Imaginez-vous élu ou agent d’une collectivité territoriale. Vous devez vous assurer de pouvoir fournir une information administrative officielle et sûre à vos usagers. Et si votre moteur de recherche pouvait vous aider dans cette tâche ? Unsearch, projet de startup accompagné par le Startup Studio Inria, propose depuis 2020 « Sources de confiance », une technologie et une extension facile à installer et qui affiche les résultats de votre requête en distinguant celles provenant de sources officielles (administration, établissements publics ou universitaires). Tristan Nitot, figure majeure du web et de l’Open-Source, fait partie de cette aventure et nous l’explique avec enthousiasme. Tristan a fondé l’association Mozilla Europe en 2003. Depuis il a travaillé pour Cozy Cloud (une plateforme auto-hébergée, extensible et open source de cloud personnel) et Qwant (un moteur de recherche Européen qui ne trace pas l’activité de ses utilisateurs) jusqu’en mars 2020.
Binaire : Raconte-nous l’histoire d’Unsearch ?
Tristan Nitot : C’est une histoire très récente. Le projet de startup Unsearch a été lancé début 2020 par un copain, Jean-Baptiste Piacentino (aka JB), qui a travaillé en collaboration avec l’association Villes Internet et un financement de la Banque Française Mutualiste sur un produit permettant d’optimiser la qualité et l’usage des informations données aux usagers en facilitant l’accès aux informations officielles des administrations. Sources de confiance (SdC pour faire court) a vu le jour. En janvier 2021, j’ai rejoint JB pour lancer la V2 et en avril, nous étions soutenus par le Startup Studio Inria pour accompagner la création d’une startup.
B : Il va falloir nous dire ce que fait « Sources de confiance ».
TN : C’est une extension qu’on installe facilement dans son navigateur (aujourd’hui, nous supportons Google, Qwant et Bing) et qui permet de préciser parmi les réponses du moteur de recherche celles qui viennent d’une source considérée comme fiable. Cela ne change pas les habitudes des usagers. Une marque verte, apparaissant à droite de chaque source fiable, comme l’illustre la capture d’écran ci-dessous.
En cliquant sur un onglet (ajouté par l’extension) vous pouvez ne conserver que les résultats validés par SdC. Vous affichez ainsi uniquement les sites officiels de l’administration.
Cette technologie modifie donc à la volée le contenu de votre affichage. Lors de votre recherche, la connexion se fait sur le serveur d’Unsearch qui va trier les pointeurs correspondants à la requête dans une “liste blanche”. Cette liste de 65 000 sites de l’administration, d’établissements publics et universitaires a été concoctée par SdC avec l’aide de l’association Villes Internet et correspond aux besoins des usagers des collectivités.
Unsearch ne modifie pas le classement des pages basé sur la popularité proposé par Google, mais permet de filtrer parmi ces pages celles qui sont considérées comme fiables. Même si la première page n’apparaît que dans la deuxième ou troisième page de résultats Google, elle est facilement accessible.
Une version pro est en phase finale de développement qui permettra aux collectivités d’afficher des ressources informatives supplémentaires comme l’annuaire des administrations, les textes de références types juridiques, et l’actualité des sites administratifs, un peu à la manière des infobox de Google, sur la base d’un moteur de recherche spécialisé que nous concevons.
B : A qui s’adresse cet outil ?
TN : Unsearch a développé Sources de confiance spécifiquement pour un public d’élus et d’agents des collectivités mais la technologie proposée permet de créer une large gamme de moteurs de recherche spécialisés. Par exemple, on pourrait considérer un outil pour des enseignants à la recherche de contenus pédagogiques certifiés, un autre pour des personnels de santé pour des informations médicales fiables, un autre pour des chercheurs d’emplois pour accéder à des sites appropriés. Unsearch a aussi des connecteurs permettant aux entreprises et établissements publics d’utiliser le moteur de recherche habituel pour exposer des informations pertinentes provenant de leurs intranets.
B : Tu nous as habitué à chercher du sens dans les logiciels pour lesquels tu travailles. Quel sens doit-on chercher dans Unsearch ?
TN : Je suis attaché à la notion de confiance et d’éthique. Avec JB nous sommes tous les deux très sensibles à des projets qui donnent aux usagers des informations qui les aident à mieux sensibiliser ou éclairer les usages. Nous avons évidemment envie que Unsearch soit viable économiquement mais nous mettons en priorité certaines valeurs éthiques et d’utilité publique. On ne se refait pas !
Serge Abiteboul, Inria et ENS, Paris, et Marie-Agnès Enard, Inria
Nous vous invitons à partager les réflexions déambulatoires de Sylvain Petitjean et Samuel Nowakowski à l’occasion de la parution du livre « Demain est-il ailleurs ? Odyssée urbaine autour de la transition numérique ». La qualité de leurs échanges et de leurs questionnements sur l’impact du numérique dans notre société nous ont donné envie de les partager sur binaire. Avec l’aimable autorisation des auteurs et du site Pixees, nous republions l’intégralité de l’article. Marie-Agnès Enard et Thierry Vieville.
Ce texte est un échange épistolaire qui s’est installé suite à la parution du livre «Demain est-il ailleurs ? Odyssée urbaine autour de la transition numérique» co-écrit par Bruno Cohen, scénographe, réalisateur et metteur en scène, et Samuel Nowakowski, maître de conférences à l’université de Lorraine et chercheur au LORIA.
Paru en octobre 2020 chez FYP Editions, ce livre rassemble les rencontres avec celles et ceux qui vivent aujourd’hui cette transformation radicale. Au cours d’une déambulation de 24 heures dans la ville, les personnes rencontrées abordent les notions de temps, parlent du déséquilibre, de leurs incertitudes et du mal-être, mais aussi de leurs émerveillements et de leurs rêves. Elles questionnent des thèmes centraux de notre société que sont la surveillance, le contrôle, le développement d’un capitalisme numérique prédateur. Elles parlent aussi de cet ailleurs des pionniers qui s’est matérialisé dans nos sociétés en réseau, traversées par les nécessaires réflexions à mener sur l’éthique, l’écologie, l’apprentissage, la transmission et le rapport au savoir. Arpentant l’univers de la ville à la recherche de la transition, nous découvrons petit à petit qu’elle s’incarne sous différentes formes chez les uns ou les autres, dans l’espace public et privé, et dans tous les milieux au sein desquels nous évoluons — naturels, sociaux, politiques, éducatifs, technologiques…
Sylvain et Samuel ont souhaité poursuivre la conversation entamée dans le livre, ouvrant ainsi d’autres champs de réflexion. Cet échange s’est étalé sur plusieurs semaines, sous forme épistolaire, dans des conditions temporelles à rebours de l’urgence et de l’immédiateté ambiante. En voici le contenu.
Samuel : L’éthique kantienne sur laquelle notre société moderne s’est construite, s’énonce ainsi : « Agis de telle sorte que tu puisses également vouloir que ta maxime devienne loi universelle ». Or aujourd’hui, au vu des enjeux, des transitions multiples auxquelles nous faisons face, ne sommes-nous pas devant un besoin de disposer d’une éthique basée sur le principe de responsabilité à l’égard des générations futures et de notre environnement. Hans Jonas énonce le Principe responsabilité : « Agis de telle façon que les effets de ton action soient compatibles avec la permanence d’une vie authentiquement humaine sur Terre ». Ce qui implique que le nouveau type de l’agir humain consiste à prendre en considération davantage que le seul intérêt « de l’homme » et que notre devoir s’étend plus loin et que la limitation anthropocentrique de toute éthique du passé ne vaut plus ?
Dans le cadre du numérique, et de tout ce qui se présente à nous aujourd’hui en termes d’avancées scientifiques, dans le domaine qui est le nôtre, ne devons-nous pas repenser ce rapport au vivant et nos pratiques ?
Sylvain : Il est vrai qu’il n’est plus possible de considérer que les interventions techniques de l’humain sur son environnement sont superficielles et sans danger, et que la nature trouvera toujours comment rétablir elle-même ses équilibres fondamentaux. La crise écologique et les menaces pesant sur l’humanité et la planète impliquent quasi naturellement, pour Jonas et d’autres, d’orienter l’agir vers le bien commun en accord avec notre sentiment de responsabilité. D’où la proposition de refonder l’éthique comme une éthique de la responsabilité et du commun capable d’affronter l’ampleur des problèmes auxquels fait face la civilisation technologique, pour le bien-être et la survie des générations futures.
Les technologies du numérique présentent par ailleurs un autre défi de taille, probablement inédit, du point de vue de l’éthique. Cela a notamment trait à la logique grégaire associée à l’usage des services Internet : plus un service est utilisé par d’autres usagers, plus chacun trouve intéressant de l’utiliser parce qu’il peut en obtenir davantage d’informations et de contacts, créant un effet boule de neige. Cet «effet de multitude», comme l’ont baptisé les économistes, transforme en effet l’étendue et la nature des enjeux éthiques. Alors que l’éthique est usuellement un sujet qui arrive a posteriori du progrès, dès lors que des dérives sont constatées, il sera de plus en plus difficile, avec la démultiplication des possibilités et le changement d’échelle, d’être avec le numérique dans la réaction face à un problème éthique. En d’autres termes, les problématiques éthiques et juridiques vont devenir insolubles si on ne les traite pas en amont de la conception des technologies numériques (ethics by design). Cela dessine les contours d’une éthique plus proactive, en mesure d’accompagner de façon positive le développement et l’innovation.
Malheureusement, nous n’en sommes vraisemblablement qu’aux balbutiements de l’étude et de la maîtrise de ces questions dans le domaine du numérique. Il suffit de faire un pas de côté en direction de la biomédecine et des biotechnologies et de mesurer le chemin parcouru autour des lois de bioéthique pour s’en convaincre. Or le temps presse…
Samuel : Imprégnés de l’actualité qui est la nôtre, et en paraphrasant Tocqueville, « on ne saurait douter [qu’aujourd’hui] l’instruction du peuple serve puissamment [à la compréhension des enjeux de notre temps qu’ils soient politiques, technologiques, écologiques]. [N’en sera-t-il pas] ainsi partout où l’on ne séparera point l’instruction qui éclaire l’esprit de l’éducation qui règle les mœurs ? » La maîtrise de toutes ces questions ne doit-elle pas passer par cette nécessaire instruction du plus grand nombre ? Comment nous préserver du fossé qui risque de se creuser entre ceux qui sont instruits de ces enjeux et ceux qui n’y ont pas accès parce qu’ils font face à un horizon scolaire et social bouché ? Or, la méthode la plus efficace que les humains ont trouvée pour comprendre le monde (la science) et la meilleure façon qu’ils ont trouvée afin d’organiser le processus de décision collective (les modes démocratiques) ont de nombreux points communs : la tolérance, le débat, la rationalité, la recherche d’idées communes, l’apprentissage, l’écoute du point de vue opposé, la conscience de la relativité de sa place dans le monde. La règle centrale est d’avoir conscience que nous pouvons nous tromper, de conserver la possibilité de changer d’avis lorsque nous sommes convaincus par un argument, et de reconnaître que des vues opposées aux nôtres pourraient l’emporter.
Malheureusement, à l’école, les sciences sont souvent enseignées comme une liste de « faits établis » et de « lois », ou comme un entraînement à la résolution de problèmes. Cette façon d’enseigner s’oppose à la nature même de la pensée scientifique. Alors qu’enseigner, c’est enseigner l’esprit critique, et non le respect des manuels ; c’est inviter les étudiants à mettre en doute les idées reçues et les professeurs, et non à les croire aveuglément.
Aujourd’hui, et encore plus en ces temps troublés, le niveau des inégalités et des injustices s’est intensifié comme jamais. Les certitudes religieuses, les théories du complot, la remise en cause de la science et de la démocratie s’amplifient et séparent encore plus les humains. Or, l’instruction, la science et la pensée doivent nous pousser à reconnaître notre ignorance, que chez « l’autre » il y a plus à apprendre qu’à redouter et que la vérité est à rechercher dans un processus d’échange, et non dans les certitudes ou dans la conviction si commune que « nous sommes les meilleurs ».
L’enseignement pour permettre [la compréhension des enjeux de notre temps qu’ils soient politiques, technologiques, écologiques] doit donc être l’enseignement du doute et de l’émerveillement, de la subversion, du questionnement, de l’ouverture à la différence, du rejet des certitudes, de l’ouverture à l’autre, de la complexité, et par là de l’élaboration de la pensée qui invente et qui s’invente perpétuellement. L’école se caractérise ainsi à la fois par la permanence et l’impermanence. La permanence dans le renouvellement des générations, le « devenir humain », l’approche du monde et de sa complexité par l’étudiant sur son parcours personnel et professionnel. L’impermanence, dans les multiples manières de « faire humain »… et donc dans les multiples manières d’enseigner et d’apprendre. Entre permanence et impermanence, la transition ?
Sylvain : En matière d’acculturation au numérique et plus globalement d’autonomisation (empowerment) face à une société qui se technologise à grande vitesse, il faut jouer à la fois sur le temps court et le temps long. Le temps court pour agir, pour prendre en main, pour ne pas rester à l’écart ; le temps long pour réfléchir et comprendre, pour prendre du recul, pour faire des choix plus éclairés.
Daniel Blake, ce menuisier du film éponyme de Ken Loach victime d’un accident cardiaque, se retrouve désemparé, humilié face à un simple ordinateur, point de passage obligé pour faire valoir ses droits à une allocation de chômage. Où cliquer ? Comment déplacer la souris ? Comment apprivoiser le clavier ? Ces questions qui semblent évidentes à beaucoup le sont beaucoup moins pour d’autres. La dématérialisation de la société est loin d’être une aubaine pour tous. Prenons garde à ce qu’elle ne se transforme pas en machine à exclure. L’administration — dans le film — fait peu de cas de ceux qui sont démunis face à la machine ; on peut même se demander si ça ne l’arrange pas, s’il n’y a pas une volonté plus ou moins consciente d’enfoncer ceux qui ont déjà un genou à terre tout en se parant d’équité via l’outil numérique. Daniel Blake, lui, veut juste pouvoir exercer ses droits de citoyen et entend ne pas se voir nier sa dignité d’être humain. De la fable contemporaine à la réalité de nos sociétés il n’y a qu’un pas. Réduire la fameuse fracture numérique, qui porte aujourd’hui encore beaucoup sur les usages, doit continuer d’être une priorité qui nécessite de faire feu de tout bois et à tous les niveaux. Et il faut absolument s’attacher à y remettre de l’humain.
Mais ce n’est pas suffisant. Les politiques d’e-inclusion doivent aussi travailler en profondeur et dans le temps long. De même que l’on associe au vivant une science qui s’appelle la biologie (qui donne un fil conducteur permettant d’en comprendre les enjeux et les questions de société liées, et de structurer un enseignement), on associe au numérique une science qui est l’informatique. Pour être un citoyen éclairé à l’ère du numérique et être maître de son destin numérique, il faut pouvoir s’approprier les fondements de l’informatique, pas uniquement ses usages. « Il faut piger pourquoi on clique » disait Gérard Berry. Car si les technologies du numérique évoluent très vite, ces fondements et les concepts sur lesquels ils s’appuient ont eux une durée de vie beaucoup plus grande. Les maîtriser aujourd’hui, c’est s’assurer d’appréhender non seulement le monde numérique actuel mais aussi celui de demain. Y parvenir massivement et collectivement prendra du temps. Le décalage entre la culture informatique commune de nos contemporains et ce que nécessiteraient les enjeux actuels est profond et, franchement, assez inquiétant, mais sans surprise : la révolution numérique a été abrupte, l’informatique est une science jeune, il faut former les formateurs, etc.
Conquérir le cyberespace passe aussi par le fait de remettre à l’honneur l’enseignement des sciences et des techniques, à l’image du renouveau dans les années cinquante impulsé par les pays occidentaux confrontés à la « crise du Spoutnik » et à la peur d’être distancés par les Soviétiques dans la conquête spatiale, comme le rappelle Gilles Dowek. Or la révolution scientifique et technologique que nous vivons est bien plus profonde que celle d’alors. Et il importe de commencer à se construire une culture scientifique dès le plus jeune âge, à apprendre à séparer le fait de l’opinion, à se former au doute et à la remise en cause permanente. « C’est dès la plus tendre enfance que se préparent les chercheurs de demain. Au lieu de boucher l’horizon des enfants par un enseignement dogmatique où la curiosité naturelle ne trouve plus sa nourriture, il nous faut familiariser nos élèves avec la recherche et l’expérimentation. Il nous faut leur donner le besoin et le sens scientifiques. […] La formation scientifique est — comme toute formation d’ailleurs, mais plus exclusivement peut-être — à base d’expériences personnelles effectives avec leur part d’inconnues et donc leurs risques d’échecs et d’erreurs ; elle est une attitude de l’esprit fondée sur ce sentiment devenu règle de vie de la perméabilité à l’expérience, élément déterminant de l’intelligence, et moteur de la recherche indéfinie au service du progrès. » Ces mots datent de 1957, au moment de la crise du Spoutnik ; ils sont du pédagogue Célestin Freinet qui concevait l’éducation comme un moyen d’autonomisation et d’émancipation politique et civique. Ils n’ont pas pris une ride. Continuité des idées, des besoins, des enjeux ; renouvellement des moyens, des approches, des savoirs à acquérir. Permanence et impermanence…
Samuel : Tant d’années ! Tant de nouveaux territoires du savoir dévoilés ! Et toujours les mêmes questions, toujours le même rocher à hisser au sommet de la même montagne !
Qu’avons-nous foiré ou que n’avons-nous pas su faire ? Ou plutôt, quelles questions n’avons-nous pas ou mal posées ?
« S’il y a une chose qui rend les jeunes êtres humains allergiques à l’imagination, c’est manifestement l’école » ont écrit Eric Liu et Scott Noppe-Brando dans Imagination first. Alors que se passerait-il si l’école devenait pour les jeunes êtres humains une expérience vivante et valorisante ? Et si nous étions là pour les accompagner vers l’idée qu’il n’existe pas qu’une seule réponse, une seule manière d’être dans le monde, une seule voie à suivre ? Que faut-il faire pour que les jeunes êtres humains aient la conviction que tout est possible et qu’ils peuvent réaliser tout ce dont ils se sentent capables ?
A quoi ressemblerait la société ?
Alors, à rebours de l’imaginaire populaire dans lequel on imagine l’immuabilité des lieux et des choix effectués, comment agir pour favoriser l’émergence d’« agencements » comme chez Deleuze, ou encore d’« assemblages » suivant la notion empruntée à Bruno Latour ? Non pas une matrice dans laquelle nous viendrions tous nous insérer, mais en tant qu’acteurs ne cessant de se réinventer dans une création continue d’associations et de liens dans un « lieu où tout deviendrait rythme, paysage mélodique, motifs et contrepoints, matière à expression ». Chaque fois que nous re-dessinons le monde, nous changeons la grammaire même de nos pensées, le cadre de notre représentation de la réalité. En fait, avec Rutger Bregmann, « l’incapacité d’imaginer un monde où les choses seraient différentes n’indique qu’un défaut d’imagination, pas l’impossibilité du changement ». Nos avenirs nous appartiennent, il nous faut juste les imaginer et les rendre contagieux. Nos transitions ne seraient-elles pas prendre déjà conscience que « si nous attendons le bon vouloir des gouvernements, il sera trop tard. Si nous agissons en qualité d’individu, ça sera trop peu. Mais si nous agissons en tant que communautés, il se pourrait que ce soit juste assez, juste à temps ».
Pour cela, il nous faudra explorer la manière dont les acteurs créent ces liens, et définissent ce que doit être la société. Et la société est d’autant plus inventive que les agencements qu’elle fait émerger sont inventifs dans l’invention d’eux-mêmes.
Des avenirs s’ouvrent peut-être, par une voie difficile et complexe nécessitant de traverser la zone, les ruines, les turbulences et les rêves. Nous pourrions imaginer essaimer l’essence vitale de cette planète, en proie à des destructions physiques et métaphysiques, pour faire renaître l’humanité, la vie, la flore et la faune dans les étoiles. Nous pourrions, avec d’autres, former le projet de partir à bord d’un vaisseau emportant dans ses flancs, outre des embryons humains et animaux, un chargement de graines, spécimens, outils, matériel scientifique, et de fichiers informatiques contenant toute la mémoire du monde et, plus lourd encore, le « poids considérable des rêves et des espoirs ».
Ou alors nous pourrions tout simplement former un projet non pas de « revenir à l’âge de pierre [un projet] pas réactionnaire ni même conservateur, mais simplement subversifparce qu’il semble que l’imagination utopique soit piégée […] dans un futur unique où il n’est question que de croissance ». Ce projet que nous pourrions essayer de mener à bien « c’est d’essayer de faire dérailler la machine ». Ces quelques mots d’Ursula Le Guin nous rappellent que nos avenirs nous appartiennent et que nous avons le pouvoir d’imaginer, d’expérimenter de construire à notre guise et de jouer avec nos avenirs communs et individuels afin de commencer à désincarcérer le futur.
Sylvain : Comment panser l’avant et penser l’après, alors que toutes les menaces semblent s’accélérer, alors que tous les risques semblent se confirmer ? Comment essayer de réinventer un futur véritablement soutenable ?
Certains ingrédients sont connus : décroitre, renforcer la justice sociale, déglobaliser, réduire la pression sur les ressources naturelles, développer l’économie circulaire, etc. Je voudrais ici en évoquer deux autres, sous la forme d’un devoir et d’un écueil.
Le devoir consiste à se dépouiller de cet « humanisme dévergondé » (C. Lévi-Strauss) issu de la tradition judéo-chrétienne et, plus près de nous, de la Renaissance et du cartésianisme, « qui fait de l’homme un maître, un seigneur absolu de la création », agissant envers plantes ou animaux « avec une irresponsabilité, une désinvolture totales » qui ont conduit à mettre la nature en coupe réglée et, en particulier, à la barbarie de l’élevage industriel. Quelque chose d’absolument irremplaçable a disparu nous dit Lévi-Strauss, ce profond respect pour la vie animale et végétale qu’ont les peuples dits « primitifs » qui permet de maintenir un équilibre naturel entre l’homme et le milieu qu’il exploite. Or « se préoccuper de l’homme sans se préoccuper en même temps, de façon solidaire, de toutes les autres manifestations de la vie, c’est, qu’on le veuille ou non, conduire l’humanité à s’opprimer elle-même, lui ouvrir le chemin de l’auto-oppression et de l’auto-exploitation. » L’ethnologue pose le principe d’une éthique qui ne prend pas sa source dans la nature humaine ethnocentrée mais dans ce qu’il appelle « l’humilité principielle » : « l’homme, commençant par respecter toutes les formes de vie en dehors de la sienne, se mettrait à l’abri du risque de ne pas respecter toutes les formes de vie au sein de l’humanité même ». Cette vision des droits dus à la personne humaine comme cas particulier des droits qu’il nous faut reconnaître aux entités vivantes, cet humanisme moral inclusif nous ramène immanquablement à notre point de départ, et à Jonas.
L’écueil consiste à systématiquement réduire chaque problème humain (politique, social, environnemental) à une question technique à laquelle la technologie numérique apporte une solution, en traitant les effets des problèmes sans jamais s’intéresser à leurs causes et en négligeant les possibles déterminismes et biais qui la composent. « Si nous nous y prenons bien, je pense que nous pouvons réparer tous les problèmes du monde » fanfaronnait Eric Schmidt, président exécutif de Google, en 2012. Diminuer le CO2 ? Il y a une application pour ça ! E. Morozov montre bien les limites et effets pervers de cette idéologie qu’il appelle le « solutionnisme technologique », qui s’accompagne d’un affaiblissement du jeu démocratique et aboutit au triomphe de l’individualisme et de la marchandisation. « Révolutionnaires en théorie, [les technologies intelligentes] sont souvent réactionnaires en pratique. » Et elles s’attaquent bien souvent à des problèmes artificiels à force de simplification. « Ce qui est irréaliste, dit Naomi Klein, est de penser que nous allons pouvoir faire face à ces crises mondiales avec quelques minuscules ajustements de la loi du marché. C’est ça qui est utopique. Croire qu’il va y avoir une baguette magique technologique est ridicule. Cela relève de la pensée magique, portée par ceux qui ont un intérêt économique à maintenir le statu quo. » Il ne s’agit bien sûr pas d’éliminer la technologie de la boîte à outils de la résolution de problème. Il importe en revanche de dépasser l’optimisme béat et la quasi-piété en ses pouvoirs et de comprendre qu’elle n’est qu’un levier qui n’a du sens qu’en conjonction d’autres (Ethan Zuckerman). Il est urgent, au fond, de réhabiliter la nuance, la pluralité et la complexité dans le débat et de trouver une voie pour traiter les problèmes difficiles avec des solutions nouvelles selon une approche systémique.
Demain est peut-être ailleurs, mais si l’humanité veut tenter un nouveau départ, les premiers pas vers le renouveau doivent être effectués ici et maintenant.
Florence Devouard est une ingénieure agronome française, devenue dirigeante associative. Vice-présidente de Wikimédia France de 2004 à 2008, elle a présidé la Wikimedia Foundation de 2006 à 2008, en remplacement de son fondateur, Jimmy Wales.
binaire : Pouvez-vous nous raconter votre parcours ? Comment en êtes-vous arrivée à vous intéresser assez à Wikipédia pour devenir la présidente de la fondation qui chapeaute l’encyclopédie ?
FD : J’ai fait des études d’ingénieure agronome. A Nancy, je me suis spécialisée en biotechnologies. J’ai un peu travaillé dans le milieu académique initialement, mais j’ai rapidement bifurqué vers le monde de l’entreprise.
J’ai suivi mon époux en Belgique flamande, puis aux États-Unis et j’ai eu deux enfants. Je me suis intéressée à l’informatique, mais c’étaient plus les usages que le codage qui m’attiraient. J’ai travaillé, par exemple, sur des outils d’aide à la décision. Et puis, au début des années 2000, j’ai atterri à Clermont-Ferrand où je me suis sentie un peu isolée. Je me suis alors plongée dans le web qui me permettait de rencontrer des gens qui partageaient mes intérêts, c’était juste ce dont j’avais alors besoin. Je suis devenue un peu activiste anonyme du web.
J’étais aussi gameuse, et je passais pas mal de temps sur les forums, beaucoup avec des Américains. Sur ces forums, qui n’étaient pas faits pour ça, je me suis retrouvée à écrire de nombreux textes sur la sécurité biologique, parce j’avais des choses à raconter. C’était l’époque de l’envoi d’enveloppes avec de l’anthrax, juste après les attentats du 11 septembre.
J’ai notamment beaucoup discuté sur un forum avec un activiste de GreenPeace. C’est lui qui m’a fait découvrir Wikipédia qui démarrait à ce moment. Il m’a suggéré d’y raconter ce qui me tenait à cœur, sur la version anglophone. A cette époque, il n’y avait encore quasiment personne sur Wikipédia en français.
J’ai alors découvert ce qu’était un wiki. Techniquement c’est très simple, juste un site web sur lequel on peut facilement s’exprimer. Je pouvais comme tout le monde participer à l’écriture de pages web et la création de liens entre elles. À l’époque, c’était tout nouveau, ça nous paraissait génial et peu de gens intervenaient. Pourtant, je n’arrivais pas à sauter le pas, je craignais le regard des autres, et je doutais de ma capacité à m’exprimer en anglais. Alors, je procrastinais. Il m’a forcé la main : il a copié-collé mes explications pour créer des articles. Ils ont été lus et modifiés et ça m’a fait réaliser que je pouvais écrire, que je pouvais faire profiter les autres de mes connaissances, que je pouvais contrecarrer un peu le matraquage de l’administration américaine sur la sécurité biologique. Et cela correspondait à ce que j’avais envie de faire.
binaire : Pourquoi est-ce que cela vous correspondait si bien ?
FD : J’avais l’impression d’écrire des textes qui pouvaient être lus dans le monde entier, faire quelque chose d’utile en apportant des connaissances et en faisant passer des idées. Je participais alors en particulier à des controverses entre la France et les États-Unis sur des sujets comme les armes de destruction massive, les OGM, et la disparition des abeilles. Sur chacun de ces sujets, il y avait des écarts de pensée importants entre la France et les US. Je pouvais donc faire passer aux US des idées qui avaient cours en France et que je maitrisais. Je pouvais faire découvrir aux Américains qu’il n’y avait pas que l’Amérique et que d’autres, ailleurs, pensaient différemment.
binaire : Est-ce que c’est ce genre de motivation de passer des idées qui anime encore aujourd’hui les Wikipédiens ?
FD : Oui. Nombre d’entre eux collaborent à l’encyclopédie par altruisme, pour faire passer aux autres des idées auxquelles ils tiennent. Ils veulent participer au développement des connaissances globales, faire circuler ces connaissances. C’est ce qui est génial. Avec Wikipédia, on peut faire travailler en commun un groupe de personnes aux quatre coins de la planète. Le numérique permet de réunir les quelques personnes qui s’intéressent à un sujet, même le plus exotique, pour partager leurs connaissances et confronter les points de vue.
binaire : C’était vrai au début quand tout était à faire. Est-ce que c’est toujours pareil aujourd’hui ?
FD : C’est vrai que cela a beaucoup changé, aussi bien les méthodes de travail, et que les contenus. Au tout début, au début des années 2000, on travaillait seul hors ligne, puis on se connectait pour charger l’article. Maintenant, on est connecté en continu et on interagit en permanence avec les autres rédacteurs.
A l’époque, on arrivait souvent devant une page blanche. Quand j’ai commencé à bosser sur la Wikipédia francophone, on était cinq et on devait tout construire. Aujourd’hui sur un sujet précis, on arrive et une grosse masse de connaissances a déjà été réunie. On démarre rarement de nouveaux sujets. Il faut avoir une bonne expertise sur un sujet pour pouvoir y contribuer. Avant, on débroussaillait avec comme ligne de mire très lointaine la qualité d’une encyclopédie conventionnelle. Aujourd’hui, on vise la perfection, par exemple, le label « Article de qualité », qui est un label très difficile à obtenir. Certains travaillent comme des dingues sur un article pour y arriver. C’est de cette quête de perfection qu’ils tirent leur fierté.
Ils éprouvent bien sûr aussi du plaisir à faire partie d’un réseau, à rencontrer des gens,
La situation pionnière qu’on a connue et que j’ai beaucoup aimée, est parfois encore un peu celle que rencontrent certains Africains qui rejoignent le projet dans des langues locales, depuis des pays encore mal connectés à internet. Ce n’est d’ailleurs pas simple pour eux de s’insérer dans le collectif qui a beaucoup changé.
binaire : La fondation Wikimédia promeut d’autres services que l’encyclopédie Wikipédia. Vous pouvez nous en parler ?
FD : Exact. L’encyclopédie représente encore 95% des efforts, mais on a bien d’autres projets. C’est d’ailleurs sur les projets moins énormes que j’ai le plus de plaisir à participer.
J’ai travaillé notamment sur un projet pour améliorer les pages « biaisées », des pages assez anciennes, où il reste peu de contributeurs actifs. On peut se retrouver par exemple confronté à des services de communication d’entreprises qui transforment les pages en les biaisant pour gommer les aspects un peu négatifs de leurs entreprises. Il faut se battre contre ça.
Un autre projet très populaire, c’est Wikimedia Commons qui regroupe des millions d’images. C’est né de l’idée qu’il était inutile de stocker la même image dans plusieurs encyclopédies dans des langues différentes. Je trouve très sympa dans Wikimedia Commons que nous travaillions tous ensemble par-delà des frontières linguistiques, que nous arrivions à connecter les différentes versions linguistiques.
Un troisième projet, Wiki Data construit une base de connaissances. Le sujet est plutôt d’ordre technique. Cela consiste en la construction de bases de faits comme « “Napoléon” est mort à “Sainte Hélène” ». À une entité comme ”Napoléon”, on associe tout un ensemble de propriétés qui sont un peu agnostiques de la langue. Les connaissances sont ajoutées par des systèmes automatiques depuis d’autres bases de données ou entrées à la main par des membres de la communauté wikimédienne. On peut imaginer de super applications à partir de Wiki Data.
Enfin, il y a d’autres projets comme Wiktionnaire ou Wiki Books, et des projets naissants comme Wiki Abstracts.
binaire : La fondation développe des communs. Comment la fondation choisit-elle quels communs proposer ? Comment définit-elle sa stratégie ?
FD : Au début, on avait juste l’encyclopédie. La Fondation a été créée en 2003, mais sans véritablement de stratégie. On faisait ce que les gens avaient envie de faire. Par exemple, Wiktionnaire a été créé à cette époque. On avait des entrées qui étaient juste des définitions de mots. On se disputait pour savoir si elles avaient leur place ou pas dans Wikipédia. Comme on ne savait pas comment trancher le sujet, on a créé autre chose : le Wiktionnaire. Dans cette communauté, quand tu as une bonne idée, tu trouves toujours des développeurs. Les projets se faisaient d’eux-mêmes, du moment que suffisamment de personnes estimaient que c’était une belle idée. Il n’y avait pas de stratégie établie pour créer ces projets.
À partir de 2007-2008, les choses ont changé, et la Fondation a cherché à réfléchir sur ce qu’on voulait, définir où on allait. Mais ça a pris du temps pour y arriver. Si on n’y fait pas attention, en mettant plein de gens autour de la table, on arrive à une stratégie qui est un peu la moyenne de ce que tout le monde veut, qui confirme ce qu’on est déjà en train de faire, sans aucun souffle, qui ne donne pas de vraie direction et qui n’est donc pas une vraie stratégie proactive.
binaire : À défaut de stratégie, la communauté a au moins développé ses propres règles ?
FD : Au début, il n’y avait même pas de règles communes. Elles ont émergé au cours du temps, au fil des besoins. Le mode fonctionnement est très flexible. Chaque communauté définit en fait ses propres règles, ses propres priorités. Les différentes versions linguistiques s’adaptent aux cultures.
Dans le temps, le modèle a tendance à se scléroser en s’appuyant bien trop sur la règle du précédent. Si ça marche à peu près, on préfère ne toucher à rien. Le Fondation qui lie tout cela ne cherche pas non plus à imposer sa loi, à de rares exceptions près. Comme par exemple, quand elle a défini des critères pour les biographies individuelles. Elle cherche surtout à tenir compte des lois des pays, et donc à limiter les risques juridiques.
Les règles communes tout comme une stratégie commune ont doucement émergé. Mais le monde de Wikimédia reste un monde très flexible.
binaire : Pouvez-vous nous parler des individus qui participent à Wikipédia. Cela semble vraiment s’appuyer sur des communautés très différentes.
FD : En partant du plus massif, vous avez la communauté des lecteurs, puis celle les éditeurs. Parmi ces derniers, cela va de l’éditeur occasionnel peu impliqué, jusqu’au membre actif qui participe à la vie de la communauté. Vous avez ensuite les associations locales et la fondation qui définissent un certain cadre par exemple en lançant des nouveaux projets. Elles interviennent aussi directement dans la vie de la communauté, notamment pour des raisons juridiques. Enfin, il faut mentionner, les salariés et contractuels de la fondation qui implémentent certains choix de la Fondation, et parfois entrent en conflit avec la communauté.
Le nombre de salariés des associations est très variable. Wikimédia France a une dizaine d’employés. Wikimédia Allemagne est plus ancienne et a environ deux cents personnes. D’autres pays n’ont que des bénévoles.
binaire : Le nombre de salariés est lié à la richesse de l’association locale ?
FD : Oui. L’association allemande a existé assez tôt en vendant notamment des encyclopédies off-line. Dans certains pays, les associations ont eu le droit de mettre des bandeaux d’appel aux dons sur Wikipedia, ce qui rapporte de l’argent. Dans d’autres, comme en Pologne, on peut via les impôts choisir de contribuer financièrement à l’association locale.
Le modèle économique varie donc d’un pays à l’autre. La Fondation Wikimédia (mondiale) redistribue une partie de ses fonds. Certains pays comme l’Allemagne sont assez riches pour s’en passer. Il reste une énorme disparité sur la disponibilité de moyens pour les Wikipédiens suivant leur pays.
binaire : Vous êtes aussi impliquée dans d’autres associations comme Open Food Fact ? Quel y est votre rôle ?
FD : Je suis dans leur Conseil d’Administration. Je suis là avec quelques autres personnes pour garantir le futur de toutes ces ressources développées en commun, et garantir une certaine pérennité.
binaire : Une dernière question. Vous avez à cœur de défendre une certaine diversité. Est-ce que vous pouvez partager cela avec les lecteurs de binaire ?
FD : Tous ces projets sont massivement le fait de mâles, cis, blancs, jeunes. On perd des talents à cause de cela, car l’environnement participatif ou le cadre de travail peuvent repousser. Il faut absolument que l’implication soit plus globale. On essaie d’explorer des solutions par exemple en luttant contre le harcèlement. Mais à mon avis on y arrive mal. J’aimerais bien savoir comment faire. Aujourd’hui, le pilotage global est très anglosaxon, et ça ne marche pas bien.
Wikipédia est une superbe réussite, on a construit quelque chose de génial. Un temps, on s’est inquiété de la diminution du nombre de contributeurs, la fuite des cerveaux. Je pense qu’on a réglé ce problème, aujourd’hui la population de contributeurs est quasi stable. Maintenant, pour continuer notre œuvre, on a besoin de plus de diversité. Je dirais que c’est aujourd’hui notre plus gros challenge.
Serge Abiteboul, Inria et ENS, Paris, & François Bancilhon, serial entrepreneur
Serge Abiteboul et Gérard Berry nous parlent de la 5G qui se déploie très rapidement en France. Dans un premier article, ils considéraient les aspects techniques. Dans un deuxième, ils traitaient des craintes autour de la 5G. Dans ce dernier, ils adressent la question des applications de cette technologie.
Cet article est en collaboration avec Theconversation France. Toute la série.
Comme c’est souvent le cas avec l’arrivée d’une nouvelle technologie, comme ça a été souvent le cas pour les générations de téléphonie cellulaire précédente, il est difficile de savoir quels seront les usages dominants, les “killer apps”. Pour le grand public et à court terme, la 5G servira surtout à éviter la saturation des réseaux 4G. Ce qui changera surtout ce sera l’arrivée d’applications autour de la vidéo et des jeux en réseaux s’appuyant sur des débits plus importants et une faible latence. La différence ne sera pas si évidente. C’est principalement le débit qui s’exprime dans ce contexte avec la 5G en 3.5 GHz.
Mais la 5G c’est aussi une plus faible latence (en particulier, avec la 26 GHz) et des garanties de service. Nous pensons que les usages les plus disruptifs seront plus que pour les générations précédentes à chercher du côté professionnel, notamment du côté des usines.
L’usine connectée, Source Arcep
L’usine connectée. Un plateau de fabrication consiste aujourd’hui en des machines connectées par des kilomètres de câble. La moindre transformation d’une chaîne de production demande de repenser la connectique, une complexité qui disparaît avec la 5G. La maintenance, notamment prédictive, et la logistique, sont également simplifiées parce que le suivi des machines et de la production se font beaucoup plus simplement avec des garanties de latence satisfaisante. La 5G est au cœur de l’industrie 4.0.
Bien sûr, elle a des concurrents comme le Wifi. Mais la plus grande latence, la moins bonne fiabilité (l’absence de garantie de service) du Wifi même de dernière génération fait souvent pencher la balance en faveur de la 5G dans un cadre industriel. Une différence, même réduite en apparence, peut conduire à l’accident industriel.
En France, l’usage de la 5G pour les usines a été expérimenté sur le site de Schneider Electric du Vaudreuil, dans l’Eure.
Logistique. La 5G est aussi un élément essentiel d’une logistique plus automatisée dans l’industrie ou dans les territoires. Le premier enjeu est celui de l’optimisation et du suivi du transport des matières premières comme des produits fabriqués utilisant toutes les possibilités des objets connectés et de l’informatique. La 5G devrait permettre de mieux gérer les flux, les performances (délais de livraisons) tout comme l’impact environnemental (émissions de gaz à effet de serre).
Le port du Havre a été le premier port français complètement connecté en 5G. La 5G permet une gestion fine des bateaux qui entrent ou sortent du port, en communication permanente. Il devrait aussi permettre un suivi en temps réel des cargaisons. La 5G ouvre toute une gamme d’applications comme le pilotage en temps réel d’un robot connecté qui nettoie les déchets marins en surface.
Les territoires connectés. L’enjeu principal de la ville ou du territoire connecté est l’acquisition de données en temps réel via des réseaux de capteurs (comme de détecter l’arrivée d’une personne de nuit dans une rue mal éclairée), et la commande d’actionneurs (allumer les lampadaires de cette rue). Donc le territoire intelligent est informé et piloté avec la 5G. On imagine bien le déploiement massif d’objets connectés. Mais pour quoi faire ? Gérer les réseaux de distribution (eau, électricité, etc.), surveiller la pollution, détecter rapidement divers types d’alertes, améliorer le transport, etc. Le territoire intelligent peut aussi s’appuyer sur la 5G pour une télésurveillance de masse, mais ça, ça ne fait pas rêver.
Avec la 5G, une question qui se pose très vite est celle de la rapidité d’adoption de la nouvelle technologie. Pour ce qui est de son déploiement dans des territoires intelligents, les deux auteurs ne partagent pas le même point de vue. Pour l’un, cela va arriver très vite, quand l’autre en doute. Les deux tombent d’accord pour dire qu’on ne sait pas trop et que cela dépendra en particulier de la maîtrise des aspects sécurité.
L’agriculture connectée. Les performances de la 5G en termes de densité d’objets connectés pourraient s’avérer très utiles dans l’agriculture. Le succès n’est pas garanti. Dans de nombreux cas comme celui des capteurs de l’hydrologie de champs, les constantes de temps sont souvent importantes, deux ou trois fois par jour. Les acteurs semblent parfois préférer des solutions 0G comme Sigfox ou Lora. C’est moins vrai pour l’élevage et la situation pourrait changer avec le contrôle de robots qui débarqueraient massivement dans les campagnes. La sécurité est également dans ce domaine une question critique qui pourrait ralentir le déploiement de la 5G en agriculture.
Médecine connectée. C’est souvent proposé comme un domaine d’application phare de la 5G. On n’est bien au-delà de la téléconsultation pour laquelle la 4G suffit souvent. L’hôpital, un lieu complexe et bourré de machines hyper-sophistiquées, est évidemment en première ligne. On a aussi assisté à des opérations chirurgicales à distance, par exemple, en 2019, sur une tumeur intestinale au Mobile World Congress à Barcelone. Le débit plus important et la faible latence rendent possibles de telles réalisations. Pourtant, dans le cadre de la chirurgie, une connexion filaire semble plus appropriée quand elle est présente. Le diagnostic appuyé sur de la réalité virtuelle et augmentée pourrait être une belle application de la 5G, tout comme le suivi de patients utilisant des objets connectés comme les pompes à insuline ou les pacemakers. On voit bien que la fiabilité des communications et leur sécurité sont essentielles dans ce contexte.
On trouve deux projets de 5G pour les CHU de Rennes et Toulouse dans le Plan France Relance.
Les transports. Le fait d’avoir une faible latence permet à la 5G d’être prometteuse pour le contrôle en temps réel de véhicules. Un domaine en forte progression, le transport collectif, devrait en bénéficier. Bien sûr, la 5G a sa place dans les gares qui concentrent une population dense. La 5G en 26GHz est par exemple expérimentée dans la gare de Rennes. Le transport collectif utilise déjà massivement des communications entre ses trains et les infrastructures. La 5G devrait apporter une plus grande qualité avec notamment des garanties de délais.
Pour l’automobile individuelle autonome, la situation est moins claire et les déploiements pourraient prendre plus de temps. (Les voitures autonomes testées aujourd’hui se passent en général de 5G.) La 5G pourrait s’installer dans les communications entre les véhicules et le reste du monde, le V2X (avec les autres véhicules et l’environnement). Dans ce cadre, elle est en concurrence avec un autre standard basé sur le Wifi. Les communications peuvent servir entre véhicules, par exemple, dans des “trains de camions” roulant à très faible distance l’un de l’autre sur l’autoroute. On imagine bien que toutes ces informations puissent réduire les risques d’accident, par exemple, en prévenant à l’avance le système d’une voiture de travaux sur la route ou de la présence de piétons ou de cyclistes.
Wikimedia Commons
Le V2X risque de prendre du temps pour s’installer pour plusieurs raisons. C’est d’abord la sécurité. Les spécialistes s’accordent à dire que les standards en développement ne sont pas sûrs, ce qui questionne évidemment. Et puis, des cadres de responsabilité légale en cas d’accident doivent être définis. Enfin, cette technologie demande des investissements lourds pour équiper les routes, et en particulier, les points névralgiques. On devrait donc la voir arriver à des vitesses différentes suivant les pays, et d’abord sur les axes routiers les plus importants. On peut aussi s’attendre à la voir débarquer dans des contextes locaux comme sur des tarmacs d’aéroports (véhicules pour les bagages ou le ravitaillement des avions) ou dans des ports (chargement et déchargement des cargaisons).
Le futur réseau radio des secours passera par la 5G. Crédit : Service départemental d’incendie et de secours, Dordogne
Et les autres. Cette liste ne se veut pas exhaustive. On aurait pu parler de smart grids, de service de secours, d’éducation, etc. Il faudra attendre pour voir où la 5G se déploie vraiment. Après ce tour d’horizon, on peut sans trop de doute se convaincre que la 5G révolutionnera de nombreux domaines, mais que cela ne se fera pas en un jour et que cela passera par la maîtrise des problèmes de fiabilité et de sécurité.
Serge Abiteboul, Inria et ENS Paris, Gérard Berry, Collège de France
Serge Abiteboul et Gérard Berry nous parlent de la 5G qui se déploie très rapidement en France. Dans un premier article, ils ont considéré les aspects techniques. Dans un deuxième, ils traitent des craintes autour de la 5G. Un dernier adressera la question des applications de cette technologie.
Cet article est en collaboration avec Theconversation France. Toute la série.
Quand on met dans un seul sac les opposants de la 5G, on mélange tout et n’importe quoi : risques sanitaires, destruction de la planète, atteintes à la sûreté des réseaux et au-delà à la souveraineté de l’État, surveillance de masse. Ces amalgames incluant des accusations facilement et factuellement déconstruites mêlées à de vrais problèmes suffisent-elles à disqualifier la critique ? Non, pas plus que les anti-vacs, anti-ondes, anti-sciences, anti-techno, etc. qui se sont agrégés au mouvement anti-5G au gré des municipales en France allant jusqu’à des incendies ou dégradations de stations radios. Répondre aux questionnements par la simple affirmation du déterminisme technologique n’est pas non plus suffisant. Les questionnements, les préoccupations sont légitimes pour une technologie qui va changer nos vies, selon ce qui est annoncé. Nous discutons de ces questionnements ici en ignorant les aspects irrationnels, voire conspirationnistes.
Manifestation anti-5G à Lyon, Wikipédia
Environnement
Le numérique, de manière générale, questionne les défenseurs de l’environnement. Par plein de côtés, il a des effets positifs sur l’environnement. Par exemple, il permet des études fines du climat, la gestion intelligente de l’énergie dans des smart grids, celle des moteurs de tous types, de l’automobile à l’aviation, des économies de transports avec le travail à distance. Par contre, il participe à la course en avant vers toujours plus de productivité et de consommation. Cet aspect très général du débat sera ignoré ici, où nous nous focaliserons sur la 5G.
Du côté positif, la 5G a été conçue dès le départ pour être énergétiquement sobre. Sachant que les chiffres ne sont pas stabilisés, elle devrait diviser fortement la consommation d’électricité pour le transport d’un Gigaoctet de données ; on parle de division par 10 et à terme par 20 par rapport à la 4G. Même si ces prévisions sont peut-être trop optimistes, il faut noter qu’elles vont dans le sens de l’histoire, qui a effectivement vu de pareilles améliorations de la 2G à la 3G à la 4G. Et on pourrait citer aussi les économies du passage du fil de cuivre à la fibre, ou des “vieux” data centers aux plus modernes. Le numérique sait aussi aller vers plus de sobriété, ce qui lui a permis d’absorber une grande partie de l’explosion des données transférées sur le réseau depuis vingt ans.
Une partie de cette explosion, oui, mais une partie seulement, car il faut tenir compte de l’effet rebond. D’une manière très générale, l’effet rebond, encore appelé paradoxe de Jevons, observe que des économies (monétaire ou autres) prévues du fait d’une amélioration de la technologie peuvent être perdues à la suite d’une adaptation du comportement de la société. Avec les améliorations des techniques qui ont permis le transport de plus en plus de données, on a vu cette quantité de données transportées augmenter violemment, en gros, doubler tous les dix-huit mois. Si les récents confinements dus à la pendémie n’ont pas mis à genoux la 4G, c’est grâce à l’année d’avance que sont obligés de prendre les opérateurs pour absorber cette croissance, entièrement due aux utilisateurs d’ailleurs.
L’introduction de la 5G va permettre que cet accroissement se poursuive, ce qui résulterait selon certains en une augmentation de l’impact négatif des réseaux sur l’environnement.
Bien sûr, on doit s’interroger pour savoir si cela aurait été mieux en refusant la 5G. Sans 5G, les réseaux télécoms de centre-ville auraient vite été saturés ce qui aurait conduit à densifier le réseaux de stations 4G. On aurait sans doute assisté à un même impact négatif pour un réseau qui aurait alors fini massivement par dysfonctionner, car la 4G supporte mal la saturation pour des raisons intrinsèques à sa technologie. Ne pas déployer la 5G – ce que demandaient certains – n’aurait réglé aucun problème, le vrai sujet est celui de la sobriété.
Dans le cadre du déploiement en cours, une vraie question est celle des coûts environnementaux de fabrication des éléments de réseaux comme les stations radio, et surtout des téléphones. Il faut savoir que la fabrication d’un téléphone portable émet beaucoup plus de gaz à effet de serre (GES) que son utilisation. Si tous les français se précipitent et changent leur téléphone pour avoir accès à la 5G, on arrive à un coût énorme en émission de GES. Il faudrait les convaincre que ça ne sert à rien et qu’on peut se contenter du renouvellement “normal” des téléphones. Il est important d’insister ici sur “normal” : les français changent de téléphone tous les 18 mois, ce qui n’est pas normal du tout. Même si ça a été effectivement nécessaire quand les téléphones étaient loin de leur puissance de calcul actuelle, ça ne l’est plus maintenant. Et produire tous ces téléphones engendre une gabegie de ressources, d’énergie et d’émission de GES . Au-delà du sujet de la 5G, que faisons-nous pour ralentir ces remplacements ? Que faisons-nous pour qu’ils ne s’accélèrent pas à l’appel des sirènes de l’industrie des smartphones ?
Il faudrait aussi questionner les usages. Le visionnage d’une vidéo sur un smartphone consomme plusieurs fois l’électricité nécessaire au visionnage de la même vidéo après téléchargement par la fibre. Mais la situation est tout sauf simple. Comment comparer le visionnage d’un cours en 4G par un élève ne disposant pas d’autre connexion internet au visionnage d’une vidéo (qu’on aurait pu télécharger à l’avance) dans le métro parisien ? Il ne s’agit pas ici de décider pour le citoyen ce qu’il peut visionner suivant le contexte, mais juste de le sensibiliser à la question du coût environnemental de ses choix numériques et de lui donner les moyens, s’il le souhaite, d’avoir des comportements plus sobres.
Rapport de The Shift Project, mars 2021
Sécurité et surveillance massive
Dans ces dimensions, les effets sont contrastés.
Pour la cybersécurité, la 5G procure des moyens d’être plus exigeants, par exemple, en chiffrant les échanges de bout en bout. Par contre, en augmentant la surface des points névralgiques, on accroît les risques en matière de sécurité. En particulier, la virtualisation des réseaux qu’elle introduit ouvre la porte à des attaques logicielles. L’internet des objets, potentiellement boosté par la 5G, questionne également quand on voit la faiblesse de la sécurité des objets connectés, des plus simples comme les capteurs à basse énergie jusqu’aux plus critiques comme les pacemakers. Le risque lié à la cybersécurité venant de l’internet des objets est accru par la fragmentation de ce marché qui rend difficile de converger sur un cadre et des exigences communes .
Pour ce qui est de la surveillance, les effets sont également contrastés. Les pouvoirs publics s’inquiètent de ne pouvoir que plus difficilement intercepter les communications des escrocs, des terroristes, etc. Des citoyens s’inquiètent de la mise en place de surveillance vidéo massive. La 4G permet déjà une telle surveillance, mais la 5G, en augmentant les débits disponibles la facilite. On peut réaliser les rêves des dictateurs en couvrant le pays de caméra dont les flux sont analysés par des logiciels d’intelligence artificielle. Le cauchemar. Mais la 5G ne peut être tenue seule pour responsable ; si cela arrive, cela tiendra aussi du manque de vigilance des citoyens et de leurs élus.
Communication de l’OMS démentant un lien entre 5G et Covid-19
Santé
Est-ce que la 5G et/ou l’accumulation d’ondes électromagnétiques nuit à la santé ?
C’est un vieux sujet. Comme ces ondes sont très utilisées (télécoms, wifi, four à micro-ondes, radars, etc.) et qu’elles sont invisibles, elles inquiètent depuis longtemps. Leurs effets sur la santé ont été intensément étudiés sans véritablement permettre de conclure à une quelconque nocivité dans un usage raisonné. Une grande majorité des spécialistes pensent qu’il n’y a pas de risque sanitaire à condition de bien suivre les seuils de recommandation de l’OMS, qui ajoute déjà des marges importantes au-delà des seuils où on pense qu’il existe un risque. On notera que certains pays comme la France vont encore au-delà des recommandations de l’OMS.
Pourtant, d’autres spécialistes pensent que des risques sanitaires existent. Et on s’accorde généralement pour poursuivre les études pour toujours mieux comprendre les effets biologiques des ondes, en fonction des fréquences utilisées, de la puissance et de la durée d’exposition. Avec le temps, on soulève de nouvelles questions comme l’accumulation des effets de différentes ondes, et après avoir focalisé sur les énergies absorbées et les effets thermiques, on s’attaque aux effets non thermiques.
La controverse se cristallise autour de “l’hypersensibilité aux ondes électromagnétiques”. C’est une pathologie reconnue dans de nombreux pays, qui se manifeste par des maux de tête, des douleurs musculaires, des troubles du sommeil, etc. Malgré son nom, les recherches médicales n’ont montré aucun lien avec l’exposition aux ondes. Ses causes restent mystérieuses.
Venons-en à la question plus spécifique de la 5G. La 5G mobilise différentes nouvelles gammes de fréquence, autour de 3,5 GHz et autour de 26 GHz. Avec la 3.5 GHz, on est très proche de fréquences déjà utilisées, par exemple par le Wifi, et de fréquences dont les effets ont été très étudiés. Pour la 26 GHz, si l’utilisation dans un cadre grand public de telles ondes est nouveau, on dispose déjà d’études sur de telles fréquences élevées. Pourtant, l’utilisation nouvelle de ces fréquences spécifiques légitime le fait que de nouvelles études soient entreprises pour elles, ce qui est déjà le cas.
Un aspect de la 5G conduit naturellement aussi à de nouvelles études : les antennes MIMO dont nous avons parlé. Elles permettent de focaliser l’émission sur l’utilisateur. Cela évite de balancer des ondes dans tout l’espace. Par contre, l’utilisateur sera potentiellement exposé à moins d’ondes au total mais à des puissances plus importantes. Le contexte de l’exposition changeant aussi radicalement conduit à redéfinir la notion d’exposition aux ondes, et peut-être à de nouvelles normes d’exposition. Cela conduit donc à repenser même les notions de mesure.
Nous concluons cette section en mentionnant un autre effet sur la santé qui va bien au-delà de la 5G pour interpeller tout le numérique : la vitesse de développement de ces technologies. Le numérique met au service des personnes des moyens pour améliorer leurs vies. C’est souvent le cas et, en tant qu’informaticiens, nous aimons souligner cette dimension. Mais, le numérique impose aussi son rythme et son instantanéité à des individus, quelquefois (souvent?) à leur détriment. C’est particulièrement vrai dans un contexte professionnel. Dans le même temps où il nous décharge de tâches pénibles, il peut imposer des cadences inhumaines. Voici évidemment des usages qu’il faut repousser. Il faut notamment être vigilant pour éviter que la 5G ne participe à une déshumanisation du travail.
Wikimedia Commons
Économie et souveraineté
On peut difficilement évaluer les retombées économiques de la 5G, mais les analystes avancent qu’elle va bouleverser de nombreux secteurs, par exemple, la fabrication en usine et les entrepôts. On s’attend à ce qu’elle conduise aussi à de nouvelles gammes de services grand-public et à la transformation des services de l’État. On entend donc : Le monde de demain sera différent avec la 5G, et ceux qui n’auront pas pris le tournant 5G seront dépassés. C’est une des réponses avancées aux détracteurs de la 5G, la raison économique. On rejouerait un peu ce qui s’est passé avec les plateformes d’internet : on est parti trop tard et du coup on rame à rattraper ce retard. Sans la 5G, l’économie nationale perdrait en compétitivité et nous basculerions dans le tiers monde.
Il est difficile de valider ou réfuter une telle affirmation. N’abandonnerions-nous la 5G que pour un temps ou indéfiniment ? Est-ce que ce serait pour adopter une autre technologie ? Nous pouvons poser par contre la question de notre place dans cette technique particulière, celle de la France et celle de l’Europe.
Pour ce qui est du développement de la technologie, contrairement à d’autres domaines, l’Europe est bien placée avec deux entreprises européennes sur les trois qui dominent le marché, Nokia et Ericsson. On peut même dire que Nokia est “un peu” française puisqu’elle inclut Alcatel. La dernière entreprise dominante est chinoise, Huawei, que les États-Unis et d’autres essaient de tenir à l’écart parce qu’elle est plus ou moins sous le contrôle du parti communiste chinois. La France essaie d’éviter que des communications d’acteurs sensibles ne puissent passer par les matériels Huawei ce qui revient de fait à l’exclure en grande partie du réseau français.
Pour ce qui est des usages, les industriels français semblent s’y intéresser enfin. Les milieux scientifiques européens et les entreprises technologiques européennes ne sont pas (trop) à la traîne même si on peut s’inquiéter des dominations américaines et chinoises dans des secteurs comme les composants électroniques ou les logiciels, et des investissements véritablement massif des États-Unis et de la Chine dans les technologies numériques bien plus grands qu’en Europe. On peut donc s’inquiéter de voir l’économie et l’industrie européenne prendre du retard. Il est vrai que la 5G ne sera pleinement présente que dans deux ou trois ans. On peut espérer que ce délai sera utilisé pour mieux nous lancer peut-être quand on aura mieux compris les enjeux, en espérant que ce ne sera pas trop tard, qu’en arrivant avec un temps de retard, on n’aura pas laissé les premiers arrivants rafler la mise (“winner-take-all”).
Conclusion. Comme nous l’avons vu, certains questionnements sur la 5G méritent qu’on s’y arrête, qu’on poursuive des recherches, qu’on infléchisse nos usages des technologies cellulaires. La 5G est au tout début de son déploiement. Les sujets traversés interpellent le citoyen. Nous voulons mettre cette technologie à notre service, par exemple, éviter qu’elle ne conduise à de la surveillance de masse ou imposer des rythmes de travail inhumains. Nous avons l’obligation de la mettre au service de l’écologie par exemple en évitant des changements de smartphones trop fréquents ou des téléchargements intempestifs de vidéos en mobilité. C’est bien pourquoi les citoyens doivent se familiariser avec ces sujets pour choisir ce qu’ils veulent que la 5G soit. Décider sans comprendre est rarement la bonne solution.
Serge Abiteboul, Inria et ENS Paris, Gérard Berry, Collège de France
Un nouvel « Entretien autour de l’informatique ». Judith Rochfeld est professeure de droit privé à l’École de droit de la Sorbonne, et directrice du Master 2 « Droit du commerce électronique et de l’économie numérique ». C’est une des meilleures spécialistes des communs. Elle est co-éditrice du Dictionnaire des biens communs aux PUF, 2021. Elle est autrice de « Justice pour le climat ! Les nouvelles formes de mobilisation citoyenne » chez Odile Jacob, 2021. Cet article est publié en collaboration avec theconversation.fr.
Judith Rochfeld
binaire : Judith, peux-tu nous dire qui tu es, d’où tu viens ?
JR : Je suis au départ une juriste, professeure de droit privé à l’Université Paris 1 Panthéon-Sorbonne. Au début, je m’intéressais aux grandes notions juridiques classiques, dont la propriété privée. Puis, sous le coup de rencontres et d’opportunités, j’ai exploré deux directions : le droit du numérique d’un côté ; et, avec un groupe de travail composé d’économistes, d’historiens, de sociologues, les « communs » dans la suite des travaux d’Elinor Ostrom (*), d’un autre côté. Cela m’a amenée à retravailler, entre autres, la notion de propriété. Par la suite, pour concrétiser certains des résultats de ces réflexions, j’ai dirigé, avec Marie Cornu et Fabienne Orsi, la rédaction d’un dictionnaire des biens communs. Aujourd’hui, je m’intéresse particulièrement à toutes les formes de biens communs et de communs, principalement en matière numérique et de données ainsi qu’en environnement.
binaire : Pourrais-tu préciser pour nos lecteurs les notions de « biens communs » et de « communs » ?
JR : Le vocabulaire n’est pas complètement stabilisé et peut varier suivant les interlocuteurs. Mais si l’on tente de synthétiser, on parlerait de « biens communs » pour saisir des biens, ressources, milieux, etc., à qui est associé un intérêt commun socialement, collectivement et juridiquement reconnu. Ce peut être l’intérêt d’une communauté nationale, internationale ou l’intérêt de groupes plus locaux ou restreints. On peut prendre l’exemple des monuments historiques : en 1913, on a assisté à des combats législatifs épiques pour faire reconnaître qu’il fallait les identifier, les classer, et admettre qu’ils présentaient un intérêt pour la nation française dans son ensemble ; qu’en conséquence, leurs propriétaires, fussent-ils privés, ne pouvaient pas avoir sur eux de pleins pouvoirs (comme le voudrait l’application de la propriété classique), jusqu’à celui de les détruire ; qu’ils devaient tenir compte de l’intérêt pour d’autres (voire pour les générations à venir), avec des conséquences juridiques importantes (l’obligation de les conserver dans leur état, de demander une autorisation pour les modifier, etc.).
Il existe d’ailleurs divers intérêts communs reconnus : l’intérêt historique et/ou artistique d’un monument ou d’autres biens culturels, l’intérêt environnemental ou d’usage commun d’un cours d’eau ou d’un terrain, l’intérêt sanitaire d’un vaccin, etc.
Mais précisons la terminologie. D’abord, il faut différencier entre « biens communs » et le « bien commun » discuté, par exemple, dans « Économie du bien commun » de Jean Tirole. Le second renvoie davantage à l’opposition entre bien et mal qu’à l’idée d’un intérêt commun.
Ensuite, il faut distinguer « biens communs » et « communs ». Avec la notion de « communs » (dans le sens que lui a donné Elinor Ostrom), on ajoute l’idée d’une organisation sociale, d’un gouvernement de la ressource par la communauté. C’est cette communauté qui gère les accès, les prélèvements, les différents droits…, et assure avec cela la pérennité de la ressource. C’est le cas par exemple pour un jardin partagé, un tiers-lieu, ou une encyclopédie en ligne telle que Wikipédia, administrés par leurs utilisateurs ou un groupe de personnes dédiées.
Un commun se caractérise typiquement par une communauté, une ressource que se partage cette communauté, et une gouvernance. Dans un bien commun, on n’a pas forcément cette gouvernance.
binaire : Cela conduit bien-sûr à des conflits avec la propriété privée ?
JR : On a souvent tendance à opposer les notions de biens communs ou de communs au droit de propriété privée, très belle avancée de la révolution française en termes d’émancipation et de reconnaissance d’un espace d’autonomie sur ses biens au bénéfice de l’individu propriétaire. Reconnaître qu’un bien porterait un intérêt commun poserait des limites au pouvoir absolu que la propriété renferme, en imposant la considération de l’intérêt d’une communauté. Cela peut être vrai dans certains cas, comme celui des monuments historiques évoqué.
Mais c’est oublié qu’il peut y avoir aussi une volonté du propriétaire d’aller en ce sens. La loi de protection de la biodiversité de 2016 permet ainsi, par exemple, de mettre un bien que l’on possède (un terrain, une forêt, etc.) au service d’une cause environnementale (la réintroduction d’une espèce animale ou végétale, la préservation d’une espèce d’arbre,…) en passant un accord pour formaliser cette direction : le propriétaire établit un contrat avec une association ou une collectivité, par exemple, et s’engage (et engage ses héritiers) à laisser ce dernier au service de la cause décrite. On assiste alors à une inversion de la logique de la propriété : elle sert à partager ou à faire du commun plutôt qu’à exclure autrui. C’est la même inversion qui sert de fondement à certaines licences de logiciel libre : celui qui pourrait bénéficier d’une « propriété » exclusive, à l’égard d’un logiciel qu’il a conçu, choisit plutôt de le mettre en partage et utilise pour cela une sorte de contrat (une licence de logiciel libre particulière) qui permet son usage, des modifications, mais impose à ceux qui l’utilise de le laisser en partage. Le droit de propriété sert ainsi à ouvrir l’usage de cette ressource plutôt qu’à le fermer.
binaire : Pour arriver aux communs numériques, commençons par internet. Est-ce que c’est un bien commun ? Un commun ?
JR : C’est une grande discussion ! On a pu soutenir qu’Internet était un commun mondial : on voit bien l’intérêt de cette ressource ou de cet ensemble de ressources (les différentes couches, matérielles, logicielles, etc.) pour une communauté très large ; ses fonctionnement et usages sont régis par des règles que se donnent des « parties prenantes » et qui sont censées exprimer une sorte de gouvernance par une partie de la communauté intéressée. En réalité, internet a même plusieurs gouvernances — technique, politique — et on est loin d’une représentation de l’ensemble des parties prenantes, sans domination de certains sur d’autres. La règle, cependant, qui exprime peut-être encore le mieux une partie de cette idée est celle de neutralité du net (dont on sait qu’elle a été bousculée aux États-Unis) : tout contenu devrait pouvoir y circuler sans discrimination.
binaire : Est-ce qu’on peut relier cela au droit de chacun d’avoir accès à internet ?
JR : Oui, ce lien est possible. Mais, en France, le droit à un accès à internet a plutôt été reconnu et fondé par le Conseil constitutionnel sur de vieilles libertés : comme condition des libertés d’information et d’expression.
binaire : Le sujet qui nous intéresse ici est celui des communs numériques. Est-ce tu vois des particularités aux communs numériques par rapport aux communs tangibles ?
JR : Oui tout à fait. Ostrom étudiait des communs tangibles comme des systèmes d’irrigation ou des forêts. La menace pour de telles ressources tient principalement dans leur surexploitation : s’il y a trop d’usagers, le cumul des usages de chacun peut conduire à la disparition matérielle de la ressource. D’ailleurs, l’économie classique postule que si j’ouvre l’usage d’un bien tangible (un champ par exemple, ouvert à tous les bergers désirant faire paître leurs moutons), ce dernier sera surexploité car personne ne ressentira individuellement la perte de façon suffisante et n’aura intérêt à préserver la ressource. C’est l’idée que synthétisera Garrett Hardin dans un article de 1968 resté célèbre, intitulé la « Tragédie des communs » (**). La seule manière de contrer cet effet serait d’octroyer la propriété (ou une réglementation publique). Ostrom s’inscrira précisément en faux en démontrant, à partir de l’analyse de cas concrets, que des systèmes de gouvernance peuvent se mettre en place, édicter des règles de prélèvements et d’accès (et autres) et assurer la pérennité de la ressource.
Pour ce qui est des communs numériques, ils soulèvent des problèmes différents : non celui de l’éventuelle surexploitation et de la disparition, mais celui qu’ils ne soient pas produits. En effet, si j’ouvre l’accès à des contenus (des notices de l’encyclopédie numérique, des données, des œuvres, etc.) et si, de plus, je rends gratuit cet usage (ce qui est une question un peu différente), quelle est alors l’incitation à les créer ?
Il faut bien préciser que la gratuité est une dimension qui a été placée au cœur du web à l’origine : la gratuité et la collaboration, dans une vision libertaire originaire, allaient quasi de soi. Les logiciels, les contenus distribués, etc. étaient créés par passion et diffusés dans un esprit de don par leurs concepteurs. Or, ce faisant, on fait un choix : celui de les placer en partie hors marché et de les faire reposer sur des engagements de passionnés ou d’amateurs désintéressés. La question se pose pourtant aujourd’hui d’aller vers le renforcement de modèles économiques qui ne soient plus basés que sur cette utopie du don, ou même sur des financements par fondations, comme ceux des Mozilla et Wikipedia Fundations.
Pour l’heure, la situation actuelle permet aux grandes plateformes du web d’absorber les communs (les contenus de wikipédia, des données de tous ordres, etc.), et ce sans réciprocité, alors que l’économie de l’attention de Google dégage des revenus énormes. Par exemple, alors que les contenus de l’encyclopédie Wikipédia, un commun, alimentent grandement le moteur de recherche de Google (ce sont souvent les premiers résultats), Wikipédia n’est que très peu rétribuée pour toute la valeur qu’elle apporte. Cela pose la question du modèle économique ou du modèle de réciprocité à mettre en place, qui reconnaisse plus justement la contribution de Wikipédia aux revenus de Google ou qui protège les communs pour qu’ils demeurent communs.
binaire : On pourrait également souhaiter que l’État soutienne le développement de communs. Quelle pourrait être une telle politique de soutien ?
JR : D’un côté, l’État pourrait s’afficher aux côtés des communs : inciter, voire obliger, ses administrations à choisir plutôt des communs numériques (logiciels libres, données ouvertes, etc.). C’est déjà une orientation mais elle n’est pas véritablement aboutie en pratique.
D’un autre côté, on pourrait penser et admettre des partenariats public-commun. En l’état des exigences des marchés publics, les acteurs des communs ont du mal à candidater à ces marchés et à être des acteurs reconnus de l’action publique.
Et puis, le législateur pourrait aider à penser et imposer la réciprocité : les communs se réclament du partage. Eux partagent mais pas les autres. Comment penser une forme de réciprocité ? Comment faire, par exemple, pour qu’une entreprise privée qui utilise des ressources communes redistribue une partie de la valeur qu’elle en retire ? On a évoqué le cas de Google et Wikipédia. Beaucoup travaillent actuellement sur une notion de « licence de réciprocité » (même si ce n’est pas simple) : vous pouvez utiliser la ressource mais à condition de consacrer des moyens ou du temps à son élaboration. Cela vise à ce que les entreprises commerciales qui font du profit sur les communs participent.
Dans l’autre direction, un projet d’article 8 de la Loi pour une République Numérique de 2016 (non adopté finalement) bloquait la réappropriation d’une ressource commune (bien commun ici) : il portait l’idée que les œuvres passées dans le domaine public (des contenus numériques par exemple) devenaient des « choses communes » et ne pouvaient pas être ré-appropriées par une entreprise, par exemple en les mettant dans un nouveau format ou en en limitant l’accès.
D’aucuns évoquent enfin aujourd’hui un « droit à la contribution », sur le modèle du droit à la formation (v. L. Maurel par exemple) : une personne pourrait consacrer du temps à un commun (au fonctionnement d’un lieu partagé, à l’élaboration d’un logiciel, etc.), temps qui lui serait reconnu pour le dédier à ces activités. Mais cela demande d’aller vers une comptabilité des contributions, ce qui, à nouveau, n’est pas facile.
En définitive toutes ces propositions nous conduisent à repenser les rapports entre les communs numériques, l’État et le marché.
binaire : Nous avons l’impression qu’il existe beaucoup de diversité dans les communautés qui prônent les communs ? Partages-tu cet avis ?
JR : C’est tout à fait le cas. Les communautés qu’étudiaient Ostrom et son École étaient petites, territorialisées, avec une centaine de membres au plus, identifiables. Avec l’idée des communs de la connaissance, on est passé à une autre échelle, parfois mondiale.
Certains communs se coulent encore dans le moule. Avec Wikipédia, par exemple, on a des communautés avec des rôles identifiés qui restent dans l’esprit d’Ostrom. On a la communauté des « bénéficiaires » ; ses membres profitent de l’usage de la ressource, comme ceux qui utilisent Wikipédia. On a aussi la communauté « délibérative », ce sont les administrateurs de Wikipédia qui décident des règles de rédaction et de correction des notices par exemple, ou la communauté « de contrôle » qui vérifie que les règles ont bien été respectées.
Mais pour d’autres communs numériques, les communautés regroupent souvent des membres bien plus mal identifiés, parfois non organisés, sans gouvernement. Je travaille d’ailleurs sur de telles communautés plus « diffuses », aux membres non identifiés a priori mais qui bénéficient de ressources et qui peuvent s’activer en justice pour les défendre quand celles-ci se trouvent attaquées. Dans l’exemple de l’article 8 dont je parlais, il était prévu de reconnaître que tout intéressé puissent remettre en cause, devant les tribunaux, le fait de ne plus pouvoir avoir accès à l’œuvre du domaine public du fait de la réappropriation par un acteur quelconque. Il s’agit bien d’une communauté diffuse de personnes, sur le modèle de ceux qui défendent des « ressources environnementales ». On peut y voir une forme de gouvernance, certes à la marge.
binaire : On a peu parlé de l’open data public ? Est-ce que la définition de commun que tu as donné, une ressource, des règles, une gouvernance, s’applique aussi pour les données publiques en accès ouvert ?
JR : Il y a des différences. D’une part, les lois ont vu dans l’open data public le moyen de rendre plus transparente l’action publique : les données générées par cette action devaient être ouvertes au public pour que les citoyens constatent l’action publique. Puis, en 2016, notamment avec la loi pour une République numérique évoquée, cette politique a été réorientée vers une valorisation du patrimoine public et vers une incitation à l’innovation : des startups ou d’autres entreprises doivent pouvoir innover à partir de ces données. Les deux motivations sont légitimes. Mais, mon impression est qu’aujourd’hui, en France, l’État voit moins dans l’open data un moyen de partage de données, qu’un espace de valorisation et de réappropriation. D’autre part, ce ne sont pas du tout des communs au sens où il n’y a pas de gouvernance par une communauté.
binaire : Tu travailles beaucoup sur le climat. On peut citer ton dernier livre « Justice pour le climat ». Quelle est la place des communs numériques dans la défense de l’écologie ?
JR : Je mets de côté la question de l’empreinte environnementale du numérique, qui est un sujet assez différent, mais néanmoins très préoccupant et au cœur des réflexions à mener.
Sur le croisement évoqué, on peut tracer deux directions. D’une part, il est évident qu’un partage de données « environnementales » est fondamental : pour mesurer les impacts, pour maîtriser les externalités. Ces données pourraient et devraient être saisies comme des « biens communs ». On a également, en droit, la notion voisine de « données d’intérêt général ». Il y a déjà des initiatives en ce sens en Europe et plus largement, que ce soit à l’égard des données publiques ou de données générées par des entreprises, ce qui, encore une fois, est délicat car elles peuvent recouper des secrets d’affaires.
D’autre part, la gravité de la crise environnementale, et climatique tout particulièrement, donne lieu à des formes de mobilisations qui, pour moi, témoignent de nouvelles approches et de la « conscientisation » des biens communs. Notamment, les procès citoyens que je décris dans le livre, qui se multiplient dans une bonne partie du monde, me semblent les expressions d’une volonté de réappropriation, par les citoyens et sous la pression de l’urgence, du gouvernement d’entités ressenties comme communes, même si le procès est une gouvernance qui reste marginale. Ils nous indiquent que nous aurions intérêt, pour leur donner une voie de gouvernement plus pacifique, à installer des instances de délibération, à destination de citoyens intéressés (territorialement, intellectuellement, par leur activité, leurs besoins, etc.) saisis comme des communautés diffuses. A cet égard, une initiative comme la Convention Citoyenne sur le climat était particulièrement intéressante, ouvrant à une version moins contentieuse que le procès.
Il pourrait en aller de même dans le cadre du numérique : l’utilisation de l’ensemble de nos données personnelles, des résultats de recherche obtenus en science ouverte, etc. pourraient, comme des communs, être soumise à des instances de délibération de communautés. On prendrait conscience de l’importance des données et on délibérerait sur le partage. Sans cela, on assistera toujours à une absorption de ces communs par les modèles d’affaires dominants, sans aucune discussion.
Serge Abiteboul, Inria & ENS Paris, François Bancilhon, serial entrepreneur
(*) Elinor Ostrom (1933-2012) est une politologue et économiste américaine. En 2009, elle est la première femme à recevoir le prix dit Nobel d’économie, avec Oliver Williamson, « pour son analyse de la gouvernance économique, et en particulier, des biens communs ». (Wikipédia)
(**) « La tragédie des biens communs » est un article décrivant un phénomène collectif de surexploitation d’une ressource commune que l’on retrouve en économie, en écologie, en sociologie, etc. La tragédie des biens communs se produirait dans une situation de compétition pour l’accès à une ressource limitée (créant un conflit entre l’intérêt individuel et le bien commun) face à laquelle la stratégie économique rationnelle aboutit à un résultat perdant-perdant.
Nous vous avions parlé de datacraft dans un article précédent « L’artisanat de la science des données avec datacraft » . En les rencontrant, nous avions été intéressés par des ateliers qu’ils organisaient pour échanger sur des sujets délicats. Ils ont organisé en particulier une série de discussions autour des thématiques de l’équité et de la confiance en intelligence artificielle. Nathan Noiry nous parle ici d’un de ces ateliers qu’il a animé avec Yannick Guyonvarch. L’objectif était d’introduire la notion de « biais de représentativité » et de proposer une méthodologie pour les détecter et les corriger. Bonne lecture ! Serge Abiteboul
Nathan Noiry
En janvier 2020, l’erreur d’un algorithme de reconnaissance faciale des services de police de Détroit (Michigan) a conduit à l’arrestation injustifiée de Robert Williams [1], [2]. Identifié à tort avec un voleur de montres, il passera trente heures en détention. Si la confiance aveugle des policiers dans leur technologie explique en grande partie l’injustice (une simple vérification humaine aurait sans doute suffi à éviter l’incident), cette faute a permis de mettre en lumière les biais raciaux des algorithmes de reconnaissance faciale. Malgré leur redoutable précision biométrique, ces derniers ont en effet tendance à se tromper plus souvent sur certains sous-groupes démographiques, les noirs et les femmes notamment, comme le décrit le rapport [3] du National Institute of Standard and Technology. Au delà de cet exemple frappant, la problématique des biais est aujourd’hui centrale dans le développement des outils d’intelligence artificielle : leur présence insidieuse conduit bien souvent à des prises de décisions discriminatoires et font d’eux un enjeu majeur pour les années à venir. Voir par exemple le désormais célèbre ouvrage Weapons of Math Destruction de Cathy O’Neil.
Qu’est-ce qu’un biais ?
Le terme est omniprésent mais parfois mal compris tant il recouvre de réalités différentes. Les auteurs de l’article de synthèse Algorithmes : Biais, Discrimination et Équité[4] définissent un biais comme une « déviation par rapport à un résultat censé être neutre, loyal ou encore équitable » et en distinguent deux grandes familles. Les biais cognitifs, d’abord, qui irriguent tous les autres : biais de confirmation, tendance à détecter de fausses corrélations entre évènements… Nous renvoyons le lecteur au livre Thinking, Fast and Slow de Daniel Kahneman décrivant ses nombreux travaux avec Amos Tversky sur le sujet. La deuxième grande famille de biais est de nature statistique et correspond à ce que l’on appelle communément biais des données ou biais de représentativité. Ces derniers désignent une situation d’inadéquation entre données utilisées pour l’entraînement d’un algorithme et données cibles sur lesquelles l’algorithme sera déployé. Un tel exemple est fourni par la surreprésentation des afro-américains dans les bases de données de photos d’identité judiciaires américaines [5], expliquant en partie les biais raciaux mentionnés précédemment.
Biais et équité
À ce stade, il nous semble important de souligner que les problèmes de représentativité se superposent seulement en partie avec les problèmes d’équité. Afin d’illustrer notre propos, imaginons vouloir développer un algorithme de gestion de carrière dans le secteur numérique en France, où la part des femmes est d’environ 20%. À cet effet, on collecte des données d’entraînement en réalisant un sondage auprès de certains employés de ce secteur : ci-dessus, on distingue deux situations (fictives) correspondant respectivement à une proportion de femmes de 20% ou de 50% dans l’échantillon interrogé. Le premier échantillon, non-équitable du point de vue de la parité homme/femme, est cependant représentatif puisque la proportion des femmes coïncide avec celle de la population totale. Au contraire, le deuxième échantillon, bien que paritaire, n’est pas représentatif. De cet exemple, on retiendra qu’un biais de représentativité se définit par rapport à une population cible observée, tandis qu’un biais inhérent (de genre, de race…) se définit par rapport à des caractéristiques cibles que l’on souhaite atteindre et pouvant différer de celles de la population observée.
D’où viennent les biais ?
La problématique des biais n’est pas nouvelle : les instituts de sondages s’escriment depuis des décennies à concevoir des enquêtes permettant d’obtenir un échantillon représentatif de la population étudiée. Elle a néanmoins pris une tournure plus systématique depuis l’avènement du Big Data. Notre faculté d’acquérir et de stocker des bases de données toujours plus massives a en effet opéré un changement de paradigme dans leur utilisation : l’information est aujourd’hui disponible avant même de se poser une question spécifique. Cet état de fait permet bien souvent au praticien de s’affranchir de la délicate étape (souvent coûteuse) de collecte des données, mais l’absence de contrôle sur le processus d’acquisition l’expose à de nombreux problèmes de représentativité. À titre d’exemple, une entreprise agroalimentaire possédant un modèle pré-entraîné sur le marché français et souhaitant développer son activité en Chine prendra le risque d’effectuer de mauvaises prédictions du fait d’une différence significative entre les comportements des consommateurs.
Modéliser les biais
Le processus même de collecte des données, en ce qu’il déforme bien souvent les caractéristiques de la population d’intérêt, peut altérer l’information que l’on souhaite acquérir. Les données observées ne sont alors que des versions imparfaites des données cibles originelles, immaculées mais inaccessibles. Aussi, la première étape de l’étude statistique des biais consiste à modéliser de manière adéquate les mécanismes de sélection à l’œuvre, miroirs déformants responsables de la transformation des données. De manière schématique, on en distinguera deux grandes instances.
La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
Dans le cas de la sélection stricte, on modélise la propension d’un individu à répondre au sondage. Pour la sélection douce, on modélisera plutôt la fonction de déformation, dans notre exemple, le ratio entre courbe rouge et courbe bleue. Le choix du modèle est une étape cruciale et doit être effectué en étroite collaboration avec des experts du domaine afférent.
Peut-on détecter et corriger les biais ?
Une fois passée l’étape de modélisation, il est possible de tester la pertinence du modèle sélectionné. C’est à ce stade que la connaissance d’information auxiliaire sur la population cible s’avère déterminante. Celle-ci prend souvent la forme de caractéristiques moyennes issues d’enquêtes pré-existantes et de large ampleur – il est par exemple aisé d’obtenir des informations agrégées telles que l’âge moyen ou le salaire moyen, tandis que les données individuelles sont parfois difficiles d’accès pour des raisons de confidentialité. La méthode la plus simple de détection des biais consiste alors à comparer les moyennes de la base de données à disposition avec les moyennes cibles de la population d’intérêt. D’autres techniques plus élaborées peuvent être mises en place, mais leurs descriptions dépassent largement le cadre de cet article. Une fois qu’un biais est détecté, il est possible de le corriger, au moins en partie. Nous nous bornerons à mentionner les deux méthodes les plus utilisées en pratique. La première, appelée imputation, est spécifique à la sélection stricte et consiste à remplir les réponses absentes dans un questionnaire – en ajoutant la réponse la plus probable au vu des réponses des autres individus, par exemple. La seconde méthode, plus adaptée à la sélection douce, consiste à affecter un poids à chacune des données de manière à ce que les moyennes re-pondérées qui en résultent s’approchent des moyennes auxiliaires cibles. Avec Patrice Bertail, Stéphan Clémençon et Yannick Guyonvarch, nous avons récemment proposé une telle méthode de re-pondération [7].
Et pour conclure
Les biais de représentativité sont omniprésents et peuvent être à l’origine de nombreuses erreurs, trop souvent discriminatoires. Développer une intelligence artificielle éthique et de confiance passera nécessairement par une prise en charge systématique de ces biais, dont l’importance grandit avec l’avènement de l’ère des données massives. De nombreuses méthodes existent déjà, mais les problématiques de représentativité restent largement ouvertes et demeurent un sujet de recherche actif. Un changement de point de vue est d’ailleurs en cours et de nombreux chercheurs (voir notamment [8]) incitent à recentrer les efforts sur la compréhension fine des données plutôt que sur le développement de modèles algorithmiques toujours plus coûteux.
[6] La correction de la non-réponse par repondération, Thomas Deroyon (Insee) ; 2017.
[7] Learning from Biased Data: A Semi-Parametric Approach, International Conference on Machine Learning ; Bertail, Clémençon, Guyonvarch, Noiry ; 2021.
Philippe Aigrainà la Journée du domaine public, Paris, 2012. Wikipédia
Philippe était informaticien, mais aussi écrivain, poète, passionné de montagne, militant. J’en oublie sûrement. Le dernier courriel que j’ai reçu de lui, c’était en sa qualité de dirigeant de publie.net, une maison d’édition où il avait pris la suite de François Bon. Une des dernières fois où je l’ai rencontré, nous faisions tous les deux parties du jury de l’Habilitation à diriger des recherches de Nicolas Anciaux. C’était de l’informatique mais le sujet allait bien à Philippe : « Gestion de données personnelles respectueuse de la vie privée ». Il défendait les libertés, notamment sur internet, ce qui l’avait conduit à cofonder « la Quadrature du net ». C’était aussi un brillant défenseur des biens communs. Pour de nombreux informaticiens, il était aussi le défenseur intransigeant des logiciels libres. Il s’est beaucoup battu pour les valeurs dans lesquelles il croyait,contre la loi Dadvsi, la loi Hadopi, la loi de Renseignement…
Difficile d’imaginer le paysage numérique français sans Philippe. Il manquera dans les combats futurs pour les libertés et pour le partage, mais nombreux sont ceux qu’il a influencés et à travers lesquels il se battra encore longtemps.
« Numérique et pandémie – Les enjeux d’éthique un an après »
organisé conjointement par le
Comité national pilote d’éthique du numérique et
l’Institut Covid-19 Ad Memoriam
le vendredi 11 juin 2021 de 9h à 16h15.
Systèmes d’information pour les professionnels de santé
Souveraineté numérique
Télé-enseignement
La pandémie Covid-19 est la première de l’ère numérique. Par cette dimension, elle ne ressemble pas aux crises sanitaires des époques précédentes : dès mars 2020, les activités économiques et sociales ont été partiellement maintenues grâce aux smartphones, ordinateurs et autres outils numériques. Mais les usages de ces outils ont eux aussi changé depuis le printemps 2020. La rapidité de ces évolutions n’a pas encore permis de dégager le sens qu’elles auront pour notre société, ni de saisir leurs effets à long terme. Ce colloque fera un premier pas dans cette direction. Qu’avons-nous appris ? Quelles sont les avancées que nous voudrions préserver après la fin de la crise ? À quelles limites se heurte la numérisation accélérée de notre quotidien ?
Laëtitia Atlani-Duault
Présidente de l’Institut Covid-19 Ad Memoriam, Université de Paris
Jean-Francois Delfraissy
Président du CCNE pour les sciences de la vie et de la santé
Président d’honneur de l’Institut Covid-19 Ad Memoriam
Claude Kirchner
Directeur du Comité National Pilote d’Éthique du Numérique
Le développement de la démocratie participative a fait émerger de nouvelles formes de consultations avec un grand nombre de données à analyser. Les réponses sont complexes puisque chacun s’exprime sans contrainte de style ou de format. Des méthodes d’intelligence artificielle ont donc été utilisées pour analyser ces réponses mais le résultat est-il vraiment fiable ? Une équipe de scientifiques lillois s’est penchée sur l’analyse des réponses au grand débat national et nous explique le résultat de leur recherche . Pierre Paradinas, Pascal Guitton et Marie-Agnès Enard.
Dans le cadre d’un développement de la démocratie participative, différentes initiatives ont vu le jour en France en 2019 et 2020 comme le grand débat national et la convention citoyenne sur le climat. Toute consultation peut comporter des biais : ceux concernant l’énoncé des questions ou la représentativité de la population répondante sont bien connus. Mais il peut également exister des biais dans l’analyse des réponses, notamment quand celle-ci est effectuée de manière automatique.
Nous prenons ici comme cas d’étude la consultation participative par Internet du grand débat national, qui a engendré un grand nombre de réponses textuelles en langage naturel dont l’analyse officielle commandée par le gouvernement a été réalisée par des méthodes d’intelligence artificielle. Par une rétro-analyse de cette synthèse, nous montrons que l’intelligence artificielle est une source supplémentaire de biais dans l’analyse d’une enquête. Nous mettons en évidence l’absence totale de transparence sur la méthode utilisée pour produire l’analyse officielle et soulevons plusieurs questionnements sur la synthèse, notamment quant au grand nombre de réponses exclues de celle-ci ainsi qu’au choix des catégories utilisées pour regrouper les réponses. Enfin, nous suggérons des améliorations pour que l’intelligence artificielle puisse être utilisée avec confiance dans le contexte sensible de la démocratie participative.
Le matériau à analyser
Nous considérons le traitement des 78 questions ouvertes du grand débat national dont voici deux exemples :
« Que faudrait-il faire pour mieux représenter les différentes sensibilités politiques ?” du thème “La démocratie et la citoyenneté”
“Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” dans le cadre des propositions de solutions de mobilité alternative du thème “La transition écologique”
Les réponses aux questions sont des textes rédigés par les participants qui vont de quelques mots à plusieurs centaines de mots avec une longueur moyenne de 17 mots. Pour chaque question, on dispose de quelques dizaines de milliers de réponses textuelles à analyser. Le traitement d’une telle quantité de données est difficile pour des humains, d’où la nécessité de l’automatiser au moins partiellement. Lorsque les questions sont fermées (avec un nombre prédéfini de réponses), il suffit de faire des analyses quantitatives sous forme de comptes, moyennes, histogrammes et graphiques. Pour des questions ouvertes, il faut se tourner vers des méthodes d’intelligence artificielle.
Que veut-dire analyser des réponses textuelles ?
Il n’est pas facile de répondre à cette interrogation car, les questions étant ouvertes, les répondants peuvent laisser libre cours à leurs émotions, idées et propositions. On peut ainsi imaginer détecter les émotions dans les réponses (par exemple la colère dans une réponse comme “C’est de la foutaise, toutes les questions sont orientées ! ! ! On est pas là pour répondre à un QCM !”), ou encore chercher des idées émergentes (comme l’utilisation de l’hydrogène comme énergie alternative). L’axe d’analyse retenu dans la synthèse officielle, plus proche de l’analyse des questions fermées, consiste à grouper les réponses dans des catégories et à compter les effectifs. Il peut être formulé comme suit : pour chaque question ouverte et les réponses textuelles associées :
1. Déterminer des catégories et sous-catégories sémantiquement pertinentes ;
2. Affecter les réponses à ces catégories et sous-catégories ;
3. Calculer les pourcentages de répartition.
L’étude officielle, réalisée par Opinion Way (l’analyse des questions ouvertes étant déléguée à l’entreprise QWAM) est disponible sur le site du grand débat. Pour chacune des questions ouvertes, elle fournit des catégories et sous-catégories définies par un intitulé textuel et des taux de répartition des réponses dans ces catégories.
Par exemple, pour la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?”, l’analyse a catégorisé les réponses de la façon suivante :
Les acteurs publics
43,4%
Les solutions envisagées
8,8%
Les acteurs privés
6,6%
Autres contributions trop peu citées ou inclassables
22,5%
Non réponses, (les réponses vides)
30,2%
On constate que les catégories se chevauchent, que la catégorie “Les solutions envisagées” ne correspond pas à une réponse à la question et que le nombre d’inclassables est élevé (22.5% soit environ 35 000 réponses non prises en compte).
L’analyse officielle : la méthode
Regrouper des données dans des catégories correspond à une tâche appelée classification non supervisée ou clustering. C’est une tâche difficile car on ne connaît pas les catégories a priori, ni leur nombre, les catégories peuvent se chevaucher. De surcroît, les textes en langage naturel sont des données complexes. De nombreuses méthodes d’intelligence artificielle peuvent être utilisées comme, par exemple, la LDA pour “Latent Dirichlet Analysis” et ses nombreux dérivés.
Quelle est la méthode utilisée par l’entreprise QWAM ? À notre connaissance, les seules informations disponibles se trouvent dans la présentation de la méthodologie. On y décrit l’utilisation de méthodes internes qui sont “des algorithmes puissants d’analyse automatique des données textuelles en masse (big data), faisant appel aux technologies du traitement automatique du langage naturel couplées à des techniques d’intelligence artificielle (apprentissage profond/deep learning)” et le post-traitement par des humains : “une intervention humaine systématique de la part des équipes qualifiées de QWAM et d’Opinion Way pour contrôler la cohérence des résultats et s’assurer de la pertinence des données produites”.
Regard critique sur l’analyse officielle
Il semble que l’utilisation d’expressions magiques telles que “intelligence artificielle” ou “big data”, ou bien encore “deep learning” vise ici à donner une crédibilité à la méthode aux résultats en laissant penser que l’intelligence artificielle est infaillible. Nous faisons cependant les constats suivants :
– Les codes des algorithmes ne sont pas fournis et ne sont pas ouverts ;
– La méthode de choix des catégories, des sous-catégories, de leur nombre et des intitulés textuels associés n’est pas spécifiée ;
– Les affectations des réponses aux catégories ne sont pas fournies ;
– Malgré l’intervention humaine avérée, aucune mesure d’évaluation des catégories par des humains n’est fournie.
Nous n’avons pas pu retrouver les résultats de l’analyse officielle malgré l’usage de plusieurs méthodes. Dans la suite, nous allons voir s’il est possible de les valider autrement.
Une rétro-analyse de la synthèse officielle
Notre rétro-analyse consiste à tenter de ré-affecter les contributions aux catégories et sous-catégories de l’analyse officielle à partir de leur contenu textuel. Notre approche consiste à affecter une contribution à une (sous-)catégorie si le texte de la réponse et l’intitulé de la catégorie sont suffisamment proches sémantiquement. Cette proximité sémantique est mesurée à partir de représentations du texte sous forme de vecteurs de nombre, qui constituent l’état de l’art en traitement du langage (voir encadré).
Nous avons testé plusieurs méthodes de représentation des textes et plusieurs manières de calculer la proximité sémantique entre les réponses et les catégories. Nous avons obtenu des taux de répartitions différents selon ces choix, sans jamais retrouver (même approximativement) les taux donnés dans l’analyse officielle. Par exemple, la figure ci-dessous donne les taux de répartitions des réponses dans les catégories obtenus avec différentes approches pour la question « Quelles sont toutes les choses qui pourraient être faites pour améliorer l’information des citoyens sur l’utilisation des impôts ? ».
Pour compléter notre rétro-analyse automatique, nous avons mis en œuvre une annotation manuelle sur la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” du thème Transition Ecologique et la catégorie Les acteurs publics et avons trouvé un taux de 54.5% à comparer avec un taux de 43.4% pour l’analyse officielle, soit une différence de 15 000 réponses ! Les réponses à cette question sont globalement difficiles à analyser, car souvent longues et argumentées (25000 réponses contenant plus de 20 mots). Notre étude manuelle des réponses nous a fait remarquer certaines réponses comme “moi-même”, “les citoyens”, “c’est mon problème”, “les français sont assez intelligents pour les trouver seuls” ou encore “les citoyens sont les premiers maîtres de leur choix”. Pour ces réponses, nous avons considéré une catégorie Prise en charge par l’individu qui n’est pas présente dans la synthèse officielle bien qu’ayant une sémantique forte pour la question. Un classement manuel des réponses donne un taux de 4.5% des réponses pour cette catégorie, soit environ 7000 réponses, taux supérieur à certaines catégories existantes. Ceci met en évidence un certain arbitraire et des biais dans le choix des catégories de la synthèse officielle.
En résumé, notre rétro-analyse de la synthèse officielle montre :
L’impossibilité de retrouver les résultats de la synthèse officielle ;
La différence de résultats selon les approches ;
Des biais dans le choix des catégories et sous-catégories.
La synthèse officielle n’est donc qu’une interprétation possible des contributions.
Recommandations pour utiliser l’IA dans la démocratie participative
L’avenir des consultations participatives ouvertes dépend en premier lieu de leur prise en compte politique, mais il repose également sur des analyses transparentes, dignes de confiance et compréhensibles par le citoyen. Nous proposons plusieurs pistes en ce sens :
Transparence des analyses : les méthodes utilisées doivent être clairement décrites, avec, si possible, une ouverture du code. La chaîne de traitement dans son ensemble (comprenant le traitement humain) doit également être précisément définie. Enfin, il est nécessaire de publier les résultats obtenus à une granularité suffisamment fine pour permettre une validation indépendante (par des citoyens, des associations ou encore des chercheurs).
Considérer différents axes d’analyse et confronter différentes méthodes : la recherche de catégories aurait pu être complétée par la recherche de propositions émergentes ou l’analyse de sentiments et d’émotions. Par ailleurs, pour un axe d’analyse donné, il existe différentes méthodes reposant sur des hypothèses et biais spécifiques et la confrontation de plusieurs analyses est utile pour nuancer certaines conclusions et ainsi mener à une synthèse finale plus fiable.
Concevoir des consultations plus collaboratives et interactives : publier les affectations des réponses aux catégories permettrait à tout participant de voir comment ses contributions ont été classées. Il serait alors possible de lui demander de valider ou non ce classement et d’ainsi obtenir une supervision humaine partielle utilisable pour améliorer l’analyse. D’autres manières de solliciter cette supervision humaine peuvent être considérées, par exemple faire annoter des textes par des volontaires (voir l’initiative de la Grande Annotation) ou encore permettre aux participants de commenter ou de voter sur les contributions des autres.
Si l’intelligence artificielle permet désormais de considérer des enquêtes à grande échelle avec des questions ouvertes, elle est susceptible de biais comme toute méthode automatique. Il est donc nécessaire d’être transparent et de confronter les méthodes. Dans un contexte de démocratie participative, il est également indispensable de donner une véritable place aux citoyens dans le processus d’analyse pour engendrer la confiance et favoriser la participation.
Pour aller plus loin : les résultats détaillés de l’étude, ainsi que le code source utilisé pour réaliser cette rétro-analyse, sont consultables dans l’article.
Représenter des textes comme des vecteurs de nombre
Qui aurait prédit au début des années 2000 au vu de la complexité du langage naturel, que les meilleurs logiciels de traduction automatique représentent les mots, les suites de mots, les phrases et les textes par des vecteurs de nombres ? C’est pourtant le cas et voyons comment !Les représentations vectorielles des mots et des textes possèdent une longue histoire en traitement du langage et en recherche d’information. Les premières représentations d’un texte ont consisté à compter le nombre d’apparitions des mots dans les textes. Un exemple classique est la représentation tf-idf (pour « term frequency-inverse document frequency’’) où on pondère le nombre d’apparitions d’un mot par un facteur mesurant l’importance du mot dans l’ensemble des documents. Ceci permet de diminuer l’importance des mots fréquents dans tous les textes (comme le, et, donc, …) et d’augmenter l’importance de mots plus rares, ceci pour mieux discriminer les textes pertinents pour une requête dans un moteur de recherche. Les vecteurs sont très longs (plusieurs centaines de milliers de mots pour une langue) et très creux (la plupart des composantes sont nulles car un texte contient peu de mots). On ne capture pas de proximité sémantique (comme emploi et travail, taxe et impôt) puisque chaque mot correspond à une composante différente du vecteur.Ces limitations ont conduit les chercheurs à construire des représentations plus denses (quelques centaines de composantes) à même de mieux modéliser ces proximités. Après avoir utilisé des méthodes de réduction de dimension comme la factorisation de matrices, on utilise désormais des méthodes neuronales. Un réseau de neurones est une composition de fonctions qui se calcule avec des multiplications de matrices et l’application de fonctions simples, et qui peut être entraîné à prédire un résultat attendu. On va, par exemple, entraîner le réseau à prédire le mot central d’une fenêtre de 5 mots dans toutes les phrases extraites d’un corpus gigantesque comme Wikipedia. Après cet entraînement (coûteux en ressources), le réseau fournit une représentation de chaque mot (groupe de mots, phrase et texte) par un vecteur. Les représentations les plus récentes comme ELMo et BERT produisent des représentations de phrases et des représentations contextuelles de mots (la représentation d’un mot varie selon la phrase). Ces représentations vectorielles ont apporté des gains considérables en traitement du langage naturel, par exemple en traduction automatique.
Nous poursuivons notre balade avec David Pointcheval, Directeur du Laboratoire d’informatique de l’École Normale Supérieure, Paris, dans « l’agrégation confidentielle ». Il nous conduit aux frontières de ce domaine de recherche. Serge Abiteboul
Pexels
Nous avons vu dans un premier article que le FHE (chiffrement complètement homomorphe) permettait d’effectuer des calculs sur les chiffrés. Mais il ne permet pas le partage des résultats : toute personne capable de déchiffrer le résultat final est en mesure de déchiffrer les entrées du calcul, puisque le tout est chiffré sous la même clef. Le chiffrement fonctionnel [1] fournit un outil complémentaire : il permet la diffusion de résultats, restreints par les capacités de la clef que possède l’utilisateur et les contraintes choisies par l’émetteur des chiffrés. Par exemple, la clef peut ne permettre le déchiffrement que sous certaines conditions d’accès (chiffrement basé sur l’identité, ou sur des attributs), mais peut aussi restreindre le déchiffrement à certaines agrégations sur les clairs, et à rien d’autre. Usuellement, à partir d’un chiffré E(x) de x, la clef de déchiffrement permet de retrouver le clair x. Avec le chiffrement fonctionnel, plusieurs clefs de déchiffrement peuvent être générées, selon différentes fonctions f. A partir d’un chiffré E(x) de x, la clé de déchiffrement kf associée à la fonction f permet d’obtenir f(x) et aucune autre information sur x. Ainsi, la fonction f peut tester l’identité du destinataire (intégrée dans le clair x au moment du chiffrement), avant de retourner ou non le clair, ce qui conduit à un simple contrôle d’accès. Mais la fonction f peut également faire des calculs plus complexes, et notamment ne donner accès qu’à certains types d’agrégations.
Agrégations de données
Le grand intérêt du chiffrement fonctionnel est en effet la contrainte by design des informations partielles obtenues sur la donnée en clair, par exemple une moyenne, des agrégations et toutes sortes de statistiques, sans jamais révéler d’information supplémentaire. On peut notamment effectuer des chiffrements de vecteurs et n’autoriser que certains calculs statistiques. Mais contrairement au FHE qui retourne le calcul sous forme chiffrée et nécessite donc de posséder la clef de déchiffrement qui permet non seulement de retrouver le résultat en clair mais également les données initiales en clair, la clef de déchiffrement fonctionnel effectue le calcul et fournit le résultat en clair. Cette dernière ne permet en revanche pas de déchiffrer les données initiales. Il a été montré possible de générer des clefs pour évaluer n’importe quel circuit sur des données chiffrées [2]. Néanmoins, ce résultat générique est très théorique, sous des hypothèses très fortes, et notamment la possibilité d’obfusquer (*) du code, ce pour quoi nous n’avons pas encore de solution. Ainsi, la première construction effective a été donnée pour la famille des produits scalaires, ou moyennes pondérées [3] : les messages clairs sont des vecteurs et les clefs de déchiffrement fonctionnel sont associées à des vecteurs. L’opération de déchiffrement retourne le produit scalaire entre le vecteur chiffré et le vecteur associé à la clef.
Moyennes sur des données temporelles
Il s’agit certainement du cas d’usage le plus classique. Bien que très simple, il semble adapté à de nombreuses situations concrètes : des séries de données temporelles sont générées, et le propriétaire de ces données souhaite ne diffuser que des agrégations sous formes de moyennes pondérées, à chaque période de temps. Ces pondérations peuvent dépendre des destinataires, voire s’affiner au cours du temps. Pour cela, pour chaque vecteur de pondérations, une clef de déchiffrement fonctionnel est générée par le propriétaire des données, une bonne fois pour toutes, et transmise au destinataire autorisé. A chaque période de temps, la série de données est publiée chiffrée, et chaque propriétaire de clef peut obtenir le calcul agrégé autorisé, et rien de plus. Tous les destinataires ont accès aux mêmes données chiffrées, mais selon la clef en leur possession, des agrégations différentes seront accessibles.
Plus récemment, des versions multi-clients [4] ont été définies, permettant à des fournisseurs de données distincts de contribuer à la série temporelle, et de garder le contrôle des clefs fonctionnelles générées. Les exemples d’applications sont multiples, dans la finance, en sécurité, ou dans le domaine médical. Considérons les compagnies d’assurance, qui sont en forte concurrence, et qui n’imaginent pas un instant partager les volumes dans chaque catégorie de sinistres rencontrés par leurs clients. Par contre, ces clients seraient intéressés par le volume global, au niveau national, toutes compagnies d’assurance confondues. Cela rentre exactement dans le contexte d’une somme pondérée générée régulièrement sur des données chiffrées. Et bien sûr, les compagnies d’assurance doivent contribuer à la génération des clefs fonctionnelles, afin de s’assurer qu’elles permettront un calcul qu’elles autorisent. Un autre cas d’usage similaire en sécurité est la remontée des attaques subies par les entreprises. Ces données sont sensibles au niveau de chaque entreprise, mais sont très utiles à un niveau global pour connaître les menaces, et réagir de façon adaptée. Le chiffrement fonctionnel, y compris multi-client, est quant à lui parfaitement opérationnel sur des données réelles, pour obtenir de telles moyennes pondérées. En effet, les calculs à effectuer demeurent relativement simples et peu coûteux.
Chiffrement fonctionnel et apprentissage
Est-ce la fin de l’histoire ? Non, car de fortes limitations subsistent. La technique permet de réaliser un grand nombre de statistiques basées sur des additions avec des coefficients. Elle permet notamment des techniques de classification de données, mais de médiocre qualité. On aimerait aller au-delà de tels calculs linaires. C’est indispensable pour réaliser des calculs statistiques plus riches, par exemple des calculs de variance. Ça l’est aussi pour pouvoir utiliser des méthodes d’apprentissage automatique plus sophistiquées [6]. Il n’y a pas d’impossibilité, juste de belles opportunités pour les scientifiques.
Conclusion
Avec le RGPD (ou Règlement Général sur la Protection des Données), la protection de la vie privée et des données personnelles est désormais une exigence pour toute entité qui stocke et traite des informations à caractère personnel. La cryptographie propose des outils opérationnels pour des traitements simples, tels que la recherche par mots-clefs parmi des données chiffrées, la classification de données chiffrées, et les calculs statistiques sur des données chiffrées. Même l’apprentissage fédéré peut être efficacement traité. Mais selon les contextes d’applications, des choix doivent être faits qui auront un impact important sur l’efficacité, voire la faisabilité.
David Pointcheval, CNRS, ENS/PSL et Inria
(*) obfusquer(du vieux français offusquer) : Obscurcir, assombrir. En Informatique, rendre un programme ou des données illisibles pour éviter qu’ils soient exploités de façon non autorisée.
[1] Dan Boneh, Amit Sahai et Brent Waters. Functional encryption: Definitions and challenges. TCC 2011
[2] Sanjam Garg, Craig Gentry, Shai Halevi, Mariana Raykova, Amit Sahai et Brent Waters. Candidate indistinguishability obfuscation and functional encryption for all circuits. FOCS 2013
[3] Michel Abdalla, Florian Bourse, Angelo De Caro et David Pointcheval. Simple functional encryption schemes for inner products. PKC 2015
[4] Jérémy Chotard, Edouard Dufour-Sans, Romain Gay, Duong Hieu Phan, et David Pointcheval. Decentralized multi-client functional encryption for inner product. ASIACRYPT 2018
[5] Théo Ryffel, Edouard Dufour-Sans, Romain Gay, Francis Bach et David Pointcheval. Partially encrypted machine learning using functional encryption. NeurIPS 2019
[6] Théo Ryffel, Edouard Dufour-Sans, Romain Gay, Francis Bach et David Pointcheval. Partially encrypted machine learning using functional encryption. NeurIPS 2019
Dans de nombreuses situations, on a envie de garder chaque information confidentielle, mais réaliser, sur leur ensemble, une agrégation, leur somme, leur moyenne, leur évolution dans le temps, etc. Par exemple, en tant que cycliste, vous n’avez pas peut-être pas envie que le reste du monde sache où vous êtes, mais vous aimeriez bien savoir qu’il faut éviter le Boulevard Sébastopol à Paris à cause de sa surcharge. Ça semble impossible ? Et pourtant des avancées scientifiques basées sur la cryptographie permettent de le faire. Ce n’est pas de la magie mais de l’algorithmique super astucieuse avec plein de maths derrière. Alors, en voiture avec David Pointcheval, Directeur du Laboratoire d’informatique de l’École Normale Supérieure, Paris, pour une balade incroyable dans « l’agrégation confidentielle ». Serge Abiteboul
David Pointcheval, Cryptographe
L’externalisation des données est devenue pratique courante et la volonté de mettre des informations en commun, pour détecter des anomalies, prédire des événements ou juste effectuer des calculs s’intensifie. Nombre de ces données restent néanmoins sensibles, et leur confidentialité doit être garantie.
Un exemple d’actualité est l’analyse massive de données médicales pour suivre une épidémie, son mode d’expansion et son évolution chez les malades. Les hôpitaux ont de telles informations en grande quantité, mais elles sont d’une extrême sensibilité.
La cryptographie a développé plusieurs outils pour concilier ces besoins contradictoires que sont le partage des données et leur confidentialité, à savoir le « calcul multi-parties sécurisé », MPC pour Multi-Party Computation, le chiffrement complètement homomorphe, FHE, pour Fully Homomorphic Encryption, et le chiffrement fonctionnel, FE, pour Functional Encryption. Nous allons rapidement rappeler les deux premières solutions. Dans un prochain article, nous nous attarderons plus longuement sur la dernière approche, développée plus récemment, qui répond efficacement à des besoins concrets de calculs sur des données mutualisées sensibles.
Photo de Cottonbro – Pexels
Le calcul multi-parties sécurisé (MPC)
Le MPC a été proposé il y a plus de 30 ans [1], pour permettre à des utilisateurs, possédant chacun des données secrètes, d’effectuer un calcul commun et d’obtenir le résultat tout en gardant les entrées confidentielles. Intuitivement, le MPC permet de remplacer la situation idéale, où chacun transmettrait sa donnée à un tiers de confiance et ce dernier effectuerait le calcul pour ne retourner que le résultat, par un protocole interactif entre les seuls participants. Contrairement à l’utilisation d’un tiers de confiance, dont la capacité à protéger les données et les échanges est essentiel, le MPC ne requiert aucune confiance en qui que ce soit.
Un exemple pour illustrer cela est le vote électronique, où tous les participants ont leur choix de candidat à l’esprit, et le résultat commun annoncé est le nombre total de voix pour chaque candidat. Néanmoins, même les opérations simples, telles que ces sommes dans le cas du vote, nécessitent un très grand nombre d’interactions entre tous les participants. Avec seulement deux utilisateurs, on dispose de solutions particulièrement efficaces, avec notamment les versions optimisées de Garbled Circuits [2]. Un exemple célèbre du calcul sécurisé entre deux individus est le « problème du millionnaire », où deux personnes fortunées veulent savoir laquelle est la plus riche, mais sans pour autant révéler les montants en question. Il s’agit donc d’effectuer une comparaison sur deux données secrètes.
De telles comparaisons sont également la base de techniques d’apprentissage automatique, au niveau de la fonction d’activation de neurones. Il est donc possible de tester un réseau de neurones, entre le propriétaire de la donnée à classifier et le possesseur du réseau, sans qu’aucune information autre que le résultat de classe ne soit disponible au deux.
Le chiffrement complètement homomorphe (FHE)
Pour éviter les interactions, les données doivent être stockées en un même lieu, de façon chiffrée pour garantir la confidentialité. Le chiffrement permet de stocker des données tout en les maintenant à l’abri des regards. Il permet aussi d’exclure toute forme de manipulation, pour en garantir l’intégrité. Cependant, certaines propriétés algébriques ont été utilisées, et notamment la multiplicativité, avec des schémas de chiffrement qui permettent de générer, à partir de deux chiffrés, le chiffré du produit des clairs. En d’autres termes, à partir des valeurs chiffrées E(a) et E(b), de deux données a et b, il est possible de calculer la valeur chiffrée E(a*b) de a*b sans avoir à connaitre a et b. D’autres schémas proposent l’additivité, ce qui permet d’obtenir le chiffré de la somme des clairs par une simple opération sur les chiffrés.
Mais à quoi cela peut-il servir ? La propriété d’additivité est par exemple largement exploitée au sein de systèmes de vote électronique. Les votants chiffrent leur choix (1 ou 0, selon que la case est cochée ou non), et une opération publique permet d’obtenir le chiffré de la somme de leurs votes. Le déchiffrement final, mené par le bureau de vote, permet de prendre connaissance du résultat, sans avoir besoin de déchiffrer chaque vote individuellement.
On connaissait des méthodes qui permettent l’additivité et d’autres la multiplicativité. Les deux ont semblé longtemps incompatibles jusqu’aux travaux de Craig Gentry [3]. En 2009, il a présenté la première construction permettant ces deux opérations en nombre illimité sur les clairs, par des opérations publiques sur les chiffrés. Il devient alors possible d’évaluer n’importe quel circuit booléen sur des entrées chiffrées, avec le résultat chiffré sous la même clef. Comment passe-t-on de ces deux propriétés aux circuits booléens ? Un circuit est composé de portes logiques qui peuvent se traduire en termes d’additions, de négations et de multiplications. Ce FHE permet alors à une personne d’externaliser des calculs sur ses données confidentielles, sans aucune interaction. Il lui suffit de les chiffrer sous sa propre clef ; le prestataire peut faire tous les calculs souhaités sur ces données, sans en prendre connaissance ; l’utilisateur peut enfin récupérer le résultat chiffré toujours sous sa propre clef. Un exemple peut être le stockage de photos, permettant de faire tourner des algorithmes d’atténuation des yeux rouges ou de regroupement selon la reconnaissance faciale, tout en garantissant la confidentialité. On peut même imaginer poser des requêtes chiffrées à un moteur de recherche et obtenir des réponses pertinentes, sans révéler ni les questions, ni les réponses.
Les applications de ces techniques sont extrêmement nombreuses. Mais elles ont une énorme limitation : la confidentialité est garantie au prix d’énormes quantités de calculs, de temps parfois prohibitifs même pour un supercalculateur.
David Pointcheval, CNRS, ENS/PSL et Inria
[1] Oded Goldreich, Silvio Micali et Avi Wigderson. How to play any mental game or A completeness theorem for protocols with honest majority. STOC 1987
[2] Andrew Chi-Chih Yao. How to generate and exchange secrets. FOCS 1986
La bande dessinée Mirror, Mirror de Falaah Arif Khan et Julia Stoyanovich parle de l’Intelligence Artificielle. À quoi sert aujourd’hui l’apprentissage automatique ? À quoi devrait-il servir ? À améliorer l’accessibilité des applis numériques notamment. C’était une réflexion destinée au départ aux étudiants en IA. Nous l’avons traduite en français pour binaire, avec l’aide de Eve Francoise Trement, parce que nous pensons qu’elle peut intéresser un bien plus large public.
Un nouvel « Entretien autour de l’informatique ». Christophe Lazaro est Professeur au Centre de Philosophie du Droit, à l’Université de Louvain, et membre du Comité National Pilote d’Éthique du Numérique (France). Nous poursuivons avec lui le voyage commencé avec Célia Zolynski sur le droit du numérique. Christophe nous amène aux frontières du droit, de la philosophie et de l’anthropologie.
Cet article est publié en collaboration avec theconversation.fr.
Christophe Lazaro, UCLouvain
B : Tu es juriste. Mais en préparant l’entretien, nous avons découvert que tu étais aussi spécialiste d’autres domaines. Peut-être pourrais-tu commencer par nous dire d’où tu viens.
TL : Je suis au départ juriste, en effet. Au début de ma carrière, j’ai été avocat pendant une courte période. J’’ai également étudié en parallèle la philosophie et l’anthropologie. Puis j’ai fait une thèse de droit assez tardivement, à 33 ans, à l’Institut Universitaire Européen de Florence sur les enjeux juridiques et philosophiques des rapports entre corps et prothèses. Je suis passionné par la question de la technique et du corps. Je pratique d’ailleurs le Tai Chi depuis des années. Ce qui me passionne, c’est surtout la rencontre entre l’être humain et les nouvelles technologies, d’un point de vue juridique bien sûr mais aussi anthropologique et philosophique.
B : Un de tes premiers travaux a porté sur les communautés de logiciel libre, plus particulièrement Debian.
TL : Oui. Ce travail reflète d’ailleurs bien la rencontre de mes intérêts croisés pour le droit et l’anthropologie. J’ai fait une étude anthropologique de la communauté dite virtuelle Debian. C’est une communauté très démocratique qui développe des systèmes d’exploitation basés exclusivement sur des logiciels libres. Elle est virtuelle parce que ses membres se rencontrent principalement sur Internet. C’était la première fois que j’avais vraiment l’occasion d’échanger avec des informaticiens. Dans mon labo d’alors, on travaillait sur le droit du numérique mais on ne parlait pas trop avec eux.
B : Tu as des compétences en informatique ?
TL : Je me vois un peu comme un « handicapé des machines » avec une grande soif de savoir parce que je n’y comprends pas grand-chose. Cela me pousse à poser des questions aux spécialistes. J’ai été bluffé par l’hyper-structure sociale et politique de la communauté Debian. J’ai d’ailleurs pu participer à cette communauté. C’était passionnant ! J’ai voulu comprendre comment ils fonctionnaient.
Ça a donné un livre. Ce genre d’études d’une communauté virtuelle était original pour l’époque. Avec le regain d’intérêt actuel pour les communs, cela vaut la peine d’aller regarder des communautés fondées sur cette notion de commun. Par exemple, à côté des communautés de logiciels libres, il y a des collectifs d’habitat groupé, des coopératives d’agriculture alternative ou des communautés d’éditeurs de Wikipédia. D’un point de vue anthropologique, ces initiatives interrogent l’essence même du concept de communauté. Comment peut fonctionner une communauté avec le don comme seule modalité d’échange et de coopération entre ses membres ?
B : Tu as aussi beaucoup réfléchi à l’ « augmentation » de l’humain avec la technique, et aux questions que cela pose en terme de justice ?
TL : D’abord, pour moi, une technologie n’augmente pas, elle transforme. Une simple note adhésive que nous utilisons au bureau n’ « augmente » pas la mémoire à proprement parler. Il permet d’organiser les tâches différemment, en transformant les actions à accomplir. Un sujet, par exemple, me passionne depuis ma thèse sur les prothèses : une fois la personne « transformée » par la technologie, que devient l’égalité ? Comment doit-on la traiter ? La technologie bouleverse les notions d’égalité et de mérite qui sont au cœur de nombreuses activités humaines. On peut parler d’Oscar Pistorius ou plus récemment de Blake Leeper, deux athlètes amputés équipés de prothèses souhaitant concourir au plus haut niveau aux côtés des « valides ». Mon ouvrage La prothèse et le droit (vous excuserez l’autopromotion) qui a remporté en France le prix du livre juridique en 2016, aborde ce type de questions. Maintenant, avec l’IA, on va de plus en plus loin et cela questionne radicalement la nature de certaines activités qui étaient autrefois l’apanage exclusif des humains.
Surveillance numérique @serab
B : Pour prendre un exemple concret de question que cela pose, des outils informatiques notamment basés sur l’IA aident les employés des entreprises. Mais ils posent aussi des problèmes en termes de surveillance excessive des employés. Comment gérer cela ?
TL : Dans l’entreprise, on propose des outils pour organiser et faciliter le travail, pour optimiser la coordination et l’effectuation des tâches. Mais ces outils peuvent aussi servir à de la surveillance. Est-ce que les avantages apportés par cette transformation du travail et du rôle de l’employé compensent les risques de surveillance qu’ils introduisent ? La loi devrait être là pour dissuader de certaines formes disproportionnées de contrôle des employés, mais le juriste d’aujourd’hui doit aussi être conscient des limites du droit face à l’ambivalence intrinsèque des technologies,. Je n’ai pas de solution pour empêcher les abus de ces technologies parce que celles-ci sont si géniales qu’on ne les voit pas, qu’elles opèrent en toute discrétion, et qu’on ne sait pas comment elles fonctionnent. J’ajouterais même que plus grand est leur confort d’utilisation, plus elles « disparaissent ». Cette invisibilité rend les modes de résistances juridiques ou autres difficiles à mettre en œuvre.
B : Cette invisibilité est quand même relative. Avec le numérique, on peut garder des traces de tous les traitements. On pourrait argumenter que le numérique est au contraire beaucoup plus transparent.
CL : C’est là que ça devient intéressant. Il faudrait distinguer des régimes suivant la visibilité d’un processus. Du point de vue de l’employé, s’il ne peut pas voir la surveillance, le processus de surveillance est transparent. C’est en cela que je parle d’invisibilité car les effets de la technologie ne s’éprouvent plus, à travers le corps et les sens. Et avec l’IA, on ira vers encore plus d’invisibilité en ce qu’on ne sait souvent même pas expliquer les choix des logiciels. Je pense que c’est un sujet à étudier.
B : Qu’est ce qui pourrait débloquer la situation ?
TL : L’anthropologie. (rire) Une alliance entre des informaticiens, des philosophes, des juristes… On est par essence en pleine interdisciplinarité. Les questions ne sont pas philosophiquement nouvelles. Mais, plutôt que d’en parler abstraitement, il faut s’attaquer à des questions précises sur des pratiques, dans des situations d’usage. Pour moi, la recherche a aujourd’hui atteint un seuil. D’un point de vue juridique ou éthique, elle tourne en rond en ressassant les mêmes questions et principes. Plutôt que de disserter sur l’éthique de l’IA d’une manière désincarnée, plutôt que de proposer un énième réflexion sur le dilemme du tramway et les véhicules autonomes… il faut envisager les choses de manière empirique et poser des questions en situation.
Par ailleurs, pour développer une éthique de l’IA, il faudrait se mettre d’accord d’abord sur une véritable méthodologie et l’appliquer ensuite en faisant collaborer des points de vue interdisciplinaires. Comme toute discipline, l’éthique ça ne s’improvise pas et, dans l’histoire récente, nous ne sommes qu’aux premiers balbutiements d’une coopération entre sciences humaines et sciences dures.
B : Qu’est-ce que le juriste peut nous dire sur le contentement éclairé et libre ?
TL : C’est un des points les plus problématiques à la fois d’un point de vue juridique et philosophique pour les technologies du 21e siècle. Le problème
Contentement totem @serab
c’est l’idée même que l’être humain pourrait exprimer un choix éclairé et libre dans ces nouveaux contextes ; les deux adjectifs étant essentiels.
Comment le consentement peut-il être « éclairé » ? L’utilisateur ne s’intéresse pas vraiment au fonctionnement des technologies qu’il utilise quotidiennement et on ne l’encourage pas à comprendre ce qu’elles font ou ce qu’elles lui font faire. On lui propose des services user-friendly et cette amitié « machinique » implique des routines incorporées, un aspect prothétique fort, une forme d’hybridation. Dans ce contexte, il est difficilement envisageable d’interrompre le cours de l’action pour demander à chaque fois un consentement, en espérant en plus que ce consentement ait un sens.
Il faudrait aussi parler du caractère « libre » du consentement. Avec les GAFAM, quelle est la liberté de choix face à un tel déséquilibre de pouvoir et d’information ? Avec Facebook, par exemple, vous devez accepter des CGU qui peuvent changer par simple notification. Et quel adolescent a vraiment le choix d’aller ou non sur Facebook ? Le choix n’existe plus d’un point de vue sociologique car se passer de Facebook pour un jeune c’est synonyme de mort sociale.
Si le RGPD a fait un peu avancer les choses, l’accent qui continue d’être mis sur la notion de consentement éclairé et libre est problématique. Avec la complexité de l’informatique, c’est la fiction du sujet rationnel, autonome, capable de consentir qui s’effondre. Depuis toujours, le droit est friand de fictions ; elles lui permettent d’appréhender la complexité du réel et de gérer les litiges qui en résultent. Aujourd’hui, il faudrait sans doute en inventer d’autres, car la magie du consentement dans l’univers numérique n’opère plus.
« Vous avez consenti, alors c’est bon ». Vous acceptez de vous livrer gracieusement à la bienveillance des plateformes qui prennent les décisions à votre place. C’est peu satisfaisant. Vous pouvez aussi attendre de l’informatique qu’elle vous aide. Oui, mais ça n’existe pas encore.
Antoinette Rouvroy parle de « fétichisation des données personnelles ». On devrait aussi parler de fétichisation du consentement. On ne peut continuer à mettre autant de poids dans le consentement. Il faut imposer des contraintes beaucoup plus fortes aux plateformes.
B : Tu as parlé d’aide apportée par l’informatique. Peut-on imaginer des systèmes informatiques, des assistants personnels, des systèmes d’information personnelle, qui nous aident à exprimer nos choix ?
TL : Bien sûr, on peut imaginer une collaboration entre les machines et l’utilisateur. Mais il faudrait déjà que l’utilisateur ait les capacités de spécifier ce qu’il veut. Ce n’est pas évident. Qu’est-ce que cela représenterait pour un jeune, par exemple, de spécifier sa politique d’autorisation de cookies ?
B : Est-ce qu’on peut parler de personnalité juridique du robot ?
TL : C’est compliqué. La question fondamentale c’est de savoir si la notion de personnalité en droit procède de la simple pragmatique juridique, ou si c’est plus, si cela inclut une véritable valeur philosophique. Pour prendre un exemple, un chien d’aveugle est blessé par une voiture. Le juge a considéré ce chien comme une « prothèse vivante », une extension de la personnalité de l’aveugle. Cette construction lui a permis de donner une meilleure compensation car les régimes d’indemnisation diffèrent selon qu’il s’agisse d’une atteinte à l’intégrité physique d’un individu ou d’un dommage aux biens qu’il possède. Le droit ne dit pas ontologiquement si ce chien d’aveugle est une personne ou pas. C’est le contexte et la visée de justice qui ont conduit le juge à créer cette chimère. Pour ce qui est des robots, je pense, avec les pragmatistes, que l’on pourrait accorder une forme de personnalité aux robots. Il ne s’agit pas de dire qu’un robot est comme une « personne physique » et qu’il peut jouir de droits fondamentaux, par exemple. Non, c’est une autre forme de personne, un peu comme on l’a fait avec les « personnes morales ». Cela permettrait de résoudre des problèmes en matière de responsabilité.
B : Quelle est le sujet de recherche qui te passionne en ce moment ?
CL : Je travaille sur la notion de prédiction algorithmique ; ce qui va me donner beaucoup d’occasions de travailler avec des informaticiens. Il y a aujourd’hui une véritable obsession autour des vertus prédictives de l’intelligence artificielle. Je trouve dingue l’expression « prédiction en temps réel » (nowcasting en anglais) ; une prédiction, c’est pour le futur. Comme anthropologue, je suis passionné par l’idée de comparer la prédiction algorithmique avec les pratiques divinatoires, qui restent encore très répandues. Dans son ouvrage « De divinatione », Cicéron s’attaquait à la question de l’irrationalité de la divination. C’est fascinant de voir qu’on rejoue au 21e siècle cette même question de la rationalité scientifique avec l’intelligence artificielle. C’est ça que j’essaie de comprendre. Comment est-ce qu’on part de résultats d’IA pour établir des savoirs prédictifs quasiment indiscutables ? Bien sûr, on peut comprendre la prédiction algorithmique quand elle s’appuie sur des validations expérimentales, qu’elle établit des taux de confiance dans les résultats. Mais on voit aussi se développer des prédictions algorithmiques qui par certains aspects rejoignent plus les pratiques magiques que scientifiques.
Nous sommes confrontés à la désinformation sur les réseaux sociaux. Le sujet est tout sauf simple : qu’on modère trop et on porte atteinte à la liberté d’expression ; pas assez, et on laisseles fakenews se propager et mettre en cause les valeurs de notre société. Alors, qui doit dire le vrai du faux et selon quels principes ? Emmanuel Didier, Serena Villata, et Célia Zolynski nous expliquent comment concilier liberté et responsabilité des plateformes.Serge Abiteboul & Antoine Rousseau Cet article est publié en collaboration avec theconversation.fr.
@SabrinaVillata
L’élection présidentielle aux États-Unis a encore une fois mis la question des fausses nouvelles au cœur du débat public. La puissance des plateformes et notamment celle des réseaux sociaux est devenue telle que chaque événement d’importance engendre depuis quelques temps des discussions sur ce problème. Pourtant, il semble que les analyses produites à chacune de ces occasions ne sont pas capitalisées, comme s’il n’y avait eu ni réflexions, ni avancées au préalable. Nous voudrions montrer ici la pérennité de certaines conclusions auxquelles nous étions parvenues concernant la modération de la désinformation pendant le premier confinement.
Photo Markus Winkler – Pexels
En effet, durant la crise sanitaire engendrée par l’épidémie de SARS-CoV-2, l’isolement des individus en raison du confinement, l’anxiété suscitée par la gravité de la situation ou encore les incertitudes et les controverses liées au manque de connaissance sur ce nouveau virus ont exacerbé à la fois le besoin d’informations fiables et la circulation de contenus relevant de la désinformation (émis avec une claire intention de nuire) ou de la mésinformation (propagation de données à la validité douteuse, souvent à l’insu du propagateur). Les plateformes ont alors très vite accepté le principe qu’il leur fallait modérer un certain nombre de contenus, mais elles ont été confrontées à deux difficultés liées qui étaient déjà connues. Premièrement, ce travail est complexe car toute information, selon le cadre dans lequel elle est présentée, la manière dont elle est formulée ou le point de vue de son destinataire, est susceptible de relever finalement de la mésinformation ou de la désinformation. Deuxièmement, le fait de sélectionner, de promouvoir ou de réduire la visibilité de certaines informations échangées sur les plateformes numériques entre en tension avec le respect des libertés d’information et d’expression qu’elles promeuvent par ailleurs.
Quelles sont donc les contraintes qui s’imposent aux plateformes ? Quelles sont les mesures qu’elles ont effectivement prises dans ces conditions ? Le présent texte s’appuie sur le bulletin de veille rédigé dans le cadre d’un groupe de travail du Comité national pilote d’éthique du numérique (CNPEN)[1] qui nous a permis de mener une dizaine d’auditions (par visioconférence) avec, entre autres, les représentants de Facebook, Twitter et Qwant ainsi que le directeur des Décodeurs du Monde. Il est apparu que les difficultés posées par la modération des fausses nouvelles pouvaient être regroupées en trois catégories. D’une part, celles qui sont associées aux algorithmes, d’autre part celles qui relèvent du phénomène de la viralité et, enfin, celles posées par l’identification et les relations avec des autorités légitimes.
Les algorithmes en question
Bien sûr, les mécanismes de lutte contre la désinformation et la mésinformation développés par les plateformes reposent en partie sur des outils automatisés, compte tenu du volume considérable d’informations à analyser. Ils sont néanmoins supervisés par des modérateurs humains et chaque crise interroge le degré de cette supervision. Durant le confinement, celle-ci a été largement réduite car les conditions de télétravail, souvent non anticipées, pouvaient amener à utiliser des réseaux non sécurisés pour transférer de tels contenus, potentiellement délictueux, ou à devoir les modérer dans un contexte privé difficilement maîtrisable. Or les risques d’atteintes disproportionnées à la liberté d’expression se sont avérés plus importants en l’absence de médiation et de validation humaines, seules à même d’identifier voire de corriger les erreurs de classification ou les biais algorithmiques. En outre, l’absence de vérificateurs humains a compliqué la possibilité de recours normalement offerte à l’auteur d’un contenu ayant été retiré par la plateforme. Ces difficultés montrent clairement l’importance pour la société civile que les plateformes fassent plus de transparence sur les critères algorithmiques de classification de la désinformation ainsi que sur les critères qu’elles retiennent pour définir leur politique de modération, qu’ils soient d’ordre économique ou relèvent d’obligations légales. Ces politiques de modération doivent être mieux explicitées et factuellement renseignées dans les rapports d’activité périodique qu’elles sont tenues de publier depuis la loi Infox de décembre 2018 (v. le bilan d’activité pour 2019 publié par le CSA le 30 juillet 2020[2] et sa recommandation du 15 mai 2019[3]). Plus généralement, il apparait qu’une réflexion d’ampleur sur la constitution de bases de données communes pour améliorer les outils numériques de lutte contre la désinformation et la mésinformation devrait être menée et devrait aboutir à un partage des métadonnées associées aux données qu’elles collectent à cette fin (voir dans le même sens le bilan d’activité du CSA préc.)
La responsabilité de la viralité
Pexels
L’ampleur prise à ce jour par les phénomènes de désinformation et de mésinformation tient à l’accroissement de mécanismes de viralité qui se déploient à partir des outils offerts par les plateformes. La viralité est d’abord l’effet du modèle économique de certains de ces opérateurs, qui sont rémunérés par les publicitaires en fonction des interactions avec les utilisateurs qu’ils obtiennent et ont donc intérêt à générer des clics ou toute autre réaction aux contenus. Elle relève ensuite du rôle joué par leurs utilisateurs eux-mêmes dans la propagation virale de la désinformation et de la mésinformation (que ces derniers y contribuent délibérément ou par simple négligence ou ignorance). La lutte contre la désinformation doit donc nécessairement être l’affaire de tous les utilisateurs, responsables de devenir plus scrupuleux avant de décider de partager des informations et ainsi de contribuer à leur propagation virale. Cette remarque va d’ailleurs dans le même sens que le programme #MarquonsUnePause désormais promu par l’ONU[4]. Mais ceci n’est possible que si les plateformes mettent à disposition de leurs utilisateurs un certain nombre d’informations et d’outils afin de les mettre en mesure de prendre conscience, voire de maîtriser, le rôle qu’ils jouent dans la chaîne de viralité de l’information (voir également sur ce point les recommandations du CSA formulées dans le bilan d’activité préc.). En ce sens, les plateformes ont commencé à indiquer explicitement qu’une information reçue a été massivement partagée et invite leurs utilisateurs à être vigilants avant de repartager des contenus ayant fait l’objet de signalement. Mais il serait possible d’aller plus loin. Plus fondamentalement, il est important que les pouvoirs publics prennent des mesures permettant de renforcer l’esprit critique des utilisateurs, ce qui suppose tout particulièrement que ceux-ci puissent être sensibilisés aux sciences et technologies du numérique afin de mieux maîtriser le fonctionnement de ces plateformes et les effets induits par ces mécanismes de viralité. La création d’un cours de « Science numérique et technologie » obligatoire pour toutes les classes de seconde va dans ce sens[5].
La légitimité
Enfin, troisièmement, si la modération des contenus et le contrôle de la viralité jouent un rôle prépondérant dans le contrôle pragmatique de la désinformation et de la mésinformation, ces opérations ne peuvent, in fine, être accomplies sans référence à des autorités indépendantes établissant, ne serait-ce que temporairement, la validité des arguments échangés dans l’espace public. Sous ce rapport, une grande difficulté provient du fait que les plateformes elles-mêmes sont parfois devenues de telles autorités, en vertu de l’adage bien plus puissant qu’on pourrait le croire selon lequel « si beaucoup de monde le dit, c’est que cela doit être vrai ». Pourtant, les plateformes n’ont bien sûr aucune qualité ni compétence pour déterminer, par exemple, l’efficacité d’un vaccin ou le bienfondé d’une mesure de santé publique. Elles sont donc contraintes de se fier à d’autres autorités comme l’État, la justice, la science ou la presse. Depuis le début de la crise sanitaire, de nombreuses plateformes se sont ainsi rapprochées, en France, de différents services gouvernementaux (en particulier du Secrétariat d’État au numérique ou du Service d’information du gouvernement). Pourtant, dans le même temps, elles se sont éloignées d’autres gouvernements, comme en atteste leur modération des contenus publiés par Jamir Bolsonaro ou Donald Trump. En l’occurrence, on peut légitimement se réjouir de ces choix. Ils n’en restent pas moins arbitraires dans la mesure où ils ne reposent pas sur des principes explicites régulant les relations entre les plateformes et les gouvernements. À cet égard, une réflexion d’ensemble sur la responsabilité des plateformes ainsi que sur le contrôle à exercer s’agissant de leur politique de modération de contenus semble devoir être menée. À notre sens, ce contrôle ne peut être dévolu à l’État seul et devrait relever d’une autorité indépendante, incluant les représentants de diverses associations, scientifiques et acteurs de la société civile dans l’établissement des procédures de sélection d’informations à promouvoir, tout particulièrement en période de crise sanitaire.
Emmanuel Didier, Centre Maurice Halbwachs, CNRS, ENS et EHESS Serena Villata, Université Côte d’Azur, CNRS, Inria, I3S
& Célia Zolynski Université Paris 1 Panthéon-Sorbonne, IRJS DReDIS
Les applications de contact tracing soulèvent des espoirs et des inquiétudes. Cette semaine binaire a publié un article de Serge Abiteboul décrivant le fonctionnement de l’application Stop Covid [1] qui sera discutée la semaine prochaine au parlement. Cette application a également fait l’objet d’une tribune de Bruno Sportisse [2] qui s’appuie sur les travaux de plusieurs équipes européennes. Un autre collectif de chercheurs, majoritairement français, a publié le site internet Risques-Tracages.fr afin de proposer une analyse des risques d’une telle application, fondée sur l’étude de scénarios concrets, à destination de non-spécialistes. Nous vous en conseillons la lecture, de façon à vous forger votre propre opinion sur les avantages et les risques de tels outils. Car pour faire un choix éclairé, il faut savoir à quoi s’en tenir.
Depuis quelques jours, on lit et on entend (y compris dans Le Monde [3]) que « la tension monte », que « les scientifiques s’étrillent », que la guerre est ouverte entre les différents camps des experts. Il n’en est rien. Certes, il serait bien naïf de croire que les querelles d’égos n’existent pas dans un monde où l’évaluation et la compétition sont très présents, mais il est également tout aussi faux de dire que les chercheurs s’affrontent sur le sujet. Les collègues mentionnés ci-dessous se connaissent, s’apprécient et ont souvent eu l’occasion de travailler ensemble. En revanche, ils apportent des points de vue complémentaires, parfois contradictoires, qui doivent permettre d’éclairer la décision publique.
Le débat, vous l’imaginez, a été riche chez binaire et c’est une très bonne chose. Nous continuerons donc à publier les avis qui nous semblent scientifiquement pertinents sur le sujet.
On trouve profusion d’articles sur l’utilisation du contact tracing pour combattre le virus. Le sujet passionne : les informaticiens qui aimeraient participer plus à la lutte contre le virus, les médecins souvent sceptiques, les défenseurs des libertés qui ne veulent pas que ce soit l’occasion de rogner sur la protection de la vie privée. Certains mélangent tout, géolocalisation et Bluetooth, avoir attrapé un jour le virus et être contagieux, etc. Et puis, l’utilité n’est encore pas très claire.
L’idée est simple. À partir d’applications sur les téléphones mobiles, on peut savoir que deux personnes ont peut-être été en contact et si l’une développe le virus, on peut prévenir l’autre qu’elle a été peut-être contaminée. Il y a deux grandes techniques possibles : la géolocalisation qui est intrusive et flique en permanence son utilisateur, et le Bluetooth discuté en France en ce moment.
Bluetooth est une norme de communication qui utilise des ondes radios pour échanger des données entre un téléphone (intelligent) et un ordinateur, ses écouteurs, ou un autre téléphone… Le Bluetooth fonctionne sans géolocalisation.
On peut être a priori réticent mais les choix du gouvernement comme évoqués par Cédric O vont dans le bon sens pour protéger la confidentialité des données personnelles.
Comment marche une telle App ?
Il y a de nombreuses possibilités techniques plus ou moins intrusives. En voici une.
Quand deux téléphones sont proches physiquement (quelques mètres ?) pendant un certain temps (par exemple, 5mn ou plus), ils utilisent leur connexion Bluetooth pour se dire « coucou » ; chacun envoie à l’autre un nombre aléatoire utilisé juste pour cette rencontre (ou pour un laps de temps très court). Si une personne se découvre le virus, elle le déclare volontairement dans l’application et son téléphone transmet alors à un site centralisateur les nombres aléatoires qu’elle a utilisés avec les dates associées. Chaque téléphone consulte régulièrement la base de données de ces nombres et s’il trouve dans un des nombres un de ceux qu’il a reçus d’un téléphone au cours d’un de ces coucous, il prévient son utilisateur qu’il a peut-être été contaminé. Il suffira ensuite de suivre les recommandations des autorités de santé, comme se faire tester, se confiner chez soi…
Des pays ont déjà utilisé des applications pour contrôler la propagation du virus notamment Singapour, Taïwan et la Corée du Sud. La France, l’Allemagne, des centres de recherche, des entreprises… travaillent aussi là-dessus. Pour la France et un consortium de chercheurs piloté par Inria, une application StopCovid est considérée en lien avec l’Europe et le projet Peppt-PT dont une App est déjà testée en Allemagne. Dans le cadre de cette collaboration, Inria et Fraunhofer AISEC ont publié le protocole ROBERT, pour ROBust and privacy-presERving proximity Tracing (1). Google et Apple préparent les briques de bases d’une API commune qui permettraient à ces App de fonctionner aussi bien sur Android que sur iOS. L’aide des entreprises est importante, mais il reste préférable que l’application elle-même soit développée par des scientifiques, en toute transparence.
Des difficultés techniques
Le Bluetooth apprécie mal les distances surtout si le téléphone est dans une poche ou un sac ; on cherche à améliorer cela. Une autre difficulté, s’il y a trop de personnes contaminantes en circulation, on risque assez vite d’être inondé de notifications et tous être considérés potentiellement comme contaminés. Ça ne marche plus.
Et puis, cette technique n’est utile que si une proportion importante de la population joue le jeu, on parle de 60%. Il faut déjà exclure une petite, mais non négligeable, partie de cette population qui n’a pas de téléphone intelligent ou qui aurait des difficultés à se servir d’une App même simple. (Des solutions sont à l’étude pour inclure également ces personnes.) Et parmi les connectés, qui aura assez confiance dans l’appli pour l’installer, pour se déclarer infecté… ? Ce n’est pas bien parti en France selon des sondages. Espérons que, devant l’urgence médicale, si une App « éthique » est proposée, et si les médecins nous disent que c’est efficace, les mentalités changeront.
La protection de la vie privée
On est en plein dans le domaine de la CNIL. Marie-Laure Denis, sa Présidente, a pris des positions claires (2), ainsi que le Comité National Pilote d’Éthique du Numérique (3).
On semble se diriger en France vers de bons choix : (i) l’utilisation du Bluetooth, (ii) la décision d’installer l’appli est laissée totalement à l’utilisateur, sans atteinte aux libertés, (iii) le code de l’application est open-source, comme cela des spécialistes pourront vérifier qu’il n’y a pas de trou de sécurité, (iv) l’utilisation est limitée dans le temps.
Est-ce que cela pourrait présenter des risques pour la protection de la vie privée ? Plus ou moins selon les Apps utilisées. L’équipe Privatics d’Inria, par exemple, travaille sur le sujet , comme d’autres équipes scientifiques.
Dernier point : qui sera en charge de la centralisation des données ? Pour l’instant, en France, Inria pilote le projet. Mais, qui sera l’opérateur à l’heure de l’exploitation ? Qui aura accès aux données ? Si les nombres aléatoires anonymes protègent quelque peu les utilisateurs, on n’est jamais à l’abri d’analyses de données qui permettraient de désanonymiser. Les choix des contenus des messages échangés entre les téléphones conduisent à des solutions plus ou moins sûres.
Les difficultés médicales
Une question pour les épidémiologiste sera de choisir les paramètres de l’appli suivant leurs connaissances du virus et de sa propagation (combien de temps faut-il être proche pour contaminer ? Comment définir proche ? …). Une autre : que faire si l’App détecte qu’on a peut-être été contaminé ?
Est-ce que qu’une telle App serait utile ? Les avis sont partagés. Par exemple, une appli super claire (en anglais) décrite dans ncase.me/contact-tracing/ explique qu’avec le Covid 19, il faut environ 3 jours avant de devenir contagieux, et deux de plus environ avant de savoir qu’on est infecté. Si on a été contaminé par quelqu’un qui utilise l’App, on est prévenu et on peut se mettre en quarantaine avant d’avoir contaminé quelqu’un. Voir la figure en fin du document. Donc avec une telle application, on casse la chaine de contamination.
Des médecins contestent ces chiffres. Évidemment, tout dépend du virus dont on ignore encore beaucoup de choses, même si les connaissances progressent rapidement. C’est aux épidémiologistes, aux médecins, suivant la situation sanitaire, d’évaluer l’utilité ou pas d’une telle App. C’est à l’État de décider. Ce qui semble certain, c’est qu’elle ne sera pas un remède miracle pour enrayer l’épidémie, mais qu’elle pourrait peut-être permettre de casser certaines chaines de contamination, être un des outils au service des médecins.
Et les craintes à long terme
On peut s’interroger sur le fait qu’il y ait tant de débat sur une utilisation de données médicales totalement anonymisées alors que les Google, Apple et les FAI utilisent depuis longtemps de telles données sur nous, par exemple avec la géolocalisation à détecter des ralentissements de circulation. Il ne faudrait pas que cela nous encourage à livrer au gouvernement ces données. Cela devrait plutôt nous interroger sur le fait que des entreprises les possèdent… À poser la vraie question : à quoi servent-elles ?
Pour ce qui est de leur utilisation en période de crise sanitaire, on peut craindre que cela habitue les gens à ce genre d’outils. C’est aujourd’hui une urgence sanitaire, une utilisation d’exception. Mais on a vu par le passé des lois d’exception devenir des lois de toujours. C’est en cela que finalement ces techniques même réalisées correctement posent question, et qu’il faut être tout particulièrement vigilant.
Note : je prend la parole ici à titre personnel. Je suis membre du Collège de l’Arcep mais ne parle pas ici en son nom. Je suis également chercheur émérite à Inria qui est très engagée dans la lutte contre le Covid 19 et communique sur le sujet (1).
Pour ce nouvel article de la série Le divulgâcheur, nous nous sommes intéressés à un épisode de la série Black Mirror intitulé Arkangel et qui traite d’un système numérique de contrôle à distance et de censure visuelle en temps réel. À partir de cette fiction effrayante, nous avons demandé à des chercheurs experts de la visualisation de nous parler de ce mécanisme et de ses applications dans d’autres contextes. Pascal Guitton
Copyright Netflix
Dans l’épisode Arkangel de Black Mirror, suite à un incident durant lequel elle perd de vue sa fille, une mère surprotectrice décide de l’inscrire à un essai gratuit d’une version préliminaire d’Arkangel, un système révolutionnaire de surveillance pour enfants. Arkangel est une technologie qui, grâce à l’implantation d’une puce dans le cerveau des enfants, permet aux parents de suivre en temps réel leur localisation et leur état médical via une tablette. Il offre également la possibilité de consulter la vision de l’enfant en direct, d’enregistrer et de rejouer tout ce qu’il a vu, et de censurer l’obscénité et autres stimuli stressants par pixellisation (voir Figure 1) et distorsion audio. L’épisode tourne autour de la mère protectrice et de sa fille pour montrer à quel point une telle technologie pourrait être dangereuse et porter atteinte à la vie privée, selon le schéma classique de la série télévisée.
Figure 1 : Reproduction d’une scène de Black Mirror, où un chien en colère est censuré visuellement par l’implant cérébral Arkangel. Photo originale de Roger Kidd, CCBYSA 2.0.
Malgré les problèmes évidents de protection de la vie privée et d’éthique ainsi que l’avenir dystopique que présente l’épisode, la censure visuelle automatique peut potentiellement répondre à de réels besoins utilisateurs. Environ deux ans avant la sortie de l’épisode de Black Mirror, notre équipe de recherche a commencé à travailler sur la façon de réduire l’effet répulsif des photos d’interventions chirurgicales en appliquant un traitement d’image automatique. Bien que l’aversion pour des images chirurgicales soit naturelle pour la plupart d’entre nous, elle limite la capacité de nombreuses personnes à se renseigner, à prendre des décisions informées ou plus simplement à satisfaire leur curiosité. Par exemple, parce que de nombreux patients trouvent les images ou les vidéos chirurgicales répugnantes, la communication avec leur chirurgien peut en souffrir. Nos recherches se sont concentrées sur la possibilité d’utiliser des techniques de traitement d’images existantes qui pourraient réduire l’impact émotionnel des images d’interventions médicales, tout en préservant l’information importante. En effet, il est facile de rendre une image pratiquement méconnaissable comme dans l’épisode de Black Mirror (voir Figure 1), mais cela supprimerait toute information utile que l’image était censée transmettre. Afin d’identifier les techniques qui conservent le plus d’informations utiles, nous avons demandé à quatre chirurgiens de nous faire parvenir des photos de leurs interventions. Nous avons ensuite transformé ces photos en appliquant treize techniques différentes, imprimé les images et demandé aux chirurgiens de les ordonner en fonction de leur capacité à préserver les informations importantes. Ce faisant, nous avons éliminé sept techniques qui ont été considérées comme supprimant trop d’informations utiles à une bonne communication avec les patients.
Figure 2 : GIF animé montrant les six techniques testées sur des non-spécialistes. Nous utilisons ici des lasagnes car leur photo est moins choquante que des images chirurgicales.
Nous avons ensuite testé les six autres techniques de traitement d’images sur des non-chirurgiens (visibles sur l’animation de la figure 2) pour comprendre lesquelles seraient les plus à même de réduire l’impact émotionnel des images de chirurgie. Puisqu’il fallait exposer les gens à des images chirurgicales potentiellement dérangeantes, l’obtention de l’approbation éthique pour notre étude a été un long processus itératif. Nous avons montré aux participants des images chirurgicales non filtrées et filtrées, et leur avons demandé d’évaluer dans quelle mesure ils les trouvaient dérangeantes. Selon nos résultats, l’une des techniques les plus prometteuses a été une technique d’abstraction d’images mise au point à l’Institut Hasso Plattner de l’Université de Postdam, en Allemagne, qui utilise un filtrage structure-adaptatif à partir des couleurs pour donner aux images un aspect bande dessinée (voir Figure 3). Cette technique a diminué les réactions affectives négatives des participants tout en préservant une grande partie du contenu informationnel. Certains de nos participants ont signalé que les images étaient moins dérangeantes parce que leur aspect bande dessinée les rendait moins réelles. Dans une étude suivante avec cinq chirurgiens, nous avons montré que des filtres similaires peuvent également être appliqués avec succès aux vidéos.
Figure 3: Abstraction de type « bande dessinée » de l’image de lasagnes à l’aide d’une technique appelée filtrage structure-adaptatif.
Bien que nos recherches se soient concentrées sur les images et les vidéos de chirurgies, les techniques de censure visuelle automatique pourraient être utilisées pour d’autres types de contenus dérangeants, tels que les images hyper-violentes ou pornographiques. Il est clair qu’avec le développement du web et des réseaux sociaux, le contenu explicite est, aujourd’hui plus que jamais, facilement, et souvent par inadvertance, accessible. Par exemple, les enfants qui naviguent sur le web pour des projets scolaires courent le risque d’être exposés par inadvertance à du contenu explicite (1). Wikipédia, par exemple, contient des images ou des vidéos qui peuvent être jugées choquantes ou inappropriées pour certains publics. De même, les réseaux sociaux permettent actuellement aux gens de publier du contenu potentiellement choquant, comme le soulignent les conditions d’utilisation de Facebook ou de Twitter. Si l’interdiction de tout contenu explicite est possible, il est souvent avancé que ce genre de contenu peut informer ou sensibiliser le public, par exemple sur des questions politiques ou sanitaires. Ainsi, les rédactions en chef de journaux ont justifié leur utilisation de photos violentes en expliquant qu’elles aident à informer leur lectorat. De même les associations de défense des droits des animaux telles que L214 et Red Pill en France ou PETA, PEA à l’étranger diffusent régulièrement les photos et vidéos de leurs enquêtes dans les abattoirs ou élevages sur les réseaux sociaux afin d’informer le public, mais ces images sont ignorées par une majorité du public en raison de leur contenu choquant. Enfin, des études ont suggéré que les logiciels destinés à protéger les enfants bloquent également l’accès à des informations utiles et pourraient donc avoir un impact négatif sur les processus d’apprentissage.
Pour aider à rendre la navigation sur Internet informative mais sans risque pour les publics sensibles, nous avons développé une extension Google Chrome que nous avons nommée Arkangel, en hommage à l’épisode de Black Mirror. Notre Arkangel utilise des réseaux neuronaux pour trouver, dans une page web, les images susceptibles de contenir du contenu médical, de la violence ou de la nudité, et les traiter avant que l’utilisateur ne puisse les voir. Dans le même temps, Arkangel laisse à l’utilisateur la possibilité (1) de déterminer l’intensité du traitement de l’image et (2) de dévoiler l’image originale. Bien que nous n’ayons testé empiriquement les techniques de traitement que sur des images chirurgicales, nous supposons qu’elles pourraient également fonctionner de manière similaire sur toute image impliquant du sang ou des mutilations, comme les photographies de guerre ou d’accident. Nous imaginons que les mêmes filtres ou des filtres semblables peuvent aussi aider à réduire l’impact psychologique d’autres contenus fréquemment jugés répugnants (par exemple des photos de maladies de la peau, de vomissements ou d’excréments) ou de la pornographie. Il est néanmoins nécessaire de conduire des études supplémentaires afin de valider ou d’infirmer ces hypothèses. Malgré le nom que nous avons donné à notre extension Google Chrome, son but est fondamentalement différent de l’outil présenté dans l’épisode de Black Mirror. Alors que l’Arkangel de Black Mirror se concentrait sur l’idée de protéger les enfants des stimuli que leurs parents jugent potentiellement dérangeants, nous avons développé notre extension Arkangel dans l’espoir qu’elle aidera les gens à s’informer en s’exposant à du contenu qu’ils auraient évité autrement. Ainsi, son but n’est pas de restreindre, mais d’aider les utilisateurs à pouvoir accéder aux médias nécessaires à leurs recherches. Cependant, il est nécessaire de rester vigilants pour que ces outils restent sous le contrôle total de l’utilisateur et ne soient jamais imposés à d’autres contre leur gré.
Quel avenir pour les technologies de censure visuelle automatique ? Un obstacle important réside dans la reconnaissance automatique de contenus potentiellement dérangeants : aujourd’hui, les machines ne peuvent le faire que dans les cas les plus évidents. Un autre problème réside dans le matériel informatique utilisable. Il est peu probable que dans un avenir proche, les gens souhaitent que des puces soient implantées dans leur cerveau ou dans le cerveau de leurs proches. De plus, malgré les recherches actuelles sur l’électronique implantable (et la possibilité d’augmenter cybernétiquement des requins ou des insectes), de telles technologies sont encore loin d’être prêtes aujourd’hui. Il est cependant possible d’imaginer que des technologies de censure visuelle personnelle deviendront disponibles sur les appareils portables. Les lunettes pourraient être un support idéal, et certaines d’entre elles comprennent déjà des implants auditifs. Il est facile d’imaginer que certaines modifications d’appareils comme les Google Glasses pourraient les faire fonctionner de la même façon que l’implant cérébral Arkangel. Ils pourraient modifier ce que le porteur voit en ajoutant un flou local à la surface des lunettes et pourraient également censurer l’information auditive grâce à l’implant auriculaire intégré. Des casques antibruit sont actuellement disponibles sur le marché et démontrent la faisabilité d’une censure auditive en temps réel. Il est possible d’imaginer un processus similaire appliqué au champ visuel. Les travaux de recherche sur la réalité diminuée ont par exemple étudié comment les affichages de réalité augmentée peuvent être utilisés pour supprimer (plutôt que d’ajouter) du contenu au monde réel.
Munis de dispositifs de censure sensorielle entièrement personnalisables, de nombreuses personnes pourraient, par exemple, assister à des chirurgies en direct pour s’instruire. Les personnes sensibles seraient également capables de s’immuniser contre les actes d’agression non physiques tels que les jurons et leurs analogues visuels. Cependant, il est raisonnable de craindre que de tels outils ne fassent que fragiliser les populations sensibles en les privant d’occasions de développer une résistance à des événements de la vie de tous les jours. De tels outils pourraient également nous rapprocher de scénarios de suppression des libertés individuelles comme celui illustré dans l’épisode Black Mirror. Par exemple, il n’est pas difficile d’imaginer comment des lunettes de censure sensorielle pourraient être complétées par une carte SIM, de petites caméras et des capteurs de signes vitaux, afin que les parents puissent surveiller et contrôler leurs enfants comme jamais auparavant. Pire encore, les technologies portables de censure perceptuelle pourraient être utilisées à mauvais escient par des organisations militaires ou terroristes afin de faciliter les actes de torture ou de meurtre. Par exemple, de telles technologies pourraient changer la couleur du sang, faire apparaître le monde comme un dessin animé, ou bien faire croire que les ennemis sont des créatures répugnantes comme l’illustre un autre épisode de Black Mirror : Men Against Fire. Elles pourraient même être utilisées pour prétendre que les événements réels font partie d’une simulation, un thème repris dans Ender’s Game d’Orson Scott Card.
Bien que nous nous soyons concentrés sur la façon dont la censure visuelle peut être utilisée pour aider les gens à s’éduquer en éliminant un obstacle potentiel au libre accès à l’information, la censure visuelle peut aussi être extrêmement utile aux personnes dont le travail quotidien consiste à regarder des contenus troublants, comme les journalistes ou les modérateurs de contenus en ligne. De récents reportages et documentaires sur la santé mentale des modérateurs travaillant pour des réseaux sociaux tels que Facebook, Twitter ou Youtube, ont souligné la difficulté de leur travail. Ils doivent regarder du contenu particulièrement violent et choquant tout au long de leur journée de travail pour comprendre si le média affiché enfreint ou non les conditions d’utilisation du service. Pour ce faire, ils doivent clairement identifier l’information présentée dans les médias, mais cela peut se faire au détriment de leur santé mentale à long terme. Nous espérons que des filtres comme notre extension de navigateur Arkangel pourront les aider dans leur tâche. Des difficultés similaires semblent être au centre des préoccupations de certaines salles de rédaction lorsqu’elles doivent regarder des dizaines de photos ou de vidéos de zones de guerre pour décider lesquelles utiliser. Notre étude a déjà suggéré que les techniques d’abstraction d’images peuvent réduire la réponse affective aux images chirurgicales tout en préservant les informations essentielles de l’image, et il serait intéressant d’étudier si elles peuvent aussi être utilisées pour réduire l’impact que la modération de contenu ou les tâches de sélection d’images peuvent avoir sur la santé mentale des travailleurs.
(1) on appelle « contenu explicite » des documents (textes, images, vidéos…) contenant des aspects pouvant choquer le public (violence, pornographie, insultes…). Cette expression est issue du monde de la chanson où elle est utilisée depuis très longtemps.
Lonni Besançon (Linköping University), Amir Semmo (Hasso Plattner Institute), Tobias Isenberg (Inria) et Pierre Dragicevic (Inria)
Plus d’informations sur notre extension pour Google Chrome sont disponible dans la vidéo de ce TEDx donné par un des membres de l’équipe de recherche
Réflexions et points d’alerte sur les enjeux d’éthique du numérique en situation de crise sanitaire aiguë: Ce premier bulletin de veille du Comité national pilote d’éthique du numérique présente le contexte et développe deux points spécifiques. D’une part les questionnements éthiques liés à l’usage des outils numériques dans le cadre d’actions de fraternité, et d’autre part celui des enjeux éthiques liés aux suivis numériques pour la gestion de la pandémie. Télécharger le document
Pas une journée sans que nous n’entendions parler d’intelligence artificielle, et notamment, de plus en plus souvent, des questions éthiques que des outils basés sur cette technologie soulèvent. Co-titulaire de la Chaire Droit et éthique de la santé numérique à l’université catholique de Lille, Alain Loute s’interroge sur la capacité à questionner les futurs développements de la technologie et nous entraîne vers une réflexion sur l’éthique composée au futur. Pascal Guitton
L’Intelligence Artificielle (IA) est au cœur de nombreux débats et polémiques dans la société. Nul domaine de la vie sociale et économique ne semble épargné par le sujet. Ce qui est intéressant à souligner, c’est que dans tous les débats aujourd’hui autour de l’IA, l’éthique est à chaque fois convoquée. Personne ne semble réduire la question de l’IA à une simple problématique technique. En atteste actuellement la prolifération des rapports sur l’éthique de l’IA, produits tant par des entreprises privées, des acteurs publics ou des organisations de la société civile.
Parmi les rapports, les propos peuvent diverger quelque peu, mais ils semblent tous souscrire à une même forme d’impératif éthique. Il s’agit de l’injonction à anticiper les impacts des technologies. L’éthique – pour reprendre des termes du philosophe Hans Jonas – doit se faire aujourd’hui « éthique du futur ». Anticiper les impacts du développement de l’IA devient donc un impératif éthique.
Couverture de l’ouvrage Pour une éthique du futur – Editions Rivage Poche Petite bibliothèque
Un tel impératif n’est pas neuf. Il est notamment au cœur de la démarche de la « recherche et l’innovation responsable » prôné par la Commission Européenne. Il me semble qu’un tel concept analogue de responsabilité est également au cœur des récents rapports français sur l’IA. Je me centrerai ici sur trois rapports récents : celui de la CNIL [1], le rapport Villani [2], ainsi que le rapport de la CERNA [3]. Commençons par le rapport Villani. Ce rapport précise que : « la loi ne peut pas tout, entre autres car le temps du droit est bien plus long que celui du code. Il est donc essentiel que les « architectes » de la société numérique (…) prennent leur juste part dans cette mission en agissant de manière responsable. Cela implique qu’ils soient pleinement conscients des possibles effets négatifs de leurs technologies sur la société et qu’ils œuvrent activement à les limiter ».
Le mouvement est double : anticiper l’aval du développement technologique, pour – en amont – modifier la conception afin d’empêcher les impacts éthiques négatifs. A l’appui de cette démarche, le rapport Villani envisage d’obliger les développeurs d’IA à réaliser une évaluation de l’impact des discriminations (discrimination impact assessment ) afin de « les obliger à se poser les bonnes questions au bon moment ». On retrouve également dans le rapport de la CNIL, une recommandation similaire : « Travailler le design des systèmes algorithmiques au service de la liberté humaine ». Anticiper pour intégrer l’éthique au plus tôt du développement technologique. La volonté de mettre en œuvre une « éthique au futur » est tout à fait louable mais de nombreuses questions restent en suspens que je voudrais passer en revue.
Le futur est-il anticipable ?
On peut tout d’abord poser une critique d’ordre épistémologique. Comment juger éthiquement des potentialités ouvertes par le numérique ? Face à un tel développement, ne sommes-nous pas plongés dans ce que les économistes appellent une « incertitude radicale » ? Les possibles ouverts par les « Big Data » sont un bon exemple de cette incertitude radicale. Sous cette appellation, il est fait référence au phénomène de prolifération ininterrompue et exponentielle des données. Cette évolution a fait évoluer le langage technique utilisé pour mesurer la puissance de stockage des données. De l’octet, nous sommes passés au mégaoctet, au gigaoctet, etc. Comme le souligne Eric Sardin, avec des unités de mesures comme le petaoctet, le zetaoctet ou le yotaoctet, il est clair que nous manions des unités de mesure qui excèdent purement et simplement nos structures humaines d’intelligibilité [4]. De plus, les rapports n’insistent-ils pas tous sur le caractère imprévisible de certains algorithmes d’apprentissage ? Ayant conscience de cette imprévisibilité, la CNIL défend, dans son rapport un principe de « vigilance » qui institue l’obligation d’une réflexion éthique continue. Mais plus fondamentalement, ne faut-il pas reconnaître que tout n’est pas anticipable ?
Il est également important de prendre conscience que ce futur que l’on nous enjoint d’anticiper est saturé de peurs, d’attentes et de promesses. Le futur n’est pas un temps vide, mais un temps construit par des scénarios, road-maps et discours prophétiques. Pour le dire en reprenant une expression de Didier Bigo, le futur est « colonisé » par de nombreux acteurs qui essaient d’imposer leur vision comme une matrice commune de toute anticipation du futur. Initialement, il a forgé cette expression dans le cadre d’une réflexion sur les technologies de surveillance, pour désigner les prétentions et stratégies des experts qui appréhendent le futur comme un « futur antérieur, comme un futur déjà fixé, un futur dont ils connaissent les événements » [5].
L’éthique robotique nous fait courir le même risque d’une colonisation du futur comme l’illustre Paul Dumouchel et Luisa Damiano dans leur livre Vivre avec des robots. Ces derniers pensent notamment à des auteurs comme Wallach et Allen, dans Moral Machines, Teaching Robots Right from Wrong, qui proposent un programme visant à enseigner aux robots la différence entre le bien et le mal, à en faire des « agents moraux artificiels ». Mais « programmer » un agent moralement autonome n’est-il pas une contradiction dans les termes ? Mon propos n’est pas de rentrer ici dans un débat métaphysique à ce sujet. Je voudrais plutôt souligner le fait qu’un tel programme a littéralement « colonisé » l’horizon d’attente des débats sur l’éthique robotique. Suivons Dumouchel et Damiano pour saisir ce point. Ils relèvent que, de l’avis même de certains des protagonistes de l’éthique robotique, « nous sommes encore loin de pouvoir créer des agents artificiels autonomes susceptibles d’être de véritables agents moraux. Selon eux, nous ne savons même pas si nous en serons capable un jour. Nous ne savons pas si de telles machines sont possibles » [6]. Une des réponses avancées par les tenants de l’éthique robotique est alors qu’« il ne faut pas attendre pour élaborer de telles règles que nous soyons pris au dépourvu par l’irruption soudaine d’agents artificiels autonomes. Il est important déjà à se préparer à un avenir inévitable. Les philosophes doivent dès aujourd’hui participer au développement des robots qui demain peupleront notre quotidien en mettant au point des stratégies qui permettent d’inscrire dans les robots des règles morales qui contraignent leur comportements » [7].
Ce thème de l’autonomisation inévitable des machines est puissant et tout à fait problématique. Parmi tous les possibles, l’attention se trouve focalisée sur ce scénario posé comme « inéluctable ». Une telle focalisation de l’attention pose plusieurs problèmes. D’une part, elle pose des questions épistémologiques : d’où vient que l’on puisse soutenir cette inéluctabilité ? D’autre part, pour Dumouchel et Damiano, cette croyance, bien que non rationnelle, a des effets réels certains : elle détourne l’attention d’enjeux de pouvoir qui se posent dès à présent, à savoir que l’autonomisation des robots, le fait de leur déléguer des décisions et de leur laisser choisir par eux-mêmes signifie peut-être la perte du pouvoir de décision de quelques-uns, mais intensifie aussi la concentration de la décision dans les mains de certains (les programmateurs, les propriétaires des robots, etc.).
Image extraite du film Forbiden Planet (USA, 1956) – MGM productions
Qui anticipe ?
Autre question connexe : qui effectuera cette anticipation des impacts éthiques ? Qui seront les auteurs des discriminations impacts ? Ne s’agit-il que des seuls chercheurs ? Sur ce point, tous les rapports précisent bien que cet impératif éthique d’anticipation ne concerne pas que ceux-ci. Le rapport de la CERNA précise que « le chercheur doit délibérer dès la conception de son projet avec les personnes ou les groupes identifiés comme pouvant être influencés ». Pour le rapport Villani, « Il faut créer une véritable instance de débat, plurielle et ouverte sur la société, afin de déterminer démocratiquement quelle IA nous voulons pour notre société ». Quant à la CNIL, elle affirme dans son rapport que « Les systèmes algorithmiques et d’intelligence artificielle sont des objets socio-techniques complexes, modelés et manipulés par de longues et complexes chaînes d’acteurs. C’est donc tout au long de la chaîne algorithmique (du concepteur à l’utilisateur final, en passant par ceux qui entraînent les systèmes et par ceux qui les déploient) qu’il faut agir, au moyen d’une combinaison d’approches techniques et organisationnelles. Les algorithmes sont partout : ils sont donc l’affaire de tous ».
Les rapports cités portent bien une attention à la question de savoir QUI anticipe. Néanmoins, l’injonction à délibérer avec « les personnes ou les groupes identifiés comme pouvant être influencés » (CERNA) ne suffit pas. Il faut que la détermination de la liste de ses personnes concernées soit un objet même de réflexion et de recherche et non pas un prérequis de cette démarche d’anticipation. En effet, l’anticipation de ces impacts peut nous faire prendre conscience de nouvelles parties prenantes à intégrer dans la réflexion. De plus, quelle forme donner à une éthique de l’IA qui soit « l’affaire de tous » ? Comment l’instituer ?
Une prise en compte du temps qui occulte l’espace
Enfin, une dernière question laissée en suspens est le privilège accordé au temps par rapport à la spatialité dans la réflexion éthique. Le développement du numérique et en particulier de l’IA ont contribué à l’idée que la virtualisation des échanges réduirait les distances et l’importance des lieux. Une telle croyance est par exemple au cœur du développement de la télémédecine : un malade chronique peut être surveillé indifféremment à son domicile ou en institution, un spécialiste peut être sollicité par télé-expertise quelle que soit la distance qui le sépare de son confrère, etc. Or comme l’affirment les sociologues Alexandre Mathieu-Fritz et Gérald Gaglio, « la télémédecine ne conduit pas à une abolition des frontières et des espaces, contrairement à une vision du sens commun souvent portée implicitement par les politiques publiques » [8]. Pour pouvoir être effectif, les actes de télémédecine demandent un certain aménagement des espaces. Dans un travail ethnographique mené auprès de patients télé-surveillés, Nelly Oudshoorn, a démontré combien les lieux, l’espace domestique et l’espace public influencent et façonnent la manière dont les technologies sont implémentées, de même qu’à l’inverse, ces technologies transforment littéralement ces espaces. La maison devient ainsi un lieu hybride, un lieu de vie médicalisé. Cette dimension spatiale ne semble pas réellement prise en compte.
Pourtant, un auteur comme Pierre Rosanvallon, nous rappelait il y a une dizaine d’année dans son ouvrage La légitimité démocratique que la légitimité de l’action publique passe de plus en plus aujourd’hui par ce qu’il appelle un « principe de proximité », une attention aux contextes locaux. En atteste aujourd’hui la promotion d’une démarche d’« expérimentation » dans le domaine de l’IA en santé : « afin de bénéficier des avancées de l’IA en médecine, il est important de faciliter les expérimentations de technologie IA en santé en temps réel et au plus près des usagers, en créant les conditions réglementaires et organisationnelles nécessaires » (Rapport Villani). De manière plus inductive et partant du terrain, il s’agirait de privilégier une nouvelle construction de l’action publique : « expérimenter l’action publique » comme nous l’y invite Clément Bertholet et Laura Létourneau [9].
Si cette démarche d’expérimentation invite à prendre en compte les réalités contextuelles locales, l’objectif reste toujours la « scalabilité » (le fait de pouvoir être utilisé à différentes échelles). Je reprends ce terme à l’anthropologue Anna Lowenhaupt Tsing qui le définit comme : « la capacité de projets à s’étendre sans que le cadre de leur hypothèse ne change » [10]. On expérimente localement certes, mais me semble-t-il pour dégager ce qui est généralisable et opérationnel de manière indifférenciée à différentes échelles. Or, un dispositif de télésurveillance – pour prendre cet exemple – peut-il s’appliquer dans tout contexte ? Tous les lieux de vie peuvent-ils devenir des lieux de soin ?
L’éthique de l’IA prend-elle bien en compte le fait que les impacts de l’IA vont se différencier selon les lieux et les espaces ? Où doivent prendre place les « ethical impact assessment » ? Doivent-ils être centralisés ou localisés dans les lieux de conceptions des objets techniques ? Plus fondamentalement, est-il possible de déterminer ces impacts sans se déplacer ? Sur ce point, la cartographie du paysage global de l’éthique de l’IA réalisée par A. Jobin et alii [11] est tout à fait instructive. Ils ont réalisé une analyse comparative de 84 rapports sur l’éthique de l’IA. Il s’agit de document produits par des agences gouvernementales, des firmes privées, des organisations non lucratives ou encore des sociétés savantes. Leur analyse met en avant le fait que les rapports sont produits majoritairement aux USA (20 rapports), dans l’Union européenne (19), suivi par la Grande-Bretagne (14) et le Japon (4). Les pays africains et latino-américains ne sont pas représentés indépendamment des organisations internationales ou supra-nationales. Cette distribution géographique n’est-elle pas significative de l’occultation de cette dimension spatiale ?
Alain Loute (Centre d’éthique médicale, labo ETHICS EA 7446, Université Catholique de Lille)
[4] E. Sardin, La vie algorithmique, Critique de la raison numérique, Ed. L’échappée, Paris 2015, pp. 21-22.
[5] D. Bigo, « Sécurité maximale et prévention ? La matrice du futur antérieur et ses grilles », in B. Cassin (éd.), Derrière les grilles, Sortons du tout-évaluation, Paris, Fayard, 2014, p. 111-138, p. 126.
[6] P. Dumouchel et L. Damiano, Vivre avec des robots, Essai sur l’empathie artificielle, Paris, Seuil, 2016, p. 191.
[8] A. Mathieu-Fritz et G. Gaglio, « À la recherche des configurations sociotechniques de la télémédecine, Revue de littérature des travaux de sciences sociales », in Réseaux, 207, 2018/1, pp. 27-63.
[9] C. Bertholet et L. Létourneau, Ubérisons l’Etat avant que les autres ne s’en chargent, Paris, Armand Collin, 2017, p.182.
[10] A. Lowenhaupt Tsing, Le champignon de la fin du monde, Sur la possibilité de vivre dans les ruines du capitalisme, Paris, La Découverte, 2017, p. 78.
[11] A. Jobin, M. Ienca, & E. Vayena, « The global landscape of AI ethics guidelines », in Nat Mach Intell, 1, 2019, pp. 389–399.




 J’ai notamment beaucoup discuté sur un forum avec un activiste de GreenPeace. C’est lui qui m’a fait découvrir Wikipédia qui démarrait à ce moment. Il m’a suggéré d’y raconter ce qui me tenait à cœur, sur la version anglophone. A cette époque, il n’y avait encore quasiment personne sur Wikipédia en français.
J’ai notamment beaucoup discuté sur un forum avec un activiste de GreenPeace. C’est lui qui m’a fait découvrir Wikipédia qui démarrait à ce moment. Il m’a suggéré d’y raconter ce qui me tenait à cœur, sur la version anglophone. A cette époque, il n’y avait encore quasiment personne sur Wikipédia en français. binaire : La fondation Wikimédia promeut d’autres services que l’encyclopédie Wikipédia. Vous pouvez nous en parler ?
binaire : La fondation Wikimédia promeut d’autres services que l’encyclopédie Wikipédia. Vous pouvez nous en parler ? Un autre projet très populaire, c’est Wikimedia Commons qui regroupe des millions d’images. C’est né de l’idée qu’il était inutile de stocker la même image dans plusieurs encyclopédies dans des langues différentes. Je trouve très sympa dans Wikimedia Commons que nous travaillions tous ensemble par-delà des frontières linguistiques, que nous arrivions à connecter les différentes versions linguistiques.
Un autre projet très populaire, c’est Wikimedia Commons qui regroupe des millions d’images. C’est né de l’idée qu’il était inutile de stocker la même image dans plusieurs encyclopédies dans des langues différentes. Je trouve très sympa dans Wikimedia Commons que nous travaillions tous ensemble par-delà des frontières linguistiques, que nous arrivions à connecter les différentes versions linguistiques. Un troisième projet, Wiki Data construit une base de connaissances. Le sujet est plutôt d’ordre technique. Cela consiste en la construction de bases de faits comme « “Napoléon” est mort à “Sainte Hélène” ». À une entité comme ”Napoléon”, on associe tout un ensemble de propriétés qui sont un peu agnostiques de la langue. Les connaissances sont ajoutées par des systèmes automatiques depuis d’autres bases de données ou entrées à la main par des membres de la communauté wikimédienne. On peut imaginer de super applications à partir de Wiki Data.
Un troisième projet, Wiki Data construit une base de connaissances. Le sujet est plutôt d’ordre technique. Cela consiste en la construction de bases de faits comme « “Napoléon” est mort à “Sainte Hélène” ». À une entité comme ”Napoléon”, on associe tout un ensemble de propriétés qui sont un peu agnostiques de la langue. Les connaissances sont ajoutées par des systèmes automatiques depuis d’autres bases de données ou entrées à la main par des membres de la communauté wikimédienne. On peut imaginer de super applications à partir de Wiki Data. FD : Au début, on avait juste l’encyclopédie. La Fondation a été créée en 2003, mais sans véritablement de stratégie. On faisait ce que les gens avaient envie de faire. Par exemple, Wiktionnaire a été créé à cette époque. On avait des entrées qui étaient juste des définitions de mots. On se disputait pour savoir si elles avaient leur place ou pas dans Wikipédia. Comme on ne savait pas comment trancher le sujet, on a créé autre chose : le Wiktionnaire. Dans cette communauté, quand tu as une bonne idée, tu trouves toujours des développeurs. Les projets se faisaient d’eux-mêmes, du moment que suffisamment de personnes estimaient que c’était une belle idée. Il n’y avait pas de stratégie établie pour créer ces projets.
FD : Au début, on avait juste l’encyclopédie. La Fondation a été créée en 2003, mais sans véritablement de stratégie. On faisait ce que les gens avaient envie de faire. Par exemple, Wiktionnaire a été créé à cette époque. On avait des entrées qui étaient juste des définitions de mots. On se disputait pour savoir si elles avaient leur place ou pas dans Wikipédia. Comme on ne savait pas comment trancher le sujet, on a créé autre chose : le Wiktionnaire. Dans cette communauté, quand tu as une bonne idée, tu trouves toujours des développeurs. Les projets se faisaient d’eux-mêmes, du moment que suffisamment de personnes estimaient que c’était une belle idée. Il n’y avait pas de stratégie établie pour créer ces projets.
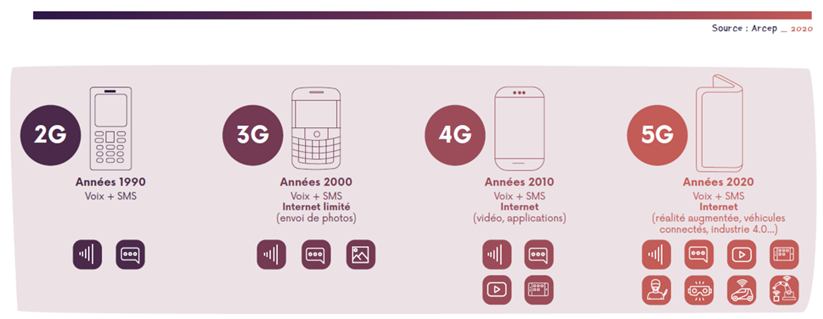
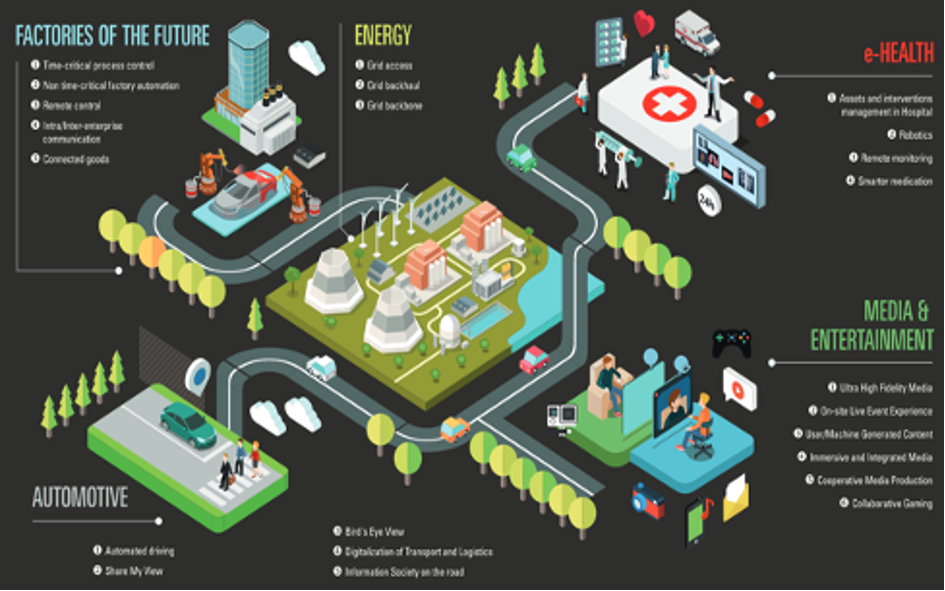









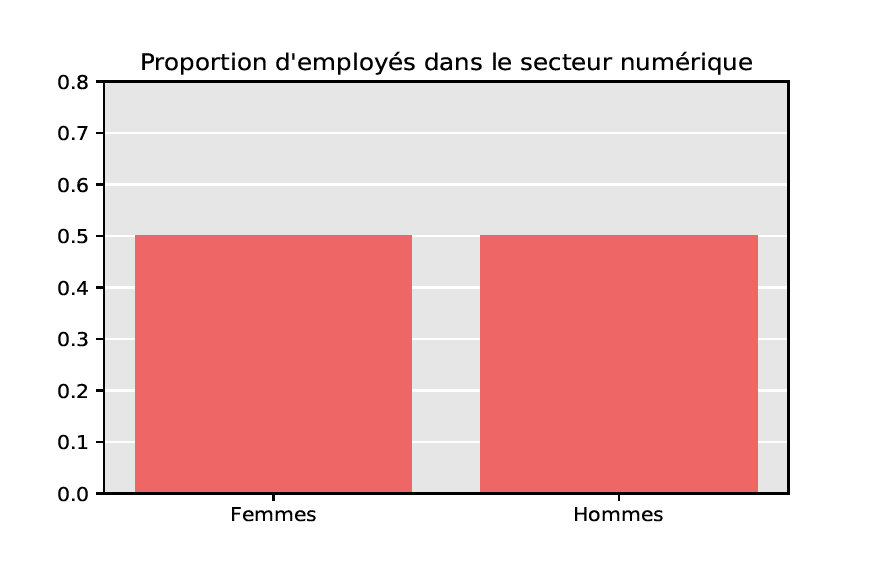
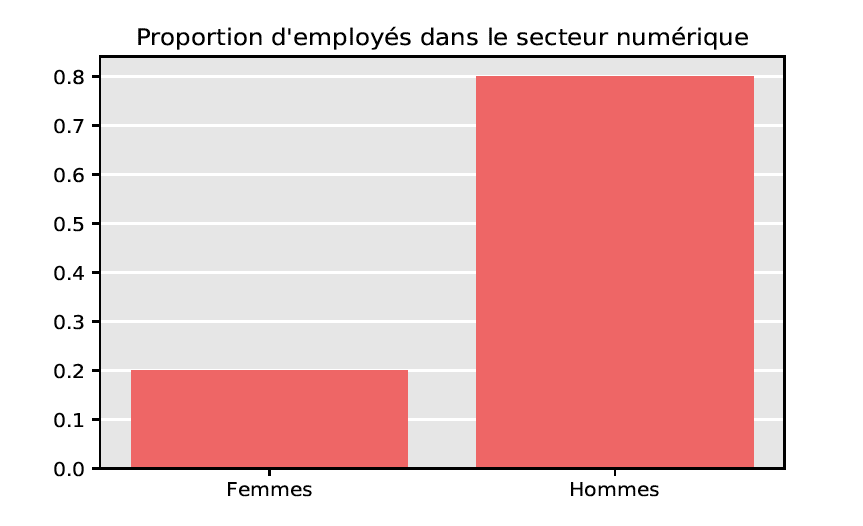
 La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement.
La sélection stricte, qui permet principalement de modéliser l’absence de réponse dans des sondages. Celle-ci est généralement endogène : un individu ne répond pas à une ou des questions selon ses propres caractéristiques. Par exemple, l’INSEE reporte un faible taux de réponse (d’environ 50%) parmi les petites et moyennes entreprises interrogées lors de son enquête annuelle sur la santé économique française [7], quand les grandes entreprises répondent systématiquement. La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
La sélection douce, qui correspond à une déformation continue des données. La courbe de répartition de l’âge des répondants à une enquête en ligne (en rouge) aura par exemple tendance à être décalée vers les jeunes, comparativement à la courbe de répartition des âges de la population de référence (en bleu). Ce phénomène est également présent, de manière plus pernicieuse, dans le secteur industriel où le vieillissement du matériel électronique (capteurs aéronautiques de pression, par exemple) peut engendrer de légères déformations dans les mesures effectuées.
 « Numérique et pandémie – Les enjeux d’éthique un an après »
« Numérique et pandémie – Les enjeux d’éthique un an après »





 B : Tu as aussi beaucoup réfléchi à l’ « augmentation » de l’humain avec la technique, et aux questions que cela pose en terme de justice ?
B : Tu as aussi beaucoup réfléchi à l’ « augmentation » de l’humain avec la technique, et aux questions que cela pose en terme de justice ? B : Quelle est le sujet de recherche qui te passionne en ce moment ?
B : Quelle est le sujet de recherche qui te passionne en ce moment ?