Un nouvel « entretien de la SIF ». Claire Mathieu et Serge Abiteboul interviewent Susan McGregor qui est professeur à l’Université de Columbia et directeur adjoint du Centre Tow pour le journalisme numérique. En plus d’être une journaliste, Susan est aussi informaticienne. Donc, c’est vraiment la personne à interroger sur l’impact de l’informatique sur le journalisme.
Cet entretien parait simultanément sur Binaire et sur 01net. Traduction Serge Abiteboul. Version originale.
 Professeur McGregor © Susan McGregor
Professeur McGregor © Susan McGregor
B : Susan, qui êtes-vous?
S : Je suis professeur à l’Ecole d’études supérieures de journalisme de Columbia et directeur adjoint du Centre Tow pour le journalisme numérique. Je me suis intéressée depuis longtemps à l’écriture d’essais et je me suis impliquée dans le journalisme à l’université, mais ma formation universitaire est en informatique, sur la visualisation de l’information, et les technologies de l’éducation. Avant de rejoindre Colombia, j’ai été Programmeur senior de l’équipe News Graphics au Wall Street Journal pendant quatre ans, et encore avant ça, dans une start-up spécialisée dans la photographie d’événements en temps réel. Bien que j’aie toujours travaillé comme programmeur, ça a toujours été comme programmeur dans des équipes de design. Les équipes de design peuvent être un défi si vous venez de l’informatique, car il existe une tension entre programmation et conception. Les priorités de la programmation vont vers des composants modulaires, réutilisables et des solutions générales, alors que les conceptions doivent toujours être le plus spécifiques possibles pour une situation donnée. Mon intérêt pour la visualisation et pour la facilité d’utilisation a commencé au cours d’une année de césure entre l’école secondaire et l’université, dont j’ai passé une partie à travailler sur des tâches administratives dans une grande entreprise. J’ai pu observer comment mes collègues (qui ne connaissaient rien à la technique) étaient extrêmement frustrés avec leurs ordinateurs. Grâce à un cours d’informatique suivi au lycée, je pouvais voir les endroits où la conception du logiciel reflétait juste la technologie sous-jacente. Des choix d’interface – qui étaient essentiellement des choix de communication – étaient guidés par la technologie alors qu’ils auraient dû l’être par les besoins de l’utilisateur ou dans l’intérêt des tâches réalisées.
La littératie informatique est essentielle pour les journalistes …
B : Selon vous, qu’est-ce qu’un journaliste devrait savoir en informatique aujourd’hui ?
S : La culture informatique est essentielle pour les journalistes ; l’informatique est devenue tellement importante pour le journalisme pour des tas de raisons, que nous avons commencé à proposer un double diplôme en informatique et journalisme à Columbia.
Tout d’abord, les journalistes ont besoin de comprendre la vie privée et la sécurité numérique, parce qu’ils ont l’obligation de protéger leurs sources. Il leur faut comprendre comment les métadonnées des courriels et des communications téléphoniques peuvent être utilisées pour identifier ces sources. Ensuite – et c’est sans doute l’aspect le plus connu – nous allons trouver la place dans les rédactions pour des personnes avec des compétences techniques pour construire les outils, les plates-formes et les visualisations qui sont essentiels dans le monde de l’édition numérique en pleine évolution. Et puis, des concepts de l’informatique comme les algorithmes et l’apprentissage automatique se retrouvent maintenant dans presque tous les produits, les services, les industries, et influencent de nombreux secteurs des intérêts du public. Par exemple, les offres de cartes de crédit et de prêts hypothécaires sont accordées selon des algorithmes ; la compréhension de leurs biais potentiels est donc critique pour être capable d’évaluer leurs impacts sur les droits civils. Afin de rendre compte avec précision et efficacité de la technologie en général, plus de journalistes ont besoin de comprendre comment ces systèmes fonctionnent et ce qu’ils peuvent faire. À l’heure actuelle, la technologie est souvent couverte plus du point de vue des consommateurs que d’un point de vue scientifique.
Depuis que j’ai rejoint Columbia, j’ai pris de plus en plus conscience des tensions entre les scientifiques et les journalistes. Les scientifiques veulent que leurs travaux soient racontés mais ils sont rarement satisfaits du résultat. Les journalistes ont besoin de plus en plus de faire comprendre la science, mais de leur côté, les scientifiques devraient également faire plus d’efforts pour communiquer avec les non-spécialistes. Les articles scientifiques sont écrits pour un public scientifique ; fournir des textes complémentaires orientés vers une véritable transmission des savoirs pourrait améliorer à la fois la qualité et la portée du journalisme scientifique.
B : Comment voyez-vous l’avenir du journalisme en tenant compte de l’évolution de la place de l’informatique dans la société?
S : Le journalisme est de plus en plus collaboratif, avec les citoyens journalistes, le crowd sourcing de l’information, et plus d’interactions en direct avec le public. On a pu observer un grand changement ces quinze dernières années ! Ça va continuer, même si je pense que nous allons aussi assister à un retour vers des formes plus classiques, avec des travaux journalistiques plus approfondis. Internet a généré beaucoup plus de contenu que ce dont nous disposions avant, mais pas nécessairement plus de journalisme original. Même si vous pensez qu’il n’est pas nécessaire d’avoir de talent particulier ou de formation pour être un journaliste, vous ne pouvez pas empêcher que la réalisation d’un reportage original demande du temps. Trouver des sources prend du temps ; mener des interviews prend du temps. Et si des ordinateurs peuvent réaliser des calculs incroyables, le genre de réflexions nécessaires pour trouver et raconter des histoires qui en valent la peine est encore quelque chose que les gens font mieux que les ordinateurs.
 Clip de journal, ©FBI
Clip de journal, ©FBI
B : En tant que journaliste, que pensez-vous du traitement du langage naturel pour l’extraction de connaissances à partir de texte?
S : De ce que je comprends de ces sujets particuliers, la perspective la plus prometteuse pour les journalistes est le collationnement et la découverte de connaissances. Il y a encore quelques années seulement, les agences de presse avaient souvent des documentalistes, et vous commenciez une nouvelle histoire ou une nouvelle investigation en examinant un classeur de « clips ». Tout cela a disparu parce que la plupart des archives sont devenues numériques, et parce qu’il n’y a généralement plus de département dédié à l’indexation des articles. Mais si le TNL (traitement naturel de la langue) et la résolution d’entités pouvaient nous aider à relier de façon significative la couverture d’un sujet à travers le temps et ses aspects, ils pourraient remplacer très différemment le classeur. Beaucoup d’organes de presse disposent de dizaines d’années d’archives mais ne disposent pas de moyens réellement efficaces pour exploiter tout ça, pour avoir vraiment accès à toute cette connaissance.
Le volume de contenus augmente, mais le volume d’informations originales pas nécessairement.
B : Vous utilisez souvent (dans la version anglaise) le terme « reporting » ? Que signifie ce mot pour vous ?
S : L’équivalent scientifique de « reporting » c’est la conduite d’une expérience ou d’observations ; il s’agit de générer de nouveaux résultats, de nouvelles observations. L’idée de « reporting » implique l’observation directe, les interviews, la collecte de données, la production de médias et l’analyse. Aujourd’hui, on trouve souvent des variantes du même élément d’information à plein d’endroits, mais ils ont tous la même origine ; le volume de contenus augmente, mais le volume d’informations originales pas nécessairement. Par exemple, quand j’ai couvert l’élection présidentielle en 2008, j’ai appris que pratiquement tous les organes de presse obtenaient leurs données électorales de l’Associated Press. Beaucoup de ces organes de presse produisent leurs propres cartes et graphiques le jour du scrutin, mais ils travaillent tous à partir des mêmes données au même moment. Il peut vous sembler que vous avez de la diversité, mais la matière brute est la même pour tous. Aujourd’hui, vous avez souvent plusieurs organes de presse couvrant un sujet quand, de façon réaliste, un ou deux suffiraient. Dans ces cas, je pense que les autres devraient concentrer leurs efforts sur des thèmes sous-représentés. Voilà ce dont nous avons vraiment besoin : des reportages plus originaux et moins de répétitions.
B : Vous pourriez probablement dire aussi ça pour la science. Dès que quelqu’un a une idée intéressante, tout le monde se précipite et la répète. Maintenant, en tant que journaliste, que pensez-vous de l’analyse du « big data » (des data masses) ?
S : « Big Data » est un terme assez mal défini, englobant tout, depuis des statistiques à l’apprentissage automatique, suivant la personne que vous interrogez. Les données utilisées en journalisme de données sont presque toujours de taille relativement petites. Le journalisme de données (« data journalism »), cependant, occupe une place de plus en plus importante dans notre domaine. Aux États-Unis, nous avons maintenant des entreprises fondées exclusivement sur le journalisme de données. La popularité de ce genre de journalisme provient en partie, je pense, du fait que l’idéal américain de journalisme est « l’objectivité » ; nous avons une notion profondément ancrée dans notre culture avec ses origines dans la science, que les chiffres et les données sont objectifs, qu’ils incarnent une vérité impartiale et apolitique. Mais d’où viennent les données ? Les données sont la réponse aux questions d’une interview. Eh bien, quelles étaient les motivations de la personne qui a choisi ces questions ? Il faut être critique vis à vis de tout cela. Le scepticisme est une composante nécessaire du journalisme, une notion essentielle de cette profession. À un certain niveau, vous ne devez jamais croire complètement quelque source que ce soit et un tel scepticisme doit s’étendre aux données. La corroboration des données et leur contexte sont des points essentiels.
Pour moi, c’est également un point clé des données et de l’analyse des données dans le cadre du journalisme : l’analyse de données seulement n’est pas du journalisme. Vous devez d’abord comprendre, puis présenter la signification des données d’une manière qui est pertinente et significative pour votre auditoire. Prenez les prix des denrées alimentaires, par exemple. Nous avons des données de qualité sur ce sujet. Et si j’écris un article disant que les pommes Gala se vendaient 43 dollars le baril hier ? C’est un fait – et en ce sens il « est vrai ». Mais à moins que je n’inclue aussi le coût du baril la semaine dernière, le mois dernier ou l’année dernière, cette information n’a aucun sens. Est-ce que 43 dollars le baril c’est beaucoup ou c’est peu? Et si je n’inclus pas les perspectives d’un expert qui explique pourquoi les pommes Gala se sont vendues pour 43 dollars le baril hier, on ne peut rien faire de cette information. Pour bien faire, le journalisme doit fournir des informations avec lesquelles les gens puissent prendre de meilleures décisions pour ce qui est de leur vie. Sans de telles explications, c’est des statistiques, pas du journalisme.
La communication, l’éducation et la technologie informatique
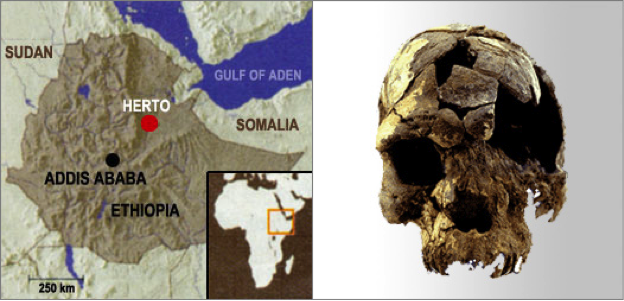
 Découverte de cranes d’homo sapiens à Herto, Ethiopie, ©Bradshaw Foundation
Découverte de cranes d’homo sapiens à Herto, Ethiopie, ©Bradshaw Foundation
B : Parfois nous sommes frustrés que les journalistes parlent si peu des progrès essentiels en informatique et beaucoup, en comparaison, de la découverte de quelques os en Afrique, par exemple.
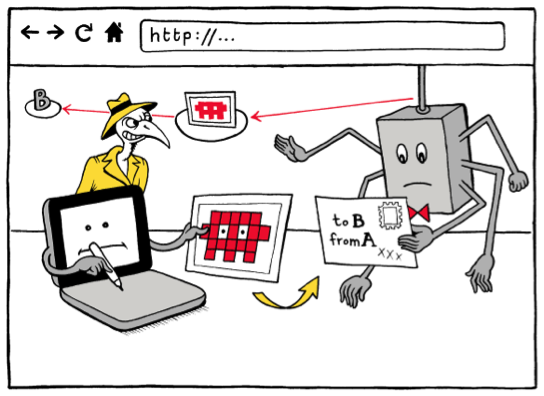
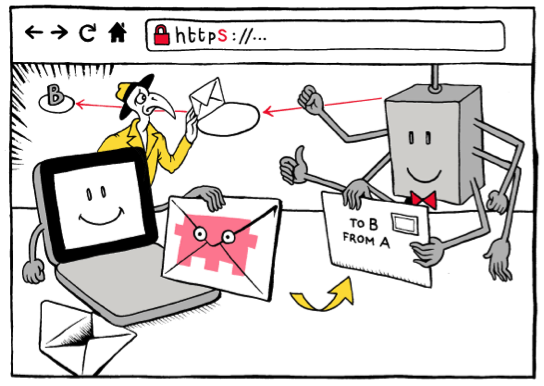
S : Les êtres humains sont des créatures visuelles. Des os en Afrique, vous pouvez prendre des photos. Mais les découvertes de la recherche en informatique sont rarement visuelles. La vision est parmi tous les sens humains, celui qui a la bande passante la plus élevée. Nous savons que les lecteurs sont attirés par les images à l’intérieur d’un texte. J’ai cette hypothèse « jouet » que des visualisations peuvent être utilisées, essentiellement, pour transformer des concepts en mémoire épisodique – par exemple, des images iconiques, ou de la propagande politique et des caricatures peuvent être utilisées. Et parce que les visuels peuvent être absorbés en un clin d’œil et mémorisés (relativement) facilement, des idées accompagnées de visuels associés sont bien plus facilement disséminées. C’est une des raisons pour lesquelles j’utilise des visuels dans mon travail sur la sécurité numérique et ce depuis toujours.
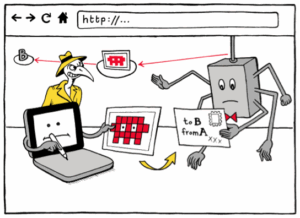
 http vs. https, visualisés. © Matteo Farinella & Susan McGregor
http vs. https, visualisés. © Matteo Farinella & Susan McGregor
B : En parlant de théorie de l’éducation, que pensez-vous des Flots (*)?
S : Je doute que les Flots persistent dans leur forme actuelle, parce qu’en ce moment on se contente essentiellement de répliquer sur le Web le modèle de l’université classique. Je pense par contre que les techniques et les technologies que l’on développe en ce moment vont influencer les méthodes d’enseignement, et qu’il y aura une augmentation de l’apprentissage informel auto-organisé. Les vidéos en ligne ont et continueront à transformer l’éducation. Des exercices interactifs avec des évaluations intégrées continueront à être importants. Les salles de classe seront moins le lieu où on donne des cours et plus des endroits où on pose des questions. Bien sûr, tout cela dépend de l’accès universel à des connexions Internet de bonne qualité, ce qui n’est pas encore une réalité, même pour de nombreuses parties des États-Unis.
La littératie informatique est essentielle pour tous.
B : Que pensez-vous de l’enseignement de l’informatique à l’école primaire ?
S : La pensée informatique est une littératie indispensable pour le 21e siècle. Je ne sais pas si cette idée est très nouvelle : L’approche des « objets à penser » de Seymour Papert avec la pédagogie constructiviste et le développement du langage de programmation Logo date de près de cinquante ans. J’ai commencé à jouer avec Logo à l’école primaire, quand j’avais huit ans. L’idée de considérer la pensée informatique comme une littératie nécessaire est incontestable pour moi. Je peux même imaginer la programmation élémentaire utilisée comme une méthode pour enseigner les maths. Parce que j’enseigne à des journalistes adultes, je fais l’inverse : j’utilise le récit pour enseigner la programmation.
Par exemple, quand j’enseigne à mes étudiants Javascript, je l’enseigne comme une « langue », pas comme de l’ « informatique. » Voilà, je montre un parallèle entre l’écriture d’une langue naturelle et l’écriture d’un programme. Par exemple, en journalisme, nous avons cette convention sur l’introduction d’un nouveau personnage. Quand on parle de quelqu’un pour la première fois dans un article, on l’introduit, comme : « M. Smith, un plombier de l’Indiana, de 34 ans. » Eh bien, c’est ce qu’on appelle une déclaration de variable en programmation ! Sinon, si plus tard, vous parlez de Smith sans l’avoir introduit, les gens ne savent pas de qui vous parlez. La façon dont les ordinateurs « lisent » des programmes, en particulier des programmes très simples, est très semblable à la façon dont les humains lisent du texte. Vous pouvez étendre l’analogie : l’idée d’un lien hypertexte tient de la bibliothèque externe, et ainsi de suite. La grammaire de base de la plupart des langages de programmation est vraiment très simple comparée à la grammaire d’une langue naturelle : vous avez des conditionnelles, des boucles, des fonctions – c’est à peu près tout.
 Exemple de diapositives d’une présentation Enseigner JavaScript comme une langue naturelle à BrooklynJS, Février 2014.
Exemple de diapositives d’une présentation Enseigner JavaScript comme une langue naturelle à BrooklynJS, Février 2014.
B : Une dernière question: que pensez-vous du blog Binaire? Avez-vous des conseils à nous donner ?
S : Le temps de chargement des pages est trop long. Pour la plupart des organes de presse, une part croissante des visiteurs vient du mobile. Le système doit savoir qu’un lecteur a une faible bande passante et s’y adapter.
B : Et est-ce qu’il y a autre chose que vous aimeriez ajouter?
S : En ce qui concerne la programmation et la technologie informatiques, et le public qui n’y connaît rien, je voudrais dire : vous pouvez le faire ! Douglas Rushkoff a fait un grand parallèle entre la programmation et la conduite d’une voiture : il faut probablement le même niveau d’effort pour atteindre une compétence de base dans les deux cas. Mais alors que nous voyons des gens – toute sorte de gens – conduire, tout le temps, l’informatique et la programmation sont par contre invisibles, et les personnes qui jouissent du plus de visibilité dans ces domaines ont tendance à se ressembler. Pourtant, on peut dire que programmer et conduire sont aussi essentiels l’un que l’autre dans le monde d’aujourd’hui. Si vous voulez être en mesure de choisir votre destination, vous devez apprendre à conduire une voiture. Eh bien, de nos jours, si vous voulez être en mesure de vous diriger dans le monde, vous devez apprendre la pensée informatique.
Explorez la pensée informatique. Vous pouvez le faire !
Susan McGregor, Université de Columbia
(*) En anglais, Mooc, cours en ligne massifs. En français, Flot, formation en ligne ouverte.

 Salle de vote à New-York en 1900 (E. Benjamin Andrews – Source Wikimedia)
Salle de vote à New-York en 1900 (E. Benjamin Andrews – Source Wikimedia)





















 Afin de faire découvrir aux jeunes l’informatique et les sciences du numérique, et après le grand succès de la troisième édition 2013 (plus de 170 000 élèves dont 48% de filles et près de 1200 collèges ou lycées français ont participé), une nouvelle édition commence aujourd’hui : les épreuves 2014 se déroulent du 12 au 19 novembre 2014.
Afin de faire découvrir aux jeunes l’informatique et les sciences du numérique, et après le grand succès de la troisième édition 2013 (plus de 170 000 élèves dont 48% de filles et près de 1200 collèges ou lycées français ont participé), une nouvelle édition commence aujourd’hui : les épreuves 2014 se déroulent du 12 au 19 novembre 2014.







{kind=link}