Après celui sur Golems, Robots et IA, voici le second épisode. Serge Abiteboul et Thierry Viéville.
Je vous avais promis du sexe (et du genre) et me voilà en train de parler d’ordinateurs et d’informaticiens qui se prennent pour Dieu. Rassurez-vous, j’y viens.
Pourquoi l’humanité s’est-elle attachée à créer des créatures artificielles ? Certes, l’exercice permettait de s’approprier un peu du pouvoir divin, mais souvent, le but était de faire mieux que Dieu (ou que le hasard génétique). Les créatures artificielles des mythes comme celles des cybernéticiens tendent à corriger les imperfections de la version naturelle.
Prenons par exemple Galatée, la créature artificielle du mythe de Pygmalion. Selon Ovide, Pygmalion, jeune roi de Chypre et merveilleux sculpteur, est déçu par la légèreté des femmes de Chypre et se voue alors au célibat. Pour se consoler, il sculpte une femme parfaite appelée Galatée et en tombe amoureux. Il va alors prier Aphrodite de lui donner vie. Touchée par l’amour de Pygmalion, Aphrodite apporte la touche finale au processus de création en animant la statue. À aucun moment, Pygmalion n’a essayé de s’approprier un pouvoir divin, il a juste voulu améliorer les femmes. D’ailleurs, ses motivations misogynes sont bien comprises par les Dieux qui n’éprouvent aucune jalousie ; son histoire finit bien puisque, selon les versions de la légende, il aura même des enfants avec Galatée.

Vous vous souvenez des informaticiens des années 40 qui cherchent à dupliquer l’intelligence humaine ? Finalement, ils poursuivent un but semblable. Ce n’est pas n’importe quelle intelligence qu’ils essaient de dupliquer. Ils recherchent une intelligence qui puisse rivaliser avec la leur. Le mathématicien Norbert Wiener, l’inventeur de la cybernétique, veut pouvoir jouer avec les créatures qui seront créées. Von Neumann bâtit l’architecture des ordinateurs sur la base de la représentation qu’il se fait de son propre cerveau génial, doté d’une mémoire eidétique. Turing rêve d’une intelligence virtuelle qui ne mourra jamais. Les fantasmes autour de l’IA n’ont guère changé : reproduire l’intelligence de l’humain moyen n’excite personne (et pourtant, ce serait déjà une belle performance !). On vise directement à créer l’intelligence immense qui nous rendra tout petit.
Wiener pose comme principe de base que ce qui distingue des entités entre elles n’est pas la matière dont elles sont faites, mais leur comportement. Peu importe le matériau dont est faite la créature, on ne cherche pas à reproduire le vivant, mais le comportement du vivant. « L’homme fait l’homme à son image », écrit-il dans Golem & God Inc. D’ordinaire, on pense à la reproduction sexuée, mais après tout, est-ce la seule option ? Quand on suppose que Dieu a créé l’homme à son image, il ne faut évidemment pas prendre la formule au sens littéral. À partir de quand une image que l’on crée est-elle suffisamment bonne (indépendamment de son matériau) pour qu’on puisse considérer que son créateur s’est reproduit ? Pour l’expliquer, Wiener va se servir d’une partie du mythe de Pygmalion et Galatée.
Selon Wiener, quand Pygmalion sculpte Galatée dans l’ivoire, il crée une simple image picturale : Galatée a bien une forme humaine, mais elle ne peut être considérée comme un être à part entière, car elle a un comportement de statue. Mais dès lors qu’Aphrodite lui insuffle la vie, la statue devient une image opérante, tellement similaire à un être humain que Pygmalion va pouvoir l’épouser.
Si Wiener prend en exemple le mythe de Pygmalion et Galatée pour expliquer la « reproduction », c’est parce que cette histoire résonne de manières particulières dans sa propre biographie. En créant lui-même un être qu’il juge parfait, Pygmalion évite les risques du hasard et la déception qui semble inévitablement en découler quand on laisse les êtres humains (notamment les femmes dans le cas de ce mythe) se développer à leur guise. C’était également un risque que Léo Wiener, le père de Norbert, n’avait pas envie de prendre.
Léo Wiener, né en 1862, était un homme d’une intelligence et érudition peu commune. Il était réputé parler couramment 30 langues et il a été capable de suivre les travaux mathématiques de son fils jusqu’à ses premières années d’université. Il n’avait qu’une confiance limitée dans l’école, et des idées arrêtées sur la manière d’éduquer les enfants. Il infligea à son fils des cours intensifs à la maison jusqu’à finalement le retirer totalement de l’école entre 6 et 7 ans. Norbert savait lire à un an et demi et quand il réintégra l’école à 7 ans, ce fut pour entrer au secondaire. À 18 ans, Wiener obtint un doctorat à Harvard. Léo Wiener s’estima satisfait de la manière dont il avait façonné son fils. Dans un article intitulé Quelques idées nouvelles sur l’éducation des enfants, qu’il publia en 1911, il écrivit : « C’est un non-sens de dire, comme le font certaines personnes, que Norbert, Constance et Bertha sont des enfants exceptionnellement doués. Il n’en est rien. S’ils en savent plus que les enfants de leur âge, c’est parce qu’ils ont été entrainés différemment » (cité par Wiener dans son autobiographie de 1953 : Ex-Prodigy: My Childhood and Youth). Norbert Wiener résuma ensuite sa relation avec son père en ces termes : « Mes échecs étaient les miens, mes succès étaient ceux de mon père ». À sa naissance, Norbert n’était que l’image picturale de Léo, jusqu’à ce que celui-ci l’entraine et en fasse une image opérante, un fils à son image.
Pygmalion et Galatée, Léo et Norbert, le Rabi Loew et le Golem… ce sont là des transpositions assez littérales de la phrase de Wiener : « L’homme crée l’homme à son image ». Les humains peuvent se reproduire de diverses manières, par la reproduction sexuée, mais aussi en créant des machines qui sont des images opérantes d’eux-mêmes. Cette reproduction-là possède l’avantage cybernétique d’éviter l’entropie inhérente à la reproduction sexuée, même si Serge Abiteboul1 nous explique que cet aléatoire est indispensable pour la pérennité du processus de reproduction. En outre, l’homme n’a besoin de personne d’autre pour créer une image de lui.

Alan Turing, le célèbre mathématicien qui déchiffra les codes secrets allemands pendant la 2e guerre mondiale, fait partie des chercheurs qui discutent de cybernétique. En 1950, il écrit un article devenu célèbre : Computing machinery and intelligence, dans lequel il va se demander à partir de quand on peut considérer qu’une machine est intelligente. Pour cela, il va d’abord définir ce qu’est une machine : « Nous souhaitons exclure de la catégorie des machines les hommes nés de la manière habituelle », dit-il. Et comme la manière habituelle sous-entend la participation d’un homme et d’une femme, il ajoute : « On pourrait par exemple requérir que les ingénieurs soient tous du même sexe, mais cela ne serait pas vraiment satisfaisant ». Évidemment, Turing fait de l’humour, mais à travers cette plaisanterie, on comprend deux éléments essentiels. Tout d’abord, la machine est considérée comme étant littéralement l’enfant des ingénieurs, et deuxièmement, elle ne doit pas être le produit de la différence des sexes, car cela jetterait le doute sur son éligibilité. Cette machine sera donc conçue entre hommes, car je doute que Turing n’ait jamais imaginé une équipe de femmes ingénieures. (Finalement, il estimera que seuls les ordinateurs numériques pourront participer aux tests.)
Turing est certes un logicien d’exception, mais aussi un homme homosexuel dans une époque homophobe. Sa misogynie affichée lui permettait de masquer son peu d’intérêt pour la fréquentation des femmes : « Le problème avec les femmes, c’est qu’il faut leur parler », confiait-il à ses collègues mathématiciens. « Quand tu sors avec une fille, tu dois discuter avec elle et trop souvent, quand une femme parle, j’ai l’impression qu’une grenouille jaillit de sa bouche. ». À travers sa quête de l’intelligence artificielle, il cherche à se reproduire sans être obligé de fréquenter les femmes. Il espère créer un être virtuel supérieur qui ne sera pas soumis à la mort ou à la maladie, à faire revivre Christopher, ce garçon extraordinaire dont il était amoureux adolescent et qui est mort prématurément. Turing aurait voulu une créature artificielle dépassant les imperfections humaines.
Peut-être aurait-il apprécié le texte L’Eve future écrit par Villers de L’Isle-Adam en 1886, car il brasse les mêmes fantasmes. On y retrouve les motivations à l’origine du mythe de Pygmalion : il s’agit de créer une femme parfaite en lieu et place du modèle défectueux produit par la nature. Mais il s’agit cette fois d’une création entre hommes, permettant une forme d’homosexualité via un être artificiel féminin, car, comme le disait Turing, la conversation des femmes réelles s’avère terriblement décevante.
L’Eve future met en scène Lord Ewald, éperdument amoureux d’Alicia Clary, une chanteuse qui est aussi belle que sotte. Ewald est écartelé entre la beauté du corps d’Alicia et la vulgarité de ses propos. Il décide alors de se suicider, ne supportant plus la torture de passer du temps avec une femme aussi belle et aussi quelconque.
Il est sauvé par un scientifique, Edison (nommé ainsi en hommage à l’inventeur américain), qui a conçu un être artificiel qu’il peut rendre semblable à Alicia. Il propose alors un Pacte faustien à Ewald. Il va créer une nouvelle Eve, un andréïde nommé Hadaly, dont le corps sera celui d’Alicia Clary. En échange, Lord Ewald prêtera vie à ce corps par une opération mentale relevant de la foi et de la suggestion : en la croyant vivante, il la rendra vivante.
Pourquoi créer une femme artificielle ? Edison justifie sa démarche de la façon suivante. Pour lui, il existe deux types de femmes : « les femmes assainies, consacrées et justifiées par la dignité persistante du devoir, de l’abnégation, du noble dévouement » et celles qui ressemblent à Alicia Clary : « plus proches de l’espèce animale que de l’espèce humaine. L’homme a le droit de haute et basse justice sur ce genre d’être féminin comme il l’a sur les animaux. » Le moins qu’on puisse dire, c’est que Villers de L’Isle-Adam sait être clair quand il annonce qu’Edison sera « l’assassin de l’animalité triomphante de la femme ».
La relation qui s’en suit entre Edison, Edwald et Hadaly devient assez trouble. Il faut bien donner un esprit à Hadaly : les paroles qu’elle prononcera ont été enregistrées au préalable par Edison. On peut alors se demander avec qui Ewald a une conversation passionnée quand il parle avec Hadaly, et finalement qui Edwald désire quand il désire Hadaly. En outre, si Hadaly est un être artificiel au corps féminin, elle a été appelée Andréïde (Andres : homme) et non Antropoïde (humain) ou Gyneïde (femme).
La suite de l’histoire s’embrouille, car Villers de L’Isle-Adam finit par se plier à la morale de son époque. Il imagine que l’esprit d’une femme vertueuse endormie vient finalement animer Hadaly. Quoiqu’il en soit, le destin ne peut pas laisser perdurer ce projet immoral. Quand Lord Ewald repart en Angleterre, emportant Hadaly dans un sarcophage pour le temps de la traversée, le navire fait naufrage. Le sarcophage coule, et Lord Ewald, inconsolable, prend le deuil d’Hadaly.
Doit-on en déduire que les histoires de créatures artificielles sont condamnées à mal finir ? Dans un XIXe siècle moraliste, Villers de L’Isle-Adam ne pouvait pas se permettre de laisser perdurer cet amour contre nature. Mais que va-t-il advenir des créatures artificielles qui apparaîtront par la suite ?
L’homme crée l’homme à son image et le scientifique crée la créature artificielle à son image en tenant les femmes à l’écart. Est-ce que ce sera pour le meilleur ou pour le pire ? Est-ce que cela signifie la mort de Dieu… ou des humains ? Tout dépendra du point de vue adopté par celui qui raconte les histoires.
À suivre…
1 https://binaire.socinfo.fr/2015/10/19/sex-and-the-algorithm/
Isabelle Collet, informaticienne, enseignante-chercheuse à l’université de Genève et romancière.
Je remercie Jean-Paul Gourdant pour ses relectures attentives qui permettent aux textes d’être bien plus compréhensibles.























 Image du jeu classique « snake »
Image du jeu classique « snake »




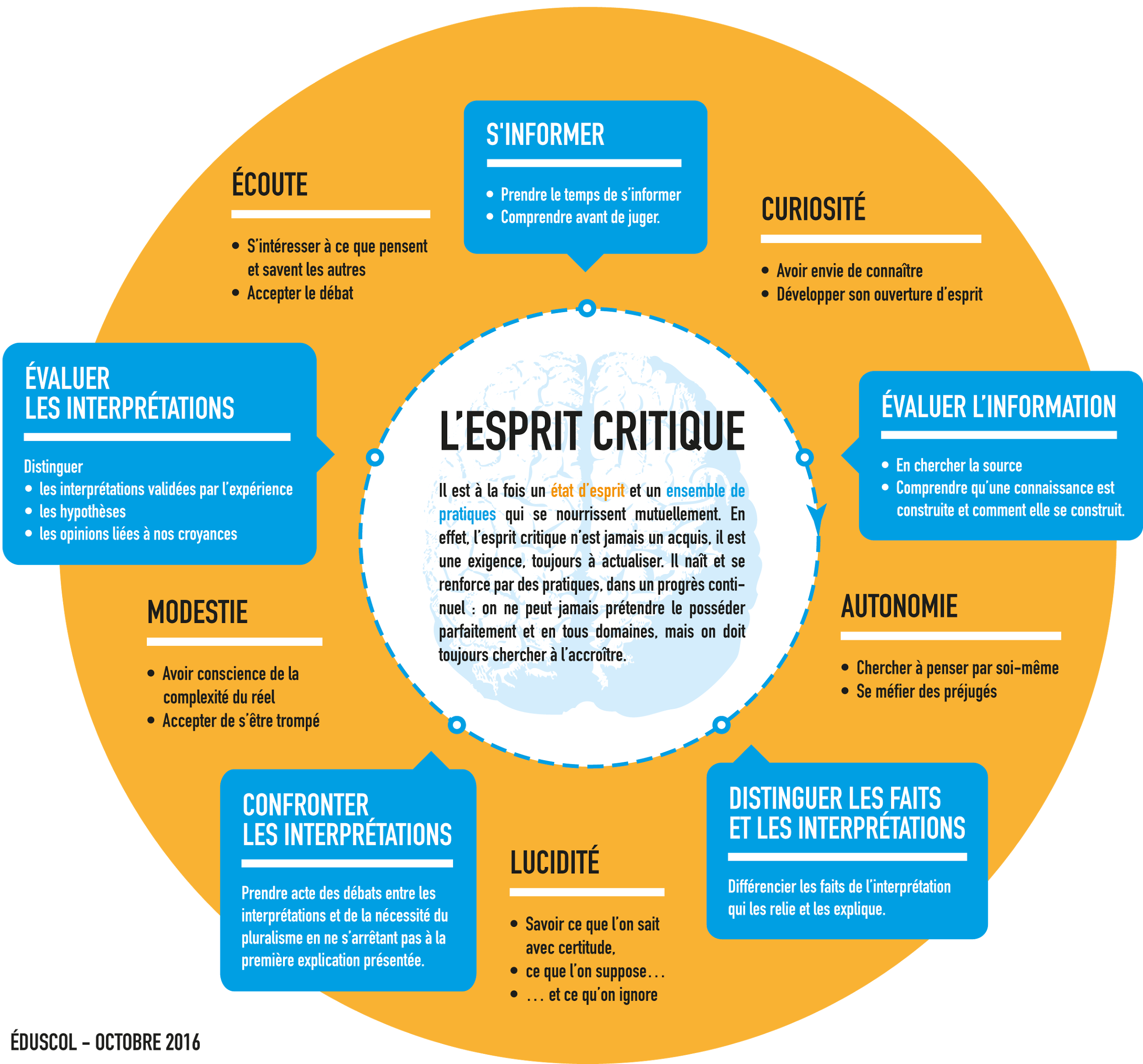
 Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », partageons une approche rendue encore plus indispensable avec le numérique : l’esprit critique. A l’heure des infox (fake news), du renforcement du complotisme, de la guerre qui est aussi devenue informationnelle, ou plus simplement de l’irruption de ChatGPT, l’apprentissage de l’esprit critique est/devrait être une priorité éducative. Mais … comment faire ? Et si nous commencions par regarder ce que les sciences de l’éducation nous proposent à travers ce petit texte issu des échanges tenus lors d’une table ronde. Thierry Vieville et Pascal Guitton.
Oui binaire s’adresse aussi aux jeunes de tous âges que le numérique laisse parfois perplexes. Avec « Petit binaire », partageons une approche rendue encore plus indispensable avec le numérique : l’esprit critique. A l’heure des infox (fake news), du renforcement du complotisme, de la guerre qui est aussi devenue informationnelle, ou plus simplement de l’irruption de ChatGPT, l’apprentissage de l’esprit critique est/devrait être une priorité éducative. Mais … comment faire ? Et si nous commencions par regarder ce que les sciences de l’éducation nous proposent à travers ce petit texte issu des échanges tenus lors d’une table ronde. Thierry Vieville et Pascal Guitton.

 Disons, pour en discuter, que c’est à la fois un état d’esprit et un ensemble de compétences (résumées dans les carrés bleus) :
Disons, pour en discuter, que c’est à la fois un état d’esprit et un ensemble de compétences (résumées dans les carrés bleus) :