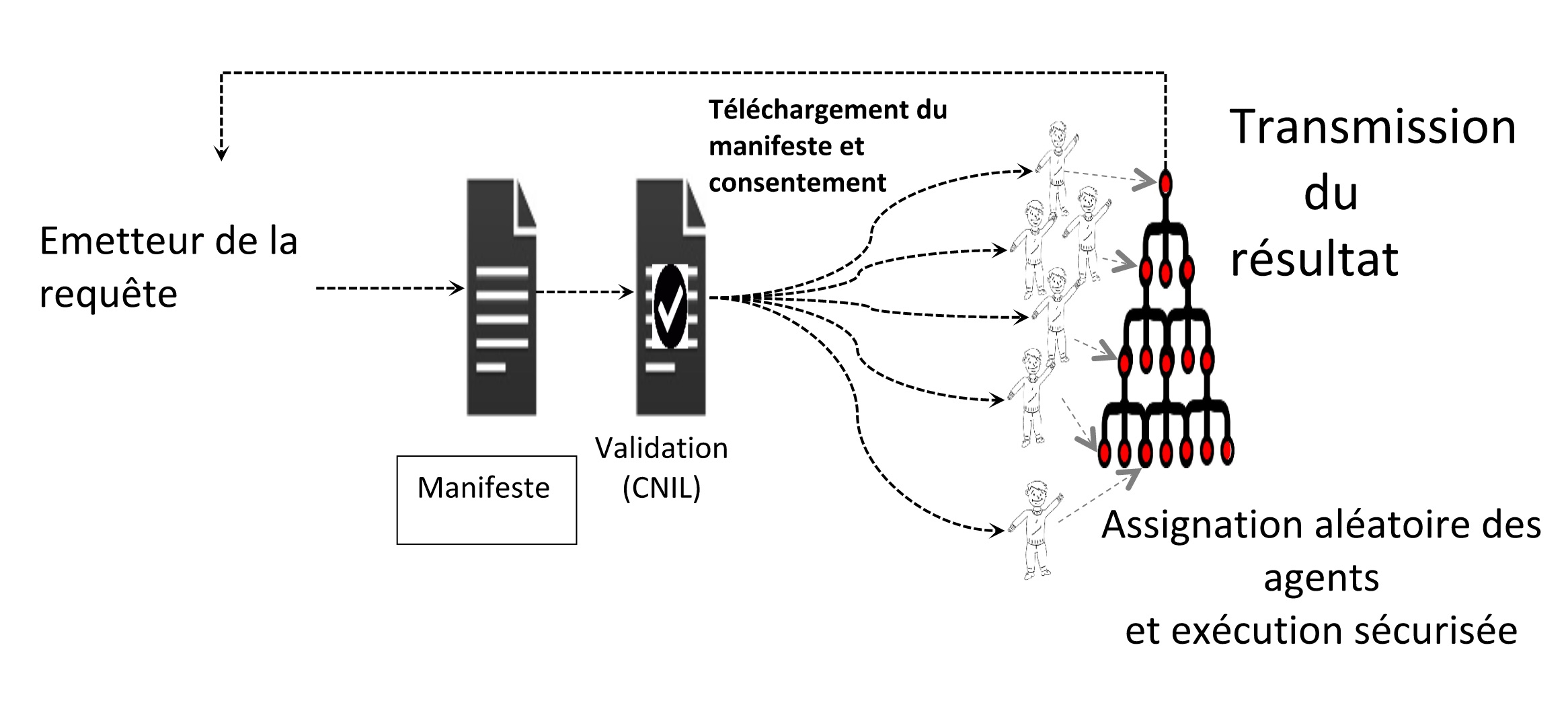
Un nouvel entretien autour de l’informatique.
Michel Beaudouin-Lafon est un chercheur en informatique français dans le domaine de l’interaction humain-machine. Il est professeur depuis 1992 à l’université de Paris-Saclay. Ses travaux de recherche portent sur les aspects fondamentaux de l’interaction humain-machine, l’ingénierie des systèmes interactifs, le travail collaboratif assisté par ordinateur et plus généralement les nouvelles techniques d’interaction. Il a co-fondé et a été premier président de l’Association francophone pour l’interaction humain-machine. Il est membre senior de l’Institut universitaire de France, lauréat de la médaille d’argent du CNRS, ACM Fellow, et depuis 2025 membre de l’Académie des sciences. Cet article est publié en collaboration avec The Conversation.

Binaire : Pourrais-tu nous raconter comment tu es devenu un spécialiste de l’interaction humain-machine ?
MBL : J’ai suivi les classes préparatoires au lycée Montaigne à Bordeaux. On n’y faisait pas d’informatique, mais je m’amusais déjà un peu avec ma calculatrice programmable HP29C. Ensuite, je me suis retrouvé à l’ENSEEIHT, une école d’ingénieur à Toulouse, où j’ai découvert l’informatique… un peu trop ardemment : en un mois, j’avais épuisé mon quota de calcul sur les cartes perforées !
À la sortie, je n’étais pas emballé par l’idée de rejoindre une grande entreprise ou une société de service. J’ai alors rencontré Gérard Guiho de l’université Paris-Sud (aujourd’hui Paris-Saclay) qui m’a proposé une thèse en informatique. Je ne savais pas ce que c’était qu’une thèse : nos profs à l’ENSEEIHT, qui étaient pourtant enseignants-chercheurs, ne nous parlaient jamais de recherche.

Fin 1982, c’était avant le Macintosh, Gérard venait d’acquérir une station graphique dont personne n’avait l’usage dans son équipe. Il m’a proposé de travailler dessus. Je me suis bien amusé et j’ai réalisé un logiciel d’édition qui permettait de créer et simuler des réseaux de Pétri, un formalisme avec des ronds, des carrés, des flèches, qui se prêtait bien à une interface graphique. C’est comme ça que je me suis retrouvé à faire une thèse en IHM : interaction humain-machine.
Binaire : Est-ce que l’IHM existait déjà comme discipline à cette époque ?
MBL : Ça existait mais de manière encore assez confidentielle. La première édition de la principale conférence internationale dans ce domaine, Computer Human Interaction (CHI), a eu lieu en 1982. En France, on s’intéressait plutôt à l’ergonomie. Une des rares exceptions : Joëlle Coutaz qui, après avoir découvert l’IHM à CMU (Pittsburgh), a lancé ce domaine à Grenoble.
Binaire : Et après la thèse, qu’es-tu devenu ?
MBL : J’ai été nommé assistant au LRI, le laboratoire de recherche de l’Université Paris-Sud, avant même d’avoir fini ma thèse. Une autre époque ! Finalement, j’ai fait toute ma carrière dans ce même laboratoire, même s’il a changé de nom récemment pour devenir le LISN, laboratoire interdisciplinaire des sciences du numérique. J’y ai été nommé professeur en 1992. J’ai tout de même bougé un peu. D’abord en année sabbatique en 1992 à l’Université de Toronto, puis en détachement à l’Université d’Aarhus au Danemark entre 1998 et 2000, et enfin plus récemment comme professeur invité à l’université de Stanford entre 2010 et 2012.
En 1992, au cours d’un workshop au Danemark, j’ai rencontré Wendy Mackay, une chercheuse qui travaillait sur l’innovation par les utilisateurs. Un an plus tard, nous étions mariés ! Cette rencontre a été déterminante dans ma carrière pour combiner mon parcours d’ingénieur, que je revendique toujours, avec son parcours à elle, qui était psychologue. Wendy est spécialiste de ce qu’on appelle la conception participative, c’est-à-dire d’impliquer les utilisateurs dans tout le cycle de conception des systèmes interactifs. Je vous invite d’ailleurs à lire son entretien dans Binaire. C’est cette complémentarité entre nous qui fait que notre collaboration a été extrêmement fructueuse sur le plan professionnel. En effet, dans le domaine de l’IHM, c’est extrêmement important d’allier trois piliers : (1) l’aspect humain, donc la psychologie ; (2) le design, la conception, la créativité ; et (3) l’ingénierie. Ce dernier point concerne la mise en œuvre concrète, et les tests avec des vrais utilisateurs pour voir si ça marche (ou pas) comme on l’espère. Nous avons vécu la belle aventure du développement de l’IHM en France, et sa reconnaissance comme science confirmée, par exemple, avec mon élection récente à l’Académie des Sciences.
Binaire : L’IHM est donc une science, mais en quoi consiste la recherche dans ce domaine ?
MBL : On nous pose souvent la question. Elle est légitime. En fait, on a l’impression que les interfaces graphiques utilisées aujourd’hui par des milliards de personnes ont été inventées par Apple, Google ou Microsoft, mais pas vraiment ! Elles sont issues de la recherche académique en IHM !
Si on définit souvent l’IHM par Interface Humain-Machine, je préfère parler d’Interaction Humain-Machine. L’interaction, c’est le phénomène qui se produit lorsqu’on est utilisateur d’un système informatique et qu’on essaie de faire quelque chose avec la machine, par la machine. On a ainsi deux entités très différentes l’une de l’autre qui communiquent : d’un côté, un être humain avec ses capacités cognitives et des moyens d’expression très riches ; et de l’autre, des ordinateurs qui sont de plus en plus puissants et très rapides mais finalement assez bêtes. Le canal de communication entre les deux est extrêmement ténu : taper sur un clavier, bouger une souris. En comparaison des capacités des deux parties, c’est quand même limité. On va donc essayer d’exploiter d’autres modalités sensorielles, des interfaces vocales, tactiles, etc., pour multiplier les canaux, mais on va aussi essayer de rendre ces canaux plus efficaces et plus puissants.
Ce phénomène de l’interaction, c’est un peu une sorte de matière noire : on sait que c’est là, mais on ne peut pas vraiment la voir. On ne peut la mesurer et l’observer que par ses effets sur la machine et sur l’être humain. Et donc, on observe comment l’humain avec la machine peuvent faire plus que l’humain seul et la machine seule. C’est une idée assez ancienne : Doug Engelbart en parlait déjà dans les années 60 (voir dans Interstices). Et pourtant, aujourd’hui, on a un peu tendance à l’oublier car on se focalise sur des interfaces de plus en plus simples, où c’est la machine qui va tout faire et on n’a plus besoin d’interagir. Or, je pense qu’il y a vraiment une valeur ajoutée à comprendre ce phénomène d’interaction pour en tirer parti et faire que la machine augmente nos capacités plutôt que faire le travail à notre place. Par extension, on s’intéresse aussi à ce que des groupes d’humains et de machines peuvent faire ensemble.

La recherche en IHM, il y a donc un aspect recherche fondamentale qui se base sur d’autres domaines (la psychologie mais aussi la sociologie quand on parle des interactions de groupes, ou encore la linguistique dans le cadre des interactions langagières) qui permet de créer nos propres modèles d’interaction, qui ne sont pas des modèles mathématiques ; et ça, je le revendique parce que je pense que c’est une bonne chose qu’on ne sache pas encore mettre le cerveau humain en équation. Et puis il y a une dimension plus appliquée où on va créer des objets logiciels ou matériels pour mettre tout ça en œuvre.
Pour moi, l’IHM ne se résume pas à faire de nouveaux algorithmes. Au début des années 90, Peter Wegener a publié dans Communications of the ACM – un des journaux de référence dans notre domaine – un article qui disait “l’interaction est plus puissante que les algorithmes”. Cela lui a valu pas mal de commentaires et de critiques, mais ça m’a beaucoup marqué.
Binaire : Et à propos d’algorithmes, est-ce que l’IA soulève de nouvelles problématiques en IHM ?
MBL : Oui, absolument ! En ce moment, les grandes conférences du domaine débordent d’articles qui combinent des modèles de langage (LLM) ou d’autres techniques d’IA avec de l’IHM.
Historiquement, dans une première phase, l’IA a été extrêmement utilisée en IHM, par exemple pour faire de la reconnaissance de gestes. C’était un outil commode, qui nous a simplifié la vie, mais sans changer nos méthodes d’interaction.
Aux débuts de l’IA générative, on est un peu revenu 50 ans en arrière en matière d’interaction, quand la seule façon d’interagir avec les ordinateurs, c’était d’utiliser le terminal. On fait un prompt, on attend quelques secondes, on a une réponse ; ça ne va pas, on bricole. C’est une forme d’interaction extrêmement pauvre. De plus en plus de travaux très intéressants imaginent des interfaces beaucoup plus interactives, où on ne voit plus les prompts, mais où on peut par exemple dessiner, transformer une image interactivement, sachant que derrière, ce sont les mêmes algorithmes d’IA générative avec leurs interfaces traditionnelles qui sont utilisés.
Pour moi, l’IA soulève également une grande question : qu’est-ce qu’on veut déléguer à la machine et qu’est-ce qui reste du côté humain ? On n’a pas encore vraiment une bonne réponse à ça. D’ailleurs, je n’aime pas trop le terme d’intelligence artificielle. Je n’aime pas attribuer des termes anthropomorphiques à des systèmes informatiques. Je m’intéresse plutôt à l’intelligence augmentée, quand la machine augmente l’intelligence humaine. Je préfère mettre l’accent sur l’exploitation de capacités propres à l’ordinateur, plutôt que d’essayer de rendre l’ordinateur identique à un être humain.
Binaire : La parole nous permet d’interagir avec les autres humains, et de la même façon avec des bots. N’est-ce pas plus simple que de chercher la bonne icône ?
MBL : Interagir par le langage, oui, c’est commode. Ceci étant, à chaque fois qu’on a annoncé une nouvelle forme d’interface qui allait rendre ces interfaces graphiques (avec des icônes, etc.) obsolètes, cela ne s’est pas vérifié. Il faut plutôt s’intéresser à comment on fait cohabiter ces différentes formes d’interactions. Si je veux faire un schéma ou un diagramme, je préfère le dessiner plutôt que d’imaginer comment le décrire oralement à un système qui va le faire (sans doute mal) pour moi. Ensuite, il y a toujours des ambiguïtés dans le langage naturel entre êtres humains. On ne se contente pas des mots. On les accompagne d’expressions faciales, de gestes, et puis de toute la connaissance d’un contexte qu’un système d’IA aujourd’hui n’a souvent pas, ce qui le conduit à faire des erreurs que des humains ne feraient pas. Et finalement, on devient des correcteurs de ce que fait le système, au lieu d’être les acteurs principaux.
Ces technologies d’interaction par la langue naturelle, qu’elles soient écrites ou orales, et même si on y combine des gestes, soulèvent un sérieux problème : comment faire pour que l’humain ne se retrouve pas dans une situation d’être de plus en plus passif ? En anglais, on appelle ça de-skilling : la perte de compétences et d’expertise. C’est un vrai problème parce que, par exemple, quand on va utiliser ces technologies pour faire du diagnostic médical, ou bien prononcer des sentences dans le domaine juridique, on va mettre l’être humain dans une situation de devoir valider ou non la décision posée par une IA. Et en fait, il va être quand même encouragé à dire oui, parce que contredire l’IA revient à s’exposer à une plus grande responsabilité que de constater a posteriori que l’IA s’est trompée. Donc dans ce genre de situation, on va chercher comment maintenir l’expertise de l’utilisateur et même d’aller vers de l’upskilling, c’est-à-dire comment faire pour qu’un système d’IA le rende encore plus expert de ce qu’il sait déjà bien faire, plutôt que de déléguer et rendre l’utilisateur passif. On n’a pas encore trouvé la façon magique de faire ça. Mais si on reprend l’exemple du diagnostic médical, si on demande à l’humain de faire un premier diagnostic, puis à l’IA de donner le sien, et que les deux ont ensuite un échange, c’est une interaction très différente que d’attendre simplement ce qui sort de la machine et dire oui ou non.
Binaire : Vous cherchez donc de nouvelles façons d’interagir avec les logiciels, qui rendent l’humain plus actif et tendent vers l’upskilling.
MBL : Voilà ! Notre équipe s’appelle « Ex Situ », pour Extreme Situated Interaction. C’est parti d’un gag parce qu’avant, on s’appelait « In Situ » pour Interaction Située. Il s’agissait alors de concevoir des interfaces en fonction de leur contexte, de la situation dans laquelle elles sont utilisées.
Nous nous sommes rendus compte que nos recherches conduisaient à nous intéresser à ce qu’on a appelé des utilisateurs “extrêmes”, qui poussent la technologie dans ses retranchements. En particulier, on s’intéresse à deux types de sujets, qui sont finalement assez similaires. D’un part, les créatifs (musiciens, photographes, graphistes…) qui par nature, s’ils ont un outil (logiciel ou non) entre les mains, vont l’utiliser d’une manière qui n’était pas prévue, et ça nous intéresse justement de voir comment ils détournent ces outils. D’autre part, Wendy travaille, depuis longtemps d’ailleurs, dans le domaine des systèmes critiques dans lequel on n’a pas droit à l’erreur : pilotes d’avion, médecins, etc.
Dans les industries culturelles et créatives (édition, création graphique, musicale, etc.), les gens sont soit terrorisés, soit anxieux, de ce que va faire l’IA. Et nous, ce qu’on dit, c’est qu’il ne s’agit pas d’être contre l’IA – c’est un combat perdu de toute façon – mais de se demander comment ces systèmes vont pouvoir être utilisés d’une manière qui va rendre les humains encore plus créatifs. Les créateurs n’ont pas besoin qu’on crée à leur place, ils ont besoin d’outils qui les stimulent. Dans le domaine créatif, les IA génératives sont, d’une certaine façon, plus intéressantes quand elles hallucinent ou qu’elles font un peu n’importe quoi. Ce n’est pas gênant au contraire.
Binaire : L’idée d’utiliser les outils de façon créative, est-ce que cela conduit au design ?
MBL : Effectivement. Par rapport à l’ergonomie, qui procède plutôt selon une approche normative en partant des tâches à optimiser, le design est une approche créative qui questionne aussi les tâches à effectuer. Un designer va autant mettre en question le problème, le redéfinir, que le résoudre. Et pour redéfinir le problème, il va interroger et observer les utilisateurs pour imaginer des solutions. C’est le principe de conception participative, qui implique les acteurs eux-mêmes en les laissant s’approprier leur activité, ce qui donne finalement de meilleurs résultats, non seulement sur le plan de la performance mais aussi et surtout sur l’acceptation.
Notre capacité naturelle d’être humain nous conduit à constamment réinventer notre activité. Lorsque nous interagissons avec le monde, certes nous utilisons le langage, nous parlons, mais nous faisons aussi des mouvements, nous agissons sur notre environnement physique ; et ça passe parfois par la main nue, mais surtout par des outils. L’être humain est un inventeur d’outils incroyables. Je suis passionné par la facilité que nous avons à nous servir d’outils et à détourner des objets comme outils ; qui n’a pas essayé de défaire une vis avec un couteau quand il n’a pas de tournevis à portée de main ? Et en fait, cette capacité spontanée disparaît complètement quand on passe dans le monde numérique. Pourquoi ? Parce que dans le monde physique, on utilise des connaissances techniques, on sait qu’un couteau et un tournevis ont des propriétés similaires pour cette tâche. Alors que dans un environnement numérique, on a besoin de connaissances procédurales : on apprend que pour un logiciel il faut cliquer ici et là, et puis dans un autre logiciel pour faire la même chose, c’est différent.

C’est en partant de cette observation que j’ai proposé l’ERC One, puis le projet Proof-of Concept OnePub, qui pourrait peut-être même déboucher sur une startup. On a voulu fonder l’interaction avec nos ordinateurs d’aujourd’hui sur ce modèle d’outils – que j’appelle plutôt des instruments, parce que j’aime bien l’analogie avec l’instrument de musique et le fait de devenir virtuose d’un instrument. Ça remet en cause un peu tous nos environnements numériques. Pour choisir une couleur sur Word, Excel ou Photoshop, on utilise un sélecteur de couleurs différent. En pratique, même si tu utilises les mêmes couleurs, il est impossible de prendre directement une couleur dans l’un pour l’appliquer ailleurs. Pourtant, on pourrait très bien imaginer décorréler les contenus qu’on manipule (texte, images, vidéos, son…) des outils pour les manipuler, et de la même façon que je peux aller m’acheter les pinceaux et la gouache qui me conviennent bien, je pourrais faire la même chose avec mon environnement numérique en la personnalisant vraiment, sans être soumis au choix de Microsoft, Adobe ou Apple pour ma barre d’outils. C’est un projet scientifique qui me tient à cœur et qui est aussi en lien avec la collaboration numérique.

Binaire : Par rapport à ces aspects collaboratifs, n’y a-t-il pas aussi des verrous liés à la standardisation ?
MBL : Absolument. On a beau avoir tous ces moyens de communication actuels, nos capacités de collaboration sont finalement très limitées. À l’origine d’Internet, les applications s’appuyaient sur des protocoles et standards ouverts assurant l’interopérabilité : par exemple, peu importait le client ou serveur de courrier électronique utilisé, on pouvait s’échanger des mails sans problème. Mais avec la commercialisation du web, des silos d’information se sont créés. Aujourd’hui, des infrastructures propriétaires comme Google ou Microsoft nous enferment dans des “jardins privés” difficiles à quitter. La collaboration s’établit dans des applications spécialisées alors qu’elle devrait être une fonctionnalité intrinsèque.
C’est ce constat qui a motivé la création du PEPR eNSEMBLE, un grand programme national sur la collaboration numérique, dont je suis codirecteur. L’objectif est de concevoir des systèmes véritablement interopérables où la collaboration est intégrée dès la conception. Cela pose des défis logiciels et d’interface. Une des grandes forces du système Unix, où tout est très interopérable, vient du format standard d’échange qui sont des fichiers textes ASCII. Aujourd’hui, cela ne suffit plus. Les interactions sont plus complexes et dépassent largement l’échange de messages.

C’est frustrant car on a quand même fait beaucoup de progrès en IHM, mais il faudrait aussi plus d’échanges avec les autres disciplines comme les réseaux, les systèmes distribués, la cryptographie, etc., parce qu’en fait, aucun système informatique aujourd’hui ne peut se passer de prendre en compte les facteurs humains. Au-delà des limites techniques, il y a aussi des contraintes qui sont totalement artificielles et qu’on ne peut aborder que s’il y a une forme de régulation qui imposerait, par exemple, la publication des API de toute application informatique qui communique avec son environnement. D’ailleurs, la législation européenne autorise le reverse engineering dans les cas exceptionnels où cela sert à assurer l’interopérabilité, un levier que l’on pourrait exploiter pour aller plus loin.
Cela pose aussi la question de notre responsabilité de chercheur pour ce qui est de l’impact de l’informatique, et pas seulement l’IHM, sur la société. C’est ce qui m’a amené à m’impliquer dans l’ACM Europe Technology Policy Committee, dont je suis Chair depuis 2024. L’ACM est un société savante apolitique, mais on a pour rôle d’éduquer les décideurs politiques, notamment au niveau de l’Union européenne, sur les capacités, les enjeux et les dangers des technologies, pour qu’ils puissent ensuite les prendre en compte ou pas dans des textes de loi ou des recommandations (comme l’AI ACT récemment).
Binaire : En matière de transmission, sur un ton plus léger, tu as participé au podcast Les petits bateaux sur Radio France. Pourrais-tu nous en parler ?
MBL : Oui ! Les petits bateaux. Dans cette émission, les enfants peuvent appeler un numéro de téléphone pour poser des questions. Ensuite, les journalistes de l’émission contactent un scientifique avec une liste de questions, collectées au cours du temps, sur sa thématique d’expertise. Le scientifique se rend au studio et enregistre des réponses. A l’époque, un de mes anciens doctorants [ou étudiants] avait participé à une action de standardisation du clavier français Azerty sur le positionnement des caractères non alphanumériques, et j’ai donc répondu à des questions très pertinentes comme “Comment les Chinois font pour taper sur un clavier ?”, mais aussi “Où vont les fichiers quand on les détruit ?”, “C’est quoi le com dans .com ?” Évidemment, les questions des enfants intéressent aussi les adultes qui n’osent pas les poser. On essaie donc de faire des réponses au niveau de l’enfant mais aussi d’aller un petit peu au-delà, et j’ai trouvé cela vraiment intéressant de m’adresser aux différents publics.

Je suis très attaché à la transmission, je suis issu d’une famille d’enseignants du secondaire, et j’aime moi-même enseigner. J’ai dirigé et participé à la rédaction de manuels scolaires des spécialités informatiques SNT et NSI au Lycée. Dans le programme officiel de NSI issu du ministère, une ligne parle de l’interaction avec l’utilisateur comme étant transverse à tout le programme, ce qui veut dire qu’elle n’est concrètement nulle part. Mais je me suis dit que c’était peut-être l’occasion d’insuffler un peu de ma passion dans ce programme, que je trouve par ailleurs très lourd pour des élèves de première et terminale, et de laisser une trace ailleurs que dans des papiers de recherche…
Serge Abiteboul (Inria) et Chloé Mercier (Université de Bordeaux)
https://binaire.socinfo.fr/les-entretiens-de-la-sif/


























 B : Tu as aussi beaucoup réfléchi à l’ « augmentation » de l’humain avec la technique, et aux questions que cela pose en terme de justice ?
B : Tu as aussi beaucoup réfléchi à l’ « augmentation » de l’humain avec la technique, et aux questions que cela pose en terme de justice ? B : Quelle est le sujet de recherche qui te passionne en ce moment ?
B : Quelle est le sujet de recherche qui te passionne en ce moment ?