L’enseignement de l’informatique est un enjeu majeur dans la formation des adultes de demain. Dans cette société où la technologie est de plus en plus présente, cet enseignement commence seulement à arriver dans nos pays francophones. L’équipe de CAI (Communauté d’Apprentissage de l’Informatique) nous présente son initiative. Lonni Besançon
Dans ce contexte, le projet de Communauté d’Apprentissage de l’Informatique (CAI) vise la mise en communauté d’enseignant·e·s pour faciliter la découverte de l’informatique et leur permettre d’accéder aux outils nécessaires pour son enseignement aux élèves de 10 à 18 ans : entraide entre enseignant·e·s et autres professionnel·le·s de l’éducation, partages d’expériences et de ressources pédagogiques, co-construction de projets, via une méta-plateforme https://cai.community en phase de déploiement.
C’est par exemple le cas du projet Canopé de “Collection Open Badges Robotique Educative” à propos de robotique éducative ou de nos #CAIchat qui permettent de partager sur des sujets comme «Informatique et société» ou l’enseignement du Numérique et Sciences Informatiques (NSI) au niveau lycée. À bientôt à Ludovia pour se rencontrer sur ces sujets.
Qu’y fait-on concrètement ?
On y partage, identifie, évalue ou construit des ressources; on échange, s’accompagne et partage nos pratiques; on se donne des rendez-vous et on se rencontre pour s’entraider sur internet ou les territoires. Tout est librement réutilisable en CC-BY et CeCILL-C.
Nous sommes au service des enseignant·e·s et éducatrices et éducateurs francophones au sens large, toute personne intéressée (ex: parent) est bienvenue. Nous sommes régis par une charte qui tient en quelques mots :
Une vue de la plateforme résultat de la réflexion partagées ici et des spécifications proposées, on y voit le choix d’une présentation minimale, les différentes rubriques qui correspondent aux fonctionnalités proposées ici et le lien avec les réseaux sociaux les plus usités par les personnes qui vont l’utiliser.
Comment ça marche ?
Très simplement 😉
1/ on édite et consulte des “ressources” (de formation, activités, outils logiciels, …) qui sont définis par des méta-données, et peuvent former des “parcours”; on trouve aussi des profils de personnes (avec qui on partage et s’entraide), des “rendez-vous” (en ligne ou sur un territoire), ou des simples “brèves” (actualité, bonne-feuille, liens utiles, …).
2/ on “partage” sur des fils de discussion qui sont structurés en catégories et s’ouvrent et se ferment selon nos besoins, on y pose des questions, on y propose des retours sur les ressources, on y invite à co-créer des ressources, on y organise des rendez-vous en ligne ou sur un territoire
Une vue de la page de ressources, on peut rechercher une ressource par recherche textuelle, différentes métadonnées, et il y a aussi la possibilité d’une aide pour rechercher un ressource, en proposer, ou en co-créer.
À quel niveau aider les collègues enseignant·e·s ?
Notre projet cherche simplement à offrir ce qui semble manquer dans l’écosystème actuel.
• Assistance documentaire : beaucoup de belles ressources, partagées au fil de messages sur des mailing listes, ont besoin d’être thésaurisées et recevoir des métadonnées permettant de facilement les retrouver. Pour couvrir ce besoin, il faut un référentiel de référencement et une véritable aide humaine documentaire avec un support en matière de secrétariat numérique.
• Espaces de co-construction : les ressources actuelles sont majoritairement individuelles ou le fait de petites équipes locales, à contrario de produits comme les ouvrages scolaires ou les ressources numériques issues de travaux d’équipes qui permettent de rassembler une intelligence collective. Pour couvrir ce besoin il faut proposer un process et des outils usuels de travail collaboratif.
• Bureau d’accueil individuel : il y a un vrai besoin de contact “personnel” en contrepoint des discussions collectives, pour des problèmes spécifiques ou moins faciles à exprimer publiquement, ou des demandes dont la formulation est encore préliminaire. Pour couvrir ce besoin, une personne animatrice de communauté est disponible.
• Service pour les rencontres hybrides : au-delà des échanges asynchrones (mails ou forum) le besoin de rencontres en ligne ou sur un territoire est couvert de manière un peu disparate, et (i) une solution de rendez-vous en ligne est proposée: ouverte, sécurisée et facile d’utilisation tandis qu’un (ii) outil minimal connectable aux agendas numériques usuels permettant de poser des rendez-vous est déployé.
• Navigation entre plateformes : entre les dialogues par courriels, utilisation des réseaux sociaux, sites webs personnels sous forme de blogs, de dépôts de ressources ou de banques, multiples outils d’échange et co-travail synchrone en ligne, il y a vraiment besoin de mettre en lien ces différents espaces de ressources, partages ou rendez-vous. Pour couvrir ce besoin, une méta-plateforme est déployée à capot ouvert .
Maintenant que l’on commence à enseigner l’informatique en secondaire et primaire, il faut surtout se demander comment le monde de l’enseignement supérieur et de la recherche peut continuer de s’orienter au service et aider à la continuation de la réussite de cette mutation.
Les initiatives sont multiples, et la présente est une des briques de ce mouvement de soutien à ce qui va permettre à nos enfants, avec l’aide des enseignants, de maîtriser le numérique, en apprenant les bases de l’informatique.
LUDOMAG nous fait part de la sortie d’un livre documentaire pour les enfants dès 7 ans, » Les robots et l’IA », écrits par Didier Roy et Pierre-Yves Oudeyer. Est-ce qu’un robot a un cerveau ? Un robot peut-il apprendre à parler ? Qu’est-ce que l’intelligence artificielle ? Qui a inventé le premier robot ? Comment vont évoluer les robots?
Autant de questions que se posent petits et grands et auxquelles répondent avec des mots de tous les jours et des illustrations claires deux chercheurs spécialistes des apprentissages, des robots et de l’intelligence artificielle, levant ainsi le voile sur des phénomènes majeurs du monde d’aujourd’hui, qui fascinent et inquiètent à la fois.
Une occasion de comprendre leur fonctionnement, leur utilité pour l’homme, leurs usages raisonnables, de trier le vrai du faux, et de connaître les recherches en cours.
Nous avons le plaisir de reprendre ici l’interview des auteurs, Didier Roy et Pierre-Yves Oudeyer sur LUDOMAG.
Pourquoi ce livre pour enfants ?
Dans un monde où l’intelligence artificielle et les robots ont un impact croissant sur la société, il nous a semblé important d’aider les enfants à comprendre de quoi il s’agit, leur donner des repères pour trier le vrai du faux, les motiver pour être acteurs du monde dans lequel ils vivent.
Les robots et l’intelligence artificielle sont très présents dans les médias mais finalement très mal connus. Fantasmes, craintes excessives ou à l’inverse confiance aveugle, prédictions gratuites, théories: il n’est pas facile, surtout pour les enfants, de comprendre de quoi on parle et pourquoi on en parle comme ça.
Je suis toujours étonné de voir circuler des informations complètement farfelues sur les robots ou l’IA alors que sont ignorées des choses incroyables et pourtant bien réelles !
Au fur et à mesure que notre monde a évolué, en se complexifiant de plus en plus, des découvertes ont été faites, de nouvelles sciences sont apparues et avec elles de nouveaux savoirs à transmettre. Il en est ainsi par exemple des sciences physiques, chimiques, humaines, et aujourd’hui de la science informatique dont la connaissance des bases permet d’éclairer notre compréhension de ce monde devenu largement numérique. Ce livre s’inscrit dans ce mouvement de transmission vers les enfants, pour que peu à peu leur culture s’enrichisse d’informations les plus fiables possibles, pour nourrir leur curiosité mais aussi pour que leur choix d’adultes à venir soit les plus avisés.
C’est aussi une occasion de fournir des outils aux adultes pour échanger avec leurs enfants. Un livre pour enfants est souvent un moyen efficace de parler aussi aux parents : sans doute beaucoup préfèrent acheter un livre sur les robots et l’intelligence artificielle pour leurs enfants plutôt que d’en acheter un pour eux-mêmes, mais finissent quand même par le lire et en discuter avec eux. Nous apprenons nous même une foule de choses en lisant des livres avec des enfants !
L’un de nous (Didier Roy) a été longtemps enseignant dans le secondaire et formateur d’enseignants de primaire avant de devenir chercheur, et sait combien l’adhésion des parents, leur participation active dans la construction des connaissances de leurs enfants, est un atout majeur pour leur motivation et leur développement !
Que trouve-t-on dans le livre ?
Des éléments sur les robots, sur l’intelligence artificielle, l’apprentissage automatique (machine learning), les les réseaux de neurones, l’apprentissage par renforcement, sur les enjeux sociétaux… présentés de façon scientifiquement juste mais avec des mots simples et accessibles aux enfants. Il y est même question de “curiosité artificielle”, un thème de recherche phare de l’équipe Flowers dans laquelle nous travaillons.
Le livre contient aussi une frise historique du 1er siècle avant JC jusqu’en 2019, avec les grandes dates de la robotique et de l’intelligence artificielle. On y trouve notamment l’histoire du premier vrai robot en 1912, le “chien électrique” des ingénieurs Hammond et Miessner, histoire que la plupart des chercheurs en robotique et en intelligence artificielle ne connaissent pas ! De façon générale, l’histoire des sciences est jalonnée d’événements absolument passionnants et c’est un éclairage important des concepts en jeu.
N’est-ce pas un peu dérisoire pour des chercheurs comme vous plutôt habitués à produire des conférences et des publications de haut-niveau scientifique ?
Pas du tout dérisoire, bien au contraire ! S’adresser aux enfants est très gratifiant, et les voir avec le livre en mains inspire un sentiment de fierté qui n’a rien à envier aux moments les plus intenses de notre vie de chercheur. Ça été une très belle expérience que l’écriture de ce petit ouvrage, nous nous sommes régalés !
Et quand on transmet des connaissances scientifiques et techniques, on peut aussi donner les intentions des chercheurs et des ingénieurs qui travaillent dans ce domaine en entendant directement leur point de vue.
Côté chercheur, s’efforcer d’expliquer en termes simples le domaine sur lequel on travaille et son impact sur la société est une façon efficace de prendre du recul et de voir les opportunités, les menaces et les priorités, de donner du sens.
D’une certaine manière, nous avons le sentiment que certaines actions de vulgarisation scientifique que nous sommes amenés à réaliser en tant que chercheurs en IA peuvent parfois avoir un impact plus important sur la société que la production d’une énième contribution à une conférence scientifique prestigieuse.
L’un de nous (Pierre-Yves Oudeyer) s’est rendu il y a quelques semaines dans une école primaire pour expliquer les robots et l’intelligence artificielle, et ça a été l’occasion de merveilleuses discussions avec des enfants de 6 à 9 ans. Certains n’avaient aucune idée de ce que pouvait être un « scientifique », et sont repartis les yeux brillants en multipliant les “Merci !”. Nous sommes persuadés que ces minuscules graines de science semées dans ces moments-là sont très importantes.
Entre nous, est-ce que les robots et l’intelligence artificielle sont une menace pour l’humanité ?
C’est dans le livre. La réponse est très simple : les robots et l’intelligence artificielle seront ce que les humains veulent qu’ils soient, ni plus ni moins. D’où l’importance de diffuser au plus grand nombre les connaissances sur ces sujets, pour éclairer les choix à faire.
Pierre-Yves Oudeyer* et Didier Roy** sont chercheurs en informatique et en intelligence artificielle. Ils travaillent à Inria (Institut National de Recherche en Sciences et Technologies du Numérique), où ils décodent avec l’IA les mécanismes du cerveau et mettent au point des machines qui apprennent des tâches variées de manière plus autonome.
*Directeur de recherche à Inria, responsable de l’équipe Flowers
**Chercheur à Inria et au Centre LEARN EPFL (Ecole Polytechnique Fédérale de Lausanne)
Nous sommes confrontés à la désinformation sur les réseaux sociaux. Le sujet est tout sauf simple : qu’on modère trop et on porte atteinte à la liberté d’expression ; pas assez, et on laisseles fakenews se propager et mettre en cause les valeurs de notre société. Alors, qui doit dire le vrai du faux et selon quels principes ? Emmanuel Didier, Serena Villata, et Célia Zolynski nous expliquent comment concilier liberté et responsabilité des plateformes.Serge Abiteboul & Antoine Rousseau Cet article est publié en collaboration avec theconversation.fr.
@SabrinaVillata
L’élection présidentielle aux États-Unis a encore une fois mis la question des fausses nouvelles au cœur du débat public. La puissance des plateformes et notamment celle des réseaux sociaux est devenue telle que chaque événement d’importance engendre depuis quelques temps des discussions sur ce problème. Pourtant, il semble que les analyses produites à chacune de ces occasions ne sont pas capitalisées, comme s’il n’y avait eu ni réflexions, ni avancées au préalable. Nous voudrions montrer ici la pérennité de certaines conclusions auxquelles nous étions parvenues concernant la modération de la désinformation pendant le premier confinement.
Photo Markus Winkler – Pexels
En effet, durant la crise sanitaire engendrée par l’épidémie de SARS-CoV-2, l’isolement des individus en raison du confinement, l’anxiété suscitée par la gravité de la situation ou encore les incertitudes et les controverses liées au manque de connaissance sur ce nouveau virus ont exacerbé à la fois le besoin d’informations fiables et la circulation de contenus relevant de la désinformation (émis avec une claire intention de nuire) ou de la mésinformation (propagation de données à la validité douteuse, souvent à l’insu du propagateur). Les plateformes ont alors très vite accepté le principe qu’il leur fallait modérer un certain nombre de contenus, mais elles ont été confrontées à deux difficultés liées qui étaient déjà connues. Premièrement, ce travail est complexe car toute information, selon le cadre dans lequel elle est présentée, la manière dont elle est formulée ou le point de vue de son destinataire, est susceptible de relever finalement de la mésinformation ou de la désinformation. Deuxièmement, le fait de sélectionner, de promouvoir ou de réduire la visibilité de certaines informations échangées sur les plateformes numériques entre en tension avec le respect des libertés d’information et d’expression qu’elles promeuvent par ailleurs.
Quelles sont donc les contraintes qui s’imposent aux plateformes ? Quelles sont les mesures qu’elles ont effectivement prises dans ces conditions ? Le présent texte s’appuie sur le bulletin de veille rédigé dans le cadre d’un groupe de travail du Comité national pilote d’éthique du numérique (CNPEN)[1] qui nous a permis de mener une dizaine d’auditions (par visioconférence) avec, entre autres, les représentants de Facebook, Twitter et Qwant ainsi que le directeur des Décodeurs du Monde. Il est apparu que les difficultés posées par la modération des fausses nouvelles pouvaient être regroupées en trois catégories. D’une part, celles qui sont associées aux algorithmes, d’autre part celles qui relèvent du phénomène de la viralité et, enfin, celles posées par l’identification et les relations avec des autorités légitimes.
Les algorithmes en question
Bien sûr, les mécanismes de lutte contre la désinformation et la mésinformation développés par les plateformes reposent en partie sur des outils automatisés, compte tenu du volume considérable d’informations à analyser. Ils sont néanmoins supervisés par des modérateurs humains et chaque crise interroge le degré de cette supervision. Durant le confinement, celle-ci a été largement réduite car les conditions de télétravail, souvent non anticipées, pouvaient amener à utiliser des réseaux non sécurisés pour transférer de tels contenus, potentiellement délictueux, ou à devoir les modérer dans un contexte privé difficilement maîtrisable. Or les risques d’atteintes disproportionnées à la liberté d’expression se sont avérés plus importants en l’absence de médiation et de validation humaines, seules à même d’identifier voire de corriger les erreurs de classification ou les biais algorithmiques. En outre, l’absence de vérificateurs humains a compliqué la possibilité de recours normalement offerte à l’auteur d’un contenu ayant été retiré par la plateforme. Ces difficultés montrent clairement l’importance pour la société civile que les plateformes fassent plus de transparence sur les critères algorithmiques de classification de la désinformation ainsi que sur les critères qu’elles retiennent pour définir leur politique de modération, qu’ils soient d’ordre économique ou relèvent d’obligations légales. Ces politiques de modération doivent être mieux explicitées et factuellement renseignées dans les rapports d’activité périodique qu’elles sont tenues de publier depuis la loi Infox de décembre 2018 (v. le bilan d’activité pour 2019 publié par le CSA le 30 juillet 2020[2] et sa recommandation du 15 mai 2019[3]). Plus généralement, il apparait qu’une réflexion d’ampleur sur la constitution de bases de données communes pour améliorer les outils numériques de lutte contre la désinformation et la mésinformation devrait être menée et devrait aboutir à un partage des métadonnées associées aux données qu’elles collectent à cette fin (voir dans le même sens le bilan d’activité du CSA préc.)
La responsabilité de la viralité
Pexels
L’ampleur prise à ce jour par les phénomènes de désinformation et de mésinformation tient à l’accroissement de mécanismes de viralité qui se déploient à partir des outils offerts par les plateformes. La viralité est d’abord l’effet du modèle économique de certains de ces opérateurs, qui sont rémunérés par les publicitaires en fonction des interactions avec les utilisateurs qu’ils obtiennent et ont donc intérêt à générer des clics ou toute autre réaction aux contenus. Elle relève ensuite du rôle joué par leurs utilisateurs eux-mêmes dans la propagation virale de la désinformation et de la mésinformation (que ces derniers y contribuent délibérément ou par simple négligence ou ignorance). La lutte contre la désinformation doit donc nécessairement être l’affaire de tous les utilisateurs, responsables de devenir plus scrupuleux avant de décider de partager des informations et ainsi de contribuer à leur propagation virale. Cette remarque va d’ailleurs dans le même sens que le programme #MarquonsUnePause désormais promu par l’ONU[4]. Mais ceci n’est possible que si les plateformes mettent à disposition de leurs utilisateurs un certain nombre d’informations et d’outils afin de les mettre en mesure de prendre conscience, voire de maîtriser, le rôle qu’ils jouent dans la chaîne de viralité de l’information (voir également sur ce point les recommandations du CSA formulées dans le bilan d’activité préc.). En ce sens, les plateformes ont commencé à indiquer explicitement qu’une information reçue a été massivement partagée et invite leurs utilisateurs à être vigilants avant de repartager des contenus ayant fait l’objet de signalement. Mais il serait possible d’aller plus loin. Plus fondamentalement, il est important que les pouvoirs publics prennent des mesures permettant de renforcer l’esprit critique des utilisateurs, ce qui suppose tout particulièrement que ceux-ci puissent être sensibilisés aux sciences et technologies du numérique afin de mieux maîtriser le fonctionnement de ces plateformes et les effets induits par ces mécanismes de viralité. La création d’un cours de « Science numérique et technologie » obligatoire pour toutes les classes de seconde va dans ce sens[5].
La légitimité
Enfin, troisièmement, si la modération des contenus et le contrôle de la viralité jouent un rôle prépondérant dans le contrôle pragmatique de la désinformation et de la mésinformation, ces opérations ne peuvent, in fine, être accomplies sans référence à des autorités indépendantes établissant, ne serait-ce que temporairement, la validité des arguments échangés dans l’espace public. Sous ce rapport, une grande difficulté provient du fait que les plateformes elles-mêmes sont parfois devenues de telles autorités, en vertu de l’adage bien plus puissant qu’on pourrait le croire selon lequel « si beaucoup de monde le dit, c’est que cela doit être vrai ». Pourtant, les plateformes n’ont bien sûr aucune qualité ni compétence pour déterminer, par exemple, l’efficacité d’un vaccin ou le bienfondé d’une mesure de santé publique. Elles sont donc contraintes de se fier à d’autres autorités comme l’État, la justice, la science ou la presse. Depuis le début de la crise sanitaire, de nombreuses plateformes se sont ainsi rapprochées, en France, de différents services gouvernementaux (en particulier du Secrétariat d’État au numérique ou du Service d’information du gouvernement). Pourtant, dans le même temps, elles se sont éloignées d’autres gouvernements, comme en atteste leur modération des contenus publiés par Jamir Bolsonaro ou Donald Trump. En l’occurrence, on peut légitimement se réjouir de ces choix. Ils n’en restent pas moins arbitraires dans la mesure où ils ne reposent pas sur des principes explicites régulant les relations entre les plateformes et les gouvernements. À cet égard, une réflexion d’ensemble sur la responsabilité des plateformes ainsi que sur le contrôle à exercer s’agissant de leur politique de modération de contenus semble devoir être menée. À notre sens, ce contrôle ne peut être dévolu à l’État seul et devrait relever d’une autorité indépendante, incluant les représentants de diverses associations, scientifiques et acteurs de la société civile dans l’établissement des procédures de sélection d’informations à promouvoir, tout particulièrement en période de crise sanitaire.
Emmanuel Didier, Centre Maurice Halbwachs, CNRS, ENS et EHESS Serena Villata, Université Côte d’Azur, CNRS, Inria, I3S
& Célia Zolynski Université Paris 1 Panthéon-Sorbonne, IRJS DReDIS
La robotique déformable est un domaine de recherche prometteur et surprenant par la diversité des champs d’applications qu’il concerne. Eulalie Coevoet, ingénieure R&D à l’Université de Naples Federico II, a reçu le prix de la meilleure thèse du GDR Robotique qui récompense de jeunes scientifiques dont les travaux ont permis une avancée de la recherche par des contributions au progrès des connaissances scientifiques et/ou aux innovations techniques en robotique. Dans la série Il était une fois ma thèse, Eulalie nous présente les travaux de sa thèse soutenue en 2019 au sein de l’équipe de recherche Defrost d’Inria Lille. Marie-Agnès Enard et Pascal Guitton.
Dans l’imaginaire collectif, un robot est fait de métal, et prend souvent la forme d’un humanoïde ou d’un bras robotisé sur une chaîne industrielle. La robotique déformable casse les codes de la robotique rigide traditionnelle avec des mouvements d’un nouveau genre et des formes atypiques, souvent inspirés d’animaux tels que la pieuvre, la méduse, le serpent, la chenille etc. Un robot déformable (ou robot souple) est fabriqué à partir de matériaux flexibles, comme le silicone, le plastique, ou encore les tissus et papiers. Par définition, ces robots créent le mouvement en déformant leur structure (à l’aide de câble, ou de pression dans des cavités par exemple), en contraste avec les robots classiques qui basent leurs mouvements sur des mécanismes d’articulations. En plus d’élargir le champ des possibles en termes de mouvements, l’utilisation de ces types de matériaux à l’avantage de rendre ces robots plus sûrs pour les objets ou personnes avec qui ils interagissent. Comme par exemple pour la robotique chirurgicale.
Ce pan de la robotique est jeune d’une trentaine d’années. La recherche dans ce domaine est aujourd’hui très active et vient soulever des problématiques dans le design, la fabrication, et le pilotage des robots. C’est ce dernier sujet sur lequel je me suis penchée pendant ma thèse. En effet, la modélisation des mouvements d’un robot déformable est complexe. Dans le cas des robots traditionnels articulés, l’actionnement (rotation d’axe par exemple) qui amène le robot à une forme cible, peut être déduit de la seule géométrie du robot, c’est-à-dire des articulations et des parties rigides entre les articulations. Ce n’est pas aussi simple pour un robot déformable notamment parce que les propriétés mécaniques des matériaux qui le constituent jouent un rôle très important dans ses mouvements. Par exemple, si on applique une même pression dans deux ballons d’élasticité différente, la forme finale des deux ballons ne sera pas la même. De la même manière si on gonfle un ballon entre deux parois étroites, la forme finale du ballon ne sera pas la même qu’à l’air libre. Tous ces phénomènes doivent être pris en compte pour pouvoir piloter efficacement un tel robot.
@EC
Dans ma thèse je propose donc des solutions pour le pilotage de robot déformable qui prennent en compte les effets des obstacles sur les mouvements du robot. Les autres solutions qui existent aujourd’hui sont généralement peu performantes quand le robot interagit avec son environnement, or c’est le cas dans la plupart des applications. Les algorithmes que je propose dans ma thèse se basent sur la modélisation et la simulation du robot et de son environnement, à l’aide entre autres de la méthode des éléments finis. Cette méthode très connue en analyse numérique, repose sur une représentation des objets en petits éléments géométriques (par exemple des tétraèdres en 3D); les calculs nécessaires à la simulation sont ensuite réalisés en chaque sommet des éléments. Je propose également d’étudier les problématiques de leur actionnement et des contacts en m’appuyant sur le concept de résolution de problème d’optimisation sous contraintes. On entend par là le fait d’optimiser leur actionnement pour atteindre une cible, alors même que le robot est contraint par les objets qui l’entourent. La problématique principale de ma thèse a été de proposer des algorithmes peu coûteux en calcul, afin de pouvoir piloter ces robots en temps réel, et dans un environnement changeant.
@EC
J’ai pu démontrer durant ma thèse que les méthodes que je propose sont applicables à un large type de robots, c’est-à-dire avec des géométries et actionnements différents. Le développement de ces nouvelles techniques pour le pilotage est important pour la création de robots de plus en plus complexes, et aux capacités de plus en plus riches.
Binaire, a demandé à Véronique Torner, co-fondatrice et présidente de alter way , membre du CA du Syntec Numérique, présidente du programme Numérique Responsable et membre du Conseil Scientifique de la SIF (Société informatique de France) de nous parler de l’initiative Planet Tech’Care. Marie Paule Cani et Pierre Paradinas.
Binaire: Véronique peux tu nous dire en quoi consiste le projet Planet Tech’Care? Véronique Torner : Planet Tech’Care est une plateforme qui met en relation des entreprises et des acteurs de la formation qui souhaitent s’engager pour réduire l’empreinte environnementale du numérique avec un réseau de partenaires, experts du numérique et de l’environnement.
En s’engageant autour d’un manifeste, les signataires ont accès gratuitement à un programme d’accompagnement composé d’ateliers conçus par les partenaires de l’initiative.
La plateforme est animée par le programme Numérique Responsable de Syntec Numérique. Le projet a été initié sous l’impulsion du Conseil National du Numérique.
Binaire : Qui sont les membres de Planet Tech’Care ?
Véronique : Vous avez d’un côté les signataires du manifeste, des entreprises de tous secteurs et de toutes tailles (du CAC40 à la start-up) et des écoles, universités, instituts de formation et d’un autre côté les partenaires, organisations professionnelles, associations, think tanks, spécialistes du sujet Numérique & Environnement.
Binaire : Que contient le manifeste de Planet Tech’Care
Véronique : Les signataires du manifeste Planet Tech’Care reconnaissent que le numérique génère une empreinte environnementale et s’engagent à mesurer puis réduire les impacts environnementaux de leurs produits et services numériques. Ils s’engagent également à sensibiliser leurs parties prenantes afin que tous les acteurs de l’écosystème numérique soient en mesure de contribuer à réduire leurs impacts sur leurs périmètres de responsabilité. En parallèle, les acteurs de l’enseignement, ainsi que les acteurs du numérique proposant des formations à leurs collaborateurs, s’engagent à intégrer des formations au numérique responsable et écologiquement efficient dans leur curriculum de cours. Ainsi, la nouvelle génération de professionnels sera en capacité de développer des produits et services technologiques numériques bas carbone et durables.
Binaire : Qui peut rejoindre le projet ? Pourquoi et comment impliquer les jeunes ?
Véronique : Toute entreprise et tout acteur du domaine de l’éducation peuvent nous rejoindre. Rassembler suffisamment de signataires dans le domaine de l’éducation sera essentiel pour impliquer massivement les jeunes. On peut à terme imaginer d’intégrer des formations au numérique responsable adaptées à tous les programmes des universités et autres établissement d’enseignement supérieur, des formations spécialisées en informatique à tous les secteurs utilisant le numérique, mais aussi d’associer une sensibilisation au numérique responsable aux programmes d’initiation au numérique au collège et au lycée. Nous comptons ensuite sur l’énergie et l’enthousiasme des jeunes pour que ces nouveaux usages diffusent à l’ensemble de la société.
Binaire : Comment sera évalué l’intérêt du projet Planet Tech’Care ?
Véronique : Nous ferons un premier bilan dans un an qui sera constitué de plusieurs indicateurs : le nombre de signataires, la qualité des ateliers, un baromètre de maturité de notre communauté. Nous comptons pour le lancement plus de 90 signataires et plus de 10 partenaires qui démontrent déjà l’intérêt d’une telle initiative. Notre enjeux est de :
– créer une dynamique autour d’acteurs engagés pour le numérique éco-responsable,
– fédérer les expertises pour passer de l’engagement à l’action,
– et enfin créer des communs pour passer à l’échelle.
Binaire : Tu es dans le CA du Syntec Numérique et le CS de la SiF, pourquoi ces instances se mobilisent-elles sur la question de la responsabilité sociale et plus particulièrement sur les impacts environnementaux ?
Véronique : Syntec Numérique est en première ligne sur les enjeux du Numérique Responsable qui constitue un des cinq programmes stratégiques de notre organisation professionnelle. Nous œuvrons depuis plusieurs années sur l’inclusion sociale et sur l’éthique du numérique. En ce qui concerne les enjeux environnementaux, notre industrie a un double challenge à relever. Nous devons bâtir des solutions numériques au service de la transition écologique, car nous le savons Il n’y aura pas de transition écologique réussie sans numérique. Et nous devons aussi, comme toutes les industries, réduire notre empreinte environnementale. Nous avons un groupe de travail très actif sur le sujet et nous animons désormais la plateforme Planet Tech’Care.
Par ailleurs, la SiF, Société informatique de France, qui anime la communauté scientifique et technique en informatique, a déjà montré son engagement pour une double transition numérique et écologique lors de son congrès annuel 2020, qui a porté sur ce thème. Diffuser plus largement cette réflexion est indispensable pour agir plus largement non seulement sur les acteurs socio-éconimique mais aussi, et en particulier via l’éducation, sur l’ensemble de la société. En particulier, le conseil scientifique de la SIF a tout de suite montré un grand enthousiasme pour le projet Planet Tech’ Care, jugé essentiel pour que le numérique devienne un véritable levier pour les transitions sociétales et écologiques !
Isabelle Guérin-Lassous est présidente du jury du nouveau CAPES Numérique et Sciences Informatiques (NSI) qui a auditionné les futurs professeurs qui enseigneront dès cette rentrée les sciences du numérique comme option au lycée en classes de première et terminale. Elle revient sur la mise en place de cette première édition du concours.
Article repris du site du CNRS.
Crédit photo Centre Jacques Cartier
L’informatique est devenue incontournable dans nos sociétés actuelles. Comment aurions-nous vécu le confinement sans les outils informatiques, tant d’un point de vue personnel que professionnel ? La période de confinement aurait sûrement été très différente : pas de continuité pédagogique pour les élèves, un plus grand nombre de professions et d’entreprises à l’arrêt, une communication plus réduite entre la famille et les amis, un accès à la culture encore plus limité, etc.
L’informatique est donc incontournable et pourtant… Peu de gens ont une idée, même assez générale, de ce qui se passe derrière ces outils informatiques. Les métiers de l’informatique sont constamment en tension et en recherche de profils compétents depuis de nombreuses années.
Si l’informatique est enseignée depuis le début des années 1970 dans l’enseignement supérieur, l’enseignement de l’informatique au lycée est un long chemin fait d’avancées et de reculs. Il y a eu des premières expériences d’enseignement en informatique, dès le début des années 1970, dans quelques lycées. Puis diverses options d’informatique ont vu le jour entre 1982 et 2015. Mais il faut attendre septembre 2019 pour que l’informatique soit enseignée au lycée comme discipline à part entière !
Depuis la rentrée scolaire 2019, la discipline informatique est enseignée au sein de deux nouveaux enseignements introduits lors de la réforme du lycée. SNT (Sciences Numériques et Technologie) est enseigné aux élèves de seconde générale et technologique. C’est un enseignement commun qui balaye les principaux concepts et enjeux de l’informatique. NSI (Numérique et Sciences Informatiques) est proposé comme enseignement de spécialité aux élèves de première et de terminale de la voie générale. Le programme de NSI est vaste et organisé au sein de quatre thèmes-clés de l’informatique que sont les données, les algorithmes, les langages et les machines.
Cet enseignement répond à deux objectifs principaux. Il doit apporter une culture générale sur l’informatique permettant de comprendre les grands principes sous-jacents à l’informatique et aux outils extrêmement utilisés de nos jours (comme par exemple le Web ou les réseaux sociaux). Il doit aussi faire prendre conscience de l’impact de l’informatique sur nos sociétés et inciter à l’adoption de bonnes pratiques. Le deuxième objectif, avec l’enseignement de NSI, est d’apporter une formation large aux élèves intéressés par cette discipline, permettant d’aborder le supérieur avec un socle significatif de connaissances.
Si l’arrivée de l’informatique dans l’enseignement au lycée est une avancée majeure pour la discipline qui était attendue depuis longtemps, un autre enjeu, de taille, est de disposer d’enseignants experts dans cette discipline. Les enseignants qui assuraient les précédentes options en informatique possèdent déjà un bagage avéré dans la discipline, mais le programme de NSI est bien plus large et le nombre d’élèves à former bien plus conséquent. Il était donc indispensable d’avoir plus d’enseignants aptes à enseigner l’informatique.
Si l’arrivée de l’informatique dans l’enseignement au lycée est une avancée majeure pour la discipline, un autre enjeu de taille est de disposer d’enseignants experts dans cette discipline.
,
Des enseignants volontaires ont pu suivre le DIU (Diplôme Inter-Universitaire) Enseigner l’informatique au lycée qui s’est mis en place dès le printemps 2019. Les enseignants qui valident ce DIU peuvent alors enseigner NSI. En parallèle, un CAPES, dénommé CAPES NSI, a été créé pour un premier recrutement en 2020.
Organiser le premier concours d’un CAPES repose sur de nombreux défis : trouver un jury constitué de membres aux origines professionnelles du monde de l’enseignement et compétences informatiques variées, sans oublier le respect de la (presque) parité ; élaborer les sujets des épreuves d’admissibilité et les leçons des épreuves d’admission, ce qui n’est pas une tâche facile quand tout est à inventer ; mettre au point un système informatique léger, rapide et robuste, équipé de multiples logiciels utiles au concours, sur lequel chaque candidat pourra préparer, en temps limité, sa présentation orale ; recruter des futurs enseignants qui ont une culture informatique large et solide sur les attendus du programme et qui seront capables d’enseigner la discipline à des jeunes souvent accro au numérique mais sans réelle connaissance des mécanismes sous-jacents aux outils utilisés.
Le concours du CAPES NSI en 2020 est une cuvée spéciale. C’est certes le premier concours, mais le calendrier du concours a été fortement chamboulé par la crise sanitaire actuelle, comme beaucoup de concours de recrutement. Dans ce contexte, les épreuves orales ont été annulées et les épreuves écrites, qui sont devenues les épreuves d’admission, ont eu lieu fin juin. Ce n’est évidemment pas une configuration idéale pour effectuer un premier recrutement, mais l’important est que le concours ait été maintenu et qu’il permette de recruter les premiers enseignants disposant du CAPES NSI pour la rentrée 2020. Le concours de cette année va d’ailleurs être hautement sélectif, tout particulièrement pour l’enseignement public avec 30 postes mis au concours pour le CAPES externe et un peu plus de 300 candidats présents aux épreuves et 7 postes ouverts pour le 3e concours et presque 150 candidats présents aux épreuves.
Le nombre de postes mis au concours en 2020 est certes modeste mais il est normal de prendre la température au lancement d’une nouvelle discipline, notamment sur le nombre d’élèves prenant la spécialité NSI en première, puis en terminale, mais aussi sur le vivier de candidats prêts à présenter le concours du CAPES NSI, ou sur le nombre de préparations au CAPES proposées dans les universités et le nombre d’étudiants inscrits à ces préparations. Mais il est fort probable que le nombre d’enseignants aptes à enseigner l’informatique au lycée devra être significativement augmenté dans le futur. Avoir des enseignants compétents et motivés sur tout le territoire est une étape incontournable pour l’essor de l’enseignement de l’informatique au lycée, car ne l’oublions pas, au-delà de la culture générale, le France a besoin de plus de jeunes qui se tournent vers les formations en informatique, et plus leur expérience sera bonne au lycée, plus ils seront enclins à poursuivre vers ces formations !
Isabelle Guérin-Lassous
Professeur à l’Université Claude Bernard Lyon 1, membre du LIP
La pandémie de COVID-19 en France et dans le monde a été l’occasion de débats scientifiques et médiatiques parfois violents. Ces débats ont montré les limites d’un système de recherche trop opaque et complexe qui a permis de répandre de fausses informations ou de partager des conclusions sans réels supports scientifiques. L’Open Science est une approche qui permet de limiter ces biais. Plusieurs chercheurs ont utilisé des technologies actuelles afin d’évaluer et d’analyser les articles de recherche sur la Covid-19 et ainsi quantifier la qualité et la véracité des informations relayées.
Photo de Prateek Katyal provenant de Pexels
Depuis plus de 10 ans, des centaines de scientifiques ont commencé à promouvoir l’Open Science ou science ouverte en Français. L’Open Science un mouvement qui cherche à rendre la recherche scientifique et les données qu’elle produit accessibles à tous et dans tous les niveaux de la société.
Pour rappel, le processus de publication scientifique est le même dans toutes les disciplines. Les scientifiques soumettent le résultat de leurs travaux à d’autres scientifiques du même domaine afin qu’ils évaluent la pertinence, la reproductibilité et qualité des résultats. Cette “revue” d’article fait l’objet d’un rapport (qui n’est pas systématiquement rendu publique). L’article est ensuite corrigé (ou pas) et mis à disposition sur des plateformes accessibles à tous s’il est accepté.
Avec l’Open Science, la démarche consiste à aller plus loin, en s’engageant à détailler toutes les étapes des travaux et leurs résultats, et en rendant accessibles, compréhensibles et réutilisables ces travaux à tous et toutes (amateurs comme experts). Face à l’urgence liée à la pandémie de COVID-19, les articles de recherche sur COVID-19 ont été vérifiés par d’autres scientifiques de façon bien plus rapide, de nombreux résultats scientifiques contradictoires et débats entre scientifiques ont été exposés au grand public et ont semé la confusion parmi chercheurs, journalistes ou citoyens.
Avec mes co-auteurs, de domaines de recherche différents, nous avons donc décidé d’analyser les articles de recherche sur COVID-19 afin d’évaluer le niveau de transparence, la qualité du travail scientifique et la rigueur des évaluations faites sur ces travaux. Cette étude fait l’objet d’un article qui, sur le principe de l’Open Science, est actuellement en attente de relecture par nos pairs : https://www.biorxiv.org/content/10.1101/2020.08.13.249847v1.full. Notre article fait l’état des lieux de la démarche de transparence et des erreurs commises dans les publications scientifiques sur la COVID-19 et propose des pistes d’améliorations (reposant sur les principes de l’Open Science) afin de les éviter à l’avenir.
Pour binaire, nous nous sommes principalement intéressés à deux questions :
1. Est-ce que la revue accélérée par les pairs a été faite de façon rigoureuse ?
2. Est-ce que les journalistes ont partagé des résultats non validés par la communauté scientifique ?
Revue accélérée par les pairs.
Nous avons analysé les articles scientifiques disponibles sur PubMed (la base de données de référence d’articles de médecine) pour retrouver les articles sur COVID-19 (12 682 articles quand nous avons débuté notre analyse) en utilisant un programme pour trouver tous les articles dont les métadonnées donnent le temps qu’ont passé les pairs pour la revue de ces articles. Sur l’ensemble des articles dont les temps de revue sont disponibles (8455 articles), 700 ont été validé par les pairs en moins de 24h. La durée classique d’une revue par les pairs, bien que dépendante du domaine de recherche, est en général bien plus longue (en général plusieurs semaines/mois). Nous nous sommes donc intéressés à ces 700 articles en particulier en les classant par catégorie :
– 123 lettres éditoriales
– 74 articles de recherche “courts”
– 503 articles de recherche ”classique”
Parmi ces deux dernières catégories, nous avons pu observer que les auteurs de certains articles étaient également membres du comité éditorial de la revue dans laquelle l’article est publié, constituant ainsi ce que l’on appelle un conflit éditorial. C’est le cas pour 41% des articles de recherche et 37% des articles courts. Bien que cela ne soit pas rare, la combinaison d’un conflit éditorial et d’un temps de revue très court est particulièrement suspecte, notamment lorsque les rapports de revue ne sont pas disponibles publiquement.
Partage de résultats non validés dans les médias
En étudiant les données, nous avons constaté que les articles non encore validés par les pairs avaient presque 10 fois plus de couverture médiatique si leur sujet était COVID-19. Bien qu’il soit normal de reporter des résultats de recherche récents, les articles non validés par les pairs peuvent contenir des approximations, des erreurs ou mêmes des conclusions non fondées par les données collectées. Un partage des contenus de ces articles participe donc directement à la potentielle désinformation du grand public.
Quelles solutions pour éviter ce genre de dérapages à l’avenir ?
Il s’agit en fait d’adopter directement les principes de transparence évoqués au début de cet article et de respecter leurs usages. Ils peuvent directement aider à rendre la recherche plus fiable, plus sérieuse et plus robuste. En voici l’illustration sur deux des points mentionnés :
1. Adopter les revues par les pairs ouvertes à tous. Cela permet de rendre disponible directement en ligne le rapport de revue avec l’article de recherche et de savoir si la revue a été faite de façon rigoureuse ou non.
2. Bien que le partage d’articles non validé par les pairs soit un des principes de la science ouverte et transparente, le public scientifique les consulte avec prudence quand à la validité des travaux. Cette approche de prudence et de réserve est le point central pour des publics non avertis. Si les médias s’en emparent pour une communication grand public, ils doivent eux aussi être transparents et mentionner que les conclusions de l’article pourraient changer une fois la revue par les pairs effectuée et que celui-ci est en attente de vérification par un public scientifique.
D’autres principes de l’Open Science qui auraient pu aider pendant cette pandémie sont mentionnés dans notre article. Nous évoquons par exemple l’article de The Lancet qui a du être rétracté de la revue scientifique pour soupçons de fabrication ou falsifications des données. Dans ce cas, le fait de devoir partager, en parallèle de la publication d’un manuscrit scientifique, le jeu de données sur lequel le manuscrit se base, est une solution évidente.
En attendant la relecture et publication officielle de notre manuscrit, nous avons entamé une démarche de co-signature de l’article par d’autres scientifiques qui a déjà collecté plus de 400 signatures à l’heure actuelle. L’appel à signature est disponible ici: http://tiny.cc/cosigningpandemicopen. Nous sommes convaincus qu’il y a un réel enjeu technologique, éthique et sociétal à participer à cette démarche Open Science. Nous espérons que le monde de la recherche puisse enfin devenir ce qu’il aurait dû toujours être: un bien commun, accessible avec une transparence complète et gage de qualité et de confiance.
Lonni Besançon, chercheur associé à l’université Monash (Australie)
StopCovid a agité les médias avant de passer pour quelques temps dans un relatif oubli. Le répit dans la propagation du virus le rendait relativement inutile. Mais le Corona revient et repose de manière critique la question de limiter sa propagation. En première ligne, la méthode manuelle de traçage de contact qui semble à la peine. On peut s’inquiéter d’entendre que ce n’est pas toujours simple de se faire tester, que les résultats tardent, que les personnes impliquées sont parfois réticentes à participer, que les services humains mis en place sont débordés, etc. La réactivité de la détection est critique si on veut bloquer la propagation du virus.
A coté de l’approche classique par enquêtes intensives, le traçage numérique a été proposé comme complément indispensable. En France, c’est StopCovid. Alors, quid de StopCovid ?
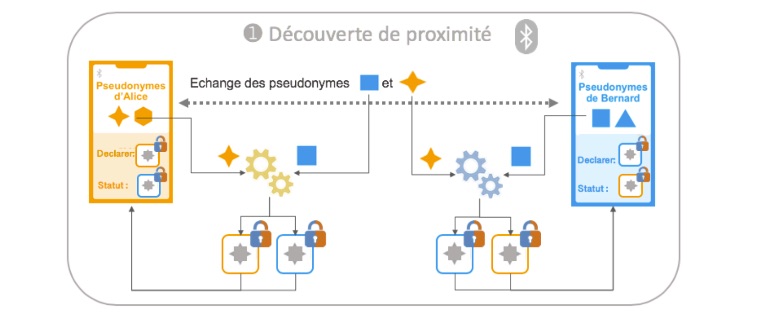
Une vidéo des Décodeurs explique clairement les deux formes de détection, humaine et numérique [11]Préambule : c’est clairement un sujet miné, une machine à prendre des baffes y compris de ses meilleurs amis. Nous tenons à préciser que nous sommes parmi ceux qui ont plutôt accueilli positivement l’approche française autour d’Inria. Nous pensons que c’est ok de donner au gouvernement des informations personnelles pour ralentir la pandémie, mais que le maximum doit être fait pour en garantir, autant que possible bien sûr, sa confidentialité mais aussi son efficacité.
Au 19 août, selon la DGS [1], « l’application a été téléchargée près de 2,3 millions de fois, sur les plateformes Android et Apple, depuis sa mise en service le 2 juin […] 1 169 QR codes ont été utilisés et 72 contacts à risque notifiés ». C’est évidemment décevant :
– Pas tant par le nombre d’installations : avec quasiment pas de publicité et d’autres sujets de préoccupation autrement plus importants comme les vacances, il ne fallait pas s’attendre à des miracles.
– Les 1169 QR codes correspondent aux personnes qui ont installé StopCovid et se sont déclarées contaminées. Cela représente 0,05% des 2,3 millions de ceux qui ont installé StopCovid, sans doute un peu plus si on considère qu’une personne peut l’avoir installée plusieurs fois. Ça reste très peu. Les gens qui installent StopCovid sont-ils beaucoup moins touchés que les autres par le virus (protégés par StopCovid 🙂 ? Ceux qui ont été contaminés n’ont-ils pas reçu de code à saisir, ne l’ont-ils pas déclaré ? On aimerait comprendre.
– 72 contacts notifiés pour 1169 QR codes, ça fait 0,06 contacts par personne malade. Comme il est peu probable que les gens qui ont installé StopCovid ne croisent quasiment jamais personne, faudrait-il croire qu’ils ne croisent que des gens qui n’ont pas installé ou pas activé StopCovid ? Ou alors est-ce que StopCovid ne fonctionne pas comme on le pense ?
Crédit image Pexels-bongkarn-thanyakij
Des utilisateurs de l’application s’interrogent :
– “Elle passe ses vacances avec sa fille testée positive au coronavirus, l’application Stop Covid ne l’alerte pas” [2].
– “J’ai été testé positif au #Covid19 vendredi et j’avais l’application #StopCovid […] j’ai donc voulu jouer le jeu en me déclarant positif sur l’application, et c’est là que je me suis heurté à un mur” [3].
On ne sait quoi répondre. De fait, on manque terriblement d’information publique sur l’App.
On sait ce qu’il faut faire pour l’installer, on connaît les principes selon lesquels elle a été conçue (utilisation de la technologie Bluetooth, architecture centralisée, protocole ROBERT). Mais on ne sait pas précisément comment l’App fonctionne une fois installée, quelles sont ses limites, et quelle est son efficacité. Nous avons bien inspecté son code (disponible en open-source [4], merci!) mais s’il permet aux plus initiés de voir comment l’application a été implémentée, il n’explique pas pourquoi elle l’a été de cette manière. Pourquoi une rotation de 90° d’un iPhone sur lequel tourne l’application fait-elle disparaître les informations présentes à l’écran et diminuer sa luminosité, par exemple ? Pour relativiser nos remarques qui peuvent paraître critiques, les applications de traçage de contacts développées dans les autres pays ne fournissent pas beaucoup plus d’informations sur ce qu’elles font une fois lancées, comment elles le font ou pourquoi elles le font de cette manière.
On dispose peu de suivi statistique de l’utilisation de StopCovid. Les Suisses, entre autres, pourraient nous donner des leçons de transparence [5]. Le projet était pourtant prometteur en termes de transparence, au départ. Une des conditions évoquées pour la réussite de ce dispositif était le nombre de téléchargements par les citoyens, mais au-delà des débats qui ont agité sa mise à disposition, la campagne d’information qui n’a duré que peu de temps n’a pas été convaincante. Il est dommage de constater que les illustrations des bonnes pratiques à adopter proposées par le gouvernement (“Luttons ensemble contre le Covid-19”, [6]) n’intègrent pas le téléchargement de l’application.
On aimerait une évaluation approfondie et publique de l’état des lieux et une information plus régulière sur l’application.
StopCovid a été réalisé dans l’urgence sous la pression publique. On ne pouvait pas s’attendre à ce que l’App soit directement parfaite. OK. Mais, maintenant, améliorons-la ! Deux questions ont éclipsé les autres : la protection des données et la souveraineté nationale (pour la question de l’accès à Bluetooth). On peut approfondir ces sujets.
Le système actuel n’utilise pas l’interface de programmation “Exposure Notification” d’Apple et Google (GAEN, [7]). En termes de souveraineté, c’est parfait, l’État gardant la maîtrise des données et de la gestion de l’épidémie. Mais les développeurs de StopCovid ont-ils réussi à s’affranchir des limites techniques imposées par Apple ou Google sur toutes les applications Bluetooth et qui rendent le traçage de contact difficile sans GAEN [8] ? Dans quelle mesure l’application peut-elle communiquer par Bluetooth lorsqu’elle n’est pas visible à l’écran, lorsqu’une autre application est utilisée ou que le téléphone est verrouillé ? Y-a-t-il des choses à faire ou ne pas faire pour que la communication se fasse dans de bonnes conditions ? Si des solutions techniques ont été trouvées, si des contraintes en résultent, elles méritent d’être expliquées. Si les limites imposées par Apple et Google ne peuvent être que mal contournées, si l’application doit être le plus souvent possible visible, au premier plan sans que le téléphone soit verrouillé, il faut le savoir et s’en souvenir pour lancer à court terme un plan d’enfer européen pour pouvoir se passer d’iOS et d’Android .
Pourquoi ne passe-t-on pas au nouveau protocole développé par Inria, DESIRE [9] ? Il a l’air trop cool. Est-ce qu’il y a des raisons techniques pour ne pas l’adopter ? Est-ce que ce serait trop compliqué de changer de protocole au milieu de la pandémie ? La base installée n’est pourtant pas si gigantesque.
A côté de ces deux aspects très discutés, un sujet hyper important a été, à notre humble avis, ignoré : l’App fonctionne trop comme une boîte noire. Si on veut que le numérique participe à régler les questions parfois existentielles posées à notre société de l’écologie aux épidémies, l’approche boîte noire ne fonctionne pas.
Certains ont reproché le manque d’aspect ludique de l’App, son niveau gaming très faible. Le fait que les gens la trouvent sympa et voient un intérêt personnel à l’utiliser n’est pas à négliger, évidemment. Mais l’enjeu principal n’est pas de faire une appli cool pour “jouer avec le Covid”. Ce qui est en jeu c’est avant tout la bonne compréhension de ce que fait l’application, de ce qu’il faut faire (ou pas) pour qu’elle fonctionne correctement une fois installée et qu’elle puisse être utile à la gestion de l’épidémie.
Je suis en train de parler à ma fille, je veux savoir si nos deux StopCovid se sont causées. OK, c’est une violation potentielle de confidentialité, mais si elle est d’accord et moi aussi ? Je devrais pouvoir vérifier que ça marche, regarder ce qui se passe si elle met son tél dans sa poche, ou au fond de son sac… Si on peut assister en direct à la rencontre de nos deux App qui se font coucou, on comprendra un peu mieux ce qui se passe.
Je veux savoir ce que sait faire le système et ce qu’il ne sait pas faire. Au minimum, j’aimerais savoir ce qu’il est en train de faire, ce qu’il a fait récemment. Si je ne sais pas répondre à de telles questions, est-ce que je vais réellement utiliser cette App ?
Qu’on ne se méprenne pas, nous ne proposons pas d’arrêter l’expérience. On ne pouvait pas s’attendre à ce que StopCovid soit immédiatement parfait. Nous on veut que cela fonctionne et nous aide à combattre la pandémie. Maintenant, améliorons-le ! C’est une belle occasion pour montrer comment réussir un projet collectif qui met le numérique au service de la société.
Serge Abiteboul, Claude Hinn, et Dominique Normane
En août, binaire prend ses quartiers d’été
et vous retrouve à la rentrée.
Après une année chargée pour tout le monde, binaire se met en pause estivale mais vous accompagne en vous proposant quelques relectures. Nous avons pour cela sélectionné les articles les plus consultés et il est amusant de constater que leurs sujets « collent » très fidèlement aux thématiques centrales traitées par binaire : cybersécurité, environnement, mécanismes d’apprentissage, Internet…
Profitez des vacances pour les redécouvrir et les partager avec votre entourage !
Des codes malveillants jusque dans la poche : une question majeure. De quoi s’agit-il ? Comment fonctionnent-ils ? Comment les détecter et s’en protéger ? Partons à leur découverte.
Les modèles mathématiques : miracle ou supercherie ? : nous sommes souvent confrontés à une avalanche de chiffres, basés sur des modèles mathématiques, voici les bénéfices mais aussi les limites de telles approches.
Les algorithmes de recommandation comment marchent-ils, eux qui nous disent ce qu’ont acheté les autres acteurs ou nous enferment dans une bulle informationnelle ? Décryptage en nous expliquant le « comment ça marche ».
Apprendre sans le savoir ? Les algorithmes d’intelligence artificielle sont basés sur des apprentissages et des connaissances issus de plusieurs domaines dont les sciences cognitives, comparons ici avec l’apprentissage humain.
Le numérique, l’individu, et le défi du vivre-ensemble. Ancien banquier entré chez les Dominicains , Éric Salobir, prêtre, est un expert officiel de l’Église catholique en nouvelles technologies et favorise le dialogue entre les tenants de l’intelligence artificielle et l’Église, alors lisons le.
Bonnes vacances et surtout prenez bien soin de vous et des autres en cette période compliquée.
Depuis 2014, le blog binaire du Monde est réalisé par un groupe d’éditeurs, d’amis, qui veulent partager leur passion pour le monde numérique, ses avancées scientifiques, ses innovations technologiques, ses enjeux sociétaux majeurs, etc. Avec l’aide d’une communauté d’auteurs et autrices passionnés comme nous par le sujet, nous sommes arrivés à construire le meilleur magazine en français sur l’informatique et le numérique – selon nous en tous cas 🙂 . Nous n’y serions jamais arrivé sans le soutien d’un réseau de partenaires, le plus souvent incarnés par des amis : la Société informatique de France et son bulletin 1024, Interstices, la Fondation Blaise Pascal, le CNRS, Inria et son association d’alumni, Theconversation, et d’autres.
Le blog binaire, c’est aussi une communauté de lectrices et lecteurs, souvent fidèles. C’est vous !
Pendant le confinement, soutenus par notre communauté d’auteurs et autrices nous avons accéléré la publication pour aller jusqu’à un article par jour. Vous lecteurs avez été au rendez-vous. Nous sommes montés jusqu’à 5000 à 10000 lecteurs par semaine (contre environ 2000 à 3000 en temps normal). Merci !
Continuez à nous lire ! N’hésitez pas à nous interpeller pour nous critiquer, nous suggérer des sujets, dénoncer des auteurs potentiels, ou juste pour nous dire que vous aimez trop binaire. Parlez de nos publications autour de vous et sur les réseaux sociaux !
Dans le contexte de la crise sanitaire inédite que nous vivons, le numérique est clairement un allié. Au-delà du télétravail, il nous permet d’espérer, grâce aux mécanismes d’apprentissage machine qui peuvent analyser un énorme volume de données, des techniques de dépistages rapides du COVID19, un médicament, voire un vaccin. Il nous permet aussi de modéliser l’évolution du virus pour mieux lutter contre sa propagation grâce aux algorithmes épidémiques. Deux professeurs de l’EPFL nous parlent des algorithmes épidémiques et de ce qu’ils peuvent nous apprendre sur les épidémies. Serge Abiteboul et Pascal Guitton
Dessin de pixabay
Mais qu’est ce donc qu’un algorithme épidémique?
Un algorithme épidémique est par essence réparti, c’est à dire qu’il ne s’exécute pas sur une seule mais sur plusieurs machines, typiquement des milliers ou des millions, qui collaborent pour exécuter une tâche. Sa caractéristique principale est le mode de communication entre les machines. Périodiquement, chaque machine communique avec un sous-ensemble, de petite taille, d’autres machines que l’on appelle ses voisins. Ces voisins, peuvent être statiques, c’est à dire ne jamais changer, comme dans un centre de données par exemple, mais ils peuvent également périodiquement changer au cours du temps et de manière plus ou moins aléatoire, comme entre des téléphones portables par exemple. On peut ainsi voir cet ensemble de machines comme un graphe qui les connecte, statique dans le premier cas, dynamique dans le second. Ainsi si une machine produit une information et la communique à ses voisins, que ces voisins sont choisis de manière aléatoire, et si chaque voisin retransmet à son tour l’information à ses propres voisins, celle ci se diffuse de manière très rapide (exponentielle) et très robuste (malgré la perte de certains messages ou l’arrêt de certaines machines). Ça ne vous rappelle rien ? Ce mode de propagation de l’information dans un grand réseau commence à singulièrement ressembler à celui de la propagation d’un virus dans le cas d’une épidémie, d’où les algorithmes éponymes.
Pour la petite histoire, il ressemble aussi au mode de propagation des rumeurs et on les appelle parfois des algorithmes de gossip, même si dans le cas d’un système informatique on ne considère pas nécessairement que la rumeur est déformée ou transformée comme dans le cas des commérages propagés au sein d’une population.
Les applications informatiques des algorithmes épidémiques
Les algorithmes épidémiques ont d’abord été utilisés dans le contexte des bases de données dupliquées (Demers et al, 87) : lorsqu’une modification est faite sur l’un des réplicas (une copie d’un fichier), elle est ensuite propagée aux autres. Les solutions cloud d’Amazon ont été parmi les premières à utiliser de tels algorithmes pour gérer la duplication des informations, mise en œuvre à la fois pour tolérer d’éventuelles défaillances et pour améliorer la performance de la dissémination. Les algorithmes épidémiques ont ensuite été appliqués à d’autres contextes comme l’agrégation d’information dans les réseaux de capteurs, l’allocation de ressources réparties (comme de choisir où stocker l’information quand des disques sont disponibles sur de nombreuses machines), la construction de réseaux privés virtuels[1], la dissémination de messages, ou encore le streaming vidéo.
D’où vient la puissance des algorithmes épidémiques?
La raison pour laquelle ces algorithmes ont été adoptés dans autant de cadres applicatifs est, comme nous l’avons souligné plus haut, liée à la rapidité de leur diffusion d’information et ce, malgré des défaillances de certaines machines et/ou la perte de messages. Cette propriété a été analysée théoriquement et vérifiée empiriquement : les résultats sont spectaculaires. Ces algorithmes sont aussi robustes aux défaillances qu’un virus qui chercherait à se propager dans une population qui pourtant aurait essayé de résister en imposant quelques gestes barrières. C’est cette capacité à résister qui nous intéresse ici.
Avant d’aller plus loin et de résumer ce que nous avons appris sur les algorithmes épidémiques pendant ces dernières années, au lieu de parler de machines, parlons de n noeuds d’un graphe. Pour pousser l’analogie avec ce que nous vivons aujourd’hui, considérons une topologie dynamique (le graphe n’est jamais le même) et poussons même jusqu’à imaginer que la topologie change aléatoirement en permanence. On peut imaginer que ces noeuds du graphe sont des personnes qui se déplacent, qui rencontrent d’autres personnes et qui leur transmettent leur virus le cas échéant.
Ce que nous apprennent les algorithmes épidémiques sur la propagation des épidémies
Les théoriciens de l’informatique se sont rapidement emparés du problème et ont étudié les algorithmiques épidémiques sous toutes les coutures, en particulier pour la dissémination de messages. Des premiers résultats théoriques ont étudié la vitesse de propagation de l’information transmise (du virus) dans des modèles où chaque nœud choisit périodiquement un autre nœud au hasard et lui transmet le virus avec une certaine probabilité. On peut transposer cela à Alice qui croise Bob dans l’ascenseur tous les matins et qui est infectée par le coronavirus : combien de fois faudrait-il qu’elle le croise avant que Bob ne soit infecté, sachant qu’il croise, et elle aussi, d’autres personnes au cours de sa journée. Il a été démontré par Karp et al (Karp 2000) qu’en supposant un temps global, si à chaque unité de temps, chaque nœud infecté contamine exactement un autre nœud choisi au hasard alors il faudra un nombre logarithmique d’étapes pour infecter tous les nœuds du système avec une très grande probabilité.
Évidemment, comme souvent en théorie, les résultats reposent sur des hypothèses qui peuvent parfois limiter leur applicabilité. Ainsi ce modèle suppose que les nœuds vont tous à la même vitesse et que tous contaminent d’autres nœuds avant d’arrêter. Ce modèle dit « synchrone » n’est pas très réaliste. En particulier, dans le contexte d’une épidémie, les ne vont pas à la même vitesse et certains nœuds, même infectés ne contaminent personne (e.g., ceux guéris, morts ou confinés). D’autres ne sont pas contaminés même quand ils sont en contact avec des malades (e.g., vraisemblablement les enfants dans le cas du Covid). Et bien figurez-vous que ces résultats marchent également en « synchrone » pour peu que le confinement ne soit pas total ou très ciblé.
D’autres travaux ont montré que dans un modèle où chaque nœud transmet une information à un nombre logarithmique d’autres nœuds choisis aléatoirement et uniformément dans le système, là on imagine plutôt Alice qui, porteuse du coronavirus, éternue au milieu d’un rayon de supermarché, ou d’un ascenseur bien rempli dans lesquels aucun geste barrière n’est appliqué, alors il faudra seulement un nombre logarithmique d’étapes pour contaminer l’ensemble de la population, si chacun prend la peine d’éternuer en public à son tour. Dans ce cas, même si 50% des gens infectés, décidaient de ne pas tousser ou de le faire dans leur coude, ou encore restaient confinés, chaque individu aurait quand même une proportion extrêmement élevée d’être contaminé. Là on parle d’un RO (vous savez ce terme qu’adorent les médias qui reflète le nombre de personnes qu’une personne infectée peut contaminer) de l’ordre du logarithme (pour rappel 6 pour un million, 9 pour un milliard). On voit très bien que même si sur la population, nous ne croisons que 3 personnes, la dissémination peut aller vite. Très vite.
Tout cela nous permet de comprendre intuitivement pourquoi certaines épidémies deviennent des pandémies et de mieux apprécier ce que disait Churchill : les fausses rumeurs, que l’on aime diffuser à nos proches, ont le temps de faire le tour du monde avant que la vérité, souvent moins drôle à raconter, n’ait le temps de mettre son pantalon.
Ce que peuvent nous apprendre les algorithmes épidémiques sur la manière d’arrêter une épidémie
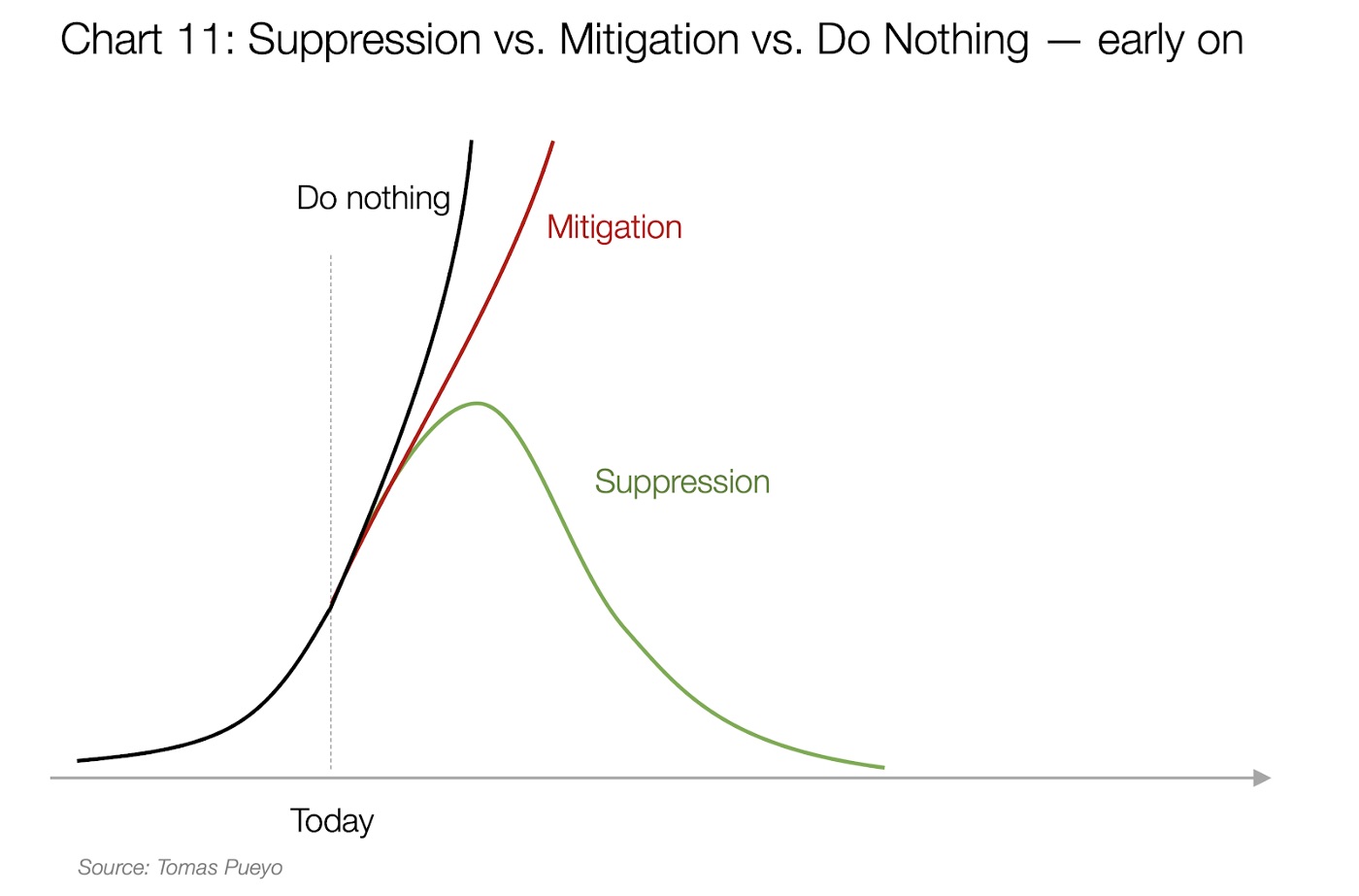
Tous ces modèles, créés, prouvés et expérimentés pour améliorer l’efficacité de nos systèmes informatiques, nous fournissent des informations très pertinentes concernant la dissémination d’un virus dans la population. On comprend ainsi les deux phases d’une dissémination : la phase exponentielle, le pic et la phase descendante. Dans la phase exponentielle, dès qu’une personne tousse, elle peut contaminer plusieurs personnes, qui elles-mêmes en contaminerons d’autres etc., et cela de manière exponentielle. La notion de pic, ne veut pas dire qu’il y a moins de malades mais veut dire que le degré de contamination diminue, pourquoi ? Parce qu’on a trouvé un vaccin ? Non simplement parce que dès qu’on croise des gens, beaucoup sont déjà infectés, donc le R0 diminue. Atteindre ce pic pour immuniser la population a été le choix de la Suède, des Pays-Bas et du Royaume-Uni, avant qu’ils ne changent d’avis (d’aucun depuis leur lit de réa). Le choix de beaucoup d’autres pays a été d’essayer de prendre des mesures pour aplatir la courbe (la rendre moins exponentielle) afin de s’assurer que le nombre de malades gravement atteints correspondait au nombre de lits en réa. Quand on sait qu’en France aujourd’hui moins de 6% de la population a été infectée, on peut se questionner sur la pertinence de l’objectif sanitaire d’immuniser toute une population (c’est à dire que les gens infectés croiseront majoritairement des gens déjà infectés).
D’ailleurs, les travaux sur les algorithmes épidémiques ont montré qu’il y avait une transition de phase (un passage d’un état à un autre) plutôt qu’une courbe linéaire de dissémination, en dessous d’un certain seuil du nombre de voisins (le nombre de personnes qui reçoivent les postillons), la dissémination est proche de 0 et le virus s’éteint, au-delà la probabilité devient immédiatement très élevée d’infecter tout le monde. Bien entendu, une manière d’arrêter une épidémie est un confinement total. Mais cela n’est pas viable à très long terme et un confinement ciblé est clairement plus désirable. Pour mieux appréhender cette question, et d’utiliser un concept phare de l’informatique répartie d’une manière légèrement différente.
Ce concept est celui d’adversaire en informatique. Quand on cherche à disséminer un message dans un système informatique avec un algorithme épidémique, on veut le faire, vite, bien et en dépit de problèmes dans le système (des pannes d’ordinateurs, des pannes de réseaux, des bugs…). Dans les systèmes informatiques, tous ces problèmes potentiels, qu’ils soient involontaires (panne d’électricité et bug) ou volontaires (cyber-attaque) sont appelés des adversaires. Ce concept a occupé la communauté d’algorithmique répartie depuis un certain temps (et continue du reste). Typiquement un adversaire est vu comme une entité maléfique qui s’oppose à un algorithme réparti. Par exemple, l’adversaire est une entité qui, pour retarder au maximum la diffusion d’un message, adopte une stratégie qui consiste par exemple à choisir certains nœuds à les désactiver pour stopper toute la dissémination. En général, on suppose que l’adversaire a un budget de f nœuds à désactiver.
Vous nous voyez venir ? L’adversaire est un allié pour nous, si on se place dans le contexte sanitaire actuel. La question ici est donc: que doit faire cet allié pour arrêter la diffusion d’une épidémie ? Et là, les résultats obtenus dans le cadre des algorithmes épidémiques peuvent être exploités à l’envi.
Supposons que l’adversaire informatique décide de désactiver f nœuds, i.e., de confiner f personnes. Il a été démontré que si l’adversaire ne connait pas l’état de propagation de l’épidémie à chaque instant, il ne peut pas faire grand chose : l’épidémie progressera inexorablement. Autrement dit, si on ne mesure rien, qu’on ne teste rien, qu’on ne maintient aucune statistique sur la dissémination, aucune stratégie ne pourra fonctionner pour endiguer l’épidémie, à part le confinement total.
Mais on sait aussi que si l’adversaire est adaptatif et qu’il peut connaitre à chaque instant l’état de l’épidémie, plus de dommages sont possibles dans un système informatique ce qui se traduit par plus d’opportunités dans la population. Supposons par exemple que l’on peut quasiment connaître l’état de la diffusion à chaque instant grâce à un algorithme de traçage et un mécanisme de détection (on peut supposer pour simplifier que les gens peuvent savoir s’ils sont infectés en toussant dans leur téléphone – application proposée par l’EPFL) et on sait qui a rencontré qui (par bluebooth ou GPS). Il a été démontré ici que même avec un petit f, on peut stopper l’épidémie en confinant uniquement quelques personnes. À bon entendeur …
Voilà ce que peuvent apporter tous les travaux de l’algorithmique épidémique pour la lutte contre le Covid 19, des modélisations pour prédire où nous en serons, quand, des stratégies pour éviter la dissémination, cibler les bons nœuds (personne à confiner) , les bons endroits du graphes (les régions), etc.
On peut même aller jusqu’à imaginer utiliser ces algorithmes pour dénicher le patient 0, cette première personne à avoir eu le virus ? Autrement dit, celui ou celle qui a embrassé la chauve-souris et mangé le steak de pangolin avant de tomber malade et de tousser sur ses voisins. Les premiers travaux sur ce sujet sont très récents. En fait, on peut démontrer qu’il est très difficile, voire impossible, dans le cas général de trouver le patient zéro si les gens guérissent très vite ou sont confinés rapidement Mais si la dissémination se prolonge et n’est pas arrêtée, on peut vite y remonter. Vu le temps que cela a pris au monde pour réagir, tous les espoirs sont permis.
Résumons-nous. Inspirés à la base par les épidémies, les algorithmes épidémiques ont permis de mieux appréhender de nombreux problèmes informatiques. Il se trouve que l’étude de ces algorithmes pourrait en fait nous permettre aussi d’aller dans l’autre sens, c’est à dire d’apprendre à mieux appréhender les épidémies. La piste suggérée ici consiste à considérer leurs adversaires comme nos alliés.
Rachid Guerraoui & Anne-Marie Kermarrec, EPFL.
Pour aller plus loin
(Demers et al, 1987) A. J. Demers, D. H. Greene, C. Hauser, W. Irish, J. Larson, S. Shenker, H. E. Sturgis, D. C. Swinehart, D. Terry. Epidemic Algorithms for Replicated Database Maintenance. PODC 1987.
(Eugter et al, 2004) P. Eugster, R. Guerraoui, A.M. Kermarrec, L. Massoulié. Epidemic Information Dissemination in Distributed Systems. IEEE Computer 37(5), 2004.
(Karp et al, 2000) R. M. Karp, C. Schindelhauer, S. Shenker, and B. Vocking. Randomized rumor spreading. IEEE Symposium on Foundations of Computer Science, pages 565– 574, 2000.
(Kermarrec, 2016) A.-M. Kermarrec Si j’étais un algorithme, je serai épidémique. Blog Binaire 2016 https://www.lemonde.fr/blog/binaire/2016/10/10/lalgorithme-epidemique/
(Pittel, 1987) Boris Pittel. On spreading a rumor. SIAM J. Appl. Math., 47(1):213–223, 1987.
[1] En informatique, un réseau privé virtuel est un système permettant de créer un lien direct entre des ordinateurs distants qui isole leurs échanges du reste du trafic se déroulant sur des réseaux de télécommunication publics.
Quel lien entre Covid 19 et 5G ? Des sites conspirationnistes tentent de répondre à la question en inventant une relation de causalité conduisant parfois à des actes violents. Nos amis Jean-Jacques Quisquater et Charles Cuvelliez nous décrivent une conséquence potentielle de la survenue de la pandémie au milieu des débats sur le passage à la 5G et l’utilisation d’équipements de la société chinoise Huawei. Le virus va-t-il faire pencher la balance du coté de l’interdiction ? Ou comment numérique, santé et géopolitique se rejoignent. Pascal Guitton
Les astres sont désormais alignés pour permettre aux Etats-Unis de réaliser leur rêve : non seulement interdire Huawei (et ZTE) de leur marché mais enfin convaincre leurs alliés de faire de même. Tous les pays évoquent désormais le retour sur leur sol du tissu industriel qu’ils ont laissé filer en Chine dans un refrain unanime : « Plus jamais ça ! ».
Ce n’est pas tellement l’espionnage qui devrait effrayer les Etats-Unis: il suffit au fond de chiffrer tout ce qui transite par des équipements Huawei pour être tranquille. C’est plutôt la menace que la Chine ordonne un jour à Huawei (ou menace) d’arrêter tous les réseaux télécom de son cru à travers le monde en cas de conflit ou de tensions géopolitiques extrêmes.
Cette dépendance vis à vis de l’étranger surprend dans le cas des Etats-Unis car, effectivement, ce pays si technologique ne dispose plus d’aucun équipementier télécom : ils dépendent de Nokia et Ericsson et un peu de Huawei présent au sein des réseaux opérateurs ruraux US.
Comment est-on arrivé là ?
Les Etats-Unis hébergeaient pourtant les Bell Labs qui ont donné naissance à Lucent. Ce dernier était devenu l’équipementier attitré et neutre des opérateurs télécom américains (un peu comme Siemens et Alcatel l’étaient en Europe). Pour le Canada, c’était Nortel, issu lui aussi des Bell Labs en 1949. Lucent a raté le virage internet : la société pensait pouvoir développer son propre protocole. Lucent était aussi leader dans les technologies de réseau optique avec Nortel et était donc en pole position pour le boom d’Internet sauf que ces capacités ont été déployées bien plus vite que la demande. La bulle Internet du début des années 2000 en a résulté.
Site des Laboratoires Bell à Murray Hill – Extrait de WikiPedia
Lucent possédait également une technologie 3G supérieure (avec le CDMA) mais n’a pas réussi à capturer les marchés européen et asiatique qui avaient déjà opté pour la norme GSM et son successeur UMTS pour la 3G. Toutes ces opportunités ratées ont amené leur lot de fusions et d’acquisitions : Ericsson a absorbé Nortel après sa faillite en 2009. Nokia a acquis Motorola Solution en 2011, puis la partie télécom de Siemens. En 2006, Alcatel absorbait Lucent pour être finalement lui-même absorbé par Nokia ! Pendant ces temps douloureux, deux acteurs ZTE et Huawei émergeaient, au bon moment, juste après la bulle Internet, en profitant du marché chinois qu’il fallait équiper. Qui allait imaginer que les lois anti-trusts aux Etats-unis en cassant ATT en 1982, allaient donner un avantage énorme à Huawei (fondé en 1987), ZTE (1985) et un peu Samsung (1938) ? Et qu’aujourd’hui, l’histoire se retourne en laissant les Etats-Unis les mains vides …
Pour les Américains, interdire leur territoire à Huawei n’est pas suffisant si la menace résulte de la capacité à stopper tous les réseaux équipés par Huawei à travers le monde en cas de conflit. Les opérations militaires nord-américaines ne s’arrêtent pas aux frontières de leur territoire. Et de rappeler, dans une étude américaine de la National Defense University, qui émane du département de la Défense US que les réseaux télécoms en Irak sont équipés par Huawei. Les États-Unis ne peuvent pas complètement se baser sur les satellites et dans le monde interconnecté aujourd’hui, utiliser des fibres dans un pays « ami » ne garantira pas que les communications ne passent pas par un équipement contrôlé par ZTE ou Huawei.
Les alliés pas très partants
Les pays alliés ont répondu aux États-Unis en expliquant qu’ils localiseraient les équipements Huawei aux extrémités du réseau et pas en son cœur (comme la France) mais en 5G, la différence entre cœur de réseaux et ses extrémités est évanescente. Qui plus est, lorsqu’on passera à la 5G qui fera plus que simplement augmenter la vitesse, le cœur de réseau devra passer à la 5G aussi. Les entreprises chinoises ont une longueur d’avance en innovation technologique sur la 5G, les Américains s’en désolent d’autant plus que leurs concurrents asiatiques planchent déjà sur la 6G qui se greffera sur les équipements 5G qu’on installe aujourd’hui.
C’est dire l’urgence à trouver une alternative à Huawei et ZTE pour les États-Unis. Des experts ont songé à priver Huawei des composants, toujours fournis par les Américains mais on sait la résilience des chinois à se sortir de tels embargos. Ces équipements, de plus, ne sont plus fabriqués sur le sol nord-américain mais à Taïwan !
Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire.
Sauf qu’aujourd’hui, la politique américaine est plutôt guidée par le slogan « buy, don’t make ».
C’est pourquoi les 3 options du gouvernement nord-américain sont, d’après cette étude américaine (1) :
– Supporter les équipementiers télécoms européens et sud-coréens (car Samsung s’y est mis aussi) : ils sont fortement présents aux États-Unis par leur filiales et le gouvernement nord-américain pourrait leur donner un coup de pouce via la fiscalité, des garanties d’Etat, les achats en masse pour stabiliser leurs finances et booster leur R&D.
– Acheter Nokia ou Ericsson ou au moins une minorité de contrôle. D’après cette même étude (1), Samsung n’est pas une cible car détenant trop peu de parts de marché. La 5G n’est qu’une composante non autonome d’une stratégie globale de ces chaebols, le nom fleuri donné aux énormes conglomérats coréens qui n’ont plus d’équivalent ailleurs dans le monde, qu’on ne peut sortir de ce fait de leur contexte. Ceci dit, les Européens pourraient s’y opposer maintenant qu’ils se sont réveillés face aux prises de participations étrangères de leurs champions.
– Créer un consortium américain à savoir par un jeu d’achats, d’investissement et de financement, ramener sous un même toit les compétences locales diverses avec les brevets et la propriété intellectuelle dont d’ailleurs Nokia et Alcatel dépendent toujours pour créer un nouveau champion. Le gouvernement des États-Unis s’allierait avec des investisseurs. Nokia et Ericsson seraient évidemment des partenaires ou des fournisseurs attitrés de ce consortium histoire de ne pas repartir à zéro. On y associerait les entreprises des alliés des USA : le réseau Five Eyes ainsi que l’Allemagne, la France, le Japon, la Corée. Le succès dépendra des prix et des incitations à travailler avec ce nouveau venu. Ce n’est pas gagné.
Ce qui est clair, c’est que les États-Unis ne vont pas lâcher le morceau. La crise qui s’annonce et qui va fragiliser le monde entier va certainement leur permettre de mettre en œuvre une de ces stratégies en réciprocité de services (au sens large) que leur demanderont d’autres pays.
Jean-Jacques Quisquater (Université de Louvain, Ecole Polytechnique de Louvain et MIT) & Charles Cuvelliez (Université de Bruxelles, Ecole Polytechnique de Bruxelles)
Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines. Lêmy Godefroy nous explique aujourd’hui l’initiative du décret Datajust, un décret permettant l’utilisation du machine learning afin d’aider certaines décisions judiciaires. Elle nous éclaire aussi sur la limite d’applicabilité de ces algorithmes. Lonni Besançon
Le décret Datajust
Le gouvernement a adopté le décret dénommé Datajust le 27 mars dernier, en pleine période de confinement lié au coronavirus. Ce texte à l’étude depuis deux ans organise la mise en place d’un traitement des données des décisions de justice rendues en appel entre le 1er janvier 2017 et le 31 décembre 2019 par les juridictions administratives et judiciaires dans les contentieux portant sur l’indemnisation des préjudices corporels.
Les buts visés sont l’élaboration d’un référentiel indicatif d’indemnisation des préjudices corporels, l’information des parties, l’aide à l’évaluation du montant de l’indemnisation à laquelle les victimes peuvent prétendre afin de favoriser un règlement amiable des litiges et la mise à disposition d’une source nouvelle de documentation pour les juges appelés à statuer sur ces demandes d’indemnisation1. Plus précisément, il s’agit de traiter algorithmiquement les décisions rendues par les juridictions d’appel en matière d’indemnisation des préjudices corporels2.
Le chiffrage des dommages-intérêts versés en réparation de ces préjudices est depuis longtemps l’objet de barèmes destinés à aider les juges à les estimer.
Ces barèmes sont indicatifs et le juge s’en sert comme d’un référentiel.
Avec le déploiement des systèmes de machine learning, des algorithmes publics ont été à l’étude pour affiner le chiffrage de ces indemnités. Le traitement et la modélisation par ces algorithmes de masses de décisions rendues dans ce domaine éclairent la jurisprudence « concrète »3. Celle-ci devient exploitable. Elle offre au juge une meilleure connaissance du « droit en action ». Il se forme alors une collégialité judiciaire numérique circonscrite à un ressort territorial ou étendue à l’ensemble du territoire national : Chaque juge peut savoir « de quelle manière, dans la pratique, les différents juges de France traiteront telle question précise qui leur sera soumise (…) »4.
Les enjeux du décret
Ces chiffrages algorithmiques, comme les barèmes, sont des aides à la décision. Ils n’ont pas vocation à se substituer à l’appréciation du juge. Ils l’assistent dans sa fonction de dire le droit (existence d’un préjudice) et dans sa mission de concrétisation du droit ainsi prononcé qui se traduit par le chiffrage du montant des dommages-intérêts. En d’autres termes, « quand bien même il souhaiterait suivre la tendance majoritaire que lui restitue un outil algorithmique, le juge ne saurait y procéder qu’en se réappropriant le raisonnement qui se donne à voir. La décision de justice ne saurait être motivée (exclusivement) par l’application d’un algorithme sans encourir la censure qui, au visa de l’article 455 du code de procédure civile, s’attache à l’absence de motivation, à laquelle elle serait assimilable »5.
Les bénéfices attendus sont importants : une justice plus proche des justiciables et de leurs individualités. Par exemple, en matière d’indemnisation du préjudice corporel, les tendances algorithmiques permettraient un débat utile en ne plaidant pas « au premier euro », mais en déplaçant l’analyse sur les éléments de spécificité du préjudice. La décision de justice gagnerait ainsi en finesse de raisonnement en mettant en évidence les spécificités d’un préjudice non prises en compte par les standards d’indemnisation. Par exemple, une situation familiale atypique justifiant un ajustement des indemnités versées. La discussion entre les parties portant dans une affaire déterminée sur les écarts à ces standards est de nature à enrichir le débat judiciaire et à introduire des données d’évolution sociales susceptibles de faire évoluer la jurisprudence.
Datajust et covid-19 : la confusion
Très vite, sur internet, certains ont avancé que le décret Datajust allait servir à estimer la valeur des préjudices des victimes du coronavirus.
Or c’est précisément ce type de situation qui échappe au champ de compétence des algorithmes.
Ceux-ci ne sont fiables qu’en présence d’affaires typiques, reproductibles, comportant un nombre suffisamment important de décisions pour asseoir l’élaboration de modèles mathématiques capables de fournir des tendances quant aux montants probables de dommages-intérêts dans un cas similaire futur. Ils chiffrent, comparent, comptent, mesurent les répétitions pour extraire des corrélations.
Leur usage n’est pas envisageable en présence d’affaires qui, par leur singularité, nécessitent « un traitement individuel »6.
Une affaire est singulière notamment parce qu’elle est juridiquement spécifique. La spécificité vise les différends qui méritent un examen approfondi en raison de la nouveauté ou de l’actualité du problème juridique ou du caractère inédit des faits. Le juge clarifie ici les modalités d’exécution de règles qui n’ont été, jusque-là, que pas ou peu confrontées aux faits atypiques d’une espèce.
Ce contentieux dit qualitatif ne relève pas du champ de compétence des algorithmes. Il en va différemment du contentieux quantitatif qui se démarque par des problématiques récurrentes et par des solutions stables qui s’accordent à la nature mathématique des algorithmes. Leur champ d’action est donc celui des contentieux où des modélisations peuvent être opérées à partir de critères factuels connus, identifiables, reproductibles et chiffrables.
Le caractère inédit de la pandémie qui frappe aujourd’hui le monde et donc l’absence de précédents judiciaires font que, par nature, la question soulevée par certains de l’indemnisation des préjudices corporels des victimes du coronavirus ne peut pas être résolue par un calcul algorithmique.
Dans ce contexte difficile pour les corps et les âmes, prenons garde aux informations trop vite relayées de sites en sites et qui circulent sur les réseaux.
Lêmy Godefroy, Enseignante, chercheuse en droit, GREDEG UMR 7321, Université Côte D’Azur
Références et notes:
[1] Décret n° 2020-356 du 27 mars 2020 portant création d’un traitement automatisé de données à caractère personnel dénommé « DataJust », JORF n°0077 du 29 mars 2020, texte n°2.
[3] « La mémoire numérique des décisions judiciaires », D. E. Buat-Menard, P. Giambiasi, 2017, p.1483. P. Delmas-Goyon, op.cit., p.93 : « Au-delà de la conception traditionnelle de la jurisprudence (quelle est l’interprétation retenue de la règle de droit ?), il s’agit de savoir concrètement, dans une situation donnée, à quelle décision s’attendre si la justice est saisie (quelle pension alimentaire compte tenu de la situation respective des conjoints qui se séparent, quel montant de dommages-intérêts pour un préjudice donné, quel mode de poursuite pour une infraction déterminée, quelle durée de suspension du permis de conduire, quel aménagement de la peine, etc.) ».
[4] La prudence et l’autorité. L’office du juge au XXIe siècle, A. Garapon, S. Perdriolle, B. Bernane, C. Kadri, rapport de l’IHEJ, mai 2013.
Un sujet agite beaucoup le monde des informaticiens : le traçage numérique. Binaire a déjà parlé du sujet dans « Contact tracing contre Covid 19 » et des risques inhérents au traçage numérique dans « Le traçage anonyme, dangereux oxymore ». Entre un système centralisé ou distribué, et si il y avait une troisième voix ? binaire
Le consortium piloté par Inria vient de rendre public une partie du code de StopCovid basé sur le protocole Robert. Un vote par le parlement et un déploiement éventuel sont prévus.
Un nouveau protocole vient d’Inria, Désiré : « Une troisième voix pour un système européen de notification d’exposition » selon ses auteurs. Tout le monde a compris que les fuites de données dépendent du protocole choisi, c’est-à-dire d’un algorithme. Le but n’est pas ici de comparer les mérites de ces différents protocoles ou de dire si celui-ci en particulier est utilisable en pratique.
Nous pensons que le protocole Désiré est non seulement intéressant mais également compréhensible par tous. C’est pourquoi nous vous proposons d’aller le consulter. Si nous nous sommes trompés, n’hésitez pas à nous le dire dans les commentaires.
Cliquer sur le dessin pour consulter la description de Désiré
Le télétravail s’est imposé à nous en cette période de confinement. Comment le vivons-nous ? Quelles difficultés et opportunités nous offre-t-il ? Corona-work est un groupe de volontaires qui recueille et partage des données sur le télétravail, afin de répondre à ces questions. François Bancilhon, multi-entrepreneur et passionné par les données, est un des initiateurs de ce projet, et vient nous en parler dans binaire. Pauline Bolignano
J’avoue humblement que le confinement m’a totalement pris par surprise. Le 15 mars, des amis du 17ème m’ont annoncé : “l’armée va fermer Paris demain matin, nous le savons de source sûre par quelqu’un de haut placé”, suite à quoi, ils ont chargé leur voiture et sont partis pour l’Île de Ré.
Quand le vrai confinement a été annoncé le lundi 16 mars de façon moins dramatique, l’armée française restant dans ses casernes, et appliqué ce mardi 17 mars, je n’ai pas réalisé ce que cela voulait dire. Par exemple je n’ai pas pensé à stocker des piles pour mes appareils auditifs, ni pensé que les audioprothésistes allaient tous fermer d’un coup d’un seul. Quand, comme beaucoup de Parisiens, nous sommes partis le 16 mars nous installer à la campagne, je pensais partir pour quelques jours. Ma première impression était que ce confinement serait une courte parenthèse de quelques semaines et que la vie reprendrait normalement une fois cette parenthèse fermée. Donc il s’agissait pour moi essentiellement de continuer à travailler comme avant pendant ce bref tunnel.
Puis petit à petit, j’ai pris conscience de ce qui se passait, de la profondeur du bouleversement que nous vivions. Le petit groupe dont je faisais partie et qui travaillait à un business plan de startup, a continué son activité normale (réunions, interviews, rencontres, partages et rédaction de documents), le tout en mode confiné. Puis le groupe s’est demandé ce qu’il pouvait faire d’intelligent et quelle contribution il pouvait apporter dans cette situation nouvelle.
Comme le dit la citation (probablement apocryphe) d’Abraham Maslow “A l’homme qui n’a comme outil qu’un marteau, tout problème ressemble à un clou”, les amateurs de technologies se laissent guider par leurs outils. Suivant ce bon principe, notre “ADN technologique” étant le recueil, la gestion, la présentation et l’analyse de données, nous avons pensé que recueillir et analyser les données sur la crise était la bonne approche. Ajustant un peu notre approche, nous avons pensé qu’il fallait choisir le bon problème (donc celui qui ressemblait le plus à un clou). Et notre choix est tombé sur ce qui nous était imposé du jour au lendemain, le télétravail confiné.
Le télétravail est loin d’être une nouveauté : plus de cinq millions de personnes le pratiquaient en France avant le confinement. Ce qui était nouveau en revanche, c’était le télétravail confiné, donc un télétravail subi, plutôt que choisi. Si le télétravail choisi avait un goût de liberté (je choisis de rester chez moi plutôt que d’aller au bureau), le télétravail subi a plutôt celui de la contrainte (ma seule solution est de bosser chez moi).
Ce clou-là avait l’intérêt d’être nouveau et d’être actuel. Était-il mesurable ? Oui, si nous recueillions les données via des interviews. Nous avons commencé par une série de d’interviews semi-directifs, donc faits à partir d’une grille de questions ouvertes laissant largement l’interviewé s’exprimer librement. Nous en avons fait une quinzaine, en essayant de balayer le plus largement possible les situations des télétravailleurs confinés. Le résultat m’a ébloui : de vraies tranches de vies, saisies sur le vif, émouvantes, drôles, ou tragiques. Entre la télétravailleuse qui s’offre un petit pétard en fin de matinée pour se récompenser d’avoir bien travaillé, le télétravailleur qui se réjouit d’échapper enfin aux inquisitions de son boss, celle qui en profite enfin pour être en caleçon toute la journée, ou la mère de famille qui gère enfants, mari et télévision pour se libérer le temps de travail, la variété et la vérité des situations était impressionnante.
De ce matériau brut, nous avons extrait des thèmes et à partir de ces thèmes, nous avons construit un questionnaire sur le télétravail confiné. Nous l’avons testé sur un petit groupe pour en vérifier la fluidité et la longueur. Le questionnaire fait de l’ordre de 45 questions. Nous sommes ensuite passés au recrutement des interviewés, qui s’est fait largement par viralité sur les réseaux sociaux (numériques ou non). A l’heure où j’écris ces lignes, nous en sommes à plus de 1600 réponses.
Notre idée est de faire deux choses avec ces données : les mettre à disposition en open data de la communauté scientifique (ou de toute personne voulant les consulter ou les réutiliser) et les utiliser nous-mêmes pour faire des analyses.
Pour les mettre à disposition en open data, nous les avons installées sur la plateforme d’OpenDataSoft (notons au passage que l’outil est bien adapté pour des gens comme nous qui voulions poster des données et pour ceux qui veulent les réutiliser)
Pour analyser nos données, nous avons utilisé un outil spécifique d’analyse de sondage, baptisé Sherlock, qui permet de comparer rapidement et simplement des populations différentes sur tel ou tel sujet.
L’ensemble de ce travail a été réalisé en quelques jours : les entretiens semi-directifs en moins d’une semaine, le questionnaire en 3 jours, le site et sa mise en ligne en 3 jours aussi (en utilisant la plateforme Wix) et la barre des 1000 réponses a été franchie en moins d’une semaine.
Deux mini-études ont été publiées. L’une d’elles compare le comportement des moins de 40 ans aux plus de 40 ans (nous éviterons de dire les jeunes et les moins jeunes) et montre que les premiers résistent mieux (curieusement) que les seconds. Les jeunes sont plus nombreux à dire que leur bien-être a augmenté pendant ces deux premières semaines de confinement. En allant plus loin : les jeunes en profitent pour faire plus de sport, ils boivent moins d’alcool, ils prennent plus soin de leur apparence, ils travaillent moins, ils sont moins fatigués, ils respectent plus les consignes de confinement. Ceci n’est qu’un exemple du type d’analyse que l’on peut faire de ces données. Parmi les questions que l’on peut aborder : est-ce que les gens qui avaient déjà une expérience de télétravail s’en sortent vraiment mieux ? est ce que les réponses aux questions sont différentes (et comment) après 5 semaines de télétravail de celles faites après 2 semaines ?
Nous avons noté quelques autres études du même type, faites par des scientifiques de la santé et du travail et leur avons proposé de collaborer. Tous nous ont répondu en exprimant leur intérêt mais arguant de leur surcharge de travail pour remettre à plus tard une collaboration. Dans tous les cas, ils ont accès à nos données qui peuvent complémenter les leurs.
La suite de l’aventure ?
Continuer des analyses : nous n’avons qu’à peine effleuré le sujet et les recherches de corrélations devraient être fructueuses,
Faire croître les données : continuer les campagnes de SEO et SMO pour augmenter le nombre de répondants,
Valoriser la communauté ainsi constituée, ce que nous voudrions faire sans harceler ceux qui ont pris la peine de répondre à nos 45 questions
François Bancilhon a eu une double carrière : une première dans la recherche académique (chercheur à l’INRIA et MCC, professeur à l’Université de Paris XI), et une deuxième dans l’industrie : il a co-fondé et/ou dirigé plusieurs entreprises, (O2 Technology, Arioso, Xylème, Ucopia, Mandrakesoft/Mandriva et Data Publica/C-Radar). Il a partagé sa vie professionnelle entre la France et les États-Unis. Il vient de quitter son poste de directeur de l’innovation chez Sidetrade, et réfléchit à son futur projet. Il est membre de la commission d’évaluation d’INRIA.
Références
Le site Corona Work est ici https://www.corona-work.fr/, on y trouve le questionnaire et la description de l’équipe .
Le confinement a bouleversé profondément toutes nos conditions de vie : familiale, sociale, professionnelle. Quid des étudiants, des personnels et des enseignants ? Nous vous proposons de partager un témoignage rédigé par un collectif de personnels et d’enseignants de l’IUT de Bordeaux qui nous font part de leurs expériences et qui dressent un premier bilan de la période de confinement où il a fallu faire face à l’imprévu et tenter de maintenir un enseignement à distance. Pascal Guitton
Comme certainement toutes les universités de France, le jeudi 12 mars à l’annonce de la fermeture des campus, l’équipe enseignante du département informatique de l’IUT de Bordeaux n’était pas prête. Parmi toutes les problématiques liées notamment à la précarité des étudiants, à leurs stages, etc., l’un des mots d’ordre était d’assurer la continuité pédagogique. Mais comment faire ? Trop de questions sans réponses : tous les étudiants ont-ils un ordinateur ? Une connexion internet de qualité ? Un espace pour travailler ? Doit-on maintenir tel quel l’emploi du temps (36h/semaine) ? Fait-on les cours par visio ? Par chat ? Avec quels outils ?
Première bonne surprise, les quatre jours qui nous séparaient du début du confinement total ont suffi à répondre aux questions d’ordre matériel. La direction des études et le service technique de l’IUT ont réussi à s’organiser en un temps record pour fournir un ordinateur aux étudiants qui en avaient besoin et recenser les très rares étudiants qui prévoyaient d’avoir des difficultés pour accéder à internet.
A contrario, la question des solutions logicielles nous a posé plus de problèmes. L’équipe de techniciens de l’IUT a fourni un très gros travail pour accélérer le déploiement sur nos serveurs de logiciels pouvant nous aider à assurer cette continuité pédagogique (machines virtuelles, bureaux accessibles à distance…). Si nous avions déjà à notre disposition un très bon outil de chat textuel (mattermost), côté outils de visioconférence, le bilan était sans appel. L’université n’était pas préparée à l’enseignement à distance. La majorité des outils (notamment Rendez-vous de Renater, et l’ancienne version de Big Blue Button) fonctionnent mal, surtout dès qu’on dépasse un certain nombre de présents, ou n’offrent pas toutes les fonctionnalités nécessaires au bon déroulement d’un cours : chat textuel, partage d’écran, canal séparé pour répondre à un étudiant, par exemple.
Côté solutions commerciales, Zoom et Discord rassemblaient ces fonctionnalités, tout en tenant la charge, sans dégrader la qualité audio/vidéo. Par contre, nous avons très vite identifié que ces plateformes propriétaires posent de graves problèmes auxquels nous ne souhaitions pas exposer nos étudiants. Dans les deux cas, cela oblige à accepter des conditions d’utilisations contraires à nos valeurs : recueil d’informations personnelles, réception de SMS, cession d’informations à des « compagnies liées », etc. (Voir les Conditions Générales d’Utilisation de Discord, et cet article paru dans Libération). Se pose même la question de la légalité d’imposer de telles conditions à nos étudiants, et de la conformité au RGPD.
De plus, ces plateformes nécessitent l’installation d’un client propriétaire, qui peut donc potentiellement accéder à toutes les données de l’utilisateur, notamment via des malwares. Pas une semaine sans qu’un article dans la presse ne fasse mention de problèmes de sécurité avec Zoom. Plus de 500 000 comptes auraient été piratés. Les données de ces comptes seraient en vente sur le darkweb (cf source). Cela a abouti à des approches contradictoires : Zoom est par exemple préconisé par l’université, mais interdit à l’Inria.
Toutes ces solutions commerciales posent également le problème de l’accès aux sessions par partage de liens publics et de mots de passe communs à tous les participants. Autant dire que c’est un jeu d’enfant pour une personne étrangère à l’université de s’infiltrer dans ces cours virtuels et d’y semer la zizanie (voir cet article paru dans Marianne). Quelques incidents ont déjà été remontés par des collègues de l’université de Bordeaux.
Consciente de ces problèmes, l’université de Bordeaux, via la structure MAPI (Mission d’Appui à la Pédagogie et à l’Innovation) et la DSI (Direction des systèmes d’information), a réussi à mettre en place en trois semaines un serveur de visio-conférence avec la nouvelle version de Big Blue Button. Celle-ci coche nos critères essentiels en termes de fonctionnalités, de performances, de sécurité, et de respect de la vie privée. Désormais nous pouvons nous passer de Discord, Zoom, Skype…
Nous en sommes à maintenant cinq semaines de cours à distance et nous pouvons également tirer un premier bilan de ce nouveau type d’enseignement. Étudiants et enseignants ont fait part de leur ressenti. Pour les étudiants, la majorité fait remonter une charge de travail supplémentaire et une fatigue accrue par la répétition des cours à distance. Quelle que soit la solution choisie (visio, chat textuel ou capsule vidéo) le rythme est trop soutenu, la difficulté à interagir avec l’enseignant est réelle.
Pour les enseignants, ces nouvelles conditions ont généré une charge de travail énorme dans un temps contraint. Dès la première semaine, le temps de préparation et d’adaptation des cours a explosé. Il en est de même pour le temps passé à assurer la continuité de la direction et le suivi des étudiants (en particulier les stages) avec un calendrier global qui n’a pas bougé d’un iota.
De l’avis général des collègues du département informatique de l’IUT de Bordeaux, il est compliqué d’enseigner à distance dans de bonnes conditions. Ainsi il est difficile, voire impossible, de ressentir si le cours se passe bien ou pas, si le groupe avance ou pas. Interagir avec des étudiants à qui l’on a donné une série d’exercices reste également complexe. Certains étudiants ne prennent pas la parole, d’autres un peu trop, et traiter un canal par étudiant devient vite ingérable. Si nous essayons de nous adapter en transformant nos cours (pédagogie inversée, approche par projet, capsules audio ou vidéo), il n’existe pas de solution miracle. Le manque de cours en face à face se fait déjà ressentir, et ralentit globalement la progression. Dans les faits, chaque enseignant réduit, dans la mesure du possible, son cours aux compétences jugées essentielles. Au final, l’enseignement à distance représente un effort supplémentaire pour tous, pour un résultat moindre.
Depuis l’annonce présidentielle de la non-reprise des cours avant l’été, d’autres défis s’annoncent pour l’équipe enseignante. Par exemple, comment noter le travail à distance alors qu’il est impossible de garantir une équité (accès à un ordinateur, à une connexion internet, à un environnement calme) ? Quelle est la valeur d’une évaluation dont on ne peut garantir l’authenticité de l’auteur, ni l’absence de fraude ? Pour le moment, notre équipe pédagogique n’entrevoit aucune solution satisfaisante.
Dans une vidéo postée le 15 avril, le président de l’Université de Bordeaux dresse un premier bilan très positif de cet enseignement à distance : « les enseignants donnent une formidable impulsion à la dynamique de transformation pédagogique que nous avions souhaitée et dont nous saurons tirer les leçons demain ». L’expérience de ces cinq dernières semaines nous pousse à modérer ces propos. Hors période de confinement, nous restons convaincus des bienfaits et de l’efficacité d’assurer nos missions d’enseignement en face à face. Pour le bien de tous (étudiants, enseignants, personnel technique et administratif), il faut que cela reste la norme et que l’enseignement à distance reste l’exception.
Neuza Alves, Michel Billaud, Romain Bourqui, Brigitte Carles, Sophie Cartier, Arnaud Casteigts, Isabelle Dutour, Patrick Félix, Stéphane Fossé, Olivier Gauwin, Romain Giot, Olivier Guibert, Michel Hickel, Colette Johnen, Nicholas Journet, Sidonie Marty, Bruno Mery, Sylvie Michel, Alexandra Palazzolo, Grégoire Passault, Arnaud Pecher, Pierre Ramet, Karine Rouet, Eric Sopena, Christine Uny, Eric Woirgard (Enseignants et personnels de l’IUT de Bordeaux)
Le Travail d’Initiative Personnelle Encadré (TIPE) est une épreuve commune à la plupart des concours d’entrée aux grandes écoles scientifiques. Il permet d’évaluer les étudiant·e·s non pas sur une épreuve scolaire mais à travers un travail de recherche et de présentation d’un travail personnel original. C’est un excellent moyen d’évaluer les compétences. Cela peut être aussi une épreuve inéquitable dans la mesure où selon les milieux on accède plus ou moins facilement aux ressources et aux personnes qui peuvent aider. Pour aider à maintenir l’équité, les chercheuses et les chercheurs se sont mobilisés pour offrir des ressources et du conseil à toute personne pouvant les solliciter. Thierry Viéville.
Free-Photos Pixabay
TIPE ? Comme tous les ans, en lien avec sillages.info et l’UPS pour les CGPE, Interstices et Pixees vous proposent des ressources autour des sciences du numérique, informatique et mathématiques.
Le thème pour l’année 2020-2021 du TIPE commun aux filières BCPST, MP, PC, PSI, PT, TB, TPC et TSI est intitulé : enjeux sociétaux. Ce thème pourra être décliné sur les champs suivants : environnement, sécurité, énergie.
À l’heure où ces lignes sont écrites, une partie de l’humanité est confinée pour maîtriser la propagation de l’épidémie de coronavirus Covid-19. Cette crise sanitaire exceptionnelle en désagrégeant nos vies et nos organisations, a relativisé l’importance de nombreuses questions et a bousculé de nombreuses croyances. Bien malin qui peut décrire les conséquences à long terme de cette épidémie. Bien sûr, les rumeurs et les fausses informations sont toujours bien présentes mais une idée a retrouvé une place centrale dans le débat public : la science.
En cherchant à partir d’observations et de raisonnements rigoureux à construire des connaissances, la science permet de comprendre, d’expliquer mais aussi d’anticiper et parfois de prédire. Et aujourd’hui, les sciences du numérique (modélisation, simulation, communication, information…) ont un rôle capital.
Les thématiques abordées ci-dessous sont majeures : risques naturels, énergies, sécurité informatique, sobriété numérique, avec souvent des sujets reliant science et société. C’est l’occasion pour vous d’exercer vos connaissances, votre curiosité, votre capacité de synthèse. L’objectif n’est pas tant de résoudre l’une de ces questions que d’y donner un éclairage personnel et scientifique. Chacune des problématiques décrites ci-dessous ne constitue pas exactement un sujet de TIPE mais plutôt un thème duquel vous pourrez extraire votre sujet. Le TIPE s’articule souvent autour de la trilogie théorie/expérience/programme. Les recherches décrites ici portent sur les sciences du numérique, l’expérimentation numérique y a une grande place.
Même si, suite à l’épidémie de coronavirus Covid-19, les destructions ne sont pas matérielles, beaucoup est à refonder, à rebâtir. Et vous qui êtes étudiantes et étudiants de filières scientifiques, votre rôle sera prépondérant.
Pour conclure cette brève présentation et insister à nouveau sur l’importance de la science, je rappellerai l’article 9 de la charte de l’environnement (texte à valeur constitutionnelle) : « La recherche et l’innovation doivent apporter leur concours à la préservation et à la mise en valeur de l’environnement. »
En cette période de crise sanitaire, nous sommes confrontés à une avalanche de chiffres, soit en les consultant directement, soit en les voyant utilisés par des experts ou des décideurs. Au delà des chiffres bruts, un point commun : le recours à des modèles mathématiques pour expliquer ou justifier une position. Devant la difficulté à bien comprendre de quoi il s’agit, Frédéric Alexandre, chercheur en neurosciences computationnelles, nous présente les bénéfices mais aussi les limites de cette approche. Pascal Guitton et Serge Abiteboul
Comme la plupart de mes concitoyen.ne.s, en cette période particulière de confinement, j’essaie de me tenir au courant en parcourant le déluge de chiffres qui nous parvient, évoquant différentes caractéristiques de cette épidémie. Mais comme beaucoup également, j’oscille entre inquiétude et optimisme, selon les chiffres que je considère, ce qui finit par se traduire par un certain découragement car je ne sais pas identifier les informations importantes et donc par un sentiment d’impuissance à comprendre les enjeux de la situation critique que nous vivons.
Alors, je me suis dit : « je suis un scientifique, je vais essayer de comprendre cette situation, au lieu de garder les yeux fixés sur des indicateurs peu clairs », mais après avoir parcouru quelques publications d’épidémiologie, j’ai vite compris que ce domaine scientifique était trop éloigné du mien pour que je puisse y développer une pensée critique me permettant d’analyser ses productions et donc de vraiment les comprendre.
Par contre, j’ai observé que ce domaine utilise le même type de modèles mathématiques que ceux que j’utilise dans ma pratique scientifique, ce qui m’a permis de mieux comprendre certaines analyses des modèles d’épidémiologie que l’on trouve facilement sur internet.
Ce que je propose ici n’est donc en aucune manière une analyse scientifique sur la pandémie que nous vivons actuellement mais plutôt quelques éléments d’explication des modèles utilisés en épidémiologie et une introduction au sens critique pour permettre d’exploiter ces outils mathématiques avec discernement.
Des modèles pour les systèmes dynamiques
Commençons par le commencement, un modèle mathématique a pour but de décrire le plus précisément possible un objet, un phénomène, un mécanisme à l’aide d’équations afin de vérifier, comprendre, prédire certaines propriétés ou comportements. Ainsi, on peut modéliser la charpente d’un bâtiment en détaillant finement sa forme et ses matériaux, juste pour la visualiser mais aussi pour vérifier sa résistance avant de l’assembler ; grâce à cette description formelle, on peut la tester dans des conditions normales de charge mais aussi en cas de contraintes extraordinaires (simulation de secousses sismiques ou de tempêtes).
Modèle 3D d’une charpente – Société Lamécol
Charpente réelle – Société Lamécol
Si on utilise des modèles pour décrire un phénomène, c’est parfois son évolution qu’on veut comprendre. C’est ce que permet l’utilisation d’équations différentielles ordinaires qui décrivent la variation d’une quantité Q par rapport au temps. Cette variation est positive si Q augmente, négative si Q diminue. Soulignons un cas particulier important dans certains domaines comme la biologie ou la chimie : la variation peut dépendre de la quantité elle-même. On peut ainsi observer une variation positive qui est proportionnelle à Q, par exemple qui double ou quadruple à chaque itération comme quand une personne contaminée en contamine deux ou quatre autres, en moyenne. On assiste alors à une augmentation de plus en plus rapide, et on parle de croissance exponentielle pour décrire un tel emballement : si en moyenne une personne en contamine quatre autres non déjà contaminées, elle touchera 1, 4, 16, 64, 256, 1024 autres, et à la 12 étape, l’équivalent de la France entière sera contaminée (d’où la nécessité du confinement). À l’inverse, s’il n’y a plus qu’une chance sur deux de contaminer quelqu’un alors à partir des 80 000 personnes contaminées début avril, le nombre de contamination deviendra négligeable en une vingtaine d’étape.
Une autre qualité de ce type de modélisation des systèmes dynamiques, est son déterminisme : tout se passe toujours de la même manière. Cela encourage l’utilisation d’outils de modélisation pour faire des prédictions sur les évolutions à venir à partir des observations jusqu’à présent. Mais ce déterminisme est parfois discutable, d’une part parce que de tels modèles simples n’arrivent pas toujours à capturer toute la complexité des phénomènes dont ils veulent rendre compte mais aussi pour des raisons que j’évoque par la suite.
Les modèles compartimentaux en épidémiologie
Les principaux modèles utilisés en épidémiologie (en particulier pour tracer la plupart des courbes qu’on nous montre actuellement) considèrent une épidémie comme un système dynamique et décrivent principalement son évolution avec ce type d’équations. On peut consulter une description de ces modèles sur Wikipédia et un simulateur sur GitHub.
On les appelle modèles compartimentaux car ils découpent la population en classes, selon le cycle d’une épidémie (individus susceptibles d’être malades S, exposés E, infectés I, hospitalisés H, guéris R ou décédés D) et que les équations décrivent la dynamique des passages d’un état à un autre, selon des proportions mesurées expérimentalement et dépendant parfois des conditions de l’environnement (par exemple, mise en confinement). Les changements d’état correspondant à une proportion de la population considérée, nous sommes bien dans le cas où la variation est proportionnelle à la valeur (comme on peut le vérifier dans les équations mentionnées dans les deux sites web mentionnés plus haut), ce qui explique les phénomènes exponentiels dont on parle régulièrement.
Pourquoi les modèles sont intéressants
Ces modèles sont utiles car ils décrivent des phénomènes qu’on a généralement du mal à appréhender intuitivement. Autant nous pouvons par exemple comprendre facilement la variation de la position d’une voiture qui se déplace (mais qui reste une voiture), autant appréhender les changements d’une quantité qui accumule ses changements pour varier d’autant plus vite n’est pas intuitif. C’est la même chose avec cette dynamique de population. Et même si c’est parfois assez difficile à accepter, on peut constater que nous sommes tous soumis à ces variations et que les calculs issus de ces modèles aboutissent à des résultats finalement assez fiables. Les données visualisées sur ce site web montrent que, face à cette épidémie, tous les pays suivent la même trajectoire de variation, jusqu’au moment où ils sortent de cette logique d’épidémie.
Mais, il faut aussi accepter que tous ces modèles reposent sur des observations et sur des paramètres qui peuvent être approximatifs et donc sujets à des erreurs. En fait, ces modèles ne sont pas faits pour obtenir des résultats très précis mais pour produire des tendances, considérées comme fiables même si elles combinent un ensemble d’approximations, ( cf Estimation de Fermi). C’est ce qu’on appelle estimer des ordres de grandeur.
Pourquoi il faut se méfier des modèles
Cependant, ces modèles peuvent aussi induire des erreurs importantes si on les utilise mal. Autant (comme l’expliquait bien Fermi) combiner plusieurs valeurs entachées d’erreur peut permettre de trouver un ordre de grandeur acceptable, autant cumuler des erreurs dans le temps peut se révéler problématique. C’est en particulier le cas quand on utilise ces modèles pour faire de la prédiction. Si on prédit une valeur pour le jour d’après et qu’on se sert de cette valeur pour prédire celle du jour suivant, une erreur commise lors de la première prédiction va s’amplifier sur les jours suivants en suivant également cette loi exponentielle, ce qui fait que ces modèles sont en général peu fiables pour la prédiction en boucle ouverte, c’est à dire sans les recaler régulièrement avec des mesures réelles.
Une autre erreur également commise fréquemment est que l’on considère souvent l’environnement comme passif alors qu’il peut inclure lui même d’autres systèmes dynamiques modifiant certains des paramètres du modèle qui ne pourra pas donc être utilisé comme tel trop longtemps. Dans cet article, l’auteur explique que certains pays ont préféré ne pas prendre des mesures fortes de confinement car les modèles épidémiologiques leur expliquaient qu’elles se bornaient à retarder la crise. Ils oubliaient seulement que le temps gagné peut aussi servir à se préparer et donc ne plus être dans les mêmes conditions qu’au début de l’épidémie pour affronter la crise…
Simulation des conséquences des différents scénarios – Extrait de l’article de T. Pueyo
Alors, les modèles mathématiques, à quoi ça peut servir ?
Le même auteur avait auparavant proposé un article très consulté depuis sa sortie. Dès le début mars, en se basant sur ce type de modèles, il expliquait qu’il fallait choisir le confinement, considérant notre état de préparation et que, finalement, un critère majeur à suivre (comme l’explique Jérôme Salomon, le directeur général de la santé) était le nombre d’admission en réanimation car le nombre de morts dépend principalement de la robustesse et la capacité des systèmes de santé et des mesures qui peuvent étaler ou faire baisser le nombre de cas (ce qui dans les deux cas permet aux systèmes de santé de mieux supporter la vague).
Par ailleurs, tout ce temps gagné nous permet de mieux nous préparer pour être dans de meilleures conditions pour combattre l’épidémie, en ayant stocké des masques, des respirateurs (ou des vaccins) et en ayant surtout eu le temps de changer les mentalités et les procédures, pour reprendre des activités (presque) normales en sachant protéger les plus faibles.
Alors les modèles mathématiques sont-il inutiles pour soigner des gens (cf la tribune de D. Raoult) ?
C’est vrai qu’un modèle mathématique ne constitue pas une thérapie et ne peut être utilisé pour soigner et guérir un patient individuel. Mais si l’on considère la population globale, alors oui, les modèles mathématiques ont démontré une nouvelle fois leur importance et oui, ils ont permis de sauver de nombreuses vies !
Frédéric Alexandre (Inria, Institut des maladies neurogénératives, NeuroCampus Bordeaux)
Pour aller plus loin, nous vous proposons de lire cet article rédigé par François Rechenmann et publié sur le site Interstices
Les applications de contact tracing soulèvent des espoirs et des inquiétudes. Cette semaine binaire a publié un article de Serge Abiteboul décrivant le fonctionnement de l’application Stop Covid [1] qui sera discutée la semaine prochaine au parlement. Cette application a également fait l’objet d’une tribune de Bruno Sportisse [2] qui s’appuie sur les travaux de plusieurs équipes européennes. Un autre collectif de chercheurs, majoritairement français, a publié le site internet Risques-Tracages.fr afin de proposer une analyse des risques d’une telle application, fondée sur l’étude de scénarios concrets, à destination de non-spécialistes. Nous vous en conseillons la lecture, de façon à vous forger votre propre opinion sur les avantages et les risques de tels outils. Car pour faire un choix éclairé, il faut savoir à quoi s’en tenir.
Depuis quelques jours, on lit et on entend (y compris dans Le Monde [3]) que « la tension monte », que « les scientifiques s’étrillent », que la guerre est ouverte entre les différents camps des experts. Il n’en est rien. Certes, il serait bien naïf de croire que les querelles d’égos n’existent pas dans un monde où l’évaluation et la compétition sont très présents, mais il est également tout aussi faux de dire que les chercheurs s’affrontent sur le sujet. Les collègues mentionnés ci-dessous se connaissent, s’apprécient et ont souvent eu l’occasion de travailler ensemble. En revanche, ils apportent des points de vue complémentaires, parfois contradictoires, qui doivent permettre d’éclairer la décision publique.
Le débat, vous l’imaginez, a été riche chez binaire et c’est une très bonne chose. Nous continuerons donc à publier les avis qui nous semblent scientifiquement pertinents sur le sujet.
Dans le contexte de la crise sanitaire, les escrocs ne se mettent pas au chômage. Les cyberattaques se multiplient au contraire, visant même parfois le système de santé. Bruno Teboul et Thierry Berthier nous parlent des risques que courent les TPE-PME, les grands groupes, les collectivités territoriales, et les individus. #cybersécurité #vigilance Clémentine Maurice et Serge Abiteboul
Alors que le gouvernement français déroule son plan de lutte contre la propagation du Coronavirus, les entreprises et les administrations incitent leurs salariés à privilégier le travail à distance lorsque cela est possible. Par principe, les options du télétravail et du téléenseignement vont ralentir la diffusion du virus tout en garantissant la continuité d’activité des entreprises et des administrations.
Une fois cette option choisie, les généralisations momentanées du télétravail, des télé-transactions, des téléconsultations et du téléenseignement vont mettre à l’épreuve l’ensemble des infrastructures numériques du pays. Certaines n’ont pas été dimensionnées pour encaisser une montée en charge brutale alors que d’autres passent à l’échelle facilement. Dans les zones géographiques rurales, les questions des débits internet insuffisants, du non-déploiement de la fibre ou de l’absence de couverture compliquent considérablement la transition vers le télétravail. Ces disparités territoriales mettent en lumière la fameuse fracture numérique, déjà difficilement subie en temps de paix sanitaire par les habitants concernés, mais encore plus difficilement acceptée en temps de crise et d’isolement forcé. L’école à distance, l’Université en mode « remote » sont des merveilleux concepts sur le papier que nous allons tester en vraie grandeur dans les prochaines semaines.
Bien entendu, nous devons relativiser ces potentielles difficultés techniques face aux drames humains en cours et face à la pression croissante que le secteur de la santé doit encaisser. Au-delà du bilan sanitaire, cette crise pandémique agit également comme un impitoyable révélateur de la robustesse ou de la fragilité des organisations, des systèmes et des infrastructures. Elle vient nous rappeler, au passage, que nous ne sommes jamais à l’abri des cygnes noirs si bien décrits par Nassim Nicholas Taleb (*) en 2010 et qu’il convient de raisonner en termes de risques acceptables.
Le travail à distance généralisé et l’utilisation des moyens numériques au service de l’entreprise en dehors de ses murs étendent considérablement le périmètre du risque cyber. La distribution de ce risque est loin d’être uniforme. Certaines structures vont être plus exposées que d’autres, c’est la raison pour laquelle il convient de bien distinguer les contextes et d’identifier les « points chauds ».
Pour les entreprises habituées aux mécanismes du télétravail, la transition se fera dans une relative sérénité renforcée par l’expérience acquise et des bonnes pratiques mises en place. Les télétravailleurs habituels auront moins de mal à s’adapter à plusieurs semaines d’isolement en maintenant leur activité sans prise de risque supplémentaire.
Dans les grands groupes, le RSSI (responsable de la sécurité des systèmes d’information) a peut-être mis en place un plan de continuité d’activité qui intègre les situations de travail à domicile, souvent à partir des machines de l’entreprise dotées de bonnes protections. Le transfert de données sensibles entre le travailleur posté à son domicile et le système d’information de son entreprise pourra être sécurisé via du chiffrement et les systèmes utilisés auront été mis à jour (OS, antivirus, clients de messagerie, plateformes pro déportées).
Les choses se compliquent lorsque l’entreprise est une TPE-PME ou une grande entreprise, avec peu d’expérience dans la gestion d’employés en télétravail. Le contexte typique est celui d’une TPE-PME qui n’a pas les moyens d’avoir de spécialiste de sécurité ou de faire appel à des entreprises spécialisées pour cela, qui ne dispose pas de plan de continuité d’activité et dont le système d’information n’est protégé que par des outils de cybersécurité basiques. Le basculement de la majorité des salariés vers le télétravail modifie la trajectoire des données, leur flux entrant et sortant. La partie des données qui est traitée en interne en fonctionnement normal est amenée à sortir du système d’information et à transiter sur des postes à distance. C’est cette modification des flux de données qui créé de la vulnérabilité et qui engendre un risque accru de captation, d’exfiltration ou de destruction de données sensibles pour l’entreprise. Dans ce contexte dégradé, le risque d’usurpation d’identité, de fraude au Président, de fraude au faux virement, au faux fournisseur ou au faux support technique augmente considérablement. Il est important de sensibiliser les salariés travaillant à distance et de leur signaler qu’ils deviennent des cibles privilégiées pour les attaquants.
Les collectivités territoriales sont également concernées par l’augmentation du risque cyber induit par la « distanciation sociale ». Les attaquants savent parfaitement exploiter les contextes dégradés et les vulnérabilités créées par une situation d’urgence pour monter des opérations lucratives. Chacun doit savoir qu’il n’y aura aucune trêve durant ces semaines de confinement forcé.
Au titre individuel, nous pouvons tous devenir une cible de fraude via nos boites mails, en recevant un avis de colis recommandé urgent contenant un lien malveillant, un avis de trop perçu, une alerte de résultat d’analyse médicale en ligne, un avis de facture urgente à régler ou un message envoyé par un « ami » qui vous indique qu’il a été testé positif au Coronavirus et qui vous demande de l’aide en ligne… L’environnement de crise est propice à la mise en place d’architectures de données fictives immersives destinées à tromper une cible et à la faire agir contre ses intérêts.
Dans tous les cas, il faut rester vigilant. Les premiers cas de cyberfraude ont été enregistrés en Italie et en Suisse. Des réponses se mettent en place. Par exemple, L’ANSSI sensibilise et transmet des recommandations de sécurité à destination des collectivités territoriales. Et des spécialistes de cybersécurité mettent gratuitement leurs services à disposition des entreprises exposées pour le durée de confinement.
L’épreuve pandémique sans précédent que nous traversons aujourd’hui doit nous rendre plus résilient et plus prudent face à la montée des menaces. Notre plasticité cérébrale et nos capacités cognitives devraient nous y aider !
Bruno Teboul est Docteur de l’Université Paris-Dauphine, spécialiste de Philosophie et de Sciences Cognitives. Chercheur associé à l’Université de Technologie de Compiègne (Costech). Il a été le cofondateur de la Chaire Data Scientist de l’École polytechnique. Entrepreneur et directeur Conseil, Data, IA & Blockchain dans plusieurs ESN en France. Il est membre du groupe « Sécurité Intelligence Artificielle » du Hub France IA. .
Thierry Berthier est Maître de conférences en mathématiques. Il est chercheur associé au CREC Saint-Cyr et à la Chaire de cyber défense Saint-Cyr. Expert en cybersécurité & cyberdéfense, Il copilote le groupe « Sécurité Intelligence Artificielle » du Hub France IA. Il est par ailleurs cofondateur des sites VeilleCyber, SécuritéIA et fondateur du blog Cyberland

 Dans ce contexte, le projet de Communauté d’Apprentissage de l’Informatique (CAI) vise la mise en communauté d’enseignant·e·s pour faciliter la découverte de l’informatique et leur permettre d’accéder aux outils nécessaires pour son enseignement aux élèves de 10 à 18 ans : entraide entre enseignant·e·s et autres professionnel·le·s de l’éducation, partages d’expériences et de ressources pédagogiques, co-construction de projets, via une méta-plateforme https://cai.community en phase de déploiement.
Dans ce contexte, le projet de Communauté d’Apprentissage de l’Informatique (CAI) vise la mise en communauté d’enseignant·e·s pour faciliter la découverte de l’informatique et leur permettre d’accéder aux outils nécessaires pour son enseignement aux élèves de 10 à 18 ans : entraide entre enseignant·e·s et autres professionnel·le·s de l’éducation, partages d’expériences et de ressources pédagogiques, co-construction de projets, via une méta-plateforme https://cai.community en phase de déploiement. Une vue de la plateforme résultat de la réflexion partagées ici et des spécifications proposées, on y voit le choix d’une présentation minimale, les différentes rubriques qui correspondent aux fonctionnalités proposées ici et le lien avec les réseaux sociaux les plus usités par les personnes qui vont l’utiliser.
Une vue de la plateforme résultat de la réflexion partagées ici et des spécifications proposées, on y voit le choix d’une présentation minimale, les différentes rubriques qui correspondent aux fonctionnalités proposées ici et le lien avec les réseaux sociaux les plus usités par les personnes qui vont l’utiliser.






 Dans l’imaginaire collectif, un robot est fait de métal, et prend souvent la forme d’un humanoïde ou d’un bras robotisé sur une chaîne industrielle. La robotique déformable casse les codes de la robotique rigide traditionnelle avec des mouvements d’un nouveau genre et des formes atypiques, souvent inspirés d’animaux tels que la pieuvre, la méduse, le serpent, la chenille etc. Un robot déformable (ou robot souple) est fabriqué à partir de matériaux flexibles, comme le silicone, le plastique, ou encore les tissus et papiers. Par définition, ces robots créent le mouvement en déformant leur structure (à l’aide de câble, ou de pression dans des cavités par exemple), en contraste avec les robots classiques qui basent leurs mouvements sur des mécanismes d’articulations. En plus d’élargir le champ des possibles en termes de mouvements, l’utilisation de ces types de matériaux à l’avantage de rendre ces robots plus sûrs pour les objets ou personnes avec qui ils interagissent. Comme par exemple pour la robotique chirurgicale.
Dans l’imaginaire collectif, un robot est fait de métal, et prend souvent la forme d’un humanoïde ou d’un bras robotisé sur une chaîne industrielle. La robotique déformable casse les codes de la robotique rigide traditionnelle avec des mouvements d’un nouveau genre et des formes atypiques, souvent inspirés d’animaux tels que la pieuvre, la méduse, le serpent, la chenille etc. Un robot déformable (ou robot souple) est fabriqué à partir de matériaux flexibles, comme le silicone, le plastique, ou encore les tissus et papiers. Par définition, ces robots créent le mouvement en déformant leur structure (à l’aide de câble, ou de pression dans des cavités par exemple), en contraste avec les robots classiques qui basent leurs mouvements sur des mécanismes d’articulations. En plus d’élargir le champ des possibles en termes de mouvements, l’utilisation de ces types de matériaux à l’avantage de rendre ces robots plus sûrs pour les objets ou personnes avec qui ils interagissent. Comme par exemple pour la robotique chirurgicale.




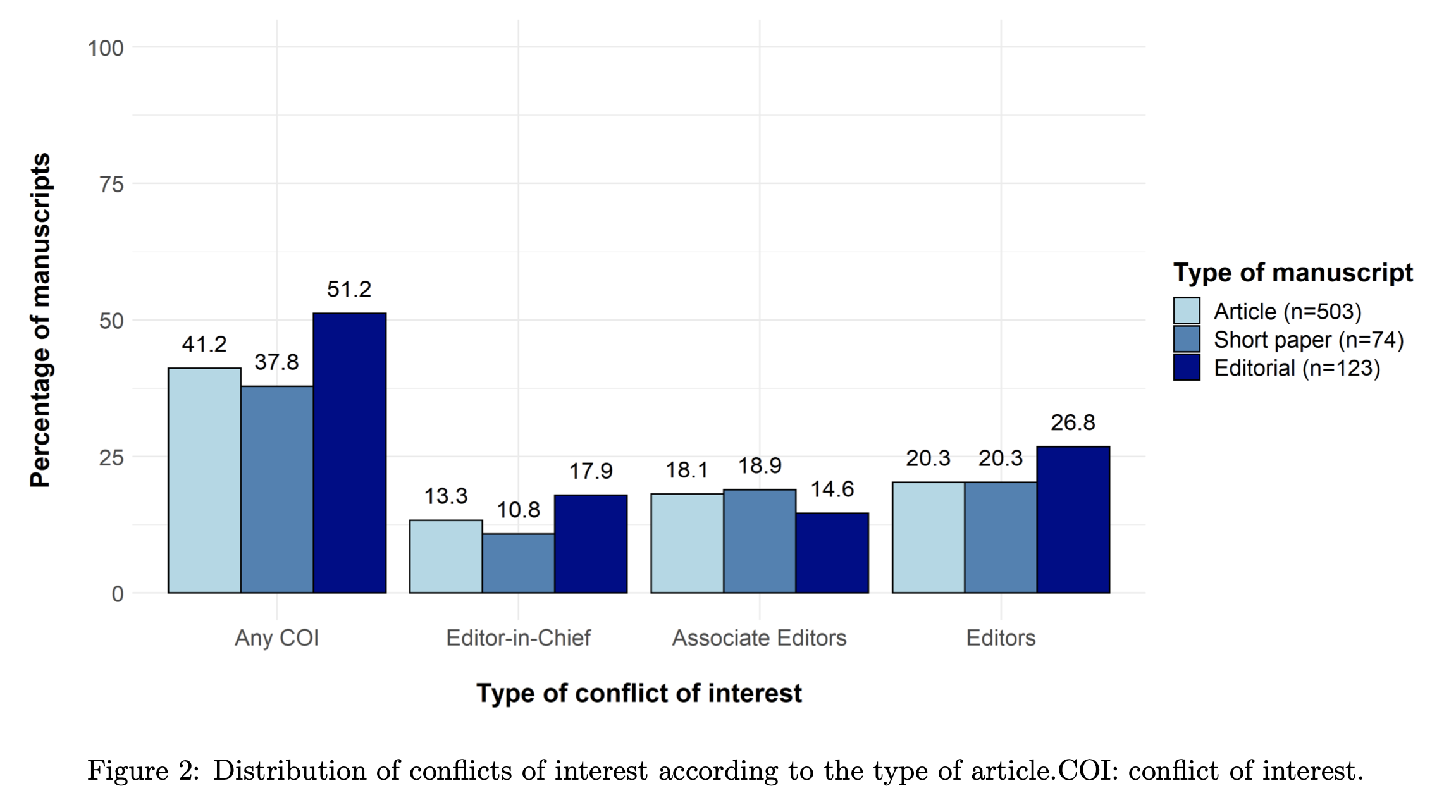
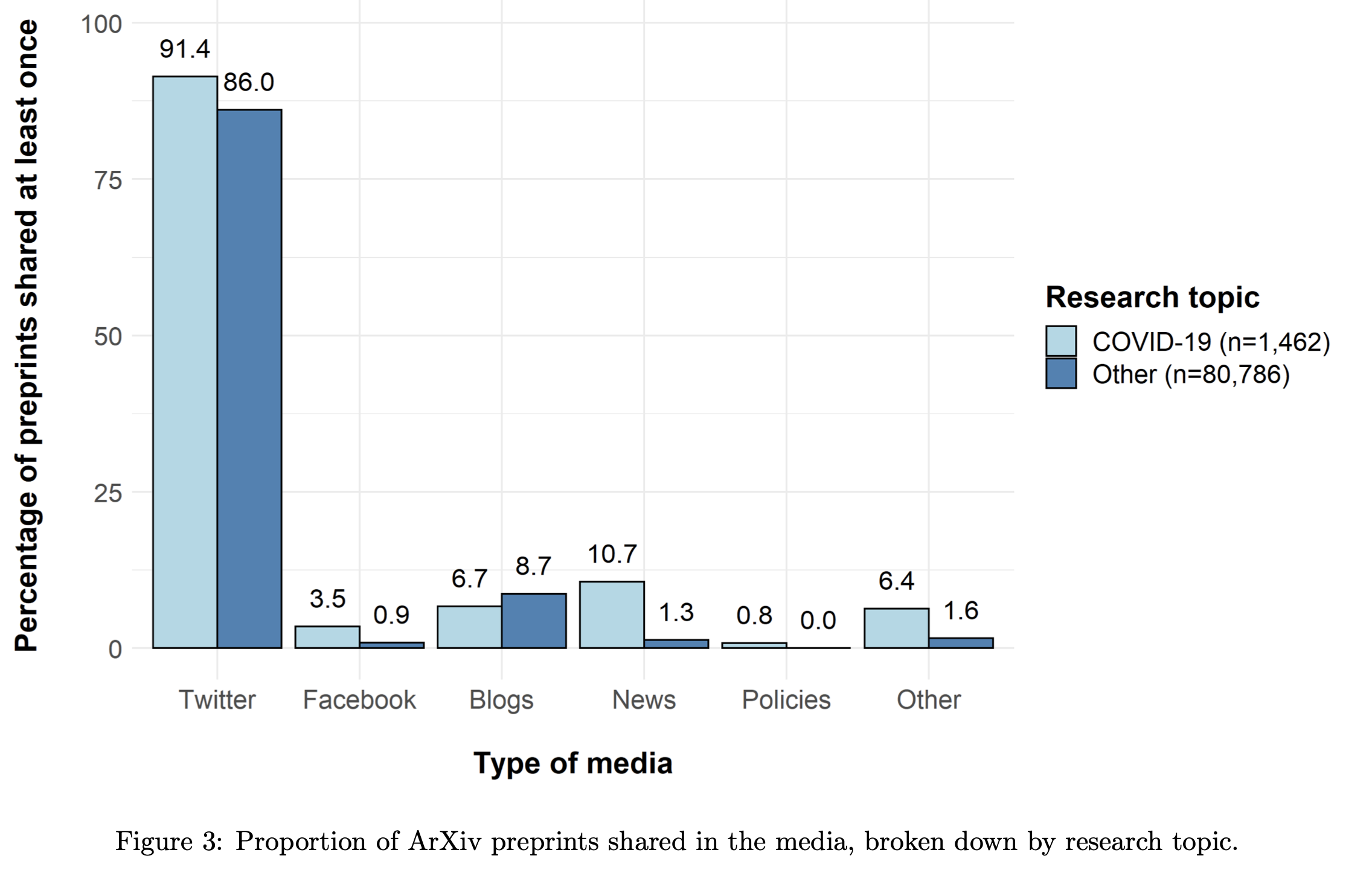




 Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire.
Quand les États-Unis envisagent de créer leur propre champion, ils ont en tête le programme Apollo : là aussi, les Soviétiques avaient subitement acquis une avance technologique stratégique dans l’espace. Qu’à cela ne tienne : l’implication du gouvernement américain a suffi à créer une industrie de toute pièce qui a finalement damé le pion à l’URSS. Autres exemples : la Silicon Valley elle aussi émanation des programmes militaires de la fin de la seconde guerre mondiale ou encore Intelsat et Inmarsat à l’origine de l’industrie du satellite qui résultaient d’investissements d’état et sans compter Internet, un protocole qui devait résister à une déflagration nucléaire. Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines.
Il n’est pas rare d’entendre que des algorithmes de machine learning sont utilisés dans divers domaines afin d’assister ou de remplacer les décisions humaines.