A l’occasion de la Journée Internationale des Droits des Femmes, nous nous intéressons cette année non aux informaticiennes, mais aux usagères des technologies d’Intelligence Artificielle : devront-elles, ici comme ailleurs, affronter un sexisme malveillant ? Comme d’habitude, plus, moins ? Et surtout, pourquoi ? Au détour de cette question certes un peu bateau, Anne-Marie Kermarrec nous offre à la fois un panorama des différentes sources de biais qu’on trouve dans les technologies informatiques et une réflexion sur l’IA, miroir de nos propres sexismes et autres déplorables habitudes. Binaire
L’Intelligence Artificielle (IA pour les intimes) a le vent en poupe et est partout : elle traduit vos documents, guide vos recherches, vous recommande des films, vous suggère quoi manger, quand courir, nourrit votre fil d’actualité, vous aide à trouver un job, à vous garer, à vous marier, à vous soigner, à vous informer et ce n’est que le début. Avec tout cela, l’IA est autant un sujet de fantasme que d’incertitude, d’optimisme que d’inquiétude, le monde oscille entre admiration et crainte, s’épate de voir un programme apprendre « tout seul » comment gagner aux échecs, s’inquiète de savoir quels métiers vont disparaître et à quel point nous allons être manipulés, aidés, augmentés et j’en passe.
Dans cet enchevêtrement de questionnements et de doutes, d’aucun peut s’interroger sur la capacité de l’IA à corriger les maux de notre société. Ou est-ce qu’au contraire, elle reproduit voire amplifie les travers d’un monde rongé par les inégalités en tous genres ? Si ces biais potentiels peuvent concerner de multiples volets de notre société, inégalités sociales, raciales, que sais-je, je ne m’intéresse en cette journée internationale du droit des femmes 2018 qu’aux inégalités hommes/femmes que peut continuer à colporter l’IA. Est ce que nos dernières inventions numériques continuent bien gentiment de véhiculer le sexisme ou est ce qu’au contraire tenons nous là un puissant remède aux stéréotypes de genre ?
L’IA est-elle neutre ?
L’IA est un « vieux » domaine académique, à l’échelle temporelle de l’informatique, qui doit son succès récent à la présence de données massives combinées à des capacités de calcul gigantesques. Plus précisément, l’IA repose sur trois éléments essentiels : des algorithmes, des données et des ordinateurs. On peut accorder aux ordinateurs, dont la taille a diminué au fil des années à mesure que leur puissance de calcul a augmenté qu’ils adoptent un principe « matériel » intrinsèque de neutralité et ne peuvent être taxés de biais. Qu’en est-il des algorithmes et des données ? Les deux peuvent être biaisés à des degrés arbitraires. Et si on parle tant de la transparence des algorithmes aujourd’hui, c’est que justement on craint ces biais, pour une large part parce qu’ils sont algorithmiques. La plate-forme APB en est un excellent exemple, qui a été jugée beaucoup plus sévèrement qu’un autre algorithme, plus ancien, mais mis en œuvre par les humains qui consistait à faire la queue et à accepter les étudiants sur la base du premier arrivé premier servi. Pas tellement plus juste qu’une sélection aléatoire algorithmique en dernier recours pourtant.

Les données sont-elles biaisées ?
Mais il est aussi tout aussi légitime de parler de besoin de transparence des données. Rappelez vous Tay, un bot, planqué derrière une image de jeune fille, lancé par Microsoft en 2016, qui imitant un millenial se retrouve après quelques tweets à tenir des propos sexistes comme gamergate is good and women are inferior, alors même que la promesse du géant américain était que, plus Tay s’entretiendrait avec des humains sur les réseaux sociaux, plus son « intelligence » s’aiguiserait. Même si Tay a été manipulée (et ça n’a pas été très difficile du reste), ce comportement est simplement dû au fait que les données sur lesquelles elle avait été entrainée sont juste un reflet navrant de la société. Comme souvent, les algorithmes ont juste un peu accéléré le mouvement.
Plus récemment la jeune doctorante du MediaLab du MIT, Joy Buolamwini, en étudiant plusieurs algorithmes de reconnaissance faciale a constaté qu’ils marchaient très bien sur… les hommes blancs. Pourquoi ? Simplement parce que ceux-ci sont beaucoup plus représentés dans les banques de données utilisées par l’apprentissage d’une part et que d’autre part, les benchmarks pour les évaluer, c’est à dire les ensembles de tests, sont tout aussi biaisés. Pour simplifier, un algorithme de reconnaissance faciale est considéré comme bon par la communauté, s’il obtient de bonnes performances sur ces benchmarks, c’est-à-dire qu’il est capable de reconnaître des hommes blancs avec une forte probabilité.
Ainsi, on peut assez facilement imaginer qu’un algorithme qui guide dans le choix des formations proposera plus naturellement à une jeune fille de faire médecine ou du droit et à un jeune homme de tenter une prépa scientifique s’il repose uniquement sur les statistiques et corrélations des dix dernières années. On comprend aussi pourquoi une femme négociera moins bien son salaire qu’un homme à poste équivalent car si elle interroge son application favorite sur le sujet, les statistiques sont claires et donc les données utilisées pour rendre l’algorithme intelligent sont évidemment biaisées. De fait les résultats de l’algorithme aussi.
Et les exemples sont nombreux. Ainsi, des expériences lancées à l’université de Boston ont montré que des algorithmes d’intelligence artificielle, entrainés sur des textes issus de Google news, à qui on demandait de compléter la phrase : Man is to computer programmers as woman is to x, répondaient homemaker [1]. Sans commentaire. Dans une autre étude [2], il est encore montré que les collections d’images utilisées par Microsoft et Facebook pour les algorithmes de reconnaissance d’images associent les femmes aux cuisines et au shopping quand le sport est plutôt relié aux hommes. Et évidemment, les algorithmes, non seulement reproduisent ces biais, mais les amplifient, accentuant au cours du temps ces associations. De même, lorsque les traducteurs automatiques traduisent une phrase d’un langage sans genre à un langage ou le genre doit être explicite, les biais sont évidents. They are programmers sera naturellement traduit en français par « ils sont programmeurs » et They are nurses par « elles sont infirmières ». Essayez vous-même comme je viens de le faire !
 Et si les algorithmes pouvaient rectifier le tir ?
Et si les algorithmes pouvaient rectifier le tir ?
Les exemples précédents sont autant d’exemples où les machines sont neutres, les algorithmes sont neutres et l’IA résultante est biaisée uniquement car les données le sont.
Encore une fois il est difficile de biaiser une machine, mais un algorithme est conçu et développé par des informaticien.ne.s qui peuvent en faire à peu près ce qu’ils en veulent. Si l’IA a été conçue initialement pour imiter l’ « intelligence » humaine, avec des algorithmes qui tentaient de reproduire au plus près les comportements humains, reflétés par les données, son emprise est telle aujourd’hui que l’on peut imaginer saisir cette opportunité pour rationaliser cette « intelligence » et surtout lui éviter de reproduire ces biais dont la société n’arrive pas à se débarrasser naturellement. Ainsi les algorithmes ne représenteraient plus une menace mais pourraient devenir les vrais Zorros du 21ème siècle.
Est-ce si simple quand on compte autant d’obstacles éthiques que techniques ? Tout d’abord, les industriels aujourd’hui n’ont pas tous accusé réception de ce problème de biais [3]. En fait, détecter les biais est une première étape qui n’est pas complètement naturelle car nous sommes malheureusement très habitués à certains d’entre eux. Quand bien même on observe ces biais, les traiter n’est pas non plus nécessairement évident. Imaginons un algorithme de ressources humaines qui doit sélectionner 10 personnes pour un entretien parmi n candidats à un poste de développeur Web. Il est clair que si on laisse faire un algorithme d’apprentissage classique, compte tenu de la disproportion notoire femmes/hommes de ces filières, il risque de sélectionner 10 hommes. Imaginons maintenant que nous forcions de manière explicite, le nombre de candidates à être supérieur ou égal à 5, ou de manière probabiliste en augmentant la probabilité de retenir une femme, malgré le biais des données. Ceci est alors équivalent à instaurer un quota, stratégie sur laquelle de nombreux comités n’ont pas réussi à converger indépendamment d’une mise en œuvre algorithmique.
Techniquement, il n’est pas simple de garantir la validité des modèles et leur évaluation si on « nettoie » les données pour éviter les biais. En outre le problème de certains algorithmes d’intelligence artificielle aujourd’hui est qu’on a du mal à expliquer leurs résultats, c’est le cas de l’apprentissage profond (Deep Learning), selon les experts du domaine eux-mêmes. On sait et on observe que ces algorithmes fonctionnent plutôt bien, mais sans complètement comprendre pourquoi. C’est d’ailleurs l’un des prochains défis scientifiques du domaine. Quels seraient donc alors les paramètres à ajuster pour que le tout fonctionne de manière non biaisée ?
Un autre problème concerne la détection et la génération des biais : la sous-représentation des femmes dans le domaine est telle que les algorithmes qui ressemblent à leurs concepteurs, véhiculent leur mentalité, leurs biais et donc leur culture masculine à 90%. De là à les taxer de sexisme, c’est peut-être y aller un peu fort mais clairement notre société est si « genrée » aujourd’hui qu’il n’est pas exclu que le manque de diversité dans ce domaine soit un frein à la détection et l’évitement de biais. Ceci ne fait que confirmer le fait que nous avons besoin de plus de femmes en informatique, également pour le bien de nos algorithmes.
Pour conclure, il est assez clair que si l’IA cherche à modéliser le monde au plus près, elle absorbera ses travers et les normes culturelles biaisées de tous cotés et en particulier concernant les inégalités hommes femmes, voire les exacerbera en les renforçant, grâce à ces immenses capacités à calculer des corrélations en tous genres et surtout les plus présentes. Il est donc urgent de saisir cette opportunité algorithmique pour soigner notre société. Ce n’est pas simple mais un grand nombre de scientifiques sont d’ores et déjà sur le front !
Anne-Marie Kermarrec, Mediego, Inria
@AMKermarrec
Pour aller plus loin :
- http://www.telegraph.co.uk/news/2017/08/24/ai-robots-sexist-racist-experts-warn/
- http://www.newsweek.com/2017/12/22/ai-learns-sexist-racist-742767.html
- https://www.technologyreview.com/s/608248/biased-algorithms-are-everywhere-and-no-one-seems-to-care/










 À notre connaissance, ce sont les
À notre connaissance, ce sont les  Tout au long du programme, l’étudiant est amené à réfléchir sur son propre projet à l’éclairage des différents enseignements qui lui sont proposés. Il est accompagné pendant son parcours de manière personnalisée grâce à l’expertise d’enseignants-chercheurs et de partenaires industriels. Le programme permet aussi de découvrir certains domaines dits “disruptifs” de la pédagogie : remise en cause des modèles pédagogiques et des savoirs dominants, recentrage de l’apprentissage sur la créativité et l’analyse critique,
Tout au long du programme, l’étudiant est amené à réfléchir sur son propre projet à l’éclairage des différents enseignements qui lui sont proposés. Il est accompagné pendant son parcours de manière personnalisée grâce à l’expertise d’enseignants-chercheurs et de partenaires industriels. Le programme permet aussi de découvrir certains domaines dits “disruptifs” de la pédagogie : remise en cause des modèles pédagogiques et des savoirs dominants, recentrage de l’apprentissage sur la créativité et l’analyse critique, Comprendre aussi comment se passe l’éducation ailleurs, ouvrir des possibilités de collaborations internationales sont deux des bénéfices de cette volonté d’ouverture.
Comprendre aussi comment se passe l’éducation ailleurs, ouvrir des possibilités de collaborations internationales sont deux des bénéfices de cette volonté d’ouverture.


 Mais les modèles économiques de ces deux formations sont très différents. La première aboutit à un diplôme national et est entièrement financée avec l’argent de l’État ; elle est donc accessible aux étudiant·e·s avec des frais d’inscription minimaux. L’autre est une
Mais les modèles économiques de ces deux formations sont très différents. La première aboutit à un diplôme national et est entièrement financée avec l’argent de l’État ; elle est donc accessible aux étudiant·e·s avec des frais d’inscription minimaux. L’autre est une 

 Le psychodrame du printemps, c’est
Le psychodrame du printemps, c’est 















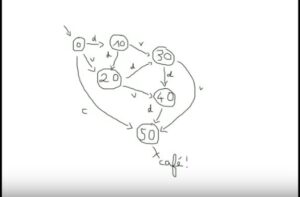
 Ces preuves circulaires, un peu inhabituelles vont s’avérer utiles pour la vérification de systèmes. Un système réactif correspond à peu près à n’importe quoi qui interagit avec son environnement, et qui évolue dans le temps : un ascenseur, une machine à café, une centrale nucléaire… La vérification d’un système correspond au fait de s’assurer que le système satisfait certaines propriétés, répond aux attentes qu’on peut en avoir, appelées spécifications : si j’appuie sur le bouton de la machine à café, j’obtiens un café… Pour pouvoir utiliser ces notions, on va alors abstraire, remplacer le système et les spécifications par des objets de logique que l’on sait manipuler. En l’occurrence,
Ces preuves circulaires, un peu inhabituelles vont s’avérer utiles pour la vérification de systèmes. Un système réactif correspond à peu près à n’importe quoi qui interagit avec son environnement, et qui évolue dans le temps : un ascenseur, une machine à café, une centrale nucléaire… La vérification d’un système correspond au fait de s’assurer que le système satisfait certaines propriétés, répond aux attentes qu’on peut en avoir, appelées spécifications : si j’appuie sur le bouton de la machine à café, j’obtiens un café… Pour pouvoir utiliser ces notions, on va alors abstraire, remplacer le système et les spécifications par des objets de logique que l’on sait manipuler. En l’occurrence,  Nous avions partagé avec vous notre enthousiasme pour cet ouvrage cité en référence à
Nous avions partagé avec vous notre enthousiasme pour cet ouvrage cité en référence à  Tahina Ralitera, jeune informaticienne malgache, actuellement en troisième année de doctorat au Laboratoire d’Informatique et de Mathématiques de l’Université de La Réunion, figure parmi les lauréates.
Tahina Ralitera, jeune informaticienne malgache, actuellement en troisième année de doctorat au Laboratoire d’Informatique et de Mathématiques de l’Université de La Réunion, figure parmi les lauréates.