Vous connaissez la méthode « agile » ? Non ? Vous n’êtes pas informaticien·ne alors ! Vous connaissez quelqu’un qui ressemble à un « nerd´´ ou un « geek´´ ? Ça ne doit pas être un·e informaticien·ne alors ! Dans ce billet, Pauline Bolignano avec la complicité de Camille Wolff pour les illustrations, déconstruit des idées reçues et nous explique ce que méthode « agile´´ veut dire. Serge Abiteboul et Thierry Viéville
Après quelques jours de confinement, une amie me dit : « je travaille dans la même pièce que mon coloc’, il passe sa journée à parler ! Je n’aurais jamais imaginé que votre travail était si sociable !». Son coloc’, tout comme moi, fait du développement informatique. L’étonnement de mon amie m’a étonnée, mais il est vrai que l’on n’associe pas naturellement « informaticien·ne » à « sociable ». D’ailleurs, si je vous demande de fermer les yeux et d’imaginer un·e informaticien·ne, vous me répondrez surement un homme aux cheveux cachés sous la capuche de son sweat-shirt, tout seul devant son écran, et pas sociable pour un sous :
Un geek quoi. En réalité, le métier d’ingénieur·e informaticien·ne demande énormément de collaboration. Je voulais donc plonger dans cet aspect du métier qui me semble être rarement mis en avant.
Les spécificités du domaine informatique
Lorsqu’on construit un logiciel, les contraintes et les possibilités sont différentes que lorsque l’on construit un édifice. Prenez par exemple la construction d’un pont. L’architecte passe de longs mois à dessiner le pont. Les ingénieur·es civil·e·s passent des mois, voir des années, à étudier le terrain, les matériaux et faire tous les calculs nécessaires. Puis les conducteurs/trices de travaux planifient et dirigent la construction pendant quelques années. Ensuite le pont ne bouge plus pendant des centaines d’années.
En informatique, c’est tout à fait différent. D’une part, il arrive que l’ingénieur·e soit à la fois l’architecte, le/a planificateur/rice, et le.a programmatrice/teur du logiciel. D’autre part, les cycles sont en général beaucoup plus courts. Pour reprendre la comparaison avec le pont, avant même de commencer l’architecture, on sait qu’il est possible que dans quelques mois le sol ait bougé, et qu’il faille adapter les fondations. Les ingénieur·e·s de l’équipe doivent sans cesse se synchroniser car il y a une forte dépendance entre les tâches de chacun·e.
Le développement logiciel offre plein de nouvelles possibilités. Il donne l’opportunité de construire de manière incrémentale, d’essayer des choses et de changer de direction, de commencer petit et d’agrandir rapidement. C’est comme si vous construisiez un pont piéton, puis que vous puissiez par la suite l’agrandir en pont à voiture en l’espace de quelques semaines ou mois, sans bloquer à aucun moment le trafic piéton.
L’organisation de la collaboration
La malléabilité et la mouvance du logiciel demandent une grande collaboration dans l’équipe. C’est d’ailleurs ce que prône la méthode Agile [1]. Ce manifeste met la collaboration et les interactions au centre du développement logiciel. Déclinée en diverses implémentations, la méthode Agile est largement adoptée dans l’industrie. Scrum est une implémentation possible de la méthode Agile, bien que la mise en place varie fortement d’une équipe à l’autre.
Prenons un exemple concret d’organisation du travail suivant la méthode Scrum : la vie de l’équipe est typiquement organisée autour de cycles, disons 2 semaines, que l’on appelle des « sprints ». A chaque début de sprint, l’équipe se met d’accord sur la capacité de travail de l’équipe pour le sprint, et sur le but qu’elle veut atteindre pendant ce sprint. Les tâches sont listées sur un tableau, sur lequel chacun notera l’avancement des siennes. Tous les jours, l’équipe se réunit pour le « stand-up ». Le « stand-up » est une réunion très courte, où chaque membre de l’équipe dit ce qu’ille a fait la veille, ce qu’ille compte faire aujourd’hui et si ille rencontre des éléments bloquant. Cela permet de rebondir vite, et de s’entraider en cas de problème. Régulièrement, au cours du sprint ou en fin de sprint, un ou plusieurs membres de l’équipe peuvent présenter ce qu’illes ont fait au cours de « démos ». Enfin, à la fin du sprint, l’équipe fait une « rétro ». C’est une réunion au cours de laquelle chacun·e exprime ce qui s’est bien passé ou mal passé selon lui.elle, et où l’on réfléchit ensemble aux solutions. Ces solutions seront ajoutées comme des nouvelles tâches aux sprints suivants dans une démarche d’amélioration continue.

Une pratique très courante dans les équipes travaillant en Agile est la programmation en binôme. Comme son nom l’indique, dans la programmation en binôme, deux programmeuses/eurs travaillent ensemble sur la même machine. Cela permet au binôme de réfléchir ensemble à l’implémentation ou de détecter des erreurs en amont. Le binôme peut aussi fonctionner de manière asymétrique, quand l’une des deux personnes aide l’autre à progresser ou monter en compétence sur une technologie.
Ainsi si vous vous promenez dans un bureau d’informaticien·ne·s, vous y croiserez à coup sûr des groupes de personnes devant un écran en train de débugger un programme, une équipe devant un tableau blanc en train de discuter le design d’un système, ou une personne en train de faire une « démo » de son dernier développement. Bien loin de Mr Robot, n’est ce pas ?
De Monsieur robot à Madame tout le monde
On peut également enlever son sweat-shirt à capuche à notre représentation de l’informaticien·ne, puisque développer du logiciel peut a priori être fait dans n’importe quelle tenue. En revanche, notre représentation de l’informaticien a bien une chose de vraie : dans la grande majorité des cas, c’est un homme. Si vous vous promenez dans un bureau d’informatique, vous ne croiserez que très peu de femmes. En France, il y a moins de 20 % de femmes en informatique, tant dans la recherche que dans l’industrie [2]. À l’échelle d’une équipe, cela veut dire que, si vous êtes une femme, vous ne travaillez probablement qu’avec des hommes.
Ceci est surprenant car l’informatique est appliquée à tellement de secteurs qu’elle devrait moins souffrir des stéréotypes de genre que d’autres domaines de l’ingénierie. L’informatique est utilisée en médecine, par exemple pour modéliser la résistance d’une artère à l’implantation d’une prothèse. Elle est utilisée dans le domaine de l’énergie, pour garantir l’équilibre du réseau électrique. L’informatique est aussi elle-même sujet d’étude, quand on souhaite optimiser un algorithme ou sécuriser une architecture [3,4]. Elle est même souvent une combinaison des deux. Quand l’informatique est appliquée à des domaines considérés comme plus « féminins » comme la biologie, la médecine, les humanités numériques, le déséquilibre est d’ailleurs moins marqué.
Il y a encore du chemin à faire pour établir l’équilibre, mais je suis assez optimiste. Beaucoup d’entreprises et institutions font un travail remarquable en ce sens, non seulement pour inverser la tendance, mais aussi pour que tout employé·e se sente bien et s’épanouisse dans son environnement de travail.
Pour inverser la tendance, il me semble important de sortir les métiers de leur case, car sinon on prend le risque de perdre en route tout·te·s celles et ceux qui auraient peur de ne pas rentrer dans cette case. En particulier, il me semble que cette image du développeur génie solitaire, en plus d’être peu représentative de la réalité, peut être intimidante et délétère pour la diversité. Dans ce court article, j’espére en avoir déconstruit quelques aspects.
En conclusion, cher·e·s étudiant·e·s, si vous vous demandez si le métier d’ingénieur·e informaticien·ne est fait pour vous, ne vous arrêtez pas aux stéréotypes. À la question « à quoi ressemble un·e ingénieur·e informaticien·ne ?», je réponds : « si vous choisissez cette voie … à vous, tout simplement ! ».
Pauline Bolignano, docteure en Informatique, Ingénieure R&D chez Amazon, Les vues exprimées ici sont les miennes..
Camille Wolff, ancienne responsable communication en startup tech en reconversion pour devenir professeur des écoles, et illustratrice ici, à ses heures perdues.
Références :
[1] Manifeste pour le développement Agile de logiciels
[2] Chiffres-clés de l’égalité femmes-hommes (parution 2019):
[3] L’optimisation est dans les crêpes
[4] La cybersécurité aux multiples facettes

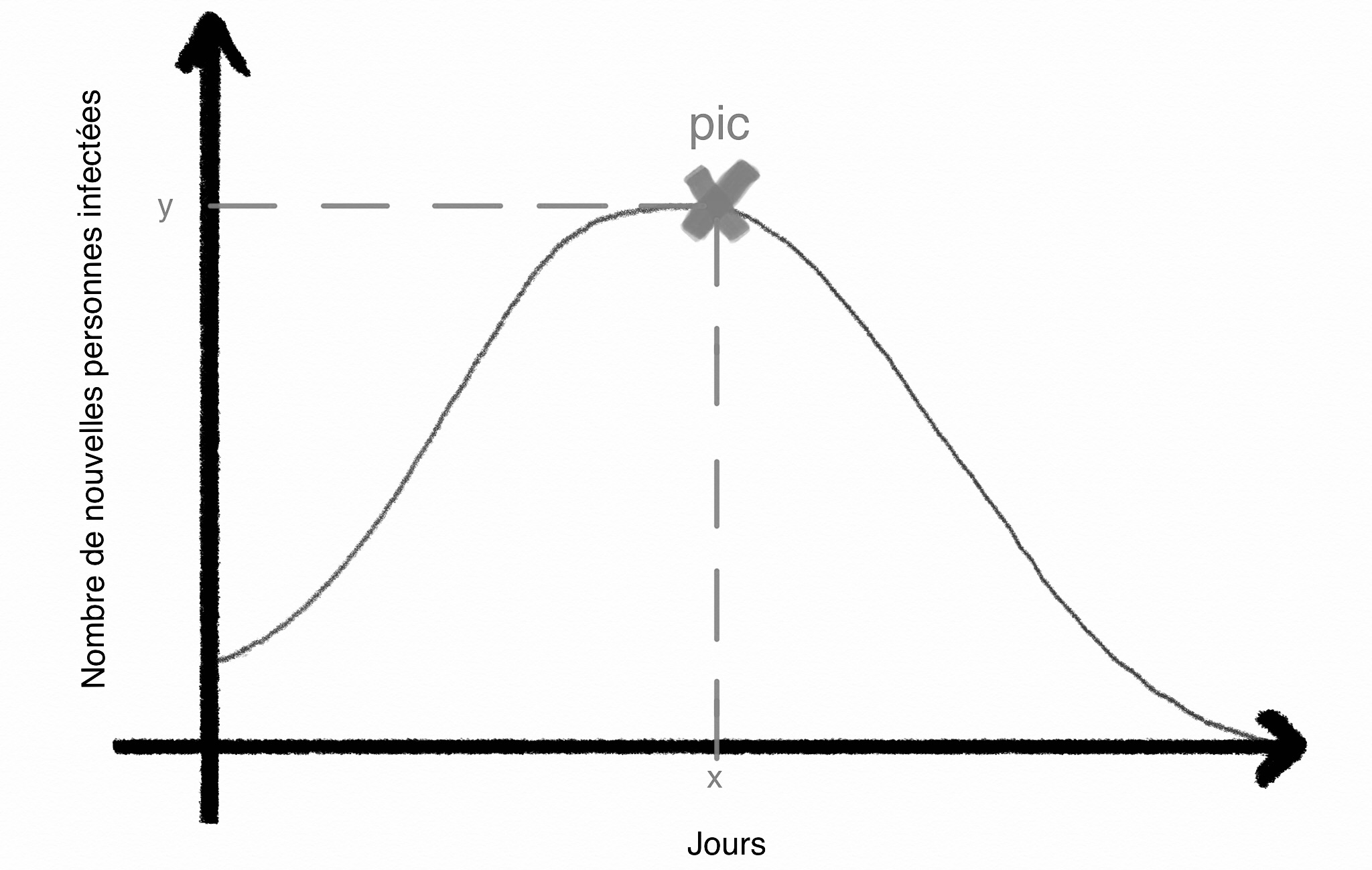
 Nous entendons beaucoup : il faut aplatir la courbe. Mais de quoi s’agit il ?
Nous entendons beaucoup : il faut aplatir la courbe. Mais de quoi s’agit il ? 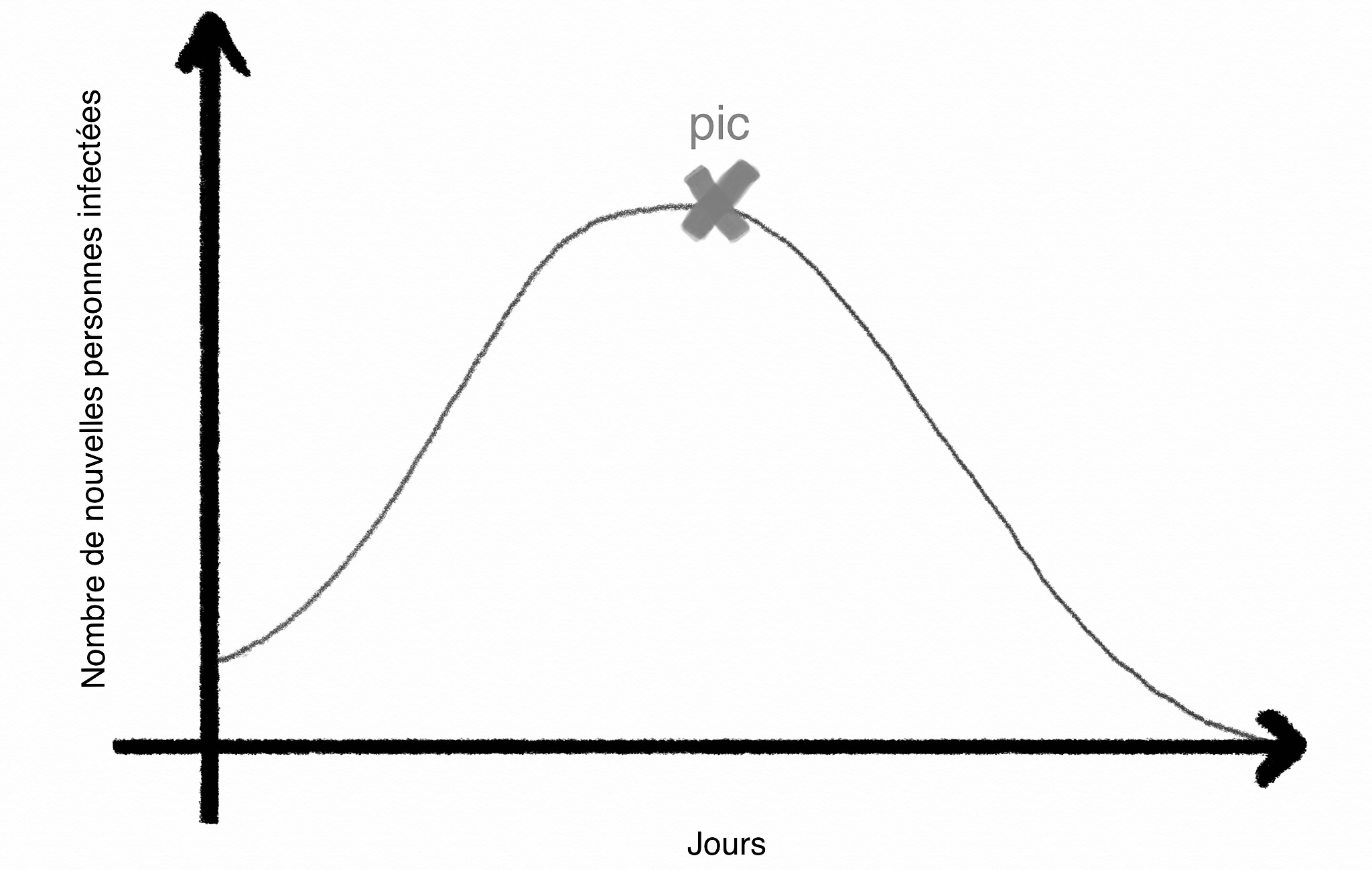

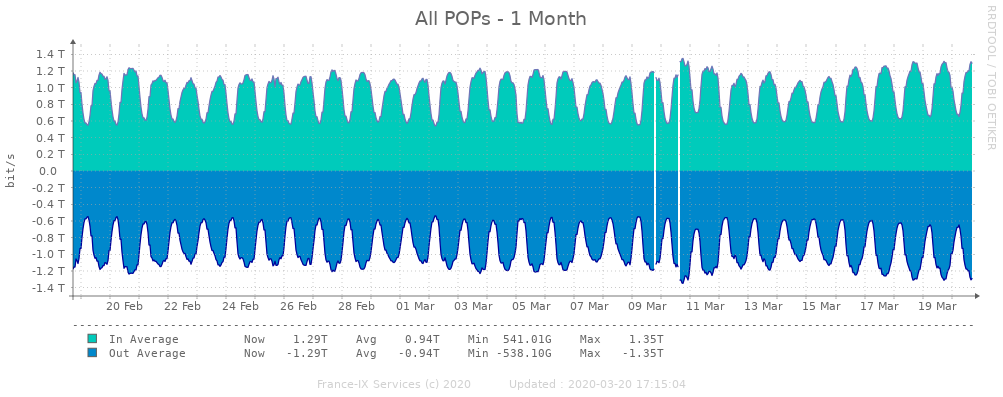
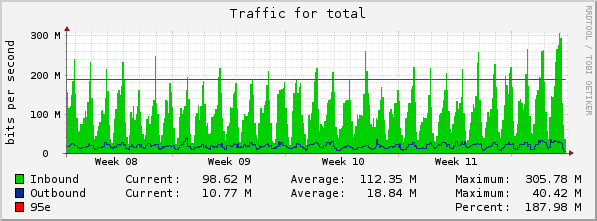
 Son créateur, Joseph Kahn (avec Vinton Cerf), déclarait encore récemment [4] qu’il était optimiste par raport aux défis extraordinaires qu’Internet allait devoir de toute façon relever en période “normale” : milliards d’objets connectés, lutte contre la cybercriminalité par exemple. Il est aujourd’hui remarquable de constater qu’alors que des cercles de rush et de pénurie s’instaurent dangereusement dans plusieurs secteurs, nous continuons à mener nos tâches, loisirs et communications virtuelles toujours aussi efficacement.
Son créateur, Joseph Kahn (avec Vinton Cerf), déclarait encore récemment [4] qu’il était optimiste par raport aux défis extraordinaires qu’Internet allait devoir de toute façon relever en période “normale” : milliards d’objets connectés, lutte contre la cybercriminalité par exemple. Il est aujourd’hui remarquable de constater qu’alors que des cercles de rush et de pénurie s’instaurent dangereusement dans plusieurs secteurs, nous continuons à mener nos tâches, loisirs et communications virtuelles toujours aussi efficacement.
 Il n’a pas écrit que cela. En Italie, c’est un auteur à succès, très présent dans les médias, il écrit des romans, des essais, du théâtre, des films, des chroniques dans des journaux, et il a refusé le Ministère de la Culture. C’est un auteur avec un style indéniable (qui plaît ou pas), un avis, un humour et un bel optimisme sur la vie.
Il n’a pas écrit que cela. En Italie, c’est un auteur à succès, très présent dans les médias, il écrit des romans, des essais, du théâtre, des films, des chroniques dans des journaux, et il a refusé le Ministère de la Culture. C’est un auteur avec un style indéniable (qui plaît ou pas), un avis, un humour et un bel optimisme sur la vie.
 Vers un confinement sélectif basé sur les informations personnelles ?
Vers un confinement sélectif basé sur les informations personnelles ? 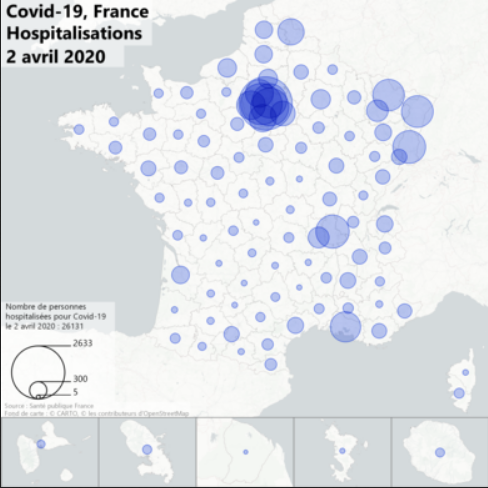




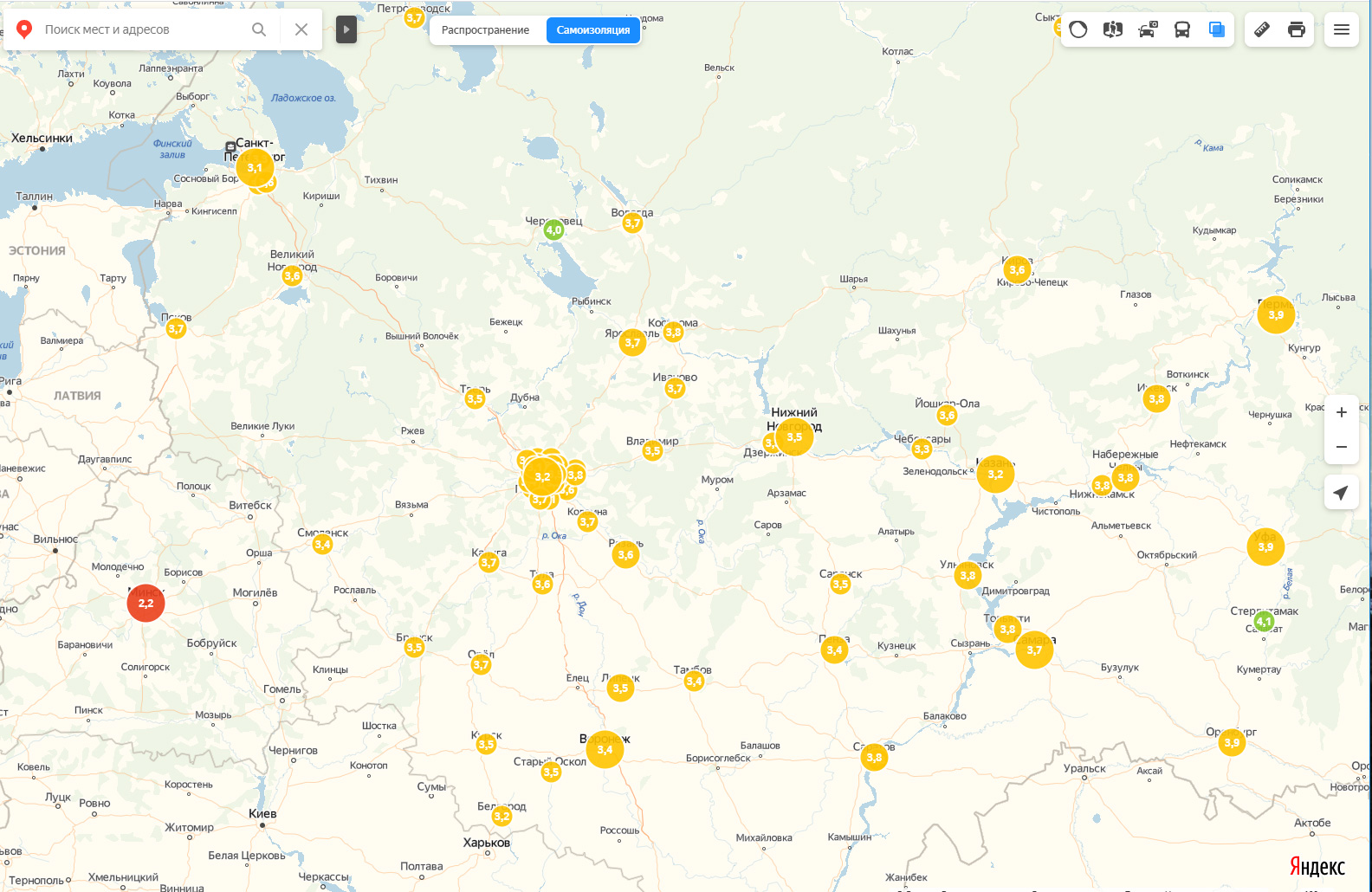 Utiliser les données des applications qui tournent en permanence sur nos smartphones pour évaluer le respect du confinement ?
Utiliser les données des applications qui tournent en permanence sur nos smartphones pour évaluer le respect du confinement ? 






 L’association
L’association  On parle beaucoup en ce moment d’une « saturation des réseaux », de « risques pour l’Internet » … entre info et intox, alors donnons la parole à
On parle beaucoup en ce moment d’une « saturation des réseaux », de « risques pour l’Internet » … entre info et intox, alors donnons la parole à 
 Comment vivre au mieux cette période de confinement ? En en profitant pour lire
Comment vivre au mieux cette période de confinement ? En en profitant pour lire