B – Tu peux nous parler un peu de ton parcours ?
MT – Je viens de la psychologie. J’ai choisi de faire un doctorat en neuroscience à la Salpêtrière (Université Pierre et Marie Curie) en 2007. Puis j’ai fait un post-doc à Londres sur la cartographie des réseaux cérébraux. Je suis depuis 2012 au CNRS. Nous utilisons beaucoup l’imagerie numérique. Nous faisons aussi un peu d’analyse postmortem pour vérifier que ce que nous avons vu dans les images correspond à une réalité.
B – Il nous faudrait partir un peu de la base. Qu’est-ce que c’est l’imagerie du cerveau pour les neurosciences ?
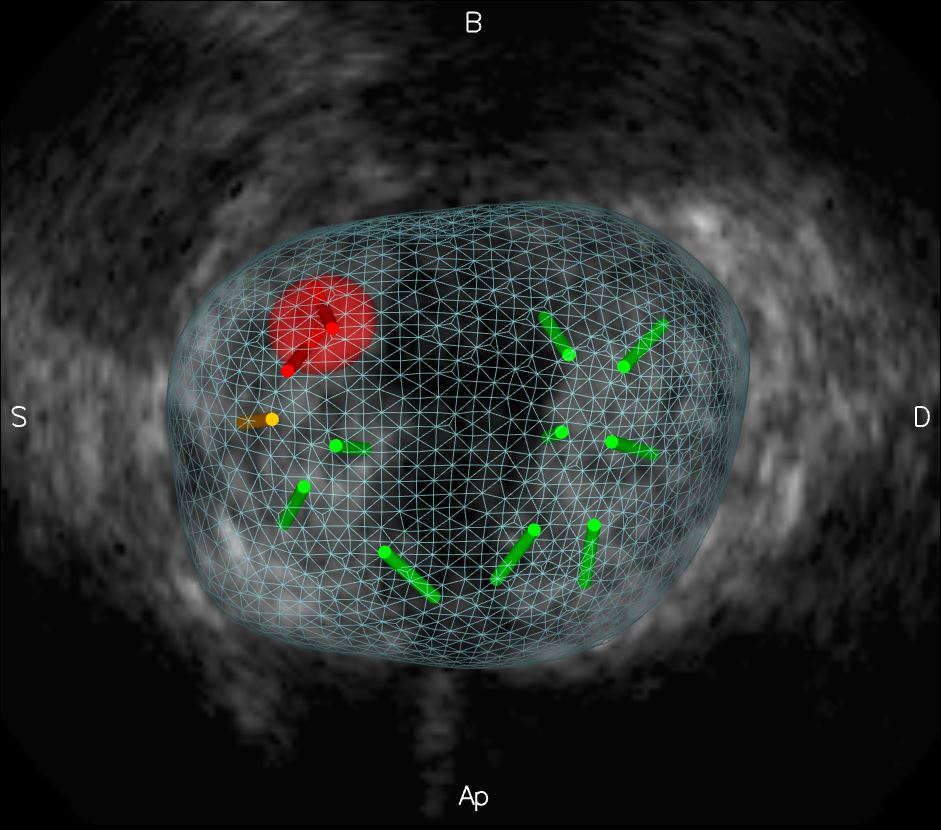
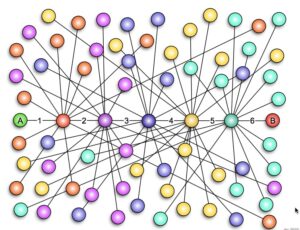
MT – À l’aide de l’Imagerie par résonance magnétique, on peut étudier soit la forme et le volume des organes (IRM anatomique), soit ce qui se passe dans le cerveau quand on réalise certaines activités mentales (IRM fonctionnelle). À partir des données d’IRM, on peut dessiner les réseaux du cerveau humain. Les axones des neurones sont des petits câbles de 1 à 5 micromètres, avec autour une gaine de myéline pour que l’électricité ne se perde pas, ils se regroupent en grand faisceaux de plusieurs milliers d’axones (Figure 1). C’est ce qui construit dans le cerveau des autoroutes de l’information. On peut faire une analogie avec un réseau informatique : les neurones sont les processeurs tandis que les axones des neurones forment les connexions.
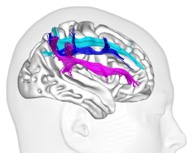
B – Et ces connexions sont importantes ?
MT – Super importantes ! Un de mes premiers travaux a été de réaliser un atlas des connexions cérébrales afin de savoir quelles structures étaient reliées entre elles par ces autoroutes. En effet, pour chaque traitement cognitif, plusieurs régions doivent fonctionner en collaboration et s’échanger des informations (exactement comme différents processeurs dans nos ordinateurs). On voit aussi l’importance des connexions cérébrales quand certaines sont rompues suite à une maladie, un AVC, un accident. Cela conduit à des incapacités parfois très lourdes pour la personne.
On estime que la vitesse de transmission de l’information dans ces réseaux est comprise entre 300 et 350 km/h ; la même que celle du TGV qui me transporte de Bordeaux à Paris mais bien loin de la vitesse de transmission de l’information dans une fibre optique. Heureusement, les distances sont petites.
B – Ça a l’air un peu magique. Comment est-ce qu’on met en évidence les connexions entre des régions du cerveau ?
MT – Tout d’abord il faut préciser qu’on doit faire des mesures sur plusieurs personnes car, même si nos cerveaux possèdent des similarités, il existe des différences notables entre individus. Il faut faire une moyenne des résultats obtenus pour chaque sujet pour obtenir une cartographie en moyenne.
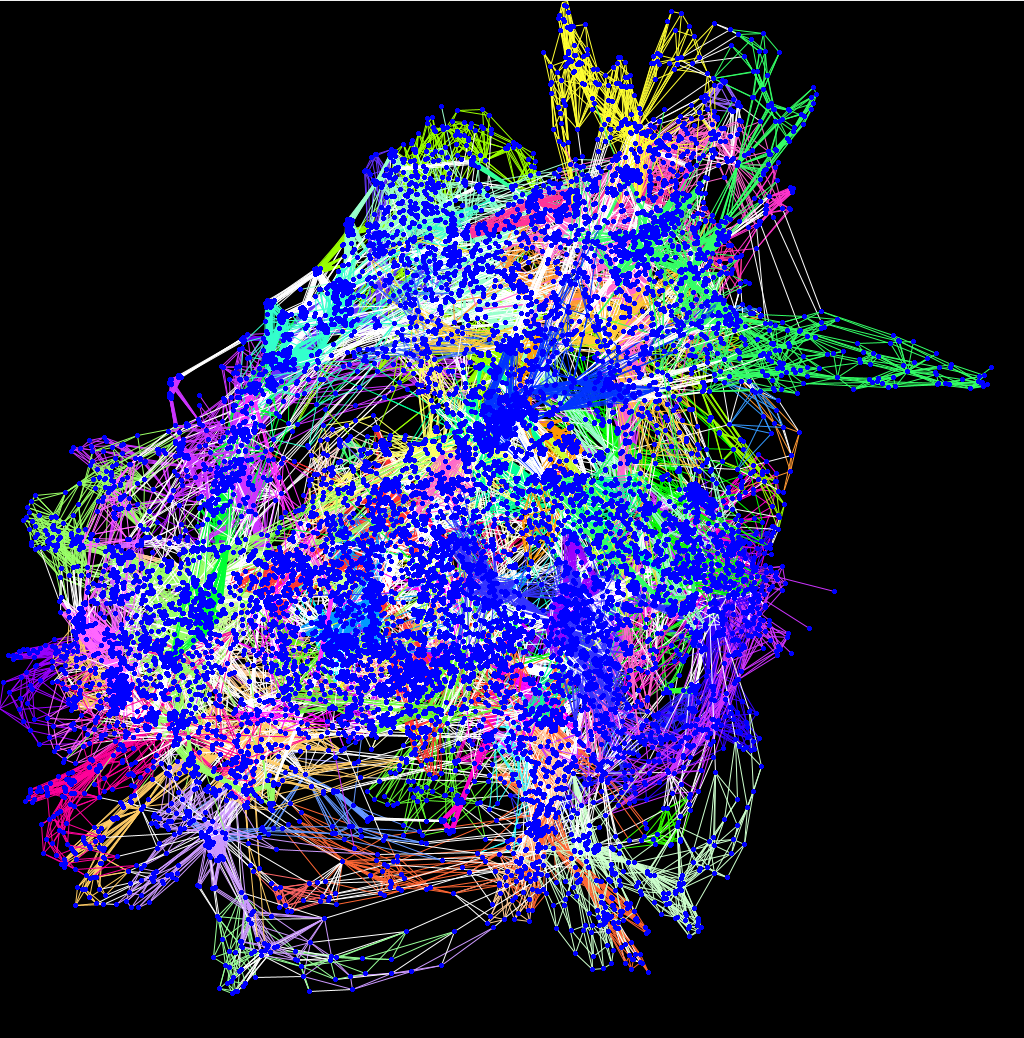
L’IRM est en mesure de détecter les mouvements de particules d’eau et grâce à la myéline autour des axones qui joue le rôle de l’isolant d’un fil électrique, les mouvements de particules d’eau sont contraints dans la direction de l’axone. Ainsi en suivant cette direction on peut reconstruire les grandes connexions cérébrales. On obtient alors une carte des connexions qui ressemble à un plat de nouilles. Imaginez qu’à un millimètre de résolution, on détecte environ 1 million de connexions cérébrales qui sont repliées sur elles-mêmes dans un volume d’environ 1,5 litre ; c’est très dense !
Il faut donc ensuite démêler ces connexions pour pouvoir les analyser finement. Au début, on partait des atlas anatomiques dessinés au 19e siècle et on essayait de reconnaître (d’apparier) les réseaux détectés avec les structures connues. Puis, on a essayé d’obtenir ces connexions en les extrayant manuellement à l’aide de requêtes comme « afficher les connexions qui relient les zones A et B sans passer par la zone C ». Aujourd’hui, on utilise des algorithmes d’extraction automatique qui détectent des composantes principales (des tendances) pour construire des faisceaux de connexion. Ces systèmes s’inscrivent dans ce qui s’appelle les neurosciences computationnelles.
B – Ces réseaux ne sont pas rigides. Ils évoluent dans le temps.
MT – Oui. Un bébé naît avec beaucoup plus de connexions que nécessaire. Puis, pendant toute l’adolescence, ça fait un peu peur, on perd des connexions en masse ; on avance le chiffre de 300 000 connexions perdues par seconde. Mais dans la même période, on spécialise et on renforce celles qui nous sont utiles ; leur utilisation augmente le diamètre et donc le débit de la connexion.
On considère que le cerveau atteint sa maturité autour de 20 ans ; après, il est plus difficile de changer notre réseau de connexions, on se contente d’ajuster le « câblage ». Il est donc fondamental d’acquérir de nombreux apprentissages dans sa jeunesse afin d’arriver au plus haut potentiel cérébral au moment où commence le déclin cognitif.
Il est aussi clairement démontré que l’activité cérébrale aide à mieux vieillir. Un neurone qui ne reçoit pas d’information via ses connexions avec d’autres neurones réduit sa taille et peut finir par mourir. On peut faire une analogie avec les muscles qui s’atrophient s’ils ne sont pas sollicités. En utilisant son cerveau, on développe sa plasticité.
Enfin, si à la suite d’un traumatisme, la voie directe entre deux régions du cerveau est endommagée, le cerveau s’adaptera progressivement. L’information prendra un autre chemin, moins direct, même à l’âge adulte. Mais la transmission d’information sera souvent plus lente et plus limitée.
B – Est-ce que nous avons tous des cerveaux différents ? De naissance ? Parce que nous les faisons évoluer différemment ?
MT – On observe une grande variabilité entre les cerveaux. Leurs anatomies présentent de fortes différences. Leurs fonctionnements aussi. On travaille pour mieux comprendre la part de l’inné et de l’acquis dans ces différences. On a comparé les cerveaux de chefs cuisiniers et de pilotes de F1. On a aussi analysé les cerveaux d’individus avant et après avoir développé une grande expertise dans un domaine comme le jonglage ou le jeu vidéo. On avance mais on ignore encore presque tout dans ce domaine.
B – Tu peux nous parler un peu des sciences que vous utilisez ?
MT – Nous utilisons beaucoup de statistiques pour modéliser les propriétés de régions du cerveau. Nous utilisons aussi l’apprentissage automatique pour comprendre quelque chose aux masses de données que nous récoltons. Comme dans d’autres sciences, il s’agit de diminuer les dimensions de nos données pour pouvoir explorer la structure de la nature.
Plus récemment, nous avons commencé à utiliser des réseaux de neurones profonds. D’un point de vue médical, cela nous pose des problèmes. Nous voulons comprendre et une proposition de diagnostic non étayé ne nous apprend pas grand-chose et pose des problèmes d’éthique fondamentaux.
B – Est-ce que l’utilisation de ce genre de techniques affaiblit le caractère scientifique de vos travaux ?
MT – Il y a bien sûr un risque si on fait n’importe quoi. Le cerveau, c’est un machin hyper compliqué et on ne s’en sortira pas sans l’aide de machines et d’intelligence artificielle : certains fonctionnements sont beaucoup trop complexes pour être explicitement détectés et compris par les neuroscientifiques. Mais il ne faut surtout pas se contenter de prendre un superbe algorithme et de le faire calculer sur une grande masse de données. Si les données ne sont pas bonnes, le résultat ne veut sans doute rien dire. Ce genre de comportement n’est pas scientifique.
B – On a surtout parlé des humains. Mais les animaux ont aussi des cerveaux ? Les singes, par exemple, ont-ils des cerveaux très différents de ceux des humains ?
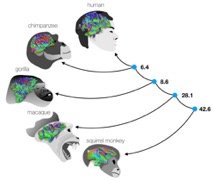
MT – Je vous ai parlé de la très grande variabilité du cerveau entre les individus. On a cru pendant un temps que les cerveaux des singes ne présentaient pas une telle variabilité. Pour vérifier cela, on est parti d’un modèle de déformation. Et en réalité non, selon les régions, la variabilité est relativement comparable chez le singe et chez l’humain. Ce qui est passionnant c’est qu’on s’aperçoit que les régions qui présentent plus de variabilité chez l’humain sont des régions comme celles du langage ou de la sociabilité alors que c’est la gestion de l’espace pour les singes. Pour des régions comme celles de la vision qui sont apparues plus tôt dans l’évolution des espèces, le singe et l’humain présentent des variabilités semblables et plus faibles.
B – Tu vois comment faire avancer plus vite la recherche ?
Il faudrait que les chercheurs apprennent à travailler moins en compétition et beaucoup plus en collaboration y compris au niveau international car la complexité du problème est telle qu’il serait illusoire d’imaginer qu’une équipe seule parvienne à le résoudre. Avec l’open data et l’open science, on progresse. Certains freinent des deux pieds, il faut qu’ils comprennent que c’est la condition pour réussir. Il faut par exemple transformer la plateforme de diffusion des résultats en neurosciences, lancer des revues sur BioRxiv, l’archive de dépôt de preprints dédiée aux sciences biologiques.
B – On a quand même l’impression, vu de l’extérieur, que ton domaine a avancé sur l’observation mais peu sur l’action. Nous comprenons mieux le fonctionnement du cerveau. Mais peut-on espérer réparer un jour les cerveaux qui présentent des problèmes ?
MT – Vous avez raison. On voit arriver des masses d’articles explicatifs mais quand on arrive aux applications, il n’y a presque plus personne. Si une connexion cérébrale est coupée, ça ne fonctionne plus ; que faire ? La solution peut sembler simple : reconstruire des connexions par exemple avec un traitement médicamenteux. Sauf qu’on ne sait pas le faire.
Dans un tel contexte, il est indispensable de prendre des risques, ce qui pour un scientifique signifie ne pas publier d’articles présentant des résultats positifs pendant « un certain temps ». En France, nous avons, encore pour l’instant, une grande chance, celle d’offrir à des chercheurs la stabilité de leur poste, ce qui nous permet de mener des projets ambitieux et nous autorise à prendre des risques sur du plus long terme. Ce n’est pas le cas dans la plupart des autres pays.
On répare bien le cœur pourquoi ne pas espérer un jour faire de même pour le cerveau ? C’est un énorme défi et c’est celui de ma vie scientifique !
Serge Abiteboul (Inria, ENS Paris) et Pascal Guitton (Inria, Université de Bordeaux)
@MichelTdS





























 JK : Bien évidemment, il y a eu des changements dans la vie quotidienne, dont sont conscients tous ceux qui ont vécu les années 90. Nous avons désormais des outils qui nous permettent, dès qu’on a une question factuelle, d’obtenir la réponse quasi immédiatement. Cela nous semble maintenant normal, mais ça n’existait pas dans les années 80. Deuxième conséquence, alors qu’autrefois seules quelques personnes avaient la responsabilité de produire et partager l’information dans des médias traditionnels, désormais ce sont des centaines de millions de personnes qui produisent et partagent l’information. Du coup, chacun doit désormais adopter une démarche similaire à celle de la recherche académique, en évaluant l’information, en comparant des sources différentes sur un même sujet, en tenant compte des objectifs probables et des biais potentiels de ceux qui ont écrit l’information. Par exemple, allez sur internet et recherchez combien de temps des restes de poulet peuvent se garder dans un réfrigérateur. La diversité des réponses est phénoménale. On peut trouver un blog avec une opinion très tranchée sur la question, mais on ne sait pas si l’auteur est crédible, une page sur le site d’une entreprise d’agro-alimentaire, mais on ne sait pas si on peut leur faire confiance, une page sur le site du ministère de la santé, mais on ne sait pas exactement d’où ça sort. Ainsi, toutes ces sources prétendent une expertise qu’on n’a pas moyen d’évaluer, ils tentent tous de répondre à la même question, et les résultats sont tous différents. Ce genre de choses, on le voit tous les jours.
JK : Bien évidemment, il y a eu des changements dans la vie quotidienne, dont sont conscients tous ceux qui ont vécu les années 90. Nous avons désormais des outils qui nous permettent, dès qu’on a une question factuelle, d’obtenir la réponse quasi immédiatement. Cela nous semble maintenant normal, mais ça n’existait pas dans les années 80. Deuxième conséquence, alors qu’autrefois seules quelques personnes avaient la responsabilité de produire et partager l’information dans des médias traditionnels, désormais ce sont des centaines de millions de personnes qui produisent et partagent l’information. Du coup, chacun doit désormais adopter une démarche similaire à celle de la recherche académique, en évaluant l’information, en comparant des sources différentes sur un même sujet, en tenant compte des objectifs probables et des biais potentiels de ceux qui ont écrit l’information. Par exemple, allez sur internet et recherchez combien de temps des restes de poulet peuvent se garder dans un réfrigérateur. La diversité des réponses est phénoménale. On peut trouver un blog avec une opinion très tranchée sur la question, mais on ne sait pas si l’auteur est crédible, une page sur le site d’une entreprise d’agro-alimentaire, mais on ne sait pas si on peut leur faire confiance, une page sur le site du ministère de la santé, mais on ne sait pas exactement d’où ça sort. Ainsi, toutes ces sources prétendent une expertise qu’on n’a pas moyen d’évaluer, ils tentent tous de répondre à la même question, et les résultats sont tous différents. Ce genre de choses, on le voit tous les jours.
 Enfin, d’autres chercheurs travaillent sur l’apprentissage non supervisé. Un programme observe ce qui se passe autour de lui, et construit à partir de cette observation un modèle du monde. C’est essentiellement de cette façon que les oiseaux, les mammifères, que nous mêmes fonctionnons. Ce n’est pas si simple ; les algorithmes que nous concevons aujourd’hui attendent des prédictions du monde qui soient exactes, déterministes. Mais si vous laissez tomber un stylo (voir photo), vous ne pouvez pas prédire de quel côté il va tomber. Nos programmes d’apprentissage retiennent qu’il est tombé, par exemple, à gauche puis devant. Il faudrait apprendre qu’il peut tomber n’importe où aléatoirement. Il y a des travaux passionnants dans cette direction. Cela ouvre des portes pour de l’intelligence artificielle, au-delà de l’analyse de contenu.
Enfin, d’autres chercheurs travaillent sur l’apprentissage non supervisé. Un programme observe ce qui se passe autour de lui, et construit à partir de cette observation un modèle du monde. C’est essentiellement de cette façon que les oiseaux, les mammifères, que nous mêmes fonctionnons. Ce n’est pas si simple ; les algorithmes que nous concevons aujourd’hui attendent des prédictions du monde qui soient exactes, déterministes. Mais si vous laissez tomber un stylo (voir photo), vous ne pouvez pas prédire de quel côté il va tomber. Nos programmes d’apprentissage retiennent qu’il est tombé, par exemple, à gauche puis devant. Il faudrait apprendre qu’il peut tomber n’importe où aléatoirement. Il y a des travaux passionnants dans cette direction. Cela ouvre des portes pour de l’intelligence artificielle, au-delà de l’analyse de contenu.





 Comment définir l’informatique. La question est complexe, les réponses parfois passionnelles.
Comment définir l’informatique. La question est complexe, les réponses parfois passionnelles.