Le prix Turing va aux deux inventeurs de la cryptographie à clé publique
@Maev59
Des connexions sécurisées par milliards. Quotidiennement, les utilisateurs d’Internet établissent des connexions sécurisées en ligne avec les banques, les sites de commerce électronique, les serveurs de messagerie ou ceux hébergeant des données en nuage. Typiquement, une telle connexion est repérable par les initiales «https», où le « s » indique que la sécurité est activée pour protéger la communication, parfois aussi par la présence d’un cadenas qui s’affiche sur le navigateur. Dans un cadre plus professionnel, le processus de dématérialisation, qui est la marque de la transformation numérique de notre société, conduit-il à ce que les contrats, les virements, les bons de commande etc. soient de plus en plus authentifiés, non plus de façon manuscrite, mais par l’intermédiaire d’une signature électronique ?
Ceux sont donc globalement des transactions d’un montant colossal qui sont permises par ces milliards de connexions sécurisées et de signatures électroniques. Mais c’est aussi la vie privée de nos concitoyens qui est protégée par l’inviolabilité ainsi apportée aux communications en ligne.
Crédit photo ACM
Cette année, le Prix Turing a été décerné à deux chercheurs américains, Whitfield Diffie et Martin Hellman, dont l’invention, la cryptologie à clé publique, est directement à l’origine de ces deux technologies. Le prix est souvent considéré comme l’équivalent du prix Nobel pour la communauté de l’informatique. Il est doté d’une récompense d’un million de dollars.
En 1976 en Californie. Pour comprendre la genèse de l’invention de Diffie et Hellman, il faut revenir 40 années en arrière près de la baie de San Francisco. Quelques années auparavant, deux ordinateurs s’étaient échangés des messages, on ne disait pas encore des mèls, d’un bout à l’autre de cette baie. S’ouvrait ainsi la possibilité d’accéder, par un réseau analogue à celui du téléphone, à des fichiers contenant des livres, des journaux, l’horaire des compagnies aériennes… mais aussi la possibilité de transmettre son carnet d’adresse ou des données à caractère personnel. Alors jeunes chercheurs, Whitfield Diffie et Martin Hellman se mirent à réfléchir à deux questions fondamentales : comment, dans ce monde sans papier, saura-t-on remplacer l’enveloppe et la signature ? En d’autres termes, quels mécanismes pourront empêcher que le contenu d’un message ne soit intercepté par un tiers ou modifié de façon malveillante.
Tout naturellement, Diffie et Hellman se tournèrent vers la cryptographie, technique ayant pour objet d’assurer la confidentialité et l’authenticité des communications écrites. Pratiquée depuis les temps anciens, la cryptographie convertit des informations lisibles de manière claire en un texte totalement incompréhensible, le cryptogramme. Cette opération, appelée chiffrement est effectuée à l’aide d’une clé, combinaison de lettres ou de chiffres constituant une sorte de mot de passe. L’opération inverse, le déchiffrement, restaure les informations initiales à partir du cryptogramme en mettant en œuvre la même clé. Le mot «clé» évoque la fermeture d’une serrure enfermant les informations dans une forme de coffre-fort virtuel et le déchiffrement apparaît alors comme l’utilisation de la clé pour ouvrir la serrure du coffre.
D’emblée, Diffie et Hellman comprirent que la cryptographie traditionnelle n’offrait pas, en l’état, de solution aux deux problèmes de l’enveloppe et de la signature. Une limitation majeure des méthodes alors connues était en effet liée à l’ingénierie complexe de la gestion des clés, impliquant notamment la nécessité d’un moyen sécurisé de transfert de clé, totalement non transposable aux communications électroniques ouvertes.
@Maev59
De la serrure au cadenas. Dans leur quête, Diffie et Hellman comprirent qu’il fallait casser le caractère symétrique des opérations de chiffrement et de déchiffrement. Pour reprendre l’analogie avec la fermeture puis l’ouverture du coffre-fort, il fallait introduire une asymétrie en substituant un cadenas à la serrure : chacun peut fermer le cadenas mais seul le détenteur de la clé peut l’ouvrir. La cryptographie à clé publique était née : c’est une méthode de chiffrement des données dans laquelle chaque partie dispose d’une paire de clés, l’une, la clé publique qui peut être partagée publiquement, et l’autre, appelée clé privée, qui doit rester secrète et n’est connue que par une unique entité. Il est possible pour quiconque de chiffrer un message en utilisant la clé publique du destinataire. Cependant, le cryptogramme ne peut être déchiffré qu’à l’aide de la clé privée correspondante.
Ces idées ont été exposées pour la première fois en 1976 par Diffie et Hellman dans l’article fondateur de la cryptographie moderne, intitulé « New Directions in Cryptography ». Cet article, visionnaire et lumineux, a fait faire à la discipline un pas de géant couronnant un cheminement de plusieurs siècles. Beaucoup de temps avait été nécessaire, en effet, pour distinguer la méthode de chiffrement, on dirait aujourd’hui l’algorithme, c’est-à-dire la suite des opérations à effectuer pour obtenir le cryptogramme à partir du texte clair d’origine, de la clé. Ce qui avait conduit à l’énoncé en 1883 du principe de Kerckhoffs : Il faut qu’il [le système de chiffrement] n’exige pas le secret, et qu’il puisse sans inconvénient tomber entre les mains de l’ennemi. D’une certaine façon, le paradoxe qui sous-tend l’invention de Diffie et Hellman est une version extrême de ce principe : même la clé publique de chiffrement peut tomber aux mains de l’ennemi, seule compte la clé privée !
La cryptographie à clé publique résout parfaitement le problème de l’enveloppe évoqué plus haut et permet de communiquer de façon sure sur un canal qui ne l’est pas : en effet, une connexion sécurisée peut être établie en utilisant la cryptographie à clé publique pour transporter une clé de chiffrement symétrique, laquelle est utilisée pour chiffrer les communications ultérieures.
D’une pierre deux coups. Comme l’ont montré Diffie et Hellman, la cryptographie à clé publique résout également le second problème posé plus haut celui de la signature électronique. Là encore, les méthodes traditionnelles échouaient : on savait bien que la production simultanée d’un message et de son cryptogramme constituait une forme dégradée de signature, puisque seul un détenteur de la clé de chiffrement pouvait en être l’auteur. Toutefois, dans la mesure où la clé était partagée entre (au moins) deux parties, cette « signature » n’identifiait pas son auteur de manière unique et, de plus, ne pouvait être « vérifiée » que par l’un des détenteurs de la clé. Avec les méthodes à clé publique, l’ambiguïté disparaît : pour produire une signature on applique l’algorithme de déchiffrement au texte à signer à l’aide de la clé privée ; pour vérifier, on a seulement à utiliser l’algorithme de chiffrement. Une telle vérification est accessible à tous puisque la clé de chiffrement est publique !
Informatique et cryptographie. Ce n’est pas la première fois que des chercheurs en cryptographie sont récompensés par le prix Turing. Le prix a été décerné à Ronald Rivest, Adi Shamir et Leonard Adleman en 2002 et à Silvio Micali et Shafi Goldwasser en 2012. Auxquels s’ajoutent Manuel Blum et Andrew Yao lauréats respectivement en 1995 et 2000 pour des travaux liant complexité algorithmique et cryptographie. C’est donc cette fois enfin le tour des fondateurs ! Il n’est pas inutile non plus de rappeler que le nom du prix évoque la mémoire du mathématicien et logicien britannique Alan Turing qui a formulé les bases mathématiques des algorithmes informatiques et en a montré les limites intrinsèques. Il a été aussi un grand spécialiste de cryptographie, puisqu’il a joué un rôle décisif dans le « décryptement » (sans la clé donc !) des messages chiffrés produits par la machine allemande Enigma pendant la Seconde guerre mondiale. Tout cela illustre l’importance que la communauté des informaticiens accorde à la cryptographie, véritable clé de voûte de la sécurité sur Internet.
Lee Sedol Source Wikipédia – photo Cyberoro ORO • CC BY 3.0
Cet article est publié en collaboration avec TheConversation.
Après les échecs et la victoire de Deep Blue d’IBM sur Kasparov en 1996, après Jeopardy! et la victoire de Watson d’IBM en 2011, le jeu de Go résistait parmi les rares jeux où les humains dominaient encore les machines. En mars 2016, un match en cinq manches a opposé une star du Go, le sud coréen Lee Sedol à AlphaGo, le logiciel de Google DeepMind.
Score final : AlphaGo 4 – Lee Sedol 1
AlphaGo se voit décerner le titre de Grand Maître du Go
Classée 4ème dans le classement de Go mondial devant Lee Sedol
L’événement est surtout symbolique pour le monde de la recherche en informatique qui s’attendait à ce que cette frontière tombe un jour. Certains pensaient que les champions de Go résisteraient plus longtemps : le jeu avec son nombre considérable de positions possibles pose des difficultés à des algorithmes qui gagnent surtout par leur capacité de considérer d’innombrables alternatives. C’était sans compter sur les énormes progrès des ordinateurs, de leurs processeurs toujours plus nombreux, plus rapides, de leurs mémoires toujours plus massives, et sans compter surtout sur les avancées considérables de la recherche en intelligence artificielle.
Copyright Wikipedia
Lee Sedol a été battu par une batterie de techniques super sophistiquées notamment : l’apprentissage profond (deep learning), des techniques de recherche Monte-Carlo (Monte Carlo tree search) et des techniques d’analyse massive de données (big data).
L’apprentissage profond. L’apprentissage profond ou deep learning est une technique qui permet d’entraîner des réseaux de neurones comprenant de nombreuses couches cachées (c’est à dire des modèles de calcul dont la conception est très schématiquement inspirée du fonctionnement des neurones biologiques, les différentes couches correspondant à différents niveaux d’abstraction des données). Ces techniques ont tout d’abord été utilisées pour la reconnaissance de formes. Yann le Cun (Chaire Informatique et Sciences du Numérique cette année au Collège de France) a par exemple utilisé cette technique pour la reconnaissance de caractères manuscrits. Des développements plus récents ont permis des applications en classification d’images et de voix.
Les réseaux de neurones profonds allient la simplicité et la généralité. Ils sont capables de créer leurs propres représentations des caractéristiques du problème pour arriver à des taux de réussites bien meilleurs que les autres méthodes proposées. Ils reposent sur des apprentissages qui demandent des temps assez longs pour les plus gros réseaux. Pour accélérer l’apprentissage, les concepteurs de réseaux profonds utilisent des cartes graphiques puissantes comme celles de Nvidia qui permettent de réaliser très rapidement des multiplications de grandes matrices. Malgré cela, le temps d’apprentissage d’un gros réseau peut se compter en jours voire en semaines.
Copyright Wikipedia
Les réseaux utilisés pour AlphaGo sont par exemple composés de 13 couches et de 128 à 256 plans de caractéristiques. Pour les spécialistes : ils sont « convolutionnels » avec des filtres de taille 3×3, et utilisent le langage Torch, basé sur le langage Lua. Pour les autres : ils sont très complexes. AlphaGo utilise l’apprentissage profond en plusieurs phases. Il commence par apprendre à retrouver les coups d’excellents joueurs à partir de dizaines de milliers de parties. Il arrive à un taux de reconnaissance de 57 %. Il joue ensuite des millions de parties contre différentes versions de lui même pour améliorer ce premier réseau. Cela lui permet de générer de nouvelles données qu’il va utiliser pour apprendre à un second réseau à évaluer des positions du jeu de Go. Une difficulté est ensuite de combiner ces deux réseaux avec une technique plus classique de « recherche Monte-Carlo » pour guider le jeu de l’ordinateur.
La recherche Monte-Carlo. Le principe de la recherche Monte-Carlo est de faire des statistiques sur les coups possibles à partir de parties jouées aléatoirement. En fait, les parties ne sont pas complètement aléatoires et décident des coups avec des probabilités qui dépendent d’une forme, le contexte du coup. Tous les états rencontrés lors des parties aléatoires sont mémorisés et les statistiques sur les coups joués dans les états sont aussi mémorisées. Cela permet lorsqu’on revient sur un état déjà visité de choisir les coups qui ont les meilleures statistiques. AlphaGo combine l’apprentissage profond avec la recherche Monte-Carlo de deux façons. Tout d’abord, il utilise le premier réseau qui prévoit les coups pour essayer en premier ces coups lors des parties aléatoires. Ensuite il utilise le second réseau qui évalue les positions pour corriger les statistiques qui proviennent des parties aléatoires.
L’analyse massive de données. AlphaGo fait appel à des techniques récentes de gestion et d’analyse massive de données. Un gros volume de données consiste d’abord dans les très nombreuses parties d’excellents joueurs disponibles sur internet ; ces données sont utilisées pour amorcer l’apprentissage : AlphaGo commence par apprendre à imiter le comportement humain. Un autre volume considérable de données est généré par les parties qu’AlphaGo joue contre lui-même pour continuer à s’améliorer et finalement atteindre un niveau super-humain.
Bravo ! La défaite de Lee Sedol doit être interprétée comme une victoire de l’humanité. Ce sont des avancées de la recherche en informatique qui ont permis cela, ce sont des logiciels écrits par des humains qui ont gagné.
Les techniques utilisées dans AlphaGo sont très générales et peuvent être utilisées pour de nombreux problèmes. On pense en particulier aux problèmes d’optimisation rencontrés par exemple en logistique, ou dans l’alignement de séquences génomiques. L’apprentissage profond est déjà utilisé pour reconnaître des sons et des images. AlphaGo a montré qu’il pourrait être utilisé pour bien d’autres problèmes.
Émerveillons-nous de la performance d’AlphaGo. Il a fallu s’appuyer sur les résultats de chercheurs géniaux, utiliser les talents de d’ingénieurs, de joueurs de Go brillants pour concevoir le logiciel d’AlphaGo, et disposer de matériels très puissants. Tout cela pour vaincre un seul homme.
Émerveillons-nous donc aussi de la performance du champion Lee Sedol ! Il a posé d’énormes difficultés à l’équipe de Google et a même gagné la 4ème partie. Il était quand même bien seul face au moyens financiers de Google, à tous les processeurs d’AlphaGo.
Les humains réalisent quotidiennement des tâches extrêmement complexes comme de comprendre une image. Prenons une de ces tâches très emblématiques, la traduction. Si les logiciels de traduction automatique s’améliorent sans cesse, ils sont encore bien loin d’atteindre les niveaux des meilleurs humains, sans même aller jusqu’à un Baudelaire traduisant Les Histoires Extraordinaires d’Edgar Poe. Il reste encore bien des défis à l’intelligence artificielle.
Tristan Cazenave est un spécialiste mondial en intelligence artificielle. Il a de nombreuses contributions autour du jeu de Go. Il est aussi l’auteur du livre L’intelligence artificielle, une approche ludique. La France est assez en pointe sur l’intelligence artificielle autour du jeu de Go, avec des chercheurs comme Remi Coulom ou Olivier Teytaud. Binaire
Cet article est publié en collaboration avec TheConversation.
L’an dernier, Binaire se demandait où sont les femmes : on le sait, bien trop peu de jeunes filles choisissent les sciences [1], en particulier l’informatique et les mathématiques. On le constate, on le déplore, on travaille à les encourager, les motiver, les convaincre. Certaines finissent par s’y lancer. Quelles carrières se présentent alors à cette minorité aventurière ? Est ce qu’on la chouchoute ou continuons-nous tranquillement à nous engluer dans les stéréotypes tenaces concernant les femmes et les sciences ? Où en est-on 40 ans après l’officialisation des Nations Unies de célébrer les droits des femmes chaque année le 8 mars ? Serge Abiteboul
2013, Bruxelles, dans le temple de l’excellence scientifique européen, le président de l’ERC (European Research Council) rappelle aux évaluateurs, qui s’apprêtent à passer la semaine à plancher sur les meilleurs dossiers tous domaines confondus, qu’aucun critère lié aux pays d’origine, à la parité ou au domaine de recherche ne doit être retenu dans l’évaluation.
2015, même endroit, même président, sensiblement mêmes évaluateurs : le discours a singulièrement évolué. Certes l’excellence scientifique reste le critère le plus important mais la vigilance au sujet de la parité est de mise, suite aux résultats issus du groupe de travail en charge de l’équilibre des genres[2]. Ces études montrent en effet que le pourcentage de dossiers féminins acceptés au premier tour d’évaluation est significativement plus faible que celui des candidatures masculines. L’échantillon étant indéniablement statistiquement significatif, de deux choses l’une : soit les femmes sont en moyenne moins brillantes que leurs homologues masculins, soit des biais s’immiscent dans le processus.
Il semblerait bien, qu’insidieusement, les préjugés se perpétuent, rampants, pour continuer d’écarter les femmes des postes prestigieux et limiter leur ascension dans nos institutions académiques. Elles s’en écartent parfois elles-mêmes du reste, par manque de confiance, ou parce que cela implique de faire quelques aménagements familiaux qu’elles redoutent ou encore qui les forceraient à s’éloigner des lieux communs.
Ce plafond de verre existe toujours bel et bien dans les carrières scientifiques et est du en grande partie à une concomitance de facteurs aggravants.
Facteur numéro 1 : le vocabulaire.
La plupart des fiches de postes à responsabilité regorgent d’un vocabulaire saillant, de métaphores sportives (plutôt football américain que danse classique) voire d’épithètes guerrières dans lesquelles les femmes se reconnaissent parfois difficilement. Il faut être solide pour accepter de se présenter comme un leader charismatique quand il va de soi qu’une femme doit être douce et compréhensive et surtout ne jamais se montrer autoritaire au risque d’émasculer son fragile entourage. Attirer l’attention de nos dirigeants sur l’importance d’une formulation neutre (e.g. capacité à rassembler plutôt que leadership) permettrait aux femmes de se projeter davantage dans ces postes, sans pour autant pénaliser les hommes.
Facteur numéro 2 : les ruptures de carrières.
Certes les choses évoluent, les congés de paternité s’allongent, les hommes mettent un tablier, mais les ruptures de carrières liées à la grossesse restent l’apanage des femmes. En outre ces ruptures surviennent à une période clé de la carrière, celle où on est le plus productif, où on doit faire ses preuves, travailler d’arrache pied pour asseoir ses résultats, allonger sa liste de publications et voyager pour faire connaître son travail. Malgré la joie dont elles sont généralement assorties, elles ne représentent jamais un avantage pour l’avancement. Ces ruptures sont du reste de plus en plus prises en compte explicitement dans les textes qui régissent recrutements et promotions. L’ERC, par exemple, accorde 18 mois par enfant aux femmes (si il y a une limite dans le dépôt d’une candidature, par exemple s’il est possible de candidater à un projet jusqu’à 12 ans après une thèse, pour une femme avec deux enfants cette limite ira jusqu’à 15 ans après la thèse). Et pourtant. J’ai parfois entendu que la croissance du h-index ne s’arrêtait pas pendant un congé de maternité…
Facteur numéro 3 : les préjugés involontaires
Il est aujourd’hui avéré que le style varie selon que l’auteur d’un dossier est un candidat ou une candidate mais aussi qu’il ou elle soit le sujet des discussions. Certes c’est un peu caricatural mais on pourrait presque aller jusqu’à dire que les femmes subissent la double peine. Non seulement elles ont moins tendance à utiliser un style incisif, à présenter des dossiers ambitieux ou à faire preuve d’autosatisfaction et d’assurance, qui sont autant d’attributs associés à l’excellence chez un homme, mais en plus, si une femme s’y engouffre, on risque de la trouver arrogante et prétentieuse. Et ceux ou celles qui trouvent que mes propos sont exagérés n’ont pas fréquenté assez de jurys.
Les évaluateurs ou les rédacteurs de lettres de références (dans le milieu académique, les lettres de recommandations émanant de personnalités du domaine sont décisives dans le processus de recrutement et promotion) tombent eux aussi dans ce piège. Là encore les clichés sont activés, souvent inconsciemment évidemment. Au point que cela fait par exemple l’objet de recommandations particulières de la part du programme des chaires de recherche au Canada (http://www.chairs-chaires.gc.ca/program-programme/referees-repondants-fra.aspx#prejuges) qui consacre plusieurs paragraphes sur la manière de limiter ces préjugés involontaires. En un mot, les lettres de recommandation pour les femmes sont plus brèves, moins complètes, comptent moins de termes dithyrambiques et beaucoup plus d’éléments semant le doute (certes elle est excellente mais elle a travaillé sous la direction de X, éminent chercheur du domaine).
L’article intitulé Exploring the color of glass: letters of recommendation for female and male medical faculty [3] présente une analyse empirique de près de 300 lettres de recommandation dans le domaine médical. Les études montrent des biais très clairs des « recommandeurs », essentiellement des hommes d’âge respectable, représentatifs des personnalités scientifiques que l’on contacte dans ce genre de cas. L’étude présentée montre que les lettres écrites pour les femmes sont plus courtes, alors même que la même étude conclue que plus la lettre est longue, mieux elle est perçue. On trouve aussi beaucoup plus de termes relatifs au genre dans les lettres pour femmes et une habitude qui tend insidieusement à conjuguer l’effort au féminin et le talent au masculin, l’enseignement au féminin et la recherche au masculin. Ces différences de traitement, souvent involontaires, reflètent des stéréotypes profondément enracinés, qui peuvent s’avérer réellement discriminatoires dans le recrutement et la promotion des femmes
Une ébauche de solution ? Ne jamais négliger ces facteurs
Il est donc crucial de se forcer à la vigilance, tous, candidates et jurys de recrutement, de promotions, ou de sélections, instituts de recherche et universités, pour surveiller les carrières de nos jeunes recrues comme du lait sur le feu et tenter à la fois de rééquilibrer nos laboratoires et de faire évoluer les choses. Veillons à chaque étape du recrutement à éviter la perte en ligne injustifiée. Il ne s’agit pas de décider que toutes les femmes ont des dossiers exceptionnels mais à l’issue d’un concours ayant 15% de candidatures féminines, en moyenne le taux de femmes admises doit rester sensiblement le même. Il n’y a pas de raisons objectives que cela ne le soit pas.
L’ERC a mis un peu de temps mais redouble maintenant de vigilance, c’est aussi le cas du CNRS, avec la mission pour la place des femmes, ou des universités qui ont adopté une charte pour l’égalité. Un comité nouvellement créé à Inria, coordonné par Serge Abiteboul et Liliana Cucu-Grosjean, s’est également penché sur le sujet, et a proposé des recommandations concrètes et une charte , sorte de guide aux jurys de recrutement et promotions.
Pour conclure, il ne suffit pas d’inciter les jeunes filles à faire des sciences, il faut également rester infiniment attentif quant au développement de leur carrière. On peut rêver d’inverser la tendance, de voir disparaître petit à petit les stéréotypes solidement ancrés dans la société et les institutions, y compris celles qui se targuent de la plus grande prudence à cet égard, et imaginer qu’un jour évoquer la parité soit ringard. C’est un processus long, très long. En attendant, il faut accuser réception de ces biais, qui suintent des comités de sélections, à leur insu, et les combattre pour rétablir un équilibre que l’on mérite amplement. Enfin, laissons aussi aux femmes le loisir d’être leurs propres ambassadrices : je me suis vue, alors que, en comité de sélection, j’attirais l’attention du jury sur l’un de ces biais inconscients, me faire gentiment rétorquer, de la part de personnes, certes paternalistes mais dont je sais qu’elles sont de bonne foi et sensibles au sujet : « Pour ce qui concerne la défense des candidatures féminines : laisse ça aux hommes, ma chère, cela aura plus de poids. »
Remerciements : à tous mes collègues du groupe recrutement des chercheurs de la commission parité/égalité Inria, avec qui nous avons longuement discuté sur le sujet et concocté la charte.
Références :
[1] Why so Few ? Women in Science, Technology, engineering and mathematics. Catherine Hill, Christianne Corbett, Andresses St Rose. AAUW
[2] ERC funding activities 2007-2013 Key facts, patterns and trends
[3] Exploring the color of glass: letters of recommendation for female and male medical faculty. France Strix and Carolyn Psenka, Sage publications 2003, diversity.berkeley.edu/sites/default/files/exploring-the-color-of-glass.pdf
La vente d’espace publicitaire sur le web a priori ce n’est pas particulièrement notre tasse de thé. Ce genre de pub nous paraît tenir souvent de la pollution. Pourtant, il nous paraissait intéressant de comprendre comment une startup française pouvait devenir une licorne. Le livre de Jean-Baptiste Rudelle, « On m’avait dit que c’était impossible » aux éditions Stock, a été une agréable surprise : Enfin un patron de startup français optimiste, et content de ce qu’offre la France.
Rudelle raconte son expérience de créateur de 3 startups : un échec, un résultat mitigé, et le grand succès Criteo. Criteo, valorisée à plus de 2 milliards de dollars, est aujourd’hui présente dans 85 pays. Avec ses algorithmes de prédiction, elle achète et revend en quelques millisecondes des emplacements publicitaires sur internet. Elle affiche une belle croissance à deux chiffres.
Le fait que Rudelle vive et travaille à moitié en France et à moitié aux US lui permet de faire des comparaisons intéressantes, bien loin du French Bashing des américains, des français, des « Pigeons » en particulier. Les impôts sont plutôt plus bas en France, les employés plus productifs, l’administration pas pire qu’ailleurs.
Autre thèse originale de Rudelle : l’importance du jeu collectif. Pour lui, une startup ne se crée pas seul mais avec des associés complémentaires, des employés de top qualité, des vicis intelligents ; les stocks options doivent être partagées entre tous les employés.
Au delà du récit d’une expérience intéressante entre la France et les Etats-Unis, Rudelle touche de nombreux sujets : le partage des ressources avec des références appuyées à Piketty, les impôts, l’héritage, le capital risque, l’art du pivot pour les startups, la pub bien sûr… Est-ce à cause de son éducation (mère historienne, père artiste peintre) que Jean-Baptiste Rudelle sait si bien raconter, et qu’il est capable d’une telle distance ?
Des contributeurs/contributrices de Wikipédia ont conçu un MOOC (cours en ligne, gratuit et ouvert à tous) pour découvrir Wikipédia et apprendre à y contribuer. Les inscriptions au WikiMOOC sont ouvertes sur la plateforme FUN (France Université Numérique) jusqu’au 29 février.
Wikipédia est aujourd’hui le septième site le plus visité au monde. C’est aussi l’un des rares sites connus à être hébergé par une fondation à but non-lucratif. Étudiants, professeurs, professionnels, particuliers : nombreux sont les internautes à utiliser cette encyclopédie en ligne, qui compte plus de 36 000 000 d’articles en 280 langues, dont 1,7 million en français.
Si vous souhaitez découvrir le fonctionnement de l’un des sites les plus visités au monde, source majeure d’information, et/ou apprendre à y contribuer vous-même pour aider à partager la connaissance au plus grand nombre, ce cours est fait pour vous. Et cela que vous soyez étudiant(e), chercheuse ou chercheur, professionnel(le) de n’importe quel secteur d’activité, inactif ou inactive, ou bien encore retraité(e).
On rappelle que Binaire est à l’initiative d’une série d’actions regroupées sous le nom de code « Cabale Informatique de France ». Il s’agit de contribuer aux pages de Wikipédia sur l’informatique, en français. C’est co-organisé avec la Société Informatique de France et Wikimédia France, donc Binaire ne peut que soutenir ce MOOC.
Cet article est publié en collaboration avec TheConversation.
L’internet est désormais utilisé par plus de trois milliards de personnes, soit plus de 45% de la population de la planète. L’importance de l’Internet dans la vie des usagers est telle que l’on entend souvent la question : Qui gouverne l’internet ? Binaire a posé la question à un ami, Jean-François Abramatic, Directeur de recherche Inria. Si quelqu’un en France peut répondre à la question, c’est sans doute lui. Serge Abiteboul
Jean-François Abramatic, Wikipédia
Jean-François a partagé sa carrière entre la recherche (Inria, MIT) et l’industrie (Ilog, IBM). Il a présidé le World Wide Web Consortium (W3C) de 1996 à 2001. Il a été administrateur de l’ICANN (1999-2000). Il est, aujourd’hui, membre du Conseil Inaugural de la NETmundial initiative.
La gouvernance de l’internet est en pleine évolution alors que l’internet poursuit son déploiement au service de la société à travers le monde. La définition même de la gouvernance de l’internet fait l’objet de débats. Michel Serres, par exemple, explique qu’après l’écriture et l’imprimerie, l’internet est la troisième révolution de la communication. Alors que personne n’a jamais parlé de gouvernance de l’écriture ou de l’imprimerie, faut-il parler de gouvernance de l’internet ?
Pour aborder la question de manière plus détaillée, il est utile de comprendre comment a été créé l’internet afin d’identifier les acteurs dont les décisions ont conduit à l’évolution fulgurante que nous avons connue (plus de 800% de croissance pour la période 2000-2015).
L’internet est la plateforme de la convergence entre l’informatique, les télécommunications et l’audiovisuel. Dans un monde où les données sont numériques, l’internet permet d’envoyer ces données n’importe où sur la planète, les ordinateurs peuvent alors traiter ces données et extraire les informations utiles à l’usager. La convergence de l’informatique, des télécommunications et de l’audiovisuel a permis de créer un environnement universel de communication et d’interactions entre les personnes. L’internet est, ainsi, un enfant de l’informatique venu au monde dans un univers de communication dominé par les télécommunications et l’audiovisuel. Si les télécommunications et l’audiovisuel ont grandi dans des environnements gouvernementaux (avant d’évoluer à travers la mise en œuvre de politiques de dérégulation), l’internet a grandi dans un environnement global, ouvert et décentralisé dès le premier jour.
L’espace : Une gouvernance globale dès le premier jour
Lorsqu’un environnement de communication se développe, le besoin de gouvernance apparaît pour concevoir et déployer les standards (protocoles et conventions qui permettent aux composants, appareils et systèmes de communiquer) ainsi que pour répartir les ressources rares ou uniques (par exemple les bandes de fréquence ou les numéros de téléphone). Pour les télécommunications et l’audiovisuel, des organismes nationaux et internationaux ont été créés pour conduire les actions de standardisation et gérer l’attribution des ressources rares ou uniques.
Pour l’internet, l’approche a été globale dès le début et aucune organisation nationale ou régionale n’a été mise en place pour développer les standards de l’internet. L’attribution des ressources rares ou uniques (adressage et nommage) a été décentralisée régionalement après avoir été conçue globalement. De plus, la mise en place de l’infrastructure a été conduite par les concepteurs techniques. La fameuse citation de David Clark « We reject kings, presidents and voting, we believe in rough consensus and running code.» traduit l’état d’esprit qui régnait lors de la conception et le déploiement des standards qui sont au cœur de l’internet d’aujourd’hui.
Ainsi sont nées depuis les années 80 de nombreuses organisations (IETF, ISOC, W3C, ICANN) internationales, indépendantes des pouvoirs politiques et dédiées à des tâches précises nécessaires au bon fonctionnement de l’internet. Prises dans leur ensemble, ces organisations ont exercé le rôle de gouvernance de l’internet. Elles conçoivent les standards de l’internet et attribuent (ou délèguent l’attribution) des ressources rares ou uniques.
« Qui Dirige Internet » par Lynnalipinski of ICANN via Wikimedia Commons
Le temps : le développement et le déploiement simultanés des innovations
Les concepteurs de l’internet ont coutume de mettre en avant qu’ils ont fait le choix de « mettre l’intelligence aux extrémités du réseau». Ce choix d’architecture a permis à des centaines de milliers d’innovateurs de travailler en parallèle et de rendre disponibles les terminaux et les services que nous utilisons tous les jours.
Pour être plus concret, les développeurs de Wikipedia ou Le Bon Coin, de Google ou d’Amazon, de Le Monde ou Au féminin ont travaillé et travaillent encore en parallèle pendant que les ordinateurs personnels ou les tablettes, les téléphones portables intelligents ou les consoles de jeux s’équipent des logiciels qui permettent d’accéder à ces services. Les choix d’architecture technique ont donc permis le déploiement fulgurant, sans équivalent dans l’histoire, de ce que l’on appelle aujourd’hui, l’internet.
Les défis sociétaux de la gouvernance d’internet
Le déploiement de l’internet dans le grand public a été provoqué par l’arrivée du World Wide Web au début des années 90. Les pouvoirs publics se sont donc intéressés à son impact sur nos sociétés. Aux questions de gouvernance relatives au développement technique d’internet (standards et ressources rares ou uniques) se sont ajoutées les questions de gouvernance des activités menées sur l’internet.
En France, dès 1998, le rapport présenté au conseil d’état par Isabelle Falque-Pierrotin (aujourd’hui présidente de la CNIL) recommande d’adapter la réglementation de la communication à la convergence de l’informatique, de l’audiovisuel et des télécommunications. De manière à faire croître la confiance des utilisateurs, le rapport recommande de protéger les données personnelles et la vie privée, de sécuriser les échanges et les transactions, de reconnaître la signature électronique, d’adapter la fiscalité et le droit des marques, de valoriser les contenus par la protection de la propriété intellectuelle et la lutte contre la contrefaçon, de lutter contre les contenus illicites. Enfin, le rapport recommande d’adapter le droit existant et de ne pas créer un droit spécifique à internet.
Depuis le début des années 2000, ces sujets ont fait l’objet, à des degrés divers, de travaux aux niveaux local et international. Le Sommet Mondial sur la Société de l’Information (SMSI) organisé par les Nations Unies, puis l’Internet Governance Forum (IGF), et plus récemment la NETmundial initiative ont fourni ou fournissent un cadre pour ces travaux.
Construire une gouvernance multi-acteurs globale et décentralisée
Même si la gouvernance d’internet a profondément évolué, des règles générales se sont imposées au fil des quarante dernières années. Aucune personne, aucune organisation, aucune entreprise, aucun gouvernement ne gouverne l’internet. La gouvernance d’internet est exercée par un réseau de communautés d’acteurs comprenant les pouvoirs publics, les entreprises, le monde académique et la société civile. Certaines communautés associent des personnes physiques, d’autres des organisations publiques ou privées. Ces communautés choisissent leur mode de fonctionnement en respectant des principes partagés tels que l’ouverture, la transparence ou la recherche du consensus.
L’importance prise par l’internet a attiré l’attention sur son mode de fonctionnement. Il est apparu clairement que les questions posées en 1998 dans le rapport au conseil d’état étaient devenues, pour la plupart, des défis planétaires. En particulier, les révélations relatives à la surveillance de masse ont provoqué une prise de conscience à tous les niveaux de la société (gouvernements, entreprises, monde académique, société civile).
La complexité des problèmes à résoudre est, cependant, souvent sous-estimée. Pour de nombreuses communautés, il est tentant de projeter des mécanismes de gouvernance qui ont eu leur succès avant l’émergence d’internet. Il est rare qu’une telle approche soit efficace. Qu’il s’agisse de standards techniques ou de règlementations relatives à la protection de la vie privée, d’extension de la capacité d’adressage ou de contrôle de la diffusion de contenus illicites, de langages accessibles pour les personnes handicapées ou de surveillance de masse, la résolution des problèmes demande la contribution coopérative du monde académique, des entreprises, des gouvernements et de représentants de la société civile. De plus, ces contributions doivent tenir compte des différences d’environnements juridique, fiscal ou tout simplement culturel de milliards d’usagers.
La gouvernance d’internet devient donc un objet de recherche et d’innovation puisque aucune expérience passée ne permet de construire cette gouvernance par extension d’une approche existante.
C’est au grand défi de la mise en place d’une gouvernance multi-acteurs, globale et décentralisée que nous sommes donc tous confrontés pour les années qui viennent.
Si le nom de Marvin Minsky, qui vient de décéder à Boston à l’âge de 88 ans, est indissociable du domaine de l’Intelligence Artificielle, dont il est un fondateur et reste un des chercheurs les plus influents, son impact a été encore plus large, aussi bien dans le domaine de l’informatique (prix Turing en 1969) que dans celui de la philosophie de l’esprit ou des sciences cognitives. Il a en effet aussi bien travaillé à décrire les processus de pensée des humains en termes mécaniques qu’à développer des modèles d’intelligence artificielle pour des machines.
Connu pour son charisme et la qualité de ses cours, il était professeur d’informatique au MIT à Boston, où il a créé dès 1959 le laboratoire d’IA avec John Mac Carthy (autre prix Turing, inventeur du terme “Intelligence Artificielle”). Ce laboratoire et le plus récent Media Lab auquel il a également appartenu, ont eu des impacts très importants dans de nombreux domaines de l’informatique.
Ce que l’on retient en général de Marvin Minsky, c’est sa participation, avec Mac Carthy, mais aussi Newell et Simon, à la conférence de Dartmouth en 1956, généralement considérée comme fondatrice du domaine de l’intelligence artificielle. Il avait péché alors par excès d’optimisme en prédisant que le problème de la création d’une intelligence artificielle serait résolu d’ici une génération. La tradition veut qu’on retienne également sa participation, avec Seymour Papert, à un livre qui allait montrer les limitations des réseaux de neurones de type Perceptron et participer à ce que certains ont appelé l’hiver de l’intelligence artificielle, quand dans les années 70 les financeurs se sont détournés de ce domaine jugé trop irréaliste.
Ce que Minsky a cherché à montrer tout au long de ses travaux c’est que l’intelligence est un phénomène trop complexe pour être capturé par un seul modèle ou un seul mécanisme. Selon lui, l’intelligence n’est pas comme l’électromagnétisme : au lieu de chercher un principe unificateur, il vaut mieux la décrire comme la somme de composants divers, chacun avec sa justification. Il parlait ainsi d’intelligence artificielle débraillée (‘scruffy’ en anglais). Il insistait cependant sur le fait que chacun de ces composants pouvait être lui-même dépourvu d’intelligence.
Ce positionnement est très bien rendu dans son livre le plus connu, publié en 1985, “The society of mind”, où il décompose l’intelligence en un grand nombre de modules, ou d’agents, hétérogènes et parfois extrêmement simples, ce qui alimentait sa vision de l’esprit réductible à une machine. Il a poursuivi cette description dans un livre plus récent (“The emotion machine”, en 2006), avec d’autres processus plus abstraits, comme les sentiments. Avant ces écrits pour le grand public, il avait déjà proposé des contributions similaires pour le domaine de l’informatique, avec ses travaux sur le raisonnement de sens commun et la représentation de connaissances à l’aide de ‘frames’ qui, dans les années 70, peuvent être vues comme précurseur de la programmation orientée-objet et qui lui ont en tout cas permis d’explorer de nombreux domaines de l’informatique relatifs à la perception visuelle et au langage naturel, ce qui l’a amené à être consulté par Stanley Kubrick pour son film “2001, Odyssée de l’espace”, pour savoir comment les ordinateurs pourraient parler en 2001…
Parmi les multiples domaines d’intérêt de ce touche-à-tout génial (dont la musique et les extra-terrestres), notons que ses premières recherches sur l’intelligence l’ont aussi amené à réaliser des travaux pionniers en robotique, incluant des dispositifs tactiles, mécaniques et optiques. Il a par exemple inventé et construit le premier microscope confocal. Autres réalisations à mettre à son actif : des machines inutiles, dont une inventée lorsqu’il était sous la direction de Claude Shannon aux Bells Labs et qui a inspiré un personnage de la Famille Adams.
Enfin, ce que je veux retenir également de Marvin Minsky, c’est que des générations d’enseignants en intelligence artificielle lui sont redevables d’une des définitions les plus robustes de ce domaine et qui, passé le moment d’amusement, reste au demeurant un des meilleurs moyens de lancer un débat fructueux avec les étudiants : l’intelligence artificielle est la science de faire faire à des machines des choses qui demanderaient de l’intelligence si elles étaient faites par des humains (artificial intelligence is the science of making machines do things that would require intelligence if done by men).
Dans le cadre d’une nouvelle rubrique « Il était une fois… ma thèse », Binaire a demandé à Pauline Bolignano, qui effectue sa thèse à Inria Rennes Bretagne Atlantique et dans la société Prove & Run de nous présenter ses travaux. Par ailleurs, Binaire tient à remercier Pauline et Charlotte qui en discutant ont initié l’idée de cette rubrique. Nous attendons impatiemment la suite des autres histoires de thèses… Binaire.
« – Tu penses que c’est possible que quelqu’un pirate ton portable et écoute tes conversations, ou accède à tes données bancaires ?
– Non ça n’arrive que dans les séries ça ! Et puis moi de toute façon je ne télécharge que des applis de confiance…»
En fait, avec en moyenne 25 applications installées sur un téléphone, nous ne sommes pas à l’abri d’un bug dans l’une d’entre elles.
Il y a même fort à parier que nos applications contiennent toutes plusieurs bugs. Or, certains bugs permettent à une personne mal intentionnée, sachant l’exploiter, d’accéder à des ressources privées. Ce problème est d’autant plus préoccupant que de plus en plus de données sensibles transitent sur nos téléphones et peuvent interférer entre elles. C’est encore pire quand les téléphones servent à la fois pour un usage personnel et professionnel !
Actuellement, l’accès aux ressources (appareil photo, micro, répertoire et agendas,…) dans un smartphone se fait un peu comme dans un bac à sable : toutes les applications peuvent prendre le seau et la pelle des autres, et rien n’empêche une application de détruire le château d’une autre… L’angoisse !
Pour mettre de l ‘ordre dans tout ça, une solution est d’ajouter une couche de logiciel qui contrôle de manière précise l’accès aux ressources, une sorte de super superviseur ; d’ailleurs, on appelle ça un hyperviseur. L’hyperviseur permet par exemple d’avoir deux « bacs à sable » sur son téléphone, de telle manière qu’aucune information sensible ne fuite entre les deux. Cela n’empêche pas les occupants d’un même bac à sable de se taper dessus avec des pelles mais on a la garantie que cela n’a pas d’impact sur le bac d’à coté. L’hyperviseur peut également interdire aux applications l’accès direct aux ressources. Il autorise les occupants du bac à sable de faire un pâté mais c’est lui qui tient le seau. Il peut de cette manière imposer qu’un voyant lumineux s’allume lorsque le micro est en marche. On a ainsi la certitude que lorsque le voyant est éteint, le micro est éteint et que personne ne peut nous écouter.
Vous l’avez peut être remarqué, il nous reste un problème majeur : comment s’assurer que l’hyperviseur n’a pas de bug ? L’hyperviseur ayant accès à toutes les ressources, un bug chez lui peut avoir des conséquences très graves. Il devient donc une cible de choix pour des pirates. Si on se contente de le tester, on passe potentiellement à coté de nombreux bugs. En effet la complexité d’un hyperviseur est telle que les tests ne peuvent pas prévoir tous les cas d’usage. La seule solution qui permette de s’approcher de l’absence de bug est la preuve formelle de programme. L’idée est d’exprimer des propriétés sur le programme, par exemple « les occupants d’un bac à sable n’interfèrent pas avec les occupants d’un autre bac à sable », puis de les prouver mathématiquement. Les propriétés sont exprimées dans un langage informatique et on les prouve grâce un outil qui vérifie que nos preuves sont correctes (et qui parfois même fait les preuves à notre place !).
Actuellement la preuve de programme n’est pas très répandue car elle est très couteuse et longue à mener. Elle est réservée aux systèmes critiques. Par exemple, des propriétés formelles ont été prouvées sur les lignes automatiques (1 et 14) du métro parisien. Je prouve en ce moment des propriétés d’isolation sur la ressource « mémoire » d’un hyperviseur, c’est à dire qu’il n’y a pas de mélange de sable entre deux bacs à sable. Le but de ma thèse est de fournir des méthodes afin d’alléger l’effort de preuve sur ce type de systèmes.
Binaire : Antoinette Rouvroy, qui êtes-vous ?
Antoinette Rouvroy : J’ai fait des études de droit, que j’ai poursuivies par une thèse de doctorat en philosophie du droit à l’Institut universitaire européen de Florence (*). Je m’intéresse depuis lors aux enjeux philosophiques, politiques et juridiques de la « numérisation » du monde et de ses habitants et de l’autonomisation croissante des systèmes informatiques .
Le problème de la protection des données personnelles se pose aujourd’hui de façon aigüe ?
Il est vrai que le phénomène des « données massives » (Big data) met les régimes juridiques de protection des données personnelles « en crise ». Ce qui pose problème, avec la prolifération exponentielle, extrêmement rapide, de données numériques diverses, c’est tout d’abord que les régimes de protection des données semblent peu aptes à faire face aux défis inédits posés par les phénomènes de profilage et de personnalisation propres à la société numérisée.
Aujourd’hui, toute donnée numérique est potentiellement susceptible de contribuer à nous identifier ou à caractériser très précisément nos comportements singuliers si elle est croisée avec d’autres données même peu « personnelles ». Ce qui paraît nous menacer, dès-lors, ce n’est plus prioritairement le traitement inapproprié de données personnelles, mais surtout la prolifération et la disponibilité même de données numériques, fussent-elles impersonnelles, en quantités massives. Les informaticiens le savent : l’anonymat, par exemple est une notion obsolète à l’heure des Big data. Les possibilités illimitées de croisements de données anonymes et de métadonnées (données à propos des données) permettent très facilement de ré-identifier les personnes quand bien même toutes les données auraient été anonymisées.
C’est la quantité plus que la qualité des données traitées qui rend le traitement éventuellement problématique.
Ces quantités massives de données et les Big data entrent en opposition frontale avec les grands principes de la protection des données : la minimisation (on ne collecte que les données nécessaires au but poursuivi), la finalité (on ne collecte les données qu’en vue d’un but identifié, déclaré, légitime), la limitation dans le temps (les données doivent être effacées une fois le but atteint, et ne peuvent être utilisées, sauf exceptions, à d’autres fins que les fins initialement déclarées). Les Big data, c’est au contraire une collecte maximale, automatique, par défaut, et la conservation illimitée de tout ce qui existe sous une forme numérique, sans qu’il y ait, nécessairement, de finalité établie a priori. L’utilité des données ne se manifeste qu’en cours de route, à la faveur des pratiques statistiques de datamining, de machine-learning, etc.
Darpa Big data. Wikimedia Commons
Pourtant, on ne peut pas étendre le champ des données protégées ? Cela reviendrait à soumettre aux régimes juridiques de protection des données quasiment toutes les données numériques, cela signerait la mise à mort de l’économie numérique européenne. Il y a autre chose à faire ?
L’urgence, aujourd’hui, c’est de se confronter à ce qui fait réellement problème plutôt que de continuer à fétichiser la donnée personnelle tout en flattant l’individualisme possessif de nos contemporains à travers des promesses de contrôle individuel accru, voire de propriété et de libre disposition commerciale de chacun sur « ses » données. Si l’on se place du point-de-vue de l’individu, d’ailleurs, le problème n’est pas celui d’une plus grande visibilité sociale ni d’une disparition de la sphère privée. On assiste au contraire à une hypertrophie de la sphère privée au détriment de l’espace public.
Les technologies contemporaines de l’information et de la communication ne nous rendent pas vraiment plus « visibles ». Les « demoiselles du téléphone » de jadis, entremetteuses incontournables et pas toujours discrètes des rendez-vous galants dans des microcosmes sociaux avides de rumeurs, représentaient une menace au moins aussi importante pour la protection des données personnelles et de la vie privée des personnes que les algorithmes aveugles et sourds des moteurs de recherche d’aujourd’hui. Peut-être n’avons-nous jamais été moins « visibles », moins « signifiants » dans l’espace public en tant que sujets, en tant que personnes, qu’aujourd’hui. La prolifération des selfies et autres performances identitaires numériques est symptomatique à cet égard. L’incertitude d’exister induit une pulsion d’édition de soi sans précédent : se faire voir pour croire en sa propre existence.
Le vrai enjeu : la disparition de la « personne »
Ce qui intéresse les bureaucraties privées et publiques qui nous « gouvernent », c’est de détecter automatiquement nos « potentialités », nos propensions, ce que nous pourrions désirer, ce que nous serions capables de commettre, sans que nous en soyons nous-mêmes parfois même conscients. Une propension, un risque, une potentialité, ce n’est pas encore une personne. L’enjeu, ce n’est pas la donnée personnelle, mais bien plutôt la disparition de la « personne » dans les deux sens du terme. Il nous devient impossible de n’être « personne », d’être « absents » (nous ne pouvons pas ne pas laisser de traces) et il nous est impossible de compter en tant que « personne ». Ce que nous pourrions dire de nous mêmes ne devient-il pas redondant, sinon suspect, face à l’efficacité et à l’objectivité machinique des profilages automatiques dont nous faisons l’objet ?
Les traces parlent de/pour nous mais ne disent pas qui nous sommes : elles disent ce dont nous sommes capables. Aux injonctions explicites de performance-production et de jouissance-consommation qui caractérisaient le néolibéralisme s’ajoute la neutralisation de « ce dont nous serions capables », de « ce que nous pourrions vouloir ». Dans le domaine militaire et sécuritaire, c’est l’exécution par drones armés ou les arrestations préventive de potentiels combattants ou terroristes. Dans le domaine commercial, il ne s’agit plus tant de satisfaire la demande, mais de l’anticiper.
N’y-a-t-il pas contradiction entre la disparition de la « personne » et l’hyperpersonnalisation ?
Oui, il peut paraître paradoxal que, dans le même temps, l’on fasse l’expérience à la fois de la personnalisation des environnements numériques, des interactions administratives, commerciales, sécuritaires,… grâce à un profilage de plus en plus intensif et de la disparition de la personne ! L’hyperpersonnalisation des environnements numériques, des offres commerciales, voire des interactions administratives, porte moins la menace d’une disparition de la vie privée que celle d’une hypertrophie de la sphère privée au détriment de l’espace public. D’une part, il devient de plus en plus rare, pour l’individu, d’être exposé à des choses qui n’ont pas été prévues pour lui, de faire, donc, l’expérience d’un espace public, commun ; d’autre part, les critères de profilage des individus échappent à la critique et à la délibération collective,… alors même qu’ils ne sont, pas plus que la réalité sociale dont ils se prétendent le reflet passif, justes et équitables. Par ailleurs, les individus sont profilés non plus en fonction de catégories socialement éprouvées (origine ethnique, genre, expérience professionnelle, etc.) dans lesquelles ils pouvaient se reconnaître, à travers lesquels ils pouvaient faire valoir des intérêts collectifs, mais en fonction de « profils » produits automatiquement en fonction de leurs trajectoires et interactions numériques qui ne correspondent plus à aucune catégorie socialement éprouvée. Ce qui me semble donc surtout menacé, aujourd’hui, ce n’est pas la sphère privée (elle est, au contraire, hypertrophiée), mais l’espace public, l’ « en commun ».
Nous intéressons les plateformes, comme Google, Amazon, ou Facebook, en tant qu’émetteurs et agrégats temporaires de données numériques, c’est-à-dire de signaux calculables. Ces signaux n’ont individuellement peu de sens, ne résultent pas la plupart du temps d’intentions particulières d’individu, mais s’apparentent plutôt aux « traces » que laissent les animaux, traces qu’ils ne peuvent ni s’empêcher d’émettre, ni effacer, des phéromones numériques, en quelque sorte. Ces phéromones numériques nourrissent des algorithmes qui repèrent, au sein de ces masses gigantesques de données des corrélations statistiquement significatives, qui servent à produire des modèles de comportements. Les causes, les raisons, les motivations, les justifications des individus, les conditions socio-économiques ou environnementales ayant présidé à tel ou tel état du « réel » transcrit numériquement n’importent plus du tout dans cette nouvelle forme de rationalité algorithmique. Non seulement on peut s’en passer, mais en plus la recherche des causes, des motivations psychologiques, l’explicitation des trajectoires biographiques devient moralement condamnable : « Expliquer, c’est déjà un peu vouloir excuser », disait Manuel Vals le 10 janvier à l’occasion d’une cérémonie organisée sur la Place de la République à Paris en mémoire des victimes d’une attaque terroriste. On est dans une logique purement statistique, purement inductive. Il ne reste aux « sujets » plus rien à dire : tout est toujours déjà « pré-dit ». Les données parlent d’elles-mêmes ; elles ne sont plus même censées rien « représenter » car tout est toujours déjà présent, même l’avenir, à l’état latent, dans les données. Dans cette sorte d’idéologie technique, les Big data, avec une prétention à l’exhaustivité, seraient capables d’épuiser la totalité du réel, et donc aussi la totalité du possible.
Le processus de formalisation et d’expression du désir est court-circuité.
Ce qui intéresse les plateformes de commerce en ligne, par exemple, c’est de court-circuiter les processus à travers lesquels nous construisons et révisons nos choix de consommation, pour se brancher directement sur nos pulsions pré-conscientes, et produire ainsi du passage à l’acte d’achat si possible en minimisant la réflexion préalable de notre part. L’abandon des catégories générales au profit du profilage individuel conduit à l’hyper-individualisation, à une disparition du sujet, dans la mesure où, quelles que soient ses capacités d’entendement, de volonté, de réflexivité, d’énonciation, celles-ci ne sont plus ni présupposées, ni requises. L’automatisation fait passer directement des pulsions de l’individu à l’action ; ses désirs le précèdent. Ce que cela met à mal – et on pourrait se rapporter pour cela à Deleuze et Spinoza – c’est la puissance des sujets, c’est-à-dire, leur capacité à ne pas faire tout ce dont ils sont capables. Du fait de la détection automatique de l’intention, le processus de formalisation et d’expression du désir est court-circuité.
Je ne condamne pas ici dans l’absolu l’ « intelligence des données », ni la totalité des usages et applications qui peuvent être faits des nouveaux traitements de données de type Big data. Il y a des applications formidables, dans de nombreux domaines scientifiques notamment. La « curiosité automatique » des algorithmes capables de naviguer dans les données sans être soumis au joug de la représentation et sans être limités par l’idée du point-de-vue toujours situé de l’observateur humain, tout cela ouvre des perspectives inédites et promet des découvertes inattendues. Ce dont je m’inquiète ici, c’est des usages contemporains de cette rationalité algorithmique pour la modélisation et le gouvernement des comportements humains.
Mais, est-ce que c’est nouveau ? L’individu fait ses choix et décide en fonction de ce qu’il sait. Quand un algorithme fait une recommandation, n’est-ce pas une chance, pour l’individu d’être mieux informé, et donc de faire des choix plus éclairés, moins arbitraires ?
Bien sûr, nous n’avons jamais été les êtres parfaitement rationnels et autonomes, unités fondamentales du libéralisme fantasmés notamment par les économistes néoclassiques. La seule liberté que nous ayons, écrivait Robert Musil, c’est celle de faire volontairement ce que nous voulons involontairement. Mais, si nous ne maîtrisons pas ce qui détermine effectivement nos choix, il doit nous être néanmoins possible, après coup, de nous y reconnaître, de nous y retrouver, d’adhérer au fait d’avoir été motivés dans nos choix, dans nos décisions, par tel ou tel élément que nous puissions, après-coup, identifier, auquel nous puissions, après coup toujours, souscrire. La liberté consiste donc, pour moi, en la capacité que nous avons de rendre compte de nos choix alors même que nous ne maîtrisons pas les circonstances qui ont présidé à la formation de nos préférences.
Par contre, il n’est pas vrai, à mon sens, que l’individu fasse toujours des choix et prenne des décisions seulement ni prioritairement en fonction de ce qu’il connaît. La détection des profils psychologiques de consommateurs et la personnalisation des offres en fonction de ces profils permet d’augmenter les ventes, mais pas nécessairement d’émanciper les individus, qui pourraient très bien, alors qu’ils sont de fait extrêmement sensibles à l’argument de la popularité, préférer parfois cultiver l’objet rare ou, alors qu’ils sont victimes de leurs pulsions tabagiques ou alcooliques, préférer n’être pas incités à consommer ces substances addictives. Le profilage algorithmique, dans le domaine du marketing, permet l’exploitation des pulsions conformistes ou addictives dont les individus peuvent préférer n’être pas affectés. C’est bien d’un court-circuitage des processus réflexifs qu’il s’agit en ce cas.
Les algorithmes de recommandation automatique pourraient aussi intervenir dans la prise de décision administrative ou judiciaire à l’égard de personnes. Imaginez par exemple un système d’aide à la décision fondé sur la modélisation algorithmique du comportement des personnes récidivistes. Alors qu’il ne s’agit en principe que de « recommandations » automatisées laissant aux fonctionnaires toute latitude pour suivre la recommandation ou s’en écarter, il y a fort à parier que très peu s’écarteront de la recommandation négative (suggérant le maintien en détention plutôt qu’une libération conditionnelle ou anticipée) quelle que soit la connaissance personnelle qu’ils ont de la personne concernée et quelle que soit leur intime conviction quant aux risques de récidive, car cela impliquerait de prendre personnellement la responsabilité d’un éventuel échec. De fait, la recommandation se substitue en ce cas à la décision humaine, et les notions de choix, mais aussi de décision, et de responsabilité, sont éclipsées par l’opérationnalité des machines.
Dans le cas de la libération conditionnelle, entre un algorithme qui se trompe dans 5% des cas et un décideur qui se trompe dans 8% des cas, il faut se méfier de l’algorithme et ne croire qu’en la dimension humaine ?
En premier lieu, il est difficile de dire quand exactement un algorithme « se trompe ». Si l’on peut effectivement évaluer le nombre de « faux négatifs » (le nombre de récidivistes non détectés et donc libérés), il est en revanche impossible d’évaluer le nombre de « faux positifs » (les personnes maintenues en détention en raison d’un « profil » de récidivistes potentiels, mais qui n’auraient jamais récidivé si elles avaient été libérées). Faut-il tolérer un grand nombre de faux positifs si cela permet d’éviter quelques cas de récidive ? C’est une question éthique et politique qui mérite d’être débattue collectivement. La problématique est assez similaire à celle d’une éventuelle arrestation préventive de personnes désignées, sur la seule base d’un profilage algorithmique, comme terroristes potentiels. En principe, la présomption d’innocence fait encore partie du fond commun de la culture juridique dans nos pays. Il ne faudrait pas que cela change sans qu’il en soit débattu politiquement. La modélisation algorithmique du comportement récidiviste peut être utile et légitime, mais seulement à titre purement indicatif. La difficulté est de maintenir ce caractère « purement indicatif », de ne pas lui accorder d’avantage d’autorité. La décision de libération peut être justifiée au niveau de la situation singulière d’un individu dont pourtant le comportement correspond au modèle d’un comportement de futur récidiviste. Beaucoup des éléments qui font la complexité d’une personne échappent à la numérisation. De plus, une décision à l’égard d’une personne a toujours besoin d’être justifiée par celui qui la prend en tenant compte de la situation singulière de l’individu concerné. Or les recommandations automatiques fonctionnent bien souvent sur des logiques relativement opaques, difficilement traduisibles sous une forme narrative et intelligible. Les algorithmes peuvent aider les juges, mais ne peuvent les dispenser de prendre en compte l’incalculable, le non numérisable, ni de justifier leurs décisions au regard de cette part d’indécidable.
Les algorithmes sont toxiques si nous nous en servons pour optimiser l’intolérable en abdiquant de nos responsabilités – celle de nous tenir dans une position juste par rapport à notre propre ignorance et celle de faire usage des capacités collectives que nous avons de faire changer le monde. Les algorithmes sont utiles, par contre, lorsqu’ils nous permettent de devenir plus intelligents, plus sensibles au monde et à ses habitants, plus responsables, plus inventifs. Le choix de les utiliser d’une manière paresseuse et toxique ou courageuse et émancipatrice nous appartient.
(*) Antoinette Rouvroy, Human Genes and Neoliberal Governance. A foucauldian Critique, Routledge-Cavendish, 2007.
Pour aller plus loin :
Mireille Hildebrandt & Antoinette Rouvroy (eds.), Law, Human Agency and Autonomic Computing. The Philosophy of Law Meets the Philosophy of Technology, Routledge, 2011.
La préparation de cette émission avec le Labo des Savoirs a commencé avant les attentats de novembre. Il s’agissait pour nous d’ouvrir la boite noire des dispositifs de renseignement. Nous allons donc parler de surveillance numérique avec, comme binaire aime le faire, un regard technique.
Marie-Paule Cani rêve de logiciels qui permettraient à chacun de créer en 3D. En savoir plus ? Voici un podcast sympatique comme Marie Paule sur France Inter, avec Fabienne Chauvière pour Les Savanturiers.
Véronique Cortier est une spécialiste de la vérification qui a déjà écrit plusieurs articles passionnants pour Binaire, notamment sur le vote électronique. Elle intervient cette fois au Café techno d’Inria Alumni.
Café techno : Inria Alumni, en partenariat avec NUMA et le blog binaire, vous invite à débattre avec Véronique Cortier, Cnrs, Loria, le Lundi 18 janvier 2016, de 18:30 à 20:30.
NUMA Sentier, 39 rue du Caire, 75002 Paris
Peut-on avoir confiance dans le vote électronique ?
L’irruption des scrutins par voie numérique (on parle de « vote électronique ») soulève de nombreux enjeux en termes de garanties de bon fonctionnement et de sécurité informatique : comment m’assurer que mon vote sera bien pris en compte ? Est-ce qu’un tiers peut savoir comment j’ai voté ? Puis-je faire confiance au résultat annoncé ? Ces questions sont parfaitement légitimes et les systèmes de vote électronique n’y apportent pas encore de réponse claire. Mais les mêmes questions se posent pour les scrutins plus classiques qui ont recours au « papier ».
À quoi servent les mathématiques ? Il faut évidemment rappeler que « […] le but unique de la science, c’est l’honneur de l’esprit humain et […] sous ce titre, une question de nombres vaut autant qu’une question de système du monde »
Mais cela ne les empêche pas de nous aider aussi au quotidien et il y a bien peu de secteurs de l’activité humaine dont elles soient absentes. C’est particulièrement vrai pour la compréhension de notre environnement : climat, économie, géologie, écologie, science spatiale, régulation démographique, politique mondiale, etc.
Aller sur le site
Le livre collectif Brèves de maths (Éditions Nouveau Monde) illustre, de façon accessible, la variété des problèmes scientifiques dans lesquels la recherche mathématique actuelle joue un rôle important. Cet ouvrage propose une sélection des meilleures contributions du projet Un jour, une brève de l’initiative internationale Mathématiques de la planète Terre.
Ce conte pour enfant, un spectacle « coup de cœur » de binaire, passe à la Cité des Sciences. Voir l’article de Valérie Schafer. Entrée libre dans la limite des places disponibles.
La recherche aime bien avoir ses challenges qui galvanisent les énergies. L’intérêt d’un tel challenge peut avoir de nombreuses raisons, la curiosité (le plus ancien os humain), l’importance économique (une énergie que l’on puisse stoker), la difficulté technique (le théorème de Fermat). En informatique, un problème tient de ces deux dernières classes : c’est l’«isomorphisme de graphe» (nous allons vous dire ce que c’est !) . On comprendra l’excitation des informaticiens quand un chercheur de la stature de Laszlo Babai de l’Université de Chicago a annoncé une avancée fantastique dans notre compréhension du problème. Binaire a demandé à une amie, Christine Solnon, Professeure à l’INSA de Lyon, de nous parler de ce problème. Serge Abiteboul, Colin de la Higuera.
À la rencontre de Laszlo et de son problème
Laszlo Babai, professeur aux départements d’informatique et de mathématiques de l’université de Chicago, a présenté un exposé le 10 novembre 2015 intitulé Graph Isomorphism in Quasipolynomial Time. Si le nom « isomorphisme de graphes » ne vous dit rien, vous avez probablement déjà rencontré ce problème, et vous l’avez peut être même déjà résolu « à la main » en comparant, par exemple, des schémas ou des réseaux, afin de déterminer s’ils ont la même structure.
Le problème est déroutant et échappe à toute tentative de classification : d’une part, il est plutôt bien résolu en pratique par un algorithme qui date du début des années 80 ; d’autre part, personne n’a jamais réussi à trouver un algorithme dont l’efficacité soit garantie dans tous les cas. Mais surtout, il est un atout sérieux pour tenter de prouver ou infirmer la plus célèbre conjecture de l’informatique : P≠NP.
Nous allons donc présenter ici un peu plus en détails ce problème, en quoi il occupe une place atypique dans le monde de la complexité des problèmes, et pourquoi l’annonce de Babai a fait l’effet d’une petite bombe dans la communauté des chercheurs en informatique.
Qu’est-ce qu’un graphe ?
Pour résoudre de nombreux problèmes, nous sommes amenés à dessiner des graphes, c’est-à-dire des points (appelés sommets) reliés deux à deux par des lignes (appelées arêtes). Ces graphes font abstraction des détails non pertinents pour la résolution du problème et permettent de se focaliser sur les aspects importants. De nombreuses applications utilisent les graphes pour modéliser des objets. Par exemple:
By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
Un réseau de transport (routier, ferroviaire, métro, etc) peut être représenté par un graphe dont les sommets sont des lieux (intersections de rues, gares, stations de métro, etc) et les arêtes indiquent la possibilité d’aller d’un lieu à un autre (par un tronçon de route, une ligne de train ou de métro, etc.)
By This SVG image was created by Medium69. Cette image SVG a été créée par Medium
Une molécule peut être représentée par un graphe dont les sommets sont les atomes, et les arêtes les liaisons entre atomes.
Un réseau social peut être représenté par un graphe dont les sommets sont les membres, et les arêtes les relations entre membres
Le problème d’isomorphisme de graphes
Étant donnés deux graphes, le problème d’isomorphisme de graphes (Graph Isomorphism Problem) consiste à déterminer s’ils ont la même structure, c’est-à-dire, si chaque sommet d’un graphe peut être mis en correspondance avec exactement un sommet de l’autre graphe, de telle sorte que les arêtes soient préservées (deux sommets sont reliés par une arête dans le premier graphe si et seulement si les sommets correspondants sont reliés par une arête dans le deuxième graphe). Considérons par exemple ces trois graphes :
G1
Les graphes G1 et G2 sont isomorphes car la correspondance
{ a ↔ 1; b ↔ 2; c ↔ 3; d ↔ 4; e ↔ 5; f ↔ 6; g ↔ 7}
préserve toutes les arêtes.
Par exemple :
– a et b sont reliés par une arête dans G1, et 1 et 2 aussi dans G2
– a et c ne sont pas reliés par une arête dans G1, et 1 et 3 non plus dans G2 ;
etc.
En revanche, G1 n’est pas isomorphe à G3
(ce qui n’est pas évident à vérifier).
G2
G3
Notons qu’il est plus difficile de convaincre quelqu’un que les graphes G1 et G3 ne sont pas isomorphes car nous ne pouvons pas fournir de « certificat » permettant de vérifier cela rapidement, comme nous venons de le faire pour montrer que G1 et G2 sont isomorphes. Pour se convaincre que deux graphes ne sont pas isomorphes, il faut se convaincre qu’il n’existe pas de correspondance préservant les arêtes, et la question de savoir si on peut faire cela efficacement (autrement qu’en énumérant toutes les correspondances possibles) est véritablement au cœur du débat.
Ce problème se retrouve dans un grand nombre d’applications : dès lors que des objets sont modélisés par des graphes, le problème de la recherche d’un objet identique à un objet donné, par exemple, s’y ramène. Il est donc de première importance de disposer d’algorithmes efficaces.
Mais, au delà de cet aspect pratique, le problème occupe aussi une place très particulière dans un monde théorique au sein de la science informatique : celui de la complexité .
Petite digression sur la complexité des problèmes
La théorie de la complexité s’intéresse à la classification des problèmes en fonction de la complexité de leur résolution.
La classe des problèmes faciles (P). La classe P regroupe tous les problèmes « faciles ». Nous dirons qu’un problème est facile s’il existe un algorithme « efficace » pour le résoudre, et nous considèrerons qu’un algorithme est efficace si son temps d’exécution croît de façon polynomiale lorsqu’on augmente la taille du problème à résoudre. Par exemple, le problème consistant à trouver un chemin reliant deux sommets d’un graphe appartient à la classe P car il existe des algorithmes dont le temps d’exécution croît de façon linéaire par rapport à la taille du graphe (son nombre de sommets et d’arêtes).
La classe des problèmes dont les solutions sont faciles à vérifier (NP). La classe NP regroupe l’ensemble des problèmes pour lesquels il est facile de vérifier qu’une combinaison donnée (aussi appelée certificat) est une solution correcte au problème. Par exemple, le problème de recherche d’un chemin entre deux sommets appartient également à NP car étant donnée une succession de sommets, il est facile de vérifier qu’elle correspond bien à un chemin entre les deux sommets. De fait, tous les problèmes de P appartiennent à NP.
La question inverse est plus délicate, et fait l’objet de la célèbre conjecture P≠NP.
La classe des problèmes difficiles (NP-complets). Certains problèmes de la classe NP apparaissent plus difficiles à résoudre dans le sens où personne ne trouve d’algorithme efficace pour les résoudre. Les problèmes les plus difficiles de NP définissent la classe des problèmes NP-complets.
Considérons par exemple le problème consistant à rechercher dans un réseau social un groupe de personnes qui sont toutes amies deux à deux. Le problème est facile si on ne pose pas de contrainte sur la taille du groupe. Il devient plus difficile si on impose en plus que le groupe comporte un nombre fixé à l’avance de personnes. Si on modélise le réseau social par un graphe dont les sommets représentent les personnes et les arêtes les relations entre les personnes, alors ce problème revient à chercher un sous-ensemble de k sommets tous connectés deux à deux par une arête. Un tel sous-ensemble est appelé une clique.
Si nous avons un sous-ensemble de sommets candidats, alors nous pouvons facilement vérifier s’il forme une clique ou non. En revanche, trouver une clique de taille donnée dans un graphe semble plus difficile. Nous pouvons résoudre ce problème en énumérant tous les sous-ensembles possibles de sommets, et en testant pour chacun s’il forme une clique. Cependant, le nombre de sous-ensembles candidats explose (c’est-à-dire, croît exponentiellement) en fonction du nombre de sommets des graphes, ce qui limite forcément ce genre d’approche à des graphes relativement petits.
Actuellement, personne n’a trouvé d’algorithme fondamentalement plus efficace que ce principe fonctionnant par énumération et test. Évidemment, il existe des algorithmes qui ont de bien meilleures performances en pratique (qui utilisent des heuristiques et des raisonnements qui permettent de traiter des graphes plus gros) mais ces algorithmes ont toujours des temps d’exécution qui croissent de façon exponentielle par rapport au nombre de sommets.
La question pratique qui se cache derrière la question « P≠NP ? » est : Existe-t-il un algorithme efficace pour rechercher une clique de k sommets dans un graphe ?
Autrement dit : est-ce parce que nous ne sommes pas malins que nous n’arrivons pas à résoudre efficacement ce problème, ou bien est-ce parce que cela n’est pas possible ?
Il existe un très grand nombre de problèmesNP-complets, pour lesquels personne n’a réussi à trouver d’algorithme efficace. Ces problèmes interviennent dans de nombreuses applications de la vie quotidienne : faire un emploi du temps, ranger des boites rectangulaires dans un carton sans qu’il n’y ait de vide, chercher un circuit passant exactement une fois par chacun des sommets d’un graphe, etc. Pour ces différents problèmes, on connait des algorithmes qui fonctionnent bien sur des problèmes de petite taille. En revanche, quand la taille des problèmes augmente, ces algorithmes sont nécessairement confrontés à un phénomène d’explosion combinatoire.
Un point fascinant de la théorie de la complexité réside dans le fait que tous ces problèmes sont équivalents dans le sens où si quelqu’un trouvait un jour un algorithme efficace pour un problème NP-complet (n’importe lequel), on saurait en déduire des algorithmes polynomiaux pour tous les autres problèmes, et on pourrait alors conclure que P = NP. La question de savoir si un tel algorithme existe a été posée en 1971 par Stephen Cook et n’a toujours pas reçu de réponse. La réponse à cette question fait l’objet d’un prix d’un million de dollars par l’institut de mathématiques Clay.
La classe des problèmes ni faciles ni difficiles (NP-intermédiaires). Le monde des problèmes NP serait bien manichéen s’il se résumait à cette dichotomie entre les problèmes faciles (la classe P) et les problèmes dont on conjecture qu’ils sont difficiles (les problèmes NP-complets). Un théorème de Ladner nous dit qu’il n’en est rien : si la conjecture P≠NP est vérifiée, alors cela implique nécessairement qu’il existe des problèmes de NP qui ne sont ni faciles (dans P) ni difficiles (NP-complets). Ces problèmes sont appelés NP-intermédiaires. Notons que le théorème ne nous dit pas si P est différent de NP ou pas : il nous dit juste que si P≠NP, alors il existe au moins un problème qui est NP-intermédiaire… sans nous donner pour autant d’exemple de problème NP-intermédiaire. Il faudrait donc réussir à trouver un problème appartenant à cette classe pour démontrer que P≠NP. On dispose d’une liste (assez courte) de problèmes candidats (voir par exemple https ://en.wikipedia.org/wiki/NP-intermediate)… et c’est là que l’isomorphisme de graphes entre en jeu.
Que savait-on sur la complexité de l’isomorphisme de graphes jusqu’ici ?
Nous pouvons facilement vérifier que deux graphes sont isomorphes dès lors qu’on nous fournit une correspondance préservant les arêtes (comme nous l’avons fait précédemment pour les graphes G1 et G2). On peut donc facilement vérifier les solutions, nous sommes dans la classe NP. Mais sa complexité exacte n’est pas (encore) connue. Des algorithmes efficaces (polynomiaux) ont été trouvés pour des cas particuliers, les plus utilisés étant probablement pour les arbres (des graphes sans cycle) et les graphes planaires (des graphes qui peuvent être dessinés sur un plan sans que leurs arêtes ne se croisent). Dans le cas de graphes quelconques, les meilleurs algorithmes connus jusqu’ici ont une complexité exponentielle. Pour autant, personne n’a réussi à démontrer que le problème est NP-complet.
Il est donc conjecturé que ce problème est NP-intermédiaire. C’est même sans aucun doute le candidat le plus célèbre pour cette classe, d’une part parce qu’il est très simple à formuler, et d’autre part parce qu’on le retrouve dans de nombreux contextes applicatifs différents.
Que change l’annonce de Babai ?
L’annonce de Babai n’infirme pas la conjecture selon laquelle le problème est NP-intermédiaire, car son nouvel algorithme est quasi-polynomial, et non polynomial.
Plus exactement, pour les matheuses et les matheux, si les graphes comportent n sommets, alors le temps d’exécution de l’algorithme croît de la même façon que la fonction 2log(n)c où c est une valeur constante. Si c est égal à 1, alors l’algorithme est polynomial. Ici, c est supérieur à 1, de sorte que l’algorithme n’est pas polynomial, mais son temps d’exécution se rapproche plus de ceux d’algorithmes polynomiaux que de ceux d’algorithmes exponentiels.
Ce résultat est une avancée majeure parce qu’il rapproche le problème de la classe P, mais aussi parce que l’existence de cet algorithme quasi-polynomial ouvrira peut être une piste pour trouver un algorithme polynomial, ce qui permettrait d’éliminer le problème de la courte liste des problèmes dont on conjecture qu’ils sont NP-intermédiaires. Notons que le dernier problème qui a été enlevé de cette liste est le problème consistant à déterminer si un nombre entier donné est premier, pour lequel un algorithme polynomial a été trouvé en 2002.
D’un point de vue purement pratique, en revanche, cette annonce risque fort de ne pas changer grand chose quant à la résolution du problème, car on dispose déjà d’algorithmes performants : ces algorithmes sont capables de le résoudre pour la très grande majorité des graphes, et n’ont un temps d’exécution exponentiel que pour très peu de graphes.
De l’annonce au résultat établi. Le résultat de Babai en est encore au stade de l’annonce. Il faut maintenant qu’il soit détaillé dans un ou plusieurs articles, vérifiés par ses pairs, puis publiés dans des journaux. Ce résultat viendra alors grandir le corpus des vérités scientifiques établies. Il peut arriver que lors de ce cheminement, on trouve des « trous » dans la démonstration ; c’est arrivé pour le théorème de Fermat et ils ont été comblés. Il se peut aussi qu’on trouve une erreur dans la démonstration (y compris après la publication de l’article) ce qui renvoie les scientifiques à leurs tableaux noirs .
Pour un exemple d’algorithme pratique, l’algorithme Nauty 4 introduit en 1981 par Brendan McKay.
László Babai, né le 20 juillet 1950 à Budapest, est un professeur de mathématiques et d’informatique hongrois, enseignant actuellement à l’université de Chicago. Il est connu pour les systèmes de preuve interactive, l’introduction du terme « algorithme de Las Vegas » et l’utilisation de méthodes de la théorie des groupes pour le problème de l’isomorphisme de graphes. Il est lauréat du prix Gödel 1993. Wikipedia (2016).
Montée du niveau des mers, érosion côtière, perte de biodiversité… Les impacts sociétaux de ces bouleversements dus au réchauffement climatique ne seront pas dramatiques dans un futur proche si et seulement si nous changeons radicalement nos comportements collectifs et individuels et mettont en place de vraies solutions.
Joanna Jongwane
L’informatique et les mathématiques appliquées contribuent à relever le défi de la transition énergétique, pour changer par exemple l’usage des voitures en ville ou encore pour contrôler la consommation d’énergie dans les bâtiments. A contrario, quand la nature et la biodiversité inspirent les informaticiens, cela aboutit à des projets d’écosystèmes logiciels qui résistent mieux à divers environnements.
Accéder au dossier
C’est sur Interstices, la revue de culture scientifique en ligne qui invite à explorer les sciences du numérique, à comprendre ses notions fondamentales, à mesurer ses enjeux pour la société, à rencontrer ses acteurs que chercheuses et chercheurs nous proposent de découvrir quelques grains de science sur ces sujets. Morceaux choisis :
Accéder au document
«Le niveau des mers monte, pour différentes raisons liées au réchauffement climatique. Les glaciers de l’Antarctique et du Groenland, qu’on appelle calottes polaires ou inlandsis, jouent un rôle majeur dans l’évolution du niveau des mers. Peut-on prévoir l’évolution future de ces calottes polaires et en particulier le vêlage d’icebergs dans l’océan ?»
Accéder au document
«À l’heure de la COP21, toutes les sonnettes d’alarme sont tirées pour alerter sur l’urgence climatique. Si les simulations aident à prédire les évolutions du climat, elles peuvent aussi être vues comme un outil de dialogue science-société, selon Denis Dupré. On en parle avec lui dans cet épisode du podcast audio.»
Accéder au document
«Si au lieu de distribuer des millions de copies identiques, les fabricants de logiciels avaient la possibilité de distribuer des variantes, et que ces variantes avaient la possibilité de s’adapter à leur environnement, ces « écosystèmes logiciels » ne pourraient-ils pas renforcer la résistance de tous les services qui nous accompagnent au quotidien ?»
Extraits d’Interstices, Joanna Jongwane, Rédactrice en chef d’Interstices et Jocelyne Erhel, Directrice de Recherche et Responsable scientifique du comité éditorial, avec Christine Leininger et Florent Masseglia membres du comité exécutif.
Dérèglement climatique ? Problèmes d’énergie et dégradations que nous faisons subir à notre planète ? La Conférence de Paris de 2015 sur le climat (qui inclut la COP21) est une excellente occasion de mettre la transition écologique au cœur du débat. De plus, nous baignons dans une autre transition, la transition numérique dont on mesure chaque jour un peu plus en quoi elle transforme notre monde de façon si fondamentale. Deux disruptions. Comment coexistent-elles ?
www.greenit.fr, un site de partage de ressources à propos d’informatique durable
Commençons par ce qui fâche le fana d’informatique que je suis : le coût écologique du numérique. Le premier ordinateur, Eniac, consommait autant d’électricité qu’une petite ville. Les temps ont changé ; votre téléphone intelligent a plus de puissance de calcul et ne consomme quasiment rien. Oui mais des milliards de telles machines, d’objets connectés, et les data centers ? La consommation énergétique de l’ensemble est devenue une part importante de la consommation globale ; plus inquiétante encore est la croissance de cette consommation. Et puis, pour fabriquer tous ces objets, il faut des masses toujours plus considérables de produits chimiques, et de ressources naturelles, parfois rares. Et je vous passe les déchets électroniques qui s’amoncellent. Il va falloir apprendre à être économes ! Vous avez déjà entendu cette phrase. Certes ! On ne fait pas faire tourner des milliards d’ordinateurs en cueillant silencieusement des fleurs d’Udumbara.
D’un autre coté, le monde numérique, c’est la promesse de nouveaux possibles, scientifiques, médicaux, économiques, sociétaux. C’est, entre tellement d’autres choses, la possibilité pour un adolescent de garder contact avec des amis partout dans le monde; pour un jeune parent, de travailler de chez lui en gardant un enfant malade ; pour une personne au fin fond de la campagne, au bout du monde, d’avoir accès à toute la culture, à tous les savoirs du monde ; pour une personne âgée de continuer à vivre chez elle sous une surveillance médicale permanente. C’est tout cela : de nouveaux usages, de nouveaux partages, de nouveaux modes de vie. Alors, il n’est pas question de « se déconnecter » !
Les transitions écologiques et numériques doivent apprendre à vivre ensemble.
Penser écologie quand on parle de numérique
Quand le numérique prend une telle place dans notre société, il faut que, comme le reste, il apprenne à être frugal. Cela conduit à la nécessité de construire des ordinateurs plus économes en électricité, d’arrêter de dépenser d’énormes volumes de temps de calcul pour mieux cibler quelques publicités. Cela conduit aussi à modifier nos habitudes en adoptant un faisceau de petits gestes : ne pas changer d’ordinateur, de téléphone intelligent, de tablette tous les ans juste pour pouvoir frimer avec le dernier gadget, ne pas inonder la terre entière de courriels, surtout avec des pièces jointes conséquentes, etc. Nous avons pris de mauvaises habitudes qu’il est urgent de changer. Les entreprises doivent aussi limiter leurs gaspillages d’énergie pour le numérique. On peut notamment réduire de manière significative l’impact écologique d’un data center, le rendre plus économe en matière d’énergie, voire réutiliser la chaleur qu’il émet. Bref, il faut apprendre à penser écologie quand on parle de numérique.
Oui, mais les liens entre les deux transitions vont bien plus loin. Le numérique et l’écologie se marient en promouvant des manières nouvelles, collectives de travailler, de vivre. Les réseaux sociaux du Web, des encyclopédies collaboratives comme Wikipedia, ne préfigurent-ils pas, même avec leurs défauts, le besoin de vivre ensemble, de travailler ensemble ? L’innovation débridée autour du numérique n’est-elle pas un début de réponse à l’indispensable nécessité d’innover pour répondre de manière urgente aux défis écologiques, dans toute leur diversité, avec toute leur complexité ?
adapté de pixabay.com
L’informatique et le numérique sont bien des outils indispensables pour résoudre les problèmes écologiques fondamentaux qui nous sont posés. Philippe Houllier, le PDG de l’INRA, peut, par exemple, bien mieux que moi expliquer comment ces technologies sont devenues incontournables dans l’agriculture. Il nous parle dans un article à venir sur binaire de l’importance des big data pour améliorer les rendements en agriculture, un sujet d’importance extrême quand les dérèglements climatiques et la pollution des sols tendent à faire diminuer ces rendements.
On pourrait multiplier les exemples mais il faut peut-être mieux se focaliser sur un fondement de la pensée écologique :
penser global, agir local.
On avait tendance à penser des équipements massifs, globaux, par exemple une centrale nucléaire, une production agricole intensive destinée à la planète, etc. Les temps changent. On parle maintenant d’énergie locale, diversifiée, d’agriculture de proximité. Mais si cette approche conduit à une économie plus durable, elle est plus complexe à mettre en place ; elle demande de faire collaborer de nombreuses initiatives très différentes, de s’adapter très vite et en permanence, de gérer des liens et des contraintes multiples. Elle ne peut se réaliser qu’en s’appuyant sur le numérique ! On peut peut-être faire fonctionner une centrale nucléaire sans ordinateur – même si je n’essaierais pas – mais on n’envisagerait pas de faire fonctionner un « smart-grid » (réseau de distribution d’électricité « intelligent ») sans. Un peu à la manière dont nos ordinateurs s’échangent des données sans cesse, on peut imaginer des échanges d’électricité entre un très grand nombre de consommateurs et plus nouveau de fournisseurs (panneaux solaires, éolienne, etc.), pour adapter en permanence production et consommation, pour en continu optimiser le système. Il s’agit bien d’une question d’algorithme. Et l’informatique est également omniprésente quand nous cherchons à modéliser le climat, les pollutions, à les prévoir.
Nous découvrons sans cesse de nouvelles facettes de la rencontre entre ces deux transitions. Nous découvrons sans cesse de nouveaux défis pour la recherche et le développement à leur frontière.
Le groupement de Service (G.D.S.) ÉcoInfo : des ingénieurs et des chercheurs (CNRS, INRIA, ParisTech, Institut Mines Télécom, RENATER, UJF…) à votre service pour réduire les impacts écologiques et sociétaux des TIC.
Vous avez peut-être déjà bloqué devant des parfois « infâmes » EULA, en anglais pour « End User License Agreement », ou CGU en français pour Conditions générale d’utilisation (voir Dangerous Terms: A User’s Guide to EULAs). Ces conditions sous lesquelles vous avez accès à un produit ou à un service sur le Web sont souvent longues, rébarbatives, incompréhensives pour un profane. D’ailleurs, on ne les lit pas, on clique, et on se livre à la merci de leur contenu. C’est le syndrome du « TL;DR », pour « Too long; didn’t read » : trop long, pas lu. Binaire a demandé à Nicolas Rougier de nous parler du sujet. Serge Abiteboul.
En 2005, PC Pitstop offrait 1000 dollars à qui lirait ses conditions générales d’utilisation. Et bien entendu, l’offre était écrite dans les dites conditions générales d’utilisation. Ils durent attendre 4 mois avant que quelqu’un ne réclame les 1000$ (voir It Pays To Read License Agreements).
Pour le 1er avril 2010, la chaîne de magasin gamestation qui était spécialisée dans les jeux vidéos d’occasion, ajouta le petit paragraphe suivant à ses conditions d’utilisation:
« By placing an order via this Web site on the first day of the fourth month of the year 2010 Anno Domini, you agree to grant Us a non transferable option to claim, for now and for ever more, your immortal soul. Should We wish to exercise this option, you agree to surrender your immortal soul, and any claim you may have on it, within 5 (five) working days of receiving written notification from gamesation.co.uk or one of its duly authorised minions… We reserve the right to serve such notice in 6 (six) foot high letters of fire, however we can accept no liability for any loss or damage caused by such an act. If you a) do not believe you have an immortal soul, b) have already given it to another party, or c) do not wish to grant Us such a license, please click the link below to nullify this sub-clause and proceed with your transaction. »
En résumé, gamestation demandait à chaque utilisateur de leur céder leur âme immortelle. Ce qu’ont fait joyeusement 88% de ses utilisateurs.
Dans un autre registre, vous seriez surpris d’apprendre que les conditions d’utilisation du service iTunes vous empêchent explicitement d’utiliser iTunes pour fabriquer des armes nucléaires :
« Vous acceptez également de ne pas utiliser ces produits à des fins prohibées par le droit des États-Unis, ceci y compris et sans toutefois s’y limiter, le développement, la conception, la fabrication ou la production d’armes nucléaires, de missiles ou d’armes chimiques ou biologiques. » (iTunes Store – Conditions générales du service).
On n’est jamais trop prudent ! Parce qu’il s’agit bien ici d’essayer de se protéger par tous les moyens. Les avocats ont la gâchette facile aux États-Unis (où la plupart de ces services voient le jour).
Et la réalité qu’elles cachent
Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple Terms of Services, Didn’t read) et même des bandes dessinées. Ainsi, vous seriez surpris d’apprendre les droits que s’arrogent Google, Facebook ou Twitter sur tous les contenus que vous postez. Pour en savoir plus, je ne saurais trop vous conseiller « Les Nouveaux Loups du Web » qui sortira le 6 janvier 2016 et qui nous apprend, entre autre chose, que toutes ces licences sont généralement irrévocables, mondiales, perpétuelles, illimitées, transférables, modifiables, etc.
Oh, une dernière chose, une espèce de petite cerise sur la gâteau si vous comptiez effacer tout vos contenus suite à la lecture de ce court billet : sachez que ces service n’oublient rien. Mais vraiment rien. En 2010, Max Schrems, un étudiant en droit autrichien, demanda à Facebook l’ensemble des données relatives à son compte en vertu des lois européennes (Facebook Europe étant basée à Dublin). Quelle ne fût pas sa surprise de recevoir un document PDF de 1200 pages relatant toute son histoire ainsi que tous les contenus postés, y compris… ceux qu’il avait effacés (voir Max Schrems, le « gardien » des données personnelles qui fait trembler les géants du Web).
La semaine prochaine, du 14 au 21 novembre, se déroule le concours Castor informatique ! L’édition 2014 avait touché plus de 220 000 élèves ! L’édition Française est organisée par l’association France-ioi, Inria et l’ENS Cachan, grâce à la contribution de nombreuses personnes. Ce concours international est organisé dans 36 pays. Plus de 920 000 élèves ont participé à l’épreuve 2014 dans le monde.
Les points à retenir, le concours est :
entièrement gratuit ;
organisé sur ordinateur ou sur tablette sous la supervision d’un enseignant ;
il dure 45 minutes ;
entre le 14 et 21 novembre 2015, à un horaire choisi par l’enseignant ;
avec une participation individuelle ou par binôme ;
aucune connaissance préalable en informatique n’est requise.
Nouveautés 2015 :
Ouverture aux écoles primaires : le concours est désormais ouvert à tous les élèves du CM1 à la terminale !
Niveau adaptable : chaque défi est interactif et se décline en plusieurs niveaux de difficultés pour accommoder les élèves de 9 à 18 ans.
Il est encore temps de s’inscrire pour les enseignants (vous pouvez le faire jusqu’au dernier jour, même si nous vous conseillons d’anticiper).
En attendant, ou si vous n’êtes plus à l’école, vous pouvez vous amuser à tester les défis des années précédentes depuis 2010, et en particulier les défis interactifs de 2014 !
C’est une pièce de théâtre écrite et mise en scène par Orah de Mortcie, direction d’acteurs par Laetitia Grimaldi. Le Prochain Train parle très intelligemment des liens entre les personnes à l’ère du numérique. Où nous conduit cette nouvelle technologie ? Comment les réseaux sociaux, les blogs, les tweets, toutes ces applications vont-elles nous transformer ? Ce beau texte attaque bille en tête ces sujets complexes avec de l’humour, accompagné d’une jolie musique pas numérique du tout.
Vincent est un de ces « workaholics » que l’on croise de plus en plus, soumis à la dictature des mails. Karine est la spécialiste qu’il embauche pour gérer sa vie numérique. La pièce les plonge dans des rapports improbables. « J’ai grandi avec Internet et le numérique… j’ai du mal à utiliser Twitter, instatruc, et toutes ses applications qui arrivent chaque jour », avoue Elsa de Belilovsky qui joue le rôle de Karine. Pourtant, pendant une heure et demi nous avons cru qu’elle était la Reine du Numérique. Quel talent !
Le Prochain Train passe à la Manufacture des Abesses, à Paris, jusqu’à la fin de novembre. Il reste des places, courrez-y !










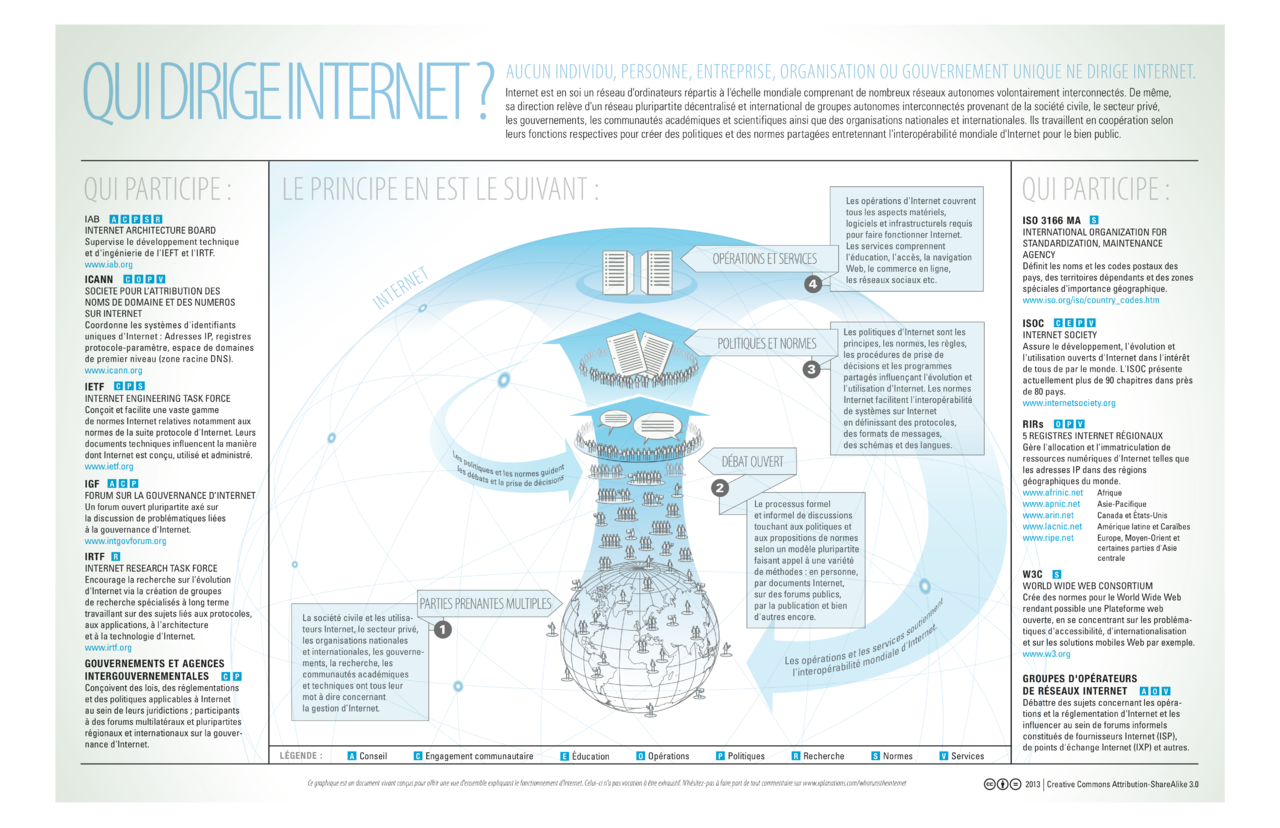









![By Tibidibtibo (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://binaire.socinfo.fr/wp-content/uploads/2015/11/Plan_metro_tram_chemin.svg_.png)
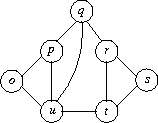
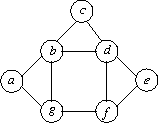
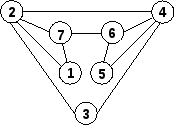









 Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple
Mais en dehors de ces exemples amusants, se cache une réalité bien plus préoccupante notamment concernant les données personnelles car les droits d’utilisation sont savamment cachés dans ces conditions générales parfaitement indigestes . Heureusement, on voit apparaitre des traducteurs, (voir par exemple 


{kind=link}