence mécanique et de nombreux outils développés dans ce cadre, abordons la question passionnante de la modélisation de l’intelligence humaine ! Regardons ici comment quelques scientifiques essayent d’aborder cette question. Antoine Rousseau
Promouvoir une Intelligence Artificielle (IA) responsable et éthique en ouvrant une réflexion approfondie sur l’IA, par exemple la manière dont elle va impacter les différents aspects de la société, l’Observatoire des Impacts Technologiques Économiques et Sociétaux de l’Intelligence Artificielle (OTESIA) de la Côte d’Azur en a fait sa mission.
Comprendre pour maîtriser et non subir
Pour bien profiter de ce que l’IA propose, il faut comprendre comment ça marche, et ce n’est pas uniquement un enjeu technologique : nous devons développer nos compétences en matière de pensée informatique, c’est à dire bien comprendre ce qui peut être mécanisé au niveau du traitement de l’information (d’où le mot “informatique”), pour justement que notre pensée humaine ne se limite pas à cela.
Nous savons que plus le problème à résoudre est spécifique, plus une méthode algorithmique sera efficace, possiblement plus que la cognition humaine, tandis qu’à l’inverse plus le problème à résoudre est général, moins un algorithme ne pourra intrinsèquement être performant, quelle que soit la solution.
C’est une double approche, créative et d’esprit critique, vis-à-vis du numérique. Nous y contribuons avec ClassCode. On y montre aussi que le développement de l’intelligence artificielle modifie notre vision de ce que peut être l’intelligence humaine.
On se pose souvent la question “symétrique” de savoir si une machine peut être ou devenir intelligente : le débat est interminable, car – en gros – il suffit de changer la définition de ce que l’on appelle intelligence pour répondre “oui, pourquoi-pas” ou au contraire “non, jamais”. La vraie définition de l’IA est de “faire faire à une machine ce qui aurait été intelligent si réalisé par un humain”, ce qui évite de considérer cette question mal posée.
L’intelligence artificielle comme modèle de l’intelligence naturelle
L’IA permet aussi de mieux étudier notre intelligence. Pas uniquement en fournissant des techniques pour améliorer l’apprentissage d’une personne, mais aussi en tentant de mieux comprendre les apprentissages humains. En effet, pour faire fonctionner des intelligences algorithmiques on dispose de modèles de l’apprentissage mécanique, de plus en plus sophistiqués. Dans quelle mesure peuvent-ils aussi aider à modéliser l’apprentissage humain pour mieux l’appréhender ?
Pour répondre à cette question, le projet AIDE construit un formalisme, une ontologie, permettant de réaliser une modélisation de la personne apprenante, de la tâche et des observables au cours de l’activité, ceci afin de développer un modèle applicable aux données qui puisse être exploité pour les analyser avec des approches computationnelles, et modéliser les tâches de résolution créative de problèmes.
Modéliser la tâche d’apprentissage et se donner des observables
Pour cela, il faut observer les traces d’apprentissage, avoir des sources de mesure. Ces traces d’apprentissages sont relevées lors de l’utilisation d’un logiciel (mesure des déplacements de la souris, des saisies au clavier…), en analysant des vidéos des activités, mais aussi grâce à des capteurs employés dans des situations pédagogiques sans ordinateur (par exemple une activité physique dans une cours d’école, observée avec des capteurs visuels ou corporels). Exploiter ces mesures impose alors non seulement de formaliser la tâche d’apprentissage elle-même, mais en plus, de modéliser la personne apprenante (pas dans sa globalité bien entendu, mais dans le contexte de la tâche).
Une approche pluridisciplinaire
L’apprenant·e est ainsi modélisé·e à partir de connaissances issues des neurosciences cognitives. Dans ce cadre, on structure les facultés cognitives humaines selon deux dimensions.
La première dimension prend en compte les différentes formes d’association entre entrées sensorielles externes ou internes et les réponses à y apporter, des plus simples (schémas sensori-moteurs, comportements liés aux habitudes) aux plus complexes (comportements dirigés par un but, décisions après délibérations ou raisonnements).
La deuxième dimension prend en compte le fait que ces associations peuvent être apprises et exécutées pour quatre différentes classes de motivations (pour aider à identifier un ‘objet’ de l’environnement comme but possible du comportement, pour le localiser ou y prêter attention, pour le manipuler ou encore pour définir en quoi il répond à une motivation).
Cette modélisation inscrit ces différents concepts au sein de l’architecture cérébrale, permettant de spécifier ainsi le rôle fonctionnel de ces régions (cortex préfrontal, boucles impliquant les ganglions de la base, incluant l’amygdale, en lien avec le thalamus et l’hippocampe).
En explicitant les différentes fonctionnalités liées à ces deux dimensions, on rend compte de nombreuses fonctions cognitives, en particulier relatives à la résolution de problèmes. Il s’agit donc d’un cadre de description intéressant car il est structuré, relativement compact et rend compte de ce qui semble s’être développé pour élaborer l’architecture cognitive du cerveau.
Ontologie et modèle de données pour l’étude d’une activité d’apprentissage médiatisée par des robots pédagogiques (Romero, Viéville & Heiser, 2021).
Un exemple de questionnement : exploration versus exploitation
Dans des activités de résolution de problèmes, on peut considérer que les sujets alternent entre deux principaux modes de raisonnement : l’exploration vise à “expérimenter des nouvelles alternatives” pour générer de nouvelles connaissances (par exemple la recombinaison de connaissances pour développer une nouvelle idée), tandis que l’exploitation est l’usage des connaissances (déclaratives, procédurales) existantes dans une situation donnée.
Dans une situation que le sujet reconnaît comme familière, le sujet peut exploiter ses connaissances pour résoudre la situation existante s’il vise un objectif de performance (performance goal). Mais, dans cette même situation, il pourrait également décider d’explorer la situation de manière différente s’il a des buts de maîtrise ou, même, si au moment de développer une première solution, il avait envisagé plusieurs idées de solution qu’il avait laissées de côté au moment de réussir la situation-problème une première fois.
Dans des situations problèmes, le sujet est face à une double-incertitude, sur la manière mais aussi sur les moyens d’arriver au but. Dans ces circonstances, les connaissances (déclaratives et procédurales) pour arriver au but ne sont pas clairement structurées et le sujet se doit d’explorer les moyens à sa disposition pour pouvoir développer des connaissances lui permettant de développer une idée de solution.
La régulation des modes exploration/exploitation pour accomplir la tâche.
Les tâches simples nécessitent juste l’exploitation, cependant, les tâches plus complexes nécessiteraient l’exploration pour être complétées, nécessitant ainsi de pouvoir combiner les deux modes.
Exploration et exploitation selon la (mé)connaissance des moyens en lien aux objectifs (Busscher et al 2019).
Ce domaine en est encore à ses débuts et des actions de recherches exploratoires qui allient sciences de l’éducation, sciences du numérique (dont intelligence artificielle symbolique et numérique) et neurosciences cognitives se développent.
Au-delà de ce projet, dans le cadre d’OTESIA, on étudie aussi l’impact de l’apprentissage machine sur les compétences professionnelles pour contribuer à une compréhension des processus d’apprentissage par lesquels les entreprises développent de nouvelles capacités technologiques, c’est un autre projet. Par ailleurs, les liens entre IA et santé, pour décrypter les multiples dimensions et impacts de l’usage du numérique dans les établissements médico-sociaux, notamment les EHPAD, et analyser le lien entre soin et numérique sont aussi étudiés. Enfin, la prévention du cyber-harcèlement et de la cyber-haine, à travers le développement d’un logiciel de détection des messages haineux à partir d’une analyse du langage naturel pour comprendre permettre aux victimes de développer leur esprit critique et un contre-discours pour une meilleure lutte contre ce fléau.
Lisa Roux, Margarida Romero, Frédéric Alexandre et Thierry Viéville.
Class´Code IAI : Ouvert en avril 2020, le Mooc Class’Code IAI “Intelligence Artificielle avec Intelligence” offre une initiation à l’Intelligence artificielle, gratuite et attestée, via une formation citoyenne qui a attiré jusqu’à présent plus de 18800 personnes. Son approche ludique et pratique et la diversité de ses supports – vidéos conçues avec humour, tutos et activités pour manipuler, ressources textuelles pour aller plus loin, un forum pour échanger et enfin des exercices pour s’évaluer – a remporté un grand succès chez nos mooqueurs et mooqueuses qui se disent satisfaits à plus de 94%.
Omniprésente dans les médias depuis quelques années, l’intelligence artificielle est décrite tantôt comme l’avenir de l’humanité, tantôt comme sa fossoyeuse. Nous reprenons un article de Fabien Gandon consacré à la notion d’intelligence et publié par The Conversation. Thierry Viéville.
Les IA ne saisissent pas les finalités, les conséquences et le contexte de ce qu’on leur demande. studiostoks / shutterstock
Que ce soit dans vos choix de séries TV à regarder, dans l’analyse de vos résultats médicaux, dans vos rencontres amoureuses, dans l’attribution de votre prêt ou dans les réglages de vos prises de photos – les IA mettent leur grain de sel partout. Ce qui rend peut-être d’autant plus surprenante la réponse à cette question : non, aujourd’hui, les IA ne comprennent pas ce qu’elles font.
Par contre, décomposer la question et détailler la réponse permet de soulever beaucoup de problèmes, d’ambiguïtés et d’enjeux de l’« intelligence » artificielle. « Intelligence » avec des guillemets, car les méthodes actuelles sont essentiellement des simulations très spécifiques et convaincantes, sur lesquelles nous projetons beaucoup plus que ce qu’elles renferment réellement, à commencer par cette impression de compréhension. Il est difficile de savoir si, dans le futur, les IA continueront à ne pas comprendre. Mais, en l’état des connaissances, la réponse est « non »… jusqu’à preuve du contraire.
Si on parcourt des dictionnaires, on peut lire que « comprendre », c’est saisir le sens, les finalités, les causes et conséquences, les principes. Comprendre quelque chose, c’est recevoir ou élaborer une représentation de cette chose, c’est s’approprier une conceptualisation reçue ou construite, qui permettra notamment de produire un comportement intelligent.
Du Graal de l’« IA forte » à la réalité de l’IA
Pour ce qui est des intelligences artificielles, une première catégorie est celle de l’« IA forte » ou « généralisée » : un seul et même système qui serait capable d’apprendre et d’effectuer tout type d’activité intelligente. Un tel système n’existe pas à ce jour et donc, pour ce cas, la question est close. On peut tout de même remarquer au passage que l’une des distinctions parfois faites entre « IA forte » et « IA faible » est justement la capacité de comprendre et d’être conscient.
Un système d’« IA faible » est un système conçu par l’humain pour simuler de la façon la plus autonome possible un comportement intelligent spécifique. En l’état actuel de la recherche, c’est l’homme qui produit le système artificiel qui va simuler un comportement intelligent – ce n’est pas une intelligence artificielle qui, par sa compréhension, créerait son propre comportement. En IA faible, l’homme choisit la tâche pour laquelle on a besoin d’automatiser un comportement intelligent, les données qu’il fournit au système et leurs représentations informatique, les algorithmes utilisés pour simuler ce comportement (par exemple, un réseau de neurones spécifique), les « variables de sorties » ou les objectifs qu’il attend du système (par exemple, différencier les chats des chiens) et la façon dont ils seront intégrés à une application (par exemple, trier automatiquement les photos sur votre téléphone). La méthode d’IA faible ne comprend pas le contexte dans lequel elle est exécutée, ni de ce que ces différents aspects choisis par l’homme représentent.
Il existe beaucoup d’approches et de méthodes différentes pour produire des systèmes d’IA faible, mais elles partagent toutes cette absence de compréhension.
Différentes méthodes d’IA faible, dont aucune ne saisit la signification de ses calculs
On peut différencier différents systèmes d’IA faible par les données sur lesquelles ils travaillent, par exemple un texte, un graphe de connaissances, des vidéos ou un mélange de différents types de données.
Les systèmes d’IA faible se différencient aussi par les techniques qu’ils utilisent. On peut citer par exemple d’une part les réseaux de neurones pour apprendre de façon plus ou moins supervisée par un humain, d’autre part des « systèmes experts » pour déduire de nouvelles connaissances en utilisant un moteur d’inférence à partir de connaissances établies, ou encore des « systèmes multi-agents » pour simuler des comportements sociaux. Dans toutes ces méthodes, les buts sont fixés par l’humain, ainsi que l’évaluation des performances de l’IA.
Prenons l’exemple de différentes approches d’apprentissage automatique. Dans l’apprentissage supervisé dit « actif », l’IA est capable de solliciter d’elle-même des exemples à lui fournir pour améliorer son apprentissage, mais sans compréhension de ce qu’elle fait au-delà de cette optimisation. Dans le cas de l’apprentissage « non supervisé », l’humain ne fixe pas exactement les catégories de sorties attendues, mais le but reste fixé : il s’agit de découvrir des structures sous-jacentes à des données – l’IA propose d’elle-même des regroupements, mais elle est pilotée par des fonctions d’évaluation de ses performances qui sont fixées par son concepteur. Il en va de même pour l’apprentissage par renforcement dont le principe consiste à répéter des expériences pour apprendre les décisions à prendre de façon à optimiser une récompense, décidée par l’humain, au cours du temps.
Un autre exemple concerne la branche de l’IA qui ne s’intéresse pas à l’apprentissage, mais à l’inférence. Le composant central, dit « moteur d’inférences » cherche à déduire un maximum de conclusions à partir des connaissances qu’on lui fournit. Dans cette approche, la capacité intelligente que l’on souhaite simuler est essentiellement une forme de raisonnement. Mais ici encore, les inférences à faire et les méthodes utilisées sont déterminées par le concepteur et restent complètement en dehors du champ de vision et d’action du système : l’IA ne comprend rien à son contexte, elle simule des inférences ciblées.
Une métaphore utilisée pour cette situation est celle de la chambre chinoise de Searle : une personne non sinophone est enfermée dans une pièce et fait illusion quant à sa capacité de comprendre et de s’exprimer en chinois, car elle répond à des questions inscrites sur des papiers reçus de l’extérieur uniquement à l’aide d’un livre indiquant quelle réponse donner à quelle question. Comme notre captif, les méthodes d’IA faible n’ont aucun accès à la signification de leur tâche, aucune mise en contexte. Cette simulation d’un comportement spécifique ne vient pas avec tout le reste des capacités que nous mobilisons à chaque instant et dans lequel notre comportement intelligent s’inscrit.
Sommes-nous dupes de notre propre farce ?
Le danger de l’IA c’est que lorsqu’elle simule assez bien une forme de comportement intelligent, on peut projeter beaucoup de choses sur elle, bien au-delà de ce qu’elle fait réellement. En particulier, on peut lui prêter une compréhension ou d’autres traits qu’elle n’a pas comme nous allons l’illustrer.
Prenons l’exemple des leurres conversationnels qui sont de petits systèmes très simples dont le seul but est de relancer la conversation pour que nous continuions à parler au système sans aucune compréhension de sa part. Le plus ancien et le plus connu est le chatbot Eliza qui dans les années 60 singeait une séance de psychothérapie avec des modèles de phrases toutes faites comme « et comment vous-sentez vous à propos de […] ? ». Plus récemment le chatbot vocal peu sophistiqué Lenny utilise juste un ensemble de phrases préenregistrées afin de faire parler le plus longtemps possible une personne vous appelant pour du démarchage par téléphone. Eliza et Lenny montrent comment un programme simpliste peut nous duper : par conception, le programme ne comprend rien, mais l’utilisateur va se comporter, interagir et finir même par croire qu’il comprend.
Ce sont là moins des démonstrations de prouesses d’intelligence artificielle que des preuves des limites de l’intelligence humaine et ces limites peuvent participer à faire qu’une IA, même « faible », soit dangereuse. On voit des soldats-démineurs s’attacher à leurs robots-démineurs au point d’interroger sur leur capacité à accepter de les mettre en danger alors que leur raison d’être est celle d’artefacts que l’on souhaite sacrifier à la place d’humains.
C’est parce qu’elle semble agir comme si elle était intelligente que nous projetons sur elle des caractéristiques qu’elle n’a pas, et que nous commençons à lui donner une place qu’elle ne devrait pas forcément occuper – ou du moins, pas seule.
Pourquoi l’absence de compréhension est-elle une limitation très importante pour nos utilisations de l’IA ?
Plus que de s’inquiéter de ce que les IA comprennent trop, il faudrait s’inquiéter de ce que les humains ne comprennent pas assez : les biais des données et des algorithmes, l’impact sur la société d’une gouvernementalité algorithmique, etc.
De plus, alors que les chatbots Eliza et Lenny « dupent » les humains, l’expérience du détournement du chatbot Tay de Microsoft montre ce qui se passe quand quelques humains peuvent retourner la situation. Ils comprennent comment la simulation d’intelligence fonctionne et utilisent cette compréhension contre elle pour manipuler l’IA, l’influencer et la dévier du but pour lequel elle était conçue, mais qu’elle ne comprend pas – la laissant incapable de comprendre son propre détournement (un prérequis pour le corriger).
Le documentaire de Netflix sur l’affaire Cambridge Analytica.
Mais surtout, il est très dangereux actuellement de laisser des IA qui ne comprennent absolument pas ce qu’elles font aux commandes de systèmes dans lesquels les humains ne réalisent plus ce qui se passe, soit parce qu’ils n’ont pas su identifier les implications de leur système, soit parce que celui-ci commet des erreurs non détectées ou à une vitesse bien au-dessus de nos temps de réaction d’humains (par exemple, des algorithmes de « flash trading »).
Les « bulles de filtrage » qui se forment autour de nous lorsque nous ne voyons plus du Web que ce que nos applications nous recommandent, les suggestions racistes parce que personne n’avait détecté les biais des données, l’exposition à des nouvelles déprimantes pour vendre des voyages sont autant d’exemples de dérives de systèmes d’IA faible qui ne savent qu’optimiser leurs objectifs sans comprendre ce qu’ils font et, a fortiori, les dégâts qu’ils causent. Et ne parlons pas à nouveau des cas où leurs concepteurs sont mal intentionnés : ne comptez pas sur l’IA faible pour comprendre que ce qu’elle fait est mal.
Une combinaison particulièrement dangereuse actuellement est donc celle d’une IA faible (par exemple, un système de recommandation) déployée dans une application ayant énormément d’utilisateurs (par exemple, un grand réseau social) et prenant des décisions à une vitesse bien au-delà de notre temps de réaction d’humain. Car de la même façon que les intelligences artificielles faibles peuvent produire des résultats très impressionnants, une bêtise artificielle (même faible) peut produire des dégâts énormes.
Ainsi, c’est précisément parce que les IA ne comprennent pas que nous ne devons pas leur donner des responsabilités pour lesquelles il est vital de comprendre. C’est aussi pour cette raison que développer les capacités d’explication des IA est actuellement un enjeu majeur. Et, si les chercheurs utilisent parfois la métaphore de la chambre chinoise de Searle pour souligner le manque de compréhension de la machine, il semble aussi important que nous soyons vigilants à ce que la complexité, l’opacité et la vitesse des systèmes que nous concevons ne nous enferment pas à notre tour dans cette chambre d’incompréhension.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible que tout n’est pas vrai ou faux en informatique on peut aussi … modéliser une vérité contingente. Marie-Agnès Enard, Pascal Guitton etThierry Viéville.
Il ne l’écoutait que d’une oreille. Elle parlait de science. Lui, il aimait plutôt voyager en imagination au sein de toutes sortes de mondes possibles, certains mondes étant accessibles à d’autres … Il aimait se dire que la vérité dépend tellement du contexte où nous sommes, ou encore qu’une chose peut être seulement possible, sans être toujours vraie, que … Quoi ? Qu’est ce qu’elle dit là l’informaticienne de service ?
Lui : Mais qu’est ce que tu racontes, en informatique l’information est forcément binaire : si une chose n’est pas vraie, elle est fausse, et voilà, 1 ou 0, point.
Elle : Est-ce qu’il y a une vie après la mort ?
Lui : Ben, je sais pas …
Elle : Tu as donc besoin de plus de deux valeurs pour coder ton sentiment. Il t’en faut au moins trois : vrai, faux, inconnu.
Lui : C’est même un peu plus compliqué, on peut y croire ou pas.
Elle : Exact, tu as donc – pour faire simple – deux modalités possibles, la première si une vie après la mort existe et la seconde où elle n’existe pas.
Lui : Oui, je comprends
Elle : On peut aller plus loin et s’interroger pour savoir si cette vie après la mort est proche de ce que nous avons connu avant ou bien si elle est totalement différente. Pourquoi pas ! Du coup il y a encore deux modalités, autrement dit deux autres mondes qui dérivent du monde où il y a une vie post-mortem. Bref : tu as donc besoin de préciser dans quel “monde” (ou modalité), c’est à dire dans quel contexte tu es, pour dire …
Lui : OK, selon le “monde” ou la modalité, on peut dire qu’il y a des choses possibles ou impossibles, des choses nécessaires, des choses … oh là là je m’embrouille un peu.
Elle : Tu as raison il faut bien poser les choses, écoute : « quelque chose est nécessaire dans un contexte donné s’il n’est pas possible que ce soit logiquement faux » autrement dit si tu peux pas montrer que quelque chose est faux, quelle que soit la manière dont tu t’y prends, alors cette chose là est nécessaire, et si tu ne peux pas montrer qu’elle est toujours fausse alors elle est possible.
Lui : Wouaouhh, est-ce que tu es en train de me dire que les informaticiens ont envisagé et modélisé tout ça ? Moi je croyais qu’ils …
Lui : Oups, pardon. Je croyais donc qu’illes représentaient les choses incertaines avec des probabilités.
Elle : Oui, c’est vrai, mais attention l’incertitude c’est différent : il y a des choses plus ou moins connues, qui peuvent être possibles ou impossibles ou au contraire nécessaires, et puis des choses incertaines par exemple :
– quand tu jettes une pièce de monnaie, tu es absolument certain qu’il y a une chance sur deux que ce soit pile ou face, c’est un phénomène certes incertain mais pas inattendu,
– mais si ta pièce de monnaie reste en l’air ou tombe sur la tranche alors là ce n’est plus incertain : c’est inattendu, c’est à dire que ton modèle initial “pile ou face” est à revoir …
Lui : Ah mais oui, et en plus le fait qu’elle tombe sur la tranche est possible mais le fait qu’elle reste en l’air est impossible car il est nécessaire qu’elle retombe dans un monde “normal”.
Elle : Exactement.
Lui : Dis-moi si mes souvenirs sont bons : les probabilités sont bien représentées par des valeurs
entre 0 (quand c’est impossible) et 1 (quand c’est certain) ?
Elle : Rassure-toi, tu as bien retenu ton cours de math ! Donc, on va aussi représenter la possibilité par des valeurs
entre 0 (si totalement impossible) et 1 (si parfaitement possible)
et la nécessité par des valeurs
entre 0 (si rien ne dit qu’elle est nécessaire) et 1 (si absolument nécessaire).
Sur la courbe , tu vois que le niveau de possibilité est représenté horizontalement alors que le niveau de nécessité l’est verticalement.
Lui : D’accord et si j’ai bien compris,
– quelque chose est assurément faux si c’est impossible, donc du coup pas nécessaire du tout, et c’est le coin en bas à gauche, tandis que
– quelque chose est assurément vrai, si c’est absolument nécessaire, donc du coup totalement possible, et c’est le coin en haut à droite.
Elle : Oui, c’est bien ça. Et de ce fait quelque chose de complètement inconnu est à la fois complètement possible (comme quand on dit « pourquoi pas ? ») et absolument pas nécessaire (puisque l’on ne peut rien en dire), c’est le coin en bas à droite.
Lui : Ce que je trouve le plus intéressant, tu sais, c’est que dans une discussion j’ai l’impression qu’on va parfois jusqu’à se disputer, alors qu’on est peut-être même pas vraiment en désaccord, juste parce qu’on utilise une vision trop “binaire” de la vérité, alors qu’elle est plus en nuances, et surtout qu’elle dépend souvent du contexte.
Elle : Oui tu peux même relier cela à la probabilité que quelque chose se produise, c’est à dire relier cela à la notion d’aléatoire :
0 ≤ nécessité ≤ probabilité ≤ possibilité ≤ 1
La modélisation de l’incertitude est de plus en plus utilisée notamment en intelligence artificielle ou dans les ordinateurs quantiques dont tu as entendu parler.
Lui : Euh … stop ! Cela fait trop de choses d’un coup. Laisse moi avec cette idée géniale, qu’on a pu modéliser une notion de vérité bien plus ouverte que “vrai” ou “faux” avec le droit de dire “on ne sait pas encore” et des nuances entre ce qui est plus ou moins possible ou nécessaire. Et c’est très utile bien au-delà du champ de l’informatique elle-même !
Elle : Oui, tu as entièrement raison. Et toi, à ton tour, est-ce que tu peux me faire partager les mondes imaginaires que tu as dans ta tête ?
Lui : Mais … comment as tu deviné ce qu’il y a dans ma tête … comment c’est possible ?
Elle : Parce que tu es mon frère, gros bêta, et … est-ce nécessaire de tout expliquer ?
Les liens entre Intelligence Artificielle et Éducation sont multiples : L’IA comme outil pour mieux apprendre, comme outil pour mieux comprendre comment on apprend, comme sujet à part entière et enfin comme objet d’enseignement. Pascal Guitton et Thierry Viéville nous parlent de ces différentes facettes. Serge Abiteboul.
L’IA comme outil pour mieux apprendre
C’est le premier usage auquel on pense, utiliser des algorithmes d’IA pour proposer des outils afin de mieux apprendre. Bien entendu, il y a beaucoup de mythes et de croyances à dépasser pour concrétiser cette première idée.
Pixabay
Le point clé est l’apprentissage adaptatif : en analysant les traces d’apprentissage de l’apprenant·e, par exemple ses résultats à des questionnaires, son interaction avec le logiciel…, le système va modifier son fonctionnement, notamment à travers la sélection de contenus, pour essayer de s’adapter à la personne.. Même si les fondements scientifiques n’en sont pas encore totalement stabilisés, on peut aussi exploiter une analyse de son “comportement” via l’utilisation de capteurs. Cela va d’une caméra sur son portable jusqu’à des interfaces cerveau-ordinateur en laboratoire. Ce principe d’adaptation se rencontre le plus souvent dans un contexte ludique et individuel, un jeu pédagogique avec la machine, mais existe également dans d’autres situations, par exemple avec plusieurs personnes.
Cette approche implique au préalable un travail souvent colossal pour formaliser complètement les savoirs et savoir-faire à faire acquérir. Cette formalisation est en soi intéressante car elle oblige à bien expliciter et à structurer les compétences, les connaissances et les pratiques qui permettent de les acquérir. Il faut cependant prendre garde à ne pas “sur-organiser” l’apprentissage qui demeure dans tous les cas une tâche cognitive complexe.
Par ailleurs, cette approche nécessite de travailler dans un contexte d’apprentissage numérique qui s’accompagne des contraintes bien connues comme les besoins de matériels, de formation aux logiciels, les limites à l’usage d’écrans, etc.
On peut mentionner plusieurs impacts pédagogiques de cet apprentissage algorithmique. En tout premier lieu, il génère en général un meilleur engagement de la personne apprenante, car interagir autrement avec les contenus offre une chance supplémentaire de bien les comprendre. Par ailleurs, la machine ne “juge pas” -comme un humain-, ce qui peut contribuer à maintenir cet engagement. Ensuite, et sans doute surtout, le fait que la difficulté soit adaptée à l’apprenant permet de limiter, voire d’éviter le découragement ou la lassitude. Ce type d’apprentissage nécessite cependant un investissement cognitif important. Enfin, si l’aspect ludique est “trop” prépondérant, il ne faut pas négliger le risque de se disperser au lieu de s’investir dans l’apprentissage escompté.
L’usage de ces nouveaux outils conduit le rôle de l’enseignant·e à évoluer. Ainsi, profitant que sa classe est plus investie dans des activités d’apprentissage autonomes, il a plus de disponibilités pour individualiser sa pratique pédagogique, avec les élèves qui en ont le plus besoin. De même, cela permet de se libérer – comme en pédagogie inversée – d’une partie du passage des savoirs ou de l’accompagnement de l’acquisition de savoir-faire, avec des contenus multimédia auto-évalués et des exercices d’entraînement automatisés, pour se concentrer sur d’autres approches pédagogiques, par exemple, par projets. Par rapport à des outils numériques classiques, sans IA, le degré d’apprentissage en autonomie peut être bien plus élevé et s’applique plus largement, par exemple, avec des exercices auto-corrigés et des parcours complets d’acquisition de compétences. Ces outils sont particulièrement d’actualité dans des situations d’école distancielle avec la crise sanitaire, et questionnent sur l’organisation du temps de travail scolaire.
L’utilisation de tels outils peut s’accompagner de dérives possibles dont on doit se protéger : traçage omniprésent et omnipotent des personnes apprenantes permettant de les “catégoriser”, tentation de réduire l’offre humaine en matière d’enseignement, renforcement des inégalités en lien avec l’illectronisme, etc… Le risque est accru quand ces traces sont reliées à celles émanant d’autres facettes de son comportement : achats, consultations de vidéos/lectures…
L’IA comme outil pour mieux comprendre comment on apprend
Pixabay
La possibilité de mesurer ces traces d’apprentissage n’offre pas uniquement une technique pour améliorer “immédiatement” l’apprentissage d’une personne, mais fournit aussi des sources de mesures pour mieux comprendre sur le long terme les apprentissages humains. Ces traces d’apprentissages sont relevées lors de l’utilisation d’un logiciel, par la mesure des déplacements de la souris, des saisies au clavier…, mais aussi grâce à des capteurs employés dans des situations pédagogiques sans ordinateur. On pense par exemple à une activité physique dans une cours d’école, observée avec des capteurs visuels ou corporels. Exploiter ces mesures impose alors non seulement de formaliser la tâche d’apprentissage elle-même, mais en plus, de modéliser la personne apprenante. Pas dans sa globalité bien entendu, mais dans le contexte de la tâche.
Il faut noter que ces algorithmes d’apprentissage machine reposent sur des modèles assez sophistiqués. Ils ne sont pas forcément limités à des mécanismes d’apprentissage supervisés où les réponses s’ajustent à partir d’exemples fournis avec la solution, mais fonctionnent aussi par “renforcement”, c’est à dire quand l’apprentissage se fait à partir de simples retours positifs (autrement dit par des récompenses) ou négatifs, le système devant inférer les causes qui conduisent à ce retour, parfois donc en construisant un modèle interne de la tâche à effectuer. Ils peuvent s’appliquer aussi en présence de mécanismes qui ajustent au mieux les comportements exploratoires (qualifiés de divergents) d’une part et les comportements exploitant ce qui est acquis (qualifiés de convergents) d’autre part. Ces modèles sont opérationnels, c’est-à-dire qu’ils permettent de créer des algorithmes effectifs qui apprennent. Il est passionnant de s’interroger dans quelle mesure ces modèles pourraient contribuer à représenter aussi l’apprentissage humain. Rappelons que, en neuroscience, ces modèles dits computationnels (c’est-à-dire qui représentent les processus sous forme de mécanismes de calculs ou de traitement de l’information) sont déjà largement utilisés pour expliquer le fonctionnement du cerveau au niveau neuronal. Dans ce contexte, ce serait de manière plus abstraite au niveau cognitif.
Ce domaine en est encore à ses débuts et des actions de recherches exploratoires qui allient sciences de l’éducation, sciences du numérique et neurosciences cognitives se développent.
L’IA comme sujet d’enseignement
https://classcocde.fr/iai une formation citoyenne à l’intelligence artificielle intelligente.
Bien entendu pour maîtriser le numérique et pas uniquement le consommer, au risque de devenir un utilisateur docile voir même crédule, il faut comprendre les principes de son fonctionnement à la fois au niveau technique et applicatif.
Il est essentiel de comprendre par exemple que ces algorithmes ne se programment pas explicitement à l’aide “d’instructions”, mais en fournissant des données à partir desquelles ils ajustent leurs paramètres. Il est aussi nécessaire de se familiariser au niveau applicatif avec les conséquences juridiques, par exemple, d’avoir dans son environnement un “cobot” c’est-à-dire un mécanisme robotique en interaction avec notre vie quotidienne. Ce système n’est quasiment jamais anthropomorphique (c’est à dire possédant une forme approchant celle de l’humain), c’est par exemple une machine médicale qui va devoir prendre en urgence des décisions thérapeutiques quant à la santé d’une personne que la machine monitore. On voit dans cet exemple que la chaîne de responsabilité entre conception, construction, installation, paramétrisation et utilisation est très différente de celle d’une machine qui fonctionne sans algorithme, donc dont le comportement n’est pas partiellement autonome.
Le MOOC https://classcode.fr/iai sur l’IA est justement là pour contribuer à cette éducation citoyenne, et faire de l’IA un sujet d’enseignement.
L’IA comme un objet d’enseignement qui bouleverse ce que nous devons enseigner.
En effet, la mécanisation de processus dits intelligents change notre vision de l’intelligence humaine : nous voilà déléguer à la machine des tâches que nous aurions qualifiées intelligentes si nous les avions exécutées nous mêmes. Nous allons donc avoir moins besoin d’apprendre des savoir-faire que nous n’aurons plus à exécuter, mais plus à prendre de la hauteur pour avoir une représentation de ce que les mécanismes “computent” (c’est-à-dire calculent sur des nombres mais aussi des symboles) pour nous.
C’est un sujet très concret. Par exemple, avec les calculettes … devons nous encore apprendre à calculer ? Sûrement un peu pour développer son esprit, et comprendre ce qui se passe quand s’effectue une opération arithmétique, mais nous avons moins besoin de devenir de « bons calculateurs ». Par contre, ils nous faudra toujours être entraînés au calcul des ordres de grandeurs, pour vérifier qu’il n’y a pas d’erreur quand on a posé le calcul, ou s’assurer que le calcul lui-même est pertinent. De même avec les traducteurs automatiques, l’apprentissage des langues va fortement évoluer, sûrement avec moins le besoin de savoir traduire mot à mot, mais plus celui de prendre de la hauteur par rapport au sens et à la façon de s’exprimer, ou pas … c’est un vrai sujet ouvert.
Finalement, si nous nous contentons d’utiliser des algorithmes d’IA sans chercher à comprendre leurs grands principes de fonctionnement et quelles implications ils entraînent sur notre vie, nous allons perdre de l’intelligence individuelle et collective : nous nous en remettrons à leurs mécanismes en réfléchissant moins par nous-même.
Au contraire, si nous cherchons à comprendre et à maîtriser ces processus, alors la possibilité de mécaniser une partie de l’intelligence nous offre une chance de nous libérer en pleine conscience de ces tâches devenues mécaniques afin de consacrer notre intelligence humaine à des objectifs de plus haut niveau, et à considérer des questions humainement plus importantes.
Pascal Guitton et Thierry Viéville.
P.S.: pour aller plus loin Inria partage un livre blanc « Education et Numérique : enjeux et défis », organisé en cinq volets : – état des lieux de l’impact du numérique sur le secteur de l’éducation; – identification des défis du secteur ;
– présentation des sujets de recherche liés au domaine de l’éducation au numérique ;
– analyse des enjeux français dans le domaine ;
– et enfin mise en avant de sept recommandations pour la transformation numérique de l’éducation.

 binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible … comment les mots prennent du sens dans notre cerveau et ainsi mieux comprendre la différence entre l’intelligence naturelle et algorithmique.
binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible … comment les mots prennent du sens dans notre cerveau et ainsi mieux comprendre la différence entre l’intelligence naturelle et algorithmique.











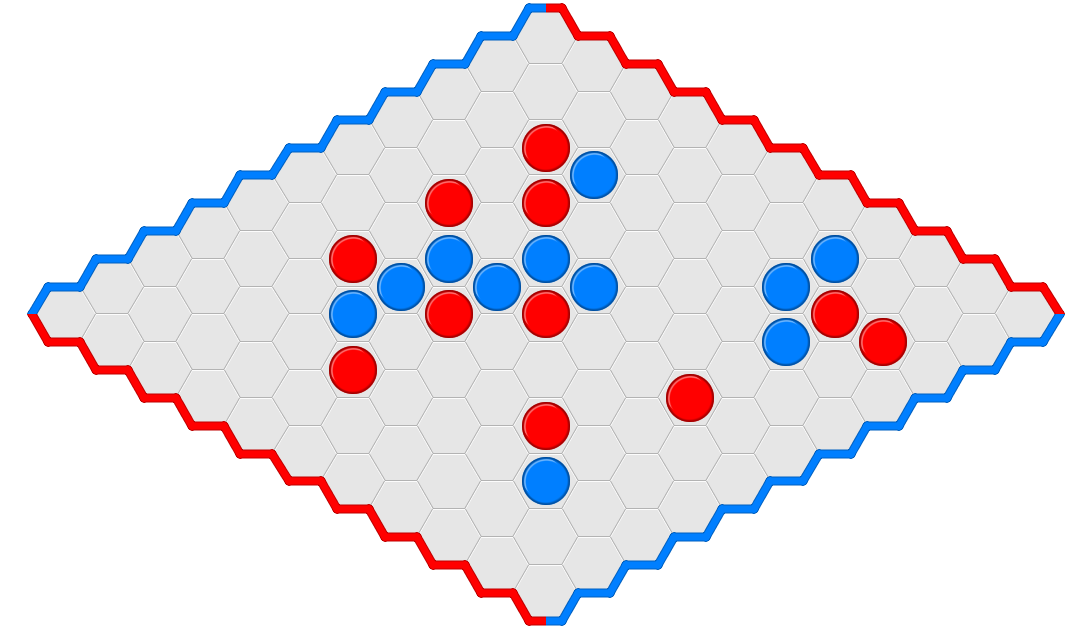
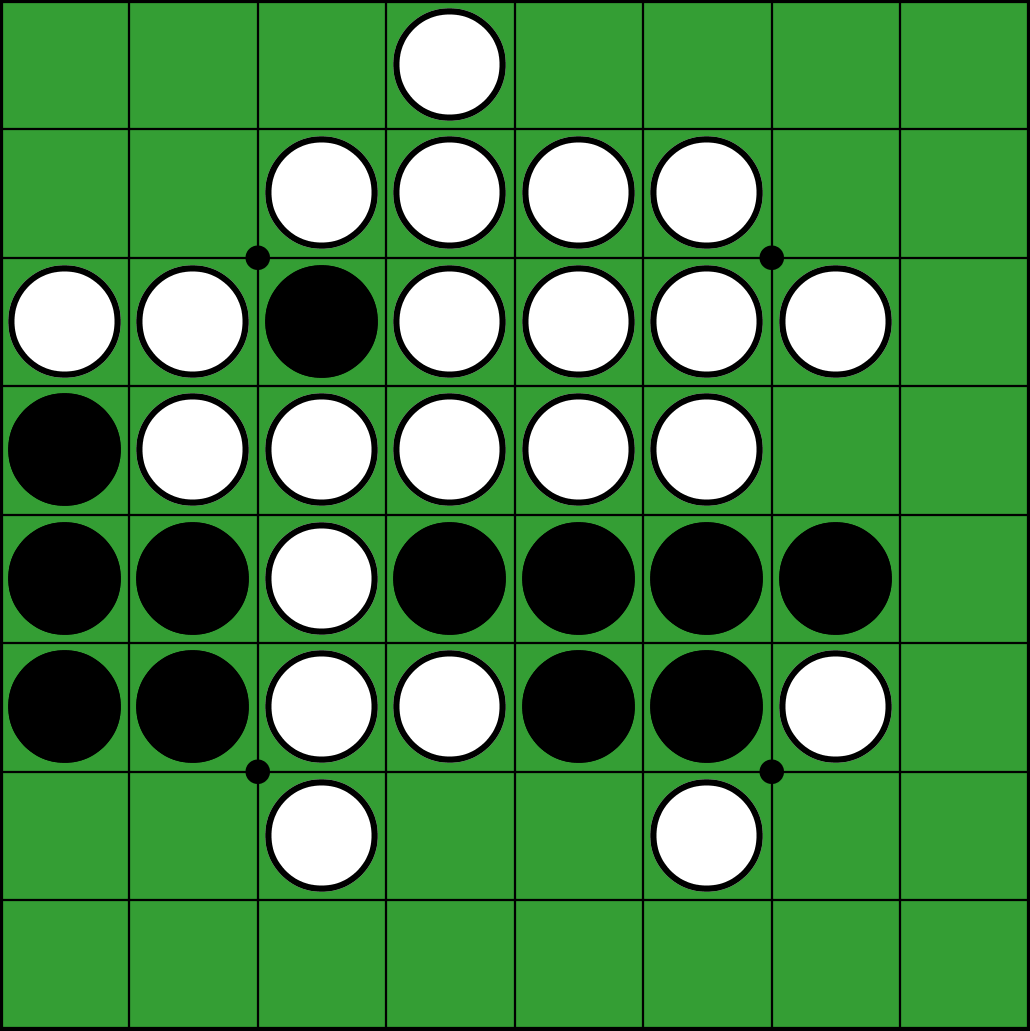

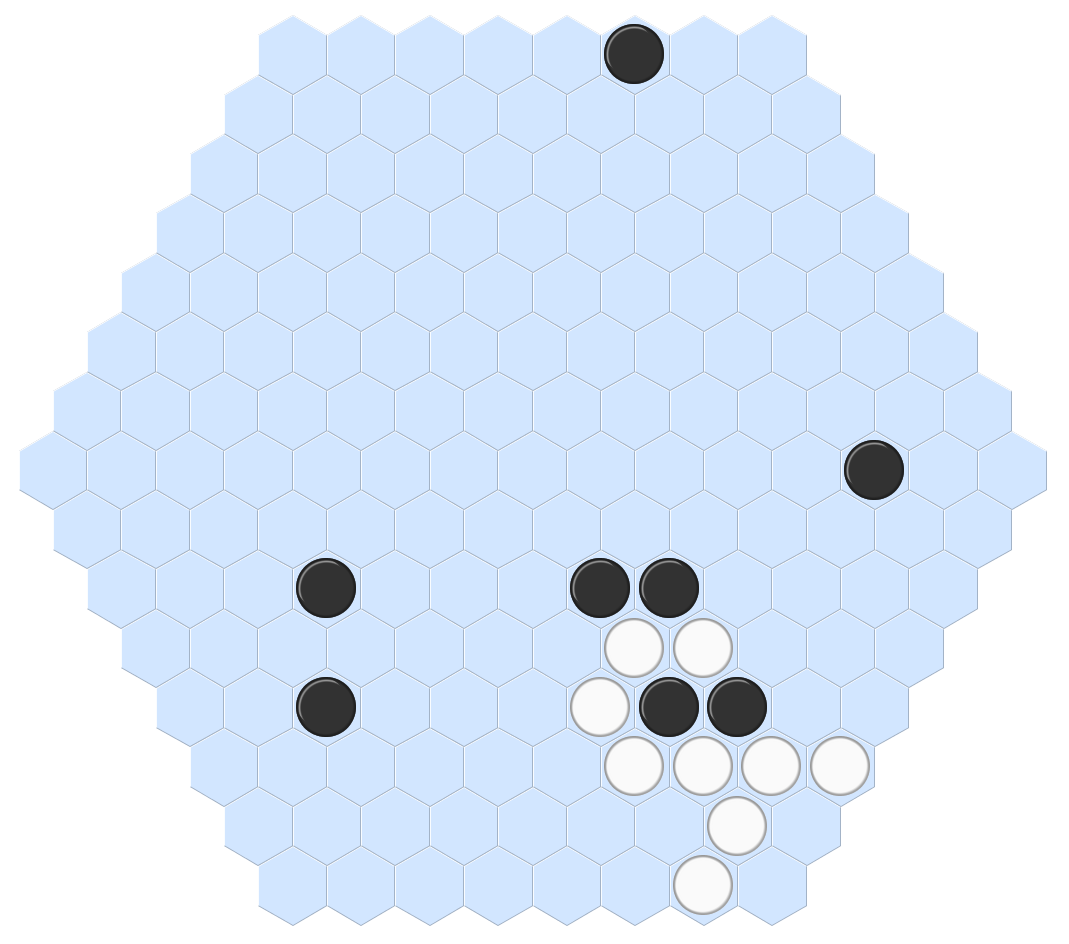


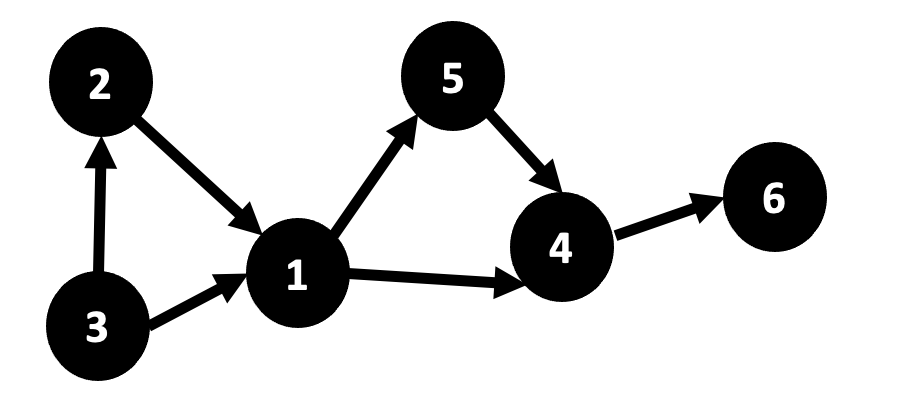
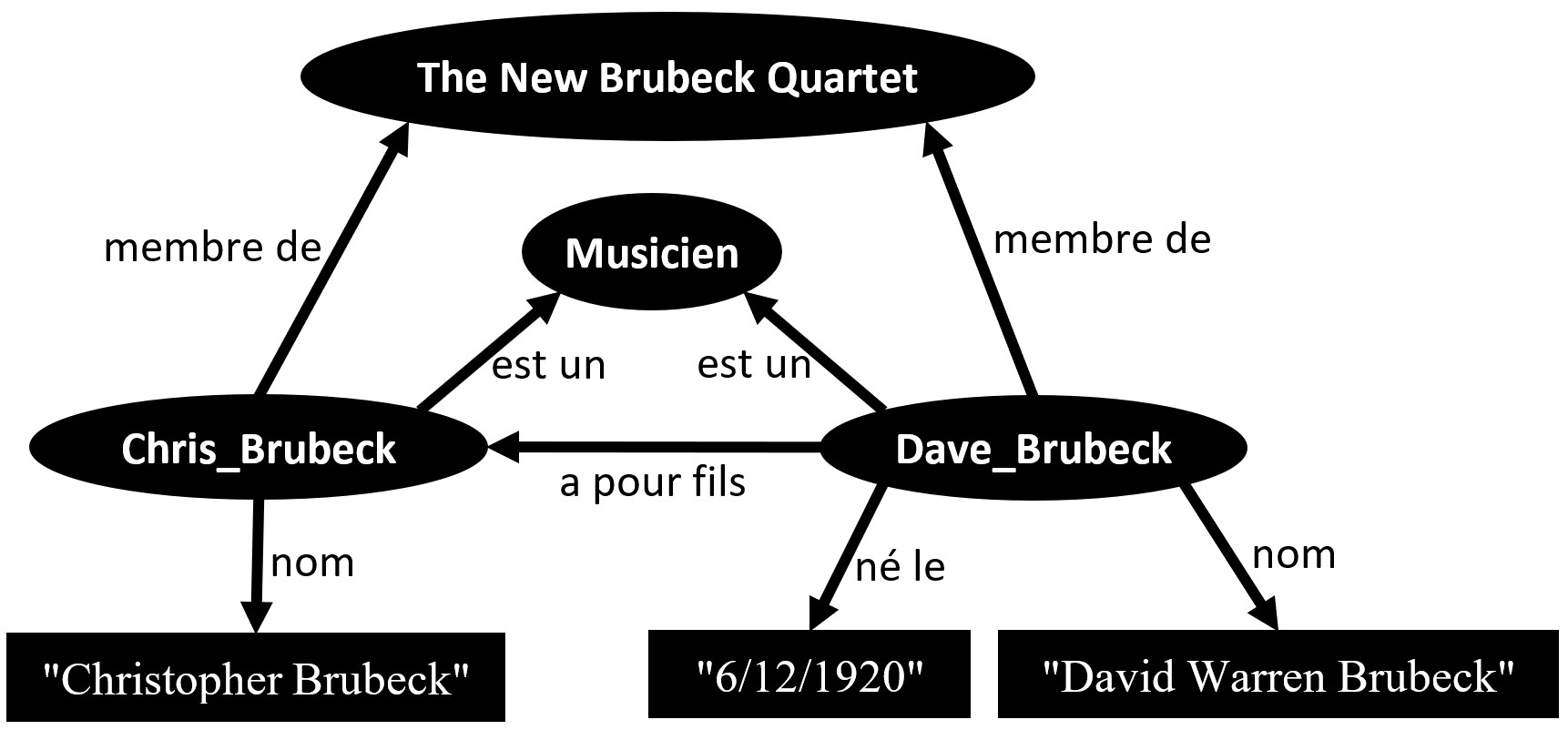
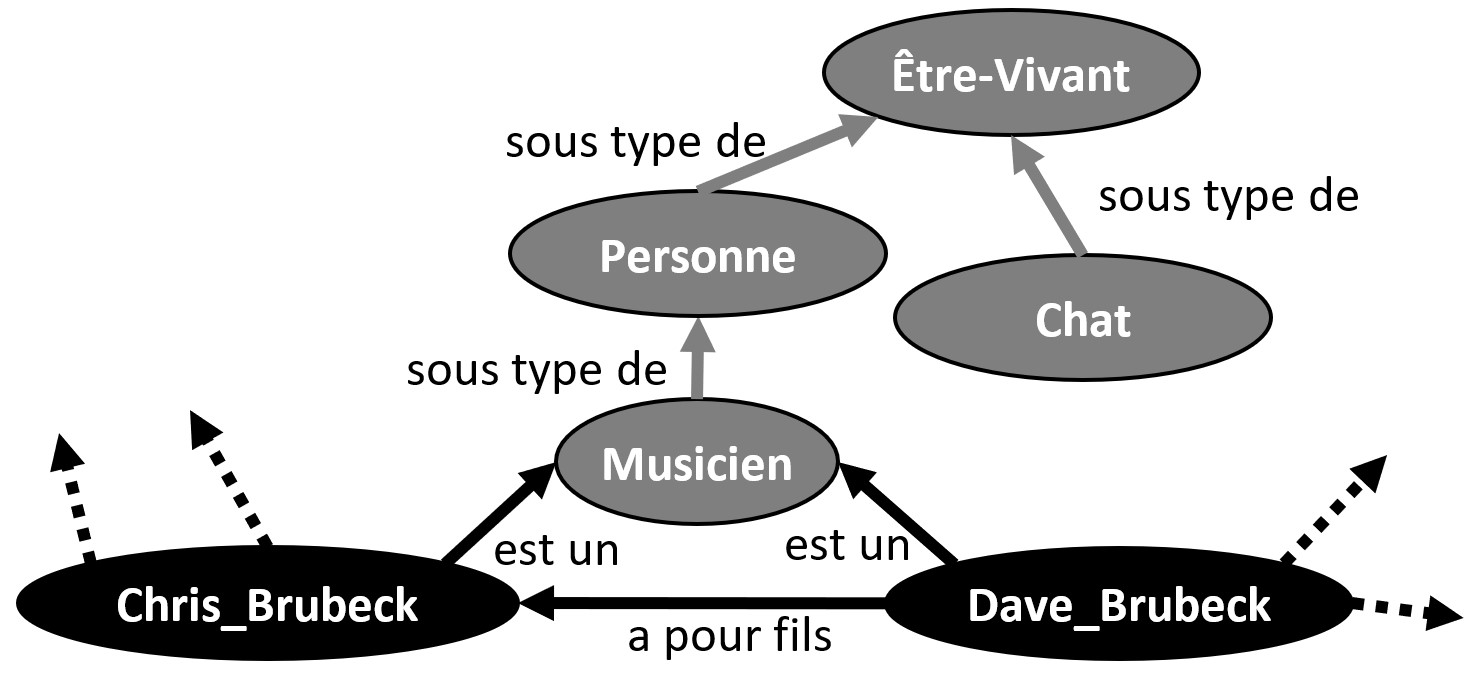
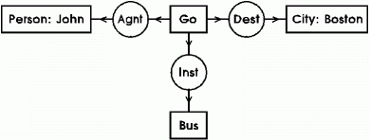





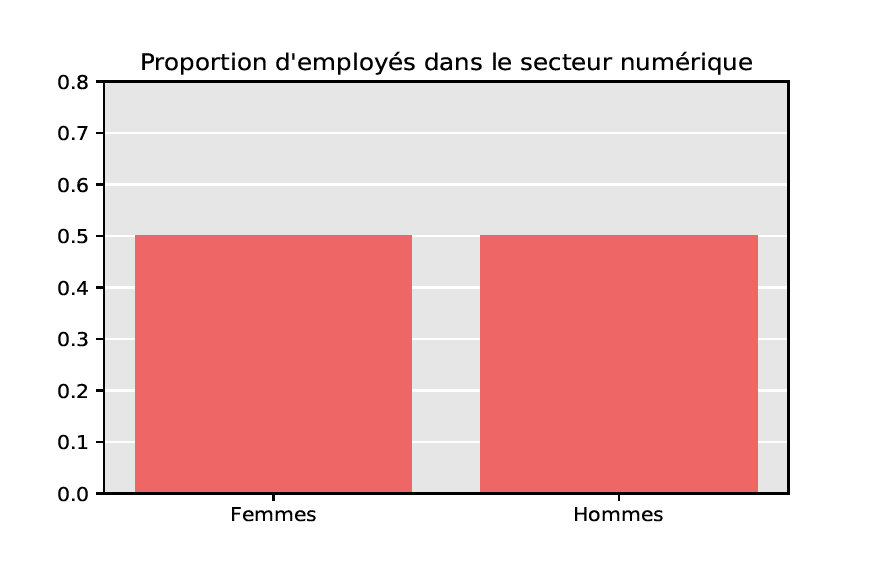
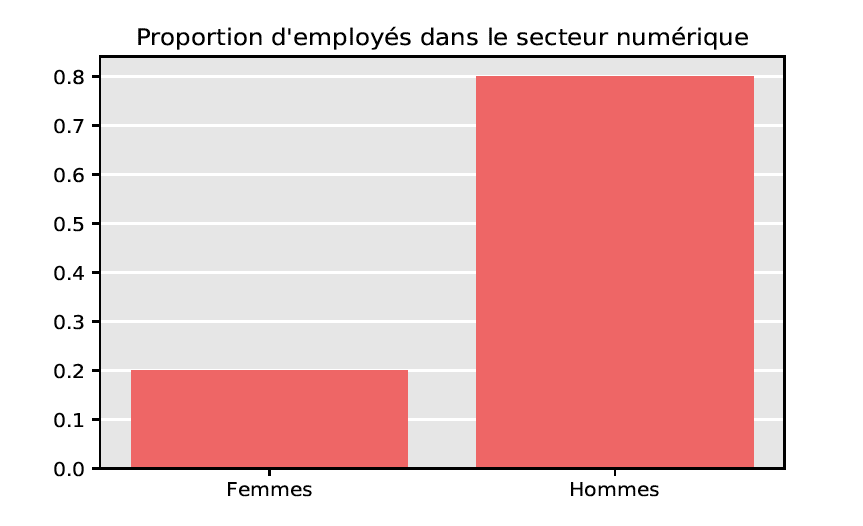
 La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.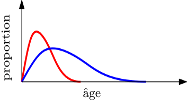 La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées. Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection
Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection 



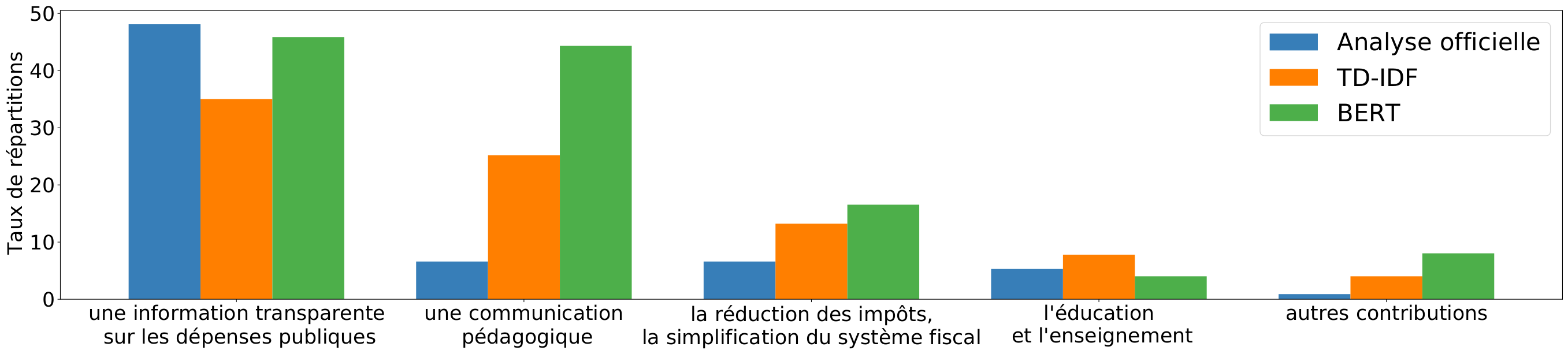




 Ce qui rend ce cours unique, par rapport aux autres offres connues, est un forum pour échanger et des webinaires et rencontres en ligne ou en présentiel sur ces sujets, à la demande des personnes participantes : la formation sert de support pour des rencontres avec le monde de la recherche. Cette possibilité de dialogue direct entre personnes participantes, de proposer des ressources ou des liens en fonction des besoins est vécu comme un point majeur de cette formation.
Ce qui rend ce cours unique, par rapport aux autres offres connues, est un forum pour échanger et des webinaires et rencontres en ligne ou en présentiel sur ces sujets, à la demande des personnes participantes : la formation sert de support pour des rencontres avec le monde de la recherche. Cette possibilité de dialogue direct entre personnes participantes, de proposer des ressources ou des liens en fonction des besoins est vécu comme un point majeur de cette formation. Au niveau des perspectives, nous invitons les personnes à suivre ensuite par exemple Elements Of AI
Au niveau des perspectives, nous invitons les personnes à suivre ensuite par exemple Elements Of AI 


 Nous vous l’avions annoncé
Nous vous l’avions annoncé  Teemu Roos (TR):
Teemu Roos (TR): TR:
TR:  TR:
TR:  TR:
TR:  TR:
TR:  TR:
TR:  La formation des Européens aux enjeux technologiques et en particulier leur acculturation aux défis transverses de l’intelligence artificielle (IA) sont devenus des éléments incontournables des différentes stratégies IA présentées ces dernières années par les États membres de l’Union. Les défis sont de taille.
La formation des Européens aux enjeux technologiques et en particulier leur acculturation aux défis transverses de l’intelligence artificielle (IA) sont devenus des éléments incontournables des différentes stratégies IA présentées ces dernières années par les États membres de l’Union. Les défis sont de taille. 










.png){kind=link}