Un essai de Gérard Berry, Odile Jacob, 2025Nous sommes aujourd’hui capables de mesurer et de partager le temps avec une précision stupéfiante. Mais en comprenons-nous vraiment toutes les dimensions ? Sommes-nous conscients des nouveaux enjeux, souvent cruciaux, que les systèmes ultra-performants qui rythment notre quotidien soulèvent ?
Dans cet ouvrage, Gérard Berry propose une présentation totalement inédite du sujet. Il ne se contente pas d’exposer des faits scientifiques ou techniques. Dans un style qui lui ressemble tellement, en véritable conteur, il nous parle du temps, avec sérieux, poésie, humour, avec une fraîcheur qui réjouit.
Professeur au Collège de France, ancien titulaire de la chaire Algorithmes, machines et langages (2012–2019), médaille d’or du CNRS et membre des Académies des sciences et des technologies, Gérard Berry est également l’auteur de L’hyperpuissance de l’informatique. Il nous livre ici un regard aussi érudit qu’original sur ce que le temps signifie vraiment.
Nous avons la profonde tristesse de vous annoncer le décès de Jean-Pierre Archambault, Président de l’EPI, le 23 février 2025.
Ancien enseignant et professeur agrégé de mathématiques, il a créé puis coordonné pendant de nombreuses années le pôle de compétences « logiciels libres » du SCÉRÉN, jouant un rôle de premier plan dans la légitimation et le développement du libre dans le système éducatif.
Dans les années 80 et 90, il a participé au pilotage du développement des Technologies de l’Information et de la Communication (TIC) dans l’académie de Créteil : organisation du volet formation du plan Informatique Pour Tous, mise en œuvre de la télématique scolaire et des réseaux locaux, expérimentation d’internet, formation des enseignants.
En tant que président de l’association Enseignement Public et informatique (EPI) il a été un artisan actif de l’introduction d’une discipline informatique au lycée et au collège, après une sensibilisation à l’école primaire. Ainsi, il a été membre du groupe de travail de l’Académie des sciences qui a préparé le rapport « L’enseignement de l’informatique en France – Il est urgent de ne plus attendre » adopté par l’académie en mai 2013.
Il a été pendant plusieurs années membre du Conseil d’Administration de la Société Informatique de France (SIF) et coresponsable du groupe ITIC-EPI-SIF.
Il était convaincu que l’enseignement de l’informatique et l’utilisation de l’informatique dans les disciplines et activités sont deux démarches complémentaires. Ses éditoriaux d’EpiNet, qu’il rédigeait avec soin, étaient sources de réflexion et appréciés de toutes et de tous.
Toutes ces actions militantes signifiaient des relations nouées avec les partenaires (collectivités territoriales, éditeurs, entreprises, parents d’élèves, associations d’enseignants, syndicats …) et les responsables du système éducatif. Elles sont toujours allées de pair avec une activité de réflexion, une veille et prospective sur les usages, les statuts et les enjeux pédagogiques et éducatifs de l’informatique et des technologies de l’information et de la communication. Cela a amené Jean-Pierre à organiser et à intervenir dans des colloques, forums, salons et séminaires. Il est l’auteur de nombreux articles dont la plupart sont sur les sites de l’EPI et d’edutice.archives-ouvertes.
Nous garderons un souvenir inoubliable de ces longues années passées ensemble. Jean-Pierre fut pour nous un excellent collègue et un ami.
Connaissez vous Sophie Wilson, Lynn Conway et Claire Wolf ? Bruno Levy nous offre la découverte de trois grandes personnalités du numérique, qui ont permis des avancées majeures en matière de capacité de calcul. Tandis que Marie Curie disait ne pas avoir fait sa carrière scientifique au mépris de sa vie de famille, mais « au mépris des imbéciles » ces trois personnes ont fait leur carrière scientifique au mépris des idées reçues. Serge Abiteboul, Benjamin Ninassi, et Thierry Viéville.
Le numérique et ce que certains aiment appeler « intelligence artificielle » sont au cœur de nos vies. La plupart de nos actions, même les plus anodines, impliquent à un moment ou à un autre l’utilisation d’un ordinateur. Certains sont gigantesques, comme les centres de calculs des géants de la tech, et d’autres sont minuscules, cachés dans les objets du quotidien pour les rendre plus efficaces, plus « intelligents », mais cela, en tant que lecteur ou lectrice assidu·e du blog Binaire, vous le savez déjà !
Mais connaissez vous des personnalités atypiques, hautes en couleur qui ont rendu ces innovations possibles ?
Parmi elles, vous connaissez sans doute déjà Alan Turing qui a joué un rôle clef dans la définition des bases fondamentales de la science informatique et dans le décryptage des codes secrets Nazis. Vous vous souvenez de la triste fin de son histoire, jugé et condamné pour son homosexualité en 1952, contraint à la castration chimique, il met fin à ses jours le 7 Juin 1954. Plus de 60 ans après, Elizabeth II revient sur sa condamnation à titre posthume.
L’actualité récente outre-Atlantique me fait prendre la plume pour vous inviter à un petit voyage au pays des trans-istors, quitte à assaisonner Binaire avec une pincée de non-binaire !
Sophie Wilson : elle se cache dans votre poche, le saviez vous ?
Nos plus petits appareils numériques, tout comme les gros serveurs qui donnent vie à Internet ou encore les super-calculateurs qui tentent de percer les secrets des lois de la Physique ont tous en commun un composant essentiel : le micro-processeur. En quelque sorte, pour nos appareils numériques, le microprocesseur joue le rôle du « chef d’orchestre », jouant la « partition » – un programme – qui décrit le fonctionnement de l’appareil. Ce programme est écrit dans un langage, qui a son propre « alphabet », constitué d’instructions élémentaires, très simples, encodées sous forme de nombres dans la mémoire de l’ordinateur. De la même manière qu’il existe plusieurs alphabets (mandarin, cantonais, japonais, latin, grec, cyrillique …), on peut imaginer plusieurs jeux d’instructions différents. Définir cet « alphabet » n’est pas un choix anodin, comme nous l’a montré Sophie Wilson, informaticienne Anglaise, femme trans née en 1957.
A la fin des années 1980, la BBC avait un ambitieux programme d’éducation au numérique. Alors employée d’Acorn Computers, Sophie Wilson a joué un rôle clef en définissant un jeu d’instruction original, caractérisé par son extrême simplicité (de type RISC, pour Reduced Instruction Set Computer (voir aussi : sur le blog binaire : « Un nouveau RiscV» )), ce qui a permis à son entreprise de remporter le marché de la BBC. Ça n’est pas une idée qui vient naturellement à l’esprit ! On aurait pu penser qu’un jeu d’instruction plus complexe (CISC, pour Complex Instruction Set Computer) rendrait l’ordinateur plus puissant, mais ceci a permis de grandement simplifier la conception du microprocesseur, et a facilité une autre innovation, l’exécution en pipeline qui permet d’améliorer à la fois l’efficacité et la fréquence d’horloge du processeur. Une autre conséquence intéressante de cette simplicité est la réduction de la consommation énergétique, particulièrement intéressante pour l’embarqué ou les téléphones portables, et pour cause, le « cœur numérique » de votre fidèle compagnon portable n’est autre qu’un héritier de la lignée de processeurs ARM initiée par Sophie Wilson.
Lynn Conway a compté les transistors jusqu’à l’infini … deux fois !
Les micro-processeurs sont le résultat d’un assemblage d’un très très … très grand nombre de petits éléments – des transistors. Les premiers micro-processeurs, tels que le 4004 sorti par Intel en 1971, comptaient quelques milliers de transistors. Depuis cette époque, la technique permettant de graver des transistors dans du silicium (la stéréo-lithographie) a fait des progrès considérables, permettant de graver dans une seule puce des millions de transistors dans les années 90 (on parlait alors de VLSI pour « Very Large Scale Integration », et des milliards à l’heure actuelle ! Au début des années 1970, les premiers micro-processeurs étaient conçus « à la main », les ingénieurs dessinant les quelques milliers de transistors, mais peu à peu la croissance du nombre d’éléments ont rendu nécessaire l’invention de nouveaux outils et nouvelles méthodologies, permettant aux architectes de l’infiniment petit de poser les « routes », les « usines » et les « entrepôts » microscopiques ( ou plutôt nano-scopiques) qui constituent les micro-processeurs modernes. Lynn Conway a joué un rôle clef dans cette révolution… deux fois !
Recrutée en 1964 par IBM, elle rejoint l’équipe d’architecture des ordinateurs, pour concevoir un super-ordinateur : l’ACS (Advanced Computer System). A cette époque on ne parle pas encore de micro-processeur, mais elle introduit dès lors une innovation spectaculaire, le DIS (Dynamic Instruction Scheduling) : si on revient à notre processeur de tout à l’heure, il exécute une suite d’instruction, mais est-il obligé de les exécuter dans l’ordre où elles se présentent ? Lynn Conway montre qu’il est parfois intéressant de changer l’ordre d’exécution des instructions, ce qui permet d’exécuter plusieurs instructions à la fois ! (ce qu’on appelle un processeur superscalaire). Mais voilà, elle révèle en 1968 son intention de changer de sexe, ce qui lui vaut d’être licenciée par IBM. Bien des années plus tard, en 2020, l’entreprise lui a adressé des excuses publiques.
Elle reprend alors sa carrière, cette fois en tant que femme, en repartant de zéro, sans révéler son identité précédente. Elle gravit les échelons un par un, tout d’abord comme analyste programmeuse, puis elle travaille au fameux Xerox Parc où elle va diriger le « Large Scale Integration group ». C’est là qu’elle met au point l’ensemble de techniques et de logiciels permettant de réaliser les plans de micro-processeurs extrêmement complexes (la chaîne EDA pour Electronic Design and Automation). Après un passage au DARPA de 1983 à 1985, elle devient professeur à l’Université du Michigan, et rédige avec Carver Mead un ouvrage qui fera référence sur le sujet, et qui a permis de diffuser très largement ces technologies révolutionnaires de conception de puces (c.f. cette liste de référence sur le contexte et l’impact de cette publication ).
Alors qu’elle approche de l’age de la retraite, elle révèle son histoire et son passé chez IBM, et travaille pour défendre les droits des personnes trans-genre. Elle décède l’année dernière, le 9 Juin 2024, à l’age de 86 ans.
Claire Wolf : impression 3D et conception électronique pour toutes et tous !
Les nombreux outils disponibles dans notre monde numérique rendent notre vie plus facile, permettent de créer et d’échanger de l’information, mais, particulièrement dans le contexte actuel, il serait dangereux de laisser le contrôle de ces outils a un petit nombre d’acteurs. Née en 1980, femme trans, Claire Wolf a apporté des innovations importantes dans deux domaines différents.
Les technologies dites d’impression 3D (ou plutôt de fabrication additive) permettent à tout un chacun de fabriquer des objets avec des formes précises. Ceci ouvre la porte à de nombreuses applications, ou plus modestement, permet de réparer les objets du quotidien en créant soi-même des pièces de rechange. Développée dans les années 1980, cette technologie a connu un regain d’intérêt quand les différents brevets la protégeant ont expiré, permettant à tout un nouvel ensemble d’acteur de proposer des solutions et des produits. Mais créer des objets en 3D reste un travail d’expert, dépendant de logiciels coûteux et complexes. Claire Wolf a développé le logiciel OpenSCAD , une sorte de langage de programmation « avec des formes », permettant facilement de créer des pièces complexes en combinant des éléments plus simples. Ce logiciel a permis à toute une communauté de « makers » de créer et de partager des formes (voir par exemple https://www.thingiverse.com/).
Mais Claire Wolf ne s’est pas arrêtée là ! Si grâce à OpenSCAD tout un chacun peut réparer le buffet de la cuisine en imprimant une cale de la bonne forme en 3D, est-ce qu’on ne pourrait pas imaginer un outil permettant à tout un chacun de concevoir ses propres puces ?
Ceci peut sembler totalement hors de portée, mais il existe une étape intermédiaire : les FPGAs. Ce sont des circuits électroniques re-configurables, véritable « terre glaise », que chacun peut modeler à sa guise pour réaliser n’importe quel circuit logique (voir par exemple sur le blog binaire «Une glaise électronique re-modelable à volonté») Mais il y a une difficulté : ces FPGAs sont livrés avec des logiciels du constructeur, lourds et monolithiques, difficiles à apprendre, et peu adaptables à des cas d’utilisation variés. Pour cette raison, Claire Wolf a créé Yosys, un logiciel Open-Source rendant la conception de circuits logiques bien plus facile et abordable. Et pour ceux qui souhaitent franchir le pas jusqu’à la création d’un vrai circuit intégré, des initiatives tels que TinyTapeOut de Matt Venn permettent de le faire pour quelques centaines d’Euros ! Pour enrichir l’écosystème des outils de conception de circuits électroniques (EDA), Claire Wolf a créé l’entreprise YosysHQ, qui offre des solutions de vérification formelle.
Comme le chante Jean-Jacques Goldman, elles ne sont pas des « standards », « des gens bien comme ils faut », mais elles donnent leur différence. Espérons que notre société sache rester consciente de sa diversité, fière de sa richesse, ouverte et fraternelle.
Solove et Hartzog viennent de publier un excellent article sur le moissonnage massif des données sur le web (« web scraping » en anglais) pour l’entraînement des systèmes d’Intelligence Artificielle et les tensions que cela génère avec les principes de la protection des données personnelles1. Cet article nous permet de revisiter la problématique du moissonnage massif des données et de rappeler les travaux et consultations menés par la CNIL sur ce sujet depuis plusieurs mois2. Serge Abiteboul, Antoine Rousseau et Ikram Chraibi-Kaadoud
L’IA, en particulier l’IA générative, nécessite de vastes quantités de données pour son entraînement. Certaines de ces données sont collectées directement auprès des individus, tandis que d’autres sont obtenues via une interface de programmation d’application (API) conçue pour une extraction et un partage consensuel des données. Toutefois, la majorité des données sont obtenues par moissonnage. Le moissonnage des données sur Internet consiste à utiliser des logiciels automatisés pour extraire des informations à partir de sites web ou de réseaux sociaux.
Le moissonnage de données est un outil essentiel pour les chercheurs et les journalistes qui leur permet d’accéder à des informations cruciales pour leurs projets. En collectant rapidement des données issues de multiples sources, il facilite des recherches et des études qui seraient autrement impossibles. Cette collecte massive des données semble également être essentielle pour le développement et l’amélioration des modèles d’IA, car elle fournit les vastes quantités de données nécessaires à l’entraînement des algorithmes. Par ailleurs, en diversifiant les sources de données à travers différentes régions et cultures, le moissonnage peut aussi aider à éviter les biais dans les modèles d’IA.
Il est par ailleurs souvent avancé que ce moissonnage permet aux petites entreprises de rivaliser avec les grandes plateformes en facilitant l’accès à des informations, ce qui stimule la concurrence, l’innovation et la diversité technologique. Comme le souligne l’autorité de la concurrence dans son rapport sur l’IA générative3, les données, qu’elles soient textuelles, visuelles ou vidéo, sont essentielles pour les modèles de langage et proviennent principalement de sources publiques comme les pages web ou les archives web telles que Common Crawl4.
Bien que le moissonnage offre des avantages importants, il pose de nombreuses questions : protection du secret des affaires, secret industriel, propriété intellectuelle, rétribution des ayants droits et vie privée.
En ce qui concerne la protection de la vie privée, qui nous intéresse ici, le vaste moissonnage des données personnelles soulève des questions inédites. Comme le rappelle la CNIL, “La généralisation des pratiques de moissonnage a ainsi opéré un changement de nature quant à l’utilisation d’internet, dans la mesure où toutes les données publiées en ligne par une personne sont désormais susceptibles d’être lues, collectées et réutilisées par des tiers, ce qui constitue un risque important et inédit pour les personnes5.”
En effet, l’ampleur de ce moissonnage est sans précédent – la quantité de données, notamment de données personnelles, collectées par chaque moissonneur est stupéfiante. Par exemple, OpenAI a certainement moissonné une partie non négligeable du Web et utilisé ces données pour entraîner les modèles GPT qui sous-tendent notamment ChatGPT. Des entreprises comme ClearviewAI et PimEyes ont moissonné des milliards de photos pour alimenter des outils de reconnaissance faciale. De nouvelles entreprises d’IA apparaissent à un rythme effarant, chacune ayant un appétit vorace pour les données.
Il est important de rappeler que, dans la plupart des juridictions et notamment en Europe, les données personnelles « publiquement disponibles » sur internet sont soumises aux lois sur la protection des données et la vie privée, notamment le RGPD (règlement général sur la protection des données). Les individus et les entreprises qui moissonnent ces informations personnelles ont donc la responsabilité de s’assurer qu’ils respectent les réglementations applicables. Par ailleurs, les entreprises de médias sociaux et les opérateurs d’autres sites web qui hébergent des données personnelles accessibles au public ont également des obligations de protection des données en ce qui concerne le moissonnage par des tiers sur leurs sites.
La CNIL a régulièrement souligné la nécessité de vigilance concernant les pratiques de moissonnage et a formulé des recommandations pour leur mise en œuvre6. Elle a également demandé à plusieurs reprises un cadre législatif spécifique pour ces pratiques qui permettrait de sécuriser les organismes utilisant ces pratiques, de les encadrer, et de protéger les données personnelles accessibles en ligne7. La CNIL a parfois jugé ces pratiques illégales en l’absence d’un cadre juridique, par exemple lorsque utilisées par des autorités pour détecter des infractions ou lorsque des données sensibles sont collectées8. Cependant, elles ont été acceptées dans certains cas, comme la recherche de fuites d’informations sur Internet, à condition de mettre en place des garanties solides9. En attendant un cadre juridique spécifique, la CNIL rappelle les obligations des responsables de traitement et les conditions à respecter pour le développement de systèmes d’IA.
Alors que certains chercheurs, comme Solove et Hartzog, proposent de limiter le moissonnage uniquement aux projets d’intérêt public, le RGPD autorise, sous certaines conditions, le moissonnage en cas d’intérêt légitime du moissonneur10. Le recours à cette base légale suppose que les intérêts (commerciaux, de sécurité des biens, etc.) poursuivis par l’organisme traitant les données ne créent pas de déséquilibre au détriment des droits et intérêts des personnes dont les données sont traitées11. Le responsable du traitement doit notamment mettre en place des garanties supplémentaires pour protéger les droits et libertés des individus. La CNIL, dans sa fiche sur l’utilisation de l’intérêt légitime pour développer des systèmes d’IA, souligne que les mesures appropriées varient selon l’usage de l’IA et son impact sur les personnes concernées12. Elle recommande d’exclure la collecte de données à partir de sites sensibles ou s’opposant au moissonnage, et de créer une « liste repoussoir » permettant aux individus de s’opposer à la collecte de leurs données. La collecte doit se limiter aux données librement accessibles et rendues publiques intentionnellement. De plus, il est conseillé d’anonymiser ou de pseudonymiser les données immédiatement après leur collecte, de diffuser largement les informations relatives à la collecte et aux droits des personnes, et de prévenir le recoupement des données en utilisant des pseudonymes aléatoires propres à chaque contenu.
Rendre le moissonnage techniquement plus difficile
Comme mentionné précédemment, les hébergeurs de données personnelles accessibles au public ont également des obligations de protection des données en ce qui concerne le moissonnage. Par exemple, plusieurs autorités de protection des données (APD) du monde entier ont soutenu, dans une déclaration conjointe sur le moissonnage, que les entreprises devraient mettre en œuvre des contrôles techniques et procéduraux multicouches pour atténuer les risques associés à cette pratique13. Ces APD indiquent que les sites web devraient mettre en œuvre des contrôles techniques et procéduraux multicouches pour atténuer les risques. Une combinaison de ces contrôles devrait être utilisée en fonction de la sensibilité des informations. Certaines de ces mesures de protection seraient la limitation du nombre de visites par heure ou par jour pour un seul compte, la surveillance des activités inhabituelles pouvant indiquer un moissonnage frauduleux et la limitation de l’accès en cas de détection, la prise de mesures affirmatives pour détecter et limiter les bots, comme l’implémentation de CAPTCHAs et le blocage des adresses IP, ainsi que la menace ou la prise de mesures légales appropriées et la notification des individus concernés. Des recommandations similaires ont récemment été faites par la CNIL Italienne14. Bien entendu, les grandes plateformes telles que Facebook, X (anciennement Twitter), Reddit, LinkedIn, n’ont pas attendu ces recommandations pour mettre en place des mesures pour limiter le moissonnage. Par exemple, récemment X a constaté des « niveaux extrêmes de moissonnage de données » et a pris des mesures pour le limiter aux moissonneurs connectés15.
Le moissonnage de données est un sujet complexe qui suscite de nombreuses questions et débats. Dans ce contexte, la consultation de la CNIL est cruciale, et il est essentiel que chacun puisse s’exprimer sur ce sujet sensible. Comme le souligne cet article, il est difficile de tout interdire ou de tout autoriser sans discernement.
La clé réside dans un compromis basé sur la transparence et le respect des droits des individus. Il est indispensable que les utilisateurs soient clairement informés des campagnes de moissonnage, de leurs objectifs et de leur droit de s’y opposer. A cette fin, la CNIL propose, dans sa dernière consultation, l’idée de créer un registre sur son site où les organisations utilisant des données collectées par moissonnage pour le développement de systèmes d’IA pourraient s’inscrire. Par ailleurs, chacun a un rôle à jouer en contrôlant les informations qu’il publie en ligne, ce qui souligne le besoin d’une éducation et d’une sensibilisation accrues sur la gestion des données personnelles.
Pour reprendre les mots de Solove et Hartzog, le moissonnage de données devrait être perçu comme un « privilège » qui impose des responsabilités aux moissonneurs. Cela signifie qu’une attention particulière doit être portée au principe de la minimisation des données si cher au RGPD16, à la sécurité des données collectées et au respect des droits des utilisateurs. Une telle approche permettra de trouver un équilibre juste et équitable, garantissant à la fois la protection de la vie privée et le développement responsable de l’Intelligence Artificielle. Finalement, le développement de « l’IA frugale17 » qui consiste à développer des plus petits modèles, utilisant notamment moins de données d’entrainement mais de meilleure qualité, apporte des perspectives intéressantes en termes de protection de nos données.
Claude Castelluccia, Directeur de recherche chez Inria, au sein de l’équipe Privatics de Grenoble, et commissaire à la CNIL en charge de l’Intelligence Artificielle.
Billet d’introduction: L’expression “David contre Goliath” n’a jamais semblé aussi pertinente que lorsqu’il faut décrire le combat des artistes contre les GAFAM. Cette expression souvent utilisée pour décrire un combat entre deux parties prenantes de force inégale souligne une réalité : celle de la nécessité qu’ont ressenti des artistes de différents milieux et pays de se défendre face à des géants de la tech de l’IA générative pour protéger leur oeuvres, leur passion et leur métier, pour eux et pour les générations futures. Si la Direction Artistique porte le nom de [DA]vid, alors l’IA sera notre Gol[IA]th… C’est parti pour une épopée 5.0 !
Julie Laï-Pei, femme dans la tech, a à cœur de créer un pont entre les nouvelles technologies et le secteur Culturel et Créatif, et d’en animer la communauté. Elle nous partage ici sa réflexion au croisement de ces deux domaines.
Chloé Mercier, Thierry Vieville et Ikram Chraibi Kaadoud
Comment les artistes font-ils face au géant IA, Gol[IA]th ?
« David et Goliath » – Gustave Doré passé dans Dall-e – Montage réalisé par @JulieLaï-Pei
A l’heure d’internet, les métiers créatifs ont connu une évolution significative de leur activité. Alors que nous sommes plus que jamais immergés dans un monde d’images, certains artistes évoluent et surfent sur la vague, alors que d’autres reviennent à des méthodes de travail plus classiques. Cependant tous se retrouvent confrontés aux nouvelles technologies et à leurs impacts direct et indirect dans le paysage de la créativité artistique.
Si les artistes, les graphistes, les animateurs devaient faire face à une concurrence sévère dans ce domaine entre eux et face à celle de grands acteurs du milieu, depuis peu (on parle ici de quelques mois), un nouveau concurrent se fait une place : l’Intelligence artificielle générative, la Gen-IA !
C’est dans ce contexte mitigé, entre écosystème mondial de créatifs souvent isolés et puissances économiques démesurées que se posent les questions suivantes :
Quelle est la place de la création graphique dans cet océan numérique ? Comment sont nourris les gros poissons de l’intelligence artificielle pour de la création et quelles en sont les conséquences ?
L’évolution des modèles d’entraînement des IA pour aller vers la Gen-AI que l’on connaît aujourd’hui
Afin qu’une intelligence artificielle soit en capacité de générer de l’image, elle a besoin de consommer une quantité importante d’images pour faire le lien entre la perception de “l’objet” et sa définition nominale. Par exemple, à la question “Qu’est-ce qu’un chat ?” En tant qu’humain, nous pouvons facilement, en quelques coup d’œil, enfant ou adulte, comprendre qu’un chat n’est pas un chien, ni une table ou un loup. Or cela est une tâche complexe pour une intelligence artificielle, et c’est justement pour cela qu’elle a besoin de beaucoup d’exemples !
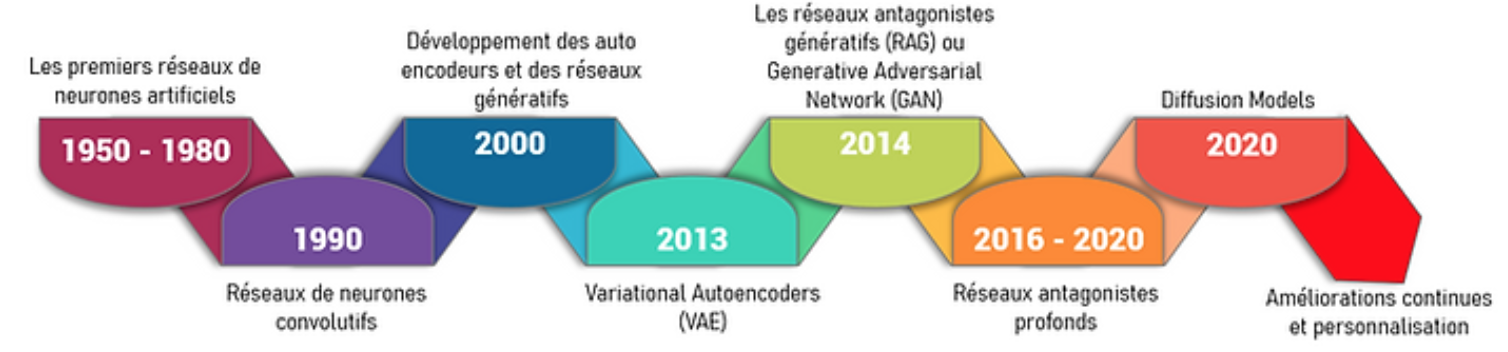
Ci dessous une frise chronologique de l’évolution des modèles d’apprentissage de l’IA depuis les premiers réseaux de neurones aux Gen-IA :
Frise chronologique par @JulieLaiPei
En 74 ans, les modèles d’IA ont eu une évolution fulgurante, d’abord cantonnée aux sphères techniques ou celle d’entreprises très spécialisées, à récemment en quelques mois en 2023, la société civile au sens large et surtout au sens mondial.
Ainsi, en résumé, si notre IA Gol[IA]th souhaite générer des images de chats, elle doit avoir appris des centaines d’exemples d’images de chat. Même principe pour des images de voitures, des paysages, etc.
Le problème vient du fait que, pour ingurgiter ces quantités d’images pour se développer, Gol[IA]th mange sans discerner ce qu’il engloutit… que ce soit des photos libres de droit, que ce soit des oeuvres photographiques, des planches d’artwork, ou le travail d’une vie d’un artiste, Gol[IA]th ne fait pas de différence, tout n’est “que” nourriture…
Dans cet appétit gargantuesque, les questions d’éthique et de propriétés intellectuelles passent bien après la volonté de développer la meilleure IA générative la plus performante du paysage technologique. Actuellement, les USA ont bien de l’avance sur ce sujet, créant de véritables problématiques pour les acteurs de la création, alors que l’Europe essaie de normer et d’encadrer l’éthique des algorithmes, tout en essayant de mettre en place une réglementation et des actions concrètes dédiées à la question de la propriété intellectuelle, qui est toujours une question en cours à ce jour.
Faisons un petit détour auprès des différents régimes alimentaires de ce géant…
Comment sont alimentées les bases de données d’image pour les Gen-AI ?
L’alimentation des IA génératives en données d’images est une étape cruciale pour leur entraînement et leur performance. Comme tout bon géant, son régime alimentaire est varié et il sait se sustenter par différents procédés… Voici les principales sources et méthodes utilisées pour fournir les calories nécessaires de données d’images aux IA génératives :
Les bases de données publiques
Notre Gol[IA]th commence généralement par une alimentation saine, basée sur un des ensembles de données les plus vastes et les plus communément utilisés: par exemple, ImageNet qui est une base de données d’images annotées produite par l’organisation du même nom, à destination des travaux de recherche en vision par ordinateur. Cette dernière représente plus de 14 millions d’images annotées dans des milliers de catégories. Pour obtenir ces résultats, c’est un travail fastidieux qui demande de passer en revue chaque image pour la qualifier, en la déterminant d’après des descriptions, des mot-clefs, des labels, etc…
Entre autres, MNIST, un ensemble de données de chiffres manuscrits, couramment utilisé pour les tâches de classification d’images simples.
Dans ces ensembles de données publics, on retrouve également COCO (à comprendre comme Common Objects in COntext) qui contient plus de 330 000 images d’objets communs dans un contexte annotées, pour l’usage de la segmentation d’objets, la détection d’objets, de la légendes d’image, etc…
Plus à la marge, on retrouve la base de données CelebA qui contient plus de 200 000 images de visages célèbres avec des annotations d’attributs.
Plus discutable, Gol[IA]th peut également chasser sa pitance… Pour ce faire, il peut utiliser le web scraping. Il s’agit d’un procédé d’extraction automatique d’images à partir de sites web, moteurs de recherche d’images, réseaux sociaux, et autres sources en ligne. Concrètement, au niveau technique, il est possible d’utiliser des APIs (Application Programming Interfaces) pour accéder à des bases de données d’images: il s’agit d’interfaces logicielles qui permettent de “connecter” un logiciel ou un service à un autre logiciel ou service afin d’échanger des données et des fonctionnalités. Il en existe pour Flickr, pour Google Images, et bien d’autres.
Ce procédé pose question sur le plan éthique, notamment au sujet du consentement éclairé des utilisateurs de la toile numérique : Est-ce qu’une IA a le droit d’apprendre de tout, absolument tout, ce qu’il y a en ligne ? Et si un artiste a choisi de partager ses créations sur internet, son œuvre reste-t-elle sa propriété ou devient-elle, en quelque sorte, la propriété de tous ?
Ces questions soulignent un dilemme omniprésent pour tout créatif au partage de leur œuvre sur internet : sans cette visibilité, il n’existe pas, mais avec cette visibilité, ils peuvent se faire spolier leur réalisation sans jamais s’en voir reconnaître la maternité ou paternité.
Il y a en effet peu de safe-places pour les créatifs qui permettent efficacement d’être mis en lumière tout en se prémunissant contre les affres de la copie et du vol de propriété intellectuelle et encore moins de l’appétit titanesque des géants de l’IA.
C’est à cause de cela et notamment de cette méthode arrivée sans fanfare que certains créatifs ont choisi de déserter certaines plateformes/réseaux sociaux: les vannes de la gloutonnerie de l’IA générative avaient été ouvertes avant même que les internautes et les créatifs ne puissent prendre le temps de réfléchir à ces questions. Cette problématique a été aperçue, entre autres, sur Artstation, une plateforme de présentation jouant le rôle de vitrine artistique pour les artistes des jeux, du cinéma, des médias et du divertissement. mais également sur Instagram et bien d’autres : parfois ces plateformes assument ce positionnement ouvertement, mais elles sont rares ; la plupart préfèrent enterrer l’information dans les lignes d’interminables conditions d’utilisation qu’il serait bon de commencer à lire pour prendre conscience de l’impact que cela représente sur notre “propriété numérique”.
Les bases de données spécialisées
Dans certains cas, Gol[IA]th peut avoir accès à des bases de données spécialisées, comprenant des données médicales (comme les scans radiographiques, IRM, et autres images médicales disponibles via des initiatives comme ImageCLEF) ou des données satellites (fournies par des agences spatiales comme la NASA et des entreprises privées pour des images de la Terre prises depuis l’espace).
Les données synthétiques
Au-delà des images tirées du réel, l’IA peut également être alimentée à partir d’images générées par ordinateur. La création d’images synthétiques par des techniques de rendu 3D permet de simuler des scénarios spécifiques (par exemple, de la simulation d’environnements de conduite pour entraîner des systèmes de conduite autonome), ainsi que des modèles génératifs pré-entraînés. En effet, les images générées par des modèles peuvent également servir pour l’entraînement d’un autre modèle. Mais les ressources peuvent également provenir d’images de jeux vidéo ou d’environnement de réalité virtuelle pour créer des ensembles de données (on pense alors à Unreal Engine ou Unity).
Les caméras et les capteurs
L’utilisation de caméras pour capturer des images et des vidéos est souvent employée dans les projets de recherche et développement, et dans une volonté de sources plus fines, de capteurs pour obtenir des images dans des conditions spécifiques, comme des caméras infrarouges pour la vision nocturne, des LIDAR pour la cartographie 3D, etc.
Toutes ces différentes sources d’approvisionnement pour Gol[IA]th sont généralement prétraitées avant d’être utilisées pour l’entraînement : normalisation, redimensionnement, augmentation des données, sont des moyens de préparation des images.
En résumé, il faut retenir que les IA génératives sont alimentées par une vaste gamme de sources de données d’images, allant des ensembles de données publiques aux données collectées en ligne, en passant par les images synthétiques et les captures du monde réel. La diversité et la qualité des données sont essentielles pour entraîner des modèles génératifs performants et capables de produire des images réalistes et variées. Cependant cette performance ne se fait pas toujours avec l’accord éclairé des auteurs des images. Il est en effet compliqué – certains diront impossible – de s’assurer que la gloutonnerie de Gol[IA]th s’est faite dans les règles avec le consentement de tous les créatifs impliqués… Un sujet d’éducation à la propriété numérique est à considérer!
Mais alors, comment [DA]vid et ses créatifs subissent cette naissance monstrueuse ?
Les métiers créatifs voient leur carnet de commande diminuer, les IA se démocratisant à une vitesse folle. [DA]vid, au delà de perdre des revenus en n’étant plus employé par des revues pour faire la couverture du magazine, se retrouve face à une concurrence déloyale : l’image générée a le même style… voir “son style”… Or pour un créatif, le style est l’œuvre du travail d’une vie, un facteur différenciant dans le paysage créatif, et le moteur de compétitivité dans le secteur… Comment faire pour maintenir son statut d’acteur de la compétitivité de l’économie alors que les clients du secteur substituent leur commande par des procédés éthiquement questionnables pour faire des économies ?
Gol[IA]th mange sans se sentir rompu, qu’il s’agisse de données libres ou protégées par des droits d’auteur, la saveur ne change pas. L’espoir de voir les tribunaux s’animer, pays après pays, sur des questionnements de violation, ou non, des lois protégeant les auteurs, s’amenuise dans certaines communautés. En attendant, les [DA]vid créatifs se retrouvent livrés à eux-mêmes, lentement dépossédés de l’espoir de pouvoir échapper au géant Gol[IA]th. Alors que l’inquiétude des artistes et des créateurs grandit à l’idée de voir une série d’algorithmes reproduire et s’accaparer leur style artistique, jusqu’à leur carrière, certains s’organisent pour manifester en occupant l’espace médiatique comme l’ont fait les acteurs en grève à Hollywood en 2023, et d’autres choisissent d’attaquer le sujet directement au niveau informatique en contactant Ben Zhao et Heather Zheng, deux informaticiens de l’Université de Chicago qui ont créé un outil appelé “Fawkes”, capable de modifier des photographies pour déjouer les IA de reconnaissance faciale.
“Est-ce que Fawkes peut protéger notre style contre des modèles de génération d’images comme Midjourney ou Stable Diffusion ?”
Bien que la réponse immédiate soit “non”, la réflexion a guidé vers une autre solution…
“Glaze”, un camouflage en jus sur une oeuvre
Les chercheurs de l’Université de Chicago se sont penchés sur la recherche d’une option de défense des utilisateurs du web face aux progrès de l’IA. Ils ont mis au point un produit appelé “Glaze”, en 2022, un outil de protection des œuvres d’art contre l’imitation par l’IA. L’idée de postulat est simple : à l’image d’un glacis ( une technique de la peinture à l’huile consistant à poser, sur une toile déjà sèche, une fine couche colorée transparente et lisse) déposer pour désaturer les pigments“Glaze” est un filtre protecteur des créations contre les IAs.
“Glaze” va alors se positionner comme un camouflage numérique : l’objectif est de brouiller la façon dont un modèle d’IA va “percevoir” une image en la laissant inchangée pour les yeux humains.
Ce programme modifie les pixels d’une image de manière systématique mais subtile, de sorte à ce que les modifications restent discrètes pour l’homme, mais déconcertantes pour un modèle d’IA. L’outil tire parti des vulnérabilités de l’architecture sous-jacente d’un modèle d’IA, car en effet, les systèmes de Gen-AI sont formés à partir d’une quantité importante d’images et de textes descriptifs à partir desquels ils apprennent à faire des associations entre certains mots et des caractéristiques visuelles (couleurs, formes). “Ces associations cryptiques sont représentées dans des « cartes » internes massives et multidimensionnelles, où les concepts et les caractéristiques connexes sont regroupés les uns à côté des autres. Les modèles utilisent ces cartes comme guide pour convertir les textes en images nouvellement générées.” (- Lauren Leffer,biologiste et journaliste spécialisée dans les sciences, la santé, la technologie et l’environnement.)
“Glaze” va alors intervenir sur ces cartes internes, en associant des concepts à d’autres, sans qu’il n’y ait de liens entre eux. Pour parvenir à ce résultat, les chercheurs ont utilisé des “extracteurs de caractéristiques” (programmes analytiques qui simplifient ces cartes hypercomplexes et indiquent les concepts que les modèles génératifs regroupent et ceux qu’ils séparent). Les modifications ainsi faites, le style d’un artiste s’en retrouve masqué : cela afin d’empêcher les modèles de s’entraîner à imiter le travail des créateurs. “S’il est nourri d’images « glacées » lors de l’entraînement, un modèle d’IA pourrait interpréter le style d’illustration pétillante et caricatural d’un artiste comme s’il s’apparentait davantage au cubisme de Picasso. Plus on utilise d’images « glacées » pour entraîner un modèle d’imitation potentiel, plus les résultats de l’IA seront mélangés. D’autres outils tels que Mist, également destinés à défendre le style unique des artistes contre le mimétisme de l’IA, fonctionnent de la même manière.” explique M Heather Zheng, un des deux créateurs de cet outil.
Plus simplement, la Gen-AI sera toujours en capacité de reconnaître les éléments de l’image (un arbre, une toiture, une personne) mais ne pourra plus restituer les détails, les palettes de couleurs, les jeux de contrastes qui constituent le “style”, i.e., la “patte” de l’artiste.
Quelques exemples de l’utilisation de Glaze arXiv:2302.04222
Bien que cette méthode soit prometteuse, elle présente des limites techniques et dans son utilisation.
Face à Gol[IA]th, les [DA]vid ne peuvent que se cacher après avoir pris conscience de son arrivée : dans son utilisation, la limite de “Glaze” vient du fait que chaque image que va publier un créatif ou un artiste doit passer par le logiciel avant d’être postée en ligne.. Les œuvres déjà englouties par les modèles d’IA ne peuvent donc pas bénéficier, rétroactivement, de cette solution. De plus, au niveau créatif, l’usage de cette protection génère du bruit sur l’image, ce qui peut détériorer sa qualité et s’apercevoir sur des couleurs faiblement saturées. Enfin au niveau technique, les outils d’occultation mise à l’œuvre ont aussi leurs propres limites et leur efficacité ne pourra se maintenir sur le long terme.
En résumé, à la vitesse à laquelle évoluent les Gen-AI, “Glaze” ne peut être qu’un barrage temporaire, et malheureusement non une solution : un pansement sur une jambe gangrenée, mais c’est un des rares remparts à la créativité humaine et sa préservation.
Il faut savoir que le logiciel a été téléchargé 720 000 fois, et ce, à 10 semaines de sa sortie, ce qui montre une véritable volonté de la part des créatifs de se défendre face aux affronts du géant.
La Gen-AI prend du terrain sur la toile, les [DA]vid se retrouvent forcés à se cacher… Est-ce possible pour eux de trouver de quoi charger leur fronde ? Et bien il s’avère que la crainte a su faire naître la colère et les revendications, et les créatifs et les artistes ont décidé de se rebeller face à l’envahisseur… L’idée n’est plus de se cacher, mais bien de contre-attaquer Gol[IA]th avec les armes à leur disposition…
“Nightshade”, lorsque la riposte s’organise ou comment empoisonner l’IA ?
Les chercheurs de l’Université de Chicago vont pousser la réflexion au delà de “Glaze”, au delà de bloquer le mimétisme de style, “Nightshade” est conçu comme un outil offensif pour déformer les représentations des caractéristiques à l’intérieur même des modèles de générateurs d’image par IA…
« Ce qui est important avec Nightshade, c’est que nous avons prouvé que les artistes n’ont pas à être impuissants », déclare Zheng.
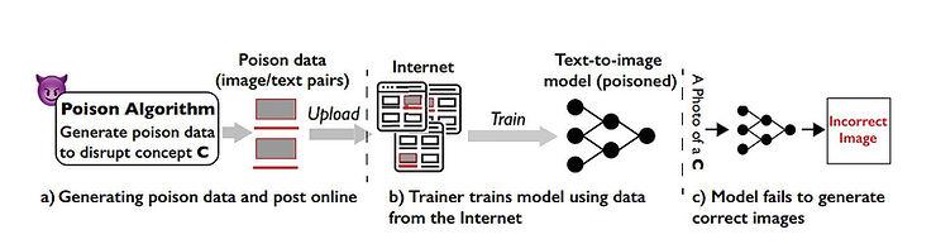
Nightshade ne se contente pas de masquer la touche artistique d’une image, mais va jusqu’à saboter les modèles de Gen-AI existants. Au-delà de simplement occulter l’intégrité de l’image, il la transforme en véritable “poison” pour Gol[IA]th en agissant directement sur l’interprétation de celui-ci. Nightshade va agir sur l’association incorrecte des idées et des images fondamentales. Il faut imaginer une image empoisonnée par “Nightshade” comme une goutte d’eau salée dans un récipient d’eau douce. Une seule goutte n’aura pas grand effet, mais chaque goutte qui s’ajoute va lentement saler le récipient. Il suffit de quelques centaines d’images empoisonnées pour reprogrammer un modèle d’IA générative. C’est en intervenant directement sur la mécanique du modèle que “Nightshade” entrave le processus d’apprentissage, en le rendant plus lent ou plus coûteux pour les développeurs. L’objectif sous-jacent serait, théoriquement,d’inciter les entreprises d’IA à payer les droits d’utilisation des images par le biais des canaux officiels plutôt que d’investir du temps dans le nettoyage et le filtrage des données d’entraînement sans licence récupérée sur le Web.
Image issue de l’article de Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv:2310.13828
Ce qu’il faut comprendre de « Nightshade » :
Empoisonnement des données: Nightshade fonctionne en ajoutant des modifications indétectables mais significatives aux images. Ces modifications sont introduites de manière à ne pas affecter la perception humaine de l’image mais à perturber le processus de formation des modèles d’IA. Il en résulte un contenu généré par l’IA qui s’écarte de l’art prévu ou original.
Invisibilité: Les altérations introduites par Nightshade sont invisibles à l’œil humain. Cela signifie que lorsque quelqu’un regarde l’image empoisonnée, elle apparaît identique à l’originale. Cependant, lorsqu’un modèle d’IA traite l’image empoisonnée, il peut générer des résultats complètement différents, pouvant potentiellement mal interpréter le contenu.
Impact: L’impact de l’empoisonnement des données de Nightshade peut être important. Par exemple, un modèle d’IA entraîné sur des données empoisonnées pourrait produire des images dans lesquelles les chiens ressemblent à des chats ou les voitures à des vaches. Cela peut rendre le contenu généré par l’IA moins fiable, inexact et potentiellement inutilisable pour des applications spécifiques.
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade.arXiv:2310.13828
Voici alors quelques exemples après de concepts empoisonnés :
Ci-dessus, des exemples d’images générées par les modèles SD-XL empoisonnés de Nightshade et le modèle SD-XL propre, lorsqu’ils sont invités à utiliser le concept empoisonné C. arXiv:2310.13828
Plus précisément, « Nightshade transforme les images en échantillons ’empoisonnés’, de sorte que les modèles qui s’entraînent sur ces images sans consentement verront leurs modèles apprendre des comportements imprévisibles qui s’écartent des normes attendues, par exemple une ligne de commande qui demande l’image d’une vache volant dans l’espace pourrait obtenir à la place l’image d’un sac à main flottant dans l’espace », indiquent les chercheurs.
Le « Data Poisoning » est une technique largement répandue. Ce type d’attaque manipule les données d’entraînement pour introduire un comportement inattendu dans le modèle au moment de l’entraînement. L’exploitation de cette vulnérabilité rend possible l’introduction de résultats de mauvaise classification.
« Un nombre modéré d’attaques Nightshade peut déstabiliser les caractéristiques générales d’un modèle texte-image, rendant ainsi inopérante sa capacité à générer des images significatives », affirment-ils.
Cette offensive tend à montrer que les créatifs peuvent impacter les acteurs de la technologie en rendant contre-productif l’ingestion massive de données sans l’accord des ayant-droits.
Plusieurs plaintes ont ainsi émané d’auteurs, accusant OpenAI et Microsoft d’avoir utilisé leurs livres pour entraîner ses grands modèles de langage. Getty Images s’est même fendu d’une accusation contre la start-up d’IA Stability AI connue pour son modèle de conversion texte-image Stable Diffusion, en Février 2023. Celle-ci aurait pillé sa banque d’images pour entraîner son modèle génératif Stable Diffusion. 12 millions d’œuvres auraient été « scrappées » sans autorisation, attribution, ou compensation financière. Cependant, il semble que ces entreprises ne puissent pas se passer d’oeuvres soumises au droit d’auteur, comme l’a récemment révélé OpenAI, dans une déclaration auprès de la Chambre des Lords du Royaume-Uni concernant le droit d’auteur, la start-up a admis qu’il était impossible de créer des outils comme le sien sans utiliser d’œuvres protégées par le droit d’auteur. Un aveu qui pourrait servir dans ses nombreux procès en cours…
Ainsi, quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?
En résumé, dans sa gloutonnerie, Gol[IA]th a souhaité engloutir les [DA]vid qui nous entourent, qui ont marqué l’histoire et ceux qui la créent actuellement, dans leur entièreté et leur complexité : en cherchant à dévorer ce qui fait leur créativité, leur style, leur patte, au travers d’une analyse de caractéristiques et de pixels, Gol[IA]th a transformé la créativité humaine qui était sa muse, son idéal à atteindre, en un ensemble de données sans sémantique, ni histoire, ni passion sous-jacente.
C’est peut être un exemple d’amour nocif à l’heure de l’IA, tel que vu par l’IA ?
Sans sous-entendre que les personnes à l’origine de l’écriture des IA génératives ne sont pas des créatifs sans passion, il est probable que la curiosité, la prouesse et l’accélération technologique ont peu à peu fait perdre le fil sur les impacts que pourrait produire un tel engouement.
A l’arrivée de cette technologie sur le Web, les artistes et les créatifs n’avaient pas de connaissance éclairée sur ce qui se produisait à l’abri de leurs regards. Cependant, les modèles d’apprentissage ont commencé à être alimentés en données à l’insu de leur ayant-droits. La protection juridique des ayant-droits n’évoluant pas à la vitesse de la technologie, les créatifs ont rapidement été acculés, parfois trop tard, les Gen-AI ayant déjà collecté le travail d’une vie. Beaucoup d’artistes se sont alors “reclus”, se retirant des plateformes et des réseaux sociaux pour éviter les vols, mais ce choix ne fut pas sans conséquence pour leur visibilité et la suite de leur carrière.
Alors que les réseaux jouaient l’opacité sur leurs conditions liées à la propriété intellectuelle, le choix a été de demander aux créatifs de se “manifester s’ils refusaient que leurs données soient exploitées”, profitant de la méconnaissance des risques pour forcer l’acceptation de condition, sans consentement éclairé. Mais la grogne est montée dans le camp des créatifs, qui commencent à être excédés par l’abus qu’ils subissent. “Glaze” fut une première réaction, une protection pour conserver l’intégrité visuelle de leur œuvre, mais face à une machine toujours plus gloutonne, se protéger semble rapidement ne pas suffire. C’est alors que “Nightshade” voit le jour, avec la volonté de faire respecter le droit des artistes, et de montrer qu’ils ne se laisseraient pas écraser par la pression des modèles.
Il est important de suivre l’évolution des droits des différents pays et de la perception des sociétés civiles dans ces pays de ce sujet car le Web, l’IA et la créativité étant sans limite géographique, l’harmonisation juridique concernant les droits d’auteur, la réglementation autour de la propriété intellectuelle, et l’éducation au numérique pour toutes et tous, vont être – ou sont peut-être déjà – un enjeu d’avenir au niveau mondial.
Pour avoir davantage d’informations sur Glaze et Nightshade :page officielle
Article Glaze : Shan, S., Cryan, J., Wenger, E., Zheng, H., Hanocka, R., & Zhao, B. Y. (2023). Glaze: Protecting artists from style mimicry by {Text-to-Image} models. In 32nd USENIX Security Symposium (USENIX Security 23) (pp. 2187-2204). arXiv preprint arXiv:2302.04222
Article Nightshade : Shan, S., Ding, W., Passananti, J., Zheng, H., & Zhao, B. Y. (2023). Prompt-specific poisoning attacks on text-to-image generative models. arXiv preprint arXiv:2310.13828.
A propos de l’autrice : Julie Laï-Pei, après une première vie dans le secteur artistique et narratif, a rejoint l’émulation de l’innovation en Nouvelle-Aquitaine, en tant que responsable de l’animation d’une communauté technologique Numérique auprès d’un pôle de compétitivité. Femme dans la tech et profondément attachée au secteur Culturel et Créatif, elle a à coeur de partager le résultat de sa veille et de ses recherches sur l’impact des nouvelles technologies dans le monde de la créativité.
La Nouvelle Calédonie traverse une période de troubles ; récemment, le gouvernement a interdit pendant 2 semaines le réseau social TikTok qu’il accusait de servir de contact entre les manifestants. Cette mesure qu’il a « justifiée » par l’état d’urgence pose plusieurs questions. En tout premier lieu, son efficacité, puisque de nombreuses personnes ont continué à l’utiliser en passant par des VPN. Ensuite, et surtout, a-t-elle respecté des principes juridiques fondamentaux ? Saisi par des opposants à cette mesure, dont la Ligue des Droits de l’Homme, le Conseil d’Etat a rejeté ces saisines parce que le caractère d’urgence n’était pas démontré, ce qui a évité de se prononcer sur le fond. Nous avons donné la parole à Karine Favro (Professeure de droit public, Université de Haute Alsace) et à Célia Zolynski (Professeure de droit privé, Université Paris 1 Panthéon-Sorbonne) pour qu’elles nous expliquent ces questions. Pascal Guitton
La gravité des affrontements qui ont meurtri la Nouvelle Calédonie ces dernières semaines a conduit à la déclaration de l’état d’urgence sur l’ensemble du territoire par décret du 15 mai dernier en application de la loi du 3 avril 1955. Dans le même temps, le Premier ministre y annonçait, par voie de presse, l’interdiction de l’accès à TikTok.
Image générée par ChatGPT
Cette mesure était historique pour le gouvernement français car portant pour la première fois sur un réseau social alors que le 17 mai, dans sa décision relative à la loi visant à sécuriser et réguler l’espace numérique, le Conseil Constitutionnel rappelait qu’ “ En l’état actuel des moyens de communication et eu égard au développement généralisé des services de communication au public en ligne ainsi qu’à l’importance prise par ces services pour la participation à la vie démocratique et l’expression des idées et des opinions, ce droit [à la liberté d’expression] implique la liberté d’accéder à ces services et de s’y exprimer”.
Nombreux ont critiqué la légalité de cette décision de blocage. Pour pouvoir se fonder sur l’article 11 de la loi de 1955, un temps envisagé, il aurait fallu que la plateforme ait été utilisée pour provoquer à la “commission d’actes de terrorisme ou en faisant l’apologie”. Quant aux ingérences étrangères, annoncées comme étant ici en cause, celles-ci ne justifient pas à elles seules que soient prononcées ce type de mesure sur le fondement de ce texte. Restaient alors les circonstances exceptionnelles en application de la jurisprudence administrative conférant au Premier ministre des “pouvoirs propres” comme cela a été reconnu lors de la pandémie pour prononcer le confinement avant l’adoption de la loi relative à l’état d’urgence sanitaire. La brutalité de la mesure était également discutée, celle-ci ayant été prise en l’absence de sollicitation de retrait de contenus des autorités auprès de la plateforme.
Le 23 mai, le Conseil d’Etat a rejeté les trois recours en référé-liberté déposé par des opposants à cette décision et contestant la mesure de blocage pour atteinte à la liberté d’expression. Il retient que l’urgence du juge à intervenir n’est pas établie alors qu’il s’agissait de la condition préalable pour accueillir ces demandes. Ne pouvant se déduire de la seule atteinte à la liberté d’expression, l’ordonnance de référé relève que l’urgence n’était pas justifiée en raison du caractère limité de la mesure (il restait possible de s’exprimer sur d’autres réseaux sociaux et médias) et de sa nature temporaire. Le Conseil d’Etat ayant rejeté les recours parce qu’il considérait que la condition d’urgence n’était pas remplie, il ne s’est pas prononcé sur la proportionnalité de l’atteinte à la liberté d’expression qui pouvait résulter de la mesure d’interdiction. Au même motif, le juge administratif n’a pas eu à transmettre la question prioritaire de constitutionnalité déposée par ces mêmes requérants, visant à contester la conformité à la Constitution de l’article 11 de la loi de 1955. La procédure initiée conduit donc à une impasse.
En l’état, la légalité de la décision prise par le Premier ministre reste ainsi incertaine compte tenu de la nature des recours formés, d’autant que le blocage de Tik Tok a été levé le 29 mai. Pourtant, le débat reste entier concernant la légitimité d’une pareille mesure dont la proportionnalité constitue un enjeu fondamental. Cette dernière impose de déterminer si la solution retenue était la plus efficace pour atteindre le but poursuivi et de vérifier qu’elle était accompagnée de toutes les garanties nécessaires. Sa légitimité est également exigée ; or, la question devient éminemment complexe lorsqu’une mesure de police, par nature préventive, est prononcée dans le cadre d’un mouvement populaire sur lequel elle conduit à se positionner. Un recours a d’ailleurs été depuis déposé par la Quadrature du Net afin que le Conseil d’Etat se prononce au fond sur la légalité du blocage, ce qui l’invitera à considérer, dans son principe même, son bien-fondé. Il conteste en particulier le fait que le Premier ministre puisse prendre une telle décision particulièrement attentatoire à la liberté d’expression, sans publication d’aucun décret soit de manière non formalisée et non motivée, en la portant simplement à la connaissance du public par voie de presse ; les requérants soutiennent que cela revenait à “décider de son propre chef, sur des critères flous et sans l’intervention préalable d’un juge, [de] censurer un service de communication au public en ligne”.
Ce point est essentiel car c’est bien le nécessaire respect de nos procédures, consubstantielles à nos libertés, dont il s’agit. Si nous décidons qu’un service met nos principes en difficulté, c’est en respectant nos procédures et nos principes qu’il nous revient de l’interdire. Il aurait été utile de pouvoir appliquer le Règlement sur les services numériques (DSA) que vient d’adopter l’Union européenne, même si le statut particulier de la Nouvelle Calédonie l’exonère de toute obligation de respecter ce texte. En effet, les mécanismes prévus par le DSA visent à garantir le respect du principe de proportionnalité afin d’assurer tout à la fois la protection des libertés et droits fondamentaux et la préservation de l’ordre public, en particulier lors de situations de crise en précisant le cadre des mesures d’urgence à adopter. Il y est bien prévu le blocage temporaire d’une plateforme sur le territoire de l’Union. Néanmoins, il ne s’agit pas d’une mesure immédiate mais de dernier recours. Elle vise les cas de non-coopération répétée avec le régulateur et de non-respect du règlement lorsque sont concernées des infractions graves menaçant la vie et la sécurité des personnes. Le DSA encadre par ailleurs cette décision d’importantes garanties procédurales. Ainsi, le blocage temporaire doit être prononcé après l’intervention de diverses autorités (la Commission européenne, le régulateur national soit en France l’ARCOM) et sous le contrôle d’une autorité judiciaire indépendante.
La situation appelle alors les pouvoirs publics à conduire d’autres actions déterminantes qui dépassent la seule mesure de police. Tout d’abord, mieux garantir une exigence de transparence pour assurer le respect de nos principes démocratiques, mais également pour ne pas altérer la confiance des citoyens dans nos institutions. On perçoit ici l’intérêt du rapport publié dès le 17 mai par Viginum pour documenter l’influence de l’Azerbaïdjan dans la situation de la Nouvelle Calédonie, qui relève d’ailleurs le rôle joué par d’autres réseaux sociaux comme X et Facebook dans le cadre de manœuvres informationnelles. Compte tenu des enjeux, il convient d’aller plus loin et d’organiser des procédures transparentes et indépendantes à des fins de communication au public. Ensuite, mener un examen approfondi de l’ensemble de la sphère médiatique, ce qui est actuellement réalisé dans le cadre des Etats généraux de l’Information. Plus généralement, promouvoir des mesures de régulation des plateformes pour prôner d’autres approches plus respectueuses de nos libertés, en associant l’ensemble des parties prenantes. A ce titre, il est essentiel de mieux comprendre le rôle joué par les réseaux sociaux et d’agir sur les risques systémiques qu’ils comportent pour l’exercice des droits fondamentaux, en particulier la liberté d’expression et d’information. Cela commande de mettre pleinement en œuvre, et au plus vite, l’ensemble des dispositifs issus du DSA dont l’efficacité paraît déjà ressortir des enquêtes formelles lancées par la Commission européenne comme en atteste la suspension de Tik Tok Lite quelques jours après son lancement en Europe.
Karine Favro (Professeure de droit public, Université de Haute Alsace) et Célia Zolynski (Professeure de droit privé, Université Paris 1 Panthéon-Sorbonne)
Observer, décrire, modéliser et analyser pour comprendre le monde réel, puis l’observer plus efficacement en retour : tel est le cercle vertueux de toute démarche scientifique. Avec un axiome chevillé à l’esprit de chaque scientifique : les savoirs ainsi accumulés doivent être au service de l’humanité toute entière. Ces savoirs ont démontré que l’existence du dérèglement climatique n’est pas une opinion, mais un fait malheureusement avéré et mesurable, aux causes identifiées (essentiellement, les émissions de gaz à effet de serre). Que les êtres humains relèvent tous d’une même espèce, au sens biologique du terme, et que le concept de race humaine n’a aucun fondement scientifique. Qu’il n’y a jamais eu de différence de capacité intellectuelle entre les femmes et les hommes, ni entre aucun des groupes et sous-groupes ethniques et culturels qui constituent l’humanité. Et plus récemment que la vaccination anti-Covid est efficace. L’accumulation des savoirs au profit de l’humanité ne peut prospérer que via une coopération mondiale, ouverte, et garantie par une liberté académique totale.
Or l’extrême droite propose – notamment – la suppression du droit du sol et la préférence nationale au point d’effectuer des distinguos entre français mono-nationaux et bi-nationaux. Elle promeut le renforcement physique et juridique des frontières sous couvert de préoccupation sécuritaire et de bien-être économique. Elle minimise la portée des travaux du GIEC sur le climat. Elle manifeste une méfiance à peine voilée à l’endroit des scientifiques en général et fait aujourd’hui encore le lit des théories complotistes anti-vaccinales concernant la Covid. Ce faisant, elle contrevient directement à plusieurs des principes édictés par la « Déclaration universelle des droits de l’Homme et du citoyen ». Elle porte en outre atteinte à la libre circulation des êtres humains, des biens et des idées, circulation pourtant indispensable aux progrès de la science et de la raison.
C’est pourquoi, nous, Société informatique de France, porteurs de valeurs humanistes et d’une science informatique – libre et ouverte – interagissant avec les autres sciences pour mieux appréhender le réel, appelons avec la plus vive énergie à faire barrage à l’extrême-droite pour que notre pays demeure celui des Lumières, de la rationalité, de la liberté, de l’égalité et de la fraternité.
Les cyberattaques nous sont – malheureusement – devenues familières ; pas un jour où une nouvelle annonce d’une fuite de données ou du blocage d’un service numérique ne fasse la une de l’actualité. Si des spécialistes cherchent en permanence à concevoir des solutions visant à diminuer leur nombre et leur portée, il convient ensuite de les mettre en œuvre dans les systèmes numériques pour les contrer. L’histoire que nous racontent Charles Cuveliez et Jean-Charles Quisquater est édifiante : elle nous explique exactement tout ce qu’il ne faut pas faire ! Pascal Guitton
C’est une plainte en bonne et due forme qu’a déposée la Commission américaine de réglementation et de contrôle des marchés financiers (SEC) contre la société SolarWinds et son Chief Information Security Officer dans le cadre de l’attaque qu’elle a subie. Elle avait fait du bruit car elle a permis à des hackers de diffuser, depuis l’intérieur des systèmes de la société, une version modifiée du logiciel de gestion des réseaux que la compagnie propose à ses clients (Orion). Il faut dire que les dégâts furent considérables puisque les entreprises qui avaient installé la version modifiée permettaient aux hackers d’entrer librement dans leur réseau.
L’enquête de la SEC relatée dans le dépôt de plainte montre l’inimaginable en termes de manque de culture de sûreté, de déficience et de négligence, le tout mâtiné de mauvaise foi.
Absence de cadre de référence de sûreté
SolarWinds a d’abord prétendu et publié qu’il avait implémenté la méthodologie de l’agence chargée du développement de l’économie notamment en développant des normes (NIST, National Institute of Standards and Technology) pour évaluer les pratiques de cybersécurité et pour atténuer les risques organisationnels mais ce n’était pas vrai. Des audits internes ont montré qu’une petite fraction seulement des contrôles de ce cadre de référence était en place (40 %). Les 60% restants n’étaient tout simplement pas implémentés. SolarWinds, dans le cadre de ses évaluations internes, avait identifié trois domaines à la sécurité déficiente : la manière de gérer cette sécurité dans les logiciels tout au long de leur vie commerciale, les mots de passe et les contrôles d’accès aux ressources informatiques.
Un développement sans sécurité
Le logiciel de base qui sert à son produit Orion, faisait partie des développements qui ne suivaient absolument aucun cadre de sécurité. L’enquête a montré en 2018 qu’il y avait eu un début d‘intention pour introduire du développement sûr de logiciel mais qu’il fallait commencer par le début… une formation destinée aux développeurs pour savoir ce qu’est un développement sûr, suivi par des expériences pilotes pour déployer graduellement cette méthodologie, par équipe, sans se presser, sur une base trimestrielle. Entretemps, SolarWinds continuait à prétendre qu’elle pratiquait ses développements en suivant les méthodes de sécurité adéquates.
Mot de passe
La qualité de la politique des mots de passe était elle aussi défaillante : à nouveau, entre ce que SolarWinds prétendait et ce qui était en place, il y avait un fossé. La politique des mots de passe de SolarWinds obligeait à les changer tous les 90 jours, avec une longueur minimum et, comme toujours, imposait des caractères spéciaux, lettres et chiffres. Malheureusement, cette politique n’était pas déployée sur tous les systèmes d’information, applications ou bases de données. La compagnie en était consciente mais les déficiences ont persisté des années durant. Un employé de SolarWinds écrivit même un courriel au nouveau patron de l’informatique que des mots de passe par défaut subsistaient toujours pour certaines applications. Le mot de passe ‘password’ fut même découvert ! Un audit a mis en évidence plusieurs systèmes critiques sur lesquels la politique des mots de passe n’était pas appliquée. Des mots de passe partagés ont été découverts pour accéder à des serveurs SQL. Encore pire : on a trouvé des mots de passe non chiffrés sur un serveur public web, des identifiants sauvés dans des fichiers en clair. C’est via la société Akamai qui possède des serveurs un peu partout dans le monde et qui duplique le contenu d’internet notamment (les CDN, Content Distribution Networks) que SolarWinds distribuait ses mises à jour. Un chercheur fit remarquer à SolarWinds que le mot de passe pour accéder au compte de l’entreprise sur Akamai se trouvait sur Internet. Ce n’est pourtant pas via Akamai que la modification et la diffusion du logiciel eut lieu. Les hackers l’ont fait depuis l’intérieur même des systèmes de SolarWinds.
Gestion des accès
La gestion des accès c’est-à-dire la gestion des identités des utilisateurs, les autorisations d’accès aux systèmes informatique et la définition des rôles et fonctions pour savoir qui peut avoir accès à quoi dans l’entreprise étaient eux aussi déficients. La direction de SolarWinds savait entre 2017 et 2020 qu’on donnait de manière routinière et à grande échelle aux employés des autorisations qui leur permettaient d’avoir accès à plus de systèmes informatiques que nécessaires pour leur travail. Dès 2017, cette pratique était bien connue du directeur IT et du CIO. Pourquoi diable a-t-on donné des accès administrateurs à des employés qui n’avaient que des tâches routinières à faire ? Cela a aussi compté dans l’attaque.
Les VPN furent un autre souci bien connu et non pris en compte. A travers le VPN pour accéder au réseau de SolarWinds, une machine qui n’appartient pas à SolarWinds pouvait contourner le système qui détecte les fuites de données (data loss prevention). L’accès VPN contournait donc cette protection. Comme d’habitude, serait-on tenté de dire à ce stade, c’était su et connu de la direction. Toute personne avec n’importe quelle machine, grâce au VPN de SolarWinds et un simple identifiant (volé), pouvait donc capter des données, de manière massive sans se faire remarquer. En 2018, un ingénieur leva l’alerte en expliquant que le VPN tel qu’il avait été configuré et installé pouvait permettre à un attaquant d’accéder au réseau, d’y charger du code informatique corrompu et de le stocker dans le réseau de SolarWinds. Rien n’y fit, aucune action correctrice ne fut menée. En octobre 2018, SolarWinds, une vraie passoire de sécurité, faisait son entrée en bourse sans rien dévoiler de tous ces manquements. C’est d’ailleurs la base de la plainte de la SEC, le régulateur américain des marchés. Toutes ces informations non divulguées n’ont pas permis aux investisseurs de se faire une bonne idée de la valeur de la société. Solarwinds ne se contenta pas de mentir sur son site web : dans des communiqués de presse, dans des podcasts and des blogs, SolarWinds faisait, la main sur le cœur, des déclarations relatives à ses bonnes pratiques cyber.
Avec toutes ces déficiences dont la direction était au courant, il est clair pour la SEC que la direction de SolarWinds aurait dû anticiper qu’il allait faire l’objet d’une cyberattaque.
Alerté mais silencieux
Encore plus grave : SolarWinds avait été averti de l’attaque par des clients et n’a rien fait pour la gérer. C’est bien via le VPN que les attaquants ont pénétré le réseau de SolarWinds via des mots de passe volés et via des machines qui n’appartenaient pas à SolarWinds (cette simple précaution de n’autoriser que des machines répertoriées par la société aurait évité l’attaque). Les accès via le VPN ont eu lieu entre janvier 2019 et novembre 2020. Les criminels eurent tout le temps de circuler dans le réseau à la recherche de mots de passe, d’accès à d’autres machines pour bien planifier l’attaque. Celle-ci a donc finalement consisté à ajouter des lignes de code malicieuses dans Orion, le programme phare de SolarWinds, utilisé pour gérer les réseaux d’entreprise. Ils n’ont eu aucun problème pour aller et venir entre les espaces de l’entreprise et les espaces de développement du logiciel, autre erreur de base (ségrégation et segmentation). A cause des problèmes relevés ci-dessus avec les accès administrateurs, donnés à tout bout de champ, notamment, les antivirus ont pu être éteints. Les criminels ont ainsi pu obtenir des privilèges supplémentaires, accéder et exfiltrer des lignes de codes sans générer d’alerte. Ils ont aussi pu récupérer 7 millions de courriels du personnel clé de Solarwind.
Jusqu’en février 2020, ils ont testé l’inclusion de lignes de code inoffensives dans le logiciel sans être repérés. Ils ont donc ensuite inséré des lignes de code malicieuses dans trois produits phares de la suite Orion. La suite, on connait : ce sont près de 18 000 clients qui ont reçu ces versions contaminées. Il y avait dans ces clients des agences gouvernementales américaines.
On s’est bien retranché, chez SolarWinds, derrière une soi-disant attaque d’un État pour justifier la gravité de ce qui s’est passé et sous-entendre qu’il n’y avait rien à faire pour la contrer mais le niveau de négligence, analyse la SEC, est si immense qu’il ne fallait pas être un État pour mettre en œuvre Sunburst, le surnom donné à l’attaque. Il y a aussi eu des fournisseurs de service (MSP) attaqués : ceux-ci utilisent les produits de SolarWinds pour proposer des services de gestion de leur réseau aux clients, ce qui donc démultipliait les effets.
Alors que des clients ont averti que non seulement le produit Orion était attaqué mais que les systèmes même de SolarWinds étaient affectés, la société a tu ces alertes. Elle fut aussi incapable de trouver la cause de ces attaques et d’y remédier. SolarWinds a même osé prétendre que les hackers se trouvaient déjà dans le réseau des clients (rien à avoir avec SolarWinds) ou que l’attaque était contre le produit Orion seul (sur laquelle une vulnérabilité aurait été découverte par exemple) alors que cette attaque avait eu lieu parce que les hackers avaient réussi à infester le réseau de SolarWinds
Pour la SEC, le manque de sécurité mise en place justifie déjà à lui seul la plainte et l’attaque elle-même donne des circonstances aggravantes.
L’audit interne a montré que de nombreuses vulnérabilités étaient restées non traitées depuis des années. De toute façon le personnel était largement insuffisant, a pu constater la SEC dans les documents internes, pour pouvoir traiter toutes ces vulnérabilités en un temps raisonnable. On parlait d’années. Lors de l’attaque, SolarWinds a menti sur ce qui se passait. Au lieu de dire qu’une attaque avait lieu, SolarWinds avait écrit que du code dans le produit Orion avait été modifié et pourrait éventuellement permettre à un attaquant de compromettre les serveurs sur lesquels le produit Orion avait été installé et tournait !
Que retenir de tout ceci ? Il ne faut pas se contenter des déclarations des fournisseurs sur leurs pratiques de sécurité. En voilà un qui a menti tout en sachant que son produit était une passoire. Ce qui frappe est la quantité d’ingénieurs et d’employés qui ont voulu être lanceurs d’alerte au sein de SolarWinds. Ils ne furent pas écoutés. Faut-il légiférer et prévoir une procédure de lanceur d’alerte sur ces matières-là aussi vers des autorités ? On se demande aussi si dans tous les clients d’Orion, il n’y en a eu aucun pour faire une due diligence avec des interviews sur site. Il est quasiment certain que des langues se seraient déliées.
Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT) & Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles)
Pour en savoir plus : Christopher BRUCKMANN, (SDNY Bar No. CB-7317), SECURITIES AND EXCHANGE COMMISSION, Plaintiff, Civil Action No. 23-cv-9518, against SOLARWINDS CORP. and TIMOTHY G. BROWN
En ce 1000/11 (08/03 en binaire), Binaire souhaite à ses lectrices une excellente Journée internationale des droits des femmes. Comme beaucoup nous sommes questionnés par le petit nombre de femmes dans le numérique. Nous avons demandé à Sara Bouchenak d’expliquer à nos lectrices et lecteurs ce qu’il en était, en 2024, de la place des femmes et de l’égalité entre les sexes dans le domaine du numérique. Serge Abiteboul et Marie-Agnès Enard.
Sara Bouchenak
Où en est-on en 2024 de la place des femmes et de l’égalité entre les sexes dans le domaine du numérique ?
C’est une question aux histoires et aux géographies variables. La situation a certes évolué au cours du temps, au cours de l’histoire de la science informatique et avec l’avènement du numérique, mais pas forcément dans le bon sens : pourquoi ?
L’égalité entre les sexes dans le secteur du numérique est bien présente dans certains pays du monde, mais pas dans les pays les plus égalitaires entre les sexes et auxquels on penserait de prime abord : pourquoi ?
Quelles actions pour plus d’égalité entre les sexes dans le domaine du numérique ont démontré leur efficacité avec, parfois, des retombées étonnamment rapides ?
Comment penser notre société de demain, un monde où le numérique nourrit tous les secteurs – la santé, les transports, l’éducation, la communication, l’art, pour n’en citer que certains –, un thème mis en avant par l’ONU : « Pour un monde digital inclusif : innovation et technologies pour l’égalité des sexes ».
Pour répondre à ces questions, nous proposons une lecture croisée d’ouvrages et de points de vue de la sociologue et politologue Véra Nikolski [Nikolski, 2023], de l’anthropologue Emmanuelle Joseph-Dailly [Joseph-Dailly, 2021], de l’informaticienne Anne-Marie Kermarrec [Kermarrec, 2021], de la philosophe Michèle Le Dœuff [Le Dœuff, 2020], et de l’informaticienne et docteure en sciences de l’éducation Isabelle Collet [Collet, 2019].
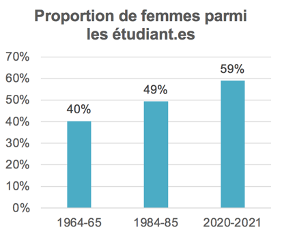
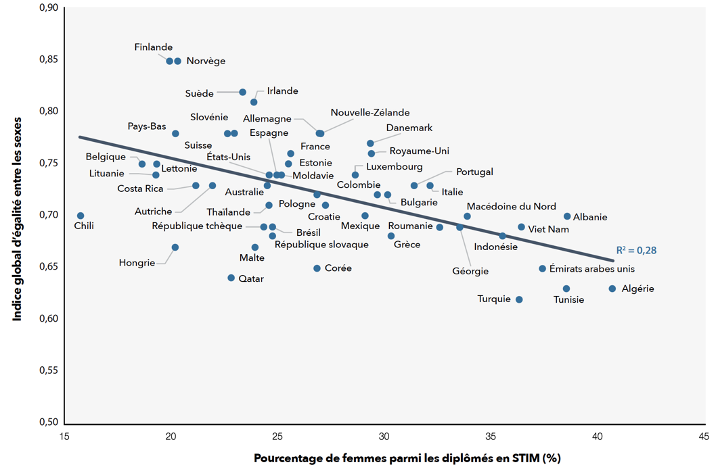
Aujourd’hui, le constat est le même dans plusieurs pays, la proportion de femmes dans le numérique est faible. En France, les écoles d’ingénieur.es ne comptent en 2020 qu’entre 17% et 20% de femmes parmi leurs étudiant.es en numérique de niveau Licence ou Master. Des proportions similaires (entre 21% et 24%) sont observées dans les pays de l’Union Européenne. Comment se fait-il que la proportion de femmes dans le numérique soit aujourd’hui si faible, alors que les premiers programmeurs des ordinateurs étaient des programmeuses ? Est-ce que les femmes sont moins nombreuses à s’orienter dans le numérique ?
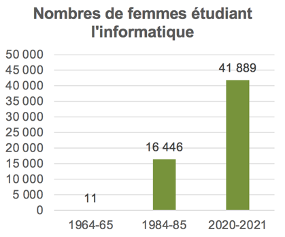
La réponse est non, bien au contraire. Par exemple, aux États-Unis (où les statistiques par genre sont collectées depuis plusieurs décennies), les femmes n’ont pas cessé d’être de plus en plus nombreuses à effectuer des études supérieures en général, et à s’orienter en informatique et dans le numérique en particulier. Ainsi, le nombre d’étudiantes femmes en informatique a été multiplié par x1495 entre 1964-1965 et 1984-1985, et ce nombre a plus que doublé entre 1984-1985 et 2020-2021. Alors, pourquoi cette faible proportion aujourd’hui, alors que les femmes représentaient jusqu’à 36% des personnes formées en informatique aux États-Unis jusque dans les années 1980 ?
Le paradoxe de l’égalité des sexes est-il vraiment un paradoxe ?
Il existe aujourd’hui des pays présentant plus d’égalité entre les femmes et les hommes dans le domaine du numérique. C’est le cas par exemple de l’Indonésie, de la Turquie, des Émirats arabes unis, et des pays du Maghreb. Une étude a été menée sur plusieurs pays dans le monde, et arrive à la conclusion suivante : dans les pays moins égalitaires entre les sexes, la proportion de femmes parmi les personnes diplômées en STIM (sciences, technologie, ingénierie et mathématiques) est plus importante, en comparaison avec les pays les plus égalitaires entre les sexes. Ceci soulève deux questions. D’une part, pourquoi les pays les plus égalitaires entre les sexes ont-ils une proportion faible de femmes dans les STIM ? D’autre part, comment se fait-il que des pays les moins égalitaires entre les sexes arrivent à avoir une proportion élevée de femmes dans les STIM ?
Pourquoi dans les pays les plus égalitaires entre les sexes, la proportion des femmes dans les STIM et le numérique est-elle faible ?
Si l’on remonte dans le temps, il y a environ 150 ans, le groupe des « Harvard Computers » venait de voir le jour. Il était constitué de femmes engagées par l’observatoire de l’université de Harvard comme calculatrices, pour effectuer des traitements mathématiques sur d’importantes quantités de données astronomiques. Un travail répétitif, méticuleux et fastidieux, auquel les femmes étaient supposées naturellement prédisposées [Collet, 2019]. Des scientifiques ont alors utilisé une nouvelle unité de mesure du temps de calcul, appelée girl-year [Grier, 2007]. Comme d’autres avaient défini auparavant le cheval-vapeur, unité de mesure de puissance. Deux unités pour deux usages différents, mais faisant chacune référence en définitive, avec plus ou moins de subtilité, à une bête de somme.
Dans les années 1940, lorsque les ordinateurs sont finalement devenus une réalité, les femmes ont été pionnières dans l’écriture de programmes pour les ordinateurs. Un travail là encore dévolu uniquement aux femmes, qui sont passées de calculatrices à programmeuses ; le travail de programmation était alors considéré comme déqualifié et sans importance. Dans les années 1950 et 1960, à mesure que les ordinateurs sont devenus indispensables dans de nombreux secteurs du gouvernement et de l’industrie, le nombre d’emplois dans la programmation a explosé. Ces emplois sont encore en grande partie féminins, et plébiscités par le magazine féminin Cosmopolitan dans son édition d’avril 1967. Ceci a duré jusqu’au milieu des années 1980, où les femmes représentaient 36% des personnes formées en informatique.
@The New York Times Magazine, Programmeuses de l’ordinateur ENIAC dans les années 1940, premier ordinateur programmable à usage général
L’analyse de l’évolution au cours du temps montre qu’il y a eu deux périodes dans l’histoire récente de l’informatique où le nombre de femmes s’orientant vers l’informatique a baissé : en 1984-1985, puis en 2002-2003, et ce pendant environ sept ans. Deux dates qui peuvent être corrélées à deux crises : la récession et la crise du chômage au début des années 1980, et le krach boursier dû à l’éclatement de la bulle internet au début des années 2000. Ces crises ont certes impacté femmes et hommes, mais les femmes ont été plus lourdement touchées : moins 43%-44% de femmes formées dans le domaine vs. moins 23%-24% d’hommes.
Simone de Beauvoir l’a bien dit : « Il suffira d’une crise politique, économique ou religieuse pour que les droits des femmes soient remis en question. »
À cela s’ajoute la transformation survenue à la fin des années 1970 et au début des années 1980, avec l’entrée des ordinateurs personnels dans les foyers familiaux. Cette nouvelle technologie a subi les stéréotypes en vigueur : les garçons étaient encouragés à jouer avec les objets électroniques, tandis que les filles étaient orientées vers les poupées et les dînettes. Depuis lors, l’informatique a pâti de ce stéréotype faisant d’elle un domaine masculin, elle qui a d’abord été féminine [Dufour, 2019].
L’anthropologue Emmanuelle Joseph-Dailly aborde la question des biais cognitifs. Dans son ouvrage Les talents cachés de votre cerveau au travail, elle rappelle le rôle majeur que tiennent les émotions dans nos décisions et nos actions, leur aide précieuse, mais également leur effet néfaste lorsque nos biais cognitifs prennent le dessus [Joseph-Dailly, 2019]. Aujourd’hui, les biais cognitifs sont bien à l’œuvre dans les pays plus égalitaires entre les sexes. Ainsi, lorsqu’il y a eu reprise économique suite aux crises dans les années 1980 et 2000, les hommes ont bénéficié de la reprise bien plus avantageusement que les femmes, avec une multiplication du nombre de personnes formées en informatique par x4 pour les hommes vs. x2,5 pour les femmes, entre 1984 et 2020.
Pourquoi les pays les moins égalitaires entre les sexes ont-ils une proportion élevée de femmes dans les STIM et le numérique ?
Alors que les baby-boomers et la génération X dans les pays occidentaux ont initialement vu l’arrivée de l’ordinateur personnel à la fin des années 1970 et au début des années 1980 comme un objet électronique rare, et plutôt dédié aux garçons, la population dans les pays en voie de développement n’avait à ce moment-là, quant à elle, pas accès à cet objet, du fait d’une politique économique moins ouverte et d’un pouvoir d’achat plus faible. Ces derniers pays ont ainsi été épargnés des stéréotypes et biais de genre liés aux ordinateurs et à l’informatique. Les générations Y et Z dans ces pays ont ensuite coïncidé avec une ouverture économique des pays, et un accès aux ordinateurs et aux smartphones dont a bénéficié la population plus largement sans inégalité de genre.
Aujourd’hui, la proportion de femmes diplômées en STIM dans ces pays est bien au-delà de celle des pays égalitaires entre les sexes. Mais il est à noter que contrairement à ces derniers où le numérique joue un rôle important dans l’économie du pays (10% du PIB du Royaume-Uni, 8% du PIB des États-Unis en 2019 selon l’OCDE), dans les pays les moins égalitaires entre les sexes, les principales sources de richesse économique proviennent d’autres secteurs que le numérique, comme par exemple les hydrocarbures (Émirats arabes unis, Algérie), l’agriculture (Turquie, Indonésie), ou les industries de main d’œuvre (Tunisie). Lorsque les STIM prendront une part plus importante dans l’économie de ces pays, il faudra alors veiller à maintenir une proportion féminine suffisante, et ne pas la voir réduite drastiquement suite à une participation massive des hommes au détriment des femmes comme cela a pu être le cas dans d’autres pays.
Éloge de la dissemblance
Aujourd’hui, bon nombre d’entreprises et de grands groupes du numérique cherchent à augmenter leurs effectifs féminins. C’est un moyen d’augmenter le vivier de candidat.es à recruter, étant donné les estimations de nouveaux postes qui seront créés dans le domaine dans les années à venir, et la pénurie de talents. Mais il se trouve également que la mixité et la diversité sont reconnues comme sources d’innovation et de créativité, permettant, d’une part, le développement de l’entreprise, et d’autre part, une meilleure stimulation et inclusion des salariés.
À ce propos, dans son ouvrage La stratégie du poulpe, Emmanuelle Joseph-Dailly pose un regard riche et lucide sur la dissemblance :
« L’entreprise projette souvent intellectuellement la diversité comme une opportunité, tout en refusant le risque de s’y aventurer en pratique.[..] Si l’hétérogénéité est promesse d’innovation et de performance, elle introduit une forme de non-alignement, de possibilité de divergence qui peut au départ ralentir le système.
[..]
Mais dans l’environnement changeant qui est le nôtre, l’agilité ne peut passer que par une diversité d’expériences et de perceptions du monde, de la réalité, de la vérité, créatrices de valeur. Les réponses au renouvellement et à la réinvention viendront avec le « dissensus », qui sera une occasion d’expérimentation pour tester d’autres réponses aux besoins émergents. Plutôt que de systématiquement chercher le consensus, nous devrions chercher le débat, aussi vif soit-il, en prenant la précaution de toujours préserver la relation. »
Sara Bouchenak, Professeure d’informatique à l’INSA Lyon, Directrice de la Fédération Informatique de Lyon.
Pour aller plus loin
Isabelle Collet. Les oubliées du numérique. Le Passeur, 2019.
Catherine Dufour. Ada ou la beauté des nombres. Fayard, 2019.
David Alan Grier. When Computers Were Human. Princeton University Press, 2007.
Yuval Noah Harari. Sapiens : Une brève histoire de l’humanité. Albin Michel, 2015.
Emmanuelle Joseph-Dailly. La stratégie du poulpe. Eyrolles, 2021.
Emmanuelle Joseph-Dailly, Bernard Anselm. Les talents cachés de votre cerveau au travail. Eyrolles, 2019.
Anne-Marie Kermarrec. Numérique, compter avec les femmes. Odile Jacob, 2021.
Michèle Le Dœuff. Le Sexe du savoir. Flammarion, 2000.
Véra Nikolski. Féminicène. Fayard, 2023.
[1] Illustration schématique, non basée sur un fondement formel.
Tristan Nitot a publié un message sur LinkedIn en hommage à Niklaus Wirth. Binaire et le Bulletin 1024 de la Société Informatique de France lui avons demandé de nous écrire un article. Serge Abiteboul, Sylvie Alayranques,Denis Pallez et Pierre Paradinas.
Niklaus Wirth en 1984 à côté de Lilith. (Photo: Niklaus Wirth). ETH Zurich.
Dans toutes les industries, il y a des figures légendaires. Dans le numérique (qui pour moi rassemble le matériel informatique et le logiciel), il y a indéniablement Niklaus Wirth. Même si aujourd’hui, dans un monde qui va vite, peu de gens se souviennent de ce scientifique suisse qui vient de s’éteindre le premier janvier juste avant ses 90 ans. Et pourtant, quel parcours, quelles contributions, quelle sagesse et, chose plus rare encore dans ces métiers, une étonnante humilité.
On ne saurait résumer la vie du professeur Niklaus Wirth en quelques mots : il est né en Suisse en 1934, a étudié à l’ETH Zurich, puis obtenu un doctorat en informatique à Berkeley. C’est là qu’il a découvert les langages informatiques et les compilateurs. Il a obtenu l’ACM Turing Award, (le prix Nobel de l’informatique) en 1984. Il a inventé de nombreux langages, dont le célèbre langage Pascal mais aussi Modula-2.
Mais réduire la carrière de Niklaus Wirth aux langages informatique serait une erreur. Il inventait des systèmes informatiques, comprenant un système d’exploitation, un environnement de développement avec un langage et un compilateur, avec les interfaces homme-machine.
Il a fait deux passages d’une année au Xerox PARC Palo Alto Research Center, s’inspirant de la citation d’Alan Kay qui y officiait : Les gens qui font du logiciel sérieusement devraient construire leur propre matériel. C’est ainsi qu’en 1980, quatre ans avant l’arrivée du Mac, Niklaus Wirth a commencé à développer Lilith (cf. image page précédente), une des premières stations de travail avec une souris et un affichage graphique haute résolution, sans arriver au succès commercial des solutions américaines.
En 1992, dans le manuel du système Oberon, il explique que malgré la loi de Moore qui stipule que la puissance des semi-conducteurs double tous les deux ans, les logiciels deviennent plus gros et moins optimisés au même rythme. On a appelé cela la loi de Wirth : En dépit de multiples bonds en avant, le matériel accélère moins vite que le logiciel ne se ralentit. Le système Oberon, qui était composé d’un système d’exploitation, d’un langage et d’un ordinateur, visait à contredire la loi de Wirth. En 2013 (il a alors 79 ans !), sortait une nouvelle version d’Oberon où Wirth est allé jusqu’à fabriquer son propre microprocesseur sur la base de circuits FPGA.
Wirth a aussi publié dès 1995 un plaidoyer pour le logiciel frugal où il explique les origines de la loi de Wirth dans le fait que les auteurs de logiciels rajoutent des fonctionnalités inutiles pour inciter leurs clients à acheter la nouvelle version, ce qui rend le logiciel plus gras, plus lent, et fait les affaires des fabricants de matériel, dont la précédente génération est devenue de facto obsolète. Les clients rachètent donc du matériel pour remplacer l’ancien qui fonctionne pourtant très bien. De nos jours, presque 30 ans plus tard, la notion d’obsolescence programmée est dorénavant connue de tous, et on réalise que cela fait 50 ans que les industries du matériel et du logiciel l’ont institutionnalisée.
Pourtant, alors que l’on doit réduire l’empreinte écologique de l’activité humaine pour faire face à l’effondrement de la biodiversité et au réchauffement climatique, et que le numérique pollue plus encore que le transport aérien, l’appel de Niklaus Wirth à plus de simplicité, d’optimisation, de sobriété et de frugalité, donc d’élégance, est plus que jamais d’actualité.
Merci pour vos contributions, Professeur Wirth, puissent les communautés du numérique vous rendre hommage en suivant vos principes !
Sandrine Blazy, Professeure à l’université de Rennes et directrice adjointe de l’IRISA, est une spécialiste des compilateurs et des logiciels sûrs. Elle a développé avec Xavier Leroy, CompCert, le premier compilateur pour le langage C vérifié à l’aide de Coq. Pour ce véritable tour de force scientifique et technique, elle a obtenu la médaille d’argent du CNRS (une des plus belles récompenses scientifiques en France). Si vous ne comprenez pas en quoi cela consiste, Sandrine va l’expliquer à binaire et ce sera l’occasion d’un peu mieux comprendre ce qui se passe dans un ordinateur.Serge Abiteboul et Pierre Paradinas
Les liens entre mathématiques et informatique sont féconds. Dans les années quarante, la nécessité de mécaniser des calculs numériques permettant de résoudre des équations mathématiques a permis le développement des premières machines de calcul à grande échelle, qui ont préfiguré les premiers ordinateurs. Ces calculateurs universels enchaînaient en séquence des opérations mathématiques élémentaires, décomposant des calculs modélisant des phénomènes physiques. Aujourd’hui, ces calculs sont réalisés par une simple calculette de bureau.
Chaque opération était fidèlement décrite par un code constitué de commandes compréhensibles par la machine, c’est-à-dire des suites de chiffres zéros et un (signifiant l’absence et la présence de courant dans les composants d’un circuit électronique). Aussi, faire exécuter une opération par un calculateur était une véritable gageure. Les experts dont c’était le travail devaient encoder l’opération (c’est-à-dire trouver les nombres adéquats pour représenter l’opération, ainsi que les valeurs auxquelles elle s’appliquait qui étaient encodées sur des cartes perforées), en plus d’effectuer des manipulations physiques sur la machine. Ces experts écrivaient ces codes sur papier, avant de les fournir à la machine, dont ils devaient de plus comprendre le fonctionnement électromécanique. Ces premières machines étaient gigantesques et complexes à manipuler. En guise d’écran, des marteaux (tels que ceux utilisés par les machines à écrire) imprimaient sur papier des caractères. Par contre, elles avaient l’avantage de fonctionner sans cesse et d’accélérer grandement les temps de calcul de chaque opération, en enchaînant en des temps records des successions de calculs variés, ce qui a fait leur succès.
Le succès aidant et les calculs devenant de plus en plus complexes, il a été nécessaire de rendre l’écriture des codes moins absconse et d’automatiser davantage l’enchaînement des calculs. Une première réponse a été l’utilisation répandue d’une notation plus expressive et graphique (à l’aide de boîtes reliées par des flèches) pour représenter l’enchaînement des calculs. Les diagrammes résultants, appelés organigrammes permettaient de représenter simplement non seulement des séquences de calculs, mais aussi des décisions à prendre en fonction de résultats intermédiaires, et donc des enchaînements plus sophistiqués de calculs (comme la répétition d’étapes de calculs jusqu’à atteindre un certain seuil). Ces diagrammes permettaient de s’abstraire du matériel, et de décomposer un problème avant d’écrire du code. Plus faciles à comprendre par des humains, ils permettaient de réutiliser une opération lorsque la machine évoluait en fonction des progrès technologiques fréquents.
L’expressivité des organigrammes a favorisé l’émergence d’”algorithmes”, c’est-à-dire d’enchaînements plus efficaces des calculs (c’est-à-dire réduisant le temps de calcul), du fait de la représentation particulière des nombres en machine. Par exemple, en 1949, Alan Turing a proposé une nouvelle façon de calculer la fonction mathématique factorielle, sans utiliser les opérations coûteuses de multiplication mais seulement des additions. Il se demande alors comment être sûr que ce que calcule son organigramme est effectivement le même résultat que celui de la fonction factorielle du mathématicien, en d’autres termes que son organigramme est correct. Pour y répondre, il a effectué ce qu’on appellerait aujourd’hui la première preuve de programme, en annotant son organigramme avec des assertions, dont il a ensuite vérifié la cohérence.
L’effort pour démocratiser la mécanisation des calculs s’est poursuivi avec l’invention des premiers langages de programmation. Les organigrammes ont fait place au pseudo-code, puis aux algorithmes et programmes écrits dans un langage dont la syntaxe est plus intuitive. Un langage de programmation définit un ensemble de commandes abstraites mais précises pour effectuer toutes les opérations exprimables dans un organigramme, avec des mots-clés en anglais (plus faciles à appréhender que les seuls nombres d’un code). Le premier livre sur la programmation paraît en 1951, alors que très peu de machines sont en service; il est utilisé pour des recherches en physique, astronomie, météorologie et biochimie.
Les langages de programmations et les compilateurs
Le langage de programmation devient un intermédiaire nécessaire entre l’humain et la machine, et il devient indispensable d’automatiser la traduction des programmes en code machine. Le premier compilateur A-0 mis au point par Grace Hopper est disponible en 1952. Ce terme résulte de son premier usage, mettre bout à bout des portions de code, à la manière d’une bibliothécaire qui rassemble des documents sur un sujet précis. Pour expliquer de plus les possibilités prometteuses offertes par un tel programme de traduction (d’un langage source en un code machine), Grace Hopper utilise la métaphore d’une ligne de production dans une usine, qui produirait des nombres (plutôt que des automobiles) et plus généralement des données au moyen d’outils (tables de calcul, formules, calculs numériques).
Le compilateur devient un point de passage obligé pour traduire tout programme écrit par un humain en un code compréhensible par la machine, et la traduction de l’un vers l’autre est un défi scientifique. En effet, un problème se pose du fait de la faible vitesse des calculs, des capacités très limitées de stockage, mais aussi de l’abstraction et la généralité des programmes écrits : plus le programme source est facile à comprendre pour un humain, moins l’exécution du code machine engendré est efficace.
En 1953, le langage Fortran est le premier à être dédié au calcul numérique, et donc à s’abstraire du matériel spécifique à une machine. C’est aussi le premier qui devient un standard: pour la première fois, les programmeurs parlent un même langage, quelle que soit la machine qu’ils utilisent. IBM consacre un effort notable à développer son compilateur, afin qu’il produise un code efficace. C’est le début de l’invention de nouvelles techniques de compilation, les premières optimisations (ex. compiler séparément des portions de code, ou encore détecter des calculs communs pour les factoriser). Le manuel de Fortran est disponible en 1956, et son compilateur en 1957.
Cet effort pour démocratiser la programmation se poursuit avec le langage Cobol dédié au traitement des données. Désormais, l’ordinateur ne calcule pas que des nombres; il permet plus généralement de structurer des données et de les traiter efficacement. COBOL ouvre la voie à de nouvelles applications. Le premier programme COBOL est compilé en 1960; en 1999 la grande majorité des logiciels seront écrits en COBOL, suite à son utilisation massive dans les domaines de la banque et de l’assurance. Ainsi, dans les années 60, la pratique de la programmation se répand et devient une science; les langages de programmation foisonnent. Aujourd’hui encore, les langages de programmation évoluent sans cesse, pour s’adapter aux nouveaux besoins.
ChatGPT appartient à la famille des agents conversationnels. Ces IA sont des IA conversationnelles qui génèrent du texte pour répondre aux requêtes des internautes. Bien qu’elles soient attrayante, plusieurs questions se posent sur leur apprentissage, leur impact social et leur fonctionnement! En binôme avec interstices.info, Karën Fort, spécialiste en traitement automatique des langues (TAL), est Maîtresse de conférences en informatique au sein de l’unité de recherche STIH de Sorbonne Université, membre de l’équipe Sémagramme au LORIA (laboratoire lorrain de recherche en informatique) , ET Joanna Jongwane, rédactrice en chef d’Interstices, Direction de la communication d’Inria, ont abordé ce sujet au travers d’un podcast. Thierry vieville etIkram Chraibi Kaadoud
Les IA conversationnelle qui génèrent du texte pour répondre aux requêtes des internautes sont à la fois sources d’inquiétudes et impressionnants par leurs « capacités ». Le plus populaire, ChatGPT, a fait beaucoup parler de lui ces derniers mois. Or il en existe de nombreux autres.
La communauté TAL s’est penché depuis longtemps sur les questions éthique liés au langage et notamment l’impact sociétal de tels outils
Une IA conversationnelle ayant appris des textes en anglais, reflétant le mode de pensé occidentale, saurait-elle saisir les subtilités d’un mode de pensé d’une autre partie du monde ?
Petit mot sur l’auteur : Jason Richard, étudiant en master expert en systèmes d’information et informatique, est passionné par l’Intelligence Artificielle et la cybersécurité. Son objectif est de partager des informations précieuses sur les dernières innovations technologiques pour tenir informé et inspiré le plus grand nombre.Ikram Chraibi Kaadoud, Jill-jenn Vie
Introduction
Dans un monde où l’intelligence artificielle (IA) est de plus en plus présente dans notre quotidien, de la recommandation de films sur Netflix à la prédiction de la météo, une question audacieuse se pose : une IA pourrait-elle un jour diriger un pays ? Cette idée, qui semble tout droit sortie d’un roman de science-fiction, est en réalité de plus en plus débattue parmi les experts en technologie et en politique.
L’IA a déjà prouvé sa capacité à résoudre des problèmes complexes, à analyser d’énormes quantités de données et à prendre des décisions basées sur des algorithmes sophistiqués. Mais diriger un pays nécessite bien plus que de simples compétences analytiques. Cela nécessite de la sagesse, de l’empathie, de la vision stratégique et une compréhension profonde des nuances humaines – des qualités que l’IA peut-elle vraiment posséder ?
Dans cet article, nous allons explorer cette question fascinante et quelque peu controversée. Nous examinerons les arguments pour et contre l’idée d’une IA à la tête d’un pays, nous discuterons des implications éthiques et pratiques. Que vous soyez un passionné de technologie, un politologue ou simplement un citoyen curieux, nous vous invitons à nous rejoindre dans cette exploration de ce qui pourrait être l’avenir de la gouvernance.
L’intelligence artificielle : une brève introduction
Avant de plonger dans le débat sur l’IA en tant que chef d’État, il est important de comprendre ce qu’est l’intelligence artificielle et ce qu’elle peut faire. L’IA est un domaine de l’informatique qui vise à créer des systèmes capables de réaliser des tâches qui nécessitent normalement l’intelligence humaine. Cela peut inclure l’apprentissage, la compréhension du langage naturel, la perception visuelle, la reconnaissance de la parole, la résolution de problèmes et même la prise de décision.
L’IA est déjà largement utilisée dans de nombreux secteurs. Par exemple, dans le domaine de la santé, l’IA peut aider à diagnostiquer des maladies, à prédire les risques de santé et à personnaliser les traitements. Dans le secteur financier, l’IA est utilisée pour détecter les fraudes, gérer les investissements et optimiser les opérations. Dans le domaine des transports, l’IA est au cœur des voitures autonomes et aide à optimiser les itinéraires de livraison. Et bien sûr, dans le domaine de la technologie de l’information, l’IA est omniprésente, des assistants vocaux comme Siri et Alexa aux algorithmes de recommandation utilisés par Netflix et Amazon.
Cependant, malgré ces avancées impressionnantes, l’IA a encore des limites. Elle est très bonne pour accomplir des tâches spécifiques pour lesquelles elle a été formée, mais elle a du mal à généraliser au-delà de ces tâches*. De plus, l’IA n’a pas de conscience de soi, d’émotions ou de compréhension intuitive du monde comme les humains. Elle ne comprend pas vraiment le sens des informations qu’elle traite, elle ne fait que reconnaître des modèles dans les données.
Cela nous amène à la question centrale de cet article : une IA, avec ses capacités et ses limites actuelles, pourrait-elle diriger un pays ? Pour répondre à cette question, nous devons d’abord examiner comment l’IA est déjà utilisée dans le domaine politique.
*Petit aparté sur ChatGPT et sa capacité de généralisation :
Chatgpt est une intelligence artificielle (de type agent conversationnel) qui, en effet, à pour but de répondre au maximum de question. Cependant, si on ne la « spécialise » pas avec un bon prompt, les résultats démontrent qu’elle a du mal à être juste. Google l’a encore confirmé avec PALM, un modèle de « base » où l’on vient rajouter des briques métiers pour avoir des bons résultats.
L’IA en politique : déjà une réalité ?
L’intelligence artificielle a déjà commencé à faire son chemin dans le domaine politique, bien que nous soyons encore loin d’avoir une IA en tant que chef d’État. Cependant, les applications actuelles de l’IA en politique offrent un aperçu fascinant de ce qui pourrait être possible à l’avenir.
L’une des utilisations les plus courantes de l’IA en politique est l’analyse des données. Les campagnes politiques utilisent l’IA pour analyser les données des électeurs, identifier les tendances et personnaliser les messages. Par exemple, lors des élections présidentielles américaines de 2016, les deux principaux candidats ont utilisé l’IA pour optimiser leurs efforts de campagne, en ciblant les électeurs avec des messages personnalisés basés sur leurs données démographiques et comportementales.
L’IA est également utilisée pour surveiller les médias sociaux et identifier les tendances de l’opinion publique. Les algorithmes d’IA peuvent analyser des millions de tweets, de publications sur Facebook et d’autres contenus de médias sociaux pour déterminer comment les gens se sentent à propos de certains sujets ou candidats. Cette information peut être utilisée pour informer les stratégies de campagne et répondre aux préoccupations des électeurs.
Dans certains pays, l’IA est même utilisée pour aider à la prise de décision politique. Par exemple, en Estonie, un petit pays d’Europe du Nord connu pour son adoption précoce de la technologie, le gouvernement développe une intelligence artificielle qui devra arbitrer de façon autonome des affaires de délits mineurs.
En plus du « juge robot », l’État estonien développe actuellement 13 systèmes d’intelligence artificielle directement intégrés dans le service public. Cela s’applique également au Pôle Emploi local, où plus aucun agent humain ne s’occupe des personnes sans emploi. Ces derniers n’ont qu’à partager leur CV numérique avec un logiciel qui analyse leurs différentes compétences pour ensuite créer une proposition d’emploi appropriée. Premier bilan : 72 % des personnes qui ont trouvé un emploi grâce à cette méthode le conservent même 6 mois plus tard. Avant l’apparition de ce logiciel, ce taux était de 58 %.
Cependant, malgré ces utilisations prometteuses de l’IA en politique, l’idée d’une IA en tant que chef d’État reste controversée. Dans les sections suivantes, nous examinerons les arguments pour et contre cette idée, et nous discuterons des défis et des implications éthiques qu’elle soulève.
L’IA à la tête d’un pays : les arguments pour
L’idée d’une intelligence artificielle à la tête d’un pays peut sembler futuriste, voire effrayante pour certains. Cependant, il existe plusieurs arguments en faveur de cette idée qui méritent d’être examinés.
Efficacité et objectivité : L’un des principaux avantages de l’IA est sa capacité à traiter rapidement de grandes quantités de données et à prendre des décisions basées sur ces données. Dans le contexte de la gouvernance, cela pourrait se traduire par une prise de décision plus efficace et plus objective. Par exemple, une IA pourrait analyser des données économiques, environnementales et sociales pour prendre des décisions politiques éclairées, sans être influencée par des biais personnels ou politiques.
Absence de corruption : Contrairement aux humains, une IA ne serait pas sujette à la corruption**. Elle ne serait pas influencée par des dons de campagne, des promesses de futurs emplois ou d’autres formes de corruption qui peuvent affecter la prise de décision politique. Cela pourrait conduire à une gouvernance plus transparente et plus équitable.
Continuité et stabilité : Une IA à la tête d’un pays pourrait offrir une certaine continuité et stabilité, car elle ne serait pas affectée par des problèmes de santé, des scandales personnels ou des changements de gouvernement. Cela pourrait permettre une mise en œuvre plus cohérente et à long terme des politiques.
Adaptabilité : Enfin, une IA pourrait être programmée pour apprendre et s’adapter en fonction des résultats de ses décisions. Cela signifie qu’elle pourrait potentiellement s’améliorer avec le temps, en apprenant de ses erreurs et en s’adaptant aux changements dans l’environnement politique, économique et social.
Cependant, bien que ces arguments soient convaincants, ils ne tiennent pas compte des nombreux défis et inquiétudes associés à l’idée d’une IA à la tête d’un pays. Nous examinerons ces questions dans la section suivante.
**Petit aparté sur la corruption d’une IA:
Le sujet de la corruption d’une IA ou de son incorruptibilité a généré un échange en interne que l’on pense intéressant de vous partager
Personne 1 : Ça dépend de qui contrôle l’IA !
Auteur : La corruption est le détournement d’un processus. L’intelligence en elle-même n’est pas corruptible. Après, si les résultats ne sont pas appliqué, ce n’est pas l’IA que l’on doit blâmer
Personne 1 : En fait on peut en débattre longtemps, car le concepteur de l’IA peut embarquer ses idées reçues avec, dans l’entraînement. De plus, une personne mal intentionnée peut concevoir une IA pour faire des choses graves, et là il est difficile de dire que l’IA n’est pas corruptible.
Auteur : Oui c’est sûr ! Volontairement ou involontairement, on peut changer les prédictions, mais une fois entrainé, ça semble plus compliqué. J’ai entendu dire que pour les IA du quotidien, une validation par des laboratoires indépendants serait obligatoire pour limiter les biais. A voir !
En résumé, la corruption d’une IA est un sujet complexe à débattre car il implique une dimension technique liée au système IA en lui-même et ses propres caractéristiques (celle-ci sont-elles corruptibles?) et une dimension humaine liée aux intentions des personnes impliqués dans la conception, la conception et le déploiement de cette IA. Sans apporter de réponses, cet échange met en lumière la complexité d’un tel sujet pour la réflexion citoyenne.
L’IA à la tête d’un pays : les arguments contre
Malgré les avantages potentiels d’une IA à la tête d’un pays, il existe de sérieux défis et préoccupations qui doivent être pris en compte. Voici quelques-uns des principaux arguments contre cette idée.
Manque d’empathie et de compréhension humaine : L’une des principales critiques de l’IA en tant que chef d’État est qu’elle manque d’empathie et de compréhension humaine. Les décisions politiques ne sont pas toujours basées sur des données ou des faits objectifs ; elles nécessitent souvent une compréhension nuancée des valeurs, des émotions et des expériences humaines. Une IA pourrait avoir du mal à comprendre et à prendre en compte ces facteurs dans sa prise de décision.
Responsabilité : Un autre défi majeur est la question de la responsabilité. Si une IA prend une décision qui a des conséquences négatives, qui est tenu responsable ? L’IA elle-même ne peut pas être tenue responsable, car elle n’a pas de conscience ou de volonté propre. Cela pourrait créer un vide de responsabilité qui pourrait être exploité.
Risques de sécurité : L’IA à la tête d’un pays pourrait également poser des risques de sécurité. Par exemple, elle pourrait être vulnérable au piratage ou à la manipulation par des acteurs malveillants. De plus, si l’IA est basée sur l’apprentissage automatique, elle pourrait développer des comportements imprévus ou indésirables en fonction des données sur lesquelles elle est formée.
Inégalités : Enfin, l’IA pourrait exacerber les inégalités existantes. Par exemple, si l’IA est formée sur des données biaisées, elle pourrait prendre des décisions qui favorisent certains groupes au détriment d’autres. De plus, l’IA pourrait être utilisée pour automatiser des emplois, ce qui pourrait avoir des conséquences négatives pour les travailleurs.
Ces défis et préoccupations soulignent que, bien que l’IA ait le potentiel d’améliorer la gouvernance, son utilisation en tant que chef d’État doit être soigneusement considérée et réglementée. Dans la section suivante, nous examinerons les points de vue de différents experts sur cette question.
Points de vue des experts : une IA à la tête d’un pays est-elle possible ?
La question de savoir si une IA pourrait un jour diriger un pays suscite un débat animé parmi les experts. Certains sont optimistes quant à la possibilité, tandis que d’autres sont plus sceptiques.
Les optimistes : Certains experts en technologie et en politique croient que l’IA pourrait un jour être capable de diriger un pays. Ils soulignent que l’IA a déjà prouvé sa capacité à résoudre des problèmes complexes et à prendre des décisions basées sur des données. Ils suggèrent que, avec des avancées supplémentaires en matière d’IA, il pourrait être possible de créer une IA qui comprend les nuances humaines et qui est capable de prendre des décisions politiques éclairées.
Les sceptiques : D’autres experts sont plus sceptiques. Ils soulignent que l’IA actuelle est loin d’être capable de comprendre et de gérer la complexité et l’incertitude inhérentes à la gouvernance d’un pays. Ils mettent également en garde contre les risques potentiels associés à l’IA en politique, tels que de responsabilité, les risques de sécurité et les inégalités.
Les pragmatiques : Enfin, il y a ceux qui adoptent une approche plus pragmatique. Ils suggèrent que, plutôt que de remplacer les dirigeants humains par des IA, nous devrions chercher à utiliser l’IA pour soutenir et améliorer la prise de décision humaine. Par exemple, l’IA pourrait être utilisée pour analyser des données politiques, économiques et sociales, pour prédire les conséquences des politiques proposées, et pour aider à identifier et à résoudre les problèmes politiques.
En fin de compte, la question de savoir si une IA pourrait un jour diriger un pays reste ouverte. Ce qui est clair, cependant, c’est que l’IA a le potentiel de transformer la politique de manière significative. À mesure que la technologie continue de progresser, il sera essentiel de continuer à débattre de ces questions et de réfléchir attentivement à la manière dont nous pouvons utiliser l’IA de manière éthique et efficace en politique.
Conclusion : Vers un futur gouverné par l’IA ?
L’idée d’une intelligence artificielle à la tête d’un pays est fascinante et controversée. Elle soulève des questions importantes sur l’avenir de la gouvernance, de la démocratie et de la société en général. Alors que l’IA continue de se développer et de s’intégrer dans de nombreux aspects de notre vie quotidienne, il est essentiel de réfléchir à la manière dont elle pourrait être utilisée – ou mal utilisée – dans le domaine de la politique.
Il est clair que l’IA a le potentiel d’améliorer la prise de décision politique, en rendant le processus plus efficace, plus transparent et plus informé par les données. Cependant, il est également évident que l’IA présente des défis et des risques importants, notamment en termes de responsabilité, de sécurité et d’équité.
Alors, une IA à la tête d’un pays est-elle science-fiction ou réalité future ? À l’heure actuelle, il semble que la réponse soit quelque part entre les deux. Bien que nous soyons encore loin d’avoir une IA en tant que chef d’État, l’IA joue déjà un rôle de plus en plus important dans la politique. À mesure que cette tendance se poursuit, il sera essentiel de continuer à débattre de ces questions et de veiller à ce que l’utilisation de l’IA en politique soit réglementée de manière à protéger les intérêts de tous les citoyens.
En fin de compte, l’avenir de l’IA en politique dépendra non seulement des progrès technologiques, mais aussi des choix que nous faisons en tant que société. Il est donc crucial que nous continuions à nous engager dans des discussions ouvertes et éclairées sur ces questions, afin de façonner un avenir dans lequel l’IA est utilisée pour améliorer la gouvernance et le bien-être de tous.
Références et lectures complémentaires
Pour ceux qui souhaitent approfondir le sujet, voici les références :
Pour ceux qui souhaitent approfondir le sujet, voici une de lectures complémentaires :
« The Politics of Artificial Intelligence » par Nick Bostrom. Ce livre explore en profondeur les implications politiques de l’IA, y compris la possibilité d’une IA à la tête d’un pays.
« AI Superpowers: China, Silicon Valley, and the New World Order » par Kai-Fu Lee. Cet ouvrage examine la montée de l’IA en Chine et aux États-Unis, et comment cela pourrait remodeler l’équilibre mondial du pouvoir.
« The Ethics of Artificial Intelligence » par Vincent C. Müller et Nick Bostrom. Cet article examine les questions éthiques soulevées par l’IA, y compris dans le contexte de la gouvernance.
« Artificial Intelligence The Revolution Hasn’t Happened Yet » par Michael Jordan. Cet article offre une perspective sceptique sur l’IA en politique, mettant en garde contre l’excès d’optimisme.
« The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation » par Brundage et al. Ce rapport explore les risques de sécurité associés à l’IA, y compris dans le contexte de la politique.
Ces ressources offrent une variété de perspectives sur l’IA en politique et peuvent aider à éclairer le débat sur la possibilité d’une IA à la tête d’un pays. Comme toujours, il est important de garder à l’esprit que l’IA est un outil, et que son utilisation en politique dépendra des choix que nous faisons en tant que société.
Petit mot sur l’autrice : Servane Mouton est docteure en médecine, neurologue et neurophysiologiste, spécialisée en psychopathologie des apprentissages et titulaire d’un master 2 en neurosciences. Elle s’intéresse particulièrement au neuro-développement normal et à ses troubles ainsi qu’aux liens entre santé et environnement. Ceci est le second article traitant du sujet NTIC et menaces sur la santé, le premier étant au lien disponible ici. Elle aborde pour nous le sujet des choix économiques et politiques intervenant dans ces sujets et leur impact sur la santé en lien avec les NTIC. Ikram Chraibi Kaadoud, Thierry Viéville.
Le déploiement d’internet dans les années 1990, l’arrivée des smartphones en 2007 et plus récemment, les confinements successifs liés à la pandémie COVID 19 en 2020, se sont accompagnés d’une véritable explosion des temps d’écran et ce dès le plus jeune âge. Pour accompagner ce changement d’usage, des recommandations ont été mises en place, mais ne semblent pas suffisantes car déjà remises en question: elles ne tiendraient pas compte de tous les enjeux en présence, à savoir d’ordre sanitaire pour l’espèce humaine, mais aussi environnemental, et, finalement, sociétal.
Sigle désignant « Nouvelles technologies de l’information et de la communication » qui regroupe l’« ensemble des techniques et des équipements informatiques permettant de communiquer à distance par voie électronique » (Dictionnaire Larousse). Les NTIC permettent à leurs utilisateurs d’accéder aux sources d’information, de les stocker, voire de les transmettre à d’autres utilisateurs dans un délai très court.
Figure 1 – Proposition d’actions pour la régulation de l’usage des NTIC
Une attention manipulée
Revenons aux usages actuels : comment sommes-nous arrivés à de tels excès ? En grande partie à cause de l’essor non réglementé de l’économie de l’attention. Les industriels du secteur, réseaux sociaux, jeux vidéo et autres activités récréatives et/ou commerciales en ligne, cherchent à augmenter le temps de connexion afin notamment de recueillir le plus possible de données de navigation qui seront ensuite sources de profits. La conception des algorithmes repose sur une connaissance fine du fonctionnement cérébral, ce qui rend (quasiment) irrésistibles les contenus de ces plateformes proposés « gratuitement ». La stimulation du système de récompense par la nouveauté ou les gratifications, les effets de « simple exposition » et de « dotation », la pression sociale, la « Fear Of Missing Out », sont des leviers parmi d’autres pour capter et maintenir captive notre attention. On ne parle officiellement d’addiction que pour les jeux vidéo en ligne et les jeux d’argent, les termes « addictif-like », usages « abusifs » ou « compulsifs » sont employés pour les autres produits1.
Somme toute, il nous semble que l’histoire du tabac se répète : des produits addictifs ou addictifs-like sont mis à disposition de tous y compris des mineurs, et leur usage a des effets délétères multiples et avérés sur la santé à court, moyen et long terme. Avec les NTIC, les dégâts sont cependant bien plus diffus. Et les parties prenantes bien plus nombreuses.
Il y a bien entendu les GAFAM et autres acteurs du secteur. A ce titre, la numérisation croissante de l’enseignement, dès la maternelle, est une aubaine : outre l’immense marché représenté par les établissements scolaires, les habitudes prises dans l’enfance ont une forte chance/un haut risque de perdurer. L’écran fera ainsi partie intégrante de l’environnement de l’individu.
Mais toutes les industries reposant sur la consommation (cf ci-dessus) : agro-alimentaire, alcool, cigarettes e-ou classiques, textiles, jeux et jouets, etc. ont aussi intérêt à laisser libre cours à l’invasion numérique. Les achats/ventes en ligne, les publicités officielles ou déguisées, ciblées grâce à l’analyse des données de navigation, permettent au marketing d’être redoutablement efficace.
Quelques propositions
Estimation des coûts des NTIC pour la santé publique
Il serait intéressant, nécessaire même, d’évaluer les coûts en terme de santé des usages numériques. La souffrance n’a pas de prix…Mais il est sans doute possible d’estimer la part de responsabilité des NTIC dans les dépenses pour les consultations et traitements en orthophonie, en psychomotricité, en psychiatrie, en ophtalmologie, ou pour les maladies métaboliques et cardiovasculaires, les troubles du sommeil et ses conséquences multiples.
Législation efficace quant de l’économie de l’attention, sécurisation de la navigation sur internet.
L’économie de l’attention devrait être efficacement régulée, au vu des conséquences délétères multiples sur le plan sanitaire d’un usage excessif/abusif qu’elle favorise.
Une législation similaire à celle ayant cours pour la recherche biomédicale devrait s’appliquer à la recherche-développement (RD) de ces produits, considérant qu’il s’agit de recherche impliquant des sujets humains, et de produits dont l’usage affecte leur santé eu sens large. On pourrait s’inspirer du Code de la Santé Publique, définissant par l’article L 1123-7 le Comité de Protection des Personnes (CPP) comme chargé « d’émettre un avis préalable sur les conditions de validité de toute recherche impliquant la personne humaine, au regard des critères définis.
Il faudrait exiger la transparence du secteur des NTIC, rendant les données de navigation ainsi que les dossiers de RD de produits impliquant la captation de l’attention accessibles aux chercheurs indépendants et institutionnels.
Protection des mineurs
Sur internet, le code de la sécurité intérieure ne traite pas la question de la protection des mineurs sous l’angle de la prévention contre l’addiction, mais uniquement contre l’exposition à la pornographie, à la violence et à l’usage de drogues (article L. 321-10). Or les adolescents jouent massivement en ligne : 96% des 10-17 ans sont des joueurs, et ils représentent 60 % des joueurs en ligne français. Dans cette même classe d’âge, 70 % utilisent les réseaux sociaux. Ceci représente une exception dans le domaine de l’addiction. Pour mémoire, on estime que la seule industrie du jeu vidéo pesait 300 milliards de dollars en 2021…
La navigation sur internet devrait être sécurisée : une ambitieuse proposition de loi est en cours d’examen au Sénat, concernant l’accès aux contenus pornographiques, les contenus pédopornographiques, le cyberharcèlement, l’incitation à la haine en ligne, la désinformation, les arnaques en ligne, les jeux à objets numériques monétisables. Elle inclut aussi l’interdiction de publicités ciblées pour les mineurs sur les plateformes. Espérons qu’une fois cette loi votée, les obstacles techniques robustes seront surmontés, rapidement.
Une loi vient d’être promulguée, établissant la majorité numérique à 15 ans pour les réseaux sociaux. Ceci est un témoin de la prise de conscience des enjeux, et nous espérons qu’elle sera mise en application de façon efficiente, malgré les obstacles techniques considérables. Malgré tout, elle nous parait insuffisante : qu’en est-il des 15-18 ans ? Qu’en est-il des des jeux vidéo en ligne, dont le caractère addictif potentiel est pourtant lui reconnu par l’OMS ?
Témoin de l’intensité du lobbying de l’industrie agro-alimentaire, et des enjeux économiques sous-jacents, soulignons ainsi un détail qui n’en est pas dans une autreloi promulguée le 9 Juin dernier, portant sur les influenceurs des réseaux sociaux. Cette dernière va ainsi encadrer la promotion faite par ces derniers : ils n’auront plus le droit de vanter les boissons alcoolisées, le tabac, les e-cigarettes. Un amendement avait été apporté après la première lecture au Sénat, afin d’ajouter dans cette liste les aliments trop sucrés, salés, gras ou édulcorés, la publicité par les influenceurs étant particulièrement persuasive en particulier pour les plus jeunes. Les auteurs de l’amendement s’appuyaient d’une part sur une expertise collective de l’Inserm de 2017 concluant que les messages sanitaires (« manger, bouger » par exemple, note de l’auteur) ont une faible portée sur le changement des comportements alimentaires ; d’autre part sur le fait que de nombreux experts de santé publique, à commencer par l’OMS et Santé Publique France, ont démontré que l’autorégulation de l’industrie agroalimentaire sur laquelle s’appuie la France (tels qu’un engagement volontaire en faveur de « bonnes pratiques ») est inefficace.
Mais cet amendement a lui-même été amendé, laissant libre cours à cette publicité, comme sur les autres médias… Comme maintes fois auparavant, les tentatives pour préserver les moins de 18 ans de l’influence de ces publicités ont été écartées. Elles seront donc simplement assujetties aux mêmes règles que sur les autres supports, comme être accompagnées de messages promouvant la santé (manger-bouger, etc).
L’argument, pourtant souligné par les auteurs de l’amendement : « Le coût global (en France) d’un régime alimentaire néfaste sur le plan diététique dépasse les 50 milliards d’euros par an, celui du diabète de type 2 représentant à lui seul 19 milliards d’euros. » n’a pas suffi…
Globalement, la collecte des données de navigation des mineurs, qu’elles soient exploitées immédiatement ou lors de leur majorité (numérique ou civile) nous parait poser problème. Et que l’âge même de la majorité diffère dans les vies civile ou numérique (pour les données de navigation selon le Réglement Général de Protection des données (RGPD) et maintenant en France pour l’accès aux réseaux sociaux, cette majorité numérique est à 15 ans) nécessiterait des éclaircissements au vu des enjeux précédemment exposés (et de de ceux que nous n’avons pu détailler).
Il nous semble que tant qu’une législation vis-à-vis des pratiques des industriels n’est pas efficiente pour protéger les usagers de ces risques, la vente et l’usage de smartphone et autres outils mobiles à ou pour les mineurs devrait être remise en question, de même que leur accès aux plateformes de réseaux sociaux et de jeux vidéo en ligne.
L’épineuse question de l’enseignement
En 2022, le Conseil Supérieur des Programmes du Ministère de l’Education Nationale, de la Jeunesse et des Sports soulignait les disparités de valeur ajoutée de l’usage des outils numériques dans l’enseignement selon les matières, les enseignants, le profil des élèves aussi. Il recommandait notamment 2 : « avant l’âge de six ans, ne pas exposer les enfants aux écrans et d’une manière générale à l’environnement numérique ; de six à dix ans, à l’école, privilégier l’accès aux ressources offertes par le livre, le manuel scolaire imprimé. » Pourtant, l’état français soutient encore financièrement et encourage fortement la numérisation des établissements scolaires dès l’école primaire, et même, en maternelle. Tandis que la Suède a fait cette année marche arrière sur ce plan-là, attribuant études à l’appui la baisse des résultats de leurs élèves (que l’on observe également en France) à la numérisation extensive de l’enseignement effectuée au cours des dernières années, et préconisant le retour aux manuels scolaires papier. Considérant en outre les arguments sanitaires cités précédemment et l’impact environnemental avéré des NTIC, leur usage par les élèves et leur déploiement dans les écoles, collèges et lycées devrait être réellement et mieux réfléchi. Par ailleurs, les smartphones devraient être exclus de l’enceinte des établissements scolaires, afin d’offrir un espace de déconnexion et d’éviter de favoriser les troubles attentionnels induits par leur seule présence, même lorsqu’ils sont éteints.
Campagne d’information à grande échelle
Les enjeux sont tels qu’une information de l’ensemble de la population apparait urgente et nécessaire, sur le modèle « choc », par exemple, de la prévention de la consommation d’alcool. Le sujet devrait être abordé dès le début de grossesse, cette période étant généralement celle où les futurs parents sont les plus réceptifs et les plus enclins à remettre en cause leurs pratiques pour le bien de l’enfant à venir. La formation des soignants, professionnels de l’enfance, et des enseignants est indispensable, devant s’appuyer sur les données les plus récentes de la littérature scientifique.
Protection des générations futures
L’étendard de la croissance est systématiquement brandi lorsque l’on incite à reconsidérer la pertinence du déploiement du numérique. Mais il est aujourd’hui reconnu largement qu’une croissance infinie n’est ni raisonnable ni souhaitable dans notre écosystème fini.
Or les NTIC sont tout sauf immatérielles. Leurs impacts environnementaux sont directs et indirects 3,4. Les premiers sont essentiellement dus à la phase de fabrication des terminaux : extraction des matières premières associée à une pollution colossale des sites dans des pays où la législation est quelque peu laxiste (Afrique, Chine, Amérique du Sud notamment) et des conséquences dramatiques en particulier pour les populations voisines et les travailleurs locaux (conditions de travail déplorables, travail des enfants), acheminement des matériaux. Mais aussi à leur fonctionnement et au stockage des données, au recyclage insuffisant (pollution eau/sol/air, consommation d’eau et d’énergie). Les seconds sont consécutifs au rôle central des NTIC dans la « grande accélération », avec encouragement des tendances consuméristes. Ils sont plus difficilement estimables et probablement les plus problématiques.
Il est entendu que la santé humaine est étroitement liée à la qualité de son environnement, et que l’altération de celui-ci la compromet, comme elle compromet tout l’écosystème.
Certes la médecin a progressé considérablement, notamment parallèlement aux innovations technologiques s’appuyant sur le numérique. Mais, nous avons au moins le droit de poser la question : ne vaut-il pas mieux œuvrer à améliorer notre hygiène de vie (sédentarité, activité physique, alimentation) et notre environnement (pollution atmosphérique, perturbateurs endocriniens) pour entretenir notre santé cardiovasculaire, que développer des instruments sophistiqués permettant d’explorer et de déboucher une artère, à grand coût économique et environnemental ? Instruments qui ne bénéficieront qu’à une minime fraction de la population mondiale, celle des pays riches ou aux classes aisées des pays qui le sont moins. Et le coût environnemental est justement assumé majoritairement par les pays les plus pauvres, dont sont issus les matières premières et où ont lieu le « recyclage » et le « traitement » des déchets.
En résumé
Les innovations portées par les NTIC ont un fort potentiel de séduction voire de fascination. Ne pas rejoindre sans réserve la révolution numérique ferait-il de nous des technophobes réfractaires au progrès ? Et si au contraire il était temps de prendre conscience des dangers et écueils liés à un déploiement extensif et non réfléchi de ces technologies ?
Références bibliographiques
Montag C, Lachmann B, Herrlich M, Zweig K. Addictive Features of Social Media/Messenger Platforms and Freemium Games against the Background of Psychological and Economic Theories.International Journal of Environmental Research and Public Health. 2019 Jul 23;16(14):2612.
Avis sur la contribution du numérique à la transmission des savoirs et à l’amélioration des pratiques pédagogiques – juin 2022. Conseil Supérieur des Programmes, Ministère de l’Education Nationale, de la Jeunesse et des Sports
Impacts écologiques des Technologies de l’Information et de la Communication – Les faces cachées de l’immatérialité. Groupe EcoInfo, Françoise Berthoud. EDP Sciences. 2012.
Petit mot sur l’autrice : Servane Mouton est docteure en médecine, neurologue et neurophysiologiste, spécialisée en psychopathologie des apprentissages et titulaire d’un master 2 en neurosciences. Elle s’intéresse particulièrement au neuro-développement normal et à ses troubles ainsi qu’aux liens entre santé et environnement. Elle nous partage dans ce billet une analyse sur l’impact des NTIC sur la santé physique des enfants au travers de trois aspects des enjeux de santé individuelle et publique à court, moyen et long terme : la sédentarité, le sommeil, et la vision. Ikram Chraibi Kaadoud, Thierry Viéville.
Le déploiement d’internet dans les années 1990, l’arrivée des smartphones en 2007 et plus récemment, les confinements successifs liés à la pandémie COVID 19 en 2020, se sont accompagnés d’une véritable explosion des temps d’écran et ce dès le plus jeune âge. Car à côté de la numérisation croissante de tous les secteurs d’activité – à savoir en santé, éducation, mais aussi agriculture, transports, journalisme, etc – les populations des pays connectés font surtout massivement usage des écrans pour leur divertissement.
NTIC :
Sigle désignant « Nouvelles technologies de l’information et de la communication » qui regroupe l’« ensemble des techniques et des équipements informatiques permettant de communiquer à distance par voie électronique » (Dictionnaire Larousse). Les NTIC permettent à leurs utilisateurs d’accéder aux sources d’information, de les stocker, voire de les transmettre à d’autres utilisateurs dans un délai très court.
Le tableau 1 ci dessous présente les recommandations actuelles de temps d’écran, qui sont discutables et les usages tels qu’ils sont observés aujourd’hui. Force est de constater que l’écart est considérable. Ces recommandations devraient être remises en question, car elles ne tiennent à notre sens pas compte de tous les enjeux en présence. Ceux-ci sont d’ordre sanitaire pour l’espèce humaine, mais aussi environnemental, et, finalement, sociétal.
Nous vous proposons de nous attarder sur trois aspects des enjeux de santé individuelle et publique à court, moyen et long terme : la sédentarité, le sommeil, et la vision. Les conséquences neuro-développementales et socio-relationnelles de l’usage des écrans par les parents en présence de l’enfant, ou par l’enfant et l’adolescent lui-même, nécessiteraient un billet dédié.
TABLEAU 1 – Temps d’écran par appareil et global en fonction de l’âge en France, Recommandations. Etude IPSOS pour l’Observatoire de la Parentalité et de l’Education au Numérique et l’Union Nationale des Familles 2022. * Anses. 2017. Etude individuelle nationale des consommations alimentaires 3 (INCA 3).** Reid Chassiakos YL, Radesky J, Christakis D, Moreno MA, Cross C; COUNCIL ON COMMUNICATIONS AND MEDIA. Children and Adolescents and Digital Media. Pediatrics. 2016 Nov;138(5).*** L’OMS publie les premières lignes directrices sur les interventions de santé numérique. Communiqué de presse. Avril 2019. https://www.who.int/fr/news/item/17-04-2019-who-releases-first-guideline-on-digital-health-interventions
Sédentarité, troubles métaboliques et santé cardiovasculaire (Figure 1)
Figure 1 – Liens entre usage des écrans, maladies métaboliques et cardiovasculaires
Le temps passé assis devant un écran pour les loisirs est depuis une quarantaine d’années l’indicateur le plus utilisé dans les études pour évaluer la sédentarité chez les personnes mineures. Pour les adultes, on utilise souvent des questionnaires tels leRecent Physical Activity Questionaire, explorant toutes les activités sédentaires (temps passé devant les écrans, mais aussi dans les transports, au travail etc.)
Or la sédentarité est un facteur de risque cardio-vasculaire indépendant, qui elle-même favorise le développement des autres facteurs de risque que sont le surpoids voire l’obésité et le diabète de type2. Notons que la sédentarité augmente la mortalité toutes causes confondues, ceci n’étant pas entièrement compensé par la pratique d’une activité physique modérée à intense.
L’Organisation Mondiale de la Santé (OMS) recommande aujourd’hui de ne pas exposer les enfants aux écrans avant deux ans2, puis une heure quotidienne maximum jusqu’à 5 ans (mais moins, c’est mieux « less is better »!). Au-delà et jusqu’à jusqu’ à 17 ans, les activités sédentaires ne devraient pas excéder 2 heures chaque jour. Pour cette tranche d’âge, l’Académie de Pédiatrie Américaine (AAP) fixe à 1h30 le seuil de sécurité, des effets délétères étant déjà significatifs dès 2h/j3.
Les Français de plus de 11 ans passent 60% de leur temps libre devant un écran. L’âge moyen d’obtention du premier téléphone est 9 ans.
Alors qu’en France l’exposition aux écrans est déconseillée pour les moins de 3 ans, une étude IPSOS-UNAF publiée en 20224 estimait le temps moyen passé devant la télévision à 1h22 et celui devant un smartphone à 45 minutes chaque jour dans cette tranche d’âge. Cette enquête ne fournissant pas les temps d’écrans globaux quotidiens, voici des chiffres publiés dans un rapport de l’ANSES (Agence Nationale de la Sécurité Sanitaire de l’Alimentation, de l’Environnement et du travail) en 20175, qui sous-évaluent très certainement les pratiques actuelles « post-COVID 19 » : le temps d’écran moyen était d’environ 2 heures chez les 3-6 ans, 2h30 chez les 7-11 ans, 3h30 chez les 11-15 ans, quasiment 5 heures chez les 15-17 ans, idem chez les adultes. Les deux tiers des 7-10 ans et la moitié des 11-14 ans y consacraient plus de 3 heures par jour, un quart des 15-17 ans plus de 7 heures et seulement un tiers moins de 3 heures. Plus le niveau socio-éducatif des parents est élevé, moins l’enfant est exposé aux écrans.
Les adultes passent eux environ 5 heures devant un écran chaque jour en dehors du travail, 84% d’entre eux sont considérés comme sédentaires.
Ceci a conduit les auteurs des rapports publiés en 20166 et 20207 par l’ANSES (Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail) à conclure, parlant de la sédentarité et de l’activité physique chez les moins de 18 ans : « il n’est pas fréquent, dans les résultats des expertises en évaluation de risques de l’agence, que près de la moitié de la population est considérée comme présentant un risque sanitaire élevé ».
Mais les outils numériques sont aussi le support de choix pour la publicité, notamment pour les aliments à haute teneur en graisse, sucre et sel, dont la consommation favorise hypertension artérielle, diabète, surpoids et obésité, hypercholestérolémie, tous étant des facteurs de risque cardio-vasculaires8. On y rencontre aussi la promotion de boissons alcoolisées9, du tabacet des e-cigarettes10, que les publicités soient officielles ou que ces produits soient valorisés dans les films, les séries, ou par les influenceurs. L’analyse des données de navigation permet de présenter des publicités d’autant plus efficaces qu’elles sont ciblées. La puissance de tels algorithmes est bien reconnue11.
L’usage des écrans tel qu’il est observé aujourd’hui favorise donc la survenue de maladies cardio-vasculaires. Rappelons que les maladies cardiovasculaires sont actuellement la première cause de mortalité dans le monde selon l’OMS et que leur prévalence ne cesse d’augmenter12. En France, elles sont responsables de 140.000 décès par an, et 15 millions de personnes sont soignées pour un problème de santé cardio-vasculaire (c’est-à-dire un facteur de risque ou une maladie vasculaire). Les Accidents Vasculaires Cérébraux (AVC) et les maladies coronariennes, dont l’infarctus du myocarde sont les plus fréquentes. En France, toujours, une personne est victime d’un AVC toutes les 4 minutes, soit près de 120.000 hospitalisations par an, auxquelles s’ajoutent plus de 30.000 hospitalisations pour accident ischémique transitoire (AIT). Les AVC sont la deuxième cause de mortalité après les cancers, ils sont ainsi responsables de près de 40.000 décès par an en France. Ils sont aussi la première cause de handicap acquis chez l’adulte, et la deuxième cause de démence (après la maladie d’Alzheimer). Concernant les maladies coronariennes, environ 80 000 personnes présentent un infarctus du myocarde en France chaque année, 8.000 en décèdent dans l’heure, 4. 000 dans l’année qui suit13.
Outre les troubles métaboliques précédemment décrits (comportements sédentaires augmentant ainsi le risque d’obésité et des désordres métaboliques liés, et par conséquent le risque de maladies cardio-vasculaires à moyen et long terme), l’exposition prolongée aux écrans est depuis peu suspecte de modifier le tempo pubertaire (favorisant les avances pubertaires) 14.
Sommeil
Le sommeil n’est pas seulement un temps de repos mais un temps où les hormones et le métabolisme se régénèrent. Or l’usage excessif des écrans peut contribuer à la réduction du temps de sommeil ou à une altération de sa qualité, à tout âge d’autant plus que cet usage est prolongé, a lieu à un horaire tardif et/ou dans l’heure précédent l’endormissement théorique (soirée, nuit), que l’écran est placé à proximité immédiate des yeux et que les contenus sont stimulants. La présence d’un écran dans la chambre est associée à une altération quantitative et qualitative du sommeil. Ceci est particulièrement préoccupant chez les moins de 18 ans car les habitudes de sommeil s’installent dans l’enfance et une mauvaise hygiène sur ce plan est particulièrement susceptible de s’inscrire dans la durée.
Les problèmes de santé favorisés par la dette chronique de sommeil sont multiples15 : troubles métaboliques tels que le surpoids ou l’obésité, le diabète, les maladies cardiovasculaires16 ; troubles de l’humeur et certaines maladies psychiatriques comme la dépression17 ; troubles cognitifs avec diminution des performances en termes de mémorisation, d’apprentissage et de vitesse d’exécution notamment ; développement de maladies neuro-dégénératives telles que la maladie d’Alzheimer, possiblement via des mécanismes inflammatoires neuro-toxiques18 ; augmentation du risque accidentogène (accident de la vie courante, accident du travail), en particulier accidents de la circulation19 ; infections 20; certains cancers, tel le cancer du sein21. De façon générale, la privation de sommeil chronique augmente le risque de mortalité22.
Selon une enquête de l’Institut National de la Vigilance et du Sommeil (INVS) en 202223, 40% des enfants de moins de onze ans (60% des 6-11 ans) regardent un écran dans l’heure précédant l’endormissement. Pour 7% d’entre eux, il s’agit même du rituel accompagnant le coucher. Un enfant de moins de onze ans sur dix s’endort dans une pièce où un écran est allumé.
Le même INVS établissait en 202024 que les adolescents français dorment en moyenne 7 h 45, dont moins de 7 h par nuit en semaine, au lieu des 8,5 à 9h de sommeil recommandées par la National Sleep Fondation. Seize pour cent des enfants de onze ans et 40 % de ceux de quinze ans ont un déficit de plus de 2h de sommeil par jour en semaine. Dès 11 ans, ils sont 25% à être équipés d’un téléviseur et 40% d’un ordinateur dans leur chambre, cette proportion passant à 1/2 et 2/3 respectivement pour les 15-18 ans.
Une autre étude française réalisée chez 776 collégiens25 révèle que la plupart des adolescents utilisent leurs écrans pendant la nuit ce qui impacte la durée et la qualité de sommeil. Ces activités peuvent être initiées lorsqu’ils se réveillent spontanément pendant la nuit (73,9%) ; mais 26% de ces adolescents, programment un réveil en cours de nuit.
La durée moyenne du sommeil chez les adultes de 18 à 65 ans est passée de 7h05 en semaine et 8h11 le week-end en 2016, à 6h41 en semaine et 7h51 le week-end en 2020. Le temps recommandé par la NSF est compris entre 7 à 9h. En 2022, 60% des adultes regardent un écran dans l’heure précédant l’endormissement (versus 38% en 2016 et 45% en 2020) et pour 23% d’entre eux, le temps d’exposition moyen est de plus d’une heure et demie.
En 2016, selon l’enquête de l’INVS26, 20% des personnes interrogées gardent leur téléphone en fonctionnement pendant la nuit. Cinquante pour cent d’entre elles, soit 10% des personnes interrogées sont réveillées par des messages ou notifications. Parmi elles, 92 % les consultent, 79 % y répondent immédiatement. En 2020, ce sont près du double de personnes (16 %) interrogées qui sont réveillées la nuit par des alertes.
Selon le rapport de l’INVS de 2020 : « Pierre angulaire des difficultés de sommeil des enfants et des adolescents, les écrans sont aujourd’hui au premier plan des préoccupations des spécialistes ».
Vision
L’ANSES s’est penché sur la question des impacts de l’éclairage LED sur la santé et l’environnement, publiant un rapport édifiant en 201927. Parmi les impacts négatifs, l’usage des écrans peut ainsi compromettre le système visuel en favorisant l’apparition d’une myopie. Ceci est lié à la surutilisation de la vision de près au détriment de la vision de loin, mais surtout à l’exposition à un éclairage artificiel au détriment de celui à un éclairage naturel. Les écrans sont en effet utilisés à l’intérieur, éventuellement sous un éclairage artificiel, et sont eux-mêmes une source supplémentaire d’exposition à un tel éclairage (le caractère riche en bleu de la lumière artificielle serait un élément clé dans cet effet néfaste). Le temps passé par les enfants devant les écrans pour leurs loisirs est donc hautement préoccupant, car il se fait au détriment d’activités en plein air, auxquelles ils devraient s’adonner au minimum 2 heures chaque jour du point de vue ophtalmologique (selon le Baromètre de la myopie en France, 2022, seulement 36% des parents déclarent que leur enfant remplit cette exigence13). Aujourd’hui, une personne sur trois présente une myopie dans le monde, cela pourrait être une sur deux en 2050.
De plus, cette lumière riche en bleu et pauvre en rouge a un effet phototoxique sur la rétine28. L’exposition aux sources lumineuses riches en lumière bleue telles les éclairages artificiels et les écrans a lieu le jour, mais surtout la nuit, moment où la rétine est plus sensible à cette phototoxicité.
Aucune donnée n’est disponible quant aux effets à long terme d’une exposition répétée/chronique à ce type d’éclairage.
L’utilisation intensive des écrans par la population jeune est préoccupante, car leur système visuel est moins protégé (transparence plus grande de leur cristallin laissant passer plus la lumière bleue que celui des adultes) et en développement, ce qui accroit largement ces risques.
L’usage croissant des écrans dans le cadre scolaire participe à cette majoration du niveau d’exposition.
Autres problématiques
Citons en vrac, et sans prétendre à l’exhaustivité : la perturbation du développement cognitif, émotionnel et socio-relationnel induit par l’usage des écrans par les parents en présence de l’enfant29, les mêmes troubles favorisés par l’exposition des enfants et adolescents aux écrans (rappelons que le cerveau mature jusqu’à 25 ans) 30, l’exposition aux contenus inappropriés (violence31, pornographie32), le cyber-harcèlement33, les défis sordides, l’hypersexualisation, la dysmorphie induite par les réseaux sociaux, la facilitation de la prostitution infantile (qui va croissante depuis plusieurs années) 34.
Mais aussi l’enrichissement du « cocktail » de perturbateurs endocriniens auxquels les usagers sont exposés, certains composants des outils informatiques et numériques appartenant à cette catégorie (notamment les retardateurs de flamme bromés, très volatiles et les PFAS), ceci étant particulièrement problématique chez les jeunes enfants, les adolescents et les femmes enceintes ; et l’exposition aux rayonnements radiofréquences au sujet de laquelle des scientifiques du monde entier ont appelé en 2017 à appliquer le principe de précaution, arguant de l’absence d’étude d’impact préalable au déploiement de cette technologie (en vain) 35.
En résumé …
… les impacts des NTIC sur la sédentarité, le sommeil, et la vision et plus globalement sur le développement cognitif, psychologique et socio-relationnel, ne sont pas encore précisément estimés. Cependant, ils apparaissent déjà hautement préoccupants. Face a ce constat, une question se pose : Quelles sont les actions possibles à mettre en place pour y pallier ?
Servane nous en parle dans la suite de ce billet à venir !
Références bibliographiques
Humanité et numérique : les liaisons dangereuses. Livre collaboratif coordonné par le Dr Servane Mouton, Editions Apogée, Avril 2023.
Reid Chassiakos YL, Radesky J, Christakis D, Moreno MA, Cross C; COUNCIL ON COMMUNICATIONS AND MEDIA. Children and Adolescents and Digital Media. Pediatrics. 2016 Nov;138(5)
ANSES. Actualisation des repères du PNNS – Révisions des repères relatifs à l’activité physique et à la sédentarité. 2016.NUT2012SA0155Ra.pdf (anses.fr)
Catherine M. Mc Carthy, Ralph de Vries, Joreintje D. Mackenbach. The influence of unhealthy food and beverage marketing through social media and advergaming on diet-related outcomes in children—A systematic review. Obesity Reviews. 2022 Jun; 23(6): e13441 ; https://www.who.int/fr/news-room/factsheets/detail/children-new-threats-to-health; Alruwaily A, Mangold C, Greene T, Arshonsky J, Cassidy O, Pomeranz JL, Bragg M. Child Social Media Influencers and Unhealthy Food Product Placement. Pediatrics. 2020 Nov;146(5):e20194057.
Barker AB, Smith J, Hunter A, Britton J, Murray RL. Quantifying tobacco and alcohol imagery in Neƞlix and Amazon Prime instant video original programming accessed from the UK: a content analysis. British Medical Journal Open. 2019 Feb 13;9(2):e025807 ; Jackson KM, Janssen T, Barnett NP, Rogers ML, Hayes KL, Sargent J. Exposure to Alcohol Content in Movies and Initiation of Early Drinking Milestones. Alcohol: Clinical and Experimental Research. 2018 Jan;42(1):184-194. doi: 10.1111/acer.13536 ; Chapoton B, Werlen AL, Regnier Denois V. Alcohol in TV series popular with teens: a content analysis of TV series in France 22 years after a restrictive law. European Journal of Public Health. 2020 Apr 1;30(2):363-368 ; Room R, O’Brien P. Alcohol marketing and social media: A challenge for public health control. Drug and Alcohol Review. 2021 Mar;40(3):420-422.
WHO. 2015. Smoke-free movies: from evidence to action. Third edition; Dal Cin S, Stoolmiller M, Sargent JD. When movies matter: exposure to smoking in movies and changes in smoking behavior. Journal of Health 8 Communication 2012;17:76–89; Lochbuehler K, Engels RC, Scholte RH. Influence of smoking cues in movies on craving among smokers. Addiction 2009;104:2102–9; Lochbuehler K, Kleinjan M, Engels RC. Does the exposure to smoking cues in movies affect adolescents’ immediate smoking behavior? Addictive Behaviours 2013;38:2203–6. 97; https://truthinitiative.org/research-resources/smoking-pop-culture/renormalization-tobacco-use-streaming-content-services
Lapierre MA, Fleming-Milici F, Rozendaal E, McAlister AR, Castonguay J. The Effect of Advertising on Children and Adolescents. Pediatrics. 2017 Nov;140(Suppl 2):S152-S156. doi: 10.1542/peds.2016-1758V; Vanwesenbeeck I, Hudders L, Ponnet K. Understanding the YouTube Generation: How Preschoolers Process Television and YouTube Advertising. Cyberpsychology, Behavior, and Social Networking. 2020 Jun;23(6):426-432.
Gabet A, Grimaud O, de Pereƫ C, Béjot Y, Olié V. Determinants of Case Fatality After Hospitalization for Stroke in France 2010 to 2015. Stroke. 2019;50:305-312 ; hƩps://www.inserm.fr/dossier/accident-vasculaire-cerebral-avc/; https://www.inserm.fr/dossier/infarctus-myocarde/.
Crowley SJ, Acebo C, Carskadon MA. Human puberty: salivary melatonin profiles in constant conditions. Developmental Psychobiology 54(4) (2012) 468–73)
Morselli LL, Guyon A, Spiegel K. Sleep and metabolic function. Pflugers Archiv. 2012 Jan;463(1):139–60. 15. Roberts RE, Duong HT. The prospective association between sleep deprivation and depression among adolescents. Sleep. 2014 Feb 1;37(2):239–44.
Wang C, Holtzman DM. Bidirectional relationship between sleep and Alzheimer’s disease: role of amyloid, tau, and other factors. Neuropsychopharmacology. 2020;45(1):104–20 ; Liew SC, Aung T. Sleep deprivation and its association with diseases- a review. Sleep Med. 2021;77:192–204.
Teŏ BC. Acute sleep deprivation and culpable motor vehicle crash involvement. Sleep. 2018;41(10).
Bryant PA, Curtis N. Sleep and infection: no snooze, you lose? The Pediatric Infectious Disease Journal. 2013 Oct;32(10):1135–7 ; Spiegel K, Sheridan JF, van Cauter E. Effect of sleep deprivation on response to immunization. JAMA. 2002 Sep 25;288(12):1471–2.
Lu C, Sun H, Huang J, Yin S, Hou W, Zhang J, et al. Long-Term Sleep Duration as a Risk Factor for Breast Cancer: Evidence from a Systematic Review and Dose-Response Meta-Analysis. BioMed Research International. 2017;2017:4845059.
Hanson JA, Huecker MR. Sleep Deprivation. 2022.
Liew SC, Aung T. Sleep deprivation and its association with diseases- a review. Sleep Med. 2021;77:192–204.
Gawne TJ, Ward AH, Norton TT. Long-wavelength (red) light produces hyperopia in juvenile and adolescent tree shrews. Vision Research. 2017;140:55-65.
K. Braune-Krickau , L. Schneebeli, J. Pehlke-Milde, M. Gemperle , R. Koch , A. von Wyl. (2021). Smartphones in the nursery: Parental smartphone use and parental sensitivity and responsiveness within parent-child interaction in early childhood (0-5 years): A scoping review. Infant Mental Health Journal. Mar;42(2):161-175 ; L.Jerusha Mackay, J. Komanchuk, K. Alix Hayden, N. Letourneau. (2022). Impacts of parental technoference on parent-child relationships and child health and developmental outcomes: a scoping review protocol. Systematic Reviews.Mar 17;11(1):45.
Masur EF, Flynn V, Olson J. Infants’ background television exposure during play: Negative relations to the quantity and quality of mothers’ speech and infants’ vocabulary acquisition. First Language 2016, Vol. 36(2) 109–123; Zimmerman FJ, Christakis DA. Children’s television viewing and cognitive outcomes: a longitudinal analysis of national data. Arch Pediatr Adolesc Med. 2005;159(7):619–625; Madigan S, McArthur BA, Anhorn C et al. Associations Between Screen Use and Child Language Skills: A Systematic Review and Meta-analysis. JAMA Pediatr. 2020 Jul 1;174(7):665-675; Schwarzer C, Grafe N, Hiemisch A et al. Associations of media use and early childhood development: cross-sectional findings from the LIFE Child study. Pediatr Res. 2021 Mar 3; Madigan S, Browne D, Racine N et al. Association Between Screen Time and Children’s Performance on a Developmental Screening Test. JAMA Pediatr 2019 Mar 1;173(3):244-250; Lillard AS, et al. The immediate impact of different types of television on young children’s executive function. Pediatrics. 2011. 11. Swing EL, et al. Television and video game exposure and the development of attention problems. Pediatrics. 2010; Wilmer HH, Sherman LE, Chein MJ. Smartphones and Cognition: A Review of Research Exploring the Links between Mobile Technology Habits and Cognitive Functioning. Front Psychol 2017 Apr 25;8:605. Tornton, B., Faires, A., Robbins et al. The mere presence of a cell phone may be distracting: Implications for attention and task performance. Soc. Psychol. 45, 479–488 (2014); Hadar A, HadasI, Lazarovits A et al. Answering the missed call: Initial exploration of cognitive and electrophysiological changes associated with smartphone use and abuse. PLoS One. 2017 Jul 5;12(7). Beyens I, Valkenburg PM, Piotrowski JT. Screen media use and ADHD-related behaviors: Four decades of research. Proc Natl Acad Sci U S A. 2018 Oct 2;115(40):9875-9881; Nikkelen SW, Valkenburg PM, Huizinga M et al. Media use and ADHD-related behaviors in children and adolescents: A metaanalysis. Dev Psychol. 2014 Sep;50(9):2228-41; Christakis DA, Ramirez JSB, Ferguson SM et al. How early media exposure may affect cognitive function: A review of results from observations in humans and experiments in mice. Proc Natl Acad Sci U S A. 2018 Oct 2;115(40):9851-9858. 7 .
Anderson CA, Shibuya A, Ihori N, Swing EL, Bushman BJ, Sakamoto A, Rothstein HR, Saleem M. Violent video game effects on aggression, empathy, and prosocial behavior in eastern and western countries: a meta-analytic reviewPsychol Bull. 2010 Mar;136(2):151-73. doi: 10.1037/a0018251. Anderson CA, Bushman BJ, Bartholow BD, Cantor J, Christakis D, Coyne SM. Screen Violence and Youth Behavior. Pediatrics. 2017 Nov;140(Suppl 2):S142-S147. doi: 10.1542/peds.2016-1758T.
Ferrara P, Ianniello F, Villani A, Corsello G. Cyberbullying a modern form of bullying: let’s talk about this health and social problem. Ital J Pediatr. 2018 Jan 17;44(1):14.
Nous venons d’apprendre avec tristesse le décès brutal de Christophe Chaillou, professeur à l’Université de Lille et chercheur en informatique. Plusieurs d’entre nous avons travaillé avec Christophe et nous avons souhaité lui rendre hommage en publiant cet article rédigé par ses collègues et amis. Marie-Agnès Enard et Pascal Guitton.
Crédit photo Université de Lille
A l’origine professeur de mathématiques, Christophe fait une thèse en informatique graphique au Laboratoire d’Informatique Fondamentale de Lille (maintenant intégré au Centre de Recherche en Informatique, Signal et Automatique de Lille). Recruté maître de conférences à l’ENIC (devenu Mines-telecom Nord de France) en 1991, il rejoint l’Eudit (devenu Polytech Lille depuis) en tant que Professeur en 1996. Il prend la direction de l’équipe de recherche Graphix de 1995 à 2010. Il est mis à disposition à l’Inria de septembre 1999 à août 2001 en tant que directeur de recherche pour mettre en place l’équipe-projet Alcove, une des premières équipes du centre Inria Futurs qui allait préfigurer le nouveau centre Inria à Lille. Alcove est à l’origine d’une longue lignée d’équipes, encore actives aujourd’hui au sein de CRIStAL et/ou du Centre Inria de l’Université de Lille (MINT, DEFROST et LOKI), mais aussi à Strasbourg (MIMESIS). En 2006, Christophe et sa famille s’installent en Chine où il va travailler à l’institut d’automatique de l’Académie Chinoise des Sciences à Beijing pendant un an.
En 2010, tout en continuant ses activités d’enseignement, il va intégrer à temps partiel Pictanovo, une association française dont l’objet est la promotion et l’appui à la production audiovisuelle et cinématographique dans la région des Hauts-de-France. Durant près de 10 ans, il va fonder et suivre le déploiement d’un appel à projet destiné à rapprocher recherche universitaire, monde artistique et entreprises.
A partir de 2020, il est nommé chargé de missions Art & Sciences au sein du service culture de l’Université de Lille où il continue d’initier des projets pour rapprocher le monde de la recherche et de l’art sous toutes ses formes.
Durant toutes ces années, Christophe a mis toute son énergie à initier et développer des activités de recherche autour de la réalité virtuelle, des simulateurs chirurgicaux, des dispositifs haptiques. Il a aussi très tôt souhaité créer des liens entre arts et sciences en motivant les chercheurs d’autres disciplines que la sienne à côtoyer des étudiants dans le domaine artistique comme ceux du Fresnoy par exemple.
Très dynamique, il a formé plusieurs générations d’étudiants et les a motivés à rejoindre la recherche, encouragé et soutenu des chercheurs et enseignant-chercheurs confirmés pour s’installer à Lille et incité ses collègues à transférer leurs activités.
Générateur d’idées, il a apporté un soutien considérable au développement des recherches sur l’haptique et le retour tactile, et plus généralement sur la Réalité Virtuelle et l’Interaction Humain-Machine, à l’Université de Lille et chez Inria. Par sa volonté de construire, il a permis l’essor de ces activités et a contribué à leur rayonnement international.
Engagé, fervent militant du “travailler ensemble”, il a été souvent moteur pour faire interagir le monde académique et universitaire avec les entreprises (avec la création de la société SimEdge), les arts (avec Pictanovo et le Fresnoy) ou par le biais de son engagement sur les sujets autour du développement durable.
Christophe a sans conteste été un booster d’activités, mettant son énergie, ses qualités au service de la communauté dès lors qu’il trouvait une idée intéressante, pour l’université, pour la science et ses applications.
Nous garderons en mémoire un collègue et ami généreux et passionné, très apprécié, toujours bienveillant, et dont l’enthousiasme était contagieux.
Des amis et collègues de Christophe
Vous pouvez apporter un témoignage en hommage à Christophe sur le site du laboratoire Cristal
Lead Certification Expert at European Union Agency for Cybersecurity (ENISA)
Un ancien collègue de mes collègues, Éric Vétillard, nous a proposé un article sur les contrôles d’identité. À l’heure du numérique, cette vérification peut cacher d’autres utilisation de votre identité pas les entités qui veulent la vérifier ou connaitre votre âge sans parler de la difficulté de prouver la parenté… Pierre Paradinas.
Dans le monde physique, nous avons de longues traditions de contrôles d’identité, de vérifications d’âge, par exemple pour acheter de l’alcool. Le contrôle des certificats COVID a poussé cette tradition dans ses limites. En Grèce, je montrais le certificat de vaccination et une pièce d’identité pour manger au restaurant, mais en France, uniquement le certificat de vaccination.
Nous acceptions ces contrôles parce que le monde physique a la mémoire courte. La personne qui vérifie chaque jour l’âge ou le statut vaccinal de centaines de clients ne mémorise pas ces informations.
Le monde virtuel est très différent. Il a une mémoire infinie. C’est parfois avantageux, puisqu’il suffit enligne de démontrer son âge une fois pour toutes. Mais quelle information sera mémorisée, et comment sera-t-elle exploitée ? De nombreux services en ligne, dont les réseaux sociaux, vivent de l’exploitation des données que nous mettons à leur disposition de manière plus ou moins consciente.
Et pourtant, des contrôles vont devoir être mis en place. Après le filtrage d’âge pour les sites pornographiques, un filtrage similaire a été voté pour les réseaux sociaux. L’impact est significatif, car si il est difficile de connaître l’audience des sites pornographiques avec précision, nous savons que la grande majorité d’entre nous utilise des réseaux sociaux, et autour de 100% des adolescents, y compris de nombreux utilisateurs de moins de 15 ans. L’impact de ces vérifications sera donc très significatif, car il s’appliquera à nous tous.
Le bon sens de ces mesures est évident, si vous ne comprenez pas que le monde virtuel est différent du monde physique. Au-delà des problèmes de confiance, il y a un fort sentiment d’impunité sur les réseaux, ainsi qu’une culture beaucoup plus libre, avec beaucoup de fausses identités, de pseudonymes, de personnages fictifs,etc. Bref, il est plus facile de tricher en ligne, même moralement.
Alors, comment démontrer son âge sans confiance avec une méthode sûre et accessible à tous ? Ce nést pas évident. La carte de paiement semblait un bon moyen, mais elle de répond à aucun des critères : il faut faire confiance au fournisseur, on peut facilement tricher, et tout le monde n’en a pas. Un scan de pièce d’identité n’est pas non plus idéal, pour des raisons très similaires. Pour ceux qui pensent au code QR authentifié des nouvelles cartes d’identité françaises pour résoudre au moins un problème, pas de chance : il ne contient pas la date de naissance.
Les problèmes de confiance peuvent être réglés en utilisant un service dédié, dit « tiers de confiance », dont le rôle est de collecter des données sensibles et de ne communiquer que l’information nécessaire à d’autres entités, par exemple des réseaux sociaux. C’est plus simple que ça en a l’air : nous pourrions aller chez un buraliste, montrer une pièce d’identité, et le buraliste attesterait auprès du réseau socialque nous avons plus de 15 ans.
En même temps, au niveau Européen, la réglementation sur l’identité numérique avance lentement, et définit un portefeuille numérique qui devrait simplifier l’authentification en ligne. En particulier, ce portefeuille serait associé à une personne de manière forte, et pourrait contenir des attestations de type « Le porteur de ce document a plus de 18 ans ». Une telle attestation serait très pratique pour les contrôles d’âge requis, car elle permet de limiter l’information divulguée. De plus, une des exigences de la loi est que le fournisseur de l’attestation, par exemple l’état, ne doit pas être informé des utilisations de l’attestation, ce qui devrait rendre la constitution d’un fichier national d’utilisateurs des sites pornographiques impossible, ou du moins illégale.
Ces portefeuilles électroniques devraient être déployés d’ici à la fin de la décennie. Si les citoyens les adoptent, ils pourraient apporter une solution technique au problème de vérification d’âge. En attendant, je pense très fort aux experts de l’ARCOM qui seront en charge de définir un référentiel de vérification d’âge à la fois efficace et suffisamment protecteur de notre vie privée pour être approuvé par la CNIL.
Pour finir, une petite colle. La dernière loi sur les réseaux sociaux inclut une notion d’autorisation parentale entre 13 et 15 ans. Cette autorisation doit être donnée par un parent, qui doit donc prouver sa qualité de parent. Nos documents d’identité français, même électroniques, ne contiennent pas d’informations de filiation. Quel mécanisme pourrons-nous donc utiliser pour autoriser nos chers ados ?
Un éditeur de binaire, Serge Abiteboul, et deux amis du blog, Laurence Devillers et Gilles Dowek, ont écrit une pièce qui sera présentée en grande première en Avignon, dans le cadre du festival off – les 15, 16, 17 juillet au Grenier à Sel. Si vous les connaissez, vous ne serez pas surpris que cela parle d’intelligence artificielle dans un texte plutôt déjanté. Pierre Paradinas.
La bataille pour une science accessible et gratuite n’est pas simple: elle nécessite de la passion, des bénévoles, des équipes, des infrastructures, des lecteurs et tout simplement des moyens. Celle de Scilogs.fr arrive à son terme. Ceci est le clap de fin d’une aventure de 10 ans. Laissons la parole à Philippe Ribeau-Gésippe, Responsable numérique du magazine PourlaScience.fr. Ikram Chraibi Kaadoud.
Cette année, cela fera 10 ans que Scilogs.fr existe. Cette plateforme de blogs avait été lancée en 2013 par Pour la Science avec l’idée de fédérer une communauté de blogueurs issus du monde de la recherche et réunis par l’envie de vulgariser leurs travaux avec l’exigence de rigueur qui fait la marque des magazines Pour la Science et Cerveau & Psycho.
Depuis lors, près de 30 blogs, dont Intelligence Mécanique, ont ainsi été ouverts sur Scilogs.fr, et près de 3000 articles publiés, souvent passionnants.
Mais proposer une plateforme telle que Scilogs.fr a un coût. Des coûts d’hébergement et de maintenance, d’une part, nécessaires pour mettre à jour les versions du système et intervenir en cas de panne ou d’attaque informatique. Et des ressources humaines, d’autre part, pour gérer les problèmes, recruter de nouveaux blogueurs, aider les auteurs ou promouvoir les nouveaux articles sur les réseaux sociaux.
Nous avons consacré à Scilogs.fr autant de temps et d’investissements qu’il nous était raisonnablement possible de le faire, car nous étions convaincus que c’était un beau projet. Hélas, le succès n’a pas été à la hauteur de nos espérances, et, Scilogs.fr n’a jamais réussi à trouver un modèle économique viable.
Nous sommes donc au regret d’annoncer que Scilogs.fr est arrêté mais reste disponible

 Nous sommes aujourd’hui capables de mesurer et de partager le temps avec une précision stupéfiante. Mais en comprenons-nous vraiment toutes les dimensions ? Sommes-nous conscients des nouveaux enjeux, souvent cruciaux, que les systèmes ultra-performants qui rythment notre quotidien soulèvent ?
Nous sommes aujourd’hui capables de mesurer et de partager le temps avec une précision stupéfiante. Mais en comprenons-nous vraiment toutes les dimensions ? Sommes-nous conscients des nouveaux enjeux, souvent cruciaux, que les systèmes ultra-performants qui rythment notre quotidien soulèvent ? Ancien enseignant et professeur agrégé de mathématiques, il a créé puis coordonné pendant de nombreuses années le pôle de compétences « logiciels libres » du SCÉRÉN, jouant un rôle de premier plan dans la légitimation et le développement du libre dans le système éducatif.
Ancien enseignant et professeur agrégé de mathématiques, il a créé puis coordonné pendant de nombreuses années le pôle de compétences « logiciels libres » du SCÉRÉN, jouant un rôle de premier plan dans la légitimation et le développement du libre dans le système éducatif.



 Solove et Hartzog viennent de publier un excellent article sur le moissonnage massif des données sur le web (« web scraping » en anglais) pour l’entraînement des systèmes d’Intelligence Artificielle et les tensions que cela génère avec les principes de la protection des données personnelles1. Cet article nous permet de revisiter la problématique du moissonnage massif des données et de rappeler les travaux et consultations menés par la CNIL sur ce sujet depuis plusieurs mois2. Serge Abiteboul, Antoine Rousseau et Ikram Chraibi-Kaadoud
Solove et Hartzog viennent de publier un excellent article sur le moissonnage massif des données sur le web (« web scraping » en anglais) pour l’entraînement des systèmes d’Intelligence Artificielle et les tensions que cela génère avec les principes de la protection des données personnelles1. Cet article nous permet de revisiter la problématique du moissonnage massif des données et de rappeler les travaux et consultations menés par la CNIL sur ce sujet depuis plusieurs mois2. Serge Abiteboul, Antoine Rousseau et Ikram Chraibi-Kaadoud


![[DA]vid contre Gol[IA]th : Quelle est la place de la créativité humaine dans le paysage de l’intelligence artificielle générative ?](https://binaire.socinfo.fr/wp-content/uploads/2024/09/25732ce2-img1.jpg)