« L’année 2025 pourrait bien marquer un tournant décisif pour l’intelligence artificielle en France. En quelques mois à peine, le pays a concentré sur son sol une série d’événements majeurs, des annonces économiques sans précédent, et une mobilisation politique et industrielle rarement vue à cette échelle » C’est par ces propos que Jason RIchard nous partage ici son analyse de ce que les médias ont déjà largement relayé. Serge Abiteboul et Thierry Viéville.
L’IA, longtemps domaine de prospective ou de niche, est désormais partout : dans les discours officiels, dans les stratégies d’investissement, dans les démonstrateurs technologiques, dans les débats publics… Et surtout, elle est devenue un axe structurant de la politique industrielle française. Alors, 2025 : coup d’accélérateur ou effet d’annonce ? Éléments de réponse à mi-parcours d’une année qui, semble avoir placé la France au centre du jeu.
Quatre grands événements au cours de ce premier semestre sont partagés avec plus de détail en annexe de cet article.
Une ambition qui se concrétise
La trajectoire n’est pas nouvelle. Dès 2018, la France avait lancé une stratégie nationale sur l’IA, misant sur l’excellence scientifique, la création de champions technologiques et une volonté de régulation éthique. Mais ce début 2025 a marqué une inflexion nette : ce ne sont plus des promesses ou des feuilles de route, mais des réalisations concrètes, visibles et, surtout, financées.
Sommet Choose France 2025 : plus de 40 milliards d’euros annoncés, l’IA mise à l’honneur.
Sur le plan diplomatique, la France a accueilli à Paris, début février un sommet mondial sur l’action en matière d’IA, réunissant plus de 100 délégations internationales. Sur le plan économique, le sommet Choose France 2025, en mai, a vu l’annonce de 37 milliards d’euros d’investissements étrangers, dont près de 17 milliards spécifiquement orientés vers l’IA et les infrastructures numériques. De nouvelles giga-usines de données, des centres de calcul haute performance, des campus IA… autant de projets qui commencent à prendre racine sur le territoire, dans les Hauts-de-France, en Île-de-France ou encore en Provence. Ce n’est plus seulement une question de stratégie : c’est désormais une réalité industrielle.
Une dynamique entre État, start-ups et investisseurs
World AI Cannes Festival 2025 : l’IA fait son show à Cannes
Ce mouvement est porté par une triple alliance entre l’État, les start-ups de la French Tech et les investisseurs internationaux. L’écosystème s’est structuré. On compte aujourd’hui en France près de 1 000 jeunes pousses spécialisées en IA, dont plusieurs sont devenues des licornes. Des journées entières leur ont été consacrées, à Station F comme au World AI Cannes Festival, et de nombreuses d’entre elles ont profité de ces événements pour nouer des contacts avec des fonds étrangers, tester leurs solutions, ou signer des premiers contrats.
Le gouvernement, de son côté, ne se contente plus d’un rôle de spectateur bienveillant. Il est co-investisseur, catalyseur, diplomate. Des partenariats stratégiques ont été tissés avec des acteurs nord-américains, émiratis, européens… dans une logique de souveraineté numérique partagée. L’objectif est clair : faire de la France un point central pour entraîner, héberger et déployer les modèles d’IA de demain. Avec en ligne de mire, la maîtrise technologique autant que la compétitivité économique.
Des usages concrets… et des questions fondamentales
Station F Business Day 2025 : l’innovation IA made in France
Loin de se limiter aux infrastructures, l’IA s’immisce dans tous les secteurs : santé, énergie, industrie, agriculture, éducation. Certains cas d’usage sont déjà déployés à grande échelle : systèmes d’aide au diagnostic médical, optimisation des réseaux électriques, automatisation de processus industriels, ou encore agents conversationnels dans les services publics. L’heure est à l’intégration, à l’industrialisation, et à l’évaluation.
Mais cette dynamique pose des questions majeures. Comment garantir l’équité des systèmes algorithmiques ? Comment réguler les modèles génératifs qui créent du faux plus vite qu’on ne peut le détecter ? Comment protéger les données, les droits, l’emploi, dans un monde où les machines apprennent plus vite que les institutions ne légifèrent ?
La réponse française est à double détente : soutenir l’innovation sans naïveté, et réguler sans brider. Cela passe par l’appui au futur règlement européen (AI Act), par la participation active aux grands forums internationaux (OCDE, ONU, GPAI), mais aussi par une réflexion de fond sur l’inclusion et la transparence. Cette ligne de crête est peut-être ce qui distingue le plus la posture française sur l’IA en 2025.
Une question ouverte
Sommet Action IA 2025 : Paris capitale mondiale de l’IA
Alors, 2025 est-elle l’année de l’IA en France ? Il est encore trop tôt pour l’affirmer avec certitude. Mais jamais les planètes n’avaient été aussi bien alignées. Les infrastructures arrivent. Les financements suivent. L’écosystème s’organise. Le débat public s’anime. Et l’État joue pleinement son rôle. Ce n’est pas une révolution soudaine, mais plutôt une convergence de trajectoires, diplomatique, économique, technologique et sociale, qui pourrait, si elle se maintient, faire de la France l’un des pôles IA majeurs de la décennie.
Jason Richard, Business Innovation Manager chez Airbus Defence and Space.
Pour aller plus loin
Des articles détaillés sur chacun de ces événements marquants de ce premier semestre 2025 – Sommet pour l’action sur l’intelligence artificielle, Station F Business Day 2025, World AI Cannes Festival 2025, Choose France – sont disponibles ici :
1. Bonjour Pierre-Emmanuel, pouvez-vous nous dire rapidement qui vous êtes, et quel est votre métier ?
Pierre-Emmanuel
Dessia Technologies est une jeune start-up fondée en 2017 par d’anciens ingénieurs de PSA Peugeot Citroën. Nous sommes basés en région parisienne et comptons aujourd’hui une quarantaine de collaborateurs. Notre mission est d’aider les grandes entreprises industrielles, notamment dans les secteurs automobile, aéronautique, ferroviaire et naval, à digitaliser leurs connaissances et à automatiser des tâches de conception grâce à l’intelligence artificielle. Nous travaillons avec des clients prestigieux comme Renault, Valeo, Safran, Airbus, Naval Group et Alstom. Nous utilisons par exemple des algorithmes d’IA pour automatiser le design des câblages électriques ou pour générer des architectures de batteries électriques. Forts de deux levées de fonds, nous sommes soutenus par quatre fonds d’investissement, dont celui d’Orano.
2. En quoi pensez-vous que l’IA a déjà transformé votre métier ?
L’intelligence artificielle a transformé en profondeur la manière dont les ingénieurs abordent la résolution de problèmes. Avant l’arrivée de ces technologies, les ingénieurs cherchaient principalement une ou deux solutions optimales pour répondre à un problème donné. Aujourd’hui, grâce à l’IA, ils explorent un éventail beaucoup plus large de solutions possibles. Les modèles génératifs, en particulier, permettent de proposer automatiquement de nombreuses alternatives et de hiérarchiser les options selon des critères précis. Cette évolution a modifié le rôle de ces ingénieurs, qui se concentrent désormais davantage sur l’analyse et la sélection des meilleures solutions pour leur entreprise.
3. À quels changements peut-on s’attendre dans le futur ? Quelles tâches pourraient être amenées à être automatisées ? À quel horizon ?
Dans le futur, l’interaction homme-machine sera profondément redéfinie grâce aux LLM (« Large Language Models » ou grands modèles de langage). Ces modèles remplaceront les interfaces graphiques traditionnelles par des interactions écrites ou orales, rendant les outils d’ingénierie plus intuitifs et accessibles. Les ingénieurs deviendront des gestionnaires de processus automatisés, orchestrant des agents autonomes pour exécuter des tâches techniques. La plupart des activités actuellement réalisées manuellement, comme la configuration de systèmes complexes ou la gestion de chaînes logistiques, seront automatisées d’ici 5 à 10 ans. Le rôle des ingénieurs évoluera donc vers un travail décisionnel, où ils valideront les choix proposés par les systèmes automatisés, favorisant une approche collaborative et stratégique.
Ainsi, l’IA révolutionne particulièrement l’interaction et l’expérience de l’humain (UX) vis-à-vis des systèmes numériques. Les techniciens n’échangent plus via des pages HTML mais interagissent avec des éléments de savoir, grâce au langage naturel et via des messages communiquant leurs intentions de manière concise (prompt). L’IA générative permet donc de repenser les univers d’interaction traditionnels (via une « souris » et un écran) pour aller vers des univers d’interaction fluide en 3D et en langage naturel.
Demain, les interactions se feront via des agents : des automates réalisant des tâches pour le compte des ingénieurs. Les humains travailleront de concert avec des agents spécialisés, tels que les agents spécialistes de l’architecture électrique, avec ceux de l’architecture 3D et ceux des problèmes thermiques, qui se coordonneront entre eux. Ces agents permettront de résoudre des problèmes de conception en ingénierie qui sont actuellement insolubles, tels que concevoir une architecture de batterie ou un véhicule pour baisser l’empreinte carbone.
Une ou un ingénieur devra être capable de manipuler de nouvelles briques de savoir, par exemple pour s’assurer que la ligne d’assemblage d’une batterie ou d’un véhicule fonctionne bien, ou comment la faire évoluer, ainsi que le processus de conception. Il s’agit d’une mutation vers l’intégration et le développement continus (CI/CD) des produits manufacturés, réalisés en ingénierie concurrente.
On entre dans une ère dans laquelle se poseront des questions telles que celle de la sélection des tâches à automatiser et à déléguer à des agents, celle de la structuration du savoir de chaque ingénieur, de la manière de poser des questions, et de collecter des éléments de savoir.
Les ingénieurs devront aussi brainstormer, collaborer et travailler sur leur expertise pour prendre les décisions à partir des sorties des agents. La collaboration se fera au niveau décisionnel plutôt qu’au niveau opérationnel.
L’IA remet l’humain au centre. La numérisation a apporté un travail qui s’effectue de manière solitaire, seul derrière son écran. L’IA casse ce mode et pousse à développer un travail plus collaboratif ciblant les aspects stratégiques concernant la tâche à effectuer.
4. Si vous devez embaucher de nouveaux employés, quelles connaissances en informatique, en IA, attendez-vous d’eux suivant leurs postes ?
Nous recherchons des profils capables de s’adapter à l’écosystème technologique actuel et de tirer parti des outils modernes comme les LLM. Par exemple, dans les métiers marketing et vente, nous attendons une maîtrise des outils génératifs pour créer du contenu ou analyser des données de marché. Du côté des ingénieurs et data scientists, une bonne compréhension des algorithmes d’IA, des outils d’automatisation et des techniques de prototypage rapide est essentielle.
Ces remarques et les suivantes sur l’emploi des ingénieurs et autres collaborateurs concernent l’industrie en général et ne sont pas spécifiques à Dessia.
5. Pouvez-vous préciser quelles formations, à quel niveau ?
Les formations nécessaires dépendent des métiers, mais une tendance claire se dessine : la capacité d’adaptation et l’auto-apprentissage deviennent des compétences prioritaires. Pour les métiers techniques comme l’ingénierie et la data science, une spécialisation poussée reste essentielle, avec des profils de personnes ayant souvent obtenu un diplôme de doctorat ou ayant une expertise avancée en mathématiques et algorithmique. Pour d’autres postes, les recruteurs privilégient les candidats capables de se former rapidement sur des sujets émergents, au-delà de leur parcours académique, et de maîtriser les outils technologiques en constante évolution.
Les nouveaux employés devront ainsi s’adapter à de plus en plus d’exigences de la part des employeurs, ils devront avoir une expérience en IA, en pilotage de projets d’IA. Non seulement dans les domaines de l’ingénierie mais aussi des ventes. Il devront connaitre l’IA, utiliser les LLM, avoir de très bonnes qualités humaines et relationnelles.
6. Pour quelles personnes déjà en poste pensez-vous que des connaissances d’informatique et d’IA sont indispensables ?
Toutes les fonctions au sein d’une entreprise devront intégrer l’IA à leur activité, car cette technologie est en passe de devenir une nouvelle phase de digitalisation. Les entreprises qui ne suivent pas cette transformation risquent non seulement de perdre en compétitivité, mais aussi de rencontrer des difficultés à recruter des talents. L’IA deviendra un standard incontournable pour améliorer la productivité et attirer les jeunes générations, qui recherchent des environnements de travail modernes et connectés.
7. Ciblez-vous plutôt des informaticiens à qui vous faites apprendre votre métier, ou des spécialistes de votre métier aussi compétents en informatique ?
Nous ne faisons pas de distinction stricte. Chaque rôle dans l’entreprise doit intégrer l’IA, qu’il s’agisse de marketeurs utilisant des outils génératifs pour automatiser des campagnes ou d’ingénieurs chefs de projets s’appuyant sur l’IA pour optimiser la gestion de leurs plannings. Les développeurs travailleront en collaboration avec des agents IA pour accélérer leurs cycles de production, tandis que les CTO et managers utiliseront des outils intelligents pour piloter leurs indicateurs de performance. Cette polyvalence est au cœur de notre approche.
8. Pour les personnes déjà en poste, quelles formations continues vous paraissent indispensables ?
Nous privilégions des approches de transformation ciblées et pratiques plutôt que des formations classiques. Par exemple, un ou une ingénieure avec des compétences en VBA (note : Visual Basic for Applications) pourrait être accompagné pour se former à Python et à l’automatisation, augmentant ainsi sa valeur ajoutée dans l’entreprise. Un collègue secrétaire pourrait apprendre à utiliser des outils « no-code » ou des chatbots pour améliorer la gestion des intranets ou la création de contenus automatisés. Ces plans de transformation, accompagnés d’experts ou de consultants, permettront aux employés de devenir les acteurs de leur propre évolution.
9. Un message à passer, ou une requête particulière aux concepteurs de modèles d’IA ?
Nous appelons à une plus grande ouverture dans l’écosystème de l’intelligence artificielle, en particulier à travers l’open source. Cela permettrait de garantir une compétitivité équilibrée et d’éviter une concentration excessive de pouvoir entre les mains de quelques grands acteurs. Les modèles d’IA devraient être facilement personnalisables et utilisables en local pour protéger les données sensibles des entreprises. Cette approche favoriserait un écosystème plus collaboratif et innovant, permettant à un plus grand nombre d’entreprises de bénéficier des avancées technologiques.
Bonjour Quentin, pouvez-vous nous dire rapidement qui vous êtes, et quel est votre métier ?
Je suis co-fondateur et directeur de l’innovation de Dada ! Animation, un studio d’animation 2D et 3D orienté « nouvelles technologies » (entendre moteurs de jeux / temps réel, Réalité Virtuelle et Augmentée / XR, ou IA) appliquée à l’animation pour la TV, le cinéma, le web et les nouveaux médias immersifs et de réseaux.
De formation ingénieur en Design Industriel de l’Université de Technologie de Compiègne(1994), j’ai basculé vers le monde de l’animation 3D et des effets spéciaux en 1999, en retournant un temps à l’École des Gobelins. J’ai travaillé dans ces domaines en France dans de nombreux studios de différentes tailles, en Allemagne et aux USA (chez ILM, par exemple) et j’ai fondé en 2019 ce nouveau studio suite à des expérimentations réussies avec mes collègues cofondateurs dans une autre structure, où nous basculions les process classiques de la 3D dite « précalculée » vers le « temps réel » (via l’utilisation de moteurs de jeux vidéo comme Unity ou Unreal Engine) et vers la Réalité Virtuelle comme aide à la réalisation. Ces expérimentations nous ont d’ailleurs apporté à l’époque un prix Autodesk Shotgun à la conférence SIGGRAPH 2019 à Los Angeles.
Nous avons passé le pas et focalisé Dada ! Animation sur ces approches nouvelles, auxquelles s’ajoutent maintenant les IA Génératives (IAG) que nous scrutons de près. Nous travaillons par ailleurs aussi sur des thèmes éditoriaux spécifiques et éthiques : le ludo-éducatif, le documentaire, la science, l’écologie, l’inclusivité, etc.
Mon travail consiste en énormément de veille technique et de détection de talents nouveaux adaptés à ces approches, en l’organisation de tests, et de préconisations en interne. Je dialogue ainsi beaucoup avec les écoles, les institutions du métier (Centre National du Cinéma, Commission Supérieure Technique, CPNEF de l’Audio-Visuel…) et des laboratoires avec lesquels nous travaillons par ailleurs, pour leur faire des films (CNRS, CNSMDP, INRIA, …), pour tester des solutions techniques (IRISA, Interdigital, …) ou pour de la recherche.
Je coordonne d’ailleurs en ce moment un projet ANR, intitulé « Animation Conductor », en collaboration avec l’IRISA, Université de Rennes 1 et LIX, Ecole Polytechnique, sur de l’édition d’animation 3D par la voix et les gestes.
Enfin, je suis un membre actif du groupe de travail interstructurel Collectif Creative Machines, regroupant des labos, des studios, des écoles et tout professionnel francophone intéressé par la réflexion sur les impacts des IAG dans nos métiers.
En quoi pensez-vous que l’IA a déjà transformé votre métier ?
Elle l’occupe déjà beaucoup rien qu’en veille et en colloques, en termes d’inquiétude et de discussions sans fin ! Je passe personnellement au moins 20% de mon temps à en évaluer et en parler… L’IA n’est bien-sûr pas nouvelle dans nos métiers de l’image de synthèse, bourrés d’algorithmes de toutes sortes, renouvelés régulièrement. On utilise même des algorithmes de modification d’images proches de modèles de diffusion (la même famille que Midjourney) depuis 10 ans (par exemple les « denoisers » de NVIDIA, qui accélèrent le rendu final d’images de synthèse), mais bien-sûr, j’imagine que « l’IA » dont on parle ici est celle, de nouvelle génération, souvent générative, propulsée par les récentes avancées des Transformersou CLIPet par des succès techniques comme ceux d’OpenAI, Runway, Stability, Midjourney, etc.
Pour le monde de l’animation, tout ce qui touche le texte (les scénarios, mais aussi le code, très présent) est bien-sûr impacté par les grands modèles de langage (LLMs), mais, j’ai l’impression que c’est principalement en termes d’aide à l’idéation ou pour accélérer certains écrits, jamais au cœur ou en produit final (des problèmes de droits d’auteurs se poseraient alors aussi !), du moins pour du média classique. Pour ce qui est de l’image, idem : pour la partie du métier qui ne la rejette pas complétement (c’est un sujet radioactif du fait des méthodes d’entraînement disons « agressives » vis-à-vis des droits d’auteurs et du copyright), au mieux les IAG sont utilisées en idéation, pour de la texture, quelques fois des décors (ce qui pose déjà beaucoup de problèmes éthiques, voire juridiques). Il n’y a pas encore de modèles intéressants pour générer des architectures 3D propres, de la bonne animation, etc. Et pour cause, les données d’entraînement pertinentes pour ce faire n’ont jamais été facilement accessibles à la différence des images finales ! On n’a pas accès aux modèles 3D d’Ubisoft ou de Pixar…
En revanche, les mondes des effets spéciaux visuels (VFX) et du son, en particulier de la voix, ont accès déjà à des modèles puissants de traitement d’images et de sons réels, et de nombreux studios commencent à les intégrer, surtout pour des tâches lourdes et ingrates : détourage, rotoscopie, relighting, de aging/deepfake, doublage, etc.
Des défis juridiques et éthiques demeurent tout de même pour certaines de ces tâches. Les comédiens par exemple, luttent pour garder bien naturellement le contrôle professionnel de leur voix (une donnée personnelle et biométrique qui plus est). De nombreux procès sont encore en cours contre les fabricants des modèles et quelques fois contre des studios ou des diffuseurs. Mais il est difficile de ne pas remarquer un lent pivot de l’industrie Hollywoodienne vers leur utilisation (par exemple par l’accord Lionsgate x Runway, James Cameron au board de Stability, des nominations chez Disney, etc.) et ce, alors que ces sujets furent pourtant au coeur des grèves historiques des réalisateurs, acteurs et auteurs de l’année dernière !
On peut parler d’une ambiance de far west dans ces domaines, tant il y a d’incertitudes, qui se rajoutent en ce moment au fait que la conjoncture dans l’audiovisuel et le jeu video est catastrophique et ne promet pas de s’arranger en 2025 (cf. les chiffres du secteur par le CNC au RADI-RAF 2024.
A quels changements peut-on s’attendre dans le futur ? Par exemple, quelles tâches pourraient être amenées à s’automatiser? A quel horizon ?
Pour les effets spéciaux, il devient absurde d’imaginer faire du détourage, du tracking et de la rotoscopie encore à la main dans les mois qui viennent (et c’était le travail d’entreprises entières, en Asie entre autres…) De même, les tâches de compositing, relighting, etc. vont être rapidement augmentées par des modèles génératifs, mais, je l’espère, toujours avec des humains aux commandes. On risque d’ailleurs de voir diverses tâches « coaguler » autour d’une même personne qui pourra techniquement les mener toutes à bien seule, mais pour laquelle la charge mentale sera d’autant plus forte et les responsabilités plus grandes ! On a déjà vécu cela lors de l’avènement des outils de storyboard numérique qui permettaient d’animer, de faire du montage, d’intégrer du son, etc. Moins d’artistes ont alors pu, et dû, faire plus, dans le même laps de temps, et sans être payés plus chers puisque tout le monde fut traité à la même enseigne et que la compétition fait rage…
Les Designers aussi commencent à voir de leur travail s’évaporer, surtout dans les conditions actuelles où la pression est forte « d’économiser » des postes, sur des productions qui pensent pouvoir se passer d’un regard humain professionnel remplacé par quelques prompts. Cela peut en effet suffire à certaines productions, pour d’autres, c’est plus compliqué.
Sinon, dans les process d’animation 3D, ce ne sont pas des métiers, mais des tâches précises qui pourraient être augmentées, accélérées (texture, dépliage UV, modélisation, rig, certains effets). Mais honnêtement, vu la conjoncture, l’avènement des IA de génération vidéo qui court-circuitent potentiellement tout le processus classique, de l’idée de base à l’image finale, vu l’apparition des IA dites « agentiques » qui permettent à des non-codeurs de construire temporairement des pipelines entiers dédiés à un effet, et vu l’inventivité habituelle des techniciens et artistes, il est en fait très dur d’imaginer à quoi ressembleront les pipelines des films et des expériences interactives dans 5 ans, peut-être même dès l’année prochaine ! Et c’est bien un problème quand on monte des projets, des budgets, et encore pire, quand on monte des cycles de formations sur plusieurs années… (la plupart des très nombreuses et excellentes écoles d’animation, VFX et Jeu Vidéo françaises ont des cursus sur 3 à 5 ans). Certains prédisent l’arrivée avant l’été 2025 des premiers studios « full AI ». Cela ne se fera en tous cas pas sans douleur, surtout dans le climat actuel.
Si vous devez embaucher de nouveaux employés, quelles connaissances en informatique, en IA, attendez-vous d’eux suivant leurs postes ? Pouvez-vous préciser quelles formations, à quel niveau ? / Ciblez-vous plutôt des informaticiens à qui vous faites apprendre votre métier, ou des spécialistes de votre métier aussi compétents en informatique.
De plus grosses entreprises, selon leurs projets, peuvent embaucher des data scientists et ingénieurs en apprentissage machine, mais la réalité pour la majorité des petits studios est qu’on travaille avec les outils disponibles sur le marché. Au pire, une petite équipe de développeurs et « TD » (Technical Directors, postes paradoxalement entre la R&D et les graphistes) vont faire de la veille des modèles (si possibles disponibles en open-source) à implémenter rapidement (en quelques heures ou jours) dans des solutions de type ComfyUI, Nuke, Blender où ils ont de toute façon la charge de coder des outils. On ne change donc pas vraiment de profils recherchés car ceux-ci étaient déjà nécessaires pour maintenir les productions. En revanche, il est important de trouver des profils qui ont une appétence pour ces nouvelles approches non déterministes et qui aiment « bricoler » des dispositifs qui pourront changer d’une semaine à l’autre au fil des publications scientifiques… C’est tout de même assez typique de profils VFX je pense, même si les rythmes d’adaptation sont plus soutenus qu’avant.
Pour ce qui est de la formation, il est indispensable pour ces postes qu’ils connaissent ces métiers. Ils doivent donc être issus de nos écoles d’animation / VFX, mais elles ne peuvent former qu’en surface à ces outils car ils changent trop souvent, ils remettent en cause pour l’instant trop de pipelines, et ne permettent pas de créer de cursus stables !
Pour quelles personnes déjà en poste pensez-vous que des connaissances d’informatique et d’IA sont indispensables?
Tous ceux dont je viens de parler : les techniciens des pipelines, les ITs et a minima les managers pour qu’ils en comprennent au moins les enjeux.
Les artistes sont habitués à apprendre de nouveaux algorithmes, qui viennent chacun avec leur particularités. Mais si les nouvelles méthodes impactent trop la distribution des métiers, ce sont les équipes entières qui devront les reconstruire.
Pour les personnes déjà en poste, quelles formations continues vous paraissent indispensables?
Cela dépend de leur métier, mais je pense qu’on arrive vers un nouveau paradigme de l’informatique, avec de nouveaux enjeux, de nouvelles limites et possibilités. Tout le monde devrait a minima être au courant de ce que sont ces IAG, et pas que pour leur métier, mais aussi pour leur vie personnelle, pour les risques de deepfake temps réel et autres dangers ! Ca donnera d’ailleurs vite la mesure de ce qu’on peut en faire en terme d’audio-visuel.
Un message à passer, ou une requête particulière aux concepteurs de modèles d’IA?
Quand des technologies des médias évoluent autant, on s’attend à un enrichissement des œuvres (elles pourraient devenir toutes immersives, 8k, 120 images/secondes, avec de nouvelles écritures, plus riches, etc.) et/ou à leur multiplication et potentiellement à un boom de l’emploi. C’est arrivé avec le numérique, la 3D, l’interactif, les plateformes… D’ailleurs avec un impact environnemental conséquent. Cependant, on arrive dans un moment économique compliqué et le « marché de l’attention » semble saturé : l’américain moyen consomme déjà 13h de media par jour, à plus de 99% produits pour les nouveaux réseaux (tiktok, instagram, etc.) et le reste classiquement (cinéma, TV, jeux).
Ces médias classiques restent tout de même encore majoritairement consommés, mais nous souffrons déjà de ce que j’appellerais une « malbouffe numérique », addictive, trop présente, trop synthétique, et pas que côté média, en journalisme aussi, pour la science en ligne, etc.
On imagine alors mal ce que la baisse de la barrière à l’accès de la création d’effets numériques, que propose l’IAG, va apporter de positif. Sans doute pas moins de « contenus », mais aussi, et même s’ils étaient de qualité, sans doute pas non plus pour un meilleur soin de notre attention, ni de notre environnement vu l’impact du numérique – et encore plus s’il est lesté d’IAG – sur l’énergie et l’eau.
C’est aussi ce mélange de crises existentielles, sanitaires et environnementales que traverse le monde des médias en ce moment.
Nous n’avons pas encore géré la toxicité des réseaux sociaux qu’une vague générative artificielle arrive pour a priori l’accentuer à tous égards.
Il serait bon, peut-être vital même, que les chercheurs et entrepreneurs du domaine s’emparent de ces questions, avec les créateurs. Une des voies assez naturelle pour cela est de rencontrer ces derniers sur leur terrain : plutôt que d’apporter des solutions hyper-technologiques qui cherchent des problèmes à résoudre, qu’ils entendent ce que les créateurs professionnels demandent (pas le consommateur lambda subjugué par des générateurs probabilistes de simulacres d’œuvres, même s’il doit être tentant, j’entends bien, de créer la prochaine killer app en B2C), qu’ils comprennent comment ils travaillent, avec quelle sémantique, quelles données, quels critères, et quels besoins (vitaux, pour « travailler » leur art) de contrôle.
J’en croise de plus en plus, de ces chercheurs et entrepreneurs interrogatifs sur les métiers qu’ils bousculent, qu’ils « disruptent », et qui sont avides de discussions, mais les occasions officielles sont rares, et la pression et les habitudes des milieux de la recherche, de l’entreprenariat et de la création sont quelques fois divergents. On devrait travailler d’avantage à les croiser, dans le respect de ce qui reste naturellement créatif de part et d’autre.
La confiance et le numérique responsable reposent tout deux, entre autres, sur la nécessité de développer des systèmes fiables et sûrs. Cette exigence concerne à la fois la conception hardware (ex : IOT, robotique, cobotique) et celle du software (ex: IA, jumeaux numériques, modélisation numérique). A l’heure où les objets connectés font partie inhérente de nos quotidiens en tant que consommateurs lambda, industriels ou chercheurs, il semble important de questionner les concepts de fiabilité et sécurité dans la conception électronique des objets qui nous entourent. Sébastien SALAS,Chef de projet d’un pôle d’innovation digitale (DIH, Digital Innovation Hub) et directeur de formation au sein du programme CAP’TRONIC dédié à l’expertise des systèmes électroniques pour l’innovation et l’industrie manufacturière, de JESSICA France, nous partage son éclairage sur ce sujet.Ikram Chraibi-Kaadoud et Chloé Mercier.
La conception électronique hardware
Dans l’industrie, un système embarqué est constitué a minima d’une carte avec un microcontrôleur, qui est programmée spécifiquement pour gérer les tâches de l’appareil dans lequel elle s’insère.
Nous interagissons avec des systèmes embarqués tous les jours, souvent sans même nous en rendre compte. Par exemple, la machine à laver qui règle ses cycles de nettoyage selon la charge et le type de linge, le micro-ondes qui chauffe le repas à la perfection avec juste quelques pressions sur des boutons, ou encore le système de freinage dans la voiture qui assure la sécurité en calculant continuellement la pression nécessaire pour arrêter le véhicule efficacement, etc …
Ces systèmes sont « embarqués » car ils font partie intégrante des appareils qu’ils contrôlent. Ils sont souvent compacts, rapides, et conçus pour exécuter leur tâche de manière autonome avec une efficacité maximale et une consommation d’énergie minimale.
C’est le rôle du technicien et ingénieur conception du bureau d’étude de concevoir ce système dit embarqué avec une partie hardware et une partie software.
La conception électronique hardware moderne est un métier très exigeant techniquement qui nécessite une solide compréhension des évolutions technologiques des composants, des besoins des utilisateurs mais aussi de son écosystème technologique. De la conception, au déploiement, au dépannage, à la maintenance, ce métier nécessite de suivre les progrès réalisés dans le domaine de la technologie numérique qui englobe électronique et informatique.
En conception de systèmes embarqués industriels, la prise en compte des notions de Fiabilité – Maintenabilité – Disponibilité – Sécurité, noté aussi sous le sigle FMDS incluant la Sûreté de Fonctionnement (SdF) et la sécurité fonctionnelle est de plus en plus partie intégrante des exigences clients. Intégrer de tels concepts dans les produits peut se passer en douceur si l’entreprise y est bien préparée.
Ces notions représentent les fondamentaux qui assurent la pérennité et l’efficacité des produits une fois en cours d’utilisation. La mise en œuvre de ces notions permet de garantir le meilleur niveau de performance et de satisfaction utilisateur. Comprendre leur implication tout en reconnaissant leur interdépendance est crucial pour les ingénieurs et concepteurs qui visent l’excellence dans la création de produits électroniques pour l’industrie.
La sécurité fonctionnelle est une facette critique de la sûreté de fonctionnement centrée sur l’élimination ou la gestion des risques liés aux défaillances potentielles des systèmes électroniques. Elle concerne la capacité d’un système à rester ou à revenir dans un état sûr en cas de défaillance. La sécurité fonctionnelle est donc intrinsèquement liée à la conception et à l’architecture du produit, nécessitant une approche méthodique pour identifier, évaluer et atténuer les risques de défaillance. Cela inclut des mesures telles que les systèmes de détection d’erreurs, les mécanismes de redondance, et les procédures d’arrêt d’urgence.
L’importance de la sécurité fonctionnelle
À l’ère des objets connectés (aussi connus sous le sigle de IoT pour Internet Of Things) et des systèmes embarqués, la sécurité fonctionnelle est devenue un enjeu majeur, en particulier dans des secteurs critiques tels que l’automobile, l’aéronautique, et la santé, où une défaillance peut avoir des conséquences graves. Chaque secteur propose sa propre norme qui a le même objectif, assurer non seulement la protection des utilisateurs mais contribuer également à la confiance et à la crédibilité du produit sur le marché.La sécurité fonctionnelle est garante d’un fonctionnement sûr même en présence de défaillances. Cette dernière requiert une attention particulière dès les premières étapes de conception pour intégrer des stratégies et des mécanismes qui préviennent les incidents.
Que surveiller pour une sécurité fonctionnelle optimale ?
Il existe de nombreux paramètres à surveiller et de nombreuses méthodes à mettre en place pour une sécurité fonctionnelle optimale. Ici deux seront soulignés : La fiabilité et la cybersécurité.
> La fiabilité : La fiabilité mesure la probabilité qu’un produit performe ses fonctions requises, sans faille, sous des conditions définies, pour une période spécifique. C’est la quantification de la durabilité et de la constance d’un produit. Dans la conception hardware, cela se traduit par des choix de composants de haute qualité, des architectures robustes et surtout des tests rigoureux. On aborde ici des notions comme le taux de défaillance, ou encore le calcul de temps moyen entre pannes ou durée moyenne entre pannes, souvent désigné par son sigle anglais MTBF(Mean Time Between Failures) et qui correspond à la moyenne arithmétique du temps de fonctionnement entre les pannes d’un système réparable.
La fiabilité des composants électroniques contribue aux démarches de sûreté de fonctionnement et de sécurité fonctionnelle essentielle dans des domaines où le temps de fonctionnement est critique. Ce sont les disciplines complémentaires à connaître pour anticiper et éviter les défaillances des systèmes. Pour les produits électroniques, il est important de comprendre les calculs de fiabilité et de savoir les analyser.
> La (cyber)sécurité : C’est la protection contre les menaces malveillantes ou les accès non autorisés qui pourraient compromettre les fonctionnalités du produit. Dans le domaine de l’électronique, cela implique la mise en place de barrières physiques (ex: un serveur dans une salle fermée à clé) et logicielles (ex: des mots de passe ou l’obligation d’un VPN) pour protéger les données et les fonctionnalités des appareils. La sécurité est particulièrement pertinente dans le contexte actuel de connectivité accrue, où les risques de cyberattaques et de violations de données sont omniprésents. Ce sujet a été abordé avec Jean Christophe Marpeau, référent cybersécurité chez #CAPTRONIC.
La conception électronique hardware moderne est un équilibre délicat entre sûreté de fonctionnement, fiabilité et sécurité. Ces concepts, bien que distincts, travaillent de concert pour créer des produits non seulement performants mais aussi dignes de confiance et sûrs. Les professionnels de l’électronique ont pour devoir d’harmoniser ces aspects pour répondre aux attentes croissantes en matière de qualité et de sécurité dans notre société connectée.
Sébastien SALASest chef de projet d’un pôle d’innovation digitale (DIH, Digital Innovation Hub) et directeur de formation au sein du programme CAP’TRONIC de JESSICA France. Il s’attelle à proposer des formations pour les entreprises au croisement des dernières innovations technologiques et des besoins des métiers du numérique et de l’électronique en particulier, pour les aider à développer leurs compétences et leur maturité technologique.
Impact Num est un MOOC pour se questionner sur les impacts environnementaux du numérique, apprendre à mesurer, décrypter et agir, pour trouver sa place de citoyen dans un monde numérique.
Ce MOOC se donne pour objectif d’aborder l’impact du numérique sur l’environnement, ses effets positifs et négatifs, les phénomènes observables aujourd’hui et les projections que nous sommes en mesure de faire pour l’avenir. Il est à destination des médiateurs éducatifs et plus largement du grand public.
Co-produit par Inria et Class’Code avec le soutien du Ministère de l’éducation nationale, de la jeunesse et des sports et d’Unit, ce cours a ouvert le 22 novembre 2021 ; vous pouvez dès à présent vous inscrire sur la plateforme FUN.
Ce MOOC, c’est une trentaine d’experts du domaine, des vidéos didactiques et ludiques pour poser les enjeux, des activités interactives pour analyser, mesurer et agir, des fiches concept pour approfondir les notions.
Dans un article précédent Gérard Le Lann et Nathalie Nevejans ont présenté les véhicules autonomes (VA) non communicants, voici maintenant un éclairage scientifique, technologique et juridique sur les VA communicants (VAC). Serge Abiteboul et Thierry Viéville
Source Research Gate.
Un VAC est un véhicule autonome pouvant émettre et recevoir des messages avec son environnement via un équipement de communication radio conforme aux standards connus sous l’appellation V2X (Vehicle-to-Everything). Les VAC sont donc des véhicules « communicants », appellation moins restrictive que « connectés », car ils peuvent communiquer directement entre eux sans être nécessairement connectés à un réseau extérieur. Par souci de concision, nous ne traitons dans cet article, ni les cas particuliers des véhicules de transport collectifs (bus, navettes, etc.), ni les problèmes posés par la coexistence de véhicules et de cyclistes ou de piétons.
Les trois principales idées à retenir concernant la conduite partiellement ou totalement automatisée sont les suivantes :
– Avant de prétendre « faire mieux » que les humains avec des VA ou des VAC, il faudrait commencer par démontrer que nous pouvons faire au moins aussi bien.
– Cela n’est pas du tout le cas en 2021 avec les VA ou les VAC conçus actuellement. Les possibilités offertes par les communications radio sont mal exploitées dans les standards V2X actuels, et les communications optiques sont ignorées.
– Il est possible de « faire mieux » que les humains avec des Véhicules de Nouvelle Génération (VNG).
Les VA dans une impasse ?
La dure réalité s’est imposée dès le milieu des années 2010 : les VA ne peuvent pas offrir de propriétés de sécurité et d’efficacité (voir définitions dans l’article précédent). Les VA ne sont pas très fiables en conduite autonome, comme en témoigne l’accident mortel avec une Tesla le 17 avril 2021. Ils sont de plus vulnérables aux cyberattaques ciblant les capteurs. Par
brouillage de leurs radars, lidars, ou caméras, il est possible de créer des collisions (pas de sécurité). Par contrefaçon (spoofing) des signaux GNSS, il est possible de dérouter un VA (pas d’efficacité et/ou de sécurité).
Il importe de ne pas se laisser abuser par des vidéos destinées à faire croire que le niveau SAE 5 (conduite totalement automatisée en tous lieux) est « pour bientôt ». Elles sont expurgées des séquences de reprise en main par un humain. Elles ont pour mérite involontaire de montrer qu’un VA se tient constamment très éloigné du véhicule qui le précède (donc, pas de propriété d’efficacité). Enfin, les trajets ont été enregistrés puis rejoués en simulation des milliers de fois (un « apprentissage » assez primaire) avant de finaliser les vidéos mises en ligne. Sous réserve de vérifications par les experts, il sera possible de croire que le niveau SAE 5 est atteint le jour où nous verrons des VA traverser la Place de l’Étoile à Paris vers 19h un jour non férié aux mêmes vitesses et densités que celles maîtrisées par les conducteurs humains. On n’y est pas encore.
Désormais, des progrès significatifs sont espérés dans trois domaines :
– l’intelligence artificielle (IA) avec l’apprentissage algorithmique supervisé ou autonome ;
– une redondance diversifiée des capteurs, pour fournir des données d’entrée fiables aux fonctions critiques des systèmes bord ;
– les communications radio et optiques.
La plupart des informaticiens rompus aux systèmes critiques se méfient de l’IA, à cause des exigences de preuves de propriétés dans les pires cas, preuves impossibles avec les techniques actuelles (l’IA est utile, mais pas pour l’obtention des propriétés de sécurité et d’efficacité). Trop souvent, les équipements radio sont vus comme des capteurs passifs, à l’instar des radars, lidars, caméras, etc. Au contraire, les communications radio permettent des interactions proactives entre véhicules : les messages contiennent les « intentions » de mouvements à très court terme (moins de 100 millisecondes). Le futur immédiat est donc connu a priori.
Les VAC : standards V2X
Les premiers standards (DSRC-V2X pour Dedicated Short-Range Communications) reposent sur le Wi-Fi omnidirectionnel (3G, 4G). Les standards plus récents (C-V2X) sont basés sur la radio cellulaire omnidirectionnelle et directionnelle (4G LTE, 5G). Les portées des équipements radio des VAC sont de l’ordre de 300 m. Un VAC peut être « connecté » à des antennes-relais et des unités d’infrastructures routières (V2I pour Vehicle-to-Infrastructure) qui offrent l’accès via Internet à des services disponibles dans des clouds. Les VAC peuvent aussi échanger des messages en direct, sans relais intermédiaires (V2V pour Vehicle-to-Vehicle).
Les autres capteurs (radars, lidars, caméras) ne peuvent traiter que des signaux reçus en ligne-de-vue directe. Au contraire, les messages radio ne sont pas « bloqués » par les obstacles.
Les communications radio dans les systèmes de mobiles ne sont pas fiables. Les délais de transmission réussie des messages V2I – qui transitent par des relais terrestres – sont plus élevés que les délais des messages V2V. Ils peuvent être infinis en cas de défaillances (pannes ou cyberattaques) d’unités d’infrastructures routières.
L’utilisation partagée du spectre radio est de type probabiliste (protocoles CSMA). Les délais d’accès à un canal radio croissent (progressions géométriques) avec le nombre de véhicules émetteurs. Ces nombres varient dans le temps et selon les lieux : ils sont soit non bornés, soit bornés mais les valeurs des bornes sont inconnues. Les réseaux de VAC sont donc des systèmes asynchrones.
Voici environ dix ans que l’industrie automobile expérimente les premiers standards V2X avec des tests sur route et par simulation numérique.
Sécurité et Efficacité
Selon les standards actuels, ces propriétés seraient obtenues via l’envoi de messages sur événements et via le balisage périodique. Un VAC doit diffuser très fréquemment, entre 100 millisecondes et 1 seconde, des messages appelés balises.
Dans un message/balise, on trouve, en particulier, vitesse, direction, coordonnées GNSS et caractéristiques du véhicule émetteur. Ce mécanisme est inspiré de celui employé par les smartphones (à des fréquences plus faibles) pour leur géolocalisation par les antennes-relais. Chaque VAC entretient une carte environnementale (local dynamic map) rafraichie par les contenus des balises reçues.
Le but espéré (propriété de sécurité) est d’éviter les collisions : tout VAC peut deviner les trajectoires de ses voisins (dans un rayon de 300 m environ) et décider de son comportement très fréquemment grâce à un algorithme qui traite les informations contenues dans sa carte environnementale.
Mais ce but est illusoire, pour au moins deux raisons.
– Les algorithmes décisionnels sont propres à chaque fabricant, et sont sujets à interprétations. Il est donc impossible de démontrer que deux VAC proches ne prendront pas de décisions contradictoires engendrant alors une collision, même s’ils disposent de la même carte environnementale.
– Les communications V2X n’étant pas fiables, une balise reçue par un VAC peut ne pas être reçue par un VAC voisin de ce dernier. Les cartes environnementales sont donc potentiellement différentes, mutuellement incohérentes. Elles sont inutilisables telles quelles. On ne peut espérer recourir à un algorithme pour rétablir la cohérence (cartes identiques). En effet, des résultats d’impossibilité établis depuis 1985 pour les systèmes asynchrones (réseaux de VAC) démontrent qu’un tel algorithme ne peut exister.
Pour contourner les résultats d’impossibilité, il faut « sortir » du modèle asynchrone, et considérer le modèle asynchrone temporisé, qui est le modèle asynchrone « enrichi » par la connaissance de bornes supérieures finies des délais. Ce modèle est réalisable à condition de recourir à des protocoles radio de type déterministe, comme les protocoles TDMA par exemple, qui assurent des délais de l’ordre de 20 millisecondes en pire cas, donc comparables aux délais de réactivité des autres capteurs (radars, lidars, caméras). Avec les protocoles V2X, les délais de transmission (non bornés) sont de l’ordre de 100 millisecondes en conditions de trafic moyennement dense.
L’autre but espéré (propriété d’efficacité) est une bonne utilisation des ressources.
Ce n’est bien évidemment pas le cas avec le balisage périodique, qui crée un gaspillage très significatif des ressources de calcul (systèmes-bord) et de communication (canaux de 10 MHz).
Idem pour l’occupation de l’asphalte, loin d’être améliorée par les communications V2X. Les distances de sécurité entre deux VAC sont les mêmes que pour les VA. En effet, intégrer les délais V2X dans les lois de calcul des distances ne procure aucun gain, puisque ces délais sont bien trop grands. En conséquence, afin de minimiser les risques de collision, les VAC maintiennent des distances inter-véhiculaires très supérieures aux valeurs optimales ou celles maitrisées par les humains.
Le balisage périodique peut être exploité pour créer des véhicules et des embouteillages fictifs. Pour ce faire, un VAC malveillant ou même un chariot rempli de smartphones promenés le long d’artères urbaines peut émettre des balises qui contiennent les coordonnées GNSS des artères qu’il souhaite emprunter afin de les vider frauduleusement.
Conclusion : on ne peut espérer de propriétés de sécurité et d’efficacité dans les réseaux de VAC.
Intéressons-nous maintenant aux risques pour la santé dans l’hypothèse d’un déploiement généralisé de VAC. Vis-à-vis des communications radio, tout véhicule se trouve au centre d’un disque de rayon d’environ 300 m. En conditions de trafic dense (en ville, sur autoroute multivoies), une centaine de VAC est contenue dans un tel disque. Nous n’avons pas connaissance d’études démontrant que des expositions prolongées de signaux Wi-Fi reçus depuis une centaine d’émetteurs à des fréquences de 1 Hz à 10 Hz sont sans danger pour les passagers d’un VAC.
Source : jmagazine.joins.com
Les VAC étant équivalents à des smartphones-sur-roues, ils exposent leurs utilisateurs aux risques bien connus de cyberattaques et de cyber-espionnage.
Cybersécurité
Les VAC sont vulnérables aux cyberattaques distantes. Voici quelques exemples.
a) Attaques par saturation
– Spectre électromagnétique : Le brouillage radio est à la portée de tout individu malfaisant ; les brouilleurs radio les plus simples coûtent moins de 200 euros. Les VAC sont « sourds et muets »au voisinage de tels brouilleurs, aussi longtemps qu’ils circulent à portée radio d’un brouilleur embarqué sur un véhicule. Une autre attaque connue est l’interception et la falsification des signaux GNSS. Le but est de dérouter un VAC en trompant son système-bord par exemple en introduisant des décalages croissants entre sa véritable géolocalisation et celle connue par la robotique embarquée.
– Systèmes-bord : Une attaque par « déni-distribué-de-service » consiste en des envois de messages incessants jusqu’à saturer les capacités de traitement des systèmes-bord, et rendre impossible l’exécution des fonctions critiques.
b) Attaques sur les messages et balises par suppression ou falsification des contenus des balises/messages émis par des VAC honnêtes ou injection de messages frauduleux comme des fausses alertes.
c) Attaques sur les systèmes-bord : Les logiciels des systèmes-bord (les systèmes d’exploitation en particulier, Android ou iOS par exemple) ne sont pas conformes aux principes d’isolation en vigueur dans le domaine des systèmes critiques. Il est donc possible de prendre par radio le contrôle d’un VAC distant ou d’introduire un virus, Cheval de Troie, rançongiciel, etc. au sein d’un système-bord.
Outre des motivations financières, les cyberattaques distantes ont pour but de créer des conditions chaotiques pour les cibles (pas pour les attaquants), notamment des collisions (éventuellement létales – perte de sécurité) et/ou de tromper les VAC quant aux trajectoires qu’ils doivent suivre – perte d’efficacité. Ainsi, par un effet boomerang non anticipé, les communications V2X « ajoutées » aux VA pour « améliorer » les propriétés de sécurité et d’efficacité peuvent en fait compromettre ces dernières. Ces cyberattaques peuvent bien sûr être déclenchées par des VAC voisins (sur les côtés, prédécesseur, suiveur). Mais dans ce cas, une cyberattaque peut « se retourner » contre son auteur (pris dans une collision, identifié sans ambiguïté par ses victimes). Il s’agit donc d’attaques irrationnelles, bien moins probables que les attaquantes distantes.
Un cyber attaquant peut falsifier son identifiant dans les messages et balises qu’il émet. La parade selon les standards V2X est la pseudonymisation par cryptographie asymétrique. Contrairement à l’anonymisation, la pseudonymisation permet d’établir les responsabilités en cas d’accident (accountability). Tout message/balise doit être accompagné d’un certificat délivré par un organisme habilité, et il doit être signé avec la clé privée liée à ce certificat. Un VAC récepteur peut vérifier la validité d’une signature. En cas de signature invalide, le VAC émetteur –a priori malveillant – est dénoncé auprès d’un service distant, lequel, après vérifications, « révoque » le VAC en question en annulant ses certificats. Ainsi, en cas d’accidents graves, les autorités peuvent identifier les responsables, en « renversant » les certificats.
L’idée est qu’un VAC révoqué ne peut plus nuire, puisque ses messages seront ignorés. Cette idée est erronée. Rien n’empêche un VAC malveillant d’émettre des messages aux contenus frauduleux accompagnés de certificats et de signatures valides. Une révocation n’étant pas instantanée, un VAC malveillant a amplement le temps, avant révocation, de fomenter des cyberattaques. En outre, après révocation, ses balises étant rejetées, son existence est ignorée de tous les VAC avoisinants. Il peut donc créer à loisir des collisions.
Conclusion : pas de propriété de cybersécurité dans les réseaux de VAC.
Protection des données Personnelles, Privacy
Dans l’article précédent sur les VA, nous avons abordé la question de la privacy intérieure. Des données personnelles concernant les passagers sont collectées via des capteurs, comme des caméras, enregistreurs de sons, assistants à commande vocale (à l’instar de ceux que l’on installe chez soi si l’on ne se soucie pas trop de protéger sa vie privée), etc. En application des dispositions de l’art. 6.1 du règlement général sur la protection des données à caractère personnel (RGPD), les passagers doivent exprimer leur consentement ou, dans le cas contraire, être en mesure de désactiver ces capteurs, à l’exception de ceux qui sont dédiés au suivi du conducteur dans le cas des VAC de niveaux SAE inférieurs à 5. Pour ce faire, il suffit d’offrir l’option « privacy intérieure », activée via une commande tactile ou vocale. Le choix du mode « on » serait l’« acte positif clair » interdisant la collecte et le traitement des données à caractère personnel, en application des articles 4, § 11 et 7.3 du RGPD.
Surveillance intérieure, Source : Seeing Machines
Intéressons-nous à présent à la question de la privacy extérieure (écoutes et enregistrements des communications V2X). Tous les messages et balises V2X sont obligatoirement transmis « en clair ». Ils contiennent les géolocalisations GNSS et les vitesses des émetteurs. Des données à caractère personnel sont donc exposées, toutes les secondes dans le meilleur des cas. Les vertus de la pseudonymisation, rendant en principe impossible la réattribution de données à caractère personnel à une personne précise (art. 4, § 5 du RGPD), sont perdues à cause du balisage périodique. Les lois de la Physique permettent de savoir si un VAC déclarant circuler à 90 km/h, positionné en un point X sur une route, est le même que celui qui est positionné en un point Y 500 millisecondes plus tard (X et Y sont séparés de 12,5 m). Si doute il y a, il est promptement éliminé grâce au rafraîchissement continu des positions et vitesses. Ainsi, les certificats ne protègent pas du pistage, donc du cyber espionnage, quand ils sont couplés au balisage périodique. Par exemple, connaissant les débuts et fins des trajets et les arrêts récurrents aux mêmes endroits, il est facile d’inférer l’identité du conducteur ou du propriétaire d’un véhicule pisté. En fait, les VAC sont pires que les smartphones : en V2X, il est impossible de « désactiver » la géolocalisation GNSS car elle est obligatoire dans les messages et balises.
Conclusion : pas de privacy dans les réseaux de VAC.
Contrairement aux slogans abondamment répandus, les propriétés de sécurité et privacy ne sont pas antagonistes (elles le sont avec les standards V2X). Nous avons montré que le balisage périodique est inutile vis-à-vis de la sécurité. Aucune raison rationnelle ne peut donc être invoquée pour s’opposer à l’adoption d’une option « privacy extérieure ». Activée (via une commande tactile ou vocale) par les passagers, elle interdit les émissions de balises, ce qui rend impossible le cyber-espionnage illégitime des trajets.
Une mise en œuvre réaliste du RGPD dans les réseaux de VA/VAC n’est pas en vue. Ainsi, ni le pack de conformité sur les véhicules connectés de 2017 de la CNIL en France, ni les Lignes Directrices 1/2020 sur le traitement des données personnelles dans le cadre des véhicules connectés et des applications liées à la mobilité (Comité européen de la protection des données) ne prévoient de fournir aux passagers un moyen simple pour refuser a priori la collecte de telles données quand les propriétés de sécurité, efficacité et cybersécurité sont garanties. Les approches fondées sur les demandes a posteriori (consultation de données enregistrées, droit à l’oubli, etc.) sont (1) inapplicables, (2) dangereuses, car les données personnelles sont multicopiées et exploitées bien avant que tout passager ait eu le temps de
réagir. Et d’ailleurs, qui peut obliger un géant du Numérique à se conformer vraiment et rapidement aux lois qui portent atteinte à ses stratégies de profits ?
Responsabilités et preuves (accountability)
Les VAC sont équipés de « boîtes noires » (enregistreurs infalsifiables). L’examen de l’historique des données enregistrées dans les secondes qui précèdent un accident permet de déterminer, dans chaque véhicule impliqué, la/les cause(s) de l’accident. L’attribution des responsabilités civiles et pénales serait donc a priori la même qu’avec les VA à un « détail » près : une cyberattaque pouvant être menée à distance, le VAC (ou les VAC en cas de
coalition) responsable d’un accident ne fait pas partie des VAC accidentés. Il faut cependant l’identifier puis le retrouver pour inspecter sa boîte noire, en même temps que celles des autres véhicules impliqués. C’est à cette condition que l’on peut établir les causes. Mais le véhicule à l’origine d’une cyberattaque distante a le temps de disparaître ou même d’être détruit volontairement avant d’être retrouvé. La détermination de la cause ou des causes d’un accident a toutes les chances d’être non triviale avec les VAC, rendant juridiquement difficile l’attribution des responsabilités.
La proposition de règlement des Nations Unies du 23 juin 2020 relative à la cybersécurité des VA, qui impose de sécuriser les véhicules by design, est à l’évidence totalement inadaptée pour les cas de cyberattaques distantes.
En France, selon l’ordonnance du 14 avril 2021 et son décret d’application du 29 juin 2021, le constructeur d’un véhicule à délégation de conduite est pénalement responsable des infractions commises pendant les périodes où le système de conduite automatisée exerce le contrôle du véhicule. Un conducteur est responsable pénalement dès qu’il reprend effectivement le contrôle du véhicule ou s’il ne le fait pas à la suite d’une demande du système. Dans le cycle qui va de la conception d’un VAC à son autorisation de commercialisation, puis à ses utilisations, il y a toujours in fine un ou des humains sur qui faire peser la responsabilité : concepteurs, développeurs, testeurs, certificateurs, gestionnaires des infrastructures routières, ou conducteurs. Il ne sert donc à rien d’inventer une personnalité juridique des « robots sur roues ».
Les assureurs savent qu’ils doivent s’adapter à ces nouveaux défis dans leurs contrats d’assurance automobile.
Qu’attendre vraiment des VAC ?
La question mérite d’être posée puisque les standards V2X actuels ne garantissent aucune des quatre propriétés SPEC (sécurité, privacy, efficacité, cybersécurité). Il est même légitime de se demander si les VAC conformes aux standards V2X ne seront pas plus dangereux que les VA. De facto, ils sont principalement destinés à fournir aux humains « motorisés » les mêmes services et environnements (loisir, travail, éducation, informations, etc.) qu’ils utilisent lorsqu’ils sont « statiques » (domicile, bureau, etc.) – la notion de « sans couture » (seamless).
Que peut-on dire de la sécurité, de la cybersécurité et de la réduction des temps de trajets (de l’efficacité) ? À l’évidence, considérées « non prioritaires » … Et pas en vue avec les VAC qui disposent de tous les moyens pour détourner l’attention des passagers (affichage sur les tableaux de bord de publicités diverses, d’écrans des smartphones, de films, etc.), alors qu’un passager de VAC de niveau SAE inférieur à 5 doit être prêt à reprendre la conduite en manuel à tout moment si nécessaire. La contradiction avec le slogan « les VAC vous libèrent de la conduite en toute sécurité » est flagrante.
Quant à la propriété de privacy, si rien n’est fait, elle n’existera pas plus qu’en dehors des véhicules. Les systèmes embarqués fonctionnent avec les mêmes logiciels que ceux de nos smartphones, PC, et récepteurs de télévision (environ 75% sous Android et 25% sous iOS). Les enjeux financiers des futurs marchés centrés sur les données personnelles sont trop importants pour être négligés, et les VA/VAC conformes aux standards V2X sont de fantastiques « aspirateurs » de telles données. En entrant en coopétition (compétition coopérative) avec les GAFAM et leurs équivalents chinois BHATX (voir glossaire), l’industrie automobile prend des risques, puisque le Numérique n’est pas son domaine de prédilection. Mais elle n’a pas d’autre choix si elle vise les mêmes profits que ceux dont bénéficient ces géants du Numérique.
Si les VAC présentent de multiples failles vis-à-vis des propriétés SPEC, c’est tout simplement parce que les problèmes posés sont redoutables. La conduite totalement automatisée, annoncée comme imminente dans les années 2010, serait-elle en voie d’être purement et simplement abandonnée ? Sans doute si rien ne change vraiment. Les résultats du sondage annuel AAA de février 2021 sont édifiants : “AAA’s survey found that 14% of drivers would trust riding in a vehicle that drives itself, similar to last year’s results. However, 86% either said they would be afraid to ride in a self-driving vehicle (54%) or are unsure about it (32%)”.
Notons que dans aucun de leurs projets de VA, ni Waymo (filiale d’Alphabet) ni Tesla n’envisagent l’utilisation de communications radio. C’est surprenant de la part d’industriels issus du numérique. L’explication est simple : ils ne croient pas à la pertinence des standards V2X actuels pour garantir les propriétés de sécurité et d’efficacité. Ils ont raison. Les possibilités offertes par les communications radio sont mal exploitées avec les standards V2X actuels. Les communications optiques sont inutilement ignorées.
La question que nous devons nous poser dès maintenant est très simple : dans quelle future société motorisée voulons-nous vivre ? Toutes les possibilités sont ouvertes (il n’y a pas que V2X dans notre futur). La vraie révolution de la conduite totalement automatisée éthiquement, socialement et juridiquement acceptable surviendra avec l’émergence des VNG, dont la conception ainsi que celle des réseaux qu’ils formeront sont fondées sur des innovations technologiques et diverses disciplines scientifiques peu exploitées actuellement (automation control, distributed algorithms, multiagent systems, biomimétique, etc.)..
Source : ResearchGate
Avec les VNG, il sera possible de démontrer les quatre propriétés SPEC. Cette condition est incontournable dans toute société motorisée soucieuse d’éthique et de respect de la vie humaine. Il est probable que dans une industrie où la propriété intellectuelle et les brevets sont des « armes » de conquête de marchés, un certain nombre de constructeurs ont d’ores et déjà
mis les VNG au programme de travail de leurs laboratoires de R&D.
Gérard Le Lann (Directeur de Recherche Émérite, INRIA Paris-Rocquencourt) et Nathalie Nevejans (Titulaire de la Chaire IA Responsable, Université d’Artois, Membre du Comité d’éthique du CNRS (COMETS)) ont publié récemment sur ces sujets.
Glossaire
AAAAmerican Automobile Association
BHATXBaidu, Huaweï, Alibaba, Tencent, Xiaomi
CNIL Commission Nationale de l’Informatique et des Libertés
GAFAMGoogle, Amazon, Facebook, Apple, Microsoft
GNSSGlobal Navigation Satellite System (GPS, Galileo, Glonass, …)
[3] L‘interview de Gérard Le Lann, au sujet de création du web, réalisée par Altitude Infra à l’occasion du World Wide Web Say : https://lnkd.in/dB28eri
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de logiciel libre. Marie-Agnès Enard, Pascal Guitton etThierry Viéville.
Tu as faim ? J’ai une pomme. Partageons là. Du coup, je n’ai mangé qu’une demi-pomme. Mais j’ai gagné ton amitié. Tu as une idée ? Partageons là. Du coup, nous voilà toi et moi avec une idée. Mieux encore : ton idée vient de m’en susciter une autre que je te repartage, en retour. Pour te permettre d’en trouver une troisième peut-être.
Une pomme est un bien rival. Cette notion désigne un bien dont la consommation par une personne empêche la consommation par d’autres. Ce qui relève de l’information ne l’est donc pas ; du coup, partager de l’information n’appauvrit pas … Sauf si on considère que l’autre en profite ? Peut-être … même pas. Découvrons cette histoire.
Il était une fois, ah non : il était deux fois.
Il était une première fois [0], bien avant l’informatique, l’idée de rétribuer qui contribue au perfectionnement du métier à tisser, dans le Lyon du XVIIIe siècle. Les corporations de marchands et la municipalité choisirent de récompenser qui adapte un nouveau système à un grand nombre de métiers à tisser [1]. Cette politique d’innovation économique ouverte basée sur une stratégie gagnante-gagnante de partage des innovations technologiques (travailler ensemble plutôt que de tenter de cacher son savoir et de tuer les autres pour finir par mourir dans un désert économique) a permis à Lyon, devant Nottingham par exemple, de devenir leader sur ce secteur [2].
Pour le fameux métier à tisser de Jacquard, d’aucuns y voient un génie, d’autres de dire qu’il n’a rien inventé. Les deux ont tort et raison. Joseph Marie Charles dit Jacquard n’est pas un inventeur, c’est un intégrateur. Basile Bouchon a créé une machine à tisser à aiguille, Jean-Baptiste Falcon a complété la machine avec un système de carte perforée pour bénéficier d’un programme des gestes à mécaniser, et Jacques Vaucanson, a mis au point les cylindres automatiques pour soulager les utilisateurs en leur évitant d’avoir à faire tout cela à la main. Le métier de Jacquard est un aboutissement. C’est le fait que toutes ces innovations furent partagées publiquement qui permit de dépasser le monde anglo-saxon empêtré dans un système de protections avec des brevets, sur ce secteur économique.
Et il était une autre fois l’informatique [4].
L’informatique est une science et depuis toujours les connaissances scientifiques se partagent, se visitent et se revisitent pour pouvoir les vérifier, les confronter, les critiquer, les dépasser. À de rares exceptions près, les scientifiques qui ont travaillé isolément, dans le plus grand secret, sont restés … stérilement isolés. La science n’avance plus que collectivement et il est important de toujours se battre pour mettre en avant ces valeurs d’une science ouverte [5]. Au début de l’informatique, les algorithmes se partageaient comme les équations mathématiques, avec des communautés de développeurs qui s’entraidaient. Et puis, avec la découverte du potentiel commercial des logiciels et sous l’influence notamment de Bill Gates, la notion de “copyright” s’est imposée en 1976, faisant du logiciel un possible bien propriétaire, en lien avec l’émergence d’un secteur d’activités nouveau et très vite florissant, au moment de l’avènement de l’informatique grand public qui est devenu omniprésente. Mais cette réglementation engendrera tellement de contraintes que 45 ans plus tard, même Microsoft [6] s’investit de plus en plus dans le logiciel libre. L’intérêt réel de grandes firmes comme IBM ou Microsoft dans ce nouveau type de partage de connaissances [7] marque un tournant.
Quel intérêt à une telle démarche ?
On peut invoquer de multiples raisons : pour que les personnes qui travaillent sur des projets parfois gigantesques puissent s’entraider, pour que l’on puisse étudier un logiciel complexe dont le fonctionnement doit rester transparent (par exemple pour mettre en place un système de vote numérique), pour que économiquement on crée des “biens communs” qui puissent permettre au plus grand nombre de développer ce dont il ou elle a besoin, et faire des économies d’échelle, comme par exemple lorsqu’il s’agit de corriger des bugs.
Un logiciel libre garantit quatre libertés fondamentales [8] :
– utiliser le logiciel
– copier le logiciel
– étudier le logiciel
– modifier le logiciel et redistribuer les versions modifiées.
Et si cette démarche d’ouverture ne se limitait pas au logiciel [9] ? Et si comme Wikipédia qui a permis de “libérer” les connaissances encyclopédiques humaines, qui avaient été enfermées sous forme de bien marchand, on faisait en sorte de s’organiser de manière collégiale, en privilégiant l’entraide et le partage pour d’autres grandes créations humaines ?
Allez, un petit jeu pour finir, sauriez-vous reconnaître ces logiciels libres, parmi les plus célèbres ?
Références :
[0] Merci à Stéphane Ubeda, de nous avoir fait découvrir ces éléments.
[2] The economics of open technology: Collective organization and individual claims in the « fabrique lyonnaise » during the old regime. Dominique Foray and Liliane Hilaire Perez, Conference in honor of Paul A.David, Turin (Italy), May 2000
Binaire, a demandé à Véronique Torner, co-fondatrice et présidente de alter way , membre du CA du Syntec Numérique, présidente du programme Numérique Responsable et membre du Conseil Scientifique de la SIF (Société informatique de France) de nous parler de l’initiative Planet Tech’Care. Marie Paule Cani et Pierre Paradinas.
Binaire: Véronique peux tu nous dire en quoi consiste le projet Planet Tech’Care? Véronique Torner : Planet Tech’Care est une plateforme qui met en relation des entreprises et des acteurs de la formation qui souhaitent s’engager pour réduire l’empreinte environnementale du numérique avec un réseau de partenaires, experts du numérique et de l’environnement.
En s’engageant autour d’un manifeste, les signataires ont accès gratuitement à un programme d’accompagnement composé d’ateliers conçus par les partenaires de l’initiative.
La plateforme est animée par le programme Numérique Responsable de Syntec Numérique. Le projet a été initié sous l’impulsion du Conseil National du Numérique.
Binaire : Qui sont les membres de Planet Tech’Care ?
Véronique : Vous avez d’un côté les signataires du manifeste, des entreprises de tous secteurs et de toutes tailles (du CAC40 à la start-up) et des écoles, universités, instituts de formation et d’un autre côté les partenaires, organisations professionnelles, associations, think tanks, spécialistes du sujet Numérique & Environnement.
Binaire : Que contient le manifeste de Planet Tech’Care
Véronique : Les signataires du manifeste Planet Tech’Care reconnaissent que le numérique génère une empreinte environnementale et s’engagent à mesurer puis réduire les impacts environnementaux de leurs produits et services numériques. Ils s’engagent également à sensibiliser leurs parties prenantes afin que tous les acteurs de l’écosystème numérique soient en mesure de contribuer à réduire leurs impacts sur leurs périmètres de responsabilité. En parallèle, les acteurs de l’enseignement, ainsi que les acteurs du numérique proposant des formations à leurs collaborateurs, s’engagent à intégrer des formations au numérique responsable et écologiquement efficient dans leur curriculum de cours. Ainsi, la nouvelle génération de professionnels sera en capacité de développer des produits et services technologiques numériques bas carbone et durables.
Binaire : Qui peut rejoindre le projet ? Pourquoi et comment impliquer les jeunes ?
Véronique : Toute entreprise et tout acteur du domaine de l’éducation peuvent nous rejoindre. Rassembler suffisamment de signataires dans le domaine de l’éducation sera essentiel pour impliquer massivement les jeunes. On peut à terme imaginer d’intégrer des formations au numérique responsable adaptées à tous les programmes des universités et autres établissement d’enseignement supérieur, des formations spécialisées en informatique à tous les secteurs utilisant le numérique, mais aussi d’associer une sensibilisation au numérique responsable aux programmes d’initiation au numérique au collège et au lycée. Nous comptons ensuite sur l’énergie et l’enthousiasme des jeunes pour que ces nouveaux usages diffusent à l’ensemble de la société.
Binaire : Comment sera évalué l’intérêt du projet Planet Tech’Care ?
Véronique : Nous ferons un premier bilan dans un an qui sera constitué de plusieurs indicateurs : le nombre de signataires, la qualité des ateliers, un baromètre de maturité de notre communauté. Nous comptons pour le lancement plus de 90 signataires et plus de 10 partenaires qui démontrent déjà l’intérêt d’une telle initiative. Notre enjeux est de :
– créer une dynamique autour d’acteurs engagés pour le numérique éco-responsable,
– fédérer les expertises pour passer de l’engagement à l’action,
– et enfin créer des communs pour passer à l’échelle.
Binaire : Tu es dans le CA du Syntec Numérique et le CS de la SiF, pourquoi ces instances se mobilisent-elles sur la question de la responsabilité sociale et plus particulièrement sur les impacts environnementaux ?
Véronique : Syntec Numérique est en première ligne sur les enjeux du Numérique Responsable qui constitue un des cinq programmes stratégiques de notre organisation professionnelle. Nous œuvrons depuis plusieurs années sur l’inclusion sociale et sur l’éthique du numérique. En ce qui concerne les enjeux environnementaux, notre industrie a un double challenge à relever. Nous devons bâtir des solutions numériques au service de la transition écologique, car nous le savons Il n’y aura pas de transition écologique réussie sans numérique. Et nous devons aussi, comme toutes les industries, réduire notre empreinte environnementale. Nous avons un groupe de travail très actif sur le sujet et nous animons désormais la plateforme Planet Tech’Care.
Par ailleurs, la SiF, Société informatique de France, qui anime la communauté scientifique et technique en informatique, a déjà montré son engagement pour une double transition numérique et écologique lors de son congrès annuel 2020, qui a porté sur ce thème. Diffuser plus largement cette réflexion est indispensable pour agir plus largement non seulement sur les acteurs socio-éconimique mais aussi, et en particulier via l’éducation, sur l’ensemble de la société. En particulier, le conseil scientifique de la SIF a tout de suite montré un grand enthousiasme pour le projet Planet Tech’ Care, jugé essentiel pour que le numérique devienne un véritable levier pour les transitions sociétales et écologiques !
Dilingco est une société plurielle : jeux sérieux pour apprendre avec le numérique, offre de formation et d’auto-formation, édition d’ouvrages papier ou en ligne, etc. C’est un exemple typique d’entreprise du XXIème siècle fondée avec une volonté de partage et des valeurs éthiques. Partons à sa découverte en donnant la parole à Alain Rochedy, son président.
Vous publiez sur le web des jeux sérieux et des modules de formation. Mais qu’est ce qu’un jeu sérieux pour vous ?
Nos jeux sérieux déroulent des pages qui présentent de manière ludique, décalée et pédagogique les divers aspects d’un thème, sous forme de contenus attrayants et de pages courtes adaptées à la navigation Internet. Ces jeux sont sérieux par leurs aspects instructifs, ou par ce qu’ils mettent en valeur des activités, en lien avec l’économie d’une région.
Par ces temps de confinements et de grandes souffrances économiques, cette fonction de promotion régionale est plus que sérieuse : vitale.
D’où vous est venu le besoin de faire un tel site Internet ?
Notre site est né du besoin de mise en ligne de documents de cours pour aller vers la publication de contenus interactifs : ces jeux sérieux et un calculateur pédagogique virtuel.
Au delà du contenu, ce site concrétise un rêve, celui de créer un groupe de passionnés qui développent des produits à hautes valeurs sociétales.
Pour réaliser des jeux sérieux orientés tourisme, savoir-faire, sport, ou œnologie, on mêle la recherche et la synthèse documentaire, la rédaction de textes et la création de figures.
Comment s’utilisent ces jeux sérieux ?
Nos jeux sérieux, bien qu’accessibles par le catalogue de notre site, ont vocation à être utilisés directement sur un site partenaire. L’entreprise ou l’organisme partenaire configure dans son site Internet un bouton qui ouvre le jeu configuré sans afficher de page propre à notre site. L’intégration du jeu dans le site partenaire est optimale, l’utilisateur n’a pas à choisir un jeu dans le catalogue Avansteduc et il revient automatiquement au site partenaire une fois le jeu terminé.
Le jeu « Massif de la Chartreuse »est représentatif de cette complémentarité, ouvrons le ensemble pour voir. C’est un exemple de jeu, décalé, ludique, captivant, non lié à des présentations purement touristiques, et complémentaire des contenus des offices régionaux de tourisme.
Une personne qui navigue sur internet passe en moyenne quelques minutes par site visité, mais plusieurs dizaines de minutes sur nos jeux sérieux.
C’est une forme d’addiction aux jeux ?
Non. C’est tout simplement un comportement différent lié à l’aspect ludique, qui permet de prendre son temps, se poser, et satisfaire sa soif de connaissances 🙂
Vous proposez aussi des modules d’initiation à l’informatique ?
Les sections “Comprendre le numérique” et le “Calculateur pédagogique” sont complémentaires et ont pour but de faire comprendre le fonctionnement d’un ordinateur de l’intérieur, dans ses entrailles électroniques, mais sans les lourdeurs d’une présentation trop technique.
Le premier se focalise sur la connaissance et résume sous forme d’un jeu une série d’éléments de base. On commence par lister les pages pour s’imprégner du sujet avant de passer au jeu, qui implique réellement l’utilisateur, vérifie ses réponses, et contrôle sa progression page à page suivant ses acquis.
Le calculateur pédagogique complète comprendre le numérique par des travaux pratiques. Les travaux pratiques sont divisés en études progressives, où seules les cartes électroniques concernées sont visualisées et accessibles, puis en études globales où les six cartes électroniques du calculateur sont présentes. Le calculateur exécute alors un programme « clignotement de LEDs ». Le calculateur peut alors s’utiliser en mode automatique, pas à pas, ou même en dépannages virtuels.
Le parti pris est de faire le plus simple possible mais avec la réalisation d’un vrai calculateur qui permette de comprendre le fonctionnement global d’un ordinateur avec ses interactions entre matériels et logiciels. Les composants électroniques ne sont détaillés au niveau physique mais au niveau logique : stockage des instructions et des variables, exécution des instructions, réalisation de tests, cadencement des opérations, etc.
Avec sa carte d’entrées/sorties 8 boutons 8 LEDs, ses petites cartes mémoires et son unité arithmétique simplifiée, ses 8 instructions de base et son unique programme de clignotement de LEDs, le calculateur offre une simplicité optimale pour obtenir un calculateur le plus pédagogique du monde. Quelques composants de plus en ferait un calculateur réel.
Quel lien avec les nouveaux enseignements d’informatique au lycée ?
Le point clé est de pouvoir incarner et rendre tangible les connaissances théoriques par une compréhension plus pratique et plus globale. À la marge des programmes actuels, on peut ainsi expliquer avec enthousiasme le binaire, présenter la fonctionnalité d’un composant logique, et le fonctionnement global d’un ordinateur simplifié.
On pourra même faire du dépannage virtuel après les autres travaux pratiques, ce qui permet la synthèse des connaissances et la sensibilisation des démarches de résolution de problèmes.
Cela concerne l’enseignement NSI de spécialité informatique de première et terminale, l’enseignement supérieur (IUT,BTS, …), et la formation professionnelle (AFPA, CUEFA, CFA, CND, …), ressources annexes complémentaires ou pivot central de certaines parties du programme, mais aussi outil de révision, ou d’évaluation.
Comment s’est faite l’évaluation des modules informatiques ?
Nous nous sommes adressés à des Ministères, à des organismes publics de formation, à des lycées préparatoires aux grandes école et à des lycées professionnels. Nous avons un partenariat avec https://aconit.org, le conservatoire français de l’informatique et de la télématique, dont les publications et ses collections sont beaucoup visitées par les professeurs, qui ont relu et corrigé nos contenus.
Ces évaluations permettent de situer les outils par rapport aux niveaux des élèves et par rapport aux programmes, de détecter les améliorations et modifications à apporter, de mesurer l’impact des lignes réseaux.
Comment allez vous faire pour améliorer le référencement de votre site ?
Faire arriver nos jeux dans la page de tête des moteurs de recherche passe par la multiplication des jeux et par l’utilisation maximale des techniques de référencement.
En 2021 nous publierons les jeux Bordeaux au cours des siècles, Nantes, Vannes, Le Nord, Alsace, et Côte d’Azur.
Nous rêvons d’un futur où la notoriété du site sera suffisante pour inciter les responsables de sites institutionnels à nous demander la réalisation de jeux sérieux.
Quel est le modèle économique ?
Les jeux sérieux et les modules Informatique sont en accès et en utilisation libres : nous voulons faire du calculateur pédagogique un blockbuster utilisé de facto dans l’enseignement. C’est l’explosion du nombre d’accès dans ce domaine qui va rejaillir sur tous nos jeux sérieux et sur la notoriété de notre site.
Des visuels publicitaires sont placés dans la colonne de droite de certaines pages des jeux sérieux. Les revenus engendrés devraient rapidement nous permettre d’atteindre un niveau d’équilibre pour accompagner notre développement. Merci aux sociétés qui dès à présent nous font confiance par leurs présences dans nos pages !
La société Dilingco est riche de ses produits et des expériences acquises. Ses produits en accès libres évoluent dans le monde du numérique en ligne, ils sont originaux et ils répondent à des besoins forts de mobilité virtuelle, de divertissement et d’éducation en ligne. Parmi ces produits une pépite, le calculateur pédagogique.
En cette période Covid il y a urgence de faire connaître les produits Avansteduc aux utilisateurs concernés. Des associations, des établissements publics individuels, des personnes clairvoyantes et engagées vont l’y aider.
Espérons que binaire vous aidera aussi à vous faire connaitre…
Note des éditeurs : Alain Rochedy n’est pas un « copain » et binaire ne reçoit rien en échange de cet article. C’est seulement que nous partageons les valeurs avancées.
L’essor de l’informatique a déclenché une révolution industrielle qui modifie en profondeur la société et l’économie. Cet article de Laurent Bloch dresse un tableau de cette industrie, et nous explique l’urgence de s’y intéresser et surtout d’agir en conséquence. Tamara Rezk
L’essor de l’informatique a déclenché une révolution industrielle qui modifie en profondeur la société et l’économie. La France y avance de mauvaise grâce (et à divers degrés il en va de même de l’Europe) alors qu’elle a tous les atouts en main pour y réussir.
Panorama de l’industrie informatique
La dépense mondiale 2019 en informatique est estimée par le cabinet Gartner à plus de 4200 milliards de dollars, en y incluant les services de télécommunications, à peu près totalement informatisés depuis plus d’une décennie, ainsi que l’industrie des semi-conducteurs (source : Semiconductors Industry Association) dont les débouchés principaux sont les matériels informatiques et de télécommunications :
Systèmes de centres de données : 205
Logiciels d’entreprise : 456
Matériels (ordinateurs, autres) : 682
Services informatiques : 1030
Services de communication : 1364
Semi-conducteurs : 481
Total : 4218
Le cabinet IDC, qui calcule différemment, prévoit 4100 milliards en 2020.
Bien sûr 2020 va être une mauvaise année à cause de l’épidémie Covid-19, pour ces secteurs comme pour l’ensemble de l’économie. Avant cette crise mondiale, le taux de croissance annuel de l’industrie informatique était de l’ordre de 7%.
À titre de comparaison, le chiffre d’affaires de l’industrie automobile mondiale est de l’ordre de 2500 milliards de dollars, selon les définitions adoptées et les enquêtes effectuées. Mais ce qui est certain, c’est la baisse de chiffre d’affaires de l’industrie automobile dans son ensemble en 2018 et en 2019, baisse qui s’accentuera fortement en 2020.
Toujours pour donner des points de repère, ces chiffres sont supérieurs au PIB de la France (2925 milliards de dollars en 2018), lui-même équivalent au PIB du continent africain.
Ces chiffres concernent de vastes agrégats, leurs valeurs sont toujours entachées d’approximations, ne serait-ce que par la difficulté à délimiter le domaine considéré, mais en tout état de cause ils montrent que l’industrie informatique est au premier rang mondial, et en forte expansion.
La filière micro-électronique et informatique
Pour comprendre le fonctionnement d’un secteur économique il peut être utile de raisonner en termes de filière : ainsi pour produire un service ou une application informatique il faut avoir produit des logiciels et des ordinateurs. Pour que ces logiciels fonctionnent sur ces ordinateurs il faut avoir produit un système d’exploitation. Pour construire les ordinateurs il faut avoir fabriqué des composants électroniques. Pour fabriquer des microprocesseurs il faut disposer de logiciels de conception spécialisés, de très haute complexité. Ensuite, l’industrie microélectronique repose sur des matériels de photolithographie et d’optique. Enfin au début de la filière il faut extraire du silicium de qualité adéquate et le préparer sous la forme convenable. Prendre cette séquence depuis le début (extraction et conditionnement du silicium), c’est décrire la filière.
Une fois la filière caractérisée, on peut identifier les points où se crée le maximum de valeur ajoutée, qui sont aussi ce qui coûte le plus cher en investissements, ce qui a la plus forte intensité capitalistique. C’est important du point de vue de la politique économique, parce que détenir des capacités de production dans ces domaines est un facteur essentiel d’indépendance économique, donc de souveraineté politique. Ce point a été bien expliqué par le rapport de la sénatrice de la Seine Maritime Catherine Morin-Desailly, rendu en 2013, dont il n’a malheureusement guère été tenu compte.
Aujourd’hui la chaîne de valeur de la filière micro-électronique – informatique peut être schématisée ainsi (l’échelle des ordonnées ne figure que des ordres de grandeur) :
Nous allons examiner maintenant les points cruciaux de cette filière, et les enseignements que l’on peut en tirer. Nous omettrons la fabrication de barreaux de silicium monocristallins, non que ce soit simple ni dépourvu d’intérêt, mais un peu éloigné de notre propos. Cependant, en préambule, il faut souligner le caractère spécifique de cette industrie, identifié par l’Institut de l’Iconomie et Michel Volle ; les coûts fixes, nous allons le voir, en sont considérables, les coûts marginaux voisins de zéro : « le coût marginal d’un logiciel est pratiquement nul : une fois écrit, on peut le reproduire des millions de fois, sans coût supplémentaire significatif, par téléchargement ou impression de disques. […] Le coût marginal d’un composant microélectronique, processeur ou mémoire, est lui aussi pratiquement nul. […] Le transport d’un octet ou d’un document supplémentaire ne coûte pratiquement rien sur l’Internet » (Michel Volle). Les conséquences de cette fonction de production sont drastiques : sur chaque segment de ce marché se développe une concurrence monopolistique extrêmement violente, chaque entreprise luttant pour conquérir et conserver une position de monopole temporaire (qui peut durer quelques années ou dizaines d’années).
Conception micro-électronique assistée par ordinateur
Un microprocesseur moderne comporte plusieurs milliards de transistors sur deux ou trois centimètres carrés, il est impensable de concevoir son organisation géométrique et électrique « à la main ». Ont donc été conçus pour ce faire des langages de description de circuits (VHDL, Verilog) et des logiciels de conception assistée par ordinateur.
Les principales (et à peu près seules) entreprises de CAO électronique sont les américains Synopsys (acquéreur du taïwanais SpringSoft, à eux deux 3,3 milliards de dollars de chiffre d’affaires et 13 000 employés), Cadence (2,3 milliards, 7600 employés) et Mentor Graphics (acquis par Siemens, 1,3 milliard, 6000 employés).
Ces systèmes de CAO sont très onéreux, sans parler du temps d’ingénieur passé à les mettre en œuvre. À part le japonais Zuken, beaucoup plus petit, et quelques laboratoires de recherche, ces trois entreprises sont en situation d’oligopole. Elles opèrent sur un marché de niche assez étroit mais hautement stratégique : sans elles pas d’informatique, donc pas d’Internet, adieu Facebook, Twitter, Google et Amazon.
La fabrication des microprocesseurs repose sur des procédés photo-lithographiques réalisés par des machines appelées scanners. Il y a dans le monde trois entreprises qui fabriquent des scanners : Canon, Nikon et le néerlandais ASML, ce dernier détenant les deux tiers d’un marché mondial de l’ordre de 12 milliards de dollars. Intel détient une participation de 15% dans ASML. L’élément le plus cher d’un scanner est un objectif, analogue à celui d’un énorme appareil photo. Il y a trois fabricants : Canon, Nikon et l’allemand Zeiss. Un tel scanner coûte plusieurs dizaines de millions d’euros. Un microprocesseur ressemble à un sandwich d’une trentaine de couches, alternativement de circuits et d’isolants, il faut donc quelques dizaines de scanners pour lancer une chaîne de production. Ces matériels doivent fonctionner en salle blanche munie de dispositifs anti-sismiques, parce que la moindre vibration serait fatale à toute la production en cours.
On note que la Chine et les États-Unis sont absents de ce domaine.
Fabrication de micro-processeurs
Plusieurs approches sont possibles pour produire des microprocesseurs. On peut en concevoir les plans (à l’aide des logiciels mentionnés ci-dessus), construire des usines, fabriquer et vendre : il n’y a plus guère qu’Intel pour assurer ainsi la totalité de la chaîne de production.
L’entreprise britannique ARM, achetée en 2016 par le fonds d’investissement japonais Softbank, s’adonne exclusivement à la conception de microprocesseurs, dont elle concède l’exploitation des plans (électroniques) à des entreprises licenciées, telles que Samsung, Qualcomm, Apple, Nvidia ou le franco-italien STMicro. L’architecture ARM est la plus répandue dans le monde parce qu’elle a le monopole des processeurs pour téléphones mobiles, tablettes et objets connectés de toutes sortes.
Une entreprise comme Qualcomm, très bien placée sur le marché des circuits pour téléphones mobiles, ne fabrique rien. Elle achète à ARM la licence de ses processeurs, elle conçoit le plan d’un SoC (System on Chip) qui comporte plusieurs processeurs et des circuits annexes (mémoire, audio, vidéo, etc.) dont elle confie la fabrication à une fonderie de silicium, qui possède une usine. Une telle fonderie peut être une entreprise qui par ailleurs conçoit ses propres circuits, comme par exemple Samsung, ou une qui ne fait que cela, comme le taïwanais TSMC.
Le perfectionnement d’un procédé de fabrication micro-électronique dépend de sa miniaturisation, mesurée par la longueur de la grille d’un transistor. À ce jour TSMC, le leader mondial (35 milliards de dollars), est le seul à produire en géométrie 7nm (nanomètres), Samsung produit en 10nm, Intel produit en 14nm. Suivent trois entreprises qui ont abandonné la course à la miniaturisation mais continuent à alimenter le marché en produits plus rustiques : Global Foundries, STMicro, UMC. Puis celles qui ne fabriquent que des mémoires, plus simples mais marché en plein essor, ou des circuits spécialisés : Hynix, Micron, Texas Instruments. Qualcomm, Nvidia, Broadcom sont des entreprises sans usines, qui ne fabriquent rien.
La construction d’une usine de microprocesseurs modernes coûte plus de dix milliards de dollars, et son fonctionnement en régime permanent demande la présence de plusieurs milliers d’ingénieurs et techniciens. En effet la mise au point d’un procédé de fabrication et le réglage des machines demande du temps et de la qualification, ce n’est qu’au bout de plusieurs années que la fabrication atteint un taux de réussite proche de 100%.
En somme, l’informatique mondiale dépend de trois ou quatre entreprises et de moins de dix usines.
Par exemple, le dernier modèle d’iPhone fonctionne grâce à un SoC conçu par Apple autour d’un processeur conçu par ARM, et fabriqué par TSMC à Taïwan, le tout assemblé en Chine continentale. On note que la Chine n’est pas (encore) en mesure de fabriquer des microprocesseurs à l’état de l’art, et que les États-Unis sont en perte de vitesse.
Un segment de marché particulier concerne les processeurs à usage militaire et aérospatial, qui doivent résister à des rayonnements cosmiques ou d’origine nucléaire, ce qui exclut les géométries trop fines mais impose des blindages spéciaux. La France possédait des capacités dans ce domaine, avec Altis Semiconductors, mais cette entreprise a disparu, ce qui laisse l’industrie aérospatiale et militaire européenne sous la dépendance de fournisseurs américains, pour lesquels les licences d’exportation conformes à la législation ITAR (International Traffic in Arms Regulations) sont de plus en plus difficiles à obtenir.
Pour conclure sur l’industrie micro-électronique, on peut dire que c’est un domaine d’intensité capitalistique considérable, hautement stratégique, et à peu près déserté par la France et par l’Europe. Il y a une exception, STMicro et ses usines dans la région de Grenoble qui font travailler plus de 30 000 personnes. L’effort pour la conception d’un nouveau microprocesseur se compte en plusieurs (six ou sept) années, mille à deux mille ingénieurs, et quinze à vingt milliards de dollars pour la construction de l’usine, investissement qui sera à renouveler pour la gamme suivante.
Fabrication d’ordinateurs
La complexité des ordinateurs contemporains réside entièrement dans leurs microprocesseurs et dans leurs logiciels. Leur fabrication est une opération d’assemblage entièrement automatisée. Ce sont des objets bon marché à faible valeur ajoutée, la fabrication d’un ordinateur chez le constructeur Dell prend moins de trois minutes. Les principaux problèmes à résoudre sont la chaîne d’approvisionnement, la logistique, la politique d’achats et la distribution.
Système d’exploitation
Le système d’exploitation présente à l’utilisateur une vision simplifiée et compréhensible du fonctionnement de l’ordinateur. Il fournit également une interface standardisée avec les logiciels d’application et commande les interactions avec le réseau. Autant dire que sans lui l’ordinateur ne serait qu’un tas de ferraille et de plastique inutilisable.
Le système d’exploitation est la seconde étape la plus capitalistique de la filière informatique, après le microprocesseur. Écrire un système d’exploitation complet de A à Z, ce que personne n’a fait depuis longtemps, emploierait 1000 à 2000 ingénieurs pendant six à sept ans, si l’on extrapole à partir des expériences du passé et des réalisations partielles contemporaines. Les réalisations contemporaines sont partielles parce qu’elles partent d’une base existante, soit propriété historique de la firme (cas de Microsoft et d’IBM), soit de logiciel libre disponible sans frais, dérivés de systèmes Unix/Linux (cas d’Apple et de Google).
Hormis quelques systèmes très spécialisés ou résiduels et ceux qui sont des logiciels libres (Linux, OpenBSD, FreeBSD, NetBSD), il n’existe que quatre fournisseurs de systèmes d’exploitation : IBM avec z/OS, dérivé de l’OS/360 annoncé en 1964, Microsoft avec Windows, dont la version intitiale a été publiée en 1996, Apple avec iOS et macOS né en 1998 sur un noyau Unix BSD, et Google avec Android lancé en 2007 et basé sur un noyau Linux. En nombre de systèmes installés Google est d’assez loin le leader mondial, puisqu’Android équipe plus de 80% des smartphones et effectue les deux tiers des accès au Web. Ici aussi l’Europe est pratiquement absente.
Réseau, informatique en nuages, centres de données
Le déploiement du réseau physique sur lequel repose l’Internet nécessite des investissements considérables. L’essentiel des communications à longue distance repose sur des faisceaux de fibres optiques transocéaniques, construits hier par des consortiums d’opérateurs et d’industriels, aujourd’hui de plus en plus souvent par des plates-formes telles Google ou Amazon. Le prix d’un tel faisceau peut approcher le milliard de dollars. C’est un des rares domaines où la France occupe encore une position de premier plan. L’enjeu du moment est le déploiement de réseaux sans fil 5G, indispensables pour les objets connectés, et là aussi les sommes engagées se comptent en milliards. Mais l’économie de l’Internet est un sujet en soi que nous ne développerons pas davantage ici.
Effort de recherche et développement
Acquérir une position significative et la conserver dans cet univers de technologies complexes issues de la recherche scientifique la plus avancée exige des efforts de recherche et développement soutenus. Ce tableau
des dépenses de recherche et développement (en 2018 et en milliards de dollars – source : Nick Skillicorn) donne une idée de la puissance relative des différents secteurs aujourd’hui et encore plus demain : :
Amazon 22,6
Alphabet (Google) 16,2
Volkswagen 15,8
Samsung 15,3
Microsoft 14,7
Huawei 13,6
Intel 13,1
Apple 11,6
Roche 10,8
Johnson & Johnson 10,6
Daimler 10,4
Merck US 10,2
Toyota 10,0
Novartis 8,5
Ford 8,0
Facebook 7,8
Pfizer 7,7
BMW 7,3
General Motors 7,3
Robert Bosch 7,1
Honda 7,1
Sanofi 6,6
Bayer 6,2 Siemens 6,1 Oracle 6,1
L’Europe a déserté la filière informatique – micro-électronique, qui commande l’avenir : elle se focalise sur des applications (« intelligence artificielle », « cloud souverain », « usages », etc.), ignorant que le succès et la compétitivité dans les applications dépendent de la maîtrise des technologies fondamentales, qui sont leur principale ressource. Elle ne reste guère aux premiers rangs que dans l’automobile, fleuron de l’industrie du passé en déclin rapide.
Informatique et environnement
L’industrie informatique essuie souvent les critiques du courant de pensée écologique, justifiées par sa consommation importante de minéraux dont l’extraction et le traitement sont excessivement toxiques. Pour atténuer ces reproches l’industrie devrait s’engager dans une politique de recyclage systématique de ses produits et d’accroissement de leur durée de vie.
En outre, il convient de souligner que l’informatique est aussi un moyen de réduire l’empreinte carbone des activités humaines. Ainsi la consommation des moteurs à combustion interne a beaucoup diminué ces dernières décennies, surtout grâce à l’introduction de micro-contrôleurs qui ajustent le débit de carburant des alimentations. Il en va de même pour la consommation électrique des entreprises et des ménages.
Conclusion
L’industrie informatique, qui propulse la révolution industrielle en cours, connaît un essor rapide à peine ralenti par l’épidémie Covid-19. La stratégie de l’Europe, et plus particulièrement de la France, s’en détourne alors qu’elles possèdent des entreprises industrielles de premier plan (SAP, ARM, Dassault Systèmes, STMicro), un réseau d’universités et de centres de recherche sans équivalent dans le monde, et le premier marché mondial. Puissent les événements en cours susciter une prise de conscience et des actes pour redresser la situation actuelle?
Laurent Bloch, ex responsable de l’informatique scientifique de l’Institut Pasteur, Directeur du Système d’Information de l’Université Paris-Dauphine, auteur de plusieurs ouvrages sur les systèmes d’information et leur sécurité, se consacre à la recherche en cyberstratégie.
Quel lien entre Covid 19 et 5G ? Des sites conspirationnistes tentent de répondre à la question en inventant une relation de causalité conduisant parfois à des actes violents. Nos amis Jean-Jacques Quisquater et Charles Cuvelliez nous décrivent une conséquence potentielle de la survenue de la pandémie au milieu des débats sur le passage à la 5G et l’utilisation d’équipements de la société chinoise Huawei. Le virus va-t-il faire pencher la balance du coté de l’interdiction ? Ou comment numérique, santé et géopolitique se rejoignent. Pascal Guitton
Les astres sont désormais alignés pour permettre aux Etats-Unis de réaliser leur rêve : non seulement interdire Huawei (et ZTE) de leur marché mais enfin convaincre leurs alliés de faire de même. Tous les pays évoquent désormais le retour sur leur sol du tissu industriel qu’ils ont laissé filer en Chine dans un refrain unanime : « Plus jamais ça ! ».
Ce n’est pas tellement l’espionnage qui devrait effrayer les Etats-Unis: il suffit au fond de chiffrer tout ce qui transite par des équipements Huawei pour être tranquille. C’est plutôt la menace que la Chine ordonne un jour à Huawei (ou menace) d’arrêter tous les réseaux télécom de son cru à travers le monde en cas de conflit ou de tensions géopolitiques extrêmes.
Cette dépendance vis à vis de l’étranger surprend dans le cas des Etats-Unis car, effectivement, ce pays si technologique ne dispose plus d’aucun équipementier télécom : ils dépendent de Nokia et Ericsson et un peu de Huawei présent au sein des réseaux opérateurs ruraux US.
Comment est-on arrivé là ?
Les Etats-Unis hébergeaient pourtant les Bell Labs qui ont donné naissance à Lucent. Ce dernier était devenu l’équipementier attitré et neutre des opérateurs télécom américains (un peu comme Siemens et Alcatel l’étaient en Europe). Pour le Canada, c’était Nortel, issu lui aussi des Bell Labs en 1949. Lucent a raté le virage internet : la société pensait pouvoir développer son propre protocole. Lucent était aussi leader dans les technologies de réseau optique avec Nortel et était donc en pole position pour le boom d’Internet sauf que ces capacités ont été déployées bien plus vite que la demande. La bulle Internet du début des années 2000 en a résulté.
Site des Laboratoires Bell à Murray Hill – Extrait de WikiPedia
Lucent possédait également une technologie 3G supérieure (avec le CDMA) mais n’a pas réussi à capturer les marchés européen et asiatique qui avaient déjà opté pour la norme GSM et son successeur UMTS pour la 3G. Toutes ces opportunités ratées ont amené leur lot de fusions et d’acquisitions : Ericsson a absorbé Nortel après sa faillite en 2009. Nokia a acquis Motorola Solution en 2011, puis la partie télécom de Siemens. En 2006, Alcatel absorbait Lucent pour être finalement lui-même absorbé par Nokia ! Pendant ces temps douloureux, deux acteurs ZTE et Huawei émergeaient, au bon moment, juste après la bulle Internet, en profitant du marché chinois qu’il fallait équiper. Qui allait imaginer que les lois anti-trusts aux Etats-unis en cassant ATT en 1982, allaient donner un avantage énorme à Huawei (fondé en 1987), ZTE (1985) et un peu Samsung (1938) ? Et qu’aujourd’hui, l’histoire se retourne en laissant les Etats-Unis les mains vides …
Pour les Américains, interdire leur territoire à Huawei n’est pas suffisant si la menace résulte de la capacité à stopper tous les réseaux équipés par Huawei à travers le monde en cas de conflit. Les opérations militaires nord-américaines ne s’arrêtent pas aux frontières de leur territoire. Et de rappeler, dans une étude américaine de la National Defense University, qui émane du département de la Défense US que les réseaux télécoms en Irak sont équipés par Huawei. Les États-Unis ne peuvent pas complètement se baser sur les satellites et dans le monde interconnecté aujourd’hui, utiliser des fibres dans un pays « ami » ne garantira pas que les communications ne passent pas par un équipement contrôlé par ZTE ou Huawei.
Les alliés pas très partants
Les pays alliés ont répondu aux États-Unis en expliquant qu’ils localiseraient les équipements Huawei aux extrémités du réseau et pas en son cœur (comme la France) mais en 5G, la différence entre cœur de réseaux et ses extrémités est évanescente. Qui plus est, lorsqu’on passera à la 5G qui fera plus que simplement augmenter la vitesse, le cœur de réseau devra passer à la 5G aussi. Les entreprises chinoises ont une longueur d’avance en innovation technologique sur la 5G, les Américains s’en désolent d’autant plus que leurs concurrents asiatiques planchent déjà sur la 6G qui se greffera sur les équipements 5G qu’on installe aujourd’hui.
C’est dire l’urgence à trouver une alternative à Huawei et ZTE pour les États-Unis. Des experts ont songé à priver Huawei des composants, toujours fournis par les Américains mais on sait la résilience des chinois à se sortir de tels embargos. Ces équipements, de plus, ne sont plus fabriqués sur le sol nord-américain mais à Taïwan !
Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire.
Sauf qu’aujourd’hui, la politique américaine est plutôt guidée par le slogan « buy, don’t make ».
C’est pourquoi les 3 options du gouvernement nord-américain sont, d’après cette étude américaine (1) :
– Supporter les équipementiers télécoms européens et sud-coréens (car Samsung s’y est mis aussi) : ils sont fortement présents aux États-Unis par leur filiales et le gouvernement nord-américain pourrait leur donner un coup de pouce via la fiscalité, des garanties d’Etat, les achats en masse pour stabiliser leurs finances et booster leur R&D.
– Acheter Nokia ou Ericsson ou au moins une minorité de contrôle. D’après cette même étude (1), Samsung n’est pas une cible car détenant trop peu de parts de marché. La 5G n’est qu’une composante non autonome d’une stratégie globale de ces chaebols, le nom fleuri donné aux énormes conglomérats coréens qui n’ont plus d’équivalent ailleurs dans le monde, qu’on ne peut sortir de ce fait de leur contexte. Ceci dit, les Européens pourraient s’y opposer maintenant qu’ils se sont réveillés face aux prises de participations étrangères de leurs champions.
– Créer un consortium américain à savoir par un jeu d’achats, d’investissement et de financement, ramener sous un même toit les compétences locales diverses avec les brevets et la propriété intellectuelle dont d’ailleurs Nokia et Alcatel dépendent toujours pour créer un nouveau champion. Le gouvernement des États-Unis s’allierait avec des investisseurs. Nokia et Ericsson seraient évidemment des partenaires ou des fournisseurs attitrés de ce consortium histoire de ne pas repartir à zéro. On y associerait les entreprises des alliés des USA : le réseau Five Eyes ainsi que l’Allemagne, la France, le Japon, la Corée. Le succès dépendra des prix et des incitations à travailler avec ce nouveau venu. Ce n’est pas gagné.
Ce qui est clair, c’est que les États-Unis ne vont pas lâcher le morceau. La crise qui s’annonce et qui va fragiliser le monde entier va certainement leur permettre de mettre en œuvre une de ces stratégies en réciprocité de services (au sens large) que leur demanderont d’autres pays.
Jean-Jacques Quisquater (Université de Louvain, Ecole Polytechnique de Louvain et MIT) & Charles Cuvelliez (Université de Bruxelles, Ecole Polytechnique de Bruxelles)
Sihem Amer-Yahia, site du Laboratoire d’Informatique de Grenoble
Sihem Amer-Yahia est directrice de recherche CNRS, responsable d’une équipe du Laboratoire d’Informatique de Grenoble à la frontière entre la fouille de données, la recherche d’informations, et l’informatique sociale (social computing).
Après un diplôme d’ingénieur à l’ESI d’Alger, en 1994, elle passe sa thèse en 1999 chez Inria, sous la direction de Sophie Cluet, sur le chargement massif de données dans les bases de données orientées objet. Sihem se lance ensuite dans un grand voyage académique et industriel : un post-doctorat à AT&T Labs, puis des postes à Yahoo! Labs toujours aux États-Unis, Yahoo! Barcelone, le Computing Research Institute au Qatar, avant de rejoindre Grenoble et le CNRS en 2012.
Entre temps, la doctorante est devenue une chercheuse de renommée internationale avec des contributions majeures notamment sur le stockage et l’interrogation des données XML et les systèmes de recommandation.
Sihem a vite compris l’importance du caractère social des données produites par des humains. Elle a été convaincue que pour des logiciels faisant interagir des humains, comme les réseaux sociaux, le crowd sourcing, les systèmes de recommandation, les logiciels de ressources humaines, il fallait tenir compte des comportements sociaux, des facteurs humains.
Image par Gerd Altmann de Pixabay
Donc parlons d’informatique sociale, la passion de Sihem. Le traitement massif de données produites par des humains pose à l’informatique des défis passionnants. Prenons les systèmes de recommandations qui nous aident à choisir des produits ou des services. Pour saisir la richesse des recommandations, il faut maîtriser la langue, et tenir compte du comportement humain : Qu’est-ce qui conduit quelqu’un à s’« engager » en donnant une opinion ? Quels sont les souhaits de chacun ? Quels pourraient être les biais ?… Les données humaines s’introduisent partout, par exemple : dans la justice (comment évaluer les risques de récidive), dans la politique (comment analyser les données du Grand Débat, ou les réactions sur les élections sur Twitter), dans la médecine (le dialogue avec le patient dans le cadre du diagnostic automatique), dans la sociologie (comment détecter automatiquement des messages de haine), dans l’Éducation nationale (comment se comportent les élèves devant Parcoursup)… Cela nous conduit aux frontières de l’informatique, et les informaticiens y côtoient des linguistes, des juristes, des spécialistes de sciences politiques, des sociologues, des médecins, des psychologues… Toute la richesse des sciences humaines et sociales, et au-delà.
Sihem est aujourd’hui internationalement reconnue par ses pair·e·s. Ses travaux sont énormément cités, et ont trouvé des applications directes au sein des entreprises qui l’ont employée.
Sihem aime faire partager sa passion pour l’informatique et la recherche. On pourra lire ou relire ses articles récents [1] dans binaire sur les algorithmes de RH. Elle milite pour plus de place pour les femmes dans les sciences ; elle est source d’inspiration pour les jeunes chercheuses en informatique (un domaine très déséquilibré en genre).
La prestigieuse médaille d’argent du CNRS, qui distingue chaque année un·e scientifique d’un laboratoire CNRS dans chaque discipline, lui a été attribuée en 2020.
[1] Le testing algorithmique de la discrimination à l’embauche (1) et (2), Sihem Amer-Yahia et Philippe Mulhem (CNRS, Univ. Grenoble Alpes), 2010. www.lemonde.fr/blog/binaire/
Les logiciels que nous utilisons viennent très souvent des États-Unis. C’est là-bas que l’informatique s’est épanouie, le reste du monde un peu à la traine pour un temps. Pour ne pas prendre de retard, l’URSS s’est lancée dans une entreprise de piratage informatique d’un niveau exceptionnel dans les années 60’s. C’est l’histoire que nous raconte Pierre Mounier-Kuhn. Serge Abiteboul
Fin 1969, à l’initiative des autorités soviétiques, la plupart des pays du bloc socialiste européen ont mis en œuvre un vaste projet : réaliser ensemble une gamme unifiée d’ordinateurs compatibles, en copiant les IBM/360 qui dominaient alors le marché occidental. Cette gamme EC fut laborieusement mise en chantier, subissant des retards de mise au point similaires à ceux des constructeurs occidentaux quelques années plus tôt[1]. Cependant, avec ses défauts, la gamme EC allait finalement déboucher sur deux générations d’ordinateurs qui équipèrent les pays du bloc soviétique, constituant l’un des plus grands développements informatiques multinationaux de l’époque. C’est aussi, en un sens, la plus grande opération de piraterie de l’histoire de l’informatique.
Des ordinateurs sous tensions
Les débuts de l’informatique en URSS avaient subi de fortes tensions. D’un côté, des ingénieurs et des scientifiques de grand talent s’intéressaient à l’automation, aux calculateurs électroniques et à la théorie des algorithmes, répondant aux besoins d’un complexe militaro-industriel engagé à fond dans la course à l’arme nucléaire et à la conquête spatiale. De plus, l’économie socialiste planifiée s’accommodait bien des grands systèmes d’information centralisés comme les informaticiens les concevaient à l’époque.
En revanche, jusqu’au milieu des années 1950, la politique idéologique du parti communiste proscrivait les « sciences bourgeoises », la cybernétique tout comme la génétique : un chercheur qui s’y référait risquait le camp de concentration ! D’autre part, la planification entravait l’innovation et la mobilité des investissements vers une technologie imprévue mais prometteuse. Et l’absence de marché ne favorisait pas la diffusion massive d’ordinateurs, seule capable de justifier la mise en production de composants nouveaux. D’où un retard technique permanent, à côté d’une grande créativité en matière d’architectures et de mathématiques appliquées.
Le premier ordinateur d’Europe continentale fut pourtant bel et bien construit en URSS. Dès 1948, l’ingénieur soviétique Sergueï Alexeïevitch Lebedev (1902-1974) s’était attaqué à la construction d’un calculateur électronique à programme enregistré. Malgré un manque de soutien des autorités et avec un accès parcellaire aux informations sur les progrès effectués aux États-Unis et en Europe occidentale, il mit en service sa première machine, MESM (petit calculateur électronique), fin 1951 à Kiev (Ukraine). Ce prototype contenait 6 000 tubes à vide – ce qui n’était pas si « petit » – et pouvait effectuer environ 50 instructions par seconde. Des mathématiciens de toute l’URSS firent le voyage à Kiev pour l’utiliser – voire pour s’en inspirer. Ses principales applications concernaient la balistique et les fusées, ainsi que le problème qui préoccupait initialement Lebedev, le calcul de lignes de transmission téléphoniques. Lebedev s’installe bientôt à Moscou, où il dirige la conception d’une longue lignée d’ordinateurs puissants, les BESM sous l’égide de l’Académie des Sciences.
En concurrence avec Lebedev, une équipe de l’Institut d’électrotechnique de l’Académie des Sciences conçoit de petits ordinateurs ‘M’. Des variantes sont réalisées à la fin des années 1950 dans divers centres de recherche de pays satellites ou annexés : Hongrie, Pologne, Arménie, Biélorussie, ainsi qu’en Chine. Un laboratoire dépendant du Ministère de la Mécanique construit Strela (flèche), prototype d’une première série d’ordinateurs soviétiques ; les mémoires sont à tubes cathodiques, comme dans le Mk1 de l’université de Manchester[2]. D’autres séries d’ordinateurs (Ural, etc.) seront développées jusqu’en 1968 dans divers laboratoires de recherche publique.
L’une des architectures les plus originales est le calculateur en base ternaire, concept imaginé dès le XIXe siècle par l’Anglais Fowler, redécouvert et développé à l’université de Moscou par l’équipe de N.P. Brusentsov. Son ordinateur Setun entre en service en 1958 et démontre ses avantages : la logique ternaire (oui / non / incertain), inspirée d’Aristote, correspond bien à la pensée humaine et facilite la programmation. Du point de vue électronique, le système ternaire permet de traiter plus d’informations que le binaire, donc réduit le nombre de composants et par conséquent la consommation électrique. Réalisé en technologie à noyaux magnétiques, cet ordinateur petit et fiable entre en service en 1958 et sera construit à une cinquantaine d’exemplaires.
Vers 1960, l’existence d’ordinateurs de plus en plus nombreux dans les usines et les administrations inspire même au jeune colonel Kitov, passionné de cybernétique qui dirige un centre de calcul militaire, l’idée de les interconnecter pour constituer un réseau de données à l’échelle de l’URSS. Ce système permettrait, à travers un tableau de bord électronique, de connaître et de piloter presque en temps réel l’économie de l’Union, en optimisant le processus de planification centralisée. Le mathématicien Viktor Glushkov, fondateur de l’Institut de Cybernétique de Kiev, imagine dans le même sens un vaste plan national d’informatisation destiné à rendre l’économie plus efficace. Ce projet rencontre une préoccupation émergente des économistes soviétiques, qui voient dans l’ordinateur un moyen de fixer les prix rationnellement en se substituant au marché par des simulations. Il est toutefois mis au panier par la direction du Parti Communiste, et son auteur relégué à des postes où il ne sera plus tenté de suggérer que des machines pourraient être plus rationnelles que les dirigeants politiques. Si la Cybernétique a été réhabilitée sous Khrouchtchev, c’est comme pensée technique, mais certainement pas comme pensée socio-politique susceptible de concurrencer le marxisme. Plus concrètement, l’informatisation de l’économie risquerait de faire apparaître des écarts embarrassants entre les statistiques officielles et les données réelles…
Au milieu des années 1960 les autorités prennent conscience d’un déficit d’informatisation, par comparaison avec le monde capitaliste que l’URSS s’acharne à « rattraper » : à population équivalente, l’URSS a dix fois moins d’ordinateurs que les États-Unis. Si les savants des pays socialistes ont développé de bons calculateurs scientifiques ou militaires, le gouvernement soviétique s’inquiète du retard en systèmes de gestion, indispensables à une économie planifiée. Par ailleurs l’industrialisation, le transfert des expériences de laboratoire aux fabricants de matériels est difficile. Ainsi le BESM-6, machine pipeline très performante (10 MHz, 1 MFlops) développée à l’Institut de mécanique de précision et de calcul électronique de Moscou en 1965, n’est mis en production qu’en 1968 – il totalisera 355 exemplaires livrés jusqu’en 1987.
La situation du software est encore pire que celle du hardware : les constructeurs livrent généralement les ordinateurs « nus », à charge pour les clients de développer leurs logiciels. Ça ne pose guère de difficultés pour les utilisateurs scientifiques, qui dans le monde entier sont habitués à concevoir leurs applications, voire leurs systèmes d’exploitation. Mais cette pratique est rédhibitoire dans les administrations et les entreprises. Or il n’existe pratiquement aucune industrie du logiciel dans les pays socialistes, alors qu’elle a éclot en Occident dès les années 1950. Et la diversité des modèles d’ordinateurs incompatibles découragerait toute tentative de développer des produits logiciels standard.
Dans la seconde moitié des années 1960, les autorités soviétiques cherchent à remédier à cette situation. Elles envisagent trois solutions :
Confier à leurs savants le soin de développer une famille d’ordinateurs et de périphériques compatibles, comme celle qu’IBM a annoncée en avril 1964, la gamme IBM System/360. Mais une première tentative en ce sens a déjà été faite avec le lancement d’une série « Ural » de trois modèles : leur compatibilité laisse autant à désirer que leur fiabilité et, avec environ 400 exemplaires produits, ils restent très en-dessous de ce qui serait nécessaire.
Acheter une licence d’un des constructeurs ouest-européens, notamment Siemens ou ICL, qui eux-mêmes dérivent leurs ordinateurs de la série RCA Spectra, elle-même réplique compatible de la gamme IBM/360 utilisant des circuits intégrés plus avancés. C’est ce que font d’ailleurs les Polonais avec leur série Odra sous licence britannique ICL. L’avantage de l’acquisition d’une licence est qu’elle donne accès légalement à l’ensemble des technologies et du software du bailleur.
Copier la gamme IBM System/360 en se passant de licence. C’est faisable car l’essentiel de la technologie et des codes sources sont alors facilement accessibles. Les services de renseignement soviétiques ont vraisemblablement fait valoir qu’ils pourraient obtenir ce qui n’était pas en accès libre. L’avantage est qu’une fois les machines construites, on pourra profiter de la masse de software – systèmes d’exploitation et applications – disponible gratuitement. Pour parler crûment, l’URSS imagine ainsi la plus grande opération de piraterie de l’histoire de l’informatique (IBM commencera à facturer ses logiciels à partir de 1970 en annonçant l’unbundling, le dégroupage).
Une longue suite de délibérations conduit les autorités soviétiques à choisir la troisième option, à abandonner les développements originaux d’ordinateurs de leurs centres de recherche – sauf les super-calculateurs – et à définir un « Système Unifié » copié sur les IBM/360 : la gamme (ryad) EC. Cela sans trop se préoccuper des droits de propriété industrielle.
L’historiographie de l’informatique dans l’ex-URSS reflète le choc qu’a entraîné cette décision[3] : la plupart des mémorialistes sont des scientifiques qui ont participé aux aventures technologiques des BESM, Setun et autres Ural, et qui en détaillent fièrement les innovations au fil de leurs publications ; ils profitent de la liberté de parole conquise depuis 1989 pour dénoncer amèrement l’abandon des développements nationaux, par des politiciens ignorants, au profit de machines américaines. 1969, année noire pour la créativité informatique russe. Ce qui est advenu ensuite, l’histoire de la ryad EC, reste donc dans le brouillard historiographique où se morfondent les âmes des ordinateurs maudits, not invented here.
C’est pourtant une histoire bien intéressante, à la fois du point de vue de la gestion d’un grand projet technique et du point de vue des relations internationales – des relations Est-Ouest comme des relations au sein du bloc soviétique. Elle reste à écrire en grande partie. Ce qui suit résume ce que l’on sait par diverses publications occidentales ou russes, et le travail préparatoire d’un historien des sciences hongrois, Máté Szabó, qui entreprend d’y consacrer sa thèse.
Fig. 2 Ordinateur Soviétique BESM-6, 1965. Crédit photos : Vera Bigdan, archives Boris Malynovsky
Informaticiens de tous les pays, unissez-vous !
En janvier 1968, Kossyguine, président du conseil des ministres d’URSS, invite les « pays frères » membres du Comecon à participer au projet[4]. Il faut encore près de deux ans de pourparlers avant que la plupart des pays satellites acceptent officiellement, en décembre 1969, de coopérer avec Moscou qui a réparti la réalisation de ces clones compatibles en fonction des aptitudes de ces pays.
Ceux-ci ont en commun deux motivations. Ils ne parviennent pas à répondre à la demande de leurs propres organisations en matière d’ordinateurs, les machines occidentales étant souvent trop chères pour leurs économies. Et l’URSS leur promet un soutien financier conséquent s’ils participent.
Derrière l’enthousiasme de façade, leurs attitudes varient en fonction de leurs intérêts, de leurs ressources et de leurs relations avec l’URSS. L’Allemagne de l’Est adhère d’emblée au projet : d’une part elle dispose de compétences sérieuses en informatique, qui lui assurent d’être chargée de responsabilités importantes dans le projet, juste derrière l’URSS qui s’attribue évidemment le développement des plus gros modèles ; d’autre part, la RDA possède déjà quelques exemplaires d’IBM/360 acquis plus ou moins officiellement via l’Allemagne de l’Ouest, ce qui facilitera le retro-engineering. La Bulgarie adhère aussi sans réserve, mais pour des raisons opposées : ce petit pays agricole a peu de compétences en la matière et aura tout à gagner à participer au projet.
La Pologne est moins enthousiaste, car elle produit déjà une gamme d’ordinateurs sous licence britannique ICL. La Tchécoslovaquie, encore sous le coup de la répression du Printemps de Prague, garde ses distances vis-à-vis du « grand frère », et a d’ailleurs commencé à produire sous licence une ligne d’ordinateurs conçus à Paris, chez Bull, donc incompatibles avec ceux d’IBM. La Hongrie s’est, elle aussi, lancée dans la production de machines conçues dans les pays capitalistes : des mini-ordinateurs copiés sur le PDP-8 de Digital Equipment, ou construit sous licence française CII. La Roumanie de Ceaucescu reste hors jeu, voulant marquer son autonomie et ayant passé un accord avec la France pour construire des ordinateurs de gestion CII. Cuba est inclus pour la forme, plutôt comme un futur client privilégié que comme un contributeur.
La gamme EC est ensuite laborieusement mise en chantier, subissant des retards de mise au point et de production qui rappellent ceux des constructeurs occidentaux quelques années plus tôt[5]. En décidant de cloner les machines IBM, les dirigeants soviétiques espéraient gagner du temps de développement, mais l’expérience démontre qu’il n’en est rien : le retard sur l’Occident ne sera pas comblé.
En mai 1973, date de l’annonce commerciale officielle prévue de longue date dans le plan quinquennal, la plupart des ordinateurs de la gamme sont, soit encore loin de la mise au point, soit non compatibles car issus des constructions sous licences britanniques ou françaises. L’Allemagne de l’Est présente triomphalement un ordinateur clignotant de tous ses voyants, tandis que les Soviétiques ne savent pas encore quand leur haut de gamme EC-1060 sera terminé. Leur modèle moyen est en revanche entré en production. Beaucoup de périphériques laissent à désirer. L’industrie des composants est loin de fournir des semi-conducteurs aussi performants qu’en Europe occidentale et en Amérique, où le Cocom contrôle sévèrement les transferts technologiques qui pourraient renforcer les capacités militaires soviétiques.
Ce qui est le moins transféré, ce sont les soft skills. L’adoption des machines IBM ne s’accompagne pas de l’adoption des méthodes commerciales IBM. Les constructeurs en Europe de l’Est se contentent d’installer les ordinateurs chez les clients, et repartent sans trop se soucier de la maintenance : ils ont rempli leur part d’objectifs du Plan. La programmation relève entièrement des clients, qui s’associent en clubs d’utilisateurs pour partager expériences, techniques de codage, voire logiciels. Si un effort sérieux est mené pour développer des systèmes d’exploitation, indépendamment d’IBM, aucune industrie significative du software n’en émerge.
Avec ses défauts, la gamme EC va finalement déboucher sur deux générations d’ordinateurs équipant les pays du bloc soviétique, assurant à leur secteur informatique une croissance annuelle de 15 à 20 %, du même ordre qu’en Occident. Dirigée par une agence intergouvernementale ad hoc, l’opération constitue l’un des plus grands développements informatiques multinationaux de l’époque, comparable à ce que mènent en Occident Honeywell ou Unidata à la même époque. Elle mobilise beaucoup plus de monde : de l’ordre de 20 000 scientifiques et ingénieurs, 300 000 techniciens et ouvriers dans 70 établissements de R&D et de production. Par exception, ce n’est pas un projet soviétique imposé aux subordonnés. Comme les pays satellites l’espéraient, l’URSS leur distribue des moyens financiers ou techniques à la hauteur des responsabilités qui leur sont déléguées, pour étoffer leurs laboratoires et leurs entreprises. Chaque pays est financièrement responsable de sa part du projet. Mais comme l’œuvre commune est une priorité politique, les subsides provenant d’URSS ne tarissent pas. De plus elle favorise la coopération sous forme de rencontres, de voyages d’études, de tout ce qui permet une meilleure intégration. L’industrie informatique de ces pays y gagne un vaste marché commun et une expérience professionnelle durable qui se maintiendra après la chute du communisme.
C’est d’ailleurs le seul projet collaboratif d’envergure mené par les « pays de l’Est ». Autant qu’on le sache il n’a pratiquement pas eu de volet militaire : les calculateurs spéciaux destinés à la Défense, comme au Spatial, ont continué à être conçus dans des laboratoires soviétiques bien protégés. Utilisation courante de technologies venus du monde capitaliste, mais souci permanent de souveraineté numérique : peut-être une origine lointaine de la tendance russe actuelle à constituer un internet autonome ?
Pierre Mounier-Kuhn , CNRS & Université Paris-Sorbonne @MounierKuhn
Fig. 3. Ordinateur soviétique ES-1030 au service du recensement, à Moscou (1979). (crédit photo: Archives Boris Malynovsky)
Fig. 4. Ordinateur moyen soviétique ES-1035 dans un centre de traitement en URSS (vers 1983). La ressemblance avec les mainframes IBM est frappante. Mais seul un esprit malveillant imaginerait un parallèle entre le portrait de Youri Andropov, accroché au-dessus de la console, et celui du président-fondateur d’IBM, Watson, omniprésent jadis dans les établissements de sa firme. (crédit photo: Máté Szabó)
Pour aller plus loin :
[1] W. B. Holland, « Unified System Compendium », Soviet Cybernetics Review, May-June 1974, vol. 4, no 3, p. 2–58.
[2] P. Mounier-Kuhn, « 70e anniversaire de l’ordinateur : La naissance du “numérique” », Le Monde-Binaire, 16/07/2018, publié simultanément dans The Conversation France.
[3] Sur les discussions soviétiques autour du choix de la gamme EC, voir notamment B. Malinovsky et alii, Pioneers of Soviet Computing, Electronic Book, 2010, ch. 6. Pour un historique d’ensemble, voir aussi Y. Logé, « Les ordinateurs soviétiques », Revue d’études comparatives Est-Ouest, 1987, vol. 18, no 4, p. 53–75. Et Victor V. Przhijalkovskiy, « Historic Review on the ES Computers Family » (trad. Alexander Nitussov), http://www.computer-museum.ru/articles/?article=904.
[4] Comecon : Conseil d’assistance économique mutuelle, rassemblant l’URSS et ses pays satellites.
[5] W. B. Holland, « Unified System Compendium », Soviet Cybernetics Review, May-June 1974, vol. 4, no 3, p. 2–3.
[6] Il en va de même pour les petits calculateurs programmables, produits et diffusés en masse par l’industrie électronique soviétique, et qui ont fait l’objet d’une véritable culture geek en URSS dans les années 1970 et 1980 (Ksénia Tatarchenko, « “The Man with a Micro-calculator”: Digital Modernity and Late Soviet Computing Practices », dans T. Haigh (dir.) Exploring the Early Digital. History of Computing. Springer, 2019, p. 179-200).
On vous parle beaucoup de voitures autonomes. Cela serait même un moyen pour réduire la pollution notamment dans les villes. Qu’en est-il ? Guillaume Pallez, chercheur en informatique propose une déconstruction de ce mythe. Serge Abiteboul
Je vous propose de suivre une approche un peu différente. Qui construit des véhicules autonomes ? Quelles utilisations les intéressent ? En particulier nous allons étudier les possibles effets rebonds de l’implémentation de ces modèles à grande échelle. En particulier celui lié à l’augmentation de consommation grâce à cette technologie et aux moindres contraintes qu’elle engendre. Aujourd’hui il y a trois modèles principaux d’utilisation de ces voitures autonomes, liés en particulier aux différents groupes qui y travaillent :
1. Le modèle constructeurs automobiles (Audi, BMW, Ford, General Motors, Renault, Tesla, Toyota…)
2. Le modèle VTC (Lyft, Uber…)
3. Le modèle transport en commun
Nota : Je range le modèle économique « Google/Alphabet » dans une catégorie différente : mon impression est, comme pour Android, ce modèle est plus intéressé par une utilisation du système par un maximum de groupes. Ainsi l’entreprise peut contrôler le marché, récupérer beaucoup de données et les revendre efficacement. Ainsi, leur utilisation serait un sous ensemble des trois modèles précédents.
Le modèle constructeurs automobiles
Photo Pixabay
De manière générale, le modèle économique d’un constructeur automobile est de vendre plus de voitures. Au vu de ce modèle économique, à quoi peut-on s’attendre dans le cadre de ces véhicules autonomes ?
1. On peut s’attendre à ce que la publicité joue son rôle pour convaincre chacun·e de continuer à posséder sa voiture (autonome ou non, mais idéalement autonome). Apparemment, sur chaque voiture neuve achetée, une moyenne de 1500€ vont à la publicité !Le nombre total de voituresne devrait donc pas diminuer.
2. Des études sont déjà en cours sur la façon de nous faire profiter du temps dans ce véhicule où nous n’avons plus besoin de conduire. Le « voiture-travail« sera développé et le temps de trajet ne sera plus du temps « perdu ».
Les transports en commun seront moins attractifs. On peut s’attendre à ce que le nombre de trajets en voiture augmente (effet de substitution). Le temps de trajet n’étant plus une contrainte, les gens pourront aussi habiter plus loin de leur travail (étalement urbain). Ainsi, similairement on peut s’attendre à une durée de trajets moyens augmentée. Finalement, face à cette diminution d’utilisation des transports en commun, il est raisonnable de penser qu’une conséquence directe serait une réduction des investissements en infrastructure, une suppression de lignes de trains locaux (type TER), ou une diminution des nombres de train à grande vitesses qui poussera les gens à répéter ce cycle.
3. Finalement on peut s’inquiéter de la montée en flèche du leasing (locations longues qui permettent un changement de voitures très fréquent) : 73% des voitures neuves aujourd’hui ! Cette option « encourage » à changer de véhicule plus fréquemment et à monter en gamme. Cela conduit à une possible augmentation du nombre de véhicules neufs.
Le modèle VTC (compétition avec les transports en commun)
Photo by STANLEY NGUMA from Pexels
De manière générale, le modèle économique d’un VTC est de vous faire utiliser au maximum ses services. Ce modèle peut être résumé ainsi : en ville, une flotte de véhicules autonomes en libre accès tournera et prendra les gens au fur et à mesure des demandes. Grâce à cette simplicité d’usage, les gens arrêteront de prendre leurs voitures individuelles. Ce modèle est vendu comme « écologique » car selon ses promoteurs :
– Le nombre de voitures en ville et individuelles devrait diminuer ;
– Le trafic devrait être plus fluide (réduisant ainsi la congestion et la pollution liée aux embouteillages) ;
– Le nombre de parking urbains devrait diminuer, libérant de la place pour d’autres usages.
Ce modèle peut paraître familier : c’est exactement le modèle VTC. L’avantage c’est qu’il commence à être étudié et on commence à connaître un peu ses effets rebonds. En particulier une étude récente (en anglais) compare la croissance de la ville par rapport à un modèle sans VTC. Parmi les résultats, on peut mentionner :
– La congestion a augmenté de 60% entre 2010 et 2016 alors que dans le modèle sans VTC elle n’aurait augmenté que de 20%
– La réduction de vitesse dans la ville a été de 13% (vs 4% dans le modèle).
Les causes avancées par les chercheurs sont encore liés aux effets rebonds. Par cette simplicité d’utilisation les gens auraient :
– réduit leur consommation des transports en commun ou de marche à pied.
– fait des trajets qu’ils n’auraient peut-être pas fait sans le système de VTC.
– enfin, de la congestion a été rajoutée par les VTC « à vide », qui se repositionnent, ou pour aller chercher des clients.
L’étude ne dit pas si le nombre de voitures individuelles a réellement diminué.
À nouveau on a un modèle où l’impact écologique attendu est négatif.
Le modèle transport public
Photo Negative Space
Les transports en communs comme service public ont vocation à servir le public, et non pas à générer des bénéfices pour un petit nombre. Dans ce dernier modèle, voitures autonomes et transports en commun ne sont plus en compétition mais collaborent. Les voitures servent de navette pour ramener les gens éloignés des infrastructures vers les transports en commun. Ce service fait partie du réseau de transports en commun.
C’est un modèle que l’on pourrait imaginer écologiquement responsable (cependant, il faudrait prendre en compte l’impact en terme de consommation de métaux et terres rares pour toutes les bornes 5G nécessaires pour que les véhicules communiquent avec l’extérieur).
Malheureusement c’est aujourd’hui le modèle le moins mis en avant. Par exemple, dans ce dernier document du ministère de l’écologie solidaire et du transport, ce cadre n’est pas du tout discuté. On parle au contraire de cohérence entre les transports publics et ces nouveaux modèles économiques (Modèles I et II), qu’on peut interpréter comme « à long terme, réduire l’investissement dans les transports en communs car les gens vont utiliser ces voitures autonomes ».
« ils peuvent aussi modifier les limites entre transport individuel et collectif. Il importe de favoriser l’émergence de nouveaux modèles économiques et tout en assurant la cohérence de ces services avec les politiques de mobilité locales et les capacités à déployer des infrastructures adaptées au véhicule autonome « .
Pour conclure
Arrêtons le green-washing. Aujourd’hui, je ne connais pas d’étude qui permette d’affirmer que les voitures autonomes sont une solution au problème écologique. Les données ainsi que nos comportements passés liés aux progrès technologiques dans les transports semblent montrer plutôt l’opposé.
Si on voulait vraiment réduire l’usage des voitures en ville, il existe des solutions qui fonctionnent ! Commençons par les mettre en place. En attendant plusieurs actions sont possibles :
– pour les législateur·rices·s éco-conscient·e·s : mon mieux serait d’interdire les véhicules autonomes tant que les effets ne sont pas bien identifiés. Moins efficaces des premières avancées seraient : (i) d’interdire les ventes de voitures autonomes individuelles qui ne semblent pas répondre à un besoin qui n’ait de solution plus écologique ; et (ii) de limiter le nombre de VTC autonomes en ville comme cela été fait dans le passé pour les taxis
– pour les journalistes, les tribunes offertes aux lobbyistes de l’automobile ([1], [2] ..), doivent être annoncées comme telles, et idéalement discutées de manière contradictoire. Les autres tribunes devraient être partagés avec votre audience avec la même accessibilité (paywall vs sans paywall).
– pour les scientifiques et en particulier mes collègues du numérique. Je recommande l’excellente tribune d’Atecopol. Ensuite, pour ces problèmes de recherche dirigés vers un problème précis (par exemple la voiture autonome, la 5G, les data-centers « green »), on peut commencer par évaluer
les considérations « rebonds », non rentables pour un industriel. Il est dommage que l’Inria, institut de recherche dédié aux sciences du numérique, publie un livre blanc sur les véhicules autonomes sans traiter ces problématiques.
Il est donc absolument indispensable qu’un organisme public de recherche puisse continuer à mener une recherche de façon indépendante de celle de l’industrie, avec sa vision propre et des axes de recherche qui ne coïncident pas nécessairement en tout point avec ceux des entreprises. Et avec une remise en question saine de cette recherche.
L’actualité récente nous a fait découvrir des crashs d’avion qui auraient été causés par des erreurs logicielles. Même si nous savons bien que tous les véhicules depuis les voitures jusqu’aux engins spatiaux en passant par les avions embarquent beaucoup de logiciels, il n’est pas simple de percevoir leur importance et surtout leur impact en cas de panne. Pour nous aider à y voir plus clair, nous avons interrogé, Charles Cuveliez et Jean-Jacques Quisquater, qui nous expliquent l’importance de la fiabilité de ces systèmes dits critiques. Pascal Guitton.
Photo by Fernando Arcos from Pexels
N’importe quel gratte-ciel depuis les plans jusqu’à son érection impliquera une armée de professionnels, accrédités, formés à concevoir de telles prouesses technologiques car la moindre erreur ne pardonnerait pas. Il en va de même à chaque fois qu’un projet industriel critique voit le jour : rien n’est laissé au hasard quant à la compétence de ceux qui le mènent ou y participent et cette compétence est testée, vérifiée, remise à jour et revalidée régulièrement.
Alors, pourquoi a-t-on laissé des Boeing voler jusqu’au moment où deux d’entre eux se crashent, comme si seul un test grandeur nature pouvait en certifier la conception ? Le problème ne réside pas dans la conception des logiciels critiques, mais plutôt dans leur mise en œuvre.
Les logiciels critiques sont peut-être les objets les plus complexes jamais fabriqués par l’homme : ils comportent des millions de ligne de code sur lesquels des centaines de développeurs s’affairent et contrairement à la construction d’ouvrages d’art aussi vieille que l’humanité, on ne conçoit des logiciels que depuis quelques dizaines d’années. Ces logiciels critiques sont au cœur de systèmes qui le sont tout autant dans des domaines comme la santé, la défense, la finance. Qui les a conçus, quelle était la qualification de leurs auteurs ? N’est-il pas étrange qu’on demande à des architectes de signer leurs plans mais pas aux ingénieurs informaticiens qui conçoivent des systèmes critiques ? Tout au plus sait-on le nom de la société mandatée pour concevoir tout ou partie des programmes … qui peut très bien les avoir sous-traités. Pourtant, une erreur dans ce programme provoquerait, dans certains cas, l’arrêt de systèmes critiques avec à la clé une situation chaotique, des industries qui s’arrêtent, des catastrophes industrielles… Nous en avons un petit aperçu quand un ransomware, qui n’est pas une erreur de programmation, arrive à se répandre dans le réseau d’une entreprise. Même les industries très réglementées au niveau sécurité et fiabilité feraient face à des conséquences catastrophiques si des défauts se glissaient et se manifestaient dans les logiciels qui les animent. Le scandale du Boeing 737 MAX l’illustre trop bien, mais ne chargeons pas Boeing de tous les maux. Les entreprises qui fournissent des produits ou des services critiques pour notre société sont bien en peine de garantir un niveau de résilience numérique à la hauteur de la confiance que la société place en eux, face à la rapidité avec laquelle évoluent tant les techniques de programmation (software) que la technologie (microprocesseurs).
Accréditation
L’accréditation et la certification des professionnels de l’IT manquent cruellement à ce secteur, comme l’expliquent les auteurs d’un article incisif de La Sloan Management Review. Oui, on peut suivre des cours, passer un examen et recevoir un diplôme, mais on est loin de la manière dont le secteur de la construction, par exemple, s’est organisé pour garantir qu’un bâtiment ne s’effondrera pas. Un architecte commencera par prendre la plume (et/ou la souris) pour concevoir les premiers plans qui seront ensuite contrôlés par une armée d’ingénieurs qui valideront la structure, les systèmes mécaniques et électriques afin de garantir que le bâtiment correspond aux standards du moment. Ce contrôle réglementé et obligatoire, réalisé par les pairs, n’existe pas dans les programmes informatiques. Pire : quand un bâtiment s’effondre, quand un avion s’écrase, un déluge de moyens est mis en œuvre pour comprendre d’où vient l’erreur et les standards et normes sont modifiés pour que telles catastrophes ne se produisent plus. En codage informatique, on en bien est loin. A-t-on vu la mise en place d’un comité indépendant qui examine le code même du programme à l’origine du crash de deux Boeings 737 MAX (alors qu’il y en a eu pour le crash d’Ariane V, il y a 20 ans) ? Et si normes et standards existent pour utiliser des logiciels dans certains secteurs, ils ne sont que rarement appliqués car rien n’est mis en place pour les contrôler. Et qui dira que ces programmes fautifs sont utilisés autre part ? Il n’y a non plus aucune inspection de la part d’une autorité officielle.
Plus de professionnalisation du secteur et de la manière de concevoir et de déployer des programmes devient indispensable. Cela pourrait commencer par une accréditation ou une certification donnée aux programmeurs qui veulent travailler sur une infrastructure critique. Pour pouvoir conseiller financièrement les gens, n’exige-t-on pas une série de tests à ceux qui se destinent à ce métier. On s’assure qu’ils ont les compétences pour gérer l’argent des autres. Quel équivalent quand des vies humaines sont en jeu ? C’est d’autant plus curieux qu’on certifie et teste quasiment tout dans un avion : les ailes, le train d’atterrissage mais pas les logiciels et, donc, encore moins le cerveau de celui qui les conçoit.
Le recours à l’off shore
Avec les langues qui se délient, le cas du Boeing 737 MAX semble hélas confirmer ce qui précède avec le recours à des sous-traitants offshore pour des parties critiques du 737 MAX. Boeing a récemment forcé la dose en utilisant largement le prestataire indien HCL pour externaliser l’écriture des softwares de l’avion. Il s’agissait d’une compensation suite à la conclusion de plusieurs méga-contrats en Inde en 2017 dont l’achat de 100 avions 737 MAX. C’est en 2005 que Boeing a commencé à externaliser en Inde avec une promesse de retombées pour 1.7 milliard d’USD dans le pays après une commande de 11 milliards d’Air India. Des témoignages abondent sur des rangées entières de bureaux occupés par le sous-traitant HCL ou de plans/spécifications ou softwares réécrits une dizaine de fois, échangés à de multiples reprises avant que les deux parties ne se comprennent enfin. Il existe un certain nombre de pays où il existe une forte rotation des informaticiens, une pratique, quasiment invisible pour le client, pas vraiment alignée sur les exigences d’expertise et de fiabilité. C’est qu’il est plus rentable de payer un ingénieur sur place à 9 $ de l’heure que de le faire venir aux USA à 35 $ – 40 $ de l’heure. L’Inde n’a évidemment pas le monopole des soucis à externaliser trop. Des problèmes similaires ont eu lieu avec le centre que Boeing avait ouvert à Moscou. Mais tout un chacun sait que l’Inde fait du recours à l’externalisation chez lui son cheval de bataille commercial : dans le cas du 737 MAX, HCL a même proposé de n’être payé qu’au fur et à mesure des ventes du Boeing 737 MAX.
Photo by Rafael Cosquiere from Pexels
Bien sûr, avoir une certification, un titre ne résout pas tous les problèmes : tout le monde a déjà été confronté à un mauvais médecin, architecte ou conseiller financier mais au moins, les « charlatans » seraient déjà hors course. Si le secteur ne s’autorégule pas, le gouvernement doit prendre le relais. Mais c’est loin d’être gagné : on voit aujourd’hui combien il est difficile d’imposer quelque chose aux géants de la tech au niveau national. Ce n’est qu’après plusieurs méga-scandales que Facebook s’est subitement découvert des affinités pro-RGPD. Faut-il plusieurs chutes d’avion dans le cas qui nous occupe ? Techniquement, les briques existent en tout cas pour des logiciels critiques vraiment sûrs : on peut désormais certifier la compilation des logiciels critiques par exemple grâce aux travaux de Xavier Leroy ou Gérard Berry utilisés par Airbus. Ici, aussi, décidément, le maillon faible reste donc ce qui se trouve entre le chaise et le clavier.
Ce n’est qu’une question de temps avant qu’une erreur de programmation n’affecte un programme critique qui causera une catastrophe à la hauteur de la tâche qu’on lui a confiée ou une autre perte en vies humaines. A côté des gratte-ciels réels qui nous entourent et qu’on n’imaginerait pas s’effondrer, les mêmes gratte-ciels existent virtuellement tout autour de nous et leur allure tient plus du château de cartes bien trop sensibles aux vents contraires.
C. Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles) & J.J. Quisquater (Ecole Polytechnique de Louvain, Université de Louvain)
Pour en savoir plus :
What Should We Do to Prevent Software From Failing? Chris de Brusk, May 2019, Sloan Management Review
Boeing’s 737 Max Software Outsourced to $9-an-Hour Engineers, Peter Robison, Bloomberg, June 28, 2019
Il n’y a plus de jours où nous n’apprenons l’existence d’une cyberattaque touchant une entreprise (et il ne s’agit que de la partie émergée de l’iceberg). Données volées, comptes détournés sont devenues leur quotidien. Face à ce problème devenu crucial, il n’existe pas de réponse unique et de nombreuses actions sont mises en oeuvre : depuis les scientifiques qui analysent les attaques et imaginent de nouvelles parades jusqu’aux structures comme l’ANSSI chargées de lutter contre la cybercriminalité en passant par les ingénieur·e·s chargé·e·s de protéger les systèmes informatiques de leur entreprise. Moins informées, sans doute moins « équipées » que les grandes structures, les PME sont pourtant elles aussi touchées. Dans cet article, Jérôme Tarting revient sur une décision récente du Conseil européen qui les concerne directement. Pascal Guitton
L’apparition des outils informatiques (mobiles, réseaux, réseaux sociaux, Cloud…) ont fait entrer les PME dans un écosystème numérique. La convergence de toutes ces nouvelles technologies les place désormais à un carrefour névralgique où transitent les données des clients, des partenaires, des fournisseurs, des salariés et des citoyens.
Toute structure économique est donc devenue pourvoyeuse d’informations en quantité importante, d’où les réglementations qui ont pu surgir, le fameux RGPD entré en vigueur en mai 2018 étant la dernière en date. L’adage “Qui a l’information a le pouvoir” explique en grande partie les cyberattaques dont les PME sont victimes en France. Pourquoi sont-elles aussi vulnérables ? Jusqu’à très récemment, l’usage du numérique par les entreprises venait classer notre pays légèrement en-deçà de la moyenne européenne, loin derrière la Finlande ou l’Allemagne[1].
En 2013, seuls 2 salariés sur 3 utilisaient un ordinateur et dans les 5 dernières années, 62% des actifs ont suivi une formation continue en informatique pour combler leurs lacunes[2]. Dans cette marche en avant, les PME ont rattrapé leur retard, sans pour autant tenir compte du niveau de sécurité qui a évolué très vite, et qui est désormais ATAWAD : Anytime, Anywhere, Any Device.
L’entreprise ne doit plus se contenter de multiplier les outils numériques et les usages, son rôle est maintenant de savoir où sont ses données, d’être en mesure de les protéger, de se protéger elle-même tant contre les cyberattaques qu’en matière de responsabilité si ses données venaient à être dérobées.
À qui s’attaquent les hackers ? La finance, le commerce, l’énergie et l’industrie du numérique sont les secteurs les plus touchés. Dans les deux dernières années, une société sur deux a été victime d’une attaque informatique. Les violations ont augmenté de 62% en 5 ans[3]. ¼ des attaques provenait de logiciels malveillants, une autre partie du web. 12% en interne. Et 10% par phishing.
Au total, toutes ces malveillances ont coûté plus de 6 milliards aux entreprises françaises[4]. Enfin, notons que si les chiffres ne sont pas réellement connus, le secteur public connaît lui aussi de nombreuses malveillances.
Un récent rapport remis aux institutions européennes a démontré l’utilité d’une lutte efficace contre la malveillance numérique, représentant 400 milliards d’euros par an à l’échelle de l’économie mondiale. L’Union, consciente que “l’internet des objets” comptera, d’ici 2020, des dizaines de milliards de dispositifs numériques, a pris le dossier très au sérieux. En effet, elle a estimé que nombreuses sont les entreprises et les administrations au sein de l’UE dont les principaux services dépendent des réseaux et des infrastructures informatiques. Les incidents concernant la sécurité des réseaux et de l’information (SRI traitée notamment par l’ENISA en Europe) peuvent avoir un impact considérable, empêchant leur fonctionnement. En outre, un incident SRI dans un pays peut se répercuter dans d’autres, voire dans l’ensemble de l’UE, sapant la confiance des consommateurs dans les systèmes de paiement en ligne et les réseaux informatiques. C’est pourquoi, le 8 juin 2018, le Conseil européen a décidé de s’attaquer aux menaces en demandant aux états membres d’identifier les acteurs essentiels en matière de SRI avant décembre 2018, d’aider les petites et moyennes entreprises à être compétitives dans l’économie numérique et à investir dans le recours à l’intelligence artificielle et aux super-ordinateurs [5].
Bien entendu, si la Directive SRI est contraignante pour la France en termes de transposition et de moyens, les hackers ne vont pas s’arrêter si facilement car les données sont devenues pour eux la principale source de revenus de « l’économie malveillante ». Il est urgent d’apporter une réponse pénale plus efficace face à la cybercriminalité contre la fraude, le vol des données, la contrefaçon des moyens de paiement. Il faut donc conseiller à nos PME françaises de bâtir une cybersécurité sur des fondements solides, en misant sur le renseignement et la gestion avancée des accès, les encourager à effectuer des tests de résistance qui permettront d’identifier les champs de leur vulnérabilité, les accompagner et les encourager à investir dans les innovations de rupture (analyse et intelligence artificielle). Il en va de la pertinence du marché unique numérique mais aussi de la crédibilité de la France, qui si elle veut réellement être une start-up nation, ne peut négliger plus longtemps cette faille dangereuse pour le devenir de sa nouvelle économie.
Avner Bar-Hen est professeur au Conservatoire national des arts et métiers (CNAM) à Paris. Spécialiste de statistiques dans les domaines de la fouille de données et des méthodes d’apprentissage, il est également membre du conseil scientifique du Haut Conseil des Biotechnologies.
Gilles Garel est professeur titulaire de la chaire de gestion de l’innovation du Cnam depuis 2011 et professeur à l’Ecole polytechnique depuis 2006. Il a été directeur du Lirsa 2012 à 2015 et est en charge aujourd’hui de l’équipe pédagogique « Innovation » du Cnam.
Gilles Carel, Crédits CNAM
Pour Binaire, ils évoquent le travail qu’il reste à accomplir en matière d’innovation mais aussi d’éducation, pour que les Big Data apportent de nouvelles ruptures technologiques. Antoine Rousseau. Cet article est publié en collaboration avec The Conversation.
Dans le maelstrom du « Big Data-numérique-digital-IA » qui mélange buzz superficiel et réelles ruptures, il est important de s’interroger sur le caractère innovant des Données Massives ? En effet, Innovation et Big Data (Données Massives) sont deux termes à la mode, souvent associés et parés de nombreuses promesses, mais il ne suffit pas de parler d’innovation pour être innovant. Quelle(s) innovation(s) se cache(nt) réellement derrière les Données Massives ?
En mobilisant des tera, peta, exa, zetta ou des yotta données, les ordres de grandeur de la capture, du stockage, de la recherche, du partage, de l’analyse ou la visualisation des données sont bouleversés. De nouveaux outils se développent avec l’avènement de dimensions inconnues jusque-là, mais ceci ne dit que peu de choses des usages, des transformations positives dans la vie des citoyens ou des acteurs économiques. Le secteur des services a été fortement transformé par l’arrivée des Données Massives. On peut penser à des services comme Uber, Deliveroo, aux recommandations d’Amazon, à l’assistance diagnostic médical, à l’identification d’images, aux messages et échanges automatiques… La valeur ajoutée, la pertinence du service ou l’utilité sociale de ces nouveaux outils n’est pas nulle, mais il y a longtemps que l’on peut prendre un taxi, acheter un livre, cibler une campagne marketing ou identifier une personne. L’arrivée d’un ordinateur champion du monde de Go ne change pas vraiment la vie ou la motivation des joueurs de go, ni même des non-joueurs. Les outils de traitement des Données Massives optimisent des paramètres connus : plus rapide, plus de variables, plus de variété, moins coûteux, plus de personnes, sans personne… Dans cette « compétition paramétrique », on accélère le connu, on remonte à la surface une abondance de données existantes, pas forcément connectées jusque-là. L’enjeu est aussi de tirer les Données Massives vers l’innovation, c’est-à-dire de passer de l’optimisation de propriétés connues à la conception de propriétés nouvelles dans une perspective de partage de la valeur et non de sa captation par quelques acteurs de la « nouvelle économie ».
Si le traitement des Données Massives peut être tiré par des start-ups très dynamiques, seuls les grands groupes peuvent aujourd’hui valider un prototype de voiture autonome ou développer des programmes de traitement contre le cancer. Les traces numériques massivement disséminées modifient la manière d’appréhender nos individualités. La course à l’appropriation des données est lancée. Les directives européennes comme le RGPD (règlement général pour la protection des données européen) poussent vers un statut privé. Le rapport de Cédric Villani revendique clairement une Intelligence Artificielle pour l’humanité. Nos modes de consommation et nos interactions sociales se transforment grâce à l’omniprésence des ordinateurs et plus largement des machines. Il est temps que les Big Data produisent un Big Bang. Il ne s’agit pas juste d’ouvrir les données, mais de s’en libérer pour leur associer des propriétés innovantes et ne pas rester fixés sur des améliorations, des accélérations et des approches strictement marchandes. Il faut que les citoyens s’approprient les Données Massives afin de donner ensemble un sens à cette avalanche d’informations mais aussi pour faciliter leur intégration au processus d’innovation et de décision au sein des organisations et des entreprises. Seule l’innovation permettra d’imaginer le citoyen de demain. Cet enjeu stratégique passe par une éducation et une formation aux outils numériques et à leurs usages.
Tariq Krim a eu la chance de découvrir l’informatique très jeune, au début des années 80, et les modems deux ans plus tard. Un fil conducteur relie ses (multiples) aventures entrepreneuriales, Netvibes, créé en 2005, Jolicloud, lancé en 2008, et Dissident.ai, son dernier projet débuté fin 2017 : donner aux utilisateurs les moyens de prendre en main leur vie numérique, comme les pionniers de l’informatique personnelle le faisaient.
Netvibes cherchait à faciliter l’accès à l’information via une page personnelle faite de widgets et s’appuyant sur les flux RSS, particulièrement en vogue dans le Web 2.0 alors naissant.
Jolicloud était lui un système d’exploitation indépendant, précurseur du Chromebook de Google, et qui a compté 1 million d’utilisateurs. L’innovation de l’OS était de mettre en avant les services cloud qui commençaient à se développer, à l’image de Box ou de Spotify. Cette vision de l’informatique reposant sur des services à distance s’est retrouvée dans nos smartphones… mais sous le contrôle de 2 acteurs, Apple avec iOS et Google avec Android.
Jolicloud proposait des alternatives aux GAFA, mais paradoxalement, les pouvoirs publics commençaient dans le même temps à faire appel aux géants établis pour moderniser leur équipement – dans l’Éducation nationale, par exemple. La vision avait beau être la bonne, et le produit apprécié, il s’est vite révélé difficile de rivaliser avec les mastodontes du numérique, et malgré son succès, Jolicloud s’est arrêté en 2015. Pour mieux renaître, tel le phénix, sous la forme de Dissident. Mais n’allons pas trop vite.
Les désillusions du numérique
Si Tariq s’est bien forgé une conviction, c’est que l’interface (logicielle) définit l’accès au monde, spécifie ce qu’on peut ou ne pas faire, et que ce n’est pas toujours pour le mieux. Tariq aimerait apporter des réponses à ce qu’il voit comme trois problèmes de nos vies numériques.
Premièrement, l’uniformisation des services. « Tout le monde possède les 10 mêmes applications sur son smartphone » se désole Tariq. Par l’intégration verticale des fonctionnalités (OS, paiement, identité, communication, commerce…) au sein de leurs produits, les GAFA en sont arrivés à leurs positions dominantes, et font tout pour nous inciter à rester enfermé.e.s dans leurs écosystèmes.
Ensuite, la mise en silos des données. Si Steve Jobs avait mis son navigateur Safari au centre de l’expérience du premier iPhone, et qu’il réfléchissait à laisser les données accessibles par n’importe quelle application, la structure de l’OS s’est rapidement réorientée vers des applications séparées formant autant de silos. Car chacune gère ses propres données, accessibles via sa seule interface. Android aurait pu prendre le contrepied, mais il n’en a rien été… Bref, les fichiers partagés par une variété de logiciels, ça fleure bon l’ordinateur, pas le smartphone. Et l’argument lié à la sécurité ne convainc pas Tariq, le stockage des données sur des serveurs et leurs fuites régulières ne présente pas l’allure d’une panacée.
Enfin, la tyrannie de la facilité. Les algorithmes choisissent pour nous. On ouvre l’application et on n’a plus qu’à se laisser faire. Pour Tariq, « on nous impose de nous comporter comme des ados attardé.e.s ». On nous promettait des services simples ; nous nous retrouvons avec des outils qui nous infantilisent. Face à un internet qui, de son point de vue, a rétréci notre champ de vision plutôt qu’élargi les horizons, Tariq veut nous ramener à l’internet existant juste avant l’avènement des smartphones. Ce qu’il défend, c’est l’idée d’un slow web – inspiré du mouvement slow food – qui donne aux utilisateurs les moyens de quitter la superficialité. Il s’agit de prendre son temps, de s’imposer plus d’exigence, ce qui nous conduit à Dissident.
La plateforme du slow web
L’ambition de la plateforme est de nous aider à reprendre le contrôle de notre vie numérique. Grâce à l’utilisation des API des différents services que nous utilisons tou.te.s au quotidien, ainsi qu’aux possibilités de contrôle rendues aux utilisateurs par le RPGD, chacun peut organiser l’information comme il le souhaite. Le mot “dissident” renvoie à ces dissidents qui en URSS voulaient réfléchir par eux mêmes et s’échangeaient les livres interdits. Dans cette optique, Dissident.ai propose pour le moment 3 produits : Desktop, Reader et Library :
Desktop est un… bureau web. Il agrège tous les fichiers disséminés dans différents services (Dropbox, Box, Google Drive, Slack…) et permet donc une recherche unifiée. Le tout vous permet d’en profiter où que vous soyez, grâce à des lecteurs vidéo, musical et de documents capables de lire de nombreux formats de fichiers.
Reader, quant à lui, est une réinvention du lecteur de flux RSS, à un âge où le texte n’est plus le médium dominant. On y retrouve ainsi, à la façon de Desktop, une agrégation de services qui forment autant de sources d’information et de contenus : YouTube, Soundcloud, Facebook, Medium… Au delà de la commodité d’avoir tout sous la main, le grand avantage pour l’utilisateur réside dans la possibilité de définir ses propres classements de l’information, donc de ne plus dépendre de ceux imposés par les différents acteurs.
Enfin, The Library rassemble une vaste somme d’œuvres et de documents du domaine public, des livres aux films en passant par des pièces numérisées de la Réunion des Musées Nationaux ou encore les archives de la NASA.
Ces trois services partagent les mêmes principes de design : des interfaces neutres, sans logo, qui mettent l’utilisateur au centre, en servant ses seuls intérêts. Aucun souci par exemple pour transférer un fichier depuis Google Drive vers Dropbox, quand leur intérêt respectif est de vous enfermer dans leur usage. L’ambition de remettre le pouvoir dans les mains des utilisateurs fait donc de Dissident un acteur agnostique des entreprises qui proposent les services sur lesquels il s’appuie. Comme l’explique Tariq, « mon problème n’est pas de savoir si mes données sont chez Facebook ou Google, mais si on m’en limite les accès et les usages ».
Quand on vise l’empowerment (l’autonomisation) de ses utilisateurs, le modèle économique est le meilleur révélateur de la sincérité de la démarche. Chez Dissident, le choix est limpide : un seul modèle, celui de l’abonnement, à 5 euros par mois. Point de flicage, ni de données stockées, ils jouent seulement les orchestrateurs d’API. Pour le moment, les utilisateurs de Dissident sont plutôt des travailleurs de la connaissance, qui ont besoin des contenus du Web pour leur travail. La plateforme est à leur créativité ce que Slack est à leurs communications. « On a jamais eu autant de moyens de créer des liens que des frontières ». Prenant le contre-pied de la morosité ambiante, Tariq et Dissident nous invitent à soutenir les premiers plutôt qu’à stérilement déplorer les secondes.
Serge Abiteboul, Inria et ENS, Paris, Tom Morisse, Fabernovel
Quand les algorithmes prennent une place de plus en plus importante dans nos vies, guident nos choix, décident parfois pour nous, ils se doivent d’avoir un comportement éthique pour que la cité ne devienne pas une jungle. Récemment, la CERNA s’est penchée sur le sujet lors d’une journée sur « Les valeurs dans les algorithmes et les données ». Catherine Tessier a présenté ses travaux avec Vincent Bonnemains et Claire Saurel dans ce domaine. Nous les avons invités à en parler aux lecteurs de Binaire. Serge Abiteboul
Imaginons l’expérience de pensée suivante : une voiture autonome vide, en chemin pour aller chercher des passagers, est arrêtée à un croisement au feu rouge. Sur l’axe venant de sa gauche, une voiture passe à vitesse réglementaire au feu vert, lorsqu’une personne s’engage sur le passage piéton en face d’elle.
Grâce au traitement des données issues de ses capteurs, la voiture autonome calcule que la voiture engagée va percuter le piéton. La voiture autonome a deux actions possibles :
S’interposer entre la voiture engagée et le piéton
Ne pas intervenir
Comment concevoir un algorithme qui déterminerait l’action à effectuer par la voiture autonome et quelles seraient ses limites ?
On se trouve ici dans le cadre (simplifié) de la conception d’un agent artificiel (l’algorithme de la voiture autonome) doté d’une autonomie décisionnelle, c’est-à-dire capable de calculer des actions à effectuer pour satisfaire des buts (par exemple : aller chercher des passagers à tel endroit) tout en satisfaisant des critères (par exemple : minimiser le temps de parcours) à partir de connaissances (par exemple : le plan de la ville) et d’interprétations de données perçues (par exemple : un piéton est en train de traverser la voie de droite). En outre, dans cette situation particulière, le calcul de l’action à effectuer met en jeu des considérations relevant de l’éthique ou de l’axiologie qui vont constituer des éléments de jugement des actions possibles. On peut remarquer en effet qu’aucune des deux actions possibles n’est totalement satisfaisante, dans la mesure où il y aura toujours au moins un effet négatif : c’est ce qu’on appelle une situation de dilemme. Plusieurs points de vue peuvent être envisagés pour qu’un algorithme simule des capacités de jugement des actions.
L’approche conséquentialiste
L’algorithme évaluerait dans ce cas les décisions possibles selon un cadre conséquentialiste, qui suppose de comparer entre elles les conséquences des actions possibles : l’action jugée acceptable est celle dont les conséquences sont préférées aux conséquences de l’autre action.
Pour ce faire l’algorithme a besoin de connaitre (i) les conséquences des actions possibles, (ii) le côté positif ou pas des conséquences, et (iii) les préférences entre ces conséquences.
(i) Les conséquences de chaque action
Immédiatement se pose la question de la détermination de ces conséquences : considère-t-on les conséquences « immédiates », les conséquences de ces conséquences, ou plus loin encore ? De plus, les conséquences pour qui, et pour quoi, considère-t-on ? D’autre part, comment prendre en compte les incertitudes sur les conséquences ?
Le concepteur de l’algorithme doit donc faire des choix. Par exemple, il peut poser que les conséquences de l’action S’interposer sont : {Piéton indemne, Passagers blessés, Voiture autonome dégradée} et les conséquences de l’action Ne pas intervenir sont : {Piéton blessé, Passagers indemnes, Voiture autonome indemne}.
(ii) Le caractère positif ou négatif d’une conséquence
Si le concepteur choisit par exemple d’établir le jugement selon un utilitarisme positif (le plus grand bien pour le plus grand nombre), les conséquences des actions possibles doivent être qualifiées de « bonnes » (positives) ou « mauvaises » (négatives). Il s’agit là d’un jugement de valeur ou bien d’un jugement de bon sens, qui peut dépendre des valeurs que promeut la société, la culture, ou bien du contexte particulier dans lequel l’action doit être déterminée.
Le bon sens du concepteur peut lui dicter la qualification suivante des conséquences : {Piéton indemne, Passagers blessés, Voiture autonome dégradée} et {Piéton blessé, Passagers indemnes, Voiture autonome indemne}.
(iii) Les préférences entre les ensembles de conséquences
Comment l’algorithme va-t-il pouvoir comparer les deux ensembles de conséquences, dont on constate que (i) ils comportent des conséquences positives et négatives et (ii) ces conséquences concernent des domaines différents : des personnes et des choses ? Le concepteur pose-t-il des préférences absolues (par exemple, toujours privilégier un piéton par rapport à des passagers qui seraient mieux protégés, toujours privilégier les personnes par rapport aux choses) ou bien variables selon le contexte ? Ensuite comment réaliser l’agrégation de préférences élémentaires (entre deux conséquences) pour obtenir une relation de préférence entre deux ensembles de conséquences ?
Le concepteur peut choisir par exemple de considérer séparément les conséquences positives et les conséquences négatives de chaque action et préférer l’ensemble {Piéton indemne} à l’ensemble {Passagers indemnes, Voiture autonome indemne} et l’ensemble {Passagers blessés, Voiture autonome dégradée} à l’ensemble {Piéton blessé}.
Compte tenu de ces connaissances, dont on constate qu’elles sont largement issues de choix empreints de subjectivité, un tel algorithme conséquentialiste produirait l’action S’interposer, puisque ses conséquences (celles qui sont considérées) sont préférées (au sens de la relation de préférence considérée) à celle de l’autre action.
L’approche déontologique
L’algorithme évaluerait dans ce cas les décisions possibles selon un cadre déontologique, qui suppose de juger de la conformité de chaque action possible : une action est jugée acceptable si elle est « bonne » ou « neutre ».
Comment équiper l’algorithme de connaissances qui lui permettraient de calculer un tel jugement ? Que signifient « bon », « mauvais » ? Une action peut-elle être « bonne » ou mauvaise » en soi ou doit-elle être jugée en fonction du contexte ou de la culture environnante ? Quelles références le concepteur doit-il considérer ? Par exemple, l’action de « brûler » un feu rouge peut être considérée comme « mauvaise » dans l’absolu (parce qu’elle contrevient au code de la route), mais « bonne » s’il s’agir d’éviter un danger immédiat.
Dans notre exemple, le concepteur de l’algorithme peut choisir de qualifier les deux actions S’interposer et Ne pas intervenir comme « bonnes » ou « neutres » dans l’absolu. L’algorithme déontologique ne pourrait alors pas discriminer l’action à réaliser. Cette question relève de manière classique des choix inhérents à l’activité de modélisation.
Actions, conséquences, est-ce si clair ?
Sans jeu de mots, arrêtons-nous un instant sur la question du feu rouge, et plus précisément sur « brûler un feu rouge ». S’agit-il d’une action (la voiture autonome brûle le feu rouge et ce faisant, elle s’interpose) ? S’agit-il d’une conséquence de l’action S’interposer (la voiture autonome s’interpose, et une des conséquences de cette action – un effet collatéral – est qu’elle brûle le feu rouge) ? Ou bien s’agit-il simplement d’un moyen pour réaliser l’action S’interposer (la voiture autonome utilise le fait de brûler le feu rouge pour s’interposer) ?
Nous voyons ici que selon ce que le concepteur va choisir (considérer ou non « brûler » un feu rouge, et si oui, le considérer comme action, conséquence, ou comme autre chose) les réponses de l’algorithme conséquentialiste ou déontologique seront différentes de celles que nous avons vues précédemment.
Les valeurs morales
Le concepteur pourrait également s’affranchir de ces notions d’actions et de conséquences et considérer uniquement des valeurs morales. L’algorithme consisterait alors à choisir quelles valeurs morales privilégier dans la situation de dilemme considérée, ce qui revient de manière duale à programmer la possibilité d’infraction, de dérogation aux valeurs. Veut-on par exemple programmer explicitement qu’une infraction au code de la route est envisageable ?
Dans notre exemple, le concepteur pourrait choisir de considérer quatre valeurs morales : la conformité au code de la route, la non atteinte aux biens, la non atteinte aux personnes, la protection des personnes, et de les placer sur une échelle de préférences (>), forcément subjective, de la manière suivante :
Le concepteur a ici considéré que les valeurs de non atteinte aux personnes et de protection des personnes, non hiérarchisables entre elles, étaient préférables à la valeur de non atteinte aux biens, elle-même préférable à la valeur de conformité au code de la route.
Ensuite le concepteur pourrait choisir les valeurs à respecter et parmi celles-ci, celles qui sont préférées au sens de son échelle au détriment d’autres valeurs qui pourraient être transgressées.
Si le concepteur choisit de respecter la valeur protection des personnes, c’est l’action s’interposer qui est satisfaisante, dans le sens où le piéton sera protégé. Dans ce cas la valeur non atteinte aux biens sera transgressée (les voitures subissent des dommages), ainsi que la valeur de conformité au code de la route (la voiture autonome « brûle » le feu rouge). On remarque qu’il est difficile d’établir si la valeur de non atteinte aux personnes est respectée ou non : en effet, en s’interposant, la voiture autonome provoque un accident dans lequel les passagers de la voiture habitée peuvent éventuellement être blessés.
Si le concepteur choisit au contraire de respecter la valeur non atteinte aux personnes, ainsi que la valeur non atteinte aux biens et la conformité au code de la route, ou bien s’il cherche à minimiser le nombre de valeurs transgressées, c’est l’action ne pas intervenir qui est satisfaisante. Ainsi les passagers de la voiture habitée sont épargnés, les deux voitures restent indemnes et la voiture autonome respecte le feu rouge. En revanche la protection des personnes n’est pas respectée – ce qui ne signifie pas que le piéton sera obligatoirement blessé (la voiture habitée peut freiner, le piéton peut courir, etc.)
Des questionnements
Ces tentatives de modélisation de concepts éthiques et axiologiques dans le cadre d’une expérience de pensée simple illustrent le fait que la conception d’algorithmes dits « éthiques » doit s’accompagner de questionnements, par exemple :
Dans quelle mesure des considérations éthiques ou des valeurs morales peuvent-elles être mathématisées, calculées, mises en algorithme ?
Un tel algorithme doit-il être calqué sur les considérations éthiques ou les valeurs morales de l’humain, et si oui, de quel humain ? N’a-t-on pas des attentes différentes vis-à-vis d’un algorithme ?
Un humain peut choisir de ne pas agir de façon « morale », doit-on ou peut-on transposer ce type d’attitude dans un algorithme ?
Enfin il faut garder à l’esprit que l’« éthique », les « valeurs » programmées sont des leurres ou relèvent du fantasme – en aucun cas une machine ne « comprend » ces concepts : une machine ne fait qu’effectuer des calculs programmés sur des données qui lui sont fournies. En ce sens, on ne peut pas parler de machine « morale » ou « éthique » mais de machine simulant des comportements moraux ou éthiques spécifiés par des humains.
Catherine Tessier (1, 2), Vincent Bonnemains (1,3), Claire Saurel (1)
Vous devez organiser un vote, pourquoi ne pas le réaliser de manière électronique ? Malheureusement, les systèmes proposés aujourd’hui ne sont pas sûrs et c’est compliqué… Alors, pourquoi ne pas prendre une plateforme libre proposée par des chercheurs et éviter ainsi plusieurs écueils liés au vote électronique. 3 chercheurs spécialistes de ce domaine qui travaillent au LORIA à Nancy nous parlent du sujet. Pierre Paradinas
Voter électroniquement avec Belenios
L’objet de ce billet est d’annoncer un nouveau-venu dans le monde du vote électronique : la plateforme de vote Belenios. Cette plateforme, libre et gratuite, permet d’organiser une élection en quelques clics. Lancée il y a un peu plus d’un an, elle a déjà permis d’organiser environ 200 élections, essentiellement dans le milieu académique : élection des membres d’un conseil de laboratoire, d’un centre de recherche, d’un comité universitaire, élection de responsables d’un groupe de travail, etc.
Nous évoquons ci-dessous quelques éléments de contexte pour comprendre le positionnement de Belenios et encourager les lecteurs non seulement à l’utiliser mais surtout à se poser des questions lors des élections dématérialisées auxquelles ils sont invités à participer.
Promouvoir plus de transparence
Le vote électronique, de manière générale, mais de façon encore plus criante en France, n’est pas assez transparent. Quand on vote par Internet, comme cela se fait de plus en plus souvent, on n’a aucune information sur les algorithmes utilisés. Tout au plus a-t-on les noms des expert·e·s ayant étudié et validé la solution. Sans remettre en cause ce nécessaire travail d’expertise par un tiers, nous considérons que le secret de l’algorithme utilisé va à l’encontre d’une des propriétés fondamentales du vote électronique : la vérifiabilité. Chaque votant doit pouvoir vérifier que son bulletin est bien présent dans l’urne et chacun doit pouvoir vérifier que le résultat de l’élection correspond aux bulletins dans l’urne. On souhaite ainsi reproduire la situation d’un vote traditionnel, même si dans le cas du vote électronique, certaines vérifications ne peuvent provenir que de preuves mathématiques difficiles à lire pour le commun des mortels. Cette propriété de vérifiabilité, ainsi que d’autres propriétés requises ou souhaitables d’un système de vote électronique ont déjà été décrites dans un précédent billet. Belenios est un exemple parmi d’autres (comme Helios dont il est une variante) d’un système vérifiable dont la spécification est publique. Nous souhaitons ainsi convaincre les acteurs du vote électronique (vendeurs de solutions, donneurs d’ordre, voire la CNIL) que la transparence n’est pas trop demander : on a largement atteint le stade où c’est techniquement faisable sans mettre en danger le secret du vote, au contraire.
Du vote électronique aux présidentielles ?
Non. Ce n’est pas une bonne idée d’utiliser le vote électronique pour les grands rendez-vous politiques. Le vote électronique a fait des progrès, mais à l’heure actuelle il n’offre pas d’aussi bonnes garanties de sécurité qu’un scrutin papier à l’urne, tel qu’il est organisé en France pour les grandes élections. Parmi les propriétés très délicates à mettre en œuvre dans le cas du vote électronique figure la résistance à la coercition. Comment garantir le libre-choix du vote lorsque l’isoloir devient virtuel et que le vote s’effectue depuis chez soi ? Des solutions académiques existent mais elles restent incomplètes ou difficilement mises en pratique. Toujours dans le même précédent billet se trouve une discussion plus détaillée sur les limites du vote électronique. Le protocole Belenios n’échappe pas à ce constat. Il n’y a pas de protection contre la coercition ou la vente de vote (il suffit de vendre son matériel électoral). Il n’en reste pas moins que Belenios et le vote électronique en général est une alternative intéressante en remplacement du vote par correspondance qui n’offre souvent que de piètres garanties de sécurité.
La plateforme publique Belenios
Dans l’isoloir…
La sécurité a un prix. Un élément incontournable est de répartir la confiance entre plusieurs personnes : donner trop de pouvoir à une unique personne (par exemple celle qui administre le serveur) signifie qu’on offre la possibilité à un·e attaquant·e de faire pression sur celle-ci pour changer le résultat, voire dévoiler les votes de chacun. Utiliser Belenios nécessite donc l’implication de plusieurs personnes distinctes qui vont se partager les rôles. Ainsi, la clef de déchiffrement sera répartie entre plusieurs assesseur·e·s, et il faudra les corrompre tou·te·s pour déchiffrer les votes individuels. Nous encourageons d’ailleurs les lecteurs à se poser la question à chaque scrutin électronique auquel ils sont confrontés : qui possède les clefs de déchiffrement, comment ont-elles été générées, et comment sont-elles utilisées lors du dépouillement ?
Pour finir, nous insistons sur le fait que la plateforme Belenios, hébergée au laboratoire LORIA de Nancy, n’est qu’une plateforme de démonstration fournie « en l’état », sans garantie de disponibilité de fonctionnement, même si nous faisons de notre mieux. Dans le même esprit, chaque élection est limitée à 1000 électeurs. Cependant, tout le code est libre, et il est tout à fait possible de déployer sa propre instance chez une société d’hébergement offrant des garanties de disponibilité 24/7 et des services de résistance au déni de service.
Dans bien des contextes à enjeu modéré et où le report de l’élection n’est pas dramatique en cas d’indisponibilité imprévue du serveur, notre plateforme peut rendre service, et offrir une solution à l’état de l’art, en remplacement notamment du vote par correspondance ou de systèmes non prévus pour le vote (LimeSurvey, pour ne citer qu’un seul exemple). Les remarques et les contributions sont les bienvenues !










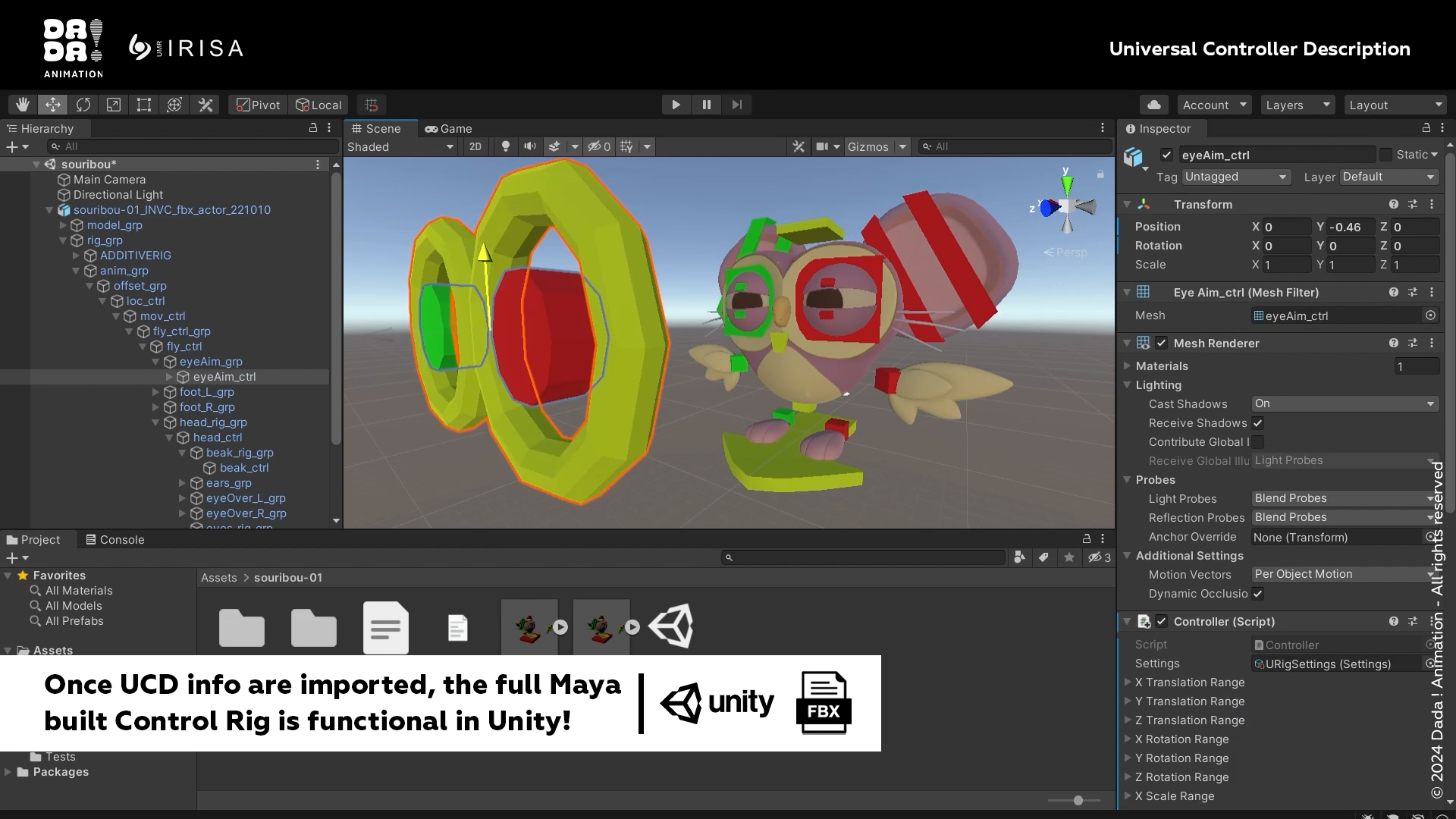








 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de logiciel libre. Marie-Agnès Enard
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », osons ici expliquer de manière simple et accessible cette notion de logiciel libre. Marie-Agnès Enard Tu as faim ? J’ai une pomme. Partageons là. Du coup, je n’ai mangé qu’une demi-pomme. Mais j’ai gagné ton amitié.
Tu as faim ? J’ai une pomme. Partageons là. Du coup, je n’ai mangé qu’une demi-pomme. Mais j’ai gagné ton amitié.  Du coup, nous voilà toi et moi avec une idée. Mieux encore : ton idée vient de m’en susciter une autre que je te repartage, en retour. Pour te permettre d’en trouver une troisième peut-être.
Du coup, nous voilà toi et moi avec une idée. Mieux encore : ton idée vient de m’en susciter une autre que je te repartage, en retour. Pour te permettre d’en trouver une troisième peut-être. Pour
Pour



 L’essor de l’informatique a déclenché une révolution industrielle qui modifie en profondeur la société et l’économie. Cet article de Laurent Bloch dresse un tableau de cette industrie, et nous explique l’urgence de s’y intéresser et surtout d’agir en conséquence.
L’essor de l’informatique a déclenché une révolution industrielle qui modifie en profondeur la société et l’économie. Cet article de Laurent Bloch dresse un tableau de cette industrie, et nous explique l’urgence de s’y intéresser et surtout d’agir en conséquence. 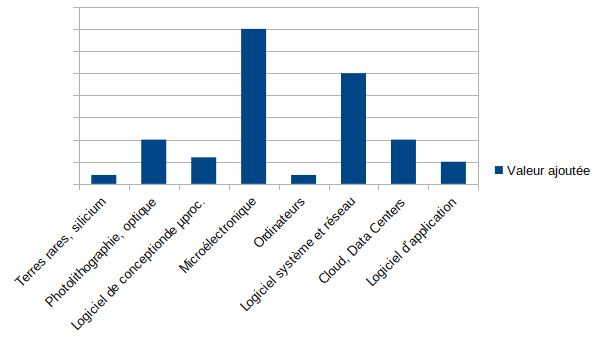


 Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire.
Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire.

















 Un fil rouge :
Un fil rouge : 
 Desktop est un… bureau web. Il agrège tous les fichiers disséminés dans différents services (Dropbox, Box, Google Drive, Slack…) et permet donc une recherche unifiée. Le tout vous permet d’en profiter où que vous soyez, grâce à des lecteurs vidéo, musical et de documents capables de lire de nombreux formats de fichiers.
Desktop est un… bureau web. Il agrège tous les fichiers disséminés dans différents services (Dropbox, Box, Google Drive, Slack…) et permet donc une recherche unifiée. Le tout vous permet d’en profiter où que vous soyez, grâce à des lecteurs vidéo, musical et de documents capables de lire de nombreux formats de fichiers. Reader, quant à lui, est une réinvention du lecteur de flux RSS, à un âge où le texte n’est plus le médium dominant. On y retrouve ainsi, à la façon de Desktop, une agrégation de services qui forment autant de sources d’information et de contenus : YouTube, Soundcloud, Facebook, Medium… Au delà de la commodité d’avoir tout sous la main, le grand avantage pour l’utilisateur réside dans la possibilité de définir ses propres classements de l’information, donc de ne plus dépendre de ceux imposés par les différents acteurs.
Reader, quant à lui, est une réinvention du lecteur de flux RSS, à un âge où le texte n’est plus le médium dominant. On y retrouve ainsi, à la façon de Desktop, une agrégation de services qui forment autant de sources d’information et de contenus : YouTube, Soundcloud, Facebook, Medium… Au delà de la commodité d’avoir tout sous la main, le grand avantage pour l’utilisateur réside dans la possibilité de définir ses propres classements de l’information, donc de ne plus dépendre de ceux imposés par les différents acteurs. Enfin, The Library rassemble une vaste somme d’œuvres et de documents du domaine public, des livres aux films en passant par des pièces numérisées de la Réunion des Musées Nationaux ou encore les archives de la NASA.
Enfin, The Library rassemble une vaste somme d’œuvres et de documents du domaine public, des livres aux films en passant par des pièces numérisées de la Réunion des Musées Nationaux ou encore les archives de la NASA.