Pourquoi les citoyennes et citoyens, dont les scientifiques, organisent-ils une marche mondiale, le 22 avril, pour les Sciences ?
L’origine d’une marche. Née aux Etats-Unis à la suite d’une conversation sur Reddit, l’initiative, devait être initialement limitée aux chercheurs américains, en première ligne face à la nouvelle administration Trump « qui menace d’entraver davantage la capacité des chercheurs à mener à bien leurs recherches et à diffuser leurs résultats ». Elle est en train de prendre une toute autre dimension. En effet, la marche pour les sciences est devenue un mouvement mondial. En France, Marche pour les sciences rassemble plus d’une dizaine d’initiatives citoyennes, soutenues par les plus grands instituts scientifiques français.
Sources: communiqué du CNRS, communiqué Inria, Numérama: pourquoi-les-scientifiques-organisent-une-marche-mondiale.
Quel est l’enjeu ?
Défendre la recherche scientifique, en particulier quand elle s’engage dans une démarche d’ouverture et de partage citoyen des enjeux et des résultats de la recherche : volonté de faire des données de la science des données ouvertes, de développer des paradigmes de sciences participatives, de faire de la vulgarisation scientifique une facette incontournable des métiers de la recherche, d’associer citoyennes et citoyens aux réflexions sur les enjeux de la recherche. Une telle démarche devient rapidement dérangeante quand le pouvoir veut verrouiller les discussions sur certains sujets.
Et au delà ?
Oui, il y a un « au delà » : il s’agit aussi de défendre l’esprit critique, le décodage de la vérité, le respect des lois naturelles et humaines (notre environnement, notre justice), la nécessité que chacune et chacun puisse se construire une vision éclairée des faits. Que notre regard ne se trumpe pas de direction : argumenter sur des « fake news », utiliser les chiffres sans fondement comme des arguments magiques, remettre en cause la justice, ce n’est pas un danger localisé ailleurs. Il est aussi bien de chez nous.
Alors que ferez-vous le 22 avril ? Nous, nous marcherons !
Pour les passionnés d’histoire, le CNAM organise un Séminaire d’Histoire de l’informatique. Le prochain séminaire traite du Plan Calcul. Ça se passe le jeudi 13 avril 2017 de 14h30 à 17h00, dans l’amphi C « Abbé Grégoire » du CNAM, 292 rue Saint-Martin, 75003 Paris. Inscription obligatoire auprès de : isabelle.astic(@)cnam.fr. Un ami de binaire, Pierre Mounier-Kuhn, nous parle du Plan Calcul. Serge Abiteboul, Pierre Paradinas
Un demi-siècle de politique française en informatique
Au début des années 1960, l’industrie électronique française affrontait une concurrence états-unienne de plus en plus redoutable dans les composants semi-conducteurs et les ordinateurs. Les multinationales comme IBM ou Texas Instruments, profitant du traité de Rome et d’accords commerciaux transatlantiques, multipliaient les investissements directs en Europe et y vendaient leurs produits déjà bien amortis sur le marché nord-américain. Ce « défi américain » allait bientôt inspirer aux experts et aux gouvernements européens des réflexions alarmistes sur le « fossé technologique » qui se creusait entre les deux rives de l’Atlantique.
De l’affaire Bull au Plan Calcul
Au printemps 1964 éclate l’affaire Bull : le principal constructeur européen de systèmes informatiques subit une crise, l’une des plus graves de l’histoire industrielle française. Plusieurs montages échafaudés sous l’égide gouvernementale avec des banques et des firmes d’électronique achoppent, et Bull préfère passer sous le contrôle de General Electric. C’est vécu comme une défaite économique par le gouvernement gaulliste, au moment où l’on commence à percevoir l’informatique et les télécommunications comme des secteurs stratégiques, « le système nerveux » des nations modernes.
Les comités d’experts qui cherchaient une solution aux problèmes de Bull, et qui disposent de crédits de R&D, bâtissent un montage de rechange en s’efforçant de rapprocher les petites entreprises françaises constituées depuis une décennie pour produire des ordinateurs. Leur mission est presque impossible : il s’agit de combiner la politique d’indépendance gaulliste, les intérêts des industriels concurrents abonnés aux subventions et les desiderata des grands clients du secteur public. Leur activisme en faveur d’une politique de l’informatique reçoit une justification supplémentaire lorsque Washington décrète un embargo sur les supercalculateurs commandés par la division militaire du CEA. Il aboutit, fin 1966-début 1967, au lancement d’un des plus grands projets de la Ve République, officialisé par une convention Plan Calcul le 13 avril 1967.
Une Délégation à l’informatique est créée au niveau gouvernemental comme maître d’œuvre du Plan. Une Compagnie internationale pour l’informatique (CII), filiale des groupes privés CGE, Thomson et CSF, fusionne deux petits constructeurs de calculateurs scientifiques avec pour mission essentielle de développer une « gamme moyenne de gestion » et de participer à terme à la constitution d’une informatique européenne. Le dispositif est complété l’année suivante par la création d’une société pour les périphériques, d’une autre pour les composants résultant de la fusion des filiales spécialisées de Thomson et de CSF. Et d’un Institut de recherches en informatique et automatique (IRIA, devenu depuis Inria), seul survivant aujourd’hui de cet ambitieux programme.
Signature de la convention Plan Calcul le 13 avril 1967 par Michel Debré, Ministre de l’Économie et des Finances, avec les patrons de l’industrie électronique française et des start-ups d’informatique. Photo : Archives Bull.
De la CII à Unidata
La CII démarre difficilement, soutenue à bout de bras par les subventions et les achats préférentiels des administrations, mais déchirée par des conflits internes résultant d’une fusion forcée. Elle vend d’abord surtout des machines développées en Californie par son partenaire Scientific Data Systems (SDS). Puis cette firme d’ingénieurs réalise des systèmes techniquement avancés (séries Iris, Mitra et Unidata), les premiers ordinateurs commerciaux en circuits intégrés d’Europe. Les axes de développement visent les ordinateurs temps réel, les systèmes en réseaux, les périphériques magnétiques. La CII tentera même d’assembler un gros quadri-processeur, atteignant les limites de la technologie de l’époque.
Iris 50 présenté au salon de l’informatique Sicob (septembre 1968). Les anciens de la CII associent leurs souvenirs du Sicob 1968 avec celui de « l’Iris 50 en bois », maquette d’exposition dont les seuls éléments en état de marche étaient les périphériques d’origine américaine. Les concurrents ont pu ironiser : « au moins sur cette machine, les problèmes de parasites pourront être traités au Xylophène ». Une fois mis au point, cet ordinateur moyen sera vendu à plusieurs centaines d’exemplaires, production honorable à l’époque. Photo : Archives historiques Bull.
Après une reprise en mains managériale en 1970, le champion national semble avoir son avenir assuré. Cherchant à devenir un constructeur normal sur le marché, la CII remporte des succès commerciaux hors du secteur public et à l’export, et négocie des accords avec d’autres constructeurs européens. De son côté l’IRIA, s’il a connu lui aussi un démarrage cahoteux, abrite notamment l’équipe qui développera le réseau Cyclades, l’un des prédécesseurs d’Internet. Quant à la Délégation à l’informatique, elle soutient les premières grandes SSII françaises en veillant à ce qu’elles ne passent pas sous contrôle américain, et initie les premières expériences de la programmation au lycée. L’ambiance générale du Plan Calcul favorise aussi l’extension de l’enseignement de l’informatique dans toutes les universités et écoles d’ingénieurs, avec la création de nouveaux diplômes (maîtrises, doctorats, MIAGE, etc.) pour répondre à la demande massive d’informaticiens.
En 1973 la CII s’associe avec Siemens et Philips dans Unidata, constructeur européen d’ordinateurs, qui produit rapidement une nouvelle gamme compatible IBM. Toutefois ce nouveau meccano industriel pose autant de problèmes qu’il en résout – les demandes de subventions continuent pour financer la croissance de la firme. Le Plan Calcul dépendait du volontarisme des gouvernements gaulliens et de la prospérité économique française. Or l’élection de Valéry Giscard d’Estaing coïncide avec le premier choc pétrolier, tandis qu’une coalition d’industriels français se ligue contre la CII et Unidata. Une série de décisions gouvernementales conduit à tuer la configuration européenne et à la remplacer par une configuration franco-américaine : la CII est absorbée en 1976 par Bull (entre temps revendue par GE à Honeywell). Deux ans plus tard, Cyclades, réseau d’informaticiens, est mis en extinction pour faire place au réseau conçu par le corps des Télécommunications : Transpac, dont le terminal le plus connu sera le Minitel.
Nœud de réseau Cyclades-Cigale à l’université de Grenoble, au centre CII-IMAG (1974). Cette photo associe deux réussites incontestables du Plan Calcul : le réseau Cyclades, réalisé à l’IRIA par l’équipe de Louis Pouzin, et le mini-ordinateur CII Mitra 15, conçu sous la direction d’Alice Recoque. Photo : Archives Bull
La fin du Plan Calcul ne sonne pas pour autant le glas des politiques technologiques ou industrielles dans le numérique. D’une part celles-ci se déploient avec succès dans les télécommunications. D’autre part les socialistes, arrivés au pouvoir en 1981, lancent une « filière électronique » et une nouvelle vague de restructurations assorties de nationalisations. Ces ambitions se heurteront vite aux réalités et à la concurrence irrésistible des « petits dragons » asiatiques. Les préoccupations qui motivèrent le Plan Calcul, il y a cinquante ans, inspirent toujours au XXIe siècle des projets, généralement à l’échelle européenne, de maîtrise du Big Data et de l’internet, de « systèmes d’exploitation souverains », de soutien à l’éducation comme aux entreprises du numérique.
Pierre Bellanger, La Souveraineté numérique, Éditions Stock, 2014.
Laurent Bloch, Révolution cyberindustrielle en France, Economica, coll. Cyberstratégie, 2015.
Jean-Pierre Brulé, L’Informatique malade de l’État, Les Belles-Lettres, 1993.
Emmanuel Lazard et Pierre Mounier-Kuhn, Histoire illustrée de l’informatique, (préface de Gérard Berry, professeur au Collège de France), EDP Sciences, 2016.
Pierre Mounier-Kuhn, L’Informatique en France de la seconde guerre mondiale au Plan Calcul. L’Émergence d’une science, préface de Jean-Jacques Duby, Presses de l’Université Paris-Sorbonne, 2010.
Jean-Michel Quatrepoint et Jacques Jublin, French ordinateurs. De l’affaire Bull à l’assassinat du Plan Calcul, Alain Moreau, 1976.
Les élections présidentielles arrivent à grand pas. Pour ces prochaines élections 4 bits d’information suffiront pour le premier tour (pour 11 candidats) et un seul au second. Des débats d’idées sur la politique prennent place, sur les thèmes bien connus qui préoccupent les Français.es, comme le chômage, les impôts ou la sécurité. Mais débat-on assez de nouveaux sujets qui impacteront la vie de nos concitoyens dans 10 ou 20 ans ? Des sujets dont les décisions d’aujourd’hui feront notre prospérité de demain ?
Consciente de l’importance de l’informatique dans notre monde numérique, la Société informatique de France a posé à tous les candidat.e.s des questions relatives à l’informatique dans notre monde numérique, en se focalisant principalement sur les questions de formation. Il est en effet indispensable de donner aux citoyen.ne.s et aux jeunes en particulier la culture générale de leur époque, culture qui inclut désormais l’informatique. C’est l’avenir du pays qui est en jeu, tant sur le plan sociétal que sur les plans scientifique et économique.
La SIF n’a obtenu pour l’heure que peu de réponses. Elle en fera une synthèse une fois qu’elle en aura reçu suffisamment.
Arrêtons-nous sur le quinquennat qui va se terminer. Sur la lancée de l’introduction de l’enseignement de l’ISN (Informatique et Sciences du Numérique) sous la mandature de Nicolas Sarkozy, la présidence de François Hollande a connu une vraie prise de conscience politique de l’importance du sujet, et des prises de décisions fortes.
Saluons le travail du secrétariat au numérique. La French Tech, la loi sur la république numérique, sont par exemple, de vraies avancées. Saluons aussi de réelles avancées au ministère de l’Éducation nationale, telles que l’initiation à la programmation à l’école, l’enseignement de l’informatique dans le tronc commun au collège et sous forme optionnelle au lycée.
Mais, nous ne sommes qu’au milieu du gué. Par exemple, le problème de la formation des Maîtres reste critique pour l’Éducation nationale. On y confond encore trop souvent littératie numérique (qui peut être inculquée par tous les enseignants) et enseignement de l’informatique (qui ne peut être effectué que par des professeurs d’informatique). Ces enseignements sont indispensables pour former les citoyens et les créateurs du 21ème siècle.
Profitons de cette période particulière pour la démocratie qu’est celle de l’élection de nos responsables pour discuter de sujets essentiels pour notre pays : le passage au numérique de l’administration, de la médecine, de l’enseignement…, la poursuite de la modernisation de notre économie par l’informatique, le développement de la participation des citoyens à la vie de la cité par l’informatique, les problèmes de transparence et d’équité de la mise en œuvre des algorithmes, etc. Les sujets de société sont nombreux, qui mettent en jeu l’informatique et le numérique. Il est urgent que les candidats s’en emparent et que les citoyens en discutent.
Le monde numérique rend possible des accès à l’information, aux connaissances, inimaginables encore récemment. Mais il permet aussi la diffusion de toutes les erreurs, tous les mensonges, toutes les désinformations. Que puis-je croire dans le flot d’information qui me submerge ? Comment séparer le bon grain de l’ivraie ? Fake news, fact checking, post-news. Le vocabulaire est anglais, mais les sujets nous concernent au plus haut point. Binaire a demandé à une directrice de recherche d’Inria qui travaille sur le fact checking de nous faire partager son expérience. Serge Abiteboul.
Ioana Manolescu
Avez-vous fait des courses récemment ? Si oui, vous reste-t-il un ticket de caisse ? Retournez-le, et vous avez des fortes chances d’y lire « Imprimé sur du papier ne contenant pas de BPA ». Le BPA, quésaco ? Appelé plus cérémonieusement bisphénol A, c’est une substance chimique longtemps utilisée, entre autres, dans le procédé dit « thermique » d’impression des tickets de caisse, mais aussi pour tapisser l’intérieur des cannettes et boîtes de conserve, pour les empêcher de réagir chimiquement avec les boissons et autres aliments contenus. De la sorte, le BPA nous évite de boire ou manger la rouille et autres produits peu ragoûtants de ces réactions chimiques…
Malheureusement, ses bons services s’accompagnent de sacrés risques sanitaires, car le BPA est un perturbateur endocrinien ; chez les souris, même une faible exposition in utero conduit à des changements hormonaux observés sur 4 générations… Fâcheux, quand on pense que trois millions de tonnes en sont produites encore chaque année dans le monde. (Voir wikiwix.)
Mère de deux enfants, j’ai ma petite histoire avec le BPA. Lorsque mon premier utilisait des biberons, le BPA était déjà interdit dans la composition des biberons, et sa réputation noircie sur la place publique, au Canada… mais pas encore en Europe. En France, des amies mamans me conseillaient gentiment d’arrêter la paranoïa et d’utiliser sans râler les mêmes biberons que tout le monde… Lorsqu’il a fallu biberonner mon deuxième, l’on enseignait « déjà » ici à toute jeune maman les dégâts potentiels du BPA et on leur apprenait à l’éviter.
Nous avons constamment à faire des choix. Dans le pays qui a donné au monde Descartes, nous nous targuons de faire ces choix sur la base de faits, en pesant tant que faire se peut le pour et le contre, en nous appuyant sur les informations dont nous disposons. La loi proscrit aujourd’hui le BPA même des tickets de caisse, non seulement des biberons ; il n’en était rien, il y a de cela quelques années.
Le processus est classique. La science émet des doutes. De longues études sont menées. Après examen par les élus, les doutes se transforment en certitudes, conduisent à des réglementations, des lois. Mais, ce processus est lent et peut prendre des années.
On le voit, la construction de la vérité est longue et ardue : il est bien plus facile de croire, que de savoir. Mais cette construction est à la base de tout processus de connaissance et de pensée, depuis que nos ancêtres ont dû être bien certains des baies et racines que l’on peut manger, si on ne veut pas finir ses jours empoisonné… De nos jours, scientifiques, journalistes, et experts de tout poil s’y attèlent. Il nous apportent tantôt l’interdiction du BPA, tantôt des gros mensonges à résultats tragiques comme l’étude truquée faisant croire à un lien entre les vaccins et l’autisme, retirée depuis par la revue l’ayant publiée, mais étude gardant des croyants bien tenaces, au grand dam des autorités sanitaires.
Quoi de neuf, alors, dans cet effort vieux comme le monde pour démêler le vrai du faux ?
Le Web, évidemment ! Il n’a jamais été si simple de publier une idée, information, rumeur ou bobard, et tout cela se propage plus vite et plus rapidement que jamais. Le travail de vérification de ces informations est-il devenu impossible ? Non, parce que l’informatique peut donner un coup de main, nous aider à détecter les mensonges.
Un politicien s’attribue le mérite d’une réduction spectaculaire du chômage pendant son mandat ? Des algorithmes proposés à l’Université de Duke, aux Etats-Unis permettent de voir que cette réduction était en fait bien amorcée avant le début de son mandat, et ne peuvent donc pas être mise à son crédit. Cette connaissance n’est accessible qu’en s’appuyant sur une base de données de référence, dans ce cas des statistiques du chômage dans lesquelles on a confiance. De telles bases de données sont, par exemple, celles construites à grands frais par des instituts financés par les États, tels que l’INSEE ou des instituts de veille sanitaire en France.
Cet exemple illustre le fact checking (vérification de faits), c’est-dire la comparaison d’une affirmation (« M. X a fait baisser le chômage ») avec une base de référence (évolution du chômage dans le temps), ce qui permet soit de prouver que M. X aurait avancé un chiffre faux, soit (dans notre cas) que l’interprétation qu’il en faisait n’était pas correcte.
Les limites de ces approches sont atteintes lorsque les données de référence sont muettes ou incomplètes sur un sujet, soit parce qu’un problème n’a pas été quantifié ou documenté, soit parce qu’il ne l’a été que par des acteurs s’accusant mutuellement de partialité ou directement de mensonge. Un exemple en est fourni par les débats très vif autour de l’introduction des OGM dans l’alimentation, notamment concernant les expériences de M. Seralini.
L’informatique permet ainsi de vérifier un fait, en s’appuyant sur d’autres ; elle ne permettrait donc d’établir que ce que l’on savait déjà ! Mais son aide est essentielle lorsque les volumes de données et informations à traiter dépassent (de loin) la capacité humaine.
Un autre scénario de fact checking exploite de façon ingénieuse l’intelligence humaine, recueillie, coordonnée et analysée par l’informatique. Il s’agit du crowd-sourcing, où l’on demande à des multiples utilisateurs de résoudre des « tâches » (déterminer si un paragraphe parle d’un certain sujet, étiqueter une photo…) puis on croise et intègre leurs réponses par des moyens informatiques et statistiques. Dans le domaine journalistique, une première approche collaborative de ce genre a été constituée par l’International Consortium of Investigative Journalism, à l’origine des publications du grand scandale d’évasion fiscale « Panama Papers » : des rédactions de journaux du monde entier ont mis en commun leurs données et leurs traitements, afin de « connecter les points » et de faire émerger l’histoire.
Dans l’histoire récente, une grosse partie des mensonges, manipulations et bobards sont publiés et propagés par les réseaux sociaux. Ceux-ci sont, d’un côté une arme puissante dans les mains des manipulateurs, mais ils fournissent en même temps une clé pour les débusquer : examiner les connexions sociales d’un utilisateur permet de se faire une idée de son profil et de la bonne foi et la véracité des informations qu’il ou elle propage. Les journalistes ne s’y trompent pas, qui utilisent des plateformes d’analyse et classification de contenus publiés sur les réseaux sociaux ainsi que de leurs auteurs.
Enfin, au delà de la vérification par des données et de la vérification par le réseau social, le style et les mots utilisés dans un document peuvent être exploités par les algorithmes d’analyse du langage naturel. Une telle classification permet par exemple de savoir si un texte est plutôt d’accord, plutôt pas d’accord, plutôt neutre ou complètement étranger à un certain propos, tel que « Donald Trump est soutenu par le Pape ». Une fois que l’énorme masse de textes à analyser a été ainsi classifiée par la machine, l’attention précieuse des humains peut se concentrer juste sur les textes qui soutiennent tel propos, ou encore, cibler l’analyse sociale (cf. ci-dessus) juste sur les auteurs de ceux-ci. Il s’agit ici d’utiliser le pouvoir informatique pour épargner l’effort humain, le plus cher et le plus précieux, puisqu’il peut effectuer des tâches « fines » d’analyse qu’on ne sait pas encore complètement automatiser. C’est dans cette optique que le problème de classification de texte ci-dessus a été proposé pour la première édition du Fake News Challenge, une compétition organisée conjointement par des journalistes et des informaticiens.
Ceci nous amène à une autre remarque fondamentale : le journaliste est seul capable de choisir les faits à partir desquels tirer un article, à choisir la nuance des mots pour en parler, et ceci demande de connaître ses lecteurs, la tradition du journal, l’angle de présentation etc. Les outils informatiques de fact checking sont des aides, des « bêtes à besogne », même s’ils sont loin d’être bêtes. Leur but est d’aider… des humains à communiquer avec des humains, pas de remplacer les journalistes.
Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?
Dans un magnifique article intitulé « Défense contre les forces des ténèbres : propagande et contre-propagande en réseau », Jonathan Stray cite une étude qui estime que le gouvernement chinois publie, par le biais de ses employés dédiés à cette tâche, 448 millions messages sur les réseaux sociaux, avec notamment une production de « nouvelles » accrues les jours où des informations défavorables au gouvernement circulent sur les mêmes réseaux. La stratégie est très simple » noyer le message indésirable dans la masse des contenus favorables, pour le rendre invisible. J. Stray note aussi, amèrement, que le fact checking vient nécessairement après un coup de désinformation, et que si celui-ci a été bien calculé et amplement diffusé, la fausse image créée dans les esprits va s’imposer. Mais cet article donne aussi une piste vers la solution : contre l’armée des forces des ténèbres, constituer l’armée des bons sorciers, qui, en mode crowd-sourcing (évidemment !), établiront l’atlas des sources de désinformation, afin que la connaissance gagnée par les uns profite à tous.
Le projet CrossCheck, un partenariat d’une vingtaine de grands médias dont Le Monde, est un pas dans cette direction.
Les scientifiques travaillent aussi sur le fact checking. Dans le projet ContentCheck, financé par l’Agence Nationale de la Recherche (ANR), nous élaborons par exemple des modèles de données et des outils pour le fact checking s’appuyant sur les contenus tels que les données ou les textes. La lutte contre la désinformation et les fake news (fausses nouvelles) est un sujet très actif dans la fouille des données ou l’analyse des réseaux… La consolidation des données contradictoires et partielles en des bases de confiance, avec ou sans appel au crowd-sourcing, apporte aussi un soutien évident au fact checking.
Mais, finalement, on pourrait se demander si le sujet est vraiment si important ? Nous vivons dans un monde qui doit gérer des guerres, des famines, du terrorisme international et les changements climatiques. Est-ce bien raisonnable d’investir des efforts pour savoir si ce que l’on vous dit est vrai ? La réponse à cette question, je ne la trouve pas uniquement dans mes expériences d’enfance dans une dictature, la Roumanie communiste, où la vérité était encore plus rare à trouver que les denrées de première nécessité. Je la trouve dans cette simple phrase : La liberté, c’est la liberté de dire que deux et deux font quatre. Si on vous accorde cela, tout le reste va suivre, Orwell, 1984.
Quand nous parlons d’informatique avec « le gouvernement », nous avons souvent l’impression d’être incompris. Avec le secrétariat au numérique, Fleur Pellerin et Axelle Lemaire, avec la French Tech, la loi sur la république numérique, notamment, la situation a changé.
Axelle Lemaire, Photo Claude Truong-Ngoc / Wikimedia Commons – cc-by-sa-3.0
Profitons de l’occasion pour remercier ici Axelle Lemaire dont nous avons pu apprécier l’intelligence, les compétences, la passion, et le travail acharné. Nous avons besoin de personnes comme elle pour concilier les angoisses des uns et les attentes irréalistes des autres sur le monde numérique, pour faire bouger les lignes.
Les robots sont depuis longtemps dans des usines de fabrication de boules de pétanques. Ce n’est que récemment qu’ils se sont invités sur les terrains de jeu de pétanque même.
La pétanque (du provençal pèd : pieds, et tanca : planté ; (lou) jo à pèd-tanca, le jeu à pieds-plantés, ou (la) petanco, la pétanque) est un jeu de boules dérivé du jeu provençal. C’est le dixième sport en France par le nombre de licenciés. Fin 2007, on compte 558 898 licenciés répartis dans 78 pays. À ces chiffres, il convient de rajouter les pratiquants occasionnels, en vacances notamment, c’est-à-dire plusieurs millions d’amateurs. C’est un sport principalement masculin (seulement 14 % des licenciés sont des femmes en France). Néanmoins, c’est l’un des rares sports où des compétitions mixtes sont organisées. Wikipédia
Un scoop binaire : l’intelligence artificielle a fini par vaincre l’humanité.
Trois robots ont battu la semaine dernière une triplette de champions. Après les échecs, le go, Jeopardy !, c’est un des derniers bastions de la domination humaine qui cède.
Il a fallu pour battre les humains à ce jeu pourtant très simple combiner les talents d’informaticiens d’Inria Paris et de roboticiens bordelais du CNRS, des spécialistes de robotiques, d’apprentissage automatique, et de géométrie computationnelle, sans compter bien entendu leurs collègues universitaires marseillais, en pointe sur tous les sujets du deep-learning à la pétanque. Nous avons rencontré le responsable de l’équipe, Lagneau Ennepé.
Pour confronter les robots, la ville d’Aubagne a réuni une triplette de choc – on a parlé de dream team. Emilie, Redouane, et Marcel sont des habitués des tournois, bardés de médailles. Emilie a été championne du monde, Redouane champion du Maroc, et Marcel champion de Provence.
Reachy, le bras robotique bio-inspiré et open source
Les trois robots, Fanny, Marius et Aimée, en fait identiques, ont été développés à partir de Reachy, le bras robotique bio-inspiré et open source, de Pollen Robotics. Un premier défi a été le poids de la boule de pétanque, trop lourd pour Reachy. Malgré l’insistance des ingénieurs, la fédération de pétanque a refusé les boules en plastiques (même peintes couleur argent). L’équipe de Lagneau a dû revoir complètement la mécanique du bras.
Une autre difficulté a été la nature souvent imprévisible des terrains de pétanque. Les pentes, les trous, les irrégularités… Les robots s’appuient sur un premier réseau de neurones pour découvrir le terrain et apprendre à s’y adapter, mais surtout sur la notion de robotique incarnée qui déporte l‘intelligence vers la mécanique elle -même.
Les robots ont perdu leur première partie de manière inhabituelle pour une partie de pétanque. C’était au tour d’Aimée de jouer. Elle est restée bloquée pendant de longues minutes sans bouger, avant que l’arbitre ne déclare la triplette humaine vainqueur. Emilie Noether, la pointeuse de la triplette humaine, a déclaré : « Bonne mère ; ça t’arrive d’hésiter, mais, putaing, tu te fais crier dessus et tu joues, cong. Je n’avais jamais vu cela en tournoi. »
Lagneau nous a expliqué : « Il existe deux façons de lancer les boules : pointer comme un têtu et tirer comme un testard. Une des plus grandes difficultés techniques a été de résoudre ce simple questionnement, pointer ou tirer. C’est d’ailleurs la cause d’innombrables disputes à la pétanque. »
Ce qui s’est passé est dramatiquement simple. Les robots ont joué des milliers de parties à un contre un. Le but était d’entrainer leurs réseaux de neurones pour apprendre à décider sur le dilemme : tirer ou pointer. Ils n’ont donc pas tous joué les mêmes parties. Dans la situation de la première partie, Marius pensait qu’il fallait tirer quand Fanny était convaincue qu’il fallait pointer. Ils ont transmis leurs avis par Bluetooth à Aimée. Le problème que l’équipe de Lagneau n’avait pas envisagé, c’est qu’Aimée était arrivée à des probabilités si voisines qu’elle a choisi de s’en remettre à l’avis des autres : et là égalité et blocage. C’était totalement imprévisible.
Ce problème n’est jamais plus arrivé. Nous avons cru comprendre que la solution de l’équipe de Lagneau était très low tech (une ligne de code) : en cas de désaccord, suivre l’opinion de Fanny. En fait, ils ont suivi le conseil de Corine Lercier : « Les femmes ont toujours raison. Et même si elles ont tort c’est qu’elles ont tarpé une raison d’avoir tort. » Est-ce vrai aussi pour les robottes ? La féminité des robots étant un sujet toujours délicat, la question reste en discussion dans les communautés d’intelligence artificielle.
Fanny, Marius et Aimée n’ont cessé de s’améliorer. Les humains ont commencé à douter et finalement perdu. La dernière partie s’est conclue sur le score de 13 à zéro. Cela a conduit les participants à suivre une vieille coutume provençale « embrasser Fanny ». Il s’agit d’embrasser le postérieur d’une Fanny. Comme un des robots s’appelle Fanny, la fin s’imposait. Redouane a commencé par dire : « le cul de la radasse ? T’es con toi ! » Mais, devant les huées de la foule, il a dû s’y résoudre. Il a embrassé comme les deux autres le postérieur de Fanny !
Serge Abiteboul, Marie-Agnès Enard, Pierre Paradinas, Charlotte Truchet, Thierry Vieille,
Il y a un an, pile
Un article de binaire sur le Big data et les objets connectés avait fait beaucoup réagir : La data du vibromasseur (binaire du 1er avril 2016). Le sujet reste d’actualité. Voir l’article du Monde : Un fabricant de sextoys connectés va indemniser les utilisateurs qu’il a espionnés (LeMonde.fr du 15 mars 2017). La Société Informatique de France a créé une commission sur ces sujets ; n’hésitez pas à la contacter.
Nous prenons de plus en plus conscience de l’importance que les algorithmes ont pris dans nos vies, et du fait qu’il ne faut pas accepter qu’ils soient utilisés pour faire n’importe quoi. Nous entendons de plus en plus parler de régulation, de responsabilité, d’éthique des algorithmes. François Pellegrini, professeur au LaBRI à Bordeaux, nous a fait part de critique d’éléments de langage, de son point de vue. Nous avons pensé que cela devrait intéresser nos lecteurs.Serge Abiteboul, Pierre Paradinas.
Crédit : Marion Bachelet – Inria
De plus en plus, dans le débat public, apparaissent les termes de « loyauté des algorithmes » ou d’« éthique des algorithmes ». Ces éléments de langage sont à la fois faux et dangereux.
Ils sont faux parce que les algorithmes n’ont ni éthique ni loyauté : ce sont des constructions mathématiques purement abstraites, conçues pour répondre à un problème scientifique ou technique. Ils appartiennent au fonds commun des idées, et sont de libre parcours une fois divulgués.
Ils sont dangereux, parce qu’ils amènent à confondre les notions d’algorithme (l’abstrait), de programme (ce que l’on veut faire faire à un ordinateur) et de traitement (ce qui s’exécute effectivement et peut être soumis à des aléas et erreurs transitoires issues de l’environnement).
Toute activité de recherche s’inscrivant dans un contexte socio-culturel, les questions éthiques ne sont bien évidemment pas absentes des étapes de conception. Les scientifiques qui, en 1942, travaillaient à l’optimisation de la fission nucléaire incontrôlée, savaient bien qu’ils participaient à la création d’une arme. Pour autant, si la décision de participer à un projet scientifique relève de choix moraux individuels, la question de l’usage effectif des technologies doit être traitée au niveau collectif, à la suite d’un débat public, par la mise en place de législations adaptées.
Ces éléments de langage focalisent donc improprement le débat sur la phase de conception algorithmique, alors que l’enjeu principal concerne les conditions de mise en œuvre effective des traitements de données, majoritairement de données personnelles. Ce sont les responsables de ces traitements qui, en fonction de leur mise en œuvre logicielle et de leurs relations économiques avec des tiers, choisissent de rendre un service déloyal ou inéquitable à leurs usagers (comme par exemple de calculer un itinéraire passant devant le plus de panneaux publicitaires possible).
Cela est encore plus évident dans le cas des algorithmes auto-apprenants. La connaissance de l’algorithme importe moins que la nature du jeu de données qui a servi à l’entraîner dans le contexte d’un traitement spécifique. C’est du choix de ce jeu de données que découlera l’existence potentielle de biais qui, en pénalisant silencieusement certaines catégories de personnes, détruiront l’équité supposée du traitement.
L’enjeu réel de ces débats est donc la régulation des rapports entre les usagers et les responsables de traitements. Un traitement ne peut être loyal que si son responsable informe explicitement les usagers, dans les Conditions générales d’utilisation de ses services, de la finalité du traitement, de sa nature et des tiers concernés par les données collectées et/ou injectées. Cette « transparence des traitements » (et non « des algorithmes ») a déjà été instaurée par la loi « République numérique » pour les traitements mis en œuvre par la puissance publique ; il est naturel qu’elle soit étendue au secteur privé. La description fonctionnelle abstraite des traitements n’est pas de nature à porter atteinte au secret industriel et rassurera les usagers sur la loyauté des traitements et l’éthique de leurs responsables.
« Mal nommer les choses, c’est ajouter au malheur de ce monde », disait Camus. N’y participons pas. Laissons les algorithmes à leur univers abstrait, et attachons-nous plutôt aux humains et à leurs passions.
Nous, chercheurs en informatique (en bases de données et apprentissage automatique), pensons que nos recherches peuvent aussi servir les gens. Un des domaines dans lesquels ces recherches pourraient servir est celui de l’emploi. Comment trouver un premier emploi, comment retrouver un emploi après un licenciement ou une interruption ? C’est souvent le problème le plus important pour les personnes concernées ; c’est aussi un des problèmes les plus difficiles pour l’État. Or, le big data peut apparemment tout (ou presque) pour l’innovation, la santé, le commerce, etc. ; peut-il quelque chose pour l’emploi ? Cet article est publié en collaboration avec The Conversation.
E-coaching. La recherche d’un emploi s’apparente à un parcours du combattant, à une loterie, à un examen scolaire, à un concours. Il faut rédiger un curriculum vitae. Comment mettre en valeur ce qu’on a fait ? Comment décrire ses hobbies ? Comment répondre à des questions comme : quel est votre principal point faible ? On peut se repasser de bonnes réponses entre amis (mon défaut est d’être trop perfectionniste) ; mais une bonne réponse trop connue n’est plus une bonne réponse (1).
Idéalement, un conseiller infatigable et dévoué, au courant de votre cas personnel, de l’état de l’emploi dans votre branche, des aides gouvernementales, de la situation régionale, etc., vous donnerait jour après jour les meilleurs conseils. Il commencerait par apprendre à vous connaître, pour vous aider : à faire le tri, à chercher aux bons endroits, à ne pas se décourager.
Philippe Tastet, Creative Commons
E-commerce. On peut aussi s’inspirer de ce qui existe dans le domaine du commerce sur Internet. Après tout, on cherche un emploi un peu comme on cherche un produit dans un site de commerce en ligne. Dans les deux cas, la personne cherche ce qui correspond le mieux à ses besoins. Il y a évidemment de grandes différences. Par exemple, l’emploi ne s’achète pas, l’information est rare. Une similitude est la difficulté de trouver, de choisir. Un site de commerce en ligne (par exemple Amazon) propose énormément plus de produits qu’un magasin physique. Le catalogue des produits est plus long qu’une encyclopédie ; il faut donc aider le client à s’y retrouver. Ainsi apparaissent les moteurs de recommandation. Les techniques qu’ils utilisent pourraient-elles nous aider à recommander des emplois ? Dans la vente par correspondance, on s’inquiète par exemple des produits de la « longue traine » (**), c’est-à-dire les produits moins populaires, très nombreux, qui sont, du coup, délaissés. Dans l’emploi aussi.
Comment fonctionne un moteur de recommandation.
Une première stratégie se résume à recommander « plus de la même chose ». Vous êtes allé à Romorantin ; le moteur continue de vous proposer des voyages pour Romorantin, ce qui est pertinent si votre petit ami vient de déménager à Romorantin mais ce qui l’est moins si vous avez rompu avec lui. Une autre approche consiste à utiliser des corrélations simples : Vous avez aimé les couches P, vous aimerez les bières K. Pourquoi ? Parce que dans les faits les gens qui ont acheté des couches P ont aussi souvent acheté des bières K. Cela ne donne pas non plus les meilleures recommandations.
En fait, ce qui marche bien, c’est une troisième méthode. Elle a été popularisée en 2006 avec le Concours Netflix, doté d’un prix d’un million de dollars, dont le but était de recommander à une personne les films que cette personne aimerait. Les données utilisées sont les notes données par les clients aux films que chaque client a vus. Même si chaque client a vu une poignée de films, l’ensemble des clients permet de couvrir une masse considérable de films. L’idée de cette technique est que si quelqu’un a vu et apprécié une partie des films que j’ai vus et appréciés, j’aimerai peut-être les autres films que cette personne a appréciés, même si, pour certains d’entre eux, je n’en ai jamais entendu parler. L’algorithme essaie donc de découvrir des proximités de goût entre des clients et base ses recommandations sur ces proximités. Des proximités entre des clients qui ne se sont le plus souvent jamais rencontrés !
Typiquement, les moteurs de recommandation s’intéressent à des clients qui viennent et reviennent sur la plate-forme d’achat — qu’on finit donc par connaitre assez bien en fonction de leurs achats passés. Par contre, un demandeur d’emploi cherche en général un seul emploi, et s’arrête de chercher une fois qu’il l’a trouvé. Il faudra faire avec le peu d’information dont on dispose. On connait son CV, les offres auxquelles il a postulé, celles qui lui ont accordé un entretien, etc. On applique une approche à la Netflix.
Des sites de recherche d’emploi comme LinkedIn, Indeed, Monster, MindMatcher, ou Qapa, ont développé des algorithmes pour mesurer la « distance » entre un CV et une offre d’emploi. Un tel site peut utiliser des algorithmes de traitement de la langue naturelle sur les documents (CV et offres), ou analyser les données des graphes sociaux. Il essaie de « matcher » les CV avec les offres d’emplois. Si l’histoire de Sarah ressemble à celle de Sylvie, on peut lui signaler un emploi qui ressemble à celui que Sylvie a obtenu (ou pour le moins pour lequel elle a eu un entretien).
Le site bob-emploi, par exemple, accompagne le chercheur d’emploi (voir encadré). Il lui demande de décrire rapidement son profil (moins de 5 minutes), fait de bonnes suggestions, signale des ressources utiles, s’adapte à votre niveau d’énergie du jour (trois niveaux). Certains conseils sont de bon sens comme : n’envoyez pas un CV par mail sans y joindre une lettre de motivation, expliquant pourquoi vous voulez le poste, et pourquoi le poste vous veut ; ou utilisez les réseaux professionnels, mais attention aux traces que vous laissez sur Internet, qui vous suivront comme un « casier judiciaire social ». D’autres conseils sont plus obscurs. Par exemple, formulez vos savoir-faire en termes de verbes plutôt que de noms ; ce conseil se fonde sur le fait que les recruteurs cliquent plus (toutes choses égales par ailleurs) sur un CV rédigé avec des verbes, qu’avec des mots. Ces observations peuvent être expliquées a posteriori : les verbes font plus dynamique, plus précis, montrent qu’on ne subit pas son sort, etc. Mais la raison en fin de compte est empirique : d’après les données, ça marche mieux. Ça marche en général. Mais est-ce que cela fonctionnera avec recruteurs pertinents pour votre recherche d’emploi, qui sont les seuls qui vous intéressent après tout ? Et surtout, est-ce que cela marchera encore quand le conseil aura été rabâché dans toutes les revues et magazines ?
Au début 2017, le site bob-emploi est en mode rodage (version bêta). Une certaine frustration des utilisateurs est parfois visible, due à l’écart entre leurs attentes et le fonctionnement actuel du site. Le site indique fréquemment qu’il est en phase d’apprentissage, demande si l’utilisateur a trouvé utiles les conseils fournis, et rappelle que le site s’enrichit au fur et à mesure des réponses.
La satisfaction de l’utilisateur – disons Georges – dépend naturellement de la qualité des conseils que le site lui donne, et surtout du fait que ces conseils soient bien adaptés à la situation particulière de Georges. Il faut donc que le site soit bien nourri : qu’il connaisse le profil de Georges, ou qu’il connaisse des gens semblables à Georges et qu’il sache ce que ces gens ont aimé… Et puis, quand on s’attaque à un problème humain comme l’emploi, on fait face – comme on pouvait s’y attendre – à la difficulté des relations avec les humains… Supposons que l’algorithme découvre ce qui bloque les candidatures de Georges et les empêche de déboucher sur un entretien. Faut-il lui annoncer ? Oui sans doute ; mais comment ? Comment mettre cette connaissance à son service, sans le décourager : c’est tout sauf simple.
Une frustration exprimée dans le forum est : Ce site est fait pour les super-diplômés, moi qui suis serveuse, ça ne me sert à rien. Peut-être est-ce parce qu’il n’y a encore peu de données sur les serveuses dans bob-emploi ? Un problème général est qu’on a peu de données utiles pour les gens qui ont le plus besoin d’aide : si les gens sont peu ou pas diplômés (17% de chômage pour les non-diplômés en Janvier 2015), leurs CV contiennent peu d’information ; et la situation est pire pour les jeunes non diplômés (presque 40% pour les moins de 29 ans) (***). Il faut laisser du temps à bob-emploi.
Et puis, n’oublions pas ce nombre important de demandeurs d’emploi qui n’a pas accès à des sites comme bob-emploi, peut-être parce qu’ils n’ont pas les moyens de s’offrir un accès à Internet, un ordinateur, ou parce qu’ils ne sont pas à l’aise avec l’informatique. Des associations comme Emmaüs Connect les aident à écrire leur CV, à acquérir le coup de main pour les interactions de base avec Internet.
Pour écrire cet article, nous avons rencontré Paul Duan, le fondateur de bob-emploi : avec enthousiasme et simplicité, avec résolution et modestie, il conçoit des algorithmes et services web pour servir les gens. Il n’assène pas de certitudes ; il sait qu’on apprend en marchant ce qui est utile, ce qui sert, et il sait qu’il y a encore beaucoup de chemin à parcourir. Il se pose la question d’être utile dans le temps, sans nuire aux utilisateurs :
le service doit vivre et se déployer,
les données, forcément confidentielles, ne doivent pas se retourner contre les gens vulnérables,
les algorithmes doivent être ouverts, vérifiables, pour que d’autres puissent les améliorer, ou vérifier leur absence de biais…
Nous avons demandé à Paul où il allait. Sa réponse : « à court terme, nous voulons améliorer bob-emploi. A long terme : l’étendre pour d’autres pays ; et développer des services pour les gens dans d’autres domaines. »
Bien sûr, d’autres pays ont des problèmes d’emploi… Et, dans bien d’autres domaines, les gens auraient l’utilité d’un site qui agrège les informations, les règles, les aubaines, et aide chacun : pour l’orientation scolaire, pour la création d’entreprises… Des associations s’attaquent déjà à ces domaines : les besoins et les possibilités sont immenses…
Paul Duan, fondateur de Bayes Impact et de bob-emploi, a un parcours assez particulier, de Trappes au Sentier, en passant par Berkeley ; de Sciences Po aux Sciences des données, en passant par l’économie et l’informatique. Il y a quelques années, il bosse comme data scientist dans une start-up de la Silicon Valley. Mais il est convaincu que la vie ne peut se limiter à s’enrichir avec des startups ; il veut aussi aider les moins chanceux que lui. Il donne alors un coup de main dans une soupe populaire. Oui, à la Mecque des milliardaires d’aujourd’hui, les laissés-pour-compte ne manquent pas, tout comme chez nous.
Et puis un jour, Paul se dit que ses compétences qui font pousser les dollars pourraient être mieux utilisées au service de la collectivité.
Bayes Impact. ll crée Bayes Impact, une ONG qui aide d’autres ONG, en réalisant pour elles leurs analyses de données. Par exemple, une ONG développe du microcrédit. Elle pourrait améliorer considérablement son offre en comprenant mieux les données dont elle dispose. Seulement elle n’a pas de data scientist. Bayes Impact résout le problème. C’est comme en économie traditionnelle, où les entreprises font appel à des startups spécialisées dans le big data quand elles ne disposent pas de cette technologie en interne. La différence c’est que les gens de Bayes Impact aident les ONG parce qu’ils partagent leurs valeurs et leur vision ; et aussi, leur salaire est bien en dessous de ce qu’il serait dans une boite de big data classique.
Bayes Impact est un succès mais l’exercice est frustrant. Les casques bleus, les data scientists, débarquent dans un projet, au contact de gens qui essaient de changer le monde. Ils donnent un coup de main. Et puis il faut partir car, pour optimiser l’impact, il leur faut aller ailleurs. Est-ce que le résultat est durable ?
Au service du service public. Paul et ses copains décident alors de se fixer sur des projets précis et de les mener à terme. Ils aident le gouvernement US pour des problèmes concrets (l’accompagnement des retours des vétérans de la guerre d’Irak ; les réhospitalisations). Ils peuvent apporter des solutions concrètes et voir les résultats des décisions prises en fonction des données. Mais qui dit ce qu’il faut optimiser ? Les critères sont politiques et/ou opaques…
Au service des citoyens. Ils pivotent – c’est à dire, que dans la tradition des startups classiques, ils changent de business modèle. Plutôt que de travailler pour le gouvernement, pourquoi ne pas travailler pour le citoyenavec le gouvernement ? Il s’agit donc de s’attaquer aux problèmes rencontrés par des citoyens et d’utiliser le numérique pour aider ces derniers à les surmonter. Commençons par l’emploi : le résultat, c’est bob-emploi, pour aider les chercheurs d’emploi à comprendre ce qui se passe, comment faire, quelles sont les priorités, comment ne pas s’épuiser, comment se faire aider par Pôle emploi, comment ne pas abandonner leur vie sociale…
Pourquoi « bob-emploi » ? Le nom de code du robot que Paul Duan et ses copains imaginaient pour accompagner les demandeurs d’emploi était bob le bot ; c’est devenu « bob-emploi ».
Le cœur de compétence de Bayes Impact – la science des données – est encore peu utilisé dans bob-emploi. Mais cela devrait monter progressivement en puissance : il faut d’abord acquérir les données. Donc, allez-y ! Chercheur d’emploi, nourrissez le site, donnez votre avis, vos tuyaux… C’est l’auberge espagnole de l’intelligence : chacun en apporte un peu, et chacun l’a tout entière.
Voir aussi :
(*) Les règles du jeu (2014), film réalisé par Claudine Bories et Patrice Chagnard; Le quai de Ouistreham, 2010, Florence Aubenas; Les tribulations d’un précaire (2007), Iain Levison. The bait and the switch (2005), Barbara Ehrenreich.
(**) La longue traîne, de Chris Anderson (2004).
(***) http://www.inegalites.fr/spip.php?page=article&id_article=1585.
Nous avons demandé à une amie, Florence Sedes toulousaine de la SiF de nous présenter les travaux de Nina Miolane, une « numéricienne » parmi les 30 lauréates de la bourse L’Oréal-Unesco pour les Femmes et la Science : « Vers la médecine de demain : une aide numérique au diagnostic humain ». Pierre Paradinas.
Sélectionnée parmi plus de 1 000 candidates, Nina Miolane est récompensée, après un parcours d’exception et un doctorat obtenu entre Nice et Stanford, entre mathématiques et médecine.
Photo : Nina Miolane.
Comment utiliser les mathématiques et les hautes technologies pour transformer la recherche en médecine ? Pouvons-nous créer des outils numériques améliorant la pratique médicale courante et hospitalière ? Le travail de recherche de Nina Miolane développe un des piliers de la médecine de demain : l’anatomie numérique.
La médecine prévoit d’être transformée au cours des prochaines années grâce aux nouvelles technologies : d’un côté, les technologies d’imagerie (scanners, IRM, etc) et de l’autre côté les technologies du numérique permettant l’analyse de ces images (superordinateurs, calcul distribué, etc). Sa recherche en anatomie numérique s’appuie sur ces deux technologies pour construire, dans l’ordinateur, un modèle de l’anatomie humaine.
Le modèle d’anatomie numérique contient tout d’abord la forme de chaque organe dans son état sain, ainsi que toutes les formes de l’organe qui correspondent à ses variations saines – par exemple dues à la taille du patient – ou pathologiques. De nombreuses pathologies sont en effet visibles sur les images médicales, comme par exemple la maladie d’Alzheimer qui se caractérise par une atrophie du cortex cérébral et une expansion des ventricules, ces cavités du cerveau contenant le liquide céphalorachidien.
Dans le cadre du projet récompensé par la bourse l’Oréal-UNESCO, Nina s’est intéressée plus particulièrement à l’anatomie du cerveau. Une hypothèse classique suppose l’existence d’une unique anatomie cérébrale saine de référence. Toutefois, la variabilité des topologies du cerveau, par exemple au niveau des sillons du cortex cérébral, est telle qu’il n’est souvent pas possible de représenter l’anatomie par un cerveau unique. Celui-ci sera soit consistant mais flou au niveau des sillons, soit inconsistant car il représentera seulement une topologie particulière des sillons.
Ainsi, le modèle d’anatomie développé a la forme d’un arbre : les niveaux élevés représentent l’anatomie saine à grande échelle comme la boite crânienne, et les niveaux bas représenteront les anatomies saines à petite échelle, comme le nombre de sillons. Grâce à la bourse l’Oréal-UNESCO, Nina va pouvoir suivre une (courte) formation en neuro-anatomie et neurosciences, pour confronter l’anatomie obtenue avec son modèle à la connaissance actuelle des spécialistes, et poursuivre ses recherches pot-doctorales entre les Etats-Unis et la France.
« Nous espérons mieux comprendre, caractériser et diagnostiquer les maladies cérébrales ou neurodégénératives. De plus, ce projet est bien sûr centré sur le cerveau mais est suffisamment générique pour être appliqué ensuite aux autres organes. »
L’anatomie numérique doit même permettre d’aller plus loin : le projet est de fournir, à terme, la probabilité que le patient développe telle ou telle maladie dans le futur. En effet, l’outil numérique permet de détecter des variations subtiles de formes d’organes et permet de tendre vers un diagnostic avant que les symptômes se développent. Détecter une maladie neurodégénérative de façon pré-symptomatique, comme Alzheimer par exemple, permettrait non pas de la guérir ou de la stopper, mais plutôt de ralentir sa progression de façon à ce que la vie quotidienne du patient ne soit pas affectée.
Quand on croit dur comme fer à l’égalité homme-femme, on peut être un peu mal-à-l’aise devant des initiatives « mono-genre ». Quand Julien Dorra nous a parlé de ce programme de formation de développeuses, donc « réservé aux femmes », nous nous sommes interrogés : Pourquoi ce n’est pas mixte ? Et puis nous nous sommes souvenus d’avoir vu des garçons accaparer les claviers, les temps de paroles, exclure – pas forcément méchamment – les filles. Alors, s’il faut en passer par là, pour encourager la parité en informatique…
Comment l’idée est-elle née ? Julien est, avec des copains, à l’origine des « coding gouters ». Si c’était ouvert à tous, ces gouters étaient fréquentés par de nombreuses femmes qui venaient avec leurs enfants s’initier au plaisir de la programmation informatique. Ces femmes avaient parfois envie d’aller plus loin, d’en faire une profession. Mais rien n’était prévu…
L’idée simple d’ « À mon tour de programmer ! » c’est de prendre une petite cohorte de femmes de tous âges, déjà un peu codeuses, et d’en faire de vraies développeuses, de les encourager, les aider à construire un projet professionnel, de leur donner les moyens de le réaliser.
Comment ? Dans le monde de Julien, la solution passe souvent par un écosystème d’associations.
La technique avec /ut7: Il faut consolider, structurer tout ce que ces dames savent déjà. Nous sommes à des années lumières de l’Ecole 42, individualiste, machiste, un peu puérile. Le développement de code est ici collectif, inclusif, social. apprend à programmer ensemble. Le but est surtout de démystifier le sujet pour que demain chacune d’entre elles puisse sans complexe affronter de nouveaux problèmes, de nouveaux environnements de programmation. Cela passe par des projets et, par exemple, la familiarisation avec plusieurs langages de programmation.
Le projet professionnel avec Social Builder. Pour cela, le programme s’appuie sur du mentorat et de l’accompagnement professionnel. Les participantes ont l’occasion de concevoir un projet, de le mettre au point. On développe ensemble. On discute avec d’autres. On se critique. On s’aide.
L’insertion dans une communauté avec Ladies of Code: La troisième et dernière facette du programme est essentiellement du networking au sens le plus noble du terme. Les participantes sont intégrées dans les activités de Ladies of code, petits déjeuners, apéros, ateliers de co-travail…
Le programme de mars à novembre 2017 n’est pas un temps plein mais exige une grande disponibilité. Il est soutenu par la Mairie de Paris dans le cadre de Paris Code, et a obtenu le label « Grande école du numérique ». Les douze participantes ont été sélectionnées pour cette première édition. Espérons que, comme Museomix et d’autres idées de Julien et ses amis, « À mon tour de programmer ! » sera un beau succès et sera répété de nombreuses fois.
On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
Parmi les domaines notoirement touchés par la féminisation, on compte l’enseignement, la médecine et la magistrature qui, au fil des ans, ont perdu de leur panache. Pour plusieurs raisons : ces métiers se sont largement démocratisés à mesure que les jeunes filles poursuivaient elles aussi des études, que ces métiers embrassaient des scénarios moins prestigieux, par exemple un avocat traite aujourd’hui davantage de cas de divorce ou de petite délinquance que de subtiles affaires propices à faire briller la défense ; l’enseignement primaire et secondaire ont pâti du fait que, compte tenu de l’allongement des études, il devenait moins exceptionnel de mener des élèves au bac qu’auparavant, ou encore la salarisation de la profession, puisque nombre de femmes médecins aujourd’hui s’accordent le mercredi pour s’occuper des enfants. Ceci représente un mode d’exercice propre aux femmes – puisqu’on en est encore là – qui contribue à banaliser la profession [2]. Ceci étant, même dans ces domaines, les stéréotypes sont bien gardés, puisque les femmes sont plutôt des juges pour enfants que des présidentes d’assises et les avocates plutôt surreprésentées en droit de la famille quand les avocats d’affaires sont plutôt des hommes de pouvoir. À ceci s’ajoute un facteur purement objectif, les jeunes filles sont meilleures dans les études et de fait plus propices à obtenir des concours compétitifs comme ceux de médecine ou de la magistrature.
Benjamin Carro, Mediego, Creative Commons
Irons-nous jusqu’à conclure que lorsqu’une profession perd en prestige, elle se féminise comme le prétendait Bourdieu en 1978, où est ce le fait que les femmes l’embrassent pour d’autres raisons qui la rend moins virile et de fait la dévalorise [2] ? Il s’avère que les femmes s’approprient souvent un secteur plutôt parce qu’il est délaissé par les hommes que parce qu’elles en rêvent. Ainsi les domaines de prédilection des hommes après avoir été l’enseignement, le droit ou la médecine sont désormais l’ingénierie, la finance ou l’entrepreneuriat. Les femmes viennent rarement marcher sur ces plates-bandes masculines, elles se faufilent dans les places laissées vacantes. L’armée néanmoins reste une exception en la matière, son prestige ne cesse de décliner sans qu’elle ne se féminise pour autant [1] !
L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion.
Les algorithmes, s’ils existent depuis très longtemps, sont clairement associés aux informaticiens qui les créent, les implémentent et les optimisent depuis l’apparition de la discipline. Leur importance n’a cessé de s’affirmer au point qu’aujourd’hui on pense à les taxer et leur inventer une justice. Ils sont ubiquitaires, dans nos ordinateurs, nos téléphones, ils décident du film que nous allons voir, de l’ordre dans lequel nos recherches dans les moteurs sont ordonnées, de celui des posts de nos amis sur les réseaux sociaux, du cours de la bourse, du montant de nos primes d’assurances, du prix de nos billets d’avion. Ils permettent d’éclairer les villes ou de réguler le trafic routier. Ils sont aux commandes des médias, rendent virales certaines informations, voire nous font avaler des couleuvres avec de fausses informations, ils assistent nos chirurgiens, ils nous battent au jeu de go, sont capables de bluffer au poker, sont en passe de conduire nos voitures, servent de moyen de contraception [3] et nous font aujourd’hui miroiter des espérances de vie allant jusqu’à 150 ans. On leur attribue à l’envi intelligence, bienveillance ou encore machiavélisme. Ils nous effraient parce qu’ils nous manipuleraient, ou encore parce qu’ils menacent de nombreux métiers. Ils sont transversaux à tous les domaines de notre société des médias à la santé, des transports aux cours de la bourse.
Si l’avenir appartenait certes à ceux qui se lèvent tôt, il appartient bien davantage à ceux d’entre nous qui sauront concevoir et mettre en œuvre des algorithmes.
Un algorithme n’a pas de sexe mais il semble aujourd’hui clair que leurs concepteurs en ont un, souvent le même. À l’instar d’une étude récente qui montre que des enfants attribuent naturellement l’intelligence aux hommes et la bienveillance aux femmes, notre monde conjugue les algorithmes au masculin.
Notre société évolue à deux à l’heure sur le sujet malgré un cadre législatif pourtant bien en place. Le plafond de verre existe toujours bel et bien, les femmes sont jugées à une autre aune que leurs homologues masculins, on encense bien moins, et on punit moins aussi d’ailleurs, les petites filles que les petits garçons, les femmes gagnent en moyenne 15% de moins à qualifications égales, en France les levées de fond des startups dirigées par les femmes représentent 13% de la totalité pour un montant qui ne représente que 7%. Hors la loi, le sexisme, cette croyance qu’il existe une hiérarchie entre les hommes et les femmes, est tenace qui diffuse son venin au quotidien dans les médias, les publicités, les pauses café, etc. Profitons du cadre législatif égalitaire, des nombreux élans de parité et faisons de nos jeunes filles des déesses du numérique, des entrepreneuses du Web. Convainquons nos jeunes filles que les carrières du futur sont celles qui riment avec numérique, algorithme et informatique et aidons les à y accéder sans qu’elles aient besoin d’attendre leur déclin (qui pour l’heure semble infiniment lointain).
Ce serait d’autant plus juste que l’informatique menace surtout les femmes. Des études montrent que les nanotechnologies, la robotique et l’intelligence artificielle remplaceront environ 5 millions d’emplois en 2020 [4]. Il s’avère que l’automatisation affecte majoritairement des secteurs féminins (administration, marketing, opérations financières). À l’inverse les hommes s’accaparent les secteurs générateurs d’emplois comme ingénierie, informatique, mathématiques. À ce rythme, les femmes seront les plus grandes victimes des algorithmes et tout cela ne fera qu’accroitre les inégalités existantes.
Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion
Il faut aussi exploiter les « role models », favoriser le mentorat qui permet aux femmes de s’entretenir avec un supérieur, ou une personne plus senior dans la profession, sur leurs carrières de manière explicite, de lever l’autocensure et de pallier le manque de confiance qui est parfois un frein à l’ambition et l’avancement des carrières féminines.
[1] Cacouault-Bitaud Marlaine, « La féminisation d’une profession est-elle le signe d’une baisse de prestige ? », Travail, genre et sociétés, 1/2001 (N° 5), p. 91-115.
[2] Malochet Guillaume, « La féminisation des métiers et des professions. Quand la sociologie du travail croise le genre », Sociologies pratiques, 1/2007 (n° 14), p. 91-99.
[3] Natural Cycle, Elina Berglund
[4] Future of Jobs, The World Economic Forum’s (Future of Jobs).
Le 23 mars 2017, de 14 à 17h30, à Paris, Inria Alumni organise une Jam Session sur ce sujet en partenariat avec la Société informatique de France.
Les logiciels sont construits à partir du savoir et des connaissances des personnes, souvent des informaticiens, qui les conçoivent. Ils ont, comme les objets scientifiques, techniques, comme les objets du quotidien, une durée de vie limitée. A chaque disparition, c’est un peu de l’humanité et de son savoir qui disparait. En cela, les logiciels font partie de notre patrimoine, et les préserver est devenu un enjeu à la fois technique et épistémologique.
Cette Jam Session a pour but, avec le concours de professionnels impliqués dans le “patrimoine logiciel”, de discuter différentes approches et problématiques de la sauvegarde du logiciel.
En ce 11 février, journée internationale des femmes et des filles de science, binaire a souhaité mettre en lumière une initiative lilloise dont l’objectif principal est de promouvoir l’informatique auprès de jeunes femmes. Laetitia Jourdan et Philippe Marquet, tous deux enseignants-chercheurs au laboratoire d’informatique de l’université de Lille – sciences et technologies, nous présentent les différentes actions qu’ils portent et les résultats prometteurs qu’ils obtiennent autour de l’ « Informatique au féminin« . Marie-Agnès Enard.
Les entreprises du domaine de l’informatique déplorent l’absence de candidates féminines alors qu’elles cherchent à augmenter la mixité dans leurs équipes. Cette difficulté est directement liée au faible pourcentage d’étudiantes dans les formations en informatique (10% de filles parmi les étudiant-e-s de licence et master d’informatique à l’université Lille 1). Pourtant dans les années 80, on comptait 20% de filles dans les filières informatiques. Isabelle Collet, informaticienne de formation, chercheuse en sciences de l’éducation à l’université de Genève, s’est penchée sur la question et a fait émerger les représentations liées aux métiers de l’informatique et pourquoi elles en éloignent les femmes [ref : http://archive-ouverte.unige.ch/unige:18794 par exemple]. En particulier, depuis l’avènement du micro-ordinateur dans les années 80, l’informaticien est en effet souvent considéré comme un être solitaire et asocial passant sa journée à faire des tâches répétitives et de la programmation. Pourtant les métiers de l’informatique sont très nombreux et font appel à de multiples compétences.
Informatique un métier d’homme ? Bien sûr que non !
Le projet lillois “Informatique au féminin” est né d’une réunion en novembre 2013 organisée par IBM France sur le site d’EuraTechnologies à Lille qui questionnait la gestion de la diversité. IBM s’interrogeait sur la difficulté à féminiser son effectif. Les entreprises et les organismes de formation présents ont tous fait le même constat : cette difficulté était due à l’absence de candidates et l’absence d’étudiantes. De là, avec plusieurs collègues, nous avons monté un groupe de réflexion sur les femmes et l’informatique en vue de faire changer les choses. Le groupe est transverse sur l’université Lille sciences et technologies et implique les composantes IUT, école d’ingénieurs et UFR. Via le service relations entreprises de l’université, nous avons réussi à entrainer des entreprises “marraines” pour financer des actions : Absys-Cyborg, Adéo, AFG, Capgemini, CGI, Décathlon, DSI-Auchan, IBM services center, Leroy-Merlin, OVH.com, Sopra Steria, SII, SPIE.
Agissons pour une informatique au féminin
La conjonction du financement des entreprises partenaires et de la volonté des enseignants-chercheurs du groupe “Informatique au féminin” permet donc de mener des actions variées d’observation de la place des jeunes filles dans nos formations, d’information sur les métiers de l’informatique, de soutien aux jeunes femmes qui s’engagent dans des études d’informatique, et de vulgarisation autour de l’informatique.
Informaticien, un métier d’homme ? Parlons-en !
Le groupe “Informatique au féminin” organise chaque année des tables rondes avec pour objectif de présenter les métiers et de combattre les préjugés en mettant en avant des femmes travaillant dans l’informatique. Cette organisation est aidée par des étudiants de 2e année de master informatique dans le cadre de leur projet de communication.
Ouvertes à toutes et à tous, les annonces de ces tables rondes sont diffusées aux étudiant-e-s de premier cycle et dans les établissements d’enseignement secondaire. Sept tables rondes ont été réalisées depuis 2014 dont une durant la soirée des partenaires du projet.
Informaticiennes, nos métiers
Afin de diffuser plus largement les témoignages de femmes travaillant dans l’informatique, nous réalisons de courtes vidéos de 3 à 4 minutes. Ces vidéos disponibles sur le site web “Informatique au féminin” sont librement accessibles. Douze portraits vidéos sont déjà en ligne, trois autres portraits en post-traitement. Les CIO, centres d’information et d’orientation, s’appuient sur ces portraits pour montrer à de jeunes lycéen-ne-s intéressé-e-s ce que peuvent être les métiers de l’informatique.
Bourses pour étudier l’informatique
crédit photo Informatique au féminin
L’attribution de bourses d’études est l’action phare de notre groupe. Ces bourses d’étude ont été mises en place pour palier au manque de jeunes filles dans les filières d’étude en informatique, et favoriser ainsi la parité en amont du marché du travail. Cette opération ambitieuse est aussi un élément fort de communication assurant globalement une bonne visibilité à notre démarche.
Ces bourses sont attribuées aux bachelières, étudiantes de Licence 1, ou de 1re année de DUT qui s’engagent à suivre un cursus de trois ans en vue de l’obtention d’un diplôme BAC+3 en informatique à Université Lille 1 ou Polytech’Lille. Ces bourses d’un montant annuel de 4000€ sont financées par le mécénat d’entreprises.
Depuis 2015, 31 bourses ont été allouées. Cette année 2016-2017, 21 étudiantes sur l’université Lille – sciences et technologies sont bénéficiaires de la bourse. Les lauréates sont étudiantes à l’IUT, à Polytech’Lille ou en licence informatique.
Au delà du mécénat, les entreprises assurent un rôle de marraine auprès des étudiantes et les accompagnent tout au long de lors scolarité, que ce soit sous la forme d’un suivi régulier pendant les études, de découverte de l’entreprise, de mini-stage… Les étudiantes sont elles les ambassadrices de l’entreprise.
Découvrir l’informatique, ses métiers
Une meilleure sensibilisation à l’informatique et au numérique passe certainement par une action très en amont, dès le plus jeune âge afin de combattre les apriori. Nous avons donc la volonté de nous investir au sein d’Informatique au féminin dans des activités de médiation scientifique de l’informatique spécialement vers un public de filles. C’est ainsi qu’en novembre 2016, nous avons participé à “Numériqu’ELLEs” organisée par IBM, le CORIF – Conseil recherche ingénierie formation pour l’égalité femmes-hommes –, la Direction régionale aux droits des femmes et à l’égalité Hauts-de-France, et l’Académie de Lille. Plus de 400 jeunes collégiennes et lycéennes ont été sensibilisées aux métiers du numérique via des stands présentant les formations, le recrutement et les métiers du numérique. Nous avons animé des stands de découverte de concepts de la science informatique à l’aide d’activités d’informatique débranchée. Les sondages réalisés à l’issue de la journée montrent l’apparition d’un changement de mentalité chez les participantes et font même état de vocations !
Elles codent, elles créent dès le collège
Le support des entreprises nous permet également de financer des actions de médiation dans les collèges. Ainsi l’action « L codent, L créent » qui débute ces jours-ci propose d’établir un lien direct entre des élèves (filles uniquement) de collège et des étudiantes en informatique de différentes formations de l’université de Lille via des ateliers de création d’œuvres numériques et de programmation créative.
Cette action est portée par des enseignants-chercheurs de l’université qui développent un support de formation ad hoc. Les étudiantes, formées à la médiation et rémunérées via le programme “Informatique au féminin”, vont intervenir sur 8 séances de 45 minutes les midis dans trois collèges de Villeneuve d’Ascq. “L codent, L créent” se conclura par une exposition en présence des parents, de toutes les intervenantes, mais aussi de créateurs d’art numérique, encore une occasion de communiquer sur nos actions.
Des formations en informatique qui se féminisent
Notre première action a été de collecter et observer les proportions de filles dans les effectifs des formations en informatique de l’université, à savoir l’IUT informatique, la filière GIS – Génie informatique et statistiques – de l’école Polytech Lille, et les licences et masters informatique et MIAGE regroupés à l’UFR au sein du FIL – Formation en informatique de Lille. La répartition femmes/hommes était et reste différente selon les formations. Ainsi, le manque d’effectif féminin au début de l’action se faisait moins ressentir au sein de Polytech Lille qu’au sein de l’IUT informatique.
Pour la première année d’IUT, le pourcentage de femmes a progressé de 5,34% en 2010-11 à 12,12% en 2016-17 (sur 132 étudiants). Pour la 2e année, le pourcentage de femmes est passé de 2,38% à 12,87% (sur 101 étudiants).
Au niveau des licences et masters, la progression est globalement de 11,59% à 18,41% sur 666 étudiants. Cette hausse est plus significative sur les premières années, puisque de 10% nous sommes passés à plus de 24,87% en 2e année de licence informatique (la 1re année de licence est commune à d’autres disciplines).
Nos actions semblent donc avoir un impact sur les formations en entrée des cursus ce qui est très prometteur pour la suite. D’autres éléments peuvent aussi expliquer cette féminisation de nos effectifs. L’introduction progressive de l’informatique dans les cursus du lycée, en particulier la création de la spécialité ISN, a permis à de jeunes filles de découvrir de multiples facettes de l’informatique, élément indispensable à un choix positif d’orientation pour leurs études supérieures.
L’informatique peut se conjuguer au féminin !
crédit photo Informatique au féminin
Grâce à l’implication des enseignants-chercheurs et de l’environnement socio-économique, de nombreuses actions diversifiées ont pu être mises en place pour combattre les idées reçues que l’informatique c’est pour les garçons. Les mentalités évoluent rapidement quand on médiatise le sujet.
En relativement peu de temps, la répartition homme/femme dans nos formations s’est fortement améliorée pour toutes les formations. Nos actions semblent porter leurs fruits et nous espérons que dans peu de temps, il ne faudra plus convaincre que l’informatique c’est pour tout le monde !
Ce 7 février, jour du Safer Internet Day et tout au long du mois, Internet sans Crainte mobilise tous les acteurs de la communauté éducative autour de la mise en place d’actions de sensibilisation sur deux thèmes : la citoyenneté numérique et le cyberharcèlement.
La citoyenneté numérique pour toutes et tous.
En ces temps d’explosion des usages des réseaux sociaux par la jeune génération, mais aussi par leurs parents et grands-parents, l’accent est mis sur la citoyenneté numérique : si le fait de posséder des équipements est la condition matérielle sinequanone pour surfer et socialiser sur les réseaux, celle d’acquérir des compétences pour s’en servir avec recul est la clé pour participer en “citoyenne ou citoyen éclairé” à la société numérique.
La compréhension des enjeux de l’Internet, du fonctionnement des réseaux sociaux, du partage de l’information, de sa vérification, et de l’importance des données qu’on consent à partager sont autant de savoir-faire et de savoir-être à transmettre. La culture numérique n’est pas un acquis généralisé et le Safer Internet Day donne l’occasion à tout un chacun de participer à sa diffusion.
Du développement de l’esprit critique, au partage des superbes opportunités (par exemple pour développer un projet), de nombreuses ressources d’éducation critique sont disponibles pour aider.
Des cyberviolences à leur résilience.
Le risque est réel, un des plus importants auxquels peuvent être confrontés les jeunes internautes aujourd’hui. Si les observateurs ont constaté une baisse du harcèlement scolaire dans sa forme traditionnelle cette année, les cyberviolences, et notamment le cyberharcèlement, est un phénomène en pleine augmentation (de 7 à 12 % entre 2010 et 2014, ref : Eukidsonline) tout comme le cybersexisme (20% des filles affirment avoir été insultées en ligne sur leur apparence physique en 2016, ref : Centre Hubertine Auclert).
De telles cyberviolences prennent racine dans la violence banalisée du quotidien, et peuvent souvent échapper aux adultes, se situant dans la sphère numérique. Elles rendent encore plus indispensable le travail d’éducation aux médias et aux usages du numérique.
Reconnaître les signes de ce harcèlement chez nos enfants (à travers une série de vidéos destinées aux parents et aux éducateurs), dénoncer pour faire réaliser aux jeunes harceleurs le mal qu’il font sans en prendre la pleine mesure, sanctionner aussi, former au numérique dans ses usages et ses fondements, ici on dépasse le constat, on offre des solutions.
Comment se mobiliser ?
C’est le moment de revisiter les ressources proposées, d’ouvrir le dialogue sur ces sujets en famille, au bureau ou dans notre entourage, d’organiser des actions de sensibilisation à ces sujets.
C’est aussi le moment de se former pour initier les jeunes à la pensée informatique pour que tout cela prenne du sens pour eux et qu’au fur et à mesure de l’évolution des usages, elles et ils puissent acquérir les fondamentaux qui leur permettront de maîtriser le numérique.
Nous, partenaires de Class´Code, avec le Blog binaire, soutenons avec enthousiasme cette initiative.
Émilie Peinchaud et Thierry Viéville.
Le Safer Internet Day est un événement mondial annuel organisé dans plus de 110 pays par le réseau européen Insafe/inhope pour la Commission européenne au mois de février pour promouvoir un Internet meilleur pour les jeunes. En France, le Safer Internet Day est organisé par Internet Sans Crainte, le programme national de sensibilisation des jeunes aux risques et enjeux de l’Internet opéré par Tralalere , au sein du Centre Safer Internet France.
Quelques ressources
Aborder le thème de l’utilisation de ses données personnelles sur les téléphones portables et celui du cyberharcèlement avec les 7 à 12 ans.>>>
Initier aux données grâce à une application ludique, comprendre la data pour mieux comprendre comment tout le monde s’informe en ligne, partage ses données et crée des contenus numériques, pour les 9 à 14 ans.>>>
Découvrir des grands enjeux de la citoyenneté numérique: liberté d’expression, identité numérique, éducation au numérique, gouvernance d’internet, géolocalisation, sous forme d’un jeu en ligne, pour les 12 à 16 ans.>>>
Former toutes personnes désireuses d’initier les jeunes de 8 à 14 ans aux fondements du numérique. Le module #4 de Class’Code (Web, Internet, site, adresse, serveur) permet de faire découvrir la face cachée des réseaux, pour les éducateurs.>>>
La CNIL lance un vaste débat public sur les algorithmes. On s’en réjouit. Nous soutenons cette initiative et voulons nous mettre au service de ce débat.
Parler des algorithmes, vraiment ?
Mais, de quoi parle-t-on ? Voici ce qu’on a pu en dire :
Cette définition, publiée par la CNIL, accumule les imprécisions*, montre combien tout se mélange dans nos esprits.
Quand les algorithmes deviennent aussi importants dans nos vies, quand l’État s’en inquiète au point de vouloir les réguler, il faut faire attention à comprendre ce qu’on dit.
La CNIL, a d’ailleurs corrigé sa définition suite aux nombres réations que sa publication a suscitées.
(*) un algorithme n’est pas une formule mathématique, ce n’est pas une formule, et ce n’est pas des maths; des modèles statistiques, il y en a parfois, mais c’est aussi tant d’autres choses…
Alors c’est quoi un algorithme ?
Cela s’explique en quelques secondes à une ou un collégien-ne :
et pour aller au delà de cette notion de base, la Société Informatique de France a proposé une définition de l’Informatique : Informatique – Quèsaco ?. Tandis qu’un livre arrive nous expliquer simplement ce que sont les algorithmes Le temps des Algorithmes.
Un article du monde laisse à penser que le débat sur ce que l’on fait aujourd’hui des algorithmes pourrait se faire sans ceux qui les créent et qui les comprennent, c’est-à-dire les informaticiennes et les informaticiens.
On se retrouve du coup dans une démarche qui conforte ceux qui sont derrière les algorithmes pour faire du profit, dominer les autres, nous instrumentaliser au travers de nos données. Ceux qui défendent leurs intérêts en la matière, à notre détriment.
Le principe est de personnifier les algorithmes pour leur attribuer finalement la responsabilité de la façon dont ils sont utilisés. « Ce n’est pas moi, M’sieur, c’est mon algorithme.
Pour cela il faut accepter l’idée que finalement les gens ne comprennent pas et ne comprendront jamais trop bien comment ça marche. Poser l’obscurantisme comme un préalable. Il faut donc en exclure les chercheur-e-s en science informatique ».
Le débat est-il vraiment sur les algorithmes ?
Heureusement, cet obscurantisme va prendre fin : les algorithmes s’apprennent désormais au lycée, et maintenant au collège et se découvrent même en primaire. Nos enfants* ne diront bientôt plus « les algorithmes vont me prendre mon job, me condamner à mort … ». Ils se tourneront non pas vers les algorithmes mais vers ceux qui utilisent les algorithmes et les dénonceront d’autant mieux qu’ils comprendront comment c’est fait.
Que le débat commence.
Toute l’équipe de Binaire.
(*) Et les plus grands peuvent tout de même profiter de Binaire pour devenir des citoyennes et citoyens éclairés sur le sujet 🙂
Ce vendredi 27 janvier parait ce livre qui vous tient tant à cœur à Gilles et toi: « Le temps des algorithmes » aux éditions du Pommier. Tu ne voulais pas (par déontologie) en faire la pub sur ce blog dont tu es le fondateur, mais nous lisons régulièrement vos écrits et sommes intimement convaincus que cet ouvrage nous aidera à nous poser des questions fondamentales sur la place des algorithmes dans notre société.
Alors l’ensemble de l’équipe de Binaire (sauf toi !) avons décidé, comme pour toutes les autres productions de ce type, d’en faire très simplement l’annonce. En attendant, compte sur nous, pour en faire aussi la critique 🙂
Nous vous invitons à découvrir le principe de fonctionnement des algorithmes de recommandation, ceux utilisés pas les grandes plateformes de vente du Web qui vous disent ce qu’ont acheté les autres acteurs ou qui vous enferment dans une bulle informationnelle. Nous nous concentrons ici sur les aspects techniques et auront sans doute d’autres occasions de considérer des aspects sociétaux, comme l’importance de la recommandation sur les résultats d’élections. Nous avons demandé à Raphaël Fournier-S’niehotta, spécialiste de ces algorithmes, de nous en dire plus. Pierre Paradinas
Dans les jours qui ont suivi l’annonce des résultats de l’élection présidentielle, le 8 novembre dernier, la polémique a enflé : comment la plupart des sondeurs et des journalistes avaient-ils pu autant sous-estimer le nombre d’électeurs de Donald Trump ? Ceux-ci représentent au final quasiment la même proportion d’Américains que ceux d’Hillary Clinton. Les réseaux sociaux, Facebook en tête, ont été pointés du doigt, accusés d’avoir enfermé de nombreux utilisateurs dans une « bulle personnelle d’information ». Chacun d’entre eux ne verrait avant tout que des contenus proches de ses idées, le conduisant à ignorer l’existence d’autres personnes aux avis opposés. Ces ”bulles” sont créées par les algorithmes de filtrage et de recommandation mis en place pour sélectionner les contenus affichés sur le réseau social.
Figure 1 – REUTERS/Mike Segar
Un peu d’histoire
L’apparition des ordinateurs, à la moitié du XXe siècle, a permis de numériser l’information, en commençant par les ouvrages stockés dans les bibliothèques. Une suite naturelle a consisté à développer les moyens d’automatiser la recherche dans ces ouvrages : c’est ainsi que sont nés les premiers moteurs de recherche. Avec la création du Web en 1989, la taille des collections documentaires est progressivement devenue colossale. À tel point que les requêtes effectuées renvoyaient trop de résultats, et les utilisateurs ne pouvaient envisager de les consulter tous. Plutôt que de s’en remettre exclusivement au seul classement effectué par les machines, l’idée est venue de réintégrer des humains dans le processus, par l’intermédiaire de leurs avis.
En 1992, Paul Resnick et John Riedl, deux chercheurs en informatique, ont proposé le premier système de recommandation, pour les articles d’Usenet*. Ce système collecte des notes données par les utilisateurs lorsqu’ils lisent des articles. Ces notes sont ensuite utilisées pour prédire à quel point les personnes n’ayant pas lu un article sont susceptibles de l’apprécier. Cette recommandation automatisée repose, comme hors ligne, sur l’évaluation par les pairs : si les amis d’Alice lui suggèrent de lire un livre qu’ils ont aimé, il est probable qu’elle le lise et l’apprécie aussi, davantage qu’un livre que ses proches n’auraient pas lu ou pas aimé.
Un peu de technique
Ce principe, à l’origine des premiers systèmes de recommandation, s’appelle le ”filtrage collaboratif”. L’idée qui sous-tend cet algorithme est la suivante : si Alice a des idées similaires à Bob sur un sujet, alors il y a des chances qu’Alice partage son avis sur un autre sujet, plutôt que celui de quelqu’un pris au hasard.
Lorsqu’un système veut proposer des objets intéressants à Alice, il doit tâcher de prédire ses opinions sur ces objets. Il collecte les avis des utilisateurs sur les objets qui constituent sa collection. Les ”objets” sur Facebook, ce sont les statuts et articles partagés ; sur Amazon, ce sont les produits ; ce sont des morceaux de musique ou des films sur Spotify ou Netflix. Les avis collectés peuvent être explicitement donnés par les utilisateurs du système, comme le sont les ”likes” Facebook, les notes sur Netflix, les favoris sur Twitter, etc. Ils peuvent aussi être extrapolés à partir de l’observation du comportement de l’utilisateur : temps passé sur une page, achat d’un livre, visionnage d’un film. Cet ensemble de ”notes” constituent une représentation (plus ou moins fidèle) des centres d’intérêts de l’utilisateur. Elle permet d’enrichir le profil (déjà constitué des noms, professions, âge, genre, etc.).
L’étape suivante consiste à rechercher les utilisateurs qui ont les avis les plus similaires à ceux d’Alice, en se servant des notes de chacun. Le système détermine ensuite facilement les objets que ces utilisateurs ont vus mais qu’Alice n’a pas encore consultés. Avec leurs avis, il est ensuite possible d’estimer la note qu’elle pourrait donner à chacun de ces objets. L’algorithme n’a alors plus qu’à rassembler ces notes, les trier de la meilleure à la moins bonne, et afficher les 5 ou 10 objets les mieux classés.
Mathématiquement, il existe de nombreuses variations sur la façon d’effectuer la détermination des utilisateurs les plus proches (combien en retient-on, comment estime-t-on la proximité d’opinions, etc.) ainsi que la prédiction des notes (moyenne simple, moyenne pondérée, etc.). La représentation commune repose sur une matrice, dont chaque ligne correspond à un utilisateur, et chaque colonne correspond à un produit. Chaque case de la matrice de coordonnées (i,j) contient la note que l’utilisateur i a attribué à l’objet j.
Figure 2 – L’utilisateur u1 a donné la note de 5 à l’objet i3, la note de 2 à l’objet i4. Le système de recommandation doit tenter de prédire les notes là où les cases sont vides.
Une manière de prédire la note d’un utilisateur i pour un objet j est d’agréger les notes de tous les autres utilisateurs sous la forme d’une moyenne, celle-ci étant pondérée par un score de similarité. Ainsi, plus les avis passés sont similaires, plus l’avis de cette personne compte dans le calcul, et inversement. Pour vous impressionner, voici une formule qui peut être utilisée pour estimer la note :
(où dans la formule, r^ij désigne la note de l’utilisateur i sur l’objet j que l’on cherche à estimer, r ̄i est la moyenne des notes de l’utilisateur i, U est l’ensemble des utilisateurs, les ωu′,i sont les scores de similarité entre les utilisateurs.) Même si vous ne comprenez pas, reconnaissez-lui une certaine esthétique !
Bien entendu, ces techniques ont été raffinées et améliorées durant les vingt dernières années. Il s’avère en pratique que calculer des similarités entre utilisateurs est souvent très complexe. Il est plus efficace de renverser le problème en cherchant d’abord des similarités entre produits. C’est ce que fait Amazon en indiquant les articles que ”les clients ayant achetés cet article ont aussi acheté”. L’expérience prouve que les résultats sont beaucoup moins probants.
Figure 4 – Des recommandations de produits sur Amazon.
Quelques difficultés à surmonter
Les systèmes de recommandation automatisés posent divers problèmes techniques à leurs concepteurs. Il est en effet régulièrement nécessaire d’évaluer les opinions de millions d’utilisateurs sur des dizaines de milliers de produits. Effectuer les comparaisons de chaque ligne de la matrice avec toutes les autres nécessite beaucoup d’opérations, coûteuses en terme de performance. Si certains éléments du calcul peuvent être conservés et réutilisés, d’autres doivent tenir compte des mises à jour de la matrice (quand les utilisateurs notent un objet, par exemple). La taille des systèmes a aussi un autre effet qui diminue la possibilité de proposer des recommandations pertinentes : chaque objet n’a généralement été noté que par un ensemble très réduit de personnes, rendant délicate la recherche d’utilisateurs similaires. (En d’autres termes, la matrice est pleine de zéros ; on parle de matrice très « creuse »).
Outre ces problèmes de dimension, pour lesquelles diverses techniques ont été développées, les systèmes de recommandation doivent confronter d’autres difficultés. comme, par exemple, le ”démarrage à froid ». C’est ce qui désigne le problème particulier que posent les nouveaux utilisateurs du système. Comme on ne sait rien d’eux, comment leur faire des recommandations pertinentes ? Il faut se limiter à leur recommander des objets populaires (les meilleures ventes, par exemple) au risque de leur recommander des produits qu’ils ont déjà ou qui ne les intéressent en rien.
Nous mentionnerons un dernier problème majeur, la diversité, ou plutôt l’absence de diversité. Cela se manifeste à deux niveaux, global (pour tout le système) et local (pour chaque utilisateur).
L’absence de diversité globale consiste à ne recommander aux utilisateurs que les objets populaires. Un objet très peu vu ne reçoit que peu de notes et ne se retrouve quasiment jamais recommandé. Inversement, recommander systématiquement des objets populaires conduit à accroitre encore leur popularité.
L’absence de diversité locale consiste à ne recommander à un utilisateur que des objets en rapport avec les centres d’intérêts que le système lui connaît. Cet effet se renforce de lui-même avec le temps. Ainsi, un amateur de films d’horreur aura peu de chances de se voir proposer des comédies romantiques ou, dans un autre contexte, un partisan d’Hillary Clinton à se voir exposé à des articles en faveur de Donald Trump.
Pour compenser l’absence de diversité, il est bien entendu possible de modifier l’algorithme au cœur du système, par exemple, pour introduire plus de sérendipité pour l’utilisateur ou pour mieux équilibrer les profits commerciaux entre tous les vendeurs qui proposent des produits.
Les algorithmes ne sont que des transpositions informatiques de règles adoptées par des humains. Lorsque celles-ci ne nous satisfont pas, nous pouvons les faire évoluer… et du coup transformer les algorithmes qui leurs sont associés.
Raphaël Fournier-S’niehotta, maître de conférences en informatique au Conservatoire national des Arts et Métiers.
(*) Usenet est un système de discussion en ligne, que l’on peut voir comme l’ancêtre des forums actuels (voire de la fonctionnalité ”Groupes” sur Facebook)
À propos de l’analyse du rôle de Facebook dans l’élection américaine:
L’auteur de ces lignes est membre du projet ANR Algodiv, qui étudie la diversité au sein des algorithmes de recommandation ;
Un atelier interdisciplinaire sur les systèmes de recommandation aura lieu les 22 et 23 mai prochains à Paris ;
Sur l’impact social et politique des algorithmes de filtrage, outre les travaux de Dominique Cardon (Science-Po/Medialab), également membre d’Algodiv, les lecteurs intéressés pourront lire le blog du chercheur Olivier Ertzscheid ;
Pour approfondir les connaissances sur les divers algorithmes mis en œuvre, les annales de la conférence ACM RecSys constituent une référence.
2016 est l’année Shannon – Claude Shannon aurait eu 100 ans cette année. Il est le génial inventeur de la théorie de l’information, qui a des impacts importants en informatique, par exemple pour la compression de données. Binaire a demandé à Vincent Gripon de nous expliquer le concept théorique « d’information » au sens de Shannon. Essayez de sentir le lien avec ce que nous appelons aujourd’hui « information » ou « données ». Serge Abiteboul.
Cet article est publié en collaboration avec TheConversation.
Graffiti représentant Claude Shannon, Demeure du Chaos de Saint-Romain-au-Mont-d’Or, d’après une photo de 1963. Wikipedia
Mesurer l’information
Signal, données, contenu, sémantique, pas facile de s’y retrouver… Il se cache pourtant une grandeur mesurable parmi ces quatre notions, étudiée depuis le milieu du XXe siècle par les mathématiciens, les physiciens et les informaticiens. Cette grandeur, c’est l’information. Mais c’est quoi, au juste, un élément d’information ?
Réfléchissez-y. Vous pouvez vous représenter ce qu’est un mètre, un litre, un gramme, mais pouvez- vous déterminer ce qu’est une unité d’information ? Par exemple, si je vous dis que la milliardième décimale de π est un 9, combien vous ai-je transmis d’unités d’information ?
Le comble de cet exemple est que je ne peux moi-même pas vous répondre. Ou plus exactement tout dépend : si vous le saviez déjà alors je ne vous ai transmis aucune information. À l’opposé, si vous n’en aviez pas la moindre idée alors je vous ai transmis suffisamment d’unités d’information pour déterminer lequel des 10 chiffres possibles est le bon.
C’est contre-intuitif, mais la notion d’information est étroitement liée à celle d’événements aléatoires. Pour mieux comprendre, prenons un exemple. Je tire à pile ou face une pièce de monnaie et je vous communique le résultat. À priori, il y a autant de chances pour que je vous dise “pile” ou “face”. Avoir deux possibilités avec la même probabilité correspond exactement à une unité binaire d’information. On l’appelle le Shannon, en hommage au père de la théorie de l’information. Si je lance maintenant deux fois de suite ma pièce et vous communique les deux résultats obtenus, je vous transmettrai donc deux Shannons. Si par contre ma pièce de monnaie est irrégulière et a plus de chances de donner “pile” que “face” (et que vous le savez), alors je ne vous transmettrai plus exactement deux Shannons d’information, mais un peu moins, car vous pouvez prédire partiellement le résultat. Dans le cas extrême où ma pièce de monnaie est truquée et ne peut que donner “face”, je ne vous transmets plus aucune information. S’il n’y a plus d’aléatoire, il n’y a plus d’information !
En général, la quantité d’unités d’information est relative à celui qui la reçoit. C’est le cas avec l’exemple de la milliardième décimale de Pi. En mathématiques, on est davantage intéressé par une notion universelle d’information, définie indépendamment de celui qui la manipule. C’est le cas avec l’exemple de la pièce de monnaie : tant que la pièce n’a pas été lancée, personne ne peut prédire le résultat.
En théorie de l’information, tout part donc du principe que la réalisation d’un événement aléatoire ayant peu de chances de se produire porte beaucoup d’unités d’information, alors que celle d’un événement aléatoire ayant beaucoup de chances de se produire n’en porte presque pas. C’est logique non ? Si je vous dis que demain le soleil va se lever, je ne vous aurais pas transmis beaucoup de Shannons. Si je vous dis que mon numéro de carte bleue se termine par 142857, je vous en aurais transmis beaucoup.
Information et données
Tous les jours nous échangeons, notamment par le biais de l’Internet, des quantités astronomiques de données, codées sous la forme de valeurs binaires (des “bits”), mais bien moins d’unités d’information.
Pour comprendre la notion d’information, il est essentiel de la différencier de celle de donnée. Prenons un exemple. J’ai une amie qui vient d’accoucher. Je lui envoie un SMS pour lui demander le sexe du nouveau-né. Dans ma vision des choses, il y a autant de chances pour qu’il s’agisse d’un garçon ou d’une fille. Sa réponse me transmettra donc exactement un Shannon. Pour me répondre, elle m’enverra probablement une phrase constituée de plusieurs caractères, chacun étant représenté par plusieurs bits. Je vais donc recevoir plusieurs dizaines de bits de données pour un seul Shannon.
Notre cerveau est coutumier du fait. On estime à cent millions de bits par seconde la quantité de données transmises depuis le cortex visuel vers les aires profondes de notre néocortex. La plupart de ces données nous sont complètement inutiles, et portent par ailleurs bien peu d’éléments d’information.
Faire en sorte qu’un bit de donnée corresponde exactement à un Shannon, c’est le rêve des spécialistes de la compression. En effet, compresser, c’est réduire la taille des données en maintenant exactement la même quantité d’information. C’est par exemple ce que vous faites quand vous compressez un fichier informatique. Un résultat fondamental de la théorie de l’information est qu’un bit de donnée ne peut pas correspondre à plus d’un Shannon. Par exemple, si je crée un fichier informatique en y inscrivant des valeurs 0 ou 1 et en tirant chaque bit à pile ou face, je ne pourrai pas le compresser : il contiendra déjà autant de bits que de Shannons.
La redondance
Une information n’est utile que si elle est manipulée. En pratique il s’agit souvent de la transmettre ou de la stocker. Et ce n’est pas si simple !
Quand on discute dans un endroit bruyant, on est coutumier du fait de manquer des bouts de conversation. Il en va de même pour les systèmes numériques. Toute transmission d’un message est sujette à altérations. La cause ? Les interférences, les atténuations, les erreurs dans les systèmes traitant l’information… Il est alors nécessaire de la protéger.
Du fait de la miniaturisation des composants et de leur multiplication, les systèmes de stockage ont perdu en fiabilité. Il ne s’agit pas uniquement de pertes de données, mais aussi de corruption de leur contenu. Ils requièrent donc des mécanismes de protection de l’information. C’est en particulier le cas des circuits électroniques que nous utilisons au quotidien.
Pour protéger l’information vis-à-vis des perturbations, on utilise de la “redondance”. C’est une forme subtile de répétition. Les théoriciens de la redondance ont imaginé plein de stratégies efficaces pour créer de la redondance. Aujourd’hui la plupart des systèmes utilisés s’appuient sur le principe du codage distribué, un principe qui vous est bien plus familier que vous ne l’imaginez…
Le meilleur exemple de codage distribué, c’est la grille de Sudoku. Le principe du Sudoku est une façon efficace de protection de l’information. En effet, le but du jeu consiste à retrouver le contenu des cases effacées à partir de celui des cases restantes : c’est exactement la robustesse que l’on recherche dans les systèmes numériques. La grille de Sudoku n’est pas définie par une seule règle très compliquée, mais plutôt en combinant 27 règles simples : 9 pour les lignes, 9 pour les colonnes, et 9 pour les petits carrés.
Chacune de ces règles prise indépendamment des autres n’est pas très robuste. Prenez par exemple une ligne d’une grille de Sudoku sur laquelle manquent deux chiffres. Vous pouvez déduire des chiffres restants quels sont les chiffres manquants, mais vous ne pouvez pas retrouver leurs emplacements. Par contre, quand vous mettez ensemble les 27 règles, vous parvenez à retrouver les chiffres manquants de la grille, même dans certaines situations où ils représentent plus de la moitié des 81 cases.
3
8
7
4
1
?
5
9
?
Où sont le 2 et le 6?
Si vous avez tout compris à cet article, la prochaine fois que vous résoudrez un Sudoku vous saurez que vous ne cherchez pas de l’information manquante, mais des données manquantes, et la prochaine fois que vous ferez répéter au téléphone, vous ne ferez qu’augmenter le taux de redondance !
Incroyable le nombre de prix qui sont décernés en Sciences ! Et encore l’informatique en a relativement peu : le Prix Turing (que l’on peut considérer comme le « Nobel d’Informatique»), le Prix Milner, le Prix Gödel, le Prix Gilles Kahn (pour les doctorants), etc. J’aime beaucoup un prix qui n’a pas de prix, le prix Serge Hocquenghem*. Cette année, Mathieu Blossier** et Didier Roy ont été récompensés par ce prix avec Éva Corot.
Éva Corot ? C’est elle qui du haut de ses 10 ans a proposé de rendre « le sourire aux rues de Paris » en développant le projet d’un robot (équipé d’un mécanisme imprimé en 3D) qui dessine à la craie de couleur sur le sol. Au-delà du buzz, c’est sur son «Blog fait par les enfants pour les enfants» qu’il faut aller découvrir ce que robotique créative et programmation ludique veut dire. On y parle d’un « bon gros géant qui met des rêves dans la tête des enfants».
Vous savez quoi ? Je crois bien que ce bon géant là, c’est Didier. Didier Roy est un professeur de mathématiques qui s’est mis au service des autres professionnels de l’éducation pour créer des ressources qui aident à mieux enseigner et aimer les mathématiques, l’informatique et la robotique. Offrir aux enfants une seconde chance de réussir, c’est son but à lui.
En participant à des travaux qui mettent l’apprentissage algorithmique au service des logiciels didactiques, Didier est devenu chercheur en informatique et science de l’éducation à 57 ans ! Dans le monde de l’enseignement, avec l’initiation au code, quasiment tout le monde en France connait ses travaux, parfois sans même savoir qu’il en est l’auteur. Il est le créateur d’Inirobot ainsi que de multiples ressources pédagogiques libres et gratuites, pour que les enseignants encore en formation sur ces sujets, puissent faire connaître la pensée informatique, s’initier à la démarche de recherche… bref accompagnent nos enfants dans la maîtrise du numérique. On le retrouve sur Class’Code pour former à ces activités.
Et nous ? Qu’allons-nous créer d’inouï, de rigolo, d’utile ou de joli avec le numérique ?
Thierry Viéville.
(*) Serge Hocquenghem est un pionnier en France de la géométrie interactive qui permet aux enfants d’apprendre les objets mathématiques en les manipulant, comme des objets du quotidien. Il a lui aussi conçu des outils didactiques comme Geoplan-Geospace, sur des bases mathématiques rigoureuses.
(**) Mathieu Blossier a été récompensé cette année par le prix Serge Hocquenghem pour ses superbes travaux de mathématiques interactives. Ce prix piloté par l’Association des Professeurs de Mathématiques de l’Enseignement Public, il l’a partagé avec Didier, et Éva aussi.





 Mais, nous ne sommes qu’au milieu du gué. Par exemple, le problème de la formation des Maîtres reste critique pour l’Éducation nationale. On y confond encore trop souvent littératie numérique (qui peut être inculquée par tous les enseignants) et enseignement de l’informatique (qui ne peut être effectué que par des professeurs d’informatique). Ces enseignements sont indispensables pour former les citoyens et les créateurs du 21ème siècle.
Mais, nous ne sommes qu’au milieu du gué. Par exemple, le problème de la formation des Maîtres reste critique pour l’Éducation nationale. On y confond encore trop souvent littératie numérique (qui peut être inculquée par tous les enseignants) et enseignement de l’informatique (qui ne peut être effectué que par des professeurs d’informatique). Ces enseignements sont indispensables pour former les citoyens et les créateurs du 21ème siècle.


 Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?
Une vague de pessimisme est venue dernièrement rafraîchir l’enthousiasme des « croyants » aux vertus du fact checking. A quoi bon vérifier, dans une époque de « post-vérité », où chacun reste enfermée dans sa sphère sociale et médiatique et n’écoutera pas des arguments allant à l’encontre de ses croyances ?


 Lagneau nous a expliqué : « Il existe deux façons de lancer les boules : pointer comme un têtu et tirer comme un testard. Une des plus grandes difficultés techniques a été de résoudre ce simple questionnement, pointer ou tirer. C’est d’ailleurs la cause d’innombrables disputes à la pétanque. »
Lagneau nous a expliqué : « Il existe deux façons de lancer les boules : pointer comme un têtu et tirer comme un testard. Une des plus grandes difficultés techniques a été de résoudre ce simple questionnement, pointer ou tirer. C’est d’ailleurs la cause d’innombrables disputes à la pétanque. »
 Nous, chercheurs en informatique (en bases de données et apprentissage automatique), pensons que nos recherches peuvent aussi servir les gens. Un des domaines dans lesquels ces recherches pourraient servir est celui de l’emploi. Comment trouver un premier emploi, comment retrouver un emploi après un licenciement ou une interruption ? C’est souvent le problème le plus important pour les personnes concernées ; c’est aussi un des problèmes les plus difficiles pour l’État. Or, le big data peut apparemment tout (ou presque) pour l’innovation, la santé, le commerce, etc. ; peut-il quelque chose pour l’emploi ?
Nous, chercheurs en informatique (en bases de données et apprentissage automatique), pensons que nos recherches peuvent aussi servir les gens. Un des domaines dans lesquels ces recherches pourraient servir est celui de l’emploi. Comment trouver un premier emploi, comment retrouver un emploi après un licenciement ou une interruption ? C’est souvent le problème le plus important pour les personnes concernées ; c’est aussi un des problèmes les plus difficiles pour l’État. Or, le big data peut apparemment tout (ou presque) pour l’innovation, la santé, le commerce, etc. ; peut-il quelque chose pour l’emploi ? 
 Le site
Le site 


 Le projet professionnel avec Social Builder. Pour cela, le programme s’appuie sur du mentorat et de l’accompagnement professionnel. Les participantes ont l’occasion de concevoir un projet, de le mettre au point. On développe ensemble. On discute avec d’autres. On se critique. On s’aide.
Le projet professionnel avec Social Builder. Pour cela, le programme s’appuie sur du mentorat et de l’accompagnement professionnel. Les participantes ont l’occasion de concevoir un projet, de le mettre au point. On développe ensemble. On discute avec d’autres. On se critique. On s’aide. L’insertion dans une communauté avec
L’insertion dans une communauté avec  On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
On parle de féminisation de certaines professions, processus qui désigne un accroissement du nombre de femmes dans un domaine historiquement masculin. L’informatique a ceci d’original qu’elle est plutôt sujette à la masculinisation, du moins dans le monde occidental. Pour preuve, là où on comptait 37% d’étudiantes en informatique aux États-Unis dans les années 80, on en compte aujourd’hui 18% et à quelques exceptions près les statistiques restent en berne.
 L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion.
L’informatique est un cas très particulier, une science récente, une croissance exponentielle, un brillant avenir. Elle avait d’ailleurs séduit les femmes à son apparition, lorsque personne encore n’y croyait. Les domaines de l’intelligence artificielle ou du traitement naturel des langues, quand ils étaient balbutiants et encore peu crédibles, regorgeaient de femmes. C’est aujourd’hui le terrain de jeux des chercheurs les plus brillants. On est passé d’un secteur méconnu et peu stéréotypé, à un secteur dynamique et prometteur que les hommes se sont approprié. Dommage que les femmes n’aient pas conservé ce bastion. Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion
Pour y arriver, il faut multiplier les messages explicites contre les stéréotypes. Il est rafraichissant que la publicité radiophonique diffusée le mois dernier au sujet de l’application post bac brave tous les clichés et implique une lycéenne qui souhaite s’orienter vers l’informatique et un lycéen vers la gestion Le 23 mars 2017, de 14 à 17h30, à Paris, Inria Alumni organise une Jam Session sur ce sujet en partenariat avec la
Le 23 mars 2017, de 14 à 17h30, à Paris, Inria Alumni organise une Jam Session sur ce sujet en partenariat avec la 








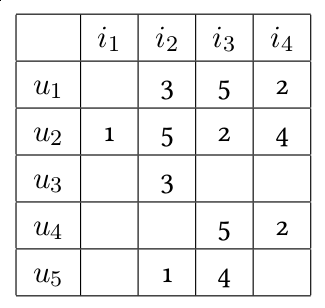
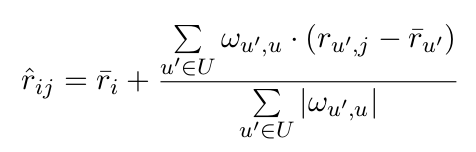


 La redondance
La redondance Éva Corot ? C’est elle qui du haut de ses 10 ans a proposé de rendre « le sourire aux rues de Paris » en développant le projet d’un robot (équipé d’un mécanisme imprimé en 3D) qui dessine à la craie de couleur sur le sol. Au-delà
Éva Corot ? C’est elle qui du haut de ses 10 ans a proposé de rendre « le sourire aux rues de Paris » en développant le projet d’un robot (équipé d’un mécanisme imprimé en 3D) qui dessine à la craie de couleur sur le sol. Au-delà  Vous savez quoi ? Je crois bien que ce bon géant là, c’est
Vous savez quoi ? Je crois bien que ce bon géant là, c’est 