Wendy Mackay est Directrice de Recherche à Inria Saclay, responsable de l’équipe InSitu. Elle est en sabbatique à l’Université de Stanford. Pionnière de l’IHM, elle est une des spécialistes les plus connues dans le domaine de l’interface humain machine. Elle nous fait partager sa passion pour ces aspects si essentiels de l’informatique, qui sont souvent au cœur des réussites comme des échecs des nouveaux logiciels et des nouveaux objets numériques.
 © Inria / Photo G. Maisonneuve
© Inria / Photo G. Maisonneuve
B : Bonjour Wendy. Pour commencer, une de tes grandes caractéristiques, c’est quand même d’être Américaine… Une Américaine qui fait de la recherche en France, c’est…
WM : C’est assez rare.
B : En effet. Est-ce que tu pourrais nous dire rapidement pourquoi tu as choisi la France pour faire ta recherche ?
WM : La réponse courte, c’est que je suis mariée avec un Français et il fallait choisir entre la France et les États-Unis. Si on veut fonder une famille avec deux chercheurs qui travaillent tout le temps, c’est beaucoup mieux en France qu’aux États-Unis. Nous avions des offres à Xerox PARC, à San Diego, à Toronto, mais finalement les raisons personnelles l’ont emportées. La réponse qui serait plus longue à détailler, c’est que j’avais envie de voyager. Je suis née au Canada, j’ai grandi aux États-Unis, j’ai fait mes études et j’ai travaillé sur la côte Est et sur la côte Ouest… Ce qui est intéressant c’est que l’IHM était déjà un domaine de recherche bien connu aux États-Unis mais pas en France pourtant c’est un domaine important, qui est derrière les succès d’Apple, de Google, et de beaucoup d’autres choses. Quand je suis arrivée en France, ce qui m’a frappée c’est qu’il n’y avait que les mathématiques qui étaient importantes en informatique et les aspects utilisation par les humains étaient délaissés. J’ai eu la chance de pouvoir créer quelque chose de nouveau ici et saisi l’opportunité de créer mon équipe de recherche au sein d’Inria Futurs (structure de recherche qui incubait les futurs centres de Bordeaux, Lille et Saclay).
B : Ainsi est née InSitu, première équipe de recherche d’Inria à Saclay ?
WM : À l’époque on pouvait embaucher des gens, avoir de l’espace. On a commencé avec quatre permanents et un thésard. Maintenant on a huit permanents et trois membres de l’équipe ont créé leur propre équipe. L’interaction est devenue l’un des thèmes stratégiques d’Inria. Même si c’est plus large que notre définition de l’IHM, cela inclut tout ce qui concerne l’être humain, comme par exemple l’interaction avec les robots.
B : Qu’est ce que l’interaction homme-machine?
WM : L’interaction homme-machine, c’est un domaine vraiment pluridisciplinaire, avec trois grands axes. Il y a la partie informatique : comment concevoir le système. Un système interactif, ça ne marche pas tout seul, il faut un va-et-vient avec l’être humain, cela pose des problèmes informatiques. Le deuxième axe, c’est la psychologie, la sociologie et tous les aspects humains. L’attention, la perception, la mémoire, la motricité, tout cela : quelles sont les capacités et les limites de l’être humain. Et le troisième axe, c’est le design : comment concevoir le système interactif. Ce n’est pas seulement l’aspect esthétique, mais la conception de…
B : L’ergonomie ?
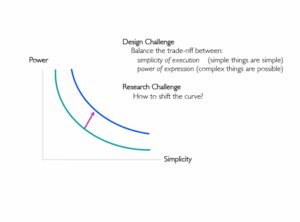
WM : Pour moi l’ergonomie cela concerne plutôt l’évaluation du système que la conception. C’est l’un des outils que l’on utilise lorsque l’on crée un système interactif, mais ce n’est pas vraiment le design. Par exemple, une idée répandue est qu’il faut faire des choses simples à utiliser. Mais pour nous ce n’est pas simple de faire des choses simples, et il y a toujours un compromis, un trade-off, entre la simplicité et la puissance. L’une des règles est qu’il faut pouvoir faire les choses simples simplement, mais il faut aussi avoir la possibilité de faire des choses complexes. Alors on ne veut pas compliquer ce qui est simple mais on veut aussi donner la possibilité de faire des choses plus avancées.
B : D’apprendre aussi ?
WM : Oui. L’apprentissage c’est l’adaptation du côté de l’être humain et c’est très intéressant. En fait c’est une grande partie de ma recherche actuelle. Je travaille sur un concept qu’on appelle co-adaptive instruments. Je veux réinventer les interfaces actuelles, les GUI ou graphical user interfaces. Ce sont tous les dossiers, les fichiers, les fenêtres que l’on trouve sur tous les ordinateurs. Ces interfaces graphiques ont été conçues à Xerox PARC il y a 35 ans. C’était destiné aux secrétaires de direction et c’est la raison pour laquelle on parle de couper / coller, de fichiers et de dossiers, etc. : parce que c’est leur univers. Ça a été une grande réussite, mais c’était conçu à l’époque où les machines étaient très chères et le coût du travail d’un salarié beaucoup moins élevé qu’actuellement. La plupart des ordinateurs étaient faits pour des experts. L’interface créée par Xerox était la première destinée à des non-experts, mais il s’agissait quand même d’utilisateurs dont le but était de travailler sur ordinateur. Depuis cette époque, on utilise cette métaphore du bureau pour tout, mais on se rend compte qu’elle ne marche plus vraiment car cela crée plein de limites pour de nouvelles fonctions. Sur le web aussi : on a gagné la possibilité de distribuer les documents très largement mais on a perdu beaucoup du côté de l’interaction. Finalement, ce que l’on peut faire sur un site web est assez limité : cliquer des liens et remplir des formulaires, la plupart du temps. Et puis maintenant il y a les applications sur smartphones et tablettes. C’est encore une autre façon de concevoir l’interaction. Ces appareils sont incroyables, mais ils poussent à une interaction simple, et parfois simpliste. Il y a des barrières entre les applications et on ne peut pas partager des choses si facilement que ça. On voit qu’il y a eu une évolution dans trois directions pour des raisons historiques et techniques sur les interfaces graphiques, le web et les applications, mais on n’a pas vraiment pensé à la perspective de l’utilisateur. Si on change de perspective et qu’on pense aux capacités de l’être humain plutôt qu’à celles de la technologie, on doit se demander : qu’est-ce que l’utilisateur veut faire et peut-on lui offrir ce dont il a besoin ?
 Paper Tonnetz; © Inria / Photo H. Raguet
Paper Tonnetz; © Inria / Photo H. Raguet
B : On touche là les questions qui touchent ton sujet de recherche en particulier ?
WM : En effet. Je vais prendre l’exemple du clavier. En France vous avez des claviers AZERTY. Moi j’utilise un clavier QWERTY, et mes doigts savent taper vite sur ce clavier. Aux États-Unis, on apprend à taper au clavier dès le lycée, et c’est très utile ! Mais quand je suis sur un clavier AZERTY, je suis plus lente que quelqu’un qui tape avec deux doigts parce que j’ai appris sur un clavier un différent. C’est un peu la même chose quand on demande aux gens, à chaque fois qu’ils changent d’application ou de machine, de réapprendre comment effectuer les mêmes fonctions. On est toujours en train d’imposer aux utilisateurs de changer entre QWERTY et AZERTY. Ça bouscule les habitudes et on y perd en efficacité. La vision que je défends dans ma recherche, c’est que les méthodes d’interaction doivent accompagner l’utilisateur et ne pas lui être imposées par le système.
B : Pour faire une analogie, en gestion de connaissances, on retrouve un peu la même problématique. Pour utiliser un système d’information, il vous faut apprendre la terminologie de ce système, son ontologie, alors que vous devriez pouvoir l’interroger ou interagir avec en utilisant votre propre langage, votre propre ontologie. Ça correspond à ce que tu expliques ?
WM : Oui, c’est la même chose. Comme êtres humains, nous sommes très forts pour apprendre des choses, mais pas très forts pour ré-apprendre des choses un peu différentes. C’est un peu comme si pour un pianiste, on changeait l’ordre des touches ou l’ordre des lignes sur la portée de temps en temps, aléatoirement. « Allez, jouez ! » Au comprend bien qu’au niveau moteur, de ce qu’on appelle la « mémoire des muscles », c’est un problème. Mais l’exemple que tu as donné était sur la terminologie, et c’est le même problème. Par exemple on a travaillé récemment sur la sélection de couleurs. Pourquoi est-ce différent dans Word, Excel, InDesign, PowerPoint ? Même dans Word, c’est différent si je change la couleur de texte ou la couleur de fond ! Ce que je veux, c’est choisir la façon dont je veux choisir une couleur et l’utiliser dans n’importe quelle application. En plus de faciliter l’apprentissage, ce qui est intéressant c’est que ça permet à différents utilisateurs d’utiliser différents sélecteurs. Et ça permet aussi à un même utilisateur de choisir un sélecteur différent selon la situation.
B : C’est-à-dire que tout le monde n’a pas forcément envie d’utiliser le même crayon.
WM : Exactement. Si je prends une artiste graphique, on imagine qu’elle a vraiment besoin de pouvoir choisir ses couleurs de manière précise et de créer des palettes de couleurs. Elle a pris le temps d’apprendre à utiliser des outils complexes et puissants. Mais un fois rentrée chez elle, cette même artiste a envie de dessiner avec sa fille de 4 ans, et là elle a juste besoin de choisir entre 4 couleurs. C’est la même personne, mais dans des contextes différents, avec des buts différents et des personnes différentes. Il faut donc bien comprendre comment les gens utilisent l’ordinateur, quels sont leurs besoins dans ces différentes situations. Il faut aussi que quand on passe d’un ordinateur à un autre, d’un laptop à un smartphone, il y ait une continuité. Bien sûr, il y a des différences : un clavier physique est différent d’un clavier tactile. Mais c’est l’utilisateur qui doit pouvoir décider comment interagir selon son contexte d’usage.
Alors nous avons créé le concept d’instrument d’interaction et de substrate, de support d’information. Nous voulons que les instruments d’interaction soient des objets de première classe, qui appartiennent aux utilisateurs et qu’ils puissent les conserver et les utiliser dans n’importe quelle application. Les substrates permettent de filtrer l’information, de créer un contexte pour présenter les données, et que les mêmes données puissent être présentées dans différents substrates, par exemple du texte, un tableau ou un graphe. Le résultat est que cela change le business model pour le logiciel. Si on est Microsoft, on ne vend plus des grosses applications monolithiques avec des barrières étanches, mais une collection d’instruments et de substrates que les gens peuvent choisir et assembler à leur façon.
B : Est-ce que ça ne demande pas de définir quelque chose qui serait des API d’interaction, qu’on pourrait ensuite intégrer dans différents outils ?
WM : Oui, en effet, on travaille sur ces API d’interaction. Mais c’est encore assez récent et cela soulève plein de questions intéressantes : comment le système peut-il aider à apprendre à utiliser un nouvel instrument ? Comment adapter un instrument à ses besoins ? En fait on imagine quelque chose qu’on pourrait appeler une physique de l’information. Par exemple, si j’ai le concept de couleur, je peux avoir des outils pour tester les couleurs, les changer, les archiver – c’est assez universel. Je peux les utiliser même si l’application ne l’a pas prévu. Et puis les gens vont s’en servir aussi de manière non prévue. Si je prends l’exemple d’un outil physique, par exemple un tournevis, c’est fait pour enfoncer des vis, mais je peux aussi m’en servir pour ouvrir une boite de conserve, pour attacher mes cheveux, pour caler la porte, pour…
B : Assassiner quelqu’un avec un tournevis ?
WM : Je n’espère pas ! Mais l’idée c’est que les gens adaptent les objets physiques tout le temps. Tout le temps. C’est ce qu’on fait en tant qu’êtres humains. Et bizarrement on a créé des systèmes informatiques qu’on ne peut pas facilement adapter à nos usages. Et c’est pour cela que je m’intéresse aux usages de l’ordinateur pour la créativité. Car les créatifs n’ont pas peur de tester les limites des outils pour voir ce que ça donne, de faire des combinaisons qui n’étaient pas prévues par les concepteurs, etc.
B : Est-il possible de faire cela sans écrire de code ? Est-ce que spécifier comment on va utiliser une séquence d’outils l’un après l’autre et dire que si tel outil ne marche pas, allez alors utiliser tel autre, etc. C’est déjà un peu écrire du code ?
WM : Oui. Et on peut le faire de manière assez visuelle, ou en disant : « Regarde-moi : j’ai fait ça et ça. ». Mais on retombe sur cette question de puissance et de simplicité. Comment faire un système où ce que je fais en temps normal reste simple, mais où j’ai aussi la possibilité de faire des choses plus complexes, ou de travailler avec quelqu’un de plus expert qui ne fait pas les choses pour moi mais me permet d’acquérir de l’expertise ? C’est un peu la vision de mon projet. C’est ambitieux et si j’étais immodeste je dirais que ça peut changer le monde… Le point important, c’est qu’on veut montrer comment repenser l’interaction. Par exemple, pour gérer les grandes quantités de données, il y a les langages de requête, les ontologies, etc. Mais c’est plutôt destiné aux experts. On peut aussi utiliser une approche visuelle, comme mon collègue Jean-Daniel Fekete qui travaille sur la visualisation interactive d’information. En fait on peut imaginer plein de façons d’interagir avec une base de données, mais on n’a pas de bonne conception des outils nécessaires pour interagir de façon cohérente pour un utilisateur qui n’est pas expert. Et je pense que si l’on considère l’interaction comme un objet de première classe, on peut répondre à ces questions et faire en sorte que des êtres humains normaux – pas des informaticiens ! – peuvent gérer des informations complexes.

B : Peux-tu nous dire quelles ont été les grandes transformations ou les grandes avancées de ton domaine ?
WM : Depuis 20 ans, l’interaction est sortie de l’écran et du clavier. J’ai participé au lancement de la réalité augmentée, qui à l’époque était vue comme l’inverse de la réalité virtuelle. Cela a aussi abouti aux interfaces tangibles, où on utilise des objets physiques pour interagir. Le papier interactif, sur lequel je travaille beaucoup, est une combinaison des deux. Plus récemment, il y a un grand intérêt pour l’interaction gestuelle avec les tablettes, les Kinect, etc., et puis le crowdsourcing, qui essaient d’utiliser l’intelligence humaine quand l’ordinateur ne sait pas faire. J’oublie plein de choses, bien sûr.
On peut aussi parler de l’impact industriel. Par exemple, j’ai passé deux ans à Stanford, au HCI Lab, dirigé par Terry Winograd. Larry Page était son thésard. Il n’a jamais terminé sa thèse, mais il a créé Google. Pas mal ! En 2009, je me souviens avoir parlé avec Mike Krieger, toujours à Stanford, de mes recherches sur la communication à distance entre personnes proches et de notre notion de communication ambiante, et aussi de vidéo, etc. J’ai essayé de le prendre comme thésard mais il n’a pas voulu car il travaillait sur un petit projet. C’est devenu SnapChat… Il y a beaucoup d’exemples comme ça aux États-Unis.
En France, ce n’est pas pareil. C’est dur de convaincre les industriels. On leur dit : « voilà une bonne interface » et ils répondent « oui, mais il y en a une qui marche déjà bien ». C’est l’avantage d’avoir habité dans plusieurs pays : on voit l’influence de la culture. En informatique, la culture américaine est très présente. Je commence à le voir après 20 ans passés en dehors des États-Unis, mais je reste américaine !
B : : Il semble y avoir un changement de comportement par rapport aux modes traditionnels d’accès à l’information. On constate par exemple que les jeunes semblent avoir du mal avec l’écrit ?
WM : En effet. Ce que je vois c’est que tout le monde pense que l’accès à l’information passe forcément par les interfaces graphiques actuelles. Moi j’ai « grandi » avec une Lisp Machine d’un côté, une station Sun sous Unix de l’autre. Avec Hal Abelson et Andy diSessa au MIT on a travaillé sur un système qui s’appelait Boxer, une sorte de Lisp visuel. Il y avait aussi Lego Logo, plein d’autres systèmes avec des hypothèses différentes. Aujourd’hui les gens ne connaissent que Windows, les applications, et le web, et c’est extrêmement limité. Et même les étudiants de nos Masters ont vraiment du mal à penser plus largement que ça et c’est un dommage. Et pour les plus jeunes, c’est vrai qu’ils ont du mal à écrire, peut-être parce qu’ils tapent tout le temps des SMS ?
B : Avec les interfaces graphiques, les gens apprennent-ils autre chose que l’écriture dite classique ?
WM : Je me souviens du moment où je suis passé de la recopie de texte écrit à la main à la rédaction directement sur l’ordinateur. Il y a des écrivains qui n’ont jamais fait ce pas et, de nos jours, des jeunes n’ont jamais fait la première partie : rédiger sur papier. C’est très différent, comme interaction. L’écriture, c’est très physique. Mais de pouvoir taper au clavier, c’est un bon changement en fait. Le champ des possibles su le papier est aussi varié : on peut aussi dessiner, faire des schémas, écrire de la musique. En fait, je travaille sur le papier interactif depuis 20 ans maintenant. Il y a des technologies comme Anoto, qui permettent de capturer ce que l’on écrit sur papier, et puis il y a des écrans qui ressemblent à du papier, comme celui du Kindle. Le papier électronique, c’est un peu cela le rêve : combiner ces deux technologies pour faire du papier interactif. C’est une question de temps. Mais ce qui m’intéresse, c’est que lorsque j’étudie des gens qui doivent utiliser l’ordinateur, comme les biologistes qui ont besoin de bases de données de gènes, d’algorithmes de séquençage, etc. Ils utilisent toujours le papier pour prendre des notes.
B : Même les jeunes ?
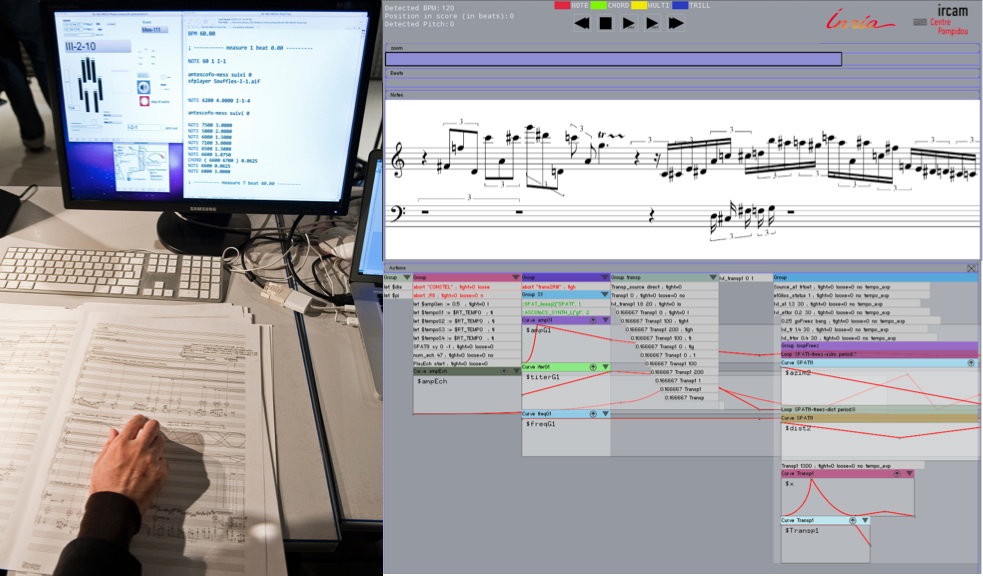
WM : Oui, même les jeunes. On essaye de comprendre les raisons de cela. En ce moment on travaille avec des musiciens et des compositeurs à l’IRCAM. On les appelle des « utilisateurs extrêmes » car ils poussent les limites de la technologie. Ils utilisent beaucoup l’ordinateur, mais ils travaillent aussi sur papier. Ils ont besoin des deux. Ce qui est très intéressant, c’est de comprendre quels sont les aspects du papier qui sont importants pour eux. Et la réponse est : pour pouvoir exprimer leurs idées plus facilement. Quand je suis sur l’ordinateur, je suis dans une application et je ne peux faire que ce qui a été prévu par ses concepteurs. Avec le papier, j’ai une grande souplesse d’expression. Je peux faire des schémas, tracer des courbes, écrire du texte. Les compositeurs veulent exprimer une idée musicale sous forme de dessin. Ils ne savent pas forcément encore ce que c’est. Alors comment créer une application sur un ordinateur pour aider quelqu’un à exprimer quelque chose qui est dans sa tête et n’est pas encore parfaitement défini ? C’est ça, en partie, la créativité dont je parlais tout à l’heure. En plus, chaque compositeur veut être unique : si je conçois une application qui répond exactement au besoin d’un compositeur, un autre ne voudra pas l’utiliser. Il faut donc réaliser un système que les utilisateurs peuvent personnaliser dès le début, mais avec lequel ils peuvent aussi immédiatement exprimer leurs idées. C’est un vrai défi. Et nous avons réalisé une série d’outils pour relever ce défi, et certains sont utilisés par des compositeurs pour des pièces qui vont être jouées en public. Et là aussi on utilise notre notion de substrate. Je vous fais une explication sur le tableau.
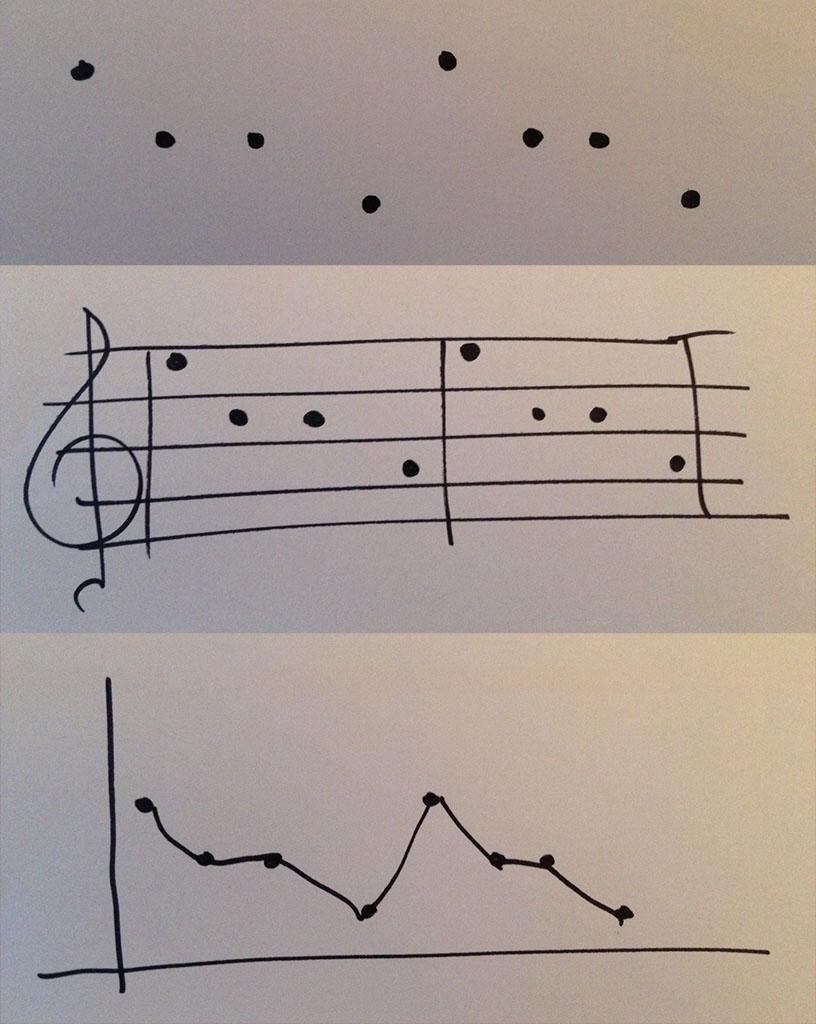
Si je fais une série de points (Wendy met des points apparemment au hasard sur le tableau…) et que je dis à l’ordinateur : « interprète cela », ça peut être plein de choses. Mais si j’ajoute ça (Wendy dessine cinq lignes), maintenant tout le monde comprend : c’est une portée. Mais qu’est-ce qui se passe si je fais ça (Wendy dessine deux axes perpendiculaires) ? C’est un graphe, du papier millimétré. L’idée, c’est qu’on peut créer différents contextes pour les données. Les points sont les données et la portée ou les axes, c’est ce qu’on appelle le substrate. C’est un moyen d’organiser les données, mais aussi de les interpréter, de définir ce que l’on peut faire avec. Cela touche aussi à ce que certains chercheurs font en base de données : comment organiser les données.
 © Wendy Mackay
© Wendy Mackay
B : Si l’on se penche sur le nom de ton équipe : Insitu. Dans le domaine artistique, in situ, c’est l’art qui est dans son contexte, l’art qui est dans sa position. Comme le street art. C’est lié à ça, le choix du mot in situ ?
WM : Un peu. InSitu, c’est aussi l’abréviation de « interaction située ». C’est l’idée que les êtres humains utilisent toujours l’ordinateur dans un certain contexte et qu’il ne faut pas considérer l’interaction de façon abstraite, mais par rapport à ce contexte. Bien sûr, on utilise des abstractions pour concevoir le système, mais il ne faut pas oublier le contexte. Il y a un autre aspect, c’est que je travaille toujours avec de vrais utilisateurs et de vraies situations. J’ai observé les contrôleurs du trafic aérien, les biologistes de l’Institut Pasteur, les compositeurs de l’IRCAM pendant des dizaines d’heures. Nous travaillons avec eux, on fait des ateliers, on conçoit des prototypes qu’ils peuvent utiliser pour jouer leur musique, analyser leurs données biologiques, utiliser le même simulateur de trafic aérien sur lequel ils s’entraînent. C’est très important de voir comment les prototypes marchent dans ces situations réelles.
B : Est-ce que ça veut dire que la valeur de votre travail dépend du moment de l’histoire où on est ? Ou est-ce que vous avez des théorèmes ou des axiomes, des principes intemporels ?
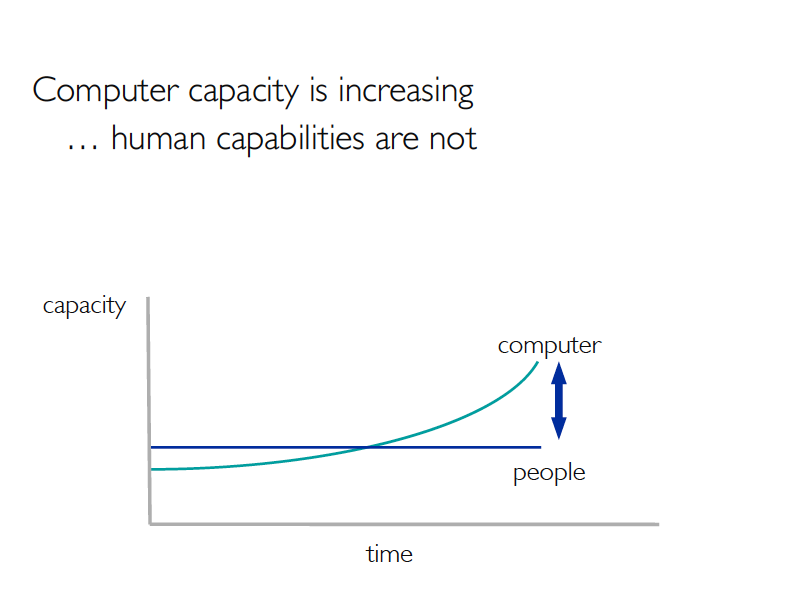
WM : Avec ma formation en psychologie expérimentale, ce qui m’intéresse c’est que l’on travaille avec des êtres humains. Si je regarde l’évolution de l’être humain au niveau cognitif depuis, disons, l’invention de l’ordinateur, j’ai une courbe plate. Peut-être que ça bouge un peu, on parlait des jeunes tout à l’heure, mais c’est à peu près plat. Mais pour les ordinateurs, avec la loi de Moore, on a une courbe comme exponentielle. C’est la capacité de stockage, la capacité de calcul, les réseaux.
B : Donc là, tu as marqué sur ton dessin que les machines sont devenues plus « quelque chose » que les êtres humains aux alentours de 1980… Plus intelligentes ?
WM : (rire) Non, ce n’est pas ça… Il y a des gens comme Ray Kurzweil qui croient à ce point de convergence, la « grande singularité » où les machines vont dépasser l’homme. Moi je n’y crois pas parce que les êtres humains ne fonctionnent pas de la même façon que les ordinateurs. Mais il y a cette idée que la capacité de l’ordinateur augmente et que la complexité de ce que l’on traite avec l’ordinateur augmente de façon spectaculaire, alors que nos capacités à gérer toute cette information n’ont pas augmenté. C’est la raison de l’information overload.
B : La surcharge d’information ?
WM : C’est ça. Nos capacités sont de plus en plus limitées par rapport à la quantité d’informations et la complexité du système qu’on utilise. Alors il faut que les systèmes prennent bien en compte ces limitations. Il y a des normes, des capacités de l’être humain qu’on connaît et qu’on utilise dans la conception de nos systèmes. Par exemple il y a la Loi de Fitts, qui peut prédire précisément le temps qu’il faut pour déplacer le curseur vers une cible, comme un bouton, en connaissant la distance et la taille de la cible. Il y a aussi des connaissances qui viennent des sciences sociales, de la psychologie, même de la biologie. On peut utiliser cette connaissance de ce qui ne change pas beaucoup pour gérer cette augmentation de complexité du côté de l’ordinateur.
B : Wendy, un dernier point que tu aurais aimé souligner, que nous n’aurions pas abordé ?
WM : Je suis née au Canada, j’ai grandi aux États-Unis, et j’ai passé une grande partie de ma carrière en Angleterre et en Europe. Ce sont les quatre endroits où il se passe beaucoup de choses dans notre domaine. J’ai l’impression que pour beaucoup d’informaticiens, la culture n’a pas beaucoup d’influence sur leur domaine. Mais en interaction homme-machine, c’est important. Du côté européen, c’est plus théorique, du côté nord-américain, c’est plus pratique. L’IHM est très présente maintenant dans les meilleures universités aux États-Unis, au Canada et en Angleterre. C’est moins le cas dans le reste de l’Europe. Par exemple, Stanford a sa d.School et Carnegie Mellon University a le HCI Institute, le plus grand centre d’IHM au monde. Il y a aussi le MIT, l’Université de Toronto, Berkeley, etc. Et ils sont toujours à côté d’une école de design, ce qui est intéressant. Côté design, en Europe, le Royal College of Art à Londres a été le premier à enseigner le design pour l’IHM et en Italie il y a eu Ivrea qui était aussi une école de design mais liée à l’informatique. Au Pays-Bas, le design est très développé et Philips à Eindhoven a aussi poussé en ce sens. En France, c’est très difficile. On est très monodisciplinaire en France.
 B : Il n’y a pas assez de connexions ou de relations entre les écoles de design françaises et les écoles d’informatique selon toi ?
B : Il n’y a pas assez de connexions ou de relations entre les écoles de design françaises et les écoles d’informatique selon toi ?
WM : Beaucoup trop peu. On a essayé avec l’ENSCI (l’Ecole Nationale Supérieure de Création Industrielle) plusieurs fois. Quand on a réussi, c’était très intéressant mais très difficile car les écoles de design sont gérées de façon différente, il est très dur pour un étudiant de prendre des cours des deux côtés. L’ENSCI a des liens avec le CEA, c’est sans doute plus facile pour des groupes de recherche industrielle. Mais en France, le manque de pluridisciplinarité vient du fait que les étudiants sont orientés très tôt. Ça crée des problèmes. Par exemple nous avons deux Masters en IHM à Paris-Sud : l’un pour les entrepreneurs, l’autre pour les chercheurs. Ils sont enseignés en anglais et la plupart de nos étudiants (100% des entrepreneurs et 90% du Master recherche) ne sont pas français. Je trouve ça dommage. L’autre chose, c’est que les étudiants en France ne savent pas ce qu’est la recherche. Ça arrive très tard, à la fin du M2 avec le stage de recherche. Et ils n’ont pas non plus l’expérience de définir leurs propres projets, ce sont les enseignants qui imposent le sujet. Quand on va au MIT, il y a des espaces partout pour faire des projets. Les étudiants sont toujours en train de travailler sur des projets. Il y a même un système qui s’appelle UROP, Undergraduate Research Opportunities Program pour qu’ils puissent travailler, dès le début de la licence, dans un labo et être payés (pas beaucoup) pour participer à la recherche dès le début de leur scolarité. Et ça change tout : les gens sont plus curieux, plus ouverts, plus autonomes. En France, un étudiant fait un Master de deux ans et il commence son premier stage de recherche à la fin de tous les cours.
B : C’est un peu vrai à l’université. C’est un petit peu moins vrai dans les grandes écoles
WM : C’est vrai, mais c’est vraiment dommage, et c’est vraiment trop tard.
Comment savoir si on veut faire de la recherche ? La recherche, ce n’est pas juste une question d’intelligence. C’est aussi une question de curiosité, de personnalité. Il y a des gens qui sont faits pour être chercheur, d’autres non… Il faut être un peu rebelle pour être un bon chercheur, je pense. Comment savoir, si c’est à l’âge de 23 ans qu’on fait pour la première fois un peu de recherche ? Comment décider, après seulement quelques semaines de stage, si on veut candidater à une thèse ? Il y a des étudiants qui manquent de confiance et qui disent : « ah, je ne suis pas sûr de pouvoir le faire ». Et d’autres pensent : « bon, il faut travailler dans l’industrie parce qu’il faut gagner sa vie ». Mais c’est une belle vie, la recherche, pour les gens qui ont les capacités… Alors je trouve qu’on est en retard pour cette ouverture sur la recherche, et c’est aussi dommage pour ceux qui vont dans l’industrie. Moi, j’ai passé une partie de ma vie dans l’industrie, d’abord dans la R&D. Les travaux qu’on a fait en recherche sont devenus des produits qui ont rapporté du bénéfice et j’ai été chef d’un groupe où l’on a développé plein de logiciels. Au bout d’un moment, je me suis lassée et je me suis dit : non, c’est beaucoup mieux de faire de la recherche. Je suis revenue dans la recherche et j’adore ça. Mais je comprends les deux aspects, le développement de produits et la recherche, et cela m’a aidé des deux côtés. Il y a toujours des problèmes quand on fait des vrais produits dans le monde réel. Il y a les plannings à respecter, les spécifications fonctionnelles, etc. ; il y a la réalité, qui est très différente. Soit on s’adapte, soit on est absolument bloqué. je pense que si l’on fait un peu de recherche quand on est plus jeune, quand on va dans l’industrie ça donne un peu plus de souplesse pour gérer ces situations. Voilà, c’est l’interaction située, encore une fois ! En conclusions, j’aime beaucoup faire de la recherche en France. C’est difficile aux États-Unis en ce moment, car il y a beaucoup de pression pour faire des choses utiles à l’industrie. Moi, j’aime la capacité de pouvoir penser à plus long terme.


 B : Que sait-on dans ce domaine ?
B : Que sait-on dans ce domaine ?