Depuis le 25 septembre 2021, la Maison des Mathématiques et de l’Informatique à Lyon a rouvert ses portes et présente une nouvelle exposition sur l’intelligence artificielle, « Entrez dans le monde de l’IA ». Quelle chance ils ont ces Lyonnais ! Serge Abiteboul et Laurence Chevillot
L’intelligence artificielle (IA), tout le monde en a sans doute entendu parler mais personne ne parle de la même chose. Pourtant, elle est présente dans votre quotidien, des publicités que vous recevez à votre appli de transport en passant par les jeux vidéo. Cette exposition vous permettra de découvrir et de tester des applications de l’IA, des plus sérieuses aux plus amusantes. Certaines sont tellement impressionnantes que vous aurez forcément envie de voir ce qui se cache derrière.
En manipulant et en expérimentant, venez découvrir l’apprentissage machine (« machine learning »), les réseaux de neurones, l’apprentissage profond (« deep learning ») ou encore l’apprentissage par renforcement. Pour comprendre comment une machine peut devenir « intelligente », le mieux, c’est encore de la voir apprendre en direct et, pourquoi pas, d’essayer de faire mieux qu’elle !
Cette exposition vous permettra d’entrer dans l’histoire de l’IA, sans se limiter au Deep Learning. Au travers d’une grande frise, vous découvrirez qu’elle est faite d’âges d’or et d’hivers, et qu’elle s’inspire de nombreuses disciplines (mathématiques, informatique, neurosciences, robotique…). Les regards croisés de spécialistes vous permettront de vous forger une réponse à la question : qu’est-ce donc que l’intelligence artificielle ?
Pourquoi iriez-vous voir une exposition sur l’IA ?
Dans les médias, l’IA est soit la solution à tous vos problèmes soit synonyme de catastrophe. Ces deux extrêmes ne reflètent pas la réalité de la recherche en IA, qui, si elle devenue récemment populaire dans l’industrie, s’est développée depuis 70 ans dans le monde académique. En donnant la parole à des chercheurs et chercheuses universitaires qui ont fait et font encore l’IA, cette exposition porte un regard apaisé sur l’IA, loin des projecteurs.
« Entrez dans le monde de l’IA » a été créée par Fermat Science, la Maison des Mathématiques et de l’Informatique, l’Institut Henri Poincaré, sous la responsabilité de deux commissaires scientifiques de l’ENS de Lyon, Aurélien Garivier et Alexeï Tsygvintsev. Ce sont des spécialistes d’horizons variés travaillant dans le domaine de l’intelligence artificielle qui ont permis de vous proposer un discours mesuré et raisonnable.
Montrer ce qu’est l’IA, ce qu’elle peut, ce qu’elle ne peut pas, ce qu’elle pourra peut-être : voilà ce que vous découvrirez !
Et concrètement, quelles manipulations pourrez-vous faire dans l’exposition ?
L’intelligence artificielle et les jeux sont de bons amis. AlphaGo Zero a battu des champions du jeu de Go, en apprenant par lui-même, sans observer les humains. Dans l’exposition, vous pourrez jouer contre une machine physique qui apprend à jouer… au jeu des allumettes, moins complexe que le jeu de Go. La règle du jeu ? 8 allumettes sont placées en ligne entre deux joueurs. À tour de rôle, chaque joueur doit enlever une ou deux allumettes. Celui qui enlève la dernière a perdu. Réfléchissez à la meilleure stratégie pour vous assurer la victoire et venez ensuite défier cette intelligence artificielle sans ordinateur !
La machine est constituée de huit poches, correspondant aux huit allumettes sur la table. Dans chacune se trouve des billes jaunes et noires qui sont, au départ, en nombre égal. Vous jouez une partie contre elle en retirant des allumettes et quand c’est à elle de jouer, vous tirez une bille dans la poche en face de l’allumette qu’elle peut enlever. Si la bille est jaune, la machine enlève une allumette. Si elle est noire, elle prend deux allumettes. Une fois la partie terminée, il y a deux possibilités :
Vous avez gagné : il faut punir la machine pour qu’elle apprenne de ses erreurs. Vous défaussez les billes tirées. Dans les poches, il y a moins de billes de couleurs qui correspondent à une mauvaise succession de coups. Les parties suivantes, la machine aura moins tendance à les jouer.
Vous avez perdu : il faut récompenser la machine en renforçant ses coups. Vous allez remettre pour chaque poche jouée la bille tirée et en rajouter une de la même couleur. La machine aura plus de chance de jouer cette série de coups gagnants.
Et la machine apprend ! Elle joue au hasard du début à la fin mais le renforcement change les probabilités de chaque coup. Petit à petit, la machine va avoir de plus en plus de chances de faire les bons coups, ceux que vous avez trouvé en réfléchissant à la stratégie optimale.
En intelligence artificielle, ce principe est appelé l’apprentissage par renforcement. Sans avoir besoin de maîtriser un quelconque langage de programmation, cette machine vous montre simplement et sans ordinateur, comment un tel apprentissage fonctionne.
« Entrez dans le monde de l’IA » est ouverte du 25 septembre 2021 au 30 juin 2022, à la Maison des Mathématiques et de l’Informatique (MMI), 1, place de l’Ecole, 69007 Lyon.
La MMI propose de nombreuses visites guidées mais aussi de multiples activités et ateliers autour de l’IA au public les samedis après-midis. Informations et réservations sur mmi-lyon.fr.
Olivier Druet, directeur de la MMI, et Nina Gasking, chargée de médiation de la MMI
Un nouvel « Entretien autour de l’informatique ». Judith Rochfeld est professeure de droit privé à l’École de droit de la Sorbonne, et directrice du Master 2 « Droit du commerce électronique et de l’économie numérique ». C’est une des meilleures spécialistes des communs. Elle est co-éditrice du Dictionnaire des biens communs aux PUF, 2021. Elle est autrice de « Justice pour le climat ! Les nouvelles formes de mobilisation citoyenne » chez Odile Jacob, 2021. Cet article est publié en collaboration avec theconversation.fr.
Judith Rochfeld
binaire : Judith, peux-tu nous dire qui tu es, d’où tu viens ?
JR : Je suis au départ une juriste, professeure de droit privé à l’Université Paris 1 Panthéon-Sorbonne. Au début, je m’intéressais aux grandes notions juridiques classiques, dont la propriété privée. Puis, sous le coup de rencontres et d’opportunités, j’ai exploré deux directions : le droit du numérique d’un côté ; et, avec un groupe de travail composé d’économistes, d’historiens, de sociologues, les « communs » dans la suite des travaux d’Elinor Ostrom (*), d’un autre côté. Cela m’a amenée à retravailler, entre autres, la notion de propriété. Par la suite, pour concrétiser certains des résultats de ces réflexions, j’ai dirigé, avec Marie Cornu et Fabienne Orsi, la rédaction d’un dictionnaire des biens communs. Aujourd’hui, je m’intéresse particulièrement à toutes les formes de biens communs et de communs, principalement en matière numérique et de données ainsi qu’en environnement.
binaire : Pourrais-tu préciser pour nos lecteurs les notions de « biens communs » et de « communs » ?
JR : Le vocabulaire n’est pas complètement stabilisé et peut varier suivant les interlocuteurs. Mais si l’on tente de synthétiser, on parlerait de « biens communs » pour saisir des biens, ressources, milieux, etc., à qui est associé un intérêt commun socialement, collectivement et juridiquement reconnu. Ce peut être l’intérêt d’une communauté nationale, internationale ou l’intérêt de groupes plus locaux ou restreints. On peut prendre l’exemple des monuments historiques : en 1913, on a assisté à des combats législatifs épiques pour faire reconnaître qu’il fallait les identifier, les classer, et admettre qu’ils présentaient un intérêt pour la nation française dans son ensemble ; qu’en conséquence, leurs propriétaires, fussent-ils privés, ne pouvaient pas avoir sur eux de pleins pouvoirs (comme le voudrait l’application de la propriété classique), jusqu’à celui de les détruire ; qu’ils devaient tenir compte de l’intérêt pour d’autres (voire pour les générations à venir), avec des conséquences juridiques importantes (l’obligation de les conserver dans leur état, de demander une autorisation pour les modifier, etc.).
Il existe d’ailleurs divers intérêts communs reconnus : l’intérêt historique et/ou artistique d’un monument ou d’autres biens culturels, l’intérêt environnemental ou d’usage commun d’un cours d’eau ou d’un terrain, l’intérêt sanitaire d’un vaccin, etc.
Mais précisons la terminologie. D’abord, il faut différencier entre « biens communs » et le « bien commun » discuté, par exemple, dans « Économie du bien commun » de Jean Tirole. Le second renvoie davantage à l’opposition entre bien et mal qu’à l’idée d’un intérêt commun.
Ensuite, il faut distinguer « biens communs » et « communs ». Avec la notion de « communs » (dans le sens que lui a donné Elinor Ostrom), on ajoute l’idée d’une organisation sociale, d’un gouvernement de la ressource par la communauté. C’est cette communauté qui gère les accès, les prélèvements, les différents droits…, et assure avec cela la pérennité de la ressource. C’est le cas par exemple pour un jardin partagé, un tiers-lieu, ou une encyclopédie en ligne telle que Wikipédia, administrés par leurs utilisateurs ou un groupe de personnes dédiées.
Un commun se caractérise typiquement par une communauté, une ressource que se partage cette communauté, et une gouvernance. Dans un bien commun, on n’a pas forcément cette gouvernance.
binaire : Cela conduit bien-sûr à des conflits avec la propriété privée ?
JR : On a souvent tendance à opposer les notions de biens communs ou de communs au droit de propriété privée, très belle avancée de la révolution française en termes d’émancipation et de reconnaissance d’un espace d’autonomie sur ses biens au bénéfice de l’individu propriétaire. Reconnaître qu’un bien porterait un intérêt commun poserait des limites au pouvoir absolu que la propriété renferme, en imposant la considération de l’intérêt d’une communauté. Cela peut être vrai dans certains cas, comme celui des monuments historiques évoqué.
Mais c’est oublié qu’il peut y avoir aussi une volonté du propriétaire d’aller en ce sens. La loi de protection de la biodiversité de 2016 permet ainsi, par exemple, de mettre un bien que l’on possède (un terrain, une forêt, etc.) au service d’une cause environnementale (la réintroduction d’une espèce animale ou végétale, la préservation d’une espèce d’arbre,…) en passant un accord pour formaliser cette direction : le propriétaire établit un contrat avec une association ou une collectivité, par exemple, et s’engage (et engage ses héritiers) à laisser ce dernier au service de la cause décrite. On assiste alors à une inversion de la logique de la propriété : elle sert à partager ou à faire du commun plutôt qu’à exclure autrui. C’est la même inversion qui sert de fondement à certaines licences de logiciel libre : celui qui pourrait bénéficier d’une « propriété » exclusive, à l’égard d’un logiciel qu’il a conçu, choisit plutôt de le mettre en partage et utilise pour cela une sorte de contrat (une licence de logiciel libre particulière) qui permet son usage, des modifications, mais impose à ceux qui l’utilise de le laisser en partage. Le droit de propriété sert ainsi à ouvrir l’usage de cette ressource plutôt qu’à le fermer.
binaire : Pour arriver aux communs numériques, commençons par internet. Est-ce que c’est un bien commun ? Un commun ?
JR : C’est une grande discussion ! On a pu soutenir qu’Internet était un commun mondial : on voit bien l’intérêt de cette ressource ou de cet ensemble de ressources (les différentes couches, matérielles, logicielles, etc.) pour une communauté très large ; ses fonctionnement et usages sont régis par des règles que se donnent des « parties prenantes » et qui sont censées exprimer une sorte de gouvernance par une partie de la communauté intéressée. En réalité, internet a même plusieurs gouvernances — technique, politique — et on est loin d’une représentation de l’ensemble des parties prenantes, sans domination de certains sur d’autres. La règle, cependant, qui exprime peut-être encore le mieux une partie de cette idée est celle de neutralité du net (dont on sait qu’elle a été bousculée aux États-Unis) : tout contenu devrait pouvoir y circuler sans discrimination.
binaire : Est-ce qu’on peut relier cela au droit de chacun d’avoir accès à internet ?
JR : Oui, ce lien est possible. Mais, en France, le droit à un accès à internet a plutôt été reconnu et fondé par le Conseil constitutionnel sur de vieilles libertés : comme condition des libertés d’information et d’expression.
binaire : Le sujet qui nous intéresse ici est celui des communs numériques. Est-ce tu vois des particularités aux communs numériques par rapport aux communs tangibles ?
JR : Oui tout à fait. Ostrom étudiait des communs tangibles comme des systèmes d’irrigation ou des forêts. La menace pour de telles ressources tient principalement dans leur surexploitation : s’il y a trop d’usagers, le cumul des usages de chacun peut conduire à la disparition matérielle de la ressource. D’ailleurs, l’économie classique postule que si j’ouvre l’usage d’un bien tangible (un champ par exemple, ouvert à tous les bergers désirant faire paître leurs moutons), ce dernier sera surexploité car personne ne ressentira individuellement la perte de façon suffisante et n’aura intérêt à préserver la ressource. C’est l’idée que synthétisera Garrett Hardin dans un article de 1968 resté célèbre, intitulé la « Tragédie des communs » (**). La seule manière de contrer cet effet serait d’octroyer la propriété (ou une réglementation publique). Ostrom s’inscrira précisément en faux en démontrant, à partir de l’analyse de cas concrets, que des systèmes de gouvernance peuvent se mettre en place, édicter des règles de prélèvements et d’accès (et autres) et assurer la pérennité de la ressource.
Pour ce qui est des communs numériques, ils soulèvent des problèmes différents : non celui de l’éventuelle surexploitation et de la disparition, mais celui qu’ils ne soient pas produits. En effet, si j’ouvre l’accès à des contenus (des notices de l’encyclopédie numérique, des données, des œuvres, etc.) et si, de plus, je rends gratuit cet usage (ce qui est une question un peu différente), quelle est alors l’incitation à les créer ?
Il faut bien préciser que la gratuité est une dimension qui a été placée au cœur du web à l’origine : la gratuité et la collaboration, dans une vision libertaire originaire, allaient quasi de soi. Les logiciels, les contenus distribués, etc. étaient créés par passion et diffusés dans un esprit de don par leurs concepteurs. Or, ce faisant, on fait un choix : celui de les placer en partie hors marché et de les faire reposer sur des engagements de passionnés ou d’amateurs désintéressés. La question se pose pourtant aujourd’hui d’aller vers le renforcement de modèles économiques qui ne soient plus basés que sur cette utopie du don, ou même sur des financements par fondations, comme ceux des Mozilla et Wikipedia Fundations.
Pour l’heure, la situation actuelle permet aux grandes plateformes du web d’absorber les communs (les contenus de wikipédia, des données de tous ordres, etc.), et ce sans réciprocité, alors que l’économie de l’attention de Google dégage des revenus énormes. Par exemple, alors que les contenus de l’encyclopédie Wikipédia, un commun, alimentent grandement le moteur de recherche de Google (ce sont souvent les premiers résultats), Wikipédia n’est que très peu rétribuée pour toute la valeur qu’elle apporte. Cela pose la question du modèle économique ou du modèle de réciprocité à mettre en place, qui reconnaisse plus justement la contribution de Wikipédia aux revenus de Google ou qui protège les communs pour qu’ils demeurent communs.
binaire : On pourrait également souhaiter que l’État soutienne le développement de communs. Quelle pourrait être une telle politique de soutien ?
JR : D’un côté, l’État pourrait s’afficher aux côtés des communs : inciter, voire obliger, ses administrations à choisir plutôt des communs numériques (logiciels libres, données ouvertes, etc.). C’est déjà une orientation mais elle n’est pas véritablement aboutie en pratique.
D’un autre côté, on pourrait penser et admettre des partenariats public-commun. En l’état des exigences des marchés publics, les acteurs des communs ont du mal à candidater à ces marchés et à être des acteurs reconnus de l’action publique.
Et puis, le législateur pourrait aider à penser et imposer la réciprocité : les communs se réclament du partage. Eux partagent mais pas les autres. Comment penser une forme de réciprocité ? Comment faire, par exemple, pour qu’une entreprise privée qui utilise des ressources communes redistribue une partie de la valeur qu’elle en retire ? On a évoqué le cas de Google et Wikipédia. Beaucoup travaillent actuellement sur une notion de « licence de réciprocité » (même si ce n’est pas simple) : vous pouvez utiliser la ressource mais à condition de consacrer des moyens ou du temps à son élaboration. Cela vise à ce que les entreprises commerciales qui font du profit sur les communs participent.
Dans l’autre direction, un projet d’article 8 de la Loi pour une République Numérique de 2016 (non adopté finalement) bloquait la réappropriation d’une ressource commune (bien commun ici) : il portait l’idée que les œuvres passées dans le domaine public (des contenus numériques par exemple) devenaient des « choses communes » et ne pouvaient pas être ré-appropriées par une entreprise, par exemple en les mettant dans un nouveau format ou en en limitant l’accès.
D’aucuns évoquent enfin aujourd’hui un « droit à la contribution », sur le modèle du droit à la formation (v. L. Maurel par exemple) : une personne pourrait consacrer du temps à un commun (au fonctionnement d’un lieu partagé, à l’élaboration d’un logiciel, etc.), temps qui lui serait reconnu pour le dédier à ces activités. Mais cela demande d’aller vers une comptabilité des contributions, ce qui, à nouveau, n’est pas facile.
En définitive toutes ces propositions nous conduisent à repenser les rapports entre les communs numériques, l’État et le marché.
binaire : Nous avons l’impression qu’il existe beaucoup de diversité dans les communautés qui prônent les communs ? Partages-tu cet avis ?
JR : C’est tout à fait le cas. Les communautés qu’étudiaient Ostrom et son École étaient petites, territorialisées, avec une centaine de membres au plus, identifiables. Avec l’idée des communs de la connaissance, on est passé à une autre échelle, parfois mondiale.
Certains communs se coulent encore dans le moule. Avec Wikipédia, par exemple, on a des communautés avec des rôles identifiés qui restent dans l’esprit d’Ostrom. On a la communauté des « bénéficiaires » ; ses membres profitent de l’usage de la ressource, comme ceux qui utilisent Wikipédia. On a aussi la communauté « délibérative », ce sont les administrateurs de Wikipédia qui décident des règles de rédaction et de correction des notices par exemple, ou la communauté « de contrôle » qui vérifie que les règles ont bien été respectées.
Mais pour d’autres communs numériques, les communautés regroupent souvent des membres bien plus mal identifiés, parfois non organisés, sans gouvernement. Je travaille d’ailleurs sur de telles communautés plus « diffuses », aux membres non identifiés a priori mais qui bénéficient de ressources et qui peuvent s’activer en justice pour les défendre quand celles-ci se trouvent attaquées. Dans l’exemple de l’article 8 dont je parlais, il était prévu de reconnaître que tout intéressé puissent remettre en cause, devant les tribunaux, le fait de ne plus pouvoir avoir accès à l’œuvre du domaine public du fait de la réappropriation par un acteur quelconque. Il s’agit bien d’une communauté diffuse de personnes, sur le modèle de ceux qui défendent des « ressources environnementales ». On peut y voir une forme de gouvernance, certes à la marge.
binaire : On a peu parlé de l’open data public ? Est-ce que la définition de commun que tu as donné, une ressource, des règles, une gouvernance, s’applique aussi pour les données publiques en accès ouvert ?
JR : Il y a des différences. D’une part, les lois ont vu dans l’open data public le moyen de rendre plus transparente l’action publique : les données générées par cette action devaient être ouvertes au public pour que les citoyens constatent l’action publique. Puis, en 2016, notamment avec la loi pour une République numérique évoquée, cette politique a été réorientée vers une valorisation du patrimoine public et vers une incitation à l’innovation : des startups ou d’autres entreprises doivent pouvoir innover à partir de ces données. Les deux motivations sont légitimes. Mais, mon impression est qu’aujourd’hui, en France, l’État voit moins dans l’open data un moyen de partage de données, qu’un espace de valorisation et de réappropriation. D’autre part, ce ne sont pas du tout des communs au sens où il n’y a pas de gouvernance par une communauté.
binaire : Tu travailles beaucoup sur le climat. On peut citer ton dernier livre « Justice pour le climat ». Quelle est la place des communs numériques dans la défense de l’écologie ?
JR : Je mets de côté la question de l’empreinte environnementale du numérique, qui est un sujet assez différent, mais néanmoins très préoccupant et au cœur des réflexions à mener.
Sur le croisement évoqué, on peut tracer deux directions. D’une part, il est évident qu’un partage de données « environnementales » est fondamental : pour mesurer les impacts, pour maîtriser les externalités. Ces données pourraient et devraient être saisies comme des « biens communs ». On a également, en droit, la notion voisine de « données d’intérêt général ». Il y a déjà des initiatives en ce sens en Europe et plus largement, que ce soit à l’égard des données publiques ou de données générées par des entreprises, ce qui, encore une fois, est délicat car elles peuvent recouper des secrets d’affaires.
D’autre part, la gravité de la crise environnementale, et climatique tout particulièrement, donne lieu à des formes de mobilisations qui, pour moi, témoignent de nouvelles approches et de la « conscientisation » des biens communs. Notamment, les procès citoyens que je décris dans le livre, qui se multiplient dans une bonne partie du monde, me semblent les expressions d’une volonté de réappropriation, par les citoyens et sous la pression de l’urgence, du gouvernement d’entités ressenties comme communes, même si le procès est une gouvernance qui reste marginale. Ils nous indiquent que nous aurions intérêt, pour leur donner une voie de gouvernement plus pacifique, à installer des instances de délibération, à destination de citoyens intéressés (territorialement, intellectuellement, par leur activité, leurs besoins, etc.) saisis comme des communautés diffuses. A cet égard, une initiative comme la Convention Citoyenne sur le climat était particulièrement intéressante, ouvrant à une version moins contentieuse que le procès.
Il pourrait en aller de même dans le cadre du numérique : l’utilisation de l’ensemble de nos données personnelles, des résultats de recherche obtenus en science ouverte, etc. pourraient, comme des communs, être soumise à des instances de délibération de communautés. On prendrait conscience de l’importance des données et on délibérerait sur le partage. Sans cela, on assistera toujours à une absorption de ces communs par les modèles d’affaires dominants, sans aucune discussion.
Serge Abiteboul, Inria & ENS Paris, François Bancilhon, serial entrepreneur
(*) Elinor Ostrom (1933-2012) est une politologue et économiste américaine. En 2009, elle est la première femme à recevoir le prix dit Nobel d’économie, avec Oliver Williamson, « pour son analyse de la gouvernance économique, et en particulier, des biens communs ». (Wikipédia)
(**) « La tragédie des biens communs » est un article décrivant un phénomène collectif de surexploitation d’une ressource commune que l’on retrouve en économie, en écologie, en sociologie, etc. La tragédie des biens communs se produirait dans une situation de compétition pour l’accès à une ressource limitée (créant un conflit entre l’intérêt individuel et le bien commun) face à laquelle la stratégie économique rationnelle aboutit à un résultat perdant-perdant.
Chut! est un média qui interroge l’impact du numérique sur nos vies. C’est à la fois un magazine en ligne chut.media et un magazine papier trimestriel de 100 pages illustrées. Mais c’est aussi une chaîne de podcast Chut! Radio. A l’occasion d’une série de podcast, avec l’intervention de plusieurs membres et amis de binaire, nous avions envie de vous faire découvrir ce nouvel acteur de la culture du numérique. Serge Abiteboul et Marie-Agnès Enard.
Les contenus de Chut ! interrogent des sujets de société et notre rapport au numérique. Ils mettent en avant la diversité, l’inclusion, l’éthique et encouragent à aller vers un monde technologique mixte et responsable, intégrant la diversité de tous et toutes. La ligne éditoriale est assumée : des contenus féministes et engagés. Le travail de pédagogie et de vulgarisation est soigné. Le lecteur de tout niveau peut découvrir ou approfondir certains sujets, se questionner ou façonner son opinion.
Le site chut.media propose une diversité de contenus et de formats tous en lien avec le numérique. Nous apprécions tout particulièrement la conception graphique de l’édition papier du magazine. Si vous êtes pressés, vous pouvez consulter des articles ou écouter des podcasts sélectionnés pour leur durée qui varie entre 3, 5 ou 10 minutes. Si vous avez un peu plus de temps, la Chut !radio propose tout une collection d’articles sonores ou de podcast de durées variables.
Nous vous invitons aujourd’hui à écouter la série de podcast La Puce à l’oreille. Chacun évoque en seulement cinq minutes un outil du numérique de notre quotidien. La réalisation est de Nolwenn Mauguen, une étudiante en Humanités numériques.
Les premiers sujets et les personnalités interrogées vont vous sembler familiers, puisqu’ils donnent la parole à des auteurs amis ou des éditeurs de binaire :
1. L’ordinateur ordonne-t-il le monde ? avec Valérie Schafer
2. Logique, le logiciel ? avec Gérard Berry
3. Jusqu’à quel point les algos rythment-ils nos vies ? avec Anne-Marie Kermarrec
4. Les données personnelles, le trésor du XXIème siècle ? avec Serge Abiteboul
Nous souhaitons à Chut ! de faire entendre sa voix sous toutes ses formes et pour longtemps.
Philippe Aigrainà la Journée du domaine public, Paris, 2012. Wikipédia
Philippe était informaticien, mais aussi écrivain, poète, passionné de montagne, militant. J’en oublie sûrement. Le dernier courriel que j’ai reçu de lui, c’était en sa qualité de dirigeant de publie.net, une maison d’édition où il avait pris la suite de François Bon. Une des dernières fois où je l’ai rencontré, nous faisions tous les deux parties du jury de l’Habilitation à diriger des recherches de Nicolas Anciaux. C’était de l’informatique mais le sujet allait bien à Philippe : « Gestion de données personnelles respectueuse de la vie privée ». Il défendait les libertés, notamment sur internet, ce qui l’avait conduit à cofonder « la Quadrature du net ». C’était aussi un brillant défenseur des biens communs. Pour de nombreux informaticiens, il était aussi le défenseur intransigeant des logiciels libres. Il s’est beaucoup battu pour les valeurs dans lesquelles il croyait,contre la loi Dadvsi, la loi Hadopi, la loi de Renseignement…
Difficile d’imaginer le paysage numérique français sans Philippe. Il manquera dans les combats futurs pour les libertés et pour le partage, mais nombreux sont ceux qu’il a influencés et à travers lesquels il se battra encore longtemps.
Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection A la plage, Dunod, juin 2020)
Le titre de ce livre pourrait laisser croire à une nouvelle biographie d’Alan Turing dans la lignée du film « Imitation game » ou de la pièce « La machine de Turing » or il n’en est rien. Le sous-titre, « L’Intelligence Artificielle dans un transat », a toute son importance : il s’agit d’une introduction, très accessible, à l’intelligence artificielle. Le lien avec Turing ? Des références permanentes à ses écrits, des citations qui mettent en avant l’aspect précurseur de Turing, des extraits de ses articles qui parlent de l’informatique telle que nous la connaissons, ses questionnements qui sont toujours d’actualité.
Le livre commence avec les notions d’algorithmes et de machines, des dispositifs tout d’abord mécaniques puis électroniques qui réalisent ces algorithmes. Très vite, la formalisation de la notion d’algorithme et ses limites — qui ont constitué le cœur des travaux d’Alan Turing avant guerre, avec en particulier la fameuse machine de Turing, modèle théorique d’algorithme — sont abordées. Les progrès pratiques, en termes de puissance de calcul, y sont présentés.
Or les algorithmes sont le composant fondamental des intelligences artificielles. De plus en plus souvent, les performances des intelligences artificielles nous surprennent, comme nous le montre le livre, que ce soit en battant des champions aux jeux d’échecs ou de go, ou en reconnaissant des chats dans des images. Le livre présente aussi, rapidement, les notions de complexité des problèmes et les questions encore ouvertes en ce domaine, comme « P versus NP » ou « P versus NC » (voir l’article la théorie de la complexité algorithmique).
Turing avait anticipé le fait que, quand la difficulté des tâches à résoudre augmente, la difficulté à écrire les algorithmes correspondants deviendrait intraitable par un humain et il avait déjà proposé, en 1950, le principe des learning machines, principe sous-jacent aux algorithmes auto-apprenants, très présents dans l’intelligence artificielle que nous connaissons aujourd’hui.
Se pose alors la question de savoir distinguer une intelligence humaine d’une intelligence artificielle : du célèbre « test de Turing » publié en 1950 à d’autres expériences (de pensée ou non), de l’art avec ce que cela suppose de créativité, aux algorithmes inspirés par la nature comme les automates cellulaires ou les algorithmes génétiques, différentes approches sont exposées.
Avant de conclure sur la « théorie hérétique » de Turing que nous vous laissons le plaisir de (re-)découvrir, les auteurs présentent aussi les facettes inquiétantes de l’utilisation des intelligences artificielles, qu’il s’agisse d’usages malveillants ou d’effets secondaires non anticipés et non désirés.
Ce livre peut tout à fait se lire à la plage, dans un transat, dans un hamac ou sous un plaid au coin du feu : il aborde très clairement les notions fondamentales de l’intelligence artificielle, avec une grande variété et une grande pertinence dans les exemples choisis. S’il faut toutefois mettre un léger bémol à cet enthousiasme, on pourra parfois regretter une transposition de certains résultats de l’informatique à la vie de tous les jours, comme par exemple avec le choix de cette citation de Scott Aronson au sujet de la question « P versus NP » : « Si P = NP, alors le monde est un endroit profondément différent de ce qu’on imagine habituellement. Il n’y aurait aucune valeur spécifique au « saut créatif », aucun fossé séparant le fait de résoudre un problème et celui de reconnaître la validité d’une solution trouvée. Tous ceux capables d’apprécier une symphonie seraient Mozart ; tous ceux capables de suivre un raisonnement étape par étape seraient Gauss. » Certes les auteurs ne sont pas responsables de cette citation, mais ils ont choisi de relayer une telle extrapolation, peut-être quelque peu excessive.
« Numérique et pandémie – Les enjeux d’éthique un an après »
organisé conjointement par le
Comité national pilote d’éthique du numérique et
l’Institut Covid-19 Ad Memoriam
le vendredi 11 juin 2021 de 9h à 16h15.
Systèmes d’information pour les professionnels de santé
Souveraineté numérique
Télé-enseignement
La pandémie Covid-19 est la première de l’ère numérique. Par cette dimension, elle ne ressemble pas aux crises sanitaires des époques précédentes : dès mars 2020, les activités économiques et sociales ont été partiellement maintenues grâce aux smartphones, ordinateurs et autres outils numériques. Mais les usages de ces outils ont eux aussi changé depuis le printemps 2020. La rapidité de ces évolutions n’a pas encore permis de dégager le sens qu’elles auront pour notre société, ni de saisir leurs effets à long terme. Ce colloque fera un premier pas dans cette direction. Qu’avons-nous appris ? Quelles sont les avancées que nous voudrions préserver après la fin de la crise ? À quelles limites se heurte la numérisation accélérée de notre quotidien ?
Laëtitia Atlani-Duault
Présidente de l’Institut Covid-19 Ad Memoriam, Université de Paris
Jean-Francois Delfraissy
Président du CCNE pour les sciences de la vie et de la santé
Président d’honneur de l’Institut Covid-19 Ad Memoriam
Claude Kirchner
Directeur du Comité National Pilote d’Éthique du Numérique
Suite à l’article dans Binaire, « L’informatique, quelques questions pour se fâcher entre amis », nous avons reçu une proposition d’article à propos de l’absence ou du manque de considération porté aux systèmes d’exploitation de Éric Sanchis. La pluralité des points de vue nous parait essentielle, c’est pourquoi vous retrouverez ici son point de vue, à vous de vous faire une idée, puis sans se fâcher, d’engager la discussion… Pierre Paradinas
Algorithme par-ci, algorithme par-là : des titres comme « Ma vie sous algorithmes », « A quoi rêvent les algorithmes », « Algorithmes : la bombe à retardement » ou bien « Le temps des algorithmes » font florès dans les librairies ! Dans le prolongement du billet « L’informatique, quelques questions pour se fâcher entre amis », on pourrait se demander si la place accordée au concept d’algorithme et aux notions connexes (langage, formalisation) n’est pas exagérée au sein même de la discipline informatique. En d’autres termes, est ce que la «pensée algorithmique » serait l’alpha et l’oméga de la « pensée informatique » ? Au risque de provoquer quelque agacement, je répondrais par la négative. Bien sûr, cette position doit être précisée.
Tout d’abord, insistons sur le fait que la notion d’algorithme était à la fois connue et utilisée bien avant la naissance de l’informatique. Il en est de même pour les aspect langages formels et calcul. Alors qu’est ce qui apporte ce supplément d’originalité à notre discipline ? Nul doute que chacun, suivant sa spécialité, pourrait apporter sa propre réponse. Quant à moi, pour expliciter mon point de vue, je mettrai de côté la définition de l’informatique définie par la SIF :
L’informatique est la science et la technique de la représentation de l’information d’origine artificielle ou naturelle, ainsi que des processus algorithmiques de collecte, stockage, analyse, transformation, communication et exploitation de cette information, exprimés dans des langages formels ou des langues naturelles et effectués par des machines ou des êtres humains, seuls ou collectivement.
au profit de celle-ci :
L’informatique est la discipline réunissant la science, la technique et la technologie relatives au traitement et à la gestion automatisés de l’information discrétisée.
Même s’il n’est pas possible de commenter dans ce billet les différents aspects contenus dans cette caractérisation, j’en relèverai deux utiles à mon propos. Tout d’abord, l’informatique est une discipline multiniveau. Ces niveaux étant fortement hétérogènes, il semble difficile qu’une « pensée unique » puisse les animer. Ensuite, selon mon point de vue, ce qui est porteur d’originalité dans la discipline informatique n’est pas la partie traitement automatisé (déjà effectué de manière sommaire par des dispositifs préexistants à l’informatique) mais plutôt la partie gestion automatisée. Celle-ci est mise en œuvre par le système d’exploitation de la machine. Mais que peut bien avoir d’original cette couche logicielle ? Ce sont ses fonctions d’exécution et de de partage optimal des ressources physiques et logiques.
On pourrait objecter qu’un système d’exploitation n’est qu’un (gros) programme écrit dans un langage de programmation classique. En fait, pas tout à fait : c’est plutôt un ensemble de programmes en interaction, interaction portée par le matériel. Il en résulte que bien des concepts et problèmes liés à cette couche ont peu à voir avec ceux traités par la « pensée algorithmique ». Abordons quelques-uns de ces concepts et problèmes. Tout d’abord, un système d’exploitation est un logiciel confronté à un matériel perpétuellement changeant (périphériques). Concevoir une interface qui sépare efficacement ce qui change de ce qui reste stable est bien plus complexe que la conception d’une interface uniquement confrontée à un environnement logiciel. Même si la décomposition en couches est la solution privilégiée, elle reste néanmoins limitée. Cette limitation est essentiellement due aux impératifs d’efficience. C’est la raison pour laquelle le nombre de couches présentes dans un système d’exploitation est relativement faible vis-à-vis du nombre de services qu’il réalise. Ce sont ces mêmes impératifs d’efficience qui ont conduit les concepteurs de systèmes d’exploitation à s’autoriser le court-circuitage de couches, écornant le principe théorique de décomposition en couches strictement ordonnées.
Illustrons cette « pensée système » à l’aide d’un deuxième et dernier exemple : l’allocation de ressources et le problème de l’interblocage. La littérature spécialisée regorge de propositions de solutions. Or il s’avère qu’une bonne partie d’entre elles sont inutilisables en pratique. Les concepteurs du système UNIX ont simplement décidé d’ignorer le problème. Pourquoi ? Parce que la fréquence d’apparition d’un interblocage dans un système est largement inférieure à la fréquence d’arrêt de ce système dû à d’autres causes (défaillances matérielles, bogues au sein du système d’exploitation ou autres). Pour des raisons de performances, il est alors plus judicieux d’ignorer la théorie et d’adopter une solution pragmatique.
Diagramme montrant les principaux systèmes d’exploitation Unix et ses dérivés.
En conclusion, réduire la « pensée informatique » à l’unique « pensée algorithmique » appauvrirait sérieusement notre discipline, la privant d’un savoir et savoir-faire qui ont largement contribué à son épanouissement. À l’heure où l’enseignement de l’informatique entre pleinement dans les lycées, il est primordial de redonner à la « pensée système » la place qui lui revient [1].
Eric Sanchis
Université Toulouse Capitole
[1] Le domaine des systèmes d’exploitation qui véhicule cette « pensée système » est quasiment absent des ouvrages destinés à l’enseignement de l’option ISN :
dans l’ouvrage « Introduction à la science informatique » (Repères pour agir), 2011 : environ 3 pages dans une section « Compléments » (sic)
dans l’ouvrage « Informatique et sciences du numérique » (Gilles Dowek), Eyrolles, 2012 : 2 pages
TIPE ? C’est cette épreuve des concours des écoles d’ingénieur·e·s où les élèves ne sont pas uniquement jugé de manière « scolaire´´ mais sur leur capacité à choisir un sujet, mener un projet, s’organiser … du vrai travail d’ingénieur·e quoi ! Oui … mais comment les aider pour que ce soit équitable ? C’est là que Pixees et Interstices, s’associent pour proposer des ressources et des pistes. En miroir de leur contenu, reprenons cela ici. Thierry Viéville et Pascal Guitton
TIPE ? Comme tous les ans, en lien avec sillages.info et l’UPS pour les CGPE, Interstices et Pixees vous proposent des ressources autour des sciences du numérique, de l’information et des mathématiques.
les textes ci-dessous pour aider à débroussailler le sujet (coordination Hugues Berry, Adjoint au directeur scientifique d’Inria pour la biologie et la santé numérique),
Comme probablement tous les secteurs de l’activité humaine, le numérique est en train de s’ancrer profondément en santé. Cette tendance a débuté il y a longtemps avec les premiers logiciels liés à l’imagerie médicale et la généralisation des outils numériques de gestion médico-administrative, comme les dossiers patients informatisés ou l’informatisation des données de remboursement de soins. Avec cette évolution, les données de santé sont devenues de plus en plus accessibles aux chercheurs et aux chercheuses dans des volumes importants, ce qui permet principalement d’envisager aujourd’hui la mise en place de systèmes capables d’assister les médecins lors des étapes de la décision médicale personnalisée: diagnostic, prédiction de l’évolution de la maladie ou choix de la meilleure thérapie.
Le domaine de la prévention des maladies est lui aussi impacté par cette évolution. Au niveau médical par exemple, l’émergence de données « de vie réelle » capturées hors des salles de soin proprement dites (caméras, smartphones, capteurs) promet un suivi automatisé et personnalisé de l’évolution de la pathologie des patients. Au niveau de la population, de nouveaux outils numériques permettent d’analyser les données des bases médico-administratives pour des objectifs issus de l’épidémiologie, c’est-à-dire l’étude de la fréquence, la distribution et les facteurs associés aux problèmes de santé de la population et la surveillance de leur évolution. Bien entendu, les crises actuelles liées aux maladies infectieuses fournissent elles aussi le cadre d’une implication accrue du numérique, par exemple pour optimiser les politiques d’intervention, concernant les stratégies de confinement, de test, de vaccination, ou de gestion des populations de vecteur animaux. Les exemples ci-dessous illustrent quelques-unes des nombreuses applications du numérique dans le domaine de la santé et de la prévention.
Hugues Berry, Adjoint au directeur scientifique d’Inria pour la biologie et la santé numérique
La reconnaissance vidéo d’activités pour le suivi personnalisé de patients atteints de troubles cognitifs
Les progrès récents de la vision artificielle permettent aujourd’hui d’observer et d’analyser nos comportements. On pense immédiatement à Big Brother, mais bien d’autres applications, tout à fait louables, sont envisagées. En particulier dans un domaine qui manque cruellement de réponses : le diagnostic, le suivi de patients présentant des déficits cognitifs liés au vieillissement et à l’apparition de maladies neurodégénératives comme la maladie d’Alzheimer, et le maintien à domicile de ces personnes âgées.
Les recherches de l’équipe Stars visent notamment à quantifier le déclin cognitif des patients Alzheimer. Il est important de détecter le plus tôt possible les premiers signes annonciateurs de difficultés à venir. Nous testons par exemple au CHU de Nice un dispositif visant à évaluer la situation d’un patient en lui proposant de passer cinq minutes dans une pièce équipée de capteurs vidéo, où il doit effectuer une liste de tâches comme préparer une boisson, téléphoner, lire, arroser des plantes… Nos logiciels permettent ainsi d’obtenir automatiquement une évaluation normalisée des éventuels déficits cognitifs de chaque patient et ainsi de leur proposer un traitement adapté.
A. König, C. Crispim, A. Covella, F. Bremond, A. Derreumaux, G. Bensadoum, R. David, F. Verhey, P. Aalten and P.H. Robert. Ecological Assessment of Autonomy in Instrumental Activities of Daily Living in Dementia Patients by the means of an Automatic Video Monitoring System, Frontiers in Aging Neuroscience – open access publication and the eBook – http://dx.doi.org/10.3389/fnagi.2015.00098, 02 June 2015
S. Das, S. Sharma, R. Dai, F. Bremond et M. Thonnat. VPN: Learning Video-Pose Embedding for Activities of Daily Living. ECCV 2020. ⟨hal-02973787⟩ https://hal.archives-ouvertes.fr/hal-02973787
D. Yang, R. Dai, Y. Wang, R. Mallick, L. Minciullo, G. Francesca et F. Bremond. Selective Spatio-Temporal Aggregation Based Pose Refinement System: Towards Understanding Human Activities in Real-World Videos. WACV 2021. ⟨hal-03121883⟩https://hal.archives-ouvertes.fr/hal-03121883
Nouvelles approches d’optimisation pour définir les tests groupés – ou « group testing »
Afin de dépister une population, on peut soit tester l’ensemble des individus un par un, ce qui implique un nombre important de tests, ou bien tester des groupes d’individus. Dans ce cas, toutes les personnes subissent un prélèvement, et l’on réalise un seul test dans le groupe : s’il s’avère négatif, cela signifie que tout le groupe est négatif ; s’il est positif, on procède alors à des tests individuels complémentaires. Cette approche permet ainsi de réduire nettement le nombre d’analyses à réaliser, tout en restant fiable.
D’autres approches basées sur le même principe mais plus complexes peuvent être considérées.
Les chercheurs de l’équipe projet Inocs (Integrated Optimization with Complex Structure) du centre Inria Lille-Nord Europe ont apporté une réponse à la question suivante dans le cadre de la Covid 19: Comment former ces groupes – et selon quels critères – afin de garantir l’efficacité de la procédure ?
Plus précisément des modèles d’optimisation basés sur la théorie des graphes ont été définis. Des méthodes de résolutions exactes ont été développées afin de déterminer la taille optimale des groupes ainsi que leurs constitution de façon à atteindre différents objectifs en tenant compte de contraintes spécifiques des tests. Les objectifs peuvent être la minimisation du nombre de tests, la minimisation du nombre de faux négatifs, la minimisation du nombre de faux positifs ou une combinaison de ces critères.
L’efficacité des méthodes de résolutions est prouvéepar des tests sur des données publiques ou des données issues du CHU de Lille.
Pour aller plus loin :
Références scientifiques :
T. Almeftah 1 L. Brotcorne 1 D. Cattaruzza B. Fortz 1 K. Keita 1 M. Labbé 1 M. Ogier 1 F. Semet, « Group design in group testing for COVID-19 : A French case-study », https://hal.archives-ouvertes.fr/hal-03000715/
H. Aprahamian, D. R. Bish, E. K. Bish, Optimal risk-based group testing, Management Science 65 (9) (2018) 4365–4384, https://doi.org/10.1287/mnsc.2018.3138
Épidémiologie numérique : améliorer l’efficacité des soins et prévenir les risques grâce aux données
L’épidémiomogie est révolutionnée par l’utilisation des outils numériques [1,2]. L’épidémiologie s’intéresse à faire des corrélations entre des facteurs (génétiques, démographiques, traitements) et la survenue d’événements médicaux. Des questions usuelles sont par exemple: un traitement est-il réellement efficace ou non ? dans quelles circonstances un traitement à des effets indésirables ?
L’utilisation de méthodes d’analyse statistique, d’analyse de données ou d’intelligence artificielle appliquées à de grandes bases de données médicales offre de nouvelles perspectives à l’épidémiologie : elles permettent de répondre rapidement aux questions de santé publique, et elles permettent d’identifier des corrélations à propos des situations rares grâce à leur capacité à traiter de très grands volumes de données.
Mais quelles bases de données peuvent être utilisées ? Ce peut être des bases constituées spécifiquement pour répondre à une question mais les épidémiologistes disposent également de base de données collectées auprès des patients dans les hôpitaux [3] ou par l’asurrance maladie [4]. Ces dernières permettent de reconstruire nos parcours de soins.
Dans un cadre réglementaire strict, ces données peuvent servir à répondre à certaines questions épidémiologiques. L’épidéliologiste devient alors un analyste : face à ces bases de données, il doit les faire « parler » et mobiliser pour cela toute une
panoplie d’outils numériques qui vont l’aider à sélectionner des cohortes de patients, détecter des facteurs/événements médicaux
d’intérêt, identifier les corrélations et les relier à des connaissances médicales. Et pour faire face à la complexité et à la volumétrie des données, il utilise les techniques numériques les plus avancées en analyse de données et intelligence artificielle.
De la dengue à la lutte antivectorielle biologique
Le virus de la dengue, mais aussi ceux du chikungunya, de la fièvre zika, de la fièvre jaune, sont transmis aux humains par plusieurs espèces de moustiques du genre Aedes. La fièvre jaune est la plus grave de ces maladies. Elle touche 200.000 personnes par an dans le monde entier, dont 30.000 décèdent. Aucun remède n’est connu, mais un vaccin préventif existe, sûr et efficace (obligatoire par exemple pour voyager en Guyane…).
Pour les autres maladies, il n’existe actuellement aucun vaccin satisfaisant, et aucun remède. La plus répandue est la dengue, avec près de 400 millions de cas annuels, dont 500.000 prennent une forme hémorragique grave, mortelle dans 2,5% des cas. Ainsi, la mortalité de la dengue est bien inférieure à celle de la fièvre jaune, mais l’ordre de grandeur des décès qu’elles provoquent est le même.
Près de 4 milliards de personnes vivent dans des zones où elles risquent d’attraper la dengue. Initialement présente dans les régions tropicales et subtropicales du monde, cette maladie s’étend aux zones tempérées des deux hémisphères, en suivant la lente invasion de ces régions (probablement favorisée par le réchauffement climatique) par l’espèce Aedes albopictus — le fameux moustique tigre, plus résistant au froid que le vecteur « historique » qui peuple les régions tropicales, Aedes ægypti. Non détecté en France métropolitaine avant 2004, le moustique tigre est maintenant considéré comme installé dans 64 de ses départements.
La dengue a touché l’Europe dans le prolongement de cet essor, apportée de zones endémiques par des voyageurs infectés, puis transmise lors d’une piqûre à des moustiques locaux. En 2020, 834 cas de dengue importés ont été confirmés en France métropolitaine, mais aussi 13 cas autochtones.
En l’absence de vaccin, la prévention individuelle contre ces maladies consiste essentiellement en des mesures de protection contre les piqûres. La prévention collective repose sur divers moyens de lutte antivectorielle. Il s’agit en premier lieu de mesures d’éducation sanitaire et de mobilisation sociale destinées à réduire les gîtes de ponte. Par ailleurs, l’usage d’insecticides tend actuellement à diminuer: non seulement l’absence de spécificité de ces produits les rend dangereux à d’autres espèces, mais ils induisent un phénomène de résistance qui réduit leur efficacité.
Des méthodes de lutte biologique, plus spécifiques, sont maintenant étudiées. La plus ancienne est la technique de l’insecte stérile, consistant à lâcher dans la nature de grandes quantités de moustiques mâles élevés en laboratoire, et stérilisés par irradiation dans des installations spécialisées: leur accouplement avec les femelles en liberté a pour effet de réduire la taille de la population sauvage, et de diminuer ainsi la propagation des virus. Une autre méthode, plus récemment conçue, consiste à inoculer ces moustiques avec une bactérie appelée Wolbachia, naturellement présente chez la plupart des arthropodes. Cette bactérie a la propriété remarquable de réduire leur capacité de transmettre la dengue, le zika et le chikungunya à ceux qu’ils piquent. Elle passe de la mère à la progéniture, et c’est en lâchant des moustiques intentionnellement infectés en laboratoire par Wolbachia que l’on compte réaliser sa mise en œuvre. Des essais correspondants commencent à avoir lieu en plusieurs points du globe, y compris en Nouvelle-Calédonie. Les mathématiques appliquées participent à l’analyse qualitative et quantitative de la faisabilité de ces méthodes de lutte contre des infections graves émergeant en Europe.
Cet entretien avec deux lycéennes de Haute-Savoie réalisé par David Roche, nous donne une vision sur ce nouvel enseignement de spécialité des fondements du numérique et des sciences informatiques au lycée en première et en terminale : il est tellement important que notre jeunesse, les deux moitiés de notre jeunesse, maîtrisent le numérique au delà de l’utiliser. Laissons leur la parole, grâce à la revue 1024 de la Société Informatique de France, d’où ce contenu est repris. Thierry Viéville.
Alors que les statistiques nationales indiquent que les filles sont peu nombreuses à choisir la spécialité « Numérique et sciences informatiques », elles représentent 40 % de l’effectif de la classe de terminale de David Roche au lycée Guillaume Fichet à Bonneville en Haute-Savoie. 1024 a donc demandé à David de recueillir les témoignages de quelques unes de ses élèves pour tenter une explication. Mélisse Clivez et Émeline Cholletont accepté de jouer le jeu.
Si vous suivez ce qu’il s’est passé depuis 2012 au lycée, mise en place de la spécialité « informatique et sciences du numérique » puis récemment de « numérique et sciences informatiques » (NSI), vous avez sûrement déjà croisé la route de David Roche. Initialement professeur de physique, reconverti en professeur d’informatique, il a produit pour ses enseignements d’informatique de nombreux supports de qualité qu’il met à la disposition de la communauté sous forme de ressources éducatives libres sur https://pixees.fr/informatiquelycee.
Ces ressources accompagnent toujours bon nombre d’enseignants et leur ont parfois évité quelques nuits blanches. N’oubliez pas de le citer si vous utilisez sa production (sous licence Creative Commons).
– David Roche, D. R. : « Pourquoi avez-vous choisi NSI en première ? »
– Mélisse Clivaz, M. C. : À ce stade de ma scolarité et de mon parcours avenir, je n’étais pas encore décidée entre mes deux choix d’orientation qui étaient le social et l’informatique. Mes trois choix de spécialité se sont donc porté sur SES (pour le social), NSI (pour l’informatique) et AMC puisque l’anglais est, pour moi, toujours utile.
– Émeline Chollet, É. C. : J’ai choisi NSI en première car j’avais pris informatique aussi en seconde. Pour le choix de mes spécialités, j’ai pris maths, physique-chimie, et après j’avais le choix entre SVT et informatique. Puis, au fur et à mesure de l’année j’ai préféré l’informatique aux sciences de la vie et de la terre.
–D. R. : « Pourquoi avez-vous choisi de continuer NSI en terminale ? »
– M. C. : Mon choix de spécialité fait en classe de première fut, en réalité, un choix stratégique. Il avait pour objectif de me laisser le plus de liberté possible pour mon orientation future. Le choix de terminale fut en totale cohérence avec mon parcours avenir qui s’est affiné au fil du temps. La spécialité NSI est un moyen de garder un lien avec les mathématiques même si vous ne vous considérez pas comme quelqu’un de « matheux ». De plus, les cours de NSI sont totalement différents des cours magistraux dans la plupart des autres matières ; ce sont des cours qui mélangent théorie et pratique. Ceci permet de se rendre compte en temps réel de l’utilité de ce qu’on apprend.
– É. C. : En terminale, nous devons enlever une de nos trois spécialités. Je devais garder obligatoirement maths, mais ensuite, j’avais le choix entre physique et informatique. D’un côté, je voulais garder une plus grande diversité en termes de connaissances, pour éviter de me fermer des portes dès la classe de terminale et avoir moins de difficultés ensuite dans le supérieur si je choisis une classe préparatoire. D’un autre coté, j’avais de très bonnes notes en informatique ce qui n’était pas le cas en physique et j’aimais cette matière. Alors, je me suis décidée à garder NSI aussi en terminale et j’ai bien fait. En NSI, les cours sont totalement différents d’un autre cours, ce ne sont pas des cours magistraux, et notre professeur a fait un site dans lequel il y a tout le cours bien organisé et bien expliqué ; ce qui nous permet d’avan- cer à notre rythme. Quand tout le monde a fini un point du cours, il nous fait un résumé au tableau. Une fois par mois environ, nous faisons des projets où l’on doit programmer quelque chose ; ces projets sont très enrichissants et nous entraînent à programmer. J’apprécie cette manière de travailler car on a pas mal d’autonomie et on est assez libre, tout en avançant sur le programme rapidement.
– D. R. : « Est-ce que NSI a un rapport avec votre orientation ? »
– M. C. : Comme dit précédemment, mon parcours avenir s’est créé au fil du temps ; notamment grâce au cours d’informatique mais également grâce à des stages en en- treprise. Je souhaite travailler dans le domaine du Web Design, et mes deux années d’informatique constitueront un point positif sur mon CV lorsque je candidaterai à des écoles formant à ces métiers (ces écoles accordant une valeur importante à la connaissance technique lorsqu’elle vient en plus des aspects créatifs).Il est certain que le domaine de l’informatique est très peu fréquenté par les filles car le stéréotype des filles littéraires et des garçons scientifiques persiste. De plus, l’image que l’on a d’un cours d’informatique et des personnes qui le suivent est celle de garçons scotchés devant leur ordinateur depuis la naissance alors, qu’en réalité, n’importe qui ayant un minimum de curiosité pour la technologie et l’informatique peut suivre ce cours, le comprendre et y prendre goût.
– É. C. : L’année prochaine, je veux suivre un cursus master en ingénierie en informa- tique à Chambéry. Je pense que mes trois années d’informatique au lycée m’aideront bien. Par ailleurs, cette année, j’ai aussi pris maths expertes dans le but d’avoir un bon niveau en maths.
– D. R. : « Une fille pour une classe de garçons ? »
– É. C. : Je n’ai pas peur d’être dans une classe de garçons. D’un côté, je préfère être dans une classe formée que de garçons plutôt que dans une classe composée uniquement de filles. Et puis, leur compagnie ne me dérange pas. Souvent, ils savent plus de choses que moi alors ils m’apprennent des choses et inversement.
1024, c’est aussi le bulletin de la Société informatique de France (SIF). Il est imprimé et distribué gratuitement deux fois par an à tous ses adhérents et partenaires et consultable en accès libre sur le site de la SIF. Pour Binaire, 1024, ce sont des copains avec qui nous échangeons sur les sujets que nous voulons traiter, avec qui nous partageons parfois des articles. Serge Abiteboul & Thierry Viéville
À qui s’adresse-il et que partage-t-il ?
Il s’adresse à toute personne pour qui l’informatique est un métier, une passion, toute personne désireuse de se tenir au courant de nouvelles expériences pédagogiques ou d’approfondir les thématiques scientifiques du domaine. 1024 propose aussi des articles à connotation scientifique ou historique, des dossiers thématiques; il met en lumière les actualités des associations partenaires et propose aux jeunes docteurs de résumer leurs travaux de recherche en 1024 caractères exactement. À chaque numéro, une partie récréative présente une énigme algorithmique résolue dans le numéro suivant. Les femmes y sont également à l’honneur avec une rubrique qui leur est dédiée.
L’informatique s’enseigne aussi au lycée désormais ?
Le dernier numéro d’avril 2021 publie un dossier spécial dédié au tsunami numérique nommé « Numérique et sciences informatiques », et enseignement de spécialité d’informatique au lycée qui permet enfin de former vraiment nos jeunes à l’informatique pour qu’elles et ils deviennent créateurs ou développeuses de la société numérique d’aujourd’hui et demain.
On y donne la parole à plusieurs personnes impliquées dans ce changement : Jean-Marie Chesneaux, inspecteur général de mathématiques en charge de NSI nous éclaire sur ce que signifie concrètement l’introduction d’une nouvelle discipline au lycée ; Isabelle Guérin Lassous, présidente du jury du nouveau CAPES NSI, accompagnée de Fabien Tarissan et Marie Duflot-Kremer, nous présente le concours et nous propose un retour sur la première édition ; Charles Poulmaire, professeur de mathématiques et informatique, formateur dans l’académie des Yvelines, partage avec nous son regard sur l’introduction de l’informatique au lycée; Marc de Falco et Yann Salmon, professeurs d’informatique en classes préparatoires nous expliquent comment ces dernières s’adaptent à l’arrivée des nouveaux bacheliers, en modifiant leurs programme mais aussi en créant une nouvelle filière spécifique MPI (mathématiques, physique, informatique) pour l’accueil des bacheliers NSI. Enfin, grâce à David Roche, professeur de physique et d’informatique, nous recueillons le témoignage de deux lycéennes de Haute-Savoie qui ont choisi de suivre la spécialité NSI en première et terminale. Nous le savions déjà, l’informatique est aussi une affaire de femmes ! Pour ce numéro, nous aurions également souhaité avoir le point de vue des IUT (instituts universitaires de technologie) qui sont actuellement obligés de réviser leur programme pédagogique national suite à la mise en place du BUT (bachelors universitaires de technologie) et des universités qui accueillent des bacheliers avec des profils différents .
Nous vous invitons à suivre la sortie du prochain bulletin en novembre 2021 pour en savoir davantage, et n’hésitez pas à nous faire parvenir vos témoignages ou expériences sur l’accueil de ces nouveaux bacheliers ou sur tout autre sujet à cette adresse 1024@societe-informatique-de-france.fr.
où on retrouve chaque chiffre entre 0 et 9 une fois et une seule …
Plus sérieusement, comme 1024 = 210, c’est aussi une mesure de stockage, le kilobyte, la taille mémoire adressable avec une adresse de 10 octets. Mais, comme c’est presque 1000 = 10^3, on passe vite à un système décimal. Il fallait être un peu geek pour choisir cela comme titre d’un magazine.
Et même certain de ressentir la poésie de 2^10, la beauté de 2x2x2x2x2x2x2x2x2x2.
D’ailleurs … et à votre avis ? N’hésitez pas à proposer vos réponses dans les commentaires.
Denis Pallez, Chercheur en Informatique à l’Université Côte d’Azur.
Le développement de la démocratie participative a fait émerger de nouvelles formes de consultations avec un grand nombre de données à analyser. Les réponses sont complexes puisque chacun s’exprime sans contrainte de style ou de format. Des méthodes d’intelligence artificielle ont donc été utilisées pour analyser ces réponses mais le résultat est-il vraiment fiable ? Une équipe de scientifiques lillois s’est penchée sur l’analyse des réponses au grand débat national et nous explique le résultat de leur recherche . Pierre Paradinas, Pascal Guitton et Marie-Agnès Enard.
Dans le cadre d’un développement de la démocratie participative, différentes initiatives ont vu le jour en France en 2019 et 2020 comme le grand débat national et la convention citoyenne sur le climat. Toute consultation peut comporter des biais : ceux concernant l’énoncé des questions ou la représentativité de la population répondante sont bien connus. Mais il peut également exister des biais dans l’analyse des réponses, notamment quand celle-ci est effectuée de manière automatique.
Nous prenons ici comme cas d’étude la consultation participative par Internet du grand débat national, qui a engendré un grand nombre de réponses textuelles en langage naturel dont l’analyse officielle commandée par le gouvernement a été réalisée par des méthodes d’intelligence artificielle. Par une rétro-analyse de cette synthèse, nous montrons que l’intelligence artificielle est une source supplémentaire de biais dans l’analyse d’une enquête. Nous mettons en évidence l’absence totale de transparence sur la méthode utilisée pour produire l’analyse officielle et soulevons plusieurs questionnements sur la synthèse, notamment quant au grand nombre de réponses exclues de celle-ci ainsi qu’au choix des catégories utilisées pour regrouper les réponses. Enfin, nous suggérons des améliorations pour que l’intelligence artificielle puisse être utilisée avec confiance dans le contexte sensible de la démocratie participative.
Le matériau à analyser
Nous considérons le traitement des 78 questions ouvertes du grand débat national dont voici deux exemples :
« Que faudrait-il faire pour mieux représenter les différentes sensibilités politiques ?” du thème “La démocratie et la citoyenneté”
“Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” dans le cadre des propositions de solutions de mobilité alternative du thème “La transition écologique”
Les réponses aux questions sont des textes rédigés par les participants qui vont de quelques mots à plusieurs centaines de mots avec une longueur moyenne de 17 mots. Pour chaque question, on dispose de quelques dizaines de milliers de réponses textuelles à analyser. Le traitement d’une telle quantité de données est difficile pour des humains, d’où la nécessité de l’automatiser au moins partiellement. Lorsque les questions sont fermées (avec un nombre prédéfini de réponses), il suffit de faire des analyses quantitatives sous forme de comptes, moyennes, histogrammes et graphiques. Pour des questions ouvertes, il faut se tourner vers des méthodes d’intelligence artificielle.
Que veut-dire analyser des réponses textuelles ?
Il n’est pas facile de répondre à cette interrogation car, les questions étant ouvertes, les répondants peuvent laisser libre cours à leurs émotions, idées et propositions. On peut ainsi imaginer détecter les émotions dans les réponses (par exemple la colère dans une réponse comme “C’est de la foutaise, toutes les questions sont orientées ! ! ! On est pas là pour répondre à un QCM !”), ou encore chercher des idées émergentes (comme l’utilisation de l’hydrogène comme énergie alternative). L’axe d’analyse retenu dans la synthèse officielle, plus proche de l’analyse des questions fermées, consiste à grouper les réponses dans des catégories et à compter les effectifs. Il peut être formulé comme suit : pour chaque question ouverte et les réponses textuelles associées :
1. Déterminer des catégories et sous-catégories sémantiquement pertinentes ;
2. Affecter les réponses à ces catégories et sous-catégories ;
3. Calculer les pourcentages de répartition.
L’étude officielle, réalisée par Opinion Way (l’analyse des questions ouvertes étant déléguée à l’entreprise QWAM) est disponible sur le site du grand débat. Pour chacune des questions ouvertes, elle fournit des catégories et sous-catégories définies par un intitulé textuel et des taux de répartition des réponses dans ces catégories.
Par exemple, pour la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?”, l’analyse a catégorisé les réponses de la façon suivante :
Les acteurs publics
43,4%
Les solutions envisagées
8,8%
Les acteurs privés
6,6%
Autres contributions trop peu citées ou inclassables
22,5%
Non réponses, (les réponses vides)
30,2%
On constate que les catégories se chevauchent, que la catégorie “Les solutions envisagées” ne correspond pas à une réponse à la question et que le nombre d’inclassables est élevé (22.5% soit environ 35 000 réponses non prises en compte).
L’analyse officielle : la méthode
Regrouper des données dans des catégories correspond à une tâche appelée classification non supervisée ou clustering. C’est une tâche difficile car on ne connaît pas les catégories a priori, ni leur nombre, les catégories peuvent se chevaucher. De surcroît, les textes en langage naturel sont des données complexes. De nombreuses méthodes d’intelligence artificielle peuvent être utilisées comme, par exemple, la LDA pour “Latent Dirichlet Analysis” et ses nombreux dérivés.
Quelle est la méthode utilisée par l’entreprise QWAM ? À notre connaissance, les seules informations disponibles se trouvent dans la présentation de la méthodologie. On y décrit l’utilisation de méthodes internes qui sont “des algorithmes puissants d’analyse automatique des données textuelles en masse (big data), faisant appel aux technologies du traitement automatique du langage naturel couplées à des techniques d’intelligence artificielle (apprentissage profond/deep learning)” et le post-traitement par des humains : “une intervention humaine systématique de la part des équipes qualifiées de QWAM et d’Opinion Way pour contrôler la cohérence des résultats et s’assurer de la pertinence des données produites”.
Regard critique sur l’analyse officielle
Il semble que l’utilisation d’expressions magiques telles que “intelligence artificielle” ou “big data”, ou bien encore “deep learning” vise ici à donner une crédibilité à la méthode aux résultats en laissant penser que l’intelligence artificielle est infaillible. Nous faisons cependant les constats suivants :
– Les codes des algorithmes ne sont pas fournis et ne sont pas ouverts ;
– La méthode de choix des catégories, des sous-catégories, de leur nombre et des intitulés textuels associés n’est pas spécifiée ;
– Les affectations des réponses aux catégories ne sont pas fournies ;
– Malgré l’intervention humaine avérée, aucune mesure d’évaluation des catégories par des humains n’est fournie.
Nous n’avons pas pu retrouver les résultats de l’analyse officielle malgré l’usage de plusieurs méthodes. Dans la suite, nous allons voir s’il est possible de les valider autrement.
Une rétro-analyse de la synthèse officielle
Notre rétro-analyse consiste à tenter de ré-affecter les contributions aux catégories et sous-catégories de l’analyse officielle à partir de leur contenu textuel. Notre approche consiste à affecter une contribution à une (sous-)catégorie si le texte de la réponse et l’intitulé de la catégorie sont suffisamment proches sémantiquement. Cette proximité sémantique est mesurée à partir de représentations du texte sous forme de vecteurs de nombre, qui constituent l’état de l’art en traitement du langage (voir encadré).
Nous avons testé plusieurs méthodes de représentation des textes et plusieurs manières de calculer la proximité sémantique entre les réponses et les catégories. Nous avons obtenu des taux de répartitions différents selon ces choix, sans jamais retrouver (même approximativement) les taux donnés dans l’analyse officielle. Par exemple, la figure ci-dessous donne les taux de répartitions des réponses dans les catégories obtenus avec différentes approches pour la question « Quelles sont toutes les choses qui pourraient être faites pour améliorer l’information des citoyens sur l’utilisation des impôts ? ».
Pour compléter notre rétro-analyse automatique, nous avons mis en œuvre une annotation manuelle sur la question “Et qui doit selon vous se charger de vous proposer ce type de solutions alternatives ?” du thème Transition Ecologique et la catégorie Les acteurs publics et avons trouvé un taux de 54.5% à comparer avec un taux de 43.4% pour l’analyse officielle, soit une différence de 15 000 réponses ! Les réponses à cette question sont globalement difficiles à analyser, car souvent longues et argumentées (25000 réponses contenant plus de 20 mots). Notre étude manuelle des réponses nous a fait remarquer certaines réponses comme “moi-même”, “les citoyens”, “c’est mon problème”, “les français sont assez intelligents pour les trouver seuls” ou encore “les citoyens sont les premiers maîtres de leur choix”. Pour ces réponses, nous avons considéré une catégorie Prise en charge par l’individu qui n’est pas présente dans la synthèse officielle bien qu’ayant une sémantique forte pour la question. Un classement manuel des réponses donne un taux de 4.5% des réponses pour cette catégorie, soit environ 7000 réponses, taux supérieur à certaines catégories existantes. Ceci met en évidence un certain arbitraire et des biais dans le choix des catégories de la synthèse officielle.
En résumé, notre rétro-analyse de la synthèse officielle montre :
L’impossibilité de retrouver les résultats de la synthèse officielle ;
La différence de résultats selon les approches ;
Des biais dans le choix des catégories et sous-catégories.
La synthèse officielle n’est donc qu’une interprétation possible des contributions.
Recommandations pour utiliser l’IA dans la démocratie participative
L’avenir des consultations participatives ouvertes dépend en premier lieu de leur prise en compte politique, mais il repose également sur des analyses transparentes, dignes de confiance et compréhensibles par le citoyen. Nous proposons plusieurs pistes en ce sens :
Transparence des analyses : les méthodes utilisées doivent être clairement décrites, avec, si possible, une ouverture du code. La chaîne de traitement dans son ensemble (comprenant le traitement humain) doit également être précisément définie. Enfin, il est nécessaire de publier les résultats obtenus à une granularité suffisamment fine pour permettre une validation indépendante (par des citoyens, des associations ou encore des chercheurs).
Considérer différents axes d’analyse et confronter différentes méthodes : la recherche de catégories aurait pu être complétée par la recherche de propositions émergentes ou l’analyse de sentiments et d’émotions. Par ailleurs, pour un axe d’analyse donné, il existe différentes méthodes reposant sur des hypothèses et biais spécifiques et la confrontation de plusieurs analyses est utile pour nuancer certaines conclusions et ainsi mener à une synthèse finale plus fiable.
Concevoir des consultations plus collaboratives et interactives : publier les affectations des réponses aux catégories permettrait à tout participant de voir comment ses contributions ont été classées. Il serait alors possible de lui demander de valider ou non ce classement et d’ainsi obtenir une supervision humaine partielle utilisable pour améliorer l’analyse. D’autres manières de solliciter cette supervision humaine peuvent être considérées, par exemple faire annoter des textes par des volontaires (voir l’initiative de la Grande Annotation) ou encore permettre aux participants de commenter ou de voter sur les contributions des autres.
Si l’intelligence artificielle permet désormais de considérer des enquêtes à grande échelle avec des questions ouvertes, elle est susceptible de biais comme toute méthode automatique. Il est donc nécessaire d’être transparent et de confronter les méthodes. Dans un contexte de démocratie participative, il est également indispensable de donner une véritable place aux citoyens dans le processus d’analyse pour engendrer la confiance et favoriser la participation.
Pour aller plus loin : les résultats détaillés de l’étude, ainsi que le code source utilisé pour réaliser cette rétro-analyse, sont consultables dans l’article.
Représenter des textes comme des vecteurs de nombre
Qui aurait prédit au début des années 2000 au vu de la complexité du langage naturel, que les meilleurs logiciels de traduction automatique représentent les mots, les suites de mots, les phrases et les textes par des vecteurs de nombres ? C’est pourtant le cas et voyons comment !Les représentations vectorielles des mots et des textes possèdent une longue histoire en traitement du langage et en recherche d’information. Les premières représentations d’un texte ont consisté à compter le nombre d’apparitions des mots dans les textes. Un exemple classique est la représentation tf-idf (pour « term frequency-inverse document frequency’’) où on pondère le nombre d’apparitions d’un mot par un facteur mesurant l’importance du mot dans l’ensemble des documents. Ceci permet de diminuer l’importance des mots fréquents dans tous les textes (comme le, et, donc, …) et d’augmenter l’importance de mots plus rares, ceci pour mieux discriminer les textes pertinents pour une requête dans un moteur de recherche. Les vecteurs sont très longs (plusieurs centaines de milliers de mots pour une langue) et très creux (la plupart des composantes sont nulles car un texte contient peu de mots). On ne capture pas de proximité sémantique (comme emploi et travail, taxe et impôt) puisque chaque mot correspond à une composante différente du vecteur.Ces limitations ont conduit les chercheurs à construire des représentations plus denses (quelques centaines de composantes) à même de mieux modéliser ces proximités. Après avoir utilisé des méthodes de réduction de dimension comme la factorisation de matrices, on utilise désormais des méthodes neuronales. Un réseau de neurones est une composition de fonctions qui se calcule avec des multiplications de matrices et l’application de fonctions simples, et qui peut être entraîné à prédire un résultat attendu. On va, par exemple, entraîner le réseau à prédire le mot central d’une fenêtre de 5 mots dans toutes les phrases extraites d’un corpus gigantesque comme Wikipedia. Après cet entraînement (coûteux en ressources), le réseau fournit une représentation de chaque mot (groupe de mots, phrase et texte) par un vecteur. Les représentations les plus récentes comme ELMo et BERT produisent des représentations de phrases et des représentations contextuelles de mots (la représentation d’un mot varie selon la phrase). Ces représentations vectorielles ont apporté des gains considérables en traitement du langage naturel, par exemple en traduction automatique.
En cette période de pandémie de Covid-19, l’association Enseignement Public et Informatique fête son 50e anniversaire.
Il y a dix ans, nous intitulions l’éditorial de notre numéro spécial « 40 ans : un bel âge pour une association ». Une décennie plus tard, nous n’avons pas pu résister à l’idée de reprendre ce titre, en l’actualisant bien sûr ! L’EPI a été fondée en 1971 (JO du 1er février) par les premiers stagiaires « lourds » chez les constructeurs de l’époque (IBM, CII, Honeywell-Bull). Depuis cette date, l’EPI a été partie prenante de tous les épisodes du déploiement, parfois hésitant voire chaotique, parfois accéléré – on pense au Plan Informatique pour Tous de 1985 –, de l’informatique pédagogique au sein du système éducatif.
Des fils d’Ariane se sont imposés dès le départ. Ils demeurent : la pluralité des approches ; leur complémentarité, ainsi l’informatique est-elle à la fois instrument pédagogique et objet d’enseignement pour tous car élément de la culture générale à notre époque ; l’impérieuse nécessité d’une solide formation diversifiée de tous les enseignants ; une didactique appropriée ; une recherche pédagogique active. Et l’EPI, force de proposition inscrit son action dans le Service public à la promotion duquel elle est attachée.
Nous parlons de déploiement parfois chaotique de l’informatique pédagogique et il nous est arrivé d’avoir raison trop tôt, mais les faits sont têtus. Il faut se souvenir qu’à la fin du siècle dernier, il était encore de bon ton dans certains milieux de proclamer que l’informatique était une mode et que comme toute mode elle passerait. Le développement d’Internet a définitivement tordu le cou à ce genre de propos. Ces résistances à l’émergence du « nouveau informatique » ne sont pas une exception. Au contraire c’est la loi du genre qui ne date pas d’hier. Si le « nouveau » finit par s’imposer, c’est toujours dans une certaine douleur. Déjà, Confucius mettait en garde : « Lorsque tu fais quelque chose, sache que tu auras contre toi ceux qui voulaient faire la même chose, ceux qui voulaient faire le contraire et l’immense majorité de ceux qui ne voulaient rien faire. »
Pour se faire sa place, le « nouveau informatique » a dû aider à une clarification des problématiques car les résistances s’accompagnent d’une certaine confusion. Il a fallu dire que les enjeux et les statuts de l’informatique dans le système éducatif sont divers et qu’il faut les distinguer. L’informatique est un outil pédagogique, transversal et spécifique, qui a fait ses preuves et qu’il faut utiliser à bon escient d’une manière raisonnée. L’informatique contribue à l’évolution de l’« essence » des disciplines (leurs objets, leurs outils et leurs méthodes). Il suffit de penser aux sciences expérimentales avec l’EXAO et la simulation, à la géographie avec les SIG, aux disciplines des enseignements techniques et professionnels. L’informatique est outil de travail personnel et collectif des enseignants, des élèves, de l’ensemble de la communauté éducative. Et l’informatique est discipline scientifique et technique, composante de la culture générale scolaire au XXIe siècle. Tous ces statuts sont complémentaires et se renforcent mutuellement. Ils doivent être tous présents. Et l’un ne saurait se substituer à l’autre.
Cette dernière décennie, l’EPI s’est inscrite dans la continuité des périodes précédentes. Des actions ont été menées en étroite relation avec des personnalités, des associations de spécialistes informatiques, en premier lieu la SIF, l’APRIL, association du logiciel libre, les parents d’élèves de la PEEP… Ce furent des rencontres au ministère de l’Éducation nationale, notamment auprès de l’Inspection générale, des conférences avec nos partenaires, des articles dans la presse nationale, la publication de notre revue mensuelle gratuite EpiNet.
En 2013, l’EPI a participé au groupe de travail qui a préparé le rapport de l’Académie des sciences L’enseignement de l’informatique en France – Il est urgent de ne plus attendre[1].
Parmi les nombreuses rencontres de la décennie passée, mentionnons qu’avec la Ligue des Droits de l’Homme, la Ligue de l’Enseignement, la PEEP, la SIF et Creis-Terminal, la FCPE étant excusée, l’EPI a rencontré le 27 novembre 2017 la Mission sur « Les données numériques à caractère personnel au sein de l’Éducation nationale ». La rencontre s’inscrivait dans la continuité de la demande d’audience que nous avions faite au ministre de l’Éducation nationale suite au courrier du directeur du numérique du 12 mai 2017, courrier qui avait suscité une grande et légitime émotion de la part des parents d’élèves, de syndicats d’enseignants, d’associations. Nous avons réaffirmé que l’on ne doit pas donner les clés de la maison Éducation nationale aux GAFAM et rappelé que si les GAFAM sont là, c’est aussi parce que l’institution éducative les invite depuis de longues années.
Tout en gardant le cap de « la complémentarité des approches », l’EPI a amplifié ses efforts, avec d’autres, pour obtenir des pouvoirs publics une intégration de l’informatique dans l’enseignement de culture générale pour tous les élèves. L’omniprésence de cette science qui sous-tend le numérique, les besoins d’informaticiens nécessitent des efforts considérables du système éducatif. On se souvient que, dans les années 90, il y avait eu les suppressions de l’option informatique puis la création du B2i : un désert explicatif. En 2007, notre rencontre à l’Élysée avait relancé et élargi l’action pour l’informatique. le groupe ITIC avait été créé, au sein de l’ASTI, à l’initiative de l’EPI. La décennie qui vient de s’écouler a vu la création d’ISN, SNT, NSI et la création d’un Capes NSI. Des avancées significatives mais il reste encore beaucoup à faire : nombre de postes mis au concours correspondant aux besoins, et on attend toujours la création d’une agrégation d’informatique. L’EPI n’est plus seule, les choses évoluent même si elles évoluent trop lentement. Ainsi la pratique du numérique dans les différentes disciplines et activités ne se développe-t-elle pas à la mesure de son intérêt didactique et pédagogique. Toujours et encore l’insuffisante formation des enseignant·e·s.
Pour terminer ce numéro spécial d’EpiNet, nous disons merci à tous les amis, compagnons de route dont vous pourrez lire les témoignages. Merci à toutes celles et ceux qui ont participé à la réalisation de ce numéro spécial. Merci à tous ceux qui se sont investis au fil des années pour que l’informatique et le numérique aient leur place pleine et entière dans le système éducatif. Merci à tous les fidèles lecteurs d’EpiNet. Et nous aurons une pensée pour notre ami Maurice Nivat qui nous a quittés le 21 septembre 2017. Maurice était membre d’honneur de l’EPI.
L’Association Epi (enseignement public et informatique) fête cette année ses 50 ans.
A cette occasion la revue EpiNET sort un numéro spécial recueil de témoignages plus intéressants les uns que les autres racontant les campagnes « militantes », les déploiements chaotiques, les victoires, la persévérance, toujours, des membres de l’association … pour développer, intégrer et maintenir l’informatique comme instrument pédagogique et objet d’enseignement.
Si Pixees ne devait en retenir qu’un pour vous donner envie de lire les autres ? Peut-être serait-ce celui de Monique Grandbastien : une pionnière qui raconte comment sa carrière est intimement liée à l’enseignement de l’informatique.
Rappel : l’EPI crée en 1971 veut faire de l’informatique, et des technologies de l’information et de la communication en général, un facteur de progrès et un instrument de démocratisation.
Liliana Cucu-Grosjean est chercheuse à l’Inria. Elle est aussi , avec son complice Steve Kremer, co-présidente du comité Parité et Égalité des Chances à l’Inria. Ce groupe de réflexion et de proposition travaille depuis 2015 sur des sujets aussi variés que la valorisation des profils internationaux, l’inclusion des personnes LGBTI+ au sein de l’Institut, ou encore la place des femmes qui représente aujourd’hui moins de 20% des effectifs scientifiques dans les sciences du numérique. En ce 8 mars, Liliana nous recommande une lecture… Antoine Rousseau
Chaque année à l’approche du 8 mars, je me pose la question de comment souligner l’importance de cette date, qui rappelle qu’on doit, encore et toujours, se battre pour les droits des femmes. D’ailleurs, toute personne mordue par cette bataille cherche un cadeau ou un moyen pour rappeler (ou crier) que nous sommes le 8 mars, tout en se disant qu’un jour cette date n’aurait plus lieu d’être fêtée tellement les choses auraient évolué.
Cette année les adeptes des droits des femmes sont gâtés par la sortie du livre d’Anne-Marie Kermarrec début mars. Coïncidence ou choix délibéré ? Anne-Marie reste un petit miracle dans ce monde binaire, en faisant partie de celles et ceux qui n’attendent pas qu’on leur demande pour nous offrir des belles surprises. L’autrice admet, aussi, passer de plus en plus du temps sur la cause des femmes. Je dirais, donc, un choix délibéré.
J’ai appris via le réseau linkedin l’apparition du livre et je me suis dépêchée pour l’avoir entre mes mains, bon, plutôt devant mes yeux car je suis passée par une version électronique. Pourquoi me dépêcher ? Car j’ai pu constater par le passé l’absence de langue de bois dans les interventions d’Anne-Marie sur le sujet de la parité et, surtout, la pertinence de ses propos. Et je n’ai pas été déçue. J’avais pris le livre comme une lecture de soir et je me suis retrouvée à la dévorer jusqu’à des heures pas possibles ; cela ne m’était plus arrivé depuis le dernier volume des Milléniums (désolée pour la sortie de piste sans aucun lien avec ce billet), mais le livre m’y oblige par sa grande honnêteté.
Comment Anne-Marie attaque des sujets chauds, contradictoires, voire tabous des discussions sur la parité, impressionne la lectrice que je suis. Prenons sa discussion sur les quotas. Sujet sensible en France, Anne-Marie ose le mettre sur la table et le disséquer. Quels sont ces préjugés sur les quotas et pourquoi en sommes-nous là ? Un frein ou l’arme ultime ? Pour convaincre le lecteur ou la lectrice, Anne-Marie gagne sa confiance par le fil rouge de son livre qui est, à la fois historique, en faisant rentrer dans ses pages Grace Murray Hopper ou Sheryl Sandberg (avec la même aisance), et thématique, en passant par le décodage des idées reçues ou encore la vague #metoo dans le numérique (toujours avec la même honnêteté).
Mon passage préféré reste la discussion sur la question “Les femmes sont-elles des pestes entre elles ?” et la référence au syndrome “Queen Bee” m’a fait du bien, un peu comme dans les contes pour les enfants quand seulement la (belle-)mère est méchante et veut nuire à ses enfants, jamais le père, comme me l’a fait remarquer une de mes filles.
Je parle d’une attaque en décrivant l’écriture d’Anne-Marie car son style est frais et direct, il fait penser à une pièce de stand-up. Anne-Marie se met à table et nous partage ses doutes, l’évolution de ses opinions et, surtout, propose d’une manière constructive comment faire évoluer nos préjugés. Dans le feu de la lecture, je n’étais pas d’accord avec une ou deux de ses opinions et, maintenant après avoir dormi dessus, je me demande si ses opinions ne rentrent pas en conflit avec mes préjugés.
Êtes-vous prêts ou prêtes à quitter vos préjugés ? Si la réponse est oui, alors faites-vous du bien et lisez ce livre. Si vous pensez ne pas en avoir, lisez-le pour vous en assurer.
À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec retrouve binaire pour nous parler de difficultés rencontrées par les femmes au temps du Covid. La route est longue, on le savait, jusqu’à la vraie parité. On le vérifie. Serge Abiteboul et Pauline Bolignano
PS : binaire est fier de réaliser que nombre des chapitres du dernier livre d’Anne-Marie Kermarrec, ont été d’abord « testés » dans ses colonnes.
Le 8 mars dernier nous observions, encore d’un peu loin, avec une once, une once seulement, quels naïfs nous faisions, d’inquiétude les dégâts du coronavirus en Asie, lançant les paris sur l’éventualité d’un confinement que nous imaginions durer une ou deux semaines. Le couperet est tombé un peu plus d’une semaine après, nous coinçant là où nous étions ce soir du 16 mars 2020. Confinés, un mot un peu nouveau dans notre vocabulaire courant, dont il a fallu s’accommoder et que l’on ne finit de conjuguer depuis à tous les temps. Les écoles et les universités sont passées intégralement aux cours en ligne mettant au défi parents et enseignants, les commerces ont baissé leur rideau avec dépit, les soignants se sont mobilisés, les entreprises ont généralisé le télétravail, l’état s’est démené pour déclencher des aides, les familles se sont recroquevillées ou épanouies ensemble selon les cas, les parents se sont transformés en enseignants du jour au lendemain, les étudiants se sont retrouvés un peu à l’étroit dans leurs 20m2 ou au contraire ont filé dare-dare chez leurs parents pour avoir plus d’espace et bénéficier de la logistique familiale, certains parisiens ont débarqué dans leur résidence secondaire en Bretagne ou Normandie sous l’œil, parfois, réprobateur et méfiant des autochtones, qui les imaginaient trimballer le virus dans leurs poches.
Le numérique à la rescousse
Finalement nous avons survécu, certains mêmes, les plus chanceux, ont pu apprécier cette parenthèse hors norme où le temps s’étirait. Le numérique s’est avéré extrêmement salutaire pour tous dans cette période. En un mot, il a évité que le monde ne s’écroule pendant cette pandémie. C’est grâce au numérique que nous avons pu continuer à travailler, redoublant de créativité pour travailler en équipe, à grand renfort de Zoom, Teams, que sais-je, comparant dans le processus les avantages et inconvénients de chaque plateforme. Les professeurs ont pu effectuer leurs cours en ligne. Familles et amis se sont retrouvés pour des apéritifs virtuel, les artistes ont redoublé d’imagination pour pallier la fermeture des lieux de culture, et ont organisé des concerts virtuels depuis leur salon, des ballets synchronisés sur Internet. Les animaux en tous genres on refait surface en ville. Les radios en un tour de main ont organisé leurs émissions à distance. Les conférences, hauts lieux de rencontres académiques, se sont organisées à distance. Les scientifiques, largement aidés par des algorithmes d’apprentissage se sont lancés dans la quête du vaccin. D ’autres encore se sont lancés dans les applications de traçage ou la modélisation de la propagation du virus.
Et tout ça aura peut-être même un effet salvateur pour notre planète. En effet les plus de 3 millions de trajets qui ont ainsi pu être évités en France chaque semaine grâce au télétravail [1] ont certainement eu un impact non négligeable sur la pollution. On n’a jamais vu le ciel des mégalopoles chinoises aussi clair que début 2020. Même si on peut déplorer que les grosses entreprises de transport aériens aient beaucoup souffert dans le processus, nous avons pris de nouvelles habitudes qui potentiellement pourraient contribuer à la quête d’une empreinte carbone atténuée, y compris sur le long terme. Nous n’en sommes pas encore sortis et il est encore difficile de dresser un bilan. Espérons que le naturel ne revienne pas au galop sur tous les fronts. En particulier maintenant qu’il est avéré qu’une réunion sur zoom face à la mer n’est pas moins efficace qu’une réunion en présentiel (tiens encore un nouveau mot à notre arc) qui aurait nécessité un aller-retour Paris-Oslo dans la journée.
Outre qu’il nous a sauvé, le numérique a été le grand bénéficiaire de cet épisode. À la faveur de cette pandémie qui a mis des millions de personnes sur la paille, Eric Yuanle fondateur de Zoom, au contraire, a vu sa fortune grandir exponentiellement et le placer parmi les 400 américains les plus riches. Amazon, dont la place était d’ores et déjà bien établie, a vu ses bénéfices monter en flèche au troisième trimestre 2020 et tripler grâce aux ventes pandémiques. Un quart de la population s’est abonné à une nouvelle plateforme de streaming vidéo pendant cette période. Le e-commerce a fait un bond, y compris pour les plus petits acteurs, de nouvelles applications sont nées, la télémédecine s’est enfin imposée, etc. Bon, ça ce sont les bonnes nouvelles. On sait bien évidemment que malheureusement de nombreux secteurs ont pâti de cette crise et que de bien nombreuses personnes ont souffert (et continuent) financièrement, psychologiquement voire même physiquement. Comme on ne peut évoquer tous les sujets, je me propose en ce 8 mars de nous interroger, sur l’impact, en particulier celui du télétravail généralisé pendant le confinement, sur les femmes ?
Crédit photo: wocintechchat.com
Le télétravail au féminin : la vraie fausse bonne idée ?
Le télétravail, oui…
Dans certains pays, le télétravail est un véritable atout pour attirer les femmes dans des domaines peu féminisés, comme celui de l’informatique par exemple [2]. Cela dit, c’est un argument à double tranchant puisque la raison principale est qu’il permet en effet d’apporter une certaine flexibilité quant à l’organisation de son temps, le rendant ainsi compatible avec le fait de rester à la maison pour les enfants. Cette flexibilité peut cependant s’avérer assez salutaire, ainsi si certaines mettent un frein à une carrière exigeante qui leur demande de voyager à l’autre bout du monde pour une réunion de quelques heures, le faire depuis son salon leur permet d’être plus présentes dans le milieu professionnel. Ou encore leur laisse l’opportunité d’accepter une réunion tardive qui n’entre pas en conflit avec les horaires scolaires. Bien sûr la raison est que les femmes ont une petite tendance à ne pas souhaiter déroger à leurs obligations familiales pour gagner des galons. Mais puisque nous en sommes encore là, le télétravail peut s’avérer salutaire et ouvrir des portes aux femmes en particulier dans le domaine du numérique qui s’y prête particulièrement. Le télétravail peut ainsi représenter une excellente opportunité sur le long terme pour permettre aux femmes de s’ouvrir à des carrières qu’elles n’auraient pas considérées autrement.
…mais pas en pandémie
D’ailleurs, il se trouve que le travail chez les cadres s’est généralisé à la faveur de cette crise sanitaire dont nous ne sommes pas encore sortis. Un quart de la population a eu recours au télétravail des mars 2020 [1]. Si les entreprises ont dû transformer leurs pratiques managériales dans le processus, elles ont accusé réception des avantages potentiels comme des besoins réduits de mètres carrés de locaux et ont même parfois observé des gains de productivité.
Mais le bât blesse encore et toujours. Et si ces habitudes de travailler depuis la maison, faisaient partir en fumée 25 ans de lutte pour l’égalité homme-femme [3] ? Si le télétravail creusait les inégalités contre lesquelles on lutte depuis tout ce temps ?
Tout d’abord, tous les métiers ne se prêtent pas au télétravail, et c’est en majorité les cadres qui s’y sont collés à 86% pendant le premier confinement. Et bien c’est justement dans cette catégorie que les inégalités sont les plus importantes quant au meilleur spot de la maison pour travailler. Ainsi chez les cadres, 29% des femmes disposait d’un bureau à la maison contre 47% des hommes [4]. Pourquoi donc ? Est-ce parce que le bureau va plutôt à la personne du foyer qui occupe le poste le plus important ? Comme on sait que les hommes, s’ils ne préfèrent pas les blondes nécessairement, sont rarement en couple avec des femmes plus diplômées [6]. Et même à diplôme égale, il n’est pas rare que la carrière féminine n’ait pas suivi la même trajectoire et à la même rapidité. Il n’est pas exclu que les femmes elles-mêmes se portent volontaires pour laisser le bureau à leur conjoint.
La conséquence directe est, qu’outre que la répartition naturelle des tâches domestiques dans un couple, qui si elle s’est vaguement améliorée reste largement inégalitaire [7], que ce sont les femmes qui ont assuré en majorité les tâches domestiques pendant les confinements. Tâches du reste d’autant plus importantes que la famille entière prend ses repas à la maison matin, midi et soir en confinement, ce qui augmente singulièrement le volume de courses, cuisine et ménage. Et devinez qui a en majorité jouer à l’institutrice puisque Maman travaillait dans le salon ?
Crédit photo : https://nappy.co/alyssasieb
D’ailleurs, ce télétravail « pandémique » a eu un effet désastreux sur les femmes du milieu académique, celles- là même qui ont déjà bien du mal à gravir les échelons [2]. Ainsi les dernières études sur le sujet montrent que les femmes ont soumis proportionnellement beaucoup moins d’articles scientifiques que les hommes pendant cette pandémie [8].
Pour finir, selon les données de l’ONU, les violences conjugales ont augmenté de 30% en France pendant le confinement, à l’instar de ce qui s’est passé dans de très nombreux pays d’ailleurs. De là à dire que le télétravail augmente la probabilité de se faire taper dessus est exagéré. Mais il semblerait quand même que pour une proportion non négligeable de femmes, la maison n’est pas nécessairement l’endroit le plus sûr.
Pour conclure, le télétravail qui est désormais une option beaucoup plus répandue et probablement le restera, n’a pas été nécessairement un cadeau pendant cette pandémie. Mais espérons que dans le monde d’après, le télétravail permettra aux femmes de saisir de nouvelles opportunités que ce soit dans le numérique ou ailleurs.
Les centres de sciences La Casemate (Grenoble) et le Quai des Savoirs (Toulouse) organisent du 11 au 14 mars prochain un éditathon Wikipédia intitulé « Femmes de l’Intelligence artificielle VS Femmes des sciences de la Terre : le match ». Binaire souhaite donner un coup de projecteur à cette initiative, en profitant de l’occasion pour inciter à aller enrichir l’encyclopédie libre pour mettre en lumière de manière plus large les femmes de l’informatique. Marie-Agnès Enard
Sarah Krichen WMFr CC BY-SA 4.0
Qu’est-ce qu’un éditathon Wikipédia ?
Un édithathon est un évènement organisé par des communautés pour que des contributeurs créent, modifient et améliorent des articles sur un thème, sujet ou un type spécifique de contenu. Ici, ce marathon d’édition a lieu sur Wikipédia que l’on ne présente plus. Vous n’avez jamais contribué à Wikipédia, pas de panique, les nouveaux contributeurs y reçoivent généralement une formation de base à l’édition et tout type de profils sont recherchés pour améliorer ces contenus.
Une battle dédiée au femmes
« Femmes de l’Intelligence artificielle VS Femmes des sciences de la Terre : le match ». Choisissez votre équipe et défendez-la sur Wikipédia. Pendant 4 jours, que vous soyez un.e contributeur.trice habitué.e ou débutant.e, enrichissez les biographies de femmes dans ces deux disciplines. Tous les coups (ou presque) sont permis : création d’article, traduction d’un article depuis un Wikipédia étranger, enrichissement / correction d’un article existant, ajout de sources, légende de photos… A la fin, ce sont les femmes qui gagnent ! 😉
Le programme
Cet évènement est entièrement en ligne.
A partir du 11 février 2021, début du repérage et de la collecte des ressources pour préparer l’éditathon
Jeudi 11 mars matin, initiation à la plateforme Wikipédia, en ligne
Du jeudi 11 au dimanche 14 mars : éditathon avec soutien de Wikipédiens bénévoles sur un canal de messagerie Discord
Cet éditathon s’insère dans une semaine où d’autres événements « femmes et sciences » sont programmés à Toulouse et Grenoble (dont des conférences accessibles à tous). Plus d’infos sur la page projet sur Wikipédia
La bande dessinée Mirror, Mirror de Falaah Arif Khan et Julia Stoyanovich parle de l’Intelligence Artificielle. À quoi sert aujourd’hui l’apprentissage automatique ? À quoi devrait-il servir ? À améliorer l’accessibilité des applis numériques notamment. C’était une réflexion destinée au départ aux étudiants en IA. Nous l’avons traduite en français pour binaire, avec l’aide de Eve Francoise Trement, parce que nous pensons qu’elle peut intéresser un bien plus large public.
« Compte tenu de l’importance croissante du numérique dans notre société, il est essentiel de comprendre comment fonctionne l’informatique. La fondation Blaise Pascal procure de superbes occasions d’apprendre à vivre dans un monde numérique en s’amusant. »
Serge Abiteboul, Président de la Fondation Blaise Pascal
La fondation Blaise Pascal a pour vocation de promouvoir, soutenir, développer et pérenniser des actions de médiation scientifique en mathématiques et informatique à destination de toute citoyenne et citoyen français, sur l’ensemble du territoire. Ses actions se portent plus particulièrement vers les femmes et les jeunes défavorisés socialement et géographiquement, et ce dès l’école primaire.
Créée en 2016 sous égide de la Fondation pour l’Université de Lyon par l’Université de Lyon et le CNRS rejoints en 2019 par Inria, la fondation Blaise Pascal est présidée par Serge Abiteboul, et animé par toute une équipe.
Reconnue d’utilité publique, la fondation vise à donner le goût des mathématiques et de l’informatique au plus grand nombre ainsi que plus largement à faire rayonner la culture scientifique. À travers deux appels à projets par an, son ambition est de démultiplier l’impact des acteurs de la médiation en mathématiques et en informatique et stimuler l’émergence des projets de médiation innovants. Entre 2017 et 2020, ce sont 227 projets partout en France, touchant plus d’un million et demi de personnes, qui furent soutenus.
Parce que la fondation se veut au plus près des besoins du terrain et des enjeux de société, ses actions agissent en faveur de la mixité, de la diversité en science et de la sensibilisation à un numérique responsable et frugal. Elles ont pour objectif de lutter contre les discriminations de genre, lever les freins sociaux et culturels, et attirer plus de filles vers les métiers scientifiques. Aux côtés de ses partenaires associatifs engagés, elle œuvre ainsi pour positionner ces disciplines au cœur de la formation des jeunes générations afin d’anticiper les besoins en compétences clés des métiers de demain.
Car aujourd’hui, et encore davantage demain, les enjeux liés au numérique sont et seront au cœur de notre société, comme la protection des données, l’intelligence artificielle, la cyber-sécurité, les crypto-monnaies… Il est donc essentiel que chaque citoyenne et chaque citoyen puisse les appréhender avec discernement.
Quel est le point commun entre Grace Hopper, Linus Torvalds et Tim Berners-Lee ? Ce sont trois géant.e.s des communs du numérique que nous célèbrerons cette année. Grace Hopper ne se voyait sûrement pas comme une pionnière des communs du numérique. Vous ne la voyiez probablement pas comme cela. Pourtant, son premier compilateur était bel et bien un extraordinaire bien commun. Et puis, surtout, nous sommes fanas de Grace dans binaire, alors nous nous sommes permis de l’associer à l’année des communs du numérique.
L’équipe de binaire vous souhaite une bonne année 2021
🥰🥰🥰








 Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection
Un livre de Rachid Guerraoui et Lê Nguyên Hoang (Collection  « Numérique et pandémie – Les enjeux d’éthique un an après »
« Numérique et pandémie – Les enjeux d’éthique un an après »




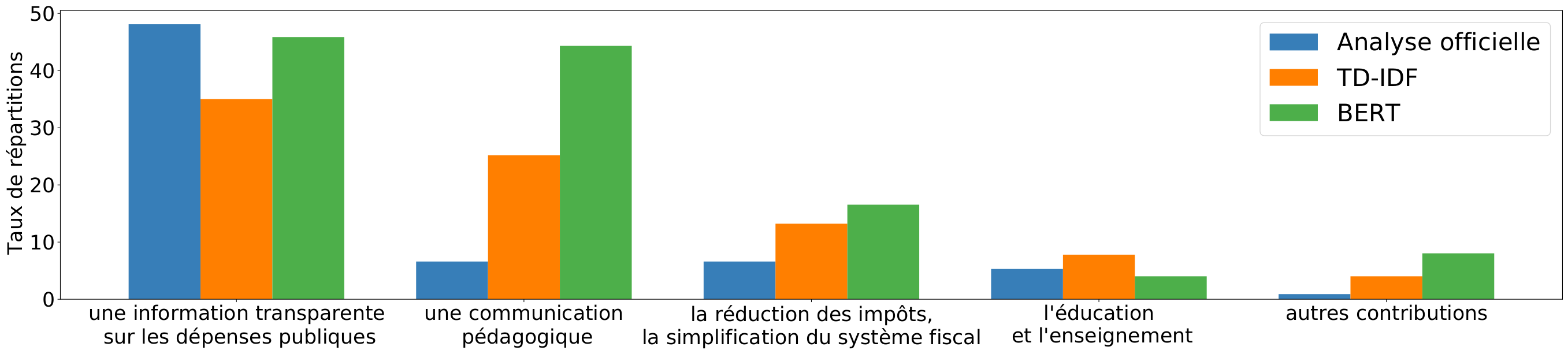


 complice Steve Kremer, co-présidente du comité
complice Steve Kremer, co-présidente du comité 
 À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec retrouve binaire pour nous parler de difficultés rencontrées par les femmes au temps du Covid. La route est longue, on le savait, jusqu’à la vraie parité. On le vérifie. Serge Abiteboul et Pauline Bolignano
À l’occasion de la Journée Internationale des Droits des Femmes, Anne-Marie Kermarrec retrouve binaire pour nous parler de difficultés rencontrées par les femmes au temps du Covid. La route est longue, on le savait, jusqu’à la vraie parité. On le vérifie. Serge Abiteboul et Pauline Bolignano Le 8 mars dernier nous observions, encore d’un peu loin, avec une once, une once seulement, quels naïfs nous faisions, d’inquiétude les dégâts du coronavirus en Asie, lançant les paris sur l’éventualité d’un confinement que nous imaginions durer une ou deux semaines. Le couperet est tombé un peu plus d’une semaine après, nous coinçant là où nous étions ce soir du 16 mars 2020. Confinés, un mot un peu nouveau dans notre vocabulaire courant, dont il a fallu s’accommoder et que l’on ne finit de conjuguer depuis à tous les temps. Les écoles et les universités sont passées intégralement aux cours en ligne mettant au défi parents et enseignants, les commerces ont baissé leur rideau avec dépit, les soignants se sont mobilisés, les entreprises ont généralisé le télétravail, l’état s’est démené pour déclencher des aides, les familles se sont recroquevillées ou épanouies ensemble selon les cas, les parents se sont transformés en enseignants du jour au lendemain, les étudiants se sont retrouvés un peu à l’étroit dans leurs 20m2 ou au contraire ont filé dare-dare chez leurs parents pour avoir plus d’espace et bénéficier de la logistique familiale, certains parisiens ont débarqué dans leur résidence secondaire en Bretagne ou Normandie sous l’œil, parfois, réprobateur et méfiant des autochtones, qui les imaginaient trimballer le virus dans leurs poches.
Le 8 mars dernier nous observions, encore d’un peu loin, avec une once, une once seulement, quels naïfs nous faisions, d’inquiétude les dégâts du coronavirus en Asie, lançant les paris sur l’éventualité d’un confinement que nous imaginions durer une ou deux semaines. Le couperet est tombé un peu plus d’une semaine après, nous coinçant là où nous étions ce soir du 16 mars 2020. Confinés, un mot un peu nouveau dans notre vocabulaire courant, dont il a fallu s’accommoder et que l’on ne finit de conjuguer depuis à tous les temps. Les écoles et les universités sont passées intégralement aux cours en ligne mettant au défi parents et enseignants, les commerces ont baissé leur rideau avec dépit, les soignants se sont mobilisés, les entreprises ont généralisé le télétravail, l’état s’est démené pour déclencher des aides, les familles se sont recroquevillées ou épanouies ensemble selon les cas, les parents se sont transformés en enseignants du jour au lendemain, les étudiants se sont retrouvés un peu à l’étroit dans leurs 20m2 ou au contraire ont filé dare-dare chez leurs parents pour avoir plus d’espace et bénéficier de la logistique familiale, certains parisiens ont débarqué dans leur résidence secondaire en Bretagne ou Normandie sous l’œil, parfois, réprobateur et méfiant des autochtones, qui les imaginaient trimballer le virus dans leurs poches.





