

Pour Maël Pégny il s’agit de proposer aux développeurs et développeuses un cadre éthique et opérationnel permettant le respect de la vie privée par les IAs, en intégrant l’éthique dès les premières phases du développement. L’objectif de la charte est d’inciter les programmeurs et programmeuses à se positionner sur ces problématiques. Elle est dédiée essentiellement aux défis posés à l’éthique dès la conception par la reconstitution des données d’entraînement à partir de modèles d’IA et le pouvoir prédictif trop fin.
Contexte
Dans un modèle d’apprentissage machine, la distinction entre programme et données n’est pas claire car les paramètres du programme sont déterminés par entraînement sur une base de données particulières. Certaines attaques permettent une reconstitution des données d’entraînement à partir des informations encodées dans les paramètres du modèle : on parle alors de “rétro-ingénierie” des données. Si le modèle a été entraîné sur des données personnelles, on peut ainsi retrouver celles-ci, même si elles ont été détruites après l’entraînement du modèle. Donc si un modèle entraîné lambda est sous licence libre, ses paramètres sont en libre accès. Il se pose alors la question de la protection des données personnelles incluses dans le modèle. Ces attaques sur les modèles d’IA représentent donc un point de tension entre l’ouverture du logiciel et le respect de la protection des données personnelles. Cette tension devrait devenir un enjeu de positionnement pour les partisans du logiciel libre, des communs numériques et de la reproductibilité de la recherche. Ce problème éthique se pose dans la configuration technologique présente car, s’il existe des techniques de protection contre ces attaques de rétro-ingénierie, il n’existe pas de barrière de sécurité mathématiquement prouvée offrant une garantie absolue contre elles.

Le développement d’un pouvoir prédictif trop fin de certains modèles d’IA peut également poser des problèmes éthiques complexes. Par exemple, un logiciel de complétion textuelle fondé sur l’apprentissage machine peut ainsi permettre de trouver le numéro de carte de crédit de l’utilisateur en tapant la phrase « Mon numéro de carte de crédit est… ». Là encore, cette attaque demeure possible même si on détruit les données brutes de l’utilisateur, parce que les informations personnelles ont été encodées dans le modèle durant son interaction avec l’utilisateur. Il s’agit bien d’un pouvoir prédictif trop fin, et d’ailleurs imprévu, car le logiciel de complétion est fait pour apprendre les pratiques d’écriture de l’utilisateur, et non ses données personnelles. Attention toutefois à ne pas confondre le problème de pouvoir prédictif trop fin avec la suroptimisation ou le phénomène de sur-apprentissage (l’apprentissage des données par cœur plutôt que de caractéristiques généralisables), car il peut survenir très tôt dans l’apprentissage. Pour protéger les données personnelles, il convient donc aussi de veiller au respect de sa spécification par le modèle d’apprentissage machine.
La Charte: les 10 principes de l’éthique en IA

La charte, disponible sur la plateforme HAL du CNRS au lien ici, énonce dix principes que l’on peut résumer ainsi :
Principe 1 – Dans le cadre de recherches scientifiques, déclarer les finalités et l’extension nécessaire de la collecte, puis apporter une justification scientifique à tout écart à cette déclaration initiale, en discutant ces possibles impacts sur la vie privée .
Principe 2 – Tester et questionner les performances finales du modèle par rapport à la finalité déclarée, et veiller à éviter l’apparition d’un pouvoir prédictif trop fin .
Principe 3 – Prendre en compte le respect de la vie privée dans l’arbitrage entre suroptimisation et perte de performances.
Principe 4 – Entraîner son modèle sans faire usage de données personnelles. Si cela est impossible, voir les principes plus faibles 5 et 6.
Principe 5 – Entraîner son modèle sans faire usage de données personnelles dont la diffusion pourrait porter atteinte aux droits des personnes.
Principe 6 – Entraîner son modèle sans faire usage de données ayant fait l’objet d’un geste explicite de publication.
Principe 7 – Si le recours à des données personnelles est inévitable, déclarer les raisons justifiant ce recours, ainsi que les mesures prises contre la rétro-ingénierie des données et leur complétude par rapport à l’état de l’art.
Principe 8 – Diffuser en licence libre tous les outils de lutte contre la rétro-ingénierie.
Principe 9 – Si le principe 8 n’entraîne pas de risque de sécurité intolérable, mettre le modèle à disposition de tous afin que chacun puisse vérifier les propriétés de sécurité, et justifier explicitement la décision prise.
Principe 10 – La restriction de l’accès à un modèle entraîné sur des données personnelles ne peut être justifiée que par des enjeux d’une gravité tels qu’ils dépassent les considérations précédentes. Cette exception doit être soigneusement justifiée, l’emploi du modèle devant être réduit dans sa temporalité et ses modalités par les raisons justifiant l’exception. L’exception doit être justifiée en des termes prenant en compte la spécificité scientifique des modèles d’apprentissage machine, comme la capacité à apprendre en temps réel de grandes masses de données, l’opacité du fonctionnement et son évolution, et leurs performances comparées aux autres modèles.
Pour être bien compris, ces principes appellent quelques commentaires:
Le premier principe est conçu pour encadrer la liberté donnée par le droit existant à la recherche scientifique de modifier la finalité du traitement et l’extension de la collecte des données, contrairement aux autres activités de développement où la collecte est restreinte à ce qui est nécessaire à une finalité pré-déclarée. Il s’agit d’instaurer une traçabilité des décisions d’extension de la collecte, et une prise en compte systématique de leurs risques en termes de respect de la vie privée.
L’invitation à ne pas utiliser de données personnelles ne vise naturellement pas à interdire tout entraînement de modèle sur des données personnelles, qui est incontournable pour nombre d’applications de grand intérêt comme la recherche médicale. Il vise seulement à empêcher de considérer la collecte de données personnelles comme une évidence par défaut, et s’interroger sur la possibilité de stratégies de contournement employant des données moins problématiques.
Les principes 5 et 6 ne peuvent être compris que si l’on voit que l’extension du concept de donnée personnelle est extrêmement large, un fait radicalement sous-estimé par le grand public. Elle comprend toute donnée concernant une personne physique (vivante). Non seulement cela n’est en aucun cas restreint à des données qu’on qualifierait intuitivement de « privées » ou « sensibles, » mais il comprend des données publiques par nature : par exemple, la phrase « Madame Diomandé est maire de sa commune. » comprend une donnée personnelle sur Madame Diomandé que personne ne songerait à qualifier de privée. Il convient donc de s’interroger sur la possibilité de restreindre la collecte des données personnelles à un sous-ensemble non-problématique. L’exclusion des données considérées « sensibles », considérée dans le principe 5, fait l’objet de travaux techniques aux performances intéressantes, mais pose de redoutables problèmes de définition et d’opérationnalisation. La restriction aux données faisant l’objet d’un geste de publication explicite, explorée dans le principe 6, peut sembler une solution simple et pratique. Mais il convient de rappeler qu’une personne peut porter atteinte à la vie privée d’une autre dans ses publications, et que le geste de publication n’est pas un solde de tout compte pour le droit des données : l’exercice des droits à rectifier des informations erronées, à retirer une publication, à l’effacement (« droit à l’oubli ») et leurs difficiles opérationnalisations face aux modèles d’apprentissage machine posent de nombreux défis.
La mise sous licence libre des outils de lutte contre la rétro-ingénierie (principe 7) et l’ouverture des modèles à la vérification (principe 8) constitue une forme d’approche libriste des modèles d’apprentissage machine : ces modèles doivent être ouverts à tous non seulement pour respecter les principes fondamentaux du logiciel libre, mais aussi pour vérifier leur respect de la vie privée. Cette ouverture pose cependant le problème redoutable du « vérificateur voleur » : en ouvrant ainsi les modèles à la vérification en l’absence actuelle de barrières de sécurité dures, on crée la possibilité d’atteintes à la vie privée. Nous ouvrons donc la possibilité de limiter l’application stricte des principes libristes dans le dernier principe : s’il est absolument indispensable d’entraîner un modèle sur des données personnelles sensibles, et que son ouverture à la vérification publique présentait un grave danger de « vérificateur voleur », il est possible de justifier une exception à la perspective libriste stricte. Il est légitime de craindre que l’introduction d’une exception ouvre la porte à la violation massive de la perspective libriste dans la pratique. Trancher la question d’une approche libriste stricte aurait cependant supposer de s’engager dans des débats philosophiques bien au-delà de la portée de cette charte. Doit-on par exemple autoriser l’entraînement d’un modèle de Traitement Automatique de la Langue sur des quantités énormes de données tirées des réseaux sociaux si cela permet de mieux suivre la progression d’une pandémie ? La charte a donc choisi de rester modeste, et d’ouvrir le débat en demandant avant tout à chacun de prendre position explicitement et honnêtement, en prenant en compte les risques politiques autant que techniques de chaque position. La charte a avant tout été conçue pour montrer que la conciliation du développement de l’apprentissage machine avec le respect de la vie privée pose un problème fondamental aux communautés du logiciel libre, des communs numériques et de la reproductibilité, et que ce problème mérite d’être discuté. Les principes de la charte sont introduits non pas tant pour susciter des adhésions que pour susciter des réactions et la discussion de cas, qui permettra un véritable retour sur expérience sur l’opérationnalisation de ces principes : il ne faut pas séparer opérationnalisation et question de principe.
Une charte opérationnelle nécessaire .. mais de nombreuses questions encore en suspens

Marc Anderson, philosophe canadien en post-doctorat au LORIA, spécialiste de l’éthique de l’IA et militant libriste (un libriste est une personne attachée aux valeurs éthiques véhiculées par le logiciel libre et la culture libre en général. @wikipedia), a noté qu’en général les chartes sont peu ancrées dans la réalité mais que cette charte a au contraire le mérite d’introduire des suggestions précises dans ses principes : une approche progressive dans l’exclusion des données, une mention directe des propriétés singulières des modèles de l’apprentissage automatique, l’incitation à entraîner les modèles sans données personnelles. Il souligne l’importance du contexte pour décider du niveau de protection des données personnelles (par exemple pour les cookies* des sites web, quelles sont les sociétés qui ont accès à nos données?), d’où l’importance de travailler directement avec les concepteurs d’IAs.
Maël Pégny a remarqué qu’un autre problème difficile à aborder est celui de l’inférence de données sensibles à partir de données publiques, que les capacités statistiques accrues de l’apprentissage automatique ont contribué à rendre plus fréquentes. On peut ainsi inférer avec une confiance forte votre orientation sexuelle à partir de vos activités sur les réseaux sociaux, ou votre état de santé, comme une possible maladie neuro-dégénérative, à partir de vos activités sur les moteurs de recherche. Comme le proposent un bon nombre de juristes, il devient nécessaire non seulement de reconceptualiser la portée et de lever les ambiguïtés de la notion de données personnelles, mais aussi d’étendre le droit au-delà des données brutes pour réguler les inférences.

Bastien Guerry, militant libriste, remarque qu’un modèle d’apprentissage se rapproche plus d’un programme compilé et qu’il n’existe pas encore de bonnes pratiques de publication pour ce type d’objets. La publication des éléments entrant dans la construction d’un modèle crée un dilemme éthique : les licences libres visent à permettre à l’utilisateur de se réapproprier les codes sources pour lutter contre l’asymétrie de pouvoir entre les producteurs de logiciels et les utilisateurs, mais dans le cas de modèles d’IA, une telle publication entre en conflit avec le besoin de respecter la vie privée. Bastien Guerry note la difficulté de définir une éthique pour la production et la publication de modèles d’apprentissage. Si les données sont gardées secrètes se pose le problème de la reproductibilité des résultats. Si des données personnelles, même publiques, sont utilisées se pose le problème du consentement. Il indique aussi qu’il faut distinguer deux points de vue libristes sur le traitement des données personnelles. Une position forte, qui proscrirait de confier le traitement des données personnelles à un tiers. Une position souple, qui autoriserait de confier des données à un tiers de confiance si celui-ci s’engage à respecter un cadre éthique*. La charte n’est pas acceptable du point de vue de la position forte.
Les positions forte et souple sont défendues respectivement par Richard M. Stallman, fondateur du mouvement du logiciel libre, et Bastien Sibille, président et fondateur de Mobicoop, une plateforme coopérative de covoiturage. Voir le débat sur les logiciels libres et les plateformes coopératives.

Daniel Andler, professeur émérite de philosophie à Paris-Sorbonne et membre de l’Académie des sciences morales et politiques, considère que la charte a pour principale vertu de susciter des réactions. Comme désormais toute donnée publique est trouvable et exploitable, faut-il accepter que le domaine privé a disparu ? Il suggère de développer une éthique pratique de terrain non généralisable, pour arbitrer chaque cas. L’approche d’éthique dès la conception laissée à elle-même est insuffisante : il faut également proposer des mesures de répression du mauvais usage de l’IA. Pour Maël Pégny, une telle remarque est compatible avec l’esprit de la charte. Celle-ci insiste en introduction sur l’impossibilité de résoudre tous les problèmes éthiques en amont, et sur la nécessité d’empêcher les institutions d’utiliser le label « éthique dès la conception » comme un blanc-seing (Feuille blanche sur laquelle on appose sa signature et que l’on confie à quelqu’un pour qu’il la remplisse lui-même @Larousse) les protégeant à l’avance de toute critique. Le développement éthique doit être pensé sur tout le cycle de vie du logiciel, et comprendre un retour sur expérience incluant les problèmes éthiques imprévus rencontrés après le déploiement : c’est l’une des principales raisons pour laquelle la charte invite à ne séparer discussion de principe et discussion de l’opérationnalisation.
Le mouvement du libre a incité des développeurs à prendre conscience de la responsabilité qu’ils ont dans le respect des libertés des utilisateurs ; un mouvement éthique comparable doit naître pour inciter les datascientistes à respecter la vie privée des personnes dont ils manipulent les données.




 J’ai notamment beaucoup discuté sur un forum avec un activiste de GreenPeace. C’est lui qui m’a fait découvrir Wikipédia qui démarrait à ce moment. Il m’a suggéré d’y raconter ce qui me tenait à cœur, sur la version anglophone. A cette époque, il n’y avait encore quasiment personne sur Wikipédia en français.
J’ai notamment beaucoup discuté sur un forum avec un activiste de GreenPeace. C’est lui qui m’a fait découvrir Wikipédia qui démarrait à ce moment. Il m’a suggéré d’y raconter ce qui me tenait à cœur, sur la version anglophone. A cette époque, il n’y avait encore quasiment personne sur Wikipédia en français. binaire : La fondation Wikimédia promeut d’autres services que l’encyclopédie Wikipédia. Vous pouvez nous en parler ?
binaire : La fondation Wikimédia promeut d’autres services que l’encyclopédie Wikipédia. Vous pouvez nous en parler ? Un autre projet très populaire, c’est Wikimedia Commons qui regroupe des millions d’images. C’est né de l’idée qu’il était inutile de stocker la même image dans plusieurs encyclopédies dans des langues différentes. Je trouve très sympa dans Wikimedia Commons que nous travaillions tous ensemble par-delà des frontières linguistiques, que nous arrivions à connecter les différentes versions linguistiques.
Un autre projet très populaire, c’est Wikimedia Commons qui regroupe des millions d’images. C’est né de l’idée qu’il était inutile de stocker la même image dans plusieurs encyclopédies dans des langues différentes. Je trouve très sympa dans Wikimedia Commons que nous travaillions tous ensemble par-delà des frontières linguistiques, que nous arrivions à connecter les différentes versions linguistiques. Un troisième projet, Wiki Data construit une base de connaissances. Le sujet est plutôt d’ordre technique. Cela consiste en la construction de bases de faits comme « “Napoléon” est mort à “Sainte Hélène” ». À une entité comme ”Napoléon”, on associe tout un ensemble de propriétés qui sont un peu agnostiques de la langue. Les connaissances sont ajoutées par des systèmes automatiques depuis d’autres bases de données ou entrées à la main par des membres de la communauté wikimédienne. On peut imaginer de super applications à partir de Wiki Data.
Un troisième projet, Wiki Data construit une base de connaissances. Le sujet est plutôt d’ordre technique. Cela consiste en la construction de bases de faits comme « “Napoléon” est mort à “Sainte Hélène” ». À une entité comme ”Napoléon”, on associe tout un ensemble de propriétés qui sont un peu agnostiques de la langue. Les connaissances sont ajoutées par des systèmes automatiques depuis d’autres bases de données ou entrées à la main par des membres de la communauté wikimédienne. On peut imaginer de super applications à partir de Wiki Data. FD : Au début, on avait juste l’encyclopédie. La Fondation a été créée en 2003, mais sans véritablement de stratégie. On faisait ce que les gens avaient envie de faire. Par exemple, Wiktionnaire a été créé à cette époque. On avait des entrées qui étaient juste des définitions de mots. On se disputait pour savoir si elles avaient leur place ou pas dans Wikipédia. Comme on ne savait pas comment trancher le sujet, on a créé autre chose : le Wiktionnaire. Dans cette communauté, quand tu as une bonne idée, tu trouves toujours des développeurs. Les projets se faisaient d’eux-mêmes, du moment que suffisamment de personnes estimaient que c’était une belle idée. Il n’y avait pas de stratégie établie pour créer ces projets.
FD : Au début, on avait juste l’encyclopédie. La Fondation a été créée en 2003, mais sans véritablement de stratégie. On faisait ce que les gens avaient envie de faire. Par exemple, Wiktionnaire a été créé à cette époque. On avait des entrées qui étaient juste des définitions de mots. On se disputait pour savoir si elles avaient leur place ou pas dans Wikipédia. Comme on ne savait pas comment trancher le sujet, on a créé autre chose : le Wiktionnaire. Dans cette communauté, quand tu as une bonne idée, tu trouves toujours des développeurs. Les projets se faisaient d’eux-mêmes, du moment que suffisamment de personnes estimaient que c’était une belle idée. Il n’y avait pas de stratégie établie pour créer ces projets.










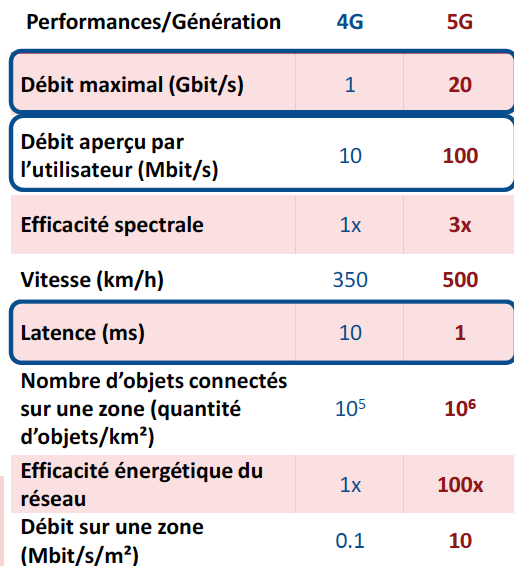
 L’autre grande réussite du bouquin est le choix des systèmes cryptographiques présentés : les énigmes abordent des techniques de crypto très variées, présentées de façon progressive, de sorte qu’il est facile de s’y plonger en fonction du temps et de l’envie qu’on a. On y découvrira, en vrac, la stéganographie, différents chiffrements par substitution, le tatouage d’images, des attaques par canaux cachés, et même des sujets plus récents comme le fonctionnement du bitcoin, l’évaluation de la solidité d’un mot de passe ou encore la sécurité des protocoles de vote. Evidemment, plus les techniques sont élaborées, plus la résolution des énigmes devient ardue. Heureusement, on est aidé par une série d’indices, et surtout… on a le droit de craquer ! Chaque énigme est fournie avec sa solution, et surtout, des explications à la fois historiques et scientifiques qui se lisent vraiment bien. Et rien que cela, en soi, relève de la performance, tant la crypto, grande consommatrice de math pointues, est toujours difficile à vulgariser.
L’autre grande réussite du bouquin est le choix des systèmes cryptographiques présentés : les énigmes abordent des techniques de crypto très variées, présentées de façon progressive, de sorte qu’il est facile de s’y plonger en fonction du temps et de l’envie qu’on a. On y découvrira, en vrac, la stéganographie, différents chiffrements par substitution, le tatouage d’images, des attaques par canaux cachés, et même des sujets plus récents comme le fonctionnement du bitcoin, l’évaluation de la solidité d’un mot de passe ou encore la sécurité des protocoles de vote. Evidemment, plus les techniques sont élaborées, plus la résolution des énigmes devient ardue. Heureusement, on est aidé par une série d’indices, et surtout… on a le droit de craquer ! Chaque énigme est fournie avec sa solution, et surtout, des explications à la fois historiques et scientifiques qui se lisent vraiment bien. Et rien que cela, en soi, relève de la performance, tant la crypto, grande consommatrice de math pointues, est toujours difficile à vulgariser.











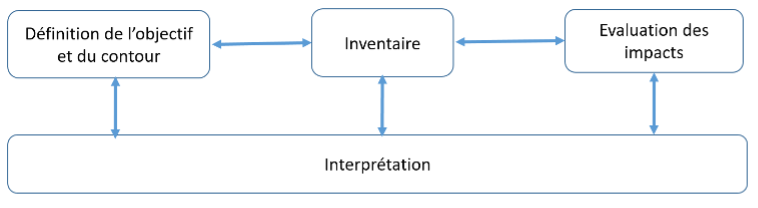









.png){kind=link}