
 (original)
(original) (résultat)
(résultat)Effet spécial sur une séquence vidéo : suppression automatique d’un personnage. A. Newson, A. Almansa, M. Fradet, Y. Gousseau, P. Pérez – Télécom ParisTech et Technicolor
Henri Maître est Professeur émérite à Télécom ParisTech où il était jusque récemment Directeur de la Recherche. C’est un spécialiste du traitement d’images et de reconnaissance des formes. Il nous raconte son parcours qui conduit aux fonctions si sophistiquées des appareils photos modernes et au Graal, « la sémantique des images ». Il nous fait partager sa passion pour ces aspects si dynamiques de l’informatique, le traitement numérique du signal et de l’image et sa vision sur l’évolution et les perspectives qui s’offrent à l’image.
Entretien avec Henri Maître réalisé par Claire Mathieu, Directrice de Recherche CNRS à l’ENS Paris et Serge Abiteboul, Directeur de Recherche Inria à l’ENS Cachan.
Binaire : Bonjour Henri Maître. Pour commencer, peux-tu nous raconter comment tu es devenu chercheur en traitement du signal, jusqu’à devenir directeur de la recherche à Télécom.
Henri Maître : Si je fais partir le début de ma carrière de mon expérience d’étudiant à Centrale Lyon, où j’ai étudié essentiellement les maths appli et la mécanique des fluides, on est loin de ma recherche future. Mais en parallèle, je me suis passionné pour l’holographie, l’optique et la physique des images… Le point commun entre l’holographie et la mécanique des fluides, c’est la transformée de Fourier tridimensionnelle et les traitements qui tournent autour… Dans les premières années de 70, ce n’était pas l’outil courant de l’ingénieur et je pensais pouvoir mettre à profit cette double compétence à l’ONERA pour l’étude par holographie des écoulements, mais ça n’a pas marché et comme je cherchais à me rapprocher de Paris, j’ai fait un stage en holographie numérique à l’ENST, l’actuel Télécom ParisTech qui démarrait une activité sur ce sujet.
B : Et tu t’es plu à Télécom ; tu y es resté toute ta carrière ?
HM : Oui. J’ai commencé en mars 1971 et j’ai été remercié en mars 2013 ! Et j’ai même droit à une petite rallonge avec un poste émérite sur place. Ce qu’on me proposait, c’était du traitement de l’information et c’était de l’holographie. Comme je n’étais pas un grand spécialiste de l’optique, j’ai été à l’Institut d’Optique faire un DEA d’optique cohérente dans une superbe équipe qui était pilotée par Serge Lowenthal à l’époque, c’était vraiment le haut du panier mondial en holographie. L’École des Télécoms était en train de créer ses labos. Le premier labo avait été monté par Claude Guéguen et Gérard Battail deux ans auparavant en traitement du signal et en théorie du codage. Jacques Fleuret montait un labo d’holographie et de traitement optique des images juste avant mon arrivée, montage auquel j’ai participé.
Replaçons nous dans le contexte des années 70. L’ordinateur fonctionnait bien. Il avait quand même beaucoup de mal à travailler sur des images trop grosses pour sa mémoire, les temps d’entrée/sortie étaient considérables et la piste de l’optique laissait entrevoir du temps réel sur de larges images, sans avoir besoin de les transformer par une numérisation. On espérait à l’époque pouvoir faire des traitements très compliqués. Les Américains avaient déjà fait des systèmes optiques de reconstruction d’images de radar à vision latérale embarqués dans des avions. Il y avait des systèmes de reconnaissance de routes ou de rivières en télédétection, de caractères pour le tri postal, de cellules pour l’imagerie médicale. C’était la piste concurrente du traitement de l’image par ordinateur
B : Une image ne tenait pas dedans ?
HM : Non, alors, l’image ne tenait pas dans l’ordinateur. Les temps de calcul étaient très longs mais surtout les entrées et sorties étaient très lourdes. Disposer d’une mémoire d’image était une grande fierté pour une équipe (à Télécom comme à l’Inria ou au CNRS). Pierre Boulez est venu voir chez nous ce qui pouvait être utile pour son prototype de 4X qu’il faisait développer alors à l’IRCAM. Notre mémoire, c’était un truc qui faisait 40 cm sur 40 cm sur 20 cm, et sur lequel il y avait 512 x 512 x 8 octets distribués dans des dizaines de boîtiers. Ça permettait d’afficher une image en temps réel devant des spectateurs émerveillés. Pour l’analyse, on passait par un microdensitomètre, prévu pour analyser des spectrogrammes, mais modifié pour balayer le film selon les deux dimensions. On lançait l’analyse le soir (elle durait 8 h et il fallait éviter les vibrations et les lumières parasites ; grâce au ciel il n’y a pas de métro rue Barrault !). Pour sortir les résultats on collait côte-à-côte des morceaux de listings où les teintes de gris provenaient de la superposition de caractères et l’on prenait ça en photo à 20 mètres en défocalisant un peu pour lisser les hautes fréquences.
Donc, le traitement numérique de l’image existait déjà mais de façon balbutiante : il y avait quelques équipes en France. Je pense à Albert Bijaoui à l’Observatoire de Nice, à Serge Castan à Toulouse, à Daniel Estournet à l’ENSTA ; et Jean-Claude Simon, faisait venir tous les ans dans son château de Bonas la fine-fleur internationale de la reconnaissance des formes. Mais je ne faisais pas de traitement numérique d’images alors. On calculait par ordinateur des filtres complexes par holographie numérique que l’on introduisait dans des montages optiques en double diffraction sur des tables de marbre. Une semaine de calcul du filtre puis quinze jours d’expérimentation en optique pour décider qu’il fallait changer de paramètre du filtre et recommencer le cycle. Ce n’était pas tenable. On a donc décidé de simuler le traitement optique … et on est donc arrivé au traitement numérique !
B : Les débuts du traitement numérique d’image ?
HM : Oui, On simulait le filtre optique mais le filtre optique, ce n’était jamais qu’un filtre de corrélation que l’on faisait par une double transformée de Fourier. A l’époque, une double transformée de Fourier, ça vous prenait deux heures sur la machine, même si Cooley-Tukey étaient passés par là. On s’est rendu compte que c’était infiniment plus efficace que de le faire en optique. Que c’était plus rapide, plus souple et que finalement les nouveaux systèmes d’affichage d’image (des oscillos qu’on modulait devant un polaroïd), ou les mémoires d’image devenaient opérationnels. Et effectivement, honnêtement, le bilan scientifique, c’est que les méthodes optiques de traitement des images n’étaient pas compétitives face au traitement numérique. Mon collègue Jacques Fleuret a continué à faire du traitement plutôt optique pour des applications spécialisées ; on a continué à utiliser nos tables d’holographie, en marbre, nos bains photo, nos émulsions, mais on a multiplié les terminaux, gonflé notre mémoire et renforcé notre réseau.
Je suis parti une année sabbatique en Allemagne dans un labo d’optique cohérente en pôle position dans la communauté de l’holographie, celui d’Adolf Lohmann. Mon cours expliquait le traitement numérique des images à des opticiens.
B : C’était en quelle année ?
HM : En 1980. Et je suis revenu avec une étiquette de traiteur numérique des images et à partir de là, je n’ai plus fait que ça.
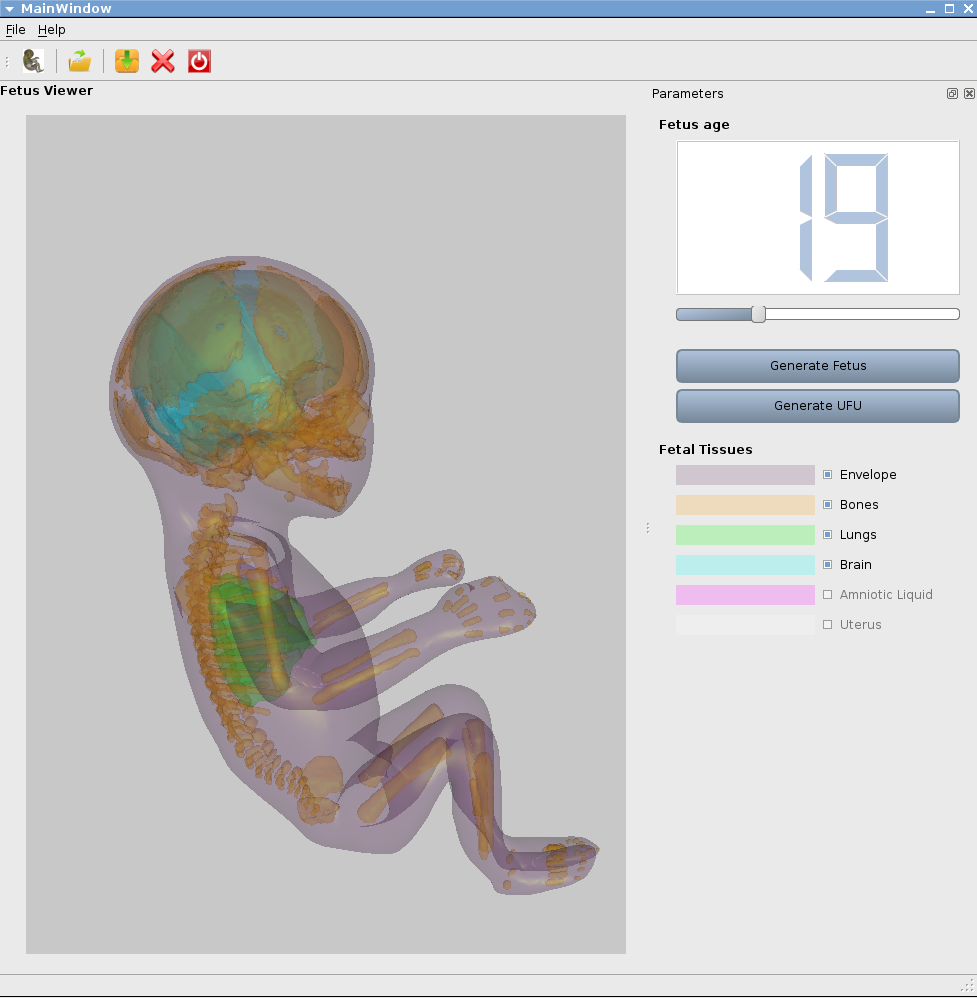 Modélisation anatomique d’un fœtus : l’opérateur choisit le stade de croissance,
Modélisation anatomique d’un fœtus : l’opérateur choisit le stade de croissance,
l’orientation globale dans l’utérus et la position des membres.
S. Dahdouh, J. Wiart, I. Bloch, Whist Lab, Télécom ParisTech et Orange Labs.
B : Est-ce que c’est correct de dire qu’aux alentours des années 80, le traitement de l’image a basculé ou commencé à basculer vers le numérique ?
HM : La piste du traitement numérique remonte à 1965 et ses résultats sont déjà très nombreux en 1980 mais, effectivement, dans les années 80, le traitement numérique des images est la solution au problème alors qu’avant, elle était une des solutions possibles. Il y avait eu beaucoup plus de crédits dans le traitement optique car les militaires surtout de l’autre côté de l’Atlantique, mettaient beaucoup d’argent pour avoir des traitements embarqués en temps réel. Par contre, le traitement numérique a mis plus de temps car les infrastructures (calculateurs assez puissants, composants, …) n’étaient pas là. Comment est-ce que le traitement numérique est passé devant ? Incontestablement, c’est la conquête spatiale américaine qui a fait basculer le traitement numérique au premier plan.
B : Et techniquement des choses comme la baisse du coût des mémoires ?
HM : Bien sûr, l’évolution des composants surtout …. Mais qu’est-ce qui a entraîné l’autre ? Je ne sais pas. Il y a une chose extrêmement intéressante à voir rétrospectivement. Dans les années 70 à 80, lors de la compétition féroce entre les Américains et les Russes pour l’espace, les Américains, partis en retard, ont rattrapé les Russes à coups de technologie très avancée. Les Russes, eux, ont continué à faire une politique s’appuyant sur leurs points forts de base dans laquelle ils envoyaient des hommes dans l’espace. L’essentiel de la conquête de l’espace des Américains, comme des Russes, était destinée à améliorer la surveillance de l’autre. Les Russes le faisaient avec des jumelles depuis les satellites. Ils observaient des cibles, préparées sur des plannings, après des entraînements spécifiques qui leur permettaient de détecter, suivre et identifier les bateaux qui se trouvaient dans un port pendant les quelques minutes où la cible était en visibilité. Résultat : les Russes ont acquis une compétence extraordinaire sur la biologie dans l’espace, les capacités et les évolutions du corps humain, les effets de la gravité sur les performances du système visuel, le fait que, par exemple, la rétine, en apesanteur, ne voit pas les mêmes couleurs de la même façon. Pendant ce temps les Américains envoyaient des caméras prendre des photos et développaient des machines de traitement de l’image pour les exploiter. On voit le résultat quelques années plus tard : les Américains dominent complètement ce marché de la télédétection en haute résolution, tandis que les Russes ont acquis un savoir-faire exceptionnel sur les longs séjours des cosmonautes.
Cet effort particulier des Américains lancé dans les années 70 à 75 commençait à retomber en pluie fine sur les universités et les labos de recherche. Dans les années 80, le traitement numérique des images était bien établi et, évidemment, s’appuyait sur l’informatique à fond.
B : Est-ce le progrès du matériel qui a précipité le développement du traitement numérique d’image ou l’inverse ?
HM :
Les deux ont été vrais : l’exemple de la mémoire d’image est typiquement un point sur lequel le traitement de l’image a demandé des choses qui n’existaient pas à l’industrie des composants et les progrès ont bénéficié à l’ensemble de l’informatique. C’est probablement aussi le cas des disques à très haute capacité qui servent aujourd’hui avant tout à la sauvegarde des films et des images du grand-public, mais aussi à des applications commercialement moins porteuses mais potentiellement très riches comme les grandes bases de données du web.
B : Et, à cette époque, tu es où ?
HM : À Télécom ParisTech, l’ENST d’alors. Serge, c’est peut-être là d’ailleurs qu’on s’est connus ?
Serge : J’y étais élève. Et tu étais mon prof.
B : Qu’est-ce qui a évolué dans la recherche, en ce qui concerne le traitement du signal, de l’image, entre ce qui se faisait disons, dans les années 80, et ce qu’on fait maintenant ? Est-ce que c’est juste qu’on le fait mieux ou est-ce qu’il y a eu de nouveaux sujets qui ont émergé, des nouvelles pratiques ?
HM : C’est assez clair : jusqu’aux années 85-90, le traitement de l’image était porté par des applications qui étaient très consommatrices de gros moyens informatiques. C’était l’imagerie satellitaire, j’en ai déjà parlé : pour la défense, la surveillance, la cartographie. On pouvait le mâtiner d’applications civiles, du genre surveillance des ressources terrestres, suivi des cultures, des forêts, … mais, en gros, c’était quand même essentiellement piloté par des applications militaires. Deuxièmement : l’imagerie médicale. Marché très important démarré avec l’analyse des radiographies et le comptage cellulaire. C’est à ce moment la naissance de la tomographie, de l’imagerie ultrasonore, de l’IRM. Une véritable révolution dans le domaine de la santé, qui renouvelle totalement le diagnostic médical. Matériels très chers, développés par des entreprises hautement spécialisées et très peu nombreuses. Le traitement des images dans ce domaine, c’est du travail de super pros qui s’appuient sur une très étroite relation avec le corps médical. Troisième domaine d’application très professionnel, les applications de traitement de l’image pour les contrôles dans les entreprises : surveillance des robots, lecture automatique dans les postes, dans les banques, pilotage des outils. Si c’est de plus petite taille, ça reste quand même très professionnel.
Ce tableau s’applique, jusqu’aux années 90. Et là, la bascule s’est produite avec la démocratisation de la photo numérique dans des applications liées au web, à la photo personnelle, aux individus et au grand public, Bref le marché de la société civile. Là, on a trouvé des gens qui se sont intéressés aux mosaïques d’images, à la reconstruction 3D, à la reconnaissance de visages simplement pour des applications familiales ou entre amis.
B : Les photographes amateurs et les réseaux sociaux ?
HM : Oui, les réseaux sociaux. Ça ne s’appelait pas encore comme ça, mais c’était bien ça. Cette profusion d’images numériques dans les téléphones, les ordinateurs, les tablettes a fait basculer le traitement de l’image des domaines professionnels au domaine du grand public. Aujourd’hui, c’est le grand public qui tire, c’est très clair. Les développements des matériels, les appareils photos … Tout le monde a son appareil photo à 15 mégapixels, c’est absolument incroyable quand on voit le temps qu’il a fallu pour avoir une image numérique de 100 koctets !. Tous mes cours, commençaient par : « Une image, c’est 512 x 512 pixels.». Une base d’images numériques (comme celle du GdR Isis en France), c’était 30 images. Maintenant, tout le monde a sur son disque dur, des centaines d’images de plusieurs méga-octets. Ça, c’est le nouveau contexte du traitement de l’image. Je pense que cette nouveauté-là réagit très fortement sur les métiers du traiteur d’image. Si vous vous intéressez au renseignement militaire vous aurez probablement autant de renseignements en allant naviguer sur Google Earth qu’en envoyant des mecs se balader sur le terrain ou en lançant un nouveau satellite espion.
B : Et la science là-dedans ? Est-ce qu’il reste des problèmes durs ? Des problèmes ouverts, le Graal du traitement de l’image aujourd’hui ? Ou bien, est-ce que le plus gros est fait, qu’il ne reste plus qu’à nettoyer ici ou là ?
HM : Les problèmes nouveaux, oui, on a plein, parce qu’à la fin du siècle précédent, on considérait que si on voulait faire une application, la première chose qu’on demandait, c’est qu’il y ait des professionnels qui prennent les images avec du matériel pro. On se mettait toujours dans un contexte professionnel. Typiquement, pour la radiographie médicale, on achète un appareil à 15 millions d’euros, on prend deux techniciens à temps plein toute l’année et on fait des images dans des conditions parfaitement contrôlées. Donc on se met dans les meilleures conditions d’acquisition de l’image et à partir de là, bien sûr, on tire bon an mal an de bons résultats. Bon an mal an, parce que ce n’est pas si facile que ça. Mais dans les conditions naturelles de la vie : l’éclairage, l’attitude, le mouvement, le bruit, varient sans contrôle et rendent la tâche plus complexe. On dispose cependant de beaucoup plus d’images et de capteurs bien meilleurs et il faut réinventer les algorithmes avec ces nouvelles données. Naissent ainsi des problématiques nouvelles, extrêmement intéressantes, mais difficiles. Il faut trouver les bons invariants, jouer avec les lois de distribution pour détecter les anomalies, savoir faire abstraction des problèmes de géométrie. Et tout cela doit être caché à l’utilisateur qui n’a aucun intérêt aux invariants projectifs, aux matrices fondamentales, aux hypothèses a contrario …
B : Passons à un autre sujet. Au départ, tu étais physicien. Ensuite, tu es passé au traitement de l’image. Nous, on te revendique maintenant comme informaticien, mais quel est ton point de vue à toi ? Est-ce que tu te considères comme informaticien, ou sinon, qu’est-ce que tu es ? Dans le cadre général de la classification des sciences, tu te places où ?
HM : Je me sens tout à fait bien dans le monde de l’informatique, mais je revendique d’avoir non seulement une culture mais une sensibilité et une compétence qui vont au-delà, en particulier vers la physique, mais pas seulement. Par exemple je suis extrêmement soucieux de me maintenir en physique à un niveau qui soit suffisant, car je pense qu’on ne peut pas faire, dans mon domaine, de bonnes choses si on ne sait pas ce qu’est une réflectance, une albédo, ou une source secondaire.
B : Toute l’optique ?
HM : Une bonne partie de l’optique. Savoir ce qu’est une aberration, un système centré. Donc l’optique est importante. J’ai des sensibilités dans d’autres domaines : autour de la perception, du fonctionnement du cerveau, comment on traite la sémantique…
B : Des sciences cognitives ?
HM : Oui, ça pourrait relever de la science cognitive et c’est très important pour traiter les images. On ne peut pas parler d’image sans avoir une petite compétence en psycho-physiologie de la perception.
B : Est-ce que tu pourrais nous dire comment tu as vu l’enseignement changer au cours de ta carrière à Télécom et comment tu vois le futur de cet enseignement dans un monde où on parle beaucoup de MOOC et de choses comme ça qui font couler beaucoup d’encre ?
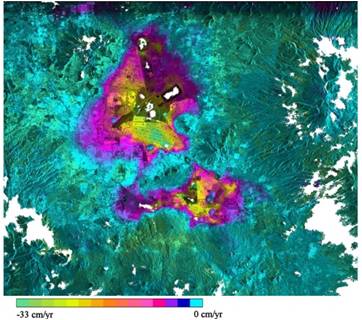 Mesure par interférométrie radar de la subsidance du bassin de Mexico
Mesure par interférométrie radar de la subsidance du bassin de Mexico
due à l’appauvrissement de la nappe phréatique : P. Lopez-Quiroz, F. Tupin, P. Briole
Télécom ParisTech et Ecole Normale Supérieure
HM : Puisque l’on destine cet entretien à la communauté de l’informatique, parlons d’elle tout d’abord. Cet enseignement m’a longtemps semblé beaucoup trop utilitaire à l’école. Afin de se laisser le temps d’aborder les domaines les plus pointus des réseaux, des mobiles ou des services en ligne, on passait très vite sur des fondements théoriques qui me semblent cependant indispensables pour structurer une carrière orientée par exemple vers le développement de très grands systèmes ou de réseaux complexes. Je vois d’un très bon œil que, dans le cadre de notre participation à l’Idex de Paris Saclay nous puissions confronter notre expérience pédagogique à celle d’équipes qui ont dans ce domaine de l’enseignement supérieur de l’informatique de très beaux résultats. J’en attends d’une part une nouvelle pédagogie beaucoup plus en profondeur pour un petit nombre d’élèves destinés à y consacrer leur première carrière, d’autre part pour tous les autres un renforcement net de leurs compétences par une meilleure compréhension des enjeux du numérique.
Je ne crois pas beaucoup à l’effet des MOOC dans ce domaine. Je les réserverais plutôt pour des domaines où la pédagogie est moins primordiale, peut-être vers les applications.
B : Qu’est-ce qui t’a le plus intéressé dans ta carrière ?
HM : La plus passionnante des expériences a été de travailler avec les laboratoires de recherche des musées de France, et en général c’est vers les applications que j’ai trouvé les plus grandes satisfactions, en frottant mes connaissances de traiteur d’image aux compétences d’experts d’autres domaines, qu’ils soient dans la restauration des peintures, dans la cartographie urbaine ou dans la détermination de l’altimétrie de la Guyane.
 Etude de la géométrie d’une œuvre de Georges de la Tour
Etude de la géométrie d’une œuvre de Georges de la Tour
(Saint Joseph Charpentier, Louvres)
mettant en évidence les principes de construction.
JP Crettez, Télécom ParisTech et Réunion des Musées Nationaux.
B : Tu as des exemples d’applications que tu as réalisées ?
HM : C’était avec les laboratoires de recherche des musées de France. Ça s’appelle maintenant le C2RMF. On a lancé dans les années 83-88 les bases des grands projets européens d’archivage des musées. On a essayé de mettre sur pied non pas des standards mais des critères qui permettent d’établir ces standards, sur la résolution spatiale, l’éclairage, la colorimétrie des bases de données de peintures. Nous étions les partenaires du Louvre et on a travaillé avec l’Alte Pinakothek à Munich, la National Gallery de Londres, et la Galleria degli uffizi de Florence, bien avant que Google s’intéresse au projet. Des projets européens, on en a monté cinq ou six sur les peintures mais aussi sur les objets à 3D, les statues et les vases C’était passionnant et particulièrement stimulant de discuter avec des conservateurs qui ne voulaient surtout pas voir leurs peintures ramenées à un boisseau de pixels.
HM : Un autre exemple de ce qui m’a beaucoup plu : définir la façon d’indexer les images de la nouvelle famille de satellites Pléïades qui a une résolution de 50 à 75 cm au sol, (toutes les minutes et demi, il tombe 640 méga-octets). Les gens ne peuvent plus traiter les images pour voir individuellement ce que chacune contient. On s’est posé la question de savoir comment indexer les images automatiquement quand elles arrivent, de façon à pouvoir répondre à des questions que l’on se posera dans 10 ans ou 20 ans. Il y a une grande partie de l’information qui est contrainte parce qu’on connait précisément la géographie, donc on sait que ce n’est pas la même chose si on observe du côté de Bakou ou de la Corne de l’Afrique. Mais derrière, il faut pouvoir identifier les champs, les rivières, les zones urbaines, les réseaux routiers, … Savoir s’il y a encore de la neige, ou du vent de sable, de telle façon qu’après, quand on recherchera des images, on retrouve toutes celles qui présentent une configuration identique. Pour cela, il a fallu tout construire de zéro car ça n’a bien sûr qu’un lointain rapport avec les bases de données d’images sur le web. On est obligé de faire des indexations hiérarchiques parce qu’il faut à la fois être précis lorsqu’on a trouvé la zone d’intérêt et rapide pour traiter des milliers d’images, chacune couvrant 1000 km2. Il a fallu discuter avec les utilisateurs : agronomes, géologues, urbanistes, cartographes, pour savoir comment faire les classes. Les gens qui s’occupent d’agronomie, veulent connaître le blé, l’orge, le riz, alors que, comme traiteur d’images, si j’ai reconnu des céréales, je suis très content ! Tu vas voir les urbanistes. Ils te disent : «Moi, je veux les quartiers résidentiels, les quartiers d’affaire, les banlieues, les zones commerciales, industrielles, etc. » et ainsi de suite. Il faut savoir quelles sont les classes qui sont raisonnablement utilisables et donc les questions que la société peut avoir face à l’image. Et je pense qu’à ce niveau-là, l’informatique a encore du boulot devant elle. Elle a encore du boulot parce qu’on va encore lui en poser des questions de ce type. La question n’est pas encore à l’ordre du jour sur le web « social », mais ça ne saurait tarder. Il n’y a qu’à voir comment à ce jour est indexée la musique pour comprendre où se situe le problème. Classer Brel dans la « musique du monde », pourquoi pas, mais qui en est satisfait ?
B : Dans la suite de l’entretien, Henri Maître partagera sa vision de l’évolution de l’image et des perspectives sociétales qu’elle peut avoir. Nous vous donnons rendez-vous demain pour découvrir sa vision…
 Henri Maitre, © Serge Abiteboul
Henri Maitre, © Serge Abiteboul





